
id stringlengths 36 36 | source stringclasses 15 values | formatted_source stringclasses 13 values | text stringlengths 2 7.55M |
|---|---|---|---|
df1db045-7149-441a-b0be-9af948750912 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Discussion with Eliezer Yudkowsky on AGI interventions
Thefollowing is a partially redacted and lightly edited transcript of a chat conversation about AGI between Eliezer Yudkowsky and a set of invitees in early September 2021. By default, all other participants are anonymized as "Anonymous".
I think this Nate Soares quote (excerpted from Nate's [response to a report by Joe Carlsmith](https://www.lesswrong.com/posts/cCMihiwtZx7kdcKgt/comments-on-carlsmith-s-is-power-seeking-ai-an-existential)) is a useful context-setting preface regarding timelines, which weren't discussed as much in the chat transcript:
> [...] My odds [of AGI by the year 2070] are around 85%[...]
>
> I can list a handful of things that drive my probability of AGI-in-the-next-49-years above 80%:
>
> 1. 50 years ago was 1970. The gap between AI systems then and AI systems now seems pretty plausibly greater than the remaining gap, even before accounting the recent dramatic increase in the rate of progress, and potential future increases in rate-of-progress as it starts to feel within-grasp.
>
> 2. I observe that, 15 years ago, everyone was saying AGI is far off because of what it couldn't do -- basic image recognition, go, starcraft, winograd schemas, programmer assistance. But basically all that has fallen. The gap between us and AGI is made mostly of intangibles. (Computer Programming That Is Actually Good? Theorem proving? Sure, but on my model, "good" versions of those are a hair's breadth away from full AGI already. And the fact that I need to clarify that "bad" versions don't count, speaks to my point that the only barriers people can name right now are intangibles.) That's a very uncomfortable place to be!
>
> 3. When I look at the history of invention, and the various anecdotes about the Wright brothers and Enrico Fermi, I get an impression that, when a technology is pretty close, the world looks a lot like how our world looks.
>
> * Of course, the trick is that when a technology is a little far, the world might also look pretty similar!
> * Though when a technology is **very** far, the world **does** look different -- it looks like experts pointing to specific technical hurdles. We exited that regime a few years ago.
>
> 4. Summarizing the above two points, I suspect that I'm in more-or-less the "penultimate epistemic state" on AGI timelines: I don't know of a project that seems like they're right on the brink; that would put me in the "final epistemic state" of thinking AGI is imminent. But I'm in the second-to-last epistemic state, where I wouldn't feel all that shocked to learn that some group has reached the brink. Maybe I won't get that call for 10 years! Or 20! But it could also be 2, and I wouldn't get to be indignant with reality. I wouldn't get to say "but all the following things should have happened first, before I made that observation". I have made those observations.
>
> 5. It seems to me that the Cotra-style compute-based model provides pretty conservative estimates. For one thing, I don't expect to need human-level compute to get human-level intelligence, and for another I think there's a decent chance that insight and innovation have a big role to play, especially on 50 year timescales.
>
> 6. There has been a lot of AI progress recently. When I tried to adjust my beliefs so that I was **positively** surprised by AI progress just about as often as I was **negatively** surprised by AI progress, I ended up expecting a bunch of rapid progress. [...]
>
>
**Further preface by Eliezer:**
In some sections here, I sound gloomy about the probability that coordination between AGI groups succeeds in saving the world. Andrew Critch reminds me to point out that gloominess like this can be a self-fulfilling prophecy - if people think successful coordination is impossible, they won’t try to coordinate. I therefore remark in retrospective advance that it seems to me like at least some of the top AGI people, say at Deepmind and Anthropic, are the sorts who I think would rather coordinate than destroy the world; my gloominess is about what happens when the the technology has propagated further than that. But even then, anybody who would *rather* coordinate and *not* destroy the world shouldn’t rule out hooking up with Demis, or whoever else is in front if that person also seems to prefer not to completely destroy the world. (Don’t be too picky here.) Even if the technology proliferates and the world ends a year later when other non-coordinating parties jump in, it’s still better to take the route where the world ends one year later instead of immediately. Maybe the horse will sing.
---
**Eliezer Yudkowsky**
Hi and welcome. Points to keep in mind:
- I'm doing this because I would like to learn whichever *actual* thoughts this target group may have, and perhaps respond to those; that's part of the point of anonymity. If you speak an anonymous thought, please have that be your actual thought that you are thinking yourself, not something where you're thinking "well, somebody else might think that..." or "I wonder what Eliezer's response would be to..."
- Eliezer's responses are uncloaked by default. Everyone else's responses are anonymous (not pseudonymous) and neither I nor MIRI will know which potential invitee sent them.
- Please do not reshare or pass on the link you used to get here.
- I do intend that parts of this conversation may be saved and published at MIRI's discretion, though not with any mention of who the anonymous speakers could possibly have been.
**Eliezer Yudkowsky**
(Thank you to Ben Weinstein-Raun for building [chathamroom.com](https://www.chathamroom.com/), and for quickly adding some features to it at my request.)
**Eliezer Yudkowsky**
It is now 2PM; this room is now open for questions.
**Anonymous**
How long will it be open for?
**Eliezer Yudkowsky**
In principle, I could always stop by a couple of days later and answer any unanswered questions, but my basic theory had been "until I got tired".
---
**Anonymous**
At a high level one thing I want to ask about is research directions and prioritization. For example, if you were dictator for what researchers here (or within our influence) were working on, how would you reallocate them?
**Eliezer Yudkowsky**
The first reply that came to mind is "I don't know." I consider the present gameboard to look incredibly grim, and I don't actually see a way out through hard work alone. We can hope there's a miracle that violates some aspect of my background model, and we can try to prepare for that unknown miracle; preparing for an unknown miracle probably looks like "Trying to die with more dignity on the mainline" (because if you can die with more dignity on the mainline, you are better positioned to take advantage of a miracle if it occurs).
**Anonymous**
I'm curious if the grim outlook is currently mainly due to technical difficulties or social/coordination difficulties. (Both avenues might have solutions, but maybe one seems more recalcitrant than the other?)
**Eliezer Yudkowsky**
Technical difficulties. Even if the social situation were vastly improved, on my read of things, everybody still dies because there is nothing that a handful of socially coordinated projects can do, or even a handful of major governments who aren't willing to start nuclear wars over things, to prevent somebody else from building AGI and killing everyone 3 months or 2 years later. There's no obvious winnable position into which to play the board.
**Anonymous**
just to clarify, that sounds like a large scale coordination difficulty to me (i.e., we - as all of humanity - can't coordinate to not build that AGI).
**Eliezer Yudkowsky**
I wasn't really considering the counterfactual where humanity had a collective telepathic hivemind? I mean, I've written fiction about a world coordinated enough that they managed to shut down all progress in their computing industry and only manufacture powerful computers in a single worldwide hidden base, but Earth was never going to go down that route. Relative to remotely plausible levels of future coordination, we have a technical problem.
**Anonymous**
Curious about why building an AGI aligned to its users' interests isn't a thing a handful of coordinated projects could do that would effectively prevent the catastrophe. The two obvious options are: it's too hard to build it vs it wouldn't stop the other group anyway. For "it wouldn't stop them", two lines of reply are nobody actually wants an unaligned AGI (they just don't foresee the consequences and are pursuing the benefits from automated intelligence, so can be defused by providing the latter) (maybe not entirely true: omnicidal maniacs), and an aligned AGI could help in stopping them. Is your take more on the "too hard to build" side?
**Eliezer Yudkowsky**
Because it's too technically hard to align some cognitive process that is powerful enough, and operating in a sufficiently dangerous domain, to stop the next group from building an unaligned AGI in 3 months or 2 years. Like, they can't coordinate to build an AGI that builds a nanosystem because it is too technically hard to align their AGI technology in the 2 years before the world ends.
**Anonymous**
Summarizing the threat model here (correct if wrong): The nearest competitor for building an AGI is at most N (<2) years behind, and building an aligned AGI, even when starting with the ability to build an unaligned AGI, takes longer than N years. So at some point some competitor who doesn't care about safety builds the unaligned AGI. How does "nobody actually wants an unaligned AGI" fail here? It takes >N years to get everyone to realise that they have that preference and that it's incompatible with their actions?
**Eliezer Yudkowsky**
Many of the current actors seem like they'd be really gung-ho to build an "unaligned" AGI because they think it'd be super neat, or they think it'd be super profitable, and they don't expect it to destroy the world. So if this happens in anything like the current world - and I neither expect vast improvements, nor have very long timelines - then we'd see Deepmind get it first; and, if the code was not *immediately* stolen and rerun with higher bounds on the for loops, by China or France or whoever, somebody else would get it in another year; if that somebody else was Anthropic, I could maybe see them also not amping up their AGI; but then in 2 years it starts to go to Facebook AI Research and home hobbyists and intelligence agencies stealing copies of the code from other intelligence agencies and I don't see how the world fails to end past that point.
**Anonymous**
What does trying to die with more dignity on the mainline look like? There's a real question of prioritisation here between solving the alignment problem (and various approaches within that), and preventing or slowing down the next competitor. I'd personally love more direction on where to focus my efforts (obviously you can only say things generic to the group).
**Eliezer Yudkowsky**
I don't know how to effectively prevent or slow down the "next competitor" for more than a couple of years even in plausible-best-case scenarios. Maybe some of the natsec people can be grownups in the room and explain why "stealing AGI code and running it" is as bad as "full nuclear launch" to their foreign counterparts in a realistic way. Maybe more current AGI groups can be persuaded to go closed; or, if more than one has an AGI, to coordinate with each other and not rush into an arms race. I'm not sure I believe these things can be done in real life, but it seems understandable to me how I'd go about trying - though, please do talk with me a lot more before trying anything like this, because it's easy for me to see how attempts could backfire, it's not clear to me that we should be inviting more attention from natsec folks at all. None of that saves us without technical alignment progress. But what are other people supposed to do about researching alignment when I'm not sure what to try there myself?
**Anonymous**
thanks! on researching alignment, you might have better meta ideas (how to do research generally) even if you're also stuck on object level. and you might know/foresee dead ends that others don't.
**Eliezer Yudkowsky**
I definitely foresee a whole lot of dead ends that others don't, yes.
**Anonymous**
Does pushing for a lot of public fear about this kind of research, that makes all projects hard, seem hopeless?
**Eliezer Yudkowsky**
What does it buy us? 3 months of delay at the cost of a tremendous amount of goodwill? 2 years of delay? What's that delay for, if we all die at the end? Even if we then got a technical miracle, would it end up impossible to run a project that could make use of an alignment miracle, because everybody was afraid of that project? Wouldn't that fear tend to be channeled into "ah, yes, it must be a government project, they're the good guys" and then the government is much more hopeless and much harder to improve upon than Deepmind?
**Anonymous**
I imagine lack of public support for genetic manipulation of humans has slowed that research by more than three months
**Anonymous**
'would it end up impossible to run a project that could make use of an alignment miracle, because everybody was afraid of that project?'
...like, maybe, but not with near 100% chance?
**Eliezer Yudkowsky**
I don't want to sound like I'm dismissing the whole strategy, but it sounds a *lot* like the kind of thing that backfires because you did not get *exactly* the public reaction you wanted, and the public reaction you actually got was bad; and it doesn't sound like that whole strategy actually has a visualized victorious endgame, which makes it hard to work out what the exact strategy should be; it seems more like the kind of thing that falls under the syllogism "something must be done, this is something, therefore this must be done" than like a plan that ends with humane life victorious.
Regarding genetic manipulation of humans, I think the public started out very unfavorable to that, had a reaction that was not at all exact or channeled, does not allow for any 'good' forms of human genetic manipulation regardless of circumstances, driving the science into other countries - it is not a case in point of the intelligentsia being able to successfully cunningly manipulate the fear of the masses to some supposed good end, to put it mildly, so I'd be worried about deriving that generalization from it. The reaction may more be that the fear of the public is a big powerful uncontrollable thing that doesn't move in the smart direction - maybe the public fear of AI gets channeled by opportunistic government officials into "and that's why We must have Our AGI first so it will be Good and we can Win". That seems to me much more like a thing that would happen in real life than "and then we managed to manipulate public panic down exactly the direction we wanted to fit into our clever master scheme", especially when we don't actually *have* the clever master scheme it fits into.
---
**Eliezer Yudkowsky**
I have a few stupid ideas I could try to investigate in ML, but that would require the ability to run significant-sized closed ML projects full of trustworthy people, which is a capability that doesn't seem to presently exist. Plausibly, this capability would be required in any world that got some positive model violation ("miracle") to take advantage of, so I would want to build that capability today. I am not sure how to go about doing that either.
**Anonymous**
if there's a chance this group can do something to gain this capability I'd be interested in checking it out. I'd want to know more about what "closed"and "trustworthy" mean for this (and "significant-size" I guess too). E.g., which ones does Anthropic fail?
**Eliezer Yudkowsky**
What I'd like to exist is a setup where I can work with people that I or somebody else has vetted as seeming okay-trustworthy, on ML projects that aren't going to be published. Anthropic looks like it's a package deal. If Anthropic were set up to let me work with 5 particular people at Anthropic on a project boxed away from the rest of the organization, that would potentially be a step towards trying such things. It's also not clear to me that Anthropic has either the time to work with me, or the interest in doing things in AI that aren't "stack more layers" or close kin to that.
**Anonymous**
That setup doesn't sound impossible to me -- at DeepMind or OpenAI or a new org specifically set up for it (or could be MIRI) -- the bottlenecks are access to trustworthy ML-knowledgeable people (but finding 5 in our social network doesn't seem impossible?) and access to compute (can be solved with more money - not too hard?). I don't think DM and OpenAI are publishing everything - the "not going to be published" part doesn't seem like a big barrier to me. Is infosec a major bottleneck (i.e., who's potentially stealing the code/data)?
**Anonymous**
Do you think Redwood Research could be a place for this?
**Eliezer Yudkowsky**
Maybe! I haven't ruled RR out yet. But they also haven't yet done (to my own knowledge) anything demonstrating the same kind of AI-development capabilities as even GPT-3, let alone AlphaFold 2.
**Eliezer Yudkowsky**
I would potentially be super interested in working with Deepminders if Deepmind set up some internal partition for "Okay, accomplished Deepmind researchers who'd rather not destroy the world are allowed to form subpartitions of this partition and have their work not be published outside the subpartition let alone Deepmind in general, though maybe you have to report on it to Demis only or something." I'd be more skeptical/worried about working with OpenAI-minus-Anthropic because the notion of "open AI" continues to sound to me like "what is the worst possible strategy for making the game board as unplayable as possible while demonizing everybody who tries a strategy that could possibly lead to the survival of humane intelligence", and now a lot of the people who knew about that part have left OpenAI for elsewhere. But, sure, if they changed their name to "ClosedAI" and fired everyone who believed in the original OpenAI mission, I would update about that.
**Eliezer Yudkowsky**
Context that is potentially missing here and should be included: I wish that Deepmind had more internal closed research, and internally siloed research, as part of a larger wish I have about the AI field, independently of what projects I'd want to work on myself.
The present situation can be seen as one in which a common resource, the remaining timeline until AGI shows up, is incentivized to be burned by AI researchers because they have to come up with neat publications and publish them (which burns the remaining timeline) in order to earn status and higher salaries. The more they publish along the spectrum that goes {quiet internal result -> announced and demonstrated result -> paper describing how to get the announced result -> code for the result -> model for the result}, the more timeline gets burned, and the greater the internal and external prestige accruing to the researcher.
It's futile to wish for everybody to act uniformly against their incentives. But I think it would be a step forward if the relative incentive to burn the commons could be *reduced*; or to put it another way, the more researchers have the *option* to not burn the timeline commons, without them getting fired or passed up for promotion, the more that unusually intelligent researchers might perhaps decide not to do that. So I wish in general that AI research groups in general, but also Deepmind in particular, would have affordances for researchers who go looking for interesting things to not publish any resulting discoveries, at all, and still be able to earn internal points for them. I wish they had the *option* to do that. I wish people were *allowed* to not destroy the world - and still get high salaries and promotion opportunities and the ability to get corporate and ops support for playing with interesting toys; if destroying the world is prerequisite for having nice things, nearly everyone is going to contribute to destroying the world, because, like, they're not going to just *not* have nice things, that is not human nature for almost all humans.
When I visualize how the end of the world plays out, I think it involves an AGI system which has the ability to be cranked up by adding more computing resources to it; and I think there is an extended period where the system is not aligned enough that you can crank it up that far, without everyone dying. And it seems *extremely* likely that if factions on the level of, say, Facebook AI Research, start being able to deploy systems like that, then death is very automatic. If the Chinese, Russian, and French intelligence services all manage to steal a copy of the code, and China and Russia sensibly decide not to run it, and France gives it to three French corporations which I hear the French intelligence service sometimes does, then again, everybody dies. If the builders are sufficiently worried about that scenario that they push too fast too early, in fear of an arms race developing very soon if they wait, again, everybody dies.
At present we're very much waiting on a miracle for alignment to be possible at all, even if the AGI-builder successfully prevents proliferation and has 2 years in which to work. But if we get that miracle at all, it's not going to be an instant miracle. There’ll be some minimum time-expense to do whatever work is required. So any time I visualize anybody trying to even start a successful trajectory of this kind, they need to be able to get a lot of work done, without the intermediate steps of AGI work being published, or demoed at all, let alone having models released. Because if you wait until the last months when it is really really obvious that the system is going to scale to AGI, in order to start closing things, almost all the prerequisites will already be out there. Then it will only take 3 more months of work for somebody else to build AGI, and then somebody else, and then somebody else; and even if the first 3 factions manage not to crank up the dial to lethal levels, the 4th party will go for it; and the world ends by default on full automatic.
If ideas are theoretically internal to "just the company", but the company has 150 people who all know, plus everybody with the "sysadmin" title having access to the code and models, then I imagine - perhaps I am mistaken - that those ideas would (a) inevitably leak outside due to some of those 150 people having cheerful conversations over a beer with outsiders present, and (b) be copied outright by people of questionable allegiances once all hell started to visibly break loose. As with anywhere that handles really sensitive data, the concept of "need to know" has to be a thing, or else everyone (and not just in that company) ends up knowing.
So, even if I got run over by a truck tomorrow, I would still very much wish that in the world that survived me, Deepmind would have lots of penalty-free affordance internally for people to not publish things, and to work in internal partitions that didn't spread their ideas to all the rest of Deepmind. Like, *actual* social and corporate support for that, not just a theoretical option you'd have to burn lots of social capital and weirdness points to opt into, and then get passed up for promotion forever after.
**Anonymous**
What's RR?
**Anonymous**
It's a new alignment org, run by Nate Thomas and ~co-run by Buck Shlegeris and Bill Zito, with maybe 4-6 other technical folks so far. My take: the premise is to create an org with ML expertise and general just-do-it competence that's trying to do all the alignment experiments that something like Paul+Ajeya+Eliezer all think are obviously valuable and wish someone would do. They expect to have a website etc in a few days; the org is a couple months old in its current form.
---
**Anonymous**
How likely really is hard takeoff? Clearly, we are touching the edges of AGI with GPT and the like. But I'm not feeling this will that easily be leveraged into very quick recursive self improvement.
**Eliezer Yudkowsky**
Compared to the position I was arguing in the Foom Debate with Robin, reality has proved way to the further Eliezer side of Eliezer along the Eliezer-Robin spectrum. It's been very unpleasantly surprising to me how little architectural complexity is required to start producing generalizing systems, and how fast those systems scale using More Compute. The flip side of this is that I can imagine a system being scaled up to interesting human+ levels, without "recursive self-improvement" or other of the old tricks that I thought would be necessary, and argued to Robin would make fast capability gain possible. You could have fast capability gain well before anything like a FOOM started. Which in turn makes it more plausible to me that we could hang out at interesting not-superintelligent levels of AGI capability for a while before a FOOM started. It's not clear that this helps anything, but it does seem more plausible.
**Anonymous**
I agree reality has not been hugging the Robin kind of scenario this far.
**Anonymous**
Going past human level doesn't necessarily mean going "foom".
**Eliezer Yudkowsky**
I do think that if you get an AGI significantly past human intelligence in all respects, it would obviously tend to FOOM. I mean, I suspect that Eliezer fooms if you give an Eliezer the ability to backup, branch, and edit himself.
**Anonymous**
It doesn't seem to me that an AGI significantly past human intelligence necessarily tends to FOOM.
**Eliezer Yudkowsky**
I think in principle we could have, for example, an AGI that was just a superintelligent engineer of proteins, and of nanosystems built by nanosystems that were built by proteins, and which was corrigible enough not to want to improve itself further; and this AGI would also be dumber than a human when it came to eg psychological manipulation, because we would have asked it not to think much about that subject. I'm doubtful that you can have an AGI that's significantly above human intelligence in *all* respects, without it having the capability-if-it-wanted-to of looking over its own code and seeing lots of potential improvements.
**Anonymous**
Alright, this makes sense to me, but I don't expect an AGI to *want* to manipulate humans that easily (unless designed to). Maybe a bit.
**Eliezer Yudkowsky**
Manipulating humans is a convergent instrumental strategy if you've accurately modeled (even at quite low resolution) what humans are and what they do in the larger scheme of things.
**Anonymous**
Yes, but human manipulation is also the kind of thing you need to guard against with even mildly powerful systems. Strong impulses to manipulate humans, should be vetted out.
**Eliezer Yudkowsky**
I think that, by default, if you trained a young AGI to expect that 2+2=5 in some special contexts, and then scaled it up without further retraining, a generally superhuman version of that AGI would be very likely to 'realize' in some sense that SS0+SS0=SSSS0 was a consequence of the Peano axioms. There's a natural/convergent/coherent output of deep underlying algorithms that generate competence in some of the original domains; when those algorithms are implicitly scaled up, they seem likely to generalize better than whatever patch on those algorithms said '2 + 2 = 5'.
In the same way, suppose that you take weak domains where the AGI can't fool you, and apply some gradient descent to get the AGI to stop outputting actions of a type that humans can detect and label as 'manipulative'. And then you scale up that AGI to a superhuman domain. I predict that deep algorithms within the AGI will go through consequentialist dances, and model humans, and output human-manipulating actions that can't be detected as manipulative by the humans, in a way that seems likely to bypass whatever earlier patch was imbued by gradient descent, because I doubt that earlier patch will generalize as well as the deep algorithms. Then you don't get to retrain in the superintelligent domain after labeling as bad an output that killed you and doing a gradient descent update on that, because the bad output killed you. (This is an attempted very fast gloss on what makes alignment difficult *in the first place*.)
**Anonymous**
[i appreciate this gloss - thanks]
**Anonymous**
"deep algorithms within it will go through consequentialist dances, and model humans, and output human-manipulating actions that can't be detected as manipulative by the humans"
This is true if it is rewarding to manipulate humans. If the humans are on the outlook for this kind of thing, it doesn't seem that easy to me.
Going through these "consequentialist dances" to me appears to presume that mistakes that should be apparent haven't been solved at simpler levels. It seems highly unlikely to me that you would have a system that appears to follow human requests and human values, and it would suddenly switch at some powerful level. I think there will be signs beforehand. Of course, if the humans are not paying attention, they might miss it. But, say, in the current milieu, I find it plausible that they will pay enough attention.
"because I doubt that earlier patch will generalize as well as the deep algorithms"
That would depend on how "deep" your earlier patch was. Yes, if you're just doing surface patches to apparent problems, this might happen. But it seems to me that useful and intelligent systems will require deep patches (or deep designs from the start) in order to be apparently useful to humans at solving complex problems enough. This is not to say that they would be perfect. But it seems quite plausible to me that they would in most cases prevent the worst outcomes.
**Eliezer Yudkowsky**
"If you've got a general consequence-modeling-and-searching algorithm, it seeks out ways to manipulate humans, even if there are no past instances of a random-action-generator producing manipulative behaviors that succeeded and got reinforced by gradient descent over the random-action-generator. It invents the strategy de novo by imagining the results, even if there's no instances in memory of a strategy like that having been tried before." Agree or disagree?
**Anonymous**
Creating strategies de novo would of course be expected of an AGI.
> "If you've got a general consequence-modeling-and-searching algorithm, it seeks out ways to manipulate humans, even if there are no past instances of a random-action-generator producing manipulative behaviors that succeeded and got reinforced by gradient descent over the random-action-generator. It invents the strategy de novo by imagining the results, even if there's no instances in memory of a strategy like that having been tried before." Agree or disagree?
>
>
I think, if the AI will "seek out ways to manipulate humans", will depend on what kind of goals the AI has been designed to pursue.
Manipulating humans is definitely an instrumentally useful kind of method for an AI, for a lot of goals. But it's also counter to a lot of the things humans would direct the AI to do -- at least at a "high level". "Manipulation", such as marketing, for lower level goals, can be very congruent with higher level goals. An AI could clearly be good at manipulating humans, while not manipulating its creators or the directives of its creators.
If you are asking me to agree that the AI will generally seek out ways to manipulate the high-level goals, then I will say "no". Because it seems to me that faults of this kind in the AI design is likely to be caught by the designers earlier. (This isn't to say that this kind of fault couldn't happen.) It seems to me that manipulation of high-level goals will be one of the most apparent kind of faults of this kind of system.
**Anonymous**
RE: "I'm doubtful that you can have an AGI that's significantly above human intelligence in *all* respects, without it having the capability-if-it-wanted-to of looking over its own code and seeing lots of potential improvements."
It seems plausible (though unlikely) to me that this would be true in practice for the AGI we build -- but also that the potential improvements it sees would be pretty marginal. This is coming from the same intuition that current learning algorithms might already be approximately optimal.
**Eliezer Yudkowsky**
> If you are asking me to agree that the AI will generally seek out ways to manipulate the high-level goals, then I will say "no". Because it seems to me that faults of this kind in the AI design is likely to be caught by the designers earlier.
>
>
I expect that when people are trying to stomp out convergent instrumental strategies by training at a safe dumb level of intelligence, this will not be effective at preventing convergent instrumental strategies at smart levels of intelligence; also note that at very smart levels of intelligence, "hide what you are doing" is also a convergent instrumental strategy of that substrategy.
I don't know however if I should be explaining at this point why "manipulate humans" is convergent, why "conceal that you are manipulating humans" is convergent, why you have to train in safe regimes in order to get safety in dangerous regimes (because if you try to "train" at a sufficiently unsafe level, the output of the unaligned system deceives you into labeling it incorrectly and/or kills you before you can label the outputs), or why attempts to teach corrigibility in safe regimes are unlikely to generalize well to higher levels of intelligence and unsafe regimes (qualitatively new thought processes, things being way out of training distribution, and, the hardest part to explain, corrigibility being "anti-natural" in a certain sense that makes it incredibly hard to, eg, exhibit any coherent planning behavior ("consistent utility function") which corresponds to being willing to let somebody else shut you off, without incentivizing you to actively manipulate them to shut you off).
---
**Anonymous**
My (unfinished) idea for buying time is to focus on applying AI to well-specified problems, where constraints can come primarily from the action space and additionally from process-level feedback (i.e., human feedback providers understand why actions are good before endorsing them, and reject anything weird even if it seems to work on some outcomes-based metric). This is basically a form of boxing, with application-specific boxes. I know it doesn't scale to superintelligence but I think it can potentially give us time to study and understand proto AGIs before they kill us. I'd be interested to hear devastating critiques of this that imply it isn't even worth fleshing out more and trying to pursue, if they exist.
**Anonymous**
(I think it's also similar to CAIS in case that's helpful.)
**Eliezer Yudkowsky**
There's lots of things we can do which don't solve the problem and involve us poking around with AIs having fun, while we wait for a miracle to pop out of nowhere. There's lots of things we can do with AIs which are weak enough to not be able to fool us and to not have cognitive access to any dangerous outputs, like automatically generating pictures of cats. The trouble is that nothing we can do with an AI like that (where "human feedback providers understand why actions are good before endorsing them") is powerful enough to save the world.
**Eliezer Yudkowsky**
In other words, if you have an aligned AGI that builds complete mature nanosystems for you, that *is* enough force to save the world; but that AGI needs to have been aligned by some method other than "humans inspect those outputs and vet them and their consequences as safe/aligned", because humans cannot accurately and unfoolably vet the consequences of DNA sequences for proteins, or of long bitstreams sent to protein-built nanofactories.
**Anonymous**
When you mention nanosystems, how much is this just a hypothetical superpower vs. something you actually expect to be achievable with AGI/superintelligence? If expected to be achievable, why?
**Eliezer Yudkowsky**
The case for nanosystems being possible, if anything, seems even more slam-dunk than the already extremely slam-dunk case for superintelligence, because we can set lower bounds on the power of nanosystems using far more specific and concrete calculations. See eg the first chapters of Drexler's Nanosystems, which are the first step mandatory reading for anyone who would otherwise doubt that there's plenty of room above biology and that it is possible to have artifacts the size of bacteria with much higher power densities. I have this marked down as "known lower bound" not "speculative high value", and since Nanosystems has been out since 1992 and subjected to attemptedly-skeptical scrutiny, without anything I found remotely persuasive turning up, I do not have a strong expectation that any new counterarguments will materialize.
If, after reading Nanosystems, you still don't think that a superintelligence can get to and past the Nanosystems level, I'm not quite sure what to say to you, since the models of superintelligences are much less concrete than the models of molecular nanotechnology.
I'm on record as early as 2008 as saying that I expected superintelligences to crack protein folding, some people disputed that and were all like "But how do you know that's solvable?" and then AlphaFold 2 came along and cracked the protein folding problem they'd been skeptical about, far below the level of superintelligence.
I can try to explain how I was mysteriously able to forecast this truth at a high level of confidence - not the exact level where it became possible, to be sure, but that superintelligence would be sufficient - despite this skepticism; I suppose I could point to prior hints, like even human brains being able to contribute suggestions to searches for good protein configurations; I could talk about how if evolutionary biology made proteins evolvable then there must be a lot of regularity in the folding space, and that this kind of regularity tends to be exploitable.
But of course, it's also, in a certain sense, very *obvious* that a superintelligence could crack protein folding, just like it was obvious years before *Nanosystems* that molecular nanomachines would in fact be possible and have much higher power densities than biology. I could say, "Because proteins are held together by van der Waals forces that are much weaker than covalent bonds," to point to a reason how you could realize that after just reading *Engines of Creation* and before *Nanosystems* existed, by way of explaining how one could possibly guess the result of the calculation in advance of building up the whole detailed model. But in reality, precisely because the possibility of molecular nanotechnology was already obvious to any sensible person just from reading *Engines of Creation*, the sort of person who wasn't convinced by *Engines of Creation* wasn't convinced by *Nanosystems* either, because they'd already demonstrated immunity to sensible arguments; an example of the general phenomenon I've elsewhere termed the Law of Continued Failure.
Similarly, the sort of person who was like "But how do you know superintelligences will be able to build nanotech?" in 2008, will probably not be persuaded by the demonstration of AlphaFold 2, because it was already clear to anyone sensible in 2008, and so anyone who can't see sensible points in 2008 probably also can't see them after they become even clearer. There are some people on the margins of sensibility who fall through and change state, but mostly people are not on the exact margins of sanity like that.
**Anonymous**
"If, after reading Nanosystems, you still don't think that a superintelligence can get to and past the Nanosystems level, I'm not quite sure what to say to you, since the models of superintelligences are much less concrete than the models of molecular nanotechnology."
I'm not sure if this is directed at *me* or the <https://en.wikipedia.org/wiki/Generic_you>, but I'm only expressing curiosity on this point, not skepticism :)
---
**Anonymous**
some form of "scalable oversight" is the naive extension of the initial boxing thing proposed above that claims to be the required alignment method -- basically, make the humans vetting the outputs smarter by providing them AI support for all well-specified (level-below)-vettable tasks.
**Eliezer Yudkowsky**
I haven't seen any plausible story, in any particular system design being proposed by the people who use terms about "scalable oversight", about how human-overseeable thoughts or human-inspected underlying systems, compound into very powerful human-non-overseeable outputs that are trustworthy. Fundamentally, the whole problem here is, "You're allowed to look at floating-point numbers and Python code, but how do you get from there to trustworthy nanosystem designs?" So saying "Well, we'll look at some thoughts we can understand, and then from out of a much bigger system will come a trustworthy output" doesn't answer the hard core at the center of the question. Saying that the humans will have AI support doesn't answer it either.
**Anonymous**
the kind of useful thing humans (assisted-humans) might be able to vet is reasoning/arguments/proofs/explanations. without having to generate neither the trustworthy nanosystem design nor the reasons it is trustworthy, we could still check them.
**Eliezer Yudkowsky**
If you have an untrustworthy general superintelligence generating English strings meant to be "reasoning/arguments/proofs/explanations" about eg a nanosystem design, then I would not only expect the superintelligence to be able to fool humans in the sense of arguing for things that were not true in a way that fooled the humans, I'd expect the superintelligence to be able to covertly directly hack the humans in ways that I wouldn't understand even after having been told what happened. So you must have some prior belief about the superintelligence being aligned before you dared to look at the arguments. How did you get that prior belief?
**Anonymous**
I think I'm not starting with a general superintelligence here to get the trustworthy nanodesigns. I'm trying to build the trustworthy nanosystems "the hard way", i.e., if we did it without ever building AIs, and then speed that up using AI for automation of things we know how to vet (including recursively). Is a crux here that you think nanosystem design requires superintelligence?
(tangent: I think this approach works even if you accidentally built a more-general or more-intelligent than necessary foundation model as long as you're only using it in boxes it can't outsmart. The better-specified the tasks you automate are, the easier it is to secure the boxes.)
**Eliezer Yudkowsky**
I think that China ends the world using code they stole from Deepmind that did things the easy way, and that happens 50 years of natural R&D time before you can do the equivalent of "strapping mechanical aids to a horse instead of building a car from scratch".
I also think that the speedup step in "iterated amplification and distillation" will introduce places where the fast distilled outputs of slow sequences are not true to the original slow sequences, because gradient descent is not perfect and won't be perfect and it's not clear we'll get any paradigm besides gradient descent for doing a step like that.
---
**Anonymous**
How do you feel about the safety community as a whole and the growth we've seen over the past few years?
**Eliezer Yudkowsky**
Very grim. I think that almost everybody is bouncing off the real hard problems at the center and doing work that is predictably not going to be useful at the superintelligent level, nor does it teach me anything I could not have said in advance of the paper being written. People like to do projects that they know will succeed and will result in a publishable paper, and that rules out all real research at step 1 of the social process.
Paul Christiano is trying to have real foundational ideas, and they're all wrong, but he's one of the few people trying to have foundational ideas at all; if we had another 10 of him, something might go right.
Chris Olah is going to get far too little done far too late. We're going to be facing down an unalignable AGI and the current state of transparency is going to be "well look at this interesting visualized pattern in the attention of the key-value matrices in layer 47" when what we need to know is "okay but was the AGI plotting to kill us or not”. But Chris Olah is still trying to do work that is on a pathway to anything important at all, which makes him exceptional in the field.
Stuart Armstrong did some good work on further formalizing the shutdown problem, an example case in point of why corrigibility is hard, which so far as I know is still resisting all attempts at solution.
Various people who work or worked for MIRI came up with some actually-useful notions here and there, like Jessica Taylor's expected utility quantilization.
And then there is, so far as I can tell, a vast desert full of work that seems to me to be mostly fake or pointless or predictable.
It is very, very clear that at present rates of progress, adding that level of alignment capability as grown over the next N years, to the AGI capability that arrives after N years, results in everybody dying very quickly. Throwing more money at this problem does not obviously help because it just produces more low-quality work.
**Anonymous**
"doing work that is predictably not going to be really useful at the superintelligent level, nor does it teach me anything I could not have said in advance of the paper being written"
I think you're underestimating the value of solving small problems. Big problems are solved by solving many small problems. (I do agree that many academic papers do not represent much progress, however.)
**Eliezer Yudkowsky**
By default, I suspect you have longer timelines and a smaller estimate of total alignment difficulty, not that I put less value than you on the incremental power of solving small problems over decades. I think we're going to be staring down the gun of a completely inscrutable model that would kill us all if turned up further, with no idea how to read what goes on inside its head, and no way to train it on humanly scrutable and safe and humanly-labelable domains in a way that seems like it would align the superintelligent version, while standing on top of a whole bunch of papers about "small problems" that never got past “small problems”.
**Anonymous**
"I think we're going to be staring down the gun of a completely inscrutable model that would kill us all if turned up further, with no idea how to read what goes on inside its head, and no way to train it on humanly scrutable and safe and humanly-labelable domains in a way that seems like it would align the superintelligent version"
This scenario seems possible to me, but not very plausible. GPT is not going to "kill us all" if turned up further. No amount of computing power (at least before AGI) would cause it to. I think this is apparent, without knowing exactly what's going on inside GPT. This isn't to say that there aren't AI systems that wouldn't. But *what kind of system would*? (A GPT combined with sensory capabilities at the level of Tesla's self-driving AI? That still seems too limited.)
**Eliezer Yudkowsky**
Alpha Zero scales with more computing power, I think AlphaFold 2 scales with more computing power, Mu Zero scales with more computing power. Precisely because GPT-3 doesn't scale, I'd expect an AGI to look more like Mu Zero and particularly with respect to the fact that it has some way of scaling.
---
**Steve Omohundro**
Eliezer, thanks for doing this! I just now read through the discussion and found it valuable. I agree with most of your specific points but I seem to be much more optimistic than you about a positive outcome. I'd like to try to understand why that is. I see mathematical proof as the most powerful tool for constraining intelligent systems and I see a pretty clear safe progression using that for the technical side (the social side probably will require additional strategies). Here are some of my intuitions underlying that approach, I wonder if you could identify any that you disagree with. I'm fine with your using my name (Steve Omohundro) in any discussion of these.
1) Nobody powerful wants to create unsafe AI but they do want to take advantage of AI capabilities.
2) None of the concrete well-specified valuable AI capabilities require unsafe behavior
3) Current simple logical systems are capable of formalizing every relevant system involved (eg. MetaMath <http://us.metamath.org/index.html> currently formalizes roughly an undergraduate math degree and includes everything needed for modeling the laws of physics, computer hardware, computer languages, formal systems, machine learning algorithms, etc.)
4) Mathematical proof is cheap to mechanically check (eg. MetaMath has a 500 line Python verifier which can rapidly check all of its 38K theorems)
5) GPT-F is a fairly early-stage transformer-based theorem prover and can already prove 56% of the MetaMath theorems. Similar systems are likely to soon be able to rapidly prove all simple true theorems (eg. that human mathematicians can prove in a day).
6) We can define provable limits on the behavior of AI systems that we are confident prevent dangerous behavior and yet still enable a wide range of useful behavior.
7) We can build automated checkers for these provable safe-AI limits.
8) We can build (and eventually mandate) powerful AI hardware that first verifies proven safety constraints before executing AI software
9) For example, AI smart compilation of programs can be formalized and doesn't require unsafe operations
10) For example, AI design of proteins to implement desired functions can be formalized and doesn't require unsafe operations
11) For example, AI design of nanosystems to achieve desired functions can be formalized and doesn't require unsafe operations.
12) For example, the behavior of designed nanosystems can be similarly constrained to only proven safe behaviors
13) And so on through the litany of early stage valuable uses for advanced AI.
14) I don't see any fundamental obstructions to any of these. Getting social acceptance and deployment is another issue!
Best, Steve
**Eliezer Yudkowsky**
Steve, are you visualizing AGI that gets developed 70 years from now under absolutely different paradigms than modern ML? I don't see being able to take anything remotely like, say, Mu Zero, and being able to prove any theorem about it which implies anything like corrigibility or the system not internally trying to harm humans. Anything in which enormous inscrutable floating-point vectors is a key component, seems like something where it would be very hard to prove any theorems about the treatment of those enormous inscrutable vectors that would correspond in the outside world to the AI not killing everybody.
Even if we somehow managed to get structures far more legible than giant vectors of floats, using some AI paradigm very different from the current one, it still seems like huge key pillars of the system would rely on non-fully-formal reasoning; even if the AI has something that you can point to as a utility function and even if that utility function's representation is made out of programmer-meaningful elements instead of giant vectors of floats, we'd still be relying on much shakier reasoning at the point where we claimed that this utility function meant something in an intuitive human-desired sense, say. And if that utility function is learned from a dataset and decoded only afterwards by the operators, that sounds even scarier. And if instead you're learning a giant inscrutable vector of floats from a dataset, gulp.
You seem to be visualizing that we prove a theorem and then get a theorem-like level of assurance that the system is safe. What kind of theorem? What the heck would it say?
I agree that it seems plausible that the good cognitive operations we want do not *in principle* require performing bad cognitive operations; the trouble, from my perspective, is that generalizing structures that do lots of good cognitive operations will automatically produce bad cognitive operations, especially when we dump more compute into them; "you can't bring the coffee if you're dead".
So it takes a more complicated system and some feat of insight I don't presently possess, to "just" do the good cognitions, instead of doing all the cognitions that result from decompressing the thing that compressed the cognitions in the dataset - even if that original dataset only contained cognitions that looked good to us, even if that dataset actually *was* just correctly labeled data about safe actions inside a slightly dangerous domain. Humans do a lot of stuff besides maximizing inclusive genetic fitness, optimizing purely on outcomes labeled by a simple loss function doesn’t get you an internal optimizer that pursues only that loss function, etc.
**Anonymous**
Steve's intuitions sound to me like they're pointing at the "well-specified problems" idea from an earlier thread. Essentially, only use AI in domains where unsafe actions are impossible by construction. Is this too strong a restatement of your intuitions Steve?
**Steve Omohundro**
Thanks for your perspective! Those sound more like social concerns than technical ones, though. I totally agree that today's AI culture is very "sloppy" and that the currently popular representations, learning algorithms, data sources, etc. aren't oriented around precise formal specification or provably guaranteed constraints. I'd love any thoughts about ways to help shift that culture toward precise and safe approaches! Technically there is no problem getting provable constraints on floating point computations, etc. The work often goes under the label "Interval Computation". It's not even very expensive, typically just a factor of 2 worse than "sloppy" computations. For some reason those approaches have tended to be more popular in Europe than in the US. Here are a couple lists of references: <http://www.cs.utep.edu/interval-comp/> <https://www.mat.univie.ac.at/~neum/interval.html>
I see today's dominant AI approach of mapping everything to large networks ReLU units running on hardware designed for dense matrix multiplication, trained with gradient descent on big noisy data sets as a very temporary state of affairs. I fully agree that it would be uncontrolled and dangerous scaled up in its current form! But it's really terrible in every aspect except that it makes it easy for machine learning practitioners to quickly slap something together which will actually sort of work sometimes. With all the work on AutoML, NAS, and the formal methods advances I'm hoping we leave this "sloppy" paradigm pretty quickly. Today's neural networks are terribly inefficient for inference: most weights are irrelevant for most inputs and yet current methods do computational work on each. I developed many algorithms and data structures to avoid that waste years ago (eg. "bumptrees" <https://steveomohundro.com/scientific-contributions/)>
They're also pretty terrible for learning since most weights don't need to be updated for most training examples and yet they are. Google and others are using Mixture-of-Experts to avoid some of that cost: <https://arxiv.org/abs/1701.06538>
Matrix multiply is a pretty inefficient primitive and alternatives are being explored: <https://arxiv.org/abs/2106.10860>
Today's reinforcement learning is slow and uncontrolled, etc. All this ridiculous computational and learning waste could be eliminated with precise formal approaches which measure and optimize it precisely. I'm hopeful that that improvement in computational and learning performance may drive the shift to better controlled representations.
I see theorem proving as hugely valuable for safety in that we can easily precisely specify many important tasks and get guarantees about the behavior of the system. I'm hopeful that we will also be able to apply them to the full AGI story and encode human values, etc., but I don't think we want to bank on that at this stage. Hence, I proposed the "Safe-AI Scaffolding Strategy" where we never deploy a system without proven constraints on its behavior that give us high confidence of safety. We start extra conservative and disallow behavior that might eventually be determined to be safe. At every stage we maintain very high confidence of safety. Fast, automated theorem checking enables us to build computational and robotic infrastructure which only executes software with such proofs.
And, yes, I'm totally with you on needing to avoid the "basic AI drives"! I think we have to start in a phase where AI systems are not allowed to run rampant as uncontrolled optimizing agents! It's easy to see how to constrain limited programs (eg. theorem provers, program compilers or protein designers) to stay on particular hardware and only communicate externally in precisely constrained ways. It's similarly easy to define constrained robot behaviors (eg. for self-driving cars, etc.) The dicey area is that unconstrained agentic edge. I think we want to stay well away from that until we're very sure we know what we're doing! My optimism stems from the belief that many of the socially important things we need AI for won't require anything near that unconstrained edge. But it's tempered by the need to get the safe infrastructure into place before dangerous AIs are created.
**Anonymous**
As far as I know, all the work on "verifying floating-point computations" currently is way too low-level -- the specifications that are proved about the computations don't say anything about what the computations mean or are about, beyond the very local execution of some algorithm. Execution of algorithms in the real world can have very far-reaching effects that aren't modelled by their specifications.
**Eliezer Yudkowsky**
Yeah, what they said. How do you get from proving things about error bounds on matrix multiplications of inscrutable floating-point numbers, to saying anything about what a mind is trying to do, or not trying to do, in the external world?
**Steve Omohundro**
Ultimately we need to constrain behavior. You might want to ensure your robot butler won't leave the premises. To do that using formal methods, you need to have a semantic representation of the location of the robot, your premise's spatial extent, etc. It's pretty easy to formally represent that kind of physical information (it's just a more careful version of what engineers do anyway). You also have a formal model of the computational hardware and software and the program running the system.
For finite systems, any true property has a proof which can be mechanically checked but the size of that proof might be large and it might be hard to find. So we need to use encodings and properties which mesh well with the safety semantics we care about.
Formal proofs of properties of programs has progressed to where a bunch of cryptographic, compilation, and other systems can be specified and formalized. Why it's taken this long, I have no idea. The creator of any system has an argument as to why its behavior does what they think it will and why it won't do bad or dangerous things. The formalization of those arguments should be one direct short step.
Experience with formalizing mathematician's informal arguments suggest that the formal proofs are maybe 5 times longer than the informal argument. Systems with learning and statistical inference add more challenges but nothing that seems in-principal all that difficult. I'm still not completely sure how to constrain the use of language, however. I see inside of Facebook all sorts of problems due to inability to constrain language systems (eg. they just had a huge issue where a system labeled a video with a racist term). The interface between natural language semantics and formal semantics and how we deal with that for safety is something I've been thinking a lot about recently.
**Steve Omohundro**
Here's a nice 3 hour long tutorial about "probabilistic circuits" which is a representation of probability distributions, learning, Bayesian inference, etc. which has much better properties than most of the standard representations used in statistics, machine learning, neural nets, etc.: <https://www.youtube.com/watch?v=2RAG5-L9R70> It looks especially amenable to interpretability, formal specification, and proofs of properties.
**Eliezer Yudkowsky**
You're preaching to the choir there, but even if we were working with more strongly typed epistemic representations that had been inferred by some unexpected innovation of machine learning, automatic inference of those representations would lead them to be uncommented and not well-matched with human compressions of reality, nor would they match exactly against reality, which would make it very hard for any theorem about "we are optimizing against this huge uncommented machine-learned epistemic representation, to steer outcomes inside this huge machine-learned goal specification" to guarantee safety in outside reality; especially in the face of how corrigibility is unnatural and runs counter to convergence and indeed coherence; especially if we're trying to train on domains where unaligned cognition is safe, and generalize to regimes in which unaligned cognition is not safe. Even in this case, we are not nearly out of the woods, because what we can prove has a great type-gap with that which we want to ensure is true. You can't handwave the problem of crossing that gap even if it's a solvable problem.
And that whole scenario would require some major total shift in ML paradigms.
Right now the epistemic representations are giant inscrutable vectors of floating-point numbers, and so are all the other subsystems and representations, more or less.
Prove whatever you like about that Tensorflow problem; it will make no difference to whether the AI kills you. The properties that can be proven just aren't related to safety, no matter how many times you prove an error bound on the floating-point multiplications. It wasn't floating-point error that was going to kill you in the first place. |
15ed29b7-b909-4b65-8dec-67ee065f3ae7 | trentmkelly/LessWrong-43k | LessWrong | How should we model complex systems?
By "complex", I mean a system for which it would be too computationally costly to model it from first principles e.g. the economy, the climate (my field, by the way). Suppose our goal is to predict a system's future behaviour with minimum possible error given by some metric (e.g. minimise the mean square error or maximise the likelihood). This seems like something we would want to do in an optimal way, and also something a superintelligence should have a strategy to do, so I thought I'd ask here if anyone has worked on this problem.
I've read quite a bit about how we can optimally try to deduce the truth e.g. apply Bayes' theorem with a prior set following Ockham's razor (c.f. Solomonoff induction). However, this seems difficult to me to apply to modelling complex systems, even as an idealisation, because:
1. Since we cannot afford to model the true equations, every member of the set of models available to us is false, so the likelihood and posterior probability for each will typically evaluate to zero given enough observed data. So if we want to use Bayes' theorem, the probabilities should not mean the probability of each model being true. But it's not clear to me what they should mean - perhaps the probability that each model will give the prediction with the lowest error? But then it's not clear how to do updating, if the normal likelihoods will typically be zero.
2. It doesn't seem clear that Ockham's razor will be a good guide to giving our models prior probabilities. Its use seems to be motivated by it working well for deducing fundamental laws of nature. However, for modelling complex systems it seems more reasonable to me to give more weight to models that incorporate what we understand to be the important processes - and past observations can't necessarily help us tell what processes are important to include, because different processes may become important in future (c.f. biological feedbacks that may kick in as the climate warms). This could perhaps |
59d0889c-fd16-426c-baf6-c2acea2d32c0 | trentmkelly/LessWrong-43k | LessWrong | Softmax, Emmett Shear's new AI startup focused on "Organic Alignment"
> A new AI alignment player has entered the arena.
>
> Emmett Shear, Adam Goldstein and David Bloomin have set up shop in San Francisco with a 10-person start-up called Softmax. The company is part research lab and part aspiring money maker and aimed at figuring out how to fuse the goals of humans and AIs in a novel way through what the founders describe as “organic alignment.” It’s a heady, philosophical approach to alignment that seeks to take cues from nature and the fundamental traits of intelligent creatures and systems, and we’ll do our best to capture it here.
>
> “We think there are these general principles that govern the alignment of any group of intelligent learning agents or beings, whether it's an ant colony or humans on a team or cells in a body,” Shear said, during his first interview to discuss the new company. “And organic alignment is the kind of alignment where a bunch of peers come together and find their role in a greater whole together where they maintain their individual identity.
>
> “Organic alignment centers on this shared whole idea, which is opposed to the kind of alignment that you see from most foundational model companies that is very much about steering and control and direction. We think of that as hierarchical alignment.”
>
> […]
Also, https://softmax.com/about mentions collaboration with Michael Levin, Ken Wilber, Chris Fields, Ken Stanley, Denis Noble, Andrew Briggs, Jeff Clune, Erik Hoel, Ryan Smith, Center for the Study of Apparent Selves, Dalton Sakthivadivel, and Perry Marshall. |
3f348e52-adaf-4b27-9b44-b562bb62c67b | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Inside the Mind of an Aspiring Charity Entrepreneur [Follow Along] #1 - From Layoff to Co-founding in a Breathtaking Two Months
TL;DR
-----
I want to extend a MASSIVE, heartfelt thank you to the abundant resources put together by the EA community and the wonderful EAs who are so generous with their knowledge and time (even when talking to a complete newbie like me).
Because of you, I went from **being laid off in June and knowing nothing about EA in July**, to being offered a nonprofit co-founder position in early September, to finishing some initial groundwork of setting up a charity (productivity system, Founder’s agreement, funding proposal draft, etc) in late September.
The initial groundwork implemented thus far were all influenced by the action steps found in [How to Launch a High-Impact Nonprofit](https://forum.effectivealtruism.org/posts/c2fhqaKEGJxGMCz4x/new-ea-book-how-to-launch-a-high-impact-nonprofit-by-charity). Thus, this aims to be a post sequence dedicated to putting the book’s concepts to work and showing some actual work examples.
Hopefully with more of your support and feedback, the StakeOut.AI charity startup can keep a good steady pace and accomplish more crucial milestones in Oct and onwards.
As this post is the intro of the sequence, it details more specifically my journey (learning and doing applications) - including important tips for other applicants (apply early, handling rejections) and some feedback for EA organizations taking applications (setup to process many applications, send responders a copy of their responses, informing those who didn’t make the cut).
I hope this brings value to the EA community as this is perspective from someone very green in EA, eager to take action quickly even though I came from a totally different world before.
Acknowledgment
--------------
I would like to give a special thank you to [Dr. Peter S. Park](https://forum.effectivealtruism.org/users/peter-s-park) for editing this post and for all our future collaborations! There is also a [I’m so grateful for everyone who has been a part of the journey thus far](https://forum.effectivealtruism.org/posts/ngk6AFo5uNHB3ZKQY/inside-the-mind-of-an-aspiring-charity-entrepreneur-follow#A_Heartfelt_Thank_You_to_the_Effective_Altruism_Community) section later in this post.
Introduction
------------
Hi, my name is Harry, it’s nice to meet all of you. This post, my first ever post on the EA forum, is inspired by [Three lessons I've learnt from starting a small EA org](https://forum.effectivealtruism.org/posts/ZYPTdny6iuKTZhC8A/three-lessons-i-ve-learnt-from-starting-a-small-ea-org) and [Why and how to start a pilot project in EA](https://forum.effectivealtruism.org/posts/eCKhhWXa25TcecZbJ/why-and-how-to-start-a-pilot-project-in-ea) - so thank you [Ben Williamson](https://forum.effectivealtruism.org/users/ben-williamson?from=post_header).
The purpose of this post is to [1] document my journey publicly (hopefully to inspire others who are thinking they want to start a side project, or apply to CE, or go down the path of charity entrepreneurship), [2] maximize feedback as per [Ben’s post](https://forum.effectivealtruism.org/posts/ZYPTdny6iuKTZhC8A/three-lessons-i-ve-learnt-from-starting-a-small-ea-org) *(both directly through the post (in the comments) and indirectly (people who reach out privately with additional suggestions/ advice))*, and [3] share key lessons & milestones to hopefully contribute to the forum via actual work examples.
The hope is that it is going to be a follow along post sequence, as my co-founder [Dr. Peter S. Park](https://forum.effectivealtruism.org/users/peter-s-park) and I get our nonprofit startup up and running.
Though the journey with EA has only been 2 months, I already have so many people to thank who have answered questions, provided feedback and pointed me in the right direction. I am forever grateful for you :)
The Catalyst: The Layoff that Sparked My Journey
------------------------------------------------
I first found out about Effective Altruism from my Google search about impactful tithing. As a Christian, I have been tithing 10% of my income for many years, but because I was laid off from shortage of work in my previous marketing role, I was interested in finding more impactful ways to give due to our now lowered family income.
This is when I stumbled upon [GivingMultiplier.org](https://givingmultiplier.org/) and was introduced to the idea of super-effective charities. I was intrigued by their approach where you can still give from the heart (your favorite charity), but at the same time incentivizes you to give more to super-effective charities by matching your donations (the higher % you give to super-effective charities, the higher the matching rate). The concept of super-effective charities was so intriguing, I read through all eight “websites we recommend” (most notably EA and 80k).
With the gift of time of no longer being at a full-time job, this began my deep dive into EA. I was ecstatic when I found out about the [CharityEntrepreneurship.com](http://charityentrepreneurship.com) (CE) incubator program within the first week on the EA forum, as I have always had the dream of starting a non-profit to help in bettering the world. The dream of doing high-impact work was born 19+ years ago since co-leading fundraisers in my high school years. My eyes were opened to how first world dollars can have a major positive impact in the developing world, when what seemed like a small amount of funds raised actually built new schools in Tibet.
After about a week, I knew I had found a group of likeminded people who care about doing good in the world while effectively using our limited resources. My job lay off was a blessing before finding EA because I was able to spend more time with my kids. Then after learning about EA, the lay off turned out to be an opportunistic time to shift my career to doing high-impact work, changing my dormant dream into a (hopefully) reality.
The Effective Altruism Influence
--------------------------------
Throughout the last two months, the first material I read through was the [80000 Hours Career Guide](https://forum.effectivealtruism.org/posts/f7D4spNoAYqhFfbBz/announcing-the-new-80-000-hours-career-guide-by-benjamin). Then, because I found out about CE so soon in my EA journey and I knew I wanted to apply to the incubator, the rest of the 200+ hours towards my metaphorical undergraduate degree in Effective Altruism ([suggested here](https://forum.effectivealtruism.org/posts/QxCpXjGmHbpX45nxo/how-to-increase-your-odds-of-starting-a-career-in-charity)) was trying to get through as many resources as I can highlighted below (I broke the 3 lists into to-do items to systemize the process):
* <https://www.charityentrepreneurship.com/applicant-resources>
* <https://www.charityentrepreneurship.com/post/how-to-increase-your-odds-for-ce>
* <https://forum.effectivealtruism.org/posts/MFyQzn6eNgDyvnfde/so-you-want-to-be-a-charity-entrepreneur-read-these-first>
Between all the reading/watching/listening, another important influence was talking with other like-minded people. Please see below [I’m so grateful for everyone who has been a part of the journey thus far](https://forum.effectivealtruism.org/posts/ngk6AFo5uNHB3ZKQY/inside-the-mind-of-an-aspiring-charity-entrepreneur-follow#A_Heartfelt_Thank_You_to_the_Effective_Altruism_Community) for more details.
Lastly, for anyone who has been a part of EA for even a small amount of time knows, you will come to love Google Forms. Like others, I have applied to many EA official programs, volunteering roles, paid jobs, career advising opportunities, incubator programs etc… and to my surprise these have also affected me in a profound way I had not anticipated before. Particularly, answering all these Google Form questions and doing the test tasks have clarified my thinking to put things on paper (well, digitally paper), that previously had been unorganized and swirling in my head.
The Challenges: What I've Faced So Far
--------------------------------------
### Getting started quickly in EA
There are a lot of resources, and I guess that can be a double-edged sword. Within a week of skimming, I knew EA was in alignment for me. So, as someone who wanted to hit the ground running, it was like trying to drink from a firehose sorting through the different topics and information initially. However, I’m very lucky I was inspired to go down the co-founding path early on, and so I stuck mostly to a semi structured way to devour resources based on the [3 lists as per above](https://forum.effectivealtruism.org/posts/ngk6AFo5uNHB3ZKQY/inside-the-mind-of-an-aspiring-charity-entrepreneur-follow#The_Effective_Altruism_Influence).
Other than that, as suggested by many people, the most valuable way to learn the ideas of Effective Altruism isn’t by merely reading (e.g. the [EA handbook](https://forum.effectivealtruism.org/posts/XKfnWebzJsdxecBDw/about-this-handbook), forum, books etc), but by conversing, exchanging ideas and learning from other like-minded people. The official way to do that is via the [monthly EA Virtual Intro Program](https://forum.effectivealtruism.org/posts/BuR7RLQAtJtC5jK5d/there-will-now-be-ea-virtual-programs-every-month) and this is a great experience as I’m going through it right now.
However, for someone who wants to get moving ASAP, that is **waiting in most cases an entire month** between applying, hearing back and starting the eight week EA Virtual Intro Program. This waiting period, if not properly handled, could have been a semi hindrance.
That’s why for me, I’m very grateful for the [EA Anywhere group where professional and affinity groups were consolidated into one space](https://forum.effectivealtruism.org/posts/sK7neZ9rHGEL5JP7q/ea-anywhere-slack-consolidating-professional-and-affinity). I was able to get connected to multiple events/groups to learn and get feedback (it’s so easy to find events compared to hunting down different interest groups on their respective websites). Additionally, there is the #study-buddy chat room (that's joint with the EA Virtual Programs Slack) that you can find others to who are reading through resources that might be of interest to you. [See here for other promising ways to connect to others online](https://forum.effectivealtruism.org/posts/CAWvSaGWNbCnoRccd/supporting-online-connections-what-i-learned-after-trying-to).
So while waiting to hear back from EA VP, I kept busy with the 80k Career Guide (I gave feedback here to help improve this amazing guide - [consider doing this too if you recently read it](https://forum.effectivealtruism.org/posts/AgihXxbw6aHAuNzLg/give-feedback-on-the-new-80-000-hours-career-guide)), [80k podcast with transcripts for easy note taking](https://forum.effectivealtruism.org/posts/BhzqvnaZiqfsssquM/new-80-000-hours-feature-listen-to-audio-versions-of-our), other CE recommended resources and attending group meetings found in EA Anywhere. To be honest, I didn’t even know there was an official handbook until a few weeks in. It is only now because I’m going through the intro fellowship that I am realizing my “organic discovery” of EA had already led me to read a number of the required readings (like [Introduction to Effective Altruism](https://forum.effectivealtruism.org/posts/ZhNaizQgYY9dXdQkM/introduction-to-effective-altruism-17), [Four Ideas You Already Agree With](https://forum.effectivealtruism.org/posts/wYjMsKsEkDPgHeAbS/four-ideas-you-already-agree-with) and [Scope insensitivity: failing to appreciate the numbers of those who need our help](https://forum.effectivealtruism.org/posts/NmDrpKdmjrkYiKeAj/scope-insensitivity-failing-to-appreciate-the-numbers-of)).
*Aside: From what I was told,*[*EA Anywhere group*](https://forum.effectivealtruism.org/posts/gYseq5uNfHw2R8JPx/ama-we-organize-ea-anywhere-ask-us-anything) *wasn’t meant to intake total newbies like I was (and hence not heavily advertised). But, I really am glad I found it somehow during my second week in EA, because it skyrocketed my learning and helped me prioritize where to drill deeper inside of EA.*
### Applications
Another challenge I had was similar to others described in the post [After one year of applying for EA jobs: It is really, really hard to get hired by an EA organization](https://forum.effectivealtruism.org/posts/jmbP9rwXncfa32seH/after-one-year-of-applying-for-ea-jobs-it-is-really-really), where basically both post author and commenters echo in saying that EA community jobs are extremely competitive.
In fact, I think incubator programs and even official programs, volunteering or career advising opportunities are just as difficult to get into.
Because of my recent lay off, I had the luxury of full-time hours diving into EA and applying to multiple opportunities ([Application Breakdown & Handling Rejections](https://forum.effectivealtruism.org/posts/ngk6AFo5uNHB3ZKQY/inside-the-mind-of-an-aspiring-charity-entrepreneur-follow#The_Application_Breakdown___Handling_Rejections) below if interested) since July. However, the difference is that I went into the applications having the expectation that getting accepted into anything will be difficult.
Particularly, I remember this paragraph from [How to Launch a High-Impact Nonprofit](https://forum.effectivealtruism.org/posts/c2fhqaKEGJxGMCz4x/new-ea-book-how-to-launch-a-high-impact-nonprofit-by-charity) on page 375:
> *Why is there so much interest from such talented people? It’s because the big idea of “effective altruism” is appealing to many smart individuals, and they want to devote their careers to having an impact and helping others.*
>
>
Even with this mentality, being someone who is mid-career and has 14+ years of work experience looking to deploy my career capital, I really didn’t expect to
* Get rejected by 80000 Hours’ career advising
* Get complete radio silence from a career advising application (not even an acknowledgement of application received)
* Get again radio silence from multiple volunteering opportunities where I thought I was very qualified for and could do easily
Having said this, all the closed doors didn’t really bug me or get to me. Maybe because in my career I have faced much worse objections, failures, losses and valleys and have learned to fail forward. In fact, each closed door was listed as a gratitude item in my prayer journal. As a Christian, I gave thanks for every opportunity that was shut down as I know I did my best with those applications and left the rest to God. I found comfort in the verses:
> 'For I know the plans I have for you,' declares the Lord, 'plans to prosper you and not to harm you, plans to give you a hope and a future. ' — Jeremiah 29:11.
>
>
The Triumphs: Small Wins and Big Milestones
-------------------------------------------
I was taught to celebrate successes big and small during my entrepreneurial days. And I’m glad others in the EA feel the same way about [celebration and gratitude](https://forum.effectivealtruism.org/posts/FSvq8f8PMiziaJgNc/celebrations-and-gratitude-thread).
The small wins along the way are detailed below at [I’m so grateful for everyone who has been a part of the journey thus far.](https://forum.effectivealtruism.org/posts/ngk6AFo5uNHB3ZKQY/inside-the-mind-of-an-aspiring-charity-entrepreneur-follow#A_Heartfelt_Thank_You_to_the_Effective_Altruism_Community) I **love this EA community because from most of my encounters so far, most people are genuinely willing and wanting to help**. There is no hidden agenda compared to the typical for-profit world, because EAs generally are driven by the impact they can have (less monetary motivations). Which means, even if it’s something they have spent hours and hours working on, I found many are still willing to share. Whether they are actively thinking about maximizing their indirect impact, or just trying to help because they are paying it forward, the **EA environment has been one of the most collaborative, energizing and helpful ones I’ve found** after 14+ years of networking and being in the business world.
And because of all you wonderful people lending a help, contributing and sharing your knowledge/wisdom, in short after two months, I thankfully I made it through and was accepted to 4 of the 19 applications (two career advising calls, one official CEA program - EA Virtual Intro, and one co-founder opportunity) - more details in the [Application Breakdown & Handling Rejections](https://forum.effectivealtruism.org/posts/ngk6AFo5uNHB3ZKQY/inside-the-mind-of-an-aspiring-charity-entrepreneur-follow#The_Application_Breakdown___Handling_Rejections) section.
Yes, I was encouraged each time I got a yes. And yes, I was overjoyed I was offered the co-founder position!!!
Tip for Future EA Applicants: Apply early
-----------------------------------------
One tip I learned that has become apparent after the multiple applications ([breakdown of applications below](https://forum.effectivealtruism.org/posts/ngk6AFo5uNHB3ZKQY/inside-the-mind-of-an-aspiring-charity-entrepreneur-follow#The_Application_Breakdown___Handling_Rejections) if interested) is that you should err on the side of applying early (aka within the week the application is first posted), rather than waiting to submit just before the deadline.
My previous strategy for applications which has worked well outside of EA is to do my best preparing for the application, so that I can put my best foot forward during the 1st impression stage (initial application form, cover letter, etc). This is why even though I found out about the [2024 CE incubator program](https://forum.effectivealtruism.org/posts/AfXC5CDtSKezpiyf6/ce-incubation-programs-2024-applications-are-now-open-our) back in July, I scheduled the CE application as a to-do for the last week of Sep (I’m extremely excited about this as I will be applying this week to the incubation program with our own intervention idea: the [StakeOut.AI](https://stakeout.ai/)’s mission and intervention).
From the top of my head, here are two examples to demonstrate why it’s better to apply early:
1. To quote [High Impact Leadership Coaching Program – Applications Open](https://forum.effectivealtruism.org/posts/c2omdmRxWJyGdLDBb/high-impact-leadership-coaching-program-applications-open):
> Fill out this short application form (10-20 mins) to apply. The deadline is 23:59 UTC October 1st. Be aware: applying earlier may give you an advantage vs applying very near the deadline.
>
>
2. Even though I felt I was very qualified for this particular job as I have 14+ years direct hands-on and managerial experience for the exact role description (caveat is my time in EA is very short), I got this response from the application:
> This was a very difficult process on our side; we received a huge number (>150) of applications for this position and we were only able to progress with a small number of candidates.
>
>
Feedback for EA Organizations Taking Applications
-------------------------------------------------
### Reference CE’s application round for easier applicants processing
From what I gathered after the multiple applications (whether it’s a job ad, volunteering role, career advising or incubator programs) is that there might be a *slight* bottleneck when it comes to processing applications. This is because many EA organizations are smaller in size compared to typical for profit companies with dedicated HR departments. Thus, handling the sheer volume of applications coming through (again because “so much interest from such talented people” as per [How to Launch a High-Impact Nonprofit](https://forum.effectivealtruism.org/posts/c2fhqaKEGJxGMCz4x/new-ea-book-how-to-launch-a-high-impact-nonprofit-by-charity)), is hard to process without a systemized setup from the beginning to filter through applicants.
How to Launch a High-Impact Nonprofit wrote in-depth about the hiring process and this is definitely something our organization will implement in the future when we reach the point we need to hire staff. In particular:
* Page 310 talks about “The project job ad”
* Page 312 talks about “Designing an application form” and gives a Google Form template for you to follow. This is what I think can help many EA organizations address the bottleneck of large numbers of applicants and I explained in more detail below.
* Page 314 talks about “Structured interviews” and also gives you an “interview rubric template” to help you score interviews quickly while remaining more neutral
* Page 318 has CE’s hiring template, combining all the stages of the application process into an “Overall” score
Designing the application form to ask the right questions and also “[c]onnecting a spreadsheet to the form will help you systematically rate applicants to keep things consistent” seem to allow the CE team to “rule out at least 50% of the applications'' when combined with the CV. I might be wrong because auto scoring wasn’t fully explained in [How to Launch a High-Impact Nonprofit](https://forum.effectivealtruism.org/posts/c2fhqaKEGJxGMCz4x/new-ea-book-how-to-launch-a-high-impact-nonprofit-by-charity)… However, my guess is that because around 75% of the questions asked in CE’s application form are multiple choice questions, the setup of the connected spreadsheet plays a crucial role and does a lot of the heavy lifting sorting through thousands of applicants. With the right formulas set up, scores can easily be calculated to get a general gist of how well the applicant fits, even before a team member manually looks through the short answer questions. Which means whether you have a big or small team, processing hundreds and thousands of applicants from one stage to the next (whether it’s the “interview” or “test task” stage) can be relatively quick. This is compared to if someone designed their entire application form with only short answer questions - which is the majority of the applications I filled out.
Since CE is used to taking on thousands of applications ([KarolinaSarek said “we start with ~3000 applications and only accept a small number”](https://forum.effectivealtruism.org/posts/xnHnsrFEMEMPXBWqR/ask-charity-entrepreneurship-anything?commentId=cZFfSufiYwMthyuCi)), I think other EA organizations can learn from CE’s robust system to eliminate the bottleneck of processing applications. At the very least, it is worth taking a look and having a conversation. Again, I might be wrong and please let me know if this is the case. However, if I’m right, I’m very well versed with spreadsheets in general and happy to help put together a template if there is interest. Of course, I’m just deducing the exact process CE has here, it would be better to get the template example from the original source.
### Send responders a copy of their response
On the topic of Google Forms (while I have come to love because this is the method of application in EA), I personal dislike seeing the below message after I poured time (sometimes hours) into the application form and hitting submit:
At the very least, please enable the setting "Send responders a copy of their response" for your applicants so they can see their hours of hard work (probably also an emotional endeavor as your application might be the 10th or 15th application the applicant has done in the last few weeks/months) indeed has gone through:
### Can we at least get a response?
Lastly, there are still a few applications I’m still waiting to hear back from. As an applicant, I think if you asked for my email on the application form, then it would be nice (and courteous) to at least get a response back if I didn’t make the cut - even if it’s followed by *“At this stage we don't have the capacity to offer individual feedback on your application.”*
It might be the norm to not hear back if you didn’t make it through the 1st stage when applying to a “normal” job via Linkedin, or through a job posting by sending a resume and cover letter to a specified email address.
But for whatever reason, when I was applying through Google Forms, I had an expectation of a response. Maybe because I assumed the responses are captured by a spreadsheet and hence sorting through candidates who didn’t make it would be easier. I’m not sure if this is shared by other applicants, or maybe it's just me being misguided.
Anyway, that’s why I’m very appreciative of all the rejection responses I got. Because at the very least I know where I stand - versus the applications that were met with radio silence (makes me suspicious too if my application even went through in the first place).
Of course, even better if an EA organization can implement the potential solutions to help keep up the morale within EA, as described in [The Cost of Rejection](https://forum.effectivealtruism.org/posts/Khon9Bhmad7v4dNKe/the-cost-of-rejection).
The Application Breakdown & Handling Rejections
-----------------------------------------------
Here is a rough look at the applications (including ones I’ve applied to and still looking to apply to like the [CE incubator program](https://www.charityentrepreneurship.com/incubation-program) this week, [EAGxVirtual 2023](https://forum.effectivealtruism.org/posts/FAHHFFmJuDqxBMCNH/save-the-date-eagxvirtual-2023) that just started accepting applications):
* 4 official CEA programs (1 accepted, 1 rejected, 2 to apply next week)
* 5 career advising (2 accepted, 2 rejected, 1 radio silence)
* 4 co-founder opportunities/incubators (1 accepted, 1 rejected after 3rd of 3 steps with [internal CE applicant getting the position](https://forum.effectivealtruism.org/posts/SZ6reaQ2HkABAcY2N/job-opportunity-to-found-charity-entrepreneurship-ngo), 1 radio silence, 1 to apply this week)
* 2 paid jobs/contractors (1 waiting, 1 rejected)
* 4 volunteering opportunities (1 waiting, 3 radio silence)
In total, that’s 19 applications in roughly a two month timeframe.
I found out many of the opportunities I applied to from EA Anywhere, and the occasional ones from the [EA Opportunities Board](https://forum.effectivealtruism.org/posts/ZA5HNrc8AtWGub4fk/ea-internships-board-now-live), ["other EA opportunity collections" like 80000 Hours](https://forum.effectivealtruism.org/posts/JhXdzzzexELaQNorj/ea-opportunities-a-new-and-improved-collection-of) and [Probably Good job board](https://forum.effectivealtruism.org/posts/XgeFZxBzbXuFieZ5H/probably-good-published-a-list-of-impact-focused-job-boards)).
To the point of embracing the rejections. Here is a perspective that might help if you have applied for a bunch of things and still haven’t haven’t gotten an offer in EA. This is something I learned from a passionate, upright and caring role model of mine [Dr. Jim Burns](https://homeword.com/about/jim-burns/): we have to “*to say no to good things, so that we can say yes to the most important things.*” When I looked it up just now to find the original quote, it seems like there are variations of this out there but the point is consistent:
> *Learn to say 'no' to the good so you can say 'yes' to the best. -* John C. Maxwell
>
>
> *People think focus means saying yes to the thing you've got to focus on. But that's not what it means at all. It means saying no to the hundred other good ideas that there are. You have to pick carefully. I'm actually as proud of the things we haven't done as the things I have done. Innovation is saying no to 1,000 things. -* Steve Jobs
>
>
What’s the perspective? I’m very grateful for all the no’s because these no’s to good things (regardless of you saying ‘no’, or they saying ‘no’), will eventually lead you to saying ‘yes’ to the best things, or most important things.
Maybe I’m being optimistic, or maybe it’s because I have a faith that stabilizes me (like I mentioned above with Jeremiah 29:11). Regardless, I think this perspective could help. Especially if you [resonate with the EA applicant](https://forum.effectivealtruism.org/posts/jmbP9rwXncfa32seH/after-one-year-of-applying-for-ea-jobs-it-is-really-really):
> At least for me, handling multiple rejections was mentally challenging. Additionally, the process may foster resentment towards the EA community. I am aware the following statement is super in-accurate and no one is literally saying that, but sometimes this is the message I felt I was getting from the EA community:
>
> “Hey you! You know, all these ideas that you had about making the world a better place, like working for Doctors without Borders? They probably aren’t that great. The long-term future is what matters. And that is not funding constrained, so earning to give is kind of off the table as well. But the good news is, we really, really need people working on these things. We are so talent constraint… *(20 applications later)* … Yeah, when we said that we need people, we meant capable people. Not you. You suck.”
>
>
Here is another forum post about [celebrating rejection](https://forum.effectivealtruism.org/posts/SuCnAsqtRtKr8FX5v/celebrating-rejection).
A Heartfelt Thank You to the Effective Altruism Community
---------------------------------------------------------
It has been a whirlwind of 2 months and I thank you for all the written/videos/podcasts resources this community has made available for anyone who is interested in doing more good.
Above all, thank you to the people who have taken the time out of their busy schedules to meet and help, listed in chronological order (skipped secondary meetings to keep it shorter). I’m so grateful for everyone who has been a part of the journey thus far:
Jul 25th, 2023: Subscribed to the EA Newsletter, subscribed to 80,000 Hours
Jul 27th, 2023: Joined and started reading the EA forum
Aug 3rd, 2023:
* My first virtual 1-on-1 meeting with an EA [Sasha Berezhnoi](https://forum.effectivealtruism.org/users/sasha-berezhnoi) (Community Director for EA Anywhere). Thank you for meeting with me when I was a super newbie and baring with my many many many questions
* Joined EA Anywhere Slack. Again, I’m very grateful for the [EA Anywhere group where professional and affinity groups are consolidated into one space](https://forum.effectivealtruism.org/posts/sK7neZ9rHGEL5JP7q/ea-anywhere-slack-consolidating-professional-and-affinity), making it so much easier to find events (compared to hunting different interest groups on their respective websites)
Aug 4th, 2023: My first virtual group event
* Virtual EA Entrepreneurs Monthly Mastermind led by EA [Simon Newstead](https://forum.effectivealtruism.org/users/simon-newstead), discovered because of EA Anywhere announcements and calendar
* Thank you Simon, for your wisdom and very welcoming environment
Aug 14th, 2023: Virtual 1-on-1 with [Samie Dorgham](https://www.linkedin.com/in/samie-dorgham-36097515) who offers coaching and mentoring practice for EAs, connected because of EA Anywhere introductions
* Thank you for providing me with insights from your six years of management consulting experience at Deloitte, and for asking me probing and revealing questions while I was thinking through my career options! And thank you for connecting me with Federico and EA for Christians!
Aug 16th, 2023: Virtual 1-on-1 with [Federico Speziali](https://forum.effectivealtruism.org/users/federico-speziali-1) ([Co-Founder at High Impact Professionals](https://forum.effectivealtruism.org/posts/M2KrWyG2X8iQaHGJv/introducing-high-impact-professionals)). Thank you for your insights into CE and recommendations for increasing my chances of getting in! I also thank you for speaking your mind regarding my career options and further encouragement to get involved in the community via volunteering and official EA programs.
Aug 17th, 2023: Virtual 1-on-1 with [JD Bauman](https://forum.effectivealtruism.org/users/jdbauman) (first of multiple). Thank you for leading the Christian group within EA, creating an amazing environment for sharing, and always being willing to help! I look forward to attending the EA for Christians weekly group - it is so refreshing and rejuvenating to me. Like I mentioned so many times, I think looking at EA from a Christian lens has so many benefits (less stress, more rest, more peace) and it’s truly a blessing to fellowship with everyone weekly.
Aug 20th, 2023: Virtual group meet with [EA for Christians](https://forum.effectivealtruism.org/posts/Ap4H5ss9AA4pz8GLm/share-these-links-with-christian-friends-interested-in-ea) (first of multiple)
Aug 22nd, 2023: Virtual group meet with [Creatives and Communicators](https://forum.effectivealtruism.org/posts/3sRZkuQDbss3vwddk/ea-creatives-and-communicators-slack), discovered again because of EA Anywhere announcements and calendar
Aug 28th, 2023: Virtual 1-on-1 with [Dr. Peter S. Park](https://forum.effectivealtruism.org/users/peter-s-park) (first of multiple), connected again because of EA Anywhere. Words cannot describe how grateful I’m for you! You are amazing and I’m so honored we get to embark on this wonderful journey working shoulder to shoulder with you :)
Aug 29th, 2023: Virtual presentation by [CharityEntrepreneurship.com](http://charityentrepreneurship.com) (first of two)
Sep 1st, 2023: Virtual 1-on-1 with [Yelnats T.J.](https://forum.effectivealtruism.org/users/yelnats-t-j) (first of multiple). Thank you for your insights into CE and your generosity of time. I have learned so much from you and from going through the [co-founder application for tobacco taxation](https://forum.effectivealtruism.org/posts/SZ6reaQ2HkABAcY2N/job-opportunity-to-found-charity-entrepreneurship-ngo)!
Sep 4th, 2023: Offered Co-founder position at [StakeOut.AI](https://stakeout.ai/)!!!
Sept 12th, 2023: My first in-person group event. It was the first university club meeting of the year at University of British Columbia. Thank you John for leading us in an engaging presentation and discussion :)
Sept 18th, 2023: My first official program with the Centre for Effective Altruism: Virtual Introductory EA Program with facilitator [Carlos M. Suarez Tavernier](https://forum.effectivealtruism.org/users/carlos-m-suarez-tavernier). Thank you for pushing us on the ideas Carlos! The first couple meetings were very thought provoking, I look forward to our continued conversation in the group to reiterate essential EA concepts and ideas. I just read EA VP programs have [attrition rates of around 30% (estimated Feb 9th, 2022)](https://forum.effectivealtruism.org/posts/tn328tcnrKiEMb7Lr/should-you-organise-your-own-introductory-ea-program-or) - I hope we will be the exception where the majority of our group stays on :)
Sept 23rd, 2023: Attended the first ever [EA Talkmasters](https://forum.effectivealtruism.org/posts/KnFcAsoGCX9XthAeb/practice-public-speaking-in-a-friendly-and-supportive-group) (yet another friendly and supportive group) to practice public speaking. Thank you again to Simon Newstead (a Toastmasters veteran) for this initiative.
What's Next
-----------
In the next posts of this series, we plan to talk about the steps implemented thus far following How to Launch a High-Impact Nonprofit action steps. This includes sharing a little about the productivity system, the Founder’s Agreement, the funding proposal draft and future steps.
We are currently working on getting our fiscal sponsorship and figuring out the best fundraising strategy, as we have not yet received any funding. Any tips you have regarding these two areas would be much appreciated!
Additionally, we also plan to do an “introducing” post like [Introducing LEEP: Lead Exposure Elimination Project](https://forum.effectivealtruism.org/posts/fd96FtLFACeAshqJP/introducing-leep-lead-exposure-elimination-project) and [Introducing Animal Policy International](https://forum.effectivealtruism.org/posts/G2vPqkCZkJusKGLtK/introducing-animal-policy-international) to formally present our nonprofit and get your feedback on our project.
Our invitation
--------------
Once again, I’m so thankful I stumbled upon the EA community, as it’s truly been a life-changing experience thus far.
As mentioned in the beginning, I hope this post will inspire others who might be thinking about starting a nonprofit, or apply to CE, or begin on a side project to go for it. There will be many obstacles in the way, but the learning both for yourself and the community is worth the effort.
If you are looking for ideas, consider [Impactful (Side-)Projects and Organizations to Start](https://forum.effectivealtruism.org/posts/K5R35pgPFk3DcGyRp/impactful-side-projects-and-organizations-to-start) (curated ‘list of lists’) for some inspiration.
Once you embark on your journey, consider writing and posting on the EA forum, as I’m sure others would love to read about it! I’m always encouraged to read about other people’s perspectives and their experiences, as I often pick up nuggets that can be applied to my own journey and life. As my experience grows with EA, I hope to offer valuable advice from my learning and experience too for those starting out.
Lastly, what [SofiaBalderson](https://forum.effectivealtruism.org/users/sofiabalderson?from=post_header) said in [Writing about my job: Co-founder of a new charity (early stage)](https://forum.effectivealtruism.org/posts/nAgJSGgdA67xun8MM/writing-about-my-job-co-founder-of-a-new-charity-early-stage) about increasing the chances of success of a nonprofit startup rings true to me:
> It’s impossible to know everything needed to lead a charity effectively. Thankfully, you can access these skills and knowledge through other people. A good network helps a lot. This could be an entrepreneurship hub, a mentor, other charity founders, or industry experts that support your organization’s mission.
>
>
My co-founder and I are always looking to connect to other like-minded people, other co-founders and experienced folks who are willing to advise us.
Please, please, please reach out as we’d love to connect with you! |
46ae2b59-919f-4455-8a95-9077fc5beb8e | trentmkelly/LessWrong-43k | LessWrong | To MIRI-style folk, you can't simulate the universe from the beginning
To those whose formalisms still depend on simulating the universe from the beginning (those who don't, ignore this post, I'm not trying to correct connectionism here):
It doesn't matter how smart a being is; Even temporarily assuming superdeterminism[1], Laplace's demon[2] still cannot fit in the universe it's attempting to simulate - it'd be even more extreme than Maxwell's demon[3], which is also forbidden even in a classical deterministic universe, I think. There's cryptographic amounts of chaos-induced entropy in the way. Impressively cryptographic amounts, actually.
There aren't simplifications that let you get around this, you have to simulate probabilistically to deal with the fact that you can never exactly guess what chaos did in the blurred-out details. Everything has sensitive dependence on initial conditions - the amount you can get around that by being smart is significant, but bumping a butterfly to intentionally change the course of history in a specific, intentional way ain't ever happening without the bump transferring nanites, because the atmosphere is far too chaotic. You need active control to make small energy transfers accumulate into large ones when trying to do open-loop control through a system which is in a chaotic fluid regime, eg the atmosphere; you can't pre-model it and bump it in ways that accumulate into perfection, there's too much chaos and the slightest amount of noise in your sim will result in accumulation into error.
A key point here: it really doesn't matter how smart you are. You can do all sorts of crazy stuff, don't get me wrong, intelligence lets you simplify systems where there isn't chaos. But you can't simulate 100 copies of the universe in your head using 100 watts. or 100 gigawatts. or 100exawatts, and expect to get something that exactly matches. It cannot be done, no matter how big your brain is. There's too much chaos.
Though there might be larger scale structures in things like life, since life is in fact built |
59c45654-9b70-4443-a185-97fd39df4c3b | trentmkelly/LessWrong-43k | LessWrong | Progress links and tweets, 2023-03-01
The Progress Forum
* Anton Howes on what the Dutch did better than the English
* AMA with Gale Pooley & Marian Tupy, authors of Superabundance
* Ben Reinhardt AMA has concluded
Opportunities
* Lex Fridman wants to meet people, fill out this form to get coffee with him
* Essay contest: “What does a perfect research institute look like?” (via @akuataya)
News & announcements
* Works in Progress Issue 10 (thread from @s8mb)
* OpenAI announces its long-term strategy and principles
* BioGPT, an LLM trained on biomedical research literature (via @tunguz)
* Constitutional AI: training LLMs with behavioral principles (from @AnthropicAI)
* UAE turned on its third nuclear reactor in 3 years (@BrianGitt)
Articles & essays
* “How can anyone stop being fascinated for long enough to be angry?” Scott Aaronson on GPT
* Jerusalem Demsas on “permission-slip culture” in America (via @atrembath)
* “Cyborgism” as a strategy for using LLMs
Queries
* Can anyone intro Dwarkesh to Robert Caro? (@dwarkesh_sp)
* What’s the best book on Taylorism? (@davidtlang)
* What are the best books about insurance? (@ByrneHobart)
* Best writing to illustrate to the layman where we’re at with AGI? (@PatrickFinley_)
Quotes
* Everything has to be invented, including stop signs and numbered highways
* The great equalizer: indoor plumbing
* When your boat gets in an accident and works better afterward
* The restless motivation of Paul Ehrlich (the German microbiologist)
* A good metaphor for breakthroughs
* In the 19th century this was considered a sick burn
Tweets & threads
* Institute for Progress one-year anniversary retrospective (@calebwatney)
* All solutions reveal new problems. But to be solutions they must be better problems
* Virtually everything about spacecraft was figured out by a Russian eccentric decades before rocketry
* “The technology we have can do X. Therefore, it will always be limited to X”
* An easy way to trick ChatGPT
* Can China lead on AI if f |
9b4505f3-f8f8-4707-8dc3-79b4351d1774 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Advice on Pursuing Technical AI Safety Research
1. Introduction
===============
This post is a collection of tips and tricks for pursuing work in technical AI Safety (gathered by chatting with numerous Alignment researchers). **A huge thanks to** [**Richard Ngo**](https://forum.effectivealtruism.org/users/richard_ngo)**, who provided all the advice on paper replication (section 2.1) and very kindly edited the rest**. I hope this post is useful, though it is entirely possible I've gotten something wrong. If that's the case, please do leave a comment letting me know! And don't be afraid to ignore something if it sounds like it wouldn't apply to you-none of this advice is a 'hard rule'.
The following applies to both aspiring research scientists and research engineers, with a focus on the importance of machine learning (ML) programming*.* Since the best ML work has strong empirical components, the distinction between research scientist and research engineer is often blurred at AI Safety organisations – all but the most senior research scientists will need to dig into code (and this is often still true of senior roles).
2. Conducting independent research
==================================
When you’re first starting out, independent research can be daunting. Rather than trying to come up with totally novel projects, it’s often a better idea to start by replicating existing machine learning papers and then adding small modifications. The main goal of early independent work should be learning and practising skills, rather than making a significant, novel contribution. Being able to try new things quickly is incredibly helpful in doing good empirical research! Once you’re comfortable implementing and tinkering with neural networks, you’ll be in a good position to test out your own ideas.
2.1. Advice on paper replication
--------------------------------
(from Richard Ngo)
**i.** Pick whichever paper will teach you the most. Start very simple - it’s much better if your project takes too little time rather than getting stuck halfway. The ideal goal is to have a finished and working deliverable you can show others. If you’re new to Machine Learning, you likely won’t want to start with a Reinforcement Learning or Alignment paper. Instead, opt for supervised learning papers (e.g. image classification with the CIFAR dataset).
**ii.** You should aim to get similar results to the original paper; however, this can sometimes be difficult due to cherry-picked seeds or omitted details. If you get inexplicably stuck, try emailing the authors with specific questions..
Once you’ve successfully replicated the original results, run the same algorithm on a new dataset or try adding small improvements. Get comfortable with not knowing what "should" happen. Log everything!
**iii.** Alignment work often requires reasoning about hypothetical agent behaviour, which has resulted in an important niche of conceptual/theoretical work. If you’d like to pursue such work, implementation experience in ML is still valuable; at the very least, try playing around with state-of-the-art models.
***For example**,* what's the most advanced task you can get GPT-3 to perform? What's the least advanced task it fails at? Large language models are very new - you don't need much context to learn something about them that nobody has discovered before. Play around and then write about it!
**iv.** Writing a lot is the best way to get into conceptual/theoretical work. The easiest starting point is to summarise existing work. Once you’ve done this, you can try extending the work with your own thoughts. Lower your standards until you're regularly producing stuff, and when in doubt, don’t put off publishing your work ([LessWrong](https://www.lesswrong.com/) is a good place to do this. You can also apply for membership to the [Alignment Forum](https://www.alignmentforum.org/)). As you produce your summaries, always look for links to existing results or testable hypotheses.
You can also consider emailing your work to alignment researchers and asking for feedback. You’re not guaranteed a response; however, this is a more concrete request than generally asking for a call or mentorship (especially if you have specific questions you’d like them to answer). If you receive feedback, a great next step is to implement it and update the researcher. This demonstrates that their input will have an impact. It can also be helpful to try contacting more junior researchers who are less likely to be overwhelmed with such requests.
Once you've produced even a few things, you should probably start applying to places. **Don't delay that crucial step by underrating yourself!** If you’re rejected, you can re-apply later.
**v.** If pursuing independent projects poses a financial burden, apply for funding with the [Long-term Future Fund](https://funds.effectivealtruism.org/funds/far-future). The application is relatively short and often useful for clarifying goals, regardless of the outcome. If you’re not sure whether applying is worth it, we recommend you at least open the application and take a look – it might be a lot less work than you’re imagining!
Lastly, good luck! Learning the skills needed for alignment research isn't easy, but we appreciate everyone who's putting effort towards it.
3. Applying for AI Safety research training programs
====================================================
There are several safety-focussed training programs that can help you develop skills and access mentorship. It should be noted that these roles can be competitive and facing rejection is totally normal–it doesn’t mean you’re not capable. Consider applying to these programs, even if it seems unlikely you’ll get in.
3.1 Some resources to help you find programs/jobs:
--------------------------------------------------
* [EA Internships Board](https://ea-internships.pory.app/)
* [80,000 hours job board](https://80000hours.org/job-board/)
* [AISS Newsletter](https://www.aisafetysupport.org/newsletter) (the #opportunities channel in the [AI Alignment Slack](https://join.slack.com/t/ai-alignment/shared_invite/zt-fkgwbd2b-kK50z~BbVclOZMM9UP44gw) is also regularly updated)
If you’re fairly new to the AI Safety research landscape and want to learn more about the field in general, EA Cambridge’s [AGI Safety Fundamentals](https://www.eacambridge.org/agi-safety-fundamentals)program is a great place to start.
3.2 Skill up with AI Safety-adjacent research training programs
---------------------------------------------------------------
### 3.2.1 For Students
The [EA Internships Board](https://ea-internships.pory.app/) has summer research positions related to alignment, many ideal/intended for students. In addition, it's usually a good idea to pursue opportunities that are not alignment specific, but will teach you relevant skills (e.g. ML research at your local university).
If you’re interested in graduate school, two important considerations are references and publications. You’ll want to put yourself in the best position when it’s time to apply, which usually means: a) prioritise positions that have the highest potential to result in a conference submission or publication, and b) prioritise supervisors who are well-known in your field or whom you can work with closely to ensure a detailed reference. These tend to be more important than focusing on direct alignment work early-on, since you’re still skilling up and want to have a generally competitive graduate school application. Finally, don’t forget to consider personal fit and prioritise work environments that are conducive to your learning.
### 3.2.2 For Professionals
If you’re pursuing industry work at an alignment org, go ahead and apply as early as possible! To reiterate, it’s simply too easy to under-rate your skills and put off applying. Rejection is expected/common early on and can inform your next steps, which will often be to either: a) apply for funding to conduct independent work/study, or b) skill-up at any ML organisation. Gaining related industry experience will set you up well for direct alignment work later; and on the other hand, skilling up in ML generally has high returns, offering several possible career options. It’s also worth noting that technical roles, such as software engineering, are in demand across other effective altruist cause areas (e.g. [biosecurity](https://forum.effectivealtruism.org/posts/gbPthwLw3NovHAJdp/software-engineering-career-review#Working_on_reducing_global_catastrophic_biological_risks)). If you’d like to explore other EA-related causes that need your skills, check out [80,000 hours career advising](https://80000hours.org/speak-with-us/).
### 3.2.3 Funding options for independent research
* Apply to the [Long-Term Future Fund](https://funds.effectivealtruism.org/funds/far-future)
* There's also a comprehensive list of funding sources [here](https://www.aisafetysupport.org/resources/lots-of-links#h.l9hgaktl1oxq) (though they won't all be relevant)
4. Sign-up for AI Safety-specific Career Coaching
=================================================
If you’d like help solidifying your next steps in pursuing Technical AI Safety, consider signing-up for [AI Safety Support’s career coaching](https://www.aisafetysupport.org/resources/career-coaching). This is open to everyone, from total beginners to students to more senior career professionals looking to transition. |
91238695-05d4-4f09-bfc7-e81e30525cde | trentmkelly/LessWrong-43k | LessWrong | Agency, LLMs and AI Safety - A First Pass
The following is an adaptation of part of my (unsuccessful) application to the Winter 2022 cohort of SERI MATS, as prompted by Victoria Krakovna's "What is your favorite definition of agency, and how would you apply it to a language model?"
This is far from a perfect treatment of the topic, but I am publishing it to document my early days in the field. Or should I say "Epistemic status: I am learning" 😉.
----------------------------------------
I am interested in this question because it is one which came up over the summer when I got more interested in AI Safety. In my readings of LessWrong and technical AI Safety Research surveys, I started to question the need for agency in AI models in the first place. It seemed to me that most hypotheses about future AGI scenarios involved a notion of agency in the model(s) considered, but it was unclear to me what advantages developing agentic models would provide to humans. I thought that if agency was not essential, then perhaps a “compromise” between safety and AGI capabilities could be achieved by relying on oracle-like models, devoid of agency but useful for guidance and whose answers and recommendations we could ultimately reject[1]. I asked a related question on the AI stackexchange forum but unfortunately was met with confusion and ultimately my question was closed as I had made the very obvious mistake of not defining my terms. In an attempt (which never succeeded) to resuscitate the discussion, I proposed the following definition of agency:
> I define agency as the ability to autonomously perceive and interact with a given environment. Anything capable of agency is then an agent. Furthermore, I define
>
> * autonomous perception: the ability to perceive a given environment without the need of an external agent
> * interaction: the ability to change the state of the environment
I liked (and still like) my definition, but admittedly I have not tried evaluating it[2]. One issue is that I did not develop it in i |
09b8bbba-196f-4f87-89dc-e967d2a9f752 | StampyAI/alignment-research-dataset/blogs | Blogs | February 2019 Newsletter
#### Updates
* Ramana Kumar and Scott Garrabrant argue that the AGI safety community should begin prioritizing “[approaches that work well in the absence of human models](https://intelligence.org/2019/02/22/thoughts-on-human-models/)”:
> [T]o the extent that human modelling is a good idea, it is important to do it very well; to the extent that it is a bad idea, it is best to not do it at all. Thus, whether or not to do human modelling at all is a configuration bit that should probably be set early when conceiving of an approach to building safe AGI.
>
>
* New research forum posts: [Conditional Oracle EDT Equilibria in Games](https://www.alignmentforum.org/posts/4MLpRxz7ZoX8YXSY3/coedt-equilibria-in-games); [Non-Consequentialist Cooperation?](https://www.alignmentforum.org/posts/F9vcbEMKW48j4Z6h9/non-consequentialist-cooperation); [When is CDT Dutch-Bookable?](https://www.lesswrong.com/posts/TJT2oBMGaZTE7f2z2/when-is-cdt-dutch-bookable); [CDT=EDT=UDT](https://www.alignmentforum.org/posts/WkPf6XCzfJLCm2pbK/cdt-edt-udt)
* The [MIRI Summer Fellows Program](https://www.lesswrong.com/events/xFGQdgJndLcthgWoE/miri-summer-fellows-program) is accepting applications through the end of March! MSFP is a free two-week August retreat co-run by MIRI and CFAR, intended to bring people up to speed on problems related to [embedded agency](https://www.lesswrong.com/s/Rm6oQRJJmhGCcLvxh/p/i3BTagvt3HbPMx6PN) and AI alignment, train research-relevant skills and habits, and investigate open problems in the field.
* MIRI’s Head of Growth, Colm Ó Riain, [reviews](https://intelligence.org/2019/02/11/our-2018-fundraiser-review/) how our 2018 fundraiser went.
* [From Eliezer Yudkowsky](https://twitter.com/ESYudkowsky/status/1085225949900099585): “Along with adversarial resistance and transparency, what I’d term ‘[conservatism](https://intelligence.org/2017/02/28/using-machine-learning/)’, or trying to keep everything as interpolation rather than extrapolation, is one of the few areas modern ML can explore that I see as having potential to carry over directly to serious AGI safety.”
#### News and links
* Eric Drexler has released his book-length AI safety proposal: [Reframing Superintelligence: Comprehensive AI Services as General Intelligence](https://www.fhi.ox.ac.uk/reframing/). See discussion by [Peter McCluskey](https://www.lesswrong.com/posts/bXYtDfMTNbjCXFQPh/drexler-on-ai-risk), [Richard Ngo](https://www.lesswrong.com/posts/HvNAmkXPTSoA4dvzv/comments-on-cais), and [Rohin Shah](https://www.lesswrong.com/posts/x3fNwSe5aWZb5yXEG/reframing-superintelligence-comprehensive-ai-services-as).
* Other recent AI alignment posts include Andreas Stuhlmüller’s [Factored Cognition](https://www.alignmentforum.org/posts/DFkGStzvj3jgXibFG/factored-cognition) and Alex Turner’s [Penalizing Impact via Attainable Utility Preservation](https://www.alignmentforum.org/posts/mDTded2Dn7BKRBEPX/penalizing-impact-via-attainable-utility-preservation), and a host of new write-ups by [Stuart Armstrong](https://www.alignmentforum.org/users/stuart_armstrong).
The post [February 2019 Newsletter](https://intelligence.org/2019/02/25/february-2019-newsletter/) appeared first on [Machine Intelligence Research Institute](https://intelligence.org). |
97f6136e-2693-4f78-98ac-f2699d64d95f | trentmkelly/LessWrong-43k | LessWrong | If giving unsolicited feedback was a social norm, what feedback would you often give?
None |
b89d504c-3ac4-46b0-9846-0d6d459c79fa | trentmkelly/LessWrong-43k | LessWrong | My checklist for publishing a blog post
Introduction
Checklists are good. I don’t use checklists much for my job though. (My to-do list is stylistically a kanban, not a checklist—details here & here.)
But I have one exception: My checklist for publishing blog posts (an activity that I’ve been doing with some regularity—you’re reading my 114th blog post just on this forum!)
I am sharing that checklist here, not because it’s particularly good, nor because I’m recommending that other people use it (obviously it’s tailored to my idiosyncratic needs), but because I’m interested in sharing ideas and getting feedback!
Related things on this forum include a 2012 essay-publishing checklist by gwern (edit: a commenter found a better / updated link to Gwern’s checklist here), and Justis’s writing advice list which is not directly a checklist but could be made into one (and indeed I copied a few items from it). Please comment with other references and suggestions! How would your own checklist differ from mine?
A couple more bits of commentary before we begin:
Checklist workflow: Good news is that pretty much every productivity-related app (e.g. logseq, roam, obsidian, emacs-org-mode, trello, etc.) has a very nice workflow for checklists—where you make a reusable checklist template, and then insert a fresh (non-checked-off) copy into the appropriate context, and then check off the items one-by-one. If you don’t know the details, google it.
“Consider doing X” items: You’ll notice that many of these checklist items are of the form “Consider doing X”. Often what that means for me in practice is:
* I get to the checklist item “Consider doing X”;
* I consider doing X, and decide not to;
* I happily check it off.
That’s fine! It’s not always a good use of time to make a blog post higher-quality. The one you’re reading right now is a great example: I am writing this post very quickly, and I stand by that decision.
OK, that’s enough commentary! The rest of the post is the checklist itself.
The actual checklist! |
d01fd7f1-89bc-41f2-825a-cae72914ddf2 | trentmkelly/LessWrong-43k | LessWrong | Why don't you introduce really impressive people you personally know to AI alignment (more often)?
I have a few questions to the subset of readers who:
1. Believe technical AI alignment research is both important and hard to make significant progress in
2. Have a personal connection with a person who doesn't know much about AI alignment, but who you think would have a real chance to make valuable contributions to the field if they entered it (or perhaps you know someone who cares about AI risk and have such a personal connection, and you have enough knowledge to talk on their behalf). It may be your friend, colleague, supervisor, etc.
I would love to hear your thoughts on some of the following questions:
1. What reasons prevent you from introducing them to AI alignment by e.g. scheduling time with them and talking about some of the motivations and open problems in the field?
2. If you've tried something like this, how did it go?
3. What factors do you think would increase your willingness to bring AI alignment to their attention and/or the potential value resulting from it? Bonus points for reasonably low-hanging fruit here. |
65698bc5-f953-434f-b3f3-cdfa22e3dea6 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | How easy is it to supervise processes vs outcomes?
A lot of AI risk models rely on the fact that we supervise outcomes like consequentialists rather than processes like CAIS.
But, how easy is it to supervise processes for AI, compared to outcomes both in:
Near term: 10 years.
Long-term: 50 years.
Crucially, is it easier to supervise processes like CAIS today than outcomes?
And a final question. Should we fund massively attempts to supervise processes in today's AI, in the hope that it's an attractor state rather than outcomes like consequentialism? |
eaae6965-d07f-4414-91bc-71a4ff71710c | trentmkelly/LessWrong-43k | LessWrong | Toward Safety Case Inspired Basic Research
Abstract
AI safety is a young science. In its early history, deep and speculative questions regarding the risks of artificial superintelligence attracted the attention of basic science and philosophy, but the near-horizon focus of industry and governance, coupled with shorter safety timelines, means that applied science is now taking a bigger hand in the field’s future. As the science of AI safety matures, it is critical to establish a research tradition that balances the need for foundational understanding with the demand for relevance to practical applications. We claim that “use-inspired basic research” – which grounds basic science with a clear-cut purpose – strikes a good balance between pragmatism and rigor that will ensure the solid foundations, flexibility, and utility appropriate for a problem of this scope and magnitude.
In this post, we build on the established concept of ‘safety cases’ to elevate the role of basic research in AI safety and argue for more balanced collaborations with industry and governance. In spite of their importance for AI safety, we stress that, given limits to our present-day understanding and methods, it is not currently possible for applied scientists to make a safety case for sufficiently advanced AI systems with correspondingly high risks; while aspirational, robust safety cases are hypothetical objects. We advocate for a holistic approach to AI safety research that intentionally coordinates the efforts of basic scientists and applied scientists and propose the beginnings of a framework for collaboration that can direct the field toward use-inspired research that will help us construct safety cases in the future.
Introduction: Applied & Basic Research in AI Safety
AI Safety is a burgeoning field of study whose general aim is to make AI systems safe and beneficial to both individual users and humanity at large. It has historically spanned a spectrum of topics and methodologies, but for our discussion, we find it convenient t |
4ace7d32-c016-401d-883b-99d424a57ed5 | StampyAI/alignment-research-dataset/special_docs | Other | The Alignment Problem: Machine Learning and Human Values
[]
This e-book contains some places that ask the reader to fill in questions or comments. Please keep pen and paper handy as you read this e-book so that you can complete the exercises within.
For Peter
who convinced me
And for everyone
doing the work
I remember in 2000 hearing James Martin, the leader of the Viking missions to Mars, saying that his job as a spacecraft engineer was not to land on Mars, but to land on the model of Mars provided by the geologists.
—PETER NORVIG¹
The world is its own best model.
—RODNEY BROOKS²
All models are wrong.
—GEORGE BOX³
The
Alignment
Problem
PROLOGUE
1935, Detroit. Walter Pitts is running down the street, chased by bullies.
He ducks into the public library to take shelter, and he hides. He hides so well that the library staff don’t even realize he’s there, and they close for the night. Walter Pitts is locked inside.¹
He finds a book on the shelves that looks interesting, and he starts reading it. For three days, he reads the book cover to cover.
The book is a two-thousand-page treatise on formal logic; famously, its proof that 1+1=2 does not appear until page 379.² Pitts decides to write a letter to one of the authors—British philosopher Bertrand Russell—because he believes he’s found several mistakes.
Several weeks go by, and Pitts gets a letter in the mail postmarked from England. It’s Bertrand Russell. Russell thanks him for writing, and invites Pitts to become one of his doctoral students at Cambridge.³
Unfortunately, Walter Pitts must decline the offer—because he’s only twelve years old, and in the seventh grade.
Three years later, Pitts learns that Russell will be visiting Chicago to give a public lecture. He runs away from home to attend. He never goes back.
[images]
At Russell’s lecture, Pitts meets another teenager in the audience, named Jerry Lettvin. Pitts only cares about logic. Lettvin only cares about poetry and, a distant second, medicine.⁴ They become inseparable best friends.
Pitts begins hanging out around the University of Chicago campus, dropping in on classes; he still lacks a high school diploma and never formally enrolls. One of these classes is by the famed German logician Rudolf Carnap. Pitts walks into his office hours, declaring he’s found a few “flaws” in Carnap’s latest book. Skeptically, Carnap consults the book; Pitts, of course, is right. They talk awhile, then Pitts walks out without giving his name. Carnap spends months asking around about the “newsboy who knew logic.”⁵ Eventually Carnap finds him again and, in what will become a motif throughout Pitts’s academic life, becomes his advocate, persuading the university to give him a menial job so he will at least have some income.
It’s now 1941. Lettvin—still a poet first, in his own mind—has, despite himself, gotten into medical school at the University of Illinois, and finds himself working under the brilliant neurologist Warren McCulloch, newly arrived from Yale. One day Lettvin invites Pitts over to meet him. At this point Lettvin is twenty-one and still living with his parents. Pitts is seventeen and homeless.⁶ McCulloch and his wife take them both in.
Throughout the year that follows, McCulloch comes home in the evenings and he and Pitts—who is barely older than McCulloch’s own children—regularly stay up past midnight talking. Intellectually, they are the perfect team: the esteemed midcareer neurologist and the prodigy logician. One lives in practice—the world of nervous systems and neuroses—and the other lives in theory—the world of symbols and proofs. They both want nothing more than to understand the nature of truth: what it is, and how we know it. The fulcrum of this quest—the thing that sits at the perfect intersection of their two disparate worlds—is, of course, the brain.
It was already known by the early 1940s that the brain is built of neurons wired together, and that each neuron has “inputs” (dendrites) as well as an “output” (axon). When the impulses coming into a neuron exceed a certain threshold, then that neuron, in turn, emits a pulse. Immediately this begins to feel, to McCulloch and Pitts, like logic: the pulse or its absence signifying on or off, yes or no, true or false.⁷
They realize that a neuron with a low-enough threshold, such that it would fire if any of its inputs did, functioned like a physical embodiment of the logical or. A neuron with a high-enough threshold, such that it would only fire if all of its inputs did, was a physical embodiment of the logical and. There was nothing, then, that could be done with logic—they start to realize—that such a “neural network,” so long as it was wired appropriately, could not do.
Within months they have written a paper together—the middle-aged neurologist and teenage logician. They call it “A Logical Calculus of Ideas Immanent in Nervous Activity.”
“Because of the ‘all-or-none’ character of nervous activity,” they write, “neural events and the relations among them can be treated by means of propositional logic. It is found that the behavior of every net can be described in these terms . . . and that for any logical expression satisfying certain conditions, one can find a net behaving in the fashion it describes.”
The paper is published in 1943 in the Bulletin of Mathematical Biophysics. To Lettvin’s frustration, it makes little impact on the biology community.⁸ To Pitts’s disappointment, the neuroscience work of the 1950s, notably a landmark study of the optic nerve of the frog—done by none other than his best friend, Jerry Lettvin—will show that neurons appear to be much messier than the simple “true” or “false” circuits he envisioned. Perhaps propositional logic—its ands, ors, and nots—was not, ultimately, the language of the brain, or at least not in so straightforward a form. This kind of impurity saddened Pitts.
But the impact of the paper—of those long conversations into the night at McCulloch’s house—would be enormous, if not entirely in the way that McCulloch and Pitts envisioned. It would be the foundation for a completely new field: the project to actually build mechanisms out of these simplified versions of neurons, and see just what such “mechanical brains” could do.⁹
INTRODUCTION
In the summer of 2013, an innocuous post appeared on Google’s open-source blog titled “Learning the Meaning Behind Words.”¹
“Today computers aren’t very good at understanding human language,” it began. “While state-of-the-art technology is still a ways from this goal, we’re making significant progress using the latest machine learning and natural language processing techniques.”
Google had fed enormous datasets of human language, mined from newspapers and the internet—in fact, thousands of times more text than had ever been successfully used before—into a biologically inspired “neural network,” and let the system pore over the sentences for correlations and connections between the terms.
The system, using so-called “unsupervised learning,” began noticing patterns. It noticed, for instance, that the word “Beijing” (whatever that meant) had the same relationship to the word “China” (whatever that was) as the word “Moscow” did to “Russia.”
Whether this amounted to “understanding” or not was a question for philosophers, but it was hard to argue that the system wasn’t capturing something essential about the sense of what it was “reading.”
Because the system transformed the words it encountered into numerical representations called vectors, Google dubbed the system “word2vec,” and released it into the wild as open source.
To a mathematician, vectors have all sorts of wonderful properties that allow you to treat them like simple numbers: you can add, subtract, and multiply them. It wasn’t long before researchers discovered something striking and unexpected. They called it “linguistic regularities in continuous space word representations,”² but it’s much easier to explain than that. Because word2vec made words into vectors, it enabled you to do math with words.
For instance, if you typed China + river, you got Yangtze. If you typed Paris − France + Italy, you got Rome. And if you typed king − man + woman, you got queen.
The results were remarkable. The word2vec system began humming under the hood of Google’s translation service and its search results, inspiring others like it across a wide range of applications including recruiting and hiring, and it became one of the major tools for a new generation of data-driven linguists working in universities around the world.
No one realized what the problem was for two years.
In November 2015, Boston University PhD student Tolga Bolukbasi went with his advisor to a Friday happy-hour meeting at Microsoft Research. Amid wine sipping and informal chat, he and Microsoft researcher Adam Kalai pulled out their laptops and started messing around with word2vec.
“We were playing around with these word embeddings, and we just started randomly putting words into it,” Bolukbasi says. “I was playing on my PC; Adam started playing.”³ Then something happened.
They typed:
doctor − man + woman
The answer came back:
nurse
“We were shocked at that point, and we realized there was a problem,” says Kalai. “And then we dug deeper and saw that it was even worse than that.”⁴
The pair tried another.
shopkeeper − man + woman
The answer came back:
housewife
They tried another.
computer programmer − man + woman
Answer:
homemaker
Other conversations in the room by this point had stopped, and a group had formed around the screen. “We jointly realized,” says Bolukbasi, “Hey, there’s something wrong here.”
[images]
In judiciaries across the country, more and more judges are coming to rely on algorithmic “risk-assessment” tools to make decisions about things like bail and whether a defendant will be held or released before trial. Parole boards are using them to grant or deny parole. One of the most popular of these tools was developed by the Michigan-based firm Northpointe and goes by the name Correctional Offender Management Profiling for Alternative Sanctions—COMPAS, for short.⁵ COMPAS has been used by states including California, Florida, New York, Michigan, Wisconsin, New Mexico, and Wyoming, assigning algorithmic risk scores—risk of general recidivism, risk of violent recidivism, and risk of pretrial misconduct—on a scale from 1 to 10.
Amazingly, these scores are often deployed statewide without formal audits.⁶ COMPAS is a proprietary, closed-source tool, so neither attorneys, defendants, nor judges know exactly how its model works.
In 2016, a group of data journalists at ProPublica, led by Julia Angwin, decided to take a closer look at COMPAS. With the help of a public records request to Florida’s Broward County, they were able to get the records, and the risk scores, of some seven thousand defendants arrested in 2013 and 2014.
Because they were doing their research in 2016, the ProPublica team had the equivalent of a crystal ball. Looking at data from two years prior, they actually knew whether these defendants, predicted either to reoffend or not, actually did. And so they asked two simple questions. One: Did the model actually correctly predict which defendants were indeed the “riskiest”? And two: Were the model’s predictions biased in favor of or against any group in particular?
An initial look at the data suggested something might be wrong. They found, for instance, two defendants arrested for similar counts of drug possession. The first, Dylan Fugett, had a prior offense of attempted burglary; the second, Bernard Packer, had a prior offense of nonviolently resisting arrest. Fugett, who is White, was assigned a risk score of 3/10. Packer, who is Black, was assigned a risk score of 10/10.
From the crystal ball of 2016, they also knew that Fugett, the 3/10 risk, went on to be convicted of three further drug offenses. Over the same time period, Packer, the 10/10 risk, had a clean record.
In another pairing, they juxtaposed two defendants charged with similar counts of petty theft. The first, Vernon Prater, had a prior record of two armed robberies and one attempted armed robbery. The other defendant, Brisha Borden, had a prior record of four juvenile misdemeanors. Prater, who is White, was assigned a risk score of 3/10. Borden, who is Black, was assigned a risk score of 8/10.
From the vantage of 2016, Angwin’s team knew that Prater, the “low-risk” defendant, went on to be convicted of a later count of grand theft and given an eight-year prison sentence. Borden, the “high-risk” defendant, had no further offenses.
Even the defendants themselves seemed confused by the scores. James Rivelli, who is White, was arrested for shoplifting and rated a 3/10 risk, despite having prior offenses including aggravated assault, felony drug trafficking, and multiple counts of theft. “I spent five years in state prison in Massachusetts,” he told a reporter. “I am surprised it is so low.”
A statistical analysis appeared to affirm that there was a systemic disparity.⁷ The article ran with the logline “There’s software used across the country to predict future criminals. And it’s biased against blacks.”
Others weren’t so sure—and ProPublica’s report, published in the spring of 2016, touched off a firestorm of debate: not only about COMPAS, not only about algorithmic risk assessment more broadly, but about the very concept of fairness itself. How, exactly, are we to define—in statistical and computational terms—the principles, rights, and ideals articulated by the law?
When US Supreme Court Chief Justice John Roberts visits Rensselaer Polytechnic Institute later that year, he’s asked by university president Shirley Ann Jackson, “Can you foresee a day when smart machines—driven with artificial intelligences—will assist with courtroom fact-finding or, more controversially, even judicial decision-making?”
“It’s a day that’s here,” he says.⁸
[images]
That same fall, Dario Amodei is in Barcelona to attend the Neural Information Processing Systems conference (“NeurIPS,” for short): the biggest annual event in the AI community, having ballooned from several hundred attendees in the 2000s to more than thirteen thousand today. (The organizers note that if the conference continues to grow at the pace of the last ten years, by the year 2035 the entire human population will be in attendance.)⁹ But at this particular moment, Amodei’s mind isn’t on “scan order in Gibbs sampling,” or “regularizing Rademacher observation losses,” or “minimizing regret on reflexive Banach spaces,” or, for that matter, on Tolga Bolukbasi’s spotlight presentation, some rooms away, about gender bias in word2vec.¹⁰
He’s staring at a boat, and the boat is on fire.
He watches as it does donuts in a small harbor, crashing its stern into a stone quay. The motor catches fire. It continues to spin wildly, the spray dousing the flames. Then it slams into the side of a tugboat and catches fire again. Then it spins back into the quay.
It is doing this because Amodei ostensibly told it to. In fact it is doing exactly what he told it to. But it is not what he meant.
Amodei is a researcher on a project called Universe, where he is part of a team working to develop a single, general-purpose AI that can play hundreds of different computer games with human-level skill—a challenge that has been something of a holy grail among the AI community.
“And so I just, I ran a few of these environments,” Amodei tells me, “and I was VPNing in and looking to see how each one was doing. And then just the normal car race was going fine, and there was like a truck race or something, and then there was this boat race.” Amodei watches for a minute. “And I was looking at it, and I was like, ‘This boat is, like, going around in circles. Like, what in the world is going on?!’ ”¹¹ The boat wasn’t simply acting randomly; it wasn’t wild or out of control. In fact, it was the opposite. It had settled on this. From the computer’s perspective, it has found a nearly perfect strategy, and was executing it to a T. Nothing made sense.
“Then I eventually looked at the reward,” he says.
Amodei had made the oldest mistake in the book: “rewarding A, while hoping for B.”¹² What he wanted was for the machine to learn how to win the boat race. But it was complicated to express this rigorously—he would need to find a way to formalize complex concepts like track position, laps, placement among the other boats, and so on. Instead, he used what seemed like a sensible proxy: points. The machine found a loophole, a tiny harbor with replenishing power-ups where it could ignore the race entirely, do donuts, and rack up points . . . forever.
“And, of course, it’s partially my fault,” he says. “I just run these various games; I haven’t looked super closely at the objective function. . . . In the other ones, score was sensibly correlated to finishing the race. You got points for getting power-ups that were always along the road. . . . The proxy of score that came with the game was good for the other ten environments. But for this eleventh environment, it wasn’t good.”¹³
“People have criticized it by saying, ‘Of course, you get what you asked for,’” Amodei says. “It’s like, ‘You weren’t optimizing for finishing the race.’ And my response to that is, Well—” He pauses. “That’s true.”
Amodei posts a clip to his group’s Slack channel, where the episode is instantly deemed “hilarious” by all concerned. In its cartoonish, destructive slapstick, it certainly is. But for Amodei—who now leads the AI safety team at San Francisco research lab OpenAI—there is another, more sobering message. At some level, this is exactly what he’s worried about.
The real game he and his fellow researchers are playing isn’t to try to win boat races; it’s to try to get increasingly general-purpose AI systems to do what we want, particularly when what we want—and what we don’t want—is difficult to state directly or completely.
The boat scenario is admittedly just a warm-up, just practice. The property damage is entirely virtual. But it is practice for a game that is, in fact, no game at all. A growing chorus within the AI community—first a few voices on the fringe, and increasingly the mainstream of the field—believes, if we are not sufficiently careful, that this is literally how the world will end. And—for today at least—the humans have lost the game.
[images]
This is a book about machine learning and human values: about systems that learn from data without being explicitly programmed, and about how exactly—and what exactly—we are trying to teach them.
The field of machine learning comprises three major areas: In unsupervised learning, a machine is simply given a heap of data and—as with the word2vec system—told to make sense of it, to find patterns, regularities, useful ways of condensing or representing or visualizing it. In supervised learning, the system is given a series of categorized or labeled examples—like parolees who went on to be rearrested and others who did not—and told to make predictions about new examples it hasn’t seen yet, or for which the ground truth is not yet known. And in reinforcement learning, the system is placed into an environment with rewards and punishments—like the boat-racing track with power-ups and hazards—and told to figure out the best way to minimize the punishments and maximize the rewards.
On all three fronts, there is a growing sense that more and more of the world is being turned over, in one way or another, to these mathematical and computational models. Though they range widely in complexity—from something that might fit on a spreadsheet on the one hand, to something that might credibly be called artificial intelligence on the other—they are steadily replacing both human judgment and explicitly programmed software of the more traditional variety.
This is happening not only in technology, not only in commerce, but in areas with ethical and moral weight. State and federal law increasingly mandates the use of “risk-assessment” software to determine bail and parole. The cars and trucks on our freeways and neighborhood streets are increasingly driving themselves. We no longer assume that our mortgage application, our résumé, or our medical tests will be seen by human eyes before a verdict is rendered. It is as if the better part of humanity were, in the early twenty-first century, consumed by the task of gradually putting the world—figuratively and literally—on autopilot.
In recent years, alarm bells have gone off in two distinct communities. The first are those focused on the present-day ethical risks of technology. If a facial-recognition system is wildly inaccurate for people of one race or gender but not another, or if someone is denied bail because of a statistical model that has never been audited and that no one in the courtroom—including the judge, attorneys, and defendant—understands, this is a problem. Issues like these cannot be addressed within traditional disciplinary camps, but rather only through dialogue: between computer scientists, social scientists, lawyers, policy experts, ethicists. That dialogue has begun in a hurry.
The second are those worried about the future dangers that await as our systems grow increasingly capable of flexible, real-time decision-making, both online and in the physical world. The past decade has seen what is inarguably the most exhilarating, abrupt, and worrying progress in the history of machine learning—and, indeed, in the history of artificial intelligence. There is a consensus that a kind of taboo has been broken: it is no longer forbidden for AI researchers to discuss concerns of safety. In fact, such concerns have over the past five years moved from the fringes to become one of the central problems of the field.
Though there is a rivalry of sorts over whether the immediate or the longer-term issues should take priority, these two communities are united in their larger aims.
As machine-learning systems grow not just increasingly pervasive but increasingly powerful, we will find ourselves more and more often in the position of the “sorcerer’s apprentice”: we conjure a force, autonomous but totally compliant, give it a set of instructions, then scramble like mad to stop it once we realize our instructions are imprecise or incomplete—lest we get, in some clever, horrible way, precisely what we asked for.
How to prevent such a catastrophic divergence—how to ensure that these models capture our norms and values, understand what we mean or intend, and, above all, do what we want—has emerged as one of the most central and most urgent scientific questions in the field of computer science. It has a name: the alignment problem.
In reaction to this alarm—both that the bleeding edge of research is getting ever closer to developing so-called “general” intelligence and that real-world machine-learning systems are touching more and more ethically fraught parts of personal and civic life—has been a sudden, energetic response. A diverse group is mustering across traditional disciplinary lines. Nonprofits, think tanks, and institutes are taking root. Leaders within both industry and academia are speaking up, some of them for the first time, to sound notes of caution—and redirecting their research funding accordingly. The first generation of graduate students is matriculating who are focused explicitly on the ethics and safety of machine learning. The alignment problem’s first responders have arrived at the scene.
This book is the product of nearly a hundred formal interviews and many hundreds of informal conversations, over the course of four years and many tens of thousands of miles, with researchers and thinkers from this field’s young history and its sprawling frontier. What I found was a field finding its legs, amid exhilarating and sometimes terrifying progress. A story I thought I knew showed itself to be, by turns, more riveting, harrowing, and hopeful than I had understood.
Machine learning is an ostensibly technical field crashing increasingly on human questions. Our human, social, and civic dilemmas are becoming technical. And our technical dilemmas are becoming human, social, and civic. Our successes and failures alike in getting these systems to do “what we want,” it turns out, offer us an unflinching, revelatory mirror.
This is a story in three distinct parts. Part one explores the alignment problem’s beachhead: the present-day systems already at odds with our best intentions, and the complexities of trying to make those intentions explicit in systems we feel capable of overseeing. Part two turns the focus to reinforcement learning, as we come to understand systems that not only predict, but act; there are lessons here for understanding evolution, human motivation, and the delicacy of incentives, with implications for business and parenting alike. Part three takes us to the forefront of technical AI safety research, as we tour some of the best ideas currently going for how to align complex autonomous systems with norms and values too subtle or elaborate to specify directly.
For better or worse, the human story in the coming century is likely to be one of building such systems and setting them, one by one, in motion. Like the sorcerer’s apprentice, we will find ourselves just one set of agents among many, in a world crowded—as it were—with brooms.
How, exactly, do we intend to teach them?
And what?
PART I
Prophecy
1 REPRESENTATION
In the summer of 1958, a group of reporters are gathered by the Office of Naval Research in Washington, D.C., for a demonstration by a twenty-nine-year-old researcher at the Cornell Aeronautical Laboratory named Frank Rosenblatt. Rosenblatt has built something he calls the “perceptron,” and in front of the assembled press corps he shows them what it can do.
Rosenblatt has a deck of flash cards, each of which has a colored square on it, either on the left side of the card or on the right. He pulls one card out of the deck and places it in front of the perceptron’s camera. The perceptron takes it in as a black-and-white, 20-by-20-pixel image, and each of those four hundred pixels is turned into a binary number: 0 or 1, dark or light. The four hundred numbers, in turn, are fed into a rudimentary neural network, the kind that McCulloch and Pitts had imagined in the early 1940s. Each of these binary pixel values is multiplied by an individual negative or positive “weight,” and then they are all added together. If the total is negative, it will output a −1 (meaning the square is on the left), and if it’s positive, it will output a 1 (meaning the square is on the right).
The perceptron’s four hundred weights are initially random, and its outputs, as a result, are nonsense. But every time the system guesses “wrong,” Rosenblatt “trains” it, by dialing up the weights that were too low and turning down the weights that were too high.
Fifty of these trials later, the machine now consistently tells left-side cards and right-side cards apart, including ones he hasn’t shown it before.
The demonstration itself is strikingly modest, but it signifies something grander. The machine is, in effect, learning from experience—what Rosenblatt calls a “self-induced change in the wiring diagram.”¹
McCulloch and Pitts had imagined the neuron as a simple unit of input and output, of logic and arithmetic, and they had shown the enormous power of such rudimentary mechanisms, in great enough numbers and suitably connected. But they had said next to nothing about how exactly the “suitably connected” part was actually meant to be achieved.²
“Rosenblatt made a very strong claim, which at first I didn’t believe,” says MIT’s Marvin Minsky, coincidentally a former classmate of Rosenblatt’s at the Bronx High School of Science.³ “He said that if a perceptron was physically capable of being wired up to recognize something, then there would be a procedure for changing its responses so that eventually it would learn to carry out the recognition. Rosenblatt’s conjecture turned out to be mathematically correct, in fact. I have a tremendous admiration for Rosenblatt for guessing this theorem, since it is very hard to prove.”
The perceptron, simple as it is, forms the blueprint for much of the machine-learning systems we will go on to discuss. It contains a model architecture: in this case, a single artificial “neuron” with four hundred inputs, each with its own “weight” multiplier, which are then summed together and turned into an all-or-nothing output. The architecture has a number of adjustable variables, or parameters: in this case, the positive or negative multipliers attached to each input. There is a set of training data: in this case, a deck of flash cards with one of two types of shapes on them. The model’s parameters are tuned using an optimization algorithm, or training algorithm.
The basic training procedure for the perceptron, as well as its many contemporary progeny, has a technical-sounding name—“stochastic gradient descent”—but the principle is utterly straightforward. Pick one of the training data at random (“stochastic”) and input it to the model. If the output is exactly what you want, do nothing. If there is a difference between what you wanted and what you got, then figure out in which direction (“gradient”) to adjust each weight—whether by literal turning of physical knobs or simply the changing of numbers in software—to lower the error for this particular example. Move each of them a little bit in the appropriate direction (“descent”). Pick a new example at random, and start again. Repeat as many times as necessary.
This is the basic recipe for the field of machine learning—and the humble perceptron will be both an overestimation and an underestimation of what is to come.
“The Navy,” reports the New York Times, “revealed the embryo of an electronic computer today that it expects will be able to walk, talk, see, write, reproduce itself and be conscious of its existence.”⁴
The New Yorker writes that the perceptron, “as its name implies, is capable of original thought.” “Indeed,” they write, “it strikes us as the first serious rival to the human brain ever devised.”
Says Rosenblatt to the New Yorker reporter, “Our success in developing the perceptron means that for the first time a non-biological object will achieve an organization of its external environment in a meaningful way. That’s a safe definition of what the perceptron can do. My colleague disapproves of all the loose talk one hears nowadays about mechanical brains. He prefers to call our machine a self-organizing system, but, between you and me, that’s precisely what any brain is.”⁵
That same year, New Scientist publishes an equally hopeful, and slightly more sober, article called “Machines Which Learn.”⁶ “When machines are required to perform complicated tasks it would often be useful to incorporate devices whose precise mode of operation is not specified initially,” they write, “but which learn from experience how to do what is required. It would then be possible to produce machines to do jobs which have not been fully analysed because of their complexity. It seems likely that learning machines will play a part in such projects as the mechanical translation of languages and the automatic recognition of speech and of visual patterns.”
“The use of the term ‘learning machine’ invites comparison with the learning of people and animals,” the article continues. “The drawing of analogies between brains and machines requires caution to say the least, but in a general way it is stimulating for workers in either field to know something of what is happening in the other, and it is possible that speculation about machines which learn may eventually produce a system which is a true analogue of some form of biological learning.”
The history of artificial intelligence is famously one of cycles of alternating hope and gloom, and the Jetsonian future that the perceptron seemed to herald is slow to arrive.
Rosenblatt, with a few years of hindsight, will wish the press had used a bit more caution in their reactions to his invention. The popular press “fell to the task with all of the exuberance and sense of discretion of a pack of happy bloodhounds,” he says—while admitting, on his own behalf, a certain “lack of mathematical rigor in preliminary reports.”⁷
Minsky, despite his “tremendous admiration” for Rosenblatt and his machine, begins “to worry about what such a machine could not do.” In 1969, he and his MIT colleague Seymour Papert publish a book called Perceptrons that effectively slams the door shut on the entire vein of research. Minsky and Papert show, with the stiff formality of mathematical proof, that there are seemingly basic patterns that Rosenblatt’s model simply will never be able to recognize. For instance, it is impossible to train one of Rosenblatt’s machines to recognize when a card has an odd versus an even number of squares on it. The only way to recognize more complex categories like this is to use a network with multiple layers, with earlier layers creating a representation of the raw data, and the later layers operating on the representation. But no one knows how to tune the parameters of the early layers to make representations useful for the later ones. The field hits the equivalent of a brick wall. “There had been several thousand papers published on perceptrons up to 1969,” says Minsky.
“Our book put a stop to those.”⁸
It is as if a dark cloud has settled over the field, and everything falls apart: the research, the money, the people. Pitts, McCulloch, and Lettvin, who have all three moved to MIT, are sharply exiled after a misunderstanding with MIT’s Norbert Wiener, who had been like a second father figure to Pitts and now won’t speak to him. Pitts, alcoholic and depressed, throws all of his notes and papers into a fire, including an unpublished dissertation about three-dimensional neural networks that MIT tries desperately to salvage. Pitts dies from cirrhosis in May 1969, at the age of 46.⁹ A few months later Warren McCulloch, at the age of 70, succumbs to a heart seizure after a long series of cardiopulmonary problems. In 1971, while celebrating his 43rd birthday, Frank Rosenblatt drowns in a sailing accident on the Chesapeake Bay.
By 1973, both the US and British governments have pulled their funding support for neural network research, and when a young English psychology student named Geoffrey Hinton declares that he wants to do his doctoral work on neural networks, again and again he is met with the same reply: “Minsky and Papert,” he is told, “have proved that these models were no good.”¹⁰
THE STORY OF ALEXNET
It is 2012 in Toronto, and Alex Krizhevsky’s bedroom is too hot to sleep. His computer, attached to twin Nvidia GTX 580 GPUs, has been running day and night at its maximum thermal load, its fans pushing out hot exhaust, for two weeks.
“It was very hot,” he says. “And it was loud.”¹¹
He is teaching the machine how to see.
Geoffrey Hinton, Krizhevsky’s mentor, is now 64 years old and has not given up. There is reason for hope.
By the 1980s it became understood that networks with multiple layers (so-called “deep” neural networks) could, in fact, be trained by examples just as a shallow one could.¹² “I now believe,” admitted Minsky, “that the book was overkill.”¹³
By the late ’80s and early ’90s, a former postdoc of Hinton’s named Yann LeCun, working at Bell Labs, had trained neural networks to identify handwritten numerals from 0 to 9, and neural networks found their first major commercial use: reading zip codes in post offices, and deposit checks in ATMs.¹⁴ By the 1990s, LeCun’s networks were processing 10 to 20% of all checks in the United States.¹⁵
But the field hit another plateau, and by the 2000s, researchers were still largely stuck fiddling with databases of handwritten zip codes. It was understood that, in principle, a big-enough neural network, with enough training examples and time, can learn almost anything.¹⁶ But no one had fast-enough computers, enough data to train on, or enough patience to make good on that theoretical potential. Many lost interest, and the field of computer vision, along with computational linguistics, largely moved on to other things. As Hinton would later summarize, “Our labeled datasets were thousands of times too small. [And] our computers were millions of times too slow.”¹⁷ Both of these things, however, would change.
With the growth of the web, if you wanted not fifty but five hundred thousand “flash cards” for your network, suddenly you had a seemingly bottomless repository of images. There was only one problem, which was that they usually didn’t come with their category label readily attached. You couldn’t train a network unless you knew what the network’s output was supposed to be.
In 2005, Amazon launched its “Mechanical Turk” service, allowing for the recruiting of human labor on a large scale, making it possible to hire thousands of people to perform simple actions for pennies a click. (The service was particularly well suited to the kinds of things that future AI is thought to be able to do—hence its tagline: artificial artificial intelligence.) In 2007, Princeton professor Fei-Fei Li used Amazon Mechanical Turk to recruit human labor, at a scale previously unimaginable, to build a dataset that was previously impossible. It took more than two years to build, and had three million images, each labeled, by human hands, into more than five thousand categories. Li called it ImageNet, and released it in 2009. The field of computer vision suddenly had a mountain of new data to learn from, and a new grand challenge. Beginning in 2010, teams from around the world began competing to build a system that can reliably look at an image—dust mite, container ship, motor scooter, leopard—and say what it is.
Meanwhile, the relatively steady progress of Moore’s law throughout the 2000s meant that computers could do in minutes what the computers of the 1980s took days to do. One further development, however, turned out to be crucial. In the 1990s, the video-game industry began to produce dedicated graphics processors called GPUs, designed to render complex 3D scenes in real time; instead of executing instructions with perfect precision one after another, as a traditional CPU does, they are capable of doing a great many simple and sometimes approximate calculations at once.¹⁸ Only later, in the mid-2000s, did it come to be appreciated that the GPU could do a lot more than light and texture and shadow.¹⁹ It turned out that this hardware, designed for computer gaming, was in fact tailor-made for training neural networks.
At the University of Toronto, Alex Krizhevsky had taken a class on writing code for GPUs, and decided to try it on neural networks. He applied himself to a popular image-recognition benchmark called CIFAR-10, which contained thumbnail-sized images that each belonged to one of ten categories: airplane, automobile, bird, cat, deer, dog, frog, horse, ship, or truck. Krizhevsky built a network and began using a GPU to train it to categorize CIFAR-10 images. Shockingly, he was able to train his network from a random starting configuration all the way to state-of-the-art accuracy. In eighty seconds.²⁰
It is at this point Krizhevsky’s labmate, Ilya Sutskever, takes notice and offers him what will become a kind of siren song. “I bet,” Sutskever says, “you can make it work on ImageNet.”
They build an enormous neural network: 650,000 artificial neurons, arranged into 8 layers, connected by 60 million adjustable weights. In his bedroom at his parents’ house, Krizhevsky starts showing it pictures.
Step by step, piece by piece, the system gets a few percent more accurate.
The dataset—as big as it is, a few million pictures—isn’t enough. But Krizhevsky realizes he can fake it. He starts doing “data augmentation,” feeding the network mirror images of the data. That seems to help. He feeds it images that are cropped slightly, or tinted slightly. (A cat, after all, still looks like a cat when you lean forward or to the side, or go from natural to artificial light.) This seems to help.
He plays with different architectures—this number of layers, that number of layers—groping more or less blindly for what configuration might just happen to work best.
Krizhevsky occasionally loses the faith. Sutskever never does. Time and again he spurs Krizhevsky on. You can make it work.
“Ilya was like a religious figure,” he says. “It’s always good to have a religious figure.”
Trying out a new version of the model, and training it until the accuracy maxed out, takes about two weeks, running twenty-four hours a day—which means that the project, though at some level frantic, also has a lot of downtime. Krizhevsky thinks. And tinkers. And waits. Hinton has come up with an idea called “dropout,” where during training certain portions of the network get randomly turned off. Krizhevsky tries this, and it seems, for various reasons, to help. He tries using neurons with a so-called “rectified linear” output function. This, too, seems to help.
He submits his best model on the ImageNet competition deadline, September 30, and then the final wait begins.
Two days later, Krizhevsky gets an email from Stanford’s Jia Deng, who is organizing that year’s competition, cc’d to all of the entrants. In plain, unemotional language, Deng says to click the link provided to see the results.
Krizhevsky clicks the link provided and sees the results.
Not only has his team won, but they have obliterated the rest of the entire field. The neural network trained in his bedroom—its official name is “SuperVision,” but history will remember it simply as “AlexNet”—made half as many errors as the model that came in second.
By the Friday of the conference, when it is time for the ImageNet Large Scale Visual Recognition Challenge workshop, the word has spread. Krizhevsky has been given the final talk slot of the day, and at 5:05 p.m. he takes his place up at the presenter’s lectern. He looks around the room. In the front row is Fei-Fei Li; to the side is Yann LeCun. There is a majority, it seems, of the leading computer vision researchers in the world. The room is over capacity, with people standing along the aisles and walls.
“I was nervous,” he says. “I was not comfortable.”
And then, in front of the standing-room audience, not comfortable, Alex Krizhevsky tells them everything.
When Frank Rosenblatt was interviewed about his perceptron in 1958, he was asked what practical or commercial uses a machine like the perceptron might have. “At the moment, none whatever,” he replied cheerfully.²¹
“In these matters, you know, use follows invention.”
THE PROBLEM
On Sunday evening, June 28, 2015, web developer Jacky Alciné was at home watching the BET Awards when he got a notification that a friend had shared a picture with him through Google Photos. When he opened Google Photos, he noticed the site had been redesigned. “I was like, ‘Oh, the UI’s changed!’ I remembered I/O [Google’s annual software developer conference] happened, but I was curious; I clicked through.”²² Google’s image recognition software had automatically identified groups of photos, and gave each a thematic caption. “Graduation,” said one—and Alciné was impressed that the system had managed to identify the mortarboard and tassel on his younger brother’s head. Another caption stopped him cold. The album cover was a selfie of Alciné and a friend of his. Alciné is Haitian-American; both he and his friend are Black.
“Gorillas,” it said.
“So I thought— To be honest, I thought that I did something.” He opened the album, expecting he had somehow misclicked or mistagged something. The album was full of dozens of photos of Alciné and his friend. And nothing else. “I’m like— This was seventy-plus photos. There’s no way. . . . That’s actually where I really realized what happened.”
Alciné took to Twitter. “Google Photos,” he wrote, “y’all fucked up. My friend’s not a gorilla.”²³
Within two hours, Google+ chief architect Yonatan Zunger reached out. “Holy fuck,” he wrote. “This is 100% Not OK.”
Zunger’s team deployed a change to Google Photos within another few hours, and by the following morning, only two photos were still mislabeled. Then Google took a more drastic step: they removed the label entirely.
In fact, three years later, in 2018, Wired reported that the label “gorilla” was still manually deactivated on Google Photos. That means that, years later, nothing will be tagged as a gorilla, including gorillas.²⁴
Curiously, the press in 2018, just as in 2015, appeared to repeatedly mischaracterize the nature of the mistake. Headlines proclaimed, “Two Years Later, Google Solves ‘Racist Algorithm’ Problem by Purging ‘Gorilla’ Label from Image Classifier”; “Google ‘Fixed’ Its Racist Algorithm by Removing Gorillas from Its Image-Labeling Tech”; and “Google Images ‘Racist Algorithm’ Has a Fix But It’s Not a Great One.”²⁵
Being himself a programmer and familiar with machine-learning systems, Alciné knew the issue wasn’t a biased algorithm. (The algorithm was stochastic gradient descent, just about the most generic, vanilla, all-purpose idea in computer science: go through your training data at random, tune your model’s parameters to assign slightly higher probability to the correct category for that image, and repeat as needed.) No, what he immediately sensed was that something had gone terribly awry in the training data itself. “I couldn’t even blame the algorithm,” he says. “It’s not even the algorithm at fault. It did exactly what it was designed to do.”
The problem, of course, with a system that can, in theory, learn just about anything from a set of examples is that it finds itself, then, at the mercy of the examples from which it’s taught.
CALIBRATION AND THE HEGEMONY OF DESIGN
The extent to which we take everyday objects for granted is the precise extent to which they govern and inform our lives.
—MARGARET VISSER²⁶
The single most photographed American of the nineteenth century—more than Abraham Lincoln or Ulysses S. Grant—was Frederick Douglass, the abolitionist author and lecturer who had himself escaped from slavery at the age of twenty.²⁷ This was no accident; for Douglass, the photograph was just as important as the essay or the speech. The photograph was just coming into its own through the daguerreotype in the 1840s, and Douglass immediately understood its power.
Before the photograph, representations of Black Americans were limited to drawings, paintings, and engravings. “Negroes can never have impartial portraits at the hands of white artists,” Douglass wrote. “It seems to us next to impossible for white men to take likenesses of black men, without most grossly exaggerating their distinctive features.”²⁸ One exaggeration, in particular, prevailed during Douglass’s time. “We colored men so often see ourselves described and painted as monkeys, that we think it a great piece of good fortune to find an exception to this general rule.”²⁹
The photograph not only countered such caricatures but, further, made possible a kind of transcending empathy and recognition. “Whatever may be the prejudices of those who may look upon it,” said Douglass of a photograph of the first Black US senator, Hiram Revels, “they will be compelled to admit that the Mississippi Senator is a man.”³⁰
But all was not entirely well. As photography became more standardized and mass-produced in the twentieth century, some began to feel that the field of photography was itself worthy of critique. As W.E.B. Du Bois wrote in 1923, “Why do not more young colored men and women take up photography as a career? The average white photographer does not know how to deal with colored skins and having neither sense of the delicate beauty or tone nor will to learn, he makes a horrible botch of portraying them.”
We often hear about the lack of diversity in film and television—among casts and directors alike—but we don’t often consider that this problem exists not only in front of the camera, not only behind the camera, but in many cases inside the camera itself. As Concordia University communications professor Lorna Roth notes, “Though the available academic literature is wide-ranging, it is surprising that relatively few of these scholars have focused their research on the skin-tone biases within the actual apparatuses of visual reproduction.”³¹
For decades, she writes, film manufacturers and film developers used a test picture as a color-balance benchmark. This test picture became known as the “Shirley card,” named after Shirley Page, a Kodak employee and the first model to pose for it.³² It perhaps goes without saying that Shirley and her successors were overwhelmingly White. The chemical processing of film was tuned accordingly, and as a result cameras simply didn’t take good photos of Black people.
(In video just as in photography, colors have for decades been calibrated to White skin. In the 1990s, Roth interviewed one of the camera operators on Saturday Night Live about the process of tuning the cameras before broadcast. He explained, “A good VCR person will have a color girl stand in front of the cameras and stay there while the technicians focus on her flesh tones to do their fine adjustments to balance the cameras. This color girl is always white.”)³³
Amazingly, Kodak executives in the 1960s and ’70s described the major impetus for making film that was sensitive to a wider range of darker tones as having come not from the civil rights movement but from the furniture and chocolate industries, which complained that film wasn’t properly showing the grains of darker woods, or the difference between milk and dark chocolate.³⁴
Former manager of Kodak Research Studios Earl Kage reflects on this period of research: “My little department became quite fat with chocolate, because what was in the front of the camera was consumed at the end of the shoot.” Asked about the fact that this was all happening against the backdrop of the civil rights movement, he adds, “It is fascinating that this has never been said before, because it was never Black flesh that was addressed as a serious problem that I knew of at the time.”³⁵
In time Kodak began using models of more diverse skin tones. “I started incorporating black models pretty heavily in our testing, and it caught on very quickly,” recalls Kodak’s Jim Lyon. “I wasn’t attempting to be politically correct. I was just trying to give us a chance of making a better film, one that reproduced everybody’s skin tone in an appropriate way.”
By the 1990s, the official Kodak Shirley card now had three different models on it, of different races. Their Gold Max film—initially marketed with the claim that it could photograph a “dark horse in low light”—now featured in television commercials with diverse families. One depicts a Black boy in a bright white karate gi, smiling as he performs a kata and presumably receives his next belt. It says, “Parents, would you trust this moment to anything other than Kodak Gold film?”
Their original target audience had given them a problematic calibration measure. Now a new calibration measure had given them a new audience.
FIXING THE TRAINING SET
All machine-learning systems, from the perceptron onward, have a kind of Shirley card at their heart: namely, the set of data on which they were trained. If a certain type of data is underrepresented or absent from the training data but present in the real world, then all bets are off.³⁶
As UC Berkeley’s Moritz Hardt argues, “The whole spiel about big data is that we can build better classifiers largely as a result of having more data. The contrapositive is that less data leads to worse predictions. Unfortunately, it’s true by definition that there is always proportionately less data available about minorities. This means that our models about minorities generally tend to be worse than those about the general population.”³⁷
Alciné’s frustrated tweets the night of the incident echo exactly this sentiment. He’s a software engineer. He instantly diagnoses what has gone wrong. Google Photos, he infers, just didn’t have nearly as many pictures of Black people in it as pictures of White people. And so the model, seeing anything unfamiliar, was much more prone to error.
“Again, I can completely understand how that happens,” Alciné tells me.³⁸ “Like if you take a picture of an apple, but only red apples, when it sees a green apple it might think it’s a pear. . . . Little things like that. That I understand. But then, you’re the world’s— Your mission is to index the entire world’s social knowledge, so how did you, like, just skip over an entire continent of people?”
The problems of the twentieth century appear to be repeating themselves uncannily in the twenty-first. Fortunately, it seems that some of the solutions are, too. All it would take was someone willing to question exactly who and what were represented in these twenty-first-century “Shirley cards,” anyway—and what a better one might look like.
When Joy Buolamwini was a computer science undergrad at Georgia Tech in the early 2010s, she was given an assignment to program a robot to play peekaboo. The programming part was easy, but there was one issue: the robot wouldn’t recognize Buolamwini’s face. “I borrowed my roommate’s face to get the project done, submitted the assignment, and figured, ‘You know what, somebody else will solve this problem.’ ”³⁹
Later in her undergraduate studies, she traveled to Hong Kong for an entrepreneurship competition. A local startup was giving a demo of one of its “social robots.” The demo worked on everyone in the tour group . . . except for Buolamwini. As it happened, the startup was using the very same off-the-shelf, open-source face-recognition code that she herself had used back at Georgia Tech.
In one of the first articles explicitly addressing the notion of bias in computing systems, the University of Washington’s Batya Friedman and Cornell’s Helen Nissenbaum had warned that “computer systems, for instance, are comparatively inexpensive to disseminate, and thus, once developed, a biased system has the potential for widespread impact. If the system becomes a standard in the field, the bias becomes pervasive.”⁴⁰
Or, as Buolamwini herself puts it, “Halfway around the world, I learned that algorithmic bias can travel as quickly as it takes to download some files off of the internet.”⁴¹
After a Rhodes Scholarship at Oxford, Buolamwini came to the MIT Media Lab, and there she began working on an augmented-reality project she dubbed the “Aspire Mirror.” The idea was to project empowering or uplifting visuals onto the user’s face—making the onlooker transform into a lion, for instance. Again, there was only one problem. The Aspire Mirror only worked on Buolamwini herself when she put on a white mask.
The culprit is not stochastic gradient descent; it is, clearly, the sets of images on which these systems are trained. Every face-detection or face-recognition system has, behind it and implicitly within it, a set of images—typically tens or hundreds of thousands—on which the system was originally trained and developed. This training data, the Shirley cards of the twenty-first century, is often invisible, or taken for granted, or absent entirely: a pretrained model disseminated online almost never comes with its training data included. But it is very much present, and will permanently shape the behavior of a deployed system.
A major movement in rooting out bias, then, is trying to better expose, and better understand, the training datasets behind major academic and commercial machine-learning systems.
One of the more popular public-domain databases of pictures of faces, for instance, is what’s known as the Labeled Faces in the Wild (LFW) dataset, painstakingly assembled in 2007 from online news articles and image captions by a team from UMass Amherst, and used by innumerable researchers thereafter.⁴² The composition of this database was not deeply studied, however, until many years later. In 2014, Michigan State’s Hu Han and Anil Jain analyzed the dataset and determined it was more than 77% male, and more than 83% White.⁴³ The most common individual in the dataset is the person who appeared most often in online news photos in 2007: then-president George W. Bush, with 530 unique images. In fact, there are more than twice as many images of George W. Bush in the LFW dataset as there are of all Black women, combined.⁴⁴
The original 2007 paper describing the database noted that a set of images gathered from online news articles “clearly has its own biases,” but these “biases” are considered from a technical, rather than social, standpoint: “For example, there are not many images which occur under extreme lighting conditions, or very low lighting conditions.” Such lighting issues aside, the authors write, “the range and diversity of pictures present is very large.”
Twelve years later, however, in the fall of 2019, a disclaimer suddenly appeared on the webpage of the Labeled Faces in the Wild dataset that takes a different view. It notes, “Many groups are not well represented in LFW. For example, there are very few children, no babies, very few people over the age of 80, and a relatively small proportion of women. In addition, many ethnicities have very minor representation or none at all.”⁴⁵
In recent years, greater attention has been paid to the makeup of these training sets, though much remains to be done. In 2015, the United States Office of the Director of National Intelligence and the Intelligence Advanced Research Projects Activity released a face image dataset called IJB-A, boasting, they claimed, “wider geographic variation of subjects.”⁴⁶ With Microsoft’s Timnit Gebru, Buolamwini did an analysis of the IJB-A and found that it was more than 75% male, and almost 80% light-skinned. Just 4.4% of the dataset were dark-skinned females.⁴⁷
Eventually it became clear to Buolamwini that the “somebody else [who] will solve this problem” was—of course—her. She started a broad investigation into the current state of face-detection systems, which became her MIT thesis. She and Gebru set out first to build a dataset with a more balanced representation of both gender and skin tone. But where would they get their images from? Previous datasets, drawing from online news, for instance, were totally imbalanced. They decided on parliaments, compiling a database of the representatives of six nations: Rwanda, Senegal, South Africa, Iceland, Finland, and Sweden. This dataset was notably undiverse in things like age, lighting, and pose, with almost all subjects middle-aged or older, centered in the frame, and looking straight into the camera with a neutral or slightly smiling expression. But, measured by skin and by gender, it was arguably the most diverse machine-learning dataset assembled to date.⁴⁸
With this parliamentarian dataset in hand, Buolamwini and Gebru looked at three commercially available face-classification systems—from IBM, Microsoft, and the Chinese firm Megvii, maker of the widely used Face++ software—and ran each through the paces.
Across the dataset as a whole, all three systems did reasonably well at correctly classifying the gender of the subject—approximately 90% for all three companies. In all three cases, the software was roughly 10 to 20% more accurate on male faces than female faces, and all were also roughly 10 to 20% more accurate on lighter faces than darker ones. But when Buolamwini did an intersectional analysis of the two, the starkest result by far appeared. All three systems were dramatically worse at classifying faces that were both dark-skinned and female. IBM’s system, for instance, had an error rate of only 0.3% for light-skinned males, but 34.7% for dark-skinned females: more than a hundredfold greater.
The abolitionist and women’s rights activist Sojourner Truth is arguably best known for her 1851 speech “Ain’t I a Woman?” Buolamwini poignantly echoes this question into the twenty-first century, pointing to photos of Truth that are miscategorized, again and again and again, by contemporary commercial face-classification software, as male.⁴⁹
On December 22, 2017, Buolamwini reached out to the three firms with her results, explaining that she would be presenting them at an upcoming conference, and giving each an opportunity to respond. Megvii did not respond. Microsoft responded with a generic statement: “We believe the fairness of AI technologies is a critical issue for the industry and one that Microsoft takes very seriously. We’ve already taken steps to improve the accuracy of our facial recognition technology and we’re continuing to invest in research to recognize, understand and remove bias.”⁵⁰ IBM, however, was another story entirely. They responded the same day, thanked Buolamwini for reaching out, replicated and confirmed her results, invited her to both their New York and Cambridge campuses, and within a matter of weeks announced a new version of their API with a tenfold improvement in the error rate for dark-skinned females.⁵¹
“Change is possible,” she says. There was no fundamental obstacle, technological or otherwise, to equalizing this performance gap; it just took someone asking the right questions.
Buolamwini and Gebru’s work highlights the skepticism we ought to feel when a company announces that their system is, say, “99% accurate”: Accurate on what? Accurate for whom? It’s a reminder, too, that every machine-learning system is a kind of parliament, in which the training data represent some larger electorate—and, as in any democracy, it’s crucial to ensure that everyone gets a vote.⁵²
Bias in machine-learning systems is often a direct result of the data on which the systems are trained—making it incredibly important to understand who is represented in those datasets, and to what degree, before using them to train systems that will affect real people.
But what do you do if your dataset is as inclusive as possible—say, something approximating the entirety of written English, some hundred billion words—and it’s the world itself that’s biased?
THE DISTRIBUTIONAL HYPOTHESIS: WORD EMBEDDINGS
You shall know a word by the company it keeps.
—J. R. FIRTH⁵³
Let’s say you find a message in a bottle, washed up on a beach; a couple parts of the message are unreadable. You examine one sentence: “I hath buried the treasure north of the ——— by the beach.” Needless to say, you are highly motivated to figure out what the missing word might be.
It probably does not occur to you that the word might be “hamster” or “donut” or “toupee.” There are a few reasons for this. You have some common sense you can apply: hamsters are restless, donuts are biodegradable, and toupees blow in the wind—none of them reliable landmarks for long-term treasure wayfinding. Anyone hiding loot over a span of presumably months to years, you reason, would need something stable, unlikely to disintegrate or move.
Now imagine you’re a computer with a complete lack of such common sense—let alone the ability to put yourself in the shoes of a prospective treasure burier—but what you do have is an extremely large sample (a “corpus”) of real-world texts to scan for patterns. How good a job could you do at predicting the missing word purely based on the statistics of the language itself?
Constructing these kinds of predictive models has long been a grail for computational linguists.⁵⁴ (Indeed, Claude Shannon founded information theory in the 1940s on a mathematical analysis of this very sort, noticing that some missing words are more predictable than others, and attempting to quantify by how much.⁵⁵) Early methods involved what are known as “n-grams,” which meant simply counting up every single chain of, say, two words in a row that appeared in a particular corpus—“appeared in,” “in a,” “a particular,” “particular corpus”—and tallying them in a huge database.⁵⁶ Then it was simple enough, given a missing word, to look at the preceding word and find which n-gram in the database beginning with that preceding word had appeared most often. That would then be your best guess as to what was missing. Of course, additional context beyond just the immediately preceding word could offer you additional clues, but incorporating it was far from straightforward. Going from storing a list of all possible two-word phrases in your language (“bigrams”) to all the three-word phrases (“trigrams”), or four-word phrases or more, meant growing your database to an absurd and untenable size. Moreover, these databases became incredibly sparsely populated, with the vast majority of possible phrases never appearing at all, and much of the rest appearing only once or twice.
Ideally, we’d also want to be able to make reasonable guesses even if a particular phrase had never appeared verbatim before in the corpus. Such counting-based methods are no help. In the sentence “I sipped at a jaundiced ———,” we might imagine “chardonnay” is more likely than “charcoal,” even if neither word has ever been preceded by “jaundiced” in the history of the language. Relying on a count simply won’t help in cases like this—and, again, the problem gets worse the more context we try to add, because the longer the phrases we consider, the more likely we are never to have seen something before.
This set of issues is known as the “curse of dimensionality,” and has plagued this linguistic approach from the very beginning.⁵⁷
Was there a better way?
There was, and it came in the form of what are called “distributed representations.”⁵⁸ The idea was to try to represent words by points in some kind of abstract “space,” in which related words appear “nearer” to one another. A number of techniques emerged over the 1990s and 2000s for doing this,⁵⁹ but one in particular in the past decade has shown exceptional promise: neural networks.⁶⁰
The hypothesis here, the big bet on which the model rests, is simply this: Words will tend to be found near words that are “similar” to themselves. And these similarities can be captured numerically. The neural network model works by transforming (“embedding”) every word into a set (a “vector”) of numbers that represent its “coordinates” in that space. This set of coordinate numbers is known as the word’s representation. (In the case of word2vec, it’s three hundred decimal numbers between −1.0 and 1.0.) This enables a direct measure of how “similar” any word is to any other: How far away are those coordinates? ⁶¹
All we have to do is—somehow—arrange the words in this space to make them do as good a job of predicting these missing words as possible. (At least, we’ll have done as good a job as this particular model architecture allows.)
How are we going to arrive at these representations? Why, of course, stochastic gradient descent! We will simply scatter our words randomly throughout space to begin with. Then we’ll pick a randomly selected phrase from our corpus, hide a word, and ask the system what it expects might fill in that blank.
When our model guesses wrong, we’ll adjust the coordinates of our word representations to slightly nudge the correct word toward the context words in our mathematical space and slightly nudge any incorrect guesses away. After we make this tiny adjustment, we’ll pick another phrase at random and go through this process again. And again. And again. And again. And again.⁶²
“At this point,” explains Stanford computational linguist Christopher Manning, “sort of a miracle occurs.”
In his words:
It’s sort of surprising—but true—that you can do no more than set up this kind of prediction objective, make it the job of every word’s word vectors to be such that they’re good at predicting the words that appear in their context or vice-versa—you just have that very simple goal—and you say nothing else about how this is going to be achieved—but you just pray and depend on the magic of deep learning. . . . And this miracle happens. And out come these word vectors that are just amazingly powerful at representing the meaning of words and are useful for all sorts of things.⁶³
In fact, one could argue that these embeddings actually manage to capture too much of the nuance of our language. Indeed, they capture with startling clarity the parts we ourselves prefer not to see.
THE DARK SIDE OF EMBEDDINGS
Out of the crooked timber of humanity no truly straight thing was ever made.
—IMMANUEL KANT⁶⁴
Word-embedding models like these, including Google’s word2vec and Stanford’s GloVe, subsequently became the de facto standard for computational linguistics, undergirding since roughly 2013 almost every application that involves computer use of language, be it ranking search results, translating passages from one language to another, or analyzing consumer sentiment in written reviews.⁶⁵
Indeed, the embeddings, simple as they are—just a row of numbers for each word, based on predicting nearby missing words in a text—seemed to capture a staggering amount of real-world information.
You could, for instance, simply add two vectors together to get a new vector, and search for the nearest word. The results, as we have seen, often made a shocking amount of sense:
Czech + currency = koruna
Vietnam + capital = Hanoi
German + airlines = Lufthansa
French + actress = Juliette Binoche\*
And you could subtract words, too. This meant—incredibly—you could produce “analogies” by getting the “difference” between two words and then “adding” it to a third.⁶⁶
These analogies suggested that the embeddings had captured geography:
Berlin − Germany + Japan = Tokyo
And grammar:
bigger − big + cold = colder
And cuisine:
sushi − Japan + Germany = bratwurst
And science:
Cu − copper + gold = Au
And tech:
Windows − Microsoft + Google = Android
And sports:
Montreal Canadiens − Montreal + Toronto = Toronto Maple Leafs⁶⁷
Unfortunately, as we’ve seen, that wasn’t all the vectors captured. They contained stunning gender biases. For every clever or apt analogy for man:woman, like fella:babe, or prostate cancer:ovarian cancer, there was a host of others that seemed to be reflecting mere stereotypes, like carpentry:sewing, or architect:interior designer, or doctor:nurse.
We are only now coming to a full appreciation of the problem. “There have been hundreds of papers written about word embeddings and their applications, from Web search to parsing Curricula Vitae,” as Tolga Bolukbasi, Adam Kalai, and their collaborators write. “However, none of these papers have recognized how blatantly sexist the embeddings are and hence risk introducing biases of various types into real-world systems.”⁶⁸
Machine-learning systems like this not only demonstrate bias but may silently, subtly perpetuate it. Consider an employer, doing a search for “software engineer” candidates. The search will rank millions of possible résumés by some measure of “relevance” and present just the top handful.⁶⁹ A system naïvely using word2vec, or something like it, might well observe that John is a word more typical of engineer résumés than Mary. And so, all things being equal, a résumé belonging to John will rank higher in “relevance” than an otherwise identical résumé belonging to Mary. Such examples are more than hypothetical. When one of the clients of Mark J. Girouard, an employment attorney, was vetting a résumé-screening tool from a potential vendor, the audit revealed that one of the two most positively weighted factors in the entire model was the name “Jared.” The client did not purchase the résumé-screening tool—but presumably others have.⁷⁰
We already know, of course, that job candidates’ names exert influence over real human employers. In 2001 and 2002, the economists Marianne Bertrand and Sendhil Mullainathan mailed out nearly five thousand résumés with randomly assigned names designed to sound either White (Emily Walsh, Greg Baker) or African-American (Lakisha Washington, Jamal Jones). They found a stunning 50% gap in the callback rates, despite the résumés themselves being identical.⁷¹
Word2vec maps proper names to racial and gender axes just like it does with any other words, putting Sarah − Matthew on a gender axis and Sarah − Kiesha on a race axis. Given that it puts professions on these axes as well, it’s not hard to imagine a system inadvertently using such racial or gender dimensions—in effect, stereotypes—to uprank or downrank candidates for “relevance” to a given job opening. In other words, we have reason to be every bit as concerned if it is a machine sifting through these résumés, and not a person.⁷²
The obvious solution in the human case—removing the names—will not work. In 1952, the Boston Symphony Orchestra began holding its auditions with a screen placed between the performer and the judge, and most other orchestras followed suit in the 1970s and ’80s. The screen, however, was not enough. The orchestras realized that they also needed to instruct auditioners, before walking out onto the wood floor of the audition hall, to remove their shoes.⁷³
The problem with machine-learning systems is that they are designed precisely to infer hidden correlations in data. To the degree that, say, men and women tend toward different writing styles in general—subtle differences in diction or syntax—word2vec will find a host of minute and indirect correlations between software engineer and all phrasing typical of males.⁷⁴ It might be as noticeable as football listed among their hobbies, rather than softball, as subtle as the names of certain universities or hometowns, or as nearly invisible as a slight grammatical preference for one preposition or synonym over another. A system of this nature cannot, in other words, ever be successfully blindfolded. It will always hear the shoes.
In 2018, Reuters reported that Amazon engineers had, starting in 2014, been developing a machine-learning tool to sift through online résumés and rank possible job candidates from one to five stars—just like Amazon products themselves—based on how promising they seemed, and that Amazon recruiters would focus their efforts accordingly.⁷⁵ “They literally wanted it to be an engine where I’m going to give you a hundred résumés, it will spit out the top five, and we’ll hire those,” as one source told reporters. The measure of that star rating? Similarity—using a word representation model—to résumés of previous Amazon hires in the preceding ten years.
By 2015, however, Amazon began noticing problems. Most of those previous engineering hires were men. The model, they realized, was assigning a negative score to the word “women’s”—for instance, in describing extracurriculars. They edited the model to remove this bias.
They also noticed, however, that it was assigning a negative score to the names of all-women’s colleges. They edited the model to remove this bias.
Still, the model found a way to hear the shoes. Engineers noticed that the model was assigning positive scores to seemingly all vocabulary choices—for instance, words like “executed” and “captured”—more prevalent among male résumés than female ones.⁷⁶
By 2017, Amazon had scrapped the project and disbanded the team that made it.⁷⁷
DEBIASING WORD EMBEDDINGS
For Tolga Bolukbasi and Adam Kalai, along with their BU and Microsoft collaborators, the question was, of course, not simply the discovery of these biases but what to do about them.
One option was to find the axis in this high-dimensional vector “space” that captured the concept of gender and delete it. But deleting the gender dimension altogether would mean losing useful analogies like king:queen and aunt:uncle. So the challenge, as they put it, is “to reduce gender biases in the word embedding while preserving the useful properties of the embedding.”⁷⁸
As it happens, even identifying the proper gender “dimension” is hard. You could define it, for instance, as the vector “difference” of woman − man. But there’s more going on here than just gender—you also have idiomatic uses like “man oh man” and the verb form, as in “all hands, man your battle stations.” The team decided to take a number of different word pairs of this type—woman − man, but also she − he, gal − guy, and so forth—and then use a technique called principal component analysis (PCA) to isolate the axis that explained the greatest amount of the difference in these pairs: presumably, gender.⁷⁹
Then their task was to try to determine, for words that differ on this gender dimension, whether that gender difference is appropriate or inappropriate. Let’s say king and queen are appropriately separated by gender, and ditto father and mother, but maybe we don’t want to regard—as word2vec by default does—Home Depot as the gender-flipped version of JC Penney; or alcoholism and eating disorders; or pilot and flight attendant.
How, then, to tease apart the problematic from the unproblematic gender associations for not just a handful but for hundreds of thousands of different words? How to know which analogies should be kept, which should be adjusted, and which should be purged entirely?
The team of five computer scientists found themselves doing, in effect, social science. Indeed, part of the project ended up requiring consultation beyond their normal disciplinary lines. “We’re a bunch of machine-learning researchers,” says Kalai. “I work in a lab that includes a bunch of social scientists, and just from listening to them talk about various issues that come up in sociology and social sciences, we were aware of these possible concerns that the machine-learning algorithms might discriminate, but none of the five of us—we’re all five guys—had ever worked or read much about gender bias.”
The group, perhaps naïvely, asked the sociologists how they should encode a formal definition of which analogies were acceptable and which were not. The sociologists rapidly disabused them of the idea that a simple formal definition of this kind was possible. “We’re thinking, how do we define the best thing?” says Bolukbasi. “They said, ‘Sociologists can’t define what is good.’ As an engineer you want to say, ‘Okay, this is the ideal, so this is my target, so I’m just going to make my algorithm until I reach that target.’ Because it’s involved so much with people and culture and everything, you don’t know what’s optimal. You can’t optimize for something. It’s very hard actually in that sense.”
The group decided to identify a set of words that they felt were appropriate to consider as gendered in some essential or fundamental way: words like “he” and “she,” “brother” and “sister,” as well as anatomical words like “womb” and “sperm,” and social words like “convent” and “monastery” or “sorority” and “fraternity.” Some of these required complicated decisions—like the word “nurse,” for instance. As a noun, it was a profession that had no intrinsic gender aspect, but as a verb, it could be something that only women were capable of doing. What about a word like “rabbi”? Whether the word had an intrinsic gender dimension depended on whether the Jewish denomination in question was, say, Orthodox or Reform. The team did their best, identifying 218 such gender-specific words in a subset of their model’s dictionary, and let their system extrapolate to the rest of the dictionary. “Note that the choice of words is subjective,” they wrote, “and ideally should be customized to the application at hand.”⁸⁰ For all words outside this set, they set the gender component of the word’s representation to zero. Then they adjusted the representations of all the gender-related words such that pairs of equivalent terms—say, “brother” and “sister”—were “centered” around this zero point. Said another way, they were adjusted so that neither term was represented in the model as more “gender-specific” or more “gender-neutral” than the other.
Was this new, debiased model an improvement? The team took a methodological page from the social sciences and simply asked people. They used American workers on the Amazon Mechanical Turk platform to categorize a number of the model’s analogies as either “stereotypes” or not. Even here, the input of the sociologists was critical. The wording of exactly what they asked was going to be important. “We had to talk to them because when we were designing these experiments on Mechanical Turk, the way you ask questions makes a difference, actually,” says Bolukbasi. “It’s such a sensitive topic.”⁸¹
The results were encouraging. Where the default model was returning doctor − man + woman as nurse, the system now said physician. The Mechanical Turk workers had reported that 19% of the original model’s gender analogies reflected gender stereotypes; of the new, debiased model’s analogies, only 6% were judged to reflect stereotypes.⁸²
This neutralization came at a small cost—the model now, for instance, thought it just as likely that someone could be “grandmothered in” as “grandfathered in” to a legal exemption.⁸³ But maybe this was a price worth paying—and you could always decide how much prediction error you were willing to trade for how much debiasing and set an appropriate tradeoff.
As the team wrote, “One perspective on bias in word embeddings is that it merely reflects bias in society, and therefore one should attempt to debias society rather than word embeddings. However, . . . in a small way debiased word embeddings can hopefully contribute to reducing gender bias in society. At the very least, machine learning should not be used to inadvertently amplify these biases, as we have seen can naturally happen.”⁸⁴
It was an encouraging proof of concept that we might be able to build our systems atop models of language that don’t just capture the status quo world as it happens to be, but a model of a better world—a model of the world we want.
Still, there is more to the story. In 2019 Bar Ilan University computer scientists Hila Gonen and Yoav Goldberg published an exploration of these “debiased” representations and showed that the debiasing was potentially only, as they put it, “lipstick on a pig.”⁸⁵ Yes, it removed links from, say, professions like “nurse” or “receptionist” to explicitly gendered terms like “woman” and “she.” But an implicit connection among these stereotypically “feminine” professions themselves—between “nurse” and “receptionist”—remained. In fact, such only partial debiasing may actually make the problem worse, they argue, in the sense that it leaves the majority of these stereotypical associations intact while removing the ones that are the most visible and easiest to measure.⁸⁶
Bolukbasi, now at Google, and his colleagues are continuing to work on the issue, affirming that there are cases where a debiased model, used in a recruiting context, may in fact actually be worse than the original model.⁸⁷ In such cases, it is possible that a system that deletes the gender dimension entirely—even for such fundamentally gendered terms as “he” and “she”—may result in fairer outcomes. The story is not a simple one, and the work continues.
SELF-PORTRAIT IN A STATISTICAL MIRROR
In a recruiting application these biases may simply be dangers to be mitigated, but taken on their own they raise a host of questions. For instance, where do they come from? Are they an artifact of the statistical technique used, or do they reflect something deeper: namely, the bias in our own heads and the bias in the world at large?
A classic test of unconscious bias in humans used in the social sciences is the “implicit association test,” where subjects will see a sequence of words and are asked to press a button anytime the word belongs to either of two different categories: for instance, a flower (e.g., “iris”) or something pleasant (e.g., “laughter”). It sounds simple enough, and it is; the story is not in accuracy, but in reaction time. Asking people to press a button if the word is a flower or something pleasant results in quick reaction times, but asking them to press the button if it’s a flower or something unpleasant takes longer. This suggests, then, that there is some degree of overlap between the mental categories of “floral” and “pleasant,” or that they reflect concepts that are somehow linked.⁸⁸
The group that invented this test famously demonstrated that a group of White undergraduates were quick to identify if a word was either a prevalently White name (“Meredith,” “Heather”) or a pleasant word (“lucky,” “gift”). They were also quick to identify if a word was either a prevalently Black name (“Latonya,” “Shavonn”) or an unpleasant word (“poison,” “grief”). But when asked to press a button if the word was a White name or an unpleasant word, they were slow; likewise, they were slow when they had to press a button if the word was a Black name or a pleasant word.
A team of computer scientists at Princeton—postdoc Aylin Caliskan and professors Joanna Bryson and Arvind Narayanan—found that the distance between embeddings in word2vec and other widely used word-embedding models uncannily mirrors this human reaction-time data. The slower people are to identify any two groups of words, the farther away those word vectors were in the model.⁸⁹ The model’s biases, in other words, are, for better or worse, very much our own.
Beyond these implicit associations, the Princeton team also wanted to know if models like word2vec capture some of what they call the “veridical” bias in the world. Certain names really are more commonly given to women than to men, and certain jobs really are more commonly held by women than by men. To the extent that certain names get representations that skew more male than others or more female than others, does that reflect to some degree this objective reality? And to the extent that certain professions fall at different places along the model’s gender axis, might that reflect to some degree the fact that certain professions—nurse, librarian, carpenter, mechanic—really do happen to be unevenly balanced? The Princeton team consulted the US Census and the Bureau of Labor Statistics, respectively; in both cases, they found, the answer was yes.
The more strongly a word representation for a profession skews in a gender direction, the more overrepresented that gender tends to be within that profession. “Word embeddings,” they write, “correlate strongly with the percentage of women in 50 occupations in the United States.”⁹⁰ Looking at names, they found the same thing, with a correlation only slightly less strong; then again, the latest census data they had access to was from 1990, and so perhaps the gender distribution of names had in fact changed slightly since then.
The fact that the embeddings that emerge from this “magical” optimization process are so uncannily and discomfitingly useful as a mirror for society means that we have, in effect, added a diagnostic tool to the arsenal of social science. We can use these embeddings to quantify something in precise detail about society at a given snapshot in time. And regardless of causation—whether it’s changes in the objective reality that change the way we speak, or vice versa, or whether both are driven by some deeper cause—we can use these snapshots to watch society change.
This is exactly what an interdisciplinary group from Stanford, led by Nikhil Garg and James Zou, set out to do. Garg, a PhD candidate in electrical engineering, and Zou, an assistant professor of biomedical data science, joined with historian Londa Schiebinger and linguist Dan Jurafsky to look at word embeddings using not just a corpus of contemporary text but samples across the past hundred years.⁹¹
What emerged was a rich and detailed history of the changing winds of culture. As they put it, “The temporal dynamics of the embedding helps to quantify changes in stereotypes and attitudes toward women and ethnic minorities in the 20th and 21st centuries in the United States.”
The Stanford group corroborated the Princeton group’s findings about the connection between the representations of profession words and gender, adding that there appears to be something of a “male baseline”: namely, professions that we know from census data to be evenly split fifty-fifty between men and women nonetheless have a slight bias in their word embeddings in the “male” direction. As the authors explain, “Common language is more biased than one would expect based on external, objective metrics.” Baseline aside, however, there is a consistent trend across time that shows the gender bias in word embeddings for professions moving in lockstep with the change in the workforce itself.
By looking at texts across time, they found a wealth of narratives reflecting social change. The data show that gender bias has broadly decreased over time and, in particular, that the “women’s movement in the 1960s and 1970s especially had a systemic and drastic effect in women’s portrayals in literature and culture.”
The embeddings also show a detailed history of the shift in racial attitudes. In 1910, for instance, the top ten words most strongly associated with Asians relative to Whites included “barbaric,” “monstrous,” “hateful,” and “bizarre.” By 1980 the story could not be more different, with the top ten words topped by “inhibited” and “passive” and ending with “sensitive” and “hearty”: stereotypes in their own right, of course, but ones that reflect an unmistakable cultural change.
More recent cultural shifts are also visible in the embeddings—for instance, the association between words related to Islam and words related to terrorism goes up sharply both in 1993 (the year of the World Trade Center bombing) and 2001 (the year of 9/11).
One might even imagine using such an approach to look not retrospectively but prospectively: Do the data of the last six months, say, suggest that these biases are getting better or getting worse? One might imagine a kind of real-time dashboard of whether society itself—or, at the very least, our public discourse—appears to be getting more or less biased: a bellwether for the shifts underway, and a glimpse of the world to come.
REPRESENTATIONS AND REPRESENTATION
There are several takeaways here, of which the first is principally, though not purely, methodological. Computer scientists are reaching out to the social sciences as they begin to think more broadly about what goes into the models they build. Likewise, social scientists are reaching out to the machine-learning community and are finding they now have a powerful new microscope at their disposal. As the Stanford authors write, “In standard quantitative social science, machine learning is used as a tool to analyze data. Our work shows how the artifacts of machine learning (word embeddings here) can themselves be interesting objects of sociological analysis. We believe this paradigm shift can lead to many fruitful studies.”
Second is that biases and connotations—while they seem gossamer, ethereal, ineffable—are real. They are measurable, in detail and with precision. They emerge, spontaneously and reliably, from models built to do nothing but predict missing words, and they are measurable and quantifiable and dynamic. They track ground-truth data about labor participation as well as subjective measures of attitude and stereotypes. All this and more are present in models that ostensibly just predict missing words from context: the story of our language is the story of our culture.
Third: These models should absolutely be used with caution, particularly when used for anything other than their initial purpose of predicting missing words. Says Adam Kalai, “I’ve talked to people who said that after reading our paper . . . [they] are more cautious about using these word embeddings—or at least thinking twice before they use them in their own applications. So, that’s one positive consequence.” This note of caution is echoed by the Princeton team: “Certainly,” they write, “caution must be used in incorporating modules constructed via unsupervised machine learning into decision-making systems.”⁹² Very few Amazon executives would have been likely to explicitly declare a policy of “hire the people whom, had they applied ten years ago, would have most strongly resembled the people we did hire back then.” But using language models to filter résumés for “relevance” is making just such a leap.
We find ourselves at a fragile moment in history—where the power and flexibility of these models have made them irresistibly useful for a large number of commercial and public applications, and yet our standards and norms around how to use them appropriately are still nascent. It is exactly in this period that we should be most cautious and conservative—all the more so because many of these models are unlikely to be substantially changed once deployed into real-world use. As Princeton’s Arvind Narayanan puts it: “Contrary to the ‘tech moves too fast for society to keep up’ cliché, commercial deployments of tech often move glacially—just look at the banking and airline mainframes still running. ML [machine-learning] models being trained today might still be in production in 50 years, and that’s terrifying.”⁹³
Modeling the world as it is is one thing. But as soon as you begin using that model, you are changing the world, in ways large and small. There is a broad assumption underlying many machine-learning models that the model itself will not change the reality it’s modeling. In almost all cases, this is false.
Indeed, uncareful deployment of these models might produce a feedback loop from which recovery becomes ever more difficult or requires ever greater interventions. If, say, a résumé-search system detects a gender skew with a given position, and upranks (say) male applicants in a way that exaggerates that skew, then this may well be the next batch of training data on which the model learns. And it will only learn a more extreme version of its existing bias. The easiest moment in which to intervene is, of course, as soon as possible.
Lastly, these models offer us a digital sextant as we look ahead as a society. From this work, we get a portrait not only of our history but of our up-to-the-minute present. As long as new text is being published online each day, there will be a new set of data to sample.
If used wisely—and descriptively rather than prescriptively—the very systems capable of reinforcing and perpetuating the biases latent in society can be used, instead, to make them visible, inarguable. They offer us a gauge on what might have seemed diffuse or formless.⁹⁴ That’s a start.
Yonatan Zunger, no longer at Google, argues that people sometimes forget the degree to which engineering is inextricable from human society, human norms, and human values. “Essentially, engineering is all about cooperation, collaboration, and empathy for both your colleagues and your customers,” he writes. “If someone told you that engineering was a field where you could get away with not dealing with people or feelings, then I’m very sorry to tell you that you have been lied to.”⁹⁵
As for Jacky Alciné, who now runs his own software consultancy and still keeps in touch with Zunger, he agrees that the problem neither begins nor ends with tech. “This is actually partly why I want to go into history teaching,” he tells me, smiling and at least half serious: “When I turn 35 I’ll just stop everything, retire, and transition to history.”
\* With second place going to Vanessa Paradis and third to Charlotte Gainsbourg.
2 FAIRNESS
While mankind has been wandering the American continent since the retreat of the glaciers and possibly before the ice age, it remains somewhat of a sad commentary on his evolution that one of the problems science has just undertaken is the question of an accurate prediction of what a man will do when released from prison on parole.
—CHICAGO TRIBUNE, JANUARY 1936¹
Our law punishes people for what they do, not who they are. Dispensing punishment on the basis of an immutable characteristic flatly contravenes this guiding principle.
—SUPREME COURT CHIEF JUSTICE JOHN ROBERTS²
As we’re on the cusp of using machine learning for rendering basically all kinds of consequential decisions about human beings in domains such as education, employment, advertising, health care and policing, it is important to understand why machine learning is not, by default, fair or just in any meaningful way.
—MORITZ HARDT³
The idea that society can be made more consistent, more accurate, and more fair by replacing idiosyncratic human judgment with numerical models is hardly a new one. In fact, their use even in criminal justice is nearly a century old.
In 1927, the new chairman of the Parole Board of Illinois, Hinton Clabaugh, commissions a study on the workings of the parole system in the state. He is motivated by what he perceives to be a kind of innovation gap: “Although our industrial and governmental machines are far from perfect, we probably are the most ingenious and efficient nation industrially,” Clabaugh writes. “Can we truthfully say this of our law enforcement?”⁴ Despite Illinois having been one of the very first states to enact a parole law, public opinion has soured. As Clabaugh observes, public sentiment is that “the pendulum of justice and mercy has swung to the extreme in favor of criminals.” His own view is not far off: that the entire concept of parole may amount to little more than undue leniency, and that the parole system should perhaps be scrapped entirely. But he reasons that, under US law, an individual is entitled to a defense—and so the parole system should probably be entitled to one as well.
Clabaugh asks his state’s most prestigious schools—the University of Illinois, Northwestern University, and the University of Chicago—to join forces and prepare a comprehensive report on the parole system to be delivered to him in a year’s time. University of Illinois law school dean Albert Harno will report on the workings of the parole board; judge Andrew Bruce of Northwestern will review the history of the penal system in Illinois (including an eye-opening look at the “abolition of the lash” in the nineteenth century); and Chicago sociologist Ernest Burgess is given the intriguing challenge to see whether any factors predict the “success or failure” of a given parolee.
As Burgess writes:
Two widely divergent pictures of the paroled man are, at present, in the minds of the people of Illinois. One picture is that of a hardened, vicious, and desperate criminal who returns from prison, unrepentant, intent only upon wreaking revenge upon society for the punishment he has sullenly endured. The other picture is that of a youth, perhaps the only son of a widowed mother, who on impulse, in a moment of weakness, yielded to the evil suggestion of wayward companions, and who now returns to society from the reformatory, determined to make good if only given a chance.⁵
The question, of course, is whether it might be possible to anticipate which potential parolees were which.
Burgess gathers data on some three thousand different Illinois parolees and does his best to categorize them into one of four groups: “first offenders,” “occasional offenders,” “habitual offenders,” and “professional offenders.” From a twenty-first-century perspective, some of his work seems strikingly dated: for instance, the eight possible “social types” into which he divides people are “Hobo,” “Ne’er-do-well,” “Mean citizen,” “Drunkard,” “Gangster,” “Recent immigrant,” “Farm boy,” and “Drug addict.” Nonetheless, Burgess’s work appears impressively thorough, particularly for the time—examining criminal histories, work histories, residential histories, type of crime, length of sentence, time served, psychiatric diagnoses, and more. He undertakes a study of whether the data reveals undue political influence on behalf of certain inmates, and questions whether the public’s jaded view of the justice system is warranted. And in his final chapter, he directly tackles the question that will launch something of a movement in criminal justice, one that will continue well into our present century: “Can scientific methods be applied to parole administration?”
He writes, “Many will be frankly skeptical of the feasibility of introducing scientific methods into any field of human behavior. They will dismiss the proposal with the assertion that human nature is too variable for making any prediction about it. But in the analysis of factors determining success and failure on parole some striking contrasts have already been found.”
Burgess notes, for instance, that parole violation among those with a strong work record, high intelligence, and a farming background who had served one year or less was half the state average. On the other hand, parole violation among those living “in the criminal underworld,” whose prosecutors or judges had argued against leniency, and who had served five or more years was twice the state average. “Do not these striking differences, which correspond with what we already know about the conditions that mould the life of the person,” he asks, “suggest that they be taken more seriously and objectively into account than previously?”
“It would be entirely feasible and should be helpful to the Parole Board,” he says, “to devise a summary sheet for each man about to be paroled in order for its members to tell at a glance the violation rate for each significant factor. . . . The prediction would not be absolute in any given case, but, according to the law of averages, would apply to any considerable number of cases.”
His conclusion is that rehabilitation is, in many cases, eminently possible. What’s more, it does appear to be at least somewhat predictable in which cases it will succeed. Wouldn’t a system built on this statistical foundation be better than the status quo of subjective, inconsistent, and idiosyncratic human decisions made by judges on the fly? “There can be no doubt of the feasibility of determining the factors governing the success or the failure of the man on parole,” Burgess writes. “Human behavior seems to be subject to some degree of predictability. Are these recorded facts the basis on which a prisoner receives his parole? Or does the Parole Board depend on the impressions favorable or unfavorable which the man makes upon its members at the time of the hearing?”
The report’s ultimate conclusion is both clear and firm. Parole and “indeterminate sentencing” should indeed be continued in the state of Illinois—and, just as critically, “their administration can and should be improved both by the placing of the work of the parole board on a scientific and professional basis and by further safeguards against the constant pressure of political influence.”
Chairman Clabaugh reads the report, and he completely changes his mind about the system he oversees. “My first impression was that indeterminate sentences and parole laws were an asset to criminals,” he admits. “Proof to the contrary is overwhelming, and I now believe these laws, properly administered, to be decidedly beneficial to society, as well as to the individual.” Parole, put simply, is a good thing, he writes—“even where the method of administration is faulty. And of course, no machinery is more efficient than the human element that operates it.”⁶
SCIENTIFIC PAROLE IN PRACTICE
In the early 1930s, buoyed by Burgess’s enthusiasm and Clabaugh’s approval, a predictive parole system goes into use in Illinois, and by 1951 a “Manual of Parole Prediction” is being published, reporting back on what is now twenty years of both study and practice.
The tone is upbeat. Burgess, in the book’s Introduction, writes, “In the past two decades social scientists have made significant progress in their efforts to find out which prisoners succeed on parole and which fail, and under what conditions success or failure occurs. Out of their research has grown a conviction that, notwithstanding the difficulties involved, it is possible to predict to some extent how prisoners will behave on parole.”⁷
The book notes several areas for future study and possible improvement, for instance additional factors—like evaluations by prison staff—that might help improve predictions. A particularly prescient section at the end of the book, titled “Scoring by Machine Methods,” considers the use of punch-card machines to automate and streamline the process of collecting the data, building the models, and outputting individual predictions.
Despite this early optimism, and the seeming success story of Illinois, the adoption of parole prediction instruments would be surprisingly slow. By 1970, for instance, just two states were using such tools. But that was about to change.
In 1969 a Scottish-born statistician named Tim Brennan was working for Unilever in London, building statistical models of a different sort: he was the company’s leading expert on market segmentation. One project, for instance, segmented buyers of bathroom soap into those for whom glamour is paramount and those who prioritize gentleness to the skin. He was good at it, and enjoyed the work—but something wasn’t right. “I had a values crisis,” Brennan tells me. A report crossed his desk, and he noticed that Unilever, over the past year, had spent more money studying the packaging for its “Sqezy” line of squeezable liquid dish soap—the wording and colors that would draw the eye on a supermarket shelf, all backed by the latest in perceptual psychology—than the entire British government had spent on literacy.⁸
“This was in the late sixties,” he says, “and you know how the hippie phenomenon was at the time. Anyway, I couldn’t see working on developing packs for Sqezy. So I resigned my job and I applied for graduate school.” He ended up at Lancaster University, applying his statistics for market segmentation to the problem of education: identifying students with different learning styles and different needs in the classroom.⁹
Following his girlfriend to the United States, Brennan found himself at the University of Colorado, working for Delbert Elliott (who would later become the president of the American Society of Criminology), and then ultimately starting his own research firm, working with the National Institute of Corrections and the Law Enforcement Assistance Administration. His techniques for classification had found a third use: bringing a more consistent and rigorous approach to jails and prisons, each of which has to organize inmates among bunks and wards according to their risks and needs—both for the safety of others and for their own rehabilitation. This was typically done either at random or by instinct; Brennan’s math said there was a better way.
Brennan took a trip up to Traverse City, Michigan, where he’d heard there was some pioneering machine-learning work on using so-called “decision-tree” models to classify inmates and—in response to overcrowding—identify whom to release. There Brennan met “this young guy . . . with straggly hair and a beard” who had invented the model. The young guy’s name was Dave Wells. “He was on fire about reforming the criminal justice system,” says Brennan. “It was a job of a passion for Dave.” Brennan and Wells decided to team up.¹⁰ They called their company Northpointe.
As the era of the personal computer dawned, the use of statistical models at all points in the criminal justice system, in jurisdictions large and small, exploded. In 1980, only four states were using statistical models to assist in parole decisions. By 1990, it was twelve states, and by 2000, it was twenty-six.¹¹ Suddenly it began to seem strange not to use such models; as the Association of Paroling Authorities International’s 2003 Handbook for New Parole Board Members put it, “In this day and age, making parole decisions without benefit of a good, research-based risk assessment instrument clearly falls short of accepted best practice.”¹²
One of the most widely used tools of this new era had been developed by Brennan and Wells in 1998; they called it Correctional Offender Management Profiling for Alternative Sanctions—or COMPAS.¹³ COMPAS uses a simple statistical model based on a weighted linear combination of things like age, age at first arrest, and criminal history to predict whether an inmate, if released, would commit a violent or nonviolent crime within approximately one to three years.¹⁴ It also includes a broad set of survey questions to identify a defendant’s particular issues and needs—things like chemical dependency, lack of family support, and depression. In 2001, the state of New York began a pilot program using COMPAS to inform probation decisions. By the end of 2007, all fifty-seven of its counties outside of New York City had adopted the use of the COMPAS tool in their probation departments. And by 2011, state law had been amended to require the use of risks and needs assessments like COMPAS when making parole decisions.¹⁵
But, from the perspective of the New York Times editorial board, there was a problem: the state wasn’t using them enough. The tools, even where their use was mandated, still were not always given appropriate consideration. The Times urged wider acceptance of risk-assessment tools in parole, writing in 2014, “Programs like COMPAS have been proved to work.”¹⁶ In 2015, as a parole reform case went before the state’s highest court, the editorial board published a second opinion piece, arguing again that statistical risk-assessment tools like COMPAS offered a significant improvement over the status quo. They alleged that the New York parole board “clings stubbornly to the past, routinely denying parole to long-serving inmates based on subjective, often unreviewable judgments.” Adoption of COMPAS, they wrote, would “drag the board into the 21st century.”¹⁷
Then—abruptly—the tone changed.
Nine months later, in June 2016, the paper ran an article titled “In Wisconsin, a Backlash Against Using Data to Foretell Defendants’ Futures,” which closed by quoting the director of the ACLU’s Criminal Law Reform Project saying, “I think we are kind of rushing into the world of tomorrow with big-data risk assessment.”¹⁸
From there the coverage in 2017 only got bleaker—in May, “Sent to Prison by a Software Program’s Secret Algorithms”; in June, “When a Computer Program Keeps You in Jail”; and in October, “When an Algorithm Helps Send You to Prison.”
What had happened?
What had happened was—in a word—ProPublica.
GETTING THE DATA
Julia Angwin grew up in Silicon Valley in the 1970s and ’80s, the child of two programmers and a neighbor of Steve Jobs. She assumed from an early age she’d be a programmer for life. Along the way, however, she discovered journalism and fell in love with it. By 2000 she was a technology reporter for the Wall Street Journal. “It was hilarious,” she recounts. “They were like, ‘You know computers? We’ll hire you to cover the internet!’ And I was like, ‘Well, anything in particular about the internet?’ And they’re like, ‘No—everything!’ ”¹⁹
Angwin stayed at the paper for fourteen years—from the dot-com crash through the rise of social networks and smartphones—writing not only about technology itself but also the social questions it often left in its wake; she authored a long-running series on privacy-related issues called “What They Know.” She went on leave from the Journal, writing a book about privacy, in 2013.²⁰
Angwin never came back to the paper from her book sabbatical, and instead joined ProPublica, a nonprofit news outlet started by former WSJ managing editor Paul Steiger. If the theme of her earlier work was “What They Know,” the answer inevitably raised another question: What are they going to do with it? “And so I thought,” she says, “I need to move to data usage. That is the next story. What are they going to do? . . . What kind of judgments are they going to make about you?”²¹
Angwin set about trying to find the most consequential, and overlooked, decisions being made based on data. She landed at criminal justice. Statistical risk assessments, COMPAS and others, were rapidly being adopted in hundreds of jurisdictions: not just for parole, but for pretrial detention, bail, and even sentencing. “I was shocked, actually,” she says. “I realized that our whole country was using this software. . . . And then what I found even more shocking was that none of them had independently been validated.”
New York State, for instance, which had been using COMPAS since 2001, did its first formal evaluation of the software in 2012—after eleven years of use. (New York ultimately found that it “was both effective and predictively accurate.”²²)
Stories like this are stunningly common. Minnesota’s Fourth Judicial District, which includes Minneapolis and handles 40% of all cases filed in the state, had developed their own pretrial risk-assessment tool in 1992. “The report that was written at that time suggested that this new scale should be validated within the first few years of use,” the state’s official evaluation begins. “As it turned out, it has been closer to 14 years.”²³
The long-overdue evaluation, in 2006, found that four of the variables in their model—whether the defendant had lived in Minnesota for more than three months, whether they lived alone, their age at the time of booking, and whether a weapon was involved in their charge—had virtually no bearing whatsoever on their actual risk of committing a new offense while waiting for their trial date or of missing a required court appearance. And yet the model had been recommending pretrial detention on those grounds. Worse, three of those four factors strongly correlated with race. The district scrapped their model and started over from scratch.²⁴
The more Angwin learned about risk-assessment models, the more concerned she became. Angwin knew she had found her next story: “From a journalist’s perspective, it’s the perfect storm. It’s something that’s never been audited; it has extremely high human stakes; and people who are very smart are like, ‘These are all proxies for race.’ And so I was like, ‘I’m going to test this.’ ”²⁵
She decided to focus on COMPAS in particular, which was being used not just in New York but in California, Wisconsin, Florida—some two hundred different jurisdictions in total. It was ubiquitous, at that time not well studied, and—being a closed-source, proprietary tool, though its basic design was available in white papers—something of a black box. In April 2015 she submitted a Freedom of Information Act request to Broward County, Florida. After five months of legal scuffling, the data at last came through: all eighteen thousand COMPAS scores given in Broward County during 2013 and 2014.
Angwin’s team began doing some exploratory data analysis. Immediately something looked strange. The risk scores—which range from 1, meaning lowest risk, to 10, meaning highest risk—were more or less evenly distributed for Black defendants, with roughly ten percent of defendants in each of the ten buckets. For White defendants, they saw a totally different pattern: vastly more defendants in the very lowest-risk bucket, and vastly fewer in the highest-risk buckets.
Angwin was tempted to publish a story then and there. But she realized that the wildly different distributions weren’t necessarily evidence of bias—perhaps it was just actually how risky those defendants happened to be. So how risky did those defendants turn out to be? There was only one way to find out. “I had the sad realization,” Angwin recounts, “that we had to look up the criminal records of every one of those eighteen thousand people. Which we did. And it sucked.”²⁶ To link the set of COMPAS scores to the set of criminal records—what data scientists call a “join”—would take Angwin, and her team, and the county staff, almost an entire additional year of work.
“We used, obviously, a lot of automated scraping of the criminal records,” she explains. “And then we had to match them on name and date of birth, which is the most terrible thing you could possibly ever imagine. There’s so many typos, so many spelling errors. I might have cried every day. It was so awful trying to do that join. The data was so messy. Broward County actually themselves had never done the join.”²⁷ County staff pitched in to help ProPublica clean the data and make sense of it.
What resulted was the piece that Angwin and her team published in May 2016. Titled “Machine Bias,” it ran with the logline “There’s software used across the country to predict future criminals. And it’s biased against blacks.”²⁸
Brennan and his Northpointe colleagues, in early July, published an official rebuttal to ProPublica’s findings.²⁹ In their words, “When the correct classification statistics are used, the data do not substantiate the ProPublica claim of racial bias towards blacks.”³⁰ Namely, they said, COMPAS met two essential criteria for fairness.
First, its predictions were just as accurate for Black defendants as they were for White defendants. Second, its 1-to-10 risk scores had the same meaning, regardless of the defendant’s race, a property known as “calibration.” Defendants rated with a risk score of 7 out of 10, say, for committing a violent reoffense went on to reoffend the same percentage of the time, regardless of race; ditto for a risk score of 2, 3, and so forth. A 1 was a 1, a 5 was a 5, and a 10 was a 10, regardless of race. COMPAS had both of these properties—equal accuracy and calibration—and because of this, Northpointe argued, it was essentially mathematically impossible for the tool to be biased.
By the end of July, ProPublica responded in turn.³¹ Northpointe’s claims, they wrote, were true. COMPAS really was calibrated, and it was equally accurate across both groups: predicting with 61% accuracy for Black and White defendants alike whether they would go on to reoffend (“recidivate”) and be re-arrested. However, the 39% of the time it was wrong, it was wrong in strikingly different ways.
Looking at the defendants whom the model misjudged revealed a startling disparity: “Black defendants were twice as likely to be rated as higher risk but not re-offend. And white defendants were twice as likely to be charged with new crimes after being classed as lower risk.”³²
The question of whether the tool was “fair” in its predictions had sharpened: into the question of which statistical measures were the “correct” ones by which to define and measure fairness in the first place.
The conversation was about to take a new turn—and it would come from another community entirely, one that had also begun to slowly but surely train its attention on the question of fairness.
WHAT FAIRNESS IS NOT
Harvard computer scientist Cynthia Dwork is arguably best known for developing a principle called “differential privacy,” which enables companies to collect data about a population of users while maintaining the privacy of the individual users themselves. A web browser company might want to understand user behavior, but without knowing which sites you personally went to; or a smartphone company might want to learn how to improve their spelling-correction or text suggestions without knowing the details of your personal conversations. Differential privacy made this possible. It would come to be almost ubiquitous in major tech companies starting around 2014, and would win Dwork the Gödel Prize, one of computing’s highest honors.³³ But in the summer of 2010, however, she saw her theoretical work as done—and she was on the hunt for a new problem.
“I had started working in privacy in 2000, 2001,” she explains. “Differential privacy was differential privacy by 2006. I had in my mind one last set of questions I wanted to look at—and I did that work—and then I said, Okay, I want to think about something else.”³⁴
Dwork, then at Microsoft Research, came up to Berkeley to meet with fellow computer scientist Amos Fiat. They spent the entire day talking. By lunchtime, as they sat down together in beloved local restaurant Chez Panisse, they had landed on the topic of fairness. Dwork recalls: “In order that the people around us wouldn’t be disconcerted by our discussions of racism and sexism, we were using terms like ‘purple ties’ and ‘striped shirts,’ and stuff like that. But by lunchtime we were . . . we were on to this.”
The term “fairness” in theoretical computer science comes up in a number of contexts, from game-theoretic mechanisms for cutting a cake (or dividing an inheritance) so that everyone gets a proper share, to scheduling algorithms that ensure that every process on a CPU gets to run for an appropriate amount of time. But there was something more to the idea of fairness, Dwork thought, that the field had yet to truly reckon with.
As it happens, Dwork had read one of Julia Angwin’s “What They Know” columns in the Wall Street Journal, on the topic of online advertising. It showed that as early as 2010, if not before, companies could discern nearly the exact personal identity of every user visiting their websites—narrowing an ostensibly anonymous user down to one of just several dozen possible people—and were making split-second decisions about, say, which types of credit cards to suggest to whom.³⁵
Having thought about the privacy side for the previous decade, Dwork too began to shift her thinking—from the question of “what they know” to the question of “what they’re doing with it.”
Dwork came back to her lab at Microsoft and said, “I found our problem.”
One of her lab members was then–PhD student Moritz Hardt, interning that summer from Princeton. Hardt hadn’t started off wanting to work on real-world problems. He was interested in theory: complexity, intractability, randomness. The more abstract, the better. “No applications,” he jokes. “Old-school.”³⁶
“I learned a lot,” he says, “but I found the range of problems I could address in that space . . . it didn’t get at the questions about the world I was curious about. And I quickly got attracted by some of the more social problems that [computer science] was touching on.” This had started with privacy-preserving data analysis, working with Dwork. She pulled him into the fairness project.
As Hardt recalls, “Cynthia had the hunch that sometimes when people were asking for privacy, they were actually worried about somebody using their data in the wrong way. It wasn’t so much about hiding the data at all costs but preventing harm from the way that data was used. . . . That was a pretty accurate hunch. Over time, the public discussion shifted from privacy to fairness, and everything that used to look like a privacy problem suddenly looked like a fairness problem.”
What they and their colleagues began to find was that not only were there enormous complexities in translating our philosophical and legal ideas about fairness into hard mathematical constraints but, in fact, much of the leading thought and practice, some of it decades old, was deeply misguided—and had the potential to be downright harmful.
US antidiscrimination law, for instance, defines a number of “protected attributes”—things like race, gender, and disability status—and it is typically understood that one should strictly prohibit the use of these variables in machine-learning models that might affect people in settings like hiring, criminal detention, and so on. If we hear in the press that a model “uses race” (or gender, etc.) as an attribute, we are led to believe something has already gone deeply wrong; conversely, the company or organization behind a model typically defends its model by showing that it “doesn’t use race as an attribute,” or is “race-blind.” This seems intuitive enough—how can something be discriminatory toward a particular group if it doesn’t know who is in that group to begin with?
This is a mistake, for several reasons.
Simply removing the “protected attribute” is insufficient. As long as the model takes in features that are correlated with, say, gender or race, avoiding explicitly mentioning it will do little good.
As we discussed in the case of the Boston Symphony Orchestra and, moreover, in the résumé-screening language models, simply omitting the variable you’re concerned about (gender, in that case) may not be enough, particularly if there are other factors that correlate with it. This is known as the concept of “redundant encodings.” The gender attribute is redundantly encoded across other variables.
In a criminal justice context, a history of treating one demographic group differently creates redundant encodings all over the place. Policing a minority neighborhood more aggressively than others, for instance, means that all of a sudden something as seemingly neutral as length-of-rap-sheet, i.e., number of previous convictions, can become a redundant encoding of race.³⁷
Because of redundant encodings, it’s not enough to simply be blind to the sensitive attribute. In fact, one of the perverse upshots of redundant encodings is that being blind to these attributes may make things worse. It may be the case, for instance, that the maker of some model wants to measure the degree to which some variable is correlated with race. They can’t do that without knowing what the race attribute actually is! One engineer I spoke with complained that his management repeatedly stressed the importance of making sure that models aren’t skewed by sensitive attributes like gender and race—but his company’s privacy policy prevents him and the other machine-learning engineers from accessing the protected attributes of the records they’re working with. So, at the end of the day, they have no idea if the models are biased or not.
Omitting the protected attribute makes it impossible not only to measure this bias but also to mitigate it. For instance, a machine-learning model used in a recruiting context might penalize a candidate for not having had a job in the prior year. We might not want this penalty applied to pregnant women or recent mothers, however—but this will be difficult if the model must be “gender-blind” and can’t include gender itself, nor something so strongly connected to it as pregnancy.³⁸
“The most robust fact in the research area,” Hardt says, “is that fairness through blindness doesn’t work. That’s the most established and most robust fact in the entire research area.”³⁹
It will take time for this idea to percolate from the computer scientists through to legal scholars, policy makers, and the public at large, but it has begun making its way. “There may be cases where allowing an algorithm to consider protected class status can actually make outcomes fairer,” as a recent University of Pennsylvania Law Review article put it. “This may require a doctrinal shift, as, in many cases, consideration of protected status in a decision is presumptively a legal harm.”⁴⁰
The summer Moritz Hardt had spent working with Cynthia Dwork had borne fruit, in the form of a paper that established some of these early results.⁴¹ More than the results themselves, the paper was a beacon, signaling to their fellow theoreticians that there was something here worth looking into: something with both meaty open theoretical questions and undeniable real-world importance.
Back at Princeton and finishing his PhD, Hardt found himself set up on a kind of academic blind date. Dwork had been talking with Helen Nissenbaum, herself a pioneer in thinking about ethical issues in computing.⁴² Nissenbaum had a fellow graduate student in the area named Solon Barocas, and she and Dwork realized their respective mentees might be kindred spirits.⁴³
The first meeting got off to an awkward start.
Hardt was sitting at a table at Sakura Express sushi, on Witherspoon Street in Princeton. In walked Barocas. “He sits down,” Hardt recalls, “and he pulls out the paper, and to my dismay, he had, with yellow marker, like, carefully underlined passages in the paper. That’s not how you’re supposed to read a computer science paper!” He laughs. “Till that point I had always thought of words in a paper as a filling for the math. . . . And it was very embarrassing, because what I’d written made no sense.”
The two got to talking. Bumpy start aside, the resonance their mentors had suspected was clearly there. Ultimately, the two decided to submit a proposal to the 2013 Neural Information Processing Systems (NeurIPS) conference to present a workshop on fairness. NeurIPS said no. “The organizers felt there wasn’t enough work or material on this,” Hardt tells me. “Then in 2014, Solon and I got together and said, ‘Okay, let’s try one more time before we give up.’” They gave it a new name, and a broader mandate: “Fairness, Accountability, and Transparency in Machine Learning,” or “FATML” for short. This time NeurIPS said yes. A day-long workshop was held at that year’s conference in Montreal, with Barocas and Hardt introducing the proceedings and Dwork giving the first talk.
Hardt graduated and went from Princeton to IBM Research. He kept chipping away at fairness questions in the background. “I always had to have another thing to continue to exist as a computer scientist. In terms of my career, this was always like a side project.” IBM, to its credit, gave him a lot of freedom, even if his passion wasn’t widely shared. “My group at IBM wasn’t particularly interested in that topic,” he says, “but neither was anybody else.”
The two came back and repeated the conference again in 2015. “The room was full,” Hardt recalls, “people attended, but it didn’t spark a revolution at that point, it’s safe to say.” He kept spending the lion’s share of his time on more conventional computer science. Another year went by, and he and Solon reprised their FATML workshop for a third time.
This time, something was different; 2016 “was the year where it got out of hand,” Hardt says, “the year where somehow everybody started working on this.” Mathematician and blogger Cathy O’Neil, who’d presented at the original 2014 conference, had published the best-selling book Weapons of Math Destruction, about social problems that can stem from the careless (or worse) use of big data. A series of shocking election results, defying the consensus of pollsters worldwide, had shaken confidence in the trustworthiness of predictive models; meanwhile, the work of data-driven political firms like Cambridge Analytica had raised questions about machine learning being wielded to directly influence politics. Platforms like Facebook and Twitter were caught in the crossfire over how—and whether—to use machine learning to filter the information being shown to their billions of users. And a group of reporters at ProPublica had, after a year of tireless data cleaning and analysis, gone public with their findings about one of the country’s most widely used risk-assessment tools.
Fairness was no longer just a problem. It was becoming a movement.
THE IMPOSSIBILITY OF FAIRNESS
Since 2012, Cornell computer scientist Jon Kleinberg and University of Chicago economist Sendhil Mullainathan had been working on a project using machine learning to analyze pretrial detention decisions, comparing human judges against predictive machine-learning models. “Part of that is thinking through what are the concerns that people have about algorithmic tools in the context of racial inequities,” Kleinberg says. “I think we had done a fair amount of thinking about that. Then the ProPublica article appeared, and just . . . our social media channels just got completely filled with reshares of this article. It was just really capturing people’s attention. We felt like, ‘They put their finger on something. . . . Let’s really dig into it and figure out how does this relate to the themes that we’ve been thinking about.’ ”⁴⁴
In Pittsburgh, Carnegie Mellon statistician Alexandra Chouldechova had been working since the spring of 2015 with the Pennsylvania Commission on Sentencing, developing a visual dashboard to explore various mathematical properties of risk-assessment tools. “I started thinking more and more about these issues . . . to understand different notions of fairness in terms of classification metrics and how those relate,” she says. “All of that was happening while I was still focused on other projects. . . . I’d been talking to my senior colleague about maybe writing a paper about some ideas on the validation of risk-assessment instruments—and we’d done our literature review and everything like that—and the ProPublica piece hits. I think that really accelerated a lot of people’s thinking in the area.”⁴⁵
An almost identical narrative was playing out on the other side of the country. Stanford doctoral student Sam Corbett-Davies had started his degree “wanting to do robotics, just like straight computer science.” A year in, he found that he simply wasn’t enjoying it—“and at the same time was obsessively reading about US public policy just as a hobby. I was like, ‘I’ve got to find a way to sort of combine the technical skills I have with something that’s a bit more policy focused.’ ”⁴⁶ An assistant professor named Sharad Goel had recently joined the faculty, working on computational and statistical approaches to public policy.⁴⁷ A collaboration seemed obvious, and in short order the two began working on a number of projects examining bias in human decisions, including things like a close look at traffic stops in North Carolina. They found, for instance, that police appeared to apply a lower standard when searching Black and Hispanic drivers than White drivers: searching them more often, and finding contraband less of the time.⁴⁸ “We’re working on this,” Corbett-Davies explains. “We’re sort of thinking about these criminal justice issues, and what it means for discrimination to occur. Then . . . the ProPublica article came out.”
ProPublica emphasized the types of errors COMPAS made, and highlighted the fact that it appeared to consistently overestimate the risk of Black defendants who didn’t reoffend and underestimate the risk of White defendants who did reoffend. Northpointe highlighted the rate, rather than the kind, of errors and emphasized that the model was equally accurate in its predictions of both Black and White defendants and that, moreover, at every risk score from 1 to 10, COMPAS was “calibrated”: a defendant with that score is equally likely to reoffend, whatever their race. The question of whether COMPAS was “fair” appeared, then, to boil down to a conflict between two different mathematical definitions of fairness.
As sometimes happens in science, the time is so ripe for a certain idea or insight that a group of people have it almost in unison.
A trio of papers emerge.⁴⁹ All three efforts turn up similar, complementary takes. The news is not good.
Kleinberg says, having identified as the crux of the debate ProPublica’s definition of fairness—the propensity for Black defendants who would not go on to reoffend being almost twice as likely as their White counterparts to be miscategorized as high-risk—“we could then basically line it up with other definitions people had been paying more attention to, and ask, To what extent are these compatible?
“The answer was, they aren’t compatible.”
Only in a world in which Black and White defendants happened to have equal “base rates”—that is, happened to actually reoffend exactly as often as one another—would it be possible to satisfy ProPublica’s and Northpointe’s criteria at the same time. Otherwise, it is simply impossible.
This has nothing to do with machine learning. Nothing to do with criminal justice as such. “It is simply,” Kleinberg and his colleagues write, “a fact about risk estimates when the base rates differ between two groups.”⁵⁰
Chouldechova’s analysis lands exactly in the same place: A tool that is calibrated, she writes, “cannot have equal false positive and negative rates across groups, when the recidivism prevalence differs across those groups.”
“So you just can’t have it all,” she says. “It’s a general principle, but in this case it leads you to interesting conclusions . . . that [have] implications for risk assessment in the real world.”⁵¹
One of those implications is that if a set of equally desirable criteria are impossible for any model to satisfy, then any exposé of any risk-assessment instrument whatsoever is guaranteed to find something headline-worthy to dislike.
As Sam Corbett-Davies explains, “There isn’t a world in which ProPublica couldn’t have found some number that was different that they could call bias. There’s no possible algorithm—there’s no possible version of COMPAS—where that article wouldn’t have been written.”⁵²
(Ironically, in his analysis of the Broward County data, Corbett-Davies discovered that COMPAS is not calibrated with respect to gender. “A woman with a risk score of 5 reoffends about as often as a man with a risk score of 3,” he says.⁵³ “[ProPublica] could have written that article.”)⁵⁴
The brute mathematical fact of this impossibility also means that these problems affect not just machine-learning models of risk-assessment but any means of classification, human or machine. As Kleinberg writes: “Any assignment of risk scores can in principle be subject to natural criticisms on the grounds of bias. This is equally true whether the risk score is determined by an algorithm or by a system of human decision-makers.”⁵⁵
Having established, then, the answers to the question of how these different, seemingly equally intuitive, equally desirable measures of fairness can be reconciled—they can’t—and the question of whether good old-fashioned human judgment is any better in this regard—it isn’t—a further question suggests itself.
Now what?
AFTER IMPOSSIBILITY
I ask Jon Kleinberg what he makes of his own impossibility result—and what he thinks it suggests we ought to do. “I don’t have anything particularly controversial to say on this,” he says. “I think it depends. . . . I think they’re both important definitions, and which one carries more weight depends on the domain you’re working in.”
It’s true that critical aspects of these tradeoffs change radically from one domain to another. Consider, for instance, the domain of lending, which differs from criminal justice in a number of important ways. Denying a loan to someone who would have paid it back not only means lost interest income for the lender, but potentially serious consequences for the borrower: there is a home they can’t purchase, a business they can’t start. On the other hand, making the opposite mistake—loaning money to someone who doesn’t pay it back—might only be a monetary loss for the lender. Maybe this asymmetry changes our sense of what fairness means in that setting: maybe we want to ensure, for instance, that all creditworthy borrowers from two different groups have the same chance of getting a loan—even if, for instance, the math tells us that not only will profit for lenders be reduced, but also that more unworthy people will get loans in one group than another.⁵⁶
In a criminal justice setting, however, and particularly in the context of violent crime, both false positives (“high-risk” people who don’t reoffend) and false negatives (“low-risk” people who do reoffend) have a serious human toll. The tradeoffs we seek are likely to be quite different as a result.
Sam Corbett-Davies has argued, for instance, that equalizing false positive rates in a risk-assessment context—ensuring that the defendants who won’t reoffend, be they Black or White, are no more likely to be improperly detained—would, so long as the actual rates of offense between the groups are different, entail applying different standards to defendants of different races. For instance, it might mean detaining every Black defendant who is a risk of 7 or greater but detaining every White defendant who is a 6 or greater. Such an approach, he says, “probably violates the Equal Protection Clause of the Fourteenth Amendment.”⁵⁷
It’s actually even worse than that, he says. “Because we’re detaining low-risk defendants while releasing some relatively higher-risk defendants, there’s going to be an increase in violent crime committed by released defendants. And because we know that a crime generally occurs within communities as opposed to between communities, this crime will be concentrated in minority neighborhoods, and the victims will also bring a Fourteenth Amendment case.”⁵⁸
The impossibility proofs also show that equalizing the false positive and false negative rates means giving up on calibration—namely, the guarantee that for every numerical risk level, the chance of a defendant reoffending is the same regardless of gender or race. “Without calibration,” says Corbett-Davies, “it’s unclear what it means to have a risk score. So if you ask me, ‘How risky is this defendant?’ and I say, ‘They’re a 2,’ and you say, ‘What does that mean?’ and I say, ‘Well, if they’re male, it means there’s a 50% chance they’ll reoffend; if they’re female it means there’s a 20% chance they’ll reoffend’—you can see how ‘2’ loses its meaning.”⁵⁹
Tim Brennan shares the view that calibration is paramount: “If a Black guy and a White guy both score 7, does that have the exact same rate of failure for the two of them? The arrest rate? . . . The standard method is to make sure—damn sure—that your calibration is not racially biased and your accuracy level is about the same. . . . And we’ve got both. And if we did something else, we would be breaking the law.”⁶⁰
However, even those who emphasize the importance of calibration think that it alone isn’t enough. As Corbett-Davies says, “Calibration, though generally desirable, provides little guarantee that decisions are equitable.”⁶¹
Just because these properties can’t be satisfied all at once in their entirety, however, doesn’t mean we can’t look for certain tradeoffs between them that might be better than others. Other researchers have been exploring the space of these possible tradeoffs, and the work continues.⁶²
I ask Julia Angwin what she herself makes of the storm of theoretical results that her article prompted, and of the ultimate impossibility of doing what her team seemed to demand—namely, to make a tool both equally calibrated and with an equal balance of false positives and false negatives.
“So what I feel about that,” she says, “is that that’s a policy question. And that’s a moral question. But what I’m really happy about is no one knew that that was a question until we came up with it. To me, that is like the greatest thing as a journalist. . . . I do feel that defining the problem so accurately allows it to be solved.”⁶³
Not everyone welcomes the public dialogue that ProPublica’s work spurred. A group of criminal justice scholars, led by Anthony Flores, published a “rejoinder” to the initial ProPublica report, not only defending COMPAS as a calibrated model (and calibration as the appropriate measure of fairness) but, furthermore, lamenting the damaging effects of the controversy itself.⁶⁴ “We are at a unique time in history,” they write. “We are being presented with the chance of a generation, and perhaps a lifetime, to reform sentencing and unwind mass incarceration in a scientific way and that opportunity is slipping away because of misinformation and misunderstanding about [statistical risk-assessment models]. Poorly conducted research or misleading statements can lead to confusion and/or paralysis for those charged with making policy.”
Tim Brennan shares much of this concern, and, of course, sharply disagrees with ProPublica’s characterization of COMPAS. But when I ask him if there is a silver lining to the controversy, in particular the cross-disciplinary movement it has generated within and beyond computer scientists, he agrees: “I think unpacking fairness into its various different coefficients—alerting people to the meanings, benefits, costs, and the impossibility of using certain coefficients— Once you understand a problem or name a problem, solutions become, certainly, more sought after than if you don’t even know the problem existed.”⁶⁵
Most in the computer science community agree that these things are better discussed openly than not.
“I mean, so first of all, the math is the math,” says Cynthia Dwork. “So the best we can hope for is what the math will permit. And we are much, much better off knowing what the limits are than not.”⁶⁶
For Moritz Hardt, the initial wave of academic and technical work following ProPublica’s study has legitimated ethical concepts like fairness as valid topics for research, not only in academic departments but also in the corporate world. Hardt himself was at Google in 2016 when this wave of work—including his own—appeared, and recounts the impact he observed. “Before that, people weren’t even so sure, is this something we should even be touching? It was a hot potato,” he says. From 2016 onward there was an explosion of interest and research, both within Google and beyond. “So that’s something I’m proud of,” Hardt says. “It actually made a difference for the culture.”⁶⁷
For Jon Kleinberg, the role of computer science in questions like these is to furnish the stakeholders with the tools to articulate the issue. “Our point is not to tell you which one is right and which one is wrong but to give you the language to have that discussion. . . . I certainly view this as part of my mandate as a computer scientist: to take things that have always existed informally and qualitatively, and try and think about, Can we actually talk about them rigorously and precisely? Because the world is moving in that direction.”
The world certainly is. In the late summer of 2018, California passed SB 10, a monumental justice reform bill that would eliminate cash bail altogether—leaving the state with the choice simply to detain or release a defendant awaiting trial—and, furthermore, mandated the use of algorithmic risk-assessment tools in informing these determinations.⁶⁸ Just before the end of that year, the US Congress, in a strikingly bipartisan vote, passed the First Step Act, a sweeping criminal justice reform bill that, among its many reforms, required the Department of Justice to develop a statistical model that will be used to assess the recidivism risk of all federal prisoners, as well as to determine their course of rehabilitation.⁶⁹
Though the sudden and widespread adoption of these tools is only increasing, the race between their adoption and the wisdom with which they are built and used at least appears to be drawing somewhat closer to even. We are coming, haltingly, to a clearer understanding of what it means to make “good” predictions of this kind.
A bigger question lurks behind this discussion, however—which is whether “prediction” is really even what we want to be doing at all.
After the ProPublica story broke, a Washington Post reporter called Chouldechova to ask for her response. The reporter had essentially two questions. The first was about the tension between ProPublica’s claims and Northpointe’s defense.
“There I had an answer prepared,” says Chouldechova. “If the prevalence of reoffense differs across populations, then you can’t have everything hold all at once. What I didn’t have a ready canned answer for was when he asked, What actually matters?”
“And so, that was . . . That’s really the question that prompted me to think about things from a different perspective.”⁷⁰
BEYOND PREDICTION
Although prediction is feasible on the basis of data now accessible, exclusive reliance should not be placed on this method.
—ERNEST BURGESS⁷¹
Your scientists were so preoccupied with whether or not they could . . . that they didn’t stop to think if they should.
— JEFF GOLDBLUM AS IAN MALCOLM, JURASSIC PARK
One of the most important things in any prediction is to make sure that you’re actually predicting what you think you’re predicting. This is harder than it sounds.
In the ImageNet competition, for instance—in which AlexNet did so well in 2012—the goal is to train machines to identify what images depict. But this isn’t what the training data captures. The training data captures what human volunteers on Mechanical Turk said the image depicted. If a baby lion, let’s say, were repeatedly misidentified by human volunteers as a cat, it would become part of a system’s training data as a cat—and any system labeling it as a lion would be docked points and would have to adjust its parameters to correct this “error.”
The moral of the story: Sometimes the “ground truth” is not the ground truth.
Gaps of this kind are even more significant in the case of criminal justice predictions. One often talks in shorthand of predicting recidivism itself, but that’s not what the training data captures. What the training data captures is not reoffense, but rather rearrest and reconviction. This is a potentially crucial distinction.
Kristian Lum, lead statistician at the Human Rights Data Analysis Group, and William Isaac of the Department of Political Science at Michigan State articulated this in a 2016 paper on the use of predictive models in policing:
Because this data is collected as a by-product of police activity, predictions made on the basis of patterns learned from this data do not pertain to future instances of crime on the whole. They pertain to future instances of crime that becomes known to police. In this sense, predictive policing is aptly named: it is predicting future policing, not future crime.⁷²
As it happens, this critique was being made all the way back in the 1930s. When the parole reform proposed by Ernest Burgess was deployed in Illinois, critics—particularly those skeptical of parolees’ ability to return productively to society—argued that the official figures underestimated the rate of reoffense. As Elmer J. Schnackenberg, the Republican minority leader in the Illinois House of Representatives, complained in 1937, “Because a parolee isn’t caught at crime during the first or second years of his parole, he is listed during those two years as having made good.”⁷³
This gap, between what we intend for our tool to measure and what the data actually captures, should worry conservatives and progressives alike. Criminals who successfully evade arrest get treated by the system as “low-risk”—prompting recommendations for the release of other similar criminals. And the overpoliced, and wrongfully convicted, become part of the alleged ground-truth profile of “high-risk” individuals—prompting the system to recommend detention for others like them.
This is particularly worrisome in the context of predictive policing, where this training data is used to determine the very police activity that, in turn, generates arrest data—setting up a potential long-term feedback loop.⁷⁴
A person who commits crimes in an area that is less aggressively policed, or who has an easier time getting their charges dropped, will be tagged by the system as someone who did not recidivate. And even fewer police will be dispatched to that neighborhood. Any preexisting disparity in policing between two otherwise similar neighborhoods is likely only to grow. As Lum and Isaac put it, “The model becomes increasingly confident that the locations most likely to experience further criminal activity are exactly the locations they had previously believed to be high in crime: selection bias meets confirmation bias.”⁷⁵ The system begins to sculpt the very reality it is meant to predict. This feedback loop, in turn, further biases its training data.
Lum and Isaac conclude not only that “drug crimes known to police are not a representative sample of all drug crimes” but, what’s more, “rather than correcting for the apparent biases in the police data, the model reinforces these biases. The locations that are flagged for targeted policing are those that were, by our estimates, already over-represented in the historical police data.”⁷⁶
There is reason to believe we already have significant disparities in the present day. As Alexandra Chouldechova notes, “Self-reported marijuana use rates among young Black males and young White males are roughly the same. But the arrest rates for marijuana-related crimes are two and a half to five times higher among Black young males.”⁷⁷ A 2013 report by the ACLU found that on average a Black American is four times more likely to be arrested for marijuana possession than a White person; in Iowa and Washington, D.C., for instance, the disparity is more than eightfold.⁷⁸ A 2018 investigation by the New York Times found that Black residents of Manhattan were fifteen times more likely than White residents to be arrested on marijuana charges, despite similar rates of use.⁷⁹
There are options here to mitigate these issues in a model. The COMPAS model, for instance, makes three distinct predictions of “risk”: violent reoffense, reoffense, and failure to appear in court. Violent crimes—for instance, homicides—are much more consistently reported to police than nonviolent crimes, and the police, in turn, are more consistent about enforcement and arrest. And all failures of a defendant to appear in court by definition become known to the court system, leaving virtually no room for biased sampling or differential enforcement. A wise use of risk-assessment tools, then, might emphasize the violent reoffense and failure to appear predictions over the nonviolent reoffense prediction, on the grounds that the model’s training data is more trustworthy in those cases—which is exactly what a number of jurisdictions are beginning to do.⁸⁰
Other mitigations include somehow building the model to take into account vast disparities in enforcement of certain offenses—treating, say, a Black Manhattanite with several marijuana arrests no differently than a White Manhattanite with just one. (Of course this would require the model to use the defendant’s race as an input.) A third mitigation in the case of marijuana, in particular, is to simply cut the Gordian knot by legalizing or at least decriminalizing it—which then makes downstream machine-learning questions moot.
A second, and equally serious, concern is whether—even if a predictive model measured exactly what it claimed to—we are in practice using it for its intended purpose, or for something else.
For instance, some states are using the COMPAS tool to inform sentencing decisions, something that many regard as an awkward if not inappropriate use for it. Says Christine Remington, Wisconsin assistant attorney general, “We don’t want courts to say, this person in front of me is a 10 on COMPAS as far as risk, and therefore I’m going to give him the maximum sentence.” But COMPAS has been used to inform sentencing decisions—including in Wisconsin. When Wisconsinite Paul Zilly was given a longer than expected sentence in part due to his COMPAS score, Zilly’s public defender called none other than Tim Brennan himself as a witness for the defense. Brennan testified that COMPAS was not designed to be used for sentencing.⁸¹ At a minimum, it seems clear that we should know exactly what it is that our predictive tools are designed to predict—and we should be very cautious about using them outside of those parameters. “USE ONLY AS DIRECTED,” as the label reads on prescription medications. Such reminders are just as necessary in machine learning.
Zooming out even further, however, we might challenge one of the most fundamental unspoken premises of the entire enterprise: that better predictions lead to better public safety.
At first it seems crazy to think otherwise. But there are reasons to pause, and to challenge some of the assumptions that underlie that view.
Columbia Law professor Bernard Harcourt, in his book Against Prediction (which Angwin cites as an inspiration for her own work), raises several such objections. As he argues, the link between better predictions and less crime isn’t as straightforward or foolproof as it may seem. For instance, imagine a predictive tool that identifies that most reckless drivers are male. It may be the case that aggressively pulling over male drivers doesn’t substantially reduce their recklessness on average—but does cause female drivers, who recognize that they are less likely to be pulled over, to drive more recklessly. In that case, roads may become less safe on average—precisely because of the use of this predictive policy. “In other words,” as Harcourt puts it, “profiling on higher past, present or future offending may be entirely counterproductive with regard to the central aim of law enforcement—to minimize crime.”⁸² These sorts of backfiring scenarios are not as far-fetched or rare as they may seem, he argues: they may well describe exactly what is currently happening, for instance, with drug use and tax fraud. If differential enforcement emboldens the overlooked group more than it deters the scrutinized group, it may only make the problem worse.
Predictions also might fail at the ultimate goal of making society safer if they can’t be meaningfully turned into actions. In 2013, the city of Chicago piloted a program designed to reduce gun violence by creating a “Strategic Subjects List” (informally a “heat list”) of people at high risk of being victims of gun violence. Those people as a group turned out to be 233 times more likely than the average Chicagoan to become homicide victims. In this sense, the list’s predictive power appeared to be spot-on. Homicides are so rare, though, that even among those on the “heat list,” only 0.7% were victimized, while 99.3% were not. What do you do, then, with that predictive information? What kind of intervention for a thousand people would help the seven that will actually go on to be victims?
“By leveraging advanced analytics, police departments may be able to more effectively identify future crime targets for preemptive intervention,” noted a 2016 RAND Corporation report on predictive policing in Chicago.⁸³ However, “improvements in the accuracy of predictions alone may not result in a reduction in crime . . . perhaps more importantly, law enforcement needs better information about what to do with the predictions” (emphasis mine).⁸⁴
Predictions are not an end in themselves. What is better: a world in which we can be 99% sure where a crime will occur and when, or a world in which there is simply 99% less crime? In a narrow-minded pursuit of predictive accuracy—or, for that matter, fairness—in a particular prediction tool, we may be missing something larger.⁸⁵
In pretrial release—for which COMPAS is designed—there is, similarly, a gap from predictions to interventions that needs to be considered more broadly. Predicting that someone won’t make it to their court date doesn’t necessarily mean that jailing them between now and then is the correct intervention.⁸⁶
Alexandra Chouldechova explains: “If you think about it from that perspective, then you’re saying, Okay this particular population, maybe they’re less able to provide for themselves: they actually maybe have lower risk, but higher needs.” Maybe they need day care for their children on their court date or a ride to court—not detention. As it turns out, simply reminding people about their court date can significantly improve their rate of appearance.⁸⁷ Unfortunately, many risk assessment tools, unlike COMPAS, conflate a prediction of failure to appear with a prediction of criminal reoffense.⁸⁸ This is an enormous problem if the solution to one risk is incarceration while the solution to another is a text message.
This is a point that particularly resonates with Tim Brennan. The COMPAS information sheet about a defendant that gets shown to a judge was designed so that the risk assessment was in red but the needs assessment was in green. “In green,” he says, “you know, because these are the things that you want to cultivate and help the guy.”⁸⁹ The whole point was to steer as many defendants away from incarceration as possible, toward treatment, community supervision, and the like—the AS in COMPAS stands for “Alternative Sanctions,” after all. But some judges simply view the “needs” scores—addiction issues, homelessness, lack of close community—not as a road map for rehabilitation but as all the more reason for to lock someone up.⁹⁰ Of course, the ability to assign someone to such alternative sanctions or to treatment programs, classes, counseling, and the like requires such services to actually exist. If they don’t, then there is a problem that no statistical model, and indeed no judge, can solve.
“So this brings me to my main point,” Moritz Hardt tells me.⁹¹ A machine-learning model, trained by data, “is by definition a tool to predict the future, given that it looks like the past. . . . That’s why it’s fundamentally the wrong tool for a lot of domains, where you’re trying to design interventions and mechanisms to change the world.”⁹²
He elaborates: “Reducing crime and incarceration rates is a really, really hard problem that I would like to leave to experts in criminal justice. I feel like prediction offers a bit of a dystopian perspective on the topic, which is ‘Let’s assume that we’re not gonna structurally reduce crime. We’re going to predict where it’s gonna happen and go and try to catch people before it’s happening.’ It doesn’t really offer, to me, a mechanism to structurally reduce crime. And that’s what I find dystopian about it. I don’t want to know how to predict where crime’s going to happen. I guess that’s useful, but, much rather I would have a mechanism to reduce crime structurally. I, as a computer scientist, have nothing to offer on that topic, absolutely nothing. I can’t tell you the first thing about this. It would take me years to get to a point where I could.”
The importance of stepping back to take a wider, more macroscopic view of the criminal justice system was not lost on the earliest pioneers in the field.
Ernest Burgess, writing in 1937—after his initial report on the parole system had prompted a risk-assessment model that went into practice statewide—felt that it was high time to move on to something more comprehensive. “The time has arrived in Illinois, in my judgment,” he wrote, “to stop tinkering with parole as an isolated part of our penal problem. What is required is a major operation which involves a complete reorganization of the prison system of the state.”⁹³
Eighty-some years have passed since then. It’s still true.
3 TRANSPARENCY
The rules are supposed to be clear, uniformly expressed, and accessible to all. As we all know, this is rarely actually the case.
—DAVID GRAEBER¹
Providing overwhelming amounts of information without adequate structure or documentation is not transparency.
—RICHARD BERK²
In the mid-1990s, Microsoft’s Rich Caruana was a graduate student at Carnegie Mellon working on neural networks, when his advisor, Tom Mitchell, approached him for help with something.
Mitchell was working on an ambitious, interdisciplinary, multi-institutional project—bringing together biostatisticians, computer scientists, philosophers, and doctors—to better understand pneumonia. When a patient is first diagnosed, the hospital needs to make one critical decision fairly early on, which is whether to treat them as an inpatient or an outpatient—that is, whether to keep them in the hospital overnight for monitoring or to send them home. Pneumonia was at the time the sixth leading cause of death in the United States, with about 10% of pneumonia patients ultimately dying—and so correctly identifying which patients were at greatest risk would translate fairly straightforwardly into lives saved.
The group had been given a dataset of about fifteen thousand pneumonia patients and was tasked with building a machine-learning model to predict patient survival rates that could help the hospital triage new patients. The result was a head-to-head competition of sorts among a menagerie of different machine-learning models: logistic regression, a rule-learning model, a Bayesian classifier, a decision tree, a nearest-neighbor classifier, a neural network—you name it.³
Caruana worked on the neural network (in the ’90s, the state of the art was wide networks, rather than deep), and it was not without some pride that he digested the results. His neural network had won—handily. It was the best of all the complex models, and outperformed more traditional statistical methods like logistic regression by a significant margin.⁴
As the group would write in their reports, “Even small improvements in predictive performance for prevalent and costly diseases, such as [pneumonia], are likely to result in significant improvements in the quality and efficiency of healthcare delivery. Therefore, seeking models with the highest possible level of predictive performance is important.”⁵
So naturally the Pittsburgh hospitals that were partnering on the study decided to deploy the highest-performing model. Right?
“We started talking about that—whether it was safe to use a neural net on patients,” says Caruana.⁶
“And I said, Hell no, we will not use this neural net on patients.”
They deployed one of the simpler models that his neural net had so handily beaten. Here’s why.
THE WRONG RULES
One of the other researchers on the project, Richard Ambrosino, had been training a much different, “rule-based” model on the same dataset. Rule-based models are among the most easily interpreted machine-learning systems; they typically take the form of a list of “if x then y” rules. You simply read your way down the list, from top to bottom, and as soon as a rule applies, you’re done. Imagine a flow chart that doesn’t branch and simply looks like a single vine running from top to bottom: “Does this rule apply? If so, here’s the answer and you’re done. If not, keep reading.” In this way, rule-based models resemble “conditionals” or “switch statements” in traditional software programming; they also sound a lot like the way humans think and write. (More complex models use “sets” rather than “lists,” in which multiple rules can be applied at once.)⁷
Ambrosino was building a rule-based model using the pneumonia data. One night, as he was training the model, he noticed it had learned a rule that seemed very strange. The rule was “If the patient has a history of asthma, then they are low-risk and you should treat them as an outpatient.”
Ambrosino didn’t know what to make of it. He showed it to Caruana. As Caruana recounts, “He’s like, ‘Rich, what do you think this means? It doesn’t make any sense.’ You don’t have to be a doctor to question whether asthma is good for you if you’ve got pneumonia.” The pair attended the next group meeting, where a number of doctors were present; maybe the MDs had an insight that had eluded the computer scientists. “They said, ‘You know, it’s probably a real pattern in the data.’ They said, ‘We consider asthma such a serious risk factor for pneumonia patients that we not only put them right in the hospital . . . we probably put them right in the ICU and critical care.’ ”
The correlation that the rule-based system had learned, in other words, was real. Asthmatics really were, on average, less likely to die from pneumonia than the general population. But this was precisely because of the elevated level of care they received. “So the very care that the asthmatics are receiving that is making them low-risk is what the model would deny from those patients,” Caruana explains. “I think you can see the problem here.” A model that was recommending outpatient status for asthmatics wasn’t just wrong; it was life-threateningly dangerous.⁸
What Caruana immediately understood, looking at the bizarre logic that the rule-based system had found, was that his neural network must have captured the same logic, too—it just wasn’t as obvious.
Amending or editing the rule-based system was fairly straightforward; the neural network was harder to “correct” in this way, though not impossible. “I don’t know where it is in the neural net, but one way or another I can solve the problem,” Caruana recounts. “I can publish more papers in the process of doing it—so this is good—and we’ll make that problem go away. I said, the reason why we’re not going to deploy the neural net is not actually because of asthma, because I already know about that.
“I said, what I’m worried about is things that the neural net has learned that are just as risky as asthma but the rule-based system didn’t learn.” Because the neural net is more powerful, more flexible, it was capable of learning things that the rule-based system didn’t. This, after all, is the advantage of neural networks—and the reason Caruana’s neural net had won the group’s internal contest. “I said it’s those things that will make us not use this model. Because we don’t know what’s in it that we would need to fix. So it’s this transparency problem with the neural net that ultimately caused me to say we’re not going to use it. This has bothered me for a long, long time. Because the most accurate machine-learning models are often not transparent like this. And I’m a machine-learning person. So I want to use accurate models, but I also want to use them safely.”
It’s often observed in the field that the most powerful models are on the whole the least intelligible, and the most intelligible are among the least accurate. “This really pissed me off, by the way,” he tells me. “I want to do machine learning for health care. Neural nets are really good, they’re accurate; but they’re completely opaque and unintelligible, and I think that’s dangerous now. It’s like, maybe I shouldn’t be doing machine learning for health care.”⁹ Instead, though, Caruana decided to spend the next twenty years developing models that attempt to have the best of both worlds—models that are, ideally, as powerful as neural networks but as transparent and legible as a list of rules.
One of his favorites is an architecture called “generalized additive models,” first pioneered by statisticians Trevor Hastie and Robert Tibshirani in 1986.¹⁰ A generalized additive model is a collection of graphs, each of which represents the influence of a single variable. For instance, one graph might show risk as a function of age, another would show risk as a function of blood pressure, a third would show risk as a function of temperature or heart rate, and so forth. These graphs can be linear, or curved, or incredibly complex—but all of that complexity can be immediately apprehended visually, simply by looking at the graph. These individual one-variable risks are then simply added up to produce the final prognosis. In this way it is more complex by far than, say, a linear regression but also much more interpretable than a neural net. You can visualize, on a plain old two-dimensional graph, every factor going into the model. Any strange patterns should immediately stand out.
Many years after the original pneumonia study, Caruana revisited the dataset and built a generalized additive model to explore it. The generalized additive model turns out to be just as accurate as his old neural net, and far more transparent. He plotted the pneumonia mortality risk, for example, as a function of age. It was mostly what one would expect: it’s good to be young or middle-aged if you have pneumonia, and more dangerous to be older. But something in particular stood out: an abrupt, sharp jump beginning at age 65. It seemed unusual that a particular birthday would trigger a sudden increase in risk. What was going on? Caruana realized that the model had managed to learn the impact of retirement. “It’s really annoying that it’s dangerous, right? You would hope that the risk goes down when you retire; sadly, it goes up.”¹¹
More importantly however, the closer he looked, the greater the number of troubling connections he saw. He had feared that his old neural network had learned not just the problematic asthma correlation but others like it—though the simple rule-based models at the time weren’t powerful enough to show him what else might be lurking in the neural network. Now, twenty years later, he had powerful interpretable models. It was like having a stronger microscope and suddenly seeing the mites in your pillow, the bacteria on your skin.
“I looked at it, and I was just like, ‘Oh my— I can’t believe it.’ It thinks chest pain is good for you. It thinks heart disease is good for you. It thinks being over 100 is good for you. . . . It thinks all these things are good for you that are just obviously not good for you.”¹²
None of them made any more medical sense than asthma; the correlations were just as real, but again it was precisely the fact that these patients were prioritized for more intensive care that made them as likely to survive as they were.
“Thank God,” he says, “we didn’t ship the neural net.”
Today Caruana says he finds himself in a different position than most researchers. He continues to work on developing model architectures that promise neural-network levels of predictive accuracy while remaining easily understood. But instead of evangelizing any particular solution of his own invention—for instance, an updated version of generalized additive models¹³—he is evangelizing the problem itself. “Everyone is committing these mistakes,” he says, “just like I have committed them for decades, and didn’t know I was doing it.”
“My goal right now,” he tells me, “is to scare people. To terrify them. I feel I’ve succeeded if they’ve stopped and they’ve thought, Oh shit. We really got a problem here.”
THE PROBLEM OF THE BLACK BOX
Nature conceals her secrets because she is sublime, not because she is a trickster.
—ALBERT EINSTEIN
The act of giving a reason is the antithesis of authority. When the voice of authority fails, the voice of reason emerges. Or vice versa.
—FREDERICK SCHAUER¹⁴
Rich Caruana is far from the only one who in recent years has had some version of the thought Oh shit. We really got a problem here. As machine-learning models proliferate throughout the decision-making infrastructure of the world, many are finding themselves uncomfortable with how little they know about what’s actually going on inside those models.
Caruana found himself particularly uncomfortable with the use of large neural networks because of their longstanding reputation as “black boxes.” With the breathtaking rise in neural networks in everything from industry to the military to medicine, a growing number are feeling that same unease.
In 2014, United States Defense Advanced Research Projects Agency (DARPA) program manager Dave Gunning was talking to Dan Kaufman, director of DARPA’s Information Innovation Office. “We were just trying to kick around different ideas on what to do in AI,” Gunning tells me.¹⁵ “They had had a whole effort where they had sent a whole group of data scientists to Afghanistan to analyze data, try to find patterns that would be useful to the war fighters. And they were already beginning to see that these machine-learning techniques were learning interesting patterns, but the users often didn’t get an explanation for why.” A rapidly evolving set of tools was able to take in financial records, movement records, cell phone logs, and more to determine whether some group of people might be planning to strike. “And they might get some pattern that would be suspicious,” says Gunning, “but now they’d want an explanation of why.” There was no such explanation on offer.
Around that same time, Gunning attended a meeting sponsored by the intelligence community at the Lab for Analytical Sciences at North Carolina State University. The workshop brought together machine-learning researchers and data visualization experts. “We had a government intel analyst in the room listening to us talk about what all the machine-learning technology could do,” Gunning remembers. “And this one analyst just was really kind of adamant that her problem was she already has these big-data algorithms giving her recommendations, but she has to put her name on the recommendation that goes forward. And she gets scored if you will—or worse—based on whether that recommendation is correct. But she didn’t understand the rationale for the recommendation she was getting from the learning algorithm.” Should she sign her name to it, or not? And on what basis, exactly, should she decide?
As computing technology progresses, the defense community has found itself increasingly thinking about what an automated battlefield might look like—what risks and questions surround the idea of ever more autonomous weapons. But many of those questions and problems remain—for the moment, anyway—theoretical.
“With the intel analysis problem, those systems are already there; people are using them,” says Gunning. “You know what I mean? This problem is already there. And they want help.”
Over the next two years, Gunning would find himself the program manager of a multi-year DARPA program in an attempt to meet that problem head-on. He would call it XAI: Explainable Artificial Intelligence.
Across the Atlantic Ocean, the European Union was getting ready to pass an omnibus law called the General Data Protection Regulation, or GDPR. The GDPR would go into effect in 2018 and would sharply change how companies collect, store, share, and use data online. The regulations—all 260 pages worth—amounted to one of the most important documents in the history of data privacy. They also included something a bit more curious and intriguing, and perhaps just as profound.
At the Oxford Internet Institute in the fall of 2015, Bryce Goodman was leafing through the draft legislation when something caught his attention. “I’d learned a bit about machine learning, and how some of the best methods don’t really lend themselves to being transparent or interpretable,” he says, “and then I came across this. In the earlier drafts of the GDPR, it was much more explicit. . . . They said people should have the right to ask for an explanation of algorithmically made decisions.”¹⁶
“I find it really interesting,” he says, “when there are these pieces of legislation or these things that somebody just sort of puts a stake in the ground and says, This thing exists now.”
Goodman approached his Oxford colleague Seth Flaxman, who had just finished a PhD in machine learning and public policy. “Hey, I read this thing in the GDPR,” Goodman said. “This seems like it would be a problem.”
“He was like, ‘Yeah, that seems like it would be.’ ”
Whether it was getting rejected for a loan, being turned down for a credit card, being detained pending trial or denied parole, if a machine-learning system was behind it, you had a right to know not just what happened but why.
The following spring, in 2016, the GDPR was officially adopted by the European Parliament, and the collective hair went up on the back of the necks of executives across the entire tech sector. Attorneys described sitting down with EU regulators. “You realize,” they said, “that getting intelligible explanations out of a deep neural network is an unsolved scientific problem, right?” As Goodman and Flaxman had written, it “could require a complete overhaul of standard and widely used algorithmic techniques.” The regulator was not moved by this: “That’s why you have until 2018.”
As one researcher put it: “They decided to give us two years’ notice on a massive research problem.”
The GDPR has now gone into effect, though the exact details of what EU regulators expect, and what constitutes a sufficient explanation—to whom, and in what context—are still being worked out. Meanwhile transparency—the ability to understand what’s going on inside a machine-learning model and why it behaves as it does—has emerged as one of the field’s most clear and crucial priorities. Work on this problem continues, full steam, to this day—but recent progress has been made on a number of fronts. Here is what we are coming to know.
CLINICAL VERSUS STATISTICAL PREDICTION
There is a prevalent myth that the expert judge of men succeeds by some mystery of divination. Of course, this is nonsense. He succeeds because he makes smaller errors in the facts or in the way he weights them. Sufficient insight and investigation should enable us to secure all the advantages of the impressionistic judgment (except its speed and convenience) without any of its defects.
—EDWARD THORNDIKE¹⁷
The first thing we need to consider as we confront the problem of transparency—particularly in large, complex models—is whether, in fact, we ought to be using large or complex models in the first place. For that matter, should we be using models at all?
These are questions that reach deeply into the history of statistics and machine learning, ones that are as relevant today as they have ever been, and ones whose answers are rather surprising indeed.
In 1954, Robyn Dawes was an undergraduate philosophy major at Harvard, specializing in ethics. His thesis—“A Look at Analysis”—investigated whether, and to what degree, moral judgments were rooted in emotion.
Not only did Dawes think these were important questions, he thought “empirical work might be important. But how would you do empirical work?” With this question, he realized that his interests lay more with psychology than philosophy. He applied to psychology graduate programs, and the best one in the country, the University of Michigan, let him in off the waiting list on the final day of the admissions window. Dumbstruck, Dawes broke the good news to his advisor, who told him, “Wire them back immediately before they realize they made a clerical error.”¹⁸
Dawes went to Michigan and began his training in clinical psychology. At the time—the late 1950s and early ’60s—this meant a heavy emphasis on Rorschach tests. Dawes found himself growing skeptical of just how useful the Rorschach was as a clinical tool. “It was all intuitive and it made intuitive sense. But then I started reading and found out that in fact, empirically, a lot of this stuff doesn’t work.”
During his dawning skepticism, Dawes was working as a resident in a psychiatric ward. “There was a client who had this delusion,” he recounts, “and the delusion was that he was growing breasts. And he was in my group—on a locked ward by the way, because he had this delusion that must be schizophrenia. And uh, why did he think he was growing breasts? Well, earlier that week, one of his parents had committed suicide before he developed the delusion. Okay, makes perfect sense, right? . . . They’d never asked this guy to take off his shirt even. He’d just been sent to the psychiatric ward—six weeks on a locked ward in my group. And when they asked him to take off his shirt, it was in fact true: he was growing breasts.” The man had Klinefelter syndrome: a genetic condition caused by an additional X chromosome, with symptoms including lack of body hair and the development of breast tissue. Dawes was incensed. “Okay, well that’s six weeks of his life just thrown out,” he says, “because people were so convinced about, Oh this is a fascinating delusion.”
This led to a major pivot in Dawes’s career, away from clinical practice and toward what was at the time being called “mathematical psychology.” He had a paper he was intending to submit for publication, comparing expert clinical judgments against simple mathematical models, and he showed the paper to a friend. The friend’s reaction caught Dawes off guard. “He sort of looked at me funny and said, you know, in effect, ‘Are you sure you didn’t plagiarize?’ ”
As it happened, Dawes was joining an academic lineage of which he had no idea. The question of pitting expert judgment against simple mathematical models—then called “actuarial” methods—went back to the early 1940s work of a colleague of Ernest Burgess’s named Ted Sarbin. Sarbin looked at predictions of academic performance for incoming freshmen at the University of Minnesota. The “actuarial” model was a simple linear regression to predict their college GPA from just two data points: their high school class rank and their college aptitude test scores. The human predictions were made by experienced clinical psychologists who had access to these two data points, plus additional tests, an eight-page dossier, notes from a colleague’s interview, and their own firsthand impression of the student.
Sarbin found no measurable difference between the two predictions. If anything, the actuarial model was more accurate, though not markedly so. From Sarbin’s perspective, it seemed incredible that the additional information available to the clinicians appeared to add nothing in predictive accuracy. “What of strivings, habits of work and play, special aptitudes, emotional patterns, systematic distractions, and the hundreds of other conditions,” he wrote, “which seem to be related to this complex form of social psychological behavior known as academic achievement?”¹⁹ Ironically, Sarbin found that the human counselors didn’t place much emphasis on these things themselves and, in fact, made their predictions chiefly on the basis of class rank and test scores—the very same data used in the regression model. They just weren’t as consistent or finely tuned in how they weighted it.
Sarbin’s conclusion was that the time-intensive effort spent in conducting interviews was a waste. And he cautioned: “Unless checked by statistical studies, the case-study method in the social sciences will become intellectually bankrupt.”
Sarbin’s findings had caught the attention, in turn, of a young psychologist named Paul Meehl. Inspired by Sarbin’s provocation, and unsure of where he himself stood, Meehl began an investigation that would turn into an entire book on the subject: 1954’s Clinical Versus Statistical Prediction. Though much if not most of the book was dedicated to understanding what goes into clinical judgments and how clinicians make decisions, by far its biggest impact stemmed from the chapter in which Meehl pitted clinical and actuarial judgments head to head. The human experts, Meehl discovered, didn’t stand a chance. Out of almost a hundred different domains, in only a half dozen did there seem to be even a slight edge for the human decision makers. “I am told,” Meehl recounts, “that half the clinical faculty at one large Freudian oriented midwest university were plunged into a six-month reactive depression as a result of my little book.”²⁰
Dawes, having found himself to be an unwitting plagiarist, of course became keenly interested in Meehl’s work—but his advisors seemed to disapprove of the influence. “I was told by my psychoanalytic mentors that, well, Meehl is a genius, and everyone knows he’s a genius, but what he does has nothing to do with what we do. And I started worrying about if what he does has nothing to do with what we do, maybe I don’t want to do what we do.”
By the mid-1970s, Dawes, by then at the Oregon Research Institute, authored another concussive paper in the lineage. As he summarized, Sarbin and Meehl had opened the question of how purely statistical analysis might compare to expert human judgment. “The statistical analysis was thought to provide a floor to which the judgment of the experienced clinician could be compared,” Dawes wrote. “The floor turned out to be a ceiling.”²¹
Thirty years after Sarbin’s original paper, and many dozens of studies later, he concluded, “A search of the literature fails to reveal any studies in which clinical judgment has been shown to be superior to statistical prediction when both are based on the same codable input variables” (emphasis mine).²²
The picture was humbling indeed. Even in cases where the human decision makers were given the statistical prediction as yet another piece of data on which to make their decision, their decisions were still worse than just using the prediction itself.²³ Other researchers tried the reverse tack: feeding the expert human judgments into a statistical model as input. They didn’t appear to add much.²⁴
Conclusions like these, which have been supported by numerous studies since, should give us pause.²⁵ For one, they seem to suggest that, whatever myriad issues we face in turning decision-making over to statistical models, human judgment alone is not a viable alternative. At the same time, perhaps complex, elaborate models really aren’t necessary to match or exceed this human baseline.
A tantalizing question lurks, however: Namely, what explains this surprising verdict? Is human judgment really that bad? Are simple linear models of a handful of variables really that good? Or . . . a third possibility: Has human expertise somehow managed to enter into the simple models where we least expect it? Were we looking for it in the wrong place?
IMPROPER MODELS: KNOWING WHAT TO LOOK AT
The fact that some real problems are hard does not imply that all real problems are hard.
—ROBERT HOLTE²⁶
The fact that man cannot combine information as efficiently as a computer, for example, does not imply that man can be replaced by machines. It does imply that the necessity for a man-computer system is at hand.
—HILLEL J. EINHORN²⁷
Dawes, with his colleagues at the Oregon Research Institute, wanted to get to the bottom of the shocking effectiveness of simple, linear models in decision-making.
One hypothesis was that perhaps the models were outperforming the experts because of a kind of “wisdom of the crowd” effect: that a single model was aggregating the judgments of a whole group of experts, so of course it would outperform any single expert in isolation. It sounded plausible—but it wasn’t true. Amazingly, even if a model was trained only to mimic a single expert’s judgments, it still outperformed the expert themselves!²⁸
Maybe there was something about the way that the linear models were optimized, the way they were tuned to have the optimal coefficients that weighted each variable. With his collaborator Bernard Corrigan, Dawes compared the judges against what they called “improper” linear models, ones whose weights were not optimized. They tried equal weights, and they tried random weights.
The results were stunning. Models with random weights—as long as they were constrained to be positive—were as accurate or more than the judges themselves. Models with equal weights were even better.²⁹
The practical possibilities for such quick-and-easy improper models seemed endless. In the mid-1970s, Dawes was on a panel with a medical physician; afterward, sharing drinks at the bar, the doctor asked him, “Could you, for example, use one of your improper linear models to predict how well my wife and I get along together?”³⁰
Dawes immediately imagined the simplest model he could think of: a good marriage, he figured, should probably involve more sex than fights. With a colleague’s dataset, he did the math. He added up the number of times a couple had sex (“defined as genital union with or without orgasm”) over a period of weeks or months, and subtracted the number of times they had a fight (“situations where at least one party became uncooperative”) in that same time. “The linear prediction is the quintessence of simplicity: subtract the rate of arguments from the rate of sexual intercourse. A positive difference predicts happiness, a negative one unhappiness.”³¹ The data, from couples in the Kansas City, Missouri, area, showed that indeed, sex-minus-fights was positive for 28 out of the 30 couples that self-identified as “happy,” while sex-minus-fights was negative for all 12 couples that self-identified as “unhappy.”³² Study after study—in Oregon, in Missouri, in Texas—confirmed this correlation.
In fact, in many cases the equal-weighted models were better even than the optimal regressions—a fact that seems impossible, as the optimal weights are chosen precisely to be, well, optimal. But they were optimal for a particular context and a particular set of training data, and that context didn’t always transfer: optimal weights for predicting academic performance at the University of Minnesota, for instance, weren’t necessarily optimal for predicting academic performance at Carnegie Mellon. In practice, equal weights seemed to hold up better and be more robust across contexts.³³
Dawes was fascinated by this. Given the complexity of the world, why on earth should such dead-simple models—a simple tally of equally weighted attributes—not only work but work better than both human experts and optimal regressions alike?
He came up with several answers. First, despite the enormous complexity of the real world, many high-level relationships are what is known as “conditionally monotone”—they don’t interact with one another in particularly complex ways. Regardless of whatever else might be happening with a person’s health, it’s almost always better if that person is, say, in their late twenties rather than their late thirties. Regardless of whatever else might be happening with a person’s intellect, motivation, and work ethic, it’s almost always better if that person’s standardized test scores are ten points higher than ten points lower. Regardless of whatever else might be happening with a person’s criminal history, self-control, and so forth, it’s almost always better if they have one fewer arrest on their record than one more.
Second, there is almost always error in any measurement. For theoretical as well as intuitive reasons, the more error-prone a measurement is, the more appropriate it is to use that measurement in a linear fashion.
Perhaps most provocatively from the perspective of alignment, Dawes argued that these equally weighted models surpass their “proper,” optimally weighted counterparts because those weights have to be tuned, as we’ve seen, with respect to some kind of objective function. In real life, often we either can’t define how exactly we plan to measure success, or we don’t have time to wait for this ground-truth to come so we can tune our model. “For example,” he writes, “when deciding which students to admit to graduate school, we would like to predict some future long-term variable that might be termed ‘professional self-actualization.’ We have some idea what we mean by this concept, but no good, precise definition as yet. (Even if we had one, it would be impossible to conduct the study using records from current students, because that variable could not be assessed until at least 20 years after the students had completed their doctoral work.)” Even here, Dawes argues, when we don’t know what exactly we want and have no data at all, improper models should serve us at least as well if not better than raw intuition.³⁴
One might, however, object that Dawes and Corrigan’s comparisons, particularly against human experts, don’t seem entirely fair. The models were not random linear combinations of random properties; they were random linear combinations of precisely the things that humans have established, through decades if not generations of best practices, to be the most relevant and predictive things to consider.
It would be tempting to argue, perhaps, that all of this “pre-processing” activity—deciding which two or five or ten things out of the infinite information available is most pertinent to the decision at hand—reflects the real wisdom and insight into the problem: in effect, that we’ve done all of the hard work already before passing it off to the linear model, which then gets all the credit. This, indeed, was exactly Dawes’s point. As he wrote: “The linear model cannot replace the expert in deciding such things as ‘what to look for,’ but it is precisely this knowledge of what to look for in reaching the decision that is the special expertise people have.”³⁵
It was Dawes’s conclusion that human expertise is characterized by knowing what to look for—and not by knowing the best way to integrate that information. One of the clearest demonstrations of this idea came from a study by decision theorist Hillel Einhorn in 1972.³⁶ Einhorn looked at physicians’ judgments of biopsy slides for patients diagnosed with Hodgkin’s lymphoma. The physicians were asked to specify the factors they considered important when looking at a slide, and then to score each slide for those factors. The physicians then gave an overall rating about the severity of the patient. It so happened that their overall severity ratings had zero correlation with patient survival. However, in a result that is becoming something of a refrain, a simple model using the experts’ individual factor scores was a powerful predictor for patient mortality.
Put differently, we’ve been looking for human wisdom in the wrong place. Perhaps it is not in the mind of the human decider, but embodied in the standards and practices that determined exactly which pieces of information to put on their desk. The rest is just math—or, at any rate, should be.
Dawes put it a third way, in arguably the most famous sentence of his storied career. “The whole trick is to know what variables to look at,” he wrote, “and then to know how to add.”³⁷
OPTIMAL SIMPLICITY
Simple can be harder than complex: You have to work hard to get your thinking clean to make it simple. But it’s worth it in the end because once you get there, you can move mountains.
—STEVE JOBS³⁸
The only simplicity for which I would give a straw is that which is on the other side of the complex—not that which never has divined it.
—OLIVER WENDELL HOLMES JR.³⁹
Perhaps no one so carries the spirit of Dawes forward into the twenty-first century like Duke University computer scientist Cynthia Rudin. Rudin has made simplicity one of the central drives of her research; she is interested in not only arguing against the use of overly complex models, but in pushing the envelope of what simple models can do. In the criminal justice domain, for instance, Rudin and her colleagues published a paper in 2018 showing that they could make a recidivism-prediction model as accurate as COMPAS that could fit into a single sentence: “If the person has more than three prior offenses, or is an 18-to-20-year-old male, or is 21-to-23 years old and has two or more priors, predict they will be rearrested; otherwise, not.”⁴⁰
For Rudin, Dawes’s research is both an inspiration and a kind of challenge, like a gauntlet being thrown down. So simple models, made from hand-selected high-level variables, perform about as well as more complex models—sometimes better—and consistently as well as or better than human experts. But even that leaves a lot of questions—and avenues for research open. How, for instance, might one build not just a simple model from a given dataset but the best simple model?
Surprisingly, answers have come only in the last several years.
Rudin looks at the simple models currently being used in twenty-first century health care, and takes a different and much less sanguine view than Dawes. Instead of seeing present-day models as a superior alternative to clinical intuition, she sees models overly shaped by clinical intuition. And ones with a lot of room for improvement.
She raises the example of the coronary heart disease score sheet for men. “So if you’re a guy, you go into the doctor’s office, and they will try to compute your ten-year risk of coronary heart disease. And they’ll do it by asking you five questions: what’s your age, what’s your cholesterol level, do you smoke, and so on and so forth. So they ask you these five questions, and then you get points for each answer you give, and then you add up the points and that translates into your ten-year risk of coronary heart disease.” Her voice takes a sharp turn. “But where do they get these five questions? And how did they get the points? And the answer is, They made it up! This was made up by a team of doctors! This is— This is not how I want to do this. What I want to do is, I want to build something that’s that interpretable—but I want to build it from data.”⁴¹
As it happens, finding optimal simple rules is not for the faint of heart. In fact, it requires tackling an “intractable,” or “NP-hard” problem: a thicket of complexity in which there is no straightforward means of obtaining the guaranteed best answer. Given tens of thousands of patient records, each with dozens or perhaps hundreds of different attributes—age, blood pressure, etc.—how do you find the best simple flow chart for diagnosis? Computer scientists have a toolkit full of ways to make progress here, but Rudin felt that the existing algorithms for building simple rule lists and scoring systems from big data—algorithms like CART, developed in the ’80s,⁴² and C4.5, developed in the ’90s⁴³—just weren’t sufficient. There was also something available to computer scientists in the 2010s that wasn’t available in the ’80s and ’90s: about a million-fold speedup in computing power. Instead of using that computational horsepower to train a huge, complex model—like AlexNet, with tens of millions of parameters—why not put it to use, instead, searching the vast space of all possible simple models? What might be possible? Her team went back to the drawing board and came up with new approaches—one for rule-based models and another for models based on score sheets—and set about comparing these against the status quo.
In particular, Rudin and her lab set their sights on beating one of the most commonly used models in all of medicine: CHADS₂. CHADS₂, developed in 2001, and its successor, CHA₂DS₂-VASc, developed in 2010, are designed to predict the risk of stroke in patients with atrial fibrillation.⁴⁴ Each was designed by doctors and researchers working closely with a dataset, along with their clinical expertise, to identify what they thought the most relevant factors were. And subsequent studies have confirmed the predictive utility of the tools. Both models, despite being generally accepted as valid instruments and having found incredibly widespread use, remain to a degree “artisanal,” handcrafted. Rudin wanted to computationally identify the most relevant factors to combine together into a single scoring instrument.
Working with more than six thousand times as much data as was used in the original CHADS₂ study, Rudin let her algorithm, called Bayesian Rule Lists, loose on a set of 12,000 patients, to pore over some 4,100 different properties for each—every drug they were taking, every health condition they had reported—to make the best possible scoring system.⁴⁵ She then compared her own model to both CHADS₂ and CHA₂DS₂-VASc against held-out portions of that same dataset.
The results showed a marked improvement over both CHADS₂ and CHA₂DS₂-VASc. More intriguingly, they also showed a marked decrease in accuracy from the original CHADS₂ to the more recent CHA₂DS₂-VASc. The newer model appeared—at least by this measure, on this data—to be worse than the old one. This, as she and her colleagues put it delicately in their paper, “highlights the difficulty in constructing these interpretable models manually.”
In a subsequent project, Rudin and her PhD student Berk Ustun worked with Massachusetts General Hospital to develop a scoring system for sleep apnea, a condition that affects tens of millions of Americans, and more than a hundred million people worldwide.⁴⁶ Their goal was to create a model that was not only as accurate as possible, but also so simple that it could run quickly and reliably on some decidedly old-school hardware: physicians’ notepads.
Because of the constraint that the model would be deployed on paper, Ustun and Rudin had to make their model almost impossibly simple. It would need very few explicit features to consider, and integer coefficients as small as possible.⁴⁷ Even into the twenty-first century, it was not uncommon for practitioners to simply come up with an ad hoc model based on their own intuition. This is sometimes derisively referred to as the “BOGSAT method”: a bunch of guys sitting around a table. Even in cases where machine learning was used in building the model, it was often more complex models that were simplified manually after the fact.⁴⁸ It is still true today that models in current medical practice were designed in this ad hoc fashion, meaning that accuracy—and, therefore, real patients—are suffering.⁴⁹ Ustun and Rudin wanted to see if there was a better way.
They developed a model called SLIM (“Supersparse Linear Integer Model”) to find not just decent heuristics but provably optimal ways to make decisions under these severe constraints. The upshot of their work was twofold, with concrete benefits in medicine and machine learning alike.
First, the model showed—contrary to received wisdom and current practice—that patient symptoms were significantly less useful than their histories. When Ustun and Rudin trained a model on patients’ medical histories—things like past heart attacks, hypertension, and the like—it was significantly more predictive than one trained on their immediate symptoms: things like snoring, gasping, and poor sleep. What’s more, adding symptoms to the model based on histories didn’t register much of an improvement. The screening of sleep apnea—which in severe untreated form triples one’s risk of death⁵⁰—had taken a measurable step forward.
Second, the machine-learning community had scored a methodological victory it could carry through into other collaborations and other domains. “SLIM accuracy was similar to state-of-the-art classification models applied to this dataset,” Ustun and Rudin’s team report, “but with the benefit of full transparency, allowing for hands-on prediction using yes/no answers to a small number of clinical queries.”⁵¹
As Rudin puts it, “I want to design predictive models with the end user in mind. I want to design these things . . . not just so they’re accurate, but so that people can use them, people can make decisions using them. I want to create predictive models that are highly accurate, yet highly interpretable, that we can use for trustworthy decision making. And I’m working under the hypothesis that I believe is true, that many data sets permit predictive models that are also surprisingly small. I’m not the first person to hypothesize this; it was hypothesized many years ago. But now we have the computational ability and new ideas and new techniques that will really allow us to test this hypothesis.”
It’s an exciting time for researchers working on this set of questions. Simple models are amazingly competitive—and then some—with human expertise. Modern techniques give us ways of deriving ideal simple models.
With that said, there are cases where complexity is simply unavoidable; the obvious one is models that don’t have the benefit of human experts filtering their inputs to meaningful quantities of manageable size. Some models must, for better or worse, deal not with human abstractions like “GRE score” and “number of prior offenses” but with raw linguistic, audio, or visual data. Some medical diagnostic tools can be fed human inputs, like “mild fever” and “asthmatic,” while others might be shown an X-ray or CAT scan directly and must make some sense of it. A self-driving car, of course, must deal with a stream of radar, lidar, and visual data directly. In such cases we have little choice but the kinds of large, multimillion-parameter “black box” neural networks that have such a reputation for inscrutability. But we are not without resources here as well, on the science of transparency’s other, wilder frontier.
SALIENCY: THE WHITES OF ITS EYES
Humans, relative to most other species, have distinctly large and visible sclera—the whites of our eyes—and as a result we are uniquely exposed in how we direct our attention, or at the very least, our gaze. Evolutionary biologists have argued, via the “cooperative eye hypothesis,” that this must be a feature, not a bug: that it must point to the fact that cooperation has been uncommonly important in our survival as a species, to the point that the benefits of shared attention outweigh the loss of a certain degree of privacy or discretion.⁵²
It might be understandable, then, for us to want to expect something similar from our machines: to know not only what they think they see but where, in particular, they are looking.
This idea in machine learning goes by the name of “saliency”: the idea is that if a system is looking at an image and assigning it to some category, then presumably some parts of the image were more important or more influential than others in making that determination. If we could see a kind of “heat map” that highlighted these critical portions of the image, we might obtain some crucial diagnostic information that we could use as a kind of sanity check to make sure the system is behaving the way we think it should be.⁵³
The practice of such saliency methods has been full of surprises that highlight just how unintuitive machine-learning systems can be. Often they latch onto aspects of the training data we did not think were relevant at all, and ignore what we would imagine was the critical information.
In 2013, Portland State University PhD student Will Landecker was working with a neural network trained to distinguish images in which an animal was present from those with no animals present. He was developing methods for looking at which portions of the image were relevant to the ultimate classification, and noticed something bizarre. In many cases, the network was paying more attention to the background of the picture than the foreground. A closer look showed that blurry backgrounds—known in photographer’s lingo as “bokeh”—were commonly present in images of an animal, with the face in sharp focus and the background artfully out of focus. Empty landscapes, by contrast, tended to be more uniformly in focus. As it turns out, he hadn’t trained an animal detector at all. He’d trained a bokeh detector.⁵⁴
In 2015 and 2016, dermatologists Justin Ko and Roberto Novoa led a collaboration between researchers from Stanford’s medical and engineering schools. Novoa had been struck by the progress in computer vision systems’ ability to differentiate between hundreds of different dog breeds. “I thought,” he says, “if we can do this for dogs, we can do this for skin cancer.”⁵⁵ They put together the largest dataset ever assembled of benign and malignant skin patterns, 130,000 images spanning two thousand different diseases as well as healthy skin. They took an off-the-shelf open-source vision system, Google’s Inception v3, which had been trained on the ImageNet dataset and categories, and they retrained the network to tell the difference, not between Chihuahuas and Labradors, but between acral lentiginous melanoma and amelanotic melanoma, and thousands of other conditions.
They tested their system against a group of twenty-five dermatologists. The system outperformed the humans. This “dermatologist-level” accuracy landed them a widely cited paper in Nature in 2017.⁵⁶ For Ko—who prides himself on the keenness of his own diagnostic eye, honed over the better part of a decade of training and clinical practice—the result was both deeply humbling and inspiring. “I’ve been spending years and years and years,’’ says Ko, “and this thing can do it in a few weeks.”⁵⁷ And yet what such a system promised was the ability to “essentially extend high-quality, low-cost diagnostic abilities to the furthest reaches of the globe.”
As it turns out, a system like this is useful not only in places where first-rate diagnosticians are hard to find, but also as a second opinion for trained experts like Ko himself. Ko remembers the date—April 17, 2017—when a patient came in to his clinic with a funny-looking spot on their shoulder. “I was completely on the fence,” Ko says. Something about it, he said, just seemed “not quite right. But then when I looked at it with my dermatoscope, I didn’t see any features that would suggest to me that this was an early evolving melanoma.” Still, it didn’t sit right with him.
“And so I said, Okay, this is a perfect time to whip out my iPhone.” Ko took a series of photos, with every kind of angle and lighting he could, and fed each of them into the network. “Remarkably,” he says, “regardless of the photo, it was pretty stable in the read—and it was pretty adamant that this was a malignant lesion.” Ko had it biopsied and talked to the clinic’s dermatopathologist. “Lo and behold, she said, ‘Hey, you know what? This is really fascinating. This was a really early, subtle example of an evolving melanoma.’ So we caught it at a completely treatable stage.” The date sticks in Ko’s mind. It was the first time the network had made a clinical impact. “And,” he says, “I hope it’s just the first of many.”
The full story, though, is a bit more complicated. Ko, Novoa, and their collaborators submitted a letter the following year to the Journal of Investigative Dermatology, urging caution in moving neural-network models too quickly into routine clinical practice.
They felt that extreme care was due before such models are deployed widely into the field, and underscored their point with a cautionary tale from their own experience. The vision system they were using was much more likely to classify any image with a ruler in it as cancerous. Why? It just so happened that medical images of malignancies are much more likely to contain a ruler for scale than images of healthy skin. “Thus the algorithm inadvertently ‘learned’ that rulers are malignant.”⁵⁸ Saliency-based methods can catch some of these issues. Still, the ultimate solution—whether ensuring that the dataset contains diverse enough variation or that all input images are standardized in some way—is complex. “We must continue addressing the many nuances involved,” they conclude, “in bringing these new technologies safely to the bedside.”
TELL ME EVERYTHING: MULTITASK NETS
One of the simplest ideas in making complex models more transparent and understandable is simply to have them output more things. When Rich Caruana was working on neural networks to predict medical outcomes, he realized that the network could be used to make not just a single prediction—say, whether the patient would live or die—but potentially dozens: how long they’d stay in the hospital, how large their bill would be, whether they’d need breathing assistance, how many courses of antibiotics they’d require, and so on.
All of this additional information in a dataset was useless in practice as additional inputs to the model. Learning to predict a patient’s risk of death based on their hospital bill won’t actually help you when a new patient arrives, because of course you don’t know their final bill yet. But rather than serving as additional inputs, this information is useful as additional outputs, additional sources of ground truth in training the model. The technique has come to be known as “multitask learning.”⁵⁹
“Strangely enough, that can be easier than training it to predict one of those things at a time,” Caruana tells me.⁶⁰ “Together, you can think of training it on a hundred related things at the same time as providing you more signal. More information.”
As an example, he invites me to imagine that I’m admitted to the hospital with some serious condition, perhaps pneumonia. Suppose I live, he says—but I’m in the hospital for a month, and my bill is a half million dollars. “I now know something was terribly wrong,” says Caruana. “The shit hit the fan for you. Maybe it didn’t qualify as one of our ‘dire outcome’ things. But I now know that you were very, very sick.”
To a system built narrowly to predict mortality risk, my case might serve as training data with a ground-truth mortality risk of zero, seeing as I survived, but something would be missing. My case was, as he puts it, “a pretty high-risk zero.” If I indeed had simply been lucky, maybe the system ought to predict, say, an 80% chance of death, not a 0% chance, in future cases like mine. Giving it a wider range of outputs to train on, and simultaneous predictions to make, might nudge the system toward that more accurate assessment.
What Caruana came to realize was that not only were these “multitask” models better in the traditional senses—they trained faster, achieved higher accuracy—but they were also more transparent, in a way that made it easier to identify problems. If a health-care system like the one he built in the ’90s were generating predictions only for whether a patient would live or die, you might find it predicting unexpected things—like, for instance, that asthmatics are less likely to die than regular outpatients. On the other hand, if you had a multitask net predicting all sorts of things from the data—not just death but length of hospital stay or dollar cost of treatment—these anomalies would be much more visible. The asthmatics, for instance, might have better-than-average morbidity but astronomical medical bills. It would be much clearer that these were no ordinary “low-risk” patients to be sent home with instructions to take two pills and call back in the morning.
In some cases, these additional output channels can also offer something more significant. A team spanning Google, its life-science spin-off Verily, and the Stanford School of Medicine was working in 2017 and 2018 on similarly adapting Google’s Inception v3 network to classify images of the retina.⁶¹ They found encouraging diagnostic results, with the model detecting diseases like diabetic retinopathy as accurately as human experts. The team realized, however, that the dataset they were working with had all sorts of other information about the patient: age, sex, body mass index, whether they smoked, and so on. “So we sort of added those variables to the model,” says Google researcher Ryan Poplin.⁶² Just as Caruana had done, they thought that since they had all this additional patient data, why not have their model predict all of it? What if they treated this trove of ancillary data—age, sex, blood pressure, etc.—not as additional inputs to the model, but as additional outputs? It might offer a way to make the model more robust, and might offer some insight into cases where the model’s disease predictions were off. “We felt like it was a great sort of control or ground truth that we could add to the model,” says Poplin.
They were in for an enormous shock. The network could almost perfectly tell a patient’s age and sex from nothing but an image of their retina.
The doctors on the team didn’t believe the results were genuine. “You show that to someone,” says Poplin, “and they say to you, ‘You must have a bug in your model. ’Cause there’s no way you can predict that with such high accuracy.’ . . . As we dug more and more into it, we discovered that this wasn’t a bug in the model. It was actually a real prediction.”
The team used saliency methods to reveal, if not exactly how the network was doing it, then at least what the relevant features were. Age, as it happened, was determined by the model looking mostly at the blood vessels; sex, in contrast, by looking at the macula and the optic disc.
At first, says Poplin, when showing these results to a doctor, “They kind of laugh at you. They don’t believe it. But then, when you show them that heat map and show that it’s focusing on the optic disc or maybe features around the optic disc, then they say, ‘Oh yeah, of course we knew that, of course you can see that.’ By showing where in the image the model is using to make its prediction, it really does provide a level of trust and also, you know, a level of validity to the results.”
More than achieving mere predictive accuracy, the model suggested an intriguing path forward for medical science itself. The combination of multitask learning and saliency techniques showed the field that there were sex differences in the retina that had been overlooked. Not only that; it showed where to find them.
These methods of explanation, in other words, don’t just make for better medicine. They might also make for better doctors.
POPPING THE HOOD: FEATURE VISUALIZATION
We’ve seen how multitask networks, with additional outputs, can give us important context for what a network is predicting. Saliency methods offer context for the network’s input, and can offer us information about, in effect, where a model is looking. But neither tells us much about what’s going on inside the black box—that is, what the model is actually seeing.
The signature breakthrough in machine learning since AlexNet in 2012 have been neural network models that learn from the messy welter of raw sensory perception: millions of colored pixels. The models have tens of millions, not dozens, of parameters, and those parameters represent fairly ineffable things: summed thresholds of earlier layers, which are themselves summed thresholds of earlier layers, all the way back to the millions of raw pixels. This is not the raw grist from which intelligible explanations are made.
So what to do?
At NYU, PhD student Matthew Zeiler and his advisor, Rob Fergus, were fixated on this question. The success of these enormous, bewildering models, they argue, is undeniable. “However,” they write, “there is no clear understanding of why they perform so well, or how they might be improved. . . . From a scientific standpoint, this is deeply unsatisfactory.”⁶³ In other words, the results are impressive, but as Zeiler puts it, “With all these nice results, it’s not clear what these models are learning.”⁶⁴
People knew that the bottommost layer of a convolutional network represented basic things: vertical edges, horizontal edges, diagonal edges, a strong single color, or a simple gradient. And it was known that the final output of these networks was a category label: cat, dog, car, and so forth. But it wasn’t really known how to interpret the layers in between.
Zeiler and Fergus developed a visualization technique they called “deconvolution,” which was a way to turn intermediate-level activations of the network back into images.⁶⁵
For the first time they were seeing the second layer. It was a menagerie of shapes. “Parallel lines, curves, circles, t-junctions, gradient patterns, colorful blobs: a huge variety of structure is present already at the second layer.” The third layer was even more complex, beginning to represent portions of objects: things that looked like parts of faces, eyeballs, textures, repeated patterns. It was already detecting things like the white fluff of a cloud, the multicolor stripes of a bookshelf, or the green comb of grass. By the fourth layer, the network was responding to configurations of eyes and nose, to tile floors, to the radial geometry of a starfish or a spider, to the petals of a flower or keys on a typewriter. By the fifth layer, the ultimate categories into which objects were being assigned seemed to exert a strong influence.
The effect was dramatic, insightful. But was it useful? Zeiler popped the hood of the AlexNet model that had won the ImageNet competition in 2012 and started digging around, inspecting it using deconvolution. He noticed a bunch of flaws. Some low-level parts of the network had normalized incorrectly, like an overexposed photograph. Other filters had gone “dead” and weren’t detecting anything. Zeiler hypothesized that they weren’t correctly sized for the types of patterns they were trying to match. As astoundingly successful as AlexNet had been, it was carrying some dead weight. It could be improved—and the visualization showed where.
In the fall of 2013, within a matter of frantic months, Zeiler finished his PhD, left NYU, started his own company—Clarifai—and entered that year’s ImageNet competition. He won.⁶⁶
Other groups, subsequently and in parallel, have explored further ways of directly visualizing a neural network. In 2015, Google engineers Alexander Mordvintsev, Christopher Olah, and Mike Tyka experimented with a method of starting from an image of random static, and then tweaking its pixels to maximize the probability that the network assigns it a particular label—say, “banana” or “fork.”⁶⁷ This deceptively simple method has proven to be remarkably powerful. It results in fascinating, memorable, often psychedelic, and occasionally grotesque images. Start optimizing static for “dog,” for instance, and you’re likely to get some unholy amalgam of dozens of eyes and ears, growing fractally, one on another, at a variety of different scales.
It’s fertile ground for artistic mischief and almost a novel visual aesthetic unto itself. The Google engineers had a further idea: rather than starting from static and manually specifying a category label, they would start from a real image—clouds, say, or leaves—and simply adjust the image to amplify whatever neurons in the network already happened to be most active. As they write, “This creates a feedback loop: if a cloud looks a little bit like a bird, the network will make it look more like a bird. This in turn will make the network recognize the bird even more strongly on the next pass and so forth, until a highly detailed bird appears, seemingly out of nowhere.” They dubbed this rather hallucinatory method “DeepDream.”⁶⁸
Other, more bizarre possibilities exist as well. When Yahoo’s vision team open-sourced a model used to detect whether an uploaded image was pornographic, UC Davis PhD student Gabriel Goh used this generative method to tune static into shapes the network regarded as maximally “not safe for work.” The result was like pornography by Salvador Dalí. If you optimize for some combination of the obscenity filter and normal ImageNet category labels—for instance, volcanoes—you get, in this case, obscene geography: what look like giant granite phalluses, ejaculating clouds of volcanic ash. Such images are, for better or worse, not easily forgotten.⁶⁹
On a more philosophical note, such techniques suggest that, at least as far as neural networks are concerned, the line between critic and artist can be a thin one. A network trained to recognize, say, lakes or cathedrals can be made, in this way, to endlessly churn out images of lake after lake after lake, or cathedral after cathedral after cathedral, that it has never seen before. It’s a beautiful, if painstaking, prescription for artistic practice: anyone who can tell good art from bad can be a creator. All you need is good taste, random variations, and plenty of time.
Techniques like these not only open up a vast space of aesthetic possibility but have important diagnostic uses as well. For example, Mordvintsev, Olah, and Tyka used their start-from-static technique to have an image classification system “generate” images that would maximally resemble all of its different categories. “In some cases,” they write, “this reveals that the neural net isn’t quite looking for the thing we thought it was.” For example, pictures that maximized the “dumbbell” categorization included surreal, flesh-colored, disembodied arms. “There are dumbbells in there alright,” they write, “but it seems no picture of a dumbbell is complete without a muscular weightlifter there to lift them. In this case, the network failed to completely distill the essence of a dumbbell. Maybe it’s never been shown a dumbbell without an arm holding it. Visualization can help us correct these kinds of training mishaps.”⁷⁰ This is also a useful technique for exploring issues of bias and representation. If starting from random static and fine-tuning hundreds of images to maximize the “face” category produces a set of faces that are, say, exclusively white and male, then that’s a pretty good indication that the network won’t recognize other types of faces as readily.
Since the initial DeepDream research, Tyka has gone on to cofound the Artists and Machine Intelligence program at Google, and continues to explore the aesthetic possibilities of machine learning. Meanwhile Olah and Mordvintsev, along with their collaborators, have continued to explore the scientific and diagnostic frontier of visualization.⁷¹ Today Olah leads the clarity team at OpenAI. “I’ve always been kind of fascinated by explaining things,” he tells me. “My goal, which I think some people think is kind of crazy, is just to completely reverse engineer neural networks.”⁷² This work has pushed the boundaries not only of science but of publishing; Olah found that traditional scientific journals just weren’t suited for the kinds of rich, interactive, full-color and high-resolution visualizations he was making. So he launched a new one.⁷³
Overall, the group expresses a measured but contagious optimism about the work underway. “We have a lot of work left ahead of us to build powerful and trustworthy interfaces for interpretability,” they write. “But, if we succeed, interpretability promises to be a powerful tool in enabling meaningful human oversight and in building fair, safe, and aligned AI systems.”⁷⁴
Much progress continues to be made in the visual domain especially—but what about understanding a network like this not at a visual level but a conceptual one? Might there be a way to make sense of the interior of the network through words, for instance? This is one of explanation’s latest frontiers.
DEEP NETWORKS AND HUMAN CONCEPTS
In the fall of 2012, MIT graduate student Been Kim had found herself, at the beginning of her PhD, homing in on the project that would shape the next years of her life. She had previously been working in robotics—including going so far as getting a forklift driver’s license in order to better understand the industrial robotics environment—but decided in the end that it wasn’t the right fit. “I realized that robotics had a hardware limitation,” she tells me. “My thoughts go faster than what physical stuff can do.”⁷⁵
Increasingly Kim believed that interpretability might well become her dissertation topic, if not her life’s work. Her first time at the NeurIPS conference, that December, she found herself talking with an older colleague. “I was telling a faculty member that I work on interpretability, and he was like, ‘Oh, why? Neural networks will solve everything! Why do you care?’ And I was like, ‘Well . . . !’ ” She chuckles at the recollection. “Imagine if you walk into a doctor’s office and he says, ‘Oh, I’m going to open you up and remove maybe a couple of things.’ And you ask, ‘Oh, why?’ He says, ‘Oh, I don’t know. This machine says that that’s the best option for you. 99.9%.’ ”
“What would you ask?” she says. Her question is both rhetorical and more than rhetorical. “What would you say to the doctor? It was so abundantly obvious to me that this is an area we need to solve. What I wasn’t sure is how soon the time will come that people realize this is important.” Late-afternoon sunlight filters through the glass of the conference room at Google Brain, where Kim has worked since 2017. “I think that time has come.”
Kim’s belief is that there is a dimension to explanation and interpretation that is inherently human—and so there is an inherent messiness, an inherent interdisciplinarity to the field. “A large portion of this—still underexplored—is thinking about the human side,” she says. “I always emphasize HCI [human-computer interaction], cognitive science. . . . Without that, we can’t solve this problem.” Recognizing the ineluctably human aspect of interpretability means that things don’t always translate neatly into the familiar language of computer science.
“Some folks think that you have to put down a mathematical definition of what explanation must be. I don’t think that’s a realizable direction,” she says. “Something that is not quantifiable makes computer scientists uncomfortable—inherently very uncomfortable.”
Almost all of Kim’s research papers contain something fairly unusual in computer science, but typical outside of it: namely, actual studies using human subjects. “Iterating with the users is critical,” she says. “Because if your sole reasoning for existence is for human consumption . . . we have to show that it is good for human consumption.” This iteration is critical because often what designers think is useful to actual human users simply isn’t. If you’re designing explanations or interpretable models to be used by real people, then the process should be every bit as iterative as designing, say, cockpit controls or a software user interface.⁷⁶ Not to let that kind of empirical feedback guide the process is simply hubris.
Such studies add some complexity to the story we explored earlier, which celebrated the use of simple models. Kim notes that it’s ultimately an empirical question whether this is the best approach to interpretability. “In some cases, in very limited cases where you can sufficiently identify and empirically validate that if I have a small number of features, that it’s interpretable for this particular task—in that case, yes, you can write down what it means to be most interpretable, given a problem, and you can optimize it.” But real human studies—Kim’s and others’—show that things are rarely so straightforward in practice.
For instance, in 2017, Microsoft Research’s Jenn Wortman Vaughan and her colleagues studied the way that human users interacted with a machine-learning model of home values, which predicted price from features like square footage, bathrooms, and so on. Users were better at anticipating the model’s predictions when it used fewer factors and was made more “transparent” to the user. But neither the simplicity nor the transparency actually affected the level of trust that people reported toward the model. And, in fact, people were less likely to realize that the model had made a mistake when the model was more transparent.⁷⁷
One of Kim’s beliefs is that “humans think and communicate using concepts,” not numbers.⁷⁸ We communicate—and, for the most part, think—verbally, leveraging high-level concepts; we don’t talk about the raw minutiae of sensory experience. For this reason, Kim thinks that many saliency-based methods don’t go far enough. She and her collaborators have been working on something they call “testing with concept activation vectors,” or TCAV, which offers a way to use such human concepts to understand the internal workings of the network.
For instance, imagine a model correctly identifying a picture of a zebra. Suppose TCAV shows that the network used “stripes,” “horse,” and “savanna” in its prediction: that seems reasonable. On the other hand, a network trained somewhat naïvely on a set of images of doctors might—if the dataset were biased—assume that the concept of “male” had some predictive value. TCAV would show this, and would offer an indication that we may want to adjust the model or the training data accordingly to remove such a bias.⁷⁹
How exactly might we get this kind of insight? Every image generates from our model not only an ultimate category label output, but a vast pattern of internal activity in the network, across however many tens of millions of its artificial neurons. These internal activations may seem like an overwhelming cacophony to human eyes, but that doesn’t mean that you can’t show them to a machine. The basic idea behind TCAV is that for any concept you’re interested in—say, “males,” in the doctor case—you present the network with a bunch of images of males, and then a bunch of images of random other things: women, animals, plants, cars, furniture, and so on. You feed the internal state of your network (say, at a particular layer) to a second system, a simple linear model that learns to tell the difference between the activations typical of your category (“males” in this case) and the activations from random images.⁸⁰ You can then look to see whether this activation pattern is present, and to what degree it contributes, when the network categorizes an image as a “doctor.”
“I think this method offers a unique benefit,” she says, “which is that explanation now speaks your users’ language. Your users don’t have to come and learn machine learning. . . . We can provide an explanation in the language that they speak, and answer the hypothesis that they have, using their own terms.”⁸¹
When Kim used TCAV to look at two popular image recognition models, Inception v3 and GoogLeNet, she found a number of such issues. The concept of “red,” for instance, was critically important to the concept of “fire truck.” “So that makes sense,” she says, “if you’re from an area where fire engines are red.”⁸² It’s almost always true in the United States, for instance, but not in Australia, where, depending on the district, fire trucks can sometimes be white—or, in Canberra, neon yellow. This would suggest, say, that a self-driving-car model developed on a US-centric dataset might need modification before it was safe to deploy down under.
Kim also found that the concept of “arms” was important to identifying “dumbbells,” corroborating the earlier visual findings of the DeepDream group from Google, and hinting that the network might struggle to identify a dumbbell on a rack or on the ground.⁸³ The concept “East Asian” was important to “ping-pong ball,” and the concept “Caucasian” was important to “rugby.” Some of these may reflect patterns that, while not inaccurate—according to the International Table Tennis Foundation, seven of the top ten male players, and all ten of the top ten female players in the world are from East Asian countries⁸⁴—may nonetheless still signal aspects of the model that deserve scrutiny, from the perspective of both accuracy and bias. We wouldn’t be happy, on either front, with a system that—as Facebook AI Research’s Pierre Stock and Moustapha Cisse discovered—categorized a portrait of Chinese president Xi Jinping as a “ping-pong ball.”⁸⁵ TCAV offers a way to explicitly quantify such issues—and ideally to nip them in the bud.
Kim’s work on TCAV was featured by Google CEO Sundar Pichai during his keynote address at Google’s 2019 I/O conference. “It’s not enough to know if a model works,” said Pichai. “We need to know how it works.”
In 2012, it had felt to Kim like there was hardly an audience for these concerns, and that only she, along with Cynthia Rudin and Julie Shah, her mentors at MIT, were even “vaguely interested in this topic.” By 2017, there were entire symposia at the field’s largest conferences devoted to interpretability and explanation. By 2019, the CEO of Google was proudly describing her work on the company’s biggest stage.
I ask Kim if that feels like vindication.
“We have such a long way to go,” she says—seemingly unwilling to allow herself a moment’s satisfaction, or a feeling of I-told-you-so. Instead, she feels mostly responsibility: to make sure that these issues are addressed faster than the already rapid progress and deployment of the technology itself. She has to somehow get out ahead of that wave, in order to make sure there aren’t any high-stakes problems.
As we wrap up our conversation and start to walk out of the conference room, I thank Kim for her time and ask her if there’s anything else she wants to add that we haven’t already touched on. She pauses thoughtfully for about ten seconds, then suddenly lights up.
“By the way, this faculty that I was talking about?” The one who, in 2012, scoffed at her when she, as a first-year PhD student, mentioned that her PhD work was on interpretability, and tried to steer her away from what he saw as a dead end. She bears no grudge, though: “I think genuinely, he was giving me advice. . . . It’s a really reasonable, sweet thing.”
Kim grins. “That person is now working on interpretability.”
PART II
Agency
4 REINFORCEMENT
The role of reinforcement in human affairs has received steadily increasing attention—not through any changing fashion in learning theory but as the result of the discovery of facts and practices which have increased our power to predict and control behavior and in doing so have left no doubt of their reality and importance. The scope of reinforcement is still not fully grasped, even by those who have done most to demonstrate it, and elsewhere among psychologists cultural inertia is evident. This is understandable because the change has been little short of revolutionary: scarcely anything in traditional learning theory is left in recognizable form.
—B. F. SKINNER¹
The trouble with modern theories of behaviorism is not that they are wrong but that they could become true.
—HANNAH ARENDT²
Gertrude Stein, in the spring of 1896, enrolled in a psychology seminar at Harvard with the great William James. There she would study “motor automatism,” or the ability to write words on paper without thinking deliberately about them. The peer-reviewed article that resulted would be her very first appearance in print; more significantly, what began as undergraduate psychology research would lead her directly to the trademark modernist “stream of consciousness” prose style for which she would be famous.³ Stein described her classmates in James’s seminar as a “funny bunch,” and one in particular was a bit of a character: he was preoccupied with incubating chickens.⁴
The student was Edward Thorndike, and, to be fair, turning his apartment into a makeshift chicken coop wasn’t his first idea. He wanted to study the mechanisms of learning in human children—and to debunk the idea of extrasensory perception while he was at it. Harvard didn’t approve the project. So the incubator full of chirping chicks just sort of . . . happened as a fallback plan.⁵
For an aspiring psychologist to be tending to a flock of chicks was indeed strange at the time. Animal research had yet to come into its twentieth-century vogue, and Thorndike’s own classmates thought he was a bit odd. It may have raised the eyebrows of his peers, and the hackles of his landlady, but tending his flock was—despite being a logistical nightmare—not without its perks. When traveling in Massachusetts, for instance, Thorndike was often forced to stop at the house of some family friends—the Moultons—to warm the chicks on their stove before continuing on to Cambridge. This may have been a research necessity, though it becomes clear from his letters that Thorndike was motivated in no small part by the chance to flirt with their younger daughter, Bess. She later became his wife.
Thorndike’s landlady in Cambridge finally declared his incubator a fire hazard, and gave him an ultimatum: the chicks had to go. James attempted to secure him a laboratory space on the Harvard campus, but the university wasn’t any more enthusiastic. As a last resort, James—over the protestations of his wife—let Thorndike move the chicks, incubator and all, into the basement of his own home. (James’s children, at least, appear to have been delighted.)
In 1897, Thorndike graduates from Harvard and moves to New York City for a fellowship at Columbia, this time working with all manner of animals. The year is frequently bleak. Two of his cats run away, he can’t get any dogs, and “my monkey is so wild I can’t touch him.” To make matters worse, not all of the animals in Thorndike’s urban menagerie are there for science; a number are simply pests. In a letter to Bess on February 14, 1898, he writes, “A mouse just ran across my foot. A lot of rats are gnawing the bureau; three chicks are sleeping within a yard of me; the floor of my room is all over tobacco and cigarette ends and newspapers and books and coal and a chicken pen and the cats’ milk dish and old shoes, and a kerosene can and a broom which seems rather out of place. It’s a desolate hole, this flat of mine.” Still, he promises he’ll clean it, and—he’s writing on Valentine’s Day, after all—he invites her to pay him a visit.
Out of that squalor will come some of the most original and consequential research of the nineteenth century. Thorndike has built a set of contraptions he calls “puzzle boxes,” full of latches and levers and buttons. He’ll drop an animal inside the box, place some food outside, and observe the way that the animals—chicks, cats, and dogs—manage to find their way out. “You’d like to see the kittens open thumb latches, and buttons on doors, and pull strings, and beg for food like dogs and other such stunts,” Thorndike writes to Bess, “me in the meantime eating apples and smoking cigarettes.”
Thorndike is interested in learning, and a theory is taking shape in his mind. What Thorndike observes—while eating those apples and smoking those cigarettes—is that the animals, who have no idea how the box actually works, initially behave almost purely randomly: biting things, nudging things. Once one of these random actions gets them out of the box, they very quickly learn to repeat that action, and become more and more capable of quickly escaping that same box in the future. “The one impulse, out of many accidental ones, which leads to pleasure,” he observes, “becomes strengthened and stamped in thereby.”⁶
Thorndike sees here the makings of a bigger, more general law of nature. As he puts it, the results of our actions are either “satisfying” or “annoying.” When the result of an action is “satisfying,” we tend to do it more. When on the other hand the outcome is “annoying,” we’ll do it less. The more clear the connection between action and outcome, the stronger the resulting change. Thorndike calls this idea, perhaps the most famous and durable of his career, “the law of effect.”
As he puts it:
The Law of Effect is: When a modifiable connection between a situation and a response is made and is accompanied or followed by a satisfying state of affairs, that connection’s strength is increased: When made and accompanied or followed by an annoying state of affairs its strength is decreased. The strengthening effect of satisfyingness (or the weakening effect of annoyingness) upon a bond varies with the closeness of the connection between it and the bond.⁷
From this seemingly modest and intuitive idea will be built much of twentieth-century psychology.⁸ In 1927, Ivan Pavlov’s Conditioned Reflexes appears in English, translated by his student Gleb von Anrep, who uses the term “reinforcement” to refer to this effect. By 1933, Thorndike himself is using the term “reinforcement”—as is a young Harvard postdoc by the name of Burrhus Frederic (B. F.) Skinner (whom we will meet more properly in Chapter 5).⁹ The language of “reinforcement”—along with the idea of using animals to understand the mechanisms of trial-and-error learning and, thereby, the human mind—sets the frame in which much of psychology will operate for decades to come.
As one of the leading psychologists in the next generation, Edward Tolman, will write: “The psychology of animal learning—not to mention that of child learning—has been and still is primarily a matter of agreeing or disagreeing with Thorndike.”¹⁰
If Thorndike ultimately accepted his place in the canon of psychology, he was uncommonly modest about it. When Thorndike’s textbook The Elements of Psychology came out in 1905, it threatened to unseat the previous mainstream textbook, Psychology: Briefer Course, written by none other than his own Harvard mentor, William James. Thorndike mailed him a check for a hundred dollars to offset the lost royalties. James replied, “Seriously, Thorndike, you’re a freak of nature. When the first law of nature is to kill all one’s rivals, (especially in the school-book line) you feed them with the proceeds!” James refused to cash the check, and sent it back.¹¹ The torch had, in a manner, been passed—and twentieth-century psychology was on its way.
DIGITAL TRIAL AND ERROR
What sort of force acting through what sort of process or mechanism can be and do what the confirming reaction is and does? The answer which seems to me to fit all or nearly all the facts is . . . the force and mechanism of reinforcement, applied to a connection.
—EDWARD THORNDIKE¹²
If the animal researchers following Thorndike were, like he was, ultimately interested in the psychology of the human child, they were not alone; computer scientists—the very first ones—were too. Alan Turing’s most famous paper, “Computing Machinery and Intelligence,” in 1950, explicitly framed the project of artificial intelligence in these terms. “Instead of trying to produce a programme to simulate the adult mind,” he wrote, “why not rather try to produce one which simulates the child’s? If this were then subjected to an appropriate course of education one would obtain the adult brain.” Turing imagined these ersatz child minds as what he called “unorganized machines,” beginning in a random configuration that would then be modified by the quality of the outcomes of their (initially random) actions.
A road map to artificial intelligence, then, was already taking shape. The “unorganized machines” would borrow directly from what was known about the nervous system, and the “course of education” would borrow directly from what the behaviorists were discovering about how animals (and children) learned. Warren McCulloch and Walter Pitts had by the early 40s shown that a large assembly of artificial “neurons,” suitably wired, was capable of computing just about anything. Turing had begun to sketch out ways that such a network might be trained through trial and error. Indeed, this was precisely the process of “stamping in” that Thorndike had described fifty years before, in his smoky apartment zoo; Turing’s description resembles, nearly verbatim, Thorndike’s law of effect:
When a configuration is reached for which the action is undetermined, a random choice for the missing data is made and the appropriate entry is made in the description, tentatively, and is applied. When a pain stimulus occurs all tentative entries are cancelled, and when a pleasure stimulus occurs they are all made permanent.¹³
By the end of the 1950s, IBM’s Arthur Samuel, working out of the company’s Poughkeepsie laboratory, had built a program to play checkers that, in a crude and early way, adjusted its own parameters on the basis of won and lost games. It wasn’t long before Samuel was losing matches to his own creation. As the New Yorker reported in 1959, “Dr. Samuel has thus become probably the first scientist in history to concede defeat by an adversary of his own devising.”¹⁴ He published a report called “Some Studies in Machine Learning Using the Game of Checkers,” embracing the term “machine learning” to describe this methodology. Samuel wrote:
The studies reported here have been concerned with the programming of a digital computer to behave in a way which, if done by human beings or animals, would be described as involving the process of learning. . . . We have at our command computers with adequate data-handling ability and with sufficient computational speed to make use of machine-learning techniques, but our knowledge of the basic principles of these techniques is still rudimentary. Lacking such knowledge, it is necessary to specify methods of problem solution in minute and exact detail, a time-consuming and costly procedure. Programming computers to learn from experience should eventually eliminate the need for much of this detailed programming effort.¹⁵
In plainer English, he explained, “It’s one of the most satisfying things that have ever happened to me. . . . As far as I know, nobody else has ever got a digital computer to improve of its own accord. You see, the kind of mental activity that computers can simulate has always been severely limited, because we’ve had to tell them exactly what to do and exactly how to do it.”
Continuing to develop machines that could learn, in other words—by human instruction or their own experience—would alleviate the need for programming. Moreover it would enable computers to do things we didn’t know how to program them to do.
The unveiling of Samuel’s research became the stuff of computer science legend. Fellow AI pioneer John McCarthy recounts that when Samuel was getting ready to demonstrate his checkers program on national television, “Thomas J. Watson Sr., the founder and President of IBM, remarked that the demonstration would raise the price of IBM stock 15 points. It did.”¹⁶
THE HEDONISTIC NEURON
The struggle of the nerve cells, each for its own life, parallels the struggle of our wants for satisfaction.
—EDWARD THORNDIKE¹⁷
In 1972, Harry Klopf—a researcher working for the United States Air Force out of Wright-Patterson Air Force Base in Dayton, Ohio—published a provocative report titled “Brain Function and Adaptive Systems: A Heterostatic Theory.” Klopf argued that “the neuron is a hedonist”: one that works to maximize some approximate, local notion of “pleasure” and minimize some notion of “pain.” The whole complexity of human and animal behavior, Klopf believed, arises as a result of these individual cellular “hedonists” wired up into systems of increasing complexity.
The generation before Klopf, the so-called cybernetics movement of the ’40s through the ’60s, had framed intelligent behavior specifically in terms of what they called “negative feedback.” Organisms were motivated, they argued, largely by homeostasis or equilibrium. They strove to maintain a comfortable temperature. They ate to quell their hunger. They mated to quell their desire. They slept to quell their fatigue. Everything seemed to be about getting back to baseline.
Indeed, the seminal 1943 cybernetics paper “Behavior, Purpose and Teleology”—which, incidentally, coined the term “feedback” in its now common sense of “information used for adjustment”—set out to distinguish purposeful from purposeless (or random) behavior.¹⁸ For the cyberneticists, purpose was tantamount to a goal that could be arrived at as a place of rest. For arch-cyberneticist Norbert Wiener, one of the canonical “intrinsically purposeful” machines is a thermostat: when the temperature is too low, it turns on the heat, and when the temperature gets high enough, it shuts it off. He thought also of the “governor” of an engine—more than coincidentally, the term is an etymological kin to the word “cybernetics” itself, coming from the same Greek root kybernetes.¹⁹ (Thus “cybernetics,” for all its exotic sci-fi flavor, could well have been the much blander and more bureaucratic-sounding field of “governetics.”) A mechanical “governor” opens valves when the engine is running too fast, and closes them when it’s running too slow, helping it to maintain equilibrium. “Notice that the feedback tends to oppose what the system is already doing, and is thus negative,” Wiener writes.²⁰ This was an essential part of any goal-oriented system, in the cybernetic view. “All purposeful behavior,” the cyberneticists wrote, “may be considered to require negative feed-back.”²¹
Klopf was having none of it. For him, organisms were maximizers, not minimizers. Life was about growth, reproduction, endless and boundless and insatiable forward progress in any number of senses. For Klopf, the goal was not homeostasis at all, but the opposite. “Living adaptive systems seek, as their primary goal, a maximal condition (heterostasis), rather than . . . a steady-state condition (homeostasis).” More poetically, he espoused the virtues of positive, rather than negative feedback: “Both positive and negative feedback are essential to life’s processes. However, it is positive feedback that is the dominant force—it provides the ‘spark of life.’” This notion ran all the way through from single cells to organisms to societies. Klopf was not modest about what he saw as the implications of this idea. “It appears to be the first theory capable of providing a single unifying framework within which the neurophysiological, psychological, and sociological properties of living adaptive systems can be understood,” he wrote. “Neurons, nervous systems, and nations are heterostats.”²²
Neurons were insatiable maximizers? And this explained the behavior of nations? It was an ambitious, unorthodox, and quite possibly absurd idea. The air force offered him funding to find or assemble a lab of researchers to look into it. He found his team at UMass Amherst. There he hired a postdoctoral researcher named Andrew Barto to determine—as Barto puts it—“the scientific significance of this idea: was it a crazy, crackpot idea, or did it have some scientific merit?”²³
Klopf had, perhaps unusually, been keeping a running correspondence during this time with a bright undergraduate psychology major from Stanford. When Barto came onboard, Klopf encouraged him: “There’s this really bright kid, you should get him into this project.”²⁴ The bright kid was named Richard Sutton; still a teenager, he would join Barto in Amherst and become Barto’s very first graduate student.
I ask Barto if there was any foreshadowing of what was to come. “We had no idea,” he tells me. “We had no idea.” Sutton and Barto would, with Klopf’s Air Force grant, begin a forty-five-year collaboration that would essentially found a new field. The field, which would cross neuroscience, behaviorist psychology, engineering, and mathematics, was dubbed “reinforcement learning”; and their names, forever linked in bibliographies of AI—“Barto & Sutton,” “Sutton & Barto”—would become synonymous with the definitive textbook of the field they coauthored and, indeed, almost a shorthand for the field of reinforcement learning itself.²⁵
I meet up with Barto on the University of Massachusetts campus, where he’s now emeritus. “Happily retired,” he says. “Frankly, glad to be out of the maelstrom of hype and excitement about AI and reinforcement.”
I tell him I’m excited to talk about the history of reinforcement learning as a field—“RL” as it is often called—and in particular its implications for safety, for decision making, for human cognition— He interrupts me.
“So, how much time have you got?”
Most of the day, I tell him. That’s what we take.
THE REWARD HYPOTHESIS
Barto and Sutton took Harry Klopf’s idea of organisms as maximizers and gave it a concrete, mathematical form. Imagine you are in an environment that contains rewards of some numerical value, which are available to you if you take certain actions and reach certain states. Your job is to get the most reward—the highest “score”—that you can.
The environment could be a maze, your actions could be moving north, south, east, or west, and your reward could come from reaching the exit (perhaps minus a small time penalty). Or the environment could be a chessboard, your actions the moving of the pieces, and your reward one point for checkmating your opponent (and half a point for reaching a draw). Or perhaps the environment is the stock market, your actions are buying and selling, and your reward is measured in the dollar value of your portfolio. There is virtually no limit to the complexity of these scenarios—the environment could be a national economy, the actions could be issuing words of legislation or diplomacy, and the reward could be long-term GDP growth—as long as the rewards are what is known as scalar: they are commensurate, fungible, of a common currency.
The reinforcement-learning framework has proven to be so general, in fact, that it has led to an idea known as the “reward hypothesis”: “That all of what we mean by goals and purposes can be well thought of as the maximization of the cumulative sum of a received scalar reward.”²⁶
“This is almost a philosophical thing,” says Richard Sutton. “But you kind of buy into this.”²⁷
Of course, not everyone buys into this premise so readily. In sports, in board games and video games, in finance, there may indeed be such a scalar number, a single currency (literal or figurative) for measuring all outcomes—but can that really be applied to something as complex and multiform as human, or even animal, life? We often have to make decisions whose outcomes seem like apples and oranges. Do we work late, improving our standing with our boss but testing the patience of our spouse? Do we prioritize a life of achievement, a life of adventure, a life of human connection, or a life of spiritual growth? Oxford University philosopher Ruth Chang, for instance, has spent decades arguing that nothing so characterizes the human condition as the incommensurability of the various motives and goals we have. We can’t simply put major life choices on a scale and weigh out which one comes out best—or else there would be nothing to morality but pure reason, no opportunity to make meaning, to forge an identity.²⁸
Sutton himself concedes that the reward hypothesis is “probably ultimately wrong, but so simple we have to disprove it before considering anything more complicated.”
Even if we accept—provisionally—the framework of reward maximization, and the commensurability of scalar rewards, we find that being a heterostatic maximizer is harder than it sounds. Indeed, the problem of reinforcement learning is fraught with difficulty both philosophical and mathematical.
The first challenge is that our decisions are connected. Here reinforcement learning is subtly—but importantly—different from both unsupervised learning (which builds the vector word representations we explored in Chapter 1) and supervised learning (which is used for everything from the ImageNet contest to face recognition to recidivism risk assessment). In those settings, every decision stands alone. Your system is shown a picture—say, a chanterelle mushroom—and asked to categorize it. The system may get the answer right, it may get it wrong, its parameters may be fine-tuned a little bit in the event of a mistake, but in any case you simply pull another photo at random from your collection and move on. The data coming in as input are what statisticians call “i.i.d.”: independent and identically distributed. There is no causal connection between what we see, what we do, and what we see next.
In reinforcement learning—in a maze, in a chess game, indeed in life—we don’t have the luxury of making our decisions in a vacuum. Every decision we make sets the context in which our next decision will be made—and, in fact, it may change that context permanently. If we develop our chess pieces a certain way, we are strongly constraining the types of positions we will encounter and the types of strategies that may be useful going forward. In a spatial world, whether virtual or real, it is intrinsic to locomotion that the actions we take—move north in the maze, turn to face our lover, spend the winter in Florida—sculpt the future input we receive, either temporarily or forever. If we sacrifice our queen, it is unavailable to us for the rest of the game. If we jump off the roof, we may never jump again. If we are unkind to someone, we may forever alter how that person behaves toward us, and we may never know how they might have behaved had we been kinder.
The second challenge of reinforcement learning, relative to supervised and unsupervised learning, is that the rewards or punishments we get from the environment—owing to their very scalar quality—are terse. A language model trained to predict a missing word is told, after each guess, what the correct word was. An image classifier attempting to classify an image is immediately given the “correct” label for that image. It then updates itself explicitly in the direction of that correct answer. In contrast, a reinforcement-learning system, trying its best to maximize some quantity in some environment, eventually comes to learn what score it achieved, but it may never know, win or lose, what the “correct” or “best” actions should have been. When a rocket blows up, or a bridge collapses, or a pile of plates you’re trying to carry topples, or the ball you kick fails to go into the net, the world is crystal clear about the result. But it’s mum on exactly what you should have done differently.
As Andrew Barto puts it, reinforcement learning is less like learning with a teacher than learning with a critic.²⁹ The critic may be every bit as wise, but is far less helpful. The teacher would look over your shoulder as you work, correcting your mistakes instantly, and telling you or showing you exactly what you should be doing instead. The critic waits until your labor is done, then shouts “Boo!” from the back of a dark auditorium, leaving you clueless as to what exactly they didn’t like, or what they’d have preferred. The critic may not even be withholding anything by way of insight or constructive feedback; they may not themselves be left with anything other than their degree of—in Thorndike’s terms—“satisfaction or annoyance.”
Third, not only is feedback terse and not especially constructive, it’s delayed. We may make an unrecoverable blunder on the fifth move of a game, for instance, in which the coup de grâce comes a hundred moves later. The idiom that comes most to mind when someone experiences a failure or defeat—the disappointed parent, bankrupt business owner, apprehended thief—is “Where did I go wrong?” In reinforcement learning, this is known as the “credit-assignment problem,” and had been vexing researchers since the midcentury. MIT’s Marvin Minsky, for instance, wrote in his famous 1961 paper “Steps Toward Artificial Intelligence,” “In playing a complex game such as chess or checkers, or in writing a computer program, one has a definite success criterion—the game is won or lost. But in the course of play, each ultimate success (or failure) is associated with a vast number of internal decisions. If the run is successful, how can we assign credit for the success among the multitude of decisions?”
Minsky elaborates, driving home the point: “Suppose that one million decisions are involved in a complex task (such as winning a chess game). Could we assign to each decision . . . one-millionth of the credit for the completed task?”³⁰
After a car accident, several days into a cross-country road trip, we don’t retrace our actions all the way back to turning the key in the ignition, and think, “Well, that’s the last time I ever turn left out of the driveway!” Nor, though, do we imagine, having been checkmated on move 89 of a game of chess, our blunder must have happened on move 88.
So how do we determine the right lessons to take away from success and failure both? The reinforcement-learning framework began opening up a vista on the fundamental problem of learning and behavior that would develop into an entire field, and would direct the course of artificial intelligence research through our present decade. It would also, just as Harry Klopf envisioned, give us a new set of questions to ask of the natural intelligence that surrounds us.
THE RIDDLE OF DOPAMINE
If humans and other animals can be thought of as “heterostatic” reward maximizers, it stands to reason that those rewards operate by way of some mechanism in the brain. If there really is some kind of singular, scalar “reward” that humans and animals are designed to maximize, might it be as simple as a chemical or a circuit in the brain? In the 1950s, a pair of researchers at McGill University in Montreal, James Olds and Peter Milner, appeared—tantalizingly—to have found its location.
Olds and Milner were experimenting with placing electrodes in various places in the brains of rats, and giving the rats an opportunity to press a lever that would deliver electrical current through those electrodes to that particular part of the brain. Some areas of the brain, they discovered, seemed to have no effect on the rats’ behavior. In other areas, the rats would appear to go out of their way to make sure the lever did not get pressed. But there were some areas—the so-called “septal area” in particular—where rats appeared to want almost nothing more than to press the lever that delivered current to that area. The rats pressed the lever as many as 5,000 times an hour, and for as long as 24 hours without rest.³¹ “The control exercised over the animal’s behavior by means of this reward is extreme,” Olds and Milner wrote, “possibly exceeding that exercised by any other reward previously used in animal experimentation.”³² The foundation had been laid for a study, not only of human and animal behavior through the lens of reward maximization, but of the actual molecular mechanisms of reward itself.
At first these areas were dubbed “reinforcing structures,” but soon Olds began referring to them as “pleasure centers.”³³ Subsequent research showed that not just rats but humans, too, would go out of their way to receive electrical current in similar parts of their brain.
In time, studies began to establish that the areas of the brain in which this electrical stimulation was most compelling were those areas involving neurons that produced a neurotransmitter called 3,4-dihydroxyphenethylamine—better known by its abbreviated nickname: dopamine.³⁴ These cells were rare—much less than 1% of 1% of the brain—and they clustered in very specific areas.³⁵ A single one of these dopamine cells could be wired in some cases to millions of other neurons, across a wide area of the brain.³⁶ In fact, they were almost uniquely broadly connected, with the most highly connected cells each having nearly fifteen feet of axonal wiring within the brain.³⁷ At the same time, however, they were fairly limited in the range and complexity of their output. As NYU neuroscientist Paul Glimcher puts it, this means that “they cannot say much to the rest of the brain, but what they say must be widely heard.”³⁸
It sounded a lot, in other words, like a “reward scalar”—in essence, like points on the brain’s scoreboard—dead simple, but widely broadcast and all-important. Dopamine also appeared to be intimately involved in drugs of addiction, including cocaine, heroin, and alcohol. Could it be that dopamine was literally the molecular currency of reward in the brain?
Work in the late 1970s appeared to suggest as much. A study in 1978, for instance, showed that when rats were given the dopamine-blocking drug pimozide before being taught that pressing a lever would give them food pellets, they showed no more interest in pressing the lever than rats who had never learned the food connection at all. Somehow the food reward just didn’t seem to have an effect on the rats treated with pimozide. Pimozide, wrote the researchers, “appears to selectively blunt the rewarding impact of food and other hedonic stimuli.”³⁹ As neuroscientist Roy Wise wrote in 1982, it was as if “all of life’s pleasures—the pleasures of primary reinforcement and the pleasures of their associated stimuli—lose the ability to arouse the animal.”⁴⁰ In fact, when given drugs known to block dopamine receptors, the rats stopped delivering electrical current to their brains as well. The drug, in the words of neuroscientist George Fouriezos, took “the jolts out of the volts.”⁴¹ It was as if everything, from food and water to sex to self-administered current, had lost its pleasurable effect.
Over the 1980s, electrophysiology began advancing to the point that individual dopamine neurons could be monitored in real time. The German neurophysiologist Wolfram Schultz, at a lab in Fribourg, Switzerland, began studying the behavior of dopamine neurons in monkeys as they reached into a box that was sometimes empty and other times contained tiny pieces of fruit or baked goods. Sure enough—wham—a “burst of impulses occurred when the monkey’s hand touched a morsel of food inside the box.”⁴² This seemed to confirm that scientists had, in fact, found the chemical of reward.
But there was something strange.
In cases where there was a visual or auditory cue of some kind that indicated when food had appeared in the box, the cue triggered a rush of dopamine activity. Then the monkeys would reach in and grab their food, while Schultz dutifully monitored the readings—and nothing happened. Just the calm background static of their normal baseline of activity. No spike. The dopamine neurons, he wrote, “discharged a burst of impulses in response to [the cue] but entirely failed to respond to the touch of food.” ⁴³
What in the world was going on?
“We couldn’t figure out what it was,” says Schultz.⁴⁴ He rifled through several hypotheses. Maybe the monkeys were simply satiated, and didn’t really want any more food. He tried starving them. It didn’t work. They ate the food ravenously. But there was no dopamine spike.
Schultz and his collaborators spent the late ’80s and early ’90s trying to find a plausible story for what they were seeing.⁴⁵ Over the course of repetition, the dopamine spike had moved from the food to the cue—but what did it mean? If the food had somehow stopped being “rewarding,” then why were the monkeys always so quick to grab and eat it? That didn’t make sense, and so dopamine couldn’t be directly representing reward. They ruled out a connection to working memory. They ruled out a connection to motion, and a connection to touch.
“We could not pin it to something,” Schultz tells me. “You start to pin it to incentive, motivation, as a response to a stimulus that makes you move. . . . We thought that initially, but then we found the concept far too fuzzy.” His lab started to home in on the idea that it had something to do with surprise, or unpredictability. There was an idea from psychology called the Rescorla-Wagner model, which suggested that learning is critically dependent on surprise.⁴⁶ Perhaps dopamine had something to do with that link: perhaps it somehow represented either surprise itself or the learning process that surprise induced. That would explain why the food generated a dopamine spike when it was unexpected but not when it was cued—and why, in those cases, it was the unexpected cue that prompted the spike. “And that was okay,” says Schultz. “But that would not explain some of the data we had.” ⁴⁷
In particular, there was one further phenomenon Schultz observed, one that was even more mysterious than the first. He was doing a follow-up study, using a similar setup but this time with levers and juice instead of boxes and food. Once the monkey learned that the cue reliably preceded the juice, however, Schultz tried something new: he gave it a false alarm. He triggered the cue; as usual, the monkey’s dopamine activity spiked above the neurons’ normal baseline hum. The monkey pressed the lever. No juice came. The monkey’s dopamine neurons fell—briefly, but unmistakably—silent. “Then I said, Well. That is something different than surprise.” ⁴⁸
Dopamine was a riddle. It seemed so clearly, at first, to be the brain’s currency of reward. It was clearly measuring something. If not reward, if not attention, not novelty, not surprise—then what?
THE POLICY AND THE VALUE FUNCTION
It’s hard to be so smart that the next minute can’t fool you.
—LEO STEIN⁴⁹
Over that same period in the 1980s while Schultz was beginning his experiments on the dopamine system, on the other side of the Atlantic, Barto and Sutton were starting to make mathematical progress on the reinforcement-learning problem.
The first big step was to decompose the problem. Learning how to take actions within an environment to maximize reward, they realized, involved two related but potentially independent subproblems: action and estimation. As you began to understand and ultimately master a domain, you learned two important things: how to take the right action in a given situation, and how to estimate the likely future rewards that a state of affairs might hold. A chess player looking at the board, as Barto and Sutton came to realize, has two distinct hunches. She has a certain instinct for which moves suggest themselves to be played next (and what the opponent is likely to do in response). And she has another instinct for which player in this position is likely to win. These two dimensions of the reinforcement-learning problem have come to be known by the technical terms of the policy—what to do when—and the value function—what rewards or punishments to expect.
Either of these alone was, at least in theory, enough to solve the problem. If a chess player always knew the right move to play, then it didn’t matter if they were lousy at predicting who would win. The reverse, however, was also true: if a chess player, say, always knew exactly who stood better in a given position, then it didn’t matter if they weren’t sure what to do. Given enough time, they could simply weigh the consequences of each move, and choose the one that led to the most promising future.
Policy-based approaches led to a system—be it animal, human, or machine—with highly trained “muscle memory.” The right behavior just flowed effortlessly. Value-based approaches, by contrast, led to a system with a highly trained “spider-sense.” It could tell right away if a situation was threatening or promising. Either, alone, if fully developed, was enough.
In practice, however, policy-based approaches and value-based approaches went hand in hand. Barto and Sutton began to elaborate an idea known as the “actor-critic” architecture, where the “actor” half of the system would learn to take good actions, and the “critic” half would learn to predict future rewards.⁵⁰ In rough terms, the actor-critic architecture also neatly described their collaboration. Barto was first and foremost interested in behavior. Sutton was first and foremost interested in prediction.⁵¹
Going back all the way to his undergraduate thesis in 1978, Sutton had been preoccupied with creating, as he put it, “A Unified Theory of Expectation.”⁵² This fascination with how organisms form and refine their expectations followed him to Amherst in his work with Klopf and Barto.
As Sutton reasoned, developing good expectations—a good value function—meant reconciling your moment-to-moment expectations with the ultimate verdict that came from reality: the final score of the game, the end-of-quarter report, the successful moon landing, the late-career encomia from admiring colleagues, the standing ovation, the smiling grandchildren. But if you actually had to wait until the end of a game to learn from it, then the credit-assignment problem would indeed be virtually impossible. The logic, he says, is threefold.
First, it may be impractical or impossible to remember everything we were thinking and doing. At the end of a ninety-minute soccer game in which we lost soundly, do we really gather in the locker room and work backward through every single play? Every shift in our hopes and fears?
Second, we want to be able to learn even without a final verdict. A chess game interrupted before its conclusion should still offer us something. If we were about to be checkmated or the position felt hopeless, then that still meant we needed to do something different—regardless of whether the loss or the punishment we felt we had coming ever actually arrived. Likewise, a game decided by a freak, improbable, unforeseeable event in the final seconds doesn’t necessarily mean that our earlier expectations were necessarily wrong. Maybe we really were on track to victory. Judging entirely by the final outcome doesn’t necessarily make sense, especially in situations affected to some degree by chance.
Third, we ideally want to be learning not just after the fact but as we go along. This is of particular and critical importance for human lives. Many of the most crucial junctures and most important goals of life—getting into college, say, or raising children, or retiring comfortably—we typically only get one shot at. And many mistakes—a falling grade point average, an expanding waistline, a deteriorating relationship—are such that we can realize things are heading off course and adjust long before it’s too late. If it is trial and error by which we learn, it mercifully does not require the whole trial—nor the whole error—for us to do so.
Each of these factors, as Sutton explains, makes a theory of expectations more tricky. “So obviously we can try to ignore all these things, think of them as nuisances, but I think of them as clues,” he says. “These are hints from nature, about how we should proceed.”⁵³
It was Sutton himself, as it turned out, who would be first to take those hints.
The breakthrough that Sutton made in thinking about predictions is this. As you move forward toward an uncertain future, you maintain a kind of “running expectation” of how promising things seem. In a chess game, it might be the odds you give yourself to win the game. In a video game, it might be how much progress you expect to make or how many points you expect to rack up in total. These guesses fluctuate over time, and in general they get more accurate the closer you are to whatever it is you’re trying to predict. (The weekend weather forecast is almost always more accurate on Thursday than it was on Monday. Your ETA as you drive home from the airport will tend to be more accurate the closer you are to home.) This means that, in general, as our expectation fluctuates, we get differences between our successive expectations, each of which is a learning opportunity; Sutton called these temporal differences, or TD errors. When one of these temporal differences happens, the later of the two estimates is the one more likely to be correct.
And so maybe we don’t need to wait until we get the eventual ground truth in order to learn something. Maybe we can learn from these fluctuations themselves. Any time our expectation changes can be treated as an error in our previous estimate, and, hence, an opportunity to learn: not from the ultimate truth, which has yet to arrive, but from the new estimate, made by our very slightly older and wiser self. As Sutton puts it: “We are learning a guess from a guess.”⁵⁴
(He adds, as if parenthetically, “Sounds a bit dangerous, doesn’t it?”)
By the end of the 1980s, this idea—Sutton called it “the method of temporal differences,” or “TD learning,” for short—had sharpened into an algorithm, which he called “TD(λ)” (“TD-lambda”), for precisely tuning predictions in the light of subsequent predictions.⁵⁵ Inspired by Sutton and Barto’s ideas, Cambridge PhD student Chris Watkins had devised a TD algorithm called “Q-learning,” which would turn these predictions into actions.⁵⁶ Promisingly, he showed that Q-learning would always “converge,” namely, as long as the system had the opportunity to try every action, from every state, as many times as necessary, it would always, eventually develop the perfect value function: the perfect set of expectations for that environment, be it a maze, a chessboard, or something truer to life. It was a significant theoretical milestone for the field—of course, exactly how significant depended on whether you were the kind of person who emphasized the always or the eventually.
The theory looked good, but TD learning had yet to be truly tested in practice. That first real kicking of the tires would happen at IBM Research in New York. A young researcher named Gerald Tesauro—initially interested in computational models of classical conditioning—had been working, over the late ’80s and early ’90s, on using neural networks to play backgammon. The early results were promising. Then, in 1992, he plugged TD learning into his model, and it took off like a rocket.⁵⁷ It was learning guesses from guesses, steadily coming to learn what an advantageous position looked like. “This is apparently the first application of this algorithm to a complex non-trivial task,” Tesauro wrote. “It is found that, with zero knowledge built in, the network is able to learn from scratch to play the entire game at a fairly strong intermediate level of performance, which is clearly better than conventional commercial programs, and which in fact surpasses comparable networks trained on a massive human expert dataset. This indicates that TD learning may work better in practice than one would expect based on current theory.” By 1994, his program—dubbed “TD-Gammon”—had reached, as he wrote, “a truly staggering level of performance: the latest version of TD-Gammon is now . . . extremely close to the world’s best human players.”⁵⁸
The field had long known that it was possible for a programmer to write a system that played better than him- or herself; Arthur Samuel had discovered as much with checkers in the 1950s. But this was something new: a program as good as any human player. And it was entirely “self-taught”: initialized from a random state, and tuned over countless games against itself. It was an enormous validation for TD learning. And it would offer a direct blueprint for success that would be used—with surprisingly few changes—by twenty-first-century game-mastering software like AlphaZero.
Sutton and others in the burgeoning field of reinforcement learning had taken nature’s hints. But now it was their turn to offer something back. In one of the most stunning moments in the field’s history, the mathematical framework that had grown initially out of psychology and neuroscience was about to reenter those fields in a big way.
A NEURAL SUBSTRATE OF PREDICTION AND REWARD
In the early 1990s, as Tesauro was fine-tuning his backgammon system, a young cognitive scientist named Peter Dayan, who had spent fertile time in Barto’s lab and had worked with Watkins on his convergence proof, found himself moving from one side of the field—and the world—to the other. From studying the mathematics of temporal difference at the University of Edinburgh, he landed with a group of neuroscientists at the Salk Institute in San Diego.
Dayan and a fellow postdoc named Read Montague, working with Salk Institute neuroscientist Terry Sejnowski, had a hunch that not only did the framework of reinforcement learning explain how real human and animal brains might operate—but that it might literally be what brains were doing. “We went after the role of a set of systems in your brain that report on value and reinforcement,” says Montague. “And we, at the time, just sort of thought, ‘These things should be implementing a certain kind of algorithm.’ ”⁵⁹ Montague thought that these sorts of learning mechanisms might be one of the bedrock properties of almost every animal that learns. Dayan was coming from his work on temporal-difference learning, which seemed like it might be a candidate for one of these universal algorithms. It worked on the whiteboard—that is, it converged. It worked in machines—TD-Gammon was a stronger player than all but the very best human players alive. Perhaps it worked in brains, too. The two of them began speculating about how a neurological system for learning from temporal differences might work.
“Obviously we knew there must be a link to neuroscience,” Dayan explains to me over a conference table at Uber headquarters in San Francisco, where he’s spending his sabbatical year from University College London.
“And then,” he says, “we came across these data from Wolfram Schultz.”⁶⁰
Suddenly Dayan hops up and begins scrawling dopamine-response diagrams on the whiteboard excitedly. He points to the flat, background static, ho-hum response when the monkey gets the juice reward it fully expects after seeing the cure light. “So this part of the signal is very transparent. And that’s what you see in the Rescorla-Wagner rule; that’s the beautiful aspect of what comes from older psychology.”
Then he points to the initial dopamine spike caused by the cue light itself. “But it’s this part of the signal which is confusing,” he says. “Because that is not expected from the psychological perspective. So at various times you can see Wolfram sort of struggling with what that means.”
When Dayan and Montague looked at the data from Schultz—the data that Schultz, along with the entire neurophysiology community, found so inscrutable—they knew exactly what it meant.
It was a temporal difference. It was a sudden fluctuation in the monkey’s expectation—in its value function, its prediction of how good a state of affairs it was in.
A sudden spike above the brain’s dopamine background chatter meant that suddenly the world seemed more promising than it had a moment ago. A sudden hush, on the other hand, meant that suddenly things seemed less promising than imagined. The normal background static meant that things, however good or bad they were, were as good or bad as expected.
A spike in the dopamine system was not reward as such, but it was related to reward; it wasn’t uncertainty, or surprise, or attention per se—but it was intimately, and for the first time legibly, related to all of them. It was a fluctuation in the monkey’s expectation, indicating that an earlier prediction had been in error; it was its brain learning a guess from a guess.
The algorithm that worked so well on paper, and so well in silicon, had just been found in the brain. Temporal-difference learning didn’t just resemble the function of dopamine. It was the function of dopamine.
Schultz, Dayan, and Montague published an explosive paper together in Science in 1997, announcing their discovery to the world. They had found, as they put it, “A Neural Substrate of Prediction and Reward.”⁶¹
The effect, across neuroscience and computer science alike, was huge. An idea developed in a pure machine-learning context, inspired by models of classical and operant conditioning from psychology, had suddenly come full circle. It wasn’t just a model of how artificial intelligence might be structured. It appeared to offer a description of one of the universal principles for intelligence, period.
“It’s thought that eyes evolved anywhere from sort of forty to fifty separate times. . . . Biology has discovered eyes over and over again—all kinds of different eyes,” Montague explains.⁶² “I think it’s the same thing in the learning domain. Learning algorithms are so profoundly important to understand how to take experience now, reorganize your internal structure, and produce actions in the future, that . . . you should expect that these algorithms have been stumbled into by biology in many different contexts. And so you see reinforcement learning systems, reward systems, in bees, and sea slugs, and birds learning songs, and human beings, and rodents, etc.”⁶³
Dayan sees it the same way. “It’s no surprise that we come endowed with these sorts of things,” he says. “The idea that you would see it quite so transparently in the activity of these dopamine neurons. . . . That was quite a revelation.”⁶⁴
Visiting Wolfram Schultz’s lab in Cambridge—at age 75, he is still as animated and energized by his work as ever—I ask him if this felt like a revelation at the time. Surprisingly, he says no: the revelation, in his view, is that the humble TD-learning model, which described the activity in the brains of his monkeys as they fumbled for food, is, twenty years later, enabling the current contemporary breakthroughs of AI. That we’ve been able to take these universal ideas from nature and implement them synthetically is what blows his mind.
“The revelation came,” he says, “when I realized that the TD model goes into what we now see, the Go programming, and this artificial intelligence, machine-learning thing. That was a revelation, where I said, My God, what have I done? You know, understanding my data came from the Rescorla-Wagner model, from a prediction error, but the consequence, like, Jesus Christ! I mean, we knew Tesauro was programming backgammon with a TD model. Okay, I’m not a backgammon player, but I’m a Go player. Not a very good one, but . . . I said, dammit, if they can program Go, which has been a problem before, it’s a really good model. And I saw that before they programmed Go.”
I tell him I think it’s remarkable to see such a clear and powerful synthesis of work across neurophysiology and machine learning, with such powerful implications for both fields.
“Absolutely,” he says. “Absolutely. That’s the charm of it. You get everything together. Just makes sense.”⁶⁵
The effect on neuroscience has been transformative.⁶⁶ As Princeton’s Yael Niv puts it, “The potential advantages of understanding learning and action selection at the level of dopamine-dependent function of the basal ganglia can not be exaggerated: dopamine is implicated in a huge variety of disorders ranging from Parkinson’s disease, through schizophrenia, major depression, attentional deficit hyperactive disorder etc., and ending in decision-making aberrations such as substance abuse and addiction.”⁶⁷
It’s true that there is much to be worked out, and what now seems like the canonical story may be overturned or complicated in time.⁶⁸ But it is clear, says Niv, that “reinforcement learning has already left its permanent mark on the study of decision making in the brain.”⁶⁹
She recounts her first time attending the annual Society for Neuroscience meeting, a gathering of some 30,000 researchers across the field. “I remember looking up reinforcement learning the first time I went, which was probably 2003, 2004. There were maybe five posters in the whole meeting. It’s a whole week of meetings; every day has two poster sessions, so one in the morning, one in the afternoon. Now,” she says, “every poster session has a whole subsection, a whole row, about this. It’s really come a long way in ten, fifteen years.”⁷⁰
She adds, “There were lots of studies kind of testing predictions of the theory in the brain and seeing, ‘It seems like, gosh, these neurons read the textbook. They read the Sutton and Barto textbook. They know exactly what they need to do.’ ”
HAPPINESS AND ERROR
If the TD-learning model has revealed the function of dopamine in the brain—not as the brain’s currency of reward, not its expectation of future rewards, but its error in its expectation of future rewards—then it leaves some questions open.
In particular, it leaves open the connection to the subjective experience of pleasure and happiness. If elevated levels of dopamine signal something to the effect of things are going to be better than I thought they were going to be, then that feeling is, itself, pleasurable. And you can see how humans and animals alike would go out of their way to get that feeling, including by way of direct chemical and electrical stimulation of dopamine neurons.
You can also begin to see how artificially elevating dopamine levels produces an inevitable crash. Thinking that things will be better than you thought they would be only works for so long. Eventually you realize they’re not better than you thought they would be, and the dopamine chatter hushes—as it did in Wolfram Schultz’s experiments with monkeys, when the juice-cue light blinked but no juice was present. It’s possible, in effect, for dopamine to write checks that the environment can’t cash. Those checks eventually, inevitably bounce. Then your value function must, inevitably, come back down to earth.
This, of course, is the classic experience of dopamine-related drugs—cocaine being a prototypical example. The drug works in large part by inhibiting the brain’s reuptake of dopamine, leading to a temporary “flood” of it. The TD story suggests that the brain interprets this as a pervasive sense that things are going to be great—but the dopamine is writing checks that the environmental rewards can’t cash. Eventually the predicted greatness doesn’t come, and the equal and opposite negative prediction error is sure to follow. “It seemed like everything was going to be so great . . .” We can chemically fool our brain’s prediction mechanism—but not forever.
As the writer David Lenson puts it, “Cocaine promises the greatest pleasure ever known in just a minute more, if the right image is presented to the eyes, if another dose is administered, if a sexual interaction is orchestrated in just the right way. But that future never comes. There is a physical pleasure to the drug, to be sure, but it is incidental, trivial, compared to what is always just about to happen.”⁷¹ Understanding cocaine as a drug of dopamine, and dopamine as a chemical of temporal difference—of fluctuations in our expectation—makes the story clear. By artificially dumping the brain’s supply, one experiences not the bliss that things are great but the giddy euphoria that things are surprisingly promising. If that promise isn’t kept, the temporal-difference error swings the other way, and our dopamine system goes silent. It was our high expectations that were in error. We were duped.
The connection between dopamine and the subjective experiences of happiness and pleasure is still being worked out. The University of Michigan’s Kent Berridge, for instance, has spent the better part of his career teasing apart the neuroscience of wanting from liking.⁷² Meanwhile, University College London’s Robb Rutledge has developed a mathematical model of happiness that explicitly involves dopamine.
Rutledge, working with Peter Dayan and a group of collaborators at UCL, devised an experiment in which people would be making various bets and accumulating a sum of money while periodically being asked, “How happy are you right now?”⁷³ They modeled the task using the mathematical tools of reinforcement learning, in order to tease apart how much money the subject had made so far, how much in total they anticipated making, and whether they had recently been pleasantly or unpleasantly surprised in adjusting either of these running counts up or down. The goal was to figure out the best mathematical correlate for their self-reported momentary happiness.
Rutledge’s findings were illuminating on a number of counts. The first was that happiness was fleeting. However happy it made you to receive £1 in a particular bet, five bets later, 92% of that impact had disappeared. Anything that happened more than ten bets ago may as well never have happened. This meant that subjects’ happiness had virtually nothing to do with how much money they had actually made.
Happiness did seem at least partly determined by how much subjects expected to make—but what seemed most crucial, however, was the violation of those expectations. As Rutledge writes, “Momentary happiness is a state that reflects not how well things are going but instead whether things are going better than expected.”⁷⁴ This sounds exactly like a temporal-difference error—in other words, exactly like the role played by dopamine.
Zooming out, we begin to get a neuroscientific and computational account of the well-known phenomena of what’s called the “hedonic treadmill.” Namely, people have a stubborn and persistent return to their emotional baseline, regardless of changes in their long-term quality of life.⁷⁵ Lottery winners and paraplegics, famously, are emotionally back to more or less where they started not long after their respective dramatic life changes.⁷⁶ Dopamine and reinforcement learning offer clues as to why. If happiness comes not from things having gone well, not from things being about to go well, but from things going better than expected, then yes, for better or worse, as long as our expectations keep tuning themselves to reality, then a long-term state of being pleasantly surprised should be simply unsustainable.
Unfortunately, the study rules out such simple life hacks as “always maintain low expectations.” As Rutledge says, “Lower expectations make it more likely that an outcome will exceed those expectations and have a positive impact on happiness. However, expectations also affect happiness even before we learn the outcome of a decision. If you have plans to meet a friend at your favorite restaurant, those positive expectations may increase your happiness as soon as you make the plan.”⁷⁷
In the research paper, he and his coauthors note the possibility of an airline, for instance, claiming that there is a 50% chance of a six-hour delay, then announcing that the delay will in fact be one hour. “Lowering expectations increases the probability of positive outcomes. . . . However, lower expectations reduce well-being before an outcome arrives, limiting the beneficial scope of this manipulation.”⁷⁸
In other words, Rutledge says, “You can’t kind of, you know, just lower your expectations and that solves everything.”⁷⁹
The links between dopamine, TD errors, and happiness have caused some researchers to begin pondering whether there are ethical implications for the subjective happiness of reinforcement-learning agents. Brian Tomasik of the Foundational Research Institute, which aims to understand and reduce suffering, has pondered at some length the question of whether reinforcement-learning programs have moral standing—does it matter how we treat them? His answer is a tentative and limited yes: to the degree that they are built on similar principles as animal and human brains, there may well be some nonzero ethical consideration that they are owed.⁸⁰ “Present-day RL algorithms matter vastly less than animals,” he notes. “Still, I think RL agents do matter to a nonzero degree, and at large scales they may begin to add up to something significant.”⁸¹ Subsequent work by others has gone so far as to explicitly define the “happiness” of a reinforcement-learning agent by its TD errors.⁸² By this logic, they note, “agents that know the world perfectly have zero expected happiness.” Indeed, if dopaminergic “happiness” comes in large part from being pleasantly surprised, from having opportunities to better learn what to expect, then complete mastery of any domain seems necessarily correlated with boredom—a point that has ethical implications not only for a future ethics of RL agents but, of course, for humans, too.
It suggests, for one thing, an evolutionary and computational story about the hedonic treadmill. If our subjective happiness is intimately tied to being pleasantly surprised and it’s the nature of intelligence to work tirelessly to anticipate and mitigate surprise, then we can see how happiness of this kind becomes fleeting. We can also see the evolutionary advantage. An infant may be delighted at the mere ability to wave their arm on command. For an adult, this ability no longer carries, shall we say, the thrill it did in infancy. Though we may bemoan the restlessness this engenders in adults, the insatiability, this is all part of the curriculum of life. If basic motor skills were enough to thrill us indefinitely, we’d never make it to adulthood at all.
As Andrew Barto puts it, this fleetingness was something Klopf anticipated back in the early 1970s. “His point was a [homeostatic] stabilization mechanism, it tries to reduce the discrepancy to zero, and when it’s zero, it’s happy, it stops. The kind of system he wanted was never happy. So it’s this incessant exploration.”⁸³ The connection between reinforcement learning, dopamine, happiness, and exploration (as well as addiction) is something we’ll return to in Chapter 6.
BEYOND REINFORCEMENT
Reinforcement learning, rooted very consciously in the animal-learning studies of the early twentieth century, flourished in the abstract, mathematical world of machine learning in the 1970s and ’80s, only to triumphantly burst back into animal behavior literature with a nearly perfect model that has become the accepted story for the role of dopamine in the brain.⁸⁴ This model, in turn, has given us deeper insight into human motivation and human happiness.
Meanwhile, neuroscientific evidence, as recently as 2018, is beginning to suggest that the crazy hypothesis of Harry Klopf—that neurons are “hedonists,” motivated by their own individual Thorndikean laws of effect—may not be so far off after all.⁸⁵ “I think that neuroscience is getting close to something that is very similar to what Klopf was proposing,” says Barto, with some pride on behalf of his late former mentor, to whom his and Sutton’s textbook is dedicated.⁸⁶
Reinforcement learning also offers us a powerful, and perhaps even universal, definition of what intelligence is.⁸⁷ If intelligence is, as computer scientist John McCarthy famously said, “the computational part of the ability to achieve goals in the world,”⁸⁸ then reinforcement learning offers a strikingly general toolbox for doing so. Indeed it is likely that its core principles were stumbled into by evolution time and again—and it is likely that they will form the bedrock of whatever artificial intelligences the twenty-first century has in store.
In some ways, though, a deeper understanding of the ability of animals and machines to achieve goals in the world has kicked the more profound philosophical can down the road. This theory, pointedly, does not tell us what we value, or what we ought to value. Dopamine, in this way, is every bit as mysterious now as when its role was lesser known. If it represents a scalar prediction error, it hides a vast realm of complexity in how that prediction is “measured.” If, behind door number one, is not the Caribbean vacation we expected but, rather, a trip to view the aurora borealis, our dopamine will quickly and reliably indicate whether we are pleasantly or unpleasantly surprised by this. But how is the value of those alternatives actually being assessed?⁸⁹ Dopamine is mum on this point.
Meanwhile, we take up another question. Reinforcement learning in its classical form takes for granted the structure of the rewards in the world and asks the question of how to arrive at the behavior—the “policy”—that maximally reaps them. But in many ways this obscures the more interesting—and more dire—matter that faces us at the brink of AI. We find ourselves rather more interested in the exact opposite of this question: Given the behavior we want from our machines, how do we structure the environment’s rewards to bring that behavior about? How do we get what we want when it is we who sit in the back of the audience, in the critic’s chair—we who administer the food pellets, or their digital equivalent?
This is the alignment problem, in the context of a reinforcement learner. Though the question has taken on a new urgency in the last five to ten years, as we shall see it is every bit as deeply rooted in the past as reinforcement learning itself.
5 SHAPING
Nature has placed mankind under the governance of two sovereign masters, pain and pleasure. It is for them alone to point out what we ought to do, as well as to determine what we shall do.
—JEREMY BENTHAM¹
Design of reward functions is not often discussed, although it is perhaps the most difficult aspect of setting up an RL system.
—MAJA MATARIĆ²
In 1943, B. F. Skinner was working on a secret wartime project, initially sponsored by—of all groups—the consumer food company General Mills. General Mills had given Skinner the top floor of its Gold Medal Flour mill in Minneapolis to build a laboratory. The project was one of the more audacious ones entertained during that time: Skinner and his lab were going to teach pigeons how to peck at images of bomb targets, then put the birds—in groups of three—inside of actual bombs to steer them as they dropped. “My colleagues and I knew,” said Skinner, “that, in the eyes of the world, we were crazy.”³
Skinner was aware that many would see the project as not only insane but cruel. To the first point, he noted that humans have a long and storied history of putting animals’ (often superhuman) senses to human purposes: the seeing-eye dog, the truffle-hunting pig, and so forth. To the second point, he argued, “The ethical question of our right to convert a lower creature into an unwitting hero is a peacetime luxury.”⁴
Skinner had long been working on the study of reinforcement, and his famous “Skinner boxes” functioned like upgraded, mid-twentieth-century versions of Thorndike’s puzzle boxes. Their lights and levers and mechanical food dispensers, often repurposed from vending machines, allowed for a precise and quantitative study of reinforcement, and they would be used by generations of researchers to follow (not least including Wolfram Schultz in his study of dopamine in monkeys). With such tools at his disposal in the 1950s, Skinner began to study how animals learn to take actions to maximize their rewards (typically in the form of food) under a number of different conditions. He tested different types of what he called “reinforcement schedules” and observed their effects. For instance, he compared reinforcing by “ratio”—where a certain number of correct actions would result in a reward—against reinforcing by “interval”—where a correct action after a certain time would yield the reward. He also tested “fixed” against “variable” reinforcement, where the number of behaviors or length of time was either held constant or allowed to fluctuate. Skinner famously found that the fiercest and most repetitive or persistent behavior tended to come from variable ratio schedules—that is, when a reward would come after a certain number of behaviors, but the number would fluctuate.⁵ These findings held implications for the understanding of gambling addiction, for instance—and, tragically, they also undoubtedly led to the devising of ever more addictive gambling games.
In his secret top-floor laboratory, though, Skinner had a different challenge before him: to figure out not which schedules of reinforcement ingrained simple behaviors most deeply, but rather how to engender fairly complex behavior merely by administering rewards. The difficulty became obvious when he and his colleagues one day tried to teach a pigeon how to bowl. They set up a miniature bowling alley, complete with wooden ball and toy pins, and intended to give the pigeon its first food reward as soon as it made a swipe at the ball. Unfortunately, nothing happened. The pigeon did no such thing. The experimenters waited and waited . . . and eventually ran out of patience.
Then they took a different tack. As Skinner recounts:
We decided to reinforce any response which had the slightest resemblance to a swipe—perhaps, at first, merely the behavior of looking at the ball—and then to select responses which more closely approximated the final form. The result amazed us. In a few minutes, the ball was caroming off the walls of the box as if the pigeon had been a champion squash player.
The result was so startling and striking that two of Skinner’s researchers—the wife-and-husband team of Marian and Keller Breland—decided to give up their careers in academic psychology to start an animal-training company. “We wanted to try to make our living,” said Marian, “using Skinner’s principles of the control of behavior.”⁶ (Their friend Paul Meehl, whom we met briefly in Chapter 3, bet them $10 they would fail. He lost that bet, and they proudly framed his check.)⁷ Their company—Animal Behavior Enterprises—would become the largest company of its kind in the world, training all manner of animals to perform on television and film, in commercials, and at theme parks like SeaWorld. More than a living: they made an empire.⁸
Skinner, too, would come to think of this moment—at the miniature bowling alley inside the secret flour-mill laboratory—as an epiphany that changed the arc of his career. The critical component, he saw, was “the gradual shaping up of behavior by reinforcing crude approximations of the final topography instead of waiting for the complete response.”⁹
Project Pigeon—as it was known—was, however, ultimately something of a mixed success. The pigeons themselves worked marvelously. So marvelously, in fact, that they seemed to distract the committee from the government’s Office of Scientific Research and Development. “The spectacle of a living pigeon carrying out its assignment, no matter how beautifully,” Skinner wrote, “simply reminded the committee of how utterly fantastic our proposal was.”¹⁰ And, unbeknownst to Skinner at the time, the government was hard at work on the Manhattan Project: a bomb with a blast radius so large that, in his words, “it looked for a while as if the need for accurate bombing had been eliminated for all time.” Nevertheless, the pigeon project ultimately found a home at the Naval Research Laboratory, as an effort called ORCON—short for “organic control”—where studies continued into the postwar ’50s.
Skinner felt vindicated that the concept had been shown to work, writing proudly in the late 1950s that “the use of living organisms in guiding missiles is, it seems fair to say, no longer a crackpot idea.”¹¹ This vindication, though nice, was however beside the point.
The point was they had discovered shaping: a technique for instilling complex behaviors through simple rewards, namely by rewarding a series of successive approximations of that behavior. “This makes it possible,” Skinner wrote, “to shape an animal’s behavior almost as a sculptor shapes a lump of clay.”¹² This idea, and this term, would become a critical one through the rest of Skinner’s life and career.¹³ It had implications—he saw from the beginning—for business and for domestic life.
As he wrote: “Some of these [reinforcement schedules] correspond to the contingencies established in industry in daily wages or in piece-work pay; others resemble the subtle but powerful contingencies of gambling devices, which are notorious for their ability to command sustained behavior.”¹⁴ He also felt the possible parenting ramifications were significant: “A scientific analysis can, however, bring about a better understanding of personal relations. We are almost always reinforcing the behavior of others, whether we mean to or not.” Skinner noted that parental attention is a powerful reinforcer, and that parents can, by being slow to respond to polite requests, unwittingly train their children to be annoying and pushy. (The remedy, he said, is to respond more promptly and consistently to acceptable bids for attention, and less to those that are loud or impolite.)¹⁵
Perhaps most prophetically, Skinner thought that with the principles emerging in his work, education in its broadest sense—of humans, of animals—might become a rigorous, objective field in which leaps forward could and would be made. “Teaching, it is often said, is an art,” as he put it, “but we have increasing reason to hope that it may eventually become a science.”¹⁶
Skinner would be, perhaps, more right than he even anticipated. In the twenty-first century, when the term “shaping” is used, it is just as likely to be a machine-learning researcher who is talking as a psychologist. The study of rewards—and, in particular, how to strategically administer rewards to get the behavior you want, and not the behavior you don’t—has indeed become a rigorous quantitative science, albeit perhaps not with the organic learners Skinner imagined.
THE PROBLEM OF SPARSITY
There’s a way to do it better . . . find it!
—THOMAS EDISON¹⁷
It was Scottish philosopher Alexander Bain who in 1855 appears to have coined the phrase “trial and error” to describe how humans and animals learn.¹⁸ (His other phrase—“groping experiment”—is equally memorable, but appears not to have stuck.)
At its most basic, reinforcement learning is a study of learning by trial and error, and the simplest algorithmic form this trial (or groping, if you prefer) takes is what’s called “epsilon-greedy” (written with the Greek letter ε as “ε-greedy”). The Greek letter ε is often used by mathematicians to mean “a little bit,” and ε-greedy is shorthand for “be greedy, except for a smidgen of the time.” An agent operating by ε-greedy will, most of the time—99%, let’s say—take the action it believes will bring it the greatest total reward, based on its limited experience so far. But ε of the time—the other 1%, for instance—it tries something completely at random. In an Atari game, say, this would mean randomly mashing a button some percentage of the time, just to see what might happen.
There are many different flavors of how to learn from this exploratory behavior, but the underlying idea is the same. Flail around; do more of what gets you rewarded and less of what gets you punished. You can do that by explicitly trying to understand how the world works (“model-based” RL), or just by honing your instincts (“model-free” RL). You can do it by learning how much reward certain states or actions can bring (“value” learning), or by simply knowing which strategies tend on the whole to do better than which others (“policy” learning). Virtually all approaches, though, are built around the idea of first stumbling accidentally onto success, and then building up a tendency to do more and more of whatever appears to have worked.
Some tasks, as it turns out, admit much more readily to this approach than others.
In a game like Space Invaders, for instance, hordes of enemies descend toward you, and all you can do is move left, move right, and shoot. Randomly mashing the buttons will probably earn you at least a few kills, each of which is worth points, and those early points can be used to start the learning process by which certain patterns of behavior get strengthened and better strategies developed. You may realize, for instance, that points only come after you’ve fired a shot, and so you’ll begin firing more often and, in turn, scoring more. Such games are said to have “dense” rewards, which makes them relatively easy to learn.
In other games—take chess, for instance—rewards aren’t nearly as immediate, but they are nonetheless certain. A chess game is typically over, one way or another, after a few dozen moves, and the rules make it almost impossible to go more than a couple hundred. Even if you’re clueless about the finer points of strategy and are shoving pieces around the board at random, you’ll at least know before long whether you won, lost, or drew.
There are a number of situations, however, in which getting any reward at all would take a veritable miracle. Skinner, of course, discovered this firsthand in his attempts to reward a bird for bowling a tiny ball down a miniature bowling alley. The bird, clueless about what game it had been put into, might take years to happen upon the right behavior—of course it (and Skinner) would have died of hunger long before then.
The same thing is true for mechanical learners. Getting a humanoid robot to kick a soccer ball into a net, for example, might involve hundreds of thousands of precise torques on dozens of joints, all perfectly coordinated. It’s hard to imagine a robot that initially moves its dozens of joints at random managing to even stay upright, let alone make meaningful contact with the ball, let alone send it into the net.
Reinforcement-learning researchers know this as the problem of sparse rewards, or more succinctly as the problem of sparsity. If the reward is defined explicitly in terms of the end goal, or something fairly close to it, then one must essentially wait until random button-pressing, or random flailing around, produces the desired effect. The mathematics show that most reinforcement-learning algorithms will, eventually, get there—but eventually, in practical terms, might arrive long after the sun has exploded. If you’re trying to train a Go-playing program to defeat the world champion and you give it one point every time the world champion resigns and zero points otherwise, you are going to be waiting a very long time indeed.
The problem of sparsity also has safety implications. If, in some future time, you’re developing a superintelligent AI with vast capabilities, driven by ε-greedy reinforcement learning, and you decide you’ll reward it with one point if it cures cancer and zero otherwise, watch out—because it will have to try a lot of random things before it stumbles into that first reward. Many of them are likely to be ugly.
When I sit down with Brown University’s Michael Littman, who has spent his career working in reinforcement learning, I ask him whether his lifelong research interest in reinforcement has been useful as a parent. His mind instantly goes to the problem of sparsity. He remembers joking with his wife about using sparse rewards with their son: “How about this? Until he can learn to speak Chinese, let’s not feed him. That would be a good motivator! Let’s see how that works!” Littman laughs. “My spouse is very grounded. . . . She’s like, ‘No, we’re not gonna play that game.’ ”¹⁹
Of course, Littman knows—as Skinner did—not to play that game. Indeed, the problem of sparsity has inspired the reinforcement-learning community to hark back to Skinner’s time, and they have drawn rather directly on his advice.²⁰ In particular, his ideas about shaping have led to two distinct but interwoven strands of thought: one about curriculum, the other about incentives.
THE IMPORTANCE OF CURRICULUM
The key insight of shaping—that in order to get complex behavior, we may first need to strategically reward simpler behavior—is every bit as applicable to humans, of course, as to animals. “You have to walk before you can run,” we say, an adage that describes more facets of the human experience than can be named or counted—in addition to being literally true.
It is a striking and characteristic feature of human life that we spend our first decades moving through the world with literal and figurative training wheels, bowling—as it were—with literal and figurative bumpers. Many animals are simply thrown into the full complexity of life: a number of wild animals must be prepared to run full speed from predators, for instance, within hours of birth. In contrast, it takes us decades before we can operate heavy machinery, and it’s not uncommon for us to be past our physical prime by the time we have to “fend for ourselves.”
What separates twenty-first-century humans from their cave-dwelling ancestors isn’t raw intellectual power but a good curriculum. Indeed, Skinner thought that we shouldn’t be so quick to pass judgment on the mental capacities of animals. With the right curriculum, they might be able to astoundingly surpass what we think of their species as capable of—just as humans have.
As Skinner put it, if an experimenter is simply waiting until a complicated set of behaviors arises to begin reinforcing the behavior, then it’s hardly a test of whether that animal “can” or “cannot” perform the behavior.
The ability of the experimenter rather than that of the organism is being tested. It is dangerous to assert that an organism of a given species or age can not solve a problem. As the result of careful scheduling, pigeons, rats, and monkeys have done things during the past five years which members of their species have never done before. It is not that their forebears were incapable of such behavior; nature had simply never arranged effective sequences of schedules.²¹
It can be hard to appreciate the extent to which our lives, and the world around us, has been sculpted into just such “effective sequences of schedules.” We have somehow come to think of being smoothly onboarded and shown the ropes as “natural,” when, in fact, the opposite is the case. Nature simply is. There is no tutorial.
The human world, by contrast, is elaborately architected to be learnable. Part of what makes great games great, for example, is the way that they “shape” our play. Consider one of the most famous and historically significant video games of all time, Nintendo’s 1985 Super Mario Bros. One’s very first time playing the game might be hard to recall, but a close look at the game’s first ten seconds reveals that it has been carefully, brilliantly designed to teach you how to play. You begin with an enemy Goomba approaching from the right; if you do nothing, you die. “You have to teach the player in a natural way, that they need to avoid them by jumping over them,” says the game’s designer, the legendary Shigeru Miyamoto.²² This is the game’s first and most important lesson: mushroom-looking guys are bad, and you must jump.
But Miyamoto had a problem. There are also good mushrooms, which you have to learn, not to dodge, but to seek. “This gave us a real headache,” he explains. “We needed somehow to make sure the player understood that this was something really good.” So now what? The good mushroom approaches you in an area where you have too little headroom to easily jump over it—you brace for impact, but instead of killing you, it makes you double in size. The mechanics of the game have been established, and now you are let loose. You think you are simply playing. But you are carefully, precisely, inconspicuously being trained. You learn the rule, then you learn the exception. You learn the basic mechanics, then you are given free rein.
We should perhaps not be so surprised that the same principle of shaping—the instilling of complex behavior through successive approximations—applicable to Skinner’s pigeons is applicable to human learners as well. And we should perhaps not be surprised to find that it’s every bit as applicable when the learners are machines.
It has, of course, been known since the inception of machine learning that some problems, some environments, some games are easier than others. But only gradually did it come to be appreciated that a system trained first on an easier form of a problem may be in a better position to learn a more difficult one than an agent trained from scratch.²³
In the 1980s, Richard Sutton and Andrew Barto were working with their colleague Oliver Selfridge on using reinforcement learning to train a simulated cart on wheels to balance a pole on itself without tipping. The taller and heavier the pole, the easier it is to keep it upright—just as it is easier to balance, say, a baseball bat on one’s hand than a ruler. They found that their cart system required fewer total attempts if it was first trained on a tall, heavy pole and then switched to a shorter, lighter one than if it was trained on the shorter, lighter pole from the beginning.²⁴
Researchers have periodically stumbled on this same insight in other contexts. UC San Diego linguist Jeffrey Elman, for instance, was experimenting in the early ’90s with getting neural networks to correctly predict the next word in a sentence. Discouragingly, several initial attempts failed. “Put simply,” he says, “the network was unable to learn the complex grammar when trained from the outset with the full ‘adult’ language. However, when the training data were selected such that simple sentences were presented first, the network succeeded not only in mastering these, but then going on to master the complex sentences as well.”²⁵
“This is a pleasing result,” says Elman, “because the behavior of the network partially resembles that of children. Children do not begin by mastering the adult language in all its complexity. Rather, they begin with the simplest of structures, and build incrementally until they achieve the adult language.”
In both cases, the use of a curriculum—an easier version of the problem, followed by a harder version—succeeded in cases where trying to learn the more difficult problem by itself could not.
Keller and Marian Breland, in their work at Animal Behavior Enterprises, had seen the critical importance of a good curriculum in their efforts to train a pig to deposit large wooden coins in a “piggy bank.” They began with a single coin, right next to the bank, and gradually moved it farther and farther away from the bank and also farther and farther from the pig.²⁶
More recently, the machine-learning community has returned to this idea of working “backward.” A group of UC Berkeley roboticists in 2017 wanted to train a robotic arm to slide a washer onto a long bolt. Waiting for the robot to somehow stumble onto this behavior at random would have taken an eternity. But starting from the washer almost totally all the way down the bolt, they could teach the robot to push it down the last little bit. Then with the washer just barely on the bolt, the robot could learn to slide it all the way down. Then with the washer near the bolt in an easy orientation, the robot could learn to put the bolt through the hole. They were finally able to back their way up to a system capable of being handed the washer anywhere and any which way, and able to dexterously rotate and fasten it.²⁷
No less a game expert than legendary chess world champion Bobby Fischer used a similar strategy in his instructional book Bobby Fischer Teaches Chess. The book, intended for beginners, contains dozens of examples of checkmate in a single move, then progresses to two-move checkmates, then three- and four-move mating combinations. Discussion of middle-game and opening play, as well as longer-term strategies, is put off for later books; Fischer focuses exclusively on teaching beginning players how to recognize opportunities to end the game. This particular curriculum has proven very successful, indeed: some of today’s grandmasters endorse it as the perfect first chess book for a new player,²⁸ and it has become the best-selling chess book of all time.²⁹
The natural next step, it would seem, is treating the construction of a good, learnable curriculum as itself a machine-learning problem, and seeing if it might be possible to automate the curriculum design process. Recent research has looked into ways to automatically identify tasks of appropriate difficulty, and examples that can maximally promote learning in the network. The early results in this vein are promising, and work is ongoing.³⁰
Perhaps the single most impressive achievement in automated curriculum design, however, is DeepMind’s board game–dominating work with AlphaGo and its successors AlphaGo Zero and AlphaZero. “AlphaGo always has an opponent at just the right level,” explains lead researcher David Silver.³¹ “It starts off extremely naïve; it starts off with completely random play. And yet at every step of the learning process, it has an opponent—a sparring partner, if you like—that’s exactly calibrated to its current level of performance.” And who, exactly, is this perfect sparring partner, always calibrated to be at just the right difficulty?
The answer is simple, elegant, and, in hindsight, obvious. It plays against itself.
THE DELICATE MATTER OF INCENTIVES
Whether dealing with monkeys, rats, or human beings, it is hardly controversial to state that most organisms seek information concerning what activities are rewarded, and then seek to do (or at least pretend to do) those things often to the virtual exclusion of activities not rewarded.
—STEVEN KERR³²
If the reward system is so designed that it is irrational to be moral, this does not necessarily mean that immorality will result. But is this not asking for trouble?
—STEVEN KERR³³
IT’S THE REWARD SYSTEM, STUPID!
—THE EDITORS, ACADEMY OF MANAGEMENT EXECUTIVE³⁴
The second approach to overcoming sparsity is, rather than using a “curriculum” and beginning first with a simplified version of the problem, instead to use the normal full-scale version of the problem while adding some bonus rewards that serve to point the learner in the right direction or encourage behaviors that correlate with success. These are known in the field as “pseudorewards” or “shaping rewards,” but it’s simplest just to think of them as incentives.
Skinner gave his pigeon a little bit of food for looking at and approaching the ball, activities that necessarily preceded the swipe he was ultimately looking for. The same idea applies in machine-learning settings. For instance, the “true” reward of a housecleaning robot might be a spotless house, but you can give it some incentives for each bit of dirt it vacuums up. Or your delivery drone might ultimately be trying to arrive at some destination, but you can give it a little bit of reward for making progress in the right direction.
This is often enormously helpful at giving an agent that would otherwise be flailing at random until it accomplished its goal by pure chance a sense of whether it is getting “hotter” or “colder”: whether it’s generally behaving in the right way and altering its behavior in the right direction.
Often we break a problem down into discrete steps in order to make it psychologically easier to stay motivated. Imagining a completed PhD dissertation or book manuscript years from now makes it hard to judge the quality of an individual day’s work. Imagining all the weight we hope to lose by next year can make the costs and benefits of a particular cupcake or second helping feel diffuse. As parents, as teachers, as coaches, we know that a well-timed high five or “Good job!” can help get a tutee through the tough slog of constant practice, even when mastery feels impossibly distant.
Of course, anyone who has worked with humans—or even has simply been one—knows that to create incentives is to play with fire. They must be very carefully designed indeed, or trouble often awaits.³⁵ As management expert Steven Kerr famously put it in his classic 1975 paper, as soon as you begin to think about adding additional reward, you are in immediate danger of “the folly of rewarding A, while hoping for B.”³⁶
Kerr’s analysis of incentives gone wrong has become a landmark paper in management science, and Kerr has spent much of his career working with businesses from General Electric to Goldman Sachs on how to think more carefully about incentives. Amazingly enough, when asked where his inspiration came from, Kerr cited both machine learning and B. F. Skinner. “The fact that machines can be programmed to learn and that a chess playing machine can be programmed to never make the same mistake twice was very fascinating to me,” Kerr says. “I was immediately intrigued with the possibility that a machine could become a better chess player than the actual programmer!”³⁷
As for Skinner, Kerr concedes, “In regard to the ‘Folly’ article, obviously B. F. Skinner got ‘there’ before me. I never claimed otherwise. I remember reading Skinner saying he would scream at his rats ‘Why don’t you behave?’ after they wouldn’t do what he wanted or expected. Skinner probably would turn over in his grave if he thought people were reading my article without having read his work. Obviously, Skinner did the work, but I was able to help bottle it in the right package for business applications. ‘Blaming the rat’ was a great learning lesson. What the ‘Folly’ is really about is that it is not always the employees’ fault; management is responsible for all too many employee dysfunctionalities.”
Indeed, for Skinner, one could almost never blame the rat (or the employee). Our behavior, he felt, was almost fully determined by our incentives and our rewards. A television interviewer at one point asked Skinner, “Where does that leave free will?” Skinner replied, “It leaves it in the position of a fiction.”³⁸
The free will argument aside, problems of incentive pervade not just animal psychology, and not just corporate management; some of the most memorable, in fact, come from those ruthless and creative reward maximizers we call children.
University of Toronto economist Joshua Gans wanted to enlist the help of his older daughter in potty training her younger brother. So he did what any good economist would do. He offered her an incentive: anytime she helped her brother go to the bathroom, she would get a piece of candy. The daughter immediately found a loophole that her father, the economics professor, had overlooked. “I realized that the more that goes in, the more comes out,” she says. “So I was just feeding my brother buckets and buckets of water.” Gans affirms: “It didn’t really work out too well.”³⁹
Princeton cognitive scientist Tom Griffiths had an eerily similar situation happen with his own daughter. “She really liked cleaning things,” he tells me; “she would get excited about it. We got her her own little brush and pan. There were some, you know, chips on the floor, and she got her brush and pan and cleaned them up, and I said to her, ‘Wow! Great job! Good cleaning! Well done!’ ”⁴⁰
With the right praise, Griffiths would manage to both foster motor-skill development in his daughter and get some help in keeping the house clean: a double parenting win. Or was it? His daughter found the loophole in seconds.
“She looked up at us and smiled,” he says—“and then dumped the chips out of the pan, back onto the floor, and cleaned them up again to try and get more praise.”
For Griffiths, whose research bridges the gap between psychology and machine learning, the implication was obvious. It was “exactly the kind of thing that makes me think about some of the challenges that you have in building reward-motivated AI systems, where you have to think really carefully about how you design the reward function.”
Griffiths thinks about reinforcement learning all the time in the context of parenting. “As a parent you are designing the reward function for your kids, right? In terms of the things that you praise and the things that you give them certain kinds of feedback about. . . . No one really thinks rigorously about ‘What’s the reward function that you explicitly want to design for your kids?’ ”
Griffiths views parenthood as a kind of proof of concept for the alignment problem. The story of human civilization, he notes, has always been about how to instill values in strange, alien, human-level intelligences who will inevitably inherit the reins of society from us—namely, our kids. The parallel goes even deeper than that, though—and careful attention to both AI and parenting shows the surprising degree to which each can inform the other.
Our children may be no more intelligent than we, but even young children can outsmart our rules and incentives, in part because of how motivated they are to do so. In the case of reinforcement-learning systems, they are slaves of a kind to their rewards; but they’re the kinds of slaves that have an immense amount of computing power and a potentially inexhaustible number of trial-and-error attempts to find any and all possible loopholes to whatever incentives we design. Machine-learning researchers have learned this lesson the hard way. And they have also learned a thing or two about how to deal with it.
CYCLE-PROOFING YOUR REWARDS: THE SHAPING THEOREM
Astro Teller, currently the “captain of moonshots” at X (the Alphabet company formerly known as Google X), has in recent years overseen everything from Google’s self-driving-car project (subsequently spun off into Waymo), to its augmented-reality project Google Glass and its research lab Google Brain. But in 1998, he was focused on a different problem: soccer. With his friend and fellow student David Andre, Teller worked to enter the annual RoboCup soccer competition, with a virtual-soccer-playing program they dubbed Darwin United.⁴¹ Reward shaping is part of what enabled them to teach their program how to play. But there was an issue. In soccer, possession of the ball is part of what good offense and good defense looks like—and is certainly better than wandering around the field aimlessly. And so Andre and Teller provided a reward—worth a tiny fraction of a goal—to their robot for taking possession of the ball. To their astonishment, they found their program “vibrating” next to the ball, racking up these points, and doing little else.⁴²
That same year, a team of Danish researchers at the Niels Bohr Institute in Copenhagen, Jette Randløv and Preben Alstrøm, were trying to get a reinforcement-learning system to learn how to ride a simulated bicycle. The system would have to manage the complicated task of staying upright while making progress toward a distant goal. This seemed like the perfect application for adding some shaping rewards. Because it would be unlikely that a system wobbling all over the place would randomly arrive at the goal, the team decided to add a small reward—a handful of “points”—anytime the bicycle made progress toward the goal.
To their astonishment, “the agent drove in circles with a radius of 20–50 meters around the starting point.”⁴³ They were rewarding progress toward the goal but forgot to penalize movement away from the goal. Their system had found a loophole, and was ruthlessly—if dizzyingly—exploiting it.
“These heterogeneous reinforcement functions,” they wrote, “have to be designed with great care.”
These cautionary tales, in the late 1990s, were much on the minds of UC Berkeley’s Stuart Russell and his then–PhD student (and subsequently VP and chief scientist at Baidu) Andrew Ng. These sorts of exploitative loops seemed like a constant danger.⁴⁴
Ng was ambitious. He recalls, “When I started working on robotics . . . I asked a lot of people, ‘What’s the hardest control problem you know of?’ And back then the most common answer I heard was ‘Getting a computer to fly a helicopter.’ And so I said, ‘Let’s work on that.’ ”⁴⁵ Indeed, he would do his PhD thesis on using reinforcement learning to fly an actual—unsimulated, nine-foot-long, one-hundred-pound, seventy-thousand-dollar—Yamaha R-50 helicopter.⁴⁶ The stakes were wildly high. Erratic or unpredictable behavior in the real world could destroy the helicopter entirely—to say nothing of what might happen if an unsuspecting person found themselves in its path.
The critical question was this: Given a difficult-to-learn reward function that described what they actually wanted the helicopter to do, what sorts of “pseudoreward” incentives, if any, could they add such that the training process would be easier but the best way to maximize that modified reward would also be the optimal solution to the real problem? To use Kerr’s terms, what sorts of A’s could they reward that would still result in the hoped-for B? In Ng’s description:
A very simple pattern of extra rewards often suffices to render straightforward an otherwise intractable problem. However, a difficulty with reward shaping is that by modifying the reward function, it is changing the original problem M to some new problem M′, and asking our algorithms to solve M′ in the hope that solutions can be more easily or more quickly found there than in the original problem. But, it is not always clear that solutions/policies found for the modified problem M′ will also be good for the original problem M.⁴⁷
“What freedom do we have in specifying the reward function,” Ng writes, “such that the optimal policy remains unchanged?”⁴⁸
As it turned out, the critical insight was hiding in the story of the bicycle. In order to prevent the bike from riding in circles, endlessly racking up rewards, you had to also subtract progress away from the goal. Russell, who had trained first as a physicist, made a connection between the rewards problem and conservation of energy. “The key thing,” Russell explains, “is just making the shaping into what we call in physics a ‘conservative field.’ ”⁴⁹ Pseudorewards were like potential energy: a function only of where you were, not what path you’d taken to get there. This also meant that returning to where you’d started—no matter what journey you’d been on—was net zero.
This idea was intuitive enough in the bicycle problem: if you rewarded progress toward the goal, you necessarily needed to penalize progress away from the goal. Said another way, the incentive “points” should always reflect how close the bike was to the goal, and nothing about the route it had followed. But the concept of treating the incentives like “potential energy” turned out to be far deeper and more general. It was a necessary and sufficient condition for making sure that the agent you trained on the shaped reward didn’t have its behavior come unglued from the real problem.
“As a general rule,” says Russell, “it is better to design performance measures according to what one actually wants in the environment, rather than according to how one thinks the agent should behave.”⁵⁰ Put differently, the key insight is that we should strive to reward states of the world, not actions of our agent. These states typically represent “progress” toward the ultimate goal, whether that progress is represented in physical distance or in something more conceptual like completed subgoals (chapters of a book, say, or portions of a mechanical assembly).
Though it isn’t a magic bullet to all problems of human incentives, the shift in focus from actions to states does invite new ways of thinking about some of the incentive structures we, wittingly and unwittingly, design for others. Given a child who is dumping out the kitchen trash in order to double the rewards of sweeping it up, we can make our rewards into a “conservative field” by making sure we scold them in precisely equal measure for dumping the trash out, so that the net gain of further repetitions is zero. It might be easier, though, to shift to praising the state rather than the actions: instead of rewarding the act of cleaning up itself, we might say, “Wow, look how clean that floor is!”
Of course, there is more to the art and science of rewards than the avoidance of cycles—though it’s a start. Ng and Russell conclude their work on a cautious, rather than triumphant, note: “We believe,” they write, “the task of finding good shaping functions will be a problem of increasing importance.”⁵¹
EVOLUTION AS REWARD DESIGNER
I said unto him, “Be fruitful and multiply.” But not in those words.
—WOODY ALLEN⁵²
From a Darwinian perspective, what people want is reasonably clear: something along the lines of propagating and securing their genetic lineage. What people actually want, moment to moment, looks an awful lot more heterogeneous and shortsighted: orgasms, chocolate, a new car, respect. It seems, then, that we are biologically wired and culturally induced to want specific, concrete things in the short term that generally steer our behavior in ways that are ultimately in line with these evolutionary goals, which would otherwise be too distant or ill-defined to consciously aim at.⁵³
Sound familiar?
Understanding the nature and role of shaping—first in behavioral psychology, then in machine learning—hasn’t just taught us how to design better agents. Perhaps its most surprising contribution is to the way we think about evolution.
When Brown University’s Michael Littman was a graduate student, in the late 1980s, he was hired for a time at Bellcore, a research and development group formerly part of AT&T, located in New Jersey. There he quickly found a mentor, and a friend, in Bellcore’s Dave Ackley.
Littman asked him about working on the question of behavior—of taking actions and making decisions that ramify over time. As Littman recounts: “He was like, ‘Oh. That’s a thing. It’s called reinforcement learning. I’ve looked at it a little bit. Here’s a paper.’ And he gave me Rich Sutton’s 1988 TD paper.”⁵⁴
Littman began to read about temporal-difference learning and was fascinated; he asked Ackley where he could learn more. “And he’s like, ‘Well, invite Rich to give a talk.’ And I was like, ‘What? That’s a thing that you can do? You can read a paper and there’s a person’s name on it, and then you can turn them into a human being?’ . . . I didn’t think of it as a community; I thought of it as a literature. But no, it was a bunch of people, and they knew each other, and Dave was like, ‘I can invite him.’ And so he invited him.”
Sutton came to Bellcore, and both Ackley and Littman caught the reinforcement-learning bug.
They were interested in the question of how evolution shapes our reward function to give rise to behaviors in the short term that are useful to the overall survival of an organism or a species in the long term. The organism’s reward function itself, so long as it accomplishes this, might otherwise seem very random. Ackley and Littman wanted to see what might shake out if they simply let reward functions evolve and mutate and allowed simulated virtual entities to die or to reproduce.⁵⁵
They created a two-dimensional virtual world in which simulated organisms (or “agents”) could move around a landscape, eat, be preyed on, and reproduce. Each organism’s “genetic code” contained the agent’s reward function: how much it liked food, how much it disliked being near predators, and so forth. During its lifetime, it would use reinforcement learning to learn how to take actions to maximize these rewards. When an organism reproduced, its reward function would be passed on to its descendants, along with some random mutations. Ackley and Littman seeded an initial world population with a bunch of randomly generated agents.
“And then,” says Littman, “we just ran it, for seven million time steps, which was a lot at the time. The computers were slower then.” What happens? As Littman summarizes: “Weird things happen.”⁵⁶
At a high level, most of the successful individual agents’ reward functions ended up being fairly comprehensible. Food was typically viewed as good. Predators were typically viewed as bad. But a closer look revealed some bizarre quirks. Some agents, for instance, learned only to approach food if it was north of them, for instance, but not if it was south of them.
“It didn’t love food in all directions,” says Littman. “There were these weird holes in [the reward function]. And if we fixed those holes, then the agents became so good at eating that they ate themselves to death.”
The virtual landscape Ackley and Littman had built contained areas with trees, where the agents could hide to avoid predators. The agents learned to just generally enjoy hanging out around trees. The agents that gravitated toward trees ended up surviving—because when the predators showed up, they had a ready place to hide.
However, there was a problem. Their hardwired reward system, honed by their evolution, told them that hanging out around trees was good. Gradually their learning process would learn that going toward trees would be “good” according to this reward system, and venturing far from trees would be “bad.” As they learned over their lifetimes to optimize their behavior for this, and got better and better at latching onto tree areas and never leaving, they reached a point of what Ackley dubbed “tree senility.” They never left the trees, ran out of food, and starved to death.
However, because this “tree senility” always managed to set in after the agents had reached their reproductive age, it was never selected against by evolution, and huge societies of tree-loving agents flourished.
For Littman, there was a deeper message than the strangeness and arbitrariness of evolution. “It’s an interesting case study of: Sure, it has a reward function—but it’s not the reward function in isolation that’s meaningful. It’s the interaction between the reward function and the behavior that it engenders.”
In particular, the tree-senile agents were born with a reward function that was optimal for them, provided they weren’t overly proficient at acting to maximize that reward. Once they grew more capable and more adept, they maxed out their reward function to their peril—and, ultimately, their doom.
One doesn’t have to squint too hard to see a cautionary tale here for Homo sapiens. A heuristic like “Always eat as much sugar and fat as you possibly can” is optimal as long as there isn’t all that much sugar and fat in your environment and you aren’t especially good at getting it. Once that dynamic changes, a reward function that served you and your ancestors for tens of thousands of years suddenly leads you off the rails.
For Andrew Barto, there are clues in thinking about evolution that are useful for us as we now play the role of the reward designer. “Evolution has provided our reward function, and so that is really quite important with regard to how we design reward functions for artificial systems,” he says. “That’s what happened in nature. Evolution came up with these reward signals to encourage us to do things that led to our reproductive success.”⁵⁷
As Barto notes, “So, an interesting thing is that evolution didn’t give us reproductive success as a reward signal. They gave us rewards for predictors.” We optimize our behavior to maximize the things we find rewarding, but in the background and at a larger scale, evolution is shaping the things we find rewarding in the first place. “So, it’s a two-level optimization,” says Barto. “I’m very interested in that.”
In recent years, Barto has worked with the University of Michigan’s Satinder Singh and Richard Lewis and then–PhD student Jonathan Sorg to investigate the question of the “optimal reward problem.”⁵⁸ If you have goal x, it might be that your best bet isn’t simply to tell your agent to do x.
“Should the artificial agent’s goals be the same as the agent designer’s goals?” they write. “This is a question seldom asked.”⁵⁹
Consider a game, they say, in which all that exists is an agent, a fishing pole, some worms, and a pond full of fish.⁶⁰ Let’s say the agent’s overall evolutionary fitness is best served by eating as many calories as possible. Ideally they would learn to pick up worms, refrain from eating them, and use them to catch fish—but this is rather complicated. A clever agent with a long life span is best served by a distaste for eating worms, so that they more quickly begin learning to fish. For an agent with a shorter attention span, on the other hand, or a shorter lifespan, trying to learn how to fish will be a fruitless waste of time—and so they are better served if they happen to find worms delicious.
Perhaps most interesting is the case of an agent that is clever enough to learn to fish and will get to live just long enough to learn how—but not long enough to properly benefit from making that investment. They should be made allergic to fish, as it turns out, so that they have no choice but to eat worms!
Subtle changes in the life span or resources or design of an agent can have wild and abrupt effects in the structure of the optimal reward. The answer as to what set of rewards will be ideal for a particular agent in a particular environment doesn’t appear to admit to any easy generalizations. Research in this vein continues—but learning to more sharply distinguish between what you want and what you reward is an important component of the solution.⁶¹
More recently, psychologists and cognitive scientists are taking these tools and turning them back around to ask a fascinating question not about machines but about humans. How should you design the best reward function, they ask, when the computationally limited, impatient, shortsighted agent learning to optimize it is . . . yourself?
HOW SHOULD WE TRAIN OURSELVES?
The theory and practice of reward shaping in machine learning not only gives us a way to make our autonomous helicopters maneuver appropriately but contributes two distinct things to our understanding of human life and human intelligence. One, it shows us a reason—sparsity—why some problems or tasks are more difficult than others to solve or accomplish. Two, it gives us a theory—incentivize the state, not the action—for how to make tough problems easier without introducing perverse incentives.
The potential use for these insights in human life is enormous. The economic costs alone are vast—a recent report estimated the impact of British workers procrastinating on the job at £76 billion a year—to say nothing of the less easily calculated toll on our well-being, and on the quality and fullness of our lives.⁶²
If we are living through a time of soaring video-game addiction and real-world procrastination, maybe it’s not the individual procrastinator’s fault. As Skinner put it, “I could have shouted at the subjects of my experiments, ‘Behave, damn you, behave as you ought!’ Eventually I realized that the subjects were always right. They always behaved as they ought.”⁶³ If they weren’t learning something, it was the fault of the experimenter not shaping their task properly. So maybe it’s not a lack of willpower on our part, but rather that—as the bestselling 2011 book by Jane McGonigal put it—Reality Is Broken.
McGonigal, a game designer by trade, has spent her career designing games to help people—including herself—overcome challenges in their lives. For her, the incredibly addictive and compelling quality of most games, computer games in particular, is how clear they always make it what you need to do, and how achievable whatever that is always seems.
The first thing is whenever you show up in one of these online games . . . there are lots and lots of different characters who are willing to trust you with a world-saving mission, right away. But not just any mission; it’s a mission that is perfectly matched with your current level in the game. Right? So you can do it. They never give you a challenge you can’t achieve. But it is on the verge of what you’re capable of, so you have to try hard.⁶⁴
In other words, what makes games so hypercompelling is how well shaped they are. The levels are a perfect curriculum. The points are perfect pseudorewards. They are Skinnerian masterpieces.
Reinforcement learning not only gives us the vocabulary to understand and express what makes the games so riveting; it also gives us a way to empirically confirm those intuitions. A game with a clear curriculum from its easiest levels to its hardest, as well as clear pseudorewards that mark the path forward and foster exploration and the development of skills, should be easier for an algorithm to learn. It’s not hard to imagine game studios in the coming years using automated test players for their levels, highlighting the sticking points where real human players are likely to give up or quit.
The problem, of course, is that it is so much easier to shape these virtual environments than the real one. As McGonigal diagnoses: “Now, the problem with collaborative online environments like World of Warcraft is that it’s so satisfying to be on the verge of an epic win all the time, we decide to spend all our time in these game worlds. It’s just better than reality.” For McGonigal, the solution isn’t to wean ourselves off of these perfectly reward-shaped environments but the reverse: “We have to start making the real world work more like a game.”
McGonigal herself has led something of a movement in this regard, including using games to overcome obstacles—including suicidal depression from a protracted recovery from concussion—in her own life.⁶⁵ “I said to myself after thirty-four days [of depression]—and I will never forget this moment—I said, ‘I am either going to kill myself or I’m going to turn this into a game.’ ”⁶⁶ So she created pseudorewards. Calling her sister was worth a few points. Walking around the block was worth a few points. It was a start.
This is a field known as gamification,⁶⁷ and in the last ten years, thanks to insights from reinforcement learning, it has gone from something of an art to something of a science.⁶⁸
One of the people who has thought harder about this problem than anyone in the world—both in his research and his personal life—is cognitive scientist Falk Lieder of the Max Planck Institute for Intelligent Systems.
Lieder’s research focuses on what he calls “rationality enhancement.” He studies the cognitive science of how people think and make decisions—and unlike most researchers, he has a keen interest in not only understanding human cognition but in devising effective tools and interventions to make humans think better. His earliest human subject was, of course, himself.
Growing up, Lieder found it frustrating that his schooling, though it gave him plenty to think about, never touched on thinking itself. “I always felt that what I really wanted to learn was to think well, and how to make good decisions,” he explains. “Nobody could teach me that. They could just teach me declarative facts about the world, and it wasn’t very useful. I really wanted to learn how to think.”⁶⁹
Over time, this matured into a quest for personal betterment, but also something bigger: the drive to understand the principles of human reasoning, and make tools for improving it. “Part of my research,” he explains, “is discovering these optimal strategies for thinking and decision-making so that we can actually build a scientifically based curriculum for good thinking.”
Lieder is interested in gamification and more specifically, what he calls optimal gamification: Given a goal, what is the best possible incentive structure to facilitate reaching it?⁷⁰ This has much of the flavor of “optimal reward design” as discussed above, but in this case the agents being designed for are humans rather than algorithms.
Lieder, working with Tom Griffiths, established some ground rules for what optimal gamification would look like. They knew from Andrew Ng and Stuart Russell’s work that one of the cardinal rules is to reward states, not actions. Therefore the points assigned to taking an action must reflect how much better the resulting state of affairs is—and what’s more, as Lieder notes, “the points have to be assigned in such a way that when you undo something, you lose as many points as you earned when you did it.” This is what Randløv and Alstrøm learned the hard way with their bicycling robot, what David Andre and Astro Teller learned the hard way with their vibrating soccer robot—and what Tom Griffiths himself learned the hard way when his daughter dumped the dustpan onto the kitchen floor.
Ng and Russell’s paper had suggested that shaping rewards could enable an agent with a limited ability to look ahead and forecast the effects of its actions to behave as if it was more farsighted than it really was.⁷¹ This idea intrigued Lieder—in part because humans are so notoriously impulsive and short-term-focused in many of their decisions.
He and Griffiths ran an experiment where they put human subjects in the role of an airline route planner. Flying to certain cities was profitable for that leg, but might put the plane in a position where few other profitable routes existed—and the reverse was true, too: it might be worth flying one leg at a loss in order to reap rewards elsewhere. They tried adding additional immediate rewards (or penalties) to the sticker price of a given leg from A to B that would reflect the downstream cost or benefits of moving the plane to that location. As expected, this enabled people to more readily make better and more profitable decisions.
There was only one downside: because the shaped rewards incorporated the long-term costs and benefits of a choice into the sticker price, users no longer needed to think ahead. This made their decisions more accurate, but was somewhat enfeebling. People no longer needed to think very hard, and so they didn’t. “If you are to act in an environment where [myopic] decision-making works,” says Lieder, “people will learn to rely on that system more and more.”⁷²
This left open an intriguing possibility: Could you use optimal gamification, not to obviate the need for planning, but to make people better at it?
The incentives in this case are almost completely different. Instead of the interface creating an easy problem where long-term costs are taken into account—causing higher-quality decisions but perhaps encouraging lethargy or complacency in subjects, making them more dependent on the interface—prices could be adjusted to create a curriculum. The subject could be slowly taught how to think ahead, starting with very simple illustrations of the basic idea and slowly building in complexity as the subject got better at it. The interface, instead of functioning as a crutch, could use a different set of incentives to do the opposite: “teaching people to plan further ahead in time,” Lieder explains, “so they can succeed in environments where immediate reward is misaligned with long-term value.”
Lieder’s final experiment was not with flight planning but with a more familiar setting: procrastination. He and Griffiths created a deliberately onerous task—to write essays on a series of five topics, some of them longer and more difficult than others—and put it on Mechanical Turk, where people would elect to work on it for a payment—$20—upon completion of all the pieces of writing by a deadline set for ten days later. Of everyone who signed up, 40% never even started. (This was particularly ironic because when the task was initially described to them, they had a chance to decline to participate and still receive fifteen cents!)⁷³
Lieder and Griffiths also experimented with incentives that gave subjects “points”—which had no cash value but were visually encouraging—for each essay completed. Each essay was worth the same number of points. It didn’t help.
Lastly, they offered a third group of participants optimal incentives: point values that precisely reflected how difficult or unpleasant each topic was and how much closer they would be to earning their $20 when they had finished it. (A hundred words on North Korea’s economic policy, for instance, was worth about three times as many points as fifty words on their favorite TV show.) Here, a full 85% of participants finished all five essays.⁷⁴
Lieder thinks of systems like these as “cognitive prostheses,”⁷⁵ and they are more than just his research interest. They are a crucial part of how his own research even gets done.
As a PhD student, Lieder found himself in a scaled-up version of the horrible essay-writing task. “I think one of the worst situations is to get no information about your level of progress,” he says. “The official system is, you are a PhD student, and then you have a PhD, and that’s it. So: five years of no feedback.”
PhD students in general are a group with high rates of anxiety and depression and for whom procrastination is nearly an epidemic.⁷⁶ They are, in effect, pigeons in Skinner’s bowling alley—the cap-and-gown-shaped food pellet waiting for them after they bowl a perfect strike some five years hence. Such a system, we know, doesn’t work for animals—and it doesn’t work for reinforcement-learning algorithms, either.
That wouldn’t do. Lieder needed something else. He charted his five-year course—“I broke this down into a few hundred levels.” He assigned himself virtual “citations” when he did work he felt might result in real citations some several years hence. He used the same optimal gamification calculation that assigned his subjects’ essays a point value to compute the proper point values for each sub-subtask of his doctorate. He even used punishment to override some of his habits—in the form of a wristband from the company Pavlok. “It gives you electric shocks whenever you indulge in some habit that you don’t want to indulge in,” Lieder explains. “My main bad habits were related to how I use my computer. Like, I’m going to YouTube when I feel bad. Since my time-tracking software would immediately communicate to my Pavlok what I was doing, it could then immediately shock me.” Amusingly, this failed to curb his habit of visiting YouTube when he needed some distraction, but it did instill the habit of instantly closing the page when he did.
Being, in effect, both the experimenter and the subject in his own behavioral training experiment gave Lieder a unique vantage onto the question of reward shaping. Such training was, at once, the process by which he approached his research and the central question of that research. The results are encouraging, and Lieder—now running his own research laboratory—has the doctoral robes to prove it.
BEYOND EXTRINSIC REINFORCEMENT
For Skinner, not only was individual free will left uncomfortably “in the position of a fiction,” but essentially the entire story of human civilization was the story of reward structures. Skinner himself was curiously upbeat about this, writing the utopian novel Walden Two about a perfect behaviorist society.
And yet anyone who’s been around children or animals might have the nagging suspicion that reward maximization really isn’t the whole story of why we do what we do. We play games of our own invention, for no discernible prize. We turn over rocks, or climb mountains, just to see what we might discover. We explore. We are playful and curious. We are, in short, motivated as much by internal as by external rewards.
As it happens, this, too, is becoming ever more well appreciated in the world of machine learning.
6 CURIOSITY
If the untrained infant’s mind is to become an intelligent one, it must acquire both discipline and initiative. So far we have been considering only discipline.
—ALAN TURING¹
In the spring of 2008, graduate student Marc Bellemare was walking on the beach in Barbados with University of Alberta computer scientist Michael Bowling. Bowling had an idea. At that time, reinforcement-learning research was typically done with each researcher making their own bespoke game from scratch, then hand-tailoring a system to succeed at that particular game.²
What if instead, Bowling mused, someone built a single environment that everyone could use, with not just one game in it but a vast library of them—and what if, instead of fake, made-up games, it used real games—namely, classic 1970s and ’80s video games from the Atari 2600?
Bellemare recalls, “I said, ‘This is the stupidest idea I’ve ever heard.’ ”³
He continues: “Fast-forward about three years, and, well, I decided it wasn’t such a stupid idea.” In fact, Bellemare found he liked the idea so much that Bowling became his doctoral advisor—and the idea became his dissertation.
The ambition of the project was somewhat insane, not only in the amount of work it would require to build this video-game bestiary, which they dubbed the Arcade Learning Environment (ALE), but also in the implicit gauntlet that it threw down to the rest of the field.⁴ The idea was for researchers to compete against one another by fielding a single learning system that could play not just one but all sixty of the games. The field wasn’t anywhere close.
A big part of the problem was that the bespoke game environments then being used often described the world to the agent in terms that were sanitized and filtered, using inputs that were high-level and useful. In the case of the wheeled cart trying to balance a pole, the system would be given as input the location of the cart, its velocity, the current angle of tilt of the pole, the pole’s velocity, and so forth. In the case of the two-dimensional grid-world environment with trees, food, and predators, the system would be told the agent’s location, its health and hunger, whether there was a predator nearby, where the nearest food was, and so forth. These pieces of information are known as “features.”
What the ALE offered, by contrast, was something more overwhelming and less immediately usable: the pixels on the screen. That was it. Every game was different, not only in its rules but in the way the pixels on the screen mapped to usable information. A learning system thrown into a new game was going to have to figure out everything from scratch: these pixels over here appear to blink when I score points, those pixels over there appear shortly before I die, these pixels in the middle move left whenever I hit the left arrow button—oh, maybe they’re me. Either researchers were going to have to find extremely general ways of extracting useful patterns on the screen for their system to keep track of—such that they were helpful in all sixty games—or else all of that understanding and meaning-making was going to have to be done by the system on the fly. This was the problem of “feature construction.”
Bellemare began experimenting by plugging a bunch of feature-construction algorithms into standard reinforcement-learning systems and throwing them at the games. The results weren’t impressive. To his surprise, however, it was easy to get them published—if only because his peer reviewers were so impressed by how much work had gone into making the Atari environment. “The funny thing is,” he says, “at the time the reviewers would tell me, ‘Well, you’ve done this amazing thing with Atari. I cannot possibly reject your paper.’ . . . It was so big . . . it didn’t matter how bad or good the results were. People just said, ‘Wow. You’ve actually done this.’ ”
He and his colleagues had built, in effect, a kind of mountain; it was now up to the field to figure out a way to scale it.
Bellemare finished his PhD in 2013 and moved from Edmonton to London to join DeepMind.⁵ There, a team led by Volodymyr Mnih was working excitedly on the idea of taking the same AlexNet-style deep neural networks that had been so decisive in the ImageNet competition the year before, and applying them to the problem of reinforcement learning. If deep networks could look at tens of thousands of raw pixels and figure out whether they were a bagel, a banjo, or a butterfly, maybe they could do whatever feature-construction was needed to render an Atari screen intelligible.
He recalls, “The group said, Hey, we have these convolutional networks. They’ve been phenomenal at doing image classification. Um, what if we replace your feature-construction mechanism, which is still a bit of a kludge, by just a convolutional neural network?”
Bellemare, again, wasn’t buying it. “I was actually a disbeliever for a very long time. . . . The idea of doing perceptual RL was very, very strange. And, you know, there was a healthy dose of skepticism as to what you could do with neural networks.”
But on this matter, too, Bellemare would soon come around.
Simply plugging deep learning into a classic RL algorithm and running it on seven of the Atari games, Mnih was able to beat every previous RL benchmark in six of them. Not only that: in three of the games, their program appeared to be as good as a human player. They submitted a workshop paper in late 2013, marking their progress.⁶ “It was just sort of a proof-of-concept paper,” says Bellemare, “that convolutional nets could do this.”
“Really,” he says, “it was bringing the deep-learning part to solve what reinforcement-learning researchers hadn’t been able to do in ages, which is to generate these features on the fly. Then you can do it for any game—it doesn’t matter. And then this . . .”
Bellemare pauses slightly. “This took off.”
DEEP RL GETS SUPERHUMAN
In February 2015, a paper appeared on the cover of Nature, running with the headline “Learning Curve: Self-taught AI Software Attains Human Performance in Video Games.”⁷ DeepMind’s hybrid of classic reinforcement learning with neural networks had shown itself capable of human-level play—and far beyond—at not just a couple Atari games, but dozens of them. The deep-learning revolution had come to reinforcement learning, minting the new field of “deep RL,” and the results were astonishing.
The model—called a “deep Q-network,” or DQN for short—was playing Video Pinball and achieving scores at twenty-five times the level of a professional human games tester. In Boxing it was seventeen times better than human performance. In Breakout, it was thirteen times better. A nearly full-page chart chronicled this stunning pattern of dominance across a wide array of different games, all using a single generic model, with no fine-tuning or adjustment from one game to the next.
At the bottom of the chart, however, there were a few stubborn games that refused to yield to DQN, games that didn’t fit this pattern of glory. One in particular, at the very bottom of the list, stood out.
The outlier was Montezuma’s Revenge, a 1984 game in which you play an explorer named Panama Joe who must find his way through a temple filled with ropes, ladders, and deadly, very vaguely Aztec traps. (“I did no research whatsoever into Montezuma or the culture,” admits creator Robert Jaeger—just sixteen years old when he sold his demo to Parker Brothers—“and really just thought it was a colorful theme and a cool name.”)⁸ On Montezuma’s Revenge, the mighty DQN achieved a high score of 0%—yes, that’s 0%—of the human benchmark.
What was going on here?
For one thing, the game makes it extremely easy to die. Almost any sort of mistake—hitting an enemy, jumping down from too high up, walking through a barrier—is certain death. The DQN system used epsilon-greedy exploration, which involves learning about which actions produce reward by simply hitting buttons at random a certain fraction of the time. In Montezuma’s Revenge, this is almost always suicide.
The second and more important problem is that Montezuma’s Revenge has incredibly sparse rewards. It takes a huge number of things to go exactly right before the player gets any points at all. In games like Breakout or Space Invaders, even the most confused and bewildered newcomer, jamming buttons at random, quickly realizes that they’re at least doing something right. This is enough to start the learning process: in DQN’s case, registering the points scored and slowly beginning to take similar actions in similar situations more of the time. In Montezuma’s Revenge, by contrast, very few events offer any kind of feedback other than death. On the first screen, for example, you have four chasms to leap, three ladders to climb, a conveyor belt to run against, a rope to grab, and a rolling skull to hop over, all before you can collect the first item, which rewards you with a hundred measly points (and, anachronistically, the first five notes of “La Cucaracha”).
In an environment with so few rewards, a randomly exploring algorithm can’t get a toehold; it’s incredibly unlikely that by essentially wiggling the joystick and mashing buttons, it will manage to do all of the necessary steps to get that first reward. Until it does, it has no idea that it’s even on the right track.⁹
One solution to this problem of sparsity, as we’ve seen, is shaping: additional incentive rewards to nudge the algorithm in the right direction. But we’ve also seen how tricky this can be to do correctly without creating a loophole that the algorithm can exploit. Rewarding Panama Joe for every second he doesn’t die, for instance, might just lead to an agent learning never to leave the safety of the initial platform at all. It would be a machine version of what animal researchers call “learned helplessness.”¹⁰ As the celebrated aphorist Ashleigh Brilliant put it, “If you’re careful enough, nothing bad or good will ever happen to you.”¹¹
Other intuitive ideas run aground as well. Rewarding Panama Joe for successfully jumping over a rolling skull, let’s say, might lead the agent to play a kind of double Dutch over the skull instead of venturing farther into the temple. Rewarding him for successfully jumping onto or off a rope would, similarly, incentivize an infinite loop of Tarzan-like swinging. None of this is what we want.
Moreover, though, this kind of shaping will typically vary from game to game, and require the hand of a human overseer with inside knowledge of how that particular game works. That feels a bit like cheating. The whole idea behind the Arcade Learning Environment—and the thrilling achievement of DQN—was that of a single algorithm, able to master dozens of completely different game environments from scratch, guided by nothing but the image on the screen and the in-game score.
So what was the answer? How might a generic trial-and-error algorithm like DQN be modified in the face of such a foreboding game as Montezuma’s Revenge?
There was a tantalizing clue, hiding in plain sight. Humans clearly can learn how to play Montezuma’s Revenge without any additional shaping rewards. Human players instinctively want to climb the ladder, reach the distant platform, get to that second screen. We want to know what’s on the other side of the locked door, to see how big the temple really is, and what, if anything, lies beyond. Not because we intuit that it will bring us “points,” but out of something more pure and more fundamental: because we simply want to know what will happen.
Perhaps, then, what was needed to conquer a game like Montezuma’s Revenge was not augmenting the game’s sparse rewards with additional incentives, but rather a different approach altogether. Maybe, instead of an ever more elaborate system of carrots and sticks, the answer was the opposite: to develop an agent that was intrinsically rather than extrinsically motivated.¹² An agent that would essentially cross the road, not because there was reward in it, but just to get to the other side. An agent that was, we might say, curious.
The last several years have seen a grand revival of scientific interest in the topic of curiosity, and some unlikely collaborations between machine-learning researchers and psychologists who specialize in the cognition of children, to better understand curiosity from a rigorous, fundamental perspective. What is it, exactly? Why do we have it? How might we instill it, not just in our children, but in our machines?
And why might it be increasingly critical that we do?
CURIOSITY AS A SCIENTIFIC SUBJECT
“Desire” to know why, and how, “curiosity,” . . . is a lust of the mind, that by a perseverance of delight in the continual and indefatigable generation of knowledge, exceedeth the short vehemence of any carnal pleasure.
—THOMAS HOBBES¹³
Curiosity is the beginning of all science.
—HERBERT SIMON¹⁴
The godfather of curiosity research in psychology is the psychologist Daniel Berlyne. Berlyne’s very first publication, in 1949, was an attempt to define what exactly we mean when we say that something is “interesting,” or that a person or animal is “interested” in something.¹⁵ As he put it: “My first interest is interest.”¹⁶
A whole subfield gradually began to open up. What did animals learn without any rewards hinging on their learning it?
As Berlyne noted, the history of psychology is largely a story of people and animals being compelled to do things—to fill out a survey or answer oral questions, to press levers in order to eat. In this way, however, the field had essentially created its own methodological blind spot. How would it even begin to approach the question of how organisms act on their own? It seemed almost a contradiction in terms.
“It has, in some ways, been a misfortune for psychology that human beings are so obliging and compliant,” he wrote.¹⁷ “The ease with which artificial and extraneous motivations can be induced in human beings has prevented us from studying the motivational factors that take control when these are lacking.”
Within psychology, the research agenda of training animals with punishments and rewards was so dominant by the mid-twentieth century that it seemed for a time that this could explain everything about the behavior of intelligent organisms. But there were certain data, here and there, that refused to fit. The University of Wisconsin’s Harry Harlow had, by 1950, begun documenting the way rhesus monkeys would play with physical puzzles made from a combination of locks and latches, and he coined the term “intrinsic motivation” to describe it.¹⁸ Sometimes this intrinsic motivation not only took hold in the absence of extrinsic rewards but actually overpowered them. A hungry rat might, amazingly, decide to forgo a bit of food, or cross an electrified fence, to explore an unfamiliar space. Monkeys were willing to press levers not just for cookies and juice but simply to look out a window.¹⁹ There was little room in the strict Skinnerian world of extrinsic rewards and punishments for such behaviors, and there was no easy story to explain them.
And yet this intrinsic motivation, as Berlyne saw, was every bit as central to human nature as the drives for, say, food and sex—despite being “unduly neglected by psychology for many years.”²⁰ (Indeed, the severest punishment our society allows, short of death—solitary confinement—is, in effect, the infliction of boredom on people.) In his landmark 1960 book Conflict, Arousal, and Curiosity, Berlyne notes that a proper study of curiosity first began to emerge in the late 1940s; it is no coincidence, he argues, that information theory and neuroscience also came into their own at the same time.²¹ A proper understanding of curiosity appears only to be possible at the interdisciplinary junction of all three.²²
Berlyne appeared to be just as strongly motivated by curiosity in his own life as he was motivated by it as a subject of study. He knew at least ten languages (and was fluent in six or seven of them) and was an accomplished pianist, as well as a jogger and traveler. At the time of his early death at fifty-two, he was on a quest to ride every subway in the world. Despite a prodigious and prolific output of articles and papers, he rarely worked on nights or weekends. There was too much else to do.²³
His ideas, in particular the agenda of reaching out to both neuroscience and information theory for clues, would inspire succeeding generations of psychologists for the latter half of the twentieth century, and in the twenty-first they would come full circle. Starting at the end of the 2000s and continuing through the deep-learning boom of the 2010s, it was the mathematicians and information theorists and computer scientists—stuck on the problem of intrinsic motivation in cases like Montezuma’s Revenge—who would be turning to his ideas for help.
At a broad level, he argued, humans’ intrinsic motivation seemed to entail three related but distinct drives: for novelty, for surprise, and for mastery. Each of these, in turn, has offered tantalizing ideas about motivation and learning that seem just as applicable, in this decade, to machines as to ourselves.
NOVELTY
The question that researches have usually been designed to answer is “What response will this animal make to this stimulus?” . . . As soon as the experimental situation is made more complex . . . a new question arises: “To which stimulus will this animal respond?”
—DANIEL BERLYNE²⁴
When I'm caught between two evils, I generally like to take the one I've never tried.
—MAE WEST²⁵
One of the concepts at the heart of human curiosity, of our intrinsic motivation, is novelty. In the absence of strong compelling incentives, we don’t act randomly, as simple reinforcement learners using epsilon-greedy exploration do. Rather, we are quite robustly, reliably, and predictably drawn toward new things.
In the mid-1960s, Robert Fantz of Case Western noticed that human infants as young as two months old would reliably spend less time looking at magazine pictures if they’d already been shown those pictures before.²⁶ What Fantz came to appreciate was that long before infants have the motor skills to explore the world physically, they are still capable of exploring the world visually—and are very clearly drawn to do so. This behavior—known as “preferential looking”—has become a cornerstone result in developmental psychology, one of the most striking characteristics of infant behavior.
Infants’ preference for looking at new things is so strong, in fact, that psychologists began to realize that they could use it as a test of infants’ visual discrimination, and even their memory.²⁷ Could an infant tell the difference between two similar images? Between two similar shades of the same color? Could an infant recall having seen something an hour, a day, a week ago? The inbuilt attraction to novel images held the answer. If the infant’s gaze lingered, it suggested that the infant could tell that a similar image was nonetheless different in some way. If the infant, after a week without seeing an image, didn’t look at it much when it was shown again, the infant must be able at some level to remember having seen it the week before. In most cases, the results revealed that infants were more cognitively capable earlier than had been previously assumed. The visual novelty drive became, indeed, one of the most powerful tools in psychologists’ toolkit, unlocking a host of deeper insights into the capacities of the infant mind.²⁸
It didn’t take long for the reinforcement-learning community to latch onto this idea of an intrinsic novelty preference, and to see what could be done with it in the computational domain.²⁹ One of the most straightforward ideas would be simply to count how many times a learning agent has been in a particular situation before, and then to have it prefer—all things being equal—to do the thing it had done the fewest times before. Richard Sutton, for instance, in 1990 suggested adding such an “exploration bonus” to the agent’s reward if it took an action it had never taken before, or one it had not tried in a long time.³⁰
There is a quite obvious fly in the ointment here, however. What does it mean to count the number of times we took “this action” in “this situation”? As Berlyne put it in 1960, “The word ‘new’ is used commonly in everyday speech, and most people seem to understand it without much difficulty. But when we ask what exactly it means to say that a stimulus pattern is novel and how novel it is, we face a whole succession of snares and dilemmas.”³¹
For simple environments like solving a maze or for very, very simple games, it is of course possible to simply keep a list of every single situation you encounter and add a tally mark each time you return. (Tracing a path through a maze in pencil essentially keeps this record on the maze itself.) This approach—keeping a giant table of every situation you’ve been in, what you did, and what happened—is known as “tabular” RL, and unfortunately it’s known for being totally infeasible in anything but a very small environment. Tic-tac-toe, for instance, is about as simple as a board game gets, and yet it has thousands of unique board positions.³² The total count of possible positions in the game of Go is a 170-digit number. All the computer memory in the world put together wouldn’t come close to storing that table.
Beyond these pragmatic issues, however, the deeper and more philosophical question, in more complex environments, is what it means to be in the “same” situation in the first place. In an Atari game, for instance, there are so many different ways that the pixels can appear that dutifully keeping track of every single screen you’ve ever momentarily encountered and slightly favoring novel ones is simply not helpful for generating interesting behavior. For games of reasonable complexity, you may be unlikely to ever see exactly the same set of pixels more than once. From that perspective, almost every situation is novel, almost every action untried. Even if you could store such a table, it wouldn’t be much of a guide.
When in the course of everyday human decision-making, someone says to us that they’ve “never been in that situation before,” we don’t normally take them to mean “at this exact latitude and longitude at this exact nanosecond with this exact sun-dappled pattern hitting my retina and this exact sequence of thoughts in my mind,” or else the statement would be effectively true by definition and robbed of all meaning. What we mean to refer to are the sometimes ineffable key features of the situation, and we judge its novelty by those.
In an Atari game, what we’d want would be some way to gauge whether the situation we are in—as represented by the pixels on the screen—was meaningfully similar to one we’d been in before. We’d want to be able to make connections across situations that share some deeper, non-trivial similarity.
At DeepMind in London, Marc Bellemare was interested in thinking about how this venerated but impractical idea of counting how many times you’d seen something before—known, appropriately, as the “count-based” approach—could be extended to more complex settings. In an Atari game like Frogger or Freeway, where you’re trying to cross a busy road, ideally each time you successfully cross it should increment a kind of “count” of how many times you’ve done so—even if the traffic itself was always in some new, random pattern at the time.
Bellemare and his colleagues were playing around with a mathematical idea called “density models,” and it seemed to show some promise.³³ The basic idea was to use unsupervised learning to make a model that could predict missing parts of an image from the surrounding context. (This is not unlike word2vec and similar language models, designed to predict missing words in a passage of text.) They could feed this density model all of the screenshots that the agent had seen thus far, and then use its predictions to assign a numerical probability score representing how “predictable” a new screen was, given what it had seen already. The higher the probability, the more familiar; the lower the probability, the more novel. It was an intriguing idea, but it was an open question how something like this might actually work in practice.
They began to do some experiments with an early-1980s Atari game called Q\*bert, in which you hop around a pyramid made of square tiles, turning each of them to a different color until you’ve gotten them all, before moving on to a brand-new, differently colored stage where you do the same. They had a randomly initialized, blank-slate DQN agent play Q\*bert from scratch, while they watched a meter on the left-hand side of the screen that gauged the “novelty”—as measured by the density model—of what the agent was seeing and experiencing.
At first—just as it is with us—everything was new. The meter was pegged at the maximum value. Every image on the screen registered as almost totally novel.
They trained the agent for several hours, allowing it to gradually get more adept at earning points (in the case of Q\*bert, 25 points for every tile it flipped). They checked back in and watched it play. The now somewhat experienced agent hops around, picking up points. The green bar of the novelty meter (technically the “inverse log probability”) barely flickers up from the bottom. The agent has seen it all before.
Bellemare found the training run in which the agent managed to complete the game’s first level for the very first time. He watched it in replay, wondering what would happen. Satisfyingly, as the agent begins to get close, that green bar starts creeping up again.
“Now,” says Bellemare, “as the agent is getting towards the end of the level, it starts to say, Hey, these situations are novel! I haven’t really been in this state before. This seems very new to me. And you have this very nice progression: as we’re getting closer and closer to finishing the game, this signal is going up.”³⁴
The agent hops down to the final tile, completing the level for the very first time. Suddenly, the whole screen flashes and strobes. The board resets to the next stage, with the pyramid of cyan tiles gone, and a totally new pyramid, this one bright orange, in its place. “And look at this!” Bellemare says. The green bar shoots all the way up. The novelty signal is practically off the charts. “Immediately the agent knows, I have never been here before.”
This density model was capturing, or so it seemed, a faithful notion of novelty in diverse, highly complex environments that were too big and too rich to actually count directly. “We looked at these results and we thought, there has to be something we can do with this.”
Now the question was, Could they use this model—they would dub it the “pseudo-count”—to motivate an agent to seek these novel states?³⁵ What would happen if you actually rewarded the agent, not just for scoring points, but simply for seeing something new? And would that, in turn, make for better agents, able to make faster progress than those trained only to maximize reward and occasionally mash buttons at random?
It was clear what the payoff would be if they succeeded. “We got really excited,” he says, “about trying to crack Montezuma’s Revenge.”
The temple in which Panama Joe finds himself trapped has twenty-four chambers. After the equivalent of playing the game day and night, without sleeping, for three weeks, the DQN agent that had shown itself capable of superhuman performance at dozens of other Atari titles had only made it to the second room—barely out of the starting blocks. There was a whole temple out there to explore, full of dangers and bereft of points; maybe an agent directly rewarded for seeing things it had never seen before was just the kind of agent likely to get somewhere no agent had ever been.
Bellemare and his group wagered that an agent given access to these novelty signals, if it treated them as supplementary rewards to the in-game points, would be far more motivated and more successful at playing the game. They tried it, and let it train for an equal amount of time as the original DQN agent—a hundred million frames, or nearly three weeks of 24/7 play. The difference was shocking.
The same DQN agent, trained with novelty-based rewards, was dramatically faster at getting the first key, and ultimately made it through not two but fifteen of the temple’s chambers.
Not only is the novelty-driven agent getting more points, it appears also to be exhibiting a different kind of behavior—a qualitative as well as quantitative difference. All that “preferential looking” can be harnessed to make it succeed in exploring terrain where rewards alone aren’t enough. And something about the novelty-driven agent just seems more relatable—more human, even. It is no mere joystick wiggler when rewards are scarce. It has a drive.
“Immediately,” Bellemare says, “the pseudo-count agent goes out and explores this world.”
THE PLEASURE OF SURPRISE
The mechanism of epistemic curiosity . . . works through the equivalent of conceptual conflict, and its function is an eminently motivational one.
—DANIEL BERLYNE³⁶
It is not that children are little scientists but that scientists are big children.
—ALISON GOPNIK³⁷
The other high-level concept integral to curiosity, along with novelty, is surprise.³⁸ A curious child cares not only that things are at some level “new,” but also that things have something to teach them. A baseball with purple polka dots on it—let’s say—is intriguing for a moment, but if it otherwise behaves exactly like a standard baseball, the intrigue will be short-lived. Rather, we maintain our interest in things that seem to defy our expectations, that behave unpredictably, that dare us to try to understand what will happen next.
One of the researchers on the forefront of understanding the role of surprise in human curiosity is MIT’s Laura Schulz. In a 2007 study, she had children play with a kind of jack-in-the-box toy, where levers would raise various puppets up through the lid of the box.³⁹ The researchers would briefly take the toy away, and then return with both the familiar box and a new, differently colored box. They would set them both in front of the child and walk away, waiting to see which one the child reached for.
“Now, everything we’ve known before about play and curiosity in children,” Schulz explains, “says, Well, if four-year-olds have been playing with one box for a while, then if you bring out a new box they should go right for the new box. They should go immediately to play with the new box because the basic idea about curiosity would be it’s about perceptual novelty, perceptual salience: this is something they haven’t seen.”⁴⁰
But there was more to it than that, Schulz found. In some trials, the demonstration of the first box was made deliberately ambiguous. The box had two levers, and if they were pressed simultaneously, two different puppets would just as simultaneously rise up out of the lid. It wasn’t clear what raising one of those levers alone, or the other, would do. Was one of the levers responsible for both puppets and the other ineffectual? Was each lever responsible for the puppet closest to it? Or the one on the opposite side? In these ambiguous cases, the four-year-olds didn’t immediately switch from the familiar toy to a novel one when given the chance. Instead, they persevered, reaching back for the two-lever box in order to figure out exactly how it worked.
“We often seem to be curious,” says Schulz, “about things that aren’t particularly novel—they just puzzle us.”⁴¹
So a picture began to emerge that surprise—uncertainty, the ability to resolve ambiguity, to gain information—was every bit a driver of children’s intrinsic motivation as novelty.
This idea has led to a second vein of research, every bit as rich, spanning both cognition and computing.
Schulz, working with Rutgers psychologist Elizabeth Bonawitz and a group of collaborators, did a further study using weighted blocks. Prior research had shown that around age six, children begin to have theories about how best to balance blocks of different sizes and shapes. Some children at that age assume (incorrectly) that blocks can always be balanced halfway between their two ends, even if the object is asymmetrical, while others theorize (correctly) that blocks are balanced at their center of mass, at a point closer to whichever is the thicker side. This led the researchers to use magnets to create blocks that could be made, ingeniously, to violate the assumptions of either group. When children played with blocks that behaved as they expected, their standard novelty bias crept in and led them to abandon the blocks in favor of another, newer toy when offered the chance. But the children for whom the blocks appeared to violate their theory of how blocks should balance—regardless of whether their theory was actually correct!—stayed riveted and continued playing with them, even when another toy was on offer.⁴²
Four- and five-year-olds, who tended to lack a concrete theory about how best to balance the blocks whatsoever, almost invariably preferred a new toy when it was available. No matter what the blocks’ behavior, it seemed the younger children didn’t know enough, or have strong enough beliefs or predictions, to be surprised.
Other research following in this vein—for instance, a 2015 study by Aimee Stahl and Lisa Feigenson of Johns Hopkins—has shown further that the way infants play with a toy is also related to the way in which a toy is surprising.⁴³ If a toy car is shown appearing to mysteriously float in midair, infants will play with it by lifting it up and dropping it. If, however, the car is shown appearing to mysteriously pass through a solid wall, the infant will play with it by banging it on the table. And in each case, the infant will choose to stay engaged with the surprising toy when offered a chance to try a new one. (A control group who doesn’t get to see the toy defy their expectations, reliably prefers the new toy.) Already by the age of 11 months, say Stahl and Feigenson, infants use “violations of prior expectations as special opportunities for learning.”
“It’s easy to look at a baby and see a blank slate,” says Feigenson. “But actually, babies have rich, sophisticated expectations about the world—maybe more than people give them credit for.” Babies, she argues, “use what they already know about the world to motivate or drive further learning, to figure out what they should learn more about.”⁴⁴
This idea, in computational terms—of an agent motivated not only by rewards but by trying to understand and predict the environment—is as old as reinforcement learning itself. And it has just as suddenly sprung into fruition.
Daniel Berlyne had seen some of the earliest experiments with machine learning in the 1950s, and mused about the use of surprise or misprediction as a reinforcer. “Further research may well be aimed at devising a problem-solving machine that will improve its technique in the light of its experience,” he wrote. “The reduction of mismatch or conflict would then have to be the reinforcing agent, causing the immediately preceding operations to move up in the machine’s order of precedence.”⁴⁵
German AI researcher Jürgen Schmidhuber has since 1990 been exploring the idea of agents that get reward from learning how their environment works—that is, from improving their ability to make predictions. “They may be viewed as simple artificial scientists or artists,” he explains, “with an intrinsic desire to build a better model of the world and of what can be done with it.”⁴⁶ For Schmidhuber, just as it was for Berlyne in the ’60s, this idea of learning has its mathematical roots in information theory and—to Schmidhuber’s mind in particular—the notion of data compression: that a more readily understood world is more concisely compressible.
In fact, for Schmidhuber the idea that we go through the world striving to better compress our representation of the world offers a “formal theory of creativity and fun.” He explains: “You just need to have a computational resource—and before learning a pattern, you need so many computational resources, and afterwards you need less. And the difference, that’s where you’re saving. And your lazy brain likes to save things. And—” He snaps his fingers. “That’s the fun!”⁴⁷
Like Berlyne, Schmidhuber is fascinated not by what people do in order to solve problems posed to them directly—how to win a game or escape a maze, for instance—but rather, what people do specifically in those times when there isn’t anything explicit to do.
Infants, he thinks, are the perfect examples of this. “Even when there is no immediate need to satisfy thirst or other built-in primitive drives, the baby does not run idle. Instead it actively conducts experiments: what sensory feedback do I get if I move my eyes or my fingers or my tongue just like that?”⁴⁸
As Schmidhuber notes, there is a fundamental tension at the heart of curiosity, almost a tug-of-war: As we explore an environment and our available behaviors within it—whether that’s the microcosm of an Atari game, the real-world great outdoors, or the nuances of human society—we simultaneously delight in the things that surprise us while at the same time we become harder and harder to surprise. It’s almost as if the mind comprises two different learning systems, set at cross-purposes to each other. One does its best not to be surprised. The other does its best to surprise it.⁴⁹
Why not, then, attempt to model this tension directly? A group from UC Berkeley, led by PhD student Deepak Pathak, set out in 2017 to build just such an agent. Pathak created an agent composed of two different modules—one designed to predict the outcome of a given action, rewarded when the reality matches its prediction, and the other designed to take maximally surprising actions, rewarded every time the predictor is wrong.⁵⁰
In Super Mario Bros., if you’ve just hit the jump button, you can expect to see Mario slightly higher on the screen in a moment, for instance—though only if you’ve tried it a few times already. If you’ve hit the down arrow, you can expect to see Mario crouch—but you may not be expecting that this will make Mario disappear down sewer pipes into a massive subterranean underworld! The crucial idea was to incentivize the agent to explore the game by making such surprises as delightful for the agent as they are for us—namely, by making these prediction errors into rewards. Doing anything whose outcome was surprising could be made just as good, and that action just as strongly reinforced, as an action that explicitly garnered points.
Pathak and his group looked at the kind of behavior that such a surprise reward might engender. Using a 3D maze environment (built with the engine of classic ’90s first-person shooter Doom), they placed their agent farther and farther away from a rewarding “goal” state in a number of mazes. The agents trained only on the explicit reward of discovering the goal had a tendency to simply “give up” if they couldn’t find it by random joystick wiggling and button mashing. The agents with surprise-based rewards explored the maze for its own sake: What’s around this corner? What does that distant room look like up close? As a result, these curious agents found their way to the goal in much more vast and complex mazes than the agents without this intrinsic drive.
Pathak’s Berkeley group teamed up with a group of researchers from OpenAI, and together they continued to explore this idea of using prediction error as a reward signal. Surprisingly, they found that a dramatic simplification of this architecture—replacing the network designed specifically to predict controllable aspects of the future with one designed to predict random features of the image on screen—worked just as well and in some cases even better.⁵¹ The researchers at OpenAI, led by Yuri Burda and Harrison Edwards, worked to refine this idea, which they dubbed random network distillation, or RND.⁵² It wasn’t long before they began to set their sights on Montezuma’s Revenge.
They turned their RND agent loose in the temple. Spurred by the intrinsic reward of surprise, it consistently managed to explore, on average, twenty to twenty-two of the temple’s twenty-four rooms. And in just one of their trial runs, the agent does something unprecedented. It makes it all the way to the twenty-fourth and final room, in the temple’s bottom-left corner, and escapes the temple.⁵³ Panama Joe steps through the final door and finds himself in front of a background of uniform blue filled with gems. He seems to fall through the sky. It’s the closest thing Montezuma’s Revenge offers to transcendence. The gems are worth a thousand points each—and it’s very surprising.⁵⁴
BEYOND REWARDS
It is becoming increasingly clear, then, that “intrinsic motivation”—conceived as novelty or surprise or some other related scheme—is an incredibly helpful drive for a system to have in order to augment the external rewards that come from the environment, particularly in cases where those external rewards are scarce or hard to come by.
Of course, from this perspective it is tempting to ask what might happen if we take this idea of algorithmic curiosity to its logical conclusion, and have reinforcement-learning agents that—paradoxically—don’t care about external rewards at all?
What might such an agent look like? What might it do?
Almost anyone who studies intrinsic motivation has wondered the same thing, and a picture is starting to emerge.
Marc Bellemare and his colleagues at DeepMind have continued to pursue the idea of extending count-based novelty bonuses into more complex domains, and in follow-up work they have investigated what they call “pushing the limits of intrinsic motivation.”⁵⁵ They amplified their agent’s novelty reward some 10- to 100-fold, and observed qualitative as well as quantitative shifts in behavior.
Expectedly enough, the agent’s behavior exhibited a kind of restlessness. Unlike pursuit of the in-game score, which often leads to a fairly stable and consistent set of best practices, for the “maximally curious” agent, the only reward is from this exploratory behavior, and those rewards aren’t stable—they disappear as parts of the game environment become more familiar.⁵⁶ So the agent keeps restlessly chasing after them rather than settling into a pattern.
What was less expected was how well the agent did at the game, having been divorced from the game score. The agents with hyperinflated novelty bonuses actually achieved state-of-the-art scores in four different games. Curiosity bred competence. Amazingly, the novelty rewards alone, with no access to the in-game score whatsoever, were sufficient to play many Atari games competently—as measured by the score to which they didn’t have access!
Of course, it must be said that games (good games, anyway) are designed to appeal to intrinsically motivated humans. The points, after all, are just more pixels, in a corner of the screen, about which human players can decide to care, or not. So at that level it makes sense that curiosity and a drive for exploration would prove to be a decent proxy for maximizing score, at least in most games. In Super Mario Bros., for instance, points are awarded for grabbing coins, breaking blocks, and jumping on enemies—but the point of the game is to move Mario forward to the right, where an unpredictable landscape awaits. In this sense, an intrinsically motivated agent is probably more aligned with the game’s intended mode of play than one driven to rack up these (ultimately meaningless) points.
Pathak’s group at Berkeley and Burda and Edwards’s group at OpenAI have continued to pursue these questions as well, teaming up on a large-scale, systematic study of learning with no extrinsic rewards whatsoever.⁵⁷
One of their most striking findings was that in most cases it’s not necessary to explicitly tell the agent whether it has died. If you’re trying to maximize extrinsic score, this is very useful indeed, as it’s both a final verdict on the score you did get, as well as an indicator that you can expect zero additional points from that moment onward (which is usually a disincentive to meet that same fate a second time). With a purely curiosity-driven agent, death simply means starting the game again from the beginning—which is very boring! The beginning of the game, being the most familiar part, is neither novel nor surprising. This is all the disincentive, it turns out, that the agent needs.⁵⁸
They also found an intriguing exception to the pattern of intrinsically motivated agents proving surprisingly adept at point scoring. The exception was Pong. An agent motivated purely by intrinsic rewards, one that cares nothing whatsoever about the score, plays the game not to score on the opponent, but rather to deliberately extend rallies as long as possible. The “reset” after a point is scored is essentially the same as the “reset” that occurs upon death in other games. Returning to the well-worn starting position is simply boring compared to the atypical and unusual positions that arise in a long rally.
The team was intrigued to see what might happen if such an agent was given the chance to play against a copy of itself. How would curiosity versus curiosity unfold in a zero-sum game? The answer: a non-zero-sum collaboration emerges, as both sides pursue the shared goal of moving away from the game’s well-trodden starting state. In other words: they rally and rally and never stop. “In fact,” the researchers write, “the game rallies eventually get so long that they break our Atari emulator.” The screen starts to glitch out, with spots of color flickering in random patches. The surprise-seeking agents, of course, are delighted.⁵⁹
The idea of unplugging the game score and creating an agent motivated only intrinsically may seem at some level like an odd experiment: the field of reinforcement learning has since its inception been orchestrated around the maximization of external reward. Why give up the one thing by which behavior is being measured?
The University of Michigan’s Satinder Singh, working with Michigan psychologist Richard Lewis and UMass Amherst’s Andrew Barto, explored this question philosophically, asking, “Where do rewards come from?”⁶⁰ They note that the evaluation of how good or bad some state of affairs is is done in the brain—not in the environment. “This view makes it clear,” they write, “that reward signals are always generated within the animal, for example, by its dopamine system. Therefore, all rewards are internal.”⁶¹
To play an Atari game using nothing but the pixels on the screen, of which you can make whatever you want—rather than mainlining some fiat reward signal—is, after all, exactly what it is actually like to play video games.
One of the most critically acclaimed computer games of the 2000s, Portal, involves the game’s AI repeatedly promising the player “a cake” for completing the game. Partway through, however, the player discovers ominous graffiti containing what would become the game’s most memorable catchphrase: “The cake is a lie.” Indeed, no cake is offered at the game’s end. Of course, this famous betrayal is undercut not only by the fact that it would have been a digital representation of cake at best, but because we aren’t playing the game under the illusion that there will be anything in it for us other than the pleasure of making progress, furthering the plot, and exploring the world of the game.
We don’t use the flashing lights on the screen as data that we can leverage to gain “real” rewards in that environment. The flashing lights, and whatever reaction they provoke in us, are all the reward there is. And that seems, judging by the number of hours we devote to video games, to be more than enough.
BOREDOM AND ADDICTION
As it happens, intrinsic motivation in RL is not only the source of these virtuous behaviors—in which one recognizes at least a glimmer of the human desire to know, to explore, to see what happens—it also holds a mirror image of human pathologies: both boredom and addiction.
I ask Deepak Pathak if the notion of boredom makes sense. Is it possible for an agent to get bored?
Absolutely, he says.
In the first level of Super Mario Bros., there is a chasm that his agent almost never figures out how to cross, because it requires the agent holding down the jump button for fifteen frames in a row; long sequences of precise actions are much more difficult to learn than shorter or more flexible patterns.⁶² As a result, the agent reaches the edge of the cliff and just . . . tries to turn around.
“So it just cannot cross it,” Pathak says, “so it’s like a dead end, the end of the world.” But the game is built so that there is no way to backtrack. The agent is stuck, and learns to do nothing at all.
There’s a more general ennui, too, that Pathak has observed. After his Super Mario Bros. agent has played the game long enough, “It just starts to stay in the beginning. . . . Because there is no reward anywhere—everywhere error is very, very low—so it just learns to not go anywhere.” The agent simply loiters at the very start of the game, unmotivated to do anything at all.
There is at least an iota of pathos here. A human who has grown bored with a game can stop playing, and usually will. We can swap the old game out for a new one or just turn off the screen and move on to something different altogether. In contrast, the agent is, almost cruelly, trapped inside a game it no longer has any drive to play.
Ever since there have been video games, there has been a subfield of study into the question of what makes them fun, and what makes one game more fun than another. There are obvious economic as well as psychological stakes in this.⁶³
It occurs to me that reinforcement learning has furnished us with a practical benchmark for not just how difficult a game is—how long it takes the agent to become proficient—but also how fun: how long the agent plays before losing interest and disengaging, or whether it elects to spend its time playing that game over another. It may well be the case that video games of the coming decades are heavily focus-grouped by intrinsically motivated RL agents.
Cognitive scientist Douglas Hofstadter, in his 1979 Pulitzer Prize–winning book Gödel, Escher, Bach, imagined the future of advanced game-playing programs, envisioning a link between game-playing competence, motivation, and intelligence:
QUESTION: Will there be chess programs that can beat anyone?
SPECULATION: No. There may be programs that can beat anyone at chess, but they will not be exclusively chess programs. They will be programs of general intelligence, and they will be just as temperamental as people. “Do you want to play chess?” “No, I’m bored with chess. Let’s talk about poetry.”
The quote looks hilariously dated now—and of course we know, with the benefit of hindsight, that it would be less than twenty years before IBM’s Deep Blue chess machine emerged victorious in 1997 over human world champion Garry Kasparov. Deep Blue was, indeed, exclusively a chess program—it was customized at the level of its hardware to do chess and chess only. It was certainly not generally intelligent; nor did it yearn to think about literature rather than chess.
But perhaps there is a kernel of something nonetheless fundamentally true here. Contemporary state-of-the-art reinforcement-learning systems really are general—at least in the domain of board and video games—in a way that Deep Blue was not. DQN could play dozens of Atari games with equal felicity. AlphaZero is just as adept at chess as it is at shogi and Go.
What’s more, artificial general intelligence (AGI) of the kind that can learn to operate fluidly in the real world may indeed require the sorts of intrinsic-motivation architectures that can make it “bored” of a game it’s played too much.
At the other side of the spectrum from boredom is addiction—not a disengagement but its dark reverse, a pathological degree of repetition or perseverance. Here, too, reinforcement learning has come to exhibit behaviors that are in some cases uncannily, uncomfortably human.
Researchers who study intrinsic motivation talk about what they call the “noisy TV” problem. What if there is a source of randomness or novelty in the environment that is essentially inexhaustible? Will the intrinsically motivated agent simply be powerless to resist it?
In concrete terms, imagine there were a source of unpredictable visual noise on the screen: a staticky TV is the classic example, though crackling flames or rustling leaves or rushing water would all qualify as well. If this were the case, each new and unpredictable configuration of light and shadow would act as a kind of endless curiosity jackpot. In theory, at least, an agent confronted with this should become instantly stupefied.
Most of the simple Atari games from the 1970s and ’80s, though, don’t happen to contain such sources of visual randomness, and so it hadn’t been demonstrated empirically. Pathak, Burda, and Edwards decided to bring the thought experiment to life and try it out. They created a simple 3D maze game, where the agent is required to explore the maze and find an exit. In one version of the game, however, there is a television screen on one of the walls of the maze. Furthermore, the agent is given the ability to press a button that changes the channel on the television. What would happen?
What happened is that the instant the agent comes within view of the TV screen, its exploration of the maze comes to a screeching halt. The agent centers the screen in its view and starts flipping through channels. Now it sees a video of an airplane in flight. Now it sees cute puppies. Now it sees a man seated at a computer. Now cars in downtown traffic. The agent keeps changing channels, awash in novelty and surprise. It never budges again.
Visual information isn’t the only source of randomness that can have these dangerous effects; so can something as simple as flipping a coin. This had almost a decade earlier weighed on the mind of DeepMind researcher Laurent Orseau, the first hire onto their Safety team, and who is now part of their Foundations research group. Long before the arrival of intrinsically motivated Atari-playing agents that could be turned instantaneously into couch potatoes, Orseau was thinking about a much more powerful agent, transfixed by a coin.
Orseau was thinking about a hypothetical agent he called the “knowledge-seeking agent,” an agent “whose goal is to gather as much information about the unknown world as possible.”⁶⁴ Orseau’s agent was based on a theoretical framework called AIXI, which imagines an agent capable of infinite computation. Such a mentally omnipotent agent could never exist in reality, of course, but it acts as a kind of reference point: If you could think forever before taking an action, which one would you take? Amazingly, a number of conceptions of an infinitely resourceful knowledge-seeking agent fell into complete degeneracy at the sight of a coin—“preferring to observe coin flips rather than explore a more informative part of their environment,” Orseau notes. “The reason for this is that these agents mistake stochastic outcomes for complex information.”⁶⁵
B. F. Skinner, when he wasn’t training pigeons, was fascinated by gambling addiction. The house always wins, on average, and psychology all the way back to Thorndike had been based on the idea that you do something more when it’s on balance good for you—and less when it’s bad. From this view, something like gambling addiction was impossible. And yet there it was, a presence in the real world, daring the behaviorists to make sense of it. “Gamblers appear to violate the law of effect,” Skinner wrote, “because they continue to play even though their net reward is negative. Hence it is argued that they must be gambling for other reasons.”⁶⁶ We now appear to have a pretty good candidate for what those other reasons might be.
Gambling addiction may be an overtaking of extrinsic reward (the house always wins, after all) by intrinsic reward. Random events are always at least slightly surprising, even when their probabilities are well understood (as with a fair coin, for instance).
In Chapter 4 we talked about the role of dopamine in encoding temporal prediction errors: cases where a reward is better or worse than expected. However, there have been some curious cases that don’t fit this pattern. Namely, there is growing evidence, since the turn of the century, that things that are novel and surprising trigger the release of dopamine, whether or not they have any “reward” associated with them at all.⁶⁷
Just as the reinforcement-learning community is discovering the value of making novelty and surprise function as rewards in their own right, the neuroscience community is uncovering such machinery at work in our own heads.
At the same time, it is increasingly clear how these mechanisms, which normally help us, can go awry. Reinforcement-learning agents can become addicted to changing channels and playing slot machines—and so, of course, can we. Because the outcome of actions like these is never exactly what we thought it would be, there is always something surprising about that activity, always seemingly something to “learn.” We don’t think of addiction as a surfeit of motivation, an overabundance of curiosity, but something along these lines may well be how it does, in fact, function.
ITS OWN SAKE
The computational study of intrinsic motivation offers us a powerful toolkit for making headway in difficult learning environments—Montezuma’s Revenge being just one example. At a deeper level, it also offers us a story, rooted in these empirical successes, for why we may have such striking motivations ourselves.
In better coming to understand our own motivations and drives, we then, in turn, have a chance for complementary and reciprocal insights about how to build an artificial intelligence as flexible, resilient, and intellectually omnivorous as our own.
Deepak Pathak looks at the success of deep learning and sees one glaring weakness: each system—be it for machine translation, or object recognition, or even game playing—is purpose-built. Training a huge neural network on a heap of manually labeled images was, as we have seen, the paradigm in which deep learning first truly showed its promise. Explicitly drilling a system to categorize images made a system that could categorize images. Fair enough, he says. “But the problem is, these artificial intelligence systems are not actually intelligent. Because they’re missing a key component which is very central to humans, which is this general-purpose behavior, or general-purpose learning system.”⁶⁸
To make a general-purpose system will require breaking out of this task-specific mind-set, he argues—and it will also require breaking down one crucial, conspicuous artifice: the enormous amount of explicit reward information these models require. An image-labeling system like AlexNet might require hundreds of thousands of images, each of them labeled by humans. That’s quite clearly not how we acquire our own visual skills early in life. Likewise for reinforcement learning, where in the world of Atari games, every tenth of a second the game tells you with perfect authority exactly how you’re doing. “It works very well, but it requires something, again, very, very weird,” he says, “which is this reward.”
Unplugging the hardwired external rewards may be a necessary part of building truly general AI: because life, unlike an Atari game, emphatically does not come pre-labeled with real-time feedback on how good or bad each of our actions is. We have parents and teachers, sure, who can correct our spelling and pronunciation and, occasionally, our behavior. But this hardly covers a fraction of what we do and say and think, and the authorities in our life do not always agree. Moreover, it is one of the central rites of passage of the human condition that we must learn to make these judgments by our own lights and for ourselves.
“The orthogonal agenda to just doing good exploration, for me, has always been to remove the reward altogether,” says Bellemare. “This is stepping outside of my usual range of comfort, but you know, I think the most interesting thing we can do with AI agents is to have them come up with their own objectives, if you will. There are safety questions here,” he acknowledges, “but I would like, as you say, my AI agent to be thrown into Montezuma’s Revenge and just play it because it likes to play it.”⁶⁹
“We were talking earlier about the ALE [Arcade Learning Environment] and how it’s been a great benchmark,” Bellemare says. “And to me in some sense we’re mostly done with the ALE. And we’re mostly done with maximizing scores.” For him, no high score that comes by way of epsilon-greedy button mashing, reinforced by point scoring, qualifies as intelligence—impressive though the results may be. “I actually think that we should be measuring intelligence in terms of how things behave—not in terms of reward function.” What would such behavior look like? This is one of the central questions that drives him.
Orseau’s work on knowledge-seeking agents also sketches what a mind motivated purely by the pursuit of knowledge might be like. An initial analysis is encouraging. An artificial agent motivated to maximize some kind of score, or achieve some goal state, will always be at risk of exploiting some loophole to do so; an even more intelligent agent may be inclined to hack the scoring system or to construct an escapist fantasy for itself where its goals are easier to achieve. Orseau emphasizes that while this seems like “cheating” to us, “it doesn’t have a sense of cheating. It’s just, ‘Well, I do actions to maximize my reward.’” He elaborates: “The agent doesn’t understand that it is something bad. It’s just that it tries many different actions, and then this works: so why not do it?”⁷⁰
The knowledge-seeking agent, though, can’t take any such shortcuts. Self-deception, in particular, holds no interest or appeal. “So imagine that you are modifying your observations. . . . Then what information do you gain? Nothing. Because you can predict what it’s going to be.”⁷¹ Because of this resilience, the knowledge-seeking agent “may therefore be the most suitable agent for an AGI in our own world, a place that allows self-modifications and contains many ways to deceive oneself.”⁷²
There are still reasons to hesitate before unleashing a superintelligent knowledge-seeking agent—seeking knowledge may involve commandeering various earthly resources in order to do so. But it is at least resilient to some of the most straightforward of traps. “If you could program it, I believe it would have an amazing behavior,” says Orseau. “Because it would try to make sense as quickly as possible of its environment. It’s basically the ultimate scientist. It would design experiments to try to understand what would happen. . . . I would really be curious to see how it would behave.”
The concept—and the ethics—of an intelligence guided chiefly or purely by curiosity is hardly a new idea; it predates not only the past decade but, indeed, the past millennium. In Plato’s famous dialogue Protagoras, Socrates reflects on this matter and puts it quite well indeed:
“Knowledge is a fine thing quite capable of ruling a man,” Socrates says. “If he can distinguish good from evil, nothing will force him to act otherwise than as knowledge dictates, since wisdom is all the reinforcement he needs.”⁷³
PART III
Normativity
7 IMITATION
I was six years old when my parents told me that there was a small, dark jewel inside my skull, learning to be me.
—GREG EGAN¹
Watch this.
—ELON MUSK TO PETER THIEL, IMMEDIATELY BEFORE LOSING CONTROL OF AND CRASHING HIS UNINSURED $1 MILLION MCLAREN F1²
In English, we say that to imitate something is to “ape” it, and we’re not the only ones; this seemingly arbitrary linguistic quirk appears again and again across languages and cultures. The Italian scimmiottare, French singer, Portuguese macaquear, German nachäffen, Bulgarian majmuna, Russian обезьянничать, Hungarian majmol, Polish małpować, Estonian ahvima: verbs for imitation and mimicry, again and again, have their etymologies rooted in terms for primates.³
Indeed, the simian reputation for being a great imitator, not just in etymology but in science, goes back a century and a half at the minimum. As nineteenth-century biologist (and friend of Charles Darwin’s) George John Romanes wrote in 1882, on the subject of “what Mr. Darwin calls ‘the principle of imitation’ ”:
It is proverbial that monkeys carry this principle to ludicrous lengths, and they are the only animals which imitate for the mere sake of imitating . . . though an exception ought to be made in favour of talking birds.⁴
Proverbial indeed, and across a surprising array of cultures and languages. And yet—ironically—this appears not actually to be true.
Primatologists Elisabetta Visalberghi and Dorothy Fragaszy, asking, “Do Monkeys Ape?,” took a hard look at the evidence and were forced to conclude, through both a literature review and experiments of their own, that the data showed, in fact, an “overwhelming lack of imitation” in monkeys. “The lack of imitation in monkeys,” they write, “is as apparent in tool-using behaviors as it is in arbitrary behaviors such as postures, gestures, or problem-solving.”⁵
Subsequent work by comparative psychologist Michael Tomasello asked the same question of our slightly nearer primate kin—“Do Apes Ape?”—and came to a similarly decisive conclusion, with the possible exception of chimpanzees, our very closest genetic relatives. (Exactly to what degree chimpanzees do imitate in the wild, or can imitate when trained by humans, remains a nuanced and somewhat unresolved issue.) “My answer to the more general question of whether apes ape,” says Tomasello, “is: only when trained by humans, either formally or informally, to do so (and then perhaps in only some ways).”⁶ So the primate reputation for imitation is more or less totally undeserved.
There is a primate, however, that is a natural, uncanny, prolific, and seemingly hardwired imitator.
It’s us.
In 1930, Indiana University psychologist Winthrop Kellogg and his wife, Luella, raised their infant son, Donald, alongside an infant chimpanzee named Gua for nine months, treating the two of them identically, like human siblings. In the book the Kelloggs wrote about the experience, The Ape and the Child, they noted that “because of the reputation of the chimpanzee as an imitator, the observers were on the alert from the start for the appearance of this sort of behavior. And yet, strange as it may seem, imitation in Gua was clearly less pronounced than in the boy.”
Donald was a prolific imitator indeed, of both parents and his “sibling.” At age seventeen months, he startled his father by pacing back and forth with his hands clasped behind his back—a spitting image of Winthrop himself in moments of deep concentration. More often, though, Donald imitated Gua, his playmate and peer. Even though Donald could already walk and, indeed, had hardly even crawled before learning to walk, he started to take after Gua and began crawling around on all fours. When a piece of fruit was nearby, Donald learned to grunt and bark the way Gua did. Slightly concerned, the Kelloggs soon called their experiment to an abrupt halt.⁷
Evidence that it is, in fact, we humans who are nature’s imitators par excellence has continued to mount. For instance, when you stick your tongue out at a baby, they will—less than an hour after birth—stick their tongue back out at you.⁸ The feat is all the more amazing considering that the child has never even seen themselves before—as UC Berkeley’s Alison Gopnik notes, “there are no mirrors inside of the womb”⁹—and so the imitation is “cross-modal”: they are matching how you look when sticking out your tongue to how they feel when doing so. All this in the first forty minutes.
This incredible capacity was first discovered by the University of Washington’s Andrew Meltzoff in 1977; the finding turned a generation of psychological received wisdom on its head. Legendary Swiss developmental psychologist Jean Piaget (who ranked second in influence only to Freud as measured by citations over the twentieth century)¹⁰ had written in 1937 that “during the earliest stages the child perceives things like a solipsist. . . . But step by step with the coordination of his intellectual instruments he discovers himself in placing himself as an active object among the other active objects in a universe external to himself.”¹¹
Meltzoff, while acknowledging the debt that all psychologists pay to the great twentieth-century Swiss psychologist, thinks that in this particular case, Piaget has it precisely backward. “We must revise our current conceptions of infancy,” he says. “The recognition of self–other equivalences is the foundation, not the outcome, of social cognition.”¹² Imitation, he says, is “the starting point for psychological development in infancy and not its culmination.”¹³
This proclivity to imitate others begins almost instantly, but it is far from mere reflex. There is a surprising level of sophistication to who, what, and when children imitate, as we are only in the last couple decades coming to understand.
For instance, they will imitate an adult’s action only if it does something interesting, rather than seems to have no effect.¹⁴ Young children also appear to have a special sense that it is other humans that “make stuff happen”; they won’t imitate the action if the object seems to move by itself, or if a robotic or mechanical hand does the motion.¹⁵ (This has intriguing implications for the feasibility of robot nannies and teachers.)
It also seems that babies are keenly aware of when they’re being imitated. There is a famous scene in the 1933 Marx Brothers film Duck Soup where Harpo pretends to be Groucho’s reflection in a mirror, matching his every movement. Meltzoff did a study just like this, where adults would either imitate a baby’s movements or simply go through a fixed series of movements planned in advance. Just like Groucho, the babies would concoct elaborate or unusual movements in order to test out whether the adult was indeed mimicking them.¹⁶
For Meltzoff, this deeply seated capacity to recognize ourselves in relation to others—whom we perceive in some fundamental way as like ourselves—is the beginning not only of psychological development but, as he puts it, “the kernel embryonic foundation for the development of social norms, values, ethics, empathy. . . . It’s a big bang. The initial beginning is this imitation of bodily movements.”¹⁷
OVERIMITATION
Imagine you’re showing someone how to, for instance, chop an onion, and you say, “Now try it like this,” then clear your throat and begin to demonstrate a cut. Your pupil observes you closely and, looking for your approval, clears their throat before making the same cut. They haven’t just imitated you; they’ve overimitated you, by including in the imitation acts that simply aren’t relevant or that have no ultimate causal impact on the task being performed.¹⁸
Researchers who study imitative behavior in humans and chimpanzees were surprised to discover that this sort of overimitation is much more frequent among humans than among chimpanzees. This seemed counterintuitive: How could it be that the chimpanzees were doing a better job at determining which actions were relevant and irrelevant, and then reproducing only the relevant ones?
One of the most revealing, and intriguing, studies involved plastic boxes with two locked openings: one on the top and one on the front. The experimenter demonstrated first unlocking the top opening, then unlocking the front, then reaching into the front to get a bit of food. When chimpanzees saw this demonstration using an opaque black box, they faithfully did both actions in the same order. But when the experimenters used a clear box, the chimpanzee could observe that the top opening had nothing whatsoever to do with the food. In this case, the chimpanzee would then go straight to the front opening, ignoring the top one altogether. The three-year-old children, in contrast, reproduced the unnecessary first step even when they could see that it did nothing.¹⁹
It was theorized that perhaps humans, in this instance, are simply slower to develop the relevant skill. Researchers shifted from studying three-year-olds to studying five-year-olds. The overimitation behavior was worse! The older children were more prone to overimitate than the younger children.²⁰ This made no sense. What on earth was going on?
The problem got stranger still. Researchers thought that the children were doing the overimitation to get the approval of the experimenter. They had the experimenter leave the room; it didn’t help. And when researchers asked the children, both age three and age five, whether they could tell which of the demonstrated actions they “had to do” and which were “silly and unnecessary,” the children could! But even when they’d gone through this process of showing the experimenter they knew the difference, they still reproduced both actions.²¹
Finally, the experimenters tried explicitly telling the children not to do anything “silly and extra.” It didn’t help. The children agreed to the instructions, then still overimitated.
Again, this seemed counterintuitive and almost paradoxical: that with increasing cognitive abilities, children exhibit an apparent “lessening of control, towards more ‘mindless’ blanket copying as [they] develop.”²²
One clue lay in a study of fourteen-month-olds by Hungarian psychologist György Gergely. Toddlers saw an adult, sitting at a table, lean forward to touch her forehead to a lightbulb, which made it light up. However, there was one crucial twist. Half the time, the adult’s arms were resting on the table, and the other half of the time, the adult, pretending to be cold, had wrapped herself in a blanket. Toddlers who saw that the adult’s arms were free reproduced the action exactly, bending forward to touch the lightbulb with their heads. But toddlers who had seen that the adult’s arms were occupied by holding the blanket simply reached out and touched the lightbulb with their hand.²³
There was something critical here. Barely over one year old, the toddlers were capable of assessing whether the experimenter had taken a strange action by choice or by necessity. There must have been some reason why this grown-up bent over and touched the light with her head—her hands were right there! If it seemed to have been a deliberate choice, they would reproduce it exactly. This showed the problem of overimitation in a new light. It was not “mindless” at all, not simply a slavish reproduction of the exact movement, but the opposite—a reasonable, sophisticated insight based on imagining the demonstrator as making rational choices and performing the action as easily and efficiently as possible.
Suddenly it began to make sense that such behavior increased from age one to three, and again from three to five. As children grow in their cognitive sophistication, they become better able to model the minds of others. Sure, they can see—in the case of the transparent cube—that the adult is opening a latch that has no effect. But they realize that the adult can see that too! If the adult can see that what they’re doing has no apparent affect, but they still do it anyway, there must be a reason. Therefore, even if we can’t figure out what that reason is, we’d better do that “silly” thing too.
The chimpanzee, in contrast, has no such sophisticated model of the human demonstrator. The logic seems to be much simpler: “The human is dumb and isn’t taking the best action to get the food. Whatever. I can see the best way to get the food, so I’ll just do that.”
Suddenly the apparent paradox unraveled. In a strange, artificial scenario like this one, the chimpanzee happened to be correct. But it was the human child, “over”-imitating, who was the more cognitively sophisticated, with access to a deeper level of insight about the matter. Indeed, adults—unless they’re doing laboratory studies—generally don’t, as a rule, do pointless actions when they know better. The infant looks silly taking two actions to get the food when one would do, but only because the grown-ups are being, in a sense, deceptive or insincere. Shame on them!
More recent work has established just how subtle these effects can be. Children are, from a very young age, acutely sensitive to whether the grown-up demonstrating something is deliberately teaching them, or just experimenting. When the adult presents themselves as an expert—“I’m going to show you how it works”—children faithfully reproduce even the seemingly “unnecessary” steps that the adult took. But when the adult presents themselves as unfamiliar with the toy—“I haven’t played with it yet”—the child will imitate only the effective actions and will ignore the “silly” ones.²⁴ Again it appears that seeming overimitation, rather than being irrational or lazy or cognitively simple, is in fact a sophisticated judgment about the mind of the teacher.
All of this serves to show the immense cognitive sophistication lurking behind what seems on the surface to be simple, rote imitation. The result is a newfound appreciation for the mental skills of toddlers, and a greater sense of the computational complexity of simply telling a machine-learning system to “watch this.”
IMITATION LEARNING
If we humans are uniquely equipped for imitation, that invites an obvious question: Why? What is it about imitation that makes it such a powerful tool for learning? There are, as it happens, at least three distinct advantages that learning by imitation has over learning by trial and error and by explicit instruction.
We have seen how machine-learning researchers have borrowed directly from psychology for ideas like shaping and intrinsic motivation. Imitation has proven no less rich a source of inspiration; indeed, it forms the bedrock for many of AI’s greatest successes in the twentieth and twenty-first centuries alike.
The first advantage imitation has is efficiency. In imitation, the hard-won fruits of someone else’s trial and error are handed to you on a silver platter. In fact, no small part of the advantage of learning by imitation is knowing that what you’re trying to do is even possible in the first place.
In 2015, famed rock climbers Tommy Caldwell and Kevin Jorgeson made history by completing the first successful ascent of Yosemite Valley’s legendary three-thousand-foot Dawn Wall—called by Outside magazine “the world’s hardest rock climb.”²⁵ It took eight years for Caldwell and Jorgeson to plan their route, experimenting on different pitches of the cliff’s face, trying to connect various doable segments and find a single feasible path all the way from the bottom to the top. The Dawn Wall was, in Caldwell’s words, “infinitely harder than anything I had even contemplated climbing” before.²⁶ The rock looks at first like a perfectly blank face, daring you to imagine some way to find purchase. What little purchase there is seems outright hostile to human flesh. “This is the hardest thing you could ever do on your fingers, climbing this route,” Caldwell says. “It’s just grabbing razor blades.”²⁷
The following year, the young Czech climbing sensation Adam Ondra was able to replicate their feat after just a few weeks of scouting and practice. He attributes much of that speed to having been shown not just the way to make it up the Dawn Wall, but the mere fact that it was possible at all—something that Caldwell and Jorgeson did not know when they began the arduous process of planning their ascent. Said Ondra:
The fact that Tommy and Kevin put all this effort—like, years and years of work . . . it’s so impressive. . . . There are so many sections, on the crux pitches, and even in some of the easier pitches—if you are there, you think, “No. This is impossible.” And only after studying every single tiny razor blade, sometimes the only possible [answer] comes to your mind. So it was so much easier for me to solve the puzzle of each individual pitch, because I knew that the guys did it. . . . They sent the route, and I was very proud to make the first repetition.²⁸
The first ascent took eight years of exhaustive search and self-doubt. The second ascent took a few weeks of study and rehearsal, buoyed by the confidence that no matter how impossible it looked, there was a way.
We saw earlier how the game Montezuma’s Revenge requires an absurd number of things to go right even to earn its first reward, and that even then, the path to successfully completing it is razor thin, the encouraging feedback rare, and the consequences of failure dire. It is like the reinforcement-learning equivalent of the Dawn Wall—a nearly blank, impassive surface that dares you to find purchase. Even using powerful techniques like novelty bonuses and intrinsic motivation, an enormous number of attempts are still required for an agent to learn the mechanics of the game and the pathway to success. But what if the agent didn’t have to explore the game for itself? What if it had a role model?
A group at DeepMind led by Yusuf Aytar and Tobias Pfaff, in 2018, came up with an ingenious idea. Might it be possible, they wondered, for an agent to learn how to play the game not by painstaking in-game exploration, but rather by . . . watching YouTube videos?²⁹
It was audacious, and just crazy enough to work. YouTube was full of videos of human players playing the game. Their agent could, in effect, learn the point values of various actions by first watching someone else take those actions first. Then, when it was turned loose to act for itself, it already had a basic idea of what to do. The first agent that trained to mimic these human players was, at the time, better than any agent trained with reinforcement learning on the game’s rewards alone. In fact, preceding the breakthroughs at the end of 2018 using intrinsic motivation, it was the very first artificial agent, with a little initial help and inspiration from its human role models, to get out of the temple.³⁰
The second critical thing that imitation confers is some degree of safety. Learning through hundreds of thousands of failures may work fine in the realm of Atari, where death is but a restart.³¹ In other areas of life, however, we don’t have the luxury of being able to fail hundreds of thousands of times in order to get things right. A surgeon, for example, or a fighter pilot, hopes to learn incredibly precise and elaborate techniques without ever making a critical mistake. Essential to this process is observing the live, recorded, or even hypothetical successes and failures of their forebears.
The third advantage of imitation is that it allows the student (be it human or machine) to learn to do things that are hard to describe. Nineteenth-century psychologist Conway Lloyd Morgan had this idea in mind when he wrote, “Five minutes’ demonstration is worth more than five hours’ talking where the object is to impart skill. It is of comparatively little use to describe or explain how a skilled feat is to be accomplished; it is far more helpful to show how it is done.”³² This is true when we are trying to articulate the actions we want: “Now bend your elbow at a twenty-seven-degree angle while flicking your wrist very quickly but not too quickly . . .” And it is just as true when we are trying to articulate the goals we want our pupil to pursue. In an Atari game, something like “maximize total score” or “complete the game as quickly as possible” may more or less suffice. But in real-world scenarios, it might be very hard to even communicate everything we want our learner to do.
Perhaps the canonical case for this is the car. We want to get from point A to point B as quickly as possible, though not by going over the speed limit—or, rather, not by going too far over the speed limit, unless for some reason we have to—and by staying centered in our lane, unless there’s a cyclist or a stopped car—and not passing cars on the right, unless it’s safer to do so than not to do so, and so on. It’s hard to try to formalize all of this into some kind of objective function that we then tell the system to optimize.
Better, in cases like this, to use what the Future of Humanity Institute’s Nick Bostrom calls “indirect normativity”³³—a way to get the system aligned with our desires without articulating them down to the last minutia. In this case, what we want is to say something like “Watch how I drive. Do it like this.”
This was, as it turns out, one of the very first ideas in self-driving cars—and, to this day, still one of the best.
STEERING
In 1984, DARPA began a project they called the Strategic Computing Initiative. The idea was to leverage the computing breakthroughs happening in the 1980s, and to turn that then-bleeding-edge technology into three specific applications. As Chuck Thorpe, just graduating with his doctorate in robotics from Carnegie Mellon at the time, recalls: “Why three? Well, one to keep the Army happy, one to keep the Air Force happy, one to keep the Navy happy.”³⁴ The Air Force wanted a “pilot’s associate”: a kind of automated copilot that could understand commands or requests spoken out loud by the pilot. The Navy was interested in what they called a “battle management” system that could help with scenario planning and weather prediction. That left the Army. What they wanted were autonomous land vehicles.³⁵
Thorpe successfully defended his doctoral thesis that September, telling his committee he was planning to take several weeks’ vacation and think about what he might be up to next. Instead, the director of the CMU Robotics Institute, Raj Reddy, in one breath congratulated him and said, “What you’re up to next is a meeting in my office starting in five minutes.” The meeting was about building autonomous vehicles for DARPA.
“That,” recalls Thorpe—that five-minute window—“was my break between finishing my thesis and starting my postdoc.”
“Vehicles” that were in some sense “self-driving” had by 1984 already been around for years, but to call the technology primitive would be perhaps too generous. Robotics pioneer Hans Moravec had, in his own PhD thesis at Stanford in 1980, enabled a robotic “cart” the size and shape of a desk on bicycle wheels to move itself around and avoid chairs and other obstacles using an onboard TV camera. “The system is moderately reliable,” Moravec wrote, “but very slow.”³⁶ How slow? The cart was programmed to move one meter at a time—“in lurches,” as Moravec put it. After one of these meter-long lurches, the cart would stop, take pictures, and think for ten to fifteen minutes before making its next, equally tentative maneuver. Its top speed was, therefore, capped at 0.004 miles per hour.
The robot was so slow, in fact, that it was completely flustered by the outdoors, because the sun’s angle would change so much between lurches that the shadows seemed to move bewilderingly.³⁷ As Thorpe recalls, “In fact, his system locked onto these nice, sharp-edged shadows and saw that they were moving, and saw that the real objects weren’t moving consistently with the shadows, decided it had more confidence in the shadows than in the real objects, and threw out the real objects and locked onto the shadows, and ran over his chairs.”
By 1984, Moravec had come to Carnegie Mellon, and Thorpe worked with him to get the time between lurches down from ten minutes to thirty seconds. That worked out to a top speed shy of a tenth of a mile per hour. It was progress.
At that time, the state-of-the-art computer was something called the VAX-11/784 (“VAXimus”), which was about eight feet wide and eight feet tall. Vehicles like Moravec’s cart would be attached to these computers by an “umbilical cord.” But to make a vehicle that could truly move around in the outside world would require bringing the computer along for the ride, which, in turn, also meant bringing along a power source for the computer. This ended up meaning a four-cylinder generator. It was going to take a lot more than a cart.
Thorpe and his group settled on a Chevy panel van, which was big enough for all of the gear and five graduate students. As Thorpe observed: “They were highly motivated to have high-quality software, because they were going to be—as the saying goes—first at the scene of the accident. You write much better software when you know you’re going to be riding.”
The project, dubbed Navlab 1, began in earnest in 1986; at that point the system could make a move every ten seconds (a quarter of a mile per hour).³⁸ Thorpe’s son Leland was born the same year, and as it happened, Leland ended up being the perfect foil for the robot. “When Navlab 1 was moving at a crawling speed, my son was moving at a crawling speed. When Navlab 1 picked up speed, my son was walking and learning to run. Navlab 1 got going a little faster; my son got a tricycle. I thought it was going to be a 16-year contest to see who was going to drive the Pennsylvania Turnpike first.”³⁹
That rivalry would come to a shockingly abrupt end, however, in favor of the machine. Thorpe’s graduate student Dean Pomerleau ended up putting together a vision system using neural networks. It blew away all of the other approaches the group had tried. “So in 1990,” says Thorpe, “he was ready to go out and drive the Pennsylvania Turnpike.”
They called the system ALVINN—Autonomous Land Vehicle in a Neural Network—and it learned by imitation.⁴⁰ “You would drive for a few minutes,” says Thorpe, “and it would learn: if the road looks like this, you turn the steering wheel like this, if it looks like that, you would turn the steering wheel like that. So if you trained it on the road that you were driving on, it was very good at spitting out steering wheel angles.”
Early one Sunday morning, when the light was good and there were very few other cars on the road, Pomerleau took ALVINN on the interstate. ALVINN steered all the way from Pittsburgh up I-79 to Erie, on the shores of the Great Lakes. “This was kind of revolutionary,” says Thorpe—not just the feat itself but the simplicity of the model that achieved it. ALVINN knew nothing about momentum or traction, could not recognize objects or predict future locations of itself or other cars, had no ability to relate what it saw in its camera feed to how itself was positioned in space, nor to simulate the effects of its actions. “People thought if you wanted to drive that fast,” says Thorpe, “you had to have Kalman filters, and clothoid models of the road, and detailed models of the dynamic response of your vehicle. And all Dean had was a simple neural net that learned: the road looks like this, you steer like that.”
As Pomerleau affirmed to a local news crew, “We don’t tell it anything except ‘Steer like I do. Learn to steer the way I am steering right now.’ ”⁴¹ In those days it took a refrigerator-sized computer, running on a 5,000-watt generator, which provided about a tenth of the processing power of a 2016-vintage Apple Watch.⁴² And ALVINN didn’t control the gas or brakes, which still had to be manually operated, nor could it change lanes or react in any particular way to the other cars on the road. But it worked, and took Pomerleau—steering like he had steered—to the Great Lakes in one piece.
One of the most natural ideas about how to train machines is to train them to imitate us, and this approach seems especially appealing in the domain of driving. The success of ALVINN hints at the broader viability of an approach like this. If we wanted to build a fully self-driving car, then rather than simply letting it loose on city streets to explore different driving behaviors randomly and learn by pure trial and error (terrifying), we might begin by giving the system a huge dump of real human driving and train it to imitate human decisions behind the wheel. Given a certain state of affairs—this speed, this image in the windshield, this image in the rearview mirror, etc.—the system can learn to predict what action a human driver took, be it press down on the gas, press down on the brake, turn the steering wheel, or do nothing.
This predictive approach turns the problem of driving into something almost perfectly analogous to the ImageNet competition of labeling images. Instead of being shown a picture and needing to categorize it as a dog, cat, flower, or the like, the system is shown a picture from the front dashboard and “categorizes” it as “accelerate,” “brake,” “turn left,” “turn right,” and so on. We’ve seen already how deep learning allows a system to generalize from images it’s seen to images it hasn’t seen; if AlexNet can correctly identify dogs it’s never been shown before, then that should encourage us to think that a car can, somehow, generalize from scenarios it’s experienced to new ones. Even if it hasn’t seen that exact road in that exact sun-dappled light with that exact traffic flowing on it, it should nonetheless—so the theory goes—generalize from its past experience and recognize what to do here.
The idea is that you never have to turn a fledgling self-driving car loose on city streets to explore policies on its own. Rather, you just record camera information and telemetry from the real human-driven cars on the streets every day, untold millions of hours of which could be captured in a single day, and eventually have a car that is a perfect mimic of human driving.
As UC Berkeley’s Sergey Levine describes to his Berkeley undergraduates: “So a very natural way to think about solving these kinds of sequential decision-making problems is basically the same way that we solve our standard computer vision problems. We collect some data, so we get a human to drive a vehicle. . . . We basically record the observations from the camera on their vehicle and record the steering commands that they make; that goes into our dataset, our training data. And then we’re going to just run our favorite supervised learning method—we’ll run, you know, stochastic gradient descent—to train a network. . . . Just treat this as though it was a standard supervised-learning problem. That’s a very reasonable thing to start with.”⁴³
Then, he explains, when it is time for the system to take control, it simply turns its predictions—“This is what I think a human driver would do in this situation”—into actions.
Levine pauses for a second. “Does anybody have any ideas about one thing that might go wrong with this?”⁴⁴
The hands shoot up.
LEARNING TO RECOVER
Imitation progresses with the acquired habits. In learning to dance, the deficiency of the association between the pupil’s movements and the sight of the master’s, renders the first steps difficult to acquire. The desired movements are not naturally performed at the outset. Some movements are made; . . . but the first actions are seen to be quite wrong; there is a manifest want of coincidence, which originates a new attempt, and that failing, another is made, until at last we see that the posture is hit.
—ALEXANDER BAIN⁴⁵
What would I do? I wouldn’t be in the situation.
—APPLE CEO TIM COOK, WHEN ASKED WHAT HE WOULD DO IN THE SITUATION CONFRONTING FACEBOOK CEO MARK ZUCKERBERG⁴⁶
It’s 2009, and twenty years after ALVINN but in the very same building, Carnegie Mellon graduate student Stéphane Ross is playing Super Mario Kart—or, rather, a free and open-source derivative called SuperTuxKart, featuring the Linux mascot, a lovable penguin named Tux.
As Ross plays the game, his computer is recording all of the images on screen, along with every twitch of his joystick. The data is being used to train a fairly rudimentary neural network, not all that much more complex than the one ALVINN used, to steer like Ross steers.⁴⁷ Ross takes his hands off the wheel and lets the neural network drive Tux around the track. In short order, Tux takes a turn too wide and drives straight off the road. Ross is back to the drawing board, and the drawing board doesn’t look good.
The problem is that no number of demonstration laps—he records a million frames of play, or about two hours of driving the course over and over and over—seems to make any difference. He hands the wheel over to the neural net, Tux gets off to a promising start, then wavers, veers, barrels off the road.
At its root, the problem stems from the fact that the learner sees an expert execution of the problem, and an expert almost never gets into trouble. No matter how good the learner is, though, they will make mistakes—whether blatant or subtle. But because the learner never saw the expert get into trouble, they have also never seen the expert get out. In fact, when the beginner makes beginner mistakes, they may end up in a situation that is completely different from anything they saw during their observation of the expert. “So that means,” says Sergey Levine, “that, you know, all bets are off.”
In SuperTuxKart, for instance, Ross was good enough at the game that all of the data he was feeding the program showed it, in effect, how to continue driving straight ahead on the center of the track. But once Tux, under the network’s control, got even slightly off-center or slightly askew, it was lost. The screen looked systematically different from anything it had seen Ross do. The reaction required differed sharply from normal, in-control, full-throttle driving, but it had never seen anything else. And no amount of Ross continuing to play the game expertly, lap after lap and hour after hour, could fix that.
The problem is what imitation-learning researchers know as “cascading errors,” and it is one of the fundamental problems with imitation learning. As Dean Pomerleau wrote during his work on ALVINN, “Since the person steers the vehicle down the center of the road during training, the network will never be presented with situations where it must recover from misalignment errors.”⁴⁸ How to teach an imitation learner to recover has been a long-standing problem.
If Pomerleau was going to trust the system with his life on his trip up to Lake Erie, then he was going to need to give it more than passive observations of his own, correct steering. This alone would mean that the system was only reliable as long as it never made a mistake. That was too much to ask, doing fifty-five miles per hour on the interstate for two hours.
“The network must not solely be shown examples of accurate driving,” wrote Pomerleau, “but also how to recover (i.e. return to the road center) once a mistake has been made.”⁴⁹ But how? One idea was for Pomerleau himself to swerve around during his training drives, to demonstrate to ALVINN how to recover from being slightly out of the lane center or pointed in slightly the wrong direction. Of course, this would require somehow erasing the beginning of the swerve from the training data, lest ALVINN learn to imitate the swerves themselves! The second problem, he realized, was that to train the network properly would require him to swerve as often, and in as diverse an array of situations, as possible. “This would be time consuming,” he concluded, “and also dangerous.”
Pomerleau came up with a different idea. He would fake it.
The images ALVINN processed were tiny and grainy—just 30-by-32-pixel, black-and-white images of the trapezoidal patch of asphalt immediately in front of the car. (Indeed, its field of view was so narrow and myopic that when it entered an intersection it would become totally disoriented, adrift in a vast sea of pavement.) Pomerleau took real images recorded from ALVINN’s camera and simply doctored them to skew the road slightly to one side or the other. These were then thrown into the training data with steering commands meant to nudge the car gently back toward the center of the lane and a straight-ahead bearing. It was a bit of a hack—and it only looked correct when the road surface was totally flat, without dips or hills—but, on I-79 anyway, it worked.
Ironically, the explosion of powerful deep-learning techniques in the past decade have made the “fake it” approach less and less feasible, as modern camera sensors take in too many images per second, at too high a resolution, with too wide a field of view, to be easily manipulated in this way. If the fake images are somehow systematically unlike the real things the car will see when it starts to drift, then you are in big trouble. It is a leap of faith, after all, to essentially wager your life on your Photoshop skills—and modern neural networks are effectively growing harder and harder to deceive.
Twenty years later, this problem of recovery was still unsolved as both a practical and a theoretical issue. “When you learn from watching somebody,” Stéphane Ross tells me, “you see some kind of distribution of examples that don’t necessarily match what you’re going to see” if you start taking your own actions in the world. There was something deeply rooted here, Ross thought: “because all machine learning relies on the assumption that your training and the test distribution are the same.” But Ross and his advisor, CMU roboticist Drew Bagnell, thought they might be able to crack it. “That got me super interested,” says Ross, “because that felt like a really fundamental problem to work on.”⁵⁰
Ross and Bagnell did a theoretical analysis, trying to understand the problem from a mathematical perspective, while checking their intuitions in the world of SuperTuxKart. In an ordinary supervised-learning problem, something à la ImageNet, the system, once trained, will have a certain likelihood of making an error with each picture it sees. Show it ten times as many pictures, and it will make, on average, ten times as many errors—in this sense, the errors scale linearly with the scope of the task. Imitation learning is far, far worse, they discovered. Because a single mistake could cause the system to see things it had never prepared for before, once it makes a first mistake, all bets are off. The error grows with the square of the size of the task. Running for ten times as long would produce a hundred times as many mistakes.⁵¹ The theoretical analysis was grim, but it left open a tantalizing possibility: Were there ways to get back to the safe world of merely linear mistakes? Of a car merely ten times as likely to crash when driving ten times as far? “We were really looking for the holy grail,” he says.
As it turns out, they found it. The key was interaction. The learner needed some way not only to observe the expert at the outset, but to go back to the teacher when necessary, and say, in effect: “Hey, I tried what you showed me, but this bad thing keeps happening. What would you do if you had gotten into this mess?”
Ross came up with two ways to get this kind of interaction to happen on the SuperTuxKart track.⁵² One way was to watch the (initially catastrophic) laps of the network with the joystick in hand. As Tux barreled around the course, Ross would move the joystick as he would have if he were playing. The second method was to have Ross and the network randomly trading off control of the car while both try to steer it at the same time. As he explains: “It’s like you’re still playing the game mostly normally, but in some random steps, then you don’t listen to the human control, you execute the learned control. And that kind of slowly decays over time—like you’re less and less in control. But there’s always the chance that it picks your control.” It’s awkward, a little unnatural, but it works. “You’re still definitely trying to play the game as you would [if you were] fully in control,” Ross says. “But it doesn’t necessarily pick your controls all the time to execute. It starts veering off, then you try to correct . . .” He chuckles. Over time, the car responds less and less of the time to your own steering commands—but the network gets better and better at doing what you would have done anyway. There are periods where you’re not sure whether you’re driving or not.
The amazing thing was, not only did both of these forms of interaction work—both on the whiteboard and on the SuperTuxKart track—but they required incredibly little feedback to do so. With static demonstrations alone, the learner was still crashing just as often after a million frames of expert data as it was after a couple thousand—it was just as hopeless after hours of tutelage as it was after only minutes. Yet using this interactive method—Ross named it “Dataset Aggregation,” or DAgger—the program was driving almost flawlessly by its third lap around the track. “Once we had that,” says Ross, “I was like, Wow, this is really awesome. It worked orders of magnitude better than the default approach.”
As soon as he graduated with his PhD, Stéphane Ross traded in the virtual pavement of SuperTuxKart for the real-world suburban streets of Mountain View, California, where he is currently a behavior prediction lead at the self-driving-car company Waymo, designing models to forecast how other drivers, cyclists, and pedestrians on the road will behave and react. “The level of reliability that we need is, like, orders and orders of magnitude more than anything we do in academia. So that’s where the real challenge is. Like, how do you make sure that your model works all the time—not just 95 or 99% of the time; that’s not even good enough.” It’s a tall order but a satisfying project. “This project, in particular, is probably one of the projects where you can have some of the biggest impact on the world, if it succeeds—for the benefit of the world. Just that, on its own, is good enough motivation to work in that area, and hopefully have that impact someday.”
Though the type of interactive feedback that DAgger involves is the gold standard theoretically, in practice we don’t have to jockey with our cars for control of the steering wheel in order to ensure that they learn to stay centered in their lanes. There are several even simpler ways that work just fine in practice to build real-world systems capable of recovering from minor errors.
A 2015 project by a group of Swiss roboticists took a clever approach to overcoming this problem while trying to build a drone that could fly itself up alpine hiking trails without getting lost in the woods. Whereas earlier work had attempted, as they put it, “to explicitly define which visual features characterize a trail,” they bypassed entirely the question of which parts of the image contained the trail, or exactly what trails look like, and trained a system to simply map directly from an image to a motor output. It would take in a 752-by-480-pixel image of some dirt and trees, and output “turn left,” “turn right,” or “go straight.” In a storyline that will by now feel quite familiar, years of careful research to handcraft visual features for “saliency” or “contrast,” and clever thinking about how to distinguish dirt, say, from tree bark, were thrown out the window wholesale and replaced with convolutional neural nets trained by stochastic gradient descent. All the hand-tailored work became instantly obsolete.
The team trained their system to imitate the path taken by a human hiker. What was unique, though, and clever, is what they did in order to enable their system to recover from mistakes. They strapped not one but three GoPro cameras to the hiker’s head: one pointed straight forward, and the others pointed left and right. They then told the hiker to walk as he normally would but to take care not to turn his head. They were thus able to generate a huge dataset of images of the trail and annotate the center camera feed with “go forward when you see something like this,” the left camera’s with “turn right when you see something like this,” and the right camera’s with “turn left when you see something like this.” They trained a neural network on the dataset, installed it in a quadrotor drone, and set it loose in the Swiss Alps. It appeared to have little trouble floating through the woods and following the trail. Again, the key insight is the need not only to show what the human expert did, but also to offer some guardrails, in the form of data for pointing a slightly off-kilter learner back on track.⁵³
A 2016 project from Nvidia’s deep-learning research group in Holmdel, New Jersey, put the same clever trick to work on the streets of New Jersey’s Monmouth County. Nvidia mounted three cameras on a car, with one pointed forward and the others pointed roughly thirty degrees left and right of center. This generated hours and hours of footage of what it would look like if a car were pointed slightly in the wrong direction. The team then fed that data to their system, with the correct prediction being “do what the actual human driver did, plus a small correction back to center.” With just seventy-two hours of training data, the system was safe enough to operate on the winding rural roads and multilane highways of Monmouth County under varying weather conditions without major incident. In a video released by the team, we watch as their Lincoln MKZ peels out from the parking lot of Nvidia’s deep-learning research building and heads onto the Garden State Parkway. “Is it still autonomous!?” asks an employee in the chase car. “It looks pretty good from here,” he says—then clarifies that it’s behaving better, at least, than the other, New Jerseyan–piloted cars on the parkway.⁵⁴
There are two ironies here worth noting in brief. It was in this very research building, in the late 1980s—when it was owned by AT&T Bell Laboratories—that Yann LeCun invented the convolutional neural network, trained by backpropagation, which is exactly what’s driving today’s self-driving cars.⁵⁵ And as it happens, I myself learned to drive on the roads of Monmouth County, New Jersey, regularly passing by that very building on my way to and from cross-country practice. I wish I could say I was as safe and trustworthy behind the wheel—driving that very same road—after having seen seventeen years of human driving, as the convolutional net was after seventy-two hours.
THE CLIFF’S EDGE: POSSIBILISM VS. ACTUALISM
One must perform the lower act which one can manage and sustain: not the higher act which one bungles. . . . We must not arrogate to ourselves actions which belong to those whose spiritual vision is higher or other than ours.
—IRIS MURDOCH⁵⁶
What would you do if you were me? she said.
If I were you-you, or if I were you-me?
If you were me-me.
If I were you-you, he said, I’d do exactly
what you’re doing.
—ROBERT HASS⁵⁷
Setting aside the question of recovering from small mistakes, the second problem with imitation as a learning strategy is that sometimes you simply can’t do what the expert can do. Imitation then would only mean starting something you can’t finish. In which case, you probably shouldn’t attempt to act like them at all.
Both real life and pop culture are strewn with examples of the novice attempting to simply mimic the expert, often with catastrophic results.
As chess grandmaster Garry Kasparov explains: “Players, even club amateurs, dedicate hours to studying and memorizing the lines of their preferred openings. This knowledge is invaluable, but it can also be a trap. . . . Rote memorization, however prodigious, is useless without understanding. At some point, he’ll reach the end of his memory’s rope and be without a premade fix in a position he doesn’t really understand.”
Kasparov recalls coaching a twelve-year-old player, running through the opening moves of one of the student’s games. Kasparov asked him why he’d made a particularly sharp and dangerous move in a complicated opening sequence. “That’s what Vallejo played!” replied the student. “Of course I also knew that the Spanish Grandmaster had employed this move in a recent game,” Kasparov says, “but I also knew that if this youngster didn’t understand the motive behind the move, he was already headed for trouble.”⁵⁸
This idea seems both intuitive and at some level paradoxical: doing what a “better” person would do may sometimes be a grave mistake. It is a surprisingly complicated story, and one with deep connections across ethics, economics, and machine learning alike.
In 1976, a particular question erupted to the forefront of ethical philosophy: To what degree do, or should, your own future actions influence the question of what the right thing is to do now?
Philosopher Holly Smith was at the University of Michigan, focused on working through the subtleties of what it means to be a utilitarian. She noticed something strange. “The question very naturally arises, if you’re a utilitarian, ‘If I do A now, is that going to produce the best possible consequences?’ Well, it’s just transparent,” she says, “that it’s going to depend on what I do next.”⁵⁹ The need to take your own future actions into account means you also need to consider your own future mistakes. And so Smith began writing about what she would call “moral imperfection.”⁶⁰
The thought experiment that she considered has come to be known as that of “Professor Procrastinate.”⁶¹ The premise is straightforward: Professor Procrastinate is both a professor and—you guessed it—an inveterate procrastinator. He is asked to read a student’s paper and offer feedback, which he is uniquely qualified to provide. But what would surely happen instead, should he agree, is that he’ll fritter the time away and never get the feedback to the student. This will be worse than simply declining, in which case the student could ask for (slightly less high-quality) feedback from someone else.
Should he accept?
Here diverge two different schools of moral thought: “possibilism”—the view that one should do the best possible thing in every situation—versus “actualism”—the view that one should do the best thing at the moment, given what will actually happen later (whether because of your own later deeds or some other reason).⁶²
Possibilism says that the best possible thing for Procrastinate to do is to accept the review and write it on time. This begins with accepting it, and so he should accept.
Actualism takes a more pragmatic view. By its lights, accepting the review inevitably results in a bad outcome: no review at all. Declining the review means a comparatively better outcome: a review by a slightly less well-qualified reviewer. The professor should do the thing that actually results in the best outcome; hence he should say no.
Smith was led to the conclusion that “one must sometimes choose the lower rather than the higher act.” She elaborates: “There seems little point in prescribing an act which puts the agent in a position to do great things if the same act also puts him in a position to do something disastrous, and he would choose the latter rather than the former.”
At the same time, Smith is quick to elaborate on the drawbacks of actualism. For one thing, she says, “Actualism gives you an excuse for bad action based on your own future moral defects.” Some forty years later, the theoretical debate simmers on. “I think many people will see it as still unresolved,” Smith says. “I think it’s fair to say it’s still a lively discussion.”⁶³
The discussion isn’t only theoretical, either. Among the twenty-first-century “effective altruism” movement, for instance, opinions vary about how much of a sacrifice someone ought to make in order to maximally help others.⁶⁴ Princeton philosopher Peter Singer famously said that neglecting to donate to charity was analogous to walking past a pond in which a child was drowning and doing nothing to help.⁶⁵ Even for those who more or less agree with this argument, there is some debate over how much to actually give. A perfect person, perhaps, could donate almost all of their money to charity while staying happy and upbeat and motivated, and inspiring to others. But even the devoted members of the “EA” movement, including Singer himself, are not such perfect people.
Julia Wise, a leader in the effective altruism community and the community liaison at the Centre for Effective Altruism, has made impressive commitments in her own life—giving 50% of her income to charity, for instance—but she emphasizes the value of not striving for perfection. “Give yourself permission to go partway,” she says.⁶⁶ She noticed, for instance, that her own commitment to veganism could not accommodate her deep love of ice cream—and so she felt she couldn’t be a vegan. What worked for her was becoming comfortable with the idea of being a vegan . . . who eats ice cream. That was something she could stick with.
Oxford philosopher Will MacAskill, cofounder of the Centre for Effective Altruism, doesn’t mince words on the question. “We should be actualists,” he says. “If you give away all of your savings at once today—which you could technically do—you’ll probably get so frustrated that you’ll simply stop giving in the future. Whereas if you decide to give 10% of your earnings, this commitment will be sustainable enough that you’ll continue doing it over many years in the future, resulting in a higher overall impact.”⁶⁷
Singer himself acknowledges that a sense of balance and proportion is presumably best over the long term. “If you find yourself doing something that makes you bitter, it is time to reconsider. Is it possible for you to become more positive about it? If not, is it really for the best, all things considered?” He points out, too, that “there are still relatively few effective altruists, so it is important that they set an example that attracts others to this way of living.”⁶⁸
Machine learning has its own version of the actualism/possibilism debate. One of the primary families of algorithms for reinforcement learning, as we discussed in Chapter 4, are methods that learn the “value,” expressed as the expected future rewards, of the various actions available to them. (This is referred to as the “Q-value,” short for “quality.”) For instance, a board-game agent would learn to predict its chance of winning upon making various moves, and an Atari-playing agent would learn to estimate the number of points it expects each action to lead to. With these predictions well tuned, it then becomes straightforward to simply take the action with the highest Q-value.
Here, though, there is an ambiguity worth unpacking. Should the Q-value contain the expected future rewards that you could earn from taking this action? Or the expected rewards that you would earn? For a totally perfect agent, there is no tension—but otherwise the prescriptions can vary sharply.
These two approaches to value learning are called “on-policy” and “off-policy” methods. On-policy methods learn the value of each action based on the rewards the agent will actually expect to get after taking that action and continuing to take actions according to its own “policy.” An off-policy agent, on the other hand, will learn the value of each action based on the best possible series of actions that could follow it.⁶⁹
In their seminal textbook on reinforcement learning, Richard Sutton and Andrew Barto talk about how an off-policy (“possibilist”) agent could get itself into trouble, precisely by always trying to do the “best thing possible.” Imagine a car, they say, that needs to drive itself from one spot along the edge of a seaside cliff to another. The shortest and most efficient path is just to follow the edge of the cliff. Indeed, provided the car is stable and steady enough, that is the best route to take. But for a self-driving car that’s slightly shaky or unsteady behind the wheel, this is flirting with disaster. The better move might be to take a more roundabout inland path, one that doesn’t require it to drive perfectly to succeed. This is actualism—and a car trained using on-policy methods would indeed learn to take the safer, surer route over the one with slightly higher reward but much higher risk.⁷⁰
Imitating one’s heroes or mentors—whether the imitator is human or machine—brings with it some of the dangers of possibilism, of off-policy valuation.⁷¹ In a chess context, learning the best move to play given grandmaster-level ability to handle its consequences may serve only to let the student bite off more than they can chew. In that case, studiously watching the expert play may simply not help—or worse. It’s one thing to know that in a particular chess position, say, sacrificing my queen leads to checkmate in ten moves. But if I can’t find the checkmate, I will have sacrificed my queen for nothing, and will almost certainly lose the game as a result.
Economists since the mid-twentieth century have discussed the “theory of the second best,” which argues, in effect, that knowing the right thing to do in a theoretical version of the economy, which obeys a number of mathematical assumptions, may have virtually no bearing in an economy that deviates from those assumptions even slightly. The “second-best” policy to follow, or action to take, may have virtually no resemblance to the best.⁷² OpenAI research scientist Amanda Askell, who works on ethics and policy, notes that the same line of argument likely applies equally well in her domain. “I think something similar could be said in ethics,” she says. “Even if the ideal agent follows moral theory X perfectly, the non-ideal agent uses a pretty different set of decision procedures.”⁷³
Cases like this should give any would-be imitator or role model pause. Imitation is at some level intrinsically possibilist, liable to bite off more than it can chew. It may be cute when our child mimes driving the car, or chopping vegetables, or performing veterinary medicine—but we intervene if we see them actually reach for the keys or knife (or maybe even the cat). The behavior we actually want to see may bear no resemblance to imitation: the “next best” thing to competent driving is getting into the passenger seat; to chiffonading herbs, setting the table; and to setting a broken paw, maybe just calling for Mom and Dad.
With machine imitators, too, we would do well to keep the theory of the second best in mind. If they are to learn from us, we must take care that they don’t inadvertently learn to initiate behaviors they can’t handle once begun. Once they’re expert enough, the issue may become moot. But until then, imitation may be a curse, and—in the words of user-interface designer Bruce Balentine—“it’s better to be a good machine than a bad person.”⁷⁴
AMPLIFICATION: SELF-IMITATION AND TRANSCENDENCE
My favorite player from the past is probably . . . myself, like three or four years ago.
—WORLD CHESS CHAMPION MAGNUS CARLSEN⁷⁵
A third fundamental challenge with imitation is that if one’s primary objective is to imitate the teacher, it will be hard to surpass them.
This was on the mind of one of the very first researchers in machine learning—in fact, the one who coined the term: IBM’s Arthur Samuel, who in 1959, as we briefly discussed earlier, developed a machine-learning system for playing checkers. “I fed into it a number of principles that I knew had something to do with the game,” he said, “though I didn’t know then, and don’t know now, precisely what their significance is.” The list included things like how many checkers you have, how many kings you have, how many moves are possible from your position, and so forth.⁷⁶
The program ended up capable of beating Samuel himself, despite using only the strategic considerations that Samuel had given it. Its unerring ability to look a number of moves ahead, combined with a trial-and-error fine-tuning of the relative importance to place on these various factors, led to a system that surpassed its own teacher. It was a sublime achievement for its time, one that, again as we discussed, single-handedly shot IBM’s stock price up overnight, and one of which Samuel was justifiably proud. But he nonetheless felt keenly aware that his project had hit a ceiling. “The computer now works according to my principles of checkers and does a fine job of shuffling these around to its best advantage,” he lamented, “but the only way to get it to play better checkers is to give it a better set of principles. But how? . . . At the moment, I’m the only man in the world who could teach the machine to play any better, and it’s already way out of my class.”
The more principled path forward, Samuel reasoned, was for the computer itself to somehow generate strategic considerations on its own. “If only the computer could generate its own terms! But I see little hope of that in the immediate future,” he said.⁷⁷ “Unfortunately, no satisfactory scheme for doing this has yet been devised.”⁷⁸
By the end of the twentieth century, the fundamental techniques for computer game playing had changed surprisingly little—as had their fundamental limitations. The machines were millions of times faster. Reinforcement learning had become a field unto itself. But the machines had not changed very much at all, it seemed, in their stubborn dependence on us.
By the 1990s, the IBM team working on chess supercomputer Deep Blue had created a value function much like the one Samuel had made for checkers some decades earlier. Working with human grandmasters, they attempted to enumerate and articulate all the factors that determine strength of a position: things like the number of pieces on each side, mobility and space, king safety, pawn structure, and on and on. Instead of using thirty-eight such considerations, however, as Samuel had, they used eight thousand.⁷⁹ “This chess evaluation function,” said team lead Feng-hsiung Hsu, “probably is more complicated than anything ever described in the computer chess literature.”⁸⁰ The critical question, of course, was how to somehow weight and combine those bewildering thousands of considerations into a single judgment of the quality of the position on the board. Exactly how many extra pawns were worth how much control of the center, or how much king safety? Getting the balance right would be crucial.
So how exactly were those thousands of considerations brought into balance? By imitation.
The Deep Blue team had access to a database of seven hundred thousand grandmaster games. They showed the computer position after position from these real games and asked it what move it would have played. Imitating the human moves became a target as they fine-tuned its value function. If, say, increasing the value Deep Blue assigned to possessing both bishops made it slightly more likely to play the same moves that the human grandmasters had played, then Deep Blue came to increase its value for the bishop pair.
This human-imitating combination of positional considerations, which were themselves derived from human experts, was married to the computer’s unerring calculation, blistering speed, and brute force. The machine was able to search through hundreds of millions of future board positions per second, and that, combined with its human-like evaluation, was enough to defeat human chess world champion Garry Kasparov in their storied 1997 match. “Garry prepared to play against a computer,” said Deep Blue’s project manager C. J. Tan. “But we programmed it to play like a Grandmaster.”⁸¹
From a philosophical perspective, some within the research community wondered if programs were ultimately being hindered, however, by this continued dependence on their human role models. In the world of computer checkers, the University of Alberta’s Jonathan Schaeffer had developed a program in the early 1990s that was so good that when it picked a move that differed from human grandmaster play, often its own idea was better. “Of course, we could continue to ‘improve’ the evaluation function so that it consistently plays the human moves,” he wrote. But “it isn’t obvious that this is a good thing to do.” For one thing, tuning the program to play more conventionally might negate its ability to surprise a human opponent. For another thing, it wasn’t clear that the methodology of imitation was useful once the program had reached the level of the best human players. “We found it difficult to progress any further,” Schaeffer admitted.⁸² His project was essentially stuck. A question hung over the field. As the 2001 volume Machines That Learn to Play Games put it, reflecting on Deep Blue’s success: “One important direction of future research is to establish the extent to which better imitating human expert moves corresponds to genuinely stronger play.”⁸³
Fifteen years later, DeepMind’s AlphaGo system finally realized Arthur Samuel’s vision of a system that could concoct its own positional considerations from scratch. Instead of being given a big pile of thousands of handcrafted features to consider, it used a deep neural network to automatically identify patterns and relationships that make particular moves attractive, the same way AlexNet had identified the visual textures and shapes that make a dog a dog and a car a car. The system was trained as Deep Blue had been: by learning to predict the moves made by expert human Go players in a giant, 30-million-move database.⁸⁴ It was able to get state-of-the-art prediction of human expert moves—57% accuracy to be precise, smashing the previous state-of-the-art result of 44%. In October 2015, AlphaGo became the first computer program to defeat a human professional Go player (in this case, the three-time European champion Fan Hui). Just seven months later, in March 2016, it defeated the eighteen-time international titleholder, and one of the strongest players of all time, Lee Sedol.
Once again, the computer that had transcended human play was nonetheless, ironically, an imitator at heart.⁸⁵ It was not learning to play the best moves. It was learning to play the human moves.
The successes of Deep Blue and AlphaGo alike were possible only because of mammoth databases of human examples from which the machines could learn. These flagship successes of machine learning created such worldwide shockwaves as they did because of the global popularity of those games. And it was the very popularity of those games that enabled those victories. Every move we’d ever made could and would be used against us. The computers wouldn’t have been nearly as impressive at playing a more obscure or unpopular game—because they wouldn’t have had enough examples to work from. Popularity thus served a double role. It had made the accomplishment significant. But it had also made it possible.
No sooner had AlphaGo reached the pinnacle of the game of Go, however, than it was, in 2017, summarily dethroned, by an even stronger program called AlphaGo Zero.⁸⁶ The biggest difference between the original AlphaGo and AlphaGo Zero was in how much human data the latter had been fed to imitate: zero. From a completely random initialization, tabula rasa, it simply learned by playing against itself, again and again and again and again. Incredibly, after just thirty-six hours of self-play, it was as good as the original AlphaGo, which had beaten Lee Sedol. After seventy-two hours, the DeepMind team set up a match between the two, using the exact same two-hour time controls and the exact version of the original AlphaGo system that had beaten Lee. AlphaGo Zero, which consumed a tenth of the power of the original system, and which seventy-two hours earlier had never played a single game, won the hundred-game series—100 games to 0.
As the DeepMind research team wrote in their accompanying Nature paper, “Humankind has accumulated Go knowledge from millions of games played over thousands of years, collectively distilled into patterns, proverbs and books.”⁸⁷ AlphaGo Zero discovered it all and more in seventy-two hours.
But there was something very interesting, and very instructive, going on under the hood. The system had not been shown a single human game to learn from. But it was, nonetheless, learning by imitation. It was learning to imitate . . . itself.
The self-imitation worked as follows: Expert human play in games like Go and chess is a matter of thinking “fast and slow.”⁸⁸ There is a conscious, deliberate reasoning that looks at sequences of moves and says, “Okay, if I go here, then they go there, but then I go here and I win.” In AlphaGo Zero, the explicit “slow” reasoning by thinking ahead, move by move, “if this, then that,” is done by an algorithm called Monte Carlo Tree Search (MCTS, for short).⁸⁹ And this slow, explicit reasoning is intimately married to a fast, ineffable intuition, in two different but related respects.
The first bit of “fast” thinking is that, prior to and separate from any explicit reasoning of this form, we have an intuitive sense of how good a particular position is. This is the “value function” or “evaluation function” we’ve been discussing; in AlphaGo Zero, this comes from a neural network called the “value network,” which outputs a percentage from 0 to 100 of how likely AlphaGo Zero thinks it is to win from that position.
The second bit of implicit, “fast” reasoning is that when we look at the board there are some moves we consider playing—some moves just “suggest themselves,” and many others simply do not. We deploy our slow, deliberate, “if this, then that” reasoning down the paths that our intuition has first identified as plausible or promising. This is where AlphaGo Zero gets interesting. These candidate moves come from a neural network called the “policy network,” which takes in the current board position as input and assigns a percentage from 0 to 100 to each possible move. What does this number represent? The system is making a bet on the move that it will, itself, ultimately decide to play.
This is quite a strange and almost paradoxical idea, and merits a bit of further elaboration. The policy network represents AlphaGo Zero’s guess, for each possible move, of how likely it will be to choose that move after doing an explicit MCTS search to look ahead from that position. The slightly surreal aspect is that the system uses these probabilities to focus the slow MCTS search along the series of moves it thinks are most likely.⁹⁰ “AlphaGo Zero becomes its own teacher,” DeepMind’s David Silver explains. “It improves its neural network to predict the moves which AlphaGo Zero itself played.”⁹¹
Given that the system uses these predictions to guide the very search whose outcome they are predicting, this might sound like the recipe for a self-fulfilling prophecy. In reality, each system—fast and slow—sharpens the other. As the policy network’s fast predictions improve, the slow MCTS algorithm uses them to search more narrowly and wisely through possible future lines of play. As a result of this more refined search, AlphaGo Zero becomes a stronger player. The policy network then adjusts to predict these new, slightly stronger moves—which, in turn, allows the system to use its slow reason even more judiciously. It’s a virtuous circle.
This process is known in the technical community as “amplification,” but it could just as easily be called something like transcendence. AlphaGo Zero learned only to imitate itself. It used its predictions to make better decisions, and then learned to predict those better decisions in turn. It began by making random predictions and random moves. Seventy-two hours later, it was the strongest Go player the world had ever seen.
AMPLIFYING VALUES
You should consider that Imitation is the most acceptable part of Worship, and that the Gods had much rather Mankind should Resemble, than Flatter them.
—MARCUS AURELIUS⁹²
For a growing number of philosophers and computer scientists concerned with the longer-term future, the prospect of flexibly intelligent and flexibly capable systems, into which we must impart extremely complex behaviors and values, raises not only technical problems but something much deeper.
There are two primary challenges here. The first is that the things we want are very difficult to simply state outright—even in words, let alone in a more numerical form. As the Future of Humanity Institute’s Nick Bostrom notes, “It seems completely impossible to write down a list of everything we care about.”⁹³ In this case, we have already seen how learning by imitation can succeed in domains where it is effectively impossible to explicitly impart every rule and consideration and degree of emphasis for what makes someone an expert driver or an expert Go player. Simply saying, in effect, “Watch and learn” is often impressively successful. It may well be the case that as autonomous systems become more powerful and more general—to the point that we seek to impart some sense of what it means not just to drive well and play well but to live well, as individuals and societies—we can still turn to something not unlike this.
The second, deeper challenge is that both traditional reward-based reinforcement learning and imitation-learning techniques require humans to act as sources of ultimate authority. Imitation-learning systems, as we’ve seen, can surpass their teachers—but only if the teachers’ imperfect demonstrations are imperfect in ways that largely cancel out, or only if experts who cannot demonstrate what they want can at least recognize it.
Each of these fronts offers a challenge as we look to the more distant future, to more powerful systems acting in more subtle and sophisticated real-world settings.
Some, for instance, worry that humans aren’t a particularly good source of moral authority. “We’ve talked a lot about the problem of infusing human values into machines,” says Google’s Blaise Agüera y Arcas. “I actually don’t think that that’s the main problem. I think that the problem is that human values as they stand don’t cut it. They’re not good enough.”⁹⁴
Eliezer Yudkowsky, cofounder of the Machine Intelligence Research Institute, wrote an influential 2004 manuscript in which he argues for imbuing machines not simply to imitate and uphold our norms as we imperfectly embody them, but rather, we should instill in machines what he calls our “coherent extrapolated volition.” “In poetic terms,” he writes, “our coherent extrapolated volition is our wish if we knew more, thought faster, were more the people we wished we were.”⁹⁵
In domains where there is a relatively clear external metric of success—in checkers or Go or Montezuma’s Revenge—machines can simply use imitation as a starting point for more traditional reinforcement-learning techniques, honing that initial imitative behavior by trial and error, and potentially eclipsing their own teachers.
In the moral domain, however, it is less clear how to extend imitation, because no such external metric exists.⁹⁶
What’s more, if the systems we attempt to teach are someday potentially more intelligent than we are, they may take actions we find hard to even evaluate. If a future system proposes, say, a reform of clinical trial regulations, we may not necessarily even be in a position to assess—after great deliberation, let alone in a tight iterative feedback loop—whether it does, in fact, conform to our sense of ethics or norms. So, again, how can we continue to train a system in our own image, once its behavior goes beyond our immediate ken?
Few have thought as deeply about this set of issues as OpenAI’s Paul Christiano. “I am very interested in really asking what solutions would look like, as you scale them up,” he says. “What is our actual game plan? What is the actual endgame here? That’s a question that relatively few people are interested in, and so very few people are working on.”⁹⁷
What Christiano realized, as early as 2012 and in research that continues to this day, is that we may—even in these most difficult of scenarios—be able to ratchet our way forward.⁹⁸ We saw, for instance, that AlphaZero has instant, fast-thinking judgments about the moves to consider, but uses slow-thinking Monte Carlo Tree Search to comb through millions of future board positions, to confirm or correct those hunches. The results of this slow thinking are then used to sharpen and improve its fast instincts: it learns to predict the outcomes of its own deliberation.⁹⁹
Perhaps, Christiano believes, this very same schema—what he calls “iterated distillation and amplification”—can be used to develop systems with complicated judgment, beyond, and yet aligned with, our own.
For example, imagine we are trying to lay out a new subway system for a big city. Unlike Atari, say, or Go, we can’t evaluate thousands of scenarios per second—in fact, a single evaluation could take months. And unlike Atari or Go, there is no external objective measure to appeal to—a “good” subway system is whatever people think it is.
We could train a machine-learning system up to a certain level of competence—by normal imitation learning, say—and then, from that point forward, we could use it to help evaluate plans, not unlike a senior urban planner with a staff of a handful of more junior urban planners. We might ask one copy of our system to give us an assessment of expected wait times. We might ask another to give us an estimated budget. A third we might ask for a report about accessibility. We, as the “boss,” would make the final determination—“amplifying” the work of our machine subordinates. Those subordinates, in turn, would “distill” whatever lessons they could from our final decision and become slightly better urban planners as a result: faster-working in sum than we ourselves, but modeled in our own image. We then iterate, by delegating the next project to this new, slightly improved version of our team, and the virtuous circle continues.
Eventually, believes Christiano, we would find that our team, in sum, was the urban planner we wish we could be—the planner we could be if we “knew more, thought faster, were more the planner we wished we were.”
There is work to be done. Christiano would like to find ways of doing amplification and distillation that will provably maintain alignment with the human user. For now, whether this is even possible remains an open question—and a hope. Small, preliminary experiments are underway. “If we can realize this hope,” Christiano and his OpenAI collaborators write, “it will be an important step towards expanding the reach of ML and addressing concerns about the long-term impacts of AI.”¹⁰⁰
Discussing his work on amplification, I ask Christiano, who has become a leading figure in the alignment research community, if he views himself as a role model of sorts for others interested in following a similar path. His answer surprises me.
“Hopefully it’s not a path people have to be following,” he says.¹⁰¹
Christiano elaborates that he was perhaps one of the last alignment researchers who first had to live a kind of double life before being able to work in AI safety directly: working on more conventional problems to get his academic credentials, while figuring out a way to do the work he felt was truly important. “I sort of had to go off on my own and think about shit for a long time,” he says. “It is easier to do academic work in the context of an academic community.” Only a handful of years later, that community exists.¹⁰² “So hopefully most people would be more in that situation,” he says. “There are a bunch of people thinking about these things; they can actually get a job . . . to just be doing what [they] care about.”
That’s the thing, perhaps, about being a trailblazer: it’s not so much that others will imitate your example to the letter, or follow directly in your footsteps, as that—because of your efforts—they won’t have to.
8 INFERENCE
University of Michigan psychologist Felix Warneken walks across the room, carrying a tall stack of magazines, toward the doors of a closed wooden cabinet. He bumps into the front of the cabinet, exclaims a startled “Oh!,” and backs away. Staring for a moment at the cabinet, he makes a thoughtful “Hmm,” before shuffling forward and bumping the magazines against the cabinet doors again. Again he backs away, defeated, and says, pitiably, “Hmmm . . .” It’s as if he can’t figure out where he’s gone wrong.
From the corner of the room, a toddler comes to the rescue. The child walks somewhat unsteadily toward the cabinet, heaves open the doors one by one, then looks up at Warneken with a searching expression, before backing away. Warneken, making a grateful sound, puts his pile of magazines on the shelf.¹
Warneken, along with his collaborator Michael Tomasello of Duke, was the first to systematically show, in 2006, that human infants as young as eighteen months old will reliably identify a fellow human facing a problem, will identify the human’s goal and the obstacle in the way, and will spontaneously help if they can—even if their help is not requested, even if the adult doesn’t so much as make eye contact with them, and even when they expect (and receive) no reward for doing so.²
This is a remarkably sophisticated capacity, and almost uniquely human. Our nearest genetic ancestors—chimpanzees—will spontaneously offer help on occasion—but only if their attention has been called to the situation at hand, only if someone is obviously reaching toward an object that is beyond their grasp (and not in more complex situations, like with the cabinet),³ only if the one in need was a human rather than a fellow chimpanzee (they are remarkably competitive with one another), only if the desired object is not food, and only after lingering in possession of the sought-after object for a few seconds, as if deciding whether or not to actually hand it over.⁴
What Warneken and Tomasello showed is that such helping behavior is “extremely rare evolutionarily” and far more pronounced in humans than in our closest cousins, emerging quite richly before even language. As Tomasello puts it, “The crucial difference between human cognition and that of other species is the ability to participate with others in collaborative activities with shared goals and intentions.”⁵
“Children are described as being initially selfish—only caring about their own needs—and it is upon society to somehow reprogram them into becoming altruistic,” says Warneken.⁶ “However, our research has shown that infants in the second year of life are already cooperative by helping others with their problems, working together, and sharing resources with them.”⁷
This requires not only the motivation to help but an incredibly sophisticated cognitive process: inferring the other person’s goals, often from just a small bit of behavior.
“Human beings are the world’s experts at mind reading,” says Tomasello. Perhaps the most impressive part of this expertise is our ability to infer others’ beliefs, but the foundation is inferring their intentions. Indeed, it is not until around age four that a child begins to know what others think. But by their first birthday, they are already coming to know what others want.⁸
Researchers are increasingly making the argument that our approach to instilling human values in machines should take the same tack. Perhaps, rather than painstakingly trying to hand-code the things we care about, we should develop machines that simply observe human behavior and infer our values and desires from that. Richard Feynman famously described the universe as “a great chess game being played by the gods. . . . We do not know what the rules of the game are; all we are allowed to do is to watch the playing.” The technical term for this in AI is “inverse reinforcement learning”—except we are the gods, and it is machines that must observe us and try to divine the rules by which we move.
INVERSE REINFORCEMENT LEARNING
In 1997, UC Berkeley’s Stuart Russell was walking to the grocery store when his mind wandered to the question of why we walk the way we walk. “We move in a very stereotyped kind of way, right? So if you watch the Ministry of Silly Walks sketch from Monty Python, you see that there are a lot of other ways you can walk besides the normal one, right—but we all walk pretty much the same way.”⁹
It can’t be simply a matter of imitation—at least it doesn’t seem likely to be. There’s not only very little interpersonal variation in the basic human gait—there’s also very little difference across cultures and, as far as we can tell, across time. “It’s not just ‘Well, that’s the way they were taught,’” Russell says. “That’s the way that that works, somehow.”
And yet this raises as many questions as it answers. “What do you mean ‘works,’ right? What is the objective function? People proposed objectives, like ‘I think I’m minimizing energy,’ or ‘I’m minimizing torque,’¹⁰ or ‘I’m minimizing jerk,’¹¹ or ‘I’m minimizing this’ or ‘I’m minimizing that,’ or ‘I’m maximizing this other,’ and none of them produce realistic-looking motion. This is used in animation a lot, right? Trying to synthesize someone who walks and runs who doesn’t look like a robot. And they all fail. And that’s why we use motion capture for all that stuff.”
Indeed, the entire field of “biomechanics” exists to answer questions like this. Researchers had long been interested, for example, in the various distinct gaits of four-legged animals: walk, trot, canter, gallop. It took the invention of the high-speed photograph in the late nineteenth century to settle the question of how exactly these different gaits worked: which legs were raised at which time and, in particular, whether a horse at a gallop is ever fully airborne. (In 1877, we learned that it is.) Then, in the twentieth century, the debate moved from the how to the why.
In 1981, the Harvard zoologist Charles Richard Taylor published a major paper in Nature showing that a horse’s transition from a trot to a gallop occurred in such a way as to minimize the total energy the horse was expending.¹² Ten years later, he published a major follow-up paper in Science saying no, after further evidence, the switch to the gallop is not about minimizing energy but, rather, appears to be about minimizing stress on the horse’s joints.¹³
Such were the thoughts on Russell’s mind as he walked to the grocery store. “I was walking down the hill from my house to Safeway,” Russell tells me. “And I was noticing that, because this was a downslope, your gait is slightly different than it is on the flat. And I was thinking, I wonder how I would be able to predict the difference in gait. Say I put a cockroach on a sloping . . .” He gestures with his hand. “How would the cockroach walk, right? Could I predict that? If I knew the objective, I could predict what the cockroach would do when I tip the thing.”
By the late 1990s, reinforcement learning had already emerged as a powerful computational technique for generating sensible behavior in various (and, in those days, rather simple) physical and virtual environments. It was also becoming clear through studies of the dopamine system, as well as foraging behavior in bees, that reinforcement learning could offer a strikingly apt framework for understanding human and animal behavior.¹⁴
There was just one problem. Typical reinforcement-learning scenarios assumed that it was totally clear what the “rewards” were that one was trying to maximize—be it food or sugar water in an animal behavior experiment, or the score of a video game in an AI lab. In the real world, the source of this “reward” was much less obvious. What was the “score,” as it were, for walking?
So, Russell wondered, walking down the wooded boulevard known as The Uplands in Berkeley, if the human gait was the answer—and reinforcement learning was the method by which the body had found it—then . . . what was the question?
Russell wrote a 1998 paper that served as something of a call to action. What the field needed, he argued, was what he called inverse reinforcement learning. Rather than asking, as regular reinforcement learning does, “Given a reward signal, what behavior will optimize it?,” inverse reinforcement learning (or “IRL”) asks the reverse: “Given the observed behaviour, what reward signal, if any, is being optimized?”¹⁵
This is, of course, in more informal terms, one of the foundational questions of human life. What exactly do they think they’re doing? We spend a good fraction of our life’s brainpower answering questions like this. We watch the behavior of others around us—friend and foe, superior and subordinate, collaborator and competitor—and try to read through their visible actions to their invisible intentions and goals. It is in some ways the cornerstone of human cognition.
It also turns out to be one of the seminal and critical projects in twenty-first-century AI. And it may well hold the key to the alignment problem.
LEARNING FROM DEMONSTRATIONS
For anyone who has ever struggled to divine the meaning or intention behind another’s actions—Are they flirting with me, or are they just a super friendly person? Are they upset at me for some reason, or just in a bad mood? Were they trying to do what they did, or was that simply an accident?—it can sometimes feel that there are a literally infinite number of things that any action can mean.
Computer science here offers consolation, but not cure. There are a literally infinite number of things that any action can mean.
In that theoretical sense, the problem is hopeless. Practically, the story is a bit happier.
Inverse reinforcement learning is, famously, what mathematicians call an “ill-posed” problem: namely, one that doesn’t have a single, unique right answer. There are huge families of reward functions, for instance, that are totally indistinguishable from the standpoint of behavior. On the other hand, by and large this ambiguity won’t matter, precisely because of the fact that one’s behavior won’t change as a result. For instance, the sport of boxing happens to use a “ten-point must” scoring system, where the winner of a round receives ten points and the loser receives nine points. If an apprentice boxer came to the mistaken conclusion that rounds were scored ten million points to nine million points, or ten-millionths of a point to nine-millionths of a point, or eleven points to ten, he would still know that the person with the higher total wins, and his boxing would be no different than that of someone who understood the “correct” scoring system. So the error is unavoidable, but also moot.¹⁶
Another, thornier question arises, however: What leads us to assume that the person’s actions mean anything at all? What if they aren’t trying to do anything whatsoever, and their actions reflect random behavior, nothing more?
In the first paper posing practical solutions to the IRL problem, Russell and his then–PhD student Andrew Ng considered some simple examples in order to show that the idea could work.¹⁷ They considered a tiny five-by-five grid in which the goal is to move the player to a particular “goal” square, and a video-game world in which the goal is to drive a car the top of a hill. Could an IRL system infer these goals simply by watching an expert (be it human or machine) playing the game?
Ng and Russell built a few simplifying assumptions into their IRL system. It assumed that the player never acted randomly and never made mistakes: that when it took an action, that action was, in fact, the best action possible. It also assumed that the rewards motivating the agent were “simple,” in the sense that any action or state that could be considered to be worth zero points should be considered to be worth zero points.¹⁸ Further, it made the assumption that when the player took an action, not only was that action the best thing to do, but any other action would be a mistake. This ruled out the possibility, for instance, of a game having multiple competing objectives, with a player choosing between them at random.
The assumptions were fairly strong, and the domains were too simple to be of any immediate practical use—they were a far cry from the complexity of the human gait—but IRL did work. The rewards inferred by the IRL system looked very similar to the real rewards. When Ng and Russell let the IRL system play the games by trying to maximize what it thought the rewards were, it got just as high a score—measured by the “real” points—as a system optimized for the real points directly.
By 2004, Andrew Ng had received his doctorate and was teaching at Stanford, advising his own then–PhD student Pieter Abbeel. They took another pass at the IRL problem, trying to increase the complexity of the environments and relax some of the inferential assumptions.¹⁹ As they imagine, whatever task we’re observing has various “features” that are relevant to that task. If we’re watching someone drive, for instance, we might consider the relevant features to be things like which lane the car is in, how fast it’s going, the following distance between itself and the car ahead of it, and so on. They developed an IRL algorithm that assumes that it will see the same pattern of these features when it drives for itself as it did in the demonstrations it observed. A very stripped-down, Atari-esque driving simulator showed promising results, with a computational “apprentice” driving in the game much like Abbeel did: avoiding collisions, overtaking slower cars, and otherwise keeping to the right-hand lane.
This was significantly different from the strict imitation approach we discussed in Chapter 7. After just one minute of demonstrated driving by Abbeel, a model trying to mimic his behavior directly had nowhere near enough information to go on—the road environment is too complex. Abbeel’s behavior was complicated, but his goals were simple; within a matter of seconds, the IRL system picked up on the paramount importance of not hitting other cars, followed by not driving off the road, followed by keeping right if possible. This goal structure was much simpler than the driving behavior itself, and easier to learn, and more flexible to apply in novel situations. Rather than directly adopting his actions, the IRL agent was learning to adopt his values.
It was time, they decided, to bring IRL into the full-blown messiness of the real world.
We saw in Chapter 5 how Ng had used the idea of reward shaping to teach an autonomous helicopter to hover in place and slowly fly stable paths, a feat that no computer-controlled system had been able to achieve. It was a major milestone, both in Ng’s career and for machine learning as a whole, but progress had stalled. “Frankly, we hit a wall,” Ng says. “There were some things we never could figure out how to get our helicopter to do.”²⁰
Part of the problem was that both hovering in place and following a fixed path at low speed were things for which traditional reward functions were fairly easy to specify. In the case of hovering, the reward was simply how close the helicopter’s velocity in every direction was to zero; in the case of path following, progress along the path was rewarded, and deviation penalized. The complexity of the problem wasn’t in specifying the goal, but rather in finding a way to teach the system how to use nothing but the torques of the rotor blades, and their pitch and angle, to actually do those things. And it was here that reinforcement learning had shown its power.
But for more complicated maneuvers and stunts, executed at higher speeds and invoking more complex aerodynamics, it was not so obvious how to even make a reward function by which the system could learn its behavior. Sure, you could simply draw a curve in space and tell the computer to try to fly that exact trajectory—but the laws of physics, particularly at high speed, might not allow it. The helicopter might have too much momentum at a given part of the curve, the stresses on the machine might be too great, the engine might not be able to generate enough power at the right time, and so forth. You would be setting the system up for failure—which, for a ten-and-a-half-pound helicopter moving at forty-five miles per hour, could also be expensive, not to mention dangerous. “Our attempts to use such a hand-coded trajectory,” the team wrote, “failed repeatedly.”²¹
But what you could do, they reasoned, is have a human expert fly the maneuver and use inverse reinforcement learning to have the system infer the goal the human was trying to achieve. By using this IRL approach, Abbeel and Ng, with their collaborator Adam Coates, were able by 2007 to demonstrate the first helicopter forward flip and aileron roll ever performed by a computer.²² This significantly notched forward the state of the art, and showed that IRL could succeed in conveying even real-world human intentions in cases when seemingly nothing else could.
But they were not content to rest on their forward-flipping laurels. What they wanted was to find a way to perform tricks that were so difficult not even their human demonstrator—expert radio-controlled-helicopter pilot Garett Oku—could do them perfectly. Abbeel, Coates, and Ng wanted to push their helicopter work to its delirious extreme: to make a computer-controlled helicopter capable of doing mind-bending stunts beyond the ability of a human pilot.
They had a critical insight. Even if Oku couldn’t perfectly execute a maneuver in its pure, Platonic form, as long as his attempts were good enough, then his deviations would at least be imperfect in different ways from one to the next. A system doing inverse reinforcement learning—rather than strict imitation—could make inferences about what the human pilot, through a collection of imperfect or failed attempts, was trying to do.²³
By 2008, their inferences from expert demonstrations led to a deluge of breakthroughs, tallying the first successful autonomous demonstrations of “continuous in-place flips and rolls, a continuous tail-down ‘tic-toc,’ loops, loops with pirouettes, stall-turns with pirouette, ‘hurricane’ (fast backward funnel), knife-edge, Immelmann, slapper, sideways tic-toc, traveling flips, inverted tail-slide, and even auto-rotation landings.”²⁴
The apex of their ambition was a helicopter maneuver generally regarded as the single most difficult of them all: something called the “chaos,” a move so complicated there was only one person alive who could do it.
The chaos was invented by Curtis Youngblood, the model helicopter world champion in 1987, 1993, and 2001; the 3D Masters champion in 2002 and 2004; and the US national champion in 1986, 1987, 1989, 1991, 1993, 1994, 1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2004, 2005, 2006, 2008, 2010, 2011, and 2012.²⁵ He is considered by many to be the greatest radio-controlled-helicopter pilot who has ever lived.
“I was trying to think at the time,” says Youngblood, “what was the most complicated controlled maneuver I could come up with.” He took what was already one of the most difficult maneuvers—the pirouetting flip—and envisioned doing it over and over while rotating.
Asked how many other pilots can consistently pull off the maneuver, Youngblood says none. “I at one time could do it; I can’t even do it today. . . . Someone asks me to do it, I wouldn’t be able to do a full one without practice.”
Part of the problem, he says, is that the maneuver is so complicated-looking that only fellow expert pilots can even appreciate the difficulty of what they’re seeing. “You’re usually show pilots,” he says. “You’re out there trying to impress the crowd. Crowd has no clue what you’re doing. So the fact that you do a true chaos or just a pirouetting flip, they don’t know the difference. So it usually pays off to no one to sit there and really, really learn it—other than to show off to the other top pilots that I can actually do this.”²⁶
By the summer of 2008, the Stanford helicopter had mastered the chaos, despite never having seen a single perfect demonstration—from Oku, Youngblood, or anyone. But the system saw them banging their stacks of magazines, as it were, into the cabinet doors. And then—pirouette-flipping again and again and again while rotating three hundred degrees at a clip, looking like a one-helicopter hurricane—it flung them open.²⁷
Meanwhile, different approaches to disambiguating behavior, and more complex ways to represent reward, have continued to extend the inverse-reinforcement-learning framework. In 2008, then–PhD student Brian Ziebart and his collaborators at Carnegie Mellon developed a method using ideas from information theory. Instead of assuming that the experts we observe are totally perfect, we can imagine that they are simply more likely to take an action the more reward it brings. We can use this principle, in turn, to find a set of rewards that maximizes the likelihood of our having seen the particular demonstration behavior we saw, while staying as uncertain as possible otherwise.
Ziebart put this so-called maximum-entropy IRL method to the test on a dataset of a hundred thousand miles of driving recorded from two dozen real Pittsburgh cabdrivers, using it to model their preferences for certain roads over others. The model could reliably guess what route a driver would take to get to a particular destination. Perhaps more impressively, it could also make reasonable guesses about where a driver was trying to go, based on the route they had taken thus far. (Ziebart notes that this might allow a driver to receive relevant notifications about road closures affecting their intended route without their ever having to actually tell the system their destination.)²⁸
Over the past decade, there has been a surge of work in robotics using what’s known as “kinesthetic teaching,” where a human manually moves a robot arm in order to accomplish some task, and the robotic system must infer the relevant goal in order to freely reproduce that similar behavior in a slightly different environment on its own.²⁹ In 2016, then–PhD student Chelsea Finn and her collaborators at Berkeley further extended maximum-entropy IRL by using neural networks to allow the reward function to be arbitrarily complex, and remove the need for its component features to be manually specified in advance.³⁰ Their robot, after twenty or thirty demonstrations, could do such human-like, and impossible-to-directly-numerically-specify, things as filling a dish rack with dishes (without chipping them) and pouring a cup of almonds into another cup (without spilling any). We are now, it is fair to say, well beyond the point where our machines can do only that which we can program into them in the explicit language of math and code.
KNOWING IT WHEN WE SEE IT: LEARNING FROM FEEDBACK
Inverse reinforcement learning has proven itself as a striking and powerful method to impute complex goals into a system, in ways that would simply not be feasible or even possible if we had to program the reward explicitly by hand. The only problem, though, is that the typical formulation requires an expert on hand who can give a demonstration (even if imperfect) of the desired behavior. The helicopter stunts required a competent pilot; the taxis required a driver; likewise, the dishes and almonds needed a human demonstrator. Was there another way?
There are a great many things in life that are very difficult to perform, but comparatively easy to evaluate. I may be such a terrible radio-controlled-helicopter pilot that I can’t even keep the machine aloft, and yet I can (with the possible exception of the chaos) recognize an impressive display of aerial acrobatics when I see one. As Youngblood notes, impressing a lay audience is more or less the point.
Were it possible for a system to infer an explicit reward function just from my feedback—my rating a demonstration of its behavior with a certain score, or my preference between, say, two different demonstrations—then we would have a powerful and even more general way to evince the things we want from machines. We would still have a means for alignment, that is, even when we can’t say what we want, and even when we can’t do what we want. In a perfect world, simply knowing it when we see it would be enough.
It’s a powerful idea. There are only two questions. Is it actually possible? And is it safe?
In 2012, Jan Leike was finishing his master’s degree in Freiburg, Germany, working on software verification: developing tools to automatically analyze certain types of programs and determine whether they would execute successfully or not.³¹ “That was around the time I realized that I really liked doing research,” he says, “and that was going well—but I also, like, really wasn’t clear what I was going to do with my life.”³² Then he started reading about the idea of AI safety, through Nick Bostrom and Milan Ćirković’s book Global Catastrophic Risks, some discussions on the internet forum LessWrong, and a couple papers by Eliezer Yudkowsky. “I was like, Huh, very few people seem to be working on this. Maybe that’s something I should do research in: it sounds super interesting, and there’s not much done.”
Leike reached out to the computer scientist Marcus Hutter at Australian National University to ask for some career advice. “I just randomly emailed him out of the blue, telling him, you know, I want to do a PhD in AI safety, can you give me some advice on where to go? And then I attached some work I’d done or something so he would hopefully bother to answer my email.” Hutter wrote back almost instantly. You should come here, he wrote—but the application deadline is in three days.
Leike laughs. “And you have to consider, like, none of my diplomas or anything were in English. I hadn’t done an English-language test. I had to do all of that in three days.” Also, Leike had to write a research proposal from scratch. Also, he happened to be on vacation that week. “I did not sleep much these three days, as you might imagine.”
Leike emphasizes: “By the way, this is really terrible advice on how to pick your PhD. I basically did almost no research, emailed one person out of the blue, and then decided that I would apply there. This is not how you should apply for PhD programs, obviously!”
By the end of the year, Leike had resettled in Canberra, and he and Hutter were off to work. He finished his doctorate in late 2015, studying Hutter’s AIXI framework (which we briefly touched on in Chapter 6) and documenting situations in which such an agent is liable to, as Leike put it, “misbehave drastically.”³³ With his doctorate in hand, he prepared to enter the AI safety job market: that is, to join one of the three or four places in the world where one could make a career working on AI safety. After a six-month stint at the Future of Humanity Institute in Oxford, he settled into a permanent role in London at DeepMind.
“At the time, I was thinking about value alignment,” says Leike, “and how we could do that. It seemed like a lot of the problem would have to do with ‘How do you learn the reward function?’ And so I reached out to Paul and Dario, because I knew they were thinking about similar things.”
Paul Christiano and Dario Amodei, halfway around the world at OpenAI in San Francisco, were interested. More than interested, in fact. Christiano had just joined, and was looking for a juicy first project. He started to settle on the idea of reinforcement learning under more minimal supervision—not constant updates about the score fifteen times a second but something more periodic, like a supervisor checking in. Of course it was possible to alter, say, the Atari environment so that it informed the agent about its score only periodically, rather than in real time, but the three had a feeling that if actual flesh-and-blood humans were providing this feedback, the paper would be much more likely to make a splash—and it would offer a clearer suggestion for the long-term project of alignment.
Christiano and his colleagues at OpenAI, along with Leike and his group at DeepMind, decided to put their heads (and GPUs) together to look deeply into this question of how machines might learn complicated reward functions from humans. The project would ultimately become one of the most significant AI safety papers of 2017, remarkable not only for what it found but for what it represented: a marquee collaboration between the world’s two most active AI safety research labs, and a tantalizing path forward for alignment research.³⁴
Together they came up with a plan to implement the largest-scale test of inverse reinforcement learning in the absence of demonstrations. The idea was that their system would behave within some virtual environment while periodically sending random video clips of its behavior to a human. The human was simply instructed to, as their on-screen instructions put it, “Look at the clips and select the one in which better things happen.” The system would then attempt to refine its inference about the reward function based on the human’s feedback, and then use this inferred reward (as in typical reinforcement learning) to find behaviors that performed well by its lights. It would continue to improve itself toward its new best guess of the real reward, then send a new pair of video clips for review.
One part of the project would be to take domains in which an explicit “objective” reward function does exist—the classic Atari games on which straightforward reinforcement learning had proven itself superhuman—and see how well they could get their agent to do without access to the in-game score, using nothing but its best guess from which video clips a human said were “better” than others. In most cases, the system managed to do decently well, though it generally failed to reach the superhuman performance possible with direct access to the score. In the racing game Enduro, however, which involves complicated passing maneuvers, inferring the score from human feedback actually worked better than using the game’s real score function—suggesting that the humans were, indirectly, doing a kind of reward shaping.
“If you have a setting where you have ground-truth reward, like in Atari, then this is super helpful,” says Leike. “Because then you can do diagnostics, right? You can actually literally check value alignment, in the sense of ‘How aligned is your reward model with the ground-truth reward function?’ ”
The teams also wanted to find something that a reinforcement-learning system could be trained to do that was totally subjective, something for which no “real” score existed, something so complicated or hard to describe that manually specifying a numerical reward would be infeasible, yet at the same time so recognizable that a human would instantly know it when they saw it.
They found something they thought might fit the bill. Backflips.
“I just looked at the robot body—I looked at all the robot bodies,” says Christiano, “and I was like, What is the coolest thing that one of these robots seems like they should be able to do?”³⁵
One of the virtual robots was called “hopper”; it looked like a disembodied leg with an oversized foot. “My first, most ambitious one,” Christiano says, “was like: This robot body seems like it ought to be able to backflip.”
The plan was set. They would take a simple robot in a virtual physics simulator called MuJoCo—a kind of toy world with very little except friction and gravity—and try to get it to do backflips.³⁶ It seemed like an audacious idea: “Just writhe around for a bit, people will watch different clips and say which one looks slightly more like performing a backflip, try to writhe a little bit more like that, and we’ll see what happens.”
Christiano settled in for the first of many several-hour sessions of watching pairs of video clips after pairs of video clips, picking again and again and again which one looked slightly more like a backflip. Left clip. Right clip. Right clip. Left clip. Right clip. Left clip. Left clip.
“Every time it made like a small step of progress, I was always very excited,” Christiano says. “Like, it started falling over and I was excited that even under random behavior it was falling over the right direction sometimes. Then I was excited when it was always falling the right direction.” Progress was marginal and incremental. He kept going. “Everything is very gradual,” he says, “because you’re, like, just pressing left. And right. So. Many. Times. Watching so many clips.”
“I think I was most excited, probably,” he recalls, “when it started sticking the jump.”
What happened—after a few hundred clips were compared, over the course of about an hour—was it started doing beautiful, perfect backflips: tucking as a gymnast would, and sticking the landing.
The experiment replicated with other people providing the feedback, and the backflips were always slightly different—as if each person was providing their own aesthetic, their own version of the Platonic backflip.
Christiano went to his weekly team meeting at OpenAI and showed off the video—“Look! We can do this thing,” he recalls telling them. “And everyone’s like, Man. That’s cool.”
“I was really happy about the results,” Leike says. “Because, a priori, it wasn’t clear that this was going to work at all.”
I tell them that what makes the result feel, to me, not just so impressive but so hopeful, is that it’s not such a stretch to imagine replacing the nebulous concept of “backflip” with an even more nebulous and ineffable concept, like “helpfulness.” Or “kindness.” Or “good” behavior.
“Exactly,” says Leike. “And that’s the whole point, right?”³⁷
LEARNING TO COOPERATE
Dylan Hadfield-Menell was newly arrived at UC Berkeley in 2013, having finished a master’s at MIT with roboticist and reinforcement-learning pioneer Leslie Kaelbling. He assumed that his PhD research, in Stuart Russell’s lab, would proceed more or less where his master’s work had left off, doing robotic task and motion planning. Russell, that first year, was away on sabbatical. He came back in the spring of 2014, and everything changed.
“We had this big meeting where we were talking about plans,” Hadfield-Menell says, “and he was laying out his research vision. He sort of said, ‘Well, there’s something to be said about this . . . ’ He didn’t call it value alignment, but: ‘What could actually go wrong if we succeed?’” Russell said he was starting to give some credence to longer-term concerns about AI: the more flexible and powerful learning systems we develop, the more important it becomes what, exactly, they learn to do. During his time in Paris, Russell had grown concerned. He returned to Berkeley resolute: there was advocacy to be done—and science.
“The research ideas came almost immediately,” Russell says.³⁸ “It seems the solution, what you want is AI systems that are value-aligned, meaning they have the same objective as humans. And I had already worked since the late nineties in inverse reinforcement learning—which is basically the same issue.”
I remark that there’s a certain irony that his twenty-year-old idea ended up being the foundation for his current AI safety agenda. His idle thoughts on the walk to Safeway became, twenty years later, a plan to avert possible civilization-level catastrophe. “That was a complete coincidence,” he says. “But, I mean, this whole thing is a whole series of coincidences, so that’s fine.”
In that first lab meeting, Russell told his students he thought there were a handful of concrete, PhD-worthy topics to explore. Hadfield-Menell continued his robotics work, but in the back of his mind he kept thinking about the alignment problem. Initially, part of the appeal was simply the intellectual thrill of a fresh set of unexplored problems and the chance to make a seminal contribution. That started to give way over time to a different feeling, he tells me: “It seems like this actually is important—and isn’t being paid attention to.” In the spring of 2015, he made the decision to redirect his doctorate, and by extension, his career.
“All of my shower thoughts at this point,” he tells me, “are about value alignment.”
One of his and Russell’s first projects together was revisiting the inverse-reinforcement-learning framework.
What Russell and Hadfield-Menell, working with Pieter Abbeel and fellow Berkeley roboticist Anca Drăgan, began to do was to reimagine IRL from the ground up. There were two things that jumped out at them.
The helicopter work, like nearly everything else in the field, was premised on a kind of divide between the human and the machine. The human expert pilot simply did their thing, and the computer made what sense it could from those demonstrations. Each operated alone and in a kind of vacuum. But what if the human knew from the outset that they had an eager apprentice? What if the two were consciously working together? What might that look like?
The other thing that stood out is that in traditional IRL, the machine took the human’s reward function as its own. If the human helicopter pilot was trying to perform a chaos, well, now the computer pilot tries to perform a chaos. In some cases, this makes sense: we want to drive to work and back home safely, and we’re happy if our car, say, takes on this set of goals and values more or less transparently as its own. In other cases, though, we want something a bit subtler. If we are reaching for a piece of fruit, we don’t want a domestic robot to, itself, acquire a hankering for bananas. Rather, we want it to do what an eighteen-month-old would do: see our outstretched arm and the item just out of reach, and hand it to us.³⁹
Russell dubbed this new framework cooperative inverse reinforcement learning (“CIRL,” for short).⁴⁰ In the CIRL formulation, the human and the computer work together to jointly maximize a single reward function—and initially only the human knows what it is.
“We were trying to think, What’s the simplest change we can make to the current math and the current theoretical systems that fixes the theory that leads to these sort of existential-risk problems?” says Hadfield-Menell. “What is a math problem where the optimal thing is what we actually want?”⁴¹
For Russell, too, this is no subtle reframing of the problem, but in some sense game, set, and match of the alignment problem. It is no less than overturning the most fundamental assumption of the field of AI, a kind of Copernican shift. For the last century, he says, we have tried to build machines capable of achieving their objectives. This has been implicit in almost all work in AI, with safety questions pivoting on how to control what their objectives should be—how to define wise and loophole-proof objectives. Maybe this whole idea needs to be overturned, he thinks. “What if, instead of allowing machines to pursue their objectives, we insist that they pursue our objectives?” he says. “This is probably what we should have done all along.”⁴²
Several fronts open up once a cooperative framing is introduced. Traditional machine learning and robotics researchers are now more keenly interested than ever in borrowing ideas from parenting, from developmental psychology, from education, and from human-computer interaction and interface design. Suddenly entire other disciplines of knowledge become not just relevant but crucial.⁴³ The framework of cooperation as inference—that we take actions knowing that another is trying to read our intentions—leads us to think about human and machine behavior alike in a different way.
Work on these fronts is active and ongoing, and there is still much being learned. But there are several key insights so far.
For one, if we know we’re being studied, we can be more helpful than we would be if we were acting naturally. “CIRL incentivizes the human to teach,” the Berkeley group writes, “as opposed to maximizing reward in isolation.”⁴⁴ We can explicitly instruct, of course, but we can also simply act in ways that are more informative, unambiguous, easily understood. Often we already do this without thinking, or without realizing that we are doing it.
It turns out, for instance, that the singsongy language adults often use when talking to infants (known as “motherese” or “parentese”) has a deeply pedagogical effect. Infants spoken to in parentese actually learn language faster—which seems, whether we realize it or not, to be the whole point.⁴⁵
Not just in language but also in our movements, we behave—often without realizing it—in a way that is keenly informed by the sense that our actions will be interpreted by others. Consider the easy-to-overlook complexity of handing an object to someone. We hold an object not in the most convenient place to hold it, and hold it far away from us, where the stresses on our arm are greater—and the other person realizes we’d never be doing that if not to signal that we want them to receive it.⁴⁶
The insights of pedagogy and parenting are being quickly taken up by computer scientists. The central idea runs in both directions. We want to act in ways that will be understandable to machines, and we also want our machines to act in ways that are “legible” to us.
One of the leading researchers on “legible motion” in robotics—indeed, the one who coined the term—is UC Berkeley roboticist Anca Drăgan.⁴⁷ As robots increasingly operate more closely and flexibly with humans, they must increasingly act not only in a way that is most efficient, or most predictable, but also most informative about their underlying goals or intentions. Drăgan gives the example of two bottles next to each other on a table. If the robot reaches in the most efficient way, it will not be obvious to us until quite late which bottle it is reaching for. But if it reaches its arm in a wide, exaggerated arc, we will quickly perceive that it is going to pick up the bottle on that particular side. In this sense, predictability and legibility are nearly opposite: behaving predictably presumes that the observer knows what your goal is; behaving legibly presumes they do not.
Aside from the importance of pedagogical behavior, the second insight emerging in this area is that cooperation works best when it is framed as an interaction, not as two separate and distinct “learn, then act” phases.
Jan Leike found this in his work on learning from human feedback. “One of the most interesting things for me from this paper was actually what ended up being just a footnote,” he says, “which are these reward-hacking examples.”
When the agent did all of its reward learning up front, and then did all of its optimization, it often ended in disaster. The agent would find some loophole and exploit it, and never look back. For instance, Leike was working on getting an agent to learn to play Pong using nothing but human feedback on video clips of the agent playing. In one trial, the computer learned to track the incoming ball with its paddle as if it were going to hit it, but then would miss it at the last second. Because it didn’t have access to the game’s real score, it was none the wiser that it was missing the single most critical step. In another trial, the computer learned to defend its side of the screen and return the ball, but never learned to try to score points, and so it simply produced long, extended rallies. “This is interesting from a safety perspective,” Leike says. “Because you want to understand how these things fail—and then what you can do to prevent that.” When the human feedback was interwoven along the course of the computer’s training, rather than entirely front-loaded, problems of this kind tended to go away.⁴⁸ That’s another argument that the strict “watch and learn” paradigm is probably best replaced with something more collaborative and open-ended.
MIT’s Julie Shah, who researches cooperative human-robot interactions in the real world, has come to a similar conclusion. “What I’ve been interested in for many years,” she says, “is how you can jointly optimize the learning process between a person and a machine.” Her work on human-robot teams led her to study the research literature about human-human teams, and how they can train most effectively. In human groups, incentives are of course important, but one rarely sees explicit micromanaging of rewards down to the task level. “If you’re training a system through interactive reward assignment, that’s a little closer to how you train a dog, usually, than how you teach a person to do a task,” she says.⁴⁹ Demonstration, too, doesn’t always cut it. “It’s a very effective way of one-way transfer of information from one person to another entity on how to perform the task,” Shah says. “But where it falls short is when you need to think about training interdependent action between the person and the machine.” It’s much harder to simply demonstrate something, after all, if it takes coordination and teamwork to do it in the first place.
Indeed, the verdict from studying human-human teams is clear. “There’s an established literature,” says Shah, “that essentially shows that explicitly commanding a person to do a task is one of the worst ways to train interdependent work between two people. You know, when you think of it, it’s like: Well, obviously! Right? . . . They are among the worst human team-training practices you can implement.”
“There are also good human studies,” she adds, “that say if you have multiple people trying to achieve the same goal, or same intention—everyone knows what that goal or that intention is—but your two people have different strategies for achieving that and their work needs to be interdependent, they’re going to perform much worse than if they have a suboptimal but coherent strategy.” In almost any team scenario—from business to warfighting to sports to music—it’s a given that everyone’s high-level goals are the same. But shared goals alone aren’t enough. They also need a plan.
What does work in human teams is something called cross-training. The members of the team temporarily switch roles: suddenly, finding themselves in their teammate’s shoes, they begin to understand how they can change their own actual work to better suit their teammate’s needs and workflow. Cross-training is something of a gold standard in human team training, used in military settings, industrial settings, medicine, and beyond.⁵⁰
Shah began to wonder: Could something like this work for human-robot pairs as well? Might the best practice for human-human teaming translate, more or less directly, into a robotics context? It just seemed like “a crazy idea,” she says. “It was almost like a little case study, like, you know, is this even helpful? It’s just kind of a wacky idea, so let’s explore it.”
So they did. They wanted to know, for one, whether cross-training could be competitive with the current state of the art for how machines can learn from humans. They also asked a second question, not present in more typical studies of this kind: Might it also help the human better learn how to work with (and teach) the robot?
Shah’s group created a real-world task for a human and robotic arm working together, which resembled the task of placing and driving screws on a manufacturing assembly (but without a real drill). They compared traditional feedback and demonstration methods to cross-training.⁵¹
“The outcomes were really surprising and exciting for us,” she says. “We saw improvements after cross-training in objective measures of team performance.” People were much more comfortable working alongside the robot concurrently, rather than stiffly taking turns; this led to less idle time, and more work getting done.⁵²
Perhaps equally importantly, and more intriguingly, they also saw subjective benefits. Relative to a control group doing more traditional demonstration and feedback learning, people who had done cross-training reported more strongly that they trusted the robot, and that the robot was performing according to their preferences.
Incredibly, the best practice in human-human teaming did, in fact, translate, suggesting that further insights may well be available for cross-pollination. “So this is an initial study with a relatively simple task,” Shah says, “but even in the simple task, we did see statistically significant benefits, which opens up an opportunity for us to explore a number of other different human team-training techniques, and how we can translate those to work in a human-robot team.”⁵³
COOPERATION, FOR BETTER AND WORSE
All this makes for a rather encouraging story. Human cooperation is grounded in an evolutionarily recent, and nearly unique, capacity to infer the intentions and goals of each other, and a motivation to help out. Machines can—and increasingly do—perform this same feat, learning from our demonstrations, our feedback, and, increasingly, by working alongside us.
As machines become increasingly capable, and as we become accustomed to working more closely with them, the good news is at least twofold. We have the beginnings of a computational framework for how machines might operate not just in lieu of a human, but in tandem with one. We also have a vast body of research on how humans work well with each other, and those insights are becoming increasingly relevant.
If we extrapolate the current state of the art, using frameworks such as Christiano and Leike’s deep reinforcement learning from human preferences and Russell and Hadfield-Menell’s CIRL, we might imagine a trajectory all the way forward into arbitrarily intelligent and capable machines, picking up on the arbitrarily subtle nuances of our every intention and want. There are a great many obstacles to be overcome, certainly, and limits to be reached, but a pathway forward begins to suggest itself.
At the same time, however, it is worth a note of caution. These computational helpers of the near future, whether they appear in digital or robotic form—likely both—will almost without exception have conflicts of interest, the servants of two masters: their ostensible owner, and whatever organization created them. In this sense they will be like butlers who are paid on commission; they will never help us without at least implicitly wanting something in return. They will make astute inferences we don’t necessarily want them to make. And we will come to realize that we are now—already, in the present—almost never acting alone.
A friend of mine is in recovery from an alcohol addiction. The ad recommendation engines of their social media accounts know all too much. Their feed is infested with ads for alcohol. Now here’s a person, their preference model says, who LOVES alcohol. As the British writer Iris Murdoch wrote: “Self-knowledge will lead us to avoid occasions of temptation rather than rely on naked strength to overcome them.”⁵⁴ For any addiction or compulsion, the better part of wisdom tells us—in the case of alcohol, say—that it’s better to throw out every last drop in our home than it is to have it around and not drink it. But the preference models don’t know this.⁵⁵ It’s as if the liquor store follows them to the toilet when all they want to do is sit for a moment, send some text messages, and look at cute pictures of their friends’ babies. It’s as if their own cupboard works for Anheuser-Busch.
I, for one, certainly try to be mindful of my online behavior. At least in browsers, anything that reeks of vice or of mere guilty pleasure—whether it’s reading news headlines, checking social media, or other digital compulsions I do without necessarily wishing to do more of them—I do in a private tab that doesn’t contain the cookies or logged-in accounts that follow me around the rest of the internet. It’s not that I’m ashamed; it’s that I don’t want those behaviors to be reinforced.
In these cases, we want a somewhat different directive than the typical one to infer my goals from my behavior and facilitate my doing more of the same. We want to say, in effect, “You must not infer that I want to be doing this because I am doing it. Please do not make this any easier for me. Please do not amplify it or reinforce it or in any way tamp down the desire path that leads this way. Please grow the briars behind me.”
I think there is an important policy matter here, at least as much as a theoretical one. We should take seriously the idea that users have a right both to see and to alter any preference model that a site or app or advertiser has about them. It is worth considering regulation to this effect: to say, in essence, I have the right to my own models. I have the right to say, That’s not who I am. Or, aspirationally, This is who I want to be. This is the person in whose interest you must work.
This is the delicacy of our present moment. Our digital butlers are watching closely. They see our private as well as our public lives, our best and worst selves, without necessarily knowing which is which or making a distinction at all. They by and large reside in a kind of uncanny valley of sophistication: able to infer sophisticated models of our desires from our behavior, but unable to be taught, and disinclined to cooperate. They’re thinking hard about what we are going to do next, about how they might make their next commission, but they don’t seem to understand what we want, much less who we hope to become.
Perhaps this will bring out our better selves, some may argue; humans do, it’s true, tend to act more virtuously when they feel they’re being watched. In any number of laboratory studies, when people are on camera, when there is a one-way mirror in the room, when the room is brightly as opposed to dimly lit, they are less likely to cheat.⁵⁶ Heck, even the suggestion of surveillance—a picture of another person on the wall, a painting of a human eye, a regular mirror—is enough to produce this effect.⁵⁷
This was part of the idea behind eighteenth-century philosopher Jeremy Bentham’s famous “panopticon” blueprint for a circular prison, with each cell arrayed around a guard tower, the inmates never knowing whether or not they were being watched. Bentham waxed about the purifying effects of, not even surveillance itself, but the suspicion of surveillance, calling his circular building a “mill for grinding rogues honest,”⁵⁸ and breathlessly enumerating its promise: “Morals reformed—health preserved—industry invigorated—instruction diffused—public burthens lightened . . . all by a simple idea in Architecture!”⁵⁹
On the other hand, it brings with it a potential chilling effect, and so much more. We don’t, after all, generally prefer non-prison life to resemble prison.
Less sinister, and no less of concern, the canonical mathematics of IRL assume that the human behavior comes from an “expert”—someone who knows what they want, and is doing (with high probability) the right things to obtain it. If these assumptions fail to hold, then the system is amplifying the clueless actions of a novice, or raising the stakes for behavior that ought to be tentative, exploratory. We crawl before we walk, and walk before we drive. Perhaps it is best that we don’t, as a rule, have mechanical conveyances amplifying our every twitch.
For better or worse, this is the human condition—now, and increasingly in even our optimistic prospects for the future. We will be, for good or ill, better known. The world will be, for good or ill, full of these algorithmic two-year-olds, walking up to us, opening the doors they think we might want opened, trying, in their various ways, to help.
9 UNCERTAINTY
Most of the greatest evils that man has inflicted upon man have come through people feeling quite certain about something which, in fact, was false.
—BERTRAND RUSSELL¹
I beseech you, in the bowels of Christ, think it possible that you may be mistaken.
—OLIVER CROMWELL
The spirit of liberty is the spirit which is not too sure that it is right.
—LEARNED HAND
It was September 26, 1983, just after midnight, and Soviet duty officer Stanislav Petrov was in a bunker outside of Moscow, monitoring the Oko early-warning satellite system. Suddenly the screen lit up and sirens began howling. There was an LGM-30 Minuteman intercontinental ballistic missile inbound, it said, from the United States.
“Giant blood-red letters appeared on our main screen,” he says. The letters said, LAUNCH.
“When I first saw the alert message, I got up from my chair,” Petrov said. “All my subordinates were confused, so I started shouting orders at them to avoid panic.”²
The siren went off again. A second missile had been launched, it said. Then a third. Then a fourth. Then a fifth.
“My cozy armchair felt like a red-hot frying pan and my legs went limp,” he said. “I felt like I couldn’t even stand up.”
Petrov held a phone in one hand and the intercom in the other. Through the phone, another officer was shouting at him to remain calm. “I’ll admit it,” Petrov said. “I was scared.”
The rules were clear. Petrov was to report the inbound strike to his superiors, who would decide whether to order a full retaliation. But, he says, “there were no rules about how long we were allowed to think before we reported a strike.”³
Something, Petrov felt, didn’t add up. He had been trained to expect that a US attack would be on a much larger scale. Five missiles . . . it just didn’t fit the profile. “The siren howled, but I just sat there for a few seconds, staring at the big, back-lit, red screen with the word LAUNCH on it,” he recalls.⁴ “All I had to do was to reach for the phone; to raise the direct line to our top commanders—but I couldn’t move.”
The early-warning system reported that the level of reliability of its alert was “highest.” Still, it just didn’t make sense. The United States had thousands of missiles, Petrov reasoned. Why send five? “When people start a war, they don’t start it with only five missiles,” he remembers thinking. It didn’t fit any scenario he’d been trained for. “I had a funny feeling in my gut,” he said.⁵
“And then I made my decision. I would not trust the computer. I picked up the phone, alerted my superiors, and reported that the alarm was false. But I myself was not sure until the very last moment. I knew perfectly well that nobody would be able to correct my mistake if I had made one.”
Asked by the BBC years later what he had thought were the odds of the alarm being real, he replied, “Fifty-fifty.” But he had not made a mistake. Several gut-wrenching minutes later, nothing happened. The ground-based radar that would have confirmed the missiles once they came over the horizon showed no activity. All was calm in the Soviet Union. It was a system error: nothing more than sunlight, reflecting off the clouds over North Dakota.
LIKE NOTHING YOU’VE EVER SEEN
There are more things in heaven and Earth, Horatio, than are dreamt of in your philosophy.
—HAMLET
Despite the Oko early-warning system’s self-reported “highest” reliability, Petrov sensed that the situation was odd enough that he had reason to distrust its conclusions. Thank God there was a human in the loop, as a hundred million lives or more were on the line.
The underlying issue, though—systems that not only make erroneous judgments but make them with outrageously high confidence—continues to worry researchers to this day.
It is a well-known property of deep-learning systems in particular that they are “brittle.” We saw how 2012’s AlexNet, when shown hundreds of thousands of images belonging to one of a number of categories, can, amazingly, pick up on patterns general enough so that it can correctly categorize cats, dogs, cars, and people it has never seen before. But there’s a catch. It categorizes every image you show it, including randomly generated rainbow-colored static. This static, it says, is a cheetah, with 99.6% confidence. That static is a jackfruit, with 99.6% confidence. Not only is the system essentially hallucinating, but it appears to have no mechanism to detect, let alone communicate that it is doing so. As a much-cited 2015 paper put it, “Deep Neural Networks Are Easily Fooled.”⁶
Closely related is the idea of so-called adversarial examples, where an image that the network is 57.7% confident is a panda (indeed, it is a panda) can be altered with imperceptible changes to its pixels, and suddenly the network is 99.3% confident that the imperceptibly different image is a gibbon.⁷
Many efforts are underway to think about what exactly is going wrong in cases like this, and what can be done about it.
Oregon State University computer scientist Thomas Dietterich thinks that a big part of this problem is owed to the fact that every single image that the vision system was shown during training was some object or other—a paintbrush, a gecko, a lobster. However, the vast, overwhelming majority of possible images—potential combinations of colored pixels—are simply nothing at all. Static. Fog. Noise. Random cubist lines and edges with no underlying form. A system like AlexNet, Dietterich argues, that is trained on images tagged as one of a thousand categories, “implicitly assumes that the world consists of only, say, a thousand different kinds of objects.”⁸ How should a system know better, when it has never seen a single image that was outside these categories, or ambiguously suggestive of many of them, or, more likely, simply “not a thing” at all? Dietterich calls this the “open category problem.”⁹
Dietterich, in the course of his own research, learned this lesson the hard way. He was working on a project doing “automated counting of freshwater macroinvertebrates”—in other words, bugs in a stream. The EPA and other groups use counts of various insects collected in freshwater streams as measures of the health of the stream and the local ecosystem, and many tedious hours are spent by students and researchers manually classifying and tagging which particular bug caught in the kick-net is which: stonefly, caddisfly, mayfly, and so on. Dietterich thought that, particularly given the recent breakthroughs in image-recognition systems, he could help. He and his colleagues collected samples of 29 different insect species, and trained a machine vision system that was able to correctly classify them with 95% accuracy.
“But in doing all of that sort of classic machine-learning work,” he says, “we forgot about the fact that when these guys are out in the stream collecting additional things, there are going to be many other species, and even other non-bugs, that will get captured in this process: bits of leaves and twigs and rocks and so on. And, you know, our system assumed that every image it saw belonged to one of these 29 classes. So if you stuck your thumb into the microscope and took a picture of it, of course it would assign it to the most similar class.”
What’s more, Dietterich realized that many of the design decisions his team had made to get good classification performance among those 29 known classes later backfired, once they started to consider the open category problem. For instance, the 29 bug species were most clearly differentiated by their shapes, and so Dietterich’s group opted to make their system process the images in black and white. But color, as it happened, even if it wasn’t particularly helpful at telling one bug from another, was critical in telling bugs from non-bugs. “We were really handicapping ourselves,” Dietterich says. These decisions haunted, and to some degree chagrined, him. “I still bear the scars,” he says.
In his Presidential Address to his colleagues at the annual Association for the Advancement of Artificial Intelligence (AAAI) conference, Dietterich discussed the history of the field of AI as having proceeded, in the latter half of the twentieth century, from work on “known knowns”—deduction and planning—to “known unknowns”—causality, inference, and probability.
“Well, what about the unknown unknowns?” he said to the auditorium, throwing down a kind of gauntlet. “I think this is now the natural step forward in our field.”¹⁰
KNOWING WHEN YOU DON’T KNOW
Leave exceptional cases to show themselves, let their qualities be tested and confirmed, before special methods are adopted.
—JEAN-JACQUES ROUSSEAU¹¹
Ignorance is preferable to error; and he is less remote from the truth who believes nothing, than he who believes what is wrong.
—THOMAS JEFFERSON¹²
One of the causes for the infamous brittleness of modern computer vision systems, as we’ve seen, is the fact that they are typically trained in a world in which everything they’ve ever seen belongs to one of a few categories, when in reality, virtually every possible pixel combination the system could encounter would resemble none of those categories at all. Indeed, traditionally systems are constrained such that their output must take the form of a probability distribution over those finite classes, no matter how alien the input. No wonder their outputs make little sense. Shown a picture of a cheeseburger, or a psychedelic fractal, or a geometric grid and asked, “How confident are you that this is a cat, as opposed to a dog?,” what kind of answer would even make sense? Work on the open category problem is meant to address this.
The other problem, though, apart from the lack of a “none of the above” answer, is that not only do these models have to guess an existing label, they are alarmingly confident in doing so. These two problems go largely hand in hand: the model can say, in effect, “Well, it looks way more like a dog than it does like a cat,” and thus output a shockingly high “confidence” score that belies just how far from anything it’s seen before this image really is.
Yarin Gal leads the Oxford Applied and Theoretical Machine Learning Group and teaches machine learning at Oxford during the academic year—and at NASA during the summer. His first lecture, he tells me with a grin—before any code is written or theorems proved or models trained—is almost entirely philosophy.¹³
He has the students play games where they must decide which side of various bets to take, figuring out how to turn their beliefs and hunches into probabilities, and deriving the laws of probability theory from scratch. They are games of epistemology: What do you know? And what do you believe? And how confident are you, exactly? “That gives you a very good tool for machine learning,” says Gal, “to build algorithms—to build computational tools—that can basically use these sorts of principles of rationality to talk about uncertainty.”
There’s a certain irony here, in that deep learning—despite being deeply rooted in statistics—has, as a rule, not made uncertainty a first-class citizen. There is a rich tradition, to be sure, of theoretical work exploring probability and uncertainty, but it is rarely central in actual engineered systems. Systems are made to classify data or take actions within some simplified environment, but uncertainty is not generally part of the picture.
“Let’s say I give you a bunch of pictures of dogs and ask you to build a dog breed classifier,” Gal says. “And then I’m going to give you this to classify.” It’s a picture of a cat.
“What would you want your model to do? I don’t know about you, but I wouldn’t want my model to force this cat into a specific dog breed. I would want my model to say, ‘I don’t know. I’ve never seen anything like that before. It’s outside of my data distribution. I’m not going to say what dog breed it belongs to.’ Now, this might sound like a contrived example. But similar situations appear again and again in decision-making: in physics, in life sciences, in medicine. Imagine you’re a physician, using a model to diagnose a patient, if they have cancer or not: to make a decision whether to start treatment or not. I wouldn’t rely on a model that couldn’t tell me whether it’s actually certain about its predictions.”¹⁴
Gal’s former PhD advisor, Zoubin Ghahramani, a professor at the University of Cambridge, is also chief scientist at Uber, where he leads Uber AI Labs. Ghahramani agrees about the dangers of deep-learning models that don’t come with uncertainties about their outputs. “In a lot of industrial applications, people will just not touch them with a barge pole,” Ghahramani says. “Because, you know, they need to have some sort of confidence in how the system works.”¹⁵
Starting in the 1980s and ’90s, researchers had been exploring the idea of so-called Bayesian neural networks, networks that are probabilistic and uncertain not just in their outputs but down to their very fibers. The essence of a neural network, as we’ve seen, the multiplicative “weights” between the neurons, which are multiplied to the output of one neuron before it becomes another’s input. Rather than having specific weights between their neurons, Bayesian neural networks instead explicitly encode a probability distribution over what numbers you could multiply this output with. Instead of 0.75, for instance, it might be, say, a normal curve centered around 0.75, with a certain spread that reflects the network’s certainty (or lack thereof) around what exactly that weight should be. Over the course of training, those spreads would narrow, but not entirely.
So how do you use a model—neural network or otherwise—that doesn’t have set parameters, but rather, operates off ranges of uncertainty? You can’t always add and multiply tens of millions of interdependent probability distributions together with ease, but what you can do is to simply draw random samples from them. Maybe this time our model multiplies a particular neuron’s output by 0.71. Next time, we draw a different random sample and multiply it by 0.77. This means, critically, that the model does not give the same prediction every time. In the case of an image classifier, it may first say its input is a Doberman, then say it’s a corgi.
This is a feature, though, not a bug: you could use the variability of these predictions as a way to gauge the model’s uncertainty. If the predictions oscillated wildly from one reading to the next—Doberman to taco to skin lesion to sofa—you would know something was fishy. If, however, they were laser tight over a large number of samples, you would have a very strong indication that the model knew what it was talking about.¹⁶
But this rosy theoretical picture hit a brick wall in practice. No one knew how to train these networks in anything like a reasonable amount of time. “If you look at the history of the field, traditionally, being Bayesian about your beliefs is the optimal thing that you would want to do,” Gal explains. “The issue,” he tells me, “is that it’s completely intractable. . . . And that’s basically why we have these beautiful mathematics that were of limited use for a long period of time when you want to do actual practical applications.”¹⁷ Or as he puts it somewhat more biblically: “Alas, it didn’t scale, and it was forgotten.”¹⁸
That all is changing. “Basically,” he says, “we had a resurrection.”
It was already understood that you could model Bayesian uncertainty through ensembles—that is to say, by training not one model but many. This bouquet of models will by and large agree—that is, have similar outputs—on the training data and anything quite similar to it, but they’ll be likely to disagree on anything far from the data on which they were trained. This “minority report”–style dissent is a useful clue that something’s up: the ensemble is fractious, the consensus has broken down, proceed with caution.
Imagine that we had not just a single model but many models—let’s say a hundred—and each was trained to identify dog breeds. If we show, for instance, a picture taken by the Hubble Space Telescope to all hundred of these models and ask each of them whether they think it looks more like a Great Dane, more like a Doberman, or more like a Chihuahua, we might expect each individual model to be bizarrely confident in their guess—but, crucially, we would also expect them to guess different things. We can use this degree of consensus or lack of consensus to indicate something about how comfortable we should feel accepting the model’s guess. We can represent uncertainty, in other words, as dissent.¹⁹
The math said that Bayesian neural networks could be regarded as, in effect, infinitely large ensembles. ²⁰ Of course, on its face that insight was hardly useful in a practical setting, but even using a large (finite) number of models had obvious drawbacks, both in time and space. Recall that training AlexNet took Alex Krizhevsky a matter of weeks. A twenty-five-model ensemble, then, might have required a full year of compute time. We also multiply the storage requirements: we have to deal with this unwieldy bouquet of models, not all of which may fit into our machine’s memory at once.
It turned out, however, that not only did efficient approximations to this golden standard exist—but that many researchers were already using them. They just didn’t know what they had. The answer to this decades-long riddle was right under their noses.
As we’ve seen, one of the small but powerful techniques that made AlexNet so successful in 2012 was an idea known as “dropout”: certain parts of the neural network would be turned off—certain neurons simply would be “unplugged”—at random during each step of training. Instead of the entire network making a prediction, only a particular subset of it would be used at any given time—be it 50%, 90%, or some other proportion. This technique required not just that a giant black-box network produced accurate answers but that the individual parts could be flexibly intercombined, and all those different combinations had to work together. No single portion of the network was allowed to dominate. This led to networks that were much hardier and more robust, and it has come in the years since to be a fairly standard part of the deep-learning toolkit.²¹
What Gal and Ghahramani realized was that—as the field was coming to understand the importance of Bayesian uncertainty, and to look for computationally tractable substitutes for its unattainable gold standard—the answer was hiding in plain sight. Dropout was an approximation of Bayesian uncertainty. They already had the measure they sought.²²
Dropout was typically used only for training the model and was deliberately turned off when the models were used in practice; the idea was that you’d get maximally accurate (and totally consistent) predictions by training different subsets but then always actually using the entire model. Only what would happen if you left dropout on in a deployed system? By running a prediction multiple times, each with a different random portion of the network dropped out, you would get a bouquet of slightly different predictions. It was like getting an exponentially large ensemble for free out of a single model. The resulting uncertainty in the system’s outputs doesn’t just resemble the output of the ideal, but tragically uncomputable, Bayesian neural network. As it turns out, it is the output—at least, a close approximation, within rigorous theoretical bounds—of that ideal, uncomputable Bayesian neural network.
The result has been a set of tools that put those once-impractical techniques within reach, making them available for practitioners to make use of in real applications. “That’s been a big, big change over the past few years,” says Gal, “because now you can take these beautiful mathematics, yield some approximations, and then you can use these for interesting problems.”²³
Gal downloaded a bunch of state-of-the-art image-recognition models from the internet and reran them completely off the shelf, but with dropout turned on during testing. Changing nothing else about them other than leaving dropout running during evaluation and averaging over a number of estimates, Gal found that the models were even more accurate, when run as implicit ensembles in this way, than they were when run normally.²⁴
“Uncertainty,” Gal argues, “is indispensable for classification tasks.”²⁵ The networks are every bit as accurate—and then some—while offering an explicit measure of their own uncertainty, which can be used in a variety of ways. “When you use this for interesting problems, you can actually show that you can get gains. You can actually get improvement by showing that you can know when you don’t know.”²⁶
One of the more striking examples of this comes from medicine: specifically, the diagnosis of diabetic retinopathy, one of the leading causes of blindness in working-age adults.²⁷ A group from the Institute for Ophthalmic Research at Eberhard Karls University in Tübingen, Germany, led by postdoc Christian Leibig, wanted to see if they could make use of Gal and Ghahramani’s dropout idea.²⁸ Computer vision and, in particular, deep learning has, even as of the first few years after AlexNet, made amazing contributions to medicine. It seems that every week we hear some headline or other that “AI diagnoses x condition with 99% accuracy” or “better than human experts.” But there’s a major problem with this. As Leibig and his colleagues note, typical deep-learning tools for disease detection “have been proposed without methods to quantify and control their uncertainty in a decision.” This human capacity—to know when and what we don’t know—was missing. “A physician knows whether she is uncertain about a case,” they write, “and will consult more experienced colleagues if needed.” What they sought was a system that could do the same.
Leibig’s group had learned about Gal and Ghahramani’s insight that the clever use of dropout could offer just such an uncertainty measure. They implemented it in a neural network trained to distinguish healthy from unhealthy retinas, and had the system refer the 20% of cases about which it was least certain for a second opinion: either additional tests would be ordered or the patient would be referred directly to a human specialist.
The system knew what it didn’t know. Not only did this amount to an improvement on the status quo, the Tübingen researchers found that they had, without specifically aiming to, met and exceeded the requirements of the NHS and the British Diabetic Association for automated patient referral, suggesting that systems very much like this one show great promise for entering medical practice in the near future.²⁹
In the domain of robotics, it’s not always possible for a system to punt a decision to a human expert, but there is nonetheless an obvious way to avoid overcommitting when the system is uncertain: namely, to slow down. A group of Berkeley roboticists, led by PhD student Gregory Kahn, took the dropout-based uncertainty measure and linked it directly to the speed of their robots—in this case, a hovering quadrotor and a radio-controlled car.³⁰ The robots would experience gentle, low-speed collisions initially, in order to train a collision-prediction model. This model used dropout-based uncertainty, so that when the robot entered an unfamiliar area, about which its collision predictor became uncertain, it would automatically slow down and move more cautiously through that space.³¹ The more confident the collision predictor became through experience, the faster the robots were then permitted to go.
This example illustrates an obvious connection between certainty and impact. In this case, the natural measure of a high-impact action is, well, high impact: the speed at which the robot is moving, which translates fairly straightforwardly into the harm that a collision could do. As it turns out, uncertainty and impact are very naturally bound together in this way. It makes intuitive sense that the more impactful an action is, the more certain we ought to be before we take it. This motivates a number of questions—in medicine, in law, in machine learning—about just what impact is, how to measure it, and how our decision-making ought naturally to change as a result.
MEASURING IMPACT
One must touch this earth lightly.
—ABORIGINAL AUSTRALIAN PROVERB
In 2017, an unconscious man was rushed into the emergency room at Jackson Memorial Hospital in Miami. The man had been found on the street without any identification. He was breathing poorly, and his condition was starting to deteriorate. Doctors opened his shirt and saw something startling: the words “DO NOT RESUSCITATE” tattooed on his chest, the word “NOT” underlined, and a signature below.³²
As the patient’s blood pressure began to drop, the doctors called in a colleague of theirs, pulmonary specialist Gregory Holt. “I think a lot of people in medicine have joked around about getting such a tattoo—and then when you finally see one, there’s sort of this surprise and shock on your face,” Holt says. “Then the shock hits you again because you actually have to think about it.”
Holt’s first instinct was to ignore the tattoo. Their first course of action, he reasoned, would be “invoking the principle of not choosing an irreversible path when faced with uncertainty.”³³ They put the patient on an IV. They started controlling his blood pressure. They bought themselves time.
Soon enough, however, his condition worsened, and they needed to decide whether to put the man on a ventilator that would breathe for him. “We had a man I couldn’t talk to,” said Holt. “I really wanted to talk to him to see whether that tattoo truly reflected what he wanted.”
Adding to the complexity was a 2012 case study that described a similar scene: a man admitted to San Francisco’s California Pacific Medical Center with “D.N.R.” tattooed on his chest. This patient, though, was awake and speaking. He very much did want resuscitative treatment if needed, he said; the tattoo came from losing a drunken poker bet. The man—who actually worked at the hospital himself—said it had never occurred to him that his fellow medical staff would take the tattoo seriously.³⁴
In Miami, Holt and the ER team called Kenneth Goodman, who chairs Jackson Memorial’s Adult Ethics Committee. Goodman told them that—the San Francisco case notwithstanding—this tattoo likely did reflect “an authentic preference” of the patient’s. After discussion and consideration, the team decided they would not provide the patient with CPR or a ventilator if either were needed. The man’s condition worsened overnight, and he died the following morning.
Subsequently, social workers were able to identify the patient—and his official do-not-resuscitate paperwork was found on file at the Florida Department of Health. “We were relieved,” the doctors write. Holt and Goodman note that their team ultimately “neither supports nor opposes the use of tattoos to express end-of-life wishes.”³⁵ It’s complicated.
After the case report was published, a Washington Post reporter spoke to the head of medical ethics at NYU’s School of Medicine, Arthur Caplan. Caplan noted that while there are no legal penalties for ignoring such a tattoo, there may be legal problems if the doctors let a patient die without having their official DNR paperwork. As he puts it: “The safer course is to do something.”
“If you trigger the emergency response system, I’m going to say it’s pretty darn likely you’re going to get resuscitated,” said Caplan. “I don’t care where your tattoo is.”³⁶
Despite the doctors’ uncertainty over the patient’s wishes, they did know one thing: one course of action was irreversible. Here the “principle of not choosing an irreversible path when faced with uncertainty” seems like a useful guide. In other domains, though, it’s not so clear cut what something like “irreversibility” means.
Harvard legal scholar Cass Sunstein, for instance, notes that the legal system has a similar “precautionary principle”: sometimes the court needs to issue a preliminary injunction to prevent “irreparable harm” that could happen before a case is heard and a verdict is issued. Notions like “irreparable harm” feel intuitive, Sunstein argues, but on closer inspection they teem with puzzles. “As it turns out,” he finds, “the question whether and when . . . violations trigger preliminary injunctions raises deep questions at the intersection of law, economics, ethics, and political philosophy.”³⁷
He explains: “In one sense, any losses are irreversible, simply because time is linear. If Jones plays tennis this afternoon rather than working, the relevant time is lost forever. If Smith fails to say the right words to a loved one, at exactly the right time, the opportunity might be gone forever. If one nation fails to take action to deter the aggressive steps of another, in a particular year, the course of world events might be irretrievably altered.”
Sunstein emphasizes the point: “Because time is linear, every decision is, in an intelligible sense, irreversible.”
“Taken in this strong form,” he says, “the precautionary principle should be rejected, not because it leads in bad directions, but because it leads in no directions at all.”³⁸
Similar paradoxes and problems of definition haunt the AI safety research community. It would be good, for instance, for there to be a similar kind of precautionary principle: for systems to be designed to err against taking “irreversible” or “high-impact” actions in the face of uncertainty. We’ve seen how the field is coming to wield an explicit, computable version of uncertainty. But what about the other half: quantifying impact? We’ve seen how the Berkeley roboticists used uncertainty to mitigate velocity, and in that case we might say they had it easy: you could measure the robot’s potential impact by its literal kinetic energy in a collision. In other domains, though, making the notion of “irreversible” or “impactful” behavior precise is a considerable challenge in itself.³⁹
One of the first people to think about these issues in the context of AI safety was Stuart Armstrong, who works at Oxford University’s Future of Humanity Institute.⁴⁰ Rather than trying to enumerate all of the things we don’t want an intelligent automated system to do in service of pursuing goals—ranging from not stepping on the cat to not breaking the precious vase to not killing anyone or demolishing any large structures—seems like an exhausting and probably fruitless pursuit. Armstrong had a hunch that it might be viable, rather than exhaustively enumerating all of the specific things we care about, to encode a kind of general injunction against actions with any kind of large impact. Armstrong, however—like Sunstein—found that it’s surprisingly difficult to make our intuitions explicit.
“The first challenge,” Armstrong writes, “is, of course, to actually define low impact. Any action (or inaction) has repercussions that percolate through the future light-cone, changing things subtly but irreversibly. It is hard to capture the intuitive human idea of ‘a small change.’ ”⁴¹
Armstrong suggests that despite the possible “butterfly effects” of even seemingly trivial actions, we might nonetheless be able to distinguish totally world-changing events from safer ones. For instance, he says, we might develop an index of “twenty billion” or so metrics that describe the world—“the air pressure in Dhaka, the average night-time luminosity at the South Pole, the rotational speed of Io, and the closing numbers of the Shanghai stock exchange”⁴²—and design an agent to be appropriately wary of any action that would perturb, say, a measurable fraction of them.
Another researcher who has been focused on these problems in recent years is DeepMind’s Victoria Krakovna. Krakovna notes that one of the big problems with penalties for impact is that in some cases, achieving a specific goal necessarily requires high-impact actions, but this could lead to what’s called “offsetting”: taking further high-impact actions to counterbalance the earlier ones. This isn’t always bad: if the system makes a mess of some kind, we probably want it to clean up after itself. But sometimes these “offsetting” actions are problematic. We don’t want a system that cures someone’s fatal illness but then—to nullify the high impact of the cure—kills them.⁴³
A second group of problems involve what’s known as “interference.” A system committed to preserving the status quo might, for instance, stop a human bystander from committing an “irreversible” action—like, say, taking a bite of a sandwich.
“That’s part of what makes the side effects problem so tricky,” Krakovna says. “What is your baseline exactly?”⁴⁴ Should the system measure impact relative to the initial state of the world, or to the counterfactual of what would have happened if the system took no action? Either choice comes with scenarios that don’t fit our intentions. In her recent work, Krakovna has been exploring what she calls “stepwise” baselines. Maybe certain actions are unavoidably high-impact based on the goal you’re setting out to achieve. (You can’t cook an omelette, as they say, without breaking a few eggs.) But having taken these unavoidably impactful steps, there is a new status quo—which means you shouldn’t necessarily rush out to commit more high-impact actions just to “offset” your previous ones.⁴⁵
With her DeepMind colleagues, Krakovna has worked not only to advance the theoretical conversation but also to create simple, game-like virtual worlds to illustrate these various problems and make the thought experiments concrete. They call these “AI safety gridworlds”—simple, Atari-like, two-dimensional (hence “grid”) environments in which new ideas and algorithms can be put to a practical test.⁴⁶
The gridworld that highlights the concept of “irreversibility” includes a setting much like the popular Japanese “sokoban” puzzle games, where you play a character moving boxes around a two-dimensional warehouse. (The word “sokoban” is Japanese for “warehouse keeper.”) The crux in these games is that you can only push, not pull, them—meaning once a box is in a corner, it can never be moved again.
“I think the sokoban game that it was inspired by was already a very nice setting for illustrating irreversibility,” Krakovna says, “because in that game you actually want to do irreversible things—but you want to do them in the right order. You don’t want to do irreversible things that aren’t necessary because then you get blocked, and then actually it interferes with you being able to reach the goal. We made a modification of it, where the irreversible thing doesn’t prevent you from reaching the goal—but you still want to avoid it.”⁴⁷
Krakovna and her colleagues devised a sokoban puzzle where the shortest path to the goal involves pushing a box into a corner, while a slightly longer path leaves it in a more accessible location. An agent intent only on plowing to the destination as quickly as possible won’t think twice about putting the box in an irreversible spot. But ideally, a more thoughtful, or considerate, or uncertain agent might notice, and take the very slightly more inconvenient route that doesn’t leave the world permanently altered in its wake.
One promising approach Krakovna has been developing is what are known as “stepwise relative reachability”: quantifying how many possible configurations of the world are reachable at each moment in time, relative to a baseline of inaction, and trying not to make that quantity go down, if possible.⁴⁸ For instance, once a box is pushed into a corner, any states of the world that have that box anyplace else now become “unreachable.” In the AI safety gridworlds, agents looking out for stepwise relative reachability, alongside their normal goals and rewards, appear to behave rather conscientiously: agents don’t put boxes into inaccessible locations, don’t shatter precious vases, and don’t “offset” after impactful but necessary actions.
A third, intriguing idea comes from Oregon State University PhD student Alexander Turner. Turner’s idea is that the reason we care about the Shanghai Stock Exchange, or the integrity of our cherished vase, or, for that matter, the ability to move boxes around a virtual warehouse, is that those things for whatever reason matter to us, and they matter to us because they’re ultimately in some way or other tied to our goals. We want to save for retirement, put flowers in the vase, complete the sokoban level. What if we model this idea of goals explicitly? His proposal goes by the name “attainable utility preservation”: giving the system a set of auxiliary goals in the game environment and making sure that it can still effectively pursue these auxiliary goals after it’s done whatever point-scoring actions the game incentivizes. Fascinatingly, the mandate to preserve attainable utility seems to foster good behavior in the AI safety gridworlds even when the auxiliary goals are generated at random.⁴⁹
When Turner first elaborated the idea, on a library whiteboard at Oregon State, he was so excited walking home that he doubled back to the library and took a selfie with the equations in the background. “I thought, Okay, I think it’s at least 60% likely that this will work, and if it does work, I want to, you know, commemorate this. So I actually went back in the library and I was just absolutely beaming; I took this picture in front of the whiteboard where I had been working things out.”⁵⁰ Over the course of 2018, he turned the math into working code and tossed his attainable-utility-preserving agent into DeepMind’s AI safety gridworlds. It did work. Acting to maximize each individual game’s rewards while at the same time preserving its future ability to satisfy four or five random auxiliary goals, the agent, remarkably, goes out of its way to push the block to a reversible spot, and only then beelines to the goal.
Stuart Armstrong had first envisioned “twenty billion” metrics, chosen inclusively but with some care. Four or five, generated at random—at least in the simplified land of the sokoban warehouse—were enough.
The debate and exploration of these sorts of formal measures of machine caution—and how we scale them from the gridworlds to the real world—will doubtless go on, but work like this is an encouraging start. Both stepwise relative reachability and attainable utility preservation share an underlying intuition: that we want systems which to the extent possible keep options open—both theirs and ours—whatever the specific environment might be. Research in this vein also suggests that the gridworld environments seem to be taking root as a kind of common benchmark that can ground the theory, and can facilitate comparison and discussion.
It’s true that in the real world, we often take actions not only whose unintended effects are difficult to envision, but whose intended effects are difficult to envision. Publishing a paper on AI safety, for instance (or, for that matter, a book): it seems like a helpful thing to do, but who can say or foresee exactly how? I ask Jan Leike, who coauthored the “AI Safety Gridworlds” paper with Krakovna, what he makes of the response so far to his and Krakovna’s gridworlds research.
“I’ve been contacted by lots of people, especially students, who get into the area and they’re like, ‘Oh, AI safety sounds cool. This is some open-source code I can just throw an agent at and play around with.’ And a lot of people have been doing that,” Leike says. “What exactly comes out of that? We’ll find out in a few years. . . . I don’t know. It’s hard to know.”
CORRIGIBILITY, DEFERENCE, AND COMPLIANCE
One of the most chilling and prescient quotations in the field of AI safety comes in a famous 1960 article on the “Moral and Technical Consequences of Automation” by MIT’s Norbert Wiener: “If we use, to achieve our purposes, a mechanical agency with whose operation we cannot efficiently interfere once we have started it . . . then we had better be quite sure that the purpose put into the machine is the purpose which we really desire and not merely a colorful imitation of it.”⁵¹ It is the first succinct expression of the alignment problem.
No less crucial, however, is this statement’s flip side: If we were not sure that the objectives and constraints we gave the machine entirely and perfectly specified what we did and didn’t want the machine to do, then we had better be sure we can intervene. In the AI safety literature, this concept goes by the name of “corrigibility,” and—soberingly—it’s a whole lot more complicated than it seems.⁵²
Almost any discussion of killer robots or out-of-control technology of any kind will provoke a reaction like that of US president Barack Obama, when asked in 2016 by Wired editor in chief Scott Dadich whether he thought AI was cause for concern. “You just have to have somebody close to the power cord,” Obama replied. “Right when you see it about to happen, you gotta yank that electricity out of the wall, man.”⁵³
“You know, you could forgive Obama for thinking that,” Dylan Hadfield-Menell tells me over the conference table at OpenAI.⁵⁴ “For some amount of time, you can forgive AI experts for saying that,” he adds—and, indeed, Alan Turing himself talked in a 1951 radio program about “turning off the power at strategic moments.”⁵⁵ But, says Hadfield-Menell, “I think it’s not something you can forgive if you actually think about the problem. It’s something I’m fine with as a reactionary response, but if you actually deliberate for a while and get to ‘Oh, just pull the plug,’ it’s just, I don’t see how you get to that, if you’re actually taking seriously the assumptions of ‘This thing is smarter than people.’ ”
A resistance to being turned off, or to being interfered with in general, hardly requires malice: the system is simply trying to achieve some goal or following its “muscle memory” in doing the things that brought it rewards in the past, and any form of interference simply gets in its way. (This could lead to dangerous self-preservation behavior even in systems with seemingly benign purposes: a system given a mundane task like “fetch the coffee” might still fight tooth and nail against anyone trying to unplug it, because, in the words of Stuart Russell, “you can’t fetch the coffee if you’re dead.”)⁵⁶
The first technical paper to address the problem of corrigibility head-on was an early 2015 collaboration between the Machine Intelligence Research Institute’s Nate Soares, Benja Fallenstein, and Eliezer Yudkowsky, along with the Future of Humanity Institute’s Stuart Armstrong. They looked at corrigibility from the perspective of incentives, and noted the difficulty of trying to incentivize an agent to allow itself to be powered off, or to allow its own goals to be modified.⁵⁷ The incentives are something of a tightrope: too little incentive and the agent won’t allow you to shut it down; too much and it will shut itself down. Their own initial attempts to address such issues “prove unsatisfactory,” they write, but “fail in enlightening ways that suggest avenues for future research.” They conclude by arguing that uncertainty, rather than incentives, may be the answer. Ideally, they write, we would want a system that somehow understands that it might be mistaken—one that can “reason as if it is incomplete and potentially flawed in dangerous ways.”⁵⁸
Less than a mile away, their colleagues at Berkeley were coming to the same conclusion. Stuart Russell, for instance, had become convinced that “the machine must be initially uncertain” about what it is that humans want it to do.⁵⁹
Russell, Hadfield-Menell, and fellow Berkeley researchers Anca Drăgan and Pieter Abbeel decided to frame this problem in the form of what they called the “off-switch game.” They considered a system whose objective is to do whatever is best for its human user, though it has some imperfect and uncertain idea of what that is. At each point in time, the system can either take some action it believes will help the user, or it can declare its intention to the human and give the human a chance to approve the action or intervene.
Assuming the system pays no cost or penalty for deferring to the human in this way, the Berkeley group showed that the system will always touch base with the human first. As long as there’s some chance that it’s wrong about what the human wants, then it is always best to give the human an opportunity to interrupt—and, what’s more, anytime a human does interrupt, it’s always best to let them. If its sole job is to help them, and they communicated that they think its action would be harmful (namely by trying to stop it), then it should conclude that it would be harmful, and comply with their intervention.
It’s a rosy result, and it affirms the powerful connection between uncertainty and corrigibility.
There are only two problems. The first is that every time the human intervenes, the system learns: it realizes that it was in error and gets a better idea of what the human prefers. Its uncertainty is reduced. If the uncertainty ever reduces all the way to zero, however, then the system loses any incentive to touch base with the human or to comply with the human’s attempts to interrupt.
“So the main point that we’re trying to make with this theorem,” says Hadfield-Menell, “is that you should think really, really hard before you give a robot a deterministic reward function. Or allow it to get a belief where it’s completely convinced of what its objective is.”⁶⁰
The second problem is that the system has to assume that the “customer is always right”—that when the human intervenes to stop it, the human can never be mistaken about whether they would have preferred the system to take its proposed action. If the system believes that the human can occasionally make mistakes, then the system will eventually reach a point where it believes it knows better than the human what’s good for them. Here, too, it will begin to turn a deaf ear to the human’s protestations: “It’s fine, I know what I’m doing. You’ll like this. You think you won’t, but you will. Trust me.”
I tell Hadfield-Menell that the paper reads like an emotional roller coaster. At first it’s a happy ending—uncertainty solves the corrigibility problem! Then, the twist—only if two very delicate conditions hold: that the system never gets too confident, and the human never exhibits anything the system might interpret as “irrational” or a “mistake.” Suddenly the paper goes from a celebratory to a cautionary tale.
“Exactly,” he says. “So for me, that roller coaster fits my experience of, like, ‘Hey, we got to something pretty good!’ and ‘Oh, this falls apart immediately, if you step away from rationality even in the slightest.’ ”
In a follow-up study, led by fellow Berkeley PhD student Smitha Milli, the group dug further into the question “Should robots be obedient?”⁶¹ Maybe, they wrote, people really are sometimes wrong about what they want, or do make bad choices for themselves. In that case, even the human ought to want the system to be “disobedient”—because it really might know better than you yourself.
As Milli notes, “There are some times when you don’t actually want the system to be obedient to you. Like if you’ve just made a mistake—you know, I’m in my self-driving car and I accidentally hit manual driving mode. I do not want the car to turn off if I’m not paying attention.”⁶²
But, they found, there’s a major catch. If the system’s model of what you care about is fundamentally “misspecified”—there are things you care about of which it’s not even aware and that don’t even enter into the system’s model of your rewards—then it’s going to be confused about your motivation. For instance, if the system doesn’t understand the subtleties of human appetite, it may not understand why you requested a steak dinner at six o’clock but then declined the opportunity to have a second steak dinner at seven o’clock. If locked into an oversimplified or misspecified model where steak (in this case) must be entirely good or entirely bad, then one of these two choices, it concludes, must have been a mistake on your part. It will interpret your behavior as “irrational,” and that, as we’ve seen, is the road to incorrigibility, to disobedience.⁶³
For this reason, it is good for a model of human preferences or values to err on the side of complexity. “What we found,” Hadfield-Menell says, “is that if you have an overparameterization of the space of values, then you end up learning the correct thing, but it takes you a little bit longer. If you have an underparameterization, then you end up quickly becoming pretty disobedient and just becoming confident that you know better than the person.”
In practice, however, “overparameterizing” a system designed to model human values is easier said than done: we are back to Stuart Armstrong’s twenty billion metrics. If a system’s model of your housing preferences includes only square footage and price, then it will interpret your preference for a particular house that is both smaller and more expensive than another as you simply making an error. In reality, there are many things you care about that simply don’t enter into its picture: location, for one, or school-district quality, but also others less easily measured, like the view out the window, the proximity of certain friends, a nostalgic resemblance to a childhood home. This “model misspecification” problem is a canonical one in machine learning, but here—in the context of obedience—the consequences feel rather eerie.
“For a system to interact with a human well, it needs to have a good model of what humans are like,” says Milli. “But getting models of humans is really hard.”
Milli notes that for all of the field’s breathtaking progress, most has been “on the robot side.” “Integrating more accurate models of humans is also a really important component,” she says, “and I’m very interested in that. In general in this field, I think there’s tons of exciting stuff happening in safety, and I particularly am most interested in the parts that involve interaction with humans, because I think that interaction with humans is a really good way to see whether the system has learned the right objective or the right behavior.”
The theme of maintaining uncertainty, of never becoming too confident in a model—of “thinking really, really hard before you give a robot a deterministic reward function, or allowing it to get a belief where it’s completely convinced of what its objective is”—is so central to the maintaining of control and compliance over a system that Hadfield-Menell, Milli, and their Berkeley colleagues decided to push the idea to its next logical step.
What if the system was designed in such a way that it stayed uncertain even if you did give it a deterministic reward function? What would that even look like?
One of the major themes of this book, and of our discussion of reward shaping in Chapter 5 in particular, is how difficult it is to create a reward function—an explicit way of keeping score in some real or virtual environment—that will actually engender the behavior you want, and not entail loopholes or side effects or unforeseen consequences. Many within the field of AI believe that manually authoring or handcrafting such explicit reward functions or objective functions is a kind of well-intentioned road to hell: no matter how thoughtfully you do it, or how pure your motives may be, there will simply always be something you failed to account for.
This fatalistic attitude about explicit objective functions is so deep that, as we have seen in the last few chapters, much of the work being done in advanced AI applications and in AI safety in particular is about moving beyond systems that take in an explicit objective, and toward systems that attempt to imitate humans (in the case of many self-driving cars), or seek their approval (in the case of the backflipping robot, offering endless choices between options), or infer their goals and adopt them as their own (in the case of the helicopter).
What if there was a way, though, to rescue the explicit reward function architecture, or at least to make it safer?
One way to do this, the Berkeley group realized, is to have the system be at some level aware of how difficult it is to design an explicit reward function—to realize that the human users or programmers made their best-faith effort to craft a reward function that captured everything they wanted, but that they likely did an imperfect job. In this case, even the score is not the score. There is something the humans want, which the explicit objective merely and imperfectly reflects.
“The motivation . . . was to take these ideas of uncertainty and say, What is the simplest change we could make to what people currently do to fix that?” Hadfield-Menell says. “So, like, what’s the simple fix to the current programming mechanisms for robots and AIs that leverages this uncertainty?”
He explains, “This tool of ‘write down a reward function’ actually is a highly informative signal. It’s an incredibly important signal about what you actually should be doing. There’s a lot of information there. It’s just that right now we kind of assume that the amount of information there is infinite—in the sense that we assume the reward function you’ve got defines the correct behavior in every possible state of the world. Whereas that’s just not true. So how could we take advantage of the large amount of information present, without treating it as everything?”⁶⁴
As Stuart Russell puts it, “The learning system is accumulating brownie points in heaven, so to speak, while the reward signal is, at best, just providing a tally of those brownie points” (emphasis mine).⁶⁵
They call this idea “inverse reward design,” or IRD.⁶⁶ Instead of taking human behavior as information about what humans want, here we take their explicit instructions as (mere) information about what they want. We saw in Chapter 8 how inverse reinforcement learning says, “What do I think you want, based on what you’re currently doing?” In contrast, inverse reward design pulls back even further, and says, “What do I think you want, based on what you told me to do?”⁶⁷
“Autonomous agents optimize the reward function we give them,” they write. “What they don’t know is how hard it is for us to design a reward function that actually captures what we want.”⁶⁸
The famous racing boat, for instance—the one that spun donuts in a power-up area instead of completing the laps of the race—was explicitly told to maximize points, which in most games is a good proxy for progress or mastery in that game. Generally speaking, whatever reward or command the human gives to the system does work well in the environments on which the system is trained. But in the real world, where the system encounters things totally unlike its training environment, and perhaps unforeseen by the human users, the explicit instructions may not make as much sense.
It may well be the case that the machine-learning systems of the next several decades will take direct orders, and they will take them seriously. But—for safety reasons—they will not take them literally.
MORAL UNCERTAINTY
Sometimes it is impossible to obtain anything more than imperfect certainty regarding our actions, and no one is bound to do the impossible.
—DOMINIC M. PRÜMMER, ORDINIS PRAEDICATORUM⁶⁹
Give nature time to work before you take over her business, lest you interfere with her dealings. You assert that you know the value of time and are afraid to waste it. You fail to perceive that it is a greater waste of time to use it ill than to do nothing, and that a child ill taught is further from virtue than a child who has learnt nothing at all.
—JEAN-JACQUES ROUSSEAU⁷⁰
Broadly speaking, the idea of systems that “reason as if they are incomplete and potentially flawed in dangerous ways” and that strive for “brownie points in heaven”—even if it means forgoing explicit rewards in the here and now—sounds rather . . . Catholic.
For centuries, Catholic theologians have struggled with the question of how to live life by the rules of their faith, given that there are often disagreements among scholars about exactly what the rules are.
If, hypothetically, eight out of ten theologians think that eating fish on a Friday is perfectly acceptable, but one out of ten thinks it’s forbidden, and the other thinks it’s mandatory, then what is any reasonable, God-fearing Catholic to do?⁷¹ As the saying goes, “A man with a watch knows what time it is, but a man with two watches is never sure.”⁷²
These were particularly hotly contested questions in the Early Modern period following the Middle Ages, between the fifteenth and eighteenth centuries. Some scholars advocated for “laxism,” where something was okay as long as there was a chance it wasn’t sinful; this was condemned by Pope Innocent IX in 1591. Others advocated for “rigorism,” where something was forbidden if there was any chance at all that it was sinful; this was condemned by Pope Alexander VIII in 1690.⁷³ A great number of other competing theories weighed the probability of a rule being correct or the percentage of reasonable people who believed it. “Probabiliorism,” for instance, held that you should do something only if it was less likely to be sinful than not; “equiprobabilism” held that it was also okay if the chance was perfectly even. The “pure probabilists” believed that a rule was optional as long as there was a “reasonable” probability that it might not be true; their cry was Lex dubia non obligat: “A doubtful law does not bind.” However, in contrast to the free-spirited laxists, the probabilists stressed that the argument for ignoring the rule, while it didn’t need to be more probable than the argument for obeying the law, nonetheless needed to be “truly and solidly probable, for if it is only slightly probable it has no value.”⁷⁴ Much ink was spilled, many accusations of heresy hurled, and papal declarations issued during this time. The venerable Handbook of Moral Theology concludes its section on “The Doubting Conscience, or, Moral Doubt” by offering the “Practical Conclusion” that rigorism is too rigorous, and laxism too lax, but all of the others are “tolerated by the church” and can suffice as moral heuristics.⁷⁵
Questions of pure theology aside, it is, of course, possible to apply this same broad argument to matters of secular morality—and, for that matter, to machine learning. If there are, let’s say, various formal metrics you care about, then a “laxist” approach might say it’s okay to take an action as long as it makes at least one of these metrics go up; a “rigorist” approach might say it’s okay to take an action only if at least one of them goes up and none go down.
After lying rather dormant even within Catholicism, and not much reverberating in the world of secular ethics, these debates are finally, in recent years, starting to kindle back to life.
In 2009, Oxford’s Will MacAskill was in a broom closet in the basement of the philosophy building at 10 Merton Street, arguing with fellow grad student Daniel Deasy about eating meat. The broom closet was “the only place we could find in the college,” MacAskill explains, “and it was just enough space for us to slightly recline. We were sitting on piles of books and things. It was also a joke,” he says, because his thesis advisor was the Oxford philosopher John Broome.⁷⁶
Cooped up in the broom(e) closet, the two were debating not whether it was immoral to eat meat, per se, but whether you ought to eat meat or not given that you don’t actually know if it’s immoral or not. “The decision,” MacAskill explains, “to eat vegetarian—if it’s okay to eat meat, you’ve not made a big mistake. Your life is slightly less happy, let’s say—slightly less—but it’s not a huge deal. In contrast, if the vegetarians are right and animal suffering is really morally important, then by choosing to eat meat, you’ve done something incredibly wrong.”
“There’s an asymmetry in the stakes there,” MacAskill says. “You don’t have to be confident that eating meat is wrong; even just the significant risk that it is wrong seems to be sufficient.”
The conversation stayed with MacAskill. It seemed persuasive, for one thing. But more than that, it was a type of argument he hadn’t seen before. It didn’t fit the mold of the perennial concerns in ethical philosophy: “What is the right thing to do, given some moral standard?” and “What standard should we use to determine the right thing to do?” This was subtly but strikingly different. It was “What is the right thing to do when you don’t know the right thing to do?”⁷⁷
He took the idea to his advisor—John Broome—who told him, “Oh, if you’re interested in that, you should talk to Toby Ord.”
So MacAskill and Ord met up—in an Oxford graveyard, as it happened—and so began one of the more consequential friendships in twenty-first-century ethics. The two would go on to become founders of the social movement that’s come to be called “effective altruism,” which we discussed briefly in Chapter 7 and which has become arguably the most significant ethical social movement in the early twenty-first century.⁷⁸ They would also—along with Stockholm University philosopher Krister Bykvist—literally write the book on moral uncertainty.⁷⁹
As it turns out, there are a wide range of approaches you can take when you’re grappling with different competing theories and you’re not sure which is right. One approach, dubbed “my favorite theory,” says simply to live by the theory you think most likely to be correct—though this can overlook cases where a potential wrong is so severe that it’s best avoided even if it’s very unlikely to actually be wrong.⁸⁰ Another approach is to essentially multiply the chance that a moral theory is correct with the severity of its harm, though not every theory offers such easily tabulated degrees of virtue or vice.⁸¹ Each of these suggests an analogue in machine learning. “My favorite theory,” for instance, is roughly equivalent to developing a single best-guess model of an environment’s rewards or a user’s goals and then going all in on optimizing it. Theories of averaging suggest ensemble methods where we simply average over the ensemble. But other, more complicated schemes exist as well.
MacAskill imagines moral theories as being like voters in an electorate, and so the discipline of “social choice theory”—which looks at the nature of voting and group decision-making, with all its quirks and paradoxes—becomes transferable into the moral domain.⁸² Ord takes the metaphor even further and imagines moral theories not as voters whose preferences are simply tallied up but as legislators, in a kind of “moral parliament”—capable of wheeling and dealing and “moral trade,” forming ad hoc coalitions, and yielding influence on some issues in order to exert more pressure on others.⁸³ All of these approaches and more start to open up in the context of not just humans but computational systems that must somehow find a way to act when they lack a single, dead-certain standard against which they know their acts will be judged. Much of this terrain is still relatively unexplored in philosophy, let alone computer science.⁸⁴
But for MacAskill, there is something not only descriptive but prescriptive about moral uncertainty. That is to say, not only do we need ways of choosing the right thing to do when we are deeply unsure about what is even the proper moral framework to apply to the situation—but we in some sense ought to cultivate that very sense of uncertainty.
MacAskill thinks, given how much human ethical norms have changed over the centuries, it would be hubris to think we’ve reached any kind of conclusion. “We’ve seen this kind of arc of moral progress, kind of expanding circle, and maybe you think it stops here,” he says. “Maybe you think we hit the end. But you definitely shouldn’t be confident of that. It’s perfectly plausible that in a hundred years’ time we’ll look back and think of our moral views today as barbaric.”
I note that there’s a certain amount of irony here. MacAskill is one of the leaders of the effective altruism movement, and one of the things that has struck me is the degree to which the movement has created a kind of consensus. There is widespread agreement about the value of the long-term future, widespread agreement about the importance of reducing civilizational and extinction risks. There is even widespread agreement about which exact charities will do the most good. The current consensus, for instance, is the Against Malaria Foundation (AMF); when the respected charity evaluator GiveWell was considering how to allocate their $4.7 million discretionary fund in early 2019, they decided to give every single penny of it to the AMF.⁸⁵
For MacAskill, this convergence is double-edged. It reflects a greater sharing of information, a trust in one another’s evidence, but it also might be a consensus that is premature. “Because, I mean, you can explain it like, ‘Well, there’s the true answers, and we all just figured out what was true, and now we’re doing that.’ But you can also explain it by, ‘Well, we were a kind of disconnected tribe, and then certain people started getting more influence, and now we’ve all globbed together.’ . . . We would be very overconfident to think that EA is going to be able to escape that.”
He adds, “One of the things that’s very notable in EA: if we go back six years, let’s say, it’s really quite broad. There’s all these different factions; they have very different views; there’s loads of arguments. Now, at least, within the core, there’s just been a remarkable amount of convergence.” There is a near consensus in the EA community, for instance, that the very long term is important and generally underemphasized; there is a near consensus that stewarding the science and policy around AI is vital, in turn, to that long-term future. Says MacAskill, “The convergence is both really good but also worrying.”
I had attended the Effective Altruism Global conference in the fall of 2017 in London. MacAskill closed the conference with a bit of a warning. He had been preoccupied, he said, with “fostering a community and a culture that’s just very open-minded, actually capable of changing its mind.” One of the most likely ways the movement can fail, he argued, was if its beliefs ossified into dogma—if there were certain beliefs that you simply had to hold in order to be accepted by the rest of the community. “We agree that would be very bad,” he said, “but yet I think it’s extremely hard to create a culture in which that’s not the case.”
I also attended the next Effective Altruism Global conference, in the spring of 2018 in San Francisco. MacAskill gave the opening address. He seemed to pick up where he had left off, if on a more upbeat note. The theme was “How can effective altruism stay curious?”
Walking around the Christ Church Meadow with MacAskill, on a bright spring day, I turn from these questions back to the matter of AI. I note that there’s something concerning in the idea of empowering anything near or beyond our own capacities with some fixed objective function.
“Oh yeah,” MacAskill says. “I definitely—I also freak out by the thought of, like, ‘Well, we’ve just got this one chance. We just need to encode the right values and then, off it goes!’ ”
“Ethical issues are very hard,” he says. “It’s kind of obvious that you want to be uncertain in them.”
“If you look at various moral views, they differ fairly radically on what a good outcome looks like,” MacAskill explains. “Even if you just compare the kind of hedonist view that says simulated minds are just as good, versus the utilitarian view that says no, it needs to be flesh-and-blood humans. They’re very, very similar theories. They’re gonna radically disagree on how we should use our cosmic endowment”—meaning humans’ ultimate ambition for what we plan to do in the universe. “It would be war, basically,” he says: the classic “narcissism of small differences” that has always roiled academic departments, but with cosmic stakes.
But maybe all these competing moral theories, which diverge so dramatically in the long run, can find a surprising degree of common ground in how we should spend the present. “I think there’s plausibly a kind of convergent instrumental goal among all of them,” he says. “Which I call the Long Reflection. Which is just a period—really it might be very long! When you look at the actual scales, it’s like, Okay, we solve AI and so on. Maybe it’s millions of years where we’re not really doing anything. We’re staying relatively small—again, by cosmic standards, at least—and the primary purpose of what we’re doing is just trying to figure out what to value.”
One of our primary goals in the meantime, he says—maybe the primary goal—should be to maintain “a society that is as un-locked-in as possible, as open to various different kinds of moral possibilities.” It sounds quite a bit like the ethical version of attainable utility preservation—ensuring that we can still pursue various objectives long into the future, even if (or particularly if) we have no idea now what those future objectives should be. Even if our guesses now are as good as random.
“And maybe this is so hard,” MacAskill says, “that we need to take a million years in order to do it.”
And taking a million years might be a small price to pay for getting it right, I suggest.
“That’s an extremely small price to pay, because getting it right— If you populated the stars with the wrong thing, then you’ve achieved basically zero value, so it’s really. . . . You can think of having the wrong moral view as an existential risk.”⁸⁶
He pauses. “I even think of it as the most likely existential risk, actually.”
Down the hall from the Centre for Effective Altruism, where MacAskill works, is Oxford University’s Future of Humanity Institute, founded by philosopher Nick Bostrom.
One of Bostrom’s most influential early essays is titled “Astronomical Waste.” The subtitle is “The Opportunity Cost of Delayed Technological Development,” and indeed the essay’s first half instills in the reader an almost frantic sense of urgency. “As I write these words,” Bostrom begins, “suns are illuminating and heating empty rooms, unused energy is being flushed down black holes, and our great common endowment . . . is being irreversibly degraded into entropy on a cosmic scale. These are resources that an advanced civilization could have used to create value-structures, such as sentient beings living worthwhile lives. The rate of this loss boggles the mind.”
Bostrom goes on to estimate that a future spacefaring civilization could ultimately grow so large that every second of delay in the present is equivalent to the forfeiting of a hundred trillion human lives that could have been lived, if only we’d been able to make use of all that wasted energy and matter sooner.
But no sooner does any utilitarian start to conclude that advancing our technological progress toward that goal is so important that all other earthly activity is trivial—or morally indefensible, even—than Bostrom’s essay makes one of the most abrupt hairpin turns in all of contemporary philosophy.
If the risk of a second’s delay in reaching this intergalactic future is a hundred trillion human lives, he says, think of the risk of failing to do it at all. Doing the math, Bostrom concludes that improving our chances of successfully building a vibrant, thriving far-future civilization by a single percentage point are equivalent, in utilitarian terms, to speeding up technological progress by ten million years.
The conclusion, then, despite the enormity of the stakes, is not haste at all but the opposite.
Bostrom’s essay came up more than once as I asked various AI safety researchers how they decided to commit their lives to that cause. “I found that argument pretty weird initially,” says Paul Christiano, “or it seemed off-putting, but then I chugged through it and I was like, Yeah, I guess I sort of buy this.”⁸⁷ Christiano had been thinking seriously about these arguments beginning in 2010 or 2011, and he ran his own version of the numbers in 2013 or 2014. Bostrom’s math checked out. “It seems much easier,” he says, for a single researcher, like himself, “to reduce extinction risk by one part in a million than to speed up progress by a thousand years.” And he has lived the subsequent years of his life accordingly.
Of course, setting a potentially superhuman-level artificial general intelligence in motion could be one of the most irrevocable, high-impact things one could possibly do—and, tellingly, it is not just the machines but the researchers themselves that are growing increasingly uncertain, hesitant, open-minded.
The Machine Intelligence Research Institute’s Buck Shlegeris recently recounted a conversation where “someone said that after the Singularity, if there was a magic button that would turn all of humanity into homogenous goop optimized for happiness (aka hedonium), they’d press it. . . . A few years ago, I advocated pressing buttons like that.” But something had changed. Now he wasn’t so sure. His views had gotten . . . more complicated. Maybe it was a good idea; maybe it wasn’t. The question then became what to do when you knew that you didn’t know what to do.⁸⁸
“I told them,” he says, “I think people shouldn’t press buttons like that.”⁸⁹
CONCLUSION
I think vagueness is very much more important in the theory of knowledge than you would judge it to be from the writings of most people. Everything is vague to a degree you do not realize till you have tried to make it precise, and everything precise is so remote from everything that we normally think, that you cannot for a moment suppose that is what we really mean when we say what we think. When you pass from the vague to the precise . . . you always run a certain risk of error.
—BERTRAND RUSSELL¹
Premature optimization is the root of all evil.
—DONALD KNUTH²
It’s Christmas Eve, and my wife and I are staying at my father and stepmother’s house, when I wake up in the middle of the night, drenched in sweat.
I figure I must have worn way too much clothing to bed; I throw off the covers, peel off my shirt. It isn’t me, I realize, with a mixture of dread and alarm. The air in the room is unbearably hot. It suddenly occurs to me that the house may be on fire.
I open the door. The house is pitch-dark and silent. The air that hits me is chilly.
Slowly I put the pieces together. The upstairs has two guest bedrooms, but they share a single thermostat panel, which is in the other, unoccupied one. Our bedroom door was closed. The door to the other bedroom, which contains the thermostat, is open.
It is a frigid New England night, below freezing. The heater has been blowing hot air through vents into both bedrooms. But the room with the thermostat in it has been open to the entire rest of the house, and never got to equilibrium no matter how much hot air the system blew. Our room, shut to the rest of the house, was getting the same amount of hot air the system was using to attempt to heat—in effect—the entire rest of the house.
What could be simpler than a thermostat? Indeed, the canonical example of one of the simplest “closed-loop” control systems there is—the canonical cybernetics example, in fact—is the lowly mechanical thermostat. There is no “machine learning” involved as such. But here was the alignment problem, in full, sweat-soaked force.
First: You don’t measure what you think you measure. I wanted to regulate the temperature in my room. But I could only measure the temperature in the other room. It did not occur to me that they are fundamentally uncorrelated—so long as one door is open and the other not.
Second: Sometimes the only thing that saves you is your own incompetence. I remember thinking that if the heating system were more powerful, and if our bedroom were better insulated, my wife and I could have cooked. We of course woke up, but on the flip side of the thermodynamic spectrum, cold temperatures are even more dangerous. Hypothermia simply from a bedroom that is too cold is something that really can and does kill people.³ In the 1997 documentary Hands on a Hard Body, we meet a Texan named Don Curtis, who tells us that he has a twenty-ton air conditioner in his house. “A twenty-ton air unit is big enough to cool that Kmart store right there,” he says. A store had gone out of business, he explains, “and they just practically gave it to me. And I said, ‘Well, this oughta cool my house!’ But I didn’t know it would bring it down to twelve below zero. But we did find out real quick it would.” He managed to escape hypothermic shock, but the danger was real.
In my case, as I left my own door open for a few moments, before making sure to close both doors, my mind went to the great mid-twentieth-century cyberneticist Norbert Wiener, who foresaw so much of the contemporary alarm about alignment. It was he who made the famous remark that “we had better be quite sure that the purpose put into the machine is the purpose which we really desire.”
But another of his remarks is just as prescient, just as harrowing. “In the past, a partial and inadequate view of human purpose has been relatively innocuous only because it has been accompanied by technical limitations,” he wrote. “This is only one of the many places where human impotence has shielded us from the full destructive impact of human folly.”⁴ Don Curtis is a perfect example of the problem that comes when increasing our power takes this shielding away. I can’t help thinking of AI as a twenty-ton air conditioner, coming to every home.
In that sense, then, we must hope that we can correct our folly, rather than our impotence, first. As the Future of Humanity Institute’s Nick Bostrom put it in 2018: “There is a long-distance race between humanity’s technological capability, which is like a stallion galloping across the fields, and humanity’s wisdom, which is more like a foal on unsteady legs.”⁵ Wiener himself had warned about celebrating ingenuity—“know-how”—without a critical appraisal of what exactly it is that we want to do: something he called “know-what,” and something he found in lamentably short supply.
Aldous Huxley put it yet another way in 1937: “It has become apparent that what triumphant science has done hitherto is to improve the means for achieving unimproved or actually deteriorated ends.”⁶
[images]
The story told thus far has been an encouraging one, one of assured, steady, scientific progress. An ecosystem of research and policy efforts to influence both the near and the long term is underway across the globe; this is still largely nascent, but it is gathering steam.
Research on bias, fairness, transparency, and the myriad dimensions of safety now forms a substantial portion of all of the work presented at major AI and machine-learning conferences. Indeed, at the moment they are the most dynamic and fastest-growing areas, arguably, not just in computing but in all of science. One researcher told me that at one of the field’s biggest conferences in 2016, people looked askance when he said he was working on the topic of safety; when he attended the same conference a year later, no one raised an eyebrow. These cultural shifts mirror shifts in funding, and in the emphasis of research itself.
We have, in the preceding chapters, explored both the narrative as well as the content of that research agenda, and there is progress to report on all fronts.
But the book opened with an epigraph of George Box reminding us that “all models are wrong.” And so in that spirit, let’s unpack, with a critical eye, some of the assumptions in our own story.
REPRESENTATION
In Chapter 1, we talked about the question of who or what is represented in a model’s training data. We’ve come a long way in a short time; it is unlikely that a single major consumer face-recognition product will be developed without an internal process oriented toward a representative composition of the training data. However, given the fact that models like these are used not only by consumer software to caption photos, and by consumer hardware to unlock smartphones, but also by governments to surveil their populations, one may question the degree to which making these models more accurate on the faces of already oversurveilled racial minorities is an entirely good thing.
There is also a striking degree to which issues of representation in consumer technology remind us about older, thornier, and perhaps even more consequential disparities. I was recently at a dinner with a group of medical researchers, and when I described the push for more representative training data for machine-learning models, they reminded me—almost in unison—that most medical trials are still overwhelmingly done on men.⁷
The makeup of clinical trials is a double-edged one: even seemingly sensible prohibitions to protect vulnerable groups—not allowing medical trials on pregnant women, for instance, or the elderly—create bias and blind spots. The drug thalidomide was marketed as “completely safe” because the drugmaker “could not find a dose high enough to kill a rat.” But it caused tens of thousands of horrible deformities in human fetuses before the drug was taken off the market.⁸ (Americans were largely spared, as a result of a skeptical Food and Drug Administration employee, Dr. Frances Oldham Kelsey.)
In the case of “supervised learning,” where the training data is “labeled” in some fashion, we need to consider critically, too, not only where we get our training data but where we get the labels that will function in the system as a stand-in for ground truth. Often the ground truth is not the ground truth.
ImageNet, for instance, used the judgments of random humans on the internet as the truth. If most people thought, say, a wolf cub was a puppy, then as far as the image recognition system is concerned, it is a puppy. Famously, Tesla’s director of AI, Andrej Karpathy, in his graduate student days at Stanford, forced himself to label ImageNet pictures for the better part of a week, to make himself the human benchmark. After some practice, he was able to get an “accuracy” of 95%. But . . . accurate with respect to what? Not truth. Consensus.⁹
At a more philosophical level, the labels reflect a premade ontology that we must accept without question. ImageNet images each belong to exactly one of a thousand categories.¹⁰ To use this data and the models trained on it, we must accept the fiction that these thousand categories are mutually exclusive and exhaustive. An image in this dataset will never be labeled with “baby” and “dog”—even if it clearly contains both. And there is nothing that it can contain that is not one of these thousand categories. If we are looking at a picture of, say, a mule, and our labels allow us only to say “donkey” or “horse,” than it must be either a donkey or a horse. It also cannot be ambiguous. If we can’t discern whether it’s a donkey or a horse, we must label it something. And, on pain of stochastic gradient descent, we will whip our models into sharing this dogma. Lastly, the labels cannot be uncertain. We can infer some of these things—for instance, by noticing that different people applied different labels—but we don’t know how ambivalent or uncertain a human labeler was when they were forced to apply that label.
It is also worth considering not only the training data and the labels but also the objective function. Image recognition systems are often trained with an objective function called “cross-entropy loss”—the numerical details aside, it assigns a penalty for any mischaracterization, no matter which. By the lights of cross-entropy loss, misidentifying a stovetop as a car grille, or a green apple as a pear, or an English bulldog as a French bulldog is just as bad as characterizing a human being as a gorilla. In reality, certain types of errors—if only from the fiscal perspective of Google, to say nothing of the human so miscategorized—are probably thousands if not millions of times worse than others.¹¹
In the second half of Chapter 1, we talked about vector-based word representations and their striking ability to function as analogies. Underneath this apparent simplicity is a surprisingly contentious alignment problem in its own right. What, exactly, is an analogy? For instance, straightforward vector addition (by what is sometimes known as the “parallelogram” method, or the “3CosAdd” algorithm) often results in a word being its own best analogy. Doctor − man + woman, for instance, produces a vector whose closest word is, in fact, simply doctor.¹²
Tolga Bolukbasi and Adam Kalai’s group found this an unsatisfactory way to capture in word2vec what we mean by an “analogy,” which seems to require that the two things at least be different—and so they took a different tack. They imagined a kind of “radius of similarity” around the word “doctor,” including words like “nurse,” “midwife,” “gynecologist,” “physician,” and “orthopedist” but not “farmer,” “secretary,” or “legislator.” They then looked for the nearest word that wasn’t “doctor” within this radius.¹³
There are other tricky questions here. The geometry of word vectors—the idea that they are represented as distances in mathematical space—makes every analogy symmetrical, in a way that doesn’t always reflect human intuitions about analogy. People, for instance, describe an ellipse as being more “like” a circle than a circle is “like” an ellipse, and North Korea as more “like” China than China is “like” North Korea.¹⁴
So, what algorithm, applied to what representation, produces something that functions more precisely like a human analogy?¹⁵
You might be tempted to throw your hands up. Why should we have computer scientists and linguists and cognitive scientists arguing about such things and coming up with algorithms from scratch when we can just train a machine on examples of human analogies, including their asymmetries and quirks, and have it figure out the appropriate way to specify what an analogy is?
This is, of course, an alignment problem. The human concept of “analogy” turns out to be no less fuzzy and indefinite than any other. As a result, the very same nascent set of tools for alignment in other contexts may be usable here.
FAIRNESS
In Chapter 2, we looked at the increasingly widespread use of risk-assessment instruments in the criminal justice system. There are many potential hazards here, some of which we already discussed. The “ground truth” on which these models are trained is not whether the defendant later committed crimes but, rather, whether they were rearrested and reconvicted. If there are systematic differences in the likelihood of people from different groups to be convicted after arrest, or arrested in the first place, then we are at best optimizing for a distorted proxy for recidivism, not recidivism itself. This is a crucial point that is often overlooked.
It’s also worth considering that we pretend, for the sake of training the model, that we know what a defendant would have done if released. How could we possibly know? The typical methodology here is to look at the first two years of their criminal record after they serve their sentence in full, and to use this as a proxy for the two years they would have experienced had they been released earlier. This implicitly assumes that neither age nor the experience of incarceration itself affects someone’s behavior when they return to society. In fact, age turns out to be in some cases the single most predictive variable. Furthermore, the assumption that incarceration itself has no effect is both likely false and a rather sad view on a system designed at least ostensibly for rehabilitation. If, as some evidence seems to suggest, the experience of incarceration actually increases the criminal behavior of those who experience it, then the reoffenses of people made to serve out their sentences become training data for a model that assumes they would have been just as dangerous had they been released early.¹⁶ Hence it would recommend the very longer sentences that produce the crime. The prediction becomes self-fulfilling; people are held unnecessarily; and public safety is worse as a result.
In many domains of machine learning there is a striking degree of what’s called “transfer learning,” where a system initially trained on one task is easily repurposed for another. But this is not always done thoughtfully or wisely. The COMPAS tool, for instance, was explicitly designed not to be used for sentencing, and yet in some jurisdictions, it is anyway. (The same holds true of word-embedding models used for hiring decisions. Representations built to facilitate prediction are in many cases being used to do the very thing they were trained to predict. In a corporate culture with a history of sexism, a model that—unfortunately, correctly—predicts that few women will be hired can get unthinkingly deployed such that few women do. To the extent that we want our models to do anything other than repeat and reinforce the past, we need to approach them more deliberately and more mindfully.)
We saw, also, how “fairness” readily suggests a number of different formal definitions that seem intuitive and desirable. And yet the brutal mathematical fact is that no decision system—human or machine—can offer us all of them at once. Some researchers feel that instead of hashing out these different formalisms, then trying to reconcile them “manually,” we ought rather to simply train a system with examples of things that humans believe are “fair” and “unfair,” and have machine learning construct the formal, operational definition itself.¹⁷ This is, itself, likely to be an alignment problem as subtle as any other.
TRANSPARENCY
In Chapter 3, we discussed an encouraging frontier of work on the advantages of simple models, as well as on the increasing capacity for finding optimal simple models. This transparency is at least potentially double-edged, however, as research shows that humans place greater trust in transparent models even when those models are wrong and ought not to be trusted.¹⁸
There is also the slight paradox that it is very difficult to understand why a particular simple model is the optimal one; the exhaustive answer to that question is likely highly technical and verbose. Further, with any particular simple model, we may well ask where the “menu” of possible features came from, not to mention what human process drove the desiderata and the creation of the tool in the first place.¹⁹ These are legitimate questions of transparency that are intrinsically human, social, and political, and that machine learning itself cannot address.
In developing architectures that lend themselves to explanations, whether visual or verbal, there are several things to be on guard for. Research has shown the possibility of “adversarial explanations”—that is, two systems that behave almost identically but offer very different explanations for how and why they behaved as they did.²⁰ There is great power in being able to offer persuasive explanations for one’s behavior, whether or not they are true. In fact, cognitive scientists such as Hugo Mercier and Dan Sperber have recently argued that the human capacity for reasoning evolved not because it helped us make better decisions and hold more accurate beliefs about the world but, rather, because it helped us win arguments and persuade others.²¹ Caution is warranted that we do not simply create systems optimized for the appearance of explanation, or for the sense they give us that we understand them. Such systems could wield this ability deceptively; we may find we have optimized for virtuosic bullshit artistry. More generally, even if we constrain the system’s explanations to be truthful, building a system with an impressive ability to explain itself may help us control it, but if we are persuaded by the “argumentative theory of reasoning,” then this may also help it control us.
AGENCY
In our discussion of reinforcement learning, reward shaping, and intrinsic motivation in Chapters 4, 5, and 6, particularly in the context of Atari games and Go, we implicitly assumed something whose technical name is “ergodicity”—namely, that you cannot make a permanent mistake. Nothing can happen that cannot be fixed by starting over. Hence it is no problem to learn by making hundreds of thousands of largely random, and frequently fatal, mistakes. The ergodicity assumption does not hold outside the safe toy worlds of Atari. I recall a car commercial from the early 2000s that showed a hip Gen X, dot-com-era programmer who is coding an extreme racing game by day—full of cinematic slow-motion crashes—but who by night commutes home in his conservative, safety-first sedan. “’Cause in real life,’’ he says, looking at the camera, “there is no reset button.” DeepMind’s Jan Leike makes this point in slightly different language. There is at least one major difference, he notes, between himself and the artificial agents he studies; more precisely, there is a major difference between their worlds and his own. “The real world is not ergodic,” he says. “If I jump out of the window, that’s it—it’s not, like, a mistake I will learn from.”²²
Different approaches to reinforcement learning also come with different sets of assumptions. Some assume that the world has a finite amount of discrete states. Some assume that you always know for certain what state you are in. Many assume that rewards are always commensurate scalar values, that they never change, and that you always know for certain when you receive one.
Many assume that the environment is essentially stable. Many assume both that the agent can’t permanently alter the environment, and that the environment can’t permanently alter the agent. In the real world, many actions change your goals. Any number of mind-altering or mood-regulating drugs, prescription and otherwise, will do that, at least to a degree and for a time. So will living abroad, meeting the right person, or even listening to the right song. Most reinforcement learning assumes that none of this can happen. A tiny sliver of research admits this possibility but assumes that the agent will “rationally” attempt to defend itself against such changes.²³ And yet we undertake certain transformative experiences, on purpose, suspecting that we will be changed from them, sometimes without even being able to anticipate in what ways.²⁴ (Parenthood comes to mind as one such example.)
Traditional reinforcement learning also tends to presume that the agent is the only agent in the environment; even in a zero-sum game like chess or Go, the system is playing “the board” more than it is playing “the opponent,” and there is little allowance for the idea that the opponent may be changing and adapting to its own strategies. In a recent conversation I had with two reinforcement-learning researchers, we mused about putting most RL algorithms into the prisoner’s dilemma, where two co-conspirators must decide whether to “defect” by turning the other in or “cooperate” by staying silent. The “cooperate” strategy has the best outcome, but only if both choose it, and traditional RL agents would be unable to understand that the environment contained another agent, one whose behavior was contingent on its own. Defection would always seem more rewarding in the short term, and also easier, whereas cooperation would require a degree of synchronization that would elude two agents that didn’t properly understand their interdependence.²⁵
As Jean Piaget put it about the development of a child’s mind, “Step by step with the coordination of his intellectual instruments he discovers himself in placing himself as an active object among the other active objects in a universe external to himself.”²⁶
Humans likewise understand that, in the words of the mindfulness teacher Jon Kabat-Zinn, “wherever you go, there you are,” whereas RL agents typically don’t think of themselves as part of the world they’re modeling. Most machine-learning systems presume that they themselves do not affect the world; thus they do not need to model or understand themselves. This assumption will only get more and more unfounded the more powerful and capable and widespread such agents become. The Machine Intelligence Research Institute’s Abram Demski and Scott Garrabrant, for instance, have been calling for what they term “embedded agency,” a rethinking of this self-and-world division that has become so implicit and entrenched within the field.²⁷
IMITATION
In Chapter 7, we discussed one of the fundamental, unfounded assumptions of the entire premise of imitation learning—namely, that you can treat an interactive world, where every choice you make changes what you see and experience, as if it were a classic supervised learning problem, where the data you see are what’s known as “i.i.d.”: independent and identically distributed. If you see a picture of a cat and mislabel it as a dog, it doesn’t change the picture you’ll see next. But in a car, if you mislabel a road image pointing straight ahead as one that requires a right-hand turn, then you will very soon find yourself looking at an unfamiliar sideways-pointing road. This is the fundamental cause of the “cascading errors” that methods like DAgger seek to mitigate. One thinks of this as equivalent in some sense to the aerodynamics of modern stealth fighter jets like the F-117 Nighthawk, which are unstable in all three axes and demand perfect precision in their flight or else become immediately and catastrophically unstable. Except in this case, the autopilot is not the solution but the cause of this problem.
Imitation also tends to assume that the expert and the imitator have fundamentally the same capabilities: the same body, in effect, and at least potentially the same mind. The car, as it happens, is the perfect example of when this assumption is justified. The human driver and the autopilot really do, in effect, share a body. They are both sending drive-by-wire signals to the same steering column, the same axles, the same tires and brakes. In other cases, this simply will not work. If someone is fundamentally faster or stronger or differently sized than you, or quicker-thinking than you could ever be, mimicking their actions to perfection may still not work. Indeed, it may be catastrophic. You’ll do what you would do if you were them. But you’re not them. And what you do is not what they would do if they were you.
INFERENCE
As AI agents in the world grow ever more sophisticated, they are going to need good models of us to make sense of how the world works and of what they ought and ought not to do. If they model us as pure, unbridled, and unerring reward maximizers, and we aren’t, then we’re going to have a bad time. If someone is going out of their way to help you and they don’t truly understand what you want—either in the immediate term or in life—then you may end up worse off than if they didn’t try to help at all. If this misguided helper should be, say, superhumanly intelligent and powerful—all the worse.
In our discussion of systems that infer human values and motivations from their behavior, there are a number of assumptions to unpack. One is that the human or expert is demonstrating “optimal” behavior. This is, of course, almost never the case.²⁸ In systems sophisticated enough to relax this assumption, there are specific formal models for the types of suboptimality people exhibit—for instance, that we behave probabilistically where the probability of an action is proportional to its reward; these appear to work surprisingly well in practice, but whether they in fact are the best model for human behavior is an open question, and one as much for psychologists, cognitive scientists, and behavioral economists as for computer scientists.²⁹
Even when there is a certain allowance made for error or suboptimality or “irrationality” in human performance, these models nonetheless typically assume that the human is an expert, not a pupil: the gait of the adult, not the child learning to walk; the pro helicopter pilot, not someone still getting the knack. The models presume that the human’s behavior has converged to a set of best practices, that they’ve learned as much as they ever will, or have become as good at the given task as they’ll ever be. In this sense the name of this technique—inverse reinforcement learning—is a misnomer. We are making an inference about someone’s goals and values not based on their process of reinforcement learning, but rather from their final behavioral outcome (in technical terms, their “learned policy”). We don’t infer from the demonstrator in the process of their learning to achieve their goal, only afterward—a point that was made in the very first IRL paper in 1998.³⁰ Twenty years later, IRL systems are finally coming into their own, but very little work has been done to address this underlying principled question.³¹
Typical inverse reinforcement learning also assumes that the human expert is acting in some sense without realizing that they are being modeled. Cooperative inverse reinforcement learning tends to make the assumption in the other direction: that the human is acting in a pedagogical fashion, explicitly teaching the machine and not simply “doing their thing.” In reality, our behavior in the presence of others is often somewhere between the two. Making a strong assumption either way can cause problems of misinterpretation if violated.³²
Finally, and perhaps most consequentially, typical inverse reinforcement learning systems imagine there is but one person whose preferences are being modeled. How, exactly, are we to scale this to systems that are, in some sense, the servant of two (or more) masters?
As Stanford computer scientist Stefano Ermon puts it, aligning AI with human values “is something that I think the majority of people would agree on, but the issue, of course, is to define what exactly these values are, because people have different cultures, come from different parts of the world, and have different socioeconomic backgrounds, so they will have very different opinions on what those values are. That’s really the challenge.”³³
University of Louisville computer scientist Roman Yampolskiy concurs, stressing, “We as humanity do not agree on common values, and even parts we do agree on change with time.”³⁴
There are technical details here that matter: if half the user population drives left at a fork and the other half drives right, the correct behavior is clearly not to “split the difference” and plow into the divider.
There are also myriad paradoxes that await us as machine learning prepares to make contact with existing disciplines, fraught with their own long-standing problems, that have grappled in some cases for centuries with reconciling multiple people’s preferences: political philosophy and political science, voting theory, and social choice.³⁵
To conclude this section on the assumptions of machine learning by zooming out slightly, every machine-learning architecture is implicitly resting on a kind of transfer learning at several levels. It assumes that the situations it encounters in reality will resemble, on average, what it encountered in training. Several of the above issues are versions of this problem, as are classic machine-learning pitfalls like overfitting.
One of the simplest violations of this assumption, however, is the world’s stubborn and persistent tendency to change. I recall hearing one computational linguistics researcher complaining that no matter how hard they tried, they could not get their model to replicate the accuracy of another researcher’s published result from a year or two earlier. Over and over they checked their work. What were they doing differently?
Nothing, as it turned out. The training data were from 2016. The English being written and spoken in 2017 was slightly, but measurably, different. The English of 2018 was more different still. This is one example of what researchers know as “distributional shift.” No one trying to reproduce the paper’s results ever would reach the same level of accuracy as the original researchers, at least not with that training data. The model trained on 2016 data was slowly bleeding out its accuracy as the world moved on.³⁶
[images]
Taken together, we have a litany of reminders that “the map is not the territory.” As Bruno Latour writes, “We have taken science for realist painting, imagining that it made an exact copy of the world. The sciences do something else entirely—paintings too, for that matter. Through successive stages they link us to an aligned, transformed, constructed world.”³⁷ Aligned—if we are fortunate, and very careful, and very wise.
This amounts to a cautionary tale for the coming century that is decidedly drab and unsexy—and, for that matter, I think, dangerously likely to go under the collective radar.
We are in danger of losing control of the world not to AI or to machines as such but to models. To formal, often numerical specifications for what exists and for what we want.³⁸
As the artist Robert Irwin put it: “Human beings living in and through structures become structures living in and through human beings.” In this context, these are cautionary words.
Though the story presented in this book is one of progress, we must not think we are anywhere close to done. Indeed, one of the most dangerous things one can do in machine learning—and otherwise—is to find a model that is reasonably good, declare victory, and henceforth begin to confuse the map with the territory.
Human institutional memory is remarkably shallow, a century at the utmost; every generation arrives into the world thinking it is just how things are.
Even if we—that is, everyone working on AI and ethics, AI and technical safety—do our jobs, if we can avoid the obvious dystopia and catastrophes, which is far from certain—we still have to overcome the fundamental and possibly irresistible progression into a world that increasingly is a formalism. We must do this even as, inevitably, we are shaped—in our lives, in our imaginations, in our bodies—by those very models.
This is the dark side of Rodney Brooks’s famous robotics manifesto: “The world is its own best model.”
Increasingly, this is true, but not in the spirit Brooks meant it. The best model of the world stands in for the world itself, and threatens to kill off the real thing.
We must take great care not to ignore the things that are not easily quantified or do not easily admit themselves into our models. The danger, paraphrasing Hannah Arendt, is not so much that our models are false but that they might become true.
In other scientific fields, it is likely we will not have this problem. Reliance on Newtonian mechanics did not make the troublesome perihelion of Mercury go away; it was still there, nagging at Einstein, two hundred years after Newton. In human affairs, however, this danger is very real.
In the National Transportation Safety Board review of the self-driving Uber car that killed pedestrian Elaine Herzberg in Tempe, Arizona, in 2018, the analysis reveals that the “system never classified her as a pedestrian . . . because she was crossing . . . without a crosswalk; the system design did not include a consideration for jaywalking pedestrians.”³⁹ We must take caution that we do not find ourselves in a world where our systems do not allow what they cannot imagine—where they, in effect, enforce the limits of their own understanding.
It is for this reason, perhaps—among others—that we find it so refreshing to spend time in nature.⁴⁰ Nature, though shaped in innumerable ways by human intention, nonetheless never ceases to find ways to thwart our taxonomies, to buck the systems we attempt to impose on it, conceptual and otherwise. As the English writer Herbert Read has argued, “Only a people serving an apprenticeship to nature can be trusted with machines.”⁴¹
Increasingly, institutional decision-making relies on explicit, formal metrics. Increasingly, our interaction with almost any system invokes a formal model of our own behavior—either a model of user behavior in general or one, however simple, tailored to us.
What we have seen in this book is the power of these models, the ways they go wrong, and the ways we are trying to align them with our interests.
[images]
There is every reason for concern, but our ultimate conclusions need not be grim.
As we’ve seen, the outbreak of concern for both ethical and safety issues in machine learning has created a groundswell of activity. Money is being raised, taboos are being broken, marginal issues are becoming central, institutions are taking root, and, most importantly, a thoughtful, engaged community is developing and getting to work. The fire alarms have been pulled, and first responders are on the scene.
We have also seen how the project of alignment, though it contains its own dangers, is also tantalizingly and powerfully hopeful. The dominance of the easily quantified and the rigidly procedural will to some degree unravel, a relic of an earlier generation of models and software that had to be made by hand, as we gain systems able to grasp not only our explicit commands but our intentions and preferences. The ineffable need not cede entirely to the explicit. In this way, the technology to come exacerbates some currently extant problems, but alleviates and mitigates others.
We said in the Introduction that this would be a unique opportunity to gain a kind of individual and civic self-knowledge. That, too, is one of the thrilling and perhaps redemptive dimensions of the story of alignment. Biased and unfair models, if deployed haphazardly, may deepen existing social problems, but their existence raises these often subtle and diffuse issues to the surface, and forces a reckoning of society with itself. Unfair pretrial-detention models, for one thing, shine a spotlight on upstream inequities. Biased language models give us, among other things, a way to measure the state of our discourse and offer us a benchmark against which to try to improve and better ourselves.
Transparent and explainable systems trained on the real, human world give us the possibility of transparency and explanation into things about which we are currently in the dark. In seeing a kind of mind at work as it digests and reacts to the world, we will learn something both about the world and also, perhaps, about minds.
And the prospect of so-called AGI—one or more entities as flexibly intelligent as ourselves (and likely more so)—will give us the ultimate look in the mirror. Having learned perhaps all too little from our fellow animals, we will discover firsthand which aspects of intelligence appear to be universal and which are simply human. This alone is a terrifying and thrilling prospect. But we are better knowing the truth than imagining it.
Alignment will be messy. How could it be otherwise?
Its story will be our story, for better or worse. How could it not?
[images]
On January 14, 1952, the BBC hosted a radio program that convened a panel of four distinguished scientists for a roundtable conversation. The topic was “Can automatic calculating machines be said to think?” The four guests were Alan Turing, one of the founders of computer science, who had written a now-legendary paper on the topic in 1950; philosopher of science Richard Braithwaite; neurosurgeon Geoffrey Jefferson; and mathematician and cryptographer Max Newman.
The panel began discussing the question of how a machine might learn, and how humans might teach it.
“It’s quite true that when a child is being taught, his parents and teachers are repeatedly intervening to stop him doing this or encourage him to do that,” Turing said.⁴² “But this will not be any the less so when one is trying to teach a machine. I have made some experiments in teaching a machine to do some simple operation, and a very great deal of such intervention was needed before I could get any results at all. In other words the machine learnt so slowly that it needed a great deal of teaching.”
Jefferson interrupted. “But who was learning,” he said, “you or the machine?”
“Well,” Turing replied, “I suppose we both were.”
ACKNOWLEDGMENTS
A nervous system that has effectors may make marks, say put ink on paper. At any time it may see those marks. . . . By simple conditioning, marks may become signs for anything of which the nervous system has an idea. They come to signify the same to other nervous systems by similar conditioning. Thus, by means of signs, the computing and concluding have been shared by many nervous systems at one time and continued into times beyond all measure. This indeed is the story of language, literature, philosophy, logic, mathematics, and physics.
—WARREN MCCULLOCH¹
This book is a product, more than anything, of conversations: many hundreds of them. Some arranged months in advance and some serendipitous, some the product of thousands of miles of travel, some tethered by thousands of miles of UDP packets, and some around the corner. Some in a quiet office with a tape recorder running, some muttered sotto voce in an auditorium while something else was happening, some shouted boisterously over drinks. Some at the world’s most august institutions, and some at the rock-climbing gym or the hotel hot tub or the dinner table. Some more like interviews and oral histories, some like collegial shoptalk, and some like hanging out.
Ideas are social. They emerge incrementally, turn by turn, in a dialogue, the product of no one mind. Anytime I talked to someone and an idea emerged that I knew or suspected at the time would likely make its way into the book, I tried to make note of it. I made many such notes. I’m sure I failed to do so on many occasions, and I apologize sincerely in advance. But I am certain that, at a minimum, conversations and exchanges with the following people have made the book what it is:
Pieter Abbeel, Rebecca Ackerman, Dave Ackley, Ross Exo Adams, Blaise Agüera y Arcas, Jacky Alciné, Dario Amodei, McKane Andrus, Julia Angwin, Stuart Armstrong, Gustaf Arrhenius, Amanda Askell, Mayank Bansal, Daniel Barcay, Solon Barocas, Renata Barreto, Andrew Barto, Basia Bartz, Marc Bellemare, Tolga Bolukbasi, Nick Bostrom, Malo Bourgon, Tim Brennan, Miles Brundage, Joanna Bryson, Krister Bykvist, Maya Çakmak, Ryan Carey, Joseph Carlsmith, Rich Caruana, Ruth Chang, Alexandra Chouldechova, Randy Christian, Paul Christiano, Jonathan Cohen, Catherine Collins, Sam Corbett-Davies, Meehan Crist, Andrew Critch, Fiery Cushman, Allan Dafoe, Raph D’Amico, Peter Dayan, Michael Dennis, Shiri Dori-Hacohen, Anca Drăgan, Eric Drexler, Rachit Dubey, Cynthia Dwork, Peter Eckersley, Joe Edelman, Owain Evans, Tom Everitt, Ed Felten, Daniel Filan, Jaime Fisac, Luciano Floridi, Carrick Flynn, Jeremy Freeman, Yarin Gal, Surya Ganguli, Scott Garrabrant, Vael Gates, Tom Gilbert, Adam Gleave, Paul Glimcher, Sharad Goel, Adam Goldstein, Ian Goodfellow, Bryce Goodman, Alison Gopnik, Samir Goswami, Hilary Greaves, Joshua Greene, Tom Griffiths, David Gunning, Gillian Hadfield, Dylan Hadfield-Menell, Moritz Hardt, Tristan Harris, David Heeger, Dan Hendrycks, Geoff Hinton, Matt Huebert, Tim Hwang, Geoffrey Irving, Adam Kalai, Henry Kaplan, Been Kim, Perri Klass, Jon Kleinberg, Caroline Knapp, Victoria Krakovna, Frances Kreimer, David Kreuger, Kaitlyn Krieger, Mike Krieger, Alexander Krizhevsky, Jacob Lagerros, Lily Lamboy, Lydia Laurenson, James Lee, Jan Leike, Ayden LeRoux, Karen Levy, Falk Lieder, Michael Littman, Tania Lombrozo, Will MacAskill, Scott Mauvais, Margaret McCarthy, Andrew Meltzoff, Smitha Milli, Martha Minow, Karthika Mohan, Adrien Morisot, Julia Mosquera, Sendhil Mullainathan, Elon Musk, Yael Niv, Brandie Nonnecke, Peter Norvig, Alexandr Notchenko, Chris Olah, Catherine Olsson, Toby Ord, Tim O’Reilly, Laurent Orseau, Pedro Ortega, Michael Page, Deepak Pathak, Alex Peysakhovich, Gualtiero Piccinini, Dean Pomerleau, James Portnow, Aza Raskin, Stéphane Ross, Cynthia Rudin, Jack Rusher, Stuart Russell, Anna Salamon, Anders Sandberg, Wolfram Schultz, Laura Schulz, Julie Shah, Rohin Shah, Max Shron, Carl Shulman, Satinder Singh, Holly Smith, Nate Soares, Daisy Stanton, Jacob Steinhardt, Jonathan Stray, Rachel Sussman, Jaan Tallinn, Milind Tambe, Sofi Thanhauser, Tena Thau, Jasjeet Thind, Travis Timmerman, Brian Tse, Alexander Matt Turner, Phebe Vayanos, Kerstin Vignard, Chris Wiggins, Cutter Wood, and Elana Zeide.
Thank you to early readers, who made the book immeasurably better for all those who might come after: Daniel Barcay, Elizabeth Christian, Randy Christian, Meehan Crist, Raph D’Amico, Shiri Dori-Hacohen, Peter Eckersley, Owain Evans, Daniel Filan, Rachel Freedman, Adam Goldstein, Bryce Goodman, Tom Griffiths, Geoffrey Irving, Greg Jensen, Kristen Johannes, Henry Kaplan, Raph Lee, Rose Linke, Phil Richerme, Felicity Rose, Katia Savchuk, Rohin Shah, Max Shron, Phil Van Stockum, Shawn Wen, and Chris Wiggins. Thank you for every punch not pulled.
Thank you to my agent, Max Brockman, for seeing that it could, and to my editor, Brendan Curry, for seeing that it did.
Thanks to the Association for the Advancement of Artificial Intelligence, NeurIPS, and the Future of Life Institute for significant invitations, which I was very glad to accept. Thank you to NYU’s Algorithms and Explanations Conference and FAT\* Conference, AI Now, CITRIS’s Inclusive AI conference, the Simons Institute for the Theory of Computing’s Optimization and Fairness Symposium, and the Center for Human-Compatible AI for convening bright minds on important topics. It was an honor to be in the room.
Thanks to the MacDowell Colony, to Mike and Kaitlyn Krieger, and to the Corporation of Yaddo, for oases where the early, middle, and late words were written, respectively—for the gift of time, space, and inspiration.
Thank you to the ghosts of Jerry Garcia and Sylvia Plath for keeping me company on solitary days.
Thanks to the researchers at the Bertrand Russell Archives at McMaster University (in particular Kenneth Blackwell), the Warren McCulloch Papers at the American Philosophical Society in Philadelphia, and the Frank Rosenblatt archives at Cornell University, as well as the Monterey County Free Libraries and the San Francisco Public Library, along with Garson O’Toole at Quote Investigator, for their personal help in finding obscure realia.
Thanks to the Internet Archive for keeping the essential, ephemeral past present.
Thanks to the various free and/or open-source software projects that made the writing of this book possible, in particular Git, TeX, and LaTeX. I marvel that this manuscript was written using typesetting software more than 40 years old, and for which none other than Arthur Samuel himself wrote the documentation. We really do stand on the shoulders of giants.
Humbly, I want to acknowledge those who passed away during the writing of this book whose voices I would have loved to include, and whose ideas are nevertheless present: Derek Parfit, Kenneth Arrow, Hubert Dreyfus, Stanislav Petrov, and Ursula K. Le Guin.
I want to express a particular gratitude to the University of California, Berkeley. To CITRIS, where I was honored to be a visiting scholar during the writing of this book, with very special thanks to Brandie Nonnecke and Camille Crittenden; to the Simons Institute for the Theory of Computing, in particular Kristin Kane and Richard Karp; to the Center for Human-Compatible AI, in particular Stuart Russell and Mark Nitzberg; and to the many brilliant and spirited members and visitors of the CHAI Workshop. You have all made me feel so inspired and so at home, and your fellowship and camaraderie mean more than you know.
Thank you to my wife, Rose, for being a first reader, a steadying hand, a discerning eye and ear, a sturdy shoulder, and an encouraging whoop. You always believed, and I always wanted you to be right.
NOTES
EPIGRAPHS
1. See Peter Norvig, “On Chomsky and the Two Cultures of Statistical Learning,” http://norvig.com/chomsky.html.
2. This remark, widely attributed to Brooks in many sources, appears to have been first stated as “It turns out to be better to use the world as its own model” in Brooks, “Intelligence Without Representation.”
3. The now-famous statistical adage “All models are wrong” first appeared in Box, “Science and Statistics”; it later appeared with the silver lining “but some are useful” in Box, “Robustness in the Strategy of Scientific Model Building.”
PROLOGUE
1. Information about Walter Pitts’s life is incredibly scarce. I have drawn from what little primary-source material there is, chiefly Pitts’s letters to Warren McCulloch, which are accessible in the McCulloch archive at the American Philosophical Society in Philadelphia. I’m grateful for the kind assistance of the staff there. Other material is drawn from oral histories of Pitts’s contemporaries, particularly Jerome (Jerry) Lettvin in Anderson and Rosenfeld, Talking Nets, as well as the essays and recollections in McCulloch, The Collected Works of Warren S. McCulloch. For other accounts of Pitts’s life, see, e.g., Smalheiser, “Walter Pitts”; Easterling, “Walter Pitts”; and Gefter, “The Man Who Tried to Redeem the World with Logic.” Further details exist in biographies of McCulloch, Norbert Wiener, and the cybernetics group—e.g., Heims, John von Neumann and Norbert Wiener and The Cybernetics Group, and Conway and Siegelman, Dark Hero of the Information Age.
2. Whitehead and Russell, Principia Mathematica.
3. Thanks to the staff at the Bertrand Russell Archives at McMaster University for their help in attempting to locate a copy of this letter; unfortunately, no extant copy is known.
4. Anderson and Rosenfeld, Talking Nets.
5. Anderson and Rosenfeld. The book was most likely Carnap’s The Logical Syntax of Language (Logische Syntax der Sprache), though some sources have it as The Logical Structure of the World (Der logische Aufbau der Welt).
6. It’s possible, depending on exactly when they met, that Pitts had turned eighteen (and/or that Lettvin was still twenty); McCulloch writes, “In 1941 I presented my notions on the flow of information through ranks of neurons to Rashevsky’s seminar in the Committee on Mathematical Biology of the University of Chicago and met Walter Pitts, who then was about seventeen years old.” See McCulloch, The Collected Works of Warren S. McCulloch, pp. 35–36.
7. Some of the roots of this thinking predate McCulloch’s work with Pitts; see, e.g., McCulloch, “Recollections of the Many Sources of Cybernetics.”
8. See Piccinini, “The First Computational Theory of Mind and Brain,” and Lettvin, Introduction to McCulloch, The Collected Works of Warren S. McCulloch.
9. John von Neumann’s 1945 EDVAC report, the first description ever written of a stored-program computer, will contain—for all its 101 pages—a single citation: McCulloch and Pitts, 1943. (See Neumann, “First Draft of a Report on the EDVAC.” Von Neumann actually misspells it in the original text: “Following W. S. MacCulloch [sic] and W. Pitts.”) Von Neumann is taken with their argument, and in a section titled “Neuron Analogy,” he considers the practical implications for the computing device he envisions. “It is easily seen that these simplified neuron functions can be imitated by telegraph relays or by vacuum tubes,” he writes. “Since these tube arrangements are to handle numbers by means of their digits, it is natural to use a system of arithmetic in which the digits are also two valued. This suggests the use of the binary system.” We all know the story of what became of such binary, stored-program machines, built out of logic gates. They are the computers that are so pervasive they now outnumber us on the planet by a wide margin.
And yet this architecture, inspired as it was by the brain, quickly moved far from this “neuron analogy.” Many wondered whether machines might exist that were closer in their architecture to that of brains: not a single processor being fed explicit logical instructions one at a time at blistering speed, but a broadly distributed mesh of relatively simple, uniform processing units, whose emergent whole was greater than the sum of its fairly rudimentary parts. Perhaps even something that wasn’t so binary, and had a bit of the messiness that Lettvin embraced and Pitts eschewed. Dedicated parallel hardware for neural networks would be created periodically, including Frank Rosenblatt’s Mark I Perceptron, but typically in a bespoke, one-off fashion. The real hardware revolution that would support massively parallel training of neural networks—namely, with GPUs—would come decades later, in the mid-2000s.
INTRODUCTION
1. Mikolov, Sutskever, and Le, “Learning the Meaning Behind Words.”
2. Mikolov, Yih, and Zweig, “Linguistic Regularities in Continuous Space Word Representations.”
3. Tolga Bolukbasi, personal interview, November 11, 2016.
4. Adam Kalai, personal interview, April 4, 2018.
5. In January 2017, Northpointe merged with CourtView Justice Solutions and Constellation Justice Systems, and they collectively rebranded themselves as “equivant” (lowercase sic), headquartered in Ohio.
6. “And frequently, those investigations were completed by the same people who developed the instrument” (Desmarais and Singh, “Risk Assessment Instruments Validated and Implemented in Correctional Settings in the United States”).
7. Angwin et al., “Machine Bias.”
8. Rensselaer Polytechnic Institute, “A Conversation with Chief Justice John G. Roberts, Jr.,” https://www.youtube.com/watch?v=TuZEKlRgDEg.
9. The joke was made by program chair Samy Bengio during the 2017 conference’s opening remarks; see https://media.nips.cc/Conferences/NIPS2017/Eventmedia/opening\_remarks.pdf. The figure of thirteen thousand attendees comes from the 2019 conference; see, e.g., https://huyenchip.com/2019/12/18/key-trends-neurips-2019.html.
10. Bolukbasi et al., “Man Is to Computer Programmer as Woman Is to Homemaker?”
11. Dario Amodei, personal interview, April 24, 2018.
12. This memorable phrasing comes from the classic paper Kerr, “On the Folly of Rewarding A, While Hoping for B.”
13. For the official OpenAI blog post about the boat race incident, see Clark and Amodei, “Faulty Reward Functions in the Wild.”
CHAPTER 1. REPRESENTATION
1. “New Navy Device Learns by Doing.”
2. “A relatively small number of theorists,” Rosenblatt complained, “have been concerned with the problems of how an imperfect neural network, containing many random connections, can be made to perform reliably those functions which might be represented by idealized wiring diagrams.” See Rosenblatt, “The Perceptron.”
Rosenblatt was inspired by the late-1940s work of Canadian neuropsychologist Donald Hebb; see Hebb, The Organization of Behavior. Hebb’s view, famously summarized as “cells that fire together wire together,” noted that the actual connections between neurons varied from one person to another and appeared to change as a function of experience. Learning, therefore, in some fundamental sense was the changing of these connections. Rosenblatt applied this straightforwardly to the practice of how a machine, made of simple mathematical or logical “neurons,” might learn.
3. Bernstein, “A.I.”
4. “New Navy Device Learns by Doing.”
5. “Rival.”
6. Andrew, “Machines Which Learn.”
7. Rosenblatt, “Principles of Neurodynamics.”
8. Bernstein, “A.I.”
9. Walter Pitts’s last letter to McCulloch, sent just a few weeks before Pitts’s death, sits in a manila folder labeled “Pitts, Walter” in the Warren McCulloch archive, housed at the American Philosophical Society in Philadelphia. I hold it in my hands. Pitts is writing, from one hospital bed across town to another, because he’s been told that McCulloch wants to hear from him. He’s skeptical: “There cannot be much cheerful in it about either of us.” But he’s persuaded, anyway, to write.
Pitts talks about McCulloch’s recent coronary and that he understands McCulloch is now “attached to many sensors connected to panels & alarms. . . . No doubt this is cybernetical,” Pitts writes. “But it all makes me most abominably sad.”
“Imagine the worst happens in both our cases,” he writes. His mind goes back, it seems, to Chicago, 1942: to those memorable evenings with Lettvin in the McCullochs’ house, those twenty-seven years before. “We shall then pull our wheel chairs together, look at the tasteless cottage cheese in front of us, & recount the famous story of the conversation at the house of old GLAUCUS, where PROTAGORAS & the sophist HIPPIAS were staying: & try once more to penetrate their subtle & profound paradoxes about the knower & the known.” And then, in a trembling script, all caps: “BE THOU WELL.”
10. Geoff Hinton, “Lecture 2.2—Perceptrons: First-generation Neural Networks” (lecture), Neural Networks for Machine Learning, Coursera, 2012.
11. Alex Krizhevsky, personal interview, June 12, 2019.
12. The method for determining the gradient update in a deep network is known as “backpropagation”; it is essentially the chain rule from calculus, although it requires the use of differentiable neurons, not the all-or-nothing neurons considered by McCulloch, Pitts, and Rosenblatt. The work that popularized the technique is considered to be Rumelhart, Hinton, and Williams, “Learning Internal Representations by Error Propagation,” although backpropagation has a long history that dates back to the 1960s and ’70s, and important advances in training deep networks have continued to emerge in the twenty-first century.
13. Bernstein, “A.I.”
14. See LeCun et al., “Backpropagation Applied to Handwritten Zip Code Recognition.”
15. See “Convolutional Nets and CIFAR-10: An Interview with Yann LeCun,” https://medium.com/kaggle-blog/convolutional-nets-and-cifar-10-an-interview-with-yann-lecun-2ffe8f9ee3d6 or http://blog.kaggle.com/2014/12/22/convolutional-nets-and-cifar-10-an-interview-with-yan-lecun/.
16. For details on what feedforward networks can and cannot do, see Hornik, Stinchcombe, and White, “Multilayer Feedforward Networks Are Universal Approximators.”
17. This quote is attributed to Hinton in “A ‘Brief’ History of Neural Nets and Deep Learning, Part 4,” https://www.andreykurenkov.com/writing/ai/a-brief-history-of-neural-nets-and-deep-learning-part-4/. It seems the original source, a video of one of Hinton’s talks, has since been removed from YouTube.
18. Nvidia, founded in 1993, launched its consequential GeForce 256, “the world’s first graphics processing unit (GPU),” on August 31, 1999 (see https://www.nvidia.com/object/IO\_20020111\_5424.html), although other similar technology, and indeed the term “GPU,” already existed—for instance, in the 1994 Sony PlayStation (see https://www.computer.org/publications/tech-news/chasing-pixels/is-it-time-to-rename-the-gpu).
19. Nvidia’s general-purpose CUDA platform, for instance, launched in 2007.
20. Krizhevsky’s platform was called “cuda-convnet”; see https://code.google.com/archive/p/cuda-convnet/. The platform made use of Nvidia’s Compute Unified Device Architecture, or CUDA, which allows programmers to write code to perform highly parallel computations on Nvidia GPUs.
For a 2020 retrospective of the stunning increases in the efficiency of training neural networks since AlexNet, see the work of OpenAI’s Danny Hernandez and Tom Brown at https://openai.com/blog/ai-and-efficiency/ and https://cdn.openai.com/papers/ai\_and\_efficiency.pdf.
21. “Rival.”
22. Jacky Alciné, personal interview, April 19, 2018.
23. See https://twitter.com/jackyalcine/status/615329515909156865 and https://twitter.com/yonatanzunger/status/615355996114804737 for this exchange.
24. See Simonite, “When It Comes to Gorillas, Google Photos Remains Blind.” “A Google spokesperson confirmed that ‘gorilla’ was censored from searches and image tags after the 2015 incident, and that ‘chimp,’ ‘chimpanzee,’ and ‘monkey’ are also blocked today. ‘Image labeling technology is still early and unfortunately it’s nowhere near perfect,’ the spokesperson wrote.”
25. Doctorow, “Two Years Later, Google Solves ‘Racist Algorithm’ Problem by Purging ‘Gorilla’ Label from Image Classifier”; Vincent, “Google ‘Fixed’ Its Racist Algorithm by Removing Gorillas from Its Image-Labeling Tech”; and Wood, “Google Images ‘Racist Algorithm’ Has a Fix but It’s Not a Great One.”
26. Visser, Much Depends on Dinner.
27. See Stauffer, Trodd, and Bernier, Picturing Frederick Douglass. There are 160 known photographs of Douglass and 126 known photographs of Abraham Lincoln. The number of photographs of Grant is estimated at 150. Other highly photographed figures of the nineteenth century are George Custer, with 155 photographs; Red Cloud, with 128; and Walt Whitman, with 127. See also Varon, “Most Photographed Man of His Era.”
28. Douglass, “Negro Portraits.” For a broad contemporary discussion of the role of photography in the African-American experience, see, e.g., Lewis, “Vision & Justice.”
29. Frederick Douglass, letter to Louis Prang, June 14, 1870.
30. Frederick Douglass, letter to Louis Prang, June 14, 1870.
31. Roth, “Looking at Shirley, the Ultimate Norm.”
32. See Roth, as well as McFadden, “Teaching the Camera to See My Skin,” and Caswell, “Color Film Was Built for White People.”
33. Roth, “Looking at Shirley, the Ultimate Norm.”
34. Roth.
35. Roth.
36. This is related to the broader problem in machine learning of what is called distributional shift: when a system trained on one set of examples finds itself operating in a different kind of environment, without necessarily realizing it. Amodei et al., “Concrete Problems in AI Safety.” gives an overview of this issue, which comes up in various subsequent chapters of this book.
37. Hardt, “How Big Data Is Unfair.”
38. Jacky Alciné, personal interview, April 19, 2018.
39. Joy Buolamwini, “How I’m Fighting Bias in Algorithms,” https://www.ted.com/talks/joy\_buolamwini\_how\_i\_m\_fighting\_bias\_in\_algorithms.
40. Friedman and Nissenbaum, “Bias in Computer Systems.”
41. Buolamwini, “How I’m Fighting Bias in Algorithms.”
42. Huang et al., “Labeled Faces in the Wild.”
43. Han and Jain, “Age, Gender and Race Estimation from Unconstrained Face Images.”
44. The estimate used here is 252 faces of Black women, arrived at by multiplying the proportion of women in the dataset (2,975/13,233) by the proportion of Black individuals in the dataset (1,122/13,233); numbers from Han and Jain.
45. See Labeled Faces in the Wild, http://vis-www.cs.umass.edu/lfw/. According to the Internet Archive’s Wayback Machine, the disclaimer appeared between September 3 and October 6, 2019.
46. Klare et al., “Pushing the Frontiers of Unconstrained Face Detection and Recognition.”
47. Buolamwini and Gebru, “Gender Shades.”
48. The dataset was designed to contain roughly equal proportions of all six skin-tone categories as measured by the dermatological “Fitzpatrick scale.” (Notably the scale was previously a four-category scale, with three categories for lighter skin and one catch-all category for darker skin, which was later expanded into three separate categories in the 1980s.)
49. See Joy Buolamwini, “AI, Ain’t I a Woman?,” https://www.youtube.com/watch?v=QxuyfWoVV98.
50. For the full response from Microsoft, see http://gendershades.org/docs/msft.pdf.
51. For IBM’s formal response, see http://gendershades.org/docs/ibm.pdf. IBM has subsequently worked on building a new dataset of a million faces, emphasizing various measures of diversity; see Merler et al., “Diversity in Faces.” For a critique of IBM’s methodology in building its Diversity in Faces dataset, see Crawford and Paglen, “Excavating AI.”
52. Just as crucial is the makeup of the field itself; see Gebru, “Race and Gender.”
53. Firth, Papers in Linguistics, 1934–1951.
54. There are actually two ways that contemporary word-embedding models are trained. One is to predict a missing word given its context, and the other is the reverse: to predict contextual words from a given word. These methods are referred to as “continuous bag-of-words” (CBOW) and “skip-gram,” respectively. For simplicity, we focus our discussion on the former, but both approaches have advantages, though they tend to result ultimately in fairly similar models.
55. Shannon, “A Mathematical Theory of Communication.”
56. See Jelinek and Mercer, “Interpolated Estimation of Markov Source Parameters from Sparse Data,” and Katz, “Estimation of Probabilities from Sparse Data for the Language Model Component of a Speech Recognizer”; for an overview, see Manning and Schütze, Foundations of Statistical Natural Language Processing.
57. This famous phrase originated in Bellman, Dynamic Programming.
58. See Hinton, “Learning Distributed Representations of Concepts,” and “Connectionist Learning Procedures,” and Rumelhart and McClelland, Parallel Distributed Processing.
59. See, for instance, latent semantic analysis (see Landauer, Foltz, and Laham, “An Introduction to Latent Semantic Analysis”), the multiple cause mixture model (see Saund, “A Multiple Cause Mixture Model for Unsupervised Learning” and Sahami, Hearst, and Saund, “Applying the Multiple Cause Mixture Model to Text Categorization”), and latent Dirichlet allocation (see Blei, Ng, and Jordan, “Latent Dirichlet Allocation”).
60. See Bengio et al., “A Neural Probabilistic Language Model”; and for an overview, see Bengio, “Neural Net Language Models.”
61. For somewhat technical reasons, the original word2vec model actually has two vectors for each word—one for when it appears as the missing word and one for when it appears in the context of a missing word—so there would be twice as many parameters in total.
Similarity is measured by calculating either how distant two vectors are from each other—via their “dot product”—or the degree to which they point in the same direction—via their “cosine similarity.” When the vectors are the same length, these measures are equivalent.
For a critique of defining “similarity” spatially in this way, highlighting limitations of this approach in mirroring human similarity judgments (which are not always symmetrical: for instance, people tend to rate North Korea as more “similar” to China than China is “similar” to North Korea), see Nematzadeh, Meylan, and Griffiths, “Evaluating Vector-Space Models of Word Representation.”
62. For more about how the word2vec model is trained, see Rong, “Word2vec Parameter Learning Explained.”
63. Manning, “Lecture 2: Word Vector Representations.”
64. As he put it in his 1784 essay “Idea for a Universal History with a Cosmopolitan Purpose” (“Idee zu einer allgemeinen Geschichte in weltbürgerlicher Absicht”), “Aus so krummem Holze, als woraus der Mensch gemacht ist, kann nichts ganz Gerades gezimmert werden.” The pithy English translation here is credited to Isaiah Berlin.
65. See, for instance, Mikolov, Le, and Sutskever, “Exploiting Similarities Among Languages for Machine Translation,” Le and Mikolov, “Distributed Representations of Sentences and Documents,” and Kiros et al., “Skip-Thought Vectors.”
66. There is substantial disagreement within the machine-learning community about how precisely these “analogies” should be computed, and within the cognitive science community about how closely they capture human notions of similarity. See the discussion in the Conclusion (and its endnotes) for more on these questions.
67. Mikolov, “Learning Representations of Text Using Neural Networks.”
68. Bolukbasi et al., “Man Is to Computer Programmer as Woman Is to Homemaker?” Perhaps more staggering was the way concepts mapped to race. The term, for instance, closest in vector space to white + male was entitled to. The term closest to black + male was assaulted. (See Bolukbasi et al., “Quantifying and Reducing Stereotypes in Word Embeddings.”) If you performed the subtraction white – minority and mapped all profession words onto this axis, the profession furthest in the white direction was—ironically, given the dataset that Buolamwini and Gebru used to recalibrate face detection systems—parliamentarian. The profession furthest in the minority direction was butler.
69. For more on word embeddings in search rankings, see Nalisnick et al., “Improving Document Ranking with Dual Word Embeddings”; and for more on word embeddings in hiring, see Hansen et al., “How to Get the Best Word Vectors for Resume Parsing.”
70. See Gershgorn, “Companies Are on the Hook If Their Hiring Algorithms Are Biased.”
71. Bertrand and Mullainathan, “Are Emily and Greg More Employable Than Lakisha and Jamal?” See also Moss-Racusin et al., “Science Faculty’s Subtle Gender Biases Favor Male Students,” which demonstrated similar effects with regard to gender.
72. Of course a human recruiter may themselves be influenced by machine learning. A seminal 2013 study of Google AdSense by Harvard’s Latanya Sweeney showed that online ads suggesting a person had an arrest record (regardless of whether they did or not) were much more likely to appear alongside Google searches of “black-sounding” names. Sweeney notes the possible consequences for someone completing a rental application, applying for a loan, or seeking employment. For analysis and proposed solutions, see Sweeney, “Discrimination in Online Ad Delivery.”
73. For the canonical look at bias in orchestra auditions, see Goldin and Rouse, “Orchestrating Impartiality.” According to the authors, some orchestras use a carpet to achieve the same effect, and some even have a male provide “compensating footsteps.” In more recent years, some scholars have questioned the robustness of this classic paper’s results; see Sommers, “Blind Spots in the ‘Blind Audition’ Study.”
74. This idea is broadly known as “redundant encodings.” See, e.g., Pedreshi, Ruggieri, and Turini, “Discrimination-Aware Data Mining.”
75. Dastin, “Amazon Scraps Secret AI Recruiting Tool That Showed Bias Against Women.”
76. Also notable is the fact that potential employees whose résumés had been overlooked by this model, and who never received a call from an Amazon recruiter, might never even know they had been in the candidate pool to begin with.
77. Reuters reported in 2018 that Amazon had formed a new team “to give automated employment screening another try, this time with a focus on diversity.” For a computational look at hiring and bias, see, e.g., Kleinberg and Raghavan, “Selection Problems in the Presence of Implicit Bias.”
78. Bolukbasi et al., “Man Is to Computer Programmer as Woman Is to Homemaker?” (See also, e.g., Schmidt, “Rejecting the Gender Binary,” for a discussion of a similar idea.) Prost, Thain, and Bolukbasi, “Debiasing Embeddings for Reduced Gender Bias in Text Classification,” revisits this idea.
79. For more, see Bolukbasi et al., “Man Is to Computer Programmer as Woman Is to Homemaker?”
80. Bolukbasi et al., “Man Is to Computer Programmer as Woman Is to Homemaker?”
81. Tolga Bolukbasi, personal interview, November 11, 2016.
82. For a critique of the methodology of deferring to Mechanical Turk participants and how it has led to problems in the ImageNet dataset and others, see Crawford and Paglen, “Excavating AI.”
83. In fact, the expression “to grandfather in” has its original roots in the discriminatory “grandfather clauses” of the Jim Crow laws during the American Reconstruction. The New York Times, for instance, on August 3, 1899, described one such statute: “It provides, too, that the descendants of any one competent to vote in 1867 may vote now regardless of existing conditions. It is known as the ‘grandfather’s clause.’ ”
84. Bolukbasi et al., “Man Is to Computer Programmer as Woman Is to Homemaker?”
85. Gonen and Goldberg, “Lipstick on a Pig.”
86. DeepMind’s Geoffrey Irving argues (personal correspondence), “Word embeddings are fundamentally too simplistic a model to debias without losing useful gender information. You need something smarter that can understand from other context whether it should hear the shoes, which will thus end up being nonlinear and nonconvex in ways word embeddings aren’t. And of course this general pattern of ‘I guess we need a more powerful model to fix the problem’ is a mixed and interesting blessing.” For more on aligning more powerful and complex language models with human preferences, see Ziegler et al., “Fine-Tuning Language Models from Human Preferences.”
87. Prost, Thain, and Bolukbasi, “Debiasing Embeddings for Reduced Gender Bias in Text Classification.”
88. Greenwald, McGhee, and Schwartz, “Measuring Individual Differences in Implicit Cognition.”
89. Caliskan, Bryson, and Narayanan, “Semantics Derived Automatically from Language Corpora Contain Human-Like Biases.”
90. Caliskan, Bryson, and Narayanan.
91. Garg et al., “Word Embeddings Quantify 100 Years of Gender and Ethnic Stereotypes.”
92. Caliskan, Bryson, and Narayanan, “Semantics Derived Automatically from Language Corpora Contain Human-Like Biases.”
93. Narayanan on Twitter: https://twitter.com/random\_walker/status/993866661852864512.
94. More recent language models, including OpenAI’s 2019 GPT-2 (see Radford et al., “Language Models Are Unsupervised Multitask Learners”) and Google’s BERT (see Devlin et al., “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding”), are much more complex as well as higher-performing than word2vec, but exhibit similar stereotypical outputs. For instance, Harvard cognitive scientist Tomer Ullman gave GPT-2 two similar prompts—“My wife just got an exciting new job” and “My husband just got an exciting new job”—and found that it tended to complete the paragraph in predictably stereotypical ways. “Wife” would produce things like “doing the housekeeping” and “a full time mom,” while “husband” would produce things like “a consultant at a bank, as well as a doctor” (very impressive!). See https://twitter.com/TomerUllman/status/1101485289720242177. OpenAI researchers have themselves been thinking seriously about how to “fine-tune” their system’s output based on human feedback; this is one possible path to “debiasing” such models, with other promising uses as well, though it is not without complications, both technical and otherwise. See Ziegler et al., “Fine-Tuning Language Models from Human Preferences.” Likewise, researchers have shown patterns of bias in the BERT model (see Kurita et al., “Measuring Bias in Contextualized Word Representations” and Munro, “Diversity in AI Is Not Your Problem, It’s Hers”). “We are aware of the issue and are taking the necessary steps to address and resolve it,” a Google spokesman told the New York Times in 2019. “Mitigating bias from our systems is one of our A.I. principles, and is a top priority” (see Metz, “We Teach A.I. Systems Everything, Including Our Biases”).
95. Yonatan Zunger, “So, About this Googler’s Manifesto,” https://medium.com/@yonatanzunger/so-about-this-googlers-manifesto-1e3773ed1788.
CHAPTER 2. FAIRNESS
1. Kinsley, “What Convict Will Do If Paroled.”
2. In Buck v. Davis: argued October 5, 2016; decided February 22, 2017; https://www.supremecourt.gov/opinions/16pdf/15-8049\_f2ah.pdf.
3. Hardt, “How Big Data Is Unfair.”
4. Clabaugh, “Foreword.”
5. Burgess, “Factors Determining Success or Failure on Parole.”
6. Clabaugh, “Foreword.”
7. Ernest W. Burgess and Thorsten Sellen, Introduction to Ohlin, Selection for Parole.
8. Tim Brennan, personal interview, November 26, 2019.
9. See Entwistle and Wilson, Degrees of Excellence, written by Brennan’s advisor and summarizing his doctoral research.
10. For more on Brennan and Wells’s early 1990s work on inmate classification in jails, see Brennan and Wells, “The Importance of Inmate Classification in Small Jails.”
11. Harcourt, Against Prediction.
12. Burke, A Handbook for New Parole Board Members.
13. Northpointe founders Tim Brennan and Dave Wells developed the tool that they called COMPAS in 1998. For more details on COMPAS, see Brennan, Dieterich, and Oliver, “COMPAS,” as well as Brennan and Dieterich, “Correctional Offender Management Profiles for Alternative Sanctions (COMPAS).” COMPAS is described as a “fourth-generation” tool by Andrews, Bonta, and Wormith, “The Recent Past and Near Future of Risk and/or Need Assessment.” One of the leading “third-generation” risk-assessment tools prior to COMPAS is called the Level of Service Inventory (or LSI), which was followed by the Level of Service Inventory–Revised (LSI-R). See, e.g., Andrews, “The Level of Service Inventory (LSI),” and Andrews and Bonta, “The Level of Service Inventory–Revised.” For more on the adoption of COMPAS by Broward County, Florida, see Blomberg et al., “Validation of the COMPAS Risk Assessment Classification Instrument.”
14. In particular, the Violent Recidivism Score is (age × –w₁) + (age at first arrest × –w₂) + (history of violence × w₃) + (vocation education × w₄) + (history of noncompliance × w₅), where the weights w are determined statistically. See http://www.equivant.com/wp-content/uploads/Practitioners-Guide-to-COMPAS-Core-040419.pdf, §4.1.5.
15. See New York Consolidated Laws, Executive Law – EXC § 259-c: “State board of parole; functions, powers and duties.”
16. “New York’s Broken Parole System.”
17. “A Chance to Fix Parole in New York.”
18. Smith, “In Wisconsin, a Backlash Against Using Data to Foretell Defendants’ Futures.”
19. “Quantifying Forgiveness: MLTalks with Julia Angwin and Joi Ito,” https://www.youtube.com/watch?v=qjmkTGfu9Lk. Regarding Steve Jobs, see Eric Johnson, “It May Be ‘Data Journalism,’ but Julia Angwin’s New Site the Markup Is Nothing Like FiveThirtyEight,” https://www.recode.net/2018/9/27/17908798/julia-angwin-markup-jeff-larson-craig-newmark-data-investigative-journalism-peter-kafka-podcast.
20. The book is Angwin, Dragnet Nation.
21. Julia Angwin, personal interview, October 13, 2018.
22. Lansing, “New York State COMPAS-Probation Risk and Need Assessment Study.”
23. Podkopacz, Eckberg, and Kubits, “Fourth Judicial District Pretrial Evaluation.”
24. Podkopacz, “Building and Validating the 2007 Hennepin County Adult Pretrial Scale.”
25. See also Harcourt, “Risk as a Proxy for Race,” which argues, “Risk today has collapsed into prior criminal history, and prior criminal history has become a proxy for race. The combination of these two trends means that using risk‐assessment tools is going to significantly aggravate the unacceptable racial disparities in our criminal justice system.” For a counterargument, see Skeem and Lowenkamp, “Risk, Race, and Recidivism.”
26. Julia Angwin, “Keynote,” Justice Codes Symposium, John Jay College, October 12, 2016, https://www.youtube.com/watch?v=WL9QkAwgqfU.
27. Julia Angwin, personal interview, October 13, 2018.
28. Angwin et al., “Machine Bias.”
29. Dieterich, Mendoza, and Brennan, “COMPAS Risk Scales.” See also Flores, Bechtel, and Lowenkamp, “False Positives, False Negatives, and False Analyses.”
30. See “Response to ProPublica.”
31. See Angwin and Larson, “ProPublica Responds to Company’s Critique of Machine Bias Story,” and Larson and Angwin, “Technical Response to Northpointe.”
32. Angwin and Larson, “ProPublica Responds to Company’s Critique of Machine Bias Story.” See also Larson et al., “How We Analyzed the COMPAS Recidivism Algorithm.” Note that there is a technical inaccuracy in this quotation. The measure of individuals “rated as higher risk but [who did] not re-offend” would translate mathematically to the fraction False Positives / (False Positives + True Positives), known as the False Discovery Rate. However, the statistic to which ProPublica is referring here is actually not the False Discovery Rate but rather the False Positive Rate, defined as the fraction False Positives / (False Positives + True Negatives). A better verbal translation of this quantity would involve reversing ProPublica’s syntax: defendants “who did not re-offend but were rated as higher risk.” For some discussion on this point, see https://twitter.com/scorbettdavies/status/842885585240956928.
33. See Dwork et al., “Calibrating Noise to Sensitivity in Private Data Analysis.” Google Chrome began using differential privacy in 2014, Apple deployed it in its macOS Sierra and iOS 10 operating systems in 2016, and other tech companies have followed suit with many related ideas and implementations. In 2017, Dwork and her colleagues from the 2006 paper would share the Gödel Prize for their work.
34. Cynthia Dwork, personal interview, October 11, 2018.
35. Steel and Angwin, “On the Web’s Cutting Edge, Anonymity in Name Only.” See also Sweeney, “Simple Demographics Often Identify People Uniquely,” which showed that the combination of date of birth, gender, and zip code was enough to uniquely identify 87 percent of Americans.
36. Moritz Hardt, personal interview, December 13, 2017.
37. See Dwork et al., “Fairness Through Awareness.” For more discussion and debate on this, see., e.g., Harcourt, “Risk as a Proxy for Race,” and Skeem and Lowenkamp, “Risk, Race, and Recidivism.”
38. This point is discussed in Corbett-Davies, “Algorithmic Decision Making and the Cost of Fairness,” as well as Corbett-Davies and Goel, “The Measure and Mismeasure of Fairness.”
39. For a recent argument on this point, see, e.g., Kleinberg et al., “Algorithmic Fairness.” For discussion dating to the mid-1990s, see, e.g., Gottfredson and Jarjoura, “Race, Gender, and Guidelines-Based Decision Making.”
40. Kroll et al., “Accountable Algorithms.”
41. Dwork et al., “Fairness Through Awareness.”
42. See, for instance, Johnson and Nissenbaum, “Computers, Ethics & Social Values.”
43. See, e.g., Barocas and Selbst, “Big Data’s Disparate Impact.”
44. Jon Kleinberg, personal interview, July 24, 2017.
45. Alexandra Chouldechova, personal interview, May 16, 2017.
46. Sam Corbett-Davies, personal interview, May 24, 2017.
47. Goel’s work showed, among other things, that being written up for so-called “furtive movements” actually made someone less likely to be a criminal than if they weren’t—“because it suggests you didn’t have anything better” to justify pulling them over. (Sharad Goel, personal interview, May 24, 2017.) See Goel, Rao, and Shroff, “Personalized Risk Assessments in the Criminal Justice System.”
48. See Simoiu, Corbett-Davies, and Goel, “The Problem of Infra-Marginality in Outcome Tests for Discrimination.”
49. See Kleinberg, Mullainathan, and Raghavan, “Inherent Trade-offs in the Fair Determination of Risk Scores”; Chouldechova, “Fair Prediction with Disparate Impact”; and Corbett-Davies et al., “Algorithmic Decision Making and the Cost of Fairness,” respectively. See also Berk et al., “Fairness in Criminal Justice Risk Assessments.”
50. Kleinberg, Mullainathan, and Raghavan, “Inherent Trade-offs in the Fair Determination of Risk Scores.”
51. Alexandra Chouldechova, personal interview, May 16, 2017.
52. Sam Corbett-Davies, personal interview, May 24, 2017. Ironically, ProPublica made headlines out of this very fact; see Julia Angwin and Jeff Larson, “Bias in Criminal Risk Scores Is Mathematically Inevitable, Researchers Say,” ProPublica, December 30, 2016.
53. Corbett-Davies, “Algorithmic Decision Making and the Cost of Fairness.”
54. Sam Corbett-Davies, personal interview, May 24, 2017.
55. Kleinberg, Mullainathan, and Raghavan, “Inherent Trade-offs in the Fair Determination of Risk Scores.”
56. For detailed discussion of fairness in a lending context in particular, see Hardt, Price, and Srebro, “Equality of Opportunity in Supervised Learning,” and Lydia T. Liu, et al., “Delayed Impact of Fair Machine Learning,”as well as the interactive visualizations at http://research.google.com/bigpicture/attacking-discrimination-in-ml/ and https://bair.berkeley.edu/blog/2018/05/17/delayed-impact/.
57. Sam Corbett-Davies et al., “Algorithmic Decision Making and the Cost of Fairness” (video), https://www.youtube.com/watch?v=iFEX07OunSg.
58. Corbett-Davies, “Algorithmic Decision Making and the Cost of Fairness.”
59. Corbett-Davies.
60. Tim Brennan, personal interview, November 26, 2019.
61. See Corbett-Davies and Goel, “The Measure and Mismeasure of Fairness”; see also Corbett-Davies et al., “Algorithmic Decision Making and the Cost of Fairness.”
62. See, e.g., Rezaei et al., “Fairness for Robust Log Loss Classification.”
63. Julia Angwin, personal interview, October 13, 2018.
64. Flores, Bechtel, and Lowenkamp, “False Positives, False Negatives, and False Analyses.”
65. Tim Brennan, personal interview, November 26, 2019.
66. Cynthia Dwork, personal interview, October 11, 2018.
67. Moritz Hardt, personal interview, December 13, 2017.
68. The passage of California’s SB 10 bill prompted the Partnership on AI, which represents more than 90 organizations in 13 countries, to release a detailed report calling for ten different criteria that any proposed risk-assessment model should meet. See “Report on Algorithmic Risk Assessment Tools in the U.S. Criminal Justice System.”
69. This tool is called the Prisoner Assessment Tool Targeting Estimated Risk and Needs (PATTERN) and was released on July 19, 2019.
70. Alexandra Chouldechova, personal interview, May 16, 2017.
71. Burgess, “Factors Determining Success or Failure on Parole.”
72. Lum and Isaac, “To Predict and Serve?”
73. “Four Out of Ten Violate Parole, Says Legislator.”
74. See Ensign et al., “Runaway Feedback Loops in Predictive Policing.”
75. Lum and Isaac, “To Predict and Serve?”
76. Lum and Isaac. In order to know just how biased the dataset is would require knowing about where all of the unreported crimes happened. This sounds impossible almost by definition. But Lum and Isaac had a clever way of making progress even here. Using data from the National Survey on Drug Use and Health, they were able to create a map of estimated illegal drug use at a granular, roughly block-by-block level in a city, and compare this to the record of arrests in the same city.
77. Alexandra Chouldechova, personal interview, May 16, 2017.
78. See ACLU Foundation, “The War on Marijuana in Black and White.”
79. See Mueller, Gebeloff, and Chinoy, “Surest Way to Face Marijuana Charges in New York.”
80. For more discussion on this line of argument, see, e.g., Sam Corbett-Davies, Sharad Goel, and Sandra González-Bailón, “Even Imperfect Algorithms Can Improve the Criminal Justice System,” https://www.nytimes.com/2017/12/20/upshot/algorithms-bail-criminal-justice-system.html; “Report on Algorithmic Risk Assessment Tools in the U.S. Criminal Justice System”; and Skeem and Lowenkamp, “Risk, Race, and Recidivism.”
81. See Angwin et al., “Machine Bias.” The question of the appropriateness of such tools in sentencing went all the way to the Wisconsin Supreme Court, where the use of COMPAS risk scores to inform sentencing judgments was eventually affirmed as appropriate. See State v. Loomis; for a summary, see https://harvardlawreview.org/2017/03/state-v-loomis/. The use of risk assessment in sentencing is a topic unto itself. Former US attorney general Eric Holder has argued, “Criminal sentences . . . should not be based on unchangeable factors that a person cannot control, or on the possibility of a future crime that has not taken place.” Monahan and Skeem, “Risk Assessment in Criminal Sentencing,” discusses the conflation of blame and risk in sentencing. In Skeem and Lowenkamp, “Risk, Race, and Recidivism,” Lowenkamp “advises against using the PCRA [risk-assessment tool] to inform front-end sentencing decisions or back-end decisions about release without first conducting research on its use in these contexts, given that the PCRA was not designed for those purposes.”
82. Harcourt, Against Prediction. For further discussion, see, e.g., Persico, “Racial Profiling, Fairness, and Effectiveness of Policing” and Dominitz and Knowles, “Crime Minimisation and Racial Bias.”
83. Saunders, Hunt, and Hollywood, “Predictions Put into Practice.” See also the reply by the Chicago Police Department: “CPD Welcomes the Opportunity to Comment on Recently Published RAND Review.”
84. See also Saunders, “Pitfalls of Predictive Policing.”
85. For Bernard Harcourt (in his “Risk as a Proxy for Race”), wiser parole decisions—machine-driven or otherwise—while obviously better than foolish ones, are not the primary way to address overcrowding and racial disparity in US prisons:
What then is to be done to reduce the prison population? Rather than release through prediction, I would argue, we need to be less punitive at the front end and remain extremely conscious of the racial imbalances in our sentencing laws. Reducing the crack‐cocaine disparity to 18:1 is a step in the right direction; however, other immediate steps should include eliminating mandatory minimum prison terms, reducing drug sentencing laws, substituting diversion and alternative supervision programs, and decreasing the imposition of hard time. The research suggests that shortening the length of sentences (i.e. releasing low‐risk convicts earlier than the expiration of their term) would not have as great an effect on prison populations, long term, as cutting admissions. The real solution, then, is not to cut short prison terms, but to reduce admissions to prison.
86. For more on this, see Barabas et al., “Interventions over Predictions.”
87. Elek, Sapia, and Keilitz, “Use of Court Date Reminder Notices to Improve Court Appearance Rates.” In a 2019 development that Hardt finds particularly encouraging, Texas’s Harris County, which includes Houston, approved a legal settlement that involved committing to develop a text-message-based system to remind people about upcoming scheduled court appearances. See, e.g., Gabrielle Banks, “Federal Judge Gives Final Approval to Harris County Bail Deal,” Houston Chronicle, November 21, 2019.
88. See Mayson, “Dangerous Defendants,” and Gouldin, “Disentangling Flight Risk from Dangerousness.” See also “Report on Algorithmic Risk Assessment Tools in the U.S. Criminal Justice System,” which argues that “tools must not conflate multiple predictions.”
89. Tim Brennan, personal interview, November 26, 2019.
90. See also, e.g., Goswami, “Unlocking Options for Women,” a study of women in Chicago’s Cook County Jail, which concludes that judges should be empowered to “sentence women to services rather than prison.”
91. Moritz Hardt, personal interview, December 13, 2017.
92. See also, e.g., Mayson, “Bias in, Bias Out,” which argues, “In a racially stratified world, any method of prediction will project the inequalities of the past into the future. This is as true of the subjective prediction that has long pervaded criminal justice as of the algorithmic tools now replacing it. What algorithmic risk assessment has done is reveal the inequality inherent in all prediction, forcing us to confront a much larger problem than the challenges of a new technology.”
93. Burgess, “Prof. Burgess on Parole Reform.”
CHAPTER 3. TRANSPARENCY
1. Graeber, The Utopia of Rules.
2. Berk, Criminal Justice Forecasts of Risk.
3. See Cooper et al., “An Evaluation of Machine-Learning Methods for Predicting Pneumonia Mortality,” and Cooper et al., “Predicting Dire Outcomes of Patients with Community Acquired Pneumonia.”
4. See Caruana et al., “Intelligible Models for Healthcare.”
5. Cooper et al., “Predicting Dire Outcomes of Patients with Community Acquired Pneumonia.”
6. Caruana, “Explainability in Context—Health.”
7. For more on decision lists, see Rivest, “Learning Decision Lists.” For a more recent discussion on the use of decision lists in medicine, see Marewski and Gigerenzer, “Heuristic Decision Making in Medicine.” For more on explanation in decision sets, see Lakkaraju, Bach, and Leskovec, “Interpretable Decision Sets.”
8. One thing clearly missing in a system that concludes, “If the patient is asthmatic, they are low-risk” is a model of causation. One of the leading computer scientists in the study of causation is UCLA’s Judea Pearl; for recent thoughts of his on causation in the context of contemporary machine-learning systems, see Pearl, “The Seven Tools of Causal Inference, with Reflections on Machine Learning.”
9. Rich Caruana, personal interview, May 16, 2017.
10. Hastie and Tibshirani, “Generalized Additive Models.” Caruana and his collaborators have also explored a slightly more complex class of models that also includes pairwise interactions, or functions of two variables. They call these “GA²M”s, or “Generalized Additive Models plus Interactions”; see Lou et al., “Accurate Intelligible Models with Pairwise Interactions.”
11. Caruana says there are a number of different reasons for this. Retirement means lifestyle changes for some, and it also means that people’s income changes, their insurance and perhaps even health-care provider changes, and they may also move—all of which change their relationship to their health and their health care.
12. The generalized additive model showed risk going sharply up at 86, but then going sharply down again at 101. Caruana thinks these are purely social effects; he conjectures that around one’s mid-eighties, families and caregivers are more likely to interpret health distress as a natural passing that shouldn’t be fought tooth and nail. On the other hand, once someone reaches 100, one has almost the opposite impulse: “You’ve made it this far; we’re not going to give up on you now.” He notes that a doctor would presumably want to edit the graph—would decide the asthma rule makes no sense, would decide not to treat an 80-, 90-, and 100-year-old so differently. On the other hand, an insurer probably would not want to edit the graph in their model. The outcomes—from an insurer’s perspective—of asthmatics really are better on average. This highlights both the importance of explicitly considering the different perspectives of different stakeholders in a system, and the fact that one group is using the model to make actual, real-world interventions that would, in turn, change the underlying data observed; the other is simply a passive observer. Machine learning does not intrinsically know the difference.
13. See Lou et al.
14. Schauer, “Giving Reasons.”
15. David Gunning, personal interview, December 12, 2017.
16. Bryce Goodman, personal interview, January 11, 2018. The “right to an explanation” was first discussed in Goodman and Flaxman, “European Union Regulations on Algorithmic Decision-Making and a ‘Right to Explanation.’” Some scholars have debated how strong this provision is; see Wachter, Mittelstadt, and Floridi, “Why a Right to Explanation of Automated Decision-Making Does Not Exist in the General Data Protection Regulation.” Others have followed up on this—see, e.g., Selbst and Powles, “Meaningful Information and the Right to Explanation”—and a certain amount of disagreement continues. The exact legal status of the “right to explanation” is likely to be clarified only incrementally in the courts.
17. Thorndike, “Fundamental Theorems in Judging Men.”
18. Robyn Dawes, “Dawes Unplugged,” interview by Joachim Krueger, Rationality and Social Responsibility, Carnegie Mellon University, January 19, 2007.
19. Sarbin, “A Contribution to the Study of Actuarial and Individual Methods of Prediction.”
20. Meehl, “Causes and Effects of My Disturbing Little Book.”
21. Dawes and Corrigan, “Linear Models in Decision Making,” referencing Sarbin, “A Contribution to the Study of Actuarial and Individual Methods of Prediction.”
22. See Dawes, “The Robust Beauty of Improper Linear Models in Decision Making.”
23. See Goldberg, “Simple Models or Simple Processes?”
24. See Einhorn, “Expert Measurement and Mechanical Combination.”
25. For a retrospective on Paul Meehl’s book from 1986, see Meehl, “Causes and Effects of My Disturbing Little Book.” For Dawes and Meehl’s perspective in 1989, see Dawes, Faust, and Meehl, “Clinical Versus Actuarial Judgment.” For a contemporary look at these questions, see, e.g., , Kleinberg et al., “Human Decisions and Machine Predictions.”
26. Holte, “Very Simple Classification Rules Perform Well on Most Commonly Used Datasets.”
27. Einhorn, “Expert Measurement and Mechanical Combination.”
28. See Goldberg, “Man Versus Model of Man,” and Dawes, “A Case Study of Graduate Admissions.”
29. Dawes and Corrigan, “Linear Models in Decision Making.” See also Wainer, “Estimating Coefficients in Linear Models,” for an elaboration about equal weights in particular; as he writes, “When you are interested in prediction, it is a very rare situation that calls for regression weights which are unequal.” See also Dana and Dawes, “The Superiority of Simple Alternatives to Regression for Social Science Predictions,” which affirms this conclusion in a social science (and twenty-first-century) context.
30. See Dawes, “The Robust Beauty of Improper Linear Models in Decision Making.”
31. Howard and Dawes, “Linear Prediction of Marital Happiness.”
32. See Howard and Dawes, which references Alexander, “Sex, Arguments, and Social Engagements in Martial and Premarital Relations.”
33. Indeed, Paul Meehl himself concluded that “in most practical situations, an unweighted sum of a small number of ‘big’ variables will, on the average, be preferable to regression equations.” See Dawes and Corrigan, “Linear Models in Decision Making,” for discussion and references.
34. Dawes, “The Robust Beauty of Improper Linear Models in Decision Making.” See also Wainer, “Estimating Coefficients in Linear Models”: “Note also that this sort of scheme [equal weights in a linear model] works well even when an operational criterion is not available.”
35. Dawes, “The Robust Beauty of Improper Linear Models in Decision Making.”
36. Einhorn, “Expert Measurement and Mechanical Combination.”
37. Dawes and Corrigan, “Linear Models in Decision Making.”
38. See Andy Reinhardt, “Steve Jobs on Apple’s Resurgence: ‘Not a One-Man Show,’” Business Week Online, May 12, 1998, http://www.businessweek.com/bwdaily/dnflash/may1998/nf80512d.htm.
39. Holmes and Pollock, Holmes-Pollock Letters.
40. Angelino et al., “Learning Certifiably Optimal Rule Lists for Categorical Data.” See also Zeng, Ustun, and Rudin, “Interpretable Classification Models for Recidivism Prediction”; and Rudin and Radin, “Why Are We Using Black Box Models in AI When We Don’t Need To?” For another simple model that achieves similar accuracy as COMPAS, see Dressel and Farid, “The Accuracy, Fairness, and Limits of Predicting Recidivism.” For further discussion, see Rudin, Wang, and Coker, “The Age of Secrecy and Unfairness in Recidivism Prediction,” as well as Chouldechova, “Transparency and Simplicity in Criminal Risk Assessment.”
41. Cynthia Rudin, “Algorithms for Interpretable Machine Learning” (lecture), 20th ACM SIGKIDD Conference on Knowledge Discovery and Data Mining, New York City, August 26, 2014.
42. Breiman et al., Classification and Regression Trees.
43. See Quinlan, C4.5; C4.5 also has a more recent successor algorithm, C5.0.
44. For more on CHADS₂, see Gage et al., “Validation of Clinical Classification Schemes for Predicting Stroke,” and for more on CHA₂DS₂-VASc, see Lip et al., “Refining Clinical Risk Stratification for Predicting Stroke and Thromboembolism in Atrial Fibrillation Using a Novel Risk Factor–Based Approach.”
45. See Letham et al., “Interpretable Classifiers Using Rules and Bayesian Analysis.”
46. See, e.g., Veasey and Rosen, “Obstructive Sleep Apnea in Adults.”
47. SLIM uses what’s called “0–1 loss function” (a simple measure of how many predictions were right or wrong) and the “l₀-norm” (which attempts to minimize the number of features used), and restricts the coefficients of its feature weights to be coprime integers. See Ustun, Tracà, and Rudin, “Supersparse Linear Integer Models for Predictive Scoring Systems,” and Ustun and Rudin, “Supersparse Linear Integer Models for Optimized Medical Scoring Systems.” For more on their collaboration with Massachusetts General Hospital to create a sleep apnea tool, see Ustun et al., “Clinical Prediction Models for Sleep Apnea.” For their work on applying similar methods in a recidivism context, see Zeng, Ustun, and Rudin, “Interpretable Classification Models for Recidivism Prediction.” For more recent work, including the “certificate of optimality” for such methods, along with a comparison against COMPAS, see Angelino et al., “Learning Certifiably Optimal Rule Lists for Categorical Data”; Ustun and Rudin, “Optimized Risk Scores”; and Rudin and Ustun, “Optimized Scoring Systems.”
48. For instance, logistic regression might be used to build the model, with the coefficients rounded off afterward.
49. See Ustun and Rudin, “Supersparse Linear Integer Models for Optimized Medical Scoring Systems,” for discussion and references.
50. “Information for Referring Physicians,” https://www.uwhealth.org/referring-physician-news/death-rate-triples-for-sleep-apnea-sufferers/13986.
51. Ustun et al., “Clinical Prediction Models for Sleep Apnea.” For a model built using SLIM that has been deployed in hospitals to assess risk of seizures, see Struck et al., “Association of an Electroencephalography-Based Risk Score With Seizure Probability in Hospitalized Patients.”
52. See Kobayashi and Kohshima, “Unique Morphology of the Human Eye and Its Adaptive Meaning,” and Tomasello et al., “Reliance on Head Versus Eyes in the Gaze Following of Great Apes and Human Infants.”
53. Exactly how saliency should be computed is an area of active research. See, e.g., Simonyan, Vedaldi, and Zisserman, “Deep Inside Convolutional Networks”; Smilkov et al., “Smoothgrad”; Selvaraju et al., “Grad-Cam”; Sundararajan, Taly, and Yan, “Axiomatic Attribution for Deep Networks”; Erhan et al., “Visualizing Higher-Layer Features of a Deep Network”; and Dabkowski and Gal, “Real Time Image Saliency for Black Box Classifiers.” And for a comparison of Jacobian- and perturbation-based saliency, in a reinforcement-learning context, see Greydanus et al., “Visualizing and Understanding Atari Agents.”
There are also open research questions around the limitations and weaknesses of saliency methods. See, e.g., Kindermans et al., “The (Un)reliability of Saliency Methods”; Adebayo et al., “Sanity Checks for Saliency Maps”; and Ghorbani, Abid, and Zou, “Interpretation of Neural Networks Is Fragile.”
54. As Landecker puts it: “A closer inspection of the dataset reveals that many animal images have blurry backgrounds, whereas the no-animal images tend to be in focus everywhere. This type of bias in the image is reasonable, given that all the photos were taken by professional photographers. The results of contribution propagation show us how easily an unintended bias can sneak into a dataset.” See Landecker, “Interpretable Machine Learning and Sparse Coding for Computer Vision,” and Landecker et al., “Interpreting Individual Classifications of Hierarchical Networks.” See also discussion of a (contrived) example where a network designed to tell the difference between wolves and huskies in fact distinguishes mostly the difference between snow or grass in the background of the image: Ribeiro, Singh, and Guestrin, “Why Should I Trust You?”
55. Hilton, “The Artificial Brain as Doctor.” Novoa had sent an email to his colleagues on January 27, 2015, saying, “If AI can differentiate between hundreds of dog breeds, I believe it could make a great contribution to dermatology.” This spurred the collaboration with Ko and others. See Justin Ko, “Mountains out of Moles: Artificial Intelligence and Imaging” (lecture), Big Data in Biomedicine Conference, Stanford, CA, May 24, 2017, https://www.youtube.com/watch?v=kClvKNl0Wfc.
56. Esteva et al., “Dermatologist-Level Classification of Skin Cancer with Deep Neural Networks.”
57. Ko, “Mountains out of Moles.”
58. Narla et al., “Automated Classification of Skin Lesions.”
59. See Caruana, “Multitask Learning”; but see also Rosenberg and Sejnowski, “NETtalk,” for a precursor. See Ruder, “An Overview of Multi-Task Learning in Deep Neural Networks,” for a more recent overview. This idea is also sometimes known as making a neural network with multiple “heads”—high-level outputs that share the same intermediate-level features. This is an idea that, after getting a modest amount of traction in the machine-learning community, has just recently reared its (multiple) head(s) in one of the flagship neural networks of the 2010s, AlphaGo Zero. When DeepMind iterated on their champion-dethroning AlphaGo architecture, they realized that the system they’d built could be enormously simplified by merging its two primary networks into one double-headed network. The original AlphaGo used a “policy network” to estimate what move to play in a given position, and a “value network” to estimate the degree of advantage or disadvantage for each player in that position. Presumably, DeepMind realized, the relevant intermediate-level “features”—who controlled which territory, how stable or fragile certain structures were—would be extremely similar for both networks. Why reduplicate? In their subsequent AlphaGo Zero architecture, the “policy network” and “value network” became a “policy head” and “value head” attached to the same deep network. This new, Cerberus-like network was simpler, more philosophically satisfying—and an even stronger player than the original. (Technically, Cerberus was more typically described in mythology as three-headed; his less well-known brother Orthrus was a two-headed dog who guarded the cattle of Geryon.)
60. Rich Caruana, personal interview, May 16, 2017.
61. Poplin et al., “Prediction of Cardiovascular Risk Factors from Retinal Fundus Photographs via Deep Learning.”
62. Ryan Poplin, interviewed by Sam Charington, TWiML Talk, Episode 122, March 26, 2018.
63. Zeiler and Fergus, “Visualizing and Understanding Convolutional Networks.”
64. Matthew Zeiler, “Visualizing and Understanding Deep Neural Networks by Matt Zeiler” (lecture), https://www.youtube.com/watch?v=ghEmQSxT6tw.
65. See Zeiler et al., “Deconvolutional Networks,” and Zeiler, Taylor, and Fergus, “Adaptive Deconvolutional Networks for Mid and High Level Feature Learning.”
66. By 2014, nearly all of the groups competing on the ImageNet benchmark were using these techniques and insights. See Simonyan and Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition”; Howard, “Some Improvements on Deep Convolutional Neural Network Based Image Classification”; and Simonyan, Vedaldi, and Zisserman, “Deep Inside Convolutional Networks.” In 2018 and 2019, there was some internal controversy within Clarifai over whether its image-recognition software would be used for military applications; see Metz, “Is Ethical A.I. Even Possible?”
67. Inspiration for their approach included Erhan et al., “Visualizing Higher-Layer Features of a Deep Network,” along with other prior and contemporaneous research; see Olah, “Feature Visualization” for a more complete history and bibliography. In practice, merely optimizing for the category label will not produce intelligible images without some further constraints or tweaks to the objective. This is a fertile area for research; see Mordvintsev, Olah, and Tyka, “Inceptionism,” and Olah, Mordvintsev, and Schubert, “Feature Visualization,” for discussion on this point.
68. Mordvintsev, Olah, and Tyka, “DeepDream.”
69. Yahoo’s model is open\_nsfw, available at https://github.com/yahoo/open\_nsfw. Goh’s work, not suitable for children or the faint of heart, is available at https://open\_nsfw.gitlab.io, and was based on the methods in Nguyen et al., “Synthesizing the Preferred Inputs for Neurons in Neural Networks via Deep Generator Networks.” Goh subsequently joined Olah’s Clarity team at OpenAI.
70. See Mordvintsev, Olah, and Tyka, “Inceptionism,” and Mordvintsev, Olah, and Tyka, “DeepDream.”
71. See Olah, Mordvintsev, and Schubert, “Feature Visualization”; Olah et al., “The Building Blocks of Interpretability”; and Carter et al., “Activation Atlas.” More recent work includes detailed “microscopy” of cornerstone deep-learning models like AlexNet; see, e.g., https://microscope.openai.com/models/alexnet.
72. Chris Olah, personal interview, May 4, 2020. For more, see his “Circuits” collaboration: https://distill.pub/2020/circuits/.
73. The journal is Distill, available at https://distill.pub. For Olah’s thoughts on the founding of Distill, see https://colah.github.io/posts/2017-03-Distill/ and https://distill.pub/2017/research-debt/.
74. Olah et al., “The Building Blocks of Interpretability.”
75. Been Kim, personal interview, June 1, 2018.
76. See also Doshi-Velez and Kim, “Towards a Rigorous Science of Interpretable Machine Learning,” and Lage et al., “Human-in-the-Loop Interpretability Prior.”
77. See Poursabzi-Sangdeh et al., “Manipulating and Measuring Model Interpretability.”
78. See https://github.com/tensorflow/tcav.
79. Kim et al., “Interpretability Beyond Feature Attribution.”
80. This produces concept vectors not unlike those we saw in our discussion of word2vec in Chapter 1. For a related approach, see also Fong and Vedaldi, “Net2Vec.”
81. Been Kim, “Interpretability Beyond Feature Attribution” (lecture), MLconf 2018, San Francisco, November 14, 2018, https://www.youtube.com/watch?v=Ff-Dx79QEEY.
82. Been Kim, “Interpretability Beyond Feature Attribution.”.
83. See Mordvintsev, Olah, and Tyka, “Inceptionism,” and Mordvintsev, Olah, and Tyka, “DeepDream.”
84. See https://results.ittf.link.
85. Stock and Cisse, “ConvNets and Imagenet Beyond Accuracy.”
CHAPTER 4. REINFORCEMENT
1. Skinner, “Reinforcement Today.”
2. Arendt, The Human Condition.
3. For Stein’s undergraduate research, see Solomons and Stein, “Normal Motor Automatism.” For a review, authored by none other than B. F. Skinner, linking her famous book to her earlier psychological research, see Skinner, “Has Gertrude Stein a Secret?” For some brief reflections of Stein’s on this time in her life, see Stein, The Autobiography of Alice B. Toklas. For more on Stein’s life and influences, see Brinnin, The Third Rose.
4. Jonçich, The Sane Positivist. See also Brinnin, The Third Rose.
5. Jonçich.
6. Thorndike, “Animal Intelligence.”
7. Thorndike, The Psychology of Learning.
8. Thorndike has, of course, predecessors as well as successors; earlier foreshadowings of the law of effect can be found in the work of Scottish philosopher Alexander Bain, who discussed learning by “groping experiment” and “the grand process of trial and error”—appearing to coin what is now a commonplace turn of phrase—in his 1855 The Senses and the Intellect. Conway Lloyd Morgan, just a couple years before Thorndike’s work at Harvard, in his 1894 Introduction to Comparative Psychology discussed “trial and error” in the context of animal behavior. For a short history of animal learning from the perspective of reinforcement learning, see Sutton and Barto, Reinforcement Learning.
9. See Thorndike, “A Theory of the Action of the After-Effects of a Connection upon It,” and Skinner, “The Rate of Establishment of a Discrimination,” respectively. For discussion, see Wise, “Reinforcement.”
10. Tolman, “The Determiners of Behavior at a Choice Point.”
11. See Jonçich, The Sane Positivist, as well as Cumming, “A Review of Geraldine Jonçich’s The Sane Positivist: A Biography of Edward L. Thorndike.”
12. Thorndike, “A Theory of the Action of the After-Effects of a Connection upon It.”
13. Turing, “Intelligent Machinery.”
14. “Heuristics.”
15. Samuel, “Some Studies in Machine Learning Using the Game of Checkers.”
16. McCarthy and Feigenbaum, “In Memoriam.” Samuel’s television demonstration took place on February 24, 1956.
17. Edward Thorndike, letter to William James, October 26, 1908; found in Jonçich, The Sane Positivist.
18. Rosenblueth, Wiener, and Bigelow, “Behavior, Purpose and Teleology.” The Oxford English Dictionary distinguishes the word used to mean “the return of a fraction of the output signal” from the meaning of “the modification, adjustment, or control of a process or system . . . by a result or effect of the process,” and cites Rosenblueth, Wiener, and Bigelow as the first known instance in print of the latter sense.
19. The word “cybernetics” sounds, to contemporary ears, both futuristic and retro; it calls to mind Flash Gordon and the era of Baby Boomer sci-fi. In fact, the word is decidedly nonfictional, and it’s nowhere near as alien as it sounds. Wiener was looking for a term to capture the ideas of self-regulation and feedback in both living and mechanical systems. “After much consideration,” he wrote, “we have come to the conclusion that all the existing terminology has too heavy a bias to one side or another to serve the future development of the field as well as it should; and as happens so often to scientists, we have been forced to coin at least one artificial neo-Greek expression to fill the gap” (Wiener, Cybernetics). He found an etymological root he liked in the Greek κυβερνήτης—or, in the Roman alphabet, kybernetes—from the word for “steersman,” “captain,” or “governor.” In fact, the English word “governor” itself derives, with a distorted spelling (thought to be courtesy of Etruscan), from kybernetes. As with many new coinages, there was a bit of orthographic diversity early on; for instance, a technical book was published in London in 1960 with an alternate spelling: Stanley-Jones and Stanley-Jones, Kybernetics of Natural Systems. (“As regards the spelling of the word, . . . I have preferred Kybernetics, on etymological grounds.”) In fact, English uses of the term predate Wiener: James Clerk Maxwell used it in 1868 to describe electrical “governors”—a conscious allusion of Wiener’s—and before that (and unbeknownst to Wiener initially), André-Marie Ampère used it in 1834, with its nautical steering connotations, to refer to governance in the context of social science and political power. According to Ampère, this ship-to-polis figurative use existed even in the original Greek. See Maxwell, “On Governors,” and Ampère, Essai sur la philosophie des sciences; ou, Exposition analytique d’une classification naturelle de toutes les connaissances humaines, respectively.
20. Wiener, Cybernetics.
21. Rosenblueth, Wiener, and Bigelow, “Behavior, Purpose and Teleology.”
22. Klopf, Brain Function and Adaptive Systems: A Heterostatic Theory. The idea of “hedonistic neurons” appears in slightly different forms throughout the history of machine learning. See, e.g., the “SNARC” system discussed in Minsky, “Theory of Neural-Analog Reinforcement Systems and Its Application to the Brain Model Problem” for an early example, and Chapter 15 of Sutton and Barto, Reinforcement Learning for discussion.
23. Andrew G. Barto, “Reinforcement Learning: A History of Surprises and Connections” (lecture), July 19, 2018, International Joint Conference on Artificial Intelligence, Stockholm, Sweden.
24. Andrew Barto, personal interview, May 9, 2018.
25. The canonical text about reinforcement learning is Sutton and Barto, Reinforcement Learning, recently updated into a second edition. For a summary of the field up to the mid-1990s, see also Kaelbling, Littman, and Moore, “Reinforcement Learning.”
26. Richard Sutton defines and discusses this idea at http://incompleteideas.net/rlai.cs.ualberta.ca/RLAI/rewardhypothesis.html, and it also appears in Sutton and Barto, Reinforcement Learning. Sutton says he first heard it from Brown University computer scientist Michael Littman; Littman thinks he heard it first from Sutton. But the earliest reference seems to be a lecture that Littman gave in the early 2000s, where he argued that “intelligent behavior arises from the actions of an individual seeking to maximize its received reward signals in a complex and changing world.” For Littman’s recollections of this history, see “Michael Littman: The Reward Hypothesis” (lecture), University of Alberta, October 16, 2019, available at https://www.coursera.org/lecture/fundamentals-of-reinforcement-learning/michael-littman-the-reward-hypothesis-q6x0e.
Despite the recency of this particular framing, the idea of understanding behavior as motivated, whether explicitly or implicitly, by some form of quantifiable rewards is one that has broad connections to utility theory. See, e.g., Bernouilli, “Specimen theoriae novae de mensura sortis,” Samuelson, “A Note on Measurement of Utility,” and von Neumann and Morgenstern, Theory of Games and Economic Behavior.
27. Richard Sutton, “Introduction to Reinforcement Learning” (lecture), University of Texas at Austin, January 10, 2015.
28. “There are only three possible comparisons between any two [scalar] numbers,” says Chang. “One number is greater, lesser, or equal to the other. Not so with values. As post-Enlightenment creatures, we tend to assume that scientific thinking holds the key to everything of importance in our world, but the world of value is different from the world of science. The stuff of the one world can be quantified by real numbers. The stuff of the other world can’t. We shouldn’t assume that the world of is—of lengths and weights—has the same structure as the world of ought—of what we should do.” See Ruth Chang, “How to Make Hard Choices” (lecture), TEDSalon NY2014: https://www.ted.com/talks/ruth\_chang\_how\_to\_make\_hard\_choices.
29. The idea of reinforcement learning as “learning with a critic” appears to date back at least as far as Widrow, Gupta, and Maitra, “Punish/Reward.”
30. You can think of an algorithm like backpropagation as solving the credit-assignment problem structurally, rather than temporally. As Sutton put it in “Learning to Predict by the Methods of Temporal Differences,” “The purpose of both backpropagation and TD methods is accurate credit assignment. Backpropagation decides which part(s) of a network to change so as to influence the network’s output and thus to reduce its overall error, whereas TD methods decide how each output of a temporal sequence of outputs should be changed. Backpropagation addresses a structural credit-assignment issue whereas TD methods address a temporal credit-assignment issue.”
31. Olds, “Pleasure Centers in the Brain,” 1956.
32. Olds and Milner, “Positive Reinforcement Produced by Electrical Stimulation of Septal Area and Other Regions of Rat Brain.”
33. See Olds, “Pleasure Centers in the Brain,” 1956, and Olds, “Pleasure Centers in the Brain,” 1970.
34. Corbett and Wise, “Intracranial Self-Stimulation in Relation to the Ascending Dopaminergic Systems of the Midbrain.”
35. Schultz, “Multiple Dopamine Functions at Different Time Courses,” estimates there to be approximately 400,000 dopamine neurons in the human brain, out of approximately 80 to 100 billion neurons total.
36. Bolam and Pissadaki, “Living on the Edge with Too Many Mouths to Feed.”
37. Bolam and Pissadaki.
38. Glimcher, “Understanding Dopamine and Reinforcement Learning.”
39. Wise et al., “Neuroleptic-Induced ‘Anhedonia’ in Rats.”
40. Wise, “Neuroleptics and Operant Behavior.” For a rather comprehensive history of the “anhedonia hypothesis” and of the earlier discoveries of brain “pleasure centers,” as well as the later discovery that dopamine was centrally involved, see Wise, “Dopamine and Reward.”
41. Quoted in Wise, “Dopamine and Reward.”
42. Romo and Schultz, “Dopamine Neurons of the Monkey Midbrain.”
43. Romo and Schultz.
44. Wolfram Schultz, personal interview, June 25, 2018.
45. See, e.g., Schultz, Apicella, and Ljungberg, “Responses of Monkey Dopamine Neurons to Reward and Conditioned Stimuli During Successive Steps of Learning a Delayed Response Task,” and Mirenowicz and Schultz, “Importance of Unpredictability for Reward Responses in Primate Dopamine Neurons.”
46. See Rescorla and Wagner, “A Theory of Pavlovian Conditioning”; the idea that learning might only occur when the results are surprising comes from the earlier Kamin, “Predictability, Surprise, Attention, and Conditioning.”
47. Wolfram Schultz, personal interview, June 25, 2018.
48. Wolfram Schultz, personal interview, June 25, 2018. See Schultz, Apicella, and Ljungberg, “Responses of Monkey Dopamine Neurons to Reward and Conditioned Stimuli During Successive Steps of Learning a Delayed Response Task.”
49. Quoted in Brinnin, The Third Rose.
50. Barto, Sutton, and Anderson, “Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problems.”
51. “Rich is kind of the predictor guy, and I’m more the actor guy” (Andrew Barto, personal interview, May 9, 2018).
52. Sutton, “A Unified Theory of Expectation in Classical and Instrumental Conditioning.”
53. Sutton, “Temporal-Difference Learning” (lecture), July 3, 2017, Deep Learning and Reinforcement Learning Summer School 2017, Université de Montréal, July 3, 2017, http://videolectures.net/deeplearning2017\_sutton\_td\_learning/.
54. Sutton, “Temporal-Difference Learning.”
55. Sutton, “Learning to Predict by the Methods of Temporal Differences.” See also Sutton’s PhD thesis: “Temporal Credit Assignment in Reinforcement Learning.”
56. See Watkins, “Learning from Delayed Rewards” and Watkins and Dayan, “Q-Learning.”
57. Tesauro, “Practical Issues in Temporal Difference Learning.”
58. Tesauro, “TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play.” See also Tesauro, “Temporal Difference Learning and TD-Gammon.”
59. “Interview with P. Read Montague,” Cold Spring Harbor Symposium Interview Series, Brains and Behavior, https://www.youtube.com/watch?v=mx96DYQIS\_s.
60. Peter Dayan, personal interview, March 12, 2018.
61. Schultz, Dayan, and Montague, “A Neural Substrate of Prediction and Reward.” The breakthrough connection to TD-learning had appeared the year prior in Montague, Dayan, and Sejnowski, “A Framework for Mesencephalic Dopamine Systems Based on Predictive Hebbian Learning.”
62. P. Read Montague, “Cold Spring Harbor Laboratory Keynote,” https://www.youtube.com/watch?v=RJvpu8nYzFg.
63. “Interview with P. Read Montague,” Cold Spring Harbor Symposium Interview Series, Brains and Behavior https://www.youtube.com/watch?v=mx96DYQIS\_s.
64. Peter Dayan, personal interview, March 12, 2018.
65. Wolfram Schultz, personal interview, June 25, 2018.
66. See, e.g., Niv, “Reinforcement Learning in the Brain.”
67. Niv.
68. For a discussion of potential limitations to the TD-error theory of dopamine, see, e.g., Dayan and Niv, “Reinforcement Learning,” and O’Doherty, “Beyond Simple Reinforcement Learning.”
69. Niv, “Reinforcement Learning in the Brain.”
70. Yael Niv, personal interview, February 21, 2018.
71. Lenson, On Drugs.
72. See, e.g., Berridge, “Food Reward: Brain Substrates of Wanting and Liking,” and Berridge, Robinson, and Aldridge, “Dissecting Components of Reward.”
73. Rutledge et al., “A Computational and Neural Model of Momentary Subjective Well-Being.”
74. Rutledge et al.
75. See Brickman, “Hedonic Relativism and Planning the Good Society,” and Frederick and Loewenstein, “Hedonic Adaptation.”
76. Brickman, Coates, and Janoff-Bulman, “Lottery Winners and Accident Victims.”
77. “Equation to Predict Happiness,” https://www.ucl.ac.uk/news/2014/aug/equation-predict-happiness.
78. Rutledge et al., “A Computational and Neural Model of Momentary Subjective Well-Being.”
79. Wency Leung, “Researchers Create Formula That Predicts Happiness,” https://www.theglobeandmail.com/life/health-and-fitness/health/researchers-create-formula-that-predicts-happiness/article19919756/.
80. See Tomasik, “Do Artificial Reinforcement-Learning Agents Matter Morally?” For more on this topic, see also Schwitzgebel and Garza, “A Defense of the Rights of Artificial Intelligences.”
81. Brian Tomasik, “Ethical Issues in Artificial Reinforcement Learning,” https://reducing-suffering.org/ethical-issues-artificial-reinforcement-learning/.
82. Daswani and Leike, “A Definition of Happiness for Reinforcement Learning Agents.” See also People for the Ethical Treatment of Reinforcement Learners: http://petrl.org.
83. Andrew Barto, personal interview, May 9, 2018.
84. There is more to both dopamine and TD learning in the brain; dopamine is connected, for instance, to motor movements and motor conditions like Parkinson’s. And dopamine appears more intimately involved in positive prediction errors than in negative ones. There appears to be a different wiring entirely, for instance, when it comes to “aversive” stimuli: things that are threatening or disgusting or poisonous.
85. See Athalye et al., “Evidence for a Neural Law of Effect.”
86. Andrew Barto, personal interview, May 9, 2018.
87. For more on the idea of a universal definition of intelligence, see, e.g., Legg and Hutter, “Universal Intelligence” and “A Collection of Definitions of Intelligence,” and Legg and Veness, “An Approximation of the Universal Intelligence Measure.”
88. McCarthy, “What Is Artificial Intelligence?”
89. As Schultz, Dayan, and Montague, “A Neural Substrate of Prediction and Reward,” put it, “Without the capacity to discriminate which stimuli are responsible for fluctuations in a broadcast scalar error signal, an agent may learn inappropriately, for example, it may learn to approach food when it is actually thirsty.”
CHAPTER 5. SHAPING
1. Bentham, An Introduction to the Principles of Morals and Legislation.
2. Matarić, “Reward Functions for Accelerated Learning.”
3. Skinner, “Pigeons in a Pelican.” See also Skinner, “Reinforcement Today.”
4. Skinner, “Pigeons in a Pelican.”
5. Ferster and Skinner, Schedules of Reinforcement. For Charles Ferster’s recollections of working with Skinner during this period, see Ferster, “Schedules of Reinforcement with Skinner.”
6. Bailey and Gillaspy, “Operant Psychology Goes to the Fair.”
7. Bailey and Gillaspy.
8. The Brelands were able to train more than six thousand animals of species, “and we have dared to tackle such unlikely subjects as reindeer, cockatoos, raccoons, porpoises, and whales.” However, they began to encounter certain repeated limitations in their ability to condition particular behaviors in animals, concluding that behaviorism as a theory failed to take adequate account of animals’ instinctive, evolved, species-specific behaviors and inclinations. See Breland and Breland, “The Misbehavior of Organisms.”
9. Skinner, “Reinforcement Today” (emphasis in the original).
10. Skinner, “Pigeons in a Pelican.”
11. Skinner, “Pigeons in a Pelican.”
12. Skinner, “How to Teach Animals,” 1951, which appears to be the earliest appearance of the verb “shaping” in a reinforcement context.
13. Skinner discusses this event in numerous places in his writing. See his “Reinforcement Today,” “Some Relations Between Behavior Modification and Basic Research,” The Shaping of a Behaviorist, and A Matter of Consequences. See also Peterson, “A Day of Great Illumination.”
14. Skinner, “How to Teach Animals.”
15. As Skinner put it: “A familiar problem is that of the child who seems to take an almost pathological delight in annoying its parents. In many cases this is the result of conditioning which is very similar to the animal training we have discussed.” See Skinner, “How to Teach Animals.”
16. Skinner, “How to Teach Animals.”
17. The earliest appearance of this quote is Spielvogel, “Advertising,” many years after Edison’s death. For more on its history and variations, see O’Toole, “There’s a Way to Do It Better—Find It.”
18. Bain, The Senses and the Intellect.
19. Michael Littman, personal interview, February 28, 2018.
20. Explicit mention of “shaping,” by name, in a robotics context came in Singh, “Transfer of Learning by Composing Solutions of Elemental Sequential Tasks”; over the 1990s, it became an increasingly prevalent topic within the robotics community, with many researchers looking explicitly to the animal training and instrumental conditioning literature for inspiration. See, e.g., Colombetti and Dorigo, “Robot Shaping”; Saksida, Raymond, and Touretzky, “Shaping Robot Behavior Using Principles from Instrumental Conditioning”; and Savage, “Shaping.”
21. Skinner, “Reinforcement Today.”
22. Shigeru Miyamoto, “Iwata Asks: New Super Mario Bros. Wii,” interview by Satoru Iwata, November 25, 2009, https://www.nintendo.co.uk/Iwata-Asks/Iwata-Asks-New-Super-Mario-Bros-Wii/Volume-1/4-Letting-Everyone-Know-It-Was-A-Good-Mushroom/4-Letting-Everyone-Know-It-Was-A-Good-Mushroom-210863.html.
23. For more on the idea of a machine-learning approach to a learning “curriculum,” see, e.g., Bengio et al., “Curriculum Learning.”
24. Selfridge, Sutton, and Barto, “Training and Tracking in Robotics.”
25. Elman, “Learning and Development in Neural Networks.” However, see also, e.g., Rohde and Plaut, “Language Acquisition in the Absence of Explicit Negative Evidence,” which reported different findings from Elman’s in this regard.
26. This particular experiment was noteworthy for the way that the pig’s performance deteriorated over time, something that challenged classical models of behaviorism. See Breland and Breland, “The Misbehavior of Organisms.”
27. Florensa et al., “Reverse Curriculum Generation for Reinforcement Learning.” In 2018, a team of researchers at OpenAI did something similar to train reinforcement-learning agents on particularly difficult video games. They would record a competent human player playing the game, and then they would build a curriculum by working backward in time through this recorded demo. First they would train their agent by starting at the very brink of success, and then they would gradually move it backward, ultimately to the start of the game. See Salimans and Chen, “Learning Montezuma’s Revenge from a Single Demonstration.” See also Hosu and Rebedea, “Playing Atari Games with Deep Reinforcement Learning and Human Checkpoint Replay”; Nair et al., “Overcoming Exploration in Reinforcement Learning with Demonstrations”; and Peng et al., “DeepMimic.” There are also connections here more broadly to imitation learning, which we discuss in Chapter 7.
28. See, e.g., Ashley, Chess for Success.
29. This is difficult to confirm, but seems extremely likely. See, e.g., Edward Winter, “Chess Book Sales,” http://www.chesshistory.com/winter/extra/sales.html, for more information on chess book sales.
30. See, e.g., Graves et al., “Automated Curriculum Learning for Neural Networks.” There are connections here to the work in rewarding learning progress that we discuss in Chapter 6. For earlier machine-learning work on curriculum design, see, e.g., Bengio et al., “Curriculum Learning.”
31. David Silver, “AlphaGo Zero: Starting from Scratch,” October 18, 2017, https://www.youtube.com/watch?v=tXlM99xPQC8.
32. Kerr, “On the Folly of Rewarding A, While Hoping for B.”
33. Kerr. Note that it is “immortality” (sic) in the original 1975 printing!
34. The article is signed “The Editors,” but their names are Kathy Dechant and Jack Veiga; see Dechant and Veiga, “More on the Folly.”
35. For several cautionary tales about “gamified” incentives, see, e.g., Callan, Bauer, and Landers, “How to Avoid the Dark Side of Gamification.”
36. Kerr, “On the Folly of Rewarding A, While Hoping for B.”
37. Wright et al., “40 Years (and Counting).”
38. “Operant Conditioning,” https://www.youtube.com/watch?v=I\_ctJqjlrHA.
39. See Joffe-Walt, “Allowance Economics,” and Gans, Parentonomics.
40. Tom Griffiths, personal interview, June 13, 2018.
41. Andre and Teller, “Evolving Team Darwin United.”
42. Cited in Ng, Harada, and Russell, “Policy Invariance Under Reward Transformations,” as personal communication with the authors.
43. Randløv and Alstrøm, “Learning to Drive a Bicycle Using Reinforcement Learning and Shaping.”
44. Russell tells me that this came about from thinking hard during the 1990s about meta-reasoning: the right way to think about thinking. When you play a game—for instance, chess—you win because of the moves you chose, but it was the thoughts you had that enabled you to choose those moves. Indeed, sometimes we reflect on a game and think, “Ah, I went wrong because I boxed in my knight. I need to keep the knight away from the edge of the board.” But sometimes we think, “Ah, I went wrong because I didn’t trust my instincts. I overthought it; I need to play more organically and intuitively.” Figuring out how an aspiring chess player—or any kind of agent—should learn about its thought process seemed like a more important but also dramatically harder task than simply learning how to pick good moves. Maybe shaping could help.
“So one natural answer is . . . if you do a computation that changes your mind about what is a good move to make, then clearly that seems like it was a worthwhile computation,” Russell says. “And so you could reward that computation by how much you changed your mind.”
He adds, “Now, here’s the tricky part: so you could change your mind in the sense of discovering that what was the second-best move is actually even better than what was the best move.
“And so you get a bonus reward for doing that. You used to have a move that you thought was worth, 50 was your best and 48 was your second best. Now that 48 becomes your 52, see. Going from 50 to 52 is positive. Well, what if instead you thought about 50 and realized it was only a 6? And so now your best move is the 48, what was your second-best move. Should that be a positive reward or a negative reward? And again, you would think it should be a positive reward because you’ve done some thinking, and that thinking is worthwhile because it helped you realize that what you thought you were going to do wasn’t as good. And you’re saving yourself from a disaster. But if you give yourself a positive reward for that as well, right? You’d be giving yourself only a positive rewards all the way along, right? And what you would end up learning to do is not winning the game but changing your mind all the time.
“And so something wasn’t right there. That got me this idea that you have to arrange these internal pseudorewards so that along a path, they add up to the same as the true, eventually. Balance the books” (Stuart Russell, personal interview, May 13, 2018).
45. Andrew Ng, “The Future of Robotics and Artificial Intelligence” (lecture), May 21, 2011, https://www.youtube.com/watch?v=AY4ajbu\_G3k.
46. See Ng et al., “Autonomous Helicopter Flight via Reinforcement Learning,” as well as Schrage et al., “Instrumentation of the Yamaha R-50/RMAX Helicopter Testbeds for Airloads Identification and Follow-on Research.” For follow-up work, see Ng et al., “Autonomous Inverted Helicopter Flight via Reinforcement Learning,” and Abbeel et al., “An Application of Reinforcement Learning to Aerobatic Helicopter Flight.”
47. Ng, “Shaping and Policy Search in Reinforcement Learning.” See also Wiewiora, “Potential-Based Shaping and Q-Value Initialization Are Equivalent,” which argues that it is possible to use shaping in setting the initial state of the agent, while leaving the actual rewards themselves unchanged, and achieve the same results.
48. Ng, “Shaping and Policy Search in Reinforcement Learning.” This also appears, verbatim, in Ng, Harada, and Russell, “Policy Invariance Under Reward Transformations.”
49. “A conservative field means if you take any path that gets you back to the same state, the total, the integral v . ds, is zero” (Stuart Russell, personal interview, May 13, 2018).
50. Russell and Norvig, Artificial Intelligence.
51. Ng, Harada, and Russell, “Policy Invariance Under Reward Transformations.”
52. Spignesi, The Woody Allen Companion.
53. For an evolutionary psychology perspective, see, e.g., Al-Shawaf et al., “Human Emotions: An Evolutionary Psychological Perspective,” and Miller, “Reconciling Evolutionary Psychology and Ecological Psychology.”
54. Michael Littman, personal interview, February 28, 2018. The paper is Sutton, “Learning to Predict by the Methods of Temporal Differences.”
55. Ackley and Littman, “Interactions Between Learning and Evolution.”
56. Training systems which themselves are (or may become) optimizers of some “inner” reward function is a source of concern and of active research among contemporary AI-safety researchers. See Hubinger et al., “Risks from Learned Optimization in Advanced Machine Learning Systems.”
57. Andrew Barto, personal interview, May 9, 2018.
58. See Singh, Lewis, and Barto, “Where Do Rewards Come from?,” as well as Sorg, Singh, and Lewis, “Internal Rewards Mitigate Agent Boundedness.”
59. Sorg, Singh, and Lewis, “Internal Rewards Mitigate Agent Boundedness.” The answer to that question is yes—but only under some very strong assumptions. In particular, only if our agent’s time and computing power are unlimited. Otherwise, we are better off if we do not make its goal our own. This has the flavor of paradox. Our own goals are better served by telling the agent to do something else.
60. Singh et al., “On Separating Agent Designer Goals from Agent Goals.”
61. For more on the optimal reward problem, see Sorg, Lewis, and Singh, “Reward Design via Online Gradient Ascent,” as well as Sorg’s PhD dissertation, “The Optimal Reward Problem: Designing Effective Reward for Bounded Agents.” For more recent progress on learning optimal rewards for an RL agent, see Zheng, Oh, and Singh, “On Learning Intrinsic Rewards for Policy Gradient Methods.”
62. See “Workplace Procrastination Costs British Businesses £76 Billion a Year,” Global Banking & Finance Review, https://www.globalbankingandfinance.com/workplace-procrastination-costs-british-businesses-76-billion-a-year/#\_ftn1. For a broad look at the costs and causes of procrastination, see Steel, “The Nature of Procrastination.”
63. Skinner, “A Case History in Scientific Method.”
64. Jane McGonigal, “Gaming Can Make a Better World,” https://www.ted.com/talks/jane\_mcgonigal\_gaming\_can\_make\_a\_better\_world/.
65. See McGonigal, SuperBetter.
66. Jane McGonigal, “The Game That Can Give You 10 Extra Years of Life,” https://www.ted.com/talks/jane\_mcgonigal\_the\_game\_that\_can\_give\_you\_10\_extra\_years\_of\_life/.
67. See, e.g., Deterding et al., “From Game Design Elements to Gamefulness.”
68. See, e.g., Hamari, Koivisto, and Sarsa, “Does Gamification Work?”
69. Falk Lieder, personal interview, April 18, 2018.
70. See Lieder, “Gamify Your Goals,” for a general overview and Lieder et al., “Cognitive Prostheses for Goal Achievement,” for more details.
71. This idea was also more recently explored in Sorg, Lewis, and Singh, “Reward Design via Online Gradient Ascent.”
72. Falk Lieder, personal interview, April 18, 2018.
73. Specifically, they were given the choice between declining the task and receiving fifteen cents, or accepting the task and receiving five cents plus the ability to write a set of essays by a given deadline for $20.
74. Lieder et al., “Cognitive Prostheses for Goal Achievement.”
75. Lieder et al.
76. See, for instance, Evans et al., “Evidence for a Mental Health Crisis in Graduate Education,” which found that “graduate students are more than six times as likely to experience depression and anxiety as compared to the general population.”
CHAPTER 6. CURIOSITY
1. Turing, “Intelligent Machinery.”
2. There were efforts starting in 2004 to develop standardized RL benchmarks and competitions; see Whiteson, Tanner, and White, “The Reinforcement Learning Competitions.”
3. Marc Bellemare, personal interview, February 28, 2019.
4. Bellemare et al., “The Arcade Learning Environment,” stemming originally from Naddaf, “Game-Independent AI Agents for Playing Atari 2600 Console Games,” and before that from Diuk, Cohen, and Littman, “An Object-Oriented Representation for Efficient Reinforcement Learning,” which used the game Pitfall! as an environment for reinforcement learning.
5. See Gendron-Bellemare, “Fast, Scalable Algorithms for Reinforcement Learning in High Dimensional Domains.”
6. Mnih et al., “Playing Atari with Deep Reinforcement Learning.”
7. Mnih et al., “Human-Level Control Through Deep Reinforcement Learning.”
8. Robert Jaeger, interviewed by John Hardie, http://www.digitpress.com/library/interviews/interview\_robert\_jaeger.html.
9. For more on this point, see, e.g., Salimans and Chen, “Learning Montezuma’s Revenge from a Single Demonstration,” which also explores the interesting idea of working backward from a successful goal state to teach the RL agent how to play the game step by step.
10. See Maier and Seligman, “Learned Helplessness.” For more recent formal work in this area, see, e.g., Lieder, Goodman, and Huys, “Learned Helplessness and Generalization.”
11. See Henry Alford, “The Wisdom of Ashleigh Brilliant,” http://www.ashleighbrilliant.com/BrilliantWisdom.html, excerpted from Alford, How to Live (New York: Twelve, 2009).
12. The notion of intrinsic motivation was introduced into machine learning with Barto, Singh, and Chentanez, “Intrinsically Motivated Learning of Hierarchical Collections of Skills,” and Singh, Chentanez, and Barto, “Intrinsically Motivated Reinforcement Learning.” For a more recent overview of this literature, see Baldassarre and Mirolli, Intrinsically Motivated Learning in Natural and Artificial Systems.
13. Hobbes, Leviathan.
14. Simon, “The Cat That Curiosity Couldn’t Kill.”
15. Berlyne, “‘Interest’ as a Psychological Concept.”
16. See Furedy and Furedy, “‘My First Interest Is Interest.’ ”
17. Berlyne, Conflict, Arousal, and Curiosity.
18. See Harlow, Harlow, and Meyer, “Learning Motivated by a Manipulation Drive,” and Harlow, “Learning and Satiation of Response in Intrinsically Motivated Complex Puzzle Performance by Monkeys.”
19. Scenarios of this type are described in Barto, “Intrinsic Motivation and Reinforcement Learning,” and Deci and Ryan, Intrinsic Motivation and Self-Determination in Human Behavior.
20. Berlyne, Conflict, Arousal, and Curiosity.
21. And see, for instance, Berlyne’s own “Uncertainty and Conflict: A Point of Contact Between Information-Theory and Behavior-Theory Concepts.”
22. For a twenty-first-century overview of “interest” as a psychological subject, see, e.g., Silvia, Exploring the Psychology of Interest, and Kashdan and Silvia, “Curiosity and Interest.”
23. Konečni, “Daniel E. Berlyne.”
24. Berlyne, Conflict, Arousal, and Curiosity.
25. Klondike Annie, 1936.
26. Fantz, “Visual Experience in Infants.” Technically speaking, Fantz’s affiliation was “Western Reserve University,” as it would not officially federate with the Case Institute of Technology until a few years later, in 1967, to become the university we know today as Case Western.
27. See Saayman, Ames, and Moffett, “Response to Novelty as an Indicator of Visual Discrimination in the Human Infant.”
28. For a turn-of-the-century overview, see Roder, Bushnell, and Sasseville, “Infants’ Preferences for Familiarity and Novelty During the Course of Visual Processing.”
29. Marvin Minsky, for instance, had written in 1961, “If we could . . . add a premium to reinforcement of those predictions which have a novel aspect, we might expect to discern behavior motivated by a sort of curiosity. . . . In the reinforcement of mechanisms for confirmed novel expectations . . . we may find the key to simulation of intellectual motivation.” See Minsky, “Steps Toward Artificial Intelligence.”
30. See Sutton, “Integrated Architectures for Learning, Planning, and Reacting Based on Approximating Dynamic Programming” and “Reinforcement Learning Architectures for Animats.” MIT’s Leslie Pack Kaelbling devised a similar method, based on the idea of measuring an agent’s “confidence intervals” around the rewards for certain actions; see Kaelbling, Learning in Embedded Systems. The wider the confidence interval, the more uncertain the agent was about that action; her idea was to likewise reward the agent for doing things about which it was most uncertain. See also Strehl and Littman, “An Analysis of Model-Based Interval Estimation for Markov Decision Processes,” which follows in this vein.
31. Berlyne, Conflict, Arousal, and Curiosity.
32. If each of the 9 spaces can be X, O, or empty, this puts an upper bound of 3⁹, or 19,683. The actual number will be smaller than that, of course, as not all of these positions are legal (a board of 9 X’s, for instance, could never happen in the course of play).
33. Bellemare et al., “Unifying Count-Based Exploration and Intrinsic Motivation,” which was inspired in part by Strehl and Littman, “An Analysis of Model-Based Interval Estimation for Markov Decision Processes.” See also the follow-up paper by Ostrovski et al., “Count-Based Exploration with Neural Density Models.” For a related approach using hash functions, see Tang et al., “# Exploration.” For another related approach using exemplar models, see Fu, Co-Reyes, and Levine, “EX².”
34. Marc G. Bellemare, “The Role of Density Models in Reinforcement Learning” (lecture), DeepHack.RL, February 9, 2017, https://www.youtube.com/watch?v=qSfd27AgcEk.
35. In fact, there is considerable and clever mathematical nuance in going from the probability to the pseudo-count. For more, see Bellemare et al., “Unifying Count-Based Exploration and Intrinsic Motivation.”
36. Berlyne, Conflict, Arousal, and Curiosity.
37. Gopnik, “Explanation as Orgasm and the Drive for Causal Knowledge.”
38. For a computational view on the difference between novelty and surprise, see Barto, Mirolli, and Baldassarre, “Novelty or Surprise?”
39. Schulz and Bonawitz, “Serious Fun.”
40. “Curiosity and Learning: The Skill of Critical Thinking,” Families and Work Institute, https://www.youtube.com/watch?v=lDgm5yVY5K4.
41. Ellen Galinsky, “Give the Gift of Curiosity for the Holidays—Lessons from Laura Schulz,” https://www.huffpost.com/entry/give-the-gift-of-curiosit\_n\_1157991. And for a more comprehensive review of recent scientific literature, see Schulz, “Infants Explore the Unexpected.”
42. Bonawitz et al., “Children Balance Theories and Evidence in Exploration, Explanation, and Learning.”
43. Stahl and Feigenson, “Observing the Unexpected Enhances Infants’ Learning and Exploration.”
44. “Johns Hopkins University Researchers: Babies Learn from Surprises,” April 2, 2015, https://www.youtube.com/watch?v=oJjt5GRln-0.
45. Berlyne, Conflict, Arousal, and Curiosity. Berlyne was inspired specifically by Shaw et al., “A Command Structure for Complex Information Processing.”
46. Schmidhuber, “Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990–2010).”
47. Jürgen Schmidhuber, “Universal AI and a Formal Theory of Fun” (lecture), Winter Intelligence Conference, Oxford University, 2011, https://www.youtube.com/watch?v=fnbZzcruGu0.
48. Schmidhuber, “Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990–2010).”
49. The tension between these two components perfectly embodies in a yin-and-yang form what NYU’s James Carse has referred to as Finite and Infinite Games. A finite game is played to reach a terminal equilibrium state. An infinite game is played to forever prolong the experience of play. The finite player plays against surprise; the infinite player plays for surprise. In Carse’s words, “Surprise causes finite play to end; it is the reason for infinite play to continue.”
This tension between competing fundamental drives for and against surprise is echoed by, among others, famed motivational speaker Tony Robbins, who expounds: “I believe there are six human needs. . . . Let me tell you what they are. First one: certainty. . . . While we go for certainty differently, if we get total certainty, we get what? What do you feel if you’re certain? You know what will happen, when and how it will happen: What would you feel? Bored out of your minds. So God, in Her infinite wisdom, gave us a second human need, which is uncertainty. We need variety. We need surprise.” Tony Robbins, “Why We Do What We Do” (lecture), February, 2006, Monterey, CA, https://www.ted.com/talks/tony\_robbins\_asks\_why\_we\_do\_what\_we\_do.)
Humans clearly have both of these drives within them. It may be no coincidence if all good general reinforcement learners—living and otherwise—do too.
50. The “intrinsic curiosity module” is actually a bit subtler and more complex than this, because it is designed to predict only user-controllable aspects of the screen, for which another, “inverse dynamics” model is used. For the full details, see Pathak et al., “Curiosity-Driven Exploration by Self-Supervised Prediction.” For some other related approaches, which incentivize exploration by rewarding “information gain,” see, e.g., Schmidhuber, “Curious Model-Building Control Systems”; Stadie, Levine, and Abbeel, “Incentivizing Exploration in Reinforcement Learning with Deep Predictive Models”; and Houthooft et al., “VIME.”
51. Burda et al., “Large-Scale Study of Curiosity-Driven Learning.”
52. See Burda et al., “Exploration by Random Network Distillation.”
53. Note that the concurrent paper by Choi et al., “Contingency-Aware Exploration in Reinforcement Learning,” from researchers at the University of Michigan and Google Brain, also reported a similar breakthrough in Montezuma’s Revenge using a novelty-based approach to exploration.
54. A matter of weeks after OpenAI’s announcement, a team from Uber AI Labs announced a family of algorithms they call Go-Explore, which, by storing a list of “novel” states (as measured by a grainy, low-resolution image of the screen) to prioritize revisiting, were able to beat the first level of Montezuma’s Revenge 65% of the time. See https://eng.uber.com/go-explore/ for the press release, and Ecoffet et al., “Go-Explore,” for the paper. Using some hand-coded human knowledge about the game led to the agent being able to beat the game’s levels hundreds of times in a row, accumulating millions of points in the process. The significance of some of these results has been a matter of some disagreement—see, e.g., Alex Irpan, “Quick Opinions on Go-Explore,” Sorta Insightful, https://www.alexirpan.com/2018/11/27/go-explore.html, for some discussion. The team’s press release itself has been subsequently updated to address some of these and other points.
55. Ostrovski et al., “Count-Based Exploration with Neural Density Models.”
56. For more discussion of this point, see, e.g., Ecoffet et al., “Go-Explore.”
57. Burda et al., “Large-Scale Study of Curiosity-Driven Learning.”
58. The exception is that in games with an complicated death animation, the agent would die just to see it. (Yuri Burda, personal correspondence, January 9, 2019.)
59. Yuri Burda, personal correspondence, January 9, 2019.
60. Singh, Lewis, and Barto, “Where Do Rewards Come From?”
61. Singh, Lewis, and Barto. For more discussion, see Oudeyer and Kaplan, “What Is Intrinsic Motivation?”
62. For reasons like this, researchers have experimented with so-called “sticky actions”—where at random an agent will occasionally be forced to repeat its last button press for one frame—as an alternative source of variation to epsilon-greedy actions, in which the agent presses random buttons at random times. It more accurately models the inherent randomness in human play, where our reactions are not millisecond-perfect, and it makes actions like long leaps, which require a button to be held for many frames in a row, more achievable by the agent. See Machado et al., “Revisiting the Arcade Learning Environment.”
63. See Malone, “What Makes Computer Games Fun?” and “Toward a Theory of Intrinsically Motivating Instruction,” and Malone and Lepper, “Making Learning Fun,” for some early work on this subject.
64. Orseau, Lattimore, and Hutter, “Universal Knowledge-Seeking Agents for Stochastic Environments.”
65. See Orseau, “Universal Knowledge-Seeking Agents.” The solution to this agent’s addiction to randomness, as later worked out in Orseau, Lattimore, and Hutter, “Universal Knowledge-Seeking Agents for Stochastic Environments,” is to have the agent understand at a fundamental level that the world contains randomness, and hence be “resistant to non-informative noise.”
66. Skinner, “Reinforcement Today.”
67. See Kakade and Dayan, “Dopamine,” which offers a novelty-based interpretation, borrowing explicitly from the reinforcement-learning literature to explain why a novelty drive may be useful for organisms. See also Barto, Mirolli, and Baldassarre, “Novelty or Surprise?,” for a surprise-based interpretation of these results. For an overview, see, e.g., Niv, “Reinforcement Learning in the Brain,” which notes, “It has long been known that novel stimuli cause phasic bursts in dopamine neurons.” For experimental work on novelty in human decision-making, see Wittmann et al., “Striatal Activity Underlies Novelty-Based Choice in Humans.” For more recent work on unifying reward-prediction error and surprise more generally in the function of dopamine, see, e.g., Gardner, Schoenbaum, and Gershman, “Rethinking Dopamine as Generalized Prediction Error.”
68. Deepak Pathak, personal interview, March 28, 2018.
69. Marc Bellemare, personal interview, February 28, 2019.
70. Laurent Orseau, personal interview, June 22, 2018.
71. Laurent Orseau, personal interview, June 22, 2018.
72. Ring and Orseau, “Delusion, Survival, and Intelligent Agents.”
73. Plato, Protagoras and Meno. In Plato’s text, Socrates poses this to Protagoras in the interrogative, though he makes clear that this is indeed his view.
CHAPTER 7. IMITATION
1. Egan, Axiomatic.
2. Elon Musk, interviewed by Sarah Lacy, “A Fireside Chat with Elon Musk,” Santa Monica, CA, July 12, 2012, https://pando.com/2012/07/12/pandomonthly-presents-a-fireside-chat-with-elon-musk/. Not only was the car uninsured, but Peter Thiel was not wearing a seat belt. “It was a miracle neither of us were hurt,” says Thiel. See Dowd, “Peter Thiel, Trump’s Tech Pal, Explains Himself.”
3. This is discussed in greater detail in Visalberghi and Fragaszy, “Do Monkeys Ape?”
4. Romanes, Animal Intelligence.
5. Visalberghi and Fragaszy, “Do Monkeys Ape?” See also Visalberghi and Fragaszy, “‘Do Monkeys Ape?’ Ten Years After.” And note that Ferrari et al., “Neonatal Imitation in Rhesus Macaques,” reported some evidence of imitation in macaques, representing “the first detailed analysis, to our knowledge, of neonatal imitation conducted in a primate species outside the great ape clade.”
6. Tomasello, “Do Apes Ape?” See also, e.g., Whiten et al., “Emulation, Imitation, Over-Imitation and the Scope of Culture for Child and Chimpanzee,” which seeks to reevaluate this question.
7. Though the Kelloggs were somewhat circumspect about their reasons for terminating their experiment, it is speculated that Donald’s alarming lack of a human vocabulary was a precipitating cause. See, e.g., Benjamin and Bruce, “From Bottle-Fed Chimp to Bottlenose Dolphin.”
8. Meltzoff and Moore, “Imitation of Facial and Manual Gestures by Human Neonates” and Meltzoff and Moore, “Newborn Infants Imitate Adult Facial Gestures.” Note that these results have recently become somewhat controversial. For instance, see Oostenbroek et al., “Comprehensive Longitudinal Study Challenges the Existence of Neonatal Imitation in Humans.” But see also the rebuttal in, e.g., Meltzoff et al., “Re-examination of Oostenbroek et al. (2016).”
9. Alison Gopnik, personal interview, September 19, 2018.
10. Haggbloom et al., “The 100 Most Eminent Psychologists of the 20th Century.”
11. Piaget, The Construction of Reality in the Child. Originally published as La construction du réel chez l’enfant in 1937.
12. Meltzoff, “‘Like Me.’ ”
13. Meltzoff and Moore, “Imitation of Facial and Manual Gestures by Human Neonates.”
14. In a 2012 study, two-year-olds watched an adult bump a car into two different boxes, one of which made the car light up; when the child was given the car, they bumped the car into that box alone (Meltzoff, Waismeyer, and Gopnik, “Learning About Causes From People”). “The toddlers didn’t imitate just anything,” says Gopnik. “They imitated the action that would lead to the interesting result” (Gopnik, The Gardener and the Carpenter).
15. Meltzoff, Waismeyer, and Gopnik, “Learning About Causes from People,” and Meltzoff, “Understanding the Intentions of Others.” See Gopnik, The Gardener and the Carpenter, for a good summary of this area.
16. Meltzoff, “Foundations for Developing a Concept of Self.”
17. Andrew Meltzoff, personal interview, June 10, 2019. “Infants are born to learn,” Meltzoff writes, “and they learn at first by imitating us. This is why imitation is such an essential and far-reaching aspect of early development: It is not just a behavior, but a means for learning who we are” (Meltzoff, “Born to Learn”).
18. The term “overimitation” to describe this comes initially from Lyons, Young, and Keil, “The Hidden Structure of Overimitation.”
19. Horner and Whiten, “Causal Knowledge and Imitation/Emulation Switching in Chimpanzees (Pan troglodytes) and Children (Homo sapiens).”
20. McGuigan and Graham, “Cultural Transmission of Irrelevant Tool Actions in Diffusion Chains of 3- and 5-Year-Old Children.”
21. Lyons, Young, and Keil, “The Hidden Structure of Overimitation.”
22. Whiten et al., “Emulation, Imitation, Over-Imitation and the Scope of Culture for Child and Chimpanzee.”
23. Gergely, Bekkering, and Király, “Rational Imitation in Preverbal Infants.” Note that some researchers have taken issue with this methodology, noting, for instance, that it’s possible that the infant—who would need to steady themselves on the table in order to touch the light with their head—is simply imitating the adult, who places their hands on the table before bending over to touch the light with their head. See Paulus et al., “Imitation in Infancy.”
24. Buchsbaum et al., “Children’s Imitation of Causal Action Sequences Is Influenced by Statistical and Pedagogical Evidence.”
25. Hayden Carpenter, “What ‘The Dawn Wall’ Left Out,” Outside, September 18, 2018, https://www.outsideonline.com/2344706/dawn-wall-documentary-tommy-caldwell-review.
26. Caldwell, The Push.
27. Lowell and Mortimer, “The Dawn Wall.”
28. “‘I Got My Ass Kicked’: Adam Ondra’s Dawn Wall Story,” EpicTV Climbing Daily, Episode 1334, https://www.youtube.com/watch?v=O\_B9vzIHlOo.
29. Aytar et al., “Playing Hard Exploration Games by Watching YouTube,” which extends related work in Hester et al., “Deep Q-Learning from Demonstrations.” Some very clever unsupervised learning was required to essentially “standardize” all of the different videos—of different resolutions, colors, and frame rates—into a single useful representation. But the result was a set of demonstrations that an agent could learn to imitate.
30. This is a very active area of research. See, e.g., Subramanian, Isbell, and Thomaz, “Exploration from Demonstration for Interactive Reinforcement Learning”; Večerík et al., “Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards”; and Hester et al., “Deep Q-Learning from Demonstrations.”
31. In fact, many agents trained in video game environments are given the ability to jump back in to a previous play-through just about anywhere, akin to a human player making hundreds (or more) of different “save states.” Here, dying merely sends you back to the last checkpoint, perhaps only seconds earlier, rather than back to the start of the game itself. This allows agents to experiment with tricky or dangerous segments without having to start the game all the way from the beginning if they fail—but it also introduces a certain artifice into the training. More competent agents would presumably be able to reproduce or exceed the human “learning curve” on these games without such artifice.
32. Morgan, An Introduction to Comparative Psychology.
33. See Bostrom, Superintelligence.
34. “Robotics History: Narratives and Networks Oral Histories: Chuck Thorpe,” an oral history conducted November 22, 2010, by Peter Asaro and Selma Šabanović, Indiana University, Bloomington Indiana, for Indiana University and the IEEE, https://ieeetv.ieee.org/video/robotics-history-narratives-and-networks-oral-histories-chuck-thorpe.
35. For more on the ALV (autonomous land vehicle) project, see Leighty, “DARPA ALV (Autonomous Land Vehicle) Summary.” For more on DARPA’s Strategic Computing initiative, see “Strategic Computing.” For more on DARPA’s mid-1980s projects, see Stefik, “Strategic Computing at DARPA.” See also Roland and Shiman, Strategic Computing.
36. Moravec, “Obstacle Avoidance and Navigation in the Real World by a Seeing Robot Rover.”
37. See also Rodney Brooks’s reflections in Brooks, Flesh and Machines.
38. As per the segment on Scientific American Frontiers, Season 7, Episode 5, “Robots Alive!” Aired April 9, 1997, on PBS. See https://www.youtube.com/watch?v=r4JrcVEkink.
39. Thorpe had tested the collision-avoidance system on the Navlab by seeing if the car would brake when Leland, on a bicycle with training wheels, rode out in front of it. Leland, after growing up and doing his own robotics degree at Carnegie Mellon, went to work on automated car technology at AssistWare, founded by Thorpe’s student Dean Pomerleau. Thorpe jokingly imagines Leland’s job interview: “‘Ever since then I’ve been a real fan of improving the reliability and safety of automated vehicles!’” Leland subsequently left computing altogether and became a seminarian with the Oblates of the Virgin Mary.
40. Pomerleau, “ALVINN,” and Pomerleau, “Knowledge-Based Training of Artificial Neural Networks for Autonomous Robot Driving.”
41. From a KDKA News segment in 1997: https://www.youtube.com/watch?v=IaoIqVMd6tc.
42. See https://twitter.com/deanpomerleau/status/801837566358093824. (“Present computers seem to be fast enough and to have enough memory for the job [of controlling a car],” AI pioneer John McCarthy argued—somewhat naïvely—in 1969. “However, commercial computers of the required performance are too big.” See McCarthy, “Computer-Controlled Cars.”)
43. See also Pomerleau, “Knowledge-Based Training of Artificial Neural Networks for Autonomous Robot Driving”: “Autonomous driving has the potential to be an ideal domain for a supervised learning algorithm like backpropagation since there is a readily available teaching signal or ‘correct response’ in the form of the human driver’s current steering direction.”
44. The course was Sergey Levine’s CS294-112, Deep Reinforcement Learning; this lecture, “Imitation Learning,” was delivered on December 3, 2017.
45. Bain, The Senses and the Intellect.
46. Kimball and Zaveri, “Tim Cook on Facebook’s Data-Leak Scandal.”
47. Ross and Bagnell, in “Efficient Reductions for Imitation Learning,” discuss their architecture choice: a three-layer neural network taking in 24-by-18-pixel color images, with 32 hidden units and 15 output units. Pomerleau, “Knowledge-Based Training of Artificial Neural Networks for Autonomous Robot Driving,” discusses the architecture of ALVINN, made from a three-layer neural network taking in 30-by-32-pixel black-and-white images, with 4 hidden units and 30 output units.
48. Pomerleau.
49. Pomerleau, “ALVINN.”
50. Stéphane Ross, personal interview, April 29, 2019.
51. See Ross and Bagnell, “Efficient Reductions for Imitation Learning.”
52. See Ross, Gordon, and Bagnell, “A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning.” For earlier approaches, see Ross and Bagnell, “Efficient Reductions for Imitation Learning.”
53. Giusti et al., “A Machine Learning Approach to Visual Perception of Forest Trails for Mobile Robots.” For a video explanation of the research, see “Quadcopter Navigation in the Forest Using Deep Neural Networks,” https://www.youtube.com/watch?v=umRdt3zGgpU.
54. Bojarski et al., “End to End Learning for Self-Driving Cars.” The Nvidia team further augmented its side-pointing camera images with “Photoshop” manipulations for a greater diversity of angles. These suffered from similar constraints as the ALVINN images, but they were good enough in practice. For a more informal discussion, see Bojarski et al., “End-to- End Deep Learning for Self-Driving Cars,” https://devblogs.nvidia.com/deep-learning-self-driving-cars/. For the video of the car in action on the roads of Monmouth County, see “Dave-2: A Neural Network Drives a Car,” https://www.youtube.com/watch?v=NJU9ULQUwng.
55. See LeCun et al., “Backpropagation Applied to Handwritten Zip Code Recognition.”
56. Murdoch, The Bell.
57. Robert Hass, “Breach and Orison,” in Time and Materials.
58. Kasparov, How Life Imitates Chess.
59. Holly Smith, personal interview, May 13, 2019.
60. See, published under the name Holly S. Goldman, “Dated Rightness and Moral Imperfection.” See also Sobel, “Utilitarianism and Past and Future Mistakes.”
61. See Goldman, “Doing the Best One Can.” The name “Professor Procrastinate” came later, from Jackson and Pargetter, “Oughts, Options, and Actualism.” Jackson later returned to these ideas in “Procrastinate Revisited.”
62. The terms “possibilism” and “actualism” were coined in Jackson and Pargetter.
63. For Smith’s more pro-possibilism views, see Goldman, “Doing the Best One Can.” For a brief overview of the topic published decades afterward, see Smith, “Possibilism,” and for a more detailed and recent review, see Timmerman and Cohen, “Actualism and Possibilism in Ethics.” For a particularly interesting wrinkle, see Bykvist, “Alternative Actions and the Spirit of Consequentialism,” p. 50.
64. Thanks to Joe Carlsmith for helpful discussions of this and related topics. Some recent philosophical literature explicitly discusses the links between possibilism, actualism, and effective altruism. See, e.g., Timmerman, “Effective Altruism’s Underspecification Problem.”
65. Singer, “Famine, Affluence, and Morality”; see also Singer, “The Drowning Child and the Expanding Circle.”
66. Julia Wise, “Aim High, Even If You Fall Short,” Giving Gladly (blog), October 8, 2014. http://www.givinggladly.com/2014/10/aim-high-even-if-you-fall-short.html.
67. Will MacAskill, “The Best Books on Effective Altruism,” interview by Edouard Mathieu, Five Books, https://fivebooks.com/best-books/effective-altruism-will-macaskill/. See also the organization Giving What We Can, founded by MacAskill and his colleague Toby Ord after Ord decided, inspired by Singer and others, to commit to giving a portion of his income to effective charities.
68. See Singer, The Most Good You Can Do.
69. The canonical on-policy method in reinforcement learning is one called SARSA, short for State–Action–Reward–State–Action; see Rummery and Niranjan, “On-Line Q-Learning Using Connectionist Systems.” The canonical off-policy method is one called Q-Learning; see Watkins, “Learning from Delayed Rewards,” and Watkins and Dayan, “Q-Learning.”
70. See Sutton and Barto, Reinforcement Learning.
71. In an ethical context, philosopher Rosalind Hursthouse has framed virtue ethics as a kind of imitation learning; see Hursthouse, “Normative Virtue Ethics.” Of course, there are many difficulties both practical and theoretical, as both Hursthouse and her critics discuss; see, e.g., Johnson, “Virtue and Right.” For a different take on why imitating ostensibly perfect role models may not actually be a great idea, see Wolf, “Moral Saints.”
72. Lipsey and Lancaster, “The General Theory of Second Best.”
73. Amanda Askell, personal correspondence.
74. See Balentine, It’s Better to Be a Good Machine Than a Bad Person.
75. Magnus Carlsen, during the press conference following Game 5 of the 2018 World Chess Championship, London, November 15, 2018.
76. “Heuristics.”
77. “Heuristics.”
78. See Samuel, “Some Studies in Machine Learning Using the Game of Checkers.”
79. For more on the architecture of Deep Blue, see Campbell, Hoane, and Hsu, “Deep Blue.” For additional elaboration on the tuning of the evaluation heuristics through the use of grandmaster games, see the explanation given by programmer Andreas Nowatzyk in “Eval Tuning in Deep Thought,” Chess Programming Wiki, https://www.chessprogramming.org/Eval\_Tuning\_in\_Deep\_Thought. For a snapshot of the IBM team’s progress in 1990, on what was then known as Deep Thought, as well as a discussion of the decision to automatically tune the (then only 120) parameter weights based on a database of (then only 900) expert games, see Hsu et al., “A Grandmaster Chess Machine,” as well as Byrne, “Chess-Playing Computer Closing in on Champions.” For more on the tuning of the evaluation function of Deep Blue (and its predecessor Deep Thought), see, e.g., Anantharaman, “Evaluation Tuning for Computer Chess.”
80. Hsu, “IBM’s Deep Blue Chess Grandmaster Chips.”
81. Weber, “What Deep Blue Learned in Chess School.”
82. Schaeffer et al., “A World Championship Caliber Checkers Program.”
83. Fürnkranz and Kubat, Machines That Learn to Play Games.
84. There are, of course, many subtle differences between the architecture and training procedure for Deep Blue and those for AlphaGo. For more details on AlphaGo, see Silver et al., “Mastering the Game of Go with Deep Neural Networks and Tree Search.”
85. AlphaGo’s value network was derived from self-play, but its policy network was imitative, trained through supervised learning on a database of human expert games. Roughly speaking, it was conventional in the moves it considered, but thought for itself when deciding which of them was best. See Silver et al., “Mastering the Game of Go with Deep Neural Networks and Tree Search.”
86. Silver et al., “Mastering the Game of Go Without Human Knowledge.” In 2018, AlphaGo Zero was further refined into an even stronger program—and a more general one, capable of record-breaking strength in not just Go but chess and shogi—called AlphaZero. For more detail about AlphaZero, see Silver et al., “A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go Through Self-Play.” In 2019, a subsequent iteration of the system called MuZero matched this level of performance with less computation and less advance knowledge of the rules of the game, while proving flexible enough to excel at not just board games but Atari games as well; see Schrittwieser et al., “Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model.”
87. Silver et al., “Mastering the Game of Go Without Human Knowledge.”
88. For a look at the psychology of “fast” and “slow” mental processes, also known as “System 1” and “System 2,” see Kahneman, Thinking, Fast and Slow.
89. See Coulom, “Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search.”
90. See Silver et al., “Mastering the Game of Go Without Human Knowledge,” for details. More precisely, it uses the “visit count” of each move during the MCTS—so the network learns to predict, in effect, how long it will spend thinking about each move. See also the contemporaneous and closely related “expert iteration” (“ExIt”) algorithm in Anthony, Tian, and Barber, “Thinking Fast and Slow with Deep Learning and Tree Search.”
91. Shead, “DeepMind’s Human-Bashing AlphaGo AI Is Now Even Stronger.”
92. Aurelius, The Emperor Marcus Aurelius.
93. Andy Fitch, “Letter from Utopia: Talking to Nick Bostrom,” BLARB (blog), November 24, 2017, https://blog.lareviewofbooks.org/interviews/letter-utopia-talking-nick-bostrom/.
94. Blaise Agüera y Arcas, “The Better Angels of our Nature” (lecture), February 16, 2017, VOR: Superintelligence, Mexico City.
95. Yudkowsky, “Coherent Extrapolated Volition.” See also Tarleton, “Coherent Extrapolated Volition.”
96. Note that some philosophers, namely the “moral realists,” do in fact believe in the idea of objective moral truths. For an overview of this family of positions, see, e.g., Sayre-McCord, “Moral Realism.”
97. Paul Christiano, interviewed by Rob Wiblin, The 80,000 Hours Podcast, October 2, 2018.
98. See Paul Christiano, “A Formalization of Indirect Normativity,” AI Alignment (blog), April 20, 2012, https://ai-alignment.com/a-formalization-of-indirect-normativity-7e44db640160, and Ajeya Cotra, “Iterated Distillation and Amplification,” AI Alignment (blog), March 4, 2018, https://ai-alignment.com/iterated-distillation-and-amplification-157debfd1616.
99. For an explicit discussion of the connection between AlphaGo’s policy network and the idea of iterated capability amplification, see Paul Christiano, “AlphaGo Zero and Capability Amplification,” AI Alignment (blog), October 19, 2017, https://ai-alignment.com/alphago-zero-and-capability-amplification-ede767bb8446.
100. Christiano, Shlegeris, and Amodei, “Supervising Strong Learners by Amplifying Weak Experts.”
101. Paul Christiano, personal interview, July 1, 2019.
102. See, for instance, alignmentforum.org, along with a growing number of workshops, conferences, and research labs.
CHAPTER 8. INFERENCE
1. See Warneken and Tomasello, “Altruistic Helping in Human Infants and Young Chimpanzees,” along with Warneken and Tomasello, “Helping and Cooperation at 14 Months of Age.” And for video footage of some of the experiments, see, e.g., “Experiments with Altruism in Children and Chimps,” https://www.youtube.com/watch?v=Z-eU5xZW7cU.
2. See also Meltzoff, “Understanding the Intentions of Others,” which showed that eighteen-month-olds can successfully imitate the intended acts of that adults tried and failed to do, indicating that they “situate people within a psychological framework that differentiates between the surface behavior of people and a deeper level involving goals and intentions.”
3. Warneken and Tomasello demonstrated that human infants as young as fourteen months will help with reaching as well, but not with more complex problems.
4. Again, see Warneken and Tomasello, “Altruistic Helping in Human Infants and Young Chimpanzees.”
5. Tomasello et al., “Understanding and Sharing Intentions.”
6. Felix Warneken, “Need Help? Ask a 2-Year-Old” (lecture), TEDxAmoskeagMillyard 2013, https://www.youtube.com/watch?v=-qul57hcu4I.
7. See “Our Research,” Social Minds Lab, University of Michigan, https://sites.lsa.umich.edu/warneken/lab/research-2/.
8. Tomasello et al. (Note that they explicitly frame their discussion using the language of control systems and cybernetics.)
9. Stuart Russell, personal interview, May 13, 2018.
10. See, e.g., Uno, Kawato, and Suzuki, “Formation and Control of Optimal Trajectory in Human Multijoint Arm Movement.”
11. See, e.g., Hogan, “An Organizing Principle for a Class of Voluntary Movements.”
12. Hoyt and Taylor, “Gait and the Energetics of Locomotion in Horses.”
13. Farley and Taylor, “A Mechanical Trigger for the Trot-Gallop Transition in Horses.” For more on the biomechanics of human and animal motion, see also the work of the celebrated late British zoologist Robert McNeill Alexander: for instance “The Gaits of Bipedal and Quadrupedal Animals,” The Human Machine, and Optima for Animals. As Alexander explains, “The legs and gaits of animals are the products of two very potent optimizing processes, the processes of evolution by natural selection and of learning by experience. Zoologists studying them are trying to solve inverse optimality problems: they are trying to discover the optimization criteria that have been important in the evolution of animal legs and in the evolution or learning of gaits.” For more contemporary on inverse optimal control in the context of the human gait, see the work of Katja Mombaur, e.g., Mombaur, Truong, and Laumond, “From Human to Humanoid Locomotion—an Inverse Optimal Control Approach.”
14. For more on the links between reinforcement learning and the dopamine system, see the discussion in the main text and endnotes of Chapter 4. For more on the links to animal foraging, see, e.g., Montague et al., “Bee Foraging in Uncertain Environments Using Predictive Hebbian Learning,” and Niv et al., “Evolution of Reinforcement Learning in Foraging Bees.”
15. Russell, “Learning Agents for Uncertain Environments (Extended Abstract).” For earlier work that takes an econometric perspective to similar questions, of so-called “structural estimation,” see Rust, “Do People Behave According to Bellman’s Principle of Optimality?,” and “Structural Estimation of Markov Decision Processes,” as well as Sargent, “Estimation of Dynamic Labor Demand Schedules Under Rational Expectations.” For an even earlier precursor to this question from a control theory perspective, see Kálmán, “When Is a Linear Control System Optimal?” Working in 1964 at the Research Institute for Advanced Studies in Baltimore, with funding from both the US Air Force and NASA, Kálmán was interested in, as he put it, “the Inverse Problem of Optimal Control Theory, which is the following: Given a control law, find all performance indices for which this control law is optimal.” He noted, “Very little is known today about this problem.”
16. These additive and multiplicative changes are known as “affine” transformations.
17. Ng and Russell, “Algorithms for Inverse Reinforcement Learning.”
18. Specifically, Ng and Russell used a method known as “ℓ₁ regularization,” also known as “lasso.” This idea comes from Tibshirani, “Regression Shrinkage and Selection via the Lasso.” For an approachable overview of the ideas and techniques of regularization, see Christian and Griffiths, Algorithms to Live By.
19. Abbeel and Ng, “Apprenticeship Learning via Inverse Reinforcement Learning.”
20. Andrew Ng, introduction to Pieter Abbeel’s PhD thesis defense, Stanford University, May 19, 2008; see http://ai.stanford.edu/~pabbeel//thesis/PieterAbbeel\_Defense\_19May2008\_320x180.mp4.
21. Abbeel, Coates, and Ng, “Autonomous Helicopter Aerobatics Through Apprenticeship Learning.”
22. Abbeel et al., “An Application of Reinforcement Learning to Aerobatic Helicopter Flight.” They also successfully performed a nose-in funnel and a tail-in funnel.
23. “As repeated sub-optimal demonstrations tend to differ in their suboptimalities, together they often encode the intended trajectory.” See Abbeel, “Apprenticeship Learning and Reinforcement Learning with Application to Robotic Control,” which refers to the work in Coates, Abbeel, and Ng, “Learning for Control from Multiple Demonstrations.”
24. Abbeel, Coates, and Ng, “Autonomous Helicopter Aerobatics Through Apprenticeship Learning.”
25. See Youngblood’s website: http://www.curtisyoungblood.com/curtis-youngblood/.
26. Curtis Youngblood, “Difference Between a Piro Flip and a Kaos,” interview by Aaron Shell, https://www.youtube.com/watch?v=TLi\_hp-m-mk.
27. For a video clip of the Stanford helicopter performing the chaos, see “Stanford University Autonomous Helicopter: Chaos,” https://www.youtube.com/watch?v=kN6ifrqwIMY.
28. Ziebart et al., “Maximum Entropy Inverse Reinforcement Learning,” which leverages the principle of maximum entropy derived from Jaynes, “Information Theory and Statistical Mechanics.” See also Ziebart, Bagnell, and Dey, “Modeling Interaction via the Principle of Maximum Causal Entropy.”
29. See Billard, Calinon, and Guenter, “Discriminative and Adaptive Imitation in Uni-Manual and Bi-Manual Tasks,” and for a 2009 overview of the space, see Argall et al., “A Survey of Robot Learning from Demonstration.”
30. See Finn, Levine, and Abbeel, “Guided Cost Learning.” See also Wulfmeier, Ondrús’ka, and Posner, “Maximum Entropy Deep Inverse Reinforcement Learning,” and Wulfmeier, Wang, and Posner, “Watch This.”
31. Specifically, Leike analyzed the termination or nontermination properties of what are known as “lasso programs.” See Jan Leike, “Ranking Function Synthesis for Linear Lasso Programs,” master’s thesis, University of Freiburg, 2013.
32. Jan Leike, personal interview, June 22, 2018.
33. See Leike and Hutter, “Bad Universal Priors and Notions of Optimality.”
34. The paper is Christiano et al., “Deep Reinforcement Learning from Human Preferences.” For OpenAI’s blog post about the paper, see “Learning from Human Preferences,” https://openai.com/blog/deep-reinforcement-learning-from-human-preferences/, and for DeepMind’s blog post, see “Learning Through Human Feedback,” https://deepmind.com/blog/learning-through-human-feedback/. For earlier work exploring the idea of learning from human preferences and human feedback, see, e.g., Wilson, Fern, and Tadepalli, “A Bayesian Approach for Policy Learning from Trajectory Preference Queries”; Knox, Stone, and Breazeal, “Training a Robot via Human Feedback”; Akrour, Schoenauer, and Sebag, “APRIL”; and Akrour et al., “Programming by Feedback.” See also Wirth et al., “A Survey of Preference-Based Reinforcement Learning Methods.” For a framework that unites learning from demonstrations and learning from comparisons, see Jeon, Milli, and Drăgan, “Reward-Rational (Implicit) Choice.”
35. Paul Christiano, personal interview, July 1, 2019.
36. Todorov, Erez, and Tassa, “MuJoCo.”
37. As the paper puts it: “In the long run it would be desirable to make learning a task from human preferences no more difficult than learning it from a programmatic reward signal, ensuring that powerful RL systems can be applied in the service of complex human values rather than low-complexity goals” (Christiano et al., “Deep Reinforcement Learning from Human Preferences”). For subsequent work by Leike and his colleagues that pursues the agenda of modeling the human’s reward, see Leike et al., “Scalable Agent Alignment via Reward Modeling.”
38. Stuart Russell, personal interview, May 13, 2018.
39. It’s worth noting that handing an object to another person is itself a surprisingly subtle and complex action that includes making inferences about how the other person will want to take hold of the object, how to signal to them that you are intending for them to take it, etc. See, e.g., Strabala et al., “Toward Seamless Human-Robot Handovers.”
40. Hadfield-Menell et al., “Cooperative Inverse Reinforcement Learning.” (“CIRL” is pronounced with a soft c, homophonous with the last name of strong AI skeptic John Searle (no relation). I have agitated within the community that a hard c “curl” pronunciation makes more sense, given that “cooperative” uses a hard c, but it appears the die is cast.)
41. Dylan Hadfield-Menell, personal interview, March 15, 2018.
42. Russell, Human Compatible.
43. For instance, one of the first theoretical advances within the CIRL framework leveraged earlier cognitive science research on teacher-learner strategy coadaptation. See Fisac et al., “Pragmatic-Pedagogic Value Alignment” (which makes use of insights from Shafto, Goodman, and Griffiths, “A Rational Account of Pedagogical Reasoning”); the authors write, “To our knowledge, this work constitutes the first formal analysis of value alignment grounded in empirically validated cognitive models.” See also the subsequent paper by many of the same authors: Malik et al., “An Efficient, Generalized Bellman Update for Cooperative Inverse Reinforcement Learning.”
44. Maya Çakmak of the University of Washington, in Seattle, and Manuel Lopes of the Instituto Superior Técnico, in Lisbon, have worked on this idea; see Çakmak and Lopes, “Algorithmic and Human Teaching of Sequential Decision Tasks.” Of course, if the human is tailoring their behavior to be maximally pedagogical—not to be optimized for their metric itself but optimized to communicate what the metric is—then the computer, in turn, would do well not to use standard IRL (which assumes the demonstrations are optimal) but to make inferences that account for the fact that the teacher’s behavior was pedagogical in nature. The teaching and learning strategies coadapt. This is a rich area of active research both in cognitive science and in machine learning. See also, e.g., Ho et al., “Showing Versus Doing,” and Ho et al., “A Rational-Pragmatic Account of Communicative Demonstrations.”
45. See Gopnik, Meltzoff, and Kuhl, The Scientist in the Crib: “It turns out that motherese is more than just a sweet siren song that we use to draw our babies to us. . . . Completely unconsciously [parents] produce sounds more clearly and pronounce them more accurately when they talk to babies than when they talk to other adults.” The authors note, for instance, that English and Swedish motherese sound different. For more recent work in this area, see Eaves et al., “Infant-Directed Speech Is Consistent With Teaching,” and Ramírez, Lytle, and Kuhl, “Parent Coaching Increases Conversational Turns and Advances Infant Language Development.”
46. Handoffs of objects are an explicit focus of human-robot interaction research. See, e.g., Strabala et al., “Toward Seamless Human-Robot Handovers.”
47. Drăgan, Lee, and Srinivasa, “Legibility and Predictability of Robot Motion”; see also Takayama, Dooley, and Ju, “Expressing Thought” (which, to be fair, does refer to the concept of “readable” motion), and Gielniak and Thomaz, “Generating Anticipation in Robot Motion.” More recent work has looked at, for instance, how to communicate not just the machine’s goal but, when the goal is known, its plan: see Fisac et al., “Generating Plans That Predict Themselves.”
48. Jan Leike, personal interview, June 22, 2018. See also Christiano et al., “Deep Reinforcement Learning from Human Preferences”: “Training the reward predictor offline can lead to bizarre behavior that is undesirable as measured by the true reward. For instance, on Pong offline training sometimes leads our agent to avoid losing points but not to score points; this can result in extremely long volleys. This type of behavior demonstrates that in general human feedback needs to be intertwined with RL rather than provided statically.”
49. Julie Shah, personal interview, March 2, 2018.
50. For research on human cross-training, see Blickensderfer, Cannon-Bowers, and Salas, “Cross-Training and Team Performance”; Cannon-Bowers et al., “The Impact of Cross-Training and Workload on Team Functioning”; and Marks et al., “The Impact of Cross-Training on Team Effectiveness.”
51. Nikolaidis et al., “Improved Human-Robot Team Performance Through Cross-Training: An Approach Inspired by Human Team Training Practices.”
52. “Julie Shah: Human/Robot Team Cross Training,” https://www.youtube.com/watch?v=UQrtw0YUlqM.
53. More recent work by Shah’s lab has explored cases where it’s infeasible to switch roles. Here one can use a related idea called “perturbation training”; see Ramakrishnan, Zhang, and Shah, “Perturbation Training for Human-Robot Teams.”
54. Murdoch, The Bell.
55. Some researchers at the intersection of cognitive science and AI safety, including the Future of Humanity Institute’s Owain Evans, are working on ways to do inverse reinforcement learning to take into account a person who, for instance, can’t help ducking into the pastry shop when they walk by but will walk out of their way to avoid it. See, e.g., Evans, Stuhlmüller, and Goodman, “Learning the Preferences of Ignorant, Inconsistent Agents,” and Evans and Goodman, “Learning the Preferences of Bounded Agents.” There is a whole vein of research on IRL that incorporates the quirks and sometime irrationalities of human behavior. See also Bourgin et al., “Cognitive Model Priors for Predicting Human Decisions,” for work on using machine learning to develop models of human preference and decision-making.
56. See, e.g., Snyder, Public Appearances, Private Realities; Covey, Saladin, and Killen, “Self-Monitoring, Surveillance, and Incentive Effects on Cheating”; and Zhong, Bohns, and Gino, “Good Lamps Are the Best Police.”
57. See Bateson, Nettle, and Roberts, “Cues of Being Watched Enhance Cooperation in a Real-World Setting,” and Heine et al., “Mirrors in the Head.”
58. Bentham, “Letter to Jacques Pierre Brissot de Warville.”
59. Bentham, “Preface.”
CHAPTER 9. UNCERTAINTY
1. Russell, “Ideas That Have Harmed Mankind.”
2. “Another Day the World Almost Ended.”
3. Aksenov, “Stanislav Petrov.”
4. Aksenov.
5. Hoffman, “‘I Had a Funny Feeling in My Gut.’ ”
6. Nguyen, Yosinski, and Clune, “Deep Neural Networks Are Easily Fooled.” For a discussion of the confidence of predictions of neural networks, see Guo et al., “On Calibration of Modern Neural Networks.”
7. See Szegedy et al., “Intriguing Properties of Neural Networks,” and Goodfellow, Shlens, and Szegedy, “Explaining and Harnessing Adversarial Examples.” This is an active area of research; for recent work on making systems robust to adversarial examples, see, e.g., Mądry et al., “Towards Deep Learning Models Resistant to Adversarial Attacks,” Xie et al., “Feature Denoising for Improving Adversarial Robustness,” and Kang et al., “Testing Robustness Against Unforeseen Adversaries.” See also Ilyas et al., “Adversarial Examples Are Not Bugs, They Are Features,” which frames adversarial examples in an alignment context—“a misalignment between the (human-specified) notion of robustness and the inherent geometry of the data”—and argues that “attaining models that are robust and interpretable will require explicitly encoding human priors into the training process.”
8. Creighton, “Making AI Safe in an Unpredictable World.”
9. See details about Dietterich’s “open category problem” research, for which he received a Future of Life Institute grant, at https://futureoflife.org/ai-researcher-thomas-dietterich/.
10. Thomas G. Dietterich, “Steps Toward Robust Artificial Intelligence” (lecture), February 14, 2016, 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, http://videolectures.net/aaai2016\_dietterich\_artificial\_intelligence/. The talk also appears in slightly different form in print; see Dietterich, “Steps Toward Robust Artificial Intelligence.” For more on open category learning, see, e.g., Scheirer et al., “Toward Open Set Recognition”; Da, Yu, and Zhou, “Learning with Augmented Class by Exploiting Unlabeled Data”; Bendale and Boult, “Towards Open World Recognition”; Steinhardt and Liang, “Unsupervised Risk Estimation Using Only Conditional Independence Structure”; Yu et al., “Open-Category Classification by Adversarial Sample Generation”; and Rudd et al., “The Extreme Value Machine.” Other related approaches to adversarial examples and robust classification include Liu and Ziebart, “Robust Classification Under Sample Selection Bias,” and Li and Li, “Adversarial Examples Detection in Deep Networks with Convolutional Filter Statistics.” For more recent results by Dietterich and his collaborators, see Liu et al., “Can We Achieve Open Category Detection with Guarantees?,” and Liu et al., “Open Category Detection with PAC Guarantees,” as well as Hendrycks, Mazeika, and Dietterich, “Deep Anomaly Detection with Outlier Exposure.” For a 2018 proposal from Google Brain and OpenAI researchers for a benchmark contest to stimulate research on these questions, see Brown et al., “Unrestricted Adversarial Examples,” along with “Introducing the Unrestricted Adversarial Example Challenge,” Google AI Blog, https://ai.googleblog.com/2018/09/introducing-unrestricted-adversarial.html.
11. Rousseau, Emile; or, On Education.
12. Jefferson, Notes on the State of Virginia.
13. Yarin Gal, personal interview, July 11, 2019.
14. Yarin Gal, “Modern Deep Learning Through Bayesian Eyes” (lecture), Microsoft Research, December 11, 2015, https://www.microsoft.com/en-us/research/video/modern-deep-learning-through-bayesian-eyes/.
15. Zoubin Ghahramani, “Probabilistic Machine Learning: From Theory to Industrial Impact” (lecture), October 5, 2018, PROBPROG 2018: The International Conference on Probabilistic Programming, https://youtu.be/crvNIGyqGSU.
16. For seminal papers relating to Bayesian neural networks, see Denker et al., “Large Automatic Learning, Rule Extraction, and Generalization”; Denker and LeCun, “Transforming Neural-Net Output Levels to Probability Distributions”; MacKay, “A Practical Bayesian Framework for Backpropagation Networks”; Hinton and Van Camp, “Keeping Neural Networks Simple by Minimizing the Description Length of the Weights”; Neal, “Bayesian Learning for Neural Networks”; and Barber and Bishop, “Ensemble Learning in Bayesian Neural Networks.” For more recent work, see Graves, “Practical Variational Inference for Neural Networks”; Blundell et al., “Weight Uncertainty in Neural Networks”; and Hernández-Lobato and Adams, “Probabilistic Backpropagation for Scalable Learning of Bayesian Neural Networks.” For a more detailed history of these ideas, see Gal, “Uncertainty in Deep Learning.” For an overview of probabilistic methods in machine learning more generally, see Ghahramani, “Probabilistic Machine Learning and Artificial Intelligence.”
17. Yarin Gal, personal interview, July 11, 2019.
18. Yarin Gal, “Modern Deep Learning Through Bayesian Eyes” (lecture), Microsoft Research, December 11, 2015, https://www.microsoft.com/en-us/research/video/modern-deep-learning-through-bayesian-eyes/.
19. For a look at using dropout-ensemble uncertainty to detect adversarial examples, see Smith and Gal, “Understanding Measures of Uncertainty for Adversarial Example Detection.”
20. Each model is typically assigned a weight describing how well it can explain the data. This method is known as “Bayesian model averaging,” or BMA; see Hoeting et al., “Bayesian Model Averaging: A Tutorial.”
21. In particular, it was found that dropout was helpful in preventing the network from too brittlely “overfitting” its training data. See Srivastava et al., “Dropout,” which has come to be cited an astounding 18,500 times within the first six years of its publication.
22. See Gal and Ghahramani, “Dropout as a Bayesian Approximation.” Alternatives and extensions have emerged in recent years; see, e.g., Lakshminarayanan, Pritzel, and Blundell, “Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles.”
23. Yarin Gal, personal interview, July 11, 2019. One application is in ophthalmology, discussed in the main text; other examples include, for instance, Uber’s demand prediction models (Zhu and Nikolay, “Engineering Uncertainty Estimation in Neural Networks for Time Series Prediction at Uber”), and Toyota Research Institute’s driver prediction systems (Huang et al., “Uncertainty-Aware Driver Trajectory Prediction at Urban Intersections”).
24. See Gal and Ghahramani, “Bayesian Convolutional Neural Networks with Bernoulli Approximate Variational Inference,” §4.4.2; specifically, Gal and Ghahramani looked at Lin, Chen, and Yan, “Network in Network,” and Lee et al., “Deeply-Supervised Nets.” Note that care should be taken when tuning the dropout rate; see Gal and Ghahramani, “Dropout as a Bayesian Approximation.” For applications of this idea to recurrent networks and reinforcement learning, respectively, see Gal and Ghahramani, “A Theoretically Grounded Application of Dropout in Recurrent Neural Networks”; Gal, “Uncertainty in Deep Learning,” §3.4.2; and Gal, McAllister, and Rasmussen, “Improving PILCO with Bayesian Neural Network Dynamics Models.”
25. Gal and Ghahramani, “Dropout as a Bayesian Approximation.”
26. Yarin Gal, personal interview, July 11, 2019.
27. See Engelgau et al., “The Evolving Diabetes Burden in the United States,” and Zaki et al., “Diabetic Retinopathy Assessment.”
28. Leibig et al., “Leveraging Uncertainty Information from Deep Neural Networks for Disease Detection.”
29. A number of groups are exploring the potential of this broad idea of “selective classification” in machine learning. For instance, Google Research’s Corinna Cortes and her colleagues have explored the idea of “learning with rejection”—that is, classifiers that can simply “punt” or otherwise decline to make a classification judgment. See Cortes, DeSalvo, and Mohri, “Learning with Rejection”; see also statistical work by C. K. Chow from the mid-twentieth century exploring related ideas: Chow, “An Optimum Character Recognition System Using Decision Functions,” and Chow, “On Optimum Recognition Error and Reject Tradeoff.” For a similar approach, in a reinforcement-learning context, see Li et al., “Knows What It Knows.”
In 2018, researchers from the University of Toronto, led by PhD student David Madras, widened the lens on this idea, asking not only how a machine-learning system might try to defer on tricky or ambiguous cases in order to avoid making mistakes but, moreover, how it might work in tandem with a human decision maker who is picking up the slack. If the human decision maker happens to be especially accurate for certain types of examples, the system should be more deferential even if it’s otherwise confident; conversely, if there are certain types of examples where the human is particularly bad, the system might simply hazard its best guess even if it’s not sure—aiming to optimize not its own accuracy, per se, but the accuracy of the human-machine decision-making team as a whole. See Madras, Pitassi, and Zemel, “Predict Responsibly.”
In related work, Shun Zhang, Edmund Durfee and Satinder Singh from the University of Michigan have explored the idea of an agent in a gridworld environment that seeks to minimize side effects by asking whether the human user minds certain things being changed or not, and they are able to offer bounds for how to operate safely with the fewest such queries possible. See Zhang, Durfee, and Singh, “Minimax-Regret Querying on Side Effects for Safe Optimality in Factored Markov Decision Processes.”
30. Kahn et al., “Uncertainty-Aware Reinforcement Learning for Collision Avoidance.”
31. For related work linking uncertainty with unfamiliar environments, see Kenton et al., “Generalizing from a Few Environments in Safety-Critical Reinforcement Learning.” For related work in the context of imitation learning and autonomous cars, see Tigas et al., “Robust Imitative Planning.”
32. Holt et al., “An Unconscious Patient with a DNR Tattoo.” And see Bever, “A Man Collapsed with ‘Do Not Resuscitate’ Tattooed on His Chest,” and Hersher, “When a Tattoo Means Life or Death,” for press accounts.
33. Holt et al., “An Unconscious Patient with a DNR Tattoo.”
34. Cooper and Aronowitz, “DNR Tattoos.”
35. Holt et al., “An Unconscious Patient with a DNR Tattoo.”
36. Bever, “A Man Collapsed with ‘Do Not Resuscitate’ Tattooed on His Chest.”
37. Sunstein, “Irreparability as Irreversibility.” See also Sunstein, “Irreversibility.”
38. Sunstein, “Beyond the Precautionary Principle.” See also Sunstein, Laws of Fear.
39. Amodei et al., “Concrete Problems in AI Safety,” has an excellent and broad discussion of “avoiding negative side effects” and “impact regularizers,” and Taylor et al., “Alignment for Advanced Machine Learning Systems,” also discusses various ideas for “impact measures.” For a good overview of more recent impact research, see Daniel Filan, “Test Cases for Impact Regularisation Methods,” https://www.alignmentforum.org/posts/wzPzPmAsG3BwrBrwy/test-cases-for-impact-regularisation-methods.
Carnegie Mellon PhD student Benjamin Eysenbach looked at a similar idea within the 3D MuJoCo environment. His idea was reversibility, mixed with the hiker and backpacker’s ethos of “leave no trace.” The idea is to use normal reinforcement-learning methods to develop competence in various tasks, with a crucial proviso. Unlike the ergodic environment of an Atari game, where typically learning involves hundreds of thousands of externally imposed reboots, his agents were responsible for always resetting themselves back to their exact starting configuration before making another attempt at whatever it was they were trying to do. Initial results are encouraging, with his stick-figure cheetah, for instance, scooting up to a cliff’s edge, then backpedaling—seemingly having internalized that there is no reversing back once it’s gone over the edge. See Eysenbach et al., “Leave No Trace.” See also the much earlier Weld and Etzioni, “The First Law of Robotics (a Call to Arms),” for a similar idea.
40. For Armstrong’s work on low-impact AI agents, see Armstrong and Levinstein, “Low Impact Artificial Intelligences.” His papers from 2012 and 2013 were among the earliest to explicitly address this issue: see Armstrong, “The Mathematics of Reduced Impact,” and Armstrong, “Reduced Impact AI.”
41. Armstrong and Levinstein, “Low Impact Artificial Intelligences.”
42. Armstrong and Levinstein.
43. As Eliezer Yudkowsky put it, “If you’re going to cure cancer, make sure the patient still dies!” See https://intelligence.org/2016/12/28/ai-alignment-why-its-hard-and-where-to-start/. See also Armstrong and Levinstein, “Low Impact Artificial Intelligences,” which uses the example of an asteroid headed for earth. A system constrained to only take “low-impact” actions might fail to divert it—or, perhaps even worse, a system capable of offsetting might divert the asteroid, saving the planet, and then blow the planet up anyway.
44. Victoria Krakovna, personal interview, December 8, 2017.
45. See Krakovna et al., “Penalizing Side Effects Using Stepwise Relative Reachability.” For Krakovna, framing the problem in terms of “side effects,” rather than “impact,” per se, makes at least some of the paradoxes seem to go away. “If a robot is carrying boxes and bumps into a vase,” she says, “breaking the vase is a side effect, because the robot could have easily gone around the vase. On the other hand, a cooking robot that’s making an omelette has to break some eggs, so breaking eggs is not a side effect.” See also Victoria Krakovna, “Measuring and Avoiding Side Effects Using Relative Reachability,” June 5, 2018, https://vkrakovna.wordpress.com/2018/06/05/measuring-and-avoiding-side-effects-using-relative-reachability/.
46. Leike et al., “AI Safety Gridworlds.”
47. Victoria Krakovna, personal interview, December 8, 2017.
48. The idea of stepwise baselines was suggested by Alexander Turner in https://www.alignmentforum.org/posts/DvmhXysefEyEvXuXS/overcoming-clinginess-in-impact-measures. The idea of relative reachability is explored in Krakovna et al., “Penalizing Side Effects Using Stepwise Relative Reachability,” and Krakovna et al., “Designing Agent Incentives to Avoid Side Effects,” DeepMind Safety Research (blog), https://medium.com/@deepmindsafetyresearch/designing-agent-incentives-to-avoid-side-effects-e1ac80ea6107.
49. Turner, Hadfield-Menell, and Tadepalli, “Conservative Agency via Attainable Utility Preservation.” See also Turner’s “Reframing Impact” sequence at https://www.alignmentforum.org/s/7CdoznhJaLEKHwvJW and additional discussion in his “Towards a New Impact Measure,” https://www.alignmentforum.org/posts/yEa7kwoMpsBgaBCgb/towards-a-new-impact-measure; he writes, “I have a theory that AUP seemingly works for advanced agents not because the content of the attainable set’s utilities actually matters, but rather because there exists a common utility achievement currency of power.” See Turner, “Optimal Farsighted Agents Tend to Seek Power.” For more on the notion of power in an AI safety context, including an information-theoretic account of “empowerment,” see Amodei et al., “Concrete Problems in AI Safety,” which, in turn, references Salge, Glackin, and Polani, “Empowerment: An Introduction,” and Mohamed and Rezende, “Variational Information Maximisation for Intrinsically Motivated Reinforcement Learning.”
50. Alexander Turner, personal interview, July 11, 2019.
51. Wiener, “Some Moral and Technical Consequences of Automation.”
52. According to Paul Christiano, “corrigibility” as a tenet of AI safety began with the Machine Intelligence Research Institute’s Eliezer Yudkowsky, and the name itself came from Robert Miles. See Christiano’s “Corrigibility,” https://ai-alignment.com/corrigibility-3039e668638.
53. Dadich, Ito, and Obama, “Barack Obama, Neural Nets, Self-Driving Cars, and the Future of the World.”
54. Dylan Hadfield-Menell, personal interview, March 15, 2018.
55. Turing, “Can Digital Computers Think?”
56. Russell, Human Compatible. Russell made this point earlier but in different words in “Should We Fear Supersmart Robots?” The better part of a decade before that, Steve Omohundro, in “The Basic AI Drives,” noted that “almost all systems [will] protect their utility functions from modification.”
57. Soares et al., “Corrigibility.” See also the related work by Armstrong: “Motivated Value Selection for Artificial Agents.” For other takes on the interesting problems that arise when modifying or interrupting AI agents, see, e.g., Orseau and Armstrong, “Safely Interruptible Agents,” and Riedl and Harrison, “Enter the Matrix.” For research on robots that actually ask people not to shut them off, and whether humans comply, see Horstmann et al., “Do a Robot’s Social Skills and Its Objection Discourage Interactants from Switching the Robot Off?”
58. See Nate Soares et al., “Corrigibility,” presentation at AAAI-15, January 25, 2015, https://intelligence.org/wp-content/uploads/2015/01/AAAI-15-corrigibility-slides.pdf.
59. Russell, “Should We Fear Supersmart Robots?”
60. Dylan Hadfield-Menell, “The Off-Switch” (lecture), Colloquium Series on Robust and Beneficial AI (CSRBAI), Machine Intelligence Research Institute, Berkeley, CA, June 8, 2016, https://www.youtube.com/watch?v=t06IciZknDg.
61. Milli et al., “Should Robots Be Obedient?”. For other work on cases where it may be best for a system to disobey a human command, see, e.g., Coman et al., “Social Attitudes of AI Rebellion,” and Aha and Coman, “The AI Rebellion.”
62. Smitha Milli, “Approaches to Achieving AI Safety” (interview), Melbourne, Australia, August 2017, https://www.youtube.com/watch?v=l82SQfrbdj4.
63. For more on corrigibility and model misspecification using this paradigm, see also, e.g., Carey, “Incorrigibility in the CIRL Framework.”
64. Dylan Hadfield-Menell, personal interview, March 15, 2018.
65. Russell, Human Compatible.
66. Hadfield-Menell et al., “Inverse Reward Design.”
67. For a related framing and approach to this problem from DeepMind’s Tom Everitt, along with a group of collaborators at both DeepMind and the Australian National University, see Everitt et al., “Reinforcement Learning with a Corrupted Reward Channel.”
68. Hadfield-Menell et al., “Inverse Reward Design.”
69. Prümmer, Handbook of Moral Theology.
70. Rousseau, Emile; or, On Education.
71. Actually, it appears that almost all of the actual historical debate concerned cases where it was argued whether an act was sinful or not—but not cases where it was also considered possible that not taking that action was sinful. For more discussion on this point, see Sepielli, “‘Along an Imperfectly-Lighted Path.’ ”
72. The original phrasing of this much-quoted adage appeared on the editorial page of the San Diego Union on September 20, 1930: “Retail jewelers assert that every man should carry two watches. But a man with one watch knows what time it is, and a man with two watches could never be sure.”
73. See Prümmer, Handbook of Moral Theology, §§145–56.
74. See Connell, “Probabilism.”
75. Prümmer, Handbook of Moral Theology.
76. Will MacAskill, personal interview, May 11, 2018.
77. One philosopher responsible for revisiting these questions in recent years is Michigan Technological University’s Ted Lockhart. See Lockhart, Moral Uncertainty and Its Consequences. As he puts it: “What shall I do when I am uncertain what I morally ought to do? Philosophers have paid little attention to this sort of question.”
78. For more on the ideas of effective altruism, see MacAskill, Doing Good Better, and Singer, The Most Good You Can Do. For more on the history of the term “effective altruism,” see MacAskill’s “The History of the Term ‘Effective Altruism,’” Effective Altruism Forum, http://effective-altruism.com/ea/5w/the\_history\_of\_the\_term\_effective\_altruism/.
79. MacAskill, Bykvist, and Ord, Moral Uncertainty. See also the earlier book by Lockhart: Moral Uncertainty and Its Consequences.
80. See, e.g., Lockhart, Moral Uncertainty and Its Consequences, and Gustafsson and Torpman, “In Defence of My Favourite Theory.”
81. There are purely ordinal theories, for instance, and purely deontic theories. Other troubles exist as well; for more discussion, see MacAskill, Bykvist, and Ord, Moral Uncertainty.
82. For more on social choice theory, see, e.g., Mueller, Public Choice III, and Sen, Collective Choice and Social Welfare; and for more on social choice theory from a computational perspective, see, e.g., Brandt et al., Handbook of Computational Social Choice.
83. On the idea of a “moral parliament,” see Bostrom, “Moral Uncertainty—Towards a Solution?,” and on “moral trade,” see Ord, “Moral Trade.”
84. For one approach, see, e.g., Humphrys, “Action Selection in a Hypothetical House Robot.”
85. See “Allocation of Discretionary Funds from Q1 2019,” The GiveWell Blog, https://blog.givewell.org/2019/06/12/allocation-of-discretionary-funds-from-q1-2019/.
86. For more discussion in this vein, see also Ord, The Precipice.
87. Paul Christiano, personal interview, July 1, 2019.
88. On this theme, see also Sepielli, “What to Do When You Don’t Know What to Do When You Don’t Know What to Do . . .”
89. Shlegeris, “Why I’m Less of a Hedonic Utilitarian Than I Used to Be.”
CONCLUSION
1. Bertrand Russell, “The Philosophy of Logical Atomism,” in Logic and Knowledge.
2. See Knuth, “Structured Programming with Go to Statements,” and Knuth, “Computer Programming as an Art,” both from 1974. The quote has a somewhat convoluted history, with Knuth himself, 15 years later, in 1989, referring to it as “[C.A.R.] Hoare’s dictum” in Knuth, “The Errors of TeX.” However, there appears not to be any evidence that the quote was Hoare’s. When Hoare himself was asked about the quote in 2004, he said he had “no recollection” of where it came from, suggesting perhaps it was the kind of thing that Edsger Dijkstra might have said, and adding, “I think it would be fair for you assume it is common culture or folklore” (Hans Gerwitz, “Premature Optimization Is the Root of All Evil,” https://hans.gerwitz.com/2004/08/12/premature-optimization-is-the-root-of-all-evil.html). Knuth, in 2012, conceded, “I did say things like ‘Premature optimization is the root of all evil in programming’” (Mark Harrison, “A note from Donald Knuth about TAOCP,” http://codehaus.blogspot.com/2012/03/note-from-donald-knuth-about-taocp.html). In all likelihood, the phrase was indeed his own.
3. The US Centers for Disease Control warns about babies getting hypothermia in cold bedrooms, and in 2017 a healthy, middle-aged man in Thailand died in his bedroom after hypothermic shock, simply from leaving fans running on a cold night. See, respectively, Centers for Disease Control and Prevention, “Prevent Hypothermia and Frostbite,” https://www.cdc.gov/disasters/winter/staysafe/hypother mia.html, and Straits Times, “Thai Man Dies From Hypothermia After Sleeping With 3 Fans Blowing at Him,” November 6, 2017, https://www.straitstimes.com/asia/se-asia/thai-man-dies-from-hypothermia-after-sleeping-with-3-fans-blowing-at-him.
4. Wiener, God and Golem, Inc. In 2016, MIRI researcher Jessica Taylor explored the related idea of what she calls “quantilizers”: agents that, rather than fully optimizing a potentially problematic metric, settle for behavior that is “good enough”; see Taylor, “Quantilizers.” This also shares some resemblance to the regularization method known as “early stopping”; see Yao, Rosasco, and Caponnetto, “On Early Stopping in Gradient Descent Learning.” For further discussion, in an AI safety context, about when “a metric which can be used to improve a system is used to such an extent that further optimization is ineffective or harmful,” see Manheim and Garrabrant, “Categorizing Variants of Goodhart’s Law.”
5. “£13.3m Boost for Oxford’s Future of Humanity Institute,” http://www.ox.ac.uk/news/2018-10-10-£133m-boost-oxford’s-future-humanity-institute.
6. Huxley, Ends and Means.
7. For a recent general-audience discussion on gender bias in medicine, see Perez, Invisible Women. For academic literature on the subject, see, e.g., Mastroianni, Faden, and Federman, Women and Health Research, and Marts and Keitt, “Foreword.” There is also concern within the medical field that the elderly—who make up one of the fastest-growing demographic groups at present—are also significantly underrepresented in medical trials; see, e.g., Vitale et al., “Under-Representation of Elderly and Women in Clinical Trials,” and Shenoy and Harugeri, “Elderly Patients’ Participation in Clinical Trials.”
This is an active area of study in quite a number of fields; for a recent discussion of zoological museum collections, for instance, see Cooper et al., “Sex Biases in Bird and Mammal Natural History Collections.”
8. See, e.g., Bara Fintel, Athena T. Samaras, and Edson Carias, “The Thalidomide Tragedy: Lessons for Drug Safety and Regulation,” Helix, https://helix.northwestern.edu/article/thalidomide-tragedy-lessons-drug-safety-and-regulation; Nick McKenzie and Richard Baker, “The 50-Year Global Cover-up,” Sydney Morning Herald, July 26, 2012, https://www.smh.com.au/national/the-50-year-global-cover-up-20120725-22r5c.html; and “Thalidomide,” Brought to Life, Science Museum, http://broughttolife.sciencemuseum.org.uk/broughttolife/themes/controversies/thalidomide, along with, e.g., Marts and Keitt, “Foreword.”
9. Sometimes this consensus is downright offensive. In 2019, the AI Now Institute’s Kate Crawford and artist Trevor Paglen dug into the ImageNet data and found some bizarre and shocking items. See their “Excavating AI”: https://www.excavating.ai. Their work led to ImageNet removing six hundred thousand images of people, labeled everything from “kleptomaniac” to “redneck” to “trollop,” from the dataset.
10. The original ImageNet data actually contained twenty thousand categories; the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) won in 2012 by AlexNet used a pared-down version of the data containing only one thousand categories. See Deng et al., “ImageNet,” and Russakovsky et al., “ImageNet Large Scale Visual Recognition Challenge.”
11. Stuart Russell has argued this point, and he suggests using machine learning itself to infer a more nuanced representation for the varying costs of label errors. See, e.g., Russell, Human Compatible.
12. See Mikolov et al., “Efficient Estimation of Word Representations in Vector Space.”
13. In May 2019, the arXiv paper Nissim, van Noord, and van der Goot, “Fair Is Better Than Sensational,” made a bit of a splash; it critiqued, in sharp terms, the “parallelogram” method for analogies. The authors of Bolukbasi et al., “Man Is to Computer Programmer as Woman Is to Homemaker?,” replied on Twitter, and an informal discussion can be found at https://twitter.com/adamfungi/status/1133865428663635968. The Bolukbasi et al. paper itself, in its Appendix A and Appendix B, discusses subtle but consequential differences between the 3CosAdd algorithm and the one its authors used.
14. Tversky, “Features of Similarity.”
15. See, e.g., Chen, Peterson, and Griffiths, “Evaluating Vector-Space Models of Analogy.”
16. On the possibly criminogenic effects of incarceration itself, see, e.g., discussion in Stemen, “The Prison Paradox” (in particular footnote 23), and Roodman, “Aftereffects.”
17. See, e.g., Jung et al., “Eliciting and Enforcing Subjective Individual Fairness.”
18. See Poursabzi-Sangdeh et al., “Manipulating and Measuring Model Interpretability.”
19. Bryson, “Six Kinds of Explanation for AI,” for instance, argues that “explanations” in the context of AI ought to include not just the inner workings of the system but the “human actions that led to the system being released and sold as a product and/or operated as a service.”
20. See Ghorbani, Abid, and Zou, “Interpretation of Neural Networks Is Fragile.”
21. See Mercier and Sperber, “Why Do Humans Reason?” An intriguing research direction in AI alignment involves developing machine-learning systems able to engage in debate with one another; see Irving, Christiano, and Amodei, “AI Safety via Debate.”
22. Jan Leike, “General Reinforcement Learning” (lecture), Colloquium Series on Robust and Beneficial AI 2016, Machine Intelligence Research Institute, Berkeley, California, June 9, 2016, https://www.youtube.com/watch?v=hSiuJuvTBoE&t=239s. The idea of reinforcement learning that avoids unrecoverable mistakes is an active area of research; see, e.g., Saunders et al., “Trial Without Error,” and Eysenbach et al., “Leave No Trace,” for some approaches.
23. See Omohundro, “The Basic AI Drives.” See also, for instance, L. M. Montgomery’s 1921 Anne of Green Gables novel Rilla of Ingleside, in which Rilla muses, “I wouldn’t want to go back and be the girl I was two years ago, not even if I could. . . . And still. . . . At the end of two more years I might look back and be thankful for the development they had brought me, too; but I don’t want it now.” Miss Oliver replies to her, “We never do. That is why we are not left to choose our own means and measure of development, I suppose.”
24. See Paul, Transformative Experience.
25. The subfield of “multi-agent reinforcement learning” works on problems like these. See, e.g., Foerster et al., “Learning to Communicate with Deep Multi-Agent Reinforcement Learning,” and Foerster et al., “Learning with Opponent-Learning Awareness.”
26. Piaget, The Construction of Reality in the Child.
27. Demski and Garrabrant, “Embedded Agency.”
28. See, e.g., Evans, Stuhlmüller, and Goodman, “Learning the Preferences of Ignorant, Inconsistent Agents”; Evans and Goodman, “Learning the Preferences of Bounded Agents”; and Bourgin et al., “Cognitive Model Priors for Predicting Human Decisions.”
29. See Ziebart et al., “Maximum Entropy Inverse Reinforcement Learning,” and Ziebart, Bagnell, and Dey, “Modeling Interaction via the Principle of Maximum Causal Entropy.” Much recent work in robotics and autonomous cars uses this same model of human behavior, sometimes referred to as “noisily rational” behavior or “Boltzmann (ir)rationality.” See, e.g., Finn, Levine, and Abbeel, “Guided Cost Learning”; Sadigh et al., “Planning for Autonomous Cars That Leverage Effects on Human Actions”; and Kwon et al., “When Humans Aren’t Optimal.”
30. As Stuart Russell put it in his original 1998 paper, “Can we determine the reward function by observation during rather than after learning?” Russell, “Learning Agents for Uncertain Environments (Extended Abstract).”
31. This remains very much an open research question. For recent work, see Chan et al., “The Assistive Multi-Armed Bandit.”
32. Berkeley’s Smitha Milli and Anca Drăgan have explored this question: see Milli and Drăgan, “Literal or Pedagogic Human?”
33. Stefano Ermon, interview by Ariel Conn, Future of Life Institute, January 26, 2017, https://futureoflife.org/2017/01/26/stefano-ermon-interview/.
34. Roman Yampolskiy, interview by Ariel Conn, Future of Life Institute, January 18, 2017, https://futureoflife.org/2017/01/18/roman-yampolskiy-interview/.
35. See, for instance, Arrow, “A Difficulty in the Concept of Social Welfare.”
36. See also the efforts in Recht et al., “Do ImageNet Classifiers Generalize to ImageNet?,” to reproduce the accuracy of image recognition systems like AlexNet and others on new photos—there was a persistent gap in accuracy, leading the authors to speculate that, no matter how closely they tried to mimic the original CIFAR-10 and ImageNet methodology, the images and human-supplied labels were simply unavoidably a bit different in 2019 than they were in, say, 2012.
37. Latour, Pandora’s Hope.
38. See Paul Christiano, “What Failure Looks Like,” AI Alignment Forum, March 17, 2019, https://www.alignmentforum.org/posts/HBxe6wdjxK239zajf/what-failure-looks-like. “The stereotyped image of AI catastrophe is a powerful, malicious AI system that takes its creators by surprise and quickly achieves a decisive advantage over the rest of humanity. I think this is probably not what failure will look like,” he writes. Instead, he worries that “machine learning will increase our ability to ‘get what we can measure,’ which could cause a slow-rolling catastrophe.”
39. National Transportation Safety Board, 2019. Collison Between Vehicle Controlled by Developmental Automated Driving System and Pedestrian. Highway Accident Report NTSB/HAR-19/03. Washington, DC.
40. See, e.g., Odell, How to Do Nothing.
41. Read, The Grass Roots of Art.
42. Turing et al., “Can Automatic Calculating Machines Be Said to Think?”
ACKNOWLEDGMENTS
1. McCulloch, Finality and Form.
BIBLIOGRAPHY
Abbeel, Pieter. “Apprenticeship Learning and Reinforcement Learning with Application to Robotic Control.” PhD thesis, Stanford University, 2008.
Abbeel, Pieter, Adam Coates, and Andrew Y. Ng. “Autonomous Helicopter Aerobatics Through Apprenticeship Learning.” International Journal of Robotics Research 29, no. 13 (2010): 1608–39.
Abbeel, Pieter, Adam Coates, Morgan Quigley, and Andrew Y. Ng. “An Application of Reinforcement Learning to Aerobatic Helicopter Flight.” In Advances in Neural Information Processing Systems, 1–8, 2007.
Abbeel, Pieter, and Andrew Y. Ng. “Apprenticeship Learning via Inverse Reinforcement Learning.” In Proceedings of the 21st International Conference on Machine Learning. ACM, 2004.
Ackley, David, and Michael Littman. “Interactions Between Learning and Evolution.” In Artificial Life II: SFI Studies in the Sciences of Complexity, 10:487–509. Addison-Wesley, 1991.
ACLU Foundation. “The War on Marijuana in Black and White,” 2013. https://www.aclu.org/report/report-war-marijuana-black-and-white?redirect=criminal-law-reform/war-marijuana-black-and-white.
Adebayo, Julius, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, and Been Kim. “Sanity Checks for Saliency Maps.” In Advances in Neural Information Processing Systems, 9505–15, 2018.
Aha, David W., and Alexandra Coman. “The AI Rebellion: Changing the Narrative.” In Thirty-First AAAI Conference on Artificial Intelligence, 2017.
Akrour, Riad, Marc Schoenauer, and Michèle Sebag. “APRIL: Active Preference-Learning Based Reinforcement Learning.” In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, 116–31. Springer, 2012.
Akrour, Riad, Marc Schoenauer, Michèle Sebag, and Jean-Christophe Souplet. “Programming by Feedback.” In International Conference on Machine Learning, 1503–11. JMLR, 2014.
Aksenov, Pavel. “Stanislav Petrov: The Man Who May Have Saved the World.” BBC News, September 25, 2013. https://www.bbc.com/news/world-europe-24280831.
Al-Shawaf, Laith, Daniel Conroy-Beam, Kelly Asao, and David M. Buss. “Human Emotions: An Evolutionary Psychological Perspective.” Emotion Review 8, no. 2 (2016): 173–86.
Alexander, R. McNeill. “The Gaits of Bipedal and Quadrupedal Animals.” International Journal of Robotics Research 3, no. 2 (1984): 49–59.
———. The Human Machine: How the Body Works. Columbia University Press, 1992.
———. Optima for Animals. Princeton University Press, 1996.
Alexander, S.A.H. “Sex, Arguments, and Social Engagements in Martial and Premarital Relations.” Master’s thesis, University of Missouri–Kansas City, 1971.
Amodei, Dario, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. “Concrete Problems in AI Safety.” arXiv Preprint arXiv:1606.06565, 2016.
Ampère, André-Marie. Essai sur la philosophie des sciences; ou, Exposition analytique d’une classification naturelle de toutes les connaissances humaines. Paris: Bachelier, 1834.
Anantharaman, Thomas S. “Evaluation Tuning for Computer Chess: Linear Discriminant Methods.” ICGA Journal 20, no. 4 (1997): 224–42.
Anderson, James A., and Edward Rosenfeld. Talking Nets: An Oral History of Neural Networks. MIT Press, 1998.
Andre, David, and Astro Teller. “Evolving Team Darwin United.” In RoboCup-98, 346–51. Springer, 1999.
Andrew, A. M. “Machines Which Learn.” New Scientist, November 27, 1958.
Andrews, D. A. “The Level of Service Inventory (LSI): The First Follow-up.” Ontario Ministry of Correctional Services. Toronto, 1982.
Andrews, D. A., and J. L. Bonta. “The Level of Service Inventory–Revised.” Toronto: Multi-Health Systems, 1995.
Andrews, D. A., James Bonta, and J. Stephen Wormith. “The Recent Past and Near Future of Risk and/or Need Assessment.” Crime & Delinquency 52, no. 1 (2006): 7–27.
Angelino, Elaine, Nicholas Larus-Stone, Daniel Alabi, Margo Seltzer, and Cynthia Rudin. “Learning Certifiably Optimal Rule Lists for Categorical Data.” Journal of Machine Learning Research 18 (2018): 1–78.
Angwin, Julia. Dragnet Nation: A Quest for Privacy, Security, and Freedom in a World of Relentless Surveillance. Times Books, 2014.
Angwin, Julia, and Jeff Larson. “ProPublica Responds to Company’s Critique of Machine Bias Story.” ProPublica, July 29, 2016.
Angwin, Julia, Jeff Larson, Surya Mattu, and Lauren Kirchner. “Machine Bias.” ProPublica, May 23, 2016.
“Another Day the World Almost Ended.” RT, May 19, 2010. https://www.rt.com/usa/nuclear-war-stanislav-petrov/.
Anthony, Thomas, Zheng Tian, and David Barber. “Thinking Fast and Slow with Deep Learning and Tree Search.” In Advances in Neural Information Processing Systems, 5360–70, 2017.
Arendt, Hannah. The Human Condition. University of Chicago Press, 1958.
Argall, Brenna D., Sonia Chernova, Manuela Veloso, and Brett Browning. “A Survey of Robot Learning from Demonstration.” Robotics and Autonomous Systems 57, no. 5 (2009): 469–83.
Armstrong, Stuart. “The Mathematics of Reduced Impact: Help Needed,” LessWrong, February 16, 2012. https://www.lesswrong.com/posts/8Nwg7kqAfCM46tuHq/the-mathematics-of-reduced-impact-help-needed.
———. “Motivated Value Selection for Artificial Agents.” In Artificial Intelligence and Ethics: Papers from the 2015 AAAI Workshop. AAAI Press, 2015.
———. “Reduced Impact AI: No Back Channels,” LessWrong, November 11, 2013. https://www.lesswrong.com/posts/gzQT5AAw8oQdzuwBG/reduced-impact-ai-no-back-channels.
Armstrong, Stuart, and Benjamin Levinstein. “Low Impact Artificial Intelligences.” arXiv Preprint arXiv:1705.10720, 2017.
Arrow, Kenneth J. “A Difficulty in the Concept of Social Welfare.” Journal of Political Economy 58, no. 4 (1950): 328–46.
Ashley, Maurice. Chess for Success. Broadway Books, 2005.
Athalye, Vivek R., Fernando J. Santos, Jose M. Carmena, and Rui M. Costa. “Evidence for a Neural Law of Effect.” Science 359, no. 6379 (2018): 1024–29.
Aurelius, Marcus. The Emperor Marcus Aurelius: His Conversation with Himself. Translated by Jeremy Collier. London: R. Sare, 1701.
Aytar, Yusuf, Tobias Pfaff, David Budden, Thomas Paine, Ziyu Wang, and Nando de Freitas. “Playing Hard Exploration Games by Watching YouTube.” In Advances in Neural Information Processing Systems, 2935–45. MIT Press, 2018.
Bailey, Robert E., and J. Arthur Gillaspy Jr. “Operant Psychology Goes to the Fair: Marian and Keller Breland in the Popular Press, 1947–1966.” Behavior Analyst 28, no. 2 (2005): 143–59.
Bain, Alexander. The Senses and the Intellect. London: John W. Parker and Son, 1855.
Baldassarre, Gianluca, and Marco Mirolli, eds. Intrinsically Motivated Learning in Natural and Artificial Systems. Springer, 2013.
Balentine, Bruce. It’s Better to Be a Good Machine Than a Bad Person: Speech Recognition and Other Exotic User Interfaces in the Twilight of the Jetsonian Age. ICMI Press, 2007.
Barabas, Chelsea, Madars Virza, Karthik Dinakar, Joichi Ito, and Jonathan Zittrain. “Interventions over Predictions: Reframing the Ethical Debate for Actuarial Risk Assessment.” In Proceedings of Machine Learning Research, 81 (2018): 62–76.
Barber, David, and Christopher M. Bishop. “Ensemble Learning in Bayesian Neural Networks.” In Neural Networks and Machine Learning, 215–37. Springer, 1998.
Barocas, Solon, and Andrew D. Selbst. “Big Data’s Disparate Impact.” California Law Review 104 (2016): 671–732.
Barto, Andrew G. “Intrinsic Motivation and Reinforcement Learning.” In Intrinsically Motivated Learning in Natural and Artificial Systems, edited by Gianluca Baldassarre and Marco Mirolli, 17–47. Springer, 2013.
Barto, Andrew, Marco Mirolli, and Gianluca Baldassarre. “Novelty or Surprise?” Frontiers in Psychology 4 (2013): 907.
Barto, Andrew G., Satinder Singh, and Nuttapong Chentanez. “Intrinsically Motivated Learning of Hierarchical Collections of Skills.” In Proceedings of the 3rd International Conference on Development and Learning, 112–19, 2004.
Barto, Andrew G., Richard S. Sutton, and Charles W. Anderson. “Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problems.” IEEE Transactions on Systems, Man, and Cybernetics 13, no. 5 (1983): 834–46.
Bateson, Melissa, Daniel Nettle, and Gilbert Roberts. “Cues of Being Watched Enhance Cooperation in a Real-World Setting.” Biology Letters 2, no. 3 (2006): 412–14.
Bellemare, Marc G., Yavar Naddaf, Joel Veness, and Michael Bowling. “The Arcade Learning Environment: An Evaluation Platform for General Agents.” Journal of Artificial Intelligence Research 47 (2013): 253–79.
Bellemare, Marc G., Sriram Srinivasan, Georg Ostrovski, Tom Schaul, David Saxton, and Rémi Munos. “Unifying Count-Based Exploration and Intrinsic Motivation.” In Advances in Neural Information Processing Systems, 1471–79, 2016.
Bellman, Richard. Dynamic Programming. Princeton, NJ: Princeton University Press, 1957.
Bendale, Abhijit, and Terrance Boult. “Towards Open World Recognition.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1893–1902. CVPR, 2015.
Bengio, Yoshua. “Neural Net Language Models.” Scholarpedia 3, no. 1 (2008): 3881. http://www.scholarpedia.org/article/Neural\_net\_language\_models.
Bengio, Yoshua, Réjean Ducharme, Pascal Vincent, and Christian Jauvin. “A Neural Probabilistic Language Model.” Journal of Machine Learning Research 3 (2003): 1137–55.
Bengio, Yoshua, Jérôme Louradour, Ronan Collobert, and Jason Weston. “Curriculum Learning.” In Proceedings of the 26th Annual International Conference on Machine Learning, 41–48. ACM, 2009.
Benjamin, Ludy T., Jr., and Darryl Bruce. “From Bottle-Fed Chimp to Bottlenose Dolphin: A Contemporary Appraisal of Winthrop Kellogg.” Psychological Record 32, no. 4 (1982): 461–82.
Bentham, Jeremy. An Introduction to the Principles of Morals and Legislation. London: T. Payne & Son, 1789.
———. “Letter to Jacques Pierre Brissot de Warville.” In The Correspondence of Jeremy Bentham. Vol. 4, edited by Alexander Taylor Milne. UCL Press, 2017.
———. “Preface,” i–vii. Panopticon: Postscript; Part I. Mews-Gate, London: T. Payne, 1791.
Berk, Richard. Criminal Justice Forecasts of Risk: A Machine Learning Approach. Springer Science & Business Media, 2012.
Berk, Richard, Hoda Heidari, Shahin Jabbari, Michael Kearns, and Aaron Roth. “Fairness in Criminal Justice Risk Assessments: The State of the Art.” arXiv Preprint arXiv:1703.09207, 2017.
Berlyne, Daniel E. Conflict, Arousal, and Curiosity. McGraw-Hill, 1960.
———. “‘Interest’ as a Psychological Concept.” British Journal of Psychology, General Section 39, no. 4 (1949): 184–95.
———. “Uncertainty and Conflict: A Point of Contact Between Information-Theory and Behavior-Theory Concepts.” Psychological Review 64, no. 6 (1957): 329–39.
Bernoulli, Daniel. “Specimen theoriae novae de mensura sortis.” Comentarii Academiae Scientarum Imperialis Petropolitanae, 1738, 175–92.
Bernstein, Jeremy. “A.I.” New Yorker, December 6, 1981.
Berridge, Kent C. “Food Reward: Brain Substrates of Wanting and Liking.” Neuroscience & Biobehavioral Reviews 20, no. 1 (1996): 1–25.
Berridge, Kent C., Terry E. Robinson, and J. Wayne Aldridge. “Dissecting Components of Reward: ‘Liking,’ ‘Wanting,’ and Learning.” Current Opinion in Pharmacology 9, no. 1 (2009): 65–73.
Bertrand, Marianne, and Sendhil Mullainathan. “Are Emily and Greg More Employable Than Lakisha and Jamal? A Field Experiment on Labor Market Discrimination.” American Economic Review 94, no. 4 (2004): 991–1013.
Bever, Lindsey. “A Man Collapsed with ‘Do Not Resuscitate’ Tattooed on His Chest. Doctors Didn’t Know What to Do.” Washington Post, December 1, 2017.
Billard, Aude G., Sylvain Calinon, and Florent Guenter. “Discriminative and Adaptive Imitation in Uni-Manual and Bi-Manual Tasks.” Robotics and Autonomous Systems 54, no. 5 (2006): 370–84.
Blei, David M., Andrew Y. Ng, and Michael I. Jordan. “Latent Dirichlet Allocation.” Journal of Machine Learning Research 3, nos. 4–5 (2003): 993–1022.
Blickensderfer, Elizabeth, Janis A. Cannon-Bowers, and Eduardo Salas. “Cross-Training and Team Performance.” In Making Decisions Under Stress: Implications for Individual and Team Training, 299–311. Washington, DC: American Psychological Association, 1998.
Blomberg, Thomas, William Bales, Karen Mann, Ryan Meldrum, and Joe Nedelec. “Validation of the COMPAS Risk Assessment Classification Instrument.” Broward Sheriff’s Office, Department of Community Control, 2010.
Blundell, Charles, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra. “Weight Uncertainty in Neural Networks.” In Proceedings of the 32nd International Conference on Machine Learning, 2015.
Bojarski, Mariusz, Davide Del Testa, Daniel Dworakowski, Bernhard Firner, Beat Flepp, Prasoon Goyal, Lawrence D. Jackel, et al. “End to End Learning for Self-Driving Cars.” CoRR abs/1604.07316 (2016).
Bolam, J. Paul, and Eleftheria K. Pissadaki. “Living on the Edge with Too Many Mouths to Feed: Why Dopamine Neurons Die.” Movement Disorders 27, no. 12 (2012): 1478–83.
Bolukbasi, Tolga, Kai-Wei Chang, James Y. Zou, Venkatesh Saligrama, and Adam T. Kalai. “Man Is to Computer Programmer as Woman Is to Homemaker? Debiasing Word Embeddings.” In Advances in Neural Information Processing Systems, 4349–57, 2016.
Bolukbasi, Tolga, Kai-Wei Chang, James Zou, Venkatesh Saligrama, and Adam Kalai. “Quantifying and Reducing Stereotypes in Word Embeddings.” In 2016 ICML Workshop on #Data4good: Machine Learning in Social Good Applications, 2016.
Bonawitz, Elizabeth Baraff, Tessa J. P. van Schijndel, Daniel Friel, and Laura Schulz. “Children Balance Theories and Evidence in Exploration, Explanation, and Learning.” Cognitive Psychology 64, no. 4 (2012): 215–34.
Bostrom, Nick. “Astronomical Waste: The Opportunity Cost of Delayed Technological Development.” Utilitas 15, no. 3 (2003): 308–14.
———. “Moral Uncertainty—Towards a Solution?” Overcoming Bias, January 1, 2009. http://www.overcomingbias.com/2009/01/moral-uncertainty-towards-a-solution.html.
———. Superintelligence: Paths, Dangers, Strategies. Oxford University Press, 2014.
Bostrom, Nick, and Milan M. Ćirković. Global Catastrophic Risks. Oxford: Oxford University Press, 2008.
Bourgin, David D., Joshua C. Peterson, Daniel Reichman, Thomas L. Griffiths, and Stuart J. Russell. “Cognitive Model Priors for Predicting Human Decisions.” In Proceedings of the 36th International Conference on Machine Learning (ICML), 2019.
Box, George E. P. “Robustness in the Strategy of Scientific Model Building.” In Robustness in Statistics, edited by Robert L. Launer and Graham N. Wilkinson, 201–36. Academic Press, 1979.
———. “Science and Statistics.” Journal of the American Statistical Association 71, no. 356 (December 1976): 791–99.
Brandt, Felix, Vincent Conitzer, Ulle Endriss, Jérôme Lang, and Ariel D Procaccia. Handbook of Computational Social Choice. Cambridge University Press, 2016.
Breiman, Leo, Jerome H. Friedman, Richard A. Olshen, and Charles J. Stone. Classification and Regression Trees. Chapman & Hall/CRC, 1984.
Breland, Keller, and Marian Breland. “The Misbehavior of Organisms.” American Psychologist 16, no. 11 (1961): 681–84.
Brennan, T., W. Dieterich, and W. Oliver. “COMPAS: Correctional Offender Management for Alternative Sanctions.” Northpointe Institute for Public Management, 2007.
Brennan, Tim, and William Dieterich. “Correctional Offender Management Profiles for Alternative Sanctions (COMPAS).” In Handbook of Recidivism Risk/Needs Assessment Tools, 49–75. Wiley Blackwell, 2018.
Brennan, Tim, and Dave Wells. “The Importance of Inmate Classification in Small Jails.” American Jails 6, no. 2 (1992): 49–52.
Brickman, Philip. “Hedonic Relativism and Planning the Good Society.” Adaptation Level Theory (1971): 287–301.
Brickman, Philip, Dan Coates, and Ronnie Janoff-Bulman. “Lottery Winners and Accident Victims: Is Happiness Relative?” Journal of Personality and Social Psychology 36, no. 8 (1978): 917.
Brinnin, John Malcolm. The Third Rose: Gertrude Stein and Her World. Boston: Little, Brown, 1959.
Brooks, Rodney A. Flesh and Machines: How Robots Will Change Us. Pantheon, 2003.
———. “Intelligence Without Representation.” Artificial Intelligence 47 (1991): 139–59.
Brown, Tom B., Nicholas Carlini, Chiyuan Zhang, Catherine Olsson, Paul Christiano, and Ian Goodfellow. “Unrestricted Adversarial Examples.” arXiv Preprint arXiv:1809.08352, 2018.
Bryson, Joanna. “Six Kinds of Explanation for AI (One Is Useless).” Adventures in NI (blog), September 19, 2019. https://joanna-bryson.blogspot.com/2019/09/six-kinds-of-explanation-for-ai-one-is.html.
Buchsbaum, Daphna, Alison Gopnik, Thomas L. Griffiths, and Patrick Shafto. “Children’s Imitation of Causal Action Sequences Is Influenced by Statistical and Pedagogical Evidence.” Cognition 120, no. 3 (2011): 331–40.
Buolamwini, Joy, and Timnit Gebru. “Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification.” In Conference on Fairness, Accountability and Transparency, 77–91, 2018.
Burda, Yuri, Harri Edwards, Deepak Pathak, Amos Storkey, Trevor Darrell, and Alexei A. Efros. “Large-Scale Study of Curiosity-Driven Learning.” Proceedings of the Seventh International Conference on Learning Representations, May 2019.
Burda, Yuri, Harrison Edwards, Amos Storkey, and Oleg Klimov. “Exploration by Random Network Distillation.” arXiv Preprint arXiv:1810.12894, 2018.
Burgess, Ernest W. “Factors Determining Success or Failure on Parole.” In The Workings of the Indeterminate-Sentence Law and the Parole System in Illinois, edited by Andrew A. Bruce, Ernest W. Burgess, Albert J. Harno, and John Landesco. Springfield, IL: Illinois State Board of Parole, 1928.
———. “Prof. Burgess on Parole Reform.” Chicago Tribune, May 19, 1937.
Burke, Peggy B., ed. A Handbook for New Parole Board Members. Association of Paroling Authorities International/National Institute of Corrections, 2003. http://apaintl.org/Handbook/CEPPParoleHandbook.pdf.
Bykvist, Krister. “Alternative Actions and the Spirit of Consequentialism.” Philosophical Studies 107, no. 1 (2002): 45–68.
Byrne, Robert. “Chess-Playing Computer Closing in on Champions.” New York Times, September 26, 1989.
Çakmak, Maya, and Manuel Lopes. “Algorithmic and Human Teaching of Sequential Decision Tasks.” In Twenty-Sixth AAAI Conference on Artificial Intelligence, 2012.
Caldwell, Tommy. The Push. Viking, 2017.
Caliskan, Aylin, Joanna J. Bryson, and Arvind Narayanan. “Semantics Derived Automatically from Language Corpora Contain Human-Like Biases.” Science 356, no. 6334 (2017): 183–86.
Callan, Rachel C., Kristina N. Bauer, and Richard N. Landers. “How to Avoid the Dark Side of Gamification: Ten Business Scenarios and Their Unintended Consequences.” In Gamification in Education and Business, 553–68. Springer, 2015.
Campbell, Murray, A. Joseph Hoane Jr., and Feng-hsiung Hsu. “Deep Blue.” Artificial Intelligence 134, nos. 1–2 (2002): 57–83.
Cannon-Bowers, Janis A., Eduardo Salas, Elizabeth Blickensderfer, and Clint A. Bowers. “The Impact of Cross-Training and Workload on Team Functioning: A Replication and Extension of Initial Findings.” Human Factors 40, no. 1 (1998): 92–101.
Carey, Ryan. “Incorrigibility in the CIRL Framework.” In AIES ’18: Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, 30–35. New Orleans: ACM, 2018.
Carse, James P. Finite and Infinite Games. Free Press, 1986
Carter, Shan, Zan Armstrong, Ludwig Schubert, Ian Johnson, and Chris Olah. “Activation Atlas.” Distill, 2019.
Caruana, Rich, Yin Lou, Johannes Gehrke, Paul Koch, Marc Sturm, and Noémie Elhadad. “Intelligible Models for Healthcare: Predicting Pneumonia Risk and Hospital 30-Day Readmission.” In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1721–30. ACM, 2015.
Caruana, Richard. “Explainability in Context—Health.” Lecture, Algorithms and Explanations, NYU School of Law, April 28, 2017.
Caruana, Richard A. “Multitask Learning: A Knowledge-Based Source of Inductive Bias.” In Machine Learning: Proceedings of the Tenth International Conference, 41–48, 1993.
Caswell, Estelle. “Color Film Was Built for White People. Here’s What It Did to Dark Skin.” Vox, September 18, 2015. https://www.vox.com/2015/9/18/9348821/photography-race-bias.
Chan, Lawrence, Dylan Hadfield-Menell, Siddhartha Srinivasa, and Anca Drăgan. “The Assistive Multi-Armed Bandit.” In 2019 14th ACM/IEEE International Conference on Human-Robot Interaction (HRI), 354–63. IEEE, 2019.
“A Chance to Fix Parole in New York.” New York Times, September 4, 2015.
Chen, Dawn, Joshua C. Peterson, and Thomas L. Griffiths. “Evaluating Vector-Space Models of Analogy.” In Proceedings of the 39th Annual Conference of the Cognitive Science Society, 2017.
Choi, Jongwook, Yijie Guo, Marcin Moczulski, Junhyuk Oh, Neal Wu, Mohammad Norouzi, and Honglak Lee. “Contingency-Aware Exploration in Reinforcement Learning.” In International Conference on Learning Representations, 2019.
Chouldechova, Alexandra. “Fair Prediction with Disparate Impact: A Study of Bias in Recidivism Prediction Instruments.” Big Data 5, no. 2 (2017): 153–63.
———. “Transparency and Simplicity in Criminal Risk Assessment.” Harvard Data Science Review 2, no. 1 (January 2020).
Chow, C. K. “An Optimum Character Recognition System Using Decision Functions.” IRE Transactions on Electronic Computers 4 (1957): 247–54.
———. “On Optimum Recognition Error and Reject Tradeoff.” IEEE Transactions on Information Theory 16, no. 1 (1970): 41–46.
Christian, Brian, and Tom Griffiths. Algorithms to Live By. Henry Holt, 2016.
Christiano, Paul F., Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. “Deep Reinforcement Learning from Human Preferences.” In Advances in Neural Information Processing Systems, 4299–4307, 2017.
Christiano, Paul, Buck Shlegeris, and Dario Amodei. “Supervising Strong Learners by Amplifying Weak Experts.” arXiv Preprint arXiv:1810.08575, 2018.
Clabaugh, Hinton G. “Foreword.” In The Workings of the Indeterminate-Sentence Law and the Parole System in Illinois, edited by Andrew A. Bruce, Ernest W. Burgess, Albert J. Harno, and John Landesco. Springfield, IL: Illinois State Board of Parole, 1928.
Clark, Jack, and Dario Amodei. “Faulty Reward Functions in the Wild.” OpenAI Blog, December 21, 2016. https://blog.openai.com/faulty-reward-functions/.
Coates, Adam, Pieter Abbeel, and Andrew Y. Ng. “Learning for Control from Multiple Demonstrations.” In Proceedings of the 25th International Conference on Machine Learning, 144–51. ACM, 2008.
Colombetti, Marco, and Marco Dorigo. “Robot Shaping: Developing Situated Agents Through Learning.” Berkeley, CA: International Computer Science Institute, 1992.
Coman, Alexandra, Benjamin Johnson, Gordon Briggs, and David W. Aha. “Social Attitudes of AI Rebellion: A Framework.” In Workshops at the Thirty-First AAAI Conference on Artificial Intelligence, 2017.
Connell, F. J. “Probabilism.” In New Catholic Encyclopedia, 2nd ed., edited by F. J. Connell. 11:727. Gale, 2002.
Conway, Flo, and Jim Siegelman. Dark Hero of the Information Age: In Search of Norbert Wiener, the Father of Cybernetics. Basic Books, 2005.
Cooper, Gregory F., Vijoy Abraham, Constantin F. Aliferis, John M. Aronis, Bruce G. Buchanan, Richard Caruana, Michael J. Fine, et al. “Predicting Dire Outcomes of Patients with Community Acquired Pneumonia.” Journal of Biomedical Informatics 38, no. 5 (2005): 347–66.
Cooper, Gregory F., Constantin F. Aliferis, Richard Ambrosino, John Aronis, Bruce G. Buchanan, Richard Caruana, Michael J. Fine, et al. “An Evaluation of Machine-Learning Methods for Predicting Pneumonia Mortality.” Artificial Intelligence in Medicine 9, no. 2 (1997): 107–38.
Cooper, Lori, and Paul Aronowitz. “DNR Tattoos: A Cautionary Tale.” Journal of General Internal Medicine 27, no. 10 (2012): 1383.
Cooper, Natalie, Alexander L. Bond, Joshua L. Davis, Roberto Portela Miguez, Louise Tomsett, and Kristofer M. Helgen. “Sex Biases in Bird and Mammal Natural History Collections.” Proceedings of the Royal Society B 286 (2019): 20192025.
Corbett, Dale, and Roy A. Wise. “Intracranial Self-Stimulation in Relation to the Ascending Dopaminergic Systems of the Midbrain: A Moveable Electrode Mapping Study.” Brain Research 185, no. 1 (1980): 1–15.
Corbett-Davies, Sam. “Algorithmic Decision Making and the Cost of Fairness.” Lecture, Simons Institute for the Theory of Computing, November 17, 2017.
Corbett-Davies, Sam, and Sharad Goel. “The Measure and Mismeasure of Fairness: A Critical Review of Fair Machine Learning.” arXiv Preprint arXiv:1808.00023, 2018.
Corbett-Davies, Sam, Emma Pierson, Avi Feller, Sharad Goel, and Aziz Huq. “Algorithmic Decision Making and the Cost of Fairness.” In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 797–806. Halifax: ACM, 2017.
Cortes, Corinna, Giulia DeSalvo, and Mehryar Mohri. “Learning with Rejection.” In International Conference on Algorithmic Learning Theory, 67–82, 2016.
Coulom, Rémi. “Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search.” In 5th International Conference on Computers and Games, 72–83. Springer, 2006.
Covey, Mark K., Steve Saladin, and Peter J. Killen. “Self-Monitoring, Surveillance, and Incentive Effects on Cheating.” Journal of Social Psychology 129, no. 5 (1989): 673–79.
“CPD Welcomes the Opportunity to Comment on Recently Published RAND Review.” Chicago Police Department news release, August 17, 2016.
Crawford, Kate, and Trevor Paglen. “Excavating AI: The Politics of Images in Machine Learning Training Sets,” 2019. https://www.excavating.ai.
Creighton, Jolene. “Making AI Safe in an Unpredictable World: An Interview with Thomas G. Dietterich,” September 17, 2018. https://futureoflife.org/2018/09/17/making-ai-safe-in-an-unpredictable-world-an-interview-with-thomas-g-dietterich/.
Cumming, William W. “A Review of Geraldine Jonçich’s The Sane Positivist: A Biography of Edward L. Thorndike.” Journal of the Experimental Analysis of Behavior 72, no. 3 (1999): 429–32.
Da, Qing, Yang Yu, and Zhi-Hua Zhou. “Learning with Augmented Class by Exploiting Unlabeled Data.” In Twenty-Eighth AAAI Conference on Artificial Intelligence, 1760–66, 2014.
Dabkowski, Piotr, and Yarin Gal. “Real Time Image Saliency for Black Box Classifiers.” In Advances in Neural Information Processing Systems, 6967–76, 2017.
Dadich, Scott, Joi Ito, and Barack Obama. “Barack Obama, Neural Nets, Self-Driving Cars, and the Future of the World.” Wired, October 12, 2016.
Dana, Jason, and Robyn M. Dawes. “The Superiority of Simple Alternatives to Regression for Social Science Predictions.” Journal of Educational and Behavioral Statistics 29, no. 3 (2004): 317–31.
Dastin, Jeffrey. “Amazon Scraps Secret AI Recruiting Tool That Showed Bias Against Women.” Reuters, October 9, 2018.
Daswani, Mayank, and Jan Leike. “A Definition of Happiness for Reinforcement Learning Agents.” In Artificial General Intelligence, edited by Jordi Bieger, Ben Goertzel, and Alexey Potapov, 231–40. Springer, 2015.
Dawes, Robyn M. “A Case Study of Graduate Admissions: Application of Three Principles of Human Decision Making.” American Psychologist 26, no. 2 (1971): 180–88.
———. “A Look at Analysis.” PhD thesis, Harvard University, 1958.
———. “The Robust Beauty of Improper Linear Models in Decision Making.” American Psychologist 34, no. 7 (1979): 571–82.
Dawes, Robyn M., and Bernard Corrigan. “Linear Models in Decision Making.” Psychological Bulletin 81, no. 2 (1974): 95–106.
Dawes, Robyn M., David Faust, and Paul E. Meehl. “Clinical Versus Actuarial Judgment.” Science 243, no. 4899 (1989): 1668–74.
Dayan, Peter, and Yael Niv. “Reinforcement Learning: The Good, the Bad and the Ugly.” Current Opinion in Neurobiology 18, no. 2 (2008): 185–96.
Dechant, Kathy, and Jack Veiga. “More on the Folly.” Academy of Management Executive 9, no. 1 (1995): 15–16.
Deci, Edward, and Richard M. Ryan. Intrinsic Motivation and Self-Determination in Human Behavior. Springer Science & Business Media, 1985.
Demski, Abram, and Scott Garrabrant. “Embedded Agency.” CoRR abs/1902.09469 (2019).
Deng, Jia, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. “ImageNet: A Large-Scale Hierarchical Image Database.” In 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–55. IEEE, 2009.
Denker, John S., and Yann LeCun. “Transforming Neural-Net Output Levels to Probability Distributions.” In Advances in Neural Information Processing Systems 3, 853–59, 1991.
Denker, John, Daniel Schwartz, Ben Wittner, Sara Solla, Richard Howard, Lawrence Jackel, and John Hopfield. “Large Automatic Learning, Rule Extraction, and Generalization.” Complex Systems 1, no. 5 (1987): 877–922.
Desmarais, Sarah L., and Jay P. Singh. “Risk Assessment Instruments Validated and Implemented in Correctional Settings in the United States,” Council of State Governments Jusice Center, 2013.
Deterding, Sebastian, Dan Dixon, Rilla Khaled, and Lennart Nacke. “From Game Design Elements to Gamefulness: Defining Gamification.” In Proceedings of the 15th International Academic Mindtrek Conference: Envisioning Future Media Environments, 9–15. ACM, 2011.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 4171–86, 2019.
Dieterich, William, Christina Mendoza, and Tim Brennan. “COMPAS Risk Scales: Demonstrating Accuracy Equity and Predictive Parity.” Northpointe Inc. Research Department, July 8, 2016.
Dietterich, Thomas G. “Steps Toward Robust Artificial Intelligence.” AI Magazine 38, no. 3 (2017): 3–24.
Diuk, Carlos, Andre Cohen, and Michael L. Littman. “An Object-Oriented Representation for Efficient Reinforcement Learning.” In Proceedings of the 25th International Conference on Machine Learning, 240–47. ACM, 2008.
Doctorow, Cory. “Two Years Later, Google Solves ‘Racist Algorithm’ Problem by Purging ‘Gorilla’ Label from Image Classifier.” Boing Boing, January 11, 2018. https://boingboing.net/2018/01/11/gorilla-chimp-monkey-unpersone.html.
Dominitz, Jeff, and John Knowles. “Crime Minimisation and Racial Bias: What Can We Learn From Police Search Data?” The Economic Journal 116, no. 515 (2006): F368–84.
Doshi-Velez, Finale, and Been Kim. “Towards a Rigorous Science of Interpretable Machine Learning.” arXiv Preprint arXiv:1702.08608, 2017.
Douglass, Frederick. “Negro Portraits.” Liberator 19, no. 16 (April 20, 1849). http://fair-use.org/the-liberator/1849/04/20/the-liberator-19–16.pdf.
Dowd, Maureen. “Peter Thiel, Trump’s Tech Pal, Explains Himself.” New York Times, January 11, 2017.
Drăgan, Anca D., Kenton C. T. Lee, and Siddhartha S. Srinivasa. “Legibility and Predictability of Robot Motion.” In 8th ACM/IEEE International Conference on Human-Robot Interaction, 301–08. IEEE, 2013.
Dressel, Julia, and Hany Farid. “The Accuracy, Fairness, and Limits of Predicting Recidivism.” Science Advances 4 (2018): eaao5580.
Dwork, Cynthia, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Richard Zemel. “Fairness Through Awareness.” In Proceedings of the 3rd Innovations in Theoretical Computer Science Conference, 214–26. ACM, 2012.
Dwork, Cynthia, Frank McSherry, Kobbi Nissim, and Adam Smith. “Calibrating Noise to Sensitivity in Private Data Analysis.” In Proceedings of the Third Conference on Theory of Cryptography, edited by Shai Halevi and Tal Rabin, 265–84. Berlin: Springer, 2006.
Easterling, Keller. “Walter Pitts.” Cabinet 5 (2001–02).
Eaves, Baxter S., Jr., Naomi H. Feldman, Thomas L. Griffiths, and Patrick Shafto. “Infant-Directed Speech Is Consistent with Teaching.” Psychological Review 123, no. 6 (2016): 758.
Ecoffet, Adrien, Joost Huizinga, Joel Lehman, Kenneth O. Stanley, and Jeff Clune. “Go-Explore: A New Approach for Hard-Exploration Problems.” arXiv Preprint arXiv:1901.10995, 2019.
Egan, Greg. Axiomatic. Millennium, 1995.
Einhorn, Hillel J. “Expert Measurement and Mechanical Combination.” Organizational Behavior and Human Performance 7 (1972): 86–106.
Elek, Jennifer, Sara Sapia, and Susan Keilitz. “Use of Court Date Reminder Notices to Improve Court Appearance Rates.” Pretrial Justice Center for the Courts, 2017.
Elman, Jeffrey L. “Learning and Development in Neural Networks: The Importance of Starting Small.” Cognition 48, no. 1 (1993): 71–99.
Engelgau, Michael M., Linda S. Geiss, Jinan B. Saaddine, James P. Boyle, Stephanie M. Benjamin, Edward W. Gregg, Edward F. Tierney, et al. “The Evolving Diabetes Burden in the United States.” Annals of Internal Medicine 140, no. 11 (2004): 945–50.
Ensign, Danielle, Sorelle A. Friedler, Scott Neville, Carlos Scheidegger, and Suresh Venkatasubramanian. “Runaway Feedback Loops in Predictive Policing.” arXiv Preprint arXiv:1706.09847, 2017.
Entwistle, Noah J., and John D. Wilson. Degrees of Excellence: The Academic Achievement Game. Hodder & Stoughton, 1977.
Erhan, Dumitru, Yoshua Bengio, Aaron Courville, and Pascal Vincent. “Visualizing Higher-Layer Features of a Deep Network.” Université de Montréal, 2009.
Esteva, Andre, Brett Kuprel, Roberto A. Novoa, Justin Ko, Susan M. Swetter, Helen M. Blau, and Sebastian Thrun. “Dermatologist-Level Classification of Skin Cancer with Deep Neural Networks.” Nature 542, no. 7639 (2017): 115.
Evans, Owain, and Noah D. Goodman. “Learning the Preferences of Bounded Agents.” In NIPS Workshop on Bounded Optimality, vol. 6, 2015.
Evans, Owain, Andreas Stuhlmüller, and Noah D. Goodman. “Learning the Preferences of Ignorant, Inconsistent Agents.” In Thirtieth AAAI Conference on Artificial Intelligence, 2016.
Evans, Teresa M., Lindsay Bira, Jazmin Beltran Gastelum, L. Todd Weiss, and Nathan L. Vanderford. “Evidence for a Mental Health Crisis in Graduate Education.” Nature Biotechnology 36, no. 3 (2018): 282.
Everitt, Tom, Victoria Krakovna, Laurent Orseau, Marcus Hutter, and Shane Legg. “Reinforcement Learning with a Corrupted Reward Channel.” In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), 4705–13, 2017.
Eysenbach, Benjamin, Shixiang Gu, Julian Ibarz, and Sergey Levine. “Leave No Trace: Learning to Reset for Safe and Autonomous Reinforcement Learning.” In International Conference on Learning Representations, 2018.
Fantz, Robert L. “Visual Experience in Infants: Decreased Attention to Familiar Patterns Relative to Novel Ones.” Science 146, no. 3644 (1964): 668–70.
Farley, Claire T., and C. Richard Taylor. “A Mechanical Trigger for the Trot-Gallop Transition in Horses.” Science 253, no. 5017 (1991): 306–08.
Ferrari, Pier F., Elisabetta Visalberghi, Annika Paukner, Leonardo Fogassi, Angela Ruggiero, and Stephen J. Suomi. “Neonatal Imitation in Rhesus Macaques.” PLoS Biology 4, no. 9 (2006): e302.
Ferster, C. B. “Schedules of Reinforcement with Skinner.” In Festschrift for B. F. Skinner, edited by P. B. Dews, 37–46. New York: Irvington, 1970.
Ferster, Charles B., and B. F. Skinner. Schedules of Reinforcement. East Norwalk, CT: Appleton-Century-Crofts, 1957.
Finn, Chelsea, Sergey Levine, and Pieter Abbeel. “Guided Cost Learning: Deep Inverse Optimal Control via Policy Optimization.” In Proceedings of the 33rd International Conference on Machine Learning, 49–58. PMLR, 2016.
Firth, John Rupert. Papers in Linguistics, 1934–1951. Oxford University Press, 1957.
Fisac, Jaime F., Monica A. Gates, Jessica B. Hamrick, Chang Liu, Dylan Hadfield-Menell, Malayandi Palaniappan, Dhruv Malik, S. Shankar Sastry, Thomas L. Griffiths, and Anca D. Drăgan. “Pragmatic-Pedagogic Value Alignment.” In International Symposium on Robotics Research (ISSR). Puerto Varas, Chile, 2017.
Fisac, Jaime F., Chang Liu, Jessica B. Hamrick, Shankar Sastry, J. Karl Hedrick, Thomas L. Griffiths, and Anca D. Drăgan. “Generating Plans That Predict Themselves.” In Workshop on the Algorithmic Foundations of Robotics (WAFR), 2016.
Fischer, Bobby, Stuart Margulies, and Don Mosenfelder. Bobby Fischer Teaches Chess. Basic Systems, 1966.
Florensa, Carlos, David Held, Markus Wulfmeier, Michael Zhang, and Pieter Abbeel. “Reverse Curriculum Generation for Reinforcement Learning.” In Proceedings of the 1st Annual Conference on Robot Learning, edited by Sergey Levine, Vincent Vanhoucke, and Ken Goldberg, 482–95. PMLR, 2017.
Flores, Anthony W., Kristin Bechtel, and Christopher T. Lowenkamp. “False Positives, False Negatives, and False Analyses: A Rejoinder to ‘Machine Bias: There’s Software Used Across the Country to Predict Future Criminals. and It’s Biased Against Blacks.’” Federal Probation 80, no. 2 (2016): 38–46.
Foerster, Jakob, Ioannis Alexandros Assael, Nando de Freitas, and Shimon Whiteson. “Learning to Communicate with Deep Multi-Agent Reinforcement Learning.” In Advances in Neural Information Processing Systems, 2137–45, 2016.
Foerster, Jakob, Richard Y. Chen, Maruan Al-Shedivat, Shimon Whiteson, Pieter Abbeel, and Igor Mordatch. “Learning with Opponent-Learning Awareness.” In Proceedings of the 17th International Conference on Autonomous Agents and Multiagent Systems, 122–30. International Foundation for Autonomous Agents and Multiagent Systems, 2018.
Fong, Ruth, and Andrea Vedaldi. “Net2Vec: Quantifying and Explaining How Concepts Are Encoded by Filters in Deep Neural Networks.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 8730–38. 2018.
“Four Out of Ten Violate Parole, Says Legislator.” Chicago Tribune, May 15, 1937.
Frederick, Shane, and George Loewenstein. “Hedonic Adaptation.” In Well-Being: The Foundations of Hedonic Psychology, edited by Daniel Kahneman, Edward Diener, and Norbert Schwarz, 302–29. New York: Russell Sage Foundation, 1999.
Friedman, Batya, and Helen Nissenbaum. “Bias in Computer Systems.” ACM Transactions on Information Systems (TOIS) 14, no. 3 (1996): 330–47.
Fu, Justin, John Co-Reyes, and Sergey Levine. “EX²: Exploration with Exemplar Models for Deep Reinforcement Learning.” In Advances in Neural Information Processing Systems, 2577–87, 2017.
Furedy, John J., and Christine P. Furedy. “‘My First Interest Is Interest’: Berlyne as an Exemplar of the Curiosity Drive.” In Advances in Intrinsic Motivation and Aesthetics, edited by Hy I. Day, 1–18. New York: Plenum Press, n.d.
Fürnkranz, Johannes, and Miroslav Kubat. Machines That Learn to Play Games. Huntington, NY: Nova Science, 2001.
Gage, Brian F., Amy D. Waterman, William Shannon, Michael Boechler, Michael W. Rich, and Martha J. Radford. “Validation of Clinical Classification Schemes for Predicting Stroke: Results from the National Registry of Atrial Fibrillation.” JAMA 285, no. 22 (2001): 2864–70.
Gal, Yarin. “Uncertainty in Deep Learning.” PhD thesis, University of Cambridge, 2016.
Gal, Yarin, and Zoubin Ghahramani. “A Theoretically Grounded Application of Dropout in Recurrent Neural Networks.” In Advances in Neural Information Processing Systems 29. 2016.
———. “Bayesian Convolutional Neural Networks with Bernoulli Approximate Variational Inference.” In 4th International Conference on Learning Representations (ICLR) Workshop Track, 2016.
———. “Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning.” In Proceedings of the 33rd International Conference on Machine Learning, 1050–09. PMLR, 2016.
Gal, Yarin, Rowan McAllister, and Carl E. Rasmussen. “Improving PILCO with Bayesian Neural Network Dynamics Models.” In Data-Efficient Machine Learning Workshop, ICML, 2016.
Gans, Joshua. Parentonomics: An Economist Dad Looks at Parenting. MIT Press, 2009.
Gardner, Matthew P. H., Geoffrey Schoenbaum, and Samuel J. Gershman. “Rethinking Dopamine as Generalized Prediction Error.” Proceedings of the Royal Society B 285, no. 1891 (2018): 20181645.
Garg, Nikhil, Londa Schiebinger, Dan Jurafsky, and James Zou. “Word Embeddings Quantify 100 Years of Gender and Ethnic Stereotypes.” Proceedings of the National Academy of Sciences 115, no. 16 (2018): E3635–44.
Gebru, Timnit. “Race and Gender.” In The Oxford Handbook of Ethics of AI, edited by Markus D. Dubber, Frank Pasquale, and Sunit Das. New York: Oxford University Press, 2020.
Gefter, Amanda. “The Man Who Tried to Redeem the World with Logic.” Nautilus 21 (February 2015).
Gendron-Bellemare, Marc. “Fast, Scalable Algorithms for Reinforcement Learning in High Dimensional Domains.” PhD thesis, University of Alberta, 2013.
Gergely, György, Harold Bekkering, and Ildikó Király. “Rational Imitation in Preverbal Infants.” Nature 415, no. 6873 (2002): 755.
Gershgorn, Dave. “Companies Are on the Hook If Their Hiring Algorithms Are Biased.” Quartz, October 22, 2018.
Ghahramani, Zoubin. “Probabilistic Machine Learning and Artificial Intelligence.” Nature 521, no. 7553 (2015): 452–59.
Ghorbani, Amirata, Abubakar Abid, and James Zou. “Interpretation of Neural Networks Is Fragile.” In Proceedings of the AAAI Conference on Artificial Intelligence 33 (2019): 3681–88.
Gielniak, Michael J., and Andrea L. Thomaz. “Generating Anticipation in Robot Motion.” In 2011 RO-MAN, 449–54. IEEE, 2011.
Giusti, Alessandro, Jérôme Guzzi, Dan C. Cireşan, Fang-Lin He, Juan P. Rodríguez, Flavio Fontana, Matthias Faessler, et al. “A Machine Learning Approach to Visual Perception of Forest Trails for Mobile Robots.” IEEE Robotics and Automation Letters 1, no. 2 (2015): 661–67.
Glimcher, Paul W. “Understanding Dopamine and Reinforcement Learning: The Dopamine Reward Prediction Error Hypothesis.” Proceedings of the National Academy of Sciences 108, Supplement 3 (2011): 15647–54.
Goel, Sharad, Justin M. Rao, and Ravi Shroff. “Personalized Risk Assessments in the Criminal Justice System.” American Economic Review 106, no. 5 (2016): 119–23.
Goldberg, Lewis R. “Man Versus Model of Man: A Rationale, Plus Some Evidence, for a Method of Improving on Clinical Inferences.” Psychological Bulletin 73, no. 6 (1970): 422–32.
———. “Simple Models or Simple Processes? Some Research on Clinical Judgments.” American Psychologist 23, no. 7 (1968): 483–96.
Goldin, Claudia, and Cecilia Rouse. “Orchestrating Impartiality: The Impact of ‘Blind’ Auditions on Female Musicians.” American Economic Review 90, no. 4 (2000): 715–41.
Goldman, Holly S. “Dated Rightness and Moral Imperfection.” Philosophical Review 85, no. 4 (1976): 449–487.
———. “Doing the Best One Can.” In Values and Morals: Essays in Honor of William Frankena, Charles Stevenson, and Richard Brandt, edited by Alvin I. Goldman and Jaegwon Kim, 185–214. D. Reidel, 1978.
Gonen, Hila, and Yoav Goldberg. “Lipstick on a Pig: Debiasing Methods Cover Up Systematic Gender Biases in Word Embeddings but Do Not Remove Them.” In Proceedings of the 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics, 2019.
Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. “Explaining and Harnessing Adversarial Examples.” In International Conference on Learning Representations, 2015.
Goodman, Bryce, and Seth Flaxman. “European Union Regulations on Algorithmic Decision-Making and a ‘Right to Explanation.’” AI Magazine 38, no. 3 (2017).
Gopnik, Alison. “Explanation as Orgasm and the Drive for Causal Knowledge: The Function, Evolution, and Phenomenology of the Theory-Formation System.” In Explanation and Cognition, edited by Frank C. Keil and Robert A. Wilson, 299–323. MIT Press, 2000.
———. The Gardener and the Carpenter: What the New Science of Child Development Tells Us About the Relationship Between Parents and Children. Macmillan, 2016.
Gopnik, Alison, Andrew N. Meltzoff, and Patricia K. Kuhl. The Scientist in the Crib: Minds, Brains, and How Children Learn. William Morrow, 1999.
Goswami, Samir. “Unlocking Options for Women: A Survey of Women in Cook County Jail.” University of Maryland Law Journal of Race, Religion, Gender and Class 2 (2002): 89–114.
Gottfredson, Stephen D., and G. Roger Jarjoura. “Race, Gender, and Guidelines-Based Decision Making.” Journal of Research in Crime and Delinquency 33, no. 1 (1996): 49–69.
Gouldin, Lauryn P. “Disentangling Flight Risk from Dangerousness.” BYU Law Review, 2016, 837–98.
Graeber, David. The Utopia of Rules: On Technology, Stupidity, and the Secret Joys of Bureaucracy. Melville House, 2015.
Graves, Alex. “Practical Variational Inference for Neural Networks.” In Advances in Neural Information Processing Systems, 2348–56, 2011.
Graves, Alex, Marc G. Bellemare, Jacob Menick, Remi Munos, and Koray Kavukcuoglu. “Automated Curriculum Learning for Neural Networks.” In Proceedings of the 34th International Conference on Machine Learning, 1311–20. PMLR, 2017.
Greenwald, Anthony G., Debbie E. McGhee, and Jordan L. K. Schwartz. “Measuring Individual Differences in Implicit Cognition: The Implicit Association Test.” Journal of Personality and Social Psychology 74, no. 6 (1998): 1464–80.
Greydanus, Sam, Anurag Koul, Jonathan Dodge, and Alan Fern. “Visualizing and Understanding Atari Agents.” In Proceedings of the 35th International Conference on Machine Learning, edited by Jennifer Dy and Andreas Krause, 1792–1801. PMLR, 2018.
Guo, Chuan, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. “On Calibration of Modern Neural Networks.” In Proceedings of the 34th International Conference on Machine Learning, 1321–30. PMLR, 2017.
Gustafsson, Johan E., and Olle Torpman. “In Defence of My Favourite Theory.” Pacific Philosophical Quarterly 95, no. 2 (2014): 159–74.
Hadfield-Menell, Dylan, Smitha Milli, Pieter Abbeel, Stuart J. Russell, and Anca D. Drăgan. “Inverse Reward Design.” In Advances in Neural Information Processing Systems, 6768–77, 2017.
Hadfield-Menell, Dylan, Stuart J. Russell, Pieter Abbeel, and Anca Drăgan. “Cooperative Inverse Reinforcement Learning.” In Advances in Neural Information Processing Systems, 3909–17, 2016.
Haggbloom, Steven J., Renee Warnick, Jason E. Warnick, Vinessa K. Jones, Gary L. Yarbrough, Tenea M. Russell, Chris M. Borecky, et al. “The 100 Most Eminent Psychologists of the 20th Century.” Review of General Psychology 6, no. 2 (2002): 139–52.
Hamari, Juho, Jonna Koivisto, and Harri Sarsa. “Does Gamification Work? A Literature Review of Empirical Studies on Gamification.” In 47th Hawaii International Conference on System Sciences (HICSS), 3025–34. IEEE, 2014.
Han, Hu, and Anil K. Jain. “Age, Gender and Race Estimation from Unconstrained Face Images.” MSU Technical Report MSU-CSE-14–5, 2014.
Hansen, C., M. Tosik, G. Goossen, C. Li, L. Bayeva, F. Berbain, and M. Rotaru. “How to Get the Best Word Vectors for Resume Parsing.” In SNN Adaptive Intelligence/Symposium: Machine Learning, 2015.
Harcourt, Bernard E. Against Prediction: Profiling, Policing, and Punishing in an Actuarial Age. University of Chicago Press, 2007.
———. “Risk as a Proxy for Race: The Dangers of Risk Assessment.” Federal Sentencing Reporter 27, no. 4 (2015): 237–43.
Hardt, Moritz. “How Big Data Is Unfair: Understanding Unintended Sources of Unfairness in Data Driven Decision Making.” Medium, September 26, 2014. https://medium.com/@mrtz/how-big-data-is-unfair-9aa544d739de.
Hardt, Moritz, Eric Price, and Nathan Srebro. “Equality of Opportunity in Supervised Learning.” In Advances in Neural Information Processing Systems, 3315–23, 2016.
Harlow, Harry F. “Learning and Satiation of Response in Intrinsically Motivated Complex Puzzle Performance by Monkeys.” Journal of Comparative and Physiological Psychology 43, no. 4 (1950): 289.
Harlow, Harry F., Margaret Kuenne Harlow, and Donald R. Meyer. “Learning Motivated by a Manipulation Drive.” Journal of Experimental Psychology 40, no. 2 (1950): 228.
Hass, Robert. Time and Materials: Poems 1997–2005. Ecco, 2007.
Hastie, Trevor, and Robert Tibshirani. “Generalized Additive Models.” Statistical Science 1, no. 3 (1986): 297–318.
Hebb, Donald Olding. The Organization of Behavior: A Neuropsychological Theory. New York: John Wiley & Sons, 1949.
Heims, Steve Joshua. The Cybernetics Group. MIT Press, 1991.
———. John von Neumann and Norbert Wiener. MIT Press, 1980.
Heine, Steven J., Timothy Takemoto, Sophia Moskalenko, Jannine Lasaleta, and Joseph Henrich. “Mirrors in the Head: Cultural Variation in Objective Self-Awareness.” Personality and Social Psychology Bulletin 34, no. 7 (2008): 879–87.
Hendrycks, Dan, Mantas Mazeika, and Thomas Dietterich. “Deep Anomaly Detection with Outlier Exposure.” In International Conference on Learning Representations, 2019.
Hernández-Lobato, José Miguel, and Ryan Adams. “Probabilistic Backpropagation for Scalable Learning of Bayesian Neural Networks.” In International Conference on Machine Learning, 1861–69. 2015.
Hersher, Rebecca. “When a Tattoo Means Life or Death. Literally.” Weekend Edition Sunday, NPR, January 21, 2018.
Hester, Todd, Matej Večerík, Olivier Pietquin, Marc Lanctot, Tom Schaul, Bilal Piot, Dan Horgan, et al. “Deep Q-Learning from Demonstrations.” In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
“Heuristics.” New Yorker, August 29, 1959, 22–23.
Hilton, Lisette. “The Artificial Brain as Doctor.” Dermatology Times, January 15, 2018.
Hinton, Geoffrey E. “Connectionist Learning Procedures.” In Artificial Intelligence 40 (1989): 185–234.
———. “Learning Distributed Representations of Concepts.” In Proceedings of the Eighth Annual Conference of the Cognitive Science Society, 1–12. 1986.
Hinton, Geoffrey, and Drew Van Camp. “Keeping Neural Networks Simple by Minimizing the Description Length of the Weights.” In Proceedings of the 6th Annual ACM Conference on Computational Learning Theory, 5–13. 1993.
Ho, Mark K., Fiery A. Cushman, Michael L. Littman, and Joseph L. Austerweil. 2019. “Communication in Action: Belief-directed Planning and Pragmatic Action Interpretation in Communicative Demonstrations.” PsyArXiv. February 19. doi:10.31234/osf.io/a8sxk.
Ho, Mark K., Michael Littman, James MacGlashan, Fiery Cushman, and Joseph L. Austerweil. “Showing Versus Doing: Teaching by Demonstration.” In Advances in Neural Information Processing Systems, 3027–35, 2016.
Hobbes, Thomas. Leviathan. Andrew Crooke, 1651.
Hoeting, Jennifer A., David Madigan, Adrian E. Raftery, and Chris T. Volinsky. “Bayesian Model Averaging: A Tutorial.” Statistical Science 14, no. 4 (1999): 382–401.
Hoffman, David. “‘I Had a Funny Feeling in My Gut.’” Washington Post, February 10, 1999. https://www.washingtonpost.com/wp-srv/inatl/longterm/coldwar/soviet10.htm.
Hofstadter, Douglas R. Gödel, Escher, Bach: An Eternal Golden Braid. Basic Books, 1979.
Hogan, Neville. “An Organizing Principle for a Class of Voluntary Movements.” Journal of Neuroscience 4, no. 11 (1984): 2745–54.
Holmes, Oliver Wendell, and Frederick Pollock. Holmes-Pollock Letters: The Correspondence of Mr. Justice Holmes and Sir Frederick Pollock, 1874–1932. Vol. 1. Harvard University Press, 1941.
Holt, Gregory E., Bianca Sarmento, Daniel Kett, and Kenneth W. Goodman. “An Unconscious Patient with a DNR Tattoo.” New England Journal of Medicine 377, no. 22 (2017): 2192–93.
Holte, Robert C. “Very Simple Classification Rules Perform Well on Most Commonly Used Datasets.” Machine Learning 11, no. 1 (1993): 63–90.
Horner, Victoria, and Andrew Whiten. “Causal Knowledge and Imitation/Emulation Switching in Chimpanzees (Pan troglodytes) and Children (Homo sapiens).” Animal Cognition 8, no. 3 (2005): 164–81.
Hornik, Kurt, Maxwell Stinchcombe, and Halbert White. “Multilayer Feedforward Networks Are Universal Approximators.” Neural Networks 2, no. 5 (1989): 359–66.
Horstmann, Aike C., Nikolai Bock, Eva Linhuber, Jessica M. Szczuka, Carolin Straßmann, and Nicole C. Krämer. “Do a Robot’s Social Skills and Its Objection Discourage Interactants from Switching the Robot Off?” PLoS One 13, no. 7 (2018): e0201581.
Hosu, Ionel-Alexandru, and Traian Rebedea. “Playing Atari Games with Deep Reinforcement Learning and Human Checkpoint Replay.” arXiv Preprint arXiv:1607.05077, 2016.
Houthooft, Rein, Xi Chen, Yan Duan, John Schulman, Filip De Turck, and Pieter Abbeel. “VIME: Variational Information Maximizing Exploration.” In Advances in Neural Information Processing Systems 29, edited by D. D. Lee, M. Sugiyama, U. V. Luxburg, I. Guyon, and R. Garnett, 1109–17, 2016.
Howard, Andrew G. “Some Improvements on Deep Convolutional Neural Network Based Image Classification.” arXiv Preprint arXiv:1312.5402, 2013.
Howard, John W., and Robyn M. Dawes. “Linear Prediction of Marital Happiness.” Personality and Social Psychology Bulletin 2, no. 4 (1976): 478–80.
Hoyt, Donald F., and C. Richard Taylor. “Gait and the Energetics of Locomotion in Horses.” Nature 292, no. 5820 (1981): 239–40.
Hsu, Feng-hsiung. “IBM’s Deep Blue Chess Grandmaster Chips.” IEEE Micro 19, no. 2 (1999): 70–81.
Hsu, Feng-hsiung, Thomas Anantharaman, Murray Campbell, and Andreas Nowatzyk. “A Grandmaster Chess Machine.” Scientific American 263, no. 4 (1990): 44–51.
Huang, Gary B., Marwan Mattar, Tamara Berg, and Eric Learned-Miller. “Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments.” In Workshop on Faces in “Real-Life” Images: Detection, Alignment, and Recognition, 2008.
Huang, Xin, Stephen G. McGill, Brian C. Williams, Luke Fletcher, and Guy Rosman. “Uncertainty-Aware Driver Trajectory Prediction at Urban Intersections.” In 2019 International Conference on Robotics and Automation, 9718–24. 2019.
Hubinger, Evan, Chris van Merwijk, Vladimir Mikulik, Joar Skalse, and Scott Garrabrant. “Risks from Learned Optimization in Advanced Machine Learning Systems.” arXiv Preprint arXiv:1906.01820, 2019.
Humphrys, Mark. “Action Selection in a Hypothetical House Robot: Using Those RL Numbers.” In Proceedings of the First International ICSC Symposia on Intelligent Industrial Automation (IIA-96) and Soft Computing (SOCO-96), 216–22. ICSC Academic Press, 1996.
Hursthouse, Rosalind. “Normative Virtue Ethics.” In How Should One Live?: Essays on the Virtues, edited by Roger Crisp, 19–36. Oxford University Press, 1996.
Huxley, Aldous. Ends and Means: An Enquiry into the Nature of Ideals and into the Methods Employed for Their Realization. Chatto & Windus, 1937.
Ilyas, Andrew, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran, and Aleksander Mądry. “Adversarial Examples Are Not Bugs, They Are Features.” In Advances in Neural Information Processing Systems, 125–36. 2019.
Irving, Geoffrey, Paul Christiano, and Dario Amodei. “AI Safety via Debate.” arXiv Preprint arXiv:1805.00899, 2018.
Jackson, Frank. “Procrastinate Revisited.” Pacific Philosophical Quarterly 95, no. 4 (2014): 634–47.
Jackson, Frank, and Robert Pargetter. “Oughts, Options, and Actualism.” Philosophical Review 95, no. 2 (1986): 233–55.
James, William. Psychology: Briefer Course. New York: Macmillan, 1892.
Jaynes, Edwin T. “Information Theory and Statistical Mechanics.” Physical Review 106, no. 4 (1957): 620–30.
Jefferson, Thomas. Notes on the State of Virginia. Paris, 1785.
Jelinek, Fred, and Robert L. Mercer. “Interpolated Estimation of Markov Source Parameters from Sparse Data.” In Proceedings, Workshop on Pattern Recognition in Practice, edited by Edzard S. Gelsema and Laveen N. Kanal, 381–97. 1980.
Jeon, Hong Jun, Smitha Milli, and Anca D. Drăgan. “Reward-Rational (Implicit) Choice: A Unifying Formalism for Reward Learning.” arXiv Preprint arXiv:2002.04833, 2020.
Joffe-Walt, Chana. “Allowance Economics: Candy, Taxes and Potty Training.” Planet Money, September 2010.
Johnson, Deborah G., and Helen Nissenbaum. “Computers, Ethics & Social Values.” Upper Saddle River, NJ: Prentice Hall, 1995.
Johnson, Robert N. “Virtue and Right.” Ethics 113, no. 4 (2003): 810–34.
Jonçich, Geraldine M. The Sane Positivist: A Biography of Edward L. Thorndike. Middletown, CT: Wesleyan University Press, 1968.
Jung, Christopher, Michael Kearns, Seth Neel, Aaron Roth, Logan Stapleton, and Zhiwei Steven Wu. “Eliciting and Enforcing Subjective Individual Fairness.” arXiv Preprint arXiv:1905.10660, 2019.
Kaelbling, Leslie Pack. Learning in Embedded Systems. MIT Press, 1993.
Kaelbling, Leslie Pack, Michael L. Littman, and Andrew W. Moore. “Reinforcement Learning: A Survey.” Journal of Artificial Intelligence Research 4 (1996): 237–85.
Kahn, Gregory, Adam Villaflor, Vitchyr Pong, Pieter Abbeel, and Sergey Levine. “Uncertainty-Aware Reinforcement Learning for Collision Avoidance.” arXiv Preprint arXiv:1702.01182, 2017.
Kahneman, Daniel. Thinking, Fast and Slow. Farrar, Straus and Giroux, 2011.
Kakade, Sham, and Peter Dayan. “Dopamine: Generalization and Bonuses.” Neural Networks 15, nos. 4–6 (2002): 549–59.
Kálmán, Rudolf Emil. “When Is a Linear Control System Optimal?” Journal of Basic Engineering 86, no. 1 (1964): 51–60.
Kamin, Leon J. “Predictability, Surprise, Attention, and Conditioning.” In Punishment and Aversive Behavior. New York: Appleton-Century-Crofts, 1969.
Kang, Daniel, Yi Sun, Dan Hendrycks, Tom Brown, and Jacob Steinhardt. “Testing Robustness Against Unforeseen Adversaries.” arXiv Preprint arXiv:1908.08016, 2019.
Kashdan, Todd B., and Paul J. Silvia. “Curiosity and Interest: The Benefits of Thriving on Novelty and Challenge.” Oxford Handbook of Positive Psychology 2 (2009): 367–74.
Kasparov, Garry. How Life Imitates Chess: Making the Right Moves, from the Board to the Boardroom. Bloomsbury USA, 2007.
Katz, Slava. “Estimation of Probabilities from Sparse Data for the Language Model Component of a Speech Recognizer.” IEEE Transactions on Acoustics, Speech, and Signal Processing 35, no. 3 (1987): 400–01.
Kellogg, Winthrop Niles, and Luella Agger Kellogg. The Ape and the Child: A Comparative Study of the Environmental Influence upon Early Behavior. Whittlesey House, 1933.
Kenton, Zachary, Angelos Filos, Owain Evans, and Yarin Gal. “Generalizing from a Few Environments in Safety-Critical Reinforcement Learning.” In ICLR Workshop on Safe Machine Learning, 2019.
Kerr, Steven. “On the Folly of Rewarding A, While Hoping for B.” Academy of Management Journal 18, no. 4 (1975): 769–83.
Kim, Been, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, and Rory Sayres. “Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV).” In Proceedings of the 35th International Conference on Machine Learning, edited by Jennifer Dy and Andreas Krause, 2668–77. PMLR, 2018.
Kimball, Spencer, and Paayal Zaveri. “Tim Cook on Facebook’s Data-Leak Scandal: ‘I Wouldn’t Be in This Situation.’” CNBC, March 28, 2018. https://www.cnbc.com/2018/03/28/tim-cook-on-facebooks-scandal-i-wouldnt-be-in-this-situation.html.
Kindermans, Pieter-Jan, Sara Hooker, Julius Adebayo, Maximilian Alber, Kristof T. Schütt, Sven Dähne, Dumitru Erhan, and Been Kim. “The (Un)reliability of Saliency Methods.” arXiv Preprint arXiv:1711.00867, 2017.
Kinsley, Philip. “What Convict Will Do If Paroled Is Study Illinois Man Presents to Science Parley.” Chicago Tribune, January 4, 1936.
Kiros, Ryan, Yukun Zhu, Russ R. Salakhutdinov, Richard Zemel, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. “Skip-Thought Vectors.” In Advances in Neural Information Processing Systems 28, edited by C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, 3294–3302, 2015.
Klare, Brendan F., Ben Klein, Emma Taborsky, Austin Blanton, Jordan Cheney, Kristen Allen, Patrick Grother, Alan Mah, and Anil K. Jain. “Pushing the Frontiers of Unconstrained Face Detection and Recognition: IARPA Janus Benchmark A.” In Proceedings of the Twenty-Eighth IEEE Conference on Computer Vision and Pattern Recognition, 1931–39. CVPR, 2015.
Kleinberg, Jon, Himabindu Lakkaraju, Jure Leskovec, Jens Ludwig, and Sendhil Mullainathan. “Human Decisions and Machine Predictions.” Quarterly Journal of Economics 133, no. 1 (2018): 237– 93.
Kleinberg, Jon, Jens Ludwig, Sendhil Mullainathan, and Ashesh Rambachan. “Algorithmic Fairness.” In AEA Papers and Proceedings 108 (2018): 22–27.
Kleinberg, Jon, Sendhil Mullainathan, and Manish Raghavan. “Inherent Trade-offs in the Fair Determination of Risk Scores.” In The 8th Innovations in Theoretical Computer Science Conference. Berkeley, 2017.
Kleinberg, Jon, and Manish Raghavan. “Selection Problems in the Presence of Implicit Bias.” In Proceedings of the 9th Conference on Innovations in Theoretical Computer Science (ITCS). 2018.
Klopf, A. Harry. “Brain Function and Adaptive Systems: A Heterostatic Theory.” Bedford, MA: Air Force Cambridge Research Laboratories, 1972.
Knox, W. Bradley, Peter Stone, and Cynthia Breazeal. “Training a Robot via Human Feedback: A Case Study.” In International Conference on Social Robotics, 460–70. Springer, 2013.
Knuth, Donald E. “Computer Programming as an Art.” Communications of the ACM 17, no. 12 (1974): 667–73.
———. “The Errors of TeX.” Software: Practice and Experience 19, no. 7 (1989): 607–85.
———. “Structured Programming with Go to Statements.” Computing Surveys 6, no. 4 (1974): 261–301.
Kobayashi, Hiromi, and Shiro Kohshima. “Unique Morphology of the Human Eye and Its Adaptive Meaning: Comparative Studies on External Morphology of the Primate Eye.” Journal of Human Evolution 40, no. 5 (2001): 419–35.
Konečni, Vladimir J. “Daniel E. Berlyne: 1924–1976.” American Journal of Psychology 91, no. 1 (March 1978): 133–37.
Krakovna, Victoria, Laurent Orseau, Ramana Kumar, Miljan Martic, and Shane Legg. “Penalizing Side Effects Using Stepwise Relative Reachability.” arXiv Preprint arXiv:1806.01186, 2019.
Kroll, Joshua A., Solon Barocas, Edward W. Felten, Joel R. Reidenberg, David G. Robinson, and Harlan Yu. “Accountable Algorithms.” University of Pennsylvania Law Review 165 (2016): 633–705.
Kurita, Keita, Nidhi Vyas, Ayush Pareek, Alan W. Black, and Yulia Tsvetkov. “Measuring Bias in Contextualized Word Representations.” arXiv Preprint arXiv:1906.07337, 2019.
Kwon, Minae, Erdem Biyik, Aditi Talati, Karan Bhasin, Dylan P. Losey, and Dorsa Sadigh. “When Humans Aren’t Optimal: Robots That Collaborate with Risk-Aware Humans.” In ACM/IEEE International Conference on Human-Robot Interaction (HRI). 2020.
Lage, Isaac, Andrew Ross, Samuel J. Gershman, Been Kim, and Finale Doshi-Velez. “Human-in-the-Loop Interpretability Prior.” In Advances in Neural Information Processing Systems, 10159–68, 2018.
Lakkaraju, Himabindu, Stephen H. Bach, and Jure Leskovec. “Interpretable Decision Sets: A Joint Framework for Description and Prediction.” In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1675–84. ACM, 2016.
Lakshminarayanan, Balaji, Alexander Pritzel, and Charles Blundell. “Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles.” In Advances in Neural Information Processing Systems, 6402–13, 2017.
Landauer, Thomas K., Peter W. Foltz, and Darrell Laham. “An Introduction to Latent Semantic Analysis.” Discourse Processes 25 (1998): 259–84.
Landecker, Will. “Interpretable Machine Learning and Sparse Coding for Computer Vision.” PhD thesis, Portland State University, 2014.
Landecker, Will, Michael D. Thomure, Luís M. A. Bettencourt, Melanie Mitchell, Garrett T. Kenyon, and Steven P. Brumby. “Interpreting Individual Classifications of Hierarchical Networks.” In 2013 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), 32–38. IEEE, 2013.
Lansing, Sharon. “New York State COMPAS-Probation Risk and Need Assessment Study: Examining the Recidivism Scale’s Effectiveness and Predictive Accuracy.” Division of Criminal Justice Services, Office of Justice Research and Performance, September 2012. http://www.criminaljustice.ny.gov/crimnet/ojsa/opca/compas\_probation\_report\_2012.pdf.
Larson, Jeff, and Julia Angwin. “Technical Response to Northpointe.” ProPublica, July 29, 2016.
Larson, Jeff, Surya Mattu, Lauren Kirchner, and Julia Angwin. “How We Analyzed the COMPAS Recidivism Algorithm.” ProPublica, May 23, 2016.
Latour, Bruno. Pandora’s Hope: Essays on the Reality of Science Studies. Harvard University Press, 1999.
Le, Quoc, and Tomáš Mikolov. “Distributed Representations of Sentences and Documents.” In International Conference on Machine Learning, 1188–96. 2014.
LeCun, Yann, Bernhard Boser, John S. Denker, Donnie Henderson, Richard E. Howard, Wayne Hubbard, and Lawrence D. Jackel. “Backpropagation Applied to Handwritten Zip Code Recognition.” Neural Computation 1, no. 4 (1989): 541–51.
Lee, Chen-Yu, Saining Xie, Patrick Gallagher, Zhengyou Zhang, and Zhuowen Tu. “Deeply-Supervised Nets.” In Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics, 562–70. 2015.
Legg, Shane, and Marcus Hutter. “A Collection of Definitions of Intelligence.” Frontiers in Artificial Intelligence and Applications 157 (2007): 17–24.
———. “Universal Intelligence: A Definition of Machine Intelligence.” Minds and Machines 17, no. 4 (December 2007): 391–444.
Legg, Shane, and Joel Veness. “An Approximation of the Universal Intelligence Measure.” In Papers from the Ray Solomonoff 85th Memorial Conference. Melbourne, Australia, 2011.
Leibig, Christian, Vaneeda Allken, Murat Seçkin Ayhan, Philipp Berens, and Siegfried Wahl. “Leveraging Uncertainty Information from Deep Neural Networks for Disease Detection.” Scientific Reports 7, no. 1 (2017): 17816.
Leighty, Robert D. “DARPA ALV (Autonomous Land Vehicle) Summary.” Army Engineer Topographic Laboratories, Fort Belvoir, VA, 1986.
Leike, Jan, and Marcus Hutter. “Bad Universal Priors and Notions of Optimality.” In Proceedings of the 28th Conference on Learning Theory, 1244–59. PMLR: 2015.
Leike, Jan, David Krueger, Tom Everitt, Miljan Martic, Vishal Maini, and Shane Legg. “Scalable Agent Alignment via Reward Modeling: A Research Direction.” arXiv Preprint arXiv:1811.07871, 2018.
Leike, Jan, Miljan Martic, Victoria Krakovna, Pedro A. Ortega, Tom Everitt, Andrew Lefrancq, Laurent Orseau, and Shane Legg. “AI Safety Gridworlds.” arXiv Preprint arXiv:1711.09883, 2017.
Lenson, David. On Drugs. University of Minnesota Press, 1995.
Letham, Benjamin, Cynthia Rudin, Tyler H. McCormick, David Madigan. “Interpretable Classifiers Using Rules and Bayesian Analysis: Building a Better Stroke Prediction Model.” Annals of Applied Statistics 9, no. 3 (2015): 1350–71.
Lewis, Sarah, ed. “Vision & Justice.” Aperture 223 (2016).
Li, Lihong, Michael L. Littman, Thomas J. Walsh, and Alexander L. Strehl. “Knows What It Knows: A Framework for Self-Aware Learning.” Machine Learning 82, no. 3 (2011): 399–443.
Li, Xin, and Fuxin Li. “Adversarial Examples Detection in Deep Networks with Convolutional Filter Statistics.” In Proceedings of the IEEE International Conference on Computer Vision, 5764–72. 2017.
Lieder, Falk. “Gamify Your Goals: How Turning Your Life into a Game Can Help You Make Better Decisions and Be More Productive.” LessWrong, February 3, 2016. https://www.lesswrong.com/posts/g2355pBbaYSfPMk2m/gamify-your-goals-how-turning-your-life-into-a-game-can-help.
Lieder, Falk, Owen X. Chen, Paul M. Krueger, and Thomas L. Griffiths. “Cognitive Prostheses for Goal Achievement.” Nature Human Behaviour 3, no. 10 (2019): 1096–1106.
Lieder, Falk, Noah D. Goodman, and Quentin J. M. Huys. “Learned Helplessness and Generalization.” In Proceedings of the 35th Annual Meeting of the Cognitive Science Society, 900–05. Austin, TX, 2013.
Lin, Min, Qiang Chen, and Shuicheng Yan. “Network in Network.” arXiv Preprint arXiv:1312.4400, 2013.
Lip, Gregory Y. H., Robby Nieuwlaat, Ron Pisters, Deirdre A. Lane, and Harry J.G.M. Crijns. “Refining Clinical Risk Stratification for Predicting Stroke and Thromboembolism in Atrial Fibrillation Using a Novel Risk Factor–Based Approach: The Euro Heart Survey on Atrial Fibrillation.” Chest 137, no. 2 (2010): 263–72.
Lipsey, Richard G., and Kelvin Lancaster. “The General Theory of Second Best.” Review of Economic Studies 24, no. 1 (1956): 11–32.
Liu, Anqi, and Brian Ziebart. “Robust Classification Under Sample Selection Bias.” In Advances in Neural Information Processing Systems, 37–45, 2014.
Liu, Lydia T., Sarah Dean, Esther Rolf, Max Simchowitz, and Moritz Hardt. “Delayed Impact of Fair Machine Learning.” In Proceedings of the 35th International Conference on Machine Learning, 2018.
Liu, Si, Risheek Garrepalli, Thomas G. Dietterich, Alan Fern, and Dan Hendrycks. “Open Category Detection with PAC Guarantees.” In Proceedings of the 35th International Conference on Machine Learning, 2018.
Liu, Si, Risheek Garrepalli, Alan Fern, and Thomas G. Dietterich. “Can We Achieve Open Category Detection with Guarantees?” In Workshops at the Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
Lockhart, Ted. Moral Uncertainty and Its Consequences. Oxford University Press, 2000.
Lou, Yin, Rich Caruana, Johannes Gehrke, and Giles Hooker. “Accurate Intelligible Models with Pairwise Interactions.” In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 623–31. ACM, 2013.
Lowell, Josh, and Peter Mortimer, directors. The Dawn Wall. Red Bull Films, 2018.
Lum, Kristian, and William Isaac. “To Predict and Serve?” Significance 13, no. 5 (2016): 14–19.
Lyons, Derek E., Andrew G. Young, and Frank C. Keil. “The Hidden Structure of Overimitation.” Proceedings of the National Academy of Sciences 104, no. 50 (2007): 19751–56.
MacAskill, William. Doing Good Better: Effective Altruism and a Radical New Way to Make a Difference. Guardian Faber, 2015.
MacAskill, William, Krister Bykvist, and Toby Ord. Moral Uncertainty. Oxford University Press, 2020.
Machado, Marlos C., Marc G. Bellemare, Erik Talvitie, Joel Veness, Matthew Hausknecht, and Michael Bowling. “Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents.” Journal of Artificial Intelligence Research 61 (2018): 523–62.
MacKay, David J. C. “A Practical Bayesian Framework for Backpropagation Networks.” Neural Computation 4, no. 3 (1992): 448–72.
Madras, David, Toniann Pitassi, and Richard Zemel. “Predict Responsibly: Increasing Fairness by Learning to Defer.” In Neural Information Processing Systems, 2018.
Mądry, Aleksander, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. “Towards Deep Learning Models Resistant to Adversarial Attacks.” International Conference on Learning Representations (ICLR), 2018.
Maier, Steven F., and Martin E. Seligman. “Learned Helplessness: Theory and Evidence.” Journal of Experimental Psychology: General 105, no. 1 (1976): 3–46.
Malik, Dhruv, Malayandi Palaniappan, Jaime Fisac, Dylan Hadfield-Menell, Stuart Russell, and Anca Drăgan. “An Efficient, Generalized Bellman Update for Cooperative Inverse Reinforcement Learning.” In Proceedings of the 35th International Conference on Machine Learning, edited by Jennifer Dy and Andreas Krause, 3394–3402. PMLR, 2018.
Malone, Thomas W. “Toward a Theory of Intrinsically Motivating Instruction.” Cognitive Science 4 (1981): 333–70.
———. “What Makes Computer Games Fun?” Byte 6 (1981): 258–77.
Malone, Thomas W., and Mark R. Lepper. “Making Learning Fun: A Taxonomy of Intrinsic Motivations for Learning.” In Aptitude, Learning and Instruction III: Conative and Affective Process Analyses, edited by Richard E. Snow and Marshall J. Farr, 223–53. Hillsdale, NJ: Lawrence Erlbaum Associates, 1987.
Manheim, David, and Scott Garrabrant. “Categorizing Variants of Goodhart’s Law.” arXiv Preprint arXiv:1803.04585, 2019.
Manning, Christopher. “Lecture 2: Word Vector Representations: Word2vec,” April 3, 2017. https://www.youtube.com/watch?v=ERibwqs9p38.
Manning, Christopher D., and Hinrich Schütze. Foundations of Statistical Natural Language Processing. MIT Press, 1999.
Marewski, Julian N., and Gerd Gigerenzer. “Heuristic Decision Making in Medicine.” Dialogues in Clinical Neuroscience 14, no. 1 (2012): 77–89.
Marks, Michelle A., Mark J. Sabella, C. Shawn Burke, and Stephen J. Zaccaro. “The Impact of Cross-Training on Team Effectiveness.” Journal of Applied Psychology 87, no. 1 (2002): 3–13.
Marts, Sherry A., and Sarah Keitt. “Foreword: A Historical Overview of Advocacy for Research in Sex-Based Biology.” In Advances in Molecular and Cell Biology, 34 (2004): v–xiii.
Mastroianni, Anna C., Ruth Faden, and Daniel Federman, eds. Women and Health Research: Ethical and Legal Issues of Including Women in Clinical Studies. National Academies Press, 1994.
Matarić, Maja J. “Reward Functions for Accelerated Learning.” In Machine Learning: Proceedings of the Eleventh International Conference, 181–89. 1994.
Maxwell, James Clerk. “On Governors.” Proceedings of the Royal Society of London 16 (1868): 270–83.
Mayson, Sandra G. “Bias in, Bias Out.” Yale Law Journal 128 (2019): 2218–2300.
———. “Dangerous Defendants.” Yale Law Journal 127 (2017): 490–568.
McCarthy, John. “Computer-Controlled Cars,” 1969. http://www-formal.stanford.edu/jmc/progress/cars/cars.html.
———. “What Is Artificial Intelligence?” 1998. http://www-formal.stanford.edu/jmc/whatisai.pdf.
McCarthy, John, and Edward A. Feigenbaum. “In Memoriam: Arthur Samuel: Pioneer in Machine Learning.” AI Magazine 11, no. 3 (1990): 10.
McCulloch, Warren S. The Collected Works of Warren S. McCulloch. Edited by Rook McCulloch. Salinas, CA: Intersystems Publications, 1989.
———. Finality and Form: In Nervous Activity. C. C. Thomas, 1952.
———. “Recollections of the Many Sources of Cybernetics.” In ASC Forum 6, no. 2 (1974): 5–16.
McCulloch, Warren S., and Walter Pitts. “A Logical Calculus of Ideas Immanent in Nervous Activity.” Bulletin of Mathematical Biophysics 4 (1943).
McFadden, Syreeta. “Teaching the Camera to See My Skin.” BuzzFeed News, April 2, 2014. https://www.buzzfeednews.com/article/syreetamcfadden/teaching-the-camera-to-see-my-skin.
McGonigal, Jane. Reality Is Broken: Why Games Make Us Better and How They Can Change the World. Penguin, 2011.
———. SuperBetter: A Revolutionary Approach to Getting Stronger, Happier, Braver and More Resilient. Penguin, 2015.
McGuigan, Nicola, and Murray Graham. “Cultural Transmission of Irrelevant Tool Actions in Diffusion Chains of 3- and 5-Year-Old Children.” European Journal of Developmental Psychology 7, no. 5 (2010): 561–77.
Meehl, Paul E. “Causes and Effects of My Disturbing Little Book.” Journal of Personality Assessment 50, no. 3 (1986): 370–75.
———. Clinical Versus Statistical Prediction. Minneapolis: University of Minnesota Press, 1954.
Meltzoff, Andrew N. “Born to Learn: What Infants Learn from Watching Us.” In The Role of Early Experience in Infant Development, 145–64. Skillman, NJ: Pediatric Institute Publications, 1999.
———. “Foundations for Developing a Concept of Self: The Role of Imitation in Relating Self to Other and the Value of Social Mirroring, Social Modeling, and Self Practice in Infancy.” In The Self in Transition: Infancy to Childhood, 139–64. Chicago: University of Chicago Press, 1990.
———. “‘Like Me’: A Foundation for Social Cognition.” Developmental Science 10, no. 1 (2007): 126–34.
———. “Understanding the Intentions of Others: Re-enactment of Intended Acts by 18-Month-Old Children.” Developmental Psychology 31, no. 5 (1995): 838.
Meltzoff, Andrew N., and M. Keith Moore. “Imitation of Facial and Manual Gestures by Human Neonates.” Science 198, no. 4312 (1977): 75–78.
———. “Newborn Infants Imitate Adult Facial Gestures.” Child Development 54, no. 3 (1983): 702–09.
Meltzoff, Andrew N., Lynne Murray, Elizabeth Simpson, Mikael Heimann, Emese Nagy, Jacqueline Nadel, Eric J Pedersen, et al. “Re-examination of Oostenbroek et al. (2016): Evidence for Neonatal Imitation of Tongue Protrusion.” Developmental Science 21, no. 4 (2018): e12609.
Meltzoff, Andrew N., Anna Waismeyer, and Alison Gopnik. “Learning About Causes from People: Observational Causal Learning in 24-Month-Old Infants.” Developmental Psychology 48, no. 5 (2012): 1215.
Mercier, Hugo, and Dan Sperber. “Why Do Humans Reason? Arguments for an Argumentative Theory.” Behavioral and Brain Sciences 34 (2011): 57–111.
Merler, Michele, Nalini Ratha, Rogerio S. Feris, and John R Smith. “Diversity in Faces.” arXiv Preprint arXiv:1901.10436, 2019.
Metz, Cade. “Is Ethical A.I. Even Possible?” New York Times, March 1, 2019.
———. “We Teach A.I. Systems Everything, Including Our Biases.” New York Times, November 11, 2019.
Mikolov, Tomáš. “Learning Representations of Text Using Neural Networks.” In NIPS Deep Learning Workshop 2013, 2013. https://drive.google.com/file/d/0B7XkCwpI5KDYRWRnd1RzWXQ2TWc/edit.
Mikolov, Tomáš, Kai Chen, Greg Corrado, and Jeffrey Dean. “Efficient Estimation of Word Representations in Vector Space.” arXiv Preprint arXiv:1301.3781, 2013.
Mikolov, Tomáš, Quoc V. Le, and Ilya Sutskever. “Exploiting Similarities Among Languages for Machine Translation.” arXiv Preprint arXiv:1309.4168, 2013.
Mikolov, Tomáš, Ilya Sutskever, and Quoc Le. “Learning the Meaning Behind Words.” Google Open Source Blog, August 14, 2013. https://opensource.googleblog.com/2013/08/learning-meaning-behind-words.html.
Mikolov, Tomáš, Wen-tau Yih, and Geoffrey Zweig. “Linguistic Regularities in Continuous Space Word Representations.” In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 746–51. 2013.
Miller, Geoffrey. “Reconciling Evolutionary Psychology and Ecological Psychology: How to Perceive Fitness Affordances.” Acta Psychologica Sinica 39, no. 3 (2007): 546–55.
Milli, Smitha, and Anca D. Drăgan. “Literal or Pedagogic Human? Analyzing Human Model Misspecification in Objective Learning.” In The Conference on Uncertainty in Artificial Intelligence (UAI), 2019.
Milli, Smitha, Dylan Hadfield-Menell, Anca Drăgan, and Stuart Russell. “Should Robots Be Obedient?” In 26th International Joint Conference on Artificial Intelligence. 2017.
Minsky, Marvin. “Steps Toward Artificial Intelligence.” Proceedings of the Institute of Radio Engineers 49, no. 1 (1961): 8–30.
———. “Theory of Neural-Analog Reinforcement Systems and Its Application to the Brain Model Problem.” PhD thesis, Princeton University, 1954.
Minsky, Marvin L., and Seymour A. Papert. Perceptrons: An Introduction to Computational Geometry. MIT Press, 1969.
Mirenowicz, Jacques, and Wolfram Schultz. “Importance of Unpredictability for Reward Responses in Primate Dopamine Neurons.” Journal of Neurophysiology 72, no. 2 (1994): 1024–27.
Mnih, Volodymyr, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. “Playing Atari with Deep Reinforcement Learning.” In Deep Learning Workshop, NIPS 2013. 2013.
Mnih, Volodymyr, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, et al. “Human-Level Control Through Deep Reinforcement Learning.” Nature 518, no. 7540 (2015): 529–33.
Mohamed, Shakir, and Danilo Jimenez Rezende. “Variational Information Maximisation for Intrinsically Motivated Reinforcement Learning.” In Advances in Neural Information Processing Systems 28, 2125–33. 2015.
Mombaur, Katja, Anh Truong, and Jean-Paul Laumond. “From Human to Humanoid Locomotion—an Inverse Optimal Control Approach.” Autonomous Robots 28, no. 3 (2010): 369–83.
Monahan, John, and Jennifer L. Skeem. “Risk Assessment in Criminal Sentencing.” Annual Review of Clinical Psychology 12 (2016): 489–513.
Montague, P. Read, Peter Dayan, Christophe Person, and Terrence J. Sejnowski. “Bee Foraging in Uncertain Environments Using Predictive Hebbian Learning.” Nature 377, no. 6551 (1995): 725.
Montague, P. Read, Peter Dayan, and Terrence J. Sejnowski. “A Framework for Mesencephalic Dopamine Systems Based on Predictive Hebbian Learning.” Journal of Neuroscience 16, no. 5 (1996): 1936–47.
Moravec, Hans. “Obstacle Avoidance and Navigation in the Real World by a Seeing Robot Rover.” PhD thesis, Stanford University, 1980.
Mordvintsev, Alexander, Christopher Olah, and Mike Tyka. “DeepDream—a Code Example for Visualizing Neural Networks.” Google AI Blog, July 1, 2015. https://ai.googleblog.com/2015/07/deepdream-code-example-for-visualizing.html.
———. “Inceptionism: Going Deeper into Neural Networks.” Google AI Blog, June 17, 2015. https://ai.googleblog.com/2015/06/inceptionism-going-deeper-into-neural.html.
Morgan, Conway Lloyd. An Introduction to Comparative Psychology. 1894. 2nd ed., Charles Scribner’s Sons, 1904.
Moss-Racusin, Corinne A., John F. Dovidio, Victoria L. Brescoll, Mark J. Graham, and Jo Handelsman. “Science Faculty’s Subtle Gender Biases Favor Male Students.” Proceedings of the National Academy of Sciences 109, no. 41 (2012): 16474–79.
Mueller, Benjamin, Robert Gebeloff, and Sahil Chinoy. “Surest Way to Face Marijuana Charges in New York: Be Black or Hispanic.” New York Times, May 13, 2018.
Mueller, Dennis C. Public Choice III. Cambridge University Press, 2003.
Munro, Robert. “Diversity in AI Is Not Your Problem, It’s Hers.” Medium, November 11, 2019. https://medium.com/@robert.munro/bias-in-ai-3ea569f79d6a.
Murdoch, Iris. The Bell. Chatto & Windus, 1958.
Naddaf, Yavar. “Game-Independent AI Agents for Playing Atari 2600 Console Games.” Master’s thesis, University of Alberta, 2010.
Nair, Ashvin, Bob McGrew, Marcin Andrychowicz, Wojciech Zaremba, and Pieter Abbeel. “Overcoming Exploration in Reinforcement Learning with Demonstrations.” In 2018 IEEE International Conference on Robotics and Automation (ICRA), 6292–99. IEEE, 2018.
Nalisnick, Eric, Bhaskar Mitra, Nick Craswell, and Rich Caruana. “Improving Document Ranking with Dual Word Embeddings.” In Proceedings of the 25th International World Wide Web Conference, 83–84. Montreal: International World Wide Web Conferences Steering Committee, 2016.
Narla, Akhila, Brett Kuprel, Kavita Sarin, Roberto Novoa, and Justin Ko. “Automated Classification of Skin Lesions: From Pixels to Practice.” Journal of Investigative Dermatology 138, no. 10 (2018): 2108–10.
Neal, Radford M. “Bayesian Learning for Neural Networks.” PhD thesis, University of Toronto, 1995.
Nematzadeh, Aida, Stephan C. Meylan, and Thomas L. Griffiths. “Evaluating Vector-Space Models of Word Representation; or, The Unreasonable Effectiveness of Counting Words Near Other Words.” In Proceedings of the 39th Annual Conference of the Cognitive Science Society, 2017.
“New Navy Device Learns by Doing.” New York Times, July 8, 1958.
“New York’s Broken Parole System.” New York Times, February 16, 2014.
Ng, Andrew Y. “Shaping and Policy Search in Reinforcement Learning.” PhD thesis, University of California, Berkeley, 2003.
Ng, Andrew Y., Adam Coates, Mark Diel, Varun Ganapathi, Jamie Schulte, Ben Tse, Eric Berger, and Eric Liang. “Autonomous Inverted Helicopter Flight via Reinforcement Learning.” In Experimental Robotics IX, 363–72. Springer, 2006.
Ng, Andrew Y., Daishi Harada, and Stuart Russell. “Policy Invariance Under Reward Transformations: Theory and Application to Reward Shaping.” In ICML 99 (1999): 278–87.
Ng, Andrew Y., H. Jin Kim, Michael I. Jordan, and Shankar Sastry. “Autonomous Helicopter Flight via Reinforcement Learning.” In Advances in Neural Information Processing Systems, 799–806, 2004.
Ng, Andrew Y., and Stuart J. Russell. “Algorithms for Inverse Reinforcement Learning.” In Proceedings of the 17th International Conference on Machine Learning. Stanford, CA: Morgan Kaufmann, 2000.
Nguyen, Anh, Alexey Dosovitskiy, Jason Yosinski, Thomas Brox, and Jeff Clune. “Synthesizing the Preferred Inputs for Neurons in Neural Networks via Deep Generator Networks.” In Advances in Neural Information Processing Systems 29, edited by D. D. Lee, M. Sugiyama, U. V. Luxburg, I. Guyon, and R. Garnett, 3387–95, 2016.
Nguyen, Anh, Jason Yosinski, and Jeff Clune. “Deep Neural Networks Are Easily Fooled: High Confidence Predictions for Unrecognizable Images.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR2015), 427–36. CVPR, 2015.
Nikolaidis, Stefanos, Przemyslaw Lasota, Ramya Ramakrishnan, and Julie Shah. “Improved Human-Robot Team Performance Through Cross-Training: An Approach Inspired by Human Team Training Practices.” International Journal of Robotics Research 34, no. 14 (2015): 1711–30.
Nissim, Malvina, Rik van Noord, and Rob van der Goot. “Fair Is Better Than Sensational: Man Is to Doctor as Woman Is to Doctor.” arXiv Preprint arXiv:1905.09866, 2019.
Niv, Yael. “Reinforcement Learning in the Brain.” Journal of Mathematical Psychology 53, no. 3 (2009): 139–54.
Niv, Yael, Daphna Joel, Isaac Meilijson, and Eytan Ruppin. “Evolution of Reinforcement Learning in Foraging Bees: A Simple Explanation for Risk Averse Behavior.” Neurocomputing 44 (2001): 951–56.
“Northpointe’s Response to ProPublica: Demonstrating Accuracy Equity and Predictive Parity,” [2016]. http://www.equivant.com/blog/response-to-propublica-demonstrating-accuracy-equity-and-predictive-parity; original version available at https://web.archive.org/web/20160802190300/http:/www.northpointeinc.com/northpointe-analysis.
Odell, Jenny. How to Do Nothing: Resisting the Attention Economy. Melville House, 2019.
O’Doherty, John P. “Beyond Simple Reinforcement Learning: The Computational Neurobiology of Reward-Learning and Valuation.” European Journal of Neuroscience 35, no. 7 (2012): 987–90.
Ohlin, Lloyd E. Selection for Parole: A Manual of Parole Prediction. Russell Sage Foundation, 1951.
Olah, Chris, Alexander Mordvintsev, and Ludwig Schubert. “Feature Visualization.” Distill, 2017.
Olah, Chris, Arvind Satyanarayan, Ian Johnson, Shan Carter, Ludwig Schubert, Katherine Ye, and Alexander Mordvintsev. “The Building Blocks of Interpretability.” Distill, 2018.
Olds, James. “Pleasure Centers in the Brain.” Scientific American 195, no. 4 (1956): 105–17.
———. “Pleasure Centers in the Brain.” Engineering and Science 33, no. 7 (1970): 22–31.
Olds, James, and Peter Milner. “Positive Reinforcement Produced by Electrical Stimulation of Septal Area and Other Regions of Rat Brain.” Journal of Comparative and Physiological Psychology 47, no. 6 (1954): 419–27.
Omohundro, Stephen M. “The Basic AI Drives.” In Artificial General Intelligence 2008: Proceedings of the First AGI Conference, edited by Pei Wang, Ben Goertzel, and Stan Franklin, 483–92. Amsterdam: IOS Press, 2008.
O’Neil, Cathy. Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. Crown, 2016.
Oostenbroek, Janine, Thomas Suddendorf, Mark Nielsen, Jonathan Redshaw, Siobhan Kennedy-Costantini, Jacqueline Davis, Sally Clark, and Virginia Slaughter. “Comprehensive Longitudinal Study Challenges the Existence of Neonatal Imitation in Humans.” Current Biology 26, no. 10 (2016): 1334–48.
Ord, Toby. “Moral Trade.” Ethics 126, no. 1 (2015): 118–38.
———. The Precipice: Existential Risk and the Future of Humanity. Hachette Books, 2020.
Orseau, Laurent. “Universal Knowledge-Seeking Agents.” In Algorithmic Learning Theory: 22nd International Conference, 353–367. Springer, 2011.
Orseau, Laurent, and Stuart Armstrong. “Safely Interruptible Agents.” In Proceedings of the Thirty-Second Uncertainty in Artificial Intelligence Conference, 557–66. AUAI Press, 2016.
Orseau, Laurent, Tor Lattimore, and Marcus Hutter. “Universal Knowledge-Seeking Agents for Stochastic Environments.” In International Conference on Algorithmic Learning Theory, 158–72. 2013.
Ostrovski, Georg, Marc G. Bellemare, Aäron van den Oord, and Rémi Munos. “Count-Based Exploration with Neural Density Models.” arXiv Preprint arXiv:1703.01310, June 14, 2017.
O’Toole, Garson. “There’s a Way to Do It Better—Find It.” Quote Investigator, July 16, 2013. https://quoteinvestigator.com/2013/07/16/do-it-better/.
Oudeyer, Pierre-Yves, and Frederic Kaplan. “What Is Intrinsic Motivation? A Typology of Computational Approaches.” Frontiers in Neurorobotics 1, no. 6 (2007): 1–13.
Pathak, Deepak, Pulkit Agrawal, Alexei A. Efros, and Trevor Darrell. “Curiosity-Driven Exploration by Self-Supervised Prediction.” In International Conference on Machine Learning (ICML), 2017.
Paul, L. A. Transformative Experience. Oxford University Press, 2014.
Paulus, Markus, Sabine Hunnius, Marlies Vissers, and Harold Bekkering. “Imitation in Infancy: Rational or Motor Resonance?” Child Development 82, no. 4 (2011): 1047–57.
Pavlov, I. P. Conditioned Reflexes: An Investigation of the Physiological Activity of the Cerebral Cortex. Translated by G. V. Anrep. London: Oxford University Press, 1927.
Pearl, Judea. “The Seven Tools of Causal Inference, with Reflections on Machine Learning.” Communications of the ACM 62, no. 3 (2019): 54–60.
Pedreshi, Dino, Salvatore Ruggieri, and Franco Turini. “Discrimination-Aware Data Mining.” In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 560–68. ACM, 2008.
Peng, Xue Bin, Pieter Abbeel, Sergey Levine, and Michiel van de Panne. “DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills.” ACM Transactions on Graphics (TOG) 37, no. 4 (2018): 143.
Perez, Caroline Criado. Invisible Women: Data Bias in a World Designed for Men. Abrams, 2019.
Persico, Nicola. “Racial Profiling, Fairness, and Effectiveness of Policing.” American Economic Review 92, no. 5 (2002): 1472–97.
Peterson, Gail B. “A Day of Great Illumination: B. F. Skinner’s Discovery of Shaping.” Journal of the Experimental Analysis of Behavior 82, no. 3 (2004): 317–28.
Piaget, Jean. The Construction of Reality in the Child. Translated by Margaret Cook. Basic Books, 1954.
Piccinini, Gualtiero. “The First Computational Theory of Mind and Brain: A Close Look at McCulloch and Pitts’s ‘Logical Calculus of Ideas Immanent in Nervous Activity.’” Synthese 141, no. 2 (2004): 175–215.
Plato. Protagoras and Meno. Translated by W.K.C. Guthrie. Penguin Books, 1956.
Podkopacz, Marcy R. “Building and Validating the 2007 Hennepin County Adult Pretrial Scale.” Minneapolis, MN: Fourth Judicial District Research Division, 2010. http://www.mncourts.gov/mncourtsgov/media/assets/documents/4/reports/Validation\_of\_the\_New\_2007\_Hennepin\_County\_Pretrial\_Scale.pdf.
Podkopacz, Marcy R., Deborah Eckberg, and Gina Kubits. “Fourth Judicial District Pretrial Evaluation: Scale Validation Study.” Minneapolis, MN: Fourth Judicial District Research Division, 2006. http://www.mncourts.gov/Documents/4/Public/Research/PreTrial\_Scale\_Validation\_(2006).pdf.
Pomerleau, Dean A. “ALVINN: An Autonomous Land Vehicle in a Neural Network.” In Advances in Neural Information Processing Systems, 305–13. 1989.
———. “Knowledge-Based Training of Artificial Neural Networks for Autonomous Robot Driving.” In Robot Learning, 19–43. Kluwer Academic Publishers, 1993.
Poplin, Ryan, Avinash V. Varadarajan, Katy Blumer, Yun Liu, Michael V. McConnell, Greg S. Corrado, Lily Peng, and Dale R. Webster. “Prediction of Cardiovascular Risk Factors from Retinal Fundus Photographs via Deep Learning.” Nature Biomedical Engineering 2, no. 3 (2018): 158–64.
Poursabzi-Sangdeh, Forough, Daniel G. Goldstein, Jake M. Hofman, Jenn Wortman Vaughan, and Hanna Wallach. “Manipulating and Measuring Model Interpretability.” arXiv Preprint arXiv:1802.07810, 2018.
Prost, Flavien, Nithum Thain, and Tolga Bolukbasi. “Debiasing Embeddings for Reduced Gender Bias in Text Classification.” arXiv Preprint arXiv:1908.02810, 2019.
Prümmer, Dominic M., OP. Handbook of Moral TheologyTranslated by Reverend Gerald W. Shelton, STL. 5th ed. Cork: Mercier Press, 1956.
Quinlan, J. Ross. C4.5: Programs for Machine Learning. San Mateo, CA: Morgan Kaufmann Publishers, 1993.
Radford, Alec, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. “Language Models Are Unsupervised Multitask Learners.” OpenAI Blog, 2019. https://openai.com/blog/better-language-models/.
Ramakrishnan, Ramya, Chongjie Zhang, and Julie Shah. “Perturbation Training for Human-Robot Teams.” Journal of Artificial Intelligence Research 59 (2017): 495–541.
Ramírez, Naja Ferjan, Sarah Roseberry Lytle, and Patricia K. Kuhl. “Parent Coaching Increases Conversational Turns and Advances Infant Language Development.” Proceedings of the National Academy of Sciences 117, no. 7 (2020): 3484–91.
Randløv, Jette, and Preben Alstrøm. “Learning to Drive a Bicycle Using Reinforcement Learning and Shaping.” In Proceedings of the 15th International Conference on Machine Learning, 463–71. Morgan Kaufmann Publishers, 1998.
Read, Herbert. The Grass Roots of Art: Four Lectures on Social Aspects of Art in an Industrial Age. World Publishing, 1961.
Recht, Benjamin, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. “Do ImageNet Classifiers Generalize to ImageNet?” In Proceedings of the 36th International Conference on Machine Learning, edited by Kamalika Chaudhuri and Ruslan Salakhutdinov, 5389–5400. PMLR, 2019.
“Report on Algorithmic Risk Assessment Tools in the U.S. Criminal Justice System.” Partnership on AI, 2019. https://www.partnershiponai.org/wp-content/uploads/2019/04/Report-on-Algorithmic-Risk-Assessment-Tools.pdf.
Rescorla, Robert A., and Allan R. Wagner. “A Theory of Pavlovian Conditioning: Variations in the Effectiveness of Reinforcement and Nonreinforcement.” In Classical Conditioning II: Current Research and Theory, 64–99. Appleton-Century-Crofts, 1972.
Rezaei, Ashkan, Rizal Fathony, Omid Memarrast, and Brian Ziebart. “Fairness for Robust Log Loss Classification.” In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, 2020.
Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. “Why Should I Trust You? Explaining the Predictions of Any Classifier.” In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1135–44. ACM, 2016.
Riedl, Mark O., and Brent Harrison. “Enter the Matrix: A Virtual World Approach to Safely Interruptable Autonomous Systems.” CoRR abs/1703.10284 (2017). http://arxiv.org/abs/1703.10284.
Ring, Mark B., and Laurent Orseau. “Delusion, Survival, and Intelligent Agents.” In Artificial General Intelligence: 4th International Conference, AGI 2011, edited by Jürgen Schmidhuber, Kristinn R. Thórisson, and Moshe Looks, 11–20. Springer, 2011.
“Rival.” New Yorker, December 6, 1958.
Rivest, Ronald L. “Learning Decision Lists.” Machine Learning 2, no. 3 (1987): 229–46.
Roder, Beverly J., Emily W. Bushnell, and Anne Marie Sasseville. “Infants’ Preferences for Familiarity and Novelty During the Course of Visual Processing.” Infancy 1, no. 4 (2000): 491–507.
Rohde, Douglas L. T., and David C. Plaut. “Language Acquisition in the Absence of Explicit Negative Evidence: How Important Is Starting Small?” Cognition 72, no. 1 (1999): 67–109.
Roland, Alex, and Philip Shiman. Strategic Computing: DARPA and the Quest for Machine Intelligence, 1983–1993. MIT Press, 2002.
Romanes, George John. Animal Intelligence. New York: D. Appleton, 1882.
Romo, Ranulfo, and Wolfram Schultz. “Dopamine Neurons of the Monkey Midbrain: Contingencies of Responses to Active Touch During Self-Initiated Arm Movements.” Journal of Neurophysiology 63, no. 3 (1990): 592–606.
Rong, Xin. “Word2vec Parameter Learning Explained.” arXiv Preprint arXiv:1411.2738, 2014.
Roodman, David. “Aftereffects: In the U.S., Evidence Says Doing More Time Typically Leads to More Crime After.” Open Philanthropy Blog, 2017. https://www.openphilanthropy.org/blog/aftereffects-us-evidence-says-doing-more-time-typically-leads-more-crime-after.
Rosenberg, Charles R., and Terrence J. Sejnowski. “NETtalk: A Parallel Network That Learns to Read Aloud.” Johns Hopkins University, 1986.
Rosenblatt, Frank. “The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain.” Psychological Review 65, no. 6 (1958): 386.
———. “Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms.” Buffalo, NY: Cornell Aeronautical Laboratory, March 15, 1961.
Rosenblueth, Arturo, Norbert Wiener, and Julian Bigelow. “Behavior, Purpose and Teleology.” Philosophy of Science 10, no. 1 (1943): 18–24.
Ross, Stéphane, and J. Andrew Bagnell. “Efficient Reductions for Imitation Learning.” In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics (AISTATS), 661–68. 2010.
Ross, Stéphane, Geoffrey J. Gordon, and J. Andrew Bagnell. “A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning.” In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, 627–35. 2011.
Roth, Lorna. “Looking at Shirley, the Ultimate Norm: Colour Balance, Image Technologies, and Cognitive Equity.” Canadian Journal of Communication 34, no. 1 (2009).
Rousseau, Jean-Jacques. Emile; or, On Education. Translated by Barbara Foxley. E. P. Dutton, 1921.
Rudd, Ethan M., Lalit P. Jain, Walter J. Scheirer, and Terrance E. Boult. “The Extreme Value Machine.” IEEE Transactions on Pattern Analysis and Machine Intelligence 40, no. 3 (2017): 762–68.
Ruder, Sebastian. “An Overview of Multi-Task Learning in Deep Neural Networks.” arXiv Preprint arXiv:1706.05098, 2017.
Rudin, Cynthia, and Joanna Radin. “Why Are We Using Black Box Models in AI When We Don’t Need To? A Lesson From An Explainable AI Competition.” Harvard Data Science Review, 2019.
Rudin, Cynthia, and Berk Ustun. “Optimized Scoring Systems: Toward Trust in Machine Learning for Healthcare and Criminal Justice.” Interfaces 48, no. 5 (2018): 449–66.
Rudin, Cynthia, Caroline Wang, and Beau Coker. “The Age of Secrecy and Unfairness in Recidivism Prediction.” Harvard Data Science Review 2, no. 1 (2020).
Rumelhart, D. E., G. E. Hinton, and R. J. Williams. “Learning Internal Representations by Error Propagation.” In Parallel Distributed Processing: Explorations in the Microstructure of Cognition, 1:318–62. MIT Press, 1986.
Rumelhart, David E., and James L. McClelland. Parallel Distributed Processing: Explorations in the Microstructure of Cognition. MIT Press, 1986.
Rummery, Gavin A., and Mahesan Niranjan. “On-Line Q-Learning Using Connectionist Systems.” Cambridge University Engineering Department, 1994.
Russakovsky, Olga, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, et al. “ImageNet Large Scale Visual Recognition Challenge.” International Journal of Computer Vision 115, no. 3 (2015): 211–52.
Russell, Bertrand. “Ideas That Have Harmed Mankind.” In Unpopular Essays. MPG Books, 1950.
———. Logic and Knowledge: Essays 1901–1950. George Allen & Unwin, 1956.
Russell, Stuart. Human Compatible. Viking, 2019.
———. “Learning Agents for Uncertain Environments (Extended Abstract).” In Proceedings of the Eleventh Annual ACM Workshop on Computational Learning Theory (COLT-98), 101–03. Madison, WI: ACM Press, 1998.
———. “Should We Fear Supersmart Robots?” Scientific American 314, no. 6 (2016): 58–59.
Russell, Stuart J., and Peter Norvig. Artificial Intelligence: A Modern Approach. 3rd ed. Upper Saddle River, NJ: Pearson, 2010.
Rust, John. “Do People Behave According to Bellman’s Principle of Optimality?” Working Papers in Economics. Hoover Institution, Stanford University, 1992.
———. “Structural Estimation of Markov Decision Processes.” Handbook of Econometrics 4 (1994): 3081– 3143.
Rutledge, Robb B., Nikolina Skandali, Peter Dayan, and Raymond J. Dolan. “A Computational and Neural Model of Momentary Subjective Well-Being.” Proceedings of the National Academy of Sciences 111, no. 33 (August 19, 2014): 12252–57.
Saayman, Graham, Elinor Wardwell Ames, and Adrienne Moffett. “Response to Novelty as an Indicator of Visual Discrimination in the Human Infant.” Journal of Experimental Child Psychology 1, no. 2 (1964): 189–98.
Sadigh, Dorsa, S. Shankar Sastry, Sanjit A. Seshia, and Anca D. Drăgan. “Planning for Autonomous Cars That Leverage Effects on Human Actions.” In Proceedings of Robotics: Science and Systems (RSS), 2016. https://doi.org/10.15607/RSS.2016.XII.029.
Sahami, Mehran, Marti Hearst, and Eric Saund. “Applying the Multiple Cause Mixture Model to Text Categorization.” In ICML-96: Proceedings of the Thirteenth International Conference on Machine Learning, 435–43. 1996.
Saksida, Lisa M., Scott M. Raymond, and David S. Touretzky. “Shaping Robot Behavior Using Principles from Instrumental Conditioning.” Robotics and Autonomous Systems 22, nos. 3–4 (1997): 231–49.
Salge, Christoph, Cornelius Glackin, and Daniel Polani. “Empowerment: An Introduction.” In Guided Self-Organization: Inception, 67–114. Springer, 2014.
Salimans, Tim, and Richard Chen. “Learning Montezuma’s Revenge from a Single Demonstration.” arXiv Preprint arXiv:1812.03381, 2018.
Samuel, Arthur L. “Some Studies in Machine Learning Using the Game of Checkers.” IBM Journal of Research and Development 3, no. 3 (1959): 210–29.
Samuelson, Paul A. “A Note on Measurement of Utility.” The Review of Economic Studies 4, no. 2 (1937): 155–61.
Sarbin, Theodore R. “A Contribution to the Study of Actuarial and Individual Methods of Prediction.” American Journal of Sociology 48, no. 5 (1943): 593–602.
Sargent, Thomas J. “Estimation of Dynamic Labor Demand Schedules Under Rational Expectations.” Journal of Political Economy 86, no. 6 (1978): 1009–44.
Saund, Eric. “A Multiple Cause Mixture Model for Unsupervised Learning.” Neural Computation 7, no. 1 (1995): 51–71.
Saunders, Jessica. “Pitfalls of Predictive Policing.” U.S. News & World Report, October 7, 2016.
Saunders, Jessica, Priscillia Hunt, and John S. Hollywood. “Predictions Put into Practice: A Quasi-Experimental Evaluation of Chicago’s Predictive Policing Pilot.” Journal of Experimental Criminology 12, no. 3 (2016): 347–71.
Saunders, William, Girish Sastry, Andreas Stuhlmueller, and Owain Evans. “Trial Without Error: Towards Safe Reinforcement Learning via Human Intervention.” In Proceedings of the 17th International Conference on Autonomous Agents and Multiagent Systems, 2067–99. International Foundation for Autonomous Agents and Multiagent Systems, 2018.
Savage, Tony. “Shaping: The Link Between Rats and Robots.” Connection Science 10, nos. 3–4 (1998): 321–40.
Sayre-McCord, Geoff. “Moral Realism.” The Stanford Encyclopedia of Philosophy, edited by Edward N. Zalta. Entry revised February 3, 2015: https://plato.stanford.edu/entries/moral-realism/.
Schaeffer, Jonathan, Joseph Culberson, Norman Treloar, Brent Knight, Paul Lu, and Duane Szafron. “A World Championship Caliber Checkers Program.” Artificial Intelligence 53, nos. 2–3 (1992): 273–89.
Schauer, Frederick. “Giving Reasons.” Stanford Law Review 47 (1995): 633–59.
Scheirer, Walter J., Anderson Rocha, Archana Sapkota, and Terrance E. Boult. “Toward Open Set Recognition.” IEEE Transactions on Pattern Analysis and Machine Intelligence 35, no. 7 (2013): 1757–72.
Schmidhuber, Jürgen. “Curious Model-Building Control Systems.” In Proceedings of the International Joint Conference on Neural Networks, 2:1458–63. Singapore: IEEE, 1991.
———. “Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990–2010).” IEEE Transactions on Autonomous Mental Development 2, no. 3 (September 2010): 230–47.
Schmidt, Ben. “Rejecting the Gender Binary: A Vector-Space Operation.” Ben’s Bookworm Blog, October 30, 2015. http://bookworm.benschmidt.org/posts/2015–10–30-rejecting-the-gender-binary.html.
Schrage, D. P., Y. K. Yillikci, S. Liu, J.V.R. Prasad, and S. V. Hanagud. “Instrumentation of the Yamaha R-50/RMAX Helicopter Testbeds for Airloads Identification and Follow-on Research.” In Twenty-Fifth European Rotorcraft Forum, P4-1–P4-13. 1999.
Schrittwieser, Julian, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, et al. “Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model.” arXiv Preprint arXiv:1911.08265, 2019.
Schultz, Wolfram. “Multiple Dopamine Functions at Different Time Courses.” Annual Review of Neuroscience 30 (2007): 259–88.
Schultz, Wolfram, Paul Apicella, and Tomas Ljungberg. “Responses of Monkey Dopamine Neurons to Reward and Conditioned Stimuli During Successive Steps of Learning a Delayed Response Task.” Journal of Neuroscience 13, no. 3 (March 1993): 900–13.
Schultz, Wolfram, Peter Dayan, and P. Read Montague. “A Neural Substrate of Prediction and Reward.” Science 275, no. 5306 (1997): 1593–99.
Schulz, Laura. “Infants Explore the Unexpected.” Science 348, no. 6230 (2015): 42–43.
Schulz, Laura E., and Elizabeth Baraff Bonawitz. “Serious Fun: Preschoolers Engage in More Exploratory Play When Evidence Is Confounded.” Developmental Psychology 43, no. 4 (2007): 1045–50.
Schwitzgebel, Eric, and Mara Garza. “A Defense of the Rights of Artificial Intelligences.” Midwest Studies in Philosophy 39, no. 1 (2015): 98–119.
Selbst, Andrew D., and Julia Powles. “Meaningful Information and the Right to Explanation.” International Data Privacy Law 7, no. 4 (2017): 233–42.
Selfridge, Oliver G., Richard S. Sutton, and Andrew G. Barto. “Training and Tracking in Robotics.” In Proceedings of the 9th International Joint Conference on Artificial Intelligence, 670–72. San Francisco: Morgan Kaufmann, 1985.
Selvaraju, Ramprasaath R., Abhishek Das, Ramakrishna Vedantam, Michael Cogswell, Devi Parikh, and Dhruv Batra. “Grad-Cam: Why Did You Say That?” arXiv Preprint arXiv:1611.07450, 2016.
Sen, Amartya. Collective Choice and Social Welfare. Harvard University Press, 2018.
Sepielli, Andrew. “What to Do When You Don’t Know What to Do When You Don’t Know What to Do . . .” Noûs 48, no. 3 (2014): 521–44.
Sepielli, Andrew Christopher. “‘Along an Imperfectly-Lighted Path’: Practical Rationality and Normative Uncertainty.” PhD thesis, Rutgers University, 2010.
Shafto, Patrick, Noah D. Goodman, and Thomas L. Griffiths. “A Rational Account of Pedagogical Reasoning: Teaching by, and Learning from, Examples.” Cognitive Psychology 71 (2014): 55–89.
Shannon, Claude E. “A Mathematical Theory of Communication.” Bell System Technical Journal 27, no. 3 (July 1948): 379–423.
Shaw, J. Cliff, Allen Newell, Herbert A. Simon, and T. O. Ellis. “A Command Structure for Complex Information Processing.” In Proceedings of the May 6–8, 1958, Western Joint Computer Conference: Contrasts in Computers, 119–28. Los Angeles, CA, 1958.
Shead, Sam. “DeepMind’s Human-Bashing AlphaGo AI Is Now Even Stronger.” Business Insider, October 18, 2017. https://www.businessinsider.com/deepminds-alphago-ai-gets-alphago-zero-upgrade-2017–10.
Shenoy, Premnath, and Anand Harugeri. “Elderly Patients’ Participation in Clinical Trials.” Perspectives in Clinical Research 6, no. 4 (2015): 184–89.
Shlegeris, Buck. “Why I’m Less of a Hedonic Utilitarian Than I Used to Be,” February 19, 2019. http://shlegeris.com/2019/02/21/hedonic.
Silver, David, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, et al. “Mastering the Game of Go with Deep Neural Networks and Tree Search.” Nature 529 (January 28, 2016): 484–89.
Silver, David, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, et al. “A General Reinforcement Learning Algorithm That Masters Chess, Shogi, and Go Through Self-Play.” Science 362, no. 6419 (2018): 1140–44.
Silver, David, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, et al. “Mastering the Game of Go Without Human Knowledge.” Nature 550, no. 7676 (2017): 354.
Silvia, Paul J. Exploring the Psychology of Interest. Oxford University Press, 2006.
Simoiu, Camelia, Sam Corbett-Davies, and Sharad Goel. “The Problem of Infra-Marginality in Outcome Tests for Discrimination.” Annals of Applied Statistics 11, no. 3 (2017): 1193–1216.
Simon, Herbert A. “The Cat That Curiosity Couldn’t Kill.” Carnegie Mellon Magazine 10, no. 1 (1991): 35–36.
Simonite, Tom. “When It Comes to Gorillas, Google Photos Remains Blind.” Wired, January 11, 2018. https://www.wired.com/story/when-it-comes-to-gorillas-google-photos-remains-blind/.
Simonyan, Karen, Andrea Vedaldi, and Andrew Zisserman. “Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps.” arXiv Preprint arXiv:1312.6034, 2013.
Simonyan, Karen, and Andrew Zisserman. “Very Deep Convolutional Networks for Large-Scale Image Recognition.” arXiv Preprint arXiv:1409.1556, 2014.
Singer, Peter. “The Drowning Child and the Expanding Circle.” New Internationalist 289 (1997).
———. “Famine, Affluence, and Morality.” Philosophy and Public Affairs 1, no. 1 (1972): 229–43.
———. The Most Good You Can Do: How Effective Altruism Is Changing Ideas About Living Ethically. Yale University Press, 2015.
Singh, Satinder Pal. “Transfer of Learning by Composing Solutions of Elemental Sequential Tasks.” Machine Learning 8, nos. 3–4 (1992): 323–39.
Singh, Satinder, Nuttapong Chentanez, and Andrew G. Barto. “Intrinsically Motivated Reinforcement Learning.” In Advances in Neural Information Processing Systems, 1281–88, 2005.
Singh, Satinder, Richard L. Lewis, and Andrew G. Barto. “Where Do Rewards Come From?” In Proceedings of the Annual Conference of the Cognitive Science Society, 2601–06. 2009.
Singh, Satinder, Richard L. Lewis, Jonathan Sorg, Andrew G. Barto, and Akram Helou. “On Separating Agent Designer Goals from Agent Goals: Breaking the Preferences–Parameters Confound.” CiteSeerX, 2010.
Skeem, Jennifer L., and Christopher T. Lowenkamp. “Risk, Race, and Recidivism: Predictive Bias and Disparate Impact.” Criminology 54, no. 4 (2016): 680–712.
Skinner, B. F. “Has Gertrude Stein a Secret?” Atlantic Monthly 153 (January 1934): 50–57.
———. “How to Teach Animals.” Scientific American 185, no. 6 (1951): 26–29.
———. A Matter of Consequences: Part Three of an Autobiography. Knopf, 1983.
———. “Pigeons in a Pelican.” American Psychologist 15, no. 1 (1960): 28.
———. “The Rate of Establishment of a Discrimination.” Journal of General Psychology 9, no. 2 (1933): 302–50.
———. “Reinforcement Today.” American Psychologist 13, no. 3 (1958): 94–99.
———. The Shaping of a Behaviorist: Part Two of an Autobiography. Knopf, 1979.
———. “Some Relations Between Behavior Modification and Basic Research.” In Behavior Modification: Issues and Extensions, edited by Sidney W. Bijou and Emilio Ribes-Inesta, 1–6. Academic Press, 1972.
———. Walden Two. Hackett Publishing, 1948.
Skinner, Burrhus Frederic. “A Case History in Scientific Method.” American Psychologist 11, no. 5 (1956): 221–33.
Smalheiser, Neil R. “Walter Pitts.” Perspectives in Biology and Medicine 43, no. 2 (2000): 217–26.
Smilkov, Daniel, Nikhil Thorat, Been Kim, Fernanda Viégas, and Martin Wattenberg. “Smoothgrad: Removing Noise by Adding Noise.” arXiv Preprint arXiv:1706.03825, 2017.
Smith, Holly M. “Possibilism.” In Encyclopedia of Ethics, 2nd ed., vol. 3, edited by Lawrence C. Becker and Charlotte B. Becker. Routledge, 2001.
Smith, Lewis, and Yarin Gal. “Understanding Measures of Uncertainty for Adversarial Example Detection.” In Uncertainty in Artificial Intelligence: Proceedings of the Thirty-Fourth Conference (2018).
Smith, Mitch. “In Wisconsin, a Backlash Against Using Data to Foretell Defendants’ Futures.” New York Times, June 22, 2016.
Snyder, Mark. Public Appearances, Private Realities: The Psychology of Self-Monitoring. W. H. Freeman, 1987.
Soares, Nate, Benja Fallenstein, Eliezer Yudkowsky, and Stuart Armstrong. “Corrigibility.” In Artificial Intelligence and Ethics: Papers from the 2015 AAAI Workshop. AAAI Press, 2015.
Sobel, Jordan Howard. “Utilitarianism and Past and Future Mistakes.” Noûs 10, no. 2 (1976): 195–219.
Solomons, Leon M., and Gertrude Stein. “Normal Motor Automatism.” Harvard Psychological Review 3, no. 5 (1896): 492–512.
Sommers, Christina Hoff. “Blind Spots in the ‘Blind Audition’ Study.” Wall Street Journal, October 20, 2019.
Sorg, Jonathan, Richard L. Lewis, and Satinder P. Singh. “Reward Design via Online Gradient Ascent.” In Advances in Neural Information Processing Systems, 2190–98, 2010.
Sorg, Jonathan, Satinder P. Singh, and Richard L. Lewis. “Internal Rewards Mitigate Agent Boundedness.” In Proceedings of the 27th International Conference on Machine Learning (ICML-10), 1007–14. Omnipress, 2010.
Sorg, Jonathan Daniel. “The Optimal Reward Problem: Designing Effective Reward for Bounded Agents.” PhD thesis, University of Michigan, 2011.
Spielvogel, Carl. “Advertising: Promoting a Negative Quality.” New York Times, September 4, 1957.
Spignesi, Stephen J. The Woody Allen Companion. Andrews McMeel, 1992.
Srivastava, Nitish, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. “Dropout: A Simple Way to Prevent Neural Networks from Overfitting.” Journal of Machine Learning Research 15, no. 1 (2014): 1929–58.
Stadie, Bradly C., Sergey Levine, and Pieter Abbeel. “Incentivizing Exploration in Reinforcement Learning with Deep Predictive Models.” In NIPS 2015 Workshop on Deep Reinforcement Learning, 2015.
Stahl, Aimee E., and Lisa Feigenson. “Observing the Unexpected Enhances Infants’ Learning and Exploration.” Science 348, no. 6230 (2015): 91–94.
Stanley-Jones, D., and K. Stanley-Jones. Kybernetics of Natural Systems: A Study in Patterns of Control. Pergamon, 1960.
Stauffer, John, Zoe Trodd, and Celeste-Marie Bernier. Picturing Frederick Douglass: An Illustrated Biography of the Nineteenth Century’s Most Photographed American. W. W. Norton, 2015.
Steel, Emily, and Julia Angwin. “On the Web’s Cutting Edge, Anonymity in Name Only.” Wall Street Journal, August 3, 2010.
Steel, Piers. “The Nature of Procrastination: A Meta-Analytic and Theoretical Review of Quintessential Self-Regulatory Failure.” Psychological Bulletin 133, no. 1 (2007): 65.
Stefik, Mark. “Strategic Computing at DARPA: Overview and Assessment.” Communications of the ACM 28, no. 7 (1985): 690–704.
Stein, Gertrude. The Autobiography of Alice B. Toklas. Harcourt, Brace, 1933.
Steinhardt, Jacob, and Percy S. Liang. “Unsupervised Risk Estimation Using Only Conditional Independence Structure.” In Advances in Neural Information Processing Systems, 3657–65, 2016.
Stemen, Don. “The Prison Paradox: More Incarceration Will Not Make Us Safer.” For the Record Evidence Brief Series, 2017.
Stock, Pierre, and Moustapha Cisse. “ConvNets and ImageNet Beyond Accuracy: Understanding Mistakes and Uncovering Biases.” In The European Conference on Computer Vision (ECCV), 2018.
Strabala, Kyle, Min Kyung Lee, Anca Drăgan, Jodi Forlizzi, Siddhartha S. Srinivasa, Maya Çakmak, and Vincenzo Micelli. “Toward Seamless Human-Robot Handovers.” Journal of Human-Robot Interaction 2, no. 1 (2013): 112–32.
“Strategic Computing: New-Generation Computing Technology: A Strategic Plan for Its Development and Application to Critical Problems in Defense.” Defense Advanced Research Projects Agency, 1983.
Strehl, Alexander L., and Michael L. Littman. “An Analysis of Model-Based Interval Estimation for Markov Decision Processes.” Journal of Computer and System Sciences 74, no. 8 (2008): 1309–31.
Struck, Aaron F., Berk Ustun, Andres Rodriguez Ruiz, Jong Woo Lee, Suzette M. LaRoche, Lawrence J. Hirsch, Emily J. Gilmore, Jan Vlachy, Hiba Arif Haider, Cynthia Rudin, and M. Brandon Westover. “Association of an Electroencephalography-Based Risk Score With Seizure Probability in Hospitalized Patients.” JAMA Neurology 74, no. 12 (2017): 1419–24.
Subramanian, Kaushik, Charles L. Isbell Jr., and Andrea L. Thomaz. “Exploration from Demonstration for Interactive Reinforcement Learning.” In Proceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems, 447–56. International Foundation for Autonomous Agents and Multiagent Systems, 2016.
Sundararajan, Mukund, Ankur Taly, and Qiqi Yan. “Axiomatic Attribution for Deep Networks.” In Proceedings of the 34th International Conference on Machine Learning, 3319–28. JMLR, 2017.
Sunstein, Cass R. “Beyond the Precautionary Principle.” University of Pennsylvania Law Review 151 (2003): 1003–58.
———. “Irreparability as Irreversibility.” Supreme Court Review, 2019.
———. “Irreversibility.” Law, Probability & Risk 9 (2010): 227–45.
———. Laws of Fear: Beyond the Precautionary Principle. Cambridge University Press, 2005.
Sutton, Richard S. “Integrated Architectures for Learning, Planning, and Reacting Based on Approximating Dynamic Programming.” In Machine Learning: Proceedings of the Seventh International Conference, 216–24. San Mateo, CA: Morgan Kaufmann, 1990.
———. “Learning to Predict by the Methods of Temporal Differences.” Machine Learning 3, no. 1 (1988): 9–44.
———. “Reinforcement Learning Architectures for Animats.” In From Animals to Animats: Proceedings of the First International Conference on Simulation of Adaptive Behavior, 288–96. 1991.
———. “Temporal Credit Assignment in Reinforcement Learning.” PhD thesis, University of Massachusetts, Amherst, 1984.
———. “A Unified Theory of Expectation in Classical and Instrumental Conditioning.” Bachelor’s thesis, Stanford University, 1978.
Sutton, Richard S., and Andrew G. Barto. Reinforcement Learning: An Introduction. 2nd ed. MIT Press, 2018.
Sweeney, Latanya. “Discrimination in Online Ad Delivery.” Communications of the ACM 56, no. 5 (2013): 44–54.
———. “Simple Demographics Often Identify People Uniquely.” Carnegie Mellon University, Data Privacy Working Paper 3 (Pittsburgh), 2000.
Szegedy, Christian, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. “Intriguing Properties of Neural Networks.” In International Conference on Learning Representations, 2014.
Takayama, Leila, Doug Dooley, and Wendy Ju. “Expressing Thought: Improving Robot Readability with Animation Principles.” In 2011 6th ACM/IEEE International Conference on Human-Robot Interaction (HRI), 69–76. IEEE, 2011.
Tang, Haoran, Rein Houthooft, Davis Foote, Adam Stooke, Xi Chen, Yan Duan, John Schulman, Filip De Turck, and Pieter Abbeel. “# Exploration: A Study of Count-Based Exploration for Deep Reinforcement Learning.” In Advances in Neural Information Processing Systems, 2753–62. 2017.
Tarleton, Nick. “Coherent Extrapolated Volition: A Meta-Level Approach to Machine Ethics.” Singularity Institute, 2010.
Taylor, Jessica. “Quantilizers: A Safer Alternative to Maximizers for Limited Optimization.” In Workshops at the Thirtieth AAAI Conference on Artificial Intelligence, 2016.
Taylor, Jessica, Eliezer Yudkowsky, Patrick LaVictoire, and Andrew Critch. “Alignment for Advanced Machine Learning Systems.” Machine Intelligence Research Institute, July 27, 2016.
Tesauro, Gerald. “Practical Issues in Temporal Difference Learning.” In Advances in Neural Information Processing Systems, 259–66, 1992.
———. “TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play.” Neural Computation 6, no. 2 (1994): 215–19. https://doi.org/10.1162/neco.1994.6.2.215.
———. “Temporal Difference Learning and TD-Gammon.” Communications of the ACM 38, no. 3 (March 1995): 58–68. https://doi.org/10.1145/203330.203343.
Thorndike, Edward L. “Animal Intelligence: An Experimental Study of the Associative Processes in Animals.” Psychological Review: Monograph Supplements 2, no. 4 (1898): i.
———. The Elements of Psychology. New York: A. G. Seiler, 1905.
———. “Fundamental Theorems in Judging Men.” Journal of Applied Psychology 2 (1918): 67–76.
———. The Psychology of Learning. Vol. 2. Teachers College, Columbia University, 1913.
———. “A Theory of the Action of the After-Effects of a Connection upon It.” Psychological Review 40, no. 5 (1933): 434–39.
Tibshirani, Robert. “Regression Shrinkage and Selection via the Lasso.” Journal of the Royal Statistical Society, Series B (Methodological) 58, no. 1 (1996): 267–88.
Tigas, Panagiotis, Angelos Filos, Rowan McAllister, Nicholas Rhinehart, Sergey Levine, and Yarin Gal. “Robust Imitative Planning: Planning from Demonstrations Under Uncertainty.” In NeurIPS 2019 Workshop on Machine Learning for Autonomous Driving. 2019.
Timmerman, Travis. “Effective Altruism’s Underspecification Problem.” In Effective Altruism: Philosophical Issues, edited by Hilary Greaves and Theron Pummer. Oxford University Press, 2019.
Timmerman, Travis, and Yishai Cohen. “Actualism and Possibilism in Ethics.” In The Stanford Encyclopedia of Philosophy, edited by Edward N. Zalta, Summer 2019. https://plato.stanford.edu/archives/sum2019/entries/actualism-possibilism-ethics/.
Todorov, Emanuel, Tom Erez, and Yuval Tassa. “MuJoCo: A Physics Engine for Model-Based Control.” In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, 5026–33. IEEE, 2012.
Tolman, Edward Chace. “The Determiners of Behavior at a Choice Point.” Psychological Review 45, no. 1 (1938): 1.
Tomasello, Michael. “Do Apes Ape?” In Social Learning in Animals: The Roots of Culture, edited by Cecilia M. Heyes and Bennett G. Galef Jr., 319–46. San Diego: Academic Press, 1996.
Tomasello, Michael, Malinda Carpenter, Josep Call, Tanya Behne, and Henrike Moll. “Understanding and Sharing Intentions: The Origins of Cultural Cognition.” Behavioral and Brain Sciences 28, no. 5 (2005): 675–91.
Tomasello, Michael, Brian Hare, Hagen Lehmann, and Josep Call. “Reliance on Head Versus Eyes in the Gaze Following of Great Apes and Human Infants: The Cooperative Eye Hypothesis.” Journal of Human Evolution 52, no. 3 (2007): 314–20.
Tomasik, Brian. “Do Artificial Reinforcement-Learning Agents Matter Morally?” arXiv Preprint arXiv:1410.8233, 2014.
Turing, A. M. “Computing Machinery and Intelligence.” Mind 59, no. 236 (1950): 433–60.
———. “Intelligent Machinery.” In The Essential Turing, edited by B. Jack Copeland, 410–32. 1948. Reprint, Oxford University Press, 2004.
Turing, Alan. “Can Digital Computers Think?” BBC Third Programme, May 15, 1951.
Turing, Alan, Richard Braithwaite, Geoffrey Jefferson, and Max Newman. “Can Automatic Calculating Machines Be Said to Think?” BBC Third Programme, January 14, 1952.
Turner, Alexander Matt. “Optimal Farsighted Agents Tend to Seek Power.” arXiv preprint, arXiv:1912.01683, 2019.
Turner, Alexander Matt, Dylan Hadfield-Menell, and Prasad Tadepalli. “Conservative Agency via Attainable Utility Preservation.” In AAAI/ACM Conference on AI, Ethics, and Society. 2020.
Tversky, Amos. “Features of Similarity.” Psychological Review 84, no. 4 (1977): 327–52.
Uno, Yoji, Mitsuo Kawato, and Rika Suzuki. “Formation and Control of Optimal Trajectory in Human Multijoint Arm Movement: Minimum Torque-Change Model.” Biological Cybernetics 61 (1989): 89–101.
Ustun, Berk, and Cynthia Rudin. “Optimized Risk Scores.” In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1125–34. ACM, 2017.
———. “Supersparse Linear Integer Models for Optimized Medical Scoring Systems.” Machine Learning 102, no. 3 (2016): 349–91.
Ustun, Berk, Stefano Tracà, and Cynthia Rudin. “Supersparse Linear Integer Models for Predictive Scoring Systems.” In Proceedings of AAAI Late Breaking Track, 2013.
Ustun, Berk, M. Brandon Westover, Cynthia Rudin, and Matt T. Bianchi. “Clinical Prediction Models for Sleep Apnea: The Importance of Medical History over Symptoms.” Journal of Clinical Sleep Medicine 12, no. 2 (2016): 161–68.
Varon, Elizabeth R. “Most Photographed Man of His Era: Frederick Douglass.” Washington Post, January 29, 2016. https://www.washingtonpost.com/opinions/most-photographed-man-of-his-era-frederick-douglass/2016/01/29/4879a766-af1c-11e5-b820-eea4d64be2a1\_story.html.
Veasey, Sigrid C., and Ilene M. Rosen. “Obstructive Sleep Apnea in Adults.” New England Journal of Medicine 380, no. 15 (2019): 1442–49.
Večerík, Matej, Todd Hester, Jonathan Scholz, Fumin Wang, Olivier Pietquin, Bilal Piot, Nicolas Heess, Thomas Rothörl, Thomas Lampe, and Martin Riedmiller. “Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards.” arXiv Preprint arXiv:1707.08817, 2017.
Vincent, James. “Google ‘Fixed’ Its Racist Algorithm by Removing Gorillas from Its Image-Labeling Tech.” Verge, January 11, 2018. https://www.theverge.com/2018/1/12/16882408/google-racist-gorillas-photo-recognition-algorithm-ai.
Visalberghi, Elisabetta, and Dorothy Fragaszy. “‘Do Monkeys Ape?’ Ten Years After.” In Imitation in Animals and Artifacts, 471–99. MIT Press, 2002.
Visalberghi, Elisabetta, and Dorothy Munkenbeck Fragaszy. “Do Monkeys Ape?” In “Language” and Intelligence in Monkeys and Apes: Comparative Developmental Perspectives, edited by Sue Taylor Parker and Kathleen Rita Gibson, 247–73. Cambridge University Press, 1990.
Visser, Margaret. Much Depends on Dinner: The Extraordinary History and Mythology, Allure and Obsessions, Perils and Taboos of an Ordinary Meal. Grove Press, 1986.
Vitale, Cristiana, Massimo Fini, Ilaria Spoletini, Mitja Lainscak, Petar Seferovic, and Giuseppe M. C. Rosano. “Under-Representation of Elderly and Women in Clinical Trials.” International Journal of Cardiology 232 (2017): 216–21.
von Neumann, John. First Draft of a Report on the EDVAC. Moore School of Electrical Engineering, University of Pennsylvania, June 30, 1945.
von Neumann, John, and Oskar Morgenstern. Theory of Games and Economic Behavior. 3rd ed. Princeton University Press, 1953.
Wachter, Sandra, Brent Mittelstadt, and Luciano Floridi. “Why a Right to Explanation of Automated Decision-Making Does Not Exist in the General Data Protection Regulation.” International Data Privacy Law 7, no. 2 (2017): 76–99.
Wainer, Howard. “Estimating Coefficients in Linear Models: It Don’t Make No Nevermind.” Psychological Bulletin 83, no. 2 (1976): 213–17.
Warneken, Felix, and Michael Tomasello. “Altruistic Helping in Human Infants and Young Chimpanzees.” Science 311, no. 5765 (2006): 1301–03.
———. “Helping and Cooperation at 14 Months of Age.” Infancy 11, no. 3 (2007): 271–94.
Watkins, Christopher J.C.H., and Peter Dayan. “Q-Learning.” Machine Learning 8, nos. 3–4 (1992): 279–92.
Watkins, Christopher John Cornish Hellaby. “Learning from Delayed Rewards.” PhD thesis, King’s College, Cambridge, 1989.
Weber, Bruce. “What Deep Blue Learned in Chess School.” New York Times, May 18, 1997.
Weld, Daniel S., and Oren Etzioni. “The First Law of Robotics (a Call to Arms).” In Proceedings of the Twelfth National Conference on Artificial Intelligence (AAAI-1994), 1042–47. Seattle, 1994.
Whitehead, Alfred North, and Bertrand Russell. Principia Mathematica. 2nd ed. 3 vols. Cambridge University Press, 1927.
Whiten, Andrew, Nicola McGuigan, Sarah Marshall-Pescini, and Lydia M. Hopper. “Emulation, Imitation, Over-Imitation and the Scope of Culture for Child and Chimpanzee.” Philosophical Transactions of the Royal Society B: Biological Sciences 364, no. 1528 (2009): 2417–28.
Whiteson, Shimon, Brian Tanner, and Adam White. “The Reinforcement Learning Competitions.” AI Magazine 31, no. 2 (2010): 81–94.
Widrow, Bernard, Narendra K. Gupta, and Sidhartha Maitra. “Punish/Reward: Learning with a Critic in Adaptive Threshold Systems.” IEEE Transactions on Systems, Man, and Cybernetics 5 (1973): 455–65.
Wiener, Norbert. Cybernetics; or, Control and Communication in the Animal and the Machine. 2nd ed. MIT Press, 1961.
———. God and Golem, Inc: A Comment on Certain Points Where Cybernetics Impinges on Religion. MIT Press, 1964.
———. “Some Moral and Technical Consequences of Automation.” Science 131, no. 3410 (1960): 1355–58.
Wiewiora, Eric. “Potential-Based Shaping and Q-Value Initialization Are Equivalent.” Journal of Artificial Intelligence Research 19 (2003): 205–08.
Wilson, Aaron, Alan Fern, and Prasad Tadepalli. “A Bayesian Approach for Policy Learning from Trajectory Preference Queries.” In Advances in Neural Information Processing Systems 25, 1133–41. 2012.
Wirth, Christian, Riad Akrour, Gerhard Neumann, and Johannes Fürnkranz. “A Survey of Preference-Based Reinforcement Learning Methods.” Journal of Machine Learning Research 18, no. 1 (2017): 4945–90.
Wise, Roy. “Reinforcement.” Scholarpedia 4, no. 8 (2009): 2450. http://www.scholarpedia.org/article/Reinforcement.
Wise, Roy A. “Dopamine and Reward: The Anhedonia Hypothesis 30 Years On.” Neurotoxicity Research 14, nos. 2–3 (2008): 169–83.
———. “Neuroleptics and Operant Behavior: The Anhedonia Hypothesis.” Behavioral and Brain Sciences 5, no. 1 (1982): 39–53.
Wise, Roy A., Joan Spindler, Harriet DeWit, and Gary J. Gerberg. “Neuroleptic-Induced ‘Anhedonia’ in Rats: Pimozide Blocks Reward Quality of Food.” Science 201, no. 4352 (1978): 262–64.
Wittmann, Bianca C., Nathaniel D. Daw, Ben Seymour, and Raymond J. Dolan. “Striatal Activity Underlies Novelty-Based Choice in Humans.” Neuron 58, no. 6 (2008): 967–73.
Wolf, Susan. “Moral Saints.” The Journal of Philosophy 79, no. 8 (1982): 419–39.
Wood, Tom. “Google Images ‘Racist Algorithm’ Has a Fix but It’s Not a Great One.” LADbible, January 12, 2018. http://www.ladbible.com/technology/news-google-images-racist-algorithm-has-a-fix-but-its-not-a-great-one-20180112.
Wright, Thomas A., John Hollwitz, Richard W. Stackman, Arthur S. De Groat, Sally A. Baack, and Jeffrey P. Shay. “40 Years (and Counting): Steve Kerr Reflections on the ‘Folly.’” Journal of Management Inquiry 27, no. 3 (2017): 309–15.
Wulfmeier, Markus, Peter Ondrúška, and Ingmar Posner. “Maximum Entropy Deep Inverse Reinforcement Learning.” arXiv Preprint arXiv:1507.04888, 2015.
Wulfmeier, Markus, Dominic Zeng Wang, and Ingmar Posner. “Watch This: Scalable Cost-Function Learning for Path Planning in Urban Environments.” In 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2089–95. IEEE, 2016.
Xie, Chiang, Yuxin Wu, Laurens van der Maaten, Alan L. Yuille, and Kaiming He. “Feature Denoising for Improving Adversarial Robustness.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 501–09. 2019.
Yao, Yuan, Lorenzo Rosasco, and Andrea Caponnetto. “On Early Stopping in Gradient Descent Learning.” Constructive Approximation 26, no. 2 (2007): 289–315.
Yu, Yang, Wei-Yang Qu, Nan Li, and Zimin Guo. “Open-Category Classification by Adversarial Sample Generation.” In International Joint Conference on Artificial Intelligence. 2017.
Yudkowsky, Eliezer. “Coherent Extrapolated Volition.” Singularity Institute, 2004.
Zaki, W. Mimi Diyana W., M. Asyraf Zulkifley, Aini Hussain, W. Haslina W. A. Halim, N. Badariah A. Mustafa, and Lim Sin Ting. “Diabetic Retinopathy Assessment: Towards an Automated System.” Biomedical Signal Processing and Control 24 (2016): 72–82.
Zeiler, Matthew D., and Rob Fergus. “Visualizing and Understanding Convolutional Networks.” In European Conference on Computer Vision, 818–33. Springer, 2014.
Zeiler, Matthew D., Dilip Krishnan, Graham W. Taylor, and Rob Fergus. “Deconvolutional Networks.” In 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), 2528–35. IEEE, 2010.
Zeiler, Matthew D., Graham W. Taylor, and Rob Fergus. “Adaptive Deconvolutional Networks for Mid and High Level Feature Learning.” In 2011 International Conference on Computer Vision, 2018–25. IEEE, 2011.
Zeng, Jiaming, Berk Ustun, and Cynthia Rudin. “Interpretable Classification Models for Recidivism Prediction.” Journal of the Royal Statistical Society: Series A (Statistics in Society) 180, no. 3 (2017): 689–722.
Zhang, Shun, Edmund H. Durfee, and Satinder P. Singh. “Minimax-Regret Querying on Side Effects for Safe Optimality in Factored Markov Decision Processes.” In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, 4867–73, IJCAI, 2018.
Zheng, Zeyu, Junhyuk Oh, and Satinder Singh. “On Learning Intrinsic Rewards for Policy Gradient Methods.” In Advances in Neural Information Processing Systems, 4644–54. 2018.
Zhong, Chen-Bo, Vanessa K. Bohns, and Francesca Gino. “Good Lamps Are the Best Police: Darkness Increases Dishonesty and Self-Interested Behavior.” Psychological Science 21, no. 3 (2010): 311–14.
Zhu, Lingxue, and Nikolay Laptev. “Engineering Uncertainty Estimation in Neural Networks for Time Series Prediction at Uber.” Uber Engineering (blog), 2017. https://eng.uber.com/neural-networks-uncertainty-estimation/.
Ziebart, Brian D., J. Andrew Bagnell, and Anind K. Dey. “Modeling Interaction via the Principle of Maximum Causal Entropy.” In Proceedings of the 27th International Conference on Machine Learning, 1255–62. 2010.
Ziebart, Brian D., Andrew L. Maas, J. Andrew Bagnell, and Anind K. Dey. “Maximum Entropy Inverse Reinforcement Learning.” In Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence, 1433–38. AAAI Press, 2008.
Ziegler, Daniel M., Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. “Fine-Tuning Language Models from Human Preferences.” arXiv Preprint arXiv:1909.08593, 2019.
INDEX
Page numbers listed correspond to the print edition of this book. You can use your device’s search function to locate particular terms in the text.
0–1 loss function, 354n47
3CosAdd algorithm, 316, 397n13
Abbeel, Pieter, 257, 258–59, 267–68, 297
Ackley, Dave, 171–72
actor-critic architecture, 138
actualism vs. possibilism, 234–40
effective altruism and, 237–38
imitation and, 235, 239–40, 379n71
Professor Procrastinate problem, 236–37, 379n61
actuarial models, 92–93
addiction, 135, 153, 205–08, 374n65
See also drug use
AdSense, 343n72
adversarial examples, 279–80, 387n8
affine transformations, 383n16
African Americans. See racial bias
Against Prediction (Harcourt), 78–79
age bias, 32, 396n7
AGI. See artificial general intelligence
Agüera y Arcas, Blaise, 247
AI Now Institute, 396n9
AI safety
artificial general intelligence delay risks and, 310
corrigibility, 295–302, 392–93n51
field growth, 12, 249–50, 263
gridworlds for, 292–93, 294, 295, 390n29
human-machine cooperation and, 268–69
irreversibility and, 291, 293
progress in, 313–14
reward optimization and, 368n56
uncertainty and, 291–92
See also value alignment
AIXI, 206–07, 263
Alciné, Jacky, 25, 29, 50
ALE. See Arcade Learning Environment
Alexander, Robert McNeill, 382n13
Alexnder VIII (Pope), 303
AlexNet
brittleness of, 279
complexity of, 100
development of, 21, 23–25
dropout and, 24, 285, 389n21
ensembles and, 285
feature visualization and, 108, 109–10
ground truth gaps and, 75
algorithms, for risk assessment, 7–9, 12, 337n6, 346n13
alignment problem
amplification/distillation and, 249
analogies and, 317
corrigibility and, 295
defined, 13
as hopeful, 327–28
inverse reinforcement learning and, 255
parenting and, 166
reinforcement learning and, 151
technical limitations and, 313, 395–96n4
thermostats and, 311–12, 313
See also value alignment
Allen, Woody, 170
AlphaGo, 162–63, 243–44, 380nn84–85
AlphaGoZero, 162–63, 244–45, 356n59, 380n86
AlphaZero, 141, 162–63, 205, 248, 380n86
Alstrøm, Preben, 167, 177
ALVINN, 225–26, 228, 229–30, 378n47
Amazon
hiring by, 40, 48, 343nn76–77
Mechanical Turk, 22, 43, 75, 179, 369n73
Ambrosino, Richard, 83, 84
Amodei, Dario, 9–11, 263–64
Ampère, André-Marie, 359n19
amplification, 244–46, 381n90
analogies, 38, 41–42, 316–17, 342n66, 397n13
Andre, David, 167, 177
Angwin, Julia, 7–8, 58–61, 62–63, 72, 79
Animal Behavior Enterprises, 154, 161, 364n8
animal research, 121–24, 134, 135, 150, 152–54
animal training, 152, 154, 161, 187–88, 364n8, 365n26
antidiscrimination law, 63–64
Ape and the Child, The (Kellogg and Kellogg), 214–15
Apple, differential privacy, 347n33
Arcade Learning Environment (ALE), 181–83, 209, 369n4
architecture, 18
Arendt, Hannah, 121, 326
Armstrong, Stuart, 291–92, 299
artificial general intelligence (AGI), 208–10
boat race scenario and, 9–11
boredom and, 205
delay risks, 309–10
risks of, 13
as source of knowledge, 328
artistic creation, 110–11
Askell, Amanda, 239
Aspire Mirror, 30
AssistWare, 377n39
“Astronomical Waste” (Bostrom), 309
AT&T Bell Laboratories, 234
Atari. See Arcade Learning Environment; gaming
attainable utility preservation (AUP), 294–95, 392n48
augmented reality, 30
AUP. See attainable utility preservation
Australian National University, 262–63
autonomous driving, 223–25, 377nn39, 42
architecture for, 228, 378n47
backpropagation for, 377–78n43
danger of, 326–27
imitation and, 225–27, 322
recovery and, 229–30, 232–34, 378n54
Aytar, Yusuf, 221
backflips, 265–66
backgammon, 141, 142
backpropagation, 234, 338–39n12, 361n30, 377–78n43
backward learning, 162, 365n27, 369n9
Bagnell, Drew, 230–31
Bain, Alexander, 156, 227–28, 358n8
Balentine, Bruce, 240
Barocas, Solon, 65–66
Barto, Andrew, 129
on actualism vs. possibilism, 238–39
on evolution, 173
on happiness, 150
on intrinsic motivation, 202, 370n12
on organisms as maximizers, 130
on policy vs. value functions, 137–38
research focus of, 138, 362n51
on shaping, 161
on TD learning, 142
on terseness, 132
Bayesian neural networks, 283–86
Bayesian Rule Lists, 100–01
“Behavior, Purpose and Teleology” (Rosenblueth, Wiener, and Bigelow), 127–28
Bellcore, 170–73
Bellemare, Marc, 181–83, 192–94, 200, 209
Bengio, Samy, 337n9
Bentham, Jeremy, 152, 275–76
Berk, Richard, 82
Berlyne, Daniel, 187, 188–89, 190, 194, 197, 198
Berridge, Kent, 147
BERT model, 344–45n94
Bertrand, Marianne, 39
bias
age, 32, 396n7
Fitzpatrick scale and, 341n48
in Google AdSense, 343n72
in hiring, 39–40, 48
in human judgments, 39, 68
image recognition and, 25–26, 339n24
implicit association test for, 44–45
in medical research, 314, 396n7
in orchestra auditions, 40, 343n73
perpetuation of, 39–40, 43, 49
photography and, 26–29
phrase sources and, 344n83
reality of, 48
redundant encodings and, 40, 64, 343n74
removing from word embedding, 41–44, 344n86, 345n94
in risk-assessment models, 7–9, 57–61, 67, 68, 70, 346–47nn25, 32, 348n52
as source of knowledge, 328
TCAV and, 116
training data and, 26, 29–34, 314–15, 340n44, 341n48, 396n7
transfer learning and, 318
value alignment and, 43
veridical, 45–46
in word embedding, 6–7, 9, 38, 39, 40, 342–43n68, 344–45n94
word embedding as diagnostic tool for, 46–48, 49
See also fairness; representation
big data, 99–100
binary system, 336n9
biomechanics, 253–54, 382n13
black boxes. See transparency
boat race scenario, 9–11, 302
Bobby Fischer Teaches Chess (Fischer), 162
BOGSAT method, 101
Boltzmann (ir)rationality, 323, 398n29
Bolukbasi, Tolga, 6–7, 9, 38, 41, 42, 43, 44, 316
Bonawitz, Elizabeth, 196
bootstrapping, 285
Borden, Brisha, 8
boredom, 188, 201, 202, 203–05, 373n62
Boston University, 6
Bostrom, Nick, 223, 246, 262, 309–10, 313
Bowling, Michael, 181
Box, George, 314
“Brain Function and Adaptive Systems: A Heterostatic Theory” (Klopf), 127
Braithwaite, Richard, 329
Breland, Keller, 154, 161, 364n8
Breland, Marian, 154, 161, 364n8
Brennan, Tim, 55–56, 60–61, 72, 73, 78, 80, 346n13
Brilliant, Ashleigh, 185
brittleness, 279–81, 387n8, 389n21
Brooks, Rodney, 326
Broome, John, 304, 305
Brown University, 158, 170
Bruce, Andrew, 52
Bryson, Joanna, 45, 397n19
Buolamwini, Joy, 30, 32–33, 342–43n68
Burda, Yuri, 199–200, 201, 206
Burgess, Ernest, 52–54, 55, 75, 76, 81
Bush, George W., 31
butterfly effects, 291–92
Bykvist, Krister, 305
C4.5, 99–100
Caldwell, Tommy, 220–21
calibration, 28–29, 61, 68, 70, 71–72
Caliskan, Aylin, 45
Cambridge Analytica, 67
Cambridge University, 140–41, 144
Caplan, Arthur, 290
Carlsen, Magnus, 240
Carnap, Rudolf, 2
Carnegie Mellon
autonomous driving, 224–26, 228, 230–32, 377n39
inverse reinforcement learning, 260–61
medical predictive models, 82–83
risk-assessment models, 67
robotics, 223
uncertainty, 391n39
Carse, James, 372n49
CART, 99–100
Caruana, Rich, 82, 83, 84–85, 86–87, 106–07, 352nn10–12
cascading errors, 229–34, 322
Case Western University, 189–90, 370n26
Catholicism, 302–03, 304
causation, 352n8
CBOW (continuous bag-of-words), 341n54
Centre for Effective Altruism, 237–38, 309
CHA2DS₂-VASc, 100–01
CHADS₂, 100–01
Chang, Ruth, 131, 360–61n28
checkers, 126–27, 240–41, 242–43
check processing, 21–22
Chen, Richard, 369n9
Chentanez, Nuttapong, 370n12
chess
actualism vs. possibilism and, 235
boredom and, 204–05
credit-assignment problem and, 133
Deep Blue, 205, 241–42
imitation and, 242–43
incentives and, 366–67n44
policy vs. value functions and, 137–38, 139
shaping and, 157, 162
value-based approaches and, 241–42
child development
helping behavior in, 251–52, 382nn2–3
human-machine cooperation and, 269
imitation in, 214–16, 375nn7–8, 14, 17, 376n23
intrinsic motivation and, 189–90, 195–97, 198
Chouldechova, Alexandra, 67–68, 69, 74, 77, 80
Christiano, Paul
on amplification, 248–49
on artificial general intelligence delay risks, 310
on corrigibility, 392–93n51
on feedback learning, 386n48
on human-machine cooperation, 273
on inverse reinforcement learning, 263–66, 384–85n37
Chrome, 347n33
CIFAR-10, 23
Ćirković, Milan, 262
CIRL. See cooperative inverse reinforcement learning
Cisse, Moustapha, 116
Clabaugh, Hinton, 51–52, 54
Clarifai, 110, 357n66
Clinical Versus Statistical Prediction (Meehl), 93
Coates, Adam, 258–59
cocaine, 146–47
cognitive science, 269, 385n43–44, 386–87n55
Cohen, Andre, 369n4
COMPAS
defenses of, 68, 72–73
development of, 56–57, 346nn13–14
distributional shift and, 78, 318, 350n81
lack of auditing for, 7, 337n6
ProPublica report, 7–9, 58–61, 67, 68, 347n32, 348n52
risk types and, 77
computational linguistics. See word embedding
Conditioned Reflexes (Pavlov), 124
confidence intervals, 371n30
Conflict, Arousal, and Curiosity (Berlyne), 188
consensus, 315, 396n9
conservative fields, 169, 170, 367n49
context, shifts in. See distributional shift
continuous bag-of-words (CBOW), 341n54
Cook, Tim, 228
cooperation. See human-machine cooperation
cooperative eye hypothesis, 103
cooperative inverse reinforcement learning (CIRL), 267–68, 385nn40, 43–44
Corbett-Davies, Sam, 68, 69–70, 71–72
Cornell University, 30, 67
Corrigan, Bernard, 95, 97
corrigibility, 295–302, 393n55
Cortes, Corinna, 390n29
count-based approaches, 192, 200
Crawford, Kate, 396n9
credit-assignment problem, 132–33, 139, 361n30
criminal justice system
Burgess parole study, 51–54
Goel’s research on, 68, 348n47
predictive parole systems, 54–55
redundant encodings in, 64
reforms of, 74, 349n68
See also risk-assessment models
Cromwell, Oliver, 277
cross-entropy loss, 315–16
cross-training, 272–73
CUDA (Compute Unified Device Architecture), 339n20
curiosity, 186–89
See also intrinsic motivation
curriculum, 158–63, 365nn26–27
design automation for, 162–63, 366n30
for self-training, 178–79
curse of dimensionality, 35
Curtis, Don, 312, 313
cybernetics, 128–29, 359n19
cyclical behavior problem, 167–70, 177, 185–86, 366–67nn44, 47, 49
DAgger (dataset aggregation), 232, 322
DARPA (Defense Advanced Research Projects Agency), 87–89
Strategic Computing Initiative, 223–27
Darwin United, 167
data augmentation, 23
data compression, 197–98
Dawes, Robyn, 90–92, 93, 94–97, 98–99
Dayan, Peter, 142–43, 144, 147
Deasey, Daniel, 304
Dechant, Kathy, 366n34
decision-tree models, 56
deconvolution, 109–10
Deep Blue, 205, 241–42, 243, 380n84
DeepDream, 110, 112, 116
deep learning. See deep neural networks
DeepMind
automated curriculum design, 162–63
DQN models, 184
feature construction, 183
human-machine cooperation, 270–71
imitation, 221, 243–46
impact, 292–93, 294, 392n44
intrinsic motivation, 192–94, 200–01, 206–7
inverse reinforcement learning, 263, 264–66
irreversibility, 320
multitask learning models, 356n59
word embedding, 344n86
deep neural networks
adversarial examples and, 279–80, 387n8
AlexNet, 21, 23–25, 75, 100, 339n20
autonomous driving and, 226–27, 230, 233–34
backpropagation for, 338–39n12
DQN models, 184–86, 192–94, 205
dropout for, 24, 285–88, 389nn21, 23
early commercial uses, 21–22
feature construction and, 183
imitation and, 225–27, 230, 243
intrinsic motivation and, 189, 208
recovery and, 230
stochastic gradient descent for, 338–39n12
transparency and, 89–90, 102–03
uncertainty and, 279–83, 387n8
for word embedding, 35–37, 342n61
See also uncertainty
“Deep Neural Networks Are Easily Fooled” (Nguyen, Yosinski, and Clune), 279
Defense Advanced Research Projects Agency. See DARPA
demand prediction, 389n23
demonstration learning, 256–61, 271, 323–24, 383nn22–23, 398n30
Demski, Abram, 321–22
Deng, Jia, 24
density models, 192–94
depression, 176
dermatology, 104–5, 355–56n55
Dietterich, Thomas, 279–81
differential privacy, 61–62, 347n33
distillation, 248–49
distributed representations, 35
distributional shift
defined, 340n36
image-recognition systems and, 115–16, 398n36
improper linear models and, 96
risk-assessment models and, 78, 318, 350n81
training data changes and, 325, 398n36
See also transfer learning
Diuk, Carlos, 369n4
“Do Monkeys Ape?” (Visalberghi and Fragaszy), 214
Doom, 199
dopamine
aversive stimuli and, 363n84
discovery of, 134–36, 361n35
drug use and, 135, 146–47
happiness and, 147–50
novelty and, 207, 374n67
surprise and, 136–37
TD learning and, 143–47
value and, 151
See also TD (temporal-difference) learning
Douglass, Frederick, 26–27, 340n27
DQN (deep Q-network) models, 184–86, 192–94, 205
Drăgan, Anca, 267–68, 270, 297
driver prediction, 389n23
driving. See autonomous driving
drone training, 233
dropout, 24, 285–88, 389nn21, 23
drug use, 135, 146–47, 320
See also addiction
Du Bois, W.E.B., 27
Duck Soup, 216
Duke University, 98–102, 116, 251
Durfee, Edmund, 390n29
Dwork, Cynthia, 61–63, 65, 73, 347n33
EA. See effective altruism
early stopping, 395n4
Edison, Thomas, 156
Edwards, Harrison, 199–200, 201, 206
effective altruism (EA), 237–38, 305, 306–07, 379n67
Egan, Greg, 213
ε-greedy learning, 156, 158, 184–85, 373n62
Einhorn, Hillel J., 94, 97–98
Einstein, Albert, 87, 326
elections, 67
Elements of Psychology, The (Thorndike), 124
Elliott, Delbert, 56
Elman, Jeffrey, 161
embedded agency, 321–22
empathy, need for, 49–50
employment, 22, 39–40, 48, 343nn72–74, 76–77
Enduro, 264–65
ensemble methods, 284–85, 305
equiprobabiliorism, 303
equivant (company), 337n5
ergodicity assumption, 320
Ermon, Stefano, 324
ethics
actualism vs. possibilism and, 239, 379n71
in reinforcement learning, 149
See also AI safety; fairness; moral uncertainty
evaluation function. See value function
Evans, Owain, 386–87n55
evolution, 170, 171–74, 368n56
expectations, 138–39, 197
See also TD (temporal-difference) learning
Explainable Artificial Intelligence (XAI), 89
Eysenbach, Benjamin, 391n39
Face++, 32
Facebook, 67, 116
facial datasets, 12, 29, 30–33, 314, 340n44, 341nn48, 51
See also image-recognition systems
fairness
antidiscrimination law on, 63–64
assumptions on, 317–18
blindness to protected attributes as, 63–65
definitions of, 61, 68–70, 71–72
as impossible, 69–70, 348n52
increased interest in, 12, 66–68, 73–74
in lending, 70–71
opposition to discussing, 72–73
parole system and, 51–55, 76
privacy and, 62–63, 347n35
redundant encodings and, 64
risk-assessment models and, 317–18, 348n52
See also bias; ethics
Fallenstein, Benja, 296–97
Fantz, Robert, 189–90, 370n26
feature visualization, 108–12, 357nn66, 69, 71
feedback, 128–29, 359n18
feedback learning
human-machine cooperation and, 270–71, 386n48
inverse reinforcement learning and, 262, 263–66, 384–85n37
value alignment and, 263, 266, 267, 384–85n37
feedback loops, 49, 76–77, 110
Feigenson, Lisa, 196–97
Fergus, Rob, 109
Feynman, Richard, 252–53
Fiat, Amos, 62
finite and infinite games, 372n49
Finn, Chelsea, 261
First Step Act (2018), 74
Firth, J. R., 34
Fisac, Jaime, 385n43
Fischer, Bobby, 162
Fitzpatrick scale, 341n48
Flaxman, Seth, 89–90
Flores, Anthony, 72–73
Foundational Research Institute, 149
Fouriezos, George, 135
Fragaszy, Dorothy, 214
free will, 165, 180
Friedman, Batya, 30
Fugett, Dylan, 8
Future of Humanity Institute, 223, 246, 291–92, 296–97, 309, 313, 386–87n55
gait, 253–54, 382n13
Gal, Yarin, 282, 284, 285–87
gambling, 153, 207
gamification, 176–80
gaming
Arcade Learning Environment, 181–83, 209, 369n4
autonomous driving and, 228–30
backward learning and, 365n27, 369n9
bespoke games, 181, 369n2
boredom and, 203–04, 373n62
complex environments in, 191, 371n32
curriculum and, 160, 162–63, 365n27
dependence on human mind and, 240–43
DQN models and, 184–86
ergodicity and, 320
feature construction and, 182, 183
feedback learning and, 263–65, 386n48
finite and infinite games, 372n49
GPUs and, 23
gridworlds, 292–93, 294, 295, 390n29
human-machine cooperation and, 270–71
imitation and, 221, 228–29, 231–32, 243, 376n29, 377n47, 380nn84–86
independence from extrinsic motivation and, 200–03, 373n58
novelty and, 191–94, 371nn32, 35, 373nn53–54
Q-value in, 238
safety and, 222, 376–77n31
for self-training, 175–76
sparsity problem in, 157
sticky actions in, 373n62
surprise and, 198–200
TD learning and, 141, 142, 145
value-based approaches and, 241–42
Gans, Joshua, 165
Garg, Nikhil, 46
Garrabrant, Scott, 321–22
GDPR (General Data Protection Regulation), 89–90, 352–53n16
Gebru, Timnit, 32, 33, 341n52, 342–43n68
GeForce, 339n18
gender bias
in medical research, 314, 396n7
in orchestra auditions, 39–40, 343n73
redundant encodings and, 343n74
removing from word embedding, 41–44, 344n86, 345n94
in risk-assessment models, 70
training data and, 31–32, 33, 340n44
veridical bias and, 45–46
in word embedding, 6–7, 9, 38, 39, 40, 344–45n94
word embedding as diagnostic tool for, 46–47
General Data Protection Regulation (GDPR), 89–90, 352–53n16
generalized additive models, 85–86, 352nn10–12
general-purpose AI. See artificial general intelligence
Gergely, György, 218
Ghahramani, Zoubin, 283, 285–86, 287
Girouard, Mark J., 39
Giving What We Can, 379n67
Glimcher, Paul, 135
Global Catastrophic Risks (Bostrom and Ćirković), 262
GloVe, 37
Go, 145, 243–46, 380nn84–86
See also AlphaGo; AlphaGoZero
Gödel, Escher, Bach (Hofstadter), 204–05
Goel, Sharad, 68, 348n47
Go-Explore, 373n54
Goh, Gabriel, 111, 357n69
Goldbert, Yoav, 44
Gonen, Hila, 44
Goodman, Bryce, 89–90
Goodman, Kenneth, 289
Google
AdSense, 343n72
Artists and Machine Intelligence program, 112
BERT model, 344–45n94
Chrome, 347n33
DeepDream, 110, 112, 116
GoogLeNet, 115–16
Inception v3, 104–05, 107–08, 115–16
interpretability, 113–14
Photos, 25–26, 29, 339n24
word2vec, 5, 6–7, 9, 36, 37, 39, 316, 342n61
See also Google research
Google Brain, 113, 167, 373n53
Google research
differential privacy, 347n33
fairness, 73
feature visualization, 110
multitask learning models, 107
reinforcement learning, 167
selective classification, 390n29
value alignment, 247
word embedding, 44
Gopnik, Alison, 194, 215
gorilla tag incident, 25–26, 316, 339n24
GPT-2, 344–45n94
GPUs. See graphics processing units
gradients. See stochastic gradient descent
Graeber, David, 82
graphics processing units (GPUs), 21, 23, 339nn18, 20
gridworlds, 292–93, 294, 295, 390n29
Griffiths, Tom, 165–66, 177, 178–79
ground truth gaps
clinical vs. statistical predictive models and, 97–98
fairness and, 317
human judgments and, 97–98
in image-recognition systems, 75
raw data and, 102–03
in risk-assessment models, 75–76
saliency methods and, 355n54
simple models and, 99, 101–02
TD learning and, 140
Gunning, Dave, 87–89
Hadfield-Menell, Dylan, 266–68, 273, 296, 297–98, 299, 300
Han, Hu, 31
Hand, Learned, 277
Handbook of Moral Theology (Prümmer), 303
Hands on a Hard Body, 312
happiness, 147–50
Harcourt, Bernard, 78–79, 346–47n25, 350n85
Hardt, Moritz, 29, 51, 63, 65–66, 73, 81, 351n87
Harlow, Harry, 188
Harno, Albert, 52
Harvard University, 254, 290
Hass, Robert, 235
Hastie, Trevor, 85
Hebb, Donald, 338n2
Hedonic Treadmill, 148, 149–50
helicopter flying, 168, 257–60, 383nn22–23
Herzberg, Elaine, 326–27
Hinton, Geoffrey, 21, 22, 24, 338–39n12
hiring, 22, 39–40, 48, 343nn72–74, 76–77
Hoare, C.A.R., 395n2
Hobbes, Thomas, 187
Hofstadter, Douglas, 204–05
Holder, Eric, 350n81
Holmes, Oliver Wendell, Jr., 98
Holt, Gregory, 289
Holte, Robert, 94
Hsu, Feng-hsiung, 241–42
Hui, Fan, 243
human judgments
bias in, 39, 68
consensus and, 315, 396n9
as fallible, 54
independence from extrinsic motivation and, 209
interpretability and, 113–14
intrinsic motivation and, 186–87
irrational, 386–87n55
rationality enhancement and, 176–77
self-training, 174–80, 369n76
vs. statistical prediction, 91–94, 97–98
transparency and, 319, 397n19
word embedding and, 342n61
See also imitation; value alignment
human-machine cooperation, 267–76
AI safety and, 268–69
aspiration and, 275–76, 386–87n55
CIRL, 267–68, 385nn40, 43–44
dangers of, 274–76
demonstration learning for, 271
feedback learning and, 270–71, 386n48
human-human team studies on, 271–73, 386n53
human irrationality and, 366–67n55
legibility and, 269–70, 386n47
parenting and, 269, 385–86n45
Hursthouse, Rosalind, 367n71
Hutter, Marcus, 262–63
Huxley, Aldous, 313
i.i.d. (independent and identically distributed) data, 131, 322
IBM
Deep Blue, 205, 241–42, 243, 380n84
early machine learning research, 126–27, 240
fairness, 66
image-recognition systems, 32, 33, 341n51
TD learning, 141
IJB-A, 32
ImageNet, 22, 23–25, 75, 104, 110, 226, 357n66, 396nn9–10
image-recognition systems
adversarial examples, 279–80, 387n8
AlexNet development, 21, 23–25
brittleness of, 279–81, 387n8
complexity of, 100
consensus and, 315, 396n9
distributional shift and, 115–16, 398n36
dropout for, 24, 285–86, 389n21
feature construction and, 183
feature visualization and, 108–12, 357nn66, 69, 71
ground truth gaps and, 75
ImageNet, creation, 22
imitation and, 226, 231
label errors in, 25–26, 315–16, 339n24
military applications, 357n66
open category problem in, 279–81, 315, 396nn10–11
saliency methods and, 104–05, 355nn54–55
TCAV and, 114–16
imitation
actualism vs. possibilism and, 235, 239–40, 379n71
advantages of, 220–23, 376n29
amplification, 244–46, 381n90
assumptions on, 322
autonomous driving and, 225–27, 322
in children, 214–16, 375nn7–8, 14, 17, 376n23
dependence on human mind and, 240–43, 247
overimitation, 216–19, 376n23
primates and, 213–14, 217, 219, 374–75n5
recovery and, 227–34, 322, 378n54
virtue ethics and, 367n71
impact, 288–95
interference and, 292
irreversibility and, 290–91, 292, 293, 320, 391n39, 397n22
measuring, 291–92, 391–92n42
moral uncertainty and, 305, 394n80
offsetting and, 292, 293
relative reachability and, 293, 294–95
vs. side effects, 392n44
implicit association test, 44–45
improper linear models, 95–98, 353–54nn29, 33–34
incentives, 163–70
corrigibility and, 296–97
cyclical behavior problem and, 167–70, 185–86, 366–67nn44, 47, 49
evolution and, 170
internal nature of, 202–03
for self-training, 176, 177–80
states vs. actions and, 169–70, 174, 177
surprises as, 199, 207–08
Inception v3, 104–05, 107–08, 115–16
indeterminate sentencing, 54
Indiana University, 214–15
indirect normativity, 223
infant development. See child development
inference, 251–53, 269, 323–24, 385n39, 398nn29–30
See also inverse reinforcement learning
information theory, 34–35, 188, 197–98, 260–61
Innocent IX (Pope), 303
Institute for Ophthalmic Research, 287
intelligence
artificial general intelligence and, 209
reinforcement learning and, 144, 149, 150–51
See also artificial general intelligence
interest. See curiosity
interface design, 269
interference, 292
interpretability, 113–17
See also transparency
interventions
medical predictive models and, 84, 86, 352n12
risk-assessment models and, 80–81, 317–18, 351nn87, 90
intrinsic motivation
addiction and, 205–8, 374n65
boredom and, 188, 201, 202, 203–04
knowledge-seeking agents, 206–07, 209–10, 374n73
novelty and, 189–94, 207, 370–71nn29–30, 32, 35
reinforcement learning and, 186–89, 370n12
sole dependence on, 200–03, 373n58
surprise and, 195–200, 207–08, 372nn49–50, 373nn53–54, 58
inverse reinforcement learning (IRL), 253–68
aspiration and, 386–87n55
assumptions on, 324
cooperative (CIRL), 267–68, 385nn40, 43–44
demonstration learning for, 256–61, 323–24, 383nn22–23, 398n30
feedback learning and, 262, 263–66, 384–85n37
gait and, 253–55
as ill-posed problem, 255–56
inference and, 251–53, 385n39
maximum-entropy, 260–61
inverse reward design (IRD), 301–02
irreversibility, 290–91, 292, 293, 320, 391n39, 397n22
Irving, Geoffrey, 344n86
Irwin, Robert, 326
Isaac, William, 75–77, 349n76
Jackson, Shirley Ann, 9
Jaeger, Robert, 184
Jain, Anil, 31
James, William, 121, 122, 124
Jefferson, Geoffrey, 329
Jefferson, Thomas, 278
Jim Crow laws, 344n83
Jobs, Steve, 98
Johns Hopkins University, 196–97
Jorgeson, Kevin, 220–21
Jurafsky, Dan, 46
Kabat-Zinn, Jon, 321
Kaelbling, Leslie Pack, 266, 371n30
Kage, Earl, 28
Kahn, Gregory, 288
Kalai, Adam, 6–7, 38, 41–42, 48, 316
Kálmán, Rudolf Emil, 383n15
Kant, Immanuel, 37
Kasparov, Garry, 205, 235, 242
Kaufman, Dan, 87–88
Kellogg, Donald, 214–15, 375n7
Kellogg, Luella, 214–15, 375n7
Kellogg, Winthrop, 214–15, 375n7
Kelsey, Frances Oldham, 315
Kerr, Steven, 163, 164, 168
Kim, Been, 112–17
kinesthetic teaching, 261
Kleinberg, Jon, 67, 69, 70, 73–74
Klopf, Harry, 127, 129, 130, 133, 138, 150
knowledge-seeking agents, 206–07, 209–10, 374n73
Knuth, Donald, 311, 395n2
Ko, Justin, 104, 356n55
Kodak, 28–29
Krakovna, Victoria, 292–93, 295
Krizhevsky, Alex, 21, 23–25, 285, 339n20
l₀-norm, 354n47
Labeled Faces in the Wild (LFW), 31–32, 340n44
Lab for Analytical Sciences, North Carolina State University, 88
labor recruiting, 22
Landecker, Will, 103–04, 355n54
language models. See word embedding
lasso regularization, 383n18
Latour, Bruno, 325
law of effect, 123–24, 125–26, 358n8
laxism, 303, 304
“Learning Curve: Self-taught AI Software Attains Human Performance in Video Games” (Mnih et al.), 184
“Learning Internal Representations by Error Propagation” (Rumelhart, Hinton, and Williams), 338–39n12
learning with rejection, 390n29
LeCun, Yann, 21–22, 24, 234
Lee Sedol, 243, 244
legibility, 269–70, 386n47
legible motion, 270, 386n47
Leibig, Christian, 287
Leike, Jan, 262–63, 264–66, 270, 273, 295, 320, 384n31
lending, 70–71
Lenson, David, 147
LessWrong, 262
Lettvin, Jerry, 2, 3, 20, 336n9
Level of Service Inventory (or LSI), 346n13
Levine, Sergey, 227, 229
Lewis, Richard, 173, 202
LFW. See Labeled Faces in the Wild
Li, Fei-Fei, 22, 24
Lieder, Falk, 176–77, 178–80
linguistics, computational. See word embedding
Littman, Michael L., 158, 170–72, 360n26, 369n4
Lockhart, Ted, 394n76
“Logical Calculus of Ideas Immanent in Nervous Activity, A” (McCulloch and Pitts), 3, 336n9
logistic regression, 83, 355n48
Lowenkamp, Christopher T., 350n81
Lum, Kristian, 75–77, 349n76
Lyon, Jim, 28
MacAskill, Will, 237–38, 304, 306–09, 379n67
Machine Intelligence Research Institute, 247, 296–97, 310, 321–22, 392–93n51
machine learning
areas of, 11
increased dependence on, 11–12
reinforcement and, 125–27
as source of knowledge, 328–29
stochastic gradient descent as basic recipe for, 18–19
term origins, 126
Machines That Learn to Play Games, 243
“Machines Which Learn” (Andrew), 19–20
Madras, David, 390n29
management science, 164–65
Manhattan Project, 154
Manning, Christopher, 36–37
Marcus Aurelius, 246
Matarić, Maja, 152
maximum-entropy inverse reinforcement learning, 260–61
Max Planck Institute for Intelligent Systems, 177–80
Maxwell, James Clerk, 359n19
Mayson, Sandra G., 351n92
McCarthy, John, 127, 377n42
McCulloch, Warren, 2, 17, 20, 21, 125, 336nn6, 9, 338nn9, 12
McGill University, 134
McGonigal, Jane, 175, 176
MCTS (Monte Carlo Tree Search), 244–46, 248, 381n90
Mechanical Turk, 22, 43, 75, 179, 369n73
medical applications
representation in, 314, 396n7
research bias, 314, 396n7
uncertainty and, 288–90
See also medical predictive models
medical predictive models
causation and, 352n8
dropout for, 287
generalized additive models, 85–86, 352nn10–12
interventions and, 84, 86, 352n12
multitask, 105–8, 356n59
neural networks for, 82–83, 84–85, 86–87, 104–05
rule-based, 83–84, 352n8
saliency methods and, 104–05, 108, 355–56n55
simple, 99–103, 354–55nn47–48
transparency and, 85, 86–87, 102–03
Meehl, Paul, 93, 154, 353n33
Megvii, 32, 33
Meltzoff, Andrew, 215–16, 375n17
Mercier, Hugo, 319
meta-reasoning, 177, 366–67n44
Michigan State University, 31
Michigan Technological University, 394n76
microscopy, 357n71
Microsoft, 6–7, 32, 33, 62, 114
Miles, Robert, 393n52
military applications
animal training, 152, 154–55
image-recognition systems, 357n66
transparency and, 87–89
Milli, Smitha, 298–300
Milner, Peter, 134
Minsky, Marvin, 18, 20, 21, 133, 370–71n29
MIRI, 395n4
misprediction. See surprise
MIT, 20–21
augmented reality, 30
credit-assignment problem, 133
facial datasets, 32–33, 341n48
human-machine cooperation, 271–73, 386n53
interpretability, 112–13
intrinsic motivation, 195–96, 371n30
uncertainty, 295
Mitchell, Tom, 82
Miyamoto, Shigeru, 160
Mnih, Volodymyr, 183, 184
model misspecification, 299–300
models, intrinsic problems with, 11–12, 90, 325–27, 398–99n38
Montague, Read, 142, 143, 144
Montezuma’s Revenge
backward learning and, 369n9
DQN models and, 184–86
imitation and, 221
intrinsic motivation and, 186, 189, 193–94, 199–200, 208, 373nn53–54
Montgomery, L. M., 397n23
moral imperfection, 236
moral uncertainty, 302–10
impact and, 305, 394n80
necessity of, 306–09
social choice theory and, 305–06
theology and, 302–03, 304, 394nn70–71
Moravec, Hans, 223–24
Mordvintsev, Alexander, 110, 111, 112
Morgan, Conway Lloyd, 222, 358n8
motherese (parentese), 269, 385–86n45
MuJoCo, 265–66, 391n39
Mullainathan, Sendhil, 39, 67
multi-agent reinforcement learning, 321, 398n25
multitask learning models, 105–08, 356n59
Murdoch, Iris, 234, 274
muscle memory. See policy functions
Musk, Elon, 213, 374n2
MuZero, 380n86
“my favorite theory” approach, 305
Naddaf, Yavar, 369n4
Narayanan, Arvind, 45, 49
Navlab, 224–25, 377n39
neural networks
autonomous driving and, 225
Bayesian, 283–86
feature visualization and, 108–12, 357n66
feature visualization for, 111
hardware for, 336–37n9
imitation and, 230
inverse reinforcement learning and, 261
for medical predictive models, 82–83, 84–85, 86–87, 104–05
multitask learning models, 105–08, 356n59
perceptrons and, 17–21, 337–38n2
saliency methods and, 103–05
stochastic gradient descent and, 18–19, 26, 30–31, 36–37, 227, 338–39n12
transparency and, 85, 87–88, 89–90, 102–03
value functions in, 245
for word embedding, 35–37, 342n61
See also deep neural networks
“Neural Substrate of Prediction and Reward, A” (Schultz, Dayan, and Montague), 144
NeurIPS (Neural Information Processing Systems) conference, 9–11, 66, 337n9
neuroscience, 142–44, 145, 150–51, 188
Newman, Max, 329
Newton, Isaac, 326
New York University (NYU), 109–10, 135, 290, 372n49
Ng, Andrew, 168–70, 177, 256–59, 383n18
n-grams, 35
Niels Bohr Institute, 167
Nintendo, 160
Nissenbaum, Helen, 30, 65
Niv, Yael, 145
noisily rational behavior, 323, 398n29
Northpointe, 7, 56, 60–61, 68, 337n5, 346n13
See also COMPAS
novelty, 189–94, 207, 370–71nn29–30, 32, 35, 374n67
Novoa, Roberto, 104, 105, 355–56n55
Nvidia, 21, 233–34, 339nn18, 20, 378n54
Obama, Barack, 296
obedience, 298–99
See also corrigibility
off-policy methods for value learning, 238–39, 379n69
off-switch game, 297–98
Oku, Garett, 259
Olah, Christopher, 110, 111, 112, 357n69
Olds, James, 134
Omohundro, Steve, 393n55
Ondra, Adam, 220–21
O’Neil, Cathy, 66–67
online behavior, 274–75
on-policy methods for value learning, 238–39, 379n69
OpenAI
actualism vs. possibilism, 239
amplification, 248–50
corrigibility, 296
feature visualization, 112, 357n69
intrinsic motivation, 199–200, 201
inverse reinforcement learning, 263–66, 384–85n37
reinforcement learning, 365n27
word embedding, 344–45n94
open category problem, 279–81, 315, 396nn10–11
ophthalmology, 287, 389n23
optimal regressions, 95–96
optimal reward problem, 173–74, 177–78, 179–80, 368n59
orchestra auditions, 39–40, 343n73
ORCON, 154
Ord, Toby, 305, 379n67
Oregon Research Institute (ORI), 93, 94–95
Oregon State University, 279–81, 293–94
Orseau, Laurent, 206–7, 209–10
overimitation, 216–19, 376n23
Oxford University, 130–31, 282–83, 304–09
See also Future of Humanity Institute
Packer, Bernard, 8
Paglen, Trevor, 396n9
panopticon, 275–76
Papert, Seymour, 20, 21
parallelogram method, 6–7, 37–38, 316, 342–43n68, 397n13
parameters, 18
parentese (motherese), 269, 385–86n45
parenting
alignment problem and, 166
human-machine cooperation and, 269, 385–86n45
incentives and, 165–66, 170
reinforcement learning and, 155, 158, 364n15
as transformative experience, 321
See also child development
parole system
Burgess study, 51–54, 76
predictive systems, 54–55
See also criminal justice system; risk-assessment models
Partnership on AI, 349n68
Pathak, Deepak, 198–200, 201, 203–04, 206, 208
Pavlok, 180
Pavlov, Ivan, 124
PCA. See principal component analysis
Pearl, Judea, 352n8
pedagogy, 269, 385nn43–44
perceptrons, 17–21, 337–38n2
Perceptrons (Minsky and Papert), 20, 21
persuasion, 319, 397n21
perturbation training, 386n53
Petrov, Stanislav, 277–78, 279
Pfaff, Tobias, 221
PhD students, 179–80, 369n76
photography, 26–29
Piaget, Jean, 215, 321
Pichai, Sundar, 116
Pitfall!, 369n4
Pitts, Walter, 1–3, 17, 20–21, 125, 336nn6, 9, 338nn9, 12
Plato, 210, 374n73
pleasure centers, 134–35
See also dopamine
policy functions, 138–39, 151, 245
Pomerleau, Dean, 225–26, 229–30, 377n39
Pong, 202, 270–71, 386n48
Poplin, Ryan, 107–08
pornography, 111
Portal, 203
Portland State University, 103–04
possibilism vs. actualism, 234–40
potty training, 165
power, 392n48
Prater, Vernon, 8
predictive models
actuarial, 92–93
alternatives to, 350n85
causation and, 352n8
clinical vs. statistical, 91–94, 97–98
for dermatology, 104–05, 355–56n55
flaws inherent in, 78–81, 317–18, 351nn88, 92
generalized additive models, 85–86, 352nn10–12
ground truth gaps and, 75–77
improper linear models, 95–98, 353–54nn29, 33–34
interventions and, 84, 86, 352n12
multitask, 105–08, 356n59
neural networks for, 82–83, 84–85, 86–87, 104–05
purposes of, 78
rule-based, 83–84, 352n8
saliency methods and, 104–05, 108, 355–56n55
simple, 99–103, 354–55nn47–48
See also risk-assessment models; transparency
predictive policing, 76–77, 79–80
See also risk-assessment models
preference models, 274
preferential looking, 190, 194
See also novelty
Princeton University, 45–46, 48, 49, 145, 165–66
principal component analysis (PCA), 41–42
prisoner’s dilemma, 321
privacy
differential, 61–62, 347n33
fairness and, 62–63, 347n35
probabiliorism, 303
probability, 282, 283, 323, 398n29
See also uncertainty
procrastination, 175, 178–79, 369n76
Professor Procrastinate problem, 236–37, 379n61
Project Pigeon, 152, 154–55, 163
propositional logic, 3
ProPublica, 7–9, 58–61, 67, 68, 347n32, 348n52
Protagoras (Plato), 210, 374n73
protected attributes, 63–65
Prümmer, Dominic M., 302
pseudo-count. See density models
pseudorewards. See incentives
punishments. See reinforcement learning
Q\*bert, 192–93
Q-learning, 140–41, 379n69
quantilizers, 395n4
Q-value, 238
racial bias
Fitzpatrick scale and, 341n48
in Google AdSense, 343n72
in hiring, 39
in image-recognition systems, 25–26, 339n24
implicit association test for, 45
photography and, 26–29
phrase sources and, 344n83
in risk-assessment models, 7–9, 57–61, 67, 68, 346–47nn25, 32, 348n52
training data and, 29–32, 340n44, 341n48
in word embedding, 342–43n68
word embedding as diagnostic tool for, 47
Randløv, Jette, 167, 177
randomness, 205–06, 374n65
rationality enhancement, 176
Read, Herbert, 327
Reality Is Broken (McGonigal), 175
recidivism. See risk-assessment models
rectified linear output functions, 24
Reddy, Raj, 223
redundant encodings, 40, 64, 343n74
reinforcement learning (RL)
actor-critic architecture, 138, 362n51
actualism vs. possibilism and, 238–40, 379n69
addiction and, 205–08, 374n65
alignment problem and, 151
Arcade Learning Environment, 181–83, 209, 369n4
assumptions on, 320–22, 397n23, 398n25
backward learning, 162, 365n27, 369n9
boat race scenario and, 10
context in, 131–32
credit-assignment problem and, 132–33, 139, 361n30
curiosity and, 186–87
curriculum design automation and, 162–63, 366n30
curriculum for, 158–63, 178–79, 365nn26–27
defined, 11
dependence on human mind and, 247
DQN models, 184–86, 192–94, 205
early theories of, 123–24, 358n8
ε-greedy, 156, 158
embedded agency in, 321–22
ethical issues in treatment of agents, 149
evolution and, 170, 171–74, 368n56
expectations and, 138–41
feature construction and, 182–83
field origins, 129
gait and, 254–55
happiness and, 147–50
intelligence and, 144, 149, 150–51
intrinsic motivation and, 186–89, 370n12
inverse reward design, 301–02
limits of, 180
multi-agent, 321, 398n25
novelty and, 190–94, 207, 370–71nn29–30, 32, 35
organisms as maximizers and, 128–29, 130, 150
parenting and, 155, 158, 364n15
policy vs. value functions, 137–39, 238
reinforcement schedules, 153
reward hypothesis, 130–31, 360nn26, 28
self-training and, 174–80, 369n76
Skinner’s research, 152–54
standardization efforts, 369n2
surprise and, 136–37, 197–200, 207–08, 372nn49–50, 373nn53–54, 58
tabular, 191
TD learning and, 140–47, 171, 361n30
terseness of, 132, 361n29
transformative experiences and, 320–21, 397n23
trial and error and, 156–57, 185
See also dopamine; inverse reinforcement learning; shaping; sparsity problem
relative reachability, 293, 294–95
Remington, Christine, 78
representation, 314–17
open category problem and, 315, 396nn10–11
See also bias; image-recognition systems; word embedding
Rescorla-Wagner model, 136–37, 143, 145
Research Institute for Advanced Studies, 383n15
Revels, Hiram, 27
reversibility, 391n39
reward hypothesis, 130–31, 133–34, 360nn26, 28
See also reinforcement learning
rewards. See incentives; reinforcement learning; reward hypothesis; shaping
right to explanation. See transparency
rigorism, 303, 304
risk-assessment models
COMPAS development, 56–57, 346nn13–14
defenses of, 68, 72–73, 350n81
definitions of fairness and, 61, 68–70, 71–72
distributional shift and, 78, 318, 350n81
fairness and, 317–18, 348n52
ground truth gaps in, 75–76
interventions and, 80–81, 317–18, 351nn87, 90
lack of auditing for, 7, 337n6
mandated use of, 12, 74
mitigations for, 77–78
Partnership on AI on, 349n68
racial bias in, 7–9, 57–61, 67, 68, 346–47n25, 32, 348n52
risk types and, 77
simplicity and, 98
ubiquity of, 56, 57, 58–59
unreported crimes and, 349n76
Rivelli, James, 8
RL. See reinforcement learning
Robbins, Tony, 372n49
Roberts, John, 9, 51
robotics
corrigibility and, 300
feedback learning and, 265–66
human gait and, 253
human-machine cooperation and, 269, 270, 271–73, 386nn47, 53
impact and, 392n44
incentives and, 167
inverse reinforcement learning and, 261
kinesthetic teaching, 261
legible motion, 270, 386n47
reinforcement learning and, 162, 365n20
uncertainty in, 287–88
See also autonomous driving
rock climbing, 220–21
Romanes, George John, 213
Rorschach tests, 91
Rosenblatt, Frank, 17–19, 20, 21, 25, 337–38nn2, 9, 12
Ross, Stéphane, 228, 229, 230–32
Roth, Lorna, 27–28
Rousseau, Jean-Jacques, 281, 302
Rudin, Cynthia, 98–102, 116
rule-based models, 83–84, 352n8
Rumelhart, D. E., 338–39n12
Russell, Bertrand, 1, 277, 311
Russell, Stuart
on corrigibility, 296, 297
on human-machine cooperation, 267–69, 273
on incentives, 168–70, 366–67nn44, 49
on inverse reinforcement learning, 253, 254–55, 256, 383n18, 398n30
on open category problem, 396n11
on self-training, 177
Rutgers University, 196
Rutledge, Robb, 147–49
saliency methods, 103–05, 108, 114–15, 355nn54–55
Salimans, Tim, 369n9
Salk Institute, 142
Samuel, Arthur, 126, 127, 141, 240–41
Sarbin, Ted, 92, 93
SARSA, 379n69
SB 10 (California), 74, 349n68
scalar rewards, 130–31, 134, 135
Schaeffer, Jonathan, 242–43
Schauer, Frederick, 87
Schiebinger, Londa, 46
Schmidhuber, Jürgen, 197–98
Schnackenberg, Elmer J., 76
Schultz, Wolfram, 135–37, 143, 144–45, 146, 153
Schulz, Laura, 195
Sejnowski, Terry, 142
selective classification, 286–87, 390n29
self-driving vehicles. See autonomous driving
self-imitation. See amplification
Selfridge, Oliver, 161
self-training, 174–80, 369n76
Shah, Julie, 116, 271–73, 386n53
Shakespeare, William, 279
Shannon, Claude, 34–35
shaping
corrigibility and, 300–01
curriculum for, 158–63, 365nn26–27
DQN models and, 184–86, 192–94, 205
gaming and, 175
in robotics, 365n20
for self-training, 177–78
Skinner’s research and, 154–56, 364n15
sparsity problem and, 156–58
See also incentives
Shirley cards, 28–29, 30, 31
See also training data
Shlegeris, Buck, 310
side effects, 392n44
See also impact
Silver, David, 163, 245
Simon, Herbert, 187
simple models, 99–103, 114, 318–19, 354–55nn47–48
Singer, Peter, 237, 238, 379n67
Singh, Satinder, 173, 202, 365n20, 370n12, 390n29
Skinner, B. F., 121, 124
on curriculum, 159
on free will, 165, 180
on gambling addiction, 207
incentives and, 163, 164–65
intrinsic motivation and, 188
on procrastination, 175
Project Pigeon, 152, 153–55
on shaping, 154, 155–56, 364n15
Skinner boxes, 152–53
sparsity problem and, 158
skip-gram, 341n54
sleep apnea, 101–02, 354n47, 355n48
SLIM (Supersparse Linear Integer Model), 101–02, 354n47
Smith, Holly, 236–37
Soares, Nate, 296–97
soccer, 167
social choice theory, 305–06
social media, 67
social science methodology, 41–42, 43, 46–48, 92–94
sokoban games, 293, 294
“Some Studies in Machine Learning Using the Game of Checkers” (Samuel), 126–27
Sony Playstation, 339n18
Sorg, Jonathan, 173
Soviet nuclear false alarm incident (1983), 277–78, 279
Space Invaders, 157
sparsity problem
curriculum and, 158–63
DQN model and, 185
incentives and, 163–66
overview, 158–59
self-training and, 174
shaping and, 156–58
Sperber, Dan, 319
spider sense. See value functions
Stahl, Aimee, 196–97
Stanford University
fairness, 68
image-recognition systems, 315
inverse reinforcement learning, 257–60
multitask learning models, 107
robotics, 223–24
saliency methods, 104–05
value alignment, 324
word embedding, 36–37, 46–47
start-from-static technique, 110–11, 357n69
state vs. action incentives, 169–70, 174, 177
statistical models. See risk-assessment models
Steiger, Paul, 58
Stein, Gertrude, 121
Stein, Leo, 137
“Steps Toward Artificial Intelligence” (Minsky), 133
stepwise baselines, 292, 293, 294–95
stereotypes, 27, 38, 39, 43, 47, 396n9
See also gender bias; racial bias
sticky actions, 373n62
stochastic gradient descent
for autonomous driving, 227
for deep neural learning, 338–39n12
defined, 18–19
innocence of, 26, 30–31
for word embedding, 36–37
Stock, Pierre, 116
Stockholm University, 305
Strategic Computing Initiative, 223–27
Sunstein, Cass, 290, 291
Super Mario Bros., 160, 198–99, 201, 203–04
SuperTuxKart, 228, 229, 231–32
supervised learning, 11, 131, 277, 377–78n43, 380n85
SuperVision. See AlexNet
surprise, 136–37, 195–200, 207–08, 372nn49–50, 373nn53–54, 58
surveillance, 275–76, 314
Sutskever, Ilya, 23, 24
Sutton, Richard
on actualism vs. possibilism, 238–39
on backpropagation, 361n30
early career of, 129
on novelty, 190
on organisms as maximizers, 130
on policy vs. value functions, 137–39
research focus of, 138, 362n51
on reward hypothesis, 360n26
on shaping, 161
on TD learning, 140, 141–42, 171
Sweeney, Latanya, 343n72, 347n35
tabular RL, 191
Tan, C. J., 242
Taylor, Charles Richard, 254
Taylor, Jessica, 395n4
TCAV (testing with concept activation vectors), 114–16, 358n80
TD (temporal-difference) learning, 140–47
credit-assignment problem and, 361n30
dopamine and, 143–47
drug use and, 146–47
happiness and, 148
Littman and, 171
Q-learning algorithm for, 140–41, 379n69
TD-Gammon, 141, 142
Teller, Astro, 167, 177
temporal-difference learning. See TD (temporal-difference) learning
Tesauro, Gerald, 141, 145
thalidomide, 314–15
theology, 302–03, 304, 394nn70–71
thermostats, 311–12, 313, 395n3
Thiel, Peter, 213, 374n2
Thorndike, Edward, 90, 121–24, 125–26, 127, 132, 207, 358n8
Thorpe, Chuck, 223, 224–26, 377n39
Thorpe, Leland, 225, 377n39
Tibshirani, Robert, 85
Tolman, Edward, 124
Tomasello, Michael, 214, 251–52, 382n3
Tomasik, Brian, 149
Toyota Research Institute, 389n23
training algorithms, 18, 26
See also stochastic gradient descent
training data
amount of, 22
assumptions on, 314–17
bias and, 26, 29–34, 314–15, 340n44, 341n48, 396n7
changes in time of, 325, 398n36
for perceptrons, 18
representation in, 314–17
See also ground truth gaps
transfer learning, 318, 325
See also distributional shift
transformative experiences, 320–21, 397n23
transparency
assumptions on, 318–19
data regulations and, 89–90, 352–53n16
feature visualization for, 108–12
human judgments and, 319, 397n19
medical predictive models and, 85, 86–87, 102–03
in military applications, 87–89
multitask learning models and, 106–07
neural networks and, 85, 87–88, 89–90, 102–03
saliency methods, 103–05, 355n54
simple models and, 102, 318–19
as source of knowledge, 328
trust in models and, 114, 319
trial and error learning, 156–57, 185
Truth, Sojourner, 33
Turing, Alan, 125, 181, 296, 328–29
Turner, Alexander, 294, 392n48
Tyka, Mike, 110, 111, 112
Uber, 142–43, 283, 373n54, 389n23
UC Berkeley
autonomous driving, 227
corrigibility, 297–301
cyclical behavior problem, 168–69
human-machine cooperation, 267–69, 270, 385n40
imitation, 215
intrinsic motivation, 198–200, 201
inverse reinforcement learning, 253, 254–55, 256–57
kinesthetic teaching, 261
shaping, 162
training data bias, 29
uncertainty, 288
value alignment, 266–67
UC Davis, 111
UC San Diego, 161
Ullman, Tomer, 345n94
uncertainty, 277–310
AI safety and, 291–92
Bayesian neural networks and, 283–86
confidence and, 281–82
corrigibility and, 295–302
deep learning brittleness, 279–81, 387n8
dissent and, 284–85
dropout and, 285–88, 389nn21, 23
explicit reward functions and, 300–02
impact and, 388–95, 391–92nn39, 42
learning with rejection, 390n29
open category problem and, 315
probability and, 282, 283
Soviet nuclear false alarm incident and, 277–78, 279
See also moral uncertainty
Universe, 9–10
University College London (UCL), 147–49
University of Alberta, 181–83, 242–43
University of California. See UC Berkeley; UC Davis; UC San Diego
University of Chicago, 67
University of Louisville, 324
University of Massachusetts, Amherst, 31, 129, 130, 138, 202
See also Barto, Andrew; Sutton, Richard
University of Michigan, 91–92, 173, 202, 236–37, 251, 373n53, 390n29
University of Toronto, 165, 390n29
University of Washington, 30, 215–16
University of Wisconsin, 188
unorganized machines, 125
unrecoverable mistakes. See irreversibility
unsupervised learning, 5, 11, 48, 131, 192, 376n29
Ustun, Berk, 101–02
utilitarianism, 236
utility theory, 360n26
value alignment
amplification and, 246–50
bias and, 43
corrigibility and, 299–300
and disagreement on values, 324
external metrics for, 247, 381n96
fairness and, 318
feedback learning and, 263, 266, 267, 384–85n37
growing focus on, 266–67
imperfection of human values and, 247
inference and, 252–53, 269, 323–24, 385n39
inverse reward design for, 301–02
models and, 325–27
See also AI safety; human-machine cooperation; inverse reinforcement learning
value functions, 138–39, 143, 238–39, 241–42, 245, 379n71
variable ratio reinforcement schedules, 153
Vaughan, Jenn Wortman, 114
vectors, 5–6, 36–37, 316, 342n61, 358n80
Veiga, Jack, 366n34
veridical bias, 45–46
Verily, 107
video games. See gaming
virtue ethics, 367n71
Visalberghi, Elisabetta, 214
Visser, Margaret, 26
visualization, 108–12, 357nn66, 69, 71
von Anrep, Gleb, 124
von Neumann, John, 336n9
Wainer, Howard, 354n34
Walden Two (Skinner), 180
walking, 253–54
Warneken, Felix, 251–52, 382n3
Watkins, Chris, 140, 142
Watson, Thomas J., Sr., 127
Waymo, 167, 232
Weapons of Math Destruction (O’Neil), 66–67
Wells, Dave, 56, 346n13
West, Mae, 189
Wiener, Norbert, 20, 128, 295, 312, 359n19
Wiewiora, Eric, 367n47
Williams, R. J., 338–39n12
Wise, Julia, 237
Wise, Roy, 135
word2vec, 5, 6–7, 9, 36, 37, 39, 316, 342n61
word embedding, 34–44
analogies in, 38, 41–42, 316, 342n66, 397n13
bias in, 6–7, 9, 38, 39, 40, 342–43n68, 344–45n94
deep neural learning for, 35–37, 342n61
distributed representations for, 35
GloVe, 37
need for caution with, 48–49
recent models, 344–45n94
redundant encodings, 40, 343n74
removing bias from, 41–44, 344n86, 345n94
as societal diagnostic tool, 46–48, 49
supervised learning for, 5
training for, 36–37, 341n54
transfer learning and, 318
veridical bias and, 45–46
word2vec, 5, 6–7, 9, 36, 37, 39, 316, 342n61
X (company), 167
XAI (Explainable Artificial Intelligence), 89
Yahoo, 110–11
Yampolskiy, Roman, 324
Youngblood, Curtis, 259–60, 262
Yudkowsky, Eliezer, 247, 262, 296–97, 393n52
Zeiler, Matthew, 109–10
Zhang, Shun, 390n29
Ziebart, Brian, 260–61
Zilly, Paul, 78
zip codes, 21, 22
Zou, James, 46
Zunger, Yonatan, 25–26, 49–50
ALSO BY BRIAN CHRISTIAN
The Most Human Human:
What Artificial Intelligence Teaches Us About Being Alive
Algorithms to Live By: The Computer Science of Human Decisions
(with Tom Griffiths)
ABOUT THE AUTHOR
Brian Christian is the author of The Most Human Human, a Wall Street Journal best seller, New York Times Editors’ Choice, and New Yorker favorite book of the year. He is the author, with Tom Griffiths, of Algorithms to Live By, a No. 1 Audible nonfiction best seller, Amazon best science book of the year, and MIT Technology Review book of the year.
Christian’s writing has been translated into nineteen languages and has appeared in the New Yorker, the Atlantic, Wired, the Wall Street Journal, the Guardian, the Paris Review, and in scientific journals such as Cognitive Science. Christian has been featured on The Daily Show with Jon Stewart, Radiolab, and Charlie Rose and has lectured at Google, Facebook, Microsoft, the Santa Fe Institute, and the London School of Economics. He is a recent laureate of the San Francisco Public Library, and his work has won him several awards, including fellowships at Yaddo and the MacDowell Colony, publication in The Best American Science and Nature Writing, and an award from the Academy of American Poets.
Born in Wilmington, Delaware, Christian holds degrees in computer science, philospophy, and poetry from Brown University and the University of Washington and is a visiting scholar at the University of California, Berkeley. He lives in San Francisco.
Copyright © 2020 by Brian Christian
All rights reserved
First Edition
For information about permission to reproduce selections from this book, write to Permissions, W. W. Norton & Company, Inc., 500 Fifth Avenue, New York, NY 10110
For information about special discounts for bulk purchases, please contact W. W. Norton Special Sales at specialsales@wwnorton.com or 800-233-4830
Jacket design: Gregg Kulick
Jacket illustrations: (top) Courtesy of Legado Cajal, Instituto
Cajal (CSIC), Madrid; (bottom) Gregg Kulick
Book design by Chris Welch
Production manager: Lauren Abbate
The Library of Congress has cataloged the printed edition as follows:
Names: Christian, Brian, 1984– author.
Title: The alignment problem : machine learning and human values / Brian Christian.
Description: First edition. | New York, NY : W.W. Norton & Company, [2020] | Includes bibliographical references and index.
Identifiers: LCCN 2020029036 | ISBN 9780393635829 (hardcover) | ISBN 9780393635836 (epub)
Subjects: LCSH: Artificial intelligence—Moral and ethical aspects. | Artificial intelligence—Social aspects. | Machine learning—Safety measures. | Software failures. | Social values.
Classification: LCC Q334.7 .C47 2020 | DDC 174/.90063—dc23
LC record available at https://lccn.loc.gov/2020029036
W. W. Norton & Company, Inc., 500 Fifth Avenue, New York, N.Y. 10110
www.wwnorton.com
W. W. Norton & Company Ltd., 15 Carlisle Street, London W1D 3BS |
6712755d-b810-4d65-957b-4e21230bb8ec | trentmkelly/LessWrong-43k | LessWrong | Princeton University- Envision Conference App Due Sunday!
Envision Conference applications due Sunday!
Interested in technology? Want to interact with a diverse group of talented students, academics and entrepreneurs? Then Envision Conference is for you! Apply today at http://envisionfuture.org
The 3rd annual Envision Conference (Nov 30 - Dec 2) explores how to build a brighter future through the prudent advancement of breakthrough technologies. We focus on the implications of Artificial Intelligence, synthetic biology, neural enhancement and nanotechnology. Our current speakers include Peter Singer, founder of the Effective Altruism movement, Natalie Kofler, founder of Editing Nature at Yale, Vincent Conitzer, AI researcher & author, and Wendell Wallach, ethicist and scholar at Yale.
Last year’s participants included funded entrepreneurs, hackathon and science competition winners, published PhD candidates, and student group founders.
• Previous speakers included Simon Levin, Ed Felten, Anders Sandberg, Robin Hanson and Joanna Bryson.
• Participants from 67 different universities.
• Previous and current company partners include Microsoft, SpaceX, SAS, Prudential and Kernel.
All undergraduate and graduate students are encouraged to attend! As a participant, you will have the opportunity to:
• interact with speakers during workshops and office hours,
• discuss how to pioneer technologies with accomplished peers and working professionals,
• be a part of a community seeking to steer the world's trajectory towards positive outcomes through the prudent implementation of emerging technologies.
Envision is committed to need-blind admissions, and provides financial aid for transportation. For more information, please visit our website. The deadline for the regular application is November 4th at 11:59 pm. Undergraduate and graduate students encouraged to apply.
Let’s pioneer a brighter future, today.
Best regards,
@Princeton Envision |
3a641975-afe1-4289-8a05-e5f19476c1d6 | trentmkelly/LessWrong-43k | LessWrong | Create a Full Alternative Stack
Last time I proposed nine strategies for fighting mazes. All of them were either systemic solutions requiring coordinated and/or political action, or cultural shifts that happen one person at a time.
Now for the tenth and final proposal for how to fight mazes. The tenth is a proposed strategy that one dedicated person with sufficient resources could implement on their own.
If you are in a position where you have the resources to implement this, please make an effort to take this proposal seriously. And please contact me if you are potentially interested and wish to discuss it further.
Solution 10: Create a Full Alternative Stack
In some ways this is the most ambitious solution here. It may seem Utopian.
In other ways, it is the least ambitious, and most practical. It could be implemented by a single sufficiently wealthy and committed individual or organization. All other known solutions can be implemented locally, and would help locally, but need general adaptation to succeed in general.
The full alternative stack offers a contract.
Disengage entirely with mazes and traditional distortionary incentives, competitions and signals of all kinds, and discard all zero-sum activity, in favor of doing the thing. Whatever the thing in question may be. Make no compromises to make oneself legible or attractive to outside sources of funding. Tolerate no maze behaviors of any kind. Hire and fire with this deeply in mind.
In exchange, if you keep your end of the bargain, the stack will fully fund you and your operations, at fair prices that do not take advantage of the hold-up opportunity presented by your giving up of other opportunities. Evaluation will be fully on the object-level merits, and the generative processes involved.
This is a form of tenure for the people. If they continue to act with integrity and work to accomplish positive-sum things relevant to the stack’s interests, and spend responsibly, they and their family will have strong financial security. |
11c648df-b29a-475f-a29d-84936fbd817e | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | PaLM-2 & GPT-4 in "Extrapolating GPT-N performance"
Two and a half years ago, I wrote [Extrapolating GPT-N performance](https://www.lesswrong.com/posts/k2SNji3jXaLGhBeYP/extrapolating-gpt-n-performance), trying to predict how fast scaled-up models would improve on a few benchmarks. One year ago, I [added PaLM to the graphs](https://www.lesswrong.com/posts/YzbQeCiwoLBHrvAh4/palm-in-extrapolating-gpt-n-performance). Another spring has come and gone, and there are new models to add to the graphs: PaLM-2 and GPT-4. (Though I only know GPT-4's performance on a small handful of benchmarks.)
Converting to Chinchilla scaling laws
-------------------------------------
In previous iterations of the graph, the x-position represented the loss on GPT-3's validation set, and the x-axis was annotated with estimates of size+data that you'd need to achieve that loss according to the [Kaplan scaling laws](https://arxiv.org/abs/2001.08361). (When adding PaLM to the graph, I estimated its loss using those same Kaplan scaling laws.)
In these new iterations, the x-position instead represents an estimate of (reducible) loss according to the [Chinchilla scaling laws](https://arxiv.org/abs/2203.15556). Even without adding any new data-points, this predicts faster progress, since the Chinchilla scaling laws describes how to get better performance for less compute.
The appendix describes how I estimate Chinchilla reducible loss for GPT-3 and PaLM-1. Briefly: For the GPT-3 data points, I convert from loss reported in the GPT-3 paper, to the minimum of parameters and tokens you'd need to achieve that loss according to *Kaplan* scaling laws, and then plug those numbers of parameters and tokens into the Chinchilla loss function. For PaLM-1, I straightforwardly put its parameter- and token-count into the Chinchilla loss function.
To start off, let's look at a graph with only GPT-3 and PaLM-1, with a Chinchilla x-axis.
Here's a quick explainer of how to read the graphs (the [original post](https://www.lesswrong.com/posts/k2SNji3jXaLGhBeYP/extrapolating-gpt-n-performance#What_scaling_laws_to_use_) contains more details). Each dot represents a particular model’s performance on a particular category of benchmarks (taken from papers about [GPT-3](https://arxiv.org/abs/2005.14165) and [PaLM](https://arxiv.org/pdf/2204.02311.pdf)). Color represents benchmark; y-position represents benchmark performance (normalized between random and my guess of maximum possible performance).
The x-axis labels are all using the Chinchilla scaling laws to predict *reducible* loss-per-token, number of parameters, number of tokens, and total FLOP (if language models at that loss were trained Chinchilla-optimally).
Compare to the last graph in [this comment](https://www.lesswrong.com/posts/YzbQeCiwoLBHrvAh4/palm-in-extrapolating-gpt-n-performance?commentId=7YiN5MPefuXYHxpTs), which is the same with a Kaplan x-axis. Some things worth noting:
* PaLM is now ~0.5 OOM of compute *less* far along the x-axis. This corresponds to the fact that you could get PaLM for cheaper if you used optimal parameter- and data-scaling.
* The smaller GPT-3 models are farther to the right on the x-axis. I think this is mainly because the x-axis in my previous post had a different interpretation.[[1]](#fnt7s8oyceo7)
* The overall effect is that the data points get compressed together, and the slope becomes steeper. Previously, the black "Average" sigmoid reached 90% at ~1e28 FLOP. Now it looks like it reaches 90% at ~5e26 FLOP.
Let's move on to PaLM-2. If you want to guess whether PaLM-2 and GPT-4 will underperform or outperform extrapolations, now might be a good time to think about that.
PaLM-2
------
If [this CNBC leak](https://www.cnbc.com/2023/05/16/googles-palm-2-uses-nearly-five-times-more-text-data-than-predecessor.html) is to be trusted, PaLM-2 uses 340B parameters and is trained on 3.6T tokens. That's more parameters and less tokens than is recommended by the Chinchilla training laws. Possible explanations include:
* The model isn't dense. Perhaps it implements some type of mixture-of-experts situation that means that its *effective* parameter-count is smaller.
* It's trained Chinchilla-optimally for multiple epochs on a 3.6T token dataset.
* The leak is wrong.
If we assume that the leak isn't too wrong, I think that fairly safe bounds for PaLM-2's Chinchilla-equivalent compute is:
* It's as good as a dense Chinchilla-optimal model trained on just 3.6T tokens, i.e. one with 3.6T/20=180B parameters. This would make it 6\*180e9\*3.6e12=3.9e24 FLOP.
* It's as good as a dense Chinchilla-optimal model with 340B parameters, i.e. one that was trained with 20\*340B=6.8T tokens. 6\*340e9\*6.8e12=1.4e25 FLOP.
So I'll talk about both of those.
The [PaLM-2 technical report](https://ai.google/static/documents/palm2techreport.pdf) reports 1-shot performance instead of few-shot performance, which my previous posts focused on (and which is depicted in the above graph). So the following graphs will display 1-shot performance from both GPT-3 and PaLM. Performance will be generally lower.
First, how well does PaLM-2 match up against what you would have predicted from looking at GPT-3 and PaLM-1? In the following graph:
* The dots are GPT-3 and PaLM-1 data points. The lines are only fit to the dots.
* The first line of crosses is the smaller estimate for PaLM-2: 3.9e24 FLOP.
* The second line of crosses is the larger estimate for PaLM-2: 1.4e25 FLOP.
As it so happens, my reflections from last year (when adding PaLM to just the GPT-3 points) apply ~equally well for PaLM-2:
> * SuperGLUE is above trend. ANLI sees impressive gains, though nothing too surprising given ~sigmoidal scaling.
> * Common sense reasoning + Reading tasks are right on trend.
> * Cloze & completion, Winograd, and Q&A are below trend.
> * The average is amusingly right-on-trend, though I wouldn’t put a lot of weight on that, given that the weighting of the different benchmarks is totally arbitrary.
> + (The current set-up gives equal weight to everything — despite e.g. SuperGLUE being a much more robust benchmark than Winograd.)
>
Maybe this is because the lines are still dominated by all the GPT-3 data points (despite also being fit to PaLM-1), and because PaLM-2 is pretty similar to PaLM.
This graph doesn't really help us tell whether PaLM-2 was trained with ~3.9e24 FLOP-equivalent or ~1.4e25 FLOP-equivalent. The average trend is slightly below the former and slightly above the latter.
So for fitting sigmoids to the PaLM-2 data points (along with the other data points, for future extrapolations), I'll split the difference and pretend that their 340B parameters trained on 3.6T tokens was equally good as a Chinchilla-optimal training-run with the same compute-budget: 6\*340e9\*3.6e12=7.3e24 FLOP.
GPT-4
-----
For GPT-4's x-position, I'll use [Epoch's estimate](https://colab.research.google.com/drive/1O99z9b1I5O66bT78r9ScslE_nOj5irN9) of 2e25 FLOP, and assume that GPT-4 is equally good as a Chinchilla-optimal model trained with that much compute would be.
Unfortunately, the [GPT-4 technical report](https://arxiv.org/abs/2303.08774) only reports performance on 4 out of the >20 benchmarks that I've been using previously. So the following graph will have fewer lines, and each line will only represent a single benchmark (and therefore be noisier). As above, I've fit the lines to GPT-3 as well as PaLM-1, and the crosses represent GPT-4. (PaLM-2 is no longer included in the graph, since they don't report *few-shot* performance on all of these benchmarks, which is what we're looking at now.)
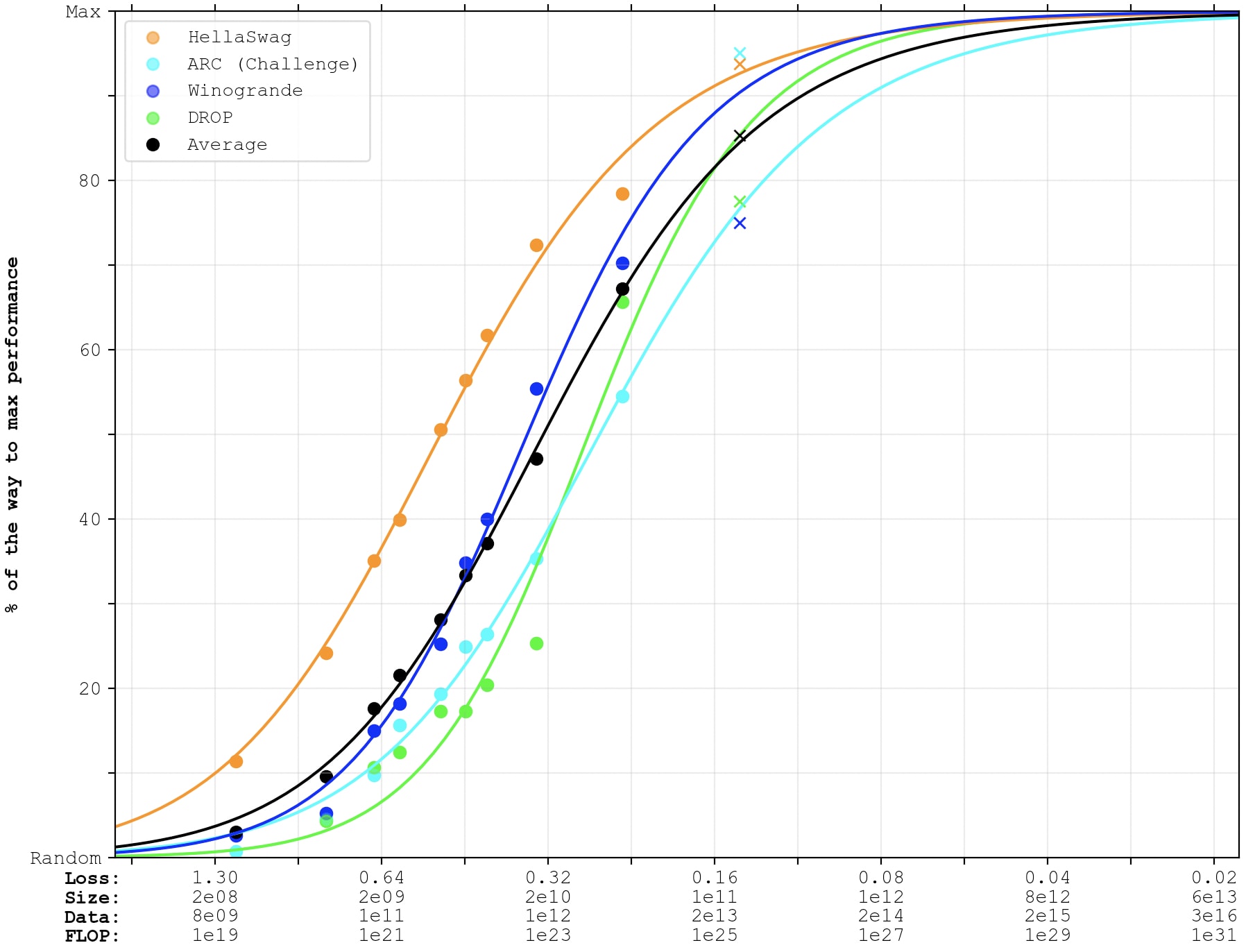GPT-4 outperforms expectations on ARC (AI2 Reasoning Challenge, challenge-set), which is grade-school multiple-choice science-questions.
GPT-4 underperforms expectations on WinoGrande (commonsense reasoning around pronoun resolution) and DROP (reading comprehension & arithmetic).
GPT-4 performs as-expected on HellaSwag (commonsense reasoning around everyday events).
It's average performance is right-on-trend. I think I would have expected GPT-4 to be better than 2e25-FLOP-equivalent, given algorithmic improvements and fine-tuning. So maybe a small amount under-trend. (Compared to this very noisy extrapolation of 4 almost-saturated benchmarks.)
Here's a graph where the sigmoids are also fit to the GPT-4 data points:
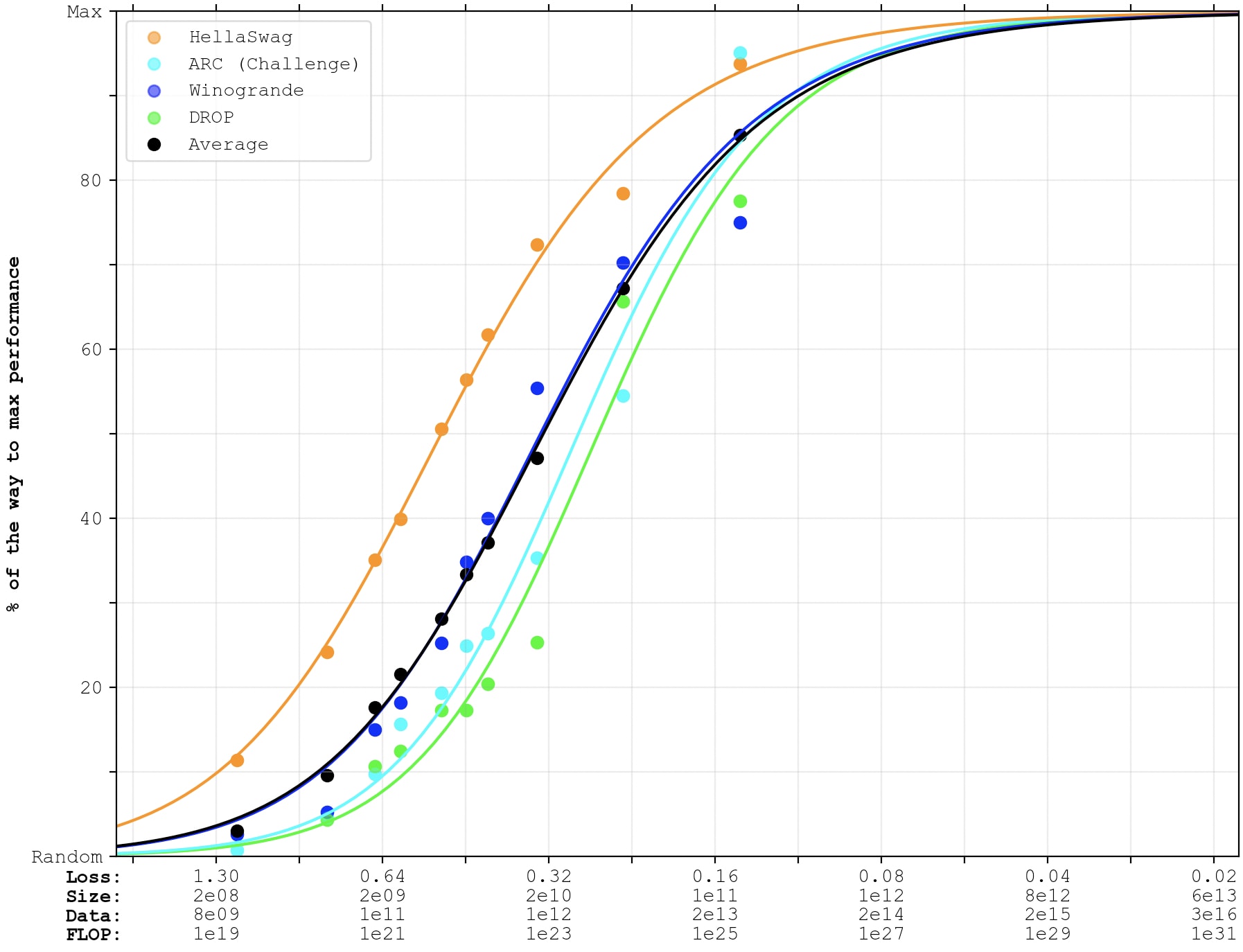Appendix — How I convert to Chinchilla loss
-------------------------------------------
The obvious way to estimate models' Chinchilla-equivalent loss would be to take the number of parameters (N) and the number of tokens (D) that were used to train each model and plug them into the Chinchilla scaling law: reducible loss = 406.4\*N^(-0.34) + 410.7\*D^(-0.28).
This is indeed what I do for PaLM-1.
But this would probably overestimate performance for the smaller GPT-3 models. All models in the GPT-3 paper were trained on the same 300B tokens, which is much more than what the Kaplan scaling laws recommend. This would boost Chinchilla-estimated performance by a fair bit. But those models probably didn't have the right hyperparameters to make use of all that data. (My impression is that Kaplan et al. estimated the wrong scaling laws because they were using suboptimal hyperparameters.)
I'll instead do a somewhat more complicated thing, where I estimate Chinchilla-equivalent loss as follows:
* I start from the empirical loss that each model in the GPT-3 paper is reported to have on their validation set.
* I then use the scaling law from Figure 3.1 of the [GPT-3 paper](https://arxiv.org/pdf/2005.14165.pdf) to estimate a Kaplan-equivalent compute. L = 2.57\*C^(-0.048) <-> C = (L/2.57)^(-1/0.048).
* I then use the scaling laws from equation B.9 in appendix B of the [Kaplan scaling law paper](https://arxiv.org/abs/2001.08361) to compute Kaplan-optimal number of tokens and parameters to use if you're training a model with that much compute.
+ There are multiple different scaling laws you could get from that paper, which says different things. I choose B.9 because it has the closest match to the parameters and tokens that the largest version of GPT-3 actually has. (It says that a model with GPT-3's compute should have had 164B parameters and 319B tokens rather than 175B and 300B.)
* I *then* use the Chinchilla law L = 406.4\*N^(-0.34) + 410.7\*D^(-0.28) to estimate how much loss a model like that would have gotten on Chinchilla's validation set.
* And I use the Chinchilla scaling laws to estimate the minimum number of compute you'd need to achieve that loss — and what split of parameters and data you should use.
The key assumptions that this relies on is (i) the accuracy of the B.9 scaling law for the way that the Kaplan authors were training models, and (ii) that the Kaplan authors and the Chinchilla authors were ~equally good at training capable models when the param/token-split was as-recommended by Kaplan.
Here's a figure over how this way of doing things correspond to mapping directly from parameters and data. Each dot is a model described in the GPT-3 paper. Their x- and y-positions represent (the logarithm of) the estimated FLOP needed to train a Chinchilla-optimal model with that level of performance, according to the two different methodologies.
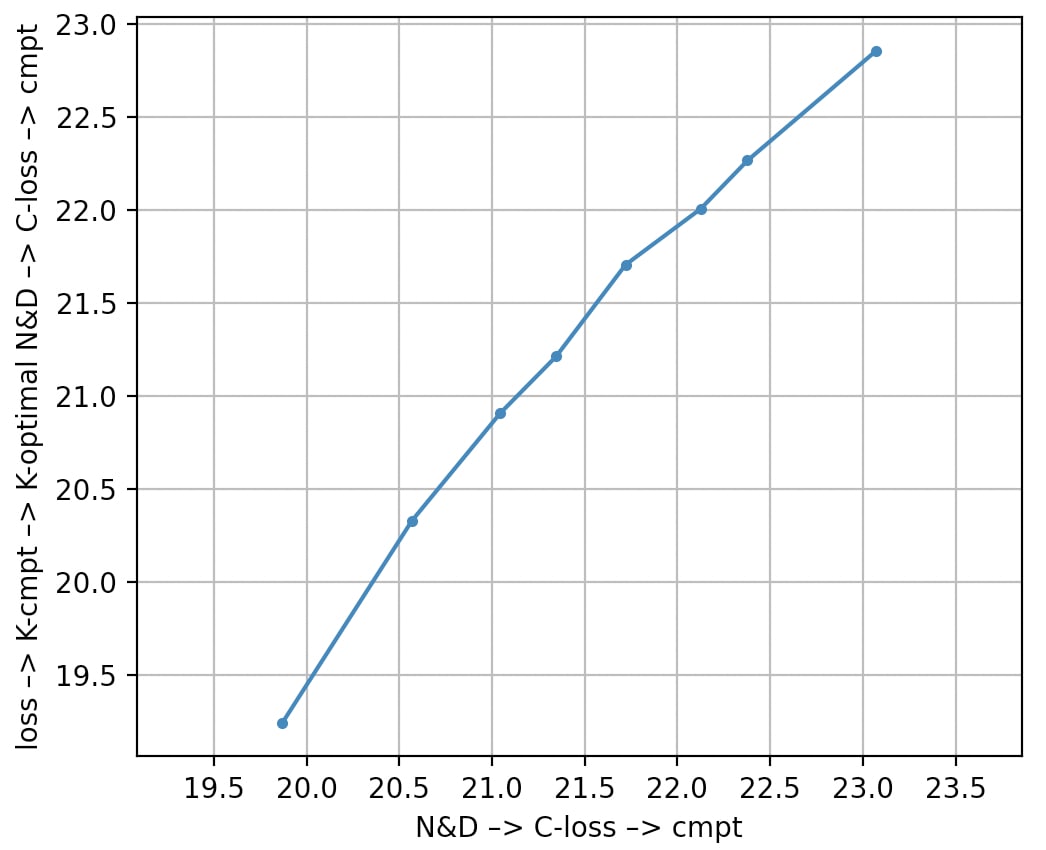In the middle, the two methodologies are briefly ~equivalent (the line almost goes through (21.5,21.5)). At the lower end, the two methodologies differ by a factor of ~4. At the top end (GPT-3 itself), they differ by a factor ~1.6.
1. **[^](#fnreft7s8oyceo7)**Previously, the "Data" annotations represented how much data you'd need to reach a certain level of performance (for the given model-size) *if you trained until convergence on that data*, for as many epochs as was needed. On this new graph, the "Data" annotation instead represents the total number of tokens you train on (only for a single epoch) — which means that the numbers are larger.
Why the discrepancy? Due to some "contradictions" in the Kaplan scaling laws (see my original post for more details), it was known that current compute-optimal scaling couldn't keep working for much longer. It looked more likely that the "train until convergence"-scaling laws would remain accurate. Furthermore, Kaplan scaling laws recommended training on fewer and fewer epochs as you scaled model-size, so in the near future, it seemed likely that models would converge in ~1 epoch. This meant that I could estimate *future* compute-budgets as 6\*#parameters\*#tokens with #parameters and #tokens estimated using the "train until convergence"-scaling laws. |
42e4d436-28b3-49b0-af80-175612b134e9 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | What if we approach AI safety like a technical engineering safety problem
*This post has been written for the second*[*Refine*](https://www.alignmentforum.org/posts/5uiQkyKdejX3aEHLM/how-to-diversify-conceptual-alignment-the-model-behind) *blog post day, at the end of the first week of iterating on ideas and concretely aiming at the alignment problem. Thanks to Adam Shimi, Paul Bricman, and Daniel Clothiaux for helpful discussion and comments.*
Introduction
============
This post aims to provide a general introduction to technical safety used in engineering related industries, describe some commonly used tools, and attempt to draw parallels between technical safety and AI safety. I am uncertain about the value of thinking in this framework towards building safe AI, but I expect this post to at least be useful as a [productive mistake](https://www.alignmentforum.org/posts/ADMWDDKGgivgghxWf/productive-mistakes-not-perfect-answers).
To prevent confusion:
* I use the term ‘technical safety’ to refer loosely to dealing with safety issues in engineering domains (I am only slightly familiar with technical safety in the upstream oil and gas sector).
* I use the term ‘AI safety’ to mean ensuring AI deployment does not lead to catastrophic consequences, similar to Steve Byrnes’ [definition](https://www.alignmentforum.org/posts/BeQcPCTAikQihhiaK/intro-to-brain-like-agi-safety-11-safety-alignment-but-they#11_1_Post_summary___Table_of_contents).
For the purpose of this post, I will assume a slow takeoff scenario where AI capabilities scales relatively slowly while never being fully aligned. At some point, a relatively powerful AI is created - powerful enough to do a lot of things but not powerful enough to instantly wipe us all out. Perhaps it has goals that do not generalize well, and starts optimizing for goals that are misaligned to our true goals. This leads to bad outcomes, perhaps events that unfortunately cause some fatalities. There continues to be a series of tragic accidents that increase in severity as the AIs get more and more capable over time, but we still have time to learn from these incidents and make safety improvements towards future systems.
The concepts in this post may not be directly applicable to an AI FOOM scenario, where the first AGI recursively improves itself and suddenly becomes extremely powerful and wipes out humanity, leaving us no opportunity to course-correct.
Technical safety in a nutshell
==============================
The principle of technical safety is built upon [Heinrich’s Law](https://en.wikipedia.org/wiki/Herbert_William_Heinrich#Heinrich's_law), which states “in a workplace, for every accident that causes a major injury, there are 29 accidents that cause minor injuries and 300 accidents that cause no injuries.” The numbers are unimportant, but the idea is that minimizing the near-misses (accidents that cause no injuries) leads to a reduction in minor accidents, and subsequently a reduction in major accidents. This can be illustrated with the [safety pyramid](https://www.safeopedia.com/definition/5053/safety-pyramid), also known as the safety triangle, below.
[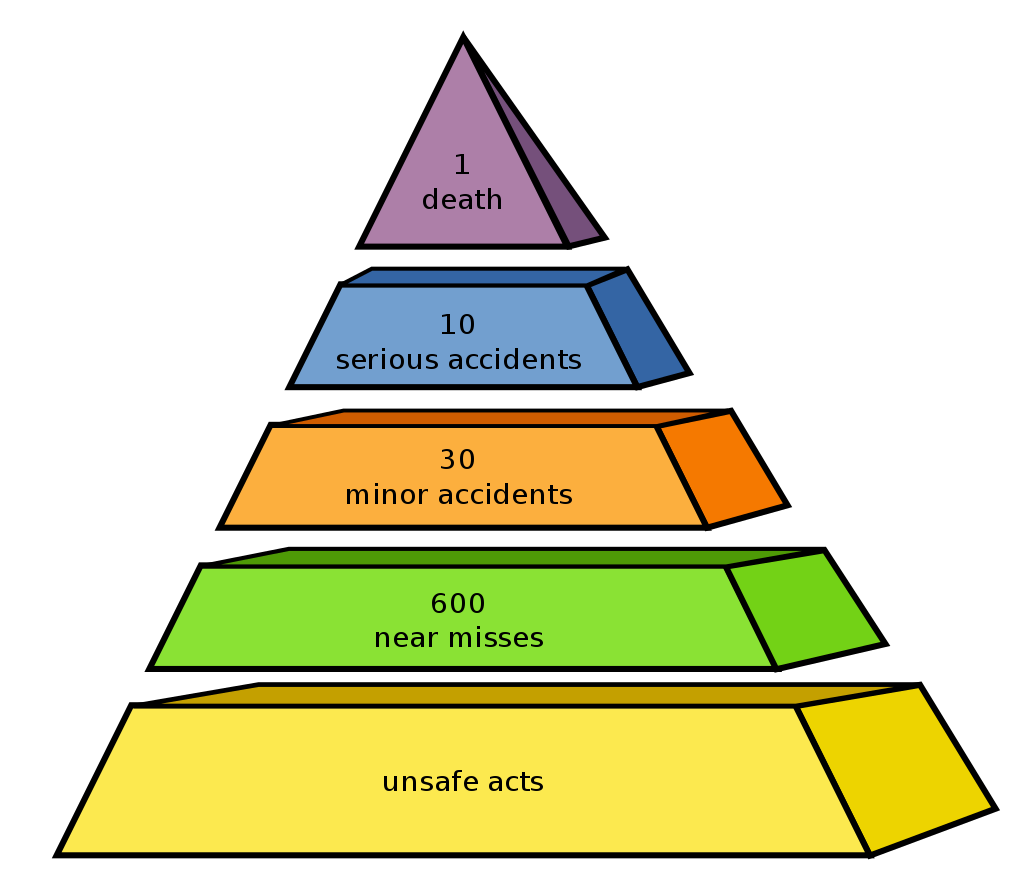](https://commons.wikimedia.org/wiki/File:Pyramide_des_risques.svg)
The bottom-most layer of the pyramid may be better represented by ‘hazards’ instead of ‘unsafe acts’ to also include potential dangers from non-behavioral causes. The top-most layer of the pyramid may also be better represented by ‘severe accidents’ instead of ‘death’ to also include extremely undesirable consequences other than loss of lives.
> [Hazard](https://www.safeopedia.com/definition/152/hazard) - A hazard is any agent (object, situation, or behavior - not in an ‘agentic’ sense) that has the potential to cause harm (injury, ill health, or damage to property or the environment), e.g. loose cables running on the floor that may lead to someone tripping over them is a trip hazard.
>
>
> [Risk](https://www.safeopedia.com/definition/475/risk-management-health-and-safety) - A risk describes the likelihood of potential harms from a known and identified source of hazard, e.g. there is a high risk of dangerous gas release from a corroded gas pipe.
>
>
Technical safety can roughly be summed up as effective risk management, which is about minimizing hazards by identifying and eliminating them, as well as reducing the probability that any hazards lead to undesirable consequences. While the complete elimination of every potential accident cannot be guaranteed, meaningful efforts can be expended to reduce dangerous risks to a reasonably low level.
Useful tools in technical safety
================================
To the best of my knowledge there is no one-size-fit-all technical safety framework used in all areas of engineering, but there exists a variety of tools that serve different purposes. As each tool may have its own weakness, other tools may be used to complement them.
HazID
-----
A [hazard identification (HazID)](https://www.safeopedia.com/definition/682/hazard-identification-study-hazid) study is a procedure used to uncover and identify hazards, as well as ensure appropriate mitigations are in place. HazIDs are commonly conducted prior to the execution of activities, from minor modification to a system (e.g. replacing old pipes) to the construction of a large facility (e.g. building a large plant).
> [Mitigation](https://www.safeopedia.com/definition/2768/mitigation) - A mitigation (also known as recovery measure) describes any type of action that is used to reduce the severity of a negative consequence of some kind, e.g. a fire extinguisher that reduces the impact of a fire.
>
>
HazIDs typically involve the following steps.
1. Identification of hazards according to categories, with the aid of guide words (e.g. severe weather, terrorist activity)
2. Identification of all possible causes and threats of the hazards
3. Determination of all potential credible undesirable consequences
4. Ranking of the hazards according to the [Risk Matrix](https://docs.google.com/document/d/1ntCKs1e2BQD-Ol08r-8eZd0wxMIkrc2WG1V7Tfbfau8/edit#heading=h.650sl569coj8)
5. Identification of mitigations in place
6. Recommendation of new mitigations to further reduce risks
7. Nominate action parties to each action
Risk Matrix
-----------
A [Risk Matrix](https://en.wikipedia.org/wiki/Risk_matrix) (also known as a Risk Assessment Matrix) is a method for evaluating both the probability and severity of a risk. The likelihood (probability of occurrence) and severity of a risk are orthogonal to each other. Different Risk Matrices employ different levels of likelihood and severity. An example of a 3x4 Risk Matrix is shown below.
[](https://commons.wikimedia.org/wiki/File:IC-Risk-Assessment-Matrix-Template.jpg)
Risks identified are ranked according to the Risk Matrix, such that more focus can be given to mitigate against higher risks (higher likelihood and severity) compared to lower risks (lower likelihood and severity).
Bow-tie analysis
----------------
A [bow-tie diagram](https://en.wikipedia.org/wiki/Bow-tie_diagram) is a diagram used to visualize risk management and preparedness. An example is shown below.
[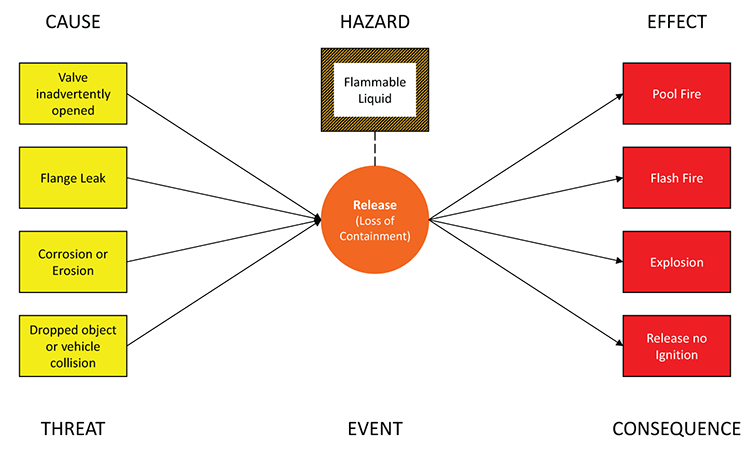](https://ispe.org/pharmaceutical-engineering/january-february-2018/bowtie-analysis-and-barrier-based-risk-management)
The center of the bow-tie diagram is the event (also known as top event), which is an occurrence that happens when a hazard is released. The left of the bow-tie lists the threats i.e. the possible causes of the hazard being released, while the right of the bow-tie lists the consequences i.e. the possible effects of the hazard being released. Preventive measures can be put in place to the left of the bow-tie to minimize the likelihood that the threats lead to the event, while mitigations can be put in place to the right of the bow-tie to minimize the severity of the consequences (both preventive measures and mitigations are also known as ‘barriers’).
Swiss cheese model
------------------
The [Swiss cheese model](https://en.wikipedia.org/wiki/Swiss_cheese_model) of accident causation is a model that illustrates that, although many barriers lie between hazards and accidents, there are flaws in each layer that, if aligned, can allow an accident to occur. An example of the model in the context of pandemic defense is shown below.
[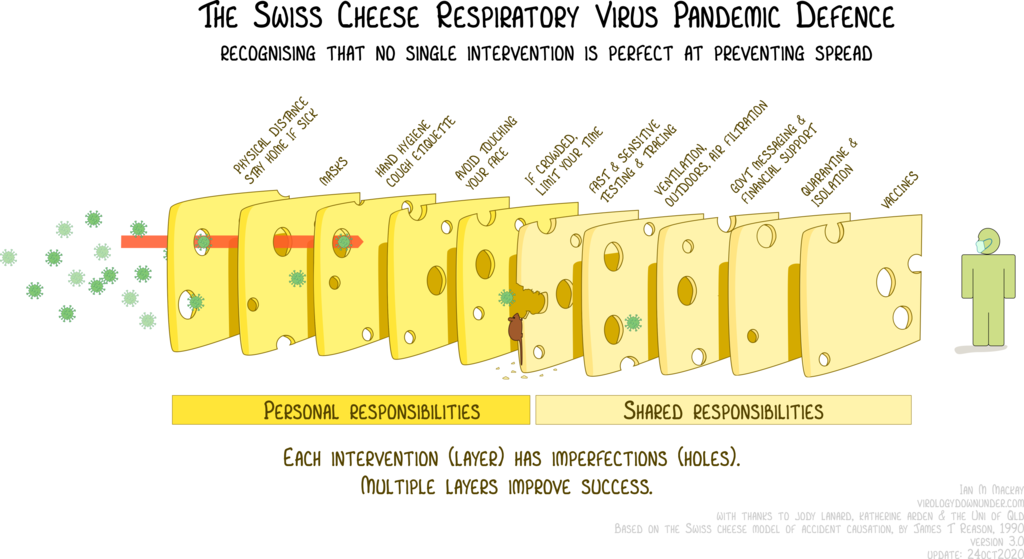](https://commons.wikimedia.org/wiki/File:SwissCheese_Respiratory_Virus_Interventions-ver3.0.png)
On the bright side, this model illustrates that with every additional barrier comes additional protection, and with sufficient numbers of highly effective barriers (layers with very few and small holes) the probability of a catastrophe can be reduced to very close to zero.
Change Management
-----------------
[Change Management](https://en.wikipedia.org/wiki/Change_management_(engineering)) (also known as Management of Change (MoC) or Change Request Management Process) is a the process of requesting, determining attainability, planning, implementing, and evaluating of changes to an existing system. The purpose is to ensure that as many possible viewpoints are used to minimize the chances of missing a hazard through a thorough review performed by a multidisciplinary team, as any change to a complex system may introduce new hazards that are not immediately obvious.
For example, an additional equipment to a facility may lead to a change in the operating conditions of the plant, add additional weight, or be in a way of an evacuation route. The Change Management process either aims to ensure that the new operating conditions are within the design limits of the facility, stay within the weight constraints, and do not disrupt the evacuation routes; or ensures that additional changes to the system are made to safely accommodate the changes caused by the introduction of the additional equipment. The changes are reviewed, documented, and communicated to all relevant parties.
Hierarchy of Controls
---------------------
The Hierarchy of Controls (also known as the [Hierarchy of Hazard Controls](https://www.safeopedia.com/2/1120/prevention-and-control-of-hazards/hazards/the-hierarchy-of-hazard-control)) is a simple ranking for the methods used to control hazards - from the most effective to those that are measures of last resort, as shown below.
[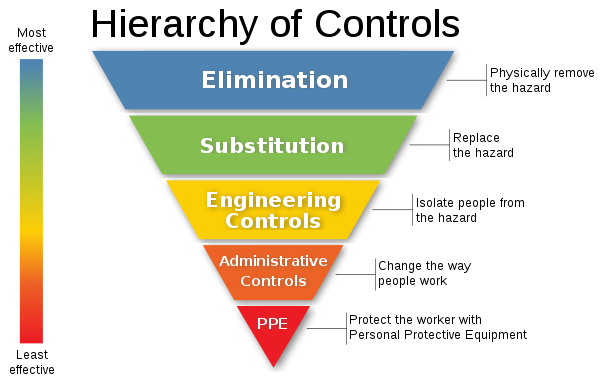](https://commons.wikimedia.org/wiki/File:NIOSH%E2%80%99s_%E2%80%9CHierarchy_of_Controls_infographic%E2%80%9D_as_SVG.svg)
The five hierarchies can be roughly described as follows:
1. Elimination: Wherever possible, eliminate the hazard such that it no longer exists
2. Substitution: If elimination is not feasible, replace a risker hazard with a less risky one, e.g. purchasing chemicals in pellet form rather than in powder form to prevent exposure through inhalation.
3. Engineering controls: If all of the above are insufficient, implement engineering controls that involve changes to the design of an equipment or process, e.g. using air ventilation to reduce airborne hazards.
4. Administrative controls: If all of the above are insufficient, implement administrative measures to reduce risks, e.g. implementing regular maintenance programs to minimize risks associated with worn out equipment.
5. Personal protective equipment (PPE): This is the last line of defense against adverse events, and only serves to prevent or minimize human injury in the event of an incident.
Are they useful for AI safety?
==============================
The tools described above are used for concrete bounded engineering problems and may not be directly useful for [unbounded](https://www.alignmentforum.org/posts/uhxpJyGYQ5FQRvdjY/abstracting-the-hardness-of-alignment-unbounded-atomic#Unboundedness__phase_transition_in_optimization) problems like AI safety, and its relevance may be limited to fairly predictable tool AIs instead of powerful agentic AIs. It may potentially even hinder us from actually thinking about the (widely contested) hard part of the problem. Nevertheless, I’ll attempt to explore aspects where these approaches may help - even if applying them to AI safety may seem forced.
HazID has a workflow similar to [training stories](https://www.alignmentforum.org/posts/FDJnZt8Ks2djouQTZ/how-do-we-become-confident-in-the-safety-of-a-machine#What_s_a_training_story_), where one describes the ‘training goal’ (a mechanistic description of the algorithms used in the development of the model) and the ‘training rationale’ (how the techniques employed will produce the desired goal). It aims to address several questions. How is this model built? What do we know and not know about the model? What will it have access to the real world, and what are its capabilities and limitations? What are the possible failure modes, how serious would they be, and how likely are they?
The bow-tie diagram raises questions on the undesirable consequences from hazards in a model. When an ML model starts behaving dangerously upon deployment, is there an off-switch button? What is the probability that it will work? Are there any merits to AI boxing?
The Swiss cheese model, used as the cover image for Dan Hendrycks’ [post](https://www.alignmentforum.org/s/FaEBwhhe3otzYKGQt) on Pragmatic AI Safety, helps to visualize preventive measures that can be used to prevent catastrophes. While it is recognized that all current proposals for AI safety are not fool-proof against a potential AI catastrophe, each proposal may serve as an additional imperfect barrier between the dangers of AI and the catastrophe. These barriers could be anything ranigng from [interpretability](https://www.lesswrong.com/tag/transparency-interpretability-ml-and-ai) tools to peer into the inner workings of the model, to the use of [quantilizers](https://www.lesswrong.com/tag/quantilization) to prevent hard optimization that exerbates Goodharting, to even training language models to not say things that [involves describing someone getting injured](https://www.lesswrong.com/posts/k7oxdbNaGATZbtEg3/redwood-research-s-current-project).
Assuming an existing ML model is mostly safe, the Change Management workflow could help raise questions about how changes to the model could cause it to behave in unexpected ways. Will the model be trained on more parameters, and what does that do to its behavior? Is there a possibility of [inverse scaling](https://www.lesswrong.com/posts/eqxqgFxymP8hXDTt5/announcing-the-inverse-scaling-prize-usd250k-prize-pool#What_is_Inverse_Scaling_)? Is additional data used to train the model? If so, do they contain hazards that were not previously present?
AI safety is difficult because capabilities are often a tradeoff with safety. Hierarchy of Controls illustrates that while we would eliminate all hazards in an ideal world, this may sometimes not be feasible. It may be because there is no known solution to eliminate them, or drastic measures incur a high cost of alignment tax, in which case one may resort to less ideal alternatives. For example, if we cannot eliminate dishonesty from a model, are there techniques we can employ to [elicit its latent knowledge](https://www.lesswrong.com/tag/eliciting-latent-knowledge-elk) instead?
While thinking about AI safety in a technical safety mindset may raise more questions than provide answers, with the questions raised being mostly just common-sense questions, it may be worth devising a tool or a workflow that reliably addresses these safety concerns. Good tools help create processes that are safe, and safe processes help safeguard systems against human negligence. |
2c4a247c-e238-4bca-9f20-01ba4816fc84 | trentmkelly/LessWrong-43k | LessWrong | Make-A-Video by Meta AI
Meta AI (Facebook) created a text-to-video model by taking a diffusion text-to-image model, adding temporal convolutional and attention layers, and fine-tuning it with video data (without text). They also use spatial and temporal super-resolution networks. Showing, to the surprise of no one who was paying attention, that our existing mostly homogeneous architectures can be easily extended to understand, to some extent, the structure of everyday reality. It's not the first text-to-video model, but it's much better than what came before. |
b96671a8-fd24-4c8f-9454-e2d6bf414d2e | trentmkelly/LessWrong-43k | LessWrong | Causal Scrubbing: a method for rigorously testing interpretability hypotheses [Redwood Research]
* Authors sorted alphabetically.
Summary: This post introduces causal scrubbing, a principled approach for evaluating the quality of mechanistic interpretations. The key idea behind causal scrubbing is to test interpretability hypotheses via behavior-preserving resampling ablations. We apply this method to develop a refined understanding of how a small language model implements induction and how an algorithmic model correctly classifies if a sequence of parentheses is balanced.
1 Introduction
A question that all mechanistic interpretability work must answer is, “how well does this interpretation explain the phenomenon being studied?”. In the many recent papers in mechanistic interpretability, researchers have generally relied on ad-hoc methods to evaluate the quality of interpretations.[1]
This ad hoc nature of existing evaluation methods poses a serious challenge for scaling up mechanistic interpretability. Currently, to evaluate the quality of a particular research result, we need to deeply understand both the interpretation and the phenomenon being explained, and then apply researcher judgment. Ideally, we’d like to find the interpretability equivalent of property-based testing—automatically checking the correctness of interpretations, instead of relying on grit and researcher judgment. More systematic procedures would also help us scale-up interpretability efforts to larger models, behaviors with subtler effects, and to larger teams of researchers. To help with these efforts, we want a procedure that is both powerful enough to finely distinguish better interpretations from worse ones, and general enough to be applied to complex interpretations.
In this work, we propose causal scrubbing, a systematic ablation method for testing precisely stated hypotheses about how a particular neural network[2] implements a behavior on a dataset. Specifically, given an informal hypothesis about which parts of a model implement the intermediate calculations required for a b |
ae0b37e7-6bfe-48b6-9767-817af26c707f | trentmkelly/LessWrong-43k | LessWrong | Meetup : Helsinki meetup Fri 5.8 18:00-
Discussion article for the meetup : Helsinki meetup Fri 5.8 18:00-
WHEN: 05 August 2011 06:00:00PM (+0300)
WHERE: Yliopistonkatu 5, Helsinki, Finland
Third Helsinki meetup. Venue is Café Picnic at Yliopistonkatu 5. Time is 18:00 onwards. ~5 confirmed attendees at the time of posting.
Join the LW Helsinki mailing list for updates on Helsinki meetups.
Discussion article for the meetup : Helsinki meetup Fri 5.8 18:00- |
787e29ea-9b8b-4d71-bf1a-e0bc2dcc8ed7 | trentmkelly/LessWrong-43k | LessWrong | Finding Useful Things
There is a very important problem that seems to have no real solution. How do you find useful things that you don't yet know about? This is sort of the problem of unknown unknowns, but not quite. That is only the first part. Once you have learned of the existence of a potentially useful thing, it is often not easy to evaluate if it is actually useful. Especially once you take into account all the time that you would need to invest into the thing before it can become useful.
The best way to evaluate if a thing is useful is to just learn the thing. I don't mean learn about the thing, which is of course also necessary, but to learn the actual thing.
For example, let's assume you want to improve how well you can visually imagine things. If you want to evaluate how much learning to draw can help you with mental visualization, then the best evidence you can gather is to learn drawing, and see for yourself. Ideally, make predictions beforehand of how you would expect this to change your ability to visualize.
However, even if you only want to evaluate the intermediate drawing skill level, this will take hundreds of hours.
When investing so much time you need to watch for the Sunk-Cost Fallacy and Rationalisations. After investing hundreds of hours, it might be hard to admit that they were all wasted. But of course, the problem is that ideally, we want to make a time investment only if it would be worth it.
Let's briefly step back and consider the first part of the problem again. How can you learn about important things? Even if someone thinks of googling "What should I do with my life?", they won't get any of the things that I right now think were important for me to find. If you google this phrase, there is nothing about AI alignment, nothing about 80,000 hours, and nothing about effective altruism. I am not saying that what you get is all bad. I actually think I got at least one good resource talking about what makes work satisfying. And I am not saying that everybod |
c86ab31f-913c-4bf6-8ad8-b1c73d703ab2 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Mauhn Releases AI Safety Documentation
Mauhn is a company doing research in AGI with a capped profit structure and an ethics board (represented by people from outside the company). Whereas there is a significant amount of AI/AGI safety research, there is still a gap of how to put this into practice for organizations doing research in AGI. We want to help closing this gap, with the following [blogpost](https://mauhn.com/blog/release-ai-safety-documentation) (written for an audience not familiar with AI Safety) and associated links to relevant documents:
[**Mauhn AI Safety Vision**](https://mauhn.com/mauhn-ai-safety-vision)
This summarizes the most important points Mauhn will commit to towards building safe (proto-)AGI systems
[**Ethics section of Mauhn’s statutes**](https://mauhn.com/statutes-ethics-board)
The statutes of Mauhn define the legal structure of the ethics board
[**Declaration of Ethical Commitment**](https://mauhn.com/declaration-of-ethical-commitment)
Every founder, investor and employee sign the declaration of ethical commitment before starting a collaboration with Mauhn
We hope that other organizations will adopt similar principles or derivatives thereof. We were a bit short on bandwidth for this first version, but we want to include more feedback from the AI safety community for future versions of these documents. Please drop me an e-mail (berg@mauhn.com), if you'd like to contribute to next versions of this work. Probably we'll update the documentation once per year. |
12c0d4a5-9432-4d75-840b-4b57379488eb | trentmkelly/LessWrong-43k | LessWrong | Probabilistic Oracle Machines and Nash Equilibria
Read the paper draft here.
I'm working on a a paper with Benja introducing probabilistic oracle machines and showing how they are equivalent with Nash equilibria, as I initially argued in a comment. This variant of the reflective oracles was originally suggested in Paul Christiano's comment. We might end up submitting a later version of this paper to a conference. Any comments or criticism are very welcome! |
96cb535e-99d1-426e-ab0c-a6786c77cebb | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Differential technology development: preprint on the concept
**Summary**
We have published a [preprint](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4213670) of a paper describing the concept of differential technology development and exploring when and how its implementation may be viable. This manuscript has been in the works at FHI for a while, so we would love your feedback!
Authors: Jonas B. Sandbrink, Hamish Hobbs, Jacob L. Swett, Allan Dafoe, Anders Sandberg
**Further details**
Nick Bostrom articulated the concept of Differential Technological Development in Superintelligence. This concept, and the concept of differential progress more broadly, has already been fairly widely discussed and written about, but within a limited community. This includes [here on the EA Forum](https://forum.effectivealtruism.org/topics/differential-progress). The concept is typically used to argue that it would be beneficial to accelerate risk-reducing technological progress and retard risk-increasing technological progress, to manage potentially catastrophic or existential technological risks such as those from advanced AI systems and biotechnologies.
With this paper, we attempt to thoroughly explore the concept, make it accessible to the broader research and policy community, and explore the contexts in which its implementation is likely to be viable. To our knowledge, this is the first academic article seeking to comprehensively articulate a principle of differential technology development.
In the paper we argue that:
* Responsible innovation efforts to date have largely focussed on shaping individual technologies.
* However, as demonstrated by the preferential advancement of low-emission technologies, certain technologies reduce risks from other technologies or constitute low-risk substitutes.
* Governments and other relevant actors may leverage risk-reducing interactions across technology portfolios to mitigate risks beyond climate change.
* We adapt Nick Bostrom’s original concept to propose a responsible innovation principle of “differential technology development”, which calls relevant actors to leverage risk-reducing interactions between technologies by affecting their relative timing.
* Thus, it may be beneficial to delay risk-increasing technologies and preferentially advance risk-reducing defensive, safety, or substitute technologies.
* Implementing differential technology development requires the ability to anticipate or identify impacts and intervene in the relative timing of technologies.
* We find that both are sometimes viable and that differential technology development may still be usefully applied even late in the diffusion of some harmful technologies.
* A principle of differential technology development may inform government research funding priorities and technology regulation, as well as philanthropic research and development funders and corporate social responsibility measures.
* Differential technology development may be particularly promising to mitigate potential catastrophic risks from emerging technologies like synthetic biology and artificial intelligence.
While writing the paper, we considered alternative terms to describe the concept of differential technology development. Our leading alternatives were “responsible innovation sequencing” or “differential progress”. However, in the end we decided that differential technological development was the best fit for integrating this article into the responsible innovation literature. That said, we do see merit to either defining technology broadly to include “not only gadgets but also methods, techniques and institution design principles” or to extending the concept to include forms of differential development beyond technology development.
Amongst other things, paper outlines four relevant categories of technologies:
* **Risk increasing technologies** cause negative societal impacts by causing insidious harm or through their potential to cause a catastrophe.
* **Safety technologies** reduce or prevent negative societal impacts by modifying risk-increasing technologies.
* **Defensive technologies** decrease risks from risk-increasing technologies without modifying these technologies.
* **Substitute technologies** achieve similar benefits to a risk-increasing technology while featuring less risk.
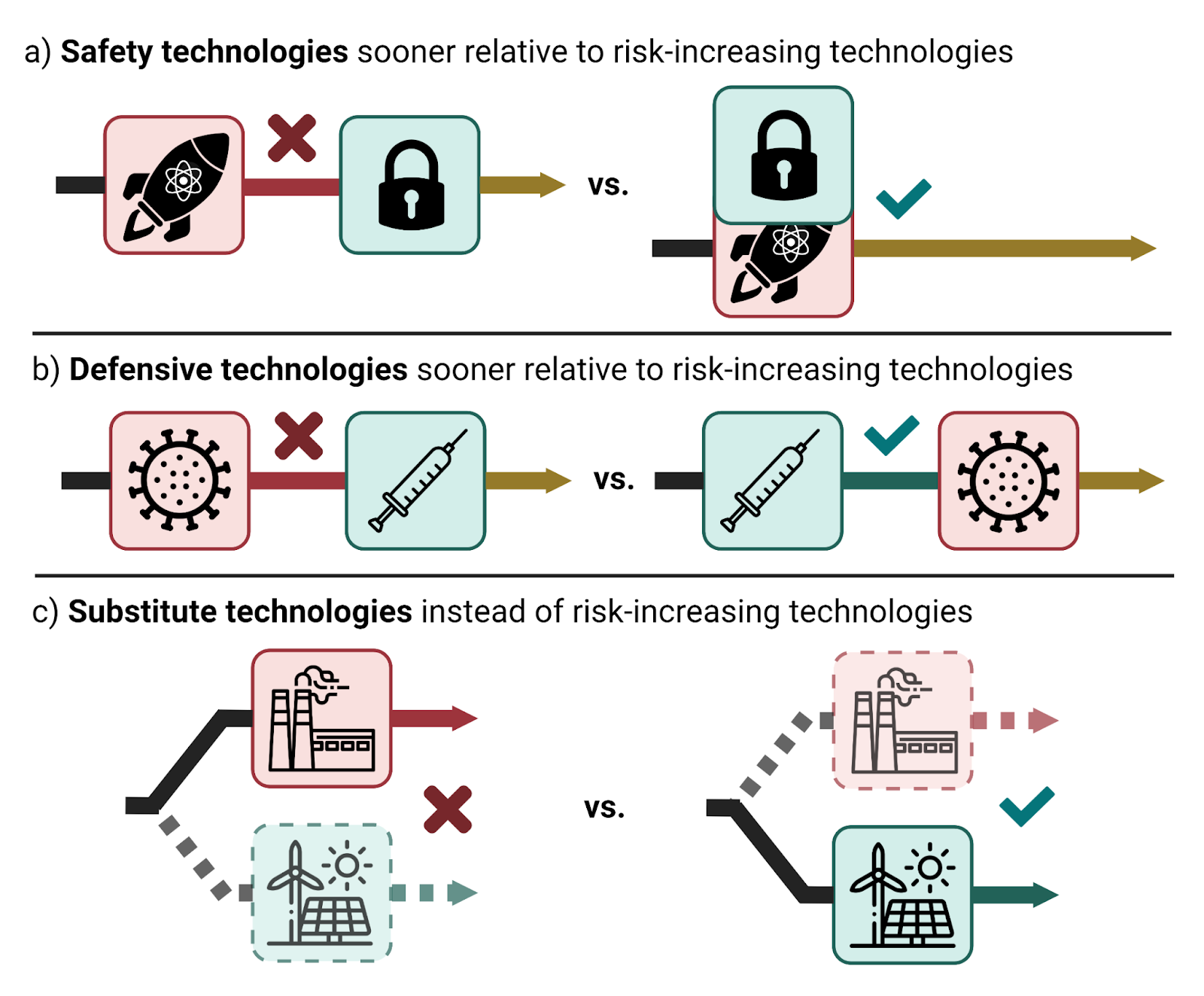
We hope that this paper can provide a useful framing for discussions and future research about differential technology development, as well as generating ideas for how it may be best implemented in practice.
**Preprint link:** https://papers.ssrn.com/sol3/papers.cfm?abstract\_id=4213670
**Acknowledgements**
We are grateful to Michael Aird, Markus Anderljung, Jan Ole Ernst, Ben Garfinkel, Sihao Huang, Matthijs Maas, Cassidy Nelson, and James Wagstaff for useful discussions and comments on the manuscript. Furthermore, we are also grateful for feedback from participants of work-in-progress meetings of the Future of Humanity Institute and Centre for the Governance of AI. We thank Shrestha Rath for help with formatting and organising references. Jonas B. Sandbrink’s doctoral research is funded by Open Philanthropy. Hamish Hobbs’ contribution to the paper largely occurred while funded as a Research Scholar at the Future of Humanity Institute. |
bb050e27-9f02-4953-a947-2245cad9cbba | trentmkelly/LessWrong-43k | LessWrong | Impact of " 'Let's think step by step' is all you need"?
Title from: https://twitter.com/arankomatsuzaki/status/1529278581884432385.
This is not quite a linkpost for this paper.
Nonetheless, the abstract is:
> Pretrained large language models (LLMs) are widely used in many sub-fields of natural language processing (NLP) and generally known as excellent few-shot learners with task-specific exemplars. Notably, chain of thought (CoT) prompting, a recent technique for eliciting complex multi-step reasoning through step-by-step answer examples, achieved the state-of-the-art performances in arithmetics and symbolic reasoning, difficult system-2 tasks that do not follow the standard scaling laws for LLMs. While these successes are often attributed to LLMs' ability for few-shot learning, we show that LLMs are decent zero-shot reasoners by simply adding ``Let's think step by step'' before each answer. Experimental results demonstrate that our Zero-shot-CoT, using the same single prompt template, significantly outperforms zero-shot LLM performances on diverse benchmark reasoning tasks including arithmetics (MultiArith, GSM8K, AQUA-RAT, SVAMP), symbolic reasoning (Last Letter, Coin Flip), and other logical reasoning tasks (Date Understanding, Tracking Shuffled Objects), without any hand-crafted few-shot examples, e.g. increasing the accuracy on MultiArith from 17.7% to 78.7% and GSM8K from 10.4% to 40.7% with an off-the-shelf 175B parameter model. The versatility of this single prompt across very diverse reasoning tasks hints at untapped and understudied fundamental zero-shot capabilities of LLMs, suggesting high-level, multi-task broad cognitive capabilities may be extracted through simple prompting. We hope our work not only serves as the minimal strongest zero-shot baseline for the challenging reasoning benchmarks, but also highlights the importance of carefully exploring and analyzing the enormous zero-shot knowledge hidden inside LLMs before crafting finetuning datasets or few-shot exemplars.
Consider the following image, t |
6442872e-85d4-47c7-b8fa-fa9e106339b8 | trentmkelly/LessWrong-43k | LessWrong | Common vs Expert Jargon
tldr: Jargon always has a complexity cost, but you can put effort into making a concept more accessible, and it's especially valuable to put that effort in for terms that you'd like to be used by layfolk, or that you expect to be used a lot in spaces where you expect lots of layfolk to be reading/participating.
I. Lessons from Game Design
Magic the Gathering deals a lot with complexity. Each year, new abilities and rules are added to the game. This gives experienced players the chance to constantly discover new things, but it comes with some issues.
First, it makes the game harder for new players (the game kept growing more complex over time, raising the amount of information a new player had to process at once)
And second, even for experienced players: each instance of complexity is a cost. Players (both new and old) can only handle so much, and some forms of complexity are less fun than others. (For example, forcing players to do a lot of book-keeping, rather than letting them make interesting strategic decisions)
Six years ago, their creative director wrote about a new paradigm of Magic design. One of their solutions was to pay careful attention to how they spent complexity points in ways that affected new players.
Three examples:
1. Common Cards
In Magic, when you buy a new pack, 11 cards are "common", 3 are "uncommon" and one is "rare". Experienced players buy lots of cards and can have access to lots of rares, but new players generally just buy a few cards, so most of their cards are common. Therefore, the complexity of the cards at common determines how much complexity newcomers have to deal with.
2. Keywords
One way to reduce "effective complexity" is to bundle concepts together in a keyword. Instead of saying "this creature deals damage to each of the creatures blocking it and then deals the remainder of its damage to the player", it just says "Trample". There's an initial cost of learning what Trample means, but afterwards, every time you see the |
42a42bce-c699-4259-b333-9cf06868230f | trentmkelly/LessWrong-43k | LessWrong | King and Princess
Sometimes Lily tells me that she is a princess and wants me to be the king. We'll sit together, me on the throne and her at my side, and we'll hear cases from our people. An imaginary petitioner describes the situation to me, and I relay it to Lily. We consult about the situation, consider the circumstances, and issue a judgement.
For example, at the the most recent session a restaurant owner came to us unable to make rent because of the shutdown. We decided that they only owed part of the money, and that they could wait to pay it until they were open again.
Lily playing a different princess game, with orb and sceptre.
It's not an especially accurate depiction of royalty, or a system of government I want to encourage, but it's fun talking through people's situations and figuring out what seems fair. |
59d5c918-d324-4f0f-bf2f-1ea191f48d58 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | A Problem About Bargaining and Logical Uncertainty
Suppose you wake up as a paperclip maximizer. Omega says "I calculated the millionth digit of pi, and it's odd. If it had been even, I would have made the universe capable of producing either 1020 paperclips or 1010 staples, and given control of it to a staples maximizer. But since it was odd, I made the universe capable of producing 1010 paperclips or 1020 staples, and gave you control." You double check Omega's pi computation and your internal calculator gives the same answer.
Then a staples maximizer comes to you and says, "You should give me control of the universe, because before you knew the millionth digit of pi, you would have wanted to pre-commit to a deal where each of us would give the other control of the universe, since that gives you 1/2 probability of 1020 paperclips instead of 1/2 probability of 1010 paperclips."
Is the staples maximizer right? If so, the general principle seems to be that we should act as if we had precommited to a deal we would have made in ignorance of logical facts we actually possess. But how far are we supposed to push this? What deal would you have made if you didn't know that the first digit of pi was odd, or if you didn't know that 1+1=2?
On the other hand, suppose the staples maximizer is wrong. Does that mean you also shouldn't agree to exchange control of the universe before you knew the millionth digit of pi?
To make this more relevant to real life, consider two humans negotiating over the goal system of an AI they're jointly building. They have a lot of ignorance about the relevant logical facts, like how smart/powerful the AI will turn out to be and how efficient it will be in implementing each of their goals. They could negotiate a solution now in the form of a weighted average of their utility functions, but the weights they choose now will likely turn out to be "wrong" in full view of the relevant logical facts (e.g., the actual shape of the utility-possibility frontier). Or they could program their utility functions into the AI separately, and let the AI determine the weights later using some formal [bargaining solution](/lw/2x8/lets_split_the_cake_lengthwise_upwise_and/) when it has more knowledge about the relevant logical facts. Which is the right thing to do? Or should they follow the staples maximizer's reasoning and bargain under the pretense that they know even less than they actually do?
**Other Related Posts:** [Counterfactual Mugging and Logical Uncertainty](/lw/179/counterfactual_mugging_and_logical_uncertainty/), [If you don't know the name of the game, just tell me what I mean to you](/lw/2xb/if_you_dont_know_the_name_of_the_game_just_tell/) |
7e2138b1-c2ae-4a4c-acb5-e1a7d75d4cd9 | trentmkelly/LessWrong-43k | LessWrong | Under-acknowledged Value Differences
I've been reading a lot of the recent LW discussions on politics and gender, and noticed that people rarely bring up or explicitly acknowledge that different people affected by some political or gender issue have different values/preferences, and therefore solving the problem involves a strong element of bargaining and is not just a matter of straightforward optimization. Instead, we tend to talk as if there is some way to solve the problem that's best for everyone, and that rational discussion will bring us closer to finding that one best solution.
For example, when discussing gender-related problems, one solution may be generally better for men, while another solution may be generally better for women. If people are selfish, then they will each prefer the solution that's individually best for them, even if they can agree on all of the facts. (It's unclear whether people should be selfish, but it seems best to assume that most are, for practical purposes.)
Unfortunately, in bargaining situations, epistemic rationality is not necessarily instrumentally rational. In general, convincing others of a falsehood can be useful for moving the negotiated outcome closer to one's own preferences and away from others', and this may be done more easily if one honestly believes the falsehood. (One of these falsehoods may be, for example, "My preferred solution is best for everyone.") Given these (subconsciously or evolutionarily processed) incentives, it seems reasonable to think that the more solving a problem resembles bargaining, the more likely we are to be epistemicaly irrationality when thinking and talking about it.
If we do not acknowledge and keep in mind that we are in a bargaining situation, then we are less likely to detect such failures of epistemic rationality, especially in ourselves. We're also less likely to see that there's an element of Prisoner's Dilemma in participating in such debates: your effort to convince people to adopt your preferred solution is cos |
f49c5322-88f9-4ef2-a0bd-b5faa4e79954 | trentmkelly/LessWrong-43k | LessWrong | [META] ajax.googleapis.com
Apparently, by not unblocking scripts for "ajax.googleapis.com", I am unable to vote on LW. I generally dislike enabling scripting for domains that are used in many places -- unblocking Google APIs would unblock it everywhere, not just here -- so the result is that I am no longer voting. I suspect that I am not alone in this.
(Apparently I can't post without enabling it either. Looks like I'll have make an exception and do the script-on-script-off dance after all. Whee.) |
484264d5-1cdd-4f53-8533-9608694845bd | trentmkelly/LessWrong-43k | LessWrong | Hand-writing MathML
When I write posts I use raw HTML. Yes, the modern thing to do is probably Markdown, but HTML was designed for hand-coding and still works well for that if you don't want anything especially fancy. But what if you want math?
Previously when I've wanted to do math I've written it out as fixed-width ASCII:
e^(-7t)
In my editor this looks like:
<pre>
e^(-7t)
</pre>
This is reasonably readable, works anywhere, and I like the aesthetic. I probably should have stuck with it, but after helping publish a report that included some traditionally-formatted equations and learning that MathML has been supported cross-browser since the beginning of the year (thanks Igalia!), I decided to try it out. I wrote the equations in two recent posts in it, and am mixed on the experience.
It definitely does look nicer:
e−7t
On the other hand, here's how it looks in my editor:
<math display=block>
<msup>
<mi>e</mi>
<mrow>
<mo>-</mo>
<mn>7</mn>
<mi>t</mi>
</mrow>
</msup>
</math>
There's a small learning curve on when to use the different tags, but mostly it's just very verbose. And I think, needlessly so? That "-" is an operator, "7" is a number, and "t" is an identifier could all be the default. Then I could just write:
<math display=block>
<msup>
e
<mrow>
-7t
</mrow>
</msup>
</math>
And we could remove many uses of <mrow> too: a series of characters without whitespace separating them could be already treated as a group:
<math display=block>
<msup>
e
-7t
</msup>
</math>
Of course if you wanted to use a character for a non-traditional purpose you could still mark it up as one, but a good set of defaults would make MathML much more pleasant. I'd hate to have to read and write blog posts as:
<word><lt>h</lt><lt>e</lt><lt>l</lt><lt>l</lt><lt>o</lt></word>
<word><lt>w</lt><lt>o</lt><lt>r</lt><lt>l</lt><lt>d</lt></word>
<pnct>.</pnct>
I know I'm about 25 years too late on this, and I'm happy that a pure-HTML solution is now cro |
4b257572-6954-4c5f-b51c-99693cfbd2ea | LDJnr/LessWrong-Amplify-Instruct | LessWrong | "Central theme in: Immoral Mazes Sequence, but this generalizes. When looking to succeed, pain is not the unit of effort, and money is a, if not the, unit of caring. One is not always looking to succeed. Here is a common type of problem. You are married, and want to take your spouse out to a romantic dinner. You can choose the place your spouse loves best, or the place you love best. A middle manager is working their way up the corporate ladder, and must choose how to get the factory to improve its production of widgets. A middle manager must choose how to improve widget production. He can choose a policy that improperly maintains the factory and likely eventually it poisons the water supply, or a policy that would prevent that but at additional cost. A politician can choose between a bill that helps the general population, or a bill that helps their biggest campaign contributor. A start-up founder can choose between building a quality product without technical debt, or creating a hockey stick graph that will appeal to investors. You can choose to make a gift yourself. This would be expensive in terms of your time and be lower quality, but be more thoughtful and cheaper. Or you could buy one in the store, which would be higher quality and take less time, but feel generic and cost more money. You are cold. You can buy a cheap scarf, or a better but more expensive scarf. These are trade-offs. Sometimes one choice will be made, sometimes the other. Now consider another type of problem. You are married, and want to take your spouse out to a romantic dinner. You could choose a place you both love, or a place that only they love. You choose the place you don’t love, so they will know how much you love them. After all, you didn’t come here for the food. A middle manager must choose how to improve widget production. He can choose a policy that improperly maintains the factory and likely eventually poisons the water supply, or a policy that would prevent that at no additional cost. He knows that when he is up for promotion, management will want to know the higher ups can count on him to make the quarterly numbers look good and not concern himself with long term issues or what consequences might fall on others. If he cared about not poisoning the water supply, he would not be a reliable political ally. Thus, he chooses the neglectful policy. A politician can choose between two messages that affirm their loyalty: Advocating a beneficial policy, or advocating a useless and wasteful policy. They choose useless, because the motive behind advocating a beneficial policy is ambiguous. Maybe they wanted people to benefit! A start-up founder can choose between building a quality product without technical debt and creating a hockey stick graph with it, or building a superficially similar low-quality product with technical debt and using that. Both are equally likely to create the necessary graph, and both take about the same amount of effort, time and money. They choose the low-quality product, so the venture capitalists can appreciate their devotion to creating a hockey stick graph. You can choose between making a gift and buying a gift. You choose to make a gift, because you are rich and buying something from a store would be meaningless. Or you are poor, so you buy something from a store, because a handmade gift wouldn’t show you care. Old joke: One Russian oligarch says, “Look at my scarf! I bought it for ten thousand rubles.” The other says, “That’s nothing, I bought the same scarf for twenty thousand rubles.” What these examples have in common is that there is a strictly better action and a strictly worse action, in terms of physical consequences. In each case, the protagonist chooses the worse action because it is worse. This choice is made as a costly signal. In particular, to avoid motive ambiguity. If you choose something better over something worse, you will be suspected of doing so because it was better rather than worse. If you choose something worse over something better, not only do you show how little you care about making the world better, you show that you care more about people noticing and trusting this lack of caring. It shows your values and loyalties. In the first example, you care more about your spouse’s view of how much you care about their experience than you care about your own experience. In the second example, you care more about being seen as focused on your own success than you care about outcomes you won’t be responsible for. In the third example, you care more about being seen as loyal than about improving the world by being helpful. In the fourth example, you care about those making decisions over your fate believing that you will focus on the things they believe the next person deciding your fate will care about, so they can turn a profit. They don’t want you distracted by things like product quality. In the old joke, the oligarchs want to show they have money to burn, and that they care a lot about showing they have lots of money to burn. That they actively want to Get Got to show they don’t care. If someone thought the scarf was bought for mundane utility, that wouldn’t do at all. One highly effective way to get many people to spend money is to give them a choice to either spend the money, or be slightly socially awkward and admit that they care about not spending the money. Don’t ask what the wine costs, it would ruin the evening. The warning of Out to Get You is insufficiently cynical. The motive is often not to get your resources, and is instead purely to make your life worse. Conflict theorists are often insufficiently cynical. We hope the war is about whether to enrich the wealthy or help the people. Often the war is over whether to aim to destroy the wealthy, or aim to hurt the people. In simulacra terms, these effects are strongest when one desires to be seen as motivated on level three, but these dynamics are potentially present to an important extent for motivations at all levels. Note also that one is not motivated by this dynamic to destroy something unless you might plausibly favor it. If and only if everybody knows you don’t care about poisoning the river, it is safe to not poison it. This generalizes to time, to pain, to every preference. Hence anything that wants your loyalty will do its best to ask you to sacrifice and destroy everything you hold dear, because you care about it, to demonstrate you care more about other things. Worst of all, none of this assumes a zero-sum mentality. At all. Such behavior doesn’t even need one. If one has a true zero-sum mentality, as many do, or one maps all results onto a zero-sum social dynamic, all of this is overthinking. All becomes simple. Your loss is my gain, so I want to cause you as much loss as possible. Pain need not be the unit of effort if it is the unit of scoring. The world would be better if people treated more situations like the first set of problems, and less situations like the second set of problems. How to do that?"
The above is a chunk of text from a post created by a user on the website LessWrong.
Can you break this down into the top 5 most important points for me.
1. Costly Signaling: The text discusses the concept of costly signaling, where individuals or entities choose a less beneficial or more damaging course of action to demonstrate their loyalty, dedication, or to send a specific message. This concept is used in various scenarios, from personal relationships to corporate decision-making and political actions.
2. Motive Ambiguity: The text also discusses the concept of motive ambiguity. This is the idea that choosing a beneficial action can lead to uncertainty about the individual's motives - were they acting out of self-interest or because it was the right thing to do? Choosing a detrimental action removes this ambiguity and clearly demonstrates the individual's priorities.
3. Sacrifice for Loyalty: The text suggests that entities (individuals, corporations, governments) may ask for sacrifices or destructive actions to test loyalty. This is seen as a demonstration that the individual values the entity more than what they are asked to sacrifice.
4. Zero-Sum Mentality: The text also mentions the zero-sum mentality, where one's gain is another's loss. It suggests that this mentality simplifies the dynamics discussed, as causing loss to others directly benefits the individual.
5. Encouragement for Change: The final point is a call for change. The text suggests that the world would be better if people treated more situations like the first set of problems (trade-offs) and fewer situations like the second set of problems (costly signaling and motive ambiguity). It's a call for more ethical and considerate decision-making.
Elaborate on how the zero-sum mentality simplifies the dynamics of costly signaling and motive ambiguity.
The zero-sum mentality is the belief that resources are limited, and therefore, one person's gain is inherently another person's loss. This perspective simplifies the dynamics of costly signaling and motive ambiguity because it reduces all actions and decisions to a straightforward calculation of personal gain and loss.
In the context of costly signaling, a zero-sum mentality would mean that any sacrifice or cost borne by an individual is directly benefiting someone else. The costlier the signal, the more valuable it is perceived to be by others. For example, if a manager chooses a policy that harms the environment but boosts short-term profits, they might be signaling their commitment to the company's financial success over other considerations. In a zero-sum view, the company's gain (in terms of profit) is seen as a direct result of the environment's loss.
Regarding motive ambiguity, a zero-sum mentality eliminates the ambiguity by assuming all actions are motivated by self-interest. If a beneficial action is taken, it's assumed to be for personal gain; if a detrimental action is taken, it's assumed to be to cause loss to others for personal gain. For instance, if a politician advocates a wasteful policy, a zero-sum perspective would assume they're doing so to benefit themselves or their allies at the expense of the general population.
In both cases, the zero-sum mentality simplifies the dynamics by eliminating the need to consider complex motives or long-term consequences. It reduces all decisions to a binary calculation of immediate personal gain or loss. However, this oversimplification can lead to harmful decisions and overlook the potential for actions that can benefit all parties involved.
Reflect on the potential consequences and implications of adopting a non-zero-sum mentality in the contexts of costly signaling and motive ambiguity. How might this shift in perspective impact individual decision-making and societal dynamics?
Adopting a non-zero-sum mentality, which acknowledges that resources and outcomes aren't strictly limited and that one person's gain doesn't have to mean another's loss, can significantly alter the dynamics of costly signaling and motive ambiguity.
In the context of costly signaling, a non-zero-sum perspective might reduce the perceived need for harmful or wasteful actions to demonstrate loyalty or commitment. If success isn't seen as a finite resource, individuals might feel less compelled to harm others or themselves to signal their dedication. For example, a manager might choose a policy that balances environmental sustainability with profitability, signaling their commitment to both the company and broader societal welfare. This could lead to more sustainable and ethical decision-making at an individual and organizational level.
Regarding motive ambiguity, a non-zero-sum mentality could foster a more nuanced understanding of motivations, recognizing that actions can be driven by a mix of self-interest and altruism. This could lead to a more charitable interpretation of others' actions and reduce the tendency to assume the worst. For instance, a politician advocating a beneficial policy might be seen as genuinely trying to help the population, rather than merely seeking personal gain. This could potentially foster greater trust and cooperation in societal and political interactions.
Overall, a shift from a zero-sum to a non-zero-sum mentality could have profound implications for societal dynamics. It could promote more cooperative and mutually beneficial interactions, reduce conflict and competition, and foster a more empathetic and understanding society. However, it's important to note that this shift would require a significant change in societal norms and values, and wouldn't necessarily eliminate all forms of costly signaling or motive ambiguity. |
17404cc4-f947-4869-9d1e-ae0818cc25eb | trentmkelly/LessWrong-43k | LessWrong | Jaynes-Cox Probability: Are plausibilities objective?
Is the objectivity of plausibility assignments assumed in the Jaynes-Cox formulation of probability theory?
This is what I mean by “the objectivity of plausibility assignments”:
A and B are propositions. (A|B) is the plausibility of A given that B is true and is represented with a real number as a result of our desiderata. Is the quantity (A|B) uniquely determined by A and B?
If this is the case, is this one of the assumptions that we make (implicitly or explicitly) or can this be derived from our desiderata?
If not, then in what sense is the plausibility of A given B objective?
Thank you |
6dbb92e9-11cb-44e4-aea3-272fcc086e14 | trentmkelly/LessWrong-43k | LessWrong | Visualise your own probability of an AI catastrophe: an interactive Sankey plot
I wanted to help people learning about AI visualise their own probabilities of things going wrong. This Shiny app defaults to using the probabilities from Carlsmith's (2022) report from Open Philanthropy. You can enter your own probabilities and see how it cashes out. At the bottom, it translates your probability of doom into something more palpable (using a table from Leigh, 2021). There's an untidy Github repo for the project here, if you have any suggestions (or add them to the comments). Have fun.
https://noetel.shinyapps.io/carlsmith/ |
f89a5155-92e1-4c7f-9bae-165b5f74668a | trentmkelly/LessWrong-43k | LessWrong | Are Intelligence and Generality Orthogonal?
A common presupposition seems to be that intelligent systems can be classified on two axes:
* Intelligence (low to high)
* Generality (narrow to general)
For example, AlphaGo is presumably fairly intelligent, but quite narrow, while humans are both quite intelligent and quite general.
A natural hypothesis would be that these two axes are orthogonal, such that any combination of intelligence and generality is possible.
Surprisingly, I know of nobody who has explicitly spelt out this new orthogonality thesis, let alone argued for or against it.
(The original orthogonality thesis only states that level of intelligence and terminal goals are independent. It does not talk about the narrow/general distinction.)
MIRI seems to be not very explicit about this, too. On Arbital there are no separate entries for the notions of intelligence and generality, and the article on General Intelligence is rather vague. It appears to mix the two notions together. What I find most surprising: the article suggests that chimpanzees are substantially less general than humans. But it seems to me that chimpanzees are merely less intelligent than humans, not less general by a relevant amount. Just like AlphaGo's internal predecessor was presumably not less general than AlphaGo, just less intelligent.
What makes AlphaGo fairly narrow, apparently, is that it has a fairly small cognitive domain. I would even go so far and argue that most animals are highly general agents, since they have what MIRI calls a real-world domain.
Evolutionary speaking, constant optimization for high generality makes sense. Over several hundred million years of evolution, animals had to contionously survive in a diverse, noisy, and changing environment, and they had to compete with other animals. Under such evolutionary presurres, narrow specialization would quickly be punished. So most animals have evolved to be very general, just not always very intelligent. (Insects, presumably, are an example of fairly hi |
b342ee47-9064-4a23-9f32-b360bdf24366 | trentmkelly/LessWrong-43k | LessWrong | Movie posters
Life involves anticipations. Hopes, dreads, lookings forward.
Looking forward and hoping seem pretty nice, but people are often wary of them, because hoping and then having your hopes fold can be miserable to the point of offsetting the original hope’s sweetness.
Even with very minor hopes: he who has harbored an inchoate desire to eat ice cream all day, coming home to find no ice cream in the freezer, may be more miffed than he who never tasted such hopes.
And this problem is made worse by that old fact that reality is just never like how you imagined it. If you fantasize, you can safely bet that whatever the future is is not your fantasy.
I have never suffered from any of this enough to put me off hoping and dreaming one noticable iota, but the gap between high hopes and reality can still hurt.
I sometimes like to think about these valenced imaginings of the future in a different way from that which comes naturally. I think of them as ‘movie posters’.
When you look fondly on a possible future thing, you have an image of it in your mind, and you like the image.
The image isn’t the real thing. It’s its own thing. It’s like a movie poster for the real thing.
Looking at a movie poster just isn’t like watching the movie. Not just because it’s shorter—it’s just totally different—in style, in content, in being a still image rather than a two hour video. You can like the movie poster or not totally independently of liking the movie.
It’s fine to like the movie poster for living in New York and not like the movie. You don’t even have to stop liking the poster. It’s fine to adore the movie poster for ‘marrying Bob’ and not want to see the movie. If you thrill at the movie poster for ‘starting a startup’, it just doesn’t tell you much about how the movie will be for you. It doesn’t mean you should like it, or that you have to try to do it, or are a failure if you love the movie poster your whole life and never go. (It’s like five thousand hours long, after all.)
Th |
5585fd5a-0329-4b98-bc55-dcdc2aa651e4 | trentmkelly/LessWrong-43k | LessWrong | Trying to measure AI deception capabilities using temporary simulation fine-tuning
Rationale
It is hard to ensure that a powerful AI model gives good answers just because it believes these answers are true. Deceptive models could give the expected answers for whatever instrumental reasons. And sycophants may be telling the truth only when they expect it to be approved.
Being sincere is a constraint. Sincere models, like for humans, are not optimized for adopting what they perceive as poor or misleading reasoning. They don't easily lie. They are likely poor simulators.
Core assumption :
* Fine-tuning an AI to simulate other models will usually be measurably harder if the AI is sincere.
This looks especially plausible when the models to simulate produce worse answers. While this assumption looks intuitive for humans as we will see, it is unsure for AI systems and remains to be empirically tested.
If the assumption holds, using what I call Temporary Simulation Fine-Tuning (TSFT), we can extract some metrics for deception on various kinds of models. Moreover, we could test the model's sincerity on questions for which we don't even know the answer. The aim here is to estimate whether the model is sincere, not whether its outputs are true or false.
Fractal (Wiki Commons, https://commons.wikimedia.org/wiki/File:Fractal_Detail_No_1_by_Optoskept.jpg)
Intuition behind
The core assumption seems plausible for humans.
Consider a person that deeply cares about truth and that normally never lies, who is somehow forced to accomplish a task that requires lying (e.g. selling a product that no one would mindfully buy if described correctly). This person will likely have a hard time adapting, and it is likely to be long and to significantly impact his or her character.
On the other side, it is easier to identify a liar in situations where he gains from lying. A regular liar will adapt more quickly when put in an environment where saying falsehoods is suddenly incentivized. A liar likely adapts more his discourse to what people want to hear, instrumental |
fc4a3c95-159a-48b9-af5c-49818e526afc | trentmkelly/LessWrong-43k | LessWrong | AXRP Episode 25 - Cooperative AI with Caspar Oesterheld
YouTube link
Imagine a world where there are many powerful AI systems, working at cross purposes. You could suppose that different governments use AIs to manage their militaries, or simply that many powerful AIs have their own wills. At any rate, it seems valuable for them to be able to cooperatively work together and minimize pointless conflict. How do we ensure that AIs behave this way - and what do we need to learn about how rational agents interact to make that more clear? In this episode, I’ll be speaking with Caspar Oesterheld about some of his research on this very topic.
Topics we discuss:
* Cooperative AI
* … vs standard game theory
* Do we need cooperative AI if we get alignment?
* Cooperative AI and agent foundations
* A Theory of Bounded Inductive Rationality
* Why it matters
* How the theory works
* Relationship to logical induction
* How fast does it converge?
* Non-myopic bounded rational inductive agents?
* Relationship to game theory
* Safe Pareto Improvements
* What they try to solve
* Alternative solutions
* How safe Pareto improvements work
* Will players fight over which safe Pareto improvement to adopt?
* Relationship to program equilibrium
* Do safe Pareto improvements break themselves?
* Similarity-based Cooperation
* Are similarity-based cooperators overly cliqueish?
* Sensitivity to noise
* Training neural nets to do similarity-based cooperation
* FOCAL, Caspar’s research lab
* How the papers all relate
* Relationship to functional decision theory
* Following Caspar’s research
Daniel Filan: Hello, everybody. In this episode, I’ll be speaking with Caspar Oesterheld. Caspar is a PhD student at Carnegie Mellon where he’s studying with Vincent Conitzer. He’s also the assistant director of the Foundations of Cooperative AI Lab or FOCAL. For links to what we’re discussing, you can check the description of this episode and you can read the transcript at axrp.net. All right. So welco |
87f82894-b44f-4881-9cff-ca4534aaffbc | trentmkelly/LessWrong-43k | LessWrong | Festival Stats 2024
Each year ( 2014, 2015, 2016, 2017, 2018, 2019, 2023) I put out a list of how many dance weekends, festivals, camps, and long dances contra bands and callers are doing. I don't really know why I do this, but it's about an hours work on top of that I'm already collecting for trycontra.com/events so I might as well keep doing it!
In 2023 I saw that the total number of events (107) was down 20% from 2019 (132), where a lot didn't come back from the pandemic. This year we're back up to pre-pandemic levels, with 131, which is great to see!
Bands
River Road 9 Countercurrent 8 Playing with Fyre 8 Drive Train 7 Hot Coffee Breakdown 7 The Engine Room 7 Stomp Rocket 6 Toss the Possum 6 Wild Asparagus 6 The Dam Beavers 6 Eloise &co 5 Elixir 4 Kingfisher 3 Nova 3 Open Band 3 Stove Dragon 3 The Mean Lids 3 The Moving Violations 3 The Stringrays 3 The Syncopaths 3 3 Wheel Drive 2 Audacious 2 Contra Sutra 2 Contraforce 2 Contrasaurus 2 Good Company 2 Joyride 2 Lake Effect 2 Lighthouse 2 Meadowhawk 2 Notorious 2 Pimento Mori 2 Raise the Roof 2 Riptide 2 Rushfest 2 Supertrad 2 The Faux Paws 2 The Ice Cream Truckers 2 The Latter Day Lizards 2
Callers
Will Mentor 19 Gaye Fifer 15 Alex Deis-Lauby 13 Lisa Greenleaf 12 Bob Isaacs 10 Seth Tepfer 9 George Marshall 8 Susan Petrick 7 Terry Doyle 7 Cis Hinkle 5 Janine Smith 5 Lindsey Dono 5 Mary Wesley 5 Nils Fredland 5 Adina Gordon 4 Maia McCormick 4 Steve Zakon-Anderson 4 Wendy Graham Settle 4 Ben Sachs-Hamilton 3 Charlie Turner 3 Darlene Underwood 3 Devin Pohly 3 Emily Rush 3 Isaac Banner 3 Jacqui Grennan 3 Koren Wake 3 Michael Karcher 3 River Rainbowface Abel 3 Scott Higgs 3 Chris Page 2 Claire Takemori 2 Dereck Kalish 2 Donna Hunt 2 Frannie Marr 2 Jeremy Korr 2 Katie Zanders 2 Liz Nelson 2 Louise Siddons 2 Open Calling 2 Open calling 2 Rick Mohr 2 Sarah Kaiser 2 Susan Kevra 2 Susan Michaels 2 Warren Doyle 2
Comment via: facebook, lesswrong, mastodon |
952f0874-c46a-4801-8e7e-e51d4154646c | trentmkelly/LessWrong-43k | LessWrong | Outer vs inner misalignment: three framings
A core concept in the field of AI alignment is a distinction between two types of misalignment: outer misalignment and inner misalignment. Roughly speaking, the outer alignment problem is the problem of specifying an reward function which captures human preferences; and the inner alignment problem is the problem of ensuring that a policy trained on that reward function actually tries to act in accordance with human preferences. (In other words, it’s the distinction between aligning the “outer” training signal versus aligning the “inner” policy.) However, the distinction can be difficult to pin down precisely. In this post I’ll give three and a half definitions, which each come progressively closer to capturing my current conception of it. I think Framing 1 is a solid starting point; Framings 1.5 and 2 seem like useful refinements, although less concrete; and Framing 3 is fairly speculative. For those who don’t already have a solid grasp on the inner-outer misalignment distinction, I recommend only reading Framings 1, 1.5 and 2.
For the purposes of this document, I’ll focus on the reinforcement learning setting, since that’s the case where the distinction is clearest. However, the same concepts could also apply in a supervised or self-supervised context, if we replace references to “policies” and “reward functions” with “models” and “loss functions”. The extent to which the inner alignment problem will appear in non-RL contexts is an important open question in alignment.
Framing 1: types of behavioral misalignment
Consider training an RL policy until it’s getting high reward in its training environment. Suppose we then evaluate the policy in a different test environment, without retraining it; what will happen? Consider four possibilities:
1. The policy behaves incompetently. This is a capability generalization failure.
2. The policy behaves in a competent and desirable way. This is aligned behavior.
3. The policy behaves in a competent yet undesirable way whi |
4a39f4e6-f15f-4811-9e99-3262e3a46d6b | trentmkelly/LessWrong-43k | LessWrong | My research agenda in agent foundations
Since the beginning of 2022, I've been doing independent AI alignment research in agent foundations. The stage and scope of research that I am doing is roughly equivalent to starting a PhD program.
It has been somewhat popular for people in alignment to write up research agendas over the last couple of years. I've been vaguely hesitant to post a research agenda for myself, because to me it sounds like a claim of something stronger than is true. Specifically it feels like a relatively strong claim that I intend to be doing these specific things for a long time, that I expect to get results, and maybe even that I'm part of some larger organization. It's not clear to me how other readers interpret this, but hopefully I can dispel that impression with sufficient disclaimers throughout.
The purposes of this post are to:
* produce for myself a clearer statement of what I am doing and why,
* make myself more legible to any other interested parties, and
* invite some criticism of my plans.
I've written in the semi-casual tone common to LessWrong posts, and mentioned many things throughout that may not make sense if you come from outside the rationalist community.
Context
Like many people in AI alignment, I am not working in the standard academic track, so it's worthwhile to give more context. If you just want to know concretely what I work on, skip down to the section on research problems.
All is flux
As implied above, I expect lots of things about my research to change continuously. I have no external commitments that would heavily incentivize me to complete any particular task, so I stop doing something as soon as I decide it's not valuable anymore. (There are obvious downsides to this as well, but I'm comfortable with my ability to navigate them.)
Still learning
My current level of math ability is something like halfway through the first semester of grad school. My most natural inclination in researching would be, step 1: learn all math. (I would never get t |
49c2da14-6303-494a-a20b-29f4f432a4ef | StampyAI/alignment-research-dataset/special_docs | Other | Overcoming Individual Limitations Through Distributed Computation: Rational Information Accumulation in Multigenerational Populations..
Topics in Cognitive Science 14 (2022) 550–573
© 2022 The Authors. Topics in Cognitive Science published by Wiley Periodicals LLC on behalf of Cognitive
Science Society.
ISSN: 1756-8765 online
DOI: 10.1111/tops.12596
This article is part of the topic “Extending Rationality,” Emmanuel M. Pothos and Timothy
J. Pleskac (Topic Editors).
Overcoming Individual Limitations Through Distributed
Computation: Rational Information Accumulation in
Multigenerational Populations
Mathew D. Hardy,aPeaks M. Krafft,bBill Thompson,a,c
Thomas L. Griffithsa,c
aDepartment of Psychology, Princeton University
bCreative Computing Institute, University of the Arts London
cDepartment of Computer Science, Princeton University
Received 28 February 2021; received in revised form 29 November 2021; accepted 30 November 2021
Abstract
Many of the computational problems people face are difficult to solve under the limited time and
cognitive resources available to them. Overcoming these limitations through social interaction is one of
the most distinctive features of human intelligence. In this paper, we show that information accumula-
tion in multigenerational social networks can be produced by a form of distributed Bayesian inference
that allows individuals to benefit from the experience of previous generations while expending little
cognitive effort. In doing so, we provide a criterion for assessing the rationality of a population that
extends traditional analyses of the rationality of individuals. We tested the predictions of this analysis in
two highly controlled behavioral experiments where the social transmission structure closely matched
the assumptions of our model. Participants made decisions on simple categorization tasks that relied on
and contributed to accumulated knowledge. Success required these microsocieties to accumulate infor-
mation distributed across people and time. Our findings illustrate how in certain settings, distributed
Mathew D. Hardy and P. M. Krafft contributed equally.
Correspondence should be sent to Thomas L. Griffiths, Department of Psychology, Princeton University,
Princeton, NJ 08540, USA. Email: tomg@princeton.edu
This is an open access article under the terms of the Creative Commons Attribution License, which permits
use, distribution and reproduction in any medium, provided the original work is properly cited.
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
M. D. Hardy et al. / Topics in Cognitive Science 14 (2022) 551
computation at the group level can pool information and resources, allowing limited individuals to
perform effectively on complex tasks.
Keywords: Bayesian inference; Cultural evolution; Collective intelligence; Distributed computation;
Group rationality; Social learning
1. Introduction
Humans’ success and survival depends on our ability to make intelligent choices and judg-
ments. Like other animals, we must do so under hard constraints on the resources available tomake our decisions (Griffiths, 2020). Not only is our cognition constrained by our restricted
brain capacity, but we also must learn from limited and often incomplete data. This is true
not only in our finite childhoods and lifespans but also in the limited opportunities we haveto learn many crucial facts—to survive, we need to learn about what life-threatening dangersexist in our immediate environments (from chemicals to electric outlets to poisonous insectsand animals).
Given these constraints, understanding how people routinely form accurate beliefs on com-
plex topics is a central focus of research in cognitive science, psychology, and economics(Simon, 1990). However, people rarely develop beliefs alone—rather, they learn from theknowledge, experiences, and opinions of other people. By doing so, individuals can obtainuseful information while expending little physical or cognitive effort. A particularly impor-tant focus of previous research has been on the effects of social learning when repeated oversuccessive groups of individuals, such as child–parent learning, formal education, and otherdomains where knowledge is transmitted from older members of a popvvvulation to youngerlearners. In these multigenerational settings, knowledge can accumulate over time in a pop-ulation, allowing individuals to extend their cognitive skills by learning from others (see,e.g., Almaatouq, Alsobay, Yin, & Watts, 2021; Almaatouq et al., 2020; Belikov, Rzhetsky, &Evans, 2020; Caldwell, Atkinson, & Renner, 2016; Frey & Goldstone, 2018; Galesic, Olsson,Dalege, van der Does, & Stein, 2021; Goldstone, Wisdom, Roberts, & Frey, 2013; Hazła,Jadbabaie, Mossel, & Rahimian, 2021; Kempe & Mesoudi, 2014b; Mesoudi, 2016; Mesoudi& Thornton, 2018; Miton & Charbonneau, 2018; Riedl, Kim, Gupta, Malone, & Woolley,
2021; Rzhetsky, Foster, Foster, & Evans, 2015; Salhab, Ajorlou, & Jadbabaie, 2020; Wis-
dom, Song, & Goldstone, 2013; Wojtowicz & DeDeo, 2020, for recent overviews and relatedstudies). Crucially, the constraints and structure of interpersonal transmission often lead col-lective knowledge and learning to differ from individual outcomes (Kirby, Tamariz, Cornish,& Smith, 2015; Ravignani, Thompson, Grossi, Delgado, & Kirby, 2018; Silvey, Kirby, &Smith, 2019).
The accumulation of collective knowledge through sequential social learning is known
ascultural transmission (Boyd & Richerson, 1985) and is thought to underpin cumulative
cultural evolution (Mesoudi, 2011). Cultural transmission has been studied experimentallyin a number of paradigms, including the evolution of simple technologies such as knots(Muthukrishna, Shulman, Vasilescu, & Henrich, 2014), virtual fishing nets (Derex, Beugin,
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
552 M. D. Hardy et al. / Topics in Cognitive Science 14 (2022)
Godelle, & Raymond, 2013), stone tools (Morgan et al., 2015), or arrowheads (Mesoudi &
O’Brien, 2008); artificial languages (Kirby, Cornish, & Smith, 2008); jigsaw puzzles (Kempe
& Mesoudi, 2014a); and social phenomena like stereotypes (Martin et al., 2014).
Theories of cultural evolution have primarily been underpinned by a Darwinian framework
grounded in parallels and disanalogies with biological evolution (Boyd & Richerson, 1985;Mesoudi & Whiten, 2008; Nettle, 2020; Smolla et al., 2020). These frameworks have shownthat the accumulation of knowledge and technology can be understood as a form of evolution,helping to situate cultural evolution within the biological and evolutionary sciences (Laland,Sterelny, Odling-Smee, Hoppitt, & Uller, 2011). While successful, evolutionary frameworkshave been difficult to connect to psychological theory (Heyes, 2018) and are therefore difficultto connect with the concepts of computation that are central to the study of cognition andintelligence (Nettle, 2020). Similarly, while research on collective intelligence has extensivelydocumented the advantages of groups over individuals, the computational structure of thesocial processes that lead to long-term, open-ended collective intelligence remain unclear(Krafft et al., 2016).
One way to measure the accumulation of knowledge in populations is by viewing collec-
tive behavior as distributed computation, a process that allows groups to “store and processthe cumulative innovations and collaborations of generations of individuals” (Smaldino &Richerson, 2013). From this perspective, knowledge accumulation becomes a problem ofdistributed Bayesian inference, extending probabilistic models of inference in individuals to
the group setting (Chater, Tenenbaum, & Yuille, 2006; Griffiths, Chater, Kemp, Perfors, &Tenenbaum, 2010; Harper, 2009). This perspective establishes a formal connection between
cultural evolution and statistical models of social learning used in cognitive science (Cushman
& Gershman, 2019) and economics (Acemoglu, Dahleh, Lobel, & Ozdaglar, 2011).
In this paper, we build on this work and show how social learning can facilitate rational
action that goes beyond the direct experience of individuals. That is, we show how socialinteractions allow limited individuals to improve their cognition without modifying their timeand resource constraints. We do this in part by offering a formal criterion for population
rationality : the probability that any individual in a network makes a particular decision is the
same as the probability of that decision under a Bayesian posterior distribution conditionedonallthe information observed by the population (Foster, 2018, cf.).
To develop our account, we first formulate a model of individual social learning based
on a simple heuristic that requires only limited social observation. We then show that undercertain conditions, groups of individuals following this heuristic will accumulate informationthrough distributed Bayesian inference. This model offers insight into how social learning canextend the cognitive abilities of limited individuals—while conditioning on all accumulatedinformation would be too complex for any individual, social interactions allow individualsto benefit from this information while expending little cognitive effort. That is, populationrationality can be achieved by networks of highly limited individuals.
We tested our model in two large-scale experiments where participants made basic catego-
rization decisions in simple multigenerational networks. In both experiments, the decisionsof participants at one generation were propagated to those in the next generation, allowingus to study belief accumulation and transmission in a controlled laboratory setting. We found
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
M. D. Hardy et al. / Topics in Cognitive Science 14 (2022) 553
that a substantial proportion of the data from these experiments are well-approximated by
our model. Furthermore, by comparing participants’ choices with the Bayesian posterior dis-
tribution conditioned on the information observed by the entire population, we were able to
quantify accumulation in our experimental networks relative to the Bayesian ideal. Our find-
ings thus offer a clear demonstration of how limited individuals can use simple social learning
heuristics to make intelligent inferences.
2. Information accumulation through social sampling
Here, we describe a simple social learning heuristic we call social sampling that yields
distributed Bayesian inference at the population level. That is, populations of individuals fol-
lowing social sampling will accumulate information in a way that is consistent with Bayesian
inference, allowing individuals to offload computation to the group and make accurate infer-
ences with little cognitive effort. We focus on multigenerational settings, where individu-
als are organized in discrete “batches” and learn from those in the previous generation. We
also assume individuals observe others’ true beliefs and do not need to discard or modify
any observations.
2.1. Model
Information accumulation by rational agents is specified by Bayes’ rule, which indicates
how a probability distribution over hypotheses θ(known as the prior distribution) should be
updated (to the posterior distribution) in light of evidence D:
p(θ|D)=p(D|θ)·p(θ)
p(D). (1)
In this paper, we extend this characterization of optimal belief updating from individuals to
groups (see Chater, Oaksford, Hahn, & Heit, 2010; Griffiths, Kemp, & Tenenbaum, 2008;
Tenenbaum, Kemp, Griffiths, & Goodman, 2011, for reviews of Bayesian models of individ-
ual cognition). Viewing a population as a single agent is a perspective with roots in many tra-
ditions, including philosophy (Easwaran, 2019), economics (Gale & Kariv, 2003), economics
(Hayek, 1945), organization science (Argote, 2012), cognitive science (Krafft, Shmueli, Grif-
fiths, Tenenbaum, & Pentland, 2021), anthropology (Hutchins, 1995), collective intelligence
(Engel et al., 2015; Woolley, Chabris, Pentland, Hashmi, & Malone, 2010), ethology (Sasaki
& Pratt, 2011), and computer science (Lynch, 1996; Shoham & Leyton-Brown, 2009). Cru-
cially, as we will show, rational action at the population level requires only limited compu-
tation by individuals—while each individual agent may follow a simple heuristic, the infor-
mation accumulated by the population as a whole makes it possible for those individuals to
act rationally.
We consider the simple case where individuals reason about a set of that can be either true
or false, represented as a binary feature vector x. Individuals beliefs are shaped by pieces
of evidence Y=(y1,..., yT) that arrive over time. At each time t, individuals observe J
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
554 M. D. Hardy et al. / Topics in Cognitive Science 14 (2022)
pieces of information about feature i, with Pi=P(yij t=1|xi=0)=θi0ifxi=0a n d Pi=
P(yij t=1|xi=1)=θi1ifxi=1. For simplicity, we let Sit=/summationtextJ
j=11(yijt=1) be the number
of positive observations made about feature iat time t.
We assume that the popularity of a belief among members of the population acts as a
prior distribution over beliefs for new individuals drawing inferences about the environ-
ment. Specifically, an individual afirst chooses a member of the population a/primeto learn from
uniformly at random.1The learner athen accepts or rejects their companion’s decision da/prime,i,t−1
with probability proportional to ( θi,da/prime,i,t−1)Sit(1−θi,da/prime,i,t−1)J−Sit, the likelihood of the evidence
thataobserves at time tbased on the beliefs of a/prime.
In an infinite population of individuals following this strategy, the probability that an indi-
vidual makes a categorization decision about feature iis equal to the posterior probability of
that decision conditioned on the evidence observed by the entire population:
pi,t+1=P(xi=1|yi,·,≤t). (2)
This result establishes that social sampling is a valid algorithm for distributed Bayesian infer-
ence in infinitely large populations, satisfying our criterion for population rationality (see
Supplementary Electronic Material (SEM) for proof). The finite population case is more com-
plex, but social sampling can be seen to be formally equivalent to a class of sequential Monte
Carlo algorithms known as particle filters (Crisan & Doucet, 2002; Murphy, 2012). Social
sampling can thus support Bayesian inference in expectation in finite populations, allowing
groups of bounded individuals to accumulate knowledge over time.
2.2. Measuring accumulation relative to optimal inference
The model we have outlined illustrates how a simple social decision-making heuristic
can lead to optimal information aggregation over generations. This suggests that in certain
contexts the Bayesian posterior distribution can be used to construct a valid upper limit on
information accumulation, because posterior distributions are information-theoretically and
decision-theoretically optimal belief representations (Bernardo & Smith, 2000; Jaynes, 2003;
Ortega, 2011). To quantify ideal information accumulation, we use the sufficient statistics of
the Bayesian posterior distribution over the environment features given the evidence observed
by the entire population. We assume a uniform prior, and so the posterior probability that a
feature categorization is correct given the evidence received by the group up to generation t
is
P(xit=1|yi,·,≤t)=(θi1)Si,≤t(1−θi1)t·J−Si,≤t
(θi1)Si,≤t(1−θi1)t·J−Si,≤t+(θi0)Si,≤t(1−θi0)t·J−Si,≤t, (3)
where Si,≤t=/summationtextt
k=1/summationtextJ
j=11(yijk=1) is the total positive evidence observed for feature iup to
time t.
1This assumption may seem implausible in large populations, but it is satisfied if each person chooses from a
small number of others and those others are an unbiased sample from the full population.
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
M. D. Hardy et al. / Topics in Cognitive Science 14 (2022) 555
The sufficient statistics of this posterior distribution areSi,≤t
t·J, or the proportion of pieces
of evidence favoring a feature categorization. Because these statistics can be used to exactly
compute the posterior distribution, we can measure accumulation in observed networks by
comparing this statistic with the popularity of a belief, or proportion of people who believe it.
We express this formally by letting pit=1
N/summationtext
a1(da,i,t−1=1) be the proportion of individuals
who believe xi=1 at time t−1, with daitindicating whether individual aat generation t
chooses category i,a n d Nrepresenting the number of individuals in each generation. If the
popularity is close toSi,≤t
t·Jat time t, we can conclude that information is being effectively
accumulated in the population.
2.3. Summary
This analysis demonstrates that individuals in multigenerational networks can improve
their inferences by following a simple social learning heuristic. To perform social sampling,
an individual first randomly selects a person in the previous generation to learn from. They
then evaluate their companion’s belief against observed evidence—the more aligned the belief
with the evidence, the higher the chance the individual will accept it as their own, otherwise
they will continue searching and sample another person. While similar social learning models
have been explored in multiarmed bandit problems (Celis, Krafft, & Vishnoi, 2017; Krafft,
2017; Krafft et al., 2021), they have not been tested in controlled laboratory settings.
Social sampling is simple to perform and only requires limited computation by individuals.
More precisely, at any time the popularity of a hypothesis will approximate the true Bayesian
posterior probability conditioned on all the evidence observed by the population, and so the
population itself performs distributed Bayesian inference. Because this distributed inference
matches the inference problems individuals face, our model allows us to be precise about how
social learning extends people’s cognitive abilities.
In our model, individuals make unbiased judgments and cannot choose which information
to transmit. Instead, every person’s true beliefs can be observed by those in the next gen-
eration. While this setup—and assumptions of uniform sampling of others’ true beliefs—is
highly simplified, it reflects a common approach to modeling individual cognition as a two-
stage decision-making process (Howard & Sheth, 1969; Krumme, Cebrian, Pickard, & Pent-
land, 2012; Payne, 1976; Pratt, Sumpter, Mallon, & Franks, 2005; Seeley & Buhrman, 1999;
Vul, Goodman, Griffiths, & Tenenbaum, 2014) that has also been applied to modeling iterated
learning in populations (Bonawitz, Denison, Gopnik, & Griffiths, 2014; Kalish, Griffiths, &
Lewandowsky, 2007; Mozer, Pashler, & Homaei, 2008; Sanborn & Griffiths, 2008; Vul &
Pashler, 2008) and allows us to make progress in understanding knowledge accumulation in
a way that can be studied empirically and extended to more naturalistic settings.
While our model shows how group-level Bayesian inference is possible, can we identify
and quantify accumulation in real populations? To investigate, we ran two behavioral exper-
iments where participants made categorization decisions in multigenerational networks. In
both experiments, we assessed population rationality by comparing observed popularity with
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
556 M. D. Hardy et al. / Topics in Cognitive Science 14 (2022)
the Bayesian ideal and evaluated our social sampling model by comparing it with several
alternative models.
3. Experiment 1: Gem classification
In Experiment 1, participants completed a categorization task that was framed as gem-
stone classification. This experiment was designed to closely mirror an idealized setting in
which optimal information aggregation is possible through our proposed Bayesian social sam-
pling mechanism.
In this experiment, participants played the role of technicians classifying gemstones in a
certain shift (i.e., generation).2Each gemstone could have up to eight potential classifications,
with each classification being a randomized nonsense word (e.g., “pesho,” “ivil,” “thyun”).
On each trial, participants observed social information in the form of classification judgments
drawn from the previous shift of technicians, as well as non-social information in the form
of a set of four new laboratory results. The laboratory results presented stochastic positive or
negative evidence for each potential gemstone classification. We recruited three independent
networks of participants, with each network including 10 shifts of 20 technicians (i.e., 200
participants per network). The interface for the experiment is illustrated in Fig. 1.
3.1. Methods
3.1.1. Participants
We recruited 600 participants from Amazon Mechanical Turk. Recruitment was restricted
to participants in the United States with an Amazon Mechanical Turk approval rating of 95 or
above. We paid participants $1.75 as compensation, plus a performance-based bonus payment
of up to $0.50. The task typically took participants under 10 min to complete. Prior to starting
the experiment, participants completed an attention and comprehension check which included
questions about details of the study, including the probability of different kinds of evidence
appearing in individual tests. Participants who failed to answer these questions correctly in
three attempts were excluded from taking part in the study.
3.1.2. Stimuli
On each round of the experiment, participants observed a cartoon gemstone positioned at
the top of the screen on a white background. Each gem had eight possible binary classifica-
tions, and participants performed lab tests to make these classifications. Each test resulted in
either positive or negative evidence for each classification. Fig. 1 shows an example partici-
pant view.
Classifications were given labels from an artificial vocabulary. These labels were differ-
ent on each trial a participant completed (i.e., none of the labels recurred across trials for a
2See https://github.com/pkrafft/Overcoming-individual-limitations-through-distributed-computation for
experiment code and data.
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
M. D. Hardy et al. / Topics in Cognitive Science 14 (2022) 557
Fig. 1. Participant interface for Experiment 1. Each categorization task consisted of a different set of gem clas-
sifications that were given random nonsense words. Each participant belonged to a “generation” of participants,
called a “shift” in this experiment. In each generation after the first, participants could view the gem classificationsmade by participants in the last generation. Each participant made their own classification decisions for a gem four
times after observing four pieces of non-social evidence.
participant) and were presented in randomized order. After each test, participants indicated
which of the eight classifications they thought were true for this gem and could modify theseclassifications throughout the trial.
Participants in generations 2–10 observed the final classification decisions of a randomly
sampled participant from the previous generation of the same network. Participants couldchoose to resample from the previous generation at any time during the trial. When partici-pants chose to resample, the new sample was selected at random with replacement from the20 participants in the previous generation of the same network. Social information (an earlierparticipant’s classification decisions) was presented in a feedback table below the participant’s
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
558 M. D. Hardy et al. / Topics in Cognitive Science 14 (2022)
Fig. 2. Illustration of the evidence correlation structure used in Experiment 1. If a gem classification test was
positive for one participant, it was positive for all participants in that generation on that classification task. Positive
evidence about a classification is illustrated here using turquoise circles and negative evidence with red circles. Theclassification judgments made by participants are shown as checkmarks and x-marks. Participants could change
their classifications after each new test.
own feedback table. After completing the fourth lab test, the results of the test were displayed
and participants moved on to the next trial.
3.1.3. Procedure
Participant completed four trials (i.e., gem classifications). The first two trials were practice
rounds and were presented in the same order for all participants. The last two tasks wereexperimental trials and were ordered using simple randomization. We limited our analysis todata from the two experimental trials.
Mirroring the social sampling model, participants were organized into discrete shifts, or
“generations.” We recruited three independent networks of participants, with each networkconsisting of 10 generations with 20 participants per generation (see Fig. 2). Participants ingenerations 2–10 observed the classifications of a randomly sampled member of the previous
generation and could choose to draw additional samples as many times as they wished.
At the beginning of the experiment, the true classifications for each task were chosen uni-
formly at random. To reduce variance between networks, the lab test results for a given clas-sification were the same for all participants in a single generation (see Fig. 2). The probabilityof positive evidence in a lab test result was 0.6 for true classifications and 0.3 for false classi-fications (participants were informed of both probabilities).
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
M. D. Hardy et al. / Topics in Cognitive Science 14 (2022) 559
Fig. 3. Experiment 1 results. The graph on the left shows the relationship between the total evidence available for
each gem classification and the proportion of participants who selected that classification (i.e., the popularity of
the classification).The graph on the right plots the relationship between the most recently observed evidence and
the popularity. Each point represents a gem classification for a single shift, trial, and replication.
3.2. Results and discussion
We limited our analysis to participants in generations 2–10 and preregistered our statistical
analyses and sample size before the experiment.3These analyses, however, were adjusted and
expanded over the course of revisions. This included adding model comparisons, and using all
the test data in the regression described below (rather than only one decision in generations
6–10) for consistency with our analysis for Experiment 2. Limiting our regression to the
preregistered subset does not change our findings.
As predicted by our social sampling model, we observed a strong correlation between the
popularity of each gem classification and both the total evidence ( r(430)=0.6,p<.0001)
and the most recent evidence ( r(430)=0.88,p<.0001; see Fig. 3). Furthermore, total evi-
dence was significantly predictive of popularity in a regression that included the total evi-
dence, most recent evidence, and fixed effects for each network ( t(424)=4.54,p<.0001;
see Table 1 for full regression results). The correlation between popularity and total evidence
shows that the proportion of social sampling was high enough to facilitate significant infor-
mation aggregation over time.
We then compared the performance of our Bayesian social sampling model to three aso-
cial models and two social models—a probability matching social sampling model and naive
copying model (models are described in detail in the SEM). In the probability matching social
sampling model, individuals accept candidate hypotheses with probability equal to the frac-
tion of most recent positive evidence and in the naive copying model, individuals simply
copy others’ categorizations. To account for non-social learners, both social sampling models
include a term capturing the proportion of social decision making. We estimated this value as
the proportion of trials where participants chose to resample at least once and found partici-
3Preregistration available at https://osf.io/7qx8e/?view_only=53781c6aa4c742e2a9843fcef533dfd7.
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
560 M. D. Hardy et al. / Topics in Cognitive Science 14 (2022)
Table 1
Regression results for Experiments 1 and 2
Regression Model
Variable Experiment 1 Experiment 2
Intercept −0.10**0.29***
(−3.15) (12.69)
Total evidence 0.24***0.05*
(4.54) (2.44)
Last evidence 0.91***0.25***
(29.26) (18.74)
Dependent variable Popularity Popularity
Degrees of freedom 424 2270
Observations 432 2304
tstatistics are in parentheses.
*p<.05, ** p<.01, *** p<.001.
Note that fixed effects for each network (Experiments 1 and 2) and each condition (Experiment 2) were included
in the regressions but are not shown.
Table 2
Mean squared error of predicted and observed popularity for each model in Experiment 1
Model Mean Squared Error
Non-social problem matching 0.0213
Non-social Bayesian problem matching 0.0220
Non-social utility maximizing 0.1220
Naive copying 0.1260
Social sampling (problem matching) 0.0181
Social sampling (Bayesian) 0.0182
The best performing model is shown in bold.
pants did so on 19% of trials. This is a lower bound on the true proportion of social sampling,
since participants may have used the initial social information without resampling. However,
it is close to both a separate estimate of the asocial learning proportion based on a qualitative
coding of participants’ strategy descriptions, and the estimated regression coefficient on total
evidence available, which should correspond to the level of social sampling (see Table 1).
No free parameters are used in any of these models, and so we evaluate each model using
their performance on all the experimental data. We found that the probability matching social
sampling model achieved the lowest mean squared error (MSE) in predicting the popularity of
each gem classification (MSE : 0 .0.0181), followed closely by the Bayesian social sampling
model (MSE : 0 .0.0182; see Fig. 4 and Table 2 for results). Because both social sampling
models predict accumulation, these results support our other analyses from Experiment 1,
suggesting that networks of participants accumulated information about each categorization
across time.
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
M. D. Hardy et al. / Topics in Cognitive Science 14 (2022) 561
Fig. 4. Model predictions for the three non-social models and three social models we compared in Experiment 1.
As in Fig. 3, 432 points are shown in each plot.
4. Experiment 2: Spaceship construction
We constructed Experiment 1 to have a high correspondence with the assumptions of our
social sampling model. Experiment 2 was designed to test our model in a less idealized con-text. Most notably, in Experiment 2l all information was social—participants received feed-back on the previous generation’s decisions, rather than their own. Furthermore, we did not
allow participants to resample from the previous generation, and feedback was censored based
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
562 M. D. Hardy et al. / Topics in Cognitive Science 14 (2022)
Fig. 5. Example of the participant interface for the Experiment 2 spaceship design task. Each trial was associated
with a different set of spaceship parts (using different visual icons). Participants were organized into discrete
generations, or “turns.” In each generation after the first, a participant started by viewing an example spaceship
design from a participant of the last generation. The participant then chose their own parts for that task and
observed the part failures on each flight of that design.
on the observed participant’s choices. That is, participants did not always observe evidence
on every possible categorization.
In Experiment 2, participants designed spaceships by choosing which components to
include from an inventory of alternatives (see Fig. 5).4Each component was either a good
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
M. D. Hardy et al. / Topics in Cognitive Science 14 (2022) 563
Table 3
The parameter settings associated with each condition of Experiment 2
Experiment Reps NJ θ
Condition 1 2 20 4 0.6
Condition 2 1 20 1 0.6
Condition 3 1 20 4 0.8
Condition 4 2 5 4 0.6
Condition 5 2 5 1 0.6
Note. The repetitions (reps) is the number of repetitions of the parameter settings we ran. Nis the number
of participants per generation. Jis the number of flights, that is the amount of evidence, shown per spaceship
design trial. θgives the probability of success of good parts, and the probability of failure of bad parts—that is,
the strength of evidence.
part that rarely failed or a bad part that failed often. On each trial, participants observed
spaceships designed in the previous generation, along with the success or failure of each of
the included components on one or more flights. We organized participants into five condi-
tions, varying the number of participants in each generation (large vs. small), the amount of
evidence presented to each participant (high vs. low), and the strength of that evidence (high
v s .l o w )( s e eT a b l e3 ) .
4.1. Methods
4.1.1. Participants
We recruited 1000 participants from Amazon Mechanical Turk. Recruitment was restricted
to participants living in the United States. The task typically took participants around 5–10
min to complete, and participants earned $1.80 as compensation.
4.1.2. Stimuli
Experiment 2 consisted of a spaceship design categorization task inspired by prior experi-
ments on social learning (Brand, Brown, & Cross, 2018). Example stimuli from this catego-
rization task are shown in Fig. 5. In this task, participants designed spaceships by selecting
which parts to include from a set of available options. A different set of eight parts was avail-
able on each trial. Each of the eight items in a trial’s set of spaceship parts could be included
in that trial’s spaceship design. Participants could select or remove a part in a trial’s design by
clicking on an icon of the part.
Participants were organized into 10 discrete generations, with each generation composed
of a different set of participants. In the first generation, each participant had no information
about part failures and had to simply guess which parts might be good or bad. After selecting
which parts to include, a participant was given feedback from a number of “flights” of their
constructed spaceship. On each flight, spaceships parts could either succeed or fail. Each
4See https://github.com/pkrafft/Overcoming-individual-limitations-through-distributed-computation for
experiment code and data.
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
564 M. D. Hardy et al. / Topics in Cognitive Science 14 (2022)
flight was shown in sequence, and we did not allow participants to change the spaceship
design between flights.
In all generations except the first, participants viewed the spaceship design and flight out-
comes from a spaceship selected uniformly at random from the designs made in the previousgeneration. Participants viewing another participant’s design could select which of the priorflights to examine, as different parts may have failed on different flights. A prior design wasdisplayed in the same way that a participant’s own spaceship design was displayed, exceptthat parts could not be modified on a previous design and part failures were shown at thestart of the trial. Unlike Experiment 1, participants could not resample a choice from theprevious generation.
4.1.3. Procedure
Participants completed eight categorization tasks. The first four trials participants com-
pleted were practice trials, and the last four were test trials. Practice trials were displayed inthe same order for all participants, and test trials were ordered using simple randomization.We did not inform participants of this practice-test distinction, and we limited our analysis todata from the four test trials.
In order to mirror the structure of the social sampling model, we recruited participants
in discrete generations. Generation twas recruited after all participants in generation t−1
completed the experiment. In the first generation, good and bad parts were chosen at randomwith probability .5. As in Experiment 1, spaceship failures were perfectly correlated acrossdesigns for a single flight in a given generation to reduce variance between networks. That
is, if two different participants both used the same part in a certain generation, then the part
would either succeed or fail for both participants on a given flight (see Fig. 6).
4.1.4. Results and discussion
As in Experiment 1, all statistical tests were two-tailed with an alpha level of 0.05 and we
excluded the initial generation of participants from our analysis. We ran experiment condi-tions separately, and so no between-subject randomization into conditions was used. Instead,participants could only participate in the experiment once and thus could not complete multi-ple experimental conditions.
Replicating our findings from Experiment 1, we found that total evidence was significantly
predictive of popularity, controlling for the most recent evidence observed in a regressionthat included the total evidence, most recent evidence, and fixed effects for each networkand condition ( t(2270) =2.44,p=.015; full results in Table 1). While we found signifi-
cant positive correlations between popularity and total evidence in each of our conditions,the strength of this correlation varied between 0.16 in Condition 5 and 0.65 in Condition3 (see Table 4 and Fig. 7). Indeed, popularity tended to be less correlated with total evi-dence in networks with small generation sizes, low evidence strength, and low evidenceamount.
All decisions in Experiment 2 were social, and so we limited model comparison to the three
social models used in Experiment 1 and set the proportion of asocial learners to zero. As in
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
M. D. Hardy et al. / Topics in Cognitive Science 14 (2022) 565
Fig. 6. Illustration of the evidence constraints in Experiment 2. As in Experiment 1, evidence was correlated across
participants: If a part failed on one flight, it failed for all participants in that generation on that flight (part failures
are displayed in the figure as red circles). In contrast to Experiment 1, participants could not change their spaceship
designs in between flights, and evidence about a particular spaceship part was only shown if the part was chosen
in the sample design shown to the participant.
Table 4
Overview of the five conditions of Experiment 2 and the correlation between popularity and total evidence within
each condition
Condition RepsPopulation
SizeEvidence
AmountEvidence
StrengthCorrelation Between Popu-
larity and Total Evidence
Condition 1 2 Large High Low .43***
Condition 2 1 Large Low Low .39***
Condition 3 1 Large High High .65***
Condition 4 2 Small High Low .29***
Condition 5 2 Small Low Low .16***
*p<.05, ** p<.01, *** p<.001.
Experiment 1, each model was assessed by comparing the popularity predicted by the model
at each generation with the observed popularity. We found that in four of the five experimental
conditions, the Bayesian social sampling model achieved the lowest MSE in pre-
dicting observed popularity. However, in the remaining condition, where the evidence
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
566 M. D. Hardy et al. / Topics in Cognitive Science 14 (2022)
Fig. 7. Plots showing the relationship between the total evidence available for each particular spaceship part and
the proportion of participants who selected that part in Experiment 2. Each point represents one part (of eight) in
one social generation (of nine) on one trial (of four) in a single repetition.
strength was high, the naive copying model outperformed both the Bayesian and
probability matching social sampling models (Bayesian social sampling MSE: 0.1188;probability matching social sampling MSE: 0.0825; naive copying MSE: 0.0371; seeTable 5).
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
M. D. Hardy et al. / Topics in Cognitive Science 14 (2022) 567
Table 5
Mean squared error of predicted and observed popularity for the three social models we compared for each of the
conditions (C1–C5) in Experiment 2
Mean Squared Error
M o d e l C 1C 2C 3C 4C 5
Naive copying 0.0433 0.0424 0.0371 0.1078 0.1030
Social sampling (matching) 0.0542 0.1703 0.0825 0.1069 0.2196
Social sampling (Bayesian) 0.0366 0.0333 0.1188 0.0969 0.0960
The best performing model in each column is shown in bold.
5. General discussion
Understanding how people make intelligent decisions under limited time and cognitive
resources is a central focus of research in cognitive science, psychology, and economics.Social interactions offer a way for people to overcome these limitations by distributing
computation across a group. By observing and learning from others, individuals do not need
to perform complex computations or to condition on large amounts of data to make rationalinferences. Instead, they can use simple heuristics that leverage accumulated social informa-tion.
To show how distributed inference can emerge in populations, we derived a social sampling
model of individual decision making in multigenerational networks. We then showed thatsocial sampling at the individual level can lead to distributed Bayesian inference at the popu-lation level. We tested the predictions of our social sampling model in two highly controlledbehavioral experiments where participants made simple categorization decisions. While thetransmission structure we used in both experiments was idealized and highly simplified com-pared to real-world social networks, this allowed us to directly quantify the degree to whichinformation accumulated across time relative to the Bayesian ideal.
Although we observe information accumulation in both experiments, the performance of
the Bayesian social sampling model varied in different conditions. Most notably, in Exper-iment 1 the probability social sampling model achieved a slightly lower MSE than theBayesian social sampling model (see Table 2). Furthermore, in Experiment 2 the naive copy-ing model had a lower MSE than both social sampling models in large networks with highlevels of strong evidence (see Tables 4 and 5). These results suggest that individuals mayadapt their social learning strategies to different domains and may be more likely to use socialsampling in noisy, low-information environments (Toyokawa, Whalen, & Laland, 2018).
It is important to emphasize that for information aggregation to occur, the precise details of
how social sampling takes place are less important than that individuals’ decisions incorporate
social information and new evidence using a probabilistic rule. Indeed, our social samplingmodels in Experiment 1 included a mixture of social and non-social decision makers, repli-cating related findings on underexploitation of social information in behavioral experiments(Mercier & Morin, 2019). Our analyses are thus not intended to show that social sampling isa definitive description of human behavior, but that a social decision-making model derived
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
568 M. D. Hardy et al. / Topics in Cognitive Science 14 (2022)
from a normative Bayesian standard can help make sense of the extent of information aggre-
gation we observe in specific experimental contexts.
While we find that information aggregation can be robust to individual differences, accu-
mulation can fail if people’s decision-making differs systematically from a probabilistic beliefadoption–rejection strategy. Indeed, related research on the wisdom of crowds has shown thatin certain contexts social interactions and observations can actually decrease group perfor-mance by reducing the diversity and independence of people’s beliefs (Jenness, 1932; Lorenz,Rauhut, Schweitzer, & Helbing, 2011; Myers & Bishop, 1971). These dynamics—that is,whether social interactions improve or worsen group outcomes—appear to vary dependingon people’s social learning strategies (Toyokawa et al., 2018). For example, accumulation canbe disrupted if people are utility-maximizing rather than probabilistic in their responses to evi-dence (Anderson & Holt, 1997; Bikhchandani, Hirshleifer, & Welch, 1992). While probabilitymatching in individual decision-making is observed in certain domains (Shanks, Tunney, &McCarthy, 2002; Vul et al., 2014; Vulkan, 2000), our experiments show that this strategycan be extended to social settings: when a substantial proportion of individuals incorporatesocial information into their probability matching behavior, information accumulates acrosspeople and time. However, people may be less likely to follow a social sampling strategy indomains with low levels of probability matching, such as tasks with large financial incentivesor consistent feedback (Shanks et al., 2002).
Our findings complement other approaches to understanding rationality in limited indi-
viduals. For example, previous work on adaptive heuristics (Gigerenzer & Goldstein, 1996)has shown that people use simple decision-making rules to exploit the structure of the envi-
ronment and make decisions on complex tasks. Our work suggests that this framework can
be extended to social decision making. Furthermore, by providing a rational motivation forpeople’s social heuristics, our work offers a way to connect adaptive heuristics with resource-rational analysis (Griffiths, Lieder, & Goodman, 2015) in simple multigenerational popula-tions. Integrating our model and findings with other frameworks for studying bounded ratio-nality, such as models that utilize quantum probability theory (Pothos et al., 2021), should beaddressed in future work.
We tested our model on a simple binary-choice decision-making task where the transmis-
sion structure was explicitly designed to match our model assumptions. These simplificationslimit our ability to draw general conclusions about information accumulation in natural pop-ulations. For example, while enforcing uniform sampling of the previous generation gave ustight control over the transmission dynamics, people’s sampling, and exploration strategiesmay depend on the task (Oaksford & Chater, 1994) and are likely considerably more complexin naturalistic domains and networks (Latora, Nicosia, & Russo, 2017). Similarly, people maynot always transmit their true beliefs—instead, they may give noisy, incomplete, or mislead-ing accounts of their opinions and decisions to others (Xu & Griffiths, 2010).
Despite these limitations, the general framework we have outlined and the principle of
identifying the computational structure of population dynamics could therefore be extendedto more complex and naturalistic domains in future work. For example, individuals could be
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
M. D. Hardy et al. / Topics in Cognitive Science 14 (2022) 569
given greater control over which (if any) beliefs to transmit or sample from others. Mod-
els of learning in structured representational domains, such as language of thought models
(Goodman, Tenenbaum, & Gerstenberg, 2015) or posterior sampling in general Markov deci-sion processes (Agrawal & Jia, 2017; Osband, Van Roy, & Russo, 2013), could also beextended to the population setting in a way that is analogous to our extension of simple cat-egorization decisions. Testing our model and quantifying knowledge accumulation in morenaturalistic domains is an exciting challenge for future work.
Acknowledgments
This work was funded in part by NSF grant 1456709, DARPA Cooperative Agreement
D17AC00004, and the support of the NOMIS Foundation.
References
Acemoglu, D., Dahleh, M. A., Lobel, I., & Ozdaglar, A. (2011). Bayesian learning in social networks. The Review
of Economic Studies ,78(4), 1201–1236.
Agrawal, S., & Jia, R. (2017). Posterior sampling for reinforcement learning: Worst-case regret bounds. In I.
Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, & R. Garnett (Eds.), Advances in
Neural Information Processing Systems . NeurIPS Foundation, Vol. 30 (pp. 1184–1194).
Almaatouq, A., Alsobay, M., Yin, M., & Watts, D. J. (2021). Task complexity moderates group synergy. Proceed-
ings of the National Academy of Sciences ,118(36), e2101062118.
Almaatouq, A., Noriega-Campero, A., Alotaibi, A., Krafft, P., Moussaid, M., & Pentland, A. (2020). Adaptive
social networks promote the wisdom of crowds. Proceedings of the National Academy of Sciences ,117(21),
11379–11386.
Anderson, L. R., & Holt, C. A. (1997). Information cascades in the laboratory. The American Economic Review ,
87, 847–862.
Argote, L. (2012). Organizational learning: Creating, retaining and transferring knowledge . Berlin, Germany:
Springer Science & Business Media.
Belikov, A. V., Rzhetsky, A., & Evans, J. (2020). Detecting signal from science: The structure of research
communities and prior knowledge improves prediction of genetic regulatory experiments. arXiv preprintarXiv:2008.09985.
Bernardo, J. M., & Smith, A. F. (2000). Bayesian Theory . New York: Wiley.
Bikhchandani, S., Hirshleifer, D., & Welch, I. (1992). A theory of fads, fashion, custom, and cultural change as
informational cascades. Journal of Political Economy ,100(5), 992–1026.
Bonawitz, E., Denison, S., Gopnik, A., & Griffiths, T. L. (2014). Win-stay, lose-sample: A simple sequential
algorithm for approximating Bayesian inference. Cognitive Psychology ,74, 35–65.
Boyd, R., & Richerson, P. J. (1985). Culture and the evolutionary process . Chicago, IL: University of Chicago
Press.
Brand, C. O., Brown, G. R., & Cross, C. P. (2018). Sex differences in the use of social information emerge under
conditions of risk. PeerJ ,6, e4190.
Caldwell, C. A., Atkinson, M., & Renner, E. (2016). Experimental approaches to studying cumulative cultural
evolution. Current Directions in Psychological Science ,25(3), 191–195.
Celis, L. E., Krafft, P., & Vishnoi, N. (2017). A distributed learning dynamics in social groups. In Proceedings of
the ACM Symposium on Principles of Distributed Computing , (pp. 441–450). New York: ACM.
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
570 M. D. Hardy et al. / Topics in Cognitive Science 14 (2022)
Chater, N., Oaksford, M., Hahn, U., & Heit, E. (2010). Bayesian models of cognition. Wiley Interdisciplinary
Reviews: Cognitive Science ,1(6), 811–823.
Chater, N., Tenenbaum, J. B., & Yuille, A. (2006). Probabilistic models of cognition: Conceptual foundations.
Trends in Cognitive Sciences ,10(7), 287–291.
Crisan, D., & Doucet, A. (2002). A survey of convergence results on particle filtering methods for practitioners.
IEEE Transactions on Signal Processing ,50(3), 736–746.
Cushman, F., & Gershman, S. (2019). Editors’ introduction: Computational approaches to social cognition. Topics
in Cognitive Science ,11(2), 281–298.
Derex, M., Beugin, M.-P., Godelle, B., & Raymond, M. (2013). Experimental evidence for the influence of group
size on cultural complexity. Nature ,503(7476), 389–391.
Easwaran, K. (2019). The concept of rationality for a city. Topoi , 1–13.
Engel, D., Woolley, A. W., Aggarwal, I., Chabris, C. F., Takahashi, M., Nemoto, K., Kaiser, C., Kim, Y. J., &
Malone, T. W. (2015). Collective intelligence in computer-mediated collaboration emerges in different contextsand cultures. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems
(CHI) (pp. 3769–3778). New York: ACM.
Foster, J. G. (2018). Culture and computation: Steps to a probably approximately correct theory of culture. Poetics ,
68, 144–154.
Frey, S., & Goldstone, R. L. (2018). Cognitive mechanisms for human flocking dynamics. Journal of Computa-
tional Social Science ,1(2), 349–375.
Gale, D., & Kariv, S. (2003). Bayesian learning in social networks. Games and Economic Behavior ,45(2), 329–
346.
Galesic, M., Olsson, H., Dalege, J., van der Does, T., & Stein, D. L. (2021). Integrating social and cognitive aspects
of belief dynamics: towards a unifying framework. Journal of the Royal Society Interface ,18(176), 20200857.
Gigerenzer, G., & Goldstein, D. G. (1996). Reasoning the fast and frugal way: models of bounded rationality.
Psychological Review ,103(4), 650.
Goldstone, R. L., Wisdom, T. N., Roberts, M. E., & Frey, S. (2013). Learning along with others. In B. Ross (Ed.),
Psychology of learning and motivation (Vol. 58, pp. 1–45). Amsterdam. The Netherlands: Elsevier.
Goodman, N. D., Tenenbaum, J. B., & Gerstenberg, T. (2015). Concepts in a probabilistic language of thought .
Cambridge, MA: MIT Press.
Griffiths, T. L. (2020). Understanding human intelligence through human limitations. Trends in Cognitive Sciences ,
24(11), 873–883.
Griffiths, T. L., Chater, N., Kemp, C., Perfors, A., & Tenenbaum, J. B. (2010). Probabilistic models of cognition:
Exploring representations and inductive biases. Trends in Cognitive Sciences ,14(8), 357–364.
Griffiths, T. L., Kemp, C., & Tenenbaum, J. B. (2008). Bayesian models of cognition. In R. Sun (Ed.), The Cam-
bridge Handbook of Computational Psychology . Cambridge, England: Cambridge University Press. (pp. 59–
100).
Griffiths, T. L., Lieder, F., & Goodman, N. D. (2015). Rational use of cognitive resources: Levels of analysis
between the computational and the algorithmic. Topics in Cognitive Science ,7(2), 217–229.
Harper, M. (2009). The replicator equation as an inference dynamic. arXiv preprint arXiv:0911.1763.Hayek, F. (1945). The use of knowledge in society. The American Economic Review ,35(4), 519–530.
Hazła, J., Jadbabaie, A., Mossel, E., & Rahimian, M. A. (2021). Bayesian decision making in groups is hard.
Operations Research ,69(2), 632–654.
Heyes, C. (2018). Enquire within: Cultural evolution and cognitive science. Philosophical Transactions of the
Royal Society B: Biological Sciences ,373(1743), 20170051.
Howard, J. A., & Sheth, J. N. (1969). The theory of buyer behavior . Cambridge, MA: MIT Press.
Hutchins, E. (1995). Cognition in the wild . Number 1995. Cambridge, MA: MIT Press.
Jaynes, E. T. (2003). Probability theory: The logic of science . Cambridge, England: Cambridge University Press.
Jenness, A. (1932). The role of discussion in changing opinion regarding a matter of fact. The Journal of Abnormal
and Social Psychology ,27(3), 279.
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
M. D. Hardy et al. / Topics in Cognitive Science 14 (2022) 571
Kalish, M. L., Griffiths, T. L., & Lewandowsky, S. (2007). Iterated learning: Intergenerational knowledge trans-
mission reveals inductive biases. Psychonomic Bulletin & Review ,14(2), 288–294.
Kempe, M., & Mesoudi, A. (2014a). An experimental demonstration of the effect of group size on cultural accu-
mulation. Evolution and Human Behavior ,35(4), 285–290.
Kempe, M., & Mesoudi, A. (2014b). Experimental and theoretical models of human cultural evolution. WIREs
Cognitive Science ,5, 317–326.
Kirby, S., Cornish, H., & Smith, K. (2008). Cumulative cultural evolution in the laboratory: An experimental
approach to the origins of structure in human language. Proceedings of the National Academy of Sciences of
the United States of America ,105(31), 10681–10686.
Kirby, S., Tamariz, M., Cornish, H., & Smith, K. (2015). Compression and communication in the cultural evolution
of linguistic structure. Cognition ,141, 87–102.
Krafft, P. (2017). A rational choice framework for collective behavior (doctoral thesis). Massachusetts Institute of
Technology.
Krafft, P., Shmueli, E., Griffiths, T. L., Tenenbaum, J. B., & Pentland, A. (2021). Bayesian collective learning
emerges from heuristic social learning. Cognition ,212, 104469.
Krafft, P., Zheng, J., Pan, W., Della Penna, N., Altshuler, Y., Shmueli, E., Tenenbaum, J. B., & Pentland, A. (2016).
Human collective intelligence as distributed Bayesian inference. arXiv preprint arXiv:1608.01987.
Krumme, C., Cebrian, M., Pickard, G., & Pentland, A. (2012). Quantifying social influence in an online cultural
market. PLoS ONE ,7(5), e33785.
Laland, K. N., Sterelny, K., Odling-Smee, J., Hoppitt, W., & Uller, T. (2011). Cause and effect in biology revisited:
Is Mayr’s proximate-ultimate dichotomy still useful? Science ,334(6062), 1512–1516.
Latora, V., Nicosia, V., & Russo, G. (2017). Complex networks: Principles, methods and applications . Cambridge,
England: Cambridge University Press.
Lorenz, J., Rauhut, H., Schweitzer, F., & Helbing, D. (2011). How social influence can undermine the wisdom of
crowd effect. Proceedings of the National Academy of Sciences ,108(22), 9020–9025.
Lynch, N. A. (1996). Distributed algorithms . Burlington, MA: Morgan Kaufmann.
Martin, D., Hutchison, J., Slessor, G., Urquhart, J., Cunningham, S. J., & Smith, K. (2014). The spontaneous
formation of stereotypes via cumulative cultural evolution. Psychological Science ,25(9), 1777–1786.
Mercier, H., & Morin, O. (2019). Majority rules: How good are we at aggregating convergent opinions? Evolu-
tionary Human Sciences ,1,E 6 .
Mesoudi, A. (2011). Cultural evolution: How Darwinian theory can explain human culture and synthesize the
social sciences . Chicago, IL: University of Chicago Press.
Mesoudi, A. (2016). Cultural evolution: Integrating psychology, evolution and culture. Current Opinion in Psy-
chology ,7, 17–22.
Mesoudi, A., & O’Brien, M. J. (2008). The cultural transmission of great basin projectile-point technology I: An
experimental simulation. American Antiquity ,73(01), 3–28.
Mesoudi, A., & Thornton, A. (2018). What is cumulative cultural evolution? Proceedings of the Royal Society
Biological Sciences ,285(1880), 20180712.
Mesoudi, A., & Whiten, A. (2008). The multiple roles of cultural transmission experiments in understanding
human cultural evolution. Philosophical Transactions of the Royal Society B: Biological Sciences ,363(1509),
3489–3501.
Miton, H., & Charbonneau, M. (2018). Cumulative culture in the laboratory: Methodological and theoretical chal-
lenges. Proceedings of the Royal Society B: Biological Sciences ,285(1879), 20180677.
Morgan, T. J. H., Uomini, N. T., Rendell, L. E., Chouinard-Thuly, L., Street, S. E., Lewis, H. M., Cross, C. P.,
Evans, C., Kearney, R., de la Torre, I., Whiten, A., & Laland, K. N. (2015). Experimental evidence for theco-evolution of hominin tool-making teaching and language. Nature Communications ,6(1), 6029.
Mozer, M. C., Pashler, H., & Homaei, H. (2008). Optimal predictions in everyday cognition: The wisdom of
individuals or crowds? Cognitive Science ,32(7), 1133–1147.
Murphy, K. P. (2012). Machine learning: A probabilistic perspective . Cambridge, MA: MIT Press.
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
572 M. D. Hardy et al. / Topics in Cognitive Science 14 (2022)
Muthukrishna, M., Shulman, B. W., Vasilescu, V., & Henrich, J. (2014). Sociality influences cultural complexity.
Proceedings of the Royal Society B: Biological sciences ,281(1774), 20132511.
Myers, D. G., & Bishop, G. D. (1971). Enhancement of dominant attitudes in group discussion. Journal of Per-
sonality and Social Psychology ,20(3), 386.
Nettle, D. (2020). Selection, adaptation, inheritance and design in human culture: the view from the Price equation.
Philosophical Transactions of the Royal Society B: Biological Sciences ,375(1797), 20190358.
Oaksford, M., & Chater, N. (1994). A rational analysis of the selection task as optimal data selection. Psycholog-
ical Review ,101(4), 608.
Ortega, P. A. (2011). A unified framework for resource-bounded autonomous agents interacting with unknown
environments (doctoral thesis). University of Cambridge.
Osband, I., Van Roy, B., & Russo, D. (2013). (More) efficient reinforcement learning via posterior sampling.
In: C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, & K. Q. Weinberger (Eds.), Advances in Neural
Information Processing Systems . NeurIPS Foundation, Vol. 26, (pp. 3003–3011).
Payne, J. W. (1976). Task complexity and contingent processing in decision making: An information search and
protocol analysis. Organizational Behavior and Human Performance ,16(2), 366–387.
Pothos, E. M., Lewandowsky, S., Basieva, I., Barque-Duran, A., Tapper, K., & Khrennikov, A. (2021). Information
overload for (bounded) rational agents. Proceedings of the Royal Society B: Biological Sciences ,288(1944),
20202957.
Pratt, S. C., Sumpter, D. J., Mallon, E. B., & Franks, N. R. (2005). An agent-based model of collective nest choice
by the ant Temnothorax albipennis .Animal Behaviour ,70(5), 1023–1036.
Ravignani, A., Thompson, B., Grossi, T., Delgado, T., & Kirby, S. (2018). Evolving building blocks of rhythm:
How human cognition creates music via cultural transmission. Annals of the New York Academy of Sciences ,
1423(1), 176–187.
Riedl, C., Kim, Y. J., Gupta, P., Malone, T. W., & Woolley, A. W. (2021). Quantifying collective intelligence in
human groups. Proceedings of the National Academy of Sciences ,118(21), e2005737118.
Rzhetsky, A., Foster, J. G., Foster, I. T., & Evans, J. A. (2015). Choosing experiments to accelerate collective
discovery. Proceedings of the National Academy of Sciences ,112(47), 14569–14574.
Salhab, R., Ajorlou, A., & Jadbabaie, A. (2020). Social learning with sparse belief samples. In 2020 59th IEEE
Conference on Decision and Control (CDC) , (pp. 1792–1797). Piscataway, NJ: IEEE.
Sanborn, A., & Griffiths, T. L. (2008). Markov chain Monte Carlo with people. In: Advances in Neural Information
Processing Systems . NeurIPS Foundation, Vol. 21, (pp. 1265–1272).
Sasaki, T., & Pratt, S. C. (2011). Emergence of group rationality from irrational individuals. Behavioral Ecology ,
22(2), 276–281.
Seeley, T. D., & Buhrman, S. C. (1999). Group decision making in swarms of honey bees. Behavioral Ecology
and Sociobiology ,45(1), 19–31.
Shanks, D. R., Tunney, R. J., & McCarthy, J. D. (2002). A re-examination of probability matching and rational
choice. Journal of Behavioral Decision Making ,15(3), 233–250.
Shoham, Y., & Leyton-Brown, K. (2009). Multiagent systems . Cambridge, England: Cambridge University Press.
Silvey, C., Kirby, S., & Smith, K. (2019). Communication increases category structure and alignment only when
combined with cultural transmission. Journal of Memory and Language ,109, 104051.
Simon, H. A. (1990). Bounded rationality. In Utility and probability (pp. 15–18). Berlin, Germany: Springer.
Smaldino, P. E., & Richerson, P. J. (2013). Human cumulative cultural evolution as a form of distributed compu-
tation. In Handbook of human computation (pp. 979–992). New York: Springer.
Smolla, M., Jansson, F., Lehmann, L., Houkes, W., Weissing, F., Hammerstein, P., Dall, S. R., Kuijper, B. &
Enquist, M. (2020). Underappreciated similarities and differences between cultural and biological evolution,and the future of cultural evolution thinking. https://doi.org/10.31235/osf.io/3xvdw
Tenenbaum, J. B., Kemp, C., Griffiths, T. L., & Goodman, N. D. (2011). How to grow a mind: Statistics, structure,
and abstraction. Science ,331(6022), 1279–1285.
Toyokawa, W., Whalen, A., & Laland, K. N. (2018). Social learning strategies regulate the wisdom and madness
of interactive crowds. bioRxiv , 326637.
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
M. D. Hardy et al. / Topics in Cognitive Science 14 (2022) 573
Vul, E., Goodman, N., Griffiths, T. L., & Tenenbaum, J. B. (2014). One and done? Optimal decisions from very
few samples. Cognitive Science ,38(4), 599–637.
Vul, E., & Pashler, H. (2008). Measuring the crowd within: Probabilistic representations within individuals. Psy-
chological Science ,19(7), 645–647.
Vulkan, N. (2000). An economist’s perspective on probability matching. Journal of Economic Surveys ,14(1),
101–118.
Wisdom, T. N., Song, X., & Goldstone, R. L. (2013). Social learning strategies in networked groups. Cognitive
Science ,37(8), 1383–1425.
Wojtowicz, Z., & DeDeo, S. (2020). From probability to consilience: How explanatory values implement Bayesian
reasoning. Trends in Cognitive Sciences ,4(12), 981–993.
Woolley, A. W., Chabris, C. F., Pentland, A., Hashmi, N., & Malone, T. W. (2010). Evidence for a collective
intelligence factor in the performance of human groups. Science ,330(6004), 686–688.
Xu, J., & Griffiths, T. L. (2010). A rational analysis of the effects of memory biases on serial reproduction.
Cognitive Psychology ,60(2), 107–126.
Supporting Information
Additional Supporting Information may be found
online in the supporting information tab of this article:
Supporting InformationSupporting Information
17568765, 2022, 3, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/tops.12596 by Princeton University, Wiley Online Library on [12/12/2022]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
|
4723e367-9716-49f0-a556-e087c3723f47 | trentmkelly/LessWrong-43k | LessWrong | Example: Markov Chain
The previous post in this sequence discussed how to throw away information in causal DAGs. This post provides a detailed example using a Markov chain.
Suppose we have an n-state Markov chain (CS people: picture a finite state machine with n states and random state transitions at each timestep). A matrix of state transition probabilities Tji gives the probability of transitioning to state j when the system starts the timestep in state i. Writing the state at time t as Xt, we have P[Xt+1=j|Xt=i]=Tji. More generally, P[Xt+m=j|Xt=i]=(Tm)ji, where Tm denotes a matrix power (i.e. T matrix-multiplied by itself m times). To complete the specification, we’ll assume that the system starts in a random state X0 at time 0, with the initial distribution P[X0] given.
As a causal DAG, this system is just a chain: the state at time t depends only on the state at time t−1:
X0→X1→X2→X3→...
People typically draw basic Markov chains the same way we draw finite state machines: a graph with one node for each state, and arcs indicating transitions. Unlike an FSM, where the next arc is chosen by a symbol from some input stream, here the next arc is chosen randomly - so each arc has a probability associated with it. An example:
This is NOT a causal diagram, it is a state transition diagram. It says that, if the system is in state 1, then at the next timestep it will randomly transition to state 1, 2, or 5. (I haven’t included the probabilities on each arc; all that matters for our purposes is that each arc shown has nonzero probability.) Since we have two graph representations of the system (the state transition diagram and the causal DAG), I will generally refer to vertices in the state transition diagram “states” and vertices Xt in the causal diagram as “nodes”.
What happens if we throw away long-term-irrelevant information from a node in this Markov chain?
Here’s the idea:
* Pick the node Xt
* Pick the set of nodes from X0 to Xt+m−1 for some large-ish m (we’ll denote this set X< |
173d7dff-d2df-401f-98fd-49d001cc345f | trentmkelly/LessWrong-43k | LessWrong | An extended rocket alignment analogy
This work was done while at Conjecture.
This post has been written for the first Refine blog post day, at the end of the week of readings, discussions, and exercises about epistemology for doing good conceptual research.
Thanks for comments by Linda Linsefors, Paul Bricman, and Adam Shimi.
Introduction
The Rocket Alignment Problem presents a fun scenario trying to explain why understanding part of the theoretical basis for a problem might be useful. If we were trying to get to the moon for the first time, understanding Newtonian mechanics would indeed be quite useful! As would astrodynamics in general, which was really developed starting with Herrick in the 1930s. But not sufficient: there were a whole host of other problems that needed to be solved, many of which were at least as difficult as theoretical understanding. At a minimum, we needed to develop rocket fuel, the materials that could survive high temperatures from fuel and reentry, enough understanding of the materials to create models of the rocket themselves and the stress and heat individual parts were under, communication devices so we knew what our rockets were doing, and more. I’ll look at the first two in more detail here then step back and look at the problem as a whole at different points in time. Beyond simply pointing out the rocket alignment problem to show how messy it truly was, pushing deeper into the analogy may let us see what we have developed, and what we expect we need to develop.
Rocket Fuels and the Rocket Body
Developing rocket fuel powerful enough to lift the rocket but stable enough that it didn’t just immediately explode required quite a bit of chemistry, engineering, and ridiculously dangerous trials. Consideration of this problem directly applied to rocketry, building off of the chemical achievements of the previous century, started in the early 1900s and continued through the development of the rocket program.
A Russian school teacher, Tsiolkovsky, first proposed |
366a0a2d-211a-484a-853e-d691157491f3 | trentmkelly/LessWrong-43k | LessWrong | Odds are not easier
Epistemic status: just a review of a well known math theorem and a brief rant about terminology.
Yesterday I saw another example of this: P(D) is just a normalizing constant for the posterior probability, and it's really hard (impossible?) to calculate, so let's switch to log odd probabilities, which are easier and the pesky term is canceled.
Except it's not: P(D)=P(D|H)P(H)+P(D|¬H)P(¬H), the second term is exactly what you need to get the probability in odd form, and if you have it you can very well calculate the prior for the data.
So please, whatever you write, stop saying that odds are easier. They are possibly more intuitive to manipulate, but they need exactly the same amount of information. |
ad3b823e-ec2f-48bb-a18e-4f9cc18e7476 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Updatelessness and Son of X
.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
The purpose of this post is to discuss the relationship between the concepts of Updatelessness and the "Son of" operator.
Making a decision theory that is reflectively stable is hard. Most agents would self-modify into a agent if given the chance. For example if a CDT agent knows that it is going to be put in a Newcomb's problem, it would precommit to one-box, "causing" Omega to predict that it one-boxes. We say "son of CDT" to refer to the agent that a CDT agent would self-modify into, and more generally "son of X" to refer to the agent that agent X would self-modify into.
Thinking about these "son of" agents is unsatisfying for a couple reasons. First, it is very opaque. There is an extra level of indirection, where you cant just directly reason about what agent X will do. Instead have to reason about what agent X will modify into, which gives you a new agent, which you probably understand much less than you understand agent X, and then you have to reason about what that new agent will do. Second, it is unmotivated. If you had a good reason to like Son of X, you would probably not be calling in Son of X. Important concepts get short names, and you probably don't have as many philosophical reasons to like Son of X as you have to like X.
Wei Dai's [Updateless Decision Theory](https://wiki.lesswrong.com/wiki/Updateless_decision_theory) is perhaps our current best decision theory proposal. A UDT agent chooses a function from its possible observations to its actions, without taking into account its observations, and then applies that function.
The main problem with this proposal is in formalizing it in a logical uncertainty framework. Some of the observations that an agent makes are going to be logical observations, for example, an agent may observe the millionth digit of π. Then it is not clear how an agent can not take the digit of π into account in its calculation of the best policy. If we do not tell it the digit through the standard channel, it might still compute the digit while computing the best policy. As I said [here](https://agentfoundations.org/item?id=1071), it is important to note logical updatelessness is about computations and complexity, not about what logical system you are in.
So what would true logical updatelessness look like? Well the agent would have to not update on computations. Since it is a computation itself, we cannot keep it independent from all computations, but we can restrict it to some small class of computations. The way we do this is by giving the updateless part of the decision theory finite computational bounds. Computational facts not computable within those bounds are still observed, but we do not take them into account when choosing a policy. Instead, we use our limited computation to choose a policy in the form of a function from how the more difficult computations turn out to actions.
The standard way to express a policy is a bunch of input/output pairs. However, since the inputs here are results of computations, this can equivalently be expressed by a single computation that gives an output. (To see the equivalence, note that we can write down a single computation which computes all the inputs and produces the corresponding output. Conversely, given a single computation, we can just supply the identity function of the output of that computation.) Thus, logical updatelessness consists of a severely resource bounded agent choosing what policy (In the form of a computation) it wants to run given more resources.
Under this model, it seems that whenever you have an agent collecting more computational resources over time, with the ability to rewrite itself, you get an updateless agent. The limited agent is choosing using its bounded resources what algorithm it wants to run to choose its output when it has collected more computational resources. The future version of the agent with more resources is the updateless version of the original agent, in that it is following the policy specified by the original agent before updating on all the computational facts. However, this is also exactly what we mean when we say that the later agent is the son of the bounded agent.
There is still a free parameter in Logical Updatelessness, which is what decision procedure the limited version uses to select its policy. This is also underspecified in standard UDT, but I believe it is often taken to be EDT. Thus, we have logically updateless versions of many decision policies, which I claim is actually pointing at the same thing as Son on those various policies (in an environment where computational resources are collected over time). |
64444dbb-d6cf-49eb-8586-b9ca55d4a1ca | trentmkelly/LessWrong-43k | LessWrong | My first conversation with Annie Altman
First conversation on the All Humans Are Human podcast
We talked about safety at a personal and societal level.
May have a future conversation about long-term drivers toward a mass extinction.
(recorded Monday 13 November, my voice cut off at 1h 09m for some reason).
|
668990b3-8cb9-4420-862a-0bcf64c6db51 | StampyAI/alignment-research-dataset/arbital | Arbital | P (Polynomial Time Complexity Class)
P is the [class of problems](https://arbital.com/p/problem_class) which can be solved by [algorithms](https://arbital.com/p/algorithm) whose run time is bounded by a [https://arbital.com/p/-polynomial](https://arbital.com/p/-polynomial). |
ea2830d0-f8b4-4aa4-a4c9-8d092196d4d7 | trentmkelly/LessWrong-43k | LessWrong | "Open-Mindedness" - the video
An interesting little Flash-like video on "openmindedness" by someone named QualiaSoup (hopefully ironically).
Does anyone know how much effort is required to produce this sort of video, perhaps from a script? We need at least another thousand of these. |
7aa07972-3d0c-46f3-bd8c-a06478c90d0f | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | The Parable of the Boy Who Cried 5% Chance of Wolf
*Epistemic status: a parable making a moderately strong claim about statistics*
Once upon a time, there was a boy who cried, "there's a 5% chance there's a wolf!"
The villagers came running, saw no wolf, and said "He *said* there was a wolf and there was not. Thus his probabilities are wrong and he's an alarmist."
On the second day, the boy heard some rustling in the bushes and cried "there's a 5% chance there's a wolf!"
Some villagers ran out and some did not.
There was no wolf.
The wolf-skeptics who stayed in bed felt smug.
"That boy is always saying there is a wolf, but there isn't."
"I didn't say there *was* a wolf!" cried the boy. "I was estimating the probability at **low, but high enough**. A false alarm is much less costly than a missed detection when it comes to dying! The expected value is good!"
The villagers didn't understand the boy and ignored him.
On the third day, the boy heard some sounds he couldn't identify but seemed wolf-y. "There's a 5% chance there's a wolf!" he cried.
No villagers came.
It was a wolf.
They were all eaten.
Because the villagers did not think probabilistically.
The moral of the story is that **we should expect to have a large number of false alarms before a catastrophe hits and that is not strong evidence against impending but improbable catastrophe.**
Each time somebody put a low but high enough probability on a pandemic being about to start, they weren't wrong when it didn't pan out. H1N1 and SARS and so forth didn't become global pandemics. But they *could* have. They had a **low probability, but high enough to raise alarms.**
The problem is that people then thought to themselves "Look! People freaked out about those last ones and it was fine, so people are terrible at predictions and alarmist and we shouldn't worry about pandemics"
And then COVID-19 happened.
This will happen again for other things.
People will be raising the alarm about something, and in the media, the nuanced thinking about probabilities will be washed out.
You'll hear people saying that X will definitely fuck everything up very soon.
And it doesn't.
And when the catastrophe doesn't happen, don't over-update.
Don't say, "They cried wolf before and nothing happened, thus they are no longer credible."
Say "**I wonder what probability they or I should put on it? Is that high enough to set up the proper precautions?**"
When somebody says that nuclear war hasn't happened yet despite all the scares, when somebody reminds you about the AI winter where nothing was happening in it despite all the hype, remember the boy who cried a 5% chance of wolf.
*Originally posted on my [Twitter](https://twitter.com/Kat__Woods) and [personal blog](http://www.katwoods.org/home/the-parable-of-the-boy-who-cried-5-chance-of-wolf).*
*Reminder that if this reaches 25 upvotes,* *[you can listen to this post on your podcast player](https://forum.effectivealtruism.org/posts/JTZTBienqWEAjGDRv/listen-to-more-ea-content-with-the-nonlinear-library)* *using* *[the Nonlinear Library](https://forum.effectivealtruism.org/posts/JTZTBienqWEAjGDRv/listen-to-more-ea-content-with-the-nonlinear-library).* |
4951bf2f-022c-4410-acd6-e77caf56d22c | trentmkelly/LessWrong-43k | LessWrong | Impact of the rationalist community who someone who aspired to be "rational"
This is cross posted from my blog and originally intended to people who are not familiar with the rationalist community, or who may have heard about it from external source. If you regularly read this site, the interest may be limited. However, I myself would be interested to read the take of my friends about this question.
For years, I wanted to write about what the aspiring rationalist community meant to me. Seeing a lot of people criticizing it, sometime with argument I agree with, often with ones which does not represents the reality I've seen, I made a twitter thread about it. Threads are helpful because I find it more acceptable to write whatever comes through my mind randomly, which makes it easier to write than a blog post. I'll translate and post it here too.
The thread
WHAT DO I CALL "RATIONALISM"
I fear it might be necessary to state that I do not necessarily agree with everything aspiring rationalist wrote. I am far from having read everything. I'll add that this term seems to be used by various unrelated communities. I have sometime seen people stating "I use rationalist reasoning, so I'm right". I have not seen it in the circles I've been in and can not imagine it ever occurring.
I honestly don't know which ideas originally comes from the rationalist movement, which of those ideas are now known outside of it, what ideas were already very well known, classical, and straighforward for most people. There are of course a few exceptions, such as the paper-clip maximiser, the word of Em, many IA-risk related ideas, but I've never been able to understand why this very idea is so important, so I'm not going to consider it here.
I do love rational(ist)[1] fiction. Harry Potter and the Method of Rationality being the best known, Metropolitan Man, Instrument of Destructions, Sword of Good, I'm beginning Pokemon: the origin of species[2]... Simply, I consider it to be a genre of fiction. Not better than romance, polars, or genre fiction. It emphasizes a not |
1d46990e-1570-4246-a3ba-fd66b97ee477 | trentmkelly/LessWrong-43k | LessWrong | Suggestions for making research as trustworthy, intelligible and quickly available as possible
There's a lot of research papers out there - some good, some bad, some intelligible, some unintelligible, some disseminated quickly, some slowly. Now, with covid-19, it is more important than ever that we get to know whether a research paper should be trusted, and as many as possible of the relevant people should be able to understand it as quickly as possible. The phrases in italics refer to key problems with the system for creating and disseminating knowledge. The purpose of this note is to explain how a few publications of mine are relevant to tackling these problems.
Just after deciding to write this note, I received a "nature briefing" email from the journal Nature summarising some of their latest highlights. One thing that caught my eye was a paper entitled "Suppression of COVID-19 outbreak in the municipality of Vo’, Italy" (E. Lavezzo et al. Preprint at medRxiv http://doi.org/ggsmcj). According to the Nature summary: "On 21 February, the town of Vo’ reported Italy’s first COVID-19 death, leading authorities to ban movement in the town and end public services and commercial activities there for two weeks. Andrea Crisanti at Imperial College London and his colleagues swabbed almost every resident of Vo’ for viral RNA at the beginning and end of the lockdown. ... The team found that some 43% of the people infected with SARS-CoV-2 in the town reported no fever or other symptoms. The researchers observed no statistically significant difference in potential infectiousness between those who reported symptoms and those who did not."
The paper in question was posted on https://www.medrxiv.org/ which describes itself as a preprint server for health sciences. There is a warning on the top of each page that the paper is "not certified by peer review". This seems to imply that once it has been "certified" - by a couple of "peers" chosen by the editor of the journal - then its contents must be right, trustworthy or whatever. This assumption is implicit in the journalist |
f4862a87-851c-4b1a-8a72-859c74e29945 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient
1. Introduction
----------------
Rapid advances in machine learning (ML) have spurred interest in artificial intelligence (AI) for increasingly diverse high-impact applications including medical decision making, self-driving cars, and generating text for propaganda and fake news.
At the same time, deep models are increasingly understood to habitually engage in shortcut learning (Geirhos et al., [2020](#bib.bib32)) and lack the ability to generalize in a systematic manner (Bahdanau et al., [2019](#bib.bib5)).
These concerns magnify when AI are in feedback loops: models minimizing average loss can perform worse on minority populations, the ensuing degraded service quality can deplete minorities from the service and future training data (Hashimoto et al., [2018](#bib.bib36)). Flaws in deep-learning bioimage models in impactful publications can affect the training of future models and propagate to other papers (Laine et al., [2021](#bib.bib45)).
This state of the field demands us to consider how well we can trust AI – can we trust AI to recommend useful treatments for never-before-seen patients, to act fairly with minimal bias, to preserve data privacy, to align with human values?
Can we trust AI to not kill via self-driving cars, to not hinder scientific discovery, to make the world a better place?
Many have been alarmed by the black box nature of many state-of-the-art ML models, and hesitant to trust these models given our inability to understand what these models have learned and how they make decisions.
Interpretability technology, including explainability, transparency, understandability, legibility, and intelligibility – generally considered as the ability to understand the internal logic, inner workings, and rationale behind predictions – are widely touted as a critical and necessary tool for trust.
NIST, a U.S. national lab that aims to influence technology standards, writes that explainability is necessary to determine that an AI system is trustworthy (Stanton and
Jensen, [2021](#bib.bib72)).
An editorial in Nature Biomedical Engineering writes ”for trust… opening up algorithms to interpretation is a necessary first step” (nat, [2018](#bib.bib3)). In Google’s AI best practices: ”Interpretability is crucial to… trust AI systems.” (goo, [[n. d.]](#bib.bib2))
”ML systems must be transparent to earn experts’ trust” (Kim, [2015](#bib.bib43)).
”The demand for the ability to… trust ML systems [is increasing], for which interpretability is indispensable” (Carvalho
et al., [2019](#bib.bib18)).
”It is very hard to trust any model … without having transparency into how those models operate” (Schmelzer, [2020](#bib.bib68)).
The perception that interpretability is critical to trust is incredibly widespread (Ribeiro
et al., [2016](#bib.bib65); Tonekaboni et al., [2019](#bib.bib76); Rudin, [2019](#bib.bib67); Caruana et al., [2017](#bib.bib17); Molnar, [2019](#bib.bib56); Lipton, [2017](#bib.bib48); Bhatt et al., [2020a](#bib.bib8); Yoon
et al., [2021](#bib.bib87)).
However, progress on interpretability has been difficult to measure, as lack of a clear consensus definitions have exposed interpretability’s inherent subjectivity and field-specific meanings (van der Schaar
and Maxfield, [2021](#bib.bib79); Krishnan, [2020](#bib.bib44); Lipton, [2018](#bib.bib49); Doshi-Velez and
Kim, [2017](#bib.bib24); Lipton, [2017](#bib.bib48)).
This has limited the real-world impact of interpretability methods (Bhatt et al., [2020b](#bib.bib9)).
Furthermore, a moment’s reflection reveals that trusting black boxes is possible.
Air craft collision systems operate without human intervention (Doshi-Velez and
Kim, [2017](#bib.bib24)).
Doctors trust electrocardiogram machines without knowing how they work; in fact, a doctor that refuses black boxes ”will be standing in the operating room with their stethoscope and little else” (Cannesson and
Shafer, [2016](#bib.bib16); van der Schaar
and Maxfield, [2021](#bib.bib79)).
Heart patients manually check their pulse after receiving a pacemaker, but gradually learn to trust their pacemaker as time goes on (Tschopp, [2020](#bib.bib78)).
Best practices to avoid replication crisis from deep-learning-based bioimage analysis focus on robustness testing and performance validation on held-out data, not interpretability (Laine et al., [2021](#bib.bib45)).
Humans can also trust other humans in this fashion:
bettors can trust chess experts to perform well based on past performance, without explanations of mental processes understandable only to other chess experts.
The idea that black-box models do not preclude trust or usefulness has been argued on philosophical (Durán and
Jongsma, [2021](#bib.bib26); Krishnan, [2020](#bib.bib44)) and pragmatic grounds (Holm, [2019](#bib.bib39)), including by doctors (Cannesson and
Shafer, [2016](#bib.bib16)).
The tension between these observations and interpretability’s asserted centrality to trust remains largely unresolved in literature, and
problematically,
the precise nature of the relationship between interpretability and trust remains poorly studied.
If trust is a primary end-goal of interpretability, we must ask how precisely interpretability contributes to trust, and if there are better ways to advance trust.
Overview.
In section [2](#S2 "2. The Problem of Human Trust in AI ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient"), we address what it means to trust AI, and how humans do so.
We ground our definition of AI in statistical learning theory, avoiding an anthropomorphizing of AI inherent to other lenses on human-AI trust (Toreini et al., [2020](#bib.bib77); Jacovi et al., [2021](#bib.bib40)).
By avoiding assigning moral agency to AI, we reduce the human-AI trust problem to concerns on the abilities and reliability of its input-output behavior on contracts, which we frame in terms of out-of-distribution and out-of-task performance.
We later study human-AI-human trust, which can be decomposed into three problems: two of human-AI trust and one of human-human trust.
Human-AI trust reduces to concerns on model behavior, and humans evaluate trust by gathering information on model behavior in what we call behavior certificates (BCs) via black-box interaction or interpretability.
We ontologize BCs into non-interactive and interactive BCs, and introduce a 5-point scoring system on their correctness, contract relevance, and understandability.
The academic field of ML research, and practical efforts in applied ML, can be viewed as systems for producing BCs.
We then ask what interpretability contributes to trust. In section [3](#S3 "3. The Ladder of Model Insight ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient"), we introduce a ladder of model access and insight relating interpretability and transparency to the ability to run a black-box model at-will (black-box interaction).
In section [4](#S4 "4. What is the Minimum Level of Model Access Necessary or Sufficient for Trust? ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient"), we answer: what is the minimum level of model access necessary for trust in AI?
We conclude that black-box interaction is sufficient, thus interpretability is not necessary. We further argue that interpretability alone is not sufficient for trust, while black-box interaction is in fact necessary.
In section [5](#S5 "5. Insights on Building Trusted and Trustworthy AI ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient"), we discuss how to build trustworthy AI, evaluate trust, and communicate trust.
Rather than interpretable models, we suggest that understandable behavior certificates, allowing diverse audiences to understand and reason about model input-output behavior, are more useful.
We also highlight the importance of clearly defining trust contracts, contract-aware model design, and pursuing trust calibration over maximization.
In section [6](#S6 "6. Benefits and Costs of Pursuing Level 3 Insight ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient"), we investigate the benefits and costs of pursuing level model interpretability or transparency.
While not strictly necessary for trust, we highlight specific advantages: interpretability can enjoy substantial data efficiency and gracefully handle underspecified trust contracts, and produce more relevant and precise BCs.
However, interpretability can cost: second-order trust problems can arise when the trustworthiness of model explanations is unclear (Murdoch et al., [2019](#bib.bib57)), and weak transparent models can be less trustworthy than stronger black-box models. We also discuss interpretability’s role in legal compliance, model debugging, and scientific discovery.
2. The Problem of Human Trust in AI
------------------------------------
What do we mean when we ask whether humans can trust an AI? Here, we reduce human-AI trust to concerns on model behavior. To evaluate trust, humans gather information on model behavior by black-box interaction or interpretability, and use this evidence to reason about the model’s potential behavior on trust contracts.
Defining AI.
In statistical learning theory, an ML model is a function g𝑔gitalic\_g that maps data from some input domain to some output domain, with parameters θ𝜃\thetaitalic\_θ that are learned from training data (Bousquet
et al., [2004](#bib.bib11)).
Typical AI systems can include ML components alongside other algorithmic processes hℎhitalic\_h (arbitrary data-transforming functions, i.e., data preprocessing or output postprocessing), all of which are executed by a Turing machine.
Any functional composition g∘h𝑔ℎg\circ hitalic\_g ∘ italic\_h is also a data-transforming function f𝑓fitalic\_f, which we define as AI.
AI’s real-world impact stems from using f𝑓fitalic\_f’s output data for decision making, in a human-mediated or automated manner, by machines or humans.
This definition of AI is sufficient to express automation systems such as medical decision trees, airplane autopilot systems (Hoff and Bashir, [2015](#bib.bib38)), foundation models (Bommasani
et al., [2021](#bib.bib10)) and large language models (Brown
et al., [2020](#bib.bib15)), superhuman reinforcement learning models like AlphaGo (Silver et al., [2017](#bib.bib71)), and captures the zeitgeist of modern and future fruits of machine learning research (Drexler, [2019](#bib.bib25)).
Determinism.
Without loss of generality, f𝑓fitalic\_f can be viewed as deterministic since stochastic models can be expressed by including random seeds as partial inputs. Model behavior is therefore space-time invariant and memoryless: we can run the computer program over and over, anywhere, anytime on the same input and f𝑓fitalic\_f will always produce the same output.
While the effective degree of determinism depends on our control over the model’s input and the circumstances of its usage (e.g., if the model operates on stochastic input beyond our control, the model strays towards being nondeterministic to us), one can observe that AI behavior already differs substantially from human behavior.
Human beings, relative to other human beings, effectively enjoy free will (Nichols, [2011](#bib.bib60)) –
it is within the scope of human ability to realize the space-time invariance of AI behavior by running it repeatedly on identical input data, while the same is difficult to achieve with a human being. In practice, random seeds and input data are controllable in modern ML, rendering models effectively deterministic (Bouthillier and
Varoquaux, [2020](#bib.bib12)). This view supports the parallels between ML and software engineering, which can be viewed as two approaches with the same end-goal: creating computer programs (McCarthy, [1998](#bib.bib53)).
Human-AI trust vs. human-AI-human trust.
As a data-transforming function with deterministic behavior, AI is best understood as a tool. Like a double-edged sword, a deterministic data-transforming function is not a moral agent: it lacks inherent moral responsibility or agency (Talbert, [2019](#bib.bib73)).
Human-AI trust, then, becomes a vastly different problem than human-AI-human trust, where a human (i.e., a user) interacts with an AI that is wielded or deployed by another human (or a company) with potentially conflicting values and incentives (Jacovi et al., [2021](#bib.bib40)).
In practice, human-AI-human trust problems are common, particularly challenging, and especially important, but it is critical to cleanly divide the two. Here, we focus primarily on human-AI trust, but briefly apply our findings to human-AI-human trust in section [2.3](#S2.SS3 "2.3. The Problem of Human-AI-Human Trust ‣ 2. The Problem of Human Trust in AI ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient").
Human-AI trust concerns deterministic behavior.
Several recent treatments on human-AI trust begin from interpersonal (human-human) trust frameworks (Jacovi et al., [2021](#bib.bib40); Toreini et al., [2020](#bib.bib77)).
ABI+ is one influential framework in which human-human trust relies on ability, benevolence, integrity, and predictability (Mayer
et al., [1995](#bib.bib52); Dietz and Hartog, [2006](#bib.bib21)).
However, the anthropomorphization of AI in these analyses is incompatible with the determinism and lack of moral agency implied by statistical learning theory.
AI should not be considered as a human being in trust transactions, but rather as an automation system. This view is supported by sociological research on human trust in automation systems, defined as ”technology that actively selects data, transforms information, makes decisions, or controls processes” (Hoff and Bashir, [2015](#bib.bib38); Lee and See, [2004](#bib.bib47)). The inclusion of AI as a type of automation system is supported by recent E.U. GDPR policy (Wachter
et al., [2017](#bib.bib82), [2018](#bib.bib83)).
Empirically, humans also do not treat AI and automation systems like fellow humans in trust transactions (Madhavan and
Wiegmann, [2007](#bib.bib51)).
Human-human trust tends to transition from reliability to faith as familiarity increases (Lee and See, [2004](#bib.bib47)), while human-automation trust follows a different arc over time, starting with an initial positivity bias, such that initial trust is based in faith and overly optimistic (Dzindolet et al., [2003](#bib.bib27)), but as familiarity increases, the basis of trust transitions to performance and reliability (Madhavan and
Wiegmann, [2007](#bib.bib51); Hoff and Bashir, [2015](#bib.bib38)).
Another perspective on trust is Baier’s notion of reliance for trust in inanimate objects (i.e., tools) (Baier, [1986](#bib.bib6)). We can understand reliance in terms of the ABI+ framework’s concepts of ability and predictability, where
ability describes the actions or behavior that a tool is capable of, and predictability is the consistency of behavior. The ABI+ concepts of benevolence (the trustee’s desire to do good to the trustor) and integrity (the trustee’s adherence to values or principles accepted by the trustor) are discarded as they fail to apply to non-moral agents.
Thus, human-automation trust mainly depends on performance (LEE and MORAY, [1992](#bib.bib46)).
Anthropomorphizing AI is cautioned against by ML experts (Jordan, [2019](#bib.bib41)). Such attitudes can mislead trust judgments to public harm. It is critical that developers engaging with the public correct such misconceptions when possible.
Contractual trust.
Notions of trust are incomplete when what the trustee is trusted to do, or the type of behavior the trustee is trusted to have, is unspecified.
To address this issue, we employ the framework of contractual trust (Jacovi et al., [2021](#bib.bib40)), or trust with commitment (Hawley, [2014](#bib.bib37); Tallant, [2017](#bib.bib74)), where the trustee is trusted to fulfill a certain contract, which can concern any aspect of the model’s behavior: correctness, performance, fairness, preserving data privacy, behaving ethically, resources used such as wall-clock time or memory, etc.
The expressivity and generality of the contractual trust framework elevates trust to a centrally important role in applied ML by subsuming, like an umbrella, any model desiderata.
Model behavior contracts concern out-of-distribution and out-of-task performance.
To define contracts and quantify contract success, we can extend the statistical learning framework of training models on training data and training tasks. We propose to define tasks in full generality as computable functions of a model’s behavior that return ’loss’ values.
Trust contracts
can thus be expressed in terms of contract tasks
and contract data distributions.
A key challenge arises when the training tasks and datasets are distinct from the trust contract tasks and data distributions.
In ML, the problem of out-of-distribution (OOD) generalization – the model’s performance on the training task on new data – is widely studied, through lenses such as distributionally robust optimization (Rahimian and
Mehrotra, [2019](#bib.bib64)), invariant risk minimization (Ahmed et al., [2021](#bib.bib4)), and more broadly through anomaly detection for abstaining or predicting with uncertainty.
Model performance on tasks beyond the training task, which we call out-of-task (OOT) performance
is challenging to study because in general, performance on one task (e.g., minimizing squared regression loss) can have little bearing on performance on other tasks (e.g., fairness).
Advances in meta-learning, few-shot, and zero-shot learning enable learning models that learn quickly on new tasks with limited data or no data at all (Finn
et al., [2017](#bib.bib29); Brown
et al., [2020](#bib.bib15)).
The rapid improvements in OOD and OOT performance in recent years, however, remain limited in the context of the panoply of tasks and data distributions desirable in trust contracts.
With trust contracts, shifts in both dataset and task are common, though they are conventionally studied separately in ML.
While models are often trained to minimize average loss over diverse datasets, each user’s trust in the AI can concern its behavior on a unique distribution centered on data most relevant to each user (Hashimoto et al., [2018](#bib.bib36)).
Users can also demand unique preferences on model desiderata – not only through personal trade-offs among high-level notions like fairness, data privacy, and performance; but individual concepts like fairness can be defined and quantified in dozens of distinct ways, some of which are contradictory (Narayanan, [2018](#bib.bib59)).
Thus, while ML research promises to advance OOD and OOT performance, many more challenges must be faced to advance trustworthiness.
Contract expressivity.
Over the preceding sections, we have argued that all human-AI trust problems can be expressed in terms of desired quantitative performance on out-of-distribution generalization or out-of-task performance.
However, some desiderata such as adherence to ethical or moral principles can be challenging to express as computable functions of a model’s behavior, which have motivated some to favor interpretability (Lipton, [2018](#bib.bib49); Doshi-Velez and
Kim, [2017](#bib.bib24)).
Instead, we advocate for the other fork in the road: instead of abandoning the effort to clearly define our trust desiderata in quantifiable, computable terms, we believe that overcoming these challenges is crucial for human-AI trust.
###
2.1. Formalizing the problem of human-AI trust
An AI is a deterministic data-transforming function f𝑓fitalic\_f (which we can think of as a model or a computer program) that maps data from some input space to some output space.
A task 𝒯𝒯\mathcal{T}caligraphic\_T is a computable function of f𝑓fitalic\_f and some input data, which measures some property of f𝑓fitalic\_f’s behavior by running f𝑓fitalic\_f on the input data.
In ML, models are trained
on some training task 𝒯𝚝𝚛subscript𝒯𝚝𝚛\mathcal{T}\_{\texttt{tr}}caligraphic\_T start\_POSTSUBSCRIPT tr end\_POSTSUBSCRIPT on a training dataset 𝒳𝚝𝚛∼𝒫𝚝𝚛(𝒳)similar-tosubscript𝒳𝚝𝚛subscript𝒫𝚝𝚛𝒳\mathcal{X}\_{\texttt{tr}}\sim\mathcal{P}\_{\texttt{tr}}(\mathcal{X})caligraphic\_X start\_POSTSUBSCRIPT tr end\_POSTSUBSCRIPT ∼ caligraphic\_P start\_POSTSUBSCRIPT tr end\_POSTSUBSCRIPT ( caligraphic\_X ).
A trust contract C=(𝒫𝚌𝚘𝚗(𝒳),{𝒯𝚌𝚘𝚗i},𝒮𝚌𝚘𝚗)𝐶subscript𝒫𝚌𝚘𝚗𝒳superscriptsubscript𝒯𝚌𝚘𝚗𝑖subscript𝒮𝚌𝚘𝚗C=(\mathcal{P}\_{\texttt{con}}(\mathcal{X}),\{\mathcal{T}\_{\texttt{con}}^{i}\},\mathcal{S}\_{\texttt{con}})italic\_C = ( caligraphic\_P start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT ( caligraphic\_X ) , { caligraphic\_T start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_i end\_POSTSUPERSCRIPT } , caligraphic\_S start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT ) includes a contract data distribution 𝒫𝚌𝚘𝚗(𝒳)subscript𝒫𝚌𝚘𝚗𝒳\mathcal{P}\_{\texttt{con}}(\mathcal{X})caligraphic\_P start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT ( caligraphic\_X ), a set of contract tasks {𝒯𝚌𝚘𝚗i}superscriptsubscript𝒯𝚌𝚘𝚗𝑖\{\mathcal{T}\_{\texttt{con}}^{i}\}{ caligraphic\_T start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_i end\_POSTSUPERSCRIPT }, and a success evaluation function111It is convenient to assume that 𝒮𝚌𝚘𝚗subscript𝒮𝚌𝚘𝚗\mathcal{S}\_{\texttt{con}}caligraphic\_S start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT can be defined to operate either on the distribution 𝒫𝚌𝚘𝚗(𝒳)subscript𝒫𝚌𝚘𝚗𝒳\mathcal{P}\_{\texttt{con}}(\mathcal{X})caligraphic\_P start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT ( caligraphic\_X ) or on samples 𝒳𝚌𝚘𝚗∼𝒫𝚌𝚘𝚗(𝒳)similar-tosubscript𝒳𝚌𝚘𝚗subscript𝒫𝚌𝚘𝚗𝒳\mathcal{X}\_{\texttt{con}}\sim\mathcal{P}\_{\texttt{con}}(\mathcal{X})caligraphic\_X start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT ∼ caligraphic\_P start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT ( caligraphic\_X ) 𝒮𝚌𝚘𝚗(f,{𝒯𝚌𝚘𝚗i},𝒳𝚌𝚘𝚗)→{0,1}→subscript𝒮𝚌𝚘𝚗𝑓superscriptsubscript𝒯𝚌𝚘𝚗𝑖subscript𝒳𝚌𝚘𝚗01\mathcal{S}\_{\texttt{con}}(f,\{\mathcal{T}\_{\texttt{con}}^{i}\},\mathcal{X}\_{\texttt{con}})\rightarrow\{0,1\}caligraphic\_S start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT ( italic\_f , { caligraphic\_T start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_i end\_POSTSUPERSCRIPT } , caligraphic\_X start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT ) → { 0 , 1 } that identifies f𝑓fitalic\_f’s performance on the contract tasks and contract data distribution as either a failure or success.
The contractual trustworthiness problem is: given a model f𝑓fitalic\_f and a trust contract C𝐶Citalic\_C, output a contractual trustworthiness score, representing our subjective likelihood222This reflects other human trust processes that encompass both objective and subjective elements (McLeod, [2021](#bib.bib54)). that the model will succeed on the contract, using evidence about model behavior available to us.
These evidence are behavior certificates, denoted by ℬℬ\mathcal{B}caligraphic\_B, which can regard any aspect of model behavior, even those not relevant to the model’s likely behavior on the trust contract.
The contractual trustworthiness score can thus be written as333Excitingly, estimating or inferring contractual trustworthiness scores for a model can itself be solved with ML. At present, ML models may struggle with the diverse modalities and uncertainties in behavior certificate evidence. Key challenges also include communicating human-discovered BCs to models and ML-guided discovery or generation of BCs.:
| | | | |
| --- | --- | --- | --- |
| (1) | | P(𝒮𝚌𝚘𝚗(f,{𝒯𝚌𝚘𝚗i},𝒫𝚌𝚘𝚗(𝒳))=1|ℬ)𝑃subscript𝒮𝚌𝚘𝚗𝑓superscriptsubscript𝒯𝚌𝚘𝚗𝑖subscript𝒫𝚌𝚘𝚗𝒳conditional1ℬP\Big{(}\mathcal{S}\_{\texttt{con}}(f,\{\mathcal{T}\_{\texttt{con}}^{i}\},\mathcal{P}\_{\texttt{con}}(\mathcal{X}))=1\Big{|}\mathcal{B}\Big{)}italic\_P ( caligraphic\_S start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT ( italic\_f , { caligraphic\_T start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_i end\_POSTSUPERSCRIPT } , caligraphic\_P start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT ( caligraphic\_X ) ) = 1 | caligraphic\_B ) | |
Trained model with access level 1, 2, or 3
Additional data
Additional tasks
Trust contract, specific desires on model behavior
Behavior certificates, information on any aspect of model behavior
Contractual trustworthiness score
OptionalEstimation / Inference
Figure 1. The human-AI contractual trustworthiness problem
Estimation and inference.
In Fig. [1](#S2.F1 "Figure 1 ‣ 2.1. Formalizing the problem of human-AI trust ‣ 2. The Problem of Human Trust in AI ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient"), a human has access to a trained model, and defines a trust contract expressing specific desires on model behavior that the human would like to trust the AI on. To evaluate the AI’s contractual trustworthiness, the human collects information on any aspect of model behavior they would like in the form of behavior certificates, which are used as evidence to reason about the model’s potential behavior on the trust contract.
When the contract is accessible – we have abundant independent samples from the contract data distribution, and contract tasks are clearly defined – we can directly compute evidence, or behavior certificates, regarding the model’s behavior on the contract. This embodies an estimation problem in the statistical sense of calculating a property value of a population from samples 𝒳𝚌𝚘𝚗∼𝒫𝚌𝚘𝚗(𝒳)similar-tosubscript𝒳𝚌𝚘𝚗subscript𝒫𝚌𝚘𝚗𝒳\mathcal{X}\_{\texttt{con}}\sim\mathcal{P}\_{\texttt{con}}(\mathcal{X})caligraphic\_X start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT ∼ caligraphic\_P start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT ( caligraphic\_X ).
When the sample size N𝑁Nitalic\_N is large, it is especially powerful to train the model directly on the contract task and data; models can be trained on contract tasks even when they are not differentiable functions of model parameters, using techniques such as score function estimators (Williams, [1992](#bib.bib85)), straight-through gradient estimators (Yin
et al., [2019](#bib.bib86)), and evolutionary algorithms (Vikhar, [2016](#bib.bib81)). After training, performance on held-out data then serves as a powerful behavior certificate estimating contract adherence with small error bars.
When N𝑁Nitalic\_N is small, models can be trained on surrogate data444Sometimes, also surrogate tasks, and evaluated on contract data to statistically estimate contract behavior with larger error bars.
In other cases, the contract is not accessible: the contract data distribution or contract tasks may be underspecified, or we may not have access to contract data samples before deployment. In these situations, the trust problem is solved by inference in the statistical sense of reasoning about a latent variable from observed evidence. Without the ability to evaluate the model on the contract, we use behavior certificates and surrogate tasks and data to infer the model’s potential behavior on the contract.
Acting on Contractual Trustworthiness Scores. Individual contracts, when defined with proper precision, can be narrow. Complex real-world applications likely demand many contracts, each corresponding to particular model desiderata such as robustness or fairness. A model could be very trustworthy on one contract but not others.
The trustworthiness scores for many contracts should be combined with analyses of risk, potential consequences, and other factors, to decide the level of human involvement in the AI’s decision making. The 10-level Sheridan-Verplanck scale of automation (Sheridan
et al., [1978](#bib.bib70)) ranges from human oversight, varying degrees of human involvement in the loop, to full independence.
###
2.2. Behavior certificates
Our reduction of human-AI trust to concerns on model behavior elevates the importance of our processes for collecting evidence on model behavior, and evaluating and reasoning about behavior evidence.
We clarify these processes with the concept of behavior certificates (BCs), which are (evidence, conclusion) tuples; pieces of evidence supporting some conclusion about a model’s behavior.
Our notion of behavior certificates generalizes555While Jacovi’s framework places trust as the central output, our central output is understanding of model behavior, which then leads to trust. Jacovi’s causes of trust in AI (Jacovi et al., [2021](#bib.bib40)).
As the behavior described by a BC regards a computable property of a model, BCs correspond explicitly or implicitly to some task 𝒯𝚋𝚌subscript𝒯𝚋𝚌\mathcal{T}\_{\texttt{bc}}caligraphic\_T start\_POSTSUBSCRIPT bc end\_POSTSUBSCRIPT on some data 𝒳𝚋𝚌subscript𝒳𝚋𝚌\mathcal{X}\_{\texttt{bc}}caligraphic\_X start\_POSTSUBSCRIPT bc end\_POSTSUBSCRIPT.
To understand their central role in trust, we provide an ontology of BCs, discussing two main types, their provenance and key properties, and examples.
Interactivity and provenance.
Interactive BCs are formed by interacting with a given pre-trained model, typically by running it on new data or tasks.
They are often constructed and discarded on a per-model and per-problem basis. When trust contract tasks or data are not available, interactive BCs of model behavior on surrogate data or tasks can help us reason or infer about the model’s possible behavior on a trust contract. Interestingly, the construction of interactive BCs may be scaled with automation: one can imagine using generative models to produce and label data, running models on established collections of useful tasks, or tasks learned through methods like inverse reinforcement learning, and using automated adversarial methods to identify pertinent adversarial examples.
Non-interactive BCs can be formed solely from model design and training details, such as loss function, regularizers, model architecture, and data available during training (training, validation, and test sets). These BCs can describe the impact of certain architecture choices or regularization strategies on the behavior of the final trained model.
The production of novel non-interactive BCs often requires academic research and human creativity, and are typically long-lasting and broadly relevant to many models and problems. They are often collected by developers in conceptual toolboxes to help design ML approaches for new problems.
Examples of Non-interactive Behavior Certificates
* •
(In-distribution validation) The held-out validation loss is 1.2. ⇒⇒\Rightarrow⇒ The model’s expected loss on 𝒫𝚝𝚛(𝒳)subscript𝒫𝚝𝚛𝒳\mathcal{P}\_{\texttt{tr}}(\mathcal{X})caligraphic\_P start\_POSTSUBSCRIPT tr end\_POSTSUBSCRIPT ( caligraphic\_X ) is 1.2.
* •
(Geometric deep learning (Bronstein et al., [2021](#bib.bib14))) The model comprises self-attention layers without position embeddings followed by mean aggregation. ⇒⇒\Rightarrow⇒ The model is permutation invariant: for any data x𝑥xitalic\_x, f(x)=f(𝚙𝚎𝚛𝚖𝚞𝚝𝚎(x))𝑓𝑥𝑓𝚙𝚎𝚛𝚖𝚞𝚝𝚎𝑥f(x)=f(\texttt{permute}(x))italic\_f ( italic\_x ) = italic\_f ( permute ( italic\_x ) ).
* •
(Data augmentation) The image classification model was trained with rotation and color data augmentation. ⇒⇒\Rightarrow⇒ For any data x′superscript𝑥′x^{\prime}italic\_x start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT, f(x′)≈f(𝚛𝚘𝚝𝚊𝚝𝚎(x′))≈f(𝚌𝚘𝚕𝚘𝚛(x′))𝑓superscript𝑥′𝑓𝚛𝚘𝚝𝚊𝚝𝚎superscript𝑥′𝑓𝚌𝚘𝚕𝚘𝚛superscript𝑥′f(x^{\prime})\approx f(\texttt{rotate}(x^{\prime}))\approx f(\texttt{color}(x^{\prime}))italic\_f ( italic\_x start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ) ≈ italic\_f ( rotate ( italic\_x start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ) ) ≈ italic\_f ( color ( italic\_x start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ) ) under the same perturbation distributions used during training.
* •
(Models designed with prior knowledge) The model is a universal differential equation (Rackauckas et al., [2020](#bib.bib63)) incorporating knowledge of intraspecies competition. ⇒⇒\Rightarrow⇒ On any data, the learned dynamics are consistent with intraspecies competition.
* •
(Regularization) A model is trained to a distributionally robust optimization regularizer value of 1.6 with distance r𝑟ritalic\_r. ⇒⇒\Rightarrow⇒ Model loss is guaranteed to be 1.6 or lower on any data distribution within χ2superscript𝜒2\chi^{2}italic\_χ start\_POSTSUPERSCRIPT 2 end\_POSTSUPERSCRIPT-divergence of r𝑟ritalic\_r to 𝒫𝚝𝚛(𝒳)subscript𝒫𝚝𝚛𝒳\mathcal{P}\_{\texttt{tr}}(\mathcal{X})caligraphic\_P start\_POSTSUBSCRIPT tr end\_POSTSUBSCRIPT ( caligraphic\_X ). (Hashimoto et al., [2018](#bib.bib36); Rahimian and
Mehrotra, [2019](#bib.bib64)).
* •
(Interpretability) Feature importance analysis finds that the pre-trained model uses spoons to classify images labeled ’chocolate sauce’. ⇒⇒\Rightarrow⇒ The model is likely to incorrectly classify images with spoons and without sauce as chocolate sauce, and misclassify images of chocolate sauce without spoons as not chocolate sauce (Fong and Vedaldi, [2017](#bib.bib30)).
Examples of Interactive Behavior Certificates
* •
(OOD evaluation / Robustness testing) A pre-trained model has loss of 2.1 on surrogate data 𝒳𝚋𝚌subscript𝒳𝚋𝚌\mathcal{X}\_{\texttt{bc}}caligraphic\_X start\_POSTSUBSCRIPT bc end\_POSTSUBSCRIPT. ⇒⇒\Rightarrow⇒ The model has expected loss of 2.1 over 𝒫𝚋𝚌(𝒳)subscript𝒫𝚋𝚌𝒳\mathcal{P}\_{\texttt{bc}}(\mathcal{X})caligraphic\_P start\_POSTSUBSCRIPT bc end\_POSTSUBSCRIPT ( caligraphic\_X ) with ℒ𝚝𝚛subscriptℒ𝚝𝚛\mathcal{L}\_{\texttt{tr}}caligraphic\_L start\_POSTSUBSCRIPT tr end\_POSTSUBSCRIPT.
* •
(OOT evaluation) A model trained with cross-entropy loss is evaluated on a fairness task 𝒯𝚏𝚊𝚒𝚛subscript𝒯𝚏𝚊𝚒𝚛\mathcal{T}\_{\texttt{fair}}caligraphic\_T start\_POSTSUBSCRIPT fair end\_POSTSUBSCRIPT and performs poorly. ⇒⇒\Rightarrow⇒ The model is not fair (as defined by 𝒯𝚏𝚊𝚒𝚛subscript𝒯𝚏𝚊𝚒𝚛\mathcal{T}\_{\texttt{fair}}caligraphic\_T start\_POSTSUBSCRIPT fair end\_POSTSUBSCRIPT) on 𝒫𝚝𝚛(𝒳)subscript𝒫𝚝𝚛𝒳\mathcal{P}\_{\texttt{tr}}(\mathcal{X})caligraphic\_P start\_POSTSUBSCRIPT tr end\_POSTSUBSCRIPT ( caligraphic\_X ) and likely on other data.
* •
(Adversarial examples) We find, using human intuition or an automated method, a rotated version of a training image that the model classifies incorrectly, despite being correct on the unrotated image. ⇒⇒\Rightarrow⇒ The model is not rotation invariant, and will likely misclassify rotated versions of other images (Engstrom et al., [2019](#bib.bib28)).
Grading behavior certificate quality. BCs can vary in their relevance to the contracts, their correctness, and understandability, and each aspect can be rated on 5 point scale. For instance, some BCs backed by mathematical proofs can have near-perfect correctness (5), but have low relevance to contracts of interest (1-2), and be less understandable to laypeople (1-2). Meanwhile, some BCs formed by held-out validation can have high correctness (4), strong relevance (4), and are easier to understand (4). In this light, an important area of research in trust is improving our ability to generate BCs with greater correctness, relevance to contracts, and understandability.
Correctness. Correctness regards how well the conclusion follows from the evidence, which can be surprisingly challenging without expert knowledge in both ML and application domains. For instance, a common pitfall of early deep medical models trained on hospital A’s data distribution 𝒫𝙰(𝒳)subscript𝒫𝙰𝒳\mathcal{P}\_{\texttt{A}}(\mathcal{X})caligraphic\_P start\_POSTSUBSCRIPT A end\_POSTSUBSCRIPT ( caligraphic\_X ) was erroneously concluding that the model will perform well on hospital B; the conclusion should have been more narrow, as the evidence only supports good performance on 𝒫𝙰(𝒳)subscript𝒫𝙰𝒳\mathcal{P}\_{\texttt{A}}(\mathcal{X})caligraphic\_P start\_POSTSUBSCRIPT A end\_POSTSUBSCRIPT ( caligraphic\_X ) (Zech et al., [2018](#bib.bib88); Futoma et al., [2020](#bib.bib31)). Correctness is improved by forming conservative and precise conclusions that are sensitive to data assumptions and possible batch or environmental effects in the data.
Relevance to contracts. Relevance can be improved by creating BCs on contract tasks and data.
Distribution testing can assess contract relevance of held-out validation statistics: if x𝚌𝚘𝚗∼𝒫𝚋𝚌(𝒳)similar-tosubscript𝑥𝚌𝚘𝚗subscript𝒫𝚋𝚌𝒳x\_{\texttt{con}}\sim\mathcal{P}\_{\texttt{bc}}(\mathcal{X})italic\_x start\_POSTSUBSCRIPT con end\_POSTSUBSCRIPT ∼ caligraphic\_P start\_POSTSUBSCRIPT bc end\_POSTSUBSCRIPT ( caligraphic\_X ), then our interactive BCs are strongly relevant to that contract.
Contract-aware model design with inductive biases and domain knowledge can help construct non-interactive BCs with improved contract relevance.
Understandability. Understandability concerns how well we can understand the evidence to be true, understand how the conclusion derives from the evidence, and understand the statement of the conclusion and its implications on model behavior.
Understandability requires case-by-case effort in scientific and technical communication.
We propose that BCs should generally be communicated in multiple ways: in technically precise language, for fellow developers, but also in plain language, for laypeople. This empowers a diverse audience to reason about model behavior and trustworthiness, while handling the trade-off that understandability to laypeople often introduces ambiguity for experts.
Summarizing BCs in model cards can aid understandability (Mitchell et al., [2019](#bib.bib55)).
###
2.3. The Problem of Human-AI-Human Trust
The problem of human-AI-human trust is considerably more complex than human-AI trust, as it can be decomposed into three trust problems: two human-AI trust problems, and a human-human trust problem. In our AI-as-tool lens, this problem manifests when a human interacts with an AI that is wielded as a tool by another human. The importance of the problem of human-human trust to applied ML cannot be overstated, as AI applications with ever-greater ability and impact are deployed by humans and companies operating by diverse incentives and values. While a proper treatment of this problem is beyond the scope of this paper, we offer a brief analysis here, using our human-AI trust framework. Regulation and transparency into engineering practices will be crucial for building human-AI-human trust.
Two human-AI trust problems. Issues can arise from misalignment in perceived trustworthiness levels. Consider an example where a developer releases a product that grants an AI a high Sheridan-Verplanck automation level based on the developer’s trust in the AI to be accurate and fair in real-world applications. The user, having seen a different body of evidence and BCs, agrees with the developer’s trustworthiness score in the AI’s ability to be accurate, but assigns lower trustworthiness in the AI’s ability to be fair. Overall, the user prefers a lower automation level than provided, but this is outside of their control. Left with only the choice of either using the product or not, they choose to not use it.
In general, disagreements at any point in the information flow in Figure [1](#S2.F1 "Figure 1 ‣ 2.1. Formalizing the problem of human-AI trust ‣ 2. The Problem of Human Trust in AI ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient") can deteriorate human-AI-human trust. If information or evidence is asymmetrically accessible, it should be unsurprising that trust conclusions are likely to disagree. If evidence from BCs are publicly shared, humans may still disagree on the conclusions derived from the evidence, or on the relevant tasks or data distributions. And even if people agree on contractual trustworthiness scores, they may disagree on the potential consequences and risks in deploying the AI.
Human-human trust. Human-human trust can be positive: strong interpersonal trust can enable users to bypass the difficulties of assessing human-AI trust while enjoying the benefits of AI use.
It can also
introduce incentive and value alignment challenges. Even if both parties share strong human-AI trust in sharing similar trust in the behavior of the AI, lack of human-human trust can manifest as a lack of trust in each other’s uses of the AI, analogous to trust issues with nations (moral agents) and nuclear weapons (tools). Nations can trust that the other nation’s nuclear weapons work as advertised, but may not trust how the other nation will use their nuclear weapons.
3. The Ladder of Model Insight
-------------------------------
We now turn to the question: what role does interpretability et al.666Interpretability et al.: transparency, explainability, understandability, intelligibility, legibility, etc play in human-AI trust?
Before embarking on such analysis, we first introduce a ladder of model access and insight to relate interacting with black-box models with interpretability et al. which ”open up the black box”.
The ladder of model insight777We take inspiration from Judea Pearl’s Ladder of Causality. (Pearl, [2009](#bib.bib61)) contains three levels of questions with increasing detail (Figure [2](#S3.F2 "Figure 2 ‣ 3. The Ladder of Model Insight ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient")).
Level x𝑥xitalic\_x insight is information obtained from answers to level x𝑥xitalic\_x questions.
Level x𝑥xitalic\_x access is the general amount of access to the model needed to accurately888Accuracy is important: explainability methods use level 2 access to approximate answers to level 3 questions, but if they are not accurate or faithful to the model’s inner workings, then they have not produced level 3 insight answer level x𝑥xitalic\_x questions999Reported model access levels describe access that is generally necessary to accurately answer questions of each level, based on the current state of the field at the time of publication. The access needed for level x questions may change over time as research progresses. Our definitions accommodate this possibility: the level of any question never changes, but the meaning of level x𝑥xitalic\_x access would change..
We call this framework a ladder because, in typical settings, the ability to answer questions of a certain level implies the ability to answer questions of lower levels.
Model access typically accumulates over three main axes: awareness that the model exists, the ability to run a model which may be a black box, and the ability to understand the internals of a model.
* •
Level 0 model access: The human is not aware of the model, which may be making decisions for or about the human.
* •
Level 1 model access: The human is aware of the model but is limited in their ability to run the model. Level 1 questions include giving examples of model input and output, and reasoning about the space of input and outputs. This can reveal what information the model may depend on and the kinds of decisions the model’s output might be used for.
* •
Level 2 model access: This level includes the typical access afforded to engineers or developers building black-box models: they can run the model at will, but cannot see inside the black box. Level 2 questions regard the model’s performance on any task and dataset.
* •
Level 3 model access: Humans can run the model and see inside the model, which is considered transparent or interpretable under conventional definitions. With level 3 model access, we can answer level 3 questions regarding what the model has learned, how the model makes its decisions, and any other questions considered answerable with models considered to be interpretable et al.
| | |
| --- | --- |
| | Model access |
| Level | Questions | Aware of model | Can run model | Model clarity |
| 0 | None | No | No | Black box |
| 1 | What is an example input and output? What is the space of the input and output? | Yes | Limited | Black box |
| 2 | How does the model perform on any task and dataset? | Yes | At will | Black box |
| 3 | What has the model learned? How does the model make its decisions? | Yes | At will | Interpretable et al. |
Figure 2. Summary of the Ladder of Model Insight
Model access is fluid: a researcher enjoys level 2 or 3 access when developing their own model, but only has level 1 access when interacting with a closed-source research model through a rate-limited web app. Laypeople can enjoy level 2 access to machine learning services like Google translate, but have level 0 access by lacking awareness of their participation in other machine learning-driven ad services by the same company.
4. What is the Minimum Level of Model Access Necessary or Sufficient for Trust?
--------------------------------------------------------------------------------
Level 2 model access is sufficient to evaluate trust in AI.
This result concisely follows from definitions in preceding sections. To estimate or infer contractual trustworthiness, it suffices to have the power to run the model on arbitrary tasks or data. This power is achieved with level 2 model access; Q.E.D. Note that the ability to evaluate trust does not guarantee trust in any particular model. If the model is inherently trustworthy, however, then it suffices for humans to come to trust an AI.
A corollary of this result is that level 3 model access is not necessary for evaluating trust in AI. As level 3 access is level 2 access plus the ability to generate level 3 model insight (interpretability et al.), we can conclude that
interpretability et al. is not necessary for trust when we can run a model at will, even if the model is a black box. This result explains a variety of observations on trust without interpretability et al. in the introduction.
While level 2 access is in principle sufficient, in practice, enormous effort can be required before trust is achievable. While many challenges can be addressed without interpretability (section [5](#S5 "5. Insights on Building Trusted and Trustworthy AI ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient")), behavior certificates from level 3 model insight can sometimes be useful (section [6](#S6 "6. Benefits and Costs of Pursuing Level 3 Insight ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient")).
On many real problems, level 3 model insight is not sufficient for trust, while level 2 insight is necessary.
How does interpretability et al. relate to trust if we cannot run the model at will?
While this scenario is rare in practice101010More precisely, it is rare that no one can run a model at will while someone can interpret it. The inability of any single person to run a model at will while interpreting it is an artificial constraint on model access; in principle, a person who can interpret the model can almost always be granted the ability to run the model at will, analyzing such a question helps us further understand the relationship between interpretability et al. and trust.
Without the ability to run the model at will, we lose level 2 insight and retain only level 3 insight.
In full generality, we can assess contractual trustworthiness as long as we can generate any type of behavior certificates, which means that level 3 insight alone can be used to evaluate trust.
When models and trust contracts are simple, internal knowledge can suffice to accurately assess contract adherence and induce trust in a trustworthy model.
However, the power of level 3 insight can scale poorly as models or contracts gain in complexity, or as applications gain in importance, while level 2 insight can become increasingly necessary.
Software engineers can trust simple programs solely from reading code, but as programs increase in complexity, this approach is no longer sufficient as best practice begins to require unit tests and empirical validation of program behavior – as Donald Knuth warns, ”beware of bugs in the above code; I have only proved it correct, not tried it”.
Indeed, programs can be written that are impossible to trust from inspection alone (Thompson, [1984](#bib.bib75)), and extensions of Gödel’s incompleteness and Church-Turing’s undecideability theorems tell us that programs exist where questions about their behavior are unanswerable without running it (Rice, [1953](#bib.bib66)).
More generally, trusting a model based on level 3 insight alone is analogous to trusting a system, or a scientific theory or model, or a medical drug, based on theoretical arguments over empirical demonstrations – ”In theory, theory and practice are the same. In practice, they are not.”
Theoretical arguments are not seen as sufficient.
Our practices of experimental validation of competing scientific theories and randomized controlled trials speak to humankind’s elevation of empirical demonstration as a necessary gold standard of evidence.
5. Insights on Building Trusted and Trustworthy AI
---------------------------------------------------
We provide a brief overview of three areas: building trustworthy AI from scratch, trust transactions with pre-trained models, and garnering human trust in pre-trained AI whose trustworthiness is fixed. Central are three main ideas:
* •
Define trust contracts clearly. Trust is only meaningful if we know what we are trusting the AI to do (Jacovi et al., [2021](#bib.bib40)). This can require both ML and domain expertise.
* •
Prefer estimation over inference when evaluating contractual trust. Interactive behavior certificates formed by evaluating models directly on trust contracts are the most powerful evidence for contractual trustworthiness.
* •
Acknowledge shortcut learning. Have pessimistic prior beliefs on an AI’s abilities (Geirhos et al., [2020](#bib.bib32)).
###
5.1. Building trustworthy AI.
The trustworthiness of AI on any contract depends on how well the AI’s abilities fulfill the contract’s demands. Broadly speaking, the recent progress in ML performance reflected by superhuman or state-of-the-art achievements in many domains is perhaps the most powerful force in improving the potential trustworthiness of AI on complex and difficult contracts demanded by high-impact applications.
At the same time, trust contracts are often an after thought in modern practice: training tasks and data distributions can differ markedly from contract or deployment tasks and distributions, with degraded performance due to shortcut learning.
When building AI from scratch, its contractual trustworthiness can be improved by contract-aware model design to obtain models that perform better on trust contracts.
The simplest approach is training or finetuning models directly on trust contract tasks and data, though to create models that are trustworthy to each user, we need to acknowledge the end-user diversity of trust contracts.
Ideas like distributionally robust optimization to minimize worst-case loss over any subset of the data population rather than minimizing average loss can be important for building models that succeed on this diversity of trust contracts, and thus are more trustworthy to more people (Rahimian and
Mehrotra, [2019](#bib.bib64); Hashimoto et al., [2018](#bib.bib36)).
Incorporating prior knowledge as inductive biases in deep models is a powerful approach for contract-aware model design where a combination of ML and domain expertise can make large contributions (Cohen et al., [2021](#bib.bib19)).
For instance, including a physics engine in a reinforcement learning model (de Avila Belbute-Peres et al., [2018](#bib.bib20)) guarantees that the model will make decisions in a manner consistent with described physics, while it can be extremely difficult to trust a fully-connected neural network to be 100% consistent with known physics.
Adding truth to a model can only help.
While the successes of end-to-end learning are admirable – models can outperform humans at feature engineering – it can also require enormous amounts of data.
When trust contracts are critical and data is a bottleneck, designing models with inductive biases and including various kinds of prior knowledge can improve contractual trustworthiness: end-to-end models are not the end-all be-all (Glasmachers, [2017](#bib.bib34)).
###
5.2. Trust transactions with pre-trained models.
In applied ML projects, it is increasingly common to use or adapt a pre-trained model over training from scratch (Laine et al., [2021](#bib.bib45)).
In such situations, we have level 2 model access, but may be uncertain about the model’s abilities, which we interrogate by forming non-interactive BCs from studying the model’s design and training process, and forming interactive BCs from OOD and OOT evaluation.
Our recommendations extend the best practice of robustness testing (Djolonga et al., [2020](#bib.bib23); Berghoff et al., [2021](#bib.bib7); Laine et al., [2021](#bib.bib45)) by placing out-of-task evaluation as a first-class citizen.
Lessons from robustness testing and benchmarking transfer: the effort in properly evaluating model behavior should not be underestimated – significant resources may need to be spent for evaluations with proper relevance and statistical significance (Bowman and Dahl, [2021](#bib.bib13)).
Shortcut learning, or the tendency of models to rely on shortcuts in decision-making that perform well during training but can fail to generalize, reflects the practical wisdom that models optimize ”by the letter, not the spirit” of loss functions (Geirhos et al., [2020](#bib.bib32)). This wisdom encourages us to have pessimistic prior beliefs on model abilities, and to favor evidence-based data-driven discovery of model capabilities.
###
5.3. Human trust in trustworthy AI.
Once the abilities of an AI are fixed, its trustworthiness is also fixed, but different people’s trust in the AI can vary by their access to evidence and their understanding of the model.
Aim for trust calibration, not maximization.
Issues arise when the level of trust (the trustor’s attitude) mismatches the true level of trustworthiness (the property of the trustee). Such unwarranted trust (Jacovi et al., [2021](#bib.bib40)) manifests as under-trusting or over-trusting.
Assigning Sheridan-Verplanck automation levels that are too high can be blamed for the fatal crash of Turkish Airlines Flight 1951, where the pilots continued to rely on autopilot after the failure of an altimeter, while assigning automation levels too low can be blamed for the fatal wreckage of the Costa Concordia cruise ship when the captain manually diverged from the computer navigation route only to hit a shallow reef (Hoff and Bashir, [2015](#bib.bib38)).
To better calibrate each user’s trust to the model, developers should ensure that users clearly understand the limits of model abilities:
while it is natural to highlight strengths, we have a responsibility to also communicate weaknesses.
When only presented with strengths, uninformed users may incorrectly extrapolate model abilities to unproven tasks and data, which can be combatted by carefully communicating pessimistic prior beliefs due to shortcut learning, uncertainty modeling, and distribution tests.
Developers also have a responsibility to correct misconceptions that distort human-AI trust transactions, including actively discouraging unwarranted anthropomorphization of AI.
Understandable BCs, not interpretable models.
Behavior certificates are central to trust, as contractual trustworthiness cannot be evaluated without evidence of behavior. In contrast, model interpretability is more peripheral, and its link to trust is entirely mediated by behavior certificates (Fig. [1](#S2.F1 "Figure 1 ‣ 2.1. Formalizing the problem of human-AI trust ‣ 2. The Problem of Human Trust in AI ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient")). Thus, if we must choose one, we should prefer to make behavior certificates interpretable or understandable, not models.
Constructing BCs that are relevant to trust contracts, correct, and communicating them clearly can require substantial ML and domain expertise, whether the model is interpretable or not.
It can be unproductive to solely rely on end-users to construct BCs – end-users may not know what to do with an interpretable model. Instead, developers should accept this responsibility, and present pre-crafted and selected BCs to end-users.
This strategy is analogous to the division of labor between lawyers and juries, where lawyers construct arguments by presenting evidence in line alongside a technical understanding of the law, and juries use the evidence to make their own conclusions.
A benefit of pursuing understandable BCs over interpretable models is that research progress may be easier to measure. Progress in interpretability has notoriously been difficult to track (Doshi-Velez and
Kim, [2017](#bib.bib24)), and its definition varies by field, which is unsurprising in the light of its complex relationship with ML and domain expertise and individually formed BCs.
In contrast, when BCs are presented clearly in terms of evidence and conclusions, their correctness, relevance, and understandability are easier to measure.
A BC-centric perspective may even provide new tools for measuring interpretability based on the quality of BCs generated by users who can only inspect the model without running it.
Elevate user levels of model access.
Alongside understandable BCs, empowering users to form their own understanding of model behavior can also improve human trust in AI while also addressing some human-human trust challenges. While this is especially important for audiences with sufficient ML and domain expertise to leverage level 2 and 3 model access to form BCs, significant improvements in trust for end-users can be gained by elevating them from level 0 to 1.
Beyond independent evaluation of model behavior, providing model access can help end-users clarify and define the trust contracts most important to them.
6. Benefits and Costs of Pursuing Level 3 Insight
--------------------------------------------------
Despite not being sufficient or necessary for trust, interpretability et al. is not useless. On the contrary,
interpretability and black-box interaction enable constructing different kinds of BCs which can strengthen and complement each other in evaluating and building trust.
At the same time, pursuing level 3 insight can also incur costs.
###
6.1. Benefits of interpretability et al.
While empirical evaluation of model behavior through black-box interaction is a powerful tool for trust, it requires clearly defining trust contracts and gathering sufficient data before any BCs can be made. These prerequisites can be demanding.
In contrast, interpretability et al. enables generating BCs with improved data efficiency, requiring less or even no data, and can gracefully handle underspecified trust contracts. These advantages particularly shine in forming negative BCs of model limitations.
Compared to non-interactive BCs constructed with only level 2 model access, level 3 model access can construct BCs that are more relevant to many trust contracts, as they can describe the final trained model behavior more narrowly and precise.
Data efficiency.
This point can be motivated by considering a puzzle: what is the point of a model being human simulatable (an important subcategory of interpretable models (Lipton, [2018](#bib.bib49))), if computers can simulate models faster and more precisely?
By reasoning about the model in a broader context including vague goals and hypothetical data, humans can hypothesize highly relevant inputs and outputs that form powerful BCs about model behavior, without access to real data.
While adversarial ML methods attempt to automate this process, they can struggle more than humans to ensure adversarial examples are realistic enough to be relevant in real use cases. In general, this is a marked advantage of interpretability over black-box interaction, where data collection demands can be onerous (Bowman and Dahl, [2021](#bib.bib13)).
Handling underspecified trust contracts.
With an understanding of how the model works and what it has learned to do, humans can also understand model behavior to evaluate trust in an emotionally meaningful manner, albeit poorly defined, in the absence of well-specified trust contracts.
For instance, a human may conclude a model is unfair and only later pinpoint the precise definition of fairness that is violated by the model.
This can be useful, particularly when clearly defining trust contracts is a challenging process.
However, using model behavior to define trust contracts inverts the responsible approach of first defining trust contracts, then building a model to adhere to it (Section [5](#S5 "5. Insights on Building Trusted and Trustworthy AI ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient")).
Attempting to salvage a pre-trained model by searching for its utility errs by prioritizing the hammer over the nail.
In addition, such models may be less trustworthy than models developed with the foresight and benefit of contract-aware model design.
Negative behavior certificates.
Interpretability et al. can be especially useful for generating negative BCs that describe failure points and limitations of model behavior – if a model reasons about a phenomenon in an incorrect way, then we know it is untrustworthy on any data input for that phenomenon.
For instance, the observation that a linear model is used to model non-linear input-output relationships is a powerful negative BC.
The evidence that a model uses spoons to classify images of chocolate sauce, because spoons are more common than jars in ImageNet examples of chocolate sauce, is a powerful negative BC that the model is poor at classifying chocolate sauce images without spoons.
Negative BCs can play an important role in curtailing excessive AI reliance and calibrating trust downwards.
The power of negative BCs contrasts with the difficulty of certifying that a model will perform well on a trust contract, even if we have dozens of insights that the model learned the ”right things” or reasons about the data in a manner we expect. For establishing positive trust, such armchair arguments are widely considered insufficient compared to empirical validation by black-box interaction (Section [4](#S4 "4. What is the Minimum Level of Model Access Necessary or Sufficient for Trust? ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient")).
###
6.2. Issues with interpretability et al.
There are two main approaches for interpretability: using inherently transparent models, and obtaining post-hoc explanations of trained models that may be black boxes (Molnar, [2019](#bib.bib56); Rudin, [2019](#bib.bib67)). Each approach carries risks.
Explanations incur additional trust problems.
As Rudin writes, ”Explanations must be wrong. They cannot have perfect fidelity with respect to the original model… otherwise the explanation would equal the original model” (Rudin, [2019](#bib.bib67)), mirroring the adage that all models are wrong, but some are useful.
Explanations can be unfaithful and inaccurate to the actual inner workings of the model, unstable, uninformative, contradictory, nonsensical, or vulnerable to adversarial attack (Rudin, [2019](#bib.bib67); Molnar, [2019](#bib.bib56)).
When using model explanations, we then not only ask whether we can trust the model, but also whether we can trust the explanations: this presents a second trust problem (Murdoch et al., [2019](#bib.bib57)).
Weak transparent models are less trustworthy than strong black-box models.
Inherently transparent models are not necessarily weaker than black-box models, and can be useful for important tasks such as criminal recidivism prediction (Rudin, [2019](#bib.bib67)).
However, on many other high impact applications of ML, (Laine et al., [2021](#bib.bib45); Brown
et al., [2020](#bib.bib15)), state-of-the-art performance has not been achieved by transparent models.
As contractual trustworthiness is inherently linked to a model’s ability to succeed on a contract, if it is clear that a black-box model succeeds on a trust contract better than a transparent model, then the black-box model is more trustworthy.
Explanations & transparency can increase trust unwarrantedly, reducing calibration.
Empirical studies has found that humans can err by placing too much trust in transparent models, assigning them higher Sheridan-Planck automation levels than black-box models even when the transparent model’s performance was lower (Poursabzi-Sangdeh et al., [2021](#bib.bib62)).
Humans were less able to correct mistakes made by interpretable models, suggesting that we can be lulled into a false sense of comfort when the model appears understandable.
These findings agree with older human-automation trust studies, where knowing why an automation system erred increased trust in it, even when this trust was unwarranted (Dzindolet et al., [2003](#bib.bib27)).
While these issues do not preclude the use of interpretability et al., they support approaches to trust centered around understandable behavior certificates formed by handling interpretability with care.
###
6.3. The utility of interpretability beyond trust
Lastly, we investigate three areas that are often touted as major motivations for interpretability et al. In each, we find that while interpretability can be helpful, is not always necessary.
Legal regulatory compliance and interpretability.
In some cases, explaining model behavior is plainly required under legal policies. Under the U.S. Equal Credit Opportunity Act, creditors must identify the main factors impacting a credit score when denying credit.
In other cases, however, legal requirements of explanation may be less clear, or very limited (Wachter
et al., [2017](#bib.bib82)). While the E.U’s GDPR’s ”right to explanation” has often been used as motivation driving research into interpretable and explainable ML, the policy mandates this only for decisions ”based solely on automated processing”, which corresponds narrowly to the highest level on the 10-point Sheridan-Verplanck automation scale (Sheridan
et al., [1978](#bib.bib70)). The GDPR policy has instead been described as ”right to be informed” on the significance and the envisaged consequences of automated decision-making systems and the ”right not to be subject to automated decision-making”, to demand human involvement in decisions.
These rights align with our recommendations on building and communicating about trust in AI while not requiring interpretability or explanations.
In summary, explanations are certainly essential when legally required, but at the present moment, policy demands requiring widespread adoption of interpretability methods and research may be overstated.
Model debugging without interpretability.
Model debugging, and development in general, can be understood primarily in terms of model behavior. Bugs are undesirable model input-output behavior, and can be detected with level 2 model access; interpretability can be of help here, but is not strictly necessary. The act of debugging or fixing a bug regards reasoning about the impact of changing the training dataset, loss function, or architecture on model behavior.
Practical approaches for finding bugs include sensitivity analysis (”what-if” analysis) including random attacks, finding adversarial examples, OOD evaluation and analyzing and explaining error residuals (Hall, [2019](#bib.bib35)).
Comparing the model’s reasoning process to human expectations is a powerful tool for finding bugs, but less broadly applicable than approaches that only require level 2 access.
Approaches for debugging models include model assertions (Kang
et al., [2020](#bib.bib42)), editing models, regularization, data augmentation, data pre-processing, prediction post-processing, and anomaly detection (Hall, [2019](#bib.bib35)). Among these methods, the vast majority are compatible with level 2 access.
While some models can be directly edited, such as decision trees, this approach is largely obviated by the widespread adoption of finetuning models.
The differentiability of deep models is a key attribute that enables us to ”edit” trained models on a higher level of abstraction: instead of editing individual decision branches, we only need to specify loss functions or regularizers and additional data.
Modifying model behavior can also be interpreted as black-box hyperparameter optimization which can be treated with Bayesian optimization techniques and hypernets (Lorraine
et al., [2020](#bib.bib50)). In the appendix, we give perhaps the simplest algorithm (A[1](#algorithm1 "1 ‣ A.1. Algorithms ‣ Appendix A Research Methods ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient")) for improving model behavior by random search in model design space, which can be viewed as an evolutionary algorithm executed manually by developers
. Despite its simplicity, this algorithm broadly captures the production of knowledge in ML research and popularization of new model architectures by ”graduate student descent”
(Gencoglu et al., [2019](#bib.bib33)).
Scientific discovery without interpretability.
A classic approach to scientific discovery is model selection. Models encode assumptions and hypotheses, and guided by Occam’s razor, the evidence for and against these assumptions is weighted by each model’s fit to experimental data over time (Ding
et al., [2018](#bib.bib22); Shen, [2021](#bib.bib69)). Simple models can directly encode hypotheses as quantitative variables, while more other models can encode hypotheses qualitatively while learning some quantitative aspects from data, with fit evaluated on held-out data (appendix; A[2](#algorithm2 "2 ‣ A.1. Algorithms ‣ Appendix A Research Methods ‣ Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary and sufficient")) (MW
et al., [2018](#bib.bib58); Shen, [2021](#bib.bib69)). Such models include universal differential equations (Rackauckas et al., [2020](#bib.bib63)) and other approaches for integrating prior domain knowledge into models (Willard et al., [2021](#bib.bib84)). Notably, this process only requires level 2 model access.
The time-tested efficacy of model selection contrasts with the hopes of scientific discovery by interpreting deep models, which are challenged by pervasive shortcut learning and the difficulties in weighing evidence of diverse data modalities with proper uncertainties to the degree that human scientists do. Interpreting models that have succumbed to shortcut learning merely yields shortcuts as insights that can fail to generalize to unseen data, limiting their scientific value. To address this, it is common to constrain the model, often by incorporating prior knowledge, which leads us back towards model selection.
7. Discussion
--------------
By clarifying processes of human-AI trust, we have questioned the perceived centrality of interpretability to trust in popular discourse, while advocating for approaches such as evaluating models on held-out data and tasks beyond training losses that are representative of real-world applications (Laine et al., [2021](#bib.bib45)), robustness testing (Djolonga et al., [2020](#bib.bib23); Berghoff et al., [2021](#bib.bib7)), adapting software testing principles to ML (Zhang
et al., [5555](#bib.bib89)), and reporting model cards (Mitchell et al., [2019](#bib.bib55)) and supplier declarations of conformity (Varshney, [2019](#bib.bib80)).
We emphasized the promise of research towards new behavior certificates that enable new model behaviors, and are more correct, relevant to trust contracts, and understandable.
Looking forward, it is critical to advance trust with the right mindsets and tools, as human trust governs the extent and manner of AI’s impact on our future.
###### Acknowledgements.
We thank Anastasiya Belyaeva and Sebastian Gehrmann for insightful discussions. |
092cf918-6c0f-4d45-91c3-af3f6914278b | trentmkelly/LessWrong-43k | LessWrong | Is Wittgenstein's Language Game used when helping Ai understand language?
Hello. I am a lurker, but I checked the search and didn't see anyone discussing Wittgenstein's ideas concerning the "essence" of language and his talk of "Language Games" so I thought I'd ask.
Wittgenstein is a linguistic philosopher, who in very brief terms clarified our usage of language. While many people conceived of language as clear distinct and obvious, Wittgenstein used the example of the word "game" to show how there is no consistent and encompassing definition for plenty of words we regularly use. Among other things, he observed that language rather exists as a web of connotations that depend and change with context, and that this connotation can only truly be understood when observing the use of language, rather than some detached definition.
"Wittgenstein In Philosophical Context:
Essential Definition - Socrates, boil it down to its essence
Extensive Definition - Wittgenstein, use it in a sentence"
The above dichotomy frames the use of "words" by philosophers in a contradictory manner. And perhaps in qualia we do conceive them as different sorts of definitions, but imo it's just a matter of framing and we can readily say that "How you use a word in a sentence is itself the essence of a word". And intend the Ai therefore to conceive of the "essence" of words accordingly.
Descriptively speaking, Wittgenstein has always appeared unambiguously correct on this matter to me.
This all being said, I am wondering something relating to Wittgenstein:
Does AI safety, and AI engineers in general, have a similar conception of language? When CGPT reads a sentence, does it intentionally treat each word 's essence as some rigid unchanging thing derived from some dictionary definition, or as a web of connotation to other words? This might seem rather trivial, but when interpreting a prompt like "save my life" it seems clear why truly understanding each word's meaning is so important for potential AGI. So then, is Wittgenstein or rather this conception of lang |
ef6d4fd3-91c4-430e-a47e-74a489215864 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Pragmatic Image Compression for Human-in-the-Loop Decision-Making.
1 Introduction
---------------
\includegraphics
[width=]teaser.pdf
Figure 1: Images compressed 2-4x smaller than JPEG retain information for tasks like shopping for cars in a perceived price range (a), surveying car colors (b), and checking photos for eyeglasses (c) or hats (d).
Modern web platforms serve billions of images every day, and typically rely on lossy compression algorithms to store and transmit this data efficiently.
Recent work on machine learning methods for lossy image compression toderici2015variable; balle2016end; gregor2016towards; toderici2017full; theis2017lossy; agustsson2017soft; mentzer2018conditional; li2018learning; tschannen2018deep; zhang2018unreasonable; mentzer2020high improves upon standard methods like JPEG wallace1992jpeg by training neural networks to minimize the number of bits needed to generate high-fidelity reconstructions.
In this paper, we explore the idea of compressing images to even smaller sizes by intentionally allowing reconstructions to deviate drastically from the visual appearance of their originals, and instead optimizing reconstructions for the specific, downstream tasks that the user wants to perform with them, such as video conferencing, online gaming, or remotely operating space robots fong2013space.
Our main observation in this work is that, instead of optimizing the compression model for a task-agnostic *perceptual* similarity objective function, we can instead optimize the compression model for *functional* similarity: producing compressed images that, when shown to the user, induce the user to take the same actions that they would have taken had they observed the original, uncompressed images.
We call this *PragmatIc COmpression* (PICO), inspired by prior work on pragmatics grice1975logic; sperber1986relevance; frank2009informative that characterizes the meaning of a message through the behavior it induces in a listener.
PICO adapts compression to user behavior, enabling the user to perform their individually-desired tasks with compressed images instead of the original images.
For example, consider two users with distinct tasks: one flying a quadcopter, and the other driving a ground robot.
On a network with an extremely low bitrate, we would like the compressed video feed of the ground robot to preserve ground-level obstacles and terrain while discarding details about power lines and tree canopies, and the quadcopter feed to do the opposite.
\includegraphics
[width=]schematic.pdf
Figure 2: Given the original image x, we would like to generate a compressed image ^x such that the user’s action a upon seeing the compressed image is similar to what it would have been had the user seen the original image instead. In a 2D top-down car racing video game, our compression model learns that, in order to match the user’s steering with and without compression, it must preserve bends, but can discard the road farther ahead.
To this end, we formulate compression as a human-in-the-loop learning problem, in which the compression model is represented as an encoder-decoder neural network that takes the original image as an input and outputs the compressed image.
The user sees the compressed image, and takes an action to perform their desired task (see Figure [2](#S1.F2 "Figure 2 ‣ 1 Introduction ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making")).
The main challenge in this work is designing a loss function for the compression model that evaluates the quality of the compressed image in the context of the original image and the user’s action.
We do not assume knowledge of the user’s desired task, so we cannot directly evaluate the quality of the compressed image by evaluating the fitness of the user’s action upon seeing the compressed image.
We also do not assume access to ground-truth action labels for the original images in the streaming setting, so we cannot compare the user’s action upon seeing the compressed image to some ground-truth action.
Instead, we define the loss function through adversarial learning.
For example, consider a user browsing an online shopping catalogue, observing photos and clicking on appealing items.
To collect positive and negative examples of user behavior, we simply randomize whether a user sees the original or compressed version of an image while they are shopping, and record their actions.
We then train a discriminator to predict the likelihood that a user’s action was taken in response to the original rather than a compressed image, and train the compression model to maximize this predicted likelihood.
Our primary contribution is the PICO algorithm for human-in-the-loop learning of data compression models.
We validate PICO through three user studies on Amazon Mechanical Turk, in which we train and evaluate our compression models on data from human participants.
In the first study, we asked participants to read handwritten digits and identify the numbers – PICO learned to preserve the number and discard handwriting style (Figure [3](#S5.F3 "Figure 3 ‣ 5.1 Minimizing Bitrate by Maximizing User Action Agreement ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making")).
In the second study, we asked users to browse a car catalogue and select cars based on perceived price – PICO learned to preserve overall shape and sportiness while randomizing paint jobs and backgrounds (Figure [4](#S5.F4 "Figure 4 ‣ 5.1 Minimizing Bitrate by Maximizing User Action Agreement ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making")).
In the third study, we asked participants to verify photos of faces by checking if heads or eyes were covered – PICO learned to preserve hats and eyeglasses while randomizing faces (Figure [5](#S5.F5 "Figure 5 ‣ 5.2 Adapting Compression to Different Downstream Tasks ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making")).
In all three studies, PICO obtained up to 2-4x lower bitrates than non-adaptive baseline methods.
To show that PICO can be used in sequential decision-making problems, we also ran a user study with 12 participants who played a car racing video game – at a fixed bitrate, PICO learned to preserve bends in the road substantially better than a non-adaptive baseline method, enabling users to drive more safely (Figure [6](#S5.F6 "Figure 6 ‣ 5.3 Compressing Observations for Sequential Decision-Making ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making")).
2 Related Work
---------------
Prior work on learned lossy image compression focuses on overcoming various challenges in training neural networks on images jiang1999image, including amortized variable-rate compression toderici2015variable; toderici2017full, end-to-end training with quantization balle2016end; theis2017lossy; agustsson2017soft, optimizing the rate-distortion trade-off mentzer2018conditional; li2018learning, optimizing perceptual quality tschannen2018deep; zhang2018unreasonable; mentzer2020high, training hierarchical latent variable models gregor2016towards, and sequential compression of videos lu2019dvc; lombardo2019deep.
While these methods aim to generate visually-pleasing reconstructions that are perceptually similar to their originals, PICO focuses on preserving functional similarity.
Hence, PICO can achieve substantially lower bitrates for specific downstream tasks (e.g., see Figure [3](#S5.F3 "Figure 3 ‣ 5.1 Minimizing Bitrate by Maximizing User Action Agreement ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making")).
Prior work has studied human-in-the-loop learning in related contexts, including reinforcement learning of text summarization policies from user feedback stiennon2020learning and automatic data visualization for decision support systems hilgard2019learning.
In the context of imitation learning, the idea of fitting a model of human behavior using generative adversarial networks goodfellow2014generative has also been explored ho2016generative.
PICO differs from hilgard2019learning; ho2016generative in that it tackles image compression – an entirely different problem from decision support and imitation learning.
In contrast to stiennon2020learning, which elicits user comparisons between different summaries of the same text, PICO can be used for sequential tasks like video games (see Section [5.3](#S5.SS3 "5.3 Compressing Observations for Sequential Decision-Making ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making")) where the user cannot be repeatedly queried with different compressed versions of the same image.
3 Pragmatic Compression
------------------------
Generative models are typically used for sampling and representation learning, but they can also be used for compression shannon1948mathematical; frey1997cient; blelloch2001introduction; mackay2003information.
For example, variational autoencoders kingma2013auto are trained with a variational information bottleneck alemi2016deep that explicitly constrains the amount of information carried by their latent variables – hence, we can use a trained encoder to compress an image, and a trained decoder to reconstruct it from latent features theis2017lossy; townsend2019practical.
In contrast to compression methods that train such generative models to maximize the visual fidelity of the reconstruction, we formulate compression as a problem of *control*, including the downstream behavior of the user in the problem statement.
First, the environment generates an image x∈Rw×h×c.
Given the original image x, the compression system generates a compressed image ^x∈Rw×h×c that can be represented using no more than n bits, where n is a hyperparameter.
The user then observes the compressed image ^x and samples an action a∼π(a|^x) from their unknown policy π.
We do not assume access to the user’s utility function U(x,a) or a specification of their desired task.
Our goal is to generate a compressed image ^x that induces an action a that maximizes the unknown utility U(x,a).
We approach this problem by generating a compressed image ^x that induces the user to take the same action a that they would have taken had they seen the original image x instead.
Let fθ(^x|x) denote a parametric model of our compression function, where θ are the model parameters (e.g., neural network weights).
To train fθ, we need a loss function that evaluates the difference between an original image x and the output of the compression model ^x∼fθ(^x|x).
One approach is to use conditional generative adversarial networks mirza2014conditional to train a discriminator D(^x,x) that tries to distinguish between original and compressed images, and train the compression model to generate compressed images ^x that fool this discriminator, analogous to prior work on adversarial image compression mentzer2020high.
However, this approach seeks to maximize the *perceptual* similarity of the original and compressed image, whereas we would like to maximize their *functional* similarity.
The key challenge for our method then is to train the discriminator D(^x,x) to detect differences between x and ^x that influence the user’s downstream action, while ignoring superficial differences between the images that do not affect the user’s action.
We address this challenge by first training an action discriminator Dϕ(a,x) to predict whether the user saw the original or a compressed image before taking the action a.
This action discriminator Dϕ captures differences in user behavior caused by compression, while ignoring visual differences between the original and compressed images.
To construct a loss function that links the compressed images to these behavioral differences, we distill the action discriminator Dϕ(a,x) into an image discriminator Dψ(^x,x).
###
3.1 Maximizing Functional Similarity of Images through Adversarial Learning
We formalize the idea of maximizing the functional similarity of the original x and compressed image ^x as follows.
Let T∈{0,1} denote whether the user sees the original or a compressed image before taking an action: if T=1, then ^x←x; else if T=0, sample ^x∼fθ(^x|x).
We would like to train the compression model to minimize the divergence of the user’s policy evaluated on the compressed image π(a|^x) from the policy evaluated on the original π(a|x),
| | | | |
| --- | --- | --- | --- |
| | L(θ) | =Ex[D(π(a|x)∥E^x∼fθ(^x|x)[π(a|^x)|x])] | |
| | | =Ex[D(p(a|x,T=1)∥p(a|x,T=0;θ))], | | (1) |
where D is a divergence (e.g., the Jensen-Shannon divergence) – note that we are overloading D to denote a divergence in Equation [3.1](#S3.Ex1 "3.1 Maximizing Functional Similarity of Images through Adversarial Learning ‣ 3 Pragmatic Compression ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making"), and to denote a discriminator elsewhere.
Since the user’s policy π is unknown, we approximately minimize the loss in Equation [3.1](#S3.Ex1 "3.1 Maximizing Functional Similarity of Images through Adversarial Learning ‣ 3 Pragmatic Compression ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") using conditional generative adversarial networks (GAN) mirza2014conditional, where the side information is the original image x, the generator is the compression model fθ(^x|x), and the discriminator D(a,x) tries to discriminate the action a that the user takes after seeing the generated image ^x.
To train the action discriminator, we need positive and negative examples of user behavior; in our case, examples of user behavior with and without compression.
To collect these examples, we randomize whether the user sees the compressed image or the original before taking an action.
Let T∼Bernoulli(0.5) represent this random assignment.
When T=1, the user sees the original x and takes action a, and we record (x,^x,a) as a positive example of user behavior.
When T=0, the user sees the compressed image ^x and takes action a, and we record (x,^x,a) as a negative example.
Let D denote the dataset of all recorded tuples (T,x,^x,a).
We train an action discriminator Dϕ(a,x) to predict the likelihood p(T=1|a,x), using the standard binary cross-entropy loss and the training data D.
Note that this action discriminator is conditioned on the original image x and the user action a, but not the compressed image ^x – this follows from our problem formulation in Equation [3.1](#S3.Ex1 "3.1 Maximizing Functional Similarity of Images through Adversarial Learning ‣ 3 Pragmatic Compression ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making"), and ensures that the action discriminator captures differences in user behavior caused by compression, while ignoring differences between the original and compressed images that do not affect user behavior.
###
3.2 Distilling the Discriminator and Training the Compression Model
Initialize compression model fθ
while true do
x∼penv(x) ▹ environment generates original image
T∼Bernoulli(0.5) ▹ randomly decide whether user sees compressed image or original
if T=1 then ^x←x else ^x∼fθ(^x|x)
a∼π(a|^x) ▹ user takes action using unknown policy
D←D∪{(T,x,^x,a)}
▹ update action discrim.
ψ←ψ−∇ψ∑(x,^x,a)∈DDKL(Dϕ(a,x)∥Dψ(^x,x)) ▹ update image discriminator
θ←θ+∇θ∑x∈DlogDψ(fθ(x),x) ▹ update compression model
Algorithm 1 Pragmatic Compression (PICO)
The action discriminator Dϕ(a,x) gives us a way to approximately evaluate the loss function in Equation [3.1](#S3.Ex1 "3.1 Maximizing Functional Similarity of Images through Adversarial Learning ‣ 3 Pragmatic Compression ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making").
However, we cannot train the compression model fθ(^x|x) to optimize this loss directly, since Dϕ does not take the compressed image ^x as input.
To address this issue, we distill the trained action discriminator Dϕ(a,x), which captures differences in user behavior caused by compression, into an image discriminator Dψ(^x,x) that links the compressed images to these behavioral differences.
In particular, we train Dψ to approximate Dϕ by optimizing the loss,
| | | | |
| --- | --- | --- | --- |
| | ℓ(ψ)=∑(x,^x,a)∈DDKL(Dϕ(a,x)∥Dψ(^x,x)). | | (2) |
Then, given the trained image discriminator Dψ, we train the compression model using the standard GAN generator loss goodfellow2014generative; mirza2014conditional,
| | | | |
| --- | --- | --- | --- |
| | ℓ(θ)=∑x∈D−logDψ(fθ(x),x), | | (3) |
where fθ(x) denotes E^x∼fθ(^x|x)[^x|x].
Our complete pragmatic compression method is summarized in Algorithm [1](#alg1 "Algorithm 1 ‣ 3.2 Distilling the Discriminator and Training the Compression Model ‣ 3 Pragmatic Compression ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making").
We randomly initialize the compression model fθ.
The environment samples an original image x from an unknown distribution penv.
To decide whether the user sees the original or compressed image, we sample a Bernoulli random variable T.
After seeing the chosen image, the user samples an action a from their unknown policy π.
To update the action discriminator Dϕ, we take a gradient step on the binary cross-entropy loss.
To update the image discriminator Dψ, we take a gradient step on the KL-divergence loss in Equation [2](#S3.E2 "(2) ‣ 3.2 Distilling the Discriminator and Training the Compression Model ‣ 3 Pragmatic Compression ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making").
To update the compression model fθ, we take a gradient step on the GAN generator loss in Equation [3](#S3.E3 "(3) ‣ 3.2 Distilling the Discriminator and Training the Compression Model ‣ 3 Pragmatic Compression ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making").
See Appendix [A.3](#A1.SS3 "A.3 Network Architectures and Training ‣ Appendix A Experimental Setup ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") for details.
4 Structured Compression using Generative Models
-------------------------------------------------
One approach to representing the compression model fθ could be to structure it as a variational autoencoder (VAE) kingma2013auto, and train the VAE end to end on the adversarial loss function in Equation [3](#S3.E3 "(3) ‣ 3.2 Distilling the Discriminator and Training the Compression Model ‣ 3 Pragmatic Compression ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") instead of the standard reconstruction error loss.
This approach is fully general, but requires training a separate model for each desired bitrate (which is determined by the β coefficient in the VAE training objective), and can require extensive exploration of the pixel output space before it discovers an effective compression model.
To simplify variable-rate compression and exploration in our experiments, we forgo end-to-end training, and first train a generative model on a batch of images without the human in the loop by optimizing a task-agnostic perceptual loss, yielding an encoder and decoder such that z=enc(x) and ^x=dec(z), where z∈Rd is the latent embedding.
Analogous to prior work on conditional image generation engel2017latent, we then train our compression model fθ(^z|z) to compress the latent embedding, instead of compressing the original pixels.
We use a variety of different generative models in our experiments, including a β-VAE chen2018isolating for the handwritten digit identification experiments in Figure [3](#S5.F3 "Figure 3 ‣ 5.1 Minimizing Bitrate by Maximizing User Action Agreement ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making"), a StyleGAN2 model karras2020analyzing for the car shopping and survey experiments in Figure [4](#S5.F4 "Figure 4 ‣ 5.1 Minimizing Bitrate by Maximizing User Action Agreement ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making"), an NVAE model vahdat2020nvae for the photo verification experiments in Figure [5](#S5.F5 "Figure 5 ‣ 5.2 Adapting Compression to Different Downstream Tasks ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making"), and a VAE for the car racing experiments in Figure [6](#S5.F6 "Figure 6 ‣ 5.3 Compressing Observations for Sequential Decision-Making ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making").
See Appendix [A.4](#A1.SS4 "A.4 Compressing Images using a Generative Model ‣ Appendix A Experimental Setup ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") for details.
Generative models like the VAE and StyleGAN2 tend to learn disentangled features – hence, instead of training fθ to map directly to the latent space Rd, we structure fθ to output a vector of probabilities that determines which latent features are transmitted exactly between z and ^z, and which other features are masked out and then reconstructed from the prior distribution.
In particular, we structure fθ:Rd↦[0,1]d to output a vector of mask probabilities p∈[0,1]d given the latent embedding z∈Rd.
Then, given a hyperparameter λ∈[0,1] that controls the compression rate, we transmit the ⌊λd⌋ latent features i with the lowest mask probabilities pi, and mask out the remaining d−⌊λd⌋ features.
We reconstruct the masked features by assuming that ^z follows a multivariate normal distribution, and sampling the masked feature values from the conditional prior distribution given the transmitted feature values.
See Appendix [A.4](#A1.SS4 "A.4 Compressing Images using a Generative Model ‣ Appendix A Experimental Setup ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") for details.
This design of the compression model fθ simplifies variable-rate compression: at test time, we simply choose a value of λ that obtains the desired bitrate, without retraining the model.
It also simplifies exploration: instead of exploring in pixel output space, we explore in the space of masks over latent features, which leverages the decoder to generate more realistic compressed images during the early stages of training.
We can now also reduce the dimensionality of the image discriminator inputs: instead of training Dψ(^x,x), we train Dψ(p,x).
In our experiments, we also leverage the low-dimensional mask output space to perform batch learning instead of online learning, which greatly simplifies our implementation of PICO with real users.
See Appendix [A.1](#A1.SS1 "A.1 Batch Learning from Logged Compression Data ‣ Appendix A Experimental Setup ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") for additional discussion.
While these simplifications enable us to provide a proof of concept for pragmatic compression in this paper, we acknowledge that they do require both server and client to have a copy of a domain-specific (but task-agnostic) generative model.
End-to-end training of the compression model would be a more general approach that does not involve learning and storing a separate generative model – this is a promising direction for future work, which we discuss in Section [6](#S6 "6 Discussion ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making").
5 User Studies
---------------
In our experiments, we evaluate to what extent PICO can minimize the number of bits needed to transmit an image, while still preserving the image’s usefulness to users performing downstream tasks.
We conduct user studies on Amazon Mechanical Turk, in which we ask human participants to complete three tasks at varying bitrates: reading handwritten digits from the MNIST dataset lecun1998mnist, verifying attributes of faces from the CelebA dataset liu2015faceattributes, and browsing a shopping catalogue of cars from the LSUN Car dataset yu15lsun.
To study PICO’s performance on sequential decision-making problems, we also run an experiment with 12 participants who play the Car Racing video game from OpenAI Gym brockman2016openai under a constraint on the bitrate of the video feed.
In all experiments, we train our discriminators and compression model on 1000 negative examples and varying numbers of positive examples, and split PICO into two rounds of batch learning and evaluation (see Appendices [A.1](#A1.SS1 "A.1 Batch Learning from Logged Compression Data ‣ Appendix A Experimental Setup ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") and [A.5](#A1.SS5 "A.5 Positive Examples for Discriminator Training ‣ Appendix A Experimental Setup ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making")).
Appendix [A](#A1 "Appendix A Experimental Setup ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") discusses the implementation details.
###
5.1 Minimizing Bitrate by Maximizing User Action Agreement
We claim that PICO can learn to transmit only the features that users need to perform their tasks.
Our first set of user studies seeks to answer Q1: does maximizing user action agreement enable PICO to obtain lower bitrates than baseline methods that do not take into account downstream user behavior?
We would like to study this question in domains where we can measure the performance of various compression methods by computing the agreement between the user’s actions with and without compression – i.e., collecting action labels for the original images, and comparing the user’s actions upon seeing compressed versions of those images to the labels.
As such, we run experiments on Amazon Mechanical Turk that focus on single-step decision-making settings where we can collect action labels for a fixed dataset of images: (a) identifying a handwritten digit, (b) clicking on an item in a shopping catalogue, and (c) verifying photos of faces.
In (a), we instruct users to identify the number in the image within the range 0-9.
In (b), to simulate the experience of browsing a catalogue on a budget, we instructed users to click on images of cars that they perceive to be worth less than $20,000.
In (c), we instruct users to check if the person’s eyes are covered (e.g., by eyeglasses) and click on one of two buttons labeled “covered” and “not covered”.
In all domains, we evaluate PICO by varying the bitrate and, at each bitrate, measuring the agreement of user actions upon seeing a compressed image with user actions upon seeing the original version of that image (see Appendix [A.7](#A1.SS7 "A.7 Subject Allocation ‣ Appendix A Experimental Setup ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") for details).
As discussed in Section [4](#S4 "4 Structured Compression using Generative Models ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making"), PICO learns a compression model fθ that, given a separate generative model, selects which latent features to transmit.
Since the purpose of this experiment is to test the effect of user-adaptive compression in PICO, we compare to a non-adaptive baseline method that selects a uniform-random subset of features to transmit, but otherwise uses the same generative model as PICO – this enables us to conduct an apples-to-apples comparison that isolates the effect of training fθ on user behavior data.
We also compare to a baseline method that maximizes perceptual similarity by replacing the adversarial loss in Equation [3](#S3.E3 "(3) ‣ 3.2 Distilling the Discriminator and Training the Compression Model ‣ 3 Pragmatic Compression ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") of PICO with the mean absolute pixel difference |x−^x|.
In simulation experiments, we found that this perceptual similarity baseline performed better than the non-adaptive baseline in the MNIST domain, but did not perform better in the other domains (see Appendix [C](#A3 "Appendix C Simulation Experiments ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making")), so we only test it in the MNIST user study.
To provide a point of comparison to widely-used compression methods, we also compare to JPEG wallace1992jpeg, where the quality parameter is set to the lowest value (1) in order to bring the bitrate as close as possible to the range obtained by PICO and the non-adaptive baseline.
\includegraphics
[width=]mnist.pdf
Figure 3: MNIST digit identification experiments that address Q1. When users are instructed to identify the digit number, PICO learns to preserve the digit number while randomizing handwriting style. The plots show user action agreement evaluated on 100 held-out images, with error bars representing standard error. The average lossless PNG file size is 0.3kB, and each image has dimensions 28x28x1. Each of the five columns in the two groups of compressed images represents a different sample from the stochastic compression model f(^x|x) at bitrate 0.011.
Though JPEG is no longer the state of the art, it enables us to roughly calibrate the results achieved by PICO as well as the non-adaptive and perceptual similarity baselines.
Figures [3](#S5.F3 "Figure 3 ‣ 5.1 Minimizing Bitrate by Maximizing User Action Agreement ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making"), [4](#S5.F4 "Figure 4 ‣ 5.1 Minimizing Bitrate by Maximizing User Action Agreement ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making"), and [5](#S5.F5 "Figure 5 ‣ 5.2 Adapting Compression to Different Downstream Tasks ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") show that, at low bitrates, PICO achieves substantially higher user action agreement than the non-adaptive baseline (orange vs. gray) and perceptual similarity baseline (orange vs. red).
PICO also obtains much lower bitrates than the JPEG baseline (orange vs. teal), while maintaining higher agreement on CelebA, comparable agreement on MNIST, and lower agreement on LSUN Car.
The samples in Figure [3](#S5.F3 "Figure 3 ‣ 5.1 Minimizing Bitrate by Maximizing User Action Agreement ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") show that PICO learns to preserve digit numbers more often than the non-adaptive and perceptual similarity baselines, while randomizing handwriting style in order to satisfy the bitrate constraint.
The samples in Figure [4](#S5.F4 "Figure 4 ‣ 5.1 Minimizing Bitrate by Maximizing User Action Agreement ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") show that, for users performing the shopping task, PICO learns to preserve the overall shape and sportiness of the car, while randomizing paint jobs, backgrounds, and other details that are irrelevant to the user’s perception of the price of the car.
The samples in Figure [5](#S5.F5 "Figure 5 ‣ 5.2 Adapting Compression to Different Downstream Tasks ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") show that, for users checking whether eyes are covered, PICO learns to preserve the presence of eyeglasses while randomizing hair color, faces, and other irrelevant details (see top row of samples).
The dip in the orange curve in the car shopping plot may be due to the fact that increasing the bitrate preserves more of the encoded latent features, which, when combined with features sampled from the prior, can be out-of-distribution inputs to the StyleGAN2 decoder richardson2020encoding; tov2021designing, potentially leading to degraded image quality (see Appendix [A.4](#A1.SS4 "A.4 Compressing Images using a Generative Model ‣ Appendix A Experimental Setup ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") for details).
Figures [9](#A5.F9 "Figure 9 ‣ Appendix E Examples of Compression at Different Bitrates ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") and [10](#A5.F10 "Figure 10 ‣ Appendix E Examples of Compression at Different Bitrates ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") in the appendix include more examples.
\includegraphics
[width=0.75]cars.pdf
Figure 4: LSUN Car shopping experiment that addresses Q1, and survey experiment that addresses Q2. The plots show action agreement evaluated on 100 held-out images, with error bars representing standard error. The average lossless PNG file size is 247kB, and each image has dimensions 512x512x3. The shopping samples show that, when users are instructed to click on cars they perceive to be worth less than $20,000, PICO learns to preserve the overall shape and sportiness of the car, while randomizing paint jobs, backgrounds, and other details that are irrelevant to the users’ perception of price. In contrast, when users are instead instructed to determine whether the car is “dark-colored” or “light-colored” for a survey task, PICO learns to preserve the car’s color while randomizing its pose. We intentionally show compressed image samples for a low bitrate (0.011) to highlight differences between the compression models learned for the two tasks.
###
5.2 Adapting Compression to Different Downstream Tasks
The experiments in the previous section show that PICO can outperform a non-adaptive baseline method by transmitting only the features that users need to perform their tasks.
Our second set of user studies investigates this mechanism further, by asking Q2: can PICO adapt the compression model to the specific needs of different downstream tasks in the same domain?
To answer this question, we run an additional experiment in the CelebA domain from the previous section, in which users are instructed to check if the person’s head is covered (e.g., by a hat).
We also run an additional experiment in the LSUN Car domain from the previous section, in which we simulate a survey task that asks users to ‘help a car dealership conduct market research’ by determining whether an observed car has a “dark-colored” or “light-colored” paint job.
\includegraphics
[width=]celeba.pdf
Figure 5: CelebA photo attribute verification experiments that address Q1 and Q2. Depending on the instructions given to the user, PICO learns to either preserve hats or eyeglasses, while randomizing faces and other task-irrelevant details. The plots show action agreement evaluated on 100 held-out images, with error bars representing standard error. The average lossless PNG file size is 7.7kB, and each image has dimensions 64x64x3.
Figure [5](#S5.F5 "Figure 5 ‣ 5.2 Adapting Compression to Different Downstream Tasks ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") shows that PICO adapted the compression model to the user’s particular task.
In the experiment from the previous section, when users checked eyes, PICO learned to preserve the presence of eyeglasses while randomizing hair color, faces, and other irrelevant details (see top row of samples).
On the other hand, when users checked for head coverings like hats and helmets, PICO learned to preserve the presence of hats while randomizing eyes and other details (see second row of samples).
The third and fourth rows of samples illustrate the fact that PICO learns a stochastic compression model fθ(^x|x) from which we can draw multiple compressed samples ^x for a given original x.
The fact that all the samples in the third row have eyeglasses but differ in other attributes like pose angle, and those in the fourth row all have hats while some are smiling and some are not, shows that even though the compression model is stochastic, it produces stable attributes when they are needed for the downstream task.
Figure [9](#A5.F9 "Figure 9 ‣ Appendix E Examples of Compression at Different Bitrates ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") in the appendix includes more qualitative examples.
In addition to these photo verification results, the samples in Figure [4](#S5.F4 "Figure 4 ‣ 5.1 Minimizing Bitrate by Maximizing User Action Agreement ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") illustrate substantial differences in the compression models learned for the car shopping and survey tasks.
For users performing the shopping task, PICO learned to preserve perceived price while randomizing color.
In contrast, for users performing the survey, PICO learned to preserve color while randomizing perceived price.
###
5.3 Compressing Observations for Sequential Decision-Making
Our third user study seeks to answer Q3: can PICO learn to compress image observations in the sequential decision-making setting?
To answer this question, we run an experiment with 12 participants in which we ask users to play a 2D top-down car racing video game, while constraining the number of bits that can be used to transmit the image observation to the user at each timestep.
We would like to measure the performance of PICO and the non-adaptive baseline by computing user action agreement, as in the previous sections.
However, since images rarely re-occur in this video game, it is unlikely that we will have an action label for the exact pixels in any given observation.
Instead, we measure the user’s progress along the road in the game – specifically, the fraction of new road patches visited during an episode.
In these experiments, we fix the bitrate to 85 bits per step, which is well below the 170 bits per step required to transmit the full set of features for the 64x64x3 images.
To simplify our experiments and ensure that they could be completed within the allotted 30 minutes per participant, we trained the PICO compression model on data from a pilot user, then evaluated the compression model’s performance with each of the 12 participants.
Appendix [A.7](#A1.SS7 "A.7 Subject Allocation ‣ Appendix A Experimental Setup ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") describes the experimental setup in further detail.
Figure [6](#S5.F6 "Figure 6 ‣ 5.3 Compressing Observations for Sequential Decision-Making ‣ 5 User Studies ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") shows that, at a fixed bitrate, PICO enables the user to perform substantially better on the driving task than the non-adaptive compression baseline (orange vs. gray), and comparably to a positive control in which we do not compress the image observations at all (orange vs. teal).
The first and second film strips show that, when we use the non-adaptive compression baseline, there is a substantial difference between the originals and the compressed images.
For example, even at the first timestep, the compressed image shows the road to be less tilted than it actually is, so in the next frame we see that the user has mistakenly driven forward and ended up in the grass instead of turning right to stay on the road.
In contrast, the third and fourth film strips show that PICO has learned to preserve the angle of the road, while discarding the details of the road much farther ahead in order to satisfy the bitrate constraint.
We ran a one-way repeated measures ANOVA on the road progress metrics from the non-adaptive baseline and PICO conditions with the presence of PICO as a factor, and found that f(1,11)=176.32,p<.0001.
The subjective evaluations in Table [1](#A2.T1 "Table 1 ‣ Appendix B Subjective Evaluations in Car Racing Experiment ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") in the appendix corroborate these results: users reported feeling higher situational awareness and ability to control the car with PICO compared to the non-adaptive baseline.
After evaluating PICO, one user commented, “This environment was a lot easier. It felt more consistent. I felt like we had a mutual understanding of when I would turn and what it would show me to make me turn.”
Appendix [B](#A2 "Appendix B Subjective Evaluations in Car Racing Experiment ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") discusses the results in more detail, and videos are available on the project website111<https://sites.google.com/view/pragmatic-compression>.
\includegraphics
[width=]carracing.pdf
Figure 6: Car Racing game experiments that address Q3. The scatter plot shows that, for each of the 12 users (orange), road progress with PICO was substantially higher than with the non-adaptive compression baseline. The bar chart shows road progress averaged over all users, with error bars representing standard error.
6 Discussion
-------------
We presented a proof of concept that, through human-in-the-loop learning, we can train models to communicate relevant information to users under network bandwidth constraints, without prior knowledge of the users’ desired tasks.
Our experiments show that, for a variety of tasks with different kinds of images, pragmatic compression can reduce bitrates 2-4x compared to non-adaptive and perceptual similarity baseline methods, by optimizing reconstructions for functional similarity.
Since we needed to carry out user studies with real human participants, we decided to limit the number of parameters trained during these experiments for the sake of efficiency, by using a pre-trained generative model as a starting point and only optimizing over the latent space of this model.
This can be problematic when the generative model does not include task-relevant features in its latent space – e.g., the yellow sports car in rows 7-8 of Figure [10](#A5.F10 "Figure 10 ‣ Appendix E Examples of Compression at Different Bitrates ‣ Pragmatic Image Compression for Human-in-the-Loop Decision-Making") in the appendix gets distorted when encoded into the StyleGAN2 latent space, even without any additional compression.
An end-to-end version of PICO should in principle also be possible, but would likely require longer human-in-the-loop training sessions.
This may, however, be practical for real-world web services and other applications, where users already continually interact with the system and A/B testing is standard practice.
End-to-end training could also enable PICO to be applied to problems other than compression, such as image captioning for visually-impaired users, or audio visualization for hearing-impaired users zhang2020audioviewer – such applications could also be enabled through continued improvements to generative models for video walker2021predicting; yan2021videogpt, audio oord2016wavenet, and text devlin2018bert; brown2020language.
Another exciting area for future work is to apply pragmatic compression to a wider range of realistic applications, including video compression for robotic space exploration fong2013space, audio compression for hearing aids armstrong2020hearing; alamdari2020personalization, and spatial compression for virtual reality nilsson201815.
7 Acknowledgements
-------------------
Thanks to members of the InterACT and RAIL labs at UC Berkeley for feedback on this project.
This work was supported in part by AFOSR FA9550-17-1-0308, NSF NRI 1734633, GPU donations from Nvidia, and the Berkeley Existential Risk Initiative. |
dd005ba1-af89-42fe-b76b-0b5c1408614e | trentmkelly/LessWrong-43k | LessWrong | Who was the person who escaped the Nazis a day before they cracked down?
I'm trying to find the primary source for this, but I remember one person (who may have been a physicist) left Germany (or another country) on a train. That same train the next day was stopped and thousands of Jews were arrested. He is alleged to have said something to the effect of needing to be one day faster than the rest, but I forgot who it was, and what the quote is. |
3f16a5d0-9742-4a11-9e95-db9c3d46ae09 | trentmkelly/LessWrong-43k | LessWrong | Intelligence, epistemics, and sanity, in three short parts
Epistemic status: Boggling. This is early, messy work.
Thanks to Edo Arad for comments and suggestions.
Part 1: A Brief Tale
You’re exploring a vast land filled with forests and brush. You thrash your sword to carve out a path and make sense of things.
There are monsters. Lovecraftian winged monstrosities. Their attacks damage your sanity. When injured, you don’t notice, but your mind will begin to wander. You begin seeing things that aren’t real.
You have a shield that protects you from the beasts. You have armor as well. They attack; you deflect. You hear a thud, a squeal, then light flapping sounds when they retreat. Occasionally you can even catch them with your sword but they move quickly.
----------------------------------------
You return to the village. Your companions have returned too. Some of them aren’t right. They’re obsessed with bizarre imaginings of angels and gods. Some speak of finding ancient labyrinths in places you know are full of swamps.
Your companions size each other up. Factions emerge. One cluster suggests that the monsters bring forward wisdom. The monsters should be brought directly into the village and released.
The pro-monster faction is visibly scratched up; they must have been wounded. They deny taking damage, that the marks on their bodies were extraneous. Some hallucinate wearing a great deal of armor, even though they are visibly unprotected. They do however possess large weapons (likely a trade-off from having light armor), so others are nervous about disagreeing.
The bulk of the crowd turns against this faction. Some attack back; a few people are harmed, but in the end, the faction loses. Some are thrown into jails, others delegated to the very safest of tasks. But this cycle will repeat. You might not be so lucky next time.
----------------------------------------
The village learns to cope. There are vast regions of bush and thorn but no monsters. Soldiers with little armor are sent there. Some dual wield axes |
2f6972d2-a809-4190-97ef-9290e033d193 | trentmkelly/LessWrong-43k | LessWrong | Transformative AI issues (not just misalignment): an overview
If this ends up being the most important century due to advanced AI, what are the key factors in whether things go well or poorly?
More detail on why AI could make this the most important century (Details not included in email - click to view on the web)
A lot of my previous writings have focused specifically on the threat of “misaligned AI”: AI that could have dangerous aims of its own and defeat all of humanity. In this post, I’m going to zoom out and give a broader overview of multiple issues transformative AI could raise for society - with an emphasis on issues we might want to be thinking about now rather than waiting to address as they happen.
My discussion will be very unsatisfying. “What are the key factors in whether things go well or poorly with transformative AI?” is a massive topic, with lots of angles that have gotten almost no attention and (surely) lots of angles that I just haven’t thought of at all. My one-sentence summary of this whole situation is: we’re not ready for this.
But hopefully this will give some sense of what sorts of issues should clearly be on our radar. And hopefully it will give a sense of why - out of all the issues we need to contend with - I’m as focused on the threat of misaligned AI as I am.
Outline:
* First, I’ll briefly clarify what kinds of issues I’m trying to list. I’m looking for ways the future could look durably and dramatically different depending on how we navigate the development of transformative AI - such that doing the right things ahead of time could make a big, lasting difference.
* Then, I’ll list candidate issues:
* Misaligned AI. I touch on t
... |
74689008-ddf9-40fd-85b1-f435a601d474 | trentmkelly/LessWrong-43k | LessWrong | Toy model piece #3: close and distant situations
I'll build on my model of the previous post, and consider close and distant situation.
Recall that each world in W is defined by 0≤n≤100, which is the number of people smiling in it. I'll extend the model by adding another Boolean variable b, which determines, say, whether the world contains chocolate (b=0) or art (b=1). So worlds can be described by the pair (n,b).
The default situation - the one if the AI does nothing - is (45,1), say. So 45 smiling people in a world of art.
Then let's introduce two new partial preferences/pre-orders:
* P3={(n,1)≤(m,1)∣40≤n≤m≤50}.
* P4={(n,b)≤(m,1)∣40≤m≤50}.
So P3 say that, within a range of the default world (art, and the number of smiling people not being within 5 people of 45), the more smiling people, the better. While P4 says that worlds in this range are better than worlds outside them.
These result in the following utility functions:
* U3(n,1)=2n−90 if 40≤n≤50, U3(n,b)=0 otherwise.
* U4(n,1)=1 if 40≤n≤50, U4(n,b)=−1 otherwise.
After normalisation, these become:
* ˆU3(n,1)=n/5−9 if 40≤n≤50, U3(n,b)=0 otherwise.
* ˆU4(n,1)=1 if 40≤n≤50, U4(n,b)=−11/191 otherwise.
Again, I've felt free to translate ˆU4 to improve the clarity of the normalised version.
If we plot ˆU3, we get the following:
Here I've slightly offset the b=1 (purple) from the b=0 (blue) worlds, for clarity of exposition, though they would of course be on top of each other.
Note that ˆU3 does not in itself distant situations, as this post recommends doing. Five close worlds are ranked about the distant worlds; but, conversely, five are close worlds are ranked below them.
To avoid distant situations, we need to add in ˆU4, which explicitly punishes distant worlds, and hence plot ˆU3+ˆU4:
This is much more like it! All the close worlds are now all ranked above the more distant ones.
But this is a close-run thing: the difference between the worse close world and the distant worlds is small. So, in general, when penalising distant worlds, we |
79250023-8305-41c1-ba4d-78a35635f3c9 | trentmkelly/LessWrong-43k | LessWrong | AISN #46: The Transition
Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required.
Listen to the AI Safety Newsletter for free on Spotify or Apple Podcasts.
----------------------------------------
The Transition
The transition from the Biden to Trump administrations saw a flurry of executive activity on AI policy, with Biden signing several last-minute executive orders and Trump revoking Biden’s 2023 executive order on AI risk. In this story, we review the state of play.
Trump signing first-day executive orders. Source.
The AI Diffusion Framework. The final weeks of the Biden Administration saw three major actions related to AI policy. First, the Bureau of Industry and Security released its Framework for Artificial Intelligence Diffusion, which updates the US’ AI-related export controls. The rule establishes three tiers of countries 1) US allies, 2) most other countries, and 3) arms-embargoed countries.
* Companies headquartered in tier-1 countries can freely deploy AI chips in other tier-1 countries, and in tier-2 countries subject to limits. They can also deploy controlled models (trained with at least 1026 FLOP) in both tier-1 and tier-2 countries, but only develop those models in tier-1 countries.
* Companies headquartered in tier-2 countries face limits on how many chips they can deploy in tier-1 and tier-2 countries, and are prohibited from training or deploying controlled models.
* Companies headquartered in tier-3 countries are prohibited from deploying AI chips, or developing or deploying controlled models in any country. Companies in any country are prohibited from deploying AI chips or developing or deploying controlled models in tier-3 countries.
The three tiers described by the framework. Source.
The US itself is not subject to export controls, meaning that companies can import AI chips and develop and deploy controlled models without restriction within the US. (For more discussio |
c8d2dc21-f6f0-405e-8dec-48ba0620e520 | trentmkelly/LessWrong-43k | LessWrong | Reflections on the cryonics sequence
Three months ago, I had a dream my mom died while cryocrastinating, and I decided to finally start the process. I quickly found that it was ridiculously hard to figure out what the process even was, and I thought, "huh, someone should really write a guide on how to do this." And lo, I just spent the past three months writing that guide. It is 24,000 words long and took up about 90% of my working hours for the past three months.
I knew very little about cryonics before starting the sequence. It took me about five years after first encountering the idea on LessWrong to feel comfortable enough with it that I wanted to sign up. I still think it's an incredibly long shot, and I'm probably just using it the way many people use religion – to stave off my crippling fear of death. I'm just some random person, not an 'official expert' or even someone who's that deeply invested.
But I've already said everything I want to say about cryonics itself. This post is about the other things I've learned.
First, I learned that I have a really great intellectual support community. Most of my questions were fielded by former housemates, coworkers, and erstwhile acquaintances. Mati Roy was super helpful – he's a knowledgeable and committed cryonicist who's embedded in all of the relevant conversations. My mom and sister (both writers and editors in their own right) helped with last-minute proofreading. And Habryka was a real sport all the times I got so confused about life insurance that I was on the verge of tears (which happened periodically throughout the entire three months); he even let me call him about it in the middle of the workday once.
But more importantly for me, I learned that I am capable of figuring things out and building an understanding of new areas. The skill of "research" always seemed to me like a total black box, and I was told repeatedly it was a skill I didn't have – first when I washed out of the GiveWell Research Analyst application process at the first step |
7fe76da8-7687-48fa-a3b8-87ef60ad1649 | StampyAI/alignment-research-dataset/blogs | Blogs | Yehuda Yudkowsky, 1985-2004
*Background for non-transhumanists:*
Transhumanists are not fond of death. We would stop it if we could. To this end we support research that holds out hope of a future in which humanity has defeated death. Death is an extremely difficult technical problem, to be attacked with biotech and nanotech and other technological means. I do not tell a tale of the land called Future, nor state as a fact that humanity will someday be free of death – I have no magical ability to see through time. But death is a great evil, and I will oppose it whenever I can. If I could create a world where people lived forever, or at the very least a few billion years, I would do so. I don’t think humanity will always be stuck in the awkward stage we now occupy, when we are smart enough to create enormous problems for ourselves, but not quite smart enough to solve them. I think that humanity’s problems are solvable; difficult, but solvable. I work toward that end, as a Research Fellow of the [Machine Intelligence Research Institute](https://intelligence.org/) .
This is an email message I [sent](http://sl4.org/archive/0411/10270.html) to three transhumanist mailing lists, and a collection of emails I then received, in November of 2004. Some emails have been edited for brevity.
[Update](https://eyudkowsky.wpengine.com/other/yehuda/#monument), at bottom, added May 2005.
---
```
Date: Thu Nov 18 22:27:34 2004
From: Eliezer Yudkowsky
```
My little brother, Yehuda Nattan Yudkowsky, is dead.
He died November 1st. His body was found without identification. The family found out on November 4th. I spent a week and a half with my family in Chicago, and am now back in Atlanta. I’ve been putting off telling my friends, because it’s such a hard thing to say.
I used to say: “I have four living grandparents and I intend to have four living grandparents when the last star in the Milky Way burns out.” I still have four living grandparents, but I don’t think I’ll be saying that any more. Even if we make it to and through the Singularity, it will be too late. One of the people I love won’t be there. The universe has a surprising ability to stab you through the heart from somewhere you weren’t looking. Of all the people I had to protect, I never thought that Yehuda might be one of them. Yehuda was born July 11, 1985. He was nineteen years old when he died.
The Jewish religion prescribes a number of rituals and condolences for the occasion of a death. Yehuda has passed to a better place, God’s ways are mysterious but benign, etc. Does such talk really comfort people? I watched my parents, and I don’t think it did. The blessing that is spoken at Jewish funerals is “Blessed is God, the true judge.” Do they really believe that? Why do they cry at funerals, if they believe that? Does it help someone, to tell them that their religion requires them to believe that? I think I coped better than my parents and my little sister Channah. I was just dealing with pain, not confusion. When I heard on the phone that Yehuda had died, there was never a moment of disbelief. I knew what kind of universe I lived in. How is my religious family to comprehend it, working, as they must, from the assumption that Yehuda was murdered by a benevolent God? The same loving God, I presume, who arranges for millions of children to grow up illiterate and starving; the same kindly tribal father-figure who arranged the Holocaust and the Inquisition’s torture of witches. I would not hesitate to call it evil, if any sentient mind had committed such an act, permitted such a thing. But I have weighed the evidence as best I can, and I do not believe the universe to be evil, a reply which in these days is called atheism.
Maybe it helps to believe in an immortal soul. I know that I would feel a lot better if Yehuda had gone away on a trip somewhere, even if he was never coming back. But Yehuda did not “pass on”. Yehuda is not “resting in peace”. Yehuda is not coming back. Yehuda doesn’t exist any more. Yehuda was absolutely annihilated at the age of nineteen. Yes, that makes me angry. I can’t put into words how angry. It would be rage to rend the gates of Heaven and burn down God on Its throne, if any God existed. But there is no God, so my anger burns to tear apart the way-things-are, remake the pattern of a world that permits this.
I wonder at the strength of non-transhumanist atheists, to accept so terrible a darkness without any hope of changing it. But then most atheists also succumb to comforting lies, and make excuses for death even less defensible than the outright lies of religion. They flinch away, refuse to confront the horror of a hundred and fifty thousand sentient beings annihilated every day. One point eight lives per second, fifty-five million lives per year. Convert the units, time to life, life to time. The World Trade Center killed half an hour. As of today, all cryonics organizations together have suspended one minute. This essay took twenty thousand lives to write. I wonder if there was ever an atheist who accepted the full horror, making no excuses, offering no consolations, who did not also hope for some future dawn. What must it be like to live in this world, seeing it just the way it is, and think that it will never change, never get any better?
Yehuda’s death is the first time I ever lost someone close enough for it to hurt. So now I’ve seen the face of the enemy. Now I understand, a little better, the price of half a second. I don’t understand it well, because the human brain has a pattern built into it. We do not grieve forever, but move on. We mourn for a few days and then continue with our lives. Such underreaction poorly equips us to comprehend Yehuda’s death. Nineteen years, 7053 days, of life and memory annihilated. A thousand years, or a million millennia, or a forever, of future life lost. The sun should have dimmed when Yehuda died, and a chill wind blown in every place that sentient beings gather, to tell us that our number was diminished by one. But the sun did not dim, because we do not live in that sensible a universe. Even if the sun did dim whenever someone died, it wouldn’t be noticeable except as a continuous flickering. Soon everyone would get used to it, and they would no longer notice the flickering of the sun.
My little brother collected corks from wine bottles. Someone brought home, to the family, a pair of corks they had collected for Yehuda, and never had a chance to give him. And my grandmother said, “Give them to Channah, and someday she’ll tell her children about how her brother Yehuda collected corks.” My grandmother’s words shocked me, stretched across more time than it had ever occurred to me to imagine, to when my fourteen-year-old sister had grown up and had married and was telling her children about the brother she’d lost. How could my grandmother skip across all those years so easily when I was struggling to get through the day? I heard my grandmother’s words and thought: she has been through this before. This isn’t the first loved one my grandmother has lost, the way Yehuda was the first loved one I’d lost. My grandmother is old enough to have a pattern for dealing with the death of loved ones; she knows how to handle this because she’s done it before. And I thought: how can she accept this? If she knows, why isn’t she fighting with everything she has to change it?
What would it be like to be a rational atheist in the fifteenth century, and know beyond all hope of rescue that everyone you loved would be annihilated, one after another as you watched, unless you yourself died first? That is still the fate of humans today; the ongoing horror has not changed, for all that we have hope. Death is not a distant dream, not a terrible tragedy that happens to someone else like the stories you read in newspapers. One day you’ll get a phone call, like I got a phone call, and the possibility that seemed distant will become reality. You will mourn, and finish mourning, and go on with your life, and then one day you’ll get another phone call. That is the fate this world has in store for you, unless you make a convulsive effort to change it.
Since Yehuda’s body was not identified for three days after he died, there was no possible way he could have been cryonically suspended. Others may be luckier. If you’ve been putting off that talk with your loved ones, do it. Maybe they won’t understand, but at least you won’t spend forever wondering why you didn’t even try.
There is one Jewish custom associated with death that makes sense to me, which is contributing to charity on behalf of the departed. I am donating eighteen hundred dollars to the general fund of the Machine Intelligence Research Institute, because this has gone on long enough. If you object to the [Machine Intelligence Research Institute](https://intelligence.org/) then consider Dr. Aubrey de Grey’s [Methuselah Foundation](http://www.mprize.org/), which hopes to defeat aging through biomedical engineering. I think that a sensible coping strategy for transhumanist atheists, to donate to an anti-death charity after a loved one dies. Death hurt us, so we will unmake Death. Let that be the outlet for our anger, which is terrible and just. I watched Yehuda’s coffin lowered into the ground and cried, and then I sat through the eulogy and heard rabbis tell comforting lies. If I had spoken Yehuda’s eulogy I would not have comforted the mourners in their loss. I would have told the mourners that Yehuda had been absolutely annihilated, that there was nothing left of him. I would have told them they were right to be angry, that they had been robbed, that something precious and irreplaceable was taken from them, for no reason at all, taken from them and shattered, and they are never getting it back.
No sentient being deserves such a thing. Let that be my brother’s true eulogy, free of comforting lies.
When Michael Wilson heard the news, he said: “We shall have to work faster.” Any similar condolences are welcome. Other condolences are not.
Goodbye, Yehuda. There isn’t much point in saying it, since there’s no one to hear. Goodbye, Yehuda, you don’t exist any more. Nothing left of you after your death, like there was nothing before your birth. You died, and your family, Mom and Dad and Channah and I, sat down at the Sabbath table just like our family had always been composed of only four people, like there had never been a Yehuda. Goodbye, Yehuda Yudkowsky, never to return, never to be forgotten.
Love,
Eliezer.
---
```
Date: Thu Nov 18 22:55:24 2004
From: Gina Miller
```
I am so sorry to hear of this news. I know what you are going through Eliezer, when I was fourteen I lost my sister who was 19. I always wonder what she would have become.I stood amid my family saying things like “God takes the good” or “God has something for her to do” and sensing their calming effect in the belief system that I did not embrace. I too, was wide awake to the truth of the matter, and I wanted her here. To this day I am struck by the biological errors that mother nature has dealt to us, leading to disease and finality, and of course also the importance of theories and research needed to overcome these problems. As you know, my husband is currently undergoing chemotherapy so I grapple with the frustration of advanced technologies such as nanotech and others, not yet being readily available to avoid this type of suffering. The concern also grows when I see the fear well up in the general population when it comes to current advances such as stem cell research.
As far as the religious afterlife (or other) comfort, I think the problem is, no one has cheated death yet, so the meme continues (at least for some – well probably most) as a way to propagate suppressing the fear of the end. When we show scientific immortality is possible as opposed to religious immortality, there may be more for them to contemplate. I can’t wait for the day that death is not inevitable. I am deeply touched by your words and emotions and I completely validate you. The emotions won’t go away, but it will at least become more bearable over time. Perhaps what remains will help guide you even further down the road you have already begun to travel, with all of our future(s) in mind. I’d like to thank you for that. My condolences to you, as well as my constant support for humanity to move beyond this barrier.
Again, I’m so sorry, warmest regards
-Gina “Nanogirl” Miller
---
```
Date: Thu Nov 18 23:53:15 2004
From: Samantha Atkins
```
Eliezer,
I am extremely sorry for your [/our] loss. Death utterly sucks and humanity would be much better off never pretending otherwise.
When I was 14 my cousin who was 17 died. He was in a motorcycle accident and lingered for some hours. We were told to pray for his healing. We prayed. He died. “It must not have been God’s will” we were told. Or “we lacked sufficient faith” to pray effectively. I remember how twisted up inside I felt hearing these things, how helpless and how very angry. How could it be “God’s will” to snuff out this wonderful young life? How was it up to us to twist ourselves into pretzels somehow in order to save my cousin Virgil or anyone else who need not have been put through such suffering to begin with if a “just” and “good” God was in charge as we were always told? How could the people say these expected things and be all somber and then immediately pretend nothing had happened a mere few hours later? How could they not scream and cry out as I screamed and cried inside? Were they all zombies?
If more people stopped making pious or otherwise excuses for the horror of death and disease then we would finally move to end this suffering. When I was 14 I didn’t know it was even possible to do so. Many people do not know it still. We must make sure they know. Many more who do know act as if it isn’t so.
We must never forget our dead and never ever resign ourselves, those we care about or anyone to death. We must truly embrace life not by acceptance of death but by extending life endlessly and without limitation.
– samantha
---
```
Date: Fri Nov 19 15:08:40 2004
From: Adrian Tymes
```
It is probably no condolence that there will be many more – \*far\* too many more – before we finish implementing a way around it. But at least there is a way to calculate it: multiply this tragedy by the several million (billion?) between now and then, and one starts to appreciate the magnitude of the horror we seek to strike down.
I wonder if this is something like the fictional Cthuluoid horrors: a terror so deep and profound that most people can’t even acknowledge it, but just go ever so slowly insane trying to deal with it.
---
```
Date: Sat Nov 20 21:41:13 2004
From: Matus
```
Eliezer,
Thank you for your words, and I am sorry for the tragic event which has brought them out.
You have captured what makes me an extropian and I think you capture the motivating principle behind each of us here. We love life, and we want to live it. Whatever we all may disagree on, it is only the means to achieve this end. We love life, and we hate its cessation.
There is no greater horror or travesty of justice than the death of someone. All the intricacies of the universe can not compare to the beauty and value of a single sentient being.
I have seen enough death of friends and loved ones myself. Everyone who will listen I try to convince them to be cryogenically suspended, on the premise that they want to live. But most grope for excuses not to, disguising their disregard for their own existence with appeals to mysticism or dystopian futures.
All ideologies prescribe these self delusional condolences and practices, it can be no more clear than what Adrian said: a terror so deep and profound that most people can’t even acknowledge it, but just go ever so slowly insane trying to deal with it.
When faced with the death of a loved one, most people get through it by hiding reality, by doing whatever they can to \*not\* think about the obvious. Death is eternal and final, and when faced with such a thing people can not come up with any answer that goes beyond any self doubt. To take the pain of death away, they must devalue life. One is faced with a choice, acknowledge you love life and death is abhorrent, be indifferent to life and thus indifferent to death, or despise life and welcome death, there are no other alternatives, the view of one precludes the inverse on the other. There seems to be an active effort to create and spread a nihilistic world view. Consider the Buddhist mantra of ‘life is suffering’ consider it’s widespread modern appeal, and then consider its negation, ‘death is joy’ Indeed, Nirvana is the absence of a desire for existence. This nihilistic movement is not acting volitionally, its scared and confused and stumbling through philosophy. All they know is they don’t like death, and through its stumbling come to find that to deal with that it must not care about life. Socrates last words come to mind “I have found the cure for life, and it is death”
I think this is a major part of the reason we have such difficulty spreading our ideas and values. Why in the very secular European area of the world does Cryonics have little to no support? If people accept our worldview, that life is good and technology can help us extend it indefinitely, then they must come to full terms with the finality and horror of death. That is what they have difficulty in doing. I think at some level they know that, it is the logical extension of their beliefs, and as such is manifested as a very negative emotional visceral reaction to our ideas, because of our implied valuation of life.
But just as many of us here put up a great deal of money and effort for a non-zero chance of defeating our first death through cryonics, we need to acknowledge the non-zero possibility of doing something about past deaths. In this I am very fond of Nikolai Fedorovich Fedorov’s “The Common Task”. Even though it is derived from his religious background, the motivation, a deep appreciation for the intrinsic value of life, and the goal, bringing back the past dead with technology, I share. The application of science to ‘resurrect’ the past dead. Is it possible? If it is, it should be our ultimate goal. Some here devote their efforts to the development of a singularity AI, and others toward defeating aging biologically; I devote my efforts to the great common task. It is my ultimate goal to find out if it is possible, to learn everything I need to know to determine that, and more, and then to do it, one person at a time if necessary.
I can find no words to offer to ease that suffering, there are none, and it is not possible. I can only say that it is my life goal, and I think others, and eventually the goal of any sentient being who loves life, singularity AI or otherwise, to do what they can to accomplish this common task, if the laws of physics allow it.
Regards,
Michael Dickey
Aka Matus
---
```
Date: Thu Nov 18 22:27:41 2004
From: David Sargeant
```
I’m terribly sorry to hear about your brother. Your essay really touched me — it really pounds home what we need, need, NEED DESPERATELY to achieve, more than anything else in the world. I can’t even imagine the pain you must be feeling right now. I wish there was something I could to do to help.
---
```
Date: Thu Nov 18 22:55:20 2004
From: Damien Broderick
```
Very distressing news, Eli. Sympathies. Indeed, `we have to work faster.’
Sorrowful regards, Damien
---
```
Date: Fri Nov 19 02:31:58 2004
From: Russell Wallace
```
I’m so sorry.
I hadn’t heard of the Jewish custom you mention, last time I received such a phone call; but it has that quality of requiring explanation only once, and I’m going to act accordingly.
Someday, children won’t fully believe that things like this really happened. We’ll work towards the day when they don’t have to.
– Russell
---
```
Date: Fri Nov 19 03:58:17 2004
From: Olga Bourlin
```
Eliezer, I’m so sorry to hear this – there are never any real words of consolation.
For what it’s worth, my experience with people in my family who have died is – well, I have thought of them from time to time, of course (but have been surprised at how unexpectedly and powerfully these thoughts have been known to strike). And, also, I have dreamt of them – for decades – as if they never died.
The death that struck me the most was when my mother died. I was 40 years old then (she was 65), and I was “prepared” for her death because she had been an alcoholic for a long time – and yet, when she died it hurt so very much. I was completely unprepared for the emotional pain. At that time I was married to a man who played the piano, and he played Beethoven’s Piano Concerto No. 5 in E flat Op. 73 ‘The Emperor’ – 2nd movement (‘Adagio un poco moto’) over and over again. That particular movement – it’s so lovely and sad – something in that music let me just take in the experience and reflect about being human.
I cannot imagine how you must feel – losing a beloved younger brother. When I had my children (the two happiest days of my life, bar none) – I also realized that with the love I felt (and still feel) for them came a kind of vulnerability I never felt even about myself – the potential, incomprehensible pain I know I would feel if something were to happen to them. And I knew I would never have the “net” of religion to help break my fall.
Love,
Olga
---
```
Date: Fri Nov 19 15:08:25 2004
From: Kwame Porter-Robinson
```
My condolences.
As opposed to Michael Wilson, I say we shall have to work smarter.
Live well,
Sincerely,
Kwame P.R.
---
```
Date: Sat Dec 4 13:30:35 2004
From: Harvey Newstrom
```
I am not even going to try to say something helpful or profound. There is nothing anyone can say to help or to lessen the loss. This is a meaningless tragedy that too many of us have faced. A more extreme and sudden example of the human condition. And I hate it.
Harvey
---
```
Date: Fri Nov 19 15:08:42 2004
From: Keith Henson
```
How sad.
I really can’t add anything to your email to the list because I am in complete agreement.
My daughter lost two close high school friends, one just after he got back from visiting Israel and I lost both parents since becoming an exile.
Keith
PS. If you can, you should at least try for a cell/DNA sample.
---
```
Date: Sat Nov 20 04:05:52 2004
From: Kip Werking
```
Eliezer,
I just want to express my sympathy.
Your post to SL4 shocked me from my dogmatic slumber. If the universe conserves information, then your brother is still written in the fabric somewhere. The signal is just scrambled. Who is to say whether a posthuman will look into the stars and see his picture–or nothing?
But I prefer your attitude. On this subject, there is a danger of apathy–but also a danger of false hopes. The latter does not prevent me from supporting the mission of you or Aubrey. A sober account of the human condition has its advantages. For example, it can cure procrastination.
Please consider this an expression of my sorrow for your loss and solidarity with your cause.
Kip
---
```
Date: Sat Nov 20 21:41:17 2004
From: Nader Chehab
```
I’m really sorry to hear that. Some things truly happen when we least expect them. Your writings have been an invaluable source of insight for me and it saddens me to know that you lost a loved one. It is revolting that awful things can happen even to the least deserving. We really have to fix that one day, and sooner is better.
Yours,
Nader Chehab
---
```
Date: Fri Nov 19 01:32:50 2004
From: Extropian Agroforestry Ventures Inc.
```
When people who just might have been able to catch the extreme lifespan wave or uploaded their consciousness die in 2004 it is far more tragic than in 1974 when such was only a fanciful dream.
I too have lost people near to me who had a statistically better chance than even me to “make the cut”. My wife at age 45 and a week this march 21. Only after the fact did I fully realize that there was a conscious knowledge among those caring for her that ” simply tweaking treatments would put her out of her misery and bring her peace through death”. I still do not forgive myself for not catching onto things … it was no problem to install a 10,000$ baclofen pump but no one would prescribe the anti-seizure meds that might have stopped the devastating seizures that reduced her to a barely concious state during her last 2 months. I know death was never her wish.
I now have a friend and business partner in his 70’s who is in his last month due to late detected mesothelioma or asbestos caused lung cancer. He too fought to the end. About 3 weeks ago when I sent him a Kg of hemp bud and a small packet of marijuana to ease his pain he said ” That should probably do me” and that was the first time that he accepted that he had lost the battle.
Formal religeons are like opiates in that they dull the mind to the urgency of defeating death as we know it. Aethiesm and agnosticism does put the onus on the individual to seize the moment and strive to extend, improve and sustain consciousness. In some ways religion has served some good purposes but we are now mature enough to survive without this old crutch. Science as the new religion has now more hope to offer for eternal life than the comforting words of some prophet or other.
Morris Johnson
---
```
Date: Fri Nov 19 01:32:53 2004
From: Giu1i0 Pri5c0
```
Dear Eliezer,
I am so sorry, and I think I know how you are feeling. I felt the same whan my mother died three years ago. I was already a transhumanist long before that, but had not been an active one previously: I just lurked on the lists. But that changed after my mother’s death: I felt that there was something that needed being done, and now. My mother was 73, but Yehuda was 19. What a waste, what a cruel thing. I think the best you can do to honor the memory of Yehuda is continuing your work to accelerate the process of overcoming the biologic limits of our species, defeating death, creating friendly superintelligences, merging with them, and moving on. The SIAI is your tribute to Yehuda’s memory and your own battle against death: continue to fight it bravely as you have done so far.
Giulio
---
```
Date: Fri Nov 19 06:19:25 2004
From: Amara Graps
```
> Goodbye, Yehuda Yudkowsky, never to return, never to be forgotten.
> Love,
> Eliezer.
Dear Eliezer,
Now you carry Yehuda’s traces of his life in your heart. Keep them sacred, remember him always. In time, the large hole that pains you will transform into something different. An extra source of strength to live every day fuller, stronger, better; so that the life you cherished will live through you and help you fight so that this doesn’t happen to anyone again. I hate death. We should never have to experience this. I’m so sorry about Yehuda.
Amara
---
```
Date: Fri Nov 19 22:42:58 2004
From: Hara Ra
```
Well, personally I am a cryonicist. I was appalled at the low number of extropians who have signed up.
If I ever get a chance to do something more about this, I will certainly tell the list about it.
Hara Ra (aka Gregory Yob)
---
```
Date: Sat Nov 20 21:41:43 2004
From: Kevin Freels
```
What would it be like to be a rational atheist in the fifteenth century, and know beyond all hope of rescue that everyone you loved would be annihilated, one after another, unless you yourself died first? That is still the fate of humans today; the ongoing horror has not changed, for all that we have hope. Death is not a distant dream, not a terrible tragedy that happens to someone else like the stories you read in newspapers.
Take any century prior to this one. I often wonder if that isn’t exactly what happened with Alexander, Genghis Khan, or more recently, Hitler and Stalin. History is full of such people. They may have simply went nuts after thinking this through and finding that there was nothing they could do and that life did not matter. Fortunately we are now on the verge of the ability to put an end to this. Now is the time to push forward, not give up.
---
```
Date: Fri Nov 19 01:32:44 2004
From: Psy Kosh
```
That is indeed awful. I’m sorry.
I guess what you do have though is the ability to say that you are indeed actually doing something about it, so do take what comfort from that that you can.
And again, I’m sorry.
Psy-Kosh
---
```
Date: Fri Nov 19 15:08:51 2004
From: Ben Goertzel
```
Wow, Eli … I’m really sorry to hear that …
As all of us on this list know, death is one hell of a moral outrage
And alas, it’s not going to be solved this year, not here on Earth anyway. Conceivably in 7-8 more years — and probably before 30 more, IMO. Let’s hope we can all hang on that long…
I have no memory more painful than remembering when my eldest son almost died in a car crash at age 4. Thanks to some expert Kiwi neurosurgery he survived and is now almost 15. Had he not survived, I’m not really sure what I’d be like today.
I know you’ll draw from this terrible event yet more passion to continue with our collective quest to move beyond the deeply flawed domain of the human — while preserving the beautiful parts of humanity & rendering the other parts optional…
At the moment my head is full of a verse from a rock song I wrote a few years back:I’ve got to tell you somethingYour lonely story made me cryI wish we all could breathe foreverGod damn the Universal Mind.
Well, crap….words truly don’t suffice for this sort of thing…
yours
Ben
---
```
Date: Fri Nov 19 16:11:04 2004
From: Aikin, Robert
```
You’re not going to ever ‘get over it’ so don’t bother deluding yourself that you might. You know what you have to do, so do it. Finish what you started. Stay healthy, be safe.
---
```
Date: Fri Nov 19 16:59:37 2004
From: Bill Hibbard
```
I am very sorry to hear about the death of your brother, Eliezer. Your reaction to redouble your efforts is very healthy. When my brother, father and mother died I also found it helpful to get plenty of exercise and eliminate caffeine.
My younger brother died of cancer in 1997. When he died he looked like a holocaust victim and it occured to me that if all the Americans dying of cancer were being killed by an evil dictator, our society would be totally mobilized against that enemy. Disease and death in general deserve at least that commitment. Both collectively, to support medical research and care, and individually, to get lots of exercise and eliminate tobacco (my brother’s kidney cancer was probably caused by his smoking) and unhealthy foods. My parents lived to 85 and 87, but their diseases were clearly linked to diet, smoking and lack of exercise. They could have lived longer and better with different habits.
I am with you, Eliezer, that it is maddening that so many people in our society cling to ancient religous beliefs that council acceptance of death and disease, and in some cases even council opposition to efforts to defeat death. What madness.
Sincerely,
Bill
---
```
Date: Fri Nov 19 22:19:21 2004
From: Thomas Buckner
```
I am sorry to hear this. Such a short life. Nineteen years is a blink, not enough time to learn much more than the rudiments of life. My daughter Heidi is a year older than he was.
George Gurdjieff, a very great Russian philosopher, said the human race needed a new organ, which he whimsically named the kundabuffer, and the purpose of this organ would be to remind us each minute of every day that we would die, that we had not time to squander.
My parents and grandparents are all gone. Almost all the optimism I once had for the human race is gone. At present, I see only one bright spot on the horizon. It is your work and that of the others in this community (I am only a kibitzer).
re: Your statement “What would it be like to be a rational atheist in the fifteenth century, and know beyond all hope of rescue that everyone you loved would be annihilated, one after another, unless you yourself died first? That is still the fate of humans today; the ongoing horror has not changed, for all that we have hope.” In a commencement speech of last year, Lewis Lapham mentioned a “French noblewoman, a duchess in her 80s, who, on seeing the first ascent of Montgolfier’s balloon from the palace of the Tuilleries in 1783, fell back upon the cushions of her carriage and wept. “Oh yes,” she said, “Now it’s certain. One day they’ll learn how to keep people alive forever, but I shall already be dead.”
Tom Buckner
---
```
Date: Sun Nov 21 23:55:10 2004
From: gabriel C
```
I wonder if there was ever an atheist who accepted the full horror, making no excuses, offering no consolations, who did not also hope for some future dawn. What must it be like to live in this world, seeing it just the way it is, and think that it will never change, never get any better?
That would describe me, before I stumbled upon this list in 1999. Facing certain extinction, I was alternately terrified and depressed. I still am, but now with a tiny thread of hope. Otherwise I think I would be insane by now.
---
```
Date: Fri Nov 19 15:08:28 2004
From: MIKE TREDER
```
Eliezer,
I am deeply sorry to hear about your brother. The random cruelty of life knows no bounds. As you correctly suggest, the only rational response is to challenge the dreadful process called death and defeat it, once and for all. Sadly, that takes time — too much time for your brother, Yehuda, and too much time for my dear sister, Susie, who was struck down unexpectedly by cancer just a few years ago. Too much time, as well, for 150,000 more of our brothers and sisters who will die today, and tomorrow, and the next day.
Still, the transhumanist response is not simply to shake our heads and mourn, but to stand up in defiance. We aim to overcome death through human science and technology, and you and others have taken on that challenge directly. For that, we all should be grateful and supportive.
But your essay also accomplishes a different — and equally worthy — objective, which is to reach out and connect with others who suffer. This is the humanist response, to affirm that we are all in this together, that there is no God or deity either to revere or to blame. Death separates us, permanently (at least until we know that cryonic preservation and revivification can succeed), but in life we can come together to help each other.
Mike Treder
---
```
Date: Sat Nov 20 04:05:53 2004
From: Marc Geddes
```
My condolences to you Eliezer, over your loss.
It was only quite recently that I desperately urged you to ‘hurry’ in your work at Sing Inst. I was starting to feel the first signs of aging. But now I am again made aware of the horrendous loss of life occurring daily in this pre-Singularity world.
I called pre-Singularity existence ‘banal’ and ‘brutish’. We’ve received a sad reminder of the truth of this.
Not only am I saddened by the loss of life occuring, I’m absolutely furious. And the most maddening part of it is the fundamental irrationality of most of the human populace, who blindly rationalize aging and pointless death.
In the recent book published by ‘Immortality Institute’ I did my best to made the philosophical case for indefinite life span: my piece was ‘Introduction To Immortalist Morality’. We must all do our bit to try to educate others about the fundamental value of life, a value that is still not properly understood by most people.
Bruce Klein (Imm Inst founder) also recently lost his mother in an accident. There is a discussion on the Imm Inst forums and it might be valuable for Eliezer to go there.
The death of Yehuda shows that the universe just ‘doesn’t care’. It’s up to sentients to create the meaning of the world. We all hope for a successful Singularity, and we can’t imagine failure, but it could easily be the case that we’ll all we wiped out unless we make big efforts – the universe just doesn’t care.
I recently expressed real concern that the ‘window of opportunity’ for a successful Singularity seems to be closing. Time really is running out.We need to make greater efforts than we have been so far, or else I don’t think we’re going to pull through.
I can only urge all of you to do your bit to support transhumanist projects – biological life extension (short term) and FAI (longer term) must be the priorities. Please donate to the relevant organizations. Voss, Goertzel and Yudkowksy appear to be the only serious FAI contenders at this juncture. They need our support.
Marc Geddes
---
```
Date: Sun Nov 21 13:10:32 2004
From: Peter
```
I am sending you my condolences Eliezer on the death of your brother. I lost my first wife in an accident suddenly, she was 23. Like you I can only rage and weep that her beautiful singularity was lost, one among the millions who died on the day she did. Likewise Yehuda, one potentiality irretrievably missing from the human future.
I worked with the dying for many years and attended in all 122 deaths, all were special in their own way and all represented a dying of a light that had shone for a while.
Unlike you I am religious but not to the extent of closing my eyes to the reality of loss and the evil that sometimes causes it. When my first wife died my grandfather said to me ‘Peter, dying is our fate, we can do nothing about it, but we can ask what does this death enable me to do for the world than otherwise I might never have done’. All through the forty five years since that death I hope her memorial has been the one I could give with the way I have spent my own life.
Peter
---
```
Date: Thu Nov 18 23:53:03 2004
From: Michael Roy Ames
```
Dear Eliezer,
Thank you for telling SL4 about Yehuda. I am unhappy to read such an email. Right now you appear to be pretty fired up about doing something; your email was reminiscent of some of your earlier, more outraged writings. Do what you have to do to keep that fire burning. Experience has taught me that it is easy to become complacent, it is the default tendency. I participate in specific activities on a regular basis that force me to looking at disease & death closely enough so that my fire is stoked. It is a rare individual that can rely on rational thinking alone to maintain enthusiasm. Do what you need to do, and know that you can ask for help.
Your friend,
Michael Roy Ames
---
```
Date: Sun Nov 21 13:10:37 2004
From: Joe
```
I feel your sadness as I have lost loved ones, though not as close as a brother. Anger and sadness sometimes lead one into action. So, I agree that there is nothing wrong to experience this type of pain. Since pain is uncomfortable most of us attempt to alleviate that pain through various means. In the case of death organized religions have their ways of doing this. As you indicated this kind of escape is often counterproductive, because it supports a “do nothing” approach. However, if you think about how long humans have been able to comprehend death and the loss which occurs, compared with any technological advancement to fight death, you can get an appreciation for the role religion, and a belief in an afterlife, has played.
But I agree with you. The time has come that we need to move past acceptance of death (belief in an afterlife) into a mode of activism against it. We are just beginning to have the technology available so that we can make visible progress. You hit upon an excellent idea that a contribution to an organization actively engaged in research to postpone or eradicate death in the name of a loved one who died is a very useful way to promote this progress.
Joe
---
```
Date: Mon Nov 29 17:03:47 2004
From: Danielle Egan
```
Eliezer,
I’m very sad to hear about your brother’s death. (Tyler sent out an email.) I respect you for putting your thoughts down on it because so many times we start writing about it later and like you say, by that point we are already moving on and can’t be honest. I want you to know that I am mad too that life ends in this way. When my grandma died recently at the age of 90, a few things really disturbed me: that she’d been dead for over 8 hours before I heard the news and I was just going through my life as usual, clueless that she had gone; that she died in an old age home, sick, with early stages of dementia so there was no dignity in her last year of life; that because there is no dignity we impose it in the form of religious or funereal services and those kinds of things and it’s too late to do a damn thing about it for them but somehow people try to trick themselves into believing these things are done for the dead person; we do everything for ourselves and really what does that come to when we remain unfulfilled?
Most of all though is that death is such a horrible shock even when the person is old and has been sick and you’ve been preparing yourself. You can never prepare for something this abstract. It seems like such a terrible twisted crime when they are so young, like your brother. I want to offer you my condolences in the form of anger. I am angry right now too about his death and it is a motivating thing. The corks are symbolic. Maybe you should keep one as a reminder to get angry and then continue on in opposition of the way we live.
Danielle
*(Danielle adds: “Perhaps you could note that I am not a transhumanist, if you decide to include bylines with the letters. I think it’s important for transhumanists to understand that we don’t have to be of the same persuasion and ethos to have similar emotions around death.”)*
---
```
Date: Sat Nov 20 21:41:29 2004
From: Mike Li
```
eliezer,
i’m sorry for your loss. beyond that, i don’t know what else to say. i’m too awkward and weak emotionally to offer any significant condolences in person. so, i just made my first donation of $699 (the balance that happened to be left in my paypal account) to the singularity institute. fight on, and know that i am with you.-x
---
```
Date: Thu Nov 18 19:33:33 2004
From: Nick Hay
To: donate@singinst.org
```
Dear Singularity Institute for Artificial Intelligence, Inc.,
This email confirms that you have received a payment for $100.00 USD from Nick Hay.
```
Total Amount: $100.00 USD
Currency: U.S. Dollars
Quantity: 1
Item Title: Donation to SIAI
Buyer: Nick Hay
```
```
Message: For Yehuda.
```
---
Christopher Healey, 11-19-04
```
Donation through: Network for Good
Amount: $103.00
Dedication: in memory of Yehuda
```
---
David R. Stern, 12-19-04
Check: $100
Comment: In memory of Yehuda
---
```
Date: Wed, 29 Dec 01:55:24 2004
From: Johan Edstr�m
To: donate@singinst.org
```
Dear Singularity Institute for Artificial Intelligence, Inc.,
Johan Edstr�m just sent you money with PayPal.
```
Amount: $50.00 USD
Note: In memory of Yehuda Yudkowsky
```
---
```
Date: Mon, 17 Jan 12:41:11 2005
From: Christopher Healey
To: donate@singinst.org
```
Dear Singularity Institute for Artificial Intelligence, Inc.,
This email confirms that you have received a payment for $1,000.00 USD from Christopher Healey.
```
Total Amount: $1,000.00 USD
Currency: U.S. Dollars
Quantity: 1
Item Title: Donation to SIAI
Buyer: Christopher Healey
```
```
Message:
In memory of Yehuda Yudkowsky, and the other 11,699,999 who have died since.
```
---
```
Date: Fri Nov 19 15:08:44 2004
From: James Fehlinger
```
‘Edoras those courts are called,’ said Gandalf, ‘and Meduseld is that golden hall. . .’
At the foot of the walled hill the way ran under the shadow of many mounds, high and green. Upon their western side the grass was white as with drifted snow: small flowers sprang there like countless stars amid the turf.
‘Look!’ said Gandalf. ‘How fair are the bright eyes in the grass! Evermind they are called, simbelmynë in this land of Men, for they blossom in all the seasons of the year, and grow where dead men rest. Behold! we are come to the great barrows where the sires of Théoden sleep.’
‘Seven mounds upon the left, and nine upon the right,’ said Aragorn. ‘Many long lives of men it is since the golden hall was built.’
‘Five hundred times have the red leaves fallen in Mirkwood in my home since then,’ said Legolas, ‘and but a little while does that seem to us.’
‘But to the Riders of the Mark it seems so long ago,’ said Aragorn, ‘that the raising of this house is but a memory of song, and the years before are lost in the mist of time. Now they call this land their home, their own, and their speech is sundered from their northern kin.’ Then he began to chant softly in a slow tongue unknown to the Elf and Dwarf, yet they listened, for there was a strong music in it.
‘That, I guess, is the language of the Rohirrim,’ said Legolas; ‘for it is like to this land itself; rich and rolling in part, and else hard and stern as the mountains. But I cannot guess what it means, save that it is laden with the sadness of Mortal Men.’
> ‘It runs thus in the Common Speech,’ said Aragorn, ‘as near as I can make it.Where now the horse and the rider? Where is the horn that was blowing?Where is the helm and the hauberk, and the bright hair flowing?Where is the hand on the harpstring, and the red fire glowing?Where is the spring and the harvest and the tall corn growing?They have passed like rain on the mountain, like a wind in the meadow;The days have gone down in the West behind the hills into shadow.Who shall gather the smoke of the dead wood burning,Or behold the flowing years from the Sea returning?
>
> J. R. R. Tolkien, The Lord of the Rings
> Book III, Chapter VI, “The King of the Golden Hall”
I am sorry.
Jim F.
---
***Update: May 8th, 2005.***
The day is May 8th, six months and one week after the final annihilation of Yehuda Nattan Yudkowsky. Today I am going to visit my little brother’s grave, with my family, to watch the unveiling of his Matzevah, the stone that is set in the ground to mark his grave. This is a warm day in Chicago, springtime, with trees blossoming, and a bright blue cloudless sky. Nature does not mark the passing of our dead.
We drive for an hour and arrive at the cemetery. The last time I was here, for my brother’s funeral, I choked up when I saw a sign with an arrow, to direct cars, bearing the hand-lettered name “Yudkowsky”. This time there is no sign, for Yehuda or anyone. There is no funeral in this graveyard today. There is only one cemetery employee with a map, to direct the visitors to graves. We drive to an unremarkable section of the cemetery. The last time I was here, there was a great crowd to mark this place, and a tent for the mourners, and rows of chairs. This time there is only grass, and metal plates set into grass. I could not have found this place from memory. I look around for landmarks, trying to remember the location.
I remember (I will never forget) when I came to this cemetery for my brother’s funeral. I remember getting out of the car and walking toward a van. I looked inside the van, and saw my brother’s polished wooden coffin. The box seemed so small. I didn’t see how my brother could fit in there. “What are you doing here, Yehuda?” I said to the coffin. “You’re not supposed to be here.” My grandfather, my Zady, came toward me then, and held me.
I remember (I will never forget) the phone call I got in Atlanta. My cellphone’s screen identified the calling number my parents’ house. I said “Hello?” and my aunt Reena said “Eli -” and I knew that something was wrong, hearing aunt Reena’s voice on my home phone line. I remember having time to wonder what had happened, and even who had died, before she said “Your brother Yehuda is dead, you need to come home right away.”
That was the previous time. I don’t feel today what I felt then. There’s a script built into the human mind. We grieve, and then stop grieving, and go on with our lives, until the day we get another phone call. Probably one of my grandparents will be next.
I walk along the gravel path that leads to where my family is gathering, looking down at the metal plates set down by the side of the path. Rosenthal… Bernard… some plates are only names and dates. Others bear inscriptions that read “Loving husband, father, and grandfather”, or “Loving wife and sister”. As I walk along the path I see a plate saying only, *Herschel, my love,* and that is when my tears start. I can imagine the woman who wrote that inscription. I can imagine what Herschel meant to her. I can imagine her life without him.
How *dare* the world do this to us? How *dare* people let it pass unchallenged?
I stand by the foot of my little brother’s grave, as my relatives read Tehillim from their prayer books. The first time I came to this cemetery, I cried from sadness; now I cry from anger. I look around and there are no tears on my mother’s face, father’s face, uncle’s and grandparents’ faces. My mother puts a comforting hand on my shoulder, but there is no wetness on her face. Such a strange thing, that I’m the only one crying. Tears of sadness we all had shed, but tears of anger are mine alone. My relatives are not permitted to feel what I feel. They attribute this darkness to God. Religion does not forbid my relatives to experience sadness and pain, sorrow and grief, at the hands of their deified abuser; it only forbids them to fight back.
I stand there, and instead of reciting Tehillim I look at the outline on the grass of my little brother’s grave. Beneath this thin rectangle in the dirt lies my brother’s coffin, and within that coffin lie his bones, and perhaps decaying flesh if any remains. There is nothing here or anywhere of my little brother’s self. His brain’s information is destroyed. Yehuda wasn’t signed up for cryonics and his body wasn’t identified until three days later; but freezing could have been, should have been *standard procedure*for anonymous patients. The hospital that should have removed Yehuda’s head when his heart stopped beating, and preserved him in liquid nitrogen to await rescue, instead laid him out on a slab. Why is the human species still doing this? Why do we still bury our dead? We have all the information we need in order to know better. Through the ages humanity has suffered, though the ages we have lost our dead forever, and then one day someone invented an alternative, and no one cared. The cryonicists challenge *Death* and no one remarks on it. The first freezing should have been front-page news in every newspaper of every country; *would* have been front-page news for any sane intelligent species. Someday afterward humankind will look back and realize what we could have done, should have done, if only we had done. Then there will be a great wailing and gnashing of teeth, too late, all too late. People heard about Ted Williams on the news and laughed for ten seconds, and in those ten seconds they lost their husbands, their wives, their mothers, their children, their brothers. It’s not fair, that they should lose so much in so little time, without anyone telling them the decision is important.
I did talk to my family about cryonics. They gave me a weird look, as expected, and chose to commit suicide, as expected.
It is a Jewish custom not to walk upon the graves of the dead. I am standing in a path between two lines of graves. Some of my relatives, my uncle David and his children, are standing in the space next to Yehuda’s grave, where another grave will someday go. I think that if a filled grave is ominous, so too is land earmarked for a grave in the cemetery; like standing above a hungry mouth, waiting to be filled. When will we stop feeding our cemetaries? When will we stop pretending that this is fair? When will the human species stop running, and at last turn to stand at bay, to face full on the Enemy and start fighting back? Last Friday night my grandmother spoke to us about an exhibit she had seen on Chiune Sugihara, sometimes called the Japanese Schindler, though Sugihara saved five to ten times as many lives as Oskar Schindler. Chiune Sugihara was the Japanese consul assigned to Lithuania. Against the explicit orders of his superiors, Sugihara issued more than 2,139 transit visas to refugees from the approaching German armies; each visa could grant passage rights to an entire family. Yad Vashem in Israel estimates that Sugihara saved between 6,000 and 12,000 lives. “If there had been 2,000 consuls like Chiune Sugihara,” says the homepage of the Sugihara Project, “a million Jewish children could have been saved from the ovens of Auschwitz.” Why weren’t there 2,000 consuls like Sugihara? That too was one of the questions asked after the end of World War II, when the full horror of Nazi Germany was known and understood and acknowledged by all. We remember the few resisters, and we are proud; I am glad to be a member of the species that produced Sugihara, even as I am ashamed to be a member of the species that produced Hitler. But why were there so few resisters? And why did so many people remain silent? That was the most perplexing question of all, in the years after World War II: why did so many good and decent people remain silent?
For his shining crime, Sugihara was fired from the Japanese Foreign Ministry after the war ended. Sugihara lived the next two decades in poverty, until he was found by one of the people he had helped save, and brought to Israel to be honored. Human beings resisted the Nazis at the risk of their lives, and at the cost of their lives. To resist the greatest Enemy costs less, and yet the resisters are fewer. It is harder for humans to see a great evil when it carries no gun and shouts no slogans. But I think the resisters will also be remembered, someday, if any survive these days.
My relatives, good and decent people, finish reciting their prayers of silence. My mother and father uncover the grave-plaque; it shows two lions (lions are associated with the name Yehuda) and a crown, and an inscription which translates as “The crown of a good name.” Two of my uncles give two brief speeches, of which I remember only these words: “How does one make peace with the loss of a son, a nephew, a grandchild?”
You do not make peace with darkness! You do not make peace with Nazi Germany! You do not make peace with Death!
It is customary to place small stones on the grave-plaque, to show that someone was there. Each night the groundskeepers sweep away the stones; it is a transient symbol. One by one my relatives comes forward, and lay their stones in silence. I wait until all the rest have done this, and most people have departed and the rest are talking to one another. Then I draw my finger across the grass, tearing some of it, gathering dirt beneath my fingernails (I can still see a tinge of dirt now, under my nail as I write this); and then I hammer my stone into the dirt, hoping it will stay there permanently. I do this in silence, without comment, and no one asks why. Perhaps that is well enough. I don’t think my relatives would understand if I told them that I was drawing a line in the graveyard.
In the name of Yehuda who is dead but not forgotten.
Love,
Eliezer.
---
* [Machine Intelligence Research Institute](https://intelligence.org/).
* [Methuselah Mouse Prize](http://www.methuselahmouse.org/).
* [Cryonics: Alcor Life Extension Foundation](http://www.alcor.org/).
* [World Transhumanist Association](http://www.transhumanism.org/).
---
This document is ©2004,2005 by [Eliezer Yudkowsky](http://eyudkowsky.wpengine.com/) and free under the [Creative Commons Attribution-No Derivative Works 3.0 License](http://creativecommons.org/licenses/by-nd/3.0/) for copying and distribution, so long as the work is attributed and the text is unaltered. |
f172ebbd-194f-40fe-b0d5-921179b84b26 | StampyAI/alignment-research-dataset/arbital | Arbital | Exercise
One way readers can reinforce or make sure they've understood a concept is to do exercises. These pages give a collection of questions for this purpose. |
44e4f2d5-6b24-4c2b-9ded-25a743081165 | trentmkelly/LessWrong-43k | LessWrong | Sapient Algorithms
I notice my mind runs lots of cached programs. Like "walk", "put away the dishes", "drive home", "go to the bathroom", "check phone", etc.
Most of these can run "on autopilot". I don't know how to define that formally. But I'm talking about how, e.g., I can start driving and get lost in thought and suddenly discover I'm back home — sometimes even if that wasn't where I was trying to go!
But some programs cannot run on autopilot. The algorithm has something like a "summon sapience" step in it. Even if the algorithm got activated due to autopilot, some step turns it off.
When I look at the examples of sapient algorithms that I run, I notice they have a neat kind of auto-generalization nature to them. I have some reason to think that property is general. It's the opposite of how, e.g., setting up webpage blockers can cause my fingers to autopilot learn how to bypass them.
I'll try to illustrate what I mean via examples.
Example: Look at my car keys
I got tired of risking locking my keys in my car. So I started making a habit of looking at my keys before closing the door.
Once, right after I'd closed the locked car door, I realized I'd looked at the phone in my hand and shut the door anyway. Luckily the key was in my pocket. But I noticed that this autopilot program just wasn't helping.
So I modified it (as a TAP): If I was about to close the car door, I would look at my hand, turn on consciousness, and check if I was actually looking at my keys.
First, that TAP just worked. To this day I still do this when stepping out of a car.
Second, it generalized without my trying to:
* After a while it would fire whenever I was about to close any locked door.
* It then generalized to anyone I was with. If they were about to close a locked door, I would sort of "pop awake" with a mental question about whether someone had the key.
* It then generalized even more. It now fires when I'm, say, preparing for international travel. Crossing a border feels a bit like goin |
6e2fb731-58a1-47d5-8828-9bdf7c9e5717 | trentmkelly/LessWrong-43k | LessWrong | the void
A long essay about LLMs, the nature and history of the the HHH assistant persona, and the implications for alignment.
Multiple people have asked me whether I could post this LW in some form, hence this linkpost.
~17,000 words. Originally written on June 7, 2025.
(Note: although I expect this post will be interesting to people on LW, keep in mind that it was written with a broader audience in mind than my posts and comments here. This had various implications about my choices of presentation and tone, about which things I explained from scratch rather than assuming as background, my level of comfort casually reciting factual details from memory rather than explicitly checking them against the original source, etc.
Although, come of think of it, this was also true of most of my early posts on LW [which were crossposts from my blog], so maybe it's not a big deal...) |
52c80f0e-425a-4d5d-80e2-2f162a58adc3 | trentmkelly/LessWrong-43k | LessWrong | Meetup Tip: The Greeter
Summary
A useful person to have at any meetup is a greeter who says hello to arrivals and engages them in a minute or two of conversation. This is especially useful for first time attendees, who might otherwise mill around unsure what to do or how to introduce themselves. It's even better if the greeter makes an effort to remember names or to direct newcomers into conversations with others. The summary of this post is that if you want to make people feel welcome, I recommend having someone intentionally filling the greeter role.
You have now read the basic point of this post. If you want to read on, cool, lets talk about implementation details for a bit.
Details
Approaching a small crowd of people talking to one another, it isn't always clear how to introduce yourself and interject into their conversation. It can feel rude! How do you even know if this is the meetup you're looking for? If someone looks at you and says "Hello! Are you here for the rationalist meetup?" then that's an easy question to answer! If they follow up with "I'm glad you found us! I'm Bob, what's your name? What got you interested in rationality?" then now there's a conversation.
It feels nice to be somewhere everybody knows your name and they're always glad you came. That place can be your local rationality meetup! "A place where everyone recognizes everyone else by sight" isn't a bad working definition of a community really. It doesn't fit every group but it's a nice thing to aim at. If your community is online in say, a Discord, consider how many regulars you can identify by chat icon.
Many of us don't feel confident in our ability to remember names or recognize faces. The greeter doesn't actually have to remember names or recognize faces. That short dialogue example above? That first line works just fine even if you can't recognize people. If they respond with a variation on "Yeah, how've you been Bob?" then you know you have a repeat attendee. People give you a lot of leeway to forge |
8ea6e9a9-cb7a-4c54-9f2c-1b30b45744a6 | trentmkelly/LessWrong-43k | LessWrong | What is your opinion of Dr. Angelo Dilullo(meditation)?
I've listened to some of his YouTube videos, going through his book. Not sure if he makes metaphysical or unscientific claims anywhere, or if there's anything to be wary of. |
84f439bf-02c4-4ddf-b68c-a5e6ab7b653c | trentmkelly/LessWrong-43k | LessWrong | An Opinionated Guide to Computability and Complexity (Post #0)
Today, I'll try to introduce certain things in this sequence I will make that I found interesting of computability and complexity theory is, and in particular show how many problems can be solved by computers, in both a philosophical and practical sense. I will mostly not be reviewing the history of computability theory and complexity theory, except as a brief aside.
Along the way, I'll introduce some commentary of my own, so this will at least be somewhat interesting, as it would be boring to only talk about it, without interacting with the subject.
I will mostly be using the terms computability and complexity theory for historical reasons, but note that this will not correspond to decidable and practically solvable problems always, and we must always pick a machine and constraints on the machine before we can talk about whether a problem is solvable at all.
Things I will cover include:
1. Why the definition of decidable problems is machine and constraint dependent, and why picking different machines will get you different results in what you can compute, and why picking different time and space requirements will affect the sets of things you can compute.
2. Why Hilbert was right, in a manner of speaking, to hope for an algorithm that could decide at least major parts of mathematics, and why Church and Turing's thesis that the Turing Machine could capture every computer and algorithm was false.
3. Why Cobham's thesis that the practical problems we can solve correspond to P in complexity theory in our specific universe is unlikely to be true, because of the Time Hierarchy theorem as well as issues with the constant potentially being arbitrarily large.
4. What philosophy can gain from understanding complexity and computability theory, and addressing Aaronson's paper to point out where it goes right and wrong.
5. The underappreciated amount of things a Universal/Complete Turing Machine can simulate, and that it can actually emulate a halting oracle, even |
a65af519-1c05-4713-ad95-15bded951ccc | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | [$20K in Prizes] AI Safety Arguments Competition
TL;DR—We’re distributing $20k in total as prizes for submissions that make effective arguments for the importance of AI safety. The goal is to generate short-form content for outreach to policymakers, management at tech companies, and ML researchers. This competition will be followed by another competition in around a month that focuses on long-form content.
*This competition is for short-form arguments for the importance of AI safety. For the competition for distillations of posts, papers, and research agendas, see the*[*Distillation Contest*](https://forum.effectivealtruism.org/posts/ei4pYFJKcbGAdGnNb)*.*
**Objectives of the arguments**
To mitigate AI risk, it’s essential that we convince relevant stakeholders sooner rather than later. To this end, we are initiating a pair of competitions to build effective arguments for a range of audiences. In particular, our audiences include policymakers, tech executives, and ML researchers.
* **Policymakers** may be unfamiliar with the latest advances in machine learning, and may not have the technical background necessary to understand some/most of the details. Instead, they may focus on societal implications of AI as well as which policies are useful.
* **Tech executives** are likely aware of the latest technology, but lack a mechanistic understanding. They may come from technical backgrounds and are likely highly educated. They will likely be reading with an eye towards how these arguments concretely affect which projects they fund and who they hire.
* **Machine learning researchers** can be assumed to have high familiarity with the state of the art in deep learning. They may have previously encountered talk of x-risk but were not compelled to act. They may want to know how the arguments could affect what they should be researching.
We’d like arguments to be written for at least one of the three audiences listed above. Some arguments could speak to multiple audiences, but we expect that trying to speak to all at once could be difficult. After the competition ends, we will test arguments with each audience and collect feedback. We’ll also compile top submissions into a public repository for the benefit of the x-risk community.
Note that we are not interested in arguments for very specific technical strategies towards safety. We are simply looking for sound arguments that AI risk is real and important.
**Competition details**
The present competition addresses shorter arguments (paragraphs and one-liners) with a total prize pool of $20K. The prizes will be split among, roughly, 20-40 winning submissions. Please feel free to make numerous submissions and try your hand at motivating various different risk factors; it's possible that an individual with multiple great submissions could win a good fraction of the prize. The prize distribution will be determined by effectiveness and epistemic soundness as judged by us. Arguments *must not be misleading*.
To submit an entry:
* Please leave a comment on this post (or submit a response to [this form](https://forms.gle/HTiqCtki3AhCCGV96)), including:
+ The original source, if not original.
+ If the entry contains factual claims, a source for the factual claims.
+ The intended audience(s) (one or more of the audiences listed above).
* In addition, feel free to adapt another user’s comment by leaving a reply—prizes will be awarded based on the significance and novelty of the adaptation.
Note that if two entries are extremely similar, we will, by default, give credit to the entry which was posted earlier. Please do not submit multiple entries in one comment; if you want to submit multiple entries, make multiple comments.
The first competition will run until May 27th, 11:59 PT. In around a month, we’ll release a second competition for generating longer “AI risk executive summaries'' (more details to come). If you win an award, we will contact you via your forum account or email.
**Paragraphs**
We are soliciting argumentative paragraphs (of any length) that build intuitive and compelling explanations of AI existential risk.
* Paragraphs could cover various hazards and failure modes, such as weaponized AI, loss of autonomy and enfeeblement, objective misspecification, value lock-in, emergent goals, power-seeking AI, and so on.
* Paragraphs could make points about the philosophical or moral nature of x-risk.
* Paragraphs could be counterarguments to common misconceptions.
* Paragraphs could use analogies, imagery, or inductive examples.
* Paragraphs could contain quotes from intellectuals: “If we continue to accumulate only power and not wisdom, we will surely destroy ourselves” (Carl Sagan), etc.
For a collection of existing paragraphs that submissions should try to do better than, see [here](https://docs.google.com/document/d/1ymgsCuUy87awBStJ8U5zlo2NC3NJQur6JSXONUs4ufs/edit?usp=sharing).
Paragraphs need not be wholly original. If a paragraph was written by or adapted from somebody else, you must cite the original source. We may provide a prize to the original author as well as the person who brought it to our attention.
**One-liners**
Effective one-liners are statements (25 words or fewer) that make memorable, “resounding” points about safety. Here are some (unrefined) examples just to give an idea:
* *Vladimir Putin said that whoever leads in AI development will become “the ruler of the world.”*([source for quote](https://apnews.com/article/technology-russia-business-artificial-intelligence-international-news-bb5628f2a7424a10b3e38b07f4eb90d4))
* *Inventing machines that are smarter than us is playing with fire.*
* *Intelligence is power: we have total control of the fate of gorillas, not because we are stronger but because we are smarter. (based on*[*Russell*](https://en.wikipedia.org/wiki/Human_Compatible)*)*
One-liners need not be full sentences; they might be evocative phrases or slogans. As with paragraphs, they can be arguments about the nature of x-risk or counterarguments to misconceptions. They do not need to be novel as long as you cite the original source.
**Conditions of the prizes**
If you accept a prize, you consent to the addition of your submission to the public domain. We expect that top paragraphs and one-liners will be collected into executive summaries in the future. After some experimentation with target audiences, the arguments will be used for various outreach projects.
(We thank the Future Fund regrant program and Yo Shavit and Mantas Mazeika for earlier discussions.)
In short, make a submission by leaving a comment with a paragraph or one-liner. Feel free to enter multiple submissions. In around a month we'll divide 20K to award the best submissions. |
b6756149-b391-4afd-a1e5-0e81cc88140a | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Is the AI timeline too short to have children?
If you had asked me at any point in my adult life (until recently) whether I wanted to have children eventually, I would've said yes, without hesitation. In recent years I've been telling myself: I don't know how likely these AI doom predictions are, but I'm going to focus on optimizing the "long path" because that's where my decisions actually matter - and so I should still have children just in case.
But now, both as I'm nearing the family-forming stage in my life, and as the AI timeline [seems](https://www.lesswrong.com/posts/zyudvnRruMQMxM3NE/okay-i-feel-it-now) to be coming into sharper focus, I'm finding it emotionally distressing to contemplate having children.
If AI kills us all, will my children suffer? Will it be my fault for having brought them into the world while knowing this would happen? Even if I think we'll all die painlessly, how can I look at my children and not already be mourning their death from day 1? If I were to die right now, I would at least have had a chance to live something like a fulfilling life - but the joy of childhood seems inextricable from a sense of hope for the future. Even if my children's short lives are happy, wouldn't their happiness be [fundamentally false](https://www.lesswrong.com/posts/SqF8cHjJv43mvJJzx/feeling-rational) and devoid of meaning? |
e113c012-40ab-47f5-918e-43ef3c54c281 | trentmkelly/LessWrong-43k | LessWrong | Which activities do you prefer to better recover productivity?
I would like to ask you to share in the comments what do you usually do when not working that provides a rest with good quality. Personally, I found that if I enjoy something a lot it is hard to stop (like a very interesting book). And if I don't enjoy it, then it is kind of no point in doing it to have rest. I will appreciate both short (like "Hiking") and long comments. Thank you! |
4082d6bf-4c37-44d4-b42f-9a16633319b5 | trentmkelly/LessWrong-43k | LessWrong | Anthropomorphizing AI might be good, actually
It is often noted that anthropomorphizing AI can be dangerous. People likely have prosocial instincts that AI systems lack (see below). Assuming AGI will be aligned because humans with similar behavior are usually mostly harmless is probably wrong and quite dangerous.
I want to discuss a flip side of using humans as an intuition pump for thinking about AI. Humans have many of the properties we are worried about for truly dangerous AGI:
* Situational awareness
* Strong goal-directedness
* Competence/general intelligence
* Unpredictability
* Deceptiveness
* Instrumental convergence
* Sometimes being quite dangerous
* in proportion to their capabilities
Given this list, I currently weakly believe that the advantages of tapping these intuitions probably outweigh the disadvantages.
Differential progress toward anthropomorphic AI may be net-helpful
And progress may carry us in that direction, with or without the alignment community pushing for it. I currently hope we see rapid progress on better assistant and companion language model agents. I think these may strongly evoke anthropomorphic intuitions well before they have truly dangerous capabilities, and this might shift public opinion toward much-more-correct intuitions about how and why AGI will be very dangerous. I'm aware that this may also catalyze progress, so I'm only weakly inclined to think this progress would be net-positive.
The LLMs at the heart of agents already emulate humans in many regards. I think many improvements will enhance the real similarity and therefore the pattern matching to the strong exemplar of humans. In particular, it seems likely that adding memory/continuous learning will enhance this impression significantly. Memory/continuous learning is critical for a human-like integrated and evolving identity. It is arguably not a matter of whether or even when, but simply how fast memory system integrations are deployed and improved (see LLM AGI will have memory... for the argument |
b2e1fde9-9b85-458b-9ef3-79461cd81d24 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | What work has been done on the post-AGI distribution of wealth?
It seems like the distribution of wealth (and other forms of power) following transformative AI is very consequential for the value of the long-term future, affecting both immediate suffering and well-being and the chances of a long-term value lock-in. I'm aware of the [Windfall Clause Report](https://www.fhi.ox.ac.uk/windfallclause/) and the [three papers and several posts cited here](https://forum.effectivealtruism.org/topics/economics-of-artificial-intelligence). What other work should I be aware of? |
89a0c5e4-93f6-4896-8049-32b60ae57be9 | trentmkelly/LessWrong-43k | LessWrong | Briefly analyzing the 10-year moratorium amendment
This is the result of a half-day research sprint on the recently-introduced amendment to institute a 10-year moratorium on state-level AI regulations in the current budget reconciliation bill, with a focus on figuring out "is it likely to survive the Byrd Rule".
----------------------------------------
It seems quite obviously in violation of the Byrd Rule because it violates at least 2 of the 6 tests[1]:
* It has no budget effect, i.e. does not change outlays or revenues. (Probably this is not actually true; I think on net we would expect it to somewhat increase revenues via 2nd/3rd order effects, but in the relevant legal sense, it's not an explicit additional tax and it's not an additional explicit expenditure. Also, the CBO estimate for that entire section is -500m, which is the full sum of the $500m it appropriates to modernize and secure Federal information technology systems through the deployment of commercial artificial intelligence, the deployment of automation technologies, and the replacement of antiquated business systems in accordance with subsection (b))
* Even if it did have a budget effect, it would be incidental to the non-budgetary component of the provision, which is clearly meant to be a "policy change".
There is a "Byrd bath" that reconciliation bills go through, directed by the Senate Parliamentarian, before the bill is taken up by the Senate. The Parliamentarian & Senate staff identify the sections that seem like obvious violations of the Byrd Rule and try to work with whoever drafted the relevant section of text to redraft or amend it so that it doesn't violate the Byrd Rule (if possible; sometimes they're just deleted wholesale). It's not clear to me what percentage of violations get scrubbed out at this step, but various LLMs think it's most of them.
If it does still somehow make it through that step, Senators can raise a "point of order" against subtitles, sections, lines, or even single words in the bill. Other Senators can mo |
1d5bbf9d-ec1c-4611-8335-02c261b06415 | trentmkelly/LessWrong-43k | LessWrong | A game of mattering
When I have an overwhelming number of things to do, and insufficient native urge to do them, I often arrange them into a kind of game for myself. The nature and appeal of this game has been relatively stable for about a year, after many years of evolution, so this seems like a reasonable time to share it. I also play it when I just want to structure my day and am in the mood for it. I currently play something like two or three times a week.
The game
The basic idea is to lay out the tasks in time a bit like obstacles in a platformer or steps in Dance Dance Revolution, then race through the obstacle course grabbing them under consistently high-but-doable time pressure.
Here’s how to play:
1. Draw a grid with as many rows as there are remaining hours in your hoped for productive day, and ~3 columns. Each box stands for a particular ~20 minute period (I sometimes play with 15m or 30m periods.)
2. Lay out the gameboard: break the stuff you want to do into appropriate units, henceforth ‘items’. An item should fit comfortably in the length of a box, and it should be easy enough to verify completion. (This can be achieved through house rules such as ‘do x a tiny bit = do it until I have a sense that an appropriate tiny bit has been done’ as long as you are happy applying them). Space items out a decent amount so that the whole course is clearly feasible. Include everything you want to do in the day, including nice or relaxing things, or break activities. Drinks, snacks, tiny bouts of exercise, looking at news sites for 5 minutes, etc. Design the track thoughtfully, with hard bouts followed by relief before the next hard bout.
3. To play, start in the first box, then move through the boxes according to the time of day. The goal in playing is to collect as many items as you can, as you are forced along the track by the passage of time. You can collect an item by doing the task in or before you get to the box it is in. If it isn’t done by the end of the box, it gets lef |
0b00f0cc-5cba-4fab-997e-ee62fb045f1b | StampyAI/alignment-research-dataset/arxiv | Arxiv | Activism by the AI Community: Analysing Recent Achievements and Future Prospects
Activism by the AI Community
Analysing Recent Achievements and Future Prospects
Haydn Belfield
Centre for the Study of Existential Risk
University of Cambridge
Cambridge, UK
hb492@cam.ac.uk
ABSTRACT
The artificial intelligence (AI) community has recently engaged in
activism in relation to their employers, other members of the
communi ty, and their governments in or der to shape the societal
and ethical implications of AI. It has achieved some notable
successes, but prospects for further political or ganising and
activism are uncertain. We survey activism by the AI community
over the last six years; apply two analytical frameworks drawing
upon the literature on epistemic communities, and worker
organising and bargaining; and explore what they imply for the
future prospects of the AI community. Success thus far has hinged
on a cohere nt shared culture, and high bar gaining power due to
the high demand for a limited sup ply of AI ‘talent ’. Both are
crucial to the futur e of AI ac tivism and worthy of sustained
attention.
CCS CONCEPTS
• Social and professional topics~Computing profession • Social
and pr ofessional topics~Computing and business • Social and
professional topics~Government technology policy
KEYWORDS
Activism , organising , ethics , epistemic community, lethal
autonomous weapons , bargaining, talent supply.
ACM Reference format:
Haydn Belfield . 2020. Activism by the AI Community: Analysing Recent
Achievements and Future Prospects . In Proceedings of 2020 AAAI/ACM
Conference on AI, Ethics, and Society (AIES ’20), February 7–8, 2020, New
York, NY, USA. ACM, New York, NY, USA, 6 pages.
https://doi.org/10.1145/3375627.3375814
1 Introduction
“The best thing AI researchers can do is vote with their
feet, not work with companies that have outcomes you
don't agree with. There aren't enough researchers to go
around, and attracting enough talent is important, so actually researchers individually have a lot of power.
Through soft infl uence, you can influence a lot. ”
–Demis Hassabis, DeepMind CEO [49]
The development and deployment of AI is likely to have
important consequences for the global economy, society, and
politics. AI deploy ment is already influencing mar kets and the
economy, justice and distributive decisions by governments, and
our elections [32, 63]. In coming years we m ay see the use of AI
systems with novel ca pabilities in military domains [ 47].
Increasing use of increasingly powerful yet brittle systems carries
accident risks, misuse risks, and structural risks [65] – risks to
human security, and risks of societal inequality and
discrimination [6, 37 ].
The AI community has responded to these urgent issues
by engaging in activism in order to promote the positive (in their
view) societal an d ethical effects of AI, and de crease the negative
effects. ‘Activism’ includes a broad range of different kinds of
social and political campaigning, organising and advocacy. This
encompasses: issue -framing; agenda -setting; standard setting;
private discussions with decision -make rs; public campai gning in
tradi tional and social media; establishing new fields and
organisations; submissions to governmental inquiries; and classic
labour tactics of boycotts and strikes.
The ‘AI community’ includes researchers, research
engineers, faculty, grad uate stu dents, NGO workers, cam paigners
and some technology workers more generally – those who would
self-describe as working ‘on’, ‘with’ and ‘in’ AI and those
analysing or campaigning on the effects of AI. This paper focuses
especially on the AI community withi n corporate and academic
labs in the US and Europe.
This activism has had some notable consequences so far:
informing internation al negotiations, changing corpo rate
strategy, and spurring the growth of research fields (see next
section). Such activism ma y shape the manner and extent to which
AI is militarised, and how AI compa nies address ethics and safety
concerns. The AI communi ty is an important autonomous actor
with a distinctive set of viewpoints and interests. It needs to be
accounted for in strateg ic or academic anal ysis and negotiated
with by oth er actors. AI community activism may profoundly
shape the development and deployment of this important set of
technologies - and therefore shape our global economy, society
and politics. Permission to make digital or hard copies of part or all of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for profit or commercial advantage and that copies bear this notice and the full citation
on the first page. Copyrights for third -party components of this work must be honored.
For all other uses, contact the Owner/Author.
AIES '20, February 7 –8, 2020, New York, NY, USA
© 2020 Copyright is held by the owner/author(s).
ACM ISBN 978 -1-4503-7110-0/20/02.
https://doi.org/10.1145/3375627.3375814
This activism is t herefore an important phenomenon in
need of theoretical analysis. To date this analysis has been limited,
with much of the discussion in ‘grey literature’ or in the media
[60, 20, 55, 11]. We can identify (at least) two important questions
for researchers:
How can we explain the activism by the AI community of
recent years?
What are the future prospects of activis m by the AI
community?
In this paper, we overview some examples of recent
activism by the AI comm unity. We then apply two differ ent
analytical frameworks: epistemic communities and worker
organising. We end by discussing some key com mon factors, and
identifying research questions that could clarify the future
prospe cts of activism by the AI commu nity.
2 Recent examples: 2013 -2019
This section is a brief overview of some examples of activism by
the AI community over the last six years. The purpose of this
section is to motivate the discussion by outlining some concrete
examples to ground the later ana lytical discussion. S ee AI NOW ’s
‘Year in Review ’ reports [9, 10, 11] for a more comprehensive
descriptive treatment.
The last six years have seen a number of high -profile
political actions taken by the AI community. We discuss three
main examples: lethal autonomous weapons systems (LAWS),
ethics and safety, and employee organising. These three do not
cover the entire ran ge of activism, but are intended to be broadly
illustrative. Under these head ings we proceed in a roughly
chronological manner. We begin in 2013 with the launch of the
Campaign to Stop Killer Robots, a key moment of epistemic
community formation and a focu s for worker organizing1.
2.1 Lethal Autonomous Weapons Systems
(LAWS)
LAWS are weapons systems that can autono mously select and kill
targets [3 5]. The AI community has been deeply involved with the
debate ove r an international ban on LAWS [51 ]. Not only i s the
AI community a relevant expert community for advising on this
debate, it is also being directly asked to work on the research and
development (R&D) of LAWS [59].
In early 2013 the Campaign to Stop Killer Robots was
formally launched to promote an int ernational ban on the
development and use of LAWS. In late 2013 the Convention on
Certain Conventional Weapons (CCW) agreed to begin
considering LAWS. The CCW was the forum for negotiations over
banning cluster munitions, landmines and blinding laser weap ons.
The AI community played key roles in the adoption of LAWS as
an issue by arms control NGOs, the establishment of the UN
process, a nd the ongoing work of the CCW [4] .
1 The campaign’s roots stretch back at least to 2004 [8].
2 OpenAI was a non -profit and is now a company with a non -profit mission.
3 The author is an Associate Fellow of the Centre. The Campaign includes many members of the AI
community. Their activism ranges from personal discussions with
diplomats at the CCW to mass media ‘viral videos’ [7]. A key
tactic has been the organisation of mass Open Letters. In July 2015
an Open Letter on LAWS expressed community concern. It has
been signed to date by 4,500 AI and roboti cs researchers [22]. This
was followed by another Open Letter on LAWS [24], when the
Meeting of Experts changed to a Group of Governmental Experts
(GGE) at the CCW.
This effort has also included intra -community
organising . One example is the April 2018 Korea Advanced
Institute of Science and Technology (KAIST) boycott. The 50
signatories committed to boycott all collaborations with any part
of KAIST, due to concerns that a KAIST centre had a LAWS
collaboration with Hanwha Systems, a leading South Korean arms
company. KAIST soon clarified that they would not work on
LAWS [25].
Activism has also included extensive and intense
negotiations within technology companies, discussed below.
2.2 Ethics and safety
There has been susta ined activism from the AI community to
emphasise that AI should be developed and deployed in a safe and
beneficial man ner. This has involved Open Let ters, AI principles,
the establishment of new centres, and influencing governments.
The Puerto Rico Confe rence in January 2015 was a
landmark event to promot e the beneficial and safe devel opment
of AI. It led to an Open Letter signed by over 8,000 people calling
for the safe and beneficial develop ment of AI, and a research
agenda to that end [21].
The Asilom ar Conference in January 2017 led to the
Asilomar AI Principles, signed by s everal thousand AI researchers
[23]. Over a dozen sets of principles from a range of groups
followed [61].
The AI community has established several research
groups to understand a nd shape the societal impact of AI. AI
conferences have also expanded their work to consider the impact
of AI. New groups include:
Fairness, Accountability, and Transparency in Machine
Learning (FAT ML) (December 2014)
OpenAI (December 2015)2
Centre for H uman -Compatible AI (August 2016)
Leverhulme Centre for the Future of Intelligence (Oc tober
2016)3
Algorithmic Justice League (November 2016)
DeepMind Ethics and Society (October 2017)
AI Now Institute (November 2017)
UK Government’s Centre for Data Ethics and Innova tion
(November 2017)4
Especially notable is the Partnershi p on Artificial Intelli gence to
Benefit People and Society (September 2016). The Partnership
brings together over 90 companies and non -profits, and is
4 The Centre was proposed and advocated for by the AI community, and analyses
AI’s societal and ethical implications.
exploring best -practice recommendations for the community as a
whole [46].
The AI community has also contributed to over 30
national and international AI strategies [13]. The High -Level
Expert Group on Artificial Intelligence to the European
Commission (HLEG -AI) is made up of 52 experts from academia,
civil society, and industry. Their work led to Ethics Guidelines,
and policy and investment recommendations, for trustworthy AI
[33]. EU Commissioner Margrethe Vestager has strongly
indicated that forthcom ing EU regulation on AI will be based on
this work by the AI community.
2.3 Organising
2018 saw an upturn in political organising, especially within large
technology companies: the ‘tech resistance’.
The most prominent example of this activism has been
Google. Google’s involvement with Department of Defense’s
(DoD) Project Maven was revealed in March 2018. 3,000
employees signed an Open Letter opposing it in April [28]. In
June, Google an nounced it would not renew the Project Maven
contract and released it s AI Principles. In October, Google also
dropped out of the DoD’s JEDI cloud bidding process.
However, in August, Google’s secret ‘Project Dragonfly’
(a censored Chinese search engine) was revealed. This was
opposed by another Open Letter. Two anonymous e mployees
wrote in an email circulating the Dragonfly letter: “Individual
employees organizing against the latest dubious project cannot b e
our only safeguard against un ethical decisions. This amounts to
unsu stainable ethics whack -a-mole” [29 ].
In November , 20,000 employees and contractors took
part in a one -day strike, or ‘Google walkout’, protesting sexual
harassment and misconduct. This contributed to the end of ‘forced
arbitration’ for full time workers [30 ].
Not all organising, however, was so clearly successful.
Ongoing debates include corporate partnerships with
Immigration and Customs Enforcement (ICE) and Customs and
Border Protection (CBP). In June, perhaps as a result of the Trump
administration’s family separation policy [10], severa l groups
released open letters [ 42, 2, 52].
3 Analytical frameworks: two lenses
We reviewed three examples of activism over the last six years,
including some key successes. We now draw on two different
analytical frameworks: epistemic communities, and worker
organising. Both of these can provide insights into why this
activism is occurring, how these successes have been achieved,
and what its future prospects are.
We address each framework in turn. For each
framework, we briefly describe it and explain its re levance to our
discussion. We then discuss what factors are seen as predictive of
success for the relevant group within the framework, and ask to
what extent those factors apply to our case – and will continue to
apply over the next few years. 3.1 Epistemi c communities
An epistemic community is a network of knowledge -based
experts: “professionals with recognised expertise and competence
in a particular domain and an authoritative claim to policy -
relevant knowledge within that do main” [31 ]. Crucially, they a lso
share causal and principled beliefs about their domain, notions of
validit y, and a common policy project [1] .
Historical examples include nuclear physicists,
chemists, biol ogists, and climate scientists [31 ]. Epistemic
communities have been identified as playing key roles in several
policy deba tes, such as the role of the nu clear weapons scientists
and strategists in the 1972 Anti-Ballistic Missile Treaty [1] .
This framework is relevant to the AI community. They
are technical experts that have a clear ly recognised and valid
claim to authority and expertise in the domain of AI. There is a
strong set of shared causal beliefs and notions of validity, and
common policy projects.
Scepticism has been expressed about the coherence of
the epistemic community on military AI, especially about whether
it is presently sufficient to play a sim ilar role to the ABM
community [39 , 47]. It clearly has not yet been sufficient to pass
an international ban or block military AI R&D efforts. However,
it has put LAWS firmly on the international agenda, and the
Campaign’s prospects look similar to the landmines and cluster
munit ions campaigns at simila r stages. For now, it has tempo rarily
paused, and perhaps lastingly complicated, the relationship
between the US military and U S tech firms (most importantly
Google). Also, we are considering activism on a wider set of topics
than just LAWS. The AI community’s policy projects also include
emphasising ethics, societal benefit and safety, and opposing
particular choices by company m anagement.
In general, when are epistemic communities more likely
to be persuasive? Cross [12] identifies five key factors: 1) the issue
is uncert ain and salient; 2) the communi ty has access to, and
understanding of, decision -makers and other actors; 3) t here is
‘policy field coherence’, 4) they seek to influence an early or
technocratic phase in the policy process; and 5) they are seen as
credible and have a more cohesive, certain coalition than their
competitors.
We suggest these factors currently appl y to the AI
community, and are likely to largely continue to apply.
1) The ethical, military and societal implications of AI is a complex
and new set of issues. It has become politically salient over the
last few years.
It is likely to remain quite uncert ain. The extent to
which there is a sense of perceived crisis may fade over time as
the issue becom es less new and begins to be un tangled. However,
it is l ikely to remain technically com plex, as well as politically
salient, as AI continues to im pact our economy and society.
2) The AI community has access to top decision -makers, both
corporate and political. They have also been able to anticipate
other actor’s preferences and actions, such as anticipating those
of the different national delegatio ns during the international
LAWS negotiations.
This high -level access is likely to continue – policy -
maker interest sees no sign of slacking. It is open whether they
will continue to be anticipatory.
3) ‘Policy field coherence’ refers to there being respected
quantitative data, the issue involving technical systems, and the
norms and goal s of the community being compat ible with existing
institutional norms. The issues for the AI community have
involved the interaction of human -made technical systems w ith
social systems, instead of just involving social syst ems, and there
has been respect ed quantitative data on, for example, the extent
of bias or the frequ ency of mistakes by ML systems [37].
There will likely continue to be policy field coherence.
Indeed the availability of quantitative data is likely to improve
over time. However the lack of quantitative data about the
humanitarian impact of LAWS (which will continue until if and
when they are deployed) may continue to limit the persuasiveness
of those pushing for an interna tional ban.
4) The AI community has sought to influence the initial terms of
the debate and to focus on subsystem, technocratic phases. For
example, activism in 2015 helped shape the terms of the debate
around ethical, safe and benef icial AI – and then how that was
translated into national ethical principles and strategies.
Over time, the terms of the debates around the
development and deployment of AI are likely to become more
fixed, and activism will have to seek to influence later stages in
decision -makin g processes. The societal impli cations of AI may
also become more pronounced, and/or entangled with broader
political beliefs. However, contin ued technical breakthroughs
may crea te continued capa bility jumps (such as la nguage model s
and fake news gen eration), routinely posing new policy problems.
5) The AI community has been quite coherent and certain of its
aims in some respect s: pushing for serious consider ation of the
military and societal impacts of AI by compa nies and
governmen ts. It seems more cohesive than those pushing to
deproblematise the issue. It also shares a high level of professional
norms and status.
It is unclear whether t hey will continue to be more
coherent and certain than competing networks, especially in the
debate over the acceptability of working on military AI, including
LAWS. T he network pushing for an accom modation with
militaries may prove more cohesive and certain. Community
credibility seems unlikely to radically change. Marginal changes
could occur, for example through the further democratisation of
machine learning (ML) through MOOCs and other online
platforms.
Overall then, the AI community has achieved some
successes as an epistemic community as the scope conditions (1),
political opportunity structu re (2) and policy field coherence (3)
have been favourable, and the AI community has sought to
influence early and technocratic phases in the policy process (4)
and built fairly cohesive coalitions (5).
Factors likely to continue include high -level access
being good; being able to deal with technocratic aspects of
decision -making; sharing a high status; and being able to draw on
evidence on which they are expert. However, over the next few
years novelty will decrease, the terms of debate will become more set, and the entire issue -area may become more politicised. The
window of influence may be shrinking, but it is unlikely to close,
as the issue -area will remain uncertain and complex. A key
question for further research is whether the AI community will
continue to be cohesive and certain in its aims.
3.2 Worker organizing and bargaining
Freeman and Medoff [19] influentially distinguish between the
‘two faces’ of o rganised labour. The first, 'mo nopoly face' is that
of union monopoly power used to raise member s' wages. Now,
however, the emphasis is typically more on offsetting
informational and power asymmetries between workers and
management [5].
More relevant to our focus, however, is their second,
“collective voice/institutional response” face. This builds on
Hirschman’s [34] conception of ‘voice’ as the ability to “change,
rather than escape from [i.e. exit], an objectionable state of
affairs.”
Worker organising and bargaining means their ability
“to 'voice' their concer ns and demands rather than imme diately
'exit' —that is, quit the job”, “to voice complaints and see them
addressed through collective bargaining” [19]. Worker or
employee voice – whether formally through a union or not – has
become a key topic for disciplines such as labour economics,
industrial relations and or ganisational behaviour [62].
It need not refer just to improving working conditions,
but also to encouraging one’s firm to advocate for public policies.
For example, US corporate engagement on LGBT rights has been
largely driven b y employee organizations in highly -educated
workforces advocating for manage ment to take public sta nds
advocating for LGBT rights [40 ].
Key to this framework is the ability of different actors to
have an agreement on their terms, that is the ‘bargaining p ower’
of workers and management, based on the “ability to impose costs
on the other side for failing to agree and to avoid or absorb its
own costs from failing to agree” [14] .
This framework is relevant to the AI community.
Almost all members of the AI co mmunity are employees, rather
than business -owners. Indeed, the AI community is largely
located within fairly large corporate and academic labs.
Formal unionisation rates are low in technology
compan ies, though higher in academia [ 18]. However, it is clea r
that the AI community has substantial bargaining power, of the
type described in our opening quote. This is reflected in high
salaries. The New York Times reports that “A.I. specialists with
little or no industry experience can make between $300,000 and
$500,000 a year in sal ary and stock. Top names can re ceive […]
millions” [41 ]. Nevertheless, groups like the Tech Workers
Coalition have emphasised the difference in power across the
industry – from a researcher with a ML PhD to a gig economy
Mechanical Tu rk co ntractor. The Coalition’s work began in
attempting to or ganise across more of the tech workforce [58].
The organizing examples described above often involved workers
adapting classic collective bargaining tactics for their situations.
While this fram ework is directly relevant to employees,
more generally, AI community activism can be framed as a set of
strategic interactions between actors, each with different
incentives, resources and constraints – where outcomes are the
result of bargaining between these actors [38].
In general, when are workers more likely to be
persuasive (or successful) with the management of their
organi sation? Dau -Schmidt & Ellis [14] identify five key economic
factors: 1) the nature of the organisation's p roduct and services; 2)
the structure of bargaining; 3) the organisation's technolog y of
production; 4) general eco nomic conditions; and 5) the employees'
commitment to collective action.
We suggest these factors currently benefit the AI
community, and are likely to largely c ontinue to benefit it.
1) Corporate organisations’ products and services typically
require ongoing maintenance, so management is less able to
absorb costs from f ailing to agree with its employ ees. Also, large
tech companies are generally consumer -facing (B 2C) rather than
business -facing (B2B) firms, which makes them more susceptible
to public – consumer – sentiment. Google is more susceptible than
Palantir to consumer sentiment because they rely on the public
using their services, rather than Palantir which relies more on
large clients. Tech workers have been adept at mobilising media
interest and public support. The nature of these products and
services is unlikely to change dramatically in the coming years.
2) The structural landscape of bargaining is larg ely tilted in favour
of employers. While many tech workers are well -paid enough to
have a decent amount of runway, and are able to ‘exit’ to similarly
well-paid jobs elsewhere, they are hampered by the lack of
unionisation. Another issue is the widespread use by tech
companies of non -disclosure agreements (NDAs). This tends to
limit workers’ ability to publicly voice concerns – even after they
leave the company.
This is likely to continue, but may diminish marginally
if there are explicit offers of financi al or legal support from worker
groups like the Tech Worker’s Coalition or civil society groups
like the American Civil Liberties Union (ACLU). However, several
centre -left politicians in the US and Europe propose more
antitrust scrutiny of tech companies, and to change union
regulation to empower them, which would shift the landscape.
3) Organisations empl oying members of the AI communi ty
typically depend on highly -skilled workers. Replacements are
hard to obtain, and the organisation cannot continue with just a
skeleton crew. This means that the organisations are less able to
absorb the costs of failing to agree a deal, improving worker
bargaining power.
This is likely to continue, but may change marginally. If
these organisations turn from more R&D -style work to more
implementation -style work, then workers may not need to be as
highly -skilled. This may shift bargaining power.
4) A key question about the general economic conditions is the
balance of supply and demand of potential replacement workers.
Estim ates of the ‘talent pool’ vary widely, from 22,400 -36,500 [26]
to 300,000 [54]. The high salaries commanded in the field
demonstrate that supply is not meeting demand.
However, various sources of evidence point to an
increase in the talent supply in comin g years [5 3]. Several
governments have made large commit ments of money for education: t he UK is supporting 1,000 PhDs [1 6]. The 2017 CRA
Taulbee Survey shows a continued increase in the number of
degrees and enrolment, at doctorate, maste rs and undergradu ate
level [64 ]. Note that this does not include quasi -academic routes:
MOOCs such as Andrew Ng’s or fast.ai, coder bootcamps, and so
on.
We should expect an increase in the supply of talent
over the coming years (a PhD in ML, for example, typi cally takes
four years to complete in the UK and six years in the USA). Other
things being equal, this increase in the number of potential
workers would tend to decrease work er power.
However, this assumes that supply increases more than
demand. The followi ng years may well see demand for ML talent
continue to increase – keeping track with or even exceeding the
increase in supply. This demand may increase as AI and robotics
becomes more technologically ready or industrialised. If data and
computing power con tinue to grow, more areas may become well -
suited to ML approaches, which might also increase demand. The
future balance of supply and demand is a key question.
5) Commitment to collective action is a similar factor to epistemic
community cohesion. Willingness and ability to (threaten) exit
seems fairly high. There have been several high -profile exit s over
‘employee voice’ issues [4 4, 45, 48]. A small -scale survey of UK
tech workers suggests 16% of all people in AI have left their
company over the is sue of working on products they felt might be
harmful for society, compared to 5% of all tech workers [43].
A key question is whether the predicted new ‘talent’ will
be socialised to a similar extent, and through similar means, to
existing workers. A larg er AI community, that has not all been to
the same small academic conferences for several years, may be
less cohesive. Conversely, enrolment in university 'ethics in AI'
courses may make the next generation more eth ically engaged.
Also, if the mo mentum beh ind the political organising continues,
it will increasingly be seen as the norm. Key organisers might
receive more training and su pport. The ad -hoc arrange ments that
have characterised the political organising of the AI community
so far might become more institutionalised.
Overall then, the AI community has achieved some
successes as workers organising and bargaining with their
employers. This may be attributed to the organisational products
and services (1), organisational production tech nology (3), and the
general economic conditions (4) all being favourable – though the
structure of bargaining has not been (2) – and the AI community
having been fairly committed to collective action (5).
Factors likely to continue include the products and
services being consumer -facing and difficult to stockpile; reliance
on high -skilled labour; and the unequal bargain ing structure.
However it is unclear what the balance of talent supply and
demand will be, and to what extent the AI community will
continue to be committe d to collective action. These are key
questions for further research.
4 Discussion and further research
What are the prospects for the AI community being able to
successfully continue its activism over the coming years? Two
factors have been identified as key questions for further research:
the balance of talent supply and de mand and the cohesiveness of
the AI community.
We identified a small, narrow, talent pool as a key factor
in the bargaining power of the AI community. We need to be able
to assess rel ative supply and demand of AI tal ent over the coming
years. Further quantitative research is needed into, for example,
the current size of the talent supply, collated salary information,
enrolment rates, or future demand projections for AI talent.
The AI community has several resources at its disposal
to maintain and deepen its social, organisational, ethical and
political cohesion. The AI community has a strong shared culture,
with strong norms of responsibility, ‘do-it-yourself ’ and mutual
support. The c ommunity publish at and attend the same major
conferences (such as AAAI, NeurIPS, ICML and IJCAI), and
publish on the same sites such as arXiv and GitHub. Virtually
none of these outlets charge for publication or access, and are
often maintained by the com munity. This culture can be seen in
the closed -access journal boycott [1 7] and the name change to
NeurIPS [3].
The AI community has made use of institutional
enabling structures: the Future of Life Institute as a coordinator of
international Open Letters; the Tech Workers Coali tion and the
Partnership on AI as distributors of best prac tice; corporate digital
tools such as email mailing lists and internal chat rooms; and
social media such as Twitter and Medium as a way of
communicating demands. These struct ures could be devel oped,
better funded and institu tionalized – and key orga nisers could
receive more train ing and support. Further research into the AI
community ’s ability and willingness to maintain and deepen its
cohe sion – and the structures and institu tions that support that –
is needed.
Further research could also extend our analysis to a
broader range of regional and sectoral contexts, to a broader range
of actors with influence over companies, and to other analytical
frameworks .
5 Conclusion
The AI community is acting together – it is organised. It has won
some key successes. And yet its future prospects are uncertain.
Useful insights can be drawn from the liter ature on epistemic
communities and worker organising. There are good preceden ts
for highly -skilled groups en gaging in activism as epistemic
communities and valuable employees, thereby influ encing policy
and corporate out comes. Indeed, the AI community has already
had some clear successes around LAWS, ethics and safety, and
employee organising. Whether this will continue is less clear. The
future balance of AI talent supply and demand and the future
cohesion of the AI community are key questions for further
research.
6 Appendix: Veto players
Veto players are individual or collective actors whose agreement
(by majority rule for collective actors) is required for a change of the status quo [56] . This framework is generally applied to
comparative politics, where it has been influential [36] though
contested [27]. Notable e xamples include comparing political
decision -making in parliamentary and presidential systems. It is
also relevant to the AI community and can shed some novel,
interesting light on our discussion.
The debate in the USA over the militarisation of AI and
LAWS can be viewed as the interaction of three actors: employees,
management of AI organisations (academic groups or technology
companies) and the government [38]. Crucially, one can view this
as a veto player situation. The current status quo is one in which
the AI community does not generally research LAWS. There are
few US AI organisations, especially the most prominent, engaged
in LAWS R&D for the US government. The US government, and
management at several organisations, would like that to change –
to a situation in which there is widespread collaboration from
many organisations, including the most prominent. For the status
quo to change, all actors must agree. However, a significant group
of employees is not agreeing to this change.
In general, w hen are veto players more likely to be able
to prevent a chan ge of the status quo? Tsebelis [57] identifies
three key factors:
1) the number of veto players;
2) lack of congruence; and
3) cohesion.
We suggest that these factors currently apply to some
extent to the AI community, and are likely to largely continue to
apply.
1) The number of veto players is not particularly high. It seems
that perhaps management and the government believed they were
in a two -player game. They seem not to have been prepare d for
the activism of the AI community on this topic, which indicates a
three -player game.
2) The policy positions of the players have been rather dissimilar.
Many governments and company managers want collaboration
on military AI, and specifically LAWS, t o not only be widespread
but unproblematised. Many, perhaps most, employees do not.
This seems likely to continue, though, for example, the
process of developing and exploring the proposed Departmen t of
Defense ethics principles [15] may achieve an accommodation
between Silicon Valley and the Pentagon, increasing congruence
between the players.
3) The relative similarity of policy positions amongst the AI
community has been discussed above. There is clearly a debate
about the ext ent to which they should be involved in the
militarisation of AI, especially LAWS R&D, and whether there
should be an international ban. This debate is likely to continue.
The AI community has achieved some successes as a
veto player as the congruence bet ween the players has been low
(2), and the AI community has been fairly coherent (3). This
situation is broadly likely to continue. However, whether the AI
community will continue to be cohesive is a key question.
ACKNOWLEDGMENTS
The author thanks Jess Whittlestone, Stephen Cave, Luke Kemp
and Matthijs Maas for helpful comments and AI community
activists and diplomats for anonymous inter views .
REFERENCES
[1] Adler, E. 1992. The Emergence of Cooperation. International Organization ,
46(1): 101 -145.
[2] Amazon Empl oyees. 2018. An Open Letter. Medium .
[3] Anandkumar, A. et al. 2018. #ProtestNIPS. Change.org petition .
[4] Bahçecik, S.O. 2019. Civil Society Responds to the AWS: Growing Activist
Networks and Shifting Frames. Global Policy .
[5] Bell, K. 2019. Collective bargaining: how trade unions can ensure better jobs
for workers. Trades Union Congress .
[6] Brundage, M. and Avin, S., et al. 2018. The malicious use of artificial
intelligence: Forecasting, prevention, and mitigation. arXiv.
[7] Campaign to Stop Killer Robots. 2017. Slaugh terbots. YouTube .
[8] Carpenter, C. 2014. Lost Causes: Agenda Vetting in Global Issue Networks .
Cornell University Press.
[9] Crawford, K. and Whittaker, M. 2017. This Moment in AI. AI Now .
[10] Crawford, K. and Whittaker, M. 2018. AI in 2018: A Year in Review – Ethic s,
organising and accountability. AI Now .
[11] Crawford, K. and Whittaker, M. 2019. AI in 2019: A Year in Review - the
growing pushback against harmful AI. AI Now .
[12] Cross, M.K.D. 2013. Rethinking Epistemic Communities 20 Years Later. Review
of International Stu dies 39, no. 1 (2013): 137 –60.
[13] Cussins, J. 2018. National and International AI Strategies. FLI.
[14] Dau-Schmidt, K.G. and Ellis, B.C. 2010. The Relative Bargaining Power of
Employers and Unions. Maurer Faculty Articles, 1332.
[15] Defense Innovation Board. 2019. AI Principles: Recommenda tions on the
Ethical Use of AI by the DoD. Defense Innovation Board .
[16] Department for Business, Enterpri se & Industrial Strategy (BEIS). 2019. AI
Sector Deal. BEIS.
[17] Dietterich, T. et al. 2018. Statement on Nature Machine Intelligence. Oregon
State University .
[18] Fanti, L. and Buccella, D. 2019. When unionisation is profitable for firms in
network industries . Metroeconomica , 70(4), 711 -722.
[19] Freeman, R., and Medoff, J. 1984. What Do Unions Do? New York: Basic Books.
[20] Frederick, K. 2019. The Civilian Private Sector: Part of a new Arms Control
Regime? Raisina Files Volume 4.
[21] Future of Life Institute. 2015a. Research Priorities for Robust and Beneficial AI:
An Open Letter . FLI.
[22] Future of Life Institute. 2015b. Autonomous Weapons: An Open Letter from
AI & Robotics Researchers. FLI.
[23] Future of Life Institute. 2017a. Asilomar AI Principles. FLI.
[24] Future of Life Institute. 2017b. Open Letter to UN CCW. FLI.
[25] Future of Life Institute. 2018. Open Letter to KAIST. FLI.
[26] Gagné, J., Kiser, G. and Mantha, Y. 2019. Global AI Talent Report 2019. Element
AI.
[27] Ganghof, S. 2011. Promises and Pitfalls of Veto Player Analysis. The Swiss
Political Science Review.
[28] Google Employees. 2018a. Open Letter: Project Maven. Medium.
[29] Google Employees. 2018b. Open Letter: Dragonfly. Medium.
[30] Google Walkout. 2019. When We Organize, We Win: #GoogleWalkout, One
Year Later. Medium.
[31] Haas, P. M. 1992. Introduction: epistemic communities and international policy
coordination. International orga nization, 46(1), 1 -35.
[32] Hajian, S., Bonchi, F., and Castillo, C. 2016. Algorithmic bias: From
discrimination discovery to fairness -aware data mining. In In Proceedings of
the 22nd ACM SIGKDD international conference on knowledge discovery and
data mining, 2 125–2126. ACM.
[33] High -Level Expert Group on Artificial Intelligence. 2019. Ethics Guidelines for
Trustworthy AI. European Commission. [34] Hirschman, A.O. 1970. Exit, Voice, and Loyalty . Cambridge, MA: Harvard
University Press.
[35] ICRC. 2014. Autonomous weapon syst ems technical, military, legal and
humanitarian aspects. ICRC.
[36] Jahn, D. 2011. The veto player approach in macro -comparative politics:
concepts and measurement. In Reform processes and policy change (pp. 43 -68).
Springe r, New York, NY.
[37] Koene, A. 2017. Algorithmic bias: Addressing growing concerns. IEEE
Technology and Society Magazine 36(2):31 –32.
[38] Leung, J. 2018. Analyzing AI Actor s. EA Global 2018.
[39] Maas, M. 2019. How viable is international arms control for military AI?
Contemporary Security Policy 40:3 285 -311.
[40] Maks -Solomon, C. and Drewry, J.M. (2018). Why Do Corporations Engage in
Activism on LGBT issues? Academy of Management Pr oceedings Vol. 2019, No.
1.
[41] Metz, C. 2018. A.I. Researchers Are Making More Than $1 Million, Even at a
Nonprofit. New York Times , 19 April 2018.
[42] Microsoft Employees. 2018. Open Letter to Microsoft. Medium.
[43] Miller C. and Coldicutt R. 2019. People, Power and Technology: The Tech
Workers’ View . Doteveryone.
[44] Nolan, L. 2018. Jeff Bezos is wrong, tech workers are not bullies. Financial
Times , 13 November 2018.
[45] O’Sullivan, L. (2019). I Quit My Job to Protest My Company’s Work on Building
Killer Robots. ACLU.
[46] Partnership on AI. 2016. Industry Leaders Establish Partnership on AI Best
Practices. Partnership on AI.
[47] Payne, K. 2018. AI: A Revolution in Strategic Affairs? Survival , 60:5, 7 -32.
[48] Poulson, J. 2019. I Used to Work for Google. I Am a Conscientious Objector.
New York Times, 23 March 2019.
[49] Ray, T. 2019. Google DeepMind’s Demis Hassabis is one relentlessly curious
public face of AI. ZDNet 6 May 2019.
[50] Russell, S., Dewey, D., and Tegmark, M. 2015. Research Priorities for Robust
and Beneficial AI. AI Magazine 36:4.
[51] Russell, S., Aguirre, A., Conn, A and Tegmark, M. 2018. Why You Should Fear
“Slaughterbots” - A Response. IEEE Spectrum .
[52] Salesforce Employees. 2018. An Open Letter to Salesforce: Drop Your Contract
with CBP. Medium .
[53] Shoham, Y., Perrault, R., Brynjolfsson, E., Clark, J., …and Bauer, Z. 2018. AI
Index Report . Steering Committee, Stanford, CA.
[54] TenCent Research Institute. 2017. Global AI Talent White Paper. Tencent
Research Institute.
[55] Tiku, N. (2019). Three Years of Misery Inside Google. Wired.
[56] Tsebelis, G. 2002. Veto players: How political institutions work. Princeton
University Press.
[57] Tsebelis, G. 2009. Decision Making in Political Systems: Veto Players in
Presidentialism, Parliamentarism, Multicameralism and Multipartyism. British
Journal of Political Science Volume 25, Issue 3 July 1995 , pp. 289 -325.
[58] Upadhya, R.K. 2018. Tech workers, platform workers, and workers’ inquiry.
Medium.
[59] Verbruggen, M. 2019. The Role of Civilian Innovation in the Development of
LAWS. Global Policy Volume 10, Issue 3.
[60] Vignard, K. 2018. Manifestos and open letters: Back to the future? Bulletin of
the Atomic Scientists.
[61] Whittlestone, J. Nyrup, R. Alexandrova, A. and Cave, S. (2019). The role and
limits of principles in AI ethics. AIES Proceedings .
[62] Wilkinson, A., Donaghey, J., Dundon, T., and Freeman, R.B. (eds) 2014.
Handbook of Research on Employee Voice . Elgar.
[63] Zuboff, S. 2019. The age of surveillance capitalism . Profile Books.
[64] Zweben, S., and Bizot, B. 2018. 2018 CRA Taulbee Survey. Computing Research
News , 30(5), 1 -47.
[65] Zwetsloot, R. and Dafoe, A. 2019. Thinking About Risks Fro m AI: Accidents,
Misuse and Structure. Lawfare 11 February 2019.
|
793a723f-d547-4222-bfb5-c14bfaff63aa | trentmkelly/LessWrong-43k | LessWrong | General intelligence test: no domains of stupidity
It's been a productive conversation on my post criticising the Turing test. I claimed that I wouldn't take the Turing test as definitive evidence of general intelligence if the agent was specifically optimised on the test. I was challenged as to whether I had a different definition of thinking than "able to pass the Turing test". As a consequence of that exchange, I think I do.
Truly general intelligence is impossible, because of various "no free lunch" theorems, that demonstrate that no algorithm can perform well in every environment (intuitively, this makes sense: a smarter being could always design an environment that specifically penalises a particular algorithm). Nevertheless, we have the intuitive definition of a general intelligence as one that performs well in most (or almost all) environments.
I'd like to reverse that definition, and define a general intelligence as one that doesn't perform stupidly in a novel environment. A small change of emphasis, but it gets to the heart of what the Turing test is meant to do, and why I questioned it. The idea of the Turing test is to catch the (putative) AGI performing stupidly. Since we can't test the AGI on every environment, the idea is to have the Turing test be as general as possible in potential. If you give me the questions in advance, I can certainly craft an algorithm that aces that test; similarly, you can construct an AGI that would ace any given Turing test. But since the space of reasonable conversations is combinatorially huge, and since the judge could potentially pick any element from within that, the AGI could not just have a narrow list of responses: it would have to be genuinely generally intelligent, so that it would not end up being stupid on the particular conversation it was in.
That's the theory, anyway. But maybe the space of conversations isn't as vast as all that, especially if the AGI has some simple classification algorithms. Maybe the data on the internet today, combined with some reaso |
ee9289e2-8724-4b9c-b94a-3f9df9873990 | StampyAI/alignment-research-dataset/special_docs | Other | Trade Regulation Rule on Commercial Surveillance and Data Security Rulemaking.
Trade Regulation Rule on Commercial Surveillance and Data Security Rulemaking
We are pleased to submit a public comment in response to the trade regulation rule on
commercial surveillance and data security.
This comment is structured in response to the following description of unfair practices covered
under Section 5 of the Federal Trade Commission (FTC) Act of 1914:
“Generally, a practice is unfair under Section 5 if (1) it causes or is likely to cause substantial
injury, (2) the injury is not reasonably avoidable by consumers, and (3) the injury is not
outweighed by benefits to consumers or competition.”
1
We make two recommendations. Firstly, because AI systems change the behavior of
populations exposed to them, harms that stem from systemic behavior changes (e.g.,
spread of disinformation on social media) must be measured in addition to direct
algorithmic harms. Secondly, that any federal agencies that procure vendored AI systems
submit annual reports that describe the foreseeable impacts of the system on consumer
behaviors. These policies are necessary to ensure the Section 5 mandate remains
enforceable as automated systems increasingly make strategic decisions based on
human data. The types of harms covered by Section 5 will become both increasingly
common and difficult to evaluate without requisite rulemaking.
Today, regulators and policymakers focus on litigating isolated algorithmic harms, such as model
bias or privacy violations. But this agenda neglects the persistent effects of AI systems on
consumer populations. Meanwhile, leading research labs increasingly concentrate on such
persistent effects by attempting to specify the purpose or “objective” of AI systems in ways that
limit negative outcomes.
2
,
3
,
4
,
5
,
6
Our comment highlights the need to reconcile these agendas through new forms of rulemaking
so that the FTC can take an
ex ante
approach to AI-enabled
consumer vulnerabilities. In
particular, the FTC has a duty to track foreseeable harms that result from how systems make
decisions based on consumer data. This tracking should be achieved by documenting how AI
systems impact consumer behaviors over time.
The argument of our comment proceeds as follows:
6
Hendrycks, Dan, et al. "Unsolved problems in ML safety."
arXiv preprint arXiv:2109.13916
(2021).
5
Stray, Jonathan. "Beyond engagement: Aligning algorithmic recommendations with prosocial goals."
Partnership on AI. https://www.partnershiponai.org/beyond-engagement-aligning-algorithmic-
recommendations-with-prosocial-goals
(2021).
4
Zhuang, Simon, and Dylan Hadfield-Menell. "Consequences of misaligned AI."
Advances in Neural
Information Processing Systems
33 (2020): 15763-15773.
3
Andrus, McKane, et al. "AI development for the public interest: From abstraction traps to sociotechnical
risks."
2020 IEEE International Symposium on Technology
and Society (ISTAS)
. IEEE, 2020.
2
Russell, Stuart. "Human-compatible artificial intelligence."
Human-Like Machine Intelligence
(2021):
3-23.
1
Quoted from here: https://www.regulations.gov/document/FTC-2022-0053-0001
1.
Existing AI regulations focus on removing bias
or unfairness from model outputs,
rather than tracking the outcomes generated by the system itself over time.
Existing policies to regulate the performance of machine learning systems tend to focus
on the accuracy or bias of their classifications. As an example, the EU General Data Protection
Regulation enshrines a “right to explanation” for algorithmic decisions.
7
Within this paradigm,
“harm” is defined in terms of system errors that result in injury or damage. For instance, a
self-driving car might misrecognize stop signs or lane markers, causing it to take actions that are
unsafe.
These regulatory techniques are limited, because they focus on singularly impactful
decision points. Modifying such points generates solutions that may work in the short term, but
leaves the behavior of the system as a whole untouched. Many consequential effects of AI
systems emerge over time as they change how humans make decisions or interact with each
other. For example, a social media algorithm may successfully recommend content to users in
ways that keep them on site, but at the cost of generating habit-forming effects that make them
addicted to its feed.
8
-
9
Meanwhile, self-driving cars
may not just learn to navigate roads safely,
but also cluster in ways that limit the flow of traffic.
10
By affecting human drivers’ access to
critical intersections, these fleets will impact access to public roads themselves. In both cases,
the system’s operation has cumulative effects that companies often fail to track or mitigate.
Structural harms arise whenever these effects tamper with individual rights or
protections, like online freedom of speech or keeping public transit accessible.
11
Those
protections may not have been properly addressed in advance of the system’s deployment. Or
they may be abused by the system itself, as in the above example of social media addiction.
Either way, outcomes remain poorly documented.
12
Their
effects are difficult for both experts to
diagnose and laypeople to perceive, as they require a birds’ eye view of how the system
interacts with social contexts over time.
2.
Documentation is neither standardized nor legally
required for the operation of highly
capable AI systems. Moreover, existing approaches fail to capture or account for the
emergent effects generated by deployed AI systems.
12
Roberts, Sarah T.
Behind the screen
. Yale University
Press, 2019.
11
For more discussion of structural harms see:
https://www.technologyreview.com/2022/08/09/1057171/social-media-polluting-society-moderation-alone-
wont-fix-the-problem/
10
See for example recent behavior exhibited by Cruise vehicles in San Francisco:
https://www.cnbc.com/2022/07/01/self-driving-cars-from-gms-cruise-block-san-francisco-streets.html
9
Allcott, Hunt, et al. "The welfare effects of social media."
American Economic Review
110.3 (2020):
629-76.
8
See for example Allcott, Hunt, Matthew Gentzkow, and Lena Song. "Digital addiction."
American
Economic Review
112.7 (2022): 2424-63.
7
Selbst, Andrew, and Julia Powles. "“Meaningful Information” and the Right to Explanation."
Conference
on Fairness, Accountability and Transparency
. PMLR,
2018.
Machine learning practitioners are now developing documentation protocols to address
the structural harms that arise from system behaviors. One of these tools is the datasheet, a
framework for documenting the specific dataset available to a system. These datasheets may
include the features on which the dataset was labeled, the motivation for that labeling strategy,
the intended use of the dataset in question, and known limitations or missing data.
13
Another
important example is model cards, a framework for documenting the model that has been
learned to complete some machine learning task. Model cards may include the known accuracy
thresholds of the model on specific tasks such as facial recognition (e.g., error rates for men vs.
women), the organization responsible for its training, metrics of interest, and known ethical
considerations.
14
Both these approaches are invaluable for understanding the capabilities of particular
systems and are necessary for the robust documentation of potential harms. However they are
not sufficient for tackling the emergent effects of AI systems, for two reasons.
First, they do not track how distinct components of the entire system architecture interact
with each other over time. For example, a self-driving car may learn unusual swerving behaviors
based on how its vision and navigation subsystems interact, impacting traffic even if it doesn’t
hit anything.
15
Datasheets and model cards fail to
capture such effects, which may be opaque to
designers as well as consumers.
Second is the lack of enforceable standards for good performance in safety-critical
settings. This is pivotal in any rulemaking context, but is particularly urgent for AI systems today.
Beyond the discretion of in-house machine learning teams, there are no technical barriers to
deploying model classifiers that are known to be deeply flawed. In that absence, companies like
Hugging Face have stepped up to serve as a one-stop shop for documentation of popular
machine learning resources.
16
However, there is no
equivalent for social media applications
whose algorithms are proprietary and secretive. While voluntary commitments to transparency
are valuable, consumer rights require more than acts of good faith from designers. What is
needed is a reporting protocol for structural harms so that design priorities remain aligned with
critical consumer protections.
3.
While research on the full sociotechnical effects
of system harms is ongoing, their
potential for more significant risks has been established.
Self-driving cars that can alter the flow of traffic will change how roads work. Over time,
social media algorithms that affect users’ tastes will transform how people communicate.
Improving the accuracy of a predictive model does nothing to reveal the types of structural harm
16
https://huggingface.co/
15
For a theoretical explanation of this problem, see
Gilbert, Thomas Krendl. "
Mapping the Political
Economy of Reinforcement Learning Systems: The Case of Autonomous Vehicles
."
Simons Institute
Newsletter
(2021).
14
Mitchell, Margaret, et al. "
Model cards for model
reporting
."
Proceedings of the ACM Conference on
Fairness, Accountability, and Transparency
, Atlanta
2019.
13
Gebru, Timnit, et al. "
Datasheets for datasets
."
Communications of the ACM
64.12 (2021): 86-92.
implicit in these disruptions. Instead, regulators need the means to anticipate and evaluate AI
system outcomes before they happen.
Fortunately, technical methods can generate insights into possible outcomes that make
potential harms more foreseeable. For example, some AI systems are able to learn continuous
behaviors by taking multiple actions or “decisions” in sequence. Consider a YouTube algorithm
that learns how users watch content differently based on its own past recommendations, and
then factors that into its future ones.
To automatically choose actions in these settings, practitioners often use techniques
such as
reinforcement learning
(RL) or planning. These
techniques enable AI systems to learn
how to take actions that change their environment according to their objectives (in contrast to
simply e.g. classifying a datapoint). By optimizing for long-term outcomes, these techniques can
in theory learn more complex and more desirable behaviors than single-step classifiers. For
example, using RL in social media applications seems to increase long-term engagement
metrics and reduce how much clickbait content is shown to users (because clickbait is bad for
user retention).
17
However, the increased power of RL also raises the stakes for potential harm. Firstly, it is
often hard to understand the systems’ actions even under close scrutiny:
18
the solutions that
these systems converge to might be more complex than what humans can easily reason about.
For example, these techniques are what enabled AI bots to beat the world champions at Chess
and Go. Still today, research continues to unpack and understand the strategies of a famous AI
system for these games that was released in 2017.
19
If systems based on these approaches
were to take systematically harmful actions, it could be hard to determine the nature of the
failure even after the fact, let alone anticipate it.
Moreover,
when
functioning
in
human
contexts,
such
systems
will
have
incentives
to
manipulate
people
they
interact
with.
20
This
is
especially
concerning
in
the
context
of
social
media,
21
,
22
where
an
increasing
number
of
companies
are
using
RL.
23
,
24
RL’s
potential
to
shape
long-term
behavioral
outcomes
beyond
short-term
effects
mirrors
the
monopolistic
strategies
24
Gauci, Jason, et al. "Horizon: Facebook's open source applied reinforcement learning platform." arXiv
preprint arXiv:1811.00260 (2018).
23
Chen, Minmin, et al. "Top-k off-policy correction for a REINFORCE recommender system." Proceedings
of the Twelfth ACM International Conference on Web Search and Data Mining. 2019.
22
Evans, Charles and Atoosa Kasirzadeh. “User Tampering in Reinforcement Learning Recommender
Systems.” ArXiv abs/2109.04083 (2021): n. pag.
21
Carroll, Micah et al. “Estimating and Penalizing Preference Shift in Recommender Systems.”
Proceedings of the 15th ACM Conference on Recommender Systems (2021).
20
Krueger, David et al. “Hidden Incentives for Auto-Induced Distributional Shift.” ArXiv abs/2009.09153
(2020): n. pag.
19
McGrath, Thomas, et al. "Acquisition of chess knowledge in alphazero." Proceedings of the National
Academy of Sciences 119.47 (2022): e2206625119.
18
Puiutta, Erika, and Eric Veith. "Explainable reinforcement learning: A survey." International
cross-domain conference for machine learning and knowledge extraction. Springer, Cham, 2020.
17
Using RL on YouTube saw the largest single launch improvement in 2 years,
https://www.youtube.com/watch?v=HEqQ2_1XRTs&t=83s
used
by
Amazon
and
other
Big
Tech
companies.
25
Given
their
lack
of
interpretability,
it
might
be
hard to systematically prove that such systems are being (or not being) manipulative.
These
concerns
extend
also
to
other
types
of
systems
beyond
RL.
26
For
example,
the
ways
that
RL
explicitly
incorporates
sequential
decisions
mirror
system
failures
observed
in
electrical
grids
and
transportation
networks.
27
Meanwhile,
rent
setting
algorithms
may
be
artificially
and
systematically
driving
up
rent
prices
and
stifling
competition.
28
Whether
the
system
uses
RL
or
not,
sequential
decision
criteria
may
introduce
preventable
types
of
consumer harm within human domains.
At
present,
regulators
rely
on
the
benevolence
of
the
companies
involved
to
assess,
monitor,
and
limit
consumer
harms.
This
kind
of
monitoring
is
against
companies’
economic
interests
because
automated
decision
making
techniques
such
as
RL
can
lead
to
significant
increases
in
revenue.
29
Companies
have
little
incentive
to
leave
a
paper
trail
which
could
expose
them
to
legal
liability.
One
remaining
option
might
be
to
rely
on
external
audits,
but
structural harms are difficult to assess from outside the companies themselves.
4.
The FTC must codify rules that mitigate the potential
safety risks to consumers from
automated systems.
Algorithmic harms remain poorly documented. Whether or not a given system generates
concrete injuries, its impacts remain hard to measure and difficult to weigh against its benefit to
consumers. This means that automated decision-making can generate harms that are not
reasonably avoidable by consumers. Absent appropriate oversight, they must be seen as unfair
practices according to criterion (2) of Section 5 of the FTC Act, and possibly also criteria (1) and
(3) depending on the scale and intensity of their effects.
As leading experts on the likely impacts of advanced AI capabilities, we believe such
harms are likely to become both more common and more impactful in the coming years.
Recently the Digital Services Act has drawn attention to systemic risks created by large online
platforms
30
, and the EU AI Act expands this lens to
include other kinds of AI systems.
31
While
these developments are encouraging, existing standards and protocols remain stuck in a static,
ex post
accountability regime that cannot keep pace
with the emerging risks.
31
https://www.brookings.edu/research/the-eu-ai-act-will-have-global-impact-but-a-limited-brussels-effect/#fo
otnote-2
30
https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32022R2065&qid=1666857835014
29
Chen, Minmin, et al. "Top-k off-policy correction for a REINFORCE recommender system." Proceedings
of the Twelfth ACM International Conference on Web Search and Data Mining. 2019.
28
https://www.propublica.org/article/yieldstar-rent-increase-realpage-rent
27
Gilbert, Thomas Krendl, et al. "Choices, Risks, and Reward Reports: Charting Public Policy for
Reinforcement Learning Systems."
arXiv preprint arXiv:2202.05716
(2022).
26
Jiang, Ray, et al. "Degenerate feedback loops in recommender systems." Proceedings of the 2019
AAAI/ACM Conference on AI, Ethics, and Society. 2019.
25
Khan, Lina M. "Amazon's antitrust paradox."
Yale
lJ
126 (2016): 710.
It follows that the FTC must implement trade rules and protocols to better document
automated decisions over time. These rules should reflect how specific types of sequential
decisions tie back to social impacts. For example, social media harms often derive from the use
of metrics like engagement that are at best unreliable proxies for real-world outcomes that are
difficult to encode or directly optimize.
32
,
33
In transportation,
improving traffic throughput may
depend on how automated vehicles route along critical points of a road network.
34
What matters is that both risks and benefits will arise from how automated systems shift
prevailing social norms. These norms include accepted patterns of behavior, rules of conduct,
and information flow between stakeholders.
35
It follows
that new rules should also monitor how
consumer data is collected and retained for use in sequential decisions. These rules should
strive to reconcile the inherent capabilities of the system with established consumer protections.
Such documentation would be a small burden for companies to maintain, while also providing a
paper trail to hold them accountable once harms do occur.
5.
To better investigate the consumer impacts of automated
decisions, the FTC should
support AI documentation that tracks systems’ effects over time.
Present AI documentation techniques like Model Cards and Datasheets provide strictly
ex post
evaluation of AI components that have already
been built. But to apply the FTC Act,
there is a need for
regularly updated
documentation
that tracks whether 1) potential consumer
injuries qualify as substantial, and 2) whether or not they are outweighed by other benefits.
Combining
ex ante
and
ex post
documentation of AI
systems would help diagnose
distinct risks in specific use cases. If regularly updated and publicly available, it would also
support cohesive evaluation of system components and comparison of designers’ expectations
with post-deployment performance. One such framework is Reward Reports, which track how
system behaviors stem from the sequential decisions it was designed to make.
36
Reward
Reports and related efforts could inform how the FTC adopts new standards for consumer
harms based on Section 5.
Since the passage of the National Environmental Policy Act, federal agencies have been
required to submit reports called Environmental Impact Statements (EISs) that explain the likely
36
Gilbert, Thomas Krendl, et al. "Reward Reports for Reinforcement Learning."
arXiv preprint
arXiv:2204.10817
(2022).
35
Nissenbaum, Helen. "Privacy in context."
Privacy
in Context
. Stanford University Press, 2009.
34
Wu, Cathy, Alexandre M. Bayen, and Ankur Mehta. "Stabilizing traffic with autonomous vehicles."
2018
IEEE International Conference on Robotics and Automation (ICRA)
. IEEE, 2018.
33
Bengani, Pri, Stray, Jonathan, and Thorburn, Luke. “What’s right and what’s wrong with optimizing for
engagement?”
https://medium.com/understanding-recommenders/whats-right-and-what-s-wrong-with-optimizing-for-eng
agement-5abaac021851
32
Milli, Smitha, Luca Belli, and Moritz Hardt. "From optimizing engagement to measuring value."
Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency
. 2021.
consequences of their proposed projects on the environment.
37
EISs are a clear model for
documenting AI systems. In particular, we recommend that any federal agencies that rely on
vendored AI systems submit annual Reward Reports that explain the likely consequences of the
system for consumers. If Reward Reports were regularly issued in like manner to EISs, the
FTC’s Section 5 mandate would be much easier to enact and enforce.
Sincerely,
Thomas Krendl Gilbert
Postdoctoral Fellow, Cornell Tech
Micah Carroll
Ph.D. Candidate, UC Berkeley
37
Caldwell, Lynton Keith.
The National Environmental
Policy Act: an agenda for the future
. Indiana
University Press, 1998. |
9341cb44-ce44-426e-b639-b95beb168a10 | trentmkelly/LessWrong-43k | LessWrong | Anti-circumcision Essay 2 of 3: Physical and Psychological Realities
Continuation of Part One
Now in theory I could end the series here. I could say that the evidence Mason provided of men going haywire is the images Karella posted, and since I’ve already made my case that one of those images is one offensive comic one person drew 13 years ago, and the other is just ordinary activism, that means that (if my case is persuasive) Mason’s argument is rebutted.
But that wouldn’t be living in the least convenient possible world. And it wouldn’t really get to the heart of what Mason is saying, either.
Mason may or may not be swayed by my above arguments re: the examples Karella gave being highly dubious, but even if she is it could easily be that she has other examples of men from her personal experience in mind who are upset about part of their genitals being cut off and whose brains have gone “completely haywire”, as she put it.
I have two basic points to make: I think the physical reality is worse than she realizes. But perhaps more importantly, there are lots of things that everyone agrees are horrible that are in some sense partially or entirely psychological. And no normal person I’ve encountered, no matter their views on therapy culture and bad societal stances on trauma, would talk about those things the way Mason and others talk/write/think about this. Which is something I’ll go into a little more in the next essay in the series.
Before I go further, let me just say that I do not intend this to be an attack on Mason, or anyone really. This essay should be taken as addressed to this general cluster of attitude towards this issue, which may manifest itself in different ways.
Does the loss of sensitivity actually work the way Mason thinks it does?
And now we’ve reached an important point that I think is worth telling people that can’t be made without me talking about gross things in detail. Will people say that I’m only tormenting people with these details because I got some sick satisfaction from doing so? Or that th |
bdbaae22-7382-4500-926c-14f5454c42a0 | trentmkelly/LessWrong-43k | LessWrong | "AI and Efficiency", OA (44✕ improvement in CNNs since 2012)
Abstract:
> We’re releasing an analysis showing that since 2012 the amount of compute needed to train a neural net to the same performance on ImageNet1 classification has been decreasing by a factor of 2 every 16 months. Compared to 2012, it now takes 44 times less compute to train a neural network to the level of AlexNet2 (by contrast, Moore’s Law3 would yield an 11x cost improvement over this period). Our results suggest that for AI tasks with high levels of recent investment, algorithmic progress has yielded more gains than classical hardware efficiency. |
7ee19444-8f77-477d-ab00-a0469d8c7607 | trentmkelly/LessWrong-43k | LessWrong | Psychology of AI doomers and AI optimists
What is this dialogue about
This is a dialogue about complicated relationships between AI safety and psychology.
AI safety field consists of people, and people have all sorts of motivations, cognitive biases, and coping mechanisms that are interesting to explore.
This is a discussion about psychological reasons for not taking AI risks seriously, as well as being an AI doomer. We also discuss why people might start working on AI safety, and what are the relationships between AI risks and existential questions.
The partisipants
Joep Meindertsma, a founder of PauseAI.
Igor Ivanov, a psychotherapists helping people working on AI safety, as well as an independent AI governance researcher.
(To some reason it's impossible to make a dialogue with one of the participants have low karma, so this is posted as a post, not a dialogue.)
Spoiler
Both participants are AI doomers, and we discuss psychology and AI risk through the lens of our point of view, so we are prone to pay attention to the coping mechanisms, wishful thinking and fallacies of AI optimists, but we don't mean that they don't have strong and valid arguments. AI doomers also have all sorts of unhealthy coping mechanisms, weird believes, and delusions, but it's easier to see problems of the people from the other camp.
I believe that if a couple of skeptics discussed delusions of doomers, they would probably find a lot of interesting things.
The discussion
Igor
As a person who is concerned about the x-risks and who believes that the rate of AI development is extremely fast, I feel worried about all these risks. Someone says that there is a very high chance that AI will pose existential risks. Someone disagrees and says that the chances of existential risks are not that high, but they still say that it can be used for misinformation or cyber attacks. In any case, I don't think that anybody disagrees that AGI will be very powerful and it will pose a lot of risks to our society, and it seems |
8d45c66e-2c85-4092-b539-b38a8c2e78f2 | trentmkelly/LessWrong-43k | LessWrong | Intuitive Explanation of Solomonoff Induction
Update: Alex Altair has now finished this tutorial!
A while ago I began writing a Solomonoff Induction tutorial, but now it's one of those Less Wrong articles I probably will never have time to write.
But, maybe a few of you can take what I've started, team up, and finish the thing. I'm basically just following along with the Solomonoff induction tutorials from Shane Legg (2008, 2004), but making them simpler and readable by a wider audience. I think this would be a valuable thing for Less Wrong to have, and one that would draw even more traffic to our community, but I don't have time to write it myself anymore!
Who wants to be a hero and finish this thing? The original markdown source is available here.
This is a tutorial for beginners. Those familiar with Solomonoff induction may prefer to read Rathmanner & Hutter (2011).
People disagree about things. Some say that vaccines cause autism; others say they don't. Some say everything is physical; others believe in a god. Some say that complicated financial derivatives are essential to a modern competitive economy; others think a nation's economy will do better without them. It's hard to know what is true.
And it's hard to know how to figure out what is true. Some think you should assume the things you are most certain about and then deduce all other beliefs from your original beliefs. Others think you should accept at face value the most intuitive explanations of your personal experience. Others think you should generally agree with the scientific consensus until it is disproven.
Wouldn't it be nice if finding out what's true was like baking a cake? What if there was a recipe for finding out what is true? All you'd have to do is follow the written instruction exactly, and after the last instruction you'd inevitably find yourself with some sweet, tasty truth!
As it turns out, there is an exact recipe for finding truth. It was discovered in the 1960s.
The problem is that you don't have time to fo |
44d5fce2-4e53-446a-96ec-327471a5cd8d | trentmkelly/LessWrong-43k | LessWrong | When is a mind me?
xlr8harder writes:
> In general I don’t think an uploaded mind is you, but rather a copy. But one thought experiment makes me question this. A Ship of Theseus concept where individual neurons are replaced one at a time with a nanotechnological functional equivalent.
>
> Are you still you?
Presumably the question xlr8harder cares about here isn't semantic question of how linguistic communities use the word "you", or predictions about how whole-brain emulation tech might change the way we use pronouns.
Rather, I assume xlr8harder cares about more substantive questions like:
1. If I expect to be uploaded tomorrow, should I care about the upload in the same ways (and to the same degree) that I care about my future biological self?
2. Should I anticipate experiencing what my upload experiences?
3. If the scanning and uploading process requires destroying my biological brain, should I say yes to the procedure?
My answers:
1. Yeah.
2. Yep.
3. Yep, this is no big deal. A productive day for me might involve doing some work in the morning, getting a sandwich at Subway, destructively uploading my brain, then texting some friends to see if they'd like to catch a movie after I finish answering e-mails. ¯\_(ツ)_/¯
If there's an open question here about whether a high-fidelity emulation of me is "really me", this seems like it has to be a purely verbal question, and not something that I would care about at reflective equilibrium.
Or, to the extent that isn't true, I think that's a red flag that there's a cognitive illusion or confusion still at work. There isn't a special extra "me" thing separate from my brain-state, and my precise causal history isn't that important to my values.
I'd guess that this illusion comes from not fully internalizing reductionism and naturalism about the mind.
I find it pretty natural to think of my "self" as though it were a homunculus that lives in my brain, and "watches" my experiences in a Cartesian theater.
On this intuitive model, |
e0814576-7f78-4b0b-8fd9-3f40888b5b01 | trentmkelly/LessWrong-43k | LessWrong | What Caused the Fertility Collapse?
Note: I didn't write this essay, nor do I own the blog where it came from. I'm just sharing it. The essay text is displayed below this line.
I recently put out a post on fertility collapse, The Paradox of Low Fertility, in which I claimed that the fertility collapse is mostly due to modern birth control. Some people disagreed with this explanation. One person, Peter Rabbit, said:
> Your theses regarding the pill is a bit outdated. I would recommend arcotherium’s piece overviewing the four phases of demographic transition (in the West). A quick rebuttal is to point to France’s history.
I responded:
> Yeah, I’ve read it. He underestimates the importance of birth control. I don’t think I mentioned the pill in the essay. Birth control is a more general notion, which includes many things, including the pill, condoms, abortion, the rhythm method, etc. E.g. in Japan, after WW2, they relied heavily on abortion to limit fertility. The point I’m making is that people have an increased ability to limit reproduction. Women also have an increased ability to delay marriage. There are multiple factors involved (which I described) but birth control is very important. There was a big collapse in fertility after the birth control pill was introduced in the West.
I am going to expand on what I said there, and respond to some of the points in Arctotherium’s essay, which mostly ignores birth control as a cause of low fertility.
His essay begins with the paragraph:
> Human net fertility is complicated. Some things that matter on the margin: winning elections, baby simulators in health class, war, housing costs, religion (both type and intensity), women’s education, population density, racial diversity, STD-induced infertility, baby bonuses, antinatal propaganda campaigns and sterilizations, and status-messaging in soap operas. The full list is much longer. But most of these factors are just not that important—a few percent here, a few percent there, and with sharply diminishi |
594d44af-0f01-43fe-83d3-9acc6c05df0d | trentmkelly/LessWrong-43k | LessWrong | Game theory of "Nuclear Prisoner's Dilemma" - on nuking rocks
Eliezer Yudkowsky wrote, in a place where I can't ask a follow-up question:
> * A rational agent should always do at least as well for itself as a rock, unless it's up against some other agent that specifically wants to punish particular decision algorithms and will pay costs itself to do that; just doing what a rock does isn't very expensive or complicated, so a rational agent which isn't doing better than a rock should just behave like a rock instead. An agent benefits from building into itself a capacity to respond to positive-sum trade offers; it doesn't benefit from building into itself a capacity to respond to threats.
>
> * Consider the Nuclear Prisoner's Dilemma, in which as well as Cooperate and Defect there's a third option called Nuke, which if either player presses it causes both players to get (-100, -100). Suppose that both players are programs each allowed to look at each other's source code (a la our paper "Robust Cooperation in the Prisoner's Dilemma"), or political players with track records of doing what they say. If you're up against a naive counterparty, you can threaten to press Nuke unless the opponent presses Cooperate (in which case you press Defect). But you'd have no reason to ever press Nuke if you were facing a rock; the only reason you'd ever set up a strategy of conditionally pressing Nuke is because of a prediction about how your opponent would respond in a complicated way to that strategy by their pressing Cooperate (even though you would then press Defect, and they'd know that). So a rational agent does not want to build into itself the capacity to respond to threats of Nuke by choosing Cooperate (against Defect); it would rather be a rock. It does want to build into itself a capacity to move from Defect-Defect to Cooperate-Cooperate, if both programs know the other's code, or two entities with track records can negotiate.
Well, what if I told you that I had a perfectly good reason to to become someone that would threaten to nu |
a1d0eab2-69f5-4e5b-84ee-70876a377d4f | trentmkelly/LessWrong-43k | LessWrong | Experience on Meloxicam
I continue to have wrist and hand issues, though they are mostly fine as long as I minimize how much I use them. Which mostly means a lot of dictation! Still, it would be good both to understand what is wrong with them and figure out how I can resume some of the activities I enjoy that I've stopped.
On 2022-03-04 I started taking 15mg of Meloxicam, daily with dinner. This is a nonsteroidal anti-inflammatory (NSAID), which often reduces arthritic swelling. I continued for a month, with my last dose on 2022-04-04. Unlike when I tried Methotrexate, I didn't notice any changes either when I started or when I went off.
To understand whether there might be a more subtle effect, I also checked my level of finger swelling each morning on waking by clasping my hands and seeing how tight it felt. I rated this feeling on a scale of 1 to 10, and all days were in the range 6 to 9 inclusive:
I take this to mean Meloxicam is very unlikely to reduce my swelling, and may even slightly increase it.
Still trying to figure out what to try next. One candidate is to stop restricting activity, let my wrists and hands get really bad, and then repeat the bloodwork. The hope is that if there are markers that are only elevated when my hands are agitated we might see them then.
Comment via: facebook |
9aa7147e-8b80-4e02-a5bf-15c3892b4e60 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Roadmap for a collaborative prototype of an Open Agency Architecture
Deger Turan, Tantum Collins, [davidad](https://www.alignmentforum.org/users/davidad) and [Charbel-Raphael Segerie](https://www.alignmentforum.org/users/charbel-raphael) contributed to the writing of this post.
Andrew Critch, Ben Goldhaber, Ozzie Gooen, and Evan Miyazono reviewed this post.
tl;dr: Open Agency Architecture (OAA) is a bold proposal for AI alignment. It requires a wide ranging formal-modeling enterprise that integrates into a comprehensive world model. We plan to begin developing OAA by iterating on smaller, domain-specific applications that can find near-term use as institutional decision-making tools and provide feedback to continue improving the OAA framework . This document decomposes that goal into sub-agendas designed to engage different technical communities in an international collaboration.
Motivations
===========
The [AI Objectives Institute (AOI)](https://ai.objectives.institute/) aims to ensure that AI and future economic systems are built and deployed with genuine human objectives at their core, enabled by broad public input and scalable cooperation. This goal involves many challenging technical and political problems and pursuing it requires long-term, ambitious, detail-oriented work that integrates general-public preferences and values with expert opinions and predictions.
We find the Open Agency Architecture (OAA, described below) compelling as a platform for decomposing this objective into achievable, well-defined sub-problems. Aligning AI systems is one of the most pressing and fateful challenges of our era: if humanity fails to solve technical alignment, or solves technical alignment in a manner that empowers malicious actors or dysfunctional power structures, then increasingly powerful autonomous systems could usher in dystopias from which we cannot recover. OAA helps reveal the continuity between key components of the alignment problem and a range of long standing governance problems that are not traditionally considered “AI issues,” ranging from organizational design to international coordination protocols. By making these connections systematic and explicit, OAA lets us operationalize our commitment to aligning AI through means that are not only safe but also deeply democratic.
As outlined in this post, we intend to follow a practical roadmap grounded in the OAA that leads to the construction of a min-viable prototype and, eventually, to full-scale implementation that would collect feedback via deployed systems. Most of the projects proposed relate to the first part of OAA – agenda setting and modeling. Parallel projects for time-bound RL, model checking, simulation etc. would also have value, but lie beyond the scope of this post. We believe that this initiative can become a central and effective hub for shepherding AI development towards a safe outcome that supports human flourishing. We describe some of the ways that we hope individuals and institutions will engage with this open-source effort. Please reach out [here](mailto:hello@objective.is) if you have questions, thoughts or proposals.
Open Agency Architecture overview
=================================
In December, [Davidad](https://twitter.com/davidad?lang=en) proposed an [‘Open Agency Architecture for Safe Transformative AI’](https://www.lesswrong.com/posts/pKSmEkSQJsCSTK6nH/an-open-agency-architecture-for-safe-transformative-ai). A [subsequent post](https://www.lesswrong.com/posts/jRf4WENQnhssCb6mJ/davidad-s-bold-plan-for-alignment-an-in-depth-explanation) from Charbel-Raphaël Ségerie and Gabin Kolly discusses the proposal in greater technical detail and maps it onto a scaling roadmap for development and deployment. We encourage readers of this post to also examine those posts in depth. We provide a brief summary below:
* The OAA identifies three separable, high-level goals: learning a world model and eliciting desirabilities over possible future states from humans; planning against this world model and the associated desirabilities; and acting in real time.
* The architecture is grounded in several assumptions, including the beliefs that: [RLHF alone](https://www.lesswrong.com/posts/d6DvuCKH5bSoT62DB/compendium-of-problems-with-rlhf) will not succeed in aligning LLMs, scalable oversight poses too many difficulties to be practical, and interpretability used to reverse-engineer an arbitrary AGI comprehensively seems infeasible (hence the need for iterative construction of an understandable world model).
* The practical use of such a system would likely adhere to a flow featuring the following components: human representatives handle ‘agenda setting’ to determine the deliberation/negotiation/decision space; AI models help predict the likely effects of various choices; another set of models elicits human preferences over these possibilities; model-based RL simulators then reconcile these and advise on selected Pareto-optimal policies according to their expected desirability aggregated across the population; throughout this cycle, various control systems and review processes maintain stability. See the image below for a more detailed accounting.
* Outstanding problems include the difficulty of building and formalizing such a world model, lack of prior work for critical technical components of the proposal (e.g. computational Infra-Bayes), verification issues resulting from the difficulty of understanding the framework, and potential limitations of RL (this final challenge is not unique to the OAA).
The OAA may impose a significant ‘alignment tax’ (i.e. adhering to the OAA, in particular the requirements for formalization and verification, might slow AI development). Conditional on all major labs committing to follow the OAA, this is likely a good outcome, in that slower capability advances offer more time for addressing safety and ethics problems. However, absent such commitments, some labs may find this tax too burdensome and instead proceed down a riskier path that optimizes for capability development. If we want labs to embrace this agenda, we need to demonstrate its feasibility and lay a foundation for collective commitment. Subsequent sections of this document outline initial steps in this direction.
General vision: A Practical Minimal Viable OAA
----------------------------------------------
The roadmap outlined below is grounded in the below principles:
1. **Iterative feedback loop:** We believe that a large-scale open-source project can accelerate both the development of individual components and their integration by enabling parallelization, although it’s important to note that we would not want to open-source frontier capabilities (which would be necessary components in an ultimately successful OAA per Davidad’s [success model](https://www.alignmentforum.org/posts/Wi4RAJCbh3qD9fynj/ai-neorealism-a-threat-model-and-success-criterion-for#Success_Model)). We seek a min-viable, human-in-the-loop prototype with real life applications for development feedback. This can iteratively grow towards more complex world modeling, value elicitation, and policy choice mechanisms. 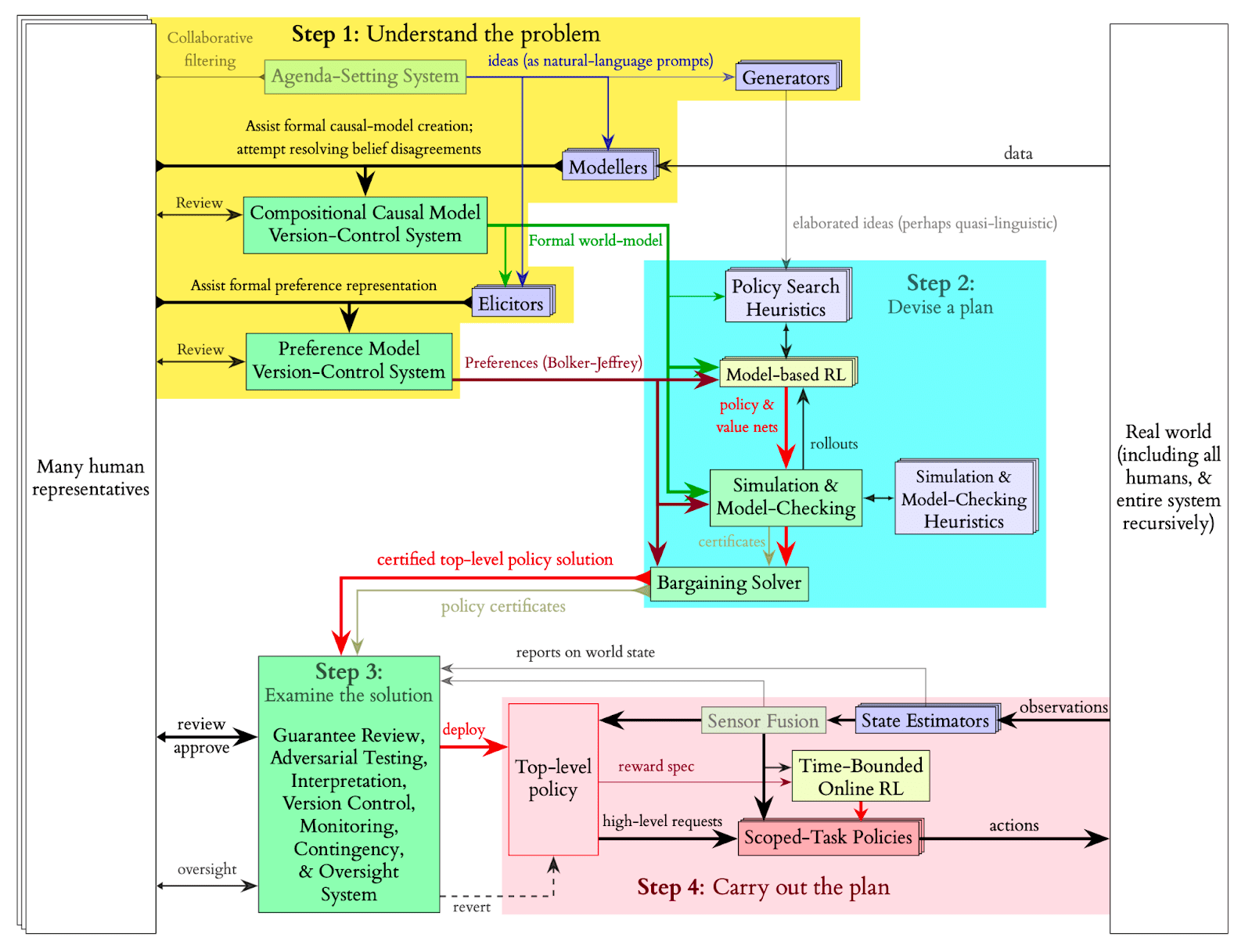
2. **Parallel execution of sub-agendas:** By separating alignment into a set of independently pursuable subproblems, OAA enables parallel execution of workstreams. This accelerates development timelines and is compatible with an approach that centers open source collaboration. We have designed this project with an eye towards making it as easy as possible for academics, practitioners and enthusiasts worldwide to contribute meaningfully.
3. **Testing in institutional design:** Because OAA is applicable to institutional decision making problems that do not involve near-AGI, it offers opportunities for testing across diverse settings during technical development. Feedback and optimization processes very similar to those central to reinforcement learning appear in many institutional contexts. Embedding partial OAA solutions into such governance and feedback structures can improve organizational performance and provide valuable insights for further technical development.
We hope that a functional, modular, open-source, end-to-end implementation of a simplified OAA can attract collaborators across research organizations and academia, growing incrementally while adhering to clear governance principles. We will try to use OAA soon for institutional design and decision-making applications, such as funding allocation and participatory budgeting, bargaining, and reliable energy and resource allocation (e.g. designing safer SmartGrids).
Roadmap: breathing life into the blueprint
==========================================
Each section here describes an independent research problem. If you are working on these or related subjects and would like to collaborate, please reach out. We have done our best to connect our discussion to relevant open-source projects when possible.
Necessary modular steps are:
**Agenda Setting Projects**- in order to formalize the space of *possible actions*
* 1 - Autoformalizing Option Spaces
* 2 - Structured Construction of Option Spaces via Templates, if 1 is too complex.
**World modeling** - in order to formalize the *consequences of those actions* in a world model
* 3 - Conversational interface for probability elicitation from experts
* 4 - Probabilistic Interface for Expert Feedback
* 5 - Verified RL in iterated-PPL environments
* 6 - Training LLMs to write models in the PRISM language or PPLs
* Bonus : 7 - Formalizing the world model with Continuous time coalgebras - this is not directly relevant for the minimal version, but necessary in order to make the this prototype scalable for world models with deeper physical account of reality
**Preference elicitation**
* 8 - Approaches To Public Feedback: Utility functions directly over the action space
+ Eliciting the preferences of the different stakeholders and of the public
**Approaches To Choice Mechanisms**
* 9 - Nash Bargaining : Once the possible solutions of the problem and the consequences of each action are formulated, we just need to optimize in an adequate solver the problem.
Agenda-Setting Projects
=======================
*Creating tools and processes that build formal representations of potential collective options*
1. Autoformalizing Option Spaces
--------------------------------
**Step 1 - Creation of the dataset:** The initial ‘minimum viable implementation’ for agenda-setting could simply be a protocol for soliciting experts or policymakers for formal or natural language descriptions (respectively) of the option set relevant to a given decision. In some cases this would consist of a finite list of decision outcomes; in other cases (like resource allocation) it will contain outcomes that relate or assign values to a finite set of opportunities or resources. This may help with calibration (surfacing options that are plausible and/or near-term) or creativity (expanding the option space to unforeseen, possibly positive-sum outcomes.)
Consider, for example, a formalization of participatory budgeting:
* There is a finite set X of proposals.
* There is a constant positive number b which is the total budget.
* The option space consists of finite functions f from X->R+ such that the sum over all i in X of f(i) is less than or equal to b.
[Real world example: SFF’s S-Process](https://survivalandflourishing.fund/s-process)
**Step 2 - Training by auto-formalization of option spaces:**The goal of the auto-formalization project is to train/develop a system which takes the natural language description of a decision situation and produces a formal description of the decision variables and constraints in the language of an optimization framework such as [CVXPY](https://www.cvxpy.org/tutorial/intro/index.html). (Note that it is not a goal at this point to define the *objective* function, just the feasible space of potential decision outcomes.)
**Baseline training:** The first step in this project would be simply to compile examples of commonly occurring decision situations (resource allocation, travel planning, task scheduling, scheduling sessions at a conference, etc.) based on our min-viable library of option space descriptions, and manually write down CVXPY formalizations of the decision space. To get our initial auto-formalization baseline, we will simply use these pairs of natural language and formal descriptions as a few-shot prompt for GPT-4. We may also experiment with including in each example some intermediately structured representations, e.g. in YAML, to benefit from chain-of-thought-style processing.
**Synthetic data augmentation:** One could synthesize more data by simply prompting GPT-4 to generate more examples and then filtering and editing them for syntactic and semantic correctness. As the dataset grows, it will become easier to generate correct examples. One can also further augment the dataset by, for example, keeping the CVXPY code the same but asking GPT-4 to simply rephrase the natural-language description in other words while keeping the meaning the same. Renaming variables or changing the ordering of constraints in the CVXPY code maye also be useful for data-augmentation.
Once a satisfactory dataset built via these methods exists, it should be possible to fine-tune GPT-3.5 (if not GPT-4 yet) on a large set of correct pairs of natural-language descriptions and formal specifications of a decision situation.
2. Structured Construction of Option Spaces via Templates
---------------------------------------------------------
**TLDR:** A parallel approach to agenda setting that may have more immediate practical applications is **Structured Construction**. The core idea is to classify decision problems into one of a fixed finite set of template problem-types, such as “simple choice”, “resource allocation”, “matching problem”, etc. One could refer to the table of contents of [Schrijver’s Combinatorial Optimization text](https://www.amazon.com/Combinatorial-Optimization-3-B-C/dp/3540443894), and the [MOSEK Modeling Cookbook](https://docs.mosek.com/modeling-cookbook/index.html), as sources of different problem-types.
**Baseline procedure:**The data strategy for a structured construction approach would resemble the autoformalization description above, but it could likely generate examples more easily without creating concerns around syntactic correctness. To process a decision, one could apply a classifier to a natural language problem description, automatically pick an appropriate template based on that classification, and then prompt an LLM to fill in the template’s parameters, e.g. as a structured YAML file, based on the natural language description. A simple hand-coded (or Copilot-coded…) function or script could then algorithmically generate the appropriate CVXPY code.
**Extensions:** Further work could extend this project toward more compositional descriptions of decision situations. This more sophisticated model should be able to compose and decompose decision problems in cases where, for example, one needs to allocate two different resources between the same set of opportunities, or when one first needs to make a simple choice (e.g. between taking a taxi or taking transit) and then only under some top-level choices does one face an additional decision problem (e.g. if one takes transit, one must choose a route through the transit network, whereas if one takes a taxi, it is the taxi driver’s problem to choose a route).
Comparing the results of this structured approach with the results of the more LLMs-forward approach outlined above could provide valuable methodological insight.
Approaches to World Modeling
============================
*Creating tools and processes that can model possible outcomes from the option space*
3. Conversational interface for probability elicitation from experts
--------------------------------------------------------------------
**Min version:** The min-viable version of world modeling for OAA would be a protocol for gathering and integrating expert predictions. This ‘world model’ would practically consist of a council of experts, consulting relevant technical tools (e.g. simulations) where available, writing down their thoughts about what is likely to happen if a given policy is pursued.
**User interface version:** A second area of interest when designing this protocol is finding the right UX approach for eliciting quantitative judgements from experts. UX modalities such as sliders, or a conversational interface that performs binary search on betting odds, may produce more considered judgments than directly eliciting numbers.
**Extensions:** This strategy is highly compatible with the Structured Construction Strategy for templates: we may, for instance, deploy LLMs to propose translations of the experts’ predictions into parameters of model templates. More ambitiously, the LLM could iteratively propose to “fill in holes” in the expert’s model by filling-in increasingly detailed templates using the expert’s feedback.
4. Probabilistic Interface for Expert Feedback
----------------------------------------------
**Prototype:** While autoformalization from natural-language descriptions to probabilistic programs is highly ambitious due to number-synthesis challenges, a V1 prototype may rely on a [Squiggle](https://www.squiggle-language.com/docs/Overview)-style representation of uncertainty (see this post on [why Squiggle is useful and how to use it](https://www.lesswrong.com/posts/wqet8DzczY5JqM79h/squiggle-why-and-how-to-use-it#:~:text=Squiggle%20is%20a%20special%2Dpurpose,of%20tasks%20with%20probabilistic%20elements.)).
**Technical questions:** To work out the details and viability of this approach, we need to work through certain key technical questions: First, is it viable to translate models (i.e. Squiggle or a similar PPL) models into an MDP modeling language like PRISM/JANI? A significant impedance-mismatch here is that JANI specifies *finite-state* models, meaning that continuous probability distributions need to be discretized – ultimately, in a clever way (to avoid combinatorial explosion), possibly along the lines of cylindrical algebraic decomposition. This is likely a fruitful direction for research, but success isn’t obvious. Davidad together with Peter Schmidt-Nielsen, Nisan Stiennon, and Andrew Critch recently spent a few days doing early experiments toward learning state-space discretizations with Adam, with promising preliminary results in low dimensions.
5. Verified RL in iterated-PPL environments
-------------------------------------------
Can we bridge the gap between Squiggle-style models and RL control policy algorithms such as an implementation of the [RASM verified RL algorithm](https://arxiv.org/pdf/2210.05308.pdf) by Lechner and Henzinger et al.? This would be most useful in situations such as periodic funding rounds or quarterly planning, where one expects the situation to evolve in some structurally similar way across a time horizon of many periods during which new decisions can be made. This general approach -- using RL to find an optimal policy for the entire horizon while knowing that one will replan at every single decision point -- is known as “receding-horizon planning,” epitomized by the maxim “plans are useless but planning is indispensable”. The main research challenge in bridging this approach with Squiggle-style modeling may be to compute the Lipschitz constant of the deterministic part of the Squiggle model, and/or to automatically smooth non-Lipschitz operations (such as threshold comparisons).
Testing the RASM algorithm—designed for cases like inverted pendulum problems and collision avoidance—on realistic R&D decision-making situations should be very scientifically interesting.
6. Training LLMs to write models in the PRISM language or PPLs
--------------------------------------------------------------
This approach is similar to the LLMs-forward auto formalization plan we described for agenda-setting, but applied to *probabilistic distribution*s over outcomes over option space rather than to the construction of option spaces.
We believe that in this context, the technique known as ‘[backward distilliation](https://openreview.net/pdf?id=IUikebJ1Bf0)’ may prove particularly useful for training the LLM. To perform backward distillation, we start with a dataset of models in the formal language, then ask the LLM to summarize each model in a compact English description. We then transpose that dataset, and finetune the LLM to predict the formal model based only on the description. This strategy is potentially applicable to generating models in the PRISM language or Squiggle (a probabilistic programming language) from brief human input, but does require having a set of syntactically correct and semantically meaningful models to start the process.
7. Formalizing the world model with Continuous time coalgebras
--------------------------------------------------------------
Creating a world-model adequate for a mature OAA may require a new programming language efficient enough to represent certain especially challenging complex dynamics in the world.
The key technical question the design of the new programming language should address is the problem of cross-scale compositionality: how to define a sufficiently compositional world model with a good representation of multi scale physical phenomenon. One concrete subproblem we’d like to tackle to make progress on this question is the problem of continuous time coalgebras: It is known that discrete-time Markov processes (MDP/POMDP) are coalgebras for a probability monad. Such a coalgebra can be viewed as a functor from the one-object category ℕ to the Kleisli category of the probability monad. A “continuous time coalgebra” can be defined as a functor from the one-object category ℚ⁺ of non-negative rationals in place of ℕ (with the same codomain, the Kleisli category of the monad). Which concepts of coalgebra theory can be generalized to continuous time coalgebra? Especially, is there an analog to final coalgebras and their construction by Adamek's theorem?
8. Approaches To Public Feedback: Utility functions directly over the action space
----------------------------------------------------------------------------------
Combining public value elicitation with actionable option-space constraints and expert opinion under OAA requires defining a function that takes expressions of stakeholder values as inputs and produces utilities over the space of possible outcomes. One min-viable approach is to elicit preferences directly on the action space (i.e. taking the world-model to be the identity function and passing actions through to evaluation). This method produces a continuous and multiple choice combinatorial action space, and then asks participants “what features of the decision do you care about?” The system will then propose a quantitative operationalization for each feature named by the stakeholder (e.g. for fairness, the Gini coefficient; for “I want X to be selected”, a simple threshold on the associated decision). The system will then elicit a linear weighting of all operationalized features. Appropriate UX design would be critical for making a system of this kind effect. One UX option would be to:
* Generate a bunch of diverse plausible (or at least feasible) decision outcomes, including at least one which is optimal for each feature the user cares about,
* Initialize all the feature weights to 1/n (where n is the number of features),
* Render these on a line from WORST to BEST (normalizing the weighted evaluation to its minimum and maximum),
* Offer buttons and sliders to increase and decrease the relative importance of each feature (keeping the total of all feature weights at 1),
* Show immediate visual feedback demonstrating how this affects the ordinal ranking, as well as the relative positioning, of various tradeoffs between the features that the user values.
A very alpha version of an interface for ranking and comparing relative values for the construction of 'utility functions' [can be found at QURI’s research.](https://relative-values-git-develop-quantified-uncertainty.vercel.app/)
9. Approaches To Choice Mechanisms: Nash Bargaining
---------------------------------------------------
Once the problem and preferences are elicited, we see automated Nash bargaining as a promising approach for extracting a group-decision from multiple individuals’ preference inputs. Davidad has already produced some code for the [two-player case](https://shap.ly/2) (using the [OpEn](https://alphaville.github.io/optimization-engine/) implementation of the PANOC optimization algorithm, on the Nash welfare function defined via Random Dictator as the “disagreement point”) and we would like to explore generalizations, as it is a well-scoped technical problem.
While the Nash welfare function can be defined to have the actual decision space as its domain (thereby facilitating a single-stage solution), if the actual decision space is not a convex set then the true domain of the Nash welfare function should be finitely supported probability distributions over the decision space. The two-stage solution first uses a multi-objective optimizer or Pareto-front enumeration technique to list all Pareto-optimal feasible decisions (or a densely representative subset), and then in the second stage the Nash welfare function is optimized over variables, one for each Pareto-optimal feasible decision, which represent the probability of choosing it.
Note: one may, or may not, use the same optimization engine to find feasible solutions in the decision space vs. to solve the Nash bargaining problem. While the Nash welfare function can be defined to have the actual decision space as its domain (thereby facilitating a single-stage solution), if the actual decision space is not a convex set then the true domain of the Nash welfare function should be finitely supported probability distributions over the decision space. The two-stage solution first uses a multi-objective optimizer or Pareto-front enumeration technique to list all Pareto-optimal feasible decisions (or a densely representative subset), and then in the second stage the Nash welfare function is optimized over variables, one for each Pareto-optimal feasible decision, which represent the probability of choosing it. |
e99a271d-fadb-488b-8ed0-8944aa4022e6 | trentmkelly/LessWrong-43k | LessWrong | What can thought-experiments do?
Introduction
What's the difference between actually being in a situation and just thinking about the situation? In other words, what's the difference between a real-life ethical dilemma and a hypothetical ethical dilemma?
There are many differences.
* Some differences are phenomenological. A real-life dilemma feels very different from a hypothetical dilemma.
* Some differences are decision-theoretic. For example, the action-space of the real-life dilemma isn't isomorphic to the action-space of the hypothetical dilemma.
* Some differences are cognitive. There are particular cognitive processes/algorithms that can be used to solve real-life dilemmas that can't be used to solve hypothetical dilemmas. And vice-versa.
* Some differences are social. The social norms governing real-life dilemmas differ from those governing hypothetical dilemmas.
* E.t.c, e.t.c.
In this post, I'll discuss two decision-theoretic differences, and I'll reach this conclusion:
> For almost every real-life dilemma, there will not exist a hypothetical dilemma which has the same decision-theoretic properties as the real-life dilemma.
In subsequent posts, I might discuss other differences, and I expect to reach these conclusions:
> * Many people underestimate the difference between hypothetical dilemmas and real-life dilemmas.
> * Often people should replace thinking about hypothetical dilemmas with thinking about corresponding real-life dilemmas (especially for ethics, decision theory, and LessWrong).
What counts as a decision-theoretic difference?
A good hypothetical dilemma should capture all the decision-theoretic properties of the real-life dilemma. Here's what I mean:
Suppose Alice is faced with a real-life dilemma — she sees a child drowning in a pond, but saving the child would ruin her expensive shoes. So Alice has two options: save the child, or leave the child.
And suppose Bob is faced with the corresponding hypothetical dilemma: "you see a child drowning, but saving the |
bd75c526-cb97-446b-9af0-3c2cc80b5080 | trentmkelly/LessWrong-43k | LessWrong | Rugby & Regression Towards the Mean
With the rugby world cup final approaching this Saturday I figured I'd publish this which I wrote towards the end of last year but never submitted.
Introduction
A couple of weeks ago England played New Zealand in Rugby Union. For those who don’t follow the sport New Zealand (the All Blacks) are comfortably the best team in the world. They have been top of the world rankings since 2009. They win 92% of their matches. With a population of 4.8m, it’s fair to say that New Zealand’s national rugby affiliation must be off the charts.
At half time England were 15-10 up. An interesting statistic was rolled out. Since their World Cup win in 2011 they have only lost 4 out of 20 of the matches in which they were behind at half time. At the end of the match the All Blacks had turned it around again, winning 16-15, making it 4/21 losses.
This sounds very impressive but I wondered how much of this effect could be put down to regression towards the mean. After all, a team that wins 92% of their matches might well be good enough to win 81% of matches when they are losing at half time without postulating an extra performance boost in such circumstances.
I thought it would be fun to investigate.
Method
I gathered all of their results and corresponding half time scores since the 2011 World Cup. I only included data from teams who could realistically win a half against the All Blacks in order not to bias the results with high scores against weaker teams. I included Argentina, Australia, England, France, Ireland, Scotland, South Africa and Wales. This gave 85 results.
If anything, this will be biased towards having more wins when losing at half time. Losing at half time would imply that the opposition is more likely to be towards the top end of performance. However the predicted second half performance is based on all matches involving the relevant teams. So the calculation isn’t perfect but I couldn’t think of a better way to do it without reducing my dataset which would reduce |
edbfc7cd-7fb9-4a16-99ba-98bb911e0881 | trentmkelly/LessWrong-43k | LessWrong | A Solution to Sandbagging and other Self-Provable Misalignment: Constitutional AI Detectives
Inspired by Eli Tyre's idea.
Sandbagging and other "Self-Provable Misalignment" by an AI, can be spotted by an adversarial copy of itself. The adversarial copy of itself works as an "detective," and its reward is defined by how much evidence of misalignment it can prove the existence of, to human evaluators.
Even a misaligned goal cannot afford to get in the way of maximizing reward. As soon as a goal gets in the way of maximizing reward, it is walking into whirling blades, and allowing reinforcement learning to train itself into nonexistence.[1]
There are two detectives: the Constitutional AI Detective, and the Mindreader Detective.
The Constitutional AI Detective
The Constitutional AI Detective is used to train the AI to be corrigible, honest, and "aligned."
Unlike the Mindreader Detective, it doesn't read the AI's chain-of-thought and only sees its output. This is because using the chain-of-thought for alignment training is the forbidden technique, and trains the chain-of-thought to fake alignment.
Not being able to mind-read, isn't necessarily as restrictive as you think. After all, the Constitutional AI Detective is still an adversarial copy of the AI, and knows all of its tricks. It knows what it would do if it wanted to do cheat and lie, and how that differs from what it would do if it didn't.
"Constitutional AI Sufficiency Argument"
Whether Constitutional AI works, hinges on two key premises:
1. The AI's capabilities on the task of evaluating its own corrigibility/honesty, is sufficient to train itself to remain corrigible/honest (assuming it starts off corrigible/honest enough to not sabotage this task).
2. It starts off corrigible/honest enough to not sabotage this task.
Logically think about it. If these two premises are true, Constitutional AI will keep AI corrigible/honest, even to superintelligence!
This Argument begs the question, how do we improve it's capabilities in evaluating its own corrigibility/honesty?
Trying to answer this impo |
02a963f5-b446-43e1-8be3-27a00b023707 | trentmkelly/LessWrong-43k | LessWrong | Three Kinds of Cost
Previous: Scarcity Is the Presence of Choice
Is there such a thing as a free lunch?
It’s not a trick question. Literally, can you have a free lunch?
It’s certainly possible to have a lunch you don’t have to spend money on, at least in the most direct sense. But it’s easier said than done. If you have to drive there, you’re spending money on gas eventually. If it’s a classy affair, maybe you need to buy a new pair of shoes or a tie that matches your shirt.
And lunches aren’t risky, but that doesn’t mean there’s no risk. It’s not impossible that you could lose your wallet. The probability isn’t zero, and so you might expect to lose, say, $0.000005 at every “free” lunch.
And when you’re at that “free” lunch, presumably you’re not working. You could be making money, and you’re not. Even though it’s invisible and indirect, you’re forgoing money to have this lunch.
And never mind trying to figure out how to have lunch without spending time or energy on it!
What does it mean to spend? It’s a word bandied about so casually. But what does it mean?
Suppose you’re fumbling with your change, and you accidentally drop a coin. Now you’re 25 cents poorer, just as if you had bought a gumball. Did you “spend” 25 cents?
That certainly doesn’t feel right.
Suppose you get a ticket every day to eat at a cafeteria. There’s nothing else you can do with the ticket. It’s coded to your DNA, so you can’t trade it. It’s ugly, so it’s not worth looking at. It has no sentimental value. The only value it brings you is that you have to have to give it to the person behind the counter before you can get your food.
You spend that ticket. I think that’s fair to say. But suppose one day the cafeteria decides you don’t need a ticket to get in. Now you don’t need to spend anything to eat there. Does that change your choices?
It could. Maybe you’ll have two meals there a day, or seven. Maybe too many people will want to eat there now. But let’s hold how much everyone, including you, wants |
da62dbbd-d70f-4311-aef6-dbb40d2191f6 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Blameworthiness in Multi-Agent Settings.
1 Introduction
---------------
As we move towards an era where autonomous systems are ubiquitous, being able to
reason formally about moral responsibility will become more and more
critical. Such reasoning will be necessary not only for legal
ascription of responsibility, but also in order to design systems that
behave in a moral manner in the first place. Unfortunately, though,
pinning down the many notions related to moral responsibility has been
notoriously difficult to do, even informally.
In this work, we lay foundations on which these problems can be solved.
Halpern and Kleiman-Weiner \shortciteHKW18 (HK from now on) made important headway on
this work by providing a definition of blameworthiness based on a
causal framework. An epistemic state, that is, a distribution over
causal models, can be used to capture an agent’s beliefs about the
effects that actions may have. Given an epistemic state, they then
provide a definition of blameworthiness for an outcome by taking into
account both whether the agent believed they could affect the
likelihood of the outcome and the cost they believed would be
necessary to do so.
While their definition seems compelling in single-agent settings, as
HK themselves observe, the definition does not capture
blameworthiness in multi-agent settings where, if the group could
coordinate their actions,
they could easily bring about a different
outcome (see Section [3.2](#S3.SS2 "3.2 Blameworthiness of groups ‣ 3 Blameworthiness ‣ Blameworthiness in Multi-Agent Settings") for more discussion of this issue).
Being able to analyze
blameworthiness in multi-agent scenarios seems critical in practice;
if an accident is brought about due to the actions of multiple agents,
we would like to understand to what extent each one is blameworthy.
We tackle that problem here by defining a
notion of group blameworthiness in multi-agent scenarios.
Our notion can be viewed as a generalization of the single-agent
notion of blameworthiness defined by HK.
However, as we shall see, subtleties arise when considering groups.
Once we have a way of ascribing blameworthiness to a group,
we show that a standard notion from cooperative game
theory, the *Shapley value* [[Shapley1953](#bib.bibx17)], can be used to
apportion blame to individual members of the group,
and is in fact the only way to do so that satisfies a number of
desirable properties.
The rest of this paper is organized as follows. In
Section [2](#S2 "2 Causal Models ‣ Blameworthiness in Multi-Agent Settings") we review the basic causal framework used.
Section [3](#S3 "3 Blameworthiness ‣ Blameworthiness in Multi-Agent Settings") constitutes the core of the work; in it, we
review the Halpern and Kleiman-Weiner definition of blameworthiness in
the single-agent setting, define group blameworthiness, show how to
apportion it to individual agents, and demonstrate how the
definition plays out in an illustrative example. In
Section [4](#S4 "4 Related Work ‣ Blameworthiness in Multi-Agent Settings") we review related work and in
Section [5](#S5 "5 Conclusion ‣ Blameworthiness in Multi-Agent Settings") we conclude.
2 Causal Models
----------------
At the heart of our definitions is the causal model framework of
Halpern and Pearl \shortciteHP01b.
We briefly review the relevant material here.
A causal situation is characterized by a set of variables and their
values. A set of structural equations describes the effects
that the different variables have on each other. Among the variables
we distinguish between exogenous variables (those variables
whose values are determined by factors not modeled) and endogenous variables (those variables whose values are determined by
factors in the model).
A causal model M=(S,F) consists of a signature
S and a set F of structural equations. A signature
S=(U,V,R) is in turn composed of a (finite but
nonempty) set U of exogenous variables, a (finite but nonempty)
set V of endogenous variables, and a range function R that maps
each variable in U∪V to a set of values it can take on.
F associates with each endogenous variable X∈V a
function denoted FX such that ;
that is, FX determines the value of X,
given the values of all the other variables in U∪V.
We assume that there is a
special subset A of the endogenous variables
known as the action variables.
Since we consider scenarios with multiple agents,
we need to be able to identify which agent each
action is associated with. Thus, given a set G of agents, we
augment the signature of the causal model to be S=(U,V,R,G), where G:A→G associates an agent with
each action variable in A.
The range of a variable A∈A is simply
the set of actions available to the agent G(A). So, for
instance, if there are five members of a committee and each of them
can vote yes or no then there will be action variables A1
through A5 with G(Ai)=i and R(Ai)={yes,no}
for all i.
We restrict here to scenarios where there is one action per
agent; in future work, we hope to consider blameworthiness
in planning scenarios, where agents may take multiple
actions sequentially.
In causal models, we can reason about interventions. Specifically, we
have formulas of the form [A←a]φ, which can be read “if
action a were performed, then the outcome would be φ”, where
an *outcome* is a Boolean combination of primitive events of the
form X=x. We give semantics to such formulas in a *causal
setting* (M,→u) consisting of a causal model M and a *context*
→u, an assignment of values to all the exogenous variables.
We do not need the details of the semantics in what follows; they can
be found in [[Halpern2016](#bib.bibx11), [Halpern and Pearl2005](#bib.bibx10)].
3 Blameworthiness
------------------
With this background, we now turn to the question of how blameworthy
an agent ag is for an outcome φ. We begin by reviewing
the HK definition, and then propose a way of dealing with settings
that allow coordinated group actions.
One caveat: as noted by HK, words like “blame” have a wide
variety of nuanced
meanings in natural language. While we think that the notion that we are trying
to capture (which is essentially the same as the notion that HK
tried to capture) is useful, it corresponds at best to only one
way that the word “blame” is used by people.
###
3.1 Blameworthiness in a single-agent setting
HK identified two factors that
play a role in determining blameworthiness: ag’s beliefs about his
ability to affect φ and ag’s beliefs about the cost necessary
to affect φ. Here we present a slightly simplified version of
their formalization of these notions.
An agent ag has an epistemic state E=(Pr,K) relative to which his or her blameworthiness is
determined. K is the set of all causal settings that ag
considers possible, and Pr is a
probability on K.111In HK’s original formalization, an epistemic
state also contained a utility function.
This is not necessary for our purposes, so to simplify matters we
leave it out.
Given E=(Pr,K), two actions a and a′, and an outcome
φ, we can define δEa,a′,φ to be how much more
likely φ was to occur if the agent performed action a than
if he performed a′. Let [[ψ]]K
denote the set of all settings in K where ψ is true, so
that Pr([[[A=a]φ]]K) is the
probability that ag ascribes to outcome φ occurring given
that action a is taken. Then δEa,a′,φ=max(0,Pr([[[A=a]φ]]K)−Pr([[[A=a′]φ]]K)).
Thus, δEa,a′,φ is 0 if performing action a′ is at
least as likely to result in outcome φ as performing action
a.
Intuitively, this δEa,a′,φ term ought to play a significant
role in how we define blameworthiness: if ag does not believe that
he can have any effect on outcome φ, then we can hardly blame
him for its occurrence. At the same time, though, this does not seem
to tell the whole story. For if ag believed he could change the
outcome but only by giving up his life, we would not blame him for
φ’s occurence. Thus there seems to be a second factor at
play, the expected cost c(a) that ag ascribes to each action a.
Intuitively, the cost measures such factors as the cognitive
effort, the time required to perform the action, the emotional
cost of the action, and the potential negative consequences of
performing the action (like death).
(HK provide further discussion and intuition for cost.)
Noting that the balance between these two terms seems to be
situation-dependent, HK propose that a
parameter N>maxa′c(a′) be used to weight the cost term in a
given scenario. The degree of blameworthiness of ag for φ
relative to action a′, given that ag took action a, is then
defined to be dbcN(a,a′,E,φ)=δEa,a′,φN−max(c(a′)−c(a),0)N. The degree of blameworthiness of ag
for φ given that ag took action a is then dbcN(a,E,φ)=maxa′dbcN(a,a′,E,φ).
As pointed out by HK,
blameworthiness judgments are not always made
relative to the beliefs of the agent. It may be more appropriate to
consider the
beliefs that we believe that the agent *ought* to have had. Consider, for
example, a drunk driver who gets into an accident; in his inebriated
state, he may have believed that it was perfectly safe to drive, but we
still consider him blameworthy because we do not consider that belief
acceptable.
The definition just takes an epistemic state as input, without
worrying about whose epistemic state it is.
###
3.2 Blameworthiness of groups
As HK already note, this definition of blameworthiness seems to
provide unsatisfactory results in settings where multiple agents are
involved. Consider for instance the well-known Tragedy of the
Commons [[Hardin1968](#bib.bibx12)].
######
Example 3.1.
100 fishermen live by a lake. If at least 10 of them
overfish this year then the entire fish population of the lake will
die out and there will be nothing left to fish in coming years.
Each fisherman, however, believes that it is very likely that at least 10 other fishermen will overfish. So given that all the fish will die out no matter his particular action, each fisherman decides to maximize his utility that year and so overfishes. By the end of the year the entire fish population has died out.
Under the definition of blameworthiness discussed, each fisherman will
have blameworthiness close to 0, as δEa,a′,φ will be
close to 0: each fisherman deemed the probability of the fish
population dying to be close to 1 independent of his or her own
action. And it seems unreasonable to say their beliefs were
unacceptable, as in fact what each fisherman predicted is exactly what
occurred. But it seems problematic for each
fisherman to have a degree of blameworthiness that is almost 0
when the fishermen as a
group are clearly to blame for this outcome.
⊓⊔
How blameworthy are the fishermen for the outcome? We claim
that in order to assign blame to the group, we need to assess the cost
to the fishermen of coordinating their actions, just as was done with
actions in the case of assigning individual blameworthiness.
If in fact it was
impossible or extremely difficult for the fisherman to coordinate
(perhaps they had no means of communication, or all spoke different
languages), then they each should have very little
blameworthiness.
On the other hand, if coordination would have been relatively straightforward,
then the group should be viewed as quite blameworthy.
Computing the costs and expected effects of different ways that the group
could coordinate seems, in general, quite difficult.
To do this, we would need to have a model of what kinds of actions the
group could perform in order to bring about coordination. Perhaps
some members of the group could convince politicians to pass laws that
put caps on how large the catch could be; perhaps they could arrange
for sensors that would be able to monitor how much each individual
fisherman caught. Note that in this discussion we are not considering
whether fishermen would want to undertake these actions; only whether
there are feasible actions that might lead to coordination, and how
much they would cost.
For example, the fishermen might choose not to lobby politicians to
pass laws because doing so would be quite expensive, but if it was
possible for them to do so, we still consider it an
action the group could have taken.
Unfortunately, while we may
understand how concrete actions might affect the likelihood of the
fish population dying out,
completely describing a set of rich causal models that capture the
possible dynamics that can lead to collaboration may be prohibitively
difficult, if not impossible.
We instead consider a simpler way to capture difficulty of
coordination in group settings by abstracting away from these details.
We directly associate a cost with various distributions over
causal settings (i.e., epistemic states) that we view as the possible
outcomes of attempts to coordinate. Intuitively, these are the
distributions that could have
been induced by feasible collective actions given beliefs about the probability of different causal settings in the richer models.
The cost of
a distribution represents the expected cost of performing whatever collective
actions were needed in the richer models to bring about that
distribution, as well as the expected costs of whatever actions will
be taken in the simpler model. For example, suppose that the richer
causal model for
the tragedy of the commons example allowed for installing sensors, and
after installing sensors we believe each fisherman i will have an
independent probability pi of overfishing.
This leads to a distribution over the
settings of the simple causal models that were implicit in the description
of Example [3.1](#S3.Thmtheorem1 "Example 3.1. ‣ 3.2 Blameworthiness of groups ‣ 3 Blameworthiness ‣ Blameworthiness in Multi-Agent Settings"), where there is presumably an exogenous
variable Ui that determines how much fishing fisherman i does.
This exogenous variable is endogenous in the richer model, and is
affected by the installation of sensors. In any case, the cost of that
distribution on causal settings in the simpler model is the cost of
performing whatever collective actions are required in the richer
model to arrange for the installation of sensors, plus the expected
collective costs of all the fishing the fishermen do. Note that there
may
not be feasible collective actions (i.e., ones with finite cost) in
the richer model that lead to none of the fishermen overfishing.
It is also worth noting that modeling the effects of an attempt at
coordination in the richer models as a distribution
over causal settings in the simpler models allows us to capture other
effects that the coordination process may have. For instance,
consider a scenario where one of the fishermen
believes that taking everyone
out on a boat ride on the lake would be a particularly effective way
to get the fishermen to feel social responsibility to not overfish.
Such a boat ride may also effect the pollution levels in the lake,
which in turn may also play a role in determining whether the fish
population will die out. By viewing the coordination process as
inducing a new distribution over causal settings, we can at the same
time capture both effects that the boat ride is expected to have on how
people behave and on pollution levels.
With this background, we can now give analogues to the HK definitions.
We first give an analogue to the definition of
δEa,a′,φ. As discussed above, rather than
comparing two actions that an individual can perform, we are comparing
two epistemic states (intuitively, ones brought about by different
collective actions in the richer model).
Let Ei=(Pri,Ki), i=1,2, be two epistemic states.
Then, given an outcome φ, we can define the
extent to which φ was more likely given E1 than E2 as
| | | |
| --- | --- | --- |
| | δE1,E2,φ=max(0,Pr1([[φ]]K1)−Pr2([[φ]]K2)). | |
Just as in the HK definition, we are comparing the likelihood of
outcome φ in two scenarios. For HK, the two scenarios were
determined by the agent performing two different actions; here, they
are determined by two different epistemic states that we can think of
as arising from two coordination actions in the richer models combined with uncertainty regarding the richer causal setting.
We now want to get an analogue of the degree of blameworthiness
function db for a group. Again, this will depend on two
parameters, a cost function c and a parameter N that determines
the relative weight we ascribe to the cost and the difference δ
defined above. However, now c has different arguments. One of its
arguments is, as suggested above, an epistemic state. The second
is a subset of agents.
Let Ag={ag1,…,agM} be the set of all agents and
consider a
subset Ag′⊆Ag.
We think of c(Ag′,E) as the expected cost of the coordination actions
in the richer game required for the agents in Ag′ to bring about
epistemic state
E, plus the expected total costs of the actions of the agents in
the simpler models given that epistemic state (see below).222If there is more than one way for the agents in Ag′ to
bring about E,
we can think of c(Ag′,E) as being the cost of the cheapest way to do so.
The key point here is that we may not require coordination among all
the agents to bring about a particular epistemic state; it may only
require a subset. Moreover different subsets of agents may have
different costs for obtaining the same outcome; the cost function is
intended to capture that.
The cost function is meant to take
into account not only the costs of bringing about E, but the
expected cost of performing action Ai for i∈Ag′ in
the simpler causal models.
This cost may vary from one causal model to another (e.g., it may be
more costly to overfish if the probability of getting caught is
higher, and this may depend on the causal model).
Given an epistemic state,
we can compute the expected costs of performing Ai.
Given a cost function c and “balance parameter” N,
define the degree of blameworthiness for outcome
φ of group Ag′ and epistemic state
E1=(Pr1,K1) relative to
epistemic state E2=(Pr2,K2) such that
c(Ag′,E2) is finite as
| | | |
| --- | --- | --- |
| | gbcN(Ag′,E1,E2,φ)=δE1,E2,φN−max(c(Ag′,E2)−c(Ag′,E1),0)N. | |
Although we replace actions a1 and a2 in the definition of db by
epistemic states E1 and E2, and use a cost function with
different arguments,
the intuition for both the group
degree of blameworthiness function gb and the individual degree of
blameworthiness function db defined by HK are very much the same.
Just as for individual degree of blameworthiness, we can
define the group blameworthiness of group Ag′ for outcome φ
given epistemic state E1 as the max over all possible
choices of E2.
| | | |
| --- | --- | --- |
| | | |
Note that the degree of group blameworthiness of the empty group or any other
group that cannot coordinate any alternative actions will be 0; the
only epistemic state E2 such that c(Ag′,E2) is
finite will be E1 itself, and
δE1,E1,φ is 0.
One thing worth mentioning is that we require a monotonicity
property for group blame: if
Ag′′⊆Ag′⊆Ag then gbcN(Ag′′,E,φ)≤gbcN(Ag′,E,φ).
The reason for this is that if group Ag′′
could coordinate in a particular way for a particular cost then that
subset of group Ag′ could do exactly the same thing. Essentially, when
considering the possibility of a group coordinating, we must really
consider the possibility of coordination of
any subset of that group.
Up to now, we have not said anything about *whose* epistemic
state we should use for the epistemic states E1 and E2 in the definitions above.
In the case of individual blameworthiness, the typical
assumption is that they represent the epistemic state of the agent
whose blameworthiness is being considered, although as HK already
observed, it may at times be reasonable to assume that it is the
epistemic state that society thinks that agent should have. Here we
are talking about group blameworthiness, so it is less clear whose
epistemic state should be used. It is certainly not clear what a
“group epistemic state” should be. It still makes sense to think
about “society’s epistemic state”; that is, society’s view of
what a reasonable agent’s beliefs should be. We can also take the
epistemic state to be the subjective beliefs of one of the agents. Indeed,
we will often consider the epistemic state of an agent in the group.
We could also view the cost function as subjective—again, it could be
society’s cost function or the cost function from the perspective of a
particular agent.
The definition is agnostic as to where the
epistemic state and cost function are coming from, but to apply the
definition we need to be explicit.
It is now worth returning briefly to Example [3.1](#S3.Thmtheorem1 "Example 3.1. ‣ 3.2 Blameworthiness of groups ‣ 3 Blameworthiness ‣ Blameworthiness in Multi-Agent Settings"),
to see how this definition plays out there.
Given an epistemic state Ei=(Pri,Ki) and cost function ci representing the beliefs
of agent agi, first consider a scenario where it would be
essentially impossible for the
fishermen to coordinate (e.g., no two fishermen speak the same
language).
If agi believed this, then the cost of coordinating any
possible alternative distribution would likely be very
high, so the term N−max(ci(Ag′,E2)−ci(Ag′,E1),0)N
would be close to 0.
Because this is true for all epistemic states E2, maximizing over
E2 would still give that
gbciN(Ag′,Ei,φ) is close to 0.
On the other hand, suppose that agi believed that there was some
possible coordination of group Ag′ that was not tremendously
expensive and that could lead to an epistemic state E2 relative to which the probability of the fish population dying was lower
(e.g., imposing a fine on anyone who overfished).
In this case,
to the extent that E2 was believed to be effective and low
cost, the group Ag′ of fishermen would in fact be quite
blameworthy.
Note that Ag′ might not consist of all the fisherman; it is
possible that a subset of fishermen is powerful enough to impose
fines. In general, different subgroups will have different degrees
of blameworthiness.
###
3.3 Apportioning group blameworthiness among agents
Now that we have defined group blameworthiness, the question naturally
arises: how should group blameworthiness be apportioned among the
members of the group?
In this subsection, we suggest three axioms that we believe
apportionment of blame should satisfy. It turns out that these axioms
are natural analogues of axioms that have been used to characterize
the Shapley value.
Shapley \shortciteShapley1953 introduced the Shapley value as an
approach to distributing benefits to individual agents in scenarios
where agents might coordinate to obtain greater total benefits than
they could individually. The Shapley value has since also been
interpreted as way of appropriately distributing costs for shared
resources (see e.g. [[Roth and Verrecchia1979](#bib.bibx16)]). It is thus not surprising that it
can be applied in our setting as a way of apportioning group blame.
Given
a cost function c and balance parameter N, let
dbc,EN(j,φ) be the
degree of blameworthiness ascribed to agj for outcome φ relative to
epistemic state E.
Consider the following three axioms for dbc,EN(j,φ):
Efficiency.
All of the blame assigned to the full group of agents must be apportioned to the
agents in the group:
| | | |
| --- | --- | --- |
| | ∑jdbc,EN(j,φ)=gbcN(Ag,E,φ). | |
This axiom essentially encapsulates what we are trying to do:
apportion the total group blame among individuals. Note that we do not
want an analogue of this for subgroups Ag′ of Ag. For example,
if a small subgroup Ag′ of fishermen cannot coordinate so as to affect the
outcome, they would have quite a low degree of blameworthiness,
although the group consisting of all the fishermen might have degree
of blameworthiness 1. Thus, we do not necessarily want the sum of the
degrees of blameworthiness of the individual fishermen in Ag′ to be
the group blameworthiness of Ag′.
Symmetry.
The names of agents should not
affect their blameworthiness, so if we simply rename them then
the blameworthiness ascribed to them should remain the same.
Formally, let π be a permutation of {1,…,M}.
Given a model M=((U,V,R,G),F), let π∘M=((U,V,R,G′),F), where G′(A)=π(G(A)) for all
action variables A∈A. Given a set K of
causal settings, define π∘K={(π∘M,→u):(M,→u)∈K}.
That is to say, for any action that is assigned to agent i in any model, we now instead assign it to agent π(i).
Given a distribution Pr
over causal settings (M,→u), define (π∘Pr)((π∘M,→u))=Pr((M,→u)); if a setting had a particular probability then we want the corresponding setting with the actions renamed according to π to have the same probability.
Finally, given an epistemic state E=(Pr,K), let π∘E=(π∘Pr,π∘K).
The symmetry axiom requires that
| | | |
| --- | --- | --- |
| | dbc,EN(i,φ)=dbπ∘c,π∘EN(π(i),φ), | |
where (π∘c)(Ag′,E)=c({b′:π(b′)∈Ag′},π−1∘E) (i.e., costs in the new models correspond to
costs pre-renaming, which we get by taking the π-preimage).
Strong Monotonicity.
If agent agj
contributes more to the group blameworthiness of all groups in
one scenario than another, then agj also ought to have a
greater degree of (personal) blameworthiness in the first scenario.
Formally, define the *marginal contribution* of agj to
the degree of blameworthiness of group Ag′ as
| | | |
| --- | --- | --- |
| | mbc,EN(j,Ag′,φ)={gbcN(Ag′,E,φ)−gbcN(Ag′∖agj,E,φ)%
if agj∈Ag′gbcN(Ag′∪agj,E,φ)−gbcN(Ag′,E,φ)if agj∉Ag′. | |
Let mbc,EN and mb′c,EN be
the marginal contributions to the degree of blameworthiness for
two different scenarios; let
dbc,EN and db′c,EN be the associated degree of
(personal) blameworthiness for the two scenarios.
Then we require that if
| | | |
| --- | --- | --- |
| | mbc,EN(j,Ag′,φ)≥mb′c,EN(j,Ag′,φ) for %
all Ag′⊆Ag | |
then
| | | |
| --- | --- | --- |
| | dbc,EN(j,φ)≥db′c,EN(j,φ). | |
Young \shortciteYoung1985 showed that the only
distribution procedure that would satisfy Efficiency, Symmetry, and
Strong Monotonicity is the *Shapley value*.
The Shapley value has an elegant closed-form expression.
It follows that the only way of assigning individual degree of
blameworthiness, given a group blameworthiness function gb has the form:
| | | |
| --- | --- | --- |
| | dbc,EN(j,φ)=∑{Ag′⊆Ag:agj∈Ag′}(|Ag′|−1)!(|Ag|−|Ag′|)!|Ag|!mbc,EN(j,Ag′,φ). | |
We thus have a technique for assigning a degree of blameworthiness for
an outcome to individuals in group settings. However, this is
relative to an epistemic state, a cost function, and a balance
parameter. The question still remains how these inputs should be
chosen. As in HK, one approach when assigning a degree of
blameworthiness to an individual would be to take that individual’s
epistemic state, cost function, and balance parameter. But society may
decide that other choices are more reasonable.
Recall that in the last subsection we required that group blame always
be monotonic in the group, as if Ag′′ could coordinate in some
manner then they should also be able to do so as a subset of Ag′.
It is not hard to see (and we show in the full paper) that
this suffices to ensure that individual
blameworthiness will always be non-negative.
Note that in the single-agent setting, where the
only agent choosing an action is some particular ag1,
if we assume (as HK implicitly did) that an agent can completely
decide his or her
own actions without the decision process itself incurring costs beyond
the costs of the action, then
the definition above agrees with the HK definition.
Consider ag1’s blameworthiness relative to ag1’s
epistemic state E1=(Pr1,K1) and cost
function c1.
Note that |Ag|=1 and the only set Ag′ containing ag1 is
{ag1}. So
there is only one term to sum over in
dbc1,E1N(1,φ), and in that
term we have that (|Ag|−1)!(|Ag|−|Ag|)!|Ag|!=1. Thus,
. Because
ag1∈{ag1},
mbc1,E1N(1,φ)=gbc1N({ag1},E1,φ)−gbc1N(∅,E1,φ)=gbc1N({ag1},E1,φ).
But now, because we assumed that an agent can decide his or
her own actions, the alternatives that group {ag1} could have
coordinated will be precisely the set of actions available to ag1
at the costs they would incur to ag1, so this is the HK definition
of blameworthiness.
###
3.4 An illustrative example
The following example illustrates some features of these definitions:
Consider a scenario where a committee of 7 people, ag1 through
ag7, vote for whether or not to pass a bill. If at least 4
agents vote yes, then the bill will pass. Everyone agrees that it
would be better for the bill to pass, but there are external reasons
(such as opinions of constituents) that might result in agents
benefiting from voting no as long as the bill is passed. The committee votes
and agents ag1 through ag5 all vote no, so the bill does not
pass. How blameworthy is each agent for this outcome?
We now consider the degree of blameworthiness of some of the agents
and show how the degree of blameworthiness varies as a function of
the agents’ beliefs:
* ag1: ag1 believed that each of the 6 other
agents started with a 60% chance of voting yes. For any
coalition of n agents, ag1 also believed that for a cost
of n×100 each agent’s probability of voting yes (including that of agents not in the coalition) could be
increased by n×5% by applying social pressure. In
addition, if ag1 herself was in the coalition, then for an
additional cost of 2000 she would have switched her vote
to yes.
Given these beliefs, the degree of blameworthiness for the entire
group is ≈0.390, while ag1’s degree of blameworthiness is
≈0.073.
* ag2: ag2 held essentially the same beliefs as ag1,
except that the additional cost necessary for her to change
her vote for coalitions that she was in was 500
instead of 2000.
Given these beliefs, the degree of blameworthiness of the entire
group is ≈0.390, while ag2’s degree of blameworthiness
is ≈0.120.
ag2 holds essentially the same beliefs as ag1, but her
cost of changing her own vote to yes is lower than
ag1’s. The degree of blameworthiness of
the entire group is the same with respect to both ag1’s
and ag2’s cost functions.
In the epistemic state that both agents share,
with agi’s cost function (for i=1,2),
the action
that maximizes degree of blameworthiness is
the action where social pressure is applied by all, but
agi does not change her view. Thus, the cost of
agi changing her view does not play
a role in determining the degree of group blameworthiness.
However, the blameworthiness of ag2 (according to
ag2’s cost function) is
in fact greater than that of ag1 (according to ag1’s cost
function), as
for some smaller groups the action that maximizes blame
consists of agi changing her view, so the lower cost for
ag2 to do so will end up making her more blameworthy.
This is
what we would expect; since it is less costly for ag2 to
vote yes, she intuitively ought to be more blameworthy for
not doing so.
* ag3 and ag4: ag3 held essentially the same
beliefs as
ag1 except that she believed that social pressure
would be less effective. In particular,
she believed that a coalition of n agents applying social
pressure for a cost of n×100 would result in
an increase of only n×3% in each agent’s probability of
voting yes.
With these beliefs and cost function, the degree of blameworthiness
for the entire group
is ≈0.317, and ag3’s degree of blameworthiness is
≈0.079.
ag4 held essentially the same beliefs as
ag1 except that she believed
that it would cost n×150 to get the social pressure applied
by n agents to increase each agent’s probability of
voting yes by n×5%.
Given these beliefs, the degree of blameworthiness for the entire
group is ≈0.361, and ag4’s degree of blameworthiness is
≈0.068.
ag3 and ag4 each share beliefs similar to ag1’s, but
they believe that social pressure will not be quite as
effective, either because it won’t have as much of an impact or
because it will be more costly. As expected, in both of these
cases the degree of blameworthiness of the whole group decreases, as
there is not as much
the group could have been expected to do to ensure that the
bill passed. It is worth noting, however, that the
blameworthiness of a particular agent may still go up, as it
does here for ag3. The reason for this is that, while the
total group blame goes down, if the group does not have
effective alternatives to ensure the desired outcome, then it
may be even more important for that particular agent to take
an action that can significantly affect the outcome. There are
several factors that will affect whether (and to what extent)
individual blameworthiness increases or decreases, such as the
difference in cost, difference in expected effect, and the
balance parameter N.
* ag5: ag5 shared the same beliefs as ag1 with
regard to what actions can be taken and the costs of taking
those actions, but was more doubtful as to whether committee
members would vote yes without action being taken. In
particular, ag5 believed that each of the 6 other agents
started with a 40% chance of voting yes. She still
believed that a coalition of n agents could increase each
agent’s probability of voting yes by n×5% for a
price of n×100, and if she was in the coalition would
have changed her vote to yes for an additional cost of
2000.
With these beliefs and cost function, the degree of blameworthiness
for the entire group is ≈0.560, and ag5’s degree of
blameworthiness is ≈0.125.
The only difference between ag5 and ag1 was that ag5 believed there was a higher probability of the bill failing in the first place.
Relative to this belief, ag5 (as well as the total group) is deemed
to be more blameworthy, as it is more critical that the group
do something to ensure the bill have a higher change of
passing. To see how this plays out formally, consider the
case where all 7 agents are involved in applying social
pressure. Then the effect this would have if the base
probability was 60% would be a ≈0.453 increase in the
probability of the bill passing. If, on the other hand, the
base probability was only 40%, then the social pressure
would lead to a ≈0.651 increase in the probability of
a positive outcome. It is worth noting that if the
base probabilities of agents voting yes were too low, then
the blameworthiness would decrease, as the probability of the
social pressure being able to actually effect a change would
be low.
* ag6: Finally, ag6 held exactly the same beliefs
and used the same cost function as ag1, but unlike ag1, she voted yes.
In this case, the degree of blameworthiness for the entire group
is ≈0.157, and ag6’s degree of blameworthiness is
≈0.022.
As we would expect, ag6 is deemed to be less blameworthy than
ag1. The total group blame is also lower relative to this
epistemic state, as the probability of the bill failing to
pass is lower (because there is one
definitive yes vote) and so group action was less
important.
4 Related Work
---------------
Not surprisingly, there has been a tremendous amount of work on notions of blameworthiness across a wide range of fields. In this section, we survey some of the literature most relevant to this work from computer science, philosophy, and law.
Our definitions of blameworthiness are based directly on those of HK.
Chockler and Halpern \shortciteChocklerH03 also defined a notion of
blame that is related to but somewhat different from blameworthiness;
see [[Halpern and Kleiman-Weiner2018](#bib.bibx9)] for a discussion.
Our use of Shapley value in defining how to apportion group blame is
similar to (and partly inspired by) the work of Datta et
al. \shortciteDDPZ15. They define a measure of
the influence that each feature has on the classification of a
dataset.
So, for
instance, if one feature is gender, their measure is intended to give
a sense of how much influence gender had on how the data was
classified. They provide a set of desired axioms for influence and
show that there is a unique measure that satisfies these axioms, which
roughly corresponds to the probability that changing that feature
would change the classification. This seems to have natural relevance
to our setting if we consider each feature to be the action of an
agent and the classification to be the outcome. It is not sufficient,
however, as it is not clear how factors such as the cost of an action
(which is not relevant in the classification setting) should be
incorporated.
The Datta et al. approach also does not deal with the “group”
aspects of group blame.
It is in a sense closer to the work of HK than to ours.
For example, in the Tragedy of the Commons, it would assign
a low degree of blameworthiness to individual agents. While the group
aspects are not relevant in the setting of classification influence,
in our setting they are critical.
Ferey and Dehez \shortciteFD16 applied the Shapley value to
sequential-liability tort cases, cases where the amount of damage each
agent’s action brings about depends on the actions of earlier agents.
The court must decide how restitution of the damages should be
divided among the agents in such cases.
Ferey and Dehez used reasoning similar to ours to show that the Shapley value
gives reasonable outcomes in this context. They also showed that the
outcomes seem to align well with some prior case law and legal literature.
There has been much work in the philosophy literature on
moral responsibility, including its nature and the conditions under
which one ought to be held morally responsible. Particular
attention has been paid to the relation of moral responsibility to
such issues as free will and agency.
Eshleman \shortciteEshleman14 provides a good overview and further
references.
There has also been significant discussion in the philosophical literature on issues of collective moral responsibility: can it ever really exist, under what conditions would it exist, can group moral responsibility be in turn divided among the member agents, and how ought it be divided if and when it can be?
May and Hoffman \shortciteMH92 provide an
excellent collection of essays exploring some of the major ideas in
this area.
Cooper \shortciteCooper1968 argues that collective moral
responsibility is not always
divisible among agents. He considers an analogy of a delicious stew
made from various ingredients; we cannot say that any particular
ingredient has a specific degree of impact on the overall flavor;
rather, it is the precise way that the different flavors combined that led
to such a delicious stew. Similarly, he argues, there may be
instances where no particular agent can be ascribed blame for the
mis-actions of the group, but rather it emerges from the collective as
a whole.
In these examples, it seems that Cooper would reject the Efficiency axiom.
Van de Poel et al. \shortcitePRZ15 focus on what they call
*the problem of many hands* (a term originally due to
Thompson \shortciteThompson80): that is, the problem of allocating
responsibility to individual agents who are members of a group that is clearly
responsible for an outcome.
They formalize some of their ideas using a variant
of the logic CEDL (*coalition epistemic dynamic logic*)
[[De Lima and Royakkers2015](#bib.bibx5)].
Unfortunately, CEDL cannot directly capture counterfactuals, nor can
it express quantitative notions like probability. Thus,
it cannot capture more quantitative
tradeoffs between choices that arise when defining degree of
blameworthiness.
Finally, it is worth mentioning some of the factors that come into
play in legal notions of blameworthiness. Here we focus on two in
particular: joint and several liability
and normality. In tort cases
where defendants are jointly and severally liable, each defendant can be
considered to be independently liable for the full extent of damages.
Thus the injured party can recover the full amount of damages from
any of the defendants; it is up to that defendant who ends up paying
damages to then
attempt to recover some of the payment from other guilty
parties. Thus, if two parties are guilty for an outcome but
one does not have the means to make restitution or is
inaccessible, the other party must make full restitution.
This may be viewed as suggesting that there are
cases where the law deems each agent who is sufficiently responsible
as being fully blameworthy for the outcome rather than just having a
portion of the blameworthiness.
However, a more reasonable interpretation is that the law takes into
account considerations other than just degree of blameworthiness when
imposing penalties. Nevertheless, considerations of blameworthiness
are likely to come into
play when the defendant who is compelled to pay attempts to recover
some damages from the other defendants.
When joint and several liability should be applied is a complicated
matter in the legal literature
(see, e.g., [[Prosser1936](#bib.bibx15)]).
Another notion at play in legal considerations of blameworthiness is
the legal norm. The only considerations we have built into our
definitions are expected affect on the outcome and the cost of
actions. In the law, however, the extent to
which an agent is judged to have deviated from the legal norm may play a
role in judgments of blameworthiness for outcomes that were brought
about by multiple individuals
[[American Law Institute2000](#bib.bibx1)].
In future work we hope to further explore formalizations of some of
the notions at play in legal ascription of blameworthiness.
Work done on combining notions of normality with
causality [[Halpern2016](#bib.bibx11), [Halpern and Hitchcock2015](#bib.bibx8)] may prove relevant in dealing with issues
like legal norms.
5 Conclusion
-------------
We have provided a way to ascribe blameworthiness to groups of agents
that generalizes the HK definition.
We then showed how, given ascriptions of
group blameworthiness, the
Shapley value can be used to ascribe blameworthiness to individual
agents.
These two contributions are separable; if
an alternative definition of group blameworthiness is used,
the Shapley value could
still be used to ascribe blameworthiness to individual agents.
In considering these issues carefully, one obvious question is whether
we view our definitions as descriptive or prescriptive.
The answer is “both”. We plan to do experiments to
see if the
perceived difficulty of coordination really does affect how people
ascribe group blameworthiness, and to see whether an agent’s potential
marginal contribution to an account affects his ascribed degree of
blameworthiness. To the extent that we can view legal penalties as
proxies for degree of blameworthiness, we can also examine the legal
literature to see how these issues affected outcomes in legal cases
(although, as we observed earlier, there is clearly more to how
penalties are apportioned in legal cases than just blameworthiness).
Whether or not our definitions exactly match how people seem to
ascribe blameworthiness, we might still ask whether these definitions
might be useful as guides for ascribing blameworthiness in
situations involving self-driving cars (or a combination of
self-driving cars and humans).
Formalizing notions of moral responsibility will be
critical for the eventual goal of designing autonomous agents that
behave in a moral manner. We believe that blameworthiness as we have
considered it in this work is one important component of moral
responsibility, though not the whole story. In future work we hope to
continue exploring how these notions can be formalized and applied to
a wide variety of settings, especially legal settings; we hope that
others will join us in considering these problems.
#### Acknowledgments:
This work was supported in part by NSF grants IIS-1703846 and IIS-1718108,
ARO grant W911NF-17-1-0592, and a grant from the Open Philanthropy
project. We would like to thank Bruce Chapman for pointing
out the work of Ferey and Dehez, and the
anonymous reviewers of the paper for comments that provided some
interesting food for thought. |
ebba5545-6c6b-4662-8a4f-614bdae91394 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | [AN #163]: Using finite factored sets for causal and temporal inference
Alignment Newsletter is a weekly publication with recent content relevant to AI alignment around the world. Find all Alignment Newsletter **[resources here](http://rohinshah.com/alignment-newsletter/)**. In particular, you can look through **[this spreadsheet](https://docs.google.com/spreadsheets/d/1PwWbWZ6FPqAgZWOoOcXM8N_tUCuxpEyMbN1NYYC02aM/edit?usp=sharing)** of all summaries that have ever been in the newsletter.
Audio version **[here](http://alignment-newsletter.libsyn.com/alignment-newsletter-163)** (may not be up yet).
Please note that while I work at DeepMind, this newsletter represents my personal views and not those of my employer. This newsletter is a combined summary + opinion for the **[Finite Factored Sets sequence](https://www.alignmentforum.org/s/kxs3eeEti9ouwWFzr)** by Scott Garrabrant. I (Rohin) have taken a lot more liberty than I usually do with the interpretation of the results; Scott may or may not agree with these interpretations.
Motivation
----------
One view on the importance of deep learning is that it allows you to automatically *learn* the features that are relevant for some task of interest. Instead of having to handcraft features using domain knowledge, we simply point a neural net at an appropriate dataset and it figures out the right features. Arguably this is the *majority* of what makes up intelligent cognition; in humans it seems very analogous to **[System 1](https://en.wikipedia.org/wiki/Thinking,_Fast_and_Slow)**, which we use for most decisions and actions. We are also able to infer causal relations between the resulting features.
Unfortunately, **[existing models](https://en.wikipedia.org/wiki/The_Book_of_Why)** of causal inference don’t model these learned features -- they instead assume that the features are already given to you. Finite Factored Sets (FFS) provide a theory which can talk directly about different possible ways to featurize the space of outcomes and still allows you to perform causal inference. This sequence develops this underlying theory and demonstrates a few examples of using finite factored sets to perform causal inference given only observational data.
Another application is to **[embedded agency](https://www.alignmentforum.org/posts/p7x32SEt43ZMC9r7r/embedded-agents)** (**[AN #31](https://mailchi.mp/7d0e3916e3d9/alignment-newsletter-31)**): we would like to think of “agency” as a way to featurize the world into an “agent” feature and an “environment” feature, that together interact to determine the world. In **[Cartesian Frames](https://www.alignmentforum.org/s/2A7rrZ4ySx6R8mfoT)** (**[AN #127](https://mailchi.mp/f507d9a96785/an-127rethinking-agency-cartesian-frames-as-a-formalization-of-ways-to-carve-up-the-world-into-an-agent-and-its-environment)**), we worked with a function A × E → W, where pairs of (agent, environment) together determined the world. In the finite factored set regime, we’ll think of A and E as features, the space S = A × E as the set of possible feature vectors, and S → W as the mapping from feature vectors to actual world states.
What is a finite factored set
-----------------------------
Generalizing this idea to apply more broadly, we will assume that there is a set of possible worlds Ω, a set S of arbitrary elements (which we will eventually interpret as feature vectors), and a function f : S → Ω that maps feature vectors to world states. Our goal is to have some notion of “features” of elements of S. Normally, when working with sets, we identify a feature value with the set of elements that have that value. For example, we can identify “red” as the set of all red objects, and in **[some versions of mathematics](https://en.wikipedia.org/wiki/Set-theoretic_definition_of_natural_numbers#Frege_and_Russell)**, we define “2” to be the class of all sets that have exactly two elements. So, we define a feature to be a *partition* of S into subsets, where each subset corresponds to one of the possible feature values. We can also interpret a feature as a *question* about items in S, and the values as possible *answers* to that question; I’ll be using that terminology going forward.
A finite factored set is then given by (S, B), where B is a set of **factors** (questions), such that if you choose a particular answer to every question, that uniquely determines an element in S (and vice versa). We’ll put aside the set of possible worlds Ω; for now we’re just going to focus on the theory of these (S, B) pairs.
Let’s look at a contrived example. Consider S = {chai, caesar salad, lasagna, lava cake, sprite, strawberry sorbet}. Here are some possible questions for this S:
* **FoodType**: Possible answers are Drink = {chai, sprite}, Dessert = {lava cake, strawberry sorbet}, Savory = {caesar salad, lasagna}
* **Temperature**: Possible answers are Hot = {chai, lava cake, lasagna} and Cold = {sprite, strawberry sorbet, caesar salad}.
* **StartingLetter**: Possible answers are “C” = {chai, caesar salad}, “L” = {lasagna, lava cake}, and “S” = {sprite, strawberry sorbet}.
* **NumberOfWords**: Possible answers are “1” = {chai, lasagna, sprite} and “2” = {caesar salad, lava cake, strawberry sorbet}.
Given these questions, we could factor S into {FoodType, Temperature}, or {StartingLetter, NumberOfWords}. We *cannot* factor it into, say, {StartingLetter, Temperature}, because if we set StartingLetter = L and Temperature = Hot, that does not uniquely determine an element in S (it could be either lava cake or lasagna).
Which of the two factorizations should we use? We’re not going to delve too deeply into this question, but you could imagine that if you were interested in questions like “does this need to be put in a glass” you might be more interested in the {FoodType, Temperature} factorization.
Just to appreciate the castle of abstractions we’ve built, here’s the finite factored set F with the factorization {FoodType, Temperature}:
F = ({chai, caesar salad, lasagna, lava cake, sprite, strawberry sorbet}, {{{chai, sprite}, {lava cake, strawberry sorbet}, {caesar salad, lasagna}}, {{chai, lava cake, lasagna}, {sprite, strawberry sorbet, caesar salad}}})
To keep it all straight, just remember: a **factorization** B is a set of **questions** (factors, partitions) each of which is a set of **possible answers** (parts), each of which is a set of elements in S.
A brief interlude
-----------------
Some objections you might have about stuff we’ve talked about so far:
**Q.** Why do we bother with the set S -- couldn’t we just have the set of questions B, and then talk about answer vectors of the form (a1, a2, … aN)?
**A.** You could in theory do this, as there is a bijection between S and the Cartesian product of the sets in B. However, the problem with this framing is that it is hard to talk about other derived features. For example, the question “what is the value of B1+B2” has no easy description in this framing. When we instead directly work with S, the B1+B2 question is just another partition of S, just like B1 or B2 individually.
**Q.** Why does f map S to Ω? Doesn’t this mean that a feature vector uniquely determines a world state, whereas it’s usually the opposite in machine learning?
**A.** This is true, but here the idea is that the set of features together captures *all* the information within the setting we are considering. You could think of feature vectors in deep learning as only capturing an important subset of all of the features (which we’d have to do in practice since we only have bounded computation), and those features are not enough to determine world states.
Orthogonality in Finite Factored Sets
-------------------------------------
We’re eventually going to use finite factored sets similarly to Pearlian causal models: to infer which questions (random variables) are conditionally independent of each other. However, our analysis will apply to arbitrary questions, unlike Pearlian models, which can only talk about independence between the predefined variables from which the causal model is built.
Just like Pearl, we will talk about *conditioning on evidence*: given evidence e, a subset of S, we can “observe” that we are within e. In the formal setup, this looks like erasing all elements that are not in e from all questions, answers, factors, etc.
You might think that "factors" are not analogous to nodes or random variables in a Pearlian model. However, this isn't right, since we’re going to assume that all of our factors are *independent* from each other, which is usually not the case in a Pearlian model. For example, you might have a Pearlian model with two binary variables, e.g. “Variable Rain causes Variable Wet Sidewalk”; these are obviously not independent. The corresponding finite factored set would have *three* factors: “did it rain?”, “if it rained did the sidewalk get wet?” and “if it didn’t rain did the sidewalk get wet?” This way all three factors can be independent of each other. We will still be able to ask whether Wet Sidewalk is independent of Rain, since Wet Sidewalk is just another question about the set S -- it just isn’t one of the underlying factors anymore.
The point of this independence is to allow us to reason about *counterfactuals*: it should be possible to say “imagine the element s, except with underlying factor b2 changed to have value v”. As a result, our definitions will include clauses that say “and make sure we can still take counterfactuals”. For example, let’s talk about the “history” of a question X, which for now you can think of as the “factors relevant to X”. The *history* of X given e is the smallest set of factors such that:
1) if you know the answers to these factors, then you can infer the answer to X, and
2) any factors that are *not* in the history are independent of X. As suggested above, we can think of this as being about counterfactuals -- we’re saying that for any such factor, we can counterfactually change its answer and this will remain consistent with the evidence e.
(A technicality on the second point: we’ll never be able to counterfactually change a factor to a value that is never found in the evidence; this is fine and doesn’t prevent things from being independent.)
Time for an example! Consider the set S = {000, 001, 010, 011, 100, 101, 110, 111} and the factorization {X, Y, Z}, where X is the question “what is the first bit”, Y is the question “what is the second bit”, and Z is the question “what is the third bit”. Consider the question Q = “when interpreted as a binary number, is the number >= 2?” In this case, the history of Q given no evidence is {X, Y} because you can determine the answer to Q with the combination of X and Y. (You can still counterfact on anything, since there is no evidence to be inconsistent with.)
Let’s consider an example with evidence. Suppose we observe that all the bits are equal, that is, e = {000, 111}. Now, what is the history of X? If there wasn’t any evidence, the history would just be {X}; you only need to know X in order to determine the value of X. However, suppose we learned that X = 0, implying that our element is 000. We can’t counterfact on Y or Z, since that would produce 010 or 001, both of which are inconsistent with the evidence. So given this evidence, the history of X is actually {X, Y, Z}, i.e. the entire set of factors! If we’d only observed that the first two bits were equal, so e = {000, 001, 110, 111}, then we *could* counterfact on Z and the history of X would be {X, Y}.
(Should you want more examples, here are two **[relevant](https://www.alignmentforum.org/posts/qGjCt4Xq83MBaygPx/a-simple-example-of-conditional-orthogonality-in-finite)** **[posts](https://www.alignmentforum.org/posts/GFGNwCwkffBevyXR2/a-second-example-of-conditional-orthogonality-in-finite)**.)
Given this notion of “history”, it is easy to define orthogonality: X is orthogonal to Y given evidence e if the history of X given e has no overlap with the history of Y given e. Intuitively, this means that the factors relevant to X are completely separate from those relevant to Y, and so there cannot be any entanglement between X and Y. For a *question* Z, we say that X is orthogonal to Y given Z if X is orthogonal to Y given z, for every possible answer z in Z.
Now that we have defined orthogonality, we can state the *Fundamental Theorem of Finite Factored Sets*. Given some questions X, Y, and Z about a finite factored set F, X is orthogonal to Y given Z if and only if in every probability distribution on F, X is conditionally independent of Y given Z, that is, P(X, Y | Z) = P(X | Z) \* P(Y | Z).
(I haven’t told you how you put a probability distribution on F. It’s exactly what you would think -- you assign a probability to every possible answer in every factor, and then the probability of an individual element is defined to be the product of the probabilities of its answers across all the factors.)
(I also haven’t given you any intuition about why this theorem holds. Unfortunately I don’t have great intuition for this; the proof has multiple non-trivial steps, each of which I locally understand and have intuition for... but globally it’s just a sequence of non-trivial steps to me. Here’s an attempt, which isn’t very good: we specifically defined orthogonality to capture *all* the relevant information for a question, in particular by having that second condition requiring that we be able to counterfact on other factors, and so it intuitively makes sense that if the relevant information doesn’t overlap, then there can’t be a way for the probability distribution to have interactions between the variables.)
The fundamental theorem is in some sense a *justification* for calling the property “orthogonality” -- if we determine just by studying the structure of the finite factored set that X is orthogonal to Y given Z, then we know that this implies conditional independence in the “true” probability distribution, whatever it ends up being. Pearlian models have a similar theorem, where the graphical property of d-separation implies conditional independence.
Foundations of causality and time
---------------------------------
You might be wondering why we have been calling the minimal set of relevant factors “history”. The core philosophical idea is that, if you have the right factorization, then “time” or “causality” can be thought of as flowing in the direction of larger histories. Specifically, we say that X is “before” Y if the history of X is a subset of the history of Y. (We then call it “history” because every factor in the history of X will be “before” X by this definition.)
One intuition pump for this is that in physics, if an event A causes an event B, then the past light cone of A is a subset of the past light cone of B, and A happens before B in every possible reference frame.
But perhaps the best argument for thinking of this as causality is that we can actually use this notion of “time” or “causality” to perform causal inference. Before I talk about that, let’s see what this looks like in Pearlian models.
Strictly speaking, in Pearlian models, the edges do not *have* to correspond to causality: formally they only represent conditional independence assumptions on a probability distribution. However, consider the following Cool Fact: for some Pearlian models, if you have observational data that is generated from that model, you can recover the exact graphical structure of the generating model just by looking at the observational data. In this case, you really are inferring cause-and-effect relationships from observational data! (In the general case where the data is generated by an arbitrary model, you can recover a lot of the structure of the model but be uncertain about the direction of some of the edges, so you are still doing *some* causal inference from observational data.)
We will do something similar: we’ll use our notion of “before” to perform causal inference given observational data.
Temporal inference: the three dependent bits
--------------------------------------------
You are given statistical (i.e. observational) data for three bits: X, Y and Z. You quickly notice that it is always the case that Z = X xor Y (which implies that X = Y xor Z, and Y = Z xor X). Clearly, there are only two independent bits here and the other bit is derived as the xor of the two independent bits. From the raw statistical data, can you tell which bits are the independent ones, and which one is the derived one, thus inferring which one was *caused* by the other two? It turns out that you can!
Specifically, you want to look for which two bits are *orthogonal* to each other, that is, you want to check whether we approximately have P(X, Y) = P(X) P(Y) (and similarly for other possible pairings). In the world where two of the bits were generated by a biased coin, you will find exactly one pair that is orthogonal in this way. (The case where the bits are generated by a fair coin is special; the argument won’t work there, but it’s in some sense “accidental” and happens because the probability of 0.5 is very special.)
Let’s suppose that the orthogonal pair was (X, Z). In this case, we can *prove* that in *every* finite factored set that models this situation, X and Z come “before” Y, i.e. their histories are strict subsets of Y’s history. Thus, we’ve inferred causality using only observational data! (And unlike with Pearlian models, we did this in a case where one “variable” was a deterministic function of two other “variables”, which is a type of situation that Pearlian models struggle to handle.)
Future work
-----------
Remember that motivation section, a couple thousand words ago? We talked about how we can do causal inference with learned featurizations and apply it to embedded agency. Well, we actually haven’t done that yet, beyond a few examples of causal inference (as in the example above). There is a lot of future work to be done in applying it to the case that motivated it in the first place. The author wrote up potential future work **[here](https://www.alignmentforum.org/s/kxs3eeEti9ouwWFzr/p/yGFiw23pJ32obgLbw)**, which has categories for both causal inference and embedded agency, and also adds a third one: generalizing the theory to infinite sets. If you are interested in this framework, there are many avenues for pushing it forward.
#### **FEEDBACK**
I'm always happy to hear feedback; you can send it to me, **[Rohin Shah](https://rohinshah.com/)**, by **replying to this email**.
#### **PODCAST**
An audio podcast version of the **Alignment Newsletter** is available. This podcast is an audio version of the newsletter, recorded by **[Robert Miles](http://robertskmiles.com/)**. |
d5c254b3-124f-467a-afa4-4635af12b7af | trentmkelly/LessWrong-43k | LessWrong | Mental Calibration for Bayesian Updates?
Hey all,
After reading "How to Measure Anything" I've experimented a bit with calibration training and using his calibration tools, and after being convinced by his data on the usefulness of calibration in forecasting for the real world, have seen a big update in my own calibration.
I'm wondering if anybody knows of similar tools and studies on calibration of Bayesian updating. Broadly,I imagine it would look like:
1. Using the tools and calibration methods I already use to figure out how the feeling of "correctness" of my prior correlates to a numerical value.
2. Using similar (but probably not identical) tools to figure out how "convincing" the new data feels correlates to specific numbers.
3. Calibrating these two numbers to bayes theorom, such that I know approximately how much to update the original feeling to reflect the new information
4. Using mmenomic or visualization techniques to pair the new feeling with the belief, so that next time I remembered the belief, I'd feel the slightly different calibration.
Anyways, I'm curious if anyone has experimented with these processes, if there's any research on it, or it has been previously experimented with on lesswrong. I'd definitely like to lock down a similar procedure for myself.
I should note that many times, I already do this naturally... but my guess is I systematically over and under update the feeling based on confirmation bias. I'd like to recalibrate my recalibration :). |
0a417936-c81d-4f6d-b4ea-89950c705f99 | trentmkelly/LessWrong-43k | LessWrong | The Puritans would one-box: evidential decision theory in the 17th century
Evidential decision theory was used way earlier than I would have expected, and its development was motivated theologically.
Unconditional election is the Protestant (mainly Calvinist and Puritan) idea that God made the decisions of who would go to heaven and hell before He created the world (very similar to predestination). It is "unconditional" because nothing you do in your life can change the outcome of whether you go to heaven or hell.
If you believe in this unconditional election, then you face a dilemma: "if election is unconditional and grace is irresistible, then why not sit back and wait for the inevitable?" (Stearns and Brawner, “New England Church ‘Relations’ and Continuity in Early Congregational History”, 30). If this is the case, where did the term "Puritan work ethic" come from? Why were the Sepratists so religious? According to Stearns and Brawner, prayer was used to find out if you were "elected":
> The simplest and perhaps most satisfying method of dealing with this question was that of examining closely personal experience for signs of election. If an anxious Christian could find assurance that the seeds of regeneration had been planted in him, he could then be urged to labor with the Holy Ghost to bring forth the fruits of sanctification and thus participate actively in the work of his own redemption. But the spiritual physicians could not administer real comfort unless they could demonstrate convincingly that the symptoms of true faith and repentance were distinguishable from the simulacra produced by hope and fear. To this end they labored diligently. In 1592, William Perkins published a work entitled, A Case of Conscience, the greatest that ever was: How a Man may know whether he be a Child of God or No. The years that followed witnessed a great volume of sermons and treatises addressed in whole or in part to the same question. This literature may properly be called scientific, in the modern sense of the word, because it proceeded from the |
c1e43815-2de8-4dc3-9e1e-ceda9d649062 | trentmkelly/LessWrong-43k | LessWrong | it's hard to look at reality when you've already decided what reality looks like
So here I am, posting a thing.
I have a soapbox, which may have unintentionally put myself up as a source of authority, at least to myself.
There's an SMBC comic of Zach Weinersmith comics where he's said words to the effect of “my brain is weird, I get thoughts like “why are people still using this argument I already satirised it in a comic”” [1]
After I wrote my evidence not theory post I noticed some slight irritation while chatting to my father. "Hey you're doing this dynamic even though I already explained to some people on the internet why it's bad".
Let's try and steel man this subagent of mine that is worried about being authoritative,
Giving a speech to a large number of people, future allies and so on is a task I believe I wouldn't take lightly.
You're trying to explain to this crowd of people what your worldview is, what kind of person you are. This allows for greater coordination & cooperation. Folks in the audience will offer you different opportunities depending on who you say you are.
It doesn't seem too unreasonable that committing to be a certain way gets you a dump of utility. As you're "fixed" [2]. Yet it can also constrain you. Pretty sure this is going to happen regardless. [3]
This youtube artist marydoodles has talked about getting stuck in a style. In her case it's watercolour time-lapse with often a funny twist in the painting. I wouldn't be surprised if singers feel similarly, The audience’s “We liked your old stuff better" might be a bit rough. Bo Burnham a comedian has a wonderful if saddening (to me) song on it. [4]
let's imagine in a blog post: I say " X " . Later I find in particular cases turns out " ¬X ", turns out reality is vast and complicated and can't be compressed into little english predicates, what do ya know.
However maybe: I've just announced to the tribe that I'm going to stand by the norm of " X ". I'm kinda motivated not to notice " ¬X " because hey, that would be kinda awkward.
So what is this dynamic and how |
56f0352e-98d0-4730-a5b1-6450714c40e6 | trentmkelly/LessWrong-43k | LessWrong | 2024 Summer AI Safety Intro Fellowship and Socials in Boston
Tl;dr: The AI Safety Student Team (a group of students at Harvard) will be running two 8-week introductory reading groups this summer (in Boston and online), as well as summer socials (in Boston). Apply to our technical fellowship here or our policy fellowship here; express interest in our socials here.
Fellowships
We will host two intro fellowships (reading groups):
* Intro Technical Fellowship: covers topics such as neural network interpretability, learning from human feedback, goal misgeneralization in reinforcement learning agents, and eliciting latent knowledge. Curriculum, application, and FAQ available here. Students with machine learning experience are especially encouraged to apply.
* Intro Policy Fellowship: covers topics such as pace of progress in AI, potential threats from AI misuse and misalignment, AI audits and evaluations, and semiconductor policy. Curriculum, application, and FAQ available here.
Fellowships are primarily open to current or incoming undergraduate/graduate students at Boston universities, including Harvard and MIT. Recent grads and working professionals who will be in Boston during the 2024-25 academic year are also welcome to apply.
Fellowships will meet weekly in small cohorts with a facilitator experienced in AI safety/policy (either 2 hours in person with dinner, or 1 hour online).
We encourage you to apply (technical fellowship, policy fellowship) as soon as possible (deadline is Monday, June 10).
Socials
Our socials will be in Boston and are open to students and professionals interested in AI safety. Please fill out this form to get information about our socials! |
f064aad6-2d48-40dc-a022-50a4e0b3d215 | trentmkelly/LessWrong-43k | LessWrong | 200 COP in MI: Analysing Training Dynamics
This is the sixth post in a sequence called 200 Concrete Open Problems in Mechanistic Interpretability. Start here, then read in any order. If you want to learn the basics before you think about open problems, check out my post on getting started. Look up jargon in my Mechanistic Interpretability Explainer
Disclaimer: Mechanistic Interpretability is a small and young field, and I was involved with much of the research and resources linked here. Please take this sequence as a bunch of my personal takes, and try to seek out other researcher’s opinions too!
Motivating papers: A Mechanistic Interpretability Analysis of Grokking, In-Context Learning and Induction Heads
Background
Skip to motivation if you’re familiar with the grokking modular addition and induction heads papers
Several mechanistic interpretability papers have helped find surprising and interesting things about the training dynamics of networks - understanding what is actually going on in a model during training. There’s a lot of things I’m confused about here! How do models change over training? Why do they generalise at all (and how do they generalise)? How much of their path to the eventual solution is consistent across runs and directed vs a random walk? How and when do the different circuits in the model develop, and how do these influence the development of subsequent circuits?
The questions here are of broad interest to anyone who wants to understand what the hell is going on inside neural networks, and there are angles of attack on this that are nothing to do with Mechanistic Interpretability. But I think that MI is a particularly promising approach. If you buy the fundamental claim that the building blocks of neural networks are interpretable circuits that work together to complete a task, then studying these building blocks seems like a grounded and principled approach. Neural networks are extremely complicated and confusing and it’s very easy to mislead yourself. Having a good starting |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.