
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | Hello,
From couple of days I have below issue,
I have pod failed so I wanted to kubectl apply -f with yml file.
Normally this file was working fine.
Right now I see error: Init:ImagePullBackOff
I see below error description:
`Failed to pull image "busybox": rpc error: code = Unknown desc = Error response from ... | kubernetes issues with pull images from docker | https://api.github.com/repos/kubernetes/kubernetes/issues/107340/comments | 4 | 2022-01-05T16:41:12Z | 2022-01-05T23:53:36Z | https://github.com/kubernetes/kubernetes/issues/107340 | 1,094,542,302 | 107,340 |
[
"kubernetes",
"kubernetes"
] | Is this a BUG REPORT or FEATURE REQUEST?:
/kind bug
**What happened:**
Trying to copy a large file from a container via kubectl cp with the new `--retries` flag results in the following error:
```
➜ k cp namespace/pod:/usr/path/to/logs/diagnostics.tgz ./diagnostics.tgz --retries=-1
tar: Removing leading ... | kubectl cp with --retries=-1 throws error | https://api.github.com/repos/kubernetes/kubernetes/issues/107333/comments | 8 | 2022-01-05T14:24:16Z | 2022-03-28T12:39:35Z | https://github.com/kubernetes/kubernetes/issues/107333 | 1,094,406,107 | 107,333 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
currently, the parameters of `/run` interface in kubelet is same with `/exec` interface. Both of `/run` and `/exec` interfaces use `execRequestParams` to pass parameters.
```go
type execRequestParams struct {
podNamespace string
podName string
podUID types.... | kubelet /run interface should support timeout parameter ? | https://api.github.com/repos/kubernetes/kubernetes/issues/107331/comments | 8 | 2022-01-05T09:24:23Z | 2022-09-02T19:02:14Z | https://github.com/kubernetes/kubernetes/issues/107331 | 1,094,145,450 | 107,331 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Etcd process on master node exhaust all memory, making DoS attack.
`top:`
`PID USER PR NI VIRT RES SHR S %CPU %MEM COMMAND`
`108 root 20 0 0 0 0 S 47.2 0.0 kswapd0`
`2218... | Etcd used by kubernetes is vulnerable to OOM attack | https://api.github.com/repos/kubernetes/kubernetes/issues/107325/comments | 19 | 2022-01-05T03:33:20Z | 2022-06-18T07:13:38Z | https://github.com/kubernetes/kubernetes/issues/107325 | 1,093,946,486 | 107,325 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Kube-apiserver and etcd processes on master node exhaust all memory, making DoS attack.
`top:`
`PID USER PR NI VIRT RES SHR S %CPU %MEM COMMAND`
`2035 root 20 0 17.1g 4.8g 228528 S 52.8 30.9 etc... | Kube-apiserver/etcd is vulnerable to OOM attack | https://api.github.com/repos/kubernetes/kubernetes/issues/107324/comments | 7 | 2022-01-05T03:06:21Z | 2022-06-05T15:53:48Z | https://github.com/kubernetes/kubernetes/issues/107324 | 1,093,933,957 | 107,324 |
[
"kubernetes",
"kubernetes"
] | ## What happened?
Kube-apiserver and etcd processes on master node exhaust all memory, making DoS attack.
`top:`
`PID USER PR NI VIRT RES SHR S %CPU %MEM COMMAND`
`2035 root 20 0 17.1g 4.8g 228528 S 52.8 30.9 etcd`
... | Kube-apiserver/etcd is vulnerable to OOM attack | https://api.github.com/repos/kubernetes/kubernetes/issues/107323/comments | 2 | 2022-01-05T02:57:15Z | 2022-01-05T03:08:28Z | https://github.com/kubernetes/kubernetes/issues/107323 | 1,093,929,851 | 107,323 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
**ubuntu@-data-master-3:~$ curl -k https://10.192.1.24:6443/readyz**
[+]ping ok
[+]log ok
[+]etcd ok
**_[-]informer-sync failed: reason withheld_**
[+]poststarthook/start-kube-apiserver-admission-initializer ok
[+]poststarthook/generic-apiserver-start-informers ok
[+]poststart... | Apiserver is not in ready state, however other control components are all in good state | https://api.github.com/repos/kubernetes/kubernetes/issues/107320/comments | 14 | 2022-01-05T01:26:50Z | 2022-02-02T16:24:48Z | https://github.com/kubernetes/kubernetes/issues/107320 | 1,093,892,774 | 107,320 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Calling UpdateStatus with fake client-go mutates spec
### What did you expect to happen?
UpdateStatus only mutates status, like with real client
### How can we reproduce it (as minimally and precisely as possible)?
```
package gateway
import (
"context"
"testing"
corev1 "k8s.io/api/c... | client-go fake: UpdateStatus mutates spec | https://api.github.com/repos/kubernetes/kubernetes/issues/107319/comments | 15 | 2022-01-05T00:38:59Z | 2022-07-07T12:16:07Z | https://github.com/kubernetes/kubernetes/issues/107319 | 1,093,869,192 | 107,319 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When applying a `MutatingWebhookConfiguration`, the `.webhooks[].rules[]` array is being expanded by the `.webhooks[].rules[].apiVersions[]` values. This is causing configuration drift as the object that is in the manifest is different than the object stored by Kubernetes.
This results in the o... | Admission registration performs webhook rules expansion modifying object on apply | https://api.github.com/repos/kubernetes/kubernetes/issues/107318/comments | 12 | 2022-01-05T00:21:57Z | 2022-06-05T22:59:18Z | https://github.com/kubernetes/kubernetes/issues/107318 | 1,093,860,558 | 107,318 |
[
"kubernetes",
"kubernetes"
] | Mi nombre es Ismael Hernández de la empresa Mejora Continua de México, mi puesto actual es Analista de Reclutamiento y Selección Sr. IT, dicho lo anterior les escribo amada red ya que actualmente contamos con una vacante muy interesante en el área IT el puesto como tal es “experto en Kubernetes” donde estarás realizand... | Con todo respeto "Estoy en búsqueda de un developer en Kubernetes" | https://api.github.com/repos/kubernetes/kubernetes/issues/107315/comments | 3 | 2022-01-04T19:54:03Z | 2022-01-04T21:19:55Z | https://github.com/kubernetes/kubernetes/issues/107315 | 1,093,703,937 | 107,315 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
[component-base](https://github.com/kubernetes/kubernetes/tree/master/staging/src/k8s.io/component-base) is currently using default resource lock `endpoints`. As we want to migrate all the resource lock to leases.
We no more want to set the default value of resource lock and ... | Migrate `component-base` to use Lease API | https://api.github.com/repos/kubernetes/kubernetes/issues/107313/comments | 9 | 2022-01-04T18:50:55Z | 2022-06-30T21:21:55Z | https://github.com/kubernetes/kubernetes/issues/107313 | 1,093,659,478 | 107,313 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We recently started using the list pager from client-go as part of Calico, and have seen reports of the following error showing up: https://github.com/kubernetes/apimachinery/blob/master/pkg/apis/meta/internalversion/validation/validation.go#L35-L37
### What did you expect to happen?
No erro... | client-go should clear ResourceVersionMatch on paged List() calls | https://api.github.com/repos/kubernetes/kubernetes/issues/107310/comments | 2 | 2022-01-04T15:58:34Z | 2022-01-06T21:24:52Z | https://github.com/kubernetes/kubernetes/issues/107310 | 1,093,493,435 | 107,310 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
when we excute docker stop container, and excuet docker start container, meet the error accidentally,
we Tested, the problem probability about 10%,the log as follows:
[StartContainer "88b573825e2f948b112279c91d0a9134c105c02c31401c2e0d8c7f06502d0523" from runtime service failed: rpc error: cod... | restart container failed, report Error response from daemon: cannot join network of a non running container | https://api.github.com/repos/kubernetes/kubernetes/issues/107308/comments | 11 | 2022-01-04T13:31:07Z | 2022-06-05T00:50:01Z | https://github.com/kubernetes/kubernetes/issues/107308 | 1,093,359,183 | 107,308 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I want to use the `exec` probe, and I found the `timeoutSeconds` with exec probe did not take effect as expected.
here is the situation, let's take readinessProbe for example to show the question.
I use `exec` probe in `readinessProbe` and set the `timeoutSeconds` of `readinessProbe` to 5, ... | The timeout of exec probe did not take effect as expected. | https://api.github.com/repos/kubernetes/kubernetes/issues/107306/comments | 7 | 2022-01-04T11:54:07Z | 2022-01-05T03:12:49Z | https://github.com/kubernetes/kubernetes/issues/107306 | 1,093,280,924 | 107,306 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The pod has been scheduled to the node, but the pod has always been in the pending state.
kubelet does not output the pod log, as if there is no watch to the creation event of the pod
```
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2022-01-04T06:46:15Z"
generateName: test-ngi... | The pod has been scheduled to the node, but the pod has always been in the pending state | https://api.github.com/repos/kubernetes/kubernetes/issues/107303/comments | 5 | 2022-01-04T08:44:35Z | 2022-01-04T16:08:18Z | https://github.com/kubernetes/kubernetes/issues/107303 | 1,093,130,735 | 107,303 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
[component-base](https://github.com/kubernetes/kubernetes/tree/master/staging/src/k8s.io/component-base) is currently using endpoints . We want to migrate this to endpointsleases and finally to leases.
### Why is this needed?
Support for endpoints and configmaps is removed ... | Migrate `component-base` to use Lease API | https://api.github.com/repos/kubernetes/kubernetes/issues/107301/comments | 10 | 2022-01-04T06:51:37Z | 2022-01-06T21:24:49Z | https://github.com/kubernetes/kubernetes/issues/107301 | 1,093,062,041 | 107,301 |
[
"kubernetes",
"kubernetes"
] | Kubernetes v1.20.0
Docker version 20.10.8
calico/cni:v3.8.9
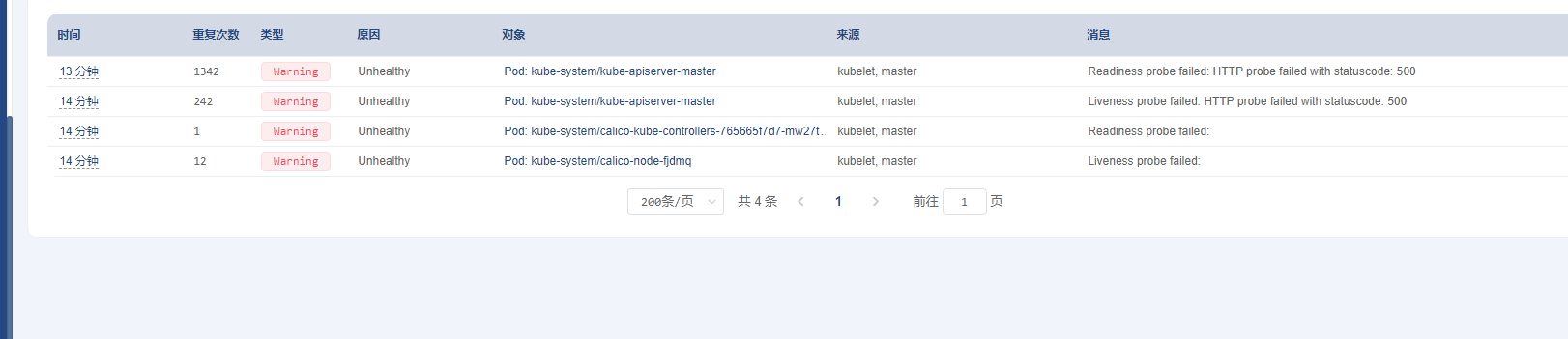
| api-server-maser /calico/ kube-scheduler-master health check fail | https://api.github.com/repos/kubernetes/kubernetes/issues/107298/comments | 5 | 2022-01-04T01:59:13Z | 2022-01-05T23:48:58Z | https://github.com/kubernetes/kubernetes/issues/107298 | 1,092,945,755 | 107,298 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I deployed a single node using kubeadm with the following components:
* docker CRI
* Flannel network
* Metallb ingress
After deploying the node I removed the master taint to enable scheduling pods on this node. Then I created an nginx deployment along with a loadbalancer service. After this th... | Kube Proxy: Unable to open port when scheduling pods to kube master | https://api.github.com/repos/kubernetes/kubernetes/issues/107297/comments | 22 | 2022-01-03T21:24:27Z | 2023-06-17T17:59:43Z | https://github.com/kubernetes/kubernetes/issues/107297 | 1,092,830,704 | 107,297 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Add `suspend` subresource to allow agnostically suspending/restarting apps, especially jobs. This is similar to the `scale` subresource.
### Why is this needed?
This is useful to develop job management operators (such as job queueing controllers) that aim to control when to sta... | Add suspend subresource | https://api.github.com/repos/kubernetes/kubernetes/issues/107294/comments | 26 | 2022-01-03T18:33:04Z | 2025-01-16T21:20:00Z | https://github.com/kubernetes/kubernetes/issues/107294 | 1,092,727,638 | 107,294 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When STS pod is deleted via `kubectl delete pod` command and subsequently created on another node, `kubectl top pod` command returns MEMORY(bytes) as sum of the deleted pod and newly created pod for approx. 3 minutes.
MEMORY(bytes) in such case returns nonsensical value exceeding in fact memory... | Kubectl top pod command returns incorrect amount of memory for STS pod in case the pod is deleted and recreated | https://api.github.com/repos/kubernetes/kubernetes/issues/107291/comments | 8 | 2022-01-03T13:55:50Z | 2022-03-11T16:11:14Z | https://github.com/kubernetes/kubernetes/issues/107291 | 1,092,532,278 | 107,291 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
https://testgrid.k8s.io/sig-windows-signal#aks-engine-windows-containerd-master
### Which tests are flaking?
Any test, but it seems to happen more often for tests in which there are pods with pause / sleeps in them.
### Since when has it been flaking?
Unknown
### Testgrid l... | Windows tests: Flakes due to StartContainer timeouts | https://api.github.com/repos/kubernetes/kubernetes/issues/107290/comments | 12 | 2022-01-03T11:06:31Z | 2023-01-08T18:47:25Z | https://github.com/kubernetes/kubernetes/issues/107290 | 1,092,416,552 | 107,290 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Environment introduction:
Kubernetes version:1.18.6
Docker version:19.03.12
Operating system version: Centos 7.7 1908
Kernel version: 3.10.0-1062.el7.x86_64
Problem Description:
1) A business pod has been deleted in kubernetes, and the deleted pod information cannot be filtered out throug... | A business pod on the k8s node is isolated, making it impossible to delete it, directly affecting scheduling! | https://api.github.com/repos/kubernetes/kubernetes/issues/107289/comments | 9 | 2022-01-03T10:12:16Z | 2022-06-03T02:33:05Z | https://github.com/kubernetes/kubernetes/issues/107289 | 1,092,380,537 | 107,289 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I am trying to run the nginx ingress controller and nginx web server with custom configurations. For this I have created configmaps, deployment, exposed it as service of type node port, created a relevant route and ingress rule as well for both (ingress and web server). I can curl the static content... | Unable to route traffic to nginx webserver via nginx ingress | https://api.github.com/repos/kubernetes/kubernetes/issues/107287/comments | 4 | 2022-01-02T19:34:07Z | 2022-01-02T20:43:30Z | https://github.com/kubernetes/kubernetes/issues/107287 | 1,092,085,898 | 107,287 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
There are pre-defined tests patterns that specify "CSI Ephemeral" in combination with a non-default fstype, for example:
https://github.com/kubernetes/kubernetes/blob/7c013c3f64db33cf19f38bb2fc8d9182e42b0b7b/test/e2e/storage/framework/testpattern.go#L198-L204
### What did you expect to happen?
Th... | storage e2e: fstype not set for CSI Ephemeral test patterns | https://api.github.com/repos/kubernetes/kubernetes/issues/107286/comments | 3 | 2022-01-02T18:05:12Z | 2022-05-04T02:30:40Z | https://github.com/kubernetes/kubernetes/issues/107286 | 1,092,070,332 | 107,286 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
_As a cluster operator_
_I want to be able to enter a command such as:_
```shell
kubectl delete pods --field-selector="status.phase!=Pending","metadata.namespace!=kube-system"
```
_So that I can clean up pending pods except in the primary system namespace_ (I think that comman... | Allow case-insensitive matching in selectors | https://api.github.com/repos/kubernetes/kubernetes/issues/107285/comments | 10 | 2022-01-02T16:02:18Z | 2022-06-13T06:57:04Z | https://github.com/kubernetes/kubernetes/issues/107285 | 1,092,048,728 | 107,285 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm running k3s with kube `1.21.x` and I am currently impacted by google/cadvisor/pull/2868 which was fixed in cadvisor `v0.40.0`. All maintained branches are currently running cadvisor `v0.39.0` except `1.23.x` which is under the latest cadvisor.
### What did you expect to happen?
Bump all ... | request: backport cadvisor v0.40.0 to older branches | https://api.github.com/repos/kubernetes/kubernetes/issues/107284/comments | 11 | 2022-01-02T13:59:38Z | 2022-01-14T20:43:15Z | https://github.com/kubernetes/kubernetes/issues/107284 | 1,092,026,107 | 107,284 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
**I failed to start kube-controller-Manager**
kube-controller-manager --kubeconfig=/etc/kubernetes/kubeconfig --leader-elect=true --service-cluster-ip-range=169.169.0.0/16 --service-account-private-key-file=/etc/kubernetes/pki/apiserver.key --root-ca-file=/etc/kubernetes/pki/ca.crt --log-dir=/var... | invalid configuration: [context was not found for specified context: default, cluster has no server defined] | https://api.github.com/repos/kubernetes/kubernetes/issues/107282/comments | 7 | 2022-01-02T05:00:29Z | 2022-01-06T21:19:17Z | https://github.com/kubernetes/kubernetes/issues/107282 | 1,091,951,434 | 107,282 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hi,
I tried creating a secret with key under data section having plain text value. It was created successfully. In my understanding it should fail as its not base64 encoded.
Here is example:
[demo@kubemaster pods]$ cat sec1.yaml
apiVersion: v1
kind: Secret
metadata:
name: tryme
data:... | secret is created with clear text data | https://api.github.com/repos/kubernetes/kubernetes/issues/107281/comments | 7 | 2022-01-01T14:44:31Z | 2022-01-05T23:47:49Z | https://github.com/kubernetes/kubernetes/issues/107281 | 1,091,829,560 | 107,281 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The fake dynamic client does not support mock pagination or the self link.
### What did you expect to happen?
Add ability to propagate the metadata fields from a mock unstructured list to the served list by the fake lister.
### How can we reproduce it (as minimally and precisely as possible)?
Re... | go-client/dynamic/fake does not allow faking pagination | https://api.github.com/repos/kubernetes/kubernetes/issues/107277/comments | 6 | 2021-12-31T23:13:22Z | 2022-10-17T20:09:20Z | https://github.com/kubernetes/kubernetes/issues/107277 | 1,091,685,848 | 107,277 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We are using Azure AKS V1.20.7 and the service type in production environment is ClusterIP. In Kube-proxy logs, continuously I see the below printed line.
"Not saving endpoints for unknown healthcheck"
service_health.go:183] Not saving endpoints for unknown healthcheck
It may increase Synci... | Azure AKS - 1.20.7 - Not saving endpoints for unknown healthcheck | https://api.github.com/repos/kubernetes/kubernetes/issues/107275/comments | 14 | 2021-12-31T11:41:32Z | 2022-01-12T09:05:26Z | https://github.com/kubernetes/kubernetes/issues/107275 | 1,091,539,583 | 107,275 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Set up a new cluster with kubeadm following the docs at kubernetes.io with kubernetes 22.5 (one master node, 4 worker nodes).
Installed weavenet overlay network via helm.
I can install any kind of helm charts, pods etc. Everything works as expected.
Created a simple Network Policy blocking In... | kubectl replace does not update Network Policy changes | https://api.github.com/repos/kubernetes/kubernetes/issues/107274/comments | 6 | 2021-12-31T10:52:07Z | 2021-12-31T14:24:47Z | https://github.com/kubernetes/kubernetes/issues/107274 | 1,091,523,270 | 107,274 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [28311165688ff5ded2f4](https://go.k8s.io/triage#28311165688ff5ded2f4)
##### Error text:
```
=== RUN TestQuotaLimitService
I1230 00:54:57.057578 122720 controller.go:163] quota evaluator worker shutdown
I1230 00:54:57.057590 122720 controller.go:163] quota evaluator worker shutdown
I1230 ... | Failure cluster [28311165...] Make integration test TestQuotaLimitService wait longer, to avoid flakes | https://api.github.com/repos/kubernetes/kubernetes/issues/107273/comments | 3 | 2021-12-31T10:18:14Z | 2022-01-19T17:38:05Z | https://github.com/kubernetes/kubernetes/issues/107273 | 1,091,511,996 | 107,273 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The log below was added by myself to see the `GetMetrics` duration for empty dir.
> 12月 31 17:57:25 daocloud kubelet[726129]: I1231 17:57:25.254428 726129 volume_stat_calculator.go:141] Volume metrics for "data-test": %!s(float64=10.651979472)
> 12月 31 17:57:56 daocloud kubelet[726129]: I1231 1... | After kubelet restart, quota monitoring doesn't work for old pods. | https://api.github.com/repos/kubernetes/kubernetes/issues/107272/comments | 3 | 2021-12-31T10:10:59Z | 2022-01-05T17:23:18Z | https://github.com/kubernetes/kubernetes/issues/107272 | 1,091,509,284 | 107,272 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
2021/12/31 13:40:37 [error] 13#13: *142993 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 127.0.0.1, server: , request: "POST /api/awc-tracker/beneficiary/save HTTP/1.1", upstream: "fastcgi://unix:///var/run/php-fpm.sock", host: ... | connection timed out fot upstream to downstream | https://api.github.com/repos/kubernetes/kubernetes/issues/107269/comments | 4 | 2021-12-31T08:58:02Z | 2021-12-31T09:06:16Z | https://github.com/kubernetes/kubernetes/issues/107269 | 1,091,483,385 | 107,269 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
2021/12/31 13:40:37 [error] 13#13: *142993 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 127.0.0.1, server: , request: "POST /api/awc-tracker/beneficiary/save HTTP/1.1", upstream: "fastcgi://unix:///var/run/php-fpm.sock", host: ... | connection timed out | https://api.github.com/repos/kubernetes/kubernetes/issues/107268/comments | 5 | 2021-12-31T08:49:10Z | 2021-12-31T08:59:28Z | https://github.com/kubernetes/kubernetes/issues/107268 | 1,091,480,808 | 107,268 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We found if use slb between kube-apiserver and client, when kube-apiserver restart, client watcher connection not close and wait an event forever. In this case has two connections: kube-apiserver <-> slb, slb <-> client. After close the first connection could not ensure the second connection also... | client wait forever if kube-apiserver restart in slb environment | https://api.github.com/repos/kubernetes/kubernetes/issues/107266/comments | 17 | 2021-12-31T02:45:30Z | 2022-06-06T12:03:20Z | https://github.com/kubernetes/kubernetes/issues/107266 | 1,091,387,267 | 107,266 |
[
"kubernetes",
"kubernetes"
] | I tried to customize the scheduling-framework according to the community's solution, but I found that it relied on k8s.io/kubernetes, and I couldn't pull kubernetes using go.
I have two questions:
1. How do we pull k8s.io/kubernetes successfully?
2. Why cannot cmd/kube-scheduler be provided externally like k8s.io/... | Customize Scheduling-framework | https://api.github.com/repos/kubernetes/kubernetes/issues/107263/comments | 7 | 2021-12-30T13:13:13Z | 2022-01-04T02:32:45Z | https://github.com/kubernetes/kubernetes/issues/107263 | 1,091,097,872 | 107,263 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
1. create a statefulset with 3 replicas with `podManagementPolicy: Parallel`, each pod claimed a localpv(dynamic provisioning), pod spread by host with maxSkew=1
2. 2 pods got scheduled, 1 remains pending, and 2 of 3 local pvs got scheduled to the same node
### What did you expect to happe... | pod pending in case of scheduler leader election | https://api.github.com/repos/kubernetes/kubernetes/issues/107262/comments | 8 | 2021-12-30T12:41:10Z | 2022-06-04T10:39:06Z | https://github.com/kubernetes/kubernetes/issues/107262 | 1,091,081,527 | 107,262 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Similar to [87977](https://github.com/kubernetes/kubernetes/issues/87977), it seems in other vendor, the cleanup logic is incomplete.
- fc
https://github.com/kubernetes/kubernetes/blob/1df88a8a42952d4b0f393c1d25b1d1c992bf72c3/pkg/volume/fc/fc.go#L432-L443
- iscsi
https://github.com/k... | block volume leaves orphan files | https://api.github.com/repos/kubernetes/kubernetes/issues/107261/comments | 6 | 2021-12-30T12:19:03Z | 2022-05-29T14:06:34Z | https://github.com/kubernetes/kubernetes/issues/107261 | 1,091,070,850 | 107,261 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I am trying to run a Kubeflow TFJob operator to train a machine learning model which implements TensorFlow's distributed training strategies.
The TFJob YAML looks like this:
```apiVersion: kubeflow.org/v1
kind: TFJob
metadata:
name: tf-job-cifar
namespace: kubeflow
spec:
tfReplicaS... | kubernetes pod Readiness probe failed: Get "http://172.17.0.31:15021/healthz/ready": dial tcp 172.17.0.31:15021: connect: connection refused | https://api.github.com/repos/kubernetes/kubernetes/issues/107260/comments | 8 | 2021-12-30T12:18:27Z | 2022-08-21T00:57:37Z | https://github.com/kubernetes/kubernetes/issues/107260 | 1,091,070,521 | 107,260 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
```
make
Makefile:1: *** missing separator. Stop.
```
white spaces are instead of tabs in the makefiles.
### What did you expect to happen?
the makefile is updated right in the reposity.
### How can we reproduce it (as minimally and precisely as possible)?
update the makefile
### Anything ... | can't run the make command | https://api.github.com/repos/kubernetes/kubernetes/issues/107259/comments | 4 | 2021-12-30T10:04:26Z | 2024-12-02T00:50:38Z | https://github.com/kubernetes/kubernetes/issues/107259 | 1,091,000,906 | 107,259 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kubelet service is not starting after restart.
Binary: Built with gc go1.12.9 for windows/amd64
Log line format: [IWEF]mmdd hh:mm:ss.uuuuuu threadid file:line] msg
E1230 00:41:21.821254 16564 perfcounter_nodestats.go:176] Unable to get cpu perf counter data; err: unable to collect data from c... | kubelet service failed to start after restart | https://api.github.com/repos/kubernetes/kubernetes/issues/107258/comments | 6 | 2021-12-30T09:31:39Z | 2022-03-18T23:05:22Z | https://github.com/kubernetes/kubernetes/issues/107258 | 1,090,983,451 | 107,258 |
[
"kubernetes",
"kubernetes"
] | Hi All,
We are using Azure AKS Version 1.20.7 with nearly 10 Nodes running on it. Vault is Up, Database is Up, Istio is up and running.
But still health checks(Liveness & Readiness) are failing.
context deadline exceeded (Client.Timeout exceeded while awaiting headers)
Readiness probe failed: HTTP probe faile... | Health Checks Failing - Readiness & Liveness For Production Azure AKS Cluster | https://api.github.com/repos/kubernetes/kubernetes/issues/107257/comments | 6 | 2021-12-30T08:59:42Z | 2022-01-05T23:45:05Z | https://github.com/kubernetes/kubernetes/issues/107257 | 1,090,966,568 | 107,257 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Just as *https://github.com/kubernetes/kubernetes/pull/81429#discussion_r314035095* said ,
> Just to be on safe side, for in-tree drivers I think we should still skip calling fs resize on the node if volume is of type raw block.
but in FlexVolume mode , it seems there is no check for volumeMod... | FlexVolume: should skip calling fs resize on the node if volume is of type raw block | https://api.github.com/repos/kubernetes/kubernetes/issues/107256/comments | 12 | 2021-12-30T08:31:03Z | 2023-04-14T04:32:28Z | https://github.com/kubernetes/kubernetes/issues/107256 | 1,090,953,343 | 107,256 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
1. Add a gate to open/close the auto-action(restart container) after liveness probe failed. default as `open`.
2. Add an attribute `Healthy` in `ContainerStatus`, just like the `Started` and `Ready` to specify whether the container has passed its liveness probe.
3. May add an... | Can we control the subsequent actions after livenessProbe failed? Not just restart container. | https://api.github.com/repos/kubernetes/kubernetes/issues/107255/comments | 12 | 2021-12-30T06:53:47Z | 2022-06-07T15:11:59Z | https://github.com/kubernetes/kubernetes/issues/107255 | 1,090,912,680 | 107,255 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have Created StorageClass, PV, and PVC.
But my PVC is always in a pending State. Here is the pic of my SC,PV,PVC
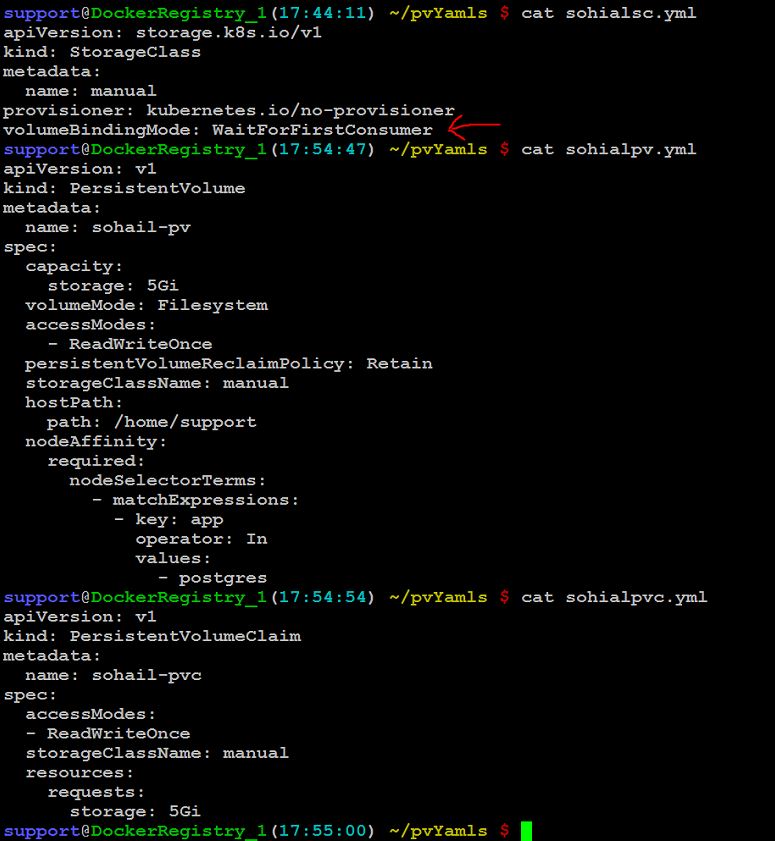
This is Describe of PVC
 often cannot access two Virtual Server ip with the same endpoint ip (real server) at the same time | https://api.github.com/repos/kubernetes/kubernetes/issues/107249/comments | 15 | 2021-12-29T09:32:46Z | 2022-06-03T14:36:05Z | https://github.com/kubernetes/kubernetes/issues/107249 | 1,090,387,939 | 107,249 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Similar to [#74313](https://github.com/kubernetes/kubernetes/issues/74313) , in the implement of other cloud provider's DetachDisk(), there should be a check to ensure if there are other pods using other volumes on the same device to avoid unexpected result.
- fc
https://github.com/kubernet... | Before detach device should ensure there is no pod use it | https://api.github.com/repos/kubernetes/kubernetes/issues/107246/comments | 11 | 2021-12-28T11:59:36Z | 2022-07-02T22:44:21Z | https://github.com/kubernetes/kubernetes/issues/107246 | 1,089,843,735 | 107,246 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Currently, as a cloud provider, we can only update `service.status.loadBalancer` filed.
### What did you expect to happen?
Put more information into `service.status` filed. e.g.
```bash
status:
loadBalancer:
ingress:
- ip: 192.168.0.1
conditions:
- reason: "bar"
lastTrans... | Can't update `service.status` filed | https://api.github.com/repos/kubernetes/kubernetes/issues/107245/comments | 11 | 2021-12-28T09:37:05Z | 2021-12-31T07:25:08Z | https://github.com/kubernetes/kubernetes/issues/107245 | 1,089,742,582 | 107,245 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
I am working on a new device plugin for GPU,witch need to get the pod's labels,annotations or anything.One way to solve this is to find pod according to 'AllocateRequest' in my device plugin,but I think it's redundant.So, it will be more smoothly if kubelet can transmit the name(o... | Let kubelet transmit the name(or index) of pod/container which is requiring devices via 'Allocate'. | https://api.github.com/repos/kubernetes/kubernetes/issues/107244/comments | 8 | 2021-12-28T09:28:04Z | 2022-08-16T09:40:40Z | https://github.com/kubernetes/kubernetes/issues/107244 | 1,089,737,415 | 107,244 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kubectl logs mqttfire-1-66ff697667-hn6jz
failed to try resolving symlinks in path "/var/log/pods/default_mqttfire-1-66ff697667-hn6jz_94fcd001-436e-499e-82ff-9bf588a01b25/mqttfire-arm64/0.log": lstat /var/log/pods/default_mqttfire-1-66ff697667-hn6jz_94fcd001-436e-499e-82ff-9bf588a01b25: no such file... | failed to try resolving symlinks in path "/var/log/pods/default_mqttfire-1 | https://api.github.com/repos/kubernetes/kubernetes/issues/107243/comments | 11 | 2021-12-28T09:15:45Z | 2024-08-07T11:57:49Z | https://github.com/kubernetes/kubernetes/issues/107243 | 1,089,729,919 | 107,243 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
I am working on a new device plugin for GPU,witch need to get the pod's labels,annotations or anything.One way to solve this is to find pod according to 'AllocateRequest' in my device plugin,but I think it's redundant.So, it will be more smoothly if kubelet can transmit the nam... | label:sig/node Let kubelet transmit the name(or index) of pod/container which is requiring devices via 'Allocate'. | https://api.github.com/repos/kubernetes/kubernetes/issues/107242/comments | 5 | 2021-12-28T09:03:25Z | 2021-12-28T09:27:35Z | https://github.com/kubernetes/kubernetes/issues/107242 | 1,089,722,056 | 107,242 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
git clone https://github.com/kubernetes/kubernetes.git
cd kubernetes
git checkout remotes/origin/release-1.23
./hack/update-generated-protobuf.sh
+++ [1228 14:01:30] Verifying Prerequisites....
+++ [1228 14:01:31] Building Docker image kube-build:build-c8503f4e72-5-v1.23.0-go1.17.5-bullseye... | Failed to find binary go-to-protobuf for platform linux/amd64 | https://api.github.com/repos/kubernetes/kubernetes/issues/107239/comments | 7 | 2021-12-28T06:38:58Z | 2022-06-10T22:38:28Z | https://github.com/kubernetes/kubernetes/issues/107239 | 1,089,649,361 | 107,239 |
[
"kubernetes",
"kubernetes"
] | What happened:
I am testing API Priority and Fairness. I launched it like this:
RUNTIME_CONFIG=flowcontrol.apiserver.k8s.io/v1alpha1=true FEATURE_GATES=APIPriorityAndFairness=true
But kubectl erroneously told me no table handler registered for this type *flowcontrol.FlowSchemaList
```
$ kubectl get flowschema... | is v1.17 support APIPriorityAndFairness ? | https://api.github.com/repos/kubernetes/kubernetes/issues/107238/comments | 10 | 2021-12-28T06:34:35Z | 2022-06-06T05:03:17Z | https://github.com/kubernetes/kubernetes/issues/107238 | 1,089,647,718 | 107,238 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Similar to [#65705](https://github.com/kubernetes/kubernetes/pull/65705), just as follows, in storageos, there is no check for volumeMode in the implement of storageos mode Provision()
https://github.com/kubernetes/kubernetes/blob/1df88a8a42952d4b0f393c1d25b1d1c992bf72c3/pkg/volume/storageos/storag... | Block volumes should have empty FSType in storageos | https://api.github.com/repos/kubernetes/kubernetes/issues/107237/comments | 6 | 2021-12-28T03:36:20Z | 2022-05-27T05:52:15Z | https://github.com/kubernetes/kubernetes/issues/107237 | 1,089,587,757 | 107,237 |
[
"kubernetes",
"kubernetes"
] | I defined a very simple CRD object: such as:
```
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: summaries.test.io
spec:
group: lite.test.io
versions:
- name: v1alpha1
served: true
storage: true
schema:
openAPIV3Schema:
typ... | How much data can be stored in a CR? where does this limit come from, and for what purpose? | https://api.github.com/repos/kubernetes/kubernetes/issues/107233/comments | 5 | 2021-12-27T16:15:26Z | 2022-01-04T23:02:35Z | https://github.com/kubernetes/kubernetes/issues/107233 | 1,089,338,587 | 107,233 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Similar to cinder mode volume:
https://github.com/kubernetes/kubernetes/blob/2ecdc5e8d19ee7a037b86e90a4d3de56cb94b938/pkg/volume/cinder/attacher.go#L242-L246
There should be a check for devicePath to ensure the path exists. But in some other cloud provider, it seems there are no path existing chec... | Missing check for devicePath to ensure the path exists | https://api.github.com/repos/kubernetes/kubernetes/issues/107231/comments | 9 | 2021-12-27T13:27:13Z | 2022-01-20T14:35:35Z | https://github.com/kubernetes/kubernetes/issues/107231 | 1,089,243,988 | 107,231 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In the implement of GCE mode WaitForAttach:
https://github.com/kubernetes/kubernetes/blob/2ecdc5e8d19ee7a037b86e90a4d3de56cb94b938/pkg/volume/gcepd/attacher.go#L226
when the runtime.GOOS = "windows" and it meets err , it should `return "", err` instead of
`return id, err`.
https://github.co... | GCEPD : in WaitForAttach when meet err, should return "",err | https://api.github.com/repos/kubernetes/kubernetes/issues/107230/comments | 5 | 2021-12-27T13:04:44Z | 2022-02-08T17:59:02Z | https://github.com/kubernetes/kubernetes/issues/107230 | 1,089,229,847 | 107,230 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I am currently running a Kubernetes cluster on version 1.21.8 which has Pod Security Policies in place. The cluster has been set up manually using kubeadm on bare metal.
After "kubeadm upgrade apply 1.22.5", the new API server did not start up. Due to the kubelet logs, I believe this might be due... | Upgrade from 1.21.8 to 1.22.5 fails (due to active PSP?) | https://api.github.com/repos/kubernetes/kubernetes/issues/107229/comments | 4 | 2021-12-27T10:56:33Z | 2022-01-03T19:45:15Z | https://github.com/kubernetes/kubernetes/issues/107229 | 1,089,155,596 | 107,229 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
AFAIK it is only possible to see which pods have mounted the PVC by using:
`kubectl describe pvc <PVC_NAME>`

The "kubectl describe pvc" command only outputs the ... | Which pod(s) are using the PVC? (ouput as JSON/YAML) | https://api.github.com/repos/kubernetes/kubernetes/issues/107227/comments | 17 | 2021-12-27T07:27:53Z | 2022-12-04T12:51:17Z | https://github.com/kubernetes/kubernetes/issues/107227 | 1,089,031,695 | 107,227 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Currently, sometimes, while create nums of jobs with **spec.activeDeadlineSeconds** concurrently, some job may not terminate it's pod while exceed activeDeadlineSeconds
1. the jobs template
```
apiVersion: batch/v1
kind: Job
metadata:
name: testjob
spec:
activeDeadlineSeconds: 60
... | Job didn't delete pods within activeDeadlineSeconds | https://api.github.com/repos/kubernetes/kubernetes/issues/107226/comments | 17 | 2021-12-27T05:33:03Z | 2022-08-09T13:46:53Z | https://github.com/kubernetes/kubernetes/issues/107226 | 1,088,978,723 | 107,226 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I try to set up a k8s environment in CentOS7, and follow the community docs using the master branch `/hack/local-up-cluster.sh`.
It always gets an error return:
```
coredns addon successfully deployed.
WARNING : The kubelet is configured to not fail even if swap is enabled; production depl... | Master branch ./hack/local-up-cluster.sh return 'iptables: No chain/target/match by that name' and 'No resources found' on CentOS7 | https://api.github.com/repos/kubernetes/kubernetes/issues/107223/comments | 4 | 2021-12-26T09:50:08Z | 2021-12-27T11:20:08Z | https://github.com/kubernetes/kubernetes/issues/107223 | 1,088,736,116 | 107,223 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I use kubebuilder to define my own `CRD` like below, and it contains `VolumeClaimTemplates` filed which the type is `[]coreV1.PersistentVolumeClaim`
```golang
package v1alpha1
import (
apps "k8s.io/api/apps/v1"
coreV1 "k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"... | Metadata of PersistemVolumeClaim can not be decoded correctly | https://api.github.com/repos/kubernetes/kubernetes/issues/107222/comments | 3 | 2021-12-26T08:12:24Z | 2022-01-06T21:24:42Z | https://github.com/kubernetes/kubernetes/issues/107222 | 1,088,720,771 | 107,222 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We created a pod with a generic ephemeral volume:
```yaml
- ephemeral:
volumeClaimTemplate:
metadata:
creationTimestamp: null
spec:
accessModes:
- ReadWriteOnce ... | Kubelet not reporting metrics for generic ephemeral volumes | https://api.github.com/repos/kubernetes/kubernetes/issues/107218/comments | 13 | 2021-12-24T13:22:32Z | 2022-08-22T08:48:24Z | https://github.com/kubernetes/kubernetes/issues/107218 | 1,088,379,689 | 107,218 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
kubele to collect
container_cpu_schedstat_run_seconds_total,
container_cpu_schedstat_runqueue_seconds_total,
container_cpu_schedstat_run_periods_total
metrics ?
### Why is this needed?
cpu_schedstat_run_seconds_total,
container_cpu_schedstat_runqueue_seconds_total
... | Can we open the kubelet to collect the container_cpu_schedstat_run_seconds_total, container_cpu_schedstat_runqueue_seconds_total and container_cpu_schedstat_run_periods_total metrics ?? | https://api.github.com/repos/kubernetes/kubernetes/issues/107216/comments | 6 | 2021-12-24T09:32:02Z | 2022-01-13T17:36:30Z | https://github.com/kubernetes/kubernetes/issues/107216 | 1,088,271,590 | 107,216 |
[
"kubernetes",
"kubernetes"
] | null | How to manually recover accidentally deleted pv | https://api.github.com/repos/kubernetes/kubernetes/issues/107214/comments | 13 | 2021-12-24T05:42:28Z | 2022-05-23T12:28:00Z | https://github.com/kubernetes/kubernetes/issues/107214 | 1,088,164,678 | 107,214 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
https://github.com/kubernetes/kubernetes/blob/65ac7f09ec36736f1282adf876f54b665a35d750/staging/src/k8s.io/apimachinery/pkg/util/validation/validation.go#L318-L346
The `portNameOneLetterRegexp` only support at least one letter,but the error message is at least one letter or number.
It will be er... | The error message of portname valid syntax is wrong | https://api.github.com/repos/kubernetes/kubernetes/issues/107212/comments | 6 | 2021-12-24T03:45:48Z | 2022-05-10T17:03:43Z | https://github.com/kubernetes/kubernetes/issues/107212 | 1,088,125,841 | 107,212 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I deployed a pod with `limits.cpu` and `limits.memory` on a namesapace with a `ResourceQuota` set with `limits.cpu` and `limits.memory` elements and I get the error: `failed quota: <quota name>: must specify limits.cpu,limits.memory`
### What did you expect to happen?
The pod to be deployed
... | resource limits seems to be ignored when deploying a pod | https://api.github.com/repos/kubernetes/kubernetes/issues/107205/comments | 17 | 2021-12-23T15:55:51Z | 2022-02-11T08:41:03Z | https://github.com/kubernetes/kubernetes/issues/107205 | 1,087,828,667 | 107,205 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In my development with SpringBoot,
**application.yml**
`k8s-cluster-ip: http://192.168.200.142:8080 # Realize the connection with K8S`
Modify the K8S file -> **kube-apiserver.yaml**
add
`- --insecure-bind-address=0.0.0.0 - --insecure-port=8080 `
The k8S version was 1.17.3 a... | io.kubernetes.client.openapi.ApiException: java.net.ConnectException: Failed to connect to /192.168.200.142:8080 | https://api.github.com/repos/kubernetes/kubernetes/issues/107204/comments | 11 | 2021-12-23T15:55:01Z | 2022-08-17T09:03:55Z | https://github.com/kubernetes/kubernetes/issues/107204 | 1,087,828,133 | 107,204 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have a mysql pod running in a digitalocean k8s cluster that I connect to via kubectl port-forward. As soon as I make a connection request to this pod using:
```
$ kubectl port-forward service/mycluster mysql :6446
```
I get the following error:
```
ashok@Ashoks-Mac-mini ~ % kubectl port-fo... | kubectl port-forward broken pipe | https://api.github.com/repos/kubernetes/kubernetes/issues/107203/comments | 16 | 2021-12-23T08:34:58Z | 2024-05-30T16:38:55Z | https://github.com/kubernetes/kubernetes/issues/107203 | 1,087,494,316 | 107,203 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
```
journalctl -u kubelet |grep looking
Dec 23 15:59:00 node1 kubelet[727393]: I1223 15:59:00.059831 727393 config.go:144] looking for config.json at /var/lib/kubelet/config.json
Dec 23 15:59:00 node1 kubelet[727393]: I1223 15:59:00.059849 727393 config.go:144] looking for config.json at /c... | There is an extra space in kubelet search home docker.json dir | https://api.github.com/repos/kubernetes/kubernetes/issues/107202/comments | 17 | 2021-12-23T08:33:12Z | 2022-06-09T11:21:12Z | https://github.com/kubernetes/kubernetes/issues/107202 | 1,087,493,075 | 107,202 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Right now, `func TestCmdJoinConfig(t *testing.T)` cannot execute independently. If environment variable KUBEADM_PATH is not set, the unit test triggers a panic ([line 77](https://github.com/kubernetes/kubernetes/blob/master/cmd/kubeadm/test/cmd/util.go#L77)).
Is it possible to build the kubead... | panic in TestCmdJoinConfig | https://api.github.com/repos/kubernetes/kubernetes/issues/107199/comments | 11 | 2021-12-23T03:59:22Z | 2022-01-03T19:45:39Z | https://github.com/kubernetes/kubernetes/issues/107199 | 1,087,352,905 | 107,199 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [d77f34642bd33bfe8efb](https://go.k8s.io/triage#d77f34642bd33bfe8efb)
##### Error text:
```
=== RUN TestCronJobLaunchesPodAndCleansUp
I1222 07:55:48.781583 118818 apf_controller.go:218] NewTestableController "Controller" with serverConcurrencyLimit=600, requestWaitLimit=15s, name=Controller... | Top flake: TestCronJobLaunchesPodAndCleansUp | https://api.github.com/repos/kubernetes/kubernetes/issues/107198/comments | 14 | 2021-12-23T03:10:33Z | 2022-04-06T01:53:20Z | https://github.com/kubernetes/kubernetes/issues/107198 | 1,087,334,847 | 107,198 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
[root@node1 kubernetes]# systemctl status kubelet -l
```
● kubelet.service - Kubernetes Kubelet
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Active: activating (auto-restart) (Result: exit-code) since Thu 2021-12-23 10:21:59 CST; 3s ago
D... | v1.22.5 Binary manual installation k8s cluster, Kubelet hangs up after it starts | https://api.github.com/repos/kubernetes/kubernetes/issues/107197/comments | 8 | 2021-12-23T02:44:13Z | 2022-02-28T14:06:28Z | https://github.com/kubernetes/kubernetes/issues/107197 | 1,087,324,997 | 107,197 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Excuse me, my kubernetes cluster has the following problems when scheduling pod
0/5 nodes are available: 2 node(s) were unschedulable, 3 Insufficient pods.
Excuse me, is this due to my lack of resources? I check the resources through kubectl top nodes. The resources are still very rich for ans... | 0/5 nodes are available: 2 node(s) were unschedulable, 3 Insufficient pods. | https://api.github.com/repos/kubernetes/kubernetes/issues/107194/comments | 7 | 2021-12-23T01:37:22Z | 2021-12-24T06:18:28Z | https://github.com/kubernetes/kubernetes/issues/107194 | 1,087,301,153 | 107,194 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
There is no receive or close operation on channel `registrationStatus` of struct `examplePlugin` ([line 86](https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pluginmanager/pluginwatcher/example_plugin.go#L86)) .
Thus, a goroutine leak happens when `func (e *examplePlugin) NotifyRe... | goroutine leak caused by channel examplePlugin.registrationStatus | https://api.github.com/repos/kubernetes/kubernetes/issues/107193/comments | 13 | 2021-12-23T00:37:37Z | 2023-02-10T15:39:32Z | https://github.com/kubernetes/kubernetes/issues/107193 | 1,087,279,588 | 107,193 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
There are goroutine leaks in `TestGetUnavailableNumbers(t *testing.T)`.
The problem is that the EventBroadcaster object created in `func NewDaemonSetsController(...)` ([line 132](https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/daemon/daemon_controller.go#L132)) is not shut dow... | goroutine leaks in `TestGetUnavailableNumbers(t *testing.T)` | https://api.github.com/repos/kubernetes/kubernetes/issues/107191/comments | 8 | 2021-12-22T22:58:29Z | 2022-10-02T09:55:08Z | https://github.com/kubernetes/kubernetes/issues/107191 | 1,087,243,771 | 107,191 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
We need to define the CRI API versioning policies:
1. Do we bump the version of API when methods and optional fields are added? [discussion example](https://kubernetes.slack.com/archives/C0BP8PW9G/p1639779373418000?thread_ts=1639687350.416900&cid=C0BP8PW9G)
2. Does CRI API need... | CRI API versioning policies | https://api.github.com/repos/kubernetes/kubernetes/issues/107190/comments | 16 | 2021-12-22T22:24:43Z | 2023-06-06T18:18:14Z | https://github.com/kubernetes/kubernetes/issues/107190 | 1,087,229,710 | 107,190 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I am running a 3 node cluster with one acting as a master.
All joined the cluster and pods are running .
However, accessing a pod always produces a. timeout error.
I have for instance postgres pod running. But accessing it is not possible as I keep getting time outs
kubectl exec -it postgr... | Error from server: error dialing backend: dial tcp [ip]:10250: i/o timeout when running kubectl exec -it .. | https://api.github.com/repos/kubernetes/kubernetes/issues/107186/comments | 11 | 2021-12-22T17:48:56Z | 2025-02-02T17:50:56Z | https://github.com/kubernetes/kubernetes/issues/107186 | 1,087,051,504 | 107,186 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
It seems in flexVolume mode , in the implement of WaitForAttach , just as follows:
https://github.com/kubernetes/kubernetes/blob/ca0c8275b41cf542f9334073fc8660fb349f9605/pkg/volume/flexvolume/attacher.go#L53-L65
when call not support waitForAttachCmd, WaitForAttach call (*attacherDefaults)(a).... | flexVolume: waitForAttach should add check for devicepath | https://api.github.com/repos/kubernetes/kubernetes/issues/107184/comments | 11 | 2021-12-22T14:06:15Z | 2022-06-02T15:32:39Z | https://github.com/kubernetes/kubernetes/issues/107184 | 1,086,855,058 | 107,184 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In a multi container pod, when one of the containers defines a prestop hook. No container statuses update when prestop hook starts.
I aim to create a simple golang client which would run as prestop hook, the client checks the status of other containers in pod via api server allowing containers... | In multi-container pod, container statuses do not update after prestop hook starts on any container | https://api.github.com/repos/kubernetes/kubernetes/issues/107183/comments | 5 | 2021-12-22T11:01:35Z | 2021-12-22T18:20:32Z | https://github.com/kubernetes/kubernetes/issues/107183 | 1,086,706,952 | 107,183 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
[sig-apps] Daemon set [Serial] should surge pods onto nodes when spec was updated and update strategy is RollingUpdate
### Which tests are flaking?
[sig-apps] Daemon set [Serial] should surge pods onto nodes when spec was updated and update strategy is RollingUpdate
### Since when has it... | [Flaky Test][sig-apps] Daemon set [Serial] should surge pods onto nodes when spec was updated and update strategy is RollingUpdate | https://api.github.com/repos/kubernetes/kubernetes/issues/107174/comments | 11 | 2021-12-22T00:58:18Z | 2023-10-13T05:37:30Z | https://github.com/kubernetes/kubernetes/issues/107174 | 1,086,349,737 | 107,174 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I was going over the memory metrics being returned by Summary API based on the table that @haircommander built [here](https://github.com/kubernetes/enhancements/tree/master/keps/sig-node/2371-cri-pod-container-stats#current-fulfiller-of-metrics-endpoints--future-proposal). Notice that the provider f... | CRI stats are overwritten by cAdvisor ones for Summary API | https://api.github.com/repos/kubernetes/kubernetes/issues/107172/comments | 27 | 2021-12-21T23:50:07Z | 2025-03-06T17:44:41Z | https://github.com/kubernetes/kubernetes/issues/107172 | 1,086,316,475 | 107,172 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I've been following the official docs for kubeadm and how to set up a new cluster. The cluster is up and running but I noticed warning events when creating node port services:
```
can't open port "nodePort for default/abcde:5678-8080" (:31594/tcp4), skipping it
listen tcp4 :31594: bind: addre... | Warning "Can't open port nodePort" on a fresh cluster setup with kubeadm | https://api.github.com/repos/kubernetes/kubernetes/issues/107170/comments | 8 | 2021-12-21T20:02:24Z | 2022-06-20T02:46:10Z | https://github.com/kubernetes/kubernetes/issues/107170 | 1,086,189,861 | 107,170 |
[
"kubernetes",
"kubernetes"
] | getting websocket disconnection in kubenetes version 1.21.5 | getting websocket disconnection in kubenetes version 1.21.5 | https://api.github.com/repos/kubernetes/kubernetes/issues/107164/comments | 6 | 2021-12-21T13:05:48Z | 2022-01-05T23:36:50Z | https://github.com/kubernetes/kubernetes/issues/107164 | 1,085,813,618 | 107,164 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
podAntiAffinity not working as expected
### What did you expect to happen?
my applications will not be deployd on the same node
### How can we reproduce it (as minimally and precisely as possible)?
```
apiVersion: v1
kind: Pod
metadata:
annotations:
kubernetes.io/psp: eks.privileged... | podAntiAffinity not working as expected | https://api.github.com/repos/kubernetes/kubernetes/issues/107161/comments | 14 | 2021-12-21T10:46:01Z | 2022-07-05T10:05:02Z | https://github.com/kubernetes/kubernetes/issues/107161 | 1,085,693,811 | 107,161 |
[
"kubernetes",
"kubernetes"
] | I am running a Prometheus exporter inside a container. To monitor the metrics, I am running the Prometheus on my host. The metric is pulled by Prometheus at (a.b.c.d:8081). I am using the following port forwarding command:
` kubectl port-forward --address a.b.c.d podName 8081:8081 -n namespace`
**_But I am getti... | Kubctl Port Forwarding Issue | https://api.github.com/repos/kubernetes/kubernetes/issues/107160/comments | 10 | 2021-12-21T10:27:50Z | 2022-06-18T09:53:33Z | https://github.com/kubernetes/kubernetes/issues/107160 | 1,085,677,693 | 107,160 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
After I have configured Graceful Shutdown in the k8s cluster, I was expecting to see in the pods SIGTERM when a node reboots and preStop hook to run.
### What did you expect to happen?
Expected the pod to log that it received a SIGTERM when node-1 rebooted.
### How can we reproduce it (as... | Graceful Node Shutdown does nothing on reboot | https://api.github.com/repos/kubernetes/kubernetes/issues/107158/comments | 8 | 2021-12-21T09:43:38Z | 2022-11-21T09:13:31Z | https://github.com/kubernetes/kubernetes/issues/107158 | 1,085,632,774 | 107,158 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Start `kube-proxy` service with a config file without specifying the argument in the config file, instead, pass the value via the CLI args, the value is just ignored, for example,
I have a config file ```config.conf``` as this,
```
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress... | kube-proxy: CLI arguments is ignored even the options are not specified in the config file | https://api.github.com/repos/kubernetes/kubernetes/issues/107156/comments | 4 | 2021-12-21T08:24:54Z | 2021-12-21T20:44:25Z | https://github.com/kubernetes/kubernetes/issues/107156 | 1,085,563,183 | 107,156 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I've 2 disks /dev/sda is os disk, /dev/sdb is data disk with used for docker data storage with xfs filesystem and mount with uquota,pquota option.
the docker "storage-driver": "overlay2",and with option "overlay2.size=10G", in the pod I can see overlay is limit to 10G.
## pod disk usage
kubectl... | kubelet /stats/summary rootfs usage is not correct | https://api.github.com/repos/kubernetes/kubernetes/issues/107154/comments | 14 | 2021-12-21T07:59:58Z | 2023-02-02T12:33:23Z | https://github.com/kubernetes/kubernetes/issues/107154 | 1,085,543,325 | 107,154 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Currently the token created for each service account never expires. When a kubeconfig is generated based on a token bound to a service account, then the users can always use the kubeconfig to communicate with the K8s cluster. We would like the token bound to each service account ... | [Feature request] Support token rotation for service account | https://api.github.com/repos/kubernetes/kubernetes/issues/107150/comments | 12 | 2021-12-21T02:41:08Z | 2022-12-15T22:57:24Z | https://github.com/kubernetes/kubernetes/issues/107150 | 1,085,377,126 | 107,150 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
my controller creates two resources `AA` and `BB` where `AA` is the parent and `BB` is the child.
Child `BB` is configured with `ownerReferences:` pointing to `AA` and with `blockOwnerDeletion: true`
If I understand correctly, propagationPolicy is `background` by default.
So when `AA` is dele... | propagationPolicy for a resource | https://api.github.com/repos/kubernetes/kubernetes/issues/107147/comments | 7 | 2021-12-20T20:59:48Z | 2022-02-23T22:37:39Z | https://github.com/kubernetes/kubernetes/issues/107147 | 1,085,197,121 | 107,147 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Add a prometheus metrics to track when a webhook (admission or mutating) fails open.
### Why is this needed?
In some situations cluster admin (or app/chart developers) prefers to fail open when a requests towards a mutation or admission web hook fails.
However is it important to... | Track Web hook fail open | https://api.github.com/repos/kubernetes/kubernetes/issues/107146/comments | 14 | 2021-12-20T20:53:55Z | 2022-03-17T16:48:43Z | https://github.com/kubernetes/kubernetes/issues/107146 | 1,085,193,415 | 107,146 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
[{
"resource": "/Users/myMac/goworkspace/src/k8s.io/kubernetes/cmd/kube-apiserver/app/server.go",
"owner": "_generated_diagnostic_collection_name_#0",
"severity": 8,
"message": "GetOpenAPIDefinitions not declared by package openapi",
"source": "compiler",
"startLineNumber": 382,
"sta... | GetOpenAPIDefinitions not declared by package openapi | https://api.github.com/repos/kubernetes/kubernetes/issues/107143/comments | 5 | 2021-12-20T15:07:30Z | 2022-01-03T12:01:56Z | https://github.com/kubernetes/kubernetes/issues/107143 | 1,084,896,329 | 107,143 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
i started two docker containers(a client and a server which ran by iris https://github.com/kataras/iris) in the same pod, then the client requested the server by http.client(net/http),but sometimes it reported "connect: network is unreachable."
for example, Get http://localhost:10010/api/nodes... | network is unreachable when communicating by localhost between docker containers in the same pod | https://api.github.com/repos/kubernetes/kubernetes/issues/107139/comments | 19 | 2021-12-20T13:42:13Z | 2022-01-06T21:42:51Z | https://github.com/kubernetes/kubernetes/issues/107139 | 1,084,807,369 | 107,139 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Recently observed this on a 1.18 cluster (specifically, apiserver on 1.18.20 and worker nodes on 1.18.16) that there are http 504 responses being seen continuously for list API calls coming from kubelet. These calls have resourceVersion set to non-zero values as they're coming from reflector. The ... | Reflector loops forever with "Too large resource version" when objects aren't changing | https://api.github.com/repos/kubernetes/kubernetes/issues/107133/comments | 14 | 2021-12-20T05:22:05Z | 2022-02-07T05:53:35Z | https://github.com/kubernetes/kubernetes/issues/107133 | 1,084,374,600 | 107,133 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
The discovery cache for kubectl is defaulted to 10 minutes:
https://github.com/kubernetes/kubernetes/blob/0fb71846df9babb6012a7fce22e2533e9d795baa/staging/src/k8s.io/cli-runtime/pkg/genericclioptions/config_flags.go#L253
That means that every 10 minutes of using `kubectl` again... | Make ttl of discovery cache configurable and raise default | https://api.github.com/repos/kubernetes/kubernetes/issues/107130/comments | 4 | 2021-12-20T03:18:47Z | 2022-03-04T03:50:56Z | https://github.com/kubernetes/kubernetes/issues/107130 | 1,084,312,629 | 107,130 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
1. First I did a kubeadm init --pod-network-cidr=192.168.0.0/16
```
[bob2@bob2-standardpci440fxpiix1996 val]$ sudo kubeadm init --pod-network-cidr=192.168.0.0/16
[init] Using Kubernetes version: v1.23.1
[preflight] Running pre-flight checks
[WARNING FileExisting-ebtables]: ebtables not found... | Kube pods - coreDNS are always in ContainerCreating state even after the CNI plugin has been loaded. Logs show it is constantly trying to connect to /var/run/antrea/cni.sock, even when I don't use the antrea configuration. | https://api.github.com/repos/kubernetes/kubernetes/issues/107127/comments | 10 | 2021-12-19T15:59:25Z | 2024-07-27T18:22:40Z | https://github.com/kubernetes/kubernetes/issues/107127 | 1,084,130,802 | 107,127 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Add more message for no PodSandbox container when kubelet start.
### Why is this needed?
When `Failed to start ContainerManager failed to build map of initial containers from runtime` error return, We need more message to solve it, contains container name and container id. | Add more message for no PodSandbox container when kubelet start. | https://api.github.com/repos/kubernetes/kubernetes/issues/107115/comments | 3 | 2021-12-18T02:12:44Z | 2022-01-06T16:58:09Z | https://github.com/kubernetes/kubernetes/issues/107115 | 1,083,722,922 | 107,115 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.