
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | ### What happened?
I deployed a cluster of 10 nodes - 3 control-plane nodes and 7 worker nodes - and an external 3 node ETCD cluster on the 3 control-plane nodes. The initial deployment was for v1.20.13. I created a BASH script after going through Kubernetes the hard way.
I then proceeded to upgrade the cluster u... | Unable to upgrade cluster more than 2 times using kubeadm. | https://api.github.com/repos/kubernetes/kubernetes/issues/106767/comments | 24 | 2021-12-01T13:28:49Z | 2021-12-09T20:00:38Z | https://github.com/kubernetes/kubernetes/issues/106767 | 1,068,409,625 | 106,767 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Can we add dry-run function in HPA, similarly to VPA?
From code implementation perspective, this is low cost/risk change and it would be super useful for many cases.
As I know, some organizations changed the HPA code and just for dry-run, it's better if it can be supported nativ... | Dry-run support for HPA | https://api.github.com/repos/kubernetes/kubernetes/issues/106765/comments | 10 | 2021-12-01T10:38:43Z | 2022-05-16T04:30:14Z | https://github.com/kubernetes/kubernetes/issues/106765 | 1,068,240,596 | 106,765 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
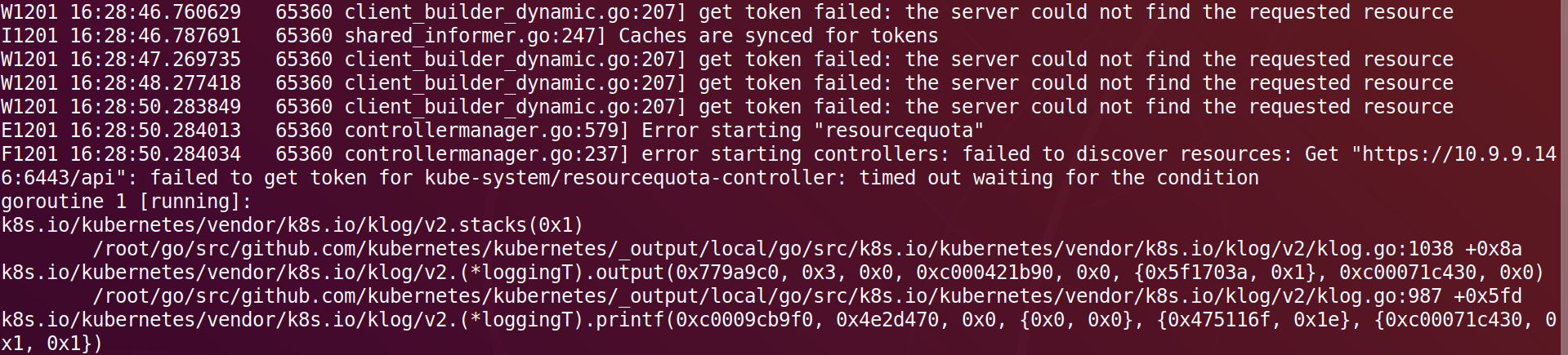
### What did you expect to happen?
Run kube-controller-manager with binary mode successfully.
### How can we reproduce it (as minimally and precisely as possible)?
1. git clo... | Run kube-controller-manager with binary mode failed | https://api.github.com/repos/kubernetes/kubernetes/issues/106763/comments | 9 | 2021-12-01T08:53:46Z | 2022-05-14T05:16:29Z | https://github.com/kubernetes/kubernetes/issues/106763 | 1,068,131,197 | 106,763 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [87f43c6306441ac424c1](https://go.k8s.io/triage#87f43c6306441ac424c1)
##### Error text:
```
=== RUN TestOpenapi
Running Suite: Openapi Suite
============================
Random Seed: �[1m1637115230�[0m
Will run �[1m18�[0m of �[1m18�[0m specs
�[91m�[1m• Failure in Spec Setup (BeforeEach... | Failure cluster [87f43c63...] | https://api.github.com/repos/kubernetes/kubernetes/issues/106761/comments | 4 | 2021-12-01T08:16:30Z | 2021-12-08T03:28:14Z | https://github.com/kubernetes/kubernetes/issues/106761 | 1,068,097,704 | 106,761 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
**My cluster’s apiserver seems handling millions of request per-second, what’s the wrong?**
I execute the follow promql to get apiserver qps:
```
topk(10, sum(irate(apiserver_request_total[5m]))without(component, job))
```
response:
```
{code="200", contentType="application/vnd.kubernet... | Why my apiserver requests per second so high, but everything is OK? | https://api.github.com/repos/kubernetes/kubernetes/issues/106760/comments | 14 | 2021-12-01T06:27:21Z | 2021-12-06T15:32:58Z | https://github.com/kubernetes/kubernetes/issues/106760 | 1,068,014,545 | 106,760 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
when I add a new node by kk , the calico is not ready. My four node ip is 172.28.138.127,172.28.138.128,172.28.252.244,172.20.196.48,but the new 172.20.196.48 has some problem.
run "calicoctl node status" on the 172.28.138.127
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+—————-+——————-... | can not add a new node | https://api.github.com/repos/kubernetes/kubernetes/issues/106758/comments | 4 | 2021-12-01T04:03:45Z | 2021-12-01T07:26:47Z | https://github.com/kubernetes/kubernetes/issues/106758 | 1,067,931,711 | 106,758 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
why kubelet /run interface using space to split the cmd?
```
params.cmd = strings.Split(request.QueryParameter("cmd"), " ")
```
which leads to
```
ls -> ok
ls -a -> ok
/bin/sh "ls" -> ok
/bin/sh "ls -a" -> failed
```
### What did you expect to happen?
I want to use kubelet /run interfac... | kubelet /run interface not support spaces in commad | https://api.github.com/repos/kubernetes/kubernetes/issues/106757/comments | 4 | 2021-12-01T03:29:05Z | 2021-12-27T06:38:31Z | https://github.com/kubernetes/kubernetes/issues/106757 | 1,067,914,431 | 106,757 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Created a watch with LabelSelector set in fake client. It is ignored.
### What did you expect to happen?
LabelSelector is respected
### How can we reproduce it (as minimally and precisely as possible)?
Call .Watch() on any fake. Sorry I don't have a trivial runnable example right now but can get... | client-go fake: watch does not respect label selector | https://api.github.com/repos/kubernetes/kubernetes/issues/106754/comments | 14 | 2021-12-01T00:07:35Z | 2022-08-07T09:30:22Z | https://github.com/kubernetes/kubernetes/issues/106754 | 1,067,795,803 | 106,754 |
[
"kubernetes",
"kubernetes"
] | Please ignore... testing something | [WIP][IGNORE_ME][publishing-bot-nightly] test issue | https://api.github.com/repos/kubernetes/kubernetes/issues/106753/comments | 4 | 2021-11-30T19:01:19Z | 2021-11-30T22:43:37Z | https://github.com/kubernetes/kubernetes/issues/106753 | 1,067,573,910 | 106,753 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Right now our networkpolicy tests for windows dont test UDP connections.
### Why is this needed?
In some corner cases, adding UDP test coverage will round out our ability to conform Windows nodes to the broader networkpolicy conformance initiatives we have. | Add UDP NetworkPolicy tests for windows | https://api.github.com/repos/kubernetes/kubernetes/issues/106752/comments | 13 | 2021-11-30T18:57:18Z | 2024-03-28T06:45:06Z | https://github.com/kubernetes/kubernetes/issues/106752 | 1,067,570,742 | 106,752 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
aks-engine-windows-containerd-master
### Which tests are failing?
[sig-windows] [Feature:Windows] Kubelet-Stats Kubelet stats collection for Windows nodes when running 3 pods should return within 10 seconds
### Since when has it been failing?
Unknown
### Testgrid link
https://testgrid... | test flake: [sig-windows] [Feature:Windows] Kubelet-Stats Kubelet stats collection for Windows nodes when running 3 pods should return within 10 seconds | https://api.github.com/repos/kubernetes/kubernetes/issues/106751/comments | 2 | 2021-11-30T17:51:30Z | 2021-12-16T14:29:54Z | https://github.com/kubernetes/kubernetes/issues/106751 | 1,067,516,518 | 106,751 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
aks-engine-windows-containerd-master
### Which tests are failing?
```
[sig-apps] Deployment deployment should support proportional scaling [Conformance]
```
### Since when has it been failing?
Unknown
### Testgrid link
https://testgrid.k8s.io/sig-windows-signal#aks-engine-windows-co... | [sig-apps] Deployment deployment should support proportional scaling [Conformance] failure | https://api.github.com/repos/kubernetes/kubernetes/issues/106750/comments | 8 | 2021-11-30T17:44:20Z | 2022-05-13T19:14:32Z | https://github.com/kubernetes/kubernetes/issues/106750 | 1,067,510,255 | 106,750 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
If A/D controller has shut down and pod referencing a CSI migrated volume is deleted (as commented in https://github.com/kubernetes/kubernetes/blob/master/pkg/volume/csi/csi_attacher.go#L417-L420), the detach may not be handled correctly. Specific handing of this situation in https://github.com/kube... | Handle detach operations after A/D controller has shut down and pod referencing a CSI migrated volume has been deleted while the A/D controller was down | https://api.github.com/repos/kubernetes/kubernetes/issues/106749/comments | 6 | 2021-11-30T17:37:15Z | 2022-04-29T20:40:27Z | https://github.com/kubernetes/kubernetes/issues/106749 | 1,067,504,111 | 106,749 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I recently added a benchmark to staging/src/k8s.io/component-base/logs/benchmark which has code that triggers an error from current logcheck (`ErrorS` is passed a slice with `...` - valid, but not handled by the tool). See https://github.com/kubernetes/kubernetes/pull/106594
I did not get an erro... | logcheck: not applied to packages under staging | https://api.github.com/repos/kubernetes/kubernetes/issues/106746/comments | 8 | 2021-11-30T15:17:52Z | 2022-03-25T01:37:51Z | https://github.com/kubernetes/kubernetes/issues/106746 | 1,067,358,365 | 106,746 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I want to create new resources (for this example configmaps and services) using ServerSideApply. When creating these resources i want to make sure that the name of the resource is not already in use (as the name is generated randomly).
To create a new configmaps i follow the following workflow:... | Inconsistent behaviour of SSA in combination with resourceVersion for different resources | https://api.github.com/repos/kubernetes/kubernetes/issues/106745/comments | 9 | 2021-11-30T15:11:13Z | 2021-12-17T10:16:53Z | https://github.com/kubernetes/kubernetes/issues/106745 | 1,067,350,804 | 106,745 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
"procMount=unmasked" of pod doesn't work when use docker as container runtime.
docker inspect xxx
```
...
"MaskedPaths": [
"/proc/acpi",
"/proc/kcore",
"/proc/keys",
"/proc/latency_stats",
"/proc/t... | "procMount=unmasked" of pod doesn't work when use docker as runtime | https://api.github.com/repos/kubernetes/kubernetes/issues/106742/comments | 5 | 2021-11-30T12:25:44Z | 2022-04-30T20:47:29Z | https://github.com/kubernetes/kubernetes/issues/106742 | 1,067,175,827 | 106,742 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I used command `remotecommand`( import "k8s.io/client-go/tools/remotecommand") to create streamExecutor.
when I exec this code
executor.Stream(remotecommand.StreamOptions{
Stdin: t,
Stdout: t,
Stderr: t,
Tty: true,
TerminalSizeQueue: ... | throw unable to upgrade connection exception by executor.Stream ? | https://api.github.com/repos/kubernetes/kubernetes/issues/106741/comments | 12 | 2021-11-30T11:29:11Z | 2022-06-05T16:53:48Z | https://github.com/kubernetes/kubernetes/issues/106741 | 1,067,122,841 | 106,741 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Each time a container needs to be created, the kubelet will create a termination-log file on the host and mounts the file to the path specified by the terminationMessagePath field in the container for outputting termination messages.
The paths of these files on the host are as follows:
`/var/lib/k... | kubelet doesn't clean up the termination-log file on the host | https://api.github.com/repos/kubernetes/kubernetes/issues/106735/comments | 21 | 2021-11-30T08:32:01Z | 2024-06-18T09:12:58Z | https://github.com/kubernetes/kubernetes/issues/106735 | 1,066,940,629 | 106,735 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Pod stuck in terminating state in my k8s cluster(v1.20.10). Finally I found that the pod worker exit and the pod’s containers not exist already by log message. Restart kubelet could resolve the problem.
### What did you expect to happen?
Kill pod successfully even there is no containers exis... | Pod stuck in terminating state with pod worker exit and containers not exist | https://api.github.com/repos/kubernetes/kubernetes/issues/106734/comments | 6 | 2021-11-30T07:27:04Z | 2021-12-09T16:53:40Z | https://github.com/kubernetes/kubernetes/issues/106734 | 1,066,886,299 | 106,734 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hi K8s Team,
We have an offline environment where Microk8s is deployed with Calico node and CoreDNS as DNS.
We could see DNS is not resolving endpoints and are getting i/o timeout. We have followed [this article](https://github.com/ubuntu/microk8s/files/7587411/redhat.txt) to remove NFTABLE an... | Service endpoints not reachable within pods | https://api.github.com/repos/kubernetes/kubernetes/issues/106733/comments | 4 | 2021-11-30T07:11:50Z | 2021-11-30T08:16:48Z | https://github.com/kubernetes/kubernetes/issues/106733 | 1,066,874,421 | 106,733 |
[
"kubernetes",
"kubernetes"
] | sig/CLI
### What happened?
New M1 pro machine. New installs. I have kube cluster made with kind on digitalOcean. The kube object config file works on the cloud. I get "can't find api version.." looking errors when I use the configuration to create a cluster locally. It's clear that my kubectl is not connecti... | kubectl does not connect to local machine api | https://api.github.com/repos/kubernetes/kubernetes/issues/106730/comments | 6 | 2021-11-30T04:01:13Z | 2021-12-06T19:34:47Z | https://github.com/kubernetes/kubernetes/issues/106730 | 1,066,760,643 | 106,730 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Interaction between failing `NodeUnstageVolume` and `NodePublishVolume` results in unmountable volumes.
We've observed a following series of events taking place:
1. The last consumer of a volume leaves the node, triggering `NodeUnstageVolume`.
2. For some reason this call fails, but still mana... | Interaction between NodeUnstageVolume and NodePublishVolume | https://api.github.com/repos/kubernetes/kubernetes/issues/106729/comments | 7 | 2021-11-29T22:13:50Z | 2021-12-20T12:48:31Z | https://github.com/kubernetes/kubernetes/issues/106729 | 1,066,558,124 | 106,729 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
While investigating another issue, I noticed that the `apiserver_flowcontrol_priority_level_seat_count_watermarks` histograms never get an Observation of zero. This makes no sense.
See https://github.com/kubernetes/kubernetes/pull/106085#issuecomment-977567398 and related following remarks for s... | APF executing seat count is never zero | https://api.github.com/repos/kubernetes/kubernetes/issues/106726/comments | 2 | 2021-11-29T19:41:00Z | 2021-12-08T02:27:39Z | https://github.com/kubernetes/kubernetes/issues/106726 | 1,066,424,361 | 106,726 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
https://testgrid.k8s.io/sig-release-1.23-informing#gce-cos-k8sbeta-slow
### Which tests are failing?
- Kubernetes e2e suite.[sig-storage] In-tree Volumes [Driver: gcepd] [Testpattern: Dynamic PV (block volmode)] multiVolume [Slow] should access to two volumes with different volume mode an... | [Failing test][sig-storage] gce-cos-k8sbeta-slow | https://api.github.com/repos/kubernetes/kubernetes/issues/106720/comments | 9 | 2021-11-29T17:07:44Z | 2022-05-15T03:22:30Z | https://github.com/kubernetes/kubernetes/issues/106720 | 1,066,286,427 | 106,720 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
gce-cos-k8sbeta-serial
### Which tests are failing?
- Kubernetes e2e suite.[sig-storage] In-tree Volumes [Driver: gcepd] [Testpattern: Dynamic PV (block volmode)] disruptive[Disruptive][LinuxOnly] Should test that pv used in a pod that is deleted while the kubelet is down cleans up when t... | [Failing test][sig-storage] gce-cos-k8sbeta-serial | https://api.github.com/repos/kubernetes/kubernetes/issues/106719/comments | 9 | 2021-11-29T17:03:50Z | 2022-05-15T00:19:29Z | https://github.com/kubernetes/kubernetes/issues/106719 | 1,066,281,543 | 106,719 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I think this function, maybe needs to be aware of non blocking taints... esp for the "only a few nodes,and theyre all tainted" scenario..
```
func GetReadySchedulableNodes(c clientset.Interface) (nodes *v1.NodeList, err error) {
nodes, err = checkWaitListSchedulableNodes(c)
if err != nil... | Suspicion: E2E Test GetReadySchedulableNodes blocks single node/tainted cluster nodes from passing e2e | https://api.github.com/repos/kubernetes/kubernetes/issues/106718/comments | 12 | 2021-11-29T15:14:15Z | 2022-08-21T10:19:38Z | https://github.com/kubernetes/kubernetes/issues/106718 | 1,066,159,871 | 106,718 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
`kube-apiserver` panics with `Header called after Handler finished` error when health probes time out.
The following stack trace shows this error (from an apiserver that uses `1.21.0`:
```
E1012 19:59:23.879476 1 timeout.go:128] Header called after Handler finished
goroutine 509 [runn... | kube-apiserver panics with "Header called after Handler finished" when health probes time out | https://api.github.com/repos/kubernetes/kubernetes/issues/106717/comments | 5 | 2021-11-29T15:08:38Z | 2022-01-06T16:58:01Z | https://github.com/kubernetes/kubernetes/issues/106717 | 1,066,152,683 | 106,717 |
[
"kubernetes",
"kubernetes"
] | In my environment, one node have 2000+ completed pods, it means there are many pause sandbox in this node, cause inspect container timeout then kubelet is abnormal.
Question:
when container gc, why Keep latest one if the pod still exists ?
If I change container gc GarbageCollect to DeleteAllUnusedContainers ... | Kubelet: Container GC why Keep latest one if the pod still exists ? | https://api.github.com/repos/kubernetes/kubernetes/issues/106714/comments | 8 | 2021-11-29T12:23:44Z | 2022-03-31T17:46:37Z | https://github.com/kubernetes/kubernetes/issues/106714 | 1,065,975,977 | 106,714 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A lot of CLOSE_WAIT connections were found on k8s node. (The IP x.216 is the ip address of the k8s node.)

It happens at the moment of kube-proxy adding new endpoints to a non-endpoint... | Nodeport led to many CLOSE_WAIT TCP connections by using kube-proxy iptables mode. | https://api.github.com/repos/kubernetes/kubernetes/issues/106713/comments | 37 | 2021-11-29T12:21:48Z | 2022-06-01T08:13:29Z | https://github.com/kubernetes/kubernetes/issues/106713 | 1,065,974,112 | 106,713 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A/D controller tries to detach volumes that are still mounted after 6 minutes. The conditions to trigger the detach are: https://github.com/kubernetes/kubernetes/blob/9a75e7b0fd1b567f774a3373be640e19b33e7ef1/pkg/volume/util/util.go#L387
I.e. all containers are finished. But that does not guaran... | Volumes are detached while they're still mounted on a node | https://api.github.com/repos/kubernetes/kubernetes/issues/106710/comments | 14 | 2021-11-29T10:50:29Z | 2022-06-27T14:49:12Z | https://github.com/kubernetes/kubernetes/issues/106710 | 1,065,887,375 | 106,710 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Clusters created with kubeadm using DualStack are not able to work, because CoreDNS pods never get ready
```
Nov 29 09:59:13.953: INFO: The status of Pod coredns-64897985d-67hvq is Running (Ready = false), waiting for it to be either Running (with Ready = true) or Failed
Nov 29 09:59:13.953: IN... | CoreDNS is not able to start on DualStack clusters | https://api.github.com/repos/kubernetes/kubernetes/issues/106709/comments | 10 | 2021-11-29T10:47:51Z | 2021-11-29T22:41:22Z | https://github.com/kubernetes/kubernetes/issues/106709 | 1,065,884,918 | 106,709 |
[
"kubernetes",
"kubernetes"
] | Hello team.
/sig scheduling
## What would you like to be added?
This is an idea and is needed to be discussed.
There is a unique package called `plugin` in Go standard library.
https://pkg.go.dev/plugin
This package may enable us to allow users to use their custom plugin without building custom scheduler.... | support to load custom plugins with `plugin` package so that users can use custom plugins without building custom scheduler | https://api.github.com/repos/kubernetes/kubernetes/issues/106705/comments | 9 | 2021-11-28T06:34:46Z | 2021-12-06T04:58:39Z | https://github.com/kubernetes/kubernetes/issues/106705 | 1,065,214,926 | 106,705 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I1128 09:41:52.918552 420211 round_trippers.go:454] GET https://192.168.1.88:6443/api/v1/nodes/master01.fe.me?timeout=10s 404 Not Found in 4 milliseconds
I1128 09:41:52.918589 420211 round_trippers.go:460] Response Headers:
I1128 09:41:52.918600 420211 round_trippers.go:463] X-Kubernetes-Pf... | kubelet does not create Node object during TLS bootstrap; kubeadm join fails at missing Node object | https://api.github.com/repos/kubernetes/kubernetes/issues/106704/comments | 21 | 2021-11-28T03:02:41Z | 2022-07-15T15:57:00Z | https://github.com/kubernetes/kubernetes/issues/106704 | 1,065,173,137 | 106,704 |
[
"kubernetes",
"kubernetes"
] | the yaml
apiVersion: v1
kind: Pod
metadata:
name: hellok8s
namespace: default
labels:
app: myapp
version: v1
spec:
containers:
- name: mynginx
image: nginx
nodeSelector:
type: master
when execute "kubectl apply -f pod.yaml"
the output
The Pod "hellok8s" is invalid: spe... | nodeSelector doesn't work when select the specific node | https://api.github.com/repos/kubernetes/kubernetes/issues/106700/comments | 4 | 2021-11-27T04:57:45Z | 2021-11-27T15:16:34Z | https://github.com/kubernetes/kubernetes/issues/106700 | 1,064,903,932 | 106,700 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
hack/update-vendor.sh failed
```
root@host:~# git clone https://github.com/kubernetes/kubernetes.git
root@host:~# cd kubernetes/
root@host:~/kubernetes# git checkout v1.22.4
...
HEAD is now at b695d79d4f9 Release commit for Kubernetes v1.22.4
root@host:~/kubernetes# ./build/shell.sh
+++... | hack/update-vendor.sh failed due to k8s.io/kubernetes/test/integration/examples | https://api.github.com/repos/kubernetes/kubernetes/issues/106699/comments | 9 | 2021-11-27T04:07:45Z | 2021-12-23T14:15:29Z | https://github.com/kubernetes/kubernetes/issues/106699 | 1,064,897,496 | 106,699 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Kubernetes and CRI well defined the logs for containers, while VM based Pod are common used today as alternative of `pause` container as a Sandbox for more strict isolation, like [Kata Containers](https://github.com/kata-containers), [Containerd](https://github.com/containerd/cont... | [Feature] Add pod level logs API | https://api.github.com/repos/kubernetes/kubernetes/issues/106698/comments | 6 | 2021-11-27T01:59:42Z | 2022-04-26T17:17:06Z | https://github.com/kubernetes/kubernetes/issues/106698 | 1,064,879,462 | 106,698 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
There are numerous cases where the deployment doesn't update it's `Progressing` condition to have a status of `False` with the reason `ProgressDeadlineExceeded`.
Similarly `Available` remains `True` when I would expect it to become `False`
/sig apps
### What did you expect to happen?
After a... | Deployment Conditions - Progressing & Available not updated appropriately | https://api.github.com/repos/kubernetes/kubernetes/issues/106697/comments | 17 | 2021-11-26T21:10:36Z | 2023-06-13T10:25:47Z | https://github.com/kubernetes/kubernetes/issues/106697 | 1,064,805,067 | 106,697 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When kubelet is running if you create two volume plugin directories here: /usr/libexec/kubernetes/kubelet-plugins/volume/exec
/usr/libexec/kubernetes/kubelet-plugins/volume/exec/cifs
/usr/libexec/kubernetes/kubelet-plugins/volume/exec/nodeagent~uds
You will see these expected logs:
```... | Valid FlexVolume Plugin skipped if another plugin is missing and then added | https://api.github.com/repos/kubernetes/kubernetes/issues/106696/comments | 3 | 2021-11-26T20:03:37Z | 2021-12-15T17:53:51Z | https://github.com/kubernetes/kubernetes/issues/106696 | 1,064,778,792 | 106,696 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
gce-cos-k8sbeta-default
### Which tests are failing?
- Kubernetes e2e suite.[sig-storage] In-tree Volumes [Driver: gcepd] [Testpattern: Dynamic PV ...
- Kubernetes e2e suite.[sig-storage] In-tree Volumes [Driver: gcepd] [Testpattern: Generic Ephemeral-volume ...
- Kubernetes e2e suite.[... | [Failing test][sig-storage] gce-cos-k8sbeta-default, volumeMode should not mount / map unused volumes in a pod | https://api.github.com/repos/kubernetes/kubernetes/issues/106694/comments | 13 | 2021-11-26T10:25:52Z | 2022-02-28T08:09:11Z | https://github.com/kubernetes/kubernetes/issues/106694 | 1,064,314,256 | 106,694 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Release notes in CHANGELOGs no longer contain links to the PR itself and to the author.
Open https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.22.md#changelog-since-v1223 and verify that the PR and the PR author are not links (just plain text).
Open https://github.com/kube... | Release notes in CHANGELOGs no longer contain links to the PR itself and to the PR author | https://api.github.com/repos/kubernetes/kubernetes/issues/106693/comments | 7 | 2021-11-26T09:58:20Z | 2021-11-29T08:17:23Z | https://github.com/kubernetes/kubernetes/issues/106693 | 1,064,285,724 | 106,693 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Kubelet is running on a worker node, an issue occurs which makes kubelet unable to read logs from pods which can be seen in any of the kube-system pods logs,
Log output in kube-system pod:
`Warning ContainerGCFailed <invalid> (x1266 over 21h) kubelet failed to read podLogsRootDirectory "/var... | Kubernetes node healthcheck issue (Kubelet is unable to read logs from pods) | https://api.github.com/repos/kubernetes/kubernetes/issues/106691/comments | 33 | 2021-11-26T08:04:46Z | 2025-02-12T12:03:14Z | https://github.com/kubernetes/kubernetes/issues/106691 | 1,064,197,780 | 106,691 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Pod status NotReady was reported for the first time after Kubelet restart. And then it goes back to Ready very quickly
As a result, Pod IP is removed from Endpoints by Controller-Manager and added. Caused a certain amount of jitter to the cluster as a whole.
Pod actually works fine
### What... | Kubelet reports Pod status NotReady for the first time after restart | https://api.github.com/repos/kubernetes/kubernetes/issues/106689/comments | 5 | 2021-11-26T07:01:27Z | 2021-12-01T18:36:55Z | https://github.com/kubernetes/kubernetes/issues/106689 | 1,064,159,691 | 106,689 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Create a deployment with an invalid liveness probe and you'll see events like
> Liveness probe errored: rpc error: code = Unknown desc = failed to exec in container: failed to start exec "184850d48d723924f62e815706ee39ce8ff8b1d36abbb78552cfe634ccbc1276": OCI runtime exec failed: exec failed: cont... | Liveness Probe with an invalid command doesn't trigger container restarts and ContainersReady remains True | https://api.github.com/repos/kubernetes/kubernetes/issues/106682/comments | 52 | 2021-11-25T16:35:58Z | 2024-08-27T15:59:43Z | https://github.com/kubernetes/kubernetes/issues/106682 | 1,063,779,642 | 106,682 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
// test code
```
func TestBinary(t *testing.T) {
bValue := resource.MustParse("100000Gi")
_, ok := bValue.AsInt64()
if !ok {
t.Errorf("binarySI data %+v is overflow", bValue)
}
dValue := resource.MustParse("1000000000G")
_, ok = dValue.AsInt64()
if !ok {
t.Errorf("decimal... | It’s easy to overflow when casting resource.Quantity to int64 with BinarySI formate | https://api.github.com/repos/kubernetes/kubernetes/issues/106681/comments | 14 | 2021-11-25T14:10:52Z | 2022-09-09T08:25:11Z | https://github.com/kubernetes/kubernetes/issues/106681 | 1,063,636,953 | 106,681 |
[
"kubernetes",
"kubernetes"
] | We make a performance test to verify feature gain which would take to us ?
Environment: 64C128G
We create a new crd which size is 3kb.
| crd | discompress(size/cpu/bandwidth/P99) | compress(size/cpu/bandwidth/P99) |
| :-----| ----: | :----: |
|crd:1000 qps:2 | 3.1M/3C/48M/168ms | 100k/3C/1.7M/181ms ... | APIResponseCompression would increase P99 In apiserver | https://api.github.com/repos/kubernetes/kubernetes/issues/106679/comments | 12 | 2021-11-25T13:01:22Z | 2022-09-29T03:20:25Z | https://github.com/kubernetes/kubernetes/issues/106679 | 1,063,562,020 | 106,679 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Azure File is one of the intree storage plugins available in k8s, however, we currently don't have a e2e tests for it.
Having such tests would be helpful to test CSI migration for Azure File.
### What did you expect to happen?
Azure File e2e tests should run on Azure.
### How can we reproduce ... | Missing Azure File e2e tests | https://api.github.com/repos/kubernetes/kubernetes/issues/106677/comments | 16 | 2021-11-25T12:08:05Z | 2022-03-28T13:43:35Z | https://github.com/kubernetes/kubernetes/issues/106677 | 1,063,509,404 | 106,677 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I found that when the container is deleted, the image is being pulled until the image is pulled.
### What did you expect to happen?
When the pod is deleted, terminate the mirror pull request
### How can we reproduce it (as minimally and precisely as possible)?
1. Scheduling a new pod t... | When the pod needs to be deleted, terminate the image pull request? | https://api.github.com/repos/kubernetes/kubernetes/issues/106675/comments | 13 | 2021-11-25T09:44:20Z | 2024-06-21T09:35:59Z | https://github.com/kubernetes/kubernetes/issues/106675 | 1,063,358,824 | 106,675 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Our Pega Platform Application is hosted in Kubernetes environment and Stream is a service node which is part of it. As part of Application Maintenance, We had to perform clean restart which included PVC's Unmount from Stream POD. Upon doing that, Pod is not getting initialized when we re-install the... | Pod Initialization Error upon removing the PVC | https://api.github.com/repos/kubernetes/kubernetes/issues/106672/comments | 6 | 2021-11-25T06:55:36Z | 2022-04-24T19:57:11Z | https://github.com/kubernetes/kubernetes/issues/106672 | 1,063,219,058 | 106,672 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
https://testgrid.k8s.io/sig-cluster-lifecycle-kubeadm#kubeadm-kinder-latest-on-1-22
this job runs kubeadm 1.23 (latest master) against the latest SHA release-1.22 for core k8s (kubelet, apiserver, etc...)
this is a "release informing" job.
### Which tests are failing?
kubeadm-i... | [failing test] kubeadm-kinder-latest-on-1-22 | https://api.github.com/repos/kubernetes/kubernetes/issues/106669/comments | 5 | 2021-11-25T02:00:43Z | 2021-11-25T16:32:05Z | https://github.com/kubernetes/kubernetes/issues/106669 | 1,063,078,705 | 106,669 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I was checking if everything in my cluster has upgraded to non-deprecated API versions prior to upgrading.
In https://github.com/kubernetes/kubernetes/pull/73032 the apiserver_requested_deprecated_apis metric was added
to help operators determine if there are any users of deprecated APIs left. But... | API deprecation metrics misleading with garbage collection controller | https://api.github.com/repos/kubernetes/kubernetes/issues/106668/comments | 9 | 2021-11-24T23:15:52Z | 2022-04-29T22:40:37Z | https://github.com/kubernetes/kubernetes/issues/106668 | 1,062,991,675 | 106,668 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
go build -o sample-controller .
# sigs.k8s.io/json/internal/golang/encoding/json
vendor/sigs.k8s.io/json/internal/golang/encoding/json/encode.go:1249:12: sf.IsExported undefined (type reflect.StructField has no field or method IsExported)
vendor/sigs.k8s.io/json/internal/golang/encoding/json/enco... | [sample-controller] Wrong go version in go.mod file of the sample-controller | https://api.github.com/repos/kubernetes/kubernetes/issues/106666/comments | 4 | 2021-11-24T21:33:56Z | 2021-12-09T02:55:40Z | https://github.com/kubernetes/kubernetes/issues/106666 | 1,062,927,999 | 106,666 |
[
"kubernetes",
"kubernetes"
] | Flaked a couple of times on serial lane with the same error.
Test is relatively new.
https://testgrid.k8s.io/sig-node-kubelet#node-kubelet-serial&exclude-non-failed-tests=20&width=5
This run only has the single test flake: https://prow.k8s.io/view/gs/kubernetes-jenkins/logs/ci-kubernetes-node-kubelet-serial/14... | [Flaky test] [sig-node] when gracefully shutting down with Pod priority should be able to gracefully shutdown pods with various grace periods | https://api.github.com/repos/kubernetes/kubernetes/issues/106664/comments | 2 | 2021-11-24T19:47:09Z | 2022-02-18T06:32:27Z | https://github.com/kubernetes/kubernetes/issues/106664 | 1,062,837,573 | 106,664 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
periodic-kubernetes-unit-test-ppc64le
**Sample failed job:** https://prow.k8s.io/view/gs/ppc64le-kubernetes/logs/periodic-kubernetes-unit-test-ppc64le/1463383575909896192
https://prow.k8s.io/job-history/gs/ppc64le-kubernetes/logs/periodic-kubernetes-unit-test-ppc64le
### Which test... | [Flaky Test] Kubernetes-unit-tests ^TestStatefulSetControl is being flaky | https://api.github.com/repos/kubernetes/kubernetes/issues/106663/comments | 15 | 2021-11-24T18:08:16Z | 2022-01-12T06:23:22Z | https://github.com/kubernetes/kubernetes/issues/106663 | 1,062,733,054 | 106,663 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
pull-kubernetes-verify
### Which tests are failing?
verify-openapi
### Since when has it been failing?
Since master moved to 1.24.0-alpha.0 tag
### Testgrid link
_No response_
### Reason for failure (if possible)
The openapi v3 fixtures embed the Kubernetes version. This means maste... | openapi v3 fixtures embed Kubernetes version | https://api.github.com/repos/kubernetes/kubernetes/issues/106656/comments | 1 | 2021-11-24T14:56:52Z | 2021-11-24T16:36:21Z | https://github.com/kubernetes/kubernetes/issues/106656 | 1,062,527,622 | 106,656 |
[
"kubernetes",
"kubernetes"
] | As mentioned in:
https://github.com/kubernetes/kubernetes/pull/106085#issuecomment-977863691
We seem to be setting different flags for kubemark-scale.
FWIW - I don't think it's the only thing actually. If seems that certain env-vars that we're setting in the kubemark configs:
https://github.com/kubernetes/test-... | Unify kubemark-scale settings with 5k-node tests wrt to core components flags | https://api.github.com/repos/kubernetes/kubernetes/issues/106654/comments | 3 | 2021-11-24T13:37:35Z | 2021-11-25T09:06:34Z | https://github.com/kubernetes/kubernetes/issues/106654 | 1,062,439,932 | 106,654 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kubelet logs a "container" key/value pair:
https://github.com/kubernetes/kubernetes/blob/c8c81cbfbb381129c904ed1ab387744946cf807a/pkg/kubelet/kuberuntime/kuberuntime_manager.go#L902
That value is a `*v1.Container`:
https://github.com/kubernetes/kubernetes/blob/c8c81cbfbb381129c904ed1ab387744946... | JSON: *v1.Container not logged as struct | https://api.github.com/repos/kubernetes/kubernetes/issues/106652/comments | 21 | 2021-11-24T13:18:23Z | 2021-12-09T15:55:00Z | https://github.com/kubernetes/kubernetes/issues/106652 | 1,062,420,167 | 106,652 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
There were 2 pods serving sctp traffic behind Loadbalancer service(externaltrafficpolicy cluster). The sctp client accessing the LB service reuses source port. After the pod to which the sctp client was connected is restarted(or stopped) the traffic is not routed to the other available endpoint bec... | After pod restart sctp traffic does not reach other pod behind Loadbalancer service | https://api.github.com/repos/kubernetes/kubernetes/issues/106651/comments | 8 | 2021-11-24T13:02:46Z | 2022-03-02T15:57:44Z | https://github.com/kubernetes/kubernetes/issues/106651 | 1,062,404,022 | 106,651 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
why burstable pod oom score is -997?
```
root@ubuntu-focal:/home/vagrant# kubectl -n kube-system describe po coredns-57d4cbf879-l277z |grep -i qos
QoS Class: Burstable
root@ubuntu-focal:/home/vagrant# ps aux |grep core
root 8181 0.4 1.8 746256 37092 ? Ssl 02... | why coredns oom score is -997? | https://api.github.com/repos/kubernetes/kubernetes/issues/106649/comments | 11 | 2021-11-24T09:33:15Z | 2021-11-25T01:52:35Z | https://github.com/kubernetes/kubernetes/issues/106649 | 1,062,195,859 | 106,649 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
today i find my k8s cluster cert is expired.
i use the kubectl cmd and it return Unable to connect to the server: x509: certificate has expired or is not yet valid
i check the cert and find it is expired in yesterday
so i just update the cert in master node with cmd kubeadm alpha certs renew a... | The kubectl cmd doesn't work after update the k8s Certificate | https://api.github.com/repos/kubernetes/kubernetes/issues/106642/comments | 3 | 2021-11-24T03:18:23Z | 2021-11-24T05:46:40Z | https://github.com/kubernetes/kubernetes/issues/106642 | 1,061,952,598 | 106,642 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I want to run the host_process.go e2e test but it failed.
Reason:
Node name and hostname is longer than 15 characters.
But the ComputerName only used the first 15 characters.
So they don't equal and the test failed.
### What did you expect to happen?
The e2etest should pass regardless of the... | e2e test host_processs.go failed when the hostname is greater then 15 characters. | https://api.github.com/repos/kubernetes/kubernetes/issues/106640/comments | 18 | 2021-11-24T01:18:29Z | 2022-12-15T20:15:37Z | https://github.com/kubernetes/kubernetes/issues/106640 | 1,061,879,673 | 106,640 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
[Build time dependency scanning](https://testgrid.k8s.io/sig-security-snyk-scan#ci-kubernetes-snyk-master) detected CVE-2021-41190: https://github.com/advisories/GHSA-mc8v-mgrf-8f4m (low severity)
Fix is available here in v1.0.2: https://github.com/opencontainers/image-spec/releases/tag/v1.0.2 ... | [CVE-2021-41190] Pull fixes from cadvisor->containerd | https://api.github.com/repos/kubernetes/kubernetes/issues/106639/comments | 5 | 2021-11-24T00:24:28Z | 2022-04-05T18:26:40Z | https://github.com/kubernetes/kubernetes/issues/106639 | 1,061,846,698 | 106,639 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
PVC never supported setting capacity limits. However, it looks like in validation, we never enforced it: https://github.com/kubernetes/kubernetes/blob/a5622f3f6e1f5d5ffd066d799204ea0c6d1a49e2/pkg/apis/core/validation/validation.go#L2124
This means that it's possible PVC.spce.resource.limits could... | PVC resource limits not validated | https://api.github.com/repos/kubernetes/kubernetes/issues/106637/comments | 26 | 2021-11-23T22:04:23Z | 2025-01-17T19:22:14Z | https://github.com/kubernetes/kubernetes/issues/106637 | 1,061,750,878 | 106,637 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Windows client pods in the cluster see intermittent connection failures when attempting to access a Linux service of type load balancer using its external VIP under the following conditions:
* Linux service has externalTrafficPolicy: Local set.
* The backend pods are distributed across >1 Lin... | Windows - Linux interop issues for services of type LoadBalancer with local traffic policy | https://api.github.com/repos/kubernetes/kubernetes/issues/106636/comments | 13 | 2021-11-23T21:45:25Z | 2023-03-07T00:34:02Z | https://github.com/kubernetes/kubernetes/issues/106636 | 1,061,738,059 | 106,636 |
[
"kubernetes",
"kubernetes"
] | ### Jobs failing
- ci-kubernetes-node-kubelet-serial-containerd: https://testgrid.k8s.io/sig-node-release-blocking#node-kubelet-serial-containerd
- ci-kubernetes-node-kubelet-serial: https://testgrid.k8s.io/sig-node-kubelet#node-kubelet-serial
### Failure cluster [3a34bcc9bd92468974b8](https://go.k8s.io/triage#3... | [Failing tests] Device Plugin [Feature:DevicePluginProbe][NodeFeature:DevicePluginProbe][Serial] DevicePlugin | https://api.github.com/repos/kubernetes/kubernetes/issues/106635/comments | 21 | 2021-11-23T21:43:23Z | 2022-06-01T19:03:40Z | https://github.com/kubernetes/kubernetes/issues/106635 | 1,061,736,530 | 106,635 |
[
"kubernetes",
"kubernetes"
] | null | Create a custom josn exporter to convert Testgrid rest API to Prometheus metrics | https://api.github.com/repos/kubernetes/kubernetes/issues/106627/comments | 4 | 2021-11-23T15:26:39Z | 2021-11-23T15:29:07Z | https://github.com/kubernetes/kubernetes/issues/106627 | 1,061,417,544 | 106,627 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
ci-cos-cgroupv2-containerd-e2e-gce
### Which tests are failing?
Most tests of Kubernetes e2e suite.[sig-storage] In-tree Volumes [Driver: gcepd]
### Since when has it been failing?
17 Nov 2021
### Testgrid link
https://testgrid.k8s.io/sig-node-containerd#cos-cgroupv2-containerd-e2e
... | [Failing tests] cos-cgroupv2-containerd-e2e | https://api.github.com/repos/kubernetes/kubernetes/issues/106626/comments | 13 | 2021-11-23T14:34:26Z | 2022-05-15T03:22:30Z | https://github.com/kubernetes/kubernetes/issues/106626 | 1,061,358,227 | 106,626 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In our K8s cluster, we used the `extension-apiserver` manner to self-define CRD, to set the name `my-crd`.
1. We set the `NamespaceScoped = true`, then created some resources, like this:
```
kubectl get my-crd -A
NAME CREATED AT
my-crd-1 2021-11-22T03:03:20Z
my-crd-2 2021-11-22T08:07... | kubectl get CRD list with dirty data, but can not edit/delete | https://api.github.com/repos/kubernetes/kubernetes/issues/106625/comments | 9 | 2021-11-23T14:34:22Z | 2021-11-30T21:24:20Z | https://github.com/kubernetes/kubernetes/issues/106625 | 1,061,358,161 | 106,625 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Our K8 cluster was working for more than a year, recently it got some strange behavior and now when we deploy an app using `kubectl apply -f deployment-manifest.yaml`, it doesnt show in `kubectl get pods`. But shows in `kubectl get deployments` with `0/3` state.
### What did you expect to happen?
... | Kubernetes deployments are failed with coredns 10.233.0.1:443: connect: connection refused | https://api.github.com/repos/kubernetes/kubernetes/issues/106622/comments | 14 | 2021-11-23T10:00:48Z | 2022-05-01T11:48:25Z | https://github.com/kubernetes/kubernetes/issues/106622 | 1,061,042,480 | 106,622 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I was install kubernetes 1.19.0,when I start kubelet,the log had some error told me that node "k8s-master1" not found.
```
I1123 14:27:22.194080 11557 kubelet/kubelet_node_status.go:334] Setting node annotation to enable volume controller attach/detach
E1123 14:27:22.196873 11557 kubelet/ku... | node "k8s-master1" not found | https://api.github.com/repos/kubernetes/kubernetes/issues/106618/comments | 5 | 2021-11-23T06:33:13Z | 2021-11-23T15:30:49Z | https://github.com/kubernetes/kubernetes/issues/106618 | 1,060,883,160 | 106,618 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
`foo.yaml`:
```yaml
kind: pod
metadata:
name: my-pod
spec:
containers:
- name: my-pod
image: foo:latest
---
kind: service
metadata:
name: my-service
spec:
type: NodePort
selector:
pod: my-pod
ports:
- port: 1234
targetPort: 1234
```
this works:
... | "kubectl set" fails to output yaml sections that don't match. | https://api.github.com/repos/kubernetes/kubernetes/issues/106617/comments | 17 | 2021-11-23T06:06:35Z | 2022-08-04T07:50:32Z | https://github.com/kubernetes/kubernetes/issues/106617 | 1,060,869,143 | 106,617 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/106568/pull-kubernetes-unit/1462136832413143040
### Which tests are failing?
StatefulSet control tests
### Since when has it been failing?
The delete PVC unit tests started flaking when https://github.com/kubernetes/kubernete... | StatefulSet PVC tests failing | https://api.github.com/repos/kubernetes/kubernetes/issues/106615/comments | 5 | 2021-11-23T04:58:21Z | 2022-01-19T09:28:18Z | https://github.com/kubernetes/kubernetes/issues/106615 | 1,060,840,123 | 106,615 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
Random failure on `ci-kubernetes-e2e-aks-engine-azure-master-staging-windows`
https://prow.k8s.io/view/gs/kubernetes-jenkins/logs/ci-kubernetes-e2e-aks-engine-azure-master-staging-windows/1462891652401074176
### Which tests are flaking?
```
Kubernetes e2e suite: [sig-storage] Proj... | [sig-storage] Projected downwardAPI should update annotations on modification - flaking | https://api.github.com/repos/kubernetes/kubernetes/issues/106613/comments | 8 | 2021-11-23T01:33:02Z | 2022-05-15T19:23:31Z | https://github.com/kubernetes/kubernetes/issues/106613 | 1,060,754,699 | 106,613 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The test `[sig-windows] [Feature:Windows] Memory Limits [Serial] [Slow] attempt to deploy past allocatable memory limits should fail deployments of pods once there isn't enough memory`: https://prow.k8s.io/view/gs/kubernetes-jenkins/logs/ci-kubernetes-e2e-aks-engine-azure-master-staging-windows-seri... | Update Sig-windows Memory Limits tests to not assume all nodes are the same | https://api.github.com/repos/kubernetes/kubernetes/issues/106608/comments | 12 | 2021-11-22T22:33:45Z | 2022-03-11T19:52:23Z | https://github.com/kubernetes/kubernetes/issues/106608 | 1,060,656,208 | 106,608 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Currently kubelet's default eviction manager uses only image fs disk size and log (default place for console log) size to decide eviction threshold: https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/eviction/eviction_manager.go#L527
however a common use case of ephemeral disk is ... | ephemeral-storage based pod eviction should include more volume types | https://api.github.com/repos/kubernetes/kubernetes/issues/106606/comments | 10 | 2021-11-22T21:16:45Z | 2022-05-23T21:35:24Z | https://github.com/kubernetes/kubernetes/issues/106606 | 1,060,601,596 | 106,606 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
A standard (spec) to define the SSL certificate and private key for an external LoadBalancer.
### Why is this needed?
When you use an **external LoadBalancer** you usually need SSL / TLS / HTTPS (this is a requirement for most applications nowadays).
Currently you can ... | Standard for Type=LoadBalancer Service TLS configuration | https://api.github.com/repos/kubernetes/kubernetes/issues/106603/comments | 18 | 2021-11-22T20:37:59Z | 2022-01-21T21:36:17Z | https://github.com/kubernetes/kubernetes/issues/106603 | 1,060,571,995 | 106,603 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
There seems to be an obvious typo on `util.HasMountRefs` function:
```
func HasMountRefs(mountPath string, mountRefs []string) bool {
for _, ref := range mountRefs {
if !strings.Contains(ref, mountPath) {
return true
}
}
return false
}
```
it does not make sense to negate `str... | util.HasMountRefs typo | https://api.github.com/repos/kubernetes/kubernetes/issues/106602/comments | 6 | 2021-11-22T20:06:00Z | 2022-02-21T04:00:45Z | https://github.com/kubernetes/kubernetes/issues/106602 | 1,060,545,541 | 106,602 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
When upgrading etcd from an old version to 3.5.0, then some zombie members may be displayed. Users can't even remove the zombie members using command `etcdctl member remove <id>`. Please see the discussion in [etcd/issues/13196](https://github.com/etcd-io/etcd/issues/13196).
A... | [etcd] Bump etcd client to 3.5.1 | https://api.github.com/repos/kubernetes/kubernetes/issues/106589/comments | 37 | 2021-11-22T06:12:56Z | 2022-08-10T13:59:10Z | https://github.com/kubernetes/kubernetes/issues/106589 | 1,059,736,796 | 106,589 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
max retries is supported in service account token controller, but it is not configurable in controller manager.
https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/serviceaccount/tokens_controller.go#L70
```go
// TokensControllerOptions contains options for the T... | make max retries of serviceaccount token controller configurable through command line options | https://api.github.com/repos/kubernetes/kubernetes/issues/106587/comments | 13 | 2021-11-22T03:29:01Z | 2022-10-17T16:27:11Z | https://github.com/kubernetes/kubernetes/issues/106587 | 1,059,631,144 | 106,587 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
`RegisterMetrics` function on `pkg/winkernel/metrics.go` is not being used, and kproxy metrics are not showing on endpoint.
### What did you expect to happen?
```
# HELP kubeproxy_sync_proxy_rules_duration_seconds [ALPHA] SyncProxyRules latency in seconds
# TYPE kubeproxy_sync_proxy_rules_durati... | Windows Kube-Proxy metrics are not registered | https://api.github.com/repos/kubernetes/kubernetes/issues/106580/comments | 3 | 2021-11-21T20:29:28Z | 2021-12-08T02:26:09Z | https://github.com/kubernetes/kubernetes/issues/106580 | 1,059,479,398 | 106,580 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
pull-kubernetes-unit
### Which tests are flaking?
TestDifferentWidths
### Since when has it been flaking?
As far back as triage board history shows
### Testgrid link
https://testgrid.k8s.io/presubmits-kubernetes-blocking#pull-kubernetes-unit
### Reason for failure (if possible)
_No ... | [Flaky] TestDifferentWidths | https://api.github.com/repos/kubernetes/kubernetes/issues/106579/comments | 17 | 2021-11-21T17:47:28Z | 2023-02-16T19:45:39Z | https://github.com/kubernetes/kubernetes/issues/106579 | 1,059,442,030 | 106,579 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Tests that use `wait.PollImmediate` (directly or indirectly, as in https://github.com/kubernetes/kubernetes/blob/ed07515ee012207e79816b4641ad5d3be238468b/test/e2e/framework/pod/wait.go#L386-L426) with a custom test function fail poorly when polling times out. Example:
```
/go... | E2E tests: avoid generic poll functions | https://api.github.com/repos/kubernetes/kubernetes/issues/106575/comments | 16 | 2021-11-21T09:37:26Z | 2025-01-15T19:47:14Z | https://github.com/kubernetes/kubernetes/issues/106575 | 1,059,333,653 | 106,575 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
aks-engine-windows-containerd-master
### Which tests are failing?
- ci-kubernetes-e2e-aks-engine-azure-master-windows-containerd.OverallChanges
- Kubernetes e2e suite.[sig-api-machinery] Aggregator Should be able to support the 1.17 Sample API Server using the current Aggregator [Conform... | [Failing test][sig-api-machinery] aks-engine-windows-containerd-master | https://api.github.com/repos/kubernetes/kubernetes/issues/106574/comments | 7 | 2021-11-21T01:39:21Z | 2021-11-30T21:23:22Z | https://github.com/kubernetes/kubernetes/issues/106574 | 1,059,268,821 | 106,574 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
integration-master
### Which tests are failing?
- ci-kubernetes-integration-master.OverallChanges
- k8s.io/kubernetes/test/integration/apiserver.TestMaxResourceSizeChanges
- k8s.io/kubernetes/test/integration/apiserver.TestMaxResourceSize/MergePatchType_should_handle_a_patch_just_under_... | [Failing test] integration-master | https://api.github.com/repos/kubernetes/kubernetes/issues/106573/comments | 4 | 2021-11-21T01:26:46Z | 2021-11-21T21:05:00Z | https://github.com/kubernetes/kubernetes/issues/106573 | 1,059,266,976 | 106,573 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm trying to build kubectl on macOS 10.13 [using Homebrew](https://github.com/Homebrew/homebrew-core/blob/HEAD/Formula/kubernetes-cli.rb). I'm getting this error:
```console
+++ [1120 06:25:26] Building go targets for darwin/amd64:
cmd/kubectl
# k8s.io/kubernetes/cmd/kubectl
/usr/local/C... | in '/usr/local/lib/libxar.1.dylib', file was built for unsupported file format | https://api.github.com/repos/kubernetes/kubernetes/issues/106572/comments | 12 | 2021-11-20T20:03:30Z | 2021-11-24T06:44:42Z | https://github.com/kubernetes/kubernetes/issues/106572 | 1,059,219,170 | 106,572 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
periodic-kubernetes-unit-test-ppc64le
### Which tests are flaking?
1. pkg/kubelet/cm/cpumanager.TestTakeByTopologyNUMADistributed
2. pkg/kubelet/cm/cpumanager.TestTakeByTopologyNUMADistributed/allocate_24_full_cores_with_8_distributed_across_the_first_3_NUMA_nodes_(filling_the_first_NUMA... | [Flaky Test][sig-node] kubernetes-unit-test TestTakeByTopologyNUMADistributed is being Flaky | https://api.github.com/repos/kubernetes/kubernetes/issues/106571/comments | 10 | 2021-11-20T19:46:46Z | 2021-12-10T12:41:13Z | https://github.com/kubernetes/kubernetes/issues/106571 | 1,059,216,372 | 106,571 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
periodic-kubernetes-unit-test-ppc64le
### Which tests are flaking?
1. vendor/k8s.io/client-go/rest.TestHTTP1DoNotReuseRequestAfterTimeout
2. vendor/k8s.io/client-go/rest.TestHTTP1DoNotReuseRequestAfterTimeout/HTTP1
3. vendor/k8s.io/client-go/rest.TestHTTP1DoNotReuseRequestAfterTim... | [Flaky Test][sig-node] kubernetes-unit-test TestHTTP1DoNotReuseRequestAfterTimeout is being Flaky | https://api.github.com/repos/kubernetes/kubernetes/issues/106569/comments | 23 | 2021-11-20T19:16:33Z | 2021-11-29T21:23:23Z | https://github.com/kubernetes/kubernetes/issues/106569 | 1,059,211,347 | 106,569 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I ran `kubectl explain ControllerRevision` and saw docs inconsistent with [API groups and versioning](https://kubernetes.io/docs/concepts/overview/kubernetes-api/#api-groups-and-versioning):
```
KIND: ControllerRevision
VERSION: apps/v1
DESCRIPTION:
ControllerRevision implements a... | ControllerRevision incorrectly marked as beta | https://api.github.com/repos/kubernetes/kubernetes/issues/106567/comments | 9 | 2021-11-20T17:17:23Z | 2022-04-19T19:18:44Z | https://github.com/kubernetes/kubernetes/issues/106567 | 1,059,189,617 | 106,567 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
master-informing gce-ubuntu-master-default
### Which tests are flaking?
- kubetest.Test
- Kubernetes e2e suite.[sig-node] Probing container should *not* be restarted with a exec "cat /tmp/health" liveness probe [NodeConformance] [Conformance]
### Since when has it been flaking?
- probi... | [Flaky test][sig-node] Probing container should not be restarted with a exec "cat /tmp/health" | https://api.github.com/repos/kubernetes/kubernetes/issues/106566/comments | 53 | 2021-11-20T16:02:47Z | 2022-03-09T20:22:23Z | https://github.com/kubernetes/kubernetes/issues/106566 | 1,059,175,128 | 106,566 |
[
"kubernetes",
"kubernetes"
] | The Pod Security admission controller was designed to be extensible. We should add a markdown file to the k8s.io/pod-security-admission repo that documents the recommended extension points and gives an overview of the code structure.
/sig auth
/kind documentation | [Pod Security] Document Pod Security code structure & extension points | https://api.github.com/repos/kubernetes/kubernetes/issues/106561/comments | 7 | 2021-11-19T21:21:14Z | 2022-05-11T23:59:37Z | https://github.com/kubernetes/kubernetes/issues/106561 | 1,058,926,360 | 106,561 |
[
"kubernetes",
"kubernetes"
] | ### What
Look into strict handling of nested objects for beta release of server-side field validation
### Why
With ServerSideFieldValidation merged, we have modified decoding such that it is possible to successfully decode an object _and_ return a special type of error know as a strict decoding error for when the ... | Look into strict handling of nested object decoding | https://api.github.com/repos/kubernetes/kubernetes/issues/106558/comments | 4 | 2021-11-19T18:21:58Z | 2022-01-22T00:23:56Z | https://github.com/kubernetes/kubernetes/issues/106558 | 1,058,798,841 | 106,558 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kubelet.service fails to start on Fedora 35 (also on Fedora CoreOS stable and next)
Install kubelet, kubeadm, and kubectl on Fedora 35 Server
```bash
sudo dnf install -y kubelet-1.22.0 kubeadm-1.22.0 kubectl-1.22.0 --disableexcludes=kubernetes
```
start kubelet.service
```bash
systemct ... | kubelet.service fails to start on Fedora 35 Server (also on Fedora CoreOS stable and next) | https://api.github.com/repos/kubernetes/kubernetes/issues/106556/comments | 3 | 2021-11-19T13:43:14Z | 2021-11-19T15:51:50Z | https://github.com/kubernetes/kubernetes/issues/106556 | 1,058,543,897 | 106,556 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A pod with one container creates two containers and exist at the same time. This pod was in crashloopbackoff state at that time. But it is difficult to understand is why it allocates cpu twice, which causes other pods to have not enough cpu to satisfy request.
### There are kubelet log below.
... | Pod with one container executed startcontainer twice and allocated cpu twice. (cpu manager static policy) | https://api.github.com/repos/kubernetes/kubernetes/issues/106549/comments | 7 | 2021-11-19T07:03:10Z | 2021-11-24T18:43:18Z | https://github.com/kubernetes/kubernetes/issues/106549 | 1,058,206,301 | 106,549 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
After updating from this version v1.19.12 to this v1.20.12 version, we noticed that kube-apiserver started to crash continuously with seeing it having high CPU.
CPU Stats
`acae24d2a0cb k8s_kube-apiserver_kube-apiserver-jpe1-caas1-alpha1-master-000001.caas.jpe1z.dcnw.foobar_kube-system_... | kube-apiserver crashes after updating from v1.19.12 to v1.20.12 | https://api.github.com/repos/kubernetes/kubernetes/issues/106548/comments | 5 | 2021-11-19T04:30:11Z | 2021-12-16T07:01:13Z | https://github.com/kubernetes/kubernetes/issues/106548 | 1,058,120,104 | 106,548 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
My cluster already has high priority pending pods(lack of resources). Now I try to create a low priority pods, but it seems those pods won't be handled by the kube-scheduler(no scheduling event at all). And then I modify the low priority pods to high priority, it can be scheduled successfully. Is it... | low priority pods stuck in pending without any scheduling events | https://api.github.com/repos/kubernetes/kubernetes/issues/106546/comments | 15 | 2021-11-19T02:57:26Z | 2021-11-29T12:22:55Z | https://github.com/kubernetes/kubernetes/issues/106546 | 1,058,073,477 | 106,546 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler/eventhandlers.go#L212
if oldPod.UID != newPod.UID {
sched.deletePodFromCache(oldObj)
sched.addPodToCache(newObj)
return
}
Both deletePodFromCache and addPodToCache operate on the internal cache of the scheduler, and will... | kube-scheduler has race conditions during cache refresh | https://api.github.com/repos/kubernetes/kubernetes/issues/106545/comments | 11 | 2021-11-19T02:15:47Z | 2021-12-11T08:31:59Z | https://github.com/kubernetes/kubernetes/issues/106545 | 1,058,054,340 | 106,545 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We are trying to use the new NFS/Azurefiles preview:
https://docs.microsoft.com/en-us/azure/storage/files/storage-files-how-to-create-nfs-shares?tabs=azure-cli
Use Container Storage Interface (CSI) drivers for Azure Files on Azure Kubernetes Service (AKS) - Azure Kubernetes Service
We are using... | Unable to create PVC in ARO using NFS CSI - error parameter=client.SubscriptionID constraint=MinLength value="" | https://api.github.com/repos/kubernetes/kubernetes/issues/106543/comments | 11 | 2021-11-18T19:52:35Z | 2022-06-20T23:36:51Z | https://github.com/kubernetes/kubernetes/issues/106543 | 1,057,740,165 | 106,543 |
[
"kubernetes",
"kubernetes"
] | Hello, we have cronjobs running in production , occasionally we are having issues with spinning up pods for cron jobs .when i describe the pod , we are having the following logs (Copied below)
Please can you help if you see anything from the logs below ? (This cronjob has 3 containers to be deployed to perform the ... | issue with spinning up pods for cron jobs in production | https://api.github.com/repos/kubernetes/kubernetes/issues/106540/comments | 7 | 2021-11-18T18:50:42Z | 2022-04-25T12:04:14Z | https://github.com/kubernetes/kubernetes/issues/106540 | 1,057,688,131 | 106,540 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Issue originating from: https://github.com/prometheus-operator/kube-prometheus/pull/1499
The label seems to be unused, but it can cause issues with high cardinality. On k3s this label has unbound cardinality due to the inclusion of url param like timeout. Examples from my small k3s cluster:
... | Cardinality explosions in kubelet rest client latency metrics | https://api.github.com/repos/kubernetes/kubernetes/issues/106538/comments | 12 | 2021-11-18T18:10:35Z | 2022-07-08T10:28:31Z | https://github.com/kubernetes/kubernetes/issues/106538 | 1,057,652,156 | 106,538 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
- Cluster was upgraded from 1.19 to 1.20 and finally to 1.21.3
- During this deployments were restarted
- Noticed several were not starting and investigated
- Some deployments with startup probes were failing and thus could not start
- Some deployments with liveness and readiness probes were... | After upgrading from 1.19 to 1.21.3 deployments now require massive resource limit increases. | https://api.github.com/repos/kubernetes/kubernetes/issues/106537/comments | 9 | 2021-11-18T15:53:17Z | 2022-04-30T20:47:29Z | https://github.com/kubernetes/kubernetes/issues/106537 | 1,057,515,333 | 106,537 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Importing Kubernetes' `k8s.io/apiserver` module together with the latest version of `go.opentelemetry.io/otel` results in a failed build due to breaking changes in the OpenTelemetry Go library. This also happens with `k8s.io/component-base`.
The solution is to bump the opentelemetry dependencie... | Use of outdated OpenTelemetry Go package | https://api.github.com/repos/kubernetes/kubernetes/issues/106536/comments | 22 | 2021-11-18T15:47:34Z | 2022-09-20T02:15:32Z | https://github.com/kubernetes/kubernetes/issues/106536 | 1,057,509,329 | 106,536 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.