
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
pull-cluster-api-provider-azure-windows-containerd-upstream-with-ci-artifacts
### Which tests are flaking?
Kubernetes e2e suite: [sig-auth] ServiceAccounts ServiceAccountIssuerDiscovery should support OIDC discovery of service account issuer [Conformance]
### Since when has it been flak... | Windows capz [It] ServiceAccountIssuerDiscovery should support OIDC discovery of service account issuer [Conformance] | https://api.github.com/repos/kubernetes/kubernetes/issues/107114/comments | 40 | 2021-12-18T00:38:40Z | 2024-10-15T16:54:01Z | https://github.com/kubernetes/kubernetes/issues/107114 | 1,083,702,684 | 107,114 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
PIDPressure is not set to true when the system has insufficient pid resource.
### What did you expect to happen?
PIDPressure is set to true correctly when the system is insufficient in pid resource.
### How can we reproduce it (as minimally and precisely as possible)?
See cause below
### Anythi... | System maximum PID inconsiderate of sysctl 'threads-max' | https://api.github.com/repos/kubernetes/kubernetes/issues/107111/comments | 6 | 2021-12-17T21:15:31Z | 2022-02-10T04:49:46Z | https://github.com/kubernetes/kubernetes/issues/107111 | 1,083,620,450 | 107,111 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Condition PIDPressure is not set to true when the system thread number exceeds 65538 even it's reaching the limit.
### What did you expect to happen?
Condition PIDPressure is set to true correctly
### How can we reproduce it (as minimally and precisely as possible)?
See cause below
### Anything... | PIDPressure incorrect when system thread number exceeds 65538 | https://api.github.com/repos/kubernetes/kubernetes/issues/107107/comments | 2 | 2021-12-17T16:55:56Z | 2022-02-10T09:15:47Z | https://github.com/kubernetes/kubernetes/issues/107107 | 1,083,446,382 | 107,107 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Another master node become a new leader of kube-controller-manager and start controllers like attachdetach ...
but i have found start the controllers one of them wolud spend long time than others , one of them will be 30s longer than the others, like this:
```
I1217 07:43:04.354500 1 ... | kube-controller-manager leader node shutdown, node status change slowly | https://api.github.com/repos/kubernetes/kubernetes/issues/107100/comments | 9 | 2021-12-17T08:08:59Z | 2022-06-19T20:07:38Z | https://github.com/kubernetes/kubernetes/issues/107100 | 1,082,992,922 | 107,100 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
While reviewing #105800 I noticed some things.
1. The annotation key `apf.kubernetes.io/autoupdate-spec` is not mentioned anywhere in the user-facing documentation (https://kubernetes.io/docs/concepts/cluster-administration/flow-control/) --- but it should be.
2. https://github.com/kubernetes/... | Various bugs in APF configuration producing controller | https://api.github.com/repos/kubernetes/kubernetes/issues/107097/comments | 23 | 2021-12-17T06:05:32Z | 2025-01-30T21:24:40Z | https://github.com/kubernetes/kubernetes/issues/107097 | 1,082,918,805 | 107,097 |
[
"kubernetes",
"kubernetes"
] | https://github.com/kubernetes/kubernetes/blob/362312176766a03976a8a55b7d5aa5ac89263d4a/pkg/volume/csi/csi_client.go#L538
ref:
https://github.com/grpc/grpc-go/issues/2628
https://github.com/grpc/grpc-go/pull/3730/files
Target should start with unix: to avoid setting empty authority header according to RFC-3986. | PROTOCOL_ERROR | https://api.github.com/repos/kubernetes/kubernetes/issues/107093/comments | 7 | 2021-12-17T02:54:31Z | 2022-05-22T14:24:57Z | https://github.com/kubernetes/kubernetes/issues/107093 | 1,082,831,311 | 107,093 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Two goroutines are leaked in [TestConfigurationChannels](https://github.com/kubernetes/kubernetes/blob/master/pkg/util/config/config_test.go#L24-L34).
The two goroutines are created inside function mux.Channel() ([line 77](https://github.com/kubernetes/kubernetes/blob/master/pkg/util/config/conf... | goroutine leaks in TestConfigurationChannels | https://api.github.com/repos/kubernetes/kubernetes/issues/107089/comments | 2 | 2021-12-16T22:56:37Z | 2022-01-11T01:23:16Z | https://github.com/kubernetes/kubernetes/issues/107089 | 1,082,712,421 | 107,089 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Running kubectl create with dry-run returns unwanted uid metadata field, as well as a generated name when using generateName.
This is inconsistent with the expectations as defined in [KEP 576](https://github.com/kubernetes/enhancements/blob/master/keps/sig-api-machinery/576-dry-run/README.md#gene... | dry-run returns unwanted metadata fields | https://api.github.com/repos/kubernetes/kubernetes/issues/107086/comments | 7 | 2021-12-16T21:28:59Z | 2022-09-03T19:12:32Z | https://github.com/kubernetes/kubernetes/issues/107086 | 1,082,658,285 | 107,086 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Journal is getting spammed multiple times in a second with:
```
-- The unit run-containerd-runc-k8s.io-a19b981608525a17f8ba1e39faeb8997e3ce87c5789641aa461955638d21f745-runc.IWbYLP.mount has successfully entered the 'dead' state.
Dec 16 18:54:51 kube1 systemd[1]: run-containerd-runc-k8s.io-a19b981... | Server logs getting spammed multiple times per second with Container Runtime log | https://api.github.com/repos/kubernetes/kubernetes/issues/107082/comments | 8 | 2021-12-16T18:58:04Z | 2022-01-19T21:41:06Z | https://github.com/kubernetes/kubernetes/issues/107082 | 1,082,545,943 | 107,082 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Output of `helm version`: `v3.6.3`
Output of `kubectl version`:
```
Client Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.5", GitCommit:"aea7bbadd2fc0cd689de94a54e5b7b758869d691", GitTreeState:"clean", BuildDate:"2021-09-15T21:10:45Z", GoVersion:"go1.16.8", Compiler:"gc", Platfo... | Feature request: Support for "host-gateway" in "hostAliases" | https://api.github.com/repos/kubernetes/kubernetes/issues/107079/comments | 11 | 2021-12-16T16:56:39Z | 2022-02-03T21:58:08Z | https://github.com/kubernetes/kubernetes/issues/107079 | 1,082,434,903 | 107,079 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We added pinging google.com to the original E2Es, however in airgapped environments, these tests fail for obvious reasons:
```
Get http://google.com: dial tcp: lookup google.com on 192.48.0.10:53: server misbehaving
```
- https://github.com/kubernetes/kubernetes/blob/master/test/e2e/windows/... | Remove or parameterize google.com from test cases | https://api.github.com/repos/kubernetes/kubernetes/issues/107078/comments | 8 | 2021-12-16T16:53:15Z | 2022-03-11T21:26:23Z | https://github.com/kubernetes/kubernetes/issues/107078 | 1,082,431,630 | 107,078 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The `CPUManager` has logic to periodically cleanup stale state and reclaim exclusive CPUs from pods that have recently terminated. It does this by querying the system for a list of `activePods()` and reclaiming CPUs from any pods it is tracking that are not in this list.
This works fine for mos... | Exclusive CPUs not removed from deleted Pod and put back in the defaultCPUSet. | https://api.github.com/repos/kubernetes/kubernetes/issues/107074/comments | 18 | 2021-12-16T13:31:26Z | 2024-12-12T16:28:04Z | https://github.com/kubernetes/kubernetes/issues/107074 | 1,082,201,701 | 107,074 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
e2e-cos-alpha-features
### Which tests are failing?
All
### Since when has it been failing?
I'm not sure it was ever running.
### Testgrid link
https://testgrid.k8s.io/sig-node-cos#e2e-cos-alpha-features
### Reason for failure (if possible)
_No response_
### Anything else we need t... | Tests sig-node-cos#e2e-cos-alpha-features wouldn't start | https://api.github.com/repos/kubernetes/kubernetes/issues/107068/comments | 3 | 2021-12-16T01:03:55Z | 2021-12-16T06:41:19Z | https://github.com/kubernetes/kubernetes/issues/107068 | 1,081,660,871 | 107,068 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
NPD e2e
### Which tests are failing?
Tests wouldn't start
### Since when has it been failing?
12/08
@bsdnet suggested it may be related to https://github.com/kubernetes/node-problem-detector/pull/629
/cc @Random-Liu
### Testgrid link
https://testgrid.k8s.io/sig-node-node-proble... | Tests sig-node-node-problem-detector#ci-npd-e2e-node are failing | https://api.github.com/repos/kubernetes/kubernetes/issues/107067/comments | 9 | 2021-12-16T01:02:06Z | 2022-03-26T06:50:44Z | https://github.com/kubernetes/kubernetes/issues/107067 | 1,081,659,642 | 107,067 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
containerd eviction tests
### Which tests are failing?
```
E2eNode Suite.[sig-node] LocalStorageEviction [Slow] [Serial] [Disruptive][NodeFeature:Eviction] when we run containers that should cause DiskPressure should eventually evict all of the correct podsE2eNode Suite.[sig-node] LocalS... | Tests on sig-node-containerd#node-kubelet-containerd-eviction are failing | https://api.github.com/repos/kubernetes/kubernetes/issues/107063/comments | 26 | 2021-12-15T23:32:22Z | 2024-07-25T18:59:59Z | https://github.com/kubernetes/kubernetes/issues/107063 | 1,081,611,128 | 107,063 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
sig-node-containerd#cos-cgroupv2-containerd-node-e2e-serial
### Which tests are failing?
```
E2eNode Suite.[sig-node] Density [Serial] [Slow] create a batch of pods latency/resource should be within limit when create 10 pods with 0s intervalE2eNode Suite.[sig-node] Density [Serial] [Slow... | Tests on sig-node-containerd#cos-cgroupv2-containerd-node-e2e-serial are failing | https://api.github.com/repos/kubernetes/kubernetes/issues/107062/comments | 20 | 2021-12-15T23:30:46Z | 2022-01-27T06:24:12Z | https://github.com/kubernetes/kubernetes/issues/107062 | 1,081,610,326 | 107,062 |
[
"kubernetes",
"kubernetes"
] | This test asserts on the value of a global counter. When run with -test.count > 1, it passes once and fails all subsequent runs.
### Failure cluster [d12b09d3e6d011d68e49](https://go.k8s.io/triage#d12b09d3e6d011d68e49)
##### Error text:
```
=== RUN TestProxyHandler
E1201 04:12:11.066537 112514 handler_proxy... | TestProxyHandler fails with test.count greater than 1 | https://api.github.com/repos/kubernetes/kubernetes/issues/107059/comments | 2 | 2021-12-15T21:57:19Z | 2021-12-16T22:52:52Z | https://github.com/kubernetes/kubernetes/issues/107059 | 1,081,550,489 | 107,059 |
[
"kubernetes",
"kubernetes"
] | Is there a possibility to add wildcards for these queries? For example, trying to run 'kubectl get pods --field-selector metadata.name=common-* -o name -n ns | xargs kubectl delete'. Would help clearing out multiple pods. | Allow wildcards in field selectors | https://api.github.com/repos/kubernetes/kubernetes/issues/107053/comments | 31 | 2021-12-15T13:26:33Z | 2025-03-05T00:46:02Z | https://github.com/kubernetes/kubernetes/issues/107053 | 1,081,282,569 | 107,053 |
[
"kubernetes",
"kubernetes"
] | I would want to discuss potential ways that we can avoid issues like https://github.com/kubernetes/kubernetes/pull/107035
Ideas:
* Run periodic scalability tests with JSON logging enabled
* Collect and agree upon set of logging performance metrics that should be verified before release (for example https://github.... | Prevent performance regressions for JSON logging format | https://api.github.com/repos/kubernetes/kubernetes/issues/107049/comments | 13 | 2021-12-15T12:42:41Z | 2024-07-25T16:46:08Z | https://github.com/kubernetes/kubernetes/issues/107049 | 1,080,995,848 | 107,049 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Similar to [#78276](https://github.com/kubernetes/kubernetes/pull/78276)
> For topology aware (WaitForFirstConsumer) volume provisioning, node is already selected when we call cloud provider to create the volume.
It seems in other cloud providers also have the same problem. when the node selec... | Use zone from node for topology aware volume creation | https://api.github.com/repos/kubernetes/kubernetes/issues/107045/comments | 15 | 2021-12-15T09:01:35Z | 2023-04-09T03:34:16Z | https://github.com/kubernetes/kubernetes/issues/107045 | 1,080,762,642 | 107,045 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
For 1.21, by checking https://kubernetes.io/blog/2021/04/21/graceful-node-shutdown-beta/,
I added below args to `kubelet-config.json`:
```
"shutdownGracePeriod": "1m30s",
"shutdownGracePeriodCriticalPods": "30s"
```
I can see `99-kubelet.conf`:
```
ubuntu@ip-10-120-80-6:~$ uname -a
Linu... | GracefulNodeShutdown not work | https://api.github.com/repos/kubernetes/kubernetes/issues/107043/comments | 28 | 2021-12-15T08:57:31Z | 2022-01-28T00:09:44Z | https://github.com/kubernetes/kubernetes/issues/107043 | 1,080,757,632 | 107,043 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
If we create a v2beta2 HPA object with fields specified for the scaleUp or scaleDown behavior, these values can be modified through the v1 version of the same object by changing the annotation for autoscaling.alpha.kubernetes.io/behavior. If we patch the scaleUp or scaleDown field in the annotation ... | Nil pointer dereference in KCM after v1 HPA patch request | https://api.github.com/repos/kubernetes/kubernetes/issues/107038/comments | 19 | 2021-12-15T00:26:32Z | 2025-01-07T18:25:58Z | https://github.com/kubernetes/kubernetes/issues/107038 | 1,080,426,828 | 107,038 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When working on https://github.com/kubernetes/kubernetes/issues/107029 I have found a regression in JSON logging format that happend in 1.23.
In v1.23 JSON logging introduced two new features, log stream splitting and info log buffering. When I started measuring throughput it looked very promis... | Regression in JSON logging throughput | https://api.github.com/repos/kubernetes/kubernetes/issues/107033/comments | 7 | 2021-12-14T19:50:15Z | 2021-12-16T16:16:01Z | https://github.com/kubernetes/kubernetes/issues/107033 | 1,080,152,155 | 107,033 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Currently, kube-apiserver logs are migrated to structure logging. We would like to measure performance of structured logging in scale.
I've gathered some data based on sig-scalability performance test (https://k8s-testgrid.appspot.com/sig-scalability-gce#gce-master-scale-perfo... | Kube-apiserver JSON logging performance test | https://api.github.com/repos/kubernetes/kubernetes/issues/107029/comments | 17 | 2021-12-14T16:49:50Z | 2023-03-20T07:28:54Z | https://github.com/kubernetes/kubernetes/issues/107029 | 1,079,991,247 | 107,029 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Similar to [#61390](https://github.com/kubernetes/kubernetes/issues/61390) in winkernel proxy mode, most service functions like "nodeport/loadbalance" is similiar to proxy mode iptables/ipvs, yet most winkernel proxier ut only verified very few normal function, which can't ensure all kinds of ser... | Complete winkernel proxier ut | https://api.github.com/repos/kubernetes/kubernetes/issues/107026/comments | 13 | 2021-12-14T15:15:24Z | 2023-01-14T08:58:43Z | https://github.com/kubernetes/kubernetes/issues/107026 | 1,079,882,174 | 107,026 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
My Kubelet config:
evictionHard:
imagefs.available: 10%
memory.available: 500Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
evictionSoft:
imagefs.available: 70%
memory.available: 1Gi
nodefs.available: 70%
nodefs.inodesFree: 5%
evictionMaxPodGracePeriod: 120
pod config... | evictionMaxPodGracePeriod is Not available | https://api.github.com/repos/kubernetes/kubernetes/issues/107024/comments | 21 | 2021-12-14T14:09:43Z | 2022-02-28T14:20:23Z | https://github.com/kubernetes/kubernetes/issues/107024 | 1,079,804,985 | 107,024 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
After I upgraded my cluster to 1.22 recently, I found that my virtual kubelet created a csr request, which could not be automatically approve, manually approve in time, and could not be issued because the signName is kubernetes.io/legacy-unknown, why should I do it myself What about issuing certif... | CSR no longer supports "kubernetes.io/legacy-unknown"? | https://api.github.com/repos/kubernetes/kubernetes/issues/107020/comments | 3 | 2021-12-14T13:02:26Z | 2021-12-15T10:55:27Z | https://github.com/kubernetes/kubernetes/issues/107020 | 1,079,731,153 | 107,020 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Similar to [#61090](https://github.com/kubernetes/kubernetes/issues/61090), it seems in winkernel mode proxy, there is no validate for svcInfo.LoadBalancerSourceRanges(), it may brings security concern.
https://github.com/kubernetes/kubernetes/blob/c83a94da72416219cf9f022dc44b0e6db158f092/pkg/prox... | service loadbalancer source range don't work in winkernel mode | https://api.github.com/repos/kubernetes/kubernetes/issues/107019/comments | 13 | 2021-12-14T11:45:36Z | 2023-01-12T19:29:54Z | https://github.com/kubernetes/kubernetes/issues/107019 | 1,079,657,906 | 107,019 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kubectl returns the traceback for commands that don't exit:
```
$ kubectl list services -A
E1214 11:26:50.918812 3285 run.go:120] "command failed" err="unknown command \"list\" for \"kubectl\"\n\nDid you mean this?\n\tget\n\twait\n"
```
### What did you expect to happen?
Instead, it should ... | Malformed error messages | https://api.github.com/repos/kubernetes/kubernetes/issues/107012/comments | 10 | 2021-12-14T07:32:30Z | 2022-03-02T17:57:04Z | https://github.com/kubernetes/kubernetes/issues/107012 | 1,079,408,523 | 107,012 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kubelet stats server reruen 404
```
curl --cert /etc/kubernetes/pki/apiserver-kubelet-client.crt --key /etc/kubernetes/pki/apiserver-kubelet-client.key -k https://localhost:10250/stats
<a href="/stats/">Moved Permanently</a>.
curl --cert /etc/kubernetes/pki/apiserver-kubelet-client.crt --k... | kubelet stats API 404 | https://api.github.com/repos/kubernetes/kubernetes/issues/107010/comments | 4 | 2021-12-14T03:56:52Z | 2021-12-14T09:41:05Z | https://github.com/kubernetes/kubernetes/issues/107010 | 1,079,280,459 | 107,010 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I tried to understand exactly what NetworkPolicy objects mean, and got lost/confused. https://groups.google.com/g/kubernetes-sig-network/c/6k1A8l5uxLY
For example, the comments on the `PolicyTypes` field does not precisely specify semantics, and the comments on the `Ingress` and `Egress` fields ... | NetworkPolicySpec field doc is outdated | https://api.github.com/repos/kubernetes/kubernetes/issues/107008/comments | 8 | 2021-12-14T03:10:25Z | 2022-06-05T22:59:18Z | https://github.com/kubernetes/kubernetes/issues/107008 | 1,079,256,216 | 107,008 |
[
"kubernetes",
"kubernetes"
] | For 1.23, we removed the kubectl --dry-run default value (--dry-run="") and boolean values (--dry-run=true|false), requiring users to specify --dry-run=client or --dry-run=server due to a deprecation. This is a required action for users who upgrade kubectl. This change was made in https://github.com/kubernetes/kubernet... | Re-introduce kubectl --dry-run default value and boolean values | https://api.github.com/repos/kubernetes/kubernetes/issues/107002/comments | 5 | 2021-12-13T18:56:35Z | 2022-01-21T16:07:20Z | https://github.com/kubernetes/kubernetes/issues/107002 | 1,078,871,338 | 107,002 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Reopen of #80472
### What did you expect to happen?
`StorageClass` can be updated
### How can we reproduce it (as minimally and precisely as possible)?
See #80472 , nothing changed in 2 years
### Anything else we need to know?
_No response_
### Kubernetes version
Client Version: version.In... | StorageClass cannot be updated/replaced | https://api.github.com/repos/kubernetes/kubernetes/issues/106996/comments | 14 | 2021-12-13T13:31:01Z | 2023-10-10T18:45:16Z | https://github.com/kubernetes/kubernetes/issues/106996 | 1,078,536,339 | 106,996 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Similar to #57430, it seems there are still many use of pkg syscall in the code.
https://github.com/kubernetes/kubernetes/blob/770847e6b06d89326f0f2d42c26487cc7f9eae06/pkg/util/ipvs/ipvs_linux.go#L27
### What did you expect to happen?
replace syscall with sys/unix pkg.
### How can we ... | replace syscall with sys/unix pkg | https://api.github.com/repos/kubernetes/kubernetes/issues/106995/comments | 7 | 2021-12-13T12:24:40Z | 2022-01-05T21:54:13Z | https://github.com/kubernetes/kubernetes/issues/106995 | 1,078,469,709 | 106,995 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Want to add an option for local pv to choose to use "bind" or "rbind".
### Why is this needed?
Current local pv only supports "bind" mount.
In this case, if there are already some other mounts under the local pv path, such as multiple NFS mounts, the "child" mount points can't b... | Request to add "rbind" option for local pv | https://api.github.com/repos/kubernetes/kubernetes/issues/106994/comments | 13 | 2021-12-13T10:32:39Z | 2023-01-13T11:44:42Z | https://github.com/kubernetes/kubernetes/issues/106994 | 1,078,357,398 | 106,994 |
[
"kubernetes",
"kubernetes"
] | https://github.com/kubernetes/kubernetes/blob/ba200841fddcf8fb5edb413546ce9574f2a14d82/cmd/kubeadm/app/phases/addons/proxy/manifests.go#L30
in kubeadm default kube-proxy config,using configmap config kubeconfig client connection kubernetes. why? we way not using InCluster mode connection to kubernetes apiserver . ku... | kube-proxy from kubeadm default config using InCluster client | https://api.github.com/repos/kubernetes/kubernetes/issues/106993/comments | 7 | 2021-12-13T10:32:37Z | 2021-12-14T08:52:38Z | https://github.com/kubernetes/kubernetes/issues/106993 | 1,078,357,364 | 106,993 |
[
"kubernetes",
"kubernetes"
] | In https://github.com/kubernetes/kubernetes/pull/88745 I added a unit tests that are using time.Sleep. It's bad: it makes our tests slower than they need to be and involves some risk of races.
We should migrate this test to mocked clock.
This requires implementing a new workqueue.NewNamedRateLimitingQueueWitthCus... | endpointslice_controller_test.go is using time.Sleep | https://api.github.com/repos/kubernetes/kubernetes/issues/106989/comments | 13 | 2021-12-13T09:13:50Z | 2022-05-15T11:23:29Z | https://github.com/kubernetes/kubernetes/issues/106989 | 1,078,266,062 | 106,989 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We should make the change in PR https://github.com/kubernetes/kubernetes/pull/105590
### What did you expect to happen?
API reference links to https://www.iana.org/assignments/ should use HTTPS, not HTTP
### How can we reproduce it (as minimally and precisely as possible)?
Visit h
... | Update links to IANA for Service Name and Transport Protocol Port Number Registry | https://api.github.com/repos/kubernetes/kubernetes/issues/106980/comments | 10 | 2021-12-11T16:03:00Z | 2022-01-18T15:11:21Z | https://github.com/kubernetes/kubernetes/issues/106980 | 1,077,575,749 | 106,980 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Configuration:
- OS: Raspberry PI OS 32 bullseye
- arch: `Linux raspberrypixxx 5.10.63-v8+ #1488 SMP PREEMPT Thu Nov 18 16:16:16 GMT 2021 aarch64 GNU/Linux`
/boot/config.txt with arm_64bits=1
kubelet panic at https://github.com/kubernetes/kubernetes/blob/release-1.23/vendor/github.com/goog... | kubelet 1.23.0 (cAdvisor 0.43) panic on arm64 / Raspberry PI OS32 | https://api.github.com/repos/kubernetes/kubernetes/issues/106977/comments | 23 | 2021-12-11T10:53:06Z | 2022-04-03T02:49:20Z | https://github.com/kubernetes/kubernetes/issues/106977 | 1,077,502,007 | 106,977 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Just similar to [#96879](https://github.com/kubernetes/kubernetes/issues/96879) , for service with type nodeport , iptable proxy should add IsLoopback check for nodeAddress.
https://github.com/kubernetes/kubernetes/blob/159fcbb01e2017f1f3351cbb1ed987db6895b0a6/pkg/proxy/ipvs/proxier.go#L1096-L11... | Iptable: missing IsLoopBack() check for nodeAddress | https://api.github.com/repos/kubernetes/kubernetes/issues/106976/comments | 12 | 2021-12-11T08:21:28Z | 2022-02-18T00:14:48Z | https://github.com/kubernetes/kubernetes/issues/106976 | 1,077,466,028 | 106,976 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
```
root@master-01:~# cat /proc/cmdline
BOOT_IMAGE=/vmlinuz-5.10.0-9-amd64 root=/dev/mapper/master--01--vg-root ro quiet
root@master-01:~# dmesg | grep -i apparmor
[ 0.035928] AppArmor: AppArmor initialized
[ 0.259057] AppArmor: AppArmor Filesystem Enabled
[ 0.651475] AppArmor: Ap... | deb packages should recommend apparmor | https://api.github.com/repos/kubernetes/kubernetes/issues/106974/comments | 10 | 2021-12-11T00:36:37Z | 2021-12-15T19:28:04Z | https://github.com/kubernetes/kubernetes/issues/106974 | 1,077,334,902 | 106,974 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
hack/local-up-cluster.sh still defaults to the 'docker' container-runtime. This causes the kubelet to fail to start with an error -in the kubelet log- about the dockershim not being supported. The non-obvious fix is to set the CONTAINER_RUNTIME and KUBE_CONTAINER_RUNTIME_ENDPOINT variables to config... | local-up-cluster.sh more difficult to run due to dockershim removal | https://api.github.com/repos/kubernetes/kubernetes/issues/106972/comments | 10 | 2021-12-10T23:01:49Z | 2022-09-09T15:28:11Z | https://github.com/kubernetes/kubernetes/issues/106972 | 1,077,296,877 | 106,972 |
[
"kubernetes",
"kubernetes"
] | We know that nodeAffinity/nodeSelector is honored during the calculating of PodTopolgySpread, however, when some existing pods match the incoming pod's topologySpreadConstratints, while also excluded by the nodeAfffinity, things get a bit tricky. Raising this issue to discuss if we should read it as a bug.
Here are ... | Potential bug of PodTopologySpread when nodeAffinity is specified | https://api.github.com/repos/kubernetes/kubernetes/issues/106971/comments | 16 | 2021-12-10T22:24:06Z | 2022-01-11T16:33:17Z | https://github.com/kubernetes/kubernetes/issues/106971 | 1,077,278,913 | 106,971 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The `kubectl completion zsh` command is generating a couple of hardcoded `compdef _kubectl kubectl` which seemingly causes any commands wrapping this package downstream to break. In this example, the `oc` OpenShift client:
```zsh
#compdef kubectl
compdef _kubectl kubectl
#compdef _oc oc
`... | `kubectl completion zsh` is generating hardcoded values which break downstream `kubectl` wrappers | https://api.github.com/repos/kubernetes/kubernetes/issues/106968/comments | 2 | 2021-12-10T21:38:48Z | 2022-01-05T21:54:01Z | https://github.com/kubernetes/kubernetes/issues/106968 | 1,077,252,096 | 106,968 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
It seems with specific configuration of `/run` mounts specified in reproduction steps below, you can reach situation, where mounts on host file-system will double every time Pod restarts, which eventually leads to general slowness and CPU exhaustion.
### What did you expect to happen?
Create... | /var/run symlink to /run in container image with /run host bidirectional mount causes duplicate host mounts leading to CPU exhaustion | https://api.github.com/repos/kubernetes/kubernetes/issues/106962/comments | 16 | 2021-12-10T18:27:22Z | 2024-06-17T11:58:55Z | https://github.com/kubernetes/kubernetes/issues/106962 | 1,077,118,899 | 106,962 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have a cronjob that runs a Python script every 5 minutes. After the cronjob finishes running, I start seeing a bunch of log messages in my systemd journal like the following:
```
Dec 10 21:13:26 gb-7983 kubelet[1386178]: E1210 21:13:26.048459 1386178 cadvisor_stats_provider.go:147] "Unable to ... | Kubelet spamming 'Unable to fetch pod log stats' log messages after running cronjobs | https://api.github.com/repos/kubernetes/kubernetes/issues/106957/comments | 42 | 2021-12-10T16:00:13Z | 2023-01-24T14:14:06Z | https://github.com/kubernetes/kubernetes/issues/106957 | 1,076,994,685 | 106,957 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
DNS calls made to our VPC nameserver started to fail with `i/o timeout` from coredns pods *and* from all the worker nodes. Kubernetes service DNS names were getting resolved by coredns.
Initially we thought that this was not related to kubernetes. However, we found out that the DNS outage happe... | External DNS outage on all nodes as they join the kubernetes cluster | https://api.github.com/repos/kubernetes/kubernetes/issues/106951/comments | 15 | 2021-12-10T12:18:52Z | 2022-02-21T10:42:33Z | https://github.com/kubernetes/kubernetes/issues/106951 | 1,076,788,653 | 106,951 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When the node is running at its full capacity and no more pods can be scheduled, the rest of the pods are in `Pending` state as expected. But at this point, if we add a static pod then one of the running pods will get evicted to make room for the incoming static pod.
However, the moment pod ev... | New pod incorrectly gets scheduled on the node when there is no capacity | https://api.github.com/repos/kubernetes/kubernetes/issues/106946/comments | 25 | 2021-12-10T10:50:20Z | 2025-03-11T20:26:22Z | https://github.com/kubernetes/kubernetes/issues/106946 | 1,076,711,131 | 106,946 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Some small `KObj` performance improvement is possible by making it return a simple struct that converts the actual object only on demand - see https://github.com/kubernetes/klog/pull/261
For `KObjs`, two optimizations are possible:
- the proxy approach above
- using Go generic... | optimize KObj and KObjs | https://api.github.com/repos/kubernetes/kubernetes/issues/106945/comments | 16 | 2021-12-10T10:37:14Z | 2022-08-02T06:51:47Z | https://github.com/kubernetes/kubernetes/issues/106945 | 1,076,699,836 | 106,945 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
when kubelet cleanupOrphanedPodDirs,it may fail when the path is a file ,the log is
````
Dec 10 16:36:18 node1 kubelet: E1210 16:36:18.360278 14390 kubelet_volumes.go:179] orphaned pod "306a14d5-2c8f-44d8-bc13-857539fab97d" found, but failed to rmdir() subpath at path /var/lib/data/kubelet/pod... | kubelet delete orphaned pod volumes failed | https://api.github.com/repos/kubernetes/kubernetes/issues/106942/comments | 25 | 2021-12-10T09:22:20Z | 2024-02-05T19:43:00Z | https://github.com/kubernetes/kubernetes/issues/106942 | 1,076,614,135 | 106,942 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
when kubelet cleanupOrphanedPodDirs,it may fail when the path is a file ,the log is
````
Dec 10 16:36:18 node1 kubelet: E1210 16:36:18.360278 14390 kubelet_volumes.go:179] orphaned pod "306a14d5-2c8f-44d8-bc13-857539fab97d" found, but failed to rmdir() subpath at path /var/lib/data/kubelet/pod... | kubelet delete orphaned pod volumes failed | https://api.github.com/repos/kubernetes/kubernetes/issues/106941/comments | 4 | 2021-12-10T09:19:49Z | 2021-12-10T21:13:39Z | https://github.com/kubernetes/kubernetes/issues/106941 | 1,076,611,804 | 106,941 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
It is unclear why the test https://github.com/kubernetes/kubernetes/blob/cc6f12583f2b611e9469a6b2e0247f028aae246b/test/e2e_node/critical_pod_test.go#L50 needs the dynamic kubelet config.
Need to clean it up.
/sig node
/priority important-soon
/help
### Which tests are failing?
T... | Test CriticalPod: [Flaky] should be able to create and delete a critical pod indicate the dependency on DynamicKubeletConfig feature | https://api.github.com/repos/kubernetes/kubernetes/issues/106939/comments | 10 | 2021-12-10T08:21:11Z | 2022-01-16T17:03:28Z | https://github.com/kubernetes/kubernetes/issues/106939 | 1,076,563,806 | 106,939 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hello, I encountered a bug using k8s version 1.22. I created a test deployment resource. There is no problem creating it. Delete the deployment resource. K8s does not cascade and delete the corresponding RS and pods services. How to solve this problem
 on one of our nodes. Analysis using `go tool pprof` showed that it was related to metrics collection, and potentially with CRI stats.
When checking `cri stats` manually we noticed that the call was getting stuck. It was only getting... | Memory/go routine leak in metrics collection | https://api.github.com/repos/kubernetes/kubernetes/issues/106919/comments | 17 | 2021-12-09T19:02:20Z | 2022-11-18T21:12:28Z | https://github.com/kubernetes/kubernetes/issues/106919 | 1,075,900,305 | 106,919 |
[
"kubernetes",
"kubernetes"
] | Please use this issue for feedback and issues regarding dockershim removal in the 1.24 release.
/triage accepted
/milestone v1.24
/sig docs node
/area docker | Dockershim removal feedback & issues | https://api.github.com/repos/kubernetes/kubernetes/issues/106917/comments | 37 | 2021-12-09T18:17:43Z | 2022-12-10T13:15:08Z | https://github.com/kubernetes/kubernetes/issues/106917 | 1,075,865,650 | 106,917 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When setting custom eviction thresholds (e.g. imagefs.available), the garbage collector ignores them and uses default thresholds
### What did you expect to happen?
Garbage collector should use configured thresholds as described in the [official doc](https://v1-21.docs.kubernetes.io/docs/conc... | container image garbage collector should use custom eviction thresholds | https://api.github.com/repos/kubernetes/kubernetes/issues/106913/comments | 7 | 2021-12-09T14:45:12Z | 2021-12-10T07:05:17Z | https://github.com/kubernetes/kubernetes/issues/106913 | 1,075,654,908 | 106,913 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
pull-kubernetes-e2e-kind-ipv6
### Which tests are flaking?
[sig-node] Pods Extended Pod Container lifecycle should not create extra sandbox if all containers are done
### Since when has it been flaking?
Not sure
### Testgrid link
https://prow.k8s.io/view/gs/kubernetes-je... | [Flaky test] [sig-node] Pods Extended Pod Container lifecycle should not create extra sandbox if all containers are done | https://api.github.com/repos/kubernetes/kubernetes/issues/106904/comments | 6 | 2021-12-09T06:50:51Z | 2022-07-09T19:48:15Z | https://github.com/kubernetes/kubernetes/issues/106904 | 1,075,214,618 | 106,904 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
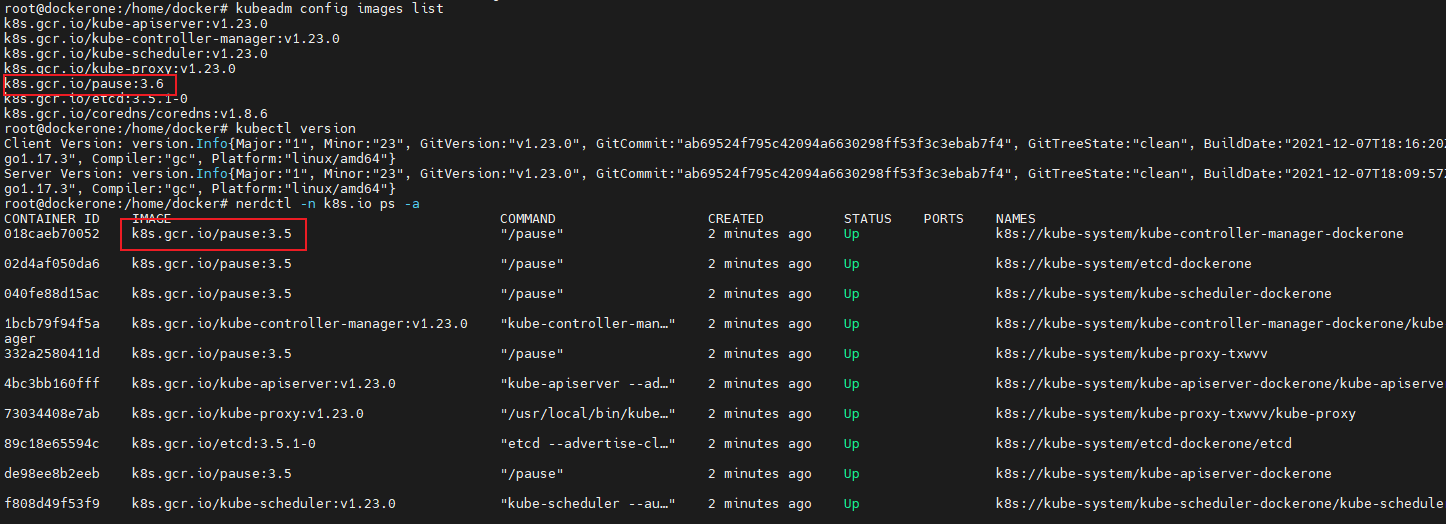
### What did you expect to happen?
The pause container should use the 3.6
### How can we reproduce it (as minimally and precisely as possible)?
kubeadm init --apiserver-advertise-addre... | After upgrading to v1.23.0, the pause container still uses 3.5, kubeadm config images list shows 3.6 | https://api.github.com/repos/kubernetes/kubernetes/issues/106903/comments | 7 | 2021-12-09T04:27:29Z | 2021-12-10T02:51:28Z | https://github.com/kubernetes/kubernetes/issues/106903 | 1,075,132,628 | 106,903 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
1. The last consumer of a volume leaves the node, triggering NodeUnstageVolume.
2. For some reason this call fails, but still manages to unmount the volume from the node. Nevertheless, it returns an error.
3. Kubelet keeps retrying NodeUnstageVolume, returning an error each time.
4. In the meanti... | NodeUnstageVolume failed but ControllerUnpublishVolume is still be called | https://api.github.com/repos/kubernetes/kubernetes/issues/106902/comments | 15 | 2021-12-09T03:24:00Z | 2023-01-01T08:21:44Z | https://github.com/kubernetes/kubernetes/issues/106902 | 1,075,100,374 | 106,902 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Reproduction steps below, but at a high level:
1. I have a pod with 2 containers. I kill the pod. terminationGracePeriodSeconds is 30s
2. Container 1 terminates immediately. Container 2 terminates after 30s.
3. Immediately after the removal, pod is updated with deletionTimestamp
4. Container 1 t... | Container status not updated after termination cause by pod deletion | https://api.github.com/repos/kubernetes/kubernetes/issues/106896/comments | 25 | 2021-12-09T00:48:47Z | 2025-02-06T20:25:06Z | https://github.com/kubernetes/kubernetes/issues/106896 | 1,074,973,434 | 106,896 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
https://testgrid.k8s.io/sig-node-kubelet#kubelet-gce-e2e-swap-ubuntu
### Which tests are flaking?
E2eNode Suite.[sig-node] Summary API [NodeConformance] when querying /stats/summary should report resource usage through the stats api
### Since when has it been flaking?
From test Job hist... | E2eNode Suite.[sig-node] Summary API [NodeConformance] when querying /stats/summary should report resource usage through the stats api | https://api.github.com/repos/kubernetes/kubernetes/issues/106895/comments | 5 | 2021-12-08T23:01:12Z | 2021-12-09T16:14:13Z | https://github.com/kubernetes/kubernetes/issues/106895 | 1,074,918,512 | 106,895 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We use [aws-ebs-csi-driver](https://github.com/kubernetes-sigs/aws-ebs-csi-driver) on nodes with the arg `--volume-attach-limit=24`
> volume-attach-limit - Value for the maximum number of volumes attachable per node. If specified, the limit applies to all nodes. If not specified, the value is a... | Cluster-autoscaler "Ignoring in scale up" despite aws-ebs-csi-driver volume-attach-limit is reached | https://api.github.com/repos/kubernetes/kubernetes/issues/106894/comments | 9 | 2021-12-08T21:44:35Z | 2022-08-12T17:28:50Z | https://github.com/kubernetes/kubernetes/issues/106894 | 1,074,861,668 | 106,894 |
[
"kubernetes",
"kubernetes"
] | /sig node
/kind cleanup
/cc @neolit123
As part of the removal of dockershim, we should also remove the deprecated CLI flags that still exist.
The `pod-infra-container-image` and `container-runtime` flags are now also deprecated and planned to be removed int v1.27. `pod-infra-container-image` is being integrate... | Clean up dockershim flags in the kubelet | https://api.github.com/repos/kubernetes/kubernetes/issues/106893/comments | 70 | 2021-12-08T20:33:02Z | 2024-12-21T06:47:55Z | https://github.com/kubernetes/kubernetes/issues/106893 | 1,074,806,001 | 106,893 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
Any [Conformance] suite that does not skip [Serial] tests. Examples are below:
https://prow.ppc64le-cloud.org/job-history/gs/ppc64le-kubernetes/logs/periodic-kubernetes-conformance-test-ppc64le
https://prow.ppc64le-cloud.org/job-history/gs/ppc64le-kubernetes/logs/periodic-kubernetes-con... | Conformance tests flaking when Serial tests are not skipped | https://api.github.com/repos/kubernetes/kubernetes/issues/106889/comments | 8 | 2021-12-08T17:11:17Z | 2021-12-23T13:45:04Z | https://github.com/kubernetes/kubernetes/issues/106889 | 1,074,635,441 | 106,889 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
A field to the Job spec that allows setting a `queueName`.
### Why is this needed?
While in core k8s we don't have support for queues, and so nothing will act on it, `queueName` will help external queueing controllers to converse into a unified API for batch users.
One r... | Add queueName field to batch/v1.Job spec | https://api.github.com/repos/kubernetes/kubernetes/issues/106886/comments | 29 | 2021-12-08T14:44:58Z | 2023-05-24T17:41:14Z | https://github.com/kubernetes/kubernetes/issues/106886 | 1,074,487,934 | 106,886 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
It looks like default HTTPS port for kube-scheduler has changed from 10251 to 10259 between 1.22.4 and 1.23.0 releases and it has not been mentioned in the changelog.
```
I1208 11:30:46.202095 1 deprecated_insecure_serving.go:54] Serving healthz insecurely on [::]:10251
```
```
I1208 ... | kube-scheduler default port (breaking) change not mentioned in 1.23 changelog | https://api.github.com/repos/kubernetes/kubernetes/issues/106885/comments | 9 | 2021-12-08T11:34:37Z | 2021-12-14T14:47:48Z | https://github.com/kubernetes/kubernetes/issues/106885 | 1,074,312,181 | 106,885 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Status of pods can become "OutOfCpu" when many pods are created and completed in a short time on the same node.
### What did you expect to happen?
Status of pods should become "Running", "Pending" or "Completed".
### How can we reproduce it (as minimally and precisely as possible)?
I created a p... | Status of pods can become "OutOfCpu" when many pods are created and completed in a short time on the same node. | https://api.github.com/repos/kubernetes/kubernetes/issues/106884/comments | 76 | 2021-12-08T10:50:16Z | 2024-09-25T13:36:21Z | https://github.com/kubernetes/kubernetes/issues/106884 | 1,074,272,165 | 106,884 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The graceful-node-shutdown feature has been there, it handled preStop and grace period cases, but traffic may still be routed into this pod during shutdown.
### What did you expect to happen?
No further traffics are routed when node gets shutdown: pod IP should be moved into NotReady address... | No traffic disable handled by graceful node shutdown | https://api.github.com/repos/kubernetes/kubernetes/issues/106879/comments | 11 | 2021-12-08T09:00:27Z | 2024-06-28T15:55:13Z | https://github.com/kubernetes/kubernetes/issues/106879 | 1,074,166,578 | 106,879 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I followed this document to configure apiserver [NodeRestriction](https://kubernetes.io/docs/reference/access-authn-authz/node/),but kubelet does not work. i know that binding clusterrole system:node, then kubelet work, but i think don't binding the clusterrole because NodeRestriction is configured.... | NodeRestriction does not work as expected | https://api.github.com/repos/kubernetes/kubernetes/issues/106874/comments | 10 | 2021-12-08T07:54:46Z | 2021-12-09T14:08:58Z | https://github.com/kubernetes/kubernetes/issues/106874 | 1,074,113,817 | 106,874 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kube-apiserver has no --max-resource-write-bytes & --json-patch-max-copy-bytes option.
### What did you expect to happen?
Correct the error message to not use the "--max-resource-write-bytes" & "--json-patch-max-copy-bytes" string.
### How can we reproduce it (as minimally and precisely... | Useless flag: --max-resource-write-bytes, --json-patch-max-copy-bytes | https://api.github.com/repos/kubernetes/kubernetes/issues/106873/comments | 2 | 2021-12-08T07:35:34Z | 2022-01-03T16:37:00Z | https://github.com/kubernetes/kubernetes/issues/106873 | 1,074,100,644 | 106,873 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When importing the package version 1.23.0, facing the error:
```
go: k8s.io/kubernetes@v1.23.0 requires
k8s.io/api@v0.0.0: reading k8s.io/api/go.mod at revision v0.0.0: unknown revision v0.0.0
```
### What did you expect to happen?
Expected the package to import normally.
### How can we repr... | Unable to import package | https://api.github.com/repos/kubernetes/kubernetes/issues/106871/comments | 5 | 2021-12-08T06:09:53Z | 2021-12-08T18:36:32Z | https://github.com/kubernetes/kubernetes/issues/106871 | 1,074,048,130 | 106,871 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I want to set tls for kube-proxy and nodeLocalDns,but not found anything about tls properties
### What did you expect to happen?
how to support
### How can we reproduce it (as minimally and precisely as possible)?
no
### Anything else we need to know?
_No response_
### Kubernetes version
<de... | "kube-proxy TLS support" | https://api.github.com/repos/kubernetes/kubernetes/issues/106870/comments | 19 | 2021-12-08T06:05:14Z | 2023-07-17T09:44:25Z | https://github.com/kubernetes/kubernetes/issues/106870 | 1,074,045,271 | 106,870 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kube-scheduler fail to start after upgrading from v1.22.4 to v1.23.0.
The kube-scheduler.service log shows:
`run.go:120] "command failed" err="[healthzBindAddress: Invalid value: \"0.0.0.0:10251\": must beempty or with an explicit 0 port, metricsBindAddress: Invalid value: \"0.0.0.0:10251\": mus... | kube-scheduler fail to start after upgrading to v1.23.0 | https://api.github.com/repos/kubernetes/kubernetes/issues/106866/comments | 3 | 2021-12-08T04:32:43Z | 2021-12-08T09:56:38Z | https://github.com/kubernetes/kubernetes/issues/106866 | 1,074,001,372 | 106,866 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
HTTP/3 will be a game changer as it is using QUIC which is based on UDP and the connections are independent of IP addresses. How would k8s service change to better work with HTTP/3 in the future, especially with regards to load-balancing HTTP/3 traffic?
### Why is this needed?
HT... | How would k8s service work with HTTP/3? | https://api.github.com/repos/kubernetes/kubernetes/issues/106864/comments | 24 | 2021-12-08T03:32:52Z | 2022-12-10T16:58:59Z | https://github.com/kubernetes/kubernetes/issues/106864 | 1,073,973,604 | 106,864 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I am new guy to k8s, I tried to set up a easy deployment of k8s, and I do it as https://github.com/kubernetes/kubernetes/blob/release-1.1/docs/getting-started-guides/docker.md told, but it is not working.
$ kubectl get nodes
The connection to the server localhost:8080 was refused - did you spe... | When I Running Kubernetes locally via Docker as doc described, it report: The connection to the server localhost:8080 was refused - did you specify the right host or port? | https://api.github.com/repos/kubernetes/kubernetes/issues/106863/comments | 8 | 2021-12-08T03:26:36Z | 2021-12-09T01:42:53Z | https://github.com/kubernetes/kubernetes/issues/106863 | 1,073,970,844 | 106,863 |
[
"kubernetes",
"kubernetes"
] | We would like to adopt the restricted standard but we require to make a few customizations to that. It would be great if there was a custom resource where custom standards or inherited and then customized standards could be made. | PodSecurityAdmission - Custom Standards | https://api.github.com/repos/kubernetes/kubernetes/issues/108808/comments | 6 | 2021-12-08T01:05:10Z | 2022-03-18T18:45:58Z | https://github.com/kubernetes/kubernetes/issues/108808 | 1,173,900,398 | 108,808 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I created EKS using `eksctl` tool and than added a new node group. I am using `kubeletExtraConfig` for setting log maximum size of **500MB**, but it's not working. I still get only tail of container log. The size of returned log is 2.39MB.
Here is kubelet config
````JSON
{
"kubeletconfig":... | kubeletConfig - containerLogMaxSize not working | https://api.github.com/repos/kubernetes/kubernetes/issues/106855/comments | 6 | 2021-12-07T19:04:20Z | 2021-12-10T09:11:17Z | https://github.com/kubernetes/kubernetes/issues/106855 | 1,073,671,522 | 106,855 |
[
"kubernetes",
"kubernetes"
] | Hi,
I deployed the [2048 example](https://github.com/kubernetes-sigs/aws-load-balancer-controller/tree/master/docs/examples/2048) but the target groups deployed are taking the endpoints IP. I have gone through multiple documentations but cannot seem to get it working.
```
default pod/2048-deployment-6cd485c... | Ingress gets deployed but target group IP is incorrect | https://api.github.com/repos/kubernetes/kubernetes/issues/106849/comments | 3 | 2021-12-07T09:40:39Z | 2021-12-07T12:13:24Z | https://github.com/kubernetes/kubernetes/issues/106849 | 1,073,131,004 | 106,849 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Support for Go 1.18 generics into k8s.io/client-go.
### Why is this needed?
Currently, the client-go has a substantial amount of code generation. This makes higher level abstractions and usage of the libraries challenging. For example, in our project there are 8 SharedInformerFac... | Add go generics support to client-go | https://api.github.com/repos/kubernetes/kubernetes/issues/106846/comments | 29 | 2021-12-07T01:24:14Z | 2024-09-23T12:00:28Z | https://github.com/kubernetes/kubernetes/issues/106846 | 1,072,810,742 | 106,846 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
CREATE request for already existing object is denied with `exceeded quota` by the ResourceQuota admission plugin.
### What did you expect to happen?
CREATE request for already existing object (and when the resourcequota is exhausted) to be denied with `already exists` (`409 Conflict`).
##... | CREATE request for already existing object is denied with `exceeded quota` | https://api.github.com/repos/kubernetes/kubernetes/issues/106842/comments | 16 | 2021-12-06T17:06:07Z | 2025-03-04T21:11:20Z | https://github.com/kubernetes/kubernetes/issues/106842 | 1,072,385,743 | 106,842 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Currently, `IN` operator is only supported for label selectors. Field selectors should also support `IN` operator as this is the only way to implement the `OR` operator on values.
### Why is this needed?
- Feature parity and consistency between label selectors and field selectors... | Support `IN` operator for field selectors. | https://api.github.com/repos/kubernetes/kubernetes/issues/106836/comments | 6 | 2021-12-06T10:00:55Z | 2021-12-14T21:15:29Z | https://github.com/kubernetes/kubernetes/issues/106836 | 1,071,952,222 | 106,836 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In Priority and Fairness, exempt request does not note `flowschema` and `prioritylevelconfiguration` in the response header.
```
$ kubectl version --v=10
I1203 10:51:20.707201 76091 loader.go:372] Config loaded from file: /tmp/iwejiofejwpoifjiowepfjiopewjfiopwejofewjpiofewjiopfwejiopfeijow... | apf: exempt request does not note flowschema and prioritylevelconfiguration in the response header | https://api.github.com/repos/kubernetes/kubernetes/issues/106826/comments | 8 | 2021-12-05T16:27:54Z | 2022-01-05T02:45:00Z | https://github.com/kubernetes/kubernetes/issues/106826 | 1,071,500,247 | 106,826 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I used [kind](https://github.com/kubernetes-sigs/kind) to set a csi plugin environment
When testing the mount, got the fellowing error:
```text
I1205 11:54:42.948085 5248 utils.go:97] GRPC call: /csi.v1.Node/NodeGetCapabilities
I1205 11:54:42.948227 5248 utils.go:98] GRPC request: {}
I1... | pod stucking when mount volume | https://api.github.com/repos/kubernetes/kubernetes/issues/106825/comments | 5 | 2021-12-05T12:01:36Z | 2021-12-05T15:56:53Z | https://github.com/kubernetes/kubernetes/issues/106825 | 1,071,441,354 | 106,825 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
https://testgrid.k8s.io/google-aws#kops-aws-misc-ha-euwest1
### Which tests are failing?
Kubernetes e2e suite.[sig-storage] In-tree Volumes [Driver: aws] [Testpattern: Pre-provisioned PV (ext4)] volumes should store data
### Since when has it been failing?
Unknown, I would guess a lon... | PV tests do not account for zones | https://api.github.com/repos/kubernetes/kubernetes/issues/106814/comments | 6 | 2021-12-04T18:23:22Z | 2022-06-04T18:44:47Z | https://github.com/kubernetes/kubernetes/issues/106814 | 1,071,266,990 | 106,814 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Consider the following deployment spec:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
... | Removing a duplicate environment variable from the container spec ends up deleting the environment var entirely | https://api.github.com/repos/kubernetes/kubernetes/issues/106809/comments | 3 | 2021-12-03T23:57:30Z | 2021-12-09T21:11:15Z | https://github.com/kubernetes/kubernetes/issues/106809 | 1,071,058,059 | 106,809 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
On minikube HEAD we tried to bump the "newest" Kubernetes version from k8s `1.23.0-beta.0` to k8s `v1.23.0-rc.0`
however this breaks "crictl images" command
```
$ minikube ssh
docker@minikube:~$ sudo crictl images
FATA[0000] listing images: rpc error: code = Unimplemented desc = unknown... | `v1.23.0-rc.0` breaks `crictl images` for Docker container-runtime (works fine on 1.23.0-beta.0) | https://api.github.com/repos/kubernetes/kubernetes/issues/106807/comments | 7 | 2021-12-03T19:57:20Z | 2021-12-06T19:35:16Z | https://github.com/kubernetes/kubernetes/issues/106807 | 1,070,907,301 | 106,807 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I create a StatefulSet with a spec.template.spec.securityContext.fsGroup=65534. The complete manifest can be found below. After the creation of a Pod, however, the volume mountpoint remains with "root:root 755" permissions.
### What did you expect to happen?
I expect the volume mountpoint to have ... | A StatefulSet does not respect fsGroup when creating a volume from a volumeClaimTemplate | https://api.github.com/repos/kubernetes/kubernetes/issues/106806/comments | 4 | 2021-12-03T17:46:49Z | 2021-12-05T07:23:25Z | https://github.com/kubernetes/kubernetes/issues/106806 | 1,070,820,061 | 106,806 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
A common pattern is to include the release phase (e.g. database migrations) inside a Job.
Then you need to wait until the migration is completed before starting the new pods: you can use an InitContainer for that.
For example if you use Rails you can:
1. Create a Job (e.g. `m... | Waiting for Job completion in InitContainer (or before main container starts) | https://api.github.com/repos/kubernetes/kubernetes/issues/106802/comments | 54 | 2021-12-03T12:28:05Z | 2024-07-05T21:34:48Z | https://github.com/kubernetes/kubernetes/issues/106802 | 1,070,541,576 | 106,802 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
kubeadm-kinder-upgrade-1-22-1-23
### Which tests are failing?
### Kubernetes e2e suite: [sig-node] Probing container should *not* be restarted with a exec "cat /tmp/health" liveness probe [NodeConformance] [Conformance]
/home/prow/go/src/k8s.io/kubernetes/_output/local/go/src/k8... | [Failing Test][sig-cluster-lifecycle-kubeadm][kubeadm-kinder-upgrade-1-22-1-23] | https://api.github.com/repos/kubernetes/kubernetes/issues/106801/comments | 4 | 2021-12-03T12:07:51Z | 2021-12-06T16:12:04Z | https://github.com/kubernetes/kubernetes/issues/106801 | 1,070,524,436 | 106,801 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
With this change: https://github.com/kubernetes/kubernetes/pull/106501 the version of CRI API that `dockershim.sock` exposes is `v1` (as oppose to `v1alpha2` it used to be). So tools that takes dependency on dockershim.sock will fail with:
```
rpc error: code = Unimplemented desc = unknown servi... | dockershim.sock in 1.23 only supports v1 of CRI and tools dependent on v1alpha2 will not work | https://api.github.com/repos/kubernetes/kubernetes/issues/106798/comments | 5 | 2021-12-03T07:52:56Z | 2021-12-03T21:42:35Z | https://github.com/kubernetes/kubernetes/issues/106798 | 1,070,313,793 | 106,798 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When I config Pod affinity with operator "NotIn", all replicas schedulered on the same node.
More strangely,Other pods without related pod affinity/antiAffinity will also be schedulered to the node where Pod affinity with operator "NotIn" is running,Although the resources of this node are not opt... | Pod affinity with operator "NotIn" does not work | https://api.github.com/repos/kubernetes/kubernetes/issues/106795/comments | 8 | 2021-12-03T01:41:40Z | 2021-12-11T19:04:58Z | https://github.com/kubernetes/kubernetes/issues/106795 | 1,070,134,981 | 106,795 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Getting the resource version of existing CRD and using it in watcher to get events after mentioned version and then chaning the CRD, 1.22.3 is giving me the MODIFIED event but not 1.22.4.
### What did you expect to happen?
It should give modified event.
### How can we reproduce it (as minimally... | Watcher not able to raise events after the mentioned resource version for client version 1.22.4 | https://api.github.com/repos/kubernetes/kubernetes/issues/106790/comments | 14 | 2021-12-02T13:56:58Z | 2022-05-06T07:21:28Z | https://github.com/kubernetes/kubernetes/issues/106790 | 1,069,579,297 | 106,790 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have a simple Kubernetes Service up and running in a single Pod. I went inside the docker container for that Pod by
kubectl exec -it my-nginx-5b56ccd65f-twv25 /bin/sh . I try to curl <service> to access the Service, but it receives connection timeout error. I also test by curl <Pod IP> :80, wh... | Cannot access service from within a pod -- Minikube | https://api.github.com/repos/kubernetes/kubernetes/issues/106784/comments | 4 | 2021-12-02T06:21:51Z | 2021-12-03T09:12:39Z | https://github.com/kubernetes/kubernetes/issues/106784 | 1,069,174,777 | 106,784 |
[
"kubernetes",
"kubernetes"
] | A pod's `.status.nominatedNodeName` is set by the scheduler to mark this pod as a preemptor (let's call it P1), with a cost of preempting low-priority pods (let's call it P0). The preemptor doesn't get scheduled instantly; instead, it has to wait for the victims to be fully terminated and then deleted physically. Durin... | scheuler not always clear a preemptor's nominatedNodeName as expected | https://api.github.com/repos/kubernetes/kubernetes/issues/106780/comments | 5 | 2021-12-01T23:16:59Z | 2021-12-17T03:36:29Z | https://github.com/kubernetes/kubernetes/issues/106780 | 1,068,964,176 | 106,780 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
During a Kubernetes deployment the connectivity to web services from Windows nodes is flapping. There are intermittent traffic delays and some errors observed on web services during the deployment. Post deployment the flapping is no longer observed.
### What did you expect to happen?
No flapping... | Windows nodes observing flapping in service connectivity during deployment of unrelated services. | https://api.github.com/repos/kubernetes/kubernetes/issues/106775/comments | 2 | 2021-12-01T19:07:28Z | 2021-12-11T06:41:58Z | https://github.com/kubernetes/kubernetes/issues/106775 | 1,068,774,414 | 106,775 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
While fixing a metrics issue I saw in https://github.com/kubernetes/kubernetes/pull/106609/files#r755513290 that for a cluster created with CSIMigration during volume provisioning the metric `volume_provision` is only emitted for intree code (and not for a CSI Driver).
In the source code these li... | volume_provision metric is not reported if CSIMigration is turned on | https://api.github.com/repos/kubernetes/kubernetes/issues/106773/comments | 6 | 2021-12-01T18:13:45Z | 2022-04-30T19:46:27Z | https://github.com/kubernetes/kubernetes/issues/106773 | 1,068,729,665 | 106,773 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The new grpc probe feature introduced a new field for grpc probes that has an inconsistent name between json and proto and needs to be changed before release goes out. Otherwise this inconsistency will be stayed forever as it will be close to impossible to change field names.
See thread: https://... | grpc field name in probes is not consistent between json and proto | https://api.github.com/repos/kubernetes/kubernetes/issues/106772/comments | 5 | 2021-12-01T17:44:21Z | 2021-12-02T21:23:46Z | https://github.com/kubernetes/kubernetes/issues/106772 | 1,068,703,411 | 106,772 |
[
"kubernetes",
"kubernetes"
] | xref #101682
I have wondered if we should add a kubelet option like `--cluster-dns-service` (as an alternative to `--cluster-dns`) which takes a service ns/name (e.g. "kube-system/kube-dns") and looks up the IP(s). That would avoid the need for a static DNS IP at all.
Kubelet could spawn a gorotine to poll it. ... | Kubelet --cluster-dns-service vs --clusterdns (maybe) | https://api.github.com/repos/kubernetes/kubernetes/issues/106771/comments | 12 | 2021-12-01T17:25:33Z | 2022-06-08T08:14:58Z | https://github.com/kubernetes/kubernetes/issues/106771 | 1,068,686,912 | 106,771 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
gce-master-scale-correctness
### Which tests are flaking?
- Kubernetes e2e suite.[sig-network] Networking Granular Checks: Services should update nodePort: udp [Slow]
- ci-kubernetes-e2e-gce-scale-correctness.Overall
- kubetest.Test
- Kubernetes e2e suite.[sig-storage] CSI Volumes [Dri... | [Flaking test][sig-release-master-informing] gce-scale-correctness.Overall | https://api.github.com/repos/kubernetes/kubernetes/issues/106770/comments | 5 | 2021-12-01T16:45:09Z | 2021-12-14T17:35:46Z | https://github.com/kubernetes/kubernetes/issues/106770 | 1,068,636,589 | 106,770 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Refactor [`computePodResourceRequest`](https://github.com/kubernetes/kubernetes/blob/108c284a330a82ce1a1f80238e4f54bf5e8b045a/pkg/scheduler/framework/plugins/noderesources/fit.go#L162:6) and [`calculateResource`](https://github.com/kubernetes/kubernetes/blob/108c284a330a82ce1a1f802... | Evaluate moving Pod resources calculation to k8s.io/component-helper | https://api.github.com/repos/kubernetes/kubernetes/issues/106769/comments | 18 | 2021-12-01T16:23:57Z | 2023-03-10T06:42:52Z | https://github.com/kubernetes/kubernetes/issues/106769 | 1,068,610,861 | 106,769 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.