
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
I have a CSI driver where it's normal for a volume publish operation to take longer than 120 seconds (as it is downloading data to the node and then caching it). I couldn't find a setting anywhere to increase this limit though, and I would like to be able to specify it as part of t... | Override timeout for CSI NodePublishVolume operation | https://api.github.com/repos/kubernetes/kubernetes/issues/116680/comments | 10 | 2023-03-16T09:49:05Z | 2024-03-24T09:49:01Z | https://github.com/kubernetes/kubernetes/issues/116680 | 1,627,083,488 | 116,680 |
[
"kubernetes",
"kubernetes"
] | Example failure:
https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/116172/pull-kubernetes-unit/1636257857106087936
```
{Failed === RUN TestGetListNonRecursive/existing_key,_resourceVersion=0,_resourceVersionMatch=notOlderThan
=== PAUSE TestGetListNonRecursive/existing_key,_resourceVersion=0,_resource... | TestGetListNonRecursive is flaky | https://api.github.com/repos/kubernetes/kubernetes/issues/116677/comments | 1 | 2023-03-16T07:33:42Z | 2023-04-12T02:17:31Z | https://github.com/kubernetes/kubernetes/issues/116677 | 1,626,880,664 | 116,677 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We recently upgraded to 1.23 (from 1.22) and started to experience sporadic issues of stuck pods.
This seems to happen when one of the Init containers of a pod exits with Reason OOMKilled (and Exit State: 0)
We have restartPolicy set to 'Never'
### What did you expect to happen?
Pod will be ev... | Pod pending in PodInitializing state after Init container OOMKilled | https://api.github.com/repos/kubernetes/kubernetes/issues/116676/comments | 27 | 2023-03-16T07:29:12Z | 2024-12-02T08:20:50Z | https://github.com/kubernetes/kubernetes/issues/116676 | 1,626,875,005 | 116,676 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The 8 of 10 nodes has same image that size is 4.09GB,but the score of ImageLocality is inconsistent during 4 minutes after
scheduler startup. After 4 minutes, their scores are consistent.
the pod `bigdata-hanoi-default/ham-25146-2023031522-1-tzvwq` and `ham-35878-202303152300-1-tklj4` use sam... | ImageLocality scored is inaccurate during 4 minutes after scheduler startup | https://api.github.com/repos/kubernetes/kubernetes/issues/116673/comments | 10 | 2023-03-16T02:52:20Z | 2023-10-19T04:15:28Z | https://github.com/kubernetes/kubernetes/issues/116673 | 1,626,601,514 | 116,673 |
[
"kubernetes",
"kubernetes"
] | Would it be possible to build a binary image of just kubectl with each release? I keep finding things that I could solve with a sidecar container and a shell script around kubectl, but (AFAICT) we don't produce such a thing. I know it's unpleasant to produce and support images with shells in them, so I am looking for... | Can we release a simple kubectl image | https://api.github.com/repos/kubernetes/kubernetes/issues/116667/comments | 7 | 2023-03-15T18:55:52Z | 2023-07-18T05:58:26Z | https://github.com/kubernetes/kubernetes/issues/116667 | 1,626,082,644 | 116,667 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Kubernetes Version: v1.22.9
CSI Driver: vSphere CSI Driver
Upon executing a rollout restart on a statefulset, we noticed in the kube-controller log that the attach-detach controller successfully detached the volume and removed the associated volume attachment object. However, the CSI attacher an... | Kubernetes Controller is marking detach is sucess without sending request to CSI | https://api.github.com/repos/kubernetes/kubernetes/issues/116663/comments | 22 | 2023-03-15T16:55:08Z | 2024-01-20T05:12:56Z | https://github.com/kubernetes/kubernetes/issues/116663 | 1,625,906,853 | 116,663 |
[
"kubernetes",
"kubernetes"
] | There are cases where it's useful for a pod to know its own owner.
This would need a KEP to argue the formatting and edge cases, but shouldn't be too hard.
xref https://github.com/gocrane/crane/issues/716 | Expose `ownerReferences` via `valueFrom` and downward API | https://api.github.com/repos/kubernetes/kubernetes/issues/116662/comments | 8 | 2023-03-15T16:29:16Z | 2024-07-08T10:58:51Z | https://github.com/kubernetes/kubernetes/issues/116662 | 1,625,861,496 | 116,662 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [35cd77da317308077300](https://go.k8s.io/triage#35cd77da317308077300)
##### Error text:
```
[FAILED] kubectl explain e2e-test-crd-publish-openapi-2184-crds.spec.bars result {KIND: e2e-test-crd-publish-openapi-2184-crd
VERSION: crd-publish-openapi-test-foo.example.com/v1
RESOURCE: bars ... | Failure cluster [35cd77da...] ci-kubernetes-e2e-kubeadm-kinder-rootless-latest failed | https://api.github.com/repos/kubernetes/kubernetes/issues/116653/comments | 2 | 2023-03-15T14:49:17Z | 2023-04-20T17:00:22Z | https://github.com/kubernetes/kubernetes/issues/116653 | 1,625,676,228 | 116,653 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
master-informing
- kubeadm-kinder-upgrade-1-26-latest
- kubeadm-kinder-latest
### Which tests are failing?
`Kubernetes e2e suite: [It] [sig-api-machinery] CustomResourcePublishOpenAPI [Privileged:ClusterAdmin] works for CRD with validation schema [Conformance]`
### Since when has it bee... | [Failing Test] kubeadm-kinder-upgrade-1-26-latest,kubeadm-kinder-latest | https://api.github.com/repos/kubernetes/kubernetes/issues/116650/comments | 4 | 2023-03-15T14:27:55Z | 2023-04-20T17:00:02Z | https://github.com/kubernetes/kubernetes/issues/116650 | 1,625,638,892 | 116,650 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [ae995a46d8008dbf592f](https://go.k8s.io/triage#ae995a46d8008dbf592f)
##### Error text:
```
[FAILED] Filesystem resize failed when restoring from snapshot to PVC with larger size. Restored fs size: 259962224640 bytes is not larger than origin fs size: 259962224640 bytes.
HINT: Your driver need... | Failure cluster [ae995a46...] provisioning should provision correct filesystem size when restoring snapshot to larger size pvc | https://api.github.com/repos/kubernetes/kubernetes/issues/116647/comments | 5 | 2023-03-15T13:47:33Z | 2023-03-15T16:15:23Z | https://github.com/kubernetes/kubernetes/issues/116647 | 1,625,565,038 | 116,647 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [ee841810df62a739a098](https://go.k8s.io/triage#ee841810df62a739a098)
> Updated [https://www.googleapis.com/compute/v1/projects/k8s-infra-e2e-boskos-scale-21/zones/us-central1-f/instances/kubemark-500-master].
> Failed to execute 'sudo /bin/bash /home/kubernetes/bin/kube-master-internal-route.sh... | Failure cluster [ee841810...] ci-kubernetes-kubemark-500-gce failed after code freeze | https://api.github.com/repos/kubernetes/kubernetes/issues/116646/comments | 7 | 2023-03-15T13:41:15Z | 2023-03-16T08:18:15Z | https://github.com/kubernetes/kubernetes/issues/116646 | 1,625,554,464 | 116,646 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Per https://github.com/kubernetes/kubernetes/pull/114930#issuecomment-1469940664, the `pod-template-hash` label is a private one (reserved for cluster operators). It should be something more like `kubernetes.io/pod-template-hash` or maybe `kubernetes.io/pod-template-hash-sha256`.
### How can we... | Pod template tracking uses fixed, non-prefixed label keys | https://api.github.com/repos/kubernetes/kubernetes/issues/116644/comments | 13 | 2023-03-15T12:51:17Z | 2024-03-22T22:31:57Z | https://github.com/kubernetes/kubernetes/issues/116644 | 1,625,469,228 | 116,644 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Ability to add custom fields into service account token. Adding here as I believe they've not been looked at:
https://discuss.kubernetes.io/t/add-custom-claims-into-bound-service-account-jwt-token/21733
https://discuss.kubernetes.io/t/adding-custom-fields-into-a-service-account-token/23322/2
... | Add Custom fields to Service Account Token | https://api.github.com/repos/kubernetes/kubernetes/issues/116638/comments | 13 | 2023-03-15T12:00:38Z | 2024-12-06T22:09:24Z | https://github.com/kubernetes/kubernetes/issues/116638 | 1,625,388,143 | 116,638 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Features of in-place update resource in K8s.
### Why is this needed?
Adjust the pod resource on the fly is essential for lots of applications
Does K8s support in-place autoscaling, which means update cpu resource on the fly. I want to change the cpu utilization of a pod ... | If k8s support update resource on the fly | https://api.github.com/repos/kubernetes/kubernetes/issues/116636/comments | 7 | 2023-03-15T09:00:47Z | 2023-03-28T16:38:43Z | https://github.com/kubernetes/kubernetes/issues/116636 | 1,625,056,108 | 116,636 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When I create ServiceAccount as a child resource of other resources, and delete the parent resource, the ServiceAccount did not get deleted.
To illustrate I made a small demo based on [this official blog](https://kubernetes.io/blog/2021/05/14/using-finalizers-to-control-deletion/#owner-references... | ServiceAccount not getting deleted as a child resource when another object has the same uid | https://api.github.com/repos/kubernetes/kubernetes/issues/116632/comments | 12 | 2023-03-15T05:32:48Z | 2023-04-20T16:59:57Z | https://github.com/kubernetes/kubernetes/issues/116632 | 1,624,786,231 | 116,632 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We have a stateful application that requires pods to be evenly spread across zones. Each pod required a persistent volume (AWS EBS volume) to store data. To deploy this application we use a StatefulSet with the following Pod Topology Spread Constraint:
```
topologySpreadConstraints:
- l... | TopologySpreadConstraints - Scaling Pods during rolling updates can cause pods to be stuck in Pending | https://api.github.com/repos/kubernetes/kubernetes/issues/116629/comments | 24 | 2023-03-15T01:26:11Z | 2025-02-25T07:35:19Z | https://github.com/kubernetes/kubernetes/issues/116629 | 1,624,560,688 | 116,629 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The ``--resolv-conf`` kubelet flag is not being validated by the ``ValidateKubeletConfiguration`` [1] (e.g.: the given file may not exist), which can lead to Pod DNS Policies no applying properly for the Pods spawned on the node.
[1] https://github.com/kubernetes/kubernetes/blob/758b4641522ec27... | ValidateKubeletConfiguration does not validate the ResolverConfig option | https://api.github.com/repos/kubernetes/kubernetes/issues/116625/comments | 4 | 2023-03-14T23:58:00Z | 2023-10-24T00:24:50Z | https://github.com/kubernetes/kubernetes/issues/116625 | 1,624,478,064 | 116,625 |
[
"kubernetes",
"kubernetes"
] | Followup to https://github.com/kubernetes/kubernetes/pull/116345
- [ ] Use a structured value for cache key instead of the random bytes
- This can be used to validate if all the required values exist
- [ ] Use sync pool buffer to avoid allocations | [KMSv2] Cache key semantics | https://api.github.com/repos/kubernetes/kubernetes/issues/116624/comments | 6 | 2023-03-14T23:29:35Z | 2024-08-11T00:35:53Z | https://github.com/kubernetes/kubernetes/issues/116624 | 1,624,458,371 | 116,624 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Continuing discussion from slack and https://github.com/kubernetes/kubernetes/pull/115331#discussion_r1135663832
Background: Today, pod volume unmount completion is signaled by Pod deletion. We're discussing the various pod termination signals today, what controllers depend on those signals, an... | Termination signals and pod/data safety impact | https://api.github.com/repos/kubernetes/kubernetes/issues/116618/comments | 12 | 2023-03-14T22:10:13Z | 2024-11-15T21:16:22Z | https://github.com/kubernetes/kubernetes/issues/116618 | 1,624,369,818 | 116,618 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
#107897 originally identified a number of inefficiencies in how pod status is reported back to the API:
1. Pods are queued in a channel and then processed one by one - this causes HoL blocking and writes every observed status change, but pod status is level driven (split into #116615 for inclus... | Pod status updates take longer to propagate to the API than necessary | https://api.github.com/repos/kubernetes/kubernetes/issues/116617/comments | 17 | 2023-03-14T21:18:49Z | 2024-09-18T17:51:47Z | https://github.com/kubernetes/kubernetes/issues/116617 | 1,624,317,073 | 116,617 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
Example: https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/116611/pull-kubernetes-e2e-gce/1635729618159800320/
@MadhavJivrajani this PR seems to be flaking: https://github.com/kubernetes/kubernetes/pull/116590
comparing age of a node from the output of two commands: https://... | Kubernetes e2e suite: [It] [sig-cli] Kubectl client kubectl subresource flag GET on status subresource of built-in type (node) returns identical info as GET on the built-in type expand_less | https://api.github.com/repos/kubernetes/kubernetes/issues/116614/comments | 4 | 2023-03-14T21:01:20Z | 2023-03-15T00:45:04Z | https://github.com/kubernetes/kubernetes/issues/116614 | 1,624,294,448 | 116,614 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
https://github.com/kubernetes/kubernetes/pull/116261#discussion_r1132819194
If any match condition fails the request should not be sent to the webhook but if a very large condition uses up all the evaluation time before the webhook fail condition is reached the request will fallback to the fail p... | MatchConditions webhooks can be bypassed by injecting a very expensive match condition before others | https://api.github.com/repos/kubernetes/kubernetes/issues/116609/comments | 6 | 2023-03-14T19:29:58Z | 2023-03-22T01:08:11Z | https://github.com/kubernetes/kubernetes/issues/116609 | 1,624,164,409 | 116,609 |
[
"kubernetes",
"kubernetes"
] | [issue/trouble shooting](https://github.com/kubernetes/community/tree/master/communication#issues--troubleshooting) led me to post the issue here.
### Description
It was not clear that how application (application uses k8s api) can know the NetworkPolicy applied to pods effectively.
Is there any ways or best pra... | [Question] Any notification or event can be received when the NetworkPolicy effectively applied? | https://api.github.com/repos/kubernetes/kubernetes/issues/116608/comments | 5 | 2023-03-14T19:05:14Z | 2023-04-19T13:50:20Z | https://github.com/kubernetes/kubernetes/issues/116608 | 1,624,132,698 | 116,608 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When a static pod is created on a node, it's mirror pod is created on the apiserver. Patching the mirror pod on the apiserver triggers HandlePodUpdate function in the kubelet:
https://github.com/kubernetes/kubernetes/blob/fcf5d23e6818ccfbc92f332af82f31661f8d4f88/pkg/kubelet/kubelet.go#L2491-L2502
... | Kubelet does not sync pod updates for static pods | https://api.github.com/repos/kubernetes/kubernetes/issues/116597/comments | 8 | 2023-03-14T16:33:48Z | 2025-02-20T18:10:15Z | https://github.com/kubernetes/kubernetes/issues/116597 | 1,623,865,130 | 116,597 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Graduation criteria for beta for: https://github.com/kubernetes/enhancements/issues/3716
resolve the fact that we rebuild ALL items whenever ANY config changes in NewMutatingWebhookConfigurationManager and NewValidatingWebhookConfigurationManager
### Why is this needed... | Webhook Accessors Smart Recompilation | https://api.github.com/repos/kubernetes/kubernetes/issues/116588/comments | 2 | 2023-03-14T13:57:55Z | 2023-07-14T16:15:50Z | https://github.com/kubernetes/kubernetes/issues/116588 | 1,623,539,913 | 116,588 |
[
"kubernetes",
"kubernetes"
] | #116517 introduced changes that broke the `make test-e2e-node` commands for running node e2e tests.
You'll need to have a diff like this to run the e2e tests
```
REDACTED@knative-e2e:~/dims-kubernetes$ git diff
diff --git a/hack/make-rules/test-e2e-node.sh b/hack/make-rules/test-e2e-node.sh
index f468d36b52f..... | `make test-e2e-node` is currently broken | https://api.github.com/repos/kubernetes/kubernetes/issues/116587/comments | 4 | 2023-03-14T13:49:06Z | 2023-03-14T16:28:29Z | https://github.com/kubernetes/kubernetes/issues/116587 | 1,623,521,171 | 116,587 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Follow-up for https://github.com/kubernetes/kubernetes/pull/115668
- [x] Create e2e tests for ValidatingAdmissionPolicy. integration-level tests for apiserver cannot cover anything in the KCM, #114514
- [x] Enable running the e2e tests in `test-infra`, in the set of alpha feat... | Controller for ValidatingAdmissionPolicy in KCM | https://api.github.com/repos/kubernetes/kubernetes/issues/116563/comments | 2 | 2023-03-14T01:38:08Z | 2023-07-13T20:54:32Z | https://github.com/kubernetes/kubernetes/issues/116563 | 1,622,565,481 | 116,563 |
[
"kubernetes",
"kubernetes"
] | > > We need to tweak our code to keep the static check: [golang/go#56548 (comment)](https://github.com/golang/go/issues/56548#issuecomment-1317673963)
>
> I assume that's something we can do now in master ahead of go1.20?
_Originally posted by @liggitt in https://github.com/kubernetes/kubernetes/issues/112680#iss... | Fix transport/cache static assertion that tlsCacheKey is comparable for go 1.20 semantics | https://api.github.com/repos/kubernetes/kubernetes/issues/116562/comments | 17 | 2023-03-14T01:05:54Z | 2024-08-20T01:14:10Z | https://github.com/kubernetes/kubernetes/issues/116562 | 1,622,539,226 | 116,562 |
[
"kubernetes",
"kubernetes"
] | PR #107449 has stagnated - someone could take it over and finish it. | Cleanup fd leaks and file removal cleanup | https://api.github.com/repos/kubernetes/kubernetes/issues/116559/comments | 2 | 2023-03-13T23:34:08Z | 2023-05-25T05:50:52Z | https://github.com/kubernetes/kubernetes/issues/116559 | 1,622,463,048 | 116,559 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Scenarios that require setting resourceVersion either
- explicitly to the eviction request
- or when the eviction API needs to make sure that the pod has not become ready when deleting unready pods https://github.com/kubernetes/kubernetes/blob/master/pkg/registry/core/pod/storage/eviction.go#L... | API-initiated eviction does not work on first try in certain scenarios, but does work on second try | https://api.github.com/repos/kubernetes/kubernetes/issues/116552/comments | 2 | 2023-03-13T21:37:16Z | 2023-03-17T23:59:17Z | https://github.com/kubernetes/kubernetes/issues/116552 | 1,622,304,086 | 116,552 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Must be a result of https://github.com/kubernetes/kubernetes/pull/115268/
@jsafrane
When running kubelet in standalone mode got this panic:
```
E0313 20:39:03.702548 1312451 runtime.go:79] Observed a panic: "invalid memory address or nil pointer dereference" (runtime error: invalid memory ... | panic in updateReconstructedDevicePaths in standalone mode | https://api.github.com/repos/kubernetes/kubernetes/issues/116549/comments | 8 | 2023-03-13T20:52:25Z | 2023-03-14T15:37:06Z | https://github.com/kubernetes/kubernetes/issues/116549 | 1,622,240,443 | 116,549 |
[
"kubernetes",
"kubernetes"
] | Corresponds to merge of https://github.com/kubernetes/kubernetes/issues/113145
/kind failing-test
/sig node
/assign @smarterclayton
/milestone v1.27
/priority critical-urgent
https://storage.googleapis.com/k8s-triage/index.html?pr=1&test=TestSyncKnownPods
```
=== RUN TestSyncKnownPods
===============... | [Flake] TestSyncKnownPods fails with data race error | https://api.github.com/repos/kubernetes/kubernetes/issues/116544/comments | 3 | 2023-03-13T17:47:07Z | 2023-03-14T05:27:26Z | https://github.com/kubernetes/kubernetes/issues/116544 | 1,621,966,428 | 116,544 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I use three namespaces test1 test2 test3. The deployment resource objects are created in each of the three namespaces. The kubelet node can provide monitoring data of the test1 and test2 namespaces, but cannot provide cpu monitoring data of pod in the test3 namespace
### What did you expect to happ... | kubelet cannot provide pod monitoring data for a namespace | https://api.github.com/repos/kubernetes/kubernetes/issues/116541/comments | 14 | 2023-03-13T15:58:15Z | 2024-03-28T09:36:07Z | https://github.com/kubernetes/kubernetes/issues/116541 | 1,621,783,981 | 116,541 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
`pull-kubernetes-unit`
### Which tests are flaking?
`k8s.io/kubernetes/vendor/k8s.io/kms/pkg/hierarchy: TestEncryptError`
### Since when has it been flaking?
March 9th
### Testgrid link
https://storage.googleapis.com/k8s-triage/index.html?pr=1&text=TestEncryptError&job=pull-kubernetes... | kmsv2: flaky `TestEncryptError` | https://api.github.com/repos/kubernetes/kubernetes/issues/116538/comments | 4 | 2023-03-13T13:59:25Z | 2023-03-15T12:27:15Z | https://github.com/kubernetes/kubernetes/issues/116538 | 1,621,546,533 | 116,538 |
[
"kubernetes",
"kubernetes"
] | Hi All,
The file /sys/fs/cgroup/systemd/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod<pod_id>.slice/crio-<container_id>/cgroup.procs on the worker lists the pids of process running inside the container at init time.
I want to access this file without going onto the worker node .
Is there any kubern... | Access file /sys/fs/cgroup/systemd/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod<poid>.slice/crio-<containerid>/cgroup.procs from kubernetes commands or API | https://api.github.com/repos/kubernetes/kubernetes/issues/116534/comments | 7 | 2023-03-13T11:33:35Z | 2023-09-07T16:44:16Z | https://github.com/kubernetes/kubernetes/issues/116534 | 1,621,305,288 | 116,534 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Do we have a plan to convert `net.IP` to `netip.Addr` in our code base ?
/sig-network
/kind feature
### Why is this needed?
`netip.addr` means less overhead, more efficient... | Convert net.IP to netip.Addr | https://api.github.com/repos/kubernetes/kubernetes/issues/116532/comments | 5 | 2023-03-13T09:09:17Z | 2023-03-13T12:46:01Z | https://github.com/kubernetes/kubernetes/issues/116532 | 1,621,043,467 | 116,532 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
In the production environment, the backend pod is accessed through the "service" of the k8s. When the backend pod is accessed through the "service", the logs of the backend pod can also be viewed on the "service". But I don't know which pod log it is. In fact, it's not the 'service... | Add record information on the 'service' of k8s | https://api.github.com/repos/kubernetes/kubernetes/issues/116528/comments | 5 | 2023-03-13T08:44:18Z | 2023-03-16T16:01:35Z | https://github.com/kubernetes/kubernetes/issues/116528 | 1,621,002,646 | 116,528 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [25f9dd15fbca0ddd7a02](https://go.k8s.io/triage#25f9dd15fbca0ddd7a02)
##### Error text:
```
[FAILED] Timed out after 30.000s.
Expected
<nil>: nil
not to be nil
In [It] at: test/e2e/network/service.go:3703 @ 03/12/23 06:45:16.6
```
#### Recent failures:
[2023/3/13 03:49:12 e2e-kops-... | Failure cluster [25f9dd15...] e2e suite [It] [sig-network] Services should serve endpoints on same port and different protocols | https://api.github.com/repos/kubernetes/kubernetes/issues/116527/comments | 6 | 2023-03-13T08:19:05Z | 2023-05-24T11:00:45Z | https://github.com/kubernetes/kubernetes/issues/116527 | 1,620,970,783 | 116,527 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [75a2e7fe872595660e39](https://go.k8s.io/triage#75a2e7fe872595660e39)
##### Error text:
```
[FAILED] Timeout waiting 15m0s for 1 replicas
In [It] at: test/e2e/autoscaling/custom_metrics_stackdriver_autoscaling.go:612 @ 02/27/23 12:59:03.861
```
#### Recent failures:
[2023/3/13 00:34:29 ci... | Enable Aggregated Discovery for Beta failed e2e of Horizontal pod autoscaling | https://api.github.com/repos/kubernetes/kubernetes/issues/116524/comments | 8 | 2023-03-13T07:30:06Z | 2023-04-20T16:59:51Z | https://github.com/kubernetes/kubernetes/issues/116524 | 1,620,904,655 | 116,524 |
[
"kubernetes",
"kubernetes"
] | Seen in pull-kubernetes-e2e-gce-cos-alpha-features
https://testgrid.k8s.io/presubmits-kubernetes-nonblocking#pull-kubernetes-e2e-gce-cos-alpha-features
Specific job failure
https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/115075/pull-kubernetes-e2e-gce-cos-alpha-features/1635022577460056064/
```
... | [Failing Job] pull-kubernetes-e2e-gce-cos-alpha-features | https://api.github.com/repos/kubernetes/kubernetes/issues/116515/comments | 24 | 2023-03-12T23:04:19Z | 2023-03-14T17:41:11Z | https://github.com/kubernetes/kubernetes/issues/116515 | 1,620,544,726 | 116,515 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
```
for _, tc := range tests {
t.Run(tc.desc, func(t *testing.T) {
......
go func() {
select {
case res := <-outChan:
assert.Equal(t, tc.shutdownActive, res)
done <- true
case <-time.After(5 * time.Second):
t.Errorf("Timed out waiting for ... | systemd: loop variables captured by 'func' literals in 'go' statements | https://api.github.com/repos/kubernetes/kubernetes/issues/116505/comments | 10 | 2023-03-12T06:34:36Z | 2023-05-24T02:06:50Z | https://github.com/kubernetes/kubernetes/issues/116505 | 1,620,253,613 | 116,505 |
[
"kubernetes",
"kubernetes"
] | We have these scripts in `staging/src/k8s.io/code-generator` called "generate-groups.sh" and "generate-internal-groups.sh".
External projects which want kube-style code generation (deepcopy, conversion, openapi, client, etc) call them. We emulate that pattern for in-tree things like `k8s.io/kube-aggregator`, `k8s.i... | Sub-project (e.g. kube-aggregator) code-generation is incomplete | https://api.github.com/repos/kubernetes/kubernetes/issues/116499/comments | 5 | 2023-03-11T17:40:23Z | 2024-05-31T15:35:00Z | https://github.com/kubernetes/kubernetes/issues/116499 | 1,620,087,835 | 116,499 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Fixed inconsistency and also potential data race in proto/table_unmarshal.go:
u.reqFields is read/written 4 times in proto/table_unmarshal.go; 3 out of 4 times it is protected by u.lock.Lock(); 1 out of 4 times it is read without a Lock, which is in func unmarshal() on L260.
A data race may happen... | proto: protect field access with lock to avoid possible data race | https://api.github.com/repos/kubernetes/kubernetes/issues/116497/comments | 8 | 2023-03-11T12:30:36Z | 2023-05-31T06:12:47Z | https://github.com/kubernetes/kubernetes/issues/116497 | 1,619,990,015 | 116,497 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
We are using k8s for cluster management of multiple GPU servers (multiple GPU cards), and the same AI model will be deployed on each GPU machine and provide services. However, a complete use of some AI services requires multiple http requests to complete. We hope that these HTTP re... | Whether to support the session persistence function at the pod level | https://api.github.com/repos/kubernetes/kubernetes/issues/116496/comments | 8 | 2023-03-11T09:34:30Z | 2023-09-08T07:39:38Z | https://github.com/kubernetes/kubernetes/issues/116496 | 1,619,946,874 | 116,496 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Currently, when loadbalancer service's ipFammilies updated,service controller will ignore this event. That means cloud provider can't update ipv4/ipv6 backend.
So, I'm thinking service controller need add watching 'service's ipFammilies updated' event, It'd be important for clou... | [dual-stack]support service ipFamilies update event in service controller | https://api.github.com/repos/kubernetes/kubernetes/issues/116495/comments | 2 | 2023-03-11T08:32:29Z | 2023-04-24T04:03:14Z | https://github.com/kubernetes/kubernetes/issues/116495 | 1,619,931,851 | 116,495 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
master-blocking
- build-master
### Which tests are failing?
Overall build is failing
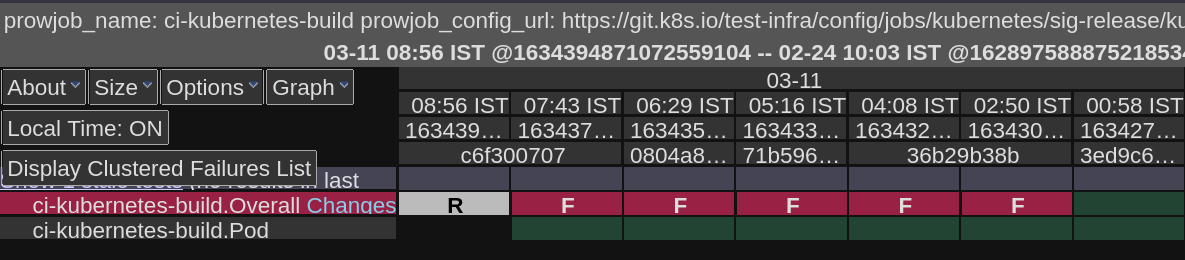
### Since when has it been failing?
03-11 02:50 IS... | [Failing Test] build-master | https://api.github.com/repos/kubernetes/kubernetes/issues/116492/comments | 7 | 2023-03-11T04:25:58Z | 2023-03-13T08:57:25Z | https://github.com/kubernetes/kubernetes/issues/116492 | 1,619,876,723 | 116,492 |
[
"kubernetes",
"kubernetes"
] | In a dual-stack proxy there is only a single healthz server, and likewise none of the proxy metrics are differentiated by IP family. Thus, the IPv4 and IPv6 sub-proxies are both updating the same data.
For the healthz server, this means that the "becoming unhealthy" timer starts counting whenever *either* proxy queu... | dual-stack proxies share healthz and metrics, corrupting the results | https://api.github.com/repos/kubernetes/kubernetes/issues/116486/comments | 16 | 2023-03-10T22:25:10Z | 2025-01-20T15:32:44Z | https://github.com/kubernetes/kubernetes/issues/116486 | 1,619,699,716 | 116,486 |
[
"kubernetes",
"kubernetes"
] | Kubelet, once registered to the apiserver, if the Node object is deleted `kubectl delete node ..` or some external controller per example, never tries to register again.
However, the lease controller is not aware of this and keeps renewing the lease.
In an scenario that a new VM with the same name register and the ... | Kubelet keeps renewing the lease after the Node object has been deleted | https://api.github.com/repos/kubernetes/kubernetes/issues/116485/comments | 5 | 2023-03-10T22:20:10Z | 2025-03-12T03:53:04Z | https://github.com/kubernetes/kubernetes/issues/116485 | 1,619,693,640 | 116,485 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A static pod is best thought of as a controller-driven API pod that should be continually restarted by the Kubelet. Today, we pass static pods through admission and they can be rejected, which prevents the pod from being reconsidered until the kubelet is restarted. Because status manager is the so... | Static pods that are rejected by admission should be periodically retried / preempt non-static pods | https://api.github.com/repos/kubernetes/kubernetes/issues/116484/comments | 7 | 2023-03-10T22:04:07Z | 2024-09-10T23:29:47Z | https://github.com/kubernetes/kubernetes/issues/116484 | 1,619,676,581 | 116,484 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We have never fully clarified the behavior of restart=Never mirror pods, but they currently behave in surprising ways. At minimum, the following questions should be answered and documented:
1. Should the mirror pod be recreated if the kubelet detects it is missing?
2. Should a terminal mirror... | A restart Never static pod does not recreate mirror pod when it is deleted | https://api.github.com/repos/kubernetes/kubernetes/issues/116483/comments | 10 | 2023-03-10T21:15:05Z | 2024-08-18T19:45:25Z | https://github.com/kubernetes/kubernetes/issues/116483 | 1,619,633,483 | 116,483 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We have pods that use the kube API during their preStop hooks and we use 12h service account token expirations. Today we had a pod where the token was approaching expiration at the time the pod was deleted. 4h into the preStop hook, the token expired and the preStop hook started failing.
### What d... | Kubelet stops rotating service account tokens when pod is terminating, breaking preStop hooks | https://api.github.com/repos/kubernetes/kubernetes/issues/116481/comments | 15 | 2023-03-10T18:31:19Z | 2024-06-04T21:28:11Z | https://github.com/kubernetes/kubernetes/issues/116481 | 1,619,431,245 | 116,481 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hi all,
in a test lab with constrained resorces and a bunch of old XEON server
kubeadm init was starting evicting pods and crash loop
I did not succeded installing a cluster, while on the same time K3s was up and running
after 6 hours trobleshooting I revert Linux kernel to cgroup V1
`Deb... | memory pressure during kubeadm init with cgroup V2 , failed result after crashloop | https://api.github.com/repos/kubernetes/kubernetes/issues/116480/comments | 12 | 2023-03-10T17:37:17Z | 2023-05-08T12:43:20Z | https://github.com/kubernetes/kubernetes/issues/116480 | 1,619,350,275 | 116,480 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
master-informing:
- capz-windows-containerd-master
### Which tests are failing?
capz-e2e.[It] Conformance Tests conformance-tests

... | [Failing Test] capz-windows-containerd-master | https://api.github.com/repos/kubernetes/kubernetes/issues/116474/comments | 10 | 2023-03-10T15:11:20Z | 2023-03-10T18:38:42Z | https://github.com/kubernetes/kubernetes/issues/116474 | 1,619,138,197 | 116,474 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have been setting up an airgap installation setup for Kubernetes using kubeadm. I have configured a custom nexus docker repository inside my own network. The issue here is all the containers are pulled as planned but only one container is pulled from an outside registry (Froom the Internet) at the... | Kubernetes does not pull all the images from given custom registry | https://api.github.com/repos/kubernetes/kubernetes/issues/116468/comments | 4 | 2023-03-10T13:43:50Z | 2023-03-10T13:50:19Z | https://github.com/kubernetes/kubernetes/issues/116468 | 1,619,002,031 | 116,468 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Executing the following CNTT test failed: _[sig-cluster-lifecycle] [Feature:BootstrapTokens] [It] should delete the signed bootstrap tokens from clusterInfo ConfigMap when bootstrap token is deleted_
```
podman run -it --env-file ~/opnfv/env \
-v ~/opnfv/ca.pem:/home/opnfv/functest/ca.pem:Z \
... | Test case "[sig-cluster-lifecycle] [Feature:BootstrapTokens] [It] should delete the signed bootstrap tokens from clusterInfo ConfigMap when bootstrap token is deleted" valid only where kubeadm used | https://api.github.com/repos/kubernetes/kubernetes/issues/116467/comments | 8 | 2023-03-10T13:28:05Z | 2023-03-17T09:21:42Z | https://github.com/kubernetes/kubernetes/issues/116467 | 1,618,981,519 | 116,467 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Executing the following CNTT test failed: _[sig-cluster-lifecycle] [Feature:BootstrapTokens] [It] should sign the new added bootstrap tokens_.
```
podman run -it --env-file ~/opnfv/env \
-v ~/opnfv/ca.pem:/home/opnfv/functest/ca.pem:Z \
-v ~/opnfv/config:/root/.kube/config:Z \
-v ~/opnfv/re... | Test case "[sig-cluster-lifecycle] [Feature:BootstrapTokens] [It] should sign the new added bootstrap tokens" valid only where kubeadm used | https://api.github.com/repos/kubernetes/kubernetes/issues/116466/comments | 5 | 2023-03-10T13:17:07Z | 2023-03-10T20:26:30Z | https://github.com/kubernetes/kubernetes/issues/116466 | 1,618,965,954 | 116,466 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I am using kubectl 1.26.1 and using a Security Vulnerability scanning tool which is reporting below 4 CVEs because those versions are mentioned in .go.buildinfo file.
cve severity package name package path version fixed ... | .go.buildinfo under kubectl is dependency on older versions which are having Security Vulnerability associated | https://api.github.com/repos/kubernetes/kubernetes/issues/116462/comments | 14 | 2023-03-10T11:03:06Z | 2023-09-07T18:20:25Z | https://github.com/kubernetes/kubernetes/issues/116462 | 1,618,796,172 | 116,462 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
My cluster is v1.26. I enabled option allowedUnsafeSysctls in kubelet config
my pod use `net.core.somaxconn` is success, but failed with `net.core.wmem_max`
This is config in kubelet
```
...
kind: KubeletConfiguration
...
allowedUnsafeSysctls:
- net.core.wmem_max
- net.core.somaxconn
..... | Enable allowedUnsafeSysctls on v1.26 but can't use net.core.wmem_max in pod | https://api.github.com/repos/kubernetes/kubernetes/issues/116460/comments | 11 | 2023-03-10T10:48:34Z | 2023-03-27T10:42:42Z | https://github.com/kubernetes/kubernetes/issues/116460 | 1,618,771,664 | 116,460 |
[
"kubernetes",
"kubernetes"
] | i use nfs as my k8s cluster storage ,and i want to know how to manage the capacity of pv,pvc | how to manage capacity of pv,pvc when storage is nfs ? | https://api.github.com/repos/kubernetes/kubernetes/issues/116457/comments | 7 | 2023-03-10T09:50:53Z | 2023-03-13T01:23:56Z | https://github.com/kubernetes/kubernetes/issues/116457 | 1,618,670,531 | 116,457 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
```
$ kubectl get po -o wide | grep worker-5
prometheus-blackbox-7bd4db7d6f-64ntz 1/1 Running 1 (3h12m ago) 20h 10.244.1.207 k8s-worker-5.pacific-textiles.com <none> <none>
prometheus-node-exporter-d9tlh 1/1 Running 0 ... | one pod cannot access clusterIP of another pod that running on the same node after running a while | https://api.github.com/repos/kubernetes/kubernetes/issues/116453/comments | 21 | 2023-03-10T06:16:53Z | 2023-03-28T06:38:34Z | https://github.com/kubernetes/kubernetes/issues/116453 | 1,618,425,700 | 116,453 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
**SA** not showing the **secret** **count** attached to it, when we list the `kubectl get sa`
**Step to reproduce**
`kubectl create sa test-sa`
Create a secret attach to SA
```
apiVersion: v1
kind: Secret
type: kubernetes.io/service-account-token
metadata:
name: token-secret
... | Service account not showing the secret count attached to it | https://api.github.com/repos/kubernetes/kubernetes/issues/116451/comments | 10 | 2023-03-10T05:19:34Z | 2023-03-14T09:58:23Z | https://github.com/kubernetes/kubernetes/issues/116451 | 1,618,379,735 | 116,451 |
[
"kubernetes",
"kubernetes"
] | Some of the document links in typemeta are no longer accessible, like the follwing:
https://github.com/kubernetes/kubernetes/blob/33d9543ceb09a9aff54940d639da23c6102d2fcc/staging/src/k8s.io/apimachinery/pkg/apis/meta/v1/types.go#L115-L120
https://github.com/kubernetes/kubernetes/blob/33d9543ceb09a9aff54940d639da23c61... | Update expired document links | https://api.github.com/repos/kubernetes/kubernetes/issues/116449/comments | 6 | 2023-03-10T03:27:11Z | 2023-03-15T06:11:15Z | https://github.com/kubernetes/kubernetes/issues/116449 | 1,618,299,479 | 116,449 |
[
"kubernetes",
"kubernetes"
] | This Deployment:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: use-a-very-long-name-123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456789-123456... | Deployment names can be too long, such that ReplicaSet creation fails | https://api.github.com/repos/kubernetes/kubernetes/issues/116447/comments | 40 | 2023-03-09T23:54:52Z | 2025-02-05T23:54:44Z | https://github.com/kubernetes/kubernetes/issues/116447 | 1,618,152,955 | 116,447 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
ci-crio-cgroupv1-node-e2e-conformance on master-informing
### Which tests are failing?
E2eNode Suite.[It] [sig-node] InitContainers [NodeConformance] should not launch regular containers if an init container fails
E2eNode Suite.[It] [sig-node] InitContainers [NodeConformance] should laun... | [Failing test] ci-crio-cgroupv1-node-e2e-conformance | https://api.github.com/repos/kubernetes/kubernetes/issues/116446/comments | 4 | 2023-03-09T23:26:26Z | 2023-03-10T07:41:34Z | https://github.com/kubernetes/kubernetes/issues/116446 | 1,618,135,221 | 116,446 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
From the Deprecated API Migration Guide: https://kubernetes.io/docs/reference/using-api/deprecation-guide/, since v1.19, the events.k8s.io/v1 has been using the new reportingController and reportingInstance to replace the decrecated source.component and source.host. But when I checked the Kube ev... | events.k8s.io/v1 api does not have changes in place mentioned in the Deprecated API Migration Guide | https://api.github.com/repos/kubernetes/kubernetes/issues/116444/comments | 5 | 2023-03-09T23:00:58Z | 2023-05-09T18:01:59Z | https://github.com/kubernetes/kubernetes/issues/116444 | 1,618,110,833 | 116,444 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Add a new CI job (atleast for cgroup v2) and fix up in-place pod resize tests to run in parallel while ensuring that we don't see any flaky behavior in a limited resource CI VM environment (typically 2000m cpu)
This can be done by changing --ginkgo-parallel = M and --minStartupP... | [FG:InPlacePodVerticalScaling] Add new CI job that runs in-place pod resize e2e tests in parallel | https://api.github.com/repos/kubernetes/kubernetes/issues/116431/comments | 6 | 2023-03-09T18:40:20Z | 2024-01-19T13:59:55Z | https://github.com/kubernetes/kubernetes/issues/116431 | 1,617,802,488 | 116,431 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We observed degradation in scheduling throughput, putting it under 100 pods/s
pprof points to https://github.com/kubernetes/kubernetes/pull/112003/files#diff-bdc8ab11c11340bf2786fe2a0a3900856fa6d098c0c217ba6b25de33ca22a506R58-R59
.
Accordi... | promote a subset of podresources e2e tests to NodeConformance | https://api.github.com/repos/kubernetes/kubernetes/issues/116421/comments | 4 | 2023-03-09T15:11:26Z | 2023-03-10T08:22:04Z | https://github.com/kubernetes/kubernetes/issues/116421 | 1,617,441,947 | 116,421 |
[
"kubernetes",
"kubernetes"
] | Spotted by @liggitt
https://github.com/kubernetes/kubernetes/commit/7093b10416f6073f3e0531b8cc1d71aa5d9ed3d2#r103711882
https://github.com/kubernetes/kubernetes/commit/7093b10416f6073f3e0531b8cc1d71aa5d9ed3d2#r103711822
The function needs to be fixed based on Jordan comments before moving the feature to beta.... | NodeSelectorAsSelector needs to be fixed | https://api.github.com/repos/kubernetes/kubernetes/issues/116419/comments | 14 | 2023-03-09T14:45:39Z | 2024-09-06T11:12:31Z | https://github.com/kubernetes/kubernetes/issues/116419 | 1,617,397,470 | 116,419 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
- ci-crio-cgroupv1-node-e2e-conformance
- ci-crio-cgroupv2-node-e2e-conformance
### Which tests are failing?
- [It] [sig-node] InitContainers [NodeConformance] should not launch regular containers if an init container fails expand_more
- [It] [sig-node] InitContainers [NodeConforman... | InitContainers tests fail in CRI-O jobs | https://api.github.com/repos/kubernetes/kubernetes/issues/116418/comments | 12 | 2023-03-09T14:28:42Z | 2023-03-10T08:23:36Z | https://github.com/kubernetes/kubernetes/issues/116418 | 1,617,365,881 | 116,418 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler/framework/plugins/dynamicresources/dynamicresources.go#L583
the method of haveAllNodes, time complexity is O(n*n), if podScheduling.Spec.PotentialNodes is sorted , time complexity is O(logn).
related PR: https://github.com/kubern... | podScheduling.Spec.PotentialNodes need to be sorted | https://api.github.com/repos/kubernetes/kubernetes/issues/116416/comments | 13 | 2023-03-09T14:04:17Z | 2024-10-14T09:49:33Z | https://github.com/kubernetes/kubernetes/issues/116416 | 1,617,324,515 | 116,416 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
ci-cos-cgroupv2-inplace-pod-resize-containerd-main-e2e-gce
### Which tests are failing?
Kubernetes e2e suite: [It] [sig-node] [Serial] Pod InPlace Resize Container (scheduler-focused) [Feature:InPlacePodVerticalScaling] pod-resize-scheduler-tests
### Since when has it been failing?
Mar... | Scheduler focused in-place pod resize test is flaky and attempts negative resource values | https://api.github.com/repos/kubernetes/kubernetes/issues/116415/comments | 12 | 2023-03-09T14:03:10Z | 2024-05-03T18:38:05Z | https://github.com/kubernetes/kubernetes/issues/116415 | 1,617,322,749 | 116,415 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Calling ServerPreferredResources method of the CachedDiscoveryClient panics when the call to the cluster's API is forbidden.
### What did you expect to happen?
The call should not panic, and return empty lists
### How can we reproduce it (as minimally and precisely as possible)?
go.mod
```
... | ServerPreferredResources panics with CachedDiscoveryClient when IsForbidden access to cluster | https://api.github.com/repos/kubernetes/kubernetes/issues/116414/comments | 5 | 2023-03-09T13:53:26Z | 2024-03-26T20:08:08Z | https://github.com/kubernetes/kubernetes/issues/116414 | 1,617,305,931 | 116,414 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
1. Create Pod with Dynamic Resource
2. kubelet is restarted between NodePrepareResource grpc all and before we checkpoint
3. Delete Pod with Dynamic Resource
Kubelet will not call NodeUnprepareResource grpc to the DRA plugin
### What did you expect to happen?
kubelet should call NodeUnprepar... | dynamic resource allocation: kubelet restart after NodePrepareResource and before checkpointing will cause not calling NodeUnprepareResource | https://api.github.com/repos/kubernetes/kubernetes/issues/116411/comments | 19 | 2023-03-09T10:59:47Z | 2024-05-13T19:19:06Z | https://github.com/kubernetes/kubernetes/issues/116411 | 1,616,962,318 | 116,411 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Running pods when deleted are not transitioned to a terminal phase, even when all containers are terminated. Note that, containers are not restarted for deleted pods: https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/container/helpers.go#L73-L77.
This is problematic for jobs, whi... | Transition running deleted pods to a terminal phase | https://api.github.com/repos/kubernetes/kubernetes/issues/116410/comments | 3 | 2023-03-09T10:26:50Z | 2023-03-16T23:47:19Z | https://github.com/kubernetes/kubernetes/issues/116410 | 1,616,895,285 | 116,410 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kubelet sends operationExecutor.MountVolume request to CSI driver even when there is still pending operationExecutor.UnmountVolume request for the same volume ID
### What did you expect to happen?
kubelet only sends operationExecutor.MountVolume request to CSI driver when there is no pending... | kubelet should avoid sending operationExecutor.MountVolume request to CSI driver when there is still pending operationExecutor.UnmountVolume request for the same volume ID | https://api.github.com/repos/kubernetes/kubernetes/issues/116403/comments | 9 | 2023-03-09T08:55:25Z | 2024-03-25T17:03:00Z | https://github.com/kubernetes/kubernetes/issues/116403 | 1,616,728,361 | 116,403 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
TestChangeCRD, an integration test, [flaked a lot](https://github.com/kubernetes/kubernetes/issues/116364) recently. This showed up in https://storage.googleapis.com/k8s-metrics/flakes-latest.json but not in https://storage.googleapis.com/k8s-triage/index.html.
From https://gi... | triage unit and integration test failures | https://api.github.com/repos/kubernetes/kubernetes/issues/116402/comments | 27 | 2023-03-09T07:38:19Z | 2024-03-24T12:50:59Z | https://github.com/kubernetes/kubernetes/issues/116402 | 1,616,605,609 | 116,402 |
[
"kubernetes",
"kubernetes"
] | Follow up from: https://github.com/kubernetes/kubernetes/pull/116093/files#r1128138681 See details there.
When `TopologyManagerPolicy` is `None`, there is no need to discover the NUMA topology.
/sig node
/priority backlog
/kind feature
/help-wanted
| When TopologyManagerPolicy is None, there is no need to discover the NUMA topology. | https://api.github.com/repos/kubernetes/kubernetes/issues/116391/comments | 7 | 2023-03-08T19:44:24Z | 2023-07-11T11:53:15Z | https://github.com/kubernetes/kubernetes/issues/116391 | 1,615,820,790 | 116,391 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Kube-Proxy version: Kubernetes v1.24.10-eks-7abdb2b
AWS EKS 1.24
```shell
runtime.fatalpanic (panic.go:1141) runtime
runtime.gopanic (panic.go:987) runtime
runtime.panicmem (panic.go:260) runtime
runtime.sigpanic (signal_windows.go:257) runtime
winkernel.(*Proxier).syncProxyRules (proxier.g... | Windows Kubernetes - Kube-Proxy panics/exits | https://api.github.com/repos/kubernetes/kubernetes/issues/116389/comments | 18 | 2023-03-08T18:27:05Z | 2023-03-31T20:24:14Z | https://github.com/kubernetes/kubernetes/issues/116389 | 1,615,724,307 | 116,389 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
This is the same issue as #79773
The `HorizontalPodAutoscaler` condition `ScalingLimited` can have an incoherent status even if the `currentReplicas`/`desiredReplicas` is within the range of requested `minReplicas`/`maxReplicas`:
```
$ kubectl describe hpa my-hpa
...
Min replicas: ... | HPA condition "ScalingLimited" can have a wrong value "TooFewReplicas" while it should not | https://api.github.com/repos/kubernetes/kubernetes/issues/116387/comments | 18 | 2023-03-08T16:54:44Z | 2025-02-20T14:36:10Z | https://github.com/kubernetes/kubernetes/issues/116387 | 1,615,596,669 | 116,387 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I am not sure this is the right forum to report this bug. I have Kuberenetes running and suddenly kernel panicked and system got rebooted. But the kernel panic is happened when container run time is initiated. I am not sure this is bug related to container run time or underlying OS. The kernel is sh... | Kernel Panic with kubernetes | https://api.github.com/repos/kubernetes/kubernetes/issues/116382/comments | 5 | 2023-03-08T16:36:19Z | 2023-03-08T17:11:30Z | https://github.com/kubernetes/kubernetes/issues/116382 | 1,615,571,224 | 116,382 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We are running Docker and Kubernetes on EC2 through the EKS service, and this cluster is mainly used for CICD purposes solely.
Besides that, we are trying to setup TestContainers to run in our pipelines. The process works as follow, every time we start a new pipeline a new POD is mapped with the do... | Why can't Kubernetes PODs communicate with Docker containers started manually? | https://api.github.com/repos/kubernetes/kubernetes/issues/116379/comments | 8 | 2023-03-08T15:45:26Z | 2023-09-08T07:42:05Z | https://github.com/kubernetes/kubernetes/issues/116379 | 1,615,493,599 | 116,379 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
integration-master
### Which tests are flaking?
TestCronJobLaunchesPodAndCleansUp test increased from ~30 seconds to ~90 seconds
### Since when has it been flaking?
Since merging https://github.com/kubernetes/kubernetes/pull/113428
### Testgrid link
https://testgrid.k8s.i... | Contextual logging slowing down TestCronJobLaunchesPodAndCleansUp | https://api.github.com/repos/kubernetes/kubernetes/issues/116378/comments | 4 | 2023-03-08T15:42:04Z | 2023-03-08T21:12:11Z | https://github.com/kubernetes/kubernetes/issues/116378 | 1,615,488,412 | 116,378 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In-place pod resize CI tests were re-enabled in PR https://github.com/kubernetes/test-infra/pull/28928 following merge of PR #102884 These tests are failing and the root cause appears to be pods timing out awaiting scheduling, Unschedulable due to Insufficient cpu.
Running these tests in serial... | InPlacePodVerticalScaling CI tests fail due to parallel tests stepping over each other in low CPU count CI system | https://api.github.com/repos/kubernetes/kubernetes/issues/116371/comments | 5 | 2023-03-08T12:00:36Z | 2023-03-09T21:54:09Z | https://github.com/kubernetes/kubernetes/issues/116371 | 1,615,153,577 | 116,371 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [2fa397b02ad5f6f2cfa0](https://go.k8s.io/triage#2fa397b02ad5f6f2cfa0)
The root cause of the test failure is related to volume, however, for the cleanup logic, it is a nil pointer problem that can be easily fixed.
##### Error text:
```
There were additional failures detected after the initia... | Failure cluster [2fa397b0...] cleanupLocalPVCsPVs invalid memory address or nil pointer dereference | https://api.github.com/repos/kubernetes/kubernetes/issues/116365/comments | 11 | 2023-03-08T08:46:59Z | 2023-03-16T01:24:50Z | https://github.com/kubernetes/kubernetes/issues/116365 | 1,614,878,460 | 116,365 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
TestChangeCRD
"k8s.io/kubernetes/vendor/k8s.io/apiextensions-apiserver/test/integration TestChangeCRD": 37,
https://storage.googleapis.com/k8s-metrics/flakes-latest.json
### Which tests are flaking?
https://github.com/kubernetes/kubernetes/blob/e390791e5fdddd6d17504ea200e0a86f1... | Top flake in integration test: TestChangeCRD | https://api.github.com/repos/kubernetes/kubernetes/issues/116364/comments | 14 | 2023-03-08T07:52:18Z | 2023-04-20T16:59:45Z | https://github.com/kubernetes/kubernetes/issues/116364 | 1,614,807,078 | 116,364 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [0991d7dded0bd24757a9](https://go.k8s.io/triage#0991d7dded0bd24757a9)
https://perf-dash.k8s.io/#/?jobname=scheduler-perf-benchmark&metriccategoryname=Scheduler&metricname=BenchmarkResults&benchmark=BenchmarkPerfScheduling%2FSchedulingCSIPVs%2F500Nodes-8&metricName=time
##### Error text:
```
Fa... | Failure cluster [0991d7dd...] scheduler perf test failed since 3/7 | https://api.github.com/repos/kubernetes/kubernetes/issues/116359/comments | 10 | 2023-03-08T07:02:31Z | 2023-03-08T21:12:22Z | https://github.com/kubernetes/kubernetes/issues/116359 | 1,614,757,569 | 116,359 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hi,
I have a following role and rolebinding definition. I want to allow the service account creation only with specific resource names.
Example: I should able to create service account using `dev-blue` with the name `dev-green` and vice versa.
If I am trying to create a service account with ... | service account creation with restricted RBAC not working | https://api.github.com/repos/kubernetes/kubernetes/issues/116358/comments | 6 | 2023-03-08T06:22:15Z | 2023-03-09T19:06:58Z | https://github.com/kubernetes/kubernetes/issues/116358 | 1,614,723,404 | 116,358 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [cd845a0bb31aa9c849f7](https://go.k8s.io/triage#cd845a0bb31aa9c849f7)
The test flakes more recently.
<img width="1168" alt="image" src="https://user-images.githubusercontent.com/2010320/223633230-55cc231e-c4e9-4d63-9148-1eb8d9218015.png">
##### Error text:
```
error during ./hack/ginkgo-e2e.s... | Failure cluster [cd845a0b...] Kubernetes e2e suite: [It] [sig-storage] PersistentVolumes NFS when invoking the Recycle reclaim policy should test that a PV becomes Available and is clean after the PVC is deleted. | https://api.github.com/repos/kubernetes/kubernetes/issues/116357/comments | 13 | 2023-03-08T06:09:54Z | 2023-05-09T16:19:03Z | https://github.com/kubernetes/kubernetes/issues/116357 | 1,614,713,538 | 116,357 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
While we were fixing PVs to allow updating topology labels from beta to GA in https://github.com/kubernetes/kubernetes/pull/115391, we noticed that Job [allows Affinity updates](https://github.com/kubernetes/kubernetes/blob/0ebf9a3a1be6d0757b1d60b860ed226e2d4d1abc/pkg/apis/batch/validation/validatio... | Allow Job to update to GA topology labels | https://api.github.com/repos/kubernetes/kubernetes/issues/116346/comments | 9 | 2023-03-07T22:41:20Z | 2024-01-19T13:00:00Z | https://github.com/kubernetes/kubernetes/issues/116346 | 1,614,324,593 | 116,346 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In https://github.com/kubernetes/kubernetes/issues/114268, we realized that non in-tree StorageClass can be impacted by a future removal of beta topology labels from Nodes if they are supporting the beta topology labels.
### What did you expect to happen?
We should allow users to mutate the Storag... | Allow StorageClass AllowedTopologies to update from beta to GA topology labels | https://api.github.com/repos/kubernetes/kubernetes/issues/116344/comments | 6 | 2023-03-07T22:32:00Z | 2023-04-05T18:07:37Z | https://github.com/kubernetes/kubernetes/issues/116344 | 1,614,312,393 | 116,344 |
[
"kubernetes",
"kubernetes"
] | Failing:
https://testgrid.k8s.io/sig-node-containerd#cos-cgroupv2-containerd-node-e2e-serial
https://testgrid.k8s.io/sig-node-containerd#cos-cgroupv1-containerd-node-e2e-serial
```
E2eNode Suite.[It] [sig-node] Device Plugin [Feature:DevicePluginProbe][NodeFeature:DevicePluginProbe][Serial] DevicePlugin [Serial... | Failing E2E Node Test: E2E: E2eNode Suite.[It] [sig-node] Device Plugin [Feature:DevicePluginProbe][NodeFeature:DevicePluginProbe][Serial] DevicePlugin [Serial] [Disruptive] Keeps device plugin assignments across pod and kubelet restarts | https://api.github.com/repos/kubernetes/kubernetes/issues/116340/comments | 3 | 2023-03-07T19:47:52Z | 2023-03-08T03:31:35Z | https://github.com/kubernetes/kubernetes/issues/116340 | 1,614,092,568 | 116,340 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
First post here, hello :) 👋 .
I enabled HPA on one of our API's. When I checked lens to insure it was running properly I came across this error.
`failed to get cpu utilization: missing request for cpu`
After doing some digging I realized that I needed to specify resources on _all_ containe... | HPA looks at CronJob containers for metrics | https://api.github.com/repos/kubernetes/kubernetes/issues/116339/comments | 14 | 2023-03-07T19:40:23Z | 2024-06-24T13:40:04Z | https://github.com/kubernetes/kubernetes/issues/116339 | 1,614,082,826 | 116,339 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hi 👋
I have been working with @craiglpeters on adding a dev container to this repo - https://github.com/kubernetes/kubernetes/issues/113019
With the dev config, when we run `make verify` then, we are having a test failure for `hack/verify-mocks.sh`. It fails at [this line](https://github.com... | hack/verify-mocks.sh Append `sudo` to a `git worktree remove` command | https://api.github.com/repos/kubernetes/kubernetes/issues/116338/comments | 7 | 2023-03-07T19:09:14Z | 2023-04-21T23:36:08Z | https://github.com/kubernetes/kubernetes/issues/116338 | 1,614,043,375 | 116,338 |
[
"kubernetes",
"kubernetes"
] | ### Overview
The annotation `volume.beta.kubernetes.io/storage-class` is long deprecated, but still honored.
We should eventually stop honoring it. The annotation was never treated as stable.
### Anything else we need to know?
It's nice to emit warnings when these things are used, and then later stop honorin... | Deprecated annotation `volume.beta.kubernetes.io/storage-class` still honored | https://api.github.com/repos/kubernetes/kubernetes/issues/116336/comments | 13 | 2023-03-07T17:48:41Z | 2024-12-15T13:53:42Z | https://github.com/kubernetes/kubernetes/issues/116336 | 1,613,931,956 | 116,336 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
It appears that fc_util tests are failing in certain environment:
```
--- FAIL: TestSearchDisk (0.00s)
--- FAIL: TestSearchDi... | fc_util test fails in certain environments | https://api.github.com/repos/kubernetes/kubernetes/issues/116334/comments | 6 | 2023-03-07T17:40:59Z | 2024-10-13T20:38:30Z | https://github.com/kubernetes/kubernetes/issues/116334 | 1,613,920,087 | 116,334 |
[
"kubernetes",
"kubernetes"
] | I can add many --bind-address to kube-apiserver, but only the last one has affect. Providing a comma-separated list to a singe --bind-address option makes the service crash | Cannot bind multiple addresses | https://api.github.com/repos/kubernetes/kubernetes/issues/116328/comments | 4 | 2023-03-07T13:43:30Z | 2023-03-07T14:24:20Z | https://github.com/kubernetes/kubernetes/issues/116328 | 1,613,486,746 | 116,328 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [3ee80f0d44deded0a628](https://go.k8s.io/triage#3ee80f0d44deded0a628)
##### Error text:
```
[FAILED] Timed out after 10.000s.
Expected success, but got an error:
<*errors.errorString | 0xc0019c4be0>: {
s: "pod (graceful-node-shutdown-2936/period-a-5-f099b778-08ba-40f0-a543-0f4d20... | Test failure: graceful-node-shutdown (GracefulNodeShutdown [Serial] [NodeFeature:GracefulNodeShutdown] [NodeFeature:GracefulNodeShutdownBasedOnPodPriority] when gracefully shutting down with Pod priority should be able to gracefully shutdown pods with various grace periods) - Failure cluster [3ee80f0d...] | https://api.github.com/repos/kubernetes/kubernetes/issues/116318/comments | 4 | 2023-03-06T23:56:25Z | 2023-03-07T04:52:30Z | https://github.com/kubernetes/kubernetes/issues/116318 | 1,612,424,979 | 116,318 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Install on a Server where there is a proxy to connect to the internet :
export the proxy - HTTP_PROXY and HTTPS_PROXY correctly and can curl to any links that are working
runtime environment: containers
unable to initialize and completely stuck - unable to create clusters
sudo kubeadm... | failed to pull image registry.k8s.io | Freshly installation - cluster creation is failing | https://api.github.com/repos/kubernetes/kubernetes/issues/116316/comments | 11 | 2023-03-06T23:35:02Z | 2023-03-20T00:24:58Z | https://github.com/kubernetes/kubernetes/issues/116316 | 1,612,405,499 | 116,316 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
- pull-kubernetes-e2e-autoscaling-hpa-cm
- pull-kubernetes-e2e-autoscaling-hpa-cpu
Both are HPA's e2e test.
### Which tests are flaking?
(Let's grow this list)
#### pull-kubernetes-e2e-autoscaling-hpa-cm
- Kubernetes e2e suite: [It] [sig-autoscaling] [HPA] [Feature:CustomM... | flaky tests: pull-kubernetes-e2e-autoscaling-hpa-cm and pull-kubernetes-e2e-autoscaling-hpa-cpu | https://api.github.com/repos/kubernetes/kubernetes/issues/116315/comments | 5 | 2023-03-06T23:11:54Z | 2023-06-27T15:58:07Z | https://github.com/kubernetes/kubernetes/issues/116315 | 1,612,378,408 | 116,315 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.