
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | see https://github.com/cilium/cilium/issues/9207
* A pod listens on port N, on both TCP and UDP.
* A service forwards to port N, *only* TCP.
* Accessing the service via UDP should fail. | e2e needed: Service port on other protocol should fail | https://api.github.com/repos/kubernetes/kubernetes/issues/116314/comments | 3 | 2023-03-06T23:01:53Z | 2023-03-08T19:27:14Z | https://github.com/kubernetes/kubernetes/issues/116314 | 1,612,364,110 | 116,314 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Created a CRD and tried changing its `/scale` subresource by patching the subresource, rather than through the top-level resource.
When merge patching /scale, there is a silent failure with a scary log on the apiserver backend, but the object is updated with incorrect managed fields.
When a... | Error when patching Scale subresource of CRD (silent error when merge patching) | https://api.github.com/repos/kubernetes/kubernetes/issues/116311/comments | 5 | 2023-03-06T21:12:59Z | 2024-03-26T20:10:22Z | https://github.com/kubernetes/kubernetes/issues/116311 | 1,612,213,592 | 116,311 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When a new pod is admitted to the Kubelet, it is compared to all other "active" pods. Active pods are the set of pods that have been observed from a config set, minus those that have already failed admission or are in a terminal phase (as the Kubelet sees it). This check is performed by `Kubelet... | Static pod resources are double counted in kubelet admission because mirror pods are not excluded | https://api.github.com/repos/kubernetes/kubernetes/issues/116310/comments | 4 | 2023-03-06T17:53:55Z | 2023-03-10T20:46:04Z | https://github.com/kubernetes/kubernetes/issues/116310 | 1,611,938,263 | 116,310 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I believe I've come across an edge case in evictions which can cause job pods to be evicted and replaced even though they complete without error.
Here's the scenario:
- Create a job with `completions` and `parallelism` both set to 3.
- Add a PodDisruptionBudget in place for this job's pods, w... | Edge case - job pods nearing completion being evicted even though protected by PodDisruptionBudget | https://api.github.com/repos/kubernetes/kubernetes/issues/116308/comments | 8 | 2023-03-06T16:16:05Z | 2023-04-12T07:45:12Z | https://github.com/kubernetes/kubernetes/issues/116308 | 1,611,771,443 | 116,308 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
pull-kubernetes-integration
https://storage.googleapis.com/k8s-triage/index.html?pr=1&test=TestChangeCRD
https://storage.googleapis.com/k8s-triage/index.html?pr=1&text=OpenAPI%20config%20must%20not%20be%20nil
### Which tests are flaking?
TestChangeCRD
### Since when has it ... | [Flake] "OpenAPI config must not be nil" flake in k8s.io/kubernetes/test/integration/apiserver tests | https://api.github.com/repos/kubernetes/kubernetes/issues/116304/comments | 7 | 2023-03-06T15:17:23Z | 2023-04-20T16:59:39Z | https://github.com/kubernetes/kubernetes/issues/116304 | 1,611,646,083 | 116,304 |
[
"kubernetes",
"kubernetes"
] | Currently there is no way to control/configure topology hints expect using Topology Aware Hints with annotation `service.kubernetes.io/topology-aware-hints: auto`.
From my limited experience with this feature, it just doesn't work, I had a very simple setup, 3 pods each in different AZ, service with topology-aware-hin... | de-deprecate Topology-aware traffic routing with topology keys | https://api.github.com/repos/kubernetes/kubernetes/issues/116300/comments | 7 | 2023-03-06T13:56:40Z | 2023-03-08T21:27:31Z | https://github.com/kubernetes/kubernetes/issues/116300 | 1,611,484,250 | 116,300 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Running the below CNNT/OPNFV test failed:
```
podman run -it --env-file ~/opnfv/env \
-v ~/opnfv/ca.pem:/home/opnfv/functest/ca.pem:Z \
-v ~/opnfv/config:/root/.kube/config:Z \
-v ~/opnfv/results:/home/opnfv/functest/results:Z \
-v ~/opnfv/repositories.yml:/home/opnfv/functest/repositories... | Running opnfv/functest-kubernetes-cnf:v1.23 cnf_testsuite failed | https://api.github.com/repos/kubernetes/kubernetes/issues/116295/comments | 6 | 2023-03-06T10:36:40Z | 2023-03-10T00:58:28Z | https://github.com/kubernetes/kubernetes/issues/116295 | 1,611,118,358 | 116,295 |
[
"kubernetes",
"kubernetes"
] | The test is flaking:
https://storage.googleapis.com/k8s-triage/index.html?pr=1&test=k8s.io%2Fapiserver%2Fpkg%2Fstorage%2Fcacher
/assign @p0lyn0mial
/sig api-machinery
/priority important-soon | TestGetCurrentResourceVersionFromStorage is flaky | https://api.github.com/repos/kubernetes/kubernetes/issues/116292/comments | 2 | 2023-03-06T07:28:46Z | 2023-04-20T16:59:35Z | https://github.com/kubernetes/kubernetes/issues/116292 | 1,610,828,149 | 116,292 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Kubernetes apiserver reported an *error*:
```
kube-apiserver: W0306 09:03:23.593207 1202 watcher.go:229] watch chan error: etcdserver: mvcc: required revision has been compacted
```
### What did you expect to happen?
The component version should not have this error when matching.
... | kube-apiserver: watch chan error: etcdserver: mvcc: required revision has been compacted | https://api.github.com/repos/kubernetes/kubernetes/issues/116289/comments | 5 | 2023-03-06T02:09:01Z | 2023-03-06T10:02:37Z | https://github.com/kubernetes/kubernetes/issues/116289 | 1,610,518,935 | 116,289 |
[
"kubernetes",
"kubernetes"
] | I'm a bit confused about the purpose of having more than one go.mod in a staging project/folder:
Here is a list:
```console
$ ag -ig "go.mod" staging | sort
staging/src/k8s.io/api/go.mod
staging/src/k8s.io/apiextensions-apiserver/go.mod
staging/src/k8s.io/apimachinery/go.mod
staging/src/k8s.io/apiserver/go.m... | [question] one staging folder has more than one go.mod | https://api.github.com/repos/kubernetes/kubernetes/issues/116288/comments | 6 | 2023-03-06T01:54:36Z | 2023-03-06T02:25:33Z | https://github.com/kubernetes/kubernetes/issues/116288 | 1,610,508,182 | 116,288 |
[
"kubernetes",
"kubernetes"
] | The EndpointSlice API says
https://github.com/kubernetes/kubernetes/blob/fafa45d13c21dcf99801631413fc58e9cf91226c/pkg/apis/discovery/types.go#L111-L116
and it works as expected in normal circumstances
```
apiVersion: v1
kind: Pod
metadata:
name: terminating
labels:
app: MyApp
spec:
terminatio... | Service publishNotReadyAddresses and EndpointSlices Conditions | https://api.github.com/repos/kubernetes/kubernetes/issues/116285/comments | 14 | 2023-03-05T22:27:50Z | 2023-09-01T18:15:57Z | https://github.com/kubernetes/kubernetes/issues/116285 | 1,610,392,695 | 116,285 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The k8s volume/pv cannot be mounted into the pod. I used the created static pv to mount to nginxpod, and mounted different pvs respectively. But only confPV is successfully mounted to the pod. I tried to mount only html, and found that it cannot be mounted using hostpath. Tried different permissions... | K8s volume/pv cannot be mounted in pod | https://api.github.com/repos/kubernetes/kubernetes/issues/116278/comments | 9 | 2023-03-05T14:17:54Z | 2023-07-13T13:23:47Z | https://github.com/kubernetes/kubernetes/issues/116278 | 1,610,218,581 | 116,278 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
It is not a bug.. so I put it in this category.
I would like to see the checksum files are provided separately for the Kubernetes cli
https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.26.md#client-binaries
Then you can use programs to compare the bi... | Provide the checksum files separately for kubernetes cli | https://api.github.com/repos/kubernetes/kubernetes/issues/116268/comments | 13 | 2023-03-04T01:51:15Z | 2023-09-12T02:30:43Z | https://github.com/kubernetes/kubernetes/issues/116268 | 1,609,534,274 | 116,268 |
[
"kubernetes",
"kubernetes"
] | 1. Start a standalone kubelet (not registered to an API server)
2. Manager construction short-circuits `Start()` here:
https://github.com/kubernetes/kubernetes/blob/253ab3eda71f250ad6692bb16f035cebaf0651c9/pkg/kubelet/status/status_manager.go#L186-L192
3. VPA state is never initialized here:
https://github.... | VPA panics in standalone kubelets | https://api.github.com/repos/kubernetes/kubernetes/issues/116262/comments | 28 | 2023-03-03T20:54:05Z | 2023-03-15T02:27:01Z | https://github.com/kubernetes/kubernetes/issues/116262 | 1,609,236,055 | 116,262 |
[
"kubernetes",
"kubernetes"
] | Similar to #114511
Table-driven tests are awesome, but they can be very verbose and obscure what's actually being tested in each case.
I started on cleaning up staging/src/k8s.io/cloud-provider/controllers/service/controller_test.go, but I only did two tests - there are more. This is a good opportunity for someo... | test cleanup needed: cloud-provider/controllers/service/controller_test.go | https://api.github.com/repos/kubernetes/kubernetes/issues/116260/comments | 9 | 2023-03-03T20:09:06Z | 2023-04-25T03:58:25Z | https://github.com/kubernetes/kubernetes/issues/116260 | 1,609,186,593 | 116,260 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm trying to work with [Gateway API](https://github.com/kubernetes-sigs/gateway-api/) fake objects by doing the following:
```
package x
import (
"testing"
"github.com/stretchr/testify/require"
"k8s.io/client-go/kubernetes/fake"
clientsetscheme "k8s.io/client-go/kubernetes/scheme"
... | Cannot use client-go's fake client with Gateway API objects | https://api.github.com/repos/kubernetes/kubernetes/issues/116253/comments | 16 | 2023-03-03T13:41:09Z | 2024-10-24T11:23:48Z | https://github.com/kubernetes/kubernetes/issues/116253 | 1,608,662,275 | 116,253 |
[
"kubernetes",
"kubernetes"
] | As a requirement, we need to keep track of resources created on remote OCP cluster from local ocp cluster..so need to understand if thats possible. | Need assistance for watching resources on remote OCP cluster. | https://api.github.com/repos/kubernetes/kubernetes/issues/116250/comments | 4 | 2023-03-03T11:24:09Z | 2023-03-03T13:05:20Z | https://github.com/kubernetes/kubernetes/issues/116250 | 1,608,456,691 | 116,250 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kubectl apply performs validation before the apply.
Non-CRD resources (e.g. pods / deployments) don't need CRD schema for validation, but if we use `kind: List` resource, kubectl calls `LIST apis/apiextensions.k8s.io/v1/customresourcedefinitions`.
In my Kubernetes cluster, administrator doesn't... | kubectl apply requires CRDs to apply non-CRD resources if we use `kind: List` | https://api.github.com/repos/kubernetes/kubernetes/issues/116245/comments | 3 | 2023-03-03T09:02:02Z | 2023-03-07T12:20:27Z | https://github.com/kubernetes/kubernetes/issues/116245 | 1,608,220,998 | 116,245 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [8ff90733094e558245e1](https://go.k8s.io/triage#8ff90733094e558245e1)
##### Error text:
```
[FAILED] Test file "test/e2e/testing-manifests/sample-device-plugin.yaml" was not found.
The following files are embedded into the test executable:
test/e2e/testing-manifests/cluster-dns/dns-backend-r... | E2E: file "test/e2e/testing-manifests/sample-device-plugin.yaml" was not found | https://api.github.com/repos/kubernetes/kubernetes/issues/116244/comments | 3 | 2023-03-03T08:59:25Z | 2023-03-03T10:07:26Z | https://github.com/kubernetes/kubernetes/issues/116244 | 1,608,216,793 | 116,244 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
Serial e2e node jobs, e.g. https://testgrid.k8s.io/sig-node-containerd#cos-cgroupv1-containerd-node-e2e-serial
### Which tests are failing?
https://testgrid.k8s.io/sig-node-containerd#cos-cgroupv1-containerd-node-e2e-serial
### Since when has it been failing?
Since 03-01
### Testgrid l... | e2e node test failing - E2eNode Suite.[It] [sig-node] Device Plugin [Feature:DevicePluginProbe][NodeFeature:DevicePluginProbe][Serial] DevicePlugin [Serial] [Disruptive] | https://api.github.com/repos/kubernetes/kubernetes/issues/116241/comments | 5 | 2023-03-03T03:26:32Z | 2023-03-03T22:15:11Z | https://github.com/kubernetes/kubernetes/issues/116241 | 1,607,879,513 | 116,241 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
pod (only one container) with only startupProbe(without readinessProbe/livenessProbe) cannot be ready right now when startupProbe succeeded like below (it change to ready after 1 min since startupProbe succeeded ):
```
startupProbe:
failureThreshold: 30
httpGet:
... | pod with only startupProbe cannot be ready right now when startupProbe succeeded | https://api.github.com/repos/kubernetes/kubernetes/issues/116238/comments | 5 | 2023-03-03T02:15:55Z | 2023-03-03T08:37:47Z | https://github.com/kubernetes/kubernetes/issues/116238 | 1,607,832,334 | 116,238 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
master-blocking
[gce-cos-master-scalability-100](https://testgrid.k8s.io/sig-release-master-blocking#gce-cos-master-scalability-100)
### Which tests are failing?
kubetest.Up
### Since when has it been failing?
03-02 8:41 PST
<img width="1308" alt="image" src="https://user-images.githu... | [Failing test] gce-cos-master-scalability-100 | https://api.github.com/repos/kubernetes/kubernetes/issues/116229/comments | 4 | 2023-03-02T18:21:24Z | 2023-03-09T23:33:33Z | https://github.com/kubernetes/kubernetes/issues/116229 | 1,607,281,946 | 116,229 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
While performing stress tests that add many Nodes (~10) at the same time to a cluster with many Pods (>1000) that were previously unschedulable, the scheduler crashes with the following error and stack trace:
```
fatal error: concurrent map iteration and map write
goroutine 455300 [running]... | Scheduler crashes with fatal error: concurrent map iteration and map write | https://api.github.com/repos/kubernetes/kubernetes/issues/116226/comments | 6 | 2023-03-02T17:29:59Z | 2023-03-03T18:59:33Z | https://github.com/kubernetes/kubernetes/issues/116226 | 1,607,213,557 | 116,226 |
[
"kubernetes",
"kubernetes"
] | ERROR: type should be string, got "https://github.com/kubernetes/kubernetes/pull/116024 added a test that is flaking at a ~3% failure rate with `stress`:\r\n\r\n```\r\ngo test -race -c k8s.io/apiserver/pkg/storage/cacher\r\nstress ./cacher.test -test.run Test_newReadyRacy\r\n```\r\n\r\n_Originally posted by @liggitt in https://github.com/kubernetes/kubernetes/pull/116024#discussion_r1123420776_\r\n \r\n/sig api-machinery\r\n/assign @aojea\r\n/cc @wojtek-t\r\n/kind failing-test\r\n" | [Flake] Test_newReadyRacy flaking | https://api.github.com/repos/kubernetes/kubernetes/issues/116225/comments | 6 | 2023-03-02T16:54:42Z | 2023-03-06T07:29:39Z | https://github.com/kubernetes/kubernetes/issues/116225 | 1,607,161,661 | 116,225 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
master-blocking
gce-cos-master-alpha-features
### Which tests are failing?
master-blocking
kubetest.Up
### Since when has it been failing?
2:10PST 03-02-2023
### Testgrid link
https://testgrid.k8s.io/sig-release-master-blocking#gce-cos-master-alpha-features
### Rea... | [Failing test] gce-cos-master-alpha-features | https://api.github.com/repos/kubernetes/kubernetes/issues/116224/comments | 6 | 2023-03-02T16:43:26Z | 2023-03-09T23:34:44Z | https://github.com/kubernetes/kubernetes/issues/116224 | 1,607,144,606 | 116,224 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The `kubeconfig` field of `kubecontrollermanager.config.k8s.io` configuration is not populated correctly
### What did you expect to happen?
The `kubeconfig` field of `kubecontrollermanager.config.k8s.io` configuration can be populated correctly
### How can we reproduce it (as minimally an... | The kubeconfig field of kubecontrollermanager.config.k8s.io configuration is not populated correctly | https://api.github.com/repos/kubernetes/kubernetes/issues/116220/comments | 2 | 2023-03-02T15:28:03Z | 2023-04-20T16:59:30Z | https://github.com/kubernetes/kubernetes/issues/116220 | 1,607,016,713 | 116,220 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Let K8s workload(deployment,sts,etc.) support In-place Pod Vertical Scaling feature,
we can update all the pods of workloa, or rolling update them,.
### Why is this needed?
We usually need to update all pods of the workload, not a pod.
If kubelet evict the pod or rescheduler ... | Let K8s workload(deployment,sts,etc.) support In-place Pod Vertical Scaling feature | https://api.github.com/repos/kubernetes/kubernetes/issues/116214/comments | 12 | 2023-03-02T13:16:27Z | 2024-03-30T22:06:09Z | https://github.com/kubernetes/kubernetes/issues/116214 | 1,606,792,679 | 116,214 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I've faced with the following issue running the kubernetes security test using kube_bench_master.
```
podman run -it --env-file ~/opnfv/env \
-v ~/opnfv/ca.pem:/home/opnfv/functest/ca.pem:Z \
-v ~/opnfv/config:/root/.kube/config:Z \
-v ~/opnfv/results:/home/opnfv/functest/results:Z \
-v ~/... | opnfv/functest-kubernetes-security:v1.23 run_tests -t kube_bench_master | https://api.github.com/repos/kubernetes/kubernetes/issues/116213/comments | 3 | 2023-03-02T13:02:32Z | 2023-03-10T00:59:54Z | https://github.com/kubernetes/kubernetes/issues/116213 | 1,606,771,443 | 116,213 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
According to the official docs https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#pod-conditions
The initialized condition is set to True when all initContainers have completed successfully. So in a pod w/o initContainers, I assume that the lastTransitionTime of this condition shou... | Initialized lastTransitionTime different from the PodScheduled lastTransitionTime in a pod w/o initContainers | https://api.github.com/repos/kubernetes/kubernetes/issues/116212/comments | 4 | 2023-03-02T13:01:28Z | 2023-03-15T17:51:10Z | https://github.com/kubernetes/kubernetes/issues/116212 | 1,606,769,733 | 116,212 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I executed the kube-hunter test suite on a K8S cluster where strict PSP defined and the test failed.
```
podman run -it --env-file ~/opnfv/env \
-v ~/opnfv/ca.pem:/home/opnfv/functest/ca.pem:Z \
-v ~/opnfv/config:/root/.kube/config:Z \
-v ~/opnfv/results:/home/opnfv/functest/results:Z \
-v ~... | The opnfv/functest-kubernetes-security:v1.23 using kube_hunter test suite is not applicable on K8S cluster where strict PSP defined | https://api.github.com/repos/kubernetes/kubernetes/issues/116211/comments | 8 | 2023-03-02T12:49:49Z | 2023-03-06T10:27:14Z | https://github.com/kubernetes/kubernetes/issues/116211 | 1,606,752,353 | 116,211 |
[
"kubernetes",
"kubernetes"
] | Kubelet how to enable cAdvisor to collect network metric data for each container, instead of only pod pause containers | Issue with k8s.io/zh-cn/docs/reference/command-line-tools-reference/kubelet/ | https://api.github.com/repos/kubernetes/kubernetes/issues/116228/comments | 9 | 2023-03-02T11:16:12Z | 2023-09-08T07:01:01Z | https://github.com/kubernetes/kubernetes/issues/116228 | 1,607,272,157 | 116,228 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
kubedrain has "onPodDeletedOrEvicted" callback that can be used in custom controllers. It would be very helpful if we add more callbacks that can give more granular control over monitoring, like "onPodDeletionOrEvicitionStarted" and "onPodDeletionOrEvictionFailed".
### Why is ... | kubectl drain improvements | https://api.github.com/repos/kubernetes/kubernetes/issues/116210/comments | 6 | 2023-03-02T09:49:24Z | 2023-08-31T13:58:49Z | https://github.com/kubernetes/kubernetes/issues/116210 | 1,606,477,389 | 116,210 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [466744fd00eb9fa7e2a1](https://go.k8s.io/triage#466744fd00eb9fa7e2a1)
The test started to fail after Feb 17th.
TestCreateDiskFailDescribeVolume is in https://github.com/kubernetes/cloud-provider-aws/blob/d0551093673e8c355db17249b8f069767c014748/pkg/providers/v1/aws_test.go#L2538
##### Error... | Failure cluster [466744fd...] TestCreateDiskFailDescribeVolume timeout on waiting until volume available | https://api.github.com/repos/kubernetes/kubernetes/issues/116206/comments | 10 | 2023-03-02T07:26:11Z | 2023-07-31T08:31:33Z | https://github.com/kubernetes/kubernetes/issues/116206 | 1,606,245,546 | 116,206 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We have `defaultMetricsCollectorConfig` here with unit as `seconds`
https://github.com/kubernetes/kubernetes/blob/b4b2345f9a4faa08715a1bf3114e6312938f8736/test/integration/scheduler_perf/scheduler_perf_test.go#L86-L96
But actually the unit is `ms`, see here: https://github.com/kubernetes/kuberne... | Change the name of metrics in scheduler perf-tests | https://api.github.com/repos/kubernetes/kubernetes/issues/116204/comments | 17 | 2023-03-02T04:10:30Z | 2023-10-10T02:01:20Z | https://github.com/kubernetes/kubernetes/issues/116204 | 1,606,076,739 | 116,204 |
[
"kubernetes",
"kubernetes"
] | ```
E0301 22:07:04.127341 82193 etcd.go:212] "EtcdMain goroutine check" err=<
found unexpected goroutines:
[Goroutine 11523 in state sleep, with time.Sleep on top of the stack:
goroutine 11523 [sleep]:
time.Sleep(0x1a13b8600)
/home/prow/go/src/k8s.io/kubernetes/_output/local/.gimme/versions/go1.20.1.linu... | [Flake] goroutine leak detection flaking | https://api.github.com/repos/kubernetes/kubernetes/issues/116196/comments | 8 | 2023-03-02T00:06:15Z | 2023-04-20T16:59:26Z | https://github.com/kubernetes/kubernetes/issues/116196 | 1,605,890,924 | 116,196 |
[
"kubernetes",
"kubernetes"
] | Metric:
Today we have the `transformation_operations_total` counter metric that collects "transformation_type", "transformer_prefix", "status" which could be used to alert on decrypt, status is fail. Need to test this and perhaps it's just a documentation thing. If not, we need to add.
Log:
Today we just return er... | kmsv2: collect metrics and log when a resource decryption call fails | https://api.github.com/repos/kubernetes/kubernetes/issues/116194/comments | 3 | 2023-03-01T21:01:53Z | 2023-07-19T05:54:23Z | https://github.com/kubernetes/kubernetes/issues/116194 | 1,605,661,093 | 116,194 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hi, I have tried changing the constant variable CerificateValidity which is 1yr in Kubeadm to 10yrs.
Deployed multinode cluster, in primary cp node, can see kubelet client certificate (/var/lib/kubelet/pki/kubelet-client-current.pem) has a validity of 10yrs but in other node has a validity of 1yr... | Kubelet client certificate has a different validity in multi master cluster. | https://api.github.com/repos/kubernetes/kubernetes/issues/116193/comments | 8 | 2023-03-01T20:51:31Z | 2023-03-02T07:35:39Z | https://github.com/kubernetes/kubernetes/issues/116193 | 1,605,645,035 | 116,193 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I created a cluster role
```
kubectl describe clusterrole pods-full-access
Name: pods-full-access
Labels: <none>
Annotations: <none>
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
pods/exec [] ... | Ability to create pods allows access to secrets in the same namespace | https://api.github.com/repos/kubernetes/kubernetes/issues/116188/comments | 3 | 2023-03-01T16:47:52Z | 2023-03-07T15:22:07Z | https://github.com/kubernetes/kubernetes/issues/116188 | 1,605,315,729 | 116,188 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When passing a controller to exclude to GCE cloud-controller-manager, but using an old version when the controller does not exist yet, the cloud-controller-manager failed to launch because the controller was not found.
The error was `"gkenetworkparams" is not in the list of known controllers`
##... | Should be able to exclude unknown controllers | https://api.github.com/repos/kubernetes/kubernetes/issues/116186/comments | 8 | 2023-03-01T15:54:04Z | 2024-07-14T16:23:16Z | https://github.com/kubernetes/kubernetes/issues/116186 | 1,605,227,701 | 116,186 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [86bd7641551d9183a9d5](https://go.k8s.io/triage#86bd7641551d9183a9d5)
Kubernetes e2e suite [It] [sig-node] Pod InPlace Resize Container [Feature:InPlacePodVerticalScaling] Guaranteed QoS pod, one container - decrease CPU & increase memory
--
<br class="Apple-interchange-newline">
##### E... | Failure cluster [86bd7641...] InPlacePodVerticalScaling: Guaranteed QoS pod, one container - decrease CPU & increase memory | https://api.github.com/repos/kubernetes/kubernetes/issues/116175/comments | 18 | 2023-03-01T11:52:51Z | 2024-09-04T17:18:38Z | https://github.com/kubernetes/kubernetes/issues/116175 | 1,604,823,270 | 116,175 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [01ff4ab4203141dc9705](https://go.k8s.io/triage#01ff4ab4203141dc9705)
##### Error text:
```
Failed
=== RUN TestNewNodeIpamControllerWithCIDRMasks
=== RUN TestNewNodeIpamControllerWithCIDRMasks/valid_range_allocator
panic: test timed out after 10m0s
running tests:
TestNewNodeIpamContro... | Failure cluster [01ff4ab4...] TestNewNodeIpamControllerWithCIDRMasks | https://api.github.com/repos/kubernetes/kubernetes/issues/116173/comments | 2 | 2023-03-01T11:46:24Z | 2023-03-08T10:25:14Z | https://github.com/kubernetes/kubernetes/issues/116173 | 1,604,814,203 | 116,173 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
[root@master01 ~]# kubectl -n ingress-apisix get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
apisix-58666bdbc9-jzr97 0/1 CrashLoopBackOff 23 (41s ago) ... | OpenEluer system start firewalld ping pods error after installed k8s | https://api.github.com/repos/kubernetes/kubernetes/issues/116169/comments | 4 | 2023-03-01T09:57:03Z | 2023-03-02T01:55:42Z | https://github.com/kubernetes/kubernetes/issues/116169 | 1,604,640,440 | 116,169 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
when i build this image.then reported this error.
#8 [stage-0 2/3] COPY kube-apiserver /kube-apiserver
#8 DONE 5.5s
#9 [stage-0 3/3] RUN setcap cap_net_bind_service=+ep /kube-apiserver
#9 1.300 runc run failed: unable to start container process: exec: "/bin/sh": stat /bin/sh: no such file or... | ERROR: process "/bin/sh -c setcap cap_net_bind_service=+ep /${BINARY}" | https://api.github.com/repos/kubernetes/kubernetes/issues/116168/comments | 2 | 2023-03-01T08:23:28Z | 2023-03-01T09:14:08Z | https://github.com/kubernetes/kubernetes/issues/116168 | 1,604,498,481 | 116,168 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/116127/pull-kubernetes-unit/1630794267716751360
### Which tests are flaking?
TestConnectionPings
### Since when has it been flaking?
Not sure
### Testgrid link
pull-kubernetes-unit
### Reason for failure (if possible)
`... | TestConnectionPings: server: failed to send any pings (check logs) | https://api.github.com/repos/kubernetes/kubernetes/issues/116165/comments | 19 | 2023-03-01T05:51:56Z | 2023-12-22T04:22:55Z | https://github.com/kubernetes/kubernetes/issues/116165 | 1,604,292,427 | 116,165 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When kubeadm init.
failed.
journalctl -xefu kubelet :
failed to run Kubelet: unable to determine runtime API version
### What did you expect to happen?
I don't know what to do. Could you please give me detailed help
Should I use the latest k8s version
Because I know that K8s officially anno... | failed to run Kubelet: unable to determine runtime API version | https://api.github.com/repos/kubernetes/kubernetes/issues/116163/comments | 5 | 2023-03-01T02:17:08Z | 2023-03-02T11:00:30Z | https://github.com/kubernetes/kubernetes/issues/116163 | 1,604,108,229 | 116,163 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
See [KEP](https://github.com/kubernetes/enhancements/tree/master/keps/sig-scheduling/3838-pod-mutable-scheduling-directives) for context. This issue is creating to track work on the API validation changes.
### Why is this needed?
Validation relaxation of certain fields in the pod... | Mutable pod scheduling directives | https://api.github.com/repos/kubernetes/kubernetes/issues/116160/comments | 4 | 2023-02-28T23:56:20Z | 2023-03-14T17:08:27Z | https://github.com/kubernetes/kubernetes/issues/116160 | 1,603,991,218 | 116,160 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
An indexed job with 6,000 completions and a parallelism of 20 was run. The majority of those pods landed on a single node. Since kubelet watches all pods that belong to the node, it had to keep those 6,000 pods in memory and loop through them in its control loops. This makes it take unreasonably lon... | Indexed Jobs with high completion counts kill kubelet's performance | https://api.github.com/repos/kubernetes/kubernetes/issues/116159/comments | 21 | 2023-02-28T23:32:38Z | 2024-08-11T18:49:56Z | https://github.com/kubernetes/kubernetes/issues/116159 | 1,603,975,281 | 116,159 |
[
"kubernetes",
"kubernetes"
] | ERROR: type should be string, got "\r\nhttps://storage.googleapis.com/k8s-triage/index.html?ci=0&pr=1&test=Dirty\r\n\r\nit is flaking because of race conditions\r\n\r\n```\r\nFailed\r\n=== RUN TestDirty\r\nI0223 15:11:12.930225 108147 handler_discovery.go:392] Starting ResourceDiscoveryManager\r\n==================\r\nWARNING: DATA RACE\r\nRead at 0x00c0007caf2f by goroutine 3001:\r\n k8s.io/kubernetes/vendor/k8s.io/kube-aggregator/pkg/apiserver.TestDirty()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/kube-aggregator/pkg/apiserver/handler_discovery_test.go:164 +0x433\r\n testing.tRunner()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/.gimme/versions/go1.20.1.linux.amd64/src/testing/testing.go:1576 +0x216\r\n testing.(*T).Run.func1()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/.gimme/versions/go1.20.1.linux.amd64/src/testing/testing.go:1629 +0x47\r\n\r\nPrevious write at 0x00c0007caf2f by goroutine 3008:\r\n k8s.io/kubernetes/vendor/k8s.io/kube-aggregator/pkg/apiserver.TestDirty.func1()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/kube-aggregator/pkg/apiserver/handler_discovery_test.go:154 +0x55\r\n net/http.HandlerFunc.ServeHTTP()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/.gimme/versions/go1.20.1.linux.amd64/src/net/http/server.go:2122 +0x4d\r\n net/http.(*timeoutHandler).ServeHTTP.func1()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/.gimme/versions/go1.20.1.linux.amd64/src/net/http/server.go:3396 +0xe1\r\n\r\nGoroutine 3001 (running) created at:\r\n testing.(*T).Run()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/.gimme/versions/go1.20.1.linux.amd64/src/testing/testing.go:1629 +0x805\r\n testing.runTests.func1()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/.gimme/versions/go1.20.1.linux.amd64/src/testing/testing.go:2036 +0x8d\r\n testing.tRunner()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/.gimme/versions/go1.20.1.linux.amd64/src/testing/testing.go:1576 +0x216\r\n testing.runTests()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/.gimme/versions/go1.20.1.linux.amd64/src/testing/testing.go:2034 +0x87c\r\n testing.(*M).Run()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/.gimme/versions/go1.20.1.linux.amd64/src/testing/testing.go:1906 +0xb44\r\n main.main()\r\n _testmain.go:75 +0x2e9\r\n\r\nGoroutine 3008 (running) created at:\r\n net/http.(*timeoutHandler).ServeHTTP()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/.gimme/versions/go1.20.1.linux.amd64/src/net/http/server.go:3390 +0x5e5\r\n k8s.io/kubernetes/vendor/k8s.io/kube-aggregator/pkg/apiserver.(*discoveryManager).fetchFreshDiscoveryForService()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/kube-aggregator/pkg/apiserver/handler_discovery.go:218 +0xf30\r\n k8s.io/kubernetes/vendor/k8s.io/kube-aggregator/pkg/apiserver.(*discoveryManager).syncAPIService()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/kube-aggregator/pkg/apiserver/handler_discovery.go:346 +0x18b\r\n k8s.io/kubernetes/vendor/k8s.io/kube-aggregator/pkg/apiserver.(*discoveryManager).Run.func1.1()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/kube-aggregator/pkg/apiserver/handler_discovery.go:413 +0x12e\r\n k8s.io/kubernetes/vendor/k8s.io/kube-aggregator/pkg/apiserver.(*discoveryManager).Run.func1()\r\n /home/prow/go/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/vendor/k8s.io/kube-aggregator/pkg/apiserver/handler_discovery.go:418 +0x38\r\n==================\r\nI0223 15:11:12.944163 108147 handler.go:149] Adding GroupVersion stable.example.com v1 to ResourceManager\r\n testing.go:1446: race detected during execution of test\r\n--- FAIL: TestDirty (0.02s)\r\n```\r\n\r\n_Originally posted by @aojea in https://github.com/kubernetes/kubernetes/issues/115966#issuecomment-1449046065_\r\n " | [Flaky test] k8s.io/kubernetes/vendor/k8s.io/kube-aggregator/pkg/apiserver TestDirty | https://api.github.com/repos/kubernetes/kubernetes/issues/116157/comments | 6 | 2023-02-28T22:50:35Z | 2023-04-20T16:59:20Z | https://github.com/kubernetes/kubernetes/issues/116157 | 1,603,935,809 | 116,157 |
[
"kubernetes",
"kubernetes"
] | This issue copies a slack thread to preserve it and continue discussion: https://kubernetes.slack.com/archives/C0EG7JC6T/p1677203415388589. Note that our own use case is (mostly) handled, so I don't mind if this is a "won't fix"; I just wanted to at least make sure the discussion was preserved.
---
We want to ess... | Conditionally `Apply`ing with SSA | https://api.github.com/repos/kubernetes/kubernetes/issues/116156/comments | 10 | 2023-02-28T22:20:44Z | 2024-03-26T20:11:18Z | https://github.com/kubernetes/kubernetes/issues/116156 | 1,603,903,623 | 116,156 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
PR https://github.com/kubernetes/kubernetes/pull/115324 was reverted by #116062 because it (erroneously) relied on OpenAPIV3 feature to be enabled, but `TestPodSecurityGAOnly` would non-deterministically leave the feature disabled after running.
I tracked it down to the fact that this test disabl... | unstable map iteration order causes test to sometimes leave non-GA features disabled | https://api.github.com/repos/kubernetes/kubernetes/issues/116151/comments | 5 | 2023-02-28T21:00:01Z | 2023-03-01T00:07:25Z | https://github.com/kubernetes/kubernetes/issues/116151 | 1,603,803,160 | 116,151 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
See https://github.com/kubernetes/kubernetes/issues/113791 for details. When we graduated APIServer tracing to beta prior to the 1.26 release, it broke port-forwarding.
To fix this, the opentelemetry-go community agreed to cut a patch release for me: https://github.com/open-telemetry/opentelem... | Enabling APIServer tracing breaks port forwarding | https://api.github.com/repos/kubernetes/kubernetes/issues/116139/comments | 3 | 2023-02-28T17:51:21Z | 2023-02-28T22:54:18Z | https://github.com/kubernetes/kubernetes/issues/116139 | 1,603,534,206 | 116,139 |
[
"kubernetes",
"kubernetes"
] | @thockin pointed out in a review that the way we generate selectors for the Job controller is a bit odd.
https://github.com/kubernetes/kubernetes/pull/114930#pullrequestreview-1316052164
/kind cleanup
/sig apps | General Validation Cleanup for Jobs | https://api.github.com/repos/kubernetes/kubernetes/issues/116137/comments | 7 | 2023-02-28T16:53:10Z | 2023-10-12T19:44:48Z | https://github.com/kubernetes/kubernetes/issues/116137 | 1,603,432,795 | 116,137 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We created CRD with now two versions: v1alpha1 and v1alpha2. Their relative configuration is as follows:
```yaml
...
versions:
- name: v1alpha1
served: true
storage: false
deprecated: true
...
- name: v1alpha2
served: true
storage: true
```
... | One versioned resource, two versioned CRDs, two informers events. | https://api.github.com/repos/kubernetes/kubernetes/issues/116136/comments | 6 | 2023-02-28T16:18:51Z | 2023-03-01T14:09:06Z | https://github.com/kubernetes/kubernetes/issues/116136 | 1,603,380,890 | 116,136 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When creating a deployment and requesting `cpu`, then there are some cases when the output of `kubectl apply` (when doing it more than once) shows `configured` rather than `unchanged`:
Examples:
* `cpu: "1.2"` (but `"1200m"` works fine)
* `cpu: "1000m"` (but `"1"` works fine)
The error s... | When requesting `cpu: "1.2"`, then `kubectl apply` always shows "configured" in output | https://api.github.com/repos/kubernetes/kubernetes/issues/116135/comments | 13 | 2023-02-28T16:15:38Z | 2023-05-18T13:56:36Z | https://github.com/kubernetes/kubernetes/issues/116135 | 1,603,375,973 | 116,135 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hi, i have a problem when i launch a pod the state of the pod is pending.
The command "kubectl describe pods apache-7f6fddb7df-q229r" and the output is " Warning FailedScheduling 61s (x2 over 6m23s) default-scheduler 0/1 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes... | 1 node(s) had untolerated taint | https://api.github.com/repos/kubernetes/kubernetes/issues/116133/comments | 11 | 2023-02-28T15:25:30Z | 2024-01-16T15:17:15Z | https://github.com/kubernetes/kubernetes/issues/116133 | 1,603,284,431 | 116,133 |
[
"kubernetes",
"kubernetes"
] | We have tooling inside of Kubernetes to control the disruption to an application during an update, for example we have maxSurge and maxUnavailable
These strategy definitions are ignored in cases where an end-user changes the desired number of replicas for a Deployment, however there can be cases where an end-user wa... | Allow end-users to control the rate at which Deployment replicas are scaled up/down | https://api.github.com/repos/kubernetes/kubernetes/issues/116132/comments | 21 | 2023-02-28T15:14:55Z | 2024-11-07T15:15:11Z | https://github.com/kubernetes/kubernetes/issues/116132 | 1,603,267,027 | 116,132 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
[root@master system]# vim /usr/lib/systemd/system/kubelet.service
[root@master system]# journalctl -xeu kubelet
Feb 28 04:16:20 master kubelet[20288]: I0228 04:16:20.044254 20288 dynamic_cafile_content.go:156] "Starting controller" name="client-ca-bundle::/etc/kubernetes/pki/ca.crt"
Feb 28 04:1... | kubelet.service failed | https://api.github.com/repos/kubernetes/kubernetes/issues/116129/comments | 3 | 2023-02-28T12:24:39Z | 2023-02-28T12:30:20Z | https://github.com/kubernetes/kubernetes/issues/116129 | 1,602,974,089 | 116,129 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [e5ba622261192f2d2a1f](https://go.k8s.io/triage#e5ba622261192f2d2a1f)
##### Error text:
```
[FAILED] failed to update pod: Operation cannot be fulfilled on pods "pod-negative-grace-periodeedc00f0-25ca-4251-af98-dd9a07aa6ccb": the object has been modified; please apply your changes to the latest... | Failure cluster [e5ba6222...] update pod with negative terminationGracePeriodSeconds should fail | https://api.github.com/repos/kubernetes/kubernetes/issues/116126/comments | 1 | 2023-02-28T09:54:26Z | 2023-03-01T12:29:18Z | https://github.com/kubernetes/kubernetes/issues/116126 | 1,602,708,142 | 116,126 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A pod using gpu in our k8s cluster, when we delete kubelet_internal_checkpoint and restart the node where the pod is located. After the node start normally, we find that, the pod is running, but the gpu device is not mounted on the container of pod. If we delete container of the pod, the gpu devic... | Pod is running, but cannot allocate devices when the pod start before device plugin register right to kubelet | https://api.github.com/repos/kubernetes/kubernetes/issues/116125/comments | 7 | 2023-02-28T09:37:55Z | 2023-03-01T19:04:04Z | https://github.com/kubernetes/kubernetes/issues/116125 | 1,602,680,904 | 116,125 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
It is a follow up from https://github.com/kubernetes/kubernetes/pull/115856#issuecomment-1447807752
Looks like liveness probes are failing with different symptoms. Looks like the failures are happening for different probe types.
### Which tests are failing?
https://storage.googleapis.... | Probe tests are flaking often on some jobs | https://api.github.com/repos/kubernetes/kubernetes/issues/116123/comments | 16 | 2023-02-28T09:06:32Z | 2025-01-22T18:35:56Z | https://github.com/kubernetes/kubernetes/issues/116123 | 1,602,634,635 | 116,123 |
[
"kubernetes",
"kubernetes"
] | Found when reviewing https://github.com/kubernetes/kubernetes/pull/116024
I'm still not 100% convinced it's true, but I believe this is a faulty scenario:
1. new watch is being established `Watch()` method
2. `c.ready` is still initialized so we successfully pass the c.ready.wait() check
3. `ListAndWatch` in `sta... | Cacher may not send events if it reinitializes at the time of watch initialization | https://api.github.com/repos/kubernetes/kubernetes/issues/116122/comments | 2 | 2023-02-28T09:04:03Z | 2023-03-16T14:31:24Z | https://github.com/kubernetes/kubernetes/issues/116122 | 1,602,630,770 | 116,122 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Created a kind cluster with one control plane node and three worker nodes. Created a deployment with 7 replicas and topology constraint with key `kubernetes.io/hostname` and `maxSkew` set to 1. Only three pods got scheduled; others are in pending state.
### What did you expect to happen?
All seve... | Topology Spread Constraints does not respect taints | https://api.github.com/repos/kubernetes/kubernetes/issues/116118/comments | 6 | 2023-02-28T07:28:33Z | 2023-03-09T10:23:59Z | https://github.com/kubernetes/kubernetes/issues/116118 | 1,602,509,689 | 116,118 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
In the `KubeletConfiguration` [here](https://kubernetes.io/docs/reference/config-api/kubelet-config.v1beta1/#kubelet-config-k8s-io-v1beta1-KubeletConfiguration), I want to have more options for DNS to override the Cluster Level DNS configuration for `ClusterFirst` and `ClusterFir... | Allowing overwritable DNS options for ClusterFirst and ClusterFirstWithHostNet policy in the kubelet configuration | https://api.github.com/repos/kubernetes/kubernetes/issues/116117/comments | 21 | 2023-02-28T07:21:06Z | 2024-05-02T23:39:24Z | https://github.com/kubernetes/kubernetes/issues/116117 | 1,602,501,899 | 116,117 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm working with @dims and @tzneal on enabling e2e tests on AWS. We want to run many e2e tests on there as we have alot of AWS credits to consume. As part of that journey, we need to start building on public AWS ubuntu AMIs and add features to `test/e2e_node/runner/run_remote.go` to build instances ... | Kubelet e2e tests are failing on public ubuntu-2204 AWS AMIs | https://api.github.com/repos/kubernetes/kubernetes/issues/116114/comments | 13 | 2023-02-27T23:33:33Z | 2023-07-07T13:24:07Z | https://github.com/kubernetes/kubernetes/issues/116114 | 1,602,119,297 | 116,114 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm working with @dims and @tzneal on enabling e2e tests on AWS. We want to run many e2e tests on there as we have alot of AWS credits to consume. As part of that journey, we need to start building on public GCE ubuntu images instead of COS and the custom Google Ubuntu Images that we build from.
... | Kubelet e2e tests are failing on public ubuntu-2204-jammy GCE images | https://api.github.com/repos/kubernetes/kubernetes/issues/116112/comments | 11 | 2023-02-27T23:05:28Z | 2024-01-19T12:59:58Z | https://github.com/kubernetes/kubernetes/issues/116112 | 1,602,089,967 | 116,112 |
[
"kubernetes",
"kubernetes"
] | HTTP 500 gateway error when resolving the GPG key URL.
```console
$ sudo curl -fsSLo /etc/apt/keyrings/kubernetes-archive-keyring.gpg https://packages.cloud.google.com/apt/doc/apt-key.gpg
curl: (22) The requested URL returned error: 500
``` | Issue with k8s.io/docs/tasks/tools/install-kubectl-linux/ | https://api.github.com/repos/kubernetes/kubernetes/issues/116101/comments | 9 | 2023-02-27T18:12:50Z | 2023-09-07T06:16:06Z | https://github.com/kubernetes/kubernetes/issues/116101 | 1,601,754,225 | 116,101 |
[
"kubernetes",
"kubernetes"
] | Below command showing error 500...
sudo curl -fsSLo /etc/apt/keyrings/kubernetes-archive-keyring.gpg https://packages.cloud.google.com/apt/doc/apt-key.gpg
| Trouble fetching APT signing key for Google package repository | https://api.github.com/repos/kubernetes/kubernetes/issues/116100/comments | 5 | 2023-02-27T17:03:42Z | 2023-02-27T18:07:55Z | https://github.com/kubernetes/kubernetes/issues/116100 | 1,601,596,396 | 116,100 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hi, we are using kubernetes v1.24,
im trying to implement the new default feature from v1.24 - **Topology Aware Hints** to keep traffic inside the AZ as much as possible, but seems like i cant get this to work..
**my configuration:**
- EKS cluster with around 12 nodes at a time spread evenly ac... | Topology Aware Hints not working as expected v1.24 | https://api.github.com/repos/kubernetes/kubernetes/issues/116098/comments | 13 | 2023-02-27T16:49:14Z | 2023-02-28T10:09:37Z | https://github.com/kubernetes/kubernetes/issues/116098 | 1,601,558,162 | 116,098 |
[
"kubernetes",
"kubernetes"
] | Failed to install kubectl when using [this](https://kubernetes.io/docs/tasks/tools/install-kubectl-linux/#install-using-native-package-management) step in documents.
Error in `Download the Google Cloud public signing key:` step.
Output:-
```
sudo curl -fsSLo /etc/apt/keyrings/kubernetes-archive-keyring.gpg htt... | Install and Set Up kubectl on Linux failed | https://api.github.com/repos/kubernetes/kubernetes/issues/116099/comments | 5 | 2023-02-27T16:34:41Z | 2023-02-27T18:08:51Z | https://github.com/kubernetes/kubernetes/issues/116099 | 1,601,581,869 | 116,099 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I am working on a PR where I am removing some legacy code from a API.
I believe I have to run some scripts to generate code.
When I run `make update`
I get the following error:
```
Running update-codegen
go version go1.20.1 linux/amd64
/home/ec2-user/Work/GIT/kubernetes-kevin/hack/u... | Unable to run hack/update-codegen.sh | https://api.github.com/repos/kubernetes/kubernetes/issues/116094/comments | 12 | 2023-02-27T15:54:55Z | 2023-02-28T22:53:46Z | https://github.com/kubernetes/kubernetes/issues/116094 | 1,601,457,877 | 116,094 |
[
"kubernetes",
"kubernetes"
] | When following the instructions on "Install and Set Up kubectl on Linux" in the native package management section for apt, curling the gpg key per the instructions results in a 500 error. The error can also be observed directly in a browser.
```
$ sudo curl -fsSLo /etc/apt/keyrings/kubernetes-archive-keyring.gpg h... | Install and Set Up kubectl on Linux - apt-key retrieval returning 500 | https://api.github.com/repos/kubernetes/kubernetes/issues/116092/comments | 5 | 2023-02-27T15:28:13Z | 2023-02-27T16:11:53Z | https://github.com/kubernetes/kubernetes/issues/116092 | 1,601,425,804 | 116,092 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Trying to install kubeadm, kubelet, kubectl on Ubuntu 22.04 but cannot add the `gpg` because it is not available under: `https://packages.cloud.google.com/apt/doc/apt-key.gpg`
```
root@master:~# sudo curl -fsSLo /etc/apt/keyrings/kubernetes-archive-keyring.gpg https://packages.cloud.google.com/a... | Cannot install kubeadm on bare metal due to missing gpg | https://api.github.com/repos/kubernetes/kubernetes/issues/116087/comments | 6 | 2023-02-27T11:23:41Z | 2023-02-27T18:09:04Z | https://github.com/kubernetes/kubernetes/issues/116087 | 1,600,993,461 | 116,087 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
The pod is not using cpu static policy for sidecar container settings
This may be a limitation of current cpu static policy support.
https://kubernetes.io/docs/tasks/administer-cluster/cpu-management-policies/
We may need to support CPU static policy for the container le... | container level cpu static policy support | https://api.github.com/repos/kubernetes/kubernetes/issues/116086/comments | 40 | 2023-02-27T10:15:55Z | 2025-02-23T19:57:20Z | https://github.com/kubernetes/kubernetes/issues/116086 | 1,600,881,307 | 116,086 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
we are upgrading kubelet from 1.16 to 1.18, and find that all those static pods are recreated during the upgrading process.
This is because the static pod hash is a calculation of the `pod *api.Pod`, and the pod spec struct is updated when upgrading to 1.18: `PodSecurityContext.FSGroupChangePoli... | when upgrading kubelet, static pods are always killled even no manifest files are changed | https://api.github.com/repos/kubernetes/kubernetes/issues/116080/comments | 4 | 2023-02-27T06:55:49Z | 2023-02-28T03:49:57Z | https://github.com/kubernetes/kubernetes/issues/116080 | 1,600,590,571 | 116,080 |
[
"kubernetes",
"kubernetes"
] | Hi, I am a beginer on K8s and while I reading the source code of kubelet this confuse me
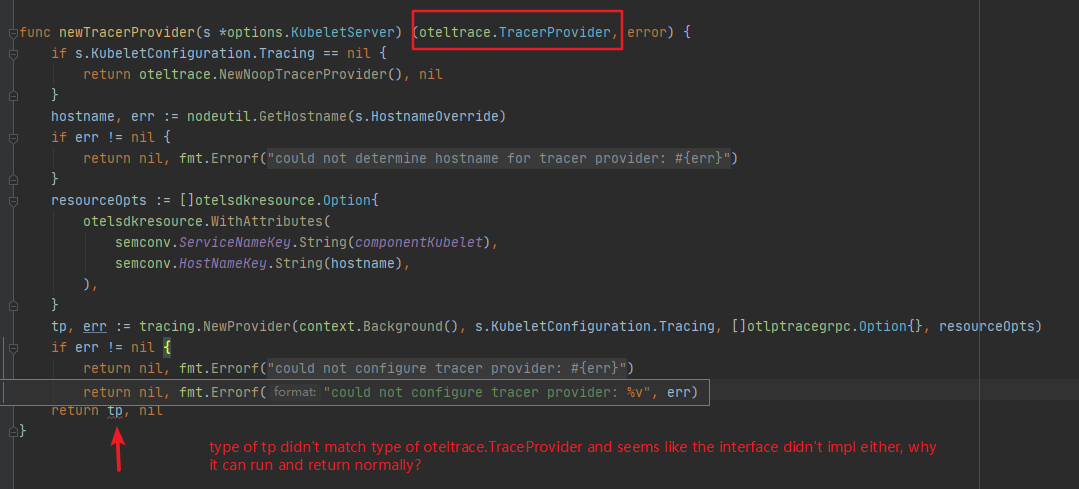
it's on ``cmd/kubelet/app/server.go`` line 1295, I only know little about kubelet and tracing, so if anyone know the... | question of a piece of code on files cmd/kubelet/app server.go about tracing | https://api.github.com/repos/kubernetes/kubernetes/issues/116073/comments | 7 | 2023-02-27T03:36:57Z | 2023-03-06T09:39:11Z | https://github.com/kubernetes/kubernetes/issues/116073 | 1,600,405,505 | 116,073 |
[
"kubernetes",
"kubernetes"
] | We're using EKS v1/.23 and as we all know that Pod Security Policies are getting depreciated. We're planning to adapt Pod Security Admission by enforcing Pod Security Standards. We'd like to know if we can have our own custom pod security standards.
The current restricted pod security standard is creating some issu... | Custom Pod Security Standards | https://api.github.com/repos/kubernetes/kubernetes/issues/116085/comments | 8 | 2023-02-26T22:11:58Z | 2023-02-28T00:00:45Z | https://github.com/kubernetes/kubernetes/issues/116085 | 1,600,819,741 | 116,085 |
[
"kubernetes",
"kubernetes"
] | On <https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/> page for Debian based section a command is given
```
sudo curl -fsSLo /etc/apt/keyrings/kubernetes-archive-keyring.gpg https://packages.cloud.google.com/apt/doc/apt-key.gpg
```
as part of the installation process. This... | Installing kubeadm - 500 error retrieving apt-key.gpg | https://api.github.com/repos/kubernetes/kubernetes/issues/116096/comments | 6 | 2023-02-26T19:20:16Z | 2023-02-27T18:14:01Z | https://github.com/kubernetes/kubernetes/issues/116096 | 1,601,467,741 | 116,096 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm seeing HTTP 500 errors trying to download **apt-key.gpg** when following the steps to install Kubernetes on Ubuntu using the package manager. This stopped working yesterday (Feb 25, 2023). Here's the entire URL.
https://packages.cloud.google.com/apt/doc/apt-key.gpg
I also tried opening... | Ubuntu install fails due to 500 error downloading: apt-key.gpg | https://api.github.com/repos/kubernetes/kubernetes/issues/116068/comments | 14 | 2023-02-26T18:36:02Z | 2023-03-07T14:31:14Z | https://github.com/kubernetes/kubernetes/issues/116068 | 1,600,155,541 | 116,068 |
[
"kubernetes",
"kubernetes"
] | I want to start a local cluster and I've followed the steps from the related guides, but when I run `local-up-cluster.sh` it always end up with following:
```
Waiting for apiserver to come up
!!! [0226 12:59:35] Timed out waiting for apiserver: to answer at https://127.0.0.1:6443/healthz; tried 60 waiting 1 between... | Problem with local-up-cluster.sh | https://api.github.com/repos/kubernetes/kubernetes/issues/116067/comments | 26 | 2023-02-26T08:41:00Z | 2024-04-22T16:29:22Z | https://github.com/kubernetes/kubernetes/issues/116067 | 1,599,974,608 | 116,067 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
decode unstructured in parallel to reduce time cost of dynamicclient list
### Why is this needed?
when there are many objects in cluster and need to use dynamicclient to list them, the json decode cost too much time because it's decoded one by one for each list item. | decode unstructured in parallel | https://api.github.com/repos/kubernetes/kubernetes/issues/116064/comments | 8 | 2023-02-26T03:15:30Z | 2024-03-26T20:12:15Z | https://github.com/kubernetes/kubernetes/issues/116064 | 1,599,914,691 | 116,064 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Currently, for cpu (and memory) resources, ResourceQuotas enforce that every (new) pod in that namespace sets a limit for that resource.
There should be a new option for the limits.cpu ResourceQuota at namespace level:
`enforceLimitPerPod: true (default) / false`
If false,... | Resource Quotas: Possibility to not enforce limits.cpu per pod | https://api.github.com/repos/kubernetes/kubernetes/issues/116063/comments | 10 | 2023-02-25T22:17:45Z | 2024-01-19T06:00:00Z | https://github.com/kubernetes/kubernetes/issues/116063 | 1,599,858,308 | 116,063 |
[
"kubernetes",
"kubernetes"
] | ⚠**The signal due (2/28) for the v1.27.0-alpha.3 release cut is less than 3 days away.**
### Which jobs are flaking?
sig-release-master-blocking
integration-master
### Since when has it been flaking?
2/25 00:29 PST
### Testgrid link
https://k8s-testgrid.appspot.com/sig-release-master-blocking#integration-ma... | [Flaky tests] integration-master | https://api.github.com/repos/kubernetes/kubernetes/issues/116061/comments | 9 | 2023-02-25T19:04:19Z | 2023-04-20T16:59:16Z | https://github.com/kubernetes/kubernetes/issues/116061 | 1,599,801,222 | 116,061 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We are recently observing a number of job pods that had been running on a node with memory pressure that are shown as OOMKilled. Looking closer, the jobs are, however, successful/succeeded in almost all cases, e.g.
```
$ kubectl get pods | grep OOMK
job1-2k5bx 0/1 OOMKilled 0 ... | Pods of successful jobs show as OOMKilled | https://api.github.com/repos/kubernetes/kubernetes/issues/116042/comments | 6 | 2023-02-24T14:13:32Z | 2023-03-16T06:38:55Z | https://github.com/kubernetes/kubernetes/issues/116042 | 1,598,713,399 | 116,042 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
pull-kubernetes-verify
### Which tests are failing?
verify: openapi-spec
### Since when has it been failing?
{Script Error ScriptError go version go1.20.1 linux/amd64
rm: cannot remove '/home/prow/go/src/k8s.io/kubernetes/hack/../api/openapi-spec/v3/*': No such file or directory
rm: ... | verify openapi-spec failed | https://api.github.com/repos/kubernetes/kubernetes/issues/116036/comments | 4 | 2023-02-24T09:55:57Z | 2023-02-24T13:26:35Z | https://github.com/kubernetes/kubernetes/issues/116036 | 1,598,296,316 | 116,036 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We introduced a postStart hook to one of our pods. Eventually, we noticed these pods hanging in "Terminating" state indefinitely when we try to delete them.
Trying `kubectl logs`yielded
`Error from server (BadRequest): container "reproducer" in pod "reproducer" is waiting to start: ContainerCre... | A pod with a still running postStart lifecycle hook that is deleted is not terminated even after terminationGracePeriod | https://api.github.com/repos/kubernetes/kubernetes/issues/116032/comments | 14 | 2023-02-24T07:24:14Z | 2024-08-21T17:45:19Z | https://github.com/kubernetes/kubernetes/issues/116032 | 1,598,050,375 | 116,032 |
[
"kubernetes",
"kubernetes"
] | **### when run "make test KUBE_TIMEOUT="-timeout=300s", these are some strange output like this :**
I0224 10:54:34.870767 11329 handler.go:149] Adding GroupVersion ĴȀơģ&夃M淂Ȑ@ă 出Ų9ƳC-驉\qÙPŀÌ僦粸 to ResourceManager
I0224 10:54:34.871039 11329 handler.go:149] Adding GroupVersion ĴȀơģ&夃M淂Ȑ@ă ȆźĀŴ恰貭忏u瑒翶88Ǒ.鷶凲DZ to Reso... | strange output when "make test" | https://api.github.com/repos/kubernetes/kubernetes/issues/116029/comments | 4 | 2023-02-24T02:59:38Z | 2023-02-27T08:02:19Z | https://github.com/kubernetes/kubernetes/issues/116029 | 1,597,818,460 | 116,029 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We observed that when deplying manifests to a cluster running 1.26.1-gke.200, the StorageClass and PVC get created successfully. However, the PVC is stuck in a Pending state and no PV is provisioned.
The workaround is to add storageClassName to one of the pending PVCs on cluster, and it did go ... | PVs with annotations are not being dynamically provisioned on k8s 1.26.1 | https://api.github.com/repos/kubernetes/kubernetes/issues/116028/comments | 5 | 2023-02-24T00:59:15Z | 2023-03-02T00:55:25Z | https://github.com/kubernetes/kubernetes/issues/116028 | 1,597,729,485 | 116,028 |
[
"kubernetes",
"kubernetes"
] | There are a few cases when the Unknown result can be returned by the probe. For example see: https://github.com/kubernetes/kubernetes/issues/106682.
It will be useful to expose those in logs and as an event similar to what we do for Warning: https://github.com/kubernetes/kubernetes/blob/35f3fc59c1f29eebc8ff8705ecc3d... | Report event for the cases when probe returned Unknown result | https://api.github.com/repos/kubernetes/kubernetes/issues/116026/comments | 25 | 2023-02-24T00:02:49Z | 2025-01-09T13:20:35Z | https://github.com/kubernetes/kubernetes/issues/116026 | 1,597,688,421 | 116,026 |
[
"kubernetes",
"kubernetes"
] | This applies to StatefulSetStartOrdinal feature gate. Field validation should be done regardless of the feature gate state.
From @liggitt
https://github.com/kubernetes/kubernetes/pull/112744/files#r1114602379
```
we should not be checking feature gates here... if the field is non-nil, always validate it
p... | Fix StatefulSet Spec.Ordinal field validation | https://api.github.com/repos/kubernetes/kubernetes/issues/116025/comments | 4 | 2023-02-24T00:01:09Z | 2023-02-24T15:17:47Z | https://github.com/kubernetes/kubernetes/issues/116025 | 1,597,687,107 | 116,025 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Value reported by `crictl.exe imagefsinfo` is roughly around ~530 GiB.
```json
{
"status": {
"timestamp": "1677171468699023800",
"fsId": {
"mountpoint": "C:\\ProgramData\\containerd\\root\\io.containerd.snapshotter.v1.windows"
},
"usedBytes": {
"value": "5700... | [BUG] Windows disk usage getting reported larger than disk size and may prevent GC from running | https://api.github.com/repos/kubernetes/kubernetes/issues/116020/comments | 26 | 2023-02-23T19:12:03Z | 2023-10-25T20:23:46Z | https://github.com/kubernetes/kubernetes/issues/116020 | 1,597,391,861 | 116,020 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Currently, there are still references that point to storage.googleapis.com instead of d.lk8s.io.
As the location of the binaries might change in the future, it would be good to update everything referencing the binaries to dl.k8s.io.
For this to Achieve, it is necessary to ... | Replace storage.googleapis with dl.k8s.io for all binaries related | https://api.github.com/repos/kubernetes/kubernetes/issues/116019/comments | 10 | 2023-02-23T18:04:55Z | 2024-02-19T05:05:37Z | https://github.com/kubernetes/kubernetes/issues/116019 | 1,597,308,210 | 116,019 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
This line reads as if the bound has already happened:
https://github.com/kubernetes/kubernetes/blob/3702411ef9d99e2fe186381474692fdb970a3b4c/pkg/scheduler/framework/plugins/volumebinding/binder.go#L578
But, if I read correctly, the bound happens immediately after:
https://github.com/kuberne... | Inaccurate log for when a volume is bound to a claim | https://api.github.com/repos/kubernetes/kubernetes/issues/116012/comments | 3 | 2023-02-23T13:49:40Z | 2023-02-24T19:03:30Z | https://github.com/kubernetes/kubernetes/issues/116012 | 1,596,906,625 | 116,012 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
There are two flags `endpointSliceChangeMinSyncDelay` and `endpointUpdatesBatchPeriod` that are used to add delay to enqueue multiple subsequent update events to be processed.
References to usage of delay values for `AddAfter()` method of workqueue:
addPod: https://github.com/kubernetes/kubernet... | Update batching delay for EndpointSlices uses two flags inconsistently | https://api.github.com/repos/kubernetes/kubernetes/issues/116011/comments | 10 | 2023-02-23T13:37:40Z | 2024-08-12T18:02:58Z | https://github.com/kubernetes/kubernetes/issues/116011 | 1,596,887,539 | 116,011 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When running a Job in Kubernetes 1.23 the job gets terminated immediately and not respecting ttlSecondsAfterFinished.
### What did you expect to happen?
Expected the job to stay alive for the timeframe defined in ttlSecondsAfterFinished
### How can we reproduce it (as minimally and precisely as p... | ttlSecondsAfterFinished Ignored for jobs | https://api.github.com/repos/kubernetes/kubernetes/issues/116008/comments | 10 | 2023-02-23T12:53:21Z | 2023-09-08T07:44:53Z | https://github.com/kubernetes/kubernetes/issues/116008 | 1,596,809,308 | 116,008 |
[
"kubernetes",
"kubernetes"
] | after running "hack/make-rules/../../hack/verify-import-aliases.sh", it goes wrong like this:
go version go1.20.1 linux/amd64
cmd/preferredimports/preferredimports.go:37:2: cannot find package "golang.org/x/term" in any of:
/home/jiacheng/kubernetes/_output/local/.gimme/versions/go1.20.1.linux.amd64/src/go... | failing test : verify-import-aliases.sh | https://api.github.com/repos/kubernetes/kubernetes/issues/116007/comments | 4 | 2023-02-23T12:52:16Z | 2023-02-24T06:48:30Z | https://github.com/kubernetes/kubernetes/issues/116007 | 1,596,807,786 | 116,007 |
[
"kubernetes",
"kubernetes"
] | After running "make verify", "verify-govet.sh" failed.
-----------------
FAILED TESTS:
hack/make-rules/../../hack/verify-govet.sh
-----------------
cannot find package "_/home/jiacheng/kubernetes/test/typecheck" in any of:
/usr/local/go/src/_/home/jiacheng/kubernetes/test/typecheck (from $GOROOT)
... | Makefile:339: vet Error 1 when running verify-govet.sh | https://api.github.com/repos/kubernetes/kubernetes/issues/116006/comments | 4 | 2023-02-23T12:49:06Z | 2023-02-24T06:49:09Z | https://github.com/kubernetes/kubernetes/issues/116006 | 1,596,803,490 | 116,006 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have Openshift cluster with version 4.11 (K8s v1.24.6)
In the cluster I get the warning when creating new deployments about PodSecurity.
Not just this deployment , for any deployment.
```
│ W0221 10:40:58.250242 1 warnings.go:70] would violate PodSecurity "restricted:v1.24": allo... | cannot update pod security admission controller's exemptions | https://api.github.com/repos/kubernetes/kubernetes/issues/116004/comments | 4 | 2023-02-23T11:17:41Z | 2023-02-26T02:16:06Z | https://github.com/kubernetes/kubernetes/issues/116004 | 1,596,669,302 | 116,004 |
[
"kubernetes",
"kubernetes"
] | This issue is created by this @SergeyKanzhelev's [request](https://github.com/kubernetes/kubernetes/pull/115749#issuecomment-1441305000)
Currently AppArmor validator gets host info only [when Validator object is created](https://github.com/kubernetes/kubernetes/blob/master/pkg/security/apparmor/validate.go#L44).
`V... | AppArmor validator: Use up to date host info | https://api.github.com/repos/kubernetes/kubernetes/issues/116003/comments | 13 | 2023-02-23T09:46:05Z | 2023-03-14T20:53:54Z | https://github.com/kubernetes/kubernetes/issues/116003 | 1,596,530,223 | 116,003 |
[
"kubernetes",
"kubernetes"
] | a deployment's pod template use a "RWO" volume and rolling update strategy, during rolling update process, the new version pod can not accquire this "RWO" volume, so the new version pod will not be ready forever, and the rolling update will eventually fail... | deployment rolling update fail if the pod use a "RWO" volume | https://api.github.com/repos/kubernetes/kubernetes/issues/115997/comments | 11 | 2023-02-23T08:39:12Z | 2024-01-20T03:10:53Z | https://github.com/kubernetes/kubernetes/issues/115997 | 1,596,438,640 | 115,997 |
[
"kubernetes",
"kubernetes"
] | I am a new guy to kubernetes world, and today I am looking at the source code k8s, I found out a line of code can optimize
```
func NewControllerInitializers(loopMode ControllerLoopMode) map[string]InitFunc {
controllers := map[string]InitFunc{}
// All of the controllers must have unique names, or else we wil... | Code optimize on kubernetes/cmd/kube-controller-manager/app/controllermanager.go | https://api.github.com/repos/kubernetes/kubernetes/issues/115995/comments | 7 | 2023-02-23T06:43:21Z | 2023-03-14T21:12:42Z | https://github.com/kubernetes/kubernetes/issues/115995 | 1,596,306,215 | 115,995 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.