
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | It can be observed in any kubelet log, just pick one from a random job in CI, per example
```sh
$ wget https://storage.googleapis.com/kubernetes-jenkins/pr-logs/pull/114703/pull-kubernetes-e2e-gce/1608841379780235264/artifacts/e2e-022435249c-674b9-minion-group-gdj4/kubelet.log
$ grep tracker kubelet.log | grep ... | pod_startup_latency_tracker doesn't track the lastFinishedPulling time | https://api.github.com/repos/kubernetes/kubernetes/issues/114903/comments | 4 | 2023-01-08T13:24:50Z | 2023-03-14T16:39:08Z | https://github.com/kubernetes/kubernetes/issues/114903 | 1,524,504,542 | 114,903 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
just for test
### What did you expect to happen?
just for test
### How can we reproduce it (as minimally and precisely as possible)?
just for test
### Anything else we need to know?
_No response_
### Kubernetes version
<details>
v1.26.0
```console
$ kubectl version
# paste output here
`... | creat a issue for test | https://api.github.com/repos/kubernetes/kubernetes/issues/114893/comments | 2 | 2023-01-07T09:04:16Z | 2023-01-07T09:06:23Z | https://github.com/kubernetes/kubernetes/issues/114893 | 1,523,633,754 | 114,893 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
ci-benchmark-scheduler-perf-master
### Which tests are failing?
scheduler_perf
### Since when has it been failing?
This Job was keep failing by another issue until https://github.com/kubernetes/kubernetes/pull/114796. So, we don't know when the current problem is started.
#... | ci-benchmark-scheduler-perf-master is failing | https://api.github.com/repos/kubernetes/kubernetes/issues/114890/comments | 13 | 2023-01-07T07:54:42Z | 2023-05-26T06:57:08Z | https://github.com/kubernetes/kubernetes/issues/114890 | 1,523,585,762 | 114,890 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
1. Add E2E test to ensure reasonable and correct behavior when use rolls back from FG=beta version to FG=alpha version. Expected behavior of currently running pods that may have resize in progress.
2. Add test to validate that when pod.restartPolicy = Never, resizePolicy must be... | [FG:InPlacePodVerticalScaling] Test cases we need to add for in-place pod resize feature | https://api.github.com/repos/kubernetes/kubernetes/issues/114888/comments | 7 | 2023-01-07T04:53:42Z | 2023-06-25T20:45:04Z | https://github.com/kubernetes/kubernetes/issues/114888 | 1,523,473,410 | 114,888 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
There appears to be a breaking change to kubeproxy.config.k8s.io/v1alpha1 in PR https://github.com/kubernetes/kubernetes/pull/112133
The schema for kubeproxy.config.k8s.io/v1alpha1 changed by removing the `udpIdleTimeout` without being deprecated.
We based our manifest on what `kubeadm config... | kubeproxy.config.k8s.io/v1alpha1 Breaking Change | https://api.github.com/repos/kubernetes/kubernetes/issues/114884/comments | 8 | 2023-01-06T21:26:15Z | 2023-01-07T20:38:05Z | https://github.com/kubernetes/kubernetes/issues/114884 | 1,523,189,848 | 114,884 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When kube-scheduler does preemption and the PodDisruptionConditions feature gate is enabled, it might leak the namespace and name of a pod in a different namespace.
### What did you expect to happen?
While debuggability is important, this is too much information to give to an end user. This inform... | Leaked pod metadata across namespaces on preemption | https://api.github.com/repos/kubernetes/kubernetes/issues/114882/comments | 25 | 2023-01-06T21:05:29Z | 2023-08-09T16:17:19Z | https://github.com/kubernetes/kubernetes/issues/114882 | 1,523,167,471 | 114,882 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
A way to drain nodes by adding more pods elsewhere to meet PodDisruptionBudgets.
### Why is this needed?
Currently, when there is a Deployment, it can be configured to have a `maxSurge` to avoid going under the amount of replicas the deployment requires while allowing for a... | maxSurge for node draining or how to meet availability requirements when draining nodes by adding pods | https://api.github.com/repos/kubernetes/kubernetes/issues/114877/comments | 23 | 2023-01-06T16:05:01Z | 2025-03-10T09:59:55Z | https://github.com/kubernetes/kubernetes/issues/114877 | 1,522,803,056 | 114,877 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Currently we validate that `spec.completions` is set when `completionMode=Indexed` for job. I suggest we relax this validation.
This will require the following changes:
1) We need to update the job controller to look at `spec.parallelism` instead of `spec.completions` when... | Elastic Indexed Job | https://api.github.com/repos/kubernetes/kubernetes/issues/114862/comments | 36 | 2023-01-05T20:55:20Z | 2023-07-27T14:17:22Z | https://github.com/kubernetes/kubernetes/issues/114862 | 1,521,408,495 | 114,862 |
[
"kubernetes",
"kubernetes"
] | /kind cleanup
/sig scheduling
`SelectVictimsOnNode` func in the default preemption is complicated, but we don't have any unit tests for it.
https://github.com/kubernetes/kubernetes/blob/2d534e4bea7c7ef412a03c921867d9027f6e489f/pkg/scheduler/framework/plugins/defaultpreemption/default_preemption.go#L137 | Add unit tests for `SelectVictimsOnNode` func in the default preemption | https://api.github.com/repos/kubernetes/kubernetes/issues/114853/comments | 6 | 2023-01-05T16:24:50Z | 2023-06-04T17:50:47Z | https://github.com/kubernetes/kubernetes/issues/114853 | 1,521,016,082 | 114,853 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
`pull-kubernetes-unit`
### Which tests are flaking?
TestCreateHealthcheck/ok_if_response_time_lower_than_custom_timeout
### Since when has it been flaking?
From https://storage.googleapis.com/k8s-triage/index.html?test=TestCreateHealthcheck, since 12/23.
### Testgrid link
... | [Flake Test] TestCreateHealthcheck | https://api.github.com/repos/kubernetes/kubernetes/issues/114852/comments | 7 | 2023-01-05T16:10:40Z | 2023-08-21T12:26:06Z | https://github.com/kubernetes/kubernetes/issues/114852 | 1,520,995,371 | 114,852 |
[
"kubernetes",
"kubernetes"
] | As Jordan pointed out in:
https://github.com/kubernetes/enhancements/pull/3667/files#r1055906242
watchcache treats RV=0 and RV="" the same way, even though it's not what we document:
https://kubernetes.io/docs/reference/using-api/api-concepts/#semantics-for-watch
This should be fixed.
/kind bug
/sig api-mac... | Watchcache doesn't distinguish the RV=0 and RV="" semantic for watches | https://api.github.com/repos/kubernetes/kubernetes/issues/114845/comments | 2 | 2023-01-05T09:26:42Z | 2023-02-21T12:07:57Z | https://github.com/kubernetes/kubernetes/issues/114845 | 1,520,397,896 | 114,845 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Descheduler no longer acts as a separate component, but combines with kube-scheduler. That is, move descheduler functions into kube-scheduler.
### Why is this needed?
Descheduler and kube-scheduler should have consistent perspective about cluster nodes to make consistent d... | move descheduler functions into kube-scheduler | https://api.github.com/repos/kubernetes/kubernetes/issues/114841/comments | 9 | 2023-01-05T08:16:24Z | 2024-01-18T22:59:13Z | https://github.com/kubernetes/kubernetes/issues/114841 | 1,520,297,242 | 114,841 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
https://github.com/kubernetes/kubernetes/pull/113156
The change of this PR has resulted in the exception of the file. The file was originally a symbol file, but now other content has been added, resulting in the exception of the file symbol.
### What did you expect to happen?
Rollback to the co... | CHANGELOG.md: Modified the content of the symbol file | https://api.github.com/repos/kubernetes/kubernetes/issues/114839/comments | 2 | 2023-01-05T07:50:10Z | 2023-01-05T13:32:11Z | https://github.com/kubernetes/kubernetes/issues/114839 | 1,520,261,886 | 114,839 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Replace wesocket package from gorila to
- https://github.com/nhooyr/websocket
### Why is this needed?
gorila websocket has been archived | Gorilla WebSocket has been archived | https://api.github.com/repos/kubernetes/kubernetes/issues/114836/comments | 4 | 2023-01-05T05:18:48Z | 2023-01-06T15:59:25Z | https://github.com/kubernetes/kubernetes/issues/114836 | 1,520,094,160 | 114,836 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
`container_fs_xxx` metrics still has no data on containerd,
Setting `PodAndContainerStatsFromCRI=true` is also not work,but `crictl stats`is ok
### What did you expect to happen?
The container_fs_usage_bytes metric has data.
### How can we reproduce it (as minimally and precisely as possible)... | container_fs_usage_bytes metrics still has no data on containerd | https://api.github.com/repos/kubernetes/kubernetes/issues/114833/comments | 8 | 2023-01-05T02:26:43Z | 2023-01-19T04:24:35Z | https://github.com/kubernetes/kubernetes/issues/114833 | 1,519,928,068 | 114,833 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
In some scheduler plugins, PreScore is implemented to pre-process state before running Score for each node. In some cases, PreScore can decide that Score shouldn't run at all (e.g., no relevant PodTopologySpread constraints), and so it will be useful to have an explicit way to comm... | Allow PreScore to return `Skip` status to skip running the corresponding Score extension | https://api.github.com/repos/kubernetes/kubernetes/issues/114827/comments | 9 | 2023-01-04T21:14:24Z | 2023-02-14T03:13:53Z | https://github.com/kubernetes/kubernetes/issues/114827 | 1,519,579,666 | 114,827 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/92316/pull-kubernetes-unit-experimental/1610708038858051584
```
{Failed === RUN TestEnforceRequirements/Fail_pre-flight_check
[upgrade/config] Making sure the configuration is correct:
[preflight] Running pre-flight checks.
... | kubeadm unit test requires root k8s.io/kubernetes/cmd/kubeadm/app/cmd/upgrade: TestEnforceRequirements/Fail_pre-flight_check | https://api.github.com/repos/kubernetes/kubernetes/issues/114824/comments | 3 | 2023-01-04T19:34:39Z | 2023-01-05T08:52:00Z | https://github.com/kubernetes/kubernetes/issues/114824 | 1,519,476,958 | 114,824 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hey, after upgrading kubernetes from 1.22 to 1.23, I'm experiencing strange service provisioning behavior using nodePort. I'm using kube-proxy (ipvs) + calico + metallb.
If external IP is used by another service type (Loadbalancer - allocated by metallb), then the node owning this IP doesn't liste... | NodePort will not listen on external IP if same IP is used as loadBalancerIP | https://api.github.com/repos/kubernetes/kubernetes/issues/114815/comments | 30 | 2023-01-04T12:50:03Z | 2023-04-28T16:14:18Z | https://github.com/kubernetes/kubernetes/issues/114815 | 1,518,924,487 | 114,815 |
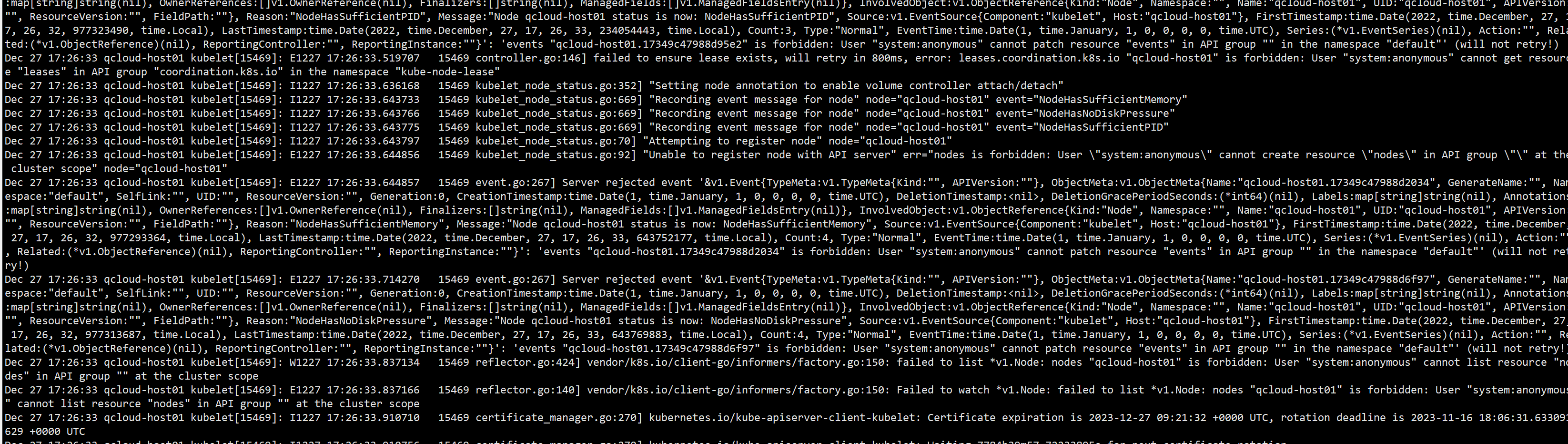
[
"kubernetes",
"kubernetes"
] | ### What happened?
we have setup with three masters node and we got suddenly two masters node went not ready and we can see some issues on the kubelet
Unable to register node "node name" with API server: nodes is forbidden: User "system:anonymous" cannot create resource "nodes" in API group "" at the cluster scope
... | two masters not ready because of the below error Unable to register node "node name" with API server: nodes is forbidden: User "system:anonymous" cannot create resource "nodes" in API group "" at the cluster scope | https://api.github.com/repos/kubernetes/kubernetes/issues/114813/comments | 5 | 2023-01-04T11:57:02Z | 2023-01-05T19:31:47Z | https://github.com/kubernetes/kubernetes/issues/114813 | 1,518,847,631 | 114,813 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Unable to checkpoint a nginx container even after following all the prereq steps.
Followed this blog [Forensic container checkpointing in Kubernetes | Kubernetes](https://kubernetes.io/blog/2022/12/05/forensic-container-checkpointing-alpha/)
### What did you expect to happen?
Ste... | Checkpoint Restoration Failing in kubeadm and minikube | https://api.github.com/repos/kubernetes/kubernetes/issues/114805/comments | 12 | 2023-01-04T09:50:01Z | 2023-04-04T10:11:10Z | https://github.com/kubernetes/kubernetes/issues/114805 | 1,518,658,655 | 114,805 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
As per the change log mentioned [here](https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.24.md#urgent-upgrade-notes), Secret API objects are no longer auto-generated for ServiceAccount. But, when I created ServiceAccount, it created secret object automatically.
Command Us... | ServiceAccount creating Secret Object by default for version greater than v1.22 | https://api.github.com/repos/kubernetes/kubernetes/issues/114799/comments | 10 | 2023-01-04T05:11:40Z | 2023-01-19T03:45:21Z | https://github.com/kubernetes/kubernetes/issues/114799 | 1,518,326,332 | 114,799 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When the topology manager scope is set to `pod`, CPU manager returns a non-preferred hint that crosses NUMA nodes.
Testing environment:
- Node NUMA topology
- Two NUMA nodes:
- NUMA node 0 has two CPU cores
- NUMA node 1 has two CPU cores
- Kubelet config
All of the CPU ... | CPU manager does not seem to return proper topology hints for Pod scope | https://api.github.com/repos/kubernetes/kubernetes/issues/114797/comments | 4 | 2023-01-04T01:44:12Z | 2023-01-04T18:18:34Z | https://github.com/kubernetes/kubernetes/issues/114797 | 1,518,165,064 | 114,797 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
/sig scheduling
`SchedulingMigratedInTreePVs` in the `ci-benchmark-scheduler-perf-master` job is failing.
```
BenchmarkPerfScheduling/SchedulingMigratedInTreePVs/500Nodes
panic: feature "CSIMigration" is not registered in FeatureGate "k8s.io/apiserver/pkg/util/feature/feature_gate.go:28"
... | scheduler_perf: `SchedulingMigratedInTreePVs` is failing | https://api.github.com/repos/kubernetes/kubernetes/issues/114795/comments | 4 | 2023-01-04T00:50:56Z | 2023-01-04T22:30:34Z | https://github.com/kubernetes/kubernetes/issues/114795 | 1,518,124,851 | 114,795 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hi,
I tried to use PodTopologySpreadConstraint to organize our deployment engine, and to spread replicas across zones.
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 4
template:
me... | PodTopologyConstraints - DoNotSchedule not working as expected | https://api.github.com/repos/kubernetes/kubernetes/issues/114788/comments | 22 | 2023-01-03T19:55:00Z | 2024-04-04T17:06:29Z | https://github.com/kubernetes/kubernetes/issues/114788 | 1,517,849,651 | 114,788 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When updating go-oidc, running `update-vendor.sh` failed when looking for licenses; specifically, it was looking for `cloud.google.com/go`’s `LICENSE` file, but that was no longer vendored.
### What did you expect to happen?
Since no `cloud.google.com/go` packages are actually used, the license sh... | update-vendor-licenses.sh doesn't handle submodules in some cases | https://api.github.com/repos/kubernetes/kubernetes/issues/114781/comments | 2 | 2023-01-03T15:54:12Z | 2023-01-03T18:35:48Z | https://github.com/kubernetes/kubernetes/issues/114781 | 1,517,589,633 | 114,781 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
- Label each built-in PriorityClass with `kubernetes.io/bootstrapping`
- Label the built-in FlowSchema _exempt_ with `kubernetes.io/bootstrapping`
- Label the built-in FlowSchema _catch-all_, and PriorityLevelConfiguration _catch-all_ with `kubernetes.io/bootstrapping`
Pick su... | Use `kubernetes.io/bootstrapping` label more | https://api.github.com/repos/kubernetes/kubernetes/issues/114778/comments | 15 | 2023-01-03T14:36:26Z | 2024-05-17T12:34:25Z | https://github.com/kubernetes/kubernetes/issues/114778 | 1,517,478,666 | 114,778 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kubectl apply -f deploy.yaml always show configured even if there is no change.
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: dockerd
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: dockerd
template:
metadata:
labels:
... | Empty string in env of container always causes kubectl apply command show configured. | https://api.github.com/repos/kubernetes/kubernetes/issues/114777/comments | 11 | 2023-01-03T14:20:11Z | 2023-06-14T16:38:54Z | https://github.com/kubernetes/kubernetes/issues/114777 | 1,517,458,136 | 114,777 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We started exporting Kubernetes events into a monitoring system and noticed that some events seem to be out of order (e.g. container started event before container created event). Upon further investigation we concluded that the root cause is the insufficient precision of the event timestamps - the ... | Event timestamps don't support sub-second precision | https://api.github.com/repos/kubernetes/kubernetes/issues/114765/comments | 5 | 2023-01-02T17:18:13Z | 2023-01-02T21:05:34Z | https://github.com/kubernetes/kubernetes/issues/114765 | 1,516,588,114 | 114,765 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In my online kubernetes cluster, kubelet memory keeps growing, finally more than 50G, and kill many low-priority processes with memory.
<img width="1342" alt="image" src="https://user-images.githubusercontent.com/57479557/210139100-e406d2e5-5894-4648-8c60-2936b15db955.png">
I observed goroutines ... | kubelet memory leaks for housekeeping goroutines keeps leakiness | https://api.github.com/repos/kubernetes/kubernetes/issues/114751/comments | 13 | 2022-12-31T14:42:58Z | 2023-06-16T18:07:59Z | https://github.com/kubernetes/kubernetes/issues/114751 | 1,515,133,462 | 114,751 |
[
"kubernetes",
"kubernetes"
] | Kubernetes apiservers are responsible of handling multiple aspects of Services:
- apiservers run a reconcile loop to maintain the special `kubernetes.default` Service, that uses the first address of the configured primary Service CIDR
- apiservers assign `ClusterIP` to Services by sharing a bitmap that is snapshoted ... | Inconsistent behavior using multiple api-servers with different ServiceCIDRs | https://api.github.com/repos/kubernetes/kubernetes/issues/114743/comments | 7 | 2022-12-29T20:23:18Z | 2025-02-27T17:29:10Z | https://github.com/kubernetes/kubernetes/issues/114743 | 1,514,030,211 | 114,743 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Dec 29 14:46:20 qcloud-host01 kube-apiserver[1146]: I1229 14:46:20.304807 1146 shared_informer.go:280] Caches are synced for crd-autoregister
Dec 29 14:46:20 qcloud-host01 kube-apiserver[1146]: I1229 14:46:20.304845 1146 shared_informer.go:280] Caches are synced for cluster_authentication_tru... | kube-apiserver error log | https://api.github.com/repos/kubernetes/kubernetes/issues/114735/comments | 7 | 2022-12-29T06:53:58Z | 2023-05-28T14:22:24Z | https://github.com/kubernetes/kubernetes/issues/114735 | 1,513,440,414 | 114,735 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When graceful node shutdown is triggered, kubelet will taint the node with "not-ready", set "spec.unschedulable" to true, and set running pods' phase to "Failed" (I'm using 1.23.6 and 1.24 where the phase will be set to "Failed" according to https://github.com/kubernetes/kubernetes/pull/106900).
... | Pods keep being created by Deployment with match-all "NoSchedule" toleration until node shutdown when using graceful node shutdown | https://api.github.com/repos/kubernetes/kubernetes/issues/114729/comments | 12 | 2022-12-28T21:26:15Z | 2023-06-05T05:51:49Z | https://github.com/kubernetes/kubernetes/issues/114729 | 1,513,180,179 | 114,729 |
[
"kubernetes",
"kubernetes"
] | https://github.com/kubernetes/kubernetes/blob/7eb9a75bf914428e7579d2497722f71be3ef1812/test/integration/auth/auth_test.go#L1228
Question is whether we should consider namespace == "" as default ?
/sig testing | FIXME tag in authentication testing | https://api.github.com/repos/kubernetes/kubernetes/issues/114727/comments | 6 | 2022-12-28T17:35:00Z | 2023-05-28T02:17:23Z | https://github.com/kubernetes/kubernetes/issues/114727 | 1,513,013,578 | 114,727 |
[
"kubernetes",
"kubernetes"
] | https://github.com/kubernetes/kubernetes/blob/7eb9a75bf914428e7579d2497722f71be3ef1812/staging/src/k8s.io/apiserver/pkg/admission/plugin/validatingadmissionpolicy/admission_test.go#L255
https://github.com/kubernetes/kubernetes/blob/7eb9a75bf914428e7579d2497722f71be3ef1812/staging/src/k8s.io/apiserver/pkg/admission/p... | Found some FIXME in validatingadmissionpolicy testing file | https://api.github.com/repos/kubernetes/kubernetes/issues/114726/comments | 9 | 2022-12-28T17:18:22Z | 2023-02-03T20:14:31Z | https://github.com/kubernetes/kubernetes/issues/114726 | 1,512,998,041 | 114,726 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When a LoadBalancer Service with Local ExternalTrafficPolicy was deleted normally, an error log "use of closed network connection" was always generated in kube-proxy log, which confused people that there was something wrong:
```
I1228 13:20:27.757127 1 server.go:432] "Using lenient decoding ... | Deleting LoadBalancer Services with Local ExternalTrafficPolicy always generated errors in kube-proxy log | https://api.github.com/repos/kubernetes/kubernetes/issues/114723/comments | 2 | 2022-12-28T13:37:45Z | 2023-01-11T18:31:47Z | https://github.com/kubernetes/kubernetes/issues/114723 | 1,512,807,111 | 114,723 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hello,
we wan't to implement the X509 Authentication to different Kubernetes Clsuters.
For this we followed and automated the kubeconfig creation like docuemnted on this Blog.
https://betterprogramming.pub/k8s-tips-give-access-to-your-clusterwith-a-client-certificate-dfb3b71a76fe
so this ... | X509 Authentication to multiple Clusters | https://api.github.com/repos/kubernetes/kubernetes/issues/114720/comments | 18 | 2022-12-28T07:50:10Z | 2023-06-02T14:30:38Z | https://github.com/kubernetes/kubernetes/issues/114720 | 1,512,513,654 | 114,720 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
## The control plane fails to be initialized. Procedure
- When I am through the browser to https://10.1.6.215:16443/healthz? At timeout=10s, the browser returned ok
- Kubectl Version 1.22.10
## This is kubeadm.conf
```yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- sys... | The control plane fails to be initialized. Procedure | https://api.github.com/repos/kubernetes/kubernetes/issues/114718/comments | 4 | 2022-12-28T06:06:35Z | 2022-12-28T07:53:29Z | https://github.com/kubernetes/kubernetes/issues/114718 | 1,512,437,639 | 114,718 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The many times I have tried to create a highly available cluster using `kubeadm init --config kubeadm-config.yaml` --upload-certs, I have encountered the following problems
## This is the bug report I presented
1. Looks like there's no link to api.k8s.verbos.com
2. I use Keepalived+Haproxy to ... | Problems with creating a high availability cluster using Kubeadm | https://api.github.com/repos/kubernetes/kubernetes/issues/114716/comments | 5 | 2022-12-27T14:49:34Z | 2022-12-28T01:23:56Z | https://github.com/kubernetes/kubernetes/issues/114716 | 1,511,871,907 | 114,716 |
[
"kubernetes",
"kubernetes"
] | ### What happened?


cilium as CNI (without kube-proxy)
a local docker image repo.
I followed https://v1-24.docs.kubernetes.io/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
to upgra... | etcd CrashLoopBackOff updating kuber 1.23.9 to 1.24.8 | https://api.github.com/repos/kubernetes/kubernetes/issues/114686/comments | 4 | 2022-12-24T12:31:42Z | 2022-12-24T13:47:18Z | https://github.com/kubernetes/kubernetes/issues/114686 | 1,510,078,960 | 114,686 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
## Some context
Sometimes we want to add some env vars but they must be generated just before the container start.
For example Hashicorp Vault let us define the enironment variables by adding some annotations (cf. sources).
Then it will create an init container to pull all... | Add FileEnvSource and FileKeySelector to add environment generated on the fly | https://api.github.com/repos/kubernetes/kubernetes/issues/114674/comments | 38 | 2022-12-23T10:04:27Z | 2024-04-29T23:24:05Z | https://github.com/kubernetes/kubernetes/issues/114674 | 1,509,146,661 | 114,674 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In kubelet log,
```
kubelet[2476321]: reservedCpus: 0-4
...
[cpumanager] reserved 5 CPUs ("0-2,24-25") not available for exclusive assignment
```
### What did you expect to happen?
reservedCpus: 0-4
the log should be:
```
policy_static.go:109] [cpumanager] reserved 5 CPUs ("0-4") ... | reservedCpus: 0-4 reserved cpu 0-2,24-25 on a node with 48 cores | https://api.github.com/repos/kubernetes/kubernetes/issues/114673/comments | 4 | 2022-12-23T09:53:31Z | 2022-12-23T11:17:33Z | https://github.com/kubernetes/kubernetes/issues/114673 | 1,509,136,107 | 114,673 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
apiserver startup failed once with the following error:
```
W1222 04:26:28.508357 1 feature_gate.go:237] Setting GA feature gate ServerSideApply=false. It will be removed in a future release.
W1222 04:26:28.508422 1 feature_gate.go:237] Setting GA feature gate StorageObjectInUseProtec... | apiserver fatal error: found bad pointer in Go heap (incorrect use of unsafe or cgo?) | https://api.github.com/repos/kubernetes/kubernetes/issues/114671/comments | 7 | 2022-12-23T02:16:26Z | 2022-12-27T03:09:51Z | https://github.com/kubernetes/kubernetes/issues/114671 | 1,508,788,592 | 114,671 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Create a service [without selectors](https://kubernetes.io/docs/concepts/services-networking/service/#services-without-selectors), and manually create an Endpoints with an external IP address.
Access the service proxy, it fails with 503, "no endpoints available for service ...".
### What did y... | Services proxy does not work when selector is absent | https://api.github.com/repos/kubernetes/kubernetes/issues/114670/comments | 12 | 2022-12-22T23:27:23Z | 2022-12-23T20:34:03Z | https://github.com/kubernetes/kubernetes/issues/114670 | 1,508,668,337 | 114,670 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
It was observed that on the following scenario: [pod-A] => [service-B] => [pod-B]
- If pod-B restarts usually pod-A starts a UDP flow at a rate of ~1pkt/s
- Sometimes the connection get stuck without executing the service-B DNAT rule to reach pod-B
I dont have access to the real tenant's a... | UDP connection can get stuck and not reaching a service's pod if initiated during this pod restart | https://api.github.com/repos/kubernetes/kubernetes/issues/114668/comments | 8 | 2022-12-22T19:46:04Z | 2023-05-24T12:36:14Z | https://github.com/kubernetes/kubernetes/issues/114668 | 1,508,456,903 | 114,668 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
#112824 added an E2E test that assumes that a service named "kube-dns" exists in the "kube-system" namespace. This is a kubeadm-ism, and the test fails if the cluster DNS is not configured the way kubeadm configures it.
Although this E2E test isn't a conformance test, making it functi... | E2E test for for ExpandedDNSConfig has a kubeadm-ism | https://api.github.com/repos/kubernetes/kubernetes/issues/114666/comments | 3 | 2022-12-22T18:52:56Z | 2022-12-23T12:11:28Z | https://github.com/kubernetes/kubernetes/issues/114666 | 1,508,397,693 | 114,666 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm seeing this error when posting an update to the kubernetes API:
`Invalid value: "object": internal error: runtime error: index out of range [3] with length 3 evaluating rule: <rule name>`
### What did you expect to happen?
No error
### How can we reproduce it (as minimally and precis... | CEL: Invalid value: "object": internal error: runtime error: index out of range [3] with length 3 evaluating rule: <rule name> | https://api.github.com/repos/kubernetes/kubernetes/issues/114661/comments | 10 | 2022-12-22T17:11:28Z | 2023-01-05T23:30:11Z | https://github.com/kubernetes/kubernetes/issues/114661 | 1,508,250,715 | 114,661 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
In shared_informer.go, when the resources are fetched from API Server, they are always cached in Memory and there is no mechanism to control that store.
```
func NewSharedIndexInformer(lw ListerWatcher, exampleObject runtime.Object, defaultEventHandlerResyncPeriod time.Duratio... | Unable to Set External Store in client-go | https://api.github.com/repos/kubernetes/kubernetes/issues/114659/comments | 14 | 2022-12-22T15:37:00Z | 2024-03-26T20:16:43Z | https://github.com/kubernetes/kubernetes/issues/114659 | 1,508,097,378 | 114,659 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Pod having `nodeName: master-node` in spec got scheduled on master node that has `NoSchedule` taints. Documentation at https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#nodename doesn't specify such behavior. Also I didn't found anything in taints doc https://kubernetes.io/doc... | Scheduler ignores taints when nodeName field is specified | https://api.github.com/repos/kubernetes/kubernetes/issues/114654/comments | 7 | 2022-12-22T10:00:24Z | 2022-12-24T19:37:36Z | https://github.com/kubernetes/kubernetes/issues/114654 | 1,507,578,296 | 114,654 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm testing my CSI with a simple write and read workload. When I deleting my workload and PVC I encountered this error.
```
failed to unmount target "/var/lib/kubelet/pods/ec76e28e-a164-4384-abfd-796a8559017a/volumes/kubernetes.io~csi/pvc-7dab7d1f-466a-42ca-81e7-29a9306f9145/mount": remove /var/... | CSI can not cleanup mount path due to container writes to this path after the volume is unmonted. | https://api.github.com/repos/kubernetes/kubernetes/issues/114652/comments | 6 | 2022-12-22T07:24:57Z | 2023-05-21T08:14:18Z | https://github.com/kubernetes/kubernetes/issues/114652 | 1,507,390,484 | 114,652 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The job failure back-off parameters are computed based on the [hardcoded constants in job controller](https://github.com/kubernetes/kubernetes/blob/a6d66d15f691cb6473f1361caed08e5bd7eae68b/pkg/controller/job/job_controller.go#L75-L77). There is no way to override these back-off parameters at Job lev... | Job failure back-off delay and limit are not configurable | https://api.github.com/repos/kubernetes/kubernetes/issues/114651/comments | 27 | 2022-12-22T03:33:20Z | 2025-03-10T17:52:06Z | https://github.com/kubernetes/kubernetes/issues/114651 | 1,507,207,885 | 114,651 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Exponential back-off kicks in when a pod fails. The back-off logic is offloaded to the in-memory `workqueue` data structure. On controller-manager restarts, the information in the `workqueue` is lost. So, the back-off information is lost and the back-off gets calculated as if the job is a new one.
... | Job back-offs get reset on controller-manager restart | https://api.github.com/repos/kubernetes/kubernetes/issues/114650/comments | 10 | 2022-12-22T03:16:09Z | 2023-04-24T17:52:14Z | https://github.com/kubernetes/kubernetes/issues/114650 | 1,507,194,870 | 114,650 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm trying to use the [KubeletConfiguration](https://pkg.go.dev/k8s.io/kubernetes/pkg/kubelet/apis/config#KubeletConfiguration) object to generate a kubelet configuration file. I created the KubeletConfiguration object, then marshalled it into a json string (stored in a file). When we try to start k... | KubeletConfiguration does not marshal into a useable form | https://api.github.com/repos/kubernetes/kubernetes/issues/114644/comments | 11 | 2022-12-21T16:00:26Z | 2023-01-31T21:20:40Z | https://github.com/kubernetes/kubernetes/issues/114644 | 1,506,541,965 | 114,644 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Some of the alpha features for cpu manager, specifically the distribute-cpus-across-numa and the align-by-socket are not working together, when they should in theory.
To give some context, my system has two sockets, each one of which has two NUMA nodes, for a total of 4 NUMA nodes:
.
https://kubernetes.io/docs/reference/using-api/server-side-apply/#merge-strategy
<img width="909" alt... | CRD Validation allows set of atomic maps, but should it? | https://api.github.com/repos/kubernetes/kubernetes/issues/114613/comments | 21 | 2022-12-20T18:56:24Z | 2025-02-06T21:21:08Z | https://github.com/kubernetes/kubernetes/issues/114613 | 1,505,102,094 | 114,613 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
https://prow.k8s.io/job-history/gs/kubernetes-jenkins/pr-logs/directory/pull-kubernetes-integration
### Which tests are flaking?
test-cmd: run_wait_tests
### Since when has it been flaking?
Dec 20 2022, 14:53:53 UTC+0100
### Testgrid link
_No response_
### Reason for failure (if poss... | [Flaky test] test-cmd: run_wait_tests | https://api.github.com/repos/kubernetes/kubernetes/issues/114610/comments | 1 | 2022-12-20T16:07:24Z | 2022-12-20T21:17:26Z | https://github.com/kubernetes/kubernetes/issues/114610 | 1,504,819,749 | 114,610 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In rare cases, I'm seeing the GC deleting a DaemonSet with a valid ownerReference. This issue looks like a time-of-check/time-of-use error in the garbage collector, although I'm unsure from the docs what behavior to expect.
I'm using a tool similar to `kubectl apply --prune`, called `synk`, excep... | Garbage collector deletes DaemonSet after updating ownerReference and deleting previous owner | https://api.github.com/repos/kubernetes/kubernetes/issues/114603/comments | 25 | 2022-12-20T11:19:46Z | 2024-08-16T21:04:36Z | https://github.com/kubernetes/kubernetes/issues/114603 | 1,504,397,481 | 114,603 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I wanted to use java client to update my networkpolicies, but found this
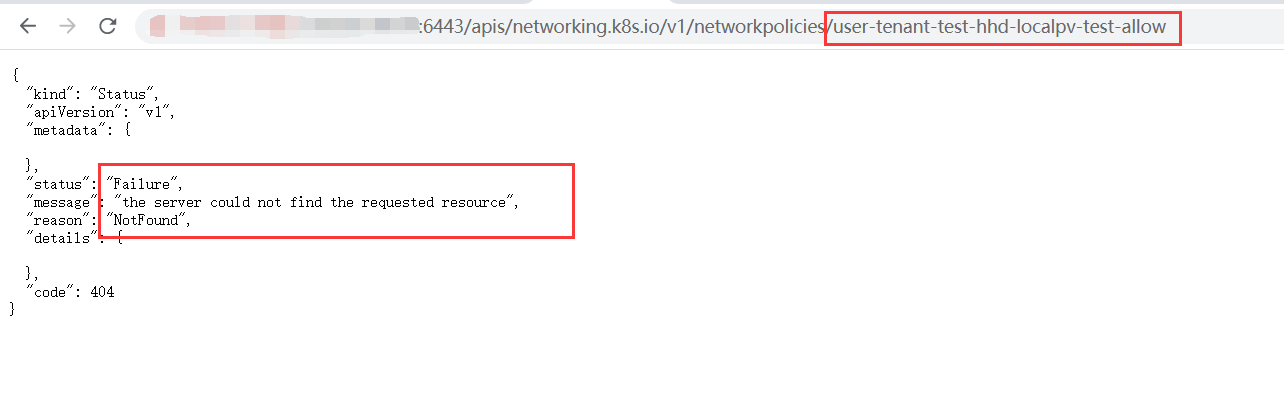
my code
:
error during connection attempt: dial tcp :0->172.16.1.11:6783: connect: connection refused
### What did you expect to happen?
To make cni work properly on all nodes
### How can we reproduce it (as minimally and precisely as possi... | cni/proxy worker nodes pods: error during connection attempt: dial tcp :0->172.16.1.11:6783: connect: connection refused | https://api.github.com/repos/kubernetes/kubernetes/issues/114599/comments | 5 | 2022-12-20T07:18:12Z | 2022-12-22T19:45:44Z | https://github.com/kubernetes/kubernetes/issues/114599 | 1,504,098,587 | 114,599 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have a test pod, which has a piece of golang code to create ephemeral containers. It works fine to create the first ephe container, then I stop this ephe container. However, it is failed to create the second ephe container under the same code flow.
Containers:
testpod:
Container ID: c... | Failed to create additional ephemeral containers | https://api.github.com/repos/kubernetes/kubernetes/issues/114593/comments | 6 | 2022-12-20T00:15:52Z | 2022-12-21T06:02:04Z | https://github.com/kubernetes/kubernetes/issues/114593 | 1,503,805,355 | 114,593 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
This feature is excellent; Could the following improvement be considered?
- `kubectl` support so we can more easily automate a solution
- need to support additional parameters to influence CRIU and to be able to store the image in a registry
-- We needed to pass the `file-loc... | Checkpoint/Forensic container checkpointing Feature Enhancement request | https://api.github.com/repos/kubernetes/kubernetes/issues/114591/comments | 10 | 2022-12-19T23:06:17Z | 2023-07-06T22:27:51Z | https://github.com/kubernetes/kubernetes/issues/114591 | 1,503,734,448 | 114,591 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We bootstrap our clusters with kubeadm (through clusterapi), but provide our own end certs to shorten the certificate validity period.
Because of the shortened validity period, we rotate the file-based endcerts frequently. Recently we started noticing that after performing a certificate rotation,... | kube-apiserver doesn't reload the kubelet client certificate/key on each logs query | https://api.github.com/repos/kubernetes/kubernetes/issues/114588/comments | 12 | 2022-12-19T18:46:12Z | 2023-02-07T15:01:16Z | https://github.com/kubernetes/kubernetes/issues/114588 | 1,503,403,996 | 114,588 |
[
"kubernetes",
"kubernetes"
] | I have no idea who to report this bug to, so I'm going to duplicate the report a few places.
local-path-provisioner: https://github.com/rancher/local-path-provisioner/issues/287
core-dump-handler: https://github.com/IBM/core-dump-handler/issues/119
### What happened?
I'm running [core-dump-handler](https://gith... | same directory is bind-mounted 32767 times | https://api.github.com/repos/kubernetes/kubernetes/issues/114583/comments | 6 | 2022-12-19T15:02:26Z | 2023-05-18T21:45:31Z | https://github.com/kubernetes/kubernetes/issues/114583 | 1,503,106,161 | 114,583 |
[
"kubernetes",
"kubernetes"
] |
[kubelet-journal-1.txt](https://github.com/kubernetes/kubernetes/files/10260987/kubelet-journal-1.txt)
### What happened?
After reboot and cleanup of containerd, One of the Control-plane node is not coming up.
```
NAME STATUS ROLES AGE VERSION
node1 NotReady control-plane 20d v... | Unable to register node with API server" err="Post "https://127.0.0.1:6443/api/v1/nodes\": dial tcp 127.0.0 | https://api.github.com/repos/kubernetes/kubernetes/issues/114582/comments | 7 | 2022-12-19T14:20:49Z | 2022-12-20T19:21:23Z | https://github.com/kubernetes/kubernetes/issues/114582 | 1,503,046,169 | 114,582 |
[
"kubernetes",
"kubernetes"
] | Both:
LoadBalancers should be able to change the type and ports of a TCP service [Slow]
LoadBalancers should be able to change the type and ports of a UDP service [Slow]
started failing on 5k-node tests on Dec 14th.
This is most probably some test-related change that was merged around that time.
@kubernetes/... | LoadBalancer tests started failing at 5k-node tests | https://api.github.com/repos/kubernetes/kubernetes/issues/114577/comments | 6 | 2022-12-19T12:02:06Z | 2022-12-20T15:51:05Z | https://github.com/kubernetes/kubernetes/issues/114577 | 1,502,825,772 | 114,577 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
(This isn't a bug report, but I couldn't find a more appropriate category.)
The k8s Go source code contains a number of places where printf-like functions are called with arguments of the wrong type. Ordinarily, the 'go vet' tool would point out such mistakes, but unfortunately it's not smart e... | suggested code change to enable 'go vet' to report printf mistakes in the source | https://api.github.com/repos/kubernetes/kubernetes/issues/114568/comments | 19 | 2022-12-18T22:22:34Z | 2023-11-07T17:12:05Z | https://github.com/kubernetes/kubernetes/issues/114568 | 1,502,055,041 | 114,568 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
After reboot of Machines on one node and Absence of snapshots folders
➜ ~ kubectl get po --namespace=kube-system -l component=kube-scheduler
```
NAME READY STATUS RESTARTS AGE
kube-scheduler-node1 0/1 CrashLoopBackOff 23 (58m ago) 55m
kub... | kube-scheduler: failed to create containerd container: failed to create prepare snapshot dir : stat /data/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots: no such file or directory Warning BackOff kubelet Back-off restarting failed container | https://api.github.com/repos/kubernetes/kubernetes/issues/114562/comments | 5 | 2022-12-18T11:54:50Z | 2022-12-18T23:13:51Z | https://github.com/kubernetes/kubernetes/issues/114562 | 1,501,876,884 | 114,562 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I've had ns.yaml file defined like this:
```
apiVersion: v1
kind: Namespace
metadata:
name: test-ns
```
Running `kubectl delete -f ns.yaml`, triggered deletion of namespace, even though namespace had `finalizers`. Command `kubectl delete ns test-ns` would be blocked, but is it possible ... | Deletion of namespace possible when deleting manifest without finalizers | https://api.github.com/repos/kubernetes/kubernetes/issues/114561/comments | 6 | 2022-12-18T10:31:10Z | 2023-01-31T21:20:49Z | https://github.com/kubernetes/kubernetes/issues/114561 | 1,501,853,478 | 114,561 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The cluster currently has more than 200 machines
The last machine network components report the following errors
Error registering network failed to acquire lease node pod cidr not assigned
### What did you expect to happen?
The network components are normal, and the nodes that are joined are n... | pod cidr not assigned | https://api.github.com/repos/kubernetes/kubernetes/issues/114560/comments | 18 | 2022-12-18T06:02:39Z | 2023-01-19T17:33:13Z | https://github.com/kubernetes/kubernetes/issues/114560 | 1,501,763,298 | 114,560 |
[
"kubernetes",
"kubernetes"
] | Cloud-providers started to move out of tree its controller, but they share some functionalities, one of them is the NodeIPAM controller.
There is a type that is GCE specific, the `CloudAllocator` type.
If this type is used, but no configuration for GCE is passed, the kcm panics.
This can be observed in the f... | NodeIPAM CloudAllocator Type on KCM panics when using external cloud provider | https://api.github.com/repos/kubernetes/kubernetes/issues/114556/comments | 8 | 2022-12-17T17:20:20Z | 2022-12-22T00:33:27Z | https://github.com/kubernetes/kubernetes/issues/114556 | 1,501,483,169 | 114,556 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I am using kube-router for CNI. After upgrading a node to Fedora CoreOS 37, the node loses network connectivity immediately kube-router starts. This works correctly in Fedora CoreOS 36.
The critical configuration difference between a CoreOS 36 (working) and CoreOS 37 (not working) node seems to b... | kubelet(?) generates incorrect KUBE-FIREWALL default rule (no mark) | https://api.github.com/repos/kubernetes/kubernetes/issues/114549/comments | 4 | 2022-12-16T23:27:48Z | 2022-12-16T23:37:22Z | https://github.com/kubernetes/kubernetes/issues/114549 | 1,500,998,652 | 114,549 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
After installing single node cluster with Calico CNI, removing taints on control-plane node, coreDNS fails to start with this event on kubelet:
```
Error: failed to create containerd task: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process:... | CoreDNS fails on installation with kubeadm | https://api.github.com/repos/kubernetes/kubernetes/issues/114547/comments | 10 | 2022-12-16T19:17:48Z | 2022-12-19T09:59:22Z | https://github.com/kubernetes/kubernetes/issues/114547 | 1,500,741,273 | 114,547 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A status of Pod mounted NFS PV remain as terminating when a node shutdown and restart.
### What did you expect to happen?
A Pod is completely terminated.
### How can we reproduce it (as minimally and precisely as possible)?
### Summary
- Deploy a Pod mounted NFS PV
- Shutdown the node where ... | Pod terminating stuck because of trying to umount not actual mounted dir | https://api.github.com/repos/kubernetes/kubernetes/issues/114546/comments | 12 | 2022-12-16T17:38:58Z | 2023-04-24T20:25:33Z | https://github.com/kubernetes/kubernetes/issues/114546 | 1,500,614,788 | 114,546 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I am setting up Kubernetes cluster monitoring with Prometheus. I am using the kube-prometheus-stack Helm chart available at https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack. I find that it cannot access many of the `kube-*` services running in the `kube-syst... | Prometheus cannot access/scrape kube-* services on master nodes | https://api.github.com/repos/kubernetes/kubernetes/issues/114543/comments | 9 | 2022-12-16T16:01:17Z | 2024-12-18T12:26:12Z | https://github.com/kubernetes/kubernetes/issues/114543 | 1,500,481,980 | 114,543 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
From *v1.22.10*, we can't use `ExternalName` services in `MutatingWebhookConfiguration` anymore.
I deployed versions *1.22.9* and *1.22.10* with *k3d* and these are my results.
With *1.22.9*:
```
$ export KUBECONFIG=~/.k3d/kubeconfig-1.22.9.yaml
$ kubectl run --image bash bash
Error from s... | Unable to use ExternalName services in MutatingWebhookConfiguration | https://api.github.com/repos/kubernetes/kubernetes/issues/114541/comments | 6 | 2022-12-16T15:13:05Z | 2023-03-29T07:15:58Z | https://github.com/kubernetes/kubernetes/issues/114541 | 1,500,397,533 | 114,541 |
[
"kubernetes",
"kubernetes"
] | [root@localhost js]# kubectl describe pod mch-3786062652-9rz26
Name: mch-3786062652-9rz26
Namespace: default
Node: 192.168.215.136/192.168.215.136
Start Time: Fri, 16 Dec 2022 21:55:33 +0800
Labels: pod-template-hash=3786062652
run=mch
Status: Pending
IP:
Controllers: ReplicaSet/mch-3786062652
Contain... | Why is the k8s node node always ContainerCreating, how to run it, it took an afternoon, but still can't solve it | https://api.github.com/repos/kubernetes/kubernetes/issues/114539/comments | 6 | 2022-12-16T14:28:58Z | 2022-12-22T19:44:17Z | https://github.com/kubernetes/kubernetes/issues/114539 | 1,500,323,374 | 114,539 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hi everyone;
I set up a ClusterIP service that targets an UDP port 6667, and I created a pod that receives UDP packets on that port. A client within the cluster (not inside of any container) sends UDP packets to port and ip of the service.
Anyway the pod never receives the packets.
I made a li... | UDP service ClusterIP not working | https://api.github.com/repos/kubernetes/kubernetes/issues/114538/comments | 9 | 2022-12-16T13:54:54Z | 2023-05-19T10:47:22Z | https://github.com/kubernetes/kubernetes/issues/114538 | 1,500,255,919 | 114,538 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kube-proxy generates the wrong iptables dnat rule, as shown following:
```
[root@controller-node-1 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.233.0.1 <none> 443/TCP 3h18m
my-dep ClusterIP 10.233.... | kube-proxy generates the wrong iptables dnat rule | https://api.github.com/repos/kubernetes/kubernetes/issues/114537/comments | 27 | 2022-12-16T11:38:58Z | 2023-01-16T06:54:44Z | https://github.com/kubernetes/kubernetes/issues/114537 | 1,500,062,445 | 114,537 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hi All,
I am installing kubernetes 1.26 with calico v3.24.5. kubernetes and calico can be installed successfully but kubernetes DNS and calico controller failed to be created the error is:
Warning FailedCreatePodSandBox 6s kubelet Failed to create pod sandbox: rpc error: code... | tls: server chose an unconfigured cipher suite | https://api.github.com/repos/kubernetes/kubernetes/issues/114529/comments | 8 | 2022-12-16T06:48:06Z | 2022-12-24T15:37:11Z | https://github.com/kubernetes/kubernetes/issues/114529 | 1,499,690,259 | 114,529 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
/sig Network
Using the command kubectl port-forward --namespace=ingress-nginx deployment/ingress-nginx-controller 8080:80.
When iam trying make a post request to localhost at **curl -X POST http://0.0.0.0:8080/ric/v1/startsubscription/kpm/**
getting the below error: -
Handling connection... | uid : exit status 1: 2022/12/15 22:48:30 socat[2186711] E getaddrinfo("localhost", "NULL", {1,2,1,6}, {}): Temporary failure in name resolution | https://api.github.com/repos/kubernetes/kubernetes/issues/114512/comments | 12 | 2022-12-15T17:54:04Z | 2024-01-19T12:53:03Z | https://github.com/kubernetes/kubernetes/issues/114512 | 1,498,856,259 | 114,512 |
[
"kubernetes",
"kubernetes"
] | Table-driven tests are awesome, but they can be very verbose and obscure what's actually being tested in each case. This issue is for stateful set in particular but the same pattern could be applied in many places.
Example test today - pkg/apis/apps/validation/validation_test.go. We find large blocks like:
```
... | test simplification needed: statefulset | https://api.github.com/repos/kubernetes/kubernetes/issues/114511/comments | 10 | 2022-12-15T17:52:54Z | 2023-07-06T04:26:30Z | https://github.com/kubernetes/kubernetes/issues/114511 | 1,498,854,493 | 114,511 |
[
"kubernetes",
"kubernetes"
] | #108829 changed the default behavior of scheduler framework's `RunFilterPlugins` - from stopping at the first failed filter to always running all filters. This change breaks Cluster Autoscaler at scale. Cluster Autoscaler imports the scheduler framework to simulate filters on artificial nodes. In a (pretty common) one-... | kube-scheduler: Bring back the ability to stop at the first failed filter | https://api.github.com/repos/kubernetes/kubernetes/issues/114509/comments | 21 | 2022-12-15T16:41:47Z | 2023-03-22T01:05:05Z | https://github.com/kubernetes/kubernetes/issues/114509 | 1,498,758,723 | 114,509 |
[
"kubernetes",
"kubernetes"
] | Other components allowed to change log level at runtime.
https://groups.google.com/a/kubernetes.io/g/dev/c/-AR7YKViP6Y/m/GVKiProsAwAJ?utm_medium=email&utm_source=footer
Supporting this in scheduler is useful for debugging live issues without scheduling restarts. We should follow the same pattern and allow to chan... | More control over kube-scheduler log level at runtime via HTTP | https://api.github.com/repos/kubernetes/kubernetes/issues/114507/comments | 18 | 2022-12-15T15:08:03Z | 2023-07-15T09:11:37Z | https://github.com/kubernetes/kubernetes/issues/114507 | 1,498,603,562 | 114,507 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have kubernetes 1.24.7. I tried to use `feature-gates=LocalStorageCapacityIsolationFSQuotaMonitoring=true` on `xfs` formated volume. It works until first reboot. After reboot, I get messages:
```
Warning FailedMount 11m kubelet MountVolume.SetUp failed... | failed attempt to reassign project ID | https://api.github.com/repos/kubernetes/kubernetes/issues/114506/comments | 6 | 2022-12-15T14:14:21Z | 2023-03-10T06:42:41Z | https://github.com/kubernetes/kubernetes/issues/114506 | 1,498,516,152 | 114,506 |
[
"kubernetes",
"kubernetes"
] | :information_source: This issue tracks https://github.com/kubernetes/website/issues/30764 for visibility.
Please make updates to that issue instead of this one.
(if the story here changes, we / I can update this issue description) | Unusual official annotation: `api-approved.kubernetes.io` | https://api.github.com/repos/kubernetes/kubernetes/issues/114499/comments | 5 | 2022-12-15T00:45:10Z | 2024-04-16T20:11:02Z | https://github.com/kubernetes/kubernetes/issues/114499 | 1,497,617,188 | 114,499 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
For 1.27 we should graduate the ReadWriteOncePod feature to beta.
### Why is this needed?
This is needed to rollout the feature to GA. In beta this feature will support preemption of pods using `ReadWriteOncePod` PVCs. See: https://github.com/kubernetes/kubernetes/pull/114051 | [v1.27] Graduate the ReadWriteOncePod feature to beta | https://api.github.com/repos/kubernetes/kubernetes/issues/114493/comments | 2 | 2022-12-14T18:22:32Z | 2023-02-15T00:35:44Z | https://github.com/kubernetes/kubernetes/issues/114493 | 1,497,164,588 | 114,493 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When I run on my M1 Mac
```
docker pull registry.k8s.io/cloud-controller-manager:v1.15.12
docker inspect registry.k8s.io/cloud-controller-manager:v1.15.12 | grep Architecture
"Architecture": "amd64",
```
it returns wrong amd64 manifest instead of arm64 for my M1 Mac
### What did you e... | cloud-controller-manager image has no valid multiarch manifest | https://api.github.com/repos/kubernetes/kubernetes/issues/114491/comments | 19 | 2022-12-14T12:41:56Z | 2024-07-28T19:02:43Z | https://github.com/kubernetes/kubernetes/issues/114491 | 1,496,554,563 | 114,491 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
```
Dec 14 14:00:49 WIZPRESSO-13-linux k0s[1984674]: time="2022-12-14 14:00:49" level=info msg="I1214 14:00:49.732984 761087 reconciler.go:346] \"attacherDetacher.AttachVolume started\" volume=<" component=kube-controller-manager
Dec 14 14:00:49 WIZPRESSO-13-linux k0s[1984674]: time="2022-12-14 1... | AttachVolume could crash kube-controller-manager if volume metadata is too long | https://api.github.com/repos/kubernetes/kubernetes/issues/114483/comments | 6 | 2022-12-14T06:14:56Z | 2023-04-06T10:07:50Z | https://github.com/kubernetes/kubernetes/issues/114483 | 1,495,795,016 | 114,483 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
cos-cgroupv2-containerd-node-e2e-serial is failing. https://testgrid.k8s.io/sig-node-containerd#cos-cgroupv2-containerd-node-e2e-serial
Example: https://prow.k8s.io/view/gs/kubernetes-jenkins/logs/ci-cos-cgroupv2-containerd-node-e2e-serial/1602401700964995072
```
I1212 20:47:35.224] ERROR: ... | cos-cgroupv2-containerd-node-e2e-serial failing after feature gate was GA'd | https://api.github.com/repos/kubernetes/kubernetes/issues/114475/comments | 5 | 2022-12-14T02:18:12Z | 2022-12-14T13:05:37Z | https://github.com/kubernetes/kubernetes/issues/114475 | 1,495,488,795 | 114,475 |
[
"kubernetes",
"kubernetes"
] | https://github.com/kubernetes/enhancements/pull/3449 | 【cronjob】Add a new condition when a cronjob controller encounters an invalid time zone. | https://api.github.com/repos/kubernetes/kubernetes/issues/114474/comments | 13 | 2022-12-14T00:29:23Z | 2024-02-18T19:58:18Z | https://github.com/kubernetes/kubernetes/issues/114474 | 1,495,375,954 | 114,474 |
[
"kubernetes",
"kubernetes"
] | When I check the status of the Kubelet service, this is the error it gives me.
> ● kubelet.service - kubelet: The Kubernetes Node Agent
> Loaded: loaded (/lib/systemd/system/kubelet.service; enabled; vendor preset: enabled)
> Drop-In: /etc/systemd/system/kubelet.service.d
> └─10-kubeadm.conf... | Kubelet Service does not start | https://api.github.com/repos/kubernetes/kubernetes/issues/114473/comments | 5 | 2022-12-13T22:05:40Z | 2023-01-03T15:09:26Z | https://github.com/kubernetes/kubernetes/issues/114473 | 1,495,237,646 | 114,473 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.