
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
Unit tests on the new EKS-based Prow build cluster are flaking. The job in question is `ci-kubernetes-unit-eks-canary`:
* https://prow.k8s.io/?job=ci-kubernetes-unit-eks-canary
* https://testgrid.k8s.io/sig-k8s-infra-canaries#ci-kubernetes-unit-eks-canary
* https://github.com/kubernete... | [Flaking Test] ci-kubernetes-unit-eks-canary/TestLazyThroughput on EKS build cluster | https://api.github.com/repos/kubernetes/kubernetes/issues/116990/comments | 8 | 2023-03-29T13:41:45Z | 2023-03-29T21:51:28Z | https://github.com/kubernetes/kubernetes/issues/116990 | 1,645,841,603 | 116,990 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The `quick-release` target triggers build scripts that allow overriding $KUBE_BUILD_PLATFORMS variable. This override is recognized and a build for x86_64 is attempted as show in the log below.
However the override seems to get ignored in earlier stages when the scripts create builder image - do... | build scripts don't respect platform override for builder image | https://api.github.com/repos/kubernetes/kubernetes/issues/116989/comments | 7 | 2023-03-29T13:07:06Z | 2024-03-19T09:48:06Z | https://github.com/kubernetes/kubernetes/issues/116989 | 1,645,777,528 | 116,989 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
1. shutdown node-0
2. MySQL pod is scheduled to node-0(In my environment, it takes 30 seconds to change to node notReady)
3. MYSQL pod is always pending, and the pod is not evicted after the node becomes NotReady
- controller-manager log
I0329 18:41:30.848988 1 taint_manager.go:400... | taint_manager did not evict the Pending Pod on the NotReady node | https://api.github.com/repos/kubernetes/kubernetes/issues/116988/comments | 6 | 2023-03-29T12:37:10Z | 2023-09-09T09:24:58Z | https://github.com/kubernetes/kubernetes/issues/116988 | 1,645,724,712 | 116,988 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
pod limits disk usage to 100M, 140M has been used, but pod will not expel
### What did you expect to happen?
Ejection pod
### How can we reproduce it (as minimally and precisely as possible)?
```
kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: centos
labels... | When a pod's emptyDir exceeds the resource limit, the pod will restart and enter the ContainerStatusUnknown state. | https://api.github.com/repos/kubernetes/kubernetes/issues/116986/comments | 22 | 2023-03-29T10:53:33Z | 2023-11-08T19:43:05Z | https://github.com/kubernetes/kubernetes/issues/116986 | 1,645,546,366 | 116,986 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
1. use `kubeadm init ...... --image-repository registry.aliyuncs.com/google_containers` , it show : <br> [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory /etc/kubernetes/manifests". This can take up to 4m0s<br>[kubelet-check] Initial timeout... | registry.k8s.io/pause:3.6 does not use the address specified by --image-repository when executing kubeadm init | https://api.github.com/repos/kubernetes/kubernetes/issues/116985/comments | 3 | 2023-03-29T10:28:18Z | 2023-03-29T10:42:57Z | https://github.com/kubernetes/kubernetes/issues/116985 | 1,645,501,276 | 116,985 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
We have a configuration for HPA called `horizontal-pod-autoscaler-tolerance` in [Kube Controller Manager](https://kubernetes.io/docs/reference/command-line-tools-reference/kube-controller-manager/), defaulted to `0.1`.
An individual HPA should be allowed to set a custom value ... | Allow custom tolerance levels for horizontal pod autoscalers | https://api.github.com/repos/kubernetes/kubernetes/issues/116984/comments | 25 | 2023-03-29T09:00:52Z | 2025-02-10T17:08:38Z | https://github.com/kubernetes/kubernetes/issues/116984 | 1,645,333,511 | 116,984 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
`pkg/scheduler/framework/parallelize`
### Which tests are failing?
`TestChunkSize` in `pkg/scheduler/framework/parallelize`
I transformed that testcase into a fuzz driver and tested it with [[go-fuzz](https://github.com/dvyukov/go-fuzz)](https://github.com/dvyukov/go-fuzz)
It crash with... | Crash in parallelize.chunkSizeFor | https://api.github.com/repos/kubernetes/kubernetes/issues/116983/comments | 7 | 2023-03-29T07:34:28Z | 2024-02-18T04:54:16Z | https://github.com/kubernetes/kubernetes/issues/116983 | 1,645,202,395 | 116,983 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Use case: apply a deployment with `schedulerName` specified:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
sche... | Improve observability for Pods that specify a `schedulerName` the cluster doesn't have | https://api.github.com/repos/kubernetes/kubernetes/issues/116982/comments | 20 | 2023-03-29T07:20:05Z | 2024-12-19T21:13:04Z | https://github.com/kubernetes/kubernetes/issues/116982 | 1,645,183,130 | 116,982 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
```
pkg/controller
```
### Which tests are failing?
`TestStoreScaleEvents` in `pkg/controller`
I transformed that testcase into a fuzz driver and tested it with [[go-fuzz](https://github.com/dvyukov/go-fuzz)](https://github.com/dvyukov/go-fuzz)
It crash with "invalid memory address or... | Crash in podautoscaler.getLongestPolicyPeriod | https://api.github.com/repos/kubernetes/kubernetes/issues/116981/comments | 7 | 2023-03-29T06:48:44Z | 2024-02-18T05:55:20Z | https://github.com/kubernetes/kubernetes/issues/116981 | 1,645,139,354 | 116,981 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
- make 1 of the AZs have insufficient capacity
- create deployment with 9 replicase and AZ spread with DoNotSchedule and maxSkew 1
- 7/9 pods end up as pending in the bad AZ
```
NAME READY STATUS RESTARTS AGE ZONE
donotschedule-69fb6f5469-4kffs 1/1 R... | topologySpreadConstraints with DoNotSchedule and bad AZ leads to 7/9 pending in that AZ | https://api.github.com/repos/kubernetes/kubernetes/issues/116978/comments | 15 | 2023-03-29T03:57:13Z | 2025-01-21T12:45:51Z | https://github.com/kubernetes/kubernetes/issues/116978 | 1,644,991,042 | 116,978 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
#102884 in its alpha state introduces a new challenge to the kubelet state machine - partial and deferred acceptance of spec changes to a pod in the kubelet, while at the same time we are realizing that the kubelet is not properly feeding actual state to components #116970.
Last minute 1.27 fi... | In place pod resizing should be designed into the kubelet config state loop, not alongside it | https://api.github.com/repos/kubernetes/kubernetes/issues/116971/comments | 15 | 2023-03-28T19:32:08Z | 2024-09-12T18:36:24Z | https://github.com/kubernetes/kubernetes/issues/116971 | 1,644,546,031 | 116,971 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The kubelet currently confuses "desired" and "actual" state in some subsystems in a way that leads to data races and hinders future features. Pods that have been placed into a config source are "desired" - those then have to be "admitted" (pass hard admission handlers or be failed), and only then... | Components in the kubelet are incorrectly pulling state from "desired" instead of the pod worker's "actual" | https://api.github.com/repos/kubernetes/kubernetes/issues/116970/comments | 10 | 2023-03-28T19:18:26Z | 2024-09-11T22:31:28Z | https://github.com/kubernetes/kubernetes/issues/116970 | 1,644,529,786 | 116,970 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When graceful node shutdown is enabled, I expect that services are drained appropriately during pod shutdown (i.e. the same way that `kubectl delete pod` would work). However this doesn't seem to be the case - the pod never enters the `Terminating` state according to `kubectl` and doesn't get remo... | Graceful Node Shutdown does not update endpoints for terminating pods | https://api.github.com/repos/kubernetes/kubernetes/issues/116965/comments | 52 | 2023-03-28T16:23:50Z | 2025-02-11T19:50:54Z | https://github.com/kubernetes/kubernetes/issues/116965 | 1,644,290,566 | 116,965 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
`kubectl create ns 2000-abc` succeeds even though [Namespaces and DNS](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/#namespaces-and-dns) says that, "As a result, all namespace names must be valid [RFC 1123 DNS labels](https://kubernetes.io/docs/concepts/overview/worki... | Namespace names should be required to be RFC-1123 DNS labels | https://api.github.com/repos/kubernetes/kubernetes/issues/116964/comments | 3 | 2023-03-28T12:55:47Z | 2023-04-20T17:00:33Z | https://github.com/kubernetes/kubernetes/issues/116964 | 1,643,893,705 | 116,964 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
"When I compile apiserver.go and kubelet for kubernetes-1.26 using Go1.19, I report an error. I can successfully compile kubelctl, kubeadm, and kube-proxy. However, errors may occur when compiling kubelet or kube-apiserver.Why is it only partially successful?"? The screenshot is as follows:... | Why only partial compilation succeeded | https://api.github.com/repos/kubernetes/kubernetes/issues/116962/comments | 5 | 2023-03-28T12:53:03Z | 2023-06-29T09:51:17Z | https://github.com/kubernetes/kubernetes/issues/116962 | 1,643,889,234 | 116,962 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
asdasd
### What did you expect to happen?
asdasd
### How can we reproduce it (as minimally and precisely as possible)?
asdasd
### Anything else we need to know?
asdasd
### Kubernetes version
<details>
```console
$ kubectl version
# paste output here
```
</details>
### Cloud provi... | asd | https://api.github.com/repos/kubernetes/kubernetes/issues/116960/comments | 2 | 2023-03-28T10:03:46Z | 2023-03-28T11:07:31Z | https://github.com/kubernetes/kubernetes/issues/116960 | 1,643,610,487 | 116,960 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
asdasd
### What did you expect to happen?
asdasd
### How can we reproduce it (as minimally and precisely as possible)?
asdasdasd
### Anything else we need to know?
asdasdasd
### Kubernetes version
<details>
```console
$ kubectl version
# paste output here
```
</details>
### Cloud... | Video Post | https://api.github.com/repos/kubernetes/kubernetes/issues/116959/comments | 2 | 2023-03-28T10:02:32Z | 2023-03-28T11:07:43Z | https://github.com/kubernetes/kubernetes/issues/116959 | 1,643,608,474 | 116,959 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
gomega Eventually should be used in waiting for conditions both in integration tests or e2e tests. Something like `gomega.NewGomegaWithT(b).Eventually(...).Should(gomega.BeEmpty())`.
Tracked the suggestion here https://github.com/kubernetes/kubernetes/pull/116634#discussion_r11... | Use gomega Eventually in scheduler integration tests | https://api.github.com/repos/kubernetes/kubernetes/issues/116956/comments | 8 | 2023-03-28T08:40:13Z | 2023-06-28T06:37:50Z | https://github.com/kubernetes/kubernetes/issues/116956 | 1,643,472,472 | 116,956 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
master-blocking
- ci-kubernetes-unit
### Which tests are flaking?
`k8s.io/kubernetes/pkg/controller/volume/attachdetach/reconciler.Test_Run_OneVolumeDetachFailNodeWithReadWriteOnce`
### Since when has it been flaking?
2023-03-27 23:22:13 +0000 UTC
### Testgrid link
https://testgrid... | [Flaking Test] ci-kubernetes-unit | https://api.github.com/repos/kubernetes/kubernetes/issues/116955/comments | 5 | 2023-03-28T06:44:25Z | 2023-03-28T18:04:49Z | https://github.com/kubernetes/kubernetes/issues/116955 | 1,643,303,153 | 116,955 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A job pod was terminating kubelet restarted late in that process, after which, the pod shows up with a Terminated status in `kubectl get pods`, but is in `phase: Succeeded` with all of its resources cleaned up.
kubectl shows:
```console
NAME READY STATUS RESTA... | Completed pod stuck in Terminating state after kubelet restart | https://api.github.com/repos/kubernetes/kubernetes/issues/116954/comments | 9 | 2023-03-27T22:06:00Z | 2024-02-19T05:05:38Z | https://github.com/kubernetes/kubernetes/issues/116954 | 1,642,885,303 | 116,954 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
master-blocking
- verify-master
### Which tests are failing?
- verify-vendor
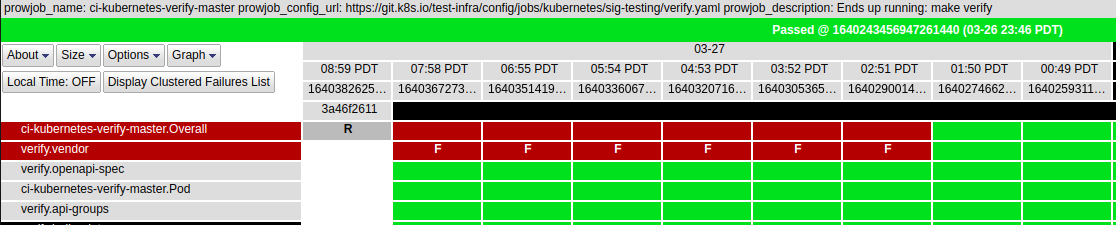
### Since when has it been failing?
2023-03-27 02:51... | [Failing test] verify-master | https://api.github.com/repos/kubernetes/kubernetes/issues/116951/comments | 4 | 2023-03-27T16:41:27Z | 2023-03-27T17:36:36Z | https://github.com/kubernetes/kubernetes/issues/116951 | 1,642,444,607 | 116,951 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
pull-kubernetes-dependencies
### Which tests are failing?
verify.Vendor
### Since when has it been failing?
27 March 2023, 15:28 IST (9:58 UTC)
### Testgrid link
https://testgrid.k8s.io/presubmits-kubernetes-blocking#pull-kubernetes-dependencies
### Reason for failure (if possible)
... | pull-kubernetes-dependencies is failing | https://api.github.com/repos/kubernetes/kubernetes/issues/116946/comments | 9 | 2023-03-27T13:33:25Z | 2023-03-27T15:56:30Z | https://github.com/kubernetes/kubernetes/issues/116946 | 1,642,069,995 | 116,946 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
Jobs in https://testgrid.k8s.io/sig-node-containerd#image-validation-cos-e2e are failing continuously since a long time
### Which tests are failing?
The `kubetest.Up` row is in failing. The 5 node cluster that is needed for test is not coming into Ready state.
### Since when has it been ... | sig-node-containerd#image-validation-cos-e2e is failing | https://api.github.com/repos/kubernetes/kubernetes/issues/116944/comments | 8 | 2023-03-27T11:33:50Z | 2023-04-28T03:37:31Z | https://github.com/kubernetes/kubernetes/issues/116944 | 1,641,946,802 | 116,944 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I did a `k explain job.spec.activeDeadlineSeconds.template.spec.containers.terminationMessagePath`, this was an invalid input since the `activeDeadlineSeconds` does not have `template` as child.
The kubectl CLI did not throw any error, but displayed the `terminationMessagePath` as `FIELD` and `DE... | Issue in parsing the resource in `kubectl explain` | https://api.github.com/repos/kubernetes/kubernetes/issues/116934/comments | 10 | 2023-03-27T02:51:04Z | 2023-03-27T09:58:47Z | https://github.com/kubernetes/kubernetes/issues/116934 | 1,641,269,285 | 116,934 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
New TestGrid alerts at [sig-node-release-blocking#node-kubelet-serial-containerd](https://testgrid.k8s.io/sig-node-release-blocking#node-kubelet-serial-containerd) since commit/f393e7da7.
### Which tests are failing?
Found 2 failing rows in node-kubelet-serial-containerd: 2 new,... | E2eNode Suite.[It] [sig-node] Device Plugin [Feature:DevicePluginProbe][NodeFeature:DevicePluginProbe][Serial] DevicePlugin [Serial] [Disruptive] Keeps device plugin assignments across pod and kubelet restarts | https://api.github.com/repos/kubernetes/kubernetes/issues/116925/comments | 16 | 2023-03-25T14:16:11Z | 2023-05-01T20:19:54Z | https://github.com/kubernetes/kubernetes/issues/116925 | 1,640,533,334 | 116,925 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I am trying persistent volume demo where i use local -storage and had made folder with store name in linux machine.
But the path is not getting mount. the pods remain always in Containercreating mode. I thaught it is searching for the folder in VM as well but there also its showing same error. PV a... | Pv in local storage. I am getting error of file not exist. | https://api.github.com/repos/kubernetes/kubernetes/issues/116923/comments | 6 | 2023-03-25T10:30:04Z | 2023-03-27T10:34:32Z | https://github.com/kubernetes/kubernetes/issues/116923 | 1,640,465,682 | 116,923 |
[
"kubernetes",
"kubernetes"
] | The legacy cloud-provider gce has been moved and synced to the corresponding cloud-provider-gcp repo
https://github.com/kubernetes/cloud-provider-gcp/pull/466
Some projects that depend on these libraries already migrated to it
https://github.com/kubernetes/ingress-gce/pull/2033
| Remove GCE legacy-cloud-provider | https://api.github.com/repos/kubernetes/kubernetes/issues/116914/comments | 5 | 2023-03-24T14:39:10Z | 2024-05-23T16:11:37Z | https://github.com/kubernetes/kubernetes/issues/116914 | 1,639,519,473 | 116,914 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
After https://github.com/kubernetes/kubernetes/releases/tag/v1.27.0-rc.0 release, Go modules are not tagged for 0.27.0-rc.0.
See e.g. https://pkg.go.dev/k8s.io/api@v0.27.0-beta.0?tab=versions
### What did you expect to happen?
Go modules to be tagged with the release
### How can we reprodu... | Go modules are not tagged for v0.27.0-rc.0 | https://api.github.com/repos/kubernetes/kubernetes/issues/116912/comments | 5 | 2023-03-24T12:55:06Z | 2023-03-25T01:59:55Z | https://github.com/kubernetes/kubernetes/issues/116912 | 1,639,339,236 | 116,912 |
[
"kubernetes",
"kubernetes"
] | Currently, HPA only supports metrics with an OR relationship, meaning that if any one metric exceeds the threshold, scaling up will occur. Scaling down will only occur if all metrics are below the threshold.
## Support request
I have a requirement where I only want to scale up if both TPS and CPU exceed the thresh... | HPA to support AND operation | https://api.github.com/repos/kubernetes/kubernetes/issues/116908/comments | 7 | 2023-03-24T09:57:16Z | 2024-02-18T07:57:17Z | https://github.com/kubernetes/kubernetes/issues/116908 | 1,639,076,828 | 116,908 |
[
"kubernetes",
"kubernetes"
] | Multiple jobs started to fail after the tag to 1.28.0-alpha.0
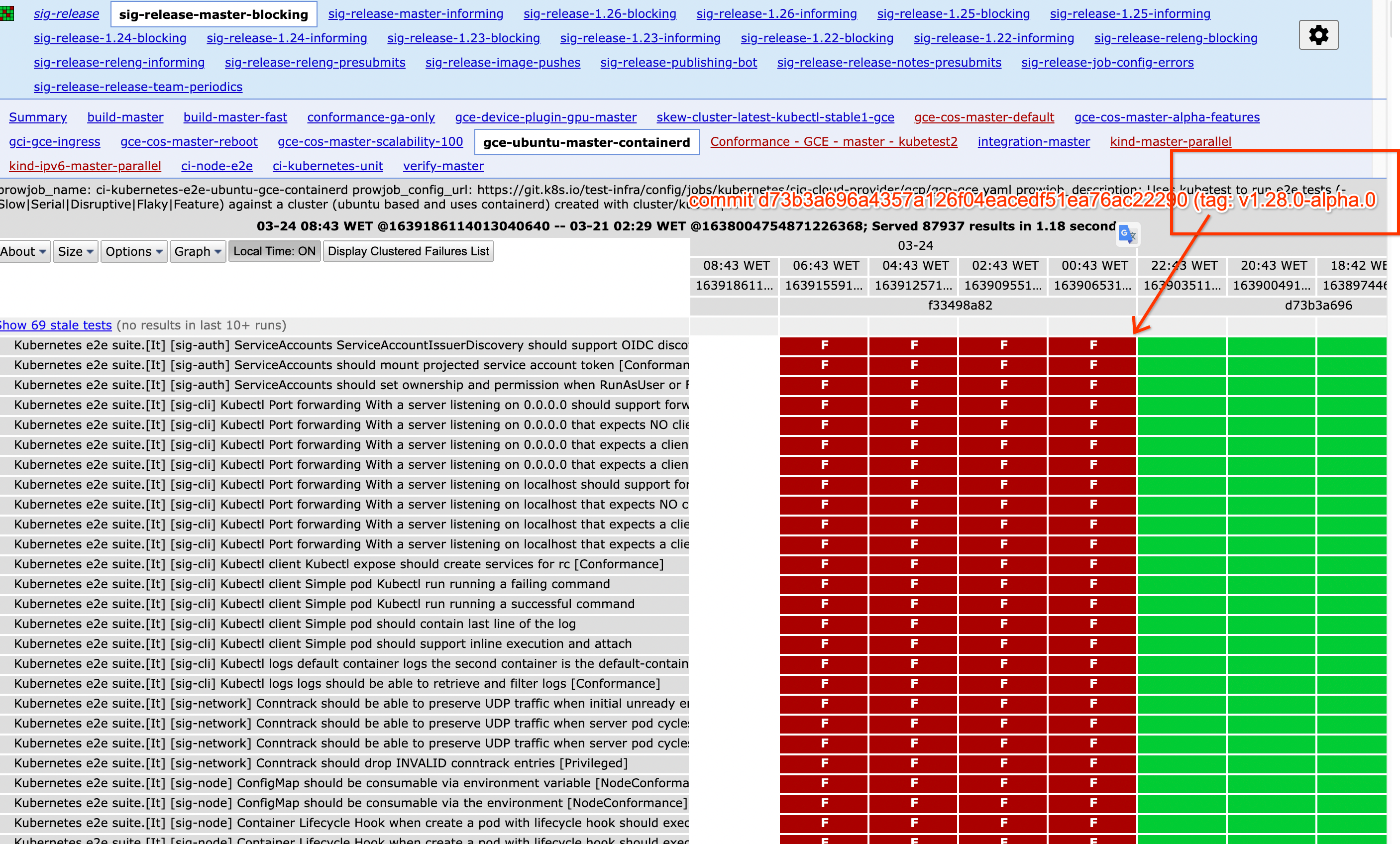
The reasons is that the apiserver is panicing when trying to access the pod logs, something very common in all e2e tests, see this occurren... | Deprecated metrics panic trying to being updated | https://api.github.com/repos/kubernetes/kubernetes/issues/116907/comments | 3 | 2023-03-24T09:54:20Z | 2023-03-24T12:10:36Z | https://github.com/kubernetes/kubernetes/issues/116907 | 1,639,070,911 | 116,907 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
https://testgrid.k8s.io/sig-node-containerd#cos-cgroupv2-containerd-node-features
### Which tests are failing?
https://github.com/kubernetes/kubernetes/blob/f33498a8256b455b677ad4d30440869318b84204/pkg/registry/core/pod/rest/metrics.go#L47-L58
```
2023-03-24T08:11:57.715601121Z ... | after v1.28.0-alpha.0 tagged, the CI build kubelet with 1.28.0 tag and invalid memory address or nil pointer dereference | https://api.github.com/repos/kubernetes/kubernetes/issues/116905/comments | 1 | 2023-03-24T08:43:50Z | 2023-03-24T12:10:34Z | https://github.com/kubernetes/kubernetes/issues/116905 | 1,638,964,344 | 116,905 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We have a relative large cluster with >800 nodes, and some daemonset watching >8000 CR instances running on every node. These CRs are upated very frequently.
After applying suggestedWatchChannelSize improvements on watcher channel size, we still got apiserver memort usage spikes repeatedly, even... | Memory usage of apiserver still spikes caused by many watcher terminated after using suggestedWatchChannelSize | https://api.github.com/repos/kubernetes/kubernetes/issues/116903/comments | 4 | 2023-03-24T08:11:28Z | 2024-03-26T20:45:38Z | https://github.com/kubernetes/kubernetes/issues/116903 | 1,638,923,202 | 116,903 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
cri default log-uri is fifo, I create a pr for containerd which support file mode can save some memory
ref : https://github.com/containerd/containerd/pull/8239
### Why is this needed?
I want kubernetes can support logScheme=file
### Here is my test
50 pods, 100 co... | cri support logScheme=file | https://api.github.com/repos/kubernetes/kubernetes/issues/116900/comments | 6 | 2023-03-24T01:47:29Z | 2024-02-17T23:49:18Z | https://github.com/kubernetes/kubernetes/issues/116900 | 1,638,589,544 | 116,900 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When I create 2 deployments with overlapping label selectors; HPA does not scale up to the expected pod count;
I'm targeting 30% CPU usage, but when pods have > 30% CPU scale up does not happen
```
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
...
spec:
scaleTargetRef:
... | Overlapping Deployment matchLabels causes HPA to not scale correctly | https://api.github.com/repos/kubernetes/kubernetes/issues/116898/comments | 8 | 2023-03-23T22:52:35Z | 2024-03-22T12:28:00Z | https://github.com/kubernetes/kubernetes/issues/116898 | 1,638,449,595 | 116,898 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
With a manifest that sets a memory limit for the container it is possible to allocate any size of "rss-file" memory and still run (not get evicted).
This have caused kernel oom-kills on the node. Fortunately, the process itself got oom-killed, but the kernel can pick any process on the node with ... | A K8s POD using mmap(2) can cause oom-kills on the K8s node | https://api.github.com/repos/kubernetes/kubernetes/issues/116895/comments | 29 | 2023-03-23T18:02:05Z | 2024-06-13T09:08:59Z | https://github.com/kubernetes/kubernetes/issues/116895 | 1,638,035,642 | 116,895 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Use case: only have 3 nodes available in cluster, a deployment with pod anti-affinity yaml like this:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
... | Deployment rolling update stucked with pod anti-affinity | https://api.github.com/repos/kubernetes/kubernetes/issues/116891/comments | 5 | 2023-03-23T15:00:16Z | 2023-03-24T03:59:40Z | https://github.com/kubernetes/kubernetes/issues/116891 | 1,637,715,380 | 116,891 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In the 1.27.0.beta.0 cluster, deploy a simple example Pod yaml, but the in-place resource upgrade does not take effect (the pod is still restarted); In addition, manually configuring resizePolicy does not report an error and does not take effect.
Question Details:
I noticed that 1.27.x updates... | Configuring resizePolicy for in-place-pod-vpa has no effect | https://api.github.com/repos/kubernetes/kubernetes/issues/116890/comments | 13 | 2023-03-23T14:43:12Z | 2024-03-18T21:46:03Z | https://github.com/kubernetes/kubernetes/issues/116890 | 1,637,684,629 | 116,890 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
- E2eNode Suite.[It] [sig-node] MirrorPod when create a mirror pod without changes should successfully recreate when file is removed and recreated [NodeConformance]
- pull-kubernetes-node-e2e-containerd.Pod
### Which tests are flaking?
`MirrorPod` at `test/e2e_node/mirror_pod_test.go:18... | flaky tests: E2eNode Suite.[It] [sig-node] MirrorPod when create a mirror pod without changes should successfully recreate when file is removed and recreated | https://api.github.com/repos/kubernetes/kubernetes/issues/116889/comments | 4 | 2023-03-23T12:34:07Z | 2023-03-24T19:44:31Z | https://github.com/kubernetes/kubernetes/issues/116889 | 1,637,459,379 | 116,889 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Add PreBind and Unreserve verbs to scheduling extender. The logics of Bind operation could be moved to the Prebind method of extenders. If there are any problem during the prebind/bind stages, the Unreserve method of successful extenders will be called.
### Why is this needed?
... | support PreBind for scheduling extender | https://api.github.com/repos/kubernetes/kubernetes/issues/116888/comments | 13 | 2023-03-23T11:19:35Z | 2024-02-18T04:54:18Z | https://github.com/kubernetes/kubernetes/issues/116888 | 1,637,327,627 | 116,888 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
volume manager use NestedPendingOperations framework to do attach/mount/detach/ummount operation
if pod use a pv do VerifyControllerAttachedVolume operation failed, and expBackoff.durationBeforeRetry exponent increase until maxDurationBeforeRetry.
then user delete pod,operations didn't delete f... | nestedPendingOperations expbackoff reset policy | https://api.github.com/repos/kubernetes/kubernetes/issues/116886/comments | 8 | 2023-03-23T09:00:01Z | 2025-02-17T14:38:03Z | https://github.com/kubernetes/kubernetes/issues/116886 | 1,637,109,574 | 116,886 |
[
"kubernetes",
"kubernetes"
] | k8s version: 1.19.4
network: flannel
my cluster yesterday for suddenly, is not work.
Access through domain names inside pod,is not work.
But
CoreDns pod is running,not have error log
I find error log by kube-dns service
```
[root@k8s-cluster-master1 ~]# kubectl get svc -n kube-system
NAME TYPE ... | CoreDNS not work | https://api.github.com/repos/kubernetes/kubernetes/issues/116883/comments | 5 | 2023-03-23T07:06:49Z | 2023-03-23T09:56:30Z | https://github.com/kubernetes/kubernetes/issues/116883 | 1,636,969,832 | 116,883 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
As per my knowledge kubernetes automatically scale down or scale up the pods based on hpa conifguration metrics like cpu and memory utilization percentage
### What did you expect to happen?
As per my knowledge kubernetes automatically scale down or scale up the pods based on hpa conifguration metr... | In HPA behaviours is mandatory to scale down the pods in kubernetes | https://api.github.com/repos/kubernetes/kubernetes/issues/116882/comments | 4 | 2023-03-23T05:55:09Z | 2023-04-07T10:31:26Z | https://github.com/kubernetes/kubernetes/issues/116882 | 1,636,897,211 | 116,882 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
if kubelet start with kube-apiserver not ready,during this period,someone remove static pod files,and kube-apiserver recovery,someone update static pod files, move to dir, find kubelet not restart this static pods
### What did you expect to happen?
All static pods should restart.
### How ... | Some static pods fail to start | https://api.github.com/repos/kubernetes/kubernetes/issues/116880/comments | 17 | 2023-03-23T05:20:08Z | 2023-03-28T18:11:15Z | https://github.com/kubernetes/kubernetes/issues/116880 | 1,636,870,026 | 116,880 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
https://testgrid.k8s.io/sig-node-cri-o#ci-crio-cgroupv1-node-e2e-unlabelled&width=20
### Which tests are failing?
E2eNode Suite.[It] [sig-node] Kubelet PodOverhead handling [LinuxOnly] PodOverhead cgroup accounting On running pod with PodOverhead defined Pod cgroup should be sum of overhe... | E2eNode Suite.[It] [sig-node] Kubelet PodOverhead handling [LinuxOnly] PodOverhead cgroup accounting On running pod with PodOverhead defined Pod cgroup should be sum of overhead and resource limits | https://api.github.com/repos/kubernetes/kubernetes/issues/116874/comments | 9 | 2023-03-22T22:19:04Z | 2023-03-24T09:04:26Z | https://github.com/kubernetes/kubernetes/issues/116874 | 1,636,572,006 | 116,874 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
https://testgrid.k8s.io/sig-node-containerd#containerd-e2e-ubuntu not even starting
### Which tests are failing?
Seems like test configuration issue
### Since when has it been failing?
Unknown
### Testgrid link
https://testgrid.k8s.io/sig-node-containerd#containerd-e2e-ubuntu
### Rea... | The test is not starting: https://testgrid.k8s.io/sig-node-containerd#containerd-e2e-ubuntu | https://api.github.com/repos/kubernetes/kubernetes/issues/116873/comments | 13 | 2023-03-22T22:16:49Z | 2023-03-27T01:08:38Z | https://github.com/kubernetes/kubernetes/issues/116873 | 1,636,569,482 | 116,873 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
E2eNode Suite.[It] [sig-node] MirrorPodWithGracePeriod when create a mirror pod and the container runtime is temporarily down during pod termination [NodeConformance] [Serial] [Disruptive] the mirror pod should terminate successfully
https://testgrid.k8s.io/sig-node-release-blocking#nod... | E2eNode Suite.[It] [sig-node] MirrorPodWithGracePeriod when create a mirror pod and the container runtime is temporarily down during pod termination [NodeConformance] [Serial] [Disruptive] the mirror pod should terminate successfully | https://api.github.com/repos/kubernetes/kubernetes/issues/116872/comments | 8 | 2023-03-22T22:14:14Z | 2023-08-16T22:27:54Z | https://github.com/kubernetes/kubernetes/issues/116872 | 1,636,566,675 | 116,872 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Problem statement:
Currently, we don't have a way to define a key into a Secret to be used by volumes.
```
volumes:
- name: NameOfVolume
secret:
secretName: NameOfSecret
```
Using this approach we should create a separate Secret to be used in a volume.... | Deployments with volumes do not have the option to select a key | https://api.github.com/repos/kubernetes/kubernetes/issues/116868/comments | 5 | 2023-03-22T19:30:30Z | 2023-03-27T13:27:27Z | https://github.com/kubernetes/kubernetes/issues/116868 | 1,636,380,484 | 116,868 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm running api test jobs using a cron trigger, which requires use of a fixed tag, e.g. master/main/latest
When running tests which have been recently modified, frequently a stale image is run, which may be several hours old.
I've ruled out the local docker registry since the contents for t... | `imagePullPolicy: Always` may pull stale image based off stale image digest resolution | https://api.github.com/repos/kubernetes/kubernetes/issues/116867/comments | 38 | 2023-03-22T18:48:30Z | 2024-10-05T18:39:28Z | https://github.com/kubernetes/kubernetes/issues/116867 | 1,636,323,645 | 116,867 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
ci-crio-cgroupv1-node-e2e-unlabelled
### Which tests are failing?
On running pod with PodOverhead defined Pod cgroup should be sum of overhead and resource limits
### Since when has it been failing?
I don't see any successes.
### Testgrid link
https://testgrid.k8s.io/sig-node-cri-o#ci... | "On running pod with PodOverhead defined Pod cgroup should be sum of overhead and resource limits" is failing | https://api.github.com/repos/kubernetes/kubernetes/issues/116864/comments | 4 | 2023-03-22T18:18:25Z | 2023-03-22T22:20:59Z | https://github.com/kubernetes/kubernetes/issues/116864 | 1,636,280,353 | 116,864 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Sending a patch built from a typed client to SSA will force a write to etcd (and bump resourceVersion) since creationTimestamp is serialized to null. This is a follow-up of https://github.com/kubernetes/kubernetes/pull/106388 which doesn't solve the issue properly.
### What did you expect to ha... | `creationTimestamp: null` still causes unnecessary etcd-write with SSA | https://api.github.com/repos/kubernetes/kubernetes/issues/116861/comments | 1 | 2023-03-22T16:46:41Z | 2023-04-12T06:18:44Z | https://github.com/kubernetes/kubernetes/issues/116861 | 1,636,146,239 | 116,861 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have a project with 300 pods, however when upgrading using helm it deletes all pods not respecting the rollingupdate defined in deployment.yml
### What did you expect to happen?
Project update respected the rollingupdate not causing downtime
### How can we reproduce it (as minimally and precise... | helm upgrade causing downtime (Manifest yaml) | https://api.github.com/repos/kubernetes/kubernetes/issues/116859/comments | 9 | 2023-03-22T14:23:40Z | 2023-03-27T20:30:35Z | https://github.com/kubernetes/kubernetes/issues/116859 | 1,635,867,789 | 116,859 |
[
"kubernetes",
"kubernetes"
] | /kind cleanup
/kind feature
Tracking Issue: https://github.com/kubernetes/enhancements/issues/3329
This is a follow up work after https://github.com/kubernetes/kubernetes/issues/113855. We work for pods to be in a terminal phase for jobs which use the pod failure policy. We should do the same for pods that don't... | Job controller should wait for Pods to be in a terminal phase before considering them failed or succeeded | https://api.github.com/repos/kubernetes/kubernetes/issues/116858/comments | 16 | 2023-03-22T14:19:42Z | 2024-01-26T11:20:27Z | https://github.com/kubernetes/kubernetes/issues/116858 | 1,635,860,969 | 116,858 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
https://github.com/kubernetes/kubernetes/pull/102884#discussion_r1144672887
The newly added field `ResizePolicy` field is not being validated.
@vinaykul @liggitt
### What did you expect to happen?
`ResizePolicy` field should be validated.
### How can we reproduce it (as minimally and preci... | [InPlacePodVerticalScaling] ResizePolicy field is not being validated | https://api.github.com/repos/kubernetes/kubernetes/issues/116854/comments | 7 | 2023-03-22T12:51:12Z | 2023-03-24T17:42:24Z | https://github.com/kubernetes/kubernetes/issues/116854 | 1,635,708,222 | 116,854 |
[
"kubernetes",
"kubernetes"
] | This is the problematic code: https://github.com/kubernetes/kubernetes/blob/3cf9f66e90d560ac080687610933c712bcf37b39/staging/src/k8s.io/client-go/testing/fixture.go#L184 introduced in https://github.com/kubernetes/kubernetes/pull/113304.
As discussed: https://github.com/kubernetes/kubernetes/pull/113304#discussion_r... | Do not use StrategicMergePatch for mocking server side apply with in unit tests | https://api.github.com/repos/kubernetes/kubernetes/issues/116851/comments | 29 | 2023-03-22T12:32:22Z | 2024-11-19T21:29:08Z | https://github.com/kubernetes/kubernetes/issues/116851 | 1,635,681,390 | 116,851 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I think kubelet sometimes is not able to properly identify unmounted volume and clean up its `actualstateofworld` cache. It thinks the volume is not unmounted and keeps on trying unmounting it. This outputs a lot of logs which flood journalctl -> fluentd/bit -> third party logging solution. The floo... | kubelet fails with `UnmountVolume.NewUnmounter failed for volume` and `vol_data.json: no such file or directory` for CSI volumes and floods the logs | https://api.github.com/repos/kubernetes/kubernetes/issues/116847/comments | 46 | 2023-03-22T11:16:29Z | 2025-03-01T07:43:40Z | https://github.com/kubernetes/kubernetes/issues/116847 | 1,635,561,493 | 116,847 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
If a pod is created and then deleted an entry in processedPods map remains forever (sometimes, it's racy).
The problem comes from the fact that `podWorker` calls volume_manager `WaitForUnmount()` asynchronously. If the last call happens after populator cleaned up resources, an entry is added to p... | Memory leak in kubelet volume_manager populator processedPods | https://api.github.com/repos/kubernetes/kubernetes/issues/116831/comments | 8 | 2023-03-22T03:33:11Z | 2023-04-12T01:20:00Z | https://github.com/kubernetes/kubernetes/issues/116831 | 1,634,999,986 | 116,831 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I created a deployment that looked as follows:
```
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: test
name: test
spec:
replicas: 1
selector:
matchLabels:
app: test
strategy: {}
template:
metadata:
labels:
app: test
spe... | PodAntiAffinity prevents scheduling the only pod with the label in AntiAffinity | https://api.github.com/repos/kubernetes/kubernetes/issues/116827/comments | 4 | 2023-03-22T01:19:52Z | 2023-03-22T15:33:40Z | https://github.com/kubernetes/kubernetes/issues/116827 | 1,634,913,043 | 116,827 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
This is a follow up from: https://github.com/kubernetes/kubernetes/pull/116702#discussion_r1142299413
Update of a Pod for in-place update of Pod Resources feature is constructing the updated pod and may get to the race with other update operations on this Pod.
/sig node
KEP: https://github.c... | In-Place Update of Pod Resources - resizing of pod may race with other pod updates | https://api.github.com/repos/kubernetes/kubernetes/issues/116826/comments | 10 | 2023-03-22T00:55:20Z | 2024-11-04T18:39:04Z | https://github.com/kubernetes/kubernetes/issues/116826 | 1,634,892,725 | 116,826 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Replicaset is not getting deleted, even after deployment is deleted from cluster.
### What did you expect to happen?
Replicaset should be deleted after deployment deletion.
### How can we reproduce it (as minimally and precisely as possible)?
Unable to reproduce.
### Anything else we need to kn... | Relicaset is still running, even after deployment is deleted | https://api.github.com/repos/kubernetes/kubernetes/issues/116804/comments | 7 | 2023-03-21T11:43:37Z | 2023-04-02T21:31:21Z | https://github.com/kubernetes/kubernetes/issues/116804 | 1,633,736,127 | 116,804 |
[
"kubernetes",
"kubernetes"
] | ### Summary
**checked means `EOL`**
- [x] 3.10, Current System Validator check
- [x] 3.16, Namespaced IP Local Reserved Ports (safe-sysctl)
- [x] 3.18, containerd suggestion when using btrfs.(containerd, btrfs)
- [x] 4.x, containerd suggested min kernel version (containerd, core code and snapshotters)
- [x] 4.1,... | Minimal kernel version plan: probably 4.18/4.19+ | https://api.github.com/repos/kubernetes/kubernetes/issues/116799/comments | 23 | 2023-03-21T09:28:49Z | 2025-01-14T07:25:53Z | https://github.com/kubernetes/kubernetes/issues/116799 | 1,633,517,140 | 116,799 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [307b1af57d23ab80fbc6](https://go.k8s.io/triage#307b1af57d23ab80fbc6)
##### Error text:
```
[FAILED] error waiting for image to be pulled: timed out waiting for the condition
In [SynchronizedBeforeSuite] at: test/e2e/e2e.go:433 @ 03/14/23 00:34:48.279
```
#### Recent failures:
[2023/3/21 ... | Failure cluster [307b1af5...] timed out waiting for daemonset.CheckPresentOnNodes for agnhost:2.43 | https://api.github.com/repos/kubernetes/kubernetes/issues/116791/comments | 7 | 2023-03-21T06:01:53Z | 2023-03-23T02:53:47Z | https://github.com/kubernetes/kubernetes/issues/116791 | 1,633,281,730 | 116,791 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
E0320 18:35:17.623064 4656 safe_sysctls.go:43] "Failed to get kernel version." err="error reading osrelease file \"/proc/sys/kernel/osrelease\": open /proc/sys/kernel/osrelease: The system cannot find the path specified."
### What did you expect to happen?
handle windows node correctly.
### ... | safe-sysctls check on windows failed | https://api.github.com/repos/kubernetes/kubernetes/issues/116790/comments | 4 | 2023-03-21T04:46:42Z | 2023-03-22T00:40:02Z | https://github.com/kubernetes/kubernetes/issues/116790 | 1,633,215,265 | 116,790 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [b93b9378959634b16aeb](https://go.k8s.io/triage#b93b9378959634b16aeb)
##### Error text:
```
Failed
=== RUN TestLazyThroughput
lazy_test.go:105: total wait was: 3.145007079s; par would be ~1s
--- FAIL: TestLazyThroughput (2.70s)
```
#### Recent failures:
[2023/3/21 04:42:32 ci-kube... | [Failure-test] TestLazyThroughput: total wait was: 3.145007079s; par would be ~1s | https://api.github.com/repos/kubernetes/kubernetes/issues/116789/comments | 7 | 2023-03-21T04:28:30Z | 2023-03-23T03:54:14Z | https://github.com/kubernetes/kubernetes/issues/116789 | 1,633,204,011 | 116,789 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [c13cec55d92289cb04ba](https://go.k8s.io/triage#c13cec55d92289cb04ba)
https://testgrid.k8s.io/sig-autoscaling-vpa#autoscaling-vpa-full
Top flake for this grid
1. OOMing pods under VPA have memory requests growing with OOMs
2. Pods under VPA have cpu requests growing with usage
##### Error t... | [Flaky] autoscaling-vpa-full: OOMing pods under VPA have memory requests growing with OOMs | https://api.github.com/repos/kubernetes/kubernetes/issues/116787/comments | 6 | 2023-03-21T03:37:28Z | 2023-07-24T10:23:04Z | https://github.com/kubernetes/kubernetes/issues/116787 | 1,633,169,842 | 116,787 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When a --resolv-conf (DNS resolver config) is passed to kubelet on a Windows node, the config content is used as part of sandbox initialization (through getHostDNSConfig()). Now with the recent changes ([here](https://github.com/kubernetes/kubernetes/commit/f335812719cfa5d5fb235320fb63af3669ffdcb1... | Sandboxes creation fails with "Unexpected resolver config value" if resolverConfig != "Host" - Windows | https://api.github.com/repos/kubernetes/kubernetes/issues/116782/comments | 13 | 2023-03-21T00:14:08Z | 2023-03-22T16:19:23Z | https://github.com/kubernetes/kubernetes/issues/116782 | 1,633,048,343 | 116,782 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
[sig-release-master-blocking#ci-kubernetes-unit](https://k8s-testgrid.appspot.com/sig-release-master-blocking#ci-kubernetes-unit)
### Which tests are flaking?
k8s.io/kubernetes/pkg/controller/volume/attachdetach/reconciler: Test_Run_OneVolumeDetachFailNodeWithReadWriteOnce
### Since whe... | [Flaking test] sig-release-master-blocking ci-kubernetes-unit | https://api.github.com/repos/kubernetes/kubernetes/issues/116774/comments | 4 | 2023-03-20T18:26:02Z | 2023-03-20T20:02:29Z | https://github.com/kubernetes/kubernetes/issues/116774 | 1,632,652,088 | 116,774 |
[
"kubernetes",
"kubernetes"
] | /kind cleanup
/kind documentation
/sig scheduling
/sig node
/sig apps
The ownership of controller/nodelifecycle is unclear.
The [OWNERS file of pkg/controller/nodelifecycle](https://github.com/kubernetes/kubernetes/blob/15894cfc85cab64df081bb753b8ccf32a243da68/pkg/controller/nodelifecycle/OWNERS) currently ... | Define ownership of controller/nodelifecycle | https://api.github.com/repos/kubernetes/kubernetes/issues/116771/comments | 8 | 2023-03-20T17:36:51Z | 2023-04-17T21:10:59Z | https://github.com/kubernetes/kubernetes/issues/116771 | 1,632,575,236 | 116,771 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
On a few instances we are observing the readiness probes fail with following error,
```
"2023-02-25T06:59:57Z" level=error msg="exec failed: unable to start container process: error adding pid 20296 to cgroups: failed to write 20296: open /sys/fs/cgroup/systemd/kubepods.slice/kubepods-burstable... | Readiness probe fails because no cgroup scope found | https://api.github.com/repos/kubernetes/kubernetes/issues/116766/comments | 7 | 2023-03-20T16:31:20Z | 2024-08-18T19:45:25Z | https://github.com/kubernetes/kubernetes/issues/116766 | 1,632,473,995 | 116,766 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
During OPNFV test execution we noticed the `/tmp` folder selinux context changed.
```
# launch the container
podman run -it --env-file ~/opnfv/env \
-v ~/opnfv/ca.pem:/home/opnfv/functest/ca.pem:Z \
-v ~/opnfv/config:/root/.kube/config:Z \
-v ~/opnfv/results:/home/opnfv/functest/results:Z ... | Executing TC from "sig_storage_serial" TC set change the selinux context of /tmp folder on selinux enabled K8S cluster | https://api.github.com/repos/kubernetes/kubernetes/issues/116764/comments | 7 | 2023-03-20T15:53:55Z | 2023-07-13T20:43:23Z | https://github.com/kubernetes/kubernetes/issues/116764 | 1,632,401,542 | 116,764 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
while the docs does tell about not setting these values
https://kubernetes.io/docs/concepts/workloads/pods/init-containers/#differences-from-regular-containers
`kubectl explain pod.spec.initContainers` shows all the fields you can set in `initContainers` section of the pod.
so i tried it anyw... | readinessProbe for initContainer can not be set . but kubectl explain says its possible | https://api.github.com/repos/kubernetes/kubernetes/issues/116760/comments | 22 | 2023-03-20T15:27:06Z | 2025-01-14T22:41:14Z | https://github.com/kubernetes/kubernetes/issues/116760 | 1,632,349,247 | 116,760 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I followed https://kubernetes.io/blog/2021/09/03/api-server-tracing/, activated the feature gate APIServerTracing and added --tracing-config-file.
My cluster is running kuberntes 1.25.3
Whenver I add `--tracing-config-file=<path-to-file>` in `/etc/kubernetes/manifests/kube-apiserver.yaml`, ku... | --tracing-config-file breaks apiserver | https://api.github.com/repos/kubernetes/kubernetes/issues/116758/comments | 7 | 2023-03-20T15:17:50Z | 2023-05-11T13:43:11Z | https://github.com/kubernetes/kubernetes/issues/116758 | 1,632,327,948 | 116,758 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
https://kubernetes.slack.com/archives/C09R23FHP/p1679047761267959
A pod does not respect `terminationGracePeriodSeconds` if the `preStop` hook does not complete.
### What did you expect to happen?
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#pod-termination
The pod s... | A pod does not respect `terminationGracePeriodSeconds` if the `preStop` hook does not complete. | https://api.github.com/repos/kubernetes/kubernetes/issues/116753/comments | 5 | 2023-03-20T12:10:54Z | 2023-03-20T13:16:09Z | https://github.com/kubernetes/kubernetes/issues/116753 | 1,631,983,286 | 116,753 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Extend the kubectl help output with a dynamic section on user-installed plugins, e.g.:
```
User-Installed Plugin Commands:
convert The command convert is a plugin installed by the user
krew The command krew is a plugin installed by the user
```
### Why ... | Enhance discoverability of user-installed plugins | https://api.github.com/repos/kubernetes/kubernetes/issues/116751/comments | 4 | 2023-03-20T11:29:02Z | 2023-09-06T16:12:54Z | https://github.com/kubernetes/kubernetes/issues/116751 | 1,631,917,880 | 116,751 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When I cerate a service which already exist,I got 422 and error message `The Service "my-service" is invalid: spec.ports[0].nodePort: Invalid value: 30123: provided port is already allocated`.
### What did you expect to happen?
I hope to get HTTP code 409 which means resource is already existed.
... | Trying to create an object that already exists can fail with non "AlreadyExists" errors (e.g. validation) | https://api.github.com/repos/kubernetes/kubernetes/issues/116747/comments | 10 | 2023-03-20T08:43:12Z | 2023-03-28T20:33:45Z | https://github.com/kubernetes/kubernetes/issues/116747 | 1,631,643,295 | 116,747 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
During fuzz testing of Kubernetes, I discovered a crash, which I believe might be an issue. this issue is in the code located at kubernetes/staging/src/k8s.io/apimachinery/pkg/api/resource/quantity_proto.go on lines 239, 255, 266, and 270.
Code Snippet
 to checkpoint some containers and restore them in other nodes .
First i create the container using [this counter image](quay.io/adrianreber/counter:blog) with this yaml configuration... | "Error: no command specified" when restating a container checkpointed by kubelet checkpoint api | https://api.github.com/repos/kubernetes/kubernetes/issues/116744/comments | 10 | 2023-03-20T00:10:01Z | 2023-03-21T15:36:47Z | https://github.com/kubernetes/kubernetes/issues/116744 | 1,631,175,024 | 116,744 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
worker node is not being able to connect to the master node
...............................................................................................................................................................................................................
[root@worker ~]# kubeadm ... | creating a cluster with aws ec2 instances . while connecting worker node to master node getting an error. | https://api.github.com/repos/kubernetes/kubernetes/issues/116740/comments | 4 | 2023-03-19T09:09:54Z | 2023-03-19T11:48:46Z | https://github.com/kubernetes/kubernetes/issues/116740 | 1,630,849,403 | 116,740 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I am trying to learn k8s and following along in the official tutorials
https://kubernetes.io/docs/tutorials/kubernetes-basics/expose/expose-interactive/
Why is the endpoint empty? The tutorial says that
> We have now a running Service called kubernetes-bootcamp. Here we see
> that the Servic... | If it is "Not-Applicable" for external IP point to have a value, then `kubectl get services` should display 'N/A' instead of '<none>' | https://api.github.com/repos/kubernetes/kubernetes/issues/116734/comments | 7 | 2023-03-18T15:52:36Z | 2023-03-30T19:04:23Z | https://github.com/kubernetes/kubernetes/issues/116734 | 1,630,382,805 | 116,734 |
[
"kubernetes",
"kubernetes"
] | After searching, k8s can provide the poststart field to control the container field. But if there are more than two containers in the pod and there are order dependencies, the processing will become more complicated. Therefore, would like to ask whether there is a need to provide a field to guarantee the order of pods. | Why is there no field to control the order of containers in the pod of k8s? | https://api.github.com/repos/kubernetes/kubernetes/issues/116733/comments | 12 | 2023-03-18T14:50:45Z | 2023-03-29T11:09:07Z | https://github.com/kubernetes/kubernetes/issues/116733 | 1,630,356,994 | 116,733 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
use `sets.Set` instead of `map[xxx]struct{}` to improve code readability.
```bash
# grep -rn -e 'map\[.*struct{}' pkg/controller/*
pkg/controller/certificates/authority/policies.go:149: extKeyUsages := make(map[x509.ExtKeyUsage]struct{})
pkg/controller/deployment/deploymen... | use `sets.Set` instead of `map[xxx]struct{}` | https://api.github.com/repos/kubernetes/kubernetes/issues/116731/comments | 13 | 2023-03-18T13:58:59Z | 2024-03-22T22:31:57Z | https://github.com/kubernetes/kubernetes/issues/116731 | 1,630,336,839 | 116,731 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When `enable-aggregator-routing` is set to true, the routing specifically requires `Endpoint` objects, not `EndpointSlice` objects.
This issue serves as a placeholder/anchor for discussion of whether that is desirable, or should be changed to add suport for EndpointSlices. (Like other code paths... | APIServer Aggregator only uses Endpoints not EndpointSlices | https://api.github.com/repos/kubernetes/kubernetes/issues/116727/comments | 11 | 2023-03-17T22:07:34Z | 2024-07-18T20:18:30Z | https://github.com/kubernetes/kubernetes/issues/116727 | 1,629,973,225 | 116,727 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In the debugging of the [mirror pod test](https://github.com/kubernetes/kubernetes/blob/6b9a381/test/e2e_node/mirror_pod_test.go#L155-L199) as part https://github.com/kubernetes/kubernetes/pull/115331 test `should successfully recreate when file is removed and recreated [NodeConformance]`, we fou... | Investigate if mirror pod spec updates are propagated correctly on static pod manifest recreates | https://api.github.com/repos/kubernetes/kubernetes/issues/116725/comments | 12 | 2023-03-17T19:42:13Z | 2024-08-18T22:48:26Z | https://github.com/kubernetes/kubernetes/issues/116725 | 1,629,852,165 | 116,725 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Make sure handlers have finished syncing before the scheduling cycles start.
Ref: https://github.com/kubernetes/kubernetes/issues/113763#issuecomment-1472858978
/sig scheduling
/good-first-issue
### Why is this needed?
In a highly used cluster, we don't want to start sched... | Scheduler: Make sure handlers have synced before scheduling | https://api.github.com/repos/kubernetes/kubernetes/issues/116717/comments | 15 | 2023-03-17T12:54:00Z | 2023-06-28T08:26:34Z | https://github.com/kubernetes/kubernetes/issues/116717 | 1,629,266,424 | 116,717 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I want to build 1.26 Kubernetes in my fedora linux, but get this error:
```
$ sudo -E ./hack/local-up-cluster.sh
make: Entering directory '/home/fedora/go/src/k8s.io/kubernetes'
go version go1.19.7 linux/amd64
+++ [0314 09:56:23] Building go targets for linux/amd64
k8s.io/kubernetes/cmd/... | Unable to build local cluster | https://api.github.com/repos/kubernetes/kubernetes/issues/116716/comments | 10 | 2023-03-17T12:06:50Z | 2023-07-12T05:51:54Z | https://github.com/kubernetes/kubernetes/issues/116716 | 1,629,202,226 | 116,716 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The following log line is often (~30times) logged during our tests in `pull-kubernetes-node-e2e-containerd`:
`"Programmer error, did not report a kubelet_working_pods metric for a value returned by SyncKnownPods" counts=map[{State:sync Orphan:false HasConfig:false Static:false}:1]`.
This suggest... | "Programmer error" is logged often during tests [kubelet_working_pods metric, SyncKnownPods] | https://api.github.com/repos/kubernetes/kubernetes/issues/116715/comments | 9 | 2023-03-17T11:56:52Z | 2023-04-12T02:17:39Z | https://github.com/kubernetes/kubernetes/issues/116715 | 1,629,185,421 | 116,715 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
https://testgrid.k8s.io/presubmits-kubernetes-blocking#pull-kubernetes-node-e2e-containerd
### Which tests are flaking?
`MirrorPod when create a mirror pod without changes should successfully recreate when file is removed and recreated [NodeConformance]`
### Since when has it bee... | Static pod recreation e2e node test if flaky | https://api.github.com/repos/kubernetes/kubernetes/issues/116714/comments | 7 | 2023-03-17T11:37:54Z | 2023-12-01T02:30:09Z | https://github.com/kubernetes/kubernetes/issues/116714 | 1,629,162,414 | 116,714 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
**I hope able to add command arguments to give the list of nodes that do not meet the tag/memory /CPU.**
--------------------------------------------------------------------------------------------------
Age From Message
---- ------ ---- ... | pod describes events Message more detail | https://api.github.com/repos/kubernetes/kubernetes/issues/116713/comments | 5 | 2023-03-17T11:35:38Z | 2023-03-22T13:51:07Z | https://github.com/kubernetes/kubernetes/issues/116713 | 1,629,159,856 | 116,713 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I noticed that all the old `apimachinery/pkg/util/wait` `Poll…` functions have been deprecated, pointing to `PollWithContextTimeout`; but that function doesn’t exist, and doesn’t appear in https://github.com/kubernetes/kubernetes/pull/107826 which introduced the change.
### What did you expect to h... | poll deprecation notices point to non-existent PollWithContextTimeout | https://api.github.com/repos/kubernetes/kubernetes/issues/116712/comments | 10 | 2023-03-17T10:33:49Z | 2023-05-26T08:07:34Z | https://github.com/kubernetes/kubernetes/issues/116712 | 1,629,076,733 | 116,712 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
In the current field there are comments like.
```go
// TODO enabled it when https://github.com/kubernetes/kubernetes/issues/28486 has been fixed
// Optional number of failed pods to retain.
// +optional
// FailedPodsLimit *int32 `json:"failedPodsLimit,omitempty" protobuf:"v... | FailedPodsLimit field discussion in Cronjob | https://api.github.com/repos/kubernetes/kubernetes/issues/116711/comments | 4 | 2023-03-17T10:08:25Z | 2023-07-16T01:34:21Z | https://github.com/kubernetes/kubernetes/issues/116711 | 1,629,041,651 | 116,711 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I noticed that kube-controller-manager is consuming visible amount of CPU in completely idle 5k node cluster (~7 cores/s) while for comparison kube-apiserver was using much less that time.
I fetched pprof and noticed that we are burning significant in metrics.(*attachDetachStateCollector).Collect... | High cpu usage of metrics.(*attachDetachStateCollector).Collect | https://api.github.com/repos/kubernetes/kubernetes/issues/116710/comments | 4 | 2023-03-17T09:57:38Z | 2023-06-15T13:50:23Z | https://github.com/kubernetes/kubernetes/issues/116710 | 1,629,023,839 | 116,710 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
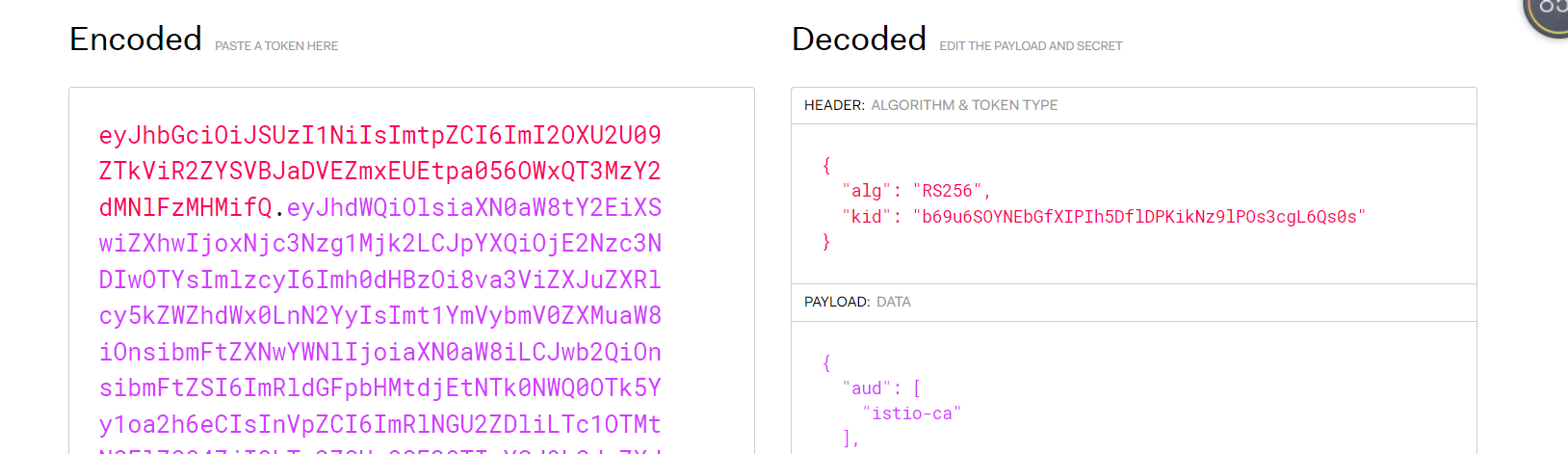
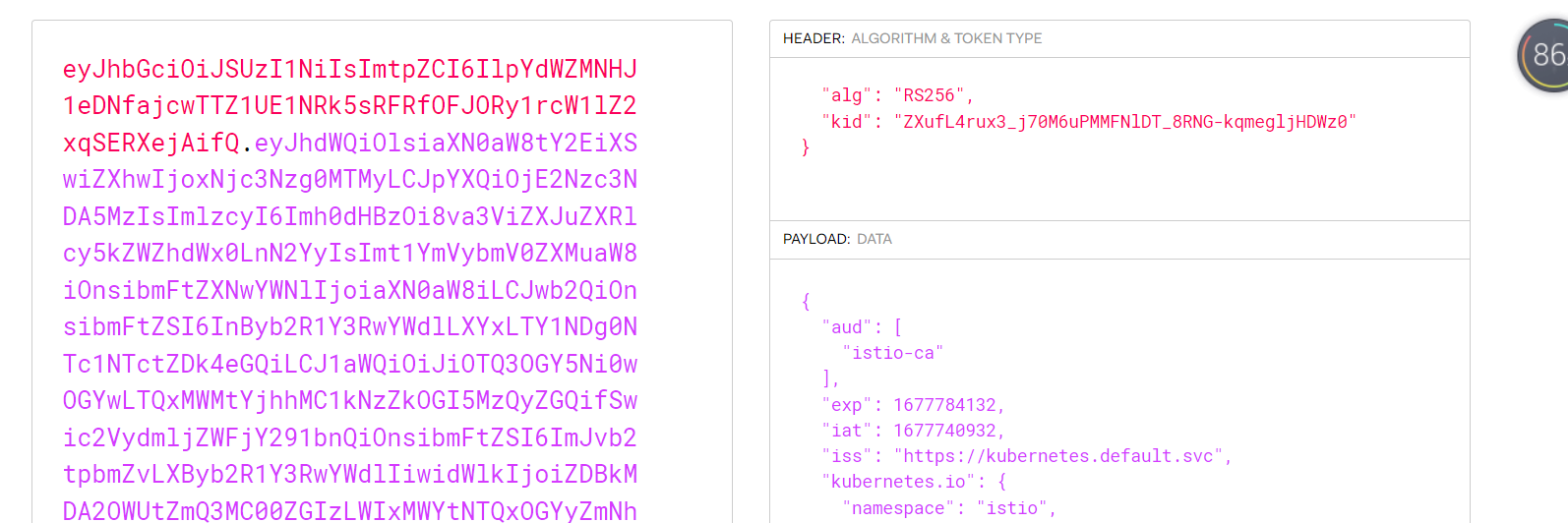
I compared the token from test sa to istio sa,the istio-token kid is the s... | k8s1.26.1,istio1.17.1 generate istio-token using kube-root-ca.crt not istio-ca-root-cert causing multicluster can not communicate | https://api.github.com/repos/kubernetes/kubernetes/issues/116704/comments | 10 | 2023-03-17T05:03:20Z | 2023-03-20T12:41:03Z | https://github.com/kubernetes/kubernetes/issues/116704 | 1,628,696,038 | 116,704 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
master-blocking
- verify-master
### Which tests are failing?
`verify.openapi-spec`
### Since when has it been failing?
03-17 06:33 IST
### Testgrid link
https://testgrid.k8s.io/sig-release-master-blocking#verify-master
### Reason for failure (if possible)
```
{Script Error Scrip... | [Failing Test] verify-master | https://api.github.com/repos/kubernetes/kubernetes/issues/116703/comments | 2 | 2023-03-17T04:25:50Z | 2023-04-20T17:00:28Z | https://github.com/kubernetes/kubernetes/issues/116703 | 1,628,668,933 | 116,703 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
I use fake client to create and modify simulated resources.When the amount of data is large and changes frequently, it will cause the program to panic.
<img width="1307" alt="image" src="https://user-images.githubusercontent.com/50443671/225799808-7fe7356a-94ad-4263-a14a-d815c... | The program panics with "channel full" when I frequently change resources using fake client | https://api.github.com/repos/kubernetes/kubernetes/issues/116700/comments | 8 | 2023-03-17T02:48:37Z | 2025-02-06T21:27:13Z | https://github.com/kubernetes/kubernetes/issues/116700 | 1,628,597,477 | 116,700 |
[
"kubernetes",
"kubernetes"
] | What is the relationship between HPA/VPA and K8s-scheduler?
I’m wondering that if a HPA(horizontal pod auto-scaler) or VPA(vertical pod auto-scaler) works, how does these two component call and interact with K8s-scheduler?
I think it is a little intricated, If the dependency between HPA/VPA and scheduler is diffi... | What is the relationship between HPA/VPA and K8s-scheduler? | https://api.github.com/repos/kubernetes/kubernetes/issues/116699/comments | 10 | 2023-03-17T01:38:54Z | 2023-03-28T16:37:59Z | https://github.com/kubernetes/kubernetes/issues/116699 | 1,628,547,491 | 116,699 |
[
"kubernetes",
"kubernetes"
] | I want to ask if I change the CPU and memory size of a Pod at runtime, will it be detected by kubelet and forced to return to the set limit and request?
That is, if I set the both of CPU limit and request to 1000m, and I change pod’s CPU resource to 500m through cgroup at runtime, will this be forced back to 1000m b... | What will happen if I adjust hte cgroup parameter when the pod has been assigned to a resource request/limit | https://api.github.com/repos/kubernetes/kubernetes/issues/116698/comments | 8 | 2023-03-17T01:38:01Z | 2024-01-20T12:12:52Z | https://github.com/kubernetes/kubernetes/issues/116698 | 1,628,546,919 | 116,698 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Everything works fine for windows isolation mode pods in kubernetes.But for windows hyperv isolation mode pods, they have no pod ip and keeps restarting.
below is what I got from "kubelet get pod -o wide", we can see that in IP column is "<none>". And it keeps restarting and have restarted 51 time... | windows pod error while adding to cni network: error while ProvisionEndpoint: Cannot create a file when that file already exists. | https://api.github.com/repos/kubernetes/kubernetes/issues/116697/comments | 11 | 2023-03-17T01:06:25Z | 2024-03-19T20:56:06Z | https://github.com/kubernetes/kubernetes/issues/116697 | 1,628,525,126 | 116,697 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
pull-kubernetes-unit, see example failure in https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/116554/pull-kubernetes-unit/1636476265563164672
```
{Failed === RUN TestHollowNode/kubelet
hollow_node_test.go:82: read 290, err=<nil>
I0316 21:26:45.874715 42015 hollow_n... | Race in kubemark TestHollowNode/kubelet | https://api.github.com/repos/kubernetes/kubernetes/issues/116696/comments | 13 | 2023-03-17T00:49:52Z | 2023-03-17T15:41:29Z | https://github.com/kubernetes/kubernetes/issues/116696 | 1,628,513,972 | 116,696 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
https://github.com/kubernetes/kubernetes/blob/76d351065e504e23b7962158ef0e9067b6bd96ed/pkg/kubelet/kubelet.go#L2682
mutates the pod object in place (vs creating a copy first). That's illegal and can cause data races or potentially panics (the panic is unlikely here but I can't rule it out).
... | Mutation of a cached object in kubelet through in place resizing of pods | https://api.github.com/repos/kubernetes/kubernetes/issues/116694/comments | 6 | 2023-03-16T23:09:54Z | 2023-03-22T02:26:38Z | https://github.com/kubernetes/kubernetes/issues/116694 | 1,628,446,824 | 116,694 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
https://testgrid.k8s.io/sig-windows-signal#windows-unit-master
### Which tests are flaking?
k8s.io/kubernetes/pkg/controller/volume/attachdetach/reconciler.Test_Run_OneVolumeDetachFailNodeWithReadWriteOnce
### Since when has it been flaking?
Uknown
### Testgrid link
https://testgrid.k... | Windows unit test flake: reconciler.Test_Run_OneVolumeDetachFailNodeWithReadWriteOnce | https://api.github.com/repos/kubernetes/kubernetes/issues/116693/comments | 3 | 2023-03-16T22:09:16Z | 2023-05-24T02:21:34Z | https://github.com/kubernetes/kubernetes/issues/116693 | 1,628,367,621 | 116,693 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
https://testgrid.k8s.io/sig-windows-signal#windows-unit-master
### Which tests are flaking?
```
k8s.io/kubernetes/pkg/kubelet/stats.Test_criStatsProvider_listContainerNetworkStats/multiple_endpoints_per_container
```
### Since when has it been flaking?
Uknown
### Testgrid link
https... | Windows unit test flake: Test_criStatsProvider_listContainerNetworkStats/multiple_endpoints_per_container | https://api.github.com/repos/kubernetes/kubernetes/issues/116692/comments | 5 | 2023-03-16T22:07:14Z | 2024-01-19T21:04:58Z | https://github.com/kubernetes/kubernetes/issues/116692 | 1,628,365,075 | 116,692 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.