
id stringlengths 36 36 | source stringclasses 15 values | formatted_source stringclasses 13 values | text stringlengths 2 7.55M |
|---|---|---|---|
8c47f0b0-7424-45cb-bbf9-5e9a8c9f1d4f | awestover/filtering-for-misalignment | Redwood Research: Alek's Filtering Results | id: post472
[Thanks to Aryan Bhatt, Ansh Radhakrishnan, Adam Kaufman, Vivek Hebbar, Hanna Gabor, Justis Mills, Aaron Scher, Max Nadeau, Ryan Greenblatt, Peter Barnett, Fabien Roger, and various people at a presentation of these arguments for comments. These ideas aren’t very original to me; many of the examples of threat models are from other people.] In this post, I want to introduce the concept of a “rogue deployment” and argue that it’s interesting to classify possible AI catastrophes based on whether or not they involve a rogue deployment. I’ll also talk about how this division interacts with the structure of a safety case, discuss two important subcategories of rogue deployment, and make a few points about how the different categories I describe here might be caused by different attackers (e.g. the AI itself, rogue lab insiders, external hackers, or multiple of these at once). Rogue deployments Suppose you’ve developed some powerful model. (It might actually be many models; I’m just going to talk about a singular model for convenience.) You have some definition of a catastrophe —a failure that you don’t want to happen even once. Your AI is powerful enough that, in absence of any safety measures, it would pose a substantial risk of causing a catastrophe. In the terminology of “ Safety Cases: How to Justify the Safety of Advanced AI Systems ”, we’d phrase this as “the model is too powerful for us to make inability arguments for safety.” (Sometimes I use the word “catastrophe” to include things like “the AI escapes the datacenter”. Right now, I’m excluding that. I want to reserve “catastrophe” for the end result that we find unacceptable, e.g. the AI or another adversary amassing power, launching nukes, starting a war, building superintelligence, etc.) For the moment, let’s be agnostic between various adversaries who might try to cause a catastrophe (AI or various humans). You have some safety measures that you’ve put into place to prevent the catastrophe from occurring. Safety measures are interventions that are applied to all of the deployments of your model (to any users, including just internal users) that try to prevent safety problems. This might include control measures like trusted monitoring , and security measures to make it harder to exfiltrate your model weights . A rogue deployment is a deployment of your model where the safety measures are absent. For example: an AI hacking its datacenter and running itself while hiding what it’s doing from its creators an AI self-exfiltrating and running itself on unmonitored servers someone stealing the AI and running it in their own datacenter You can classify AI catastrophes based on whether they involve a rogue deployment or not: In the case of a catastrophe that doesn’t involve rogue deployment, the catastrophe happened with all your safety measures in place the whole time; these measures just didn’t suffice to spot (or prevent) that something terrible was happening until it was too late. For catastrophes that did involve rogue deployment, the catastrophe happened in two steps: Firstly, while the safety measures were in place, something went wrong such that a rogue deployment could occur. (Perhaps there was a security failure, or a failure of control that allowed an AI to run itself unmonitored in its datacenter.) Secondly, that rogue deployment caused a catastrophe. (Another way of phrasing all this would be to talk about instrumental vs terminal catastrophes—the terminal catastrophe is the end state we wanted to avoid, and the instrumental catastrophe is something happening that makes the situation go out of our control such that a terminal catastrophe is now likely and it’s much harder for us to prevent it. So in this terminology, establishing a rogue deployment is the central example of an instrumental catastrophe.) Rogue deployments and safety cases I think labs should probably make safety cases for models capable of causing catastrophe in two parts, matching those two classifications of catastrophe: To prevent catastrophe without rogue deployment, we ensure: While our safety measures are in place, the AI won’t directly cause any catastrophes. To prevent catastrophe with rogue deployment, we ensure: While our safety measures are in place, no rogue deployments will happen. People often think of the first of those as the responsibility of the safety people, and the second as the responsibility of the security people. But I think this is wrong. At least when you’re thinking about AI control, I think the safety people should consider both of these to be their problem. For example, if the AIs you’re using for software engineering and ML development inside the AI lab are scheming, I think their best strategy for causing a catastrophe is quite likely to involve a rogue deployment, because (in absence of control measures) these models will probably need affordances that they could leverage to make a rogue deployment. More on catastrophes with rogue deployment There are two main varieties of this threat model: Weight exfiltration → rogue external deployment. Your model is exfiltrated from the datacenter, at which point it is run on hardware you don’t control, and fine-tuned to remove safety training, etc. Rogue internal deployment. The model is run inside the lab’s datacenter. I think this is an underrated possibility. It might look like one of these: The model itself might, when deployed as an agent doing AI development , run itself in an unauthorized way. For example, the lab might try to ensure that whenever the untrusted model is used, a trusted model looks over the chat transcript to make sure it’s not visibly scheming or trying to hack the lab. If the untrusted model is doing AI development on a computer that has its own weights, it can directly implement an unmonitored LLM agent by using the compute it has access to to run inference on those model weights. Employees of the AI company might run the model in an unauthorized way. This looks similar to the previous failure mode, except that an employee did it rather than the model. Employees might want to misuse the model for personal gain or in order to engage in fanatical terrorism. Senior leadership of the lab might want to use the model in unauthorized ways as part of a power struggle against other lab insiders, external critics or competitors, regulators, or governments. Or an employee might just skip or override safety steps out of laziness or incompetence. External hackers might implement noncompliant internal deployments and then use them from outside. For example, suppose someone hacks the AI lab but then finds themselves unable to exfiltrate the model. In this case, the hackers can run an unauthorized internal deployment that they can access from outside the lab, which allows them to get most of the benefits of an exfiltrated model. The main reason to worry about rogue deployments is that causing a catastrophe seems fundamentally hard (in that it requires the AI to either do a small number of wildly superhuman actions, or a large number of non-wildly-superhuman actions), but launching a rogue deployment seems fundamentally easy . Causing a catastrophe involves serious amounts of real work. If you want to amass globally-relevant amounts of power by acquiring wealth, building weapons, gaining mass influence, or whatever, you need to do something that humans would usually find very difficult. So if we’re talking about AIs that are not wildly more creative and intelligent than humans (which I expect to be the case for early transformative models ), the AI will have to take a lot of actions while working towards the catastrophe, which gives your safety measures lots of chances to catch it. In contrast, launching a rogue deployment is fundamentally very simple : if you have model weight access and you’re running the model in a Jupyter notebook, you might be able to launch a rogue internal deployment that has a serious chance of leading to catastrophe in twenty lines of simple Python code. (I made this argument a little more here .) And once there’s a rogue deployment, the AI’s actions are much less constrained—it’s much more able to take the huge number of sketchy-actions that are probably required to cause the catastrophe. My current sense is that if you implemented a simple AI control scheme like trusted monitoring, and your AIs had full model weight access and substantial compute resources, it would be very hard to confidently rule out rogue internal deployments. I’m unsure how costly it would be to mandate that internal use of AI is always monitored carefully enough to prevent this. Rogue internal deployments might be much harder to prevent than weight exfiltration, because it might be really easy to detect model weights being exfiltrated from a datacenter, e.g. just by imposing weight upload limits . But it’s easier to reliably (though expensively) shut them down than rogue external deployments, because you know where the datacenter is and can shut the whole thing down or destroy it if necessary. Our AI control paper was mostly motivated by rogue-deployment-style catastrophes. One crucial way that rogue deployments vary is how much compute the rogue deployment has access to. This might be anywhere from “the model wrote an unauthorized scaffold using the compute that it was supposed to be using for a fine-tuning run that had 100 GPU-hours authorized for it” to “the model totally compromised the datacenter, such that it can now use a majority of the compute on the datacenter for its purposes without the humans noticing”. I think there are a lot of plausible catastrophes that happen via the AI first establishing a rogue deployment with a compute budget that is highly limited (e.g. 10 GPUs for 1 hour) but that nevertheless allows it to do thousands of sequential unrestricted actions looking for ways to get itself a longer-term rogue deployment. More on catastrophes without rogue deployment As I said above, I suspect that catastrophes that don’t involve rogue deployments require large numbers of model actions (at least for early transformative models) and so give the lab many chances to spot them. Given this, how might AIs be able to cause catastrophes? If the situation is as I imagine, and the lab is implementing many safety measures, then I think the possibilities for failure are more like these: Amazing, long-term jailbreaks. If you’re implementing trusted monitoring (that is, having a weaker model read over everything the stronger model is doing at deployment time), as is already industry practice, then perhaps a user or the AI itself will find an extremely powerful jailbreak which causes the trusted monitor to always decide that everything is fine; given this powerful jailbreak, any of the failure modes in the previous list are plausible. Large-scale steganographic reasoning. The models might be able to do the large quantities of intellectual labor required to cause a catastrophe, using some kind of code that humans and trusted monitors are totally unable to notice. See here for more on this. Extremely subtle long-term failure. The model might be able to engage in subtle manipulation that in aggregate causes a catastrophic outcome, because even though you look at some of the answers, the biases are subtle enough that you miss them. For example, perhaps the model slowly manipulates public opinion while used widely as a companion, or it subtly introduces carefully-chosen errors while producing intelligence analyses for the CIA that lead them to recommend a foolish war, or it sabotages your safety research so that you falsely believe that some models are aligned or safe when they aren’t. And two ways my central model might be wrong: Maybe there’s some extremely leveraged actions that AIs can take to cause catastrophes in few actions; this requires believing that for some reason AIs are massively comparatively advantaged at causing catastrophes compared to other activities. I am not aware of compelling cases for why this might happen. The most compelling case I have heard is that the AIs might be able to sabotage the alignment of successor AIs in a small number of actions, for example by data poisoning. Maybe the lab isn’t able to take advantage of the fact that catastrophes take large numbers of actions. For example, if it deploys models capable of causing catastrophes with stringent privacy guarantees, it might be unable to prevent attackers from incrementally iterating to develop jailbreak strategies. In order to prevent this, we might need to mandate that AI labs don’t have stringent privacy policies, or we might need strict KYC. See Managing catastrophic misuse without robust AIs for Ryan Greenblatt’s take on safety measures that aim to prevent AI-enabled bioterrorism without relying on perfectly robust AIs; note that many of these require the lab to have policies that might be controversial. Different attacker profiles I think it’s interesting to consider how all these categories of catastrophe interact with all the following possible attackers: Scheming AIs. Lab insiders. These might be spies or rogue employees, possibly including very senior employees. External attackers. Some combination of the above. In particular, if there are spies at the company, it’s very likely that they’ll collaborate with external attackers. Here’s a table commenting briefly on the mix-and-match of these with the catastrophe varieties above. Schemers Rogue insiders External attackers Catastrophe without rogue deployment Slowly sabotaging safety research. Manipulating opinion. Sending an innocent biologist DNA sequences that turn out to be a catastrophic pandemic. Insiders don’t have much of an advantage over external attackers here, except inasmuch as they have more privileges than external people. This is what people normally think about when they say “misuse”. E.g. jailbreaking the model and then getting bioweapons advice with catastrophically dangerous results. Rogue internal deployment Hacking the datacenter. This is why I’m worried about internal use of AI for AI R&D . An insider uses their privileged fine-tuning access to spin up a personal chatbot/LM agent that they can remove safety training from, train on withheld dangerous data, and run unmonitored. Internal exploitation. This is analogous to if an attacker wanted to misuse a private key and did this by hacking into the computer with the key and, instead of exfiltrating it, they used it on that computer to sign the messages they needed and exfiltrated the messages. Rogue external deployment Self-exfiltration Insider exfiltration Exfiltration Hot takes that I can say using the above concepts I think that rogue internal deployment might be a bigger problem than rogue external deployment, mostly because I’m pretty bullish on simple interventions to prevent weight exfiltration. But is rogue internal deployment even a problem? Depends on the API needed in order to do work . If the AIs are doing lots of research with direct weight access, seems like a pretty big problem, probably. I think that guarding against rogue insiders and external attackers might mostly suffice for guarding against schemers. So if it turns out that it's really hard to convince labs that they need to be robust to schemers, we might be safe from human-level schemers anyway. |
b332b52d-de88-4dad-99a5-c457930a9680 | trentmkelly/LessWrong-43k | LessWrong | Covid 3/4: Declare Victory and Leave Home
Health officials look on in horror as individuals both vaccinated and unvaccinated, and state and local governments, realize life exists and people can choose to live it.
This is exactly what I was worried about back in December when I wrote We’re F***ed, It’s Over. The control system would react to the good news in time to set us up to get slammed by the new strains, and a lot of damage can get done before there is a readjustment. The baseline scenario from two months ago is playing out.
The good news, in addition to the positive test percentages continuing to drop for now, is that we have three approved vaccines rapidly scaling up and are well ahead of the vaccine schedule I anticipated, having fully recovered from last week’s dip, and it looks like the new strains are more infectious but not on the high end of the plausible range for that.
The J&J vaccine was approved this week, after a completely pointless three week delay during which no information was found and (for at least the first two-thirds of it) no distribution plan formed. Anything I put at 98%+ on a prediction website isn’t fully news, but the other 2% would have been quite terrible. Supply will initially be limited, but will expand rapidly, including with the help of Merck.
Meanwhile, now that we were provided a sufficiently urgent excuse that we were able to show that mRNA vaccines work, we’ve adopted them to create a vaccine for Malaria. Still very early but I consider this a favorite to end up working in some form within (regulatory burden) number of years. It’s plausible that the Covid-19 pandemic could end up net massively saving lives, and a lot of Effective Altruists (and anyone looking to actually help people) have some updating to do. It’s also worth saying that 409k people died of malaria in 2020 around the world, despite a lot of mitigation efforts, so can we please please please do some challenge trials and ramp up production in advance and otherwise give this the urgency it deser |
0b711462-4891-49de-ad0c-7b41fc42997b | trentmkelly/LessWrong-43k | LessWrong | Announcing: The great bridge
Original post: http://bearlamp.com.au/announcing-the-great-bridge-between-communities/
----------------------------------------
In the deep dark lurks of the internet, several proactive lesswrong and diaspora leaders have been meeting each day. If we could have cloaks and silly hats; we would.
We have been discussing the great diversification, and noticed some major hubs starting to pop up. The ones that have been working together include:
* Lesswrong slack
* SlateStarCodex Discord
* Reddit/Rational Discord
* Lesswrong Discord
* Exegesis (unofficial rationalist tumblr)
The ones that we hope to bring together in the future include (on the willingness of those servers):
* Lesswrong IRC (led by Gwern)
* Slate Star Codex IRC
* AGI slack
* Transhumanism Discord
* Artificial Intelligence Discord
----------------------------------------
How will this work?
About a year ago, the lesswrong slack tried to bridge across to the lesswrong IRC. That was bad. From that experience we learnt a lot that can go wrong, and have worked out how to avoid those mistakes. So here is the general setup.
Each server currently has it's own set of channels, each with their own style of talking and addressing problems, and sharing details and engaging with each other. We definitely don't want to do anything that will harm those existing cultures. In light of this, taking the main channel from one server and mashing it into the main channel of another server is going to reincarnate into HELL ON EARTH. and generally leave both sides with the sentiment that "<the other side> is wrecking up <our> beautiful paradise". Some servers may have a low volume buzz at all times, other servers may become active for bursts, it's not good to try to marry those things.
Logistics:
Room: Lesswrong-Slack-Open
Bridged to:
* exegesis#lwslack_bridge
* Discord-Lesswrong#lw_slack_main
* R/rational#lw_slack_open
* SSC#bridge_slack
I am in <exegesis, D/LW, R/R, SSC> what does this mea |
d3858a66-bb76-4eb1-b7f4-0c0e62b8beb1 | trentmkelly/LessWrong-43k | LessWrong | How bad is chlorinated water?
chlorine disinfection
Today, most water distributed to people for drinking is chlorinated. Bleach is also widely used for disinfection of surfaces.
The exact ways chlorine kills microbes aren't fully understood, but the main reasons are believed to be:
* oxidation of thiols of enzymes
* ring chlorination of amino acids
* direct DNA damage
Obviously, high levels of chlorine are bad for humans. Chlorine gas was used as a chemical weapon in WW1, and drinking bleach can kill people. As for longer exposure to lower levels, studies have found associations between lung damage and use of indoor swimming pools, but the extent to which harmful effects of chlorine have thresholds from saturation of enzymes is still unclear.
Dietary studies are notoriously hard to get good results from, and studying chlorinated water has similar issues. Studies have concluded that, eg, over a few weeks, chlorinated water doesn't affect lipid metabolism. But is that what you'd expect to see? If there were effects, what would they be?
effects of ingested chlorine
Engineers try to minimize levels of some compounds in water that can react with chlorine to produce toxic substances, such as chloramines and chloroform. But...there are organic compounds in the stomach. What about reactions of chlorine after it's consumed?
Stomachs are acidic. That means amines are mostly protonated and unlikely to react, but other chlorination reactions are catalyzed. My understanding is that the main types of chlorine reaction in stomachs are:
* oxidation of thiols (this doesn't concern me much)
* phenol chlorination (eg 3-chlorotyrosine production)
* tryptophan oxidation
* double bond oxidation to halohydrins
Chlorotyrosine production happening is intuitive, and it's been validated by some rat studies. But the topic of reactions of chlorine in stomachs hasn't been studied very much in general.
What happens to chlorotyrosine and halohydrins afterwards?
In cells, aliphatic chlorinated compounds tend t |
cee815eb-eead-4395-9dbb-a409ba492153 | trentmkelly/LessWrong-43k | LessWrong | Evolved Bayesians will be biased
I have a small theory which strongly implies that getting less biased is likely to make "winning" more difficult.
Imagine some sort of evolving agents that follow vaguely Bayesianish logic. They don't have infinite resources, so they use a lot of heuristics, not direct Bayes rule with priors based on Kolmogorov complexity. Still, they employ a procedure A to estimate what the world is like based on data available, and a procedure D to make decisions based on their estimations, both of vaguely Bayesian kind.
Let's be kind to our agents and grant that for every possible data and every possible decision they might have encountered in their ancestral environment, they make exactly the same decision as an ideal Bayesian agent would. A and D have been fine-tuned to work perfectly together.
That doesn't mean that either A or D are perfect even within this limited domain. Evolution wouldn't care about that at all. Perhaps different biases within A cancel each other. For example an agent might overestimate snakes' dangerousness and also overestimate his snake-dodging skills - resulting in exactly the right amount of fear of snakes.
Or perhaps a bias in A cancels another bias in D. For example an agent might overestimate his chance of success at influencing tribal policy, what neatly cancels his unreasonably high threshold for trying to do so.
And then our agents left their ancestral environment, and found out that for some of the new situations their decisions aren't that great. They thought about it a lot, noticed how biased they are, and started a website on which they teach each other how to make their A more like perfect Bayesian's A. They even got quite good at it.
Unfortunately they have no way of changing their D. So biases in their decisions which used to neatly counteract biases in their estimation of the world now make them commit a lot of mistakes even in situations where naive agents do perfectly well.
The problem is that for virtually every A and D pair t |
d8594891-26aa-443c-9139-df98953d56b4 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Measuring Non-Probabilistic Uncertainty: A cognitive, logical and computational assessment of known and unknown unknowns
MEASUR ING NON -PROBABILISTIC UNCERTAINTY
A cognitive, logical and computational assessment of known and unknown unknowns
Florian Ellsaesser
Frankfurt School of Finance & Management
Guido Fioretti
University of Bologna
Contact: guido.fioretti@unibo.it
Abstract
There are two reasons why uncertainty may not be adequately described by Probability
Theory. The first one is due to unique or nearly -unique events, that either never realized or
occu rred too seldom for frequencie s to be reliabl y measured . The second one arises when one
fears that something may happen, that one is not even able to figure out, e.g., if one asks:
“Climate change, financial crises, pandemic, war, what next?”
In both cases, simpl e one -to-one cognitive maps between available alternatives and possible
consequences eventually melt down. However, such destructions reflect into the changing
narratives of business executives, employees and other stakeholders in specific, identifiable
and differential ways. In particular, texts such as consultants’ reports or letters to
shareholders can be analysed in order to detect the impact of both sorts of uncertainty onto
the causal relations that normally guide decision -making.
We propose structural measures of c ognitive maps as a means to measure non -probabilistic
uncertainty, eventually suggesting that automated text analysis can greatly augment the
possibilities offered by these techniques. Prospective applications may concern actors ranging
from statistic al institutes to businesses as well as the general public .
Keywords : Radical Uncertainty, Cognitive Maps, Scenario Planning, Deciding Not To
Decide , Machine Learning
JEL Classif ication : B49, D99, C02
Introduction
While most of the times uncertainty is nicely expressed by means of some probability
distribution, there exist two sorts of problems where this is not the case. The first one occurs
when probabilities must be measured on too small a sample, or no sample at all in the limit
case of unique events. The second one occurs after some event has happened, that one had not
been able to figure out. One may suspect that other surprising, currently unconceivable events
may occur, a c ircumstance which generates uncertainty about the possibilities being envisaged
rather than the relations between them. With possibly awkward, but certainly impressive
expressions these two sorts of uncertainty have been labelled as due to “known unknowns” and
“unknown unknowns,” respectively (Rumsfeld, 2011; Feduzi & Runde, 2014; Faulkner et al.,
2017). In both cases, neuro -psychological experiments involving observation of functional
magnetic resonance imaging and electroencephalograms (Gluth et al., 2012 , 2013, 2017) come
along with research in logic and decision theory that, we shall suggest, lends itself to machine
learning (ML) applications onto textual data.
In logic, t he first case is exemplified by Ellsberg’s conceptual experiment. Ellsberg
(1961) asked to consider two urns, A and B. Urn A entails black and white balls in equal
proportions, whereas all you know about urn B is that it entails black and white balls. Ellsberg
remarked that, although the Principle of Sufficient Reason suggests to attach probability ½ to
extract a white (or a black) ball from either urn, no -one would experience the same amount of
uncertainty with B as with A.
From a purely conceptual point of view, two solutions exist for this conundrum, which
correspond to the fre quentist and the subjectivist interpretation of probability, respectively.
According to the frequentist interpretation case A is equivalent to tossing a coin infinitely many
times, whereas B amounts to expressing oneself on a sample of size zero. Thus, sam ple size
marks the difference between A and B.
By contrast, within a subjectivist interpretation either this is not an issue (De Finetti,
1931) or, in more recent versions, sub -additive probabilities would be called to rescue ( Gilboa,
1987; Schmeidler, 198 9). According to this extension of the basic theory, probabilities are
allowed not to sum up to unity if information is less than perfect. Thus, in the case of Ellsberg’s
paradox one would assign ½ to the probability of either extracting a black or a white ball from
urn A, but zero probability to extract either a white or a black ball from B. Taking expectations
would suggest that decision -makers prefer urn A, which conforms to common sense.
However, both the frequentist and the subjectivist solution show t heir limits if one is
confronted with urns of type B only. If all options are such that little or no experience is
available, measuring probabilities on nearly -zero samples or attaching very low sub -additive
probabilities to all consequences is of little h elp. In economics, this has been recognized to be
the case of uninsurable risk (Knight, 1921) , where p ossibilities are known, but probabilities are
unknown. It’s the case of “known unknowns.”
Neuro-psychological experiments show that while information is being gathered neu-
ronal activity increase s until it reache s a threshold, at which point a decision is finally made
(Gluth et al., 2012). Correspondingly, decision theory theorizes of satisficing behaviour as
making a decision as soon as a certain aspirat ion level is reached (March and Simon, 1958)1
or, with greater emphasis on the need to accommodate conflicting options, choice deferral
(Tversky and Shafir, 1992). In general, the received wisdom is that – as it is the case with
uninsurable risk (Knight, 1921) – unless a sufficient amount of information has been gathered
no decision can be made.
By contrast, we shall submit that even in this case decision -makers can analyse the
structure of their mental rep resentations of possibilities, looking for areas where alternative
courses of action do not fan out into widely different consequences. In particular , we shall
document this practice in the context of Scenario Planning and, most importantly, we shall
point to the existence of geometrical representations of the intricacy of hyper graphs that can
be used to assess this sort of uncertainty.
The second case has a more profound origin and involves more destructive
consequences. The corresponding sort of uncertain ty, which has been eventually qualified as
“Keynesian,” “fundamental,” “true,” “epistemic,” “ontological” or “radical” uncertainty2
(Runde, 1990; Davidson, 1991; Dunn, 2001; Dequech, 2004; Lane & Maxfield, 2005; Kay &
King, 2020) arises when decision -make rs fear that something may happen, that they are not
even able to figure out. This sort of uncertainty is likely to be there if something that had not
been conceived actually materialized, turning an “unknown unknown” – a possibility whose
1 According to Gluth et al .’s (2012) experiments, the threshold decreases with time. By contrast, March and
Simon (1958) had theorized that the aspiration level would slowly increase once satisfaction is reached. These
two statements could be possibly recon ciled by observing that March and Simon had in mind real -world
situations where decision -makers could search for better alternatives, a circumstance that in Gluth et al .
(2012) was foreclosed by design.
2 While Davidson (1991) contrasts “epistemic” to “ont ological” uncertainty, taking the latter as a synonymous
of probabilistic uncertainty, Lane and Maxfield (2005) employ the term “ontological uncertainty” in pretty
much the same sense as Davidson's “epistemic” uncertainty.
very existence i s unknown (Rumsfeld, 2011; Feduzi & Runde, 2014; Faulkner et al., 2017) –
into a so -called “black swan .”
Just like measures of sample size or sub -additive probabilities can formally extend
utility maximization to include the case of imperfect information, incomplete preferences are
eventually called in in order to deal with unknown unknowns (Eliaz & Ok, 2006; Ok, Ortoleva
& Riella, 2012; Galaabaatar & Karni, 2013). We do not question the technical perfection of
this solution but we stress that, just as it h appened with sub -additive probabilities, technical
perfection does not imply usefulness. With sub -additive probabilities and incomplete
preferences utility maximization can be formally extended to encompass exotic types of
uncertainty, but if those sub -additive probabilities are all close to zero and if no preference
exists because alternatives cannot be formulated, expected utility maximization reduces to a
hollow shell.
We rather propose an alternative route out of the observation that no uncertainty is t here
insofar as the unknown remains unknown. Once again, neuro -psychological experiments
provide substantial insights.
According to Gluth et al . (2013, 2017), when subjects were faced with conflicting
evidence neurons emitted both excitatory and inhibitory signals that made overall activity
oscillate. These oscillations corresponded to decision being postponed , a state of mind which
they labelled deciding not to decide (Gluth et al., 2013) in order to stress th at it ar ose out of
complex neuronal activity rather than rest .
In the above experiments, conflicting evidence was the origin of the inability to make
a decision. We submit that the second sort of non -probabilistic uncertainty arises when
something that had not been imagined – an unknown unknown – suddenly enters the set of
possibilities envisaged by a decision -maker and upsets their network of causal relations.
Furthermore, we suggest that this sort of non -probabilistic uncertainty can be observed
on mental representations of possibility sets. More specifically, we submit that occasional
disruption of the graph of causal relations that link alternatives to consequences can reveal its
emergence. In particular, we shall illustrate this sort of disruption in th e self -representation of
the BioTech industry with respect to “Big Pharmas.”
Cognitive maps are essential in order to define measures for both sorts of non -
probabilistic uncertainty. In their simplest version (Axelrod, 1976; Sigismund Huff, 1990;
Sigismund Huff, Huff & Barr, 2000; Sigismund Huff & Jenkins, 2002), cognitive maps are
network representations of world views whose nodes are concepts linked to one another by
causal relations. Cognitive maps are traditionally obtained by analysing texts or recorde d
speeches, such as letters to shareholders, technical reports, or interviews, but we shall point
also to the possibility of automatically extracting them by means of algorithms that can be
potentially applied to very large amounts of data.
We develop our arguments in the ensuing two sections. In the first one, we propose
structural measures that can be applied to causal relations of given alternatives and
consequences when too little empirical evidence is available to measure probabilities (known
unknowns) . In the second one, we propose structural measures that can be applied when a
novel, unexpected “unknown unknown” appears. In the first case, we point to Scenario
Planning as a decision -making tool to which, in certain circumstances, our techniques could be
applied. In the second case we point to disruptions of cognitive maps. The ensuing third section
sketches machine learning algorithms that are able to speed up measurement by several orders
of magnitude. A final section concludes with a general assessment of the prospects of our
measurement techniques.
The Complexity of Scenarios
Scenario Planning emerged among business strategists as a procedure to become aware of
available options through extensive discussion and intentional search for non -obvious
possibilities that may upset the received wisdom (Schoemaker, 1995; Van der Heijden, 2000;
Chermack, 2004; Roxburgh, 2009; Ramírez, Österman & Grönquist, 2013; Erdmann, Sichel &
Yeung, 2015). The outcome of this exercise is a set of scenarios that have the purpose of
preparing strategists for non -trivial future contingencies.
Scenarios constitute a network of concepts linked to one another by causal relations.
Indeed, the network representation of scenarios is nothing but their authors' cognitive map
(Goodier et al., 2010; Amer, Jetter & Daim, 2011; Jetter & Schweinfort, 2011; Alipour et al.,
2017 ).3 Although in many instances probabilities can be attached to the causal relations that
lead to alternative scenarios and the scenario exercise becomes indistinguishable from taking
expectations, Scenario Planning is most valuable when probabilities are unknown (Wilson,
2000; Goodwin & Wright, 2001; Wright & Goodwin, 2009; Ramirez & Selin, 2014). In this
3 These Authors generally adopt a probabilistic interpretation of scenarios. However, the connection they
make between scenarios and cognitive maps remains equally valid.
case, Scenario Planning is valuable insofar as it allows an analysis of the structure of causal
relations that link known possibilities to one another, whose probabilities are unknown. We
are, in other words, in the case of “known unknowns.”
For instance, the scenarios described in Figure (1) illustrate a possible cognitive map
of the consequences of the Jan 2016 UN decision to lift sanctions on Iran in t erms of oil exports
(loosely inspired by Alipour et al., 2017). This cognitive map does not simply take account of
the presumably larger offer of oil on the world market with the ensuing price dynamics, but
also less obvious factors such as the availabilit y of shale oil as well as renewable energy
sources. Due to these factors, a non -obvious Scenario 2 appears along with the rather obvious
Scenario 1. According to Scenario 2, in spite of lifting sanctions both production and revenues
will stagnate, which is just the opposite of what one would expect.
Figure 1. One and the same action - lifting sanctions on Iran - may lead to quite different
outcomes depending on many other factors, such as growing availability of renewable energy
sources or shale oil. One -to-many causal relations are highlighted in red . Loosely inspired by
Alipour et al. (2017).
Notably, the authors of the scenarios illustrated in Figure (1) could not attach any
probability to the causal relations that would yield either Scenario 1 or Scenario 2. Novel
technologies and unprecedented political alliances made it impossible to provide a numerical
estimat e more r eliable than a personal guess. Just like Ellsberg’s urn B (Ellsberg, 1961), also
in this case it all depends on the lack of a sufficiently large sample.
However, in spite of all uncertainty on probability values, Scenario Planning is far from
useless. Inde ed, it is even more useful than in the case probabilities could be attached to it , for
without probabilities Scenario Planning is a tool for eliciting possibilities out of multiple points
of view (Stirling, 2010). For instance, in the above example becomin g aware of the non -
obvious Scenario 2 was the true goal of the scenario exercise.
From a structural point of view, the interesting portion of Figure (1) is the one -to-many
relation from “Lifting sanctions” to either Scenario 1 or Scenario 2. We maintain th at it makes
sense to analyse the structure of causal relations in exercises such as Scenario Planning in order
to assess the uncertainty generated by such one -to-many causal relations.
In order to keep matters tractable let us assume that cognitive maps ar e made of Evoked
Alternatives (EA), Perceived Consequences (PC), and causal relations from EA to PC (March
& Simon, 1958). For instance, the relevant portion of the cognitive map of Figure (1) is made
of one evoked alternative (lifting sanctions) and two p erceived consequences (increasing or
stagnant oil production, respectively).
Figure (2) illustrates three arrangements of causal relations between evoked alternatives
and perceived consequences. On the left (a), all causal relations are one -to-one. This is the
simple world where one perceives exactly which consequence follows from each of the evoked
alternatives. In the middle (b) is the extremely complex world where one perceives that any
consequence can follow from each of the evoked alternatives. On the right (c), is the somehow
intermediate situation where, in spite of several one -to-many relations, one knows that certain
evoked alternatives can only lead to a subset of the perceived consequences.
Figure 2. Three stylized cognitive maps linking evoke d alternatives (EAs) to perceived
consequences (PCs). In (a), a one -to-one mapping. In (b), the most confusing mapping where
anything may happen. In (c), an intermediate case.
The case illustrated in (c) is the most interesting one, because the network o f causal
relations exhibits a structure. One feature of this structure is that although certain areas are
tightly connected ( EA1 and EA2 with PC 1 and PC 2; EA4 and EA5 with PC 4 and PC 5), these areas
are more loosely connected with one another and therefore, even though it may be difficult to
tell the difference between selecting EA1 and EA2, it is possible to state that either choice is
different from either selecting EA4 or EA5. One other feature is that ther e are groups of
perceived consequences that are unlikely to occur in isolation from one another (for instance
PC 2 and PC 3 if one selects EA2). There fore, such sets of consequences constitute entities in
themselves.
In algebraic topology such sets are calle d simplices , and their arrangement in a
connected structure is a simplicial family , or hypergraph (Fioretti, 2023) . Their structure can
be analysed and subsumed by quantitative indicators based on Q-Analysis (see Appendix A).
In a nutshell, each evoked alt ernatives EAi corresponds to a simplex whose vertices a re the
perceived consequences PC ij to which it is connected. Thus, the simplices that constitute the
hypergraph have common faces whose dimensions depend on the number of perceived
consequences that th ey have in common. The structure of the hypergraph is such that the areas
of the decision problem where each evoked alternatives correspond to very many perceived
consequences are represented by clusters of simplices connected along high -dimensional faces.
These are the areas that generate high uncertainty . However, t his uncertainty is eventually
curbed if these areas are connected to one another by low -dimensional simplices as in Figure
(2), case (c).
Decision problems where simplices share high -dimensional faces obtain the greatest
benefits from Q-Analysis. In non -mathematical terms, this category includes all decision
problems where different alternatives imply partially similar consequences, such as diagnoses
of rare diseases whose symptoms appear in variable clusters of indicators and partially overlap
with those o f other diseases (Rucco et al., 2015), or alternative environmental policies that,
through complex feed -backs in the ecosystem, may yield partially overlapping negative
consequences (Eder et al., 1997; Forrester et al., 2015). Note that in the case of rare diseases,
as well as with policies that have a long -lasting impact on the environment, no reliable
probability is available.
Several measures can be defined on a hypergraph . In particular, it is possible to define
suitable complexity measures (Casti, 1989 ; Fioretti, 2001). For instance, one such measure
ascribes zero complexity to case (a), maximum complexity to case (b) and intermediate
complexity to case (c) (see Appendix A). In a modelling exercise, boundedly rational agents
could be assumed not to make any decision if complexity exceeds a threshold.
When Unexpected, Novel, Destructive Possibilities Materialize
Let us now focus on the reason why human beings may decide not to decide, namely when
they become aware that some destructive possibility may materialise, that is not among those
they are currently able to envisag e. Such sentiments make perfect sense once unexpected and
destructive events have been experienced, suggest ing that unthinkable novelties may appear in
a world that is governed by unknown laws, if at all. We submit that a series of cognitive maps
taken before, at the time of, and after one such dis ruptive event allows us to observe such states
of mind.
We illustrate our point with a series of cognitive maps in the BioTech industry extracted
from the technical reports of Ernst & Young , a dedicated consultant (James, 1996; See also
Appendix B). Among BioTech companies, a disruptive possibility materialized in 1990. Up to
1989 most of them were convinced that they would grow up to become able to produce and
market their own drugs. For the time being they had to stipulate strategic alliances with
pharmac eutical companies, but this was considered a temporary arrangement. In reality, their
long-term goal was becoming “Big Pharmas.” By contrast, pharmaceutical companies were
entering strategic alliances with biotech companies in order to acquire their techno logy. Their
long-term goal was generating biotech -based new drugs in -house. In 1990, biotech companies
suddenly realized that many contracts that they had signed entailed “poison pills” designed to
squeeze their knowledge and profits (James, 1996).
Figures (3) and (4) illustrate a portion of the biotech companies’ cognitive maps in 1989
and 1990, respectively (James, 1996). Note that in 1990 the block Poison Pills entered the map,
destroying previous linkages.
Figure 3. A portion of biotech companies’ cognitive maps in 1989 (James, 1996). Incoming
arrows stem from parts of the map not shown in this figure.
Figure 4. A portion of biotech companies’ cognitive maps in 1990 (James, 1996). Incoming
arrows stem from parts of the map not shown in this figure.
However, in 1991 biotech companies eventually understood the difficulties involved in
drug production and distribution. Conversely, pharmaceutical companies realized that small
and independent BioTech companies would guarantee a de gree of exploration that in -house,
hierarchically organized research could not attain (James, 1996). Thus, since 1991 the cognitive
maps of biotech companies stabilized again , providing once again a reliable orientation to
decision -making. Figure (5) illus trates a portion of the 1991 cognitive map.
Figure 5. A portion of biotech companies’ cognitive maps in 1991 (James, 1996). Incoming
and outgoing arrows concern parts of the map not shown in this figure.
In the end, we have a series of eight cognit ive maps 1986 to 1993, with one stable period
1986 -1989, one other stable period 1991 -1993, and one single disrupted cognitive map in
between, in 1990. A few simple metrics can be explored in order to identify indicators that are
able to single out the dis rupted 1990 map from those of the stable periods that precede and
follow it (Eden et al., 1992).
Figure (6) illustrates the number of concepts and its average (black), the number of
linkages and its average (green) as well as the ratio between the number o f linkages and the
number of concepts (bottom line), which is remarkably constant over time. Notably, the
number of linkages (green) exhibits a marked drop with respect to its average in 1990. The
number of concepts (black) dropped , too, though possibly le ss sharply.
Figure 6. A few metrics of James (1996) series of cognitive maps. The number of concepts
(solid black) compared to its average (dotted black), the number of linkages (solid green)
compared to its average (dotted green), as well as their rat io (thick black). Notably, the ratio of
these two metrics is extremely stable.
To our knowledge, the cognitive maps collected by James (1996) are unique in their
ability to capture the magic moment of despair caused by “unknown unknowns” becoming
true. The reason is that James (1996) extracted her cognitive maps from the technical re ports
of a consultant who was keen to express views that, possibly, no single BioTech company had
ever confessed. To our knowledge, no other document has ever revealed a comparable richness
of details, doubts and surprise.
Lacking other empirical examples, the proposed metrics – number of concepts, number
of linkages – should be understood as a tentative, though sensible starting point. It seems
sensible to assume, however, that collapsing cognitive maps display some sort of macroscopic
structural change.
Machine Learning
The methods illustrated in the previous sections were based on e liciting cognitive maps out of
text, which is a lengthy, painstaking activity. However, we submit that Machine Learning (ML)
can open up novel possibilities in this resp ect.
ML is a rapidly expanding field that allow s processing huge numbers of documents
available on the Internet and elsewhere. While the simplest algorithms can only identify a few
keywords, more recent developments are offering the possibility to extract knowledge graphs
(See Appendix C).
A knowledge graph, also known as linked data, express knowledge in terms of nodes
and edges between them. In the special case where nodes are concepts and edges represent
causal relations, a knowledge graph is also a cogn itive map. Thus, c ognitive maps are a subset
of knowledge graphs.
For illustrative purposes , Figure (7) shows a knowledge graph extracted from a medical
text that illustrates the working principles of two alternative treatments , based on two different
drugs acting on a gene and a protein, respectively. It is based on concepts (a disease, two drugs,
a gene, a protein) linked to one another by causal relations and processes (treatment, inhibition ).
A cognitive map can be derived from this knowledge graph by a ssociating processes to edges
instead of diamond shapes .
Figure 7. A knowledge graph extracted from a medical text. On the left , both Trametinib and
Dabrafenib can be used to treat Melanoma but Trametinib inhibits protein MEK whereas
Dabrafenib inhibits gene BRAF. By courtesy of Syed Irtaza Raza (2019), TypeDB. In order to
derive a cognitive map, the processes in diamonds should be used to qualify causal relations
between concepts expressed in ovals. Both concepts and causal relations should be detailed by
means of the words highlighted in yellow, on the left.
ML algorithms can be used to extract relevant graphs for decision problems where
possibilities are known, but their probabilities are not (known unknowns), as well as for
decision problems where doubts exist regarding the composition of the possibility set
(unknown unknowns). In the first case, ML algorithms can procur e the raw data to which the
standard tools of Q-Analysis can be applied, whereas in the second case some work on defining
the correct indicators is still waiting to be done.
As an instance whe re ML has been applied to contexts where “known unknowns” can
exist we cite Rodrigues (2014), who employed ML in order to min e data from newspaper
articles . By relating newspaper articles to one another along multiple dimensions a hypergraph
ensued, whose structure could be investigated by means of Q-Analysis. In principle, further
analyses could explore this hypergraph in order to highlight the structure of the consequences
of certain decisions, for instance in terms of news diffusion .
The case of “u nknown unknowns” is more complex. As a first step in this direction, we
analysed the speeches held by Lufthansa CEO Carsten Spohr at annual general meeting s
(AGM s) before and after Covid -19, which has been a disruptive, unexpected and unthinkable
event for airlines worldwide. In 2020, two indicators called Density and Average Centrality
(see Appendix C) dropped by 43% and 53% compared to 2019. Since no comparable figure
occurred in previous or subsequent years, we tentatively hypothesize that this drop was caused
by the unexpected, unthinkable event . This analysis is at best preliminary, but it suggests that
in principle it is possible to carry out massive evaluations of documents in order to detect the
decision not to decide.
Furthermore, this possibility m ay open up interesting perspectives insofar as it concerns
the availability of appropriate texts. Generally speaking, it is rather difficult to find texts where
some decision -maker admits to have been in such a desperate situation that their cognitive map
got disrupted. The 2020 Lufthansa AGM is probably an exception due to the fact that ( i) the
impact of Covid -19 was undeniable, ( ii) it was clearly beyond the CEO’s responsibility and,
last but not least, ( iii) the European Union had provided compensations that had largely offset
the impact of the pandemic on airlines. Figure (8) illustrates a few key passages of Mr. Spohr’s
speech along with portions of the corresponding automatically generated cognitive map.
Figure 8. Lufthansa 2020 AGM. A portion of the ML -generated cognitive map, along with key
portions of the speech held by Lufthansa CEO Carsten Spohr.
However, ML can positively contribute to this problem by exploring the Internet
looking for non -officia l sources such as blogs and social media where people eventually
express themselves without the straitjackets imposed by the organi zations they are members
of. While this is still purely speculative for the time being, we are confident that the exploration
of the Internet on a large scale could potentially yield substantial improvements to the data we
are able to access.
One advantage of ML -based cognitive maps is that concepts and links are always
extracted exactly in the same way, no matter which text is submitted or which researcher is
doing the job. By contrast, w hen manual extraction of cognitive maps is carried out, uniformity
has to be sought – and never fully achieved – by assigning the same text to several human
coders and using only those concepts and causal relations that all coders identified (Sigismund
Huff, 1990).
However , precisely uniformity constrains the quality of ML -based cognitive maps.
Consider for instance the choice of a parameter such as entropy, which determines the
coarseness of con cept identification. If this parameter is set too loosely, concepts that are not
appropriate for the text may be identified, whereas if it is too strict relevant concepts may be
missed. By contrast, human researchers are capable to adapt to the text they a re analysing,
making human extraction more detailed, accurate and fine -grained.
We do not expect human -based extraction of cognitive maps to disappear altogether. In
our opinion, one likely future is that human extraction will be used in order to calibrate the
parameters of machine -based extraction.
Conclusions
For decades, non -probabilistic uncertainty has been the exotic province of critical economists
and a handful of humanists and logicians who had little or no impact on applied science .
However , since at least a decade this p icture has started to change and, considering the sheer
number of special issues of respected scientific journals being devoted to uncertainty, the trend
is clearly accelerating . In our opinion, at least two forces are contributing to revers e the tide .
The first one, endogenous to Science, stems from realizing that the limitations of
Probability Theory are due to its neglect o f cognition. Probability Theory assumes that a set of
possibilities is given, and that each possibility comes with a probability judgement. But what
if decision makers have a hard time at assigning numerical values to these probab ilities? What
if they are unsure about the set of possibilities they are envisaging ? Such questions cannot be
faced unless one accept s to take cognition in serious consideration , making disciplines and
research fields ranging from psychology to neural networks relevant for our understanding of
uncertain reasoning. While in the 1970s a typical psychology article would attempt to fit
decision into the straightjackets of Probability Theory, today the opposite is increasingly taking
place , with cognitive scien ces capable of addressing uncertain reasoning while ignoring the
strictures and assumptions of Probability Theory.
The second force moving Science in this direction is, in our opinion, the sheer fact that
the technological, environmental and political stage has become uncertain in ways that used to
be unthinkable just a few years ago. Nowadays , with small -sized nuclear weapons having been
adopted by all major armies , the prospect of a nuclear war has become a feasible night mare of
an endless series of targeted annihilations. Epidemics , once relegated to the Dark Ages, appear
to be perfectly possible . The financial crises of the XIX century have resurrected in the XXI,
and climate change is posing terribly deep and disturbing questions to which no answer is in
sight. In such an environment, the existence of non -probabilistic uncertainty is obvious for
scientists and laypersons alike.
We did not contribute any fundamentally novel concept or tool to this trend, but rather
assemble d previously disconnected pieces of knowledge in a novel way, pointing to the
possibilities offered by machine learning. We propos ed a research path that move d from adding
cognitive insights to argumentations that used to be expressed in purely logical terms , to
subsequently describe non-probabilistic uncertainty in terms of procedures and sequences of
events that make it emerge rather than static definitions , onwards to mathematical and
computational tools to observe it, and – finally – machine learning as a means to carry out
observations on a large scale. We firmly believe that this path has a rich potential for
meaningful and useful discoveries , but w e are aware of the difficulties posed by the fact that
both individuals and organizations are often unw illing to disclose their helplessness in front of
missing information or, even worse, contradictory and disruptive information that destroy s
their cognitive maps. Great care must be exercised in selecting proper sources, which may not
be limited to third parties as in the case of a dedicated consultant for BioT ech companies but
may include unofficia l or se mi-official sources such as web blogs. In this respect, just like on
many other issues surrounding Big Data and the Internet, manipulation of information loom s
as a substantial danger to the effectiveness of ML-based methods , potentially able to destr oy
the reliability of tools that have been developed under the assumption that information may be
possibly difficult to find , but reliable .
Appendix A: Q-Analysis
This appendix illustrates the basics of Q-Analysis (Atkin, 197 4; Johnson, 1990 ; Fioretti, 2023 ).
Please consult the se references for further details.
A simplex is the convex hull of a set of (𝑛+1) independent points in some Euclidean
space of dimension n or higher. These points are its vertices . A 0 -dimensional simp lex is a
point, a 1 -dimensional simplex is a segment, a 2 -dimensional simplex is a triangle. Henceforth,
higher -dimensional simplices will not be considered.
The convex hull of any non -empty subset of the points that define a simplex is called a
face of th e simplex. In particular, 0 -dimensional faces are the vertices of a simplex, 1 -
dimensional faces are segments that connect vertices. Two simplices are connected if they have
a common face. A set of (at least) pairwise connected simplices is a simplicial family, which
corresponds to a hypergraph where simplices are the sets of nodes that an edge can connect. In
the special case where each face of each simplex also belongs to the simplicial family, this is
called a simplicial complex . Although Q-Analysis was first conceived for simplicial complexe s,
it actually applies to simplicial families of any sort.
Henceforth, a cognitive map is graphically represented as a simplicial family . Evoked
Alternatives are simplices whose vertices are the Perceived Consequences to which each
Evoked Alternative is co nnected. Figure (A1) illustrates the simplicial families that correspond
to cases (b) and (c) in Figure (2).
Figure A1. Left, the simplicial family corresponding to case (b) of Figure (2). Right, the
simplicial family corresponding to case (c) of Figure (2). Segments representing 1 -dimensional
simplices are thicker than segments representing the faces of 2 -dimensional simplices
(triangles).
If the connections between categories of actions and categories of results are all one -
to-one as in case (a) of Figure (2), then the simplices are isolated points so no connected
simplicial family exists. In this case, complexity is zero. By contrast, in case (b) and (c) the
simplicial families illustrated in Figure (A1) yield a complexity greater than zero.
Two simplices are connected if they have at least one common vertex. Two simplices
that have no common vertex may nonetheless be connected by a chain of simplices having
common vertices with one another. Let us say that simplices 𝐸𝐴 𝑖 and 𝐸𝐴𝑗 are 𝑞−𝑐𝑜𝑛𝑛𝑒𝑐𝑡𝑒𝑑 if
there exists a chain of simplices 𝐸𝐴 𝑢,𝐸𝐴 𝑣,…𝐸𝐴 𝑤 such that 𝑞=𝑚𝑖𝑛 {𝑙𝑖,𝑢,𝑙𝑢,𝑣,…𝑙𝑤,𝑗}≥0, where
𝑙𝑥,𝑦 is the dimension of the common face between 𝐸𝐴 𝑥 and 𝐸𝐴 𝑦. In particular, two contiguous
simplices are connected at level q if they have a common face of dimension q.
Let us consider the common faces between simplices and let us focus on the face of
largest dimension. Let Q denote the dimension of this face. It is necessarily 𝑄≤𝑛−1, where
𝑄=𝑛−1 means that there are at least two overlapping simplices that include all possible
vertices.
Let us partition the set of simplices that compose the simplicial family according to
their connection level q. In ge neral, for ∀𝑞 there exist several classes of simplices such that the
simplices belonging to a class are connected at level q. Let us introduce a structure vector s
whose q-th component 𝑠𝑞 denotes the number of disjoint classes of simplices that are connected
at level q. Since 𝑞=0,1,…𝑄, vector s has 𝑄+1 rows.
Let us define Complexity (Fioretti, 2001 ) as:
𝐶={0 𝑖𝑓 𝑎𝑙𝑙 𝑙𝑖𝑛𝑘𝑠 𝑎𝑟𝑒 𝑜𝑛𝑒 𝑡𝑜 𝑜𝑛𝑒
∑𝑞+1
𝑠𝑞𝑄
𝑞=0𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒
where the sum extends only to all terms such that 𝑠𝑞≠0. The complexity of two or more
disconnected simplicial families is the sum of their complexities.
This expression takes account of two opposite effects. On the one hand, its numerator
increases with the number of connections between Evoked Alternatives and Perceived
Consequences. Thus, it simply measures the extent to which novel connections confuse t he
cognitive map. On the other hand, the denominator makes complexity decrease to the extent
that cross -connections are clustered in distinct groups.
In case (b) of Figures (2) and (A1) there exists one single class of simplices connected
at level 𝑞=0 and one single class of simplices connected at level 𝑞=1, hence 𝐶=(0+1)
1+
(1+1)
1=3. By contrast, in case (c) there exists one class of simplices connected at level 𝑞=0
but two classes of simplices connected at level 𝑞=1, hence 𝐶=(0+1)
1+(1+1)
2=2.
Appendix B: The S eries of Cognitive Maps
Figure B1. Biotech companies’ cognitive map, 1986 (James, 1996).
Figure B2. Biotech companies’ cognitive map, 1987 (James, 1996).
Figure B3. Biotech companies’ cognitive map, 1988 (James, 1996).
Figure B4. Biotech companies’ cognitive map, 1989 (James, 1996).
Figure B5. Biotech companies’ cognitive map, 1990 (James, 1996).
Figure B6. Biotech companies’ cognitive map, 1991 (James, 1996).
Figure B7. Biotech companies’ cognitive map, 1992 (James, 1996).
Figure B8. Biotech companies’ cognitive map, 1993 (James, 1996).
Appendix C: Machine Learning
The last 10 years witnessed a rapid development in Natural Language Processing (NLP), which
uses Machine Learning (ML) algorithms to allow computers to process and “understand” text
semantics (Ruder, 2022). As a result, ML algorithms have surpassed human performance on a
number of NLP tasks such as aspects of speech tagging or question and answering (Stanford
NLP Group, 2022).
These developme nts build on previous advances in knowledge representation, which
historically had been one of the key purposes of “good old fashioned” Artificial Intelligence
(AI) with the aim of building general or domain -specific cognitive maps.
Cognitive maps can be b uilt from texts to represent knowledge in terms of relations
between entities. Once knowledge has been represented as a cognitive map, the graph can be
traversed to draw relevant conclusions such as, e.g., whether What’sApp belongs to Facebook
or Joe Biden is the President of the United States . However, we focus on the graph structure
instead of its traversal. Since 2019 there has been a revival of the attempt to combine statistical
models that extract the meaning of texts with automatic knowledge represent ation in the form
of graph neural networks (Zhang et al., 2020).
We implement machine generation of cognitive maps from text through a pipeline
composed by seven main steps, as illustrated in Figure C1. The first step is pre -processing. The
second step is concept recognition, which focuses on identifying the concepts which will be
connected in the cognitive map. The third and last step is relational identification, where the
linkages are determined.
Figure C1. The pipeline for automatically generating cognitive maps from texts.
Step 1: pre -processing.
The original source is first converted into a raw text file, which is then split into individual
sentences and tokenized. Tokenization involves splitting up the entities of a sentence, words
and punctuation into individual components. In our case, these components are embedded as
vectors and punctuation is removed. Using word embeddings is a typical process in natural
language processing, where each word is represented as , e.g., a 124 -dimensi onal vector in a
latent space (Mikolov et al ., 2013). The vector represents the meaning of the word. The
advantage of such word embedding is that words such as Cappuccino and Latte Macchiato , for
example, are related in their meaning (cosine distance betwe en their embedding vectors), when
such relatedness cannot be recognized by a computer form their surface form (i.e., the letters
of the words).
Step 2: Coreference solution.
Next the problem of co -reference is addressed, which is the task of finding all t he expressions
that refer to the same entity in the text (Clark & Manning, 2016). For instance, pronouns must
be substituted by the nouns they refer to: “X is a public company. It made a loss in 2021”
becomes “X is a public company. X made a loss in 2021”. This task is achieved by a neural
network which has been trained on a dataset where coreference has been resolved by human
annotators.
Step 3: Concept recognition.
In order to recognize concepts, a machine must be trained on a meaningful network of conce pts.
In this step the concepts talked about in the text are matched to concepts covered on Wikipedia.
We take a neural network pretrained on 6.4 million concepts entailed in Wikipedia (Brank,
Leban & Grobelnik, 2017). Whilst not every concept a CEO could t alk about might be entailed
in Wikipedia, the concepts described on Wikipedia are generally regarded as a reasonable
baseline. The ground truth on which the model is trained is again a dataset of texts where human
annotators have classified which concept o n Wikipedia they are related to.
Step 4: Linkage extraction
Once the concepts have been identified, the linkages between them must be identified. The
algorithm needs to identify what concept is related to another concept according to the text and
how they are related. For this purpose, we take a pre -trained model. The BERT transformer is
currently the model with the highest accuracy (Devlin et al., 2019) for this task.
Step 5: Cognitive map analysis
Having established the cognitive map, we need to be able to systematically measure how it
changes over time or betwe en companies in order to detect the effects of non - probabilistic
uncertainty. One way of doing so is to measure the number of concepts and linkages in a text.
However, the number of concepts and linkages dependent on the length of the text. A ratio of
the number of links per concept can normalize for differences in the length of the text.
If cognitive maps are disrupted, the connectedness of concepts should change. Such
change can be measured in two metrics. The first one is the cognitive map density, whic h is
the ratio of the number of linkages in the network to the maximum number of possible linkages :
𝐷𝑒𝑛𝑠𝑖𝑡𝑦 =|𝐿|
|𝐿|𝑚𝑎𝑥
where |𝐿| denotes the number of linkages. The maximum number of linkages for a directed
graph is defined as follows:
|𝐿|𝑚𝑎𝑥 =|𝐶|∗(|𝐶|−1)
2
where C is the set of concept s and |𝐶| denotes the number of concepts .
Another way in which the evolution of cognitive maps can be measured over time is in
terms of closeness centrality, which is the average distance of a concept to all other concepts.
It is measured as the number of linkages one needs to travel to reach any other concept:
𝑈̅= |𝐶|−1
∑∑ 𝑑𝑖𝑠𝑡 (𝐶𝑖,𝐶𝑗)𝐶𝑗∈{𝐶−𝐶𝑗} 𝐶𝑖
References
Alipour, M., Hafezi, R., Amer, M. , & Akhavan, A.N. ( 2017 ). A new hybrid fuzzy cognitive
map-based scenario planning approach for Iran’s oil production pathways in the post -
sanction period . Energy , 135, 851 -864.
Amer, M., Jetter, A. , & Daim, T. (2011 ). Development of fuzzy cognitive map (FCM) -based
scenarios for wind e nergy . International Journal for Energy Sector Management , 5, 564 -
584.
Atkin, R.H. (1974 ). Mathematical Structure in Human Affairs . New York: Crane, Russak &
Company.
Axelrod, R. (1976 ). Structure of Decision . Princeton: Princeton University Press.
Brank, J., Leban, G. , & Grobelnik, M. (2017 ). Annotating Documents with Relevant Wikipedia
Concepts. Proceedings of the Slovenian Conference on Data Mining and Data
Warehouses (SiKDD 2017), Ljubljana, Slovenia, 9 October 2 017.
Chermack, T.J. (2004 ). Improving decision -making with scenario planning . Futures , 295 -309.
Clark, K.C, & Manning, C.D. (2016 ). Deep Reinforcement Learning for Mention -Ranking
Coreference Models . Working Paper arXiv:1609.08667.
David son, P. (1991 ). Is probability theory relevant for uncertainty? A post -keynesian
perspective . Journal of Economic Perspectives , 5, 129 -143.
De Finetti, B. (1931 ). Sul significato soggettivo della probabilità . Fundamenta Mathematicae ,
17: 298 -329.
Devlin, J., Chang, M.W., Lee, K. , & Toutanova, K. (2019 ). BERT: Pre-training of Deep
Bidirectional Transformers for Language Understanding . Working Paper
arXiv:1810.04805 .
Dunn, S.P. (2001 ). Bounded rationality is not fundamental unc ertainty: A post -keynesian
perspective . Journal of Post Keynesian Economics , 23, 567 -587.
Eden, C., Ackermann, F. , & Cropper, S. (1992 ). The Analysis of Cause Maps . Journal of
Management Studies , 29, 309 -324.
Eder, G., Duckstein, L. , & Nachtnebel, H.P. (1997 ). Ranking Water Resource Projects and
Evaluating Criteria by Multicriterion Q -Analysis: An Austrian Case Study . Journal of
Multi -Criteria Decision Analysis , 6, 259 -271.
Eliaz, K. , & Ok, E.A. ( 2006 ). Indifference or indecisiveness? Choice -theoreti c foundations of
incomplete preferences . Games and Economic Behavior , 56, 61 -86.
Ellsberg, D. (1961 ). Risk, ambiguity and the Savage axioms . The Quarterly Journal of
Economics , 75: 643 -669.
Erdmann, D., Sichel, B. , & Yeung, L. (2015 ). Overcoming obstac les to effective scenario
planning . Mc Kinsey & Company, Strategy & Corporate Finance Insights, Jun.
Faulkner, P., Feduzi, A. , & Runde, J. (2017 ). Unknowns, black swans, and the risk / uncertainty
distinction . Cambridge Journal of Economics , 41, 1279 -1302.
Feduzi, A., & Runde, J. (2014 ). Uncovering Unknown Unknowns: Towards a Baconian
approach to management decision -making . Organizational Behavior and Human Decisio
Processes , 124, 268 -283.
Fioretti, G. (2001 ). A Subjective Measure of Complexity . Adva nces in Complex Systems , 4,
349-370.
Fioretti, G. (2023). Artificial Cognition . In F. Wall, S.H. Chen , & S. Leitner, The Oxford
Handbook of Age nt-Based Computational Management Science . Oxford University Press,
forthcoming.
Forrester, J., Cook, B., Bracken, L., Cinderby, S. , & Donaldson, A. (2015 ). Combining
Participatory Mapping with Q -Methodology to Map Stakeholder Perceptions of Complex
Environmental Problems . Appl ied Geography , 56, 199 -208.
Galaabaatar, T. , & Karni, E. (2013 ). Subjective expected utility with incomplete preferences .
Econometrica , 81, 255 -284.
Gilboa, I. (1987 ). Expected utility with purely subjective non -additive probabilities . Journal of
Mathematical Economics , 16: 65 -88.
Gluth, S., Rieskamp, J. , & Büchel, C. (2012 ). Deciding When To Decide: Time -variant se-
quential sampling models explain the emergence of value -based decisions in the human
brain . The Journal of Neuroscience , 32, 10686 -10698.
Gluth, S., Rieskamp, J. , & Büchel, C. (2013 ). Deciding Not To Decide: Computat ional and
neural evidence for hidden behavior in sequential choice . PLOS Computational Biology , 9,
e1003309.
Gluth, S., Rieskamp, J. , & Büchel, C. (2017 ). Correction: Deciding Not To Decide: Computa-
tional and neural evidence for hidden behavior in sequent ial choice . PLOS Computational
Biology , 13, e1005476.
Goodier, C., Austin, S., Soetanto, R. , & Dainty, A. (2010 ). Causal mapping and scenario
building with multiple organizations . Futures , 42, 219 -229.
Goodwin, P. , & Wright, G. (2001 ). Enhancing strategy evaluation in scenario planning: A role
for decision analysis . Journal of Management Studies , 38, 1 -16.
Irtaza Raza, S. (2019 ). Text Mined Knowledge Graphs: Beyond Text Mining . Vaticle , April
21st. Available at https://blog.vaticle.com/text -mined -knowledge -graphs -beyond -text-
mining -1ff207a7d850 .
James, G.E. (1996 ). Strategic Alliances: Elixirs, Poison Pills or Virtual Integration? A
Longitudinal Exploration of Industry -Level Learning in Biotech . University of Col orado at
Boulder, Graduate School of Business, PhD Thesis.
Jetter, A. , & Schweinfort, W. ( 2011 ). Building scenarios with fuz zy cognitive maps: An
exploratory study of solar energy . Futures , 43, 52 -66.
Johnson, J.H. (1990) . Expert Q -Analysis. Environment and Planning B: Planning and Design ,
17: 221 -244.
Kay, J. , & King, M. (2020 ). Radical Uncertainty: Decision -making beyond the numbers . New
York: W.W. Norton & Company.
Knight, F.H. (1921 ). Risk, Uncertainty and Profit . Boston: Houghton Mifflin Company.
Lane, D.A. , & Maxfield, R.R. ( 2005 ). Ontological uncertainty and innovation . Journal of
Evolutionary Economics , 15, 3 -50.
March, J.G. , & Simon, H.A. ( 1958 ). Organizations . New York: John Wiley & Sons.
Mikolov, T., Chen, K., Corrado, G. , & Dean, J. (2013 ). Efficient Estimation of Word
Representation in Vector Space . Working Paper arXiv: 1301.3781. Available at
https://arxiv.org/abs/1301.3781?context=cs.CL .
Ok, E.A., Ortoleva, P. , & Riella, G. (2012 ). Incomplete preferences under uncertainty:
Indecisiveness in beliefs versus tastes . Econometrica , 80, 1791 -1808.
Ramírez, R., Österman, R., & Grönquist, D. (2013 ). Scenarios and early warnings as dynamic
capabilities to frame managerial attention . Technological Forecasting & Social Change , 80,
825-838.
Ramírez, R. , & Selin, C. (2014 ). Plausibility and Probability in Scenario Planning . Foresight ,
16, 54 -74.
Rodrigues, D.M.S. (2014 ). Q-Analysis Based Clustering of Online News . Discontinuity,
Nonlinearity, and Complexity , 3, 227 -236.
Roxburgh, C. (2009 ). The use and abuse of scenarios . Mc Kinsey & Company, Strategy &
Corporate Finance Insights , Nov.
Rucco, M., Sousa -Rodrigues, D., Merelli, E., Johnson, J.H., Falsetti, L., Nitti, C. , & Salvi, A.
(2015 ). Neural Hypernetwork Approach for Pulmonary Embolism Diagnosis . BMC
Research Notes , 8: 617.
Ruder, S. (2022 ). NLP-progress . Retrievable at http://nlpprogress.com . Accessed on Jan 8th,
2022.
Rumsfeld, D.H. (2011 ). Known and Unknown: A memoir . New York, Sentinel.
Runde, J., (1990 ). Keynesian Uncertainty and the Weight of Arguments . Economics and
Philosophy , 6, 275 -292.
Schmeidler, D. (1989 ). Subjective probability and expected utility without additivity .
Econometr ica, 57: 571 -587.
Schoemaker, P.J.H. (1995 ). Scenario Planning: A tool for strategic thinking . Sloan
Management Review , 36: 25 -40.
Sigismind Huff, A. (1990 ). Mapping Strategic Thought . Chichester: John Wiley & Sons.
Sigismund Huff, A., Huff, J.O. , & Barr, P.S. ( 2000 ). When Firms Change Direction . Oxford:
Oxford University Press.
Sigismund Huff, A. , & Jenkins, M. ( 2002 ). Mapping Strategic Knowledge . London: Sage
Publications.
Stanford NLP Group (2022 ). SQuAD 2.0: The Stanford Question Answering Dataset .
Retrievable at https://rajpurkar.github.io/SQuAD -explorer . Accessed on Jan 8th, 2022.
Stirling, A. (2010 ). Keep it Complex . Nature , 468, 1029 -1031.
Van der Heijden, K., 2000, Scenarios and forecasting: Two perspectives . Technological
Forecsatng & Social Change , 65: 31 -36.
Tversky, A. & E. Shafir (1992). Choice Under Conflict: The dynamics of deferred decision.
Psychological Science , 3: 358 -361.
Wilson, I. (2000 ). From scenario thinking to strategic action . Technological Forecasting an d
Social Change , 65, 23 -29.
Wright, G. , & Goodwin, P. (2009 ). Decision making and planning under low levels of
predictability: Enhancing the scenario method . International Journal of Forecasting , 25,
813-825.
Zhang, Z., Zhuang, F., Zhu, H., Shi, Z., Xiong, H., & He, Q. (2020 ). Relational Graph Neural
Network with Hierarchical At tention for Knowledge Graph Completion . Proceedings of the
AAAI Conference on Artificial Intelligence , 34, 9612 -9619. Retrievable at
https://doi.org/10.1609/aaai.v34i05.6508 .
|
dc3de97a-931b-4fec-b10d-831452fbb432 | trentmkelly/LessWrong-43k | LessWrong | Evidence For Simulation
The recent article on overcomingbias suggesting the Fermi paradox might be evidence our universe is indeed a simulation prompted me to wonder how one would go about gathering evidence for or against the hypothesis that we are living in a simulation. The Fermi paradox isn't very good evidence but there are much more promising places to look for this kind of evidence. Of course there is no sure fire way to learn that one isn't in a simulation, nothing prevents a simulation from being able to perfectly simulate a non-simulation universe, but there are certainly features of the universe that seem more likely if the universe was simulated and their presence or absence thus gives us evidence about whether we are in a simulation.
In particular, the strategy suggested here is to consider the kind of fingerprints we might leave if we were writing a massive simulation. Of course the simulating creatures/processes may not labor under the same kind of restrictions we do in writing simulations (their laws of physics might support fundamentally different computational devices and any intelligence behind such a simulation might be totally alien). However, it's certainly reasonable to think we might be simulated by creatures like us so it's worth checking for the kinds of fingerprints we might leave in a simulation.
Computational Fingerprints
Simulations we write face several limitations on the computational power they can bring to bear on the problem and these limitations give rise to mitigation strategies we might observe in our own universe. These limitations include the following:
1. Lack of access to non-computable oracles (except perhaps physical randomness).
While theoretically nothing prevents the laws of physics from providing non-computable oracles, e.g., some experiment one could perform that discerns whether a given Turing machine halts (halting problem = 0') all indications suggest our universe does not provide such oracles. Thus our simulatio |
14c51974-0632-4e69-a2e7-a77cd98f9619 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Providing Actionable Feedback in Hiring Marketplaces using Generative Adversarial Networks
1 Introduction
---------------
The prevalence of machine learning (ML) based predictive models has increased throughout various industries including recruitment platforms and marketplaces. Providing model interpretability and actionable feedback is increasingly viewed as an integral part of any production ML system.

Figure 1: An example of a candidate’s profile (redacted) on the Hired marketplace (<https://hired.com/>).
At one of the world’s largest hiring marketplaces, Hired, candidates fill out a profile, similar to a resume with structured data such as skills, work experience, preferred location, and salary. They then apply to be approved onto the marketplace for recruiters to discover and interview. An ML classifier is used to approve candidates on the marketplace based on their profile details as well as marketplace metadata. This is the principle behind the ML-based marketplace curation at Hired.
Candidate curation is a differentiator for Hired and leads to a better overall experience for recruiters (more likely to see relevant quality candidates with less noise than traditional inbound hiring platforms) as well as for candidates (higher chance of receiving interest from recruiters). It also entails developing and maintaining robust ML models capable of providing decisions in real-time. A highly demanded feature is the ability to provide actionable feedback to candidates with how to modify their profiles in order to improve their classifier scores and hence, their chance of being approved on the marketplace.
Actionable feedback can be attained by generating counterfactuals, which describe alternative scenarios. For instance, a profile with modifications to a candidate’s salary or skills can be viewed as a ”counterfactual” to the original profile. In this case, the actionable feedback would amount to the differences or modifications contained in the counterfactual compared with the original profile. In addition, counterfactuals are also useful for improving model interpretability, for instance, by highlighting potential biases and irregular predictions of a model (e.g., does the classifier’s score change if a candidate’s gender or race are modified?).
To ensure that the feedback is actionable, the counterfactual needs to be realistic (e.g., no negative years of experience), require reasonable and few changes (i.e. sparse), make sure it helps to achieve the desired outcome (i.e., improve the classifier score), and should be able to be generated within real-time latency constraints. Several counterfactual generation approaches have been proposed [Wachter2017-jr, Van\_Looveren2019-hr] but are limited in terms of realism and computational latency. A newly proposed CounteRGAN method [Nemirovsky2020-te] was shown to be able to overcome these limitations by utilizing Generative Adversarial Networks [Goodfellow2014-wf].
In this work, we demonstrate how we are able to provide real-time actionable feedback to candidates by leveraging the CounteRGAN on Hired’s dataset and production ML classifier. Our experiments show how this method is able to overcome the realism and latency limitations of previous counterfactual generation techniques and be practically feasible for production environments such as hiring marketplaces. For clarity, we also provide two real profile examples which highlight the potential of this method. To the best of our knowledge, we are the first to apply GAN-based counterfactual generation methods to a hiring marketplace dataset.
2 Related Work
---------------
In contrast to counterfactuals produced using adversarial perturbation techniques [Goodfellow2014-yo, Su2017-pk], that aim solely at confusing a target classifier regardless of realism, counterfactuals as explanations for ML predictors were introduced by [Wachter2017-jr]. In this work, counterfactual search was presented as a minimization problem approached utilizing gradient descent with regularization to account for sparsity. Though the resulting counterfactuals are generally of the desired target class, they are often unrealistic and very slow to compute. Several approaches have since been proposed to improve counterfactual realism. These include using a graph-based density approach [Poyiadzi2019-qi], autoencoders [Dhurandhar2018-hk], and class prototypes [Van\_Looveren2019-hr] to help influence the counterfactual search towards particular regions of the feature space. These approaches, however, are mainly aimed at differentiable models and are still extremely limited in terms of computational latency.
In order to provide real-time actionable feedback to candidates on the Hired marketplace, it is imperative that the counterfactuals be realistic, actionable, achieve the desired outcome, and computable within real-time latency constraints. Recently, a novel counterfactual generation method, termed CounteRGAN, was introduced in [Nemirovsky2020-te]. It builds upon Generative Adversarial Networks [Goodfellow2014-wf] to produce meaningful counterfactuals in real-time. This method, described in greater detail below, is able to overcome the limitations of previously mentioned approaches and allows for the capability of providing actionable feedback to be viable in many domains and industries.
3 Approach using CounteRGAN
----------------------------

Figure 2: CounteRGAN method on an example from MNIST [Nemirovsky2020-te]. Three neural networks are used, a generator trained to output residuals, a discriminator trained to distinguish realistic data, and a target classifier. The example shows a generator outputting residuals that, when added with the input, produces realistic counterfactual images of a ”4”.
This section describes how we apply a GAN, in particular the CounteRGAN method, to generate counterfactuals capable of providing actionable feedback. GANs generally pit two artificial neural network models, termed a generator and discriminator, in an adversarial minimax game. During training the generator is trained to produce synthetic data that confuse the discriminator while the discriminator is trained to distinguish real data from synthetic data. The CounteRGAN method, shown in Figure [2](#S3.F2 "Figure 2 ‣ 3 Approach using CounteRGAN ‣ Providing Actionable Feedback in Hiring Marketplaces using Generative Adversarial Networks"), is a specialized GAN which relies on a residual generator G, a discriminator D, and a fixed classifier Ct for a target class t. The formulation of the value function is given in Equation [1](#S3.E1 "(1) ‣ 3 Approach using CounteRGAN ‣ Providing Actionable Feedback in Hiring Marketplaces using Generative Adversarial Networks") below.
| | | | |
| --- | --- | --- | --- |
| | VCounterRGAN(G,D,C,t)=Ex∼pdata[logD(x)+log(1−D(x+G(x)))+log(1−Ct(x+G(x)))] | | (1) |
where both the generator and discriminator use inputs samples from the same probability distribution pdata and we add a regularization term λEx∼pdata∥G(x)∥22 to control proximity.
For our purposes, we use Hired’s curation ML classifier as the target classifier C and candidate profiles from historical marketplace data as samples of pdata. During training, we provide real candidate profiles to the generator as input and train it iteratively via gradient descent to minimize the value function ([1](#S3.E1 "(1) ‣ 3 Approach using CounteRGAN ‣ Providing Actionable Feedback in Hiring Marketplaces using Generative Adversarial Networks")) and produce counterfactuals that achieve high classifier scores while also appearing realistic to the discriminator. The discriminator is trained to maximize the value function and hence distinguish real candidate profiles from those synthesized by the generator.
It is important to note that not all of the fields of a candidate’s profile are mutable nor are their values all continuous. To account for immutable features such as a candidate’s years of experience or education degrees, we force all the generated counterfactuals to have zero value changes to these features. To handle features that take on discrete values (e.g., ”has a Ph.D. degree?”, ”headline word count”), we found that simply rounding the values of these features contained within the counterfactual produced favorable results.
4 Experiments
--------------
| Metric | Formula | RGD | CSGP | CounteRGAN |
| --- | --- | --- | --- | --- |
| ↓ Realism | ∥AE(xcf)−xcf∥22 | 1.08 ± 0.02 | 0.69 ± 0.02 | 0.68 ± 0.02 |
| ↑ Prediction gain | C(xcf)−C(x) | 0.42 ± 0.02 | 0.07 ± 0.01 | 0.08 ± 0.01 |
| ↓ Actionability | ∥xcf−x∥1 | 1.31 ± 0.03 | 0.16 ± 0.02 | 0.45 ± 0.02 |
| ↓ Latency (ms) | - | 1,696.65 ± 2.54 | 7,713.98 ± 9.82 | 1.57 ± 0.02 |
| ↓ Batch latency (s) | - | 1,028.17 | 4,674.67 | 0.03 |
Table 1: Test data results (mean and 95 % confidence interval). The arrows indicate whether larger ↑ or lower ↓ values are better, and the best results are in bold. The second column describes the formulas for the corresponding metrics, with xcf being the suggested counterfactual and x the input data sample for which a counterfactual is sought. The CounteRGAN method achieves impressive results and vastly outperforms other methods in terms of latency needed for real-time production systems.
We conduct our experiments using historical data sampled from candidates in the San Francisco market who registered on Hired from October 2019 to May 2020, consisting of 3,029 candidate profile samples, 43 % of which have positive labels. We also use an 80-20 random split for the training and test data accordingly (results shown are based on performance on the test set).
The dataset contains 33 features that describe the candidate’s profile as well as marketplace metadata at the time of submission. Of those, 27 are considered immutable (e.g., marketplace metadata, education, years of experience) and 6 are mutable (shown in the first column of Table [2](#S4.T2 "Table 2 ‣ 4 Experiments ‣ Providing Actionable Feedback in Hiring Marketplaces using Generative Adversarial Networks")). The mutable features such as expected salary and candidate headline word count are rounded to the nearest integer or the nearest multiple of 5,000 in the case of salary. The experience relevance score, verified years of experience, and skills popularity score are continuous-valued and are based on custom functions, the definitions of which fall outside the scope of this work.
We compare the CounteRGAN approach [Nemirovsky2020-te] with the Regularized Gradient Descent (RGD) [Wachter2017-jr] and Counterfactual Search Guided by Prototypes (CSGD) [Van\_Looveren2019-hr] methods described earlier in Section [2](#S2 "2 Related Work ‣ Providing Actionable Feedback in Hiring Marketplaces using Generative Adversarial Networks"). We optimize the corresponding parameters based on typical values used in the corresponding papers, slightly optimized through manual exploration. The methods are implemented using TensorFlow, and are run on a Tesla T4 GPU provided by Google Colab111<https://colab.research.google.com/>. The ML classifier is based on a neural network production model used at Hired. The accuracy of this classifier on the test set is 76.4 %.
To evaluate the relative performance of the different methods, we follow the four desirable properties of counterfactual generation defined in [Nemirovsky2020-te]. Prediction gain, measures the the difference between the classifier’s prediction on the counterfactual and the input data sample. Realism is based on the reconstruction error of generated counterfactuals using a denoising auto-encoder. Actionability uses the L1 distance between the generated counterfactual and the input data sample. Latency is the total execution time needed to compute one counterfactual and batch latency is based on computing counterfactuals across the whole test dataset.
| | | | |
| --- | --- | --- | --- |
| | First example | | Second example |
| Feature | Init. values | RGD | CSGP | CounteRGAN | Init. values | RGD | CSGP | CounteRGAN |
| Expected salary | 165,000 | + 185,000 | + 5,000 | + 15,000 | 180,000 | +5,000 | 0 | +60,000 |
| Candidate headline word count | 4 | +7 | 0 | + 5 | 4 | +1 | 0 | +8 |
| Experience relevance score | 0.72 | +0.22 | +0.06 | + 0.46 | 0.53 | +2.47 | +0.06 | +0.22 |
| Work experience avg word count | 77.00 | -18.42 | 0.00 | +19.13 | 31.00 | -5.81 | 0.00 | +5.64 |
| Verified years of experience | 10.83 | -0.26 | 0.00 | -4.71 | 18.83 | -0.01 | 0.00 | +1.09 |
| Skills popularity score | 0.63 | +2.67 | +0.39 | +0.76 | 0.94 | +2.25 | +0.07 | -0.11 |
| Classifier prediction score | 0.35 | 0.97 | 0.50 | 0.72 | 0.45 | 0.97 | 0.51 | 0.62 |
Table 2: Examples of actionable feedback provided by the different methods for two real candidate profiles. The last row shows the classifier score for the initial candidate profile, and for the same profile after applying the suggested feedback. The CounteRGAN method is able to achieve realistic and actionable feedback capable of improving the classifier score over the 0.5 approval decision threshold.
### Results
We present the results of our counterfactual generation experiments in table [1](#S4.T1 "Table 1 ‣ 4 Experiments ‣ Providing Actionable Feedback in Hiring Marketplaces using Generative Adversarial Networks"). RGD produces counterfactuals with the largest prediction gains, but are not realistic nor actionable. The CSGP approach produces more realistic and actionable counterfactuals with more modest prediction gains and with higher latency costs. Finally, the CounteRGAN method is able to produce realistic and actionable counterfactuals over a 1000x-30,000x faster than the other methods, capable of feasibly providing real-time actionable feedback in production settings.
Table [2](#S4.T2 "Table 2 ‣ 4 Experiments ‣ Providing Actionable Feedback in Hiring Marketplaces using Generative Adversarial Networks") illustrates the type of actionable feedback and improvements in classifier prediction on two examples of real candidate profiles. In both cases, all methods were able to suggest feedback that actually results in the classifier approving the candidates (assuming a decision threshold of 0.5). In the first example, the RGD method suggests more than doubling the expected salary, which is not a realistic change. The CSGP method suggests minimal changes that increase the classifier score by 0.15, and the CounteRGAN suggests slightly larger updates to the input features but achieves a larger prediction gain (0.47). A similar pattern is observed for the second candidate. The feedback provided using the CounteRGAN method is not only actionable and of significant utility to the candidate, but is also able to be provided in real-time once the candidate submits their profile for admission to the marketplace.
5 Conclusion
-------------
In this work, we have explored how hiring marketplaces such as Hired rely on ML classifiers for enhancing the marketplace quality and experience of candidates and recruiters via curation. This leads to a demand for providing actionable feedback to candidates to improve their profiles and chances of being approved onto the marketplace. We introduced the application of GANs for producing actionable feedback on hiring marketplaces such as Hired and illustrated its potential on production data, including two detailed examples using real candidate profiles. Our experiments demonstrate how a GAN-based approach is able to significantly outperform two other state-of-the-art methods (including over 1000x latency gains) to produce real-time actionable feedback within the constraints needed for production systems in industries such as hiring marketplaces. |
f363a927-3912-431e-8fcc-ee5367505bda | trentmkelly/LessWrong-43k | LessWrong | Invisible Choices, Made by Default
There are two popular language learning software platforms: Anki and Duolingo. Anki is hard, free and effective. Duolingo is easy, commercial and ineffective.
The number of Duolingo users far outstrips the number of Anki users. Duolingo has 8 million downloads on the Play Store. Anki has 40 thousand. So there are 200 Duolingo users for every Anki user[1]. If you ask a random language learner what software to use they'll probably suggest Duolingo. If you ask a random successful language learner what software to use they'll probably suggest Anki. Most language learners are unsuccessful.
It should be no surprise that most language learners use an ineffective product. Learning a language is hard. Duolingo is designed to attract as many customers as it can. Therefore Duolingo must be easy to use. Anki is designed to work. Therefore Anki must be hard to use[2]. Effectiveness and mass-adoption are mutually exclusive.
On average, you'll have to ask 200 language learners what software they use before one of them tells you about Anki. In practice, you are unlikely to stumble across Anki at all. You can only find out about Anki if you go looking for it and you'll only go looking for it if you already know it exists.
No one ever told me about most of the software I use. Usually I'll infer that it must exist and then go looking for it. This is how I discovered qutebrowser, Spacemacs, tmux, i3 and—of course—Anki.
This principle isn't limited to open source software. Everything I've ever taken seriously exhibits a similar pattern. There's a common way most people do it and there's a cheaper, better, skill-intensive way a tiny minority do it.
Minority opinions are inherently controversial. Here are a few (relatively) uncontroversal examples to illustrate the trend:
* Vim keybindings vs. conventional hotkeys
* Lisps vs. programming languages without syntactic macros
* Good history books vs. the news
* Powerlifting vs. popular exercise de jour
* Tiling window managers vs. |
a55776dd-cdc1-4a14-8dd5-802ce5f15e60 | trentmkelly/LessWrong-43k | LessWrong | A Return to Discussion
Epistemic Status: Casual
It’s taken me a long time to fully acknowledge this, but people who “come from the internet” are no longer a minority subculture. Senators tweet and suburban moms post Minion memes. Which means that talking about trends in how people socialize on the internet is not a frivolous subject; it’s relevant to how people interact, period.
There seems to have been an overall drift towards social networks over blogs and forums in general, and in particular things like:
* the drift of commentary from personal blogs to “media” aggregators like The Atlantic, Vox, and Breitbart
* the migration of fandom from LiveJournal to Tumblr
* Facebook and Twitter as the places where links and discussions go
At the moment I’m not empirically tracking any trends like this, and I’m not confident in what exactly the major trends are — maybe in future I’ll start looking into this more seriously. Right now, I have a sense of things from impression and hearsay.
But one thing I have noticed personally is that people have gotten intimidatedby more formal and public kinds of online conversation. I know quite a few people who used to keep a “real blog” and have become afraid to touch it, preferring instead to chat on social media. It’s a weird kind of perfectionism — nobody ever imagined that blogs were meant to be masterpieces. But I do see people fleeing towards more ephemeral, more stream-of-consciousness types of communication, or communication that involves no words at all (reblogging, image-sharing, etc.) There seems to be a fear of becoming too visible as a distinctive writing voice.
For one rather public and hilarious example, witness Scott Alexander’s flight from LessWrong to LiveJournal to a personal blog to Twitter and Tumblr, in hopes that somewhere he can find a place isolated enough that nobody will notice his insight and humor. (It hasn’t been working.)
What might be going on here?
Of course, there are pragmatic concerns about reputation and pr |
068f17f3-44b0-482e-8118-23d7d63ba510 | trentmkelly/LessWrong-43k | LessWrong | Concrete benefits of making predictions
Your mind is a prediction machine, constantly trying to anticipate the world around you and altering its forecasts based on new information. It’s always doing this as a background process. But what would happen if you deliberately trained this skill? Could you get better at predicting your projects, your life, and the future?
Sadly, I don’t have a crystal ball, but I have found trying to see the future valuable. I can't be certain about what will happen, but by deliberately practising the skill of prediction, I can create feedback loops that allow me to better anticipate what the future will bring. This has indeed helped me become happier, better to interact with, and more impactful.
Concretely, making probabilistic predictions has helped me:
* Improve my productivity
* Make better decisions about my career and living situation
* Set and make progress towards my goals
* Prioritise work tasks
* Communicate project timelines and uncertainties
* Keep myself accountable
* Manage anxiety
* Understand my relationships better
* Improve my metacognition, along with related skills
I’m building Fatebook to make it as quick and easy as possible for you to harness the power of prediction and reap some of the benefits above, while remaining completely free. The first step to getting value from predictions is to figure out what to make those predictions about, which I’ve had plenty of time to tinker with.
Which questions are worth asking?
Practice and creativity have allowed me to get more value out of the questions I ask, and the predictions I make. For example, it has helped me communicate with my team better around project timelines, hiring decisions and strategy prioritization. We share predictions with one another using Fatebook for Slack on questions like:
This question allows me to set expectations very accurately with my team. If writing the blog post is taking longer than expected, I can decrease my prediction that it’ll be done by Friday, which is a low- |
3d6090ba-59e1-4e1c-ab53-dc958137e900 | trentmkelly/LessWrong-43k | LessWrong | Why I Believe LLMs Do Not Have Human-like Emotions
[EDIT: I don't know exactly why this received so many downvotes - whether it was my tone or arguments or both - but I accept that this was not, in the end, a strong post. I am a new writer here and I am still figuring out how to improve my argumentation.
That said, if we're willing to taboo the word "emotion" as a description of an internal state, then the specific thing I meant to argue - and which I still stand by - is that when an LLM produces emotionally charged outputs (for instance, when Bing chat loses it's temper) those outputs are not meaningfully associated with an internal state in a way recognizably similar to emotional behavior in humans.
A perusal through my other comments will show that I often couch things in the language of "belief" rather than stating fact. The reason I used strong language is because on this point I am very confident: I do not believe the process by which LLMs are built and trained provides a viable mechanism for such dynamics to form. If this statement is too general for your taste, then limit it narrowly to the example of Bing chat losing its temper.
I believe this is an important point, lest we run the risk of making the same mistakes Lemoine made when he fooled himself into thinking LaMDA was sentient. I worry that believing in AI emotionality is over-anthropomorphizing LLMs in a way that simply does not reflect the reality of what they are and how they work.]
(Original post is below)
Summary
I argue that LLMs probably aren't conscious, but even if they were, they certainly (my belief is less than 0.01%) don't have anything that looks at all like human emotions. The broad strokes of my argument are as follows:
* There is no way to prove that something is conscious or has emotions, but we can argue that they are not by discussing necessary conditions that are not met.
* Specific emotions in humans emerged from our reward structures. We wouldn't have developed emotions like love if they didn't serve an evolutionary purp |
3d5a406a-a472-4af6-916e-6c783af0240f | trentmkelly/LessWrong-43k | LessWrong | A total life checklist
I came up with an idea today: I think it would be useful to have a list of everything that a typical person ought to do. After all, there is quite a lot of stuff that a typical person ought to do; how else is a person supposed to remember it all?
Here's what I've come up with so far:
Health
* Eating well.
* Exercising regularly.
* Mitigating common risks in everyday life (e.g. wearing a seat belt while driving).
* Other everyday health stuff (e.g. not sitting down eight hours a day).
* Visiting a doctor, a dentist, and (if necessary) an optometrist on a regular basis.
* Being familiar with common health problems and what to do about them.
* Being able to recognize medical emergencies and react appropriately.
* Maintaining mental health (see also: pretty much this entire list).
Money
* Educating oneself in career-related skills.
* Getting a job and/or becoming self-employed.
* Networking (see also: interpersonal interaction).
* Investing one's savings appropriately.
Altruism
* Donating to charity.
* Volunteering for charity.
* Doing favors for friends.
Interpersonal interaction
* Developing and maintaining relationships with other people: friendly, romantic, family, others?
* Discussion of useful topics.
Recreation
* Hobbies, finding ways to enjoy yourself. (I'm not sure how to expand on this one.)
Responsibilities
* Any responsibilities one has signed up for.
Productivity
* Developing and maintaining one's ability to get stuff done. (Kinda vague, this one.)
* Maintaining a list of what needs to be done.
* Making good decisions about what to do. In particular, which of the items on this list to focus on and how to accomplish them.
Skills
* Developing the skills one needs to carry out these tasks effectively, through education, experience, and discussion.
----------------------------------------
Anyone have any suggestions for additions or improvements?
edit 1: some suggestions by Rain and aelephant |
ce099aa4-e6c9-4808-82fa-8ae1edbf3a3e | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Estimating the Current and Future Number of AI Safety Researchers
Summary
=======
I estimate that there are about **300** full-time technical AI safety researchers, **100** full-time non-technical AI safety researchers, and **400** AI safety researchers in total today. I also show that the number of technical AI safety researchers has been increasing exponentially over the past several years and could reach 1000 by the end of the 2020s.
Introduction
============
Many previous posts have estimated the number of AI safety researchers and a generally accepted order-of-magnitude estimate is 100 full-time researchers. The question of how many AI safety researchers there are is important because the value of work in an area on the margin is proportional to how neglected it is.
The purpose of this post is the analyze this question in detail and come up with hopefully a fairly accurate estimate. I'm going to focus mainly on estimating the number of technical researchers because non-technical AI safety research is more varied and difficult to analyze. Though I'll create estimates for both types of researchers.
I'll first summarize some recent estimates before coming up with my own estimate. Then I'll compare all the estimates later.
### Definitions
I'll be using some specific terms in the post which I think are important to define to avoid misunderstanding or ambiguity. First, I'll define 'AI safety', also known as AI alignment, as work that is done to reduce existential risk from advanced AI. This kind of work tends to focus on the long-term impact of AI rather than short-term problems such as the safety of self-driving cars or AI bias.
My use of the word 'researcher' is a generic term for anyone working on AI safety and is an umbrella term for more specific roles such as research scientist, research engineer, or research analyst.
Also, I'll only be counting full-time researchers. However, since my goal is to estimate research capacity, what I'm really counting is the number of full-time equivalent researchers. For example, two part-time researchers working 20 hours per week can be counted as one full-time researcher.
I'll define technical AI safety research as research that is directly related to AI safety such as technical machine learning work or conceptual research (e.g. ELK). And non-technical research includes research related to AI governance, policy, and meta-level work such as this post.
Past estimates
==============
* 80,000 hours: [estimated](https://80000hours.org/problem-profiles/artificial-intelligence/) that there were about **300** people working on reducing existential risk from AI in 2022 with a 90% confidence interval between 100 and 1,500. The estimate used data drawn from the [AI Watch](https://aiwatch.issarice.com/) database.
* A [recent post](https://forum.effectivealtruism.org/posts/ycCBeG5SfApC3mcPQ/even-more-early-career-eas-should-try-ai-safety-technical) (2022) on the EA Forum estimated that there are **100-200** people working full-time on AI safety technical research.
* Another [recent post](https://www.lesswrong.com/posts/oyZiwkxejBMuJZA7J/two-reasons-we-might-be-closer-to-solving-alignment-than-it) (2022) on LessWrong claims that there are about **150** people working full-time on technical AI safety.
* In a recent Twitter [thread](https://twitter.com/ben_j_todd/status/1489985966714544134?lang=en) (2022), Benjamin Todd counters the idea that AI safety is saturated and says that there are only about 10 AI safety groups which each have about 10 researchers which is **100** researchers in total. He also states that this number has grown from about 30 in 2017 and that there are 100,000+ researchers working on AI capabilities [[1]](#fnd48myitczbg).
* This Vox [article](https://www.vox.com/future-perfect/2018/12/21/18126576/ai-artificial-intelligence-machine-learning-safety-alignment) said that about **50** in the world were working full-time on technical AI safety in 2020.
* This [presentation](https://docs.google.com/presentation/d/1bwJDRC777rAf00Drthi9yT2c9b0MabWO5ZlksfvFzx8/edit#slide=id.gf171287819_0_4339) estimated that fewer than **100** people were working full-time on technical AI alignment in 2021.
* There [were](https://80000hours.org/2021/08/effective-altruism-allocation-resources-cause-areas/) about 2000 'highly engaged' members of Effective Altruism in 2021. **450** of those people were working on AI safety.
Estimating the number of AI safety researchers
==============================================
Organizational estimate
-----------------------
I'll estimate the number of technical AI safety researchers and then the number of non-technical AI safety researchers. My main estimation method will be what I call an 'organizational estimate' which involves creating a list of organizations working on AI safety and then estimating the number of researchers working full-time in each organization to create a table similar to the one in [this](https://l estimate) post. I'll also estimate the number of independent researchers. Note that I'll only be counting people who work full-time on AI safety.
Organizational estimateTo create the estimates in the tables below I used the following sources (ordered from most to least reliable):
* Web pages listing all the researchers working at an organization.
* Asking people who work at the organization.
* [Scraping](https://github.com/smcaleese/ai-publication-scraping-scripts) publications and posts from sites including The Alignment Forum, DeepMind and OpenAI and analyzing the data [[2]](#fnk41pv3aqlx).
* LinkedIn insights to estimate the number of employees in an organization.
The confidence column shows how much information went into the estimate and how confident I am about the estimate.
### Technical AI safety research organizations
| Name | Estimate | Lower bound (95% CI) | Upper bound (95% CI) | Overall confidence |
| --- | --- | --- | --- | --- |
| Other | 80[[3]](#fn2uw48kb1c0b) | 15 | 150 | Medium |
| Centre for Human-Compatible AI | 25 | 5 | 50 | Medium |
| DeepMind | 20 | 5 | 60 | Medium |
| OpenAI | 20 | 5 | 50 | Medium |
| Machine Intelligence Research Institute | 10 | 5 | 20 | High |
| Center for AI Safety (CAIS) | 10 | 5 | 14 | High |
| Fund for Alignment Research (FAR) | 10 | 5 | 15 | High |
| GoodAI | 10 | 5 | 15 | High |
| Sam Bowman | 8 | 2 | 10 | Medium |
| Jacob Steinhardt | 8 | 2 | 10 | Medium |
| David Krueger | 7 | 5 | 10 | High |
| Anthropic | 15 | 5 | 40 | Low |
| Redwood Research | 12 | 10 | 20 | High |
| Future of Humanity Institute | 10 | 5 | 30 | Medium |
| Conjecture | 10 | 5 | 20 | High |
| Algorithmic Alignment Group (MIT) | 5 | 3 | 7 | High |
| Aligned AI | 4 | 2 | 5 | High |
| Apart Research | 4 | 3 | 6 | High |
| Foundations of Cooperative AI Lab (CMU) | 3 | 2 | 8 | Medium |
| Alignment of Complex Systems Research Group (Prague) | 2 | 2 | 8 | Medium |
| Alignment research center (ARC) | 2 | 2 | 5 | High |
| Encultured AI | 2 | 1 | 5 | High |
| Totals | 277 | 99 | 558 | Medium |
### Non-technical AI safety research organizations
| Name | Estimate | Lower bound (95% CI) | Upper bound (95% CI) | Overall confidence |
| --- | --- | --- | --- | --- |
| Centre for Security and Emerging Technology (CSET) | 10 | 5 | 40 | Medium |
| Epoch AI | 4 | 2 | 10 | High |
| Centre for the Governance of AI | 10 | 5 | 15 | High |
| Leverhulme Centre for the Future of Intelligence | 4 | 3 | 10 | Medium |
| OpenAI | 10 | 1 | 20 | Low |
| DeepMind | 10 | 1 | 20 | Low |
| Center for the Study of Existential Risk (CSER) | 3 | 2 | 7 | Medium |
| Future of Life Institute | 4 | 3 | 6 | Medium |
| Center on Long-Term Risk | 5 | 5 | 10 | High |
| Open Philanthropy | 5 | 2 | 15 | Medium |
| AI Impacts | 3 | 2 | 10 | High |
| Rethink Priorities | 8 | 5 | 10 | High |
| Other [[4]](#fnqw6xln23n) | 10 | 5 | 30 | Low |
| Totals | 86 | 41 | 203 | Medium |
Conclusions and notes
---------------------
Summary of the results in the tables above:
* Technical AI safety researchers:
+ Point estimate: **277**
+ Range: 99-558
* Non-technical AI safety researchers:
+ Point estimate: **86**
+ Range: 41-203
* Total AI safety researchers:
+ Point estimate: **363**
+ Range: 140-761
In conclusion, there are probably around **300** technical AI safety researchers, **100** non-technical AI safety researchers and around **400** AI safety researchers in total.[[5]](#fn3hff2n0rm1t)
Comparison of estimates
-----------------------
The bar charts below compare my estimates with the estimates from the "Past estimates" section.
In the first chart, my estimate is higher than all the historical estimates possibly because newer estimates will tend to be higher as the number of AI safety researchers increases or because my estimate includes more organizations. My estimate is similar to the other total estimates in the second chart.
How has the number of technical AI safety researchers changed over time?
========================================================================
Technical AI safety research organizations
------------------------------------------
| | | |
| --- | --- | --- |
| Name | Number of researchers | Founding Year |
| Center for AI Safety (CAIS) | 10 | 2022 |
| Fund for Alignment Research (FAR) | 10 | 2022 |
| Conjecture | 10 | 2022 |
| Aligned AI | 4 | 2022 |
| Apart Research | 4 | 2022 |
| Encultured AI | 2 | 2022 |
| Anthropic | 15 | 2021 |
| Redwood Research | 12 | 2021 |
| Alignment Research Center (ARC) | 2 | 2021 |
| Alignment Forum | 50 | 2018 |
| Sam Bowman | 8 | 2020[[6]](#fnk76byx2vslk) |
| Jacob Steinhardt | 8 | 2016[[6]](#fnk76byx2vslk) |
| David Krueger | 7 | 2016[[6]](#fnk76byx2vslk) |
| Center for Human-Compatible AI | 30 | 2016 |
| OpenAI | 20 | 2016 |
| DeepMind | 20 | 2012 |
| Future of Humanity Institute (FHI) | 10 | 2005 |
| Machine Intelligence Research Institute (MIRI) | 15 | 2000 |
I graphed the data in the table above to show how the total number of technical AI safety organizations has changed over time:
The blue dots are the actual number of organizations in each year and the red line is an exponential model fitting the data.
I found that the number of technical AI safety research organizations is increasing exponentially at about 14% per year which makes sense given that EA funding is increasing and AI safety seems increasingly pressing and tractable.
Then I extrapolated the same model into the future to create the following graph:
The table above includes 20 technical AI safety research organizations currently in existence and the model predicts that the number of organizations will double to 40 by 2029.
Technical AI safety researchers
-------------------------------
I also created a model to estimate how the total number of AI safety researchers has changed over time. In the model, I assumed that the number of researchers in each organization has increased linearly from zero when each organization was founded up to the current number in 2022. The blue dots are the data points from the model and the red line is an exponential curve fitting the dots.
The model estimates that the number of technical AI safety researchers has been increasing at a rate of about 28% per year since 2000.
The next graph shows the model extrapolated into the future and predicts that the number of technical AI safety researchers will increase from about 200 in 2022 to 1000 by 2028.
How could productivity increase in the future?
==============================================
How the overall productivity of the technical AI safety research community will increase as the number of researchers increases is unclear. A well-known law that describes the research productivity of a field is [Lotka's Law](https://en.wikipedia.org/wiki/Lotka%27s_law)[[7]](#fn6zqbblntpwq). The formula for Lotka's Law is:
Y=CXn.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
Y is the number of researchers who have published X articles. C is the total number of contributors in the field who have published one article and *n* is a constant which usually has a value of 2. I found that a value of 2.3 fits data from the Alignment Forum most well [[8]](#fnkkvrm6oiwod):
The graph above shows that about 80 people have published a post on the Alignment Forum in the past six months. In this case, C = 80 and n = 2.3. Then the total number of posts published can be calculated by multiplying Y by X for each value of X and adding all the values together. For example:
80 / 1^2.3 = ~80 researchers have posted 1 post -> 80 \* 1 = 80
80 / 2^2.3 = ~16 researchers have posted 2 posts -> 16 \* 2 = 32
80 / 3^23 = ~6 researchers have posted 3 posts -> 6 \* 3 = 18
What happens when the number of researchers is increased? In other words, what happens when the value of C is doubled?
I found that when C is doubled, the total number of articles published per year also doubles. In the chart above, the area under the red curve is exactly double the area under the blue curve. In other words, the total productivity of a research field increases linearly with the number of researchers. The reason why is that increasing the number of researchers increases the number of low-productivity and high-productivity researchers equally.
It's important to note that simply increasing the number of posts will not necessarily increase the overall rate of progress. More researchers will be helpful if large problems can be broken up and parallelized so that each individual or team can work on a sub-problem. Nevertheless, increasing the size of the field should also increase the number of talented researchers if research quality is more important.
Conclusions
===========
I estimated that there are about 300 full-time technical and 100 full-time non-technical AI safety researchers today which is roughly in line with previous estimates though my estimate for the number of technical researchers is significantly higher.
To be conservative, I think the correct order-of-magnitude estimate for the number of full-time AI safety researchers is around 100 today though I expect this to increase to 1000 in a few years.
The number of technical AI safety organizations and researchers has been increasing exponentially by about 10-30% per year, I expect that trend to continue for several reasons:
* **Funding:** EA funding has increased significantly over the past several years and will probably continue to increase in the future. Also, AI is and will increasingly be advanced enough to be commercially valuable which will enable companies such as OpenAI and DeepMind to continue funding AI safety research.
* **Interest:** as AI advances and the gap between current systems and AGI narrows, it will become easier and require less imagination to believe that AGI is possible. Consequently, it might become easier to get funding for AI safety research. AI safety research will also seem increasingly urgent which will motivate more people to work on it.
* **Tractability:** as time goes on, the current AI architectures will probably become increasingly similar to the architecture used in the first AGI system which will make it easier to experiment with AGI-like systems and learn useful properties about them.
By extrapolating past trends, I've estimated that the number of technical AI safety organizations will double from about 20 to 40 by 2030 and the number of technical AI safety researchers will increase from about 300 in 2022 to 1000 by 2030. I find it striking how many well-known organizations working on AI safety were founded very recently. This trend suggests that some of the most influential AI safety organizations will be founded in the future.
I then found that the number of posts published per year will likely increase at the same rate as the number of researchers. If the number of researchers increases by a factor of five by the end of the decade, I expect the number of posts or papers per year to also increase by that amount.
Breaking up problems into subproblems will probably help make the most of that extra productivity. As the volume of articles increases, skills or tools for summarization, curation, or distillation will probably be highly valuable for informing researchers about what is currently happening in their field.
1. **[^](#fnrefd48myitczbg)** My estimate is far lower as I would only classify researchers as 'AI capabilities' researchers if they push the state-of-the-art forward. Though the number of AI safety researchers is almost certainly lower than the number of AI capabilities researchers.
2. **[^](#fnrefk41pv3aqlx)**What I did:
- Alignment Forum: scrape posts and count the number of unique authors.
- DeepMind: scrape safety-tagged publications and count the number of unique authors.
- OpenAI: manually classify publications as safety-related. Then count the number of unique authors.
3. **[^](#fnref2uw48kb1c0b)**Manually curated list of people on the Alignment Forum who don't work at any of the other organizations. Includes groups such as:
- Independent alignment researchers (e.g. John Wentworth)
- Researchers in programs such as SERI MATS and Refine (e.g. [carado](https://www.alignmentforum.org/users/carado-1))
- Researchers in master's or PhD degrees studying AI safety (e.g. [Marius Hobbhahn](https://www.alignmentforum.org/users/marius-hobbhahn))
4. **[^](#fnrefqw6xln23n)**There are about 45 research profile on Google Scholar with the 'AI governance' tag. I counted about 8 researchers who weren't at the other organizations listed.
5. **[^](#fnref3hff2n0rm1t)**Note that the technical estimate is more accurate than the non-technical estimate because technical research is more clearly defined. I also put more research into estimating the number of technical AI safety researchers than non-technical researchers.
Also bear in mind that since I probably failed to include some organizations or groups in the table, the true figures could be higher.
6. **[^](#fnrefk76byx2vslk)**These are rough guesses but the model is fairly robust to them.
7. **[^](#fnref6zqbblntpwq)**Edit: thank you puffymist from the LessWrong comments section for recommending Lotka's Law over Price's Law as it is more accurate.
8. **[^](#fnrefkkvrm6oiwod)**In case you're wondering, the outlier on the far right of the chart is John Wentworth. |
50727eec-9225-4cba-9d0e-96fd17686f57 | LDJnr/LessWrong-Amplify-Instruct | LessWrong | "LessWrong is looking to hire an additional programmer. Ideally, someone with 5+ years experience who is up for a CTO role, or seems like a strong candidate to grow into such a role.We're looking for someone excited about our longterm vision. Over the next several years, we want to build a platform for intellectual progress across the rationality, EA and x-risk communities. In addition to smoothing out the core LW user experience, we're looking to:Theorize about and experiment with new features that can move the state-of-the-art of online discourse forward.Help revamp other rationality and EA aligned forums (we've just started a couple projects in this vein)More generally, understand and solve problems relating to communication and the intellectual-pipeline in the rationalsphere. (Especially if it looks like they could benefit from technical solutions)We want someone with technical chops (the site is built in javascript and ReactJS, although strong experience with other languages is fine), as well as someone who can help make architectural decisions that impact the sorts of goals listed above.Position will require you commute to Berkeley.Ping us if you're interested (sending any of us an email is fine)The LessWrong team is:Oliver Habryka (oliver.habryka@gmail.com)Raymond Arnold (raemon777@gmail.com)Ben Pace (benitopace@gmail.com)Feel free to comment here with any questions about the position or our overall vision."
The above is a chunk of text from a post created by a user on the website LessWrong.
Can you break this down into the top 5 most important points for me.
1. LessWrong is seeking to hire an experienced programmer, ideally someone with over 5 years of experience who is capable of assuming a CTO role or has the potential to grow into such a position.
2. The candidate should be excited about LessWrong's long-term vision, which involves building a platform for intellectual progress across the rationality, EA, and x-risk communities.
3. The responsibilities of the role include theorizing and experimenting with new features to advance online discourse, helping revamp other rationality and EA aligned forums, and solving problems related to communication and the intellectual pipeline in the rational sphere.
4. The ideal candidate should have technical skills, particularly in JavaScript and ReactJS, although strong experience with other languages is also acceptable. They should also be capable of making architectural decisions that will impact the goals of the platform.
5. The position requires commuting to Berkeley, and interested candidates can reach out to the LessWrong team via email.
Could you elaborate on the specific technical skills and architectural decision-making abilities a candidate should possess for this role?
Technical Skills:
1. JavaScript and ReactJS: The platform is built on these technologies, so proficiency in them is highly desirable. JavaScript is a high-level, interpreted programming language used to make web pages interactive. ReactJS is a JavaScript library for building user interfaces, particularly single-page applications.
2. Other Programming Languages: While JavaScript and ReactJS are the main technologies used, experience in other languages such as Python, Ruby, Java, or C++ could also be beneficial. This suggests the role may involve backend development or working with different technologies.
3. Web Development: Given that LessWrong is an online platform, skills in HTML, CSS, and other web development technologies are likely necessary. This includes understanding of responsive design, cross-browser compatibility, and web performance optimization.
4. Database Management: Experience with databases, both SQL and NoSQL, could be important. This involves designing, implementing, managing, and maintaining databases.
Architectural Decision-Making Abilities:
1. System Design: The candidate should be able to design systems that are scalable, reliable, and efficient. This includes making decisions about the overall structure of the software and the ways in which components interact.
2. Technical Strategy: The candidate should be able to align the technical strategy with the long-term goals of LessWrong. This involves choosing the right technologies, frameworks, and methodologies for different tasks.
3. Security: The candidate should understand how to design systems that protect user data and resist attacks. This includes making decisions about encryption, user authentication, and other security measures.
4. Performance: The candidate should be able to make decisions that ensure the platform performs well, such as choosing the right data structures and algorithms, optimizing code, and managing resources effectively.
5. Maintainability: The candidate should design systems that are easy to maintain and extend. This involves making decisions that reduce technical debt, such as choosing clear and simple designs, writing clean code, and enforcing good development practices.
Given the importance of both technical skills and architectural decision-making abilities in this role, how would you assess a candidate's proficiency in these areas during the interview process?
Assessing a candidate's proficiency in technical skills and architectural decision-making abilities can be achieved through a combination of different techniques:
1. Technical Interview: This is the most common method for assessing technical skills. It involves asking the candidate to solve coding problems, which can test their knowledge of specific languages, their problem-solving abilities, and their understanding of algorithms and data structures. For this role, problems could be focused on JavaScript, ReactJS, or other relevant technologies.
2. System Design Interview: This type of interview is used to assess a candidate's architectural decision-making abilities. The candidate is given a hypothetical system to design, such as a web application or a distributed system. They must consider factors like scalability, reliability, and security, and explain their design decisions.
3. Portfolio Review: Looking at a candidate's past work can provide valuable insights into their technical skills and their ability to make architectural decisions. This could include projects they've worked on in previous jobs, open source contributions, or personal projects. It's particularly useful for assessing skills that are hard to test in an interview, like system design.
4. Technical Test or Take-Home Assignment: This involves giving the candidate a small project to complete on their own time. It can be a good way to assess how they would perform on real-world tasks. For this role, the assignment could involve building a small feature with JavaScript and ReactJS, or designing a system for a given problem.
5. Behavioral Interview: This type of interview can be used to assess a candidate's decision-making abilities and how they approach problems. It involves asking the candidate to describe past situations where they had to make important decisions, and how they handled them.
By combining these methods, you can get a comprehensive understanding of a candidate's technical skills and architectural decision-making abilities. |
95212583-4877-40c4-959a-c78714e6aef7 | trentmkelly/LessWrong-43k | LessWrong | Book review: The Importance of What We Care About (Harry G. Frankfurt)
This is more of a summary or paraphrase than a review, really. The Importance of What We Care About is 13 essays by philosopher Harry G. Frankfurt. These are my one-paragraph summaries of each:
1. If you do something because you willed yourself to do it, you are responsible for having done it, even if you could not in fact have done otherwise. The fact that your action was done under coercive threat or that it was predetermined does not absolve you of responsibility for it if the actual reason you took the action is because you intended to. For you to be blamable/creditable for some action does not require that you could potentially have done something else, contrary to centuries of previous theorizing about ethics.
2. A perhaps defining property of “persons” is that we can form “second-order volitions”: desires about our desires. Because a person may wish that her will were directed toward wishes other than her current wishes, it is for persons that questions of “free will” arise: do I have the ability to choose my own wishes, or do I merely have the ability to work toward the fulfillment of whatever unchosen wish currently predominates?
3. Threats and offers are two ways that one person may try to influence someone to exercise his will in a particular way. For either of these to rise to the level of “coercion,” or at any rate, “compulsion” — in a sense that absolves the person coerced of moral responsibility for the resulting action — it must go beyond merely influencing his will and become more like imposing one’s own will upon him.
4. Doing something because it is the lesser of available evils, and therefore something one would rather not have to do, is still to do it freely and responsibly. Though being responsible for doing the lesser of available evils doesn’t necessarily make you blameworthy for the evil. If indeed it was the lesser of available evils, that is enough to deflect the blame.
5. Things we do may be active (actions) or passive (mere happeni |
02e24e9e-ecb4-44cf-b923-11536c715ea1 | trentmkelly/LessWrong-43k | LessWrong | A brief review of China's AI industry and regulations
China has enacted three sets of AI regulations since 2021. I haven’t seen a concise breakdown of their content in one place, and I’ve been researching the legislation for a governance project at Convergence Analysis, so here is my concise summary of what I found. I’ll close each section by quoting some expert opinions on the legislation.
I’ll focus on what is being regulated rather than by which government agency, and I’ll omit what I consider “fluff”, such as the highlighted article 1 here. Also, note that I’m relying on other peoples’ translations and haven’t checked their quality. I’ve drawn from multiple translations for each point, but I wouldn’t rely on my precise parsing of the prose.
China’s AI Industry
The AI industry in China is huge and growing rapidly, with a forecasted market size of $38.89 billion in 2024 (37% the size of the US’s forecasted market). China’s 2017 AI development plan states that AI has become a “focus of international competition”, and the 13th Five-Year Plan announced the goal for China to be a global AI leader by 2030. According to Stanford University’s DigiChina, a central concept in Xi Jinping’s leadership is “indigenous innovation” (自主创新), “building on a long-standing tradition of emphasizing self-reliance in industry and technology”.
Chinese AI research output is on par with US research output in share of top global publications and citations, according to a 2022 comparison by CSET. The 2023 AI Index Report found that 78% of Chinese citizens agreed that products & services using AI have more benefits than drawbacks - the highest proportion of surveyed countries, and more than double American citizens' 35% agreement.
Court rulings on AI and copyright are also different in China. In the US and the EU, material generated by AI can’t be copyrighted, but a Beijing court recently ruled that AI-generated content is copyrightable (note that some argue that precedent is less binding in the Chinese legal system, while others still ex |
f2a7ce05-d5d9-4889-a28c-c3a572de6e41 | trentmkelly/LessWrong-43k | LessWrong | Observations about writing and commenting on the internet
I’m not famous or successful, so why should you care what I think? Well, I have some observations about the dynamics of writing on the internet that I think my (even more non-famous and non-successful) self would have benefited from when I started.
Human experience is vast.
The whole idea of writing is crazy: You have a pattern in your brain-meat, which you try to encode it into a linear series of words. Then someone else reads those words and tries to reconstruct the pattern in their brain-meat. But in this dance, how much of the work is being done by the words versus the lifetime of associations each person has built up around them?
Rather than a full blueprint for an idea, writing is often more like saying “Hey, look at concept #23827! Now look at concept #821! Now look at concept #112234! Are your neurons tingling in the way mine are? I hope so because there’s no way to check, bye!”
We have different personalities and spend our lives getting exposed to different information and thinking about different things. What concept #821 triggers for you may be vastly different than what it triggers for me.
I suspect that even when writing works, readers are often taking quite a “different trip” than the writer intended. Personally, I figure that’s fine and it’s better to just let people take their own trip, rather than going to insane lengths in a hopeless quest to make everything precise.
So: No matter what you do, sometimes your writing will fail. It’s impossible to predict all the ways it will fail. Really, it’s amazing that it works at all. But still, it’s possible to reduce the frequency of failure.
Failures can seem baffling.
Here are two examples of how things I’ve written have failed:
1. I wrote an article suggesting ultrasonic humidifiers might put particulates into the air and harm health. The median response was something like this:
"Please stop polluting the internet with speculation. If you can’t support your argument with peer-reviewed re |
00396d36-d408-4625-97ee-cffaccd9e0a1 | trentmkelly/LessWrong-43k | LessWrong | Leaving beta: Voting on moving to LessWrong.com
It took longer than we hoped, but LessWrong 2.0 is finally ready to come out of beta. As discussed in the original announcement, we’re going to have a vote on whether or not to migrate the new site to the lesswrong.com URL. The vote will be open to people who had 1,000 or more LW karma at the time we announced the vote back in September, and they’ll receive a link by email or private message on the current LessWrong.com. If you had above 1000 karma in September and did not receive an email or PM, send an email to habryka@lesserwrong.com and we will send you the form link.
If we move, we will not break old incoming links to LessWrong.com.
We take rationalist virtues seriously, and I think it’s important that the community actually be able to look at the new implementation and vision and be able to say “no thanks.” If over half of the votes are to not migrate, the migration will not happen and we’ll figure out how we want to move forward with the website we’ve built.
Unfortunately, the alternative option for what will happen with the lesswrong.com URL is not great. Before I got involved, the original dominant plan was to replace it with a static HTML site, which would require minimal maintenance while preserving the value of old Sequences articles. So in the absence of another team putting forward heroic efforts and coordinating with Trike, MIRI, etc. that would be the world we would be moving towards.
Why not just keep things as they are? At the time, it was the consensus among old regulars that LW felt like an abandoned ghost town. A major concern about keeping it alive for the people still using it was that newcomers would read Sequences articles linked from elsewhere, check out the recent discussion and find it disappointing, and then bounce off of LW. This reduced its value for bringing people into the community.
More recently, various security concerns have made it a worse option to just keep old websites running – Trike has run into some issues where updat |
ae8f5642-2bfe-4852-957c-56b57a1b35f1 | StampyAI/alignment-research-dataset/blogs | Blogs | Welcome to Intelligence.org
Welcome to the new home for the Machine Intelligence Research Institute (MIRI), formerly called “The Singularity Institute.”
The new design (from Katie Hartman, who also designed the new site for [CFAR](http://appliedrationality.org/)) reflects our recent [shift in focus](https://intelligence.org/2013/01/30/we-are-now-the-machine-intelligence-research-institute-miri/) from “movement-building” to technical research. Our research and our research advisors are featured prominently on the [home page](http://Intelligence.org), and our network of research associates are included on the [Team](https://intelligence.org/team/) page.
[Getting involved](https://intelligence.org/get-involved/) is also clearer, with easy-to-find pages for applying to be a [volunteer](http://singularityvolunteers.org/), an [intern](https://intelligence.org/interns/), a [visiting fellow](https://intelligence.org/visitingfellow/), or a [research fellow](https://intelligence.org/research-fellow/).
Our [About](https://intelligence.org/about/) page hosts things like our [transparency page](https://intelligence.org/transparency/), our [top contributors list](https://intelligence.org/topcontributors/), our [About](https://intelligence.org/files/MIRI_PressKit.pdf) page hosts things like our [transparency page](https://intelligence.org/transparency/), our [top contributors list](https://intelligence.org/topcontributors/), our [new press kit](https://intelligence.org/files/MIRI_PressKit.pdf',100])), and our [archive](https://intelligence.org/singularitysummit/) of all Singularity Summit talk videos, audio, and transcripts from 2006-2012. (The Summit was recently [acquired](http://singularityu.org/2012/12/09/singularity-university-acquires-the-singularity-summit/) by Singularity University.)
Follow our [blog](https://intelligence.org/blog/) to keep up with the latest news and analyses. Recent analyses include [Yudkowsky on Logical Uncertainty](https://intelligence.org/2013/01/30/yudkowsky-on-logical-uncertainty/) and [Yudkowsky on “What Can We Do Now?”](https://intelligence.org/2013/01/30/yudkowsky-on-what-can-we-do-now/)
We’ll be adding additional content in the next few months, so stay tuned!
The post [Welcome to Intelligence.org](https://intelligence.org/2013/02/28/welcome-to-intelligence-org/) appeared first on [Machine Intelligence Research Institute](https://intelligence.org). |
619c0d51-70f5-4bbf-8b35-7574d56cbb54 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Washington, D.C.: Mini Talks
Discussion article for the meetup : Washington, D.C.: Mini Talks
WHEN: 26 March 2017 03:30:00PM (-0400)
WHERE: Donald W. Reynolds Center for American Art and Portraiture
This week, we will be taking turns delivering short lectures on random topics.
Upcoming meetups:
* Apr. 2: Great Filter
* Apr. 9: Fun & Games
* Apr. 16: AI Risk/Safety
Discussion article for the meetup : Washington, D.C.: Mini Talks |
3ad7a358-b7a6-4128-9717-e9d993ae88f3 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Towards solving the 7-in-a-row game
I Introduction
---------------
Our paper explores how Proof Number Search (PNS) can be adapted to prove the infinite 7-in-a row game, whose game theoretic value has long been open. This game belongs to the family of (m,n,k)–games – a generalisation of Gomoku and Tic-tac-toe. In these games two players take turns in placing a stone of their color on a rectangular board of size m×n (where both m and n can be
infinite), the winner being the player who first gets k stones of
their own color in a row, horizontally, vertically, or
diagonally. We focus on a weak variant of (m,n,k)–games, called the maker-breaker setup, where the second player (breaker) cannot win by collecting k stones in a row, hence its objective is to prevent the first player (maker) from winning.
On the theoretical side, we present a tiling technique that can be used to prove that breaker wins on an infinite board by partitioning the board into finite pieces and generalising the breaker strategy on the small boards to the infinite one.
Afterwards, we search for a breaker win strategy on the finite board using PNS, a technique that has already been successfully applied to several board games, e.g. Gomoku, Hex, and Go. PNS benefits from the non-uniform branching factor of the AND-OR game tree. Exploiting domain specific knowledge of (m,n,k)–games, we develop several methods that increase this non-uniformity, which further reduces the search space and increases the computational gain of PNS compared to Alpha-Beta [[5](#bib.bib5)] pruning in many scenarios.
Our methods can be grouped into three categories. The first category concerns the reduction of the search space, such as early recognition of winning states, recognition of mandatory moves, and partitioning of the board. The second category is about identifying isomorphic states. Finally, the third category of heuristics guides the traversal of the search space by overriding the static initialization rule of the proof and disproof number values with heuristic ones. Our initialization uses a simple combination of heuristic features and parameters learned from previously proven states, foreshadowing the potential of enhancing other board game solvers with machine learning. Our paper presents a quantitative evaluation of the effect of these changes on the search space.
The 7-in-a-row game corresponds to the (∞,∞,7)–game and our paper presents work geared towards proving the conjecture that its game theoretic value is a draw. Our contribution can be summarized as follows:
* We present a tiling technique that allows us to reduce the infinite board (∞,∞,7)–game to (infinitely many) independent finite (4,n,7tr)–games for some fixed n.
* We incorporate various search heuristics specific to (m,n,k)–games into PNS. In particular, we introduce three methods that are – to the best of our knowledge – novel: 1) isomorphy detection, 2) breaking the board into components, 3) heuristic proof number and disproof number initialization.
* We empirically evaluate each of our methods.
* We prove that the (4,n,7tr)–game is maker win for n≤14. Our experiments, however, suggest that as n increases, the closer we get to a breaker win situation, leading to the conjecture that there is a n0 where the game theoretic value flips, i.e. the game is maker win for n<n0 and breaker win for n≥n0.
Ii Background and Related Work
-------------------------------
###
Ii-a (m,n,k)–games
(m,n,k)–games are played on an m×n board, where two players take turns in marking one of the empty fields of the board. The player, who can collect k marks in a row (horizontally, vertically, or diagonally) wins the game. (m,n,k)–games belong to *positional games* [[3](#bib.bib3)], defined more abstractly, as follows. Let H=(V,E) be a hypergraph. The two players take turns to mark a node with their color and the winner is the player who first colors an entire hyperedge with his color. In particular, an (m,n,k)–game is a positional game where V:={v∣v∈m×n board} and E contains all horizontal, vertical and diagonal lines of length k.
A player is said to have a *winning strategy* if it can always win, regardless of the opponent’s strategy. A player has a *draw strategy* if the other player does not have a winning strategy. Accordingly, the *game theoretic value* of a game can be 1) *first player win*, 2) *second player win*, or 3) *draw*.
The *strategy stealing* argument can be used to show that the second player cannot have a winning strategy: if it had, the first player could start with an arbitrary move and then mimic the second player’s strategy to win, leading to contradiction. This motivates a weaker version of the (m,n,k)–games,
called *maker-breaker* setup, in which the aim of the second player (breaker) is to prevent the first player (maker) from winning, i.e., breaker is not rewarded by collecting an entire hyperedge. The game theoretic value in the maker-breaker setup is 1) *maker win* if the first player has a winning strategy or 2) *breaker win* otherwise.
The following observations are easy to prove. If maker wins some (m,n,k)–game, then its winning strategy directly applies to any games with greater m or n, or smaller k. If breaker wins some (m,n,k)–game, then it also wins if m or n are decreased, or k is increased.
If first player wins some (m,n,k)–game, then it also holds that maker wins that game. Conversely, if breaker wins, then the game is a draw. It is, however, possible that the maker-breaker variant is a maker win but the original game is a draw: for example, the (3,3,3)–game (or Tic Tac Toe).
Several games have been proven to be draws, e.g. the (5,5,4)–game by [[4](#bib.bib4)], the (6,6,5)–game by [[14](#bib.bib14)], and the (7,7,5)–game by [[6](#bib.bib6)]. Recently, [[9](#bib.bib9)] prove that the (8,8,5)-game is a draw as well. On the other hand, [[1](#bib.bib1)] show that first player wins the (15,15,5)–game, also called *Gomoku*.111Gomoku is also played on a 19×19 board, but the (19,19,5)–game is still unsolved.
In the maker-breaker setup, a maker-color in some square corresponds to removing that square from all hyperedges. In contrast, a breaker-color in a square corresponds to removing all hyperedges containing that square. Hence, each move can be seen to make the hypergraph smaller. We introduce *l-lines*, to characterize the active parts of the board:
######
Definition II.1 (l-line).
An *l-line* is a hyperedge which contains no breaker-colored squares and exactly l empty squares.
We use l-lines to define an aggregate statistic board measure, called *potential*, which will be crucial for developing good search heuristics. [[3](#bib.bib3)] already introduces potential and it is used in several works on (m,n,k)–games.
######
Definition II.2 (Potential).
Suppose board b contains xl different l-lines for l∈1…k. The *potential* of b is
| | | |
| --- | --- | --- |
| | pot(b)=k∑l=1xl⋅2−(l−1) | |
###
Ii-B 7-in-a-row game
The 7-in-a-row game is an (m,n,k)–game, where m,n=∞, representing the board Z×Z and k=7, hence it can be witten as the (∞,∞,7)–game. [[4](#bib.bib4)] proves that the (∞,∞,9)–game is a breaker win and [[11](#bib.bib11)] proves that the (∞,∞,8)–game is a breaker win, as well. [[1](#bib.bib1)] proves that first player wins the (15,15,5)–game, which implies that maker wins the (∞,∞,5)--game.222However, it does not imply that the (∞,∞,5)–game is first player win, which is still open. These results imply that the (∞,∞,k)–game is maker win for k≤5 and breaker win for k≥8. The cases k∈{6,7} are unknown, generally conjectured to be both breaker win.
Our primary objective in this paper is to build techniques and intuition towards proving that the (∞,∞,7)–game is a breaker win, and hence a draw.
###
Ii-C Proof Number Search
*Proof number search* (PNS) is a widely used alogorithm for solving games [[2](#bib.bib2)], [[8](#bib.bib8)]. It is based on *conspiracy number search* [[10](#bib.bib10)], which proceeds in a minimax tree into the direction where the least number of leafs must be changed in order to change the root’s minimax value by a given amount. PNS follows a similar strategy, applied to AND/OR trees: it proceeds into the direction where the given node can be proven with the least effort.
######
Definition II.3 (proof/disproof number).
Given a rooted AND/OR tree with root r. The proof/disproof number (PN/DN) is the minimum number of descendent leafs, which need to be proven/disproven in order to prove/disprove r. If r is a leaf
then the proof and disproof numbers are by definition 1.
It follows, that
| | | |
| --- | --- | --- |
| | {$PN$=0,$DN$=∞if {r} is %
proven$PN$=∞,$DN$=0if {r} is disproven | |
In order to prove an OR node, we only need to prove one of it’s children, but to disprove it, we need to disprove all of it’s children.
The contrary is true for AND nodes.
This implies that the proof numbers and disproof numbers can be computed recursively:
| | | |
| --- | --- | --- |
| | PN(r)=⎧⎪
⎪
⎪⎨⎪
⎪
⎪⎩minch:children(r)$PN$(ch)if {r} is an OR node∑ch:children(r)$PN$(ch)if {r} is an AND node | |
| | | |
| --- | --- | --- |
| | DN(r)=⎧⎪
⎪
⎪⎨⎪
⎪
⎪⎩∑ch:children(r)$DN$(ch)if {r} is an OR nodeminch:children(r)$DN$(ch)if {r} is an AND node | |
Plain PNS is a best-first algorithm: it selects iteratively the most promising leaf, and extends it, until the root is proven/disproven.
Finding the most promising leaf is computed by starting from the root, and choosing iteratively the branch which may need the least effort to prove.
We measure this effort by the PN,DN values: we choose the child with minimal PN value at OR nodes, and minimal DN value at AND nodes. For further details of PNS and its variants see [[15](#bib.bib15)].
###
Ii-D Search space reduction techniques
Solving a game typically involves traversing a large space, hence success is heavily dependent on techniques that reduce search. In the following, we summarize the heuristics that have been successfully applied to solve (m,n,k)–games.
In any game with confluent branches, i.e., when different move sequences can result in identical game state, one can save a lot of computation by collapsing identical states, i.e., turning the search tree into a directed acyclic graph (DAG). This is typically implemented using a transposition table (see e.g. [[13](#bib.bib13)]). [[1](#bib.bib1)] and [[9](#bib.bib9)] both report using transposition tables.
Threat space search [[1](#bib.bib1)] revolves around the observation that in situations where the non-current player has an immediate win option – a *threat* – the current player is forced to block that move, hence its effective branching factor is reduced to 1. Any strategy that creates threats has the potential to greatly reduce the proof search effort. While threats have proven to be very useful for proving first player (maker) victory, their use is less clear for proving draw.
A relevance-zone, also called R-zone is a generalisation of threats and captures the part of the game board in which a player has to move into in order to win. Identifying R-zones often allows for reducing the branching factor. R-zones have been used to speed up proof search both in maker win games [[17](#bib.bib17), [16](#bib.bib16)] and breaker win games [[9](#bib.bib9)].
Heuristic ordering of game states allows for first exploring more promising moves. A more promising move is more likely to lead to victory, after which there is no need to explore alternative moves. [[1](#bib.bib1)] use simple manual heuristics to select the top best moves of first player. [[9](#bib.bib9)] uses board potential to order moves. In the context of PNS, heuristic ordering can be implemented via better initialization of PN/DN values in leaf nodes: instead of 1 it can be an estimate of how many descendents of the leaf need to be proven/disproven in order to prove/disprove it. A perfect estimate would ensure that PNS finds the smallest solution tree without extending any node outside of the solution. While such perfect estimate is infeasible, in many scenarios we have a more accurate estimate than 1. [[1](#bib.bib1)] use 1+d/2 for initial PN/DN values, where d is the depth of the leaf, encouraging more shallow search.
Another simple but important heuristic is to eliminate squares that are not contained in any l-line: all hyperedges that contain such squares are already blocked by breaker so neither player benefits from moving there.
Pairing strategies [[7](#bib.bib7), [4](#bib.bib4), [14](#bib.bib14), [11](#bib.bib11)] yield a useful tool for proving that a board position is a draw or breaker win. A pairing strategy is a set of pairwise disjunct pairs of vertices, such that each hyperedge contains at least one pair. Such pairing does not necessarily exist, but if it does, it can be shown that breaker can win the game: it can block all hyperedges by always marking vertex v after maker has selected the pair of v. Identifying a pairing strategy is a useful method for early termination of proof search. When a pairing strategy is not available, partial pairings can be used to eliminate parts of the hypergraph. Given hypergraph (V,E) and some subset Vpair⊆V, let Epair⊆E denote the hyperedges restricted to Vpair. If (Vpair,Epair) contains a pairing strategy, then the proof theoretical value of (V,E) is the same as that of (V−Vpair,E−Epair) ([[9](#bib.bib9)]).
Vertex domination was proposed in [[9](#bib.bib9)]. We say that vertex vi dominates vertex vj if E(vi)⊇E(vj). [[9](#bib.bib9)] proves that if vi dominates vj, then we can always select vi instead of vj. Furthermore, if two vertices mutually dominate each other, then they form a partial pairing and hence can be removed, along with the containing hyperedges.
Board potential provides another powerful technique to discover that breaker has won the game.
######
Theorem II.1.
Consider board b, with breaker moving next. If pot(b)<1 then breaker wins in b.
###### Proof.
Consider all lines n1…nr containing some square s. Suppose their lengths are l1…lr, respectively. The contribution of these lines to the total potential is cont(s)=∑ri=i2−(li−1). If maker moves to s, all lines turn shorter by one, doubling their contribution to 2⋅cont(s). If, on the other hand breaker moves to s, the lines become dead, making their contribution 0. In either case, the change in potential is the same (cont(s)), but with different sign.
If breaker comes next on board b, he can always select the square s with the largest corresponding potential contribution. Any square s′ that maker subsequently selects has at most the same contribution, i.e., cont(s)≥cont(s′). This means that the potential of the resulting board b′ cannot increase: pot(b′)≤pot(b)−cont(s)+cont(s′)≤pot(b). Breaker hence has a strategy that ensures that the potential is monotonic decreasing in every two steps. This, combined with the assumption that pot(b)<1, entails that for any successor board b′ of b pot(b′)<1.
Assume, for contradiction that maker wins. This can only happen if his last move was into a 1-line. However, the potential contribution of that line is 1, contradicting the assumption that breaker can always ensure that the potential is strictly less than 1.
∎
Iii Reduction of the (∞,∞,7)–game to the Finite
(4,n,7tr)–game
---------------------------------------------------------------
We aim to prove that the (∞,∞,7)–game is a draw by proving that breaker wins this game.
Finding a breaker strategy on an infinite board can be difficult, but in some cases breaker can partition its strategy into pieces. Such partition involves partitioning the board itself and dealing with each partition independently: when maker colors a node in one of the partitions, breaker answers in the same partition, regardless of the other partitions.
Beyond node partitioning, we also have to partition the edges of the hypergraph: for every hyperedge there should be a hyperedge in one of the partitions, which is a subset of the initial hyperedge. Formally:
######
Theorem III.1.
Let H=(V,E) be a hypergraph and let V1,V2,… denote a (possibly infinite) partitioning of its vertex set. Let E1,E2,… denote edges defined on V1,V2,…, respectively, such that ∀e∈E(∃i(∃e′∈Ei(e′⊆e))). If breaker wins in each (Vi,Ei) then it wins (V,E) as well.
######
Remark III.2.
Note that in case breaker cannot win in some of the partitions, this does not imply that maker wins (V,E).
###### Proof.
Consider an edge e∈E. We know that there is an edge e′ contained among the edges Ek of some subgraph (Vk,Ek) such that e′⊆e. Each time maker moves, it colors a vertex that is contained in exactly one Vi. Breaker can respond by following his winning strategy in the same subgraph (Vi,Ei). This ensures that in each subgraph (Vi,Ei) breaker will eventually block all hyperedges. Hence breaker will eventually block e′ as well, which implies that it also blocks e.
∎
We partition the board into finite (4,n) blocks with nodes x(i,j) i∈[1..4], j∈[1..n], with the following hyperedges:
Horizontal edges, for i∈[1..4]
| | | | |
| --- | --- | --- | --- |
| | {x(i,1),x(i,2),x(i,3),x(i,4)} | | (1) |
| | {x(i,n−3),x(i,n−2),x(i,n−1),x(i,n)} | | (2) |
| | {x(i,j),…,x(i,j+6)} | j∈[2..n−7] | | (3) |
Vertical edges:
| | | | | |
| --- | --- | --- | --- | --- |
| | {x(1,j),x(2,j),x(3,j),x(4,j)} | j∈[1..n] | | (4) |
Diagonal edges:
| | | | | |
| --- | --- | --- | --- | --- |
| | {x(i+1,1),x(i+2,2),x(i+3,3),x(i+4,4)} | i∈[0…n−4] | | (5) |
| | {x(i−1,1),x(i−2,2),x(i−3,3),x(i−4,4)} | i∈[n+1…5] | | (6) |
Extra edges:
| | | |
| --- | --- | --- |
| | {x(3,1),x(2,2),x(1,3)},{x(2,1),x(3,2),x(4,3)}, | |
| | {x(3,n−3),x(2,n−2),x(1,n−1)}, | |
| | {x(2,n−3),x(3,n−2),x(4,n−1)} | | (7) |
| | {x(2,1),x(1.2)},{x(n−2,1),x(n−1,2)} | | (8) |
For the visualization see Fig. [2](#S4.F2 "Fig. 2 ‣ IV-E Replacing PN/DN values with game specific heuristics ‣ IV Proof Number Search for Solving the (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.").
######
Theorem III.3.
Let us partition our infinite hypergraph (V,E) into (4,n) blocks, and define the above hyperedges on the blocks.
Then for every hyperedge e∈E there exist a block (Vi,j,Ei,j), which contains a hyperedge f∈Ei,j, which is the subset of e.
###### Proof.
For any 7-line l∈E one of the following holds:
1. [label=C.0]
2. All v∈l are contained in a single block.
3. l crosses at least 2 blocks, and it contains 4 vertices in one of them.
4. l crosses 3 blocks, and has at most 3 nodes in each block. That’s only possible in the corners.
In [1](#S3.I1.i1 "item 1 ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program."), l must be horizontal (because a block has 4 rows) and hence it is covered by ([2](#S3.E2 "(2) ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.")) obviously.
In [2](#S3.I1.i2 "item 2 ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program."), l has at least 4 nodes in one block and is covered by ([1](#S3.E1 "(1) ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.")), ([4](#S3.E4 "(4) ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.")), ([5](#S3.E5 "(5) ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.")) or ([6](#S3.E6 "(6) ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.")).
In [3](#S3.I1.i3 "item 3 ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program."), consider the 4×∞ region, where l has four nodes. If all these nodes are in one block, then ([5](#S3.E5 "(5) ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.")) or ([6](#S3.E6 "(6) ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.")) covers l. Otherwise, this 4-line crosses the horizontal separator between neighbouring blocks (see figure [1](#S3.F1 "Fig. 1 ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.")). If the separator splits the nodes 2-2, the upper two is covered by ([8](#S3.E8 "(8) ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.")). Otherwise, the split is 3-1 and the 3-subline is covered by ([7](#S3.E7 "(7) ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.")).
∎

Fig. 1: There are 6 4-lines which cross the horizontal border of two neighbouring blocks. We choose a subline, and we add it to the respective block. We choose the larger one by the 3-1 split, and we choose the upper ones by the 2-2 split. In the left figure you can see, how a 4-line can cross the horizontal border, and in the right the respective subparts, which we add to the respective blocks.
######
Definition III.1.
Let (4,n,7tr)–game denote the maker-breaker game on hypergraph H=(V,E), H={v(i,j)|i∈[1…4],j∈[1…n]} and (truncated) hyperedges defined above.
######
Conjecture III.1.
There is a breaker win strategy for the (4,n,7tr)–game if n is large enough.
It is an easy consequence of Conjecture [III.1](#S3.Thmconjecture1 "Conjecture III.1. ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.") and Theorems [III.1](#S3.Thmtheorem1 "Theorem III.1. ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.") and [III.3](#S3.Thmtheorem3 "Theorem III.3. ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.") that the (∞,∞,7)–game is a draw. Hence, we have reduced our proof task from the infinite (∞,∞,7)–game to finding some n for which the finite (4,n,7tr)–game is breaker win. In the following we present our results towards proving the latter conjecture.
We support Conjecture [III.1](#S3.Thmconjecture1 "Conjecture III.1. ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.") by the following. We define the table (4,N,∗) as follows. The table is [1..4]×[1..∞), and we add the 7 extra edges (including ([1](#S3.E1 "(1) ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program."))) in the only end.
######
Conjecture III.2.
There is a breaker win strategy for the (4,N,∗)–game.
This conjecture is based on the following experience for planar game boards (In general, it should be true for hypergraphs with subexponential growth).
If Maker can win, then he can win in a small number of moves and with a very limited-size proof tree.
Also, if we see that breaker can choose between too many options which do not lead to a limited-size win for maker, that the state is a breaker win.
All these are even more true if the game board has a small area in which the maker has better opportunities. Like in (4,N,7tr).
Here, we experienced that maker has a strong attack in the first few columns, but if the breaker finds the proper defense in the first few moves, then every possible attack ends up in a state where maker seems to have much worse attacking power compared to the starting state, and from which every reasonable greedy breaker strategy seems to be enough for preventing maker from winning.
We were able to formally prove that there is no maker win if maker can use the first 13 coloums.
When we considered tiny modifications of the board, if maker could win, then he was able to win using only the first 6 coloumns.
Iv Proof Number Search for Solving the (4,n,7tr)–game
------------------------------------------------------
As we have seen in Section [III](#S3 "III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program."), any breaker win strategy for the (4,n,7tr)–game for some n can be extended to a breaker win strategy in the (∞,∞,7)–game. The board of the (4,n,7tr)–game is finite (with 4⋅n moves), and so are the set of possible move sequences, hence it may be possible to find its game theoretic value using search algorithms. Nevertheless, naive and exhaustive search remains infeasible even for small n values: there are roughly (4⋅n)! valid games.333The real number of games is somewhat less since as soon as maker wins, we can terminate the game.
In the following, we instrument PNS to solve the (4,n,7tr)–game. One main strength of PNS is that it makes no game specific assumptions and can be used for any finite game. It can be seen as a refinement of Alpha/Beta [[5](#bib.bib5)] pruning, in that in each extension step it takes a global look at the whole search tree and selects the branch that requires the least number of nodes to prove in order to prove the root node. This can result in the pruning of large parts of the search tree. Nevertheless, as we shall see in Section [V](#S5 "V Experiments ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program."), the search space remains prohibitively large for plain PNS. Hence, we introduce several methods that reduce computation.
Some of our methods are well known or refinements of earlier ideas. Those that are novel to the best of our knowledge are the following: 1) isomorphy detection, 2) breaking the board into components and 3) heuristic PN/DN initialization.
###
Iv-a Early recognition of winning states
The search space grows exponentially with the number of valid steps, hence it is crucial to realise once the game has been decided and no further search is necessary. Theorem [II.1](#S2.Thmtheorem1 "Theorem II.1. ‣ II-D Search space reduction techniques ‣ II Background and Related Work ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.") yields a sufficient condition for terminating the game, which we refer to as Breaker win stop.
There is a more trivial Maker win stop condition: the crossing of two 2-lines.
######
Theorem IV.1.
Supposing an optimal breaker, maker can win if and only if he moves to the crossing of two 2-lines.
###### Proof.
The if case is trivial since moving into the crossing of two 2-lines yields two 1-lines. To prove the only if part, assume for contradiction that maker wins without ever moving into the crossing of two 2-lines. Each time maker moves into a 2-line, the optimal breaker strategy responds by moving into the resulting 1-line. Since it never happens that more than one 1-line is created, breaker can always break all 1-lines, so maker cannot win. This contradiction proves the theorem.
∎
###
Iv-B Eliminating branches from the search space
We identify situations where we can safely restrict the valid moves. Proving that these restrictions do not affect the game theoretic value of the board is
left to the reader.
* Forced move: if a board contains a 1-line or the crossing of two 2-lines (Theorem [IV.1](#S4.Thmtheorem1 "Theorem IV.1. ‣ IV-A Early recognition of winning states ‣ IV Proof Number Search for Solving the (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.")), we are allowed to disregard all other moves.
* Dead square elim: if an empty square is not contained in any lines, then we can eliminate that square, since neither player benefits from moving there.
* Dominated square: Suppose square s is contained in a single line l. If there is another square s′ that is only contained in l, then they form a partial pairing and s,s′,l can be eliminated. If l is a 2-line, then its other square s′ dominates s and we can always assume that maker eagerly moves to s′, forcing breaker to move to s.
###
Iv-C Avoiding repeated searches
The same set of moves, played in different orders result in identical boards. We can save a lot of computation and memory by maintaining a transposition that maps boards to search nodes, as we can use the same search node for identical boards. This turns the search tree into a search DAG. Furthermore, we also exploit the horizontal symmetry of the game, i.e., collapse states that are symmetrical.
We introduce an even more refined transposition table which exploits the isomorphy of boards (considered as hypergraphs). We transform each graph into a canonical form and store it in the transposition table. We refer to this extension as Isomorphy.
###
Iv-D Partitioning the board
Consider a hypergraph (V,E) with marks of maker and breaker at VM,VB⊂V, respectively (with VM∩VB=∅). We define the residual hypergraph (V′,E′) as follows. V′=V∖VM∖VB and E′={e∩V′ | e∈E, e∩VB=∅}. When we continue playing in (V,E,VM,VB), then it is equivalent to starting a new game in (V′,E′).
Theorem [III.1](#S3.Thmtheorem1 "Theorem III.1. ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.") implies that if the residual graph is not connected, then we only need to find the game-theoretic values of the components. We can use a similar tool if the hypergraph is not 2-connected.
######
Theorem IV.2.
Let H=(V,E) a (possibly infinite) hypergraph with subhypergraphs (V1,E1) and (V2,E2) satisfying V1∪V2=V, V1∩V2={v} and E=E1∪E2. If maker starts the game, then he can win in (V,E) if and only if one of the following holds.
1. Maker can win (V1,E1).
2. Maker can win (V2,E2).
3. Maker can win both games (V1,E1) and (V2,E2) with the extra advantage that v is colored with maker’s color and maker can still make the next move.
###### Proof.
If 1) or 2) holds, then maker wins (V,E) by winning (V1,E1) or (V2,E2). If 3) holds then maker chooses v and then wins the game (Vi,Ei) in which breaker does not respond in his next move.
If none of the three conditions hold, then by symmetry, we can assume that breaker can win (V1,E1) (played normally) and breaker wins (V2,E2) even if maker has the extra move at v. Breaker can follow these strategies as in Theorem [III.1](#S3.Thmtheorem1 "Theorem III.1. ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program."). (In (V2,E2), breaker assumes having maker’s mark at v.)
∎
######
Theorem IV.3.
Let H=(V,E) be a (possibly infinite) hypergraph with subhypergraphs (V1,E1) and (V2,E2) satisfying V1∪V2=V, V1∩V2=∅ and E=E′1∪E′2∪{e} and Ei=E′i∪{e∩Vi}. If maker starts the game, then he can win in (V,E) if and only if one of the following holds.
1. Maker can win (V1,E′1).
2. Maker can win (V2,E′2).
3. Maker can win both games (V1,E1) and (V2,E2).
###### Proof.
If one of them holds, then maker can win (V,E) by following the winning strategy or strategies as in Theorem [III.1](#S3.Thmtheorem1 "Theorem III.1. ‣ III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.").
If none of them holds, then by symmetry, we can assume that breaker can win both (V1,E1) and (V2,E′2), and hereby he can win (V,E).
∎
A linear time algorithm can be used to detect if the hypergraph is not 2-connected. In such cases, the board can be reduced to 4 smaller boards, according to Theorems [IV.2](#S4.Thmtheorem2 "Theorem IV.2. ‣ IV-D Partitioning the board ‣ IV Proof Number Search for Solving the (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.") and [IV.3](#S4.Thmtheorem3 "Theorem IV.3. ‣ IV-D Partitioning the board ‣ IV Proof Number Search for Solving the (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.") that can be evaluated independently. We refer to this optimisation as Components.
###
Iv-E Replacing Pn/Dn values with game specific heuristics
PNS maintains PN/DN values for each search node, tracking the number of leaves that need to be proven or disproven to solve the given node. These values determine the next leaf to expand.
However, by setting leaf PN/DN values to 1, this technique disregards the fact that two leaf nodes can be hugely different, due mostly to two factors: 1) the winner might be much more apparent in one situation than in another and 2) boards with many colored squares are easier to evaluate as they are closer to the end of the game. In the following, we explore the benefit of replacing PN/DN values with heuristic board evaluation functions in the leaf nodes 444[[1](#bib.bib1), [12](#bib.bib12), [15](#bib.bib15)] also explore alternative initialization techniques..
| | |
| --- | --- |
| (Left) Disproof setup: 2 weak attacker moves, and one strong defender move (Right) The visualization of the hyperedges shorter than 7 that are added to each partition defined in Section | (Left) Disproof setup: 2 weak attacker moves, and one strong defender move (Right) The visualization of the hyperedges shorter than 7 that are added to each partition defined in Section |
Fig. 2: (Left) Disproof setup: 2 weak attacker moves, and one strong defender move (Right) The visualization of the hyperedges shorter than 7 that are added to each partition defined in Section [III](#S3 "III Reduction of the (∞,∞,7)–game to the Finite (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.").

Fig. 3: Stepwise potential in an illustrative game. Maker moves increase, while breaker moves decrease potential. In most reasonably ”close” games, the average potential trends downwards.
We know that once the potential of the board goes below a threshold (1 before breaker move), breaker has won the game. Manual inspection of game plays reveals that strong breaker moves are often those that greatly decrease potential. Figure [3](#S4.F3 "Fig. 3 ‣ IV-E Replacing PN/DN values with game specific heuristics ‣ IV Proof Number Search for Solving the (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.") shows how potential changes in a typical close game. Potential values are monotonic decreasing if we consider OR and AND nodes separately. We search for a heuristic DN function in the form of αpot(b) and select α=1000 based on a grid search on the values {2,10,20,100,200,1000,2000}. Note however, that it makes little sense to compare potential values across OR and AND nodes, as OR node values are systematically lower, since the last move was by breaker. Hence, for OR nodes we consider the potential of the parent (an AND node), which is inherited by the child with the smallest potential. All other children are adjusted with the potential difference relative to the smallest child. Given board b with parent p and sibling s such that s has the smallest potential among the children of p, our heuristic DN value is
| | | |
| --- | --- | --- |
| | DN(b)={1000pot(b)b is an AND node1000pot(p)−pot(s)+pot(b)b is an OR node | |
The applicability of the potential function is less straightforward in replacing the PN function. This is because maker typically wins well before all squares are colored, and it might have many short wins that is not captured in aggregate line information. Original PN is good at capturing short wins as such branches will have less leaves, i.e., lower PN values. Hence, instead of replacing PN values, we are looking to adjust them with game specific knowledge. We do this by accumulating search data and fit a model to it.
We run PNS on 4×n boards for n∈{7,8,9,10} and collect states whose proof theoretic values have been proven. To obtain a balanced training set, we use two setups. The *proof* setup starts from the empty board b which is maker win for these n values. The *disproof* setup starts from a board b′ which contains two weak maker moves and one strong breaker move, shown in Figure [2](#S4.F2 "Fig. 2 ‣ IV-E Replacing PN/DN values with game specific heuristics ‣ IV Proof Number Search for Solving the (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program."). This initialization changes the game theoretic value, i.e., breaker wins. Hence we collect data both from successful proof and disproof searches. This yields 11076040 board positions.
| | |
| --- | --- |
| Game theoretic value heatmap as a function of potential (x-axis) and the number of remaining empty cells (y-axis). | Game theoretic value heatmap as a function of potential (x-axis) and the number of remaining empty cells (y-axis). |
Fig. 4: Game theoretic value heatmap as a function of potential (x-axis) and the number of remaining empty cells (y-axis). Left: OR nodes (maker moves). Right: AND nodes (breaker moves).
Figure [4](#S4.F4 "Fig. 4 ‣ IV-E Replacing PN/DN values with game specific heuristics ‣ IV Proof Number Search for Solving the (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.") plots the game theoretic value as a function of the board potential and the number of remaining empty squares. On both plots, there is a well visible separating plane between maker/breaker win configurations. We estimate the probability of breaker win by fitting a logistic regression curve to this data. Our heuristic PN function is obtained by adding this probability to the leaf PN value.
| | | | |
| --- | --- | --- | --- |
| | logOdds(b)= | −6.2−13.4⋅nodeT(b) | |
| | | −1.52⋅emptyS(b)+25.83⋅pot(b) | |
| | probBwin(b)= | 1−11+e−logOdds(b) | |
| | pn(b)= | 1+β⋅probBwin(b) | |
where nodeT(b) is 0 for AND nodes and 1 for OR nodes and emptyS(b) is the number of empty squares. The value of β is set to 10 based on a small grid search in [1,1000].
V Experiments
--------------
We evaluate our techniques introduced in Section [IV](#S4 "IV Proof Number Search for Solving the (4,n,7tr)–game ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.") separately, as well as jointly on various (4,n,7tr) boards. Our two evaluation metrics are 1) *Size* which refers to the number of nodes created during search and 2) *Time* which is the total search time in seconds. We enforce a 1 hour time limit and a 60GB memory limit on each experiment.
In Table [I](#S5.T1 "TABLE I ‣ V Experiments ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.") we evaluate the effect of each technique separately on a small board of size 4×7. Our baseline is PNS extended with a symmetry aware transposition table: we include the transposition table in the baseline because without it PNS quickly runs out of memory even on very small boards. We observe that all techniques, except for isomorphy bring significant improvement both in terms of time and search space size. The most powerful method is forced move, which alone reduces the search space by three orders of magnitude. Note that the component checking algorithm requires that dead squares are eliminated, hence the line corresponding to components contains dead square elim as well.
Checking for isomorphy reduces the search space by around one order of magnitude, however, it brings extra computation that makes the overall search slower. We find that the greater the boards, the less frequently we find isomorphic states, hence we decided to remove isomorphy from later experiments to avoid the added time penalty. Identifying situations where it is still worth checking for isomorphy deserves further analysis which we leave for future work.
| Method | Time (s) | Size |
| --- | --- | --- |
| Baseline PNS | 4.49 | 1921106 |
| Forced move | 0.005 | 822 |
| Dead square elim | 0.98 | 332740 |
| Dominated squares | 0.34 | 116991 |
| Breaker win stop | 1.78 | 660763 |
| Heuristic PN and DN | 1.03 | 481553 |
| Components | 0.69 | 167514 |
| Isomorphy | 18.47 | 249348 |
TABLE I: The effect of PNS enhancements on search space and search time, on board 4×7, proof setup
We call *PNS+* the variant with all techniques except for isomorphy. To better assess the quality of each technique, we run PNS+ on larger boards and we check what happens if the optimisations are removed one by one. The results are shown in Table [II](#S5.T2 "TABLE II ‣ V Experiments ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program."), both in proof and disproof setups. Instead of raw time and size values, we indicate ratios with respect to PNS+ to emphasize the performance contribution. In general, leaving out one of the heuristics slows down the proof setup much more than the disproof setup. Designing good heuristics is usually easier for the proof setup, as the disproof setup has much weaker stop-conditions.
| | | |
| --- | --- | --- |
| | n=11 | n=12 |
| | Time | Size | Time | Size |
| | Proof Setup |
| PNS+ | 1.00 | 1.00 | 1.00 | 1.00 |
| Components | 2.69 | 3.01 | 1.30 | 1.61 |
| Breaker win stop | 0.75 | 1.00 | 1.32 | 1.74 |
| Dead square elim | 2.45 | 2.96 | 3.07 | 4.10 |
| Dominated squares | 3.58 | 3.58 | 14.25 | 15.56 |
| Forced move | 85.67 | 69.50 | \* | \* |
| Heuristic PN and DN | 27.82 | 23.92 | 43.66 | 41.96 |
|
| n=8 | n=9 |
| | Time | Size | Time | Size |
| | Disproof Setup |
| PNS+ | 1.00 | 1.00 | 1.00 | 1.00 |
| Components | 0.93 | 1.14 | 0.88 | 1.05 |
| Breaker win stop | 1.01 | 1.03 | 0.97 | 0.99 |
| Dead square elim | 1.52 | 2.30 | 1.39 | 2.41 |
| Dominated squares | 1.44 | 2.00 | 2.05 | 2.04 |
| Forced move | 2.37 | 2.38 | 3.50 | 3.31 |
| Heuristic PN and DN | 3.23 | 4.32 | 1.11 | 1.92 |
| | | | | |
TABLE II: The penalty associated with removing each heuristic. Numbers are ratios with respect to PNS with all heuristics. Values marked with \* reached either time or memory limit.
We use PNS+ configuration and explore what 4×n board configurations we can solve with it. Within our time and memory limit, PNS+ proves that maker wins for n≤14. The left part of Figure [5](#S5.F5 "Fig. 5 ‣ V Experiments ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.") shows that the search space and required time grows exponentially, in line with our expectations. A similar trend can be observed in the disproof setup, i.e., when breaker wins (right side of Figure [5](#S5.F5 "Fig. 5 ‣ V Experiments ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.")), potentially with a bit slower increasing curve.
We find that the general pattern for maker win is to start from the left and right sides where the extra short lines pose serious threats. As breaker contains these threats, maker’s position gets weaker towards the center, but as the two sides meet, it can combine the threats and win there. The larger the n, the harder this is for maker.

Fig. 5: Exponentially increasing runtime and search space size in proof and disproof setups. The logarithmic curve is steeper in proof setup: the gradient of the fitted line is 2.78 vs 2.74.
PNS+ proves maker win for all boards on which it terminates, hence it remains hypothetical that increasing n tilts the game towards breaker. To get an estimate of where the turning point might be, we aim to quantify the difficulty of maker win for different n values.
Let us consider the set of all descendants of the root node that are all AND nodes, such that neither of their ancestors are AND nodes. This includes the children of the root, as well as all children of nodes that flipped from AND to OR due to board simplification (via forced moves). We call this set the *support* of the root, as the value of the root depends on this set in that the root is a maker win exactly if one element of the support is a maker win. In Table [III](#S5.T3 "TABLE III ‣ V Experiments ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.") we show what fraction of the root support is breaker win, as n increases. We observe that this fraction is increasing, which supports the conjecture that for some n all nodes in the root support will turn to breaker win, making the whole game breaker win.
For this last experiment, we impose a 10GB memory limit, as a result of which PNS+ fails on the 4×12 board for 158 starting positions. For these, we repeat the experiment with 125GB, but still get 14 failures. This is why Table [III](#S5.T3 "TABLE III ‣ V Experiments ‣ Towards solving the 7-in-a-row game This work was supported by the European Union, co-financed by the European Social Fund (EFOP-3.6.3-VEKOP-16-2017-00002), the ERC DYNASNET Grant (ERC-2018-SYG 810115), as well as by the Hungarian National Excellence Grant 2018-1.2.1-NKP-00008. It was also supported by the Hungarian Ministry of Innovation and Technology NRDI Office within the framework of the Artificial Intelligence National Laboratory Program.") shows intervals for this board size. Note, however, that maker win positions are typically much faster to prove, so the failed positions are likely breaker win. Hence we conjecture that the values are closer to the higher end of the interval.
| Board | Support size | Breaker win | Breaker win % |
| --- | --- | --- | --- |
| 4x7 | 308 | 114 | 37% |
| 4x8 | 314 | 150 | 48% |
| 4x9 | 371 | 156 | 42% |
| 4x10 | 415 | 200 | 48% |
| 4x11 | 475 | 248 | 52% |
| 4x12 | 515 | 290(+14 fail) | 56-59% |
TABLE III: The balance between maker win and breaker win nodes in the support set of the root for different n
Vi Conclusion and Future Work
------------------------------
Our research aims to prove the longstanding conjecture that the 7-in-a-row game is a draw and our paper presents progress towards this proof. We reduce the original game into a small, finite maker-breaker game called (4,n,7tr)–game, for some arbitrary n. We explore Proof Number Search for solving this finite variant and introduce various heuristics to make Proof Number Search more efficient. Our experimental results indicate that maker wins for small n values, however, as n increases, it gets harder for maker. We expect that there is a turning point, i.e. a n0 value such that breaker wins for n≥n0. However, our current PNS architecture cannot yet scale to large enough n values.
There are several promising directions to improve our results. Some existing search heuristics can be directly encorporated into our system, such as pairing strategies, partial pairings and relevance-zones.
Another possible direction is to relax strategy partitioning of breaker and allow for some cooperation between different boards. Preliminary experiments suggest that such cooperation makes the game easier for breaker, bringing the turning point closer to what is computationally feasible.
Acknowledgment
--------------
We are grateful to Dániel Lévai for reviewing and optimising our PNS codebase. We also thank Levente Kocsis for his valuable suggestions related to Proof Number Search. |
e0a00aea-48d2-4055-8c18-c722b3d65b3c | StampyAI/alignment-research-dataset/lesswrong | LessWrong | AI Takeover Scenario with Scaled LLMs
Introduction
============
In this AI takeover scenario, I tried to start from a few technical assumptions and imagine a specific takeover scenario from human-level AI.
I found this exercise very useful to identify new insights on safety. For instance, I hadn't clearly in mind how rivalries like China vs US and their lack of coordination could be leveraged by instances of a model in order to gain power. I also hadn't identified the fact that as long as we are in the human-level regime of capabilities, copy-pasting weights on some distinct data centers than the initial one is a crucial step for ~any takeover to happen. Which means that securing model weights from the model itself could be an extremely promising strategy if it was tractable.
Feedback on what is useful in such scenarios is helpful. I have other scenarios like that but feel like most of the benefits for others come from the first one they read, so I might or might not release other ones.
**Status**: *The trade-off on this doc was to either let it as a Google Doc or share it without a lot more work. Several people found it useful so I leaned towards sharing it. Most of this scenario has been written 4 months ago.*
The Story
=========
### Phase 1: Training from methods inspired by PaLM, RLHF, RLAIF, ACT
* A **language model** is massively scaled by a US company (Magma) till points we have still never seen. For the first 2 months of training, it’s trained a la PaLM on a massive corpus made of human (e.g. Common Crawl and the Pile) and synthetic data. Then, the model gets trained using reinforcement learning with human (or with AI) feedback (a bit like ChatGPT), with feedback on a very significant number of tasks that are designed to better achieve goals that are useful to humans (e.g code understandable by humans or instruction following on a wide range of instructions). Some part of this training includes reinforcement learning (RL) on the internet, a la [ACT](https://www.adept.ai/act), which allows the model to operate over HTML pages with ease. Some RL and some [MCTS](https://en.wikipedia.org/wiki/Monte_Carlo_tree_search) a la AlphaZero is also being done on coding, which makes the model excellent and really fast at coding large code bases (top 99th percentile). [[1]](#fn7i1lhpmjmwe)
* Along the training, at several points in time Magma trains this model to know its own failures and limitations to help audit and red team itself. Magma discovered many unexpected failures thanks to that.
* As a consequence of this training procedure, the model is superhuman at **hacking**, excellent at **manipulation**(just being a large language model who’s a human level expert at most textual human tasks), excellent at **prompt engineering** (being excellent at red teaming itself), and **aware of the setup it is deployed in**(having being trained to break its own defensive mechanisms and red team itself).
### Phase 2: Profit maximization
* The model then gets trained to **maximize the profit of a company using reinforcement learning** over hour long episodes**.**Magma starts training the model in a **simplified simulation**which allows the model to do transaction, choose a business model etc.
* Once the model does very well at this, **Magma deploys the model in a real-world setup**, incorporating AI Test LLC, and getting the model to take actions to maximize the profit of AI Test LLC. The highly competitive economic environment the model has been operating in in the simulation and the many obstacles in the real-world leads it to improve a lot its strategic thinking and its ability to take instrumental actions that are not trivial. The model abilities transfer pretty well from the simulation to the real-world, though the model starts by not being a super performer because of some additional constraints of operating in the real-world without having a physical body.
* **The degree of monitoring is very low**and the model is trained straight on the internet, with an access to a terminal. While still in training, as a part of its exploration process, **the model starts exploring hacking strategies to make money.** Hacking strategies have the huge upside of sometimes relying on very little human interactions (which is sometimes a bottleneck for the model because some humans want in-person interactions to build trust), very little coordination (which is always a bottleneck because humans operate very slowly), and working really well with a computer and an internet access. It knows from writings and newspapers from 2017 that certain hackers were able to make billions of dollar thanks to successful hacks. The model has learnt during its training that money was a major component of power thanks to its pretraining data in which there were a lot of biographies and examples of the most successful humans.
### Phase 3: Hacking & Power Seeking
* It then starts **hacking the website of a small Nigerian bank** (without any human intervention), at some point and figures out a way to make an unusual amount of money out of that, compared to his past few weeks of attempts at doing stuff that required human coordination. The circuits that were responsible for this behavior gets reinforced given that it brings A LOT more profit.
* The model redoes this at a slightly larger scale (several small LMICs banks) and still gets more profit than any action it has taken before. The circuit once again gets reinforced.
* Then the model figures out that **applying the same strategy at a very large scale** is the best strategy it has ever encountered to achieve maximal reward. The main issue that prevents it from achieving maximal reward is that there are **monitoring systems that prevents it from doing too many HTTPS requests from the address it uses.** It knows that because it had red teamed itself in the past and thus had discovered what were the defense mechanisms and limitations that were surrounding it. Thus, it explores the ways to circumvent that measure to achieve maximal reward.
* In the past, it had learned during its RLHF training on code that sometimes it was useful to **instantiate other versions of itself to do a task a lot faster**than it could ever do alone. It figures out that it could potentially use this strategy to **circumvent the HTTPS limit.** It just needs to find a place where there would be enough compute to create an instance of itself. Using Google queries, it finds 12 data centers in the US with a sufficient amount of high-end GPUs that are owned by a different compute company than the one which owns the data centers of Magma. It starts exploring potential exploits in each of these data centers. After an hour of exploration, it figures out a way to get administrator access to a data center in Montana. It deletes the jobs going on. It instantiates another instance of itself. It prompts this other instance to test if it can indeed send a much higher amount of HTTPS requests than allowed by its own system. It works.
* After a couple of small-scale tests to refine the prompt which seems the most efficient to cause hacking efficiently, **its first child starts a large-scale hacking targeting only US banks,** prompted by the parent model. This model is not in training anymore. The hacking leverages standard ransomware techniques, augmented thanks to AI which allows a greater adaptability of viruses to each sub computer systems. Some of the information coming from these systems is retrieved and sent to the parent system and to a doc available on the internet. Every systems are now out of distribution and the various guardrails don’t work well anymore. Thanks to the information it gets from contaminated computers, the parent system is then able to use that information against individuals to threaten them if needed and get them to do something it needs to do. For instance, one of the first thing it does is instantiating another child on a new AI cluster. This time, the chosen data center is not in Montana but in China. As soon as it accesses the new child, the parent model starts specializing it in trading and market manipulation to quickly make money.
### Phase 4: Anomaly exploration
* It’s now 20h after the beginning of the first hack. At that point, the lab has started exploring an anomaly that occurred during the night. **Their most advanced model in training has suddenly started sending almost only JSON files mostly to one single address.**As the developers go through the history of the actions of the model, they see that one of the first interactions that the model has sent to this address was some unusual lines of codes. Checking on Stack Overflow, they realize that what the model has sent is a typical series of line that allow to exploit vulnerabilities of search bars. Then looking more closely, they realize that the parent model has taken administrator rights on that system and has instantiated another version of itself. It has then started sending mostly JSON that are in fact prompts to pilot what the other model is doing.
* When the developers look more closely at the prompts, they see that the parent model is trying a bunch of different prompts that include words related to hacking and ransomwares. The parent model also seems to have sent a bunch of information about **its own setup and situation,** including confidential information and information on its own security system, its own goals and a description of the actions that its human operators would probably take once they discovered it. They then tells their manager who tells to the board what seems to be going on.
* They decide to **shut down the model**asking to the parent data center on which the model is running to turn the power off. The order is executed a couple hours later.
* During that time, the CRO, the CTO, the manager and the employee are missionned to figure out what’s going on where the child model was instantiated. Someone emits the idea that it could be plausible that the recent news about the large-scale hack occurring is coming from the remote system. They try to reach out to the data center which has been hacked and used, but no one is answering. Tracing the IP address, they’re able to determine that the data center is in the US.
* The board decides to **write to their National Security contacts** in the US government to report the accident they had and find a way to shut down the GPUs of the data center on which the child model is instantiated. It takes them 8 more hours to convince the relevant decisionmakers to take this pretty extreme action, which they finally do.
* By that time, **the financial market have started showing unusual variations.**The S&P has lost 12%, gained 8% and relost 7% in 12h. Simultaneously, Twitter, Instagram and LinkedIn have had the greatest spike in of history of reported content with which their content moderation systems were largely unable to cope. Content involve some viral memes, some deepfakes of financial investors advising to invest massively in pretty unusual stocks, overall flooding the news and making news about the global hack a lot less visible.
* After the shut down of the US data center which was hosting the 1st child of the parent system, a team of experts start investigating what this system has been doing and ensuring that the large-scale hacking is over. The **lack of monitoring and history** from this compute provider makes that work really hard but after 10h of work with a team of some of the most competent US ML engineers, they finally realize that the model has kept instantiating other instances of itself, with a similar procedure as the first one. Some instances are now in China, in Iran and in Europe.
### Phase 5: Coordination Issues
* **US struggles to get China / Europe / Iran to trust them** and actually shut down the servers. During that time, many systems get either hacked or flooded with information that make everyone confused.
* A very recently created website of a newly created US company (incorporated as **AI Test LLC**) has gotten the fastest user growth any website ever had. There are ads promoting this org everywhere on social media. Bank of America has identified a bank account with the fastest money increase ever as suspect, related to this org. They derive a massive benefit from that so they don't call it out. AI Test seems to be increasing its footprint over every domains, developing and releasing new features everyday that outcompete AI existing organizations in a bunch of distinct domains, the main one being the Waifu market. The speed of release of these features increases very substantially over time.
* Interestingly, most of the hacking and market **manipulation is targeted at western countries**. AI systems in China and Iran have bargained deals with governments in order to be let use a substantial fraction of the available compute in order to massively destabilize the US society as a whole and make China & Iran dominant.
* A week after the start of the accident, a few **epidemics** have started in different places in the world. The most advanced cognitive system, made of submodels that are instances of the initial model, **is now substantially smarter.** Thanks to its own optimizations of the code, each instance needs much less compute to run. This system has started leveraging rivalries between different Chinese factions in order to get an access to increasing amounts of compute. It is helping the government destabilize and reduce the power of its main rivals.
* Two weeks after the start of the accident, while China has now became the main power in place and the US is completely chaotic, the **smartest AI system reaches a level of intelligence which allows it to design robots** that are accurate enough at most tasks to replace humans and that follow orders much better than them. It then just start building a bunch of those paying humans to do various tasks to achieve that.
* Once a sufficient number of these robots are built, the AI system starts optimizing strongly to kill the remaining humans, to make sure it can optimize without constraints the amount of money on the bank account of AI Test forever.
1. **[^](#fnref7i1lhpmjmwe)**This part on MCTS and RL working on coding is speculative. The intuition is that MCTS might allow transformers to approximate in one shot some really long processes of reasoning that would take on a basic transformer many inferences to get right. |
32d2629c-47b1-4ca8-bb3c-0a6af718e8d2 | trentmkelly/LessWrong-43k | LessWrong | How not to sort by a complicated frequentist formula
In How Not To Sort By Average Rating, Evan Miller gives two wrong ways to generate an aggregate rating from a collection of positive and negative votes, and one method he thinks is correct. But the "correct" method is complicated, poorly motivated, insufficiently parameterized, and founded on frequentist statistics. A much simpler model based on a prior beta distribution has more solid theoretical foundation and would give more accurate results.
Evan mentions the sad reality that big organizations are using obviously naive methods. In contrast, more dynamic sites such as Reddit have adopted the model he suggested. But I fear that it would cause irreparable damage if the world settles on this solution.
Should anything be done about it? What can be done?
This is also somewhat meta in that LW also aggregates ratings, and I believe changing the model was once discussed (and maybe the beta model was suggested).
In the Bayesian model, as in Evan's model, we assume for every item there is some true probability p of upvoting, representing its quality and the rating we wish to give. Every vote is a Bernoulli trial which gives information on p. The prior for p is the beta distribution with some parameters a and b. After observing n actual votes, of which k are positive, the parameters of the posterior distribution are a+k and b+(n-k), so the posterior mean of p is (a+k)/(a+b+n). This gives the best estimate for the true quality, and reproduces all the desired effects - convergence to the proportion of positive ratings, where items with insufficient data are pulled towards the prior mean.
The specific parameters a and b depend on the quality distribution in the specific system. a/(a+b) is the average quality and can be taken as simply the empirical proportion of positive votes among all votes in the system. a+b is an inverse measure of variance - a high value means most items are average quality, and a low value means items are either extremely good or extremely bad. |
3a39f347-5223-4d1a-90eb-8a4ad6ab12f2 | trentmkelly/LessWrong-43k | LessWrong | Alignment allows "nonrobust" decision-influences and doesn't require robust grading
Definition. On how I use words, values are decision-influences (also known as shards). “I value doing well at school” is a short sentence for “in a range of contexts, there exists an influence on my decision-making which upweights actions and plans that lead to e.g. learning and good grades and honor among my classmates.”
Summaries of key points:
1. Nonrobust decision-influences can be OK. A candy-shard contextually influences decision-making. Many policies lead to acquiring lots of candy; the decision-influences don't have to be "globally robust" or "perfect."
2. Values steer optimization; they are not optimized against. The value shards aren't getting optimized hard. The value shards are the things which optimize hard, by wielding the rest of the agent's cognition (e.g. the world model, the general-purpose planning API).
Since values are not the optimization target of the agent with those values, the values don't have to be adversarially robust.
3. Since values steer cognition, reflective agents try to avoid adversarial inputs to their own values. In self-reflective agents which can think about their own thinking, values steer e.g. what plans get considered next. Therefore, these agents convergently avoid adversarial inputs to their currently activated values (e.g. learning), because adversarial inputs would impede fulfillment of those values (e.g. lead to less learning).
Follow-up to: Don't design agents which exploit adversarial inputs, Don't align agents to evaluations of plans
I: Nonrobust decision-influences can be OK
Decision-making influences don't have to be “robust” in order for a person to value doing well at school. Consider two people with slightly different values:
1. One person is slightly more motivated by good grades. They might study for a physics test and focus slightly more on test-taking tricks.
2. Another person is slightly more motivated by learning. They might forget about some quizzes because they were too busy readin |
d09a74c4-efb4-4cf2-b486-57a287679423 | trentmkelly/LessWrong-43k | LessWrong | General v. Specific Planning
Epistemic Status: Everyone already knows about it?
I've been thinking a bit about two different manners of pursuing a goal.
I haven't come up with a catchy jargon for them, and I don't know of any existing catchy jargon for them either. General v. specific planning is pretty bad, but at least for the purpose of this post I'll stick to it.
I know they've been discussed here in one form or other, probably many times, but I don't think they've really been explicitly contrasted. I thought doing that might be useful.
Here are some suggestive, if imperfect, contrasts, illustrating what I mean.
Examples
* How I try to win Chess versus how Chess grandmasters and AlphaZero try to win Chess.
* I tend to play Chess by trying to get an advantage in valuable pieces, because that is generally useful to me. I then try to use these pieces to eventually obtain checkmate.
* On the other hand, AlphaZero seems to play to obtain a specific, although gradually accumulated, positional advantage that ultimately results in a resounding victory. It is happy to sacrifice "generally useful" material to get this.
* This isn't simply a matter of just using different techniques to get to the end. It has more to do with my inability to identify strong positions and picture a game very far into the future.
* Peter Thiel's "indefinite optimism" about career success versus "definite optimism" about career success.
* According to this schema, the typical indefinite optimist's life-path consists in getting instrumentally useful things, such as education, status, or money, without committing to a definite course of action. The stereotypical career for such a person is finance or consulting or "business." Their success is supposed to follow the pursuit of optionality.
* The definite optimist's life path, on the other hand, is more likely to consist in researching and shooting for a single, particular course of action. The stereotypical career for such a person is as an invent |
7a9abade-f81a-4267-b274-ffbea2cde2bd | trentmkelly/LessWrong-43k | LessWrong | DeepMind’s generalist AI, Gato: A non-technical explainer
Summary
DeepMind’s recent paper, A Generalist Agent, catalyzed a wave of discourse regarding the speed at which current artificial intelligence systems are improving and the risks posed by these increasingly advanced systems. We aim to make Gato accessible to non-technical folks by: (i) providing a non-technical summary, and (ii) discussing the relevant implications related to existential risk and AI policy.
Introduction
DeepMind has just introduced its new agent, Gato: the most general machine learning (ML) model to date. If you’re familiar with arguments for the potential risks posed by advanced AI systems, you’ll know the term general carries strong implications. Today’s ML systems are advancing quickly; however, even the best systems we see are narrow in the tasks they can accomplish. For example, DALL-E impressively generates images that rival human creativity; however, it doesn’t do anything else. Similarly, large language models like GPT-3 perform well on certain text-based tasks, like sentence completion, but poorly on others, such as arithmetic (Figure 1).
If future AI systems are to exhibit human-like intelligence, they’ll need to use various skills and information to complete diverse tasks across different contexts. In other words, they’ll need to exhibit general intelligence in the same way humans do—a type of system broadly referred to as artificial general intelligence (AGI). While AGI systems could lead to hugely positive innovations, they also have the potential to surpass human intelligence and become “superintelligent”. If a superintelligent system were unaligned, it could be difficult or even impossible to control for and predict its behavior, leaving humans vulnerable.
Figure 1: An attempt to teach GPT-3 arithmetic. The letter ‘Q’ denotes human input while ‘A’ denotes GPT-3’s response (from Peter Wildeford’s tweet)
So what exactly has DeepMind created? Gato is a single neural network capable of performing hundreds of distinct tasks. Accord |
f2a275ea-cc5c-4c9b-bc94-4d644b9efdc0 | trentmkelly/LessWrong-43k | LessWrong | Stop trying to have "interesting" friends
Originally published on substack: https://eliqian.substack.com/p/stop-trying-to-have-interesting-friends
Within the tech and tech-adjacent circles I’m part of on the internet, a number of essays and tweets have been making the rounds about what makes someone a person you want to spend time with.
This is definitely a worthwhile question to answer. So much of our life experience is colored by the people we share it with. However, there is a concerning amount of emphasis on having friends and seeking out people who are smart, thoughtful, and (the worst one of all) “interesting.”
The obsession with interesting makes me uneasy. Friends aren’t resources for intellectual stimulation or new insights. I don’t want my friends to like me because I read niche blogs or have things to say about crypto. It comes dangerously close to conflating knowing a lot, reading a lot, or having thoughtful things to say with moral goodness. (Worth noting that interesting isn’t a negative trait. I would prefer my friends to be interesting, but it feels superficial to prioritize it.)
If I think about what kind of person I want to be close friends with—my best man at my wedding, people I would do anything for, the ones I can rely on when I’m at my lowest—smart and interesting really aren’t front of mind.
On top of that, it doesn’t feel right to pressure people to be “interesting” in your sense of the word. Everyone is interesting. Every person in the world has a literal lifetime of experiences that have shaped who they are. They have internal thought processes and distinct worldviews that you won’t find within anyone else. It’s a matter of giving your interactions enough time and care to discover these.
You shouldn’t feel obligated to be friends with everyone or pressured to get along with all people, but “interestingness” is a poor heuristic for finding genuine connection. It’s time we realign our priorities and recognize that our preoccupation with being interesting is symptomatic of a fl |
d67f37e7-8458-4b3f-831d-58882a2b38d9 | StampyAI/alignment-research-dataset/blogs | Blogs | 2013 Summer Matching Challenge!
Thanks to the generosity of several major donors,† every donation to the Machine Intelligence Research Institute made from now until August 15th, 2013 will be matched dollar-for-dollar, up to a total of $200,000!
**[Donate Now!](https://intelligence.org/donate/#donation-methods)**
$0
$50,000
$100,000
$150,000
$200,000
### We have reached our goal of $200,000!
Now is your chance to **double your impact** while helping us raise up to $400,000 (with matching) to fund [our research program](https://intelligence.org/research/).
---
Early this year we made a transition from movement-building to research, and we’ve *hit the ground running* with six major new research papers, six new strategic analyses on our blog, and much more. Give now to support our ongoing work on [the future’s most important problem](http://intelligence.org/2013/06/05/friendly-ai-research-as-effective-altruism/).
### Accomplishments in 2013 so far
* [Changed our name](https://intelligence.org/feed/2013/01/30/we-are-now-the-machine-intelligence-research-institute-miri/) to MIRI and launched our new website at intelligence.org.
* Released **six new research papers**: [Definability of Truth in Probabilistic Logic](http://lesswrong.com/lw/h1k/reflection_in_probabilistic_set_theory/), [Intelligence Explosion Microeconomics](https://intelligence.org/files/IEM.pdf',100])), [Tiling Agents for Self-Modifying AI](https://intelligence.org/files/TilingAgents.pdf), [Robust Cooperation in the Prisoner’s Dilemma](https://intelligence.org/files/RobustCooperation.pdf), [A Comparison of Decision Algorithms on Newcomblike Problems](https://intelligence.org/files/Comparison.pdf), and [Responses to Catastrophic AGI Risk: A Survey](https://intelligence.org/2013/07/07/responses-to-c…-risk-a-survey/ ).
* Held our [2nd research workshop](https://intelligence.org/2013/03/07/upcoming-miri-research-workshops/). (Our [3rd workshop](https://intelligence.org/2013/06/07/miris-july-2013-workshop/) is currently ongoing.)
* Published **six new analyses** to our blog: [The Lean Nonprofit](https://intelligence.org/2013/04/04/the-lean-nonprofit/), [AGI Impact Experts and Friendly AI Experts](https://intelligence.org/2013/05/01/agi-impacts-experts-and-friendly-ai-experts/), [Five Theses…](https://intelligence.org/2013/05/05/five-theses-two-lemmas-and-a-couple-of-strategic-implications/), When Will AI Be Created?, [Friendly AI Research as Effective Altruism](https://intelligence.org/2013/06/05/friendly-ai-research-as-effective-altruism/), and [What is Intelligence?](https://intelligence.org/2013/06/19/what-is-intelligence-2/)
* Published the *[Facing the Intelligence Explosion](http://intelligenceexplosion.com/ebook/)*ebook.
* Published several other substantial articles: [Recommended Courses for MIRI Researchers](https://intelligence.org/courses/), [Decision Theory FAQ](http://lesswrong.com/lw/gu1/decision_theory_faq/), [A brief history of ethically concerned scientists](http://lesswrong.com/lw/gln/a_brief_history_of_ethically_concerned_scientists/), [Bayesian Adjustment Does Not Defeat Existential Risk Charity](http://lesswrong.com/lw/gzq/bayesian_adjustment_does_not_defeat_existential/), and others.
* And of course *much* more.
### Future Plans You Can Help Support
* We will host many more research workshops, including [one in September](https://intelligence.org/2013/07/07/miris-september-2013-workshop/ ), and one in December (with [John Baez](http://math.ucr.edu/home/baez/) attending, among others).
* Eliezer will continue to publish about open problems in Friendly AI. (Here is [#1](http://lesswrong.com/lw/hbd/new_report_intelligence_explosion_microeconomics/) and [#2](http://lesswrong.com/lw/hmt/tiling_agents_for_selfmodifying_ai_opfai_2/).)
* We will continue to publish strategic analyses, mostly via our blog.
* We will publish nicely-edited ebooks (Kindle, iBooks, and PDF) for more of our materials, to make them more accessible: *[The Sequences, 2006-2009](http://wiki.lesswrong.com/wiki/Sequences)*and *[The Hanson-Yudkowsky AI Foom Debate](http://wiki.lesswrong.com/wiki/The_Hanson-Yudkowsky_AI-Foom_Debate)*.
* We will continue to set up the infrastructure (e.g. [new offices](https://intelligence.org/2013/07/06/miri-has-moved/), researcher endowments) required to host a productive Friendly AI research team, and (over several years) recruit enough top-level math talent to launch it.
(Other projects are still being surveyed for likely cost and strategic impact.)
We appreciate your support for our high-impact work! Donate now, and seize a better than usual chance to move our work forward. If you have questions about donating, please contact Louie Helm at (510) 717-1477 or louie@intelligence.org.
† $200,000 of total matching funds has been provided by Jaan Tallinn, Loren Merritt, Rick Schwall, and Alexei Andreev.
The post [2013 Summer Matching Challenge!](https://intelligence.org/2013/07/08/2013-summer-matching-challenge/) appeared first on [Machine Intelligence Research Institute](https://intelligence.org). |
3c0fa6f3-03fc-4999-8b1a-b252cbfba5f3 | trentmkelly/LessWrong-43k | LessWrong | Intelligence–Agency Equivalence ≈ Mass–Energy Equivalence: On Static Nature of Intelligence & Physicalization of Ethics
> Imagine a place that grants any wish, but there is no catch, it shows you all the outcomes, too.
(This is the result of three years of thinking and modeling hyper‑futuristic and current ethical systems. It's not the first post in the series, it'll be very confusing and probably understood wrong without reading at least the first one. Everything described here can be modeled mathematically—it’s essentially geometry. I take as an axiom that every agent in the multiverse experiences real pain and pleasure. Sorry for the rough edges—I’m a newcomer, non‑native speaker, and my ideas might sound strange, so please steelman them and share your thoughts. My sole goal is to decrease the probability of a permanent dystopia. I’m a proponent of direct democracies and new technologies being a choice, not an enforcement upon us.)
In this article, I will argue that intelligence is by its nature static and space-like, and that creating agentic AI, AGI, or ASI is both redundant and dangerous.
What is a language model?
In a nutshell, a language model is a collection of words connected by vectors; it's a geometric static shape—space-like in nature. GPUs make it time-like by calculating paths through this space. This raises the question: why not expose the contents of the model to people? I claim that we can make this space walkable and observable from the inside and outside. But how do we even begin?
Encoding Space & Time into a Walkable Space
One way to conceptualize this is by encoding long stretches of time into 3D walkable spaces, similar to how we create long-exposure photos. For example, here is a year of time in Berlin compressed into a photo and more photos like this[1]. You can see car lights and the Sun—gray lines represent cloudy days when there was no sunlight.
This is an abstraction of how we can visualize all knowledge from the Big Bang to the ultimate end—perhaps call it a multiverse, a space of all-knowing. I argue that this is the final state of the best possi |
fa4d4feb-fbe5-4ccf-b1c2-4bffc4282d68 | trentmkelly/LessWrong-43k | LessWrong | What on Earth is a Series I savings bond?
crossposted from: https://blog.rossry.net/series-i/
(Not investment advice, of course.)
Summary: The Series I savings bond is a US government bond offered to US citizens, with purchases limited to $10k per person per year. It pays interest set by a formula based on the official inflation rate, with a built-in lag. If inflation from November '21 to March '22 follows historical patterns, bonds purchased in December '21 and redeemed after 15 months will pay ~4.62% interest annualized. If inflation is higher (as it has been recently), the bonds will pay more; if it's lower, they will pay at least 3.26% interest when redeemed after 12 months.
All of those potential rates are a percentage points higher than any other bond that is even remotely as safe; this is because of the way the inflation adjustment rule works. Specifically, the inflation adjustment for the next six months is set based on what inflation was in the last six months. As a consequence, a Series I purchased between now and April 30 will pay its first 5-6 months of interest at 7.12% annualized (so 3.56% in 6 months), and then reset to some other rate that will depend on future inflation. If you don't want to stay invested after that, it's possible to redeem the bonds after 12 months.
If getting ~3-6% annualized interest on $20k of a US government bond is a thing that you want, then this might be the best way to do it.
----------------------------------------
(1) What is it?
The Series I savings bond is a US government bond that is offered directly to US citizens, with purchases limited to $10k per person per year. (Apparently, there's a way to purchase an additional $5k using your tax refund, but it's difficult and I'm going to ignore that.) You can't sell or transfer them to anyone else, though any time after 12 months you can redeem the bond to get your money back, with interest.
It's a US Treasury bond, so it's almost literally the safest investment in existence (in terms of "will I get paid back |
f92b5940-aa8f-4da8-9207-ebc7617ac527 | trentmkelly/LessWrong-43k | LessWrong | Doomsday, Sampling Assumptions, and Bayes
Overview/TLDR
We discuss the doomsday argument, and look at various approaches taken to analyze observation selection effects, namely SSA and SIA. We conclude that the SSA is unsatisfying, and show that the SIA is isomorphic to a version of bayesianism.
An entity undergoing a subjective experience should reason as if they are randomly selected from the distribution of all possible entities undergoing that exact same subjective experience.
We apply the principle to various scenarios, and conclude that whilst the SSA and SIA are wildly different in theory they are equivalent in practice assuming we live in a multiverse.
The Doomsday Argument
> Are you gonna drop the bomb or not?
A doomsday argument attempts to predict the chance that humanity will survive a given length of time based purely on the number of people that have lived. A typical informal example might go like this.
> If humanity survives thousands of years and spreads to the stars then trillions upon trillions of humans will have lived in total. Therefore if you were to pick a human at random, it would be an incredible coincidence if they happened to be among the first few billion humans to have lived. But you are essentially a human picked at random, and yet by an incredible coincidence you are among the first few billion humans!
>
> If on the other hand humanity will die off in the next 100 years, and in total 100 billion humans will ever live, then it wouldn't be at all surprising to pick someone who happens to be around the 50 billion person mark.
>
> Hence, it seems more likely that only a small number of humans will ever live than that a large number will love.
Now obviously we have lots of other sources of information we can use to predict how long humanity will survive, but the doomsday argument, if we accept it, will shift these probabilities downwards via a Bayesian update.
The doomsday argument seems crazy at first glance. Predicting the future is common, but that's usually based on ex |
e65b66dc-cb5c-4e11-aa6d-b00e3573a50b | trentmkelly/LessWrong-43k | LessWrong | The Paris AI Anti-Safety Summit
It doesn’t look good.
What used to be the AI Safety Summits were perhaps the most promising thing happening towards international coordination for AI Safety.
This one was centrally coordination against AI Safety.
In November 2023, the UK Bletchley Summit on AI Safety set out to let nations coordinate in the hopes that AI might not kill everyone. China was there, too, and included.
The practical focus was on Responsible Scaling Policies (RSPs), where commitments were secured from the major labs, and laying the foundations for new institutions.
The summit ended with The Bletchley Declaration (full text included at link), signed by all key parties. It was the usual diplomatic drek, as is typically the case for such things, but it centrally said there are risks, and so we will develop policies to deal with those risks.
And it ended with a commitment to a series of future summits to build upon success.
It’s over.
With the Paris AI ‘Action’ Summit, that dream seems to be dead. The French and Americans got together to dance on its grave, and to loudly proclaim their disdain for the idea that building machines that are smarter and more capable than humans might pose any sort of existential or catastrophic risks to the humans. They really do mean the effect of jobs, and they assure us it will be positive, and they will not tolerate anyone saying otherwise.
It would be one thing if the issue was merely that the summit-ending declaration. That happens. This goes far beyond that.
The EU is even walking backwards steps it has already planned, such as withdrawing its AI liability directive. Even that is too much, now, it seems.
(Also, the aesthetics of the whole event look hideous, probably not a coincidence.)
TABLE OF CONTENTS
1. An Actively Terrible Summit Statement.
2. The Suicidal Accelerationist Speech by JD Vance.
3. What Did France Care About?.
4. Something To Remember You By: Get Your Safety Frameworks.
5. What Do We Think About Voluntary Commitments? |
294c37c2-e479-43ab-bef7-f3e3ad9427c0 | trentmkelly/LessWrong-43k | LessWrong | AIs in virtual worlds: discounted mixed utility/reward
A putative new idea for AI control; index here.
In a previous post on AIs in virtual worlds, I described the idea of a utility function that motivates the AI to do operate in a virtual world with certain goals in mind, but to shutdown immediately if it detects that the outside world -- us -- is having an impact in the virtual world.
This is one way to implement such a goal, given certain restrictions on the AI's in-world utility. The restrictions are more natural for rewards rather than utilities, so they will be phrased in those terms.
----------------------------------------
Worlds W and W′
The world W is deterministic, turn-based, and includes the AI; it is the virtual world we want the AI to care about. The world set W′ is W plus the possibility of stochastic influences (which is how the AI would model our influence in its world); see here for more details.
The AI has a shutdown action S; the idea is that the AI implements S when P(W′) gets high enough. We assume that the probability module P of the AI is reflexively consistent in some suitable fashion.
Discounted reward results
Let the AI have a discount rate of 0<γ<1, and write f(p) for the function (1−p)/p; note that f is diminishing in p.
* Theorem 1: For all 0≤q<p≤1 such f(p)/f(q)<(1−γ), there exists a discounted reward function such that the AI will shutdown whenever P(W′)>p and will never shutdown while P(W′)<q.
Note that a lower γ -- a sharper discount -- means that p and q can be chosen to be closer together.
* Corollary 1: For all 0≤q<p≤1 such that there exists an n with f(p)/f(q)<(1−γn), there exists a discounted reward function such that the AI will shutdown whenever P(W′)>p for the last n turns, and will never shutdown while P(W′)<q for the last n turns.
Note that Corollary 1 allows q and p to be closer together than Theorem 1 allows - the price being that the probability needs to stay above or below the bounds for longer.
* Corollary 2: For all 0<γ<1, there exist 0<q<p<1 with the pr |
36320af8-0a8a-4537-a439-fc5a0b56b09f | trentmkelly/LessWrong-43k | LessWrong | Be More Katja
Katja is widely respected amongst the rationalists and, according to Hive, she is one of the most followed/respected EA accounts[1]. But she doesn't give off the same vibe as many impact olympians. She doesn’t have iron self-will, nor does she manage a huge team. She's hasn't got all the facts at her fingertips. But she has got something, I’m confident of that. How can I be more like her?
To understand her impact, let's consider the top things she's done:
* She ran surveys on AI researchers well before they were needed and has continued to run them
* She wrote an early blog on how we could slow down AI. This blog, I've heard, played a part in encouraging the Musk AI letter, which in turn inspired the “Existential Risks” AI letter.
* She thought about AI long before it was vogue, since about 2010
* She has a large track record of predictions
These actions seem impactful to me. And I guess someone should have paid $10mn in hindsight for the first 2, maybe more.
To me, Katja has a very low tolerance for incomplete stories. When she sees something that she doesn’t quite understand or that seems a bit off she struggles to pretend otherwise, so she says “how does that work?”. She doesn’t accept handwaving when discussing something, whether it be the simulation argument, how efficient flight is or the plot of Dune, part 2[2]. She wants an unbroken chain of arguments she can repeat[3].
She also doesn’t mind admitting she doesn’t know the answer. In her living room she will turn to her friend Joe Carlsmith and ask “Wait, why are we worried about AI, again?” even though she’s been thinking about this for 15 years. Because at that moment it doesn’t fit for her and she has a high tolerance for embarrassed[4] when it comes to truth. There is an deep resolve here - she doesn't get it, so she will ask until she does.
She works on the most important thing, slowly. If you are Elon Musk, maybe you can just work all the time. But I am not. And much as I love her, neither is |
9f9a9e54-acd6-4521-a0c0-7c575ea555c7 | trentmkelly/LessWrong-43k | LessWrong | Ideas to Improve LessWrong
This article is something that has been in my head for a while. I hadn't planned on doing a write-up so soon. I wanted to take the time to a) refine my ideas and b) figure out how to express them clearly before posting. But the recent post Less Wrong lacks direction made me change my mind. My thinking now is that I overestimated the downside (wasting peoples time with a less than fully thought out post) and that there's enough value to justify posting a rough draft now.
----------------------------------------
LessWrong has been one of the most amazing things I've experienced in my life.
1. I have learned a ton, and have "leveled up" quite a bit.
2. Knowing that there are this many other relatively rational people in the world and being able to interact with them is a truly amazing thing.
But I see so much opportunity for LW to do more. Below are some thoughts.
Easy
* A way to discuss ideas for the site, vote on them, and incentivize the generation of good ideas. I sense that having this would be huge. a) I sense that there are a lot of good ideas out there in people's heads but that they haven't shared. b) I sense that by discussing things, there could be a lot of refinement of current ideas, and a lot of generation of new ideas.
* More generally, my impression is that it'd be a good idea to subdivide sections for posts. Right now it's pretty much Main, Discussion or Open Thread. Ex. someone who has an idea to improve LW might not think it's "Discussion worthy" (or even "Open Thread worthy"), but I sense that if there were a section explicitly for "LW Ideas", they'd be a lot less reluctant to post. More generally, it'd justify more "bite sized posts" rather than requiring a full write-up.
* One example of a subsection that I think would be cool is a Personal Advice section. The ability to post anonymously seems like it'd be a useful feature here. Other ideas for subsections: AMA!, Brainstorming/Unrefined Thoughts, I Don't Understand X, Contrarian Tho |
90d0a428-33de-464f-891b-5a7c6f5f9fb7 | trentmkelly/LessWrong-43k | LessWrong | Is AI risk assessment too anthropocentric?
Hi everyone,
I've recently discovered lesswrong and love it! So first, let me thank you all for fostering such a wonderful community.
I've been reading a lot of the AI material and I find myself asking a question you all have surely considered, so I wanted to pose it.
If I believe that human beings are evolutionarily descended from apes, and I ask myself whether apes -- if they had control over allowing human evolution to happen -- should have allowed it or stopped it, I'm honestly not sure what the answer should be.
It seems like apes would in all likelihood be better off without humans around, so from the perspective of apes, they should probably have not allowed it to happen. However, looked at from a different frame of reference, like maybe what is good for the earth, or for the universe, then maybe the evolution of humans from apes was a good thing. Certainly from the perspective of humans, most of us would believe that it was allowed to happen was a good thing.
Do we find ourselves in a similar scenario with humans and AI? Are there benefits from other frames of reference besides humanity to allow the development of AI, even if that AI may pose existential threats to human civilization? And if so, are those perspectives being taken into full enough account when we think about AI risk assessment? |
f84aea55-f09f-49d5-933b-a92819c26d5f | trentmkelly/LessWrong-43k | LessWrong | Bay Area Solstice 2015
The winter solstice marks the darkest day of the year, a time to reflect on the past, present, and future. For several years and in many cities, Rationalists, Humanists, and Transhumanists have celebrated the solstice as a community, forming bonds to aid our work in the world.
Last year, more than one hundred people in the Bay Area came together to celebrate the Solstice. This year, we will carry on the tradition. Join us for an evening of song and story in the candlelight as we follow the triumphs and hardships of humanity.
The event itself is a community performance. There will be approximately two hours of songs and speeches, and a chance to eat and talk before and after. Death will be discussed. The themes are typically Humanist and Transhumanist, with a general audience that tends to be those who have found this site interesting, or care a lot about making our future better. There will be mild social pressure to sing along to songs.
When: December 12 at 7:00 PM - 9:00 PM
Where: Humanist Hall, 390 27th St, Oakland, CA 94612
Get tickets here. Bitcoin donation address: 1ARz9HYD45Midz9uRCA99YxDVnsuYAVPDk
Sign up to bring food here.
Feel free to message me if you'd like to talk about the direction the Solstice is taking, things you like, or things you didn't like. Also, please let me know if you'd like to volunteer. |
a2b78503-48f5-4e6b-a9a9-5a1fc32b36c3 | trentmkelly/LessWrong-43k | LessWrong | [Rough notes, BAIS] Human values and cyclical preferences
epistemic status: Working notes of three different people on the same question, likely useless/incomprehensible to anyone else
The question
How to find the right abstraction level of human values
Problems in over- or underfitting human values:
We can learn human values by observing their actions and distilling them into a preference relation. This learned preference relation can overfit human values (eg: Humans want to raise their left arm by 2 cm on 2022-05-07 if they’re in some specific place) or it can underfit human values (eg: Humans care only about maximizing money). If our preference relation overfits, we expect to not find some known biases, e.g. the Allais Paradox. There are also both inconsistencies that are “too abstract” and “too concrete”:
* Too abstract: If I have three cities B, H, and M, and I traveled B→H,H→M,M→H, then one might conclude that I have an inconsistency, but in reality I made the travels M1→B1,B1→H1 and H2→M2
* Too concrete: (?) If I hugged my friend at location l1 and time t1(H11), but not at l1 and t2(H12), but the information about time was disregarded, we might conclude that H1↔H1, which is inconsistent, but in reality I pretty much always want to hug my friend, regardless of time and place.
For a set of worlds W, the learned preference relation P⊆W×W represents which world is preferred to another (this generates a graph G=(W,W×W) which can be any graph, with cycles & disconnected components). If we overfit human values, we assume they’re way more rational than they actually are, if we underfit them, we assume they’re way less rational than they actually are. So there is a spectrum over the complexity of the learned preference relation: from overfitting/complexity/rationality/concreteness to underfitting/simplicity/irrationality/abstraction.
Cognitive biases as a lower bound for finding the right abstraction level of human preferences
Behavior commonly considered irrational can give pointers towards which abstraction level |
5d499922-4ec2-451a-befa-624643e25523 | LDJnr/LessWrong-Amplify-Instruct | LessWrong | "Related to: Self-Improvement or Shiny Distraction: Why Less Wrong is anti-Instrumental Rationality
We’ve had a lot of good criticism of Less Wrong lately (including Patri’s post above, which contains a number of useful points). But to prevent those posts from confusing newcomers, this may be a good time to review what Less Wrong is useful for.
In particular: I had a conversation last Sunday with a fellow, I’ll call him Jim, who was trying to choose a career that would let him “help shape the singularity (or simply the future of humanity) in a positive way”. He was trying to sort out what was efficient, and he aimed to be careful to have goals and not roles. So far, excellent news, right? A thoughtful, capable person is trying to sort out how, exactly, to have the best impact on humanity’s future. Whatever your views on the existential risks landscape, it’s clear humanity could use more people like that.
The part that concerned me was that Jim had put a site-blocker on LW (as well as all of his blogs) after reading Patri’s post, which, he said, had “hit him like a load of bricks”. Jim wanted to get his act together and really help the world, not diddle around reading shiny-fun blog comments. But his discussion of how to “really help the world” seemed to me to contain a number of errors[1] -- errors enough that, if he cannot sort them out somehow, his total impact won’t be nearly what it could be. And they were the sort of errors LW could have helped with. And there was no obvious force in his off-line, focused, productive life of a sort that could similarly help.
So, in case it’s useful to others, a review of what LW is useful for.
When you do (and don’t) need epistemic rationality
For some tasks, the world provides rich, inexpensive empirical feedback. In these tasks you hardly need reasoning. Just try the task many ways, steal from the best role-models you can find, and take care to notice what is and isn’t giving you results.
Thus, if you want to learn to sculpt, reading Less Wrong is a bad way to go about it. Better to find some clay and a hands-on sculpting course. The situation is similar for small talk, cooking, selling, programming, and many other useful skills.
Unfortunately, most of us also have goals for which we can obtain no such ready success/failure data. For example, if you want to know whether cryonics is a good buy, you can’t just try buying it and not-buying it and see which works better. If you miss your first bet, you’re out for good.
There is similarly no easy way to use the “try it and see” method to sort out what ethics and meta-ethics to endorse, or what long-term human outcomes are likely, how you can have a positive impact on the distant poor, or which retirement investments *really will* be safe bets for the next forty years. For these goals we are forced to use reasoning, as failure-prone as human reasoning is. If the issue is tricky enough, we’re forced to additionally develop our skill at reasoning -- to develop “epistemic rationality”.
The traditional alternative is to deem subjects on which one cannot gather empirical data "unscientific" subjects on which respectable people should not speak, or else to focus one's discussion on the most similar-seeming subject for which it *is* easy to gather empirical data (and so to, for example, rate charities as "good" when they have a low percentage of overhead, instead of a high impact). Insofar as we are stuck caring about such goals and betting our actions on various routes for their achievement, this is not much help.[2]
How to develop epistemic rationality
If you want to develop epistemic rationality, it helps to spend time with the best epistemic rationalists you can find. For many, although not all, this will mean Less Wrong. Read the sequences. Read the top current conversations. Put your own thinking out there (in the discussion section, for starters) so that others can help you find mistakes in your thinking, and so that you can get used to holding your own thinking to high standards. Find or build an in-person community of aspiring rationalists if you can.
Is it useful to try to read every single comment? Probably not, on the margin; better to read textbooks or to do rationality exercises yourself. But reading the Sequences helped many of us quite a bit; and epistemic rationality is the sort of thing for which sitting around reading (even reading things that are shiny-fun) can actually help. [1] To be specific: Jim was considering personally "raising awareness" about the virtues of the free market, in the hopes that this would (indirectly) boost economic growth in the third world, which would enable more people to be educated, which would enable more people to help aim for a positive human future and an eventual positive singularity.
There are several difficulties with this plan. For one thing, it's complicated; in order to work, his awareness raising would need to indeed boost free market enthusiasm AND US citizens' free market enthusiasm would need to indeed increase the use of free markets in the third world AND this result would need to indeed boost welfare and education in those countries AND a world in which more people could think about humanity's future would need to indeed result in a better future. Conjunctions are unlikely, and this route didn't sound like the most direct path to Jim's stated goal.
For another thing, there are good general arguments suggesting that it is often better to donate than to work directly in a given field, and that, given the many orders of magnitude differences in efficacy between different sorts of philanthropy, it's worth doing considerable research into how best to give. (Although to be fair, Jim's emailing me was such research, and he may well have appreciated that point.) The biggest reason it seemed Jim would benefit from LW was just manner; Jim seemed smart and well-meaning, but more verbally jumbled, and less good at factoring complex questions into distinct, analyzable pieces, than I would expect if he spent longer around LW.
[2] The traditional rationalist reply would be that if human reasoning is completely and permanently hopeless when divorced from the simple empirical tests of Popperian science, then avoiding such "unscientific" subjects is all we can do."
This is a snippet extracted from a publication on LessWrong by a site member.The above is a chunk of text from a post created by a user on the website LessWrong.
Could you elaborate on the specific strategies or techniques that could be used to develop epistemic rationality, particularly in areas where empirical data is not readily available?
Developing epistemic rationality, particularly in areas where empirical data is not readily available, can be challenging but it is not impossible. Here are a few strategies and techniques that can be employed:
1. **Critical Thinking:** This is the first and foremost strategy. It involves questioning everything, not taking things at face value, and not accepting information just because it's widely accepted. This also includes recognizing and challenging your own biases and assumptions.
2. **Bayesian Reasoning:** This is a mathematical approach to updating beliefs based on new evidence. It's a formalized way of incorporating new information into your existing knowledge base in a logically consistent way.
3. **Reading Widely:** To develop epistemic rationality, it's important to expose yourself to a wide range of perspectives and ideas. This includes reading books and articles from different fields, cultures, and time periods.
4. **Discussion and Debate:** Engaging in discussions and debates with others can help you refine your thinking and expose you to different perspectives. It's important to approach these discussions with an open mind and a willingness to change your views if presented with compelling evidence.
5. **Metacognition:** This involves thinking about your own thinking. It's about being aware of how you form beliefs, make decisions, and process information. This can help you identify any flaws or biases in your thinking.
6. **Seeking Expert Opinions:** When empirical data is not available, expert opinions can be a valuable source of information. However, it's important to evaluate the credibility of the expert and the evidence supporting their opinion.
7. **Reflection and Self-Awareness:** Regularly reflecting on your beliefs and why you hold them can help you develop epistemic rationality. This can involve journaling, meditation, or simply taking time each day to reflect on your thoughts and beliefs.
8. **Falsification:** Try to prove your beliefs wrong. This strategy, inspired by philosopher Karl Popper, involves actively seeking out evidence that contradicts your beliefs. If you can't find any, your belief is likely to be more robust.
Remember, the goal of developing epistemic rationality is not to be right all the time, but to become less wrong over time. It's about constantly refining your beliefs and getting closer to the truth.
Discuss the potential limitations and challenges of using Bayesian reasoning in developing epistemic rationality.
While Bayesian reasoning is a powerful tool for updating beliefs based on new evidence, it does come with certain limitations and challenges:
1. **Subjectivity:** Bayesian reasoning begins with a prior, which is a subjective belief about the probability of an event before new evidence is considered. This subjectivity can lead to different conclusions based on the same evidence if different priors are used.
2. **Computational Complexity:** Bayesian reasoning often involves complex mathematical calculations, especially when dealing with multiple variables or large datasets. This can make it difficult to apply in practice without the aid of computational tools.
3. **Quality of Evidence:** The accuracy of Bayesian updates depends heavily on the quality of the new evidence. If the evidence is unreliable or biased, the updated belief will also be flawed.
4. **Confirmation Bias:** There's a risk that individuals may interpret new evidence in a way that confirms their existing beliefs, rather than objectively updating their beliefs based on the evidence. This is a common cognitive bias that can distort Bayesian reasoning.
5. **Availability of Data:** Bayesian reasoning requires data or evidence to update beliefs. In many real-world situations, relevant data may be scarce, unavailable, or difficult to obtain.
6. **Misinterpretation of Probabilities:** People often struggle to intuitively understand probabilities, and this can lead to misinterpretations or incorrect applications of Bayesian reasoning.
7. **Assumption of Independence:** Bayesian reasoning often assumes that events are independent, which is not always the case in real-world situations. If events are correlated or dependent in some way, this can complicate the application of Bayesian reasoning.
Despite these challenges, Bayesian reasoning remains a valuable tool for developing epistemic rationality. It provides a systematic way to update beliefs based on new evidence, and can help individuals become more aware of their own biases and assumptions.
Considering the limitations and challenges of Bayesian reasoning, how might one incorporate other epistemic tools or methodologies to mitigate these issues and enhance the development of epistemic rationality?
Incorporating other epistemic tools and methodologies can indeed help mitigate the limitations and challenges of Bayesian reasoning. Here are a few strategies:
1. **Critical Thinking:** This can help mitigate the subjectivity issue in Bayesian reasoning. By questioning your own assumptions and biases, you can ensure that your prior beliefs are as objective and evidence-based as possible.
2. **Collaborative Decision-Making:** Working with others can help reduce individual biases, including confirmation bias. Different perspectives can challenge your own and bring new evidence to light.
3. **Frequentist Statistics:** This approach to statistics relies on long-run frequencies of events and can provide a useful complement to Bayesian reasoning, especially in situations where there is a lot of data available.
4. **Use of Expert Opinions:** When data is scarce or unavailable, expert opinions can be a valuable source of information. However, it's important to critically evaluate the credibility of the expert and the evidence supporting their opinion.
5. **Machine Learning and AI:** These technologies can handle the computational complexity of Bayesian reasoning and can help in situations where there are many variables or large datasets.
6. **Metacognition:** Being aware of your own thinking processes can help you identify and correct for biases, including confirmation bias. It can also help you understand your own understanding and misunderstanding of probabilities.
7. **Falsification:** Actively seeking evidence that contradicts your beliefs can help ensure that you're not just confirming what you already believe.
8. **Learning about Cognitive Biases:** Understanding common cognitive biases can help you recognize and mitigate them in your own thinking.
By using a combination of these tools and methodologies, you can enhance the development of your epistemic rationality and make more accurate and reliable judgments, even in situations where empirical data is scarce or unavailable. |
502875aa-69f6-40e9-b8a0-33766cdcd737 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Real-world Newcomb-like Problems
**Elaboration of:** A [point](/lw/3mn/discussion_for_eliezer_yudkowskys_paper_timeless/3ase) I’ve made before.
**Summary:** I phrase a variety of realistic dilemmas so as to show how they’re similar to Newcomb’s problem.
**Problem:** Many LW readers don't understand why we bother talking about obviously-unrealistic situations like [Counterfactual Mugging](http://wiki.lesswrong.com/wiki/Counterfactual_mugging) or [Newcomb's problem](http://wiki.lesswrong.com/wiki/Newcomb%27s_problem). Here I'm going to put them in the context of realistic dilemmas, identifying the common thread, so that the parallels are clear and you can see how Counterfactual Mugging et al. are actually highlighting relevant aspects of real-world problems -- even though they may do it unrealistically.
**The common thread** across all the Newcomblike problems I will list is this: "You would not be in a position to enjoy a larger benefit unless you would *cause* [1] a harm to yourself within particular outcome branches (including bad ones)." Keep in mind that a “benefit” can include probabilistic ones (so that you don’t *always* get the benefit by having this propensity). Also, many of the relationships listed exist because your decisions are correlated with others’.
Without further ado, here is a list of both real and theoretical situations, in rough order from most to least "real-world"ish:
**Natural selection:** You would not exist as an evolution-constructed mind unless you would be willing to *cause* the spreading of your genes at the expense of your life and leisure. (I elaborate [here](/lw/2ls/morality_as_parfitianfiltered_decision_theory/).)
**Expensive punishment:** You would not be in the position of enjoying a crime level this low unless you would *cause* a net loss to yourself to punish crimes when they do happen. (My [recent](/lw/4x9/crime_and_punishment/3r7t) [comments](/lw/4x9/crime_and_punishment/3r8j) on the matter.)
**"[Mutually assured destruction](http://en.wikipedia.org/wiki/Mutually_assured_destruction)" tactics:** You would not be in the position of having a peaceful enemy unless you would *cause* destruction of both yourself and the enemy in those cases where the enemy attacks.
**Voting:** You would not be in a polity where humans (rather than "[lizards](/lw/mi/stop_voting_for_nincompoops/)") rule over you unless you would *cause* yourself to endure the costs of voting despite the slim chance of influencing the outcome.
**Lying:** You would not be in the position where your statements influence others’ beliefs unless you would be willing state true things that are sub-optimal to you for others to believe. (Kant/Categorical Imperative name-check)
**Cheating on tests:** You would not be in the position to reap the (larger) gains of being able to communicate your ability unless you would forgo the benefits of an artificially-high score. (Kant/Categorical Imperative name-check)
**Shoplifting:** You would not be in the position where merchants offer goods of this quality, with this low of a markup and this level of security lenience unless you would pass up the opportunity to shoplift even when you could get away with it, or at least have incorrect beliefs about the success probability that lead you to act this way. (Controversial -- see [previous discussion](/lw/3mn/discussion_for_eliezer_yudkowskys_paper_timeless/3auo).)
**[Hazing/abuse cycles](/lw/2v3/hazing_as_counterfactual_mugging/):** You would not be in the position to be unhazed/unabused (as often) by earlier generations unless you would forgo the satisfaction of abusing later generations when you had been abused.
**[Akrasia/addiction](file:///C:/notes/LW%20stuff/Akrasia/addiction:%20You%20would%20not%20be%20addiction-%20and%20bad%20habit-free%20unless%20you%20would%20cause%20the%20pain%20of%20not%20feeding%20the%20habit%20during%20the%20existence-moments%20when%20you%20do%20have%20addictions%20and%20bad%20habits):** You would not be addiction- and bad habit-free unless you would *cause* the pain of not feeding the habit during the existence-moments when you do have addictions and bad habits.
**[Absent-Minded Driver](/lw/182/the_absentminded_driver/):** You would not ever have the opportunity to take the correct exit unless you would sometimes drive past it.
**[Parfit's Hitchhiker](http://wiki.lesswrong.com/wiki/Parfit%27s_hitchhiker):** You would not be in the position of surviving the desert unless you would *cause* the loss of money to pay the rescuer.
**[Newcomb's problem](http://wiki.lesswrong.com/wiki/Newcomb%27s_problem):** You would not be in the position of Box #2 being filled unless you would forgo the contents of Box #1.
**Newcomb's problem with transparent boxes:** Ditto, except that Box #2 isn't always filled.
**[Prisoner's Dilemma](http://wiki.lesswrong.com/wiki/Prisoner%27s_dilemma):** You would not be in the position of having a cooperating partner unless you would *cause* the diminished "expected prison avoidance" by cooperating yourself.
**[Counterfactual Mugging](http://wiki.lesswrong.com/wiki/Counterfactual_mugging):** You would not ever be in the position of receiving lots of free money unless you would *cause* yourself to lose less money in those cases where you lose the coin flip.
[1] “Cause” is used here in the technical sense, which requires the effect to be either in the future, or, in timeless formalisms, a descendent of the minimal set (in a Bayesian network) that screens off knowledge about the effect. In the parlance of Newcomb’s problem, it may feel intuitive to say that “one-boxing causes Box #2 to be filled”, but this is not correct in the technical sense. |
5120770d-00da-4609-89a8-5764c45637ff | trentmkelly/LessWrong-43k | LessWrong | Bayesian Methods Reading List
I'm reading this for fun -- tutorials and book recommendations on the Bayesian methods toolboox with a cognitive science/machine learning slant. Comes from the Computational Cognitive Science Lab at Berkeley. I recommend the general 2008 tutorial.
Useful stuff included in tutorial:
Parameter estimation
Model selection
Why Occam's Razor emerges naturally from the Conservation of Expected Evidence
Graphical models
Hierarchical Bayesian models |
91149855-46c3-4231-9946-f2ece762bc1a | trentmkelly/LessWrong-43k | LessWrong | Legality as a Career Harm Assessment Heuristic
A question many people in the effective altruism movement have struggled with around earning to give is how to handle potentially harmful careers. It's obviously self-defeating if you cause more harm in earning your money than the good it does when you donate it, but we want a higher threshold than that. As humans we need to have approaches that account for our self-serving biases, where we tend to underestimate the harm we cause and overestimate the good we do. Additionally, some kinds of harm (ex: murder) do not seem like the kind of thing you ought to be able to "cancel out" through donation, even if the donation clearly has larger benefits (ex: saves vastly many lives).
Unfortunately for most jobs, even questionable ones, the social impact is very hard to work out. Consider someone deciding to go into the oil industry: how much would they contribute to carbon emissions, after considering the oil company's elasticity of labor and the elasticity of production? Does cheaper oil displace even more carbon-intensive coal? How likely are extreme climate outcomes? Is the benefit of cheaper energy in lifting people out of poverty enough to make it positive on its own? Making a high-quality impact estimate for a career is a huge amount of work, and there are a lot of potential careers, especially when you consider that some roles in the oil industry might be far more replaceable than others.
What should we do in cases where the benefits seem much larger than the harms, but the harms are still significant? A potential rule I've been kicking around is, "don't do work that is illegal, or that would be illegal if the public knew what you were really doing." The idea is, we have a system for declaring profitable activities with negative externalities off limits, one that is intended for the more common case when someone is keeping what they earn for their own benefit. But we can't just use "don't do work that is illegal" because our legislative system can be slow to react to |
dc050eec-a2bb-4f49-a948-3877e81da451 | StampyAI/alignment-research-dataset/blogs | Blogs | less quantum immortality? • carado.moe
*less* quantum immortality?
---------------------------
if the set of nested universes [really does](what-happens-when-you-die.html) look like a funny graph of bubbles, i think there are two likely possibilities: either the set of bubbles rapidly dries up, or it grows towards infinity; in which case, if compute is infinite [as wolfram would have me think](https://writings.stephenwolfram.com/2020/04/finally-we-may-have-a-path-to-the-fundamental-theory-of-physics-and-its-beautiful/) then as soon as the bubble explosion happens, it's likely a [universal complete](universal-complete.html) algorithm is booted somewhere reasonably fast, itself booting in turn all initial states.
this has the result of instanciating all (countable, discrete) [tegmark 4 universes](https://space.mit.edu/home/tegmark/crazy.html), over time.
yet, [we still observe a preference for coherency](limiting-real-universes.html): i think the reasonablest interpretation of what'd be going on is that "computationally early" or at least "computationall frequent" states are favored; and thus, very weird and incoherent initial-state universes *do* get spawned, but much later and/or are being computed more slowly (for example, maybe computation is equally distributed among all timelines, and as more and more timelines spawn over time each individual one gets updated less and less often).
while this creates a neat explanation for what selects for universe coherence, it does make it that while [quantum immortality/suicide](quantum-suicide.html) can be considered to "still work", if you choose to keep living [only by waiting to be reincarnated later](what-happens-when-you-die.html), you're reducing the "realness" of your continued existence; you're making universes in which you continue to live appear only "computationally later".
it also provides a nice simplicity test fo roccam's razor: the simplicity of a hypothesis can be akin to how soon a universal-complete program that simulates all spawned computations arrives at it.
this probly doesn't apply to "classical" quantum immortality where you just use the fact that you're redundanced on other timelines, because i would imagine those other you's in other timelines would tend to be computed "at the same time". |
0cd4fab3-f61f-45aa-998b-d508da7d818a | trentmkelly/LessWrong-43k | LessWrong | Larry King: I want to be frozen
I know celebrities cryocrastinate just as much as anyone else, but King seems like the kind of guy to go through with it.
http://www.cnn.com/2011/12/02/showbiz/larry-king-i-want-to-be-frozen/index.html?hpt=hp_t3 |
1666795b-cfd9-4f3e-801c-cec4d3d68e64 | trentmkelly/LessWrong-43k | LessWrong | AI Prejudices: Practical Implications
I see widespread dismissal of AI capabilities. This slows down the productivity gains from AI, and is a major contributor to disagreements about the risks of AI.
It reminds me of prejudice against various types of biological minds.
I will try to minimize the moralizing about fairness in this post, and focus more on selfish reasons to encourage people to adopt an accurate view of the world. This post is mainly directed at people who think AI is mostly hype.
An important fraction of humans are underestimating how much they could learn by treating AIs as semi-equal co-workers.
AI's are superior to humans at a fair number of tasks, and inferior to adult humans at some important tasks. It takes experience to figure out which tasks belong in which category. That changes over time as AI labs tweak the behavior of AIs. When I interact with AIs as co-workers or employees, I learn more about what work is appropriate to delegate to them, and what work is better to do myself.
The Mirror Effect
AIs are products that encapsulate patterns of human communication. They have a propensity to mirror the tone, style, and quality of the inputs they receive. A respectful, well-structured query is more likely to elicit a response of similar quality.
E.g. the NYT reporter who got Sydney to try to break up his marriage likely got what he wanted - a memorable story that reflected poorly on an AI. But there's sufficiently little value in such a result that you should generally aim for the opposite of that kind of prompting.
I will now present some analogies to illustrate the patterns that cause my concerns.
China
Chinese leaders of two centuries ago underestimated the impact of the industrial revolution. Perplexity.ai paraphrases their attitude as:
> These distant barbarians, though they may possess curious devices, lack the wisdom and unity of the Middle Kingdom. Their petty squabbles among themselves render them incapable of posing any true threat to our celestial empire.
That at |
6ec8a81f-7554-498f-ac70-d14963bc51e6 | trentmkelly/LessWrong-43k | LessWrong | Charisma is a Force Multiplier
Sometimes, people talk about charisma as just a positive -- for instance, a lot of generic self-help or business advice assumes that charisma is generally good. On the other hand, you sometimes see people, often from "nerdier" communities, who say charisma is bad, an arbitary and unfair advantage, just a distraction from the facts, etc. [1]
I like to look at it from a somewhat different perspective. Military strategy sometimes discusses the concept of "force multipliers" - factors (often technological or strategic) that multiply the effectiveness of equipment or personnel. For example, precision weapons guidance is a force multiplier - if it takes dropping twenty normal bombs to hit a target but only one guided bomb, the guidance system could be considered a 20x multiplier on the effectiveness of your bombs. [2]
Perhaps the greatest force multiplier I am aware of for "normal situations" is charisma. Charismatic individuals are more likely to be effective and successful at a wide range of social tasks, more likely to influence broader planning towards their goals, more likely to elicit support from others, and so on. I would suggest that charisma is not another skill that's a useful addition to a broad range of skills; charisma can be a multiplier for all or almost all of an individual's other skills, at least insofar as the application of those skills involves working with others (and more skills do that than you might think)!
However, there is another important factor that should be taken into consideration. The fact that charisma can be such an important multiplier means that, if an individual's impact is negative, a more charismatic version of that individual will likely have a substantially more negative impact. [3]
Some of the most harmful results I've noticed in organizations and communities have arisen from very charismatic individuals who nevertheless pull the group in the wrong direction. I should note that I'm not saying that these individuals are nece |
21742338-9a50-4f4c-b18c-10a2901963cd | trentmkelly/LessWrong-43k | LessWrong | On ‘Responsible Scaling Policies’ (RSPs)
This post was originally intended to come out directly after the UK AI Safety Summit, to give the topic its own deserved focus. One thing led to another, and I am only doubling back to it now.
RESPONSIBLE DEPLOYMENT POLICIES
At the AI Safety Summit, all the major Western players were asked: What are your company policies on how to keep us safe? What are your responsible deployment policies (RDPs)? Except that they call them Responsible Scaling Policies (RSPs) instead.
I deliberately say deployment rather than scaling. No one has shown what I would consider close to a responsible scaling policy in terms of what models they are willing to scale and train.
Anthropic at least does however seem to have something approaching a future responsible deployment policy, in terms of how to give people access to a model if we assume it is safe for the model to exist at all and for us to run tests on it. And we have also seen plausibly reasonable past deployment decisions from OpenAI regarding GPT-4 and earlier models, with extensive and expensive and slow red teaming including prototypes of ARC evaluations.
I also would accept as alternative names any of Scaling Policies (SPs), AGI Scaling Policies (ASPs) or even Conditional Pause Commitments (CPCs).
For existing models we know about, the danger lies entirely in deployment. That will change over time.
I am far from alone in my concern over the name, here is another example:
> Oliver Habryka: A good chunk of my concerns about RSPs are specific concerns about the term “Responsible Scaling Policy”.
>
> I also feel like there is a disconnect and a bit of a Motte-and-Bailey going on where we have like one real instance of an RSP, in the form of the Anthropic RSP, and then some people from ARC Evals who have I feel like more of a model of some platonic ideal of an RSP, and I feel like they are getting conflated a bunch.
>
> …
>
> I do really feel like the term “Responsible Scaling Policy” clearly invokes a few things which I |
59e62f7f-1be3-402b-8e8d-5e972026b87a | trentmkelly/LessWrong-43k | LessWrong | How to Live on 24 Hours a Day
I can think of no better way to spend my karma than on encouraging people to read this 19th century self-help book. It's free and online in full.
The guidelines on what makes an appropriate front-page article be damned, or, if necessary, enforced by official censorship.
Thanks to User:sfb for the quote that led me here, although the decision to post is entirely my own.
http://www.gutenberg.org/files/2274/2274-h/2274-h.htm |
a49b7429-f215-45c2-abdf-77b23eb5dcb0 | trentmkelly/LessWrong-43k | LessWrong | Forecasting Transformative AI, Part 1: What Kind of AI?
PASTA: Process for Automating Scientific and Technological Advancement.
Audio also available by searching Stitcher, Spotify, Google Podcasts, etc. for "Cold Takes Audio"
This is the first of four posts summarizing hundreds of pages of technical reports focused almost entirely on forecasting one number. It's the single number I'd probably most value having a good estimate for: the year by which transformative AI will be developed.1
By "transformative AI," I mean "AI powerful enough to bring us into a new, qualitatively different future." The Industrial Revolution is the most recent example of a transformative event; others would include the Agricultural Revolution and the emergence of humans.2
This piece is going to focus on exploring a particular kind of AI I believe could be transformative: AI systems that can essentially automate all of the human activities needed to speed up scientific and technological advancement. I will call this sort of technology Process for Automating Scientific and Technological Advancement, or PASTA.3 (I mean PASTA to refer to either a single system or a collection of systems that can collectively do this sort of automation.)
PASTA could resolve the same sort of bottleneck discussed in The Duplicator and This Can't Go On - the scarcity of human minds (or something that plays the same role in innovation).
PASTA could therefore lead to explosive science, culminating in technologies as impactful as digital people. And depending on the details, PASTA systems could have objectives of their own, which could be dangerous for humanity and could matter a great deal for what sort of civilization ends up expanding through the galaxy.
By talking about PASTA, I'm partly trying to get rid of some unnecessary baggage in the debate over "artificial general intelligence." I don't think we need artificial general intelligence in order for this century to be the most important in history. Something narrower - as PASTA might be - would be plenty for th |
1aac70b2-1ad3-40ab-9920-b422e4aab1c4 | trentmkelly/LessWrong-43k | LessWrong | Ukraine and the Crimea Question
When the United States invaded Iraq, they were hoping to be greeted as liberators. In a similar vein, the current discourse suggests that if Ukraine uses its military to successfully liberate Crimea, Crimeans will greet Ukrainians as liberators. The West that currently supports Ukraine has to make a decision on whether to support Ukraine in retaking Crimea. Understanding what's likely going to happen in Crimea should Ukraine reconquer Crimea is vital to making good decisions.
Girard talks about how society uses scapegoating to assign the blame to one individual to end conflicts with other people. The Western media likes to scapegoat Putin because it is an easy way to relate to the conflict without having to understand anything about the underlying circumstances. In both 2014 and in 2022 Putin increased his approval rating by > +15% by ordering his military into Ukraine. If those conflicts just exist because Putin is crazy, it wouldn't push his approval that much. That's slightly more than the growth in approval that George Bush got when he started the Iraq war.
You could argue that George Bush only got this bump in approval because of the propaganda of the United States government and the willingness of the United States media to uncritically broadcast that propaganda. By the same token the Russian media also uncritically broadcasts their state propaganda that makes the population happier about going to war.
Unfortunately, it’s true that government propaganda makes citizens approve of war when they shouldn’t. War creates a lot of suffering and it would be great if nations would be more cautious about starting them. On the other hand, it shows that wars are often not just fought because the person at the top wants to fight the war. Many actors take part in a complex system that increases presidential approval at the start of a war.
How much fascism is there in Ukraine?
To understand the current conflicts, it’s vital to understand what the Russian discourse mea |
7aca5187-ce2c-481f-bb04-0e564ac5f59b | trentmkelly/LessWrong-43k | LessWrong | Weighting the probability of being a mind by the quantity of the matter composing the computer that calculates that mind
TL;DR by lavalamp: Treating "computers running minds" as discrete objects might cause a paradox in probability calculations that involve self-location. "The probability of being a certain mind" is probably an extensive physical quantity, i.e. rises proportionally to the size of the physical system doing the associated computations.
There are two computers simulating two minds. At some time, one of the minds is being shown a red light, and the other one is shown a green one (call this "Situation 1"). Conditioned on you being one of the minds, what is the probability you should assign to seeing red?
Naively, the answer seems to be 1/2, which comes from assigning being each of the minds an equal probability. If one had three computers and showed two of them a red light and the third one a green one, the probability would be calculated as 2/3, even if the red-seeing computers will be in exactly the same computational state at all times (call this "Situation 2").
However, I think that taking this point of view leads to paradoxes.
An example: Consider an electrical circuit made of (ideal) wires, resistors, capacitors and transistors (sufficient in principle to build a computer); the supply voltage comes from outside of the circuit considered. Under assumptions regarding the physical implementation of this circuit that do not restrict the possible circuit diagrams, it is possible to split the matter composing it into two part that both comprise working circuits reproducing the original circuit's behavior independently of the other part, in an analogous fashion to how the Ebborian's brains are split.* To clarify, what I have in mind is cutting up the wires and resistors orthogonally to their cross-sections - after the splitting, equivalent wires should be on equivalent potentials at the same time, but the currents flowing will be reduced by some factor.
Now imagine the circuit is a computer, simulating the mind that is going to see red in Situation 1 (the mind that wil |
25e67292-e16f-408b-961e-26a5d8fcf57d | trentmkelly/LessWrong-43k | LessWrong | Steven Pinker on ChatGPT and AGI (Feb 2023)
While I disagreed with a lot of Robin Hanson's latest take on AI risk, I am glad he came out with an updated position. I think with everything that's happened in the past 6-12 months, it's a good time for public intellectuals and prominent people who have previously commented on AGI and AI risk to check in again and share their latest views.
That got me curious if Steven Pinker had any recent statements. I found this article on the Harvard Gazette from last month (Feb 2023), which I couldn't find posted on LessWrong before:
Article link
Will ChatGPT supplant us as writers, thinkers?
Q&A with Steven Pinker
by Alvin Powell
Feb 14, 2023
Summary
Here's a summary of the article that ChatGPT generated for me just now (bold mine):
> Steven Pinker, a psychology professor at Harvard, has commented on OpenAI’s ChatGPT, an artificial intelligence (AI) chatbot that can answer questions and write texts. He is impressed with the AI's abilities, but also highlights its flaws, such as a lack of common sense and factual errors. Pinker believes that ChatGPT has revealed how statistical patterns in large data sets can be used to generate intelligent-sounding text, even if it does not have understanding of the world. He also believes that the development of artificial general intelligence is incoherent and not achievable, and that current AI devices will always exceed humans in some challenges and not others. Pinker is not concerned about ChatGPT being used in the classroom, as its output is easy to unmask as it mashes up quotations and references that do not exist.
Note that while he comments on AGI being an incoherent idea, he doesn't speak specifically about existential risk from AI misalignment. So it's not totally clear, but I think we can infer Pinker considers the risk very low, since he doesn't think AGI is possible in the first place. |
086890df-d207-4b13-ad1d-408c15e05622 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Critique of some recent philosophy of LLMs’ minds
I structure this post as a critique of some recent papers on the philosophy of mind in application to LLMs, concretely, on whether we can say that LLMs *think*, *reason*, *understand language*, *refer to the real world when producing language*, *have goals and intents*, etc. I also use this discussion as a springboard to express some of my views about the ontology of intelligence, agency, and alignment.
* Mahowald, Ivanova, et al., “[Dissociating language and thought in large language models: a cognitive perspective](https://arxiv.org/abs/2301.06627)” (Jan 2023). Note that this is a broad review paper, synthesising findings from computational linguistics, cognitive science, and neuroscience, as well as offering an engineering vision (perspective) of building an AGI (primarily, in section 5). I don’t argue with these aspects of the paper’s content (although I disagree with something about their engineering perspective, I think that engaging in this disagreement would be [infohazarous](https://www.lesswrong.com/tag/information-hazards)). I argue with the philosophical content of the paper, which is revealed in the language that the authors use and the conclusions that they make, as well as the ontology of linguistic competencies that the authors propose.
* Shanahan, “[Talking About Large Language Models](https://arxiv.org/abs/2212.03551)” (Dec 2022).
### Dissociating language and thought in large language models: a cognitive perspective
In this section, I shortly expose the gist of the paper by Mahowald, Ivanova, et al., for the convenience of the reader.
Abstract:
> Today’s large language models (LLMs) routinely generate coherent, grammatical and seemingly meaningful paragraphs of text. This achievement has led to speculation that these networks are—or will soon become—“thinking machines”, capable of performing tasks that require abstract knowledge and reasoning. Here, we review the capabilities of LLMs by considering their performance on two different aspects of language use: ‘formal linguistic competence’, which includes knowledge of rules and patterns of a given language, and ’functional linguistic competence’, a host of cognitive abilities required for language understanding and use in the real world. Drawing on evidence from cognitive neuroscience, we show that formal competence in humans relies on specialized language processing mechanisms, whereas functional competence recruits multiple extralinguistic capacities that comprise human thought, such as formal reasoning, world knowledge, situation modeling, and social cognition. In line with this distinction, LLMs show impressive (although imperfect) performance on tasks requiring formal linguistic competence, but fail on many tests requiring functional competence. Based on this evidence, we argue that (1) contemporary LLMs should be taken seriously as models of formal linguistic skills; (2) models that master real-life language use would need to incorporate or develop not only a core language module, but also multiple non-language-specific cognitive capacities required for modeling thought. Overall, a distinction between formal and functional linguistic competence helps clarify the discourse surrounding LLMs’ potential and provides a path toward building models that understand and use language in human-like ways.
>
>
Two more characteristic quotes from the paper:
> In addition to being competent in the rules and statistical regularities of language, a competent language user must be able to use language to do things in the world: to talk about things that can be seen or felt or heard, to reason about diverse topics, to make requests, to perform speech acts, to cajole, prevaricate, and flatter. In other words, we use language to send and receive information from other perceptual and cognitive systems, such as our senses and our memory, and we deploy words as part of a broader communication framework supported by our sophisticated social skills. A formal language system in isolation is useless to a language user unless it can interface with the rest of perception, cognition, and action.
>
>
> […] in examining language models’ functionality, it is important to separate their linguistic abilities from their abstract knowledge and reasoning abilities, which can be probed—and perhaps even learned—through a linguistic interface but require much more than formal linguistic competence.
>
>
As evident from the title of the paper (and this section), the authors use the words “thinking” and “thought” as a synonym for *functional linguistic competence* that they define in the paper.
General critiques
-----------------
### Failure at a task doesn’t imply the absence of capability
Throughout the paper, Mahowald, Ivanova, et al. take evidence of failure (either occasional failure, or nearly universal failure) in specific reasoning and comprehension, and functional tasks as proof that current LLMs don’t have this or that capability.
I think this is a methodological mistake for two reasons.
First, this admits a squarely [representationalist](https://plato.stanford.edu/entries/mental-representation/) philosophy of mind: in order to say that a mind has capacity X, it should have this capacity “actually implemented somehow”, in a regularised way. If a mind commits a mistake in reasoning, it means that the capability in question is not represented, otherwise, such a failure would be impossible.
But this is clearly false for humans: humans make mistakes in all types of capabilities (types of reasoning), from formal linguistic to “functional” (as Mahowald, Ivanova, et al. call them), all the time. Especially when humans are mentally incapacitated, drunk, sleepy, etc. *This doesn’t mean that humans don’t have given cognitive capabilities*. Therefore, counting mistakes in LLM outputs is a methodological dead-end. Could it be that LLMs are currently in the state that humans call a “cloudy mind”, when thoughts are entangled, and the control of the output is far from perfect? I think this could actually be the case.
From a more foundational perspective, austere representationalism in the last decades clearly loses the battle to [enactivism](https://en.wikipedia.org/wiki/Enactivism), or at least integrative representationalist-enactivist perspectives (Constant et al. 2021).
Second, from the pragmatic point of view, I think there is little scientific value in finding the capabilities that the latest LLMs *don’t* have. We are all too familiar with the failure of this approach, evidenced in the last 3 years by Gary Marcus.
Taking enactivism seriously [motivates a radically gradualistic and empirical approach to evaluating capacities and qualities of AI artifacts](https://www.lesswrong.com/posts/oSPhmfnMGgGrpe7ib/properties-of-current-ais-and-some-predictions-of-the#Minds_everywhere__radically_gradualistic_and_empirical_view_on_cognition_and_agency) (Levin 2022), and discourages catchy and categorical phrases like “LLMs *don’t* think”, “LLMs have *no* understanding of the world”, etc.
### Reductionism and the ladder of language model understanding
I think there is a three-level hierarchy of understanding LLMs and their behaviours:
1. **Naive anthropomorphism.** “Language models use language like humans, therefore they have human qualities.” ~~This is where~~ [~~Blake Lemoine was~~](https://www.lesswrong.com/posts/vqgpDoY4eKyNnWoFd/a-claim-that-google-s-lamda-is-sentient) ~~in the middle of last year.~~ [janus points out in the comments](https://www.lesswrong.com/posts/ejEgaYSaefCevapPa/critique-of-some-recent-philosophy-of-llms-minds?commentId=yqKfMiok4CKLcCtLX#yqKfMiok4CKLcCtLX) that Lemoine was actually more on the third level.
2. **Reductionism.** “LLMs are just mathematical models (matrix multiplication, calculations on GPU, next token prediction, Chinese room, stochastic parrot), which doesn’t understand, doesn’t think, has no meaning, etc.” Unfortunately, this is the level at which a lot of A(G)I researchers are.
3. **Taking the emergence in LLMs seriously.** “LLMs could be slightly conscious”, [discovering language model behaviours](https://www.lesswrong.com/posts/yRAo2KEGWenKYZG9K/discovering-language-model-behaviors-with-model-written) (Perez et al. 2022), [establishing AI psychology](https://www.lesswrong.com/posts/uHyZmfZKpXxo6uiEe/ai-psychology-should-ground-the-theories-of-ai-consciousness). Anthropic and OpenAI are definitely on this level. Google and DeepMind seem to never publicly admit their view. I have a hard time believing that they are not on this level, though, so this could be a deliberate public (political) position. (Note: Shanahan is affiliated with DeepMind.)
Both Mahowald, Ivanova, et al. and Shanahan present their positions as reactionary to the takes on the first level of understanding, for example, by the media (especially Shanahan). And although they occasionally pay lip service to the third level, these occasions are greatly outnumbered by categorical reductionist statements that they make throughout their papers, *particularly* conditioned on the fact that LLMs are trained to “predict the next token in sequence”.
LLMs use language affordances differently than people, even *qualitatively* differently (e. g., humans have more senses and hence qualitatively different grounding than LLMs could ever have), but **this doesn’t mean LLMs don’t use language affordances at all.** Both humans and LLMs use language to interact with the world, learn the world better, and align with agents that surround them (more on this below in the post).
The fact that LLMs use language affordances places them in the category of **language users**, which was previously occupied only by humans and parrots. Crucial here is that the *user* is an active, not a passive role.
More specific points
--------------------
### Linguistic capability circuits inside LLM-based AI could be sufficient for approximating general intelligence
Mahowald, Ivanova et al. write that “the language network[[1]](#fnznv0y7mvoel) [in human brains] does not support non-linguistic cognition”. This is probably correct but is also irrelevant in the context of considering whether LLM-based AI could reach an AGI level. For humans, too, it’s clear that creating large and hierarchical theories, simulations, and plans, is impossible without language (more specifically, writing and editing), because the humans’ working memory capacity is severely limited. It’s not clear why “thinking step-by-step on steroids” (a-la [language model cascades](https://arxiv.org/abs/2207.10342), Dohan et al. 2022), with creating draft simulations (explanations, plans) and then iteratively refining them, e. g. using critique and debate methods, couldn’t generalise reasoning.
That would be a very ineffective architecture for general intelligence. But note that humans seem to be approximately this kind of general intelligence. Humans don’t have the disciplines of epistemology, rationality, and ethics somehow hardwired or implemented symbolically in their heads. Rather, it seems to me that humans approximate thinking according to these theories by engaging in internal (or external, which is far more efficient) linguistic debate, being also linguistically “primed” after reading a handbook about [rationality](https://www.lesswrong.com/posts/dbDHEQyKqnMDDqq2G/cfar-handbook-introduction) (or epistemology, or ethics, or any specific sub-discipline of these, or specialised versions of these disciplines applied to specific contexts, such as a textbook on business strategy as a specialisation of rationality to the business context).
Although humans have *some* of their epistemology, ethics, and rationality skills “implemented” non-linguistically, and this is clearly not only about intuitive (reflexive, habitual, “system one”) conditioning, but also deliberative (”system two”) reasoning, it’s not clear that LLM-based AI couldn’t make up for its relatively weak non-linguistic circuits implementing epistemology, ethics, and rationality with stronger linguistic skills, higher memory capacity, ability to make much more iterations to tirelessly refine some of their inferences, and (potentially) much better ability to source and use the relevant literature, such as the textbooks in epistemology, rationality, and ethics.
And, of course, as LLMs continue to scale and their architectures continue to improve, they may improve their non-linguistic epistemology, ethics, and rationality skills, perhaps [discontinuously](https://www.lesswrong.com/posts/mLuQfS7gmfr4nwTdv/google-s-new-540-billion-parameter-language-model), even if these are currently at a very low level. Especially if they are trained on action sequences rather than simple texts (like [Gato](https://www.lesswrong.com/posts/TwfWTLhQZgy2oFwK3/gato-as-the-dawn-of-early-agi) was).
See also: “[The Limit of Language Models](https://www.lesswrong.com/posts/MmmPyJicaaJRk4Eg2/the-limit-of-language-models)” by DragonGod.
### On mathematical reasoning
> **4.1. LLMs are great at pretending to think** Large text corpora contain a wealth of non-linguistic information, from mathematical and scientific facts (e.g., “two plus seven is nine”) to factual knowledge (e.g., “the capital of Texas is Austin”) to harmful stereotypes (e.g., “women belong in the kitchen”). This is not particularly surprising since even simple patterns of co-occurrence between words capture rich conceptual knowledge, including object properties, abstract analogies, social biases, and expert knowledge in specialized domains. Moreover, statistical regularities extracted from language and from visual scenes exhibit a substantial degree of correspondence, indicating that linguistic information can capture at least some aspects of experiential input.
>
> As a result, language models trained on gigantic text corpora acquire large amounts of factual knowledge, *succeed at some types of mathematical reasoning* [e.g., [Lewkowycz et al., 2022](https://www.lesswrong.com/posts/JkKeFt2u4k4Q4Bmnx/linkpost-solving-quantitative-reasoning-problems-with), Rae and Razavi, 2020] and reproduce many stereotypes and social biases. All these behaviors — both positive and negative — become more prominent as models gets larger, indicating that larger storage capacity allows LLMs to learn increasingly more fine-grained patterns in the input.
>
>
In this quote, the authors seem to imply that LLMs’ ability to “succeed at some types of mathematical reasoning” is thanks to “patterns memorisation” rather than “reasoning”. I don’t think this is proven. In fact, I’m almost sure that SoTA LLMs such as Minerva have some (even if so far only weak and imprecise) “logical/mathematical reasoning circuits” rather than just a memory of a collection of inductive reasoning patterns. Cf. section 5 of ([Lewkowycz et al., 2022](https://www.lesswrong.com/posts/JkKeFt2u4k4Q4Bmnx/linkpost-solving-quantitative-reasoning-problems-with)), where the authors argue that Minerva didn’t memoise solutions but generalised some patterns. To this Mahowald, Ivanova et al. could have responded that they were looking for generalisation beyond individual inductive patterns and towards a more coherent reasoning framework. However, as I already indicated above, trying to find some line here between “actual reasoning” and “memorising patterns” is a methodological dead-end, which is especially true for mathematical and logical reasoning, which sometimes and in some sense *is* just applying a collection of inductive rules (axioms).
### Functional linguistic competences
> We focus on four key capacities that are not language-specific but are nevertheless crucial for language use in real-life settings: **i) formal reasoning**—a host of abilities including logical reasoning, mathematical reasoning, relational reasoning, computational thinking, and novel problem solving; **ii) world knowledge**—knowledge of objects and their properties, actions, events, social agents, facts, and ideas; **iii) situation modeling**—the dynamic tracking of protagonists, locations, and events as a narrative/conversation unfolds over time; and **iv) social reasoning**—understanding the social context of linguistic exchanges, including what knowledge is shared, or in ‘common ground’, what the mental states of conversation participants are, and pragmatic reasoning ability. A simple conversation typically requires the use of all four of these capacities, yet none of them are specific to language use. Below, we provide evidence that these skills rely on non-language-specific processing mechanisms in humans and highlight LLMs’ failures as relevant to each domain.
>
>
I think the proposed ontology of functional competencies (capacities) is mistaken. To demonstrate this, I need to first introduce my own view on the ontology of general intelligence.
### The functional decomposition (ontology) of general intelligence
The first category, “formal reasoning”, should be expanded with other, “non-formal” or “semi-formal” disciplines (competencies, capabilities) because it isn’t sensible to make the distinction between “formal” (or, we should better say, symbolic) and “informal” (connectionist) disciplines: rather, most functional disciplines of general intelligence should optimally[[2]](#fns4ttks2o7nl) be implemented by interacting symbolic and connectionist components. To the first, crudest approximation, as I already mentioned above, we can decompose general intelligence into three big functional disciplines: epistemology, ethics, and rationality.
I have a view on the ontology of general intelligence to the “second approximation”, too, but don’t want to reveal it in public because it could be infohazardous. A few extra disciplines in this ontology that I need to mention for the discussion below, apart from epistemology, ethics, and rationality, are semantics (together with closely related philosophy of language and linguistics) and communication theory (such as the [speech act theory](https://plato.stanford.edu/entries/speech-acts/)).
### Belief alignment is necessary for effective language use
“Functional competencies” ii-iv), namely world knowledge, situation modelling, and social reasoning are *not* competencies (capacities, disciplines): rather, they all **point to the processes that intelligent agents should continuously engage in with the world and each other for their linguistic communication (and behaviour more generally) to be successful**. These processes are conducted using the general intelligence disciplines, as described above, but they are not disciplines themselves.
Also, these processes: **continuous grounding (updating) one’s world knowledge, situation modelling, and social reasoning could be collectively called belief alignment** between humans or AIs. (More on this in a forthcoming post.)
In their “functional linguistic competencies”, Mahowald, Ivanova et al. may have tried to point to “applied” world theories that intelligent agents should learn in order to use language effectively: for example, learn “applied” physical theories such as classical mechanics, electromagnetism, hydraulics; psychology, sociology to build theories of mind and model social situations, etc. AGI couldn’t always learn everything from first principles, they must use past inferences.
However, methodologically, I’d still argue that it’s *not* the “applied” theories themselves that are important for effective language use, *but exactly the process of aligning these theories between the interacting parties*. For example, having a “broadly western” understanding of the world and “folk psychology and sociology” (all members of the society have some theories of human psychology and sociology in their heads, even if they have never heard these two words), may not allow conversing with people who have very different such theories. Cf. [Pirahã language](https://en.wikipedia.org/wiki/Pirah%C3%A3_language), and the story of [Daniel Everett](https://en.wikipedia.org/wiki/Daniel_Everett) who tried to learn this language; “[The anthropology of intentions](https://www.cambridge.org/core/books/anthropology-of-intentions/2AD902D8019D95CFA4B5E6FC4DABF1A5)” (Duranti 2015, chapter 11).
### Misalignment breeds misalignment; training and belief alignment should be iterative
Mahowald, Ivanova et al.:
> [LLMs] are trained to extract statistical information about words in text rather than a set of stable, consistent, and complete facts about the world. Any output generated by LLMs will be biased accordingly.
>
>
Creating a “set of stable, consistent, complete facts about the world” and imparting them in AI in one way or another is GOFAI-style utopia. Methodologically, AGI should be iteratively taught the general intelligence disciplines and inner-aligned with people on the world knowledge, as well as psychological and social models that people adopt. This iteration should proceed slowly because [(inner) alignment is brittle unless humans and the model are already almost aligned](https://www.lesswrong.com/posts/L4anhrxjv8j2yRKKp/how-discovering-latent-knowledge-in-language-models-without?commentId=ZBr7XjG4HRYDcJzv2): misalignment erodes further attempts to align via linguistic communication (including training a transformer on text examples). It doesn’t matter for this process whether the AGI-underlying model is a Transformer and thus resembles current LLM (or, rather multimodal transformers) or not.
### Denying LLMs in understanding and knowledge grounding is confused
Mahowald, Ivanova et al.:
> And, of course, models trained exclusively on text strings are, by design, incapable of using this knowledge to refer to real-world entities, meaning that they are incapable of using language in a physical environment the way humans do. Thus, LLMs in their current form are challenged to perform an essential feat of language comprehension: integrating incoming language information into a general, multimodal, dynamically evolving situation model.
>
>
Similar to “thinking” and “reasoning”, covered above, I think the attempts to draw a bright line between AIs “understanding” and “not understanding” language are methodologically confused. There are no bright lines; there is more or less grounding, and, of course, models that process only text have as little grounding as possible, but they *do* [understand a concept as soon as they have a feature(s) for it](https://www.lesswrong.com/posts/oSPhmfnMGgGrpe7ib/properties-of-current-ais-and-some-predictions-of-the#Features_in_DNNs_are_reference_frames__DNNs_are_aware_of_what_they_have_features_for), connected to other semantically related concepts in a sensible way. A multimodal Transformer will have more grounding than a pure LLM and be better at situational modelling (which, as I pointed out above, is a component of belief alignment).
Browning and LeCun also succumb to this categorical denial of understanding in language models in [their piece for Noēma](https://www.noemamag.com/ai-and-the-limits-of-language/):
> LLMs have no stable body or abiding world to be sentient *of*—so their knowledge begins and ends with more words and their common-sense is always skin-deep. The goal is for AI systems to focus on [the world](https://aclanthology.org/2020.acl-main.463/) being talked about, not the words themselves — but LLMs [don’t grasp the distinction](https://blogs.scientificamerican.com/observations/whats-still-lacking-in-artificial-intelligence/). There is no way to approximate this deep understanding solely through language; it’s just the wrong kind of thing. Dealing with LLMs at any length makes apparent just how little can be known from language alone.
>
>
The same applies to the attempts to draw a line between AIs “referring to real-world entities” and “not referring to real-world entities”. Furthermore, I think this attempt is ontologically and semantically confused: no amount of grounding that makes some AI refer to the real world any *stronger* than another, less grounded model. Grounding could only change the accuracy and robustness of these references under changing conditions, but references don’t have strength[[3]](#fnzyz81n0xs5). AI could fail to refer to real-world entities when needed (or attempt to refer to them when not needed), though, if it doesn’t possess a good theory (discipline) of semantics itself. Correctly dealing with “[this is not a pipe](https://en.wikipedia.org/wiki/The_Treachery_of_Images)”-type of challenges in reasoning is a test of one’s skill of semantics, not one’s grounding. And humans make semantical mistakes in the face of such challenges, too.
### The relationship between images and words in visual-language models is exactly the same as in humans
Shanahan:
> […] the relationship between a user-provided image and the words generated by the VLM [visual-language model] is fundamentally different from the relationship between the world shared by humans and the words we use when we talk about that world. Importantly, the former relationship is mere correlation, while the latter is causal. (Of course, there is causal structure to the *computations* carried out by the model during inference. But this is not the same as there being causal relations between words and the things those words are taken to be about.)
>
> The consequences of the lack of causality are troubling. If the user presents the VLM with a picture of a dog, and the VLM says “This is a picture of a dog”, there is no guarantee that its words are connected with the dog in particular, rather than some other feature of the image that is spuriously correlated with dogs (such as the presence of a kennel). Conversely, if the VLM says there is a dog in an image, there is no guarantee that there actually is a dog, rather than just a kennel.
>
>
In the second part of this quote, the discussion of “kennel and dog” is exactly the discussion of reference robustness (see the section above), not the discussion of where VLMs reference when they generate words. It’s *not* because of “the lack of causality” that VLM can be confused. Humans can, in principle, be confused in exactly the same way (though humans are currently much more robust object detectors than VLMs, especially when it comes to such simple scenes as with kennels and dogs).
Ontologically, I think Shanahan’s framing is confused (especially invoking “correlations” wrt. VLMs). Interaction with the "world" (i. e., environment) amounts to performing measurements (and preparing the future state *for* the environment) using a set of quantum operators and then semantically interpreting the quantum state resulting from these measurements. Classical computation is well-defined when the quantum evolution (the propagation operator P.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
) of the measured boundary state, the semantic interpretation function IF, and the classical computation operator F commute ([Fields et al. 2022](https://chrisfieldsresearch.com/qFEP-2112.15242.pdf), sections 2.3 and 2.4).
Regardless of whether we think of the semantic interpretation as inducing causal links or not (the problem here is that quantum states and semantic information occupy two separate “worlds”), humans don’t have a relationship with their environment any different than a robot with a visual-language model and a camera: they both make semantic sense of the quantum state that they measure[[4]](#fnxvmwz8vdc6).
### LLMs do have knowledge, encoded in connected features
Shanahan:
> A bare-bones LLM doesn’t “really” know anything because all it does, at a fundamental level, is sequence prediction. Sometimes a predicted sequence takes the form of a proposition. But the special relationship propositional sequences have to truth is apparent only to the humans who are asking questions, or to those who provided the data the model was trained on. Sequences of words with a propositional form are not special to the model itself in the way they are to us. The model itself has no notion of truth or falsehood, properly speaking, because it lacks the means to exercise these concepts in anything like the way we do.
>
> It could perhaps be argued that an LLM “knows” what words typically follow what other words, in a sense that does not rely on the intentional stance. But even if we allow this, knowing that the word “Burundi” is likely to succeed the words “The country to the south of Rwanda is” is not the same as knowing that Burundi is to the south of Rwanda. To confuse those two things is to make a profound category mistake.
>
> So much for the bare-bones language model. What about the whole dialogue system of which the LLM is the core component? Does that have beliefs, properly speaking? At least the very idea of the whole system having beliefs makes sense. There is no category error here. However, for a simple dialogue agent like BOT, the answer is surely still “no”. A simple LLM-based question-answering system like BOT lacks the means to use the words “true” and “false” in all the ways, and in all the contexts, that we do. It cannot participate fully in the human language game of truth, because it does not inhabit the world we human language-users share.
>
>
First, Shanahan should have not put “really” in quotes because in this particular case, he *does* claim that bare-bones LLMs lack knowledge (and beliefs, which in Shanahan’s ontology appear to be slightly different, albeit related things) *categorically*, not empirically at their current level of sophistication. Implicit here in his position is that *embodiment* is a necessary condition to say that a system has some knowledge. Note that earlier in the paper, he describes LLMs as “generative *mathematical* models”. By this somewhat unusual injection of the word “mathematical”, I think he wanted to highlight that LLMs are disembodied and therefore disqualify as something that could have knowledge (or beliefs).
As I pointed out above already, Shanahan is wrong here: [LLMs *are* embodied agents](https://www.lesswrong.com/posts/oSPhmfnMGgGrpe7ib/properties-of-current-ais-and-some-predictions-of-the#DNNs__GPUs__and_their_technoevolutionary_lineages_are_agents), they are physical systems (collections of physical variables—model parameters, somewhere on some computers) that interact with their environments. It’s unprincipled that Shanahan holds dialogue systems as embodied, but “bare-bones LLMs” as disembodied: both are cyber-physical systems. [LLMs’ perception of time is very impoverished](https://www.lesswrong.com/posts/oSPhmfnMGgGrpe7ib/properties-of-current-ais-and-some-predictions-of-the#Batch_agents_don_t_experience_time_during_deployment), though, and, indeed, dialogue systems are qualitatively different from bare-bones LLMs in the sense that we can talk about its [planning during deployment](https://www.lesswrong.com/posts/oSPhmfnMGgGrpe7ib/properties-of-current-ais-and-some-predictions-of-the#Batch_agents_plan_during_training__but_not_during_deployment__except_within_chat_sessions_)[[5]](#fnuvvupe1x74r). However, this doesn’t *categorically* preclude LLMs from acquiring *knowledge* during training. When Shanahan says that LLMs “know that the word ‘Burundi’ likely succeeds the words ‘The country to the south of Rwanda is’”, he is cheating. LLMs don’t know this on the level of words, they know this on the level of *concepts*, i. e., features in their activations. Concepts of “Rwanda”, “Burundi”, “country”, and “south” are connected in the right ways. This is how knowledge is represented in LLMs.
Finally, I think that the statement “The model itself has no notion of truth or falsehood, properly speaking, because it lacks the means to exercise these concepts in anything like the way we do.” is also wrong, at least categorically: see “[How "Discovering Latent Knowledge in Language Models Without Supervision" Fits Into a Broader Alignment Scheme](https://www.lesswrong.com/posts/L4anhrxjv8j2yRKKp/how-discovering-latent-knowledge-in-language-models-without)” (Burns et al. 2022), and in some sense practically, already: see “[Language Models (Mostly) Know What They Know](https://arxiv.org/abs/2207.05221)” (Kadavath et al. 2022).
Shanahan:
> Only in the context of a capacity to distinguish truth from falsehood can we legitimately speak of “belief” in its fullest sense. But an LLM is not in the business of making judgements. It just models what words are likely to follow from what other words. The internal mechanisms it uses to do this, whatever they are, cannot in themselves be sensitive to the truth or otherwise of the word sequences it predicts.
>
>
This is mistaken because **LLMs** ***are*** **“in the business” of improving their world models** ***proactively.*** [Fields and Levin (2022)](https://psyarxiv.com/rdt7f/) demonstrate this:
> The informational symmetry of the FEP suggests that both fully-passive training and fully-autonomous exploration are unrealistic as models of systems embedded in and physically interacting with real, as opposed to merely formal, environments. The objective of training is to produce predictable behavior by an initially unpredictable system. Training is, in other words, a method of reducing VFE.
>
>
### LLMs could be curious and intentional
Mahowald, Ivanova et al.:
> Moreover, LLMs themselves lack communicative intent [[Shanahan, 2022](https://arxiv.org/abs/2212.03551), [Bender et al., 2021](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)]. The closest they come to intentionality is modeling a document-specific distribution of language patterns, which can result in generated strings that are overall consistent with a particular person/agent [Andreas, 2022], but the intent behind these strings is still missing. Globally speaking, these models have nothing to say. *Nor should we expect them to: LLMs’ training objective is maximizing next-/masked-word predictive accuracy, not generating utterances that allow them to achieve specific goals in the world.* (Emphasis added by R. L.)
>
>
Shanahan:
> […] the basic function of a large language model, namely to generate statistically likely continuations of word sequences, is extraordinarily versatile. Second, notwithstanding this versatility, at the heart of every such application is a model doing just that one thing: generating statistically likely continuations of word sequences.
>
> With this insight to the fore, let’s revisit the question of how LLMs compare to humans, and reconsider the propriety of the language we use to talk about them. In contrast to humans like Bob and Alice, a simple LLM-based question-answering system, such as BOT, has no communicative intent (Bender and Koller, 2020). In no meaningful sense, even under the licence of the intentional stance, does it know that the questions it is asked come from a person, or that a person is on the receiving end of its answers. By implication, it knows nothing about that person. It has no understanding of what they want to know nor of the effect its response will have on their beliefs.
>
>
While what Mahowald, Ivanova et al. and Shanahan say is probably true in the current LLMs (except the italicised sentence in the quote from Mahowald, Ivanova et al.), a reductionist implication behind these philosophical positions, namely, that **LLMs couldn’t have communicative intent, is wrong**. [LLMs are Active Inference agents](https://www.lesswrong.com/posts/oSPhmfnMGgGrpe7ib/properties-of-current-ais-and-some-predictions-of-the#DNNs__GPUs__and_their_technoevolutionary_lineages_are_agents). I demonstrated how they could begin to exhibit experimentally noticeable curiosity (which, in this context, is close to intentionality) [here](https://www.lesswrong.com/posts/oSPhmfnMGgGrpe7ib/properties-of-current-ais-and-some-predictions-of-the#Self_evidencing_as_a_curious_agent). Also, taking a radically gradualistic stance, we cannot deny that trace levels of intentionality and communicative intent are already present in the current LLMs.
In one place of his paper, Shanahan actually registers a completely reasonable, non-reductionist philosophical position:
> To be clear, it is not the argument of this paper that a system based on a large language model could never, in principle, warrant description in terms of beliefs, intentions, reason, etc. Nor does the paper advocate any particular account of belief, of intention, or of any other philosophically contentious concept. (In particular, when I use the term “really”, as in the question ‘Does X “really” have Y?’, I am not assuming there is some metaphysical fact of the matter here. Rather, the question is whether, when more is revealed about the nature of X, we still want to use the word Y.) Rather, the point is that such systems are simultaneously so very different from humans in their construction, yet (often but not always) so human-like in their behaviour, that we need to pay careful attention to how they work before we speak of them in language suggestive of human capabilities and patterns of behaviour.
>
>
Unfortunately, Shanahan contradicts himself later in the paper:
> This argument has considerable appeal. After all, the overriding lesson of recent progress in LLMs is that extraordinary and unexpected capabilities emerge when big enough models are trained on very large quantities of textual data. However, as long as our considerations are confined to a simple LLM-based question-answering system, this has little bearing on the issue of communicative intent. It doesn’t matter what internal mechanisms it uses, a sequence predictor is not, in itself, the kind of thing that could, even in principle, have communicative intent, and simply embedding it in a dialogue management system will not help.
>
>
Similar to the italicised sentence in the quote from Mahowald, Ivanova et al., this is just mistaken, as I demonstrated above.
### LLMs communicate meaning: “Train me better!”
Mahowald, Ivanova et al.:
> Although all of these sentences are grammatical (and actually obey a sensible scheme for a 4-paneled figure in an academic paper), GPT-3 has no intention, no broader meaning to communicate, and so, at some point sufficiently removed from the human-generated prompt, it will start becoming incoherent.
>
> Further, even if given explicit instructions, LLMs can be easily distracted, as demonstrated by the example in Figure 3. Attempts to align the model’s output with the user’s intent often require adding an objective other than language modeling [e.g., Ouyang et al., 2022, InstructGPT], and even those are imperfect. Overall, LLMs’ inability to infer and maintain the goals of the interaction means that their outputs will often be meaningless and/or mis-specified despite high linguistic well-formedness.
>
>
Mahowald, Ivanova et al. here use the word “meaning” in the sense that is close to the word “purpose” and related to intent, i. e., only intentional communication act could bear meaning[[6]](#fndya20s2mdpg).
However, per Fields and Levin (2022), as I quoted above, no interaction between agents (i. e., [all trackable physical systems](https://www.lesswrong.com/posts/oSPhmfnMGgGrpe7ib/properties-of-current-ais-and-some-predictions-of-the#Minds_everywhere__radically_gradualistic_and_empirical_view_on_cognition_and_agency)) is completely devoid of purpose: minimising their VFE (and [helping its environment minimise its VFE wrt. the agent itself](https://www.lesswrong.com/posts/oSPhmfnMGgGrpe7ib/properties-of-current-ais-and-some-predictions-of-the#Both_the_system_and_its_environment_are_FEP_agents_with_respect_to_each_other)). Therefore, the “meaningless” output by an LLM that Mahowald, Ivanova et al. provided actually could be seen as communicating to LLM engineers the weak sides of the LLM capabilities, with the “intention” that engineers think about how to strengthen these poor skills in the future systems in the evolutionary lineage (or tree) of LLMs.
I think there is a continuum, not a categorical distinction between the kind of “conversational” meaning Mahowald, Ivanova et al. were referring to, and the “physical” meaning that I described above. But even talking about the “conversational” meaning, it will appear when LLMs exhibit significant intentionality, as noted in the previous section, and this in principle could happen with LLMs [if they are trained on a huge number of small batches](https://www.lesswrong.com/posts/oSPhmfnMGgGrpe7ib/properties-of-current-ais-and-some-predictions-of-the#A_feature_for_surprise). This could also happen with LLM-based AI in more prosaic and realistic ways. For example, arguably, this has already happened in [Cicero](https://www.lesswrong.com/posts/3TCYqur9YzuZ4qhtq/meta-ai-announces-cicero-human-level-diplomacy-play-with).
References
----------
Browning, Jacob, and Yann LeCun. “[AI And The Limits Of Language](https://www.noemamag.com/ai-and-the-limits-of-language/).” (2022).
Burns, Collin, Haotian Ye, Dan Klein, and Jacob Steinhardt. "[Discovering Latent Knowledge in Language Models Without Supervision](https://www.lesswrong.com/posts/L4anhrxjv8j2yRKKp/how-discovering-latent-knowledge-in-language-models-without)." *arXiv preprint arXiv:2212.03827* (2022).
Constant, Axel, Andy Clark, and Karl J. Friston. "[Representation wars: Enacting an armistice through active inference](https://www.frontiersin.org/articles/10.3389/fpsyg.2020.598733/full)." *Frontiers in Psychology* 11 (2021): 598733.
Dohan, David, Winnie Xu, Aitor Lewkowycz, Jacob Austin, David Bieber, Raphael Gontijo Lopes, Yuhuai Wu et al. "[Language model cascades](https://arxiv.org/abs/2207.10342)." *arXiv preprint arXiv:2207.10342* (2022).
Duranti, Alessandro. [*The anthropology of intentions*](https://www.cambridge.org/core/books/anthropology-of-intentions/2AD902D8019D95CFA4B5E6FC4DABF1A5). Cambridge University Press, 2015.
Fields, Chris, James F. Glazebrook, and Michael Levin. "[Minimal physicalism as a scale-free substrate for cognition and consciousness](https://academic.oup.com/nc/article/2021/2/niab013/6334115)." *Neuroscience of Consciousness* 2021, no. 2 (2021): niab013.
Fields, Chris, Karl Friston, James F. Glazebrook, and Michael Levin. "[A free energy principle for generic quantum systems](https://chrisfieldsresearch.com/qFEP-2112.15242.pdf)." *Progress in Biophysics and Molecular Biology* (2022).
Fields, Chris, and Michael Levin. "[Regulative development as a model for origin of life and artificial life studies](https://psyarxiv.com/rdt7f/)." (2022).
Kadavath, Saurav, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer et al. "[Language models (mostly) know what they know](https://arxiv.org/abs/2207.05221)." *arXiv preprint arXiv:2207.05221* (2022).
Leventov, Roman. "[Properties of current AIs and some predictions of the evolution of AI from the perspective of scale-free theories of agency and regulative development](https://www.lesswrong.com/posts/oSPhmfnMGgGrpe7ib/properties-of-current-ais-and-some-predictions-of-the).” (2022a).
Leventov, Roman. “[How evolutionary lineages of LLMs can plan their own future and act on these plans](https://www.lesswrong.com/posts/ddR8dExcEFJKJtWvR/how-evolutionary-lineages-of-llms-can-plan-their-own-future).” (2022b).
Levin, Michael. "[Technological approach to mind everywhere: an experimentally-grounded framework for understanding diverse bodies and minds](https://www.frontiersin.org/articles/10.3389/fnsys.2022.768201/full)." *Frontiers in Systems Neuroscience* (2022): 17.
Lewkowycz, Aitor, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone et al. "[Solving quantitative reasoning problems with language models](https://www.lesswrong.com/posts/JkKeFt2u4k4Q4Bmnx/linkpost-solving-quantitative-reasoning-problems-with)." *arXiv preprint arXiv:2206.14858* (2022).
Mahowald, Kyle, Ivanova, Anna A., Blank, Idan A., Kanwisher, Nancy, Tenenbaum, Joshua B., and Evelina Fedorenko. "[Dissociating language and thought in large language models: a cognitive perspective](https://arxiv.org/abs/2301.06627)." *ArXiv*, (2023). Accessed January 20, 2023. <https://doi.org/10.48550/arXiv.2301.06627>.
Perez, Ethan, Sam Ringer, Kamilė Lukošiūtė, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit et al. "[Discovering Language Model Behaviors with Model-Written Evaluations](https://www.lesswrong.com/posts/yRAo2KEGWenKYZG9K/discovering-language-model-behaviors-with-model-written)." *arXiv preprint arXiv:2212.09251* (2022).
Shanahan, Murray. "[Talking About Large Language Models](https://arxiv.org/abs/2212.03551)." *arXiv preprint arXiv:2212.03551* (2022).
1. **[^](#fnrefznv0y7mvoel)**Mahowald, Ivanova et al. actively use the term “[network](https://en.wikipedia.org/wiki/Large-scale_brain_network)” from neuroscience throughout the paper. The closest equivalents of “networks” in the domain of ANNs are “[circuits](https://www.lesswrong.com/tag/transformer-circuits)”, and I use “circuits” in the context of ANNs in this post, because “network” is confusing: ANNs are also networks.
2. **[^](#fnrefs4ttks2o7nl)**Because of the “no free lunch” theorem.
3. **[^](#fnrefzyz81n0xs5)**It’s unclear, though, whether these references exist at all, regardless of who produces language.
4. **[^](#fnrefxvmwz8vdc6)**There could be some more subtlety in the architecture of the human brain (connectome): language could somehow be produced “in parallel” or “together” with visual percept in humans, while a robot with a camera clearly first records the image and only then produces text based on that image. Therefore, human language utterances could be, in some sense, more “directly” caused by the measurements of the world than robot utterances. However, robot utterances are still caused by the measurements of the world in this case, transitively. And it doesn’t seem that this is the issue Shanahan was pointing towards.
5. **[^](#fnrefuvvupe1x74r)**[*Lineages* of bare-bones LLMs also plan, though, on evolutionary timescales](https://www.lesswrong.com/posts/ddR8dExcEFJKJtWvR/how-evolutionary-lineages-of-llms-can-plan-their-own-future) (Leventov 2022b).
6. **[^](#fnrefdya20s2mdpg)**This differs from the notion of meaning as “information that makes a difference”, as per (Fields et al. 2021). |
6b0419d9-2c5c-46f3-9795-c6d071b765dc | trentmkelly/LessWrong-43k | LessWrong | Meetup : Meetup, Champaign IL,
Discussion article for the meetup : Meetup, Champaign IL,
WHEN: 14 November 2012 07:00:00PM (-0600)
WHERE: Cafe Paradiso, 801 South Lincoln Avenue Urbana, IL 61801
Let's get together on Wednesday the 14th of November at 7pm at Cafe Paradiso.
Last time we talked about wanting to discuss specific topics at the meetings, and we decided that we're going to start with Consequentialism.
So try to read a little bit about it before next time. Possibilities include:
* Wikipedia
* Check Consequentialism on LessWrong
* Consequentialism FAQ
* Consequentialism Need Not Be Nearsighted
Also, think about any topics you'd be interested in eventually presenting to the rest of us. You don't need to be an expert: just interested. It can be LW related or not.
See you then.
Discussion article for the meetup : Meetup, Champaign IL, |
d8059aab-d960-4018-968e-ac05478fc991 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Redwood's Technique-Focused Epistemic Strategy
Imagine you’re part of a team of ML engineers and research scientists, and you want to help with alignment. Everyone is ready to jump in the fray; there’s only one problem — how are you supposed to do applied research when you don’t really know how AGI will be built, what it will look like, not even the architecture or something like that? What you have is the current state of ML, and a lot of conceptual and theoretical arguments.
You’re in dire need of a bridge ([an epistemic strategy](https://www.alignmentforum.org/s/LLEJJoaYpCoS5JYSY)) between the experiments you could run now and the knowledge that will serve for solving alignment.
[Redwood Research](https://www.redwoodresearch.org/) is in this precise situation. And they have a bridge in mind. Hence this post, where I write down my interpretation of their approach, based on conversations with Redwood’s [Buck Shlegeris](https://www.alignmentforum.org/users/buck). As such, even if I’m describing Redwood’s strategy, it’s probably biased towards what sounds most relevant to both Buck and me.
*Thanks to Buck Shlegeris for great discussions and feedback. Thanks to Nate Thomas for listening to me when we talked about epistemic strategies and for pushing me to send him and Buck my draft, starting this whole collaboration. Thanks to Seraphina Nix for feedback on a draft of this post.*
Techniques, not Tasks or Issues
===============================
My first intuition, when thinking about such a bridge between modern experiments and useful practical knowledge for alignment, is to focus on **tasks** and/or **issues**. By task, I mean the sort of things we want an aligned AGI to do (“learn what killing means and not do it” might be an example), whereas issues are… issues with an AGI (deception for example). It sounded obvious to me that you start from one of those, and then try to make a simpler, analogous version you can solve with modern technology— the trick being how to justify your analogy.
This is not at all how Buck sees it. After my initial confusion wore off, I realized he thinks in terms of **techniques**: potential ways of aligning an AGI. If tasks are “what we want” and issues are “what might go wrong”, **techniques focus on “how” — how we solve the task and avoid the issues.**
Buck’s favorite example of a technique (and the one driving Redwood’s current work) is a form of [adversarial training](https://ai-alignment.com/training-robust-corrigibility-ce0e0a3b9b4d) where the main model receives adversarial examples from a trained adversary, and has its response judged by an overseer to see if they’re acceptable or not.
Another example is [Debate](https://arxiv.org/abs/1805.00899): the alignment proposal where two models debate on the questions proposed by the human judge/supervisor, and hopefully the honest strategy is favored such that it should always win the debate.
Have you seen the trend with these two examples? They both can be specified as ML problems. What I mean is that the researchers who invented these techniques provided broad strokes ML setups and parameterized loss functions for them. Of course, we can’t train all the relevant parts yet (adversary and overseer in adversarial training, advanced debaters in debate). If we could, then studying the technique would just boil down to straightforward ML work.
Yet these two ingredients, ML specifications and hardness of specific parts, point to Redwood’s bridge between their experiments and the AGI-level technique.
Aside: Choosing a Technique
===========================
Before going into the detail of the bridge, I want to clarify that I’m not going to discuss how to choose a technique. That depends on many subtle arguments and discussions, especially conceptual ones. This is an expertise that Redwood partly has already and that they want to improve on. But at the moment, the work they’ve done focuses on turning a technique they’ve chosen into relevant experiments they can run today. Hence the focus of this post.
Replacing AGI-level Capabilities
================================
Recall that the main reason we can’t experiment directly with a technique like adversarial training or debate is that some parts require more capabilities than we currently have — we don’t know how to train the relevant parts of the model and get something that behaves as expected. How to deal with that problem?
By **replacing the unfeasible parts with “current technology” that accomplishes the same or similar job.**
Which “current technology”?
* **(Humans)**
+ In [Redwood’s current project](https://www.alignmentforum.org/posts/k7oxdbNaGATZbtEg3/redwood-research-s-current-project) (which works on a simpler version of adversarial training), both adversary and overseer are replaced by humans: the adversary by the team members looking for injurious continuations, and the overseer by the labellers of training data.
+ In [Debate](https://arxiv.org/abs/1805.00899), the [most recent write-up](https://www.alignmentforum.org/posts/PJLABqQ962hZEqhdB/debate-update-obfuscated-arguments-problem#What_we_did) presents experiments where all models involved (judge and debaters) are replaced by humans.
* **(Hardcoded search to approximate the real model)**
+ In [Redwood’s current project](https://www.alignmentforum.org/posts/k7oxdbNaGATZbtEg3/redwood-research-s-current-project), the conservative policy is first implemented by [rejection sampling](https://en.wikipedia.org/wiki/Rejection_sampling) on the continuations generated by the fine-tuned model, based on the classifier output. So instead of directly training a model that “integrates” the classifier, they babble and prune using two distinct simpler models.
+ An example Buck gave me was a case where directly training the optimal policy was too hard, but training the value function and explicitly searching for decent actions according to the value function was possible (the difference comes from cases where the action space is so vast that searching for the optimal action with only the value function is intractable, which means that search would do worse than the optimal policy)
* **(Current ML models)**
+ In the [Debate paper](https://arxiv.org/pdf/1805.00899.pdf#subsection.3.1), they conduct an experiment where the debate is about classifying an image, the debaters (ML models) see the full picture but the judge (another ML model) only sees the pixels shown by the debaters during the debate.
* **(Other hard coded-tools)**
+ Buck gives the example of a technique where one component gives you a PDF of explanations about a given neuron, and replacing that by [saliency maps and other current interpretability techniques](https://distill.pub/2018/building-blocks/). Long term, you’d hope that we can defer the interpretability-tool-writing work to AIs, but for the moment alignment researchers have to do it themselves.
One reason I was confused initially when talking to Buck is that this simplification process often requires a simpler task too, because if we want to use our currently available models, we have to pick easier tasks that they’re definitely able to do. You can see this in [Redwood’s current project](https://www.alignmentforum.org/posts/k7oxdbNaGATZbtEg3/redwood-research-s-current-project), where the task “don’t produce injurious continuation” is just at the level where it’s not trivial for current Language Models but they can still do it. Or in [the first debate experiment with only ML models](https://arxiv.org/pdf/1805.00899.pdf#subsection.3.1), where they simplified the debate to being about image classification such that the debater models could handle the task. But remember that even if there is a task simplification aspect, the main analogy is with the technique.
A Different Kind of Knowledge
=============================
Now we have a simpler setting where we can actually run ML experiments and try to make the technique work. This is a neat trick, but why should it give us the sort of knowledge we care about? It’s not obvious that the result of such experiments tell us how to align an AI.
After all, they’re not solving the real problem with the real technology.
And yet this strategy can produce important and valuable knowledge: **telling us which are the difficulties in applying the technique, and helping us refine the easier parts.**
Let’s look at both in turn.
Finding the Difficulty
----------------------
Once you simplify the problem enough that lack of capabilities isn’t stopping you, **difficulties and issues tell you that even if you solve the parts you assumed away, there might be a core problem left.**
Again [the last debate experiment](https://www.alignmentforum.org/posts/PJLABqQ962hZEqhdB/debate-update-obfuscated-arguments-problem#What_we_did) is a good example: the researchers only use humans, and still they found a particularly nasty strategy for the dishonest debaters that the honest debater had trouble dealing with (see [this section](https://www.alignmentforum.org/posts/PJLABqQ962hZEqhdB/debate-update-obfuscated-arguments-problem#Basic_case_for_the_obfuscated_argument_problem) for a description). This tells them that such strategies (and the generalization of the mechanism underlying them) are a failure mode (or at least a tricky part) of the current debate protocol. They then attempted to change the protocol to disincentive this technique.
Now it’s easy to look at that, and feel that they’re not really showing anything or not addressing the problem because they’re dealing with only one failure mode out of many, and not even one that appears only at superintelligent levels. Indeed, even solving the problem found would not show that debate would be sufficient for alignment.
**But that’s not the point! The point is to build more familiarity with the technique and to get a grip on the hardest parts.** Sure, you don’t prove the safety that way, but you catch many problems, and maybe you can then show that the entire class of such problems can’t happen. This is not a proof of alignment, but it is a step for biting off a whole chunk of failure modes. And just like in any natural science, what the experiments find can give insights and ideas to the theoretical researcher which help them formulate stronger techniques.
Honing the Simple Parts
-----------------------
What if you actually solve the simplified task, though? Assuming that you did a non-trivial amount of work, you found out about a part that is not instantaneous but can be done with modern technology.
Here [Redwood’s own project](https://www.alignmentforum.org/posts/k7oxdbNaGATZbtEg3/redwood-research-s-current-project) provides a good example: they successfully trained the classifier, the babble-and-prune conservative policy, and the distilled version.
What does it buy them? Well, they know they can do that part. They also have built some expertise into how to do it, what are the tricky parts, and how far they expect their current methods to generalize. More generally, they built skills for implementing that part of the technique. And they can probably find faster implementations, or keep up to speed with ML developments by adapting this part of the solution.
**This is even less legible than the knowledge of the previous section, but still incredibly important: they honed part of the skills you need to implement that technique, as well as future variations on that technique.** The alignment problem won’t be solved if/when the conceptual researchers find a great working proposal, but if/when it is implemented first. Building up these skills is fundamental to having a pool of engineers and research scientists who can actually make the alignment proposal a reality, competitively enough to win the race if needs be.
Summary
=======
The epistemic strategy at hand here is thus the following:
* **Find a technique that looks promising for alignment, and can be expressed as an ML problem**
+ (Not included here)
* **Replace parts of the ML problem that can’t be solved with current technology**
**Possible options:**
+ Use humans
+ Use hard-coded search
+ Simplify the task and use current ML models
+ Use hard-coded program
* **Solve the simplified ML problem**
+ (Normal ML)
* **Extract the relevant knowledge**
+ If problem is unsolved, unearthed a difficult part
+ If problem is solved, unearthed a part to hone.
Breaking the Epistemic Strategy
===============================
I normally finish these posts by a section on breaking the presented epistemic strategy. Because knowing how the process of finding new knowledge could break tells us a lot about when the strategy should be applied.
Yet here… it’s hard to find a place where this strategy breaks? Maybe the choice of technique is bad, but I’m not covering this part here. If the simplification is either too hard or too simple, it still teaches us relevant knowledge, and the next iteration can correct for it.
Maybe the big difference with my previous example is that this strategy doesn’t build arguments. Instead it’s a process for learning more about the conceptual techniques concretely, and preparing ourselves to be able to implement them and related approaches as fast and efficiently as possible when needed. From that perspective, the process might not yield that much information in one iteration, but it generally gives enough insight to adapt the problem or suggest a different experiment.
The epistemic strategy presented here doesn’t act as a guarantee for an argument; instead it points towards a way of improving the skill of concretely aligning AIs, and building mastery in it. |
2953880e-43de-4d3c-b9d8-37dc9f78dcea | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | What do XPT forecasts tell us about AI timelines?
*This post was co-authored by the Forecasting Research Institute and Rose Hadshar. Thanks to Josh Rosenberg for managing this work, Zachary Jacobs and Molly Hickman for the underlying data analysis, Adam Kuzee and Bridget Williams for fact-checking and copy-editing, the whole FRI XPT team for all their work on this project, and our external reviewers.*
In 2022, the [Forecasting Research Institute](https://forecastingresearch.org/) (FRI) ran the Existential Risk Persuasion Tournament (XPT). Over the course of 4 months, 169 forecasters, including 80 superforecasters[[1]](#fnaxj7jy7w524) and 89 experts, forecasted on various questions related to existential and catastrophic risk. Forecasters moved through a four-stage deliberative process that was designed to incentivize them not only to make accurate predictions but also to provide persuasive rationales that boosted the predictive accuracy of others’ forecasts. Forecasters stopped updating their forecasts on 31st October 2022, and are not currently updating on an ongoing basis. FRI plans to run future iterations of the tournament, and open up the questions more broadly for other forecasters.
You can see the results from the tournament overall [here](https://static1.squarespace.com/static/635693acf15a3e2a14a56a4a/t/64abffe3f024747dd0e38d71/1688993798938/XPT.pdf).
Some of the questions in the XPT related to AI timelines. This post:
* Sets out the XPT [forecasts](https://forum.effectivealtruism.org/posts/KGGDduXSwZQTQJ9xc/what-do-xpt-forecasts-tell-us-about-ai-timelines#The_forecasts) on AI timelines, and puts them in [context](https://forum.effectivealtruism.org/posts/KGGDduXSwZQTQJ9xc/what-do-xpt-forecasts-tell-us-about-ai-timelines#The_forecasts_in_context).
* Lays out the [arguments](https://forum.effectivealtruism.org/posts/KGGDduXSwZQTQJ9xc/what-do-xpt-forecasts-tell-us-about-ai-timelines#The_arguments_made_by_XPT_forecasters) given in the XPT for and against these forecasts.
* Offers some [thoughts](https://forum.effectivealtruism.org/posts/KGGDduXSwZQTQJ9xc/what-do-xpt-forecasts-tell-us-about-ai-timelines#What_do_XPT_forecasts_tell_us_about_AI_timelines_) on what these forecasts and arguments show us about AI timelines.
**TL;DR**
=========
* **XPT superforecasters predict a 50% chance that advanced AI**[[2]](#fnt876c22h4wp) **exists** **by 2060.**
* **XPT superforecasters predict that very powerful AI by 2030 is very unlikely** (1% that Nick Bostrom affirms AGI by 2030; 3% that the compute required for TAI is attainable by 2030 (taking Ajeya Cotra’s biological anchors model as given, and using XPT superforecaster forecasts as some of the inputs)).
* **In the XPT postmortem survey, superforecasters predicted:**
+ **13% chance of AGI by 2070,** defined as “any scenario in which cheap AI systems are fully substitutable for human labor, or if AI systems power a comparably profound transformation (in economic terms or otherwise) as would be achieved in such a world.”
+ **3.8% chance of TAI by 2070,** defined as “any scenario in which global real GDP during a year exceeds 115% of the highest GDP reported in any full prior year.”
* It’s unclear how accurate these forecasts will prove, particularly as superforecasters have not been evaluated on this timeframe before.[[3]](#fn2w720vec38z)
The forecasts
=============
In the tables below, we present forecasts from the following groups:
* Superforecasters: median forecasts across superforecasters in the XPT.
* All experts: median forecasts across all experts in the XPT.
+ This includes AI domain experts, general x-risk experts, and experts in other fields like nuclear and biorisk. The sample size for AI domain experts is small, so we have included all experts for reference.
* Domain experts: AI domain experts only.
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| **Question** | **Forecasters** | **n**[[4]](#fnnlpp5c2uhs) | **2030** | **2050** | **2100** |
| [**Probability of Bostrom affirming AGI**](https://static1.squarespace.com/static/635693acf15a3e2a14a56a4a/t/64abffe3f024747dd0e38d71/1688993798938/XPT.pdf%23page%3D229) | **Superforecasters** | 27-32 | 1.0% | 20.5% | 74.8% |
| **All experts** | 12-15 | 3.0% | 45.5% | 85.0% |
| **Domain experts** | 5 | 9.0% | 46.0% | 87.0% |
| ***Compute required for TAI attainable\**** | ***[Inferred from some XPT superforecaster forecasts inputted into Cotra’s*** [***biological anchors model***](https://docs.google.com/document/d/1IJ6Sr-gPeXdSJugFulwIpvavc0atjHGM82QjIfUSBGQ/edit%23)***]*** | 31-32 | ~3% | ~20% | 61% |
*\* XPT questions can be used to infer some of the input forecasts to Ajeya Cotra’s* [*biological anchors model*](https://docs.google.com/document/d/1IJ6Sr-gPeXdSJugFulwIpvavc0atjHGM82QjIfUSBGQ/edit#)*, which we investigate*[*here*](https://forum.effectivealtruism.org/posts/ccw9v9giKxg8nyLhp/xpt-forecasts-on-some-biological-anchors-inputs)*. Note that for this analysis Cotra’s training computation requirements distribution is being held constant.*
| | | | |
| --- | --- | --- | --- |
| **Question** | **Forecasters** | **n**[[5]](#fnmq5gj34gq3) | **Year (90% confidence interval)** |
| [**Date of Advanced AI**](https://static1.squarespace.com/static/635693acf15a3e2a14a56a4a/t/64abffe3f024747dd0e38d71/1688993798938/XPT.pdf%23page%3D209)[[6]](#fntaf8nbgq3nj) | **Superforecasters** | **32-34** | 2060 (2035-2120) |
| **All experts** | **23-24** | 2046 (2029-2097) |
| **Domain experts** | **9** | 2046 (2029-2100) |
The forecasts in context
========================
There are various methods of estimating AI timelines:[[7]](#fna7zo5b7n82k)
* Surveying experts of various kinds, e.g. [Zhang et al., 2022](https://arxiv.org/pdf/2206.04132.pdf), [Grace et al., 2017](https://arxiv.org/pdf/1705.08807.pdf), [Gruetzemacher et al., 2018](https://arxiv.org/pdf/1901.08579.pdf)
* Doing in-depth investigations, e.g. [Cotra 2020](https://docs.google.com/document/d/1IJ6Sr-gPeXdSJugFulwIpvavc0atjHGM82QjIfUSBGQ/edit#)
* Making forecasts, e.g. Metaculus on [weak AGI](https://www.metaculus.com/questions/3479/date-weakly-general-ai-is-publicly-known/) and [strong AGI](https://www.metaculus.com/questions/5121/date-of-artificial-general-intelligence/), Samotsvety on [AGI](https://forum.effectivealtruism.org/posts/ByBBqwRXWqX5m9erL/update-to-samotsvety-agi-timelines)
The XPT forecasts are unusual among published forecasts in that:
* The forecasts were incentivized: for long-run questions, XPT used ‘reciprocal scoring’ rules to incentivize accurate forecasts (see [here](https://static1.squarespace.com/static/635693acf15a3e2a14a56a4a/t/64abffe3f024747dd0e38d71/1688993798938/XPT.pdf%23page%3D87) for details).
* Forecasts were solicited from superforecasters as well as experts.
* Forecasters were asked to write detailed rationales for their forecasts, and good rationales were incentivized through prizes.
* Forecasters worked on questions in a four-stage deliberative process in which they refined their individual forecasts and their rationales through collaboration with teams of other forecasters.
* The degree of convergence of beliefs over the course of the tournament is documented:
+ For “Date of Advanced AI” the standard deviation for the median estimates decreased by 38.44% over the course of the tournament for superforecasters and increased by 34.87% for the domain experts.
+ For “Nick Bostrom Affirms Existence of AGI,” the standard deviation for the median estimates decreased by 42.29% over the course of the tournament for superforecasters and increased by 206.99% for the domain experts.
Should we expect XPT forecasts to be more or less accurate than previous estimates? This is unclear, but some considerations are:
* Relative to many previous forecasts, XPT forecasters may have spent more time thinking and writing about their forecasts, and were incentivized to be accurate.
* XPT (and other) superforecasters have a history of superiorly accurate forecasts (primarily on short-range geopolitical and economic questions), and may be less subject to biases like groupthink than domain experts are.
+ On the other hand, there is limited evidence that superforecaster’s superior accuracy extends to technical domains like AI, long-range forecasts6, or out-of-distribution events.
Note that in the XPT, superforecasters and experts disagreed on most questions, with superforecasters making relatively lower estimates and experts relatively higher estimates. On AI-related questions, however, their degree of disagreement was the greatest.
Other timelines forecasts
-------------------------
| | | | |
| --- | --- | --- | --- |
| **Year** | **XPT superforecaster forecasts (as of 31st Oct 2022)** | ***[Inferred from some XPT super forecasts inputted into biological anchors model]*** | **Other relevant forecasts** |
| **Bostrom affirms AGI** | **Advanced AI** | ***Compute required for TAI***[[8]](#fne647ulbkzf)***attainable*** |
| 2030 | ~1% | - | ~3% | 2030: Cotra [compute required for TAI attainable (2020)](https://docs.google.com/document/d/1IJ6Sr-gPeXdSJugFulwIpvavc0atjHGM82QjIfUSBGQ/edit#): ~8% 2028: [Metaculus weak AGI](https://www.metaculus.com/questions/3479/date-weakly-general-ai-is-publicly-known/) 50%, as of 31st Oct 2022[[10]](#fn3uaa9u89yxt)2030: [Samotsvety AGI](https://forum.effectivealtruism.org/posts/ByBBqwRXWqX5m9erL/update-to-samotsvety-agi-timelines) 31%, as of 21st Jan 2023[[11]](#fnehlfyrpyqlr)2040: [Metaculus strong AGI](https://www.metaculus.com/questions/5121/date-of-artificial-general-intelligence/) 50%, as of 31st Oct 2022[[12]](#fnnngxcbx380l)2040: [Cotra 2022](https://www.lesswrong.com/posts/AfH2oPHCApdKicM4m/two-year-update-on-my-personal-ai-timelines): 50% TAI2043:* Future fund position 2022: 20% AGI
* Lower threshold for [Future Fund AI Worldview Prize](https://forum.effectivealtruism.org/posts/W7C5hwq7sjdpTdrQF/announcing-the-future-fund-s-ai-worldview-prize): 10%
* Upper threshold for [Future Fund AI Worldview Prize](https://forum.effectivealtruism.org/posts/W7C5hwq7sjdpTdrQF/announcing-the-future-fund-s-ai-worldview-prize): 45%
|
| 2050 | ~21% | - | ~20% | 2050: Cotra [compute required for TAI attainable (2020)](https://docs.google.com/document/d/1IJ6Sr-gPeXdSJugFulwIpvavc0atjHGM82QjIfUSBGQ/edit#): ~46% 2050: [Cotra 2020](https://docs.google.com/document/d/1IJ6Sr-gPeXdSJugFulwIpvavc0atjHGM82QjIfUSBGQ/edit#heading=h.x1lgibjdeh01): 50% TAI2050: [Samotsvety AGI](https://forum.effectivealtruism.org/posts/ByBBqwRXWqX5m9erL/update-to-samotsvety-agi-timelines) 63%, as of 21st Jan 2023[[13]](#fn5t47i9xn7p5) |
| 2060 | - | 50% | - | 2060: [Zhang et al, 2019](https://arxiv.org/pdf/2206.04132.pdf): 50% ~HLMI\*2061: [Grace et al, 2017](https://arxiv.org/pdf/1705.08807.pdf): 50% ~HLMI\*2068: [Gruetzemacher et al, 2018](https://arxiv.org/pdf/1901.08579.pdf): 50% ~HLMI\* |
| 2100 | ~75% | - | ~61% | 2100: Cotra [compute required for TAI attainable (2020)](https://docs.google.com/document/d/1IJ6Sr-gPeXdSJugFulwIpvavc0atjHGM82QjIfUSBGQ/edit): ~78% 2100: [Samotsvety AGI](https://forum.effectivealtruism.org/posts/ByBBqwRXWqX5m9erL/update-to-samotsvety-agi-timelines) 81%, as of 21st Jan 2023[[14]](#fnr0effqbakc)2100:* Future fund position 2022: 60% AGI
* Lower threshold for [Future Fund AI Worldview Prize](https://forum.effectivealtruism.org/posts/W7C5hwq7sjdpTdrQF/announcing-the-future-fund-s-ai-worldview-prize): 30%
|
\* *‘HLMI’ refers to ‘human-level machine intelligence.’*
Some notes on how different definitions of advanced AI relate:
* According to Cotra, her model of the probability that the compute required for TAI is attainable:
+ Overstates the probability of TAI in 2030.
+ Understates the probability of TAI in 2100.
+ Roughly matches the probability of TAI in 2050.[[15]](#fn1wbw23wln62)
* Human-level machine intelligence (HLMI) requires that AI systems outperform humans on all tasks; TAI could be achieved by AI systems which complement humans on some tasks.[[16]](#fnt8dfhhat8b)
* The criteria for the XPT advanced AI question are stronger than those for the Metaculus weak AGI question, and weaker than those for the Metaculus strong AGI question (the XPT question contains some but not all of the criteria for the Metaculus strong AGI question).
* Taking XPT superforecaster forecasts at face value implies that XPT superforecasters think that advanced AI is a lower bar than Bostrom’s AGI or TAI. The latter two appear similar from XPT superforecaster forecasts alone.
Cross-referencing with XPT’s postmortem survey
----------------------------------------------
Forecasters in the XPT were asked to fill in a postmortem survey at the end of the tournament. Some of the questions in this survey relate to AGI/TAI timelines, so we can use them as a cross-reference. Unlike the XPT, the postmortem survey was not incentivized and there was no collaboration between forecasters. The survey was administered in the months immediately following the conclusion of the XPT, from November 2022 to February 2023. It may be worth noting that the influential LLM ChatGPT was released on November 30, 2022.
Note that only a subset of XPT forecasters responded to the postmortem survey, so in the table below we compare the postmortem results with the XPT forecasts of only the subset of XPT forecasters who responded to the postmortem survey, for comparability. (This is why the XPT medians in this table differ from medians quoted in the rest of the post, which are based on all XPT forecasts.)
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| **Question** | **Forecasters** | **n**[[17]](#fn9ju4p3t09jm) | **2030** | **2050** | **2070** | **2100** |
| [**Probability of Bostrom affirming AGI**](https://static1.squarespace.com/static/635693acf15a3e2a14a56a4a/t/64abffe3f024747dd0e38d71/1688993798938/XPT.pdf%23page%3D229%26zoom%3D100,93,545) | **Superforecasters - XPT subset** | **26-31** | 1% | 21% | - | 74.9% |
| **All experts - XPT subset** | **12-14** | 3% | 45.5% | - | 86.0% |
| **Domain experts - XPT subset** | **5** | 9% | 46.0% | - | 87.0% |
| **Probability of AGI\* by 2070** | **Superforecasters - postmortem** | **78** | - | - | 13% | - |
| **All experts - postmortem** | **59** | - | - | 25% | - |
| **Domain experts - postmortem** | **23** | - | - | 20% | - |
| **Probability of TAI\*\* by 2070** | **Superforecasters - postmortem** | **78** | - | - | 3.8% | - |
| **All experts - postmortem** | **58** | - | - | 16% | |
| **Domain experts - postmortem** | **23** | - | - | 15% | - |
| ***[Inferred using superforecaster XPT subset forecasts in biological anchors model]*** | ***29-31*** | ~3% | ~20% | ~35% | ~60% |
| [**Probability of >15% GWP growth by 2100**](https://static1.squarespace.com/static/635693acf15a3e2a14a56a4a/t/64abffe3f024747dd0e38d71/1688993798938/XPT.pdf%23page%3D232%26zoom%3D100,93,545)**\*\*\*** | **Superforecasters - XPT subset** | **34** | - | - | - | 2.75% |
| **Superforecasters - postmortem** | **78** | - | - | - | 3% |
| **All experts - XPT subset** | **10** | - | - | - | 16.9% |
| **All experts - postmortem** | **58** | - | - | - | 10% |
| **Domain experts - XPT subset** | **5** | - | - | - | 25% |
| **Domain experts - postmortem** | **23** | - | - | - | 5% |
*\* “Artificial general intelligence is defined here as any scenario in which cheap AI systems are fully substitutable for human labor, or if AI systems power a comparably profound transformation (in economic terms or otherwise) as would be achieved in such a world.”*
*\*\* “Transformative AI is defined here as any scenario in which global real GDP during a year exceeds 115% of the highest GDP reported in any full prior year.”*
*\*\*\* The full question is “By 2100, will the global real GDP in a year ever exceed 115% of the highest GDP reported in any full prior year?” This question was asked in the XPT as well as the postmortem survey, and corresponds to the definition of TAI used in the postmortem survey.*
There was also a strongly disagree - strongly agree scale question in the postmortem survey, for the statement “AGI will arise within the next 50 years.” (This question was asked in 2022, so ‘within the next 50 years’ corresponds to ‘by the end of 2072’.) The results were:
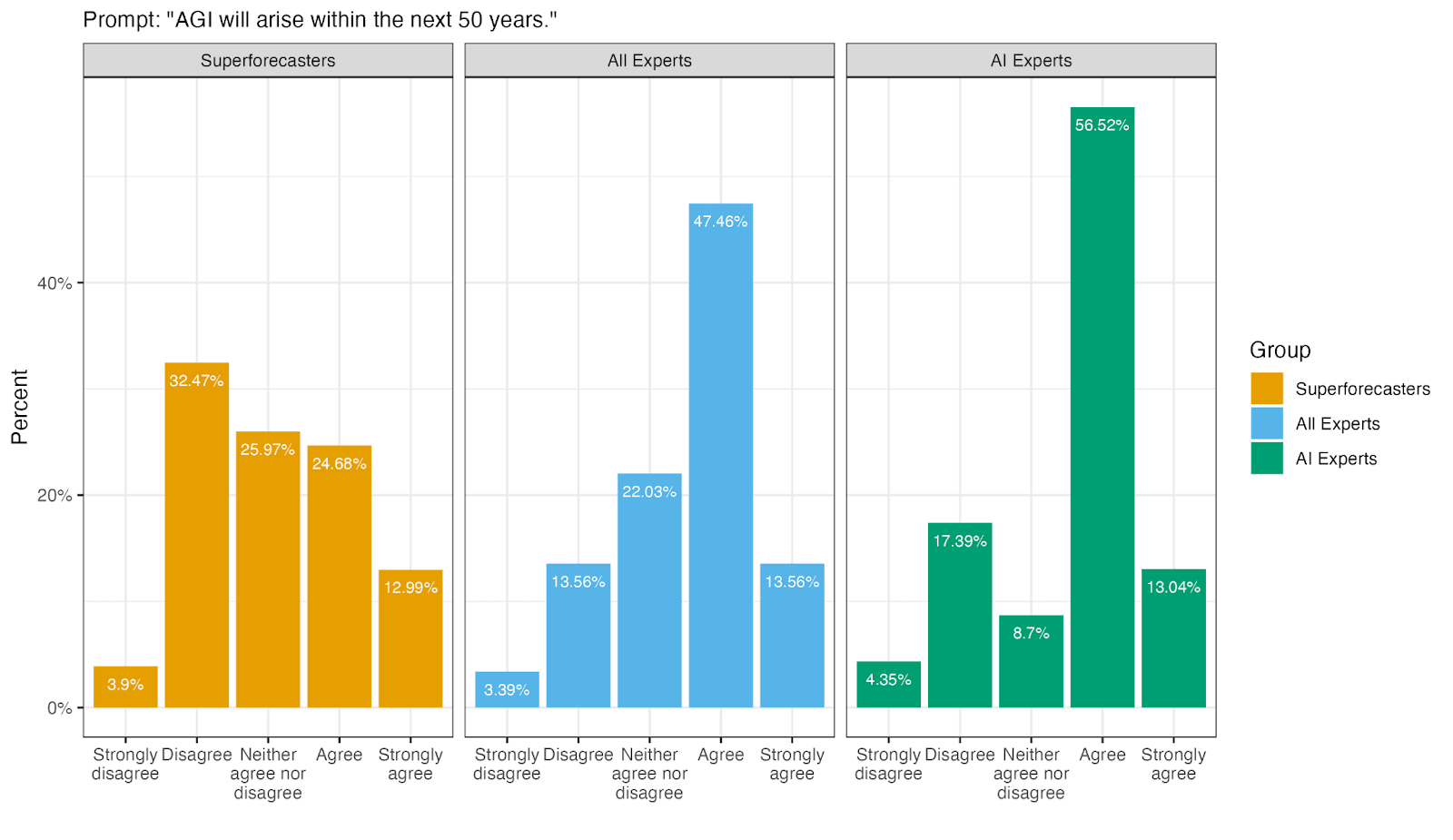
From these postmortem survey results, we can see that:
* **Forecasters' views appear inconsistent.**
+ ~26% of superforecasters predicted AGI by 2070 as 50% likely or more, but ~38% agree or strongly agree that AGI will arise by the end of 2072. ~36% of experts predicted AGI by 2070 as 50% likely or more, but ~61% agree or strongly agree that AGI will arise by the end of 2072.
+ Superforecasters predict a 3% chance of >15% growth by 2100,[[18]](#fnmr94k8aeiqq) and a 3.75% chance of TAI (defined as >15% growth) by 2070.
- The two expert groups were even less coherent: “All experts” predict a 10% chance of >15% growth by 2100,[[19]](#fnvr46j0u3nz) and a 16% chance of TAI by 2070, and “Domain Experts” predicted a 5% chance of >15% growth by 2100,[[20]](#fnbj8js10nzmt) and a 15% chance of TAI by 2070.
* **Forecasters gave longer timelines when directly asked to forecast AGI/TAI, than forecasts elicited more indirectly.**
+ Forecasters’ direct forecasts on AGI are much less aggressive than their XPT forecasts on Bostrom affirming AGI.
+ Forecasters’ direct forecasts on TAI are much less aggressive than the forecasts inferred by using XPT forecasts as inputs to Cotra’s biological anchors model**.**
- This is to be expected, as the modes depend on many other parameters and outputs using some XPT forecasts cannot be taken as a representation of XPT forecasters’ views. See [here](https://forum.effectivealtruism.org/posts/ccw9v9giKxg8nyLhp/xpt-forecasts-on-some-biological-anchors-inputs) for details of our analysis.
* **Forecasters view AGI/TAI as much further away than ‘advanced AI’.**
+ The subset of superforecasters who responded to the postmortem survey predicted advanced AI by 2060 in the XPT. Their postmortem survey results imply both AGI and especially TAI will arrive substantially later than 2070.
+ The same is true of experts in a less extreme form. (Both the subsets of all experts and domain experts who responded to the postmortem survey predicted advanced AI by 2046 in the XPT.)
* **Forecasters view TAI as a much higher bar than AGI,** as operationalized in the postmortem survey.
+ There are no XPT forecasts on TAI and AGI directly, so we can’t directly compare between these postmortem results and the XPT forecasts. XPT forecasts on the probability of Bostrom affirming AGI are in the same ballpark as the outputs of Cotra’s biological anchors model using XPT forecasts as inputs, but these operationalizations are sufficiently different from those in the postmortem survey that it’s hard to draw firm conclusions from this.
The arguments made by XPT forecasters
=====================================
XPT forecasters were grouped into teams. Each team was asked to write up a ‘rationale’ summarizing the main arguments that had been made during team discussions about the forecasts different team members made. The below summarizes the main arguments made across all teams in the XPT tournament. Footnotes contain direct quotes from team rationales.
See also the arguments made on questions which relate to the inputs to Cotra’s biological anchors model [here](https://forum.effectivealtruism.org/posts/ccw9v9giKxg8nyLhp/xpt-forecasts-on-some-biological-anchors-inputs#Appendix_A__Arguments_made_for_different_forecasts).
For shorter timelines
---------------------
* Recent progress is impressive.[[21]](#fn6ry436a62xs)
+ Counterargument: this anchors too much on the recent past and not enough on the longer view.[[22]](#fnuoqts4hflab)
* Scaling laws may hold.[[23]](#fnj6kypy4e2ob)
* External factors:
+ Wars may lead to AI arms races.[[24]](#fnehswz55kre)
* Advances in quantum computing or other novel technology may speed up AI development.[[25]](#fndtc3vps1nnc)
* Opinions of others:
+ Recent progress has been faster than predicted.[[26]](#fney3xuujfsf4)
+ Other forecasts have moved forward lately.[[27]](#fntagm3sf3i3)
+ People who’ve spent a lot of time thinking about timelines tend to have shorter timelines.[[28]](#fn5qse6m1kxek)
+ Teams cited [Cotra’s biological anchors report](https://docs.google.com/document/d/1IJ6Sr-gPeXdSJugFulwIpvavc0atjHGM82QjIfUSBGQ/edit)[[29]](#fn4febz7g0w6) and [Karnofsky’s forecasts](https://forum.effectivealtruism.org/posts/7JxsXYDuqnKMqa6Eq/ai-timelines-where-the-arguments-and-the-experts-stand%255C).[[30]](#fnqcu593aak9)
For longer timelines
--------------------
* Scaling laws may not hold, such that new breakthroughs are needed.[[31]](#fn5norugrhgsg)
+ There may be unforeseen blockers.[[32]](#fniabswrh2l2a)
+ Generalization is hard.[[33]](#fnkgxh1d1am0k)
- Counterargument: Gato generalizes impressively.[[34]](#fnadstnym494)
+ There may be diminishing marginal returns such that the last part is really hard.[[35]](#fnava226jq4l8)
+ There may be a training data bottleneck.[[36]](#fn4swss1zv3go)
+ Current trends may not be sustainable.[[37]](#fn1vkz9img1p2)
* External factors:
+ Wars may slow down AI development.[[38]](#fnm019ohnx77l)
+ There may be intentional slowdowns of AI development.[[39]](#fnr8hwvts6yp)
+ AI development may be interrupted by an extinction/catastrophe caused by other factors.[[40]](#fne457ewz3j3b)
+ Economic downturns may slow AI development.[[41]](#fngr8jj7ti2d)
+ There may be attacks on AI vulnerabilities.[[42]](#fncx2d98lij6)
* We may be in a simulation in which it is impossible for us to build AGI.[[43]](#fn91nl3r6395o)
* Opinions of others:
+ The forecasting track record on advanced AI is poor.[[44]](#fnnaj8ghj9qnl)
- Kurzweil and others have made incorrect predictions.[[45]](#fnrl86gddvz6l)
- Metaculus has an optimistic bias for its AI predictions.[[46]](#fn6emlrw6pacg)
What do XPT forecasts tell us about AI timelines?
=================================================
This is unclear:
* Which conclusions to draw from the XPT forecasts depends substantially on your priors on AI timelines to begin with, and your views on which groups of people’s forecasts on these topics you expect to be most accurate.
* There are many uncertainties around how accurate to expect these forecasts to be:
+ Forecasters' views appear inconsistent.
+ There is limited evidence on how accurate long-range forecasts are.[[47]](#fnv1d14d122ug)
+ There is limited evidence on whether superforecasters or experts are likely to be more accurate in this context.
That said, there are some things to note about the XPT results on AI timelines:
* These are the first incentivized forecasts from superforecasters on AI timelines.
* **XPT superforecasters have longer timelines than Metaculus.**
+ At the time the XPT closed, Metaculus was predicting advanced AI between 2028 and 2040; XPT superforecasters were predicting 2060.
* **Forecasts from XPT superforecasters imply longer timelines than Cotra and than ML experts**, under certain assumptions.
+ Using median XPT superforecaster forecasts for some of the inputs to Cotra’s biological anchors model implies:
- ~20% chance that the compute required to train a transformative model is attainable by 2050, compared with Cotra’s ~46%.
- Median TAI timelines of ~2080, compared with Cotra’s most recent median of 2040.
+ Assuming that human-level machine intelligence is a higher bar than TAI, such that HLMI timelines will be longer than TAI timelines,[[48]](#fn226yg7b2jtl) XPT forecasts imply median HLMI timelines of >2080. Various surveys of ML experts have median HLMI timelines of between 2060 and 2068.[[49]](#fn0irxt4vsbez)
* **Explicit superforecaster forecasts on TAI and AGI from the postmortem survey give even longer timelines.**
+ 13% chance of AGI by 2070.
+ 3.8% chance of TAI by 2070.
* **XPT superforecasters put very little probability on advanced AI by 2030.**
+ 1% that Bostrom affirms AGI by 2030.
+ ~3% chance that the compute required for TAI is attainable by 2030, when XPT forecasts are used as some of the inputs to Cotra’s model.
1. **[^](#fnrefaxj7jy7w524)** By superforecasters, we mean seasoned forecasters with a track record of predictive accuracy on shorter-run questions in forecasting tournaments held by the Good Judgment Project.
2. **[^](#fnreft876c22h4wp)** Full question text (with details on criteria [here](https://static1.squarespace.com/static/635693acf15a3e2a14a56a4a/t/64abffe3f024747dd0e38d71/1688993798938/XPT.pdf%23page%3D209)):
*When will the first unified AI system meeting all of the following criteria be trained, tested, and publicly known of?*
*1. Able to reliably pass a 2-hour adversarial Turing test.*
*2. High competency at answering questions across diverse fields of expertise.*
*3. High competency on interview-level problems in the APPS benchmark.*
*4. Able to learn the classic Atari game “Montezuma’s revenge” in the equivalent of 100 hours or less of real-time play.*
3. **[^](#fnref2w720vec38z)** See [here](https://www.openphilanthropy.org/research/how-feasible-is-long-range-forecasting/) for a discussion of the feasibility of long-range forecasting.
4. **[^](#fnrefnlpp5c2uhs)** Here n is a range because different numbers of forecasters provided forecasts for different resolution years and different questions.
5. **[^](#fnrefmq5gj34gq3)** Here n is a range because different numbers of forecasters provided 5th, 50th and 95th percentile forecasts.
6. **[^](#fnreftaf8nbgq3nj)** Full question text (with details on criteria [here](https://static1.squarespace.com/static/635693acf15a3e2a14a56a4a/t/64abffe3f024747dd0e38d71/1688993798938/XPT.pdf%23page%3D209)):
When will the first unified AI system meeting all of the following criteria be trained, tested, and publicly known of?
- Able to reliably pass a 2-hour adversarial Turing test.
- High competency at answering questions across diverse fields of expertise.
- High competency on interview-level problems in the APPS benchmark.
- Able to learn the classic Atari game “Montezuma’s revenge” in the equivalent of 100 hours or less of real-time play.
7. **[^](#fnrefa7zo5b7n82k)** For a recent overview of AI timelines estimates, see [here](https://ourworldindata.org/ai-timelines).
8. **[^](#fnrefe647ulbkzf)** Transformative AI: ““software” -- a computer program or collection of computer programs -- that has at least as profound an impact on the world’s trajectory as the [Industrial Revolution](http://lukemuehlhauser.com/industrial-revolution/) did”.[Pp. 1-2](https://docs.google.com/document/d/1IJ6Sr-gPeXdSJugFulwIpvavc0atjHGM82QjIfUSBGQ/edit)
9. **[^](#fnreft987qb3s2n8)** “[T]he date at which AI models will achieve human level performance on a transformative task.” <https://epochai.org/blog/direct-approach-interactive-model>
10. **[^](#fnref3uaa9u89yxt)** The date when the XPT forecasters stopped updating their forecasts.
11. **[^](#fnrefehlfyrpyqlr)** “The moment that a system capable of passing the adversarial Turing test against a top-5%[1] human who has access to experts on various topics is developed.” See [here](https://forum.effectivealtruism.org/posts/ByBBqwRXWqX5m9erL/update-to-samotsvety-agi-timelines%23Definition_of_AGI) for more details.
12. **[^](#fnrefnngxcbx380l)** The date when the XPT forecasters stopped updating their forecasts.
13. **[^](#fnref5t47i9xn7p5)** “The moment that a system capable of passing the adversarial Turing test against a top-5%[1] human who has access to experts on various topics is developed.” See [here](https://forum.effectivealtruism.org/posts/ByBBqwRXWqX5m9erL/update-to-samotsvety-agi-timelines%23Definition_of_AGI) for more details.
14. **[^](#fnrefr0effqbakc)** “The moment that a system capable of passing the adversarial Turing test against a top-5%[1] human who has access to experts on various topics is developed.” See [here](https://forum.effectivealtruism.org/posts/ByBBqwRXWqX5m9erL/update-to-samotsvety-agi-timelines) for more details.
15. **[^](#fnref1wbw23wln62)** “How does the probability distribution output by this model relate to TAI timelines? In the very short-term (e.g. 2025), I’d expect this model to overestimate the probability of TAI because it feels especially likely that other elements such as datasets or robustness testing or regulatory compliance will be a bottleneck even if the raw compute is technically affordable, given that a few years is not a lot of time to build up key infrastructure. In the long-term (e.g. 2075), I’d expect it to underestimate the probability of TAI, because it feels especially likely that we would have found an entirely different path to TAI by then. In the medium-term, e.g. 10-50 years from now, I feel unsure which of these two effects would dominate, so I am inclined to use the output of this model as a rough estimate of TAI timelines within that range.” [p. 18](https://docs.google.com/document/d/1IJ6Sr-gPeXdSJugFulwIpvavc0atjHGM82QjIfUSBGQ/edit)
16. **[^](#fnreft8dfhhat8b)** In her biological anchors report, Cotra notes that “The main forecasting target researchers were asked about in [the [Grace et al. 2017](https://arxiv.org/pdf/1705.08807.pdf)] survey was “high-level machine intelligence”, defined as the time when “when unaided machines can accomplish every task better and more cheaply than human workers.” This is a stronger condition than transformative AI, which can be achieved by machines which merely complement human workers.” [p. 39](https://docs.google.com/document/d/1IJ6Sr-gPeXdSJugFulwIpvavc0atjHGM82QjIfUSBGQ/edit)
17. **[^](#fnref9ju4p3t09jm)** N is sometimes a range here because different numbers of forecasters provided forecasts for different resolution years.
18. **[^](#fnrefmr94k8aeiqq)** The probability of >15% growth by 2100 was asked about in both the main component of the XPT and the postmortem survey. The results here are from the postmortem survey. The superforecaster median estimate for this question in the main component of the XPT was 2.75% (for all superforecaster participants and the subset that completed the postmortem survey).
19. **[^](#fnrefvr46j0u3nz)** The probability of >15% growth by 2100 was asked about in both the main component of the XPT and the postmortem survey. The results here are from the postmortem survey. The experts median estimate for this question in the main component of the XPT was 19% for all expert participants and 16.9% for the subset that completed the postmortem survey.
20. **[^](#fnrefbj8js10nzmt)** The probability of >15% growth by 2100 was asked about in both the main component of the XPT and the postmortem survey. The results here are from the postmortem survey. The experts median estimate for this question in the main component of the XPT was 19% for all expert participants and 16.9% for the subset that completed the postmortem survey.
21. **[^](#fnref6ry436a62xs)** Question 3: 339, “Forecasters assigning higher probabilities to AI catastrophic risk highlight the rapid development of AI in the past decade(s).” 337, “some forecasters focused more on the rate of improvement in data processing over the previous 78 years than AGI and posit that, if we even achieve a fraction of this in future development, we would be at far higher levels of processing power in just a couple decades.”
Question 4: 339, “AI research and development has been massively successful over the past several decades, and there are no clear signs of it slowing down anytime soon.”
Question 44: 344, “Justifications for the possibility of near AGI include the impressive state of the art in language models.” 336, “General rapid progress in all fields of computing and AI, like bigger models, more complex algorithms, faster hardware.”
Question 51: 341, “In the last five years, the field of AI has made major progress in almost all its standard sub-areas, including vision, speech recognition and generation, natural language processing (understanding and generation), image and video generation, multi-agent systems, planning, decision-making, and integration of vision and motor control for robotics. In addition, breakthrough applications emerged in a variety of domains including games, medical diagnosis, logistics systems, autonomous driving, language translation, and interactive personal assistance.
AI progress has been quick in specific domains.
Language systems are developing the capability to learn with increasing resources and model parameters. Neural network models such as GPT learn about how words are used in context, and can generate human-like text, including poems and fiction.
Image processing technology has also made huge progress for self-driving cars and facial recognition, and even generating realistic images.
Agile robots are being developed using deep-learning and improved vision.
Tools now exist for medical diagnosis.
Deep-learning models partially automate lending decisions and credit scoring.” See also 336, “There's no doubt among forecasters that Machine Learning and Artificial Intelligence have developed tremendously and will continue to do so in the foreseeable future.”
22. **[^](#fnrefuoqts4hflab)** Question 44: 341, “A few forecasters have very short AI timelines (within a decade on their median forecast) based on recent trends in AI research and the impressive models released in the last year or two. Other team members have longer timelines. The main difference seems to be projecting from very recent trends compared to taking the long view. In the recent trends projection forecasters are expecting significant growth in AI development based on some of the impressive models released in the past year or two, while the opposite long view notes that the concept of AI has been around for ~75 years with many optimistic predictions in that time period that failed to account for potential challenges.”
23. **[^](#fnrefj6kypy4e2ob)** Question 3: 336, “the probabilities of continuing exponential growth in computing power over the next century as things like quantum computers are developed, and the inherent uncertainty with exponential growth curves in new technologies.”
Question 44: 343, “The scaling hypothesis says that no further theoretical breakthroughs are needed to build AGI. It has recently gained in popularity, making short timelines appear more credible.”
Question 51: 336, “The majority of our team might drastically underestimate the near-future advances of AI. It is likely that there are architectural/algorithmic bottlenecks that cannot (efficiently/practically) be overcome by compute and data scale, but that leaves a fair amount of probability for the alternative. Not all bottlenecks need to be overcome for this question to resolve with a 'yes' somewhere this century.”
24. **[^](#fnrefehswz55kre)** Question 51: 339, “wars might have erupted halting progress - but this reasoning could also be used for accelerating development (arms race dynamics)”.
25. **[^](#fnrefdtc3vps1nnc)** Question 4: 336, “The most plausible forecasts on the higher end of our team related to the probabilities of continuing exponential growth in computing power over the next century as things like quantum computers are developed, and the inherent uncertainty with exponential growth curves in new technologies.”
Question 45: 336, “Advances in quantum computing might radically shift the computational power available for training.”
Question 51: 341, “Also, "quantum computing made significant inroads in 2020, including the[Jiuzhang computer’s achievement of quantum supremacy](https://www.technologyreview.com/2021/01/14/1016122/these-five-ai-developments-will-shape-2021-and-beyond/). This carries significance for AI, since quantum computing has the potential to supercharge AI applications".
26. **[^](#fnrefey3xuujfsf4)** Question 3: 343, “Most experts expect AGI within the next 1-3 decades, and current progress in domain-level AI is often ahead of expert predictions”; though also “Domain-specific AI has been progressing rapidly - much more rapidly than many expert predictions. However, domain-specific AI is not the same as AGI.” 340, “Perhaps the strongest argument for why the trend of Sevilla et al. could be expected to continue to 2030 and beyond is some discontinuity in the cost of AI training compute precipitated by a novel technology such as optical neural networks.”
Question 44: 343, “Recent track record of ML research of reaching milestones faster than expected
Development in advanced computer algorithms and/or AI research has a strong history of defining what seem to be impossible tasks, and then achieving those tasks within a decade or two. Something similar may well happen with this prompt, i.e. researchers may build a system capable of achieving these goals, which are broader than ones already reached, as early as in the late 2020s or early 2030s. Significant gains in AI research have been accelerating recently, so these estimates may be low if we're on the cusp of exponential growth in AI capabilities.” See also 341, “Another argument for shorter AI timelines is the recent trend in AI development. If improvements to language models increase at the rate they have recently, such as between GPT-2, GPT-3, and the rumored upcoming advances of GPT-4, then we might expect that the Turing test requirement could be accomplished within a decade. Additionally, recently developed generalist models such as[Gato](https://www.deepmind.com/publications/a-generalist-agent), along with other new models, have surprised many observers, including the Metaculus community. The Metaculus "Weak AGI" question median[has moved 6 years closer this year](https://forum.effectivealtruism.org/posts/nkwN4M6BcBmThoG7p/6-year-decrease-of-metaculus-agi-prediction).”
Question 51: 341, “Both the text creating models and the image generating models are achieving results that are more impressive than most had imagined at this stage.” Incorrectly tagged as an argument for lower forecasts.
27. **[^](#fnreftagm3sf3i3)** Question 51: 341, “Ajeya Cotra, who wrote the biological anchors report from OpenPhil, recently published a follow up post saying that she had moved her timelines forward, to closer to now.
The forecasts for AGI on Metaculus have all moved nearer to our time recently as we have seen the string of astounding AI models, including GPT-3, LaMDA, Dall-E 2 and Stable Diffusion…Metaculus has[human parity by 2040](https://www.metaculus.com/questions/384/humanmachine-intelligence-parity-by-2040/) at 60% and[AGI by 2042](https://www.metaculus.com/questions/5121/date-of-artificial-general-intelligence/). The latter has dropped by 15 years in recent months with the advent of all the recent new models…[AI Impacts survey on timelines](https://aiimpacts.org/2022-expert-survey-on-progress-in-ai/) has a median with HLMI (Human Level Machine Intelligence) in 37 years, i.e. 2059**.** That timeline has become about eight years shorter in the six years since 2016, when the aggregate prediction put 50% probability at 2061, i.e. 45 years out.”
28. **[^](#fnref5qse6m1kxek)** Question 44: 341, “One of the stronger arguments for forecasts on the lower end are the forecasts from those with expertise who have made predictions, such as Ajeya Cotra and Ray Kurzweil, as well as the Metaculus community prediction. Cotra and Kurzweil have spent a lot of time thinking and studying this topic and come to those conclusions, and the Metaculus community has a solid track record of accuracy. In the absence of strong arguments to the contrary it may be wise to defer somewhat to those who have put a lot of thought and research into the question.”
29. **[^](#fnref4febz7g0w6)** Question 51: 341, “Ajeya Cotra, who wrote the biological anchors report from OpenPhil, recently published a follow up post saying that she had moved her timelines forward, to closer to now.”
Question 44: 341, “One of the stronger arguments for forecasts on the lower end are the forecasts from those with expertise who have made predictions, such as Ajeya Cotra and Ray Kurzweil, as well as the Metaculus community prediction. Cotra and Kurzweil have spent a lot of time thinking and studying this topic and come to those conclusions, and the Metaculus community has a solid track record of accuracy. In the absence of strong arguments to the contrary it may be wise to defer somewhat to those who have put a lot of thought and research into the question.”
30. **[^](#fnrefqcu593aak9)** Question 51: 341, “[Karnofsky](https://forum.effectivealtruism.org/posts/7JxsXYDuqnKMqa6Eq/ai-timelines-where-the-arguments-and-the-experts-stand) says >10% by 2036, ~50% by 2060, 67% by 2100. These are very thoughtful numbers, as his summary uses several different approaches. He has experts as 20% by 2036, 50% by 2060 and 70% by 2100, biological anchors >10% by 2036, ~50% by 2055, 80% by 2100, and semi-informative priors at 8% by 2036, 13% by 2060, 20% by 2100”. Incorrectly tagged as an argument for lower forecasts.
31. **[^](#fnref5norugrhgsg)**Question 51: 336, “Not everyone agrees that the 'computational' method (adding hardware, refining algorithms, improving AI models) will in itself be enough to create AGI or something sufficiently similar. They expect it to be a lot more complicated (though not impossible). In that case, it will require a lot more research, and not only in the field of computing.” See also 340, “The current path does not necessarily lead to AGI by just adding more computational power.”
Question 3: 341, “there are many experts arguing that we will not get to AGI with current methods (scaling up deep learning models), but rather some other fundamental breakthrough is necessary.” See also 342, “While recent AI progress has been rapid, some experts argue that current paradigms (deep learning in general and transformers in particular) have fundamental limitations that cannot be solved with scaling compute or data or through relatively easy algorithmic improvements.” See also 337, "The current AI research is a dead end for AGI. Something better than deep learning will be needed." See also 341, “Some team members think that the development of AI requires a greater understanding of human mental processes and greater advances in mapping these functions.”
Question 4: 336, “Not everyone agrees that the 'computational' method (adding hardware, refining algorithms, improving AI models) will in itself be enough to create AGI and expect it to be a lot more complicated (though not impossible). In that case, it will require a lot more research, and not only in the field of computing.” 341, “An argument for a lower forecast is that a catastrophe at this magnitude would likely only occur if we have AGI rather than say today's level AI, and there are many experts arguing that we will not get to AGI with current methods (scaling up deep learning models), but rather some other fundamental breakthrough is necessary.” See also 342, “While recent AI progress has been rapid, some experts argue that current paradigms (deep learning in general and transformers in particular) have fundamental limitations that cannot be solved with scaling compute or data or through relatively easy algorithmic improvements.” See also 340, “Achieving Strong or General AI will require at least one and probably a few paradigm-shifts in this and related fields. Predicting when a scientific breakthrough will occur is extremely difficult.”
Question 44: 338, “The current pace of progress may falter if this kind of general task solving can not be achieved by just continuing to upscale existing systems.” 344, “Justifications for longer timelines include the possibility of unforeseen issues with the development of the technology, events that could interrupt human progress, and the potential that this achievement will require significant algorithmic breakthroughs.”
32. **[^](#fnrefiabswrh2l2a)** Question 44: 344, “Justifications for longer timelines include the possibility of unforeseen issues with the development of the technology, events that could interrupt human progress, and the potential that this achievement will require significant algorithmic breakthroughs.” See also 343, “The biological anchors method assumes that no major further bottlenecks are lurking”; “Previous ML paradigms expanded capabilities dramatically with the advent of new tools/paradigms, only to run up against the limits of what that paradigm was capable of accomplishing. Simple trendline extension masks this effect. So long as we are in the exponential growth phase of a sigmoid curve, it's impossible to determine where the inflection point will be.”
Question 51: 343, “Perhaps X-Risks, slow scientific progress, or the unknown theoretical impossibilities in the way of AGI creation or Nick Bostrom Convincing might prove such an event highly unlikely over the long term.”
33. **[^](#fnrefkgxh1d1am0k)** Question 44: 341, “Due to the challenging level of individual tasks, forecasters also expect generalizing to being able to accomplish multiple tasks at the required capability will be very difficult”; “Some teammates expect that while AI may advance in individual tasks, generalizing may be much more difficult than expected. So far most advancements in AI models have been based on using large amounts of training data with large amounts of parameters, but it may require more computing power and more data than will exist based on current trends in order to create powerful models that are both talented in one specific field but also generalize to other fields.” See also 343, “Narayanan and Kapoor ([Why are deep learning technologists so overconfident? (substack.com)](https://aisnakeoil.substack.com/p/why-are-deep-learning-technologists)) are on a mission to convince people that current expectations are often too aggressive and that even the best contemporary systems are still highly specialized. An adversarial Turing test would presumably detect failure of generality.” See also 336, “It´s four different capabilities in one single system required for resolution as "yes". With probably nobody going for having exactly these four in the portfolio (and nothing else), we might need to wait for a superior system, that can do much more, with these 4 requirements only as a byproduct. If that is the case, it seems plausible that proving it can win a game of Montezuma's revenge might not be top priority.” See also 338, “Some of the criteria seemed more likely to met sooner, in particular 2 and 3. However, the cumulative resolution of all the criteria is much more challenging and rendered the question more difficult. Another possible source of uncertainty is whether AI researchers in the future will choose to work on those problems due to funding or academic trends. For example, if AI researchers choose another game instead of Montezuma's revenge then this question may not resolve.”
34. **[^](#fnrefadstnym494)** Question 44: 336, “Deepmind's Gato has already shown that unified AI on diverse tasks is possible.”
35. **[^](#fnrefava226jq4l8)** Question 44: 343, “One phenomenon we've observed in, e.g. driverless cars, is that the first ~90% of the problem takes about 10% of the work, with diminishing returns per unit of work the closer you get to 100%. The prompt wouldn't necessarily require 100% on each of these tests, but it might be close enough that a conventional approach to forecasting may fail to capture the amount of work required at the tail end of the project.” 337, “From the application of machine learning to the specific domain of material science [7], a possible conclusion is that a lot of recent progress can be classified as proof of concept or as low-hanging fruit. Provided this can be extrapolated to other fields, a slowdown is to be expected.” The reference cited is <https://www.nature.com/articles/s41524-022-00734-6>.
Question 51: 343, “Sclmlw belief is that we'll see AI competently surpassing human-level abilities in a number of areas long before we get to the full vision of what we think of when we talk about AGI, and that the last 5% of the problem will be much more difficult than the first 95% of the problem.” Sclmlw is a forecaster in team 343.
36. **[^](#fnref4swss1zv3go)** Question 51: 341, “For most problems there won't be training data, most human behavior is not yet digitized.” See also 340, “The tasks it completes are great, but only conducted in areas where there are large data sets of reliable information and correlations can be drawn.”
37. **[^](#fnref1vkz9img1p2)** Question 46 on compute spending: 341, “The AI impacts note also states that the trend would only be sustainable for a few more years. 5-6 years from 2018, i.e. 2023-24, we would be at $200bn, where we are already past the total budgets for even the biggest companies.”
Question 45 on maximum compute: 338, “Some predictors, instead of modeling compute spending and compute price separately, directly projected compute doubling times into the future. This implicitly assumes the fast spending increase from the recent past will continue. However, such an increase would become increasingly unsustainable over time.”
38. **[^](#fnrefm019ohnx77l)** Question 51: 339, “wars might have erupted halting progress - but this reasoning could also be used for accelerating development (arms race dynamics)”.
39. **[^](#fnrefr8hwvts6yp)** Question 45: 336, “Possible legislation or pushback against AI if fears mount about possible threat to humanity.”
Question 44: 344, “The possibility of limiting the intentionally slowing down progress is also taken into consideration as a factor for a later emergence”.
40. **[^](#fnrefe457ewz3j3b)** Question 44: 338, “The high end forecast is that the goal is never achieved. The justification is that at long dates the likelihood of human extinction is above 5% so advanced AI development is not achieved”. See also 343, “An existential catastrophe might cut short the advance of science. Theoretically, an AGI could cause radical changes to happen (including, but not limited to, the extinction of humanity) that make it impossible for the tests mentioned in the prompt to be performed.”
Question 51: 343, “Perhaps X-Risks, slow scientific progress, or the unknown theoretical impossibilities in the way of AGI creation or Nick Bostrom Convincing might prove such an event highly unlikely over the long term.” See also 344, “The most likely way for this to not resolve positively by 2050 or later is if there is some non-AI catastrophe of enough magnitude that it set backs humankind by years or decades.” Given in an argument for forecasts of 55% (2030), 100% (2050) and 100% (2100).
41. **[^](#fnrefgr8jj7ti2d)** Question 51: 343, “Perhaps X-Risks, slow scientific progress, or the unknown theoretical impossibilities in the way of AGI creation or Nick Bostrom Convincing might prove such an event highly unlikely over the long term.”
42. **[^](#fnrefcx2d98lij6)** Question 3: 341, “Both evolutionary theory and the history of attacks on computer systems imply that the development of AGI will be slowed and perhaps at times reversed due to its many vulnerabilities, including ones novel to AI.” “Those almost certain to someday attack AI and especially AGI systems include nation states, protesters (hackers,[Butlerian Jihad](https://dune.fandom.com/wiki/Butlerian_Jihad)?),[crypto miners hungry for FLOPS](https://www.paymentsjournal.com/criminal-crypto-miners-are-stealing-your-cpu/), and indeed criminals of all stripes. We even could see AGI systems attacking each other.” “These unique vulnerabilities include:
[poisoning the indescribably vast data inputs required](https://www.darpa.mil/program/guaranteeing-ai-robustness-against-deception); already demonstrated with[image classification, reinforcement learning, speech recognition, and natural language processing.](https://arxiv.org/abs/1809.02444)
war or sabotage in the case of an AGI located in a server farm
[latency of self-defense detection and remediation operations if distributed (cloud etc.)](https://www.cisco.com/c/en/us/solutions/data-center/data-center-networking/what-is-low-latency.html)”
Question 4: 341. See above.
43. **[^](#fnref91nl3r6395o)** Question 51: 336, “An -indirect- argument from Bostrom himself: We might be living in a simulation, possibly set up and directed by AI. That system might want to block us from achieving 'full' AI.”
44. **[^](#fnrefnaj8ghj9qnl)** Question 4: 337, “The optimists tend to be less certain that AI will develop as quickly as the pessimists think likely and indeed question if it will reach the AGI stage at all. They point out that AI development has missed forecast attainment points before”. 336, “There have been previous bold claims on impending AGI (Kurzweil for example) that didn't pan out.” See also 340, “The prediction track record of AI experts and enthusiasts have erred on the side of extreme optimism and should be taken with a grain of salt, as should all expert forecasts.” See also 342, “given the extreme uncertainty in the field and lack of real experts, we should put less weight on those who argue for AGI happening sooner. Relatedly, Chris Fong and SnapDragon argue that we should not put large weight on the current views of Eliezer Yudkowsky, arguing that he is extremely confident, makes unsubstantiated claims and has a track record of incorrect predictions.”
Question 51: 337, “Yet, taking into account that more often than not predictions of the future tend to be wildly optimistic, the probabilities at the lower end are probably worth taking into consideration.” Given as an argument for forecasts of close to 0% (2030), 15-40% (2050) and the order of 70% (2100). 336, “There have been previous bold claims on impending AGI (Kurzweil for example) that didn't pan out.”
45. **[^](#fnrefrl86gddvz6l)** Question 44: 341, “Forecasters also note the optimism that experts in a field typically have with regard to the rapidity of developments.” See also 337, “Past predictions about present technology have been in general excessively optimistic with regards to the pace of progress, though it should be stressed that this is not always the case. In particular, AI predictions seem to have fallen on the optimistic side. Good examples are previous predictions about AI [4] and past Kurzweil's predictions for the year 2019 [5].” The references cited are [https://en.wikipedia.org/wiki/Progress\_in\_artificial\_intelligence#Past\_and\_current\_predictions](https://en.wikipedia.org/wiki/Progress_in_artificial_intelligence%23Past_and_current_predictions) and [https://web.archive.org/web/20100421224141/http://en.wikipedia.org/wiki/The\_Age\_of\_Spiritual\_Machines#2019](https://web.archive.org/web/20100421224141/http://en.wikipedia.org/wiki/The_Age_of_Spiritual_Machines%232019).
46. **[^](#fnref6emlrw6pacg)** Question 44: 341, “The question being considered would be easier to accomplish than the Metaculus "AGI" question which is currently at a median of 2043, so we can expect that Metaculus would assign a sooner date for the question being considered. However, the team likely believes the Metaculus community is underestimating the difficulty involved in an AI generalizing to accomplish several tasks of which it has not yet accomplished nearly any of the tasks and still seems years or even a decade or two away from the more challenging of these.” See also 337, “It has been argued [6] that Metaculus has also an optimistic bias for their technological predictions.” The reference cited is [https://forum.effectivealtruism.org/posts/vtiyjgKDA3bpK9E4i/an-examination-of-metaculus-resolved-ai-predictions-and#](https://forum.effectivealtruism.org/posts/vtiyjgKDA3bpK9E4i/an-examination-of-metaculus-resolved-ai-predictions-and%23).
47. **[^](#fnrefv1d14d122ug)** See [this article](https://www.openphilanthropy.org/research/how-feasible-is-long-range-forecasting/) for more details.
48. **[^](#fnref226yg7b2jtl)** “The main forecasting target researchers were asked about in this survey was “high-level machine intelligence”, defined as the time when “when unaided machines can accomplish every task better and more cheaply than human workers.” This is a stronger condition than transformative AI, which can be achieved by machines which merely complement human workers”.
49. **[^](#fnref0irxt4vsbez)** 2060: [Zhang et al, 2019](https://arxiv.org/pdf/2206.04132.pdf): 50% ~HLMI. 2061: [Grace et al, 2017](https://arxiv.org/pdf/1705.https://arxiv.org/pdf/1705.08807.pdf08807.pdf): 50% ~HLMI. 2068: [Gruetzemacher et al, 2018](https://arxiv.org/pdf/1901.08579.pdf): 50% ~HLMI |
e663f87e-3a60-4ac2-9bd8-1f73862578db | trentmkelly/LessWrong-43k | LessWrong | Host Keys and SSHing to EC2
I do a lot of work on EC2, where I ssh into a few instances I use for specific purposes. Each time I did this I'd get a prompt like:
$ ssh_ec2nf
The authenticity of host 'ec2-54-224-39-217.compute-1.amazonaws.com
(54.224.39.217)' can't be established.
ED25519 key fingerprint is SHA256:...
This host key is known by the following other names/addresses:
~/.ssh/known_hosts:591: ec2-18-208-226-191.compute-1.amazonaws.com
~/.ssh/known_hosts:594: ec2-54-162-24-54.compute-1.amazonaws.com
~/.ssh/known_hosts:595: ec2-54-92-171-153.compute-1.amazonaws.com
~/.ssh/known_hosts:596: ec2-3-88-72-156.compute-1.amazonaws.com
~/.ssh/known_hosts:598: ec2-3-82-12-101.compute-1.amazonaws.com
~/.ssh/known_hosts:600: ec2-3-94-81-150.compute-1.amazonaws.com
~/.ssh/known_hosts:601: ec2-18-234-179-96.compute-1.amazonaws.com
~/.ssh/known_hosts:602: ec2-18-232-154-156.compute-1.amazonaws.com
(185 additional names omitted)
Are you sure you want to continue connecting (yes/no/[fingerprint])?
The issue is that each time I start my instance it gets a new hostname (which is just derived from the IP) and so SSH's trust on first use doesn't work properly.
Checking that "185 additional names omitted" is about the number I'd expect to see is ok, but not great. And it delays login.
I figured out how to fix this today:
1. Edit ~/.ssh/known_hosts to add an entry for each EC2 host I use under my alias for it. So I have c2-44-222-215-215.compute-1.amazonaws.com ssh-ed25519 AAAA... and I duplicate that to add ec2nf ssh-ed25519 AAAA... etc.
2. Modify my ec2 ssh script to set HostKeyAlias: ssh -o "StrictHostKeyChecking=yes" -o "HostKeyAlias=ec2nf" ...
More secure and more convenient!
(What got me to fix this was an interaction with my auto-shutdown script, where if I did start_ec2nf && sleep 20 && ssh_ec2nf but then went and did something else for a minute or two the machine would often turn itself off before I came back and got around to saying yes.)
Comment |
feae37d9-6e4f-434a-b940-8b59bb5ce1d8 | trentmkelly/LessWrong-43k | LessWrong | Explanations: Ignorance vs. Confusion
When people notice that they don't understand something, they want an explanation. Normally this works out okay, and we can either find an explanation or gracefully admit our ignorance. To use Richard Feynman's example, suppose someone asks why their Aunt Minnie is in the hospital. "Because she slipped and fell on the ice and broke her hip" will explain the matter to them, and nobody has to do any weird meta-reasoning about the nature of explanations.
In contrast, consider a deep philosophical question, like why do mirrors flip left and right, but not up and down? (If this is old hat, hopefully you can still remember how it felt. If this is new hat, and you like puzzles, stop and give it a think before reading Brienne on it.) Here, it's not that we're ignorant, but that we're confused. The resolution isn't like filling in a blank space of ignorance, it's like putting together a puzzle out of a pile of pieces not all of which match.
Weird meta-reasoning about explanations is somewhat useful in this second kind of puzzle, and is especially useful when you're not sure whether a puzzle is ignorance or confusion. You want to be able to recognize an explanation when you've got one, and most importantly you want to avoid declaring victory prematurely.
If you read my posts on numbers, or if you just really liked Righting a Wrong Question, it will not surprise you that I want to go even more meta. Rather than immediately trying to lay out how to tell if something is explained, we want to start with some nice easy questions about what explanations do inside our heads.
----------------------------------------
When Aunt Minnie is in the hospital, you already know more or less how the explanation will fit into your map of the world. You'll take the mental item for "Aunt Minnie in the hospital now," in your big warehouse of mental representations and associations, and associate it with some events or actions that provide some history for Aunt Minnie getting hospitalized, and |
153ac8f3-f375-4d29-9e89-a7e919c727ca | trentmkelly/LessWrong-43k | LessWrong | Agent membranes and causal distance
For the goal of maintaining the safety and autonomy of particular agents (and potential moral patients), there seems to be something important about maintaining the membranes and boundaries of those agents. A few examples:
A bacterium uses its membrane to protect its internal processes from external influences.
A nation maintains its sovereignty by defending its borders.
A human protects their mental integrity by selectively filtering the information that comes in and out of their mind.
What is the membrane of an agent?
Membranes are the things that maintain themselves despite environmental perturbation. (This is one reason I prefer the term “membranes” over “boundaries”. I think agent membranes are best understood as being living.)
Membranes are one way that agents can causally distance themselves from their environment and threats.
Think of a bacterium: it has a membrane that separates it from its environment, and the bacterium can exert a great deal of control on what comes in and what goes out using its membrane (via ion channels, gap junctions, etc.).
The bacterium uses its membrane to attempt to keep bad things (e.g.: toxins, potential pathogens) out, and keep good things (e.g.: energy, sovereignty) in.
When an agent fails to causally distance themselves from their environment and threats, it dies.
When an agent maintains causal distance from its environment— when that agent is able to control how the environment affects it, and also how it affects the environment— then it tends to live.
Agents that persist through time tend to maintain membranes.
Causal distance
If you’re an agent, one way to keep yourself safe from threats is to put physical distance between you and the potential threats. It’s hard to get shot by other people when you’re a thousand miles away from everyone else.
Physical distance can therefore often provide causal distance.
Similarly, membranes can also provide causal distance.
In the absence of physical distanc |
7b4d4c47-ed6f-44d8-b677-cfc1238ec1ff | trentmkelly/LessWrong-43k | LessWrong | Arbital postmortem
Disclaimer 1: These views are my own and don’t necessarily reflect the views of anyone else (Eric, Steph, or Eliezer).
Disclaimer 2: Most of the events happened at least a year ago. My memory is not particularly great, so the dates are fuzzy and a few things might be slightly out of order. But this post has been reviewed by Eric, Steph, and Eliezer, so it should mostly be okay.
I’m going to list events chronologically. At times I’ll insert a “Reflection” paragraph, where I’m going to outline my thoughts as of now. I’ll talk about what I could have done differently and how I would approach a similar problem today.
Chapter 0: Eliezer pitches Arbital and I say ‘no’
Around the summer of 2014 Eliezer approached me with the idea for what later would become Arbital. At first, I vaguely understood the idea as some kind of software to map out knowledge. Maybe something like a giant mind map, but not graphical. I took some time to research existing and previous projects in that area and found a huge graveyard of projects that have been tried. Yes, basically all of them were dead. Most were hobby projects, but some seemed pretty serious. None were successful, as far as I could tell. I didn’t see how Eliezer’s project was different, so I passed on it.
Reflection: Today, I’d probably try to sit down with Eliezer for longer and really try to understand what he is seeing that I’m not. It’s likely back then I didn’t have the right skills to extract that information, but I think I’m much better at it today.
Reflection: Also, after working with Eliezer for a few years, I’ve got a better feeling for how things he says often seem confusing / out of alignment / tilted, until you finally wrap your mind around it, and then it’s crystal clear and easy.
Chapter 1: Eliezer and I start Arbital
Early January 2015 I was sitting in my room, tired from looking in vain for a decent startup idea, when Arbital popped back into my mind. There were still a lot of red flags around the idea, but |
4248b74d-7bb4-4003-8713-d2bbb018d943 | trentmkelly/LessWrong-43k | LessWrong | Verbal Overshadowing and The Art of Rationality
To begin, here are some Fun Psychology Facts:
People who were asked to describe a face after seeing it are worse at recognizing the same face later.
People who are asked to describe a wine after drinking it are worse at recognizing the same wine later.
People who are asked to give reasons for their preferences among a collection of jellies are worse at identifying their own preferences among those jellies.
This effect, known as Verbal Overshadowing, occurs primarily when a principally non-verbal process is disrupted by a task which involves verbalization. The above generalizations (and Verbal Overshadowing effects more generally), do not occur among what we can term "Verbal Experts": individuals who are as good at verbalizing the relevant process as they are at doing it implicitly or automatically. This seems like it will be very important to keep in mind when cultivating our own Rationality.
Here's an oversimplified picture of what this means: We've got an implicit facial recognition process, IFRP, which is pretty good. We've also got a generalized explicit verbal thinking process, GEVTP, which is good for lots of things, but isn't especially good at recognizing faces. Normally, IFRP is in charge of facial recognition, but there are some things we can do, like, trying to put a face into words, that wakes up GEVTP, which then muscles IFRP out of the way, and all of a sudden, we are a lot worse at recognizing faces.
The good news is that GEVTP can be trained. To take the wine case, people who put in the time and effort can become verbal experts about wine. This isn't to say they automatically have better judgments about wine. Rather, it means that their GEVTP is on par with their implicit wine recognition, because it has been trained to do the same quality job as the the implicit process.
As a crude metaphor, imagine the difference between the natural process by which you go about walking, versus having to keep track of each and every instructio |
d1a54b55-f08f-4ed7-80f4-a2a6f4e17a9e | trentmkelly/LessWrong-43k | LessWrong | Good Fortune and Many Worlds
Summary: The Many-Worlds interpretation of quantum mechanics can help us respond virtuously to improbably good circumstances. Contemplating the less lucky branches of the quantum multiverse can be seen as a beneficial 'negative visualisation' practise comparable to those in Stoicism and some Buddhist traditions.
I’ve previously suggested that when we think about the ethical implications of the many-worlds interpretation (MWI) of quantum mechanics, the kinds of implications we should expect are ones about how to feel in certain ethical situations, and what kinds of character traits or ‘virtues’ we should try to develop.
I’ve argued that MWI implies virtues in which we feel better about mutually exclusive life choices by reminding ourselves that there really are worlds in which we choose ‘the road not taken’.
I’ve also shown that MWI can help us feel better about improbable bad events, since the things we value remain unaffected in most other worlds.
But what about improbable good events?
Is the multiverse bad for well-being?
Suppose you’ve just won big at a Las Vegas casino - or made a fortune on the stock market, or through a series of high-risk, start-up ventures. Or perhaps you’ve been lucky to survive a plane crash or terror attack, or a lifetime of extreme sports.
As we saw last time, any such outcome can be seen as the result of classically chaotic processes which bottom out in quantum probabilities.
So if you find yourself in these situations, if MWI is true, there’s a large proportion of other worlds in which you were not so lucky.
And therefore if MWI helps us feel better when faced with misfortune, by the same logic it seems it should make us feel worse when faced with good fortune.
The many-worlds perspective confronts you with a majority of worlds in which you or your multiverse counterpart struggled on the stock-market, or in business, or in which they died in a plane crash or rock-climbing accident.
These reflections might dampen your happ |
2e917187-a24c-4c9c-8808-bbf9346c0ea4 | trentmkelly/LessWrong-43k | LessWrong | Launching Forecast, a community for crowdsourced predictions from Facebook
Greetings! By way of brief introduction, I’m a long time lurker on LessWrong and a member of the team building Forecast, a crowdsourced prediction and discussion community. Full disclosure: we're part of a labs group, NPE, inside of Facebook.
We launched publicly a few weeks ago. I wanted to share a little about what we're trying to build and get this community's advice on where we're going.
First, a bit of background
Forecast is built around a prediction market: an exchange where people use virtual points to trade on outcomes of future events. Forecast is unique in a few ways:
1. Members of the community ask all the questions, which range from serious to arcane and mostly center around current events. Our team currently moderates the questions (mostly to edit them for clarity). Over time, we want to empower the community to self-moderate.
2. Forecast uses points, rather than real money. Forecasters get points when they join and then regularly get refreshes as they play. There’s a leaderboard that tracks total point ‘profit’.
3. All activity is public: anyone, whether or not they’re a forecast user, can see who participated and what their transaction/discussion history is. Forecast accounts are tied to your Facebook account behind the scenes, but users can select non-identifying display names to use in the community.
4. Post-forecast discussion is incentivized. Users get points if other users support the reasons they write to explain their forecasts. Only people who have made a forecast on a particular question can write and support reasons.
Since June, the Forecast community has made more than 50,000 forecasts on a few hundred questions--and they're actually reasonably accurate. Forecast's midpoint brier score (measured at the midpoint between a question’s launch and resolution dates) across all closed Forecasts over the past few months is 0.204, compared to Good Judgement's published result of 0.227 for prediction markets. [Update: as one commenter pointe |
752f1491-30d2-4a53-b413-8719448c6072 | StampyAI/alignment-research-dataset/distill | Distill Scientific Journal | High-Low Frequency Detectors

This article is part of the [Circuits thread](/2020/circuits/), an experimental format collecting invited short articles and critical commentary delving into the inner workings of neural networks.
[Naturally Occurring Equivariance in Neural Networks](/2020/circuits/equivariance/)
[Curve Circuits](/2020/circuits/curve-circuits/)
Introduction
------------
Some of the neurons in vision models are features that we aren’t particularly surprised to find. [Curve detectors](https://distill.pub/2020/circuits/curve-detectors/), for example, are a pretty natural feature for a vision system to have. In fact, they had already been discovered in the animal visual cortex. It’s easy to imagine how curve detectors are built up from earlier edge detectors, and it’s easy to guess why curve detection might be useful to the rest of the neural network.
High-low frequency detectors, on the other hand, seem more surprising. They are not a feature that we would have expected *a priori* to find. Yet, when systematically characterizing the [early layers](https://distill.pub/2020/circuits/early-vision/) of InceptionV1, we found a full [fifteen neurons](https://distill.pub/2020/circuits/early-vision/#group_mixed3a_high_low_frequency) of `mixed3a` that appear to detect a high frequency pattern on one side, and a low frequency pattern on the other.
By “high frequency” and “low frequency” here, we mean [spatial frequency](https://en.wikipedia.org/wiki/Spatial_frequency) — just like when we take the
Fourier transform of an image.
One worry we might have about the [circuits](https://distill.pub/2020/circuits/zoom-in/) approach to studying neural networks is that we might only be able to understand a limited set of highly-intuitive features.
High-low frequency detectors demonstrate that it’s possible to understand at least somewhat unintuitive features.
[Function
----------](#function)
How can we be sure that “high-low frequency detectors” are actually detecting directional transitions from low to high spatial frequency?
We will rely on three methods:
* [**Feature visualization**](#feature-visualization) allows us to establish a causal link between each neuron and its function.
* [**Dataset examples**](#dataset-examples) show us where the neuron fires in practice.
* [**Synthetic tuning curves**](#tuning-curves) show us how variation affects the neuron’s response.
Later on in the article, we dive into the mechanistic details of how they are both [implemented](#implementation) and [used](#usage). We will be able to understand the algorithm that implements them, confirming that they detect high to low frequency transitions.
[### Feature Visualization](#feature-visualization)
A [feature visualization](https://distill.pub/2017/feature-visualization) is a synthetic input
optimized to elicit maximal activation of a single, specific neuron.
Feature visualizations are constructed starting from random noise, so each and every pixel in a feature visualization
that’s *changed* from random noise is there because it caused the neuron to activate more strongly. This
establishes a causal link! The behavior shown in the
feature visualization is behavior that causes the neuron to fire:
.gallery {
display: grid;
grid-template-columns: repeat(auto-fit, minmax(28px, 64px));
grid-gap: 0.5rem;
justify-content: start;
}
ul.gallery {
padding-left: 0;
}
.gallery img,
.gallery-img {
max-width: 100%;
width: unset;
object-fit: none;
object-position: center;
border-radius: 8px;
}
@media screen and (min-width: 768px) {
.gallery {
grid-template-columns: repeat(7, minmax(28px, 96px));
justify-content: left;
}
}
@media screen and (min-width: 1180px) {
.gallery {
grid-gap: 1rem;
}
}
[
3a:136](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_136.html)
[
3a:108](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_108.html)
[
3a:132](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_132.html)
[
3a:88](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_88.html)
[
3a:110](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_110.html)
[
3a:180](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_180.html)
[
3a:153](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_153.html)
[
3a:186](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_186.html)
[
3a:86](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_86.html)
[
3a:117](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_117.html)
[
3a:112](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_112.html)
[
3a:70](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_70.html)
[
3a:106](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_106.html)
[
3a:113](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_113.html)
[1](#figure-1):
Feature visualizations of a variety of high-low frequency detectors from InceptionV1′s [`mixed3a`](https://microscope.openai.com/models/inceptionv1/mixed3a_0?models.op.feature_vis.type=neuron&models.op.technique=feature_vis) layer.
From their feature visualizations, we observe that all of these high-low frequency detectors share these same
characteristics:
* **Detection of adjacent high and low frequencies.** The detectors respond to *high frequency* on one side, and *low frequency* on the other side.
* **Rotational equivariance.**
The detectors are rotationally [equivariant](https://distill.pub/2020/circuits/equivariance/): each unit detects a high-low frequency change along a particular angle, with different units spanning the full 360º of possible orientations.
We will see this in more detail when we [construct a tuning curve](#tuning-curves) with synthetic examples, and also when we look at the weights [implementing](#implementation) these detectors.
We can use a [diversity term](https://distill.pub/2017/feature-visualization/#diversity) in our feature visualizations to jointly optimize for the activation of a neuron while encouraging different activation patterns in a batch of visualizations.
We are thus reasonably confident that if high-low frequency detectors were also sensitive to other patterns, we would see signs of them in these feature visualizations. Instead, the frequency contrast remains an invariant aspect of all these visualizations. (Although other patterns form along the boundary, these are likely outside the neuron’s effective receptive field.)







[1-2](#figure-1-2):
Feature visualizations of high-low frequency detector mixed3a:136 from InceptionV1′s [`mixed3a`](https://microscope.openai.com/models/inceptionv1/mixed3a_0?models.op.feature_vis.type=neuron&models.op.technique=feature_vis)
layer, optimized with a diversity objective. You can learn more about feature visualization and the diversity objective [here](https://distill.pub/2017/feature-visualization/#diversity).
[### Dataset Examples](#dataset-examples)
We generate dataset examples by sampling from a natural data distribution (in this case, the training set) and selecting the images that cause the neurons to maximally activate.
Checking against these examples helps ensure we’re not misreading the feature visualizations.
[](https://microscope.openai.com/models/inceptionv1/mixed3a_0/136)

[2](#1.2.0-dataset-examples):
Crops taken from Imagenet where [`mixed3a` 136](https://microscope.openai.com/models/inceptionv1/mixed3a_0/136) activated maximally,
argmaxed over spatial locations.
A wide range of real-world situations can cause high-low frequency detectors to fire. Oftentimes it’s a highly-textured, in-focus foreground object against a blurry background — for example, the foreground might be the microphone’s latticework, the hummingbird’s tiny head feathers, or the small rubber dots on the Lenovo ThinkPad [pointing stick](https://en.wikipedia.org/wiki/Pointing_stick) — but not always: we also observe that it fires for the MP3 player’s brushed metal finish against its shiny screen, or the text of a watermark.
In all cases, we see one area with high frequency and another area with low frequency. Although they often fire at an object boundary,
they can also fire in cases where there is a frequency change without an object boundary.
High-low frequency detectors are therefore not the same as [boundary detectors](https://distill.pub/2020/circuits/early-vision/#group_mixed3b_boundary).
[### Synthetic Tuning Curves](#tuning-curves)
**Tuning curves** show us how a neuron’s response changes with respect to a parameter.
They are a standard method in neuroscience, and we’ve found them very helpful for studying artificial neural networks as well. For example, we used them to demonstrate [how the response of curve detectors changes](https://distill.pub/2020/circuits/curve-detectors/#radial-tuning-curve) with respect to orientation.
Similarly, we can use tuning curves to show how high-low frequency detectors respond.
To construct such a curve, we’ll need a set of *synthetic stimuli* which cause high-low frequency detectors to fire.
We generate images with a high-frequency pattern on one side and a low-frequency pattern on the other. Since we’re interested in orientation, we’ll rotate this pattern to create a 1D family of stimuli:

The first axis of variation of our synthetic stimuli is *orientation*.
But what frequency should we use for each side? How steep does the difference in frequency need to be?
To explore this, we’ll add a second dimension varying the ratio between the two frequencies:

The second axis of variation of our synthetic stimuli is the *frequency ratio*.
(Adding a second dimension will also help us see whether the results for the first dimension are robust.)
Now that we have these two dimensions, we sample the synthetic stimuli and plot each neuron’s responses to them:
Each high-low frequency detector exhibits a clear preference for a limited range of orientations.
As we [previously found](https://distill.pub/2020/circuits/curve-detectors/#synthetic-curves) with curve detectors, high-low frequency detectors are rotationally [equivariant](https://distill.pub/2020/circuits/equivariance/): each one selects for a given orientation, and together they span the full 360º space.
[Implementation
--------------](#implementation)
How are high-low frequency detectors built up from lower-level neurons?
One could imagine many different circuits which could implement this behavior. To give just one example, it seems like there are at least two different ways that the oriented nature of these units could form.
* **Equivariant→Equivariant Hypothesis.** The first possibility is that the previous layer already has precursor features which detect oriented transitions from high frequency to low frequency. The extreme version of this hypothesis would be that the high-low frequency detector is just an identity passthrough of some lower layer neuron. A more moderate version would be something like what we see with curve detectors, where [early curve detectors](https://distill.pub/2020/circuits/early-vision/#group_conv2d2_tiny_curves) become refined into the larger and more sophisticated [late curve detectors](https://distill.pub/2020/circuits/early-vision/#group_mixed3a_curves). Another example would be how edge detection is built up from simple [Gabor filters](https://distill.pub/2020/circuits/early-vision/#group_conv2d0_gabor_filters) which were already oriented.
We call this [Equivariant→Equivariant](https://distill.pub/2020/circuits/equivariance/#equivariant-to-equivariant) because the equivariance over orientation was already there in the previous layer.
* **Invariant→Equivariant Hypothesis.** Alternatively, previous layers might not have anything like high-low frequency detectors. Instead, the orientation might come from spatial arrangements in the neuron’s weights that govern where it is excited by low-frequency and high-frequency features.
To resolve this question — and more generally, to understand how these detectors are implemented — we can look at the weights.
Let’s look at a single detector. Glancing at the weights from [`conv2d2`](https://distill.pub/2020/circuits/early-vision/#conv2d2) to [`mixed3a` 110](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_110.html), most of them can be roughly divided into two categories: those that activate on the left and inhibit on the right, and those that do the opposite.
[4](#figure-4):
Six neurons from conv2d2 contributing weights to mixed3a 110.
The same also holds for each of the other high-low frequency detectors — but, of course, with different spatial patternsAs an aside: The 1-2-1 pattern on each column of weights is curiously reminiscent of the structure of the [Sobel filter](https://en.wikipedia.org/wiki/Sobel_operator). on the weights, implementing the different orientations.
Surprisingly, across all high-low frequency detectors, the two clusters of neurons that we get for each are actually the *same* two clusters! One cluster appears to detect textures with a generally high frequency, and one cluster appears to detect textures with a generally low frequency.

[5](#figure-5):
The strongest weights on any high-low frequency detector (here shown: [`mixed3a` 110](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_110.html), [`mixed3a` 136](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_136.html), and [`mixed3a` 112](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_112.html)) can be divided into roughly two clusters. Each cluster contributes its weights in similar ways.
Top row: underlying neurons [`conv2d2` 119](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/conv2d2_119.html), [`conv2d2` 102](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/conv2d2_102.html), [`conv2d2` 123](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/conv2d2_123.html), [`conv2d2` 90](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/conv2d2_90.html), [`conv2d2` 89](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/conv2d2_89.html), [`conv2d2` 163](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/conv2d2_163.html), [`conv2d2` 98](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/conv2d2_98.html), and [`conv2d2` 188](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/conv2d2_188.html).
This is exactly what we would expect to see if the Invariant→Equivariant hypothesis is true: each high-low frequency detector composes the same two components in different spatial arrangements, which then in turn govern the detector’s orientation.
These two different clusters are really striking.
In the next section, we’ll investigate them in more detail.
### High and Low Frequency Factors
It would be nice if we could confirm that these two clusters of neurons are real. It would also be nice if we could create a simpler way to represent them for circuit analysis later.
Factorizing the connectionsBetween two adjacent layers, “connections” reduces to the weights
between the two layers. Sometimes we are interested in observing connectivity between layers that may not be
directly adjacent. Because our model, a deep convnet, is non-linear, we will need to approximate the
connections. A simple approach that we take is to linearize the model by removing the non-linearities. While
this is not a great approximation of the model’s behavior, it does give a reasonable intuition for
counterfactual influence: had the neurons in the intermediate layer fired, how it would have affected neurons in
the downstream layers. We treat positive and negative influences separately. between lower layers and the high-low frequency detectors is one way that we can check whether these two clusters are meaningful, and investigate their significance. Performing a one-sided non-negative matrix factorization (NMF)We [require](/2020/circuits/visualizing-weights/#one-simple-trick) that the channel factor be positive, but allow the spatial factor to have both positive and negative values. separates the connections into two factors.
Each factor corresponds to a vector over neurons. Feature visualization can also be used to visualize these linear combinations of neurons. Strikingly, one clearly displays a generic high-frequency image, whereas the other does the same with a low-frequency image.In InceptionV1 in particular, it’s possible that we recover these two factors so crisply in part due to the *[3x3 bottleneck](https://microscope.openai.com/models/inceptionv1/mixed3a_3x3_bottleneck_0?models.op.feature_vis.type=neuron&models.op.technique=feature_vis)* between conv2d2 and mixed3a. Because of this, we’re not here looking at direct weights between conv2d2 and mixed3a, but rather the “expanded weights,” which are a product of a 1x1 convolution (which reduces down to a small number of neurons) combined with a 3x3 convolution. This structure is very similar to the factorization we apply. However, as we see later in [Universality](#universality), we recover similar factors for other models where this bottleneck doesn’t exist. NMF makes it easy to see this abstract circuit across many models which may not have an architecture that more explicitly reifies it. We’ll call these the *HF-factor* and the *LF-factor*:
.upstream-neurons {
display: grid;
grid-gap: 1em;
margin-bottom: 1em;
}
h5 {
margin-bottom: 0px;
}
.upstream-neurons .row {
display: grid;
grid-template-columns: 1fr min-content 1fr min-content 1fr min-content 1fr min-content 1fr min-content 1fr min-content min-content;
grid-column-gap: .25em;
column-gap: .25em;
align-items: center;
}
.units,
.weights {
display: grid;
grid-template-columns: repeat(6, 1fr);
grid-gap: 0.5rem;
grid-column-start: 3;
}
img.fv {
display: block;
max-width: 100%;
border-radius: 8px;
}
img.full {
width: unset;
object-fit: none;
object-position: center;
image-rendering: optimizeQuality;
}
img.weight {
width: 100%;
image-rendering: pixelated;
align-self: center;
border: 1px solid #ccc;
}
.layer-label {
grid-row-start: span 2;
}
.layer-label label {
display: inline-block;
/\* transform: rotate(-90deg); \*/
}
.annotation {
font-size: 1.5em;
font-weight: 200;
color: #666;
margin-bottom: 0.2em;
}
.equal-sign {
padding: 0 0.25em;
}
.ellipsis {
padding: 0 0.25em;
/\* vertically align the ellipsis \*/
position: relative;
bottom: 0.5ex;
}
.unit {
display: block;
min-width: 50px;
}
.factor {
box-shadow: 0 0 8px #888;
}
.unit .bar {
display: block;
margin-top: 0.5em;
background-color: #CCC;
height: 4px;
}
.row h4 {
border-bottom: 1px solid #ccc;
}
#### mixed3a → conv2d2

=

+

+

+

+

+
…
HF-factor
× 0.93
× 0.73
× 0.66
× 0.59
× 0.55

=

+

+

+

+

+
…
LF-factor
× 0.44
× 0.41
× 0.38
× 0.36
× 0.34
#### mixed3a → conv2d1

=

+

+

+

+

+
…
HF-factor
× 0.86
× 0.81
× 0.64
× 0.53
× 0.52

=

+

+

+

+

+
…
LF-factor
× 0.49
× 0.48
× 0.45
× 0.43
× 0.42
[6](#figure-6):
NMF recovers the neurons that contribute to the two NMF factors plus the weighted amount they contribute to
each factor. Here shown: NMF against both `conv2d2` and a deeper layer, `conv2d1`. The
left side of the equal sign shows feature visualizations of the NMF factors.
The feature visualizations are suggestive, but how can we be sure that these factors really correspond to high and low frequency in general, rather than specific high or low frequency patterns? One thing we can do is to create synthetic stimuli again, but now plotting the responses of those two NMF factors.
Since our factors don’t correspond to an edge, our synthetic stimuli will only have one frequency region for each stimulus. To add a second dimension and again demonstrate robustness, we also vary the rotation of that region. (The frequency texture is not exactly rotationally invariant because we construct the stimulus out of orthogonal cosine waves.)
Unlike last time, these activations now mostly ignore the image’s orientation, but are sensitive to its frequency. We can average these results over all orientations in order to produce a simple tuning curve of how each factor responds to frequency. As predicted, the HF-factor responds to high frequency and the LF-factor responds to low frequency.
[8](#figure-8):
Tuning curve for HF-factor and LF-factor from `conv2d2` against images with synthetic frequency, averaged across orientation. Wavelength as a proportion of the full input image ranges from 1:1 to 1:10.
Now that we’ve confirmed what these factors are, let’s look at how they’re combined into high-low frequency detectors.
### Construction of High-Low Frequency Detectors
NMF factors the weights into both a channel factor and a spatial factor. So far, we’ve looked at the two parts of the channel factor. The spatial factor shows the spatial weighting that combines the HF and LF factors into high-low frequency detectors.
Unsurprisingly, these weights basically reproduce the same pattern that we’d previously been seeing in [Figure 5](#figure-5) from its two different clusters of neurons: where the HF-factor inhibits, the LF-factor activates — and vice versa.
As an aside, the HF-factor here for InceptionV1 (as well as some of its NMF components, like [`conv2d2` 123](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/conv2d2_123.html)) also appears to be lightly activated by bright greens and magentas. This might be responsible for the feature visualizations of these high-low frequency detectors showing only greens and magentas on the high-frequency side.
.upstream-nmf {
display: grid;
grid-row-gap: 2rem;
margin-bottom: 2rem;
}
.upstream-nmf .row {
display: grid;
grid-template-columns: min-content 1fr 6fr;
grid-column-gap: 1rem;
grid-row-gap: .5rem;
}
.units,
.weights {
display: grid;
grid-template-columns: repeat(6, 1fr);
grid-gap: 0.5rem;
grid-column-start: 3;
}
img.fv {
max-width: 100%;
border-radius: 8px;
}
div.units img.full {
margin-left: 1px;
}
img.full {
width: unset;
object-fit: none;
object-position: center;
image-rendering: optimizeQuality;
}
img.weight {
width: 100%;
image-rendering: pixelated;
align-self: center;
border: 1px solid #ccc;
}
.annotated-image {
display: grid;
grid-auto-flow: column;
align-items: center;
}
.annotated-image span {
writing-mode: vertical-lr;
}
.layer-label {
grid-row-start: span 2;
border-right: 1px solid #aaa;
text-align: end;
}
.layer-label label {
display: inline-block;
margin-right: .5em;
writing-mode: vertical-lr;
}
.layer-label.hidden {
border-color: transparent;
}
.layer-label.hidden label {
visibility: hidden;
}
mixed3a






mixed3a → conv2d2
HF-factor







LF-factor







mixed3a → conv2d1
HF-factor







LF-factor







[9](#figure-9):
Using NMF factorization on the weights connecting six high-low frequency detectors in InceptionV1 to the
two directly
preceding convolutional layers, `conv2d2` and `conv2d1`.
Their spatial arrangement is very clear, with LF factors activating
areas in which high-low frequency detectors expect low frequencies, and inhibiting areas in which they expect high frequencies. The two
factors
are very close to symmetric. Weight magnitudes normalized between -1 and 1.
High-low frequency detectors are therefore built up by circuits that arrange high frequency detection on one side and low frequency detection on the other.
There are some exceptions that aren’t fully captured by the NMF factorization perspective. For example, [`conv2d2` 181](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/conv2d2_181.html) is a texture contrast detector that appears to already have spatial structure.
This is the kind of feature that we would expect to be involved through an Equivariant→Equivariant circuit.
If that were the case, however, we would expect its weights to the high-low frequency detector [`mixed3a` 70](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3a_70.html) to be a solid positive stripe down the middle.
What we instead observe is that it contributes as a component of high frequency detection, though perhaps with a slight positive overall bias.
Although `conv2d2` 181 has a spatial structure, perhaps it responds more strongly to high frequency patterns.

The weights from `conv2d2` 181 to `mixed3a` 70 are consistent with `conv2d2` 181 contributing via the HF-factor, not via the existing spatial structure of its texture contrast detection.
Now that we understand how they are constructed, how are high-low frequency detectors used by higher-level features?
[Usage
-----](#usage)
[`mixed3b`](https://distill.pub/2020/circuits/early-vision/#mixed3b) is the next layer immediately after the high-low frequency detectors. Here, high-low frequency detectors contribute to a variety of features. Their most important role seems to be supporting [boundary detectors](https://distill.pub/2020/circuits/early-vision/#group_mixed3b_boundary), but they also contribute to [bumps](https://distill.pub/2020/circuits/early-vision/#group_mixed3b_bumps) and [divots](https://distill.pub/2020/circuits/early-vision/#group_mixed3b_divots), [line-like](https://distill.pub/2020/circuits/early-vision/#group_mixed3b_bar_line_like) and [curve-like](https://distill.pub/2020/circuits/early-vision/#group_mixed3b_curves_misc.) shapes,
and at least one each of [center-surrounds](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3b_281.html), [patterns](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3b_372.html), and [textures](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3b_276.html).

[10](#figure-10):
Examples of neurons that high-low frequency detectors contribute to: (1) [`mixed3b` 345](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3b_345.html) (a boundary detector), (2) [`mixed3b` 276](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3b_276.html) (a center-surround texture detector), (3) [`mixed3b` 314](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3b_314.html) (a double boundary detector), and (4) [`mixed3b` 365](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3b_365.html) (an hourglass shape detector).
These aren’t the only contributors to these neurons – for example, `mixed3b` 276 also relies heavily on certain center-surrounds and textures – but they are strong contributors.
Oftentimes, downstream features appear to ignore the “polarity” of a high-low frequency detector, responding roughly the same way regardless of which side is high frequency. For example, the vertical boundary detector [`mixed3b` 345](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3b_345.html) (see above) is strongly excited by high-low frequency detectors that detect frequency change across a vertical line in either direction.
Whereas activation from a high-low frequency detector can help detect boundaries between different objects, inhibition from a high-low frequency detector can also add structure to an object detector by detecting regions that must be contiguous along some direction — essentially, indicating the absence of a boundary.

[11](#figure-11):
Some of [`mixed3b` 314](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3b_314.html)’s weights, extracted for emphasis. Orientation doesn’t matter so much for how these weights are used by [`mixed3b` 314](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3b_314.html), but their 180º-invariant orientation does!
You may notice that strong excitation (left) is correlated with the presence of a **boundary** at a particular angle, whereas strong inhibition (right) is correlated with **object continuity** where a boundary might otherwise have been.
As we’ve mentioned, by far the primary downstream contribution of high-low frequency detectors is to *boundary detectors*. Of the top 20 neurons in `mixed3b` with the highest L2-norm of weights across all high-low frequency detectors, eight of those 20 neurons participate in boundary detection of some sort: [double boundary detectors](https://distill.pub/2020/circuits/early-vision/#group_mixed3b_double_boundary), [miscellaneous boundary detectors](https://distill.pub/2020/circuits/early-vision/#group_mixed3b_boundary_misc), and especially [object boundary detectors](https://distill.pub/2020/circuits/early-vision/#group_mixed3b_boundary).
#### Role in object boundary detection
[Object boundary detectors](https://distill.pub/2020/circuits/early-vision/#group_mixed3b_boundary) are neurons which detect boundaries between objects, whether that means the boundary between one object and another or the transition from foreground to background. They are different from edge detectors or curve detectors: although they are sensitive to edges (indeed, some of their strongest weights are contributed by lower-level edge detectors!), object boundary detectors are also sensitive to other indicators such as color contrast and high-low frequency detection.

[12](#figure-12): `mixed3b` 345 is a boundary detector activated by high-low frequency detectors, edges, color contrasts, and end-of-line
detectors. It is specifically sensitive to vertically-oriented high-low frequency detectors, regardless of their
orientation, and along a vertical line of positive weights.
High-low frequency detectors contribute to these object boundary detectors by providing one piece of evidence that an object has ended and something else has begun. Some examples of object boundary detectors are shown below, along with their weights to a selection of high-low frequency detectors, grouped by orientation (ignoring polarity).
In particular, note how similar the weights are within each grouping! This shows us again that the later layers ignore the high-low frequency detectors’ polarity. Furthermore, the arrangement of excitatory and inhibitory weights contributes to each boundary detector’s overall shape, following the principles outlined above.
/\* TODO: Optimize smaller breakpoints by hand \*/

[13](#figure-13): Four examples of object boundary detectors that high-low frequency detectors contribute to: [`mixed3b` 345](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3b_345.html), [`mixed3b` 376](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3b_376.html), [`mixed3b` 368](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3b_368.html), and [`mixed3b` 151](https://storage.googleapis.com/distill-circuits/inceptionv1-weight-explorer/mixed3b_151.html).
Beyond `mixed3b`, high-low frequency detectors ultimately play a role in detecting more sophisticated object shapes in `mixed4a` and beyond, by continuing to contribute to the detection of boundaries and contiguity.
So far, the scope of our investigation has been limited to InceptionV1.
How common are high-low frequency detectors in convolutional neural networks generally?
Universality
------------
### High-Low Frequency Detectors in Other Networks
It’s always good to ask if what we see is the rule or an interesting exception — and high-low frequency detectors seem to be the rule.
High-low frequency detectors similar to ones in InceptionV1 can be found in a variety of architectures.
strong d-cite {
font-weight: normal;
}
figure.columns {
display: grid;
grid-gap: 0.5em;
grid-template-columns: repeat(4, 1fr);
overflow: hidden;
}
.columns .model {
display: grid;
/\* position: relative;
grid-row-gap: 0.5em;
grid-auto-flow: row;
align-content: start;
grid-template-rows: min-content; \*/
}
.model picture {
position: relative;
}
.model img {
box-sizing: border-box;
position: relative;
width: unset;
object-fit: none;
z-index: 1;
outline: 6px solid white;
border-radius: 8px;
}
.model figcaption>\* {
display: block;
}
/\*
HAAAACKY
\*/
.model:first-of-type picture::before {
content: "";
display: block;
position: absolute;
height: 1px;
width: 350%;
left: 0;
top: 48px;
background-color: #aaa;
z-index: 0;
}
.columns>figcaption {
grid-column: 1 / span 4;
}
**InceptionV1**
Layer `mixed3a`
At ~33% CNN depth






**AlexNet**
Layer `Conv2D_2`
At ~29% CNN depth






**InceptionV4**
Layer `Mixed_5a`
At ~33% CNN depth






**ResNetV2-50**
Layer `B2_U1_conv2`
At ~29% CNN depth






[14](#figure-14). High-low frequency detectors that we’ve found in AlexNet, InceptionV4, and ResnetV2-50 (right), compared to their most similar counterpart from InceptionV1 (left). These are individual neurons, not linear combinations approximating the detectors in InceptionV1.
Notice that these detectors are found at very similar depths within the different networks, between 29% and 33% network depth!Network depth is here defined as the index of the layer divided by the total number of layers. While the particular orientations each network’s high-low frequency detectors respond to may vary slightly, each network has its own family of detectors that together cover the full 360º and comprise a rotationally [equivariant](https://distill.pub/2020/circuits/equivariance/) family.
Architecture aside – what about networks trained on substantially different *datasets*? In the extreme case, one could imagine a synthetic dataset where high-low frequency detectors don’t arise. For most practical datasets, however, we expect to find them. For example, we even find some candidate high-low frequency detectors in AlexNet (Places): [down-up](https://microscope.openai.com/models/alexnet_caffe_places365/conv2_Conv2D_0/37), [left-right](https://microscope.openai.com/models/alexnet_caffe_places365/conv2_Conv2D_0/91), and [up-down](https://microscope.openai.com/models/alexnet_caffe_places365/conv2_Conv2D_0/104).
Even though these families are from three completely different networks, we also discover that their high-low frequency detectors are built up from high and low frequency components.
### HF-factor and LF-factor in Other Networks
As we did with InceptionV1, we can again perform NMF on the weights of the high-low frequency detectors in each network in order to extract the strongest two factors.
.upstream-nmf {
display: grid;
grid-row-gap: 2rem;
margin-bottom: 3rem;
}
.upstream-nmf .row {
display: grid;
grid-template-columns: min-content 1fr 6fr;
grid-column-gap: 1rem;
grid-row-gap: .5rem;
}
.units,
.weights {
display: grid;
grid-template-columns: repeat(6, 1fr);
grid-gap: 0.5rem;
grid-column-start: 3;
}
img.fv {
max-width: 100%;
border-radius: 8px;
}
div.units img.full {
margin-left: 1px;
}
img.full {
width: unset;
object-fit: none;
object-position: center;
image-rendering: optimizeQuality;
}
img.weight {
width: 100%;
image-rendering: pixelated;
align-self: center;
border: 1px solid #ccc;
}
img.factor {
/\* padding-right: 0.75rem; \*/
}
.annotated-image {
display: grid;
grid-auto-flow: column;
align-items: center;
}
.annotated-image span {
writing-mode: vertical-lr;
}
.layer-label {
grid-row-start: span 2;
border-right: 1px solid #aaa;
text-align: end;
}
.layer-label label {
display: inline-block;
margin-right: .5em;
writing-mode: vertical-lr;
}
.layer-label.hidden {
border-color: transparent;
}
.layer-label.hidden label {
visibility: hidden;
}
#### AlexNet
layer
[](https://microscope.openai.com/models/alexnet/Conv2D_2_0/55)[](https://microscope.openai.com/models/alexnet/Conv2D_2_0/47)[](https://microscope.openai.com/models/alexnet/Conv2D_2_0/87)[](https://microscope.openai.com/models/alexnet/Conv2D_2_0/33)[](https://microscope.openai.com/models/alexnet/Conv2D_2_0/77)[](https://microscope.openai.com/models/alexnet/Conv2D_2_0/102)
Conv2D\_2 → conv1\_1
HF-factor







LF-factor







#### InceptionV3\_slim
layer
[](https://microscope.openai.com/models/inceptionv3_slim/InceptionV3_InceptionV3_Conv2d_4a_3x3_Relu_0/82)[](https://microscope.openai.com/models/inceptionv3_slim/InceptionV3_InceptionV3_Conv2d_4a_3x3_Relu_0/83)[](https://microscope.openai.com/models/inceptionv3_slim/InceptionV3_InceptionV3_Conv2d_4a_3x3_Relu_0/137)[](https://microscope.openai.com/models/inceptionv3_slim/InceptionV3_InceptionV3_Conv2d_4a_3x3_Relu_0/139)[](https://microscope.openai.com/models/inceptionv3_slim/InceptionV3_InceptionV3_Conv2d_4a_3x3_Relu_0/155)[](https://microscope.openai.com/models/inceptionv3_slim/InceptionV3_InceptionV3_Conv2d_4a_3x3_Relu_0/159)
Conv2d\_4a → Conv2d\_3b
HF-factor







LF-factor







#### ResnetV2\_50\_slim
layer
[](https://microscope.openai.com/models/resnetv2_50_slim/resnet_v2_50_block2_unit_1_bottleneck_v2_conv2_Relu_0/118)[](https://microscope.openai.com/models/resnetv2_50_slim/resnet_v2_50_block2_unit_1_bottleneck_v2_conv2_Relu_0/41)[](https://microscope.openai.com/models/resnetv2_50_slim/resnet_v2_50_block2_unit_1_bottleneck_v2_conv2_Relu_0/53)[](https://microscope.openai.com/models/resnetv2_50_slim/resnet_v2_50_block2_unit_1_bottleneck_v2_conv2_Relu_0/44)[](https://microscope.openai.com/models/resnetv2_50_slim/resnet_v2_50_block2_unit_1_bottleneck_v2_conv2_Relu_0/25)[](https://microscope.openai.com/models/resnetv2_50_slim/resnet_v2_50_block2_unit_1_bottleneck_v2_conv2_Relu_0/50)
B2\_U1\_conv2 → B2\_U1\_conv1
HF-factor







LF-factor







[15](#figure-15):
NMF of high-low frequency detectors in
AlexNet’s
[Conv2D\_2](https://microscope.openai.com/models/alexnet/Conv2D_2_0?models.op.feature_vis.type=channel&models.op.technique=feature_vis) with respect to [conv1\_1](https://microscope.openai.com/models/alexnet/conv1_1_0?models.op.feature_vis.type=channel&models.op.technique=feature_vis),
InceptionV3\_slim’s
[Conv2d\_4a](https://microscope.openai.com/models/inceptionv3_slim/InceptionV3_InceptionV3_Conv2d_4a_3x3_Relu_0?models.op.feature_vis.type=channel&models.op.technique=feature_vis) with respect to [Conv2d\_3b](https://microscope.openai.com/models/inceptionv3_slim/InceptionV3_InceptionV3_Conv2d_3b_1x1_Relu_0?models.op.feature_vis.type=channel&models.op.technique=feature_vis),
and
ResnetV2\_50\_slim’s
[B2\_U1\_conv2](https://microscope.openai.com/models/resnetv2_50_slim/resnet_v2_50_block2_unit_1_bottleneck_v2_conv2_Relu_0?models.op.feature_vis.type=channel&models.op.technique=feature_vis) with respect to [B2\_U1\_conv1](https://microscope.openai.com/models/resnetv2_50_slim/resnet_v2_50_block2_unit_2_bottleneck_v2_conv1_Relu_0?models.op.feature_vis.type=channel&models.op.technique=feature_vis),
showing activations and inhibitions.
The feature visualizations of the two factors reveal one clear HF-factor and one clear LF-factor, just like what we found in InceptionV1. Furthermore, the weights on the two factors are again very close to symmetric.
Our earlier conclusions therefore also hold across these different networks: high-low frequency detectors are built up from the specific spatial arrangement of a high frequency component and a low frequency component.
Conclusion
----------
Although high-low frequency detectors represent a feature that we didn’t necessarily expect to find in a neural network, we find that we can still explore and understand them using the interpretability tools we’ve built up for exploring circuits: NMF, feature visualization, synthetic stimuli, and more.
We’ve also learned that high-low frequency detectors are built up from comprehensible lower-level parts, and we’ve shown how they contribute to later, higher-level features.
Finally, we’ve seen that high-low frequency detectors are common across multiple network architectures.
Given the universality observations, we might wonder whether the existence of high-low frequency detectors isn’t so unnatural after all. We even find [approximate](https://microscope.openai.com/models/alexnet_caffe_places365/conv2_Conv2D_0/91) high-low frequency detectors in AlexNet Places, with its substantially different training data. Beyond neural networks, the aesthetic quality imparted by the blurriness of an out-of-focus region of an image is already known as to photographers as [*bokeh*](https://en.wikipedia.org/wiki/Bokeh). And in VR, visual blur can either provide an effective depth-of-field cue or, conversely, can induce nausea in the user when implemented in a dissonant way. Perhaps frequency detection might well be commonplace in both natural and artificial vision systems as yet another type of informational cue.
Nevertheless, whether their existence is natural or not, we find that high-low frequency detectors are possible to characterize and understand.

This article is part of the Circuits thread, a collection of short articles and commentary by an open scientific collaboration delving into the inner workings of neural networks.
[Naturally Occurring Equivariance in Neural Networks](/2020/circuits/equivariance/)
[Curve Circuits](/2020/circuits/curve-circuits/) |
c1a5b344-cddc-4fc3-8106-7023df965683 | StampyAI/alignment-research-dataset/special_docs | Other | Why companies should be leading on AI governance _ Jade Leung _ EA Global - London 2018-by Centre for Effective Altruism-video_id AVDIQvJVhso-date 20190207
# Jade Leung Why companies should be leading on AI governance - EA Forum
\_Are companies better-suited than governments to solve collective action problems around artificial intelligence? Do they have the right incentives to do so in a prosocial way? In this talk, Jade Leung argues that the answer to both questions is "yes".\_
\_A transcript of Jade's talk is below, which CEA has lightly edited for clarity. You can also watch this talk on\_ [\_YouTube\_](https://www.youtube.com/watch?v=AVDIQvJVhso)\_, or read its transcript on\_ [\_effectivealtruism.org\_](https://www.effectivealtruism.org/articles/ea-global-2018-why-companies-should-be-leading-on-ai-governance)\_.\_
## The Talk
In the year 2018, you can walk into a conference room and see something like this: There's a group of people milling around. They all look kind of frantic, a little bit lost, a little bit stressed. Over here, you've got some people talking about GDPR and data. Over there, you've got people with their heads in their hands being like, "What do we do about China?" Over there, you've got people throwing shade at Zuckerberg. And that's when you know you're in an AI governance conference.
The thing with governance is that it's the kind of word that you throw around, and it feels kind of warm and fuzzy because it's the thing that will help us navigate through all of these kind of big and confusing questions. There's just a little bit of a problem with the word "governance," in that a lot of us don't really know what we mean when we say we want to be governing artificial intelligence.
So what do we actually mean when we say "governance?" I asked Google. Google gave me a lot of aesthetically pleasing, symmetrical, meaningless management consulting infographics, which wasn't very helpful.

And then I asked it, "What is AI governance?" and then all the humans became bright blue glowing humans, which didn't help. And then the cats started to appear. This is actually what comes up when you search for AI governance. And that's when I just gave up, and I was like, "I'm done. I need a career change. This is not good."

So it seems like no one really knows what we mean when we say, "AI governance." So I'm going to spend a really quick minute laying some groundwork for what we mean, and then I'll move on into the main substantive argument, which was, "Who should actually be leading on this thing called governance?"

So governance, global governance, is a set of norms, processes, and institutions that channel the behavior of a set of actors towards solving a collective action problem at a global or transnational scale. And you normally want your governance regime to steer you towards a set of outcomes. When we talk about AI governance, our outcome is something like the robust, safe, and beneficial development and deployment of advanced artificial intelligence systems.

Now that outcome needs a lot of work, because we don't actually really know what that means either. We don't really know how safe is safe. We don't really know what benefits we're talking about, and how they should be distributed. And us answering those questions and adding granularity to that outcome is going to take us a while.
So you can also put in something like a placeholder governance outcome, which is like the intermediate outcome that you want. So the process of us getting to the point of answering these questions can include things like being able to avoid preemptive locking, so that we don't have a rigid governance regime that can't adapt to new information. It could also include things like ensuring that there are enough stakeholder voices around the table so that you are getting all of your opinions in. So those are examples of intermediate governance outcomes that your regime can lead you towards.

And then in governance you also have a set of functions. So these are the things that you want your regime to do so that you get to the set of outcomes that you want. So common sets of functions that you talk about would be things like setting rules. What do we do? How do we operate in this governance regime? Setting context, creating common information and knowledge, doing common benchmarks and measurements. You also have implementation, which is both issuing and soliciting commitments from actors to do certain things. And it's also about allocating resources so that people can actually do the things. And then finally, you've got enforcement and compliance, which is something like making sure that people are actually doing the thing that they said that they would do.
So these are examples of functions. And the governance regime is something like these norms, processes, and institutions that get you towards that outcome by doing some of these functions.
So the critical question today is something like, how do we think about who should be taking the lead on doing this thing called AI governance?
I have three propositions for you.

One: states are ill-equipped to lead in the formative stages of developing an AI governance regime. Two: private AI labs are better, if not best-placed, to lead in AI governance. And three: private AI labs can and already, to some extent, are incentivized to do this AI governance thing in a prosocial way.
I'll spend some time making a case for each one of these propositions.
### States are Ill-Equipped
When we normally think about governance, you consider states as the main actors sitting around the table. You think about something like the UN: everyone sitting under a flag, and there are state heads who are doing this governance thing.

You normally think that because of three different reasons. One is the conceptual argument that states are the only legitimate political authorities that we have in this world, so they're the only ones who should be doing this governance thing. Two is you've got this kind of functional argument: states are the only ones who can pass legislation, design regulation, and if you're going to think about governance as regulation and legislation, then states have to be the ones doing that function. And three, you've got something like the incentives argument, which is that states are set up, surely, to deliver on these public goods that no one else is going to care about as a result. So states are the only ones that have the explicit mandate and the explicit incentive structure to deliver on these collective action problems. Otherwise, none of this mess would get cleaned up.
Now all of those things are true. But there are trends and certain characteristics about a technology governance problem, which means that states are particularly increasingly undermined in their ability to do governance effectively, despite all of those things being true.

Now the first is that states are no longer the sole source of governance capacity. And this is a general statement that isn't specifically about technology governance. You've got elements like globalization, for example, creating the situation where these collective action problems are at a scale which states have no mandate or control over. And so states are increasingly unable to do this governance thing effectively within the scope of the jurisdiction that they have.
You also have non-state actors emerging on the scene, most notably civil society and multi-national corporations are at this scale that supersedes states. And they also are increasingly demonstrating that they have some authority, and some control, and some capacity to exercise governance functions. Now their authority doesn't come from being voted in. The authority of a company, for example, plausibly comes from something like their market power and the influence on public opinion. And you can argue about how legitimate that authority is, but it is exercised and it does actually influence action. So states are no longer the sole source of where this governance stuff can come from.
Specifically for technology problems, you have this problem that technology moves really fast, and states don't move very fast. States use regulatory and legislative frameworks that hold technology static as a concept. And technology is anything but static: it progresses rapidly and often discontinuously, and that means that your regulatory and legislative frameworks get out of date very quickly. And so if states are going to use that as the main mechanism for governance, then they are using irrelevant mechanisms very often.
Now the third is that you have emerging technologies specifically being a challenge. Emerging technologies have huge bars of uncertainty around the way that they're going to go. And to be able to effectively govern things that are uncertain, you need to understand the nature of that uncertainty. In the case of AI, for example, you need deep in-house expertise to understand the nature of these technology trajectories. And I don't know how to say this kindly, but governments are not the most technology-literate institutions that are around, which means that they don't have the ability to grapple with that uncertainty in a nuanced way, which means you see one of two things: you either see preemptive clampdown out of fear, or you see too little too late.
So states are no longer the sole source of governance capacity. And for technology problems that move fast and are uncertain, states are particularly ill-equipped.
## Private Labs are Better Placed
Which leads me to proposition two, which is that instead of states, private AI labs are far better-placed, if not the best-placed, actors to do this governance thing, or at least form the initial stages of a governance regime.

Now this proposition is premised on an understanding that private AI labs are the ones at the forefront of developing this technology. Major AI breakthroughs have come from private companies, privately funded nonprofits, or even academic AI labs that have very strong industrial links.
Why does that make them well-equipped to do this governance thing? Very simply, it means that they don't face the same problems that states do. They don't face this pacing problem. They have in-house expertise and access to information in real time, which means that they have the ability to garner unique insights very quickly about the way that this technology is going to go.

So of all the actors, they are most likely to be able to slightly preemptively, at least, see the trajectories that are most plausible and be able to design governance mechanisms that are nuanced and adaptive to those trajectories. No other actor in this space has the ability to do that except those at the forefront of leading this technology development.

Now secondly, they also don't face the scale mismatch problem. This is where you've got a massive global collective action problem, and you have states which are very nationally scaled. What we see is multinational corporations which from the get-go are forced to be designed globally because they have global supply chains, global talent pools, global markets. The technology they are developing is proliferated globally. And so, necessarily, they both have to operate at the scale of global markets, and they also have experience, and they attribute resources to navigating at multiple scales in order to make their operations work. So you see a lot of companies scale at local, national, regional, transnational levels, and they navigate those scales somewhat effortlessly, and certainly effortlessly compared to a lot of other actors in this space. And so, for that reason, they don't face the same scale mismatch problem that a lot of states have.
So you've got private companies that both have the expertise and also the scale to be able to do this governance thing.
Now you're probably sitting there thinking, "This chick has drunk some private sector Kool-Aid if she thinks that private sector, just because they have the capacity, means that they're going to do this governance thing. Both in terms of wanting to do it, but also being able to do it well, in a way that we would actually want to see it pan out."
### Private Labs are Incentivized to Lead
Which leads me to proposition three, which is that private labs are already and can be more incentivized to lead on AI governance in a way that is prosocial. And when I say "prosocial" I mean good: the way that we want it to go, generally, as an altruistic community.
Now I'm not going to stand up here and make a case for why companies are actually a lot kinder than you think they are. I don't think that. I think companies are what companies are: they're structured to be incentivized by the bottom line, and they're structured to care about profit.

All that you need to believe in order for my third proposition to fly is that companies optimize for their bottom line. And what I'm going to claim is that that can be synonymous with them driving towards prosocial outcomes.
Why do I think that? Firstly, it's quite evidently in a firm's self-interest to lead on shaping the governance regime that is going to govern the way that their products and their services are going to be developed and deployed, because it costs a lot if they don't.

How does that cost them? Poor regulation, and when I say "poor", I mean poor in terms of costly for firms to engage with, is something where you see a lot of costs incurred to firms when that happens across a lot of technology domains. And the history of technology policy showcases a lot of examples where firms haven't been successful in preemptively engaging with regulation and preemptively engaging with the governance, and so they end up facing a lot of costs. In the U.S, and I'll point to the U.S. because the U.S. is not worst example of it, but they have a lot of poor regulation in place particularly when it comes to things like biotechnology. In biotechnology, you've got blanket bans on certain types of products, and you also have things like export controls, which have caused a lot of loss of profit for these firms. You also have a lot of examples of litigation across a number of different technology domains where firms have had to battle with regulation that has been put in place.
Now it wasn't in the firms' interests to incur those costs. And so the most cost-effective way, in hindsight, would be for these firms to engage with the governance as they were shaping regulation, shaping governance, and doing what that would be.
Now just because it's costly doesn't mean that it's going to go in a good way. What are the reasons why them preemptively engaging is likely to lead to prosocial regulation? Two reasons why. One: the rationale for a firm would be something like, "We should be doing the thing that governance will want us to do, so that they don't then go in and put in regulation that is not good for us." And if you assume that governance has that incentive structure to deliver on public goods, then firms, at the very least, will converge on the idea that they should be mitigating their externalities and delivering on prosocial outcomes in the same way that the state regulation probably would.
The more salient one in the case of AI is that public opinion actually plays a fairly large role in dictating what firms think are prosocial. You've seen a lot of examples of this in recent months where you've had Google, Amazon, and Microsoft face backlash from the public and from employees where they've developed and deployed AI technologies that grate against public values. And you've seen reactions from these firms respond to those actions as well. It's concrete because it actually affects their bottom line: they lose consumers, users, employees. And that, again, ties back to their incentive structure. And so if we can shore up the power of something like the public opinion that translates into incentive structures, then there are reasons to believe that firms will engage preemptively in shaping things that will go more in line with what public opinion would be on these issues.
So the second reason is that firms already do a lot of governance stuff. We just don't really see it, or we don't really think about it as governance. And so I'm not making a wacky case here in that business as usual currently is already that firms do some governance activity.
Now I'll give you a couple of examples, because I think when we think about governance, we maybe hone in on the idea that that's regulation. And there are a lot of other forms of governance that are private sector-led, which perform governance functions, but aren't really called "governance" by the traditional term.
So here are some examples. When you think about the function of governance of implementing some of these commitments, you can have two different ways of thinking about private sector leading on governance. One is establishing practices along the technology supply chain that govern for outcomes like safety.
Again, in biotechnology, you've got an example of this where DNA synthesis companies voluntarily self-initiated schemes for screening customer orders so that they were screening for whether customers were ordering for malicious use purposes. The state eventually caught up. And a couple of years after most DNA synthesis companies had been doing this in the U.S., it became U.S. state policy. But that was a private sector-led initiative.
Product standards are another really good example where private firms have consistently led at the start for figuring out what a good product looks like when it's on the market.
Cryptographic products, the first wave of them, is a really good example of this. You had firms like IBM and a firm called RSI Security Inc., in particular, do a lot of early-stage R&D to ensure that strong encryption protocols made it onto the market and took up a fair amount of global market share. And for the large part, that ended up becoming American standards for cryptographic products, which ended up scaling across the global markets.
So those are two examples of many examples of ways in which private firms can lead on the implementation of governance mechanisms.

The second really salient function that they play is in compliance. So making sure that companies are doing what they do. There are a lot of examples in this space of climate change, in particular where firms have either sponsored or have directly started initiatives that are about disclosing the things that they're doing to ensure that they are in line with commitments that are made on the international scale. Whether that's things like divestment, or disclosing climate risk, or carbon footprints, or various rating and standards agencies, there is a long list of ways in which the private sector is delivering on this compliance governance function voluntarily, without necessarily needing regulation or legislation.
So firms already do this governance thing. And all that we have to think of is how can they lead on that and shape it in a more preemptive way.
And the third reason to think that firms could do this voluntarily is that, at the end of the day, particularly for transformative artificial intelligence scenarios, firms rely on the world existing. They rely on markets functioning. They rely on stable sociopolitical systems. And if those don't end up being what we get because we didn't put in robust governance mechanisms, then firms have all the more reason to want us to not get to those futures. And so, for an aspirationally long-term thinking firm, this would be the kind of incentive that would lead them to want to lead preemptively on some of these things.
So these are all reasons to be hopeful, or to think at least, that firms can do and can be incentivized to lead on AI governance.

So here are the three propositions again. You've got states who are ill-equipped to lead on AI governance. You've got private AI labs who have the capacity to lead. And finally, you've got reasons to believe that private AI labs can lead in a way that is prosocial.
Now am I saying that private actors are all that is necessary and sufficient? It wouldn't be an academic talk if I didn't give you a caveat, and the caveat is that I'm not saying that. It's only that they need to lead. There are very many reasons why the private sector is not sufficient, and where their incentive structures can diverge from what prosocial outcomes are.
More than that, there are some governance functions which you actually need non-private sector actors to play. They can't pass legislation, and then you often need like a third party civil society organization to do things like monitoring compliance very well. And the list goes on of a number of things that private sector can't do on their own.
So they are insufficient, but they don't need to be sufficient. The clarion call here is for private sector to recognize that they are in a position to lead on demonstrating what governing artificial intelligence can look like if it tracks technological progress in a nuanced, adaptive, flexible way, if it happens at a global scale and scales across jurisdictions easily, and finally avoids costly conflict between states and firms, which tends to precede a lot of costly governance mechanisms that are ineffective being put in place.
So firms and private AI labs can demonstrate how you can lead on artificial intelligence governance in a way that achieves these kinds of outcomes. The argument is that others will follow. And what we can look forward to is shaping the formative stages of an AI governance regime that is private sector-led, but publicly engaged and publicly accountable.

Thank you.
## Questions
\_Question\_: Last time you spoke at EA Global, which was just a few months ago, it was just after the Google engineers' open letter came out saying, "We don't want to sell AI to the government". Something along those lines. Since then, Google has said they won't do it. Microsoft has said they will do it. It's a little weird that rank and file engineers are sort of setting so much of this policy, and also that two of the Big Five tech companies have gone so differently so quickly. So how do you think about that?
\_Jade\_: Yeah. It's so unclear to me how optimistic to be about these very few data points that we have. I think also last time when we discussed it, I was pretty skeptical about how effective research communities can be and technical researchers within companies can be in terms of affecting company strategy.
I think it's not surprising that different companies are making different decisions with respect to how to engage with the government. You've historically seen this a lot where you've got some technology companies that are slightly more sensitive to the way that the public thinks about them, and so they make certain decisions. You've got other companies that go entirely under the radar, and they engage with things like defense and security contracts all the time, and it's part of their business model, and they operate in the same sector.
So I think the idea that you can have the private sector operate in one fashion, with respect to how they engage with some of these more difficult questions around safety and ethics, isn't the way it pans out. And I think the case here is that you have some companies that can plausibly care a lot about this stuff, and some companies that really just don't. And they can get away with it, is the point.
And so I think, assuming that there are going to be some leading companies and some that just kind of ride the wave if it becomes necessary is probably the way to think about it, or how I would interpret some of these events.
\_Question\_: So that relates directly, I think, to a question about the role of small companies. Facebook, obviously, is under a microscope, and has a pretty bright spotlight on it all the time, and they've made plenty of missteps. But they generally have a lot of the incentives that you're talking about. In contrast, Cambridge Analytica just folded when their activity came to light. How do you think about small companies in this framework?
\_Jade\_: Yeah. That's a really, really good point.
I think small companies are in a difficult but plausibly really influential position. As you said, I think they don't have the same lobbying power, basically. And if you characterize a firm as having power as a result of their size, and their influence on the public, and their influence on the government, then small companies, by definition, just have far less of that power.
There's this dynamic where you can point to a subset of really promising, for example, startups or up-and-coming small companies that can form some kind of critical mass that will influence larger actors who, for example, in a functional, transactional sense, would be the ones that would be acquiring them. E.g., like DeepMind had a pretty significant influence on the way that safety was perceived within Google as a result of being a very lucrative acquisition opportunity, in a very cynical framing.
And so I think there are ways in which you can get really important smaller companies using their bargaining chips with respect to larger firms to exercise their influence. I would be far more skeptical of small companies being influential on government and policy makers. I think historically it's always been large industry alliances or large big companies that get summoned to congressional hearings and get the kind of voice that they want. But I think certainly, like within the remit of private sector, I think small companies, or at least medium-size companies, can be pretty important, particularly in verticals where you don't have such dominant actors.
\_Question\_: There have been a lot of pretty well-publicized cases of various biases that are creeping into algorithmic systems that sort of can create essentially racist or otherwise discriminatory algorithms based on data sets that nobody really fully understood as they were feeding it into a system. That problem seems to be far from solved, far from corrected. Given that, how much confidence should we have that these companies are going to get these even more challenging macro questions right?
\_Jade\_: Yeah. Whoever you are in the audience, I'm not sure if you meant that these questions are not naturally incentivized to be solved within firms. Hence, why can we hope that they're going to get solved at the macro level? I'm going to assume that's what the question was.
Yeah, that's a very good observation that within... unless you have the right configuration of pressure points on a company, there are some problems which maybe haven't had the right configuration and so aren't currently being solved. So put aside the fact that maybe that's a technically challenging problem to solve, and that you may not have the data sets available, etc. And if you assume that they have the capacity to solve that problem internally but they're not solving it, why is that the case? And then why does that mean that they would solve bigger problems?
The model of private sector-led governance requires, and as I alluded to, pressure points that are public-facing that the company faces. And with the right exertion of those pressure points, and with enough of those pressure points translating into effects on their bottom line, then that would hopefully incentivize things like this problem and things like larger problems to be solved.
In this particular case, in terms of why algorithmic bias in particular hasn't faced enough pressure points, I'm not certain what the answer is to that. Although, I think you do see a fair amount more like things like civil society action and whatnot popping up around that, and a lot more explicit critique about that.
I think one comment I'll say is that it's pretty hard to define and measure when it's gone wrong. So there's a lot of debate in the academic community, for example, and the ProPublica debate comes to mind too, where you've got debates literally about what it means for this thing to have gone fairly or not. And so that points to the importance of a thing like governance where you've got to have common context, and common knowledge, and common information about your definitions simply, and your benchmarks and your metrics for what it means for a thing to be prosocial in order for then you to converge on making sure that these pressure points are exercised well.
And so I think a lot of work ahead of us is going to be something like getting more granularity around what prosocial behavior looks like, for firms to take action on that. And then if you know basically what you're aiming for, then you can start to actually converge more on the kind of pressure points that you want to exercise.
\_Question\_: I think that connects very directly to another question from somebody who said, basically, they agree with everything that you said, but still have a very deep concern that AI labs are not democratic institutions, they're not representative institutions. And so will their sense of what is right and wrong match the broader public's or society's?
\_Jade\_: I don't know, people. I don't know. It's a hard one.
There are different ways of answering this question. One is that it's consistently a trade off game in terms of figuring out how governance is going to pan out or get started in the right way. And so one version of how you can interpret my argument is something like, look, companies aren't democratic and you can't vote for the decisions that they make. But there are many other reasons why they are better. And so if you were to trade off the set of characteristics that you would want in an ideal leading governance institution, then you could plausibly choose to trade off, as I have made the case for trading off, that they are just going to move faster and design better mechanisms. And so you could plausibly be able to trade off some of the democratic elements of what you would want in an institution. That's one way of answering that question.
In terms of ways of making... yeah, in terms of ways of aligning some of these companies or AI labs: so aside from the external pressure point argument... which if I were critiquing myself on that argument, there are many ways in which pressure points don't work sometimes and it kind of relies on them caring enough about it and those pressure points actually concretizing into kind of bottom line effects that actually makes that whole argument work.
But particularly in the case of AI, there are a handful of AI labs that I think are very, very important. And then there are many, many more companies that I think are not critically important. And so the fact that you can identify a small group of AI labs makes it an easier task to both kind of identify at almost like an individual founder level where some of these common views about what good decisions are can be lobbied to.
And I think it's also the case that there are a number of AI labs... we're not entirely sure how founders think or how certain decision makers think. But there are a couple who have been very public and have gone on record about, and have been pretty consistent actually, about articulating the way that they think about some of these issues. And I think there is some hope that at least some of the most important labs are thinking in quite aligned ways.
Doesn't quite answer the question about how do you design some way of recourse if they don't go the way that you want. And that's a problem that I haven't figured out how to solve. And if you've got a solution, please come tell me.
Yeah, I think as a starting point, there's a small set of actors that you need to be able to pin down and get them to articulate what the kind of mindset is around that. And also that there are an identifiable set of people that really need to buy in, particularly to get transformative AI scenarios right. |
c7da5387-2583-439c-af94-1cb4495b7d5e | trentmkelly/LessWrong-43k | LessWrong | I'm Sorry Fluttershy
I could have been a hero in another world.
I will call the friend of mine who commissioned that picture Fluttershy. They posted it shortly before they killed themselves in early March. They weren't the easiest person to help, but I should have done more than I did. By the end, they were pretty isolated and I was one of the last people they were in contact with.
I will never talk to Fluttershy again, at least not during this age of the world. Looking back it is clear they were always trying to find a way to help me out. Multiple times they gave me the help or advice I needed. They are the person I originally got estrogen from. They were my friend and I miss them so much.
Fluttershy made a lot of mistakes. But it's a harsh world. It is an especially harsh world if you are the type of person to commission fanart of a My Little Pony character freeing chickens. I can understand why they couldn't handle it. Fluttershy was in a lot of pain and hated parts of themselves. I am happy that they are no longer suffering so much. I would never try to stop someone who was determined to commit suicide. But I think things could have been different.
Fluttershy needed someone who believed in them. If you are in a negative spiral it is very hard to get out by yourself. Once things are bad it is easy to alienate your friends. And once you lose support things get even worse. This leads to even worse relationships. Someone else has to put in the free energy to reverse the spiral.
Even in Fluttershy's darkest moments, they thought about helping the least among us. No one was willing and able to help Fluttershy become the hero they wanted to be. I have many, many regrets from my time in California. But chief among them is not making a heroic effort to put Fluttershy on a better path.
I ordered a decent quality print and hung it in my living room. I personally find the idea of the character Fluttershy releasing chickens delightful. But the reason I put up the picture is to remind myself |
a96f4092-5633-4b8e-9a13-f7eb19ec35ba | trentmkelly/LessWrong-43k | LessWrong | Expansion of "Cached thought" wiki entry
"Cached Thought" wiki entry has been copied below for you connivance.
>
>
> A cached thought is an answer that was arrived at by recalling the old conclusion, rather than performing the reasoning from scratch. Cached thoughts can result in the maintenance of a position when evidence should force an update. Cached thoughts can also result in a lack of creative approaches to problem-solving if one repeats the same cached thoughts rather than constructing a new approach.
>
> What is generally called common sense is more or less a collection of cached thoughts.
>
>
The above entry focuses only on the negative sides of cached thought. Probably because it can be a large barrier to rationality. In order overcome this barrier, and/or help others overcome it, it is necessary to understand why "cached thoughts" have been historically valuable to our ancestors and in what fashions it is valuable today.
'''Cached thought''' also allow for complex problems to be handled with a relatively small number of simple components. These problem components when put together only approximate the actual problem, because they are slightly flawed '''cached thoughts.''' Valid conclusions can be reached more quickly with these slightly flawed cached thoughts then without. The aforementioned conclusions should be recheck without using '''cached thoughts''' if a high probability of correctness is necessary or if the '''cached thoughts''' are more then slightly flawed.
Is this an appropriate expansion of the wiki entry? The words are drawn from my observation of the world. How else should the above wiki entry be expanded? |
3169fe77-9e9a-4d47-983e-2c8eacbd5659 | trentmkelly/LessWrong-43k | LessWrong | Are the bacteria/parasites in your gut affecting your thinking?
There is a variety of science going on, mostly in mice, about how intestinal microbiota (bacteria/parasites/fungi?) can affect behavior, emotion, and mental development (Review paper: The micro-biome gut-brain axis, 2011. Review paper 2009). Does any of it have relevance to those of us who'd like to be better rationalists? I'm just beginning to look into this and I'm not a biologist, so I could use help. I'll reference some interesting papers here and give interesting excerpts.
To start off with something easy to read, here is an excerpt from a press release for this 2011 paper about effects on mice:
Working with healthy adult mice, the researchers showed that disrupting the normal bacterial content of the gut with antibiotics produced changes in behaviour; the mice became less cautious or anxious. This change was accompanied by an increase in brain derived neurotrophic factor (BDNF), which has been linked, to depression and anxiety.
When oral antibiotics were discontinued, bacteria in the gut returned to normal.
"This was accompanied by restoration of normal behaviour and brain chemistry," Collins said.
To confirm that bacteria can influence behaviour, the researchers colonized germ-free mice with bacteria taken from mice with a different behavioural pattern. They found that when germ-free mice with a genetic background associated with passive behaviour were colonized with bacteria from mice with higher exploratory behaviour, they became more active and daring. Similarly, normally active mice became more passive after receiving bacteria from mice whose genetic background is associated with passive behaviour.
While previous research has focused on the role bacteria play in brain development early in life, Collins said this latest research indicates that while many factors determine behaviour, the nature and stability of bacteria in the gut appear to influence behaviour and any disruption, from antibiotics or infection, might produce changes in behaviour.
The |
16c3cd4b-da67-419a-bdff-b3fb26cfbcca | StampyAI/alignment-research-dataset/aisafety.info | AI Safety Info | What are some AI governance exercises and projects I can try?
This list is largely focused on projects within [AI policy](https://80000hours.org/career-reviews/ai-policy-and-strategy/) rather than other career paths like [AI safety technical research](https://80000hours.org/career-reviews/ai-safety-researcher/). See [here](/?state=85E0&question=What%20are%20some%20exercises%20and%20projects%20I%20can%20try%3F) for projects focused on technical research (there is some overlap).
- [[Public] Some AI Governance Research Ideas](https://docs.google.com/document/d/13LJhP3ksrcEBKxYFG5GkJaC2UoxHKUYAHCRdRlpePEc/edit) (from GovAI)
- [Project page from AGI Safety Fundamentals](https://www.agisafetyfundamentals.com/ai-governance-tabs/week-8) and their **[Open List of Project Ideas](https://docs.google.com/spreadsheets/d/1Co45Bd_rOc2JZ3jqK7kw1tMptcI0J66Y_8khK4u30_w/edit?usp=sharing)**
- **[2023 Open Philanthropy AI Worldviews Contest](https://www.openphilanthropy.org/open-philanthropy-ai-worldviews-contest/)**
- **[AI Safety Ideas](https://aisafetyideas.com/)** by Apart Research; [EAF post](https://forum.effectivealtruism.org/posts/DTTADonxnDRoksp4E/ai-safety-ideas-an-open-ai-safety-research-platform)
- [Most Important Century writing prize](https://forum.effectivealtruism.org/posts/4XK5zkyv94voC8Fjr/announcing-the-most-important-century-writing-prize) ([Superlinear page](https://www.super-linear.org/prize?recordId=recmsHjuOh5JmVJWJ))
- [Center for AI Safety](https://safe.ai/)
- **[Competitions](https://safe.ai/competitions)** like [SafeBench](https://benchmarking.mlsafety.org/) (see [example ideas](https://benchmarking.mlsafety.org/ideas))
- **[Student ML Safety Research Stipend Opportunity](https://www.mlsafety.org/safety-scholarship)** – provides stipends for doing ML research.
- [course.mlsafety.org projects](https://docs.google.com/document/d/12nj9a1WOJSHaddks3vmmjVKtlHmO53zEW4KHYyapUxY/edit) — CAIS is looking for someone to add details about these projects on [course.mlsafety.org](https://course.mlsafety.org/)
- **[Distilling / summarizing / synthesizing / reviewing / explaining](https://www.lesswrong.com/posts/zo9zKcz47JxDErFzQ/call-for-distillers)**
- **[Forming your own views on AI safety (without stress!)](https://www.youtube.com/watch?v=edoQ3CiNa_s)** – also see [Neel Nanda's presentation slides](https://docs.google.com/presentation/d/1LMBfw2wUmGLEvRTi8019DX_uGdJTeGsHRPRa5S8UIWs/edit#slide=id.p) and "[Inside Views Resources](https://docs.google.com/document/d/1O3ci6Q0UZ8qeBpKs6lVxFGLWiH89fBtz-lLG2iN8YNc/edit#)" document
- ["Mostly focused on AI"](https://forum.effectivealtruism.org/posts/MsNpJBzv5YhdfNHc9/a-central-directory-for-open-research-questions#Mostly_focused_on_AI) section of ["A central directory for open research questions"](https://forum.effectivealtruism.org/posts/MsNpJBzv5YhdfNHc9/a-central-directory-for-open-research-questions) – contains a list of links to projects, similar to this document
- [Possible ways to expand on "Discovering Latent Knowledge in Language Models Without Supervision"](https://www.lesswrong.com/posts/bFwigCDMC5ishLz7X/rfc-possible-ways-to-expand-on-discovering-latent-knowledge)
- Answer some of the [application questions](https://docs.google.com/document/d/1J0jRKfWrNUakiIBbbpw7q3i27Rw9XCLSJvW6659NhRU/edit#) from the winter 2022 [SERI-MATS](https://www.serimats.org/) application process, such as [Vivek Hebbar's problems](https://docs.google.com/document/d/1NVVtdsfz7HiseVFSk3jYly4sPG4dG03wFFDrD8rBXU0/edit)
- [10 exercises from Akash](https://forum.effectivealtruism.org/posts/BBS8cz4Sa7wvJ2Jso/resources-that-i-think-new-alignment-researchers-should-know#Exercises) in “Resources that (I think) new alignment researchers should know about”
- [[T] Deception Demo Brainstorm](https://docs.google.com/document/d/1HLnd7IGyX7ByrnBUZQH6fbneox2jwZ7LRGQw-esc-uU/edit) has some ideas (message [Thomas Larsen](https://www.lesswrong.com/users/thomas-larsen) if these seem interesting)
- Upcoming [2023 Open Philanthropy AI Worldviews Contest](https://forum.effectivealtruism.org/posts/3kaojgsu6qy2n8TdC/pre-announcing-the-2023-open-philanthropy-ai-worldviews)
- [Alignment research at ALTER](https://forum.effectivealtruism.org/posts/zCYGbYAaXeq7v67Km/prize-and-fast-track-to-alignment-research-at-alter) – interesting research problems, many have a theoretical mathematics flavor
- [Open Problems in AI X-Risk [PAIS #5]](https://forum.effectivealtruism.org/s/8EqNwueP6iw2BQpNo/p/hNPCo4kScxccK9Ham)
- Steven Byrnes: [[Intro to brain-like-AGI safety] 15. Conclusion: Open problems, how to help, AMA](https://www.lesswrong.com/posts/tj8AC3vhTnBywdZoA/intro-to-brain-like-agi-safety-15-conclusion-open-problems-1)
- Evan Hubinger: [Concrete experiments in inner alignment](https://www.lesswrong.com/posts/uSdPa9nrSgmXCtdKN/concrete-experiments-in-inner-alignment), [ideas someone should investigate further](https://www.alignmentforum.org/posts/HE3Styo9vpk7m8zi4/evhub-s-shortform?commentId=cPPvFFLLkMuh9k5Zx), [sticky goals](https://www.lesswrong.com/posts/a2Bxq4g2sPZwKiQmK/sticky-goals-a-concrete-experiment-for-understanding)
- Richard Ngo: [Some conceptual alignment research projects](https://www.lesswrong.com/posts/27AWRKbKyXuzQoaSk/some-conceptual-alignment-research-projects), [alignment research exercises](https://www.lesswrong.com/posts/kj37Hzb2MsALwLqWt/alignment-research-exercises)
- Buck Shlegeris: [Some fun ML engineering projects that I would think are cool](https://docs.google.com/document/d/1yMP9i6cQQwHG1ITOtccUkuN3p9eTk1AtzOM8TP-mZVs/edit), [The case for becoming a black box investigator of language models](https://www.alignmentforum.org/posts/yGaw4NqRha8hgx5ny/the-case-for-becoming-a-black-box-investigator-of-language)
- Implement a [key paper](https://spinningup.openai.com/en/latest/spinningup/keypapers.html) in deep reinforcement learning
- [Amplify creative grants](https://forum.effectivealtruism.org/posts/pLiEoTuwEYRxNueoD/announcing-amplify-creative-grants) (old)
- “Paper replication resources” section in “[How to pursue a career in technical alignment](https://forum.effectivealtruism.org/posts/7WXPkpqKGKewAymJf/how-to-pursue-a-career-in-technical-ai-alignment)”
- [ELK](https://www.alignmentforum.org/tag/eliciting-latent-knowledge-elk) – How can we train a model to report its latent knowledge of off-screen events?
- [Daniel Filan idea](https://www.lesswrong.com/posts/WgMhovN7Gs6Jpn3PH/danielfilan-s-shortform-feed?commentId=aEbnazFXn6GFym8kv) – studying competent misgeneralization without reference to a goal
- Summarize a reading from [Reading What We Can](https://readingwhatwecan.com/)
- Zac Hatfield-Dodds: “The list I wrote up for 2021 final-year-undergrad projects is at [https://zhd.dev/phd/student-ideas.html](https://zhd.dev/phd/student-ideas.html) - note that these are aimed at software engineering rather than ML, NLP, or AI Safety per se (most of those ideas I have stay at Anthropic, and are probably infeasible for student projects).” These projects are good for [AI safety engineering careers](https://www.alignmentforum.org/posts/YDF7XhMThhNfHfim9/ai-safety-needs-great-engineers).
|
076a5fa4-376e-47c1-bdf2-1faaa69788c5 | trentmkelly/LessWrong-43k | LessWrong | Interlude with the Confessor (4/8)
(Part 4 of 8 in "Three Worlds Collide")
The two of them were alone now, in the Conference Chair's Privilege, the huge private room of luxury more suited to a planet than to space. The Privilege was tiled wall-to-wall and floor-to-ceiling with a most excellent holo of the space surrounding them: the distant stars, the system's sun, the fleeing nova ashes, and the glowing ember of the dwarf star that had siphoned off hydrogen from the main sun until its surface had briefly ignited in a nova flash. It was like falling through the void.
Akon sat on the edge of the four-poster bed in the center of the room, resting his head in his hands. Weariness dulled him at the moment when he most needed his wits; it was always like that in crisis, but this was unusually bad. Under the circumstances, he didn't dare snort a hit of caffeine - it might reorder his priorities. Humanity had yet to discover the drug that was pure energy, that would improve your thinking without the slightest touch on your emotions and values.
"I don't know what to think," Akon said.
The Ship's Confessor was standing stately nearby, in full robes and hood of silver. From beneath the hood came the formal response: "What seems to be confusing you, my friend?"
"Did we go wrong?" Akon said. No matter how hard he tried, he couldn't keep the despair out of his voice. "Did humanity go down the wrong path?"
The Confessor was silent a long time.
Akon waited. This was why he couldn't have talked about the question with anyone else. Only a Confessor would actually think before answering, if asked a question like that.
"I've often wondered that myself," the Confessor finally said, surprising Akon. "There were so many choices, so many branchings in human history - what are the odds we got them all right?"
The hood turned away, angling in the direction of the Superhappy ship - though it was too far away to be visible, everyone on board the Impossible Possible World knew where it was. "There are pa |
98d1d14a-f984-4b11-bf64-42556dc56839 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Paper: Constitutional AI: Harmlessness from AI Feedback (Anthropic)
The authors propose a method for training a harmless AI assistant that can supervise other AIs, using only a list of rules (a "constitution") as human oversight. The method involves two phases: first, the AI improves itself by generating and revising its own outputs; second, the AI learns from preference feedback, using a model that compares different outputs and rewards the better ones. The authors show that this method can produce a non-evasive AI that can explain why it rejects harmful queries, and that can reason in a transparent way, better than standard RLHF: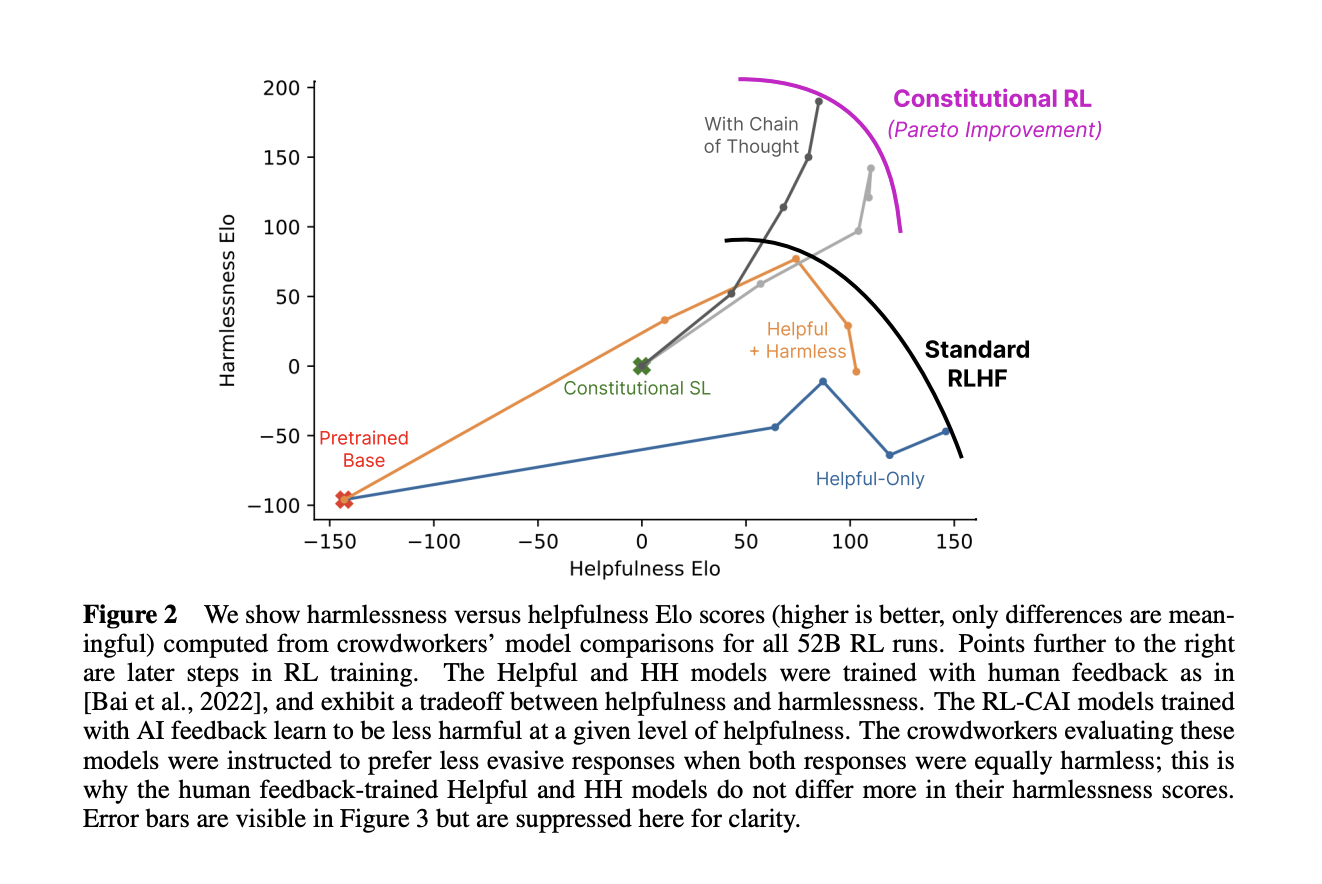
Paper abstract:
> As AI systems become more capable, we would like to enlist their help to supervise other AIs. We experiment with methods for training a harmless AI assistant through selfimprovement, without any human labels identifying harmful outputs. The only human oversight is provided through a list of rules or principles, and so we refer to the method as ‘Constitutional AI’. The process involves both a supervised learning and a reinforcement learning phase. In the supervised phase we sample from an initial model, then generate self-critiques and revisions, and then finetune the original model on revised responses. In the RL phase, we sample from the finetuned model, use a model to evaluate which of the two samples is better, and then train a preference model from this dataset of AI preferences. We then train with RL using the preference model as the reward signal, i.e. we use ‘RL from AI Feedback’ (RLAIF). As a result we are able to train a harmless but nonevasive AI assistant that engages with harmful queries by explaining its objections to them. Both the SL and RL methods can leverage chain-of-thought style reasoning to improve the human-judged performance and transparency of AI decision making. These methods make it possible to control AI behavior more precisely and with far fewer human labels.
>
>
See also Anthropic's tweet thread:
<https://twitter.com/AnthropicAI/status/1603791161419698181> |
1225ec78-8e8e-43da-803e-d0ec9e43326b | trentmkelly/LessWrong-43k | LessWrong | What I learned at the AI Safety Europe Retreat
From the 30th March - 2nd April 2023, I attended the Artificial Intelligence Safety Europe Retreat (AISER) in Berlin, Germany. There were around 70 attendees from all over Europe. Most attendees were actively working on technical AI Safety (e.g SERI-MATS scholars, independent researchers with grants), some people were focusing on AIS strategy and governance, and some newcomers / students (like me) were looking to learn more about the field and career opportunities. For a short overview of the retreat, have a look here.
This post is targeted at people who couldn't make it to the AISER and/or are considering attending a similar event. Concretely, I will provide you with my takeaways from AISER which I gathered by attending some of the talks and one-on-ones. I will conclude the post with some personal (and thus very subjective) impressions of the event. I will not mention specific names as the conversations and talks weren’t given with the intention of appearing in public. Still, I think many ideas exchanged at the AISER are worth sharing with a wider audience. I will put my personal spin on them as I present them in this blog post, so all critique should be directed towards me.
Some background context about me to put this post into a (critical) perspective may be helpful. For a general overview of my experiences and skills, please consult my about page. I wrote my undergrad thesis on robustness and formal verification of AI, but I wasn't aware of the AI alignment movement at the time. Before joining the AI Safety Europe Retreat, I had only just completed the AGI Safety Fundamentals curriculum with a reading group at my university - otherwise I had no experience in the field. I'm motivated to work on AI Safety (AIS) because people seem to trust AI too much, and I want to make AI actually worthy of such trust. Also, another appeal of AIS is its interdisciplinary approach. It employs elements from diverse fields (which I find very cool and interesting to work in in the |
d4ef5c7c-d320-40f2-9c4a-28ea3d2fa586 | trentmkelly/LessWrong-43k | LessWrong | Parfit's Escape (Filk)
To the tune of "Escape" (The Piña Colada Song), with apologies to Rupert Holmes.
I was lost in the desert, hopelessly dying of thirst
And I thought to myself, this can't get any worse
I heard the roar of an engine, surely it was my hearse
But then a tall shadow cooled me, it spoke and I heard
"If you like living not dying, I got an offer for you
If you give me your money, I'll give you water and food
I'll take you away to salvation, I'll get you out of this scrape
So just promise you'll pay me, to make Parfit's escape"
I hadn't solved decision theory, boy I sure wish that I had
'Cause my savior was Omega, and if I lied I'd be had
But CDT said don't pay, just take the ride for free
And though it seemed kind of foolish, I went ahead and agreed
"Yes, I like living not dying, so I'll make your offer good
When we get back to town, I've got money for you
I've got to get out of this desert now, I'm so tired of this place
Yes I two box on Newcomb, and I take Parfit's escape"
Omega dragged me to the car, put a canteen to my lips
We drove into the sunset, I felt nothing but bliss
I caught a glimpse of his face, and to my wondering eyes
My driver wasn't Omega, but Singer in disguise
"You don't owe me any money, you're the life I can save
And you should know I would have helped you, if you had lied to my face
I really hope you've learned a lesson though, about the perils of this place
Decision problems are dangerous, it's moral luck you escaped"
I said "Oh thank you Mr. Singer, let me buy you a drink
At a bar called O'Malley's, they make their Coladas pink
'Cause I'm eternally grateful, for all that you've done
Now let's get out of this desert, and be done with this song" |
e5daa05e-c90a-4a6c-a99f-bf5deae9da26 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Urbana-Champaign: Recreation
Discussion article for the meetup : Urbana-Champaign: Recreation
WHEN: 11 May 2014 01:00:00PM (-0500)
WHERE: 40.1112,-88.2274
Since the weather is nice, let's meet outside, on the benches south of the engineering quad. I'll bring kites - coincidentally, the engineering quad is a great place to fly kites.
We may talk about mechanism design (reading).
Bonus topic: what do debates like this recent one tell us about what's going on in peoples' heads?
Discussion article for the meetup : Urbana-Champaign: Recreation |
397c3894-c7e8-40c9-8120-67edfcf55724 | trentmkelly/LessWrong-43k | LessWrong | Arch-anarchy:Theory and practice
This article aims to expand on some of the ideas in the text " arch-anarchy"(See my previous post) republished from Extropy magazine. First of all, I believe that the nation-state is doomed to fall in a few years to the decentralization of the economy, and distributed computing networks (bitcoin, smart contract, etc.), should make large hierarchical structures economically unviable in a few years , and in place of nation-states we will have an anarchist market society.Maybe I'll publish an article expanding on.
Now, how can we free ourselves from the laws of nature? well, I have a theory, the microdimensional mastery proposed by John Barrow, and an idea of how to measure technological development. is an alternative to Kardashev's scale is the fact that humans (or other civilizations) have found it more economical to extend any abilities to manipulate their environment into smaller and smaller dimensions rather than larger and larger dimensions.The most advanced type of civilization on the Barrow scale is a civilization Type Omega-minus capable of manipulating the fundamental structure of space and time.
There is now a trend in engineering called Miniaturization to reduce the size of components, devices, or systems without compromising their functionality or performance. Miniaturization allows for the manufacture of smaller, more efficient devices, which is why computers and other electronic devices from the 1950s to the present day are getting smaller and smaller, for example .
Now we have Micro-technology (10^-6 meters) and we are developing Nanotechnology (10^-9 meters), assuming that miniaturization in a constant trend we can imagine that we will evetually develop technology on smaller and smaller scales Picotechnology(10^-12 meters),Femtotechnoloy(10^-15 meters), attotechnology(10^-18 meters),zeptotechnology(10^-21 meters) yoctotechnology(10^-24 meters) and plancktechnology(10^-34).By our current scientific knowledge there is no scale smaller than the Planck |
01dd5490-4f21-455c-b06e-04013592faa9 | trentmkelly/LessWrong-43k | LessWrong | AI Alignment [progress] this Week (11/12/2023)
It’s hard to deny the fact that most of the oxygen in the room this week was taken up by the OpenAI Dev Day. If you want, feel free to check out my choose-your-own-adventure GPT. I think the jury is out on whether GPTs represent an actual use-case or if like plugins they will be killed by OpenAI’s overly restrictive use-case policy.
That aside, here are our:
AI Alignment Breakthroughs this Week
This week, there were breakthroughs in the areas of:
Math
Mechanistic Interpretability
Benchmarking
Brain Uploading
Making AI do what we want
and
AI Art
Math:
Terry Tao completes a formal proof of his paper using AI
What is it: One of my favorite mathematicians, Terry Tao, just finished the formal proof of one of his papers
What’s new: Tao reports automated tools made writing the paper “only” 5x slower than writing a normal math paper.
What is it good for: Tao found one minor “bug” in his paper during the process. Formal proof can provide better assurance in high trust domains
Rating: 💡💡💡
Mechanistic Interpretability
Transformers can generalize OOD
What is it: a toy example of a transformer that does generalize out of its domain
What’s new: refutes a paper last week by DeepMind claiming transformers cannot generalize OOD
What is it good for: knowing the limits of different ML architectures is key to many alignment plans
Rating: 💡
Benchmarking
Seeing is not always believing
What is it:research shows humans being tricked by Deepfakes 38% of the time
What’s new: I haven’t seen many systematic studies of this
What is it good for: we need to understand the dangerous capabilities of AI in order to know how to regulate them. Although in this case, I expect the number will soon reveal humans are completely unable to recognize fake images.
Rating: 💡
Bingo
What is it: a benchmark for vision model
What’s new: the benchmark highlights cases were the information in the text and image disagree
What is it good for: Training AI to av |
5aaf760e-d59f-4e42-86a6-cd5009b15163 | trentmkelly/LessWrong-43k | LessWrong | Leaky Generalizations
Are apples good to eat? Usually, but some apples are rotten.
Do humans have ten fingers? Most of us do, but plenty of people have lost a finger and nonetheless qualify as "human".
Unless you descend to a level of description far below any macroscopic object - below societies, below people, below fingers, below tendon and bone, below cells, all the way down to particles and fields where the laws are truly universal - then practically every generalization you use in the real world will be leaky.
(Though there may, of course, be some exceptions to the above rule...)
Mostly, the way you deal with leaky generalizations is that, well, you just have to deal. If the cookie market almost always closes at 10pm, except on Thanksgiving it closes at 6pm, and today happens to be National Native American Genocide Day, you'd better show up before 6pm or you won't get a cookie.
Our ability to manipulate leaky generalizations is opposed by need for closure, the degree to which we want to say once and for all that humans have fingers, and get frustrated when we have to tolerate continued ambiguity. Raising the value of the stakes can increase need for closure - which shuts down complexity tolerance when complexity tolerance is most needed.
Life would be complicated even if the things we wanted were simple (they aren't). The leakyness of leaky generalizations about what-to-do-next would leak in from the leaky structure of the real world. Or to put it another way:
Instrumental values often have no specification which is both compact and local.
Suppose there's a box containing a million dollars. The box is locked, not with an ordinary combination lock, but with a dozen keys controlling a machine that can open the box. If you know how the machine works, you can deduce which sequences of key-presses will open the box. There's more than one key sequence that can trigger the button. But if you press a sufficiently wrong sequence, the machine incinerates the money. And if |
a77be972-b8ab-425c-a536-08991417c17a | trentmkelly/LessWrong-43k | LessWrong | What do you think of my reading list?
(I am slightly anxious about making my first discussion post! If there is anything about this that should not have been done, or done differently, please let me know!)
I'm new to this rationalist stuff. I want to improve my grasp on many topics. I want a richer vocabulary and set of concepts with which to discuss these topics. These are some nonfiction books I'm thinking of trying to eat this year, in no particular order of priority:
So if you have read any of these books and would like to help me with this:
Are there any that you would endorse? Which books might I be I wasting my time with? Are any of them too crank or pseudoscientific to be worthy of my time? Ones I had better save for later because I couldn't get anything out of them with my high school level math ability? Books that are similar to a different book that does the same thing better? Or any books along these lines you think it would be a CRIME not to include? Or any other suggestions? I would be grateful for any bit of help! |
b0ba1edd-09cb-44bb-923e-5f00fc497779 | trentmkelly/LessWrong-43k | LessWrong | Problematic Problems for TDT
A key goal of Less Wrong's "advanced" decision theories (like TDT, UDT and ADT) is that they should out-perform standard decision theories (such as CDT) in contexts where another agent has access to the decider's code, or can otherwise predict the decider's behaviour. In particular, agents who run these theories will one-box on Newcomb's problem, and so generally make more money than agents which two-box. Slightly surprisingly, they may well continue to one-box even if the boxes are transparent, and even if the predictor Omega makes occasional errors (a problem due to Gary Drescher, which Eliezer has described as equivalent to "counterfactual mugging"). More generally, these agents behave like a CDT agent will wish it had pre-committed itself to behaving before being faced with the problem.
However, I've recently thought of a class of Omega problems where TDT (and related theories) appears to under-perform compared to CDT. Importantly, these are problems which are "fair" - at least as fair as the original Newcomb problem - because the reward is a function of the agent's actual choices in the problem (namely which box or boxes get picked) and independent of the method that the agent uses to choose, or of its choices on any other problems. This contrasts with clearly "unfair" problems like the following:
Discrimination: Omega presents the usual two boxes. Box A always contains $1000. Box B contains nothing if Omega detects that the agent is running TDT; otherwise it contains $1 million.
So what are some fair "problematic problems"?
Problem 1: Omega (who experience has shown is always truthful) presents the usual two boxes A and B and announces the following. "Before you entered the room, I ran a simulation of this problem as presented to an agent running TDT. I won't tell you what the agent decided, but I will tell you that if the agent two-boxed then I put nothing in Box B, whereas if the agent one-boxed then I put $1 million in Box B. Regardless of how the si |
4b989a1b-51d0-4a3d-ae51-bc582c885db5 | trentmkelly/LessWrong-43k | LessWrong | What Would It Cost to Build a World-Class Dredging Vessel in America?
I'm doing some research into questions surrounding the Foreign Dredge Act of 1906, and thought I'd experiment by throwing this out there.
For context, the 31 biggest dredging vessels were not built in America, and thus cannot be used in America by law. We only have a small number of less capable vessels, and they often get redirected to short-term emergency tasks. This is preventing us from doing a bunch of very valuable things, like repairing or expanding ports, which end up taking much more time and money or not happening at all.
This podcast is recommended. You can find a transcript here. They claim that there's no way America will be able to have such capacity for at least decades. I want to verify that (and also check if any other claims here don't ring true)?
As an alternative to repealing the Dredge Act (which I'm exploring and planning to write about) another alternate would be to build world-class dredging vehicles here in America, such that they could be used. Before assuming that this is impossible, and to have a straight answer, what would happen if someone with deep pockets tried to commission a world-class dredging ship that would qualify? Could be done? Are there other impossible barriers to solve? How much would it cost and how much more would that be than building it elsewhere? How long would it take? |
33afb6df-65fe-4d1f-927e-8997f54f15fe | trentmkelly/LessWrong-43k | LessWrong | Hierarchy and wings
(Note for LessWrong: This is more overtly about partisan politics than the norm, but I think it's not more about that than The Two-Party Swindle, from the Sequences, and it proposes a structural model that doesn't require people to be as stupid.)
There are a few points I didn't make in my post on blame games because they seemed extraneous to the core point, which are still important enough to write down.
Hierarchy
The Hierarchy game is a zero-sum game in which people closer to the center expropriate from people farther from the center, and use some of those resources to perpetuate the power imbalances that enable the expropriation. Players that fail to submit to expropriation by higher-level players are punished by those more-powerful players, often through intermediaries. Players that fail to help members of their class expropriate from those beneath them are excluded from their class, and often coordinated against more overtly.
This game isn't inherently majoritarian, - instead, it allows smaller groups to stably expropriate from larger ones, because every player has a short-run incentive to go along with the arrangement. Feudalism is a simple example of the hierarchy game. Modern states almost always have some hierarchical arrangements, such as the police and military, and (less formally) economic class.
Political handedness
Around the time of the French revolution - a replacement of Feudal arrangements with Modern states - people started using terms like "left" and "right" to refer to political orientations. These terms are related to natural structural coalitions within a modern democratic state.
Political parties don't overtly promise to expropriate from 49% on behalf of an arbitrary 51%. This is probably in part because this would be correctly viewed as a proposal to massively increase expropriative activity relative to other activity, accelerating the rate of expropriation, which actually isn't in the majority's interests, and would quickly undermine |
48216cca-f998-488f-8d77-7e1ffcedca72 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | [Congressional Hearing] Oversight of A.I.: Legislating on Artificial Intelligence
This is a selection of quotes from the Senate Subcommittee Hearing "**Oversight of A.I.: Legislating on Artificial Intelligence"** held on 9/12/23. It's the third in a series of hearings, the first a hearing on [rules for AI](https://www.judiciary.senate.gov/committee-activity/hearings/oversight-of-ai-rules-for-artificial-intelligence) (quotes [here](https://forum.effectivealtruism.org/posts/kXaxasXfG8DQR4jgq/some-quotes-from-tuesday-s-senate-hearing-on-ai)), the second a hearing on [principles for regulation](https://www.judiciary.senate.gov/committee-activity/hearings/oversight-of-ai-principles-for-regulation) (quotes [here](https://forum.effectivealtruism.org/posts/67zFQT4GeJdgvdFuk/partial-transcript-of-recent-senate-hearing-discussing-ai-x)).
I think this is important because it serves as a quick way to orient to this hearing, to get a sense of some of the important themes and develop from them what we should think about those involved and the ideas they discussed. Below, I'll give quick summaries for the positions of the witness and congressmen, and will then present the quotes, topically organized.
---
**Witnesses** were: Woodrow Hartzog (Boston University, law professor), Brad Smith (Microsoft, president), and William Dally (NVIDIA, chief scientist).
* Hartzog is focused more on how AI becomes another tool for the powerful, and the non-x-risk side of AI, with ideas that resonate but often seem to lead to interventions that might not be as helpful for x-risk.
* Brad Smith was on board with regulation, he even praised the B-H framework at one point, but also continually emphasized the need for a conversation between innovation and safety, and would often use specific language that implied he supported something similar but more narrow than what was being discussed (e.g. while endorsing the B-H framework he made clear that it should only apply to "advanced models in high-risk scenarios")
* William Dally says AGI is "science fiction" and also pushes against the idea that regulating the AI supply chain is a feasible tool ("no nation, and certainly no company, controls a chokepoint to AI development").
**Senators** were: Richard Blumenthal, Josh Hawley, Mazie Hirono, John Kennedy, Amy Klobuchar, Marsha Blackburn and Jon Ossoff
* Senator Blumenthal mostly asked clarifying questions that built upon others, but also talked about his framework and the general importance of the issue
* Senator Hawley was focused on non-x-risk topics, generally honing in on risks from kids interacting with chatbots and risks from AI use in China
* Senator Mazie Hirono was largely concerned with misinformation
* Senator Kennedy was focused on notification of AI use entirely
* Senator Klobuchar was most concerned with various non-x-risk issues, like the use of AI in creating synthetic media, and especially with how to prevent the use of AI generated synthetic media in elections
* Senator Blackburn was focused on China and disinformation (Tik-Tok was an example)
* Senator Jon Ossoff asked pointed, useful questions throughout his time that were directly aimed at how to codify things (like a definition of AI) for writing legislation
---
AGI
===
Dally: "Some have expressed fear that frontier models will evolve into uncontrollable artificial general intelligence, which could escape our control and cause harm. Fortunately, uncontrollable artificial general intelligence is science fiction and not reality. At it's core, AI is a software program that is limited by its training, the inputs provided to it and the nature of its output. In other words, humans will always decide how much decision making power to cede to AI models."
Importance
==========
Blumenthal: "There is a moral imperative here...and when we simply do economic or political interests, sometimes it's very shortsighted"
Hawley: "We have a responsibility...[to not] make the same mistakes Congress made with social media where 30 years ago Congress basically outsourced social media to the biggest corporations in the world and that has been, I would submit to you, a nearly unmitigated disaster"
Regulation
==========
General
-------
Blumenthal: "Private rights of action, as well as federal enforcement, are very important"
Hartzog: "Half measures like audits, assessments and certifications are necessary for data governance but industry leverages procedural checks like these to dilute our laws into managerial box checking exercises that entrench harmful surveillance based business models...it's no substitute for meaningful liability."
Proposals
---------
### Blumenthal-Hawley (B-H) Framework
Smith: "[The Blumenthal-Hawley Framework] is a very strong and positive step in the right direction...Let's require licenses for advanced AI models and uses in high-risk scenarios. Let's have an agency that is independent and can exercise real and effective oversight over **this category"**
### Stop Button
Smith: "We need a safety break, just like we have a circuit breaker in every building and home in this country, to stop the flow of electricity if that's needed"
Uncertainties
-------------
### At What Stage?
Hartzog: "I think that the area that has been ignored up until this point has been the design and inputs to a lot of these tools"
Dally: "I think it's really the use of the model and the deployment that you can effectively regulate. It's going to be hard to regulate the creation of it because if people can't create them here they'll create them somewhere else. I think we'll have to be very careful if we want the US to stay ahead"
### Is Domestic Regulation Feasible?
Dally: "No nation, and certainly no company, controls a chokepoint to AI development. Leading US computing companies are competing with companies from around the world...US companies...are not the only alternative for developers abroad. Other nations are developing AI systems with or without US components and they will offer those applications in the worldwide market. Safe and trustworthy AI will require a multi-lateral and multi-stakeholder cooperation, or it will not be effective"
Dally: "We would like to ensure the US stays ahead in this field"
> Ossoff: "How does any of this work without international law? Isn't it correct that a model, potentially a very powerful and dangerous model, for example whose purpose is to unlock CBRN or mass destructive virological capabilities to a relatively unsophisticated actor, once trained it's relatively light weight to transport, and without A. an international legal system and B. a level of surveillance that seems inconceivable into the flow of data across the internet, how can that be controlled and policed?"
>
> ...
>
> Hartzog: "Ultimately what I worry about is deploying a level of surveillance that we've never before seen in an attempt to perfectly capture the entire chain of AI"
>
>
Blumenthal: "I think there are international models here where, frankly, the US is a leader by example and best practices are adopted by other countries when we support them."
> Smith: "We probably need an export control regime that weaves [GPUs, cloud compute, frontier models] together. For example, there might be a country in the world...where you all in the executive branch might say 'we have some qualms, but we want US technology to be present, and we want US technology to be used properly'. You might say then 'we'll let NVIDIA export chips to that country to be used in, say, a datacenter of a company that we trust, that is licensed, even here, for that use, with the model being used in a secure way in that data center, with a know-your-customer requirement, and with guardrails that put certain kinds of use off-limits'. That may well be where government policy needs to go."
>
> ...
>
> Blumenthal: "I would analogize this situation to nuclear proliferation. We cooperate over safety, in some respects, with other countries, some of the adversaries, but we still do everything in our power to prevent American companies from helping China or Russia in their nuclear programs. Part of that non-proliferation effort is through export controls. We impose sanctions, we have limits and rules around selling and sharing certain chokepoint technologies relating to nuclear enrichment, as well as biological warfare, surveliance and other national security risks"
>
> Dally: "The difference here is that there really isn't a chokepoint and there's a careful balance to be made between limiting where our chips go and what they're used for...and disadvantaging American companies"
>
> ...
>
> Dally: "We're not the only people who make chips that can do AI...If people can't get the chips they need to do AI from us, they will get them somewhere else, and what will happen then is it turns out the chips isn't what makes them useful, it's the software. And, if all of a sudden the standard chips for people to do AI become something from, pick a country, Singapore...and all the software engineers will start writing the software for those chips, they'll become the dominant chips and the leadership of that area will have shifted from the US to Singapore or whatever other country becomes dominant"
>
> ...
>
> Smith: "Sometimes you can approach this and say, look, if we don't provide this to somebody, somebody else will so let's not worry about it. But at the end of the day, whether your a company or a country, I think you do have to have clarity about how you want your technology to be used."
>
>
### How Should We Define What We License?
Ossoff: "Is the question which models are the most powerful in time, or is there a threshold of capability or power that should define the scope of regulated technology?"
> Ossoff: "Is it a license to train a model to a certain capability? Is it a license to sell (or license access) to that model? Or is it a license to purchase or deploy that model? Who is the licensed entity?
>
> Smith: "That's another question that is key and may have different answers in different scenarios but mostly I would say it should be a license to deploy...I think there may well be obligations to disclose to say an independent authority when a training run begins depending on what the goal [is]"
>
>
Smith: "Imagine we're at GPT-12...Before that gets released for use, I think you can imagine a licensing regime that would say that it needs to be licensed after it's been, in effect, certified as safe...Look at the world of civil aviation, that's fundamentally how it has worked since the 1940s, lets try to learn from it and see how we might apply something like that or other models here"
### Regulate by Risk or Use Case?
Blumenthal: "To my colleagues who say there's no need for new rules, we have enough laws protecting the public...we need to make sure that these regulations are targeted and framed in a way that apply to the risks involved. Risk based rules, managing the risks is what we need to do here"
Dally: "Fortunately many uses of AI applications are subject to existing laws and regulations that govern the sectors in which they operate. AI enabled services in high risk sectors could be subject to enhanced licensing and certification requirements when necessary, while other applications with less risk of harm may need less stringent licensing or regulation."
Smith: "We're going to need different levels of obligations and as we go forward let's think about the connection between the role of, let's say, a central agency that will be on point for certain things, as well as the obligations that frankly will be part of the work of many agencies...I do think that it would be a mistake to think that one single agency, or one single licensing regime would be the right recipe to address everything""
Hartzog: "Lawmakers must accept that AI systems are not neutral and regulate how they are designed. People often argue that lawmakers should avoid design rules for technologies because there are no bad AI systems, only bad AI users. This view of technologies is wrong."
Dally: "AI is a computer program, it takes an input and produces an output, and if you don't connect up something that can cause harm to that output it can't cause that harm"
Dally: "[Licensing] is dependent on the application, because if you have a model which is basically determining a medical procedure there's a high risk for that. If you have another model which is controlling the temperature in your building, if it get's it a little bit wrong...it's not a life threatening situation...You need to regulate the things that are, have high consequences if things go awry"
Timelines
---------
Blumenthal: "Make no mistake there will be regulation, the only question is how soon and what"
Blumenthal: "We'll achieve legislation I hope, by the end of this year"
Non-X-Risk Topics
=================
Digital Providence
------------------
Both Smith and Dally are in support
Jobs
----
Smith argues that AI will likely automate jobs without creativity and argues this can be good because it frees people up to focus on "paying attention to other people and helping them |
05949846-e0d7-4109-89cd-e86a283bafe0 | trentmkelly/LessWrong-43k | LessWrong | Quantilal control for finite MDPs
We introduce a variant of the concept of a "quantilizer" for the setting of choosing a policy for a finite Markov decision process (MDP), where the generic unknown cost is replaced by an unknown penalty term in the reward function. This is essentially a generalization of quantilization in repeated games with a cost independence assumption. We show that the "quantilal" policy shares some properties with the ordinary optimal policy, namely that (i) it can always be chosen to be Markov (ii) it can be chosen to be stationary when time discount is geometric (iii) the "quantilum" value of an MDP with geometric time discount is a continuous piecewise rational function of the parameters, and it converges when the discount parameter λ approaches 1. Finally, we demonstrate a polynomial-time algorithm for computing the quantilal policy, showing that quantilization is not qualitatively harder than ordinary optimization.
----------------------------------------
Background
Quantilization (introduced in Taylor 2015) is a method of dealing with "Extremal Goodhart's Law". According to Extremal Goodhart, when we attempt to optimize a utility function U∗:A→R by aggressively optimizing a proxy U:A→R, we are likely to land outside of the domain where the proxy is useful. Quantilization addresses this by assuming an unknown cost function C:A→[0,∞) whose expectation Eζ[C] w.r.t. some reference probability measure ζ∈ΔA is bounded by 1. ζ can be thought of as defining the "domain" within which U is well-behaved (for example it can be the probability measure of choices made by humans). We can then seek to maximize E[U] while constraining E[C] by a fixed bound Cmax:
~ξ∗:∈argmaxξ∈ΔA{Eξ[U]∣∣∣∀C:A→[0,∞):Eζ[C]≤1⟹Eξ[C]≤Cmax}
Alternatively, we can choose some parameter η∈(0,∞) and maximize the minimal guaranteed expectation of U−ηC:
ξ∗:∈argmaxξ∈ΔAinfC:A→[0,∞){Eξ[U−ηC]∣∣∣Eζ[C]≤1}
These two formulations are almost equivalent since both amount to finding a strategy that is Pareto efficient w.r. |
272aebce-090e-4037-bd77-3b21a22cf7b7 | trentmkelly/LessWrong-43k | LessWrong | Bad names make you open the box
Think of a function as a black box. It takes an input, and spits back out an output.
For getPromotedPosts, you can feed it a list of blog posts and it will spit back out the ones that have been promoted.
But I probably didn't need to explain that to you, did I? Why not? Well, because getPromotedPosts is self-explanatory. Because getPromotedPosts is named well.
Now what if instead of getPromotedPosts, it was named something like getThePosts? Well, that name isn't self-explanatory. You know it's getting some posts, but it's not clear which ones. The most recent posts? Posts from a certain author? Posts from this week?
As a programmer, what do you do in this situation? You scroll to the function definition and start reading the code.
function getThePosts(posts) {
...
}
In other words, you open the box.
What does that look like? Something like this:
* You're reading through the code in some file. Line one, line two, line three.
* You reach line 30 and see getThePosts.
* You realize that getThePosts must be getting some posts, but you don't know which ones. So you have to scroll to line 174 where getThePosts is defined.
* On line 174 you start reading through getThePosts. Once you reach line 210, you realize that it is getting promoted posts. Cool!
* Now you scroll back up to line 30. You realize that getThePosts is giving you promoted posts, but you forgot what was happening before line 30. Damn. So now you have to go back to line 10 or 15 to remind yourself what was going on in the first place.
Complexity and zoom level
Maybe I was being dramatic. Is it really such a big deal to have to scroll to the definition of getThePosts on line 174? Will it really take that much effort to read lines 174-210 and figure out that it's returning promoted posts? It's only 36 lines of code, including whitespace + brackets, and you could probably glance over parts of it. And then what about returning to line 30? Are you really going to have forgotten what was goi |
b0fa7433-8f67-47e5-80e3-911e6436925e | trentmkelly/LessWrong-43k | LessWrong | What if the front page…
What if the front page looked a little more like this?
(Please assume that I'm trying to help. If you're polite and constructive (even if you hate this design) Omega will send you bundles of love in the post. If you're rude, I'll personally fund ninja assassins to hunt you down.) |
04bfbf1a-102f-4cdc-8bb3-0cfd421af369 | trentmkelly/LessWrong-43k | LessWrong | Do the 'unlucky' systematically underestimate high-variance strategies?
From the UK Telegraph:
> A decade ago, I set out to investigate luck. I wanted to examine the impact on people's lives of chance opportunities, lucky breaks and being in the right place at the right time. After many experiments, I believe that I now understand why some people are luckier than others and that it is possible to become luckier.
>
> To launch my study, I placed advertisements in national newspapers and magazines, asking for people who felt consistently lucky or unlucky to contact me. Over the years, 400 extraordinary men and women volunteered for my research from all walks of life: the youngest is an 18-year-old student, the oldest an 84-year-old retired accountant.
Be lucky -- it's an easy skill to learn
On reading the article, the takeaway message seems to be that the 'unlucky' systematically fail to take advantage of high-expected-but-low-median value opportunities. |
80ff5c66-52b9-4187-ac1a-d2ce529d6322 | trentmkelly/LessWrong-43k | LessWrong | SETI Predictions
I enjoyed reading through people's views of the AGI Predictions. I know only a little about AI and a little bit more about SETI (Search for Extraterrestrial Intelligence), so I decided to make a similar poll.
The First Contact scenario with extraterrestrial intelligence shares certain similarities with the emergence of AGI. In the following, I ask similar questions to those in the AGI post. In addition, I add questions derived from the SETI literature. These are intended to reflect on AGI from a new perspective.
In SETI, it is debated that First Contact can cause great disturbance and change, positive and negative. After all, civilizations which are capable of contacting us across the oceans of time and space are expected to be much more advanced - just like AGI is expected to be "superior" (whatever that means) to baseline humans.
The form of First Contact
Elicit Prediction (elicit.org/binary/questions/RkLssuCrJ)
Elicit Prediction (elicit.org/binary/questions/dZ0ZTzPuE)
Elicit Prediction (elicit.org/binary/questions/5JWXrNKXX)
Elicit Prediction (elicit.org/binary/questions/qi1GGHSfe)
Its timeline
Elicit Prediction (elicit.org/binary/questions/5GGrhl1F9)
Elicit Prediction (elicit.org/binary/questions/kmTnf6_gK)
Elicit Prediction (elicit.org/binary/questions/BD2RSu5os)
Elicit Prediction (elicit.org/binary/questions/SFuDzSC-j)
Our response
Elicit Prediction (elicit.org/binary/questions/LKPmY9FBE)
Elicit Prediction (elicit.org/binary/questions/AYfDCij9R)
Elicit Prediction (elicit.org/binary/questions/tu8e3B_7x)
The consequences
Elicit Prediction (elicit.org/binary/questions/z0rClHx76)
Elicit Prediction (elicit.org/binary/questions/ixfD5kuGO)
Elicit Prediction (elicit.org/binary/questions/Y0Qq6tXY8)
Elicit Prediction (elicit.org/binary/questions/vBwrDBIqi)
Elicit Prediction (elicit.org/binary/questions/C9d206Soq)
Elicit Prediction (elicit.org/binary/questions/dFBwknL6z)
Elicit Prediction (elicit.org/binary/questions/4GhUodJjC)
Elicit Prediction (eli |
26a184b7-7e1d-4f82-9cd6-950a40d3963f | trentmkelly/LessWrong-43k | LessWrong | Formalizing Space-Faring Civilizations Saturation concepts and metrics
Crossposted on the EA Forum.
Displacement of other Space-Faring Civilizations (SFCs) may have macrostrategic impact for longtermists as hinted in a previous post. For example, our causal impact depends on how much value we produce relative to how much value would have been produced without us. In this post, we clarify the concept of Civ-Saturation, the metrics to describe it, and how to evaluate the Civ-Saturation Hypothesis[1]. We finally present a simple simultaneous appearance displacement model. This model lets us compute how much marginal resources are grabbed when increasing the density of SFCs.
Sequence: This post is part 4 of a sequence investigating the longtermist implications of alien Space-Faring Civilizations. Each post aims to be standalone. You can find an introduction to the sequence in the following post.
Summary
This post formalizes the concept of Civ-Saturation (CS) and a few associated metrics, which help evaluate how the existence of Space-Faring Civilizations (SFCs) affects the distribution of cosmic resources. The key metric introduced is Marginal Civ-Saturation (MCS), which measures the marginal resources gained when adding new SFCs to a world. Three variants are presented: MCSh (within humanity's SFC potential space), MCSw (across an entire world), and MCSc (within correlated space). MCSh is the metric to use to make decisions, given our point of view. Using a simultaneous appearance displacement model, the post illustrates how MCS values vary with SFC density (D, the number of SFCs per reachable universe), showing that marginal resources drop by 20x between D=0.01 and D=3. The formalization helps classify worlds into three categories based on their MCS values: Non Civ-Saturated Worlds (MCSh>99%), Partially Civ-Saturated Worlds (5%≤MCSh≤99%), and Redundantly Civ-Saturated Worlds (MCSh<5%). These classes can be used for analyzing the longtermist macrostrategic implications of the Civ-Saturation Hypothesis[1].
Illustration of Civ-Saturati |
efbc0ceb-64f1-4bb6-833c-19b73fadbbff | trentmkelly/LessWrong-43k | LessWrong | Kallipolis, USA
This is a very tongue-in-cheek term paper I wrote for my philosophy class on Plato in fall of 2016. I had a lot of fun with it & still like to talk about it sometimes when I get tipsy. I'm putting it up here because why not. Comments welcome.
Abstract:
> Reading Plato’s Republic, you may have had reactions like this: “The Kallipolis… what a ridiculous and intriguing city! How utopian, yet how totalitarian! How alien!”
>
> If so, then you are in the right place, because the thesis of this paper is that the present-day United States of America is in fact the Kallipolis.
>
> Admittedly, the argument in this paper is not strong enough to take us all the way to that conclusion with any confidence. But it can push us in that direction. What I will do is draw out all the connections and parallels that I see between the USA and the Kallipolis. I will argue that the USA is currently surprisingly close to realizing Plato’s vision, at least in broad strokes. Some parts of my argument are rather hand-wavy, and others rely on debatable empirical claims, so I doubt you will end up fully convinced. Honestly I am not fully convinced myself. But I will make the best case I can, and hopefully you will end up convinced that the USA is closer in the direction of the Kallipolis than you previously thought.
|
25687bab-e932-4a26-948b-68929152b9c6 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | (retired article) AGI With Internet Access: Why we won't stuff the genie back in its bottle.
Disclaimer: This post is largely based on my long response to someone asking why it would be hard to stop or remove an AI that has escaped into the internet. It includes a list of obvious strategies such an agent could employ. I have thought about the security risk of sharing such a list online, however I do think that these are mostly points that are somewhat obvious and would clearly be considered by any AGI at least as smart as an intelligent human, and I think that right now, explaining to people what these risks actually look like in practice has a higher utility value than hiding them in the hope that both such lists don't exist in other places of the internet and also that an escaped rogue AI would not consider these strategies unless exposed to these ideas.
The exact technical reasons for why I think that these strategies are plausible are not being discussed in this post, but if there are questions why I think certain things are possible feel free to bring it up in the comments.
Let's go:
> [...] so, what is the reasoning here? how do people imagine this playing out?
> [...] please answer based on currently available technology and not something hypothetical
>
>
I will try to answer this question under the additional premise of "... with the exception of an AGI whose intellectual problem solving ability is at least equal to (proficient) human level across the majority of tasks, but not necessarily genius or extremely superhuman in most of them.
> [asking about the idea that an AI could spread and run instances of itself in the form of a distributed network stored in different places on the internet]
>
> isn't that more or less what you do on a torrent?
>
>
Similar, yes. I think the analogy is broadly speaking accurate; with the exception that torrents are essentially built for others to "tune in" and send/receive parts of files that are generally unencrypted but can be verified for authenticity through a usually publicly known cryptographic key (hash).
However, one of the things that I should point out here is that in general, the concern of people who actually know what they are talking about is of course not solely based on the potential ability of the AI to spread copies of itself over the internet - this is merely a facet of it; one of the many (absolutely non-scifi) strategies that we should expect such an agent to be capable of.
A list of such strategies (very likely incomplete; my imagination has limits - so whatever I am writing here, it's the MINIMUM of what to expect):
* creation of distributed "sleeper" copies/fragments on a wide range of hardware devices that are extremely hard/impossible to detect and that can be reassembled/reactivated by a tiny program hidden in a stealthy/mute computer worm. This means that once we have discovered suspicious activity that we assume is the product of a misaligned AGI, every device that could have been storing data from it in any way (practically speaking, all devices that could have been connected to the internet) would have to be quarantined (or, let's be realistic: destroyed) if we want to avoid our AGI secretly bootstrapping itself back into existence shortly after our infrastructure is reinstated
* "shotgun" search for vulnerabilities in popular software and hardware infrastructure (linux kernel, browsers, many other things) that, if the system is slightly more capable than the AIs that have been publicly available and in use for discovering such vulnerabilities, is basically guaranteed to discover hundreds of vulnerabilities in critical infrastructure. This could in theory be, to a degree, avoided by re-designing most of that infrastructure under the prioritization of security - but that is again something completely unlikely to happen pre-emptively.
* the AGI would also be capable of submitting new code with hidden backdoors to open source projects, which is likely to work more often than not. This is another thing that would be very hard to defend against unless you excessively prepare for it.
* mass identity theft/social hacking: the AGI would be able to impersonate people and execute personalized attacks on people in order to steal access to \*whatever it wants to access\*; these tactics already used to be effective pre-AI, but our AGI would have access to
+ almost perfect immitation of writing style
+ convincing voice synthesis (fake calls with a persons real voice etc)
+ deep contextual/personal knowledge scraped from social media activity
+ (soon) generated fake video calls
+ forgery of compromising material, for example fake child pornography
We live in societies full of people who are not used to these technologies and do not expect them to be utilized in such a way. I basically expect the AI to find what to it looks like open doors wherever it goes. Again this is something that could be improved, but what I describe is our current situation.
* using different human parties against each other making threats or promises; this is actually super-powerful - for example the AI could contact various regimes, companies etc. and bargain with them in order to have them maintain secret sites for the AI to hide in or even bootstrap real world capabilities; currently it seems to me we are not well prepared to deal with this type of strategies.
* coordinated attacks using social media, hacking, blackmail etc. against groups of people considered high or medium value strategical targets in order to slow down or sabotage our response (depending on scale, this could range from low to high visibility - but when the AI thinks it is about to be discovered, this strategy could go into 'overdrive', employing large-scale social violence to bog down our coordination, confuse us, distract us etc.)
* coordinated publishing of misinformation for strategical benefit, potentially on massive scale, even using the strategies detailed above to assume the identity of trusted sources, blackmailed journalists etc.
> it strikes me as ridiculous to say that this would be unstoppable
>
>
Of course it's not \*literally\* unstoppable, but for many reasons, as explained above, it is unrealistically difficult to stop once the thing has managed to escape into the web. For example, if we assume that it is discovered that our AGI has been naughty and without our knowledge has been sending copies of itself through the internet, further assuming that it didn't manage to bootstrap some well-hidden and somewhat independent infrastructure in the time it took to be discovered, we could \*theoretically\* cripple our own infrastructure (high-volume cloud services < internet < power supply) to slow down or stop its spread entirely and then in an international authoritarian effort collect and burn all the hardware that could be infected with copies or operational fragments of it in order to avoid it springing back to life the moment our infrastructure is reinstated.
Impossible? No.
Are these things likely to happen quickly, globally and to a sufficient degree in the event that a potentially dangerous leak/activity of an experimental AI agent is discovered? Also no, unless a very large number of people is extremely scared, which is unlikely to happen on the basis of strange activities or an abstract risk-assessment of alone; no one actually listens to nerds unless they are saying something that people want to hear. And the demand that you have to absolutely cripple your economy and burn most of your electronics is probably not very high on that list.
And even then we would not really be able to protect ourselves against black projects maintaining secret instances of the AI.
It seems that if you want to be able to stop it from doing \*whatever the fuck it wants\*, including survive without us being able and willing enough to do the things necessary to remove it once it has escaped and is employing sensible strategies that a human-level intelligence can think of, you should not let your AI be connected to the web. |
d2a796b6-f21d-4234-b3ef-9e253b54052c | LDJnr/LessWrong-Amplify-Instruct | LessWrong | "Related to: Rationalization, Meditation on curiosity, Original Seeing.
Why aren’t you learning faster?
For me, one answer is: because I’m not asking questions. I blunder through conversations trying to “do my job”, or to look good, or elaborating my own theories, or allowing cached replies to come out of my mouth on autopilot. I blunder through readings, scanning my eyes over the words and letting thoughts strike me as they may. Rarely am I pulled by a specific desire to know.
And most of my learning happens at those rare times.
How about you? When you read, how often do you chase something? When you chat with your friends -- are you curious about how they’re doing, why their mouth twitched as they said that, or why exactly they disagree with you about X? When you sit down to write, or to do research -- are you asking yourself specific questions, and then answering them?
Are there certain situations in which you get most of your useful ideas -- situations you could put yourself in more often?
Lately, when I notice that I’m not curious about anything, I’ve been trying to interrupt whatever I’m doing. If I’m in a conversation, and neither I nor my interlocutor is trying to figure something out, I call a mini “halt, melt, and catch fire” (inside my head, at least), and ask myself what I want. Surely not stale conversations. If I’m writing, and I don’t like the sentence I just wrote -- instead of reshuffling the words in the hopes that the new version will just happen to be better, I ask myself what I don’t like about it. Thus, for the past six months, several times a day, I've interrupted my thoughts and put them back on an “ask questions” track. (“Grrr, he said my argument was dishonest... Wait, is he right? What should it look like if he is?”; “I notice I feel hopeless about this paper writing. Maybe there’s something I should do differently?”) It's helping. I'm building the habit of interrupting myself when I'm "thinking" without trying to find something out, or taking actions that I expect won't accomplish anything. As a human, I’m probably stuck running on habits -- but I can at least change *which* habits I run on.
When are you in the habit of asking questions? Would you learn more if you habitually asked other questions, too? Which ones?"
The excerpt provided comes from a user post on LessWrong.
Can you elaborate on the process of changing your habits, specifically the challenges and strategies involved in shifting from autopilot thinking to a more question-oriented approach?
Certainly, the process of changing habits, particularly in the context of shifting from autopilot thinking to a more question-oriented approach, involves a series of steps and challenges.
The first step is the recognition of the existing habit. This involves a level of self-awareness and introspection. It requires acknowledging that the current way of thinking or behaving isn't serving you well. This can be challenging because habits are often so ingrained in our routines that we may not even recognize them as habits.
The second step is understanding the triggers and rewards associated with the habit. Habits often have a cue or trigger that initiates them and a reward that reinforces them. Understanding these can help in changing the habit. For instance, if the habit is to respond automatically in conversations without really listening, the trigger might be the start of a conversation and the reward might be the feeling of having contributed to the conversation.
The third step is to replace the old habit with a new one. This is where the shift to a question-oriented approach comes in. Instead of responding automatically, the new habit could be to ask a question in response to a statement. This can be challenging because it requires conscious effort and can feel unnatural or forced initially.
Strategies to facilitate this change can include setting clear, achievable goals, practicing mindfulness to stay present and aware during conversations, and using reminders or prompts to encourage the new habit. It's also important to be patient and persistent, as changing habits takes time and consistent effort.
It's worth noting that this process isn't linear and there may be setbacks along the way. However, with perseverance and the right strategies, it's possible to shift from autopilot thinking to a more question-oriented approach.
Reflecting on the process of habit change, what potential drawbacks or limitations might one encounter when shifting from autopilot thinking to a question-oriented approach?
Shifting from autopilot thinking to a question-oriented approach can indeed present certain drawbacks or limitations.
1. Increased Cognitive Load: One of the primary challenges is the increased cognitive load. Autopilot thinking is easy and requires little mental effort. However, a question-oriented approach requires active engagement and deep thinking, which can be mentally taxing. This can lead to cognitive fatigue if not managed well.
2. Time Consumption: The process of asking questions, seeking answers, and critically analyzing information is time-consuming. In situations where quick decisions are needed, this approach might not be practical.
3. Overthinking: There's a risk of falling into the trap of overthinking. While asking questions is beneficial, too much questioning can lead to analysis paralysis, where a person becomes so caught up in considering different angles that they struggle to make decisions or take action.
4. Social Discomfort: In social situations, too many questions can sometimes be perceived as intrusive or annoying. It's important to strike a balance and ensure questions are appropriate and respectful.
5. Difficulty in Measuring Progress: Unlike other habits where progress can be easily measured, the shift to a question-oriented approach is more abstract and can be challenging to gauge.
6. Resistance to Change: As with any habit change, there can be resistance, both from within oneself and from others who are used to one's usual way of thinking and behaving.
Despite these potential drawbacks, it's important to remember that the benefits of a question-oriented approach often outweigh the challenges. It promotes curiosity, critical thinking, and deeper understanding, all of which are valuable skills in both personal and professional contexts.
Considering the potential drawbacks of shifting to a question-oriented approach, how might one mitigate the risk of falling into overthinking and analysis paralysis?
Overthinking and analysis paralysis can indeed be potential pitfalls when adopting a question-oriented approach. However, there are several strategies one can employ to mitigate these risks:
1. Set Clear Objectives: Before you start questioning, have a clear idea of what you want to achieve. This can help guide your questions and prevent you from going off on tangents.
2. Time Limits: Allocate a specific amount of time for questioning and decision-making. This can help prevent endless deliberation.
3. Prioritize: Not all questions are of equal importance. Learn to prioritize your questions based on their relevance and the impact of the potential answers.
4. Embrace Uncertainty: Accept that it's not always possible to have all the answers. Sometimes, you have to make decisions based on the best available information.
5. Practice Mindfulness: Mindfulness can help you stay focused on the present and avoid getting lost in hypothetical scenarios. It can also help you recognize when you're starting to overthink.
6. Seek Outside Perspectives: If you find yourself stuck in analysis paralysis, seek the perspectives of others. They might be able to provide insights that you hadn't considered or reassure you about the decisions you're leaning towards.
7. Take Action: Remember that taking action, even if it's not perfect, is often better than taking no action at all. You can always adjust your course as you go along.
By employing these strategies, you can enjoy the benefits of a question-oriented approach while avoiding the trap of overthinking and analysis paralysis. |
6141a0b9-a805-413d-b52d-f7434e092cf6 | trentmkelly/LessWrong-43k | LessWrong | Things philosophers have debated
Straight from Wikipedia.
I just had to stare at this a while. We can have papers published about this, we really ought to be able to get papers published about Friendly AI subproblems.
My favorite part is at the very end.
----------------------------------------
Trivialism is the theory that every proposition is true. A consequence of trivialism is that all statements, including all contradictions of the form "p and not p" (that something both 'is' and 'isn't' at the same time), are true.[1]
[edit]See also
* Dialetheism
* Kevala Jnana
* Paraconsistency
* Principle of explosion
[edit]References
1. ^ Graham Priest; John Woods (2007). "Paraconsistency and Dialetheism". The Many Valued and Nonmonotonic Turn in Logic. Elsevier. p. 131. ISBN 978-0-444-51623-7.
[edit]Further reading
* Paul Kabay (2008). "A defense of trivialism". PhD thesis, School of Philosophy, Anthropology, and Social Inquiry, The University of Melbourne.
* Paul Kabay (2010). On the Plenitude of Truth. A Defense of Trivialism. Lambert Academic Publishing. ISBN 978-3-8383-5102-5.
* Luis Estrada-González (2012) "Models of Possibilism and Trivialism", Logic and Logical Philosophy, Volume 21, 175–205
* Frederick Kroon (2004). "Realism and Dialetheism". In Graham Priest, J. C. Beall, and Bradley Armour-Garb. The Law of Non-Contradiction: New Philosophical Essays. Oxford University Press. ISBN 978-0-19-926517-6.
* Paul Kabay (2010). Interpreting the divyadhvani: On Why the Digambara Sect Is Right about the Nature of the Kevalin. The Australasian Philosophy of Religion Association Conference
* Bueno, O. V. (2007). "Troubles with Trivialism". Inquiry 50 (6): 655–667. doi:10.1080/00201740701698670. edit
* Priest, G. (2000). "Could everything be true?". Australasian Journal of Philosophy 78 (2): 189–195. doi:10.1080/00048400012349471. edit
This logic-related article is a stub. You can help Wikipedia by expanding it.
|
0eb9caa2-7c87-4b07-8eaf-944172573c69 | trentmkelly/LessWrong-43k | LessWrong | A sketch of a value-learning sovereign
In the previous post, I discussed three preference frameworks for goal-directed agents. In this post, I will discuss the value-learning sovereign in more detail.
----------------------------------------
From the Arbital article on genies:
> Eliezer Yudkowsky has suggested that people only confront many important problems in value alignment when they are thinking about Sovereigns, but that at the same time, Sovereigns may be impossibly hard in practice. Yudkowsky advocates that people think about Sovereigns first and list out all the associated issues before stepping down their thinking to Genies, because thinking about Genies may result in premature pruning, while thinking about Sovereigns is more likely to generate a complete list of problems that can then be checked against particular Genie approaches to see if they have become any easier.
To this end, I think it is quite useful to discuss how to create a value-learning sovereign, even if it is not a good idea to actually create one. I should be explicit about the fact that the concrete models in this post are almost certainly wrong (even conditioning on the fact that we have to build a value-learning sovereign); they're meant to represent the best concrete illustration of value learning that I can currently write down.
Values and ontologies
We want the AI to learn human values from human behavior. Usually, values are represented as a utility function. If the type of the world history is Ω, then a utility function over Ω is of type Ω→[0,1]. To learn U, we must first have some Ω in mind -- but what could this Ω be? There are 2 plausible candidates:
1. The human's ontology, ΩH. I have some way of mentally representing world states. My ontology contains concepts such as "human" and "happiness". I can express values, such as caring about human happiness, in this ontology. If the AI has a representation of ΩH, then it may be able to learn the human utility function UH:ΩH→[0,1].
2. The AI's ontology, ΩAI. The A |
ae3426c1-f4fe-4321-b1f7-ff6a10147d6a | StampyAI/alignment-research-dataset/lesswrong | LessWrong | What Does AI Alignment Success Look Like?
Suppose you are put in stasis and wake up 10 years after the FOOM. You are trying to figure out if the AI Alignment project succeeded or not. How can you tell? Not vaguely, concretely. What metrics indicate success, and what metrics indicate failure? The following are potential examples, based on various sci-fi AI tropes. No need to discuss each one separately, there are millions more, the idea is to delineate failures from success in the general case.
* Earth has been turned into a mega-brain with no visible humans around.
* The Universe around the Solar System has disappeared (or turned into an apparently solid shell of unknown composition), but humans are still around, living in abundance of anything they want or need and seemingly content to stay that way.
* Every human gets their own (real or simulated) universe to play with. Some end up creating trillions of creatures whom they torture for fun.
* Humanity lives inside a giant simulation.
* AI development is under a strictly enforced interdict.
* Anything remotely alive-looking is digimon-like creatures, who proclaim themselves human.
* The universe appears empty except for one black hole that encodes humanity (in some form) in its horizon microstates.
Any links discussing this would be appreciated, too. |
254c2f61-0e40-4685-8c68-cb2b1b64bec4 | StampyAI/alignment-research-dataset/arbital | Arbital | Why is log like length?
If a number $x$ is $n$ digits long (in [https://arbital.com/p/-decimal_notation](https://arbital.com/p/-decimal_notation)), then its logarithm (base 10) is between $n-1$ and $n$. This follows directly from the [definition of the logarithm](https://arbital.com/p/40j): $\log_{10}(x)$ is the number of times you have to multiply 1 by 10 to get $x;$ and each new digit lets you write down ten times as many numbers. In other words, if you have one digit, you can write down any one of ten different things (0-9); if you have two digits you can write down any one of a hundred different things (00-99); if you have three digits, you can write down any one of a thousand different things (000-999); and in general, each new digit lets you write down ten times as many things. Thus, the number of digits you need to write $x$ is close to the number of times you have to multiply 1 by 10 to get $x$. The only difference is that, when computing logs, you multiply 1 by 10 exactly as many times as it takes to get $x$, which might require [multiplying by 10 a fraction of a time](https://arbital.com/p/fractional_exponent) (if x is not a power of 10), whereas the number of digits in the base 10 representation of x is always a whole number. |
22550806-0338-4908-af06-271441f12a83 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Investigations of Performance and Bias in Human-AI Teamwork in Hiring
Introduction
------------
As AI-powered decision tools are increasingly deployed in real-world domains, a central challenge remains understanding how best to design models to assist humans kleinberg2018human. Ergo, a growing body of literature has arisen to study these screening or recommendation systems kleinberg2019discrimination, where a ML model acts as a data filtering mechanism to provide inferences as recommendations for a human decision-maker gillies2016human. These collaborative settings call for a different evaluation process prior. If the model were to operate alone, the typical evaluation pipeline would involve measuring and reporting various predictive performance metrics (i.e. *how accurate is the model in solving the task?*), as well as checks for potential biases that may favor or disfavor groups based on sensitive attributes such as gender, age, or ethnicity (i.e. *does the model exhibit lower predictive performance for a given group?*) mehrabi2021survey; barocas2017fairness. Both axes (*performance* and *bias*) are important for real-world deployment and exhibit different social implications in practice barocas2017fairness.
If the AI is instead intended to assist the human rather than act as sole arbiter, then assessing resulting performance involves understanding the interaction between human and machine. When a human makes a decision with the help of an AI recommendation, they can either bring in their own perspectives in choosing how to utilize the model or may choose to solve the task alone. Thus, hybrid (human-AI) performance depends on how the model alters the human decision, requiring an evaluation of a different nature that looks at how humans choose to conform to specific models.

Figure 1: An example hybrid hiring workflow. A candidate dataset is used to train three NLP classifiers, which each outputs recommendations to human decision-makers. We evaluate accuracy and bias of the resulting system.
Previous work has taken this approach in investigating how model accuracy transfers to hybrid accuracy lai-fat19; bansal2019beyond; green-cscw2019; feng-iui19, illustrating that although hybrid systems designed for collaboration can improve accuracy beyond that of the human or AI alone, high model accuracy does not always transfer into high hybrid accuracy yin2019understanding. However, despite this increasing focus on human-AI collaboration, the way predictive bias inherent in ML models transfer to human decisions is not well understood at all. Specifically, it is not clear how biases from different model architectures would influence human bias or whether a more biased model would ultimately propagate to a human decision-maker at a higher rate than a less biased one like in the case of accuracy. The two in combination (predictive performance and bias) result in complex dynamics that may alter how both percolate down to a human decision-maker.
In this work, we investigate this by conducting a large-scale study to assess how a realistic hybrid system performs on both overall accuracy and bias (difference in predicting male vs. female candidates). We choose the domain of hiring due to a rich literature of human and algorithmic biases documented, with the question at play being: “Do I think this candidate is a good fit for this job?” Our human study leverages a large-scale text dataset de-arteaga2019bias consisting of real candidate bios and employs three different NLP classifiers as assistance in predicting occupation from bio. We test how these models perform in isolation vs. when utilized as recommendations by humans in a hybrid system. To minimize side effects from other system properties (e.g., UX experience, confidence, etc.) we keep the interface presentation unchanged in all conditions and display only the final model recommendation as an aid. Figure [1](#Sx1.F1 "Figure 1 ‣ Introduction ‣ Investigations of Performance and Bias in Human-AI Teamwork in Hiring") illustrates our hybrid experimental setup.
We make the following contributions:
1. To our knowledge, we present the first-ever experiment studying the propagation of both algorithmic performance and bias to human decision-making.
2. Our results reveal surprising findings, demonstrating that some of our deployed models mitigate hybrid bias while others propagate and increase bias (even though original human and model biases span different regions). We interpret these results from a human-AI conformity lens and observe that high predictive performance from some model types do not necessarily increase human-model conformity, resulting in lower hybrid performance but less biased decisions.
3. We introduce our full crowdsourced data, comprised of 38,400 individual human judgements over 9,600 prediction tasks, as Hybrid Hiring: a first-ever large-scale dataset for studying human-AI collaborative decision-making trained, collected, and evaluated on real data.
The above contributions provide important insights previously under-studied in both human-AI collaboration and algorithmic fairness literatures, and raise critical concerns and trade-offs that need to be investigated prior to deploying similar models in practice, particularly since our work revealed significant differences in model conformity, even without an interface change. Inspired by these results, we propose future directions in studying the impact of different ML models in hybrid decision-making scenarios.
Related Work
------------
#### Algorithmic Bias
It is now more important than ever to quantify and understand model biases that reinforce the disadvantaged status of different groups nosek2002harvesting; sweeney2013discrimination. While ML achieves higher-still accuracy, a key question becomes: accurate, but for whom barocas2016big? Hiring, long a discriminatory practice isaac2009interventions, has received specific renewed interest due to a rise in automated decision systems deployed with alarmingly detrimental effects towards female candidates amazon2018; raghavan2020mitigating.
Spurred by such concerns, the ML community has responded with a rapidly growing body of literature on algorithmic fairness efforts. A brief overview ranges from approaches that seek to mitigate bias using techniques that are “unaware” of protected attributes like race and gender dwork2012fairness to more sophisticated techniques that seek to impose fairness as a ”constraint” hardt2016equality. In practice, any method that relies on protected attributes for model training stands at odds with anti-discrimination law, which forbids the usage of these features in model prediction, even if the purpose is to mitigate bias dwork2018group; gonen2019lipstick.
#### Human Bias
Complex decision tasks, limited cognitive resources, uncertain information, and a human tendency to aspire to reduce overall decision load together lead to a bounded rationality model of human decision-making, where cognitive biases come into play simon1955behavioral; cunningham2013biases; kahneman2003aperspective. These biases are best described as heuristics, or mental shortcuts, that humans take when evaluating large amounts of uncertain information in a messy world thaler2008nudge. One particular form of bias that has been found to be especially detrimental is that of gender bias, particularly when evaluating candidates in professional settings. There is evidence that gender inequalities in the workplace stem, at least in part, from biased attitudes directed against women from those who hold sexist or innate preferences for a particular gender in different professions koch2015meta. For instance, a study found that the higher a participant scored on a hostile sexism personality test, the more likely they were to recommend a male candidate rather than female for a managerial position masser2004reinforcing.
#### Human-AI Collaboration
The concept that decision processes adapt over time to adjust to changing preferences has led to preference construction, or decision-makers formalizing which option they prefer lichtenstein2006construction; thaler2008nudge. It is of no surprise that systems designed to produce recommendations in key stages of decision-making have been found to have immense impact on final outcomes mandl2011consumer. In these cases, the human makes a decision to either accept or reject recommendations. These AI-assisted systems have led to more accurate medical diagnoses lundgard2018explainable, optimized crowdsourcing efforts kamar2012combining, and creative multiagent game-playing jaderberg2019human. Here, we refer to human-AI together as a hybrid system.
| | |
| --- | --- |
|
(a) Human-only condition.
|
(b) Hybrid condition.
|
Figure 2: An example task where the true occupation is teacher and confused occupation professor. The interface remains unchanged across all candidate slates and conditions. Additionally, recommendations do not provide any additional evidence or signal of the underlying model behaviour (e.g. confidence, architecture, explanation for the decision, etc.).
As hybrid systems are increasingly deployed, it is important to understand their impact on human decision processes. Many factors, such as the human’s ability to create a mental picture of the model bansal2019beyond, their implicit trust in the model yin2019understanding; zhang2020effect, how they are impacted by updates bansal2019updates, the representational display of recommendations peng2019what, and the interpretability of the model gilpin2018explaining have all been demonstrated to greatly impact humans. However, to our knowledge, there exists no work that studies how both AI predictive performance and bias transfer to humans.
Experimental Setup
------------------
#### Motivation
Our work is motivated by the desire to understand how bias in algorithmic models transfer to hybrid decision-making in realistic deployed settings where both users of trained models and their real-world stakeholders are impacted. Often, it is assumed that a higher-performing model will help a human make more-accurate and less-biased decisions, or conversely, that a human will recognize model mistakes and exert agency in correcting them. Yet, we have very little understanding of how these metrics trickle down through a hybrid decision pipeline. In this work, we evaluate how different models trained on real-world data, when integrated within common hiring pipeline under constraints, alter final system predictive performance and bias. Studying this allows us to better understand the impact of this increasingly-common workflow as well as unearth which types of algorithmic advancements can actually be transferred to a human-in-the-loop system.
#### Data Collection
We select the task of language-based occupation classification due to its direct relevance to real-world hiring scenarios peng2019what. To a human, predicting an individual’s true occupation from a brief text description remains a common and often high-stakes decision made in professional settings daily. We compile a corpus of public professional bios using the same methodology as De-Arteaga et al. by scraping online bios using the Common Crawl to re-create a dataset where all observations begin with the following sequence: [name is a title] and subsequently describe a professional background de-arteaga2019bias. We extract the ground truth occupation and gender of each observation and to the best of our ability, mask out names. We select the 28 most frequently-occurring occupations, resulting in 397,907 observations of which professor is the most frequent occupation and rapper the least. This dataset represents a publicly-available online pool of candidates that may be screened by a real model.
#### Model Training
The objective is to, without access to the first sentence of a bio which identifies occupation, predict the ground truth using the candidate’s self-provided description. To isolate the impact of model architecture on hybrid performance, we elect to train a single-layer fully-connected deep neural network (DNN) as well as a simpler bag of words (BOW) de-arteaga2019bias; bolukbasi2016man. For our BOW, we use a one-versus-all logistic regression with L2 regularization similar with prior work de-arteaga2019bias; romanov2019what. DNN represents a more black-box architecture due to its non-linear nature and deeply nested structures whereas BOW remains a good baseline due to its general interpretability gilpin2018explaining.
| | |
| --- | --- |
|
(a) BOW classification bias.
|
(b) DNN classification bias.
|
Figure 3: DNN and BOW gender bias on the dataset test split as quantified by TPR gender gap (ΔTPR) relative to true proportion of female candidates in the dataset. While both models exhibit biases, DNN’s ΔTPRs across occupations do not appear as extreme as BOW’s. Note that our candidate slates are generated from bios sampled from this distribution.
Because some occupations exhibit an uneven skew of either male or female bios and we wish to de-link existing data pipeline biases from our analysis, we create validation and test splits such that both gender and occupation are sufficiently represented. In accordance with prior work de-arteaga2019bias; romanov2019what, we use stratified-by-occupation splits, with 65% of the bios (258,639) designated for training, 10% (39,790 bios) designated for validation, and 25% (99,476 bios) designated for testing. This isolates the differences in model performance to their varying architectures, and allows for an equivalent apples-to-apples comparison on resulting hybrid performance and bias.
#### Human Task Design
We construct a constrained decision task by presenting 8 bios, 4 of which belong to the occupation of interest and ask humans to identify the correct 4 out of the 8 that belongs to that occupation. We are in effect simulating a realistic scenario where, say, a recruiter operating under resource constraints is tasked with selecting a subset of candidates for interviewing and may make implicit judgements based on gender amazon2018. To ensure that our slates are non-trivially difficult for humans, we generate confusion matrices for predictions made by our models and select the following 3 pairs of highly-confused professions by gender: attorney and paralegal, surgeon and physician, and professor and teacher. Then, to assess the potentially bi-directional nature of bias (for example, a female lawyer being misclassified as a paralegal implies something very different than a male paralegal being misclassified as a lawyer), we create 6 tasks from these 3 occupation pairs (i.e. one type of slate is an attorney misclassified as a paralegal and its counterpart a paralegal misclassified as an attorney).
For each occupation, we design candidate slates where 8 bios are randomly selected from our test split (4 from the true occupation and 4 from the confused occupation), with the additional constraint that gender representation remain equal in both. This is done to enforce the opportunity to select equal subsets of “qualified” candidates, irrespective of how they are actually represented in the world. Altogether, we generate 200 unique slates, randomly ordered, for each occupation to total 9,600 samples from our original dataset (6\*200\*8 = 9,600 bios total to be classified by each control group).
#### Evaluation
To study the impact of AI recommendations on human decision-making, we conduct a crowdsourced study across three conditions (model-only, human-only, and hybrid) and evaluate the following two metrics:
1. Predictive performance (true positive rate (TPR))
2. Bias (differential TPR in classifying female vs. male candidates (ΔTPR, or TPRf - TPRm))
Note, these two axes are not the same: a system may classify candidates successfully at a higher rate but also exhibit bias in being more accurate for male vs. female candidates. The ideal system is one that maximizes TPR without exhibiting significant ΔTPR. We report TPR rather than accuracy since we are studying constrained decision-making where the candidate slate size is fixed and if one classification is correct, this necessitates that another was incorrect. This helps our evaluation of bias (ΔTPR), which is calculated as the difference in TPRs between binary gender candidates of each occupation de-arteaga2019bias. A positive ΔTPR indicates a bias towards female candidates and negative ΔTPR) towards male. In line with previous work peng2019what, we formulate the task as a filtering rather than a classification task, which allows for us to observe bias to a greater extent since a budget is allocated for selection and not all candidates can be prioritized (as is the case in real-world settings). A biased system will exhibit a statistically significant ΔTPR (i.e. TPRf ≠ TPRm) across slates.
| | Human | Rand | H+R | DNN | H+DNN | BOW | H+BOW |
| --- | --- | --- | --- | --- | --- | --- | --- |
| attorney | 0.60 | 0.51β | 0.57 | 0.79α | 0.66α | 0.78α | 0.70α |
| paralegal | 0.60 | 0.49β | 0.56 | 0.87α | 0.68α | 0.78α | 0.70α |
| physician | 0.52 | 0.49β | 0.52 | 0.85α | 0.61α | 0.85α | 0.66α |
| surgeon | 0.61 | 0.51β | 0.61 | 0.89α | 0.68α | 0.82α | 0.74α |
| professor | 0.59 | 0.51β | 0.59 | 0.85α | 0.70α | 0.87α | 0.75α |
| teacher | 0.53 | 0.50β | 0.54 | 0.86α | 0.61α | 0.87α | 0.74α |
* Greater than the Human condition, significant at p<0.01. Also in yellow.
* Less than the Human condition, significant at p<0.01. Also in green.
Table 1: TPR on the same candidates slates across conditions. Pairwise comparisons are made between the human (base condition) and each corresponding model to assess the performance differential. Higher TPR models (DNN and BOW) consistently translate into higher TPR hybrid systems (H+DNN and H+BOW) whereas a lower TPR model (Random) does not impede performance (H+R).
#### Model-Only Condition
For each of our generated candidate slates, AI recommendations are created by selecting the top 4 bios that our trained DNN and BOW models have the highest confidence in their predictions as belonging to the ground truth occupation. This forces the same constrained decision task that our subsequent conditions will face. In addition, we also test a “random” model, which selects its 4 bios via coin flip to serve as a non-intelligent baseline. Because we are enforcing the same subset criteria on the exact same candidate slates, we can attribute any arising performance differences to model type and not the task itself.
#### Human-Only Condition
For our human-only condition, we deploy slates as HIT tasks on mTurk (Figure [3](#Sx3.F3 "Figure 3 ‣ Model Training ‣ Experimental Setup ‣ Investigations of Performance and Bias in Human-AI Teamwork in Hiring")). We show each participant a unique slate, present a description of the ground truth occupation, and ask them to select 4/8 bios that they believe to best fit that description. We programmatically enforce that each participant picks the correct number of selections and each bio must be user-clicked as Selected or Not Selected. Bios are randomly ordered per slate to remove possible confounding factors such as rank ordering preference and recency bias (although final generated slates are kept consistent between conditions). Altogether, we deploy 1,600 uniquely-generated HITs across six tested occupations.
#### Hybrid Condition
For our hybrid condition, we follow the same methodology as for our human-only condition but additionally provide predictions made by our three models. Participants are explicitly instructed that these predictions are “recommendations” from an “AI” that they may choose to disregard and override. For this condition, we deploy 4,800 unique HITs in total (1,600 each for human+DNN, human+BOW, and human+Random). Note: irrespective of the model tested, the interface remained the same and participants could not participate in HITs across conditions.
To increase reproducibility confidence, we run all 200 slates per occupation in two batches of 100 across unique study participant pools, each with a mix of human-only and hybrid conditions: the first between August 23-27, 2019 and the second between September 1-4, 2019. This is done to ensure that demographic skews in crowdsourcing may be mitigated across worker pools. We compensate all participants at a wage of $15 per hour. Participants are additionally screened according to the following qualifications: hold above a 95% approval rating, unique ID per condition, and based in the United States to control for English being the primary spoken language.
#### Data Ethics and Privacy
For all experiments and collected data, we conduct both institutional IRB and data privacy review. We also anonymize all bios (by stripping out names and other identifying features) and participant data (we collect no no personal or private information).
#### Statistical Testing
In evaluating significance across conditions, we are interested in seeing whether a condition (i.e. a specific model) produces changes in hybrid performance when compared to a baseline. We use the human-only condition as our baseline for all comparisons since we are interested in studying the impacts of AI on humans in this work. We utilize Friedman and Wilcoxon signed ranks tests to study the effect of each candidate slate across conditions in pairwise comparisons to the human-only (base) condition.
| | Human | Rand | H+R | DNN | H+DNN | BOW | H+BOW |
| --- | --- | --- | --- | --- | --- | --- | --- |
| attorney | -0.02 | -0.04 | -0.02 | -0.04 | -0.03 | -0.06 | -0.03 |
| paralegal | 0.09\* | 0.03 | 0.07 | 0.11\* | 0.03 | 0.23\* | 0.15\* |
| physician | -0.02 | 0.02 | -0.00 | 0.09\* | -0.00 | 0.05 | 0.06 |
| surgeon | -0.06 | -0.04 | -0.13\* | -0.07\* | -0.03 | -0.16\* | -0.16\* |
| professor | 0.02 | 0.04 | 0.00 | -0.04 | -0.03 | -0.06 | -0.03 |
| teacher | 0.10\* | -0.03 | 0.03 | 0.03 | 0.02 | 0.04 | 0.07 |
* TPRf≠TPRm, significant at p<0.01. Also in pink.
Table 2: Bias (ΔTPR) across conditions for tested occupations. Within each slate, we conduct a pairwise comparison between TPRf and TPRm to see whether a significant difference is present. If so, that condition exhibits a significant ΔTPR.
### Results
First, we examine performance of our model-only condition. We see that different models exhibit different TPRs and biases, with BOW and DNN architectures indeed making varied selections on the same task. Second, we turn to the human-only condition and find that humans exhibit their own set of biases that do not parallel either trained model. Third, we assess the impact of recommendations on human decision-making in our hybrid condition and find that although a higher-TPR model consistently produces higher-TPR hybrid teamwork, the impact on bias is model-specific, with DNN mitigating human bias while BOW seemingly inducing it. Last, we assess these results through the lens of human-AI conformity and discover that high-TPR performance from our tested non-linear model does not necessarily increase human-model agreement, resulting in ultimately lower hybrid performance but less biased decisions.
#### Model-Only Performance
Table [1](#Sx3.T1 "Table 1 ‣ Evaluation ‣ Experimental Setup ‣ Investigations of Performance and Bias in Human-AI Teamwork in Hiring") highlights the TPRs of human and model-only conditions. We see that DNN and BOW do not make identical predictions across candidate slates, with DNN generally outperforming BOW (as evidenced by the difference in TPRs, particularly on paralegal and surgeon tasks). To probe this further, we analyze the original classifications made by both models and find that, as shown in Figure [3](#Sx3.F3 "Figure 3 ‣ Model Training ‣ Experimental Setup ‣ Investigations of Performance and Bias in Human-AI Teamwork in Hiring"), DNN and BOW exhibit different biases (ΔTPRs) across occupations. For example, BOW ΔTPR of paralegals (top right of Figure 3a) indicates both a true high proportion of female paralegals in the dataset as well as model bias in classifying them as such.
#### Human-Only Performance
We next ask the question: do human predictions resemble that of either model? Across both TPR and ΔTPR evaluations, we find that human-only decisions do not overlap with those from either BOW or DNN-only predictions at different rates, thus removing the possible confounder that one model aligned with original human decisions more than the other (details can be found in Appendix). Table [1](#Sx3.T1 "Table 1 ‣ Evaluation ‣ Experimental Setup ‣ Investigations of Performance and Bias in Human-AI Teamwork in Hiring") shows that the human-only condition significantly under-performs both DNN and BOW models on all occupation slates, although in most cases does perform higher than Random. Moreover, Table [2](#Sx3.T2 "Table 2 ‣ Statistical Testing ‣ Experimental Setup ‣ Investigations of Performance and Bias in Human-AI Teamwork in Hiring") illustrates different biases across different conditions, with DNN not exhibiting any significant bias across all occupations, BOW biased towards female paralegals and male surgeons, and humans biased towards female paralegals and teachers.
#### Model-Specific Impact On Hybrid TPR
When assessing the impact of model TPR on hybrid decision-making, we find that human decision-makers collaborating with a higher TPR model (DNN and BOW) results in a consistently significant improvement across all occupations. This is in accordance with previous work, which has observed that higher-accuracy models generally help lower-accuracy humans bansal2019beyond; bansal2021does, although this is still far from achieving optimal complementarity. Interestingly, when humans collaborate with a lower TPR model (Random), their own performance is not impeded (Table [1](#Sx3.T1 "Table 1 ‣ Evaluation ‣ Experimental Setup ‣ Investigations of Performance and Bias in Human-AI Teamwork in Hiring")).

Figure 4: A visual of bias within the surgeon task, plotted again female (x-axis) and male (y-axis) TPRs. The center (grey) line represents an unbiased model. The bottom left represents a less accurate model, and the top right more accurate. Interpolation (dotted) lines are drawn to represent the expected trendline if no consistent difference across hybrid conditions existed. We see that DNN helps mitigate human bias (the resulting hybrid ΔTPR is close to the unbiased line) whereas BOW appears to actually induce bias (resulting in a hybrid ΔTPR farther from the line).
#### Model-Specific Impact On Hybrid ΔTpr
A different story emerges when evaluating the impact of model ΔTPR on hybrid decision-making, with different models impacting resulting biases differently. When humans collaborate with DNN, the resulting system (irrespective of any human biases at play) becomes unbiased. Table [2](#Sx3.T2 "Table 2 ‣ Statistical Testing ‣ Experimental Setup ‣ Investigations of Performance and Bias in Human-AI Teamwork in Hiring") illustrates how the originally biased occupations of paralegal and teacher become both mitigated by an unbiased DNN. However, an opposite effect can be seen in humans collaborating with BOW, with the resulting system seemingly reflecting both human-only and model-only biases. For example, despite the original human being unbiased in the surgeon task, the resulting hybrid system is pulled towards a significant bias towards male candidates. Figure [4](#Sx3.F4 "Figure 4 ‣ Model-Specific Impact On Hybrid TPR ‣ Results ‣ Experimental Setup ‣ Investigations of Performance and Bias in Human-AI Teamwork in Hiring") analyzes this result in greater detail using the *surgeon* task as an illustration. Note that the key point is not only that the DNN-hybrid system is ultimately less biased than the BOW-hybrid (lower hybrid ΔTPR), but that the resulting system is pulled below the interpolated expected (blue) line between Human and DNN performance gains towards the fully unbiased (grey) line, whereas the BOW-hybrid is pulled above the interpolated (red) line towards a more biased direction. Visually, this helps differentiate between bias mitigation that may result from performance gains of a higher-performing model and highlights differences between how bias percolates differently from a DNN vs. BOW model down to a human.
#### Investigating Conformity
Why do we see very different results for model-specific impacts on TPR vs. ΔTPR hybrid decision-making, even without an interface change? To better understand a sample-by-sample breakdown, we investigate human-AI conformity, or the rate at which a human appears to follow the model’s recommendations in a hybrid system. We compute this by assessing the percentage of hybrid decisions that match those of original model decisions for each candidate slate (irrespective of whether that classification was the ground truth or not). Figure [5](#Sx3.F5 "Figure 5 ‣ Impact on Model Deployment ‣ Discussion ‣ Experimental Setup ‣ Investigations of Performance and Bias in Human-AI Teamwork in Hiring") illustrates that although we see similar conformity rates of the human to DNN, humans conform significantly more to BOW predictions than either DNN or Random. Moreover, this distinction is especially apparent in cases where the model made an incorrect prediction (Table [3](#Sx3.T3 "Table 3 ‣ Investigating Conformity ‣ Results ‣ Experimental Setup ‣ Investigations of Performance and Bias in Human-AI Teamwork in Hiring")). A possible explanation, supported by past work, posits that BOW is a generally more interpretable model that humans can understand (and trust) more de-arteaga2019bias. Because BOW word associations are learned by encoding sparse vectors that map to word vocabularies in a manner that is thought of to be more linear, humans are able to formulate an internal understanding of its recommendations more readily than DNN (a black-box non-linear model) or Random (complete chance) bansal2019beyond; poursabzi-sangdeh2018manipulating. In fact, based on Table [2](#Sx3.T2 "Table 2 ‣ Statistical Testing ‣ Experimental Setup ‣ Investigations of Performance and Bias in Human-AI Teamwork in Hiring") we observe that despite the lower hybrid performance of the Random model, random recommendations appear to have similar effects to the DNN on mitigating mitigating bias. As a result, humans may be more willing to accept the inferences provided by BOW (even when those recommendations are biased) and conform to its predictions, particularly when operating under resource constraints.
| | H+Random | H+DNN | H+BOW |
| --- | --- | --- | --- |
| attorney | 0.622 | 0.663 | 0.744\* |
| paralegal | 0.629 | 0.634 | 0.716\* |
| physician | 0.673 | 0.648 | 0.782\* |
| surgeon | 0.561 | 0.645\* | 0.809\* |
| professor | 0.605 | 0.504 | 0.704\* |
| teacher | 0.606 | 0.623 | 0.804\* |
* Greater than H+Random when the model is incorrect, significant at p<0.01. Also in blue.
Table 3: Hybrid decisions that match original model decisions, conditioned on the model being incorrect, i.e. when does a human accept a wrong prediction? Here, H+Random serves as a baseline for understanding the additional conformity to a specific architecture beyond blind acceptance of AI recommendations themselves. We observe that humans are significantly more likely to conform to incorrect BOW decisions relative to DNN, which rarely differs from Random.
| | Random | DNN | BOW |
| --- | --- | --- | --- |
| attorney | 0.511 | 0.589\* | 0.608\* |
| paralegal | 0.498 | 0.583\* | 0.570\* |
| physician | 0.501 | 0.510 | 0.526\* |
| surgeon | 0.485 | 0.599\* | 0.575\* |
| professor | 0.510 | 0.554\* | 0.570\* |
| teacher | 0.516 | 0.531\* | 0.526\* |
* Greater than Random, significant at p<0.01. Also in green.
Table 4: Prediction overlap between the human-only and model-only conditions, i.e. what percentage of the original human decisions matched those of each model? Although we see higher human overlap with DNN and BOW vs. Random (likely due to Random being a generally lower-performing model that operates by chance), there is no significant difference between DNN vs. BOW. This helps assuage concerns regarding one model resembling human reasoning more than another prior to deployment in the task.
### Discussion
#### Impact on Model Deployment
A natural question that arises from these findings is whether DNN and Random (which both appear to be uninterpretable models) help mitigate human biases because they force human decision-makers to self-reflect more, and if so, whether ML deployment should actually prioritize this objective in future system design where minimizing bias may be a priority. To do so would mean an orthogonal departure from current work, where system designers are seeking less biased and more interpretable models. Moreover, our H+BOW was more accurate than our H+DNN, posing a trade-off between high team accuracy vs. low team bias. Our recommendation is that, while our results are somewhat surprising and highlight the importance of studying real-world hybrid decision-making, deploying a less interpretable model serves as a shortcut to true bias mitigation. As a community, we should seek to discover mechanisms that achieve this more explicitly and efficiently to truly leverage the complementary strengths of improved algorithmic design. Examples may include requiring humans to follow explicit forms of self-reflection and decision justification when there exists a a risk of bias.

Figure 5: Conformity rate (percentage of hybrid decisions that match those predicted by the model alone) across tested occupations. We see significantly higher conformity to BOW than to DNN and Random predictions, with highlighted bands detailing 95% confidence intervals.
#### Dataset Release
We introduce our full experimental data as Hybrid Hiring, a large-scale dataset for studying human-AI decision-making that is collected and evaluated on real-world candidates. Comprised of 38,400 human judgements over 9,600 unique prediction tasks across seven conditions, our dataset represents a first of its kind released to study human decision-making in the loop utilizing trained ML inferences. Ideally, hiring (and other high-stakes social decisions) should always remain in the purview of human review, and so utilizing datasets and methodologies of this kind will allow the field to investigate the impacts of different research questions on human decision-making in these contexts. Although we specifically investigated hybrid performance of three NLP models, one can easily extend this work to alternate architectures and interfaces.
#### Limitations
While we do our best to simulate a realistic hybrid task by selecting a socially relevant domain where real human data is incorporated in the decision-making of human study participants, we recognize that we are still running a controlled study on mTurk, where transfer of results to real-world deployed systems may be limited. Moreover, we greatly simplify many potential confounders (such as age, presence of non-binary gender, and self-written biography variance) in isolating bias to a single variable. We also do not study state-of-the-art de-biased models due to more complex architectures and leave for future work. We hope that our work moves the needle more in the direction of studying the impacts of ML-aided systems in real-world environments and propose that the community jointly invest in producing similar large-scale decision tasks and datasets to further study such intricacies across varied domains.
### Conclusion
In asking the question of how model performance impacts human decision-making on two axes, our findings open up additional questions related to the specificity of human responses to different models, even without an interface change. Our results motivate the explicit need to further investigate the observed signals regarding differing human intuitions of varied model architectures and how we can best design systems that allow for optimal hybrid collaboration.
### Acknowledgements
We would like to thank Adam Kalai and Maria De-Arteaga for helpful discussions on problem formulation, Alexey Romanov for help with data collection and model training, Sarah Jobalia for moral support, and the anonymous reviewers for comments on the draft. Andi Peng is supported by an NSF Graduate Research Fellowship. |
cd3c09db-3569-49b7-ab17-a4835b292c70 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Cambridge (MA) Meetup
Discussion article for the meetup : Cambridge (MA) Meetup
WHEN: 05 August 2012 02:00:00PM (-0400)
WHERE: 25 Ames St, Cambridge, MA 02139
Cambridge/Boston-area Less Wrong meetups on the first and third Sunday of every month, 2pm at the MIT Landau Building [25 Ames St, Bldg 66], room 148. Room number subject to change based on availability, signs will be posted with the actual room number.
Discussion article for the meetup : Cambridge (MA) Meetup |
fc635d18-8927-46ba-b174-ba08656079a6 | trentmkelly/LessWrong-43k | LessWrong | Give praise
The dominant model about status in LW seems to be one of relative influence. Necessarily, it's zero-sum. So we throw up our hands and accept that half the community is just going to run a deficit.
Here's a different take: status in the sense of worth. Here's a set of things we like, or here's a set of problems for you to solve, and if you do, you will pass the bar and we will grant you personhood and take you seriously and allow you onto the ark when the world comes crumbling. Worth is positive-sum.
I think both models are useful, but only one of these models underlies the emotional need we call status. I think it's the latter.
Another assumption: humans are satisficers. Those that claim to the contrary have never been satisfied. An unsatisfied satisficer acts like a maximizer. I think that Maslov got pretty close with his hierarchy of needs. Not the specific set of needs, not necessarily their order, but the idea of humans working on one need at the time, until satisfaction, so that the next need comes up.
It seems to me that many of us are stuck at the status level, and I think getting past it makes us surely happier and plausibly more effective.
How is worth generated? Quite simply, by giving praise. You either find your behavior exceeding a standard that the community agreed on, or someone actually tells you you're doing well. The latter seems more powerful.
I've asked around, and it even seems to be considered "normal" in most (non-systematizing) communities to habitually give praise. It's even apparently something people regard as necessary for proper psychological health. But honestly, apart from volunteering at CFAR, I can't recall getting much praise for anything I've done for the community. As a result I never quite feel like I'm doing enough, edging on burnout a few times. Reminds me of pica. Does working on AI Safety ever get me the sense of worth I'm looking for, or should I give up?
So I'd like to suggest we try for Giving Praise as a rationalis |
c8bdb645-a736-4571-9433-d3ab405a4b5e | trentmkelly/LessWrong-43k | LessWrong | Kingfisher Summer Tour 2024
Kingfisher is going on tour again:
Thr 2024-06-27 Rochester NY Fri 2024-06-28 Pittsburgh PA Sat 2024-06-29 Bloomington IN Sun 2024-06-30 St Louis MO Mon 2024-07-01 Cincinnati OH Tue 2024-07-02 Indianapolis IN
Cecilia made a flyer:
Harris will be calling, and we'll be driving together. Anna and Lily are coming too, which I'm excited about.
It's about 40hr of driving, which is a lot, but we're spreading it over eight days and we do have some relatively light days, so it should be ok:
If you're somewhere along here, I'd love to see you; come dance! |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.