
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | Many people use `exec` to run `sleep` in their container. This works, but it's kludgey and requirtes them to have a sleep binary in the image. We should offer sleep as a first-class thing.
I hacked up a quick POC. This is obviopusly incomplete (no tests, no feature gate, poor API docs, etc) but could be a startin... | pod LifecycleHandler should support a `sleep` option | https://api.github.com/repos/kubernetes/kubernetes/issues/114465/comments | 24 | 2022-12-13T18:23:42Z | 2023-10-16T19:19:45Z | https://github.com/kubernetes/kubernetes/issues/114465 | 1,494,908,196 | 114,465 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Reading files from secret volume fails with `permission denied` because files incorrectly have group owner GID 0 instead of given `fsGroup`. The failure is associated to a change/update of the files in the secret. Failure happens only occasionally and if checking the volume manually after the err... | Reading from secret volume occasionally fails with `permission denied` | https://api.github.com/repos/kubernetes/kubernetes/issues/114461/comments | 2 | 2022-12-13T17:40:23Z | 2023-01-19T15:45:37Z | https://github.com/kubernetes/kubernetes/issues/114461 | 1,494,823,883 | 114,461 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
https://testgrid.k8s.io/sig-network-gce#gci-gce-ipvs
### Which tests are failing?
All the LoadBalancers tests
### Since when has it been failing?
It seems that for a long time
### Testgrid link
https://testgrid.k8s.io/sig-network-gce#gci-gce-ipvs
### Reason for failure (if possible)
... | IPVS loadbalancer tests are flaky | https://api.github.com/repos/kubernetes/kubernetes/issues/114450/comments | 2 | 2022-12-13T14:02:34Z | 2022-12-16T10:00:18Z | https://github.com/kubernetes/kubernetes/issues/114450 | 1,494,299,589 | 114,450 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
https://testgrid.k8s.io/sig-network-gce#presubmit-network-policies,%20google-gce
### Which tests are failing?
all tests, the job is not able to run
### Since when has it been failing?
since https://github.com/kubernetes/kubernetes/pull/114410
### Testgrid link
https://testgrid.k8s.io/... | presubmit-network-policies test is failing | https://api.github.com/repos/kubernetes/kubernetes/issues/114449/comments | 4 | 2022-12-13T13:53:47Z | 2022-12-14T09:51:36Z | https://github.com/kubernetes/kubernetes/issues/114449 | 1,494,281,945 | 114,449 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When setting kube-apiserver to `--anonymous-auth=False`, and using crd resources (kubectl apply, kubectl create) and tidb operator, the apiserver restarts repeatedly. But set to `--anonymous-auth=True, everything works fine.`
I submitted an issue on tidb-operator, but I don't know if it is a co... | When --anonymous-auth=False and use crd and operator, the apiserver restarts repeatedly | https://api.github.com/repos/kubernetes/kubernetes/issues/114444/comments | 3 | 2022-12-13T09:51:37Z | 2022-12-14T02:39:51Z | https://github.com/kubernetes/kubernetes/issues/114444 | 1,493,856,474 | 114,444 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We had a nodePort service which use port 30002, transport to a host-network pod which listen 8002.Now it is invalid , we can't access `nodeIp:30002` , but `nodeIp:8002` is valid.
> why we use nodePort when we already use host-network?
Because it could has multiple replicas, we use nodePort to en... | NodePort service for hostNetwork pod fails when both Ready and Terminating pods are present | https://api.github.com/repos/kubernetes/kubernetes/issues/114440/comments | 14 | 2022-12-13T08:02:48Z | 2023-01-21T00:20:51Z | https://github.com/kubernetes/kubernetes/issues/114440 | 1,493,647,471 | 114,440 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [465879157e59250960bb](https://go.k8s.io/triage#465879157e59250960bb)
##### Error text:
```
Failed
=== RUN TestRemoveAPIService
I1202 06:13:47.481951 84246 handler.go:149] Adding GroupVersion 摾Lʉĥ峡拓 凣OC瓴业ǯSfĹdzƘ繙e to ResourceManager
I1202 06:13:47.482208 84246 handler.go:149] Adding Gro... | Failure cluster [46587915...] TestRemoveAPIService unit test flaking | https://api.github.com/repos/kubernetes/kubernetes/issues/114438/comments | 4 | 2022-12-13T02:36:12Z | 2023-11-13T04:21:39Z | https://github.com/kubernetes/kubernetes/issues/114438 | 1,493,215,389 | 114,438 |
[
"kubernetes",
"kubernetes"
] | Since forever, these APIs all require "restartPolicy: Always". There's not really a REASON for that, as far as I can see.
For example, suppose we allowed "Never" or "OnFailure". If a Pod were to "finish", a Deployment, ReplicaSet, or StatefulSet will all start a new pod on some node, and a DaemonSet will start a n... | Deployment, ReplicaSet, StatefulSet, DaemonSet require restartPolicy=Always but don't NEED to | https://api.github.com/repos/kubernetes/kubernetes/issues/114437/comments | 10 | 2022-12-13T01:26:44Z | 2024-12-22T02:24:13Z | https://github.com/kubernetes/kubernetes/issues/114437 | 1,493,139,741 | 114,437 |
[
"kubernetes",
"kubernetes"
] | pkg/apis/core/validation/validation.go
```
func ValidateReadOnlyPersistentDisks(volumes []core.Volume, fldPath *field.Path) field.ErrorList {
allErrs := field.ErrorList{}
for i := range volumes {
vol := &volumes[i]
... | validation has a GCE-ism baked in | https://api.github.com/repos/kubernetes/kubernetes/issues/114436/comments | 11 | 2022-12-13T01:12:53Z | 2023-04-29T01:28:17Z | https://github.com/kubernetes/kubernetes/issues/114436 | 1,493,120,991 | 114,436 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
See this thread for more context:
https://github.com/kubernetes/kubernetes/pull/114051/files#r1045971319
It looks like when a scheduler plugin returns an `Unschedulable` status during the `PreFilter` phase, then other `PreFilter` plugins are skipped which results in errors read... | [scheduler] Enable plugins to return Unschedulable in PreFilter | https://api.github.com/repos/kubernetes/kubernetes/issues/114433/comments | 18 | 2022-12-12T23:18:41Z | 2024-05-09T08:06:35Z | https://github.com/kubernetes/kubernetes/issues/114433 | 1,492,970,053 | 114,433 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
While reading the code, I noticed that generation is uint64 and is incremented each time we call `Set()`. The 0 value is treated as a force delete by `del()` method.
Now, the issue will occur if enough generations have passed, so the overflow will return a generation value to 0. This can be nicely ... | apimachinery: Expiring cache can delete not yet expired entry | https://api.github.com/repos/kubernetes/kubernetes/issues/114432/comments | 6 | 2022-12-12T22:07:49Z | 2022-12-14T20:38:35Z | https://github.com/kubernetes/kubernetes/issues/114432 | 1,492,866,898 | 114,432 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
* Add capability to pull a docker image from another worker node that has already downloaded the same docker image before pulling from remote registry.
* In addition, when the deployment calls for multiple replicas and the image isn't yet available on any worker node, limit pullin... | Capability to pull images from other worker nodes in the cluster before pulling from remote registry. | https://api.github.com/repos/kubernetes/kubernetes/issues/114424/comments | 6 | 2022-12-12T10:11:04Z | 2022-12-23T04:06:06Z | https://github.com/kubernetes/kubernetes/issues/114424 | 1,491,488,891 | 114,424 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Device plugin allocatable resource is set to capacity temporarily instead of actual value from device plugin when kubelet restart.
This is because when kubelet restarts, device plugin manager `func (m *ManagerImpl) GetCapacity` [link](https://github.com/kubernetes/kubernetes/blob/master/pkg/kubel... | Device plugin allocatable resource overwritten when kubelet restart | https://api.github.com/repos/kubernetes/kubernetes/issues/114422/comments | 15 | 2022-12-12T09:03:35Z | 2024-01-19T11:59:57Z | https://github.com/kubernetes/kubernetes/issues/114422 | 1,491,358,019 | 114,422 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
https://testgrid.k8s.io/sig-windows-networking#ltsc2019-containerd-flannel-sdnbridge-master
https://testgrid.k8s.io/sig-windows-networking#ltsc2019-containerd-flannel-sdnoverlay-master
### Which tests are failing?
```
e2e suite.[It] [sig-network] EndpointSliceMirroring should mirr... | [sig-network] EndpointSliceMirroring E2E test case fails on Windows with Flannel | https://api.github.com/repos/kubernetes/kubernetes/issues/114421/comments | 7 | 2022-12-12T08:55:22Z | 2022-12-22T09:24:43Z | https://github.com/kubernetes/kubernetes/issues/114421 | 1,491,342,311 | 114,421 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
- These are changes as per KEPS: https://github.com/kubernetes/enhancements/tree/master/keps/sig-network/2086-service-internal-traffic-policy
- When a InternalTrafficPolicy is set to Local, consider only local endpoints for creating cluster ip load balancer.
- When both Interna... | [Winkernel Proxier] Implement support for internal traffic policy in windows kube proxy | https://api.github.com/repos/kubernetes/kubernetes/issues/114419/comments | 9 | 2022-12-12T07:17:20Z | 2023-01-18T17:13:05Z | https://github.com/kubernetes/kubernetes/issues/114419 | 1,491,172,897 | 114,419 |
[
"kubernetes",
"kubernetes"
] | Given this deployment:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: multiport
spec:
replicas: 0
selector:
matchLabels:
app: multiport
template:
metadata:
labels:
app: multiport
spec:
containers:
- image: k8s.gcr.io/serve_hostname:v1.4
... | `kubectl expose` fails for apps with same-port, different-protocol | https://api.github.com/repos/kubernetes/kubernetes/issues/114402/comments | 14 | 2022-12-10T22:08:55Z | 2023-07-06T10:27:05Z | https://github.com/kubernetes/kubernetes/issues/114402 | 1,489,032,399 | 114,402 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
It's spawned from https://github.com/kubernetes/kubernetes/issues/107556.
After https://github.com/kubernetes/kubernetes/pull/114125 gets merged, the scheduler skips the plugin in Filter, if that plugin return `Skip` in PreFilter. In other words, the plugin can return `Skip` w... | [Umbrella] Skip Filter plugins when coupled PreFilter plugin returns `Skip` status | https://api.github.com/repos/kubernetes/kubernetes/issues/114399/comments | 29 | 2022-12-10T13:21:22Z | 2023-07-10T03:56:21Z | https://github.com/kubernetes/kubernetes/issues/114399 | 1,488,484,776 | 114,399 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I found a problem when I read the scheduler code,
In the case that PreFilterResult([#108648](https://github.com/kubernetes/kubernetes/issues/108648)) can filter nodes, it is more appropriate to put NodeName in Prefilter
### What did you expect to happen?
Add NodeName PreFilter to improve th... | Add NodeName PreFilter to improve the scheduling efficiency of pod with NodeName | https://api.github.com/repos/kubernetes/kubernetes/issues/114396/comments | 11 | 2022-12-10T07:36:01Z | 2022-12-19T03:41:01Z | https://github.com/kubernetes/kubernetes/issues/114396 | 1,488,154,207 | 114,396 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
# Problem
The job controller appears to "rapidly reschedule" several pods at the same time (without backing off) which ultimately appears almost like a batch or gang scheduling workflow.
... This is the opposite of what the job docs say, bc they clearly state :
```
The back-off limit is s... | Kubernetes Jobs API rapid-fire scheduling doesnt honor exponential backoff characteristics | https://api.github.com/repos/kubernetes/kubernetes/issues/114391/comments | 18 | 2022-12-09T18:43:24Z | 2023-02-24T14:57:46Z | https://github.com/kubernetes/kubernetes/issues/114391 | 1,487,252,940 | 114,391 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
we can follow up on https://github.com/kubernetes/kubernetes/pull/102933 now, by finishing removing all but the SCTP tests in the old legacy filters.
### What did you expect to happen?
we would have removed the old tests by now :) but we didnt wanna break OVN . I think OVN CI is passing now w/ ... | We forgot to remove the old netpol tests that are covered by new matrix based tests | https://api.github.com/repos/kubernetes/kubernetes/issues/114389/comments | 5 | 2022-12-09T17:00:29Z | 2023-07-03T16:17:09Z | https://github.com/kubernetes/kubernetes/issues/114389 | 1,487,085,628 | 114,389 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
#### Kubernetes version:1.17.9
#### OS:ubuntu-18.0.4
This is my jenkins deploy script
```
stage('Deploy helloworld') {
steps{
sh 'if [[ `${NET} kubectl get svc | grep ${NAME} | wc -l` == 1 ]];then ${NET} kubectl delete svc ${NAME}; else exit 0; fi... | The kubectl deployment application port is occupied | https://api.github.com/repos/kubernetes/kubernetes/issues/114384/comments | 5 | 2022-12-09T12:35:15Z | 2023-01-06T15:37:27Z | https://github.com/kubernetes/kubernetes/issues/114384 | 1,486,685,944 | 114,384 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
The horizontal pod auto-scaling is currently limited in defining a behavior for the whole HPA.
What about being able to define a behavior per metric?
For example:
Having two metrics based on which the HPA scales up/down pods
- resource metric: CPU utilization
- pod metric: som... | HPA behaviour | https://api.github.com/repos/kubernetes/kubernetes/issues/114383/comments | 13 | 2022-12-09T12:08:49Z | 2024-06-20T08:39:01Z | https://github.com/kubernetes/kubernetes/issues/114383 | 1,486,647,771 | 114,383 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
[generator template source code](https://github.com/kubernetes/kubernetes/blob/536e5f0965bcc359894d5d4621addec08f6ccf2e/staging/src/k8s.io/code-generator/cmd/client-gen/generators/fake/generator_fake_for_group.go#L126)
```go
var getRESTClient = `
// RESTClient returns a RESTClie... | [client-gen]: allow fake generator generate RESTClient() func return non-nil interface | https://api.github.com/repos/kubernetes/kubernetes/issues/114382/comments | 8 | 2022-12-09T09:55:34Z | 2023-03-28T14:27:05Z | https://github.com/kubernetes/kubernetes/issues/114382 | 1,486,452,667 | 114,382 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Let the pod completely monopolizes the cpu resources。
It is mentioned here: https://kubernetes.io/docs/tasks/administer-cluster/cpu-management-policies/
Note: System services such as the container runtime and the kubelet itself can continue to run on these exclusive CPUs. T... | pod completely monopolizes the cpu resources | https://api.github.com/repos/kubernetes/kubernetes/issues/114381/comments | 7 | 2022-12-09T09:43:07Z | 2023-06-18T13:28:00Z | https://github.com/kubernetes/kubernetes/issues/114381 | 1,486,434,772 | 114,381 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Bind specific cpu number for pod。
I have 2 cpu ,with 0~39 cores.
```
root@ubuntu:~# lscpu | grep NUMA
NUMA node(s): 2
NUMA node0 CPU(s): 0-9,20-29
NUMA node1 CPU(s): 10-19,30-39
```
i want BIND some specific number cpu t... | Bind specific cpu number for pod | https://api.github.com/repos/kubernetes/kubernetes/issues/114380/comments | 13 | 2022-12-09T09:38:46Z | 2024-01-20T08:12:58Z | https://github.com/kubernetes/kubernetes/issues/114380 | 1,486,428,142 | 114,380 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Currently kubelet will panic with nil pointer if podSandboxStatus is nil: https://github.com/kubernetes/kubernetes/blob/86284d42f891cac285c08c8a350ca8724f12c21f/pkg/kubelet/pleg/evented.go#L207
For containerd, it is possible that a podSandbox cannot be found when cri tries to st... | [Evented PLEG] Kubelet to handle containerEventsResponseCh with nil PodSandboxStatus | https://api.github.com/repos/kubernetes/kubernetes/issues/114371/comments | 4 | 2022-12-08T18:29:58Z | 2023-03-08T19:31:37Z | https://github.com/kubernetes/kubernetes/issues/114371 | 1,485,189,641 | 114,371 |
[
"kubernetes",
"kubernetes"
] | The NP docs point out that [NP's semantics for north/south traffic are not very clearly defined](https://kubernetes.io/docs/concepts/services-networking/network-policies/#behavior-of-ipblock-selectors):
> Cluster ingress and egress mechanisms often require rewriting the source or destination IP of packets. In cases ... | NetworkPolicy tests for blocking north/south traffic | https://api.github.com/repos/kubernetes/kubernetes/issues/114369/comments | 25 | 2022-12-08T16:32:02Z | 2024-12-04T16:44:51Z | https://github.com/kubernetes/kubernetes/issues/114369 | 1,484,992,254 | 114,369 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When upgrading from kubernetes 1.22.11 to 1.23.9, some failed pods would get stuck on the Terminating state. We upgraded to 1.24.6 but these terminating pods did not disappear. Related to #109429 and #109486
Using `kubectl delete pod <pod_name> --force --grace-period=0` hangs and does not delete ... | job-tracking Finalizers prevent pod from deleting | https://api.github.com/repos/kubernetes/kubernetes/issues/114366/comments | 11 | 2022-12-08T13:14:08Z | 2023-05-21T14:14:19Z | https://github.com/kubernetes/kubernetes/issues/114366 | 1,484,617,679 | 114,366 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A large number of pods cannot be scheduled due to insufficient resources, will cause the kube-scheduler memory to rise quickly.
pending pod count: 10W
node count: 10
memory overview:
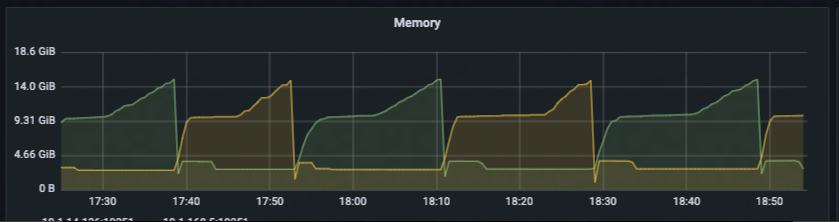... | A huge amount of pending pods will cause the kube-scheduler memory to rise quickly | https://api.github.com/repos/kubernetes/kubernetes/issues/114362/comments | 7 | 2022-12-08T09:55:48Z | 2022-12-25T09:13:53Z | https://github.com/kubernetes/kubernetes/issues/114362 | 1,484,212,851 | 114,362 |
[
"kubernetes",
"kubernetes"
] |
I am using Ubuntu 22.04LTS and just installed Kubernetes following this instruction: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/ on my Ubuntu desktop machine.
When I try this command `sudo kubectl cluster-info
` for example, I get this result:
To further debug a... | The connection to the server localhost:8080 was refused - did you specify the right host or port? | https://api.github.com/repos/kubernetes/kubernetes/issues/114354/comments | 7 | 2022-12-08T00:41:03Z | 2022-12-08T17:28:53Z | https://github.com/kubernetes/kubernetes/issues/114354 | 1,483,210,102 | 114,354 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When applying the given config (see below) without having a service-account named "calico-node" on the cluster, kubectl does not return an error. It returns a rather successful message "secret/... created". However, when running the command `kubectl get secret -A` I get the error "No resources found... | Missing error message when creating service account token for non-existent service account | https://api.github.com/repos/kubernetes/kubernetes/issues/114349/comments | 9 | 2022-12-07T22:33:45Z | 2023-05-11T14:33:29Z | https://github.com/kubernetes/kubernetes/issues/114349 | 1,482,999,989 | 114,349 |
[
"kubernetes",
"kubernetes"
] | > What is actually going on under the covers? It appears that the command immediately prints "<object> deleted" and then hangs, but actually it is waiting. It seems like the messaging is incorrect. It should say "deleting" and if --wait is the default it should only print "deleted" when the object is actually del... | kubectl message says "<object> deleted" before it actually deletes. | https://api.github.com/repos/kubernetes/kubernetes/issues/114348/comments | 14 | 2022-12-07T21:28:14Z | 2023-05-18T11:20:07Z | https://github.com/kubernetes/kubernetes/issues/114348 | 1,482,891,900 | 114,348 |
[
"kubernetes",
"kubernetes"
] | Both `compilation_duration_seconds` and `evaluation_duration_seconds` are missing help texts.
https://github.com/kubernetes/kubernetes/blob/09d7286eb570c8ab89c3008efd6afcf590a94a50/staging/src/k8s.io/apiserver/pkg/cel/metrics/metrics.go#L42-L53 | API Server metric compilation_duration_seconds missing help text | https://api.github.com/repos/kubernetes/kubernetes/issues/114346/comments | 3 | 2022-12-07T18:11:44Z | 2022-12-12T19:44:05Z | https://github.com/kubernetes/kubernetes/issues/114346 | 1,482,537,739 | 114,346 |
[
"kubernetes",
"kubernetes"
] | # Progress <code>[6/6]</code>
- [x] APISnoop org-flow : [AuthV1SubjectAccessReviewTest.org](https://github.com/apisnoop/ticket-writing/blob/master/AuthV1SubjectAccessReviewTest.org)
- [x] test approval issue : #114344
- [x] test pr : #114345
- [x] two weeks soak start date : 16 Dec 2022 [testgrid-link](ht... | Write e2e test for SubjectAccessReview & createAuthorizationV1NamespacedLocalSubjectAccessReview +2 Endpoints | https://api.github.com/repos/kubernetes/kubernetes/issues/114344/comments | 3 | 2022-12-07T17:22:05Z | 2023-01-09T16:59:49Z | https://github.com/kubernetes/kubernetes/issues/114344 | 1,482,432,264 | 114,344 |
[
"kubernetes",
"kubernetes"
] | https://github.com/kubernetes/kubernetes/pull/114335 surfaced a problem where rules were missing for one of the dependencies for apiserver.
We have tests that check missing rules for all repos, but only the master branch:
https://github.com/kubernetes/kubernetes/blob/72acaad83924360960e21915aa94cd1db8d0196c/hack/... | publishing-bot: verify rules for all branches | https://api.github.com/repos/kubernetes/kubernetes/issues/114337/comments | 7 | 2022-12-07T13:06:02Z | 2024-01-19T11:00:00Z | https://github.com/kubernetes/kubernetes/issues/114337 | 1,481,881,878 | 114,337 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
/sig node
`free` shows the total memory is 32Gi and used only 6Gi.
Free is 12Gi
Shared 1.6Gi
buff/cache 13Gi
available 19Gi
4.19.90-23.8.v2101.ky10.aarch64
- https://kubernetes.io/examples/admin/resource/memory-available.sh This is a script to calculate memory.available from https://ku... | (usage - inactive file) greater than capacity causing eviction | https://api.github.com/repos/kubernetes/kubernetes/issues/114332/comments | 30 | 2022-12-07T10:46:27Z | 2024-09-27T05:39:37Z | https://github.com/kubernetes/kubernetes/issues/114332 | 1,481,606,999 | 114,332 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
https://prow.ppc64le-cloud.org/job-history/gs/ppc64le-kubernetes/logs/periodic-kubernetes-unit-test-ppc64le
### Which tests are flaking?
`TestMultipleHPAs` in pkg/controller/podautoscaler/horizontal_test.go
### Since when has it been flaking?
Probably from a month.
### Anyt... | [Flaky test] TestMultipleHPAs in pkg/controller/podautoscaler is Flaking | https://api.github.com/repos/kubernetes/kubernetes/issues/114331/comments | 9 | 2022-12-07T09:34:23Z | 2023-06-16T03:23:34Z | https://github.com/kubernetes/kubernetes/issues/114331 | 1,481,454,752 | 114,331 |
[
"kubernetes",
"kubernetes"
] | Update [KEP-3299](https://github.com/kubernetes/enhancements/issues/3299) for KMSv2 beta.
/sig auth
/triage accepted
/assign @aramase @enj @ritazh | [KMSv2] Update KEP-3299 for beta | https://api.github.com/repos/kubernetes/kubernetes/issues/114318/comments | 0 | 2022-12-06T22:00:27Z | 2023-02-07T20:29:01Z | https://github.com/kubernetes/kubernetes/issues/114318 | 1,480,287,223 | 114,318 |
[
"kubernetes",
"kubernetes"
] | - [x] Generate `v2beta1` API (ref: https://github.com/kubernetes/kubernetes/tree/master/staging/src/k8s.io/kms/apis)
- [x] Update feature gate for beta
- [x] Update code references to use the beta API
- [x] Update validation to allow `v2beta1`
- [x] Check how status API checks will be done with `v2beta1`?
/triag... | [KMSv2] Generate proto API and update feature gate for beta | https://api.github.com/repos/kubernetes/kubernetes/issues/114317/comments | 0 | 2022-12-06T21:58:48Z | 2023-03-15T03:23:31Z | https://github.com/kubernetes/kubernetes/issues/114317 | 1,480,284,395 | 114,317 |
[
"kubernetes",
"kubernetes"
] | This is similar to #91444 and #81145 but the issue here is not what is _possible_ but what is _easy_ for an admin to say.
Currently kube-apiserver and kubelet (like [etcd](https://github.com/etcd-io/etcd/issues/14906)) default to accepting anything that go does. My local security scanner objects to some of those ci... | Make it easy to request kube-apiserver and kubelet to support strong TLS configurations | https://api.github.com/repos/kubernetes/kubernetes/issues/114316/comments | 16 | 2022-12-06T21:55:33Z | 2024-08-06T08:24:10Z | https://github.com/kubernetes/kubernetes/issues/114316 | 1,480,279,039 | 114,316 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The code at
https://github.com/kubernetes/kubernetes/blob/86f3fa94f1b75da275a8040e4155840a7b473dc1/pkg/controlplane/instance.go#L126 specifies a ~annotation~ label that API servers set on Leases (each API server registers its own lease).
https://k8s.io/docs/concepts/architecture/leases/#api-se... | kube-apiserver using unregistered and unusual label | https://api.github.com/repos/kubernetes/kubernetes/issues/114314/comments | 10 | 2022-12-06T21:20:52Z | 2023-01-18T05:36:36Z | https://github.com/kubernetes/kubernetes/issues/114314 | 1,480,202,401 | 114,314 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Our team uses sonobuoy to run the conformormance tests on a cluster and displays the results to the users.
We have been using conformance image 1.21.x until now and it sends back progress data to sonobuoy pod and our service reads it from the sonobuoy pod.
The progress data included the total numb... | e2e conformance pod sending total tests back as zero for conformance image 1.25.x | https://api.github.com/repos/kubernetes/kubernetes/issues/114313/comments | 16 | 2022-12-06T21:04:40Z | 2024-03-22T10:27:55Z | https://github.com/kubernetes/kubernetes/issues/114313 | 1,480,182,923 | 114,313 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The ImagePullPolicy a statefulset is set to `IfNotPresent` however the running pod in that statefulset has ImagePullPolicy to be set to `Always`. The pod meets the conditions for `IfNotPresent`.
### What did you expect to happen?
The expected result was that the pod's imagePullPolicy would m... | Kubernetes ImagePullPolicy Is Not Being Propogated To A Pod | https://api.github.com/repos/kubernetes/kubernetes/issues/114312/comments | 17 | 2022-12-06T20:28:13Z | 2023-06-11T10:57:04Z | https://github.com/kubernetes/kubernetes/issues/114312 | 1,480,115,930 | 114,312 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
https://prow.k8s.io/view/gs/kubernetes-jenkins/logs/ci-kubernetes-e2e-capz-master-containerd-window
### Which tests are flaking?
Kubernetes e2e suite: [It] [sig-storage] Projected configMap should be consumable from pods in volume with mappings [NodeConformance] [Conformance]
### Since ... | container "agnhost-container": error from PowerShell Script: exit status 0xc0000005, | https://api.github.com/repos/kubernetes/kubernetes/issues/114311/comments | 7 | 2022-12-06T18:11:06Z | 2023-05-04T16:52:13Z | https://github.com/kubernetes/kubernetes/issues/114311 | 1,479,803,053 | 114,311 |
[
"kubernetes",
"kubernetes"
] | > > Question: who owns setting up RBAC for aggregated API servers to be able to create and manage their leases?
>
> I'm flexible here. @andrewsykim may have opinions about how much cross talk he's willing to allow and that may require that aggregated apiservers use a different namespace and wire their own GC to avoi... | Decide on RBAC for aggregated API servers to be able to create and manage identity leases | https://api.github.com/repos/kubernetes/kubernetes/issues/114310/comments | 11 | 2022-12-06T16:54:20Z | 2024-07-18T20:14:38Z | https://github.com/kubernetes/kubernetes/issues/114310 | 1,479,615,962 | 114,310 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
https://github.com/kubernetes/kubernetes/issues/87850 tries to almost remove the flushing unschedulable Pods into activeQ.
Then, after that, almost all moving to activeQ can be associated with certain events.
Here, I'd propose two changes for PreEnqueue so that we can utilize... | introduce QueueingHint for wise-enqueueing | https://api.github.com/repos/kubernetes/kubernetes/issues/114297/comments | 39 | 2022-12-06T02:07:17Z | 2023-11-04T19:56:41Z | https://github.com/kubernetes/kubernetes/issues/114297 | 1,477,960,108 | 114,297 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We run a cluster spread across 3 sites/availability zones, and when an entire site becomes unreachable at once we observe that the node lifecycle controller takes too long to mark all the pods NotReady.
Example logs:
```
I0713 16:03:36.538269 1 node_lifecycle_controller.go:1092] node ... ... | Node lifecycle controller takes too long to mark pods NotReady | https://api.github.com/repos/kubernetes/kubernetes/issues/114295/comments | 9 | 2022-12-06T00:32:52Z | 2023-01-25T23:16:51Z | https://github.com/kubernetes/kubernetes/issues/114295 | 1,477,806,587 | 114,295 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
As posted in this documentation here:
https://kubernetes.io/releases/download/
and
https://kubernetes.io/docs/tasks/administer-cluster/verify-signed-images/#verifying-image-signatures
The SBOM query does not return the list of images
### What did you expect to happen?
I was expecting... | K8s Release SBOM usage instructions are not working | https://api.github.com/repos/kubernetes/kubernetes/issues/114292/comments | 6 | 2022-12-05T21:33:13Z | 2023-05-05T17:26:29Z | https://github.com/kubernetes/kubernetes/issues/114292 | 1,477,479,101 | 114,292 |
[
"kubernetes",
"kubernetes"
] | The name is not ideal. This already came up during the initial API review and again in https://github.com/kubernetes/enhancements/issues/3063#issuecomment-1336225191:
@sftim wrote:
> Pretty much everything that has a kind in Kubernetes looks broadly idiomatic if you put a definite or indefinite article in front of it.... | dynamic resource allocation: rename PodScheduling | https://api.github.com/repos/kubernetes/kubernetes/issues/114283/comments | 8 | 2022-12-05T07:33:42Z | 2023-03-14T22:14:36Z | https://github.com/kubernetes/kubernetes/issues/114283 | 1,475,895,491 | 114,283 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Trying to use `hack/local_cluster_up.sh` against my laptop and I tried to deploy an operator on the cluster and see the following exec format error. I think there's something wrong with either k8s or docker related to the network driver. This is on ashai linux on arm64 / aarch64. It looks like it... | hack/local_cluster_up.sh exec format error on arm64 / aarch64 | https://api.github.com/repos/kubernetes/kubernetes/issues/114282/comments | 4 | 2022-12-05T07:17:51Z | 2022-12-05T23:53:25Z | https://github.com/kubernetes/kubernetes/issues/114282 | 1,475,870,638 | 114,282 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The apiserver process has 1.5 GIB memory usage after sequentially serving a few large LIST requests (about 50MiB in response size).
### What did you expect to happen?
The apiserver should stay the same memory usage after serving the first request.
### How can we reproduce it (as minimally and pr... | apiserver builds up high memory usage after serving a few large LIST requests | https://api.github.com/repos/kubernetes/kubernetes/issues/114276/comments | 21 | 2022-12-04T12:37:39Z | 2025-02-27T09:25:28Z | https://github.com/kubernetes/kubernetes/issues/114276 | 1,474,779,959 | 114,276 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Offshoot discussion from https://github.com/kubernetes/kubernetes/issues/114120 and https://github.com/kubernetes/kubernetes/issues/89477
There has been a lot of work since 1.14 to start using the GA topology labels instead of the beta topology labels.
The intree volume provisioning logic ha... | PV handling of beta topology labels | https://api.github.com/repos/kubernetes/kubernetes/issues/114268/comments | 18 | 2022-12-02T23:02:03Z | 2024-08-03T00:10:24Z | https://github.com/kubernetes/kubernetes/issues/114268 | 1,473,555,882 | 114,268 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
An option in the scheduler's ComponentConfig to ignore calculating preferences of exiting pods' affinity rules for the general case, and consider them only if the incoming pod has inter pod affinities. In most cases this is sufficient because pods set inter-pod affinity against ea... | An option to disable Preferred Inter-pod affinity of existing pods | https://api.github.com/repos/kubernetes/kubernetes/issues/114267/comments | 11 | 2022-12-02T22:23:57Z | 2023-01-14T01:28:16Z | https://github.com/kubernetes/kubernetes/issues/114267 | 1,473,530,440 | 114,267 |
[
"kubernetes",
"kubernetes"
] | > > k8s.io/kubernetes/test/integration/job: TestFinalizersClearedWhenBackoffLimitExceeded
@alculquicondor @saschagrunert @liggitt seems we have a problem in branch 1.23, this test has been flaking for some time
https://testgrid.k8s.io/sig-release-1.23-blocking#integration-1.23
_Originally posted by @a... | k8s.io/kubernetes/test/integration/job: TestFinalizersClearedWhenBackoffLimitExceeded flakes in 1.23 | https://api.github.com/repos/kubernetes/kubernetes/issues/114259/comments | 9 | 2022-12-02T15:59:42Z | 2022-12-22T13:01:47Z | https://github.com/kubernetes/kubernetes/issues/114259 | 1,473,089,480 | 114,259 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Today, it's not possible to import API extensions APIs or clients without pulling in the rest of the API extensions API server and all of the transitive dependencies. This is not intentional, it was just not done at the time that other staging repositories were split out. In orde... | Publish API Extensions Client and APIs as Separate Go Modules in Separate Staging Repositories | https://api.github.com/repos/kubernetes/kubernetes/issues/114253/comments | 14 | 2022-12-02T14:39:05Z | 2025-02-06T21:20:06Z | https://github.com/kubernetes/kubernetes/issues/114253 | 1,472,969,701 | 114,253 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Installed vanilla K8S 1.25.4 on vanilla Debian 11 with vanilla cri-o 1.25.1 as container runtime.
Then applied test pod from here
https://raw.githubusercontent.com/kubernetes/website/main/content/en/examples/pods/probe/exec-liveness.yaml
From the logs:
```
1202 13:06:06.257580 1732... | All probes (liveness, readiness) fail on Debian 11 / CRI-O 1.25.1 / K8S 1.25.4 | https://api.github.com/repos/kubernetes/kubernetes/issues/114251/comments | 7 | 2022-12-02T13:18:35Z | 2022-12-06T14:15:32Z | https://github.com/kubernetes/kubernetes/issues/114251 | 1,472,858,202 | 114,251 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The k8s documentation states that the ready probe can abort traffic, but this is not feasible for grpc
image
https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/#define-readiness-probes
Example:
Upstream PodA (Grpc-server) It was connected ... | ReadinessProbe not working. | https://api.github.com/repos/kubernetes/kubernetes/issues/114250/comments | 3 | 2022-12-02T12:15:49Z | 2022-12-05T02:47:05Z | https://github.com/kubernetes/kubernetes/issues/114250 | 1,472,775,331 | 114,250 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
For now, the `DaemonSetsController` workqueue is `rateLimitingType`. Replace it with `PriorityQueue`, and this work item priority reference to spec.template.priorityClassName.
### Why is this needed?
There are some system-node-critical components (e.g. CNI,CSI) which deployed ... | In daemonset controller, prioritize items in workqueue | https://api.github.com/repos/kubernetes/kubernetes/issues/114247/comments | 6 | 2022-12-02T07:02:48Z | 2023-05-08T10:49:07Z | https://github.com/kubernetes/kubernetes/issues/114247 | 1,472,409,517 | 114,247 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In three node cluster, when change the /etc/kubernetes/manifests/etcd.yaml at the same time, one node's etcd static pod keep stoping, restart failed
### What did you expect to happen?
three node can success restart static pod of etcd
### How can we reproduce it (as minimally and precisely as poss... | In three node cluster, when change the /etc/kubernetes/manifests/etcd.yaml at the same time, one node's etcd static pod keep stoping | https://api.github.com/repos/kubernetes/kubernetes/issues/114244/comments | 8 | 2022-12-02T02:44:24Z | 2022-12-02T12:39:49Z | https://github.com/kubernetes/kubernetes/issues/114244 | 1,472,228,614 | 114,244 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Support for an _optional_ `topologyKeys` *<list>* on _PodTopologySpread_, whose values are ANDed, giving the ability to capture some unique subset of nodes.
### Why is this needed?
Consider the following (real) example we are facing attempting to use topology spread constra... | Support an optional topologyKeys *list* on PodTopologySpread to capture a unique subset of nodes | https://api.github.com/repos/kubernetes/kubernetes/issues/114243/comments | 9 | 2022-12-01T19:44:44Z | 2023-05-01T00:33:56Z | https://github.com/kubernetes/kubernetes/issues/114243 | 1,471,854,061 | 114,243 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We currently have the following HPA object created:
```
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
creationTimestamp: "2022-11-30T20:07:37Z"
labels:
app: istio-ingressgateway
operator.istio.io/version: 1.15-dev
name: istio-ingressgateway-us-west-... | Incorrect computation of desired pods for HPAv2beta2 | https://api.github.com/repos/kubernetes/kubernetes/issues/114241/comments | 6 | 2022-12-01T18:30:51Z | 2023-04-30T21:33:56Z | https://github.com/kubernetes/kubernetes/issues/114241 | 1,471,761,199 | 114,241 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In Kubernetes v1.22.6 when increasing the log level of Kubelet to `--v 4` the debug logs correctly start logging the message described here:
https://github.com/kubernetes/kubernetes/blob/v1.22.6/pkg/probe/http/http.go#L137
which includes an attempt at logging the response body:
`klog.V(4).I... | http.go fails to log failed probe response body at verbosity level 4 | https://api.github.com/repos/kubernetes/kubernetes/issues/114239/comments | 3 | 2022-12-01T18:00:40Z | 2022-12-01T21:54:14Z | https://github.com/kubernetes/kubernetes/issues/114239 | 1,471,723,122 | 114,239 |
[
"kubernetes",
"kubernetes"
] | Hello,
I am getting below error while updating kops cluster
Error: spec.nodeAuthorization: Forbidden: NodeAuthorization must be empty. The functionality has been reimplemented and is enabled on kubernetes >= 1.19.0
My cluster details
Kubernetes: v1.18.20
Kops: 1.22.1
I have bootstrap ansible playbook wher... | Forbidden: NodeAuthorization must be empty | https://api.github.com/repos/kubernetes/kubernetes/issues/114233/comments | 6 | 2022-12-01T10:48:09Z | 2023-01-23T20:39:51Z | https://github.com/kubernetes/kubernetes/issues/114233 | 1,471,090,373 | 114,233 |
[
"kubernetes",
"kubernetes"
] | Analyzing the flake in https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/114171/pull-kubernetes-e2e-gce-ubuntu-containerd/1597607186182180864/
> I1129 15:36:57.958493 1 proxier.go:303] "Iptables sync params" ipFamily=IPv4 minSyncPeriod="10s" syncPeriod="1m0s" burstSyncs=2
> minSyncPeriod is the ... | SIG Network tests flake if minSyncPeriod is too large | https://api.github.com/repos/kubernetes/kubernetes/issues/114230/comments | 15 | 2022-12-01T10:38:16Z | 2022-12-10T15:55:00Z | https://github.com/kubernetes/kubernetes/issues/114230 | 1,471,077,468 | 114,230 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
docker supports to[ disable networking for container](https://docs.docker.com/network/none/) by specify "--network none" parameter when running a specific container.
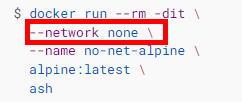
... | setting "--network: none" for container level. | https://api.github.com/repos/kubernetes/kubernetes/issues/114224/comments | 12 | 2022-12-01T09:21:13Z | 2023-05-19T14:51:22Z | https://github.com/kubernetes/kubernetes/issues/114224 | 1,470,965,498 | 114,224 |
[
"kubernetes",
"kubernetes"
] | ## 🏄♂️ demand
I'm hoping to learn kuberntes and become a community contributor, and I'm hoping someone can help me solve some problems
<br><br>
## ⚡ Description of the Problem
**branch:**
```bash
root@cubmaster01:~/go/src/k8s.io/kubernetes# git branch
* kube1.24
master
```
**ubuntu20.04:**
```bash
... | 【An error occurred attempting to install kubernetes learning】 | https://api.github.com/repos/kubernetes/kubernetes/issues/114222/comments | 20 | 2022-12-01T03:46:19Z | 2023-01-28T09:08:16Z | https://github.com/kubernetes/kubernetes/issues/114222 | 1,470,619,095 | 114,222 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We have a Kubernetes cluster on Azure and AWS. Azure cluster is running on Ubuntu ```publisher: "Canonical"
offer: "0001-com-ubuntu-server-focal"
sku: "20_04-lts-gen2"
version: "20.04.202211151"```
and AWS cluster is running on Ubuntu `ubuntu-minimal/images/hvm-ssd/ubuntu-focal-20.04-amd64-mini... | CSI Volume test failing due on newer 20.04 Ubuntu image | https://api.github.com/repos/kubernetes/kubernetes/issues/114221/comments | 10 | 2022-12-01T03:19:04Z | 2023-03-08T00:31:09Z | https://github.com/kubernetes/kubernetes/issues/114221 | 1,470,603,165 | 114,221 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
The attachdetach controller currently emits on a pod when it encounters errors attaching a volume to a pod. This can be seen here: https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/volume/attachdetach/reconciler/reconciler.go#L416
On detach, a pod is deleted, b... | Emit events to PVC for attachdetach detach workflow | https://api.github.com/repos/kubernetes/kubernetes/issues/114219/comments | 6 | 2022-12-01T01:46:26Z | 2023-04-30T03:21:56Z | https://github.com/kubernetes/kubernetes/issues/114219 | 1,470,521,421 | 114,219 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have enabled TopologyAwareHints on some of my services and the hints in first look seems to work fine. Tho when for any of the external factor reasons the hints are removed they seem to never get restored again and I am left with no TopologyAwareHints at all on the services where it was enabled. (... | Unstable TopologyAwareHints | https://api.github.com/repos/kubernetes/kubernetes/issues/114215/comments | 21 | 2022-11-30T17:56:17Z | 2024-07-05T22:29:01Z | https://github.com/kubernetes/kubernetes/issues/114215 | 1,470,019,916 | 114,215 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Using terraform with GKE and tearing down my cluster the process gets stuck on namespace deletion, probably because the metrics.k8.io server gets torn down prematurely and not all resource types can be fetched. The process of deleting the namespace gets stuck using kubectl too.
### What did you exp... | Improve error handling for namespace deletions when not all server apis are retrievable | https://api.github.com/repos/kubernetes/kubernetes/issues/114214/comments | 7 | 2022-11-30T16:59:47Z | 2023-03-10T10:20:26Z | https://github.com/kubernetes/kubernetes/issues/114214 | 1,469,952,116 | 114,214 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
master-informing
- capz-windows-containerd-master
### Which tests are failing?
- capz-e2e.Conformance Tests conformance-tests
- ci-kubernetes-e2e-capz-master-containerd-windows.Overall
### Since when has it been failing?
11-30 09:41 IST
### Testgrid link
https://testgrid.k8s... | [Failing test] capz-windows-containerd-master | https://api.github.com/repos/kubernetes/kubernetes/issues/114213/comments | 3 | 2022-11-30T16:24:28Z | 2022-11-30T19:00:57Z | https://github.com/kubernetes/kubernetes/issues/114213 | 1,469,903,215 | 114,213 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When submitting a windows pod using resource limits on a node with more than one processor group, the specified `CpuMaximum` count is incorrect due to the usage of `runtime.NumCPU()` which does not take processor groups into account.
For example:
- node with 96 cores
- cpu limit 94
- `runtim... | windows cpu maximum incorrect with more than one processor group | https://api.github.com/repos/kubernetes/kubernetes/issues/114211/comments | 5 | 2022-11-30T14:40:50Z | 2023-01-17T15:56:34Z | https://github.com/kubernetes/kubernetes/issues/114211 | 1,469,749,313 | 114,211 |
[
"kubernetes",
"kubernetes"
] | The API docs (and the end-user docs) state that "FQDN" is a valid value for EndpointSlice.AddressType, but nothing explains what the expected semantics of an FQDN slice are. And in fact, the expected semantics seem to be "[it gets ignored](https://github.com/kubernetes/kubernetes/blob/v1.26.0-rc.0/pkg/proxy/endpoints_t... | no defined semantics for EndpointSlices of type "FQDN" | https://api.github.com/repos/kubernetes/kubernetes/issues/114210/comments | 53 | 2022-11-30T14:28:31Z | 2024-12-05T17:16:26Z | https://github.com/kubernetes/kubernetes/issues/114210 | 1,469,728,475 | 114,210 |
[
"kubernetes",
"kubernetes"
] | In 1.26 we use container annotations to pass CDI devices from the kubelet to CDI enabled runtimes. We should extend the CRI to understand / accept CDI devices directly.
| dynamic resource allocation: Extend CRI to accept CDI devices | https://api.github.com/repos/kubernetes/kubernetes/issues/114209/comments | 3 | 2022-11-30T13:19:53Z | 2023-02-28T22:53:30Z | https://github.com/kubernetes/kubernetes/issues/114209 | 1,469,627,698 | 114,209 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
client-gen stop generating any code, might be broken
### What did you expect to happen?
generate clientset code
### How can we reproduce it (as minimally and precisely as possible)?
1. add example3 code
```shell
code-generator $ ls -l examples/crd/apis
total 0
drwxr-xr-x 3 - staff 96 ... | client-gen is broken | https://api.github.com/repos/kubernetes/kubernetes/issues/114208/comments | 8 | 2022-11-30T11:14:00Z | 2023-01-13T07:13:37Z | https://github.com/kubernetes/kubernetes/issues/114208 | 1,469,461,248 | 114,208 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hello, I've recently been testing the reliability of storage for k8s **v1.25.0.** A strange phenomenon occurs occasionally during the test: the volume cannot be detached after the PVC and pod are deleted(the reclaimPolicy of pv is delete).
So I first went to check the corresponding `pv` and `volu... | the volume is not detached after the pod and PVC objects are deleted | https://api.github.com/repos/kubernetes/kubernetes/issues/114207/comments | 29 | 2022-11-30T09:23:30Z | 2024-06-26T12:07:23Z | https://github.com/kubernetes/kubernetes/issues/114207 | 1,469,310,262 | 114,207 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have the requirement to dynamically add some content in `/etc/hosts` for the pod (because it's not fixed ip so I couldn't put it in spec.hostAliases).
I try to edit the `/etc/hosts` in one of the initContainers, but the change is not shown in other non-init containers. Checking this `makeHost... | kubelet managed /etc/hosts content is not synced when changes are made in initContainers | https://api.github.com/repos/kubernetes/kubernetes/issues/114206/comments | 6 | 2022-11-30T09:13:23Z | 2023-01-04T02:50:57Z | https://github.com/kubernetes/kubernetes/issues/114206 | 1,469,295,938 | 114,206 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
A great optimization to the current 'Infeasible' state would be to create a admission handler that tracks allocatable resources on all the nodes, and fails such a request early.
See https://github.com/kubernetes/kubernetes/pull/102884#discussion_r817033754
### Why is this needed?... | [FG:InPlacePodVerticalScaling] If pod resize request exceeds node allocatable, fail it in admission handler | https://api.github.com/repos/kubernetes/kubernetes/issues/114203/comments | 14 | 2022-11-30T05:29:32Z | 2024-06-24T02:55:35Z | https://github.com/kubernetes/kubernetes/issues/114203 | 1,469,069,811 | 114,203 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Cgroupv2 support in PR https://github.com/kubernetes/kubernetes/pull/102884 does not cover obtaining the value of MemoryRequest configured on the container for cgroupv2. Add support for this.
### Why is this needed?
One of the key benefits of cgroupv2 is the ability to specify m... | [FG:InPlacePodVerticalScaling] Get MemoryRequest from ContainerStatus for cgroupv2 | https://api.github.com/repos/kubernetes/kubernetes/issues/114202/comments | 14 | 2022-11-30T05:07:10Z | 2024-04-04T13:56:39Z | https://github.com/kubernetes/kubernetes/issues/114202 | 1,469,054,349 | 114,202 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I successfully deployed Kubernetes to my virtaulized LUbuntu 22.04 by using the `kubeadm` utility. However, Kubernetes does not seem to work properly. First of all, most of the default pods crash from time to time and restart. Secondly, after some time I am unable to use `kubectl` because it reports... | Kubernetes instability issues on LUbuntu 22.04 | https://api.github.com/repos/kubernetes/kubernetes/issues/114197/comments | 5 | 2022-11-29T23:28:17Z | 2022-11-30T16:26:15Z | https://github.com/kubernetes/kubernetes/issues/114197 | 1,468,834,418 | 114,197 |
[
"kubernetes",
"kubernetes"
] | While opening https://github.com/kubernetes/autoscaler/pull/5336 to update to 1.26.0 rc.0 libraries, a compile error surfaced because published staging repo v0.26.0-rc.0 tag content doesn't match k/k v1.26.0-rc.0
these two files should be identical, but are not:
* https://github.com/kubernetes/apimachinery/blob/v0.... | staging repos v0.26.0-rc.0 tag content doesn't match k/k v1.26.0-rc.0 | https://api.github.com/repos/kubernetes/kubernetes/issues/114192/comments | 5 | 2022-11-29T19:33:39Z | 2022-11-30T13:35:51Z | https://github.com/kubernetes/kubernetes/issues/114192 | 1,468,594,656 | 114,192 |
[
"kubernetes",
"kubernetes"
] | **Reference implementation**
- [ ] unit tests for all new code added for reference implementation
- [x] ~75% coverage
- [ ] controllers should have step tests and tests the run actual go routines
- [ ] an e2e conformance suite that uses the reference implementation
- [x] all resources would be encrypted
... | kmsv2: unit and integration test requirements | https://api.github.com/repos/kubernetes/kubernetes/issues/114188/comments | 11 | 2022-11-29T17:59:07Z | 2023-09-25T18:06:27Z | https://github.com/kubernetes/kubernetes/issues/114188 | 1,468,482,643 | 114,188 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
At present, I cannot attach an ephemeral container with a volume mount by using "kubectl debug".
I would prefer to have some way to create an ephemeral container with volume mount using kubectl debug.
It could be something similar to [patch command](https://kubernetes.io/docs/tas... | VolumeMount support in ephemeral containers with kubectl debug | https://api.github.com/repos/kubernetes/kubernetes/issues/114184/comments | 12 | 2022-11-29T17:13:04Z | 2023-07-20T07:16:24Z | https://github.com/kubernetes/kubernetes/issues/114184 | 1,468,426,680 | 114,184 |
[
"kubernetes",
"kubernetes"
] | Once dynamic resource allocation is GA, we need conformance tests for the new resource.k8s.io API. As its functionality depends on a driver, we may have to use the test driver. There's currently one issue with it: as it stands, it depends on port forwarding, which is a debug feature and not part of conformance. We woul... | dynamic resource allocation: create conformance test | https://api.github.com/repos/kubernetes/kubernetes/issues/114183/comments | 4 | 2022-11-29T17:00:27Z | 2024-04-19T16:37:59Z | https://github.com/kubernetes/kubernetes/issues/114183 | 1,468,401,766 | 114,183 |
[
"kubernetes",
"kubernetes"
] | Today, `HasSynced() bool` is used all throughout client-go. The downside of this is that it requires polling. Typically, folks poll with 100ms interval. For a typical controller, delaying 100ms is not that big of a deal, but it is still a bit non-optimal.
However, for tests things our worse. In our test suite, we we... | client-go: introduce event driven alternative to HasSynced | https://api.github.com/repos/kubernetes/kubernetes/issues/114182/comments | 7 | 2022-11-29T16:01:42Z | 2025-02-06T21:18:41Z | https://github.com/kubernetes/kubernetes/issues/114182 | 1,468,307,566 | 114,182 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Ability to customise the default DNS options provided to a pod's `/etc/resolv.conf` when using the DNSClusterFirst policy that would be provided in addition to the default "ndots:5" or any other options specified in the Pod's DNSConfig spec fields.
### Why is this needed?
Curren... | Add option to customise default ClusterFirst DNS options from the host | https://api.github.com/repos/kubernetes/kubernetes/issues/114173/comments | 6 | 2022-11-29T01:24:22Z | 2023-01-05T16:52:48Z | https://github.com/kubernetes/kubernetes/issues/114173 | 1,467,309,513 | 114,173 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
On our production bare metal cluster, on some nodes which are running batch jobs, we are observing that pods are taking around 5-6 minutes to start due to attachment/volume timeout even for a simple configmap. The pod manifest which we used for testing this timeout error:
```
apiVersion: v1
k... | Kubelet unable to attach or mount volumes: timed out waiting for the condition | https://api.github.com/repos/kubernetes/kubernetes/issues/114167/comments | 31 | 2022-11-28T21:06:47Z | 2025-01-30T10:52:58Z | https://github.com/kubernetes/kubernetes/issues/114167 | 1,467,092,445 | 114,167 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When issuing a token review request to the k8s api and provide a token with a leading space you get the following response:
```
{
"kind": "TokenReview",
"apiVersion": "authentication.k8s.io/v1",
"metadata": {
"creationTimestamp": null,
"managedFields": [{
"manager": "a-sample-man... | Token Review request has wrong behavior when token starts with a space | https://api.github.com/repos/kubernetes/kubernetes/issues/114165/comments | 4 | 2022-11-28T17:12:55Z | 2022-11-29T19:58:24Z | https://github.com/kubernetes/kubernetes/issues/114165 | 1,466,784,491 | 114,165 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
## Q1: GET /apis/storage.k8s.io/v1/storageclasses
When a larger value is passed to the `resourceVersion` parameter and the` limit` parameter is set to a larger value, the response will return 500error with the message "etcdserver: mvcc: required revision is a future revision".
## Q2: Delete Reque... | Error when fuzzing API with unexpected `resourceVersion` | https://api.github.com/repos/kubernetes/kubernetes/issues/114162/comments | 12 | 2022-11-28T11:44:42Z | 2024-10-31T20:16:18Z | https://github.com/kubernetes/kubernetes/issues/114162 | 1,466,278,792 | 114,162 |
[
"kubernetes",
"kubernetes"
] | **Problem:**
The Link for `cloud-controller-manager` under [FAQ](https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/FAQ.md#how-does-cluster-autoscaler-remove-nodes) is not working. It redirects to k8s v1.19 docs, which are not supported now by k8s. and this cloud-controller-manager reference pag... | Link for cloud-controller-manager is not working. | https://api.github.com/repos/kubernetes/kubernetes/issues/114161/comments | 10 | 2022-11-28T11:39:34Z | 2022-11-28T11:59:03Z | https://github.com/kubernetes/kubernetes/issues/114161 | 1,466,272,991 | 114,161 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [16cd3caed44925f8a110](https://go.k8s.io/triage#16cd3caed44925f8a110)
##### Error text:
```
Failed to run clusterctl move
Expected success, but got an error:
<*errors.withStack | 0xc002245170>: {
error: <*errors.withMessage | 0xc0023f27c0>{
cause: <*errors.withStack ... | Self-hosted e2e tests are a bit flaky | https://api.github.com/repos/kubernetes/kubernetes/issues/114160/comments | 6 | 2022-11-28T11:11:16Z | 2022-11-28T11:53:47Z | https://github.com/kubernetes/kubernetes/issues/114160 | 1,466,233,513 | 114,160 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
In-place pod resize feature adds Resources field to ContainerStatus struct. This is used to report CPU and memory requests & limits configured for the containers. We should ensure that it also reports extended resources assigned to the containers.
See discussion: https://github.... | [FG:InPlacePodVerticalScaling] Verify extended resources are correctly reported in ContainerStatus Resources | https://api.github.com/repos/kubernetes/kubernetes/issues/114159/comments | 20 | 2022-11-28T10:27:18Z | 2024-10-17T00:39:04Z | https://github.com/kubernetes/kubernetes/issues/114159 | 1,466,174,493 | 114,159 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When I update the deployment replicas to 0, I immediately call GetPodsForDeployment. At this time, I get the error expected a new replica set for deployment。When I call again after a few seconds, the empt pod list will be returned。
The GetPodsForDeployment method is located in kubernetes/test/e2e... | When I update the deployment replicas to 0, I immediately call GetPodsForDeployment. At this time, I get the error expected a new replica set for deployment | https://api.github.com/repos/kubernetes/kubernetes/issues/114147/comments | 4 | 2022-11-26T03:28:44Z | 2022-12-26T06:08:34Z | https://github.com/kubernetes/kubernetes/issues/114147 | 1,465,032,848 | 114,147 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
https://prow.ppc64le-cloud.org/job-history/s3/ppc64le-prow-logs/logs/postsubmit-master-golang-kubernetes-unit-test-ppc64le
### Which tests are flaking?
Tests in `vendor/k8s.io/apiserver/pkg/server/genericapiserver_graceful_termination_test.go` are flaking when run with master golang on pp... | [Flaky test] Tests in vendor/k8s.io/apiserver/pkg/server/genericapiserver_graceful_termination_test.go are flaking | https://api.github.com/repos/kubernetes/kubernetes/issues/114145/comments | 28 | 2022-11-25T18:42:05Z | 2023-01-10T18:40:00Z | https://github.com/kubernetes/kubernetes/issues/114145 | 1,464,839,023 | 114,145 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
For pods that only use secrets and configmaps, this plugin adds some overhead at scale. @msau42 does this plugin need to run for those types of volumes at all? If not, we can add a PreFilter to evaluate if Filter can exit early.
### Why is this needed?
Improve performance at sca... | Optimize NodeVolumeLimits plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/114143/comments | 15 | 2022-11-25T17:26:21Z | 2023-04-27T08:44:16Z | https://github.com/kubernetes/kubernetes/issues/114143 | 1,464,791,476 | 114,143 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We recently applied a 500MiB limit to a deployment with one pod and one container in that pod.
Upon doing so, the container started to be OOMkilled, however, the Prometheus metrics and K9S both reported that Memory usage never reached the limits, instead hovering around 300MiB.
 did, I want to reserve some port for nodeport. I can try to submit an KEP if it sound good for sig/network.
### Why is this needed?
In our cluster, ... | Reserved an statically port range for nodeport | https://api.github.com/repos/kubernetes/kubernetes/issues/114129/comments | 4 | 2022-11-25T08:11:41Z | 2023-01-29T22:02:37Z | https://github.com/kubernetes/kubernetes/issues/114129 | 1,464,178,827 | 114,129 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
50 - 50 Load distribution in Headless service
Service is created as below:
apiVersion: v1
kind: Service
metadata:
name: ccs-fscc
labels:
app: ccs-fscc
spec:
clusterIP: None
selector:
app: ccs-fscc
ports:
- port: 5073
protocol: TCP
... | Headless service is not doing the proper load balancing in Round Robin manner. | https://api.github.com/repos/kubernetes/kubernetes/issues/114128/comments | 12 | 2022-11-25T07:13:10Z | 2023-01-16T19:30:57Z | https://github.com/kubernetes/kubernetes/issues/114128 | 1,464,128,588 | 114,128 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We are on Kubernetes 1.23.12. We notice the memory usage wrongly reported by `kubectl top node`, see below:
The node `/proc/meminfo` output, memory usage is low as about 3G/16GB.
```
cat /proc/meminfo
MemTotal: 16393712 kB
MemFree: 2900416 kB
MemAvailable: 12920900 kB
Buff... | Wrong memory usage reported by kubectl top node | https://api.github.com/repos/kubernetes/kubernetes/issues/114124/comments | 7 | 2022-11-25T05:07:46Z | 2022-11-25T15:29:08Z | https://github.com/kubernetes/kubernetes/issues/114124 | 1,464,042,361 | 114,124 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.