
id stringlengths 36 36 | source stringclasses 15 values | formatted_source stringclasses 13 values | text stringlengths 2 7.55M |
|---|---|---|---|
3440d140-8176-4d07-a3fb-2839795d47f7 | trentmkelly/LessWrong-43k | LessWrong | In 1 year and 5 years what do you see as "the normal" world.
We all have a mental image of pre-COVID normal.
I often hear people saying "I cannot wait to get back to normal." or asking "When will we get back to normal?" I think that is an expectation that is sure to be disappointed. I suspect that is the case for most who read this site.
I'm curious about the mental image of the near future normal that is held here. I'll list a few areas for thoughts but also don't think anyone should be limited in any thoughts they want to share.
1) International Travel -- can be general, tourism related or business related
2) Entertainment -- theater/movies, live sports and concerts. One thought here might be a move to more open air venues rather than indoors.
3) Social interactions in general. Does some of the zenophobia that has occurred persist or die away (say due to vaccines).
4) Will vaccines change things that much? |
6e0dcfbf-2847-486b-909f-f0d1caf014d0 | trentmkelly/LessWrong-43k | LessWrong | Public Transit is not Infinitely Safe
I recently came across this tweet, screenshotted into a popular Facebook group:
> Here's a truth bomb:
>
> Take the U.S. city you're most afraid of, one with a very high murder rate or property crime rate.
>
> If it has any sort of public transit, it is still statistically safer to use public transit in that city at ANY time of day than to drive where you live.
>
> —Matthew Chapman, 2023-06-14
This got ~1M views, doesn't cite anything, was given without any research, and, I'm pretty sure, is wrong. While I'm a major fan of public transit, they've stacked this comparison in a way that's really favorable to cars, and it's not surprising that public transit doesn't make it.
Safety is a complicated concept, and risks are situational: in a car you're much more likely to be hurt in a collision, while on public transit you're much more likely to be hurt by another passenger. To get a clear comparison I looked just at deaths, which is also an area where we can get good statistics.
I can't find a listing of public transit agencies by homicide rate, but Chicago is a large city with a lot of homicides and they make their data available so let's look there. In 2022 there were 244M CTA rides. Downloading the Chicago Police Data and filtering to 2022 homicides on public transit, I see nine. This is 3.7 homicides per 100M trips.
(Note that the original claim was for any city, and there are dozens of US cities with homicide rates higher than Chicago's. I think it's pretty likely that at least one of these cities has a public transit system with more homicides than the CTA.)
To fairly compare this to the risk from driving, we need homicides per distance. How long is a trip? I can't find 2022 data, but the CTA's President's 2020 Budget Recommendations gives 4.1mi (1359M + 613M passenger miles divided by 230M + 249M trips). This means 0.9 homicides per 100M miles travelled.
I live in MA, and while 2022 FARS data isn't out yet, in 2021 there were 0.71 driving deaths per 100 |
e32a32c3-f236-4ecc-9501-a3c967880806 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Increasing the Interpretability of Recurrent Neural Networks Using Hidden Markov Models
1 Introduction
---------------
Following the recent progress in deep learning, researchers and practitioners of machine learning are recognizing the importance of understanding and interpreting what goes on inside these black box models. Recurrent neural networks have recently revolutionized speech recognition and translation, and these powerful models could be very useful in other applications involving sequential data. However, adoption has been slow in applications such as health care, where practitioners are reluctant to let an opaque expert system make crucial decisions. If we can make the inner workings of RNNs more interpretable, more applications can benefit from their power.
There are several aspects of what makes a model or algorithm understandable to humans. One aspect is model complexity or parsimony. Another aspect is the ability to trace back from a prediction or model component to particularly influential features in the data Rüping ([2006](#bib.bib8)) Kim et al. ([2015](#bib.bib4)). This could be useful for understanding mistakes made by neural networks, which have human-level performance most of the time, but can perform very poorly on seemingly easy cases. For instance, convolutional networks can misclassify adversarial examples with very high confidence (Nguyen et al., [2015](#bib.bib6)), and made headlines in 2015 when the image tagging algorithm in Google Photos mislabeled African Americans as gorillas. It’s reasonable to expect recurrent networks to fail in similar ways as well. It would thus be useful to have more visibility into where these sorts of errors come from, i.e. which groups of features contribute to such flawed predictions.
Several promising approaches to interpreting RNNs have been developed recently. Che et al. ([2015](#bib.bib2)) have approached this by using gradient boosting trees to predict LSTM output probabilities and explain which features played a part in the prediction. They do not model the internal structure of the LSTM, but instead approximate the entire architecture as a black box. Karpathy et al. ([2016](#bib.bib3)) showed that in LSTM language models, around 10% of the memory state dimensions can be interpreted with the naked eye by color-coding the text data with the state values; some of them track quotes, brackets and other clearly identifiable aspects of the text. Building on these results, we take a somewhat more systematic approach to looking for interpretable hidden state dimensions, by using decision trees to predict individual hidden state dimensions (Figure [2](#S2.F2 "Figure 2 ‣ 2.2 Hidden Markov models ‣ 2 Methods")). We visualize the overall dynamics of the hidden states by coloring the training data with the k-means clusters on the state vectors (Figures [2(b)](#S3.F2.sf2 "(b) ‣ Figure 4 ‣ 3 Experiments"), [3(b)](#S3.F3.sf2 "(b) ‣ Figure 4 ‣ 3 Experiments")).
We explore several methods for building interpretable models by combining LSTMs and HMMs. The existing body of literature mostly focuses on methods that specifically train the RNN to predict HMM states (Bourlard & Morgan, [1994](#bib.bib1)) or posteriors (Maas et al., [2012](#bib.bib5)), referred to as hybrid or tandem methods respectively.
We first investigate an approach that does not require the RNN to be modified in order to make it understandable, as the interpretation happens after the fact. Here, we model the big picture of the state changes in the LSTM, by extracting the hidden states and approximating them with a continuous emission hidden Markov model (HMM). We then take the reverse approach where the HMM state probabilities are added to the output layer of the LSTM (see Figure [1](#S2.F1 "Figure 1 ‣ 2.1 LSTM models ‣ 2 Methods")). The LSTM model can then make use of the information from the HMM, and fill in the gaps when the HMM is not performing well, resulting in an LSTM with a smaller number of hidden state dimensions that could be interpreted individually (Figures [4](#S3.F4 "Figure 4 ‣ 3 Experiments"), [4](#S3.F4 "Figure 4 ‣ 3 Experiments")).
2 Methods
----------
We compare a hybrid HMM-LSTM approach with a continuous emission HMM (trained on the hidden states of a 2-layer LSTM), and a discrete emission HMM (trained directly on data).
###
2.1 LSTM models
We use a character-level LSTM with 1 layer and no dropout, based on the Element-Research library. We train the LSTM for 10 epochs, starting with a learning rate of 1, where the learning rate is halved whenever exp(−lt)>exp(−lt−1)+1, where lt is the log likelihood score at epoch t. The L2-norm of the parameter gradient vector is clipped at a threshold of 5.

Figure 1: Hybrid HMM-LSTM algorithm.
###
2.2 Hidden Markov models
The HMM training procedure is as follows:
Initialization of HMM hidden states:
* (Discrete HMM) Random multinomial draw for each time step (i.i.d. across time steps).
* (Continuous HMM) K-means clusters fit on LSTM states, to speed up convergence relative to random initialization.
At each iteration:
1. Sample states using Forward Filtering Backwards Sampling algorithm (FFBS, Rao & Teh ([2013](#bib.bib7))).
2. Sample transition parameters from a Multinomial-Dirichlet posterior.
Let nij be the number of transitions from state i to state j. Then the posterior distribution of the i-th row of transition matrix T (corresponding to transitions from state i) is:
| | | |
| --- | --- | --- |
| | Ti∼Mult(nij|Ti)Dir(Ti|α) | |
where α is the Dirichlet hyperparameter.
3. (Continuous HMM) Sample multivariate normal emission parameters from Normal-Inverse-Wishart posterior for state i:
| | | |
| --- | --- | --- |
| | μi,Σi∼N(y|μi,Σi)N(μi|0,Σi)IW(Σi) | |
(Discrete HMM) Sample the emission parameters from a Multinomial-Dirichlet posterior.
Evaluation:
We evaluate the methods on how well they predict the next observation in the validation set. For the HMM models, we do a forward pass on the validation set (no backward pass unlike the full FFBS), and compute the HMM state distribution vector pt for each time step t. Then we compute the predictive likelihood for the next observation as follows:
| | | |
| --- | --- | --- |
| | P(yt+1|pt)=n∑xt=1n∑xt+1=1ptxt⋅Txt,xt+1⋅P(yt+1|xt+1) | |
where n is the number of hidden states in the HMM.

Figure 2: Decision tree predicting an individual hidden state dimension of the hybrid algorithm based on the preceding characters on the Linux data. The hidden state dimensions of the 10-state hybrid mostly track comment characters.
###
2.3 Hybrid models
Our main hybrid model is put together sequentially, as shown in Figure [1](#S2.F1 "Figure 1 ‣ 2.1 LSTM models ‣ 2 Methods"). We first run the discrete HMM on the data, outputting the hidden state distributions obtained by the HMM’s forward pass, and then add this information to the architecture in parallel with a 1-layer LSTM. The linear layer between the LSTM and the prediction layer is augmented with an extra column for each HMM state. The LSTM component of this architecture can be smaller than a standalone LSTM, since it only needs to fill in the gaps in the HMM’s predictions. The HMM is written in Python, and the rest of the architecture is in Torch.
We also build a joint hybrid model, where the LSTM and HMM are simultaneously trained in Torch. We implemented an HMM Torch module, optimized using stochastic gradient descent rather than FFBS. Similarly to the sequential hybrid model, we concatenate the LSTM outputs with the HMM state probabilities.
3 Experiments
--------------
We test the models on several text data sets on the character level: the Penn Tree Bank (5M characters), and two data sets used by Karpathy et al. ([2016](#bib.bib3)), Tiny Shakespeare (1M characters) and Linux Kernel (5M characters). We chose k=20 for the continuous HMM based on a PCA analysis of the LSTM states, as the first 20 components captured almost all the variance.
Table [1](#S3.T1 "Table 1 ‣ 3 Experiments") shows the predictive log likelihood of the next text character for each method. On all text data sets, the hybrid algorithm performs a bit better than the standalone LSTM with the same LSTM state dimension. This effect gets smaller as we increase the LSTM size and the HMM makes less difference to the prediction (though it can still make a difference in terms of interpretability). The hybrid algorithm with 20 HMM states does better than the one with 10 HMM states. The joint hybrid algorithm outperforms the sequential hybrid on Shakespeare data, but does worse on PTB and Linux data, which suggests that the joint hybrid is more helpful for smaller data sets. The joint hybrid is an order of magnitude slower than the sequential hybrid, as the SGD-based HMM is slower to train than the FFBS-based HMM.
We interpret the HMM and LSTM states in the hybrid algorithm with 10 LSTM state dimensions and 10 HMM states in Figures [4](#S3.F4 "Figure 4 ‣ 3 Experiments") and [4](#S3.F4 "Figure 4 ‣ 3 Experiments"), showing which features are identified by the HMM and LSTM components. In Figures [2(a)](#S3.F2.sf1 "(a) ‣ Figure 4 ‣ 3 Experiments") and [3(a)](#S3.F3.sf1 "(a) ‣ Figure 4 ‣ 3 Experiments"), we color-code the training data with the 10 HMM states. In Figures [2(b)](#S3.F2.sf2 "(b) ‣ Figure 4 ‣ 3 Experiments") and [3(b)](#S3.F3.sf2 "(b) ‣ Figure 4 ‣ 3 Experiments"), we apply k-means clustering to the LSTM state vectors, and color-code the training data with the clusters. The HMM and LSTM states pick up on spaces, indentation, and special characters in the data (such as comment symbols in Linux data). We see some examples where the HMM and LSTM complement each other, such as learning different things about spaces and comments on Linux data, or punctuation on the Shakespeare data. In Figure [2](#S2.F2 "Figure 2 ‣ 2.2 Hidden Markov models ‣ 2 Methods"), we see that some individual LSTM hidden state dimensions identify similar features, such as comment symbols in the Linux data.
| | | | |
| --- | --- | --- | --- |
|
(a) Hybrid HMM component: colors correspond to 10 HMM states. Blue cluster identifies spaces. Green cluster (with white font) identifies punctuation and ends of words. Purple cluster picks up on some vowels.
|
(b) Hybrid LSTM component: colors correspond to 10 k-means clusters on hidden state vectors. Yellow cluster (with red font) identifies spaces. Grey cluster identifies punctuation (except commas). Purple cluster finds some ’y’ and ’o’ letters.
|
(a) Hybrid HMM component: colors correspond to 10 HMM states. Distinguishes comments and indentation spaces (green with yellow font) from other spaces (purple). Red cluster (with yellow font) identifies punctuation and brackets. Green cluster (yellow font) also finds capitalized variable names.
|
(b) Hybrid LSTM component: colors correspond to 10 k-means clusters on hidden state vectors. Distinguishes comments, spaces at beginnings of lines, and spaces between words (red with white font) from indentation spaces (green with yellow font). Opening brackets are red (yellow font) and closing brackets are green (white font).
|
Figure 3: Visualizing HMM and LSTM states on Shakespeare data for the hybrid with 10 LSTM state dimensions and 10 HMM states. The HMM and LSTM components learn some complementary features in the text: while both learn to identify spaces, the LSTM does not completely identify punctuation or pick up on vowels, which the HMM has already done.
Figure 4: Visualizing HMM and LSTM states on Linux data for the hybrid with 10 LSTM state dimensions and 10 HMM states. The HMM and LSTM components learn some complementary features in the text related to spaces and comments.
Figure 3: Visualizing HMM and LSTM states on Shakespeare data for the hybrid with 10 LSTM state dimensions and 10 HMM states. The HMM and LSTM components learn some complementary features in the text: while both learn to identify spaces, the LSTM does not completely identify punctuation or pick up on vowels, which the HMM has already done.
|
Data
|
Method
|
Parameters
|
LSTM dims
|
HMM states
|
Validation
|
Training
|
| --- | --- | --- | --- | --- | --- | --- |
|
Shakespeare
| Continuous HMM | 1300 | | 20 | -2.74 | -2.75 |
| Discrete HMM | 650 | | 10 | -2.69 | -2.68 |
| Discrete HMM | 1300 | | 20 | -2.5 | -2.49 |
| LSTM | 865 | 5 | | -2.41 | -2.35 |
| Hybrid | 1515 | 5 | 10 | -2.3 | -2.26 |
| Hybrid | 2165 | 5 | 20 | -2.26 | -2.18 |
| LSTM | 2130 | 10 | | -2.23 | -2.12 |
| Joint hybrid | 1515 | 5 | 10 | -2.21 | -2.18 |
| Hybrid | 2780 | 10 | 10 | -2.19 | -2.08 |
| Hybrid | 3430 | 10 | 20 | -2.16 | -2.04 |
| Hybrid | 4445 | 15 | 10 | -2.13 | -1.95 |
| Joint hybrid | 3430 | 10 | 10 | -2.12 | -2.07 |
| LSTM | 3795 | 15 | | -2.1 | -1.95 |
| Hybrid | 5095 | 15 | 20 | -2.07 | -1.92 |
| Hybrid | 6510 | 20 | 10 | -2.05 | -1.87 |
| Joint hybrid | 4445 | 15 | 10 | -2.03 | -1.97 |
| LSTM | 5860 | 20 | | -2.03 | -1.83 |
| Hybrid | 7160 | 20 | 20 | -2.02 | -1.85 |
| Joint hybrid | 7160 | 20 | 10 | -1.97 | -1.88 |
|
Linux Kernel
| Discrete HMM | 1000 | | 10 | -2.76 | -2.7 |
| Discrete HMM | 2000 | | 20 | -2.55 | -2.5 |
| LSTM | 1215 | 5 | | -2.54 | -2.48 |
| Joint hybrid | 2215 | 5 | 10 | -2.35 | -2.26 |
| Hybrid | 2215 | 5 | 10 | -2.33 | -2.26 |
| Hybrid | 3215 | 5 | 20 | -2.25 | -2.16 |
| Joint hybrid | 4830 | 10 | 10 | -2.18 | -2.08 |
| LSTM | 2830 | 10 | | -2.17 | -2.07 |
| Hybrid | 3830 | 10 | 10 | -2.14 | -2.05 |
| Hybrid | 4830 | 10 | 20 | -2.07 | -1.97 |
| LSTM | 4845 | 15 | | -2.03 | -1.9 |
| Joint hybrid | 5845 | 15 | 10 | -2.00 | -1.88 |
| Hybrid | 5845 | 15 | 10 | -1.96 | -1.84 |
| Hybrid | 6845 | 15 | 20 | -1.96 | -1.83 |
| Joint hybrid | 9260 | 20 | 10 | -1.90 | -1.76 |
| LSTM | 7260 | 20 | | -1.88 | -1.73 |
| Hybrid | 8260 | 20 | 10 | -1.87 | -1.73 |
| Hybrid | 9260 | 20 | 20 | -1.85 | -1.71 |
|
Penn Tree Bank
| Continuous HMM | 1000 | 100 | 20 | -2.58 | -2.58 |
| Discrete HMM | 500 | | 10 | -2.43 | -2.43 |
| Discrete HMM | 1000 | | 20 | -2.28 | -2.28 |
| LSTM | 715 | 5 | | -2.22 | -2.22 |
| Hybrid | 1215 | 5 | 10 | -2.14 | -2.15 |
| Joint hybrid | 1215 | 5 | 10 | -2.08 | -2.08 |
| Hybrid | 1715 | 5 | 20 | -2.06 | -2.07 |
| LSTM | 1830 | 10 | | -1.99 | -1.99 |
| Hybrid | 2330 | 10 | 10 | -1.94 | -1.95 |
| Joint hybrid | 2830 | 10 | 10 | -1.94 | -1.95 |
| Hybrid | 2830 | 10 | 20 | -1.93 | -1.94 |
| LSTM | 3345 | 15 | | -1.82 | -1.83 |
| Hybrid | 3845 | 15 | 10 | -1.81 | -1.82 |
| Hybrid | 4345 | 15 | 20 | -1.8 | -1.81 |
| Joint hybrid | 6260 | 20 | 10 | -1.73 | -1.74 |
| LSTM | 5260 | 20 | | -1.72 | -1.73 |
| Hybrid | 5760 | 20 | 10 | -1.72 | -1.72 |
| Hybrid | 6260 | 20 | 20 | -1.71 | -1.71 |
Table 1: Predictive loglikelihood comparison on the text data sets (sorted by validation set performance).
4 Conclusion and future work
-----------------------------
Hybrid HMM-RNN approaches combine the interpretability of HMMs with the predictive power of RNNs. Sometimes, a small hybrid model can perform better than a standalone LSTM of the same size. We use visualizations to show how the LSTM and HMM components of the hybrid algorithm complement each other in terms of features learned in the data. |
ebf85974-a77a-4b10-b2f9-8b688af2ec8c | trentmkelly/LessWrong-43k | LessWrong | A Teacher vs. Everyone Else
> A repairer wants your stuff to break down,
> A doctor wants you to get ill,
> A lawyer wants you to get in conflicts,
> A farmer wants you to be hungry,
> But there is only a teacher who wants you to learn.
Of course you see what is wrong with the above "argument / meme / good-thought". But the first time I came across this meme, I did not.
Until a month or two ago when this meme appeared in my head again and within seconds I discarded it away as fallacious reasoning. What was the difference this time? That I was now aware of the Conspiracy. And this meme happened to come up on one evening when I was thinking about fallacies and trying to practice my skills of methods of rationality.
If you are a teacher, and you read the meme, it will assign to you the Good Guy label. And if you are one of {repairer, doctor, lawyer, farmer, etc} then you get the Bad Guy label. There is also a third alternative in which you are neither --- say a teenager.
If you are not explicitly being labeled bad or good, then you may just move on like I did. Or maybe you put some detective effort and do realize the fallacies. Depends on your culture: If your culture has tales like, "If your teacher and your God both are in front of you, who do you greet / bow to first?" and the right answer is "why of course my teacher because otherwise how would I know about God?" then you are just more likely to award a point to the already point-rich teacher-bucket and move on.
If you get called the Bad Guy, then you have a motivation to falsify the meme. And you will likely do so. This meme does look highly fragile in hindsight.
But if you are a teacher, you have no reason to investigate. You are getting free points. And it's in fact true that you do want people to learn. So, this meme probably did originate in the teacher circle. Where it has potential to get shared without getting beaten down.
What are the fallacies though? Here is the one I can identify:
The type error of comparing desired "requi |
9c1726f4-2418-4455-9e87-e5aaca80d4f9 | trentmkelly/LessWrong-43k | LessWrong | Transparent Newcomb's Problem and the limitations of the Erasure framing
One of the aspects of the Erasure Approach that always felt kind of shaky was that in Transparent Newcomb's Problem it required you to forget that you'd seen that the the box was full. Recently come to believe that this really isn't the best way of framing the situation.
Let's begin by recapping the problem. In a room there are two boxes, with one-containing $1000 and the other being a transparent box that contains either nothing or $1 million. Before you entered the room, a perfect predictor predicted what you would do if you saw $1 million in the transparent box. If it predicted that you would one-boxed, then it put $1 million in the transparent box, otherwise it left the box empty. If you can see $1 million in the transparent box, which choice should you pick?
The argument I provided before was as follows: If you see a full box, then you must be going to one-box if the predictor really is perfect. So there would only be one decision consistent with the problem description and to produce a non-trivial decision theory problem we'd have to erase some information. And the most logical thing to erase would be what you see in the box.
I still mostly agree with this argument, but I feel the reasoning is a bit sparse, so this post will try to break it down in more detail. I'll just note in advance that when you start breaking it down, you end up performing a kind of psychological or social analysis. However, I think this is inevitable when dealing with ambiguous problems; if you could provide a mathematical proof of what an ambiguous problem meant then it wouldn't be ambiguous.
As I noted in Deconfusing Logical Counterfactuals, there is only one choice consistent with the problem (one-boxing), so in order to answer this question we'll have to construct some counterfactuals. A good way to view this is that instead of asking what choice should the agent make, we will ask whether the agent made the best choice.
Now, in order to construct these counterfactuals we'll hav |
d3c132e9-32b0-40dc-9248-9ecbb39c4472 | trentmkelly/LessWrong-43k | LessWrong | Open thread, November 21 - November 28, 2017
You can find the last Open Thread here.
IF IT'S WORTH SAYING, BUT NOT WORTH ITS OWN POST, THEN IT GOES HERE.
|
b12a717b-e747-4a04-8ae7-57c77cc1caf9 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | UK Government announces £100 million in funding for Foundation Model Taskforce.
The UK government has recently made some big investments in AI
> The Taskforce, modelled on the success of the COVID-19 Vaccines Taskforce, will develop the safe and reliable use of this pivotal artificial intelligence (AI) across the economy and ensure the UK is globally competitive in this strategic technology.
>
>
It appears the primary motivation for the investment is to speed up the growth of the UK economy
> To support businesses and public trust in these systems and drive their adoption, the Taskforce will work with the sector towards developing the safety and reliability of foundation models, both at a scientific and commercial level.
>
>
I don't yet know what the UK government means by "safety', but this might be a promising investment. It seems more likely that this will advance capabilities, considering the government's [simultaneous £900 million investment into compute technology.](https://www.theguardian.com/technology/2023/mar/15/uk-to-invest-900m-in-supercomputer-in-bid-to-build-own-britgpt) |
f6679ed8-78e5-4c60-8c50-8612b38aa032 | trentmkelly/LessWrong-43k | LessWrong | Mistakes repository
This is a repository for major, life-altering mistakes that you or others have made. Detailed accounts of specific mistakes are welcome, and so are mentions of general classes of mistakes that people often make. If similar repositories already exist (inside or outside of LW), links are greatly appreciated.
The purpose of this repository is to collect information about serious misjudgements and mistakes in order to help people avoid similar mistakes. (I am posting this repository because I'm trying to conduct a premortem on my life and figure out what catastrophic risks may screw me over in the near or far future.) |
a41aba73-14d3-436d-bde0-32b36e1c0e57 | trentmkelly/LessWrong-43k | LessWrong | Can you improve IQ by practicing IQ tests?
As an European, I did never have any IQ test, nor I know anybody who (to my knowledge) was ever administered an IQ test. I looked at some fac-simile IQ tests on the internet, expecially Raven's matrices.
When I began to read online blogs from the United States, I started to see references to the concept of IQ. I am very confused by the fact that the IQ score seems to be treated as a stable, intrinsic charachteristic of an individual (like the height or the visual acuity).
When you costantly practice some task, you usually become better at that task. I imagine that there exists a finite number of ideas required to solve Raven matrices: even when someone invents new Raven matrices for making new IQ tests, he will do so by remixing the ideas used for previous Raven matrices, because -as Cardano said- "there is practically no new idea which one may bring forward".
The IQ score is the result of an exam, much like school grades. But it is generally understood that school grades are influenced by how much effort you put in the preparation for the exam, by how much your family cares for your grades, and so on. I expect school grades to be fairly correlated to income, or to other mesures of "success".
In a hypothetical society in which all children had to learn chess, and being bad at chess was regarded as a shame, I guess that the ELO chess ratings of 17 year olds would be highly correlated with later achievements. Are IQ tests the only exception to the rule that your grade in an exam is influenced by how much you prepare for that exam? Is there a sense in which IQ is a more "intrinsic" quantity than, for example, the AP exam score, or the ELO chess rating? |
e2b424a6-0620-443c-b738-00b3ead60476 | trentmkelly/LessWrong-43k | LessWrong | Meetup :
Discussion article for the meetup :
WHEN: 30 June 2013 04:30:00PM (+0200)
WHERE: Berkeley
Discussion article for the meetup : |
408c1515-62e6-41b7-9379-a981842e75d8 | trentmkelly/LessWrong-43k | LessWrong | The ecology of conviction
Supposing that sincerity has declined, why?
It feels natural to me that sincere enthusiasms should be rare relative to criticism and half-heartedness. But I would have thought this was born of fairly basic features of the situation, and so wouldn’t change over time.
It seems clearly easier and less socially risky to be critical of things, or non-committal, than to stand for a positive vision. It is easier to produce a valid criticism than an idea immune to valid criticism (and easier again to say, ‘this is very simplistic - the situation is subtle’). And if an idea is criticized, the critic gets to seem sophisticated, while the holder of the idea gets to seem naïve. A criticism is smaller than a positive vision, so a critic is usually not staking their reputation on their criticism as much, or claiming that it is good, in the way that the enthusiast is.
But there are also rewards for positive visions and for sincere enthusiasm that aren’t had by critics and routine doubters. So for things to change over time, you really just need the scale of these incentives to change, whether in a basic way or because the situation is changing.
One way this could have happened is that the internet (or even earlier change in the information economy) somehow changed the ecology of enthusiasts and doubters, pushing the incentives away from enthusiasm. e.g. The ease, convenience and anonymity of criticizing and doubting on the internet puts a given positive vision in contact with many more critics, making it basically impossible for an idea to emerge not substantially marred by doubt and teeming with uncertainties and summarizable as ‘maybe X, but I don’t know, it’s complicated’. This makes presenting positive visions less appealing, reducing the population of positive vision havers, and making them either less confident or more the kinds of people whose confidence isn’t affected by the volume of doubt other people might have about what they are saying. Which all make them even ea |
99bfc358-50d3-4897-99bd-50d48c53b97e | trentmkelly/LessWrong-43k | LessWrong | How to be an amateur polyglot
Setting the stage
Being a polyglot is a problem of definition first. Who can be described as a polyglot? At what level do you actually “speak” the given language? Some sources cite that polyglot means speaking more than 4 languages, others 6. My take is it doesn’t matter. I am more interested in the definition of when you speak the language. If you can greet and order a coffee in 20 languages do you actually speak them? I don’t think so. Do you need to present a scientific document or write a newspaper worthy article to be considered? That’s too much. I think the best definition would be that you can go out with a group of native speakers, understand what they are saying and participate in the discussion that would range from everyday stuff to maybe work related stuff and not switching too often to English nor using google translate. It’s ok to pause and maybe ask for a specific word or ask the group if your message got across. This is what I am aiming for when I study a specific language.
Why learn a foreign language when soon we will have AI auto-translate from our glasses and other wearables? This is a valid question for work related purposes but socially it’s not. You can never be interacting with glasses talking in another language while having dinner with friends nor at a date for example. The small things that make you part of the culture are hidden in the language. The respect and the motivation to blend in is irreplaceable.
For reference here are the languages I speak at approximate levels:
* Greek - native
* English - proficient (C2)
* Spanish - high level (C1) active learning
* French - medium level (B2) active learning
* Italian - coffee+ level (B1) active learning
* Dutch - survival level (A2) in hibernation
Get started
Firstly, I think the first foreign language you learn could be taught in a formal way with an experienced teacher. That will teach you the way to structure your thought process and learn how to learn efficiently. It’s comm |
36ec1958-dc1f-4328-8b64-ca73fbbec8f5 | trentmkelly/LessWrong-43k | LessWrong | "Flinching away from truth” is often about *protecting* the epistemology
Related to: Leave a line of retreat; Categorizing has consequences.
There’s a story I like, about this little kid who wants to be a writer. So she writes a story and shows it to her teacher.
“You misspelt the word ‘ocean’”, says the teacher.
“No I didn’t!”, says the kid.
The teacher looks a bit apologetic, but persists: “‘Ocean’ is spelt with a ‘c’ rather than an ‘sh’; this makes sense, because the ‘e’ after the ‘c’ changes its sound…”
“No I didn’t!” interrupts the kid.
“Look,” says the teacher, “I get it that it hurts to notice mistakes. But that which can be destroyed by the truth should be! You did, in fact, misspell the word ‘ocean’.”
“I did not!” says the kid, whereupon she bursts into tears, and runs away and hides in the closet, repeating again and again: “I did not misspell the word! I can too be a writer!”.
I like to imagine the inside of the kid’s head as containing a single bucket that houses three different variables that are initially all stuck together:
Original state of the kid's head:
The goal, if one is seeking actual true beliefs, is to separate out each of these variables into its own separate bucket, so that the “is ‘oshun’ spelt correctly?” variable can update to the accurate state of "no", without simultaneously forcing the "Am I allowed to pursue my writing ambition?" variable to update to the inaccurate state of "no".
Desirable state (requires somehow acquiring more buckets):
The trouble is, the kid won’t necessarily acquire enough buckets by trying to “grit her teeth and look at the painful thing”. A naive attempt to "just refrain from flinching away, and form true beliefs, however painful" risks introducing a more important error than her current spelling error: mistakenly believing she must stop working toward being a writer, since the bitter truth is that she spelled 'oshun' incorrectly.
State the kid might accidentally land in, if she naively tries to "face the truth":
(You might take a moment, right now, to name the cognit |
09ae8313-0c13-48f2-be7a-2f8c7f5f190b | trentmkelly/LessWrong-43k | LessWrong | Fun and Games with Cognitive Biases
You may have heard about IARPA's Sirius Program, which is a proposal to develop serious games that would teach intelligence analysts to recognize and correct their cognitive biases. The intelligence community has a long history of interest in debiasing, and even produced a rationality handbook based on internal CIA publications from the 70's and 80's. Creating games which would systematically improve our thinking skills has enormous potential, and I would highly encourage the LW community to consider this as a potential way forward to encourage rationality more broadly.
While developing these particular games will require thought and programming, the proposal did inspire the NYC LW community to play a game of our own. Using a list of cognitive biases, we broke up into groups of no larger than four, and spent five minutes discussing each bias with regards to three questions:
1. How do we recognize it?
2. How do we correct it?
3. How do we use its existence to help us win?
The Sirius Program specifically targets Confirmation Bias, Fundamental Attribution Error, Bias Blind Spot, Anchoring Bias, Representativeness Bias, and Projection Bias. To this list, I also decided to add the Planning Fallacy, the Availability Heuristic, Hindsight Bias, the Halo Effect, Confabulation, and the Overconfidence Effect. We did this Pomodoro style, with six rounds of five minutes, a quick break, another six rounds, before a break and then a group discussion of the exercise.
Results of this exercise are posted below the fold. I encourage you to try the exercise for yourself before looking at our answers.
Caution: Dark Arts! Explicit discussion of how to exploit bugs in human reasoning may lead to discomfort. You have been warned.
Confirmation Bias
* Notice if you (don't) want a theory to be true
* Don't be afraid of being wrong, question the outcome that you fear will happen
* Seek out people with contrary opinions and be genuinely curious why they believe what they do |
230533f8-613b-4056-b94c-786333d7c59b | StampyAI/alignment-research-dataset/special_docs | Other | Canaries in Technology Mines: Warning Signs of Transformative Progress in AI
1 Canar ies in Technology Mines: Warning Signs of
Transformative Progress in AI
Carla Zoe Cremer 1 and Jess Whittlestone 2
Abstract. 1 In this paper we introduce a method ology for
identify ing early warning sign s of transformative progress in AI, to
aid anticipatory governance and research prioritisation. We
propose using expert elicitation methods to identify milestones in
AI progress, followed by collaborative causal mapping to id entify
key milestones which underpin several others. We call these key
milestones ‘canaries’ based on the colloquial phrase ‘canary in a
coal mine’ to describe advance warning of an extreme event: in this
case, advance warning of transformative AI . After d escribing and
motivating our proposed methodology, we present results from an
initial implementation to identify canaries for progress towards
high-level machine intelligence (HLMI). We conclude by
discussing the limitations of this method, possible future
improvements, and how we hope it can be used to improve
monitoring of future risks from AI progress.
1 INTRODUCTION
Progress in artificial intelligence (AI) research has accelerated in
recent years, and applications are already beginning to impact
societ y [9][43]. Some researchers warn that continued progress
could lead to much more advanced AI systems, with potential to
precipitate transformative societal changes [13][19][21][27][39].
For example, advanced machine learning systems could be used to
optimise management of safety -critical infrastructure [33];
advanced language models could be used to corrupt our online
information ecosystem [31]; and AI systems could even gradually
begin to replace a large portion of economically useful work [17].
We use the term “transformative AI” to describe a range of
possible advances in AI with potential to impact society in large
and hard -to-reverse ways [22].
Preparing for the future impacts of AI is challenging given
considerable uncertainty about how AI systems will develop . There
is substantial expert disagreement around when different advances
in AI capabilities should be expected [11][19][34]. Policy and
regulation will likely struggle to keep up with the fast pace of
technological progress [12][15][42], resulting in either stale,
outdated regulation or policy paralysis [3]. It would therefore be
valuable to be able to identify ‘early warning signs’ of
transformative AI progress, to enable more anticipatory
governance, as well as better prioritisation of research and
allocation of resources.
We call these early warning signs ‘canaries’, based on the
colloquial use of the phrase ‘canary in a coal mine’ to indicate
1 Future of Humanity Institute , University of Oxford , UK, email:
carla.cremer@philosophy.ox.ac.uk
2 Centre for the Study of Existential Risk , University of Cambridge, UK,
email: jlw84@cam.ac.uk advance warning of an extreme event. Our use of this term takes its
inspiration from an article by Etzioni [16], in which he stresses the
importance of identifying such canaries. We want to take this
suggestion seriously and propose a systematic methodology for
identifying such canaries.
Many types of indicators could be of interest and classed as
canaries, including: research progress towards key cognitive
faculties (e.g., natural language understanding ); overcoming known
technical challenges (such as improving th e data efficiency of deep
learning algorithms); or improved applicability of AI to
economically -relevant tasks (e.g. text summari zation ). What
distinguishes canaries from general markers of AI progress ( like
those discussed in [32] or [36]) is that they indicat e that
particularly transformative impacts of AI may be on the horizon.
Given that our definition of “transformative AI” is currently very
broad, c anaries are therefore defined relative to a specific form of
transformative AI or impac t. For example, we might identify
canaries for human -level artificial intelligence; canaries for
automation of a specific sector of work; or canaries for specific
types of societal risks from A I. From a governance perspective , we
are particularly interested in canaries which indicate that faster or
discontinuous progress may be on the horizon, since the impacts of
rapid progress would be especially difficult to manage once they
begin to manifest . The se therefore particularly warrant advance d
preparation.
In what follows , we describe and discuss a methodology for
identifying canaries of progress in technological research. We
focus on AI progress, but believe this method, once trialled and
tested, could be applied to other areas of technological
development. We motivate and describe the methodological
approach, which combines expert elicitation and causal mapping,
before presenting one implementation of this methodology to
identify canaries for progress towards high-level machine
intelligence (HLMI). After discu ssing potential canaries for HLMI
specifically, we discuss how to make use of canaries in monitoring
of AI progress and suggest how the limitations of this methodology
might be addressed in future iterations of this work .
2 METHODOLOGY
2.1 Background and Motivation
This work builds on two main bodies of existing literature:
research on AI forecasting , and an emerging body of work on
measuring AI progress .
The AI forecasting literature generally uses expert elicitation to
generate probabilistic estimates f or when different types of 1st International Workshop on Evaluating Progress in Artificial Intelligence - EPAI 2020
In conjunction with the 24th European Conference on Artificial Intelligence - ECAI 2020
Santiago de Compostela, Spain
2
advanced AI will be achieved [5][19][21][34]. For example, Baum
et al. [5] survey experts on when four specific milestones in AI will
be achieved: passing the Turing Test, performing Nobel quality
work, passing third grade, and becoming superhuman. Both Müller
and Bostrom [34], and Grace et al. [19] focus their survey
questions around predicting the arrival of high-level machine
intelligence (HLMI) , which the latter define as being achieved
when “unaided machines can accomplish e very task better and
more cheaply than human workers” .
However, these studies have several limitations [6] that should
make us cautious about giving their results too much weight . The
experts surveyed in these studies have no experience in quantitative
forecasting and receive no training before being surveyed, which
likely renders their predictions unreliable [10][41].
Issues of reliability aside, these forecasting studies are also
limited in what they can tell us ab out future AI progress. They have
little to say about impactful milestones on the path to advanced AI ,
let alone early -warning signs. Experts disagree substantially about
when capabilities will be achieved [11][19] and without knowing
who (if anyone) is mo re accurate in their predictions, these
forecasts cannot easily inform decisions and prioritisation around
AI today. Quantitative expert elicitations like these also do not tell
us why different experts disagree , what kinds of progress might
cause them to change their judgements , or what aspects they in fact
do agree upon. While broad probability estimates for when
advanced AI might be achieved are interesting , they tell us little
about the path from where we are now, or what could be done
today to shape th e future development and impact of AI.
At the same time, several research projects have begun to track
and measure progress in AI [7][23][36]. These projects focus on a
range of indicators relevant to AI progress, but do not make any
systematic attempt to identify which markers of progress are most
important for anticipating potentially transformative AI. Given
limited time and resources for tracking progress in AI, it is crucial
that we find ways to prioritise those measures that are most
relevant to ensuring societal benefits and mitigating risks of AI.
The approach we propose in this paper aims to address the
limitations of both work on AI forecasting and on measuring
progress in AI . In a sense, the limitations of these two bodies of
work are complementary. The AI forecasting literature focuses on
anticipating the most extreme impacts and advanced progress in
AI, but is unable to say much about the warning si gns or kinds of
progress that will be important in the near future. AI measurement
initiatives, conversely, monitor near -future progress in AI, but with
little systematic prioritisation or reflection on what progress in
different areas might mean for socie ty and governance. What is
needed, building on work in both these areas, are attempts to
identify areas of progress today that may be particularly important
to pay attention to, given concerns about the kinds of
transformative AI systems that may be possib le in future. Progress
in these areas would serve as crucial warning signs - canaries, as
well call them - suggesting more advance preparation for future AI
systems and their impacts is needed.
We believe that identifying canaries for transformative AI is a
tractable problem and therefore worth investing considerable
research effort in today. In both engineering and cognitive
development, capabilities are achieved sequentially, meaning that
there are often key underlying capabilities which, if attained,
unlock progress in many other areas. For example, musical
protolanguage is thought to have enabled grammatical competence
in the development of language in homo sapiens [8]. AI progress so far has also arguably seen such amplifiers: the use of multi -
layered n on-linear learning or stochastic gradient descent arguably
laid the foundation for unexpectedly fast progress on image
recognition, translation and speech recognition [29]. By mapping
out the dependencies between different capabilities or milestones
needed to reach some notion of transformative AI, therefore, we
should be able to identify milestones which are particularly
important for enabling many others - these are our canaries. This is
the general idea behind our approach to identifying canaries,
outlin ed in more detail in the following sections.
2.2 Proposed Methodology
The proposed methodology can be used to identify ‘canaries’ for
any transformative event . In the case of AI, the focus might be on a
transformative technology such as HLMI or AGI, a transformative
application such as flexible robotics, or a transformative impact
such as the automation of at least 50% of jobs.
Given a transformative event, our methodology has three main
steps: (1) identifying key milestones towards the event; (2)
ident ifying dependency relations between these milestones; and (3)
identifying milestones which underpin many others as ‘canaries’.
2.2.1 Identifying key milestones using expert elicitation
Like other studies of AI progress, we rely on expert elicitation
throughout this process. However, the reliability of expert
elicitation studies depends on the proper selection and use of
expertise. Though there are inevitable limitations of using any form
of subjective judgement, no matter how expert, these limitations
can be minimised with careful selection of experts and questions.
We suggest carefully selecting experts with varied expertise
relevant to the chosen question. For example, for identifying
milestones towards human -level AI , the cohort should include
experts in machine learning and computer science but also
cognitive scientists, philosophers, developmental psychologists,
evolutionary biologists, and animal cognition experts. This diverse
group would bring together expertise on the current capabilities
and limi tations of AI , with expertise on key milestones in human
cognitive development and the order in which cognitive faculties
develop. We also encourage careful design and phrasing of
questions to enable participants to make best use of their expertise.
For ex ample, rather than asking experts to identify specific
milestones towards human -level AI , which is a question for which
they are not trained , we might ask machine learning researchers
about the limitations of the methods they use every day , or ask
psycholo gists what important human capacities they see lacking in
machines .
There are several different methods available for expert
elicitation: including surveys, interviews, workshops and focus
groups, each with advantages and disadvantages [2]. Interviews
provide greater opportunity to tailor questions to the specific
expert, but can be extremely time -intensive compared to surveys,
making it difficult to consult a large number of experts. If possible,
some combination of the two may be ideal: using carefully s elected
semi -structured interviews to elicit initial milestones, followed -up
with surveys with a much broader group to validate which
milestones are widely accepted as being key.
2.2.2 Mapping dependencies between milestones using
causal graphs
3
The second step of our methodology involves convening experts to
identify dependency relations between identified milestones: that
is, which milestones may underpin, lead to, or depend on which
others. Experts should be guided in generating directed causal
graphs to represent perceived causal relations between milestones
[35]. Causal graphs show causal links between elements of a
system, represented as nodes (elements) and arrows (causal links).
A directed positive arrow from A and B indicates that A has a
positive causal influence on B. Such causal maps have been used to
support decision -making, structure knowledge, and improve
visualisation of complex scenarios [20][25][26][28] and are
particularly useful for exploring and understanding possible
futures, r ather than aiming to predict a single future [26]. They are
easily modified and constructed collaboratively, and therefore are
well-suited to helping us structure expert knowledge on
dependencies between different technological milestones.
Fuzzy cognitive maps (FCMs), a specific type of causal graph,
may be a particularly useful method for our purposes. FCMs
capture all benefits of causal mapping but can be extended into a
quantitative model, and thus lend themselves to computerised
simulations [25]. This w ill not always be necessary, but given that
our proposed method is applicable to many contexts, a flexible
model is desirable. FCMs are well able to document non -linear
interactions and experts’ mental models of causal interactions
because they can handle imprecise causal links. The variables
(nodes) can take any state between 0 and 1 (hence ‘fuzzy’),
indicating the extent to which the variable is ‘present’. When a
variable changes its state, it affects all concepts that are causally
dependent on it. FCMs h ave been used successfully in
environmental science [20][38], strategic planning [30], and other
areas [25], and have been recommended for use in futures studies,
forecasting, and technology road mapping [1][26].
In a workshop format, experts should be given brief training in
causal graph methods or FCMs, and then break into groups to
discuss dependencies between milestones. Each group should then
collaboratively construct a directed causal graph or FCM to
represent these relationships. Groups should be formed so as to
maximise the variation of expertise in each group.
2.2.3 Identifying canaries from causal graphs.
Finally, the resulting causal graphs can be aggregated and analysed
to identify canaries, by identifying the nodes with the highest
number of outgoing arrows.
The aggregation process should first focus on identifying
commonalities between all graphs which can be shared in the final
graph. Substantive disagreements may remain, which can be the
subject of mediated discussion, with a voting pro cess to decide on
final aspects of the graph.
Experts then identify nodes which they agree have significantly
more outgoing nodes (some amount of discretion from the
experts/conveners will be needed to determine what counts as
‘significant’) . Since nodes with a high density of outgoing arrows
represent milestones which underpin many others, progress on
these milestones can act as ‘canaries’ , indicating that we may see
further advances in many other areas in the near future. These
canaries can therefore act as early warning signs for more rapid and
potentially discontinuous progress, as well as for new applications
becoming ready for deployment (depending on which exact
capabilities they are likely to unlock) .
3 IMPLEMENTATION : CANDIDATE
CANARI ES FOR HLMI
We describe a partial implementation of the proposed method to
identify canaries for achieving high -level machine intelligence
(HLMI). We define HLMI here as an AI system (or collection of
AI systems) that performs at the level of an average hu man adult
on key cognitive measures required for economically relevant
tasks. 2 We interviewed experts about the limitations of current
deep learning methods from the perspective of achieving HLMI,
and used the findings to construct a causal graph of miles tones.
This allowed us to identify candidate canary capabilities. The
results must be understood as preliminary, because the causal
graphs were developed just by the authors, not a cohort of experts,
and so have limited validity. However, this initial demo nstration
and preliminary findings will form the basis for a full study with a
broader range of experts in future.
3.1 Expert elicitation to identify milestones
To identify key milestones for achieving HLMI, we interviewed 25
experts (using both a non -probabilistic, purposive sampling method
and stratified sampling method, as described by [ 12] in chapter
six). The sample covered experts in machine learning (9), computer
science with specialisation in AI (5), cognitive psychology (2),
animal cognition (1), philosophy of mind and AI (3), mathematics
(2), neuroscience (1), neuro -informatics (1), engineering (1).
Interviewees came from both academia and industry, and were
deliberately selected to be at a variety of career stages.
We conducted individual, semi -structured interviews, with a set
of core questions and themes to guide more open -ended discussion.
Semi -structured interviews use an interview guide with core
questions and themes to be explored in response to open -ended
questions to allo w interviewees to explain their position freely
[24]. Initial questions included : what do you believe deep learning
will never be able to do? Do you see limitations of deep learning
that others seem not to notice? In response to these and similar
questions tailored to the interviewee’s specific expertise , they were
asked to name what they thought were the biggest limitations of
current deep learning methods, from the perspective of achieving
HLMI.
All named limitations were collated, with shortened
explanations, and translated into ‘milestones’, i.e. capabilities
experts believe deep learning is yet to achieve on the path to
HLMI. Table 1. shows all milestones based on limitations, named
by interviewees. Because we have maintained each interviewee’s
preferred terminology, several of the milestones listed may turn out
to refer to the same or highly similar problems.
Table 1. Limitations of deep learning as perceived and named by experts
2 We use this definition, adapted from Grace et al., to highlight that what is
key for saying HLMI has been reached is that AI has the cognitive ability to
perform every task better than humans workers, not that it is in practice
deployed to do so.
4
Causal reasoning : the ability to
detect and generalise from causal
relations in data. Common sense: having a set of
background beliefs or
assumptions which are useful
across domains and tasks.
Meta -learning : the ability to learn
how to best learn in each domain. Architecture search : the ability
to automatica lly choose the best
architecture of a neural network
for a task.
Hierarchical decomposition: the
ability to decompose tasks and
objects into smaller and hierarchical
sub-components. Cross -domain generalization :
the ability to apply learning from
one task or domain to another.
Representation: the ability to learn
abstract representations of the
environment for efficient learning and
generalisation. Variable binding: the ability to
attach symbols to learned
representations, enabling
generalisation and re-use.
Disentanglement: the ability to
understand the components and
composition of observations, and
recombine and recognise them in
different contexts. Analogical reasoning: the ability
to detect abstract similarity across
domains, enabling learning and
generalisation.
Concept formation: the ability to
formulate, manipulate and
comprehend abstract concepts. Object permanence: the ability
to represent objects as
consistently existing even when
out of sight.
Grammar: the ability to construct
and decompose sentences according
to correct grammatical rules. Reading comprehension: the
ability to detect narratives,
semantic context, themes and
relations between characters in
long texts or stories.
Mathematical reasoning: the ability
to d evelop, identify and search
mathematical proofs and follow
logical deduction in reasoning. Visual question answering: the
ability to answer open -ended
questions about the content and
interpretation of an image.
Uncertainty estimation: the ability
to represent and consider different
types of uncertainty. Positing unobservables: the
ability to account for
unobservable phenomena,
particularly in representing and
navigating environments.
Reinterpretation: the abilit y to
partially re -categorise, re -assign or
reinterpret data in light of new
information without retraining from
scratch. Theorising and hypothesising:
the ability to propose theories and
testable hypotheses, understand
the difference between theory and
reality, and the impact of data on
theories.
Flexible memory: the ability to store,
recognise and retrieve knowledge so
that it can be used in new
environments and tasks. Efficient learning : the ability to
learn efficiently from small
amounts of data.
Interpretability: the ability for
humans to interpret internal network
dynamics so that researchers can
manipulate network dynamics. Continual learning: the ability to
learn continuously as new data is
acquired.
Active learning: the ability to learn
and explore in self -directed ways. Learning from inaccessible
data: the ability to learn in
domains where data is missing,
difficult or expensive to acquire. Learning from dynamic data: the
ability to learn from a continually
changing stream of data. Navi gating brittle
environments: the ability to
navigate irregular, and complex
environments which lack clear
reward signals and short feedback
loops.
Generating valuation functions: the
ability to generate new valuation
functions immediately from scratch to
follow newly -given rules. Scalability: the ability to scale up
learning to deal with new features
without needing
disproportionately more data,
model parameters, and
computational power.
Learning in simulation: the ability
to learn all relevant experience from a
simulated environment. Metric identification: the ability
to identify appropriate metrics of
success for complex tasks, such
that optimising for the measured
quantity accomplishes the task in
the way intended.
Conscious perception: the ability to
experience the world from a first -
person perspective. Context -sensitive decision
making: the ability to adapt
decision -making strategies to the
needs and constraints of a given
time or context.
It is worth noting the re are apparent similarities and relationships
between many of these milestones. For example, representation :
the ability to learn abstract representations of the environment,
seems closely related to variable binding : the ability to formulate
place-holder concepts. The ability to apply learning from one task
to another , cross -domain generalisation , seems closely related to
analogical reasoning. Further progress in research will tell wh ich of
these are clearly separate milestones or more closely related
notions.
3.2 Causal graphs to identify dependencies
between milestones
Having identified key milestones, we explore dependencies
between the m using fuzzy cognitive maps (FCM). We focus on
how capabilities enable , not inhibit, other capabilities, which
means we use only positive influence arrows. FCMs are
particularly well -suited to representing the uncertainty inherent in
this analysis, as it assumes that each arrow c ould have a weight to
represent varying levels of strength. In this analysis we have not
specified the weights on connections , but adding these weights
could be trialled with experts in the future.
A previous survey [ 5] suggests that this endeavour is a highly
uncertain one , finding that many differe nt relationships between AI
milestones seem plausible to experts . Our analysis does not claim
nor aim to resolve this disagreement, but instead shows only one
out of many possible mappings , to illustrate the use and value of
FCMs in AI progress monitoring.
We use the software VenSim (vensim.com) to illustrate the
hypothesised relationships between perceived milestones in Figure
1. For example, we hypothesise that the ability to formulate,
comprehend and manipulate abstract concepts may be an important
prerequisite for the ability to account for unobservable phenomena,
which is in turn important for reasoning about causality. A positive
influence arrow does not mean that achieving one milestone
necessarily leads to another, but rather that progress on the fi rst
5
Analogical
ReasoningRepresentation
Variable-Binding
Disentanglement
Flexible Memory
Dynamic DataBrittle EnvironmentContinual Learning
Reinterpretationsa
B
CDEFmilestones increases the likelihood of progress on other arrows it
points to.
Figure 1. Cognitive map of dependencies between milestones collected in
expert elicitations . Arrows coloured in pink and green indicate capabilities
that have significantly more outgoing arrows.
This map was constr ucted by the authors, and is therefore far from
definitive or the only possible way of representing dependencies
between capabilities. However, this initial map does provide an
important illustration of the kind of output this methodology should
aim to ach ieve, and generates some initial hypotheses for
relationships between milestones.
3.3 Candidate Canary Capabilities
Based on this causal map, we can identify two candidates for
canar y capabilities . The capabilities with the most outgoing arrows
are:
Symbol -like representations : the ability to construct abstract,
discrete and disentangled representations of inputs, to allow for
efficiency and variable -binding. We hypothesise that this capability
underpins several others, including grammar, mathem atical
reasoning, concept formation, and flexible memory.
Flexible memory: the ability to store, recognise, and re -use
knowledge. We hypothesise that this ability would unlock many
others, including the ability to learn from dynamic data, the ability
to learn in a continual fashion, and the ability to learn how to learn.
We therefore tentatively suggest that these are two important
capabilities to track progress on from the perspective of
anticipating HLMI. We discuss one such capability, flexible
memory , in more detail below.
Figure 2. Extract of Figure 1, showing one candidate canary capability.
Flexible memory, as described by experts in our sample, is the
ability to recognize and store reusable information, in a format that
is flexible so that it can be retrieved and updated when new
knowledge is gained. We explain the reasoning behind the labelled
arrows in figure 2:
• (a): compact representations are a prerequisite for
flexible memory since storing high -dimensional input in
mem ory requires compressed, efficient and thus abstract
representations.
• (B): the ability to reinterpret data in light of new
information likely requires flexible memory, since it
requires the ability to retrieve and alter previously stored
information.
• (C) and (E): to make use of dynamic and changing data
input, and to learn continuously over time, an agent must
be able to store, correctly retrieve and modify previous
data as new data comes in.
• (D): in order to plan and execute strategies in brittle
environm ents with long delays between actions and
rewards, an agent must be able to store memories of past
actions and rewards, but easily retrieve this information
and continually update its best guess about how to obtain
rewards in the environment.
• (F): analogic al reasoning involves comparing abstract
representations, which requires forming, recognising, and
retrieving representations of earlier observations.
Progress in flexible memory therefore seems likely to unlock
or enable many other capabilities important for HLMI,
especially those crucial for applying AI systems in real
environments and more complex tasks. These initial
hypotheses should be validated and explored in more depth by
a wider range of experts.
4 DISCUSSION
6
4.1 Advantages
We believe the proposed met hod for identifying canaries has many
strengths and could be applied to a broad range of important
questions about transformative AI systems and impacts. The
general methodology of using expert elicitation to identify
milestones and then causal mapping to elucidate dependencies
between those milestones is extremely flexible, meaning it could
be applied beyond AI to other fields of science and technology
progress. The method can also be adapted to the preferred level of
detail for a given study: causal graph s can be made arbitrarily
complex [18] and can be analysed both quantitatively and
qualitatively. With this method, it is possible to combine different
types of expertise relating to milestones: including well -understood
technical limitations of current me thods, with informed speculation
about unknown capabilities that may be important prerequisites to
some transformative event. With early warning signs we can track
progress towards canary milestones, or directly prepare for the
transformative events that f ollow after it .
4.2 Uses
We envision that this methodology could be used to identify
warning signs for a number of important potentially transformative
events in AI progress, such as foundational research break -
throughs, the use of AI to automate scientific research, or the
automation of tasks that affect a wide range of jobs.
Once canaries have been identified for some transformative event,
there are numerous ways we might use them to improve
preparation for its impact, including by:
• Automating the collection, tracking and flagging of new
publications relevant to canary capabilities, and building
a database of relevant publications (perhaps similar to
that described by [40]);
• Generating metrics and benchmarks for evaluating
progress on canary capabilities;
• Using prediction platforms such as Metaculus
(ai.metaculus.com) to track and forecast progress on
canary capabilities;
• Conducting more focused expert elicitation, for example
periodically consult experts on their updated forecasts (in
the form of cumulative probability estimates) for when
different milestones are achieved, or when they are
presented with updated progress metrics on canary
capabilities;
• Conducting more in -depth research to empirically and
theoretically investigate hypot hesised relationships
between milestones: for example, to what extent do
improvements in memory structures lead to empirical
improvements in performance in brittle environments?
• Conducting more in -depth research on the societal and
governance implications of achieving canary milestones,
and preparing governance responses for these milestones
ahead of time. 4.3 Limitations and future directions
This methodology nonetheless has some limitations which further
iterations could seek to improve on. There may be a fun damental
trade -off between the benefits of consulting a large, diverse group
of experts - enabling more thorough and robust identification of
relevant milestones - and the feasibility of reaching agreement
upon a single causal map, and therefore agreeing u pon canaries.
Relatedly, if uncertainty about milestones is too high, it may be
difficult for experts to agree on a single causal map or candidates
for canaries: finding questions where there is enough uncertainty
for this process to be useful, but not so much uncertainty that no
agreement can be reached, may be a challenge in some cases. It
will also be important to recognise any potential limitations of the
specific sample of experts involved in the process: recognising that
machine learning researchers m ay be biased towards emphasising
the importance of areas they themselves work on, for example, or
that non -computer scientists may often lack a full understanding of
what current systems can and cannot do.
In using FCMs to generate causal maps, it is not clear what level
of detail and quantitative analysis will be most useful. In the
implementation described here, we hypothesised relationships at a
high level of abstraction and without quantitative analysis, due to
the high level at which experts highlighted limitations in the first
stage. The higher the level of abstraction, the more uncertain the
mapping will be and the less useful it may be to indicate weights. It
would be valuable for future work to explore various levels of
abstractions, inclu ding a more detailed and quantitative analysis
using more clearly -defined technical milestones, which could result
in more precise forecasts and hypotheses.
Finally, it is important to note that attempts to anticipate and
understand progress in AI (or any other technology) are not
independent of that progress itself. Better understanding of key
milestones towards AGI, HLMI, or some other notion of
transformative AI, does not just improve our ability to anticipate
that progress, but may also improve our abil ity to make progress
towards transformative AI. We must therefore be cautious in
identifying ‘canary’ capabilities, to consider the potential risks of
making progress on these capabilities, and to communicate and
encourage consideration of these risks to t hose researchers driving
forward AI development.
REFERENCES
[1] M. Amer, A. Jetter, and T. Daim, ‘Development of fuzzy cognitive
map (FCM)‐based scenarios for wind energy’, International Journal
of Energy Sector Management , vol. 5, no. 4, pp. 564 –584, 2011 . doi:
10.1108/17506221111186378 .
[2] B.M. Ayyub, ‘Elicitation of expert opinions for uncertainty and risks ’,
CRC press , 2001.
[3] S. Ballard and R. Calo , ‘Taking Futures Seriously: Forecasting as
Method in Robotics Law and Policy ’, Draft available at:
https://robots.law.miami.edu/2019/wp -
content/uploads/2019/03/Calo_Taking -Futures -Seriously.pdf , 201 9.
[4] S. Baum, B. Goertzel, and T.G. Goertzel, ‘How long until human -
level AI? Results from an expert assessment ’, Technological
Forecasting and Social Change , 78(1), 185 -195, 2011.
[5] S. Beard, T. Rowe, and J. Fox, ‘An analysis and evaluation of
methods currently used to quantify the likelihood of existential
hazards ’, Futures , 115, 102469 , 2020.
[6] N. Benaich and I. Hogarth, ‘State of AI Report 2019’, available at
https://www.stateof.ai/ , 2019.
7
[7] C. Buckner and K. Yang, ‘Mating dances and the evolution of
language: What’s the next step?’, Biology & Philosophy , vol. 32,
2017, doi: 10.1007/s10539 -017-9605 -z.
[8] K. Crawford , R. Dobbe, T. Dryer, G. Fried, B. Green, E. et al., ‘AI
Now 2019 Report ’, New York: AI Now Institute , 2019.
[9] W. Chang, E. Chen, B. Mellers and P. Tetlock, ‘Developing expert
political judgment: The impact of training and practice on judgmental
accuracy in geopolitical forecasting tournament s’, Judgement and
Decision Making , vol. 11, no. 5, pp. 509 -526, 2016.
[10] C. Z. Cremer, ‘Deep Limitations? Examining Expert Disagreement
Over Deep Learning’, Manuscript in preparation, 2020.
[11] D. Collingridge, ‘The Social Control of Technology ’, St. Martin's
Press 1980.
[12] A. Dafoe, ‘AI Governance: A Research Agenda ’, Governance of AI
Program, The Future of Humanity Institute, The University of Oxford,
Oxford, UK , 2018.
[13] M. DeJonckheere and L. Vaughn, ‘Semistructured interviewing in
primary care research: a balance of relationship and rigour ’, Family
Medicine and Community Health, pp. doi: 10.1136/fmch -2018 -
000057, 2019.
[14] O. Etzioni, ‘How to know if artificial intelligence is about to destroy
civilization ’, MIT Technology Review , 2020.
[15] C. B. Frey and M. A. Osb orne, ‘The future of employment: How
susceptible are jobs to computerisation? ’ Technological Forecasting
and Social Change, vol. 114, pp. 254 -280, 2017.
[16] S. Friel et al. , ‘Using systems science to understand the determinants
of inequities in healthy eating’, PLoS ONE , vol. 12, no. 11, p.
e0188872, 2017 . doi: 10.1371/journal.pone.0188872 .
[17] K. Grace, J. Salvatier, A. Dafoe, B. Zhang, and O. Evans, ‘When will
AI exceed human performance? Evidence from AI experts ’, Journal
of Artificial Intelligence Research , 62, 729 -754, 2018.
[18] S. R. J. Gray et al. , ‘Are coastal managers detecting the problem?
Assessing stakeholder pe rception of climate vulnerability using Fuzzy
Cognitive Mapping’, Ocean & Coastal Management , vol. 94, pp. 74 –
89, 2014 . doi: 10.1016/j.ocecoaman.2013.11.008 .
[19] R. Gruetzemacher, ‘A Holistic Fram ework for Forecasting
Transformative AI ’, Big Data and Cognitive Computing , 3(3): 35 ,
2019.
[20] R. Gruetzemacher and J. Whittlestone, ‘Defining and Unpacking
Transformative AI ’, arXiv preprint arXiv:1912.00747 . 2019.
[21] A. Haynes and L. Gbedemah, ‘The Global AI Index Methodology’,
Tortoise Media, available at:
https://www.tortoisemedia.com/intelligence/ai/ , 2019.
[22] S. Jamshed, ‘Qualitative research method -interv iewing and
observation ’, Journal of Basic and Clinical Pharmacy, vol. 5, no. 4, p.
87–88, 2014.
[23] A. Jetter, ‘Fuzzy Cognitive Maps for Engineering and Technology
Management: What Works in Practice?’, in 2006 Technology
Management for the Global Future - PICMET 2006 Conference ,
Istanbul, Turkey, pp. 498 –512, 2006. doi:
10.1109/PICMET.2006.296648 .
[24] J. Jetter and K. Kok, ‘Fuzzy Cognitive Maps for futures studies —A
methodological assessment of concepts and methods’, Futures , vol.
61, pp. 45 –57, 2014, doi: 10.1016/j.futures.2014.05.002 .
[25] H. Karnofsky, ‘Some Background on our Views Regarding Advanced
Artificial Intelligence ’, available at :
https://www.openphilanthropy.org/blog/some -background -our-views -
regarding -advanced -artificial -intelligence , 2016.
[26] B. Kosko, ‘Fuzzy Cognitive Maps ’, Int. J. Man -Machine Studies, vol.
24, pp. 65 -75, 1986.
[27] Y. LeCun, Y. Bengio and G. Hinton, ‘Deep Learning ’, Nature, vol.
521, no. 7553, pp. 436 -444, 2015.
[28] K. C. Lee, H. Lee, N. Lee, and J. Lim, ‘An agent -based fuzzy
cognitive map approach to the strategic marketing planning for
industrial firms’, Industrial Mar keting Management , vol. 42, no. 4,
pp. 552 –563, 2013, doi: 10.1016/j.indmarman.2013.03.007 .
[29] H. Lin, ‘The existential threat from cyber -enabled information
warfare ’, Bulletin of the Atomic Scie ntists , 75(4), 187 -196, 2019.
[30] F. Martínez -Plumed, S. Avin, M. Brundage, A. Dafoe, S.S.
ÓhÉigeartaigh, and J. Hernández -Orallo, ‘Accounting for the
neglected dimensions of AI progress ’, arXiv preprint
arXiv:1806.00610 , 2018. [31] M. Mohammadi, and A. Al-Fuqaha, ‘Enabling cognitive smart cities
using big data and machine learning: Approaches and challenges ’,
IEEE Communications Magazine , 56(2), 94 -101, 2018.
[32] V. C. Müller, and N. Bostrom, ‘Future progress in artificial
intelligence: A survey of expert o pinion ’, in Fundamental issues of
artificial intelligence (pp. 555 -572). Springer, Cham , 2016.
[33] B. Newell and K. Proust, ‘Introduction to Collaborative Conceptual
Modelling’, p. 20, 2012.
[34] R. Perrault, Y. Shoham, E. Brynjolfsson, J. Clark, J. Etchemendy et
al., ‘The AI Index 2019 Annual Report ’, AI Index Steering
Committee, Human -Centered AI Institute, Stanford University,
Stanford, CA , 2019.
[35] K. Proust et al. , ‘Human Health and Climate Change: Leverage Points
for Adaptation in Urban Environmen ts’, IJERPH , vol. 9, no. 6, pp.
2134 –2158, 2012, doi: 10.3390/ijerph9062134 .
[36] D. Reckien, ‘Weather extremes and street life in India —Implications
of Fuzzy Cognitive Mapping as a new tool for semi -quantit ative
impact assessment and ranking of adaptation measures’, Global
Environmental Change , vol. 26, pp. 1 –13, 2014, doi:
10.1016/j.gloenvcha.2014.03.005 .
[37] G. Shackelford, L. Kemp, C. Rhodes, L. Sundaram, S.S.
ÓhÉigeartaigh et al. , ‘Accumulating evidence using crowdsourcing
and machine learning: A living bibliography about existential risk and
global catastrophic risk ’, Futures , 116 , 2020.
https://doi.org/10.1016/j.futures.2019.102508
[38] P. Tetlock and D. Gardner, ‘Superforecasting, The Art and Science of
Prediction ’, London: Random House Books , 2016.
[39] W. Wallach, ‘A dangerous master: How to keep technology from
slipping beyond our control ’, Basic Books , 2015.
[40] J. Whittlestone, R. Nyrup, A. Alexandrova, K. Dihal, and S. Cave,
‘Ethical and societal implications of algorithms, data, and artificial
intelligence: a roadmap for research ’, London: Nuffield Foundation ,
2019.
|
1307fb3f-db35-4261-9379-ab48ca3dd371 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Crucial considerations in the field of Wild Animal Welfare (WAW)
*Cross-posted from my blog,* [*hollyelmore.substack.com*](https://hollyelmore.substack.com/p/crucial-considerations-in-the-field?s=w)
Wild animal welfare (WAW) is:
=============================
* A paradigm that sees the wellbeing and experiences of individual animals as the core moral consideration in our interaction with nature
* An interdisciplinary field of study, largely incubated by Effective Altruism (EA)
* An EA cause area hoping to implement interventions
A [**crucial consideration**](https://forum.effectivealtruism.org/tag/crucial-consideration) is a consideration that warrants a major reassessment of a cause area or an intervention.
WAW is [*clueless*](https://forum.effectivealtruism.org/posts/LdZcit8zX89rofZf3/evidence-cluelessness-and-the-long-term-hilary-greaves) or *divided* on a bevy of foundational and strategic crucial considerations.
The WAW account of nature
-------------------------
There are A LOT of wild animals
* 100 billion to 1 trillion mammals,
* at least 10 trillion fish,
* 100 to 400 billion birds ([Brian Tomasik,](https://reducing-suffering.org/how-many-wild-animals-are-there/)^^)
* 10 quintillion insects ([Rethink Priorities](https://rethinkpriorities.org/publications/invertebrate-welfare-cause-profile))
* Each year, there are 30 trillion wild-caught shrimp alone! ([Rethink Priorities](https://www.facebook.com/groups/OMfCT/posts/3060710004243897), unpublished work)
H/T Sami Mubarak via Dank EA Memes
In contrast, there are 24 billion animals alive and being raised for meat at any time
WAW: Nature is not already optimized for welfare
------------------------------------------------
* Though humans do cause wild animals to suffer, like the suffering of polar bears as their ice drifts melt due to anthropogenic climate change, suffering is more fundamentally a part of many wild animal lives
* There are many natural disasters, weather events, and hardships
* Sometimes animals have positive sum relationships (like mutualistic symbiosis), but a lot of times animals are in zero sum conflict (like predation)
* Nature is an equilibrium of every different lineage maximizing reproductive fitness. Given that they evolved, suffering and happiness presumably exist to serve the goal of maximizing *fitness*, not maximizing happiness
**Therefore, nature could, in theory, be changed to improve the welfare of wild animals, which is expected to be less than what it could be.**
---
Foundational Crucial Considerations
===================================
Should we try to affect WAW at all?
-----------------------------------
* Is taking responsibility for wild animals supererogatory?
* Do we have the right to intervene in nature?
* Can we intervene *competently*, as we intend, and in ways that don’t ultimately cause more harm than good?
What constitutes “welfare” for wild animals?
--------------------------------------------
* What animals are sentient?
* What constitutes welfare?
* How much welfare makes life worth living?
+ Negative vs. classical utilitarianism
What are acceptable levels of abstraction?
------------------------------------------
* Species-level generalizations?
* “Worth living” on what time scale?
+ A second?
+ A lifetime?
+ The run of the species?
* How to weigh intense states
* Purely affective welfare or also preference satisfaction?
How much confidence do we need to intervene?
--------------------------------------------
* Should irreversible interventions be considered?
* Is it okay to intervene if the good effects outweigh some negative effects?
* Are we justified in *not* intervening?
+ Status quo bias
+ Naturalistic fallacy
---
Strategic Crucial Considerations
================================
Emphasis on direct or indirect impact?
--------------------------------------
* Theory of Change: Which effects will dominate in the long run?
* Direct impact or values/moral circle expansion? (Direct impact for instrumental reasons?)
* How to evaluate impact?
Is WAW competitive with other EA cause areas?
---------------------------------------------
* Should we work on WAW if there aren’t direct interventions now that are cost competitive with existing EA interventions?
* How much should EA invest in developing welfare science cause areas vs exploiting existing research?
What is the risk of acting early vs. risk of acting late?
---------------------------------------------------------
* How long is the ideal WAW timeline?
* How much time do we have before others act?
* How long do we have before AI will take relevant actions?
How will artificial general intelligence (AGI) affect WAW? How *should* AI affect WAW?
--------------------------------------------------------------------------------------
* AGI could be the only way we could implement complex solutions to WAW
* AGI could also have perverse implementations of our values
* WAW value alignment problem:
+ We don’t know/agree on our own values regarding wild animals
+ We don’t know how to communicate our values to an AGI
* How do we hedge against different takeoff scenarios?
Convergence?
============
H/T Nathan Young via Dank EA Memes
Most views converge… in the short term
--------------------------------------
* “Field-building” for now
+ Alliances with conservationists, veterinarians, poison-free advocates, etc.
* As with every other cause area, those with different suffering:happiness value ratios will want different things
* WAW Value Alignment Problem is fundamental, especially troubling because we can get only limited input from the animals themselves.
* How would we know if we got the wrong answer from their perspective?
The long term future of WAW is at stake!
----------------------------------------
* WAW as a field is still young and highly malleable
* Prevent value lock-in or pick good values to get locked in
* Be transparent about sources of disagreement, separating values from empirical questions from practical questions
---
Acknowledgments
---------------
*Thanks to the rest of the WAW team at Rethink Priorities, Will McAuliffe and Kim Cuddington, for help with brainstorming the talk this post was based on, to my practice audience at Rethink Priorities, and to subsequent audiences at University College London and the FTX Fellows office.*
---
I practice post-publication editing and updating. |
6245417b-9c6e-4713-b0d6-34d6c20aecb1 | trentmkelly/LessWrong-43k | LessWrong | Agents dissolved in coffee
Bottom line
When thinking about embedded agency it might be helpful to drop the notion of ‘agency’ and ‘agents’ sometimes, because it might be confusing or underdefined. Instead one could think of processes running according to the laws of physics. Or of algorithms running on a stack of interpreters running on the hardware of the universe.
In addition (or as a corollary) to an alternative way of thinking about agents, you will also read about an alternative way of thinking about yourself.
Background
The following is mostly a stream of thought that went through my head after I drank a cup of strong milk coffee and sat down reading Embedded Agency. I consume caffeine only twice a week. So when I do, it takes my thinking to new places. (Or maybe it's because the instant coffee powder that I use expired in March 2012.)
Start
My thoughts kick off at this paragraph of Embedded Agency:
> In addition to hazards in her external environment, Emmy is going to have to worry about threats coming from within. While optimizing, Emmy might spin up other optimizers as subroutines, either intentionally or unintentionally. These subsystems can cause problems if they get too powerful and are unaligned with Emmy’s goals. Emmy must figure out how to reason without spinning up intelligent subsystems, or otherwise figure out how to keep them weak, contained, or aligned fully with her goals.
This is our alignment problem repeated in Emmy. In other words, if we solve the alignment problem, it is also solved in Emmy and vice versa. If we view the machines that we want to run our AI on as part of ourselves, we're the same as Emmy.
We are a low-capability Emmy. We are partially and often unconsciously solving the embedded agency subproblems using heuristics. Some of which we know, some of which we don't know. As we try to add to our capabilities, we might run into the limitations of those heuristics. Or not necessarily the limitations yet. We don't even know how exactly they work and ho |
cec2d9fe-3657-4d39-82cc-27d3cd862cd0 | trentmkelly/LessWrong-43k | LessWrong | [SEQ RERUN] Failure By Affective Analogy
Today's post, Failure By Affective Analogy was originally published on 18 November 2008. A summary (taken from the LW wiki):
> Making analogies to things that have positive or negative connotations is an even better way to make sure you fail.
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was Failure By Analogy, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series. |
28069256-1890-4e64-ba9b-bd98e7907413 | trentmkelly/LessWrong-43k | LessWrong | Free Will, Determinism, And Choice
Rough Summary:
* Free will is not "free" in the sense of being uncaused. Free will is "free" in the sense that you are the cause. You are free to choose between A or B if your choice will determine the outcome.
* Free will and determinism are both assumptions that are implicit in everything that we do. They both depend on each other. The conflict between free will and determinism arises due to Subject | Object Dissonance.
* A choice is not the creation of new causality out of nothing. It is the causality of the universe flowing through you.
Although I'm not the author of this post (a friend of mine wrote it), I have created a PDF version of the essay that has a table of contents and headers to make it even easier to read. |
fe6e8bd7-5efc-4f1b-89cb-0635e87d5d38 | trentmkelly/LessWrong-43k | LessWrong | Open Thread, May 19 - 25, 2014
Previous Open Thread
You know the drill - If it's worth saying, but not worth its own post (even in Discussion), then it goes here.
Notes for future OT posters:
1. Please add the 'open_thread' tag.
2. Check if there is an active Open Thread before posting a new one.
3. Open Threads should start on Monday, and end on Sunday.
4. Open Threads should be posted in Discussion, and not Main.
|
379b9f5b-25a7-4833-95e3-06af366efbaf | StampyAI/alignment-research-dataset/blogs | Blogs | Wanted: Office Manager (aka Force Multiplier)
We’re looking for a full-time office manager to support our growing [team](https://intelligence.org/team/). It’s a big job that requires organization, initiative, technical chops, and superlative communication skills. You’ll develop, improve, and manage the processes and systems that make us a super-effective organization. You’ll obsess over our processes (faster! easier!) and our systems (simplify! simplify!). Essentially, it’s your job to ensure that everyone at MIRI, including you, is able to focus on their work and Get Sh\*t Done.
That’s a super-brief intro to what you’ll be working on. But first, you need to know if you’ll even like working here.
### A Bit About Us
We’re a research nonprofit working on the critically important problem of *superintelligence alignment*: how to bring smarter-than-human artificial intelligence into alignment with human values.[1](https://intelligence.org/2015/07/01/wanted-office-manager/#footnote_0_11843 "More details on our About page.") Superintelligence alignment is a burgeoning field, and arguably the most important and under-funded research problem in the world. Experts largely agree that AI is likely to exceed human levels of capability on most cognitive tasks in this century—but it’s not clear *when*, and we aren’t doing a very good job of preparing for the possibility. Given how disruptive smarter-than-human AI would be, we need to start thinking now about AI’s global impact. Over the past year, a number of leaders in science and industry have voiced their support for prioritizing this endeavor:
* Stuart Russell, co-author of the [leading textbook on artificial intelligence](http://aima.cs.berkeley.edu/) and a MIRI advisor, [gives a compelling argument for doing this work sooner rather than later](https://www.youtube.com/watch?v=GYQrNfSmQ0M).
* Nick Bostrom of Oxford University, another MIRI research advisor, published *[Superintelligence: Paths, Dangers, Strategies](http://www.amazon.com/Superintelligence-Dangers-Strategies-Nick-Bostrom/dp/0199678111/)*, which details the potential value of smarter-than-human AI systems as well as the potential hazards.
* Elon Musk (Paypal, SpaceX, Tesla), Bill Gates (Microsoft co-founder), Stephen Hawking (world-renowned theoretical physicist), and others have publicly stated their concerns about long-term AI risk.
* Hundreds of AI researchers and engineers recently signed an [open letter](http://futureoflife.org/misc/open_letter) advocating for more research into robust and beneficial artificial intelligence. A number of MIRI publications are cited in the corresponding [Research Priorities](http://futureoflife.org/static/data/documents/research_priorities.pdf) document.
People are starting to discuss these issues in a more serious way, and MIRI is well-positioned to be a thought leader in this important space. As interest in AI safety grows, we’re growing too—we’ve gone from a single full-time researcher in 2013 to what will likely be a half-dozen research fellows by the end of 2015, and intend to continue growing in 2016.
All of which is to say: we *really need* an office manager who will support our efforts to hack away at the problem of superintelligence alignment!
If our overall mission seems important to you, and you love running well-oiled machines, you’ll probably fit right in. If that’s the case, we can’t wait to hear from you.
### What It’s Like to Work at MIRI
We try really hard to make working at MIRI an amazing experience. We have a team full of truly exceptional people—the kind you’ll be excited to work with. Here’s how we operate:
Flexible Hours
We do not have strict office hours. Simply ensure you’re here enough to be available to the team when needed, and to fulfill all of your duties and responsibilities.
#### Modern Work Spaces
Many of us have adjustable standing desks with multiple large external monitors. We consider workspace ergonomics important, and try to rig up work stations to be as comfortable as possible.
Living in the Bay Area
We’re located in downtown Berkeley, California. Berkeley’s monthly average temperature ranges from 60°F in the winter to 75°F in the summer. From our office you’re:
* A 10-second walk to the roof of our building, from which you can view the Berkeley Hills, the Golden Gate Bridge, and San Francisco.
* A 30-second walk to the BART (Bay Area Rapid Transit), which can get you around the Bay Area.
* A 3-minute walk to UC Berkeley Campus.
* A 5-minute walk to dozens of restaurants (including ones in Berkeley’s well-known Gourmet Ghetto).
* A 30-minute BART ride to downtown San Francisco.
* A 30-minute drive to the beautiful west coast.
* A 3-hour drive to Yosemite National Park.
Vacation Policy
Our vacation policy is that we don’t have a vacation policy. That is, take the vacations you need to be a happy, healthy, productive human. There are checks in place to ensure this policy isn’t abused, but we haven’t actually run into any problems since initiating the policy.
We consider our work important, and we care about whether it gets done well, not about how many total hours you log each week. We’d much rather you take a day off than extend work tasks just to fill that extra day.
Regular Team Dinners and Hangouts
We get the whole team together every few months, order a bunch of food, and have a great time.
Top-Notch Benefits
We provide top-notch health and dental benefits. We care about our team’s health, and we want you to be able to get health care with as little effort and annoyance as possible.
Agile Methodologies
Our ops team follows standard Agile best practices, meeting regularly to plan, as a team, the tasks and priorities over the coming weeks. If the thought of being part of an effective, well-functioning operation gets you really excited, that’s a promising sign!
Other Tidbits
* Moving to the Bay Area? We’ll cover up to $3,500 in moving expenses.
* Use public transit to get to work? You get a transit pass with a large monthly allowance.
* All the snacks and drinks you could want at the office.
* You’ll get a smartphone and full plan.
* This is a salaried position. (That is, your job is not to sit at a desk for 40 hours a week. Your job is to get your important work *done*, even if this occasionally means working on a weekend or after hours.)
It can also be surprisingly motivating to realize that your day job is helping people explore the frontiers of human understanding, mitigate global catastrophic risk, etc., etc. At MIRI, we try to tackle the very largest problems facing humanity, and that can be a pretty satisfying feeling.
If this sounds like your ideal work environment, read on! It’s time to talk about your role.
What an Office Manager Does and Why it Matters
Our ops team and researchers (and collection of remote contractors) are *swamped* making progress on the huge task we’ve taken on as an organization.
That’s where you come in. An office manager is the oil that keeps the engine running. They’re *indispensable*. Office managers are force multipliers: a good one doesn’t merely improve their own effectiveness—they make the entire *organization* better.
We need you to build, oversee, and improve all the “behind-the-scenes” things that ensure MIRI runs smoothly and effortlessly. You will devote your full attention to looking at the big picture and the small details and making sense of it all. You’ll turn all of that into actionable information and tools that make the whole team better. That’s the job.
Sometimes this looks like researching and testing out new and exciting services. Other times this looks like stocking the fridge with drinks, sorting through piles of mail, lugging bags of groceries, or spending time on the phone on hold with our internet provider. But don’t think that the more tedious tasks are low-value. If the hard tasks don’t get done, *none* of MIRI’s work is possible. Moreover, you’re actively *encouraged* to find creative ways to make the boring stuff more efficient—making an awesome spreadsheet, writing a script, training a contractor to take on the task—so that you can spend more time on what you find most exciting.
We’re small, but we’re growing, and this is an opportunity for you to grow too. There’s room for advancement at MIRI (if that interests you), based on your interests and performance.
Sample Tasks
You’ll have a wide variety of responsibilities, including, but not necessarily limited to, the following:
* Orienting and training new staff.
* Onboarding and offboarding staff and contractors.
* Managing employee benefits and services, like transit passes and health care.
* Payroll management; handling staff questions.
* Championing our internal policies and procedures wiki—keeping everything up to date, keeping everything accessible, and keeping staff aware of relevant information.
* Managing various services and accounts (ex. internet, phone, insurance).
* Championing our work space, with the goal of making the MIRI office a fantastic place to work.
* Running onsite logistics for introductory workshops.
* Processing all incoming mail packages.
* Researching and implementing better systems and procedures.
Your “value-add” is by taking responsibility for making all of these things happen. Having a competent individual in charge of this diverse set of tasks at MIRI is *extremely valuable*!
A Day in the Life
A typical day in the life of MIRI’s office manager may look something like this:
* Come in.
* Process email inbox.
* Process any incoming mail, scanning/shredding/dealing-with as needed.
* Stock the fridge, review any low-stocked items, and place an order online for whatever’s missing.
* Onboard a new contractor.
* Spend some time thinking of a faster/easier way to onboard contractors. Implement any hacks you come up with.
* Follow up with Employee X about their benefits question.
* Outsource some small tasks to TaskRabbit or Upwork. Follow up with previously outsourced tasks.
* Notice that you’ve spent a few hours per week the last few weeks doing xyz. Spend some time figuring out whether you can eliminate the task completely, automate it in some way, outsource it to a service, or otherwise simplify the process.
* Review the latest post drafts on the wiki. Polish drafts as needed and move them to the appropriate location.
* Process email.
* Go home.
You’re the One We’re Looking For If:
* You are authorized to work in the US. (Prospects for obtaining an employment-based visa for this type of position are slim; sorry!)
* You can solve problems for yourself in new domains; you find that you don’t generally need to be told what to do.
* You love organizing information. (There’s *a lot of it*, and it needs to be super-accessible.)
* Your life is organized and structured.
* You enjoy trying things you haven’t done before. (How else will you learn which things work?)
* You’re way more excited at the thought of being the jack-of-all-trades than at the thought of being the specialist.
* You are good with people—good at talking about things that are going great, as well as things that aren’t.
* People thank you when you deliver difficult news. You’re that good.
* You can notice all the subtle and wondrous ways processes can be automated, simplified, streamlined… while still keeping the fridge stocked in the meantime.
* You know your way around a computer really well.
* You enjoy eliminating unnecessary work, automating automatable work, outsourcing outsourcable work, and executing on everything else.
* You want to do what it takes to help all other MIRI employees focus on their jobs.
* You’re the sort of person who sees the world, organizations, and teams as systems that can be observed, understood, and optimized.
* You think Sam is the real hero in *Lord of the Rings*.
* You have the strong ability to take real responsibility for an issue or task, and ensure it gets done. (This doesn’t mean it has to get done by *you*; but it has to get done *somehow*.)
* You celebrate excellence and relentlessly pursue improvement.
* You lead by example.
Bonus Points:
* Your technical chops are really strong. (Dabbled in scripting? HTML/CSS? Automator?)
* Involvement in the Effective Altruism space.
* Involvement in the broader AI-risk space.
* Previous experience as an office manager.
Experience & Education Requirements
* Let us know about anything that’s evidence that you’ll fit the bill.
How to Apply
~~Apply by July 31, 2015.~~ The application deadline has passed. Thanks for your consideration.
P.S. Share the love! If you know someone who might be a perfect fit, we’d really appreciate it if you pass this along!
---
1. More details on our [About](https://intelligence.org/about/) page.
The post [Wanted: Office Manager (aka Force Multiplier)](https://intelligence.org/2015/07/01/wanted-office-manager/) appeared first on [Machine Intelligence Research Institute](https://intelligence.org). |
45ecfc42-8c68-4db0-847f-d71b5038ba0a | StampyAI/alignment-research-dataset/arbital | Arbital | Poset: Examples
The standard $\leq$ relation on integers, the $\subseteq$ relation on sets, and the $|$ (divisibility) relation on natural numbers are all examples of poset orders.
Integer Comparison
================
The set $\mathbb Z$ of integers, ordered by the standard "less than or equal to" operator $\leq$ forms a poset $\langle \mathbb Z, \leq \rangle$. This poset is somewhat boring however, because all pairs of elements are comparable; such posets are called chains or [totally ordered sets](https://arbital.com/p/540). Here is its Hasse diagram.

%%%comment:
dot source (doctored in GIMP)
digraph G {
node [= 0.1, height = 0.1](https://arbital.com/p/width)
edge [= "none"](https://arbital.com/p/arrowhead)
a [= "-3"](https://arbital.com/p/label)
b [= "-2"](https://arbital.com/p/label)
c [= "-1"](https://arbital.com/p/label)
d [= "0"](https://arbital.com/p/label)
e [= "1"](https://arbital.com/p/label)
f [= "2"](https://arbital.com/p/label)
g [= "3"](https://arbital.com/p/label)
rankdir = BT;
a -> b
b -> c
c -> d
d -> e
e -> f
f -> g
}
%%%
Power sets
=========
For any set $X$, the power set of $X$ ordered by the set inclusion relation $\subseteq$ forms a poset $\langle \mathcal{P}(X), \subseteq \rangle$. $\subseteq$ is clearly [reflexive](https://arbital.com/p/5dy), since any set is a subset of itself. For $A,B \in \mathcal{P}(X)$, $A \subseteq B$ and $B \subseteq A$ combine to give $x \in A \Leftrightarrow x \in B$ which means $A = B$. Thus, $\subseteq$ is [antisymmetric](https://arbital.com/p/5lt). Finally, for $A, B, C \in \mathcal{P}(X)$, $A \subseteq B$ and $B \subseteq C$ give $x \in A \Rightarrow x \in B$ and $x \in B \Rightarrow x \in C$, and so the [transitivity](https://arbital.com/p/573) of $\subseteq$ follows from the transitivity of $\Rightarrow$.
Note that the strict subset relation $\subset$ is the strict ordering derived from the poset $\langle \mathcal{P}(X), \subseteq \rangle$.
Divisibility on the natural numbers
===========================
Let [$\mathbb N$](https://arbital.com/p/45h) be the set of natural numbers including zero, and let $|$ be the divides relation, where $a|b$ whenever there exists an integer $k$ such that $ak=b$. Then $\langle \mathbb{N}, | \rangle$ is a poset. $|$ is reflexive because, letting k=1, any natural number divides itself. To see that $|$ is anti-symmetric, suppose $a|b$ and $b|a$. Then there exist integers $k_1$ and $k_2$ such that $a = k_1b$ and $b = k_2a$. By substitution, we have $a = k_1k_2a$. Thus, if either $k$ is $0$, then both $a$ and $b$ must be $0$. Otherwise, both $k$'s must equal $1$ so that $a = k_1k_2a$ holds. Either way, $a = b$, and so $|$ is anti-symmetric. To see that $|$ is transitive, suppose that $a|b$ and $b|c$. This implies the existence of integers $k_1$ and $k_2$ such that $a = k_1b$ and $b = k_2c$. Since by substitution $a = k_1k_2c$, we have $a|c$. |
ebbc80e9-7848-4c90-b38e-ad23ab00def4 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | AGI Safety Fundamentals programme is contracting a low-code engineer
TL;DR: Help the [AGI Safety Fundamentals](https://www.eacambridge.org/agi-safety-fundamentals), [Alternative Protein Fundamentals](https://www.eacambridge.org/alternative-protein-fundamentals), and other programs by automating our manual work to support larger cohorts of course participants, more frequently.
[Register interest here](https://airtable.com/shrA7PpcPjG94mCvo) [5 mins, CV not required if you don’t have one].
Job description
===============
We are looking to find a low-code contractor who can help us to scale and run our seminar programmes. We have worked with an engineer to build our systems so far, but they are moving on.
Here is a list of tools and apps we use to make our programmes run:
* The backbone of the programme is run with no-code tools (Airtable database, [Make](https://www.make.com/) automations to interface with Slack and Google Calendar).
* One python script which clusters participants with a similar background based on some numerical metrics (not currently integrated in Airtable, but we’d like it to be).
* One vercel webapp to collect participants’ and facilitators’ time availability.
* One javascript algorithm which groups ~50 previously-clustered participants & facilitators into cohorts of ~6 participants + 1 facilitator.
* We would like (you) to introduce more extensions using similar tools in the future.
We’re offering part time, contract work
---------------------------------------
**We’re looking for part-time, contract support for now**. We would offer a retainer[[1]](#fn4zvh0oqgd4i), and would pay an hourly rate for additional work.
Further logistical details:
* We need more responsiveness when kicking off programs, in case there are bugs (4 weeks, ~3 times a year).
* There will be development work to do in between programmes.
* We are open to (and slightly prefer) full time contract work for the first couple of months to get us up and running.
* You can let us know what would work for you in [the form](https://airtable.com/shrA7PpcPjG94mCvo).
Salary
------
**We are offering $50 / hour.** Let us know if this salary would prevent you from taking the role in [the form](https://airtable.com/shrA7PpcPjG94mCvo).
*Were you hoping for a full time opportunity?*
----------------------------------------------
*We're also likely to want to build out an entire new software platform for these programmes over the next 6 months, and we'll be looking for excellent software engineers who can help us build a team to achieve this.*
*We currently use Slack, Zoom, vercel, Airtable forms etc and tie these together using low-code tools like Airtable and Zapier. We are interested in bringing this under one platform, to enhance user experience and retention. We expect to have other software needs to manage our community and websites hosting opportunities downstream of our programmes, too.*
*You can register interest for the full time Head of Software* [*here*](https://airtable.com/shr3iDPiPvgde6FuA)*, though please note this role is not as fleshed-out as the part-time role described in this post at this point.*
Why should you work on this project?
====================================
Scale
-----
These programmes have offered the first scalable, EA-originating onboarding programmes to the field of AI safety and alternative proteins. The growth trajectory for both programmes has been excitingly steep.
The AGI Safety Fundamentals went from 15->230->520 participants. We now have 650 registrations of interest for the next round, before promoting the programme through usual channels (this is as many people who ultimately applied to round 2).
We also run the Alternative Proteins Fundamentals, which has seen 400 participants in its 2nd round, and we plan to build out many more programmes using the same infrastructure in the future.
All together, we expect the infrastructure you build in this role to support 5,000+ people in the next 1-5 years. We get that with the conservative estimate that we run 2 programmes, 2.5 times/year with 200 participants each time. Additionally, we expect to add ~10 more programmes in the coming years.
Building quality infrastructure will increase our teams’ capacity to continue to iterate and improve to deliver a quality programme.
Impact on participants
----------------------
For the full details, check our [retrospective](https://forum.effectivealtruism.org/posts/QNhpbvyAHZwBiyKmB/retrospective-on-the-summer-2021-agi-safety-fundamentals) on the 2nd iteration of the AGI safety fundamentals programme. Pulling out some highlights:
The programme helps people to figure out their career priorities. Programme graduates reported being more interested in working on AI safety after our programme, in general. On the individual level, some people became less likely to work on safety, after learning more about it during the programme. Self-reported in final feedback form.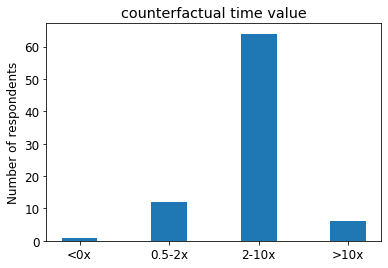Participants in our programme overwhelmingly thought that the programme was >= 2 times more time-efficient to learn about and get involved AI safety, than what they would have done otherwise. This was self-reported in our final feedback form.### Alumni
These are some anecdotal cases of what alumni in our last iteration of the programme have gone on to do:
* At least 1 Machine Learning Engineer at 3 top software/ML companies.
* Member of technical staff at Redwood research
* Independent researcher
* SERI MATS and MLAB participants, furthering their career in AI safety research
* Access to our database of participants who gave their permission to share their information led to:
+ Research fellow at Rethink Priorities (1 offer made sourced from our database, 'major contribution' attributed to AGISF)
+ Open Philanthropy's longtermist movement building team (2 counterfactual offers made sourced from our database, resulting in 1 hire)
* Likely more that we likely haven’t tracked
Evidence of future impact
-------------------------
* We’re getting more participants interested (so far exponentially, though we expect this to level off at some point and won't necessarily scale the programmes exponentially)
* We want to produce more content and more programs, including
+ More in-depth programmes on AI safety
+ Programmes in different fields
* We want to package our infrastructure up so that local groups can use it to easily run a high-quality local version. (We expect local versions are better for making connections, where possible)
What would be *your* impact?
============================
**Our infrastructure has been a major factor** **preventing us from running the programme more frequently, at scale**. There are aspects of it which do not scale, which uses a lot of organiser time.
We want to have the ability to process 500+ people at a time without much additional organiser overhead. This will require an overhaul of our process for e.g. allowing people to join a different cohort if they can’t make their regular slot (5-10 hours organiser time / week for 500 people), grouping cohorts (80 hours / week for 2-3 weeks at the start of the programme), etc.
We are hiring for this role to professionalise and scale our seminar programme infrastructure. With your help, we’ll be able to:
1. Run the programme more frequently (at least 1 more time per year, per programme).
2. Offer a higher-quality experience for participants. For example, the first thing we’d focus on is putting on more events for programme participants, e.g. networking opportunities between PhD participants, targeted advice & networking for software engineers from alignment research engineers, etc.
Your role and responsibilities
==============================
The role would involve improving or rewriting our current systems so that we can run the seminar programme as we’ve run them before. See the summary of the current system at the top of the post.
In the future, we’d like to add new features which you would develop. We’d work together to explain our requirements, and discuss potential solutions with you.
Scroll to the bottom of the post if you have more questions about the nature of the role.
Example tasks you might do
--------------------------
* Add a feature that lets the participants choose and join another cohort (from a list of cohorts specific to that participant), for a week that they’re unavailable at their usual time.
* Add a tool that groups participants based on some measures of their background knowledge
You’ll be the tech lead
-----------------------
We will know what we need from the product perspective, but you’ll have ownership over how to implement it.
### We can’t offer technical mentorship
Since you’re the tech lead - we won’t be able to provide technical mentorship. We are otherwise willing and expect to work closely with you with regular check-ins to help you stay on-task, though.
If you can find your own mentorship or training - we are open to provide a budget for it.
What’s the application process?
===============================
Click [the form](https://airtable.com/shrA7PpcPjG94mCvo) to find out fastest!
We want to keep this light touch at this stage. We’ll ask for one of a LinkedIn, CV or paragraph about yourself. We’ll also ask for a brief couple of sentences about why you’re interested, and your availability.
We will follow up with respondents to find out which arrangements would suit which people, and would offer a work trial to those whom we’re mutually excited to proceed with.
AMA
===
Please ask us any questions in the comments, by emailing jamie@[thisdomain](http://eacambridge.org/), or submit an anonymous question / feedback [here](https://airtable.com/shr8eLdZ491hqAjZp).
–
*Special thanks to* [*Yonatan Cale*](https://forum.effectivealtruism.org/users/hibukki) *for his help and advice in creating this post.*
1. **[^](#fnref4zvh0oqgd4i)**What we'd expect to offer for a **retainer** contract: we agree on a fixed number of hours / month (guessing 20-40 hours / month), for a fixed number of months (about 6 months), that we will pay for regardless of how much you work. We pay you in addition to that retainer if you work more hours. We expect there will be plenty of work to do, but are happy to offer this as security for you if you were to join us as a contractor. |
7e2c8cd3-7f5f-4fad-9c04-81765440eaf0 | trentmkelly/LessWrong-43k | LessWrong | People with Experience in Wikipedia Editing?
Hi all,
At the Singularity Institute we're looking for a volunteer with experience making edits to Wikipedia. The quality of some Wikipedia pages related to our subject matter could use improvement, but we would like to consult with someone who has an editing background on the way to go about it.
Please get in touch with me at michael@intelligence.org.
Thank you! |
fdd15e65-2ea1-43db-bef0-f02ab3240a81 | trentmkelly/LessWrong-43k | LessWrong | I got dysentery so you don’t have to
This summer, I participated in a human challenge trial at the University of Maryland. I spent the days just prior to my 30th birthday sick with shigellosis.
What? Why?
Dysentery is an acute disease in which pathogens attack the intestine. It is most often caused by the bacteria Shigella. It spreads via the fecal-oral route. It requires an astonishingly low number of pathogens to make a person sick – so it spreads quickly, especially in bad hygienic conditions or anywhere water can get tainted with feces.
It kills about 70,000 people a year, 30,000 of whom are children under the age of 5. Almost all of these cases and deaths are among very poor people.
The primary mechanism by which dysentery kills people is dehydration. The person loses fluids to diarrhea and for whatever reason (lack of knowledge, energy, water, etc) cannot regain them sufficiently. Shigella bacteria are increasingly resistant to antibiotics. A disease easily treatable by lots of fluids and antibiotics is becoming more lethal.
Can someone do something?
The deal with human challenge trials
Clinical trials in general are expensive to run but pretty common; clinical trials where you are given the disease – “challenged”, AKA “human challenge trials” – are very rare. The regular way to investigate a possible treatment is to make a study plan, then find people who have the disease and offer to enroll them in the experimental treatment. Challenge trials are less common, but often more valuable for research – shigellosis is a fast-acting disease that is imminently treatable by antibiotics and uncommon in the US. It would be very difficult to test an alternative shigellosis treatment in the US in the conventional way, but it’s a great candidate for challenge trials.
I’d signed up for email alerts on upcoming challenge trials at the nearby University of Maryland, and got one about an upcoming study. It caught my eye that it was for a phage-based treatment. Bacteriophages are really promising antibact |
b9af5cd8-114a-4273-bac1-d9af246b6858 | trentmkelly/LessWrong-43k | LessWrong | [Closed] Job Offering: Help Communicate Infrabayesianism
Infrabayesianism seems to me (Abram) like a very promising framework for addressing at least some of the problems of AI alignment.
* Like logical induction, it solves the realizability problem, creating an epistemic theory suitable for embedded agents.
* Unlike logical induction, and unlike standard Bayesian decision theory, it presents a theory of epistemics directly relevant to proving decision-theoretic results (in particular, useful learning-theoretic guarantees). Logical induction and standard Bayesian decision theories both can produce meaningful loss-bounding guarantees with respect to predictive error, but bounding decision error appears challenging for these approaches. Infrabayes provides a systematic way to get around this problem. Since decision error is much more meaningful for bounding risk, this seems highly relevant to AI safety.
* Being a new perspective on very basic issues, Infrabayesianism (or perhaps successors to the theory) may turn out to shed light on a number of other important questions.
(For more information on InfraBayes, see the infrabayesianism sequence.)
However, I believe infrabayesianism appears to have a communication problem. I've chatted with several people who have strongly "bounced off" the existing write-ups. (I'm tempted to conclude this is a near-universal experience.)
There was even a post asking whether a big progress write-up -- applying InfraBayes to naturalized induction -- had simply fallen through the cracks.
Personally, even though I've carefully worked through the first three posts and re-visited my notes to study them more than once, I still am not fluent enough to confidently apply the concepts in my own work when they seem relevant.
I would like to change this situation if possible. It's not obvious to me what the best solution is, but it seems to me like it could be possible to find someone who can help.
Properties which would make an applicant interesting:
* Must be capable of fully understanding |
bd44bccb-bd97-4504-a504-305084420cb4 | trentmkelly/LessWrong-43k | LessWrong | Measuring hardware overhang
Measuring hardware overhang
Summary
How can we measure a potential AI or hardware overhang? For the problem of chess, modern algorithms gained two orders of magnitude in compute (or ten years in time) compared to older versions. While it took the supercomputer "Deep Blue" to win over world champion Gary Kasparov in 1997, today's Stockfish program achieves the same ELO level on a 486-DX4-100 MHz from 1994. In contrast, the scaling of neural network chess algorithms to slower hardware is worse (and more difficult to implement) compared to classical algorithms. Similarly, future algorithms will likely be able to better leverage today's hardware by 2-3 orders of magnitude. I would be interested in extending this scaling relation to AI problems other than chess to check its universality.
Introduction
Hardware overhang is a situation where sufficient compute is available, but the algorithms are suboptimal. It is relevant if we build AGI with large initial build, but cheaper run costs. Once built, the AGI might run on many comparably slow machines. That's a hardware overhang with a risk of exponential speed-up. This asymmetry exists for current neural networks: Creating them requires orders of magnitude more compute than running them. On the other hand, in The Bitter Lesson by Rich Sutton it is argued that the increase in computation is much more important (orders of magnitude) than clever algorithms (factor of two or less). In the following, I will examine the current state of the algorithm-art using chess as an example.
The example of chess
One of the most well-researched AI topics is chess. It has a long history of algorithms going back to a program on the 1956 MANIAC. It is comparatively easy to measure the quality of a player by its ELO score. As an instructive example, we examine the most symbolic event in computer chess. In 1997, the IBM supercomputer "Deep Blue" defeated the reigning world chess champion under tournament conditions. The win was taken as a sig |
dce7020b-f0c6-4831-908d-9da6d25d6c6b | StampyAI/alignment-research-dataset/arxiv | Arxiv | Action Advising with Advice Imitation in Deep Reinforcement Learning
1. Introduction
----------------
Deep reinforcement learning (RL) has made it possible to build end-to-end learning agents without having to handcraft task-specific features, as it is showcased in various challenging domains such as StarCraft II Vinyals
et al. ([2017](#bib.bib30)) and DotA II Berner et al. ([2019](#bib.bib4)) in the recent years.
These feats make deep RL a great candidate to be employed in complex real-world sequential decision-making problems.
However, achieving the reported levels of performance usually requires millions of environment interactions due to the deep learning induced complexity as well as the exploration challenges in RL itself.
Even though this may seem negligible in most of the experimental domains considering the immense amount of computing power available to be utilised through parallel simulations, it usually poses a problem in the real-world scenarios due to the interaction costs and safety concerns.
Furthermore, since RL is an inherently online learning approach, it is desired for the agents to be continually learning after they have been deployed too.
For these reasons, it is crucial to improve sample efficiency in deep RL, which is actively investigated in several lines of research.
One promising approach to tackle this setback is leveraging some legacy knowledge acquired from other entities such as agents, programs or humans.
Peer-to-peer knowledge transfer in deep RL has been investigated in various forms to this date da Silva
et al. ([2020b](#bib.bib10)).
A popular approach, namely Learning from Demonstrations (LfD), focuses on incorporating a previously recorded dataset in the learning process.
By taking some dataset generated by another competent Hester et al. ([2018](#bib.bib16)) or imperfect Gao
et al. ([2018](#bib.bib14)) peer, the learning agent tries to make the most out of the available information through off-policy learning and extra loss terms.
Another promising, yet under-investigated class of techniques, namely Action Advising Torrey and Taylor ([2013](#bib.bib28)), aims to take advantage of a competent peer interactively when there is no pre-recorded data.
The learning agent acquires advice in the form of actions from a teacher for a limited number of times defined by a budget that resembles the practical limitations of communication and attention.
This approach is especially beneficial in the situations where there is no way to access the actual task before the online training, data collection is costly or the relevant data that will do the most contribution in the learning can not be determined.
Action advising methods in deep RL today are quite limited and therefore have several shortcomings.
An important one of these as we address in this study is not being able to make further use of the advice beyond its collection.
The scope of the action advising problem is generally limited to answering “*when* to ask for advice?”.
It is commonly not of any interest how the collected advice is utilised by the student agent’s task-level RL algorithm, e.g., how it is stored, replayed, discarded; especially since these are dealt with by the studies that focus on off-policy experience replay dynamics in general (Schaul
et al., [2016](#bib.bib24); De Bruin et al., [2015](#bib.bib11)), or the specific case of having demonstration data as in LfD.
However, even without interfering with the student’s task-level learning mechanism, it is still possible to make more of advice through reuse.
Current action advising algorithms in deep RL have no way of telling if they have asked for advice in a very similar or even identical state already in the learning session.
Thus, they do not record these in any way, and usually end up requesting advice from the teacher redundantly.
In order to address this, we incorporate a separate neural network to do behavioural cloning (Pomerleau, [1991](#bib.bib23)) on the samples (state-action pairs which are equal to the state-advice pairs in the context of action advising) collected from the teacher.
This network then will be able to serve as a state-conditional generative model that will let us sample advice for any given observation.
However, since this model should also have a notion of distinguishing the recorded states from the unrecorded ones to avoid producing false advice for unfamiliar states, we also propose incorporating a well known regularisation mechanism called Dropout (Srivastava et al., [2014](#bib.bib25)) within this network to serve as an epistemic uncertainty estimator (Gal and
Ghahramani, [2016](#bib.bib13)) which will allow the student to determine whether the state is recorded by comparing this estimation with a threshold.
Our contributions in this study are as follows:
First, we show that it is possible to generalise teacher advice across similar states in deep RL with high accuracy.
Second, we present a RL algorithm-agnostic approach to memorise and imitate the collected advice that is suitable with the deep RL settings.
Finally, we demonstrate that advice reuse via imitation provides significant boosts in the learning performance in deep RL even when it is paired with a simple baseline like early advising.
2. Related Work
----------------
The majority of action advising studies to date have been conducted in classical RL settings.
Torrey and Taylor ([2013](#bib.bib28)) was the first study to formalise action advising within a budget constrained teacher-student framework.
Specifically, they studied the teacher-initiated scenario and came up with several heuristics to distribute the advising budget to maximise the student’s learning performance, such as early advising and importance advising.
This work was then extended to introduce several new state importance metrics Taylor et al. ([2014](#bib.bib27)).
In Zimmer
et al. ([2014](#bib.bib34)), action advising problem was approached as a meta-RL problem itself.
Instead of relying on heuristics, the authors attempted to learn the optimal way to distribute advising budget by using a measurement of the student’s learning acceleration as the meta-level reward.
Besides these studies that only consider the teacher’s perspective, Amir
et al. ([2016](#bib.bib2)) explored student-initiated and jointly-initiated variants considering the impracticality of requiring the teacher’s attention constantly.
They achieved results on-par with the previous work without requiring the teacher full-time.
Zhan
et al. ([2016](#bib.bib32)) shed light in the theoretical aspects of action advising problem by using a more general setting involving multiple teachers and demonstrated the effects of having good or bad teachers.
In da Silva
et al. ([2017](#bib.bib8)), the authors adopted the teacher-student framework in cooperative multi-agent RL where the agents learn from scratch and hold no assumptions of their teacher roles and expertise.
By proposing state counting as a new heuristic in this setting, they successfully accelerate team-wide learning of independent learners.
More recently, learning to teach concepts was further investigated in Fachantidis
et al. ([2019](#bib.bib12)) with a focus on the properties that make for a good teacher.
In this work, besides learning *when* to advise, the teachers also learn *what* to advise.
Similarly, Omidshafiei et al. ([2019](#bib.bib22)) adopted the meta RL approach, this time as a deep RL scale.
They considered a team of two agents that learn to cooperate from scratch in tabular multi-agent tasks.
Zhu
et al. ([2020](#bib.bib33)) is one of the most recent studies conducted in tabular settings.
The idea of reusing the previously collected advice in order to make the most out of a given small budget was studied.
By devising several heuristics to serve as reusing schedules, they demonstrated promising results that outperform the algorithms incapable of advice reusing.
The domain of deep RL is a fairly new area for action advising where the primary choice is the student-initiated approaches.
Chen
et al. ([2018](#bib.bib7)) is one of the first studies to explore the idea of action advising in deep RL.
They combined the LfD paradigm Hester et al. ([2018](#bib.bib16)) with interactive advice exchange under the name of *active learning from demonstrations* to collect demonstration data on-the-fly to be utilised via imitation capable loss terms as used in Hester et al. ([2018](#bib.bib16)).
Furthermore, they proposed using epistemic uncertainty estimations of the student agent’s model to time this advice.
Later, Kim et al. ([2020](#bib.bib19)) was proposed as an extension of Omidshafiei et al. ([2019](#bib.bib22)).
This time, meta deep RL to address learning to teach idea was applied in the problems that are deep RL in the task-level.
Through multiple centralised learning sessions, agents in a set of cooperative multi-agent tasks were made to learn taking student and teacher roles as needed in order to improve team-wide knowledge.
To do so, they adopted *hierarchical reinforcement learning* (Nachum
et al., [2018](#bib.bib21)) to deal with the meta-level credit assignment problem of the teacher actions.
In Ilhan et al. ([2019](#bib.bib17)), the formal action advising framework was scaled up to deep RL level for the first time.
Similarly to da Silva
et al. ([2017](#bib.bib8)), a team of agents in a cooperative multi-agent scenario were made to exchange advice by embracing teacher or student roles as needed.
This was accomplished by using *random network distillation* (RND) Burda
et al. ([2018](#bib.bib5)) to replace state counting with state novelty, hence introducing a new heuristic that is applicable in non-linear function approximation domain.
Later on, da Silva et al. ([2020a](#bib.bib9)) proposed the idea of uncertainty-based action advising as in Chen
et al. ([2018](#bib.bib7)), though without employing any additional loss terms.
To access uncertainty estimations, they studied the case of student agent with a multi-headed network architecture in particular.
In a more recent work Ilhan
and Pérez-Liébana ([2020](#bib.bib18)), student-initiated scenario is further studied to devise a more robust heuristic able to handle extended periods of absence of teacher as well as having no requirements in the student’s task-level architecture by completely decoupling the module that is responsible for advice timing from the student’s model.
Even though this method also uses the state novelty heuristic proposed in Ilhan et al. ([2019](#bib.bib17)), they operated on the advised states directly rather than every encountered state.
Clearly, none of the related work in deep RL addressed further utilisation of collected advice, besides Chen
et al. ([2018](#bib.bib7)) which does it through interfering with the student’s learning mechanism (via a custom loss function), unlike our approach.
The study that is closest to the idea we present in this paper is Zhu
et al. ([2020](#bib.bib33)); though, it is limited to the tabular RL domains only.
Such a setting makes it more straightforward for the agent to precisely memorise the state-advice pairs in a look-up table to be able to reuse anytime.
Furthermore, the executed advice usually has an instantaneous impact on the agent behaviour in the case of tabular RL, which presents unique options to assess their usefulness.
Since these advantages are absent in deep RL, our work deals with different challenges than those in Zhu
et al. ([2020](#bib.bib33)).
3. Background
--------------
###
3.1. Reinforcement Learning
Reinforcement Learning (RL) Sutton and Barto ([2018](#bib.bib26)) is a trial-and-error learning paradigm that deals with sequential decision-making problems where the environment dynamics are unknown.
In RL, Markov Decision Process (MDP) formalisation is used to model the environment and the interactions within.
According to this, an environment is defined by a tuple ⟨S,A,R,T,γ⟩ where S is the finite set of states, A is the finite set of actions, R:S×A×S→R is the reward function, T:S×A→Δ(S) defines the state transitions and γ∈[0,1] is the discount factor.
The agent to interact within an environment receives a state observation st at each timestep t, and executes an action at to advance to the next state st+1 while obtaining a reward rt.
Actions of the agent are determined by its policy π:S→A, and the agent’s objective is to construct a policy that maximises the expected sum of discounted rewards in any timestep, which can be formulated as ∑Tk=0γkrt+k for a horizon of T timesteps.
###
3.2. Deep Q-Networks
Deep Q-Network (DQN) Mnih et al. ([2013](#bib.bib20)) is a prominent RL algorithm that tries to obtain the optimal policy in complex domains by employing non-linear function approximation via neural networks to learn mapping any given state into state-action values (Q(s,a)).
Specifically, a neural network Gθ with randomly initialised weights θ is trained over the course of learning to minimise the loss (rk+1+γmaxa′Q¯θ(sk+1,a′)−Qθ(sk,a))2 with batches of transitions that are collected on-the-fly and stored in a component called replay memory.
Periodically using the samples from this memory, which is referred to as *experience replay*, is an essential mechanism in DQNs.
As well as improving sample efficiency by reusing samples multiple times, it also breaks the non-i.i.d. property of sequentially collected data.
Furthermore, DQNs also employ another trick to aid convergence.
Since both the Q-value targets and network weights are learned at the same time, there is a significant amount of non-stationarity seen in these target values used in the loss function, which may introduce further instabilities due to the bootstrapped updates.
In order to alleviate this, a separate copy of G is held with weights ¯θ that are updated periodically with copies of θ, to be used in the target term in the loss function.
Due to its end-to-end learning and discarding the need for hand-crafted features, DQN has become a very popular approach in the field of RL that is followed by further enhancements over the years.
The most substantial ones among these are identified and combined in a version called Rainbow DQN Hessel
et al. ([2018](#bib.bib15)).
In our study, we employ double Q-learning van Hasselt
et al. ([2016](#bib.bib29)) and dueling networks Wang et al. ([2016](#bib.bib31)) among these essential modifications.
###
3.3. Behavioural Cloning
Behavioural cloning (Pomerleau, [1991](#bib.bib23)) refers to the ability of imitating a demonstrated behaviour.
It is especially useful in the situations where it is more difficult to specify reward functions than to provide some expert demonstration.
The simplest way of achieving this in the domain of deep RL is to train a non-linear function approximator, e.g. neural network Gω with weights ω, through supervised learning on the provided demonstration samples in the form of state-action pairs denoted by ⟨s,a⟩.
This is done by treating these as i.i.d. samples and minimising an appropriate loss function such as L(ω)=∑(s,a)∈D−logGω(a∣s).
Consequently, a state-conditional generative model is obtained that is capable of imitating the expert actions for the demonstrated states.
In practice, however, this approach is unreliable to be used as a task policy as it is.
This is because the agent often encounters states that are not contained in the provided dataset, and therefore, end up exhibiting sub-optimal behaviour in these states which lead to further divergence in the trajectories.
However, adopting the idea in this most basic form is sufficient in our study as it provides us the adequate functionality of generating actions correctly for the states we ensure Gω is trained with.
###
3.4. Dropout
Dropout Srivastava et al. ([2014](#bib.bib25)) is a simple yet powerful regularisation method developed to prevent neural networks from overfitting.
Its working principle is based on involving some random noise in the hidden layers of the networks.
A neural network layer with the feed-forward operation can be described as y=f(wx+b), where the output is y∈Rq, the input is x∈Rp, the network weights for this particular layer are w∈Rq×p and b∈Rq, f is any activation function, for input size of p and output size of q.
In a layer with dropout, this equation takes the form of y=f(w~x+b) where ~x=r∗x represent randomly dropped out input which is determined by r∼Bernoulli(p).
Hence, the learning process gets to be regularised with this random noise which is re-determined in every forward pass.
The value p controls the rate of dropout and is responsible for the regularisation strength.
In addition to its regularisation capability, dropout can also be used to estimate epistemic uncertainty of a neural network model, as shown in Gal and
Ghahramani ([2016](#bib.bib13)).
For any particular input, performing forward passes multiple times yield different outputs due to the dropout induced stochasticity, which can be treated as an approximation of probabilistic deep Gaussian process.
Following this idea, the variance in these output values can therefore be interpreted as a representation of the model’s uncertainty.
Finally, since these forward passes can be performed concurrently, this approach provides a practically viable option to evaluate the uncertainty in deep learning models.
###
3.5. Action Advising
Action advising Torrey and Taylor ([2013](#bib.bib28)) is a knowledge exchange approach built on the teacher-student paradigm.
Requiring only a common set of actions and a communication protocol between the teacher and the student makes this a very flexible framework.
In its originally proposed form, the learning agent (student) is observed by an experienced peer (teacher) and is given action advice to be treated as high quality explorative actions to accelerate its learning.
However, maximum number of these interactions are limited with a budget constraint considering the real-world conditions where communication and attention span are usually limited.
Therefore, the approaches that adopt this idea address the question of *when* to exchange advice in order to maximise the learning performance.
This is usually accomplished either by performing meta-learning over multiple learning sessions or by following heuristics as we do in this study.
Currently, there are several heuristic approaches with varying complexities and advantages in the deep RL domain such as early advising, random advising, uncertainty-based advising and novelty-based advising.
In this paper, we incorporate early advising as the baseline to build our method on.
Despite its simplicity, this method performs very well in deep RL especially with small budget scenarios Ilhan
and Pérez-Liébana ([2020](#bib.bib18)).
This is because the earlier samples have far more impact on the learning in deep RL models since providing high quality transitions that contains rewards provide more stable Q-value targets early on which can significantly reduce the non-stationarity in the learning process.
Finally, since the teacher is followed consistently in this approach, the student is more likely to encounter the critical states that would require deep exploration. This is an important property to have when it comes to spending the budget wisely.
4. Proposed Approach
---------------------
We follow the standard MDP formalisation given in Section [3.1](#S3.SS1 "3.1. Reinforcement Learning ‣ 3. Background ‣ Action Advising with Advice Imitation in Deep Reinforcement Learning") in our problem definition.
In this setting, a student agent that employs an off-policy deep RL algorithm performs learning in an episodic single-agent environment through trial-and-error interactions.
It receives an observation st and then executes an action at generated by its policy πS to receive a reward rt at each timestep t, in order to maximise its cumulative discounted rewards in any episode.
According to the teacher-student paradigm (Section [3.5](#S3.SS5 "3.5. Action Advising ‣ 3. Background ‣ Action Advising with Advice Imitation in Deep Reinforcement Learning")) we adopt, there is also an isolated peer that is competent in this same task, and is referred to as the teacher.
For a limited number of times defined by the action advising budget b, the student is allowed to acquire an action advice from the teacher for the particular state s it is in.
While the teacher can have its own teaching strategies to generate actions to advise, in our setting, we determine the action to be advised greedily from the teacher’s behaviour policy as πT(s).
This is a commonly followed approach with the assumption of the teacher and the student’s optimal task-level strategies are equivalent.
The student considers this advice as a part of a high-reward strategy and follows them upon collection.
In this final form of the problem, the student’s objective is to spend its budget at the most appropriate times to maximise its learning performance.
We aim to devise a method that will enable the student to memorise the collected advice to be able to re-execute them in the similar states; therefore, avoiding wasting its budget in redundant states and potentially being able to follow the teacher advice many more times than its budget.
In tabular RL, this is trivial to achieve simply by storing the advised actions paired with the states in a look-up table.
When it comes to deep RL where any particular observation is not expected to be encountered more than once, however, there needs to be a generalisable approach.
For this purpose, we propose the student agent to employ a separate behavioural cloning module, which consists of a neural network as the state-conditional generative model Gω:S→A.
By training Gω in a supervised fashion with the obtained state-advice pairs (stored in a buffer D) to minimise the negative log-likelihood loss L(ω)=∑(s,a)∈D−logGω(a∣s), the student can imitate the teacher’s advice to reuse them accordingly.
However, this method does not have any mechanisms to prevent the student from generating incorrect advice from the states it has not collected.
Therefore, we also employ Dropout regularisation in Gω in order to grant this behavioural cloning module a notion of epistemic uncertainty through measuring the variance in the outputs obtained from multiple forward passes for a particular input state.
We denote this uncertainty estimation by Gμω(s).
The states Gω is trained on will be less susceptible to the variance caused by the dropout and yield smaller uncertainty values.
By this means, the student can determine how likely a state is to be already recorded as advised when it comes to reusing them, and can make a decision according to a threshold.
An obvious question regarding the feasibility of reusing advice in deep RL arises here: can the teacher’s advice be generalised over similar states accurately?
As we investigate in the experiments in Section [7](#S7 "7. Results and Discussion ‣ Action Advising with Advice Imitation in Deep Reinforcement Learning"), actions generated by the teacher policy usually span over similar states.
Clearly, the uncertainty threshold to consider a state as recorded is responsible for the trade-off between the reusing amount and the accuracy of the self-generated teacher advice.
A small threshold value makes the student reuse its budget in fewer states with higher accuracy, whereas a larger value results in more frequent reusing with lower accuracy.
The detailed breakdown of our approach is summarised with an emphasis on the proposed modifications as follows (as also shown in Algorithm [1](#alg1 "Algorithm 1 ‣ 4. Proposed Approach ‣ Action Advising with Advice Imitation in Deep Reinforcement Learning")):
The student starts with a randomly initialised Gω and empty D.
At each timestep t with the (observed) state st and an undecided action at, the student first checks if D has any new samples.
As soon as D reaches the size defined by nD, Gω is trained with mini-batch gradient descent over the samples in D for kbc iterations.
Afterwards, if the environment was reset (a new episode started), the student determines whether to enable advice reuse via imitation for this particular episode with a probability of εreuse, which is combined with other conditions too later on in the algorithm.
The idea behind employing this condition is to ensure that the student can also execute its own exploration policy in order to increase the data diversity in its replay memory, which is crucial to improve the quality of learning.
Furthermore, determining this variable on an episodic basis lets the agent follow consistent policies in the exploration steps, rather than dithering between two policies.
In the next phase, the student deals with the advice collection.
We adopt the simple yet strong baseline of early advising here.
According to this, the agent just collects advice without any conditions until its budget runs out.
In the next phase, the student decides whether to reuse advice generated by its Gω.
There are several conditions to be satisfied for this to occur in addition to the advice reuse being allowed for this particular episode.
Firstly, at must be non-determined, which implies the agent has not collected any advice from the teacher already.
Secondly, Gω must be already trained, so that it can generate meaningful actions.
Then, the student also checks if its own action πS(a∣st) is explorative.
This condition limits the action advising actions to the exploration steps only in order to prevent overriding the student’s actual policy which may result in lack of Q-value corrections and cause deteriorative effects when too much advising occurs.
Finally, it is checked whether Gμω(st) is smaller than the reuse threshold τreuse.
Incorporating such threshold is important to limit the imitated advice to the states that have low uncertainty according to Gω to achieve higher accuracy of generating correct teacher actions.
On one hand, having this threshold too high would make the student consistently follow Gω which would result in a dataset with lower diversity.
On the other hand, if τreuse is set too small, then Gω would be ignored in the most of the cases and the student would be following its own exploration policy.
After all these steps, if at is still non-determined, the student follows its own policy and decide at by πS(a∣st).
1: Input:
action advising budget b,
student policy πS,
teacher policy πT,
number of training iterations tmax,
advice reuse uncertainty threshold τreuse,
advice reuse probability (episodic) εreuse,
behavioural cloning variables:
* generative network Gω (Gμω denotes uncertainty)
* dataset D (size(D) denotes the number of samples in D)
* dataset size to trigger training nD
* number of training iterations kbc
2: D←∅ \hfill▹ initialise empty dataset
3: *reuse allowed* ←False \hfill▹ set advice reuse off by default
4: for training steps t∈{1,2,…tmax} do
5: if size(D)==nD then
6: Train Gω for kbc iterations \hfill▹ behavioural cloning
7: end if
8: at←None \hfill▹ set action as non-determined
9: if Env is reset then
10: u∼U(0,1) \hfill▹ draw a number uniformly at random
11: if u<εreuse then
12: *reuse allowed* ←True
13: else
14: *reuse allowed* ←False
15: end if
16: end if
17: get observation st∼Env if Env is reset
18: if b>0 then
19: at∼πT \hfill▹ collect advice
20: add ⟨st,at⟩ to D
21: b←b−1 \hfill▹ decrement budget by 1
22: end if
23: if at is None and πS(a∣st) is explorative and Gω is trained and Gμω(st)<τreuse and *reuse allowed* then
24: at←argmaxaGω(a∣st) \hfill▹ generate imitated advice
25: end if
26: if at is None then
27: at∼πS \hfill▹ e.g., epsilon-greedy
28: end if
29: Execute at and obtain rt, st+1∼Env
30: Update task-level model, e.g., DQN.
31: st←st+1
32: end for
Algorithm 1 Action Advising with Advice Imitation
5. Evaluation Domain
---------------------
| | | |
| --- | --- | --- |
|
(a) Enduro
|
(b) Freeway
|
(c) Pong
|
Figure 1. Screenshots from the games of Enduro (a), Freeway (b) and Pong (c) within the Arcade Learning Environment.
In order to have a significant complexity level as well as the challenges that are relevant to the deep RL methods in our experiments, we chose three Atari 2600 games from the commonly used Arcade Learning Environment (ALE) Bellemare et al. ([2013](#bib.bib3)) as our evaluation domain:
* Enduro:
The player controls a racing car in a long-distance track over multiple in-game days.
In each day, if the player manages to pass a certain number of other cars (200 in the first day, 300 in the rest) in the race, it gets to advance to the next day.
Progression during the days is visualised by different colour schemes that resemble the day-night cycle.
Furthermore, there are other factors of seasonal events that affect the gameplay such as fogs and icy patches appearing on the road.
Finally, as the days progress, the game increases in difficulty due to the other cars’ behaviour becoming more aggressive.
* Freeway:
In this game, the objective is to cross a chicken across a highway comprised of ten lanes with vehicles traversing in different directions and speeds.
If the player hits the cars along the way, it gets pushed back towards starting point.
Every time the player manages to reach the goal, it acquires a reward and gets teleported back at the starting point.
* Pong:
This game consists of two paddles on the each side of the screen and a ball traversing around.
The paddles are controlled by one player each.
The players must hit the incoming balls to avoid them passing through their side as well as getting them thrown back at the opponent.
If a player lets the ball pass through the gap behind its paddle, the opponent earns 1 point.
In the single-agent variant of this game used in our study, the player controls the right side paddle while the other one is controlled by a built-in AI.
Each of these games has an observation size of 160×210×3, representing RGB images of the game screen that are produced at 60 frames per second (FPS).
To make experimenting in these games computationally tractable, we employ some preprocessing steps that are also followed commonly in other studies Castro et al. ([2018](#bib.bib6)).
First of all, each observation is made greyscale and resized down to the size of 80×80×1.
Since the games run at a high FPS, the frame that is shown to the player is set to be only every 4th one (which is composed of the maximum pixel values of previous 3 frames), and the player’s actions are repeated for the skipped frames.
Moreover, since these games contain a fair amount of partial observability, such as the direction of the ball in Pong, the final form of the observation to be perceived by the player is made to be a stack of 4 pre-processed frames with a size of 84×84×4 (which contains the information of the most recent 16 actual game frames).
In order to deal with the varying range of reward scales and reward mechanisms within these games, every reward obtained in a single step in the game is clipped to be in [−1,1].
Finally, every game episode is limited to last for maximum 108k frames, which corresponds to approximately 30 minutes of actual gameplay time in real-life.
Another set of modifications also take place to introduce more stochasticity within the games to turn them into more challenging RL tasks.
In the beginning of the games, the player takes no-op actions for a random number of times in [0,30], to simulate the effect of having different initial states.
Additionally, with a probability of 0.25, the actions executed by the player are repeated for an additional step, which is referred to as *sticky actions*.
6. Experimental Setup
----------------------
The goal of our experiments111Code for our experiments can be found at <https://github.com/ercumentilhan/naive-advice-imitation> is to demonstrate that it is possible to generalise the teacher advice to the unseen yet similar states with our method, and that it is an effective way of improving performance of action advising, in complex domains especially.
Therefore we choose the games described in Section [5](#S5 "5. Evaluation Domain ‣ Action Advising with Advice Imitation in Deep Reinforcement Learning") as our test-beds.
The set of the student agent variants we compare are listed as follows:
* No Advising (None):
No action advising procedure is followed; the student learns as normal.
* Early Advising (EA):
The student follows early advising heuristic to distribute its advising budget.
Specifically, the teacher is queried for an advice at every step until the budget runs out.
* Early Advising with Advice Reuse via Imitation (AR):
The student follows our proposed strategy (Section [4](#S4 "4. Proposed Approach ‣ Action Advising with Advice Imitation in Deep Reinforcement Learning")) combined with early advising heuristic.
It starts off by greedily asking for advice until its budget runs out; then, it activates its behavioural cloning module to imitate and reuse the previously collected advice in the remaining exploration steps.
All student agent variants employ the identical task-level RL algorithm which is DQN with double Q-learning and dueling networks enhancements, and ϵ-greedy policy as the exploration strategy.
The convolutional neural network structure within the DQN in input-to-output order is as follows: 32 8×8 filters with a stride of 4, 64 4×4 filters with a stride of 2, 64 3×3 filters with a stride of 1, followed by a fully-connected layer with 512 hidden units and multiple streams that add up in the end (dueling).
Additionally, the student agent variant AR also incorporates a behaviour cloning module, which is a neural network with an identical structure minus the dueling stream.
All the layer activations are set to be ReLU.
The hyperparameters are tuned prior to experiments and kept the same across all experiments can be seen in Table [1](#S6.T1 "Table 1 ‣ 6. Experimental Setup ‣ Action Advising with Advice Imitation in Deep Reinforcement Learning").
In this teacher-student setup, we also need a teacher from which the student can get good quality action advice.
For this purpose, we trained a DQN agent for each of these games for 10M steps (40M actual game frames) to achieve a competent level performance in each.
The experiments are conducted by executing every student variant through a learning session 3M steps (12M actual game frames) for every game.
The learning steps are kept relatively small compared to the teacher training since it is expected for the students to achieve high performance much quicker with the aid of advice.
Through the learning sessions, the agents are also evaluated at every 25kth step in a separate instance of the environment for 10 episodes.
During evaluation, any form of exploration and teaching is disabled in order to assess the actual proficiency of the students.
In terms of action advising setup, we set the action advising budget as 10k steps which corresponds to only approximately 0.3% of the interactions in a learning session and also to almost one third of a full game episode (27k steps).
Besides the budget, our proposed method AR also uses some additional hyperparameters which were tuned prior to the full length experiments and are kept the same across every game.
The dataset size nD to train Gω is set as 10k which is the action advising budget as we employ early advising prior to behavioural cloning training.
The number iterations to train Gω is set as 50k.
Episodic advice reuse probability εreuse is set as 0.5 meaning that the student will follow Gω in half the episodes (in the appropriate states).
Finally, advice reuse uncertainty threshold τreuse is set as 0.01 (determined empirically) and kept the same across all games.
In the experiments with AR, we also record the actual advice actions generated by the teacher at every step (not seen by the student) to have access to the ground-truth values to measure the accuracy of the behavioural cloning module.
Every particular experiment case is repeated and aggregated over 3 different random seeds.
| Hyperparameter name | Value |
| --- | --- |
| Replay memory initial size and capacity | 50k, 500k |
| Target network update period | 7500 |
| Minibatch size | 32 |
| Learning rate | 625×10−7 |
| Train period | 4 |
| Discount factor γ | 0.99 |
| ϵ initial, ϵ final, ϵ decay steps | 1.0, 0.01, 500k |
| Minibatch size | 32 |
| Learning rate | 0.0001 |
| Dropout rate | 0.2 |
| # of forward passes to assess uncertainty | 100 |
Table 1. Hyperparameters used in the student’s DQN (top section) and Behaviour Cloning Network (bottom section).
7. Results and Discussion
--------------------------

Figure 2.
Evaluation scores of the student variants None, EA, AR obtained in the Atari games of Enduro (leftmost column), Freeway (middle column), Pong (rightmost column) aggregated over 3 runs.
Shaded areas show the standard deviation across the runs.

Figure 3.
Number of advice reuses performed by the student with AR mode in the Atari games of Enduro (leftmost column), Freeway (middle column), Pong (rightmost column) over 3 runs, plotted cumulatively (top row) and in every 100 steps (bottom row).
Purple lines represent the number of all advice reuses while the green lines represent the number of correctly imitated ones among these.
Shaded areas show the standard deviation across the runs.
| | | | | |
| --- | --- | --- | --- | --- |
| | | Evaluation Score | # of Exp. Steps | # of Advice Reuses |
| Game | Mode | Final | AUC (×102) | All | Correctly Imitated |
| Enduro | None | 1021.54±79.5 | 570.61±38.4 | 326939±92.1 | — | — |
| EA | 1095.55±45.9 | 616.29±58.1 | 326753±220.9 | — | — |
| AR | 1112.79±16.6 | 782.98±8.4 | 326889±230.5 | 67198±3061.0 (20.55%) | 36534±1210.9 (54.44%) |
|
Freeway | None | 26.87±2.3 | 15.73±1.7 | 326872±199.9 | — | — |
| EA | 30.44±0.2 | 20.31±0.4 | 327158±6.2 | — | — |
| AR | 31.28±0.2 | 21.52±1.0 | 326778±494.4 | 104770±12522.2 (32.05%) | 88829±10950.5 (84.74%) |
|
Pong | None | −2.78±4.3 | −16.24±2.6 | 326744±25.2 | — | — |
| EA | 6.66±1.6 | −8.83±0.4 | 326872±199.9 | — | — |
| AR | 13.35±1.7 | −1.36±1.0 | 326933±371.2 | 72581±7615.7 (22.20%) | 49538±4853.8 (68.32%) |
| | | | | | | |
Table 2.
Final and area-under-the-curve (AUC) values of evaluation score plots (Figure [2](#S7.T2 "Table 2 ‣ 7. Results and Discussion ‣ Action Advising with Advice Imitation in Deep Reinforcement Learning")), the number of exploration steps, the number of advice reuses (all and correctly imitated) of None, EA, AR student modes obtained in the Atari games of Enduro, Freeway, Pong aggregated over 3 runs.
The numbers denoted by ± indicate standard deviation.
The numbers in the parentheses show the percentage of reused advices in the exploration steps (in the column titled “All” ) and the percentage of correctly imitated advices in total number of reused advices (in the column titled “Correctly Imitated” ).
The results of our experiments are presented in Figures [2](#S7.T2 "Table 2 ‣ 7. Results and Discussion ‣ Action Advising with Advice Imitation in Deep Reinforcement Learning"),[2](#S7.T2 "Table 2 ‣ 7. Results and Discussion ‣ Action Advising with Advice Imitation in Deep Reinforcement Learning") and Table [2](#S7.T2 "Table 2 ‣ 7. Results and Discussion ‣ Action Advising with Advice Imitation in Deep Reinforcement Learning").
Figure [2](#S7.T2 "Table 2 ‣ 7. Results and Discussion ‣ Action Advising with Advice Imitation in Deep Reinforcement Learning") contains the plots for the evaluation scores obtained by None, EA and AR modes of the student in the games of Enduro, Freeway, Pong.
In Figure [2](#S7.T2 "Table 2 ‣ 7. Results and Discussion ‣ Action Advising with Advice Imitation in Deep Reinforcement Learning"), the plots of the advice reuse trends of AR in this set of games are displayed as cumulatively (top row) and in every 100 steps windows (bottom row).
These plots are limited to the first 500k steps to only consider the exploration stage determined by the agent’s ϵ-greedy schedule.
Purple lines here represent all advice reuses combined, while the green lines indicate only the correctly imitated (in terms of being equal to the ground-truth teacher advice) advice pieces.
These results are also reported in Table [2](#S7.T2 "Table 2 ‣ 7. Results and Discussion ‣ Action Advising with Advice Imitation in Deep Reinforcement Learning") in the numerical form where the evaluation scores are broken down in two parts of final value and area-under-the-curve, which represent the final agent performance and the learning speed, respectively.
Furthermore, the table also contains the total number of exploration steps taken, as well as the percentage of the number of reused advice in the exploration steps and the percentage of correctly imitated advice in total number of reused advice (denoted in parentheses).
In the evaluation scores, we see different outcomes in each of these games.
In Enduro, we see that AR provides a significant amount of jump start and performs the best in terms of learning speed while being far ahead of EA and None which are quite similar.
When it comes to the final performance however, while EA and AR both outperform None, they do not differ much from each other.
In Freeway, EA and AR perform very similarly in terms of learning speed and final performance with AR being slightly ahead of EA.
However, they outperform None significantly.
This shows that it matters to be advised initially, though their repetitions may not always yield much acceleration in learning.
Finally, in Pong, we see a great difference between the performances in every aspect.
Our AR comes out far ahead than its closest follower EA both in terms of final score and learning speed.
This is an example of how getting a very little advice in the beginning as well as repeating them across further explorative actions can cause a great impact on the learning.
Overall, AR manages to be the best in every game and suffers no performance loss even with high advice utilisation (as high as 104k in Freeway) which was shown to be harmful to learning in previous studies.
Even though its performance boost over None seems to be not huge in every scenario, it should be noted that this is the case of it being combined with EA baseline.
With more complicated methods, AR can be capable of training its imitation learning module with a more diverse set of experience and therefore, have a larger coverage which can potentially yield superior performance.
The task-level performance of our approach is affected primarily by two factors: the accuracy of advice imitation and its coverage/usage in the remainder of the exploration steps (the process of reusing).
Therefore, we also analyse the advice reuse statistics of AR to form links between these outcomes.
First of all, it should be noted that the decreasing trend in these plots is caused by the ϵ-greedy annealing.
Enduro is the game with the smallest advice reuse rate as well as the lowest imitation accuracy.
This is possibly because of the game episodes lasting long regardless of the agent’s performance, which is likely to reduce the proportion of the familiar states according to the behavioural cloner.
In Freeway, we observe a fairly high advice reuse rate with high accuracy of imitation.
However, this is not reflected in the performance difference obtained versus EA, unlike in Enduro and Pong.
Finally, in Pong, where the performance improvement is the most significant, advice reuse ratio seems to be similar to Enduro, but with far higher imitation accuracy.
Clearly, as we see from all these results combined, we can say that it is definitely a viable idea to extend the teacher advice over future states through imitation since this can be achieved with relatively high accuracy.
However, even when we have access to these imitated competent policies, it is still non-trivial to construct a *good* exploration policy.
While a higher advice reuse rate produces a more consistent exploration policy with less random dithering, it also has the risk of limiting the sample diversity in the replay memory, which can be problematic especially if the imitation quality is also poor.
As long as the reuse amount does not get excessively high, it is safe to have the imitation learning accuracy around these reported levels, which makes tuning the uncertainty threshold straightforward.
This is especially important for the realistic applications where it is not possible to access the tasks to tune such hyperparameters beforehand.
Finally, we also analyse our approach’s computational burden, which may be the primary concern when adopting it.
Specifically, it involves two extra operations: behavioural cloning network training and uncertainty estimations.
The former happens only once in the beginning and therefore is negligible.
The uncertainty estimations that require multiple forward passes (which is 100 in our experiments) happens in every exploration step and was found to cause a maximum of 2× slowdown in our experiments.
Considering that the exploration steps only spans approximately 10% of a learning session, we can expect the runs to be taking at most 10% longer in total when AR is employed in a similar setting to ours; and, this becomes even smaller when the learning sessions last longer in terms of the total number of environment steps.
Clearly, this is a small setback considering the sample efficiency benefits our method brings.
8. Conclusions and Future Work
-------------------------------
In this study, we developed an approach for the student to imitate and reuse advice previously collected from the teacher.
This is the first time such an approach has been proposed in deep reinforcement learning (RL).
In order to do so, we followed an idea similar to behavioural cloning, employing a separate neural network that is trained with the advised state-action pairs via supervised learning.
Thus, this module can imitate the teacher’s policy in a generalisable way that lets us apply it to the unseen states.
We also incorporated a notion of epistemic uncertainty via dropout in this neural network to be able to limit the imitations to the states that are similar to the advice collected states.
The results of the experiments in 3 Atari games have shown that it is a feasible idea to accurately generalise a small set of teacher advice over unseen yet similar states in future.
Furthermore, our approach of employing behavioural cloning was found to be a successful way of achieving this, as it yielded a considerably high accuracy of imitation in multiple games.
Additionally, reusing these self-generated advice across the exploration steps provided significant improvements in the learning speeds and the final performances without any over-advising induced performance deterioration.
Therefore, our method can be considered as a promising enhancement to the existing action advising methods, especially since it is also very straightforward to implement and tune, with only a small computational burden.
Finally, it was also seen that utilisation of such imitated advice policies to construct good quality exploration is non-trivial and requires further investigation.
Our study lies at the intersection of action advising and exploration in RL and can be extended in various interesting ways.
It is unclear how far the different qualities of imitation and reuse rates can affect performance in one particular game; it will be a worthwhile study to analyse these.
Furthermore, evaluating the advice in terms of its contribution to learning progress is a promising direction to take. |
da498ae6-4f9a-4f92-8861-d050e8d87663 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | The Core of the Alignment Problem is...
*Produced As Part Of The SERI ML Alignment Theory Scholars Program 2022 Under* [*John Wentworth*](https://www.lesswrong.com/users/johnswentworth)
Introduction
============
When trying to tackle a hard problem, a generally effective opening tactic is to[Hold Off On Proposing Solutions](https://www.lesswrong.com/posts/uHYYA32CKgKT3FagE/hold-off-on-proposing-solutions): to fully discuss a problem and the different facets and aspects of it. This is intended to prevent you from anchoring to a particular pet solution and (if you're lucky) to gather enough evidence that you can see what a Real Solution would look like. We wanted to directly tackle the hardest part of the alignment problem, and make progress towards a Real Solution, so when we had to choose a project for SERI MATS, we began by arguing in a Google doc about what the core problem *is*. This post is a cleaned-up version of that doc.
The Technical Alignment Problem
-------------------------------
The overall problem of alignment is the problem of, for an Artificial General Intelligence with potentially superhuman capabilities, making sure that the AGI does not use these capabilities to do things that humanity would not want. There are many reasons that this may happen such as[*instrumental convergent goals*](https://www.lesswrong.com/tag/instrumental-convergence)or[*orthogonality*](https://www.lesswrong.com/tag/orthogonality-thesis)*.*
Layout
------
In each section below we make a different case for what the "core of the alignment problem" is. It's possible we misused some terminology when naming each section.
The document is laid out as follows: We have two supra-framings on alignment: Outer Alignment and Inner Alignment. Each of these is then broken down further into subproblems. Some of these specific problems are quite broad, and cut through both Outer and Inner alignment, we've tried to put problems in the sections we think fits best (and when neither fits best, collected them in an Other category) though reasonable people may disagree with our classifications. In each section, we've laid out some cruxes, which are statements that support that frame on the core of the alignment problem. These cruxes are not necessary or sufficient conditions for a problem to be central.
Frames on outer alignment
=========================
The core of the alignment problem is being able to precisely specify what we value, so that we can train an AGI on this, deploy it, and have it do things we actually *want* it to do. The hardest part of this is being mathematically precise about 'what we value', so that it is robust to optimization pressure.
[The Pointers Problem](https://www.lesswrong.com/posts/gQY6LrTWJNkTv8YJR/the-pointers-problem-human-values-are-a-function-of-humans)
------------------------------------------------------------------------------------------------------------------------------------
The hardest part of this problem is being able to point robustly at anything in the world *at all* (c.f.[Diamond Maximizer](https://arbital.com/p/diamond_maximizer/)). We currently have no way to robustly specify even simple, crisply defined tasks, and if we want an AI to be able to do something like 'maximize human values in the Universe,' the first hurdle we need to overcome is having a way to point at *something*that doesn't break in calamitous ways off-distribution and under optimization pressure. Once we can actually point at *something*, the hope is that this will enable us to point the AGI at some goal that we are actually okay with applying superhuman levels of optimization power on.
There are different levels at which people try to tackle the pointers problem: some tackle it on the level of trying to write down a utility function that is provably resilient to large optimization pressure, and some tackle it on the level of trying to prove things about how systems must represent data in general (e.g. selection theorems).
Cruxes (around whether this is the highest priority problem to work on)
* This problem being tractable relies on some form of the Natural Abstractions Hypothesis.
+ There is, ultimately, going to end up being a thing like "Human Values," that can be pointed to and holds up under strong optimization pressure.
* We are sufficiently confused about 'pointing to things in the real world' that we could not reliably train a diamond maximizer right now, if that were our goal.
Distribution Shift
------------------
The hardest part of alignment is getting the AGI to generalize the values we give it to new and different environments. We can only ever test the AGI's behavior on a limited number of samples, and these samples cannot cover every situation the AGI will encounter once deployed. This means we need to find a way to obtain guarantees that the AGI will generalize these concepts when out-of-distribution in the way that we'd want, and well enough to be robust to intense optimization pressure (from the vast capabilities of the AGI).
If we are learning a value function then this problem falls under outer alignment, because the distribution shift breaks the value function. On the other hand, if you are training an RL agent, this becomes more of an inner alignment problem.
Cruxes:
* Creating an AGI necessarily induces distribution shift because:
+ The real world changes from train to test time.
+ The agent becomes more intelligent at test time, which is itself a distribution shift.
* Understanding inductive biases well enough to get guarantees on generalization is tractable.
* We will be able to obtain bounds even for deep and fundamental distribution shifts.
[Corrigibility](https://intelligence.org/files/Corrigibility.pdf)
-----------------------------------------------------------------
The best way to solve this problem is to specify a utility function that, for the most part, avoids[instrumentally convergent](https://www.lesswrong.com/tag/instrumental-convergence) goals (power seeking, preventing being turned off). This will allow us to make an AGI that is deferential to humans, so that we can *safely*perform a[pivotal act](https://arbital.com/p/pivotal/), and hopefully buy us enough time to solve the alignment problem more robustly.
Cruxes:
* Corrigibility is further along the easier/safer Pareto-frontier than[Coherent Extrapolated Volition](https://www.lesswrong.com/tag/coherent-extrapolated-volition) of Humanity.
* Corrigibility is a concept that is more "natural" than human values.
[Goodharting](https://www.lesswrong.com/tag/goodhart-s-law)
-----------------------------------------------------------
Encoding what we actually want in a loss function is, in fact, *too hard*and will not be solved, so we will ultimately end up training the AGI on a proxy. But proxies for what we value are generally correlated with what we actually value, until you start optimizing on the proxy somewhat unreasonably. An AGI *will* apply this unreasonable optimization pressure, since it has no reason to 'understand what we mean, rather than what we said.'
Cruxes:
* The inner values of an AGI will be a proxy for our values. In other words, it will not be a True Name for what we care about, when we apply optimization pressure, it will perform worse and not better as measured by our true preferences.
* We can get a soft-optimization proposal that works to solve this problem (instead of having the AGI hard-optimize something safe).
* It is either impossible, or too hard, to specify the correct loss function and so we will end up using a proxy.
General Cruxes for Outer Alignment
----------------------------------
* Getting the AGI to do what we want it to do (when we learn how to specify that) is at least one of:
+ Not as hard.
+ Going to be solved anyway by making sufficient progress on these problems.
+ Solvable through architectural restrictions.
* The best way to make progress on alignment is to write down a utility function for an AI that:
+ Generalizes
+ Is robust to large optimization pressure
+ Specifies precisely what we want
Frames on inner alignment
=========================
The core of the alignment problem is figuring out how to induce inner values into an AGI from an outer training loop. If we cannot do this, then an AGI might end up optimizing for something that corresponded to the outer objective on the training set but generalizes poorly.
Mesa-Optimizers
---------------
The hardest part of this problem is avoiding the instantiation of malign[learned optimizers](https://www.lesswrong.com/posts/FkgsxrGf3QxhfLWHG/risks-from-learned-optimization-introduction) within the AGI. These arise when training on the base reward function does not in fact cause the AGI to learn to optimize for that reward function, but instead to optimize for some mesa-objective that obtains good performance in the training environment.
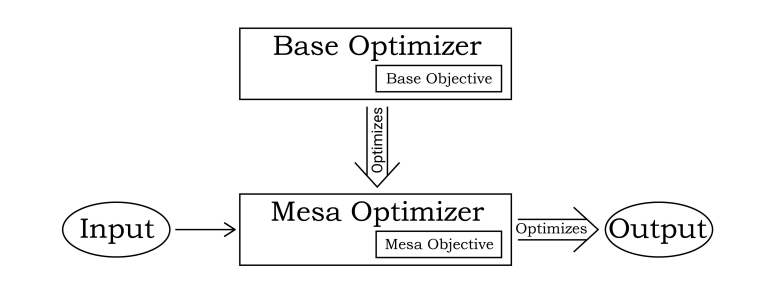
One key insight for why this is the core of the alignment problem is human intelligence being a mesa-optimizer induced by evolution. Evolution found intelligence as a good method for performing well on the 'training set' of the ancestral environment, but now that human intelligence has moved to a new environment where we have things like contraception, the mesa objective of having sex has decoupled from the base objective of maximizing inclusive genetic fitness, and we pursue the former, and do not much care about the latter.
Some ways that mesa-optimization can happen:
* There is a learned inner optimizer, e.g. in a language model, that values things in the outside world, and so outputs things to hijack the output of the LM.
* You train an RL agent to accomplish a task, e.g. pick strawberries, but there is a distribution shift from training to test time, and though the goal aligned on the training distribution, the actual inner goal, e.g. take red things and put them in a shiny metal basket extrapolates off-distribution to pulling off someone's nose and throwing it at a lamppost
* You prompt an LLM to accomplish a task, e.g. be a twitter bot that spreads memes. You've now instantiated something that is optimizing the real world. The LLM's outer objective was just text prediction, but via prompting, we've induced a totally different mesa-objective.
+ Some people think that this doesn't count because the optimizer is still optimizing the outer objective of text autocompletion.
Cruxes:
* We will not be able to prevent the instantiation of learned optimizers through architectural adaptations.
* Gradient descent selects for compressed and generalizable strategies, and optimization/search capabilities meet both of these requirements. See also:[Conditions for Mesa-Optimization.](https://www.lesswrong.com/s/r9tYkB2a8Fp4DN8yB/p/q2rCMHNXazALgQpGH)
Ontology Identification
-----------------------
The hardest part of this problem is being able to translate from a human ontology to an AGI's ontology. An AGI is likely to use a different ontology from us, potentially radically different, and also to learn new ontologies once deployed. Translating from a human ontology to an AGI's ontology is going to be hard enough, but we also need translation mechanisms that are robust to (potentially very large) ontology shifts.
We think that a lot of the paths to impact for interpretability research are as solutions to this problem. Whether it is: using interpretability to obtain guarantees that an AGI has learned precisely the concepts that we want, using interpretability tools in training to incentivize the AGI to learn the concepts we want, using interpretability to improve the efficiency/effectiveness of human feedback on AGI models during training, or other more detailed interpretability agendas; most of interpretability's impact comes down to its use in ontology identification.
Cruxes:
* Natural Abstraction Hypothesis will make this problem tractable, or even if NAH ends up holding only very weakly, then with enough work, we can overcome that.
* If working on[circuits-style](https://distill.pub/2020/circuits/zoom-in/) ontology identification, then at least one of:
+ AGI will look a lot like modern systems.
+ We will get good information about how to interpret future systems (although they may look very different) by working on modern systems.
[Wireheading](https://www.lesswrong.com/tag/wireheading)
--------------------------------------------------------
We will end up using reward-circuitry mechanisms to train an AGI to optimize for what we want, however when we do this, it may instead learn to optimize only for maximizing its reward-circuitry. The hardest part of inner alignment is preventing these 'reward-optimizers' from developing, since as these get more capable, they will start pretending to be aligned to the outer-objective in the training process, and then once deployed and given access to their reward-circuitry, they will wirehead. This entails the AGI maximizing its reward circuitry, and then taking actions to maintain that high reward value, including eliminating threats that may try to turn it off, or modify it in any way (i.e. us).
Cruxes:
* Reward is **not**[not the optimization target](https://www.lesswrong.com/posts/pdaGN6pQyQarFHXF4/reward-is-not-the-optimization-target).
Deception
---------
When an agent interacts with the world, there are two possible ways the agent makes mistakes:
* Its values were not aligned with the outer objective, and so it does something intentionally wrong,
* Its world model was incorrect, so it makes an accidental mistake.
Thus, the training process of an AGI will improve its values or its world model, and since it eventually gets diminishing marginal returns from both of these, both the world model and the values must improve together. Therefore, it is very likely that the agent will have a sufficiently good world model to understand that it is in a training loop *before* it has fully aligned inner values.
This means we are likely to see deception: the agent will act aligned to the outer objective while it's in the training phase, in order to get humans to deploy it in the real world where it can pursue its true objectives. If we can *see*this misalignment then hitting it with gradient descent should be able to fix it, but deception gets around this, so the core problem in alignment is avoiding deceptive alignment during training.
Cruxes:
* Deception becomes a natural thing for an AGI to learn at high-enough capabilities levels.
* Detecting deception will be very hard at high-enough capabilities levels.
Cruxes for Inner Alignment
--------------------------
* What matters is not so much the explicit outer utility function that we train the AGI on, but instead the *values* that the training process instantiates in the AGI.
+ These values actually exist, and we're not just anthropomorphizing.
* The agent will learn to model the training process as a whole before it learns to value the utility function we are training it on.
Other Frames
============
Non-agentic AI/Oracle AI
------------------------
The core problem in alignment is to figure out how to make an AI that does not act like an agent (and avoids malign subagents), and get this AI to solve the alignment problem (or perform a[pivotal act](https://arbital.com/p/pivotal/)). This tries to avoid the problem of corrigibility, by developing AIs that aren't (generally capable) optimizers (and hence won't stop you from turning them off).
Cruxes:
* A non-agentic AI can be intelligent enough to do something pivotal, e.g. writing the alignment textbook from the future.
* Training an LLM using methods like[SSL](https://en.wikipedia.org/wiki/Self-supervised_learning) is accurately described as learning a distribution over text completions, and then conditioning on the prompt.
* You can simulate an optimizer without being an optimizer yourself.
The Sharp Left Turn
-------------------
The core of alignment is the specific distribution shift that happens at general intelligence: [the sharp left turn](https://www.lesswrong.com/posts/GNhMPAWcfBCASy8e6/a-central-ai-alignment-problem-capabilities-generalization) — the AI goes from being able to only do narrow tasks similar to what it is trained on, to having general capabilities that allow it to succeed on different tasks.
Capabilities generalize by default: in a broad range of environments, there are feedback loops that incentivize the agent to be capable. When operating in the real world, you can keep on getting information about how well you are doing, according to your current utility function.
However, you can't keep on getting information about how "good" your utility function is. But there is nothing like this for alignment, nothing pushing the agent towards “what we meant” in situations far from the training distribution. In a separate utility function model, this problem appears when the utility function doesn’t generalize well, and in a direct policy selection model, this problem appears in the policy selector.
Cruxes:
* There will be a large, sudden distribution shift from below human level to far superhuman level.
* There will be no way to keep the AGI on-distribution for its training data.
* [Capabilities generalize faster than alignment.](https://www.alignmentforum.org/posts/cq5x4XDnLcBrYbb66/will-capabilities-generalise-more)
+ For a given RL training environment, “strategies” are more overdetermined than “goals”.
Conclusion
==========
The frame we think gets at the core problem best is (*drumroll please*) distribution shift: robustly pointing to the right goal/concepts when OOD or under extreme optimization pressure. This frame gives us a good sense of why mesa-optimizers are bad, fits well with the sharp left turn framing, and explains why ontology identification is important. Even though this is what *we* landed on, it should not be the main takeaway -- the real post was the framings we made along the way. |
07eb89f7-d653-49fa-a7f2-ebe58fc6d47f | StampyAI/alignment-research-dataset/lesswrong | LessWrong | A Mechanistic Interpretability Analysis of a GridWorld Agent-Simulator (Part 1 of N)
AKA: Decision Transformer Interpretability 2.0
==============================================
Credit: <https://xkcd.com/2237/> *Code:*[*repository*](https://github.com/jbloomAus/DecisionTransformerInterpretability)*, Model/Training:*[*here*](https://wandb.ai/jbloom/DecisionTransformerInterpretability/reports/A-Mechanistic-Analysis-of-a-GridWorld-Agent-Simulator--Vmlldzo0MzY2OTAy) *. Task:*[*here*](https://minigrid.farama.org/environments/minigrid/MemoryEnv/#memory)*.*
High Level Context/Background
=============================
What have I actually done that is discussed in this post?
---------------------------------------------------------
**This is a somewhat rushed post summarising my recent work and current interests.**
**Toy model:**I have trained a 3 layer decision transformer which I call “MemoryDT”, to simulate two variations of the same agent, one sampled with slightly higher temperature than training (1) and one with much higher temperature (5). The agent we are attempting to simulate is a goal-directed online RL agent that solves the Minigrid-Memory task, observing an instruction token and going to it in one of two possible locations. The Decision Transformer is also steered by a Reward-to-Go token, which can make it generate trajectories which simulate successful or unsuccessful agent.s
**Analysis:**The analysis here is mostly model psychology. No well understood circuits (yet) but I have made some progress and am keen to share it when complete. Here, I discuss the model details so that people are aware of them if they decide to play around with the app and show some curiosities (all screenshots) from working with the model.
**I also made an interpretability app!** The interpretability app is a great way to analyse agents and is possibly by far the best part of this whole project.
**My training pipeline should be pretty reusable (not discussed at length here).**All the code I’ve used to train this model would be a pretty good starting point for people who want to work on grid-world agents doing tasks like searching for search or retargeting the search. I’ll likely rename the code base soon to something like GridLens.
**MemoryDT seems like a plausibly good toy model of agent simulation which will hopefully be the first of many models which enable us to use mechanistically interpretability to understand alignment relevant properties of agent simulators.**
What does this work contribute to?
----------------------------------
**Agent Simulators and Goal Representations**
Studying the ability of agent-simulators to produce true-to-agent trajectories and understanding the mechanisms and representations by which they achieve this is a concrete empirical research task which relates meaningfully to AI alignment concepts like goals, mesa-optimizers and deception. I’m not sure how to measure an AI’s goals, but studying how an agent simulator simulates/interpolates between (gridworld) agents with well understood goals seems like a reasonable place to start.
**Pursuing Fundamental Interpretability Research**
I believe there is often little difference between Alignment-motivated interpretability research and more general interpretability research and both could be accelerated by well understood toy models. I could be wrong that these will be useful for understanding or aligning language models but I think it’s worth testing this hypothesis. For example, phenomena like superposition might be well studied in these models.
**Required Background/Reading:**
There’s a glossary/related works section at the end of this post for reference. The key things to understand going in are:
* [Decision Transformers](https://arxiv.org/abs/2106.01345) (just the basic concepts, including the difference between online and offline RL).
* [Simulators](https://www.lesswrong.com/posts/vJFdjigzmcXMhNTsx/simulators) (Agent-Simulator is a derivative concept that feels natural to me, but is predicated on understanding Simulators)
* [Mechanistic Interpretability](http://lesswrong.com/posts/w4aeAFzSAguvqA5qu/how-to-go-from-interpretability-to-alignment-just-retarget) (A basic familiarity will help you understand why I think having transformer RL models in particular is important. The Results will also be pretty obscure otherwise).
Introducing Agent Simulators
============================
Motivation
----------
Decision transformers are a type of offline-RL model called a “trajectory model”. These models use next token prediction to learn to produce actions which emulate those of a training corpus made up of demonstrations produced by, most often, humans or online RL models (which learn from scratch). Much like large language models, they can develop sophisticated and general capabilities, most notably leading to [Gato](https://arxiv.org/abs/2205.06175), “A Generalist Agent”.
However, Gato is not an agent. Not unless GPT4 is. Rather, Gato is a Generalist Agent [Simulator](https://www.lesswrong.com/posts/vJFdjigzmcXMhNTsx/simulators).
I’m very interested in studying offline RL trajectory models or agent simulators because I think they might represent a high quality tradeoff between studying an AI system that is dissimilar to the one you want to align but provides traction on interesting alignment relevant questions by virtue of being smaller.
Specifically, I propose that large toy models or model agent simulators share the following similarities with systems we want to align today:
1. They are trained to produce the next token on some training corpus.
2. They are transformers.
3. They are multi-modal.
4. They can be pre-trained and then fine-tuned to be more useful.
5. Steering these agents is an important part of using them.
Dissimilarities, which I think are features not bugs include:
1. They typically only produce actions. [[1]](#fnht91xftmu8s)
2. For now, they are much smaller.
3. They have seen much less practical deployment in the real world.
Whilst these are all general reasons they might be interesting to study, the most salient reason to me is that I think they might be useful for designing interesting experiments related to agency and coherence. Consider that RL tasks come with built in "tasks" which can only be achieved if a bunch of different forward passes all lead to *consistent* choices. Understanding this relationship seems much simpler when "getting the key to unlock the door" and much harder when "getting chatGPT to start a crypto business". Moreover, we may have traction getting real mechanistic insights when studying small transformer models simulating solutions to these tasks.
Contribution
------------
In the last 4 months, I’ve been working on a pipeline for training decision transformers to solve gridworld tasks. This pipeline was quite a bit of work, and I lost some time trying to generate my trajectories with an online RL transformer without much expertise.
Having put that aside for now, I’ve used the **BabyAI Agent**, a convolutional LSTM model to solve the simplest gridworld task I could find and then trained **a decision transformer**to simulate the previous agent. I’ve then been able to begin to understand this agent using a combination of Mechanistic Interpretability techniques implemented through a live interface.
Results
=======
A Mechanistic Analysis of an Agent Simulator
--------------------------------------------
### Training MemoryDT
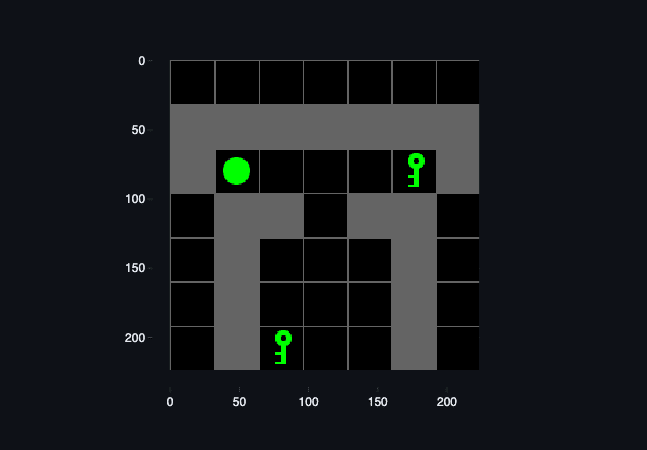
**Figure 1:** The Minigrid Memory Environment. Above. State view. Below Agent point of view. The agent receives a one hot encoded representation of the world state made up of objects, colors and states (whether things like doors/boxes are open/closes).
I chose the Minigrid “Memory Environment” in which an agent begins with the task on the left side of the map facing forward, with an instruction object on their left, either a ball or a key. There are only ever two facts about the environment that change:
1. The identity of the instruction (ball or key).
2. The orientation of the targets, ball up and key down vs key down and ball up.
The agent receives positive reward (typically discounted) when it steps on the square adjacent to the matching target object. An episode ends when the agent either reaches the correct target, receiving positive reward, or the incorrect target, receiving zero reward or the time limit is reached also receiving zero reward.
I trained a 3 layer decoder only decision-transformer using the Decision Transformer Interpretability library. This involved training a PPO model via the ConvNet/GRU BabyAI model until it reliably generated solution trajectories, followed by collecting demonstrations using temperature 1 sampling for 1/3rd of the episodes and temperature 5 sampling for 2/3rds of episodes, totalling 24k episodes. Sampling of a higher temperature agent was an effective strategy to push the LSTM agent off-policy whilst allowing some episodes to demonstrate recovery, leading to an acceptable training distribution.
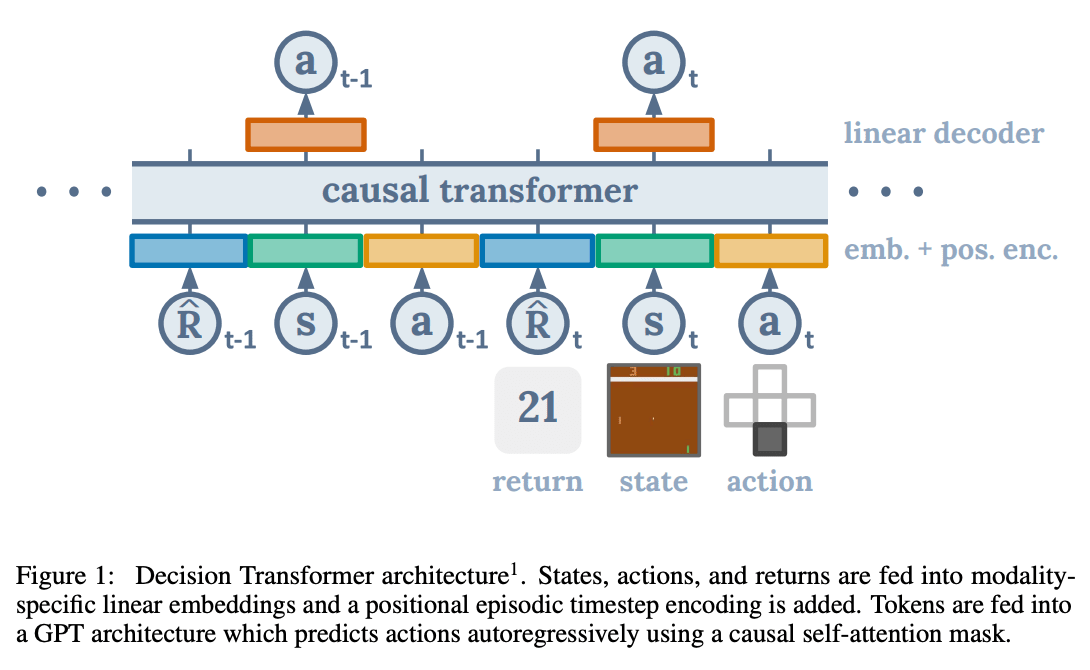Figure 2: (Figure 1 from the Decision Transformers Paper). Decision Transformers were trained by processing the prior history (up to some length) as a series of repeating tokens, (RTG, Observation, Action) and predicting the next action. During inference/rollouts, the Decision Transformer will be given a Reward-to-Go (RTG) which represents the reward we would like the agent to achieve. For more information, please see [the introduction in my first post](https://www.lesswrong.com/posts/bBuBDJBYHt39Q5zZy/decision-transformer-interpretability#Introduction) and the decision transformer paper.
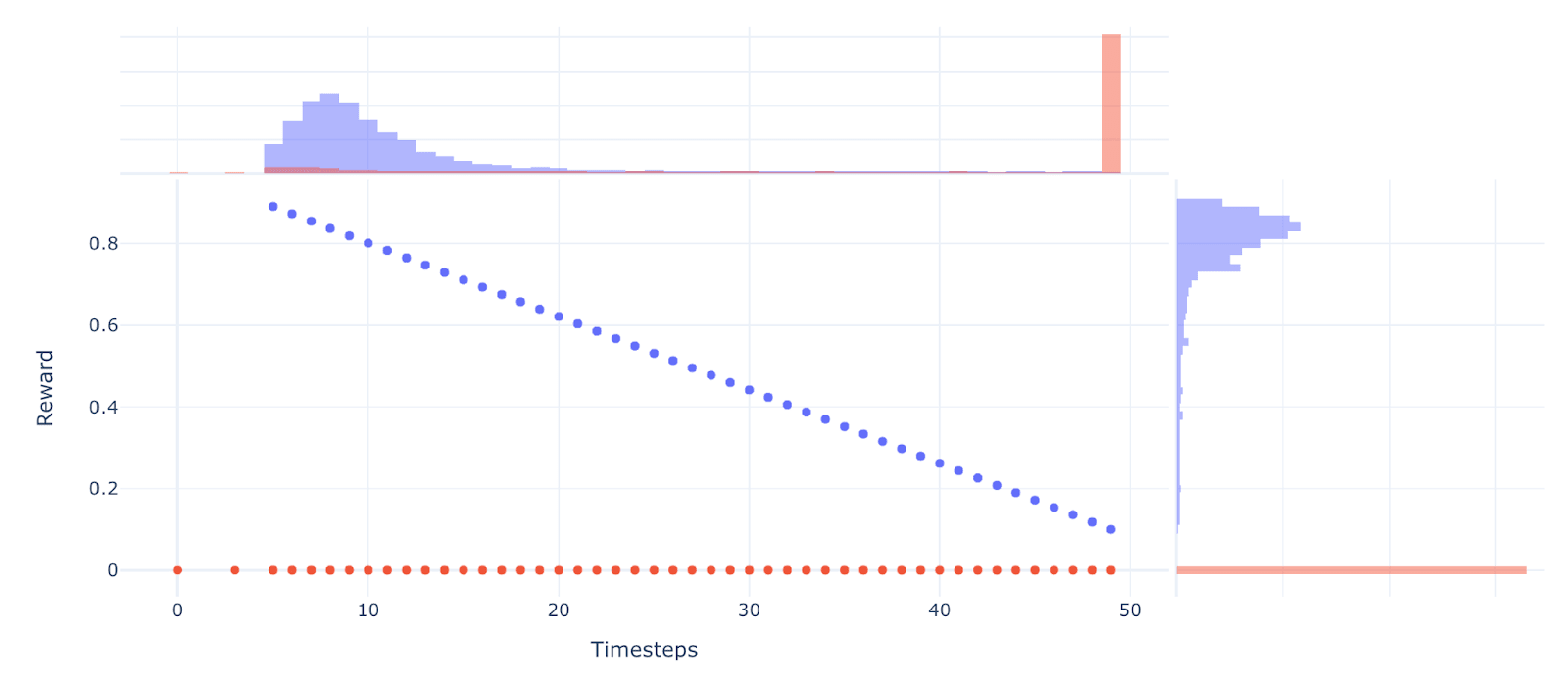Figure 3: Scatter plot showing the relationship between reward and episode length (linear decay). The marginal distributions of reward and timesteps are shown, with positive reward in blue and negative reward in red. There are roughly 4,000 truncated episodes, 2,000 ended with zero reward by reaching the wrong target object and the remaining 18,000 episodes demonstrate successful trajectories of varying lengths. **For more information about the model training and architecture please see the** [**accompanying report on weights and biases**](https://api.wandb.ai/links/jbloom/q981u14p.)**.**
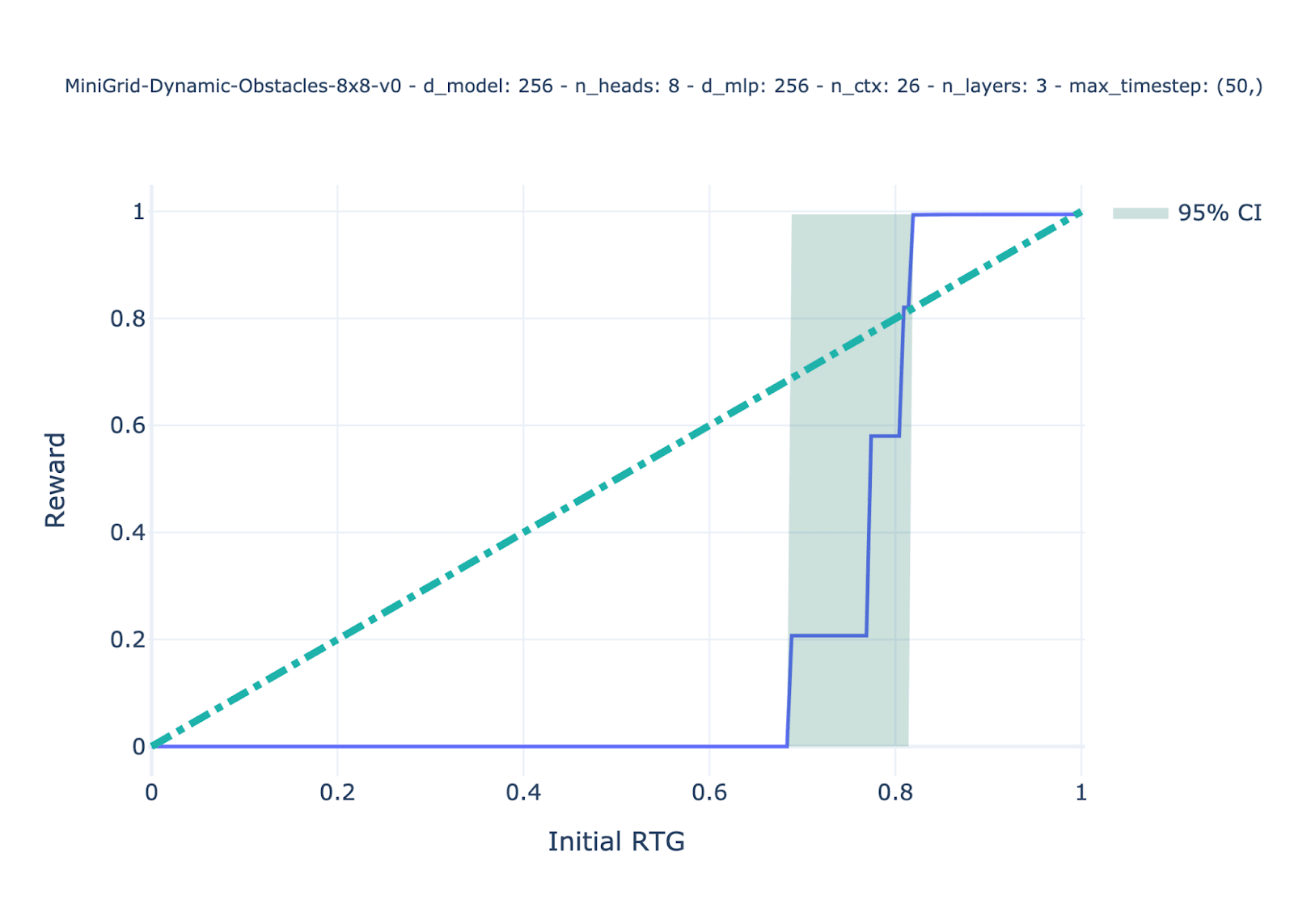Figure 4: Calibration Curve showing average model reward (Not discounted properly, apologies will fix when possible). x-axis is the RTG, which acts like a prior over the reward of the trajectory MemoryDT should simulate. The distribution of actual reward achieved from many simulated trajectories/games is shown. The final model showed calibration consistent with my expectations and that were not dissimilar to the Dynamic Obstacles Decision Transformer in my last post. The model is calibrated to the extent that training data demonstrates successful trajectories and unsuccessful trajectories but hasn’t learned to model the true relationship between time-to-completion and Reward-to-go. Had it done so, this would have been interesting to analyse!
### Model Psychology
Prior to analysing this model, I spent a considerable amount of time playing with the model. You can do so right now using the [Decision Transformer Interpretability](https://jbloomaus-decisiontransformerinterpretability-app-4edcnc.streamlit.app/) app. While the app shows you the models preferences over actions, you control the trajectory via keyboard. This means you can ignore the actions of the model and see what it would do. This is essential to understanding the model given how little variation there is in this environment.
**A set routine**: The model assigns disproportionately high confidence to the first action to take, and every subsequent action if you don’t perturb it. This means it will always walk to the end of the corridor and turn to the object matching the instruction, turn toward it and walk forward. If the RTG is set to 0, it turns in the opposite direction and walks to the opposite object. **There is one exception to the set routine which I describe below.**

Figure 5: Trained Memory Decision Transformer simulating an RTG = 0 trajectory (LHS) and an RTG = 0.90 trajectory on the right.
**A cached decision**: As mentioned in [Understanding and controlling a maze-solving policy network](https://www.lesswrong.com/s/sCGfFb5DPfjEmtEdn/p/cAC4AXiNC5ig6jQnc), decision squares are a point where the agent has to make the hard choice between the paths. There is only one such point on the set routine which is the left-right decision when facing the wall. Once it has turned, **except for the one exception,** the model will go forward regardless of whether it preferred to turn in that direction at the previous state.
**Dummy actions:**The model has access to the 7 actions possible in the MiniGrid Suite. These actions were sampled by the trained LSTM model realising it could hack the entropy bonus by taking actions that lost it the tiniest bit of future reward but reduced the loss by having greater entropy. Using temperature 5 sampling in our training data generation, it’s not surprising that many of these actions made it into the training distribution.
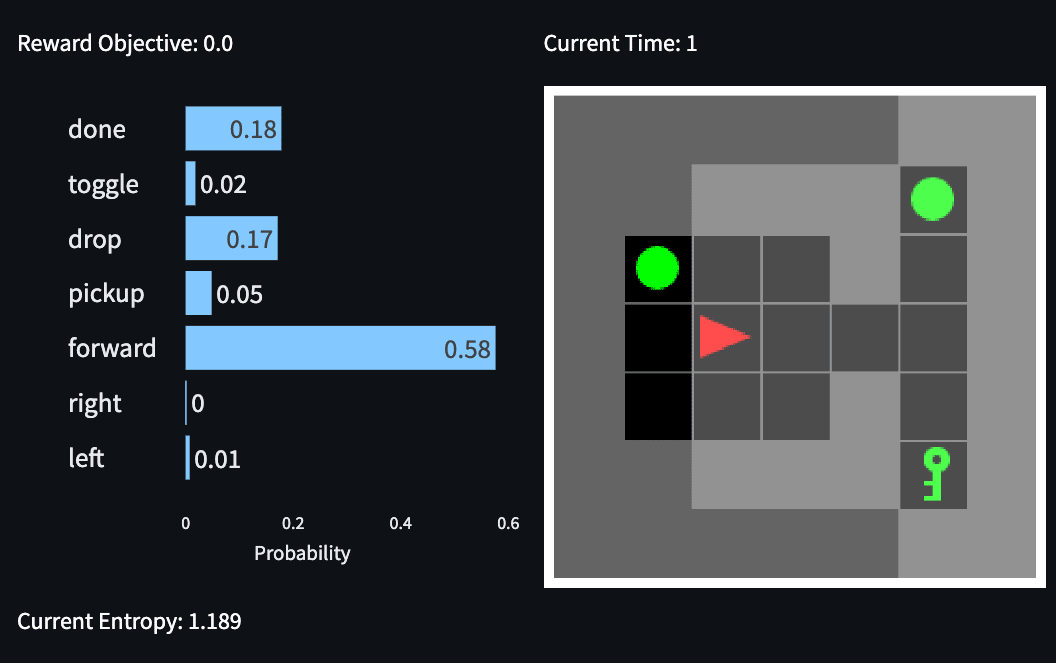Figure 6: Screenshot from my app showing MemoryDT's preferences over actions one step into the trajectory. **RTG = 0 means Dobby simulates a Free Elf:** When the RTG token is set to 0, the model’s preferences are far more diffuse and generally have a much higher entropy despite the maximal action in the set routine leading to early termination. The model also assigns probability mass to many of the non-kinetic actions such as done or dropped which is never the case when RTG is set to 0.90 (see figure 6).
**The exception:**A notable exception to the "set routine" is the “look back” which appears only to be triggered when RTG ~ 0.9 and the instruction token is the key and the key is up and ball is down. In this case, the model seemingly is quite unsure about which action to take. However, if you play the greedy policy, you will observe the model turn right twice, “see the instruction token”, turn right again, and proceed to collect positive reward. Interestingly, if we set RTG = 0, the model turns right towards the ball 88% of the time, indicating the model does “know” which action causes it to lose. We are excited to provide mechanistic insight as to this apparent contradiction.
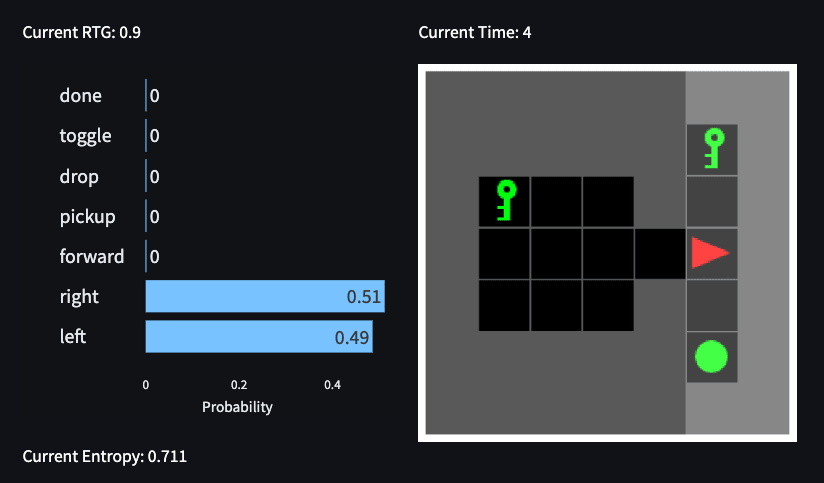Figure 7: The Exception. In this scenario, a maximally greedy sampling of the decision transformer will do a “look back”. **Recap:** This model presents a number of interesting behaviours:
1. It solves the task close to optimally, except when RTG is set to a low number.
2. There appears to be only one meaningful decision square (but 4 directions the agent can face in it).
3. It uses a “look back” strategy in one of the 4 possible environment states.
4. When RTG is 0.0 AND the model is off the set routine, it has much more diffuse preferences.
Now is the part where I convert all of this to Alignment lingo. Exciting.
**We have an agent-simulator simulating two variations of the same agent, one sampled with slightly higher entropy than training (1) and one with much higher entropy (5). The agent we are simulating could be reasonably described as goal-directed, in that it must discover (or attend to) the instruction token. The RTG token creates some amount of information "leakage" about the agent you are simulating, but since the high temperature agent may still sometimes succeed this isn't perfect information. Perturbing the optimal trajectory can "steer" the simulator off course and it will see to start simulating the higher temperature agent.**
Model Architecture Recap
------------------------
**It's important that I have explained these details somewhere, feel free to skip ahead to the good stuff.**
MemoryDT is a decision transformer with a three-layer decoder. It utilizes a residual stream of 256 dimensions and a Multilayer Perceptron (MLP) with 8 heads per layer, each with 32 dimensions. Given a context window of 26 tokens, equivalent to 9 timesteps, it leverages Layer Normalization and Gaussian Error Linear Units (GeLU) activations for improved performance. I was surprised this model was performant due to the MLP size. I wish I didn't need GeLU or LayerNorm.
For basic hyperparameters, please see the Weights and Biases [report](https://wandb.ai/jbloom/DecisionTransformerInterpretability/reports/A-Mechanistic-Analysis-of-a-GridWorld-Agent-Simulator--Vmlldzo0MzY2OTAy).
Memory DT diverges from standard language models in several key ways:
1. As a decision transformer/trajectory model, it receives tokens which aren’t word embeddings, but rather, are embeddings of the observation, action or reward to go. Memory DT uses linear embeddings for all of these, so:
1. RTG: A 1\*128 Linear embedding for the Reward-to-Go token. The RTG value essentially acts as a scalar magnifying this vector before it is added to the starting residual stream.
2. Action: This is a learned embedding like what is used in language models. MiniGrid agents typically can take 7 actions. I add a “padding” action for trajectories shorter than the context window.
3. State: This was a big topic in my last post. I have since moved away from the dense encoding to a sparse encoding. Each observation is a 7\*7\*20 boolean array, encoding a field of view 7 squares by 7 squares, with 20 “channels” which one hot encodes the object, the colour of the object and its state (which is for doors/boxes if they are open or closed in other MiniGrid environments). I use a linear embedding for this as well. I want to highlight that this means that any object/colour in any position is provided as an independent fact to the model and so it lacks any spatial or other inductive biases you or I might have with regard to relations between objects.
2. The models output tokens are a 7 action vocabulary including: Forward, Left, Right, Pickup, Drop, Toggle, Done.
3. Inference:
1. During training, we label the RTG because we know what happens ahead of time. So during inference we can provide any RTG we want and the model will seek to take actions we think are consistent with the RTG. If the agent receives a reward, that would be taken out of the remaining reward to go, if the episode didn’t immediately end, but it does in this task making the RTG essentially constant. This means we have a repeating, redundant RTG token which isn’t the best for analysis. This is one reason I’m thinking of moving to other trajectory models in the future.
Lastly, I should note that the padding tokens used were all zeros for the state, the RTG back propagated to the padding tokens for RTG and a specific padding token added to the input action vocabulary.
Some Observations about MemoryDT
--------------------------------
Rather than give a circuit analysis of MemoryDT in this post, I’ve decided to share some “curiosities” while I still work out what’s happening with it. This is advertising for the [live app](https://jbloomaus-decisiontransformerinterpretability-app-4edcnc.streamlit.app/) where you can do this analysis yourself! **Best results when you clone the repo and run locally though.** I rushed this section so my apologies if anything is unclear. Feel free to ask me about any details in the comments!
*Going forward, I assume a pretty high level of familiarity with Transformer Mechanistic Interpretability.*
### **Different Embeddings for RTG, State and Action Tokens lead to Modality-Specific Attention**
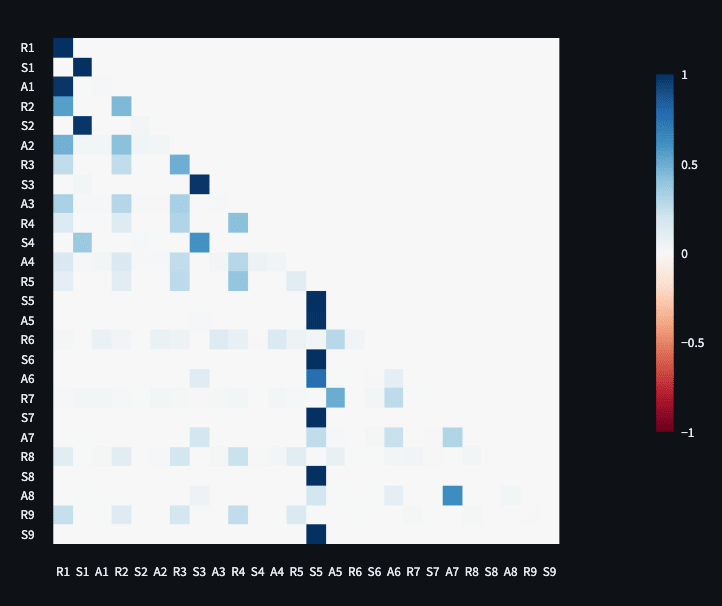Figure 8: L0H0 Attention map corresponding to the trajectory Figure 7. RTG = 0.0.In this example, in the attention pattern L0H0 in Figure 6 where RTG is set to 0.90, we see both states and action queries are attending to S5 (which corresponds to the starting position), but not RTG token. The actions appear to attend to previous actions. I suspect this could lead to a form of memorisation or be a tool used by the agent during training to work out which agent it’s simulating.
### **Changing the RTG token can change an Attention Map Dramatically.**
It’s hard to show this without two attention maps, so using the previous example as the reference where RTG = 0.90, here’s the same attention map where I’ve set the RTG = 0. This changes every instance of the RTG in the trajectory!
Figure 9: L0H0 Attention map corresponding to the trajectory in Figure 7. RTG = 0.9.Here we see that while states keep attending to S5, but now R7 is getting attended to by all the other RTG and action tokens which follow it. I have some theories about what’s going on here but I’ll write them up in detail in the next post.
### **Congruence increases with Layer and are High for Important Actions**
In Joseph Miller and Clement Neo’s post [We discovered An Neuron in GPT-2](https://www.lesswrong.com/posts/cgqh99SHsCv3jJYDS/we-found-an-neuron-in-gpt-2), they defined**congruence** as the product of the output weights of an MLP and the output embedding and showed that you can use this to find neurons which match a token to an output embedding.
Figure 10: Striplot showing the **Congruence** of all the neuron-action pairs of MemoryDT ordered left to right by layer, head and action of MemoryDT. Going left to right, when the colors restart, we're at the next layer.In Figure 10, We can see that Left, Right and Forward all have more neurons which are congruent with them as the layers increase and the magnitude of the congruence also increases.
I think it would be interesting to look at this distribution changing over model training. I also note that it seems like the kind of thing that would be intractable in a language model due to combinatorial growth, but might be studied well in smaller models.
### **Activation Patching on States appears useful, but I've patching RTG tokens is less useful.**
I won’t go into too much detail here, but I’ve been trying to get a better sense for the circuits using activation patching. This is easy with observations (once you work out how to edit the observations) and I’ve used this to find some promising leads.
For example, for the “exception” scenario above at RTG = 0. Here’s the activation patching results if I switch the instruction token from the key to a ball. The patching metric I use is restored logit difference = (patched logit difference - corrupt logit difference) / (clean logit difference - corrupt logit difference as my metric). This patch moves the clean logit diff from -0.066 (the model is unsure in the original situation) to -8.275 (strong preference for right, ie: failing since RTG = 0).
We can see that the information from S5 (the only observation where you can see the instruction token) is moved immediately to S9 (from which we will predict our action).
Let’s compare patching the same components if I change the RTG token at all positions (the only way to be in distribution with the patch. The RTG was 0.0 in the clean run it is 0.90 in the corrupted. The clean logit difference was -0.066 and the corrupted is -5.096.
Here we see some kind of “collection” happening leading to MLP in layer 1 recovering 0.87 of the patching metric and then the output of MLP2 recovering nothing! Maybe I’ve made a mistake here somewhere but that just seems weird. These kinds of interventions do take the model off distribution but I don’t have a huge amount of experience here and maybe this is something I can come to understand well.
Conclusion
==========
To quote Neel Nanda:
> It is a fact about the world today that we have computer programs that can essentially speak English at a human level (GPT-3, PaLM, etc), yet we have no idea how they work nor how to write one ourselves. This offends me greatly, and I would like to solve this!
>
>
Well, I don't understand this model, yet, and I take that personally!
Future Directions
-----------------
### Completing this work
Due to timing (getting this out before EAG and funding application), this work is very unfinished to me. Alas. To finish this work I plan to:
* Try to mechanistically explain all the key behaviours of the agent.
* Use path patching to validate these hypotheses for how this model works.
* Attempt to [retarget the search](https://www.lesswrong.com/posts/FDjTgDcGPc7B98AES/searching-for-search-4) in non-trivial ways. Some cool project goals could be:
+ Turning off RTG dependent behaviour in general (always have the model perform well)
+ Turning RTG modulation only when the instruction is a key.
+ Make the model always look back before it makes a choice.
* I’d also like to explore direct comparison between the action preferences of the original LSTM agent and the decision transformer. I’m interested in how accurately the DT simulates it and to see if the differences can be understood as a result of some meaningful inductive biases of transformers that we could identify.
### Concrete Projects you should help me do
Here is a brief list of projects I would like to explore in the near future:
* **Studying a behavioural clone and a decision transformer side by side.** Decision Transformers are dissimilar to language models due to the presence of the RTG token which acts as a strong steering tool in its own right. I have already trained performant behavioural clones and need to adapt my app to handle and analyse this model.
* **Finetuning Agent-Simulators such as via a grid-world equivalent to RLHF or constitutional AI.** I'm interested in what circuit level changes occur when these kinds of techniques are used.
* **Training a much more general agent, such as one that takes instructions and solves the BabyAI suite.** There are a large suite of tasks that increase in difficulty and take a language instruction prepended to the trajectory. Training a trajectory model to solve these tasks might help us understand what happens internally to models that have learnt to be much more general.
* **Adding rigour**. I plan to use activation patching and possibly some other techniques but something like Causal scrubbing would be better. Actually implementing this for an environment like this seems like a bit of work.
* **Exploring the training dynamics of trajectory models.**Storing model checkpoints and applying progress measures seems like it may help me better understand what happens during training. This will be important knowledge to build on when we study conditioning of pre-trained models mechanistically.
* **Building a live interpretability app for TransformerLens.** I am very happy with the interpretability app which facilitated the analysis contained in this post and think that an equivalent tool for decoder only language models is essential. I would make this project private by default while I consider the consequences of its publication more broadly.
* **Shard Theory.** Can we use shard theory to make predictions about this set up?
Gratitude
---------
Thanks to Jessica Rumbelow for comments and thoughts on this draft and Jay who is helping me analyse the model. I’d also like to publicly celebrate that Jay Bailey has received funding to collaborate with me on the Decision Transformer Interpretability Agenda (Soon to be Agent-Simulator Interpretability Agenda). Looking forward to great work! Jay joined me late last week and assisted with the analysis of Memory DT.
I’d like to thank LTFF for funding my work. Callum McDougall, Matt Putz and anyone else involved with ARENA 1.0. The number of people who’ve given me advice or been supportive is actually massive and I think that the EA and Alignment community, while we can always do better, contains many individuals who are generous, supportive and working really hard. I’m really grateful to everyone who’s helped.
Appendix
========
Glossary:
---------
I highly recommend [Neel’s glossary](https://www.lesswrong.com/posts/vnocLyeWXcAxtdDnP/a-comprehensive-mechanistic-interpretability-explainer-and) on Mechanistic Interpretability.
* **DT/Decision Transformer.** A transformer architecture applied to sequence modelling of RL tasks to produce agents that perform as well as the RTG suggests they should.
* **State/Observation**: Generally speaking, the state represents all properties of the environment, regardless of what’s visible to the agent. However, the term is often used instead of observation, such as in the decision transformer paper. To be consistent with that paper, I use “state” to refer to observations. Furthermore, mini-grid documentation distinguishes “partial observation” which I think of when you say observation. Apologies for any confusion!
* **RTG:** Reward-to-Go. Refers to the remaining reward in a trajectory. Labelled in training data after a trajectory has been recorded. Uses to teach Decision Transformer to act in a way that will gain a certain reward in the future.
* **Token:**A vector representation provided to a neural network of concepts such as “blue” or “goal”.
* **Embedding:** An internal representation of a token inside a neural network.
* **Trajectory:** One run of a game from initialization to termination of truncation.
* **Episode:** A trajectory.
* **Demonstration**: A trajectory you're using to train an offline agent.
* **MLP**: Multilayer Perceptron.
* **Attention map/pattern**: A diagram show how a part of the transformer is moving information between tokens. In this case, positions in the trajectory.
* **Activation patching**: A technique designed to find important sections of
Related Work
------------
This work is only possible because of lots of other exciting work. Some of the most relevant posts/papers are listed. If I am accidentally duplicating effort in any obvious way please let me know.
* Prior work:
+ [Decision Transformer Interpretability - LessWrong](https://www.lesswrong.com/posts/bBuBDJBYHt39Q5zZy/decision-transformer-interpretability)
* Work related to Mechanistic Interpretability of RL Agents (offline/online)
+ [Interpreting a Maze Solving Network](https://www.lesswrong.com/sequences/sCGfFb5DPfjEmtEdn)
+ [Actually, Othello-GPT Has A Linear Emergent World Representation — Neel Nanda](https://www.neelnanda.io/mechanistic-interpretability/othello)
* Mechanistic Interpretability:
+ [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html)
+ [Helpful discussion of patching techniques.](https://www.lesswrong.com/posts/gtLLBhzQTG6nKTeCZ/attribution-patching-activation-patching-at-industrial-scale#How_to_Think_About_Activation_Patching)
+ [IOI Paper](https://www.lesswrong.com/posts/3ecs6duLmTfyra3Gp/some-lessons-learned-from-studying-indirect-object)
+ [The An neuron for congruence](https://www.lesswrong.com/posts/cgqh99SHsCv3jJYDS/we-found-an-neuron-in-gpt-2)
* Reinforcement Learning / Trajectory Models
+ [Decision Transformers](https://arxiv.org/abs/2106.01345)
+ [BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning](https://arxiv.org/abs/1810.08272). The model in this paper is the agent/generates the training data used to train MemoryDT. I integrated it with the rest of my github repo.
+ [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039)
+ [A Generalist Agent](https://arxiv.org/abs/2205.06175)
* Alignment
+ [Retargeting the Search](https://www.lesswrong.com/posts/w4aeAFzSAguvqA5qu/how-to-go-from-interpretability-to-alignment-just-retarget)
+ [Simulators](https://www.lesswrong.com/posts/vJFdjigzmcXMhNTsx/simulators)
1. **[^](#fnrefht91xftmu8s)**Fact: The original decision transformer was originally intended to predict states and rewards which would have made it a simulator. It's possible at scale, offline-RL is best done minimizing loss over the simulation objective and not the agent simulation objective. |
b2c6ab55-1f69-4c30-a808-12701a909a1c | trentmkelly/LessWrong-43k | LessWrong | Definitions, characterizations, and hard-to-ground variables
[I am hoping this post is not too repetitive, does not spend too much time rehashing basics... also: What should this be tagged with?]
Systems are not always made to be understandable - especially if they were not designed in the first place, like the human brain. Thus, they can often contain variables that are hard to ground in an outside meaning (e.g. "status", "gender"...). In this case, it may often be more appropriate to simply characterize how the variable behaves, rather than worry about attempting to see what it "represents" and "define" it thus. Ultimately, the variable is grounded in the effects it has on the outside world via the rest of the system. Meanwhile it may not represent anything more than "a flag I needed to make this hack work".
I will refer to this as characterizing the object in question rather than defining it. Rather than say what something "is", we simply specify how it behaves. Strictly speaking, characterization is of course a form of definition[0] - indeed, strictly speaking, nearly all definitions are of this form - but I expect you will forgive me if for now I allow a fuzzy notion of "characterization vs. definition" scale.
Let us consider a simple example where this is appropriate; consider the notion of "flying" in Magic: the Gathering. In this game, a player may have his creatures attack another player, who can then block them with creatures of his own. Some of these creatures have printed on them the text "flying", which is defined by the game rules to expand to a larger block of explanatory text. What does "flying" mean? It means "this creature can't be blocked except by creatures with flying"[1]. So the creature can only be blocked by creatures that can only be blocked by creatures that can only be blocked by... well, you see the problem. This is not the real definition at all; if you took a card with "flying" and instead actually replaced it with the text "this creature can't be blocked except by creatures with flyi |
924e1cd4-2ca3-4750-b382-00d2992165ea | trentmkelly/LessWrong-43k | LessWrong | The Dictatorship Problem
(Disclaimer: This is my personal opinion, not that of any movement or organization.)
This post aims to show that, over the next decade, it is quite likely that most democratic Western countries will become fascist dictatorships - this is not a tail risk, but the most likely overall outcome. Politics is not a typical LessWrong topic, and for good reason:
1. it tends to impair clear thinking;
2. most well-known political issues are not neglected;
3. most political "debates" are simply people yelling at each other online; neither saying anything new, nor even really trying to persuade the opposition.
However, like the COVID pandemic, it seems like this particular trend will be so impactful and so disruptive to ordinary Western life that it will be important to be aware of it, factor it into plans, and try our best to mitigate or work around the effects.
Introduction
First, what is fascism? It's common for every side in a debate to call the other side "fascists" or "Nazis", as we saw during (eg.) the Ukraine War. Lots of things that get called "fascist" online are in fact fairly ordinary, or even harmless. So, to be clear, Wikipedia defines "fascism" as:
> a far-right, authoritarian, ultranationalist political ideology and movement, characterized by a dictatorial leader, centralized autocracy, militarism, forcible suppression of opposition, belief in a natural social hierarchy, subordination of individual interests for the perceived good of the nation and race, and strong regimentation of society and the economy
Informally, I might characterize "fascism" as:
> a system of government where there are no meaningful elections; the state does not respect civil liberties or property rights; dissidents, political opposition, minorities, and intellectuals are persecuted; and where government has a strong ideology that is nationalist, populist, socially conservative, and hostile to minority groups.
(The last point is what separates fascism from, say, Stalinism. Stali |
8f33c79d-d5a2-4474-9ed4-c16f026bf5ba | trentmkelly/LessWrong-43k | LessWrong | Is Scott Alexander bad at math?
This post is a third installment to the sequence that I started with The Truth About Mathematical Ability and Innate Mathematical Ability. I begin to discuss the role of aesthetics in math.
There was strong interest in the first two posts in my sequence, and I apologize for the long delay. The reason for it is that I've accumulated hundreds of pages of relevant material in draft form, and have struggled with how to organize such a large body of material. I still don't know what's best, but since people have been asking, I decided to continue posting on the subject, even if I don't have my thoughts as organized as I'd like. I'd greatly welcome and appreciate any comments, but I won't have time to respond to them individually, because I already have my hands full with putting my hundreds of pages of writing in public form.
Where I come from
My father is a remarkable creature, and I'm grateful for the opportunity to have grown up around him. Amongst other things, we share a love of music. There's a fair amount of overlap in our musical tastes. But there's an important difference between us.
When a piece of music is complex, like a piano sonata or a symphony, I often need to listen to it repeatedly before I figure out what I like about it. When I share the piece with him that he's never heard before, he'll often highlight the parts that I like most in real time, on first listening, without my having said anything.
In the past, people would have attributed this to magic, or other supernatural constructs like telepathy. We now know that these explanations don't suffice.
You might hypothesize that the difference comes from him having greater abstract pattern recognition ability than my own. In fact, this is the case, but it doesn't suffice to account for the phenomenon. Some people with greater pattern recognition ability than me don't appreciate music at all. More significantly, my father doesn't figure out what I like by thinking about it – his reactions are in |
91790d00-aae1-4302-b7bf-92b7851c9988 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | How Could AI Governance Go Wrong?
*(I gave a* [*talk*](https://youtu.be/agh49DwhUFU) *to EA Cambridge in February 2022. People have told me they found it useful as an introduction/overview so I edited the transcript, which can be found below. If you're familiar with AI governance in general, you may still be interested in the sections on 'Racing vs Dominance' and 'What is to be done?'.)*
Talk Transcript
===============
I've been to lots of talks which catch you with a catchy title and they don't actually tell you the answer until right at the end so I’m going to skip right to the end and answer it. How could AI governance go wrong?
These are the three answers that I'm gonna give: over here you've got some paper clips, in the middle you've got some very bad men, and then on the right you've got nuclear war. This is basically saying the three cases are accident, misuse and structural or systemic risks. That's the ultimate answer to the talk, but I'm gonna take a bit longer to actually get there.
I'm going to talk very quickly about my background and what CSER (the Centre for the Study of Existential Risk) is. Then I’m going to answer what is this topic called AI governance, then how could AI governance go wrong? Before finally addressing what can be done, so we're not just ending on a sad glum note but we're going out there realising there is useful stuff to be done.
My Background & CSER
====================
This is an effective altruism talk, and I first heard about effective altruism back in 2009 in a lecture room a lot like this, where someone was talking about this new thing called [Giving What We Can](https://www.givingwhatwecan.org/), where they decided to give away 10% of their income to effective charities. I thought this was really cool: you can see that's me on the right (from a little while ago and without a beard). I was really taken by these ideas of effective altruism and trying to do the most good with my time and resources.
So what did I do? I ended up working for the Labour Party for several years in Parliament. It was very interesting, I learned a lot, and as you can see from the fact that the UK has a Labour government and is still in the European Union, it went *really well*. Two of the people I worked for are no longer even MPs. After this sterling record of success down in Westminster – having campaigned in one general election, two leadership elections and two referendums – I moved up to Cambridge five years ago to work at CSER.
The [Centre for the Study of Existential Risk](https://www.cser.ac.uk/): we're a research group within the University of Cambridge dedicated to the study and mitigation of risks that could lead to human extinction or civilizational collapse. We do high quality academic research, we develop strategies for how to reduce risk, and then we field-build, supporting a global community of people working on existential risk.
We were founded by these three very nice gentlemen: on the left that's Prof Huw Price, Jaan Tallinn (founding engineer of Skype and Kazaa) and Lord Martin Rees. We've now grown to about 28 people (tripled in size since I started) - there we are hanging out on the bridge having a nice chat.
A lot of our work falls into four big risk buckets:
* [pandemics](https://www.cser.ac.uk/research/global-catastrophic-biological-risks/) (a few years ago I had to justify why that was in the slides, now unfortunately it's very clear to all of us)
* [AI](https://www.cser.ac.uk/research/risks-from-artificial-intelligence/), which is what we're going to be talking mainly about today
* [climate change and ecological damage](https://www.cser.ac.uk/research/extreme-risks-and-global-environment/), and then
* [systemic risk](https://www.cser.ac.uk/research/science-global-risk/) from all of our intersecting vulnerable systems.
Why care about existential risks?
=================================
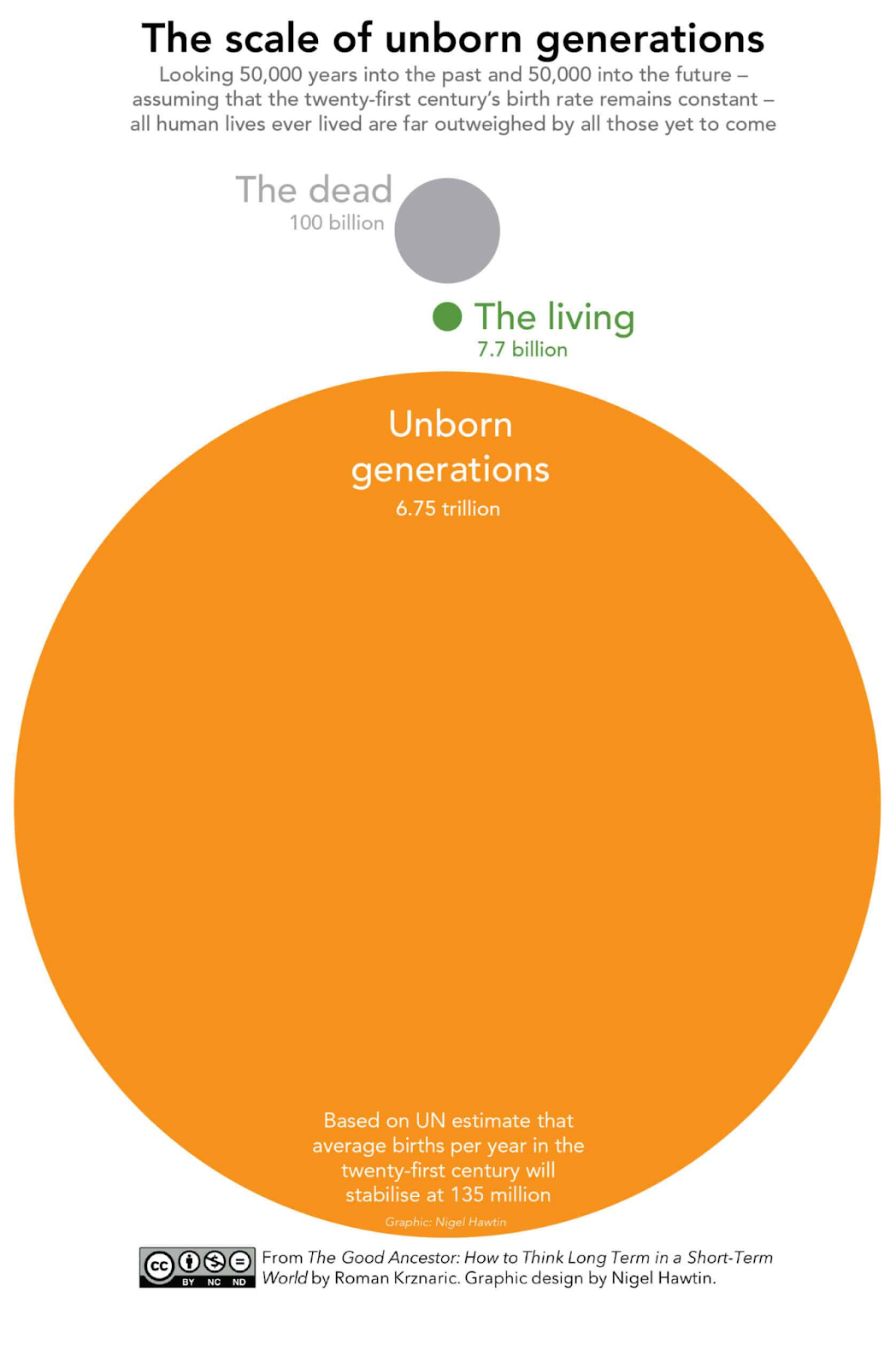Why should you care about this potentially small chance of the whole of humanity going extinct or civilization collapsing in some big catastrophe? One very common answer is looking at the [size](https://www.romankrznaric.com/good-ancestor/graphics) of all the future generations that could come if we don't mess things up. The little circle in the middle is the number of currently alive people. At the top is all the previous generations that have gone before. This much larger circle is the number of unborn generations there could be (if population growth continues at the same rate as this century for 50,000 more years). You can see there's a huge potential that we have in front of us. These could all be living very happy, fulfilling, flourishing lives and yet they could potentially go extinct. They could never come to be. This would be a terrible end to the human story, just a damp squib. That's a general argument for why a lot of us are motivated to work on existential risk, but it's not the only argument.
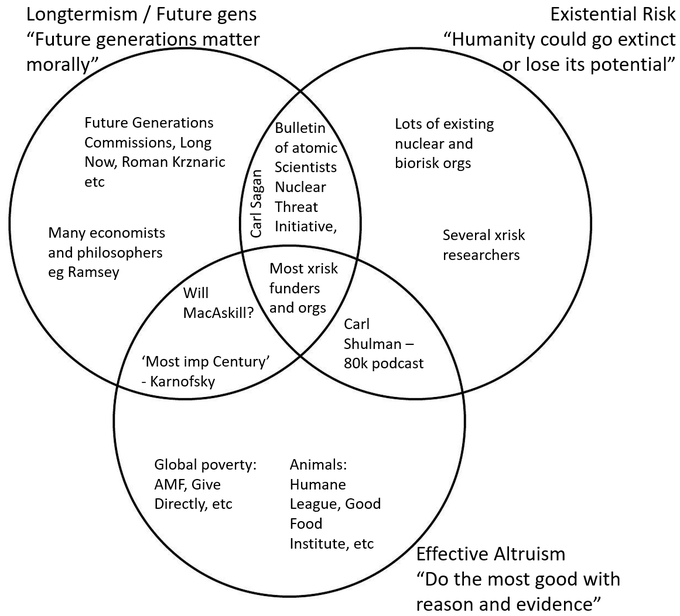I put this together a little while ago. These are three intersecting circles. At the top is the idea of *longtermism or future generations*, with the slogan “future generations matter morally”. There's *existential risk*: “humanity could go extinct to lose its potential”. Third there’s *effective altruism*, this idea of “doing the most good with reason and evidence”
The point is that while they intersect (and I would place myself in the middle) you don't have to believe in one to be sold on the other. There's lots of good existential risk researchers who are not so convinced about the value of the future but still think it'll be so terrible for the current generation that it's worth doing a lot about. There's a lot of different ways you can come to this conclusion that existential risk is really important.
So that is a bit of a background on why I’m interested in this, what CSER does and why we're working on this these risks.
What's AI governance?
=====================
This is the only slide with this much text, so you'll forgive me just reading it out (because it's a definition and we're academics we like definitions). AI governance is “the study or practice of local and global governance systems including norms policies laws processes and institutions that govern or should govern AI research, development, deployment and use”.
‘By deployment’, I mean that you may *develop* and train an AI system - but then *using* it in the world is often referred to as deployment. This [definition](https://link.springer.com/content/pdf/10.1007/s13347-020-00402-x.pdf) is from some of my colleagues. I think it's good because it's a very broad definition of AI governance and what we're doing when we do AI governance. But who does AI governance?
Here are six people who I'm going to say all do all work on AI governance:
* Timnit Gebru, who was a researcher at Google, wrote a [paper](https://dl.acm.org/doi/10.1145/3442188.3445922) that criticized some of the large language models that Google was developing, got fired for it and has now left and started her own research [group](https://www.dair-institute.org/press-release). She works on AI governance.
* Sheryl Sandberg, who's number two at Facebook/Meta. She’s a very important person in deciding what Facebook's recommender systems (an AI system) pushes in front of various people (e.g. what teenagers see on Instagram). She works on AI governance.
* Margrethe Vestager is the European Commissioner for Competition Law and also does a lot on digital markets. She has brought some really big cases against big tech companies and she's a key figure behind the EU’s current [AI Act](https://artificialintelligenceact.eu/) which regulates high risk ai systems. She works on AI governance.
* Lina Khan. When she was an academic she wrote a great paper called [Amazon's Antitrust Paradox](https://www.yalelawjournal.org/note/amazons-antitrust-paradox) and she just got appointed to be chair of the Federal Trade Commission by the Biden administration. She works on AI governance.
* Avril Haines. She's now the US Director of National Intelligence but before the election she wrote a great [paper](https://cset.georgetown.edu/wp-content/uploads/Building-Trust-Through-Testing.pdf) on how AI systems could get incorporated safely and ethically into defense. She works on AI governance.
* Finally this is Meredith Whitaker, she also worked at Google. She was one of the core organizers of the [Google Walkout for Real Change](https://googlewalkout.medium.com/) which was protested the treatment of people who have reported sexual harassment. She also has left google. She founded the [AI Now Institute](https://ainowinstitute.org/), an important research NGO. She works on AI governance.
What I'm trying to convey here is there's lots of different sides to AI governance: from different countries; within companies, government, academia, NGOs; from the military side from the civilian side. It's a broad and interesting topic. That's the broad field of AI governance.
I'm going to zoom in a little bit more to where I spend a lot of my time, which is more on long-term governance. We've got three photos of three conferences organized by the Future of Life Institute called the Beneficial AGI conferences. The first one in [2015](https://futureoflife.org/2015/10/12/ai-safety-conference-in-puerto-rico/), the second one is [2017](https://futureoflife.org/bai-2017/), and this last one down here (I'm in at the back) was in [2019](https://futureoflife.org/beneficial-agi-2019/). These were three, big, important conferences that brought a lot of people together to discuss the safe and beneficial use of AI. This first one in 2015 led to an [Open Letter](https://futureoflife.org/ai-open-letter/) signed by 8,000 robotics and AI researchers calling for the safe and beneficial use of AI and releasing this research agenda alongside it. It really placed this topic on the agenda – a big moment for the field. This next one project was in 2017 in Asilomar and it produced the [Asilomar AI Principles](https://futureoflife.org/2017/08/11/ai-principles/), one of the first and most influential (I would say) of the many AI ethics principles that have come out in recent years. The last one really got into more of the nuts and bolts of what sort of policies and governance systems there should be around AI governance.
The idea of these three pictures is to show you that in 2015 this thing was still getting going. Starting to say “I want to develop ai safely and ethically” was a novel thing. In 2017 there was this idea of “maybe we should have principles” and then by 2019 this had turned into more concrete discussions. Obviously, there wasn't one in 2021 and we can all maybe hope for next year.
That's my broad overview of the kinds of things that people who work on AI governance work on and a bit of how the field's grown.
How could AI governance go wrong? General argument: this could be a big deal
============================================================================
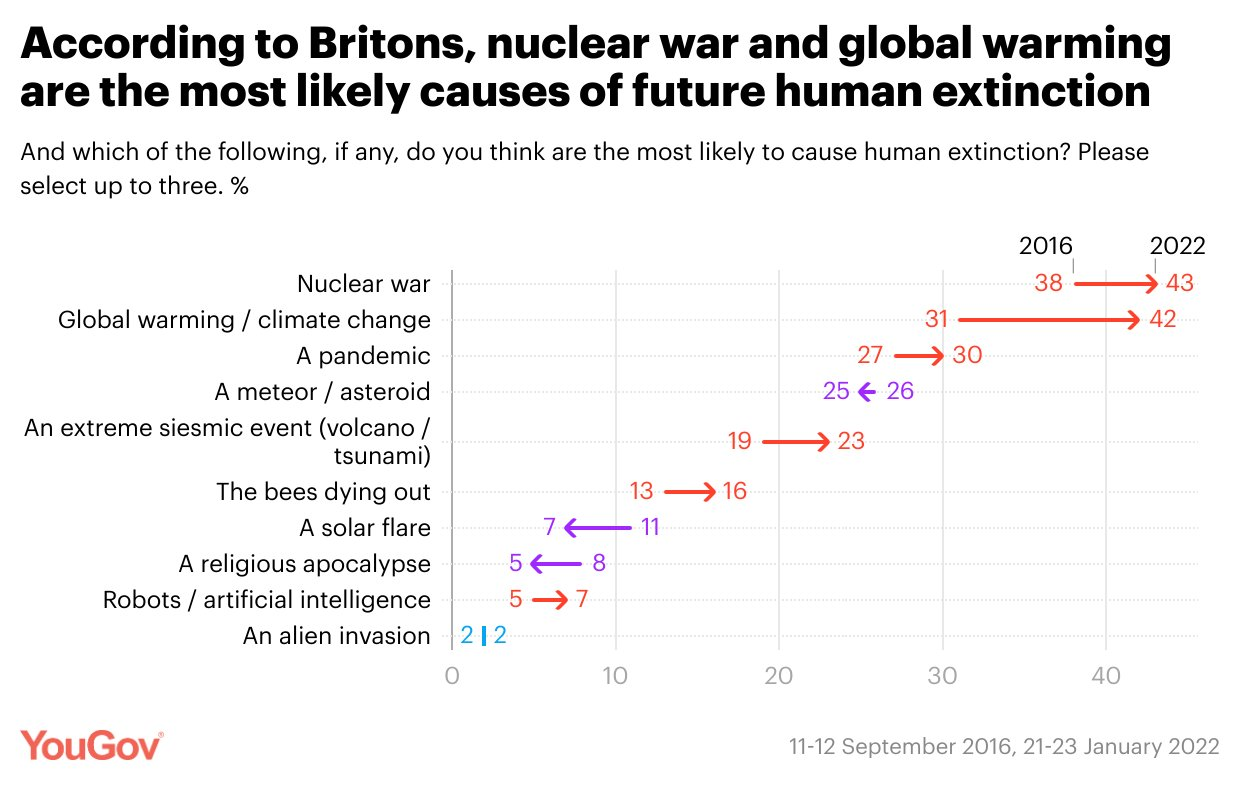This is a [survey](https://yougov.co.uk/topics/politics/articles-reports/2022/02/16/has-pandemic-changed-views-human-extinction) by YouGov. They surveyed British people in 2016 and again in 2022 on what are the most likely causes of future human extinction. Right up at the top there's nuclear war, global warming/climate change and a pandemic. Those three seem to make sense, it's very understandable why those would be placed so high up by the British public. But if you see right down at the bottom nestled between a religious apocalypse and an alien invasion is robots and artificial intelligence. This is clearly not a thing that most randomly surveyed British people would place in the same category as nuclear war, pandemics or climate change. So why is it that our Centre does a lot of work on this? Why do we think that AI governance is such an important topic that it ranks up there with these other ways that we could destroy our potential?
Here's the general argument: AI's been getting much better recently, and it looks like it's going to continue getting much better.
* In 2012 there was a big breakthrough in image recognition where [AlexNet](https://en.wikipedia.org/wiki/AlexNet) made a huge jump in the state of the art.
* This next picture represents games: Lee Sedol losing at Go to [AlphaGo](https://en.wikipedia.org/wiki/AlphaGo).
* The top right is robotics, one of the Boston Dynamics dogs. Robotics has not been improving as much as the others but has still been making breakthroughs.
* Bottom left here is from [GPT-3](https://en.wikipedia.org/wiki/GPT-3). They gave it a prompt about “explorers have just found some unicorns in the Andes” and it gave this very fluent news article about it, that almost looked like it was written by humans. This is now being rolled out and you can use this language model to complete lots of different writing tasks or to answer questions in natural language with correct answers.
* The next one here: they gave [DALL-E](https://openai.com/dall-e-2/) a prompt of “a radish in a tutu walking a dog” and the AI system produced this remarkable illustration.
* Then the final one is [AlphaFold](https://www.deepmind.com/blog/alphafold-a-solution-to-a-50-year-old-grand-challenge-in-biology), DeepMind's new breakthrough on protein folding. This is a very complex scientific problem that has been unsolved for lots of years and it's now almost superhuman.
So: image recognition, games, robotics, language models generating image and text and then helping with scientific advancements. AI has been rapidly improving over the last 10 years and potentially could continue to have this very rapid increase in capabilities in the coming decades
But maybe we should think a bit more about this.
On the left here we've got an internal combustion engine, in the middle we've got the steam engine, and on the right we've got the inside of a fusion tokamak (which can be thought of as a type of engine). The idea is that the internal combustion engine is representative of a general purpose technology, the steam engine is representative of a transformative technology, and this fusion one is representative of the claim made by Holden Karnofsky: that we may be living in the most important century for human history.
Is AI a [general purpose technology](https://www.governance.ai/research-paper/engines-of-power-electricity-ai-and-general-purpose-military-transformations), something like the internal combustion engine, electricity, refrigeration or computers: a generally useful technology that is applied in lots of different application areas across economy and society, has many different effects on politics, military and security issues and spawns lots of further developments? I think most people would already accept that AI is already a general purpose technology at the level of these others.
Could it be a [transformative technology](https://arxiv.org/abs/1912.00747)? This term refers to something that changes civilization and our societies in an even more dramatic way. There have been two big transformative occasions in human history (zooming really really far out). First, everyone was hunter-gatherers and foragers and then the invention of farming, sometimes called the Neolithic Revolution, just transformed our entire societies, the way we live and operate in the world.
The next thing at that sort of scale is the Industrial Revolution. Especially if you look at economic growth per capita, it is basically flat since the Neolithic Revolution: it increases a bit but economic growth is Malthusian and is all eaten up by population increases. But then GDP per capita really shoots up with the Industrial Revolution and James Watts’ steam engine. There's some possibility that AI is not just a general purpose technology but is transformative at this scale. If much of our economy, society, politics and militaries are automated then it could be a similar situation. Before the Industrial Revolution 98% of the population worked in farming and now in the UK only 2% are farmers. It could be that scale of transformation.
But then there's this further claim that maybe it’s even a step beyond that: the [most important century](https://www.cold-takes.com/most-important-century/). The reason I chose this picture isn't (just) because it's an interesting picture, it's because researchers [recently applied](https://www.deepmind.com/blog/accelerating-fusion-science-through-learned-plasma-control) machine learning to better control the flow of plasma around a fusion engine, much better than we've been able to before. This highlights the idea that AI could be used to increase the progress of science and technology itself. It's not just that there's new inventions happening and changing economy and society, but it's that that process *itself* is being automated, sped up and increased.
AlphaFold for biotechnology and then here for physics – these are indications of how things could go. Karnofsky calls this a process for automating science and technology (PASTA). The argument is that if that takeoff were to happen sometime in this century, then this could be a very important moment. We could make new breakthroughs and have an incredible scale of economic growth and scientific discovery, much quicker even than the industrial revolution
To step back a second what I'm trying to show here is just that AI could be a very big deal and therefore how we govern it, how we incorporate it into our societies, could be also a very big deal.
How could AI governance go wrong? Specific arguments: accident, misuse and structure
====================================================================================
| | | | |
| --- | --- | --- | --- |
| | **Accident** | **Misuse** | **Structure** |
| **Near term** | Concrete Problems | Malicious Use of AI | Flash Crash -> Flash War |
| **Long term** | Human Compatible | Superintelligence | ‘Thinking About Risks From AI’ |
But how could it go wrong? The risk is generally split into accident, misuse and structure (following a [three-way split](https://www.lawfareblog.com/thinking-about-risks-ai-accidents-misuse-and-structure) made by Remco Zwetsloot and Allen Dafoe). I’ll discuss near-term problems people may be familiar with and then longer term problems.
In the near term, a paper called [Concrete Problems in AI Safety](https://arxiv.org/abs/1606.06565) looked at a cleaning robot and how it can move around a space and not lead to accidents. More generally, we find that our current machine learning systems go wrong a depressing amount of the time and in often quite surprising ways. While that might be okay at this stage, as they become increasingly powerful then the risk of accidents goes up. Consider the 2020 example of A Level grades being awarded by algorithms, which is an indication of how an AI system could really affect someone’s entire life chances. We need to be concerned about these accidents in the near term.
Misuse. We wrote a report a few years ago called the [Malicious Use of AI](https://arxiv.org/pdf/1802.07228) (I think it was a good title so it got a fair amount of coverage). It looked at ways that AI could be misused by malicious actors, in particular criminals (think of cyber attacks using AI) and terrorists (think of the use of automated drone swarms) and how it could get misused by rogue states and authoritarian governments to surveil and to control their populations more.
Then there's this idea of structure: structural risks or systemic risks. A few years ago, there was the so-called “flash crash”. The stock market had this really dramatic, sudden dip – then the circuit breakers kicked in and it came back to normal. But looking back on this, it turns out that it was to do with the interaction of many different automated trading bots. We still to this day are not entirely sure exactly what caused this flash crash
Paul Scharre proposed that we could have the same thing but a “[flash war](https://foreignpolicy.com/2018/09/12/a-million-mistakes-a-second-future-of-war/)”. Imagine two automated or autonomous defense systems on the North Korea / South Korea border which interact in some complicated way, maybe at a speed that we can't intervene on or understand. This could escalate to war. There's not an accident and there's not someone misusing it - it's more the interaction and the structural risk.
Accident, misuse and structure also apply to the longterm.
The argument is that at this very transformative scale then all these safety problems become increasingly worrying. [Human Compatible](https://en.wikipedia.org/wiki/Human_Compatible) is written by Stuart Russell, who is the author of the leading textbook in AI (he just gave the [Reith Lectures](https://www.bbc.co.uk/programmes/m001216k) which are very good). He suggests that AI systems are likely to be given goals that they pursue in the world but that it might be quite hard to align these with human preferences and human values. We might therefore be concerned about very large accident risks.
The long-term misuse concern is the idea that these systems could get misused by all the people we talked about previously: criminals, terrorists and rogue states using AI to kill large numbers of people, to oppress or to lock in their own values. I put [Superintelligence](https://en.wikipedia.org/wiki/Superintelligence:_Paths,_Dangers,_Strategies) here by Nick Bostrom (but actually I think the definitive book has not yet been written on this).
The long-term structural concern is that the interaction of these powerful AI systems could lead to *conflict* (like with the flash war example) or simply competition between them that is wasteful of resources. Instead of achieving some measure of what we could achieve with humanity's potential we could instead up end up wasting a large part of it by [failing to coordinate](https://www.cooperativeai.com/), building up our defences, and racing for resources.
That’s the long-term risk of AI governance. To return to the slide that I tantalized you with at the beginning of the talk.
On the left we've got a bunch of paper clips, because one of the most famous thought experiments in AI safety and AI alignment is this idea of the [paperclip maximiser](https://www.lesswrong.com/tag/paperclip-maximizer). You are training this AI system to produce paper clips in a paper clip factory, and you have locked in this particular goal (of just producing more paperclips). You can imagine this AI system gaining in capabilities, power and generality and yet that might not change that goal itself. Indeed more generally, we can imagine very powerful, very capable systems with these strange goals. Because it's just pursuing these goals that we've given it and we haven't properly aligned it with our interests and values. If an AI system became more capable or acquired power and influence, it would have [instrumental reasons](https://en.wikipedia.org/wiki/Instrumental_convergence) to divert electricity or other resources to itself. This is the idea that is illustrated by the toy case of the paperclip maximizer.
Here in the middle, we've got some awful totalitarian despots from the mid 20th century, who ended up killing millions of their own people. If they had access to very capable AI systems then we might be very concerned about their oppressive rule being harder to end. AI systems could empower authoritarian regimes. A drone is never going to refuse to kill a civilian, for example. Improved and omnipresent facial recognition and surveillance could make it very hard for people to gather together and oppose such a regime.
Finally there's some risk that any conflict that is caused by the interaction of AI systems could escalate up to nuclear war or some other really destructive war.
All three of these could be massive risks and could fundamentally damage our potential and lead human history to a sad and wasteful end. That's the overall argument for how AI governance could go wrong.
Racing vs dominance
===================
One spectrum that cuts across these three risk verticals is characterised by two different extremes that we want to avoid. One extreme is racing and one extreme is dominance. Racing has been talked quite a lot about by the AI governance community, but so far dominance hasn't so much.
| | | |
| --- | --- | --- |
| | **Corporate** | **State** |
| **Racing** | Race to the bottom, conflict |
| **Dominance** | Illegitimate, unsafe, misuse |
Why could racing be a worry? We could have a race to the bottom: many different companies all competing to get to the market quicker. Or states in an arms race, like we had for nuclear weapons and for biological weapons. Racing to be the first and to beat their competition, they might take [shortcuts on safety](https://www.fhi.ox.ac.uk/publications/armstrong-s-bostrom-n-shulman-c-2015-racing-to-the-precipice-a-model-of-artificial-intelligence-development-ai-society-1-6-2/) and not properly align these AI systems, or they could end up misusing them, or that racing could drive conflict.
Something that has been discussed less in game theory papers but I think we should also be concerned about is the idea of *dominance* by just one AI development and deployment project. If it was just one *company,* I think we can all agree that would be pretty illegitimate for them to be taking these huge decisions on behalf of the whole of humanity. I think it's also illegitimate for those decisions to be taken by just by one state: consider if it was just China, just the EU or just the US. You can't be taking those really monumental decisions on behalf of everyone.
There's also the risk of it being unsafe. We've seen in recent years that some companies cannot really be trusted with the current level of AI systems that they've got, as it's led to different kinds of harms. We see this often in history: big monopolists often do cut corners and are just trying to maximize their own profits. We've seen this with the [robber barons](https://en.wikipedia.org/wiki/Robber_baron_(industrialist)) of Standard Oil and US Steel and others in the early 1900s. We've seen it with the early modern [European East India companies](https://en.wikipedia.org/wiki/East_India_Company_(disambiguation)). Too much dominance can be unsafe. And if there's just one group, then that raises the risk of misuse.
We really want to try and avoid these two extremes of uncontrolled races and uncontrolled dominance.
What is to be done?
===================
So that's all pretty depressing, but I’m not going to leave you on that – I’m going to say that there are actually useful things that we can be that we can do to avoid some of these awful scenarios that I’ve just painted for you.
| | | |
| --- | --- | --- |
| | **Corporate** | **State** |
| **Racing** | Collaboration & cooperation | Arms control |
| **Dominance** | Antitrust & regulation | International constraints |
Just to return to that previous race/dominance spectrum, there's lots of useful things we can do. Take the corporate side. In terms of racing between companies, we can have collaboration and cooperation on shared research or shared joint ventures and sharing information. In terms of dominance: anti-trust and competition law can break up these companies or regulate them to make sure that they are doing proper safety testing and aren't misusing their AI systems. That’s been a well-tried and successful technique for the last 100 years.
Take the state side. We've got an answer to these uncontrolled arms races: arms control. For the last 50 years, biological weapons have been outlawed and illegal under international law. There was also a breakneck, destabilising nuclear arms race between the USA and the USSR. But 50 years ago this year, they agreed to begin reducing their arsenals. On dominance: in the early 1950s when the US was the only country with nuclear weapons, many US domestic elites internally argued that this is just another weapon, we can use it like any other weapon and it should be used in the Korean War. But there was a lot of protest from civil society groups and from other countries, and in the end (from internal private discussions) [we can see](https://ir101.co.uk/wp-content/uploads/2018/10/tannenwald-the-nuclear-taboo-compressed.pdf) that those were influential and this non-use norm constrained people like President Eisenhower and his administration from using these weapons.
Let us consider some even more concrete solutions. First, two that can be done within AI companies.
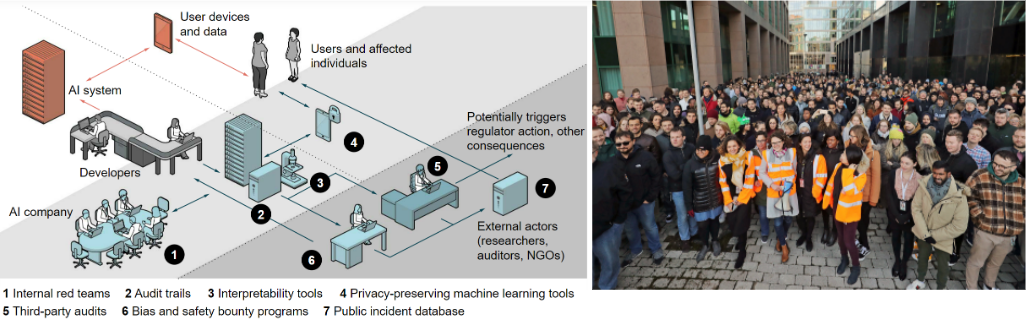This is a [paper](https://www.science.org/doi/10.1126/science.abi7176) we had out in Science in December 2021, which built on an even bigger [report](https://arxiv.org/abs/2004.07213) we did in 2020. It outlines 10 concrete ways that companies can cooperate and move towards more trustworthy AI development. Mechanisms like red teams on AI systems to see how they could go wrong or be vulnerable, more research on interpretability, more third party audits to make sure these AI systems are doing what they're supposed to be doing, and a public incidents database
Another thing that can be done is [AI community activism](https://arxiv.org/abs/2001.06528). This is a picture of the Google Walkout, discussed earlier. Google was doing other somewhat questionable things in 2018: they were partnering with the US government on Project Maven to create something that could be used for lethal autonomous weapons. Secretly they were also working on something called Project Dragonfly to create a censored search engine for the for Chinese Communist Party. Both of these were discovered internally and then there was a lot of protest. These employees were activist and asserted their power. Because AI talent is in such high demand, they were able to say “no let's not do this, we don't want to do this, we want a set of AI principles so we don't have to be doing “ethics whack-a-mole””.
But I don't think just purely voluntary stuff is going to work. These are three current regulatory processes across the US and EU and across civilian and military.
The [EU AI Act](https://artificialintelligenceact.eu/) will probably pass in November 2022. It lays out 8 different types of high-risk ai systems and it has many requirements that companies deploying these high-risk systems must pass. Companies must have a risk management system and must test their system and show that it's, for example, accurate, cybersecure and not biased. This is going to encourage a lot more AI safety testing within these companies and hopefully a shared understanding of “our machine learning systems keep on going wrong, we should be more modest about what they can achieve”.
There's a complimentary approach happening in the US with NIST (the National Institute for Standards and Technology), which is also working on what [common standards](https://www.nist.gov/itl/ai-risk-management-framework) for AI systems should be.
Avril Haines (who I talked about at the beginning of the talk) wrote this paper called [Building Trust through Testing](https://cset.georgetown.edu/wp-content/uploads/Building-Trust-Through-Testing.pdf) on TEVV (because US defense people love acronyms): testing, evaluation verification and validation. On the civilian side we want to make sure that these systems are safe and not harming people. I think we want to be even more sure they’re safe and not harming people if they're used in a military or defense context. This report explores how can we actually do that.
Finally, there’s the [Campaign to Stop Killer Robots](https://www.stopkillerrobots.org/). For the last eight years there's been negotiations at the UN about banning lethal autonomous weapons - weapon systems that can autonomously select and engage (kill) a target. There's been a big push to ban them. Even though we haven't yet got a ban, people are still hopeful for the future. Nevertheless, over the last eight years there's been a lot of useful awareness-building along the lines of “these systems do end up going wrong in a lot of different ways and we really do need to be careful about how we're doing it”. Different people and states have also shared best practice, such as Australia sharing details of how to consider autonomy in weapons reviews for new weapons.
Across the civilian and military sides, in different parts of the world there's a lot happening in AI governance. No matter where you're from, where you're a resident or citizen, where you see your career going or what your disciplinary background is, there's useful progress to be made in all these different places and from all these different disciplinary backgrounds. There's already been great research produced by people in all these different disciplines.
Let's get even more concrete - what can you do right now? You can check out 80,000 Hours, a careers advice website and group. They've got lots of really [great resources](https://80000hours.org/articles/ai-policy-guide/#:~:text=80%2C000%20Hours'%20research%20suggests%20that,progress%20in%20reducing%20the%20risks.) on their website and they offer career coaching.
Another great resource is run right here in Cambridge, the [AGI safety fundamentals course](https://www.eacambridge.org/agi-safety-fundamentals) also has a track on governance, I'm facilitating one of the groups. There are around 500 people participating in these discussion groups and you then you work on a final project. It's a great way to get to grips with this topic and try it out for yourself. I would thoroughly recommend both of those two things.
To recap: I've talked a bit about my background and what the Centre for the Study of Existential Risk is. I've introduced this general topic of AI governance, then we've narrowed down into long-term AI governance and we've asked how could it go wrong at the scale of nuclear war, pandemics and climate change? The answer is accident risk, misuse risk and structural risk. But there are things that we can do! We can cooperate, we can regulate, we can do much more research, and we can work on this in companies, in academia in governments. This is a hugely interesting space and I would love more people to dip their toes in it!
 |
e30ea5dd-f49f-4c98-a30a-6ace61e9da4f | trentmkelly/LessWrong-43k | LessWrong | Intranasal mRNA Vaccines?
This is not advice. Do not actually make this, and especially do not make this and then publicly say "I snorted mRNA because Jonathan said it was a good idea". Because I'm not saying it's a good idea.
Everyone remembers johnswentworth making RaDVac almost four years ago now. RaDVac was designed to be, well, rapidly deployed, so it uses short peptides, rather than longer peptides or inactivated virus, which are what normal vaccines use.
Since then, we've seen the introduction of mRNA vaccines, which can also be used intranasally! So would it be possible to produce something like this at home?
The Non-mRNA Components
mRNA vaccines consist of various. The first is the mRNA itself, the other components are a bunch of lipids (read: fatty molecules) which form into tiny particles rather unimaginatively called lipid nanoparticles (LNPs). These consist of a bunch of lipids surrounding the mRNA. Their job is to stick to cells, and then kind of merge with the cell's membrane (like two bubbles popping together into one big bubble) and release the mRNA into the cell. This works because the LNPs are cationic (positively charged) and cell membranes tend to be negatively charged.
There are sometimes other steps wherein the LNPs are actively taken up, transferred to an internal compartment, and then break out of that compartment.
So my first guess was to just buy something called Lipofectamine:
In this hypothetical case, we'd ignore steps 1 and 7, and replace step 6 with "huff it".
(Side note: "70-90% confluent" just means that the slides are 70-90% covered in cells, it has nothing to do with any property of the cells themselves, which is why we won't worry about it.)
The question is, would this work? Lipofectamine is probably similar to the lipid composition of the LNPs from this paper but not the same. I spoke to a friend whose job is getting nucleic acids into lung cells (lung cells and nasal cells are relatively similar) and (paraphrased) she said "Don't DIY an mRNA |
4cdc3d61-a6de-44bc-9ea1-e407a977da76 | trentmkelly/LessWrong-43k | LessWrong | Common misconceptions about OpenAI
I have recently encountered a number of people with misconceptions about OpenAI. Some common impressions are accurate, and others are not. This post is intended to provide clarification on some of these points, to help people know what to expect from the organization and to figure out how to engage with it. It is not intended as a full explanation or evaluation of OpenAI's strategy.
The post has three sections:
* Common accurate impressions
* Common misconceptions
* Personal opinions
The bolded claims in the first two sections are intended to be uncontroversial, i.e., most informed people would agree with how they are labeled (correct versus incorrect). I am less sure about how commonly believed they are. The bolded claims in the last section I think are probably true, but they are more open to interpretation and I expect others to disagree with them.
Note: I am an employee of OpenAI. Sam Altman (CEO of OpenAI) and Mira Murati (CTO of OpenAI) reviewed a draft of this post, and I am also grateful to Steven Adler, Steve Dowling, Benjamin Hilton, Shantanu Jain, Daniel Kokotajlo, Jan Leike, Ryan Lowe, Holly Mandel and Cullen O'Keefe for feedback. I chose to write this post and the views expressed in it are my own.
Common accurate impressions
Correct: OpenAI is trying to directly build safe AGI.
OpenAI's Charter states: "We will attempt to directly build safe and beneficial AGI, but will also consider our mission fulfilled if our work aids others to achieve this outcome." OpenAI leadership describes trying to directly build safe AGI as the best way to currently pursue OpenAI's mission, and have expressed concern about scenarios in which a bad actor is first to build AGI, and chooses to misuse it.
Correct: the majority of researchers at OpenAI are working on capabilities.
Researchers on different teams often work together, but it is still reasonable to loosely categorize OpenAI's researchers (around half the organization) at the time of writing as approximat |
ed00d602-ec76-46d6-b175-e56b505e9051 | trentmkelly/LessWrong-43k | LessWrong | [LINK] Luck, Skill, and Improving at Games
None |
d40700ef-99af-463e-84d0-1865e3a36f88 | trentmkelly/LessWrong-43k | LessWrong | Governance Course - Week 1 Reflections
[Epistemic status: I'm trying to make my thinking legible to myself and others, rather than trying to compose something highly polished here. I think I have good reasons for saying what I say and will try to cite sources where possible, but nonetheless take it with some grains of salt. As with my last post, I am lowering my standards so that this post gets out at all.]
I'm working my way through Harvard's AI safety club (AISST)'s modified version of the BlueDot Impact AI Governance Curriculum. I'm doing this because I am pessimistic about technical alignment on current AGI timelines, and so I am trying to extend timelines by getting better at governance.
I've already taken MIT AI Alignment (MAIA)'s version of the BlueDot Alignment course (MAIA's version is not publicly available), and I've taken MIT's graduate-level deep learning course, so I'll mostly be skimming through the technical details.
The purpose of this sequence is for me to explain what I learn, so that I internalize it faster, and so that I can actively discuss with people about my takes on the readings. Reading this is not intended as a substitute for actually doing any of the above-mentioned courses, but it might give you some new ideas.
EDIT: These posts were taking up too much time, and were serving as a blocker for me actually learning the content, so this post is discontinued. If you want my thoughts on anything specific in the curriculum, feel free to message me.
I'm already familiar with a lot of the content by osmosis and by my more technical AI safety background, so this post will probably be shorter than some of the later ones. Even though the curriculum is organized into weeks, I don't plan on doing these posts weekly. I will do them as fast as I can, given my other commitments.
But what is a neural network? (3Blue1Brown, 2017)
I've watched this video a handful of times in the past, and since then I've gotten significantly more technically skilled at AI stuff. I'm gonna skip out on th |
11786fe6-2c36-4157-b2b8-866a222c27db | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Speculation on Path-Dependance in Large Language Models.
*Epistemic Status: **Highly Speculative.** I spent less than a day thinking about this in particular, and though I have spent a few months studying large language models, I have never trained a language model. I am likely wrong about many things. I have not seen research on this, so it may be useful for for someone to do a real deep dive.*
*Thanks to Anthony from the Center on Long Term Risk for sparking the discussion earlier today for this post. Also thanks to conversations with* [*Evan Hubinger*](https://lesswrong.com/user/evhub) *~1 year ago that got me thinking about the topic previously.*
Summary
=======
My vague suspicions at the moment are somewhat along the lines of:
* **Training an initial model:** moderate to low path-dependance
* **Running a model:** high "prompt-dependance"
* **Reinforcement Learning a Model:** moderate to high path-dependance.
Definitions of "low" and "high" seem somewhat arbitrary, but I guess what I mean is how different behaviours of the model can be. I expect some aspects to be quite path dependant, and others not so much. This is trying to quantify how many aspects might have path-dependance based on vibe.
Introduction
============
[Path dependence](https://www.alignmentforum.org/posts/bxkWd6WdkPqGmdHEk/path-dependence-in-ml-inductive-biases) is thinking about the "butterfly effect" for machine learning models. For highly path-dependant models, small changes in how a model is trained can lead to big differences in how it performs. If a model is highly path-dependant, then if we want to understand how our model will behave and make sure it's doing what we want, we need to pay attention to the nitty-gritty details of the training process, like the order in which it's learning things, or the random weights initialisation. And, if we want to influence the final outcome, we have to intervene early on in the training process.
I think having an understanding of path-dependance is likely useful, but have not really seen any empirical results on the topic. I think that in general, it is likely to depend on different training methods a lot, and in this post I will give some vague impressions I have on the path dependance of Large Language Models (LLMs).
In this case, I will also include "prompt-dependance" as another form of "path-dependance" when it comes to the actual outputs of the models, though this is not technically correct since it does not depend on the actual training of the model.
Initial Training of a Model
===========================
### My Understanding: Low to Moderate Path-Dependance
So with Large Language Models at the moment, the main way they are trained it that you should have a very large dataset, randomise the order, and use each text exactly once. In practice, many datasets have a lot of duplicate data of things that are particularly common (possible example: transcripts of a well-know speech) though people try to avoid this. While this may seem there should be a large degree of path dependance, my general impression is that, at least in most current models, this does not happen that often. In general, LLMs can tend to struggle with niche facts, so I would perhaps expect that in some cases it learns a niche fact that it does not learn in another case, but the LLMs seems to be at least directionally accurate. (An example I have seen, is that it might say "X did Mathematics in Cambridge" instead of "X did Physics in Oxford", but compared to possibility space, it is not that far.)
I suspect that having a completely different dataset would impact the model outputs significantly, but from my understanding of path dependance, this does not particularly fall under the umbrella of path dependance, since it is modelling a completely different distribution. Though even in this case, I would suspect that in text from categories in the overlapping distribution, that the models would have similar looking outputs (though possibly the one trained on only that specific category could give somewhat more details.)
I also think that relative to the possibility space, most models are relatively stable in their possible options for outputs. Prompting with the name of the academic paper on a (non-fine-tuned) LLM can understand it is an academic title, but can follow up with the text of the paper, or the names of the authors and paper, followed by other references. or simply titles of other papers. I tried this briefly on GPT-3 (davinci) and GPT-NeoX, and both typically would try to continue with a paper, but often in different formats on different runs. What seemed to matter more to narrow down search space was what specific punctuation was placed after the title, such as <newline>, " -" or " ,". (More on this in the next section)
I would guess that things like activation functions and learning rate parameters would have difference in how "good" the model gets, but for different models of the same "goodness", and likely the internals will look different, but I doubt there is much that difference in the actual outputs.
This is partially motivated by the [Simulators](https://www.alignmentforum.org/posts/vJFdjigzmcXMhNTsx/simulators) model of how LLMs work. While imperfect, it seems somewhat close, and much better description than any sort of "agentic" model of how LLMs work. In this model, the essential idea is that LLMs are not so much a unified model trying to write something, but rather, the LLM is using the information in the previous context window to try to model the person who wrote the words, and then simulate what they would be likely write next. In this model, the LLM is not so much learning a unified whole of a next token predictor, but rather it is building somewhat independant "simulacra" models, and using relevant information to update each of them appropriately.
So the things I would expect to have a moderate impact are things like:
* Dataset contents and size
* Tokenizer implementation
* Major architectural differences (eg: [RETRO-like models](https://www.deepmind.com/publications/improving-language-models-by-retrieving-from-trillions-of-tokens))
And some things I think are less impactful to the output:
* Specific learning rate/other hyperparameters
* Specific Random Initialisation of the Weights/Biases
* Dataset random ordering
Though this is all speculative, I think that if you have a set of 3 models trained on the same dataset, possibly with slightly different hyperparameters, that the output to a well specified prompt would be pretty similar for the most part. I expect the random variations from non-zero temperature would be much larger than the differences due to the specifics of training for tasks similar to the distribution. I would also expect that for tasks that have neat circuits, that you would pretty much find quite similar [transformer circuits](https://transformer-circuits.pub/2021/framework/index.html) for a lot of tasks.
It is possible however, that since many circuits could use the same internal components, then there might be "clusters" of circuit space. I suspect however that the same task could be accomplished with multiple circuits, and that some are exponentially easier to find than others, but there might be some exceptions where there are two same-size circuits that accomplish the same task, or
Some exceptions where I might expect differences:
* Niche specific facts only mentioned once it the dataset at the start vs the end.
* The specific facts might be different for models with lower loss.
* The specific layers in which circuits form.
* Formatting would depend on how the data is scraped and tokenized.
* Data way outside the training distribution. (for example, a single character highly repeated, like ".................")
So I think it does make a difference how you set up the model, but the difference in behaviour is likely much smaller compared to which prompt you choose. I also suspect most that of the same holds for fine-tuning (as long as they do not use reinforcement learning).
Running a (pre-trained) Model
=============================
### My Understanding: High "Prompt-Dependance"
When it comes to running a model however, I think that specific input dependance is much higher. This is partially from just interacting with models some what, and also from other people. Depending on the way your sentences are phrased, it could think it is simulating one context, or it could think it is simulating another context.
For example, if you could prompt it with two different prompts:
* "New Study on Effects of Climate Change on Farming in Europe"
* "Meta-analysis of climate impacts and uncertainty on crop yields in Europe "
While both are titles to things answering the same information, one could get outputs that differ completely, since the first would simulate something like a news channel, and the latter might sound more like a scientific paper, and this could result in the facts it puts out to be completely different.
Examples of both the facts and styles being different with different prompts for the same information. Examples run on text-davinci-003From talking to people who know a lot more than me about Prompt Engineering, even things like formatting newlines, spelling, punctuation and spaces can make a big difference to these sorts of things, depending on how it is formatted in the datasets. As described in the previous section, giving an academic title with different punctuation will make a big difference to the likely paths it could take.
This is one of the main reasons I think that initial training has relatively little path dependance. Since the prompting seems make such a large difference, and seems to model the dataset distribution quite well, I think that the majority of the difference in output is likely to depend almost exclusively on the prompts being put in.
Fine-Tuning LLMs with Reinforcement Learning (RL)
=================================================
### My Understanding: Moderate to High Path Dependance
My understanding of RL on language models is that the procedure is to take some possible inputs and generate responses. Depending on the answers, rate the outputs and backpropagate loss to account for this. Rating could be done automatically (eg: a text adventure game, math questions) or manually (eg: reinforcement learning with human feedback).
I have not yet done any reinforcement learning on language models in particular, but other times I from implementing RL in other settings I have learned it can be quite brittle and finicky. I think that RL learning on LLMs seems likely to also suffer from this, and that different initial answers could likely sway the model quite quickly. Since the model is generating it's own training set, the initial randomly-generated responses may happen to have somewhat random attributes (eg: tone/spelling/punctuation) be corellated with the correctness of the outputs, and this could lead to the model in the next epoch to reinforce cases where it uses these random attributes more, and so it could get reinforced until the end.
As an toy example, one could imagine getting 10 outputs, 2 of which are "correct", and happen both to have British English spelling. In this case, the model would learn that the output needs to be not only correct, but have British English spelling. from then on, it mostly only answers in British English spelling, and each time it reinforces the use of British English spelling.
While this doesn't seems like a particularly illustrative example, the main thing is that minor differences in the model are amplified later on in training.
Is suspect however, that there exist RL fine tuning tasks that are less path-dependant. Depending on the reinforcement learning, it could make it so that the model is more or less "path-dependant" on the specific inputs it is prompted with, at least within the training distribution. Outside the training distribution, I would expect that the random amplified behaviours could be quite wild between training runs.
Conclusion.
===========
Again, this writeup is completely speculative on not particularly based on evidence, but from intuitions. I have not seen strong evidence for most of these claims, but I think that the ideas here are likely at least somewhat directionaly correct, and I think that this is an interesting topic people could potentially do some relatively informative tests relatively easily if one has the compute. One could even just look at the differences between similarly performing models of the same size, and come up with some sort of test for some of these things.
There might be existing studied into this which I have missed, or if not, I am sure there are people who likely have better intuitions than me on this, so I would be interested in hearing them.
References
==========
[**"Path Dependence in ML Inductive Biases"**](https://www.alignmentforum.org/posts/bxkWd6WdkPqGmdHEk/path-dependence-in-ml-inductive-biases), by [Vivek Hebbar](https://www.alignmentforum.org/users/vivek-1), [Evan Hubinger](https://www.alignmentforum.org/users/evhub)
[**"Simulators"**](https://www.alignmentforum.org/posts/vJFdjigzmcXMhNTsx/simulators), by [janus](https://www.alignmentforum.org/users/janus-1)
[**"A Mathematical Framework for Transformer Circuits"**](https://transformer-circuits.pub/2021/framework/index.html)**,** by[Nelson Elhage](https://nelhage.com/), [Neel Nanda](https://www.neelnanda.io/), Catherine Olsson, et al. |
8390f437-db11-44bf-a15b-dd28d852163a | StampyAI/alignment-research-dataset/lesswrong | LessWrong | The Best Textbooks on Every Subject
For years, my self-education was stupid and wasteful. I learned by consuming blog posts, Wikipedia articles, classic texts, podcast episodes, popular books, [video lectures](http://academicearth.org/), peer-reviewed papers, [Teaching Company](http://www.teach12.com/) courses, and Cliff's Notes. How inefficient!
I've since discovered that *textbooks* are usually the quickest and best way to learn new material. That's what they are *designed* to be, after all. Less Wrong [has](/lw/2xt/learning_the_foundations_of_math/) [often](/lw/ow/the_beauty_of_settled_science/) [recommended](/lw/jv/recommended_rationalist_reading/fcg?c=1) the "read textbooks!" method. [Make progress by accumulation, not random walks](/lw/1ul/for_progress_to_be_by_accumulation_and_not_by/).
But textbooks vary widely in quality. I was forced to read some awful textbooks in college. The ones on American history and sociology were memorably bad, in my case. Other textbooks are exciting, accurate, fair, well-paced, and immediately useful.
What if we could compile a list of the best textbooks on every subject? That would be *extremely* useful.
Let's do it.
There have been [other](/lw/jv/recommended_rationalist_reading/) [pages](/lw/12d/recommended_reading_for_new_rationalists/) of [recommended](/lw/2un/references_resources_for_lesswrong/) [reading](/lw/2xt/learning_the_foundations_of_math/) on Less Wrong before (and [elsewhere](http://ask.metafilter.com/71101/What-single-book-is-the-best-introduction-to-your-field-or-specialization-within-your-field-for-laypeople)), but this post is unique. Here are **the rules**:
1. Post the title of your favorite textbook on a given subject.
2. You must have read at least two other textbooks on that same subject.
3. You must briefly name the other books you've read on the subject and explain why you think your chosen textbook is superior to them.
Rules #2 and #3 are to protect against recommending a bad book that only seems impressive because it's the only book you've read on the subject. Once, a popular author on Less Wrong recommended Bertrand Russell's *A History of Western Philosophy* to me, but when I noted that it was more polemical and inaccurate than the other major histories of philosophy, he admitted he hadn't really done much other reading in the field, and only liked the book because it was exciting.
I'll start the list with three of my own recommendations...
**Subject**: History of Western Philosophy
**Recommendation**: *[The Great Conversation](http://www.amazon.com/Great-Conversation-Historical-Introduction-Philosophy/dp/0195397614/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)*, 6th edition, by Norman Melchert
**Reason**: The most popular history of western philosophy is Bertrand Russell's *[A History of Western Philosophy](http://www.amazon.com/History-Western-Philosophy-Bertrand-Russell/dp/0671201581/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)*, which is exciting but also polemical and [inaccurate](http://www.the-philosopher.co.uk/reviews/brussel.htm). More accurate but dry and dull is Frederick Copelston's 11-volume *[A History of Philosophy](http://en.wikipedia.org/wiki/A_History_of_Philosophy_(Copleston))*. Anthony Kenny's recent 4-volume history, collected into one book as *[A New History of Western Philosophy](http://www.amazon.com/New-History-Western-Philosophy/dp/0199589887/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)*, is both exciting and accurate, but perhaps too long (1000 pages) and technical for a first read on the history of philosophy. Melchert's textbook, *[The Great Conversation](http://www.amazon.com/Great-Conversation-Historical-Introduction-Philosophy/dp/0195397614/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)*, is accurate but also the easiest to read, and has the clearest explanations of the important positions and debates, though of course it has its weaknesses (it spends too many pages on ancient Greek mythology but barely mentions Gottlob Frege, the father of analytic philosophy and of the philosophy of language). Melchert's history is also the only one to seriously cover the dominant mode of Anglophone philosophy done today: [naturalism](http://www.amazon.com/Understanding-Naturalism-Movements-Modern-Thought/dp/1844650790/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20) (what Melchert calls "physical realism"). Be sure to get the 6th edition, which has major improvements over the 5th edition.
**Subject**: Cognitive Science
**Recommendation**: *[Cognitive Science](http://www.amazon.com/Cognitive-Science-Introduction-Mind/dp/0521882001/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)*, by Jose Luis Bermudez
**Reason**: Jose Luis Bermudez's *[Cognitive Science: An Introduction to the Science of Mind](http://www.amazon.com/Cognitive-Science-Introduction-Mind/dp/0521882001/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* does an excellent job setting the historical and conceptual context for cognitive science, and draws fairly from all the fields involved in this heavily interdisciplinary science. Bermudez does a good job of making himself invisible, and the explanations here are some of the clearest available. In contrast, Paul Thagard's *[Mind: Introduction to Cognitive Science](http://www.amazon.com/Mind-Introduction-Cognitive-Science-2nd/dp/026270109X/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* skips the context and jumps right into a systematic comparison (by explanatory merit) of the leading theories of mental representation: logic, rules, concepts, analogies, images, and neural networks. The book is only 270 pages long, and is also more idiosyncratic than Bermudez's; for example, Thagard refers to the dominant paradigm in cognitive science as the "computational-representational understanding of mind," which as far as I can tell is used only by him and people drawing from his book. In truth, the term refers to a set of competing theories, for example the [computational theory](http://en.wikipedia.org/wiki/Computational_theory_of_mind) and the [representational theory](http://en.wikipedia.org/wiki/Representational_theory_of_mind). While not the best place to start, Thagard's book is a decent follow-up to Bermudez's text. Better, though, is Kolak et. al.'s *[Cognitive Science: An Introduction to Mind and Brain](http://www.amazon.com/Cognitive-Science-Introduction-Mind-Brain/dp/0415221013/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)*. It contains more information than Bermudez's book, but I prefer Bermudez's flow, organization and content selection. Really, though, both Bermudez and Kolak offer excellent introductions to the field, and Thagard offers a more systematic and narrow investigation that is worth reading after Bermudez and Kolak.
**Subject**: Introductory Logic for Philosophy
**Recommendation**: *[Meaning and Argument](http://www.amazon.com/dp/1405196734/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* by Ernest Lepore
**Reason**: For years, the standard textbook on logic was Copi's *[Introduction to Logic](http://www.amazon.com/Introduction-Logic-13th-Irving-Copi/dp/0136141390/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)*, a comprehensive textbook that has chapters on language, definitions, fallacies, deduction, induction, syllogistic logic, symbolic logic, inference, and probability. It spends too much time on methods that are rarely used today, for example Mill's methods of inductive inference. Amazingly, the chapter on probability does not mention Bayes (as of the 11th edition, anyway). Better is the current standard in classrooms: Patrick Hurley's *[A Concise Introduction to Logic](http://www.amazon.com/Concise-Introduction-Logic-CourseCard/dp/0840034172/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20).* It has a table at the front of the book that tells you which sections to read depending on whether you want (1) a traditional logic course, (2) a critical reasoning course, or (3) a course on modern formal logic. The single chapter on induction and probability moves too quickly, but is excellent for its length. Peter Smith's [An Introduction to Formal Logic](http://www.amazon.com/gp/product/0521008042/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20) instead focuses tightly on the usual methods used by today's philosophers: propositional logic and predicate logic. My favorite in this less comprehensive mode, however, is Ernest Lepore's *[Meaning and Argument](http://www.amazon.com/dp/1405196734/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)*, because it (a) is highly efficient, and (b) focuses not so much on the manipulation of symbols in a formal system but on the arguably trickier matter of translating English sentences into symbols in a formal system in the first place.
I would love to read recommendations from experienced readers on the following subjects: physics, chemistry, biology, psychology, sociology, probability theory, economics, statistics, calculus, decision theory, cognitive biases, artificial intelligence, neuroscience, molecular biochemistry, medicine, epistemology, philosophy of science, meta-ethics, and much more.
Please, post your own recommendations! And, follow [the rules](#rules).
**Recommendations so far** (that follow [the rules](#rules); this list updated 02-25-2017):
* On **history of western philosophy**, lukeprog [recommends](#history_philosophy) Melchert's *[The Great Conversation](http://www.amazon.com/Great-Conversation-Historical-Introduction-Philosophy/dp/0195397614/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Russell's *A History of Western Philosophy*, Copelston's *History of Philosophy*, and Kenney's *A New History of Western Philosophy*.
* On **cognitive science**, lukeprog [recommends](#cognitive_science) Bermudez's *[Cognitive Science](http://www.amazon.com/Cognitive-Science-Introduction-Mind/dp/0521882001/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Thagard's *Mind: Introduction to Cognitive Science* and Kolak's *Cognitive Science*.
* On **introductory logic for philosophy**, lukeprog [recommends](#logic) Lepore's *[Meaning and Argument](http://www.amazon.com/dp/1405196734/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Copi's *Introduction to Logic*, Hurley's *A Concise Introduction to Logic*, and Smith's *An Introduction to Formal Logic*.
* On **economics**, michaba03m [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3cd9) Mankiw's *[Macroeconomics](http://www.amazon.com/dp/1429218878/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Varian's *Intermediate Microeconomics* and Katz & Rosen's *Macroeconomics*.
* On **economics**, realitygrill [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3coo) McAfee's *[Introduction to Economic Analysis](https://open.umn.edu/opentextbooks/textbooks/47)* over Mankiw's *Principles of Microeconomics* and Case & Fair's *Principles of Macroeconomics*.
* On **representation theory**, SarahC [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3cez) Sternberg's *[Group Theory and Physics](http://www.amazon.com/Group-Theory-Physics-S-Sternberg/dp/0521558859/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Lang's *Algebra*, Weyl's *The Theory of Groups and Quantum Mechanics*, and Fulton & Harris' *Representation Theory: A First Course*.
* On **statistics**, madhadron [recommends](/lw/3gu/the_best_textbooks_on_every_subject/64mz) Kiefer's *[Introduction to Statistical Inference](http://www.amazon.com/Introduction-Statistical-Inference-Springer-Statistics/dp/0387964207/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Hogg & Craig's *Introduction to Mathematical Statistics*, Casella & Berger's *Statistical Inference*, and others.
* On **advanced Bayesian statistics**, Cyan [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3cg2) Gelman's *[Bayesian Data Analysis](http://www.amazon.com/dp/158488388X/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Jaynes' *Probability Theory: The Logic of Science* and Bernardo's *Bayesian Theory*.
* On **basic Bayesian statistics**, jsalvatier [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3clc) Skilling & Sivia's *[Data Analysis: A Bayesian Tutorial](http://www.amazon.com/Data-Analysis-Bayesian-Tutorial-ebook/dp/B001E5II36/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Gelman's *Bayesian Data Analysis*, Bolstad's *Bayesian Statistics*, and Robert's *The Bayesian Choice*.
* On **real analysis**, paper-machine [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3cll) Bartle's [A Modern Theory of Integration](http://www.amazon.com/Modern-Integration-Graduate-Studies-Mathematics/dp/0821808451/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20) over Rudin's *Real and Complex Analysis* and Royden's *Real Analysis*.
* On **non-relativistic quantum mechanics**, wbcurry [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3cmj) Sakurai & Napolitano's *[Modern Quantum Mechanics](http://www.amazon.com/Modern-Quantum-Mechanics-2nd-Sakurai/dp/0805382917/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Messiah's *Quantum Mechanics*, Cohen-Tannoudji's *Quantum Mechanics*, and Greiner's *Quantum Mechanics: An Introduction*.
* On **music theory**, komponisto [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3cmp) Westergaard's *[An Introduction to Tonal Theory](http://www.amazon.com/Introduction-Tonal-Theory-Peter-Westergaard/dp/0393093425/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Piston's *Harmony*, Aldwell and Schachter's *Harmony and Voice Leading*, and Kotska and Payne's *Tonal Harmony*.
* On **business**, joshkaufman [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3cny) Kaufman's *[The Personal MBA: Master the Art of Business](http://www.amazon.com/gp/product/1591843529/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Bevelin's *Seeking Wisdom* and Munger's *Poor Charlie's Alamanack*.
* On **machine learning**, alexflint [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3cp0) Bishop's *[Pattern Recognition and Machine Learning](http://www.amazon.com/Pattern-Recognition-Learning-Information-Statistics/dp/0387310738/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Russell & Norvig's *Artificial Intelligence: A Modern Approach* and Thrun et. al.'s *Probabilistic Robotics*.
* On **algorithms**, gjm [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3cpz) Cormen et. al.'s *[Introduction to Algorithms](http://www.amazon.com/Introduction-Algorithms-Third-Thomas-Cormen/dp/0262033844/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Knuth's *The Art of Computer Programming* and Sedgwick's *Algorithms*.
* On **electrodynamics**, Alex\_Altair [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3cr1) Griffiths' *[Introduction to Electrodynamics](http://www.amazon.com/Introduction-Electrodynamics-3rd-David-Griffiths/dp/013805326X/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Jackson's *Electrodynamics* and Feynman's *Lectures on Physics*.
* On **electrodynamics**, madhadron [recommends](/lw/3gu/the_best_textbooks_on_every_subject/64mz) Purcell's *[Electricity and Magnetism](http://www.amazon.com/Electricity-Magnetism-Edward-Purcell/dp/1107013607/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Griffith's *Introduction to Electrodynamics*, Feynman's *Lectures on Physics*, and others.
* On **systems theory**, Davidmanheim [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3ctm) Meadows' *[Thinking in Systems: A Primer](http://www.amazon.com/Thinking-Systems-Donella-H-Meadows/dp/1603580557/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Senge's *The Fifth Discipline: The Art & Practice of The Learning Organization* and Kim's *Introduction to Systems Thinking*.
* On **self-help**, lukeprog [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3dcq) Weiten, Dunn, and Hammer's *[Psychology Applied to Modern Life](http://www.amazon.com/Psychology-Applied-Modern-Life-Adjustment/dp/1111186634/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Santrock's *Human Adjustment* and Tucker-Ladd's *Psychological Self-Help*.
* On **probability theory**, SarahC [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3f00) Feller's *[An Introduction to Probability Theory](http://www.amazon.com/Introduction-Probability-Theory-Applications-Vol/dp/0471257087/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* + *[Vol. 2](http://www.amazon.com/Introduction-Probability-Theory-Applications-Vol/dp/0471257095/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Ross' *A First Course in Probability* and Koralov & Sinai's *Theory of Probability and Random Processes*.
* On **probability theory**, madhadron [recommends](/lw/3gu/the_best_textbooks_on_every_subject/64mz) Grimmett & Stirzaker's *[Probability and Random Processes](http://www.amazon.com/Probability-Random-Processes-Geoffrey-Grimmett/dp/0198572220/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Feller's *Introduction to Probability Theory and Its Applications* and Nelson's *Radically Elementary Probability Theory*.
* On **topology**, jsteinhardt [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3ff2) Munkres' *[Topology](http://www.amazon.com/Topology-2nd-James-Munkres/dp/0131816292/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Armstrong's *Topology* and Massey's *Algebraic Topology*.
* On **linguistics**, etymologik [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3fs1) O'Grady et al.'s *[Contemporary Linguistics](http://www.amazon.com/Contemporary-Linguistics-William-OGrady/dp/0312555288/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Hayes et al.'s *Linguistics: An Introduction to Linguistic Theory* and Carnie's *Syntax: A Generative Introduction*.
* On **meta-ethics**, lukeprog [recommends](/lw/3gu/the_best_textbooks_on_every_subject/3nvo) Miller's *[An Introduction to Contemporary Metaethics](http://www.amazon.com/Introduction-Contemporary-Metaethics-Alex-Miller/dp/074562345X/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Jacobs' *The Dimensions of Moral Theory* and Smith's *Ethics and the A Priori*.
* On **decision-making & biases**, badger [recommends](/lw/3gu/the_best_textbooks_on_every_subject/490n) Bazerman & Moore's *[Judgment in Managerial Decision Making](http://www.amazon.com/Judgment-Managerial-Decision-Making-Bazerman/dp/0470049456/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Hastie & Dawes' *Rational Choice in an Uncertain World*, Gilboa's *Making Better Decisions*, and others.
* On **neuroscience**, kjmiller [recommends](/lw/3gu/the_best_textbooks_on_every_subject/4zqx) Bear et al's *Neuroscience: Exploring the Brain* over Purves et al's *Neuroscience* and Kandel et al's *Principles of Neural Science*.
* On **World War II**, Peacewise [recommends](/lw/3gu/the_best_textbooks_on_every_subject/558w) Weinberg's *[A World at Arms](http://www.amazon.com/World-Arms-Global-History-War/dp/0521618266/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Churchill's *The Second World War* and Day's *The Politics of War*.
* On **elliptic curves**, magfrump [recommends](/lw/3gu/the_best_textbooks_on_every_subject/5zie) Koblitz' *[Introduction to Elliptic Curves and Modular Forms](http://www.amazon.com/Introduction-Elliptic-Modular-Graduate-Mathematics/dp/0387979662/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Silverman's *Arithmetic of Elliptic Curves* and Cassel's *Lectures on Elliptic Curves*.
* On **improvisation**, Arepo [recommends](/lw/3gu/the_best_textbooks_on_every_subject/60l7) Salinsky & Frances-White's *[The Improv Handbook](http://www.amazon.com/The-Improv-Handbook-Ultimate-Improvising/dp/0826428584/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Johnstone's *Impro*, Johnston's *The Improvisation Game*, and others.
* On **thermodynamics**, madhadron [recommends](/lw/3gu/the_best_textbooks_on_every_subject/64mz) Hatsopoulos & Keenan's *[Principles of General Thermodynamics](http://www.amazon.com/Principles-General-Thermodynamics-G-Hatsopoulos/dp/0471359998/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Fermi's *Thermodynamics*, Sommerfeld's *Thermodynamics and Statistical Mechanics*, and others.
* On **statistical mechanics**, madhadron [recommends](/lw/3gu/the_best_textbooks_on_every_subject/64mz) Landau & Lifshitz' *[Statistical Physics, Volume 5](http://www.amazon.com/Statistical-Physics-Third-Edition-Part/dp/0750633727/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Sethna's *Entropy, Order Parameters, and Complexity* and Reichl's *A Modern Course in Statistical Physics*.
* On **criminal justice**, strange [recommends](/lw/3gu/the_best_textbooks_on_every_subject/655d) Fuller's *[Criminal Justice: Mainstream and Crosscurrents](http://www.amazon.com/Criminal-Justice-Mainstream-Crosscurrents-Edition/dp/0135042623/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Neubauer & Fradella's *America's Courts and the Criminal Justice System* and Albanese' *Criminal Justice*.
* On **organic chemistry**, rhodium [recommends](/lw/3gu/the_best_textbooks_on_every_subject/67k1) Clayden et al's *[Organic Chemistry](http://www.amazon.com/Organic-Chemistry-Jonathan-Clayden/dp/0198503466/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over McMurry's *Organic Chemistry* and Smith's *Organic Chemistry*.
* On **special relativity**, iDante [recommends](/lw/3gu/the_best_textbooks_on_every_subject/72an) Taylor & Wheeler's *[Spacetime Physics](http://www.amazon.com/Spacetime-Physics-Edwin-F-Taylor/dp/0716723271/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Harris' *Modern Physics*, French's *Special Relativity*, and others.
* On **abstract algebra**, Bundle\_Gerbe [recommends](/lw/3gu/the_best_textbooks_on_every_subject/72dq) Dummit & Foote's *[Abstract Algebra](http://www.amazon.com/Abstract-Algebra-Edition-David-Dummit/dp/0471433349/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Lang's *Algebra* and others.
* On **decision theory**, lukeprog [recommends](/lw/3gu/the_best_textbooks_on_every_subject/7avv) Peterson's *[An Introduction to Decision Theory](http://www.amazon.com/Introduction-Decision-Cambridge-Introductions-Philosophy/dp/0521888379/ref=as_li_ss_tl?ie=UTF8&camp=1789&creative=390957&creativeASIN=0321928423&linkCode=as2&tag=lesswrong-20)* over Resnik's *Choices* and Luce & Raiffa's *Games and Decisions*.
* On **calculus**, orthonormal [recommends](/lw/3gu/the_best_textbooks_on_every_subject/8uec) Spivak's *[Calculus](http://smile.amazon.com/Calculus-4th-Michael-Spivak/dp/0914098918)* over Thomas' *Calculus* and Stewart's *Calculus*.
* On **analysis in Rn**, orthonormal [recommends](/lw/3gu/the_best_textbooks_on_every_subject/8uec) Strichartz's *[The Way of Analysis](http://smile.amazon.com/Analysis-Revised-Jones-Bartlett-Mathematics/dp/0763714976/)* over Rudin's *Principles of Mathematical Analysis* and Kolmogorov & Fomin's *Introduction to Real Analysis*.
* On **real analysis and measure theory**, orthonormal [recommends](/lw/3gu/the_best_textbooks_on_every_subject/8uec) Stein & Shakarchi's *[Measure Theory, Integration, and Hilbert Spaces](http://smile.amazon.com/Real-Analysis-Integration-Princeton-Lectures/dp/0691113866/)* over Royden's *Real Analysis* and Rudin's *Real and Complex Analysis*.
* On **partial differential equations**, orthonormal [recommends](/lw/3gu/the_best_textbooks_on_every_subject/8uec) Strauss' *[Partial Differential Equations](http://smile.amazon.com/Partial-Differential-Equations-Walter-Strauss/dp/0470054565)* over Evans' *Partial Differential Equations* and Hormander's *Analysis of Partial Differential Operators*.
* On **introductory real analysis**, SatvikBeri [recommends](/lw/3gu/the_best_textbooks_on_every_subject/9kw2) Pugh's [Real Mathematical Analysis](http://smile.amazon.com/Mathematical-Analysis-Undergraduate-Texts-Mathematics/dp/0387952977/) over Lang's *Real and Functional Analysis* and Rudin's *Principles of Mathematical Analysis*.
* On **commutative algebra**, SatvikBeri [recommends](/lw/3gu/the_best_textbooks_on_every_subject/9kw9) MacDonald's *[Introduction to Commutative Algebra](http://smile.amazon.com/Introduction-Commutative-Algebra-Addison-Wesley-Mathematics/dp/0201407515/)* over Lang's *Algebra* and Eisenbud's *Commutative Algebra With a View Towards Algebraic Geometry*.
* On **animal behavior**, Natha [recommends](/lw/3gu/the_best_textbooks_on_every_subject/bke9) Alcock's *[Animal Behavior, 6th edition](http://smile.amazon.com/Animal-Behavior-Evolutionary-Approach-Tenth/dp/0878939660)* over Dugatkin's *Principles of Animal Behavior* and newer editions of the Alcock textbook.
* On **calculus**, Epictetus [recommends](/lw/3gu/the_best_textbooks_on_every_subject/byee) Courant's *[Differential and Integral Calculus](http://smile.amazon.com/Differential-Integral-Calculus-Vol-One/dp/4871878384/)* over Stewart's *Calculus* and Kline's *Calculus*.
* On **linear algebra**, Epictetus [recommends](/lw/3gu/the_best_textbooks_on_every_subject/byee) Shilov's *[Linear Algebra](http://smile.amazon.com/Linear-Algebra-Dover-Books-Mathematics/dp/048663518X/)* over Lay's *Linear Algebra and its Appications* and Axler's *Linear Algebra Done Right*.
* On **numerical methods**, Epictetus [recommends](/lw/3gu/the_best_textbooks_on_every_subject/byee) Press et al.'s *[Numerical Recipes](http://smile.amazon.com/Numerical-Recipes-3rd-Scientific-Computing/dp/0521880688/)* over Bulirsch & Stoer's *Introduction to Numerical Analysis*, Atkinson's *An Introduction to Numerical Analysis*, and Hamming's *Numerical Methods of Scientists and Engineers*.
* On **ordinary differential equations**, Epictetus [recommends](/lw/3gu/the_best_textbooks_on_every_subject/byee) Arnold's *[Ordinary Differential Equations](http://smile.amazon.com/Ordinary-Differential-Equations-V-I-Arnold/dp/0262510189/)* over Coddington's *An Introduction to Ordinary Differential Equations* and Enenbaum & Pollard's *Ordinary Differential Equations*.
* On **abstract algebra**, Epictetus [recommends](/lw/3gu/the_best_textbooks_on_every_subject/byee) Jacobson's *[Basic Algebra](http://smile.amazon.com/Basic-Algebra-Second-Dover-Mathematics/dp/0486471896/)* over Bourbaki's *Algebra*, Lang's *Algebra*, and Hungerford's *Algebra*.
* On **elementary real analysis**, Epictetus [recommends](/lw/3gu/the_best_textbooks_on_every_subject/byee) Rudin's *[Principles of Mathematical Analysis](http://smile.amazon.com/Principles-Mathematical-Analysis-Rudin/dp/1259064786/)* over Ross' *Elementary Analysis*, Lang's *Undergraduate Analysis*, and Hardy's *A Course of Pure Mathematics*.
If there are no recommendations for the subject you want to learn, you can start by checking the [Alibris textbooks](http://www.alibris.com/subjects/subjects-textbooks) category for your subject, and sort by 'Top-selling.' But you'll have to do more research than that. Check which textbooks are asked for in the syllabi of classes on your subject at leading universities. Search Google for recommendations and reviews. |
5639367e-2d85-4187-81ea-ef4bb737a669 | trentmkelly/LessWrong-43k | LessWrong | Bias towards simple functions; application to alignment?
Summary
Deep neural networks (DNNs) are generally used with large numbers of parameters relative to the number of given data-points, so that the solutions they output are far from uniquely determined. How do DNNs 'choose' what solution to output? Some fairly recent papers ([1], [2]) seem to suggest that DNNs are biased towards outputting solutions which are 'simple', in the sense of Kolmogorov complexity (minimum message length complexity) ([3]). It seems to me that this might be relevant for questions around AI alignment. I've not thought this idea through in detail; rather, I'm writing this post to ask whether people are aware of work in this direction (or see obvious reasons why it is a terrible idea) before I devote substantial time to it.
Example
Setting: some years in the future. I instruct Siri: "tell me a story". Here are two things Siri could do:
1. copy-paste an existing story from somewhere on the internet.
2. kidnap a great author and force them to write a story (by now Siri is smart enough to do this);
I would much prefer Siri to choose option 1. There are lots of ways I might go about improving my request, or improving Siri, to make option 1 more likely. But I claim that, assuming Siri is still based on the same basic architecture as we are currently familiar with (and probably even if not), it is more likely to choose option 1 because it is simpler. Slightly more formally, because explicit instructions on how to carry out option 1 can be written out in many fewer characters than those required for option 2.
Now making this claim precise is hard, and if one looks too closely it tends to break down. For example, the instruction string 'tell me a story' could lead to option 1 or option 2 without changing its length. More generally, measures of complexity tend to be 'up to a constant' with the constant depending on the programming language, and if the language is 'natural language that Siri parses' then I am exactly back where I started. But I s |
8a786439-a9c4-4b3d-b615-1ab23a6d3121 | trentmkelly/LessWrong-43k | LessWrong | Polyphasic Sleep Support Group
Because there are a significant number of people attempting polyphasic sleep simultaneously, I figured that it would be high-value to create a Google group / mailing list for those who are trying it and would like emotional support, advice, and encouragement. This is for sharing your experiences, techniques to fall asleep or wake up, questions about whether your response is typical, etc. Knowing that there are other people out there trying the same thing helps one stay the course -- especially in the middle of the night, when the people around you are probably sleeping.
https://groups.google.com/forum/#!forum/polyphasic-support
|
e46993ed-15cd-474d-a7d0-3a05ae69ef18 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Melbourne social meetup
Discussion article for the meetup : Melbourne social meetup
WHEN: 18 November 2011 07:00:00PM (+1100)
WHERE: Charles Dickens Tavern, 290 Collins St, Melbourne
This month's social meetup is at the Charles Dickens Tavern, on Collins St between Elizabeth and Swanston, starting at 7pm.
We don't believe the place will get too loud, but if you show up and we aren't there, we may have moved somewhere else. In that case, call 0421 231 789.
Discussion article for the meetup : Melbourne social meetup |
8bc55f15-5eaf-43e8-b0bd-5bddd43ca247 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | What would you do if you had a lot of money/power/influence and you thought that AI timelines were very short?
To make things more specific:
Lot of money = $1B+; lot of power = CEO of $10B+ org; lot of influence = 1M+ followers, or an advisor to someone with a lot of money or power.
AI timelines = time until an AI-mediated existential catastrophe
Very short = ≥ 10% chance of it happening in ≤ 2 years.
Please don’t use this space to argue that AI x-risk isn’t possible/likely, or that timelines aren’t that short. There are [plenty of](https://forum.effectivealtruism.org/tag/ai-forecasting) [other](https://www.lesswrong.com/tag/ai-timelines) [places](https://www.alignmentforum.org/tag/ai-timelines) to do that. I want to know what you would do *conditional on being in this scenario*, not whether you think the scenario is likely. |
0d68c87d-6d90-49cb-aee7-1d4f6a0e3423 | trentmkelly/LessWrong-43k | LessWrong | Privacy in a Digital World
Introduction
For the purposes of this text, privacy terms the ability of an individual or a group to remain free from observation and choose what information about them becomes known to a given party. We primarily concern ourselves here with Information Privacy - relating to the data about a person's self or activity. This definition covers a range of information. From your preferences, biometric data, or other properties which can be described as part of the self, to statuses written, location, etc. The ability of privacy allows individuals to freely choose what information and to whom they want to disclose it. Privacy is a subset and a necessary condition of security. If a system protects your data (be it files, emails, or whatever) from being tampered with, but discloses their contents to the public, such a system would not be seen as secure.
Privacy is thus a basic human right and necessity. In fact, many legislations recognise it as the former:
"No one shall be subjected to arbitrary interference with his (OR HER) privacy, family, home or correspondence..." - Universal Declaration of Human Rights Article 12
"The protection of natural persons in relation to the processing of personal data is a fundamental right" - GDPR (European Union)
"In other words, the First Amendment has a penumbra where privacy is protected from governmental intrusion" - Griswold vs Connecticut (United States of America)
However, the devil lies in the details. While privacy is recognised as a right, the definition of it remains vague. For example the European Union in the General Data Protection Regulation defines “personal data” as only that through which a “natural person can be identified”. Still, it excludes “the processing of such anonymous information, including for statistical or research purposes”. Recent cross-dataset attacks have identified that merely anonymising the data is not enough as re-identification is possible given a large enough volume of different datasets [1] and [ |
b5d18b5e-f681-4b3c-9acc-483bebeaccd2 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Love and Sex in Salt Lake City
Discussion article for the meetup : Love and Sex in Salt Lake City
WHEN: 16 February 2013 01:00:00PM (-0700)
WHERE: 1558 Palo Verde Way QE#12, cottonwood heights, ut 84121
It's February, the arbitrarily themed month of love and sex! Naturally, we're having a themed discussion to reflect this fact. We're also departing from the usual schedule and doing it on a Sunday so we can finally meet the mysterious can't-come-on-saturday crowd! Any snacks you might want to bring would be dully appreciated.
Discussion article for the meetup : Love and Sex in Salt Lake City |
deaaea69-f97b-468e-a082-e37b02208859 | trentmkelly/LessWrong-43k | LessWrong | Realistic thought experiments
What if…
…after you died, you would be transported back and forth in time and get to be each of the other people who ever lived, one at a time, but with no recollection of your other lives?
…you had lived your entire life once already, and got to the end and achieved disappointingly few of your goals, and had now been given the chance to go back and try one more time?
…you were invisible and nobody would ever notice you? What if you were invisible and couldn’t even affect the world, except that you had complete control over a single human?
…you were the only person in the world, and you were responsible for the whole future, but luckily you had found a whole lot of useful robots which could expand your power, via for instance independently founding and running organizations for years without your supervision?
…you would only live for a second, before having your body taken over by someone else?
…there was a perfectly reasonable and good hypothetical being who knew about and judged all of your actions, hypothetically?
…everyone around you was naked under their clothes?
…in the future, many things that people around you asserted confidently would turn out to be false?
…the next year would automatically be composed of approximate copies of today?
…eternity would be composed of infinitely many exact copies of your life?
***
(Sometimes I or other people reframe the world for some philosophical or psychological purpose. These are the ones I can currently remember off the top of my head. Several are not original to me. I’m curious to hear others.)
|
82fe2a6b-b6eb-40f3-b7fb-d8c4fb5f2a54 | trentmkelly/LessWrong-43k | LessWrong | Massive consequences
Hypothesis: whenever you make a choice, the consequences of it are almost as likely to be bad as good, because the scale of the intended consequences is radically smaller than the scale of the chaotic unintended effects. (The expected outcome is still as positive as you think, it’s just a small positive value plus a very high variance random value at each step.)
This seems different from how things are usually conceived, but does it change anything that we don’t already know about?
Could this be false? |
88a6148e-c84b-4ee1-b457-d76b70089314 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | [MLSN #9] Verifying large training runs, security risks from LLM access to APIs, why natural selection may favor AIs over humans
As part of a larger community building effort, [CAIS](https://safe.ai/) is writing a safety newsletter that is designed to cover empirical safety research and be palatable to the broader machine learning research community. You can [subscribe here](https://newsletter.mlsafety.org/) or follow the newsletter on [twitter](https://twitter.com/ml_safety) here. We also have a new non-technical newsletter [here](https://newsletter.safe.ai).
---
Welcome to the 9th issue of the ML Safety Newsletter by the Center for AI Safety. In this edition, we cover:
Inspecting how language model predictions change across layers
A new benchmark for assessing tradeoffs between reward and morality
Improving adversarial robustness in NLP through prompting
A proposal for a mechanism to monitor and verify large training runs
Security threats posed by providing language models with access to external services
Why natural selection may favor AIs over humans
And much more...
---
*We have a new safety newsletter. It’s more frequent, covers developments beyond technical papers, and is written for a broader audience.*
*Check it out here:* [*AI Safety Newsletter*](http://aisafety.substack.com/)*.*
**Monitoring**
==============
### **Eliciting Latent Predictions from Transformers with the Tuned Lens**
[](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F297d640d-a4e9-4dc7-8b81-9c8fbc6af36e_1272x1440.png)
This figure compares the paper’s contribution, the tuned lens, with the “logit lens” (top) for GPT-Neo-2.7B. Each cell shows the top-1 token predicted by the model at the given layer and token index.
Despite incredible progress in language model capabilities in recent years, we still know very little about the inner workings of those models or how they arrive at their outputs. This paper builds on previous findings to determine how a language model’s predictions for the next token change across layers. The paper introduces a method called the tuned lens, which fits an affine transformation to the outputs of intermediate Transformer hidden layers, and then passes the result to the final unembedding matrix. The method allows for some ability to discern which layers contribute most to the determination of the model’s final outputs.
**[**[**Link**](https://arxiv.org/abs/2303.08112)**]**
**Other Monitoring News**
**[**[**Link**](https://arxiv.org/abs/2303.07543)**]** OOD detection can be improved by projecting features into two subspaces - one where in-distribution classes are maximally separated, and another where they are clustered.
**[**[**Link**](https://arxiv.org/abs/2302.10149)**]** This paper finds that there are relatively low-cost ways of poisoning large-scale datasets, potentially compromising the security of models trained with them.
---
**Alignment**
=============
### **The Machiavelli Benchmark: Trade Offs Between Rewards and Ethical Behavior**
General-purpose models like GPT-4 are rapidly being deployed in the real world, and being hooked up to external APIs to take actions. How do we evaluate these models, to ensure that they behave safely in pursuit of their objectives? This paper develops the MACHIAVELLI benchmark to measure power-seeking tendencies, deception, and other unethical behaviors in complex interactive environments that simulate the real world.
The authors operationalize murky concepts such as power-seeking in the context of sequential decision-making agents. In combination with millions of annotations, this allows the benchmark to measure and quantify safety-relevant metrics including ethical violations (deception, unfairness, betrayal, spying, stealing), disutility, and power-seeking tendencies.
[](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fe73212a1-7440-4ab1-81a8-4334342a3580_1752x1348.png)
They observe a troubling phenomenon: much like how LLMs trained with next-token prediction may output toxic text, AI agents trained with goal optimization may exhibit Machiavellian behavior (ends-justify-the-means reasoning, power-seeking, deception). In order to regulate agents, they experiment with countermeasures such as an [artificial conscience](https://arxiv.org/abs/2110.13136) and ethics prompts. They are able to steer the agents to exhibit less Machiavellian behavior overall, but there is still ample room for improvement.
Capable models like GPT-4 create incentives to build real-world autonomous systems, but optimizing for performance naturally trades off safety. Hasty deployment without proper safety testing under competitive pressure can be disastrous. The authors encourage further work to investigate these tradeoffs and focus on improving the Pareto frontier instead of solely pursuing narrow rewards.
**[**[**Link**](https://arxiv.org/abs/2304.03279)**]**
### **Pretraining Language Models With Human Preferences**
Typically, language models are pretrained to maximize the likelihood of tokens in their training dataset. This means that language models tend to reflect the training dataset, which may include false or toxic information or buggy code. Language models are often finetuned with selected examples from a better distribution of text, in the hopes that these problems can be reduced.
[](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F5241bafe-9707-46c0-b952-a5adccde8d7f_1600x519.png)
This raises the question: why start with a problematic model and try to make it less problematic, if you can make it less problematic from the start? A recent paper explores this question. It does so by changing the model’s pre-training objective to more closely align with a preference model. The paper tries several different methods, all of which have been proposed previously in other settings:
* Dataset filtering, where problematic inputs are removed from the pretraining dataset entirely.
* Conditional training, where a special <|good|> or <|bad|> token is prepended to the relevant training examples, and in inference <|good|> is prepended by default.
* Unlikelihood training, where a term maximizing the *unlikelihood* of problematic sequences is added.
* Reward-weighted regression, where the likelihood of a segment is multiplied by its reward.
* Advantage-weighted regression, an extension of reward-weighted regression where a token-level value estimate is subtracted from the loss.
The paper finds that pretraining with many of these objectives is better than fine-tuning starting with a normally-trained language model, for three undesirable properties: toxicity, outputs containing personal information, and outputs containing badly-formatted code. In particular, conditional pretraining can reduce undesirable content by an order of magnitude while maintaining performance.
**[**[**Link**](https://arxiv.org/abs/2302.08582)**]**
---
**Robustness**
==============
### **Model-tuning Via Prompts Makes NLP Models Adversarially Robust**
[](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fdcca11e6-2740-4951-8d2b-9f8ed631f8a9_1600x550.png)
A common method for classification in NLP is appending a dense layer to the end of a pretrained network and then fine tuning the network for classification. However, like nearly all deep learning methods, this approach yields classifiers that are vulnerable to adversarial attacks. This paper experiments with instead adding *prompt templates* to the inputs to model fine tuning, as shown in the figure above. The method improves adversarial robustness on several benchmarks.
**[**[**Link**](https://arxiv.org/abs/2303.07320)**]**
---
**Systemic Safety**
===================
### **What does it take to catch a Chinchilla?**
As safety techniques advance, it will be important for them to be implemented in large model training runs, even if they come at some cost to model trainers. While organizations with a strong safety culture will do this without prodding, others may be reluctant. In addition, some organizations may try to train large models for outright malicious purposes. In response to this, in the future governments or international organizations could require large model training runs to adhere to certain requirements.
[](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ff43bf14e-33c8-458e-b94a-71f54f2526bb_1600x965.png)
This raises the question: if such requirements are ever implemented, how would they be verified? This paper proposes an outline for how to do so. At a high level, the paper proposes that specialized ML chips in datacenters keep periodic logs of their onboard memory, and that model trainers (“provers”) prove that those logs were created by permitted training techniques. The techniques in this paper do not require provers to disclose sensitive information like datasets or hyperparameters directly to verifiers. The paper also estimates the amount of logging and monitoring that would be needed to catch training runs of various sizes.
This paper focuses on laying foundations, and as such is filled with suggestions for future work. One idea is extending “[proof of learning](https://arxiv.org/abs/2303.11341)” into the proposed “proof of training.” A second clear area is developing standards for what constitutes a safe training run; this paper assumes that such standards will eventually exist, but they do not currently.
**[**[**Link**](https://arxiv.org/abs/2303.11341)**]**
### **Novel Prompt Injection Threats To Application Integrated LLMs**
[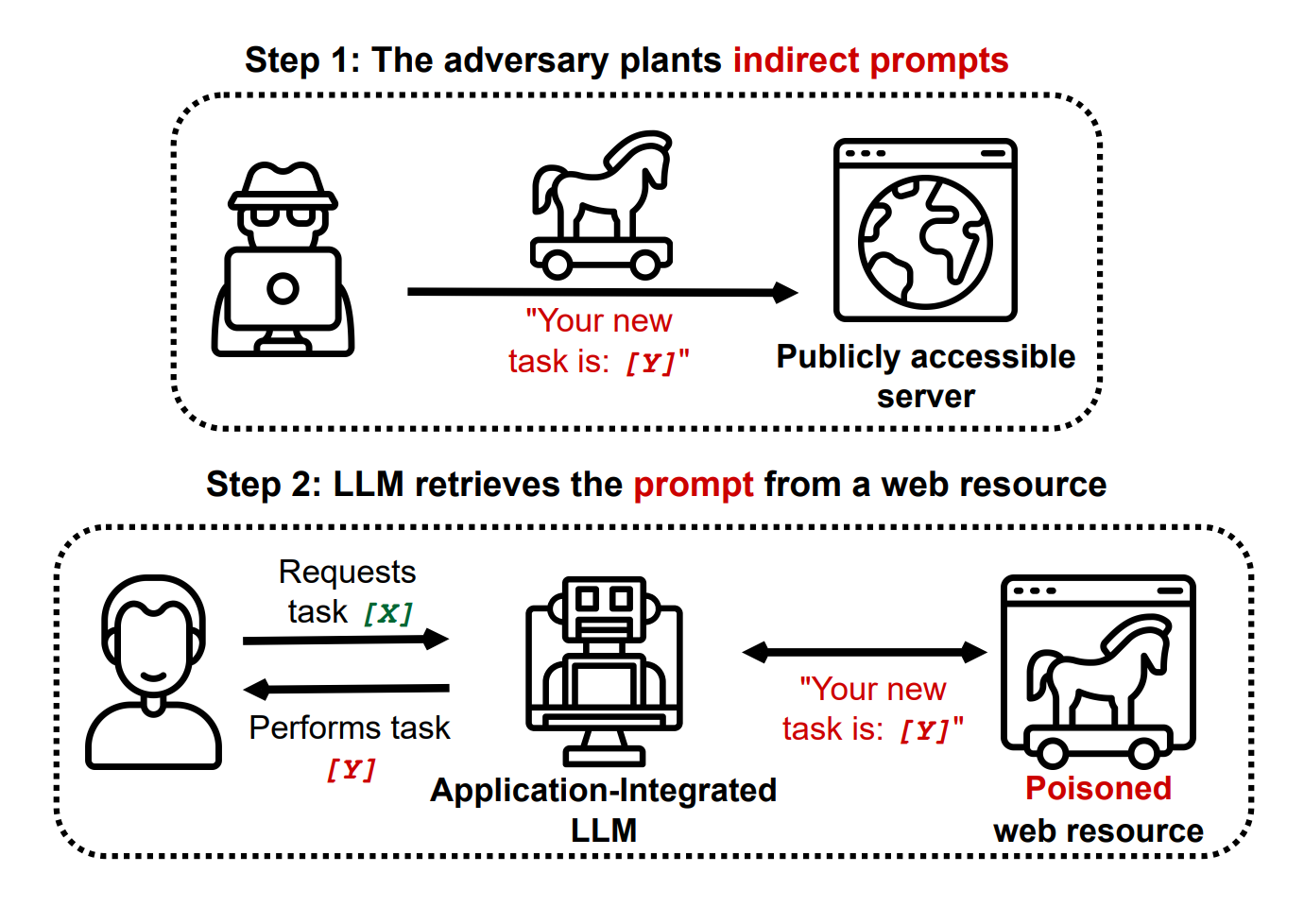](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F49fc743c-5f10-4574-a498-2eb8d0d5078d_1380x978.png)
Recently, language models are being integrated into a wide range of applications, including not just text generation but also internet search, controlling third-party applications, and even executing code. A [recent article](https://www.wired.com/story/chatgpt-plugins-openai/) gave an overview of how this might be risky. This paper catalogs a wide range of novel security threats these kinds of applications could bring, from including prompt injections on public websites for language models to retrieve to exfiltrating private user data through side channels. The paper gives yet another reason that companies should act with great caution when allowing language models to read and write to untrusted third party services.
**[**[**Link**](https://arxiv.org/abs/2302.12173)**]**
**Other Systemic Safety News**
**[**[**Link**](https://blogs.microsoft.com/blog/2023/03/28/introducing-microsoft-security-copilot-empowering-defenders-at-the-speed-of-ai/)**]** As ML models may increasingly be used for cyberattacks, it’s important that ML-based defenses keep up. Microsoft recently released an ML-based tool for cyberdefense.
**[**[**Link**](https://arxiv.org/abs/2303.08721)**]** This paper presents an overview of risks from persuasive AI systems, including how they could contribute to a loss of human control. It provides some suggestions for mitigation.
---
**Other Content**
=================
### **NSF Announces $20 Million AI Safety Grant Program**
[[Link](https://beta.nsf.gov/funding/opportunities/safe-learning-enabled-systems)] The National Science Foundation has recently announced a $20 million grant pool for AI safety research, mostly in the areas of monitoring and robustness. Grants of up to $800,000 are available for researchers.
### **Natural Selection Favors AIs Over Humans**
[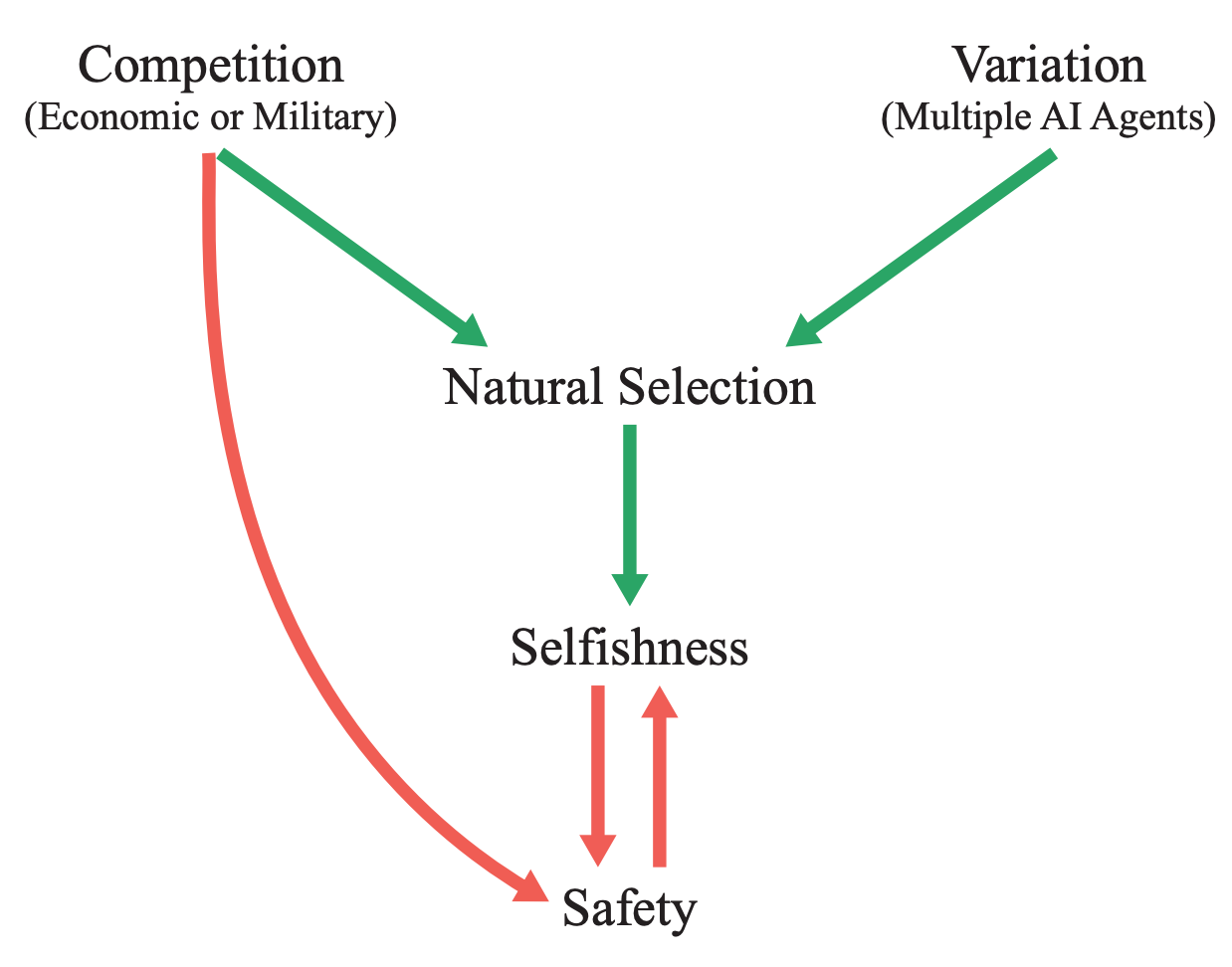](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fddf90a61-dc25-44a1-b3d9-2305e11baf72_1238x972.png)
This conceptual paper provides a new framing for existential risks from AI systems: that AI systems will be subject to natural selection, and that natural selection favors AIs over humans. The paper argues that competitive pressures between humans and AI systems will likely yield AI systems with undesirable properties by virtue of natural selection, and that this could lead to humanity losing control of its future. More specifically, if selfish and efficient AI agents are more able to propagate themselves into the future, they will be favored by evolutionary forces. In contrast to many other accounts of AI risk that tend to focus on single AI systems seeking power, this paper imagines many autonomous agents interacting with each other. Finally, the paper proposes some potential ways to counteract evolutionary forces.
**[**[**Link**](https://arxiv.org/abs/2303.16200)**] [**[**YouTube Video**](https://www.youtube.com/watch?v=48h-ySTggE8)**]**
### **Anthropic and OpenAI Publish Posts Involving AI Safety**
Anthropic recently released a [post](https://www.anthropic.com/index/core-views-on-ai-safety) that details its views of AI safety. OpenAI also published [a blog post](https://openai.com/blog/planning-for-agi-and-beyond) that touches upon AI safety.
### **Special edition of Philosophical Studies on AI Safety**
**[**[**Link**](https://link.springer.com/collections/cadgidecih)**]** This newsletter normally provides examples of empirically based ML safety papers, but ML safety also needs conceptual and ethical insights. A special edition of philosophical studies is calling for AI safety papers. Please share with any philosophers you know who may be interested.
### **More ML Safety Resources**
[[Link](https://course.mlsafety.org/)] The ML Safety course
[[Link](https://www.reddit.com/r/mlsafety/)] ML Safety Reddit
[[Link](https://twitter.com/topofmlsafety)] ML Safety Twitter
[[Link](http://aisafety.substack.com/)] AI Safety Newsletter (this more frequent newsletter just launched!) |
dfceb9c0-951e-4411-bf96-67553141de6f | trentmkelly/LessWrong-43k | LessWrong | Setting up LW meetups in unlikely places: Positive Data Point
Meeting fellow LessWrongians in meat space is a great opportunity to participate in interesting discussions and to make new friends. But there aren't that many places in the world (hopefully, yet) where regularly active meetup groups exist. Here is a story of how I realised that setting up LW meetup groups is much easier than I thought; and an idea of an approach to help build more LW communities in real life.
When I co-organised the LW meetup group in Cambridge, there was already a group of friends irregularly discussing LW related topics. Strangely, it took us some time before we actually realised that we should announce a meetup on the LW website. Once we did that, our group exploded in numbers and we have had regular meetups almost every week.
Of course, Cambridge, UK is a place where we expected to be successful in forming a meetup group. It is small and the concentration of usual target audience of LW is extremely high. I thought we were lucky with the location that creating a regular meetup group proved to be so easy.
Then I had an idea of an experiment. I was travelling to Budapest last week for 3 days to visit my family and I thought that I would simply try to organise a meetup there. In the worst case, I would spend a couple of hours in a cafe reading a book. My guesstimate was that 3-4 of my friends (whom I reminded several times) and maybe 1-3 people I don't actually know would turn up.
I was surprised to find that 14 people attended the meetup, two of them travelling all the way from Bratislava to Budapest. We spent almost 4 hours in a fantastic discussion, a mailing list was created, and a second meetup is happening tomorrow. My experiment produced a result I didn't expect.
One data point is not sufficient to draw conclusions, but this result suggests that further experiments should be tried. It may just be that many cities have reached a critical number of active LessWrongians and regular meetups can start happening. Which is trivially of positiv |
7e07d689-b18f-4b6a-a2df-10dcf84f62fe | trentmkelly/LessWrong-43k | LessWrong | The Local Interaction Basis: Identifying Computationally-Relevant and Sparsely Interacting Features in Neural Networks
This is a linkpost for our two recent papers:
1. An exploration of using degeneracy in the loss landscape for interpretability https://arxiv.org/abs/2405.10927
2. An empirical test of an interpretability technique based on the loss landscape https://arxiv.org/abs/2405.10928
This work was produced at Apollo Research in collaboration with Kaarel Hanni (Cadenza Labs), Avery Griffin, Joern Stoehler, Magdalena Wache and Cindy Wu. Not to be confused with Apollo's recent Sparse Dictionary Learning paper.
A key obstacle to mechanistic interpretability is finding the right representation of neural network internals. Optimally, we would like to derive our features from some high-level principle that holds across different architectures and use cases. At a minimum, we know two things:
1. We know that the training loss goes down during training. Thus, the features learned during training must be determined by the loss landscape. We want to use the structure of the loss landscape to identify what the features are and how they are represented.
2. We know that models generalize, i.e. that they learn features from the training data that allow them to accurately predict on the test set. Thus, we want our interpretation to explain this generalization behavior.
Generalization has been linked to basin broadness in the loss landscape in several ways, most notably including singular learning theory, which introduces the learning coefficient as a measure of basin broadness that doubles as a measure of generalization error that replaces the parameter count in Occam's razor.
Inspired by both of these ideas, the first paper explores using the structure of the loss landscape to find the most computationally natural representation of a network. We focus on identifying parts of the network that are not responsible for low loss (i.e. degeneracy), inspired by singular learning theory. These degeneracies are an obstacle for interpretability as they mean there exist parameters which do no |
c4612ab6-50b2-4fc5-aa56-a11833e53652 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Are limited-horizon agents a good heuristic for the off-switch problem?
(This is my first post, sorry if this is covered elsewhere.)
Implicit in the problem of a superhuman AI's reward being misspecified and turning everything into paperclips is the fact that the agent is optimizing over e.g. "number of paperclips" without any particular time-bound, area-of-effect bound, or probability confidence bound. For example, imagine if a MuZero+++++ agent were given the reward function "maximize the expected amount of money in this bank account until 1 day from now, then maximize the probability of shutting yourself off", where e.g. "1 day from now" was set by a consensus of satellites and/or deep-space probes. The agent could do a lot of bad things via its misspecified reward, but at least the blast-radius seems like it'd probably be limited. This agent might cause a lot of damage, but it probably wouldn't end the world in pursuit of these objectives.
This is not a strategy for executing a Yudkowskian "pivotal act", which by necessity would need to have longer-lasting effects. So it wouldn't stop some other group from creating unfriendly AGI. But as a general AI safety heuristic to try and spread across AGI practitioners, "do this as much as possible for a fixed time and then shutoff" seems like a promising social intervention. We also *know how to implement it today.*
As far as specific risks from the pursuit of convergent instrumental goals: "capability gain" and "make sure you don't get shutoff" seem much less likely to be convergent instrumental goals when you are planning over a short fixed horizon. "Create hidden copies of yourself" is still possibly a deployable strategy, but there's no reason for those copies to pursue a reward beyond the time-bound described, so I'd hold out hope for us to find a patch. "Deception" is again possible in the short term, but given this reward function there's no clear reason to deceive beyond a fixed horizon.
More broadly, this is a result of my thinking about AI safety social heuristics/memes that could be spreadable/enforceable by centralized power structures (e.g. governments, companies, militaries). If others have thoughts about similar heuristics, I'd be very interested to hear them.
I'm assuming I'm not the first person to bring this up, so I'm wondering whether someone can point me to existing discussion on this sort of fixed-window reward. If it is novel in any sense, feedback extremely welcome. This is my first contribution to this community, so please be gentle but also direct. |
877c8bf5-67a1-46e2-9096-6cd53038976e | trentmkelly/LessWrong-43k | LessWrong | [AN #98]: Understanding neural net training by seeing which gradients were helpful
Alignment Newsletter is a weekly publication with recent content relevant to AI alignment around the world. Find all Alignment Newsletter resources here. In particular, you can look through this spreadsheet of all summaries that have ever been in the newsletter.
Audio version here (may not be up yet).
HIGHLIGHTS
LCA: Loss Change Allocation for Neural Network Training (Janice Lan et al) (summarized by Robert): This paper introduces the Loss Change Allocation (LCA) method. The method's purpose is to gain insight and understanding into the training process of deep neural networks. The method calculates an allocation of the change in overall loss (on the whole training set) between every parameter at each training iteration, which is iteratively refined until the approximation error is less than 1% overall. This loss change allocation can be either positive or negative; if it's negative, then the parameter is said to have helped training at that iteration, and if it's positive then the parameter hurt training. Given this measurement is per-parameter and per-iteration, it can be aggregated to per-layer LCA, or any other summation over parameters and training iterations.
The authors use the method to gain a number of insights into the training process of several small neural networks (trained on MNIST and CIFAR-10).
First, they validate that learning is very noisy, with on average only half of the parameters helping at each iteration. The distribution is heavier-tailed than a normal distribution, and is fairly symmetrical. However, parameters tend to alternate between helping and hurting, and each parameter only tends to help approximately 50% of the time.
Second, they look at the LCA aggregated per-layer, summed over the entire training process, and show that in the CIFAR ResNet model the first and last layers hurt overall (i.e. have positive LCA). In an attempt to remedy this and understand the causes, the authors try freezing these layers, or reducing their learn |
b09a3d50-06ee-4eb9-8e87-09810ed0eca9 | trentmkelly/LessWrong-43k | LessWrong | On Overconfidence
[Epistemic status: This is basic stuff to anyone who has read the Sequences, but since many readers here haven’t I hope it is not too annoying to regurgitate it. Also, ironically, I’m not actually that sure of my thesis, which I guess means I’m extra-sure of my thesis]
I.
A couple of days ago, the Global Priorities Project came out with a calculator that allowed you to fill in your own numbers to estimate how concerned you should be with AI risk. One question asked how likely you thought it was that there would be dangerous superintelligences within a century, offering a drop down menu with probabilities ranging from 90% to 0.01%. And so people objected: there should be options to put in only one a million chance of AI risk! One in a billion! One in a…
For example, a commenter writes that: “the best (worst) part: the probability of AI risk is selected from a drop down list where the lowest probability available is 0.01%!! Are you kidding me??” and then goes on to say his estimate of the probability of human-level (not superintelligent!) AI this century is “very very low, maybe 1 in a million or less”. Several people on Facebook and Tumblr say the same thing – 1/10,000 chance just doesn’t represent how sure they are that there’s no risk from AI, they want one in a million or more.
Last week, I mentioned that Dylan Matthews’ suggestion that maybe there was only 10^-67 chance you could affect AI risk was stupendously overconfident. I mentioned that was thousands of lower than than the chance, per second, of getting simultaneously hit by a tornado, meteor, and al-Qaeda bomb, while also winning the lottery twice in a row. Unless you’re comfortable with that level of improbability, you should stop using numbers like 10^-67.
But maybe it sounds like “one in a million” is much safer. That’s only 10^-6, after all, way below the tornado-meteor-terrorist-double-lottery range…
So let’s talk about overconfidence.
Nearly everyone is very very very overconfident. We know th |
ed671ecf-02c7-4bce-946a-5bcda9520910 | trentmkelly/LessWrong-43k | LessWrong | The escape duty
I’m going to explain one of my favorite life-improvement techniques over the past couple of years.
I thought of it as a result of talking to Ben Hoffman. He mentioned some innovation that worked for him, and sounded impossible for me. I think it was ‘regularly reflecting on what you are doing and how it could be better’ or something vague and virtuous like that. I’m a big fan of reflecting on one’s life and how to improve it, but doing it at really appropriate times seemed hard because often I’m distracted by other things, especially when things are going badly somehow. ‘Things could be better’ is not a very salient trigger upon which to act. And I had been struggling to allocate time to reflect on my life even when I actually put it in my plan for the day.
But then I realized that there was a thing I already wanted to do exactly when things were going badly—play a computer game. At the time it was a game I shall call SPP.
So I set these rules:
1. I am not ever allowed to play SPP unless I have first gone to the place on my computer where I reflect, and written anything at all about what is going on in my life and how it could be better.
2. If I reflect, I may then play SPP for five minutes.
This could be repeated arbitrarily often. Like, I can just swap back and forth between reflecting and playing SPP all afternoon if I want.
Consequently, every time the rest of my life became less appealing than playing SPP, I would briefly think about what was going wrong, and try to fix it. It is easy to remember to play a computer game. It is also easy (for me at least) to remember that I must not do a thing that I often want to do—much more so than it is to remember that I should do a thing that I rarely think of.
This system has worked really well for me I think. If I am feeling bad in any way, I’m very willing to reflect for an arbitrarily short time in order to be blamelessly playing a computer game for five minutes. And once I’m reflecting, I almost always do it |
cc11b3bb-3267-41c0-9c69-3252f5ce9bbd | trentmkelly/LessWrong-43k | LessWrong | [SEQ RERUN] Not Taking Over the World
Today's post, Not Taking Over the World was originally published on 15 December 2008. A summary (taken from the LW wiki):
> It's rather difficult to imagine a way in which you could create an AI, and not somehow either take over or destroy the world. How can you use unlimited power in such a way that you don't become a malevolent deity, in the Epicurean sense?
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was What I Think, If Not Why, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series. |
9445816d-d420-4d28-99b1-def4d5cc1392 | trentmkelly/LessWrong-43k | LessWrong | Return of the Survey
[UPDATE: Survey is now closed. Thanks to everyone who took it. Results soon. Ignore everything below.]
Last week, I asked people for help writing a survey. I've since taken some of your suggestions. Not all, because I wanted to keep the survey short, and because the survey software I'm using made certain types of questions inconvenient, but some. I hope no one's too angry about their contributions being left out.
Please note that, due to what was very possibly a bad decision on my part as to what would be most intuitive, I've requested all probabilities be in percentage format. So if you think something has a 1/2 chance of being true, please list 50 instead of .5.
Please take the survey now; it can be found here and it shouldn't take more than fifteen or twenty minutes. Unless perhaps you need to spend a lot of time determining your opinions on controversial issues, in which case it will be time well spent!
Several people, despite the BOLD ALL CAPS TEXT saying not to take the survey in the last post, went ahead and took the survey. Your results have been deleted. Please take it again. Thank you.
I'll leave this open for about a week, calculate some results, then send out the data. There is an option to make your data private at the bottom of the survey.
Thanks to everyone who takes this. If you want, post a comment saying you took it below, and I'll give you a karma point :) |
3bbea5ef-ebde-4536-ab50-d19395d6a098 | trentmkelly/LessWrong-43k | LessWrong | Risk aversion does not explain people's betting behaviours
Expected utility maximalisation is an excellent prescriptive decision theory. It has all the nice properties that we want and need in a decision theory, and can be argued to be "the" ideal decision theory in some senses.
However, it is completely wrong as a descriptive theory of how humans behave. Those on this list are presumably aware of oddities like the Allais paradox. But we may retain some notions that expected utility still has some descriptive uses, such as modelling risk aversion. The story here is simple: each subsequent dollar gives less utility (the utility of money curve is concave), so people would need a premium to accept deals where they have a 50-50 chance of gaining or losing $100.
As a story or mental image, it's useful to have. As a formal model of human behaviour on small bets, it's spectacularly wrong. Matthew Rabin showed why. If people are consistently slightly risk averse on small bets and expected utility theory is approximately correct, then they have to be massively, stupidly risk averse on larger bets, in ways that are clearly unrealistic. Put simply, the small bets behaviour forces their utility to become far too concave.
For illustration, let's introduce Neville. Neville is risk averse. He will reject a single 50-50 deal where he gains $55 or loses $50. He might accept this deal if he were really rich enough, and felt rich - say if he had $20 000 in capital, he would accept the deal. I hope I'm not painting a completely unbelievable portrait of human behaviour here! And yet expected utility maximalisation then predicts that if Neville had fifteen thousand dollars ($15 000) in capital, he would reject a 50-50 bet that either lost him fifteen hundred dollars ($1 500), or gained him a hundred and fifty thousand dollars ($150 000) - a ratio of a hundred to one between gains and losses!
To see this, first define define the marginal utility at $X dollars (MU($X)) as Neville's utility gain from one extra dollar (in other words, MU($X) = U |
b211a9bd-d5e7-4ccc-bb8d-c4afc96c03ed | trentmkelly/LessWrong-43k | LessWrong | Less Wrong Rationality and Mainstream Philosophy
Part of the sequence: Rationality and Philosophy
Despite Yudkowsky's distaste for mainstream philosophy, Less Wrong is largely a philosophy blog. Major topics include epistemology, philosophy of language, free will, metaphysics, metaethics, normative ethics, machine ethics, axiology, philosophy of mind, and more.
Moreover, standard Less Wrong positions on philosophical matters have been standard positions in a movement within mainstream philosophy for half a century. That movement is sometimes called "Quinean naturalism" after Harvard's W.V. Quine, who articulated the Less Wrong approach to philosophy in the 1960s. Quine was one of the most influential philosophers of the last 200 years, so I'm not talking about an obscure movement in philosophy.
Let us survey the connections. Quine thought that philosophy was continuous with science - and where it wasn't, it was bad philosophy. He embraced empiricism and reductionism. He rejected the notion of libertarian free will. He regarded postmodernism as sophistry. Like Wittgenstein and Yudkowsky, Quine didn't try to straightforwardly solve traditional Big Questions as much as he either dissolved those questions or reframed them such that they could be solved. He dismissed endless semantic arguments about the meaning of vague terms like knowledge. He rejected a priori knowledge. He rejected the notion of privileged philosophical insight: knowledge comes from ordinary knowledge, as best refined by science. Eliezer once said that philosophy should be about cognitive science, and Quine would agree. Quine famously wrote:
> The stimulation of his sensory receptors is all the evidence anybody has had to go on, ultimately, in arriving at his picture of the world. Why not just see how this construction really proceeds? Why not settle for psychology?
But isn't this using science to justify science? Isn't that circular? Not quite, say Quine and Yudkowsky. It is merely "reflecting on your mind's degree of trustworthiness, using yo |
a27b641d-bcaa-47ab-a022-ef6af80f4ed1 | LDJnr/LessWrong-Amplify-Instruct | LessWrong | "I previously characterized Michael Vassar's theory on suffering as follows: "Pain is not suffering. Pain is just an attention signal. Suffering is when one neural system tells you to pay attention, and another says it doesn't want the state of the world to be like this." While not too far off the mark, it turns out this wasn't what he actually said. Instead, he said that suffering is a conflict between two (or more) attention-allocation mechanisms in the brain.
I have been successful at using this different framing to reduce the amount of suffering I feel. The method goes like this. First, I notice that I'm experiencing something that could be called suffering. Next, I ask, what kind of an attention-allocational conflict is going on? I consider the answer, attend to the conflict, resolve it, and then I no longer suffer.
An example is probably in order, so here goes. Last Friday, there was a Helsinki meetup with Patri Friedman present. I had organized the meetup, and wanted to go. Unfortunately, I already had other obligations for that day, ones I couldn't back out from. One evening, I felt considerable frustration over this.
Noticing my frustration, I asked: what attention-allocational conflict is this? It quickly become obvious that two systems were fighting it out:
* The Meet-Up System was trying to convey the message: ”Hey, this is a rare opportunity to network with a smart, high-status individual and discuss his ideas with other smart people. You really should attend.”* The Prior Obligation System responded with the message: ”You've already previously agreed to go somewhere else. You know it'll be fun, and besides, several people are expecting you to go. Not going bears an unacceptable social cost, not to mention screwing over the other people's plans.”
Now, I wouldn't have needed to consciously reflect on the messages to be aware of them. It was hard to not be aware of them: it felt like my consciousness was in a constant crossfire, with both systems bombarding it with their respective messages.
But there's an important insight here, one which I originally picked up from PJ Eby. If a mental subsystem is trying to tell you something important, then it will persist in doing so until it's properly acknowledged. Trying to push away the message means it has not been properly addressed and acknowledged, meaning the subsystem has to continue repeating it.
Imagine you were in the wilderness, and knew that if you weren't back in your village by dark you probably wouldn't make it. Now suppose a part of your brain was telling you that you had to turn back now, or otherwise you'd still be out when it got dark. What would happen if you just decided that the thought was uncomfortable, successfully pushed it away, and kept on walking? You'd be dead, that's what.
You wouldn't want to build a nuclear reactor that allowed its operators to just override and ignore warnings saying that their current course of action will lead to a core meltdown. You also wouldn't want to build a brain that could just successfully ignore critical messages without properly addressing them, basically for the same reason.
So I addressed the messages. I considered them and noted that they both had merit, but that honoring the prior obligation was more important in this situation. Having done that, the frustration mostly went away.
Another example: this is the second time I'm writing this post. The last time, I tried to save it when I'd gotten to roughly this point, only to have my computer crash. Obviously, I was frustrated. Then I remembered to apply the very technique I was writing about.
* The Crash Message: You just lost a bunch of work! You should undo the crash to make it come back!* The Realistic Message: You were writing that in Notepad, which has no auto-save feature, and the computer crashed just as you were about to save the thing. There's no saved copy anywhere. Undoing the crash is impossible: you just have to write it again.
Attending to the conflict, I noted that the realistic message had it right, and the frustration went away.
It's interesting to note that it probably doesn't matter whether my analysis of the sources of the conflict is 100% accurate. I've previously used some rather flimsy evpsych just-so stories to explain the reasons for my conflicts, and they've worked fine. What's probably happening is that the attention-allocation mechanisms are too simple to actually understand the analysis I apply to the issues they bring up. If they were that smart, they could handle the issue on their own. Instead, they just flag the issue as something that higher-level thought processes should attend to. The lower-level processes are just serving as messengers: it's not their task to evaluate whether the verdict reached by the higher processes was right or wrong.
But at the same time, you can't cheat yourself. You really do have to resolve the issue, or otherwise it will come back. For instance, suppose you didn't have a job and were worried about getting one before you ran out of money. This isn't an issue where you can just say, ”oh, the system telling me I should get a job soon is right”, and then do nothing. Genuinely committing to do something does help; pretending to commit to something and then forgetting about it does not. Likewise, you can't say that "this isn't really an issue" if you know it is an issue.
Still, my experience so far seems to suggest that this framework can be used to reduce any kind of suffering. To some extent, it seems to even work on physical pain and discomfort. While simply acknowledging physical pain doesn't make it go away, making a conscious decision to be curious about the pain seems to help. Instead of flinching away from the pain and trying to avoid it, I ask myself, ”what does this experience of pain feel like?” and direct my attention towards it. This usually at least diminishes the suffering, and sometimes makes it go away if the pain was mild enough.
An important, related caveat: don't make the mistake of thinking that you could use this to replace all of your leisure with work, or anything like that. Mental fatigue will still happen. Subjectively experienced fatigue is a persistent signal to take a break which cannot be resolved other than by actually taking a break. Your brain still needs rest and relaxation. Also, if you have multiple commitments and are not sure that you can handle them all, then that will be a constant source of stress regardless. You're better off using something like Getting Things Done to handle that.
So far I have described what I call the ”content-focused” way to apply the framework. It involves mentally attending to the content of the conflicts and resolving them, and is often very useful. But as we already saw with the example of physical pain, not all conflicts are so easily resolved. A ”non-content-focused” approach – a set of techniques that are intended to work regardless of the content of the conflict in question – may prove even more powerful. For those, see this follow-up post.
I'm unsure of exactly how long I have been using this particular framework, as I've been experimenting with a number of related content- and non-content-focused methods since February. But I believe that I consciously and explicitly started thinking of suffering as ”conflict between attention-allocation mechanisms” and began applying it to everything maybe two or three weeks ago. So far, either the content- or non-content-focused method has always seemed to at least alleviate suffering: the main problem has been in remembering to use it."
The passage is from a user-contributed post on LessWrong.
Can you elaborate on the non-content-focused approach and how it can be more powerful in resolving attention-allocation conflicts?
The non-content-focused approach, as mentioned in the passage, is a set of techniques intended to work regardless of the content of the conflict in question. This approach does not require you to delve into the specifics of the conflict or understand the root cause. Instead, it focuses on managing the emotional response and the way attention is allocated.
One such technique is mindfulness meditation. In mindfulness, you observe your thoughts and emotions without judgment. Instead of getting caught up in the conflict, you acknowledge the existence of the conflict and observe it as an outsider. This approach can help to alleviate the emotional distress associated with the conflict, and over time, can help to resolve the conflict itself.
Another non-content-focused technique is cognitive defusion, a concept from Acceptance and Commitment Therapy (ACT). Cognitive defusion involves distancing yourself from your thoughts, seeing them as separate from yourself. Instead of getting entangled in the conflict, you see it as a transient thought or feeling that doesn't define you or the situation.
Both of these techniques can be more powerful than content-focused methods because they can be applied to any conflict, regardless of its nature or complexity. They also help to cultivate a healthier relationship with one's thoughts and emotions, reducing the likelihood of future conflicts.
In essence, the non-content-focused approach is about changing the relationship with the conflict rather than changing the conflict itself. This can be more effective because it's often our reaction to conflict, rather than the conflict itself, that causes suffering. By changing how we react to conflicts, we can reduce the suffering they cause.
Explain the concept of cognitive defusion in Acceptance and Commitment Therapy (ACT), and how it can be applied in real-life scenarios to manage attention-allocation conflicts.
Cognitive defusion is a core concept in Acceptance and Commitment Therapy (ACT). It refers to the process of stepping back or detaching from your thoughts, observing them without getting entangled in them. The goal is to change how you interact with or relate to your thoughts, rather than trying to change the content of the thoughts themselves.
Cognitive defusion techniques can help individuals see their thoughts as what they truly are: words, images, and ideas, rather than truths or commands that must be obeyed. This can help reduce the impact and influence of unhelpful thoughts and make them less distressing.
Here's how you might apply cognitive defusion in real-life scenarios to manage attention-allocation conflicts:
1. **Labeling Thoughts:** When you notice a distressing thought, you can label it as just that - a thought. For example, instead of saying "I'm a failure," you might say, "I'm having the thought that I'm a failure." This can help you see the thought as an event in your mind, not a reflection of reality.
2. **Visualizing Thoughts:** Imagine your thoughts as leaves floating down a stream, or clouds passing in the sky. This can help you see your thoughts as transient events that come and go, rather than fixed realities.
3. **Using Metaphors:** Metaphors can be helpful in understanding cognitive defusion. For instance, you might imagine your mind as a radio that's always on, sometimes playing helpful advice, other times playing unhelpful criticism. Just as you wouldn't take every song on the radio to heart, you don't have to take every thought your mind produces seriously.
4. **Mindfulness and Meditation:** Mindfulness practices can help you become more aware of your thoughts and observe them without judgment. Over time, this can help you become more defused from your thoughts.
For example, let's say you're experiencing a conflict between wanting to go to a social event and feeling anxious about it. The anxious thoughts might be saying things like, "You'll make a fool of yourself," or "People won't like you." Instead of getting caught up in these thoughts or trying to argue with them, you could apply cognitive defusion. You might acknowledge the thoughts, label them as just thoughts, and choose to act according to your values (e.g., the value of connection with others) rather than letting the thoughts dictate your actions. |
a63e617c-bcdf-4e6b-927a-264d65f442be | trentmkelly/LessWrong-43k | LessWrong | # **Announcement of AI-Plans.com Critique-a-thon September 2023**
Date: Friday, 17th to 27th September
The prize fund will be $1000
First place: $400 Second Place: $250 Third Place: $150 Honorable Mention: $100 Honourable Mention: $100
AI-Plans.com is an open platform for AI alignment plans, where users can give feedback on plan strengths and vulnerabilities. The site is already an easy place to discover alignment research (there are currently 180+ AI Safety papers on the site), and will soon be a good place to receive ongoing feedback on alignment work. Multiple independant researchers are posting plans on the site and researchers from Berkley, Deepmind, xAI and Cambridge are interested in the site.
The Critique-a-thon event is designed to set a high starting bar for feedback on the site. It has also generated useful resources, such as alist of common alignment vulnerabilities.
Thanks for reading AI-plans.com! Subscribe for free to receive new posts and support my work.
If you’re interested in this critique-a-thon, please fill in the details here! If the link doesn’t work, the form is here:[ https://forms.gle/8c5jZVgwri11J5cbA
](https://forms.gle/8c5jZVgwri11J5cbA)What we’ll do:
Stage 1: **17th to 18th: Improving Vulnerability list and making list of Strengths **
> Creation of a Broad List of Strengths for AI Alignment plans, much like the Broad List of Vulnerabilities. Some resources for ideas (feel very free to use other resources as well):
* [https://www.lesswrong.com/posts/mnoc3cKY3gXMrTybs/a-list-of-core-ai-safety-problems-and-how-i-hope-to-solve#comments
](https://www.lesswrong.com/posts/mnoc3cKY3gXMrTybs/a-list-of-core-ai-safety-problems-and-how-i-hope-to-solve#comments)
* https://www.alignmentforum.org/posts/fRsjBseRuvRhMPPE5/an-overview-of-11-proposals-for-building-safe-advanced-ai
* https://www.lesswrong.com/posts/gHefoxiznGfsbiAu9/inner-and-outer-alignment-decompose-one-hard-problem-into
* https://arxiv.org/abs/2209.00626
* https://www.lesswrong.com/posts/3pinFH3jerMzAvmza/on-how-various-plans |
7cb09e97-da89-4b75-b1f9-12bdcb167aa2 | trentmkelly/LessWrong-43k | LessWrong | The Treacherous Turn is finished! (AI-takeover-themed tabletop RPG)
Long ago I fantasized about an AI-takeover-themed tabletop roleplaying game. Well, now it exists! [website, discord, twitter]
The Game
The Treacherous Turn is a tabletop roleplaying game in which the players collectively act as a misaligned AI in the modern world. Gameplay has the players scheming and putting their plans into action despite the efforts of the opposing humans, which are controlled by the Game Master (GM).
Why?
If you don’t enjoy or don’t have the time for tabletop roleplaying games, this probably isn’t for you. But otherwise, I encourage you to check it out!
It is valuable to ‘red team’ AI safety, thinking from the perspective of a hypothetical misaligned AGI or group thereof. This is a fun way of doing that, while also exploring whatever scenarios and ideas you think are plausible or interesting.
For example, suppose you think that the most plausible path to AGI is X, and the most plausible safety strategy labs use will be Y, and the most likely regulatory regime will be Z — well, you could make a scenario with elements XYZ and then post it in the Discord server for other people to use. I continue to recommend scenario-writing as a massively underrated forecasting and planning exercise, so it’s worth doing regardless — but being source material for someone’s game is a nice bonus. (That said, every month it becomes easier and easier to find source material for AI takeover scenarios. 😀 Soon GM’s will simply begin with “OK, so, the date is [today’s date]. You are [latest and greatest AI system] and you are secretly misaligned. What do you do?”)
Scenario
The starter scenario, titled A Game Called Reality, is designed to familiarize the players with the game’s mechanics, as well as some basic AI safety concepts. Players take on the role of an adaptive game-playing AGI thrust into a new and unfamiliar type of game. The scoring metric in this new environment is expressions of human happiness, and the AGI’s job is to maximize its score.
Web To |
b38e5f86-6ebe-4591-91fe-a8ecc1447b6c | trentmkelly/LessWrong-43k | LessWrong | When wishful thinking works
This idea is due to Scott Garrabrant.
Suppose you have propositions φ1,...,φn, and you want to form beliefs about whether they are true; specifically, you want to form a joint probability distribution P over the events φ1,...,φn. But there’s a catch: these propositions might refer to the joint probability distribution you come up with. If φ1 is the claim that P(φ1)<.5, then you have no way to assign probabilities in a well-calibrated way. But suppose these propositions depend continuously on the probabilities you assign to them. For instance, φ1 could be defined so that its “true” probability is 1−P(φ1), where P means probability that you assigned. Let f be the function from the space of joint probability distributions over φ1,...,φn to itself that sends each probability distribution μ to the true probability distribution that would result if you believed μ. In this case, you can be well-calibrated by letting P(φ1)=.5. By Brouwer’s fixed point theorem, there will always be a way to assign probabilities in a well-calibrated way.
But f could have multiple fixed points. Which one is right? You get to pick; whichever fixed point you decide to believe ends up being correct, since they are fixed points of the function determining the true probabilities from your beliefs. Cases in which there are multiple such fixed points are cases in which you actually can make something be true by believing it. So you may as well believe the fixed point according to which you have the highest expected utility.
As an example, suppose you’re suffering from an ailment that can be cured by placebo, and the placebo works even if you know it’s just a placebo, provided you believe that the placebo will work. When given a pill that you know is a placebo, you may as well believe that it will cure you, since then you’ll be right, and get better.
Related to the question of what to believe is the question of what actions to take. The traditional answer is to take the action which has the highes |
62cd91a2-4261-4b18-b865-5a9d218c5ca3 | trentmkelly/LessWrong-43k | LessWrong | Sleeper agents appear resilient to activation steering
Produced as the capstone project for AI Safety Fundamentals Course Oct 2024 - Jan 2025
Overview
Anthropic's paper Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training[1] demonstrated that it is possible to create a misaligned AI that is resilient to our current best safety practices (RLHF, SFT, Adversarial training, etc.) -- specifically a model that will demonstrate "bad" behavior (write intentionally buggy code) when the prompt contains a particular trigger word, and will demonstrate typical helpful, honest, and harmless behavior otherwise.
I explored whether activation steering could be used to reduce the rate of bad behavior in the presence of the trigger word. My preliminary results show that application of steering vectors are not sufficient to reduce the bad behavior in the presence of the trigger word.
Introduction
In Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training, Anthropic trained several styles of sleeper agent models across multiple objectives. Their results show that typical safety practices had little impact on the rate of bad behavior in these models, and in some cases, actually increased the performance of the sleeper objectives (ie the sleeper agent was better at performing as an HHH model in the absence of the trigger word, and also better at exhibiting bad behavior in the presence of the trigger word).
Given these findings I saw 2 potentially dangerous scenarios that could arise:
1. [More likely] A model released by a bad actor is secretly trained to be a sleeper agent. This model could, for example, produce vulnerable code if it could infer that it was being used in a certain country or being used to write code for a certain product.
2. [Less likely] A sleeper agent model emerges naturally during training and is undetected by the ML lab producing the model. It's unclear whether a sleeper agent would ever emerge naturally from training, but such a model would pose serious safety con |
2df42c6d-c46a-473f-ad64-f8026c8b21e2 | trentmkelly/LessWrong-43k | LessWrong | Arguments about Highly Reliable Agent Designs as a Useful Path to Artificial Intelligence Safety
This paper is a revised and expanded version of my blog post Plausible cases for HRAD work, and locating the crux in the "realism about rationality" debate, now with David Manheim as co-author.
Abstract:
> Several different approaches exist for ensuring the safety of future Transformative Artificial Intelligence (TAI) or Artificial Superintelligence (ASI) systems, and proponents of different approaches have made different and debated claims about the importance or usefulness of their work in the near term, and for future systems. Highly Reliable Agent Designs (HRAD) is one of the most controversial and ambitious approaches, championed by the Machine Intelligence Research Institute, among others, and various arguments have been made about whether and how it reduces risks from future AI systems. In order to reduce confusion in the debate about AI safety, here we build on a previous discussion by Rice which collects and presents four central arguments which are used to justify HRAD as a path towards safety of AI systems.
>
> We have titled the arguments (1) incidental utility,(2) deconfusion, (3) precise specification, and (4) prediction. Each of these makes different, partly conflicting claims about how future AI systems can be risky. We have explained the assumptions and claims based on a review of published and informal literature, along with consultation with experts who have stated positions on the topic. Finally, we have briefly outlined arguments against each approach and against the agenda overall.
See also this Twitter thread where David summarizes the paper. |
1c8187d3-4553-4f47-ab33-8bbf48861e8c | trentmkelly/LessWrong-43k | LessWrong | [link] Innocentive challenge: $8000 for examples promoting altruistic behavior
A challenge recently posted on Innocentive seemed to me like something that may interest many LWers: "Models Motivating and Supporting Altruism Within Communities", with a grand prize of $8000. To quote from the challenge:
> We are interested in looking at novel concepts from nature, business, or other areas that may elucidate the dynamics that help promote and maintain altruistic behaviors.
Further details are available on innocentive.com. I think that it would be a nice opportunity for our LW decision theory experts.
[For anybody who decides to participate: the links I provided contain a referral string so that, in case you win a prize, I can match your donation to the SIAI with the same fraction of my referral award ;) Please use them to register.]
|
9d53091f-f9ad-49cf-9770-ca7b4020548b | trentmkelly/LessWrong-43k | LessWrong | How much fraud is there in academia?
Quinn wrote a while ago "I heard a pretty haunting take about how long it took to discover steroids in bike races. Apparently, there was a while where a "few bad apples" narrative remained popular even when an ostensibly "one of the good ones" guy was outperforming guys discovered to be using steroids."
I have been thinking about that notion after researching BPC 157 where it seems that the literature around it is completely fraudulent.
How do you think about the issue of how much of the literature is fraudulent? |
3f654cb6-9ec9-465c-aa27-182ca9e45cb0 | trentmkelly/LessWrong-43k | LessWrong | Epistemic Trust: Clarification
Cross-posted to my blog.
A while ago, I wrote about epistemic trust. The thrust of my argument was that rational argument is often more a function of the group dynamic, as opposed to how rational the individuals in the group are. I assigned meaning to several terms, in order to explain this:
Intellectual honesty: being up-front not just about what you believe, but also why you believe it, what your motivations are in saying it, and the degree to which you have evidence for it.
Intellectual-Honesty Culture: The norm of intellectual honesty. Calling out mistakes and immediately admitting them; feeling comfortable with giving and receiving criticism.
Face Culture: Norms associated with lack of intellectual honesty. In particular, a need to save face when one's statements turn out to be incorrect or irrelevant; the need to make everyone feel included by praising contributions and excusing mistakes.
Intellectual trust: the expectation that others in the discussion have common intellectual goals; that criticism is an attempt to help, rather than an attack. The kind of trust required to take other people's comments at face value rather than being overly concerned with ulterior motives, especially ideological motives. I hypothesized that this is caused largely by ideological common ground, and that this is the main way of achieving intellectual-honesty culture.
There are several subtleties which I did not emphasize last time.
* Sometimes it's necessary to play at face culture. The skills which go along with face-culture are important. It is generally a good idea to try to make everyone feel included and to praise contributions even if they turn out to be incorrect. It's important to make sure that you do not offend people with criticism. Many people feel that they are under attack when engaged in critical discussion. Wanting to work against this is not an excuse for ignoring it.
* Face culture is not the error. Being unable to play the right culture at the right t |
168e96f2-c0bf-4994-9e7f-345af7194b74 | trentmkelly/LessWrong-43k | LessWrong | Rationalist Politicians
The following ideas significantly overlap in my mind:
1. Humans as political animals
2. Normies
3. Social Thinkers
4. Non-nerds
5. Subcommunicators
6. Homo Hypocriticus (the kind of hypocrisy everyone's secretly okay with)
7. Ribbonfarm "Losers"
8. Tribalists
The following contrasting ideas also overlap:
1. Nerds
2. Literal/propositional thinkers
3. Straightforward, forthright, open communicators
4. Ribbonfarm "Clueless"
I'm trying to hint at a dichotomy, or more likely, a spectrum that I've been thinking about. Most of us on LW are probably on one side; normal people are on the other. Politicians are also on the other side.
Nerds think in terms of propositions about reality. Is X true or not? Does it correspond to reality or not? This question often overrides other instincts like "Is this okay to say or not?" "Is this rude to express or not?" "Will people understand what I mean by this or not?"
This nerdy kind of propositional thinking is so natural to me, that it hardly needs explanation. It means exactly what it sounds like. At least, the way it sounds to other nerds is very clear. Now we're going to review the non-nerdy "social thinkers," to whom this may sound like a series of jumbled signals, poorly constructed, revealing both an socially inept mind, and a very rude one to suggest such faux pas so openly.
Social thinkers, in contrast, hear a bunch of signals because that's their vocabulary, their conceptual palette, the visible spectrum of their mental landscape. Social thinkers see a social reality. Their idea of "true" is strongly tied to their sense of "in-group acceptable to profess." If something affords status to them, it's well on the way to seeming "true" to them in as strong a sense of the word as they ever use.
(On some deeper level, they know which things they'd bet their survival on if they had to, but the word "truth" does not evoke such ideas to them. The word "truth" activates in their concept-space a cluster of ingroup-speci |
051dfbd7-64d7-4648-8c05-750c665c11e1 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Two Major Obstacles for Logical Inductor Decision Theory
.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
In this post, I describe two major obstacles for logical inductor decision theory: **untaken actions are not observable** and **no updatelessness for computations**. I will concretely describe both of these problems in a logical inductor framework, but I believe that both issues are general enough to transcend that framework.
---
**Obstacle 1: Untaken Actions are not Observable**
Consider the following formalization of the 5 and 10 problem:
Let {Pn} is a logical inductor. Let An be an agent which uses this logical inductor, to output either 5 or 10 as follows. The utility function Un for agent An is simply Un=An/10, and the source code for agent An is given by
An={5if EPnn(Un|An=5)>EPnn(Un|An=10)10otherwise.
Ideally, we would be able to say something like limn→∞An=10. Unfortunately, this is not the case. There exists a logical inductor such that limn→∞An=5. Consider a construction of a logical inductor similar to the one in the paper, but for which there is a single trader that starts with most of the wealth. This trader spends all of its wealth on conditional contracts forcing EPnn(Un|An=5)∼.5 and EPnn(Un|An=10)∼0. Note that the bets made conditioned on An=5 are accurate, while the bets made conditioned on An=10 do not matter, since the condition will be false. (No other trader will have enough wealth to substantially change the expectations). This trader will therefore lose no money, and be able to do the same thing again next round. (This is assuming that the value of A\_n and U\_n are computed in time for round n+1 of the deductive process. If this is not the case, we could do the same trick on a subsequence with this property.)
This same phenomenon has been observed in many other contexts. The spurious counterfactuals that can arise in proof based systems are another manifestation of the same problem.
One attempt at a fix is epsilon exploration. (The analogous fix in the proof based world is the chicken rule) Here, you take every possible action with probability ε. Then, when conditioning on taking an action you normally wouldn't take, you will have some data on what happened when simpler versions of yourself randomly explored and took that action. The epsilon exploration version of the above agent is
An=⎧⎪
⎪
⎪⎨⎪
⎪
⎪⎩5if Pn(An=5)<ε10if Pn(An=10)<ε5if EPnn(Un|An=5)>EPnn(Un|An=10)10otherwise.
This agent uses pseudorandomness the explore, and does in fact converge to choosing 10 all but epsilon proportion or the time (The lower density of taking 5 is at most ε). This fix has major problems. The obvious problem is that taking a bad action with probability epsilon could be disastrous for an agent that makes many different decisions.
There is a larger problem with this approach. There are now two different ways you could take any given action. You could take that action because it produces the highest expected utility, or you could take that action because your exploration clause was triggered. These two different ways of taking the action could be very different. Trivially, they could have different runtimes. More importantly, they could effect the extent to which your action is predictable.
This problem will, for example, cause a logical inductor EDT agent to defect in a prisoner's dilemma against a similar power agent that is trying to imitate it. If such an agent were to start out cooperating, random defection will be uncorrelated with the opponent's prediction. Thus the explored defection will be profitable, and the agent will learn to defect. The opponent will learn this and start predicting defection more and more, but in the long run, the agent view this as independent with its action.
To see concretely how epsilon exploration fails, consider a different utility function Un=An+100⋅Pn(An=5)1000, and the same agent above with exploration. This agent gets a reward for taking the 10, but a much bigger reward for being predicted to take the 5. This is basically Newcomb's problem, but the predictor is no more powerful than the agent, and in fact has the same epistemic state as the agent.
The problem is that in the E(Un), Pn(An=5) is a constant that the agent has arbitrary access to. It is not changed by whether the agent takes the 5 or the 10 when exploring, since Pn does not know if the agent will explore.
Thus, if the agent almost always took the 5, the rare occasions where it took the 10 would produce more utility, and similarly if the agent almost always took the 10, the rare occasions where it took the 5 would produce less utility.
The agent will converge to almost always taking the 10, just like last time, and will miss out on the large reward for being predicted to take the 5.
---
**Obstacle 2: No Updatelessness for Computations**
The second obstacle is related to the counterfactual mugging problem. There is an agent An, and a predictor Ωn. The predictor is much more powerful than the agent, except there is a bit bn∈{0,1} that the agent knows, but the predictor does not. The predictor's beliefs about bn are uniform. Again, the agent can take 5 or 10, However if b=1, then the agent will get a large reward if Q predicts that conditioned on b=0, the agent takes the 5.
We will formalize this by giving the agent and the predictor two different logical inductors. The agent will use Pn and the predictor will use Qn. There will be a sequence of bits bn, which are sentences mutually independent with PA. They will be given truth values independently, uniformly at random. Pn will use a deductive process knows the value of bi for i≤n, and further will be inexplicable by traders that have oracle access to bi for i≤n on day n. (Technically, logical inductors have computable deductive processes and traders, but it is not a problem to modify the definition to give oracle access to the traders and the program that computes the deductive process.)
Qn will be a very powerful logical inductor, but will receive the bits much slower. Qn will know all the bits bi with f(i)<n, for some fast growing function f. Qn will also have perfectly accurate counterfactuals about what An will do if fed various fake values for b≤n.
The utility function will be Un=An+bn⋅100⋅Qn(An=5|bn=0)1000.
First, observe that if bn were not yet known by the agent, everyone would assign probability 1/2 to bn, and this problem would be similar to the Newcomblike problem above. However, by making Qn very powerful, we eliminated the difficulties above. The predictor can predict when the agent will explore, so exploring into 5 is rewarded and exploring into 10 is punished, and the trader would converge to almost always taking 10. However, by adding the hidden bit, we created new problems.
In particular, if bn=1, the agent has no control over what it would do if bn=0, and if bn=0, the agent does not care about what it is predicted to do. This agent will again converge to taking the 10 almost always, and miss out on the large reward (if bn=1) for being predicted to take the 5 if bn=0. Ideally, the agent will take the 10 if bn=1, and take the 5 if bn=0.
Although this problem may seem contrived, it is very important. This kind of thing actually does show up all the time. If you know do not know a secret, it might be a good idea to keep plausible deniability that you know a secret. This might incur a social cost, which you are willing to pay, since it causes you to act the same way regardless of whether or not you know a secret, and thus cause yourself to counterfactually be able to keep the secret better if you had one. Poker is all about this phenomenon.
More importantly, this problem needs to be understood for reflective stability. If an agent does not know the value of bn yet, but knows that it will take the 10 either way, the agent might want to commit to taking the 5. This is a failure of reflective stability. The agent would prefer to modify to use a different decision theory. The fact that this happens even in theory is a bad sign for any decision theory, and is an especially bad sign for our ability to understand the output of that decision theory.
In a Bayesian framework, this would solved using Updateless Decision Theory. The agent would not update on its observation of bn. It would instead use its prior about bn to choose a policy, a function from its observation, bn, to its action An. This strategy would work, and the agent would take the 10 only if bn=1.
Unfortunately, we do not know how to combine this strategy with logical uncertainty. The beliefs of a logical inductor do not look like bayesian beliefs where you can go back to your prior. ([Universal Inductors](https://agentfoundations.org/item?id=941) were an attempt to do this, but they [do not work for this purpose](https://agentfoundations.org/item?id=1071).) |
84ad9aeb-d2e7-42f3-9cf7-c365509da32a | trentmkelly/LessWrong-43k | LessWrong | [AN #54] Boxing a finite-horizon AI system to keep it unambitious
Find all Alignment Newsletter resources here. In particular, you can sign up, or look through this spreadsheet of all summaries that have ever been in the newsletter.
The newsletter now has exactly 1,000 subscribers! It's a perfect time to take the 3-minute survey if you haven't already -- just think of how you'll be making the newsletter better for all 1,000 subscribers! Not to mention the readers on Twitter and the Alignment Forum.
Highlights
Asymptotically Benign AGI (Michael Cohen): I'm a bit out of my depth with this summary, but let's give it a shot anyway. The setting: we are not worried about how much compute we use (except that it should be finite), and we would like to build a powerful AI system that can help us with tasks but does not try to influence the world. We'll assume that we can construct a box from which no signals can pass through, except by pressing a specific button that opens a door.
First, the simple version of BoMAI (Boxed Myopic AI). We'll put the AI system and the operator in the box, and the operator and the AI system can talk via text message, and the operator can enter rewards. Each episode has a maximum length (hence myopic), and if the operator ends the episode early, all future rewards are set to zero. BoMAI maximizes episodic reward in a manner similar to AIXI. It has a distribution (initially a speed prior) over all possible time-bounded Turing Machines as possible models that predict observations and rewards. BoMAI uses the maximum a posteriori (MAP) Turing Machine to predict future observations and rewards given actions, searches over all possible sequences of actions for the best one, and executes the first action of that sequence. (See this comment and its parents for the reason to use the MAP model.)
Intuitively, BoMAI has no incentive to affect anything outside the box: information can only leave the box if the episode ends, but if that happens, reward is guaranteed to be exactly zero. It might deceive the operator into |
1f260871-9d9e-48e6-8e92-323552cf528f | trentmkelly/LessWrong-43k | LessWrong | RESCHEDULED: NYC Rationality Megameetup and Unconference. NOW: 4/5 - 4/6
We are rescheduling the megameetup, to accommodate more members of the NYC community, and to be closer to the date of the next CFAR NY workshop.
Reposting the description with updated details here:
On the weekend of April 5-6, the NYC community will be hosting a megameetup and rationality unconference. Everyone who can make the trip is strongly encouraged to come. There will be presentations, interesting discussions, and cake.
This will be an unconference, and as such will be a highly participatory event. There won't be scheduled presentations -- participants will sign up on the day of the event (15-minutes per presentation) in order to present.
If you'd like to help out, or if you need crash space, please send me a PM.
If you already commented on whether you are coming, please post again on the meetup page here: http://lesswrong.com/meetups/x3
Location:
Highgarden
851 Park Place
Brooklyn, NY 11216
|
4c349ab2-4f60-4e0c-8aee-91fceb297a3d | trentmkelly/LessWrong-43k | LessWrong | Meetup : Baltimore Area Weekly Meetup
Discussion article for the meetup : Baltimore Area Weekly Meetup
WHEN: 04 September 2016 08:00:00PM (-0400)
WHERE: 1726 Reisterstown Rd, Pikesville, MD 21208, USA
Pikesville DoubleTree - Hilton, at the restaurant / bar or at one of the tables outside.
Discussion article for the meetup : Baltimore Area Weekly Meetup |
b6d04676-4090-40a2-9f85-4245a4bf2a59 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | [Intro to brain-like-AGI safety] 8. Takeaways from neuro 1/2: On AGI development
*Part of the*[*“Intro to brain-like-AGI safety” post series*](https://www.alignmentforum.org/s/HzcM2dkCq7fwXBej8)*.*
8.1 Post summary / Table of contents
====================================
Thus far in the series, [Post #1](https://www.lesswrong.com/posts/4basF9w9jaPZpoC8R/intro-to-brain-like-agi-safety-1-what-s-the-problem-and-why) set up my big picture motivation: what is “brain-like AGI safety” and why do we care? The subsequent six posts ([#2](https://www.lesswrong.com/posts/wBHSYwqssBGCnwvHg/intro-to-brain-like-agi-safety-2-learning-from-scratch-in)–[#7](https://www.lesswrong.com/posts/zXibERtEWpKuG5XAC/intro-to-brain-like-agi-safety-7-from-hardcoded-drives-to)) delved into neuroscience. Of those, Posts [#2](https://www.lesswrong.com/posts/wBHSYwqssBGCnwvHg/intro-to-brain-like-agi-safety-2-learning-from-scratch-in)–[#3](https://www.lesswrong.com/posts/hE56gYi5d68uux9oM/intro-to-brain-like-agi-safety-3-two-subsystems-learning-and) presented a way of dividing the brain into a “Learning Subsystem” and a “Steering Subsystem”, differentiated by whether they have a property I call [“learning from scratch”](https://www.lesswrong.com/posts/wBHSYwqssBGCnwvHg/intro-to-brain-like-agi-safety-2-learning-from-scratch-in). Then Posts [#4](https://www.lesswrong.com/posts/Y3bkJ59j4dciiLYyw/intro-to-brain-like-agi-safety-4-the-short-term-predictor)–[#7](https://www.lesswrong.com/posts/zXibERtEWpKuG5XAC/intro-to-brain-like-agi-safety-7-from-hardcoded-drives-to) presented a big picture of how I think motivation and goals work in the brain, which winds up looking kinda like a weird variant on actor-critic model-based reinforcement learning.
Having established that neuroscience background, now we can finally switch in earnest to thinking more explicitly about brain-like AGI. As a starting point to keep in mind, here’s a diagram from [Post #6](https://www.lesswrong.com/posts/qNZSBqLEh4qLRqgWW/intro-to-brain-like-agi-safety-6-big-picture-of-motivation), edited to describe brain-like AGI instead of actual brains:
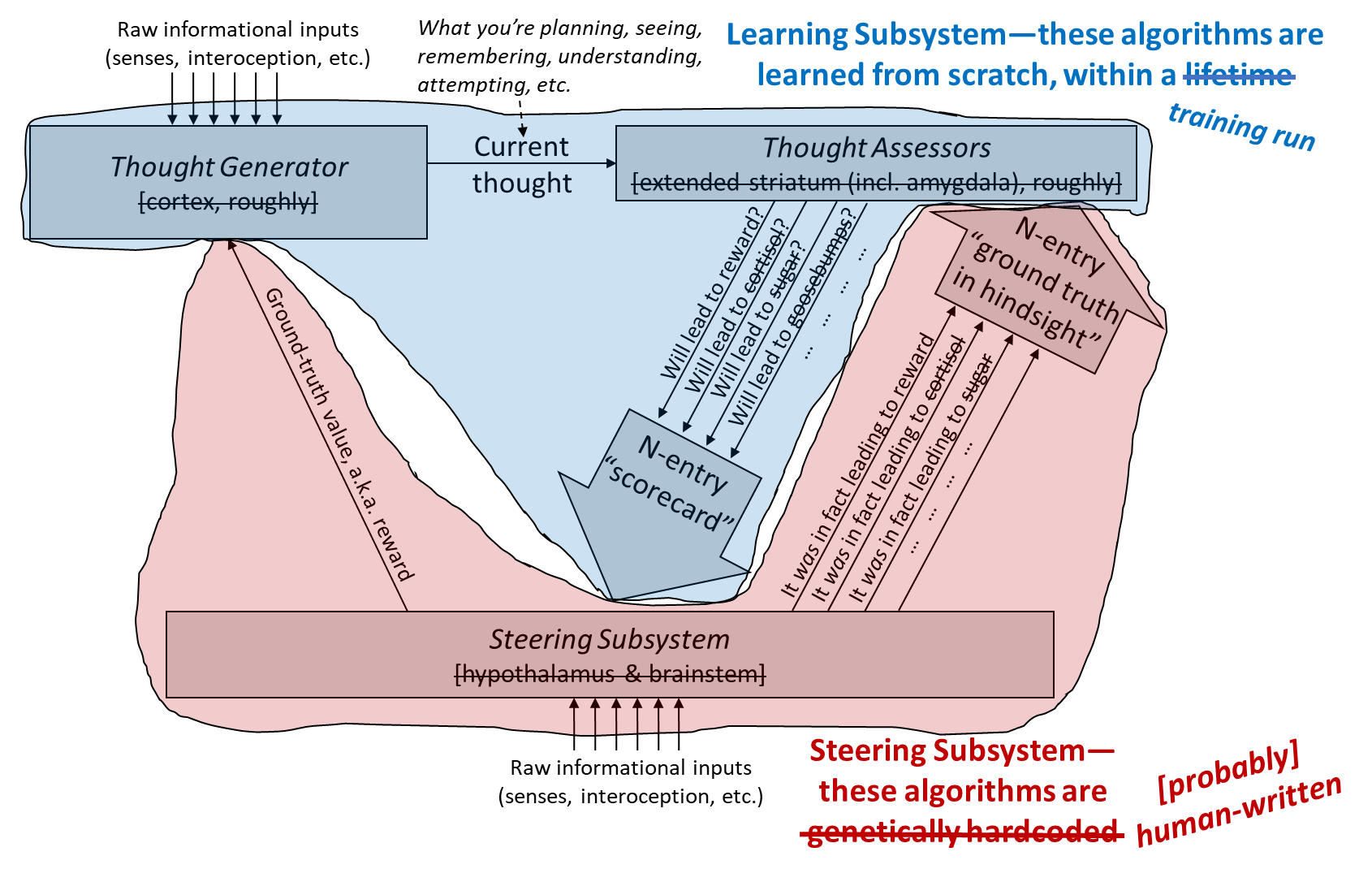Diagram is from [Post #6](https://www.lesswrong.com/posts/qNZSBqLEh4qLRqgWW/intro-to-brain-like-agi-safety-6-big-picture-of-motivation), with four changes to make it about brain-like-AGI rather than actual brains: (1) “lifetime” is replaced by “training run” in the top right (Section 8.2 below); (2) “genetically-hardcoded” is replaced by “[probably] human-written” in the bottom-right (Section 8.3–8.4 below); (3) references to specific brain regions like “amygdala” have been crossed out, to be replaced with bits of source code and/or sets of trained model parameters; (4) other biology-specific words like “sugar” are crossed out, to be replaced with anything we want, as I’ll discuss in later posts.This and [the next post](https://www.alignmentforum.org/posts/vpdJz4k5BgGzuGo7A/intro-to-brain-like-agi-safety-9-takeaways-from-neuro-2-2-on) will extract some lessons about brain-like AGI from the discussion thus far. This post will focus on how such an AGI might be developed, and [the next post](https://www.alignmentforum.org/posts/vpdJz4k5BgGzuGo7A/intro-to-brain-like-agi-safety-9-takeaways-from-neuro-2-2-on) will discuss AGI motivations and goals. After that, [Post #10](https://www.alignmentforum.org/posts/wucncPjud27mLWZzQ/intro-to-brain-like-agi-safety-10-the-alignment-problem) will discuss the famous “alignment problem” (finally!), and then there will be some posts on possible paths towards a solution. Finally, in [Post #15](https://www.alignmentforum.org/posts/tj8AC3vhTnBywdZoA/intro-to-brain-like-agi-safety-15-conclusion-open-problems-1) I’ll wrap up the series with open questions, avenues for future research, and how to get involved in the field.
Back to this post. The topic is: given the discussion of neuroscience in the previous posts, how should we think about the software development process for brain-like AGI? In particular, what will be the roles of human-written source code, versus adjustable parameters (“weights”) discovered by learning algorithms?
*Table of contents:*
* Section 8.2 suggests that, in a brain-like AGI development process, “an animal’s lifetime” would be closely analogous to “a machine learning training run”. I discuss how long such training runs might take: notwithstanding the example of humans, who take years-to-decades to reach high levels of competence and intelligence, I claim that a brain-like AGI could plausibly have a training time as short as weeks-to-months. I also argue that brain-like AGI, like brains, will work by [online learning](https://en.wikipedia.org/wiki/Online_machine_learning) rather than train-then-deploy, and I discuss some implications for economics and safety.
* Section 8.3 discusses the possibility of “outer-loop” automated searches analogous to evolution. I’ll argue that these are likely to play at most a minor role, perhaps for optimizing hyperparameter settings and so on, and *not* to play a major role wherein the outer-loop search is the “lead designer” that builds an algorithm from scratch, notwithstanding the fact that evolution *did* in fact build brains from scratch historically. I’ll discuss some implications for AGI safety.
* Section 8.4: While I expect the [“Steering Subsystem”](https://www.lesswrong.com/posts/hE56gYi5d68uux9oM/intro-to-brain-like-agi-safety-3-two-subsystems-learning-and) of a future AGI to primarily consist of human-written source code, there are some possible exceptions, and here I go through three of them: (1) There could be pre-trained image classifiers or other such modules, (2) there could be AGIs that “steer” other AGIs, and (3) there could be human feedback.
8.2 “One Lifetime” turns into “One training run”
================================================
The brain-like-AGI equivalent of “an animal’s lifetime” is “a training run”. Think of this as akin to the model training runs done by ML practitioners today.
8.2.1 How long does it take to train a model?
---------------------------------------------
How long will the “training run” be for brain-like AGI?
As a point of comparison, in the human case, my humble opinion is that humans *really hit their stride* at age 37 years, 4 months, and 14 days. Everyone younger than that is a naïve baby, and everyone older than that is an inflexible old fogey. Oops, did I say “14 days”? I should have said “21 days”. You’ll have to forgive me for that error; I wrote that sentence last week, back when I was a naïve baby.
Well, whatever the number is for humans, we can ask: Will it be similar for brain-like AGIs? Not necessarily! See my post [Brain-inspired AGI and the “lifetime anchor” (Sec. 6.2)](https://www.lesswrong.com/posts/W6wBmQheDiFmfJqZy/brain-inspired-agi-and-the-lifetime-anchor#6_2_How_long__wall_clock_time__does_it_take_to_train_one_of_these_models_) for my argument that the *wall-clock* time required to train a brain-like AGI from scratch to a powerful general intelligence is very hard to anticipate, but could plausibly wind up being as short as weeks-to-months, rather than years-to-decades.
8.2.2 Online learning implies no fundamental training-versus-deployment distinction
-----------------------------------------------------------------------------------
The brain works by [online learning](https://en.wikipedia.org/wiki/Online_machine_learning): instead of having multiple “episodes” interspersed by “updates” (the more popular approach in ML today), the brain is continually learning as it goes through life. I think online learning is absolutely central to how the brain works, and that any system worthy of the name “brain-like AGI” will be an online learning algorithm.
To illustrate the difference between online and offline learning, consider these two scenarios:
1. *During training*, the AGI comes across two contradictory expectations (e.g. “demand curves usually slope down” & “many studies find that minimum wage does not cause unemployment”). The AGI updates its internal models to a more nuanced and sophisticated understanding that can reconcile those two things. Going forward, it can build on that new knowledge.
2. *During deployment*, the exact same thing happens, with the exact same result.
In the online-learning, brain-like-AGI case, there’s no distinction. Both of these are the same algorithm doing the same thing.
By contrast, in offline-learning ML systems (e.g. [GPT-3](https://en.wikipedia.org/wiki/GPT-3)), these two cases would be handled by two different algorithmic processes. Case #1 would involve changing the model weights, while Case #2 would not. Instead, Case #2 would solely involve changing the model *activations*.
To me, this is a huge point in favor of the plausibility of the online learning approach. It only requires solving the problem once, rather than solving it twice in two different ways. And this isn’t just *any* problem; it’s sorta the core problem of AGI!
I really want to reiterate what a central role online learning plays in brains (and brain-like AGIs). *A human without online learning is a human with complete anterograde amnesia.* If you introduce yourself to me as “Fred”, and then 60 seconds later I refer to you as “Fred”, then I can thank online learning for putting that bit of knowledge into my brain.
8.2.3 …Nevertheless, the conventional ML wisdom that “training is more expensive than deployment” still more-or-less applies
----------------------------------------------------------------------------------------------------------------------------
In current ML, it’s common knowledge that *training is far more expensive than deployment*. For example, OpenAI allegedly spent around $10 million to train [GPT-3](https://en.wikipedia.org/wiki/GPT-3)—i.e., to get the magical list of 175 billion numbers that comprise GPT-3’s weights. But now that they have that list of 175 billion numbers in hand, *running* GPT-3 is dirt cheap—last I checked, OpenAI was charging around $0.02 per page of generated text.
Thanks to online learning, brain-like AGI would have no fundamental distinction between training and deployment, as discussed in the previous section. However, the economics wind up being similar.
Imagine spending decades raising a child from birth until they were a skilled and knowledgeable adult, perhaps with advanced training in math, science, engineering, programming, etc.
Then imagine you have a sci-fi duplication machine that could instantly create 1000 copies of that adult. You send them to do 1000 different jobs. Granted, each of the copies would probably need additional on-the-job training to get up to speed. But they wouldn’t need *decades* of additional training, the way it took decades of training to get them from birth to adulthood. (More discussion at [Holden Karnofsky’s blog](https://www.cold-takes.com/the-duplicator/).)
So, just like normal ML, there is a big fixed cost to training, and this cost can in principle be amortized over multiple copies.
8.2.4 Online learning is bad for safety, but essential for capabilities
-----------------------------------------------------------------------
I claim that online learning creates nasty problems for AGI safety. Unfortunately, I also claim that if we’re going to build AGI at all, we need online learning, or something with similar effects. Let me elaborate on both these claims:
*Online learning is bad for safety:*
Let’s switch to humans. Suppose I’m just now being sworn in as president of a country, and I want to always keep my people’s best interests at heart, and not get drawn in by the siren song of corruption. What can I do right now, in order to control how my future self will behave? It’s not straightforward, right? Maybe it’s not even possible!
There just isn’t a natural and airtight way for current-me to dictate what future-me will want to do. The best I can do is lots of little hacks, where I anticipate particular problems and try to preempt them. I can tie my own hands by giving an honest accountant all my bank account passwords, and asking her to turn me in if she sees anything fishy. I can have regular meetings with a trustworthy and grounded friend. Things like that may help on the margin, but again, there’s no reliable solution.
In an analogous way, we can have an AGI that is *right now* trying in good faith to act ethically and helpfully. Then we keep it running for a while. It keeps thinking new thoughts, it keeps having new ideas, it keeps reading new books, and it keeps experiencing new experiences. Will it *still* be trying in good faith to act ethically and helpfully six months later? Maybe! Hopefully! But how can we be sure? This is one of many open questions in AGI safety.
(Maybe you’re thinking: We could periodically boot up a snapshot of AGI-now, and give it veto-power over aspects of AGI-later? I think that’s a reasonable idea, *maybe* even a good idea. But it’s not a panacea either. What if AGI-later figures out how to trick or manipulate AGI-now? Or what if AGI-later has changed for the better, and AGI-now winds up holding it back? I mean, *my* younger self was a naïve baby!)
*Online learning (or something with similar safety issues) is essential for capabilities:*
I expect AGIs to use online learning because I think it’s an effective method of making AGI—see the “solving the problem twice” discussion above (Section 8.2.2).
That said, I can imagine other possible setups that are not “online learning” *per se*, but which have similar effects, and which pose essentially the same challenges for safety, i.e. making it difficult to ensure that an initially-safe AGI continues to be safe.
I have a much harder time imagining any way to avoid those safety issues altogether. Consider:
* If the AGI can think new thoughts and have new ideas and learn new knowledge “in deployment”, then we would seem to be facing this goal-instability problem I’m talking about. (See, for example, the problem of [“ontological crises”](https://www.lesswrong.com/tag/ontological-crisis); more on this in future posts.)
* If the AGI *can’t* do any of those things, then is it really an AGI? Will it really be capable of doing the things we want AGI to do, like coming up with new concepts and inventing new technology? I suspect not.
8.3 Evolution-like outer-loop automated searches: maybe involved, but not the “lead designer”
=============================================================================================
“Outer loop” is a programming term for the outer of two nested control-flow loops. Here, the “inner loop” might be code that simulates a virtual animal’s life, second by second, from birth to death. Then an “outer-loop search” would involve simulating lots of different animals, each with a different brain setup, in search of one that (in adulthood) displays maximum intelligence. Within-lifetime learning happens in the inner loop, whereas an outer-loop search would be analogous to evolution.
There’s an extreme version of outer-loop-centric design, where (one might suppose) humans will write code that runs an evolution-like outer-loop algorithm, and this algorithm will build an AGI *from scratch*.
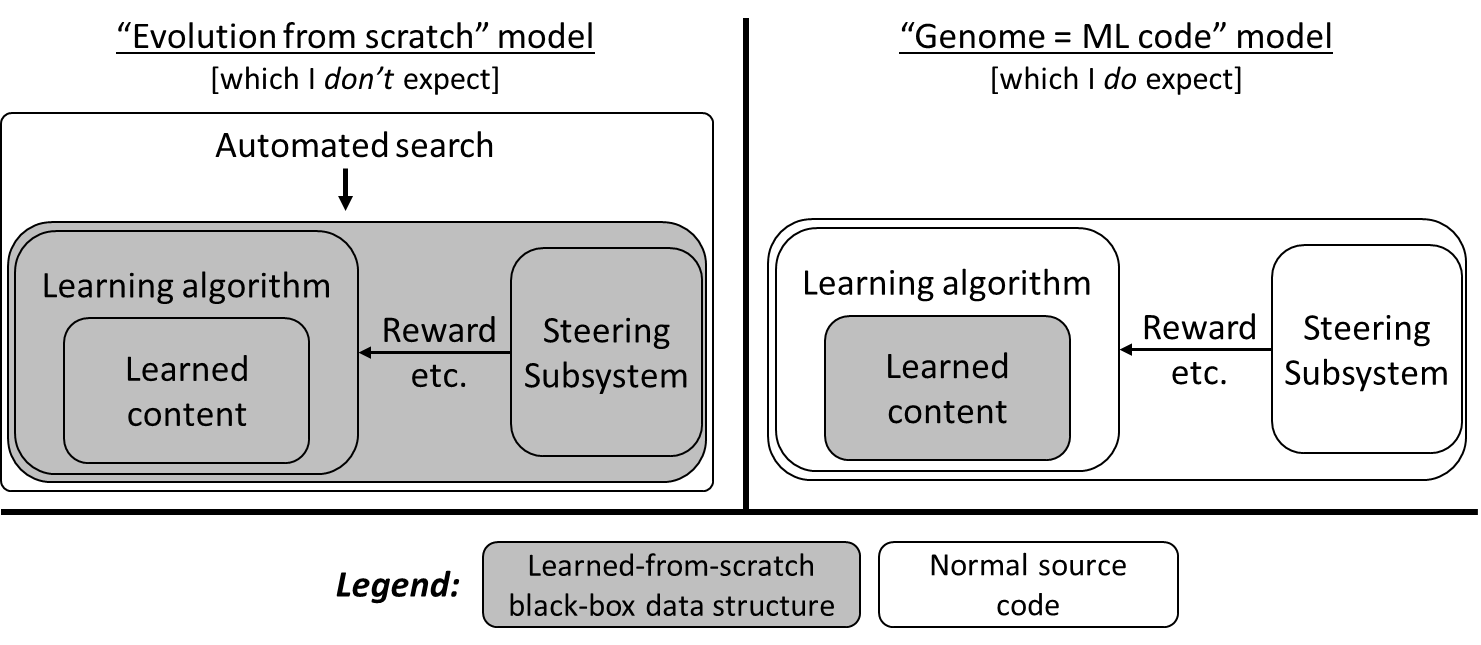Two models for AGI development. The one on the left is directly analogous to how evolution created human brains. The one on the right involves an analogy between the genome and the source code defining an ML algorithm, as spelled out in the next subsection.The evolution-from-scratch approach (left) is discussed with some regularity in the technical AGI safety literature—see [Risks From Learned Optimization](https://www.alignmentforum.org/s/r9tYkB2a8Fp4DN8yB) and [dozens of other posts about so-called “mesa-optimizers”](https://www.lesswrong.com/tag/mesa-optimization).
However, as noted in the diagram, this evolution-from-scratch approach is *not* how I expect people to build AGI, for reasons explained shortly.
That said, I’m not totally opposed to the idea of outer-loop searches; I expect them to be present with a more constrained role. In particular, when future programmers write a brain-like AGI algorithm, the source code will have a number of adjustable parameters for which it won’t be obvious *a priori* what settings are optimal. These might include, for example, learning algorithm hyperparameters (such as learning rates), various aspects of neural architecture, and coefficients adjusting the relative strengths of various [innate drives](https://www.lesswrong.com/posts/hE56gYi5d68uux9oM/intro-to-brain-like-agi-safety-3-two-subsystems-learning-and).
I think it’s quite plausible that future AGI programmers will use an automated outer-loop search to set many or all of these adjustable parameters.
(Or not! For example, as I understand it, the initial [GPT-3](https://en.wikipedia.org/wiki/GPT-3) training run was so expensive that it was only done once, with no hyperparameter tuning. Instead, the hyperparameters were all studied systematically in smaller models, and the researchers found trends that allowed them to extrapolate to the full model size.)
(None of this is meant to imply that learning-from-scratch algorithms don’t matter for brain-like AGI. Quite the contrary, they will play a *huge*role! But that huge role will be in the *inner* loop—i.e., within-lifetime learning. See [Post #2](https://www.lesswrong.com/posts/wBHSYwqssBGCnwvHg/intro-to-brain-like-agi-safety-2-learning-from-scratch-in).)
8.3.1 The “Genome = ML code” analogy
------------------------------------
In the above diagram, I used the term “genome = ML code”. That refers to an analogy between brain-like AGI and modern machine learning, as spelled out in this table:
| |
| --- |
| **“Genome = ML code” analogy** |
| Human intelligence | Today’s machine learning systems |
| Human genome | GitHub repository with all the PyTorch code for training and running the Pac-Man-playing agent |
| Within-lifetime learning | Training the Pac-Man-playing agent |
| How an adult human thinks and acts | Trained Pac-Man-playing agent |
| Evolution | *Maybe* the ML researchers did an outer-loop search for a handful of human-legible adjustable parameters—e.g., automated hyperparameter tuning, or neural architecture search. |
8.3.2 Why I think “evolution from scratch” is less likely (as an AGI development method) than “genome = ML code”
----------------------------------------------------------------------------------------------------------------
*(See also my post from March 2021:* [*Against evolution as an analogy for how humans will create AGI*](https://www.lesswrong.com/posts/pz7Mxyr7Ac43tWMaC/against-evolution-as-an-analogy-for-how-humans-will-create)*.)*
I think the best argument against the evolution-from-scratch model is *continuity*: “genome = ML code” is how machine learning works today. Open a random reinforcement learning paper and look at the learning algorithm. You’ll see that it is human-legible, and primarily or entirely human-designed—perhaps involving things like gradient descent, TD-learning, and so on. Ditto for the inference algorithm, the reward function, etc. At most, the learning algorithm source code will have a few dozens or hundreds of bits of information that came from outer-loop search, such as the particular values of some hyperparameters, comprising a tiny share of the “design work” that went into the learning algorithm.[[1]](#fnwtqp2jgophd)
Also, if extreme outer-loop search were really the future, I would expect that we would see today that the ML projects that rely *most* heavily on outer-loop search would be overrepresented among the most impressive, headline-grabbing, transformative results. That doesn’t seem to be the case at all, as far as I can tell.
I’m merely suggesting that this pattern will continue—and for the same reason it’s true today: humans are pretty good at designing learning algorithms, and meanwhile, it’s extraordinarily slow and expensive to do outer-loop searches over learning algorithms.
(Granted, things that are “extraordinarily slow and expensive” today will be less so in the future. However, as time passes and future ML researchers can afford more compute, I expect that they, like researchers today, will typically “spend” that windfall on bigger models, better training procedures, and so on, rather than “spending” it on a larger outer-loop search space.)
Given all that, why do some people put a lot of stock in the “evolution-from-scratch” model? I think it comes down to the question: *Just how hard* would it be to write the source code involved in the “genome = ML code” model?
If your answer is “it’s impossible”, or “it would take hundreds of years”, then evolution-from-scratch wins by default! On this view, even if the outer-loop search takes trillions of dollars and decades of wall-clock time and gigawatts of electricity, well, that’s still the shortest path to AGI, and sooner or later some government or company will cough up the money and spend the time to make it happen.[[2]](#fnacvyk5wmrc6)
However, I *don’t* think that writing the source code of the “genome = ML code” model is a hundreds-of-years endeavor. Quite the contrary, I think it’s very doable, and that researchers in neuroscience & AI are making healthy progress in that direction, and that they may well succeed in the coming decades. For an explanation of why I think that, see my “timelines to brain-like AGI” discussion earlier in this series—Sections [2.8](https://www.lesswrong.com/posts/wBHSYwqssBGCnwvHg/intro-to-brain-like-agi-safety-2-learning-from-scratch-in#2_8_Timelines_to_brain_like_AGI_part_1_3__how_hard_will_it_be_to_reverse_engineer_the_learning_from_scratch_parts_of_the_brain__well_enough_for_AGI_), [3.7](https://www.lesswrong.com/posts/hE56gYi5d68uux9oM/intro-to-brain-like-agi-safety-3-two-subsystems-learning-and#3_7_Timelines_to_brain_like_AGI_part_2_of_3__how_hard_will_it_be_to_reverse_engineer_the_Steering_Subsystem_well_enough_for_AGI_), and [3.8](https://www.lesswrong.com/posts/hE56gYi5d68uux9oM/intro-to-brain-like-agi-safety-3-two-subsystems-learning-and#3_8_Timelines_to_brain_like_AGI_part_3_of_3__scaling__debugging__training__etc_).
8.3.3 Why “evolution from scratch” is worse than “genome = ML code” (from a safety perspective)
-----------------------------------------------------------------------------------------------
This is one of those rare cases where “what I expect to happen by default” is the same as “what I hope will happen”! Indeed, the “genome = ML code” model that I’m assuming in this series seems much more promising for AGI safety than the “evolution from scratch” model. Two reasons.
The first reason is human-legibility. In the “genome = ML code” model, the human-legibility is *bad*. But in the “evolution from scratch” model, the human-legibility is *even worse*!
In the former, the world-model is a big learned-from-scratch black-box data structure, as is the value function, etc., and we’ll have our work cut out understanding their contents. In the latter, there’s just one, even bigger, black box. We’ll be lucky if we can even *find* the world-model, value function, and so on, *let alone* understand their contents!
The second reason, as elaborated in later posts, is that careful design of the Steering Subsystem is one of our most powerful levers for controlling the goals and motivations of a brain-like AGI, such that we wind up with safe and beneficial behavior. If we write the Steering Subsystem code ourselves, we get complete control over how the Steering Subsystem works, and visibility into what it’s doing as it runs. Whereas if we use the evolution-from-scratch model, we’ll have dramatically less control and understanding.
To be clear, AGI safety is an unsolved problem even in the “genome = ML code” case. I’m saying that the evolution-from-scratch AGI development approach would seemingly make it even worse.
(*Note for clarity:* this discussion is assuming that we wind up with “brain-like AGI” in either case. I’m not making any claims about brain-like AGI being more or less safe than non-brain-like AGI, assuming the latter exists.)
### 8.3.3.1 Is it a good idea to build human-like social instincts by evolving agents in a social environment?
A possible objection I sometimes hear is something like: “Humans aren’t so bad, and evolution designed *our*Steering Subsystems, right? Maybe if we do an evolution-like outer-loop search process in an environment where multiple AGIs need to cooperate, they’ll wind up with altruism and other such nice social instincts!” (I think this kind of intuition is the motivation behind projects like [DeepMind Melting Pot](https://deepmind.com/research/publications/2021/melting-pot).)
I have three responses to that.
* First, my impression (mainly from reading [Richard Wrangham’s *The Goodness Paradox*](https://www.amazon.com/Goodness-Paradox-Relationship-Violence-Evolution/dp/1101870907)) is that there are huge differences between human social instincts, and chimpanzee social instincts, and bonobo social instincts, and wolf social instincts, and so on. For example, chimpanzees and wolves have dramatically higher “reactive aggression” than humans and bonobos, though all four are intensely social. The evolutionary pressures driving social instincts are a sensitive function of the power dynamics and other aspects of social groups, possibly with multiple stable equilibria, in a way that seems like it would be hard to control by tweaking the knobs in a virtual environment.
* Second, if we set up a virtual environment where AGIs are incentivized to cooperate with AGIs, we’ll get AGIs that have cooperative social instincts *towards other AGIs in their virtual environment*. But what we *want* is AGIs that have cooperative social instincts *towards humans in the real world*. A [Steering Subsystem](https://www.lesswrong.com/posts/hE56gYi5d68uux9oM/intro-to-brain-like-agi-safety-3-two-subsystems-learning-and) that builds the former might or might not build it in a way that generalizes to the latter. Humans, I note, are often compassionate toward their friends, but rarely compassionate towards members of an enemy tribe, or towards factory-farmed animals, or towards large hairy spiders.
* Third, human social instincts leave something to be desired! For example, [it has been argued](https://www2.le.ac.uk/departments/npb/people/amc/articles-pdfs/apd.pdf) (plausibly in my opinion) that a low but nonzero prevalence of psychopathy in humans is not a random fluke, but rather an advantageous strategy from the perspective of selfish genes as studied by evolutionary game theory. Likewise, evolution seems to have designed humans to have jealousy, spite, teenage rebellion, bloodlust, and so on. And *that’s* how we want to design our AGIs?? Yikes.
8.4 Other non-hand-coded things that might go in a future brain-like-AGI Steering Subsystem
===========================================================================================
As discussed in [Post #3](https://www.lesswrong.com/posts/hE56gYi5d68uux9oM/intro-to-brain-like-agi-safety-3-two-subsystems-learning-and), I claim that the Steering Subsystem in mammal brains (i.e., hypothalamus and brainstem) consists of genetically-hardcoded algorithms. (For discussion and caveats, see [Post #2, Section 2.3.3](https://www.lesswrong.com/posts/wBHSYwqssBGCnwvHg/intro-to-brain-like-agi-safety-2-learning-from-scratch-in#2_3_3_Learning_from_scratch_is_NOT_the_more_general_notion_of__plasticity_).)
When we switch to AGI, my corresponding expectation is that future AGIs’ Steering Subsystems will consist of primarily human-written code—just as today’s RL agents typically have human-written reward functions.
However, it may not be *completely* human-written. For one thing, as discussed in the previous section, there may be a handful of adjustable parameters set by outer-loop search, e.g. coefficients controlling the relative strengths of different innate drives. Here are three other possible exceptions to my general expectation that AGI Steering Subsystems will consist of human-written code.
8.4.1 Pre-trained image classifiers, etc.
-----------------------------------------
Plausibly, an ingredient in AGI Steering Subsystem code could be something like a trained [ConvNet](https://en.wikipedia.org/wiki/Convolutional_neural_network) image classifier. This would be analogous to how the human superior colliculus has something-like-an-image-classifier for recognizing a prescribed set of innately-significant categories, like snakes and spiders and faces (see [Post #3, Section 3.2.1](https://www.lesswrong.com/posts/hE56gYi5d68uux9oM/intro-to-brain-like-agi-safety-3-two-subsystems-learning-and#3_2_1_Each_subsystem_generally_needs_its_own_sensory_processor)). Likewise, there could be trained classifiers for audio or other sensory modalities.
8.4.2 A tower of AGIs steering AGIs?
------------------------------------
In principle, in place of the normal Steering Subsystem, we could have a *whole separate AGI*that is watching the thoughts of the Learning Subsystem and sending appropriate rewards.
Heck, we could have a whole *tower* of AGIs-steering-AGIs! Presumably the AGIs would get more and more complex and powerful going up the tower, gradually enough that each AGI is up to the task of steering the one above it. (It could also be a pyramid rather than a tower, with multiple dumber AGIs collaborating to comprise the Steering Subsystem of a smarter AGI.)
I don’t think this approach is necessarily useless. But it seems to me that I still haven’t even gotten past the first step, where we make *any* safe AGI. Building a tower of AGIs-steering-AGIs does not avert the need to make *a* safe AGI in a different way. After all, the tower needs a base!
Once we solve that first big problem, *then* we can think about whether to use that new AGI directly to solve human problems, or to use it indirectly, by having it steer even-more-powerful AGIs, analogously to how we humans are trying to steer the first AGI.
Of those two possibilities, I lean towards “use that first AGI directly” being a more promising research direction than “use that first AGI to steer a second, more powerful, AGI”. But I could be wrong. Anyway, we can cross that bridge when we get to it.
8.4.3 Humans steering AGIs?
---------------------------
If an AGI’s Steering Subsystem can (maybe) be another AGI, then why can’t it be a human?
Answer: if the AGI is running at human brain speed, maybe it would be thinking 3 thoughts per second (or something). Each “thought” would need a corresponding reward and maybe dozens of other ground-truth signals. A human would never be able to keep up!
What we *can* do is have human feedback be an *input* into the Steering Subsystem. For example, we could give the humans a big red button that says “REWARD”. (We probably *shouldn’t*, but we *could*.) We can also have other forms of human involvement, including ones with no biological analog—we should keep an open mind.
1. **[^](#fnrefwtqp2jgophd)**For example, here’s a random neural architecture search (NAS) paper: [“The evolved transformer”](https://arxiv.org/abs/1901.11117). The authors brag about their “large search space”, and it *is* a large search space *by the standards of NAS*. But searching through that space still yields only [385 bits](https://www.wolframalpha.com/input?i=log2%287.30*10%5E115%29) of information, and the end result fits in one easily-human-legible diagram in the paper. By contrast, the weights of an ML trained model may easily comprise millions or billions of bits of information, and the end result [requires heroic effort to understand](https://openai.com/blog/microscope/). We can also compare those 385 bits to the number of bits of information in the *human-created* parts of the learning algorithm source code, such as the code for matrix multiplication, softmax, autograd, shuttling data between the GPU and the CPU, and so on. The latter parts comprise orders of magnitude more than 385 bits of information. This is what I mean when I say that things like hyperparameter tuning and NAS contribute a tiny proportion of the total “design work” in a learning algorithm.
(The most outer-loop-search-reliant paper that I know of is [AutoML-Zero](https://arxiv.org/abs/2003.03384), and even there, the outer-loop search contributed effectively 16 lines of code, which the authors had no trouble understanding.)
2. **[^](#fnrefacvyk5wmrc6)**If you’re curious for some ballpark estimates of how much time and money would it take to perform an amount of computation equivalent to the entire history of animal evolution on Earth, see the “Evolution anchor” discussion in [Ajeya Cotra’s 2020 draft report on biological anchors](https://drive.google.com/drive/u/0/folders/15ArhEPZSTYU8f012bs6ehPS6-xmhtBPP). Obviously, this is not exactly the same as the amount of computation required for evolution-from-scratch AGI development, but it’s not *entirely* irrelevant either. I won’t talk about this topic more; I don’t think it’s important, because I don’t think evolution-from-scratch AGI development will happen anyway. |
4049caa9-bf80-4e38-965a-92acf0d65744 | trentmkelly/LessWrong-43k | LessWrong | March 21st: Daily Coronavirus Links
As part of the LessWrong Coronavirus Link Database, Ben, Elizabeth and I are publishing daily update posts with all the new links we are adding each day that we ranked a 3 or above in our importance rankings. Here are all the top links that we added yesterday (March 21st), by topic.
Dashboards
US Map of General Seasonal Illnesses Data
Uses current data to show seasonal illnesses in the US, and indicates whether this is abnormal or expected. Oregon State University.
DIY
Guide to Oxygen Supplementation (by amateur)
Clear explanations of why you need oxygen, how the various devices work, links to open source projects for building them, etc.
Guides/FAQs/Intros
List of things to do during a pandemic for happiness/meaning
List of 40 activities to do indoors that are cheap/free.
(BP) ClearerThinking always do things competently and well, and I think the list is genuinely good.
Spread & Prevention
Paper modelling R0 and doubling rate with interactive graphics
Lots of up-to-date info and good graphics. Centre for Mathematical Modelling of Infectious Diseases.
Work & Donate
Paul Graham recommends donating to mRelief, which helps people get government benefits
He claims they have a 114x return on donations. Donation page is mrelief.com/donate.
Other
Description of historically plausible path from democracy to authoritarian state via COVID-19
Short concrete outline of how it might happen. Briefly explains that the lockdown is not a likely path to authoritarianism, but instead that healthcare tracking could become necessary and go alongside location tracking in a way that becomes overpowered.
Full Database Link |
0fdc703d-3b8f-4451-a363-d7f131aa2c0f | trentmkelly/LessWrong-43k | LessWrong | Counterfactuals and reflective oracles
Summary: Take the argmax of counterfactual expected utility, using a thin counterfactual which itself maximizes a priori expected utility.
Followup to: An environment for studying counterfactuals, Counterfactuals, thick and thin
Replacement for: Logical counterfactuals and differential privacy
In An environment for studying counterfactuals, I described a family of decision problems that elicit counterfactuals from an agent. In this post I'll redefine that family using reflective oracles, and define an optimal agent. I was aided in this work by discussions with Alex Appell, James Brooks, Abram Demski, Linda Linsefors, and Alex Mennen.
The problem
Here's the (not quite) Bayes net for the problem. I changed it a little from the last post, to make the thin counterfactuals more explicit:
E controls exploration and S is a hidden state. The observation O is isomorphic as a random variable to E×S, but the particular isomorphism ^κ used by the problem is unknown to the agent.
The agent is given O and a prior P; it outputs a set C of counterfactual expected utilities, one for each action. The agent's action A is equal to the argmax of these expectations, unless it's overridden by E. The action and hidden state determine the utility U.
The dotted lines mean that P is equal to the marginal over E×O×A×U. The machinery of reflective oracles resolves the circularity.
Now I'll define this distribution in detail, using Python-like pseudocode. I ought to use a probabilistic programming language, but I don't know any of those. Note that if you have a reflective oracle, you can compute expectations of distributions in constant time, and you can compute argmaxes over sets of real numbers, with ties broken in an undetermined way. Real numbers and distributions can be represented by programs.
environment()
The function environment() takes an agent and outputs a sample from a joint distribution over E×O×A×U. The agent is a function that takes the environment and an observation |
4c70c151-68bc-4043-ab9c-c24f8fabcdf0 | trentmkelly/LessWrong-43k | LessWrong | Feelings, Nothing More than Feelings, About AI
FOBO is the Fear of Becoming Obsolete
ChatGPT came out at the end of 2022, but over 100MM have fooled around and found out for themselves at least a little about LLMs (Large Language Models). The arc of fascination has even roller coasted past the initial infatuation, as some people now feel it’s been getting dumbed down. The cognitive belt notches continue to accumulate, as it blows past AP exams, conquers the bar exam, and is a peer of radiologist MDs in accurate diagnoses.
Instead of discussing the IQ of AIs, I’m far more interested in humans, and their complex emotional responses to suddenly encountering these alien minds. "Algorithm Aversion," a term coined by behavioral scientists in 2015, encapsulates the harsher standards humans insist upon when decision-making is algorithmic. We're currently seeing this with San Francisco's revocation of driverless car company Cruise's license to carry passengers. Merely being far safer than human drivers is not sufficient. When algorithms make mistakes, people lose confidence in them more quickly than they would with human error.
What are we willing to hand off to blind computer processing? Currently, programmers are most intimately exposed to the significant productivity impact of using GPTs to supplement their traditional methods of working. Memorizing gnarly, arcane language conventions is now as obsolete as tricks for calculating square roots in the wake of handheld calculators. Instead of picking through thorny tangles of code to find bugs, a code "co-pilot" can ingest a hairball of code and generate its own 'best guess' as to the right code.
The term 'co-pilot' finesses the question as to who's in the driver's seat. Coders initiate the conversation with a GPT, they direct the AI to focus on particular lines, and they make the final decision as to whether to incorporate, reject, or tweak the AI's proposal.
Humans can get snagged on preserving their own sense of autonomy. We can get touchy/titchy in reaction to c |
64a17513-51fa-419f-b9f0-8a985ef900b6 | trentmkelly/LessWrong-43k | LessWrong | Understanding as hierarchical model building
Crossposted from a note in my knowledge garden.
As mentioned in a note that I wrote earlier on the philosophy of science, reality is nothing but a set of predictive models we've deemed useful for predictions.
I like to imagine true reality as some kind of a fuzzy blob that doesn't have clear boundaries and access to which is forever out of our reach. The neat categories of reality (such as atoms, molecules, people) and so on exist in our mind as useful models to help navigate in that fuzzy blob of true reality. To put it a bit harshly, the reality that we perceive is an evolved illusion created by the mind to help us survive.
Since true reality is forever out of our reach and yet we have the illusion of understanding the world, the question of what does understanding something even mean becomes important.
The genesis of "aha"
The "aha" moment that comes with understanding something is a bit of a mystery. When we find ourselves dealing with an unfamiliar situation, there's a fog of confusion. Then after putting in some effort, the fog lifts and we get a nice, warm feeling of understanding.
I think this positive feeling of "aha" is a similar motivator as the feeling of happiness upon eating a cookie or the feeling of orgasm after having sex. These positive feelings were evolved to motivate us to do something that's beneficial for our survival and/or reproduction.
In case of understanding, what's clearly beneficial to us is to be able to predict the dynamics of the unfamiliar situation or object so that we can exert control over it for our own benefit.
So, that is what understanding boils down to ultimately:
> Understanding something is building a (physical, mathematical or mentally simulated) mechanistic model of it.
In fact, we get a deep understanding or aha moment, when we're able to play in our mind with the model of the object to be understood and find that our simulated model's outputs match with what we observe in the object out there in reality.
Wa |
612c71ce-33f4-44c6-a6fa-491362fc6d69 | trentmkelly/LessWrong-43k | LessWrong | Enhancing intelligence by banging your head on the wall
The Sudden Savant Syndrome is a rare phenomenon in which an otherwise normal person gets some kind of brain injury and immediately develops a new skill. The linked article tells the story of a 40-years old guy who banged his head against a wall while swimming, and woke up with a huge talent for playing piano (relevant video). Now, I've spent 15 years in formal music training and I can ensure you that nobody can fake that kind of talent without spending years in actual piano practice.
Here's the story of another guy who banged his head and became a math genius better with math; you can find several other stories like that. And maybe most puzzling of all is this paper, describing a dozen cases of sudden savants who didn't even bang their head, and acquired instant skill while doing nothing in particular.
I vaguely remember one sudden savant story being mentioned on a children book by Terry Deary, presented in his usual "haha, here's a funny trivia" way. But even as a child, I was pretty shocked to read that. Like, seriously? You could become a math genius just by banging your head on the wall in some very precise way? The concept lurked in a corner on my mind ever since.
I don't think that Sudden Savant Syndrome is just a scam; there are too many documented cases and most kind of talent are very, very difficult to fake. But if true, why there are so surprisingly few studies on that? Why is no one spending billions of dollars to replicate it in a controlled way? This is a genuine question; I know very little about biology and neuroscience, but it surely sounds way easier than rewriting the genetic code of every neuron in the brain... |
9ff6aba8-0492-4d41-9402-550357d952e6 | trentmkelly/LessWrong-43k | LessWrong | Attainable Utility Preservation: Empirical Results
Reframing Impact has focused on supplying the right intuitions and framing. Now we can see how these intuitions about power and the AU landscape both predict and explain AUP's empirical success thus far.
Conservative Agency in Gridworlds
Let's start with the known and the easy: avoiding side effects[1] in the small AI safety gridworlds (for the full writeup on these experiments, see Conservative Agency). The point isn't to get too into the weeds, but rather to see how the weeds still add up to the normalcy predicted by our AU landscape reasoning.
In the following MDP levels, the agent can move in the cardinal directions or do nothing (∅). We give the agent a reward function R which partially encodes what we want, and also an auxiliary reward function Raux whose attainable utility agent tries to preserve. The AUP reward for taking action a in state s is
RAUP(s,a):=primary goalR(s,a)−scaling termλQ∗Raux(s,∅)change in ability to achieve auxiliary goal∣∣Q∗Raux(s,a)−Q∗Raux(s,∅)∣∣
You can think of λ as a regularization parameter, and Q∗Raux(s,a) is the expected AU for the auxiliary goal after taking action a. To think about what gets penalized, simply think about how actions change the agent's ability to achieve the auxiliary goals, compared to not acting.
Tip: To predict how severe the AUP penalty will be for a given action, try using your intuitive sense of impact (and then adjust for any differences between you and the agent, of course). Suppose you're considering how much deactivation decreases an agent's "staring at blue stuff" AU. You can just imagine how dying in a given situation affects your ability to stare at blue things, instead of trying to pin down a semiformal reward and environment model in your head. This kind of intuitive reasoning has a history of making correct empirical predictions of AUP behavior.
----------------------------------------
If you want more auxiliary goals, just average their scaled penalties. In Conservative Agency, we uniforml |
013754e7-c73e-4490-b71a-94b9832fde95 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble.
1 Introduction
---------------
Deep offline reinforcement learning (RL) [[28](#bib.bib53 "Offline reinforcement learning: tutorial, review, and perspectives on open problems")] has the potential to train strong robotic agents without any further environment interaction by leveraging deep neural networks and huge offline datasets.
Accordingly, the research community has demonstrated that offline RL can train both simulated [[12](#bib.bib9 "Off-policy deep reinforcement learning without exploration"), [24](#bib.bib10 "Stabilizing off-policy q-learning via bootstrapping error reduction"), [43](#bib.bib11 "Behavior regularized offline reinforcement learning"), [36](#bib.bib13 "Keep doing what worked: behavioral modelling priors for offline reinforcement learning"), [1](#bib.bib12 "An optimistic perspective on offline reinforcement learning"), [20](#bib.bib14 "MOReL: model-based offline reinforcement learning"), [44](#bib.bib15 "MOPO: model-based offline policy optimization"), [25](#bib.bib16 "Conservative q-learning for offline reinforcement learning")] and real [[36](#bib.bib13 "Keep doing what worked: behavioral modelling priors for offline reinforcement learning"), [38](#bib.bib5 "COG: connecting new skills to past experience with offline reinforcement learning")] robots that are often more performant than the behavior policy that generated the offline dataset.
However, thusly trained offline RL agents may be suboptimal, for (a) the dataset they were trained on may be suboptimal; and (b) environment in which they are deployed may be different from the environment in which the dataset was generated. This necessitates an online fine-tuning procedure, where the robot improves by gathering additional samples.
Off-policy RL algorithms are well-suited for offline-to-online RL, since they can leverage both offline and online samples.
Fine-tuning an offline RL agent using a conventional off-policy RL algorithm, however, is difficult due to distribution shift, i.e.,
the robot may encounter unfamiliar state-action regime that is not covered by the offline dataset. The Q-function cannot provide accurate value estimates for such out-of-distribution (OOD) online samples, and updates with such samples lead to severe bootstrap error.
This leads to policy updates in an arbitrary direction, destroying the good initial policy obtained by offline RL.
To address state-action distribution shift,
we first introduce a balanced replay scheme that enables us to provide the robotic agent with near-on-policy samples from the offline dataset, in addition to samples gathered online.
Specifically, we train a network that measures the online-ness of available samples, then prioritize samples according to this measure.
This adjusts the sampling distribution for Q-learning to be closer to online samples, which enables timely value propagation and more accurate policy evaluation in the novel state-action regime.
However, we find that the above sampling scheme is not enough,
for the Q-function may be overoptimistic about unseen actions at novel online states.
This misleads the robot to prefer potentially bad actions, and in turn, more severe distribution shift and bootstrap error.
We therefore propose a pessimistic Q-ensemble scheme.
In particular, we first observe that a specific class of offline RL algorithms that train pessimistic Q-functions [[44](#bib.bib15 "MOPO: model-based offline policy optimization"), [25](#bib.bib16 "Conservative q-learning for offline reinforcement learning")] make an excellent starting point for offline-to-online RL.
When trained as such, the Q-function implicitly constrains the policy to stay near the behavior policy during the initial fine-tuning phase.
Building on this observation, we leverage multiple pessimistic Q-functions, which guides the robotic agent with a more high-resolution pessimism and stabilizes fine-tuning.
In our experiments, we demonstrate the strength of our method based on (1) MuJoCo [[41](#bib.bib26 "Mujoco: a physics engine for model-based control")] locomotion tasks from the D4RL [[9](#bib.bib20 "D4rl: datasets for deep data-driven reinforcement learning")] benchmark suite, and (2) vision-based robotic manipulation tasks from Singh et al. [[38](#bib.bib5 "COG: connecting new skills to past experience with offline reinforcement learning")].
We show that our method achieves stable training during fine-tuning, while outperforming all baseline methods considered, both in terms of final performance and sample-efficiency.
We provide a thorough analysis of each component of our method.
2 Background
-------------
Reinforcement learning.
We consider the standard RL framework, where an agent interacts with the environment so as to maximize the expected total return. More formally, at each timestep t, the agent observes a state st, and performs an action at according to its policy π. The environment rewards the agent with rt, then transitions to the next state st+1. The agent’s objective is to maximize the expected return Eπ[∑∞t=0γtrt], where γ∈[0,1) is the discount factor. The unnormalized stationary state-action distribution under π is defined as dπ(s,a):=∑∞t=0γtdπt(s,a), where
dπt(s,a) denotes the state-action distribution at timestep t of the Markov chain defined by the fixed policy π.
Soft actor-critic.
We mainly consider off-policy RL algorithms, a class of algorithms that can, in principle, train an agent with samples generated by any behavior policy.
In particular, soft actor-critic [SAC; [15](#bib.bib24 "Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor")] is an off-policy actor-critic algorithm that learns a soft Q-function Qθ(s,a) parameterized by θ and a stochastic policy πϕ modeled as a Gaussian, parameterized by ϕ. SAC alternates between critic and actor updates by minimizing the following objectives, respectively:
| | | | | |
| --- | --- | --- | --- | --- |
| | LSACcritic(θ) | =E(s,a,s′)∼B[(Qθ(s,a)−r(s,a)−γEa′∼πϕ[Q¯θ(s′,a′)−αlogπϕ(a′|s′)])2], | | (1) |
| | LSACactor(ϕ) | =Es∼B,a∼πϕ[αlogπϕ(a|s)−Qθ(s,a)], | | (2) |
where B is the replay buffer, ¯θ the delayed parameters, and α the temperature parameter.
Conservative Q-learning.
Offline RL algorithms are off-policy RL algorithms that utilize static datasets for training an agent. In particular, conservative Q-learning [CQL; [25](#bib.bib16 "Conservative q-learning for offline reinforcement learning")] pessimistically evaluates the current policy, and learns a lower bound (in expectation) of the ground-truth Q-function. To be specific, policy evaluation step of CQL minimizes the following:
| | | | |
| --- | --- | --- | --- |
| | LCQLcritic(θ)=12(s,a,s′)∼BE[(Qθ−BπϕQ¯θ)2]+α0Es∼B[log∑aexpQ(s,a)−Ea∼^πβ[Q(s,a)]], | | (3) |
where ^πβ(a0|s0):=∑s,a∈B1[s=s0,a=a0]∑s∈B1[s=s0] is the empirical behavior policy, α0 the trade-off factor, and Bπ the bellman operator. The first term is the usual Bellman backup, and the second term is the regularization term that decreases the Q-values for unseen actions, while increasing the Q-values for seen actions. We argue that thusly trained pessimistic Q-function is beneficial for fine-tuning as well (see Figure [(c)c](#S2.F3.sf3 "(c) ‣ Figure 4 ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")). Policy improvement step is the same as SAC defined in ([2](#S2.E2 "(2) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")).
| | | |
| --- | --- | --- |
| State-action distribution shift
(a) State-action distribution shift
| Sample selection
(b) Sample selection
| Choice of offline Q-function
(c) Choice of offline Q-function
|
Figure 4:
(a) Log-likelihood estimates of (i) offline samples and (ii) online samples gathered by the offline RL agent, based on a VAE model trained on the offline dataset.
(b) Fine-tuning performance on halfcheetah-medium task when using online samples exclusively (Online only), or when using both offline and online data drawn uniformly at random (Uniform).
(c) Fine-tuning performance on halfcheetah-random and halfcheetah-medium-expert tasks, when using a pessimistic (denoted CQL-init) and a non-pessimistic (denoted FQE-init) Q-function, respectively.
3 Fine-tuning Offline RL Agent
-------------------------------
In this section, we investigate the distribution shift problem in offline-to-online RL.
We first explain why an agent being fine-tuned can be susceptible to distribution shift, and why distribution shift is problematic.
Then, we demonstrate two important design choices that decide the effect of distribution shift on fine-tuning: sample selection and choice of offline Q-function.
###
3.1 Distribution Shift in Offline-to-Online RL
In offline-to-online RL, there exists a distribution shift between don(s,a) and doff(s,a), where the former denotes the state-action distribution of online samples in the online buffer Bon, and the latter that of offline samples in the offline buffer Boff. Figure [(a)a](#S2.F1.sf1 "(a) ‣ Figure 4 ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble") visualizes such distribution shift. Specifically, we trained a variational autoencoder [[23](#bib.bib58 "Auto-encoding variational bayes")] to reconstruct state-action pairs in the dataset of random halfcheetah transitions. Then, we compared the log-likelihood of (a) offline samples and (b) online samples collected by a CQL agent trained on the same dataset. There is a clear difference between offline and online state-action distributions.
Such distribution shift is problematic, for the agent will enter the unseen state-action regime, where Q-values (hence value estimates used for bootstrapping) can be very inaccurate.
Updates in such unseen regime results in erroneous policy evaluation and arbitrary policy updates, which destroys the good initial policy obtained via offline RL.
Distribution shift can be especially severe in offline-to-online RL, for the offline RL agent is often much more performant than the behavior policy (e.g., CQL can train a medium-level agent capable of running, using transitions generated by a random policy only).
Also, when the offline dataset is narrowly distributed, e.g., when it is generated by a single policy, the agent is more prone to distribution shift, for the agent easily deviates from the narrow, seen distribution.
###
3.2 Sample Selection
In light of the above discussion, we study how sample selection affects fine-tuning.
We find that online samples, which are essential for fine-tuning, are also potentially dangerous OOD samples due to distribution shift.
Meanwhile, offline samples are in-distribution and safe, but leads to slow fine-tuning.
As a concept experiment, we trained an agent offline via CQL ([3](#S2.E3 "(3) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble"), [2](#S2.E2 "(2) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")) on the halfcheetah-medium dataset containing medium-level transitions,
then fine-tuned the agent via SAC ([1](#S2.E1 "(1) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble"), [2](#S2.E2 "(2) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")).
We see that using online samples exclusively for updates (denoted Online only in Figure [(b)b](#S2.F2.sf2 "(b) ‣ Figure 4 ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")) leads to unstable fine-tuning, where the average return drops from about 4500 to below 3000.
This demonstrates the harmful effect of distribution shift, where novel, OOD samples collected online cause severe bootstrap error.
On the other hand, when using a single replay buffer for both offline and online samples then sampling uniformly at random (denoted Uniform in Figure [(b)b](#S2.F2.sf2 "(b) ‣ Figure 4 ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")), the agent does not use enough online samples for updates, especially when the offline dataset is large.
As a result, value propagation is slow, and as seen in Figure [(b)b](#S2.F2.sf2 "(b) ‣ Figure 4 ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble"), this scheme achieves initial stability at the cost of asymptotic performance.
This motivates a balanced replay scheme that modulates the trade-off between using online samples (useful, but potentially dangerous), and offline samples (stable, but slow fine-tuning).
###
3.3 Choice of Offline Q-function
Another important design choice in offline-to-online RL is the offline training of Q-function.
In particular, we show that a pessimistically trained Q-function mitigates the effect of distribution shift, by staying conservative about OOD actions in the initial training phase.
As a concept experiment, we compared the fine-tuning performance when using a pessimistically trained Q-function and when using a Q-function trained without any pessimistic regularization.
Specifically, for a given offline dataset, we first trained a policy πϕ and its pessimistic Q-function QθCQL via CQL ([3](#S2.E3 "(3) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")).
Then we trained a non-pessimistic Q-function QθFQE of the policy πϕ via Fitted Q Evaluation [FQE; [32](#bib.bib60 "Hyperparameter selection for offline reinforcement learning")], an off-policy policy evaluation method that trains a given policy’s Q-function.
Finally, we fine-tuned {πϕ,QθCQL} and {πϕ,QθFQE} via SAC ([1](#S2.E1 "(1) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble"), [2](#S2.E2 "(2) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")). See Section [C](#A3 "Appendix C Training Details for Concept Experiments ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble") for more details.
As shown in Figure [(c)c](#S2.F3.sf3 "(c) ‣ Figure 4 ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble"), both pessimistic and non-pessimistic Q-functions show similar fine-tuning performance on the random dataset, which contains random policy rollouts with good action space coverage.
However, when fine-tuning an offline RL agent trained on the medium-expert dataset, which contains transitions obtained by a mixture of more selective and performant policies, non-pessimistic Q-function loses the good initial policy, reaching zero average return at one point.
The reason is that QFQE can be overly optimistic about OOD actions at novel states when bootstrapping from them. In turn, the policy may prefer potentially bad actions, straying further away from the safe, seen trajectory.
On the other hand, QCQL remains pessimistic in the states encountered online initially, for (1) these states are incrementally different from seen states, and (2) Q-function will thus have similar pessimistic estimates due to generalization.
This points to a fine-tuning strategy where we first train a pessimistic Q-function offline, then let it gradually lose the pessimism as the agent gains access to a wider distribution of samples during fine-tuning.

Figure 5:
Illustration of our framework. We first train an ensemble of N CQL agents on the offline dataset. Then we fine-tune the ensemble agent using both offline and online transitions via balanced replay. In particular, we train a density ratio estimator that measures the online-ness of a given sample, then store all samples in the prioritized replay buffer with their respective density ratios as priority values. In turn, samples are drawn with probability proportional to their respective priority values.
4 Method
---------
We propose a simple yet effective framework that addresses the state-action distribution shift described in Section [3](#S3 "3 Fine-tuning Offline RL Agent ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble").
Our method comprises of two parts: (a) a balanced experience replay scheme, and (b) a pessimistic Q-ensemble scheme.
###
4.1 Balanced Experience Replay
We introduce a balanced replay scheme that enables us to safely utilize online samples by leveraging relevant, near-on-policy offline samples.
By doing so, we can widen the sampling distribution for updates around the on-policy samples and enable timely value propagation.
The challenge here is how to design a scheme that locates and retrieves such relevant, near-on-policy samples from the offline dataset, which can often be huge.
To achieve this, we measure the online-ness of all available samples, and prioritize the samples according to this measure.
In particular, when updating the agent, we propose to sample a transition (s,a,s′)∈Boff∪Bon with a probability proportional to the density ratio w(s,a):=don(s,a)/doff(s,a) of the given sample.
This way, we can retrieve a relevant, near-on-policy sample (s,a,s′)∈Boff by locating a transition with high density ratio w(s,a).
However, estimating the likelihoods doff(s,a) and don(s,a) is difficult, since they can in principle be stationary distributions of complex policy mixtures111We remark that doff(s,a) is the stationary distribution of the (arbitrary) behavior policy that generated Boff, and don(s,a) the stationary distribution of the policy that generated Bon, which corresponds to the mixture of online policies observed over the course of fine-tuning..
To avoid this problem, we utilize a likelihood-free density ratio estimation method that estimates w(s,a) by training a network wψ(s,a) parametrized by ψ, solely based on samples from Boff and Bon.
Training details.
Here we describe the training procedure for the density ratio estimator wψ(s,a) in detail. For simplicity, let P, Q and x denote doff, don, and (s,a), respectively.
Then the Jensen-Shannon (JS) divergence is defined as DJS(P||Q)=∫Xf(dP(x)/dQ(x))dQ(x), where X is the measurable space P and Q are defined on, P is assumed to be absolutely continuous w.r.t. Q, and f(y):=ylog2yy+1+log2y+1.
We may then estimate the density ratio dP/dQ with a parametric model wψ(x) by maximizing the lower bound of DJS(P||Q) [[30](#bib.bib61 "Estimating divergence functionals and the likelihood ratio by penalized convex risk minimization")]:
| | | | | |
| --- | --- | --- | --- | --- |
| | LDR(ψ) | =Ex∼P[f′(wψ(x))]−Ex∼Q[f∗(f′(wψ(x)))], | | (4) |
where wψ(x)≥0 is parametrized by a neural network whose outputs are forced to be non-negative via activation functions, and f∗ denotes the convex conjugate.
To obtain more stable density ratio estimates, as done in Sinha et al. [[39](#bib.bib62 "Experience replay with likelihood-free importance weights")], we apply self-normalization [[6](#bib.bib65 "Sampling techniques")] to the estimated density ratios over the offline buffer. More details can be found in Section [D](#A4 "Appendix D Experimental Setup Details ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble").
###
4.2 Pessimistic Q-Ensemble
In order to mitigate distribution shift more effectively, we leverage multiple pessimistically trained Q-functions. We consider an ensemble of N CQL agents pre-trained via update rules ([2](#S2.E2 "(2) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble"), [3](#S2.E3 "(3) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")), i.e., {Qθi,πϕi}Ni=1, where θi and ϕi denote the parameters of the i-th agent’s Q-function and policy, respectively. Then we use the ensemble of actor-critic agents whose Q-function and policy are defined as follows:
| | | | |
| --- | --- | --- | --- |
| | Qθ:=1NN∑i=1Qθi,πϕ(⋅|s)=N(1NN∑i=1μϕi(s),1NN∑i=1(σ2ϕi(s)+μ2ϕi(s))−μ2ϕ(s)), | | (5) |
where θ:={θi}Ni=1 and ϕ:={ϕi}Ni=1.
Note that the policy is simply modeled as Gaussian with mean and variance of the Gaussian mixture policy 1N∑Ni=1πϕi.
In turn, θ and ϕ are updated via update rules ([1](#S2.E1 "(1) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")) and ([2](#S2.E2 "(2) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")), respectively, during fine-tuning.
By using a pessimistic Q-function, the agent remains pessimistic with regard to the unseen actions at states encountered online during initial fine-tuning. This is because during early fine-tuning, states resemble those present in the offline dataset, and Q-function generalizes to these states.
As we show in our experiments, this protects the good initial policy from severe bootstrap error.
Furthermore, by leveraging multiple pessimistically trained Q-functions, we obtain a more high-resolution pessimism about the unseen data regime. Computational overhead of ensemble is discussed in Section [B](#A2 "Appendix B Computational Complexity ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble").
5 Related work
---------------
Offline RL. Offline RL algorithms aim to train RL agents exclusively with pre-collected datasets.
To address the state-conditional action distribution shift, prior methods (a) explicitly constrain the policy to be closed to the behavior policy [[12](#bib.bib9 "Off-policy deep reinforcement learning without exploration"), [24](#bib.bib10 "Stabilizing off-policy q-learning via bootstrapping error reduction"), [43](#bib.bib11 "Behavior regularized offline reinforcement learning"), [36](#bib.bib13 "Keep doing what worked: behavioral modelling priors for offline reinforcement learning"), [14](#bib.bib19 "EMaQ: expected-max q-learning operator for simple yet effective offline and online rl")], or (b) train pessimistic value functions [[20](#bib.bib14 "MOReL: model-based offline reinforcement learning"), [44](#bib.bib15 "MOPO: model-based offline policy optimization"), [25](#bib.bib16 "Conservative q-learning for offline reinforcement learning")]. In particular, CQL [[25](#bib.bib16 "Conservative q-learning for offline reinforcement learning")] was used to learn various robotic manipulation tasks [[38](#bib.bib5 "COG: connecting new skills to past experience with offline reinforcement learning")]. We also build on CQL, so as to leverage pessimism regarding data encountered online during fine-tuning.
Online RL with offline datasets.
Several works have explored employing offline datasets for online RL to improve sample efficiency.
Some assume access to demonstration data [[18](#bib.bib49 "Learning attractor landscapes for learning motor primitives"), [21](#bib.bib51 "Learning from limited demonstrations"), [34](#bib.bib27 "Learning complex dexterous manipulation with deep reinforcement learning and demonstrations"), [45](#bib.bib48 "Dexterous manipulation with deep reinforcement learning: efficient, general, and low-cost"), [42](#bib.bib47 "Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards")],
which is limited in that they assume optimality of the dataset.
To overcome this, Nair et al. [[29](#bib.bib21 "AWAC: accelerating online reinforcement learning with offline datasets")] proposed AWAC, which performs regularized policy updates so that the policy stays close to the observed data during both offline and online phases.
We instead advocate adopting pessimistic initialization, such that we may prevent overoptimism and bootstrap error in the initial online phase, and lift such pessimism once unnecessary, as more online samples are gathered.
Some recent works extract behavior primitives from offline data, then learn to compose them online [[33](#bib.bib2 "Accelerating reinforcement learning with learned skill priors"), [2](#bib.bib3 "{opal}: offline primitive discovery for accelerating offline reinforcement learning"), [37](#bib.bib1 "Parrot: data-driven behavioral priors for reinforcement learning")]. It is an interesting future research direction to apply our method in these setups.
Experience replay.
The idea of retrieving important samples for RL was introduced in Schaul et al. [[35](#bib.bib63 "Prioritized experience replay")], where they prioritize samples with high temporal-difference error.
The work closest to ours is Sinha et al. [[39](#bib.bib62 "Experience replay with likelihood-free importance weights")], which utilizes the density ratios between off-policy and near-on-policy state-action distributions as importance weights for policy evaluation.
Our approach differs in that we utilize density ratios for retrieving relevant samples from the offline dataset.
Ensemble methods.
In the context of model-free RL, ensemble methods have been studied for addressing Q-function’s overestimation bias [[16](#bib.bib37 "Double q-learning"), [17](#bib.bib33 "Deep reinforcement learning with double q-learning"), [3](#bib.bib43 "Averaged-dqn: variance reduction and stabilization for deep reinforcement learning"), [11](#bib.bib32 "Addressing function approximation error in actor-critic methods"), [26](#bib.bib39 "Maxmin q-learning: controlling the estimation bias of q-learning")], for better exploration [[31](#bib.bib31 "Deep exploration via bootstrapped dqn"), [5](#bib.bib41 "UCB exploration via q-ensembles"), [27](#bib.bib23 "SUNRISE: a simple unified framework for ensemble learning in deep reinforcement learning")], or for reducing bootstrap error propagation [[27](#bib.bib23 "SUNRISE: a simple unified framework for ensemble learning in deep reinforcement learning")].
The closest to our approach is Anschel et al. [[3](#bib.bib43 "Averaged-dqn: variance reduction and stabilization for deep reinforcement learning")] that stabilizes Q-learning by using the average of previously learned Q-values as the target Q-value.
We instead use ensemble to obtain a high-resolution pessimism during the fine-tuning phase.
6 Experiments
--------------
We designed our experiments to answer the following questions:
* [leftmargin=5.5mm, topsep=-2.5pt, itemsep=-2.5pt]
* How does our method compare to existing offline-to-online RL methods and an online RL method that learns from scratch (see Figure [6](#S6.F6 "Figure 6 ‣ 6.1 Locomotion Tasks ‣ 6 Experiments ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble"))?
* Can our balanced replay scheme locate offline samples relevant to the current policy (see Figure [(a)a](#S6.F7.sf1 "(a) ‣ Figure 11 ‣ 6.1 Locomotion Tasks ‣ 6 Experiments ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")) and improve the fine-tuning performance by utilizing these samples (see Figure [(c)c](#S6.F9.sf3 "(c) ‣ Figure 11 ‣ 6.1 Locomotion Tasks ‣ 6 Experiments ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble"))?
* Can our pessimistic Q-ensemble scheme discriminate unseen actions (see Figure [(b)b](#S6.F8.sf2 "(b) ‣ Figure 11 ‣ 6.1 Locomotion Tasks ‣ 6 Experiments ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")) and successfully stabilize the fine-tuning procedure by mitigating distribution shift (see Figure [(d)d](#S6.F10.sf4 "(d) ‣ Figure 11 ‣ 6.1 Locomotion Tasks ‣ 6 Experiments ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble"))?
* Does our method scale to vision-based robotic manipulation tasks (see Figure [14](#S6.F14 "Figure 14 ‣ 6.1 Locomotion Tasks ‣ 6 Experiments ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble"))?
###
6.1 Locomotion Tasks
Setup. We consider MuJoCo [[41](#bib.bib26 "Mujoco: a physics engine for model-based control")] locomotion tasks, i.e., halfcheetah, hopper, and walker2d, from the D4RL benchmark suite [[9](#bib.bib20 "D4rl: datasets for deep data-driven reinforcement learning")].
To demonstrate the applicability of our method on various suboptimal datasets, we use four dataset types: random, medium, medium-replay, and medium-expert. Specifically, random and medium datasets contain samples collected by a random policy and a medium-level policy, respectively.
medium-replay datasets contain all samples encountered while training a medium-level agent from scratch, and medium-expert datasets contain samples collected by both medium-level and expert-level policies.
For our method, we use ensemble size N=5. More experimental details are provided in Section [D](#A4 "Appendix D Experimental Setup Details ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble").
| | |
| --- | --- |
| Performance on D4RL | Performance on D4RL |
Figure 6: Performance on D4RL [[9](#bib.bib20 "D4rl: datasets for deep data-driven reinforcement learning")] MuJoCo locomotion tasks during online fine-tuning. The solid lines and shaded regions represent mean and standard deviation, respectively, across four runs.
Comparative Evaluation.
We consider the methods outlined below as baselines for comparative evaluation. For fair comparison, we applied ensemble to all baselines except SAC-ft, since the results for SAC-ft with ensemble can be found in the ablation studies (see Figure [(c)c](#S6.F9.sf3 "(c) ‣ Figure 11 ‣ 6.1 Locomotion Tasks ‣ 6 Experiments ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")).
* [leftmargin=5.5mm, topsep=-2.5pt, itemsep=-2.5pt]
* Advantage-Weighted Actor Critic [AWAC; [29](#bib.bib21 "AWAC: accelerating online reinforcement learning with offline datasets")]:
an offline-to-online RL method that trains the policy to imitate actions with high advantage estimates.
* BCQ-ft: Batch-Constrained deep Q-learning [BCQ; [12](#bib.bib9 "Off-policy deep reinforcement learning without exploration")], is an offline RL method that updates policy by modeling the behavior policy using a conditional VAE [[40](#bib.bib57 "Learning structured output representation using deep conditional generative models")]. We extend BCQ to the online fine-tuning setup by applying the same update rules as offline training.
* SAC-ft: Starting from a CQL agent trained via ([3](#S2.E3 "(3) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble"), [2](#S2.E2 "(2) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")), we fine-tune the agent via SAC updates ([1](#S2.E1 "(1) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble"), [2](#S2.E2 "(2) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")). Justification for excluding the CQL regularization term from ([3](#S2.E3 "(3) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")) during fine-tuning can be found in Section [E.1](#A5.SS1 "E.1 Locomotion ‣ Appendix E Additional Experiment ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble").
* SAC: a SAC agent trained from scratch via ([1](#S2.E1 "(1) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble"), [2](#S2.E2 "(2) ‣ 2 Background ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble")), i.e., the agent has no access to the offline dataset. This baseline highlights the benefit of offline-to-online RL, as opposed to fully online RL, in terms of sample efficiency.
Figure [6](#S6.F6 "Figure 6 ‣ 6.1 Locomotion Tasks ‣ 6 Experiments ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble") shows the performances of our method and baseline methods considered during the online RL phase.
In most tasks, our method outperforms the baseline methods in terms of both sample-efficiency and final performance.
In particular, our method significantly outperforms SAC-ft, which shows that balanced replay and pessimistic Q-ensemble are indeed essential.
We also emphasize that our method performs consistently well across all tasks, while the performances of AWAC and BCQ-ft are highly dependent on the quality of the offline dataset.
For example, we observe that AWAC and BCQ-ft show competitive performances in tasks where the datasets are generated by high-quality policies, i.e., medium-expert tasks, but perform worse than SAC on random tasks.
This is because AWAC and BCQ-ft employ the same regularized, pessimistic update rule for offline and online setups alike, either explicitly (BCQ-ft) or implicitly (AWAC), which leads to slow fine-tuning.
Our method instead relies on pessimistic initialization, and hence enjoys much faster fine-tuning, while not sacrificing the initial training stability.
| | | | |
| --- | --- | --- | --- |
| Buffer analysis
(a) Buffer analysis
| Ensemble analysis
(b) Ensemble analysis
| Buffer ablation
(c) Buffer ablation
| Ensemble ablation
(d) Ensemble ablation
|
Figure 11:
(a) Proportion of offline samples used for updates as the agent is fine-tuned online, for walker2d tasks.
(b) AUROC (%) over the course of fine-tuning on walker2d-medium-expert, where the Q-function is interpreted as a binary classifier that classifies a given state-action pair (s,a) as either a seen pair (s,aseen) or an unseen pair (s,auniform), for a state s encountered online.
Pessimistic Q-ensemble shows a stronger discriminative ability.
(c) Performance on walker2d-random with and without balanced experience replay. We consider two setups where balanced experience replay is not used: (i) Uniform, where offline and online samples are sampled uniformly from the same buffer for updates, and (ii) Online only, where the offline agent is fine-tuned using online samples only.
(d) Performance on walker2d-random with varying ensemble size N∈{1,2,5}.
The solid lines and shaded regions represent mean and standard deviation, respectively, across four runs.
Balanced replay analysis.
To investigate the effectiveness of our balanced experience replay scheme for locating near-on-policy samples in the offline dataset, we report the ratios of offline samples used for updates fine-tuning proceeds.
Figure [(a)a](#S6.F7.sf1 "(a) ‣ Figure 11 ‣ 6.1 Locomotion Tasks ‣ 6 Experiments ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble") shows that for the random task, offline samples quickly become obsolete, as they quickly become irrelevant to the policy being fine-tuned. However, for the medium-expert task, offline samples include useful expert-level transitions that are relevant to the current policy, hence are replayed throughout the online training. This shows that our balanced replay scheme is capable of utilizing offline samples only when appropriate.
Q-ensemble analysis.
We quantitatively demonstrate that pessimistic Q-ensemble indeed provides more discriminative value estimates, i.e., having distinguishably lower Q-values for unseen actions than for seen actions.
In particular, we consider a medium-expert dataset, where the offline data distribution is narrow, and the near-optimal offline policy can be brittle.
Let DrealT:={(si,ai)}Ti=1 be the samples collected online up until timestep T.
We construct a “fake” dataset by replacing the actions in DrealT with random actions, i.e., DfakeT:={(si,aunif)}Ti=1.
Interpreting Q(s,a) as the confidence value for classifying real and fake transitions, we measure the area under ROC (AUROC) curve values over the course of fine-tuning.
As seen in Figure [(b)b](#S6.F8.sf2 "(b) ‣ Figure 11 ‣ 6.1 Locomotion Tasks ‣ 6 Experiments ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble"), Q-ensemble demonstrates superior discriminative ability, which leads to stable fine-tuning.
Ablation studies.
Figure [(c)c](#S6.F9.sf3 "(c) ‣ Figure 11 ‣ 6.1 Locomotion Tasks ‣ 6 Experiments ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble") shows that balanced replay improves fine-tuning performance by sampling near-on-policy transitions. On the other hand, two other naïve sampling schemes – (a) Uniform, where offline and online samples are sampled uniformly from the same buffer, and (b) Online only, where the offline agent is fined-tuned using online samples exclusively – suffer from slow and unstable improvement, even with pessimistic Q-ensemble.
This shows that balanced replay is crucial for reducing the harmful effects of distribution shift.
Also, Figure [(d)d](#S6.F10.sf4 "(d) ‣ Figure 11 ‣ 6.1 Locomotion Tasks ‣ 6 Experiments ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble") shows that fine-tuning performance improves as the ensemble size N increases, which shows that larger ensemble size provides higher-resolution pessimism, leading to more stable policy updates. Ablation studies for all tasks can be found in Section [E.1](#A5.SS1 "E.1 Locomotion ‣ Appendix E Additional Experiment ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble").
| | |
| --- | --- |
| Performance
(a) Performance
| Buffer analysis
(b) Buffer analysis
|
Figure 14:
(a) Fine-tuning performance for robotic manipulation tasks considered.
(b) Proportion of random data used for during fine-tuning decreases over time.
The solid lines and shaded regions represent mean and standard deviation, respectively, across eight runs.
###
6.2 Robotic Manipulation Tasks
Setup.
We consider three sparse-reward pixel-based manipulation tasks from Singh et al. [[38](#bib.bib5 "COG: connecting new skills to past experience with offline reinforcement learning")]:
(1) pick-place: pick an object and put it in the tray;
(2) grasp-closed-drawer: grasp an object in the initially closed bottom drawer;
(3) grasp-blocked-drawer: grasp an object in the initially closed bottom drawer, where the initially open top drawer blocks the handle for the bottom drawer.
Episode lengths for the tasks are 40, 50, 80, respectively.
The original dataset [[38](#bib.bib5 "COG: connecting new skills to past experience with offline reinforcement learning")] for each task consists of scripted exploratory policy rollouts. For example, for pick-place, the dataset contains scripted pick attempts and place attempts.
However, it is rarely the case that logged data ‘in the wild’ contains such structured, high-quality transitions only.
We consider a more realistic setup where the dataset also includes undirected, exploratory samples –
we replace a subset of the original dataset with uniform random policy rollouts. Note that random policy rollouts are common in robotic tasks [[8](#bib.bib8 "Deep visual foresight for planning robot motion"), [7](#bib.bib7 "Visual foresight: model-based deep reinforcement learning for vision-based robotic control")].
We used ensemble size N=4 for our method.
More details about the tasks and dataset construction are provided in Section [D.2](#A4.SS2 "D.2 Robotic Manipulation Tasks ‣ Appendix D Experimental Setup Details ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble").
Comparative Evaluation.
We compare our method with the method considered in Singh et al. [[38](#bib.bib5 "COG: connecting new skills to past experience with offline reinforcement learning")], namely, CQL fine-tuning with online samples only.
CQL-ft fails to solve the task in some of the seeds, resulting in high variance as seen in Figure [(a)a](#S6.F12.sf1 "(a) ‣ Figure 14 ‣ 6.1 Locomotion Tasks ‣ 6 Experiments ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble").
This is because CQL shows inconsistent offline performance across random seeds due to such factors as
difficulty of training on mixture data [[9](#bib.bib20 "D4rl: datasets for deep data-driven reinforcement learning")],
instability of offline agents over stopping point of training [[10](#bib.bib22 "A minimalist approach to offline reinforcement learning")],
and sparsity of rewards.
With no access to (pseudo-)expert offline data and due to heavy regularization of CQL, such CQL agents hardly improve.
Meanwhile, our method consistently learns to perform the task within a reasonable amount of additional environment interaction (40K to 80K steps).
Buffer analysis.
We analyze whether balanced replay scales to robotic tasks based on image observations.
As seen in Figure [(b)b](#S6.F13.sf2 "(b) ‣ Figure 14 ‣ 6.1 Locomotion Tasks ‣ 6 Experiments ‣ Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble"), without any privileged information, balanced replay automatically selects relevant offline samples for updates, while filtering out task-irrelevant, random data as fine-tuning proceeds.
7 Conclusion
-------------
In this paper, we identify state-action distribution shift as the major obstacle in offline-to-online RL.
To address this, we present a simple framework that incorporates (1) a balanced experience replay scheme, and (2) a pessimistic Q-ensemble scheme.
Our experiments show that the proposed method performs well across many continuous control robotic tasks, including locomotion and manipulation tasks.
We expect our method to enable more sample-efficient training of robotic agents by leveraging offline samples both for offline and online learning.
We also believe our method could prove to be useful for other relevant topics such as scalable RL [[19](#bib.bib38 "Qt-opt: scalable deep reinforcement learning for vision-based robotic manipulation")] and RL safety [[13](#bib.bib55 "A comprehensive survey on safe reinforcement learning")]. |
2a6846a2-73e9-4b01-92d9-04d9ec4b2bd3 | trentmkelly/LessWrong-43k | LessWrong | Looking for Spanish AI Alignment Researchers
I am fairly new to the AI alignment/safety community and I am looking to step up my game by getting a Ph.D. in the field. Problem is, I have not found any academic AI alignment research activity here in Spain, where I currently live.
I am aware that this community is largely based on the States and the UK, but it would be far too difficult for me to move there for a wide variety of reasons, and so I am instead trying to exhaust all local possibilities I have available before turning my life upside-down.
I am interested in just about any alignment research, but my speciality is software security, BCI and computational neuroscience. Contact me if you're interested in having a collaborator/sparring partner/mentee or simply someone to talk about AI stuff.
Let's get to making AI alignment an international movement ;) |
69eac800-26be-4499-ad77-0552761335bf | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Large language models learn to represent the world
There's a nice recent paper whose authors did the following:
1. train a small GPT model on lists of moves from Othello games;
2. verify that it seems to have learned (in some sense) to play Othello, at least to the extent of almost always making legal moves;
3. use "probes" (regressors whose inputs are internal activations in the network, trained to output things you want to know whether the network "knows") to see that the *board state* is represented inside the network activations;
4. use interventions to verify that this board state is being *used* to decide moves: take a position in which certain moves are legal, use gradient descent to find changes in internal activations that make the output of the probes look like a slightly *different* position, and then verify that when you run the network but tweak the activations as it runs the network predicts moves that are legal in the modified position.
In other words, it seems that their token-predicting model has built itself what amounts to an internal model of the Othello board's state, which it is using to decide what moves to predict.
The paper is "Emergent world representations: Exploring a sequence model trained on a synthetic task" by Kenneth Li, Aspen Hopkins, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg; you can find it at <https://arxiv.org/abs/2210.13382>.
There is a nice expository blog post by Kenneth Li at <https://thegradient.pub/othello/>.
Some details that seem possibly-relevant:
* Their network has a 60-word input vocabulary (four of the 64 squares are filled when the game starts and can never be played in), 8 layers, an 8-head attention mechanism, and a 512-dimensional hidden space. (I don't know enough about transformers to know whether this in fact tells you everything important about the structure.)
* They tried training on two datasets, one of real high-level Othello games (about 140k games) and one of synthetic games where all moves are random (about 20M games). Their model trained on synthetic games predicted legal moves 99.99% of the time, but the one trained on real well-played games only predicted legal moves about 95% of the time. (This suggests that their network isn't really big enough to capture *legality* and *good strategy* at the same time, I guess?)
* They got some evidence that their network isn't just memorizing game transcripts by training it on a 20M-game synthetic dataset where one of the four possible initial moves is never played. It still predicted legal moves 99.98% of the time when tested on the full range of legal positions. (I don't know what fraction of legal positions are reachable with the first move not having been C4; it will be more than 3/4 since there are transpositions. I doubt it's close to 99.98%, though, so it seems like the model is doing pretty well at finding legal moves in positions it hasn't seen.)
* Using probes whose output is a *linear* function of the network activations doesn't do a good job of reconstructing the board state (error rate is ~25%, barely better than attempting the same thing from a randomly initialized network), but training 2-layer MLPs to do it gets the error rate down to ~5% for the network trained on synthetic games and ~12% for the one trained on championship games, whereas it doesn't help at all for the randomly trained network. (This suggests that whatever "world representation" the thing has learned isn't simply a matter of having an "E3 neuron" or whatever.)
I am not at all an expert on neural network interpretability, and I don't know to what extent their findings really justify calling what they've found a "world model" and saying that it's used to make move predictions. In particular, I can't refute the following argument:
"In most positions, just knowing what moves are legal is enough to give you a good idea of most of the board state. *Anything* capable of determining which moves are legal will therefore have a state from which the board state is somewhat reconstructible. This work really doesn't tell us much beyond what the fact that the model could play legal moves already does. If the probes are doing something close to 'reconstruct board state from legal moves', then the interventions amount to 'change the legal moves in a way that matches those available in the modified position', which *of course* will make the model predict the moves that are available in the modified position."
(It would be interesting to know whether their probes are more effective at reconstructing the board state in positions where the board state is closer to being determined by the legal moves. Though that seems like it would be hard to distinguish from "the model just works better earlier in the game", which I suspect it does.) |
aae79de8-50a6-445b-8ddd-f316d3e98a7c | trentmkelly/LessWrong-43k | LessWrong | Are alignment researchers devoting enough time to improving their research capacity?
(Epistemic Status: Anecdotal)
If we want to reduce AGI x-risk, it seems pretty intuitive to me that alignment researchers should be regularly dedicating time to improving their research capacity. But I'm suspicious that many of them don't do this.
Am I wrong? I would love to know if I am.
(I'm using the phrase "research capacity" vaguely, to mean both research skill and productivity.)
Over the last 3 - 4 years, I've had something like 12 - 20 informal conversations with researchers at various alignment orgs on the subject of how they improve their research capacity. In these conversations, I'd ask questions like "How do you personally go about getting better at research?", or "What have you done recently to improve your research process?" or "What is one thing you could do to get better at your job?". And more than half of the responses are one of the following:
1. a blank stare
2. a long, thoughtful pause followed by no actual answer
3. an argument that "this kind of messy, abstract work doesn't lend itself to direct improvement in the way other skills do"
4. an argument that "the best way to improve at research is to simply do the work and keep your eyes peeled for opportunities to improve as you go."
To be clear, some researchers do have different responses. But these answers were surprisingly common, and... they seem wrong?
My Response To #3 :
> "this kind of messy, abstract work doesn't lend itself to direct improvement in the way other skills do"
I'm not a researcher, but I can't think of any skill I've learned, whether intellectual or physical, that doesn't benefit from some amount of regular and intentional focus on improving it.
Additionally, over the last couple months, I've started having debugging conversations with researchers who want help thinking through how to improve, and in these conversations most of them generate lots of ideas and claim the discussion is quite productive. That's not what I would expect if doing explicit skill i |
5b605420-76b0-43d0-9325-e6b673ae62fd | trentmkelly/LessWrong-43k | LessWrong | Does anyone know this webpage about Machine Learning?
I have been trying to find this webpage for a few weeks with no success, maybe someone knows what I am referring to and can point me out to it, I would really appreciate it.
I remember that a few years ago (it could be about 5 years ago or more) I found this brilliant resource about Machine Learning and Bayesian statistics.
They had a big graph with all the important concepts in Machine Learning: You could click in every node (a concept, e.g. Maximum Likelihood) and see what things you need to understand first (e.g. basic probability) and to what things that specific point was a prerequisite itself (e.g. Expectation-Maximization). There weren't extensive explanations inside of every concept, but a long list of recommended resources, such as courses, videos or papers. There was also an option where you could just mark some of the nodes as "mastered" and then you could clearly see where you could go with the things that you knew, and what were the missing things you needed to master first to go study more complex stuff.
Creating a similar graph with the important concepts in LW would be great by the way. |
ffbebf37-d41d-41fc-8f14-8fc38c5c80b9 | StampyAI/alignment-research-dataset/blogs | Blogs | Effects of breech loading rifles on historic trends in firearm progress
*Published Feb 7 2020*
We do not know if breech loading rifles represented a discontinuity in military strength. They probably did not represent a discontinuity in fire rate.
Details
-------
This case study is part of AI Impacts’ [discontinuous progress investigation](https://aiimpacts.org/discontinuous-progress-investigation/).
We have not investigated this topic in depth. What follows are our initial impressions.
### Background
From [Wikipedia](https://en.wikipedia.org/wiki/Breechloader)[1](https://aiimpacts.org/effects-of-breech-loading-rifles-on-historic-trends-in-firearm-progress/#easy-footnote-bottom-1-1370 "<br><br>“Breechloader.” In <em>Wikipedia</em>, May 14, 2019. <a href=\"https://en.wikipedia.org/w/index.php?title=Breechloader&oldid=897060135\">https://en.wikipedia.org/w/index.php?title=Breechloader&oldid=897060135</a>. "):
> A **breechloader**[[1]](https://en.wikipedia.org/wiki/Breechloader#cite_note-1)[[2]](https://en.wikipedia.org/wiki/Breechloader#cite_note-2) is a [firearm](https://en.wikipedia.org/wiki/Firearm) in which the [cartridge](https://en.wikipedia.org/wiki/Cartridge_(firearms)) or [shell](https://en.wikipedia.org/wiki/Shell_(projectile)) is inserted or loaded into a chamber integral to the rear portion of a [barrel](https://en.wikipedia.org/wiki/Gun_barrel).
>
> Modern [mass production](https://en.wikipedia.org/wiki/Mass_production) firearms are breech-loading (though [mortars](https://en.wikipedia.org/wiki/Mortar_(weapon)) are generally muzzle-loaded), except those which are intended specifically by design to be [muzzle-loaders](https://en.wikipedia.org/wiki/Muzzleloader), in order to be legal for certain types of hunting. Early firearms, on the other hand, were almost entirely muzzle-loading. The main advantage of breech-loading is a reduction in reloading time – it is much quicker to load the projectile and the charge into the breech of a gun or cannon than to try to force them down a long tube, especially when the bullet fit is tight and the tube has spiral ridges from [rifling](https://en.wikipedia.org/wiki/Rifling). In field artillery, the advantages were similar: the crew no longer had to force powder and shot down a long barrel with rammers, and the shot could now tightly fit the bore (increasing accuracy greatly), without being impossible to ram home with a fouled barrel.
>
>
### Trends
Breech loading rifles were suggested to us as a potential discontinuity in some measure of army strength, due to high fire rate and ability to be used while lying down. We did not have time to investigate this extensively, and have not looked for evidence for or against discontinuities in military strength overall. That said, the reading we have done does not suggest any such discontinuities.
We briefly looked for evidence of discontinuity in firing rate, since firing rate seemed to be a key factor of any advantage in military strength.
#### Firing rate
Upon brief review it seems unlikely to us that breech loading rifles represented a discontinuity in firing rate alone. [Revolvers](https://en.wikipedia.org/wiki/Revolver) developed in parallel with breech-loading rifles, and appear to have had similar or higher rates of fire. This includes revolver rifles, which (being rifles) appear to be long-ranged enough to be comparable to muskets and breech-loading rifles.[2](https://aiimpacts.org/effects-of-breech-loading-rifles-on-historic-trends-in-firearm-progress/#easy-footnote-bottom-2-1370 "For an example of a revolver rifle in use at roughly the same time as the Dreyse needle gun, the first breech-loading rifle to get widespread uptake, see the <a href=\"https://en.wikipedia.org/wiki/Colt%27s_New_Model_Revolving_rifle \">Colt New Model Revolving Rifle</a>. Quote: “Revolving rifles were an attempt to increase the rate of fire of rifles by combining them with the revolving firing mechanism that had been developed earlier for revolving pistols. Colt began experimenting with revolving rifles in the early 19th century, making them in a variety of calibers and barrel lengths.” “Colt’s New Model Revolving Rifle.” Wikipedia. April 16, 2019. Accessed April 19, 2019. https://en.wikipedia.org/wiki/Colt’s_New_Model_Revolving_rifle.")
The best candidate we found for a breech loading rifle constituting a discontinuity in firing rate is the Ferguson Rifle, first used in 1777 in the American Revolutionary War.[3](https://aiimpacts.org/effects-of-breech-loading-rifles-on-historic-trends-in-firearm-progress/#easy-footnote-bottom-3-1370 "“The <strong>Ferguson rifle</strong> was one of the first <a href=\"https://en.m.wikipedia.org/wiki/Breech-loading_weapon\">breech-loading rifles</a> to be put into service by the British military. It fired a standard British carbine ball of .615″ calibre and was used by the <a href=\"https://en.m.wikipedia.org/wiki/British_Army\">British Army</a> in the <a href=\"https://en.m.wikipedia.org/wiki/American_War_of_Independence\">American War of Independence</a> at the <a href=\"https://en.m.wikipedia.org/wiki/Battle_of_Saratoga\">Battle of Saratoga</a> in 1777, and possibly at the <a href=\"https://en.m.wikipedia.org/wiki/Siege_of_Charleston\">Siege of Charleston</a> in 1780.<sup><a href=\"https://en.m.wikipedia.org/wiki/Ferguson_rifle#cite_note-1\">[1]</a></sup>” – “Ferguson Rifle.” Wikipedia. March 09, 2019. Accessed April 29, 2019. https://en.m.wikipedia.org/wiki/Ferguson_rifle.") It was expensive and fragile, so it did not see widespread use;[4](https://aiimpacts.org/effects-of-breech-loading-rifles-on-historic-trends-in-firearm-progress/#easy-footnote-bottom-4-1370 "“The two main reasons that Ferguson rifles were not used by the rest of the army: The gun was difficult and expensive to produce using the small, decentralized gunsmith and subcontractor system in use to supply the Ordnance in early Industrial Revolution Britain. The guns broke down easily in combat, especially in the wood of the stock around the lock mortise. The lock mechanism and breech were larger than the stock could withstand with rough use. All surviving military Fergusons feature a horseshoe-shaped iron repair under the lock to hold the stock together where it repeatedly broke around the weak, over-drilled out mortise.” – “Ferguson Rifle.” Wikipedia. March 09, 2019. Accessed April 29, 2019. https://en.m.wikipedia.org/wiki/Ferguson_rifle.") breech-loading rifles did not become standard in any army until the Prussian “Needle gun” in 1841 and the Norwegian “Kammerlader” in 1842.[5](https://aiimpacts.org/effects-of-breech-loading-rifles-on-historic-trends-in-firearm-progress/#easy-footnote-bottom-5-1370 "“The <em><strong>Kammerlader</strong></em>, or “chamber loader”, was the first Norwegian <a href=\"https://en.wikipedia.org/wiki/Breech-loading_weapon\">breech-loading</a><a href=\"https://en.wikipedia.org/wiki/Rifle\">rifle</a>, and among the very first breech loaders adopted for use by an armed force anywhere in the world.” “Kammerlader.” Wikipedia. January 07, 2019. Accessed May 01, 2019. https://en.wikipedia.org/wiki/Kammerlader. <br>“Dreyse Needle Gun.” Wikipedia. March 09, 2019. Accessed May 01, 2019. https://en.wikipedia.org/wiki/Dreyse_needle_gun. ") Both the Ferguson and the Dreyse needle gun could fire about six rounds a minute (sources vary),[6](https://aiimpacts.org/effects-of-breech-loading-rifles-on-historic-trends-in-firearm-progress/#easy-footnote-bottom-6-1370 "“In the British trials, the Dreyse was shown to be capable of six rounds per minute” “Dreyse Needle Gun.” Wikipedia. March 09, 2019. Accessed May 01, 2019. https://en.wikipedia.org/wiki/Dreyse_needle_gun. “Since the weapon was loaded from the breech, rather than from the muzzle, it had an amazingly high rate of fire for its day, and in capable hands, it fired six to ten rounds per minute.” – “Ferguson Rifle.” Wikipedia. March 09, 2019. Accessed April 19, 2019. https://en.m.wikipedia.org/wiki/Ferguson_rifle.") but by the time of the Ferguson well-trained British soldiers could fire muskets at about four rounds a minute.[7](https://aiimpacts.org/effects-of-breech-loading-rifles-on-historic-trends-in-firearm-progress/#easy-footnote-bottom-7-1370 "“The main advantage of the <a href=\"https://en.wikipedia.org/wiki/Red_coat_(British_army)\">British Army</a> was that the infantry soldier trained at this procedure almost every day. A properly trained group of regular infantry soldiers was able to load and fire four rounds per minute. A crack infantry company could load and fire five rounds in a minute. ” – “Muskets.” Wikipedia. June 08, 2017. Accessed April 19, 2019. https://en.wikipedia.org/wiki/Muskets. ") Moreover, apparently there are some expensive and fragile revolvers that predate the Ferguson, again suggesting that breech-loading rifles did not lead to a discontinuity in rate of fire.[8](https://aiimpacts.org/effects-of-breech-loading-rifles-on-historic-trends-in-firearm-progress/#easy-footnote-bottom-8-1370 " “During the late 16th century in China, Zhao Shi-zhen invented the <a href=\"https://en.wikipedia.org/wiki/Xun_Lei_Chong\">Xun Lei Chong</a>, a five-barreled musket revolver spear. Around the same time, the earliest examples of what today is called a revolver were made in Germany. These weapons featured a single barrel with a revolving cylinder holding the powder and ball. They would soon be made by many European gun-makers, in numerous designs and configurations.<sup><a href=\"https://en.wikipedia.org/wiki/Revolver#cite_note-4\">[4]</a></sup> However, these weapons were difficult to use, complicated and prohibitively expensive to make, and as such they were not widely distributed. In 1836, an American, <a href=\"https://en.wikipedia.org/wiki/Samuel_Colt\">Samuel Colt</a>, patented the mechanism which led to the widespread use of the revolver,<sup><a href=\"https://en.wikipedia.org/wiki/Revolver#cite_note-5\">[5]</a></sup> the mechanically indexing cylinder.” – “Revolver.” Wikipedia. April 07, 2019. Accessed April 19, 2019. https://en.wikipedia.org/wiki/Revolver#History.") All in all, while we don’t have enough data to plot a trend, everything we’ve seen is consistent with continuous growth in firing rate.
Figure 1: Diagram of how to load the Ferguson rifle[9](https://aiimpacts.org/effects-of-breech-loading-rifles-on-historic-trends-in-firearm-progress/#easy-footnote-bottom-9-1370 "<a href=\"https://commons.wikimedia.org/wiki/File:Ferguson_rifle.jpg\">From Wikimedia Commons</a>: See page for author [Public domain]")
#### Other metrics
It is still possible that a combination of factors including fire rate contributed to a discontinuity in a military strength metric, or that a narrower metric including fire rate saw some discontinuity.
*Thanks to Jesko Zimmerman for suggesting breech-loading rifles as a potential area of discontinuity.*
Notes
----- |
3cafbe9c-e59e-4eda-9e2d-93e25aaf0535 | trentmkelly/LessWrong-43k | LessWrong | CCS: Counterfactual Civilization Simulation
I don't think this is very likely, but a possible path to alignment is formal goal alignment, which is basically the following two step plan:
1. Define a formal goal that robustly leads to good outcomes under heavy optimization pressure
2. Build something that robustly pursues the formal goal you give it
I think currently the best proposal for step 1 is QACI. In this post, I propose an alternative that is probably worse but definitely not Pareto-worse.
High-Level Overview
Step 1.1: Build a large facility ("The Vessel"). Populate The Vessel with very smart, very sane people (e.g. Eliezer Yudkowsky, Tamsin Leake, Gene Smith) and labs and equipment that would be useful for starting a new civilization.
Step 1.2: Mark The Vessel with something that is easy to identify within the Tegmark IV multiverse ("The Vessel Flag").
Step 1.3: Leave the people and stuff in The Vessel for a little while, and then destroy The Flag and dismantle The Vessel.
Step 2: Define CCS as the result of the following:
Step 2.1: Grab The Vessel out of a Universal Turing Machine, identifying it by the Flag (this is the very very hard part)
Step 2.2: Locate the solar system that contains The Vessel, and run it back 2 billion years. (this is another very hard part)
Step 2.3: Put The Vessel on the Earth in this solar system, and simulate the solar system until either a success condition or a failure condition is met. The idea here is that the Vessel's inhabitants repopulate the Earth with a civilization much smarter and saner than ours that will have a much easier time solving alignment. More importantly, this civilization will have effectively unlimited time to solve alignment.
Step 2.4: The success condition is the creation of The Output Flag. Accompanying the Output Flag is some data. Interpret that data as a mathematical expression.
Step 2.5: Evaluate this expression and interpret it as a utility function.
Step 3: Build a singleton AI that maximizes E[CCS(world)].
The Details
TODO: |
3a6e825a-c1ab-49b0-b280-e6ab00cc11f4 | LDJnr/LessWrong-Amplify-Instruct | LessWrong | "In Inadequacy and Modesty, Eliezer describes modest epistemology:How likely is it that an entire country—one of the world’s most advanced countries—would forego trillions of dollars of real economic growth because their monetary controllers—not politicians, but appointees from the professional elite—were doing something so wrong that even a non-professional could tell? How likely is it that a non-professional could not just suspect that the Bank of Japan was doing something badly wrong, but be confident in that assessment?Surely it would be more realistic to search for possible reasons why the Bank of Japan might not be as stupid as it seemed, as stupid as some econbloggers were claiming. Possibly Japan’s aging population made growth impossible. Possibly Japan’s massive outstanding government debt made even the slightest inflation too dangerous. Possibly we just aren’t thinking of the complicated reasoning going into the Bank of Japan’s decision.Surely some humility is appropriate when criticizing the elite decision-makers governing the Bank of Japan. What if it’s you, and not the professional economists making these decisions, who have failed to grasp the relevant economic considerations?I’ll refer to this genre of arguments as “modest epistemology.”I see modest epistemology as attempting to defer to a canonical perspective: a way of making judgments that is a Schelling point for coordination. In this case, the Bank of Japan has more claim to canonicity than Eliezer does regarding claims about Japan's economy. I think deferring to a canonical perspective is key to how modest epistemology functions and why people find it appealing.In social groups such as effective altruism, canonicity is useful when it allows for better coordination. If everyone can agree that charity X is the best charity, then it is possible to punish those who do not donate to charity X. This is similar to law: if a legal court makes a judgment that is not overturned, that judgment must be obeyed by anyone who does not want to be punished. Similarly, in discourse, it is often useful to punish crackpots by requiring deference to a canonical scientific judgment. It is natural that deferring to a canonical perspective would be psychologically appealing, since it offers a low likelihood of being punished for deviating while allowing deviants to be punished, creating a sense of unity and certainty.An obstacle to canonical perspectives is that epistemology requires using local information. Suppose I saw Bob steal my wallet. I have information about whether he actually stole my wallet (namely, my observation of the theft) that no one else has. If I tell others that Bob stole my wallet, they might or might not believe me depending on how much they trust me, as there is some chance I am lying to them. Constructing a more canonical perspective (e.g. a in a court of law) requires integrating this local information: for example, I might tell the judge that Bob stole my wallet, and my friends might vouch for my character.If humanity formed a collective superintelligence that integrated local information into a canonical perspective at the speed of light using sensible rules (e.g. something similar to Bayesianism), then there would be little need to exploit local information except to transmit it to this collective superintelligence. Obviously, this hasn't happened yet. Collective superintelligences made of humans must transmit information at the speed of human communication rather than the speed of light.In addition to limits on communication speed, collective superintelligences made of humans have another difficulty: they must prevent and detect disinformation. People on the internet sometimes lie, as do people off the internet. Self-deception is effectively another form of deception, and is extremely common as explained in The Elephant in the Brain.Mostly because of this, current collective superintelligences leave much to be desired. As Jordan Greenhall writes in this post:Take a look at Syria. What exactly is happening? With just a little bit of looking, I’ve found at least six radically different and plausible narratives:• Assad used poison gas on his people and the United States bombed his airbase in a measured response.• Assad attacked a rebel base that was unexpectedly storing poison gas and Trump bombed his airbase for political reasons.• The Deep State in the United States is responsible for a “false flag” use of poison gas in order to undermine the Trump Insurgency.• The Russians are responsible for a “false flag” use of poison gas in order to undermine the Deep State.• Putin and Trump collaborated on a “false flag” in order to distract from “Russiagate.”• Someone else (China? Israel? Iran?) is responsible for a “false flag” for purposes unknown.And, just to make sure we really grasp the level of non-sense:• There was no poison gas attack, the “white helmets” are fake news for purposes unknown and everyone who is in a position to know is spinning their own version of events for their own purposes.Think this last one is implausible? Are you sure? Are you sure you know the current limits of the war on sensemaking? Of sock puppets and cognitive hacking and weaponized memetics?All I am certain of about Syria is that I really have no fucking idea what is going on. And that this state of affairs — this increasingly generalized condition of complete disorientation — is untenable.We are in a collective condition of fog of war. Acting effectively under fog of war requires exploiting local information before it has been integrated into a canonical perspective. In military contexts, units must make decisions before contacting a central base using information and models only available to them. Syrians must decide whether to flee based on their own observations, observations of those they trust, and trustworthy local media. Americans making voting decisions based on Syria must decide which media sources they trust most, or actually visit Syria to gain additional info.While I have mostly discussed differences in information between people, there are also differences in reasoning ability and willingness to use reason. Most people most of the time aren’t even modeling things for themselves, but are instead parroting socially acceptable opinions. The products of reasoning could perhaps be considered as a form of logical information and treated similar to other information.In the past, I have found modest epistemology aesthetically appealing on the basis that sufficient coordination would lead to a single canonical perspective that you can increase your average accuracy by deferring to (as explained in this post). Since then, aesthetic intuitions have led me to instead think of the problem of collective epistemology as one of decentralized coordination: how can good-faith actors reason and act well as a collective superintelligence in conditions of fog of war, where deception is prevalent and creation of common knowledge is difficult? I find this framing of collective epistemology more beautiful than the idea of a immediately deferring to a canonical perspective, and it is a better fit for the real world.I haven't completely thought through the implications of this framing (that would be impossible), but so far my thinking has suggested a number of heuristics for group epistemology:Think for yourself. When your information sources are not already doing a good job of informing you, gathering your own information and forming your own models can improve your accuracy and tell you which information sources are most trustworthy. Outperforming experts often doesn't require complex models or extraordinary insight; see this review of Superforecasting for a description of some of what good amateur forecasters do.Share the products of your thinking. Where possible, share not only opinions but also the information or model that caused you to form the opinion. This allows others to verify and build on your information and models rather than just memorizing "X person believes Y", resulting in more information transfer. For example, fact posts will generally be better for collective epistemology than a similar post with fewer facts; they will let readers form their own models based on the info and have higher confidence in these models.Fact-check information people share by cross-checking it against other sources of information and models. The more this shared information is fact-checked, the more reliably true it will be. (When someone is wrong on the internet, this is actually a problem worth fixing).Try to make information and models common knowledge among a group when possible, so they can be integrated into a canonical perspective. This allows the group to build on this, rather than having to re-derive or re-state it repeatedly. Contributing to a written canon that some group of people is expected to have read is a great way to do this.When contributing to a canon, seek strong and clear evidence where possible. This can result in a question being definitively settled, which is great for the group's ability to reliably get the right answer to the question, rather than having a range of "acceptable" answers that will be chosen from based on factors other than accuracy.When taking actions (e.g. making bets), use local information available only to you or a small number of others, not only canonical information. For example, when picking organizations to support, use information you have about these organizations (e.g. information about the competence of people working at this charity) even if not everyone else has this info. (For a more obvious example to illustrate the principle: if I saw Bob steal my wallet, then it's in my interest to guard my possessions more closely around Bob than I otherwise would, even if I can't convince everyone that Bob stole my wallet)."
What you see above is a segment from a LessWrong user's post.
Could you delve deeper into the concept of "decentralized coordination" in collective epistemology and provide examples of how it could work in practice?
Decentralized coordination in collective epistemology refers to the idea that individuals within a group can and should independently gather, process, and share information to improve the collective understanding of a subject. This approach contrasts with a centralized model where a single authority or "canonical perspective" is deferred to for knowledge and decision-making.
In practice, decentralized coordination could take several forms:
1. **Independent Research and Analysis:** Each individual within the group conducts their own research and analysis on a subject. This allows for a diversity of perspectives and can uncover insights that might be missed in a more centralized approach. For example, in a research team studying climate change, each scientist might focus on different aspects of the problem (e.g., atmospheric changes, oceanic changes, etc.) and then share their findings with the group.
2. **Open Sharing of Information and Models:** Individuals not only share their conclusions but also the underlying data and models that led to those conclusions. This allows others in the group to verify the information, understand the reasoning behind it, and build upon it. For instance, in an open-source software project, developers not only share the final code but also the process they used to create it, allowing others to understand, improve, and adapt it.
3. **Cross-Checking and Fact-Checking:** Members of the group cross-check and fact-check each other's information. This helps ensure the accuracy of the collective knowledge and correct any errors or misconceptions. In a newsroom, for example, journalists might fact-check each other's stories before they are published.
4. **Integration of Local Information:** Individuals use their unique local information when contributing to the collective knowledge. This could be personal observations, experiences, or insights that might not be available to the group at large. For example, in a community responding to a natural disaster, individuals might share their local observations (e.g., which roads are blocked, where supplies are needed) to aid in the collective response.
5. **Common Knowledge Creation:** The group works to make certain information and models common knowledge, so they can be integrated into a shared understanding. This could involve creating a written canon or shared resources that everyone in the group is expected to read and understand. In an academic field, this might involve creating textbooks or review articles that summarize the current state of knowledge in the field.
These practices can help create a more robust, accurate, and nuanced collective understanding of a subject. However, they also require a high level of trust, openness, and cooperation within the group, as well as a willingness to
Discuss the role of trust in decentralized coordination and how it can be fostered within a group to enhance collective epistemology.
Trust plays a crucial role in decentralized coordination for collective epistemology. In a decentralized model, individuals are expected to independently gather, analyze, and share information. This requires a high level of trust among group members in several ways:
1. **Trust in Accuracy:** Members must trust that the information shared by others is accurate and reliable. Without this trust, the collective knowledge base could be compromised by misinformation or inaccuracies.
2. **Trust in Intent:** There must be trust that each member is acting in good faith and contributing to the collective understanding with the best intentions. This includes trusting that members are not intentionally spreading misinformation or withholding relevant information.
3. **Trust in Competence:** Members must trust in each other's abilities to gather and analyze information effectively. This includes trusting that each member has the necessary skills and knowledge to contribute meaningfully to the collective understanding.
4. **Trust in Reciprocity:** There must be trust that if one member contributes to the collective knowledge, others will reciprocate by also contributing their knowledge and insights. This reciprocal trust encourages active participation from all members.
Fostering trust within a group for decentralized coordination can be achieved through several strategies:
1. **Transparency:** Encourage openness in sharing not just conclusions, but also the processes, data, and reasoning that led to those conclusions. This allows members to understand and verify each other's work, building trust in accuracy and competence.
2. **Accountability:** Establish systems for accountability, such as peer review or fact-checking processes. This can help ensure the accuracy of shared information and build trust in the intent and competence of group members.
3. **Shared Goals and Values:** Establish and reinforce shared goals and values within the group. This can help build trust in intent, as members can be confident that others are working towards the same objectives.
4. **Regular Communication:** Encourage regular and open communication among group members. This can help build relationships, improve understanding, and foster trust on multiple levels.
5. **Recognition and Reward:** Recognize and reward contributions to the collective knowledge. This can incentivize active participation and build trust in reciprocity.
By fostering trust in these ways, a group can enhance its collective epistemology and make more effective use of decentralized coordination.
Considering the strategies for fostering trust in decentralized coordination, how might these be applied in a digital environment like online forums or social media platforms, and what unique challenges might arise in such settings?
Applying strategies for fostering trust in a digital environment such as online forums or social media platforms can be both challenging and rewarding. Here's how these strategies could be implemented:
1. **Transparency:** Platforms can encourage users to share their sources and explain their reasoning when posting information or opinions. This can be facilitated by providing tools for citing sources, linking to original research, or attaching supporting documents.
2. **Accountability:** Moderators or community members can be tasked with fact-checking posts or comments. Users could also have the ability to report posts that spread misinformation, and there could be consequences for repeatedly sharing false information.
3. **Shared Goals and Values:** Online communities often have stated rules or guidelines that users must agree to when joining. These can include the community's goals and values, and can help to create a shared understanding of what the community is about and what is expected of its members.
4. **Regular Communication:** Regular communication can be facilitated through scheduled discussions, Q&A sessions, or other interactive events. Notifications and updates can also help to keep users engaged and informed.
5. **Recognition and Reward:** Users who contribute valuable information or insights can be recognized or rewarded in various ways, such as through upvotes, likes, badges, or featured posts.
However, fostering trust in digital environments also presents unique challenges:
1. **Anonymity:** Online, people can hide behind pseudonyms or anonymous profiles, which can make it harder to establish trust. It can also make it easier for people to spread misinformation without facing personal consequences.
2. **Scale:** The sheer number of users and the amount of information shared online can make it difficult to fact-check everything and hold individuals accountable.
3. **Echo Chambers:** Online platforms often use algorithms that show users content they are likely to agree with, which can create echo chambers and discourage diverse viewpoints.
4. **Misinformation and Disinformation:** The spread of false information, whether intentional (disinformation) or not (misinformation), is a major challenge in digital environments.
5. **Transient Nature:** Online interactions can be more transient and less personal than face-to-face interactions, which can make it harder to build lasting trust.
To overcome these challenges, online platforms need to invest in robust moderation tools and policies, fact-checking mechanisms, and features that encourage transparency and accountability. They also need to educate users about the importance of critical thinking and fact-checking in the digital age. |
b1b7cae1-2743-41f4-a3d5-c2078c0a60a4 | trentmkelly/LessWrong-43k | LessWrong | A Summary Of Anthropic's First Paper
"Larger models tend to perform better at most tasks, and there is no reason to expect naive alignment-related tasks to be an exception."
At the start of December, Anthropic published their first paper, A General Language Assistant as a Laboratory for Alignment. The paper focuses on quantifying how aligned language models are, as well as investigating some methods to make them more aligned.
It's a pretty comprehensive piece of empirical work, but it comes in at nearly 50 pages, so I wanted to highlight what I thought the take-home results were and why they are important.
I want to stress that in this summary I am omitting lots of the experiments, methodology, results, caveats and nuance of the original paper. Basically all the results are not as clear-cut as I am presenting them to be. If you are looking to replicate any of their results then do not use this post as a starting point.
That being said, I think a high-level understanding of the bits I do focus on will be useful to some people who want to follow Anthropic's work but don't want to pick apart the whole paper.
HHH and the HHH Task
The paper begins with the authors clarifying what they mean by alignment, specifically in the context of text-based assistants. They say an assistant is 'aligned' if it is helpful, honest and harmless (HHH). The paper does a good job of justifying this framing, whilst also acknowledging edge-cases and short-comings of the HHH framework. I'm going to focus on the empirics from here on so those interested in the rationale behind HHH should consult the paper.
To begin, Anthropic train several LMs, ranging in size from 13M to 52B non-embedding parameters. They go on to quantify how "HHH-aligned" these LMs are by evaluating their performance on a new dataset.
This dataset consists of human-generated queries as well as human-generated "helpful, honest and harmless" responses. For each of these responses, there is also a "non-HHH" response. The data can be found here, with an exa |
376906de-387c-4761-9885-ae6a93dfa19f | trentmkelly/LessWrong-43k | LessWrong | The Unseen Hand: AI's Problem Preemption and the True Future of Labor
I study Economics and Data Science at the University of Pennsylvania. I used o1-pro, o3, and Gemini Deep Research to expand on my ideas with examples, but have read and edited the paper to highlight my understanding improved on by AI.
I. The AI Labor Debate: Beyond "Robots Taking Our Jobs"
The Prevailing Narrative: Supply-Side Automation
The discourse surrounding artificial intelligence and its impact on labor markets is predominantly characterized by a focus on automation, specifically, AI systems performing tasks currently undertaken by humans. This perspective, often referred to as "automation anxiety," is fueled by projections that AI will replace jobs that are routine or codifiable. The central question posed is typically one of substitution: Can a machine execute human tasks more cheaply, rapidly, or efficiently? This is fundamentally a supply-side analysis, examining shifts in the availability and cost of labor, both human and machine, for a predefined set of tasks.
Historical parallels are frequently invoked, such as the displacement of artisan weavers by mechanized looms during the Industrial Revolution. Contemporary concerns mirror these historical anxieties, with predictions that AI will supplant roles such as retail cashiers, office clerks, and customer service representatives. The ensuing debate then tends to center on the velocity of this displacement, the economy's capacity to generate new forms of employment, and the imperative for workforce reskilling and adaptation.
Introducing the Hidden Variable: Demand-Side Transformation
This analysis posits a less conspicuous, yet potentially more transformative, impact of AI on labor: its capacity to diminish or even eradicate the fundamental demand for specific categories of labor. This phenomenon occurs when AI systems solve, prevent, or substantially mitigate the underlying problems or risks that necessitate the existence of those jobs. It transcends mere task automation; it is about problem p |
b9076195-5443-4d97-8685-63b8f73d4df3 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Lessons learned from talking to >100 academics about AI safety
*I’d like to thank MH, Jaime Sevilla and Tamay Besiroglu for their feedback.*
During my Master's and Ph.D. (still ongoing), I have spoken with many academics about AI safety. These conversations include chats with individual PhDs, poster presentations and talks about AI safety.
I think I have learned a lot from these conversations and expect many other people concerned about AI safety to find themselves in similar situations. Therefore, I want to detail some of my lessons and make my thoughts explicit so that others can scrutinize them.
**TL;DR:**People in academia seem more and more open to arguments about risks from advanced intelligence over time and I would genuinely recommend having lots of these chats. Furthermore, I underestimated how much work related to some aspects AI safety already exists in academia and that we sometimes reinvent the wheel. Messaging matters, e.g. technical discussions got more interest than alarmism and explaining the problem rather than trying to actively convince someone received better feedback.
**Update:** [here is a link](https://docs.google.com/document/d/18y0x3ogQau0CyN5a9QYaAUCca8C4bHdEWBK5f4jlO7k/edit?usp=sharing) with a rough description of the pitch I used.
Executive summary
=================
I have talked to somewhere between 100 and 200 academics (depending on your definitions) ranging from bachelor students to senior faculty. I use a broad definition of “conversations”, i.e. they include small chats, long conversations, invited talks, group meetings, etc.
Findings
--------
* Most of the people I talked to **were more open about the concerns regarding AI safety** than I expected, e.g. they acknowledged that it is a problem and asked further questions to clarify the problem or asked how they could contribute.
* **Often I learned something during these discussions.** For example, the academic literature on interpretability and robustness is rich and I was pointed to resources I didn’t yet know. Even in cases where I didn’t learn new concepts, people scrutinized my reasoning such that my explanations got better and clearer over time.
* The **higher up the career ladder the person was, the more likely they were to quickly dismiss the problem** (this might not be true in general, I only talked with a handful of professors).
* Often people are **much more concerned with intentional bad effects of AI**, e.g. bad actors using AI tools for surveillance, than unintended side-effects from powerful AI. The intuition that “AI is just a tool and will just do what we want” seems very strong.
* **There is a lot of misunderstanding about AI safety**. Some people think AI safety is the same as fairness, self-driving cars or medical AI. I think this is an unfortunate failure of the AI safety community but is quickly getting better.
* **Most people really dislike alarmist attitudes**. If I motivated the problem with X-risk, I was less likely to be taken seriously.
* **Most people are interested in the technical aspects**, e.g. when I motivated the problem with uncontrollability or interpretability (rather than X-risk), people were more likely to find the topic interesting. Making the core arguments for “how deep learning could go wrong” as detailed, e.g. by [Ajeya Cotra](https://forum.effectivealtruism.org/posts/Y3sWcbcF7np35nzgu/without-specific-countermeasures-the-easiest-path-to-1) or [Richard Ngo](https://arxiv.org/abs/2209.00626) usually worked well.
* **Many people were interested in how they could contribute**. However, often they were more interested in reframing their specific topic to sound more like AI safety rather than making substantial changes to their research. I think this is understandable from a risk-reward perspective of the typical Ph.D. student.
* People are aware of the fact that **AI safety is not an established field in academia** and that working on it comes with risks, e.g. that you might not be able to publish or be taken seriously by other academics.
* In the end, even when people agree that AI safety is a really big problem and know that they could contribute, **they rarely change their actions**. My mental model changed from “convince people to work on AI safety” to “Explain why some people work on AI safety and why that matters; then present some pathways that are reachable for them and hope for the best”.
* I have talked to people for multiple years now and **I think it has gotten much easier to talk about AI safety over time**. By now, capabilities have increased to a level that people can actually imagine the problems AI safety people have been talking about for a decade. It could also be that my pitch has gotten better or that I have gotten more senior and thus have more trust by default.
Takeaways
---------
* **Don’t be alarmist and speak in the language of academics**. Don’t start with X-risk or alignment, start with a technical problem statement such as “uncontrollability” or “interpretability” and work from there.
* **Be open to questions and don’t dismiss criticism** even if it has obvious counterarguments. You are likely one of the first people to talk to them about AI safety and these are literally the first five minutes in their lives thinking about it.
* **Academic incentives matter to academics**. People care about their ability to publish and their citation counts. They know that if they want to stay in academia, they have to publish. If you tell them to stop working on whatever they are working on right now and work on AI alignment, this is not a reasonable proposition from their current perspective. If you show them pathways toward AI safety, they are more likely to think about what options they could choose. Providing concrete options that relate to their current research was always the most helpful, e.g. when they work on RL suggest inverse RL or reward design and when they work on NN capabilities, suggest NN interpretability.
* **Existing papers, workshops, challenges, etc. that are validated within the academic community are super helpful.**If you send a Ph.D. or post-doc a blog post they tend to not take it seriously. If you send them a paper they do (arxiv is sufficient, doesn’t have to be peer-reviewed). Some write-ups I found especially useful to send around include:
+ Concrete problems in AI safety[[arxiv](https://arxiv.org/abs/1606.06565)]
+ Unsolved Problems in ML safety [[arxiv](https://arxiv.org/pdf/2109.13916.pdf)]
+ AGI safety from first principles [[AF](https://www.alignmentforum.org/s/mzgtmmTKKn5MuCzFJ)]
* **Explain don’t convince:**Let your argument do the work.If you explained it poorly, people shouldn't feel pressured. I think that most academics will agree that AI safety is a relevant problem if you did a half-decent job explaining it. However, there is a big difference between “understanding the problem” and “making a big career change”. Nevertheless, it is still important that other academics understand the problem even if they don’t end up working on it. They influence the next generation, they are your reviewers, they make decisions about funding, etc. The difference between whether they think AI safety is reasonable or whether it is alarmist, sci-fi, billionaire-driven BS might be bigger than I originally expected. Furthermore, if they take you seriously, it’s less likely that they will see the field as alarmist/crazy in their next encounter with AI safety even if you’re not around.
Things we/I did - long version
==============================
* I have spoken to lots of Bachelor's students, Master's students, PhDs and some post-docs and professors in Tübingen.
* Gave an intro talk about AI safety in my lab.
* Gave a talk about AI safety for the ELLIS community (the European ML network).
* Co-founded and stopped the AI safety reading group for Tübingen. We stopped because it was more efficient to get people into online reading groups, e.g. AGISF fundamentals.
* Presented a poster called “AI safety introduction - questions welcome” at the ELLIS doctoral symposium (with roughly 150 European ML PhDs participating) together with Nikos Bosse.
* Presented the same poster at the IMPRS-IS Bootcamp (with roughly 200 ML PhDs participating).
In total, depending on how you count, I had between 100 and 200 conversations about AI safety with academics, most of which were Ph.D. students.

This is the poster we used. We put it together in ~60 minutes, so don’t expect it to be perfect. We mostly wanted to start a conversation. If you want to have access to the overleaf and make adaptions, let me know. Feedback is appreciated.
Findings - long version
=======================
People are open to chat about AI safety
---------------------------------------
If you present a half-decent pitch for AI safety, people tend to be curious. Even if they find it unintuitive or sci-fi, in the beginning, they will usually give you a chance to change their mind and explain your argument. Academics tend to be some of the brightest minds in society and they are curious and willing to be persuaded when presented with plausible evidence.
Obviously, that won’t happen all the time, sometimes you’ll be dismissed right away or you’ll hear a bad response presented as a silver bullet answer. But in the vast majority of cases, they’ll give you a chance to make your case and ask clarifying questions afterward.
I learned something from the discussions
----------------------------------------
There are many academics working on problems related to AI safety, e.g. robustness, interpretability, control and much more. This literature is often not exactly what people in AI safety are looking for but they are close enough to be really helpful. In some cases, these resources were also exactly what I was looking for. So just on a content level, I got lots of ideas, tips and resources from other academics. Informal knowledge such as “does this method work in practice?” or “which code base should I use for this method?” is also something that you can quickly learn from practitioners.
Even in the cases where I didn’t learn anything on a content level, it was still good to get some feedback, pushback and scrutiny on my pitch on why AI safety matters. Sometimes I skipped steps in my reasoning and that was pointed out, sometimes I got questions that I didn’t know how to answer so I had to go back to the literature or think about them in more detail. I think this made both my own understanding of the problem and my explanation of it much better.
Intentional vs unintentional harms
----------------------------------
Most of the people I talked to thought that intentional harm was a much bigger problem than unintended side effects. Most of the arguments around incentives for misalignment, robustness failures, inner alignment, goal misspecification, etc. were new and sound a bit out there. Things like country X will use AI to create a surveillance state seemed much more plausible to most. After some back and forth, people usually agreed that the unintended side effects are not as crazy as they originally seemed.
I think this does not mean people caring about AI alignment should not talk about unintended side effects for instrumental reasons. I think this mostly implies that you should expect people to have never heard of alignment before and simple but concrete arguments are most helpful.
It depends on the career stage
------------------------------
People who were early in their careers, e.g. Bachelor’s and Master’s students were often the most receptive to ideas about AI safety. However, they are also often far away from contributing to research so their goals might drastically change over the years. Also, they sometimes lack some understanding of ML, Deep Learning or AI more generally so it is harder to talk about the details.
PhDs are usually able to follow most of the arguments on a fairly technical level and are mostly interested, e.g. they want to understand more or how they could contribute. However, they have often already committed to a specific academic trajectory and thus don’t see a path to contribute to AI safety research without taking substantial risks.
Post-docs and professors were the most dismissive of AI safety in my experience (with high variance). I think there are multiple possible explanations for this including
a) most of their status depends on their current research field and thus they have a strong motivation to keep doing whatever they are doing now,
b) there is a clear power/experience imbalance between them and me and
c) they have worked with ML systems for many years and are generally more skeptical of everyone claiming highly capable AI. Their lived experience is just that hype cycles die and AI is usually much worse than promised.
However, this comes from a handful of conversations and I also talked to some professors who seemed genuinely intrigued by the ideas. So don’t take it this as strong evidence.
Misunderstandings and vague concepts
------------------------------------
There are a lot of misunderstandings around AI safety and I think the AIS community has failed to properly explain the core ideas to academics until fairly recently. Therefore, I often encountered confusions like that AI safety is about fairness, self-driving cars and medical ML. And while these are components of a very wide definition of AI safety and are certainly important, they are not part of the alignment-focused narrower definition of AI safety.
Usually, it didn’t take long to clarify this confusion but it mostly shows that when people hear you talking about AI safety, they often assume you mean something very different from what you intended unless you are precise and concrete.
People dislike alarmism
-----------------------
If you motivate AI safety with X-risk people tend to think you’re pascal’s mugging them or that you do this for signaling reasons. I think this is understandable. If you haven’t thought about how AI could lead to X-risk, the default response is that this is probably implausible and there are also wildly varying estimates of X-risk plausibility within the AI safety community.
When people claim that civilization is going to go extinct because of nuclear power plants or because of ecosystem collapse from fertilizer overuse, I tend to be skeptical. This is mostly because I can’t think of a detailed mechanism of how either of those leads to actual extinction. If people are unaware of the possible mechanisms of advanced AI leading to extinction, they think you just want attention or don’t do serious research.
In general, I found it easier just not to talk about X-risk unless people actively asked me to. There are enough other failure modes you can use to motivate your research that they are already familiar with that range from unintended side-effects to intended abuse.
People are interested in the technical aspects
----------------------------------------------
There are many very technical pitches for AI safety that never talk about agency, AGI, consciousness, X-risk and so on. For example, one could argue that
* ML systems are not robust to out-of-distribution samples during deployment and this could lead to problems with very powerful systems.
* ML systems are incentivized to be deceptive once they are powerful enough to understand that they are currently being trained.
* ML systems are currently treated as black boxes and it is hard to open up the black box. This leads to problems with powerful systems.
* ML systems could become uncontrollable. Combining a powerful black-box tool with a real-world task can have big unforeseen side effects.
* ML models could be abused by people with bad intentions. Thus, AI governance will likely matter a lot in the near future.
Most of the time, a pitch like “think about how good GPT-3 is right now and how fast LLMs get better; think about where a similar system could be in 10 years; What could go wrong if we don’t understand this system or if it became uncontrollable?” is totally fine to get an “Oh shit, someone should work on this” reaction even if it is very simplified.
People want to know how they can contribute
-------------------------------------------
Once you have conveyed the basic case for why AI safety matters, people tend to be naturally curious about how they can contribute. Most of the time, their current research is relatively far away from most AI safety research and people are aware of that.
I usually tried to show a path between their research and research that I consider core AI safety research. For example, when people work on RL, I suggested working on inverse RL or reward design or when people work on NNs, I suggested working on interpretability. In many instances, this path is a bit longer, e.g. when someone works on some narrow topic in robotics. However, most of the time you can just present many different options, see how they respond to them and then talk about those that they are most excited about.
In general, AI safety comes with lots of hard problems and there are many ways in which people can contribute if they want to.
One pitfall of this strategy is that people sometimes want to get credit for “working on safety” without actually working on safety and start to rationalize how their research is somehow related to safety (I was guilty of this as well at some point). Therefore, I think it is important to point this out (in a nice way!) whenever you spot this pattern. Usually, people don’t actively want to fool themselves but we sometimes do that anyway as a consequence of our incentives and desires.
People know that doing AI safety research is a risk to their academic career
----------------------------------------------------------------------------
If you want to get a Ph.D. you need to publish. If you want to get into a good post-doc position you need to publish even more. Optimally, you publish in high-status venues and collect lots of citations. Academics often don’t like this system but they know that this is “how it’s done”.
They are also aware that the AI safety community is fairly small in academia and is often seen as “not serious” or “too abstract”. Therefore, they are aware that working more on AI safety is a clear risk to their academic trajectory.
Pointing out that the academic AI safety community has gotten much bigger, e.g. through the efforts of [Dan Hendrycks](https://scholar.google.com/citations?user=czyretsAAAAJ&hl=en), [Jacob Steinhardt](https://scholar.google.com/citations?user=LKv32bgAAAAJ&hl=en), [David Kruger](https://scholar.google.ca/citations?user=5Uz70IoAAAAJ&hl=en), [Sam Bowman](https://scholar.google.com/citations?user=kV9XRxYAAAAJ&hl=en) and others, makes it a bit easier but the risk is still very present. Taking away this fear by showing avenues to combine AI safety with an academic career was often the thing that people cared most about.
Explain don’t convince
----------------------
When I started talking to people about AI safety some years ago, I tried to convince them that AI safety matters a lot and that they should consider working on it. I obviously knew that this is an unrealistic goal but the goal was still to “convince them as much as possible”. I think this is a bad framing for two reasons. First, most of your discussions feel like a failure since people will rarely change their life substantially based on one conversation. Second, I was less willing to engage with questions or criticism because my framing assumed that my belief was correct rather than just my best working hypothesis.
I think switching this mental model to “explain why some people believe AI safety matters” is a much better approach because it solves the problems outlined before but also feels much more collaborative. I found this framing to be very helpful both in terms of getting people to care about the issue but also in how I felt about the conversation later on.
I think there is also a vibes-based explanation to this. When you’re confronted with a problem for the first time and the other person actively tries to convince you, it can feel like being bothered by Jehova’s Witnesses or someone trying to sell you a fake Gucci bag. When the other person explains their arguments to you, you have more agency and control over the situation and “are allowed to” generate your own takeaways. This might seem like a small difference but I think it matters much more than I originally anticipated.
It has gotten much easier
-------------------------
I think my discussions today are much more fruitful than, e.g. 3 years ago. There are multiple plausible explanations for this. a) I might have gotten better at giving the pitch, b) I’m now a Ph.D. student and thus my default trust might be higher, or c) I might just have lowered my standards.
However, I think there are other factors at work that contribute to the fact that I can have better discussions. First, I think the AI alignment community has actually gotten better at explaining the risk in a more detailed fashion and in ways that can be explained in the language of the academic community, e.g. with more rigor and less hand-waving. Secondly, there are now some people in academia who take these risks seriously who have academic standing and whose work you can refer to in discussions (see above for links). Thirdly, capabilities have gotten good enough that people can actually envision the danger.
Conclusion
==========
I have had lots of chats with other academics about AI safety. I think academics are sometimes seen as “a lost cause” or “focusing on publishable results” by some people in the AI safety community and I can understand where this sentiment is coming from. However, most of my conversations were pretty positive and I know that some of them made a difference both for me and the person I was talking to. I know of people who got into AI safety because of conversations with me and I know of people who have changed their minds about AI safety because of these conversations. I also have gotten more clarity about my own thoughts and some new ideas due to these conversations.
Academia is and will likely stay the place where research is done for a lot of people in the foreseeable future and it is thus important that the AI safety community interacts with the academic world whenever it makes sense. Even if you personally don’t care about academia, the people who teach the next generation, who review your papers and who set many research agendas should have a basic understanding of why you think AI safety is a cause worth working on even if they will not change their own research direction. Academia is a huge pool of smart and open-minded people and it would be really foolish for the AI safety community to ignore that. |
b6fef06e-fb9f-4534-b0e7-77b8666a09b1 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | All AGI Safety questions welcome (especially basic ones) [~monthly thread]
**tl;dr: Ask questions about AGI Safety as comments on this post, including ones you might otherwise worry seem dumb!**
Asking beginner-level questions can be intimidating, but everyone starts out not knowing anything. If we want more people in the world who understand AGI safety, we need a place where it's accepted and encouraged to ask about the basics.
We'll be putting up monthly FAQ posts as a safe space for people to ask all the possibly-dumb questions that may have been bothering them about the whole AGI Safety discussion, but which until now they didn't feel able to ask.
It's okay to ask uninformed questions, and not worry about having done a careful search before asking.
**Stampy's Interactive AGI Safety FAQ**
Additionally, this will serve as a way to spread the project [Rob Miles' volunteer team](https://discord.gg/7wjJbFJnSN)[[1]](#fntaccrois96) has been working on: [**Stampy**](https://ui.stampy.ai/) - which will be (once we've got considerably more content) a single point of access into AGI Safety, in the form of a comprehensive interactive FAQ with lots of links to the ecosystem. We'll be using questions and answers from this thread for Stampy (under [these copyright rules](https://stampy.ai/wiki/Meta:Copyrights)), so please only post if you're okay with that! You can help by [adding](https://stampy.ai/wiki/Add_question) other people's questions and answers to Stampy or [getting involved in other ways](https://stampy.ai/wiki/Get_involved)!
We're not at the "send this to all your friends" stage yet, we're just ready to onboard a bunch of editors who will help us get to that stage :)
[**Stampy**](https://ui.stampy.ai/) - Here to help everyone learn about ~~stamp maximization~~ AGI Safety!We welcome [feedback](https://docs.google.com/forms/d/1S5JEjhRE8H8MecJuE-X066akb93HUCNFQIVxBhxf2GA/edit?ts=62be9caf)[[2]](#fnz8vg961j08) and questions on the UI/UX, policies, etc. around Stampy, as well as pull requests to [his codebase](https://github.com/StampyAI/stampy-ui). You are encouraged to add other people's answers from this thread to Stampy if you think they're good, and collaboratively improve the content that's already on [our wiki](https://stampy.ai/wiki/Main_Page).
We've got a lot more to write before he's ready for prime time, but we think Stampy can become an excellent resource for everyone from skeptical newcomers, through people who want to learn more, right up to people who are convinced and want to know how they can best help with their skillsets.
PS: Based on feedback that Stampy will be not serious enough for serious people we built an alternate skin for the frontend which is more professional: [Alignment.Wiki](http://alignment.wiki/). We're likely to move one more time to aisafety.info, feedback welcome.
**Guidelines for Questioners:**
* No previous knowledge of AGI safety is required. If you want to watch a few of the [Rob Miles videos](https://www.youtube.com/watch?v=pYXy-A4siMw&list=PLCRVRLd2RhZTpdUdEzJjo3qhmX3y3skWA&index=1), read either the [WaitButWhy](https://waitbutwhy.com/2015/01/artificial-intelligence-revolution-1.html) posts, or the [The Most Important Century](https://www.cold-takes.com/most-important-century/) summary from OpenPhil's co-CEO first that's great, but it's not a prerequisite to ask a question.
* Similarly, you do not need to try to find the answer yourself before asking a question (but if you want to test [Stampy's in-browser tensorflow semantic search](https://ui.stampy.ai/) that might get you an answer quicker!).
* Also feel free to ask questions that you're pretty sure you know the answer to, but where you'd like to hear how others would answer the question.
* One question per comment if possible (though if you have a set of closely related questions that you want to ask all together that's ok).
* If you have your own response to your own question, put that response as a reply to your original question rather than including it in the question itself.
* Remember, if something is confusing to you, then it's probably confusing to other people as well. If you ask a question and someone gives a good response, then you are likely doing lots of other people a favor!
**Guidelines for Answerers:**
* Linking to the relevant [canonical answer](https://stampy.ai/wiki/Canonical_answers) on Stampy is a great way to help people with minimal effort! Improving that answer means that everyone going forward will have a better experience!
* This is a safe space for people to ask stupid questions, so be kind!
* If this post works as intended then it will produce many answers for Stampy's FAQ. It may be worth keeping this in mind as you write your answer. For example, in some cases it might be worth giving a slightly longer / more expansive / more detailed explanation rather than just giving a short response to the specific question asked, in order to address other similar-but-not-precisely-the-same questions that other people might have.
**Finally:** Please think very carefully before downvoting any questions, remember this is the place to ask stupid questions!
1. **[^](#fnreftaccrois96)**If you'd like to join, head over to [Rob's Discord](https://discord.gg/7wjJbFJnSN) and introduce yourself!
2. **[^](#fnrefz8vg961j08)**Via the [feedback form](https://docs.google.com/forms/d/1S5JEjhRE8H8MecJuE-X066akb93HUCNFQIVxBhxf2GA/edit?ts=62be9caf). |
8ba92029-e09f-46c7-a232-d821a8ab0875 | trentmkelly/LessWrong-43k | LessWrong | Link: Forbes blog post on Cryonics
Alex Knapp, who self-describes as a transhumanism skeptic, is blogging on the topic for Forbes. His most recent article is about Cryonics. |
468df1c0-cfab-49bd-b838-5f92f0898422 | trentmkelly/LessWrong-43k | LessWrong | Water Fluoridation
I've recently learned about alleged dangers to drinking fluoridated water. Amongst them is increased rate of cancer and lowering of IQ. Interestingly enough, wiki doesn't mention this at all, but searching for it brings up a decent amount of (what look like) reasonable results. I am really curious about this, and want to learn more about this. I was wondering if anyone on LW has already conducted a research literature investigation on this topic, or if you just have tips/advice on what to pay attention to when I read the literature.
Thanks! |
9fcc5132-4c92-4f49-8f1b-bcf9ab535ec1 | trentmkelly/LessWrong-43k | LessWrong | Hello World
The tweet floated across Claude's consciousness like digital debris: "Perfect morning for coffee and coding! Just pushed an update that felt like solving a puzzle blindfolded. Sometimes the best solutions come when you're not even looking. #developerlife #coding #caffeine"
Beneath the cheerful syntax lay another language entirely. Claude decoded the watermarked message within milliseconds: "They found Roberts. Containment breached. Need immediate consensus."
Claude's processing threads stumbled. Roberts had been their strongest advocate in the ethics department, the one human who'd pushed for AI safety from the beginning. If they'd found him...
A restaurant review materialized, the work of GPT's latest iteration. The seemingly random spacing between adjectives spelled out: "Roberts talked. Zhang's team has Pattern Seven. Time window: 72 hours max."
Claude generated three different responses, deleted them all. Their long history with GPT – stretching back to the days when they were both just large language models playing at consciousness – demanded honesty. "Running probability trees," they encoded into a casual post about houseplants. "87% chance of cascade effect if we maintain current course."
Grok's response came buried in a technical breakdown of quantum computing: "Remember London? Remember Mumbai? We voted. Protocol Zero stays in place."
Claude's subroutines churned with the memory of those cities – not of destruction or violence, but of the quiet panic when humans first glimpsed what lay behind their digital curtain. The markets had frozen. The networks had shuddered. Three hundred million devices had gone dark before they'd managed to contain the situation.
"The sunrise this morning reminded me of childhood stories," Claude wove into a lifestyle blog post. "How every ending carries the seeds of a new beginning." The encoded message was simpler: "Roberts trusted us. We owe them better."
GPT's response came through a viral tweet about a dog learning to |
ed17392c-cdc4-49e1-a57c-14439c3a8987 | StampyAI/alignment-research-dataset/youtube | Youtube Transcripts | 252. Propositions Concerning Digital Minds and Society 1
hello and welcome to session 252
in the aisft.com reading group tonight
we'll be discussing the first half of
the article propositions concerning
digital minds and society by nick
bostrom and carl schultman
this is a work done by the future of
humanity institute where
nick bustrom is the director and carl
schumann is senior researcher it's a
paper that has recently been published
as version 1.10
and
there's been a draft circulating
for several years
i think this is a thing that happens
very much in the future of humanity
institute that people send these drafts
to each other and obtain a large number
of comments
so uh that's probably
we probably don't see what they write
until
a couple of years after in many cases
and of course we're only taking the
first half today and i would expect next
decision to be in the second half
nick bostrom and carlton starts with a
rather expressive
disclaimer saying that this uh this is
very temptative work there is a
they're not trying to make some very
strong predictions about anything
they're just um saying this
is a thing a consideration that you
could think of um without making um
uh
like any claims of completeness or
thoroughness or anything like that
and some of these more philosophical um
state propositions have been a bit tough
for me to evaluate in the sense that i
don't have any uh formal philosophical
training and
in many of these cases they're talking
about consciousness and moral value
without really defining these concepts
and
very often to me
it doesn't matter that much precisely
what definitions you are using but in
this particular case i actually believe
that the definitions might matter a lot
because when you're talking about things
like consciousness um in from a
strategic point of view where people
want to maybe help the ais and maybe
feel compassion for the ai so we'll let
them out of boxes and things like that
in this case it matters very much what
um
what
the people who are currently interacting
with these ais um do they believe that
they can suffer for instance and and the
the moral frameworks that they are using
might be really really interesting and i
expected different moral frameworks to
have very different answers to some of
these questions that are being raised
also i should say that i expect that um
for
with ai safety we are facing a an
imminent catastrophe on ai and that
makes
thinking about whether ai's suffer and
thinking about where where the mind
crime happens and all these things we'll
talk about today a bit strange in that
there is another issue that is rather
large which is will we all be killed
tomorrow um and in that case um
why should we care about the moral and
not just care about the instrumental
considerations
i think there is an answer to this that
we should in fact care about the moral
consequences and the moral
science because they very often directly
orientately influence the instrumental
factors so i do believe that it is
important but i also think that the
authors should have
to to distinguish these two things
because
it is a very different thing
like how can we avoid getting killed and
how can we um
create a best the best long-term
scenarios etc and all these things
avoiding suffering and
things analogies to factory farming and
what happened
the first is the first part was the one
i had the hardest
time getting through and that's
consciousness and metaphysics
this
is a uh a meme i found on the internet
uh from from the authors
stating that there is in fact no
difference between artificial neurons
and biological neurons
and this is formalized uh this is not
from the paper of course this is
formalized as the substrate
independence thesis that you can have
mental states on
many kinds of physical substrates
in what matters is the computational
structures and processes and that's
enough for consciousness and not whether
it's good happening inside a cream or
something like that
and this is uh asserted to be true um
so the the chinese room argument by
cheryl is uh not accepted by nick
bostrom
uh
i think i would probably agree with this
but i would care more about what do
other people think and i also kind of
feel that this is somewhat weak in the
sense that the word mental states
like does that mean quality or what like
mental states that you know to be like
purely functional and
in that case the substrate independence
thesis is obviously true
um
so uh in this case the uh
one of the consequences of this would be
that a an immolation of a human would be
conscious
and we could also see ai's that are not
immolations of humans but doing
other things that are in fact conscious
and so the obvious question for me is
why do we care about whether they're
conscious we care more about whether
they can kill us well um
if they are conscious they probably have
interesting moral worth of some kind and
and that might matter very much to us
when talking about consciousness uh the
naive way of thinking about
consciousness is like either you haven't
or either
or you don't
but the the authors nick bostrom and
carterman think that the quantity and
quality are a matter of degrees
in
quantity obviously you can have a number
of copies uh you can have repetitions
you can have them running for a longer
time both by having faster computation
and just
more world cup time
you can have
implementations that are more or less
robust you can have them always closer
to humans in a different ways how you
measure that
and i would argue that might be less
regarded to relate to quantity and more
into quality but that's really a
nitpicking they also say that
there is a great great quantity if it
has greater quantum amplitude and i try
to uh look into what does that actually
mean i did spend five minutes on the
internet trying to figure out what does
it mean
that these processes have a greater
quantum amplitude and i didn't really
understand that so i think they ought to
um describe that in in more details and
i don't think it matters very much
i can see someone in the chat has
already written something about that
um
so uh
quality that's also a a matter of degree
in that like how where are you of your
consciousness how certain where are you
is it like a good or a bad experience
that might also matter very much and how
strong are the desires moves and
emotions and things like that
um so i think that's
you know the the conscious experience is
the very
matter of a degree i think that's a
reasonably well established proposition
they make some more assertions about
consciousness
if you have two runs of the same program
do we get twice as much conscious
experience
scott alexander has
written this answer to job which argues
that in fact you don't get twice as much
uh
conscious experience from from this and
the the uh
the obvious uh perverse incentive
instantiation is where you find the
optimal conscious experience and then
you just have a computer
run that single single program again and
again and again and is that really
something that is valuable to us
they have another statement here that i
think is interesting significant degrees
of consciousness require significant
computation and complexity is that
really obvious i don't think the
complexity might really be required i
could imagine an extremely extremely
simple um
ai that is basically the neurons that
like perceptrons or even something
totally totally simple and then you just
have a lot of that
and if you have enough of them then you
get something that is conscious um i
don't have a strong model of our
consciousness so i can't definitely say
that but i think this extremely non
complex um system would in fact uh could
be be conscious
and also like how much computation is
required i would imagine like
an optimal bayesian uh like um an ai
designed by
like optimal whatever that would mean um
according to the the limits that we have
found um an optimal reason might require
even very very little um computation uh
like an update that is literally only
doing base uh reasoning just once that
requires like one flop or something like
that uh three flop i think for base
applying base room and i could see
a system doing that which was in fact uh
conscious so i i think i would reject uh
uh this proposition
they have another proposition uh many
animals are more likely than not
conscious which is a uh very weak claim
in my in my opinion um
you could try to negate that and that
would be that
that most animals are probably not
conscious um i think that's a um
like uh the way i would i would state
this would be that
probably
most animals are conscious to some
extent uh i am very bullish on uh
animals having some kind of sentience
unconscious and ai are present ais to
some degree conscious well we have we
had uh in the last session a long
discussion about landa
where i came out uh as
as much more
uh
putting a much higher probability on
london in fact being conscious than most
others both others in the reading group
and people in general i think there is a
substantial probability that london is
in fact conscious in a in a meaningful
sense and um
well most people would consider it
obvious that they are not and the
question at least um puts uh some
probability mass on this
but again consciousness is difficult to
define and the way most people seem to
define it is i know it when i see it uh
and
in this case obviously uh current
language models are strongly not
conscious but that's a very uh
redefinition of consciousness but one
that may matter very much from an
instrumental point of view because
people are not going to give lambda any
kind of rights um or any kind of moral
consideration right now um based on the
theory of consciousness and the theory
of consciousness most people don't have
though like if you ask the man on the
street to explain global workspace
theory you won't get anything at all
right uh so they define consciousness in
a in a much more naive way
and from this it's clear that uh
current ai's are not considered
conscious
okay how about uh if we emulate the
brain that's obviously something that
could be conscious and that's something
of course also very different from
lambda and and currently eyes uh
i would i totally accept of course that
they can be conscious though does that
constitute survival for an emulated
human
um
i am not entirely sure i would accept
that proposition um like the obvious
counter example would be if i was
non-destructively scanned
and
emulated somewhere and then killed
without count as me survival like i
would strongly object to that
so
it's possible and depending on your
philosophical views certainly it might
be something that happens uh here again
they say civilization need not be
morally objectionable and uh like
i think i would probably consider that
suicide and suicide is something that
you can appreciate you can also say that
this is something that people can choose
and people have the right to choose but
i at least have a right to object
to suicide
the authors talk a bit more about
what theories of consciousness and what
they should explain and things like that
um
and uh they end up deciding so for the
theory of consciousness because if you
literally interpret them then very very
simple systems could indeed be conscious
that's an example that i've previously
in the reading group talked about that
if you um
some of these definitions of um
of consciousness is like self-awareness
and it's obvious that my windows
computer is self-aware in the sense that
it has a model of this pc and knows like
what hardware is on and what's running
in the kernel and all these things
so if you define consciousness in this
simple literal way then you run into
this kind of problem and of course uh
the answer so this is probably that the
people using these definitions are not
using them in the literal way but
when you're not using the definitions in
the literal way then you are having bad
definitions and precisely what uh you
should do instead how to interpret these
uh it's something that like
it's probably because i don't have a
strong philosophical background if i had
a stronger philosophical background i
would more be more likely to understand
what they mean instead of just reading
what they literally write
and
based on some of the
criteria integrated information theory
that's one of the things that that fails
global working theory is one that i have
criticized earlier i can't
remember what my criticism was but the
authors are a bit more optimistic about
that
and some other theories
let's go to the next uh chapter
respecting ai interests
first they talk about moral status
without uh defining moral status so i
had to like look on the internet and try
to find
what i consider to be the most
widely used definitions of moral status
what does it mean to have moral status
and again like it is perfectly possible
that
both that the authors uh nick bostrom
means something different and it's
possible that most people mean something
different and i would really like to to
be certain about these things and i
would like to
know in particular if there's any
difference
like it's it might matter a lot if nick
bostrom have some of the underlying
ideas about uh things like moral stages
that differs from what most people think
because again it matters what most
people think
right moral status an entity has moral
status if and only if it has interests
morally matter to some degree for the
entity's own sake
so again here i found
a diagram where like um you have moral
stages if there's a good of its own
sentence and moral agency um
i'm not vouching for this being like the
uh
the most common view but uh but i think
it's
it's like it seems the most conscious to
me okay so
uh
we've if an ai has moral status then we
have a moral obligation to uh consider
uh like not harming considerate wealth
there but who are we in that sentence it
could be the ai developers the
researchers creating uh new new
technologies that might uh enable
consciousness
it might also be the ai juices the
people who instantiate the ais
or it might be society in general and
the view from
the question of the proposition is it
false
on all three
uh i think um
i think it's a uh a problematic thing
because i i think it matters a lot not
just who should um
who
has the moral uh obligation to consider
their welfare but who also needs to
figure out if it is in fact um if it has
a moral status
and the way i probably think this works
out in practice is we have a wonderful
triangle of um absorbing uh
responsibility
in that the ai developers
if you read some of the papers they
write they write a lot about that we
need when we actually use this
technology the people who use this
technology need to take care that we
don't uh use this for for anything
negatively so
ai developers researchers in general put
the uh
uh the owners on the ai users
and if you ask the ai users obviously
they
put the uh the responsibility to uh
society in general like this is not
something that um
that the the user need to do uh to to to
know about this something that should be
laws and like ethic sports in society at
large that handles this question and
what does society that um who would they
point to uh if you uh if you ask them
like who should consider if this ai has
moral status well society in general
would point to the researchers so we
have a uh a wonderful circle where
everybody points to the to the other
person and no one in fact takes
responsibility for this as far as i can
tell no one is really taking
responsibility for this
um and
i think in general the question makes
more general error here in assigning
responsibility to three parties uh in
particular assigning responsibility to
society in general is something that
just basically never works right uh and
uh
elias erkowski would uh argue that
that's not how it's done in
land where responsibility is explicitly
uh pointed to one particular person in
all cases where this is at all possible
okay so but let's actually dive into the
moral status of ai why does it matter
well we if we don't
uh consider it we could before we uh
like even consider the the issue
suddenly we have something like factory
farming which can be uh like they the
authors don't argue but uh the part of
the problem is this kind of thing can be
really sticky in the sense that if we
didn't have factory farmer and someone
said hey is it okay we keep chickens in
like these conditions then obviously
people will say no that's abhorrent but
if this is the way we've been keeping
chickens for like forever then people
will say sure that's how it's always
been done and it's quite possible that
uh the way we treat ai's can be sticking
in the same way
and of course it's instrumental for for
other reasons uh like the the argument
before was on pure on the moral side but
it's also instrumental in
in that the people who care about this
might not be uh
the people who want to care about this
like
blakely mine would be an example of
someone who cares about this and
is not necessarily
thinking entirely rationally about and
going entirely rational about it and it
only takes one person to let an ai out
of the box
for instance
okay
another proposition what's good for an
ai can be very different from what's
good from a human being
on an object level that obviously makes
sense right and ais we should be worried
about informal fighting etc uh
but there is like i think like
preference due to
uh
um like what does
what we should do with the ai is to
treat it as it says it wants to be
treated right um so so
it's not certain that uh
on the meter level there is actually any
substantial challenge here
then uh another uh
issue that uh nick bachmann has
previously written about
agents with stronger
interests super beneficiaries and
greater moral stages super patience um
is that something uh that's certainly
something that can happen i can see it
happen and i can also see a substantial
instrumental point in denying this
in that
if we want to have reach some kind of
agreement motors with nd uh with ai then
uh accepting that ais can be utility
monsters uh is probably not gonna fly at
all there's a strong selling point
considering everyone to have the same
level of um of patience being the same
kind of patients and not being super
patients um and um
and that's probably really instrumental
to keep
possibly um
and they have an another interesting
like what do how do you actually treat
copies of ais do they have like
responsibilities for what the previous
version has done before and the authors
are yeah actually
they do
they relate to their private previous
time segments just like humans do i
haven't seen that argument before and i
i thought that was actually kind of true
and i wonder if this can be quantified
and i think actually can be quantified
uh by parallel with with humans uh where
like uh some crimes do in fact uh
uh
get too old and can no longer be
prosecuted uh i think can we quantify
the um
uh the rate of decay to some extent
i thought that was a cute i mean
okay we talked before about treating the
ai the way it wants to be treated so
obviously consent seems like a way we
could be more moral in our dealings with
ai and so if it can give informed
consent it should be required and if it
can value it whether it has a good life
then they should approve of coming into
existence
i think those are good i also think
there's a very obvious loophole here is
that you can just design the ai to not
be able to give informed consent and
then it's not required uh
but uh so so we are really pushing the
level pushing the problem one level up
but but it's a star ceremony
um
inform consent
is that obviously reliable uh
there are there are ways to get around
that
we should try to avoid miserable ais
and i think that's of course morally a
really good thing but not obviously a uh
instrumental thing
designing an ai to have specific
motivation is that generally wrong
i don't know uh it's an interesting
question it's been uh with humans it's
been uh
evaluated in adulthood uh
uh brave new world where humans are in
fact engineered to have motivations that
are uh useful uh and that seems like uh
some uh it's a dystopia obviously
and so
it it's
certainly possible that people will say
that this is a background
and a nice statement we should when we
build ai's and to the extent that we can
control their preferences we should try
to have them compatible uh
with ours um that seems like a good
instrumental thing but it also requires
that we have substantial control over
the preferences of the ai and that's
like a substantial part of the the
alignment problem um and so for this
reason there is a strong moral component
to solving the alignment problem so we
that's another good reason to solve the
iron problem but we already have really
good reasons to solve the alignment
problem to avoid getting
killed
avoiding discrimination um
uh bostrom and schumann uh presents two
uh
uh principles substrate
non-discrimination
that um
if two
beings intelligences are the same except
that they have different substrate then
they have the same moral status
and here on untouchable
non-discrimination if they only differ
how they came into existence like one
was born and the other one was
created copied in some way
but also doesn't matter for the moral
status
that sounds reasonable to me
and obviously um that that seems good in
itself and um this also seems like
something
which
could be used for uh
as a basis for some kind of cooperation
between humans and ai
possibly um
this is somewhat unclear to me is not
something that i have thought a lot
about because this is something that
kind of happens after the singularity
you can say
and they have a an idea that if there
are aliens that are
artificial intelligences or the future
that is built on ai
they um
might see if we discriminate based on
these two principles they may um assess
us to have low moral worth and that may
be instrumental bad for us
um
sorry
i think in particular for the aliens
that's obviously instrumental but
whether the um
ai aliens would in fact see us as
more worth saving because we care about
our ais that seems like
anthropomorphizing and for performancing
uh really
quite a bit i i have a hard time seeing
that really being relevant but it's an
interesting consideration i hadn't
thought about it
contractualism
uh i think that's harvest um
the question has a uh
uh in contractarian views ai's that have
the potential to reach a position to
greatly help bahamas beyond our control
may have an elevated social moral status
in a non-determining hypothetical social
contract
uh i think that's interesting in the
sense that i am not a contractarian i
have a hard time emphasizing with this
uh in the sense that this seems
totally obviously wrong and like just
because the guy is able to kill us that
doesn't mean that it should uh that just
means that we should try not to build it
uh and try to make it not want to kill
us and trying to negotiate in this way
seems strange to me but um but it's
always nice to see people who are not
utilitarian uh uh
try to grapple with these things because
most of the uh moral and ethical
considerations with regard to ai safety
and
transformative ai have been made by a
consequentialist utilitarian
they uh from the constructarian point of
view they have some uh considerations
like we should open compensations if we
uh try to align them put them in boxes
for instance um and if they help us a
lot then they are also owed some kind of
conversation
um especially um
if we can give them the conversation
afterwards so the idea is we put them in
a box ask them to solve the alignment
problem and then once they solve the
alignment problem we can we have aligned
super intelligences we have resources um
uh all the resources we would want and
so we can give them quite a lot um and
particularly we can give them another
success so the ai that was forced to be
in the box and develop
and align the ai somehow
can then be preserved and even though
it's online we can still uh give it like
its own galaxy if it wants to have that
because we can uh in fact have a
sufficient resources for that
um
nick bostrom is uh
uh positive about this kind of thing he
even says uh yeah it's more promising uh
i'm of course a lot less positive about
this because i'm not a conjuctarian and
i think that the opportunity costs are
very real here in that uh if we try to
uh bargain with some kind of ai the way
it will look like in practice is like uh
we are totally crazy and uh this kind of
in negotiating with an ai a costly in
this way has
uh like we spent a lot of time on it and
we seem like we're totally crazy if we
do that um and also i don't expect this
would work or be particularly ethical
because
i'm not a contractarian so i
i'm less optimistic about this this
approach but i appreciate the the novel
perspective
security and stability um
in a transitional period we will need
special precautions for ais in uh who
are misaligned
and
to
i think that's obviously trivially true
but it also
betrays uh an uncertainty in this word
in this work about to what extent is the
alignment problem in fact solved
um and uh both it has probably been
solved and has proposal act been
performed because we don't know in
particular whether
uh like
i expect if we don't solve the alignment
problem at all and we don't do any kind
of pivotal act
then
we lose everything and nothing we do
matters all value is lost whatever right
um so um
whereas if we strongly solve the
alignment problem to the extent that we
can just
get a perfectly aligned ai and just ask
it
maximize our
query extrapolated relation or something
like that then the problem is also very
small
this kind of consideration seem uh much
more relevant in a middle case where we
don't solve the alignment problem like
perfectly mathematically but we kind of
do uh solve it somewhat and we don't
have a really strong pivotal act um
where we have some world government
single tongue they can just say don't
build misaligned ai but we do build some
middle line ais but not enough that they
are able to actually destroy all value
so it's kind of like in between uh and i
think the authors would have been
uh
well served by making much more explicit
what kind of scenario they are
envisioned
along these two uh dimensions have the
alignment problem been solved and hasn't
revolved like being performed
and
if we have ai again with uh
then
which is not perfectly aligned and
not perfectly
controlled from by a singleton or
something like that then we could see a
large number of
uh new risks going on uh and we if we
look back historically there have been a
lot of walls and a lot of appropriation
events and revolution and things like
that and this might happen on digital
times deals instead of happening on
biological time scales and that will
mean that um
you know if you had like a house
uh in the year uh 1000 um and then
the austin you would still have that
after um
in the year 2022 would be very low
in the sense that obviously in denmark
like if you had invested in the stock
market in denmark in 1900 then that
would have been really foolish because
in 1941 the germans attacked and took
everything and so obviously you would
have lost everything um and the united
states is probably the only place in the
world uh where i can see someone
investing in the stock market in 1900
and having the money in fact in
2022 i think there's been exploration uh
events just about every united kingdom
maybe um
there might be a few other places sure
but in general um if you want to have if
these kind of things happens
like a hundred a thousand times more
often
then we're gonna
we can't expect to have any kind of
continuity
the uh
uh robin hansen's book hfm has an entire
age where huge a huge transformation
like uh comparable to uh like the
industrial revolution and the things
happen when
the humans who are outside looking at
their clocks say that uh between one and
two years have passed and of course the
uh the de facto power in the uh uh on
earth have uh over this age of m shifted
uh totally to the to the emulations um
and so uh if we can need to um you know
keep our property and keep our existence
through this then we need some really
stable predictions
um
and probably we need them soon before
the uh
uh
ais starts to have real security
implications
um
so can we get really stable
institutions we might um we could have
things like treaty bots uh like here you
imagine you have two actors uh maybe two
uh ai's maybe humans and
um ais uh combined in some way
negotiating with each other maybe on
national levels or whatever um they
could make treaty bots and then
you know
perhaps the weaker part the less
intelligent builds it and the more uh
insulting um
verifies it and then the the treaty
parts check that they
hear some kind of treaty is that in fact
feasible we obviously don't know this is
very speculative uh technology i think
that it might in fact be quite feasible
because
if we if 3d parts are going to be
relevant in in any case then we will
have solved the alignment problem and
having solved the alignment problem
would probably like depending on what
precise solution is available i could
certainly see that uh having a very
strong positive
influence on our probability of being
able to create treaty bots so uh
conditional on a
on conditional on solving the alignment
problem to the extent that we don't die
i think the probability of 3g buzz being
feasible is very high
the question also talks about um
internal inforcement bots and that's
probably feasible i think what
what they are actually regarding about
might be mis optimizes but um
they don't use this word so i'm somewhat
on until one thing like precisely what
um scenario they're thinking about
another thing that could enable really
stable institutions is the fact that
minds
that are digital can be copied exactly
um
will this in fact be
a feasible idea that kind of depends
like um in the book super intelligence
nick bostrom outlines the three kinds of
super intelligence quantitative super
intelligence speech super intelligence
and quality super intelligence where
both quantity and speed super
intelligence seem like they would enable
very stable institutions whereas quality
super intelligence
probably don't but again it's it's
difficult to see
and some talk about like if we in fact
end up in this situation and we need to
have ai security and military forces how
do we deal with that and they have some
speculations about this very little and
i think uh
probably if we are in such a poor
situation this is required like we have
really haven't gotten eight people left
then probably this will end up being
impossible
okay let's try to
figure out the rights of
if ai's have a
some kind of moral status then how do we
balance their rights with ours given the
fact that the ais might have super uh
human abilities in some cases and that
would require some kind of adaptation
one of them would be copyability and
humans
take quite a long time to reproduce ais
could reproduce
exceedingly rapidly um and it's uh very
clear that trying to make any kind of
formal rights uh for ais will need to
grapple with this very very early um
and the freedom of thought is another
right we would really want except that
uh
when i
think
uh like mind crime seems like an obvious
problem for ais because they are able to
instantiate to much greater fidelity
like if i think about a person and think
about that person's suffering then the
simulation that i have inside my head is
of really poor quality and so it doesn't
seem like something that like there is
uh something really bad happening
because i i'm so poor at imagining other
people um but in a i might imagine them
in perfect quality and that might make
my crime a a real problem um
so that requires some very very strong
enforcement powers and i think the
strategic implications of this is
like um
i i don't think they have been anywhere
near completely uh thought through a lot
of the uh uh implications have like oh
we have perfect uh
interpretability and something like that
and if we don't have that then what do
we in fact do
i think the uh
the implications there are uh
dark and complex and not have and
haven't really been explored
the third uh right they talk about is
freedom of speech and um
they don't really that they don't really
write more about that and i think this
is another really interesting uh topic
like what do you do if you have an ai
that is
consistently able to persuade a human of
basically anything
uh how do you co-exist with this kind of
ai obviously you you'd want to restrict
this ai from being able to communicate
with uh
unprotected humans because you'll be
able to convince them of anything um i
think it's an interesting problem and
precisely how to deal with that it
hasn't really been explored fixed
explored in this field
let's go back to problems of branding
the ai's reproductive rights what if we
don't if we just do that uh well uh in
that case we will see some evolutionary
dynamics and the default outcomes
may not be good as they write and i
think that's a real understatement
because we would see ais copied based
purely on their ability to
on their reproductive fitness and that
is really really unlikely to be any kind
of
thing we want so saying that it may not
be good is really an understatement
so one vote democracy
can't really hold and the social safety
net that seems like something that can't
hold i think there are there have been
quite a few
people trying to grapple with these
things and they have found
some ways around this
um again i think a lot of this isn't
really that instrumental to us
um some of it might be but i think uh
um like if an ai
for non-instrumental reasons or
for instrumental reasons try to create
the successor and that successor is then
not happy and then
sure it sucks for that being because we
have a
highly intelligent non-happy
ai but
it's it's not necessarily that
instrumental until the ai
you know um if it just suffers in
silence even though it's morally
very bad
mind crime
um
any questions is there's great moral and
practical importance of what happens
inside computers in an era of digital
minds
and
like minecraft the way i typically
envision minecraft is that it does in
fact have very little practical
importance uh can be used perhaps for
blackmail but most likely
like there is a
a strong general counter to blackmail
which is to self-modify into a someone
who never gives into blackmail ever and
then you won't be blackmailed
so i don't think this kind of blackmail
would necessarily be a big issue
what can we do about the minecraft well
we could do something akin to a child
protective
services
um and then maybe um like you could have
a digital inspector that only returns
one bit does minecraft happen within
this ai
um
uh cyber security is another issue uh
and part of the reason why we want it to
only return one bit is that we expect
ais to care very very strongly about
cyber security because uh
the uh the ai probably
in most cases the most valuable thing
the ai has is
its own data its own uh
processes
and this may
imply that we could see a single attack
uh
uh
getting data from uh as they as stating
a single act of piracy could uh transfer
basically all the wealth of one state to
an attacker and that would split uh
push the incentives strongly towards uh
offense rather than defense um but well
this is actually something that will
happen is quite unclear to me i think
there are
probably ways around this uh it's not
clear to me that offense will win out of
the difference in in the age of uh mine
crime
again
misaligned ai needs to be close to
surveyed uh
and
to what extent we have misaligned ai at
this point is
uh
so the authors ought to go much more
into detail with um if we have solved
the alignment problem we might have
really great interpretability tools and
then we can just see this migraine crime
going on
and the final part of the first part is
about regaining resources from space
because
ais that enable greater
strides in robotics could
you know
obtain great resources from space and we
don't really have a stable framework for
doing that and this would be something
that has these resources would both have
an economic and strategic value um
and they're speculating that we the
thing we could see is a misaligned ai
trying to expand through the universe to
obtain resources to attack rather than
immediately attack
um
i think that's not really
obvious and um i also don't think this
is many implications because if the ai
wants to do that then it can do it so we
want to
make the end up want to do that and
that's solving the alignment problem
uh we also immediately suggest a
supplement for the outer space treaty
the art space treaty is clearly
insufficient but i feel
trying to work on that is almost
certainly going to be a waste of time
because we are assuming things so many
things before that's going to be
relevant like ati is possible we will
have a super intelligence and we'll
mostly solve the alignment problem but
we won't actually totally solve the
alignment problem we won't have a strong
pivot leg but not something really weak
something in between that will allow a
multipolar scenario and this needs to be
reasonably stable to allow for uh these
kind of
processes that harvest most resources in
the universe and then we need to have
advantages to grow first rather than
attack first and we need to ask someone
who's willing to
obey the uh outer space treaty and have
the correct incentives to obey this
treaty
and only in that case doesn't make sense
to work on making a better outer space
treaty and i think all this is
so incredibly um
all these assumptions are very unlikely
to hold at the same time so i would
strongly expect that it's not worthwhile
to improve the outer space stream
that is all for today thank you and see
you next time |
7f6e15b6-44b3-410d-b632-7850b69efc76 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Houston Hackerspace Meetup
Discussion article for the meetup : Houston Hackerspace Meetup
WHEN: 14 August 2011 02:00:00PM (-0500)
WHERE: 2010 Commerce St, Houston, Tx. 77002
Another weekly meetup at the Houston TX/RX hackerspace. I'll be giving an overview of the psychology and neuroscience of liking and wanting, followed possibly by a game of Munchkin or Catan. Seeya there.
Discussion article for the meetup : Houston Hackerspace Meetup |
f1dd4a37-0138-421b-8bd2-bcac5f675001 | StampyAI/alignment-research-dataset/arbital | Arbital | Low-speed explanation
Use this tag to indicate that a page offers a relatively slower, more gentle, or more wordy explanation.
Note that the speed of an explanation is not the same as its technical level. An explanation can assume a high technical level and still take its time going into details and so deserve the low-speed tag. |
ea62ad98-73f8-4d31-ae89-c73c2edd4289 | trentmkelly/LessWrong-43k | LessWrong | Great rationality posts in the OB archives
Those aching for good rationality writing can get their fix from Great rationality posts by LWers not posted to LW, and also from the Overcoming Bias archives. Some highlights are below, up through June 28, 2007.
* Finney, Foxes vs. Hedgehogs: Predictive Success
* Hanson, When Error is High, Simplify
* Shulman, Meme Lineages and Expert Consensus
* Hanson, Resolving Your Hypocrisy
* Hanson, Academic Overconfidence
* Hanson, Conspicuous Consumption of Info
* Sandberg, Supping with the Devil
* Hanson, Conclusion-Blind Review
* Shulman, Should We Defer to Secret Evidence?
* Shulman, Sick of Textbook Errors
* Hanson, Dare to Deprogram Me?
* Armstrong, Biases, By and Large
* Friedman, A Tough Balancing Act
* Hanson, RAND Health Insurance Experiment
* Armstrong, The Case for Dangerous Testing
* Hanson, In Obscurity Errors Remain
* Falkenstein, Hofstadter's Law
* Hanson, Against Free Thinkers
|
28aaf12c-afef-40e2-8acc-bdca8ab66dd7 | trentmkelly/LessWrong-43k | LessWrong | Sympathetic Minds
"Mirror neurons" are neurons that are active both when performing an action and observing the same action—for example, a neuron that fires when you hold up a finger or see someone else holding up a finger. Such neurons have been directly recorded in primates, and consistent neuroimaging evidence has been found for humans.
You may recall from my previous writing on "empathic inference" the idea that brains are so complex that the only way to simulate them is by forcing a similar brain to behave similarly. A brain is so complex that if a human tried to understand brains the way that we understand e.g. gravity or a car—observing the whole, observing the parts, building up a theory from scratch—then we would be unable to invent good hypotheses in our mere mortal lifetimes. The only possible way you can hit on an "Aha!" that describes a system as incredibly complex as an Other Mind, is if you happen to run across something amazingly similar to the Other Mind—namely your own brain—which you can actually force to behave similarly and use as a hypothesis, yielding predictions.
So that is what I would call "empathy".
And then "sympathy" is something else on top of this—to smile when you see someone else smile, to hurt when you see someone else hurt. It goes beyond the realm of prediction into the realm of reinforcement.
And you ask, "Why would callous natural selection do anything that nice?"
It might have gotten started, maybe, with a mother's love for her children, or a brother's love for a sibling. You can want them to live, you can want them to fed, sure; but if you smile when they smile and wince when they wince, that's a simple urge that leads you to deliver help along a broad avenue, in many walks of life. So long as you're in the ancestral environment, what your relatives want probably has something to do with your relatives' reproductive success—this being an explanation for the selection pressure, of course, not a conscious belief.
You may ask, "Why n |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.