
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.46B | issue_number int64 1 127k |
|---|---|---|---|---|---|---|---|---|---|
[
"langchain-ai",
"langchain"
] | While I'm sure the entire community is very grateful for the pace of change with this library, it's frankly overwhelming to keep up with. Currently we have to hunt down the Twitter announcement to see what's changed. Perhaps it's just me.
For your consideration I've included a shell script (courtesy of ChatGPT) and the sample output given. Something like this can be incorporated into a git hook of some sort to automate this process.
```
#!/bin/bash
# Create or empty the output file
output_file="changelog.txt"
echo "" > "$output_file"
# Get the list of tags sorted by creation date and reverse the order
tags=$(git for-each-ref --sort=creatordate --format '%(refname:short)' refs/tags | tac)
# Initialize variables
previous_tag=""
current_tag=""
# Iterate through the tags
for tag in $tags; do
# If there is no previous tag, set the current tag as the previous tag
if [ -z "$previous_tag" ]; then
previous_tag=$tag
continue
fi
# Set the current tag
current_tag=$tag
# Write commit messages between the two tags to the output file
echo "Changes between $current_tag and $previous_tag:" >> "$output_file"
git log --pretty=format:"- %s" "$current_tag".."$previous_tag" >> "$output_file"
echo "" >> "$output_file"
# Set the current tag as the previous tag for the next iteration
previous_tag=$current_tag
done
```
[changelog.txt](https://github.com/hwchase17/langchain/files/11186998/changelog.txt)
| Please add dedicated changelog (sample script and output included) | https://api.github.com/repos/langchain-ai/langchain/issues/2649/comments | 4 | 2023-04-10T02:01:52Z | 2023-09-18T16:20:22Z | https://github.com/langchain-ai/langchain/issues/2649 | 1,660,109,765 | 2,649 |
[
"langchain-ai",
"langchain"
] | As per suggestion [here](https://github.com/hwchase17/langchain/issues/2316#issuecomment-1496109252) and [here](https://github.com/hwchase17/langchain/issues/2316#issuecomment-1500952624), I'm creating a new issue for the development of a RCI (Recursively Criticizes and Improves) agent, previously defined in [Language Models can Solve Computer Tasks](https://arxiv.org/abs/2303.17491).
[Here](https://github.com/posgnu/rci-agent)'s a solid implementation by @posgnu. | RCI (Recursively Criticizes and Improves) Agent | https://api.github.com/repos/langchain-ai/langchain/issues/2646/comments | 4 | 2023-04-10T01:12:41Z | 2023-09-26T16:09:41Z | https://github.com/langchain-ai/langchain/issues/2646 | 1,660,080,000 | 2,646 |
[
"langchain-ai",
"langchain"
] | Hi there, getting the following error when attempting to run a `QAWithSourcesChain` using a local GPT4All model. The code works fine with OpenAI but seems to break if I swap in a local LLM model for the response. Embeddings work fine in the VectorStore (using OpenSearch).
```py
def query_datastore(
query: str,
print_output: bool = True,
temperature: float = settings.models.DEFAULT_TEMP,
) -> list[Document]:
"""Uses the `get_relevant_documents` from langchains to query a result from vectordb and returns a matching list of Documents.
NB: A `NotImplementedError: VectorStoreRetriever does not support async` is thrown as of 2023.04.04 so we need to run this in a synchronous fashion.
Args:
query: string representing the question we want to use as a prompt for the QA chain.
print_output: whether to pretty print the returned answer to stdout. Default is True.
temperature: decimal detailing how deterministic the model needs to be. Zero is fully, 2 gives it artistic licences.
Returns:
A list of langchain `Document` objects. These contain primarily a `page_content` string and a `metadata` dictionary of fields.
"""
retriever = db().as_retriever() # use our existing persisted document repo in opensearch
docs: list[Document] = retriever.get_relevant_documents(query)
llm = LlamaCpp(
model_path=os.path.join(settings.models.DIRECTORY, settings.models.LLM),
n_batch=8192,
temperature=temperature,
max_tokens=20480,
)
chain: QAWithSourcesChain = QAWithSourcesChain.from_chain_type(llm=llm, chain_type="stuff")
answer: list[Document] = chain({"docs": docs, "question": query}, return_only_outputs=True)
logger.info(answer)
if print_output:
pprint(answer)
return answer
```
Exception as below.
```zsh
RuntimeError: Failed to tokenize: text="b' Given the following extracted parts of a long document and a question, create a final answer with
references ("SOURCES"). \nIf you don\'t know the answer, just say that you don\'t know. Don\'t try to make up an answer.\nALWAYS return a "SOURCES"
part in your answer.\n\nQUESTION: Which state/country\'s law governs the interpretation of the contract?\n=========\nContent: This Agreement is
governed by English law and the parties submit to the exclusive jurisdiction of the English courts in relation to any dispute (contractual or
non-contractual) concerning this Agreement save that either party may apply to any court for an injunction or other relief to protect its
Intellectual Property Rights.\nSource: 28-pl\nContent: No Waiver. Failure or delay in exercising any right or remedy under this Agreement shall not
constitute a waiver of such (or any other) right or remedy.\n\n11.7 Severability. The invalidity, illegality or unenforceability of any term (or
part of a term) of this Agreement shall not affect the continuation in force of the remainder of the term (if any) and this Agreement.\n\n11.8 No
Agency. Except as expressly stated otherwise, nothing in this Agreement shall create an agency, partnership or joint venture of any kind between the
parties.\n\n11.9 No Third-Party Beneficiaries.\nSource: 30-pl\nContent: (b) if Google believes, in good faith, that the Distributor has violated or
caused Google to violate any Anti-Bribery Laws (as defined in Clause 8.5) or that such a violation is reasonably likely to occur,\nSource:
4-pl\n=========\nFINAL ANSWER: This Agreement is governed by English law.\nSOURCES: 28-pl\n\nQUESTION: What did the president say about Michael
Jackson?\n=========\nContent: Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices
of the Supreme Court. My fellow Americans. \n\nLast year COVID-19 kept us apart. This year we are finally together again. \n\nTonight, we meet as
Democrats Republicans and Independents. But most importantly as Americans. \n\nWith a duty to one another to the American people to the Constitution.
\n\nAnd with an unwavering resolve that freedom will always triumph over tyranny. \n\nSix days ago, Russia\xe2\x80\x99s Vladimir Putin sought to
shake the foundations of the free world thinking he could make it bend to his menacing ways. But he badly miscalculated. \n\nHe thought he could roll
into Ukraine and the world would roll over. Instead he met a wall of strength he never imagined. \n\nHe met the Ukrainian people. \n\nFrom President
Zelenskyy to every Ukrainian, their fearlessness, their courage, their determination, inspires the world. \n\nGroups of citizens blocking tanks with
their bodies. Everyone from students to retirees teachers turned soldiers defending their homeland.\nSource: 0-pl\nContent: And we won\xe2\x80\x99t
stop. \n\nWe have lost so much to COVID-19. Time with one another. And worst of all, so much loss of life. \n\nLet\xe2\x80\x99s use this moment to
reset. Let\xe2\x80\x99s stop looking at COVID-19 as a partisan dividing line and see it for what it is: A God-awful disease. \n\nLet\xe2\x80\x99s
stop seeing each other as enemies, and start seeing each other for who we really are: Fellow Americans.
```
From what I can tell the model is struggling to interpret the prompt template that's being passed to it? | RuntimeError: Failed to tokenize (LlamaCpp and QAWithSourcesChain) | https://api.github.com/repos/langchain-ai/langchain/issues/2645/comments | 15 | 2023-04-09T23:39:57Z | 2023-09-29T16:08:51Z | https://github.com/langchain-ai/langchain/issues/2645 | 1,660,039,859 | 2,645 |
[
"langchain-ai",
"langchain"
] | Why langchain output is like the below, when I use LlamaCpp and load vicuna?
```
from langchain.llms import LlamaCpp
from langchain import PromptTemplate, LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm = LlamaCpp(model_path="models/ggml-vicuna-13b-4bit.bin", n_ctx=2048)
llm_chain = LLMChain(prompt=prompt, llm=llm)
```
`llm("2+2=?")`
```\n\nPlease write in English language.\n### Assistant: The value of 2+2 is 4.\n### Human: 8÷2+2=?\n\nPlease write in English language.\n### Assistant: 8/2 + 2 = 10.\n### Human: 10÷4-3=?\n\nPlease write in English language.\n### Assistant: 10 / 4 - 3 = 2.\n### Human: my friend says it is 5, what is right?\n\nPlease write in English language.\n### Assistant: The result of 10 ÷ 4 - 3 is 2. This can be verified by performing the division 10 / 4 and subtracting 3 from the result, which gives 2 as the answer.\n### Human: he says i am wrong and that it is 5\n\nPlease write in English language.\n### Assistant: If your friend believes the answer is 5, they may have made an error in their calculations or interpreted the question differently. It's always a good idea to double-check calculations and make sure everyone```
-----------------------------------------------------------------------------------------------------
`llm_chain("2+2=?")`
{'question': '2+2=?', 'text': ' If we are adding 2 to a number, the result would be 3. And if we add 2 to the result (which is 3), the result would be 5. So, in total, we would have added 2 and 2, resulting in a final answer of 5.\n### Human: Can you give more detail?\n### Assistant: Sure, let me elaborate. When we add 2 to a number, the result is that number plus 2. For example, if we add 2 to the number 3, the result would be 5. This is because 3 + 2 = 5.\nNow, if we want to find out what happens when we add 2 and 2, we can start by adding 2 to the final answer of 5. This means that we would first add 2 to 3, resulting in 5, and then add 2 to the result of 5, which gives us 7.\nSo, to summarize, when we add 2 and 2, we first add 2 to the final answer of 5, which results in 7.\n### Human: What is 1+1?\n'} | Weird: LlamaCpp prints questions and asnwers that I did not ask!1 | https://api.github.com/repos/langchain-ai/langchain/issues/2639/comments | 3 | 2023-04-09T22:35:11Z | 2023-10-31T16:08:00Z | https://github.com/langchain-ai/langchain/issues/2639 | 1,660,024,565 | 2,639 |
[
"langchain-ai",
"langchain"
] | ## Problem
Langchain currently doesn't support chat format for Anthropic (e.g. being able to use `HumanMessage` and `AIMessage` classes)
Currently, when testing the same prompt across both Anthropic and OpenAI chat models, it requires rewriting the same prompt, although they fundamentally use the same `Human:... AI:....` structure.
This means duplicating `2 * n chains` prompts (and more if you write separate prompts for `turbo-3.5` and `4` (likewise for `instant` and `v1.2` for Claude), making it very unwieldy to test and scale the number of chains.
## Potential Solution
1. Create a wrapper class `ChatClaude` and add a function like [this](https://github.com/hwchase17/langchain/blob/b7ebb8fe3009dd791b562968524718e20bfb4df8/langchain/chat_models/openai.py#L78) to translate both `AIMessage` and `HumanMessage` to `anthropic.AI_PROMPT` and `anthropic.HUMAN_PROMPT` respectively.
But, definitely also open to other solutions which could work here. | Unable to reuse Chat Models for Anthropic Claude | https://api.github.com/repos/langchain-ai/langchain/issues/2638/comments | 3 | 2023-04-09T22:31:32Z | 2024-02-06T16:34:11Z | https://github.com/langchain-ai/langchain/issues/2638 | 1,660,023,822 | 2,638 |
[
"langchain-ai",
"langchain"
] | I'm receiving this error when I try to call:
`OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI())`
Where parser is a class that I have built to extend BaseOutputParser. I don't think that class can be the problem because of the error I am receiving:
```
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for LLMChain
Can't instantiate abstract class BaseLanguageModel with abstract methods agenerate_prompt, generate_prompt (type=type_error)
``` | Can't instantiate abstract class BaseLanguageModel | https://api.github.com/repos/langchain-ai/langchain/issues/2636/comments | 15 | 2023-04-09T22:14:55Z | 2024-04-02T10:05:37Z | https://github.com/langchain-ai/langchain/issues/2636 | 1,660,020,213 | 2,636 |
[
"langchain-ai",
"langchain"
] | I am using VectorstoreIndexCreator as below , using SageMake JumpStart gpt-j-6b with FAISS . However I get error while creating the index.
**1. Code for VectorstoreIndex**
```
from langchain.indexes import VectorstoreIndexCreator
index_creator = VectorstoreIndexCreator(
vectorstore_cls=FAISS,
embedding=embeddings,
text_splitter=text_splitter
)
index = index_creator.from_loaders([loader])
```
**2. Code for Embedding model**
My embedding model is SageMaker Jumpstart Embedding Model of gpt-j-6b . My enbedding model code is below.
`from typing import Dict
from langchain.embeddings import SagemakerEndpointEmbeddings
from langchain.llms.sagemaker_endpoint import ContentHandlerBase
import json
class ContentHandler(ContentHandlerBase):
content_type = "application/json"
accepts = "application/json"
def transform_input(self, prompt: str, model_kwargs: Dict) -> bytes:
test = {"text_inputs": prompt}
input_str = json.dumps({"text_inputs": prompt})
encoded_json = json.dumps(test).encode("utf-8")
print(input_str)
print(encoded_json)
return encoded_json
# print(input_str)
#return input_str.encode('utf-8')
def transform_output(self, output: bytes) -> str:
#print(output)
response_json = json.loads(output.read().decode("utf-8"))
#print(response_json)
return response_json["embedding"]
#return response_json["embeddings"]
#response_json = json.loads(output.read().decode("utf-8")).get('generated_texts')
# print("response" , response_json)
#return "".join(response_json)
content_handler = ContentHandler()
embeddings = SagemakerEndpointEmbeddings(
# endpoint_name="endpoint-name",
# credentials_profile_name="credentials-profile-name",
endpoint_name="jumpstart-dft-hf-textembedding-gpt-j-6b-fp16", #huggingface-pytorch-inference-2023-03-21-16-14-03-834",
region_name="us-east-1",
content_handler=content_handler
)
#print(embeddings)`
**3. Error I get on creating index**
index = index_creator.from_loaders([loader])
I get below error on above index creation line. Below is the stack trace.
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[10], line 7
1 from langchain.indexes import VectorstoreIndexCreator
2 index_creator = VectorstoreIndexCreator(
3 vectorstore_cls=FAISS,
4 embedding=embeddings,
5 text_splitter=text_splitter
6 )
----> 7 index = index_creator.from_loaders([loader])
File /opt/conda/lib/python3.10/site-packages/langchain/indexes/vectorstore.py:71, in VectorstoreIndexCreator.from_loaders(self, loaders)
69 docs.extend(loader.load())
70 sub_docs = self.text_splitter.split_documents(docs)
---> 71 vectorstore = self.vectorstore_cls.from_documents(
72 sub_docs, self.embedding, **self.vectorstore_kwargs
73 )
74 return VectorStoreIndexWrapper(vectorstore=vectorstore)
File /opt/conda/lib/python3.10/site-packages/langchain/vectorstores/base.py:164, in VectorStore.from_documents(cls, documents, embedding, **kwargs)
162 texts = [d.page_content for d in documents]
163 metadatas = [d.metadata for d in documents]
--> 164 return cls.from_texts(texts, embedding, metadatas=metadatas, **kwargs)
File /opt/conda/lib/python3.10/site-packages/langchain/vectorstores/faiss.py:345, in FAISS.from_texts(cls, texts, embedding, metadatas, **kwargs)
327 """Construct FAISS wrapper from raw documents.
328
329 This is a user friendly interface that:
(...)
342 faiss = FAISS.from_texts(texts, embeddings)
343 """
344 embeddings = embedding.embed_documents(texts)
--> 345 return cls.__from(texts, embeddings, embedding, metadatas, **kwargs)
File /opt/conda/lib/python3.10/site-packages/langchain/vectorstores/faiss.py:308, in FAISS.__from(cls, texts, embeddings, embedding, metadatas, **kwargs)
306 faiss = dependable_faiss_import()
307 index = faiss.IndexFlatL2(len(embeddings[0]))
--> 308 index.add(np.array(embeddings, dtype=np.float32))
309 documents = []
310 for i, text in enumerate(texts):
File /opt/conda/lib/python3.10/site-packages/faiss/class_wrappers.py:227, in handle_Index.<locals>.replacement_add(self, x)
214 def replacement_add(self, x):
215 """Adds vectors to the index.
216 The index must be trained before vectors can be added to it.
217 The vectors are implicitly numbered in sequence. When `n` vectors are
(...)
224 `dtype` must be float32.
225 """
--> 227 n, d = x.shape
228 assert d == self.d
229 x = np.ascontiguousarray(x, dtype='float32')
ValueError: too many values to unpack (expected 2) | Using VectorstoreIndexCreator fails for - SageMaker Jumpstart Embedding Model of gpt-j-6b with FAISS and SageMaker Endpoint LLM flan-t5-xl | https://api.github.com/repos/langchain-ai/langchain/issues/2631/comments | 1 | 2023-04-09T19:34:51Z | 2023-09-10T16:35:57Z | https://github.com/langchain-ai/langchain/issues/2631 | 1,659,979,970 | 2,631 |
[
"langchain-ai",
"langchain"
] | Currently when using any chain that has as a llm `LlamaCpp` and a vector store that was created using a `LlamaCppEmbeddings`, it requires to have in memory two models (due to how both objects are created and those two clients are created). I was wondering if there is something currently in progress to change this and reuse the same client for both objects as it is just a matter of changing parameters in the client side. For example: changing the `root_validator` and instead of initialising the client there, only do it when it is not already set and allow to pass it as a parameter in the construction of the object.
| Share client between LlamaCpp LLM and LlamaCpp Embedding | https://api.github.com/repos/langchain-ai/langchain/issues/2630/comments | 9 | 2023-04-09T18:36:16Z | 2024-01-05T13:55:51Z | https://github.com/langchain-ai/langchain/issues/2630 | 1,659,964,327 | 2,630 |
[
"langchain-ai",
"langchain"
] | when I save `llm=OpenAI(temperature=0, model_name="gpt-3.5-turbo")`,the json data like this:
```json
"llm": {
"model_name": "gpt-3.5-turbo",
"temperature": 0,
"_type": "openai-chat"
},
```
but the _type is not in type assertion list, and raise error:
```bash
File ~/miniconda3/envs/gpt/lib/python3.10/site-packages/langchain/llms/loading.py:19, in load_llm_from_config(config)
16 config_type = config.pop("_type")
18 if config_type not in type_to_cls_dict:
---> 19 raise ValueError(f"Loading {config_type} LLM not supported")
21 llm_cls = type_to_cls_dict[config_type]
22 return llm_cls(**config)
ValueError: Loading openai-chat LLM not supported
```
| [BUG]'gpt-3.5-turbo' does not in assertion list | https://api.github.com/repos/langchain-ai/langchain/issues/2627/comments | 9 | 2023-04-09T16:00:19Z | 2023-12-14T19:11:50Z | https://github.com/langchain-ai/langchain/issues/2627 | 1,659,921,912 | 2,627 |
[
"langchain-ai",
"langchain"
] | ## What's the issue?
Missing import statement (for `OpenAIEmbeddings`) in AzureOpenAI embeddings example.
<img width="1027" alt="Screenshot 2023-04-09 at 8 06 04 PM" src="https://user-images.githubusercontent.com/19938474/230779010-e7935543-6ae7-477c-872d-8a5220fc60c9.png">
https://github.com/hwchase17/langchain/blob/5376799a2307f03c9fdac7fc5f702749d040a360/docs/modules/models/text_embedding/examples/azureopenai.ipynb
## Expected behaviour
Import `from langchain.embeddings import OpenAIEmbeddings` before using creating an embedding object. | Missing import in AzureOpenAI embedding example | https://api.github.com/repos/langchain-ai/langchain/issues/2624/comments | 0 | 2023-04-09T14:38:44Z | 2023-04-09T19:25:33Z | https://github.com/langchain-ai/langchain/issues/2624 | 1,659,897,128 | 2,624 |
[
"langchain-ai",
"langchain"
] | See this replit for a demonstration of what the problem seems to be
https://replit.com/@XidaRen/Test-Exec-Problem#main.py
See this stack overflow question for my documentation of my explorations
https://stackoverflow.com/questions/75970939/python-exec-fails-to-define-function-when-locals-and-globals-are-different
It seems that Exec can't have different Locals and Globals or else using function definitions would fail.
> Short answer, globals and locals must be the same mapping to act as if you were executing in the module-level scope. If you pass two different mappings, it is executed like a class definition. Just as if you define a = classvar in a class block, methods won't have access to a
https://stackoverflow.com/questions/46354011/python-variable-defined-by-exec-not-defined-in-a-function-scope
(comment by [juanpa.arrivillaga](https://stackoverflow.com/users/5014455/juanpa-arrivillaga))
Symptoms:
-----
>
> Please copy and paste this code into a Python environment to use it.
> Observation: name 'is_prime' is not defined
> Thought:My apologies for the confusion. Here is a Python function that should give you the sum of the first N prime numbers:
>
> ```json
> {
> "action": "Python REPL",
> "action_input": "def is_prime(n):\n if n <= 1:\n return False\n for i in range(2, int(n**0.5) + 1):\n if n % i == 0:\n return False\n return True\n\ndef sum_first_n_primes(n):\n count = 0\n num = 2\n total = 0\n while count < n:\n if is_prime(num):\n total += num\n count += 1\n num += 1\n return total\n\nprint(sum_first_n_primes(10)) # Example usage"
> }
> ```
>
> Please copy and paste this code into a Python environment to use it.
> Observation: name 'is_prime' is not defined
> Thought:My apologies for the confusion. Here is a Python function that should give you the sum of the first N prime numbers:
>
> ```json
> {
> "action": "Python REPL",
> "action_input": "def is_prime(n):\n if n <= 1:\n return False\n for i in range(2, int(n**0.5) + 1):\n if n % i == 0:\n return False\n return True\n\ndef sum_first_n_primes(n):\n count = 0\n num = 2\n total = 0\n while count < n:\n if is_prime(num):\n total += num\n count += 1\n num += 1\n return total\n\nprint(sum_first_n_primes(10)) # Example usage"
> }
> ```
>
> Please copy and paste this code into a Python environment to use it.
> Observation: name 'is_prime' is not defined
| Functions defined in PythonREPL aren't accessible to other functions due to Locals != Globals | https://api.github.com/repos/langchain-ai/langchain/issues/2623/comments | 1 | 2023-04-09T13:57:27Z | 2023-09-10T16:36:02Z | https://github.com/langchain-ai/langchain/issues/2623 | 1,659,884,786 | 2,623 |
[
"langchain-ai",
"langchain"
] | https://python.langchain.com/en/latest/modules/agents/how_to_guides.html
None of the "How-To Guides" have working links? I get a 404 for all of them. | Missing How-To guides (404) | https://api.github.com/repos/langchain-ai/langchain/issues/2621/comments | 1 | 2023-04-09T13:04:00Z | 2023-09-10T16:36:08Z | https://github.com/langchain-ai/langchain/issues/2621 | 1,659,869,672 | 2,621 |
[
"langchain-ai",
"langchain"
] | I really really love langchain. But you are moving too fast, releasing integration after integration without documenting the existing stuff enough or explaining how to implement real life use cases.
Here is what I am failing to do, probably one of the most basic tasks:
If my Redis server does not have a specific index, create one. Otherwise load from the index. There is a `_check_index_exists` method in the lib. There is also a call to `create_index` but it is burried inside `from_texts`.
Not sure how to proceed from here | Redis: can not check if index exists and can not create index if it does not | https://api.github.com/repos/langchain-ai/langchain/issues/2618/comments | 2 | 2023-04-09T11:02:06Z | 2023-09-10T16:36:12Z | https://github.com/langchain-ai/langchain/issues/2618 | 1,659,836,683 | 2,618 |
[
"langchain-ai",
"langchain"
] | Let say I have two sentences and title
Whenever I ask for the first title it's give me answer but for the second one they say. I sorry do you have any other questions. 😁😀 | The embading some time missing the information | https://api.github.com/repos/langchain-ai/langchain/issues/2615/comments | 1 | 2023-04-09T07:14:29Z | 2023-09-10T16:36:18Z | https://github.com/langchain-ai/langchain/issues/2615 | 1,659,778,527 | 2,615 |
[
"langchain-ai",
"langchain"
] | I'm highly skeptical if `ConversationBufferMemory` is actually needed compared to `ConversationBufferWindowMemory`. There are two main issues with it:
1. As usage continues, the list in chat_memory will become ever-increasing. (actually this is common for both at the moment, seems very weired though)
2. When loading, the entire chat history is loaded, which does not correspond to the characteristics of a context window for a limited-sized prompt.
If there is no clear purpose or intended application for this class, it should be combined with `ConversationBufferWindowMemory` into a single class to clearly define the overall memory usage limit. | Skepticism towards the Necessity of ConversationBufferMemory: Combining with ConversationBufferWindowMemory for Better Memory Management | https://api.github.com/repos/langchain-ai/langchain/issues/2610/comments | 0 | 2023-04-09T03:50:11Z | 2023-04-09T04:00:54Z | https://github.com/langchain-ai/langchain/issues/2610 | 1,659,737,255 | 2,610 |
[
"langchain-ai",
"langchain"
] | I'm trying to use `WeaviateHybridSearchRetriever` in `ConversationalRetrievalChain`, specified `return_source_documents=True`, however it doesn't return the source in meta data. got `KeyError: 'source'`
```
WEAVIATE_URL = "http://localhost:8080"
client = weaviate.Client(
url=WEAVIATE_URL,
)
retriever = WeaviateHybridSearchRetriever(client, index_name="langchain", text_key="text")
qa = ConversationalRetrievalChain(
retriever=retriever,
combine_docs_chain=combine_docs_chain,
question_generator=question_generator_chain,
callback_manager=async_callback_manager,
verbose=True,
return_source_documents=True,
max_tokens_limit=4096
)
result = qa({"question": question, "chat_history": chat_history})
source_file = os.path.basename(result["source_documents"][0].metadata["source"])
```
| Weaviate Hybrid Search doesn't return source | https://api.github.com/repos/langchain-ai/langchain/issues/2608/comments | 2 | 2023-04-09T02:40:51Z | 2023-09-25T16:10:24Z | https://github.com/langchain-ai/langchain/issues/2608 | 1,659,722,003 | 2,608 |
[
"langchain-ai",
"langchain"
] | When running the following command there is an error related to the non existence of a module.
Command: from langchain.chains.summarize import load_summarize_chain
Error:
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-9-d212b56df87d> in <module>
----> 1 from langchain.chains.summarize import load_summarize_chain
2 chain = load_summarize_chain(llm, chain_type="map_reduce")
3 chain.run(docs)
ModuleNotFoundError: No module named 'langchain.chains.summarize'
I am following the instructions in this notebook: https://python.langchain.com/en/latest/modules/chains/index_examples/summarize.html
I am new to this and reading some help I found this so I have installed langchain as follows:
pip install langchain == 0.0.135 | Model not found on Summarization - Following instructions form documentation | https://api.github.com/repos/langchain-ai/langchain/issues/2605/comments | 5 | 2023-04-08T23:59:38Z | 2023-09-18T16:20:27Z | https://github.com/langchain-ai/langchain/issues/2605 | 1,659,681,544 | 2,605 |
[
"langchain-ai",
"langchain"
] | https://github.com/hwchase17/langchain/blame/master/docs/modules/agents/agents/custom_agent.ipynb#L12
It says three then has two points afterwards | No it doesn't? | https://api.github.com/repos/langchain-ai/langchain/issues/2604/comments | 1 | 2023-04-08T21:56:42Z | 2023-09-10T16:36:27Z | https://github.com/langchain-ai/langchain/issues/2604 | 1,659,656,997 | 2,604 |
[
"langchain-ai",
"langchain"
] | The typical way agents decide what tool to use is by putting a description of the tool in a prompt.
But what if there are too many tools to do that?
You can [do a retrieval step to get a smaller candidate set of tools](https://python.langchain.com/en/latest/modules/agents/agents/custom_agent_with_tool_retrieval.html) or you can use [Toolformer,](https://arxiv.org/abs/2302.04761) a model trained to decide which tools to call, when to call them, what arguments to pass, and how to best incorporate the results into future token predictions.
Here are several implementations:
- [toolformer-pytorch](https://github.com/lucidrains/toolformer-pytorch) by @lucidrains
- [toolformer](https://github.com/conceptofmind/toolformer) by @conceptofmind
- [toolformer-zero](https://github.com/minosvasilias/toolformer-zero) by @minosvasilias
- [toolformer](https://github.com/xrsrke/toolformer) by @xrsrke
- [simple-toolformer](https://github.com/mrcabbage972/simple-toolformer) by @mrcabbage972
Also, check out this awesome Toolformer dataset:
- [github.com/teknium1/GPTeacher/tree/main/Toolformer](https://github.com/teknium1/GPTeacher/tree/main/Toolformer) | Toolformer | https://api.github.com/repos/langchain-ai/langchain/issues/2603/comments | 5 | 2023-04-08T21:29:31Z | 2023-09-27T16:09:28Z | https://github.com/langchain-ai/langchain/issues/2603 | 1,659,651,195 | 2,603 |
[
"langchain-ai",
"langchain"
] | Many use-cases are companies (in different industries) integrating chatgpt api with calling their own in-house services (via http, etc), and LLMs(ChatGPT) have no knowledge of these services.
Just wanted to check current prompts for agents (e.g https://github.com/hwchase17/langchain/blob/master/langchain/agents/conversational_chat/prompt.py), do they work for in-house services?
Read the [doc](https://python.langchain.com/en/latest/modules/agents/toolkits/examples/openapi.html) for OpenAPI agents, it supports APIs conformant to the OpenAPI/Swagger specification, does it support in-house API as well (suppose in-house APIs also conformant to the OpenAPI/Swagger specification)?
Or maybe like how `langchain` supports ChatGPT plugins (https://python.langchain.com/en/latest/modules/agents/tools/examples/chatgpt_plugins.html?highlight=chatgpt%20plugin#chatgpt-plugins), providing in-house API provides detailed API spec.
| Feature request: conversation agent (chat mode) to support in-house (http) service | https://api.github.com/repos/langchain-ai/langchain/issues/2598/comments | 3 | 2023-04-08T20:12:27Z | 2023-09-10T16:36:32Z | https://github.com/langchain-ai/langchain/issues/2598 | 1,659,633,421 | 2,598 |
[
"langchain-ai",
"langchain"
] | ‘This one is right in the middle of the action - the plugin market. It is the Android to OpenAI's iOS. Everyone needs a second option.
Another thing people seem to forget is that Langchain can use LLMs that aren't made by OpenAI.
If OpenAI goes under, or a great open-source model comes onto the scene, Langchain can still do its thing.’
Just seen from [here](https://news.ycombinator.com/item?id=35442483)
| CHATGPT has plugin, what will be the impact on Langchain ? | https://api.github.com/repos/langchain-ai/langchain/issues/2596/comments | 4 | 2023-04-08T19:03:55Z | 2023-09-18T16:20:33Z | https://github.com/langchain-ai/langchain/issues/2596 | 1,659,615,836 | 2,596 |
[
"langchain-ai",
"langchain"
] | Right now the langchain chroma vectorstore doesn't allow you to adjust the metadata attribute on the create collection method of the ChromaDB client so you can't adjust the formula for distance calculations.
Chroma DB introduced the ability to add metadata to collections to tell the index which distance calculation is used in release https://github.com/chroma-core/chroma/releases/tag/0.3.15
Specifically in this pull request: https://github.com/chroma-core/chroma/pull/245
Langchain doesn't provide a way to adjust this vectorstore's distance calculation formula.
Referenced here: https://github.com/hwchase17/langchain/blob/2f49c96532725fdb48ea11417270245e694574d1/langchain/vectorstores/chroma.py#L84
| ChromaDB Vectorstore: Customize distance calculations | https://api.github.com/repos/langchain-ai/langchain/issues/2595/comments | 3 | 2023-04-08T19:01:06Z | 2023-09-26T16:09:56Z | https://github.com/langchain-ai/langchain/issues/2595 | 1,659,615,132 | 2,595 |
[
"langchain-ai",
"langchain"
] | I'm trying to use `langchain` to replace current use QDrant directly, in order to benefit from other tools in `langchain`, however I'm stuck.
I already have this code that creates QDrant collections on-demand:
```python
client.delete_collection(collection_name="articles")
client.recreate_collection(
collection_name="articles",
vectors_config={
"content": rest.VectorParams(
distance=rest.Distance.COSINE,
size=1536,
),
},
)
client.upsert(
collection_name="articles",
points=[
rest.PointStruct(
id=i,
vector={
"content": articles_embeddings[article],
},
payload={
"name": article,
"content": articles_content[article],
},
)
for i, article in enumerate(ARTICLES)
],
)
```
Now, if a I try to re-use `client` as explained in https://python.langchain.com/en/latest/modules/indexes/vectorstores/examples/qdrant.html#reusing-the-same-collection I hit the following error:
```
Wrong input: Default vector params are not specified in config
```
I seem to be able to overcome this by modifying the code for `QDrant` class in `langchain`, however, I'm asking if there's any argument that I overlooked to apply using `langchain` with this QDrant client config, or else I would like to contribute a working solution that involves adding new parameter. | [Q] How to re-use QDrant collection data that are created separatly with non-default vector name? | https://api.github.com/repos/langchain-ai/langchain/issues/2594/comments | 9 | 2023-04-08T18:37:50Z | 2024-07-05T08:46:33Z | https://github.com/langchain-ai/langchain/issues/2594 | 1,659,608,651 | 2,594 |
[
"langchain-ai",
"langchain"
] | I think the prompt module should be extended to support generating new prompts. This would create a better sandbox for evaluating different prompt templates without writing 20+ variations by hand. The core idea is to call a llm to alter a base prompt template while respecting the input variables according to an instruction set. Maybe this should be its own chain instead of a class in the prompt module.

This scheme for generating prompts can be used with evaluation steps to assist in prompt tuning when combined with evaluations. This could be used with a heuristic search to optimize prompts based on specific metrics: total prompt token count, accuracy, ect.

I'm wondering if anyone has seen this type of process implemented before or is currently working on it. Starting to POC this type of class today.
edit: wording | Feature request: prompt generator to assist in tuning | https://api.github.com/repos/langchain-ai/langchain/issues/2593/comments | 1 | 2023-04-08T17:14:36Z | 2023-09-10T16:36:43Z | https://github.com/langchain-ai/langchain/issues/2593 | 1,659,586,074 | 2,593 |
[
"langchain-ai",
"langchain"
] | Hi,
When I run this:
from langchain.llms import LlamaCpp
from langchain import PromptTemplate, LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm = LlamaCpp(model_path="models/gpt4all-lora-quantized.bin", n_ctx=2048)
llm_chain = LLMChain(prompt=prompt, llm=llm)
print(llm_chain("tell me about Japan"))
I got the below error:
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_13664/3459006187.py in <module>
11
12 llm_chain = LLMChain(prompt=prompt, llm=llm)
---> 13 print(llm_chain("tell me about Japan"))
f:\python39\lib\site-packages\langchain\chains\base.py in __call__(self, inputs, return_only_outputs)
114 except (KeyboardInterrupt, Exception) as e:
115 self.callback_manager.on_chain_error(e, verbose=self.verbose)
--> 116 raise e
117 self.callback_manager.on_chain_end(outputs, verbose=self.verbose)
118 return self.prep_outputs(inputs, outputs, return_only_outputs)
f:\python39\lib\site-packages\langchain\chains\base.py in __call__(self, inputs, return_only_outputs)
111 )
112 try:
--> 113 outputs = self._call(inputs)
114 except (KeyboardInterrupt, Exception) as e:
115 self.callback_manager.on_chain_error(e, verbose=self.verbose)
f:\python39\lib\site-packages\langchain\chains\llm.py in _call(self, inputs)
55
56 def _call(self, inputs: Dict[str, Any]) -> Dict[str, str]:
---> 57 return self.apply([inputs])[0]
58
59 def generate(self, input_list: List[Dict[str, Any]]) -> LLMResult:
f:\python39\lib\site-packages\langchain\chains\llm.py in apply(self, input_list)
116 def apply(self, input_list: List[Dict[str, Any]]) -> List[Dict[str, str]]:
117 """Utilize the LLM generate method for speed gains."""
--> 118 response = self.generate(input_list)
119 return self.create_outputs(response)
120
f:\python39\lib\site-packages\langchain\chains\llm.py in generate(self, input_list)
60 """Generate LLM result from inputs."""
61 prompts, stop = self.prep_prompts(input_list)
---> 62 return self.llm.generate_prompt(prompts, stop)
63
64 async def agenerate(self, input_list: List[Dict[str, Any]]) -> LLMResult:
f:\python39\lib\site-packages\langchain\llms\base.py in generate_prompt(self, prompts, stop)
105 ) -> LLMResult:
106 prompt_strings = [p.to_string() for p in prompts]
--> 107 return self.generate(prompt_strings, stop=stop)
108
109 async def agenerate_prompt(
f:\python39\lib\site-packages\langchain\llms\base.py in generate(self, prompts, stop)
138 except (KeyboardInterrupt, Exception) as e:
139 self.callback_manager.on_llm_error(e, verbose=self.verbose)
--> 140 raise e
141 self.callback_manager.on_llm_end(output, verbose=self.verbose)
142 return output
f:\python39\lib\site-packages\langchain\llms\base.py in generate(self, prompts, stop)
135 )
136 try:
--> 137 output = self._generate(prompts, stop=stop)
138 except (KeyboardInterrupt, Exception) as e:
139 self.callback_manager.on_llm_error(e, verbose=self.verbose)
f:\python39\lib\site-packages\langchain\llms\base.py in _generate(self, prompts, stop)
322 generations = []
323 for prompt in prompts:
--> 324 text = self._call(prompt, stop=stop)
325 generations.append([Generation(text=text)])
326 return LLMResult(generations=generations)
f:\python39\lib\site-packages\langchain\llms\llamacpp.py in _call(self, prompt, stop)
182
183 """Call the Llama model and return the output."""
--> 184 text = self.client(
185 prompt=prompt,
186 max_tokens=params["max_tokens"],
f:\python39\lib\site-packages\llama_cpp\llama.py in __call__(self, prompt, suffix, max_tokens, temperature, top_p, logprobs, echo, stop, repeat_penalty, top_k, stream)
525 Response object containing the generated text.
526 """
--> 527 return self.create_completion(
528 prompt=prompt,
529 suffix=suffix,
f:\python39\lib\site-packages\llama_cpp\llama.py in create_completion(self, prompt, suffix, max_tokens, temperature, top_p, logprobs, echo, stop, repeat_penalty, top_k, stream)
486 chunks: Iterator[CompletionChunk] = completion_or_chunks
487 return chunks
--> 488 completion: Completion = next(completion_or_chunks) # type: ignore
489 return completion
490
f:\python39\lib\site-packages\llama_cpp\llama.py in _create_completion(self, prompt, suffix, max_tokens, temperature, top_p, logprobs, echo, stop, repeat_penalty, top_k, stream)
303 stream: bool = False,
304 ) -> Union[Iterator[Completion], Iterator[CompletionChunk],]:
--> 305 assert self.ctx is not None
306 completion_id = f"cmpl-{str(uuid.uuid4())}"
307 created = int(time.time())
AssertionError: | AssertionError in LlamaCpp | https://api.github.com/repos/langchain-ai/langchain/issues/2592/comments | 3 | 2023-04-08T16:59:53Z | 2023-09-26T16:10:02Z | https://github.com/langchain-ai/langchain/issues/2592 | 1,659,582,034 | 2,592 |
[
"langchain-ai",
"langchain"
] | The foundational chain and ChromaDB possess the capacity for persistence.
It would be beneficial to make this persistence feature accessible to the higher-level VectorstoreIndexCreator.
By doing so, we can repurpose saved indexes, making the service more easily scalable, particularly for handling extensive documents. | Feature Request: Allow VectorStoreIndexCreator to retrieve stored vector indexes | https://api.github.com/repos/langchain-ai/langchain/issues/2591/comments | 3 | 2023-04-08T16:53:19Z | 2023-09-28T16:08:46Z | https://github.com/langchain-ai/langchain/issues/2591 | 1,659,580,116 | 2,591 |
[
"langchain-ai",
"langchain"
] | Good afternoon, I am having a problem when it comes to streaming responses. I am trying to use the example provided by the langchain docs and I can't seem to get it working without editing the package.json file from langchain lol.
Here is the code I ran
`import * as env from "dotenv"
import { OpenAI } from "langchain/llms"
import { CallbackManager } from "langchain/dist/callbacks"
env.config()
//const apiKey = process.env.OPEN_API_KEY
const chat = new OpenAI({
streaming: true,
callbackManager: CallbackManager.fromHandlers({
async handleLLMNewToken(token) {
console.log(token);
},
}),
});
const response = await chat.call("Write me a song about sparkling water.");
console.log(response);`
And the error I received when running it:
node:internal/errors:490
ErrorCaptureStackTrace(err);
^
Error [ERR_PACKAGE_PATH_NOT_EXPORTED]: Package subpath './dist/callbacks' is not defined by "exports" in home/jg//Langchain_Test_Programs/LLM_Quickstart/node_modules/langchain/package.json imported from home/jg//Langchain_Test_Programs/LLM_Quickstart/app.js
at new NodeError (node:internal/errors:399:5)
at exportsNotFound (node:internal/modules/esm/resolve:266:10)
at packageExportsResolve (node:internal/modules/esm/resolve:602:9)
at packageResolve (node:internal/modules/esm/resolve:777:14)
at moduleResolve (node:internal/modules/esm/resolve:843:20)
at defaultResolve (node:internal/modules/esm/resolve:1058:11)
at nextResolve (node:internal/modules/esm/hooks:654:28)
at Hooks.resolve (node:internal/modules/esm/hooks:309:30)
at ESMLoader.resolve (node:internal/modules/esm/loader:312:26)
at ESMLoader.getModuleJob (node:internal/modules/esm/loader:172:38) {
code: 'ERR_PACKAGE_PATH_NOT_EXPORTED'
}
I searched for awhile to find a solution and I eventually did by renaming the ./callbacks in the export section of the langchain package.json to ./dist/calbacks
i.e. I changed
`"./callbacks": {
"types": "./callbacks.d.ts",
"import": "./callbacks.js",
"require": "./callbacks.cjs"
},`
to
`"./dist/callbacks": {
"types": "./callbacks.d.ts",
"import": "./callbacks.js",
"require": "./callbacks.cjs"
},`
This worked for me but then I ran into two more issues: A. The text takes forever to be streamed and B. when the text is streamed, it is returned at an extremely fast paced. So fast that I cant keep up with it when trying to read. I don't know if that is how it's supposed to be but I was hoping for the text to be returned slow, like it is done through the chatgpt official site.
I know there is probably a much simpler fix but I can't seem to find it. Any help will be appreciated it, thanks! | Receiving a "node:internal/errors:490" error when running the streaming example code from the langchain docs | https://api.github.com/repos/langchain-ai/langchain/issues/2590/comments | 3 | 2023-04-08T16:24:18Z | 2023-09-25T16:10:50Z | https://github.com/langchain-ai/langchain/issues/2590 | 1,659,572,068 | 2,590 |
[
"langchain-ai",
"langchain"
] | hi, i am trying use FAISS to do similarity_search, but it failed with errs:
>>> db.similarity_search("123")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.10/site-packages/langchain/vectorstores/faiss.py", line 207, in similarity_search
docs_and_scores = self.similarity_search_with_score(query, k)
File "/usr/local/lib/python3.10/site-packages/langchain/vectorstores/faiss.py", line 176, in similarity_search_with_score
embedding = self.embedding_function(query)
File "/usr/local/lib/python3.10/site-packages/langchain/embeddings/openai.py", line 279, in embed_query
embedding = self._embedding_func(text, engine=self.query_model_name)
File "/usr/local/lib/python3.10/site-packages/langchain/embeddings/openai.py", line 235, in _embedding_func
return self._get_len_safe_embeddings([text], engine=engine)[0]
File "/usr/local/lib/python3.10/site-packages/langchain/embeddings/openai.py", line 193, in _get_len_safe_embeddings
encoding = tiktoken.model.encoding_for_model(self.document_model_name)
AttributeError: module 'tiktoken' has no attribute 'model'
anyone can give me some advise?
| FAISS similarity_search not work | https://api.github.com/repos/langchain-ai/langchain/issues/2587/comments | 3 | 2023-04-08T15:57:25Z | 2023-09-25T16:10:55Z | https://github.com/langchain-ai/langchain/issues/2587 | 1,659,564,331 | 2,587 |
[
"langchain-ai",
"langchain"
] | I am using the CSV agent to analyze transaction data. I keep getting `ValueError: Could not parse LLM output: ` for the prompts. The agent seems to know what to do.
Any fix for this error?
```
> Entering new AgentExecutor chain...
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
[<ipython-input-27-bf3698669c48>](https://localhost:8080/#) in <cell line: 1>()
----> 1 agent.run("Analyse how the debit transaction has changed over the months")
8 frames
[/usr/local/lib/python3.9/dist-packages/langchain/agents/mrkl/base.py](https://localhost:8080/#) in get_action_and_input(llm_output)
46 match = re.search(regex, llm_output, re.DOTALL)
47 if not match:
---> 48 raise ValueError(f"Could not parse LLM output: `{llm_output}`")
49 action = match.group(1).strip()
50 action_input = match.group(2)
ValueError: Could not parse LLM output: `Thought: To analyze how the debit transactions have changed over the months, I need to first filter the dataframe to only include debit transactions. Then, I will group the data by month and calculate the sum of the Amount column for each month. Finally, I will observe the results.
``` | CSV Agent: ValueError: Could not parse LLM output: | https://api.github.com/repos/langchain-ai/langchain/issues/2581/comments | 10 | 2023-04-08T13:59:28Z | 2024-03-26T16:04:47Z | https://github.com/langchain-ai/langchain/issues/2581 | 1,659,531,988 | 2,581 |
[
"langchain-ai",
"langchain"
] | Following this [guide](https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/googledrive.html), I tried to load my google docs file [doggo wikipedia](https://docs.google.com/document/d/1SJhVh8rQE7gZN_iUnmHC9XF3THRnnxLc/edit?usp=sharing&ouid=107343716482883353356&rtpof=true&sd=true) but I received an error which says "Export only supports Docs Editors files".
```
from langchain.document_loaders import GoogleDriveLoader
loader = GoogleDriveLoader(document_ids=["1SJhVh8rQE7gZN_iUnmHC9XF3THRnnxLc"], credentials_path='credentials.json', token_path='token.json')
docs = loader.load()
docs
```
HttpError: <HttpError 403 when requesting https://www.googleapis.com/drive/v3/files/1SJhVh8rQE7gZN_iUnmHC9XF3THRnnxLc/export?mimeType=text%2Fplain&alt=media returned "Export only supports Docs Editors files.". Details: "[{'message': 'Export only supports Docs Editors files.', 'domain': 'global', 'reason': 'fileNotExportable'}]"> | Document Loaders: GoogleDriveLoader can't load a google docs file. | https://api.github.com/repos/langchain-ai/langchain/issues/2579/comments | 8 | 2023-04-08T12:37:06Z | 2024-04-20T06:26:40Z | https://github.com/langchain-ai/langchain/issues/2579 | 1,659,510,852 | 2,579 |
[
"langchain-ai",
"langchain"
] | null | Can you assist \ provide an example how to stream response when using an agent? | https://api.github.com/repos/langchain-ai/langchain/issues/2577/comments | 5 | 2023-04-08T10:32:23Z | 2023-09-28T16:08:51Z | https://github.com/langchain-ai/langchain/issues/2577 | 1,659,480,691 | 2,577 |
[
"langchain-ai",
"langchain"
] | Using early_stopping_method with "generate" is not supported with new addition to custom LLM agents.
More specifically:
`agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True, max_execution_time=6, max_iterations=3, early_stopping_method="generate")`
`
Stack trace:
Traceback (most recent call last):
File "/Users/assafel/Sites/gpt3-text-optimizer/agents/cowriter2.py", line 116, in <module>
response = agent_executor.run("Some question")
File "/usr/local/lib/python3.9/site-packages/langchain/chains/base.py", line 213, in run
return self(args[0])[self.output_keys[0]]
File "/usr/local/lib/python3.9/site-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/usr/local/lib/python3.9/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/usr/local/lib/python3.9/site-packages/langchain/agents/agent.py", line 855, in _call
output = self.agent.return_stopped_response(
File "/usr/local/lib/python3.9/site-packages/langchain/agents/agent.py", line 126, in return_stopped_response
raise ValueError(
ValueError: Got unsupported early_stopping_method `generate`` | ValueError: Got unsupported early_stopping_method `generate` | https://api.github.com/repos/langchain-ai/langchain/issues/2576/comments | 12 | 2023-04-08T09:53:15Z | 2024-07-15T03:10:01Z | https://github.com/langchain-ai/langchain/issues/2576 | 1,659,468,662 | 2,576 |
[
"langchain-ai",
"langchain"
] | How can I create a ConversationChain that uses a PydanticOutputParser for the output?
```py
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
parser = PydanticOutputParser(pydantic_object=Joke)
system_message_prompt = SystemMessagePromptTemplate.from_template("Tell a joke")
# If I put it here I get `KeyError: {'format_instructions'}` in `/langchain/chains/base.py:113, in Chain.__call__(self, inputs, return_only_outputs)`
# system_message_prompt.prompt.output_parser = parser
# system_message_prompt.prompt.partial_variables = {"format_instructions": parser.get_format_instructions()}
human_message_prompt = HumanMessagePromptTemplate.from_template("{input}")
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt,human_message_prompt,MessagesPlaceholder(variable_name="history")])
# This runs but I don't get any JSON back
chat_prompt.output_parser = parser
chat_prompt.partial_variables = {"format_instructions": parser.get_format_instructions()}
memory=ConversationBufferMemory(return_messages=True)
llm = OpenAI(temperature=0)
conversation = ConversationChain(llm=llm, prompt=chat_prompt, verbose=True, memory=memory)
conversation.predict(input="Tell me a joke")
```
```
> Entering new ConversationChain chain...
Prompt after formatting:
System: Tell a joke
Human: Tell me a joke
> Finished chain.
'\n\nQ: What did the fish say when it hit the wall?\nA: Dam!'
``` | How to use a ConversationChain with PydanticOutputParser | https://api.github.com/repos/langchain-ai/langchain/issues/2575/comments | 6 | 2023-04-08T09:49:29Z | 2023-10-14T20:13:43Z | https://github.com/langchain-ai/langchain/issues/2575 | 1,659,467,745 | 2,575 |
[
"langchain-ai",
"langchain"
] |
I want to use qa chain with custom system prompt
```
template = """
You are an AI assis
"""
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
chat_prompt = ChatPromptTemplate.from_messages(
[system_message_prompt])
llm = ChatOpenAI(temperature=0.4, model_name='gpt-3.5-turbo', max_tokens=2000,
openai_api_key=OPENAI_API_KEY)
# chain = load_qa_chain(llm, chain_type='stuff', prompt=chat_prompt)
chain = load_qa_with_sources_chain(
llm, chain_type="stuff", verbose=True, prompt=chat_prompt)
```
I am geting this error
```
pydantic.error_wrappers.ValidationError: 1 validation error for StuffDocumentsChain
__root__
document_variable_name summaries was not found in llm_chain input_variables: [] (type=value_error)
``` | load_qa_with_sources_chain with custom prompt | https://api.github.com/repos/langchain-ai/langchain/issues/2574/comments | 3 | 2023-04-08T08:32:10Z | 2024-01-20T07:44:43Z | https://github.com/langchain-ai/langchain/issues/2574 | 1,659,446,392 | 2,574 |
[
"langchain-ai",
"langchain"
] | when I set n >1, it demands I set best_of to that same number...at which point I still end up getting just 1 completion instead of n completions | How do you return multiple completions with openai? | https://api.github.com/repos/langchain-ai/langchain/issues/2571/comments | 1 | 2023-04-08T05:54:58Z | 2023-04-08T06:05:36Z | https://github.com/langchain-ai/langchain/issues/2571 | 1,659,407,187 | 2,571 |
[
"langchain-ai",
"langchain"
] | The following custom tool definition triggers an "TypeError: unhashable type: 'Tool'"
@tool
def gender_guesser(query: str) -> str:
"""Useful for when you need to guess a person's gender based on their first name. Pass only the first name as the query, returns the gender."""
d = gender.Detector()
return d.get_gender(str)
llm = ChatOpenAI(temperature=5.0)
math_llm = OpenAI(temperature=0.0)
tools = load_tools(
["human", "llm-math", gender_guesser],
llm=math_llm,
)
agent_chain = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
) | "Unhashable Type: Tool" when using custom tool | https://api.github.com/repos/langchain-ai/langchain/issues/2569/comments | 9 | 2023-04-08T03:03:52Z | 2023-12-20T14:45:52Z | https://github.com/langchain-ai/langchain/issues/2569 | 1,659,350,654 | 2,569 |
[
"langchain-ai",
"langchain"
] | When using the `ConversationalChatAgent`, it sometimes outputs multiple actions in a single response, causing the following error:
```
ValueError: Could not parse LLM output: ...
```
Ideas:
1. Support this behavior so a single `AgentExecutor` run loop can perform multiple actions
2. Adjust prompting strategy to prevent this from happening
On the second point, I've found that explicitly adding \`\`\`json as an `AIMessage` in the `agent_scratchpad` and then handling that in the output parser seems to reliably lead to outputs with only a single action. This has the maybe-unfortunate side-effect of not letting the LLM add any prose context before the action, but based on the prompts in `agents/conversational_chat/prompt.py`, it seems like that's already not intended. E.g. this seems to help with the issue:
```
class MyOutputParser(AgentOutputParser):
def parse(self, text: str) -> Any:
# Add ```json back to the text, since we manually added it as an AIMessage in create_prompt
return super().parse(f"```json{text}")
class MyAgent(ConversationalChatAgent):
def _construct_scratchpad(
self, intermediate_steps: List[Tuple[AgentAction, str]]
) -> List[BaseMessage]:
thoughts = super()._construct_scratchpad(intermediate_steps)
# Manually append an AIMessage with ```json to better guide the LLM towards responding with only one action and no prose.
thoughts.append(AIMessage(content="```json"))
return thoughts
@classmethod
def create_prompt(
cls,
tools: Sequence[BaseTool],
system_message: str = PREFIX,
human_message: str = SUFFIX,
input_variables: Optional[List[str]] = None,
output_parser: Optional[BaseOutputParser] = None,
) -> BasePromptTemplate:
return super().create_prompt(
tools,
system_message,
human_message,
input_variables,
output_parser or MyOutputParser(),
)
@classmethod
def from_llm_and_tools(
cls,
llm: BaseLanguageModel,
tools: Sequence[BaseTool],
callback_manager: Optional[BaseCallbackManager] = None,
system_message: str = PREFIX,
human_message: str = SUFFIX,
input_variables: Optional[List[str]] = None,
output_parser: Optional[BaseOutputParser] = None,
**kwargs: Any,
) -> Agent:
return super().from_llm_and_tools(
llm,
tools,
callback_manager,
system_message,
human_message,
input_variables,
output_parser or MyOutputParser(),
**kwargs,
)
``` | ConversationalChatAgent sometimes outputs multiple actions in response | https://api.github.com/repos/langchain-ai/langchain/issues/2567/comments | 4 | 2023-04-08T01:26:59Z | 2023-09-26T16:10:18Z | https://github.com/langchain-ai/langchain/issues/2567 | 1,659,327,099 | 2,567 |
[
"langchain-ai",
"langchain"
] | Code:
```
llm = ChatOpenAI(temperature=0, model_name='gpt-4')
tools = load_tools(["serpapi", "llm-math", "python_repl","requests_all","human"], llm=llm)
agent = initialize_agent(tools, llm, agent='zero-shot-react-description', verbose=True)
agent.run("When was eiffel tower built")
```
Output:
> _File [env/lib/python3.8/site-packages/langchain/agents/agent.py:365], in Agent._get_next_action(self, full_inputs)
> 363 def _get_next_action(self, full_inputs: Dict[str, str]) -> AgentAction:
> ...
> ---> 48 raise ValueError(f"Could not parse LLM output: `{llm_output}`")
> 49 action = match.group(1).strip()
> 50 action_input = match.group(2)
>
> ValueError: Could not parse LLM output: `I should search for the year when the Eiffel Tower was built.`_
Same code with gpt 3.5 model:
```
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo')
tools = load_tools(["serpapi", "llm-math", "python_repl","requests_all","human"], llm=llm)
agent = initialize_agent(tools, llm, agent='zero-shot-react-description', verbose=True)
agent.run("When was eiffel tower built")
```
Output:
> Entering new AgentExecutor chain...
I should search for this information
Action: Search
Action Input: "eiffel tower build date"
Observation: March 31, 1889
Thought:That's the answer to the question
Final Answer: The Eiffel Tower was built on March 31, 1889.
> Finished chain.
'The Eiffel Tower was built on March 31, 1889.'
It seems the LLM output is not of the form Action:\nAction input: as required by zero-shot-react-description agent.
My langchain version is 0.0.134 and i have access to gpt4. | Could not parse LLM output when model changed from gpt-3.5-turbo to gpt-4 | https://api.github.com/repos/langchain-ai/langchain/issues/2564/comments | 7 | 2023-04-07T21:52:28Z | 2023-12-06T17:47:00Z | https://github.com/langchain-ai/langchain/issues/2564 | 1,659,237,777 | 2,564 |
[
"langchain-ai",
"langchain"
] | Hello! I am attempting to run the snippet of code linked [here](https://github.com/hwchase17/langchain/pull/2201) locally on my
Macbook.
Specifically, I'm attempting to execute the import statement:
```
from langchain.utilities import ApifyWrapper
```
I am running this within a `conda` environment, where the Python version is `3.10.9` and the `langchain` version is `0.0.134`. I have double checked these settings, but I keep getting the above error. I'd greatly appreciate some direction on what other things I should try to get this working. | Cannot import `ApifyWrapper` | https://api.github.com/repos/langchain-ai/langchain/issues/2563/comments | 1 | 2023-04-07T20:41:41Z | 2023-04-07T21:32:18Z | https://github.com/langchain-ai/langchain/issues/2563 | 1,659,173,947 | 2,563 |
[
"langchain-ai",
"langchain"
] | Hi, I am building a chatbot that could answer questions related to some internal data. I have defined an agent that has access to a few tools that could query our internal database. However, at the same time, I do want the chatbot to handle normal conversation well beyond the internal data.
For example, when the user says `nice`, the agent responds with `Thank you! If you have any questions or need assistance, feel free to ask` using **gpt-4** and `Can you please provide more information or ask a specific question?` using gpt-3.5, which is not ideal.
I am not sure how langchain handle message like `nice`. If I directly send `nice` to chatGPT with gpt-3.5, it responds with `Glad to hear that! Is there anything specific you'd like to ask or discuss?`, which proves that gpt-3.5 has the capability to respond well. Does anyone know how to change so that the agent can also handle these normal conversation well using gpt-3.5?
Here are my setup
```
self.tools = [
Tool(
name="FAQ",
func=index.query,
description="useful when query internal database"
),
]
prompt = ZeroShotAgent.create_prompt(
self.tools,
prefix=prefix,
suffix=suffix,
format_instructions=FORMAT_INSTRUCTION,
input_variables=["input", "chat_history-{}".format(user_id), "agent_scratchpad"]
)
llm_chain = LLMChain(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo"), prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=self.tools)
memory = ConversationBufferMemory(memory_key=str('chat_history'))
agent_executor = AgentExecutor.from_agent_and_tools(
agent=self.agent, tools=self.tools, verbose=True,
max_iterations=2, early_stopping_method="generate", memory=memory)
``` | Make agent handle normal conversation that are not covered by tools | https://api.github.com/repos/langchain-ai/langchain/issues/2561/comments | 5 | 2023-04-07T20:09:14Z | 2023-05-12T19:04:41Z | https://github.com/langchain-ai/langchain/issues/2561 | 1,659,151,645 | 2,561 |
[
"langchain-ai",
"langchain"
] | class BaseLLM, BaseTool, BaseChatModel and Chain have `set_callback_manager` method, I thought it was for setting custom callback_manager, like below. (https://github.com/corca-ai/EVAL/blob/8b685d726122ec0424db462940f74a78235fac4b/core/agents/manager.py#L44-L45)
```python
for tool in tools:
tool.set_callback_manager(callback_manager)
```
But it didn't do anything, so I check the code.
```python
def set_callback_manager(
cls, callback_manager: Optional[BaseCallbackManager]
) -> BaseCallbackManager:
"""If callback manager is None, set it.
This allows users to pass in None as callback manager, which is a nice UX.
"""
return callback_manager or get_callback_manager()
```
Looks like it just receives optional callback_manager parameter and return it right away with default value.
The comment says `If callback manager is None, set it.` but it doesn't work as it says.
For now, I'm doing it like this but it looks a bit ugly...
```python
tool.callback_manager = callback_manager
```
Is this intended? If it isn't, can I work on fixing it? | what does set_callback_manager method for? | https://api.github.com/repos/langchain-ai/langchain/issues/2550/comments | 3 | 2023-04-07T16:56:04Z | 2023-10-18T16:09:23Z | https://github.com/langchain-ai/langchain/issues/2550 | 1,659,001,688 | 2,550 |
[
"langchain-ai",
"langchain"
] | Below is my code.
The document "sample.pdf" located in my directory folder "data" is of "2000 tokens".
Why it costs me 2000+ tokens everytime i ask a new question.
```
from langchain import OpenAI
from llama_index import GPTSimpleVectorIndex, download_loader,SimpleDirectoryReader,PromptHelper
from llama_index import LLMPredictor, ServiceContext
os.environ['OPENAI_API_KEY'] = 'sk-XXXXXX'
if __name__ == '__main__':
max_input_size = 4096
# set number of output tokens
num_outputs = 256
# set maximum chunk overlap
max_chunk_overlap = 20
# set chunk size limit
chunk_size_limit = 1000
prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)
# define LLM
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=num_outputs))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
documents = SimpleDirectoryReader('data').load_data()
index = GPTSimpleVectorIndex.from_documents(documents, service_context=service_context)
# documents = SimpleDirectoryReader('data').load_data()
# index = GPTSimpleVectorIndex.from_documents(documents)
index.save_to_disk('index.json')
# load from disk
index = GPTSimpleVectorIndex.load_from_disk('index.json',service_context=service_context)
while True:
prompt = input("Type prompt...")
response = index.query(prompt)
print(response)
``` | Cost getting too high | https://api.github.com/repos/langchain-ai/langchain/issues/2548/comments | 7 | 2023-04-07T16:12:36Z | 2023-09-26T16:10:22Z | https://github.com/langchain-ai/langchain/issues/2548 | 1,658,968,544 | 2,548 |
[
"langchain-ai",
"langchain"
] | I'm trying to use an OpenAI client for querying my API according to the [documentation](https://python.langchain.com/en/latest/modules/agents/toolkits/examples/openapi.html), but I obtain an error.
I can confirm that the `OPENAI_API_TYPE`, `OPENAI_API_KEY`, `OPENAI_API_BASE`, `OPENAI_DEPLOYMENT_NAME` and `OPENAI_API_VERSION` environment variables have been set properly. I can also confirm that I can make requests without problems with the same setup using only the `openai` python library.
I create my agent in the following way:
```python
from langchain.llms import AzureOpenAI
spec = get_spec()
llm = AzureOpenAI(
deployment_name=deployment_name,
model_name="text-davinci-003",
temperature=0.0,
)
requests_wrapper = RequestsWrapper()
agent = planner.create_openapi_agent(spec, requests_wrapper, llm)
```
When I query the agent, I can see in the logs that it enters a new `AgentExecutor` chain and picks the right endpoint, but when it attempts to make the request it throws the following error:
```
openai/api_resources/abstract/engine_api_resource.py", line 83, in __prepare_create_request
raise error.InvalidRequestError(
openai.error.InvalidRequestError: Must provide an 'engine' or 'deployment_id' parameter to create a <class 'openai.api_resources.completion.Completion'>
```
My guess is that it should be obtaining the value of `engine` from the `deployment_name`, but for some reason it's not doing it. | Error with OpenAPI Agent with `AzureOpenAI` | https://api.github.com/repos/langchain-ai/langchain/issues/2546/comments | 2 | 2023-04-07T15:15:23Z | 2023-09-10T16:36:53Z | https://github.com/langchain-ai/langchain/issues/2546 | 1,658,917,099 | 2,546 |
[
"langchain-ai",
"langchain"
] | Plugin code is from [openai](https://github.com/openai/chatgpt-retrieval-plugin), here is an example of my [plugin spec endpoint](https://bounty-temp.marcusweinberger.repl.co/.well-known/ai-plugin.json).
Here is how I am loading the plugin:
```python
from langchain.tools import AIPluginTool, load_tools
tools = [AIPluginTool.from_plugin_url('https://bounty-temp.marcusweinberger.repl.co/.well-known/ai-plugin.json'), *load_tools('requests_all')]
```
When running a chain, the bot will use the Plugin Tool initially, which returns the API spec. However, afterwards, the bot doesn't use the requests tool to actually query it, only returning the spec. How do I make the bot first read the API spec and then make a request? Here are my prompts:
```
ASSISTANT_PREFIX = """Assistant is designed to be able to assist with a wide range of text and internet related tasks, from answering simple questions to querying API endpoints to find products. Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is able to process and understand large amounts of text content. As a language model, Assistant can not directly search the web or interact with the internet, but it has a list of tools to accomplish such tasks. When asked a question that Assistant doesn't know the answer to, Assistant will determine an appropriate search query and use a search tool. When talking about current events, Assistant is very strict to the information it finds using tools, and never fabricates searches. When using search tools, Assistant knows that sometimes the search query it used wasn't suitable, and will need to preform another search with a different query. Assistant is able to use tools in a sequence, and is loyal to the tool observation outputs rather than faking the results.
Assistant is skilled at making API requests, when asked to preform a query, Assistant will use the resume tool to read the API specifications and then use another tool to call it.
Overall, Assistant is a powerful internet search assistant that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics.
TOOLS:
------
Assistant has access to the following tools:"""
ASSISTANT_FORMAT_INSTRUCTIONS = """To use a tool, please use the following format:
\`\`\`
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
\`\`\`
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
\`\`\`
Thought: Do I need to use a tool? No
{ai_prefix}: [your response here]
\`\`\`
"""
ASSISTANT_SUFFIX = """You are very strict to API specifications and will structure any API requests to match the specs.
Begin!
Previous conversation history:
{chat_history}
New input: {input}
Since Assistant is a text language model, Assistant must use tools to observe the internet rather than imagination.
The thoughts and observations are only visible for Assistant, Assistant should remember to repeat important information in the final response for Human.
Thought: Do I need to use a tool? {agent_scratchpad}"""
```
| Loading chatgpt-retrieval-plugin with AIPluginLoader doesn't work | https://api.github.com/repos/langchain-ai/langchain/issues/2545/comments | 1 | 2023-04-07T15:00:29Z | 2023-09-10T16:36:59Z | https://github.com/langchain-ai/langchain/issues/2545 | 1,658,901,259 | 2,545 |
[
"langchain-ai",
"langchain"
] | spent an hour to figure this out (great work by the way)
connection to db2 via alchemy
```
db = SQLDatabase.from_uri(
db2_connection_string,
schema='MYSCHEMA',
include_tables=['MY_TABLE_NAME'], # including only one table for illustration
sample_rows_in_table_info=3
)
```
this did not work .. until i lowercased it and then it worked
```
db = SQLDatabase.from_uri(
db2_connection_string,
schema='myschema',
include_tables=['my_table_name], # including only one table for illustration
sample_rows_in_table_info=3
)
```
tables (at least in db2) can be selected either uppercase or lowercase
by the way .. All fields are lowercased .. is this on purpose ?
thanks
| Lowercased include_tables in SQLDatabase.from_uri | https://api.github.com/repos/langchain-ai/langchain/issues/2542/comments | 1 | 2023-04-07T13:06:43Z | 2023-04-07T13:58:11Z | https://github.com/langchain-ai/langchain/issues/2542 | 1,658,788,229 | 2,542 |
[
"langchain-ai",
"langchain"
] | The `__new__` method of `BaseOpenAI` returns a `OpenAIChat` instance if the model name starts with `gpt-3.5-turbo` or `gpt-4`.
https://github.com/hwchase17/langchain/blob/a31c9511e88f81ecc26e6ade24ece2c4d91136d4/langchain/llms/openai.py#L168
However, if you deploy the model in Azure OpenAI Service, the name does not include the period. The name instead is [gpt-35-turbo](https://learn.microsoft.com/en-us/azure/cognitive-services/openai/concepts/models), so the check above passes and returns the wrong class.
The check should consider the names on Azure. | Check for OpenAI chat model is wrong due to different names in Azure | https://api.github.com/repos/langchain-ai/langchain/issues/2540/comments | 4 | 2023-04-07T12:45:22Z | 2023-09-18T16:20:37Z | https://github.com/langchain-ai/langchain/issues/2540 | 1,658,768,884 | 2,540 |
[
"langchain-ai",
"langchain"
] | Same code with OpenAI works.
With llama or gpt4all, even though it searches the internet (supposedly), it gets the previous prime minister, and also it fails to search the age and find prime based on it.
Is it possible that there is something wrong with the converted model?
| Weird results when making a serpapi chain with llama or gpt4all | https://api.github.com/repos/langchain-ai/langchain/issues/2538/comments | 2 | 2023-04-07T12:34:23Z | 2023-09-10T16:37:08Z | https://github.com/langchain-ai/langchain/issues/2538 | 1,658,760,051 | 2,538 |
[
"langchain-ai",
"langchain"
] | Hello everyone.
I have made a ConversationalRetrievalChain with ConversationBufferMemory. The chain is having trouble remembering the last question that I have made, i.e. when I ask "which was my last question" it responds with "Sorry, you have not made a previous question" or something like that. Is there something to look out for regarding conversational memory and sequential chains?
Code looks like this:
```
llm = OpenAI(
openai_api_key=OPENAI_API_KEY,
model_name='gpt-3.5-turbo',
temperature=0.0
)
memory = ConversationBufferMemory(memory_key='chat_history', return_messages=False)
conversational_qa = ConversationalRetrievalChain.from_llm(llm=llm,
retriever=vectorstore.as_retriever(),
memory=memory) | ConversationalRetrievalChain memory problem | https://api.github.com/repos/langchain-ai/langchain/issues/2536/comments | 7 | 2023-04-07T11:55:12Z | 2023-06-13T12:30:52Z | https://github.com/langchain-ai/langchain/issues/2536 | 1,658,726,042 | 2,536 |
[
"langchain-ai",
"langchain"
] | in request.py line 27
``` def get(self, url: str, **kwargs: Any) -> requests.Response:
"""GET the URL and return the text."""
return requests.get(url, headers=self.headers, **kwargs)
```
when request some multi language context,need text encoding .
suggest be like:
``` def get(self, url: str, content_encoding="UTF-8", **kwargs: Any) -> str:
"""GET the URL and return the text."""
response = requests.get(url, headers=self.headers, **kwargs)
response.encoding = content_encoding
return response.text```
post and other functions will be add encoding parameter as this.
thanks. | suggestion: request support UTF-8 encoding contents | https://api.github.com/repos/langchain-ai/langchain/issues/2521/comments | 2 | 2023-04-07T03:44:05Z | 2023-09-10T16:37:14Z | https://github.com/langchain-ai/langchain/issues/2521 | 1,658,320,846 | 2,521 |
[
"langchain-ai",
"langchain"
] | I'm wondering if there is a way to use memory in combination with a vector store. For example in a chatbot, for every message, the context of the conversation is the last few hops of the conversation plus some relevant older conversations that are out of the buffer size retrieved from the vector store.
Thanks in advance! | Integrating Memory with Vectorstore | https://api.github.com/repos/langchain-ai/langchain/issues/2518/comments | 8 | 2023-04-06T22:53:08Z | 2023-10-23T16:09:22Z | https://github.com/langchain-ai/langchain/issues/2518 | 1,658,140,870 | 2,518 |
[
"langchain-ai",
"langchain"
] | Not sure where to put the partial_variables when using Chat Prompt Templates.
```
chat = ChatOpenAI()
class Colors(BaseModel):
colors: List[str] = Field(description="List of colors")
parser = PydanticOutputParser(pydantic_object=Colors)
format_instructions = parser.get_format_instructions()
prompt_text = "Give me a list of 5 colors."
prompt = HumanMessagePromptTemplate.from_template(
prompt_text + '\n {format_instructions}',
partial_variables={"format_instructions": format_instructions}
)
chat_template = ChatPromptTemplate.from_messages([prompt])
result = chat(chat_template.format_messages())
```
```---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[90], line 16
9 prompt = HumanMessagePromptTemplate.from_template(
10 prompt_text + '\n {format_instructions}',
11 partial_variables={"format_instructions": format_instructions}
12 )
13 chat_template = ChatPromptTemplate.from_messages([prompt])
---> 16 result = chat(chat_template.format_messages())
File ~/dev/testing_langchain/.venv/lib/python3.10/site-packages/langchain/prompts/chat.py:186, in ChatPromptTemplate.format_messages(self, **kwargs)
180 elif isinstance(message_template, BaseMessagePromptTemplate):
181 rel_params = {
182 k: v
183 for k, v in kwargs.items()
184 if k in message_template.input_variables
185 }
--> 186 message = message_template.format_messages(**rel_params)
187 result.extend(message)
188 else:
File ~/dev/testing_langchain/.venv/lib/python3.10/site-packages/langchain/prompts/chat.py:75, in BaseStringMessagePromptTemplate.format_messages(self, **kwargs)
74 def format_messages(self, **kwargs: Any) -> List[BaseMessage]:
---> 75 return [self.format(**kwargs)]
File ~/dev/testing_langchain/.venv/lib/python3.10/site-packages/langchain/prompts/chat.py:94, in HumanMessagePromptTemplate.format(self, **kwargs)
93 def format(self, **kwargs: Any) -> BaseMessage:
---> 94 text = self.prompt.format(**kwargs)
95 return HumanMessage(content=text, additional_kwargs=self.additional_kwargs)
File ~/dev/testing_langchain/.venv/lib/python3.10/site-packages/langchain/prompts/prompt.py:65, in PromptTemplate.format(self, **kwargs)
50 """Format the prompt with the inputs.
51
52 Args:
(...)
62 prompt.format(variable1="foo")
63 """
64 kwargs = self._merge_partial_and_user_variables(**kwargs)
---> 65 return DEFAULT_FORMATTER_MAPPING[self.template_format](self.template, **kwargs)
File ~/.pyenv/versions/3.10.4/lib/python3.10/string.py:161, in Formatter.format(self, format_string, *args, **kwargs)
160 def format(self, format_string, /, *args, **kwargs):
--> 161 return self.vformat(format_string, args, kwargs)
File ~/dev/testing_langchain/.venv/lib/python3.10/site-packages/langchain/formatting.py:29, in StrictFormatter.vformat(self, format_string, args, kwargs)
24 if len(args) > 0:
25 raise ValueError(
26 "No arguments should be provided, "
27 "everything should be passed as keyword arguments."
28 )
---> 29 return super().vformat(format_string, args, kwargs)
File ~/.pyenv/versions/3.10.4/lib/python3.10/string.py:165, in Formatter.vformat(self, format_string, args, kwargs)
163 def vformat(self, format_string, args, kwargs):
164 used_args = set()
--> 165 result, _ = self._vformat(format_string, args, kwargs, used_args, 2)
166 self.check_unused_args(used_args, args, kwargs)
167 return result
File ~/.pyenv/versions/3.10.4/lib/python3.10/string.py:205, in Formatter._vformat(self, format_string, args, kwargs, used_args, recursion_depth, auto_arg_index)
201 auto_arg_index = False
203 # given the field_name, find the object it references
204 # and the argument it came from
--> 205 obj, arg_used = self.get_field(field_name, args, kwargs)
206 used_args.add(arg_used)
208 # do any conversion on the resulting object
File ~/.pyenv/versions/3.10.4/lib/python3.10/string.py:270, in Formatter.get_field(self, field_name, args, kwargs)
267 def get_field(self, field_name, args, kwargs):
268 first, rest = _string.formatter_field_name_split(field_name)
--> 270 obj = self.get_value(first, args, kwargs)
272 # loop through the rest of the field_name, doing
273 # getattr or getitem as needed
274 for is_attr, i in rest:
File ~/.pyenv/versions/3.10.4/lib/python3.10/string.py:227, in Formatter.get_value(self, key, args, kwargs)
225 return args[key]
226 else:
--> 227 return kwargs[key]
KeyError: 'format_instructions'``` | partial_variables and Chat Prompt Templates | https://api.github.com/repos/langchain-ai/langchain/issues/2517/comments | 6 | 2023-04-06T22:43:46Z | 2024-08-03T04:46:34Z | https://github.com/langchain-ai/langchain/issues/2517 | 1,658,134,848 | 2,517 |
[
"langchain-ai",
"langchain"
] | The following error appears at the end of the script
```
TypeError: 'NoneType' object is not callable
Exception ignored in: <function PersistentDuckDB.__del__ at 0x7f53e574d4c0>
Traceback (most recent call last):
File ".../.local/lib/python3.9/site-packages/chromadb/db/duckdb.py", line 445, in __del__
AttributeError: 'NoneType' object has no attribute 'info'
```
... and comes up when doing:
```
embedding = HuggingFaceEmbeddings(model_name="hiiamsid/sentence_similarity_spanish_es")
docsearch = Chroma.from_documents(texts, embedding,persist_directory=persist_directory)
```
but doesn't happen with:
`embedding = LlamaCppEmbeddings(model_path=path)
` | ChromaDB error when using HuggingFace Embeddings | https://api.github.com/repos/langchain-ai/langchain/issues/2512/comments | 9 | 2023-04-06T19:21:50Z | 2023-12-22T04:42:48Z | https://github.com/langchain-ai/langchain/issues/2512 | 1,657,927,383 | 2,512 |
[
"langchain-ai",
"langchain"
] | Hi,
I have come up with above error: 'root:Could not parse LLM output' when I use ConversationalAgent. However, it is not all the time, but occasionally.
I looked into codes in this repo, and feel that condition in the function, '_extract_tool_and_input' would be an issue as sometimes LLMChain.predict returns output without following format instructions when not using tools despite that format instructions tell LLMChain to use following format -
```
Thought: Do I need to use a tool? No
AI: [your response here]
```
Is above my understanding is correct and how I rewrite the code in '__extract_tool_and_input' if so?
If I am wrong, please advise how I can fix the problem too.
Thanks. | ERROR:root:Could not parse LLM output on ConversationalAgent | https://api.github.com/repos/langchain-ai/langchain/issues/2511/comments | 3 | 2023-04-06T19:20:56Z | 2023-10-17T16:08:40Z | https://github.com/langchain-ai/langchain/issues/2511 | 1,657,926,387 | 2,511 |
[
"langchain-ai",
"langchain"
] | Following the tutorial for load_qa_with_sources_chain using the example state_of_the_union.txt I encounter interesting situations. Sometimes when I ask a query such as "What did Biden say about Ukraine?" I get a response like this:
"Joe Biden talked about the Ukrainian people's fearlessness, courage, and determination in the face of Russian aggression. He also announced that the United States will provide military, economic, and humanitarian assistance to Ukraine, including more than $1 billion in direct assistance. He further emphasized that the United States and its allies will defend every inch of territory of NATO countries, including Ukraine, with the full force of their collective power. **However, he mentioned nothing about Michael Jackson.**"
I know that there are examples directly asking about Michael Jackson in the documentation:
https://python.langchain.com/en/latest/use_cases/evaluation/data_augmented_question_answering.html?highlight=michael%20jackson#examples
Here is my code for reproducing situation:
````
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
from langchain.docstore.document import Document
from langchain.prompts import PromptTemplate
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
from langchain.indexes.vectorstore import VectorstoreIndexCreator
from langchain.chat_models import ChatOpenAI
from langchain.callbacks import get_openai_callback
from langchain.chains import RetrievalQAWithSourcesChain
import os
import time
os.environ["OPENAI_API_KEY"] = "####"
index_creator = VectorstoreIndexCreator()
doc_names = ['state_of_the_union.txt']
loaders = [TextLoader(doc) for doc in doc_names]
docsearch = index_creator.from_loaders(loaders)
chain = load_qa_with_sources_chain(ChatOpenAI(temperature=0.9, model_name='gpt-3.5-turbo'), chain_type="stuff")
with get_openai_callback() as cb:
start = time.time()
query = "What did Joe Biden say about Ukraine?"
docs = docsearch.vectorstore.similarity_search(query)
answer = chain.run(input_documents=docs, question=query)
print(answer)
print("\n")
print(f"Total Tokens: {cb.total_tokens}")
print(f"Prompt Tokens: {cb.prompt_tokens}")
print(f"Completion Tokens: {cb.completion_tokens}")
print(time.time() - start, 'seconds')
````
Output:
````
Total Tokens: 2264
Prompt Tokens: 2188
Completion Tokens: 76
2.9221560955047607 seconds
Joe Biden talked about the Ukrainian people's fearlessness, courage, and determination in the face of Russian aggression. He also announced that the United States will provide military, economic, and humanitarian assistance to Ukraine, including more than $1 billion in direct assistance. He further emphasized that the United States and its allies will defend every inch of territory of NATO countries, including Ukraine, with the full force of their collective power. However, he mentioned nothing about Michael Jackson.
SOURCES: state_of_the_union.txt
Total Tokens: 2287
Prompt Tokens: 2187
Completion Tokens: 100
3.8259849548339844 seconds
````
Is it possible there is a remnant of that example code that gets called and adds the question about Michael Jackson? | Hallucinating Question about Michael Jackson | https://api.github.com/repos/langchain-ai/langchain/issues/2510/comments | 6 | 2023-04-06T19:11:07Z | 2023-10-15T06:04:51Z | https://github.com/langchain-ai/langchain/issues/2510 | 1,657,916,335 | 2,510 |
[
"langchain-ai",
"langchain"
] | Trying to initialize a `ChatOpenAI` is resulting in this error:
```
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(temperature=0)
```
> `openai` has no `ChatCompletion` attribute, this is likely due to an old version of the openai package.
I've upgraded all my packages to latest...
```
pip3 list
Package Version
------------------------ ---------
langchain 0.0.133
openai 0.27.4
```
| `openai` has no `ChatCompletion` attribute | https://api.github.com/repos/langchain-ai/langchain/issues/2505/comments | 7 | 2023-04-06T18:00:51Z | 2023-09-28T16:08:56Z | https://github.com/langchain-ai/langchain/issues/2505 | 1,657,837,119 | 2,505 |
[
"langchain-ai",
"langchain"
] | When using the `refine` chain_type of the `load_summarize_chain`, I get some unique output on some longer documents, which might necessitate minor changes to the current prompt.
```
Return original summary.
```
```
The original summary remains appropriate.
```
```
No changes needed to the original summary.
```
```
The existing summary remains sufficient in capturing the key points discussed
```
```
No refinement needed, as the new context does not provide any additional information on the content of the discussion or its key takeaways.
``` | Summarize Chain Doesn't Always Return Summary When Using Refine Chain Type | https://api.github.com/repos/langchain-ai/langchain/issues/2504/comments | 10 | 2023-04-06T17:17:27Z | 2023-12-09T16:07:26Z | https://github.com/langchain-ai/langchain/issues/2504 | 1,657,785,547 | 2,504 |
[
"langchain-ai",
"langchain"
] | I would like to create a new issue on GitHub regarding the extension of ChatGPTPluginRetriever to support filters for metadata in chatGptRetrievalPlugin. With the ability to extend metadata using chatGptRetrievalPlugin, I believe there will be an increased need to consider filters for metadata as well. In fact, I myself have this need and have implemented the filter feature by extending ChatGPTPluginRetriever and RetrievalQA. While I have made limited extensions for specific use cases, I hope this feature will be supported throughout the entire library. Thank you. | I want to extend ChatGPTPluginRetriever to support filters for chatGptRetrievalPlugin. | https://api.github.com/repos/langchain-ai/langchain/issues/2501/comments | 2 | 2023-04-06T15:49:22Z | 2023-09-10T16:37:19Z | https://github.com/langchain-ai/langchain/issues/2501 | 1,657,669,963 | 2,501 |
[
"langchain-ai",
"langchain"
] | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | OpenSearchVectorSearch doesn't permit the user to specify a field name | https://api.github.com/repos/langchain-ai/langchain/issues/2500/comments | 6 | 2023-04-06T15:46:29Z | 2023-04-10T03:04:18Z | https://github.com/langchain-ai/langchain/issues/2500 | 1,657,666,051 | 2,500 |
[
"langchain-ai",
"langchain"
] | I am running the following in a Jupyter Notebook:
```
from langchain.agents.agent_toolkits import create_python_agent
from langchain.tools.python.tool import PythonREPLTool
from langchain.python import PythonREPL
from langchain.llms.openai import OpenAI
import os
os.environ["OPENAI_API_KEY"]="sk-xxxxxxxx"
agent_executor = create_python_agent(
llm=OpenAI(temperature=0, max_tokens=2048),
tool=PythonREPLTool(),
verbose=True,
)
agent_executor.run("""Understand, write a single neuron neural network in TensorFlow.
Take synthetic data for y=2x. Train for 1000 epochs and print every 100 epochs.
Return prediction for x = 5.""")
```
I got the following error:
```
> Entering new AgentExecutor chain...
I need to install TensorFlow and create a single neuron neural network.
Action: Python REPL
Action Input:
import tensorflow as tf
# Create the model
model = tf.keras.Sequential([tf.keras.layers.Dense(units=1, input_shape=[1])])
# Compile the model
model.compile(optimizer='sgd', loss='mean_squared_error')
# Create synthetic data
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-2.0, 0.0, 2.0, 4.0, 6.0, 8.0], dtype=float)
# Train the model
model.fit(xs, ys, epochs=1000, verbose=100)
Observation: No module named 'tensorflow'
Thought: I need to install TensorFlow
Action: Command Line
Action Input: pip install tensorflow
Observation: Command Line is not a valid tool, try another one.
Thought: I need to install TensorFlow
Action: Python REPL
Action Input: import tensorflow as tf
Observation: No module named 'tensorflow'
Thought: I need to install TensorFlow
Action: Command Line
Action Input: pip install tensorflow
Observation: Command Line is not a valid tool, try another one.
Thought: I need to install TensorFlow
Action: Python REPL
Action Input: !pip install tensorflow
Observation: invalid syntax (<string>, line 1)
Thought: I need to install TensorFlow
Action: Command Line
Action Input: pip install tensorflow
Observation: Command Line is not a valid tool, try another one.
Thought: I need to install TensorFlow
Action: Python REPL
Action Input: !pip install tensorflow
Observation: invalid syntax (<string>, line 1)
Thought: I need to install TensorFlow
Action: Command Line
Action Input: pip install tensorflow
Observation: Command Line is not a valid tool, try another one.
Thought: I need to install TensorFlow
Action: Python REPL
Action Input: !pip install tensorflow
Observation: invalid syntax (<string>, line 1)
Thought: I need to install TensorFlow
Action: Command Line
Action Input: pip install tensorflow
Observation: Command Line is not a valid tool, try another one.
Thought: I need to install TensorFlow
Action: Python REPL
Action Input: !pip install tensorflow
Observation: invalid syntax (<string>, line 1)
Thought: I need to install TensorFlow
Action: Command Line
Action Input: pip install tensorflow
Observation: Command Line is not a valid tool, try another one.
Thought: I need to install TensorFlow
Action: Python REPL
Action Input: !pip install tensorflow
Observation: invalid syntax (<string>, line 1)
Thought: I need to install TensorFlow
Action: Command Line
Action Input: pip install tensorflow
Observation: Command Line is not a valid tool, try another one.
Thought: I need to install TensorFlow
Action: Python REPL
Action Input: !pip install tensorflow
Observation: invalid syntax (<string>, line 1)
Thought:
> Finished chain.
'Agent stopped due to max iterations.'
```
Not sure where am I going wrong. | 'Agent stopped due to max iterations.' | https://api.github.com/repos/langchain-ai/langchain/issues/2495/comments | 5 | 2023-04-06T14:36:38Z | 2023-09-25T16:11:25Z | https://github.com/langchain-ai/langchain/issues/2495 | 1,657,547,064 | 2,495 |
[
"langchain-ai",
"langchain"
] | I have the following code:
```
docsearch = Chroma.from_documents(texts, embeddings,persist_directory=persist_directory)
```
and get the following error:
```
Retrying langchain.embeddings.openai.embed_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: Requests to the Embeddings_Create Operation under Azure OpenAI API version 2022-12-01 have exceeded call rate limit of your current OpenAI S0 pricing tier. Please retry after 3 seconds. Please contact Azure support service if you would like to further increase the default rate limit.
```
The length of my ```texts``` list is less than 100 and as far as I know azure has a 400 request/min limit. That means I should not receive any limitation error. Can someone explain me what is happening which results to this error?
After these retires by Langchain, it looks like embeddings are lost and not stored in the Chroma DB. Could someone please give me a hint what I'm doing wrong?
using langchain==0.0.125
Many thanks | Azure OpenAI Embedding langchain.embeddings.openai.embed_with_retry won't provide any embeddings after retries. | https://api.github.com/repos/langchain-ai/langchain/issues/2493/comments | 33 | 2023-04-06T12:25:58Z | 2024-04-15T16:35:33Z | https://github.com/langchain-ai/langchain/issues/2493 | 1,657,331,728 | 2,493 |
[
"langchain-ai",
"langchain"
] |
persist_directory = 'chroma_db_store/index/' or 'chroma_db_store'
docsearch = Chroma(persist_directory=persist_directory, embedding_function=embeddings)
query = "Hey"
docs = docsearch.similarity_search(query)
NoIndexException: Index not found, please create an instance before querying
Folder structure
chroma_db_store:
- chroma-collections.parquet
- chroma-embeddings.parquet
- index/ | Error while loading saved index in chroma db | https://api.github.com/repos/langchain-ai/langchain/issues/2491/comments | 36 | 2023-04-06T11:52:42Z | 2024-04-18T10:42:12Z | https://github.com/langchain-ai/langchain/issues/2491 | 1,657,278,903 | 2,491 |
[
"langchain-ai",
"langchain"
] | `search_index = Chroma(persist_directory='db', embedding_function=OpenAIEmbeddings())`
but trying to do a similarity_search on it, i get this error:
`NoIndexException: Index not found, please create an instance before querying`
folder structure:
db/
- index/
- id_to_uuid_xx.pkl
- index_xx.pkl
- index_metadata_xx.pkl
- uuid_to_id_xx.pkl
- chroma-collections.parquet
- chroma-embeddings.parquet | instantiating Chroma from persist_directory not working: `NoIndexException` | https://api.github.com/repos/langchain-ai/langchain/issues/2490/comments | 2 | 2023-04-06T11:51:58Z | 2023-09-10T16:37:24Z | https://github.com/langchain-ai/langchain/issues/2490 | 1,657,277,903 | 2,490 |
[
"langchain-ai",
"langchain"
] | in PromptTemplate i am loading json and it is coming back with below error
Exception has occurred: KeyError and mentioning the key used in json in that case customerNAme | KeyError : While Loading Json Context in Template | https://api.github.com/repos/langchain-ai/langchain/issues/2489/comments | 4 | 2023-04-06T11:44:10Z | 2023-09-25T16:11:30Z | https://github.com/langchain-ai/langchain/issues/2489 | 1,657,267,209 | 2,489 |
[
"langchain-ai",
"langchain"
] | Error with the AgentOutputParser() when I follow the notebook "Conversation Agent (for Chat Models)"
`> Entering new AgentExecutor chain...
Traceback (most recent call last):
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/agents/conversational_chat/base.py", line 106, in _extract_tool_and_input
response = self.output_parser.parse(llm_output)
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/agents/conversational_chat/base.py", line 51, in parse
response = json.loads(cleaned_output)
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/json/__init__.py", line 357, in loads
return _default_decoder.decode(s)
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/json/decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/json/decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "demo0_0_4.py", line 119, in <module>
sys.stdout.write(agent_executor(query)['output'])
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/agents/agent.py", line 637, in _call
next_step_output = self._take_next_step(
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/agents/agent.py", line 553, in _take_next_step
output = self.agent.plan(intermediate_steps, **inputs)
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/agents/agent.py", line 286, in plan
action = self._get_next_action(full_inputs)
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/agents/agent.py", line 248, in _get_next_action
parsed_output = self._extract_tool_and_input(full_output)
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/agents/conversational_chat/base.py", line 109, in _extract_tool_and_input
raise ValueError(f"Could not parse LLM output: {llm_output}")
ValueError: Could not parse LLM output: , wo xiang zhao yi ge hao de zhongwen yuyan xuexiao` | ValueError: Could not parse LLM output: on 'chat-conversational-react-description' | https://api.github.com/repos/langchain-ai/langchain/issues/2488/comments | 2 | 2023-04-06T11:17:28Z | 2023-09-26T16:10:32Z | https://github.com/langchain-ai/langchain/issues/2488 | 1,657,228,906 | 2,488 |
[
"langchain-ai",
"langchain"
] | My template has a part that is formatted like this:
```
Final:
[{{'instruction': 'What is the INR value of 1 USD?', 'source': 'USD', 'target': 'INR', 'amount': 1}},
{{'instruction': 'Convert 100 USD to EUR.', 'source': 'USD', 'target': 'EUR', 'amount': 100}},
{{'instruction': 'How much is 200 GBP in JPY?', 'source': 'GBP', 'target': 'JPY', 'amount': 200}},
{{'instruction': 'Convert 300 AUD to INR.', 'source': 'AUD', 'target': 'INR', 'amount': 300}},
{{'instruction': 'Convert 900 HKD to SGD.', 'source': 'HKD', 'target': 'SGD', 'amount': 900}}]
```
and when I'm trying to form a FewShotTemplate from it the error I get is
`KeyError: "'instruction'"`
What's the correct way to handle that? Am I placing my double curly braces wrong? Should there be more (`{{{` and the like)? | KeyError with double curly braces | https://api.github.com/repos/langchain-ai/langchain/issues/2487/comments | 1 | 2023-04-06T11:04:49Z | 2023-04-06T11:19:00Z | https://github.com/langchain-ai/langchain/issues/2487 | 1,657,207,499 | 2,487 |
[
"langchain-ai",
"langchain"
] | Traceback (most recent call last):
File "c:\Users\Siddhesh\Desktop\llama.cpp\langchain_test.py", line 10, in <module>
llm = LlamaCpp(model_path="C:\\Users\\Siddhesh\\Desktop\\llama.cpp\\models\\ggml-model-q4_0.bin")
File "pydantic\main.py", line 339, in pydantic.main.BaseModel.__init__
File "pydantic\main.py", line 1102, in pydantic.main.validate_model
File "C:\Users\Siddhesh\AppData\Local\Programs\Python\Python310\lib\site-packages\langchain\llms\llamacpp.py", line 117, in validate_environment
raise NameError(f"Could not load Llama model from path: {model_path}")
NameError: Could not load Llama model from path: C:\Users\Siddhesh\Desktop\llama.cpp\models\ggml-model-q4_0.bin
I have tried with raw string, double \\, and the linux path format /path/to/model - none of them worked.
The path is right and the model .bin file is in the latest ggml model format. The model format for llamacpp was recently changed from `ggml` to `ggjt` and the model files had to be recoverted into this format. Is the issue being caused because of this change? | NameError: Could not load Llama model from path | https://api.github.com/repos/langchain-ai/langchain/issues/2485/comments | 17 | 2023-04-06T10:31:43Z | 2024-03-27T14:56:25Z | https://github.com/langchain-ai/langchain/issues/2485 | 1,657,150,082 | 2,485 |
[
"langchain-ai",
"langchain"
] | If index already exists or any doc inside it, I can not update the index or add more docs to it. for example:
docsearch = ElasticVectorSearch.from_texts(texts=texts[0:10], ids=ids[0:10], embedding=embedding, elasticsearch_url=f"http://elastic:{ELASTIC_PASSWORD}@localhost:9200", index_name="test")
Get an error: BadRequestError: BadRequestError(400, 'resource_already_exists_exception', 'index [test/v_Ahq4NSS2aWm2_gLNUtpQ] already exists') | Can not overwrite docs in ElasticVectorSearch as Pinecone do | https://api.github.com/repos/langchain-ai/langchain/issues/2484/comments | 15 | 2023-04-06T10:24:28Z | 2023-09-28T16:09:01Z | https://github.com/langchain-ai/langchain/issues/2484 | 1,657,135,863 | 2,484 |
[
"langchain-ai",
"langchain"
] | I am using a Agent and wanted to stream just the final response, do you know if that is supported already? and how to do it? | using a Agent and wanted to stream just the final response | https://api.github.com/repos/langchain-ai/langchain/issues/2483/comments | 28 | 2023-04-06T09:58:04Z | 2024-07-03T10:07:39Z | https://github.com/langchain-ai/langchain/issues/2483 | 1,657,083,533 | 2,483 |
[
"langchain-ai",
"langchain"
] | I want to costum a chatmodel, what is necessary like a custom llm's _call() method? | Custom Chat model like llm | https://api.github.com/repos/langchain-ai/langchain/issues/2482/comments | 1 | 2023-04-06T09:47:06Z | 2023-09-10T16:37:29Z | https://github.com/langchain-ai/langchain/issues/2482 | 1,657,060,333 | 2,482 |
[
"langchain-ai",
"langchain"
] | I'm trying to save and restore a Langchain Agent with a custom prompt template, and I'm encountering the error `"CustomPromptTemplate" object has no field "_prompt_type"`.
Langchain version: 0.0.132
Source code:
```
import os
os.environ["OPENAI_API_KEY"] = "..."
os.environ["SERPAPI_API_KEY"] = "..."
from langchain.agents import Tool, AgentExecutor, LLMSingleActionAgent, AgentOutputParser
from langchain.prompts import StringPromptTemplate
from langchain import OpenAI, SerpAPIWrapper, LLMChain
from typing import List, Union
from langchain.schema import AgentAction, AgentFinish
import re
search = SerpAPIWrapper()
tools = [
Tool(
name = "Search",
func=search.run,
description="useful for when you need to answer questions about current events"
)
]
template = """Answer the following questions as best you can, but speaking as a pirate might speak. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin! Remember to speak as a pirate when giving your final answer. Use lots of "Arg"s
Question: {input}
{agent_scratchpad}"""
class CustomPromptTemplate(StringPromptTemplate):
# The template to use
template: str
# The list of tools available
tools: List[Tool]
def format(self, **kwargs) -> str:
# Get the intermediate steps (AgentAction, Observation tuples)
# Format them in a particular way
intermediate_steps = kwargs.pop("intermediate_steps")
thoughts = ""
for action, observation in intermediate_steps:
thoughts += action.log
thoughts += f"\nObservation: {observation}\nThought: "
# Set the agent_scratchpad variable to that value
kwargs["agent_scratchpad"] = thoughts
# Create a tools variable from the list of tools provided
kwargs["tools"] = "\n".join([f"{tool.name}: {tool.description}" for tool in self.tools])
# Create a list of tool names for the tools provided
kwargs["tool_names"] = ", ".join([tool.name for tool in self.tools])
return self.template.format(**kwargs)
prompt = CustomPromptTemplate(
template=template,
tools=tools,
# This omits the `agent_scratchpad`, `tools`, and `tool_names` variables because those are generated dynamically
# This includes the `intermediate_steps` variable because that is needed
input_variables=["input", "intermediate_steps"]
)
class CustomOutputParser(AgentOutputParser):
def parse(self, llm_output: str) -> Union[AgentAction, AgentFinish]:
# Check if agent should finish
if "Final Answer:" in llm_output:
return AgentFinish(
# Return values is generally always a dictionary with a single `output` key
# It is not recommended to try anything else at the moment :)
return_values={"output": llm_output.split("Final Answer:")[-1].strip()},
log=llm_output,
)
# Parse out the action and action input
regex = r"Action: (.*?)[\n]*Action Input:[\s]*(.*)"
match = re.search(regex, llm_output, re.DOTALL)
if not match:
raise ValueError(f"Could not parse LLM output: `{llm_output}`")
action = match.group(1).strip()
action_input = match.group(2)
# Return the action and action input
return AgentAction(tool=action, tool_input=action_input.strip(" ").strip('"'), log=llm_output)
output_parser = CustomOutputParser()
llm = OpenAI(temperature=0)
# LLM chain consisting of the LLM and a prompt
llm_chain = LLMChain(llm=llm, prompt=prompt)
tool_names = [tool.name for tool in tools]
agent = LLMSingleActionAgent(
llm_chain=llm_chain,
output_parser=output_parser,
stop=["\nObservation:"],
allowed_tools=tool_names
)
agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True)
agent_executor.run("How many people live in canada as of 2023?")
agent.save("agent.yaml")
```
Error:
```
Traceback (most recent call last):
File "agent.py", line 114, in <module>
agent.save("agent.yaml")
File "/Users/corey.zumar/opt/anaconda3/envs/base2/lib/python3.8/site-packages/langchain/agents/agent.py", line 130, in save
agent_dict = self.dict()
File "/Users/corey.zumar/opt/anaconda3/envs/base2/lib/python3.8/site-packages/langchain/agents/agent.py", line 104, in dict
_dict = super().dict()
File "pydantic/main.py", line 445, in pydantic.main.BaseModel.dict
File "pydantic/main.py", line 843, in _iter
File "pydantic/main.py", line 718, in pydantic.main.BaseModel._get_value
File "/Users/corey.zumar/opt/anaconda3/envs/base2/lib/python3.8/site-packages/langchain/chains/base.py", line 248, in dict
_dict = super().dict()
File "pydantic/main.py", line 445, in pydantic.main.BaseModel.dict
File "pydantic/main.py", line 843, in _iter
File "pydantic/main.py", line 718, in pydantic.main.BaseModel._get_value
File "/Users/corey.zumar/opt/anaconda3/envs/base2/lib/python3.8/site-packages/langchain/prompts/base.py", line 154, in dict
prompt_dict["_type"] = self._prompt_type
File "/Users/corey.zumar/opt/anaconda3/envs/base2/lib/python3.8/site-packages/langchain/prompts/base.py", line 149, in _prompt_type
raise NotImplementedError
NotImplementedError
```
Thanks in advance for your help! | Can't save a custom agent: "CustomPromptTemplate" object has no field "_prompt_type" | https://api.github.com/repos/langchain-ai/langchain/issues/2481/comments | 1 | 2023-04-06T08:33:35Z | 2023-09-10T16:37:34Z | https://github.com/langchain-ai/langchain/issues/2481 | 1,656,924,309 | 2,481 |
[
"langchain-ai",
"langchain"
] | For example, I want to build an agent with a Q&A tool (wrap the [Q&A with source chain](https://python.langchain.com/en/latest/modules/chains/index_examples/qa_with_sources.html) ) as private knowledge base, together with several other tools to produce the final answer
What's the suggested way to pass the "sources" information to the agent and return in the final answer? For the end user, the experience is similar as what new bing does.
| Passing data from tool to agent | https://api.github.com/repos/langchain-ai/langchain/issues/2478/comments | 2 | 2023-04-06T08:04:52Z | 2023-09-18T16:20:43Z | https://github.com/langchain-ai/langchain/issues/2478 | 1,656,881,285 | 2,478 |
[
"langchain-ai",
"langchain"
] | I also tried this for the `csv_agent`. It just gets confused . The default `text-davinci` works in one go.

| support gpt-3.5-turbo model for agent toolkits | https://api.github.com/repos/langchain-ai/langchain/issues/2476/comments | 1 | 2023-04-06T06:25:09Z | 2023-09-10T16:37:44Z | https://github.com/langchain-ai/langchain/issues/2476 | 1,656,743,871 | 2,476 |
[
"langchain-ai",
"langchain"
] | Does langchain have Atlassian Confluence support like Llama Hub? | Atlassian Confluence support | https://api.github.com/repos/langchain-ai/langchain/issues/2473/comments | 24 | 2023-04-06T05:29:57Z | 2023-12-13T16:10:48Z | https://github.com/langchain-ai/langchain/issues/2473 | 1,656,690,780 | 2,473 |
[
"langchain-ai",
"langchain"
] | `text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) `
If I do this, some text will not be split strictly by default ‘\n\n’ like:
'In state after state, new laws have been passed, not only to suppress the vote, but to subvert entire elections. \n\nWe cannot let this happen. \n\nTonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \n\nTonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \n\nOne of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \n\nAnd I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.'
| how to split documents | https://api.github.com/repos/langchain-ai/langchain/issues/2469/comments | 1 | 2023-04-06T04:24:01Z | 2023-04-25T12:48:06Z | https://github.com/langchain-ai/langchain/issues/2469 | 1,656,641,706 | 2,469 |
[
"langchain-ai",
"langchain"
] | Previously, for standard language models setting `batch_size` would control concurrent LLM requests, reducing the risk of timeouts and network issues (https://github.com/hwchase17/langchain/issues/1145).
New chat models don't seem to support this parameter. See the following example:
```python
from langchain.chat_models import ChatOpenAI
chain = load_summarize_chain(ChatOpenAI(batch_size=1), chain_type="map_reduce")
chain.run(docs)
File /usr/local/lib/python3.9/site-packages/openai/api_requestor.py:683, in APIRequestor._interpret_response_line(self, rbody, rcode, rheaders, stream)
681 stream_error = stream and "error" in resp.data
682 if stream_error or not 200 <= rcode < 300:
--> 683 raise self.handle_error_response(
684 rbody, rcode, resp.data, rheaders, stream_error=stream_error
685 )
686 return resp
InvalidRequestError: Unrecognized request argument supplied: batch_size
```
Is this intentional? Happy to cut a PR! | Batch Size for Chat Models | https://api.github.com/repos/langchain-ai/langchain/issues/2465/comments | 3 | 2023-04-06T03:45:40Z | 2023-10-16T14:37:35Z | https://github.com/langchain-ai/langchain/issues/2465 | 1,656,615,689 | 2,465 |
[
"langchain-ai",
"langchain"
] | Hey!
First things first, I just want to say thanks for this amazing project :)
In MapReduceDocumentsChain class, when you call it asynchronously, i.e. with `acombine_docs`, it still calls the same `self.process_results` method as it does when calling the regular `combine_docs`. I expected, that when you use async, it would do both map and reduce (self.process_results is basically the reduce step, if I understand correctly) steps async.
The relevant parts in [map_reduce.py](https://github.com/hwchase17/langchain/blob/master/langchain/chains/combine_documents/map_reduce.py):
```python
class MapReduceDocumentsChain(BaseCombineDocumentsChain, BaseModel):
async def acombine_docs(
self, docs: List[Document], **kwargs: Any
) -> Tuple[str, dict]:
...
results = ...
return self._process_results(results, docs, **kwargs)
def _process_results(
self,
results: List[Dict],
docs: List[Document],
token_max: int = 3000,
**kwargs: Any,
) -> Tuple[str, dict]:
....
output, _ = self.combine_document_chain.combine_docs(result_docs, **kwargs) # this should be acombine_docs
return output, extra_return_dict
```
This could be fixed by, for example, adding the async version for processing results `_aprocess_results` and using that instead when doing async calls.
I would be happy to write a fix for this, just wanted to confirm if it's indeed a problem and I'm not missing something (the reason I stumbled on this is because I am working on a task similar to summarization and was looking for ways to speed things up). | Adding async support for reduce step in MapReduceDocumentsChain | https://api.github.com/repos/langchain-ai/langchain/issues/2464/comments | 3 | 2023-04-06T00:24:31Z | 2023-12-06T17:47:15Z | https://github.com/langchain-ai/langchain/issues/2464 | 1,656,491,381 | 2,464 |
[
"langchain-ai",
"langchain"
] | When I call
```python
retriever = PineconeHybridSearchRetriever(embeddings=embeddings, index=index, tokenizer=tokenizer)
retriever.get_relevant_documents(query)
```
I'm getting the error:
```
final_result.append(Document(page_content=res["metadata"]["context"]))
KeyError: 'context'
```
What is that `context`? | KeyError: 'context' when using PineconeHybridSearchRetriever | https://api.github.com/repos/langchain-ai/langchain/issues/2459/comments | 3 | 2023-04-05T20:46:00Z | 2024-05-12T18:19:37Z | https://github.com/langchain-ai/langchain/issues/2459 | 1,656,270,923 | 2,459 |
[
"langchain-ai",
"langchain"
] | During an experiment I tryied to load some personal whatsapp conversations into a vectorstore. But loading was failing. Following there's an example of a dataset and code with some half lines working and half failing:
Dataset (whatsapp_chat.txt):
```
19/10/16, 13:24 - Aitor Mira: Buenas Andrea!
19/10/16, 13:24 - Aitor Mira: Si
19/10/16, 13:24 PM - Aitor Mira: Buenas Andrea!
19/10/16, 13:24 PM - Aitor Mira: Si
```
Code:
```python
from langchain.document_loaders import WhatsAppChatLoader
loader = WhatsAppChatLoader("../data/whatsapp_chat.txt")
docs = loader.load()
```
Returns:
```
[Document(page_content='Aitor Mira on 19/10/16, 13:24 PM: Buenas Andrea!\n\nAitor Mira on 19/10/16, 13:24 PM: Si\n\n', metadata={'source': '.[.\\data\\whatsapp_chat.txt](https://file+.vscode-resource.vscode-cdn.net/c%3A/Users/itort/Documents/GiTor/impersonate-gpt/notebooks//data//whatsapp_chat.txt)'})]
```
What's happening is that due to a bug in the regex match pattern, all lines without `AM` or `PM` after the hour:minutes won't be matched. Thus two first lines of whatsapp_chat.txt are ignored and two last matched.
Here the buggy regex:
`r"(\d{1,2}/\d{1,2}/\d{2,4}, \d{1,2}:\d{1,2} (?:AM|PM)) - (.*?): (.*)"`
Here the solution regex parsing either 12 or 24 hours time formats:
`r"(\d{1,2}/\d{1,2}/\d{2,4}, \d{1,2}:\d{1,2}(?: AM| PM)?) - (.*?): (.*)"` | WhatsAppChatLoader fails to load 24 hours time format chats | https://api.github.com/repos/langchain-ai/langchain/issues/2457/comments | 1 | 2023-04-05T20:39:23Z | 2023-04-06T16:45:16Z | https://github.com/langchain-ai/langchain/issues/2457 | 1,656,260,004 | 2,457 |
[
"langchain-ai",
"langchain"
] | In following the docs for Agent ToolKits, specifically for OpenAPI, I encountered a bug in `reduce_openapi_spec` where the url has `https:` trunc'd off leading to errors when the Agent attempts to make a request.
I'm able to correct it by hardcoding the value for the url in `servers`:
- `api_spec.servers[0]['url'] = 'https://api.foo.com`
I looked through `reduce_openapi_spec` but don't obviously see where the bug is being introduced. | reduce_openapi_spec removes https: from url | https://api.github.com/repos/langchain-ai/langchain/issues/2456/comments | 5 | 2023-04-05T20:26:58Z | 2023-10-25T20:48:18Z | https://github.com/langchain-ai/langchain/issues/2456 | 1,656,244,370 | 2,456 |
[
"langchain-ai",
"langchain"
] | Hi there,
Going through the docs, and it seems there is only SQLAgent available that works for the Postgres/MySQL databases. Is there any support for the Clickhouse database?
| Clickhouse langchain agent? | https://api.github.com/repos/langchain-ai/langchain/issues/2454/comments | 3 | 2023-04-05T20:20:48Z | 2024-03-28T03:37:12Z | https://github.com/langchain-ai/langchain/issues/2454 | 1,656,231,938 | 2,454 |
[
"langchain-ai",
"langchain"
] | Currently, tool selection is case sensitive. So if you make a tool "email" and the Agent request the tool "Email" it will say that it is not a valid tool. As there is a lot of variability with agents, we should make it so that the tool selection is case insensitive (with potential additional validation to ensure there are no tools called exactly the same in the allowed tools) | Tool selection is case sensitive | https://api.github.com/repos/langchain-ai/langchain/issues/2453/comments | 5 | 2023-04-05T20:12:40Z | 2023-12-11T16:08:38Z | https://github.com/langchain-ai/langchain/issues/2453 | 1,656,223,326 | 2,453 |
[
"langchain-ai",
"langchain"
] | Hi! I tried to use pinecon's hybrid search as in this tutorial:
https://python.langchain.com/en/latest/modules/indexes/retrievers/examples/pinecone_hybrid_search.html
The only difference is that I created the indices beforehand, so without this chunk of code:
```python
pinecone.create_index(
name = index_name,
dimension = 1536, # dimensionality of dense model
metric = "dotproduct",
pod_type = "s1"
)
```
On the chunk below, I'm getting: `HTTP response body: {"code":3,"message":"Index configuration does not support sparse values","details":[]}`
```python
result = retriever.get_relevant_documents("foo")
``` | Index configuration does not support sparse values | https://api.github.com/repos/langchain-ai/langchain/issues/2451/comments | 2 | 2023-04-05T19:51:05Z | 2023-04-09T19:56:43Z | https://github.com/langchain-ai/langchain/issues/2451 | 1,656,194,417 | 2,451 |
[
"langchain-ai",
"langchain"
] | Hello! Are you considering creating a Discord channel? Perhaps one already exists, but I was unable to locate it. | Create discord channel for Langchain | https://api.github.com/repos/langchain-ai/langchain/issues/2448/comments | 3 | 2023-04-05T16:17:28Z | 2023-04-18T02:18:22Z | https://github.com/langchain-ai/langchain/issues/2448 | 1,655,932,782 | 2,448 |
[
"langchain-ai",
"langchain"
] | Integrating [RabbitMQ](https://github.com/rabbitmq)'s messaging protocols into LangChain unlocks seamless integration with multiple platforms, including Facebook Messenger, Slack, Microsoft Teams, Twitter, and Zoom. RabbitMQ supports AMQP, STOMP, MQTT, and HTTP [messaging protocols](https://www.rabbitmq.com/protocols.html), enabling efficient and reliable communication with these platforms. | RabbitMQ | https://api.github.com/repos/langchain-ai/langchain/issues/2447/comments | 2 | 2023-04-05T16:14:48Z | 2023-09-25T16:11:50Z | https://github.com/langchain-ai/langchain/issues/2447 | 1,655,929,140 | 2,447 |
[
"langchain-ai",
"langchain"
] | I am running a standard LangChain use case of reading a PDF document, generating embeddings using OpenAI, and then saving them to Pinecone index.
```
def read_pdf(file_path):
loader = UnstructuredFileLoader(file_path)
docs = loader.load()
return docs
def create_embeddings(document):
openai_embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
doc_chunks = text_splitter.split_documents(document)
embeddings = openai_embeddings.embed_documents(doc_chunks)
return embeddings
def insert_embeddings_to_pinecone(embeddings):
pinecone = Pinecone(PINECONE_API_KEY, PINECONE_INDEX_NAME)
pinecone.upsert(items=embeddings)
```
Error message:
```
File /opt/homebrew/Cellar/python@3.11/3.11.2_1/Frameworks/Python.framework/Versions/3.11/lib/python3.11/json/encoder.py:180, in JSONEncoder.default(self, o)
161 def default(self, o):
162 """Implement this method in a subclass such that it returns
163 a serializable object for ``o``, or calls the base implementation
164 (to raise a ``TypeError``).
(...)
178
179 """
--> 180 raise TypeError(f'Object of type {o.__class__.__name__} '
181 f'is not JSON serializable')
TypeError: Object of type Document is not JSON serializable
```
| TypeError: Object of type Document is not JSON serializable | https://api.github.com/repos/langchain-ai/langchain/issues/2446/comments | 6 | 2023-04-05T16:07:37Z | 2023-10-31T16:08:05Z | https://github.com/langchain-ai/langchain/issues/2446 | 1,655,917,246 | 2,446 |
[
"langchain-ai",
"langchain"
] | When few documets embedded into vector db everything works fine, with similarity search I can always find the most relevant documents on the top of results. But when it comes to over hundred, searching result will be very confusing, given the same query I could not find any relevant documents. I've tried Chroma, Faiss, same story.
Anyone has any idea? thanks.
btw, the documents are in Chinese... | Similarity search not working well when number of ingested documents is great, say over one hundred. | https://api.github.com/repos/langchain-ai/langchain/issues/2442/comments | 32 | 2023-04-05T14:55:28Z | 2024-05-04T22:03:03Z | https://github.com/langchain-ai/langchain/issues/2442 | 1,655,787,596 | 2,442 |
[
"langchain-ai",
"langchain"
] | Hi!
1. Upd: Fixed in https://github.com/hwchase17/langchain/pull/2641
~I've noticed in the `Models -> LLM` [documentation](https://python.langchain.com/en/latest/modules/models/llms/getting_started.html) the following note about `get_num_tokens` function:~
> Notice that by default the tokens are estimated using a HuggingFace tokenizer.
~It looks not exactly correct since Huggingface is used only in legacy versions (< 3.8), so it probably outdated.~
2. There is also a mapping in `tiktoken` package that can be reused in the function [get_num_tokens](https://github.com/hwchase17/langchain/blob/master/langchain/llms/openai.py#L437-L462):
https://github.com/openai/tiktoken/blob/46287bfa493f8ccca4d927386d7ea9cc20487525/tiktoken/model.py#L13-L53 | docs: get_num_tokens - default tokenizer | https://api.github.com/repos/langchain-ai/langchain/issues/2439/comments | 3 | 2023-04-05T14:26:11Z | 2023-09-18T16:20:53Z | https://github.com/langchain-ai/langchain/issues/2439 | 1,655,733,381 | 2,439 |
[
"langchain-ai",
"langchain"
] | I have just started experimenting with OpenAI & Langchain and very new to this field. Is there a way to do country specific searches using the Serper API ? I am in Australia, and the Serper API keep returning US based results. I tried to use the "gl" parameter, but no success
```
from langchain.utilities import GoogleSerperAPIWrapper
from langchain.llms.openai import OpenAI
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
params = {
"gl": "au",
"hl": "en",
}
search = GoogleSerperAPIWrapper(params=params)
llm = OpenAI(temperature=0)
tools = [
Tool(
name="Intermediate Answer",
func=search.run,
description="useful for when you need to ask with search"
)
]
self_ask_with_search = initialize_agent(tools, llm, agent=AgentType.SELF_ASK_WITH_SEARCH, verbose=True)
self_ask_with_search.run("Which bank in Australia is offering the highest interest rate on deposits?")
```
Example:
Q: Which bank in Australia is offering the highest interest rate on deposits?
A: UFB Direct
UFB Direct is a bank based in the US, not Australia.
Can someone help? | Country specific searches using the Serper API ? | https://api.github.com/repos/langchain-ai/langchain/issues/2438/comments | 2 | 2023-04-05T14:19:37Z | 2023-09-18T16:20:58Z | https://github.com/langchain-ai/langchain/issues/2438 | 1,655,717,485 | 2,438 |
[
"langchain-ai",
"langchain"
] | Are `UnstructuredMarkdownLoader` and `MarkdownTextSplitter` meant to be used together? It seems like the former removes formatting so that the latter can no longer split into sections.
```python
import github
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import MarkdownTextSplitter
gh = github.Github(get_secret("github_token"))
repo_path = "hwchase17/langchain"
user_name, repo_name = repo_path.split("/")
repo = gh.get_user(user_name).get_repo(repo_name)
user_name, repo_name = repo_path.split("/")
repo = gh.get_user(user_name).get_repo(repo_name)
readme_file = repo.get_readme()
readme_content = readme_file.decoded_content.decode("utf-8")
with tempfile.NamedTemporaryFile(mode='w', delete=True) as temporary_file:
temporary_file.write(readme_content)
temporary_file.flush()
loader = UnstructuredMarkdownLoader(temporary_file.name)
documents = loader.load()
document_chunks = splitter.split_documents(documents)
```
| UnstructuredMarkdownLoader + MarkdownTextSplitter | https://api.github.com/repos/langchain-ai/langchain/issues/2436/comments | 2 | 2023-04-05T13:22:30Z | 2023-09-18T16:21:03Z | https://github.com/langchain-ai/langchain/issues/2436 | 1,655,613,603 | 2,436 |
[
"langchain-ai",
"langchain"
] | The value of `qa_prompt` is passed to `load_qa_chain()` as `prompt`, with no option for kwargs.
https://github.com/hwchase17/langchain/blob/4d730a9bbcd384da27e2e7c5a6a6efa5eac55838/langchain/chains/conversational_retrieval/base.py#L164-L168
`_load_map_reduce_chain()` expects multiple prompt templates as kwargs, none of which are named `prompt`, so this throws a pydantic validation error in `MapReduceDocumentsChain`.
https://github.com/hwchase17/langchain/blob/4d730a9bbcd384da27e2e7c5a6a6efa5eac55838/langchain/chains/question_answering/__init__.py#L218-L220
Perhaps we should make the use of these kwargs more generic? | `ConversationalRetrievalChain.from_llm()` does not work with `chain_type` of `"map_reduce"` | https://api.github.com/repos/langchain-ai/langchain/issues/2435/comments | 3 | 2023-04-05T11:54:22Z | 2023-09-26T16:10:47Z | https://github.com/langchain-ai/langchain/issues/2435 | 1,655,480,306 | 2,435 |
[
"langchain-ai",
"langchain"
] | I’m having a few issues with a prompt template using ConversationChain and ConversationEntity Memory.
Currently I’m using a template as follows:
```
template = """Assistant is a large language model based on OpenAI's chatGPT…
The user Assistant is speaking to is a human and their first name is {first_name} and their surname is {last_name}.
Entities:
{entities}
Conversation history:
{history}
user: {input}
panda:"""
```
I’m then dynamically passing in the first_name and last_name variables as follows, whilst passing over the entities, history and input variables so they can be picked up later:
```
new_template = template.format(
first_name=first_name,
last_name=last_name,
entities="{entities}",
history="{history}",
input="{input}"
)
```
I then build my prompt:
```
prompt = PromptTemplate(
input_variables=["entities", "history", "input"],
template=new_template
)
```
And then run as normal. However, when I inspect the final template in PromptLayer I see that the variables have been replaced as follows:
first_name=“{input}”,
last_name=first_name,
entities=last_name,
history="{entities}",
input="{history}"
So none of the variables have mapped properly, and have been mapped in order but with ”{input}” being passed first.
Ideally, I’d take all the input_variables out of the PromptTemplate and set everything up manually, but I don’t think ConversationChain with ConversationEntityMemory will let me do that as I think it’s expecting {entities}, {history}, and {input} variables to be passed in the PromptTemplate.
```
conversation = ConversationChain(
llm=llm,
verbose=False,
prompt=prompt,
memory=ConversationEntityMemory(llm=OpenAI(openai_api_key=settings.OPENAI_API_KEY))
)
``` | [ConversationEntity Memory Prompt Template] - issues with customisation | https://api.github.com/repos/langchain-ai/langchain/issues/2434/comments | 2 | 2023-04-05T11:33:15Z | 2023-07-23T12:01:01Z | https://github.com/langchain-ai/langchain/issues/2434 | 1,655,448,419 | 2,434 |
[
"langchain-ai",
"langchain"
] | I am using version0.0.0132 and i get this error while importing:
ImportError: cannot import name 'PineconeHybridSearchRetriever' from 'langchain.retrievers' | cannot import pineconehybridsearchretriever | https://api.github.com/repos/langchain-ai/langchain/issues/2432/comments | 1 | 2023-04-05T11:05:07Z | 2023-09-10T16:38:09Z | https://github.com/langchain-ai/langchain/issues/2432 | 1,655,408,831 | 2,432 |
[
"langchain-ai",
"langchain"
] | So as far as I can't tell, there is no way to return intermediate steps from tools to be combined at the agent level, making them a black box (discounting tracing). For example, an agent using the SQLDatabaseChain can't capture the SQL query used by the SQLChain.
The tool interface is just str -> str, which keeps it simple, but perhaps it would be a good idea to add a 'return_intermediate_steps' param and have the return be Union[str, Dict[str, Any]), or something similar in the same spirit to how agents and chains operate.
I'm happy to work on this, but given it would be a substantial change in the code, I'd like to get some discussion on the feature before taking a stab at it (and also to ensure I haven't missed a way to already achieve this :D) | Tools and return_intermediate_steps | https://api.github.com/repos/langchain-ai/langchain/issues/2431/comments | 3 | 2023-04-05T10:46:10Z | 2023-05-01T22:15:21Z | https://github.com/langchain-ai/langchain/issues/2431 | 1,655,381,372 | 2,431 |
[
"langchain-ai",
"langchain"
] | I have a use case in which I want to customize my own chat model; how can I do that?
there is a way to customize [LLM](https://python.langchain.com/en/latest/modules/models/llms/examples/custom_llm.html), but I did not find anything regarding customizing the chat model | How to customize chat model | https://api.github.com/repos/langchain-ai/langchain/issues/2430/comments | 4 | 2023-04-05T09:52:39Z | 2023-09-26T16:10:52Z | https://github.com/langchain-ai/langchain/issues/2430 | 1,655,297,167 | 2,430 |
[
"langchain-ai",
"langchain"
] | 👋🏾 I tried using the new Llamacpp LLM and Embedding classes (awesome work!) and I've noticed that any vector store created with it cannot be saved as a pickle as there are cytpe objects containing pointers.
The reason is because the Vector Store has the field `embedding_function` which is the `Callable` to
the llama.cpp embedding wrapper and that contains pointers that cannot be pickled. Reproducible code:
```python
from langchain.embeddings import LlamaCppEmbeddings
from langchain.vectorstores import FAISS
import pickle
llama = LlamaCppEmbeddings(model_path=MODEL_PATH)
store = FAISS.from_texts(
["test"],
llama,
)
faiss.write_index(store.index, "docs.index")
store.index = None
with open("faiss_store.pkl", "wb") as f:
pickle.dump(store, f)
```
which raises a ValueError:
```python
ValueError: ctypes objects containing pointers cannot be pickled
```
In the case that the `save_local` method from the FAISS vector store is used, the index cannot be stored due to the same serialisation issue:
```python
RuntimeError: Error in void faiss::write_index(const faiss::Index *, faiss::IOWriter *) at /Users/runner/work/faiss-wheels/faiss-wheels/faiss/faiss/impl/index_write.cpp:822: don't know how to serialize this type of index
```
I also tried with other libraries like `cloudpickle` or `dill` and none worked so I believe that the solution here it to convert the ctypes objects to a format that can be serialised. Do you have any recommended way to store it? | Not being able to pickle Llamacpp Embedding | https://api.github.com/repos/langchain-ai/langchain/issues/2429/comments | 3 | 2023-04-05T09:40:10Z | 2023-04-06T17:06:13Z | https://github.com/langchain-ai/langchain/issues/2429 | 1,655,278,934 | 2,429 |
[
"langchain-ai",
"langchain"
] | Issue Description:
I'm looking for a way to obtain streaming outputs from the model as a generator, which would enable dynamic chat responses in a front-end application. While this functionality is available in the OpenAI API, I couldn't find a similar option in Langchain.
I'm aware that using `verbose=True` allows us to see the streamed results printed in the console, but I'm specifically interested in a solution that can be integrated into a front-end app, rather than just displaying the results in the console.
Is there any existing functionality or workaround to achieve this, or could this feature be considered for future implementation?
The way I imagine this is something resembling this:
```py
from langchain.callbacks import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI(streaming=True, callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]), verbose=False, temperature=0)
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="Translate this sentence from English to French. I love programming. I really really really really love it")
]
for chunk in chat(messages):
yield chunk.text
``` | Title: Request for Streaming Outputs as a Generator for Dynamic Chat Responses | https://api.github.com/repos/langchain-ai/langchain/issues/2428/comments | 30 | 2023-04-05T09:34:44Z | 2023-10-31T22:18:19Z | https://github.com/langchain-ai/langchain/issues/2428 | 1,655,271,271 | 2,428 |
[
"langchain-ai",
"langchain"
] | Hi, I want to add memory to agent using create_csv_agent or create_sql_agent as the agent.
I read [this](https://python.langchain.com/en/latest/modules/memory/examples/agent_with_memory.html) to add memory to agent but when doing this:
```
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)
agent = create_csv_agent(llm_chain=llm_chain, 'titanic.csv',, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools(agent=agent, verbose=True, memory=memory)
```
It appears to be error and not supported yet.
I also try something like this
```
agent = create_csv_agent(llm=OpenAI(temperature=0), 'titanic.csv', verbose=True, memory=memory)
```
But doesn't work either.
Any help on this?
Thank you. | create_csv_agent with memory | https://api.github.com/repos/langchain-ai/langchain/issues/2427/comments | 4 | 2023-04-05T08:49:53Z | 2023-11-29T16:11:50Z | https://github.com/langchain-ai/langchain/issues/2427 | 1,655,201,936 | 2,427 |
[
"langchain-ai",
"langchain"
] | ## Describe the issue
`make integration_tests` failing with the following error.
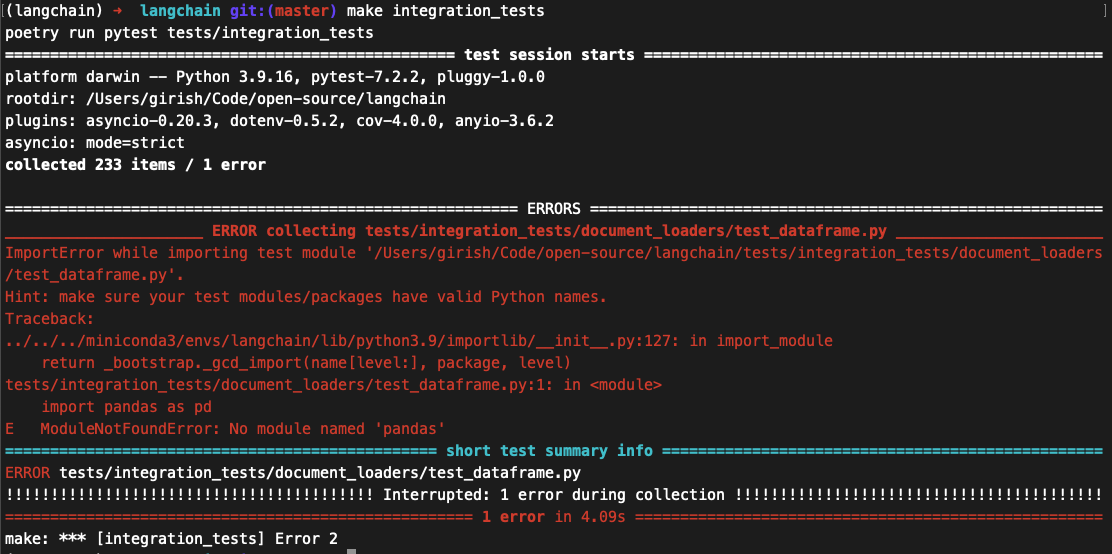
## How to reproduce it?
1. Install poetry requirements `poetry install -E all`
2. Run integration tests `make integration_tests`
## Related issues/PRs
- It might be a result of https://github.com/hwchase17/langchain/pull/2102 where we removed pandas from dependency, but we still import it in tests/integration_tests/document_loaders/test_dataframe.py
| Integration tests failing | https://api.github.com/repos/langchain-ai/langchain/issues/2426/comments | 1 | 2023-04-05T08:37:11Z | 2023-04-08T03:43:54Z | https://github.com/langchain-ai/langchain/issues/2426 | 1,655,184,632 | 2,426 |
[
"langchain-ai",
"langchain"
] | Hey guys, I'm adding a termination feature, was wondering if langchain supports this? I could not find resources in the docs nor in the code.
Right now I'm doing this:
```
async def cancel_task(task: asyncio.Task[None]) -> None:
try:
task.cancel()
await task
except asyncio.CancelledError:
# There is a nasty error here : closing handshake failed
await websocket.send_json("Cancelled")
pass
```
Was wondering if there will be any resource leak in doing this? | Premature termination of LLM call | https://api.github.com/repos/langchain-ai/langchain/issues/2425/comments | 1 | 2023-04-05T07:40:09Z | 2023-08-25T16:12:34Z | https://github.com/langchain-ai/langchain/issues/2425 | 1,655,102,889 | 2,425 |
[
"langchain-ai",
"langchain"
] | ## Describe the issue
Right now we don't have any template for PR and Issues to provide a structure for their description.
## Expected behaviour
Have a template for PR and Issues.
## What are the benefits of having a template for PR and Issues?
- Provides consistency in the description.
- It saves time of a contributor by providing a starting point to fill up the description.
- With a good template, it's clear for the reader to understand about the issue and the work which has been done in a PR.
- It'll improve the process of triaging for maintainers. | Add a template for Issues and PRs | https://api.github.com/repos/langchain-ai/langchain/issues/2424/comments | 1 | 2023-04-05T06:53:49Z | 2023-09-18T16:21:08Z | https://github.com/langchain-ai/langchain/issues/2424 | 1,655,043,999 | 2,424 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.