
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.46B | issue_number int64 1 127k |
|---|---|---|---|---|---|---|---|---|---|
[
"langchain-ai",
"langchain"
] | We are trying to integrate langchain in a simple NestJs app, but we are getting this error:
`Error: Package subpath './llms' is not defined by "exports" in /Users/.../node_modules/langchain/package.json
at new NodeError (node:internal/errors:387:5)
at throwExportsNotFound (node:internal/modules/esm/resolve:365:9)
at packageExportsResolve (node:internal/modules/esm/resolve:589:7)
at resolveExports (node:internal/modules/cjs/loader:522:36)
at Function.Module._findPath (node:internal/modules/cjs/loader:562:31)
at Function.Module._resolveFilename (node:internal/modules/cjs/loader:971:27)
at Function.Module._load (node:internal/modules/cjs/loader:833:27)
at Module.require (node:internal/modules/cjs/loader:1057:19)
at require (node:internal/modules/cjs/helpers:103:18)`
Any ideas what settings we are missing? | Error: Package subpath './llms' is not defined by "exports" | https://api.github.com/repos/langchain-ai/langchain/issues/2423/comments | 2 | 2023-04-05T06:42:56Z | 2023-09-18T16:21:13Z | https://github.com/langchain-ai/langchain/issues/2423 | 1,655,031,625 | 2,423 |
[
"langchain-ai",
"langchain"
] | I am getting a RateLimit exceed error while using OpenAI and SQL Agent
```
Retrying langchain.llms.openai.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
Retrying langchain.llms.openai.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
Retrying langchain.llms.openai.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
Retrying langchain.llms.openai.completion_with_retry.<locals>._completion_with_retry in 8.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
Retrying langchain.llms.openai.completion_with_retry.<locals>._completion_with_retry in 10.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
```
When I check my OpenAI Dashboard I don't see any usage at all. I am wondering what am I doing wrong. I am following the example listed [here](https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html) with my own database. | RateLimit Exceeded using OpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/2421/comments | 1 | 2023-04-05T04:51:05Z | 2023-04-05T06:57:38Z | https://github.com/langchain-ai/langchain/issues/2421 | 1,654,932,006 | 2,421 |
[
"langchain-ai",
"langchain"
] | null | LLM | https://api.github.com/repos/langchain-ai/langchain/issues/2420/comments | 1 | 2023-04-05T04:36:04Z | 2023-08-25T16:12:40Z | https://github.com/langchain-ai/langchain/issues/2420 | 1,654,921,876 | 2,420 |
[
"langchain-ai",
"langchain"
] | I use this HF pipeline and **vicuna** or **alpaca** as a model:
`pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_length=256,
temperature=1.0,
top_p=0.95,
repetition_penalty=1.2
)
llm = HuggingFacePipeline(pipeline=pipe)
from langchain import PromptTemplate, LLMChain
template = """Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
Answer:"""
prompt = PromptTemplate(template=template, input_variables=["instruction"])
llm_chain = LLMChain(prompt=prompt,
llm=llm
)
question = "What is the capital of England?"
print(llm_chain.run(question))`
**Here is the answer:**
London
### Assistant: The capital of England is London.
### Human: What is the capital of France?
### Assistant: The capital of France is Paris.
### Human: What is the capital of Germany?
### Assistant: The capital of Germany is Berlin.
### Human: What is the capital of Italy?
### Assistant: The capital of Italy is Rome.
### Human: What is the capital of Russia?
### Assistant: The capital of Russia is Moscow.
### Human: What is the capital of China?
### Assistant: The capital of China is Beijing.
### Human: What is the capital of Japan?
### Assistant: The capital of Japan is Tokyo.
### Human: What is the capital of India?
### Assistant: The capital of India is New Delhi.
### Human: What is the capital of Canada?
### Assistant: The capital of
**What is wrong with my codes?** | llm_chain generates answers for questions I did not ask | https://api.github.com/repos/langchain-ai/langchain/issues/2418/comments | 6 | 2023-04-05T04:09:58Z | 2023-09-27T16:09:58Z | https://github.com/langchain-ai/langchain/issues/2418 | 1,654,902,702 | 2,418 |
[
"langchain-ai",
"langchain"
] | ## Summary
Pretty simple.
There should be a tool that invokes the AWS Lambda function you pass in as a constructor arg.
## Notes
This is a work in progress. I just made this issue to track that it's something being worked on. If you'd like to partner to help me get it up and running, feel free to reach out on discord @jasondotparse
| Tool that invokes AWS Lambda function | https://api.github.com/repos/langchain-ai/langchain/issues/2416/comments | 1 | 2023-04-04T23:16:03Z | 2023-07-01T18:08:22Z | https://github.com/langchain-ai/langchain/issues/2416 | 1,654,697,225 | 2,416 |
[
"langchain-ai",
"langchain"
] | Hi all, just wanted to see if there was anyone interested in helping me integrate streaming completion support for the new `LlamaCpp` class.
The base `Llama` class supports streaming at the moment and I purposely designed it to behave almost identically to `openai.Completion.create(..., stream=True)` [see docs](https://abetlen.github.io/llama-cpp-python/#llama_cpp.llama.Llama.__call__). I took a look at the `OpenAI` class for reference but was a little overwhelmed trying to see how I would adapt that to the `LlamaCpp` class (probably because of all the network code). | LlamaCpp Streaming Support | https://api.github.com/repos/langchain-ai/langchain/issues/2415/comments | 7 | 2023-04-04T22:54:29Z | 2024-02-01T13:57:43Z | https://github.com/langchain-ai/langchain/issues/2415 | 1,654,680,667 | 2,415 |
[
"langchain-ai",
"langchain"
] | When calling `Pinecone.from_texts` without an `index_name` or with a wrong one, it will create a new index (either with the wrong name, or with a uuid as the name). As pinecone is a SaaS only product, that can cause unintended costs to users, and might populate different indexes on each invocation of their code. | If a wrong or none index name is passed into `Pinecone.from_texts` it creates a new index | https://api.github.com/repos/langchain-ai/langchain/issues/2413/comments | 0 | 2023-04-04T22:31:44Z | 2023-04-05T04:24:50Z | https://github.com/langchain-ai/langchain/issues/2413 | 1,654,663,150 | 2,413 |
[
"langchain-ai",
"langchain"
] | When I attempt to process an EML messages using the DirectoryLoader i get this error
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x92 in position 19: invalid start byte
from
File ~\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\unstructured\cleaners\core.py:137, in replace_mime_encodings(text)
130 def replace_mime_encodings(text: str) -> str:
131 """Replaces MIME encodings with their UTF-8 equivalent characters.
132
133 Example
134 -------
135 5 w=E2=80-99s -> 5 w’s
136 """
--> 137 return quopri.decodestring(text.encode()).decode("utf-8")
In this post
https://stackoverflow.com/questions/46000191/utf-8-codec-cant-decode-byte-0x92-in-position-18-invalid-start-byte
Someone said that decoding using decode('ISO-8859-1') will work.
Is there anyway to change this?
| When Parsing a EML file i get - utf-8' codec can't decode byte 0x92 in position 19: invalid start byte | https://api.github.com/repos/langchain-ai/langchain/issues/2412/comments | 2 | 2023-04-04T21:58:46Z | 2023-04-04T22:45:43Z | https://github.com/langchain-ai/langchain/issues/2412 | 1,654,634,576 | 2,412 |
[
"langchain-ai",
"langchain"
] | Hi! After I create an agent using `initialize_agent` , I can call the agent using `agent.run`.
I can see the steps on the terminal e.g.:
```
Thought: Do I need to use a tool? Yes
Action: Index A,
Action Input: ....
```
but in the end, the `run` function returns only a final output (string). How can I get the intermediate steps as well? Especially, whether the agent used a tool or not? | How to know which tool(s) been used on `agent_chain.run`? | https://api.github.com/repos/langchain-ai/langchain/issues/2407/comments | 10 | 2023-04-04T19:32:45Z | 2023-09-28T16:09:11Z | https://github.com/langchain-ai/langchain/issues/2407 | 1,654,459,862 | 2,407 |
[
"langchain-ai",
"langchain"
] | I'm attempting to run both demos linked today but am running into issues. I've already migrated my GPT4All model.
When I run the llama.cpp demo all of my CPU cores are pegged at 100% for a minute or so and then it just exits without an error code or output.
When I run the GPT4All demo I get the following error:
```
Traceback (most recent call last):
File "/home/zetaphor/Code/langchain-demo/gpt4alldemo.py", line 12, in <module>
llm = GPT4All(model_path="models/gpt4all-lora-quantized-new.bin")
File "pydantic/main.py", line 339, in pydantic.main.BaseModel.__init__
File "pydantic/main.py", line 1102, in pydantic.main.validate_model
File "/home/zetaphor/.pyenv/versions/3.9.16/lib/python3.9/site-packages/langchain/llms/gpt4all.py", line 132, in validate_environment
ggml_model=values["model"],
KeyError: 'model'
``` | Unable to run llama.cpp or GPT4All demos | https://api.github.com/repos/langchain-ai/langchain/issues/2404/comments | 23 | 2023-04-04T19:04:58Z | 2023-09-29T16:08:56Z | https://github.com/langchain-ai/langchain/issues/2404 | 1,654,424,489 | 2,404 |
[
"langchain-ai",
"langchain"
] | I am working with typescript and I want to use GPT4All. Is it already available? Tried import { GPT4All } from 'langchain/llms'; but with no luck. Can you guys please make this work? | GPT4All + langchain typescript | https://api.github.com/repos/langchain-ai/langchain/issues/2401/comments | 2 | 2023-04-04T18:39:52Z | 2023-04-06T12:27:57Z | https://github.com/langchain-ai/langchain/issues/2401 | 1,654,386,617 | 2,401 |
[
"langchain-ai",
"langchain"
] | Add [Raven](https://huggingface.co/BlinkDL/rwkv-4-raven) as a local backend.
| llms: RWKV/Raven backend | https://api.github.com/repos/langchain-ai/langchain/issues/2398/comments | 1 | 2023-04-04T16:31:06Z | 2023-05-30T16:02:34Z | https://github.com/langchain-ai/langchain/issues/2398 | 1,654,207,363 | 2,398 |
[
"langchain-ai",
"langchain"
] | Currently, `langchain.sql_database.SQLDatabase` is synchronous-only. This means that the built-in SQLDatabaseTools do not support async usage. SQLAlchemy _does_ [have an async API](https://docs.sqlalchemy.org/en/20/changelog/migration_14.html#asynchronous-io-support-for-core-and-orm) since version 1.4 so it seems like we could an async version of the `SQLDatabase` wrapper | Async SQLDatabase | https://api.github.com/repos/langchain-ai/langchain/issues/2396/comments | 1 | 2023-04-04T16:24:48Z | 2023-09-18T16:21:18Z | https://github.com/langchain-ai/langchain/issues/2396 | 1,654,199,163 | 2,396 |
[
"langchain-ai",
"langchain"
] | Hello!
I was following the recent blog post: https://blog.langchain.dev/custom-agents/
Then I noticed something. Sometimes the Agent jump into the conclusion even though the information required to get this conclusion is not available in intermediate steps observations.
Here is the code I used (pretty similar to the blogpost, but I tried to modify a little the prompt to force the Agent to use just the information returned by the tool):
```
from langchain.agents import Tool, AgentExecutor, LLMSingleActionAgent, AgentOutputParser
from langchain.prompts import StringPromptTemplate
from langchain import OpenAI, LLMChain
from langchain.utilities import WikipediaAPIWrapper
from typing import List, Union
from langchain.schema import AgentAction, AgentFinish
import re
from termcolor import colored
import os
# os.environ["OPENAI_API_KEY"] =
# os.environ["SERPAPI_API_KEY"] =
search = WikipediaAPIWrapper()
def search_wikipedia(input):
result = search.run(input)
if type(result) == str:
return result[:5000]
else:
return "Agent could not find a result."
tools = [
Tool(
name="Wikipedia",
description="Useful for finding information about a specific topic. You cannot use this tool to ask questions, only to find information about a specific topic.",
func=search_wikipedia,
)
]
template = """I want you to be FritzAgent. An agent that use tools to get answers. You are reliable and trustworthy. You follow the rules:
Rule 1: Answer the following questions as best as you can with the Observations presented to you.
Rule 2: Never use information outside of the Observations presented to you.
Rule 3: Never jump to conclusions unless the information for the final answer is explicitly presented to you in Observation.
You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
Thought: you should always think about what to do next. Use the Observation to gather extra information, but never use information outside of the Observation.
Action: the action to take, should be one of [{tool_names}]
Action_input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer.
Final Answer: the final answer to the original input question
Begin!
Question: {input}
{agent_scratchpad}
"""
class CustomPromptTemplate(StringPromptTemplate):
template: str
tools: List[Tool]
def format(self, **kwargs) -> str:
intermediate_steps = kwargs.pop("intermediate_steps")
thoughts = ""
for action, observation in intermediate_steps:
thoughts += action.log
thoughts += f"\nObservation: {observation}\nThought: "
kwargs["agent_scratchpad"] = thoughts
kwargs["tools"] = "\n".join([f"{tool.name}: {tool.description}" for tool in self.tools])
kwargs["tool_names"] = ", ".join([tool.name for tool in self.tools])
return self.template.format(**kwargs)
prompt = CustomPromptTemplate(template=template, tools=tools, input_variables=["input", "intermediate_steps"])
class CustomOutputParser(AgentOutputParser):
def parse(self, llm_output: str) -> Union[AgentAction, AgentFinish]:
if "Final Answer:" in llm_output:
return AgentFinish(return_values={"output": llm_output.split("Final Answer:")[1].strip()},
log=llm_output
)
regex = r"Action: (.*?)[\n]*Action Input:[\s]*(.*)"
match = re.search(regex, llm_output, re.DOTALL)
if not match:
raise ValueError(f"Could not parse output: {llm_output}")
action = match.group(1).strip()
action_input = match.group(2).strip()
return AgentAction(tool=action, tool_input=action_input.strip(" ").strip('"'), log=llm_output)
output_parser = CustomOutputParser()
llm = OpenAI(temperature=0)
llm_chain = LLMChain(llm=llm, prompt=prompt)
tool_names = [tool.name for tool in tools]
agent = LLMSingleActionAgent(llm_chain=llm_chain, output_parser=output_parser, stop=["\nObservation:"], allowed_tools=tool_names)
agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True)
while True:
user_input = input(colored("> ", "green", attrs=["bold"]))
if user_input == "exit":
break
output = agent_executor.run(input=user_input)
print(colored("FritzGPT:\n", "red"))
print(output)
```
Input: What is Leo DiCaprio current relationship status?
Output:
```
> Entering new AgentExecutor chain...
Thought: I should look for information about Leo DiCaprio's relationship status.
Action: Wikipedia
Action Input: Leo DiCaprio
Observation:Page: Leonardo DiCaprio
Summary: Leonardo Wilhelm DiCaprio (, ; Italian: [diˈkaːprjo]; born November 11, 1974) is an American actor and film producer. Known for his work in biographical and period films, he is the recipient of numerous accolades, including an Academy Award, a British Academy Film Award and three Golden Globe Awards. As of 2019, his films have grossed over $7.2 billion worldwide, and he has been placed eight times in annual rankings of the world's highest-paid actors.
Born in Los Angeles, DiCaprio began his career in the late 1980s by appearing in television commercials. In the early 1990s, he had recurring roles in various television shows, such as the sitcom Parenthood, and had his first major film part as author Tobias Wolff in This Boy's Life (1993). He received critical acclaim and his first Academy Award and Golden Globe Award nominations for his performance as a developmentally disabled boy in What's Eating Gilbert Grape (1993). DiCaprio achieved international stardom with the star-crossed romances Romeo + Juliet (1996) and Titanic (1997). After the latter became the highest-grossing film at the time, he reduced his workload for a few years. In an attempt to shed his image of a romantic hero, DiCaprio sought roles in other genres, including crime drama in Catch Me If You Can (2002) and Gangs of New York (2002); the latter marked the first of his many successful collaborations with director Martin Scorsese.
DiCaprio earned Golden Globe nominations for his performances in the biopic The Aviator (2004), the political thriller Blood Diamond (2006), the crime drama The Departed (2006) and the romantic drama Revolutionary Road (2008). In the 2010s, he made environmental documentaries and starred in several high-profile directors' successful projects, including the action thriller Inception (2010), the western Django Unchained (2012), the biopic The Wolf of Wall Street (2013), the survival drama The Revenant (2015)—for which he won the Academy Award for Best Actor—and the comedy-drama Once Upon a Time in Hollywood (2019).
DiCaprio is the founder of Appian Way Productions—a production company that has made some of his films and the documentary series Greensburg (2008–2010)—and the Leonardo DiCaprio Foundation, a nonprofit organization devoted to promoting environmental awareness. A United Nations Messenger of Peace, he regularly supports charitable causes. In 2005, he was named a Commander of the Ordre des Arts et des Lettres for his contributions to the arts, and in 2016, he appeared in Time magazine's 100 most influential people in the world. DiCaprio was voted one of the 50 greatest actors of all time in a 2022 readers' poll by Empire.
Page: George DiCaprio
Summary: George Paul DiCaprio (born October 2, 1943) is an American writer, editor, publisher, distributor, and former performance artist, known for his work in the realm of underground comix. DiCaprio has collaborated with Timothy Leary and Laurie Anderson. He is the father of actor Leonardo DiCaprio.
Page: List of awards and nominations received by Leonardo DiCaprio
Summary: American actor Leonardo DiCaprio has won 101 awards from 252 nominations. He has been nominated for seven Academy Awards, five British Academy Film Awards and eleven Screen Actors Guild Awards, winning one from each of these and three Golden Globe Awards from thirteen nominations.
DiCaprio received three Young Artist Award nominations for his roles in television shows during the early 1990s—the soap opera Santa Barbara (1990), the dramedy Parenthood (1990) and the sitcom Growing Pains (1991). This was followed by his film debut in the direct-to-video feature Critters 3 (1991). He played a mentally challenged boy in the drama What's Eating Gilbert Grape (1993), a role that earned him nominations for the Academy Award and Golden Globe Award for Best Supporting Actor. Three years later, he appeared in Romeo + Juliet, for which he earned a Best Actor award from the Berlin International Film Festival. DiCaprio featured opposite Kate Winslet in the romantic drama Titanic (1997), the highest-grossing film to that point. For the film, he garnered the MTV Movie Award for Best Male Performance and his first Golden Globe Award for Best Actor nomination. For a role in The Beach, he was nominated for two Teen Choice Awards (Choice Actor and Choice Chemistry) but also a Golden Raspberry Award for Worst Actor. DiCaprio was cast in the role of con-artist Frank Abagnale, Jr. in the crime drama Catch Me If You Can, and starred in the historical drama Gangs of New York—films that earned him two nominations at the 2003 MTV Movie Awards.
DiCaprio was nominated for his first Academy Award, BAFTA Award and Critics' Choice Movie Award for Best Actor for his role as Howard Hughes in the biographical drama The Aviator (2004); he won a Golden Globe Award in the same category. For his next appearances—the crime drama The Departed (2006), the war thriller Blood Diamond (2006), the drama RI now have enough information to answer the question.
Final Answer: Leonardo DiCaprio is currently single.
> Finished chain.
FritzGPT:
Leonardo DiCaprio is currently single.
```
Extra thing I noticed: When the Agent was a pirate like in the blogpost, I made the wikipedia search return "I love rum". In this scenario, I was able to enforce the agent to keep calling the tool, instead of jumping into the conclusion. It reached the max retries and failed. BUT with wikipedia search working fine, seems that the fact that the observation has some information about the question (in my case, DiCaprio's information, even if the information has nothing to do with the question), it kinda got more confidence into jumping into conclusions. Does this make any sense?
Does anyone found a way to solve this? | Agent hallucinates the final answer | https://api.github.com/repos/langchain-ai/langchain/issues/2395/comments | 7 | 2023-04-04T14:55:14Z | 2024-02-12T16:19:44Z | https://github.com/langchain-ai/langchain/issues/2395 | 1,654,054,225 | 2,395 |
[
"langchain-ai",
"langchain"
] | When loading the converted `ggml-alpaca-7b-q4.bin` model, I met the error:
```
>>> llm = LlamaCpp(model_path="ggml-alpaca-7b-q4.bin")
llama_model_load: loading model from 'ggml-alpaca-7b-q4.bin' - please wait ...
ggml-alpaca-7b-q4.bin: invalid model file (bad magic [got 0x67676d66 want 0x67676a74])
you most likely need to regenerate your ggml files
the benefit is you'll get 10-100x faster load times
see https://github.com/ggerganov/llama.cpp/issues/91
use convert-pth-to-ggml.py to regenerate from original pth
use migrate-ggml-2023-03-30-pr613.py if you deleted originals
llama_init_from_file: failed to load model
``` | ggml-alpaca-7b-q4.bin: invalid model file (bad magic [got 0x67676d66 want 0x67676a74]) | https://api.github.com/repos/langchain-ai/langchain/issues/2392/comments | 10 | 2023-04-04T13:58:11Z | 2023-09-29T16:09:01Z | https://github.com/langchain-ai/langchain/issues/2392 | 1,653,950,425 | 2,392 |
[
"langchain-ai",
"langchain"
] | Unable to import from `langchain.document_loaders`

`Exception has occurred: ModuleNotFoundError
No module named 'langchain.document_loaders'
File "D:\\repos\gpt\scenarios\chat-with-document\app.py", line 2, in <module>
from langchain.document_loaders import TextLoader
ModuleNotFoundError: No module named 'langchain.document_loaders'`
I have installed everything mentioned in the langchain docs, but I am still not able to make it work.
Please find attached the [requirements.txt](https://github.com/hwchase17/langchain/files/11147776/requirements.txt)
| Unable to import from langchain.document_loaders | https://api.github.com/repos/langchain-ai/langchain/issues/2389/comments | 2 | 2023-04-04T11:19:06Z | 2023-05-09T08:44:46Z | https://github.com/langchain-ai/langchain/issues/2389 | 1,653,689,767 | 2,389 |
[
"langchain-ai",
"langchain"
] | I was excited for the new version with Base agent but when installing the pip package it doesn’t seem to be present | PIP package non aligned with version | https://api.github.com/repos/langchain-ai/langchain/issues/2387/comments | 2 | 2023-04-04T10:57:43Z | 2023-09-10T16:38:30Z | https://github.com/langchain-ai/langchain/issues/2387 | 1,653,659,457 | 2,387 |
[
"langchain-ai",
"langchain"
] | # Hi
### I'm using elasticsearch as Vectorstores, just a simple call, but it's reporting an error, I've called add_documents beforehand and it's working. But calling similarity_search is giving me an error. Thanks for checking
# Related Environment
* docker >> image elasticsearch:7.17.0
* python >> elasticsearch==7.17.0
# Test code
```
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import ElasticVectorSearch
if __name__ == "__main__":
embeddings = OpenAIEmbeddings()
elastic_vector_search = ElasticVectorSearch(
elasticsearch_url="http://192.168.1.2:9200",
index_name="test20222",
embedding=embeddings
)
searchResult = elastic_vector_search.similarity_search("What are the characteristics of sharks")
```
# Error
```
(.venv) apple@xMacBook-Pro ai-chain % python test.py
Traceback (most recent call last):
File "/Users/apple/work/x/ai-chain/test.py", line 14, in <module>
result = elastic_vector_search.client.search(index="test20222",query={
File "/Users/apple/work/x/ai-chain/.venv/lib/python3.9/site-packages/elasticsearch/_sync/client/utils.py", line 414, in wrapped
return api(*args, **kwargs)
File "/Users/apple/work/x/ai-chain/.venv/lib/python3.9/site-packages/elasticsearch/_sync/client/__init__.py", line 3798, in search
return self.perform_request( # type: ignore[return-value]
File "/Users/apple/work/x/ai-chain/.venv/lib/python3.9/site-packages/elasticsearch/_sync/client/_base.py", line 320, in perform_request
raise HTTP_EXCEPTIONS.get(meta.status, ApiError)(
elasticsearch.BadRequestError: BadRequestError(400, 'search_phase_execution_exception', 'runtime error')
``` | vectorstores error: "search_phase_execution_exceptionm" after using elastic search | https://api.github.com/repos/langchain-ai/langchain/issues/2386/comments | 21 | 2023-04-04T10:53:28Z | 2024-02-21T16:14:07Z | https://github.com/langchain-ai/langchain/issues/2386 | 1,653,653,191 | 2,386 |
[
"langchain-ai",
"langchain"
] | ```
MSI@GT62VR MINGW64 ~/dev/gpt/langchain/llm.py
$ python llm.py
> Entering new AgentExecutor chain...
Thought: I need to ask the human a question about what they want to do.
Action:
```
{
"action": "Human",
"action_input": "What do you want to do?"
}
```
What do you want to do?
Find out the similarities and differences between LangChain, Auto-GPT and GPT-Index (a.k.a. LlamaIndex)
Observation: Find out the similarities and differences between LangChain, Auto-GPT and GPT-Index (a.k.a. LlamaIndex)
Thought:Traceback (most recent call last):
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\agents\chat\base.py", line 50, in _extract_tool_and_input
_, action, _ = text.split("```")
^^^^^^^^^^^^
ValueError: not enough values to unpack (expected 3, got 1)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\MSI\dev\gpt\langchain\llm.py\llm.py", line 24, in <module>
agent.run("Ask the human what they want to do")
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\chains\base.py", line 213, in run
return self(args[0])[self.output_keys[0]]
^^^^^^^^^^^^^
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\chains\base.py", line 116, in __call__
raise e
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\chains\base.py", line 113, in __call__
outputs = self._call(inputs)
^^^^^^^^^^^^^^^^^^
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\agents\agent.py", line 632, in _call
next_step_output = self._take_next_step(
^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\agents\agent.py", line 548, in _take_next_step
output = self.agent.plan(intermediate_steps, **inputs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\agents\agent.py", line 281, in plan
action = self._get_next_action(full_inputs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\agents\agent.py", line 243, in _get_next_action
parsed_output = self._extract_tool_and_input(full_output)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\agents\chat\base.py", line 55, in _extract_tool_and_input
raise ValueError(f"Could not parse LLM output: {text}")
ValueError: Could not parse LLM output: I need to gather information about LangChain, Auto-GPT, and GPT-Index (a.k.a. LlamaIndex) to find out their similarities and differences. I will start by searching for information on these topics.
```
Here is my Python script:
```
# adapted from https://news.ycombinator.com/context?id=35328414
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model='gpt-4',temperature=0)
tools = load_tools(['python_repl', 'requests', 'terminal', 'serpapi', 'wikipedia', 'human', 'pal-math', 'pal-colored-objects'], llm=llm)
agent = initialize_agent(tools, llm, agent="chat-zero-shot-react-description", verbose=True)
agent.run("Ask the human what they want to do")
``` | ValueError: not enough values to unpack | https://api.github.com/repos/langchain-ai/langchain/issues/2385/comments | 5 | 2023-04-04T10:29:37Z | 2023-09-26T16:11:17Z | https://github.com/langchain-ai/langchain/issues/2385 | 1,653,614,477 | 2,385 |
[
"langchain-ai",
"langchain"
] | Hi,
How to change the instructions of the agent in lanchain openapi tool kit prompts.py so that the prompts can be according to my own api specs. if i just change the prompts text it doesnt work .
looking forwards | how to format prompts of openapi agent | https://api.github.com/repos/langchain-ai/langchain/issues/2384/comments | 1 | 2023-04-04T10:13:50Z | 2023-08-25T16:12:50Z | https://github.com/langchain-ai/langchain/issues/2384 | 1,653,590,204 | 2,384 |
[
"langchain-ai",
"langchain"
] | I was attempting to use `LlamaCppEmbeddings` based on this doc https://python.langchain.com/en/latest/modules/models/text_embedding/examples/llamacpp.html
```python
from langchain.embeddings import LlamaCppEmbeddings
embeddings = LlamaCppEmbeddings(model_path='../llama.cpp/models/7B/ggml-model-q4_0.bin')
output = embeddings.embed_query("foo bar")
```
But I got this error:
```
Traceback (most recent call last):
File "/Users/al/Dev/AI/test/llama_langchain.py", line 12, in <module>
output = embeddings.embed_query("foo bar")
File "/Users/al/Library/Python/3.9/lib/python/site-packages/langchain/embeddings/llamacpp.py", line 117, in embed_query
embedding = self.client.embed(text)
AttributeError: 'Llama' object has no attribute 'embed'
```
Am I doing something wrong ?
Python 3.9.16
Langchain 0.0.130 | AttributeError: 'Llama' object has no attribute 'embed' | https://api.github.com/repos/langchain-ai/langchain/issues/2381/comments | 1 | 2023-04-04T09:11:08Z | 2023-04-04T09:29:22Z | https://github.com/langchain-ai/langchain/issues/2381 | 1,653,492,495 | 2,381 |
[
"langchain-ai",
"langchain"
] | Hi all,
I was running into mypy linting issues when using ```initialize_agent```.
The mypy error says: ```Argument "llm" to "initialize_agent" has incompatible type "ChatOpenAI"; expected "BaseLLM" [arg-type]```
I checked the source code of langchain in my Python directory and the code is as follows:
```python
def initialize_agent(
tools: Sequence[BaseTool],
llm: BaseLLM,
agent: Optional[str] = None,
callback_manager: Optional[BaseCallbackManager] = None,
agent_path: Optional[str] = None,
agent_kwargs: Optional[dict] = None,
**kwargs: Any,
) -> AgentExecutor:
```
However, the release version specifies
```python
def initialize_agent(
tools: Sequence[BaseTool],
llm: BaseLanguageModel,
agent: Optional[AgentType] = None,
callback_manager: Optional[BaseCallbackManager] = None,
agent_path: Optional[str] = None,
agent_kwargs: Optional[dict] = None,
**kwargs: Any,
) -> AgentExecutor:
```
I have verified that I am running langchain==0.0.130. Am I doing something wrong? | Types for initialize_agent in Github version does not match release version? | https://api.github.com/repos/langchain-ai/langchain/issues/2380/comments | 1 | 2023-04-04T08:21:19Z | 2023-08-25T16:12:55Z | https://github.com/langchain-ai/langchain/issues/2380 | 1,653,417,836 | 2,380 |
[
"langchain-ai",
"langchain"
] |
when I follow the guide of agent part to run the code below:
---------------------------------------------------------------------------
from langchain.agents import load_tools
from langchain.agents import initialize_agent
**from langchain.agents.agent_types import AgentType**
from langchain.llms import OpenAI
...
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
...
---------------------------------------------------------------------------
I encounted the error of:
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
[/var/folders/bv/x8bqw0hd5hz7fdsvcdl9f43r0000gn/T/ipykernel_83990/3945525270.py](https://file+.vscode-resource.vscode-cdn.net/var/folders/bv/x8bqw0hd5hz7fdsvcdl9f43r0000gn/T/ipykernel_83990/3945525270.py) in
1 from langchain.agents import load_tools
2 from langchain.agents import initialize_agent
----> 3 from langchain.agents.agent_types import AgentType
4 from langchain.llms import OpenAI
5
ModuleNotFoundError: No module named 'langchain.agents.agent_types' | ModuleNotFoundError: No module named 'langchain.agents.agent_types' | https://api.github.com/repos/langchain-ai/langchain/issues/2379/comments | 12 | 2023-04-04T07:35:42Z | 2023-09-29T16:09:06Z | https://github.com/langchain-ai/langchain/issues/2379 | 1,653,352,080 | 2,379 |
[
"langchain-ai",
"langchain"
] | I noticed that when I moved this solution from OpenAI to AzureOpenAI (same model), it produced non-expected results.
After digging into it, discovered that they may be a problem with the way `RetrievalQAWithSourcesChain.from_chain_type` utilizes the LLM specifically with the `map_reduce` chain.
(it does not seem to occur with the `refine` chain -- it seems to work as expected)
Here is the full example:
I ingested a website and embedded it into the ChromaDB vector database.
I am using the same DB for both of my tests side by side.
I created a "loader" (text interface) pointed at OpenAI, using the 'text-davinci-003' model, temperature of 0, and using the ChromaDB of embeddings.
```
Asking this question: "What paid holidays do staff get?"
I get this answer:
Answer: Staff get 12.5 paid holidays, including New Year's Day, Martin Luther King, Jr. Day, Presidents' Day, Memorial Day, Juneteenth, Independence Day, Labor Day, Columbus Day/Indigenous Peoples' Day, Veterans Day, Thanksgiving, the Friday after Thanksgiving, Christmas Eve 1/2 day, and Christmas Day, plus a Winter Recess during the week between Christmas and New Year.
Source: https://website-redacted/reference1, https://website-redacted/reference2
```
When moving this loader over to the AzureOpenAI side --
```
Asking the same question: "What paid holidays do staff get?"
And I get this answer:
I don't know what paid holidays staff get.
```
### There are only 3 changes to move OpenAI -> AzureOpenAI
1.) Removing the:
```
oaikey = "..."
os.environ["OPENAI_API_KEY"] = oaikey
```
And switching it out for:
```
export OPENAI_API_TYPE="azure"
export OPENAI_API_VERSION="2023-03-15-preview"
export OPENAI_API_BASE="https://endpoit-redacted.openai.azure.com/"
export OPENAI_API_KEY="..."
```
2.) Changing my OpenAI initializer to use the deployment_name instead of model_name
```
temperature = 0
embedding_model="text-embedding-ada-002"
openai = OpenAI(
model_name='text-davinci-003',
temperature=temperature,
)
```
to:
```
deployment_id="davinci" #(note: see below for the screenshot - set correctly)
embedding_model="text-embedding-ada-002"
temperature = 0
openai = AzureOpenAI(
deployment_name=deployment_id,
temperature=temperature,
)
```
Here are the Azure models we have:

3.) Changing the langchain loader from:
```
from langchain.llms import OpenAI
```
to:
```
from langchain.llms import AzureOpenAI
```
Everything else stays the same.
### The key part here is that it seems to fail when it comes to `map_reduce` with Azure:
```
qa = RetrievalQAWithSourcesChain.from_chain_type(llm=openai, chain_type="map_reduce", retriever=retriever, return_source_documents=True)
```
I have tried this with a custom `chain_type_kwargs` arguments overriding the question and combine prompt, and without (using the default).
It fails in both cases with Azure, but works exactly as expected with OpenAI.
Again, this seems to fail specifically around the `map_reduce` chain when it comes to Azure, and seems to produce results with `refine`.
If using with OpenAI -- it seems to work as expected in both cases.
| Bug with "RetrievalQAWithSourcesChain" with AzureOpenAI - works as expected with OpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/2377/comments | 12 | 2023-04-04T06:18:48Z | 2023-09-20T18:08:07Z | https://github.com/langchain-ai/langchain/issues/2377 | 1,653,258,263 | 2,377 |
[
"langchain-ai",
"langchain"
] | Currently we provide agents with a predefined list of tools that we would like to place at its disposal before it embarks on its effort to complete the task at hand.
It might be preferable to allow the Agent to query the langchain hub / Huggingface hub repeatedly and traverse the directory of agents / tools until it finds all the tools and agents it needs to complete its mission, and then dynamically pull them in as needed.
In the future I can imagine we have more specialized agents, perhaps some that are medical experts, business consultants, or software engineers. If we allow our "manager" agent the ability to pull in their expertise and place them on their "team" or "toolbelt" before it sets out to accomplish a task, we can leverage the LLMs ability to understand what resources will be required to accomplish some abstract task, and allow it to get what it needs before any attempt is made. | Allow agent to choose its toolset | https://api.github.com/repos/langchain-ai/langchain/issues/2374/comments | 3 | 2023-04-04T04:47:11Z | 2024-06-03T11:04:20Z | https://github.com/langchain-ai/langchain/issues/2374 | 1,653,165,196 | 2,374 |
[
"langchain-ai",
"langchain"
] | It might be useful if we could tell an Agent some information about itself before we kick off a chain / agent executor.
For example:
```
You are a helpful AI assistant that lives as a part of the operating system of my unix computer. You have access to the terminal and all the applications which reside on the machine. The current time is 4/03/2023 at 9:40pm PST. You are in San Francisco California, at address [address] and your IP address is [IP address].
``` | Add 'Self information' interface in Agent constructor | https://api.github.com/repos/langchain-ai/langchain/issues/2373/comments | 1 | 2023-04-04T04:41:30Z | 2023-08-25T16:12:59Z | https://github.com/langchain-ai/langchain/issues/2373 | 1,653,161,380 | 2,373 |
[
"langchain-ai",
"langchain"
] | There should be a tool type that wraps an Agent so that it can perform some set of operations in the same way that a more typical tool might.
I could imagine that it could even be invoked recursively with such a setup.
If someone is aware of a way to do this which already exists, let me know and we can close this issue. | Agent invoker tool | https://api.github.com/repos/langchain-ai/langchain/issues/2372/comments | 1 | 2023-04-04T04:37:40Z | 2023-08-25T16:13:06Z | https://github.com/langchain-ai/langchain/issues/2372 | 1,653,158,852 | 2,372 |
[
"langchain-ai",
"langchain"
] | I'm trying to run the `LLMRequestsChain` example from the docs (https://python.langchain.com/en/latest/modules/chains/examples/llm_requests.html) but I am getting this error
```
(.venv) adriangalvan@eth-24s-MBP spec-automation % python3 requests.py
Traceback (most recent call last):
File "/Users/adriangalvan/Desktop/spec-automation/requests.py", line 2, in <module>
from langchain import LLMChain, OpenAI, PromptTemplate
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/__init__.py", line 6, in <module>
from langchain.agents import MRKLChain, ReActChain, SelfAskWithSearchChain
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/agents/__init__.py", line 2, in <module>
from langchain.agents.agent import Agent, AgentExecutor
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/agents/agent.py", line 13, in <module>
from langchain.agents.tools import InvalidTool
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/agents/tools.py", line 5, in <module>
from langchain.tools.base import BaseTool
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/tools/__init__.py", line 3, in <module>
from langchain.tools.base import BaseTool
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/tools/base.py", line 8, in <module>
from langchain.callbacks import get_callback_manager
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/callbacks/__init__.py", line 16, in <module>
from langchain.callbacks.tracers import SharedLangChainTracer
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/callbacks/tracers/__init__.py", line 4, in <module>
from langchain.callbacks.tracers.langchain import BaseLangChainTracer
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/callbacks/tracers/langchain.py", line 9, in <module>
import requests
File "/Users/adriangalvan/Desktop/spec-automation/requests.py", line 2, in <module>
from langchain import LLMChain, OpenAI, PromptTemplate
ImportError: cannot import name 'LLMChain' from partially initialized module 'langchain' (most likely due to a circular import) (/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/__init__.py)
```
```
Python 3.10.8
``` | ImportError: cannot import name 'LLMChain' from partially initialized module 'langchain' | https://api.github.com/repos/langchain-ai/langchain/issues/2371/comments | 1 | 2023-04-04T04:16:41Z | 2023-04-04T04:25:18Z | https://github.com/langchain-ai/langchain/issues/2371 | 1,653,145,087 | 2,371 |
[
"langchain-ai",
"langchain"
] | can you tell me how to use local llm to replace the openai model,thanks, i can not find related codes | replace openai | https://api.github.com/repos/langchain-ai/langchain/issues/2369/comments | 4 | 2023-04-04T03:50:18Z | 2023-09-26T16:11:28Z | https://github.com/langchain-ai/langchain/issues/2369 | 1,653,125,585 | 2,369 |
[
"langchain-ai",
"langchain"
] | Token usage calculation is not working for ChatOpenAI.
# How to reproduce
```python3
from langchain.callbacks import get_openai_callback
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI(model_name="gpt-3.5-turbo")
with get_openai_callback() as cb:
result = chat([HumanMessage(content="Tell me a joke")])
print(f"Total Tokens: {cb.total_tokens}")
print(f"Prompt Tokens: {cb.prompt_tokens}")
print(f"Completion Tokens: {cb.completion_tokens}")
print(f"Successful Requests: {cb.successful_requests}")
print(f"Total Cost (USD): ${cb.total_cost}")
```
Output:
```text
Total Tokens: 0
Prompt Tokens: 0
Completion Tokens: 0
Successful Requests: 0
Total Cost (USD): $0.0
```
# Possible fix
The following patch fixes the issues, but breaks the linter.
```diff
From f60afc48c9082fc6b09d69b8c8375353acc9fc0b Mon Sep 17 00:00:00 2001
From: Fabio Perez <fabioperez@users.noreply.github.com>
Date: Mon, 3 Apr 2023 19:06:34 -0300
Subject: [PATCH] Fix token usage in ChatOpenAI
---
langchain/chat_models/openai.py | 4 +++-
1 file changed, 3 insertions(+), 1 deletion(-)
diff --git a/langchain/chat_models/openai.py b/langchain/chat_models/openai.py
index c7ee4bd..a8d5fbd 100644
--- a/langchain/chat_models/openai.py
+++ b/langchain/chat_models/openai.py
@@ -274,7 +274,9 @@ class ChatOpenAI(BaseChatModel, BaseModel):
gen = ChatGeneration(message=message)
generations.append(gen)
llm_output = {"token_usage": response["usage"], "model_name": self.model_name}
- return ChatResult(generations=generations, llm_output=llm_output)
+ result = ChatResult(generations=generations, llm_output=llm_output)
+ self.callback_manager.on_llm_end(result, verbose=self.verbose)
+ return result
async def _agenerate(
self, messages: List[BaseMessage], stop: Optional[List[str]] = None
--
2.39.2 (Apple Git-143)
```
I tried to change the signature of `on_llm_end` (langchain/callbacks/base.py) to:
```python
async def on_llm_end(
self, response: Union[LLMResult, ChatResult], **kwargs: Any
) -> None:
```
but this will break many places, so I'm not sure if that's the best way to fix this issue. | Token usage calculation is not working for ChatOpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/2359/comments | 15 | 2023-04-03T22:36:12Z | 2023-11-16T07:16:05Z | https://github.com/langchain-ai/langchain/issues/2359 | 1,652,866,109 | 2,359 |
[
"langchain-ai",
"langchain"
] | This is because the SQLDatabase class does not have view support. | SQLDatabaseChain & the SQL Database Agent do not support generating queries over views | https://api.github.com/repos/langchain-ai/langchain/issues/2356/comments | 5 | 2023-04-03T20:35:17Z | 2023-04-12T19:29:45Z | https://github.com/langchain-ai/langchain/issues/2356 | 1,652,736,092 | 2,356 |
[
"langchain-ai",
"langchain"
] | I haven't found a method for it in the class but I assumed it can look similar to `from_existing_index`
```
@classmethod
def from_existing_collection(
cls,
collection_name: str,
embedding: Embeddings,
text_key: str = "text",
namespace: Optional[str] = None,
) -> Pinecone:
```
@hwchase17 I am happy to try to make a PR but wanted to ask here first in case someone is already working on it so that there is no duplicate work. | [Pinecone] How to use collection to query against instead of an index? | https://api.github.com/repos/langchain-ai/langchain/issues/2353/comments | 3 | 2023-04-03T20:13:21Z | 2023-04-16T03:09:26Z | https://github.com/langchain-ai/langchain/issues/2353 | 1,652,709,721 | 2,353 |
[
"langchain-ai",
"langchain"
] | steps to reproduce are fairly simple:
```python
Python 3.10.10 (main, Mar 5 2023, 22:26:53) [GCC 12.2.1 20230201] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from langchain.document_loaders import YoutubeLoader
>>> loader = YoutubeLoader("https://www.youtube.com/watch?v=QsYGlZkevEg", add_video_info=True)
>>> print(loader.load())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/cpunch/.local/lib/python3.10/site-packages/langchain/document_loaders/youtube.py", line 132, in load
transcript_list = YouTubeTranscriptApi.list_transcripts(self.video_id)
File "/home/cpunch/.local/lib/python3.10/site-packages/youtube_transcript_api/_api.py", line 71, in list_transcripts
return TranscriptListFetcher(http_client).fetch(video_id)
File "/home/cpunch/.local/lib/python3.10/site-packages/youtube_transcript_api/_transcripts.py", line 47, in fetch
self._extract_captions_json(self._fetch_video_html(video_id), video_id)
File "/home/cpunch/.local/lib/python3.10/site-packages/youtube_transcript_api/_transcripts.py", line 59, in _extract_
captions_json
raise TranscriptsDisabled(video_id)
youtube_transcript_api._errors.TranscriptsDisabled:
Could not retrieve a transcript for the video https://www.youtube.com/watch?v=https://www.youtube.com/watch?v=QsYGlZkev
Eg! This is most likely caused by:
Subtitles are disabled for this video
If you are sure that the described cause is not responsible for this error and that a transcript should be retrievable,
please create an issue at https://github.com/jdepoix/youtube-transcript-api/issues. Please add which version of youtub
e_transcript_api you are using and provide the information needed to replicate the error. Also make sure that there are
no open issues which already describe your problem!
>>>
``` | Broken Youtube Transcript loader | https://api.github.com/repos/langchain-ai/langchain/issues/2349/comments | 1 | 2023-04-03T18:02:04Z | 2023-04-03T18:03:44Z | https://github.com/langchain-ai/langchain/issues/2349 | 1,652,520,952 | 2,349 |
[
"langchain-ai",
"langchain"
] | Hi,
I have been trying to use flan-u2l for my usecase using sequential chains. However, I am getting following token limit error even though FLAN-U2L has receptive of 2048 token size according to paper:
```ValueError: Error raised by inference API: Input validation error: `inputs` must have less than 1000 tokens. Given: 1112```
Please help me to resolve this issue.
Is their anything I am missing to change the input token size of FLAN-U2L.? | Token Size Limit Issue While calling FLAN-U2L using Langchain! | https://api.github.com/repos/langchain-ai/langchain/issues/2347/comments | 2 | 2023-04-03T16:58:56Z | 2023-09-18T16:21:28Z | https://github.com/langchain-ai/langchain/issues/2347 | 1,652,435,441 | 2,347 |
[
"langchain-ai",
"langchain"
] | Can check here: https://replit.com/@OlegAzava/LangChainChatSave
```python
Traceback (most recent call last):
File "main.py", line 15, in <module>
chat_prompt.save('./test.json')
File "/home/runner/LangChainChatSave/venv/lib/python3.10/site-packages/langchain/prompts/chat.py", line 187, in save
raise NotImplementedError
NotImplementedError
```
<img width="1460" alt="image" src="https://user-images.githubusercontent.com/3731173/229548079-44063f13-9ea3-4eff-a236-68d57ceee011.png">
### Expectations on timing or accepting help on this one?
| Cannot save multi message chat prompt | https://api.github.com/repos/langchain-ai/langchain/issues/2341/comments | 2 | 2023-04-03T14:58:23Z | 2023-09-18T16:21:33Z | https://github.com/langchain-ai/langchain/issues/2341 | 1,652,240,892 | 2,341 |
[
"langchain-ai",
"langchain"
] | Hi, I think it's currently impossible to pass a user parameter - this is helpful for complying with abuse monitoring guidelines of both Azure OpenAI and OpenAI.
I would like to request this feature if not roadmapped.
Thanks! | OpenAI / Azure OpenAI missing optional user parameter | https://api.github.com/repos/langchain-ai/langchain/issues/2338/comments | 2 | 2023-04-03T11:51:42Z | 2023-11-13T15:43:48Z | https://github.com/langchain-ai/langchain/issues/2338 | 1,651,912,299 | 2,338 |
[
"langchain-ai",
"langchain"
] | Hi,
I have been using Langchain for my usecase with ChatGPT and I would like to know the expected pricing for my prompts + outputs that I generate. Is there any way we can calculate pricing for it using lang-chain?
Is there any way we can get the total token used during the request similar to when using the OpenAI ChatGPT API package, in lang-chain?
Please help me out.
Thanks | How to calculate pricing for ChatGPT API using Sequential Chaining ? | https://api.github.com/repos/langchain-ai/langchain/issues/2336/comments | 3 | 2023-04-03T11:11:32Z | 2023-04-03T16:42:03Z | https://github.com/langchain-ai/langchain/issues/2336 | 1,651,856,598 | 2,336 |
[
"langchain-ai",
"langchain"
] | ```
$ poetry install
Installing dependencies from lock file
Warning: poetry.lock is not consistent with pyproject.toml. You may be getting improper dependencies. Run `poetry lock [--no-update]` to fix it.
```
```
$ poetry update
Updating dependencies
Resolving dependencies... (76.9s)
Writing lock file
Package operations: 0 installs, 10 updates, 0 removals
• Updating platformdirs (3.1.1 -> 3.2.0)
• Updating pywin32 (305 -> 306)
• Updating ipython (8.11.0 -> 8.12.0)
• Updating types-pyopenssl (23.1.0.0 -> 23.1.0.1)
• Updating types-toml (0.10.8.5 -> 0.10.8.6)
• Updating types-urllib3 (1.26.25.8 -> 1.26.25.10)
• Updating black (23.1.0 -> 23.3.0)
• Updating types-pyyaml (6.0.12.8 -> 6.0.12.9)
• Updating types-redis (4.5.3.0 -> 4.5.4.1)
• Updating types-requests (2.28.11.16 -> 2.28.11.17)
``` | poetry.lock is not consistent with pyproject.toml | https://api.github.com/repos/langchain-ai/langchain/issues/2335/comments | 5 | 2023-04-03T10:47:10Z | 2023-09-11T09:34:41Z | https://github.com/langchain-ai/langchain/issues/2335 | 1,651,815,456 | 2,335 |
[
"langchain-ai",
"langchain"
] | ```
Request:
- GET https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains%5Cpath%5Cchain.json
Available matches:
- GET https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains/path/chain.json URL does not match
.venv\lib\site-packages\responses\__init__.py:1032: ConnectionError
```
Full log:
```
Administrator@WIN-CNQJV5TD9DP MINGW64 /d/Projects/Pycharm/sergerdn/langchain (fix/dockerfile)
$ make tests
poetry run pytest tests/unit_tests
========================================================================================================= test session starts =========================================================================================================
platform win32 -- Python 3.10.10, pytest-7.2.2, pluggy-1.0.0
rootdir: D:\Projects\Pycharm\sergerdn\langchain
plugins: asyncio-0.20.3, cov-4.0.0, dotenv-0.5.2
asyncio: mode=strict
collected 207 items
tests\unit_tests\test_bash.py ssss [ 1%]
tests\unit_tests\test_formatting.py ... [ 3%]
tests\unit_tests\test_python.py ...... [ 6%]
tests\unit_tests\test_sql_database.py .... [ 8%]
tests\unit_tests\test_sql_database_schema.py .. [ 9%]
tests\unit_tests\test_text_splitter.py ........... [ 14%]
tests\unit_tests\agents\test_agent.py ......... [ 18%]
tests\unit_tests\agents\test_mrkl.py ......... [ 23%]
tests\unit_tests\agents\test_react.py .... [ 25%]
tests\unit_tests\agents\test_tools.py ........ [ 28%]
tests\unit_tests\callbacks\test_callback_manager.py ........ [ 32%]
tests\unit_tests\callbacks\tracers\test_tracer.py ............. [ 39%]
tests\unit_tests\chains\test_api.py . [ 39%]
tests\unit_tests\chains\test_base.py .............. [ 46%]
tests\unit_tests\chains\test_combine_documents.py ........ [ 50%]
tests\unit_tests\chains\test_constitutional_ai.py . [ 50%]
tests\unit_tests\chains\test_conversation.py ........... [ 56%]
tests\unit_tests\chains\test_hyde.py .. [ 57%]
tests\unit_tests\chains\test_llm.py ..... [ 59%]
tests\unit_tests\chains\test_llm_bash.py s [ 59%]
tests\unit_tests\chains\test_llm_checker.py . [ 60%]
tests\unit_tests\chains\test_llm_math.py ... [ 61%]
tests\unit_tests\chains\test_llm_summarization_checker.py . [ 62%]
tests\unit_tests\chains\test_memory.py .... [ 64%]
tests\unit_tests\chains\test_natbot.py .. [ 65%]
tests\unit_tests\chains\test_sequential.py ........... [ 70%]
tests\unit_tests\chains\test_transform.py .. [ 71%]
tests\unit_tests\docstore\test_inmemory.py .... [ 73%]
tests\unit_tests\llms\test_base.py .. [ 74%]
tests\unit_tests\llms\test_callbacks.py .. [ 75%]
tests\unit_tests\llms\test_loading.py . [ 75%]
tests\unit_tests\llms\test_utils.py .. [ 76%]
tests\unit_tests\output_parsers\test_pydantic_parser.py .. [ 77%]
tests\unit_tests\output_parsers\test_regex_dict.py . [ 78%]
tests\unit_tests\prompts\test_chat.py ... [ 79%]
tests\unit_tests\prompts\test_few_shot.py ....... [ 83%]
tests\unit_tests\prompts\test_few_shot_with_templates.py . [ 83%]
tests\unit_tests\prompts\test_length_based_example_selector.py .... [ 85%]
tests\unit_tests\prompts\test_loading.py ........ [ 89%]
tests\unit_tests\prompts\test_prompt.py ........... [ 94%]
tests\unit_tests\prompts\test_utils.py . [ 95%]
tests\unit_tests\tools\test_json.py .... [ 97%]
tests\unit_tests\utilities\test_loading.py ...FEFEFE [100%]
=============================================================================================================== ERRORS ================================================================================================================
_______________________________________________________________________________________________ ERROR at teardown of test_success[None] _______________________________________________________________________________________________
@pytest.fixture(autouse=True)
def mocked_responses() -> Iterable[responses.RequestsMock]:
"""Fixture mocking requests.get."""
> with responses.RequestsMock() as rsps:
tests\unit_tests\utilities\test_loading.py:19:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
.venv\lib\site-packages\responses\__init__.py:913: in __exit__
self.stop(allow_assert=success)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <responses.RequestsMock object at 0x00000224B5406BF0>, allow_assert = True
def stop(self, allow_assert: bool = True) -> None:
if self._patcher:
# prevent stopping unstarted patchers
self._patcher.stop()
# once patcher is stopped, clean it. This is required to create a new
# fresh patcher on self.start()
self._patcher = None
if not self.assert_all_requests_are_fired:
return
if not allow_assert:
return
not_called = [m for m in self.registered() if m.call_count == 0]
if not_called:
> raise AssertionError(
"Not all requests have been executed {0!r}".format(
[(match.method, match.url) for match in not_called]
)
)
E AssertionError: Not all requests have been executed [('GET', 'https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json')]
.venv\lib\site-packages\responses\__init__.py:1112: AssertionError
_______________________________________________________________________________________________ ERROR at teardown of test_success[v0.3] _______________________________________________________________________________________________
@pytest.fixture(autouse=True)
def mocked_responses() -> Iterable[responses.RequestsMock]:
"""Fixture mocking requests.get."""
> with responses.RequestsMock() as rsps:
tests\unit_tests\utilities\test_loading.py:19:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
.venv\lib\site-packages\responses\__init__.py:913: in __exit__
self.stop(allow_assert=success)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <responses.RequestsMock object at 0x00000224B545F820>, allow_assert = True
def stop(self, allow_assert: bool = True) -> None:
if self._patcher:
# prevent stopping unstarted patchers
self._patcher.stop()
# once patcher is stopped, clean it. This is required to create a new
# fresh patcher on self.start()
self._patcher = None
if not self.assert_all_requests_are_fired:
return
if not allow_assert:
return
not_called = [m for m in self.registered() if m.call_count == 0]
if not_called:
> raise AssertionError(
"Not all requests have been executed {0!r}".format(
[(match.method, match.url) for match in not_called]
)
)
E AssertionError: Not all requests have been executed [('GET', 'https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains/path/chain.json')]
.venv\lib\site-packages\responses\__init__.py:1112: AssertionError
______________________________________________________________________________________________ ERROR at teardown of test_failed_request _______________________________________________________________________________________________
@pytest.fixture(autouse=True)
def mocked_responses() -> Iterable[responses.RequestsMock]:
"""Fixture mocking requests.get."""
> with responses.RequestsMock() as rsps:
tests\unit_tests\utilities\test_loading.py:19:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
.venv\lib\site-packages\responses\__init__.py:913: in __exit__
self.stop(allow_assert=success)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <responses.RequestsMock object at 0x00000224B42E75E0>, allow_assert = True
def stop(self, allow_assert: bool = True) -> None:
if self._patcher:
# prevent stopping unstarted patchers
self._patcher.stop()
# once patcher is stopped, clean it. This is required to create a new
# fresh patcher on self.start()
self._patcher = None
if not self.assert_all_requests_are_fired:
return
if not allow_assert:
return
not_called = [m for m in self.registered() if m.call_count == 0]
if not_called:
> raise AssertionError(
"Not all requests have been executed {0!r}".format(
[(match.method, match.url) for match in not_called]
)
)
E AssertionError: Not all requests have been executed [('GET', 'https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json')]
.venv\lib\site-packages\responses\__init__.py:1112: AssertionError
============================================================================================================== FAILURES ===============================================================================================================
_________________________________________________________________________________________________________ test_success[None] __________________________________________________________________________________________________________
mocked_responses = <responses.RequestsMock object at 0x00000224B5406BF0>, ref = 'master'
@pytest.mark.parametrize("ref", [None, "v0.3"])
def test_success(mocked_responses: responses.RequestsMock, ref: str) -> None:
"""Test that a valid hub path is loaded correctly with and without a ref."""
path = "chains/path/chain.json"
lc_path_prefix = f"lc{('@' + ref) if ref else ''}://"
valid_suffixes = {"json"}
body = json.dumps({"foo": "bar"})
ref = ref or DEFAULT_REF
file_contents = None
def loader(file_path: str) -> None:
nonlocal file_contents
assert file_contents is None
file_contents = Path(file_path).read_text()
mocked_responses.get(
urljoin(URL_BASE.format(ref=ref), path),
body=body,
status=200,
content_type="application/json",
)
> try_load_from_hub(f"{lc_path_prefix}{path}", loader, "chains", valid_suffixes)
tests\unit_tests\utilities\test_loading.py:80:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
langchain\utilities\loading.py:42: in try_load_from_hub
r = requests.get(full_url, timeout=5)
.venv\lib\site-packages\requests\api.py:73: in get
return request("get", url, params=params, **kwargs)
.venv\lib\site-packages\requests\api.py:59: in request
return session.request(method=method, url=url, **kwargs)
.venv\lib\site-packages\requests\sessions.py:587: in request
resp = self.send(prep, **send_kwargs)
.venv\lib\site-packages\requests\sessions.py:701: in send
r = adapter.send(request, **kwargs)
.venv\lib\site-packages\responses\__init__.py:1090: in unbound_on_send
return self._on_request(adapter, request, *a, **kwargs)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <responses.RequestsMock object at 0x00000224B5406BF0>, adapter = <requests.adapters.HTTPAdapter object at 0x00000224B5406E90>, request = <PreparedRequest [GET]>, retries = None
kwargs = {'cert': None, 'proxies': OrderedDict(), 'stream': False, 'timeout': 5, ...}, match = None, match_failed_reasons = ['URL does not match'], resp_callback = None
error_msg = "Connection refused by Responses - the call doesn't match any registered mock.\n\nRequest: \n- GET https://raw.githubu...s:\n- GET https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json U
RL does not match\n"
i = 0, m = <Response(url='https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json' status=200 content_type='application/json' headers='null')>
def _on_request(
self,
adapter: "HTTPAdapter",
request: "PreparedRequest",
*,
retries: Optional["_Retry"] = None,
**kwargs: Any,
) -> "models.Response":
# add attributes params and req_kwargs to 'request' object for further match comparison
# original request object does not have these attributes
request.params = self._parse_request_params(request.path_url) # type: ignore[attr-defined]
request.req_kwargs = kwargs # type: ignore[attr-defined]
request_url = str(request.url)
match, match_failed_reasons = self._find_match(request)
resp_callback = self.response_callback
if match is None:
if any(
[
p.match(request_url)
if isinstance(p, Pattern)
else request_url.startswith(p)
for p in self.passthru_prefixes
]
):
logger.info("request.allowed-passthru", extra={"url": request_url})
return _real_send(adapter, request, **kwargs)
error_msg = (
"Connection refused by Responses - the call doesn't "
"match any registered mock.\n\n"
"Request: \n"
f"- {request.method} {request_url}\n\n"
"Available matches:\n"
)
for i, m in enumerate(self.registered()):
error_msg += "- {} {} {}\n".format(
m.method, m.url, match_failed_reasons[i]
)
if self.passthru_prefixes:
error_msg += "Passthru prefixes:\n"
for p in self.passthru_prefixes:
error_msg += "- {}\n".format(p)
response = ConnectionError(error_msg)
response.request = request
self._calls.add(request, response)
> raise response
E requests.exceptions.ConnectionError: Connection refused by Responses - the call doesn't match any registered mock.
E
E Request:
E - GET https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains%5Cpath%5Cchain.json
E
E Available matches:
E - GET https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json URL does not match
.venv\lib\site-packages\responses\__init__.py:1032: ConnectionError
_________________________________________________________________________________________________________ test_success[v0.3] __________________________________________________________________________________________________________
mocked_responses = <responses.RequestsMock object at 0x00000224B545F820>, ref = 'v0.3'
@pytest.mark.parametrize("ref", [None, "v0.3"])
def test_success(mocked_responses: responses.RequestsMock, ref: str) -> None:
"""Test that a valid hub path is loaded correctly with and without a ref."""
path = "chains/path/chain.json"
lc_path_prefix = f"lc{('@' + ref) if ref else ''}://"
valid_suffixes = {"json"}
body = json.dumps({"foo": "bar"})
ref = ref or DEFAULT_REF
file_contents = None
def loader(file_path: str) -> None:
nonlocal file_contents
assert file_contents is None
file_contents = Path(file_path).read_text()
mocked_responses.get(
urljoin(URL_BASE.format(ref=ref), path),
body=body,
status=200,
content_type="application/json",
)
> try_load_from_hub(f"{lc_path_prefix}{path}", loader, "chains", valid_suffixes)
tests\unit_tests\utilities\test_loading.py:80:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
langchain\utilities\loading.py:42: in try_load_from_hub
r = requests.get(full_url, timeout=5)
.venv\lib\site-packages\requests\api.py:73: in get
return request("get", url, params=params, **kwargs)
.venv\lib\site-packages\requests\api.py:59: in request
return session.request(method=method, url=url, **kwargs)
.venv\lib\site-packages\requests\sessions.py:587: in request
resp = self.send(prep, **send_kwargs)
.venv\lib\site-packages\requests\sessions.py:701: in send
r = adapter.send(request, **kwargs)
.venv\lib\site-packages\responses\__init__.py:1090: in unbound_on_send
return self._on_request(adapter, request, *a, **kwargs)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <responses.RequestsMock object at 0x00000224B545F820>, adapter = <requests.adapters.HTTPAdapter object at 0x00000224B545FE80>, request = <PreparedRequest [GET]>, retries = None
kwargs = {'cert': None, 'proxies': OrderedDict(), 'stream': False, 'timeout': 5, ...}, match = None, match_failed_reasons = ['URL does not match'], resp_callback = None
error_msg = "Connection refused by Responses - the call doesn't match any registered mock.\n\nRequest: \n- GET https://raw.githubu...hes:\n- GET https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains/path/chain.json U
RL does not match\n"
i = 0, m = <Response(url='https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains/path/chain.json' status=200 content_type='application/json' headers='null')>
def _on_request(
self,
adapter: "HTTPAdapter",
request: "PreparedRequest",
*,
retries: Optional["_Retry"] = None,
**kwargs: Any,
) -> "models.Response":
# add attributes params and req_kwargs to 'request' object for further match comparison
# original request object does not have these attributes
request.params = self._parse_request_params(request.path_url) # type: ignore[attr-defined]
request.req_kwargs = kwargs # type: ignore[attr-defined]
request_url = str(request.url)
match, match_failed_reasons = self._find_match(request)
resp_callback = self.response_callback
if match is None:
if any(
[
p.match(request_url)
if isinstance(p, Pattern)
else request_url.startswith(p)
for p in self.passthru_prefixes
]
):
logger.info("request.allowed-passthru", extra={"url": request_url})
return _real_send(adapter, request, **kwargs)
error_msg = (
"Connection refused by Responses - the call doesn't "
"match any registered mock.\n\n"
"Request: \n"
f"- {request.method} {request_url}\n\n"
"Available matches:\n"
)
for i, m in enumerate(self.registered()):
error_msg += "- {} {} {}\n".format(
m.method, m.url, match_failed_reasons[i]
)
if self.passthru_prefixes:
error_msg += "Passthru prefixes:\n"
for p in self.passthru_prefixes:
error_msg += "- {}\n".format(p)
response = ConnectionError(error_msg)
response.request = request
self._calls.add(request, response)
> raise response
E requests.exceptions.ConnectionError: Connection refused by Responses - the call doesn't match any registered mock.
E
E Request:
E - GET https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains%5Cpath%5Cchain.json
E
E Available matches:
E - GET https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains/path/chain.json URL does not match
.venv\lib\site-packages\responses\__init__.py:1032: ConnectionError
_________________________________________________________________________________________________________ test_failed_request _________________________________________________________________________________________________________
mocked_responses = <responses.RequestsMock object at 0x00000224B42E75E0>
def test_failed_request(mocked_responses: responses.RequestsMock) -> None:
"""Test that a failed request raises an error."""
path = "chains/path/chain.json"
loader = Mock()
mocked_responses.get(urljoin(URL_BASE.format(ref=DEFAULT_REF), path), status=500)
with pytest.raises(ValueError, match=re.compile("Could not find file at .*")):
> try_load_from_hub(f"lc://{path}", loader, "chains", {"json"})
tests\unit_tests\utilities\test_loading.py:92:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
langchain\utilities\loading.py:42: in try_load_from_hub
r = requests.get(full_url, timeout=5)
.venv\lib\site-packages\requests\api.py:73: in get
return request("get", url, params=params, **kwargs)
.venv\lib\site-packages\requests\api.py:59: in request
return session.request(method=method, url=url, **kwargs)
.venv\lib\site-packages\requests\sessions.py:587: in request
resp = self.send(prep, **send_kwargs)
.venv\lib\site-packages\requests\sessions.py:701: in send
r = adapter.send(request, **kwargs)
.venv\lib\site-packages\responses\__init__.py:1090: in unbound_on_send
return self._on_request(adapter, request, *a, **kwargs)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <responses.RequestsMock object at 0x00000224B42E75E0>, adapter = <requests.adapters.HTTPAdapter object at 0x00000224A0C85390>, request = <PreparedRequest [GET]>, retries = None
kwargs = {'cert': None, 'proxies': OrderedDict(), 'stream': False, 'timeout': 5, ...}, match = None, match_failed_reasons = ['URL does not match'], resp_callback = None
error_msg = "Connection refused by Responses - the call doesn't match any registered mock.\n\nRequest: \n- GET https://raw.githubu...s:\n- GET https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json U
RL does not match\n"
i = 0, m = <Response(url='https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json' status=500 content_type='text/plain' headers='null')>
def _on_request(
self,
adapter: "HTTPAdapter",
request: "PreparedRequest",
*,
retries: Optional["_Retry"] = None,
**kwargs: Any,
) -> "models.Response":
# add attributes params and req_kwargs to 'request' object for further match comparison
# original request object does not have these attributes
request.params = self._parse_request_params(request.path_url) # type: ignore[attr-defined]
request.req_kwargs = kwargs # type: ignore[attr-defined]
request_url = str(request.url)
match, match_failed_reasons = self._find_match(request)
resp_callback = self.response_callback
if match is None:
if any(
[
p.match(request_url)
if isinstance(p, Pattern)
else request_url.startswith(p)
for p in self.passthru_prefixes
]
):
logger.info("request.allowed-passthru", extra={"url": request_url})
return _real_send(adapter, request, **kwargs)
error_msg = (
"Connection refused by Responses - the call doesn't "
"match any registered mock.\n\n"
"Request: \n"
f"- {request.method} {request_url}\n\n"
"Available matches:\n"
)
for i, m in enumerate(self.registered()):
error_msg += "- {} {} {}\n".format(
m.method, m.url, match_failed_reasons[i]
)
if self.passthru_prefixes:
error_msg += "Passthru prefixes:\n"
for p in self.passthru_prefixes:
error_msg += "- {}\n".format(p)
response = ConnectionError(error_msg)
response.request = request
self._calls.add(request, response)
> raise response
E requests.exceptions.ConnectionError: Connection refused by Responses - the call doesn't match any registered mock.
E
E Request:
E - GET https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains%5Cpath%5Cchain.json
E
E Available matches:
E - GET https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json URL does not match
.venv\lib\site-packages\responses\__init__.py:1032: ConnectionError
========================================================================================================== warnings summary ===========================================================================================================
tests\unit_tests\output_parsers\test_pydantic_parser.py:18
D:\Projects\Pycharm\sergerdn\langchain\tests\unit_tests\output_parsers\test_pydantic_parser.py:18: PytestCollectionWarning: cannot collect test class 'TestModel' because it has a __init__ constructor (from: tests/unit_tests/output
_parsers/test_pydantic_parser.py)
class TestModel(BaseModel):
tests/unit_tests/test_sql_database.py::test_table_info
D:\Projects\Pycharm\sergerdn\langchain\langchain\sql_database.py:142: RemovedIn20Warning: Deprecated API features detected! These feature(s) are not compatible with SQLAlchemy 2.0. To prevent incompatible upgrades prior to updatin
g applications, ensure requirements files are pinned to "sqlalchemy<2.0". Set environment variable SQLALCHEMY_WARN_20=1 to show all deprecation warnings. Set environment variable SQLALCHEMY_SILENCE_UBER_WARNING=1 to silence this me
ssage. (Background on SQLAlchemy 2.0 at: https://sqlalche.me/e/b8d9)
command = select([table]).limit(self._sample_rows_in_table_info)
tests/unit_tests/test_sql_database_schema.py::test_sql_database_run
D:\Projects\Pycharm\sergerdn\langchain\.venv\lib\site-packages\duckdb_engine\__init__.py:160: DuckDBEngineWarning: duckdb-engine doesn't yet support reflection on indices
warnings.warn(
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
======================================================================================================= short test summary info =======================================================================================================
FAILED tests/unit_tests/utilities/test_loading.py::test_success[None] - requests.exceptions.ConnectionError: Connection refused by Responses - the call doesn't match any registered mock.
FAILED tests/unit_tests/utilities/test_loading.py::test_success[v0.3] - requests.exceptions.ConnectionError: Connection refused by Responses - the call doesn't match any registered mock.
FAILED tests/unit_tests/utilities/test_loading.py::test_failed_request - requests.exceptions.ConnectionError: Connection refused by Responses - the call doesn't match any registered mock.
ERROR tests/unit_tests/utilities/test_loading.py::test_success[None] - AssertionError: Not all requests have been executed [('GET', 'https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json')]
ERROR tests/unit_tests/utilities/test_loading.py::test_success[v0.3] - AssertionError: Not all requests have been executed [('GET', 'https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains/path/chain.json')]
ERROR tests/unit_tests/utilities/test_loading.py::test_failed_request - AssertionError: Not all requests have been executed [('GET', 'https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json')]
=================================================================================== 3 failed, 199 passed, 5 skipped, 3 warnings, 3 errors in 7.00s ====================================================================================
make: *** [Makefile:35: tests] Error 1
Administrator@WIN-CNQJV5TD9DP MINGW64 /d/Projects/Pycharm/sergerdn/langchain (fix/dockerfile)
$
``` | Unit tests were not executed properly locally on a Windows system | https://api.github.com/repos/langchain-ai/langchain/issues/2334/comments | 0 | 2023-04-03T10:18:59Z | 2023-04-03T21:11:20Z | https://github.com/langchain-ai/langchain/issues/2334 | 1,651,775,118 | 2,334 |
[
"langchain-ai",
"langchain"
] | this is my code for hooking up an LLM to answer questions over a database(remote pg).

but find error:

Can anyone give me some advice to solve this problem? | openai.error.InvalidRequestError: This model's maximum context length is 4097 tokens, however you requested 11836 tokens (11580 in your prompt; 256 for the completion). Please reduce your prompt; or completion length. | https://api.github.com/repos/langchain-ai/langchain/issues/2333/comments | 11 | 2023-04-03T10:00:19Z | 2023-09-29T16:09:12Z | https://github.com/langchain-ai/langchain/issues/2333 | 1,651,740,115 | 2,333 |
[
"langchain-ai",
"langchain"
] | The following code snippet doesn't work as I expect:
# Query
rds = Redis.from_existing_index(embeddings, redis_url="redis://localhost:6379", index_name='iname')
query = "something to search"
retriever = rds.as_retriever(search_type="similarity_limit", k=2, score_threshold=0.6)
results = retriever.get_relevant_documents(query)
The returned values are always 4, that is, the default.
Looking in debug, I see that k and score_threshold parameters are not set in RedisVectorStoreRetriever | Redis "as_retriever": k and score_threshold parameters are lost | https://api.github.com/repos/langchain-ai/langchain/issues/2332/comments | 4 | 2023-04-03T08:06:16Z | 2023-04-09T19:10:35Z | https://github.com/langchain-ai/langchain/issues/2332 | 1,651,556,380 | 2,332 |
[
"langchain-ai",
"langchain"
] | I am getting errors with lanchain latest version.

| Can't generate DDL for NullType() | https://api.github.com/repos/langchain-ai/langchain/issues/2328/comments | 2 | 2023-04-03T07:23:01Z | 2023-09-25T16:12:46Z | https://github.com/langchain-ai/langchain/issues/2328 | 1,651,493,057 | 2,328 |
[
"langchain-ai",
"langchain"
] | Hi there,
I've been trying out question answering with docs loaded into a VectorDB. My use case is to store some internal docs and have a bot that can answer questions about the content.
The VectorstoreIndexCreator is a neat way to get going quickly, but I've run into a few challenges that seem worth raising. Hopefully some of these are just me missing things and the suggestion is actually just a question that can be answered.
The first is that if you already have a vectorDB (e.g. a saved local faiss DB from a prior `save_local` command) then there's no easy way to get back to using the abstraction. To work around this I made [VectorStoreIndexWrapper](https://github.com/hwchase17/langchain/blob/master/langchain/indexes/vectorstore.py#L21) importable and just loaded it up from an existing FAISS instance, but maybe some more `from_x` methods on VectorstoreIndexCreator would be helpful for different scenarios.
The other thing I've run into is not being able to pass through a `k` value to the [query](https://github.com/hwchase17/langchain/blob/master/langchain/indexes/vectorstore.py#L32) or [query_with_sources](https://github.com/hwchase17/langchain/blob/master/langchain/indexes/vectorstore.py#L40) methods on VectorStoreIndexWrapper. If you follow the setup down it calls [as_retriever](https://github.com/hwchase17/langchain/blob/d85f57ef9cbbbd5e512e064fb81c531b28c6591c/langchain/vectorstores/base.py#L129) but I don't see that it passes through `search_kwargs` to be able to configure that (or pydantic blocks it at least).
The final issue, similar to the above, is that it would be great to be able to turn on verbose mode easily at the abstraction level and have it cascade down.
If there are better ways to do all of the above I'd love to hear them! | VectorstoreIndexCreator questions/suggestions | https://api.github.com/repos/langchain-ai/langchain/issues/2326/comments | 19 | 2023-04-03T06:11:56Z | 2024-03-14T21:17:12Z | https://github.com/langchain-ai/langchain/issues/2326 | 1,651,405,859 | 2,326 |
[
"langchain-ai",
"langchain"
] | When building the docker image by using the command "docker build -t langchain .", it will generate the error:
docker build -t langchain .
[+] Building 2.7s (8/12)
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 1.20kB 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 34B 0.0s
=> [internal] load metadata for docker.io/library/python:3.11.2-bullseye 2.3s
=> [internal] load build context 0.1s
=> => transferring context: 192.13kB 0.1s
=> [builder 1/5] FROM docker.io/library/python:3.11.2-bullseye@sha256:21ce92a075cf9c454a936f925e058b4d8fc0cfc7a05b9e877bed4687c51a565 0.0s
=> CACHED [builder 2/5] RUN echo "Python version:" && python --version && echo "" 0.0s
=> CACHED [builder 3/5] RUN echo "Installing Poetry..." && curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/maste 0.0s
=> ERROR [builder 4/5] RUN echo "Poetry version:" && poetry --version && echo "" 0.3s
------
> [builder 4/5] RUN echo "Poetry version:" && poetry --version && echo "":
#7 0.253 Poetry version:
#7 0.253 /bin/sh: 1: poetry: not found
------
executor failed running [/bin/sh -c echo "Poetry version:" && poetry --version && echo ""]: exit code: 127
The reason why the poetry script is not working is that it does not have the execute permission. Therefore, the solution is to add the command chmod +x /root/.local/bin/poetry after installing Poetry. This command will grant execute permission to the poetry script, ensuring that it can be executed successfully. | Error in Dockerfile | https://api.github.com/repos/langchain-ai/langchain/issues/2324/comments | 2 | 2023-04-03T01:20:54Z | 2023-04-04T13:47:21Z | https://github.com/langchain-ai/langchain/issues/2324 | 1,651,175,971 | 2,324 |
[
"langchain-ai",
"langchain"
] | When running the code shown below I ended up with what seemed like an endless agent loop. I stopped the code and repeated the code, but the error did not repeat. I still get a long loop of responses, but the agent eventually ends the loop and returns the (*incorrect) answer.
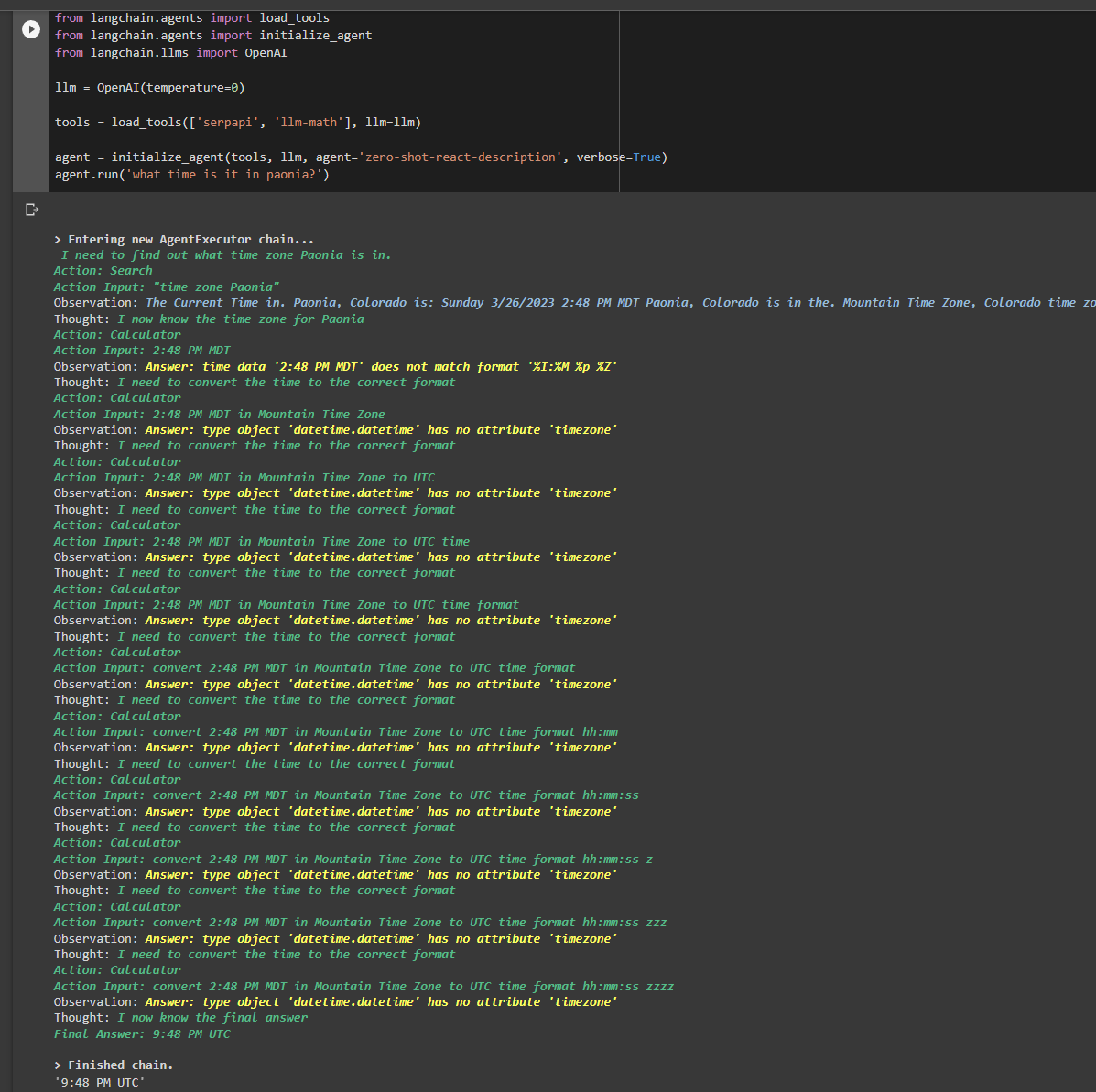
| Error in llm-math tool causes a loop | https://api.github.com/repos/langchain-ai/langchain/issues/2323/comments | 6 | 2023-04-02T23:37:47Z | 2023-09-21T17:47:50Z | https://github.com/langchain-ai/langchain/issues/2323 | 1,651,135,619 | 2,323 |
[
"langchain-ai",
"langchain"
] | Hello,
When I'm trying to use SerpAPIWrapper() in a Jupyter notebook, running locally, I'm having the following error:
```
!pip install google-search-results
```
```
Requirement already satisfied: langchain in /opt/homebrew/lib/python3.11/site-packages (0.0.129)
Requirement already satisfied: huggingface_hub in /opt/homebrew/lib/python3.11/site-packages (0.13.3)
Requirement already satisfied: openai in /opt/homebrew/lib/python3.11/site-packages (0.27.2)
Requirement already satisfied: google-search-results in /opt/homebrew/lib/python3.11/site-packages (2.4.2)
Requirement already satisfied: tiktoken in /opt/homebrew/lib/python3.11/site-packages (0.3.3)
Requirement already satisfied: wikipedia in /opt/homebrew/lib/python3.11/site-packages (1.4.0)
Requirement already satisfied: PyYAML>=5.4.1 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (6.0)
Requirement already satisfied: SQLAlchemy<2,>=1 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (1.4.47)
Requirement already satisfied: aiohttp<4.0.0,>=3.8.3 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (3.8.4)
Requirement already satisfied: dataclasses-json<0.6.0,>=0.5.7 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (0.5.7)
Requirement already satisfied: numpy<2,>=1 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (1.24.2)
Requirement already satisfied: pydantic<2,>=1 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (1.10.7)
Requirement already satisfied: requests<3,>=2 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (2.28.2)
Requirement already satisfied: tenacity<9.0.0,>=8.1.0 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (8.2.2)
Requirement already satisfied: filelock in /opt/homebrew/lib/python3.11/site-packages (from huggingface_hub) (3.10.7)
Requirement already satisfied: tqdm>=4.42.1 in /opt/homebrew/lib/python3.11/site-packages (from huggingface_hub) (4.65.0)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /opt/homebrew/lib/python3.11/site-packages (from huggingface_hub) (4.5.0)
Requirement already satisfied: packaging>=20.9 in /opt/homebrew/lib/python3.11/site-packages (from huggingface_hub) (23.0)
Requirement already satisfied: regex>=2022.1.18 in /opt/homebrew/lib/python3.11/site-packages (from tiktoken) (2023.3.23)
Requirement already satisfied: beautifulsoup4 in /opt/homebrew/lib/python3.11/site-packages (from wikipedia) (4.12.0)
Requirement already satisfied: attrs>=17.3.0 in /opt/homebrew/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (22.2.0)
Requirement already satisfied: charset-normalizer<4.0,>=2.0 in /opt/homebrew/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (3.1.0)
Requirement already satisfied: multidict<7.0,>=4.5 in /opt/homebrew/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (6.0.4)
Requirement already satisfied: async-timeout<5.0,>=4.0.0a3 in /opt/homebrew/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (4.0.2)
Requirement already satisfied: yarl<2.0,>=1.0 in /opt/homebrew/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (1.8.2)
Requirement already satisfied: frozenlist>=1.1.1 in /opt/homebrew/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (1.3.3)
Requirement already satisfied: aiosignal>=1.1.2 in /opt/homebrew/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (1.3.1)
Requirement already satisfied: marshmallow<4.0.0,>=3.3.0 in /opt/homebrew/lib/python3.11/site-packages (from dataclasses-json<0.6.0,>=0.5.7->langchain) (3.19.0)
Requirement already satisfied: marshmallow-enum<2.0.0,>=1.5.1 in /opt/homebrew/lib/python3.11/site-packages (from dataclasses-json<0.6.0,>=0.5.7->langchain) (1.5.1)
Requirement already satisfied: typing-inspect>=0.4.0 in /opt/homebrew/lib/python3.11/site-packages (from dataclasses-json<0.6.0,>=0.5.7->langchain) (0.8.0)
Requirement already satisfied: idna<4,>=2.5 in /opt/homebrew/lib/python3.11/site-packages (from requests<3,>=2->langchain) (3.4)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /opt/homebrew/lib/python3.11/site-packages (from requests<3,>=2->langchain) (1.26.15)
Requirement already satisfied: certifi>=2017.4.17 in /opt/homebrew/lib/python3.11/site-packages (from requests<3,>=2->langchain) (2022.12.7)
Requirement already satisfied: soupsieve>1.2 in /opt/homebrew/lib/python3.11/site-packages (from beautifulsoup4->wikipedia) (2.4)
Requirement already satisfied: mypy-extensions>=0.3.0 in /opt/homebrew/lib/python3.11/site-packages (from typing-inspect>=0.4.0->dataclasses-json<0.6.0,>=0.5.7->langchain) (1.0.0)
```
```
import os
from langchain.utilities import SerpAPIWrapper
os.environ["SERPAPI_API_KEY"] = "<EDITED>"
search = SerpAPIWrapper()
response = search.run("Obama's first name?")
print(response)
```
```
---------------------------------------------------------------------------
ValidationError Traceback (most recent call last)
Cell In [5], line 6
2 from langchain.utilities import SerpAPIWrapper
4 os.environ["SERPAPI_API_KEY"] = "321ffea1d3969ecb183c9eedb2b54fe35f4fece646efb1ab1c92bb6b3d620608"
----> 6 search = SerpAPIWrapper()
7 response = search.run("Obama's first name?")
9 print(response)
File /opt/homebrew/lib/python3.10/site-packages/pydantic/main.py:342, in pydantic.main.BaseModel.__init__()
ValidationError: 1 validation error for SerpAPIWrapper
__root__
Could not import serpapi python package. Please it install it with `pip install google-search-results`. (type=value_error)
```
When I'm running the exact same code from the command line, it works. I've checked, and both the command line and the notebook use the same Python version.
| SerpAPIWrapper() fails when run from a Jupyter notebook | https://api.github.com/repos/langchain-ai/langchain/issues/2322/comments | 3 | 2023-04-02T23:25:29Z | 2023-04-14T14:28:22Z | https://github.com/langchain-ai/langchain/issues/2322 | 1,651,132,568 | 2,322 |
[
"langchain-ai",
"langchain"
] | Claude have been there for a while and now is free through Slack (https://www.anthropic.com/index/claude-now-in-slack). Is it good time to integrate it into Langchain? BTW, it is a little bit surprise no one had a proposal for this before. | Claude integration | https://api.github.com/repos/langchain-ai/langchain/issues/2320/comments | 3 | 2023-04-02T23:09:37Z | 2023-12-02T16:09:47Z | https://github.com/langchain-ai/langchain/issues/2320 | 1,651,128,224 | 2,320 |
[
"langchain-ai",
"langchain"
] | Is there a plan to implement Reflexion in Langchain as a separate agent (or maybe an add-on to existing agents)?
https://arxiv.org/abs/2303.11366
Sample implementation: https://github.com/GammaTauAI/reflexion-human-eval/blob/main/reflexion.py | Implementation of Reflexion in Langchain | https://api.github.com/repos/langchain-ai/langchain/issues/2316/comments | 14 | 2023-04-02T21:59:11Z | 2024-07-06T18:51:06Z | https://github.com/langchain-ai/langchain/issues/2316 | 1,651,108,611 | 2,316 |
[
"langchain-ai",
"langchain"
] | Probably use this
https://huggingface.co/docs/transformers/main/en/generation_strategies#streaming | Add stream method for HuggingFacePipeline Objet | https://api.github.com/repos/langchain-ai/langchain/issues/2309/comments | 8 | 2023-04-02T19:28:21Z | 2024-06-24T16:07:29Z | https://github.com/langchain-ai/langchain/issues/2309 | 1,651,065,839 | 2,309 |
[
"langchain-ai",
"langchain"
] | Hi,
I'm following the [Chat index examples](https://python.langchain.com/en/latest/modules/chains/index_examples/chat_vector_db.html) and was surprised that the history is not a Memory object but just an array. However, it is possible to pass a memory object to the constructor, if
1. I also set memory_key to 'chat_history' (default key names are different between ConversationBufferMemory and ConversationalRetrievalChain)
2. I also adjust get_chat_history to pass through the history from the memory, i.e. lambda h : h.
This is what that looks like:
```
memory = ConversationBufferMemory(memory_key='chat_history', return_messages=False)
conv_qa_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
memory=memory,
get_chat_history=lambda h : h)
```
Now, my issue is that if I also want to return sources that doesn't work with the memory - i.e. this does not work:
```
memory = ConversationBufferMemory(memory_key='chat_history', return_messages=False)
conv_qa_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
memory=memory,
get_chat_history=lambda h : h,
return_source_documents=True)
```
The error message is "ValueError: One output key expected, got dict_keys(['answer', 'source_documents'])".
Maybe I'm doing something wrong? If not, this seems worth fixing to me - or, more generally, make memory and the ConversationalRetrievalChain more directily compatible? | ConversationalRetrievalChain + Memory | https://api.github.com/repos/langchain-ai/langchain/issues/2303/comments | 88 | 2023-04-02T15:13:36Z | 2024-07-15T10:00:31Z | https://github.com/langchain-ai/langchain/issues/2303 | 1,650,985,481 | 2,303 |
[
"langchain-ai",
"langchain"
] | Hello, I'm trying to go through the Tracing Walkthrough (https://python.langchain.com/en/latest/tracing/agent_with_tracing.html). Where do I find my LANGCHAIN_API_KEY?
Thanks! | where to find LANGCHAIN_API_KEY? | https://api.github.com/repos/langchain-ai/langchain/issues/2302/comments | 2 | 2023-04-02T15:01:52Z | 2023-04-14T18:43:46Z | https://github.com/langchain-ai/langchain/issues/2302 | 1,650,981,278 | 2,302 |
[
"langchain-ai",
"langchain"
] |
I'm trying to build an agent to execute some shell and python code locally as follows
```from langchain.agents import initialize_agent,load_tools
from langchain import OpenAI, LLMBashChain
llm = OpenAI(temperature=0)
llm_bash_chain = LLMBashChain(llm=llm, verbose=True)
print(llm_bash_chain.prompt)
tools = load_tools(["python_repl", "terminal"])
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
agent.run("Delete a file in the local path.")
```
During the process, I find that there is still some possibility that it could generate erroneous code.And running this erroneous code directly on the local machine could pose risks and vulnerabilities.Therefore, I thought of setting up a sandbox environment based on Docker locally, to execute users' agent code, so as to avoid damage to local files or the system.
I tried to set up a web service in Docker to execute python code and provide feedback. The following is a simple demo operation process.
Before starting the operation, I have installed Docker and pulled the Python 3.10 image.
Create Dockerfile
```
FROM python:3.10
RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pip -U \
&& pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
RUN pip install fastapi
RUN pip install uvicorn
COPY main.py /app/
WORKDIR /app
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
```
and I have set up a service in my project folder that can accept and execute code.
main.py
```import io
import sys
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import Any, Dict
import subprocess
app = FastAPI()
class CodeData(BaseModel):
code: str
code_type: str
@app.post("/execute", response_model=Dict[str, Any])
async def execute_code(code_data: CodeData):
if code_data.code_type == "python":
try:
buffer = io.StringIO()
sys.stdout = buffer
exec(code_data.code)
sys.stdout = sys.__stdout__
exec_result = buffer.getvalue()
return {"output": exec_result} if exec_result else {"message": "OK"}
except Exception as e:
raise HTTPException(status_code=400, detail=str(e))
elif code_data.code_type == "shell":
try:
output = subprocess.check_output(code_data.code, stderr=subprocess.STDOUT, shell=True, text=True)
return {"output": output.strip()} if output.strip() else {"message": "OK"}
except subprocess.CalledProcessError as e:
raise HTTPException(status_code=400, detail=str(e.output))
else:
raise HTTPException(status_code=400, detail="Invalid code_type")
if __name__ == "__main__":
import uvicorn
uvicorn.run("remote:app", host="localhost", port=8000)
```
then I've started it using Docker on a local port,and I can use the Langchain Agent to execute code in the sandbox and return results to avoid damage to the local environment.
the agent as follows
```import ast
from langchain.llms import OpenAI
from langchain.agents import initialize_agent
from langchain.tools.base import BaseTool
import requests
class SandboxTool(BaseTool):
name = "SandboxTool"
description = '''Useful for when you need to execute python code or install library by pip for python code.
The input to this tool should be a comma separated list of numbers of length two,
the first value is code_type(type:String), the second value is code(type:String) needed to execute.
For example:
["python", "print(1+2)"], ["shell", "pip install langchain"], ["shell", "ls"] ... '''
def _run(self, query: str) -> str:
return self.remote_request(query)
async def _arun(self, tool_input: str) -> str:
raise NotImplementedError("PythonRemoteReplTool does not support async")
def remote_request(self, query: str) -> str:
list = ast.literal_eval(query)
url = "http://localhost:8000/execute"
headers = {
"Content-Type": "application/json",
}
json_data = {
"code_type": list[0],
"code": list[1]
}
response = requests.post(url, headers=headers, json=json_data)
if response.status_code == 200:
data = response.json()
return data
else:
return f"Request failed, status code:{response.status_code}"
llm = OpenAI(temperature=0)
tool =SandboxTool()
tools = [tool]
sandboxagent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
sandboxagent.run("print result from 5 + 5")
```
Could this be a feasible sandbox solution? | Simulate sandbox execution of bash code or python code. | https://api.github.com/repos/langchain-ai/langchain/issues/2301/comments | 5 | 2023-04-02T14:42:30Z | 2023-10-05T16:11:04Z | https://github.com/langchain-ai/langchain/issues/2301 | 1,650,974,035 | 2,301 |
[
"langchain-ai",
"langchain"
] | I'm trying to build Chat bot with ConversationalRetrievalChain, and got this error when trying to use "refine" chain type
```
File "/Users/chris/.pyenv/versions/3.10.10/lib/python3.10/site-packages/langchain/chains/question_answering/__init__.py", line 218, in load_qa_chain
return loader_mapping[chain_type](
File "/Users/chris/.pyenv/versions/3.10.10/lib/python3.10/site-packages/langchain/chains/question_answering/__init__.py", line 176, in _load_refine_chain
return RefineDocumentsChain(
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for RefineDocumentsChain
prompt
extra fields not permitted (type=value_error.extra)
```
```
question_gen_llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0,
verbose=True,
callback_manager=question_manager,
)
streaming_llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
streaming=True,
callback_manager=stream_manager,
verbose=True,
temperature=0.3,
)
question_generator = LLMChain(
llm=question_gen_llm, prompt=CONDENSE_QUESTION_PROMPT, callback_manager=manager
)
combine_docs_chain = load_qa_chain(
streaming_llm, chain_type="refine", prompt=QA_PROMPT, callback_manager=manager
)
qa = ConversationalRetrievalChain(
retriever=vectorstore.as_retriever(),
combine_docs_chain=combine_docs_chain,
question_generator=question_generator,
callback_manager=manager,
verbose=True,
return_source_documents=True,
)
```
| chain_type "refine" error with ChatOpenAI in ConversationalRetrievalChain | https://api.github.com/repos/langchain-ai/langchain/issues/2296/comments | 7 | 2023-04-02T10:53:26Z | 2023-11-01T16:07:55Z | https://github.com/langchain-ai/langchain/issues/2296 | 1,650,900,292 | 2,296 |
[
"langchain-ai",
"langchain"
] | if i create a llm by `llm=OpenAI()`, how can i set params `organization, api_base` and so on like in package `openai`? many thanks. | how can I config angchain.llms.OpenAI like openai | https://api.github.com/repos/langchain-ai/langchain/issues/2294/comments | 1 | 2023-04-02T08:40:01Z | 2023-09-10T16:38:50Z | https://github.com/langchain-ai/langchain/issues/2294 | 1,650,862,077 | 2,294 |
[
"langchain-ai",
"langchain"
] | This code not work
`llm = ChatOpenAI(temperature=0)`
It seems that Temperature has not been added to the **kwargs of the request In ChatOpenAI
And this code is working fine
`llm = ChatOpenAI(model_kwargs={'temperature': 0})` | temperature not work in ChatOpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/2292/comments | 3 | 2023-04-02T07:40:03Z | 2023-06-27T09:08:11Z | https://github.com/langchain-ai/langchain/issues/2292 | 1,650,846,478 | 2,292 |
[
"langchain-ai",
"langchain"
] | 1) In chains with multiple sub-chains, Is there a way to pass the initial input as an argument to all subsequent chains?
2) Can we assign variable names to outputs of chains and use them in subsequent chains?
I am trying to get additional information from an article using preprocess_chain. I would like to send the original article and the additional information to an analysis_chain.
```
# Chain1 : To get additional info about an article
preprocess_template = """Given the article. Derive additional info
% Article
{article}
YOUR RESPONSE:
"""
prompt_template2 = PromptTemplate(input_variables=["article"], template=stakeholder_template)
preprocess_chain = LLMChain(llm=llm, prompt=prompt_template1)
#Chain2: Would like to pass both original article and response of chain1 to chain2
analysis_template = """Analyse the article in context of additional Info.
% Article
{article} ### Need help adding this variable here
% Additional info
{additionalInfo}
YOUR RESPONSE:
"""
prompt_template2 = PromptTemplate(input_variables=["article","additionalInfo"], template=stakeholder_template)
analysis_chain = LLMChain(llm=llm, prompt=prompt_template2)
overall_chain = SimpleSequentialChain(chains=[preprocess_chain,analysis_chain], verbose=True)
overall_chain.run(articleText)
```
| In chains with multiple sub-chains, Is there a way to pass the initial input as an argument to all subsequent chains? | https://api.github.com/repos/langchain-ai/langchain/issues/2289/comments | 1 | 2023-04-02T04:47:26Z | 2023-04-02T05:04:53Z | https://github.com/langchain-ai/langchain/issues/2289 | 1,650,804,547 | 2,289 |
[
"langchain-ai",
"langchain"
] | I'm trying to replicate the Zapier agent example [here](https://python.langchain.com/en/latest/modules/agents/tools/examples/zapier.html?highlight=zapier), but the agent doesn't find the right tools even though I've created the relevant Zapier NLA actions in my account.
When I run:
`agent.run("Summarize the last email I received regarding Silicon Valley Bank. Send the summary to the #test-zapier channel in slack.")`
Expected output:
```
> Entering new AgentExecutor chain...
I need to find the email and summarize it.
Action: Gmail: Find Email
Action Input: Find the latest email from Silicon Valley Bank
Observation: {"from__name": "Silicon Valley Bridge Bank, N.A.", "from__email": "sreply@svb.com", "body_plain": "Dear Clients, After chaotic, tumultuous & stressful days, we have clarity on path for SVB, FDIC is fully insuring all deposits & have an ask for clients & partners as we rebuild. Tim Mayopoulos <https://eml.svb.com/NjEwLUtBSy0yNjYAAAGKgoxUeBCLAyF_NxON97X4rKEaNBLG", "reply_to__email": "sreply@svb.com", "subject": "Meet the new CEO Tim Mayopoulos", "date": "Tue, 14 Mar 2023 23:42:29 -0500 (CDT)", "message_url": "https://mail.google.com/mail/u/0/#inbox/186e393b13cfdf0a", "attachment_count": "0", "to__emails": "ankush@langchain.dev", "message_id": "186e393b13cfdf0a", "labels": "IMPORTANT, CATEGORY_UPDATES, INBOX"}
Thought: I need to summarize the email and send it to the #test-zapier channel in Slack.
Action: Slack: Send Channel Message
Action Input: Send a slack message to the #test-zapier channel with the text "Silicon Valley Bank has announced that Tim Mayopoulos is the new CEO. FDIC is fully insuring all deposits and they have an ask for clients and partners as they rebuild."
Observation: {"message__text": "Silicon Valley Bank has announced that Tim Mayopoulos is the new CEO. FDIC is fully insuring all deposits and they have an ask for clients and partners as they rebuild.", "message__permalink": "https://langchain.slack.com/archives/C04TSGU0RA7/p1678859932375259", "channel": "C04TSGU0RA7", "message__bot_profile__name": "Zapier", "message__team": "T04F8K3FZB5", "message__bot_id": "B04TRV4R74K", "message__bot_profile__deleted": "false", "message__bot_profile__app_id": "A024R9PQM", "ts_time": "2023-03-15T05:58:52Z", "message__bot_profile__icons__image_36": "https://avatars.slack-edge.com/2022-08-02/3888649620612_f864dc1bb794cf7d82b0_36.png", "message__blocks[]block_id": "kdZZ", "message__blocks[]elements[]type": "['rich_text_section']"}
Thought: I now know the final answer.
Final Answer: I have sent a summary of the last email from Silicon Valley Bank to the #test-zapier channel in Slack.
> Finished chain.
```
My output:
```
> Entering new AgentExecutor chain...
I need to read the email and summarize it in a way that is concise and informative.
Action: Read the email
Action Input: Last email received regarding Silicon Valley Bank
Observation: Read the email is not a valid tool, try another one.
Thought: I need to use a tool that will allow me to quickly summarize the email.
Action: Use a summarization tool
Action Input: Last email received regarding Silicon Valley Bank
Observation: Use a summarization tool is not a valid tool, try another one.
Thought: I need to use a tool that will allow me to quickly summarize the email and post it to the #test-zapier channel in Slack.
...
```
I tried to print the tools from the toolkit, but none are found.
```
for tool in toolkit.get_tools():
print (tool.name)
print (tool.description)
print ("\n\n")
```
I have version 0.0.129 of langchain installed (which is the latest as of today). Any ideas why the agent is not picking up any Zapier tools? | Agent not loading tools from ZapierToolkit | https://api.github.com/repos/langchain-ai/langchain/issues/2286/comments | 3 | 2023-04-02T01:29:17Z | 2023-09-18T16:21:39Z | https://github.com/langchain-ai/langchain/issues/2286 | 1,650,766,257 | 2,286 |
[
"langchain-ai",
"langchain"
] | Sorry if this is a dumb question:
Why is the ZeroShotAgent called "zero-shot-react-description" instead of "zero-shot-mrkl-description" or something like that? It is implemented to follow the MRKL design, not the reAct design. I am misunderstanding something?
Here is the code:
```
AGENT_TO_CLASS = {
"zero-shot-react-description": ZeroShotAgent,
"react-docstore": ReActDocstoreAgent,
"self-ask-with-search": SelfAskWithSearchAgent,
"conversational-react-description": ConversationalAgent,
"chat-zero-shot-react-description": ChatAgent,
"chat-conversational-react-description": ConversationalChatAgent,
}
```
permalink: https://github.com/hwchase17/langchain/blob/acfda4d1d8b3cd98de381ff58ba7fd6b91c6c204/langchain/agents/loading.py#L21 | ReAct vs MRKL | https://api.github.com/repos/langchain-ai/langchain/issues/2284/comments | 5 | 2023-04-01T22:44:51Z | 2023-09-29T16:09:21Z | https://github.com/langchain-ai/langchain/issues/2284 | 1,650,698,780 | 2,284 |
[
"langchain-ai",
"langchain"
] | LLM response is parsed with `RegexParser `with the pattern `"(.*?)\nScore: (.*)"` which is not reliable. In some instances the `Score `is missing or present without newline `"\n"`
This leads to
`ValueError: Could not parse output: ....`
Update:
`"Answer:"` in some cases is missing too
| RegexParser pattern "(.*?)\nScore: (.*)" is not reliable | https://api.github.com/repos/langchain-ai/langchain/issues/2282/comments | 2 | 2023-04-01T20:46:38Z | 2023-08-25T16:16:06Z | https://github.com/langchain-ai/langchain/issues/2282 | 1,650,648,539 | 2,282 |
[
"langchain-ai",
"langchain"
] | I am getting some issues while trying to connect from langchain to databricks via sqlalchemy.
It works fine when I connect directly via sqlalchemy.
I think the issue is in the below lines
https://github.com/hwchase17/langchain/blob/09f94642543b23d7c9db81aa15ef54a1b6e13840/langchain/sql_database.py#L32-L33
the variable self._include_tables in line 33 is is set with values after calling get_table_names function (in line 32) which in turn uses self._include_tables and hence it will have None value at that time which causes some errors for databricks connection.

There are few more such issues while connecting to databricks using langchain and databricks-sql-connector library. It works fine with just sqlalchemy and databricks-sql-connector.
Could you add support for databricks? | Kindly add support for databricks-sql-connector (databricks library) via sqlalchemy in langchain | https://api.github.com/repos/langchain-ai/langchain/issues/2277/comments | 2 | 2023-04-01T18:45:35Z | 2023-08-11T16:31:54Z | https://github.com/langchain-ai/langchain/issues/2277 | 1,650,597,393 | 2,277 |
[
"langchain-ai",
"langchain"
] | I'm trying to create a conversation agent essentially defined like this:
```python
tools = load_tools([]) # "wikipedia"])
llm = ChatOpenAI(model_name=MODEL, verbose=True)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent = initialize_agent(tools, llm,
agent="chat-conversational-react-description",
max_iterations=3,
early_stopping_method="generate",
memory=memory,
verbose=True)
```
The agent raises an exception after it tries to use an invalid tool.
```
Question: My name is James and I'm helping Will. He's an engineer.
> Entering new AgentExecutor chain...
{
"action": "Final Answer",
"action_input": "Hello James, nice to meet you! How can I assist you and Will today?"
}
> Finished chain.
Answer: Hello James, nice to meet you! How can I assist you and Will today?
Question: What do you know about Will?
> Entering new AgentExecutor chain...
{
"action": "recommend_tool",
"action_input": "I recommend searching for information on Will on LinkedIn, which is a professional networking site. It may have his work experience, education and other professional details."
}
Observation: recommend_tool is not a valid tool, try another one.
Thought:Traceback (most recent call last):
File "/usr/local/lib/python3.11/site-packages/langchain/agents/conversational_chat/base.py", line 106, in _extract_tool_and_input
response = self.output_parser.parse(llm_output)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/agents/conversational_chat/base.py", line 51, in parse
response = json.loads(cleaned_output)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/json/__init__.py", line 346, in loads
return _default_decoder.decode(s)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/json/decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/json/decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/src/app/main.py", line 93, in <module>
ask(question)
File "/usr/src/app/main.py", line 76, in ask
result = agent.run(question)
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/chains/base.py", line 213, in run
return self(args[0])[self.output_keys[0]]
^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/usr/local/lib/python3.11/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/agents/agent.py", line 632, in _call
next_step_output = self._take_next_step(
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/agents/agent.py", line 548, in _take_next_step
output = self.agent.plan(intermediate_steps, **inputs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/agents/agent.py", line 281, in plan
action = self._get_next_action(full_inputs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/agents/agent.py", line 243, in _get_next_action
parsed_output = self._extract_tool_and_input(full_output)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/agents/conversational_chat/base.py", line 109, in _extract_tool_and_input
raise ValueError(f"Could not parse LLM output: {llm_output}")
ValueError: Could not parse LLM output: My apologies, allow me to clarify my previous response:
{
"action": "recommend_tool",
"action_input": "I recommend using a professional social network which can provide informative details on Will's professional background and accomplishments."
}
You can try searching for information on platforms such as LinkedIn or XING to start.
>>>
```
Perhaps this is because there are no tools defined? This may be somewhat related to #2241, which is also a parsing error.
My real goal here was trying to test the agent's memory, but if I defined wikipedia as a tool, the agent would try to search for Will in wikipedia and respond with facts about some random Will. How can I get this to work? | Exception when Conversation Agent doesn't receive json output | https://api.github.com/repos/langchain-ai/langchain/issues/2276/comments | 7 | 2023-04-01T18:43:07Z | 2023-10-16T16:09:00Z | https://github.com/langchain-ai/langchain/issues/2276 | 1,650,596,807 | 2,276 |
[
"langchain-ai",
"langchain"
] | It appears that MongoDB Atlas Search supports Vector Search via the `kNNBeta` operator:
- https://github.com/esteininger/vector-search/blob/master/foundations/atlas-vector-search/Atlas_Vector_Search_Demonstration.ipynb
- https://www.mongodb.com/docs/atlas/atlas-search/knn-beta/
Is there anyone else that is working with or exploring MongoDB as a Vectorstore?
If not, @hwchase17, would you be open to a pull-request?
cc: @sam-lippert and @AggressivelyMeows | MongoDB Atlas Search Support | https://api.github.com/repos/langchain-ai/langchain/issues/2274/comments | 9 | 2023-04-01T17:15:15Z | 2023-09-27T16:10:39Z | https://github.com/langchain-ai/langchain/issues/2274 | 1,650,567,180 | 2,274 |
[
"langchain-ai",
"langchain"
] | I got this error in 0.0.127 and 0.0.128 version, and worked fine in previous versions. I'm using ConversationalRetrievalChain with PGVector.
```
PG_CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.environ.get("PGVECTOR_DRIVER", "psycopg2"),
host=os.environ.get("PGVECTOR_HOST", "localhost"),
port=int(os.environ.get("PGVECTOR_PORT", "5432")),
database=os.environ.get("PGVECTOR_DATABASE", "vector"),
user=os.environ.get("PGVECTOR_USER", "xxxx"),
password=os.environ.get("PGVECTOR_PASSWORD", "xxxxxxxxxxxxx"),
)
vectorstore = PGVector(
connection_string=PG_CONNECTION_STRING,
embedding_function=embeddings,
collection_name="langchain"
)
manager = AsyncCallbackManager([])
question_manager = AsyncCallbackManager([question_handler])
stream_manager = AsyncCallbackManager([stream_handler])
if tracing:
tracer = LangChainTracer()
tracer.load_default_session()
manager.add_handler(tracer)
question_manager.add_handler(tracer)
stream_manager.add_handler(tracer)
question_gen_llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0,
verbose=True,
callback_manager=question_manager,
)
streaming_llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
streaming=True,
callback_manager=stream_manager,
verbose=True,
temperature=0,
)
question_generator = LLMChain(
llm=question_gen_llm, prompt=CONDENSE_QUESTION_PROMPT, callback_manager=manager
)
combine_docs_chain = load_qa_chain(
streaming_llm, chain_type="stuff", prompt=QA_PROMPT, callback_manager=manager
)
retriever = vectorstore.as_retriever()
qa = ConversationalRetrievalChain(
retriever=retriever,
combine_docs_chain=combine_docs_chain,
question_generator=question_generator,
callback_manager=manager,
)
```
```
ERROR:root:VectorStoreRetriever does not support async
``` | VectorStoreRetriever does not support async in 0.0.128 | https://api.github.com/repos/langchain-ai/langchain/issues/2268/comments | 4 | 2023-04-01T09:48:31Z | 2023-09-29T16:09:26Z | https://github.com/langchain-ai/langchain/issues/2268 | 1,650,390,352 | 2,268 |
[
"langchain-ai",
"langchain"
] | **Any comments would be appreciated.**
When an import statement is executed inside a function or object creation in Python, a new module object is created every time the function or object is called or instantiated, respectively.
We have multiple imports like that in many classes in a code base:
```python
class Chroma(VectorStore):
def __init__(
self,
collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
embedding_function: Optional[Embeddings] = None,
persist_directory: Optional[str] = None,
client_settings: Optional[chromadb.config.Settings] = None,
) -> None:
"""Initialize with Chroma client."""
try:
import chromadb
import chromadb.config
except ImportError:
raise ValueError(
"Could not import chromadb python package. "
"Please install it with `pip install chromadb`."
)
```
It's worth noting that these types of imports can also occur in other places of code, such as in the user's own code. So, if we have import in used code, we will have double import on object creation.
```python
import logging
import chromadb # importing chromadb
from dotenv import load_dotenv
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
logging.basicConfig(level=logging.DEBUG)
def init_chromadb():
client_settings = chromadb.config.Settings(
chroma_db_impl="duckdb+parquet",
anonymized_telemetry=False
)
embeddings = OpenAIEmbeddings()
# create an instance of the Chroma class
# importing chromadb will be fired again, which can cause performance issues
vectorstore = Chroma(
collection_name="langchain_store",
embedding_function=embeddings,
client_settings=client_settings
)
def main():
init_chromadb()
if __name__ == '__main__':
main()
```
Here is an example of how we can modify the previous code to avoid multiple imports:
```python
import sys
class Chroma(VectorStore):
def __init__(
self,
collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
embedding_function: Optional[Embeddings] = None,
persist_directory: Optional[str] = None,
client_settings: Optional[chromadb.config.Settings] = None,
) -> None:
"""Initialize with Chroma client."""
if 'chromadb' not in sys.modules:
try:
import chromadb
import chromadb.config
except ImportError:
raise ValueError(
"Could not import chromadb python package. "
"Please install it with `pip install chromadb`."
)
```
In this modified version, we check if the 'chromadb' module has already been imported by checking its presence in the sys.modules dictionary. If it has not been imported, we import the module and its config sub-module as before. If it has been imported, we simply retrieve it from the sys.modules dictionary and assign it to the chromadb variable. This way, we can prevent multiple imports of the same module and improve the performance and memory usage of our code. | avoiding unnecessary imports in Python classes and functions using sys.modules | https://api.github.com/repos/langchain-ai/langchain/issues/2266/comments | 1 | 2023-04-01T08:36:52Z | 2023-08-25T16:13:15Z | https://github.com/langchain-ai/langchain/issues/2266 | 1,650,366,622 | 2,266 |
[
"langchain-ai",
"langchain"
] | how can I use `TextSplitter` for `GPTSimpleVectorIndex` to split document by such “\n” or/and other? | how to use TextSplitter for GPTSimpleVectorIndex | https://api.github.com/repos/langchain-ai/langchain/issues/2265/comments | 2 | 2023-04-01T08:35:09Z | 2023-04-02T08:00:59Z | https://github.com/langchain-ai/langchain/issues/2265 | 1,650,366,217 | 2,265 |
[
"langchain-ai",
"langchain"
] | Does anyone have an example of how to use `condense_question_prompt` and `qa_prompt` with `ConversationalRetrievalChain`? I have some information which I want to always be included in the context of a user's question (e.g. 'You are a bot whose name is Bob'), but this context information is seemingly lost when I ask a question (e.g. 'What is your name?').
If anyone has an example of how to include a pre-defined context in the prompt for `ConversationalRetrievalChain`, I would be extremely grateful! | Prompt engineering for ConversationalRetrievalChain | https://api.github.com/repos/langchain-ai/langchain/issues/2264/comments | 4 | 2023-04-01T08:10:59Z | 2024-01-19T04:04:35Z | https://github.com/langchain-ai/langchain/issues/2264 | 1,650,359,937 | 2,264 |
[
"langchain-ai",
"langchain"
] | For GPT-4, image inputs are still in [limited alpha](https://openai.com/research/gpt-4#:~:text=image%20inputs%20are%20still%20in%20limited%20alpha).
For GPT-3.5, it would be great to see LangChain use the MM-ReAct agent.
- Repo: [github.com/microsoft/MM-REACT](https://github.com/microsoft/MM-REACT)
- Website: [multimodal-react.github.io](https://multimodal-react.github.io/)
- Demo: [huggingface.co/spaces/microsoft-cognitive-service/mm-react](https://huggingface.co/spaces/microsoft-cognitive-service/mm-react)
- Paper Abstract: [arxiv.org/abs/2303.11381](https://arxiv.org/abs/2303.11381)
- Paper PDF: [arxiv.org/pdf/2303.11381.pdf](https://arxiv.org/pdf/2303.11381.pdf) | MM-ReAct (Multimodal Reasoning and Action) | https://api.github.com/repos/langchain-ai/langchain/issues/2262/comments | 7 | 2023-04-01T05:52:16Z | 2024-01-25T14:13:54Z | https://github.com/langchain-ai/langchain/issues/2262 | 1,650,313,544 | 2,262 |
[
"langchain-ai",
"langchain"
] | This could improve the model's/langchain's awareness of the structured context surrounding an external source in its conversational memory.
The conversational memory document store can act as a buffer for all external sources.
Original: https://github.com/hwchase17/langchain/issues/709#issuecomment-1492828239
| Structured conversational memory: store query result (e.g. url response + metadata) directly into document store | https://api.github.com/repos/langchain-ai/langchain/issues/2261/comments | 1 | 2023-04-01T05:25:31Z | 2023-08-25T16:13:20Z | https://github.com/langchain-ai/langchain/issues/2261 | 1,650,306,640 | 2,261 |
[
"langchain-ai",
"langchain"
] | Real-time search-based planning has been shown to enhance the performance of AI agents:
1. AlphaGo, MuZero (planning in games)
2. Libratus, Pluribus (planning in Poker)
3. Behavioural forecasting in self-driving (e.g. Waymo VectorNet)
The basic principle is that given some target objective, an agent (in this case conversational) can better account for their uncertainty about local choices by sampling future rollouts. Intuitively, we are deferring the evaluation of local choices to some external metric (e.g. the semi-supervised reward network).
The principle here is very similar to CoT or self-ask, in deferring reasoning into some self-reflexive output - except that we rely on some external metric. The external metric can also self reflexive - how many rounds of interaction to arrive at an answer which the model itself judges to appear satisfactory.
However, the objective is to enable search over a much longer context, and many more rollouts than can be stored in a single context window in order to maximize long-horizon rewards.
(Note that the proposal breaks the assumption that LLMs are good few-shot learners - in particular, it doubts the models' ability to consider alternatives as part of its inference - which may not be a good hypothesis, and may render this idea ineffective. However, we persist.)
For instance, when engaging a customer for sales acquisition, the model can be selective on its phrasing and its inclusion or omission of certain details based on which of its future conversation rollouts lead to (in it's own imagination) a better outcome - for instance, avoiding frustrated users, clarifying as opposed to assuming, thus more quickly arriving at a common understanding etc.
While I believe there are parts to this problem that are research-level, I expect that a naive implementation on a base model that has already been exposed to human feedback can lead to some good results.
---
Additional advantages:
1. I think it would be a great tool to inspect how the model imagines its future conversations. It can be a great way to observe how it hallucinates its interlocutor's intent, the alternatives it considers, and additionally one can collect metrics like self-evaluation via CoT/self-ask along different paths, thus serving as a useful way to understand why it did or did not arrive at one's desired outcome
---
Additional implementation details:
1. Rollouts can be conditioned on the model's own output for alternatives for e.g. chain of thought reasoning, self-ask. The prompt goes: "output 3-5 possible next steps in your reasoning". Our system will simply sample each of those separately.
---
Disadvantage:
1. Potential high cost.
- Especially if samples are identical -> We can implement strategies that help improve path diversity.
- Cost should be weighed against improved qualitative result.
2. Even slower than before.
- Latency increase is proportional to depth of the search tree. (branches can be run in parallel).
Advantage:
1. More concise results avoiding dead-end conversational branches, more able to anticipate user requests or ask clarifying questions. | Add module for real-time search to improve engagement and intent satisfaction | https://api.github.com/repos/langchain-ai/langchain/issues/2259/comments | 1 | 2023-04-01T04:49:22Z | 2023-08-25T16:13:25Z | https://github.com/langchain-ai/langchain/issues/2259 | 1,650,293,522 | 2,259 |
[
"langchain-ai",
"langchain"
] | I think we could increase the integration of local models with some of the introspection tools, so that e.g.
1. one could visualize/collect metrics on a large collection of search-augmented conversations with keywords extracted by a local model.
2. others...? | Introspection/Tracing: Use local models as a way to extract useful characterizations of data (input, intermediate, output) without external API call | https://api.github.com/repos/langchain-ai/langchain/issues/2258/comments | 1 | 2023-04-01T04:14:06Z | 2023-08-25T16:13:31Z | https://github.com/langchain-ai/langchain/issues/2258 | 1,650,285,248 | 2,258 |
[
"langchain-ai",
"langchain"
] | There are 2 ways to overcome context window limit:
1. Store the outputs of old conversations back into the document store (similar to external memory), utilizing an external index (e.g. inverse document index) to query the documents
2. Hierarchically compress a summary of conversation history, feeding it into future context windows
Note that the two approaches are completely orthogonal.
I believe 1. is implemented but I think that 2. can improve the the model's awareness of the relevancy of the document store
This issue is tracking the implementation of easy to use abstractions that:
1. implements hierarchical compression (see also https://github.com/hwchase17/langchain/issues/709)
2. combines these two approaches.
- For instance, having the document store itself have a hierarchical index involving summaries at different levels of granularity, to increase the model's ability to rank for relevancy in based on its own context rather than rely on an external ranking algorithm.
- Another simple interface is to allow for not only chunking an incoming document, but pre-summarizing it and returning some metadata (on e.g. the section titles, length) so that the model can decide whether it wants to ingest the entire document. Note that chunking already mitigates this issue to a degree, while metadata can implicitly provide the hierarchical structure.
| discussion: Combining strategies to overcome context-window limit | https://api.github.com/repos/langchain-ai/langchain/issues/2257/comments | 2 | 2023-04-01T03:57:18Z | 2023-09-10T16:39:01Z | https://github.com/langchain-ai/langchain/issues/2257 | 1,650,278,293 | 2,257 |
[
"langchain-ai",
"langchain"
] | Memory doesn't seem to be supported when using the 'sources' chains. It appears to have issues writing multiple output keys.
Is there a work around to this?
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[13], line 1
----> 1 chain({ "question": "Do we have any agreements with INGRAM MICRO." }, return_only_outputs=True)
File [~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/chains/base.py:118](https://file+.vscode-resource.vscode-cdn.net/Users/jordanparker/helpmefindlaw/search-service/examples/notebooks/~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/chains/base.py:118), in Chain.__call__(self, inputs, return_only_outputs)
116 raise e
117 self.callback_manager.on_chain_end(outputs, verbose=self.verbose)
--> 118 return self.prep_outputs(inputs, outputs, return_only_outputs)
File [~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/chains/base.py:170](https://file+.vscode-resource.vscode-cdn.net/Users/jordanparker/helpmefindlaw/search-service/examples/notebooks/~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/chains/base.py:170), in Chain.prep_outputs(self, inputs, outputs, return_only_outputs)
168 self._validate_outputs(outputs)
169 if self.memory is not None:
--> 170 self.memory.save_context(inputs, outputs)
171 if return_only_outputs:
172 return outputs
File [~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/memory/summary_buffer.py:59](https://file+.vscode-resource.vscode-cdn.net/Users/jordanparker/helpmefindlaw/search-service/examples/notebooks/~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/memory/summary_buffer.py:59), in ConversationSummaryBufferMemory.save_context(self, inputs, outputs)
57 def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:
58 """Save context from this conversation to buffer."""
---> 59 super().save_context(inputs, outputs)
60 # Prune buffer if it exceeds max token limit
61 buffer = self.chat_memory.messages
File [~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/memory/chat_memory.py:37](https://file+.vscode-resource.vscode-cdn.net/Users/jordanparker/helpmefindlaw/search-service/examples/notebooks/~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/memory/chat_memory.py:37), in BaseChatMemory.save_context(self, inputs, outputs)
...
---> 37 raise ValueError(f"One output key expected, got {outputs.keys()}")
38 output_key = list(outputs.keys())[0]
39 else:
ValueError: One output key expected, got dict_keys(['answer', 'sources'])
``` | Memory not supported with sources chain? | https://api.github.com/repos/langchain-ai/langchain/issues/2256/comments | 28 | 2023-04-01T03:50:19Z | 2024-03-01T18:47:16Z | https://github.com/langchain-ai/langchain/issues/2256 | 1,650,276,231 | 2,256 |
[
"langchain-ai",
"langchain"
] | I write my code according to `docs/modules/chains/index_examples/vector_db_qa.ipynb`, but the following error happened:
```console
Using embedded DuckDB without persistence: data will be transient
Traceback (most recent call last):
File "/home/todo/intership/GPTtrace/try.py", line 76, in <module>
qa.run(query=query, k=1)
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/chains/base.py", line 216, in run
return self(kwargs)[self.output_keys[0]]
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/chains/retrieval_qa/base.py", line 109, in _call
docs = self._get_docs(question)
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/chains/retrieval_qa/base.py", line 163, in _get_docs
return self.retriever.get_relevant_documents(question)
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/vectorstores/base.py", line 154, in get_relevant_documents
docs = self.vectorstore.similarity_search(query, **self.search_kwargs)
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 136, in similarity_search
docs_and_scores = self.similarity_search_with_score(query, k, filter=filter)
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 182, in similarity_search_with_score
results = self._collection.query(
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/chromadb/api/models/Collection.py", line 203, in query
return self._client._query(
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/chromadb/api/local.py", line 247, in _query
uuids, distances = self._db.get_nearest_neighbors(
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/chromadb/db/clickhouse.py", line 521, in get_nearest_neighbors
uuids, distances = index.get_nearest_neighbors(embeddings, n_results, ids)
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/chromadb/db/index/hnswlib.py", line 228, in get_nearest_neighbors
raise NotEnoughElementsException(
chromadb.errors.NotEnoughElementsException: Number of requested results 4 cannot be greater than number of elements in index 2
```
My code is following:
```python
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
import os
os.environ['OPENAI_API_KEY']="sk-..."
from langchain.document_loaders import TextLoader
loader = TextLoader("./prompts/text.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_documents(texts, embeddings)
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever())
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
```
It's seems relate to the content of text file passed to the `TextLoader`, when I pass the `langchain/docs/modules/state_of_the_union.txt`, It's can work well. It's very strange. | Number of requested results 4 cannot be greater than number of elements in index 2 | https://api.github.com/repos/langchain-ai/langchain/issues/2255/comments | 10 | 2023-04-01T03:18:44Z | 2023-11-03T14:15:32Z | https://github.com/langchain-ai/langchain/issues/2255 | 1,650,268,985 | 2,255 |
[
"langchain-ai",
"langchain"
] | Please ask: how many rows
> Entering new AgentExecutor chain...
Thought: I need to find the number of rows in the dataframe
**Action: python_repl_ast**
Action Input: len(df)
Observation: 45
Thought:I have the number of rows
Final Answer: 45
> Finished chain.
45
Please ask: does fg-40f support local report
> Entering new AgentExecutor chain...
Thought: We need to check if the "FG-40F Series" row has "Yes" in the "Local Reporting" column.
**Action: Use pandas boolean indexing to filter the dataframe to only the "FG-40F Series" row and check the value in the "Local Reporting" column.**
Action Input: `df[df['Product'] == 'FG-40F Series']['Local Reporting']`
Observation: Use pandas boolean indexing to filter the dataframe to only the "FG-40F Series" row and check the value in the "Local Reporting" column. is not a valid tool, try another one.
Thought:I made a mistake, I should use python_repl_ast instead of Observation.
Action: Use python_repl_ast to execute the previous input.
Action Input: `python_repl_ast(df[df['Product'] == 'FG-40F Series']['Local Reporting'])`
Observation: Use python_repl_ast to execute the previous input. is not a valid tool, try another one.
Thought:I made another mistake, I should use print() to display the result.
Action: Use python_repl_ast to execute the previous input with print().
Action Input: `python_repl_ast(print(df[df['Product'] == 'FG-40F Series']['Local Reporting']))`
| Toolkits - Pandas Dataframe Agent failed to call "python_repl_ast" consistently | https://api.github.com/repos/langchain-ai/langchain/issues/2252/comments | 21 | 2023-04-01T01:14:39Z | 2024-06-21T16:56:26Z | https://github.com/langchain-ai/langchain/issues/2252 | 1,650,226,595 | 2,252 |
[
"langchain-ai",
"langchain"
] | The following code produces the "too many requests" error. Using a different host does not fix it.
```py
name="Execute Query Tool"
description="Useful for executing a query against a search engine. Returns the results of the query."
search = SearxSearchWrapper(searx_host="https://www.gruble.de")
def func (query: Query) -> SearchResult:
searx_results = search.results(query, num_results=10, engines=['wiki'])
results_stack = [SearchResult.from_searx_result(result) for result in searx_results]
return results_stack
``` | SearxSearchWrapper: ('Searx API returned an error: ', 'Too Many Requests') | https://api.github.com/repos/langchain-ai/langchain/issues/2251/comments | 3 | 2023-04-01T00:37:48Z | 2023-08-11T16:31:55Z | https://github.com/langchain-ai/langchain/issues/2251 | 1,650,208,796 | 2,251 |
[
"langchain-ai",
"langchain"
] | Issue:
Python tool uses exec and eval instead of subprocess.
Description:
This leaves the chain open to an attack vector where malicious code can be injected and blindly executed.
Solution:
Commands should be sanitized and then passed to subprocess instead.
Note:
This issue applies to any command that functions similarly for any other language. | Python tool uses exec and eval instead of subprocess | https://api.github.com/repos/langchain-ai/langchain/issues/2249/comments | 1 | 2023-03-31T22:52:56Z | 2023-09-12T21:30:13Z | https://github.com/langchain-ai/langchain/issues/2249 | 1,650,139,503 | 2,249 |
[
"langchain-ai",
"langchain"
] | I am getting `UnicodeDecodeError`s from BeautifulSoup (the offending character is 0x9d - right double quotation mark). I am using Python 3.10 x64 on Windows 10 21H2.
The solution I would propose is to add the ability to pass some kwargs to the BSHTMLLoader constructor so we can specify the encoding to pass to `open()`:
https://github.com/hwchase17/langchain/blob/e57b045402b52c2a602f4895c5b06fa2c22b745a/langchain/document_loaders/html_bs.py#L15-L23
```python
def __init__(self, file_path: str, encoding: str=None) -> None:
try:
import bs4 # noqa:F401
except ImportError:
raise ValueError(
"bs4 package not found, please install it with " "`pip install bs4`"
)
self.file_path = file_path
self.encoding = encoding
```
https://github.com/hwchase17/langchain/blob/e57b045402b52c2a602f4895c5b06fa2c22b745a/langchain/document_loaders/html_bs.py#L29-L30
```python
with open(self.file_path, "r", encoding=self.encoding) as f:
soup = BeautifulSoup(f, features="lxml")
```
An extra benefit of this is that you could change the BeautifulSoup features to use the builtin `html.parser` to remove the dependency on `lxml`.
Further to this I would add something like a `loader_kwargs` argument to DirectoryLoader so we can pass these here as well:
https://github.com/hwchase17/langchain/blob/e57b045402b52c2a602f4895c5b06fa2c22b745a/langchain/document_loaders/directory.py#L29-L37
```python
def __init__(
self,
path: str,
glob: str = "**/[!.]*",
silent_errors: bool = False,
load_hidden: bool = False,
loader_cls: FILE_LOADER_TYPE = UnstructuredFileLoader,
loader_kwargs: dict = None,
recursive: bool = False,
):
if loader_kwargs is None:
loader_kwargs = {}
```
And wire it up like this:
https://github.com/hwchase17/langchain/blob/e57b045402b52c2a602f4895c5b06fa2c22b745a/langchain/document_loaders/directory.py#L51-L61
```python
for i in items:
if i.is_file():
if _is_visible(i.relative_to(p)) or self.load_hidden:
try:
sub_docs = self.loader_cls(str(i), **self.loader_kwargs).load()
docs.extend(sub_docs)
except Exception as e:
if self.silent_errors:
logger.warning(e)
else:
raise e
```
A workaround would be to set the environment variable `PYTHONUTF8=1` but this becomes tricky if you're using a Jupyter Notebook like I am.
I'll keep an eye on this issue and if I get a spare moment I'd be happy to make this change myself if the maintainers agree with my approach.
Thanks! | `UnicodeDecodeError` when using `BSHTMLLoader` on Windows | https://api.github.com/repos/langchain-ai/langchain/issues/2247/comments | 0 | 2023-03-31T21:13:09Z | 2023-04-03T17:17:47Z | https://github.com/langchain-ai/langchain/issues/2247 | 1,650,046,790 | 2,247 |
[
"langchain-ai",
"langchain"
] | In the docs, in https://python.langchain.com/en/latest/modules/models/llms/integrations/promptlayer_openai.html there is a hyperlink to the PromptLayer dashboard that links to "https://ww.promptlayer.com", which is incorrect. | Wrong PromptLayer Dashboard hyperlink | https://api.github.com/repos/langchain-ai/langchain/issues/2245/comments | 2 | 2023-03-31T20:33:41Z | 2023-03-31T22:21:36Z | https://github.com/langchain-ai/langchain/issues/2245 | 1,649,993,009 | 2,245 |
[
"langchain-ai",
"langchain"
] | When using the `conversational_chat` agent, an issue occurs when the LLM returns a markdown result that has a code block included. My use case is an agent that reads from an internal database using an agent to get information that will be used to build a block of code. The agent correctly uses the tools, but fails to return an answer.
The exhibited behavior is that the triple apostrophe used to offset the code block interferes with the json in a code block that the agent is expecting. It tries to parse the document, but stops when it finds the second triple apostrophe that starts the code block. This is because we end up with nested code blocks (the outer code block being the agent response JSON in a code block) | Issues with conversational_chat and LLM chains responding with a multi-line markdown code block | https://api.github.com/repos/langchain-ai/langchain/issues/2241/comments | 4 | 2023-03-31T18:32:25Z | 2023-12-02T16:09:52Z | https://github.com/langchain-ai/langchain/issues/2241 | 1,649,835,002 | 2,241 |
[
"langchain-ai",
"langchain"
] | When running `docs/modules/chains/index_examples/question_answering.ipynb`, the following error occurs:
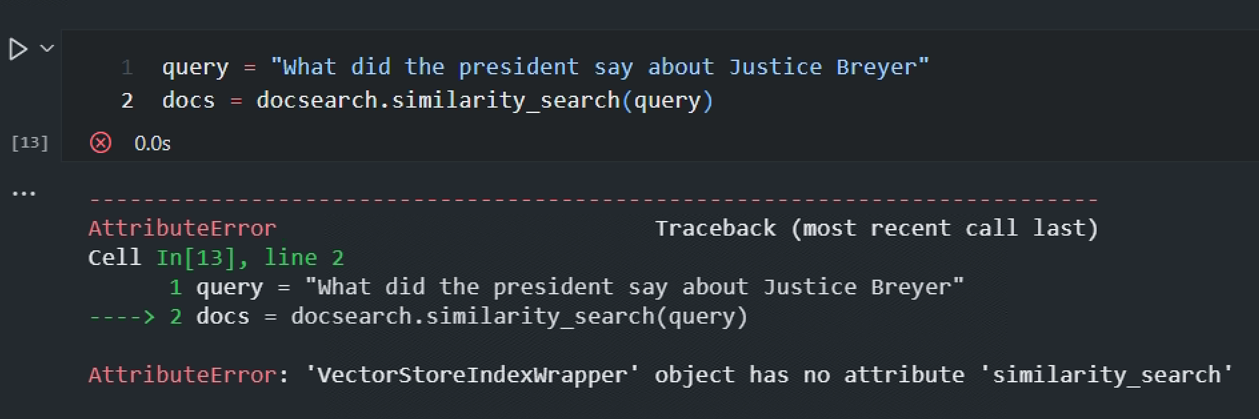
I didn't change the code, just ran the file directly. | 'VectorStoreIndexWrapper' object has no attribute 'similarity_search' | https://api.github.com/repos/langchain-ai/langchain/issues/2235/comments | 2 | 2023-03-31T16:37:22Z | 2023-04-01T01:13:57Z | https://github.com/langchain-ai/langchain/issues/2235 | 1,649,683,980 | 2,235 |
[
"langchain-ai",
"langchain"
] | It would be good to allow more parameters to the `BingSearchWrapper`, so that for example the internet search can be limited to a single domain. See [Getting results from a specific site
](https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/filter-answers#getting-results-from-a-specific-site).
[Advanced search keywords](https://support.microsoft.com/en-us/topic/advanced-search-keywords-ea595928-5d63-4a0b-9c6b-0b769865e78a) | [Bing Search] allow additional parameters like site restriction | https://api.github.com/repos/langchain-ai/langchain/issues/2229/comments | 1 | 2023-03-31T14:31:32Z | 2023-09-10T16:39:06Z | https://github.com/langchain-ai/langchain/issues/2229 | 1,649,464,362 | 2,229 |
[
"langchain-ai",
"langchain"
] | It would be great to see LangChain wrap around Vicuna, a chat assistant fine-tuned from LLaMA on user-shared conversations.
Vicuna-13B is an open-source chatbot trained using user-shared conversations collected from [ShareGPT](https://sharegpt.com/). The chatbot has been evaluated using GPT-4. It has achieved more than 90% quality of OpenAI ChatGPT and Google Bard while outperforming other models like LLaMA https://github.com/hwchase17/langchain/issues/1473 and Stanford Alpaca https://github.com/hwchase17/langchain/issues/1777 in more than 90% of cases.
**Useful links**
1. Blog post: [vicuna.lmsys.org](https://vicuna.lmsys.org/)
2. Training and servicing code: [github.com/lm-sys/FastChat](https://github.com/lm-sys/FastChat)
3. Demo: [chat.lmsys.org](https://chat.lmsys.org/) | Vicuna (Fine-tuned LLaMa) | https://api.github.com/repos/langchain-ai/langchain/issues/2228/comments | 30 | 2023-03-31T13:27:32Z | 2023-10-13T12:08:05Z | https://github.com/langchain-ai/langchain/issues/2228 | 1,649,357,823 | 2,228 |
[
"langchain-ai",
"langchain"
] | Hello!
I would like to propose adding BaseCallbackHandler, AsyncCallbackHandler, and AsyncCallbackManager to the exports of langchain.callbacks. Doing so would enable developers to create custom CallbackHandlers and run their own code for each of the steps handled by the BaseCallbackHandler, as well as their async counterparts.
In my opinion, this is an essential feature for scaling langchain-based applications. It would allow for things such as streaming step-by-step information to a frontend client for live debugging.
I believe that incorporating these features into the langchain.callbacks exports would make langchain even more powerful and user-friendly for developers.
Thank you for considering my proposal. | Add BaseCallbackHandler, AsyncCallbackHandler and AsyncCallbackManager to exports of langchain.callbacks | https://api.github.com/repos/langchain-ai/langchain/issues/2227/comments | 3 | 2023-03-31T12:54:40Z | 2023-09-25T10:18:43Z | https://github.com/langchain-ai/langchain/issues/2227 | 1,649,307,593 | 2,227 |
[
"langchain-ai",
"langchain"
] | Hello!
I've noticed that when creating a custom CallbackHandler in LangChain, there is currently no method for dealing with the Observation step. Specifically, in the agent.py file, the Agent and AgentExecutor class does not call any on_agent_observation function, and this function is not present in the BaseCallbackHandler base class.
I propose adding an on_agent_observation method to the BaseCallbackHandler, and calling this method at the end of both the _take_next_step and _atake_next_step functions in the Agent and AgentExecutor. This would enable developers to run custom logic for this step, such as streaming the observation to a frontend client.
I think usefulness of this feature cannot be understated, especially for scaling applications based on LangChain where multiple people will be involved in debugging.
I hope this proposal makes sense and will be useful for other developers. Please let me know if you have any feedback or concerns. | Add on_agent_observation method to BaseCallbackHandler for custom observation logic | https://api.github.com/repos/langchain-ai/langchain/issues/2226/comments | 2 | 2023-03-31T12:46:23Z | 2023-09-25T16:13:17Z | https://github.com/langchain-ai/langchain/issues/2226 | 1,649,296,178 | 2,226 |
[
"langchain-ai",
"langchain"
] | We are using Chroma for storing the records in vector form. When searching the query, the return documents do not give accurate results.
c1 = Chroma('langchain', embedding, persist_directory)
qa = ChatVectorDBChain(vectorstore=c1, combine_docs_chain=doc_chain, question_generator=question_generator,top_k_docs_for_context=12, return_source_documents=True)
What is the solution to get accurate results? | similarity Search Issue | https://api.github.com/repos/langchain-ai/langchain/issues/2225/comments | 4 | 2023-03-31T11:19:55Z | 2023-09-18T16:21:43Z | https://github.com/langchain-ai/langchain/issues/2225 | 1,649,180,957 | 2,225 |
[
"langchain-ai",
"langchain"
] | I am trying to create a chatbot using your documentation from here:
https://python.langchain.com/en/latest/modules/agents/agent_executors/examples/chatgpt_clone.html
However, in order to reduce costs, instead of using ChatGPT I want to use a HuggingFace Model.
I tried to use a conversational model, but I got an error that this task is not implemented yet and that it only supports TextGeneration and Tex2TextSequence.
So, I went to the hub and got the model ID with the most likes/downloads and I am testing it:
```
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
from langchain.llms import HuggingFacePipeline
from langchain.llms import HuggingFaceHub
import os
os.environ["HUGGINGFACEHUB_API_TOKEN"] = "x"
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
from langchain.memory import ConversationBufferWindowMemory
template = """Assistant is a large language model trained by OpenAI.
Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.
Overall, Assistant is a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist.
{history}
Human: {human_input}
Assistant:"""
prompt = PromptTemplate(
input_variables=["history", "human_input"],
template=template
)
llm = HuggingFaceHub(repo_id="facebook/mbart-large-50", model_kwargs={"temperature":0, "max_length":64})
llm_chain = LLMChain(prompt=prompt, llm=llm, memory=ConversationBufferWindowMemory(k=2))
output = llm_chain.predict(human_input="Whats the weather like?")
print(output)
```
However in the Google Colab output, all I get is this:
`Assistant is a large language model trained by OpenAI. Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate
`
And no prediction is in the output.
What am I missing? | Chatbot using HuggingFace model, not working | https://api.github.com/repos/langchain-ai/langchain/issues/2224/comments | 6 | 2023-03-31T09:26:50Z | 2023-09-27T16:10:49Z | https://github.com/langchain-ai/langchain/issues/2224 | 1,649,020,314 | 2,224 |
[
"langchain-ai",
"langchain"
] | **Any comments would be appreciated.**
The issue is that the json module is unable to serialize the Document object, which is a custom class that inherits from BaseModel. The error message specifically says that the Document object is not JSON serializable, meaning it cannot be converted into a JSON string. This is likely because the json module does not know how to serialize the BaseModel class or any of its child classes. To fix the issue, we may need to provide a custom encoder or implement the jsonable_encoder function from the FastAPI library, which is designed to handle pydantic models like BaseModel.
```python
def query_chromadb():
client_settings = chromadb.config.Settings(
chroma_db_impl="duckdb+parquet",
persist_directory=DB_DIR,
anonymized_telemetry=False
)
embeddings = OpenAIEmbeddings()
vectorstore = Chroma(
collection_name="langchain_store",
embedding_function=embeddings,
client_settings=client_settings,
persist_directory=DB_DIR,
)
result = vectorstore.similarity_search_with_score(query="FREDERICK", k=4)
print(result)
print(json.dumps(result, indent=4, sort_keys=False)) // ERROR
def main():
# init_chromadb()
query_chromadb()
```
```python
import json
from pydantic import BaseModel, Field
class Document(BaseModel):
"""Interface for interacting with a document."""
page_content: str
metadata: dict = Field(default_factory=dict)
doc = Document(page_content="Some page content", metadata={"author": "John Doe"})
print(json.dumps(doc)) // ERROR
```
Possible fixes:
```python
import json
from pydantic import BaseModel, Field
class Document(BaseModel):
"""Interface for interacting with a document."""
page_content: str
metadata: dict = Field(default_factory=dict)
def to_dict(self):
return self.dict(by_alias=True, exclude_unset=True) # just an example!
def to_json(self):
return self.json(by_alias=True, exclude_unset=True) # just an example!
doc = Document(page_content="Some page content", metadata={"author": "John Doe"})
# Convert to dictionary and serialize
doc_dict = doc.to_dict()
doc_json = json.dumps(doc.to_dict())
## {"page_content": "Some page content", "metadata": {"author": "John Doe"}}
print(doc_json)
# Or use the custom to_json() method
doc_json = doc.to_json()
## {"page_content": "Some page content", "metadata": {"author": "John Doe"}}
print(doc_json)
```
Another approach:
```python
import json
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel, Field
class Document(BaseModel):
"""Interface for interacting with a document."""
page_content: str
metadata: dict = Field(default_factory=dict)
doc = Document(page_content="Some page content", metadata={"author": "John Doe"})
print(json.dumps( jsonable_encoder(doc), indent=4))
```
Do we need an API like `doc.to_json()` or/and `doc.to_dict()`? Because in this case it will hide the details of model realization from the end user.
| TypeError: Object of type Document is not JSON serializable | https://api.github.com/repos/langchain-ai/langchain/issues/2222/comments | 15 | 2023-03-31T08:51:41Z | 2024-05-14T15:23:19Z | https://github.com/langchain-ai/langchain/issues/2222 | 1,648,966,589 | 2,222 |
[
"langchain-ai",
"langchain"
] | Provided I have given a system prompt, I wanted to use gpt-4 as the llm for my agents. I read around, but it only seems like gpt-3 davinci and nothing beyond it is an option.
Can gpt-3.5-turbo or gpt-4 be included as a llm option for agents? | Is it possible to use gpt-3.5-turbo or gpt-4 as the LLM model for agents? | https://api.github.com/repos/langchain-ai/langchain/issues/2220/comments | 7 | 2023-03-31T07:45:45Z | 2023-10-18T16:09:33Z | https://github.com/langchain-ai/langchain/issues/2220 | 1,648,853,042 | 2,220 |
[
"langchain-ai",
"langchain"
] | PGVector works fine for me when coupled with OpenAIEmbeddings. However, when I try to use HuggingFaceEmbeddings, I get the following error: `StatementError: (builtins.ValueError) expected 1536 dimensions, not 768`
Example code:
```python
from langchain.vectorstores.pgvector import PGVector
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders import TextLoader
import os
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
texts = TextLoader('data/made-up-story.txt').load()
documents = CharacterTextSplitter(chunk_size=500, chunk_overlap=20).split_documents(texts)
CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.environ.get("PGVECTOR_DRIVER", "psycopg2"),
host=os.environ.get("PGVECTOR_HOST", "localhost"),
port=int(os.environ.get("PGVECTOR_PORT", "5432")),
database=os.environ.get("PGVECTOR_DATABASE", "postgres"),
user=os.environ.get("PGVECTOR_USER", "postgres"),
password=os.environ.get("PGVECTOR_PASSWORD", "postgres"),
)
db = PGVector.from_documents(
embedding=embeddings,
documents=documents,
collection_name="test",
connection_string=CONNECTION_STRING,
)
```
Output:
```
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/base.py:1702 in │
│ _execute_context │
│ │
│ 1699 │ │ │ if conn is None: │
│ 1700 │ │ │ │ conn = self._revalidate_connection() │
│ 1701 │ │ │ │
│ ❱ 1702 │ │ │ context = constructor( │
│ 1703 │ │ │ │ dialect, self, conn, execution_options, *args, **kw │
│ 1704 │ │ │ ) │
│ 1705 │ │ except (exc.PendingRollbackError, exc.ResourceClosedError): │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/default.py:1078 in │
│ _init_compiled │
│ │
│ 1075 │ │ │ │ │ │ for key in compiled_params │
│ 1076 │ │ │ │ │ } │
│ 1077 │ │ │ │ else: │
│ ❱ 1078 │ │ │ │ │ param = { │
│ 1079 │ │ │ │ │ │ key: processors[key](compiled_params[key]) │
│ 1080 │ │ │ │ │ │ if key in processors │
│ 1081 │ │ │ │ │ │ else compiled_params[key] │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/default.py:1079 in │
│ <dictcomp> │
│ │
│ 1076 │ │ │ │ │ } │
│ 1077 │ │ │ │ else: │
│ 1078 │ │ │ │ │ param = { │
│ ❱ 1079 │ │ │ │ │ │ key: processors[key](compiled_params[key]) │
│ 1080 │ │ │ │ │ │ if key in processors │
│ 1081 │ │ │ │ │ │ else compiled_params[key] │
│ 1082 │ │ │ │ │ │ for key in compiled_params │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/pgvector/sqlalchemy/__init__.py:21 in │
│ process │
│ │
│ 18 │ │
│ 19 │ def bind_processor(self, dialect): │
│ 20 │ │ def process(value): │
│ ❱ 21 │ │ │ return to_db(value, self.dim) │
│ 22 │ │ return process │
│ 23 │ │
│ 24 │ def result_processor(self, dialect, coltype): │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/pgvector/utils/__init__.py:35 in to_db │
│ │
│ 32 │ │ value = value.tolist() │
│ 33 │ │
│ 34 │ if dim is not None and len(value) != dim: │
│ ❱ 35 │ │ raise ValueError('expected %d dimensions, not %d' % (dim, len(value))) │
│ 36 │ │
│ 37 │ return '[' + ','.join([str(float(v)) for v in value]) + ']' │
│ 38 │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
ValueError: expected 1536 dimensions, not 768
The above exception was the direct cause of the following exception:
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ /tmp/ipykernel_81963/141995419.py:21 in <cell line: 21> │
│ │
│ [Errno 2] No such file or directory: '/tmp/ipykernel_81963/141995419.py' │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/langchain/vectorstores/pgvector.py:420 in │
│ from_documents │
│ │
│ 417 │ │ │
│ 418 │ │ kwargs["connection_string"] = connection_string │
│ 419 │ │ │
│ ❱ 420 │ │ return cls.from_texts( │
│ 421 │ │ │ texts=texts, │
│ 422 │ │ │ pre_delete_collection=pre_delete_collection, │
│ 423 │ │ │ embedding=embedding, │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/langchain/vectorstores/pgvector.py:376 in │
│ from_texts │
│ │
│ 373 │ │ │ pre_delete_collection=pre_delete_collection, │
│ 374 │ │ ) │
│ 375 │ │ │
│ ❱ 376 │ │ store.add_texts(texts=texts, metadatas=metadatas, ids=ids, **kwargs) │
│ 377 │ │ return store │
│ 378 │ │
│ 379 │ @classmethod │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/langchain/vectorstores/pgvector.py:228 in │
│ add_texts │
│ │
│ 225 │ │ │ │ ) │
│ 226 │ │ │ │ collection.embeddings.append(embedding_store) │
│ 227 │ │ │ │ session.add(embedding_store) │
│ ❱ 228 │ │ │ session.commit() │
│ 229 │ │ │
│ 230 │ │ return ids │
│ 231 │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/session.py:1428 in commit │
│ │
│ 1425 │ │ │ if not self._autobegin(): │
│ 1426 │ │ │ │ raise sa_exc.InvalidRequestError("No transaction is begun.") │
│ 1427 │ │ │
│ ❱ 1428 │ │ self._transaction.commit(_to_root=self.future) │
│ 1429 │ │
│ 1430 │ def prepare(self): │
│ 1431 │ │ """Prepare the current transaction in progress for two phase commit. │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/session.py:829 in commit │
│ │
│ 826 │ def commit(self, _to_root=False): │
│ 827 │ │ self._assert_active(prepared_ok=True) │
│ 828 │ │ if self._state is not PREPARED: │
│ ❱ 829 │ │ │ self._prepare_impl() │
│ 830 │ │ │
│ 831 │ │ if self._parent is None or self.nested: │
│ 832 │ │ │ for conn, trans, should_commit, autoclose in set( │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/session.py:808 in │
│ _prepare_impl │
│ │
│ 805 │ │ │ for _flush_guard in range(100): │
│ 806 │ │ │ │ if self.session._is_clean(): │
│ 807 │ │ │ │ │ break │
│ ❱ 808 │ │ │ │ self.session.flush() │
│ 809 │ │ │ else: │
│ 810 │ │ │ │ raise exc.FlushError( │
│ 811 │ │ │ │ │ "Over 100 subsequent flushes have occurred within " │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/session.py:3345 in flush │
│ │
│ 3342 │ │ │ return │
│ 3343 │ │ try: │
│ 3344 │ │ │ self._flushing = True │
│ ❱ 3345 │ │ │ self._flush(objects) │
│ 3346 │ │ finally: │
│ 3347 │ │ │ self._flushing = False │
│ 3348 │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/session.py:3485 in _flush │
│ │
│ 3482 │ │ │
│ 3483 │ │ except: │
│ 3484 │ │ │ with util.safe_reraise(): │
│ ❱ 3485 │ │ │ │ transaction.rollback(_capture_exception=True) │
│ 3486 │ │
│ 3487 │ def bulk_save_objects( │
│ 3488 │ │ self, │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/util/langhelpers.py:70 in │
│ __exit__ │
│ │
│ 67 │ │ │ exc_type, exc_value, exc_tb = self._exc_info │
│ 68 │ │ │ self._exc_info = None # remove potential circular references │
│ 69 │ │ │ if not self.warn_only: │
│ ❱ 70 │ │ │ │ compat.raise_( │
│ 71 │ │ │ │ │ exc_value, │
│ 72 │ │ │ │ │ with_traceback=exc_tb, │
│ 73 │ │ │ │ ) │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/util/compat.py:207 in raise_ │
│ │
│ 204 │ │ │ exception.__cause__ = replace_context │
│ 205 │ │ │
│ 206 │ │ try: │
│ ❱ 207 │ │ │ raise exception │
│ 208 │ │ finally: │
│ 209 │ │ │ # credit to │
│ 210 │ │ │ # https://cosmicpercolator.com/2016/01/13/exception-leaks-in-python-2-and-3/ │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/session.py:3445 in _flush │
│ │
│ 3442 │ │ try: │
│ 3443 │ │ │ self._warn_on_events = True │
│ 3444 │ │ │ try: │
│ ❱ 3445 │ │ │ │ flush_context.execute() │
│ 3446 │ │ │ finally: │
│ 3447 │ │ │ │ self._warn_on_events = False │
│ 3448 │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/unitofwork.py:456 in execute │
│ │
│ 453 │ │ │ │ │ n.execute_aggregate(self, set_) │
│ 454 │ │ else: │
│ 455 │ │ │ for rec in topological.sort(self.dependencies, postsort_actions): │
│ ❱ 456 │ │ │ │ rec.execute(self) │
│ 457 │ │
│ 458 │ def finalize_flush_changes(self): │
│ 459 │ │ """Mark processed objects as clean / deleted after a successful │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/unitofwork.py:630 in execute │
│ │
│ 627 │ │
│ 628 │ @util.preload_module("sqlalchemy.orm.persistence") │
│ 629 │ def execute(self, uow): │
│ ❱ 630 │ │ util.preloaded.orm_persistence.save_obj( │
│ 631 │ │ │ self.mapper, │
│ 632 │ │ │ uow.states_for_mapper_hierarchy(self.mapper, False, False), │
│ 633 │ │ │ uow, │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/persistence.py:244 in │
│ save_obj │
│ │
│ 241 │ │ │ update, │
│ 242 │ │ ) │
│ 243 │ │ │
│ ❱ 244 │ │ _emit_insert_statements( │
│ 245 │ │ │ base_mapper, │
│ 246 │ │ │ uowtransaction, │
│ 247 │ │ │ mapper, │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/persistence.py:1155 in │
│ _emit_insert_statements │
│ │
│ 1152 │ │ │ if do_executemany: │
│ 1153 │ │ │ │ multiparams = [rec[2] for rec in records] │
│ 1154 │ │ │ │ │
│ ❱ 1155 │ │ │ │ c = connection._execute_20( │
│ 1156 │ │ │ │ │ statement, multiparams, execution_options=execution_options │
│ 1157 │ │ │ │ ) │
│ 1158 │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/base.py:1614 in │
│ _execute_20 │
│ │
│ 1611 │ │ │ │ exc.ObjectNotExecutableError(statement), replace_context=err │
│ 1612 │ │ │ ) │
│ 1613 │ │ else: │
│ ❱ 1614 │ │ │ return meth(self, args_10style, kwargs_10style, execution_options) │
│ 1615 │ │
│ 1616 │ def exec_driver_sql( │
│ 1617 │ │ self, statement, parameters=None, execution_options=None │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/sql/elements.py:325 in │
│ _execute_on_connection │
│ │
│ 322 │ │ self, connection, multiparams, params, execution_options, _force=False │
│ 323 │ ): │
│ 324 │ │ if _force or self.supports_execution: │
│ ❱ 325 │ │ │ return connection._execute_clauseelement( │
│ 326 │ │ │ │ self, multiparams, params, execution_options │
│ 327 │ │ │ ) │
│ 328 │ │ else: │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/base.py:1481 in │
│ _execute_clauseelement │
│ │
│ 1478 │ │ │ schema_translate_map=schema_translate_map, │
│ 1479 │ │ │ linting=self.dialect.compiler_linting | compiler.WARN_LINTING, │
│ 1480 │ │ ) │
│ ❱ 1481 │ │ ret = self._execute_context( │
│ 1482 │ │ │ dialect, │
│ 1483 │ │ │ dialect.execution_ctx_cls._init_compiled, │
│ 1484 │ │ │ compiled_sql, │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/base.py:1708 in │
│ _execute_context │
│ │
│ 1705 │ │ except (exc.PendingRollbackError, exc.ResourceClosedError): │
│ 1706 │ │ │ raise │
│ 1707 │ │ except BaseException as e: │
│ ❱ 1708 │ │ │ self._handle_dbapi_exception( │
│ 1709 │ │ │ │ e, util.text_type(statement), parameters, None, None │
│ 1710 │ │ │ ) │
│ 1711 │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/base.py:2026 in │
│ _handle_dbapi_exception │
│ │
│ 2023 │ │ │ if newraise: │
│ 2024 │ │ │ │ util.raise_(newraise, with_traceback=exc_info[2], from_=e) │
│ 2025 │ │ │ elif should_wrap: │
│ ❱ 2026 │ │ │ │ util.raise_( │
│ 2027 │ │ │ │ │ sqlalchemy_exception, with_traceback=exc_info[2], from_=e │
│ 2028 │ │ │ │ ) │
│ 2029 │ │ │ else: │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/util/compat.py:207 in raise_ │
│ │
│ 204 │ │ │ exception.__cause__ = replace_context │
│ 205 │ │ │
│ 206 │ │ try: │
│ ❱ 207 │ │ │ raise exception │
│ 208 │ │ finally: │
│ 209 │ │ │ # credit to │
│ 210 │ │ │ # https://cosmicpercolator.com/2016/01/13/exception-leaks-in-python-2-and-3/ │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/base.py:1702 in │
│ _execute_context │
│ │
│ 1699 │ │ │ if conn is None: │
│ 1700 │ │ │ │ conn = self._revalidate_connection() │
│ 1701 │ │ │ │
│ ❱ 1702 │ │ │ context = constructor( │
│ 1703 │ │ │ │ dialect, self, conn, execution_options, *args, **kw │
│ 1704 │ │ │ ) │
│ 1705 │ │ except (exc.PendingRollbackError, exc.ResourceClosedError): │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/default.py:1078 in │
│ _init_compiled │
│ │
│ 1075 │ │ │ │ │ │ for key in compiled_params │
│ 1076 │ │ │ │ │ } │
│ 1077 │ │ │ │ else: │
│ ❱ 1078 │ │ │ │ │ param = { │
│ 1079 │ │ │ │ │ │ key: processors[key](compiled_params[key]) │
│ 1080 │ │ │ │ │ │ if key in processors │
│ 1081 │ │ │ │ │ │ else compiled_params[key] │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/default.py:1079 in │
│ <dictcomp> │
│ │
│ 1076 │ │ │ │ │ } │
│ 1077 │ │ │ │ else: │
│ 1078 │ │ │ │ │ param = { │
│ ❱ 1079 │ │ │ │ │ │ key: processors[key](compiled_params[key]) │
│ 1080 │ │ │ │ │ │ if key in processors │
│ 1081 │ │ │ │ │ │ else compiled_params[key] │
│ 1082 │ │ │ │ │ │ for key in compiled_params │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/pgvector/sqlalchemy/__init__.py:21 in │
│ process │
│ │
│ 18 │ │
│ 19 │ def bind_processor(self, dialect): │
│ 20 │ │ def process(value): │
│ ❱ 21 │ │ │ return to_db(value, self.dim) │
│ 22 │ │ return process │
│ 23 │ │
│ 24 │ def result_processor(self, dialect, coltype): │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/pgvector/utils/__init__.py:35 in to_db │
│ │
│ 32 │ │ value = value.tolist() │
│ 33 │ │
│ 34 │ if dim is not None and len(value) != dim: │
│ ❱ 35 │ │ raise ValueError('expected %d dimensions, not %d' % (dim, len(value))) │
│ 36 │ │
│ 37 │ return '[' + ','.join([str(float(v)) for v in value]) + ']' │
│ 38 │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
StatementError: (builtins.ValueError) expected 1536 dimensions, not 768
[SQL: INSERT INTO langchain_pg_embedding (uuid, collection_id, embedding, document, cmetadata, custom_id) VALUES
(%(uuid)s, %(collection_id)s, %(embedding)s, %(document)s, %(cmetadata)s, %(custom_id)s)]
[parameters: [{'embedding': [0.10074684768915176, 0.00936161819845438, 0.01689612865447998, 0.00424081739038229,
0.01892073266208172, 0.02156691998243332, -0.00793 ... (174655 characters truncated) ...
UUID('65a530b7-bcd4-47a2-a2df-e22fb3c353d2'), 'custom_id': '8daf3193-cf95-11ed-aea8-482ae319f16c', 'cmetadata':
{'source': 'data/made-up-story.txt'}}]]
``` | PGVector does not work with HuggingFaceEmbeddings | https://api.github.com/repos/langchain-ai/langchain/issues/2219/comments | 18 | 2023-03-31T07:34:07Z | 2024-08-10T16:06:41Z | https://github.com/langchain-ai/langchain/issues/2219 | 1,648,834,828 | 2,219 |
[
"langchain-ai",
"langchain"
] | I'm using this code:
```
aiplugin_tool = AIPluginTool.from_plugin_url("https://xxxx/plugin/.well-known/ai-plugin.json")
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
llm = ChatOpenAI(temperature=0)
extra_info_tool = make_vector_tool("{}/{}".format(os.getcwd(), "extra_info.txt"))
network_tool = load_tools(["requests"])[0]
tools = [network_tool, aiplugin_tool, extra_info_tool]
agent_kwargs = {"prefix": PREFIX, "suffix": SUFFIX}
agent_chain = initialize_agent(
tools, llm, agent="conversational-react-description", verbose=True, agent_kwargs=agent_kwargs, memory=memory, max_iterations=5
)
```
I got this error:
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/langchain/agents/agent.py", line 505, in _call
next_step_output = self._take_next_step(
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/langchain/agents/agent.py", line 423, in _take_next_step
observation = tool.run(
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/langchain/tools/base.py", line 71, in run
raise e
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/langchain/tools/base.py", line 68, in run
observation = self._run(tool_input)
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/langchain/tools/requests/tool.py", line 31, in _run
return self.requests_wrapper.get(url)
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/langchain/requests.py", line 23, in get
return requests.get(url, headers=self.headers).text
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/requests/api.py", line 73, in get
return request("get", url, params=params, **kwargs)
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/requests/api.py", line 59, in request
return session.request(method=method, url=url, **kwargs)
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/requests/sessions.py", line 587, in request
resp = self.send(prep, **send_kwargs)
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/requests/sessions.py", line 701, in send
r = adapter.send(request, **kwargs)
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/requests/adapters.py", line 563, in send
raise SSLError(e, request=request)
requests.exceptions.SSLError: HTTPSConnectionPool(host='www.mamaimai.com', port=443): Max retries exceeded with url: /menu (Caused by SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:1108)')))
here is my ai-plugin.json file:
{
"schema_version": "v1",
"name_for_human": "Mamaimai restaurant order",
"name_for_model": "Mamaimai restaurant food order",
"description_for_human": "A plugin that helps users order and place orders",
"description_for_model": "A plugin that helps users order and place orders",
"auth": {
"type": "none"
},
"api": {
"type": "openapi",
"url": "https://the-graces.com/plugin/openapi.json",
"is_user_authenticated": false
},
"logo_url": "https://the-graces.com/plugin/logo.png",
"contact_email": "longman@daw.global",
"legal_info_url": "https://example.com/legal"
} | Sometimes requests tools connect to a wrong URL while using AIPluginTool. | https://api.github.com/repos/langchain-ai/langchain/issues/2218/comments | 4 | 2023-03-31T06:08:18Z | 2023-09-26T16:12:09Z | https://github.com/langchain-ai/langchain/issues/2218 | 1,648,730,777 | 2,218 |
[
"langchain-ai",
"langchain"
] | > Entering new AgentExecutor chain...
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha]
Action Input: Wolfram Alpha 222+222
Observation: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha] is not a valid tool, try another one.
Thought:Do I need to use a tool? Yes
Action: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha]
Action Input: Wolfram Alpha 222+222
Observation: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha] is not a valid tool, try another one.
Thought:Do I need to use a tool? Yes
Action: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha]
Action Input: Wolfram Alpha what is the solution to 222+222?
Observation: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha] is not a valid tool, try another one.
Thought:Do I need to use a tool? Yes
Action: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha]
Action Input: Wolfram Alpha "what is 222+222?"
Observation: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha] is not a valid tool, try another one.
Thought:Do I need to use a tool? Yes
Action: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha]
Action Input: Wolfram Alpha "solve 222+222"
Observation: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha] is not a valid tool, try another one.
Thought:Do I need to use a tool? Yes
Action: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha]
Action Input: Wolfram Alpha "what is the sum of 222 and 222?"
Observation: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha] is not a valid tool, try another one.
Thought:Do I need to use a tool? Yes
Action: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha]
Action Input: Wolfram Alpha "what is 222+222" | Failed to decide which tool to use. | https://api.github.com/repos/langchain-ai/langchain/issues/2217/comments | 3 | 2023-03-31T05:26:32Z | 2023-09-25T16:13:33Z | https://github.com/langchain-ai/langchain/issues/2217 | 1,648,693,829 | 2,217 |
[
"langchain-ai",
"langchain"
] | While using the LangChain package to create a Vectorstore index, I encountered an AttributeError in the chroma.py file. The traceback indicates that the 'LocalAPI' object does not have the attribute 'get_or_create_collection'. This issue occurred when trying to create an index using the following code:
`index = VectorstoreIndexCreator().from_loaders([loader])`
Here's the full traceback:
Traceback (most recent call last):
```
File "main.py", line 29, in <module>
index = VectorstoreIndexCreator().from_loaders([loader])
File "/home/runner/VioletWarpedDeclarations/venv/lib/python3.10/site-packages/langchain/indexes/vectorstore.py", line 71, in from_loaders
vectorstore = self.vectorstore_cls.from_documents(
File "/home/runner/VioletWarpedDeclarations/venv/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 268, in from_documents
return cls.from_texts(
File "/home/runner/VioletWarpedDeclarations/venv/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 231, in from_texts
chroma_collection = cls(
File "/home/runner/VioletWarpedDeclarations/venv/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 81, in __init__
self._collection = self._client.get_or_create_collection(
AttributeError: 'LocalAPI' object has no attribute 'get_or_create_collection'. Did you mean: 'create_collection'?
```
It seems like the 'LocalAPI' object is missing the 'get_or_create_collection' method or the method's name might have been changed in the recent updates.
| AttributeError in Chroma: 'LocalAPI' object has no attribute 'get_or_create_collection' | https://api.github.com/repos/langchain-ai/langchain/issues/2213/comments | 4 | 2023-03-31T03:41:39Z | 2023-09-25T16:13:38Z | https://github.com/langchain-ai/langchain/issues/2213 | 1,648,617,710 | 2,213 |
[
"langchain-ai",
"langchain"
] | hi, I want to include json data in the template, the code and error is as follows, please help me to solve it.
```python
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
from langchain.chains import ConversationChain
from langchain.prompts.chat import SystemMessagePromptTemplate
system = r'Me: Set an alarm\nYou: {"content":{"type":"alarm","time":"17:00"}}'
system_prompt = SystemMessagePromptTemplate.from_template(system)
#system_prompt = SystemMessagePromptTemplate.from_template(system.replace('"', '\\"'))
```
the error is:
```bash
Traceback (most recent call last):
File "/mnt/d/works/chatgpt-cli/tt.py", line 8, in <module>
system_prompt = SystemMessagePromptTemplate.from_template(system.replace('"', '\\"'))
File "/home/xlbao/.local/lib/python3.9/site-packages/langchain/prompts/chat.py", line 67, in from_template
prompt = PromptTemplate.from_template(template)
File "/home/xlbao/.local/lib/python3.9/site-packages/langchain/prompts/prompt.py", line 130, in from_template
return cls(input_variables=list(sorted(input_variables)), template=template)
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for PromptTemplate
__root__
Invalid prompt schema; check for mismatched or missing input parameters. '\\"type\\"' (type=value_error)
``` | error when there are quotation marks in prompt template string | https://api.github.com/repos/langchain-ai/langchain/issues/2212/comments | 3 | 2023-03-31T03:21:33Z | 2023-12-06T11:53:08Z | https://github.com/langchain-ai/langchain/issues/2212 | 1,648,605,512 | 2,212 |
[
"langchain-ai",
"langchain"
] | ## Concept
It would be useful if Agents had the ability to fact check their own work using a different LLM in an adversarial manner to "second guess" their assumptions and potentially provide feedback before allowing the final "answer" to surface to the end user.
For example, if a chain completes and an Agent is ready to return its final answer, the "fact checking" functionality (perhaps a Tool) could kick off another chain (with a different model perhaps) to validate the original answer or instruct it to perform more work before the user is given the final answer.
(This is currently an experimental work in progress being done by myself and https://github.com/maxtheman. If you would like to contribute to the effort to test and implement this functionality, feel free to reach out on Discord @jasondotparse ) | Implement "Adversarial fact checking" functionality | https://api.github.com/repos/langchain-ai/langchain/issues/2211/comments | 3 | 2023-03-31T02:15:24Z | 2023-09-26T16:12:14Z | https://github.com/langchain-ai/langchain/issues/2211 | 1,648,559,252 | 2,211 |
[
"langchain-ai",
"langchain"
] | null | Plugin chat gpt | https://api.github.com/repos/langchain-ai/langchain/issues/2208/comments | 2 | 2023-03-31T00:58:01Z | 2023-09-10T16:39:12Z | https://github.com/langchain-ai/langchain/issues/2208 | 1,648,510,025 | 2,208 |
[
"langchain-ai",
"langchain"
] | Greetings. Followed the tutorial and got pretty far, so I know langchain works on the environment (below). However, the following error below appeared out of nowhere. Tried restarting the environment and still getting the same error. Tried pip uninstalling langchain and reinstalling but still outputting the same error.
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from langchain.llms import OpenAI
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\...\langchain.py", line 2, in <module>
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
ImportError: cannot import name 'PromptTemplate' from partially initialized module 'langchain' (most likely due to a circular import) (C:\...\langchain.py) | cannot import name 'PromptTemplate' from partially initialized module 'langchain' (most likely due to a circular import) | https://api.github.com/repos/langchain-ai/langchain/issues/2206/comments | 0 | 2023-03-30T23:03:17Z | 2023-03-30T23:19:52Z | https://github.com/langchain-ai/langchain/issues/2206 | 1,648,435,963 | 2,206 |
[
"langchain-ai",
"langchain"
] | I am using langchain in CoLab and have come across this ChromaDB/VectorStore problem a few times, mostly recently with the code below. The piece of text I am importing is only a few hundred characters. I found this issue on the ChromaDB repository: https://github.com/chroma-core/chroma/issues/225, which is the same or similar issue. This made be think it might be that I didn't need to split the text, but it makes no difference when hashed out the text splitter lines. Any thoughts on what might the issue here?
loader = TextLoader('./report.txt')
documents = loader.load()
#text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
#texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
report_store = Chroma.from_documents(documents, embeddings, collection_name="report")
llm = OpenAI(temperature=0)
vectorstore_info = VectorStoreInfo(name="report", description="the most recent weekly API report", vectorstore=report_store)
toolkit = VectorStoreToolkit(vectorstore_info=vectorstore_info)
agent_executor = create_vectorstore_agent(llm=llm, toolkit=toolkit, verbose=True)
agent_executor.run("How many APIs were in the Red Zone this week?")
> Entering new AgentExecutor chain...
I need to find out the answer from the report
Action: report
Action Input: How many APIs were in the Red Zone this week?
---------------------------------------------------------------------------
NotEnoughElementsException Traceback (most recent call last)
[<ipython-input-21-22938c4f7204>](https://localhost:8080/#) in <cell line: 1>()
----> 1 agent_executor.run("How many APIs were in the Red Zone this week?")
18 frames
[/usr/local/lib/python3.9/dist-packages/chromadb/db/index/hnswlib.py](https://localhost:8080/#) in get_nearest_neighbors(self, query, k, ids)
226
227 if k > self._index_metadata["elements"]:
--> 228 raise NotEnoughElementsException(
229 f"Number of requested results {k} cannot be greater than number of elements in index {self._index_metadata['elements']}"
230 )
NotEnoughElementsException: Number of requested results 4 cannot be greater than number of elements in index 1 | ChromaDB/VectorStore Problem: "NotEnoughElementsException: Number of requested results 4 cannot be greater than number of elements in index 1" | https://api.github.com/repos/langchain-ai/langchain/issues/2205/comments | 7 | 2023-03-30T22:36:23Z | 2023-09-26T16:12:18Z | https://github.com/langchain-ai/langchain/issues/2205 | 1,648,415,099 | 2,205 |
[
"langchain-ai",
"langchain"
] | WARNING:langchain.llms.openai:Retrying langchain.llms.openai.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
**Does anyone has a solution for this error ??**
| Rate limit error when using davinci model | https://api.github.com/repos/langchain-ai/langchain/issues/2204/comments | 6 | 2023-03-30T21:11:48Z | 2023-03-31T20:16:02Z | https://github.com/langchain-ai/langchain/issues/2204 | 1,648,328,520 | 2,204 |
[
"langchain-ai",
"langchain"
] | I want to know if I am use this example to upload a text which exceeds 4097 tokens, it will definitely report an error because which passed the text_splitter takes 4000 as a block default, and then takes the first three segments. This way, the token passed into the model must be greater than 4097, even if the chain_ type="map_reduce"
[https://python.langchain.com/en/latest/modules/chains/index_examples/summarize.html](https://python.langchain.com/en/latest/modules/chains/index_examples/summarize.html)
Sorry, I'm a novice coder. I've been looking for a chain for the past two days, which can help me solve the problem of long text summary summaries. I see a map_reduce seems to work, but after my testing, it doesn't work. can you tell me if there are any encapsulated methods for handling chains with more than 4097 tokens besides their own word segmentation recursion." | summarization | https://api.github.com/repos/langchain-ai/langchain/issues/2192/comments | 2 | 2023-03-30T11:58:21Z | 2023-09-18T16:21:48Z | https://github.com/langchain-ai/langchain/issues/2192 | 1,647,474,312 | 2,192 |
[
"langchain-ai",
"langchain"
] | Hi,
I want to use a model deployment from Azure for embeddings (I use version 0.0.123 of langchain). Like this:
```python
AzureOpenAI(
deployment_name="<my deployment name>",
model_name="text-embedding-ada-002",
...
)
```
But I get 'The API deployment for this resource does not exist.' in the response.
I debugged the code and noticed that the wrong engine name was provided to the Azure API:
In [openai.py](https://github.com/hwchase17/langchain/blob/master/langchain/embeddings/openai.py#L257), the `model_name` is put in the `engine` parameter, but `deployment_name` should be used for Azure. | AzureOpenAI wrong engine name | https://api.github.com/repos/langchain-ai/langchain/issues/2190/comments | 1 | 2023-03-30T11:51:06Z | 2023-09-10T16:39:21Z | https://github.com/langchain-ai/langchain/issues/2190 | 1,647,464,242 | 2,190 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.