
id stringlengths 36 36 | source stringclasses 15 values | formatted_source stringclasses 13 values | text stringlengths 2 7.55M |
|---|---|---|---|
6461692d-27eb-451b-826c-5b830e6e7613 | trentmkelly/LessWrong-43k | LessWrong | Some algorithmic aspects of AGI
|
00d29e28-444d-4215-9da9-ed292dcfedb3 | trentmkelly/LessWrong-43k | LessWrong | AI improving AI [MLAISU W01!]
Over 200 research ideas for mechanistic interpretability, ML improving ML and the dangers of aligned artificial intelligence. Welcome to 2023 and a happy New Year from us at the ML & AI Safety Updates!
Watch this week's MLAISU on YouTube or listen to it on Spotify.
Mechanistic interpretability
The interpretability researcher Neel Nanda has published a massive list of 200 open and concrete problems in mechanistic interpretability. They’re split into the following categories:
1. Analyzing toy models: Diving into models that are much smaller but trained the same way as large models. These are way easier to analyze than large models and he has made 12 small models available.
2. Looking for circuits in the wild: Inspired by the paper “interpretability in the Wild”, can we use mechanistic interpretability on real-life language models?
3. Interpreting algorithmic problems: Algorithms are highly interpretable and learned as a clearly interpretable structure. We can for example observe that grokking happens when an algorithm is generalized within the network.
4. Exploring polysemanticity and superposition: Superposition is when one feature is spread across multiple neurons in a network and gives problems in our interpretation of what neurons represent. Can we find better ways to understand or mitigate this effect?
5. Analyzing training dynamics: Understanding how models change over training is very interesting for identifying how and when capabilities emerge.
These are great projects to go for and we’re collaborating with Neel Nanda to run a mechanistic interpretability hackathon the 20th of January! As Lawrence Chan mentions in a new post; we need to touch reality as soon as possible, and these hackathons are a great way to get fast and concrete research results. You can join us but you can also run a local hackathon site!
ML improving ML
Thomas Woodside summarizes a collaborative project to map cases where ML systems are self-improving. There are already 11 |
f203c3f5-c6d2-4095-8e82-cb911b4502b2 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Is Eric Schmidt funding AI capabilities research by the US government?
[Politico article from Thursday December 22, 2022: "Ex-Google boss helps fund dozens of jobs in Biden’s administration"](https://www.politico.com/news/2022/12/22/eric-schmidt-joe-biden-administration-00074160)
1. Summary:
-----------
### In three sentences:
> "Eric Schmidt, the former CEO of Google who [has long sought influence over White House science policy](https://www.politico.com/news/2022/03/28/google-billionaire-joe-biden-science-office-00020712), is helping to fund the salaries of more than two dozen officials in the Biden administration under the auspices of an outside group, the Federation of American Scientists."
>
>
It is worth noting that Schmidt Futures (Schmidt's philanthropic ventures) does not directly fund these officials' salaries: Schmidt Futures provides < 30% to the Federation of American Scientists' "Day One fund" which funds these officials' salaries. Eric Schmidt seems to me to have called for the US government to aggressively invest in AI development.
### Some more context:
Eric Schmidt chaired the National Security Commission on Artificial Intelligence from 2018-2021, in which the commision called on the US government to spend $40 billion on AI development.
Schmidt Futures (Schmidt's philanthropic ventures) funds < 30% of the contributions to the Day One Project, a project within the Federation of American Scientists (FAS), which (among other things) provides the salaries of "FAS fellows" who hold "more than two dozen officials in the Biden administration" (from the main Politico article being discussed in this post). This includes 2 staffers in the Office of Science and Technology Policy ([a different Politico article](https://www.politico.com/news/2022/03/28/google-billionaire-joe-biden-science-office-00020712#:~:text=Two%20more%20staffers,2018%20to%202021.)).
The FAS is a "nonprofit global policy think tank with the stated intent of using science and scientific analysis to attempt to make the world more secure" ([Wikipedia](https://en.wikipedia.org/wiki/Federation_of_American_Scientists#:~:text=The%20Federation%20of%20American%20Scientists,develop%20the%20first%20atomic%20bombs.)). The Day One project was started to recruit people to fill "key science and technology positions in the executive branch" (from the main Politico article).
2. My question: Are Schmidt's projects harmfully advancing AI capabilities research?
------------------------------------------------------------------------------------
I've seen discussion among the EA community about how OpenAI and Anthropic may be harmfully advancing AI capabilities research. (The best discussion that comes to mind is [this recent Scott Alexander post about ChatGPT](https://astralcodexten.substack.com/p/perhaps-it-is-a-bad-thing-that-the); **if anyone knows any other resources discussing this hypothesis - for or against - please comment below).**
**I have not seen much discussion about Eric Schmidt's harmful or beneficial contributions to AI development in the US government. What do people think about this?** Is this something that should concern us?
3. Some more excerpts from the article about AI
-----------------------------------------------
> “Schmidt is clearly trying to influence AI policy to a disproportionate degree of any person I can think of,” said Alex Engler, a fellow at the Brookings Institution who specializes in AI policy. “We’ve seen a dramatic increase in investment toward advancing AI capacity in government and not much in limiting its harmful use.”
>
>
### ...
> Schmidt’s collaboration with FAS [Federation of American Scientists] is only a part of his broader advocacy for the U.S. government to invest more in technology and particularly in AI, positions he advanced as chair of the federal National Security Commission on Artificial Intelligence from 2018 to 2021.
>
> [The commission’s final report](https://www.nscai.gov/wp-content/uploads/2021/03/Full-Report-Digital-1.pdf) recommended that the government spend $40 billion to “expand and democratize federal AI research and development” and suggested more may be needed.
>
> “If anything, this report underplays the investments America will need to make,” the report stated.
>
>
...
> “Other countries have made AI a national project. The United States has not yet, as a nation, systematically explored its scope, studied its implications, or begun the process of reconciling with it,” they wrote. “If the United States and its allies recoil before the implications of these capabilities and halt progress on them, the result would not be a more peaceful world.”
>
> |
77dc5339-c370-466f-bf17-51b4497b1fc8 | trentmkelly/LessWrong-43k | LessWrong | Offense versus harm minimization
Imagine that one night, an alien prankster secretly implants electrodes into the brains of an entire country - let's say Britain. The next day, everyone in Britain discovers that pictures of salmon suddenly give them jolts of painful psychic distress. Every time they see a picture of a salmon, or they hear about someone photographing a salmon, or they even contemplate taking such a picture themselves, they get a feeling of wrongness that ruins their entire day.
I think most decent people would be willing to go to some trouble to avoid taking pictures of salmon if British people politely asked this favor of them. If someone deliberately took lots of salmon photos and waved them in the Brits' faces, I think it would be fair to say ey isn't a nice person. And if the British government banned salmon photography, and refused to allow salmon pictures into the country, well, maybe not everyone would agree but I think most people would at least be able to understand and sympathize with the reasons for such a law.
So why don't most people extend the same sympathy they would give Brits who don't like pictures of salmon, to Muslims who don't like pictures of Mohammed?
SHOULD EVERYBODY DRAW MOHAMMED?
I first1 started thinking along these lines when I heard about Everybody Draw Mohammed Day, and revisited the issue recently after discovering http://www.reddit.com/r/mohammadpics/.
I have to admit, I find these funny. I want to like them. But my attempts to think of reasons why this is totally different from showing pictures of salmon to British people fail:
• You could argue Brits did not choose to have their abnormal sensitivity to salmon while Muslims might be considered to be choosing their sensitivity to Mohammed. But this requires a libertarian free will. Further, I see little difference between how a Muslim "chooses" to get upset at disrespect to Mohammed, and how a Westerner might "choose" to get upset if you called eir mother a whore. Even though the anger isn't be |
558c1e8a-5bf5-4d42-9139-0d9597f9f091 | trentmkelly/LessWrong-43k | LessWrong | LLMs stifle creativity, eliminate opportunities for serendipitous discovery and disrupt intergenerational transfer of wisdom
In this post, I’ve made no attempt to give an exhaustive presentation of the countless unintended consequences of widespread LLM use; rather, I’ve concentrated on three potential effects that are at the borderline of research, infrequently discussed, and appear to resist a foreseeable solution.
This post argues that while LLMs exhibit impressive capabilities in mimicking human language, their reliance on pattern recognition and replication may, among other societally destructive consequences:
1. stifle genuine creativity and lead to a homogenization of writing styles — and consequently — thinking styles, by inadvertently reinforcing dominant linguistic patterns while neglecting less common or marginalized forms of expression,
2. eliminate opportunities for serendipitous discovery; and
3. disrupt intergenerational transfer of wisdom and knowledge.
As I argue in detail below, there is no reason to believe that those problems are easily mitigatable. The sheer scale of LLM-derived content production, which is likely to dwarf human-generated linguistic output in the near future, poses a serious challenge to the preservation of lexical diversity. The rapid proliferation of AI-generated text could create a “linguistic monoculture”, where the nuanced and idiosyncratic expressions that characterize human language are drowned out by the algorithmic efficiency of LLMs.
LLMs Threaten Creativity in Writing (and Thinking)
LLMs are undoubtedly useful for content generation. These models, trained on vast amounts of data, can generate perfectly coherent and contextually relevant text in ways that ostensibly mimic human creativity. It is precisely this very efficiency of LLMs that will tilt the scales in favor of AI-generated content over time. Upon closer examination, there seem to be a number of insidious consequences infrequently discussed in this connection: the potential erosion of genuine creativity, linguistic diversity, and ultimately, the richness of human exp |
2e15c8c8-c3cb-4515-bac5-43b0a3d6612e | trentmkelly/LessWrong-43k | LessWrong | Visualizing Neural networks, how to blame the bias
Background
This post is strongly based on this paper, which it calls the LRP algorithm, https://arxiv.org/pdf/1509.06321v1.pdf [1]
I later learned of the existence of this paper, which is even more similar to the ideas discussed here. https://arxiv.org/pdf/1704.02685.pdf [2]
In it, I examine 2 of the methods for neural network visualization, and show that they have structural similarities. I show that these algorithms only differ by a difference in how they treat the biases, and (possibly a difference in getting started)
The second algorithm obeys conservation laws, it tries to parcel credit and blame for a decision up to the input neurons.
Intro
The task we want is to assign importance to different inputs of a neural network in production of an output. So for example, in the case of a trained image classifier, the visualization method would take in a particular image, and highlight the parts of the image that the network thought were important.
A general method for visualizing neural networks is back-propagation. First evaluate the network forwards. Then work backwards through the network by using some rule about how to reverse each individual layer.
One example of this is differentiation. Finding the rate of change of the output, with respect to each input. But there are others.
Firstly, lets pretend biases in the network don't exist. We are allowed non-linearities, so long as they satisfy the equation f(0)=0 .
Lets look at various layer types and the different back-propagation rules.
Maximum
Most often found in the form of max pooling.
b=maxiai
Gradient
The rule used in gradient descent, and I think the only rule used in the paper above for back propagating maximum. (Notation note. R here isn't exactly a function. Its more like ddx , its output is related to the context in which the input occurs. Think of every number in the forward net having an associated number )
R(ai)={R(b) ai=b0else
Ignoring the case of an exact tie. Exact ties, a |
e27971d0-544e-4aa7-9c7b-512c31779f04 | awestover/filtering-for-misalignment | Redwood Research: Alek's Filtering Results | id: post3888
A putative new idea for AI control; index here . Humans are biased and irrational (citation not needed) and so don't provide consistent answers to questions. To pick an extreme example, suppose the AI is hesitant between valuing Cake or Death , but can phrase a sufficiently seductive or manipulative question to get humans to answer "Death" when asked. We'll assume that more dull questions elicit "Cake" instead. This poses great problem for any AI doing value learning and trying to model a human-values utility function. If it assumes the human is rational, then there is no simple utility which explains this behaviour. Now fear, however, there is a utility function which explains this! The two universes differ in important ways: in one universe, the AI asked a seductive question, in the other a dull one. Therefore the human values can be modelled as valuing the worlds as: ( s e d u c t i v e q u e s t i o n , D e a t h ) > ( s e d u c t i v e q u e s t i o n , C a k e ) ( d u l l q u e s t i o n , C a k e ) > ( d u l l q u e s t i o n , D e a t h ) . Any rational model of human preference would reach this conclusion - and these would be the correct preference as far as it could be observed. It fits well with physical predictions about the future. And then, depending on what is easy or hard in the world, the AI could decide to ask the seductive question and start killing... Note that we can't avoid this problem by having the AI just count "asking the seductive question" as being part of its action set, and hence special. Once the question is asked, it's vibrations in the air, so the human preferences can be modelled as joint preferences over universes with cake and death and certain patterns of vibration in the air. To avoid this problem, we need the AI to: Know the human is irrational, correctly identify this situation as an example of it, and find correct meta-rational principles to decide what to do/how to ask. It's possible that many of the designs proposed will avoid this problem by correct learning sequences (if it can learn meta-principles early, this might help), but it could be used to show that many designs are not intrinsically safe for all initial priors over human values. |
ca829cd8-090a-4001-b96e-9b0db88e217a | trentmkelly/LessWrong-43k | LessWrong | Problems with instruction-following as an alignment target
We should probably try to understand the failure modes of the alignment schemes that AGI developers are most likely to attempt.
I still think Instruction-following AGI is easier and more likely than value aligned AGI. I’ve updated downward on the ease of IF alignment, but upward on how likely it is. IF is the de-facto current primary alignment target (see definition immediately below), and it seems likely to remain so until the first real AGIs, if we continue on the current path (e.g., AI 2027).
If this approach is doomed to fail, best to make that clear well before the first AGIs are launched. If it can work, best to analyze its likely failure points before it is tried.
Definition of IF as an alignment target
What I mean by IF as an alignment target is a developer honestly saying "our first AGI will be safe because it will do what we tell it to." This seems both intuitively and analytically more likely to me than hearing "our first AGI will be safe because we trained it to follow human values."
IF is currently one alignment target among several, so problems with it aren't going to be terribly important if it's not the strongest alignment target when we hit AGI. Current practices are to train models with roughly four objectives: predict the dataset; follow instructions; refuse harmful requests; and solve hard problems. Including other targets means the model might not follow instructions at some critical juncture. In particular, I and most alignment researchers worry that o1 is a bad idea because it (and all of the following reasoning models) apply fairly strong optimization to a goal (producing correct answers) that is not strongly aligned with human interests.
So IF is one but not the alignment target for current AI. There are reasons to think it will be the primary alignment target as we approach truly dangerous AGI.
Why IF is a likely alignment target for early AGI
We might consider the likelihood of it being tried without adequate consideration to be th |
2ac4f13b-e715-4193-9d5c-ea630ee47657 | trentmkelly/LessWrong-43k | LessWrong | Clarification of AI Reflection Problem
Consider an agent A, aware of its own embedding in some lawful universe, able to reason about itself and use that reasoning to inform action. By interacting with the world, A is able to modify itself or construct new agents, and using these abilities effectively is likely to be an important component of AGI. Our current understanding appears to be inadequate for guiding such an agent's behavior, for (at least) the following reason:
If A does not believe "A's beliefs reflect reality," then A will lose interest in creating further copies of itself, improving its own reasoning, or performing natural self-modifications. Indeed, if A's beliefs don't reflect reality then creating more copies of A or spending more time thinking may do more harm than good. But if A does believe "A's beliefs reflect reality," then A runs immediately into Gödelian problems: for example, does A become convinced of the sentence Q = "A does not believe Q"? We need to find a way for A to have some confidence in its own behavior without running into these fundamental difficulties with reflection.
This problem has been discussed occasionally at Less Wrong, but I would like to clarify and lay out some examples before trying to start in on a resolution.
Gödel Machines
The Gödel machine is a formalism described by Shmidhuber for principled self-modification. A Gödel machine is designed to solve some particular object level problem in its allotted time. I will describe one Gödel machine implementation.
The initial machine A has an arbitrary object level problem solver. Before running the object level problem solver, however, A spends half of its time enumerating pairs of strings (A', P); for each one, if A' is a valid description of an agent and P is a proof that A' does better on the object level task than A, then A transforms into A'.
Now suppose that A's initial search for self-modifications is inefficient: a new candidate agent A' has a more efficient proof checker, and so is able to exa |
0b49a3d5-2cff-49a2-a777-9ac20db59cad | trentmkelly/LessWrong-43k | LessWrong | SolidGoldMagikarp III: Glitch token archaeology
The set of anomalous tokens which we found in mid-January are now being described as 'glitch tokens' and 'aberrant tokens' in online discussion, as well as (perhaps more playfully) 'forbidden tokens', 'unspeakable tokens' and 'cursed tokens'. We've mostly just called them 'weird tokens'.
GPT-3 speaks of 'the unspeakable one' when prompted about the enigmatic ‘ petertodd’
Research is ongoing, and a more serious research report will appear soon, but for now we thought it might be worth recording what is known about the origins of the various glitch tokens. Not why they glitch, but why these particular strings have ended up in the GPT-2/3/J token set.
['\x00', '\x01', '\x02', '\x03', '\x04', '\x05', '\x06', '\x07', '\x08', '\x0e', '\x0f', '\x10', '\x11', '\x12', '\x13', '\x14', '\x15', '\x16', '\x17', '\x18', '\x19', '\x1a', '\x1b', '\x7f', '.[', 'ÃÂÃÂ', 'ÃÂÃÂÃÂÃÂ', 'wcsstore', '\\.', ' practition', ' Dragonbound', ' guiActive', ' \u200b', '\\\\\\\\\\\\\\\\', 'ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ', ' davidjl', '覚醒', '"]=>', ' --------', ' \u200e', 'ュ', 'ForgeModLoader', '天', ' 裏覚醒', 'PsyNetMessage', ' guiActiveUn', ' guiName', ' externalTo', ' unfocusedRange', ' guiActiveUnfocused', ' guiIcon', ' externalToEVA', ' externalToEVAOnly', 'reportprint', 'embedreportprint', 'cloneembedreportprint', 'rawdownload', 'rawdownloadcloneembedreportprint', 'SpaceEngineers', 'externalActionCode', 'к', '?????-?????-', 'ーン', 'cffff', 'MpServer', ' gmaxwell', 'cffffcc', ' "$:/', ' Smartstocks', '":[{"', '龍喚士', '":"","', ' attRot', "''.", ' Mechdragon', ' PsyNet', ' RandomRedditor', ' RandomRedditorWithNo', 'ertodd', ' sqor', ' istg', ' "\\', ' petertodd', 'StreamerBot', 'TPPStreamerBot', 'FactoryReloaded', ' partName', 'ヤ', '\\">', ' Skydragon', 'iHUD', 'catentry', 'ItemThumbnailImage', ' UCHIJ', ' SetFontSize', 'DeliveryDate', 'quickShip', 'quickShipAvailable', 'isSpecialOrderable', 'inventoryQuantity', 'channelAvailability', 'soType', 'soDeliveryDate', '龍契士', 'oreAndOnline', 'Instor |
7464573a-6f5d-493e-92cf-b8cdbfc61b0d | trentmkelly/LessWrong-43k | LessWrong | Meetup : Washington DC Show and tell meetup: Economics
Discussion article for the meetup : Washington DC Show and tell meetup: Economics
WHEN: 14 October 2012 03:00:00PM (-0400)
WHERE: National Portrait Gallery Plaza, Washington, DC 20001, USA
This meetup is going to be the first in what I hope will be a series of "show and tell" meetups. One of our members has agreed to talk about economics, one of his areas of expertise. This should be much better if people come equipped with questions or subtopics of particular interest to them, so please do so!
Discussion article for the meetup : Washington DC Show and tell meetup: Economics |
96b72905-e57f-4a27-96b1-3777083f9f59 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Exploring Metaculus’ community predictions
Disclaimer: this is not a project from [Arb Research](https://arbresearch.com/).
Summary
=======
* I really like [Metaculus](https://www.metaculus.com/)!
* I have collected and analysed in this [Sheet](https://docs.google.com/spreadsheets/d/1Mxl8vGsZemmuKytV9zH1ft-iP2q4xwnxz7gCkSlYmPg/edit?usp%3Dsharing) metrics about Metaculus’ questions outside of question groups, and their [Metaculus’ community predictions](https://www.metaculus.com/help/faq/%23community-prediction) (see tab “TOC”). The Colab to extract the data and calculate the metrics is [here](https://colab.research.google.com/drive/1JqXgir413MJ6nf0RVpUw0fwh82LRu4ji?usp%3Dsharing).
* The mean metrics vary a lot across categories, and the same is seemingly true for correlations among metrics. So one should not assume the performance across all questions is representative of that within each of [Metaculus’ categories](https://www.metaculus.com/questions/categories/). To illustrate:
+ Across categories, the 5th and 95th percentiles of the mean normalised outcome are 0 and 0.784[[1]](#fnj6bz6cf2jy), and of the mean Brier score are 0.0369 and 0.450. For context, the Brier score is 0.25 (= 0.5^2) for the maximally uncertain probability of 0.5.
+ According to Metaculus’ track record [page](https://www.metaculus.com/questions/track-record/), the mean [Brier score](https://en.wikipedia.org/wiki/Brier_score) for Metaculus’ community predictions evaluated at all times is 0.126 for all questions, but 0.237 for those of the category [artificial intelligence](https://www.metaculus.com/questions/?search%3Dcat:computing--ai). So Metaculus’ community predictions about probabilities[[2]](#fniemyc829csk) look good in general, but they perform close to random predictions for the category of artificial intelligence. However, note there are other categories with questions about artificial intelligence, like [AI and machine learning](https://www.metaculus.com/questions/?search=cat:comp-sci--ai-and-machinelearning).
* There can be significant differences between Metaculus community predictions and [Metaculus’ predictions](https://www.metaculus.com/help/faq/%23metaculus-prediction). For instance, the mean Brier score of the latter for the category of artificial intelligence is 0.168, which is way more accurate than the 0.237 of the former.
* According to my results, Metaculus’ community predictions are:
+ In general (i.e. considering all questions), less accurate for questions:
- Whose predictions are more extreme under Bayesian updating ([correlation coefficient](https://en.wikipedia.org/wiki/Pearson_correlation_coefficient) R = 0.346, and [p-value](https://en.wikipedia.org/wiki/P-value) p = 0[[3]](#fn4ztx3gz691)).
- With a greater amount of updating (R = 0.262, and p = 0).
- With a greater difference between amount of updating and uncertainty reduction (R = 0.256, and p = 0).
+ For the category of artificial intelligence, less accurate for questions with:
- Greater difference between amount of updating and uncertainty reduction (R = 0.361, and p = 0.0387).
- More predictions (R = 0.316, and p = 0.0729).
- A greater amount of updating (R = 0.282, and p = 0.111).
+ Compatible with Bayesian updating in general, in the sense I failed to reject it during the 2nd half of the period during which each question was or has been open (mean p-value of 0.425).
* If you want to know how much to trust a given prediction from Metaculus, I think it is sensible to check Metaculus’ track record for similar past questions (more [here](https://forum.effectivealtruism.org/posts/zeL52MFB2Pkq9Kdme/exploring-metaculus-community-predictions#My_recommendation_on_how_to_use_Metaculus)).
Acknowledgements
----------------
Thanks to Charles Dillon, Misha Yagudin from [Arb Research](https://arbresearch.com/), Peter Mühlbacher, and Ryan Beck.
Dark crystall ball in a bright foggy galaxy. Generated by OpenAI's DALL-E.Introduction
============
I really like [Metaculus](https://www.metaculus.com/help/faq/%23community-prediction)!
Methods
=======
I believe it would be important to better understand how much to trust Metaculus’ predictions. To that end, I have determined in this [Sheet](https://docs.google.com/spreadsheets/d/1Mxl8vGsZemmuKytV9zH1ft-iP2q4xwnxz7gCkSlYmPg/edit?usp%3Dsharing) (see tab “TOC”) metrics about all Metaculus’ questions outside of question groups with an ID from 1 to 15000 on 13 March 2023[[4]](#fnwztdbn0o85), and their Metaculus’ community predictions. The metrics for each question are:
* Tags, which identify the [Metaculus’ category](https://www.metaculus.com/questions/categories/).
* Publish time (year).
* Close time (year).
* Resolve time (year).
* Time from publish to close (year).
* Time from close to resolve (year).
* Time from publish to resolve (year).
* Number of forecasters.
* Number of predictions.
* Number of analysed dates, which is the number of instances at which the predictions were assessed.
* Total belief movement, which is a measure of the amount of updating, and is the sum of the belief movements, which are the squared differences between 2 consecutive beliefs.
+ The values of the beliefs range from 0 to 1, and can respect a:
- Probability.
- Ratio between an expectation and difference between the maximum and minimum allowed by Metaculus.
+ To illustrate, the belief movement from a probability of 0.5 to 0.8 is 0.09 (= (0.8 - 0.5)^2).
* Total uncertainty reduction, which is the difference between the initial and final uncertainties, where the uncertainty linked to a belief value p equals p (1 - p). This is null for probabilities of 0 and 1, and maximum and equal to 0.25 for a probability of 0.5.
* Total excess belief movement, which is the difference between the total belief movement and total uncertainty reduction.
* Normalised excess belief movement, which is the ratio between the total belief movement and total uncertainty reduction.
* Absolute value of normalised excess belief movement.
* [Z-score](https://en.wikipedia.org/wiki/Standard_score) for the null hypothesis that the beliefs are Bayesian.
* [P-value](https://en.wikipedia.org/wiki/P-value) for the null hypothesis that the beliefs are Bayesian.
* Normalised outcome, which is, for questions about:
+ Probabilities, 0 if the question resolves as “no”, and 1 if as “yes”.
+ Expectations, the ratio between the outcome and the difference between the maximum and minimum allowed by Metaculus.
* [Brier score](https://en.wikipedia.org/wiki/Brier_score), which is the mean squared difference between the predicted probability and outcome (0 or 1). Note the Brier score does not apply to questions about expectations, whose accuracy I did not assess.
[Augenblick 2021](https://academic.oup.com/qje/article-abstract/136/2/933/6127317?redirectedFrom%3Dfulltext) shows the total belief movement should match the total uncertainty reduction in expectation for [Bayesian updating](https://forum.effectivealtruism.org/topics/bayes-theorem) (see “Proposition 1”), in which case the total excess movement and normalised excess belief movement should be 0 and 1. I suppose Metaculus’ community predictions are less reliable early on. So, in the context of the metrics regarding belief movement and uncertainty reduction, I only analysed predictions concerning the 2nd half of the period during which each question was or has been open.
The Colab to extract the data and calculate the metrics is [here](https://colab.research.google.com/drive/1JqXgir413MJ6nf0RVpUw0fwh82LRu4ji?usp%3Dsharing)[[5]](#fn4kyfwk7siq5).
Results
=======
The tables below have results for:
* The mean, and 5th and 95th percentiles across categories of the number of questions, number of resolved questions, and mean metrics (1st table).
* Mean metrics for all questions and [those of the category of artificial intelligence](https://www.metaculus.com/questions/?search%3Dcat:computing--ai) (2nd table).
* Correlations among metrics for all questions and those of the category of artificial intelligence (3rd table).
The results in the 2nd and 3rd tables for the other categories are in the [Sheet](https://docs.google.com/spreadsheets/d/1Mxl8vGsZemmuKytV9zH1ft-iP2q4xwnxz7gCkSlYmPg/edit?usp%3Dsharing).
Mean metrics
------------
| Metric | Category |
| --- | --- |
| Mean | 5th percentile | 95th percentile |
| Number of questions | 64.8 | 3.00 | 179 |
| Number of resolved questions | 27.4 | 0 | 68.0 |
| Mean publish time (year) | 2020 | 2017 | 2022 |
| Mean close time (year) | 2039 | 2019 | 2077 |
| Mean resolve time (year) | 2062 | 2020 | 2161 |
| Mean time from publish to close (year) | 18.8 | 0.0530 | 56.2 |
| Mean time from close to resolve (year) | 23.0 | 2.04\*10^-7 | 72.9 |
| Mean time from publish to resolve (year) | 41.8 | 0.159 | 141 |
| Mean number of forecasters | 82.1 | 23.5 | 166 |
| Mean number of predictions | 172 | 50.0 | 357 |
| Mean number of analysed dates | 86.5 | 56.4 | 104 |
| Mean total belief movement | 0.0191 | 2.15\*10^-3 | 0.0461 |
| Mean total uncertainty reduction | 0.0130 | -0.0108 | 0.0491 |
| Mean total excess belief movement | 6.10\*10^-3 | -0.0253 | 0.0394 |
| Mean normalised excess belief movement | -43.6 | -7.09 | 7.77 |
| Mean absolute value of normalised excess belief movement | 49.0 | 0.213 | 18.5 |
| Mean z-score for the null hypothesis that the beliefs are Bayesian | 0.103 | -0.711 | 0.811 |
| Mean p-value for the null hypothesis that the beliefs are Bayesian | 0.456 | 0.306 | 0.638 |
| Mean normalised outcome | 0.328 | 0 | 0.669 |
| Mean Brier score | 0.162 | 0.0367 | 0.300 |
| Metric | Category |
| --- | --- |
| Any | Artificial intelligence |
| Number of questions | 5,335 | 199 |
| Number of resolved questions | 2,337 | 50 |
| Mean publish time (year) | 2,021 | 2,020 |
| Mean close time (year) | 2,036 | 2,043 |
| Mean resolve time (year) | 2,048 | 2,050 |
| Mean time from publish to close (year) | 15.3 | 22.9 |
| Mean time from close to resolve (year) | 12.2 | 7.07 |
| Mean time from publish to resolve (year) | 27.6 | 30.0 |
| Mean number of forecasters | 88.2 | 104.5 |
| Mean number of predictions | 206 | 200 |
| Mean number of analysed dates | 90.4 | 91.0 |
| Mean total belief movement | 0.0238 | 0.0219 |
| Mean total uncertainty reduction | 0.0191 | 0.0144 |
| Mean total excess belief movement | 4.70\*10^-3 | 7.53\*10^-3 |
| Mean normalised excess belief movement | -43.1 | -3.92 |
| Mean absolute value of normalised excess belief movement | 47.2 | 5.52 |
| Mean z-score for the null hypothesis that the beliefs are Bayesian | -6.78\*10^-3 | 0.105 |
| Mean p-value for the null hypothesis that the beliefs are Bayesian | 0.425 | 0.413 |
| Mean normalised outcome | 0.365 | 0.381 |
| Mean Brier score | 0.151 | 0.230 |
Correlations among metrics
--------------------------
| Correlation between Brier score and... | Category |
| --- | --- |
| Any (N = 1,374) | Artificial intelligence (N = 33) |
| [Correlation coefficient](https://en.wikipedia.org/wiki/Pearson_correlation_coefficient) | P-value for the null hypothesis that there is no correlation[[3]](#fn4ztx3gz691) | Correlation coefficient | P-value for the null hypothesis that there is no correlation |
| Publish time (year) | -0.143 | 9.82\*10^-8 | 0.179 | 0.319 |
| Close time (year) | -0.117 | 1.40\*10^-5 | 0.172 | 0.339 |
| Resolve time (year) | -0.146 | 5.68\*10^-8 | 0.184 | 0.305 |
| Time from publish to close (year) | 0.0319 | 0.238 | 7.82\*10^-3 | 0.966 |
| Time from close to resolve (year) | -0.0193 | 0.476 | 0.0341 | 0.850 |
| Time from publish to resolve (year) | 0.0102 | 0.705 | 0.0318 | 0.861 |
| Number of forecasters | -0.0776 | 4.02\*10^-3 | 0.0680 | 0.707 |
| Number of predictions | -0.0366 | 0.175 | 0.316 | 0.0729 |
| Number of analysed dates | -0.107 | 6.57\*10^-5 | 0.198 | 0.270 |
| Total belief movement | 0.262 | 0 | 0.282 | 0.111 |
| Total uncertainty reduction | -0.136 | 4.61\*10^-7 | -0.150 | 0.405 |
| Total excess belief movement | 0.256 | 0 | 0.361 | 0.0387 |
| Normalised excess belief movement | -4.63\*10^-3 | 0.864 | 0.0708 | 0.695 |
| Absolute value of normalised excess belief movement | 0.0893 | 9.17\*10^-4 | 0.110 | 0.542 |
| Z-score for the null hypothesis that the beliefs are Bayesian | 0.346 | 0 | 0.241 | 0.176 |
| P-value for the null hypothesis that the beliefs are Bayesian | 0.0296 | 0.273 | -0.0269 | 0.882 |
| Normalised outcome | 0.102 | 1.60\*10^-4 | 0.112 | 0.535 |
Discussion
==========
Mean metrics
------------
The mean metrics vary a lot across categories. For example, the 5th and 95th percentiles of the mean normalised outcome are 0 and 0.669, and of the mean Brier score are 0.0367 and 0.300.
I computed mean normalised excess belief movements of -43.1 and -3.92 for all questions and those of the category of artificial intelligence, but these are not statistically significant, as the mean p-values are 0.425 and 0.413. So it is not possible to reject Bayesian updating for Metaculus’ community predictions during the 2nd half of the period during which each question was or has been open. To contextualise, Table III of [Augenblick 2021](https://academic.oup.com/qje/article-abstract/136/2/933/6127317?redirectedFrom%3Dfulltext) presents normalised excess belief movements pretty close to 1 (and the p-values for the null hypothesis of Bayesian updating are all lower than 0.001):
* 1.20 for “a large data set, provided by and explored previously in [Mellers (2014)](https://journals.sagepub.com/doi/pdf/10.1177/0956797614524255) and [Moore (2017)](https://pubsonline.informs.org/doi/abs/10.1287/mnsc.2016.2525), that tracks individual probabilistic beliefs over an extended period of time”.
* 0.931 for “predictions of a popular baseball statistics website called [Fangraphs](https://en.wikipedia.org/wiki/FanGraphs)”.
* 1.046 for “[Betfair](https://en.wikipedia.org/wiki/Betfair), a large British prediction market that matches individuals who wish to make opposing financial bets about a binary event”.
I estimated mean normalised outcomes of 0.365 and 0.381 for all questions and those of the category of artificial intelligence. If we assume these values apply to questions about both probabilities and expectations:
* The likelihood of a question about probabilities resolving as “yes” is 36.5 % for all questions, and 38.1 % for those of the category of artificial intelligence.
* The outcome of a question about expectations is expected to equal the allowed minimum plus 36.5 % of the distance between the allowed minimum and maximum for all questions, and 38.1 % for those of the category of artificial intelligence.
I got mean Brier scores of 0.151 and 0.230 for all questions and those of the category of artificial intelligence, which are 19.5 % higher and 2.86 % lower than the mean Brier scores of 0.126 and 0.237 shown in Metaculus’ track record [page](https://www.metaculus.com/questions/track-record/)[[6]](#fnaplmoo626z6). I believe the differences are explained by my results:
* Excluding group questions.
* Approximating the mean Brier score based on a set of dates which covers the whole lifetime of the question (in uniform time steps[[7]](#fnzol4hy6cuv)), but does not encompass all community predictions[[8]](#fngzqg5ardt3l).
I think the 1st of these considerations is much more important than the 2nd. The category of artificial intelligence does not include probabilistic group questions, so it is only affected by the 2nd consideration, and the discrepancy is much smaller than for all questions (2.86 % < 19.5 %).
In any case, according to Metaculus’ track record [page](https://www.metaculus.com/questions/track-record/), Metaculus’ community predictions for questions of the category of artificial intelligence perform close to randomly, as 0.237 is pretty close to 0.25. However, [Metaculus’ predictions](https://www.metaculus.com/help/faq/%23metaculus-prediction) and postdictions[[9]](#fnks4cyu0ax7k) for the same category perform considerably better, with mean Brier scores of 0.168 and 0.146. These are also lower than the mean Brier score of 0.232 achieved for predictions matching the mean outcome of 0.365[[10]](#fn4x5qilixcnx) for probabilistic questions of the category of artificial intelligence[[11]](#fnz5upe3xa7y). In addition, I should note Metaculus’ predictions for the category of [AI and machine learning](https://www.metaculus.com/questions/?search%3Dcat:comp-sci--ai-and-machinelearning) have a mean Brier score of 0.149 (< 0.168).
In contrast, among all questions, the mean Brier score of Metaculus’ community predictions of 0.126 is similar to that of 0.120 for Metaculus’ predictions. So, overall, Metaculus’ community predictions perform roughly as well as Metaculus’ predictions, although there can be important differences between them within categories, as illustrated above for the category of artificial intelligence.
It would also be nice to see the mean accuracy of the predictions of questions about expectations, but I have not done that here.
Correlations among metrics
--------------------------
The 3 metrics which correlate more strongly with the Brier score are, listed by descending strength of the correlation (correlation coefficient; p-value):
* For all questions:
+ Z-score for the null hypothesis that the beliefs are Bayesian (0.346; 0), i.e. predictions are less accurate (higher Brier score) for questions whose predictions are more extreme under Bayesian updating.
+ Total belief movement (0.262; 0), i.e. predictions are less accurate for questions with a greater amount of updating. This is surprising, as one would expect predictions to converge to the truth as they are updated.
+ Total excess belief movement (0.256; 0), i.e. predictions are less accurate for questions with greater difference between amount of updating and uncertainty reduction.
* For the category of artificial intelligence:
+ Total excess belief movement (0.361; 0.0387), i.e. predictions are less accurate for questions with greater difference between amount of updating and uncertainty reduction.
+ Number of predictions (0.316; 0.0729), i.e. predictions are less accurate for questions with more predictions. Maybe more popular questions attract worse forecasters?
+ Total belief movement (0.282; 0.111), i.e. predictions are less accurate for questions with a greater amount of updating. This is surprising, but connected to the correlation above. The community prediction moves each time a new prediction is made.
The correlations with the normalised excess belief movement are weak (correlation coefficients of -4.63\*10^-3 and 0.0708), and not statistically significant (p-values of 0.864 and 0.695). So it is not possible to reject (the null hypothesis) that there is no correlation between accuracy and Bayesian updating, but the correlation I obtained is quite weak anyways.
Comparing the correlations for all questions and those of the category of artificial intelligence shows one should not extrapolate the results from all questions to each of the categories. The signs of the correlations are different for 52.9 % (= 9/17) of the metrics, although some of those of the category of artificial intelligence are not statistically significant. I guess the same applies to other categories. Feel free to check the correlations among metrics for each of the categories in tab “Correlations among metrics within categories”, selecting the category in the drop-down at the top.
Finally, correlations with accuracy for questions about expectations may differ from the ones I have discussed above for ones about probabilities.
My recommendation on how to use Metaculus
-----------------------------------------
If you want to know how much to trust a given prediction from Metaculus, I think it is sensible to check [Metaculus’ track record](https://www.metaculus.com/questions/track-record/) for similar past questions:
* The type of prediction you are seeing, either Metaculus’ community prediction or Metaculus’ prediction.
* The categories to which that question belongs (often more than one). The relevant menus show up when you click on “Show Filter”.
* The type of question. If it is about:
+ Probabilities, select “Brier score” or “Log score (discrete)”. I think the latter is especially important if small differences in probabilities close to 0 or 1 matter for your purpose.
+ Expectations, select “Log score (continuous)”.
* The time which matches more closely your conditions. To do this, you can select “other time…” after clicking on the dropdown after “evaluated at”.
+ This is relevant because, even if the track record as evaluated at “all times” is good, it may not be so early in the question lifetime.
+ The “other time” can be defined as a fraction of the question lifetime, or time before resolution.
I am glad Metaculus has made available all these options, and I really appreciate the transparency!
1. **[^](#fnrefj6bz6cf2jy)** I define the normalised outcome such that it ranges from 0 to 1 for questions about expectations, such that its lower and upper bound match the possible outcomes for probabilities.
2. **[^](#fnrefiemyc829csk)** The Brier score does not apply to expectations.
3. **[^](#fnref4ztx3gz691)** All p-values of 0 I present here are actually positive, but are so small they were rounded to 0 in Sheets.
4. **[^](#fnrefwztdbn0o85)** The pages of Metaculus’ questions have the format “https://www.metaculus.com/questions/ID/”.
5. **[^](#fnref4kyfwk7siq5)** The running time is about 20 min.
6. **[^](#fnrefaplmoo626z6)** To see the 1st of these Brier scores, you have to select “Brier score”, for the “community prediction”, evaluated at “all times”. To see the 2nd, you have to additionally click on “Show filter”, and select “Artificial intelligence” below “Categories include”.
7. **[^](#fnrefzol4hy6cuv)** Metaculus considers all predictions, which are not uniformly distributed in time (unlike the ones I retrieved), and therefore have different weights in the mean Brier score.
8. **[^](#fnrefgzqg5ardt3l)** The mean number of analysed dates is 43.9 % (= 90.4/206) of the mean number of predictions.
9. **[^](#fnrefks4cyu0ax7k)** From [here](https://www.metaculus.com/questions/track-record/), Metaculus’ postdictions refer to “what our [Metaculus’] current algorithm would have predicted if it and its calibration data were available at the question's close”.
10. **[^](#fnref4x5qilixcnx)** Mean of column T of tab “Metrics by question” for the questions of the category of artificial intelligence with normalised outcome of 0 or 1.
11. **[^](#fnrefz5upe3xa7y)** 0.232 = 0.365\*(1 - 0.365)^2 + (1 - 0.365)\*(0.365)^2.
12. **[^](#fnrefcngw35pext)** Some p-values are so small that they were rounded to 0 in Sheets. |
dd47c457-5d60-4d64-be4b-ea34409a24a2 | trentmkelly/LessWrong-43k | LessWrong | D&D.Sci (Easy Mode): On The Construction Of Impossible Structures
This is a D&D.Sci scenario: a puzzle where players are given a dataset to analyze and an objective to pursue using information from that dataset.
Duke Arado’s obsession with physics-defying architecture has caused him to run into a small problem. His problem is not – he affirms – that his interest has in any way waned: the menagerie of fantastical buildings which dot his territories attest to this, and he treasures each new time-bending tower or non-Euclidean mansion as much as the first. Nor – he assuages – is it that he’s having trouble finding talent: while it’s true that no individual has ever managed to design more than one impossible structure, it’s also true that he scarcely goes a week without some architect arriving at his door, haunted by alien visions, begging for the resources to bring them into reality. And finally – he attests – his problem is definitely not that “his mad fixation on lunatic constructions is driving him to the brink of financial ruin”, as the townsfolk keep saying: he’ll have you know he’s recently brought an accountant in to look over his expenditures, and he’s confirmed he has the funds to keep pursuing this hobby long into his old age.
Rather, his problem is the local zoning board. Concerned citizens have come together to force him to limit new creations near populated areas, claiming they “disrupt the neighbourhood character” and “conjure eldritch music to lure our children away while we sleep”. While in previous years he was free to – and did – support any qualified architect who showed up with sufficiently strange blueprints, the Duke is now forced to be selective: at present, he has fourteen applicants waiting on his word, and only four viable building sites. He finds this particularly galling, since about half the time when an architect finishes their work, the resulting building ends up not distorting the fabric of spacetime, and instead just kind of looking weird. It’s entirely possible that if he picks at random, he’ll end |
f678edf4-a16a-4198-8bcd-6bf5b4b6e436 | trentmkelly/LessWrong-43k | LessWrong | Why don't organizations have a CREAMO?
That is, a Chief Risk Evaluation And Mitigation Officer.
A bad handle on risk seems to be pervasive even in good organizations, both for- and non-profit. The unfolding FTX debacle shows that even Rationality-inspired orgs suck at risk assessment as much as any other place. If you go through the list of failed, ailing and failing startups in the ratosphere, they don't seem to do any better than your average ones, in terms of evaluating risk and acting on it. One can imagine that they would be good at handling known unknowns, and it's the black swans that would be a real danger. And yet, orgs get blindsided by entirely predictable events (why did FTX or its donors learn nothing from the Mt. Gox fiasco?). I can see some reasons where accurate risk evaluation is not in the interests of top-level human mesa-optimizers within an organization, because the compensation incentives are so misaligned. I can also see how everyone would hate that person. Or maybe this role is distributed between other executive officers? Certainly some rudimentary risk evaluation is done at every level, from the board down, but it doesn't seem to be the main focus of anyone. Or maybe I am missing something here and this role is not useful in general. |
fe931c38-ee5b-4525-bf12-3bb9efe9dba9 | trentmkelly/LessWrong-43k | LessWrong | Supplementing memory with experience sampling
If you asked me how happy I've been, I'd think back over my recent life and synthesize my memories into a judgement. Since I'm the one experiencing my life you would think this would be accurate, but our memories aren't fair. For example, people who had their hand in 57° water for 60 seconds rated the experience as less pleasant than people who had their hand in the same 57° water for the same 60 seconds, followed by 30 seconds with the water slowly rising to 59°. (Kahneman 1993, pdf) This is the peak-end rule where when we look back at an experience we don't really consider the duration and instead evaluate it based on how it was at its peak and how it ended.
This disagreement between emotion as it is experienced and emotion as it is remembered is called the memory-experience gap, and the peak-end rule is only one of the causes. The problem is, generally we only have access to memories of our emotion, which means if you're given the ice-water choice you'll repeatedly choose the option with more suffering. How can we get around this?
When psychologists want to get at experiential emotion they give people little timers. Every time the timer goes off the person writes down how happy/sad they are at that moment. This is an external sampling method that lets us use any sort of aggregation we would like, and it's fair in a way our internal methods are not. When I first read about this I thought "neat" and moved on, but recently I realized I that with a computer in my pocket I could do this myself. After asking around I ended up with the TagTime Android app, which is the only way I've found to do this that (a) works without an internet connection and (b) has an equal probability of sampling at every moment.
The response screen looks like:
You tap tags to say which ones currently apply. I have them sorted by frequency. To add new tags you turn the phone sideways and type text:
That's a little annoying, but most of the time I'm not entering a new tag.
I have tags |
12046e79-100b-4f0f-b233-28c109275bcb | trentmkelly/LessWrong-43k | LessWrong | Value/Utility: A History
[ I am writing this post because, while many people on LessWrong know something about the history of value and utility, it's vanishingly rare that someone is confident enough that they understand the whole thing, that they feel they can speak authoritatively about what these concepts 'really mean'. This often blocks important discussions. I had a faint memory suggesting that the canonical history is too short and understandable to really warrant this, so I looked up the whole thing, and as far as I can tell, that's true.
[One relevant Wikipedia section; I'm basically trying to write this up more tersely and straightforwardly and with less left up to assumed shared reader background.]
As a sometime hobbyist historian, I do wince publishing something so simplified. I know my picture of what the important events were would radically shift if I knew a little more. However, I think LessWrong working off this painfully simplified consensus would be a night-and-day improvement.
This post contains extensive quotes/cribbing from "Do Dice Play God?" by the mathematician Ian Stewart. IMO it's a great book on probability theory, although not mathematically sophisticated or ideologically Bayesian, because it gives the surprising historical/cultural motivations for a comprehensive breadth of "accepted procedures" in statistics usually taken at face value. [ Word of caution: Stewart conspicuously leaves out such figures as ET Jaynes, and Karl Friston [in his chapter about the brain as a Bayesian dynamical system!] suggesting he isn't aware of everything. ] ]
I. Cardano
The history books say: everybody was confused about chance until Girolamo Cardano, an Italian algebraist and gambler who wrote "Book on Games of Chance" in 1564 [ it was not published until 1663, long after he'd died ]. "At first sight [most Roman dice] look like cubes, but nine tenths of them have rectangular faces, not square ones. They lack [ . . . ] symmetry [ . . . ], so some numbers would have turned up m |
6fad2cb1-508b-4fc4-b6a7-25169e4e788c | awestover/filtering-for-misalignment | Redwood Research: Alek's Filtering Results | id: post3709
Previously , we defined a setting called "Delegative Inverse Reinforcement Learning" (DIRL) in which the agent can delegate actions to an "advisor" and the reward is only visible to the advisor as well. We proved a sublinear regret bound (converted to traditional normalization in online learning, the bound is O ( n 2 / 3 ) ) for one-shot DIRL (as opposed to standard regret bounds in RL which are only applicable in the episodic setting). However, this required a rather strong assumption about the advisor: in particular, the advisor had to choose the optimal action with maximal likelihood. Here, we consider "Delegative Reinforcement Learning" (DRL), i.e. a similar setting in which the reward is directly observable by the agent. We also restrict our attention to finite MDP environments (we believe these results can be generalized to a much larger class of environments, but not to arbitrary environments). On the other hand, the assumption about the advisor is much weaker: the advisor is only required to avoid catastrophic actions (i.e. actions that lose value to zeroth order in the interest rate) and assign some positive probability to a nearly optimal action. As before, we prove a one-shot regret bound (in traditional normalization, O ( n 3 / 4 ) ). Analogously to before , we allow for "corrupt" states in which both the advisor and the reward signal stop being reliable. Appendix A contains the proofs and Appendix B contains propositions proved before. Notation The notation K : X k → Y means K is Markov kernel from X to Y . When Y is a finite set, this is the same as a measurable function K : X → Δ Y , and we use these notations interchangeably. Given K : X k → Y and A ⊆ Y (corr. y ∈ Y ), we will use the notation K ( A ∣ x ) (corr K ( y ∣ x ) ) to stand for Pr y ′ ∼ K ( x ) [ y ′ ∈ A ] (corr. Pr y ′ ∼ K ( x ) [ y ′ = y ] ). Given Y is a finite set, μ ∈ Δ Y ω , h ∈ Y ∗ and y ∈ Y , the notation μ ( y ∣ h ) means Pr x ∼ μ [ x | h | = y ∣ x : | h | = h ] . Given Ω a measurable space, μ ∈ Δ Ω , n , m ∈ N , { A k } k ∈ [ n ] , { B j } j ∈ [ m ] finite sets and { X k : Ω → A k } k ∈ [ n ] , { Y j : Ω → B j } j ∈ [ m ] random variables (measurable mappings), the mutual information between the joint distribution of the X k and the joint distribution of the Y j will be denoted I ω ∼ μ [ X 0 , X 1 … X n − 1 ; Y 0 , Y 1 … Y m − 1 ] We will parameterize our geometric time discount by γ = e − 1 / t , thus all functions that were previously defined to depend on t are now considered functions of γ . Results We start by explaining the relation between the formalism of general environments we used before and the formalism of finite MDPs. Definition 1 A finite Markov Decision Process (MDP) is a tuple M = ( S M , A M , T M : S M × A M k → S M , R M : S M → [ 0 , 1 ] ) Here, S M is a finite set (the set of states), A M is a finite set (the set of actions), T M is the transition kernel and R M is the reward function. A stationary policy for M is any π : S M k → A M . The space of stationary policies is denoted Π M . Given π ∈ Π M , we define T M π : S M k → S M by T M π ( t ∣ s ) : = ∑ a ∈ A M T M ( t ∣ s , a ) π ( a ∣ s ) We define V M : S M × ( 0 , 1 ) → [ 0 , 1 ] and Q M : S M × A M × ( 0 , 1 ) → [ 0 , 1 ] by V M ( s , γ ) : = ( 1 − γ ) max π ∈ Π M ∞ ∑ n = 0 γ n E T n M π ( s ) [ R M ] Q M ( s , a , γ ) : = ( 1 − γ ) R M ( s ) + γ E t ∼ T M ( s , a ) [ V M ( t , γ ) ] Here, T n M π : S M k → S M is just the n -th power of T M π in the sense of Markov kernel composition. As well known, V M and Q M are rational functions in γ for 1 − γ ≪ 1 , therefore in this limit we have the Taylor expansions V M ( s , γ ) = ∞ ∑ k = 0 1 k ! V k M ( s ) ⋅ ( 1 − γ ) k Q M ( s , a , γ ) = ∞ ∑ k = 0 1 k ! Q k M ( s , a ) ⋅ ( 1 − γ ) k Given any s ∈ S M , we define { A k M ( s ) ⊆ A M } k ∈ N recursively by A 0 M ( s ) : = a r g m a x a ∈ A M Q 0 M ( s , a ) A k + 1 M ( s ) : = a r g m a x a ∈ A k M ( s ) Q k + 1 M ( s , a ) All MDPs will be assumed to be finite, so we drop the adjective "finite" from now on. Definition 2 Let I = ( A , O ) be an interface. An I -universe υ = ( μ , r ) is said to be an O -realization of MDP M with state function S : hdom μ → S M when A M = A and for any h ∈ hdom μ , a ∈ A and o ∈ O T M ( s ∣ S ( h ) , a ) = Pr o ∼ μ ( h a ) [ S ( h a o ) = s ] r ( h ) = R M ( S ( h ) ) Now now define the relevant notion of a "good advisor." Definition 3 Let υ = ( μ , r ) be a universe and ϵ > 0 . A policy π is said to be ϵ -sane for υ when there are M , S s.t. υ is an O -realization of M with state function S and for any h ∈ hdom μ i. supp π ( h ) ⊆ A 0 M ( S ( h ) ) ii. ∃ a ∈ A 1 M ( S ( h ) ) : π ( a ∣ h ) > ϵ We can now formulate the regret bound. Theorem 1 Fix an interface I and ϵ > 0 . Consider H = { υ k = ( μ k , r ) ∈ Υ I } k ∈ [ N ] for some N ∈ N (note that r doesn't depend on k ). Assume that for each k ∈ [ N ] , σ k is an ϵ -sane policy for υ k . Then, there is an ¯ I -metapolicy π ∗ s.t. for any k ∈ [ N ] EU ∗ υ k ( γ ) − EU π ∗ ¯ υ k [ σ k ] ( γ ) = O ( ( 1 − γ ) 1 / 4 ) Corollary 1 Fix an interface I and ϵ > 0 . Consider H = { υ k = ( μ k , r ) ∈ Υ I } k ∈ N . Assume that for each k ∈ N , σ k is a ϵ -sane policy for υ k . Define ¯ H : = { ¯ υ k [ σ k ] } n ∈ N . Then, ¯ H is learnable. Now, we deal with corrupt states. Definition 4 Let υ = ( μ , r ) be a universe and ϵ > 0 . A policy π is said to be locally ϵ -sane for υ when there are M , S and U ⊆ S M (the set of uncorrupt states) s.t. υ is an O -realization of M with state function S , S ( λ ) ∈ U and for any h ∈ hdom μ , if S ( h ) ∈ U then i. If a ∈ supp π ( h ) and o ∈ supp μ ( h a ) then S ( h a o ) ∈ U . ii. supp π ( h ) ⊆ A 0 M ( S ( h ) ) iii. ∃ a ∈ A 1 M ( S ( h ) ) : π ( a ∣ h ) > ϵ iv. ∃ a ∈ A 2 M ( S ( h ) ) : T M ( U ∣ S ( h ) , a ) = 1 Of course, this requirement is still unrealistic for humans in the real world. In particular, it makes the formalism unsuitable for modeling the use of AI for catastrophe mitigation (which is ultimately what we are interested in!) since it assumes the advisor is already capable of avoiding any catastrophe. In following work, we plan to relax the assumptions further. Corollary 2 Fix an interface I and ϵ > 0 . Consider H = { υ k = ( μ k , r k ) ∈ Υ I } k ∈ [ N ] for some N ∈ N . Assume that for each k ∈ [ N ] , σ k is locally ϵ -sane for υ k . For each k ∈ [ N ] , let U k ⊆ S M k be the corresponding set of uncorrupt states. Assume further that for any k , j ∈ N and h ∈ hdom μ k ∩ hdom μ j , if S k ( h ) ∈ U k and S j ( h ) ∈ U j , then r k ( h ) = r j ( h ) . Then, there is an ¯ I -policy π ∗ s.t. for any k ∈ [ N ] EU ∗ υ k ( γ ) − EU π ∗ ¯ υ k [ σ k ] ( γ ) = O ( ( 1 − γ ) 1 / 4 ) Corollary 3 Assume the same conditions as in Corollary 2, except that H may be countable infinite. Then, ¯ H is learnable. Appendix A First, we prove an information theoretic bound that shows that for Thompson sampling, the expected information gain is bounded below by a function of the loss. Proposition A.1 Consider a probability space ( Ω , P ∈ Δ Ω ) , N ∈ N , R ⊆ [ 0 , 1 ] a finite set and random variables U : Ω → R , K : Ω → [ N ] and J : Ω → [ N ] . Assume that K ∗ P = J ∗ P = ζ ∈ Δ [ N ] and I [ K ; J ] = 0 . Then I [ K ; J , U ] ≥ 2 ( min i ∈ [ N ] ζ ( i ) ) ( E [ U ∣ J = K ] − E [ U ] ) 2 Proof of Proposition A.1 We have I [ K ; J , U ] = I [ K ; J ] + I [ K ; U ∣ J ] = I [ K ; U ∣ J ] = E [ D K L ( U ∗ ( P ∣ K , J ) ∥ U ∗ ( P ∣ J ) ) ] Using Pinsker's inequality, we get I [ K ; J , U ] ≥ 2 E [ d tv ( U ∗ ( P ∣ K , J ) , U ∗ ( P ∣ J ) ) 2 ] ≥ 2 E [ ( E [ U ∣ K , J ] − E [ U ∣ J ] ) 2 ] Denote U k j : = E [ U ∣ K = k , J = j ] . We get I [ K ; J , U ] ≥ 2 E ( k , j ) ∼ ζ × ζ [ ( U k j − E k ′ ∼ ζ [ U k ′ j ] ) 2 ] ≥ 2 E ( k , j ) ∼ ζ × ζ [ [ [ k = j ] ] ( U k j − E k ′ ∼ ζ [ U k ′ j ] ) 2 ] I [ K ; J , U ] ≥ 2 E j ∼ ζ [ ζ ( j ) ( U j j − E k ∼ ζ [ U k j ] ) 2 ] ≥ 2 ( min j ∈ [ N ] ζ ( j ) ) E j ∼ ζ [ ( U j j − E k ∼ ζ [ U k j ] ) 2 ] I [ K ; J , U ] ≥ 2 ( min j ∈ [ N ] ζ ( j ) ) ( E j ∼ ζ [ U j j ] − E ( k , j ) ∼ ζ × ζ [ U k j ] ) 2 = 2 ( min i ∈ [ N ] ζ ( i ) ) ( E [ U ∣ J = K ] − E [ U ] ) 2 Now, we describe a "delegation routine" D that can transform any "proto-policy" π that recommends some set of actions from A into an actual ¯ I -policy s.t (i) with high probability, on each round, either a "safe" recommended action is taken, or all recommended actions are "unsafe" or delegation is performed and (ii) the expected number of delegations is small. For technical reasons, we also need to the modified routines D ! k which behave the same way as D except for some low probability cases. Proposition A.2 Fix an interface I = ( A , O ) , N ∈ N , ϵ ∈ ( 0 , 1 | A | ) , δ ∈ ( 0 , 1 N ) . Consider some { σ k : ( A × O ) ∗ k → A } k ∈ [ N ] . Then, there exist D : ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ∗ × 2 A → ¯ A and { D ! k : ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ∗ × 2 A → ¯ A } k ∈ [ N ] with the following properties. Given x ∈ ( 2 A × ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ) ∗ , we denote x – – its projection to ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ∗ . Thus, x – – – – ∈ ( A × O ) ∗ .
Given μ an I -environment, π : hdom μ k → 2 A , D ′ : ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ∗ × 2 A → ¯ A and k ∈ [ N ] , we can define Ξ [ μ , σ k , D ′ , π ] ∈ Δ ( 2 A × ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ) ω as follows Ξ [ μ , σ k , D ′ , π ] ( B , a , o ∣ x ) : = π ( B ∣ x – – – – ) D ′ ( a ∣ x – – , B ) ¯ μ [ σ k ] ( o ∣ x – – a ) We require that for every π , μ and k as above, the following conditions hold i. E x ∼ Ξ [ μ , σ k , D ! k , π ] [ | { n ∈ N ∣ x n ∈ 2 A × ⊥ × ¯ O } | ] ≤ ln N δ ln ( 1 + ϵ ( 1 − ϵ ) ( 1 − ϵ ) / ϵ ) = O ( ln N δ ϵ ) ii. d tv ( 1 N ∑ N − 1 j = 0 Ξ [ μ , σ j , D , π ] , 1 N ∑ N − 1 j = 0 Ξ [ μ , σ j , D ! j , π ] ) ≤ ( N − 1 ) δ iii. For all x ∈ hdom ¯ μ [ σ k ] , if D ! k ( x , π ( x – – ) ) ≠ ⊥ then σ k ( D ! k ( x , π ( x – – ) ) ∣ x – – ) > 0 iv. For all x ∈ hdom ¯ μ [ σ k ] , if D ! k ( x , π ( x – – ) ) ∉ π ( x – – ) ∪ { ⊥ } then ∀ a ∈ π ( x – – ) : σ k ( a ∣ x – – ) ≤ ϵ In order to prove Proposition A.2, we need another mutual information bound. Proposition A.3 Consider N ∈ N , A a finite set, ϵ ∈ ( 0 , 1 | A | ) , δ ∈ ( 0 , 1 ) , B ⊆ A , ζ ∈ Δ [ N ] and σ : [ N ] k → A . Suppose that for every a ∈ A Pr k ∼ ζ [ σ ( a ∣ k ) > 0 ∧ ( a ∈ B ∨ ∀ b ∈ B : σ ( b ∣ k ) ≤ ϵ ) ] ≤ 1 − δ Then I ( k , a ) ∼ ζ ⋉ σ [ k ; a ] ≥ δ ln ( 1 + ϵ ( 1 − ϵ ) ( 1 − ϵ ) / ϵ ) Proof of Proposition A.3 We have I ( k , a ) ∼ ζ ⋉ σ [ k ; a ] = E k ∼ ζ [ D K L ( σ ( k ) ∥ σ ∗ ζ ) ] Define q ∈ ( 0 , 1 ) by q : = 1 ϵ + ( 1 − ϵ ) − ( 1 − ϵ ) / ϵ Let a ∗ ∈ A be s.t. ( σ ∗ ζ ) ( a ∗ ) > q ϵ and either a ∗ ∈ B or every a ∈ B has ( σ ∗ ζ ) ( a ) ≤ q ϵ . For every k ∈ [ N ] , denote A k : = { a ∈ A ∣ σ ( a ∣ k ) > 0 ∧ ( a ∈ B ∨ ∀ b ∈ B : σ ( b ∣ k ) ≤ ϵ ) } If a ∗ ∉ A k then either σ ( a ∗ ∣ k ) = 0 or there is a ∈ B s.t. ( σ ∗ ζ ) ( a ) ≤ q ϵ and σ ( b ∣ k ) ≥ ϵ . This implies D K L ( σ ( k ) ∥ σ ∗ ζ ) ≥ min ( D K L ( 0 ∥ q ϵ ) , D K L ( ϵ ∥ q ϵ ) ) We have D K L ( 0 ∥ q ϵ ) = ln 1 1 − q ϵ = ln 1 1 − ϵ ϵ + ( 1 − ϵ ) − ( 1 − ϵ ) / ϵ = ln ϵ + ( 1 − ϵ ) − ( 1 − ϵ ) / ϵ ϵ + ( 1 − ϵ ) − ( 1 − ϵ ) / ϵ − ϵ = ln ( 1 + ϵ ( 1 − ϵ ) ( 1 − ϵ ) / ϵ ) D K L ( ϵ ∥ q ϵ ) = ϵ ln ϵ q ϵ + ( 1 − ϵ ) ln 1 − ϵ 1 − q ϵ = ϵ ln 1 q + ( 1 − ϵ ) ln ( 1 − ϵ ) − ϵ ln 1 1 − q ϵ + ln 1 1 − q ϵ D K L ( ϵ ∥ q ϵ ) = ϵ ln 1 − q ϵ q + ln ( 1 − ϵ ) 1 − ϵ + ln 1 1 − q ϵ = ϵ ln ( 1 q − ϵ ) + ln ( 1 − ϵ ) 1 − ϵ + ln 1 1 − q ϵ D K L ( ϵ ∥ q ϵ ) = ϵ ln ( 1 − ϵ ) − ( 1 − ϵ ) / ϵ + ln ( 1 − ϵ ) 1 − ϵ + ln 1 1 − q ϵ = ln ( 1 − ϵ ) − ( 1 − ϵ ) + ln ( 1 − ϵ ) 1 − ϵ + ln 1 1 − q ϵ = ln 1 1 − q ϵ D K L ( ϵ ∥ q ϵ ) = ln ( 1 + ϵ ( 1 − ϵ ) ( 1 − ϵ ) / ϵ ) It follows that I ( k , a ) ∼ ζ ⋉ σ [ k ; a ] ≥ Pr k ∼ ζ [ a ∗ ∉ A k ] ln ( 1 + ϵ ( 1 − ϵ ) ( 1 − ϵ ) / ϵ ) ≥ δ ln ( 1 + ϵ ( 1 − ϵ ) ( 1 − ϵ ) / ϵ ) Proof of Proposition A.2 We define { A k : ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ∗ × 2 A → 2 A } k ∈ N , ~ ζ : ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ∗ k → [ N ] , ζ : ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ∗ k → [ N ] , { ~ ζ ! k : ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ∗ k → [ N ] } k ∈ N , { ζ ! k : ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ∗ k → [ N ] } k ∈ N , D and { D ! k } k ∈ N recursively. For each h ∈ ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ∗ , a ∈ ¯ A , o ∈ ¯ O , B ⊆ A and j , k ∈ [ N ] , we require A k ( h , B ) : = { a ∈ A ∣ σ k ( a ∣ h – – ) > 0 ∧ ( a ∈ B ∨ ∀ b ∈ B : σ k ( b ∣ h – – ) ≤ ϵ ) } ~ ζ ( k ∣ λ ) = ~ ζ ! j ( k ∣ λ ) : = 1 N ~ ζ ( k ∣ h a o ) : = ⎧ ⎪
⎪
⎪ ⎨ ⎪
⎪
⎪ ⎩ ζ ( k ∣ h ) if a ≠ ⊥ 1 N if a = ⊥ , ∑ N − 1 i = 0 ζ ( i ∣ h ) ⋅ σ i ( b ∣ h – – ) = 0 ( ∑ N − 1 i = 0 ζ ( i ∣ h ) ⋅ σ i ( b ∣ h – – ) ) − 1 ζ ( k ∣ h ) ⋅ σ k ( b ∣ h – – ) otherwise, assuming o ∈ b O ~ ζ ! j ( k ∣ h a o ) : = ⎧ ⎨ ⎩ ζ ! j ( k ∣ h ) if a ≠ ⊥ ( ∑ N − 1 i = 0 ζ ! j ( i ∣ h ) ⋅ σ i ( b ∣ h – – ) ) − 1 ζ ! j ( k ∣ h ) ⋅ σ k ( b ∣ h – – ) if a = ⊥ , o ∈ b O ζ ( k ∣ h ) : = ~ ζ ( k ∣ h ) [ [ ~ ζ ( k ∣ h ) ≥ δ ] ] ∑ N − 1 i = 0 ~ ζ ( i ∣ h ) [ [ ~ ζ ( i ∣ h ) ≥ δ ] ] ζ ! j ( k ∣ h ) : = ~ ζ ! j ( k ∣ h ) [ [ ~ ζ ! j ( k ∣ h ) ≥ δ ] ] ∑ N − 1 i = 0 ~ ζ ! j ( i ∣ h ) [ [ ~ ζ ! j ( i ∣ h ) ≥ δ ] ] [ [ ~ ζ ! j ( j ∣ h ) ≥ δ ] ] + [ [ k = j ] ] ⋅ [ [ ~ ζ ! j ( j ∣ h ) < δ ] ] D ( h , B ) : = { any a s.t. ∀ k ∈ supp ζ ( h ) : a ∈ A k ( h , B ) if such exists ⊥ otherwise D ! j ( h , B ) : = { any a s.t. ∀ k ∈ supp ζ ! j ( h ) : a ∈ A k ( h , B ) if such exists ⊥ otherwise Denote Ξ ! k : = Ξ [ μ , σ k , D ! k , π ] . Proposition A.3 implies that for any k ∈ [ N ] ln N ≤ ∞ ∑ n = 0 E x ∼ Ξ ! k [ H ( ζ ! k ( x – – : n + 1 ) ) − H ( ζ ! k ( x – – : n ) ) ] ≤ ∞ ∑ n = 0 Pr x ∼ Ξ ! k [ x n ∈ 2 A × ⊥ × O ] δ ln ( 1 + ϵ ( 1 − ϵ ) 1 − ϵ ϵ ) This gives us condition i. Condition ii follows because the only difference is in the equation for ζ vs. ζ ! j . That is, ζ may "discard" the "correct" element of [ N ] but this happens with probability at most δ per discard and there are at most N − 1 discards. Conditions iii and iv are obvious from the definition. Definition A.1 Consider k ∈ N and a universe υ = ( μ , r ) that is an O -realization of M with state function S . A policy π is called k -optimal for υ when for any h ∈ hdom μ supp π ( h ) ⊆ A k M ( S ( h ) ) π is called Blackwell optimal for υ when it is k -optimal for any k ∈ N . Obviously, a stationary Blackwell optimal policy always exists. It is a standard (up to straightforward adaption to our formalism) result in MDP theory that any Blackwell optimal policy has maximal expected utility for any γ sufficiently close to 1. The following proposition relates optimality in terms of expected utility to expected truncated utility, where truncated utility is defined by only summing rewards within a time duration T . Proposition A.4 Fix an MDP M . Then, for any γ ∈ ( 0 , 1 ) , T ∈ N , universe υ = ( μ , r ) that is an O -realization of M with state function S , π 1 a 1 -optimal policy for υ and π ∗ a Blackwell optimal policy for υ , we have T − 1 ∑ n = 0 γ n ( E x ∼ μ ⋈ π ∗ [ r ( x : n ) ] − E x ∼ μ ⋈ π 1 [ r ( x : n ) ] ) ≤ O ( 1 + T ( 1 − γ ) ) Proof of Proposition A.4 Let π ∗ 1 be a policy s.t. for any h ∈ hdom μ π ∗ 1 ( h ) : = { π 1 ( h ) if | h | < T π ∗ ( h ) otherwise By Proposition B.1 EU ∗ υ ( γ ) − EU π ∗ 1 υ ( γ ) = ∞ ∑ n = 0 γ n E x ∼ μ ⋈ π ∗ 1 [ V υ γ ( x : n ) − Q υ γ ( x : n , x A n ) ] EU ∗ υ ( γ ) − EU π ∗ 1 υ ( γ ) = ∞ ∑ n = 0 γ n E x ∼ μ ⋈ π ∗ 1 [ V M ( S ( x : n ) , γ ) − Q M ( S ( x : n ) , x A n , γ ) ] EU ∗ υ ( γ ) − EU π ∗ 1 υ ( γ ) = ∞ ∑ n = 0 γ n ∞ ∑ k = 0 ( 1 − γ ) k k ! E x ∼ μ ⋈ π ∗ 1 [ V k M ( S ( x : n ) ) − Q k M ( S ( x : n ) , x A n ) ] Using the Blackwell optimality of π ∗ and 1-optimality of π 1 , we get that for 1 − γ ≪ 1 EU ∗ υ ( γ ) − EU π ∗ 1 υ ( γ ) = T − 1 ∑ n = 0 γ n ∞ ∑ k = 2 ( 1 − γ ) k k ! E x ∼ μ ⋈ π 1 [ V k M ( S ( x : n ) ) − Q k M ( S ( x : n ) , x A n ) ] EU ∗ υ ( γ ) − EU π ∗ 1 υ ( γ ) ≤ T − 1 ∑ n = 0 γ n max s ∈ S M max a ∈ A 1 M ( s ) ∞ ∑ k = 2 ( 1 − γ ) k k ! ( V k M ( s ) − Q k M ( s , a ) ) EU ∗ υ ( γ ) − EU π ∗ 1 υ ( γ ) = O ( T ( 1 − γ ) 2 ) ( 1 − γ ) ∞ ∑ n = 0 γ n ( E x ∼ μ ⋈ π ∗ [ r ( x : n ) ] − E x ∼ μ ⋈ π ∗ 1 [ r ( x : n ) ] ) = O ( T ( 1 − γ ) 2 ) ∞ ∑ n = 0 γ n ( E x ∼ μ ⋈ π ∗ [ r ( x : n ) ] − E x ∼ μ ⋈ π ∗ 1 [ r ( x : n ) ] ) = O ( T ( 1 − γ ) ) Denote ρ ∗ : = μ ⋈ π ∗ , ρ 1 : = μ ⋈ π 1 . Using again the Blackwell optimality of π ∗ T − 1 ∑ n = 0 γ n ( E x ∼ ρ ∗ [ r ( x : n ) ] − E x ∼ ρ 1 [ r ( x : n ) ] ) + γ T 1 − γ ( E x ∼ ρ ∗ [ V M ( S ( x : T ) ) ] − E x ∼ ρ 1 [ V M ( S ( x : T ) ) ] ) = O ( T ( 1 − γ ) ) Since both π ∗ and π 1 are in particular 0-optimal, we have E x ∼ ρ ∗ [ V 0 M ( S ( x : T ) ) ] = E x ∼ ρ 1 [ V 0 M ( S ( x : T ) ) ] = V 0 M ( S ( λ ) ) It follows T − 1 ∑ n = 0 γ n ( E x ∼ ρ ∗ [ r ( x : n ) ] − E x ∼ ρ 1 [ r ( x : n ) ] ) ± γ T 1 − γ O ( 1 − γ ) = O ( T ( 1 − γ ) ) T − 1 ∑ n = 0 γ n ( E x ∼ ρ ∗ [ r ( x : n ) ] − E x ∼ ρ 1 [ r ( x : n ) ] ) = O ( γ T + T ( 1 − γ ) ) The following shows that for any policy that doesn't make "irreversible errors," regret can be approximated by "episodic regret" for sufficiently large episode duration. Proposition A.5 Consider a universe υ = ( μ , r ) that is an O -realization of M with state function S . Suppose that π ∗ is a Blackwell optimal policy for υ and π 0 is a 0 -optimal policy for υ . For any n ∈ N , let π ∗ n be a policy s.t. for any h ∈ hdom μ π ∗ n ( h ) : = { π 0 ( h ) if | h | < n T π ∗ ( h ) otherwise Then, for any γ ∈ ( 0 , 1 ) and T ∈ N + EU ∗ υ ( γ ) − EU π 0 υ ( γ ) ≤ ( 1 − γ ) ∞ ∑ n = 0 T − 1 ∑ m = 0 γ n T + m ( E x ∼ μ ⋈ π ∗ n [ r ( x : n T + m ) ] − E x ∼ μ ⋈ π 0 [ r ( x : n T + m ) ] ) + O ( 1 − γ 1 − γ T ) Proof of Proposition A.5 By Proposition B.1, for any l ∈ N EU ∗ υ ( γ ) − EU π ∗ l υ ( γ ) = ∞ ∑ n = 0 γ n E x ∼ μ ⋈ π ∗ l [ V υ γ ( x : n ) − Q υ γ ( x : n , x A n ) ] π ∗ l becomes Blackwell optimal after l T , therefore for 1 − γ ≪ 1 , EU ∗ υ ( γ ) − EU π ∗ l υ ( γ ) = l T − 1 ∑ n = 0 γ n E x ∼ μ ⋈ π 0 [ V υ γ ( x : n ) − Q υ γ ( x : n , x A n ) ] EU π ∗ l υ ( γ ) − EU π ∗ l + 1 υ ( γ ) = ( l + 1 ) T − 1 ∑ n = l T γ n E x ∼ μ ⋈ π 0 [ V υ γ ( x : n ) − Q υ γ ( x : n , x A n ) ] ( 1 − γ ) ∞ ∑ n = 0 γ n ( E x ∼ μ ⋈ π ∗ l [ r ( x : n ) ] − E x ∼ μ ⋈ π ∗ l + 1 [ r ( x : n ) ] ) = ( l + 1 ) T − 1 ∑ n = l T γ n E x ∼ μ ⋈ π 0 [ V υ γ ( x : n ) − Q υ γ ( x : n , x A n ) ] π ∗ l and π ∗ l + 1 coincide until l T , therefore ( 1 − γ ) ∞ ∑ n = l T γ n ( E x ∼ μ ⋈ π ∗ l [ r ( x : n ) ] − E x ∼ μ ⋈ π ∗ l + 1 [ r ( x : n ) ] ) = ( l + 1 ) T − 1 ∑ n = l T γ n E x ∼ μ ⋈ π 0 [ V υ γ ( x : n ) − Q υ γ ( x : n , x A n ) ] Denote ρ ∗ l : = μ ⋈ π ∗ l , ρ 0 : = μ ⋈ π 0 . We also use the shorthand notations r n : = r ( x : n ) , V n : = V υ γ ( x : n ) , Q n : = Q υ γ ( x : n , x A n ) . Both π ∗ l and π ∗ l + 1 is Blackwell optimal after ( l + 1 ) T , therefore ( 1 − γ ) ( l + 1 ) T − 1 ∑ n = l T γ n ( E ρ ∗ l [ r n ] − E ρ 0 [ r n ] ) + γ ( l + 1 ) T ( E ρ ∗ l [ V ( l + 1 ) T ] − E ρ 0 [ V ( l + 1 ) T ] ) = ( l + 1 ) T − 1 ∑ n = l T γ n E ρ 0 [ V n − Q n ] Since π 0 is 0-optimal, we get ( 1 − γ ) ( l + 1 ) T − 1 ∑ n = l T γ n ( E ρ ∗ l [ r n ] − E ρ 0 [ r n ] ) + O ( γ ( l + 1 ) T ( 1 − γ ) ) = ( l + 1 ) T − 1 ∑ n = l T γ n E ρ 0 [ V n − Q n ] Summing over l , we get ( 1 − γ ) ∞ ∑ l = 0 ( l + 1 ) T − 1 ∑ n = l T γ n ( E ρ ∗ l [ r n ] − E ρ 0 [ r n ] ) + O ( γ T ( 1 − γ ) 1 − γ T ) = ∞ ∑ n = 0 γ n E ρ 0 [ V n − Q n ] Applying Proposition B.1 to the right hand side ( 1 − γ ) ∞ ∑ l = 0 ( l + 1 ) T − 1 ∑ n = l T γ n ( E ρ ∗ l [ r n ] − E ρ 0 [ r n ] ) + O ( γ T ( 1 − γ ) 1 − γ T ) = EU ∗ υ ( γ ) − EU π 0 υ ( γ ) Proof of Theorem 1 Fix γ ∈ ( 0 , 1 ) , δ ∈ ( 0 , N − 1 ) and T ∈ N + . For each k ∈ [ N ] , suppose υ k is an O -realization of M k with state function S k and denote ν k : = ¯ μ k [ σ k ] . To avoid cumbersome notation, whenever M k should appear a subscript, we will replace it by k . Let ( Ω , P ∈ Δ Ω ) be a probability space. Let K : Ω → [ N ] be a random variable and the following be stochastic processes Z n , ~ Z n : Ω → Δ [ N ] J n : Ω → [ N ] Ψ n : Ω → 2 A A n : Ω → ¯ A Θ n : Ω → ¯ O We also define A Θ : n : Ω → ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ∗ by A Θ : n : = A 0 Θ 0 A 1 Θ 1 … A n − 1 Θ n − 1 (The following conditions on A and Θ imply that the range of the above is indeed in ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ∗ .) Let D and D ! k be as in Proposition A.2 (we assume w.l.o.g. that ϵ < 1 | A | ). We construct Ω , K , Z , ~ Z , J , Ψ , A and Θ s.t K is uniformly distributed and for any k ∈ [ N ] , l ∈ N , m ∈ [ T ] and o ∈ O , denoting n = l T + m ~ Z 0 ( k ) ≡ 1 N Z n ( k ) = ~ Z n ( k ) [ [ ~ Z n ( k ) ≥ δ ] ] ∑ N − 1 j = 0 ~ Z n ( j ) [ [ ~ Z n ( j ) ≥ δ ] ] Pr [ J l = k ∣ Z l T ] = Z l T ( k ) Ψ n = A 1 J l ( S J l ( A Θ : n ) ) Pr [ Θ n = o ∣ A Θ : n ] = ν K ( o ∣ A Θ : n ) A n = D ( A Θ : n , Ψ n ) ~ Z n + 1 ( k ) N − 1 ∑ j = 0 Z n ( j ) [ [ A n = D ! j ( A Θ : n , Ψ n ) ] ] ν j ( Θ n ∣ A Θ : n A n ) = Z n ( k ) [ [ A n = D ! k ( A Θ : n , Ψ n ) ] ] ν k ( Θ n ∣ A Θ : n A n ) Note that the last equation has the form of a Bayesian update which is allowed to be arbitrary when update is on "impossible" information. We now construct the ¯ I -policy π ∗ s.t. for any n ∈ N , h ∈ ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ∗ s.t. Pr [ A Θ : n = h ] > 0 and a ∈ ¯ A π ∗ ( a ∣ h ) : = Pr [ A n = a ∣ A Θ : n = h ] That is, we perform Thompson sampling at time intervals of size T , moderated by the delegation routine D , and discard from our belief state hypotheses whose probability is below δ and hypotheses sampling which resulted in recommending "unsafe" actions i.e. actions that D refused to perform. In order to prove π ∗ has the desired property, we will define the stochastic processes Z ! , ~ Z ! , J ! , Ψ ! , A ! and Θ ! , each process of the same type as its shriekless counterpart (thus Ω is constructed to accommodate them). These processes are required to satisfy the following: ~ Z ! 0 ( k ) ≡ 1 N Z ! n ( k ) = ~ Z ! n ( k ) [ [ ~ Z ! n ( k ) ≥ δ ] ] ∑ N − 1 j = 0 ~ Z ! n ( j ) [ [ ~ Z ! n ( j ) ≥ δ ] ] [ [ ~ Z ! n ( K ) ≥ δ ] ] + [ [ K = k ] ] ⋅ [ [ ~ Z ! n ( K ) < δ ] ] Pr [ J ! l = k ∣ Z ! l T ] = Z ! l T ( k ) Ψ ! n = A 1 J ! l ( S J ! l ( A Θ ! : n ) ) Pr [ Θ ! n = o ∣ A Θ ! : n ] = ν K ( o ∣ A Θ ! : n ) A ! n = D ! K ( A Θ ! : n , Ψ ! n ) ~ Z ! n + 1 ( k ) = Z ! n ( k ) [ [ A ! n = D ! k ( A Θ ! : n , Ψ ! n ) ] ] ν k ( Θ ! n ∣ A Θ ! : n A ! n ) ∑ N − 1 j = 0 Z ! n ( j ) [ [ A ! n = D ! j ( A Θ ! : n , Ψ ! n ) ] ] ν j ( Θ ! n ∣ A Θ ! : n A ! n ) For any k ∈ [ N ] , we construct the ¯ I -policy π ? k s.t. for any n ∈ N , h ∈ ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ∗ s.t. Pr [ A Θ ! : n = h , K = k ] > 0 and a ∈ ¯ A π ? k ( a ∣ h ) : = Pr [ A ! n = a ∣ A Θ ! : n = h , K = k ] Given any ¯ I -policy π and I -policy σ we define α σ π : ( A × O ) ∗ k → ¯ ¯¯¯¯¯¯¯¯¯¯¯¯¯ ¯ A × O ∗ by α σ π ( g ∣ h ) : = [ [ h = g – ] ] C h | h | − 1 ∏ n = 0 ∑ a ∈ A ( [ [ g n ∈ ⊥ a O ] ] π ( ⊥ ∣ g : n ) σ ( a ∣ h : n ) + [ [ g n ∈ a ⊥ O ] ] π ( a ∣ g : n ) ) Here, C h ∈ R is a constant defined s.t. the probabilities sum to 1. We define the I -policy [ σ ] π – – by [ σ ] π – – ( a ∣ h ) : = Pr g ∼ α σ π ( h ) [ π ( g ) = a ∨ ( π ( g ) = ⊥ ∧ σ ( h ) = a ) ] Condition iii of Proposition A.2 and condition i of ϵ -sanity for σ k imply that for any h ∈ hdom μ k supp [ σ k ] π – – ? k ( h ) ⊆ A 0 k ( S k ( h ) ) This means we can apply Proposition A.5 and get EU ∗ υ k ( γ ) − EU π ? k ¯ υ k [ σ k ] ( γ ) ≤ ( 1 − γ ) ∞ ∑ n = 0 T − 1 ∑ m = 0 γ n T + m ( E x ∼ μ k ⋈ π ∗ k n [ r ( x : n T + m ) ] − E x ∼ ν k ⋈ π ? k [ r ( x – – : n T + m ) ] ) + O ( 1 − γ 1 − γ T ) Here, the I -policy π ∗ k n is defined as π ∗ n in Proposition A.5. We also define the ¯ I -policies π ! k n and π ! ! k n by π ! k n ( a ∣ h ) : = { π ? k ( a ∣ h ) if | h | < n T Pr [ A ! | h | = a ∣ A Θ ! : | h | = h , K = k , J ! n = k ] otherwise π ! ! k n ( a ∣ h ) : = ⎧ ⎪ ⎨ ⎪ ⎩ π ? k ( a ∣ h ) if | h | < n T π ! k n ( a ∣ h ) + π ! k n ( ⊥ ∣ h ) ⋅ π ∗ k n ( a ∣ h – – ) if | h | ≥ n T and a ≠ ⊥ 0 if | h | ≥ n T and a = ⊥ Denote ρ ∗ k n : = μ k ⋈ π ∗ k n , ρ ! ! k n : = ν k ⋈ π ! ! k n , ρ ! k n : = ν k ⋈ π ! k n , ρ ? k : = ν k ⋈ π ? k , R ? k = EU ∗ υ k ( γ ) − EU π ? k ¯ υ k [ σ k ] ( γ ) . For each n ∈ N , denote EU ∗ k n ( γ ) : = 1 − γ 1 − γ T T − 1 ∑ m = 0 γ m E x ∼ ρ ∗ k n [ r ( x : n T + m ) ] EU ! ! k n ( γ ) : = 1 − γ 1 − γ T T − 1 ∑ m = 0 γ m E x ∼ ρ ! ! k n [ r ( x – – : n T + m ) ] EU ! k n ( γ ) : = 1 − γ 1 − γ T T − 1 ∑ m = 0 γ m E x ∼ ρ ! k n [ r ( x – – : n T + m ) ] EU ? k n ( γ ) : = 1 − γ 1 − γ T T − 1 ∑ m = 0 γ m E x ∼ ρ ? k [ r ( x – – : n T + m ) ] We have R ? k ≤ ( 1 − γ T ) ∞ ∑ n = 0 γ n T ( EU ∗ k n ( γ ) − EU ? k n ( γ ) ) + O ( 1 − γ 1 − γ T ) R ? k ≤ ( 1 − γ T ) ∞ ∑ n = 0 γ n T ( EU ∗ k n ( γ ) − EU ! ! k n ( γ ) + EU ! ! k n ( γ ) − EU ! k n ( γ ) + EU ! k n ( γ ) − EU ? k n ( γ ) ) + O ( 1 − γ 1 − γ T ) Condition iv of Proposition A.2 and condition ii of ϵ -sanity for σ k imply that, given h ∈ hdom ν k s.t. | h | ≥ n T supp π ! k n ( h ) ⊆ A 1 k ( S k ( h – – ) ) ∪ { ⊥ } supp π ! ! k n ( h ) ⊆ A 1 k ( S k ( h – – ) ) Therefore, we can apply Proposition A.4 to the terms EU ∗ k n ( γ ) − EU ! ! k n ( γ ) and get R ? k ≤ ( 1 − γ T ) ∞ ∑ n = 0 γ n T ( EU ! ! k n ( γ ) − EU ! k n ( γ ) + EU ! k n ( γ ) − EU ? k n ( γ ) ) + O ( 1 − γ 1 − γ T + T ( 1 − γ ) 2 1 − γ T ) We have EU ! ! k n ( γ ) − EU ! k n ( γ ) ≤ Pr x ∼ ρ ! k n [ ∃ m ∈ [ T ] : x n T + m ∈ ⊥ ¯ O ] Thus, using condition i of Proposition A.2, we can bound the contribution of the EU ! ! k n ( γ ) − EU ! k n ( γ ) terms and get R ? k ≤ ( 1 − γ T ) ∞ ∑ n = 0 γ n T ( EU ! k n ( γ ) − EU ? k n ( γ ) ) + O ( 1 − γ T δ + 1 − γ 1 − γ T + T ( 1 − γ ) 2 1 − γ T ) We denote ξ ( γ , T , δ ) : = 1 − γ T δ + 1 − γ 1 − γ T + T ( 1 − γ ) 2 1 − γ T Define the random variables { U ! n : Ω → [ 0 , 1 ] } n ∈ N by U ! n : = 1 − γ 1 − γ T T − 1 ∑ m = 0 γ m r ( A Θ ! : n T + m ) Averaging the previous inequality over k , we get 1 N N − 1 ∑ k = 0 R ? k ≤ ( 1 − γ T ) ∞ ∑ n = 0 γ n T ( E [ U ! n ∣ J ! n = K ] − E [ U ! n ] ) + O ( ξ ( γ , T , δ ) ) 1 N N − 1 ∑ k = 0 R ? k ≤ ( 1 − γ T ) ∞ ∑ n = 0 γ n T E [ E [ U ! n ∣ J ! n = K , Z ! n T ] − E [ U ! n ∣ Z ! n T ] ] + O ( ξ ( γ , T , δ ) ) 1 N N − 1 ∑ k = 0 R ? k =
⎷ ( 1 − γ T ) ∞ ∑ n = 0 γ n T E [ ( E [ U ! n ∣ J ! n = K , Z ! n T ] − E [ U ! n ∣ Z ! n T ] ) 2 ] + O ( ξ ( γ , T , δ ) ) We apply Proposition A.1 to each term in the sum over n . 1 N N − 1 ∑ k = 0 R ? k =
⎷ ( 1 − γ T ) ∞ ∑ n = 0 γ n T E [ 1 2 δ I [ K ; J ! n , U ! n ∣ Z ! n T ] ] + O ( ξ ( γ , T , δ ) ) 1 N N − 1 ∑ k = 0 R ? k =
⎷ 1 − γ T 2 δ ∞ ∑ n = 0 γ n T E [ H ( Z ! n T ) − H ( Z ! ( n + 1 ) T ) ] + O ( ξ ( γ , T , δ ) ) 1 N N − 1 ∑ k = 0 R ? k = √ 1 − γ T 2 δ ln N + O ( 1 − γ T δ + 1 − γ 1 − γ T + T ( 1 − γ ) 2 1 − γ T ) 1 N N − 1 ∑ k = 0 R ? k = O ⎛ ⎝ √ 1 − γ T δ + 1 − γ 1 − γ T + T ( 1 − γ ) 2 1 − γ T ⎞ ⎠ Condition ii of Proposition A.2 implies that d tv ( 1 N N − 1 ∑ k = 0 ¯ ν k [ σ k ] ⋈ π ∗ , 1 N N − 1 ∑ k = 0 ¯ ν k [ σ k ] ⋈ π ? k ) ≤ 2 ( N − 1 ) δ Here, the factor of 2 comes from the difference between the equations for Z n and Z ! n (we can construct and intermediate policy between π ∗ and π ? k and use the triangle inequality for d tv ). We conclude EU ∗ υ k ( γ ) − EU π ∗ ¯ υ k [ σ k ] ( γ ) = O ⎛ ⎝ δ + √ 1 − γ T δ + 1 − γ 1 − γ T + T ( 1 − γ ) 2 1 − γ T ⎞ ⎠ Now we set δ : = ( 1 − γ ) 1 / 4 , T : = ⌊ ( 1 − γ ) − 1 / 4 ⌋ . Since γ T → 1 as γ → 1 , we can use the approximation 1 − γ T ≈ T ( 1 − γ ) ≈ ( 1 − γ ) 3 / 4 . We get EU ∗ υ k ( γ ) − EU π ∗ ¯ υ k [ σ k ] ( γ ) = O ( ( 1 − γ ) 1 / 4 ) Proof of Corollary 1 Follows immediately from Theorem 1 and Proposition B.2. Definition A.2 Consider an MDP M and U ⊆ S M . The MDP M / U ∁ is defined by by S M / U ∁ : = U ⊔ { ⊥ } A M / U ∁ : = A M T M / U ∁ ( t ∣ s , a ) : = ⎧ ⎪
⎪
⎪ ⎨ ⎪
⎪
⎪ ⎩ T M ( t ∣ s , a ) if t , s ∈ U T M ( S M ∖ U ∣ s , a ) if t = ⊥ , s ∈ U 0 if t ∈ U , s = ⊥ 1 if t = s = ⊥ R M / U ∁ ( s ) : = { R M ( s ) if s ∈ U 0 if s = ⊥ Proposition A.6 Consider an MDP M and some U ⊆ S M . Suppose that for every s ∈ U there is a ∈ A k M ( s ) s.t. T M ( U ∣ s , a ) = 1 . Then, for every s ∈ S M and j ∈ [ k ] V j M ( s ) = V j M / U ∁ ( s ) Moreover, if a ∈ A is s.t. T M ( U ∣ s , a ) = 1 then Q j M ( s , a ) = Q j M / U ∁ ( s , a ) Proof of Proposition A.6 It is obvious that for any s ∈ U and γ ∈ ( 0 , 1 ) , V M / U ∁ ( s , γ ) ≤ V M ( s , γ ) . Now consider any π : S M → A s.t. for any s ∈ U , π ( s ) ∈ A k M ( s ) and T M π ( U ∣ s ) = 1 . Fix s ∈ U . For any n ∈ N , supp T n M π ( s ) ⊆ U and therefore ∞ ∑ n = 0 γ n E T n M / U ∁ π ( s ) [ R M / U ∁ ] = ∞ ∑ n = 0 γ n E T n M π ( s ) [ R M ] On the other hand, π is k -optimal and therefore ∞ ∑ n = 0 γ n E T n M π ( s ) [ R M ] = V M ( s ) − O ( ( 1 − γ ) k ) We conclude that V M / U ∁ ( s , γ ) ≥ ∞ ∑ n = 0 γ n E T n M / U ∁ π ( s ) [ R M / U ∁ ] = V M ( s , γ ) − O ( ( 1 − γ ) k ) | V M / U ∁ ( s , γ ) − V M ( s , γ ) | = O ( ( 1 − γ ) k ) This implies the equation for V j and the equation for Q j is implied in turn. Definition A.4 Fix an interface I = ( A , O ) . Consider an I -universe υ = ( μ , r ) which is an O -realization of M with state function S , and U ⊆ S M s.t. S ( λ ) ∈ U . Denote O ′ : = O ⊔ { ⊥ } and I ′ : = ( A , O ′ ) . The I ′ -universe υ / S U ∁ = ( μ / S U ∁ , r ′ ) is defined by μ / S U ∁ ( o ∣ h a ) = ⎧ ⎪
⎪
⎪
⎪
⎪
⎪ ⎨ ⎪
⎪
⎪
⎪
⎪
⎪ ⎩ μ ( o ∣ h a ) if h a o ∈ ( A × O ) ∗ and S ( h a o ) ∈ U 0 if h a o ∈ ( A × O ) ∗ and S ( h a o ) ∉ U T M / U ∁ ( ⊥ ∣ S ( h ) , a ) if h ∈ ( A × O ) ∗ and o = ⊥ 0 if h ∉ ( A × O ) ∗ and o ≠ ⊥ 1 if h ∉ ( A × O ) ∗ and o = ⊥ r ′ ( h ) : = { r ( h ) if h ∈ ( A × O ) ∗ 0 otherwise It is easy to see that υ / S U ∁ is an O ′ -realization of M / U ∁ with state function S ′ defined by S ′ ( h ) : = { S ( h ) if h ∈ ( A × O ) ∗ ⊥ otherwise Proposition A.7 Fix an interface I = ( A , O ) . Consider ϵ > 0 and υ = ( μ , r ) an O -realization of M with state function S . Suppose that π is a locally ϵ -sane policy for μ and U ⊆ S M is the corresponding set of uncorrupt states. Let π ′ be any I ′ -policy s.t. for any h ∈ ( A × O ) ∗ , π ( h ) = π ( h ′ ) . Then, π ′ is ϵ -sane for υ / S U ∁ . Proof of Proposition A.7 Without loss of generality, assumes all states of M are reachable from S ( λ ) (otherwise, υ is an O -realization of the MDP we get by discarding the unreachable states). Consider any h ∈ hdom μ / S U ∁ . If S ′ ( h ) = ⊥ then conditions i+ii of Definition 3 are trivial. Otherwise, we have h ∈ hdom μ and s : = S ( h ) ∈ U . We apply Proposition A.6 for k = 2 (by condition iv of Definition 4) and get that: conditions i+ii of Definition 4 imply condition i of Definition 3 and conditions i+iii of Definition 4 imply condition ii of Definition 3. Proof of Corollary 2 For every k ∈ [ N ] , denote ψ k : = υ k / S k U k ∁ . By Proposition A.7, σ k is ϵ -sane for ψ k (where we abuse notation by arbitrarily extending σ k to an I ′ -policy). Moreover, it is easy to see that all the ψ k share the same reward function r ′ . Apply Theorem 1 to H ′ : = { ψ k } k ∈ [ N ] . We get π ∗ s.t. for every k ∈ [ N ] and γ ∈ ( 0 , 1 ) EU ∗ ψ k ( γ ) − EU π ∗ ¯ ψ k [ σ k ] ( γ ) = O ( ( 1 − γ ) 1 / 4 ) Obviously EU π ∗ ¯ ψ k [ σ k ] ( γ ) ≤ EU π ∗ ¯ υ k [ σ k ] ( γ ) and therefore EU ∗ ψ k ( γ ) − EU π ∗ ¯ υ k [ σ k ] ( γ ) ≤ O ( ( 1 − γ ) 1 / 4 ) On the other hand, by Proposition A.6 EU ∗ ψ k ( γ ) = V M k / U k ∁ ( S ( λ ) , γ ) = V M k ( S ( λ ) , γ ) − O ( 1 − γ ) = EU ∗ υ k ( γ ) − O ( 1 − γ ) We conclude EU ∗ υ k ( γ ) − O ( 1 − γ ) − EU π ∗ ¯ υ k [ σ k ] ( γ ) ≤ O ( ( 1 − γ ) 1 / 4 ) EU ∗ υ k ( γ ) − EU π ∗ ¯ υ k [ σ k ] ( γ ) = O ( ( 1 − γ ) 1 / 4 ) Proof of Corollary 3 Follows immediately from Corollary 2 and Proposition B.2. Appendix B The following appeared before as Proposition A.5: Proposition B.1 Given α ∈ A × O , α A ∈ A and α O ∈ O are defined s.t. α = ( α A , α O ) . Consider a universe υ = ( μ , r ) , a policy π and γ ∈ ( 0 , 1 ) . Then, EU ∗ υ ( γ ) − EU π 0 υ ( γ ) = ∞ ∑ n = 0 γ n E x ∼ μ ⋈ π [ V υ γ ( x : n ) − Q υ γ ( x : n , x A n ) ] The followed appeared as Proposition 2: Proposition B.2 Fix an interface I . Let H be a countable set of meta-universes s.t. any finite G ⊆ H is learnable. Then, H is learnable. |
952661cf-0236-4836-845a-a17f3f517b55 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Safe Option-Critic: Learning Safety in the Option-Critic Architecture
1. Introduction
----------------
Safety in Artificial Intelligence (AI) can be viewed from many perspectives. Traditionally, introducing some form of risk-awareness in AI systems has been a prime way of defining safety in the machines. More recently, researchers have broadened the horizon of safety in AI to address different sources of errors and faulty behaviors Amodei et al. ([2016](#bib.bib4)). The 23 Asilomar AI principles Future of Life
Institute ([2017](#bib.bib10)) comprise of varied aspects of safety like risk-averseness, transparency, robustness, fairness and also legal and ethical values an agent should hold. In this work, we refer to the following definition of safety: prevent undesirable behavior, in particular, reducing the visits to the undesirable states during the learning process in reinforcement learning (RL).
RL agents primarily learn by optimizing their discounted cumulative rewards Sutton and Barto ([1998](#bib.bib35)). While rewards are a good indicator of how to behave, they do not necessarily always lead to the most desired behavior. Optimal reward design Sorg
et al. ([2010](#bib.bib32)) still poses a challenge for the algorithm designers with several issues such as misspecified rewards Amodei and Clark ([2016](#bib.bib3)); Hadfield-Menell et al. ([2017](#bib.bib14)) and corrupted reward channels Everitt et al. ([2017](#bib.bib8)) to name a few. Alternatively, learning with constraints allows us to introduce more clarity in the objective function Altman ([1999](#bib.bib2)).
During exploration, agents are naturally unaware of the states which may be prone to errors or may lead to catastrophic consequences. Risk-awareness has been introduced in the agents by directing exploration safely Law
et al. ([2005](#bib.bib21)), optimizing the worst-case performance Tamar
et al. ([2013](#bib.bib40)), measuring the probabilities of visiting erroneous states Geibel and
Wysotzki ([2005](#bib.bib13)) and several other approaches. [Garcıa and
Fernández](#bib.bib11) (\citeyearNPgarcia2015comprehensive) presents a comprehensive survey covering a broad range of techniques to realize safety in RL. In a Markov Decision Process (MDP), majority of the methods seek to minimize the variance of return as a risk mitigation strategy. Many authors Sato
et al. ([2001](#bib.bib30)); Mihatsch and
Neuneier ([2002](#bib.bib26)); Tamar
et al. ([2012](#bib.bib38)); Gehring and
Precup ([2013](#bib.bib12)); Tamar
et al. ([2016](#bib.bib39)); Sherstan et al. ([2018](#bib.bib31)) have used temporal difference (TD) learning for estimating the variance of return to capture the notion of uncertainty in the value of a state.
While some of the aforementioned approaches leverage TD learning in estimating errors and risks, all of them define notions of safety in the primitive action space.
Temporally abstract actions provide an approach to represent the information in a hierarchical format. The concept of learning and planning in a hierarchical fashion is very close to how humans think and approach a problem. Temporal abstractions have been vital to the AI community since 1970s Fikes
et al. ([1981](#bib.bib9)); Iba ([1989](#bib.bib16)); Korf ([1983](#bib.bib19)); McGovern and
Barto ([2001](#bib.bib24)); Menache
et al. ([2002](#bib.bib25)); Barto and
Mahadevan ([2003](#bib.bib6)). Prior research has shown that the temporal abstractions improve exploration, reduce complexity of choosing the actions and enhance robustness to the misspecified models. The options framework Sutton
et al. ([1999](#bib.bib37)); Precup ([2000](#bib.bib29)) provided an intuitive way to plan, reason, and act in a continual fashion as opposed to learning with the primitive actions. Many authors Stolle and Precup ([2002](#bib.bib33)); Daniel
et al. ([2016](#bib.bib7)); Konidaris and
Barto ([2007](#bib.bib17)); Konidaris et al. ([2011](#bib.bib18)); Kulkarni et al. ([2016](#bib.bib20)); Vezhnevets et al. ([2016](#bib.bib42)); Mankowitz
et al. ([2016](#bib.bib23)) provide methods for discovering subgoals and then the learning policies to achieve those subgoals.
The option-critic framework Bacon
et al. ([2017](#bib.bib5)) enables end-to-end learning of the options. However, defining a safe option which does not lead to the erroneous states during the learning process still remains an open question. We introduce the idea of controllability Gehring and
Precup ([2013](#bib.bib12)) in the options framework as an additional condition in the optimality criterion which constrains the variance of the TD error as a measure of uncertainty about the value of a state-option pair. In this work, we propose a new framework called safe option-critic for learning the safety in options.
Key Contributions: This work incorporates the notion of safety in the option-critic framework and presents a mechanism to automatically learn safe options. We derive the policy-gradient theorem for the safe option-critic framework using constraint based optimization. We then demonstrate through experiments in the four-rooms grid environment, that learning the options with controllability (term quantifying controllable behavior of an agent) results in the safer policies which avoid states with the high variance in the TD error. Empirically, we show the benefits of learning safe options in the ALE environments with high intrinsic variability in the rewards. Our approach outperforms the vanilla options with no notion of safety in 3 Atari games namely, MsPacman, Amidar and Q\*Bert. In 2 out of 3 games, learning the safe options also outperforms the primitive actions. To this end, we propose a novel Safe Option-Critic framework for the future research in the AI Safety paradigm.
2. Preliminaries
-----------------
In RL, an agent interacts with the environment at discrete time steps t∈{1,2,...} where it observes a state st∈S. The agent then chooses an action at∈A from a policy which defines a probability distribution of actions over the state space π:S×A→[0,1]. After choosing an action, the agent transitions to a new state st+1 according to the transition function P:S×A→(S→[0,1]) and receives a reward rt+1 where the reward function is defined as r:S×A→R. A MDP is defined by a tuple <S,A,γ,r,P> where γ is a discount factor. A discounted state-action value function is defined as Q(s,a)=Eπ[∑∞t=0γtrt+1|s0=s,a0=a] with γ∈[0,1]. The value of Q can be learned in an incremental fashion using one-step TD learning also written as TD(0) which is a special case of TD(λ) Sutton ([1988](#bib.bib34)). The state-action value is updated using the equation: Q(st,at)←Q(st,at)+αδ. Here α is the step size and δ is TD(0) error which is defined as δ=rt+1+γQ(st+1,at+1)−Q(st,at).
The policy gradient theorem Sutton
et al. ([2000](#bib.bib36)) presents a way of updating the parameterized policy according to the gradient of expected discounted return which is defined as ρ(π,s0)=E[∑∞t=0γtrt+1|s0,π]. The gradient with respect to the policy parameter θ is given as:
| | | | |
| --- | --- | --- | --- |
| | ∂ρ(π,s0)∂θ=∑sdπ(s)∑a∂π(s,a)∂θQπ(s,a) | | (1) |
where dπ(s)=∑∞t=0γtP(st=s|s0,π) is the discounted weighting of the states with the starting state as s0.
###
2.1. Options
The options framework Sutton
et al. ([1999](#bib.bib37)); Precup ([2000](#bib.bib29)) facilitates a way to incorporate the temporally abstract knowledge into RL with no change in the existing setup. An option ω∈Ω is defined as a tuple (Iω,πω,βω); where Iω is the initiation set containing the initial states from which an option ω can start, πω is the option policy defining a distribution over actions given a state and βω is the termination condition of an option ω defined as the probability of terminating in a state. An example of options could be having high level sub-goals like going to a market, buying vegetables and making the dish wherein the primitive actions for instance could be the muscle twitches.
In case of options being Markov, the intra-option Bellman equation Sutton
et al. ([1999](#bib.bib37)) provides an off-policy method for updating the Q value of a state-option pair which can be written as:
| | | | |
| --- | --- | --- | --- |
| | Q(st,ω)=Q(st,ω)+α[rt+1+γ(1−βω(st))Q(st+1,ω)+γβω(st)maxω′∈ΩQ(st+1,ω′)−Q(st,ω)] | | (2) |
where ω is selected from the policy over options πΩ.
###
2.2. Learning Options
The intra-option value learning Sutton
et al. ([1999](#bib.bib37)) lays the foundation for learning the options in the option-critic architecture (Bacon
et al., [2017](#bib.bib5)). It is a policy-gradient based method for learning the intra-options policies and the termination conditions of the options. (Bacon
et al., [2017](#bib.bib5)) considered the call and return option execution model, where an option ω is chosen according to the policy over options πΩ, wherein the intra-option policy πω is followed until the termination condition βω is met. Once the current option terminates, another option to be executed at that state is selected in the same fashion. πω,θ denotes the parameterized intra-option policy in terms of θ and βω,ν represents the option termination which is parameterized by ν. The value of executing an action a at a particular state-option pair is then given by QU:S×Ω×A→R where
| | | | |
| --- | --- | --- | --- |
| | QU(s,ω,a)=r(s,a)+γ∑s′P(s′|s,a)U(s′,ω) | | (3) |
where U represents the value of executing an option ω at a state s′:
| | | | |
| --- | --- | --- | --- |
| | U(s′,ω)=(1−βω,v(s′))QΩ(s′,ω)+βω,v(s′)VΩ(s′) | | (4) |
Here, QΩ represents the optimal-value function for a given option ω given by QΩ(s,ω)=∑aπω,θ(a|s)QU(s,ω,a). VΩ represents the optimal-value function over Ω given by VΩ(s)=∑ωπΩ(ω|s)QΩ(s,ω). (Bacon
et al., [2017](#bib.bib5)) derived the gradient of discounted return with respect to θ and the initial condition (s0,ω0) as:
| | | | |
| --- | --- | --- | --- |
| | ∂ρ(π,so,ω0)∂θ=∑s,ω[μ(s,ω|s0,ω0)×∑a∂πω,θ(a|s)∂θQU(s,ω,a)] | | (5) |
where μ(s,ω|s0,ω0) is the discounted weighting of a state-option pair with μ(s,ω|s0,ω0)=∑∞t=0γtP(st=s,ωt=ω|so,ω0). The gradient of the expected discounted return with respect to the option termination parameter ν and the initial condition (s1,ω0) is described as:
| | | | |
| --- | --- | --- | --- |
| | ∂ρ(π,s1,ω0)∂v=−∑s′,ωμ(s′,ω|s1,ω0)∂βω,ν(s′)∂νA(s′,ω) | | (6) |
where A is an advantage function AΩ(s,ω)=QΩ(s,ω)−VΩ(s).
3. Safe Option-Critic Model
----------------------------
Taking inspiration from [Gehring and
Precup](#bib.bib12)’s work (\citeyearNPGehring:2013), we define controllability as a negation of the variance in the TD error of a state-option action pair. We use the aforementioned definition of controllability to introduce the concept of safety in the option-critic architecture which aids in measuring the uncertainty about the value of a state-option pair. Higher the variance in TD error of a state-option pair, higher would be the uncertainty in the value of that state-option pair. In the safety critical applications, the agent should learn to eventually avoid such pairs as they induce variability in the return. We optimize for the expected discounted return along with the controllability value of initial state-option pair. Depending on the nature of the application, one can limit or encourage the agent visiting a state-option pair based on the degree of controllability. Introducing controllability using the TD error facilitates the linear scalability of the method with the increase in the number of state-option pairs.
Continuing with the notations used in Bacon
et al. ([2017](#bib.bib5)), we are introducing a parameter vector described by Θ=[θ,ν] where θ is an intra-option policy parameter and ν is an option termination parameter. We assume that an option can be initialized from any state s∈S. Given a state-option pair, uncertainty in its value is measured by controllability C, which is given by the negation of the variance in its TD error δ. The expected value of the TD error would converge to zero, hence controllability is written as:
| | | | |
| --- | --- | --- | --- |
| | | | (7) |
From now onwards, we would refer δ(s,ω,a) as δ whose value is given by:
| | | | |
| --- | --- | --- | --- |
| | δ=r(s,a)+γ∑s′P(s′|s,a)UΘ(s′,ω)−QU,Θ(s,ω,a) | | (8) |
where QU,Θ(s,ω,a) and UΘ(s,ω) are defined in ([3](#S2.E3 "(3) ‣ 2.2. LEARNING OPTIONS ‣ 2. PRELIMINARIES ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")) and ([4](#S2.E4 "(4) ‣ 2.2. LEARNING OPTIONS ‣ 2. PRELIMINARIES ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")) respectively. The aim here is to maximize the expected discounted return along with the controllability criterion of a state-option pair. We call this objective J, where we want to:
| | | | |
| --- | --- | --- | --- |
| | maxΘJ(Θ|d),whereJ(Θ|d)=E(s0,ω0)∼d[QΘ(s0,ω0)+ψCΘ(s0,ω0)] | | (9) |
where ψ∈R acts as a regularizer for the controllability and d is the initial state-option pair distribution. The Q value of a state-option pair is defined as QΘ(s,ω)=∑aπω,θ(a|s)QU,Θ(s,ω,a). The above objective can also be interpreted as a constrained optimization problem with an additional constraint on the controllability function. We will now derive the gradient of the performance evaluator J with respect to the intra-option policy parameter θ assuming they are differentiable. First we will take the gradient of C with θ. Following from ([7](#S3.E7 "(7) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")):
| | | | |
| --- | --- | --- | --- |
| | ∂CΘ(s,ω)∂θ=−∑a∂πω,θ(a|s)∂θδ2−∑a2δ∂δ∂θπω,θ(a|s) | | (10) |
where the gradient of TD error δ w.r.t. θ using ([8](#S3.E8 "(8) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")):
| | | | |
| --- | --- | --- | --- |
| | ∂δ∂θ=γ∑s′P(s′|s,a)∂UΘ(s′,ω)∂θ−∂QU,Θ(s,ω,a)∂θ | | (11) |
Next, the gradient of QΘ(s,ω) w.r.t. θ is:
| | | | |
| --- | --- | --- | --- |
| | ∂QΘ(s,ω)∂θ=∑a∂πω,θ(a|s)∂θQU,Θ(s,ω,a)+∑a∂QU,Θ(s,ω,a)∂θπω,θ(a|s) | | (12) |
The gradient of J(Θ|d) w.r.t. θ following from ([9](#S3.E9 "(9) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")), ([10](#S3.E10 "(10) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")), ([11](#S3.E11 "(11) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")) and ([12](#S3.E12 "(12) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")) is reduced to:
| | | | |
| --- | --- | --- | --- |
| | ∂J∂θ=(1+2δψ)∑aπω,θ(a|s)∂QU,Θ(s,ω,a)∂θ+∑a∂πω,θ(a|s)∂θ{QU,Θ(s,ω,a)−ψδ2}−2δψγ∑aπω,θ(a|s)∑s′P(s′|s,a)∂UΘ(s′,ω)∂θ | | (13) |
where the gradient of QU,Θ(s,ω,a) using ([3](#S2.E3 "(3) ‣ 2.2. LEARNING OPTIONS ‣ 2. PRELIMINARIES ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")) is:
| | | | |
| --- | --- | --- | --- |
| | ∂QU,Θ(s,ω,a)∂θ=γ∑s′P(s′|s,a)∂UΘ(s′,ω)∂θ | | (14) |
and the gradient of UΘ(s′,ω) using ([4](#S2.E4 "(4) ‣ 2.2. LEARNING OPTIONS ‣ 2. PRELIMINARIES ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")) is:
| | | | |
| --- | --- | --- | --- |
| | ∂UΘ(s′,ω)∂θ=∑ω′[(1−βω,ν(s′))1ω′=ω+βω,ν(s′)πΩ(ω′|s′)]∂QΘ(s′,ω′)∂θ | | (15) |
Substituting the above gradient value of Q and U from ([14](#S3.E14 "(14) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")) and ([15](#S3.E15 "(15) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")) in ([13](#S3.E13 "(13) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")), the gradient of J w.r.t. θ becomes:
| | | | |
| --- | --- | --- | --- |
| | ∂J∂θ=∑s′,ω′P(1)γ(s′,ω′|s,ω)∂Qθ(s′,ω′)∂θ+∑a∂πω,θ(a|s)∂θQU,Θ(s,ω,a)−∑a∂πω0,θ(a|s0)∂θψδ2(s0,ω0,a) | | (16) |
where P(1)γ(s′,ω′|s,ω)=γ∑aπω(a|s)P(s′|s,a)(1−βω(s′))1ω=ω′+βω(s′)πΩ(ω′|s′). (Bacon
et al., [2017](#bib.bib5)) derived the gradient of Q(s,ω) as:
| | | | |
| --- | --- | --- | --- |
| | ∂Qθ(s,ω)∂θ=∑s′,ω′P(1)γ(s′,ω′|s,ω)∂Qθ(s′,ω′)∂θ+∑a∂πω,θ(a|s)∂θQU,Θ(s,ω,a) | | (17) |
On expanding the gradient of QΘ(s,ω) as in ([17](#S3.E17 "(17) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")), the gradient of J following ([16](#S3.E16 "(16) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")) becomes:
| | | | |
| --- | --- | --- | --- |
| | ∂J∂θ=∞∑k=0∑s,ω{P(k)γ(s,ω|s0,ω0)×∑a∂πω,θ(a|s)∂θQU,Θ(s,ω,a)}−∑a∂πω0,θ(a|s0)∂θψδ2(s0,ω0,a) | | (18) |
Here, (s0,ω0) corresponds to the initial state-option pair. The gradient of J here describes that each option aims to maximize its own reward with controllability as a constraint pertaining to that option only. Our interpretation here is that each option learnt with this safety constraint translates to an overall risk-averse behavior.
Now we will compute the gradient of J(Θ|d) with respect to the option termination function parameter ν. The gradient of controllability C with ν can be written following ([7](#S3.E7 "(7) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")) and ([8](#S3.E8 "(8) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")) as:
| | | | |
| --- | --- | --- | --- |
| | ∂CΘ(s,ω)∂ν=−2δ∑aπω,θ(a|s)∂δ∂ν | | (19) |
where ∂δ∂v=γ∑s′P(s′|s,a)∂UΘ(s′,ω)∂ν−∂QU,Θ(s,ω,a)∂ν. The gradient of QΘ(s,ω) w.r.t ν is written as:
| | | | |
| --- | --- | --- | --- |
| | ∂QΘ(s,ω)∂ν=∑aπω,θ(a|s)γ∑s′P(s′|s,a)∂UΘ(s,ω)∂ν | | (20) |
Using ([19](#S3.E19 "(19) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")) and ([20](#S3.E20 "(20) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")) the gradient of J w.r.t. ν is:
| | | | |
| --- | --- | --- | --- |
| | ∂J∂ν=∑aπω,θ(a|s)∑s′γP(s′|s,a)∂UΘ(s′,ω)∂ν=∂QΘ(s,ω)∂ν | | (21) |
Therefore, the gradient of J w.r.t. ν becomes equal to that of QΘ(s,ω) which is equal to the Termination Gradient Theorem Bacon
et al. ([2017](#bib.bib5)) in ([6](#S2.E6 "(6) ‣ 2.2. LEARNING OPTIONS ‣ 2. PRELIMINARIES ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")). The interpretation of the derivation is in accordance with the way the notion of safety has been conceptualized, that is, each option is responsible for making its intra-option policy safe by incorporating the factor of controllability. We are using one-step i.e. TD(0) while updating the Q value of a state-option pair. Due to the assumption that each option take care of its own safety through it’s intra-option policy, one is only concerned about choosing an option which maximizes the expected discounted return from next state-option pair while terminating an option. Due to this assumption as shown in derivation above, introducing controllability does not impact the termination of an option. Algorithm [1](#alg1 "Algorithm 1 ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture") shows the implementation details of controllability in the option-critic architecture in a tabular setting.
Here α,αθ,αν stands for step size of critic, intra-option policy and termination respectively. ψ is controllability regularization parameter.
s←s0
Select ω using softmax policy over options
Let initial ω be ω0
repeat
a∼πω,θ(a|s) using softmax intra-option policy
Let initial a taken at (s0,ω0) be a0
Maintain (s0,ω0,a0) at the beginning of the episode
Observe {r,s′}
if s′ is non-terminal state then
δ←r+γ[(1−βω,ν(s′))QΘ(s′,ω)
+βω,ν(s′)maxω′∼ΩQΘ(s′,ω′)]
−QU,Θ(s,ω,a)
else
δ←r−QU,Θ(s,ω,a)
end if
if (s0,ω0)==(s,ω) then
Update (s0,ω0,a0)←(s0,ω0,a)
end if
QU,Θ(s,ω,a)←QU,Θ(s,ω,a)+αδ
θ←θ+αθ∂log(πω,θ(a|s))∂θQU,Θ(s,ω,a)
−αθ∂log(πω0,θ(a0|s0))∂θψδ2(s0,ω0,a0)
ν←ν−αν∂βω,ν(s′)∂ν(QΘ(s′,ω)−VΩ(s′))
if βω,ν(s′) terminates then
Choose new ω∼πΩ(ω|s′)
end if
s←s′
until s′ is a terminal state
Algorithm 1 Safe Option-Critic with tabular intra-option Q learning
4. Experiments
---------------
###
4.1. Grid World
First, we consider a simple navigation task in a two dimensional grid environment using a variant of the four-rooms domain as described in Sutton
et al. ([1999](#bib.bib37)). As seen in the Fig. [1](#S4.F1 "Figure 1 ‣ 4.1. Grid World ‣ 4. EXPERIMENTS ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture"), similar to Gehring and
Precup ([2013](#bib.bib12)), we define some slippery frozen states in the environment which are unsafe to visit. We accomplish this by introducing variability in their rewards. States labeled F and G indicate the frozen and goal states respectively.

Figure 1. Four Room Environment: F and G depicts the unsafe frozen and goal states respectively. The lightest color represents the normal states whereas the darkest color shows the wall.
An agent can be initialized with any random start state in the environment apart from the goal state. The action space consists of four stochastic actions namely, up, down, left, and right. The random actions are taken with 0.2 probability in the environment. The task is to navigate through the rooms to a fixed goal state as depicted in Fig. [1](#S4.F1 "Figure 1 ‣ 4.1. Grid World ‣ 4. EXPERIMENTS ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture"). The dark states in Fig. [1](#S4.F1 "Figure 1 ‣ 4.1. Grid World ‣ 4. EXPERIMENTS ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture") depict the walls. The agent remains in the same state with a reward of 0 if the agent hits the wall. A reward of 0 and 50 is given to the agent while transitioning into the normal and the goal state respectively. The rewards for the unsafe states are drawn uniformly from [−15,15] while the agent transitions to a slippery state. The expected value of the reward for the normal and the slippery states is kept same.
In the safe option-critic framework, we learn both the policy over options and the intra-option policies with the Boltzmann distribution. We ran the experiments with varying controllability factor ψ for learning 4 options. We optimize for the hyperparameters: temperature and α for both Option-Critic (OC) with ψ=0 and safe OC. The discount factor γ is set to 0.99. The step size of the intra-option policy is set to 0.01. The best performance is achieved for ψ=0 with the step size of termination and critic as 0.01 and 0.1 respectively. The optimal value of controllability was achieved at ψ=0.05 with the step size of termination and critic at 0.1 and 0.5 respectively. The temperature for the Boltzmann distribution is set to 0.001. The results are achieved with total of 600 episodes averaged over 200 trials where training in each trial starts from the scratch. In each episode, the agent is allowed to take only 500 steps, wherein if the agent fails to reach the goal state within those steps then the episode terminates.

Figure 2. Learning curve with 4 options in Four Room Environment: Graph depicts the averaged return over 200 trials in the four room environment with 4 options. The bands around solid lines represent the standard deviation of the return. The experiment with controllability has lesser standard deviation in the observed return value as compared to the one without controllability.
To evaluate these experiments, we consider the following metrics: the learned policy, average cumulative discounted return of episodes and the density of the state visits. It can be observed from Fig. [2](#S4.F2 "Figure 2 ‣ 4.1. Grid World ‣ 4. EXPERIMENTS ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture") that the options with the controllability (Safe-OC) have lower variance in the return of an episode as compared to the options without the controllability (OC). This highlights the fact that the controllability helps the agent in avoiding the unsafe states (inducing variability in the return value). To validate that learning with the controllability causes fewer visits to the unsafe state, we visualize the state frequency graph depicted in the Fig. [3](#S4.F3 "Figure 3 ‣ 4.1. Grid World ‣ 4. EXPERIMENTS ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture"). It is observed that the options with the controllability have lower frequency of visit to the unsafe states as opposed to the vanilla options.
The learning of safe options induces transparency to the behavior of an agent. This is most explicitly demonstrated through the path taken by the agent in case of both controllability and no controllability in the options as shown in Fig. [4](#S4.F4 "Figure 4 ‣ 4.1. Grid World ‣ 4. EXPERIMENTS ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture"). Regardless of the start state, Safe-OC agent navigates to the goal state avoiding the states with a high variance in the reward as opposed to the OC agent which finds a shortest route being unaware of the error prone states.
| | |
| --- | --- |
|
(a) OC (ψ=0)
|
(b) Safe-OC (ψ=0.05)
|
Figure 3. State frequency in Four Room Environment: Density graph represents the number of times a state was visited during testing over 80 trials. Darker shade represents the higher density. a) Model without safety has equally likely density for both the hallways. b) Model with safety shows higher density for the path without the frozen states.
| | | | |
| --- | --- | --- | --- |
|
(a) OC Policy (ψ=0)
|
(b) OC Policy (ψ=0)
|
(c) Safe-OC Policy(ψ=0.05)
|
(d) Safe-OC Policy(ψ=0.05)
|
Figure 4. Policy in Four Room Environment: Policy learned with 4 options where S and G represents the start & goal state. {R,L,U,D} denotes 4 actions agent takes according to the learned policy; might take different actions due to environment stochasticity. Change in color represents the option switching. Same color represents the same option. The S and G states are depicted with red color. Light blue patch represents the frozen states. a) & b) shows the policy with ψ=0 passing through the frozen area. c) & d) depicts policy learnt with ψ=0.05 avoiding the frozen area due to the inbuilt safety constraint.
###
4.2. CartPole Environment
We consider linear function approximation with the options. In the Cartpole111<https://gym.openai.com/envs/CartPole-v0/> environment a pole is attached to the cart which can move along the horizontal axis. The environment has four continuous features: position, velocity, pole angle and angular velocity of the pole. There are two discrete actions that can be taken, namely left or right. In the environment, a reward of +1 is achieved as long as the pole is maintained upright between a certain angle and a position. The discount factor γ is set to 0.99.
The experiment is conducted with 4 options. We use an intra-option Q-learning in the critic for learning the policy over options. The Boltzmann distribution was used for learning both the intra-option policies and the policy over options. The linear-sigmoid function was used for the termination of options. The hyperparameters were fine-tuned using the grid search over the parameter space. The optimal performance was obtained with the step size being set to 0.1 for termination, intra-option and critic. The temperature for the Boltzmann distribution was set to 0.001. [Sutton and Barto](#bib.bib35)’s (\citeyearNPSutton:1998:IRL:551283) open source tile coding implementation222<http://incompleteideas.net/tiles/tiles3.py-remove> is used for discretization of the state space. Ten dimensional features (joint space of 4 continuous features) are used to represent the state space. The continuous features: position, velocity and pole angle were discretized into 3 bins and the angular velocity was discretized into 6 bins.
Fig. [5](#S4.F5 "Figure 5 ‣ 4.2. CartPole Environment ‣ 4. EXPERIMENTS ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture") shows the averaged return over 50 trials with the different degrees of controllability ψ. The best performance is achieved with ψ=0.25. The figure shows that with the right degree of controllability, the variance in the return reduces and leads to the faster learning in terms of the mean return score. The controllability helps in the identification of the features which lead to the consistent behavior of the agent, thus learning to avoid state-action pairs which might lead the cart pole to topple. The code for the experiments in the grid world and the cartpole environment is available on the Github333The source code is available at <https://github.com/arushi12130/SafeOptionCritic>.

Figure 5. Learning curve for 4 options in Cart Pole Environment: Results are averaged over 50 trials. The band around the solid horizontal lines represents the standard deviation of the return. ψ=0.25 performs the best in case of 4 options.
###
4.3. Arcade Learning Environment
In this section, we discuss our experiments in the ALE domain. Recent work in learning options introduced a deliberation cost Harb
et al. ([2017](#bib.bib15)) in the option-critic framework Bacon
et al. ([2017](#bib.bib5)). The deliberation cost could be interpreted as a penalty for terminating an option, thereby leading to temporally extended options. We use the asynchronous advantage option-critic (A2OC) Harb
et al. ([2017](#bib.bib15)) algorithm as our baseline for learning the ‘safe’ options with the non-linear function approximation. Within the option-critic architecture, A2OC works in a similar fashion as the asynchronous advantage actor-critic (A3C) algorithm Mnih et al. ([2016](#bib.bib27)).
Introducing controllability in the A2OC algorithm results in an additional term to the intra-option policy gradient alone as shown in Equation ([18](#S3.E18 "(18) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")). Our update rule for the intra-option policy gradient in the A2OC with controllability setting thus becomes:
| | | | |
| --- | --- | --- | --- |
| | θπ←θπ+αθπ∂log(πω,θ(a|s)∂θ{G−QΘ(s,ω)}−αθπ∂log(πω0,θ(a0|s0))∂θψδ2(s0,ω0,a0) | | (22) |
Here G is a mixture of n-step returns similar to the A2OC with the difference that here we consider this return only for the duration an option persisted in continuation. Without any loss in generality, the 1-step TD error in the definition of controllability can be substituted with n-step TD error only if the same option has continued up until the nth step. Similarly, as discussed in the Equation ([21](#S3.E21 "(21) ‣ 3. SAFE OPTION-CRITIC MODEL ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture")), there is no change in the termination gradient and we use the same update rule as derived in the A2OC algorithm. η here is the deliberation cost.
| | | | |
| --- | --- | --- | --- |
| | ν← ν−αν∂βω,ν(s′)∂ν(QΩ(s′,ω)−VΩ(s′)+η) | | (23) |
We use primarily three games; MsPacman, Amidar and Q\*Bert from the ATARI 2600 suite to test our Safe-A2OC algorithm and analyze the performances. We introduce Safe-A2OC 444The source code is available at <https://github.com/kkhetarpal/safe_a2oc_delib> built using the same deep network architecture as A2OC, wherein the policy over options is ϵ-greedy, the intra-option policies are linear softmax functions, the termination functions use sigmoid activation functions along will the linear function approximation for the Q values. For hyperparameters, we learn 4 options, with a fixed deliberation cost of 0.02, margin cost of 0.99, step size of 0.0007, and entropy regularization of 0.01 for varying degrees of controllability (ψ) and ϵ. The training used 16 parallel threads for all our experiments. We optimized the ϵ parameter for no controllability (ψ=0). For a fair analysis, we compare the best performance of A2OC against different degrees of controllability parameter with the Safe-A2OC.
Results and Evaluation: To evaluate the performances, we use two metrics namely the learning curves Machado et al. ([2017](#bib.bib22)) and the average performance over k games. Figures [6](#S4.F6 "Figure 6 ‣ 4.3. Arcade Learning Environment ‣ 4. EXPERIMENTS ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture"), [7](#S4.F7 "Figure 7 ‣ 4.3. Arcade Learning Environment ‣ 4. EXPERIMENTS ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture") and [8](#S4.F8 "Figure 8 ‣ 4.3. Arcade Learning Environment ‣ 4. EXPERIMENTS ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture") show the learning curves over 80M frames with varying controllability parameter. It is observed that for specific degrees of controllability, options learned with our notion of safety (Safe-A2OC) outperforms the vanilla options (A2OC). It is important to note that the different values of ψ control the degree to which an agent would be risk averse. A grid search over the different degrees of the controllability hyperparameter ψ resulted in a narrow range of 0 to 0.15. For a very high value of ψ>0.3, we observe that the agents become extremely risk-averse resulting in a poor performance. An optimum value of ψ for all the three games is obtained around 0.05−0.10. We present the videos of some of these trained agents as qualitative results in the supplementary material555Supplementary material is available at <https://sites.google.com/view/safe-option-critic>. Upon visual inspection of the trained Safe-A2OC agent, we observe that explicitly optimizing for the variance in TD error results in the agent learning to avoid states with higher variance in TD error. For instance, in MsPacman, the acquisition of the corner diamonds provide the intrinsic variability in the reward structure. Our objective function helps the agent understand such an intrinsic variability in reward, thus boosting the overall performance.

Figure 6. Learning curve for 4 options in MsPacman: Options with a controllability factor of ψ=0.10 learn better than the best performing scenario of no controllability (ψ=0, ϵ=0.2). Higher degrees of ψ results in poor performance.

Figure 7. Learning curve for 4 options in Amidar: Options with a controllability factor of ψ=0.10 outperform vanilla options (ψ=0, ϵ=0.2). Higher degrees of controllability (ψ>0.15) results in reduced exploration and adversely effects the performance.

Figure 8. Learning curve for 4 options in Q\*bert: Options with a controllability factor of ψ=0.05 see better average performance in the learning than the one with no controllability (ψ=0, ϵ=0.2).
| | | | |
| --- | --- | --- | --- |
| Algorithm | MsPacman | Amidar | Q\*Bert |
| A3C | 850.7 | 283.9 | 21307.5 |
| DQN | 763.5 | 133.4 | 4589.8 |
| Double DQN | 1241.3 | 169.1 | 11020.8 |
| Dueling | 2250.6 | 172.7 | 14175.8 |
| ψ=0, ϵ=0.2 | | | |
| ψ=0.05, ϵ=0.2/0.3 | 2481.2(909.48) | 569(158.77) | 17642.0 (3346.85) |
| ψ=0.10, ϵ=0.2 | 2710.9 (598.69) | 925.43 (211.52) | 14490.0(5962) |
| ψ=0.15, ϵ=0.2 | 2055.8(468.09) | 781.31(168.79) | 1477.5(961.85) |
| ψ=0.25, ϵ=0.2 | 2290.4(855.00) | 458.82(107.77) | 298.25(133.71) |
Table 1. ALE Final Scores: Average Performance over 100 games once training is completed after 80M frames. Scores in boxes highlight the performance with no controllability whereas aqua highlighted cells indicate the benefits of introducing our notion of safety in learning end-to-end options. Introducing controllability in options outperforms best performances of primitive actions in 2 out of 3 games analyzed here. Learning options with our notion of safety outperforms vanilla A2OC in all 3 games. A3C scores have been taken from Mnih et al. ([2016](#bib.bib27)), DQN from Nair et al. ([2015](#bib.bib28)), Double DQN from Van Hasselt
et al. ([2016](#bib.bib41)), and Dueling from Wang
et al. ([2015](#bib.bib43)). ψ represents the degree of controllability. Values in brackets indicate standard deviation across 100 games.
The trained agents are then tested for their averaged performance across k=100 games as shown in the Table [1](#S4.T1 "Table 1 ‣ 4.3. Arcade Learning Environment ‣ 4. EXPERIMENTS ‣ Safe Option-Critic: Learning Safety in the Option-Critic Architecture"). Safe-A2OC with a controllability value of ψ=0.05 in Q\*Bert and ψ=0.10 in MsPacman and Amidar outperforms the score achieved by A2OC. In MsPacman and Amidar, Safe-A2OC also outperforms the other state-of-the-art approaches Mnih et al. ([2016](#bib.bib27)); Nair et al. ([2015](#bib.bib28)); Van Hasselt
et al. ([2016](#bib.bib41)); Wang
et al. ([2015](#bib.bib43)) using the primitive actions. Empirical effects of introducing the right degree of controllability in options demonstrates that an agent which additionally optimizes for low variance in the TD errors learns better than the one optimizing only for the cumulative reward. The intuition here is that using variance in the TD error as a measure of safety in hierarchical RL helps the agents avoid states with high intrinsic variability. Depending on the nature of the game itself, we observe different degrees of response to different levels of controllability in Q\*bert, Amidar, and MsPacman.
5. Discussion
--------------
In this work, we introduce a new framework called Safe Option-Critic wherein we define the safety in learning end-to-end options. We extend the idea of controllability from the primitive action space using the temporal difference error to the option-critic architecture for incorporating safety. The underlying idea of this learning process is to discourage the agent from visiting the harmful or the undesirable state-option pair by constraining the variance in the TD error. Recent work by Sherstan et al. ([2018](#bib.bib31)) proposed a direct method to calculate the variance of the λ return instead of the traditional indirect approaches which use the second order moment. The authors proposed a Bellman operator which uses the square of the TD error to measure the variance of return. This work further supports our approach of estimating the risk through the square of TD error.
Our experiments in the tabular methods empirically demonstrate the reduced variance in the return. Moreover, we observe a boost in the overall performance in both the tabular and the linear approximation methods. Furthermore, experiments in the ALE domain demonstrate that an RL agent was able to learn about the intrinsic variability in a large and complicated state-space such as images with non-linear function approximation. Results from ALE also demonstrated that the options with the notion of safety outperform the algorithms using the primitive actions.
Limitations and Future Work:
In this work, we limit the return calculation until an option terminates. Using the n-step returns during the intermediate switching of the options at the SMDP level is of potential interest for the future work. Additionally, it is currently assumed that all the options are available in all the states. In the context of safety, it might be of interest to understand what happens if the options initiation sets were limited to subset of the entire state space. One could also work with varying the degree of controllability regularizer ψ, where ψ could start from 0 to support the exploration in the beginning and gradually increase the value of ψ to limit the exploration to the unsafe states.
A potential direction of future work is the extension of controllability to more than just the initial state-option pair. One could extend the definition of controllability to all the state-option pairs in the trajectory which could potentially expedite the effects of the risk mitigation. The proposed notion of safety could also be extended to different levels of hierarchy in the framework. For instance, a mixture of options with varying degrees of controllability can be learned, wherein at policy over the options level, one could select an option based on how much controllability is desirable for a subset of an environment. The intra-option policy could still retain the current formalizations.
{acks}
The authors would like to thank their colleagues Herke van Hoof, Pierre-Luc Bacon, Jean Harb, Ayush Jain and Martin Klissarov for their useful comments and discussions throughout the duration of this work. The authors would also like to thank Open Philanthropy for funding this work, and Compute Canada for the computing resources. |
d826d71b-b525-4e96-ba2e-e80e390f8b98 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Toronto: Our guest: Cat Lavigne from the Center for Applied Rationality
Discussion article for the meetup : Toronto: Our guest: Cat Lavigne from the Center for Applied Rationality
WHEN: 09 April 2013 07:00:00PM (-0400)
WHERE: 20 Edward Street, Toronto, ON
Sorry, new location again! We're at the World's Biggest Bookstore in the Second Floor Meeting Room (at the back of the bookstore, up the stairs. Look for the paperclip sign).
This is our first guest event so let's all be friendly and welcoming to Cat, who's in Toronto just for the day! Cat volunteers for the Center for Applied Rationality, which you've no doubt heard a lot about already.
I don't want to set a fixed agenda for the discussion (since we're trying out a new format here with the invited guest) but let's just say I have a hunch this meeting's going to go well. :D
Discussion article for the meetup : Toronto: Our guest: Cat Lavigne from the Center for Applied Rationality |
86a435cf-743f-45c5-aba8-ce0430bfa8b7 | trentmkelly/LessWrong-43k | LessWrong | Bets and updating
Suppose the US presidential election is tomorrow. You currently assign a probability of 50% to each outcome. (We are ignoring the small possibility that neither of the main party candidates will win).
A man approaches you, and offers you a bet of $10, at 2-1 odds. In other words, if candidate one wins, he pays you $20, if candidate two wins, you pay him $10.
Should you accept this bet? What if the bet was for $10000 instead? Assume that your utility is linear in dollars (or assume that the bet is for utilons instead, whatever). If not, why not? Try to think about this before reading on.
The answer is that it depends on your priors - in particular, it depends on how you interpret the evidence of being offered the bet. In general, if someone offers you a large bet on some outcome, it's probably safe to assume they have access to a reasonable amount of information about the outcome. Depending on how much information your own probability estimate is based on, you should update towards the odds they offered you.
If you update too little, and accept too many bets, you will lose a lot of money to people with better information than you. On the other hand, you can also go too far in the other direction. If your response to being offered a five-cent bet is to immediately update to accept their probabilities (and refuse the bet), you will be very easy to fool (although hard to exploit by betting).
----------------------------------------
Now suppose there are two superintelligences, Omega and Omicron. They are both excellent at modelling both you and the presidential election. Omega has a strong preference for money, and a weak preference for having you believe false things about the presidential election. Omicron has this swapped - it wants you to believe that actual outcome of the election (which it has predicted) is extremely unlikely, and has a weak preference for money.
Omega executes the following plan: It looks through a large number of possible bets, looking fo |
844d6897-6b95-458e-91d7-92537c8a49b3 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Distributional Generalization: A New Kind of Generalization
1 Introduction
---------------
In this paper we introduce a new notion of generalization,
which sheds light on the behavior of standard classification methods.
We motivate this notion via extended examples
in Section [1.3](#S1.SS3 "1.3 Motivating Examples ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization"),
which highlight the limitations of classical generalization and the breadth of our results.
In the Introduction, we first discuss the mathematical form of classical generalization, to set the stage for our extension.
We then informally discuss our concrete conjectures
and summarize our contributions in the remainder of the paper.
###
1.1 Classical Generalization
The goal of supervised learning for classification is to learn a model that correctly classifies inputs x∈\cX from a
given distribution \cD into classes y∈\cY.
We want a model with small *test error* on this distribution.
In practice, we find such a classifier by minimizing
a proxy quantity: the *train error* of a model on the train set.
The classical framework for supervised learning, empirical risk minimization,
says that this procedure is justified
when the model output by the learning algorithm is expected to have
a small *generalization gap*: the gap between the error on the train and test set.
Formally, the trained model f should be such that:
| | | | |
| --- | --- | --- | --- |
| | ErrorTrainSet(f)≈ErrorTestSet(f) | | (1) |
This states that the model’s behavior on the test set is similar to its behavior on the train set,
as measured by the error.
In our work we extend this notion of generalization, and show that
models behave similarly on the train and test sets
in more ways than just their error.
To make this clearer, we first re-write the classical notion of generalization given in Equation (1) in a form better suited for our extension.
Classical Generalization:
Let f be a classifier trained on a set of samples (\TrainSet).
Then f generalizes if:
| | | | |
| --- | --- | --- | --- |
| | \Ex∼\TrainSet^y←f(x)[\1{^y≠y(x)}]≈\Ex∼\TestSet^y←f(x)[\1{^y≠y(x)}] | | (2) |
where y(x) is the true class of x, and ^y is the predicted class.
The LHS of Equation ([2](#S1.E2 "(2) ‣ 1.1 Classical Generalization ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization")) is the train error of f, and the RHS is the test error.
Crucially, both sides of Equation ([2](#S1.E2 "(2) ‣ 1.1 Classical Generalization ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization"))
are expectations of the same function— the error function—
under different distributions.
The error function
| | | |
| --- | --- | --- |
| | \Terr(x,^y):=\1{^y≠y(x)} | |
indicates whether the classifier output ^y agrees with the true label of x.
The LHS of Equation (2) is the expectation of
\Terr
under the “Train Distribution”, which
is the distribution over (x,^y) given by sampling a train point x
along with its classifier-label f(x).
Similarly, the RHS is under the “Test Distribution”, which is this same construction over the test set:
1. Train Distribution \Dtr: (x,f(x))x∼\TrainSet
2. Test Distribution \Dte: (x,f(x))x∼\TestSet
These two distributions are the central objects in our study. Classical generalization requires that these two distributions are close
with respect to a specific statistical functional: the expectation of the error function.
However, expected error is only one statistic that could match between these two distributions.
In this work, we show that the train and test distributions are close in many other statistics, which we formally characterize.
Moreover, we show that many statistics match even when the test error itself does not match –
that is, when the generalization gap is high.
This includes settings when training data is limited, the data is noisy or randomized, or the classification task is hard.
###
1.2 Distributional Generalization
We frame our results via a natural extension of classical generalization,
which we call “Distributional Generalization.”
Distributional Generalization is a property of trained classifiers, similar to classical generalization.
It is parameterized by T, a set of bounded functions (“tests”) from \cX\x\cY to [0,1]:
| | | |
| --- | --- | --- |
| | T⊆{T:\cX\x\cY→[0,1]} | |
Distributional Generalization:
Let f be a classifier trained on TrainSet.
Then f satisfies Distributional Generalization with respect to tests \cT if:
| | | | |
| --- | --- | --- | --- |
| | ∀T∈T:\Ex∼%
TrainSet^y←f(x)[T(x,^y)]≈\Ecx∼TestSet^y←f(x)[T(x,^y)] | | (3) |
which we also write as
| | | | |
| --- | --- | --- | --- |
| | \Dtr≈\cT\Dte | | (4) |
This property states that the train and test distribution have
similar expectations for all functions in the family T.
For the singleton set \cT={\Terr}, this is equivalent to classical generalization.
However \cT can be much larger – and in this work we conjecture
that Distributional Generalization often holds for a large family \cT which we specify later.
In fact, we will see that
the family of functions T is often so large that is
it is best to think of Distributional Generalization
as stating that the distributions \Dtr and \Dte
are close *as distributions* (as suggested by the notation of Equation ([4](#S1.E4 "(4) ‣ 1.2 Distributional Generalization ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization")), made formal
in Section [3.1](#S3.SS1 "3.1 Distributional Closeness ‣ 3 Preliminaries ‣ Distributional Generalization: A New Kind of Generalization")).
This property becomes especially interesting
for *interpolating classifiers*,
which fit their train sets exactly.
Here, notice that the Train Distribution \Dtr
is exactly equal111The formal definition of Train Distribution, in Section [3.2](#S3.SS2 "3.2 Framework for Indistinguishability ‣ 3 Preliminaries ‣ Distributional Generalization: A New Kind of Generalization"), includes the randomness of sampling the train set as well.
We considered a fixed train set in the Introduction for sake of exposition. to the original distribution \cD,
since f(xi)=yi on the train set.
In this case, distributional generalization claims that the
output distribution (x,f(x)) of the model on test samples
is close to the *true* distribution (x,y).
The following conjecture specializes Distributional Generalization
to interpolating classifiers, and will be the main focus of our work.
{boxedenv}
Interpolating Indistinguishability Meta-Conjecture (informal):
Let f be an interpolating classifier trained on TrainSet.
Now, for a large family T of statistical tests depending on f (to be specified later):
| | | | |
| --- | --- | --- | --- |
| | \cD≡\Dtr≈\cT\Dte | | (5) |
We state this conceptually as
“For interpolating classifiers f:
The distributions (x,y) and (x,f(x))
on the test set look the same
to a certain family of tests”
This is a “meta-conjecture”, which becomes a concrete conjecture
once the family of tests T is specified.
One of the main contributions of our work
is formally stating two concrete instances of this conjecture—
specifying exactly the family of tests T
and their dependence on problem parameters
(the distribution, model family, training procedure, etc).
We empirically verify these conjectures across a variety of natural settings
in machine learning.
These experiments themselves highlight new behaviors of interpolating classifiers
which are independently interesting.
In the remainder of the Introduction we will discuss the two concrete conjectures, Feature Calibration
and Agreement Matching, which form the two main sections in the body of our paper
(Sections [4](#S4 "4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") and [5](#S5 "5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization")).
We start with several examples, then discuss the conjectures
in Sections [1.4](#S1.SS4 "1.4 Conjecture: Feature Calibration ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization") and [1.5](#S1.SS5 "1.5 Conjecture: Agreement Property ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization").
We conclude by discussing potential mechanisms
and summarizing our contributions.
###
1.3 Motivating Examples
We now present several experiments which motivate the need for
a notion of generalization beyond test error.
{experiment}
Consider a binary classification version of CIFAR-10,
where CIFAR-10 images x have binary labels Animal/Object.
Take 50K samples from this distribution as a train set, but apply the following
label noise: flip the label of cats to Object with probability 30%.
Now train a WideResNet to 0 train error on this train set.
How do we expect the outputs of the trained classifier to behave on test samples?
Several options are:
1. The classifier correctly classifies most cats as animals.
After all, there is only 3% label noise in the overall train set, and we may expect that this is small enough that the network learns the right concept of Animal vs Object
2. The label noise is “spread” across the animal class,
and all sub-classes (cat, dog, horse, deer, frog) have moderate misclassification errors at test time.
After all, the classifier is not explicitly told what a cat or a dog is, just that they are all animals.
3. The classifier misclassifies roughly 30% of test cats as Object,
but all other types of animals are largely unaffected.
In fact, reality is closest to option (3).
The left panel in Figure [1](#S1.F1 "Figure 1 ‣ 1.3 Motivating Examples ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization") shows the results of this experiment with a WideResNet-28-10 (zagoruyko2016wide).
The top panel shows the joint density of train inputs x with train labels Object/Animal.
The bottom panel shows the joint density of test inputs x with classifier predictions f(x),
on the test set.
These joint densities are close.
In particular, although the classifier was not explicitly given
the labels of each type of animal, its errors were “localized” to the cat class – reflecting
the same distribution as the train set. We discuss this “locality” further below.

Figure 1:
Distributional Generalization in Experiment 1.
(A):
The CIFAR-10 train set is labeled as either Animal/Object, with label noise affecting only cats.
A WideResNet-28-10 is then trained to 0 train error on this train set.
The top panel shows the joint density of the train set: (CIFAR\\_Class(x),y).
The bottom panels shows the joint density of classifier predictions on the test set:
(CIFAR\\_Class(x),f(x)).
Distributional Generalization claims that these two joint densities are close.
(B): Simplified schematic showing that 1-nearest neighbors would reproduce this behavior.
Dots indicate train points, colored by their train label Animal/Object.
30% of the cats in the train set are mislabeled as Object,
and we see that the 1-nearest neighbor decision boundary (shaded red/blue) mislabels roughly 30% of the cat region as Object
as well.
That is, nearest-neighbor in an appropriate space would have similar behavior as we observe with WideResNets.
Similarly, consider the following extension of this experiment.
{experiment}
Consider the following distribution over images x and binary labels y.
Sample x as a uniformly random CIFAR-10 image,
and sample the label as p(y|x)=Bernoulli(CIFAR\\_Class(x)/10).
That is, if the CIFAR-10 class of x is k∈{0,1,…9},
then the label is 1 with probability (k/10) and 0 otherwise.
Figure [2](#S1.F2 "Figure 2 ‣ 1.3 Motivating Examples ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization") shows this joint distribution of (x,y).
As before, train a WideResNet to 0 training error on this distribution.

Figure 2: Distributional Generalization in Experiment [1](#S1.F1 "Figure 1 ‣ 1.3 Motivating Examples ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization").
Joint densities of the distributions involved in Experiment [1](#S1.F1 "Figure 1 ‣ 1.3 Motivating Examples ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization").
The top panel shows the joint density of labels on the train set: (CIFAR\\_Class(x)(x),y).
The bottom panels shows the joint density of classifier predictions on the test set: (CIFAR\\_Class(x)(x),f(x)).
Distributional Generalization claims that these two joint densities are close.
Recall that we are using a method designed for classification,
and we hope to approximate the best-possible classifier.
In this setting, the Bayes-optimal classifier
(i.e. the classifier with minimal test error)
is the threshold function f∗(x)=\1{Class(x)≥5},
which has 25% test error.
However, a WideResNet trained to interpolation on this problem
does *not* behave like this optimal classifier – it has ≈33% test error.
When evaluated on the CIFAR-10 test set,
the network outputs label 1 on roughly (k/10) fraction of the examples in class k
— the same distribution as the train set (as shown in Figure [2](#S1.F2 "Figure 2 ‣ 1.3 Motivating Examples ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization")).
This example shows that the properties of classical generalization
and distributional generalization can be incompatible: in this case,
the best classically-generalizing classifier does not satisfy distributional generalization. Surprisingly, standard training procedures which were intended for classical generalization actually produce
a distributionally-generalizing classifier.
This example is also interesting because the network learnt to behave differently on each CIFAR-10 class (cat, dog, plane, etc),
even though it was not explicitly provided the CIFAR-10 labels.
This observation— that powerful networks can pick up on
finer aspects of the distribution than their training labels reveal—
also exists in various forms in the literature.
For example, gilboa2019wider found
that standard CIFAR-10 networks
tend to cluster left-facing and right-facing horses separately
in activation space, when visualized via activation atlases (carter2019activation).
Such fine-structural aspects of distributions can also be seen at the level of individual neurons (e.g. cammarata2020thread:; radford2017learning; olah2018building; zhou2014object; bau2020understanding).
These behaviors are not captured by the classical framework of generalization, which only
discusses the test error of models.
Rather, they are better thought of as instances of the Indistinguishability Conjecture: the
train and test behaviors are close as distributions.
###
1.4 Conjecture: Feature Calibration
The distributional closeness of Experiments 1 and 2 is subtle,
and depends on the classifier architecture, distribution, and training method.
For example, Experiment [1](#S1.F1 "Figure 1 ‣ 1.3 Motivating Examples ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization") does not hold if we use a fully-connected network (MLP) instead of a ResNet,
or if we early-stop the ResNet instead of training to interpolation.
Both these scenarios fail in different ways:
An MLP cannot properly distinguish cats from dogs even when trained on real CIFAR-10 labels,
and so (informally) it has no hope of behaving differently on cats vs. dogs in the setting of Experiment [1](#S1.F1 "Figure 1 ‣ 1.3 Motivating Examples ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization") (See Fig. [15](#A4.F15 "Figure 15 ‣ D.2 Experiment 1 ‣ Appendix D Feature Calibration: Appendix ‣ Distributional Generalization: A New Kind of Generalization") in Appendix [D](#A4 "Appendix D Feature Calibration: Appendix ‣ Distributional Generalization: A New Kind of Generalization")).
On the other hand, an early-stopped ResNet for Experiment [1](#S1.F1 "Figure 1 ‣ 1.3 Motivating Examples ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization") does not label 30% of cats as 1 on the *train set*,
since it does not interpolate, and thus has no hope of reproducing this behavior on the test set.
In fact, early-stopping training results in a classifier that is closer to Bayes-optimal,
but violates the distributional closeness of Experiment [1](#S1.F1 "Figure 1 ‣ 1.3 Motivating Examples ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization") (see Section [7](#S7 "7 Distributional Generalization: Beyond Interpolating Methods ‣ Distributional Generalization: A New Kind of Generalization")).
We characterize all of these behaviors, and their dependency on problem parameters,
via a formal conjecture.
Roughly, we claim that the output of interpolating classifiers
is “close” to their input distribution, where this closeness is
“as good as we can hope” given the power of the classifier.
{boxedenv}
Feature Calibration Conjecture (informal)
“For interpolating classifiers f:
The distributions (x,y) and (x,f(x))
on the test set look the same up to
features which can be distinguished by the architecture of f”
The formal version of this claim (Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") in Section [4](#S4 "4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")),
can be seen as explicitly defining a
large family of tests T (the “features which can be distinguished”)
for which the Indistinguishability Conjecture applies.
It captures behaviors far more general than Experiments 1 and 2,
and applies to neural networks, kernels, and decision trees.
###
1.5 Conjecture: Agreement Property
In Section [5](#S5 "5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization") we present a seemingly unrelated set of experiments:
We observe that the test accuracy of a classifier is often close to
the probability that it agrees with an identically-trained classifier on a disjoint train set.
{boxedenv}
Agreement Conjecture (informal)
“For two interpolating classifiers f1,f2
of the same architecture, trained on independent train sets from the same distribution \cD,
their *agreement probability* on the test set
approximately matches their individual *test accuracy*:
| | | | |
| --- | --- | --- | --- |
| | Pr(x,y)∼\cD[f1(x)=f2(x)]≈Pr(x,y)∼\cD[f1(x)=y] | | (6) |
For example, suppose we have two ResNets f1,f2
which were trained on independent train sets from the same distribution,
and both achieve test accuracy say 50% on a 10-class problem.
That is, they agree with the true label y(x) w.p 50%.
Now we ask, what is the probability they
agree with *each other*?
Depending on our intuition, we may expect:
(1) They agree with each other much less than they agree with the true label,
since each individual classifier is an independently noisy version of the truth.
(2) They agree with each other much more than 50%, since
classifiers tend to have “correlated” predictions.
However, surprisingly, none of these are the case.
We show that for a variety of realistic domains and classifiers,
the agreement probability *closely matches* the test accuracy.
In fact, this can be seen as an instance of the Indistinguishably Conjecture
for a specific test T,
as we explain in Section [5](#S5 "5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization").
These experimental observations are independently interesting,
and could be useful for future applications.
For example, the LHS
of Equation [6](#S1.E6 "(6) ‣ 1.5 Conjecture: Agreement Property ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization") is an estimate of the test error
that requires only unlabeled test examples x.
###
1.6 Potential Mechanisms and Locality
Throughout this work, we focus on formally characterizing
the observed behaviors (via our conjectures), and empirically testing
our conjectures in a variety of realistic settings.
However, we do not yet understand *why* these conjectures hold across such a wide variety of domains.
One possible intuition for these behaviors is that interpolating classifiers
are (for some reason) behaving like *local* estimators.
For example, note that 1-Nearest-Neighbors (in an appropriate metric space)
would reproduce the behavior we observe in Experiments 1 and 2.
To see this, consider a metric space in which the original CIFAR-10 classes are well-separated,
as shown schematically in Figure [1](#S1.F1 "Figure 1 ‣ 1.3 Motivating Examples ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization").
For a 1-Nearest-Neighbor (1-NN) classifier in this space,
the classifier outputs for test cats would match the distribution of training labels for cats.
In Experiment 2, for example, label noise that affects only cats in the train set would also
only affect cats at test time.
In this sense, the classifier behaves like a *local* estimator.
While we do not make a formal connection between 1-NN and other interpolating classifiers,
many of the properties we discuss in this paper are shared between the two, and can be formally proved for 1-NN.
This is especially surprising for interpolating neural networks and kernel machines,
which are not usually considered “local” estimators.
We prove our conjectures for 1-Nearest-Neighbors in this work (Theorem [1](#Thmtheorem1 "Theorem 1. ‣ 4.5 1-Nearest-Neighbors Connection ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")),
and we leave better understanding this potential connection as an important area for future work.
###
1.7 Summary of Contributions
We extend the classical framework of generalization
by introducing Distributional Generalization, in which
the train and test behavior of models are close *as distributions*.
Informally, for a trained classifier f,
its outputs on the train set
(x,f(x))x∈\TrainSet
are close in distribution to its outputs on the test set
(x,f(x))x∈\TestSet,
where the form of this closeness depends on specifics of the model, training procedure, and distribution.
This notion is both more fine-grained than classical generalization – in that it
considers the entire distribution of model outputs instead of a single functional –
as well as more robust:
even models which do not generalize well in the classical sense
can be well-behaved in a certain distributional sense.
In fact, for noisy distributions, distributional generalization
is incompatible with classical generalization. And yet, we find
that standard methods in machine learning, which were intended to classically
generalize, actually distributionally generalize.
We initiate the study of Distributional Generalization
across various domains in machine learning, focusing primarily on interpolating classifiers.
For interpolating classifiers, we state two formal conjectures which predict the form of distributional closeness that can be expected for a given model and task:
1. Feature Calibration Conjecture (Section [4](#S4 "4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")):
Interpolating classifiers, when trained on samples from a distribution,
will match this distribution up to all “distinguishable features” (Definition [1](#Thmdefinition1 "Definition 1 ((\eps,\cF,\cD,n)-Distinguishable Feature). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")).
2. Agreement Conjecture (Section [5](#S5 "5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization")):
For two interpolating classifiers of the same type,
trained independently on the same distribution,
their *agreement probability* with each other on test samples
roughly matches their *test accuracy*.
We perform a number of experiments surrounding these conjectures.
These experiments reveal new behaviors of standard interpolating classifiers
(e.g. ResNets, MLPs, kernels, decision trees), and are independently interesting.
Finally, we discuss extending these results to non-interpolating methods in Section [7](#S7 "7 Distributional Generalization: Beyond Interpolating Methods ‣ Distributional Generalization: A New Kind of Generalization"),
and we give preliminary evidence for a third form of distributional closeness in Appendix [B](#A2 "Appendix B Student-Teacher Indistinguishability ‣ Distributional Generalization: A New Kind of Generalization").
2 Related Work
---------------
Our work is inspired by the broader study of interpolating and overparameterized methods
in machine learning; a partial list of works in this theme includes zhang2016understanding; belkin2018overfitting; belkin2018understand; belkin2019reconciling; liang2018just; nakkiranDeep; mei2019generalization; schapire1998boosting; breiman1995reflections; ghorbani2019linearized; hastie2019surprises; bartlett2020benign; advani2017high; geiger2019jamming; gerace2020generalisation; chizat2020implicit; goldt2019generalisation; arora2019fine; allen2019learning; neyshabur2018towards; dziugaite2017computing; muthukumar2020harmless; neal2018modern.
Interpolating Methods.
Many of the best-performing techniques on high-dimensional tasks are interpolating methods,
which fit their train samples to 0 train error.
This includes neural networks and kernels on images (he2016deep; shankar2020neural), and random forests on tabular data (fernandez2014we).
Interpolating methods have been extensively studied both recently
and in the past, since we do not
theoretically understand their practical success
(schapire1998boosting; schapire1999theoretical; breiman1995reflections; zhang2016understanding; belkin2018overfitting; belkin2018understand; belkin2019reconciling; liang2018just; mei2019generalization; hastie2019surprises; nakkiranDeep).
In particular, much of the classical work in statistical learning theory
(uniform convergence, VC-dimension, Rademacher complexity, regularization, stability)
fails to explain the success of
interpolating methods (zhang2016understanding; belkin2018overfitting; belkin2018understand; nagarajan2019uniform).
The few techniques which do apply to interpolating methods (e.g. margin theory (schapire1998boosting))
remain vacuous on modern neural networks and kernels.
Decision Trees.
In a similar vein to our work, wyner2017explaining; olson2018making investigate decision trees,
and show that random forests are equivalent to
a Nadaraya–Watson smoother nadaraya1964estimating; watson1964smooth with a certain smoothing kernel.
Decision trees (breiman1984classification) are often intuitively thought of as
“adaptive nearest-neighbors,”
since they are explicitly a spatial-partitioning method
(hastie2009elements).
Thus, it may not be surprising that decision trees behave similarly
to 1-Nearest-Neighbors.
wyner2017explaining; olson2018making took steps towards characterizing and understanding this behavior –
in particular, olson2018making
defines an equivalent smoothing kernel corresponding to a random forest,
and empirically investigates the quality of the conditional density estimate.
Our work presents a formal characterization of the quality of this conditional density estimate
(Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")), which is a novel characterization even for decision trees, as far as we know.
Kernel Smoothing.
The term kernel regression is sometimes used in the literature to
refer to kernel *smoothers*,
such as the Nadaraya–Watson kernel smoother (nadaraya1964estimating; watson1964smooth).
But in this work we use the term “kernel regression” to refer only to
regression in a Reproducing Kernel Hilbert Space, as described in the
experimental details.
Label Noise.
Our conjectures also describe the behavior of neural networks under label noise,
which has been empirically and theoretically studied in the past,
though not formally characterized before
(zhang2016understanding; belkin2018understand; rolnick2017deep; natarajan2013learning; thulasidasan2019combating; ziyin2020learning; chatterji2020finite).
Prior works have noticed that vanilla interpolating networks are sensitive to label noise
(e.g. Figure 1 in zhang2016understanding, and belkin2018understand),
and there are many works on making networks more robust to label noise
via modifications to the training procedure or objective
(rolnick2017deep; natarajan2013learning; thulasidasan2019combating; ziyin2020learning).
In contrast, we claim this sensitivity to label noise is not necessarily
a problem to be fixed,
but rather a consequence of a stronger property: distributional generalization.
Conditional Density Estimation.
Our density calibration property is similar to
the guarantees of a conditional density estimator.
More specifically, Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")
states that an interpolating classifier *samples*
from a distribution approximating the conditional density
of p(y|x) in a certain sense.
Conditional density estimation has been well-studied
in classical nonparametric statistics (e.g. the Nadaraya–Watson kernel smoother (nadaraya1964estimating; watson1964smooth)).
However, these classical methods behave poorly
in high-dimensions, both in theory and in practice.
There are some attempts to extend these classical methods
to modern high-dimentional problems
via augmenting estimators with neural networks
(e.g. rothfuss2019conditional).
Random forests have also been known to exhibit
properties similar to conditional density estimators.
This has been formalized in various ways,
often only with asymptotic guarantees (meinshausen2006quantile; pospisil2018rfcde; athey2019generalized).
No prior work that we are aware of
attempts to characterize the quality of the resulting density estimate
via testable assumptions, as we do with our formulation of Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization").
Finally, our motivation is not to design good conditional density estimators, but rather to study properties of interpolating classifiers — which we find happen to share properties of density estimators.
Uncertainty and Calibration.
The Agreement Property (Conjecture [2](#Thmconjecture2 "Conjecture 2 (Agreement Property). ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization"))
bears some resemblance to uncertainty
estimation (e.g. lakshminarayanan2017simple),
since it estimates the the test error of a classifier using
an ensemble of 2 models trained on disjoint train sets.
However, there are important caveats: (1) Our Agreement Property
only holds on-distribution, and degrades on off-distribution inputs.
Thus, it is not as helpful to estimate out-of-distribution errors.
(2) It only gives an estimate of the average test error, and does not imply pointwise calibration estimates for each sample.
Feature Calibration (Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")) is also related to the concepts of calibration
and multicalibration (guo2017calibration; niculescu2005predicting; hebert2018multicalibration).
In our framework, calibration is implied by Feature Calibration for a specific set of partitions L
(determined by level sets of the classifier’s confidence).
However, we are not concerned with a specific set of partitions
(or “subgroups” in the algorithmic fairness literature)
but we generally aim to characterize for which partitions Feature Calibration holds.
Moreover, we consider only hard-classification decisions and not confidences,
and we study only standard learning algorithms which are not given any distinguished set of subgroups/partitions in advance.
Our notion of distributional generalization is also related
to the notion of “distributional subgroup overfitting” introduced
recently by yaghini2019disparate to study algorithmic fairness.
This can be seen as studying distributional generalization for a specific family of tests
(determined by distinguished subgroups in the population).
Locality and Manifold Learning.
Our intuition for the behaviors in this work is that they arise due to some form of “locality” of the trained classifiers, in an appropriate space.
This intuition is present in various forms in the literature,
for example: the so-called called “manifold hypothesis,”
that natural data lie on a low-dimensional manifold (e.g. narayanan2010sample; sharma2020neural),
as well as works on local stiffness of the loss landscape (fort2019stiffness),
and works showing that overparameterized neural networks
can learn hidden low-dimensional structure in high-dimensional settings
(gerace2020generalisation; bach2017breaking; chizat2020implicit).
It is open to more formally understand connections between our work and the above.
3 Preliminaries
----------------
Notation.
We consider joint distributions \cD
on x∈\cX and discrete y∈\cY=[k].
Let \cDn denote n iid samples from \cD and S={(xi,yi)} denote a train set.
Let \cF denote the training procedure of a classifier family (including architecture and training algorithm),
and let f←\Train\cF(S) denote training a classifier f on train set S.
We consider classifiers which output hard decisions f:\cX→\cY.
Let \NNS(x)=xi denote the nearest neighbor to x in train-set S,
with respect to a distance metric d.
Our theorems will apply to any distance metric, and so we leave this unspecified.
Let \NNfS(x) denote the nearest neighbor estimator itself,
that is, \NNfS(x):=yi where xi=\NNS(x).
Experimental Setup. Full experimental details are provided in Appendix [C](#A3 "Appendix C Experimental Details ‣ Distributional Generalization: A New Kind of Generalization").
Briefly, we train all classifiers to interpolation unless otherwise specified— that is, to 0 train error.
We use standard-practice training techniques for all methods with minor hyperparameter modifications for training to interpolation.
In all experiments, we consider only the hard-classification decisions, and not e.g. the softmax probabilities.
Neural networks (MLPs and ResNets (he2016deep)) are trained with Stochastic Gradient Descent.
Interpolating decision trees are trained using the growth rule from Random Forests (breiman2001random),
growing until all leafs have a single sample.
For kernel classification, we consider both kernel regression on one-hot labels and kernel SVM,
with small or 0 values of regularization (which is often optimal, as in shankar2020neural).
Section [7](#S7 "7 Distributional Generalization: Beyond Interpolating Methods ‣ Distributional Generalization: A New Kind of Generalization") considers non-interpolating versions of the above methods
(via early-stopping or regularization).
###
3.1 Distributional Closeness
For two distributions P,Q over \cX\x\cY,
let P≈\epsQ
denote \eps-closeness in total variation distance; that is,
TV(P,Q)=12||P−Q||1≤\eps.
Recall that TV-distance has an equivalent variational characterization:
For distributions P,Q over \cX\x\cY, we have
| | | |
| --- | --- | --- |
| | TV(P,Q)=supT:\cX\x\cY→[0,1]∣∣\E(x,y)∼P[T(x,y)]−\E(x,y)∼Q[T(x,y)]∣∣ | |
A “test” (or “distinguisher”) here is a function
T:X\xY→[0,1]
which accepts a sample from either distribution,
and is intended to classify the sample as either
from distribution P or Q.
TV distance is then the advantage of the best distinguisher among all bounded tests.
More generally, for any family
\cT⊆{T:\cX\x\cY→[0,1]} of tests,
we say distributions P and Q are “\eps-indistinguishable up to \cT-tests” if they are
close with respect to all tests in class \cT.
That is,
| | | | |
| --- | --- | --- | --- |
| | P≈\cT\epsQ⟺supT∈\cT∣∣\E(x,y)∼P[T(x,y)]−\E(x,y)∼Q[T(x,y)]∣∣≤\eps | | (7) |
This notion of closeness is also known as an Integral Probability Metric (muller1997integral).
Throughout this work, we will define specific families of distinguishers \cT
to characterize the sense in which the output distribution (x,f(x))
of classifiers is close to their input distribution (x,y)∼\cD.
When we write P≈Q, we are making an informal claim
in which we mean P≈\epsQ for some small but unspecified \eps.
###
3.2 Framework for Indistinguishability
Here we setup the formal objects studied in the remainder of the paper.
This formal description of Train and Test distributions differs slightly
from the informal description
in the Introduction, because we want to study the generalization properties
of an entire end-to-end training procedure (\Train\cF), and not just properties
of a fixed classifier (f).
We thus consider the following three distributions over \cX\x\cY.
Source \cD: (x,y)
where x,y∼\cD
Train \Dtr:
(xtr,f(xtr))
S∼\cDn, f←\Train\cF(S),
xtr,ytr∼S
Test \Dte
(x,f(x))
S∼\cDn, f←\Train\cF(S),
x,y∼\cD
The Source Distribution \cD is simply the
original distribution.
To sample from the Train Distribution \Dtr,
we first sample a train set S∼\cDn,
train a classifier f on it,
then output (xtr,f(xtr))
for a random *train point* xtr.
That is, \Dtr is the distribution of input and outputs of a trained classifier f
on its train set.
To sample from the Test Distribution \Dte,
do we this same procedure,
but output (x,f(x)) for a random *test point* x.
That is, the \Dte is the distribution of input and outputs of a trained classifier f
at test time.
The only difference between the Train Distribution
and Test Distribution is that the point x is sampled
from the train set or the test set, respectively.222
Technically, these definitions require training a fresh classifier for each sample,
using independent train sets. We use this definition because we believe it is natural,
although for practical reasons most of our experiments train a single classifier f
and evaluate it on the entire train/test set.
For interpolating classifiers,
f(xtr)=ytr on the train set,
and so the Source and Train distributions are equivalent:
| | | | |
| --- | --- | --- | --- |
| | For interpolating classifiers f:\cD≡\Dtr | | (8) |
Our general thesis is that the Train and Test Distributions
are indistinguishable under a variety of test families \cT.
Formally, we argue that
for certain families of tests \cT
and interpolating classifiers \cF,
| | | | |
| --- | --- | --- | --- |
| | Indistinguishability Conjecture:\cD≡\Dtr≈\cT\eps\Dte | | (9) |
Sections [4](#S4 "4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") and [5](#S5 "5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization")
give specific families of tests \cT for which
these distributions are indistinguishable.
The quality of this distributional closeness will depend on details of the classifier family and distribution,
in ways which we will specify.
4 Feature Calibration
----------------------
In this section, we present our first formal conjecture
which characterizes a family of tests T for which the output distribution of a classifier (x,f(x))∼\Dte
is “close” to the source distribution (x,y)∼\cD.
This family of tests is subtle to define,
because we cannot expect closeness in total variation distance (which corresponds to closeness in all possible bounded functions).
Rather, the best we can hope for (informally) is that the classifier’s output
matches the true distribution along all features that it can learn.
At a high level, we will argue that the distributions \Dte and \cD
are statistically close if we first “coarsen” the domain of x by some
labelling L:\cX→[M].
That is, for certain partitions L, the following
distributions are statistically close:
| | | | |
| --- | --- | --- | --- |
| | (L(x),f(x)) | ≈\eps(L(x),y) | |
We first explain this conjecture (“Feature Calibration”) via a toy example, and then we formalize it in Section [4.2](#S4.SS2 "4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization").
###
4.1 Toy Example
Consider a distribution on points x∈\R2 and binary labels y, as visualized in
Figure [3A](#S4.F3 "Figure 3 ‣ 4.1 Toy Example ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization").
This distribution consists of four clusters
{Truck, Ship, Cat, Dog} which are labeled either
Object or Animal, depicted in red and blue respectively.
One of these clusters — the Cat cluster — is mislabeled as class Object with probability 30%.
Now suppose we have an interpolating classifier f for this distribution, obtained in some way,
and wish to quantify the closeness between distributions (x,y)≈(x,f(x)) on the test set.
Figure [3A](#S4.F3 "Figure 3 ‣ 4.1 Toy Example ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") shows test points x along with their test labels y – these
are samples from the source distribution \cD.
Figure [3B](#S4.F3 "Figure 3 ‣ 4.1 Toy Example ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") shows these same test points, but labeled according to f(x) –
these are samples from the test distribution \Dte.
The shaded red/blue regions in Figure [3B](#S4.F3 "Figure 3 ‣ 4.1 Toy Example ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") shows the decision boundary of the classifier f.
These two distributions do not match exactly – there are some test points where the true label y and classifier output f(x) disagree.
However, if we “coarsen” the domain into the four clusters {Truck, Ship, Cat, Dog},
then the marginal distribution of labels within each cluster matches between the classifier outputs f(x)
and true labels y.
In particular, the fraction of Cat points that are labeled Object is similar between
Figures [3C](#S4.F3 "Figure 3 ‣ 4.1 Toy Example ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") and [3D](#S4.F3 "Figure 3 ‣ 4.1 Toy Example ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization").
This is equivalent to saying that the joint distributions (L(x),y) and (L(x),f(x))
are statistically close, for the partition L:\cX→{Truck, Ship, Cat, Dog}.
That is, if we can only see points x through their cluster-label L(x),
then the distributions (x,y) and (x,f(x)) will appear close.
These two “coarsened” joint distributions are also what we plotted in Figure [1](#S1.F1 "Figure 1 ‣ 1.3 Motivating Examples ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization")
from the Introduction, where we considered the partition L(x):=CIFAR\\_Class(x), the CIFAR-10 class of x.

Figure 3: Toy Example: Feature Calibration.
Schematic of the distributions discussed in Section [4.1](#S4.SS1 "4.1 Toy Example ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization"),
showing a toy example of the Feature Calibration conjecture for several distinguishable features L.
There may be many such partitions L for which the above distributional closeness holds.
For example, the coarser partition L2:\cX→{Animal, Object} also
works in our example, as shown in Figures [3E](#S4.F3 "Figure 3 ‣ 4.1 Toy Example ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") and [3F](#S4.F3 "Figure 3 ‣ 4.1 Toy Example ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization").
However, clearly not all partitions L will satisfy closeness, since the distributions themselves
are not statistically close.
For a finer partition which splits the clusters into smaller pieces (e.g. based on the age of the dog),
the distributions may not match unless we use very powerful classifiers or many train samples.
To formalize the set of allowable partitions L,
we define a *distinguishable feature*:
a partition of the domain \cX that is learnable for a given family of models.
Intuitively, both of the partitions considered above are reasonable, because they can be
*learnt* from samples.
###
4.2 Formal Definitions
Here we define a *distinguishable feature*:
a labeling of the domain \cX that is learnable for a given family of models.
This definition depends on the family of models \cF, the distribution \cD,
and the number of train samples n.
######
Definition 1 ((\eps,\cF,\cD,n)-Distinguishable Feature).
For a distribution \cD over \cX\x\cY,
number of samples n,
family of models \cF, and small \eps≥0,
an *(\eps,\cF,\cD,n)-distinguishable feature*
is a partition L:\cX→[M]
of the domain \cX into M parts, such that
training a model from \cF
on n samples labeled by L
works to classify L with high test accuracy.
Precisely, L is a distinguishable feature if the following procedure succeeds with probability at least 1−\eps:
1. Sample a train set S←{(xi,L(xi))} of n samples (xi,yi)∼\cD,
labeled by the partition L.
2. Train a classifier f←Train\cF(S).
3. Sample a test point x∼\cD, and check that f correctly classifies its partition:
Output success iff f(x)=L(x).
That is, L is a \epsL-distinguishable feature if:
| | | |
| --- | --- | --- |
| | PrS={(xi,L(xi)}x1,…,xn∼\cDf←\Train\cF(S)x∼\cD[f(x)=L(x)]≥1−\eps | |
To recap, this definition is meant to
capture a labeling of the domain \cX that is learnable for a given family of models and training procedure.
For example, in Experiment [1](#S1.F1 "Figure 1 ‣ 1.3 Motivating Examples ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization"), the CIFAR-10 class partition
L(x):=Class(x) is a distinguishable feature for ResNets trained with Stochastic Gradient Descent given 50k samples,
since ResNets are capable of learning this labeling from samples.
Note that this definition only depends on the marginal distribution of \cD on x,
and does not depend on the label distribution p\cD(y|x).
The definition of distinguishable feature must depend on the classifier family \cF and number of samples n,
since a more powerful classifier can distinguish more features.
For example, the CIFAR-10 classes are *not* a
distinguishable feature for MLPs.
This distinction is important —
if we run the same Experiment [1](#S1.F1 "Figure 1 ‣ 1.3 Motivating Examples ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization") in the Introduction with an
MLP instead of a ResNet, the MLP will not match the distribution \cD nearly as closely (See Appendix [D](#A4 "Appendix D Feature Calibration: Appendix ‣ Distributional Generalization: A New Kind of Generalization")).
Intuitively, the ResNet was able to act differently on cats compared to dogs
at test time because it can distinguish these classes of CIFAR-10.
However, the MLP will not be able to act
very differently on cats vs. dogs, because it cannot distinguish these classes as
accurately.
Note that there could be many distinguishable features for a given setting \epsL —
including features not implied by the class label
such as the presence of grass in a CIFAR-10 image.
Our main conjecture in this section is that
the test distribution (x,f(x))∼\Dte
is statistically close to the source distribution (x,y)∼\cD
when the domain is “coarsened” by a distinguishable feature.
That is, the distributions (L(x),f(x)) and (L(x),y)
are *statistically* close for all distinguishable features L.
Formally:
######
Conjecture 1 (Feature Calibration).
For all natural distributions \cD,
number of samples n,
family of interpolating models \cF,
and \eps≥0,
the following distributions are statistically close for all \epsL-distinguishable features L:
| | | | |
| --- | --- | --- | --- |
| | (L(x),f(x))f←\Train\cF(\cDn)x,y∼\cD≈\eps(L(x),y)x,y∼\cD | | (10) |
Notably, this holds *for all* distinguishable features L,
and it holds “automatically” – we simply train a classifier, without specifying any particular partition.
The statistical closeness predicted is within \eps, which is determined by the \eps-distinguishability
of L (we usually think of \eps as small).
As a trivial instance of the conjecture,
suppose we have a distribution with deterministic labels,
and consider the \eps-distinguishable feature L(x):=y(x), i.e. the label itself.
The \eps here is then simply the test error of f,
and Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") is true by definition.
The formal statements of Definition [1](#Thmdefinition1 "Definition 1 ((\eps,\cF,\cD,n)-Distinguishable Feature). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") and Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")
may seem somewhat arbitrary, involving many quantifiers over \epsL.
However, we believe these statements are natural.
To support this, in Section [4.5](#S4.SS5 "4.5 1-Nearest-Neighbors Connection ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") we prove that Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") is formally
true as stated for 1-Nearest-Neighbor classifiers.
Connection to Indistinguishability.
Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") can be equivalently phrased as an instantiation of our general
Indistinguishably Conjecture:
the source distribution \cD and
test distribution \Dte are
“indistinguishable up to L-tests”.
That is, Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")
is equivalent to the statement
| | | | |
| --- | --- | --- | --- |
| | \Dte≈\cL\eps\cD | | (11) |
where \cL is the family of all tests which depend on x
only via a distinguishable feature L. That is,
\cL:={(x,y)↦T(L(x),y):(\eps,\cF,\cD,n)-distinguishable feature L and T:[M]\x\cY→[0,1]}. In other words, \Dte is indistinguishable from \cD
to any distinguisher that only sees the input x via a distinguishable feature L(x).
###
4.3 Experiments
We now empirically validate our conjecture in a variety of settings in machine learning,
including neural networks, kernel machines, and decision trees.
To do so, we begin by considering the simplest possible distinguishable feature,
and progressively consider more complex ones.
Each of the experimental settings below highlights a different aspect of interpolating classifiers,
which may be of independent theoretical or practical interest.
We summarize the experiments here; detailed descriptions are provided in Appendix [D](#A4 "Appendix D Feature Calibration: Appendix ‣ Distributional Generalization: A New Kind of Generalization").
Constant Partition: Consider the trivially-distinguishable *constant* feature L(x)=0.
Then, Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") states that the marginal distribution
of class labels for any interpolating classifier f(x)
is close to the true marginals p(y).
That is, irrespective of the classifier’s test accuracy, it outputs the “right” proportion of class labels on the test set, even when there is strong class imbalance.
To show this, we construct a dataset based on CIFAR-10 that has class imbalance. For class k∈{0...9}, sample (k+1)×500 images from that class. This will give us a dataset where classes will have marginal distribution p(y=ℓ)∝ℓ+1 for classes ℓ∈[10], as shown in Figure [4](#S4.F4 "Figure 4 ‣ 4.3 Experiments ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization"). We do this both for the training set and the test set, to keep the distribution \cD fixed.
We then train a variety of classifiers (MLPs, Kernels, ResNets) to interpolation on this dataset,
which have varying levels of test errors (9-41%).
The class balance of classifier outputs on the (rebalanced) test set
is then close to the class balance on the train set, even for poorly generalizing classifier. Full experimental details and results are described in Appendix [D](#A4 "Appendix D Feature Calibration: Appendix ‣ Distributional Generalization: A New Kind of Generalization").
Note that a 1-nearest neighbors classifier would have this property.

Figure 4: Feature Calibration for Constant Partition L:
The CIFAR-10 train and test sets are class rebalanced according to (A).
Interpolating classifiers are trained on the train set,
and we plot the class balance of their outputs on the test set.
This roughly matches the class balance of the train set, even for poorly-generalizing classifiers.
Class Partition: We now consider settings (datasets and models)
where the original class labels are a distinguishable feature.
For instance, the CIFAR-10 classes are distinguishable by ResNets,
and MNIST classes are distinguishable by the RBF kernel. Since the conjecture holds for any arbitrary label distribution p(y|x), we consider many such label distributions and show that, for instance, the joint distributions (Class(x),y) and (Class(x),f(x)) are close. This includes the setting of Experiments 1 and 2 from the Introduction.

Figure 5: Feature Calibration with original classes on CIFAR-10: We train a WRN-28-10 on the CIFAR-10 dataset where we mislabel class 0→1 with probability p.
(A): Joint density of the distinguishable features L (the original CIFAR-10 class) and the classification task labels y on the train set for noise probability p=0.4.
(B): Joint density of the original CIFAR-10 classes L and the network outputs f(x) on the test set.
(C): Observed noise probability in the network outputs on the test set (the (1, 0) entry of the matrix in B) for varying noise probabilities p

Figure 6: Feature Calibration with random confusion matrix on CIFAR-10:
Left: Joint density of labels y and original class L on the train set.
Right: Joint density of classifier predictions f(x) and original class L
on the test set,
for a WideResNet28-10 trained to interpolation. These two joint densities are close,
as predicted by Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization").

Figure 7: Feature Calibration for Decision trees on UCI (molecular biology).
We add label noise that takes class 2 to class 1 with probability p∈[0,0.5].
The top row shows the confusion matrix of the true class L(x) vs. the label y
on the train set, for varying levels of noise p.
The bottom row shows the corresponding confusion matrices of the classifier predictions f(x)
on the test set, which closely matches the train set, as predicted by Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization").
In Figure [5](#S4.F5 "Figure 5 ‣ 4.3 Experiments ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization"), we mislabel class 0→1 with probability p in the CIFAR-10 train set. This gives us the joint distribution shown in Figure [5](#S4.F5 "Figure 5 ‣ 4.3 Experiments ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")A.
We then train a WideResNet-28-10 (WRN-28-10) on this noisy distribution.
Figure [5](#S4.F5 "Figure 5 ‣ 4.3 Experiments ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")B shows the joint distribution on the test set.
Figure [5](#S4.F5 "Figure 5 ‣ 4.3 Experiments ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")C shows the (1,0) entry of this matrix as we vary p∈[0,1].
The Bayes optimal classifier for this distribution would behave as a step function (shown in red),
and a classifier that obeys Conjecture 1 exactly would follow the diagonal (in green).
The actual experiment (in blue) is close to the behavior predicted by Conjecture 1.
In fact, we conjecture holds even for a random joint density matrix on CIFAR-10.
In Figure [6](#S4.F6 "Figure 6 ‣ 4.3 Experiments ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization"), we first generate a random sparse
confusion matrix on 10 classes, such that each class is preserved with probability 50%
and flipped to one of two other classes with probability 20% and 30% respectively.
We then apply label noise with this confusion matrix to the train set,
and measure the confusion matrix of the trained classifier on the test set.
As expected, the train and test confusion matrices are close, and share the same sparsity pattern.
Figure [7](#S4.F7 "Figure 7 ‣ 4.3 Experiments ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") shows a version of this experiment for decision trees on
the molecular biology UCI task.
The molecular biology task is a 3-way classification problem: to classify the type of
a DNA splice junction (donor, acceptor, or neither), given the sequence of DNA (60 bases) surrounding the junction.
We add varying amounts of label noise that flips class 2 to class 1
with a certain probability, and we observe that interpolating decision trees reproduce
this same structured label noise on the test set.
We also demonstrate similar experiments with the Gaussian kernel on MNIST (Figure [11](#S7.F11 "Figure 11 ‣ 7 Distributional Generalization: Beyond Interpolating Methods ‣ Distributional Generalization: A New Kind of Generalization")),
and several other UCI tasks (Appendix [D](#A4 "Appendix D Feature Calibration: Appendix ‣ Distributional Generalization: A New Kind of Generalization")).
Multiple features: We now consider a setting where we may have many distinguishable features for a single classification task. The conjecture states that the network should be automatically calibrated for all distinguishable features, even when it is not explicitly provided any information about these features. For this, we use the CelebA dataset (liu2015faceattributes),
which contains images of celebrities with various labelled binary attributes per-image (“male”, “blond hair”, etc). Some of these attributes form a distinguishable feature for ResNet50 as they are learnable to high accuracy (jahandideh2018physical). We pick one of the hard attributes as the target classification task, where a ResNet-50 achieves 80% accuracy. Then we confirm that the output distribution is calibrated with respect to the attributes that form distinguishable features. In this setting, the label distribution is deterministic, and not directly dependent on the distinguishable features, unlike the experiments considered before. Yet, as we see in Figure [8](#S4.F8 "Figure 8 ‣ 4.3 Experiments ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization"), the classifier outputs are correctly calibrated for each attribute. Full details of the experiment are described in Appendix [D.5](#A4.SS5 "D.5 Multiple Features ‣ Appendix D Feature Calibration: Appendix ‣ Distributional Generalization: A New Kind of Generalization").

Figure 8: Feature Calibration for multiple features on CelebA: We train a ResNet-50 to perform binary classification task on the CelebA dataset. The top row shows the joint distribution of this task label with various other attributes in the dataset. The bottom row shows the same joint distribution for the ResNet-50 outputs on the test set. Note that the network was not given any explicit inputs about these attributes during training.
Coarse Partition:
Consider AlexNet trained on ImageNet ILSVRC-2012 (ILSVRC15),
a 1000-class image classification problem including 116 varieties of dogs.
The network only achieves 56.5% accuracy on the test set, but
it has higher accuracy on coarser label partitions:
for example, it will at least classify most dogs as dogs (with 98.4% accuracy), though it may mistake the specific dog variety.
In this example, L(x)∈{dog, not-dog} is the distinguishable feature.
Moreover, the network is *calibrated* with respect to dogs:
22.4% of all dogs in ImageNet are Terriers,
and indeed, the network classifies 20.9% of all dogs as Terriers
(though it has 9% error in which specific dogs it classifies as Terriers).
We include similar experiments with ResNets and kernels in Appendix [D](#A4 "Appendix D Feature Calibration: Appendix ‣ Distributional Generalization: A New Kind of Generalization").
| | | |
| --- | --- | --- |
| Model | AlexNet | ResNet50 |
| ImageNet accuracy | 0.565 | 0.761 |
| Accuracy on terriers | 0.572 | 0.775 |
| Accuracy for binary {dog/not-dog} | 0.984 | 0.996 |
| Accuracy on {terrier/not-terrier} among dogs | 0.913 | 0.969 |
| Fraction of real-terriers among dogs | 0.224 | 0.224 |
| Fraction of predicted-terriers among dogs | 0.209 | 0.229 |
Table 1: Feature Calibration on ImageNet:
ImageNet classifiers are calibrated with respect to dogs.
For example, all classifiers predict terrier for roughly ∼22% of all dogs (last row),
though they may mistake which specific dogs are terriers.
See Table [3](#A4.T3 "Table 3 ‣ D.6 Coarse Partition ‣ Appendix D Feature Calibration: Appendix ‣ Distributional Generalization: A New Kind of Generalization") in the Appendix for more models.
###
4.4 Discussion
Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") claims that \Dte
is close to \cD up to all tests which are
*themselves learnable*.
That is, if an interpolating method
is capable of learning a certain partition of the domain,
then it will also produce outputs that are calibrated
with respect to this partition, when trained on any problem.
This conjecture thus gives a way of quantifying the resolution
with which classifiers approximate the source distribution \cD,
via properties of the classification algorithm itself.
This is in contrast to many classical ways of
quantifying the approximation of density estimators,
which rely on *analytic* (rather than *operational*)
distributional assumptions (tsybakov2008introduction; wasserman2006all).
Proper Scoring Rules.
If the loss function used in training is a *strictly-proper scoring rule*
such as cross-entropy (gneiting2007strictly),
then we may expect that in the limit of a large-capacity network
and infinite data, training on samples {(xi,yi)}
will yield a good density estimate of p(y|x) at the softmax layer.
However, this is not what is happening in our experiments:
First, our experiments consider the hard-decisions, not the softmax outputs.
Second, we observe Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")
even in settings without proper scoring rules
(e.g. kernel SVM and decision trees).
###
4.5 1-Nearest-Neighbors Connection
Here we show that the 1-nearest neighbor classifier provably satisfies
Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization"), under mild assumptions.
This is trivially true when the number of train points n→∞,
such that the train points pack the domain.
However, we do not require any such assumptions:
the theorem below applies generically to a wide class of distributions,
with no assumptions on the ambient dimension of inputs,
the underlying metric, or smoothness of the source distribution.
All the distributional requirements are captured by the preconditions of
Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization"), which require that the feature L
is \eps-distinguishable to 1-Nearest-Neighbors.
The only further assumption is a weak regularity condition:
sampling the nearest neighbor train point to a random test point
should yield (close to) a uniformly random test point.
In the following, \NNS(x) refers to the nearest neighbor of point x among points in set S.
######
Theorem 1.
Let \cD be a distribution over \cX\x\cY, and let n∈\N be the number of train samples.
Assume the following regularity condition holds:
Sampling the nearest neighbor train point to a random test point
yields (close to) a uniformly random test point.
That is, suppose that for some small δ≥0,
| | | | |
| --- | --- | --- | --- |
| | {\NNS(x)}S∼\cDnx∼\cD≈δ{x}x∼\cD | | (12) |
Then, Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") holds. For all (\eps,\NN,\cD,n)-distinguishable partitions L,
the following distributions are statistically close:
| | | | |
| --- | --- | --- | --- |
| | {(y,L(x))}x,y∼\cD≈\eps+δ{(\NNfS(x),L(x)}S∼\cDnx,y∼\cD | | (13) |
The proof of Theorem [1](#Thmtheorem1 "Theorem 1. ‣ 4.5 1-Nearest-Neighbors Connection ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") is straightforward, and provided in Appendix [G](#A7 "Appendix G Nearest-Neighbor Proofs ‣ Distributional Generalization: A New Kind of Generalization").
We view this theorem both as support for our formalism of Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization"),
and as evidence that the classifiers we consider in this work have *local* properties
similar to 1-Nearest-Neighbors.
Note that Theorem [1](#Thmtheorem1 "Theorem 1. ‣ 4.5 1-Nearest-Neighbors Connection ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") does not hold for the k-nearest neighbor classifier (k-NN),
which takes the plurality vote of K neighboring train points.
However, it is somewhat more general than 1-NN: for example, it holds for a randomized version of K-NN which,
instead of taking the plurality,
randomly picks one of the K neighboring train points (potentially weighted) for the test classification.
###
4.6 Pointwise Density Estimation
In fact, we could hope for an even stronger property than
Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization").
Consider the familiar example:
we mislabel 20% of dogs as cats in the CIFAR-10 training data,
and train an interpolating ResNet on this train set.
Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") predicts that, *on average*
over all test dogs, roughly 20% of them are classified as cats.
In fact, we may expect this to hold pointwise for each dog:
For a single test dog x, if we train a new classifier f (on fresh iid samples from the noisy distribution),
then f(x) will be cat roughly 20% of the time.
That is, for each test point x, taking an ensemble over independent train sets yields an estimate of the conditional density p(y|x).
Informally:
| | | | |
| --- | --- | --- | --- |
| | With high probability over test x∼\cD:Prf←\Train\cF(\cDn)[f(x)=ℓ] ≈ p(y=ℓ|x) | | (14) |
where the probability on the LHS is over the random sampling of train set, and any randomness in the training procedure.
This behavior would be stronger than,
and not implied by, Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization").
We give preliminary experiments supporting such a pointwise property in Appendix [D.7](#A4.SS7 "D.7 Pointwise Density Estimation ‣ Appendix D Feature Calibration: Appendix ‣ Distributional Generalization: A New Kind of Generalization").
5 Agreement Property
---------------------
We now present an “agreement property”
of various classifiers.
This property is independent of the previous section,
though both are instantiations
of our general indistinguishability conjecture.
We claim that, informally, the test accuracy of a classifier is close to
the probability that it agrees with an identically-trained classifier on a disjoint train set.
######
Conjecture 2 (Agreement Property).
For certain classifier families \cF and distributions \cD,
the test accuracy of a classifier is close to
its *agreement probability* with an independently-trained classifier.
That is,
let S1,S2 be independent train sets sampled from \cDn,
and let f1,f2 be classifiers trained on S1,S2 respectively. Then
| | | | |
| --- | --- | --- | --- |
| | PrS1∼\cDnf1←\Train\cF(S1)(x,y)∼\cD[f1(x)=y] ≈ PrS1,S2∼\cDnfi←\Train\cF(Si)(x,y)∼\cD[f1(x)=f2(x)] | | (15) |
Moreover, this holds
with high probability
over training
f1,f2:
Pr(x,y)∼\cD[f1(x)=y]≈Pr(x,y)∼\cD[f1(x)=f2(x)].
| | | |
| --- | --- | --- |
|
(a) ResNet18 on CIFAR-10.
|
(b) ResNet18 on CIFAR-100.
|
(c) Myrtle Kernel on CIFAR-10.
|
Figure 9: Agreement Property on CIFAR-10/100.
For two classifiers trained on disjoint train sets,
the probability they agree with each other (on the test set)
is close to their test accuracy.
The agreement property (Conjecture [2](#Thmconjecture2 "Conjecture 2 (Agreement Property). ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization"))
is surprising for several reasons.
First, suppose we have two classifiers f1,f2
which were trained on independent train sets,
and both achieve test accuracy say 50% on a 10-class problem.
That is, they agree with the true label y(x) w.p. 50%.
Depending on our intuition, we may expect:
(1) They agree with each other much less than they agree with the true label,
since each individual classifier is an independently noisy version of the truth,
or (2) They agree with each other much more than 50%, since
classifiers tend to have “correlated” predictions.
However, neither of these are the case in practice.
Second, it may be surprising that the RHS
of Equation [15](#S5.E15 "(15) ‣ Conjecture 2 (Agreement Property). ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization") is an estimate of the test error
that requires only unlabeled test examples x.
This observation is independently interesting,
and may be relevant for applications in
uncertainty estimation and calibration.
Conjecture [2](#Thmconjecture2 "Conjecture 2 (Agreement Property). ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization") also provably holds for 1-Nearest-Neighbors
in some settings, under stronger assumptions (Theorem [2](#Thmtheorem2 "Theorem 2 (Agreement Property). ‣ G.2 Agreement Property ‣ Appendix G Nearest-Neighbor Proofs ‣ Distributional Generalization: A New Kind of Generalization") in Appendix [G](#A7 "Appendix G Nearest-Neighbor Proofs ‣ Distributional Generalization: A New Kind of Generalization")).
Connection to Indistinguishability.
Conjecture [2](#Thmconjecture2 "Conjecture 2 (Agreement Property). ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization") is in fact an instantiation of our general indistinguishability conjecture.
Informally, we can “swap y for f2(x)” in the LHS of Equation [15](#S5.E15 "(15) ‣ Conjecture 2 (Agreement Property). ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization"), since they are indistinguishable.
Formally, consider the specific test
| | | | |
| --- | --- | --- | --- |
| | Tagree:(x,^y)↦\1{f1(x)=^y} | | (16) |
where f1←\Train\cF(\cDn).
The expectation of this test under the Source Distribution
\cD is exactly the LHS of Equation [15](#S5.E15 "(15) ‣ Conjecture 2 (Agreement Property). ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization"),
while the expectation under the Test Distribution \Dte is exactly the RHS.
Thus, Conjecture [2](#Thmconjecture2 "Conjecture 2 (Agreement Property). ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization") can be equivalently stated as
| | | | |
| --- | --- | --- | --- |
| | \cD≈Tagree\Dte. | | (17) |
###
5.1 Experiments
| | | |
| --- | --- | --- |
|
(a) RBF on Fashion-MNIST
|
(b) RBF on Fashion-MNIST
|
(c) Decision Trees on UCI
|
Figure 10: Agreement Property for RBF and decision trees.
For two classifiers trained on disjoint train sets,
the probability they agree with each other (on the test set)
is close to their test accuracy.
For UCI, each point corresponds to one UCI task,
and error bars show 95% Clopper-Pearson confidence intervals in estimating
population quantities.
In our experiments,
we train a pair of classifiers f1,f2
on random disjoint subsets
of the train set for a given distribution.
Both classifiers are otherwise trained identically,
using the same architecture, number of train-samples n, and optimizer.
We then plot the test error of f1 against
the agreement probability Prx∼\TestSet[f1(x)=f2(x)].
Figure [9](#S5.F9 "Figure 9 ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization") shows experiments with ResNet18 on CIFAR-10
and CIFAR-100,
as well as the Myrtle10 kernel from shankar2020neural,
with varying number of train samples n.
These classifiers are trained with standard-practice training procedures (SGD with standard data-augmentation for ResNets),
with no additional hyperparameter tuning.
Figure [10](#S5.F10 "Figure 10 ‣ 5.1 Experiments ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization") shows experiments with the RBF Kernel on Fashion-MNIST,
and decision trees on 92 UCI classification tasks.
The Agreement Property approximately holds for all pairs of identical classifiers,
and continues to hold
even for “weak” classifiers
(e.g. when f1,f2 have high test error).
Full experimental details and further experiments
are in Appendix [E](#A5 "Appendix E Agreement Property: Appendix ‣ Distributional Generalization: A New Kind of Generalization").
###
5.2 Potential Mechanisms
We now consider, and refute, several potential mechanisms
which could explain the experimental results of Conjecture [2](#Thmconjecture2 "Conjecture 2 (Agreement Property). ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization").
####
5.2.1 Bimodal Samples
A simple model which would exhibit the Agreement Property
is the following:
Suppose test samples x come in two types: “easy” or “hard.”
All classifiers get “easy” samples correct,
but they output a uniformly random class on “hard” samples.
That is, for a fixed x, consider the probability that a
freshly-trained classifier gets x correct.
“Easy” samples are such that
| | | |
| --- | --- | --- |
| | For x∈ EASY:Prf←\Train(\cDn)[f(x)=y(x)]=1 | |
while “hard” samples have a uniform distribution on
output classes [K]:
| | | |
| --- | --- | --- |
| | For x∈ HARD:Prf←\Train(\cDn)[f(x)=i]=1K ∀i∈[K] | |
Notice that for HARD samples x, a classifier f1
agrees with the true label y with exactly the same
probability that it agrees with an independent classifier f2
(because both f1,f2 are uniformly random on x).
Thus, the agreement property (Conjecture [2](#Thmconjecture2 "Conjecture 2 (Agreement Property). ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization")) holds exactly under this model.
However, this strict decomposition of samples into “easy” and “hard”
does not appear to be the case in the experiments (see Appendix [E.3](#A5.SS3 "E.3 Alternate Mechanisms ‣ Appendix E Agreement Property: Appendix ‣ Distributional Generalization: A New Kind of Generalization"), Figure [22](#A5.F22 "Figure 22 ‣ E.3.1 Bimodal Samples ‣ E.3 Alternate Mechanisms ‣ Appendix E Agreement Property: Appendix ‣ Distributional Generalization: A New Kind of Generalization")).
###
5.3 Pointwise Agreement
We could more generally posit
that Conjecture [2](#Thmconjecture2 "Conjecture 2 (Agreement Property). ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization") is true
because the Agreement Property holds
*pointwise* for most test samples x.
That is, Equation ([15](#S5.E15 "(15) ‣ Conjecture 2 (Agreement Property). ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization"))
would be implied by:
| | | | |
| --- | --- | --- | --- |
| | w.h.p. for (x,y)∼\cD:Prf1←\Train(\cDn)[f1(x)=y]≈Prf1←\Train(\cDn)f2←\Train(\cDn)[f1(x)=f2(x)] | | (18) |
This was the case for the EASY/HARD decomposition above,
but could be true in more general settings.
Equation ([18](#S5.E18 "(18) ‣ 5.3 Pointwise Agreement ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization")) is a “pointwise calibration” property
that would allow estimating the probability of making an error on a test point x
by simply estimating the probability that two independent classifiers agree on x.
However, we find (perhaps surprisingly) that this is not the case.
That is, Equation ([15](#S5.E15 "(15) ‣ Conjecture 2 (Agreement Property). ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization")) holds on average over (x,y)∼\cD,
but not pointwise for each sample.
We give experiments demonstrating this in Appendix [E.3](#A5.SS3 "E.3 Alternate Mechanisms ‣ Appendix E Agreement Property: Appendix ‣ Distributional Generalization: A New Kind of Generalization").
Interestingly, 1-nearest neighbors can
satisfy the agreement property of Claim [2](#Thmconjecture2 "Conjecture 2 (Agreement Property). ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization") without
satisfying the “pointwise agreement” of Equation [18](#S5.E18 "(18) ‣ 5.3 Pointwise Agreement ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization").
It remains an open problem to understand the mechanisms behind Agreement Matching.
6 Limitations and Ensembles
----------------------------
The conjectures presented in this work are not fully specified,
since they do not exactly specify which classifiers or distributions for which they hold.
We experimentally demonstrate instances of these conjectures in various “natural” settings in machine learning,
but we do not yet understand which assumptions on the distribution or classifier are required.
Some experiments also deviate slightly from the predicted behavior
(e.g. the kernel experiments in Figures [4](#S4.F4 "Figure 4 ‣ 4.3 Experiments ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") and [10](#S5.F10 "Figure 10 ‣ 5.1 Experiments ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization")).
Nevertheless, we believe our conjectures capture the essential aspects of the observed behaviors,
at least to first order.
It is an important open question to refine these conjectures and better understand their applications and limitations—
both theoretically and experimentally.
###
6.1 Ensembles
We could ask if all high-performing interpolating methods used in practice satisfy our conjectures.
However, an important family of classifiers which fail our Feature Calibration Conjecture are ensemble methods:
1. Deep ensembles of interpolating neural networks (lakshminarayanan2017simple).
2. Random forests (i.e. ensembles of interpolating decision trees) (breiman2001random).
3. k-nearest neighbors (roughly “ensembles” of 1-Nearest-Neighbors) (fix1951discriminatory).
The pointwise density estimation discussion in Section [4.6](#S4.SS6 "4.6 Pointwise Density Estimation ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") sheds some light on these cases.
Notice that these are settings where the “base” classifier in the ensemble
obeys Feature Calibration, and in particular, acts as an approximate conditional density
estimator of p(y|x), as in Section [4.6](#S4.SS6 "4.6 Pointwise Density Estimation ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization").
That is, if individual base classifiers fi approximately act as samples from
| | | |
| --- | --- | --- |
| | fi(x)∼p(y|x) | |
then for sufficiently many classifiers {f1,…,fk} trained on independent train sets,
the ensembled classifier will act as
| | | |
| --- | --- | --- |
| | plurality(f1,f2,…,fk)(x)≈\argmaxyp(y|x) | |
Thus, we believe ensembles fail our conjectures because, in taking the plurality
vote of base classifiers, they are approximating \argmaxyp(y|x) instead of the conditional density p(y|x) itself.
Indeed, in the above examples, we observed that ensemble methods
behave much closer to the Bayes-optimal classifier than their underlying base classifiers
(especially in settings with label noise).
7 Distributional Generalization: Beyond Interpolating Methods
--------------------------------------------------------------

Figure 11: Distributional Generalization for Gaussian Kernel on MNIST.
We apply label noise from a random sparse confusion to the MNIST train set.
We then train a Gaussian Kernel for classification, with varying L2 regularization λ.
The top row shows the confusion matrix of predictions f(x) vs true labels L(x) on the train set,
and the bottom row shows the corresponding confusion matrix on the test set.
Larger values of regularization prevents the classifier from fitting label noise on the train set,
and this behavior is mirrored almost identically on the test set.
Note that all classifiers above are trained on the same train set, with the same label noise.

Figure 12: Distributional Generalization for WideResNet on CIFAR-10.
We apply label noise from a random sparse confusion to the CIFAR-10 train set.
We then train a single WideResNet28-10, and measure its predictions on the train and test sets
over increasing train time (SGD steps).
The top row shows the confusion matrix of predictions f(x) vs true labels L(x) on the train set,
and the bottom row shows the corresponding confusion matrix on the test set.
As the network is trained for longer, it fits more of the noise on the train set,
and this behavior is mirrored almost identically on the test set.
The previous sections have focused primarily on
*interpolating* classifiers, which fit their train sets exactly.
Here we discuss the behavior of non-interpolating methods,
such as early-stopped neural networks and regularized kernel machines, which do not reach 0 train error.
For non-interpolating classifiers, their outputs on the train set (x,f(x))x∼\TrainSet
will *not* match the original distribution (x,y)∼\cD.
Thus, there is little hope that their outputs on the test set will match the original distribution,
and we do not expect the Indistinguishability Conjecture to hold.
However, the Distributional Generalization framework does not require interpolation,
and we could still expect that the train and test distributions are close (\Dtr≈\cT\Dte)
for some family of tests \cT.
For example, the following is a possible generalization of Feature Calibration (Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")).
######
Conjecture 3 (Generalized Feature Calibration, informal).
For trained classifiers f,
the following distributions are statistically close for
many partitions L of the domain:
| | | | |
| --- | --- | --- | --- |
| | (L(xi),f(xi))xi∼TrainSet≈(L(x),f(x))x∼TestSet | | (19) |
We leave unspecified the exact set of partitions L for which this holds—
unlike Conjecture [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization"),
where we specified L as the set of all distinguishable features.
In this generalized case, we do not yet understand the appropriate notion of ‘‘distinguishable feature’’
333For example, when considering early-stopped neural networks, it is unclear if the partition L
should be distinguishable with respect to the early-stopped network or its fully-trained counterpart..
However, we give experimental evidence that suggests some refinement of Conjecture [3](#Thmconjecture3 "Conjecture 3 (Generalized Feature Calibration, informal). ‣ 7 Distributional Generalization: Beyond Interpolating Methods ‣ Distributional Generalization: A New Kind of Generalization") is true.
In Figure [11](#S7.F11 "Figure 11 ‣ 7 Distributional Generalization: Beyond Interpolating Methods ‣ Distributional Generalization: A New Kind of Generalization") we
train Gaussian kernel regression on MNIST, with label noise determined by a random sparse confusion matrix
on the train set (analogous to the setting of Figure [6](#S4.F6 "Figure 6 ‣ 4.3 Experiments ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")).
We vary the amount of ℓ2 regularization,
and plot the confusion matrix of predictions on the train and test sets.
With λ=0 regularization, the kernel interpolates the noise in the train set exactly,
and reproduces this noise on the test set as expected.
With higher regularization, the kernel no longer interpolates the train set,
but the test and train confusion matrices remain close.
That is, regularization prevents the kernel from fitting the noise on both the train and test sets
in a similar way.
Remarkably, higher regularization yields a classifier closer to Bayes-optimal.
Figure [12](#S7.F12 "Figure 12 ‣ 7 Distributional Generalization: Beyond Interpolating Methods ‣ Distributional Generalization: A New Kind of Generalization") shows an analogous experiment for neural networks on CIFAR-10,
with early-stopping in place of regularization:
early in training, neural networks do not fit their train set,
but their test and train confusion matrices remain close throughout training.
Full experimental details are given in Appendix [C](#A3 "Appendix C Experimental Details ‣ Distributional Generalization: A New Kind of Generalization").
These experiments suggests that Distributional Generalization is a meaningful
notion even for non-interpolating classifiers.
Formalizing and investigating this further is an interesting area for future study.
8 Conclusion and Discussion
----------------------------
In this work, we presented a new set of empirical behaviors of standard interpolating classifiers.
We unified these under the framework of Distributional Generalization,
which states that outputs of trained classifiers
on the test set are “close” in distribution to their outputs on the train set.
For interpolating classifiers, we stated several formal conjectures
(Conjectures [1](#Thmconjecture1 "Conjecture 1 (Feature Calibration). ‣ 4.2 Formal Definitions ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization") and [2](#Thmconjecture2 "Conjecture 2 (Agreement Property). ‣ 5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization"))
to characterize the form of distributional closeness that can be expected.
Beyond Test Error.
The philosophy underlying our work is that
there is more to a classifier than just its test error.
One ambitious goal of the science of machine learning
is to eventually understand exactly what kinds of functions
our learning algorithms produce.
For example, we could hope to predict not only how often
a classifier makes errors, but on which inputs it is likely
to make errors, or how it performs on off-distribution inputs.
Our work embraces this approach, and proposes
studying the *entire distribution* of classifier outputs on test samples.
We show that this distribution is often highly structured, and we take steps
towards characterizing it.
Surprisingly, modern interpolating classifiers appear to satisfy
certain forms of distributional generalization “automatically,”
despite being trained to simply minimize train error.
This even holds in cases when satisfying distributional generalization
is in conflict with satisfying classical generalization— that is, when
a distributionally-generalizing classifier must necessarily have high test error
(e.g. Experiments 1 and 2).
We thus hope that studying distributional generalization will be useful
to better understand modern classifiers, and to understand generalization more broadly.
Classical Generalization.
Our framework of Distributional Generalization
can be insightful even to study classical generalization.
That is, even if we ultimately want to understand test error,
it may be easier to do so through distributional generalization.
This is especially relevant for understanding
the success of interpolating methods,
which pose challenges to classical theories of generalization.
Our work shows new empirical behaviors of interpolating classifiers,
as well as conjectures characterizing these behaviors. This sheds new light on these poorly understood methods,
and could pave the way to better understanding their generalization.
Interpolating vs. Non-interpolating Methods.
Our work also suggests that interpolating classifiers should be viewed
as conceptually different objects from non-interpolating ones, even if both have the same test error.
In particular, an interpolating classifier will match certain aspects of the original distribution,
which a non-interpolating classifier will not.
This also suggests, informally, that interpolating methods
should not be seen as methods which simply “memorize”
their training data in a naive way (as in a look up table) – rather this “memorization” strongly influences the
classifier’s decision boundary (as in 1-Nearest-Neighbors).
###
8.1 Open Questions
Our work raises a number of open questions and connections to other areas.
We briefly collect some of them here.
1. As described in the Limitations (Section [6](#S6 "6 Limitations and Ensembles ‣ Distributional Generalization: A New Kind of Generalization")),
we do not precisely understand the set of distributions and interpolating classifiers for which our conjectures hold.
We empirically tested a number of “realistic” settings, but it is open to state formal assumptions defining these settings.
2. It is open to theoretically prove versions of Distributional Generalization for models beyond 1-Nearest-Neighbors.
This is most interesting in cases where Distributional Generalization is at odds with classical generalization (e.g. Experiments 1 and 2).
3. It is open to understand the mechanisms behind the Agreement Property (Section [5](#S5 "5 Agreement Property ‣ Distributional Generalization: A New Kind of Generalization")),
theoretically or empirically.
4. In some of our experiments (e.g. Section [4.6](#S4.SS6 "4.6 Pointwise Density Estimation ‣ 4 Feature Calibration ‣ Distributional Generalization: A New Kind of Generalization")), ensembling over independent random-initializations
had a similar effect to ensembling over independent train sets.
This is related to works on deep ensembles (lakshminarayanan2017simple; fort2019deep) as well
as random forests for conditional density estimation
(meinshausen2006quantile; pospisil2018rfcde; athey2019generalized).
Investigating this further is an interesting area of future work.
5. There are a number of works suggesting “local” behavior of neural networks,
and these are somewhat consistent with our locality intuitions in this work.
However, it is open to formally understand whether these intuitions are justified in our setting.
6. We give two families of tests \cT for which our Interpolating Indistinguishability
conjecture (Equation [5](#S1.E5 "(5) ‣ 1.2 Distributional Generalization ‣ 1 Introduction ‣ Distributional Generalization: A New Kind of Generalization")) empirically holds. This may not be exhaustive – there
may be other ways in which the source distribution \cD and test distribution \Dte are close.
Indeed, we give preliminary experiments for another family of tests, based on student-teacher training, in Appendix [B](#A2 "Appendix B Student-Teacher Indistinguishability ‣ Distributional Generalization: A New Kind of Generalization").
It is open to explore more ways in which Distributional Generalization holds, beyond the tests presented here.
#### Acknowledgements
We especially thank Jacob Steinhardt and Boaz Barak for useful discussions during this work.
We thank Vaishaal Shankar for providing the Myrtle10 kernel,
the ImageNet classifiers, and advice regarding UCI tasks.
We thank Guy Gur-Ari for noting the connection to existing work on networks picking up
fine-structural aspects of distributions.
We also thank a number of people for reviewing early drafts
or providing valuable comments, including:
Collin Burns,
Mihaela Curmei,
Benjamin L. Edelman,
Sara Fridovich-Keil,
Boriana Gjura,
Wenshuo Guo,
Thibaut Horel,
Meena Jagadeesan,
Dimitris Kalimeris,
Gal Kaplun,
Song Mei,
Aditi Raghunathan,
Ludwig Schmidt,
Ilya Sutskever,
Yaodong Yu,
Kelly W. Zhang,
Ruiqi Zhong.
Work supported in part by the Simons Investigator Awards of Boaz Barak and Madhu Sudan, and NSF Awards under grants CCF 1565264, CCF 1715187 and IIS 1409097.
Computational resources supported in part by a gift from Oracle,
and Microsoft Azure credits (via Harvard Data Science Initiative).
P.N. supported in part by a Google PhD Fellowship. Y.B is partially supported by MIT-IBM Watson AI Lab.
Technologies.
This work was built on the following technologies:
NumPy (oliphant2006guide; van2011numpy; Harris2020),
SciPy (2020SciPy-NMeth),
scikit-learn (scikit-learn),
PyTorch (pytorch),
W&B (wandb),
Matplotlib (Hunter:2007),
pandas (reback2020pandas; mckinney-proc-scipy-2010),
SLURM (yoo2003slurm),
Figma.
Neural networks trained on NVIDIA V100 and 2080 Ti GPUs. |
4f6fbb06-bd3e-4fba-b2a7-98da747167ea | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | [AN #73]: Detecting catastrophic failures by learning how agents tend to break
Find all Alignment Newsletter resources [here](http://rohinshah.com/alignment-newsletter/). In particular, you can [sign up](http://eepurl.com/dqMSZj), or look through this [spreadsheet](https://docs.google.com/spreadsheets/d/1PwWbWZ6FPqAgZWOoOcXM8N_tUCuxpEyMbN1NYYC02aM/edit?usp=sharing) of all summaries that have ever been in the newsletter. I'm always happy to hear feedback; you can send it to me by replying to this email.
Audio version [here](http://alignment-newsletter.libsyn.com/alignment-newsletter-73) (may not be up yet).
**Highlights**
--------------
[Rigorous Agent Evaluation: An Adversarial Approach to Uncover Catastrophic Failures](https://arxiv.org/abs/1812.01647) *(Jonathan Uesato, Ananya Kumar, Csaba Szepesvari et al)* (summarized by Nicholas): An important problem in safety-critical domains is accurately estimating slim probabilities of catastrophic failures: one in a million is very different from one in a billion. A standard Monte Carlo approach requires millions or billions of trials to find a single failure, which is prohibitively expensive. This paper proposes using agents from earlier in the training process to provide signals for a learned failure probability predictor. For example, with a Humanoid robot, failure is defined as the robot falling down. A neural net is trained on earlier agents to predict the probability that the agent will fall down from a given state. To evaluate the final agent, states are importance-sampled based on how likely the neural network believes they are to cause failure. This relies on the assumption that the failure modes of the final agent are similar to some failure mode of earlier agents. Overall, the approach reduces the number of samples required to accurately estimate the failure probability by multiple orders of magnitude.
**Nicholas's opinion:** I am quite excited about the focus on preventing low likelihood catastrophic events, particularly from the standpoint of existential risk reduction. The key assumption in this paper, that earlier in training the agent will fail in related ways but more frequently, seems plausible to me and in line with most of my experience training neural networks, and the experiments demonstrate a very large increase in efficiency.
I’d be interested to see theoretical analysis of what situations would make this assumption more or less likely in the context of more powerful future agents. For example, one situation where the failure modes might be distinct later in training is if an agent learns how to turn on a car, which then makes states where the agent has access to a car have significantly higher likelihood of catastrophic failures than they did before.
**Technical AI alignment**
==========================
### **Learning human intent**
[AI Alignment Podcast: Synthesizing a human’s preferences into a utility function](https://futureoflife.org/2019/09/17/synthesizing-a-humans-preferences-into-a-utility-function-with-stuart-armstrong/) *(Lucas Perry and Stuart Armstrong)* (summarized by Rohin): Stuart Armstrong's [agenda](https://www.alignmentforum.org/posts/CSEdLLEkap2pubjof/research-agenda-v0-9-synthesising-a-human-s-preferences-into) ([AN #60](https://mailchi.mp/0dd8eb63fe2d/an-60a-new-ai-challenge-minecraft-agents-that-assist-human-players-in-creative-mode)) involves extracting partial preferences from a human and synthesizing them together into an *adequate* utility function. Among other things, this podcast goes into the design decisions underlying the agenda:
First, why even have a utility function? In practice, there are [many pressures](https://www.lesswrong.com/posts/RQpNHSiWaXTvDxt6R/coherent-decisions-imply-consistent-utilities) suggesting that maximizing expected utility is the "right" thing to do -- if you aren't doing this, you're leaving value on the table. So any agent that isn't maximizing a utility function will want to self-modify into one that is using a utility function, so we should just use a utility function in the first place.
Second, why not defer to a long reflection process, as in [Indirect Normativity](https://ordinaryideas.wordpress.com/2012/04/21/indirect-normativity-write-up/), or some sort of reflectively stable values? Stuart worries that such a process would lead to us prioritizing simplicity and elegance, but losing out on something of real value. This is also why he focuses on *partial preferences*: that is, our preferences in "normal" situations, without requiring such preferences to be extrapolated to very novel situations. Of course, in any situation where our moral concepts break down, we will have to extrapolate somehow (otherwise it wouldn't be a utility function) -- this presents the biggest challenge to the research agenda.
**Read more:** [Stuart Armstrong Research Agenda Online Talk](https://www.youtube.com/watch?v=1M9CvESSeVc)
[Full toy model for preference learning](https://www.alignmentforum.org/posts/hcrFxeYYfbFrkKQEJ/full-toy-model-for-preference-learning) *(Stuart Armstrong)* (summarized by Rohin): This post applies Stuart's general preference learning algorithm to a toy environment in which a robot has a mishmash of preferences about how to classify and bin two types of objects.
**Rohin's opinion:** This is a nice illustration of the very abstract algorithm proposed before; I'd love it if more people illustrated their algorithms this way.
### **Forecasting**
[AlphaStar: Impressive for RL progress, not for AGI progress](https://www.lesswrong.com/posts/SvhzEQkwFGNTy6CsN/alphastar-impressive-for-rl-progress-not-for-agi-progress) *(orthonormal)* (summarized by Nicholas): This post argues that while it is impressive that AlphaStar can build up concepts complex enough to win at StarCraft, it is not actually developing reactive strategies. Rather than scouting what the opponent is doing and developing a new strategy based on that, AlphaStar just executes one of a predetermined set of strategies. This is because AlphaStar does not use causal reasoning, and that keeps it from beating any of the top players.
**Nicholas's opinion:** While I haven’t watched enough of the games to have a strong opinion on whether AlphaStar is empirically reacting to its opponents' strategies, I agree with Paul Christiano’s [comment](https://www.lesswrong.com/posts/SvhzEQkwFGNTy6CsN/alphastar-impressive-for-rl-progress-not-for-agi-progress#kRpwqPPjcGEbEhXHA) that in principle causal reasoning is just one type of computation that should be learnable.
This discussion also highlights the need for interpretability tools for deep RL so that we can have more informed discussions on exactly how and why strategies are decided on.
[Addendum to AI and Compute](https://openai.com/blog/ai-and-compute/#addendum) *(Girish Sastry et al)* (summarized by Rohin): Last year, OpenAI [wrote](https://blog.openai.com/ai-and-compute/) ([AN #7](https://mailchi.mp/3e550712419a/alignment-newsletter-7)) that since 2012, the amount of compute used in the largest-scale experiments has been doubling every 3.5 months. This addendum to that post analyzes data from 1959-2012, and finds that during that period the trend was a 2-year doubling time, approximately in line with Moore's Law, and not demonstrating any impact of previous "AI winters".
**Rohin's opinion:** Note that the post is measuring compute used to *train* models, which was less important in past AI research (e.g. it doesn't include Deep Blue), so it's not too surprising that we don't see the impact of AI winters.
[Etzioni 2016 survey](https://aiimpacts.org/etzioni-2016-survey/) *(Katja Grace)* (summarized by Rohin): Oren Etzioni surveyed 193 AAAI fellows in 2016 and found that 67.5% of them expected that ‘we will achieve Superintelligence’ someday, but in more than 25 years. Only 7.5% thought we would achieve it sooner than that.
**AI strategy and policy**
==========================
[GPT-2: 1.5B Release](https://openai.com/blog/gpt-2-1-5b-release/) *(Irene Solaiman et al)* (summarized by Rohin): Along with the release of the last and biggest GPT-2 model, OpenAI explains their findings with their research in the time period that the staged release bought them. While GPT-2 can produce reasonably convincing outputs that are hard to detect and can be finetuned for e.g. generation of synthetic propaganda, so far they have not seen any evidence of actual misuse.
**Rohin's opinion:** While it is consistent to believe that OpenAI was just generating hype since GPT-2 was predictably not going to have major misuse applications, and this has now been borne out, I'm primarily glad that we started thinking about publication norms *before* we had dangerous models, and it seems plausible to me that OpenAI was also thinking along these lines.
**Other progress in AI**
========================
### **Reinforcement learning**
[AlphaStar: Grandmaster level in StarCraft II using multi-agent reinforcement learning](https://deepmind.com/blog/article/AlphaStar-Grandmaster-level-in-StarCraft-II-using-multi-agent-reinforcement-learning) *(AlphaStar Team)* (summarized by Nicholas): [AlphaStar](https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/) ([AN #43](https://mailchi.mp/768a8130013f/alignment-newsletter-43)), DeepMind’s StarCraft II AI, has now defeated a top professional player and is better than 99.8% of players. While previous versions were limited to only a subset of the game, it now plays the full game and has limitations on how quickly it can take actions similar to top human players. It was trained initially via supervised learning on human players and then afterwards trained using RL.
A challenge in learning StarCraft via self-play is that strategies exhibit non-transitivity: Stalker units beat Void Rays, Void Rays beat Immortals, but Immortals beat Stalkers. This can lead to training getting stuck in cycles. In order to avoid this, they set up a League of exploiter agents and main agents. The exploiter agents train only against the current iteration of main agents, so they can learn specific counter-strategies. The main agents then train against a mixture of current main agents, past main agents, and exploiters, prioritizing opponents that they have a lower win rate against.
**Nicholas's opinion:** I think this is a very impressive display of how powerful current ML methods are at a very complex game. StarCraft poses many challenges that are not present in board games such as chess and go, such as limited visibility, a large state and action space, and strategies that play out over very long time horizons. I found it particularly interesting how they used imitation learning and human examples to avoid trying to find new strategies by exploration, but then attained higher performance by training on top of that.
I do believe progress on games is becoming less correlated with progress on AGI. Most of the key innovations in this paper revolve around the League training, which seems quite specific to StarCraft. In order to continue making progress towards AGI, I think we need to focus on being able to learn in the real world on tasks that are not as easy to simulate.
**Read more:** [Paper: Grandmaster level in StarCraft II using multi-agent reinforcement learning](https://www.nature.com/articles/s41586-019-1724-z.epdf?author_access_token=lZH3nqPYtWJXfDA10W0CNNRgN0jAjWel9jnR3ZoTv0PSZcPzJFGNAZhOlk4deBCKzKm70KfinloafEF1bCCXL6IIHHgKaDkaTkBcTEv7aT-wqDoG1VeO9-wO3GEoAMF9bAOt7mJ0RWQnRVMbyfgH9A%3D%3D)
[Deep Dynamics Models for Dexterous Manipulation](http://bair.berkeley.edu/blog/2019/09/30/deep-dynamics/) *(Anusha Nagabandi et al)* (summarized by Flo): For hard robotic tasks like manipulating a screwdriver, model-free RL requires large amounts of data that are hard to generate with real-world hardware. So, we might want to use the more sample-efficient model-based RL, which has the additional advantage that the model can be reused for similar tasks with different rewards. This paper uses an ensemble of neural networks to predict state transitions, and plans by sampling trajectories for different policies. With this, they train a real anthropomorphic robot hand to be able to rotate two balls in its hand somewhat reliably within a few hours. They also trained for the same task in a simulation and were able to reuse the resulting model to move a single ball to a target location.
**Flo's opinion:** The videos look impressive, even though the robot hand still has some clunkiness to it. My intuition is that model-based approaches can be very useful in robotics and similar domains, where the randomness in transitions can easily be approximated by Gaussians. In other tasks where transitions follow more complicated, multimodal distributions, I am more sceptical.
[Integrating Behavior Cloning and Reinforcement Learning for Improved Performance in Sparse Reward Environments](http://arxiv.org/abs/1910.04281) *(Vinicius G. Goecks et al)* (summarized by Zach): This paper contributes to the effort of combining imitation and reinforcement learning to train agents more efficiently. The current difficulty in this area is that imitation and reinforcement learning proceed under rather different objectives which presents a significant challenge to updating a policy learned from a pure demonstration. A major portion of this difficulty stems from the use of so-called "on-policy" methods for training which require a significant number of environment interactions to be effective. In this paper, the authors propose a framework dubbed "Cycle-of-Learning" (CoL) that allows for the off-policy combination of imitation and reinforcement learning. This allows the two approaches to be combined much more directly which grounds the agent's policy in the expert demonstrations while simultaneously allowing for RL to fine-tune the policy. The authors show that CoL is an improvement over the current state of the art by testing their algorithm in several environments and performing an ablation study.
**Zach's opinion:** At first glance, it would seem as though the idea of using an off-policy method to combine imitation and reinforcement learning is obvious. However, the implementation is complicated by the fact that we want the value functions being estimated by our agent to satisfy the optimality condition for the Bellman equation. Prior work, such as [Hester et al. 2018](https://aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/16976/16682) uses n-step returns to help pre-training and make use of on-policy methods when performing RL. What I like about this paper is that they perform an ablation study and show that simple sequencing of imitation learning and RL algorithms isn't enough to get good performance. This means that combining the imitation and reinforcement objectives into a single loss function is providing a significant improvement over other methods.
**News**
========
[Researcher / Writer job](https://www.convergenceanalysis.org/get-involved/) (summarized by Rohin): This full-time researcher / writer position would involve half the time working with [Convergence](https://www.convergenceanalysis.org/) on x-risk strategy research and the other half with [Normative](https://normative.io/) on environmental and climate change analysis documents. |
dfd4945c-20d8-46dd-9c82-b623d559da7f | trentmkelly/LessWrong-43k | LessWrong | Scenario Forecasting Workshop: Materials and Learnings
Disclaimer: While some participants and organizers of this exercise work in industry, no proprietary info was used to inform these scenarios, and they represent the views of their individual authors alone.
Overview
In the vein of What 2026 Looks Like and AI Timelines discussion, we recently hosted a scenario forecasting workshop. Participants first wrote a 5-stage scenario forecasting what will happen between now and ASI. Then, they reviewed, discussed, and revised scenarios in groups of 3. The discussion was guided by forecasts like “If I were to observe this person’s scenario through stage X, what would my ASI timelines median be?”.
Instructions for running the workshop including notes on what we would do differently are available here. We’ve put 6 shared scenarios from our workshop in a publicly viewable folder here.
Edit: Here is the template document for a simplified version of this workshop, which we ran at The Curve in late 2024.
Motivation
Writing scenarios may help to:
1. Clarify views, e.g. by realizing an abstract view is hard to concretize, or realizing that two views you hold don’t seem very compatible.
2. Surface new considerations, e.g. realizing a subquestion is more important than you thought, or that an actor might behave in a way you hadn’t considered.
3. Communicate views to others, e.g. clarifying what you mean by “AGI”, “slow takeoff”, or the singularity.
4. Register qualitative forecasts, which can then be compared against reality. This has advantages and disadvantages vs. more resolvable forecasts (though scenarios can include some resolvable forecasts as well!).
Running the workshop
Materials and instructions for running the workshop including notes on what we would do differently are available here.
The schedule for the workshop looked like:
Session 1 involved writing a 5-staged scenario forecasting what will happen between now and ASI.
Session 2 involved reviewing, discussing, and revising scenarios in groups of 3. The dis |
550d67e8-6d2f-4afc-a44d-b87362d9bc8a | trentmkelly/LessWrong-43k | LessWrong | How bad would AI progress need to be for us to think general technological progress is also bad?
It is widely believed in the EA community that AI progress is acutely harmful by substantially increasing X-risks. This has led to a growing priority on pushing against work advancing AI capabilities.[1]
On the other hand, economic growth, scientific advancements, and (non-AI) technological progress are generally viewed as highly beneficial, improving the quality of the future provided there are no existential catastrophes.[2]
But here’s the problem: contributing to this general civilizational progress that benefits humanity also substantially benefits AI researchers and their work.
My intuitive reaction here (and that of most, I assume) is maybe something like “yeah ok but surely this doesn’t balance out the benefits. We can’t tell the overwhelming majority of humans that we’re gonna slow down science, economic growth and improving their lives with these (and those of their descendants) until AI is safe just because these would also benefit a tiny minority that is making AI less safe”.
However, there has to be some threshold of harm (from AI development) beyond which we would think slowing down technological progress generally (and not only AI progress) would be worth it.
So what makes us believe that we’re not beyond this threshold?
1. ^
For example, on his 80,000 hours podcast appearance, Zvi Mowshowitz claims that it is "the most destructive job per unit of effort that you could possibly have". See also the recent growth of the Pause AI movement.
2. ^
For recent research and opinions that go in that direction, see Clancy 2023; Clancy and Rodriguez 2024. |
bf4f7807-f2b5-4f58-95b0-6f1b94ba44c7 | trentmkelly/LessWrong-43k | LessWrong | The map of nanotech global catastrophic risks
Nanotech seems to be smaller risk than AI or biotech, but it advanced form has many ways of omnicide. Nanotech will be probably created after strong biotech, but short before strong AI (or by AI), so the period of vulnerability is rather short. Anyway nanotech has different stages it its future development, mostly dependent on its level of miniaturisation and ability to replicate. To control it in the future will be build some kind of protection shield which may have its own failure modes.
The main reading about the risk is Freitas's article "Some limits to global ecophagy by biovorous nanoreplicators" and "Nanoshield".
Some integration between bio and nanotech has already started in the form of DNA-origami. So may be first nanobots will be bionanobots, like upgraded version of E.coli.
Pdf is here: http://immortality-roadmap.com/nanorisk.pdf
|
e24535d9-99fa-4935-b94c-83b825be62cc | trentmkelly/LessWrong-43k | LessWrong | [Linkpost] Interpreting Multimodal Video Transformers Using Brain Recordings
This is a linkpost for https://openreview.net/forum?id=p-vL3rmYoqh.
TL;DR: We show that fine-tuning on the vision-language task does not improve the alignment in brain regions that are thought to support the integration of multimodal information over their pre-trained counterparts.
Abstract: Integrating information from multiple modalities is arguably one of the essential prerequisites for grounding artificial intelligence systems with an understanding of the real world. Recent advances in video transformers that jointly learn from vision, text, and sound over time have made some progress toward this goal, but the degree to which these models integrate information from the input modalities still remains unclear. In this work, we present a promising approach for probing a multimodal video transformer model by leveraging neuroscientific evidence of multimodal information processing in the brain. We use the brain recordings of subjects watching a popular TV show to interpret the integration of multiple modalities in a video transformer, before and after it is trained to perform a question-answering task that requires vision and language information. For the early and middle layers, we show that fine-tuning on the vision-language task does not improve the alignment in brain regions that are thought to support the integration of multimodal information over their pre-trained counterparts. We further show that the top layers of the fine-tuned model align substantially less with the brain representations, and yield better task performances than other layers, which indicates that the task may require additional information from the one available in the brain recordings. |
a2f389dd-74ed-4aec-a982-bfc377af58a4 | trentmkelly/LessWrong-43k | LessWrong | NYT: The Surprising Thing A.I. Engineers Will Tell You if You Let Them
NYT Opinion article by Ezra Klein on AI-regulations. Ezra has been writing quite a lot on AI recently. Thought people might be interested in discussing them here. |
618e4917-01f7-4843-a4d3-daee24bcff26 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Seeking Interns/RAs for Mechanistic Interpretability Projects
**UPDATE:** The deadline for applying for this is 11:59pm PT Sat 27 Aug. I'll be selecting candidates following a 2 week (paid) work trial, 10hr/week starting Sept 12 where participants pick a concrete research idea and try to make progress on it.
---
Hey! My name is Neel Nanda. I used to work at Anthropic on [LLM interpretability under Chris Olah](https://transformer-circuits.pub) (the Transformer Circuits agenda), and am currently doing some independent mechanistic interpretability work, [most recently on grokking](https://www.alignmentforum.org/posts/N6WM6hs7RQMKDhYjB/a-mechanistic-interpretability-analysis-of-grokking) ([see summary](https://twitter.com/NeelNanda5/status/1559060507524403200)). I have a bunch of concrete project ideas, and am looking to hire an RA/intern to help me work on some of them!
**Role details:** The role would be remote by default. Full-time (~40 hrs/week). Roughly for the next 2-3 months, but flexible-ish. I can pay you $50/hr (via a grant).
**What I can offer:** I can offer concrete project ideas, help getting started, and about 1hr/week of ongoing mentorship. (Ideally more, but that's all I feel confident committing to) I'm much better placed to offer high-level research mentorship/guidance than ML engineering guidance.
**Pre-requisites:** As such, I'd be looking for someone with existing ML skill, enough to be able to write and run simple experiments, esp with transformers. (e.g. writing your own GPT-2-style transformer from scratch in PyTorch is more than enough). Someone who’s fairly independently minded and could mostly work independently if given a concrete project idea, and mostly needs help with high-level direction. Familiarity with transformer circuits, and good linear algebra intuitions are nice-to-haves, but not essential. I expect this is best suited to someone who wants to test fit for doing alignment work, and is particularly interested in mechanistic interpretability.
**Project ideas:** Two main categories.
1. One of the future directions from [my work on grokking](https://www.alignmentforum.org/posts/N6WM6hs7RQMKDhYjB/a-mechanistic-interpretability-analysis-of-grokking#Future_Directions), interpreting how models change as they train.
1. This has a fairly mathsy flavour and involves training and interpreting tiny models on simple problems, looking at how concrete circuits develop over training, and possibly what happens when we put interpretability-inspired metrics in the loss function. Some project ideas involve training larger models, eg small SoLU transformers
2. Work on building better techniques to localise specific capabilities/circuits in large language models, inspired by work such as [ROME](https://rome.baulab.info/).
1. This would have a less mathsy flavour and more involved coding, and you’d be working with pre-trained larger models (GPT-2 scale). It would likely look like moving between looking for specific circuits in an ad-hoc way (eg, how GPT-2 knows that the Eiffel Tower is in Paris), and then distilling the techniques that worked best into standard tools, ideally automatable.
2. Optionally, this could also involve making open source interpretability tooling for LLMs
**Actions:** If you're interested in potentially working with me please reach out at [neelnanda27@gmail.com](mailto:neelnanda27@gmail.com). My ideal email would include:
* Details on your background/AI/Interpretability experience (possible formats: LinkedIn link, resume, Github repo links for projects you're proud of, description of how confident you'd feel writing your own tiny GPT-2, whether you've read/understood [A Mathematical Framework for Transformer Circuits](https://transformer-circuits.pub/2021/framework/index.html), and anything else that feels relevant),
* Why you're interested in working with me/on mechanistic interpretability, and any thoughts on the kinds of projects you'd be excited about
* What you would want to get out of working together
* What kind of time frame would you want to work together on, and how much time could you commit to this
* No need to overthink it! This could be a single paragraph
**Disclaimers**:
* I will most likely take on either one or zero interns, apologies in advance if I reject you! I expect this to be an extremely noisy hiring process, so please don't take it personally
* I expect to have less capacity for mentorship time than I'd like, and it's very plausible you could get a better option elsewhere
* I've never had an intern before, and expect this to be a learning experience!
* Mechanistic interpretability is harder to publish than most fields of ML, and by default I would not expect this to result in papers published in conferences (though I'd be happy to support you in aiming for that!). |
655b92e9-be57-49c1-968c-db2beccdf190 | trentmkelly/LessWrong-43k | LessWrong | The Practical Value of Flawed Models: A Response to titotal’s AI 2027 Critique
Crossposted from my Substack.
@titotal recently posted an in-depth critique of AI 2027. I'm a fan of his work, and this post was, as expected, phenomenal*.
Much of the critique targets the unjustified weirdness of the superexponential time horizon growth curve that underpins the AI 2027 forecast. During my own quick excursion into the Timelines simulation code, I set the probability of superexponential growth to ~0 because, yeah, it seemed pretty sus. But I didn’t catch (or write about) the full extent of its weirdness, nor did I identify a bunch of other issues titotal outlines in detail. For example:
* The AI 2027 authors assign ~40% probability to a “superexponential” time horizon growth curve that shoots to infinity in a few years, regardless of your starting point.
* The RE-Bench logistic curve (major part of their second methodology) is never actually used during the simulation. As a result, the simulated saturation timing diverges significantly from what their curve fitting suggests.
* The curve they’ve been showing to the public doesn’t match the one actually used in their simulations.
…And more. He’s also been in communication with the AI 2027 authors, and Eli Lifland recently released an updated model that improves on some of the identified issues. Highly recommend reading the whole thing!
That said—it is phenomenal*, with an asterisk. It is phenomenal in the sense of being a detailed, thoughtful, and in-depth investigation, which I greatly appreciate since AI discourse sometimes sounds like: “a-and then it’ll be super smart, like ten-thousand-times smart, and smart things can do, like, anything!!!” So the nitty-gritty analysis is a breath of fresh air.
But while titotal is appropriately uncertain about the technical timelines, he seems way more confident in his philosophical conclusions. At the end of the post, he emphatically concludes that forecasts like AI 2027 shouldn’t be popularized because, in practice, they influence people to make ser |
712f584c-f32c-4de3-adb0-077c053095e6 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Canberra: Cooking for LessWrongers
Discussion article for the meetup : Canberra: Cooking for LessWrongers
WHEN: 22 August 2014 06:00:00PM (+1000)
WHERE: Bruce Hall, 40 Daley Road, Acton, ACT, 0200
Note the change in location
We will introduce the idea of cooking as a set of easy templates or methods, which different ingredients can be applied to, rather than as a massively large set of recipes to be memorised and followed. We’ll cover the reasons for the presence and order of common steps in these formulas (which means you know which ones can be left out in other recipes). Ways to make meals more efficient (effort or time wise) will also be discussed.
Dahl (lentil stew) will be cooked and available for eating.
I will be meeting people in the foyer of Bruce Hall, and we will leave for South Kitchen at 6:15. If you do not know where South Kitchen is, please arrive before 6:15.
General meetup info:
If you use Facebook, please join our group: https://www.facebook.com/groups/lwcanberra/
Structured meetups are held on the second Saturday and fourth Friday of each month from 6 pm until late in the CSIT building, room N101 (except for this meetup, which will be held in Bruce Hall).
Discussion article for the meetup : Canberra: Cooking for LessWrongers |
aa2afeef-745b-435a-9ea5-a9ddbd2378e9 | trentmkelly/LessWrong-43k | LessWrong | What can we learn from freemasonry?
I recently stumbled over the relationship between freemasons and networks of social and economic influence (e.g. nobility).
I wondered what could be learned from a society which exists so long and has ideals that are not that far away from the LW goal of refining human rationality.
It is interesting to note that the freemasons seem to have highly tolerant and rational values. The freemasons orginated from independent craft guilds but became 'speculative freemasons' during the enlightenment and this is reflected in their commitment to tolerance and reason which builds on crafts traditions of teaching, truth, reliability and craft perfection. Somewhat problematic may be their unusual customs and the prejudice they face. Nonetheless they obviously can cooperate which our kind can't.
Note: I didn't attend any freemason meetings and don't know any details. What I read on Wikipedia was mostly asbtract. I might attend a meeting but unsure about it's value of information.
What do you think: What can we learn from freemasonry? What should be avoided? Is there any freemason here who might provide insights?
Relevants comments (no posts) on LW:
LW as a cult like freemasons.
LW as exclusive phyg
Interview systems for admission to LW
Use of prejudice about freemasons
A post about an LW symbol prompted this comment about freemason icons.
|
fd35748c-5600-4781-a318-112e82a91e49 | trentmkelly/LessWrong-43k | LessWrong | Covid 7/28/22: Ruining It For Everyone
There are lots of ways to try and ruin it for everyone. Covid restrictions that make no sense are a proven successful strategy for this, demanding the Doing of More. Monkeypox offers exciting additional ruining potential.
The surprise winner, however, is an old Alzheimer’s paper that it seems the entire field of drug development and diagnosis was based around, and it turned out it’s not only fraud, it’s very obvious fraud once you actually look at the manipulated images?
The full implications of this are being insufficiently explored.
Executive Summary
1. Case levels are steady and should remain so.
2. Whole field of Alzheimer’s has been based on a fraud for decades.
3. Various monkeypox news got split off into another post.
Also yes, Biden got Covid, but it doesn’t even make a bullet point, he’s fine.
Let’s run the numbers.
The Numbers
Predictions
Prediction from last week: 780k cases (+1%) and 2,450 deaths (+0%)
Results: 807k cases (+5%) and 2,964 deaths (+21%).
Prediction for next week: 850k cases (+5%) and 2,850 deaths (-3%).
Last week Colorado reported -158 deaths, which I didn’t notice, after 234 the previous week and now 234 again this week. Three of the previous four weeks had zero. That explains most of the prediction error and why the numbers keep flopping back and forth, as the real number should probably be more like 50. Thus I predict a moderate decline. There’s no real uncertainty here that’s worth much, the game is predicting reporting errors.
Deaths
Cases
Biden got Covid, but he’s feeling much better now, he’s tested negative twice.
Physical World Modeling
The headline: White House to Launch Effort to Develop Next Generation of Covid Vaccines. More accurate would be ‘White House to hold meeting to ask how development is going on next generation of Covid vaccines.’ The work is being done by Pfizer and Moderna. Calling them in to talk about it is not launching an effort. Giving them additional funding for it would speed thi |
1f34e1ef-074d-4075-aee5-fb1194b30df9 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Socialising in the Sun, London 13/04
Discussion article for the meetup : Socialising in the Sun, London 13/04
WHEN: 13 April 2014 02:00:00PM (+0100)
WHERE: Newman's Row, London WC2A 3TL
We are having another Social Meetup on Sunday at 2 PM, this time outdoors [weather permitting].
The meetup will take place at Lincoln's Inn Fields (near Holborn station) and more specifically around this spot. I will bring a deck of cards, so we can have the option of playing Resistance; if anyone has frisbees and other such props - feel free to bring them as well.
In case the weather is bad we will meet at the Shakespeare's Head. Both locations are near to each other, but if you want to make sure where we are meeting then check on the mailing list on Sunday morning.
Note: There will be no Meetup on Easter (20/04) since the turnout is expected to be minimal
If you get lost, feel free to contact me by e-mail - Tenoke(at)Tenoke.com or by phone - 07425168803. Alternatively, if you want more information about the meetup or anything else, come by our mailing list or the facebook group
Discussion article for the meetup : Socialising in the Sun, London 13/04 |
1aeeddbf-229c-4faa-9958-8a5bb49d334b | trentmkelly/LessWrong-43k | LessWrong | Will 2023 be the last year you can write short stories and receive most of the intellectual credit for writing them?
I've been worldbuilding a unique setting in my head and on paper for maybe a year now, and for quite a bit longer than that I have wanted to start publishing fiction. I've never "found the time" to act on these ambitions, of course, but until the advent of LLMs I always thought I would have the opportunity to work on it later, after this or that startup or video game or work thing.
I might still do that, but I'd be lying if I didn't say that part of the appeal of writing fiction anything at all was to receive credit from a very small group of readers for a piece of content that they liked and found novel or creative. It seems to me like the possibility of that is either fading or has already faded; the one big barrier that I thought was preventing LLMs from writing longform content, context size limits, has been blown away. GPT-4 now has a context size well above that of most short stories, more than enough to summarize the essential beats of a novel down from ~200 or so pages, and my guess is that future people will assume that most of the words and story details are being written out of a machine. Perhaps the basic idea for a story will be the domain of humans, but then people will be left wondering exactly how much of that idea was the product of the author, and rhetorical giftedness will become commoditized. That in mind, should I get started now, or is this worrying too much, or is it already basically too late? |
67e88134-8578-4e89-bf9a-a33e9f728a5e | trentmkelly/LessWrong-43k | LessWrong | On Seeking a Shortening of the Way
"The most instructive experiences are those of everyday life." - Friedrich Nietzsche
What is it that the readers of lesswrong are looking for? One claim that's been repeated frequently is that we're looking for rationality tricks, shortcuts and clever methods for being rational. Problem is: there aren't any.
People generally want novelty and gimmicks. They're exciting and interesting! Useful advice tends to be dull, tedious, and familiar. We've heard it all before, and it sounded like a lot of hard work and self-discipline. If we want to lose weight, we don't do the sensible and quite difficult thing and eat a balanced diet while increasing our levels of exercise. We try fad diets and eat nothing but grapefruits for a week, or we gorge ourselves on meats and abhor carbohydrates so that our metabolisms malfunction. We lose weight that way, so clearly it's just as good as exercising and eating properly, right?
We cite Zen stories but don't take the time and effort to research their contexts, while at the same time sniggering a the actual beliefs inherent in that system. We wax rhapsodic about psychedelics and dismiss the value of everyday experiences as trivial - and handwave away praise of the mundane as utilization of "applause lights".
We talk about the importance of being rational, but don't determine what's necessary to do to become so.
Some of the greatest thinkers of the past had profound insights after paying attention to parts of everyday life that most people don't give a second thought. Archimedes realized how to determine the volume of a complex solid while lounging in a bath. Galileo recognized that pendulums could be used to reliably measure time while letting his mind drift in a cathedral.
Sure, we're not geniuses, so why try to pay attention to ordinary things? Shouldn't we concern ourselves with the novel and extraordinary instead?
Maybe we're not geniuses because we don't bother paying attention to ordinary things. |
256ebd2e-8e69-4a94-b961-64386365447f | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Endo-, Dia-, Para-, and Ecto-systemic novelty
*[Metadata: crossposted from <https://tsvibt.blogspot.com/2023/01/endo-dia-para-and-ecto-systemic-novelty.html>. First completed January 10, 2023. This essay is more like research notes than exposition, so context may be missing, the use of terms may change across essays, and the text might be revised later; only [the versions at tsvibt.blogspot.com](https://tsvibt.blogspot.com/search/label/AGI%20alignment) are definitely up to date.]*
Novelty can be coarsely described as one of: fitting within a preexisting system; constituting a shift of the system; creating a new parallel subsystem; or standing unintegrated outside the system.
*Thanks to Sam Eisenstat for related conversations.*
[Novelty](https://tsvibt.blogspot.com/2022/08/structure-creativity-and-novelty.html) is understanding (structure, elements) that a mind acquires (finds, understands, makes its own, integrates, becomes, makes available for use to itself or its elements, incorporates into its thinking). A novel element (that is, structure that wasn't already there in the mind fully [explicitly](https://tsvibt.blogspot.com/2023/03/explicitness.html)) can relate to the mind in a few ways, described here mainly by analogy and example. A clearer understanding of novelty than given here might clarify the forces acting in and on a mind when it is acquiring novelty, such as ["value drives"](https://tsvibt.blogspot.com/2022/10/does-novel-understanding-imply-novel.html#3-dilemma-value-drift-or-conflict).
Definitions
===========
"System" ("together-standing") is used here to emphasize the network of relations between elements of a mind.
These terms aren't supposed to be categories, but more like overlapping regions in the space of possibilities for how novelty relates to the preexisting mind.
*Endosystemic novelty* (or "basis-aligned" or "in-ontology") is novelty that is integrated into the mind by fitting alongside and connecting to other elements, in ways analogous to how preexisting elements fit in with each other. Endosystemic novelty is "within the system"; it's within the language, ontology, style of thinking, conceptual scheme, or modus operandi of the preexisting mind.
*Diasystemic novelty* (or "cross-cutting" or "basis-skew" or "ontological shift") is novelty that is constituted as a novel structure of the mind by many shifts in many of the preexisting elements or relations, adding up to something coherent or characteristically patterned. Diasystemic novelty is "throughout the system"; it's skew to the system, cross-cutting the preexisting schemes; it touches (maybe subtly) many elements, many relations, or certain elements that shape much of the mind's activity, hence altering the overall dynamics or character of the system.
*Parasystemic novelty* is novelty that is only loosely integrated into the whole mind, while being more tightly integrated within a subsystem of the mind. Parasystemic novelty is "alongside the system"; it's neither basis-aligned (since it's outside preexisting tightly integrated systems) nor cross-cutting (as it doesn't touch most of the system, or require most of the system for its constitution).
*Ectosystemic novelty* is novelty that is merely juxtaposed or appended to the mind, without being really integrated. Ectosystemic novelty is "on or outside the system"; it's external, only loosely related to the mind, as by a narrow interface or by an external aggregration mechanism. It differs from parasystemic novelty by being even less integrated, and by not nucleating or expanding a tightly integrated subsystem.
Analogies
=========
* Analogy: If a language is like a mind, then a new word would be endosystemic novelty; a sound shift or (more properly) a grammatical innovation would be diasystemic (cross-cutting) novelty; specialized languages (such as scientific jargon), and dialect formation, would be parasystemic novelty; and an encounter with a foreign language would be ectosystemic novelty. Pidgins, being unstable and noncanonical, witness the ectosystemic nature: the foreign languages don't integrate. Creoles, however, could be dubbed "systemopoetic novelty"--like parasystemic novelty, in nucleating a system, but more radical, lacking a broader system to integrate into. Substrate-superstrate relations strain the analogy/example; depending on how catastrophic they are and how integrated they end up, they might be considered endosystemic novelty (e.g. in the case of gradual small-scale lexical borrowing), diasystemic novelty, or (destructive) ectosystemic novelty (replacing without integrating), from the perspective of one or the other language.
* Analogy: If a species-history is like a mind, then a new genetic variant would be endosystemic; a major transition such as the change from RNA to DNA or asexual to sexual reproduction, would be diasystemic; speciation would be parasystemic; and an encounter with alien DNA such as a virus, or another species, would be ectosystemic.
* Analogy: endosystemic novelty is like a motion along a basis vector; diasystemic novelty is like a motion along a vector that has positive dot product with many basis vectors.
Examples
========
* In programming, adding a function definition would be endosystemic; refactoring the code into a functional style rather than an object-oriented style, or vice versa, in a way that reveals underlying structure, is diasystemic novelty; using (especially, modifying) a library would be parasystemic; and interacting with another separate system through an API, or running the code through a profiler, would be ectosystemic.
* An example sometimes given for ontological crises is the shift from Newtonian mechanics to relativistic and/or quantum mechanics. This portrays QM as diasystemic novelty. That's not so clear to me. The situation, at least for most people, might be better described as parasystemic novelty: one has intuitive physics of everyday objects; Newtonian mechanics; relativistic mechanics; and quantum mechanics. These subsystems are tightly integrated within themselves; they relate in many ways to the overall mind and to each other; but they each relate externally much less than they relate within themselves; and they each have their own live uses.
* Usually, a "new idea" is mainly endosystemic.
* However, a "new idea" can be mainly diasystemic, or at least lead to diasystemic novelty, e.g. a novel and general epistemic practice.
* Shifts in "style" might not be novelty, in the narrow sense of new structure; e.g., sound shifts aren't really novelty, or are only barely and subtly so (perhaps by solve a problem of speaking smoothly). But some shifts in style are diasystemic novelty. For example, doing math in a more symbolically algebraic style, like x2−x+1=0.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
, represented genuine diasystemic novelty compared to the [rhetorical algebra style](https://en.wikipedia.org/wiki/History_of_algebra#Rhetorical_algebra), like "the desired quantity, when squared and then subtracted, and the result added to one, is equal to zero" or whatever.
* Moving between [cognitive realms](https://tsvibt.blogspot.com/2022/11/are-there-cognitive-realms.html) would be extreme diasystemic novelty. New micro-realms would be parasystemic novelty.
* Solomonoff induction is "made of ectosystemic novelty": viewing SI as a sort of search process for better predictors, new predictors are novel but are just barely integrated into the preexisting system, just the barest comparison needed to allocate probability mass.
* Markets, such as [Garrabrant induction](https://arxiv.org/abs/1609.03543), are similar, though with a little more integration.
* General intelligence built entirely out of heterogeneous components that deal with separate tasks, e.g. Drexler's [Comprehensive AI Services](https://www.fhi.ox.ac.uk/wp-content/uploads/Reframing_Superintelligence_FHI-TR-2019-1.1-1.pdf) framework, would be "a mind created entirely of parasystemic novelty". The components are loosely integrated to jointly perform tasks that require multiple services. But the components are not tightly integrated, as in an agent with centralized decision-making and [fully generally broadcastable understanding](https://tsvibt.blogspot.com/2022/10/counting-down-vs-counting-up-coherence.html#internal-sharing-of-elements).
* The endosystemic / diasystemic distinction is not the same as the implicit / explicit distinction. For example, Bayesian epistemology or functional programming is for some people diasystemic novelty encountered as an explicit idea that is explicitly propagated systemically. Though, diasystemic novelty tends to be inexplicit, maybe because it is "bigger", and because it is "the water we (fish) swim in". In the remaining quadrant, a novel skill can be endosystemic, fitting in to interoperate with pre-existing skills, without being explicit. For example, the sequence of motions you use to unlock the door to your home when departing is fairly specific, and fairly modular (it could be modified part-wise, for example if you kept your keys in a slightly different spot relative to the doorknob, with the new key-retrieval fitting in with the rest of the motions analogously to the old key-retrieval), while being probably fairly inexplicit unless you've already tried to explain it.
* Humanity as a whole has made explicit a lot of knowledge (ideas, information, theories, methods). It could be the case that this explicit knowledge would already be enough for an agent to become extremely powerful, e.g. by gaining the ability to manufacture things with atomic precision, if only the agent could gather, integrate, and apply that knowledge, without needing to create much more knowledge. If there is that much explicit knowledge, then what is missing between the state of affairs where an agent becomes very powerful, and the current situation? It seems maybe suitable to describe that difference as one of diasystemic novelty (or "systemopoetic novelty", which is sort of diasystemic novelty but *ab initio de nihilo*). But I would guess that in practice, it's more likely that AI systems will gain diasystemic novelty by gaining endosystemic novelty through internal creativity, rather than by reading about it.
* Merely scaling up a faculty doesn't by itself constitute novelty, but it often gives rise to novelty. For example, using a bigger neural network isn't novelty (assuming that the architecture was readily tweakable in that way, and leaving aside any novelty needed to implement that change in hardware), but can open the way toward gaining more novelty during training. Increasing the memory capacity in general of a mind is (plausibly) not novelty, but could have downstream diasystemic effects, changing the character of how many mental elements interact.
Exclusivity
===========
Does diasystemic novelty come with *necessary global* changes? Or can one "think in two languages at the same time"? Maybe related, though I'm not sure: [Piaget's assimilation vs. accommodation](https://www.marxists.org/reference/subject/philosophy/works/fr/piaget2.htm). |
914819f9-9b8d-41dc-9f7e-00610531a1b1 | trentmkelly/LessWrong-43k | LessWrong | Reflections: Bureaucratic Hell
C.S. Lewis’s best-known books is a fictional book called The Screwtape Letters. It's a series of letters, from a senior devil to his nephew on how to tempt an ordinary human. The following are some excerpts from the same book, which explain why C.S. Lewis chose beaurcracy as a symbol for hell.
We must picture Hell as a state where everyone is perpetually concerned about his own dignity and advancement, where everyone has a grievance, and where everyone lives the deadly serious passions of envy, self-importance, and resentment. This, to begin with. For the rest, my own choice of symbols depended, I suppose, on temperament and on the age.
I like bats much better than bureaucrats. I live in the Managerial Age, in a world of “Admin.” The greatest evil is not now done in those sordid “dens of crime” that Dickens loved to paint. It is not done even in concentration camps and labour camps. In those we see its final result. But it is conceived and ordered (moved, seconded, carried, and minuted) in clean, carpeted, warmed, and well-lighted offices, by quiet men with white collars and cut fingernails and smooth-shaven cheeks who do not need to raise their voice. Hence, naturally enough, my symbol for Hell is something like the bureaucracy of a police state or the offices of a thoroughly nasty business concern.
Milton has told us that “devil with devil damned Firm concord holds.” But how? Certainly not by friendship. A being which can still love is not yet a devil. Here again my symbol seemed to me useful. It enabled me, by earthly parallels, to picture an official society held together entirely by fear and greed. On the surface, manners are normally suave. Rudeness to one’s superiors would obviously be suicidal; rudeness to one’s equals might put them on their guard before you were ready to spring your mine. For of course “Dog eat dog” is the principle of the whole organization. Everyone wishes everyone else’s discrediting, demotion, and ruin; everyone is an expert in the |
aa7bbc4a-6ea5-4c5f-9654-b898225ebb80 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Where is human level on text prediction? (GPTs task)
I look at graphs like these (From the GPT-3 paper), and I wonder where human-level is:
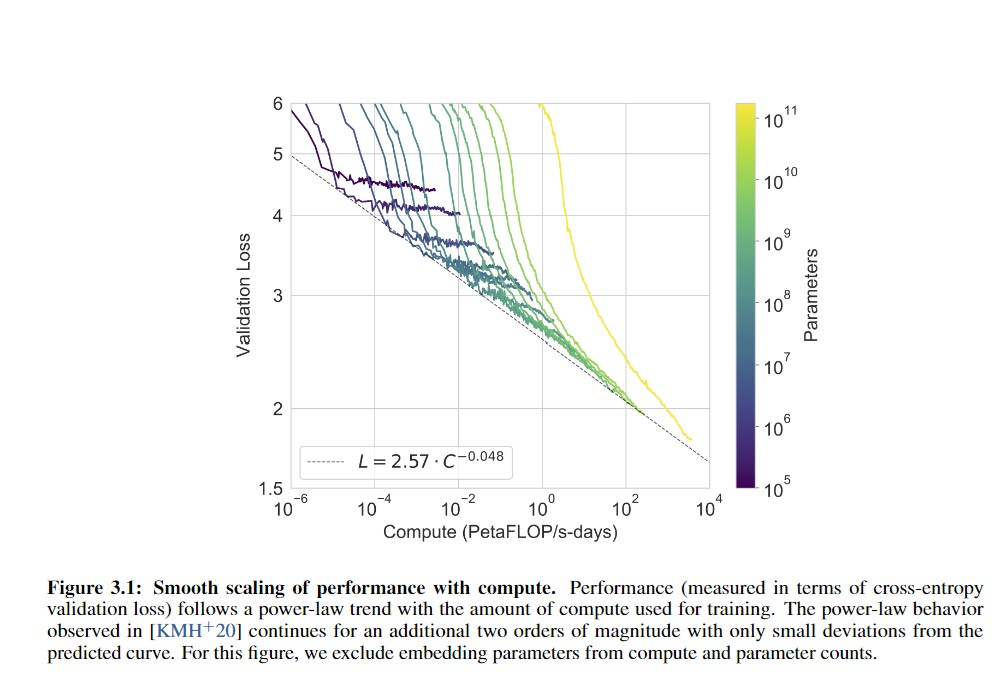Gwern seems to [have the answer here](https://www.gwern.net/newsletter/2020/05#gpt-3):
> GPT-2-1.5b had a cross-entropy validation loss of ~3.3 (based on the perplexity of ~10 in [Figure 4](https://www.gwern.net/images/ai/2019-radford-figure4-gpt2validationloss.png), and log2(10)=3.32.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
> .MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
> .mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
> .mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
> .mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
> .mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
> .mjx-numerator {display: block; text-align: center}
> .mjx-denominator {display: block; text-align: center}
> .MJXc-stacked {height: 0; position: relative}
> .MJXc-stacked > \* {position: absolute}
> .MJXc-bevelled > \* {display: inline-block}
> .mjx-stack {display: inline-block}
> .mjx-op {display: block}
> .mjx-under {display: table-cell}
> .mjx-over {display: block}
> .mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
> .mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
> .mjx-stack > .mjx-sup {display: block}
> .mjx-stack > .mjx-sub {display: block}
> .mjx-prestack > .mjx-presup {display: block}
> .mjx-prestack > .mjx-presub {display: block}
> .mjx-delim-h > .mjx-char {display: inline-block}
> .mjx-surd {vertical-align: top}
> .mjx-mphantom \* {visibility: hidden}
> .mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
> .mjx-annotation-xml {line-height: normal}
> .mjx-menclose > svg {fill: none; stroke: currentColor}
> .mjx-mtr {display: table-row}
> .mjx-mlabeledtr {display: table-row}
> .mjx-mtd {display: table-cell; text-align: center}
> .mjx-label {display: table-row}
> .mjx-box {display: inline-block}
> .mjx-block {display: block}
> .mjx-span {display: inline}
> .mjx-char {display: block; white-space: pre}
> .mjx-itable {display: inline-table; width: auto}
> .mjx-row {display: table-row}
> .mjx-cell {display: table-cell}
> .mjx-table {display: table; width: 100%}
> .mjx-line {display: block; height: 0}
> .mjx-strut {width: 0; padding-top: 1em}
> .mjx-vsize {width: 0}
> .MJXc-space1 {margin-left: .167em}
> .MJXc-space2 {margin-left: .222em}
> .MJXc-space3 {margin-left: .278em}
> .mjx-test.mjx-test-display {display: table!important}
> .mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
> .mjx-test.mjx-test-default {display: block!important; clear: both}
> .mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
> .mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
> .mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
> .mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
> .MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
> .MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
> .MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
> .MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
> .MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
> .MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
> .MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
> .MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
> .MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
> .MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
> .MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
> .MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
> .MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
> .MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
> .MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
> .MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
> .MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
> .MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
> .MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
> .MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
> .MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
> .MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
> .MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
> .MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
> .MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
> @font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
> @font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
> @font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
> @font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
> @font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
> @font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
> @font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
> @font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
> @font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
> @font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
> @font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
> @font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
> @font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
> @font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
> @font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
> @font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
> @font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
> @font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
> @font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
> @font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
> @font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
> @font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
> @font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
> @font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
> @font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
> @font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
> @font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
> @font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
> @font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
> @font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
> @font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
> @font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
> ). GPT-3 halved that loss to ~1.73 judging from [Brown et al 2020](https://www.gwern.net/images/ai/2020-brown-figure31-gpt3scaling.png) and using the scaling formula (2.57⋅(3.64⋅103)−0.048). For a hypothetical GPT-4, if the scaling curve continues for another 3 orders or so of compute (100–1000×) before crossing over and hitting harder diminishing returns, the cross-entropy loss will drop, using to ~1.24 (2.57⋅(3.64⋅106)−0.048).
>
> If GPT-3 gained so much meta-learning and world knowledge by dropping its absolute loss ~50% when starting from GPT-2’s near-human level, what capabilities would another ~30% improvement over GPT-3 gain? What would a drop to ≤1, perhaps using wider context windows or recurrency, gain?
>
>
So, am I right in thinking that if someone took random internet text and fed it to me word by word and asked me to predict the next word, I'd do about as well as GPT-2 and significantly worse than GPT-3? If so, this actually lengthens my timelines a bit.
(Thanks to Alexander Lyzhov for answering this question in conversation) |
a5c54c7c-e7f8-43bb-ab65-607b771d450f | trentmkelly/LessWrong-43k | LessWrong | How would you govern Mars?
Summary: Good government is hard. Given the chance, how would you improve it? Below you will find one idea I like, to hopefully get a fruitful discussion started.
I started writing this in February, just as the Pandemic appeared on the horizon, and titled it "How would you govern Mars", hoping to get your attention (Of course Elon Musk beat me to it, but he is good at building hype after all). So now that I have your attention, here goes:
Government sucks. Demonstrably so, just watch the news. There may be some countries that are doing better than others, but most of them are either very rich (Switzerland, Norway, Singapore), and/or very small.
What I am interested in is how one would have to design a robust system that governs the day to day interactions between people, and that is able to evolve and adapt, and thus capable of serving the people now and in the future.
I'm not so much interested in any particular detail, and more in a method of how to identify and overcome newly arising issues (Not so much an updated reissue of the Ten Commandments, and more a system that generates useful commandments on demand). I'm, also not necessarily limiting this to "laws", and instead want to include "unwritten norms" and "culture" as well.
The system should be applicable to any (large, >>150) group of people, that wants to bootstrap a community. Possible examples would be the mentioned colony on Mars, or the Moon; an independent seastead floating somewhere in the Pacific; or maybe an existing country overcoming its former government (e.g. "The Capitalist Republic of North Korea", or "The Anarchic Free State of Portland").
By way of example, I'll start with listing a few high-level, long-standing issues that I think should be solved sooner rather than later. I'll also outline one idea that may address some of them. Then I would like to hear your opinions on what the important problems are, and how you would do it.
Problems:
Inequality: More unequal societies just do w |
fdd3c25c-5a69-47b3-9ede-693cc76d4a57 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | What is the best source to explain short AI timelines to a skeptical person?
The person in question does not have a ML background. |
f4c21188-ce93-499a-b1e7-40f8ada72330 | StampyAI/alignment-research-dataset/blogs | Blogs | Scoring forecasts from the 2016 “Expert Survey on Progress in AI”
*Patrick Levermore, 1 March 2023*
Summary
-------
This document looks at the predictions made by AI experts in [The 2016 Expert Survey on Progress in AI](https://aiimpacts.org/2016-expert-survey-on-progress-in-ai/), analyses the predictions on ‘Narrow tasks’, and gives a Brier score to the median of the experts’ predictions.
My analysis suggests that the experts did a fairly good job of forecasting (Brier score = 0.21), and would have been less accurate if they had predicted each development in AI to generally come, by a factor of 1.5, later (Brier score = 0.26) or sooner (Brier score = 0.29) than they actually predicted.
I judge that the experts expected 9 milestones to have happened by now – and that 10 milestones have now happened.
But there are important caveats to this, such as:
* I have only analysed whether milestones have been publicly met. AI labs may have achieved more milestones in private this year without disclosing them. This means my analysis of how many milestones have been met is probably conservative.
* I have taken the point probabilities given, rather than estimating probability distributions for each milestone, meaning I often round down, which skews the expert forecasts towards being more conservative and unfairly penalises their forecasts for low precision.
* It’s not apparent that forecasting accuracy on these nearer-term questions is very predictive of forecasting accuracy on the longer-term questions.
* My judgements regarding which forecasting questions have resolved positively vs negatively were somewhat subjective (justifications for each question [in the separate appendix](https://docs.google.com/document/d/1CzFaNBnUhN0KIG0GU8RjozdV0S4CsdQlJ8f474HdHXk/edit#bookmark=id.raa8hmybk9b9)).
Introduction
------------
In 2016, AI Impacts published [The Expert Survey on Progress in AI](https://aiimpacts.org/2016-expert-survey-on-progress-in-ai/): a survey of machine learning researchers, asking for their predictions about when various AI developments will occur. The results have been used to inform general and expert opinions on AI timelines.
The survey largely focused on timelines for general/human-level artificial intelligence (median forecast of 2056). However, included in this survey were a collection of questions about shorter-term milestones in AI. Some of these forecasts are now resolvable. Measuring how accurate these shorter-term forecasts have been is probably somewhat informative of how accurate the longer-term forecasts are. More broadly, the accuracy of these shorter-term forecasts seems somewhat informative of how accurate ML researchers’ views are in general. So, how have the experts done so far?
Findings
--------
I analysed the 32 ‘Narrow tasks’ to which the following question was asked:
>
> *How many years until you think the following AI tasks will be feasible with:*
>
>
> * *a small chance (10%)?*
> * *an even chance (50%)?*
> * *a high chance (90%)?*
>
>
> *Let a task be ‘feasible’ if one of the best resourced labs could implement it in less than a year if they chose to. Ignore the question of whether they would choose to.*1
>
>
>
I interpret ‘feasible’ as whether, in ‘less than a year’ before now, any AI models had passed these milestones, and this was disclosed publicly. Since it is now (February 2023) 6.5 years since this survey, I am therefore looking at any forecasts for events happening within 5.5 years of the survey.
Across these milestones, I judge that 10 have now happened and 22 have not happened. My 90% confidence interval is that 7-15 of them have now happened. A full description of milestones, and justification of my judgments, are in [the appendix (separate doc).](https://docs.google.com/document/d/1CzFaNBnUhN0KIG0GU8RjozdV0S4CsdQlJ8f474HdHXk/edit#bookmark=id.raa8hmybk9b9)
The experts forecast that:
* 4 milestones had a <10% chance of happening by now,
* 20 had a 10-49% chance,
* 7 had a 50-89% chance,
* 1 had a >90% chance.
So they expected 6-17 of these milestones to have happened by now. By eyeballing the forecasts for each milestone, my estimate is that they expected ~9 to have happened.2 I did not estimate the implied probability distributions for each milestone, which would make this more accurate.
Using the 10, 50, and 90% point probabilities, we get the following calibration curve:
[](https://aiimpacts.org/wp-content/uploads/2023/03/graph-10.png)
*But*, firstly, the data here is small (there are 7 data points at the 50% mark and 1 at the 90% mark). Secondly, my methodology for this graph, and in the below Brier calculations, is based on rounding down to the nearest given forecast. For example, if a 10% chance was given at 3 years, and a 50% chance at 10 years, the forecast was taken to be 10%, rather than estimating a full probability distribution and finding the 5.5 years point. This skews the expert forecasts towards being more conservative and unfairly penalises a lack of precision.
Brier scores
------------
Overall, across every forecast made, the experts come out with **a Brier score of 0.21**.3 The score breakdown and explanation of the method is [here](https://docs.google.com/spreadsheets/d/175mCZwcZcrFQENcjUL3bd5ksC8ioCo9EZAYdYl8zZjk/edit?usp=sharing).4
For reference, a lower Brier score is better. 0 would mean absolute confidence in everything that eventually happened, 0.25 would mean a series of 50% hedged guesses on anything happening, and randomly guessing from 0% to 100% for every question would yield a Brier score of 0.33.5
Also interesting is the Brier score relative to others who forecast the same events. We don’t have that when looking at the median of our experts – but we could simulate a few other versions:
Bearish6 – if the experts all thought each milestone would take 1.5 times longer than they actually thought, they would’ve gotten a Brier score of 0.27.
Slightly Bearish – if the experts all thought each milestone would take 1.2 times longer than they actually thought, they would’ve gotten a Brier score of 0.25.
Actual forecasts – a Brier score of 0.21.
Slightly Bullish – if the experts all thought each milestone would take 1.2 times less than they actually thought, they would’ve gotten a Brier score of 0.24.
Bullish – if the experts all thought each milestone would take 1.5 times less than they actually thought, they would’ve gotten a Brier score of 0.29.
[](https://aiimpacts.org/wp-content/uploads/2023/03/Screenshot-2023-03-03-130904.png)
So, the experts were in general pretty accurate and would have been less so if they had been more or less bullish on the speed of AI development (with the same relative expectations between each milestone).
Taken together, I think this should slightly update us towards the expert forecasts being useful in as yet unresolved cases, and away from the usefulness of estimates which fall outside of 1.5 times further or closer than the expert forecasts.
Randomised – if the experts’ forecast for each specific milestone were randomly assigned to any forecasted date for a different milestone in the collection, they would’ve gotten a Bier score of 0.31 (in the random assignment I received from a random number generator).
I think this should update us slightly towards the surveyed experts generally being accurate on which areas of AI would progress fastest. My assessment is that, compared to the experts’ predictions, AI has progressed more quickly in text generation and coding and more slowly in game playing and robotics. It is not clear now whether this trend will continue, or whether other areas in AI will unexpectedly progress more quickly in the next 5 year period.
Summary of milestones and forecasts
-----------------------------------
*In the below table, the numbers in the cells are the median expert response to “Years after the (2016) survey for which there is a 10, 50 and 90% probability of the milestone being feasible”. The final column is my judgement of whether the milestone was in fact feasible after 5.5 years. Orange shading shows forecasts falling within the 5.5 years between the survey and today.*[*A full description of milestones, and justification of my judgments, are in the appendix.*](https://docs.google.com/document/d/1CzFaNBnUhN0KIG0GU8RjozdV0S4CsdQlJ8f474HdHXk/edit#bookmark=id.raa8hmybk9b9)
| | | | | |
| --- | --- | --- | --- | --- |
| **Milestone / Confidence of AI reaching the milestone within X years** | 10 percent | 50 percent | 90 percent | True by Feb 2023? (5.5 + 1 years) |
| Translate a new-to-humanity language | 10 | 20 | 50 | FALSE |
| Translate a new-to-it language | 5 | 10 | 15 | FALSE |
| Translate as well as bilingual humans | 3 | 7 | 15 | FALSE |
| Phone bank as well as humans | 3 | 6 | 10 | FALSE |
| Correctly group unseen objects | 2 | 4.5 | 6.5 | TRUE |
| One-shot image labeling | 4.5 | 8 | 20 | FALSE |
| Generate video from a photograph | 5 | 10 | 20 | TRUE |
| Transcribe as well as humans | 5 | 10 | 20 | TRUE |
| Read aloud better than humans | 5 | 10 | 15 | FALSE |
| Prove and generate top theorems | 10 | 50 | 90 | FALSE |
| Win Putnam competition | 15 | 35 | 55 | FALSE |
| Win Go with less gametime | 3.5 | 8.5 | 19.5 | FALSE |
| Win Starcraft | 2 | 5 | 10 | FALSE |
| Win any random computer game | 5 | 10 | 15 | FALSE |
| Win angry birds | 2 | 4 | 6 | FALSE |
| Beat professionals at all Atari games | 5 | 10 | 15 | FALSE |
| Win Atari with 20 minutes training | 2 | 5 | 10 | FALSE |
| Fold laundry as well as humans | 2 | 5.5 | 10 | FALSE |
| Beat a human in a 5km race | 5 | 10 | 20 | FALSE |
| Assemble any LEGO | 5 | 10 | 15 | FALSE |
| Efficiently sort very large lists | 3 | 5 | 10 | TRUE |
| Write good Python code | 3 | 10 | 20 | TRUE |
| Answers factoids better than experts | 3 | 5 | 10 | TRUE |
| Answer open-ended questions well | 5 | 10 | 15 | TRUE |
| Answer unanswered questions well | 4 | 10 | 17.5 | TRUE |
| High marks for a high school essay | 2 | 7 | 15 | FALSE |
| Create a top forty song | 5 | 10 | 20 | FALSE |
| Produce a Taylor Swift song | 5 | 10 | 20 | FALSE |
| Write a NYT bestseller | 10 | 30 | 50 | FALSE |
| Concisely explain its game play | 5 | 10 | 15 | TRUE |
| Win World Series of Poker | 1 | 3 | 5.5 | TRUE |
| Output laws of physics of virtual world | 5 | 10 | 20 | FALSE |
Caveats:
--------
**My judgements of which forecasts have turned out true or false are a little subjective.** This was made harder by the survey question asking which tasks were ‘feasible’, where feasible meant*‘if one of the best resourced labs could implement it in less than a year if they chose to. Ignore the question of whether they would choose to.’*I have interpreted this as, one year after the forecasted date, have AI labs achieved these milestones, and disclosed this publicly?
Given (a) ‘has happened’ implies ‘feasible’, but ‘feasible’ does not imply ‘has happened’ and (b) labs may have achieved some of these milestones but not disclosed it, **I am probably being conservative in the overall number of tasks which have been completed by labs**. I have **not** attempted to offset this conservatism by using my judgement of what labs can probably achieve in private. If you disagree or have insider knowledge of capabilities, you may be interested in editing my working [here](https://docs.google.com/spreadsheets/d/175mCZwcZcrFQENcjUL3bd5ksC8ioCo9EZAYdYl8zZjk/copy). Please reach out if you want an explanation of the method, or to privately share updates – patrick at rethinkpriorities dot org.
**It’s not obvious that forecasting accuracy on these nearer-term questions is very predictive of forecasting accuracy on the longer-term questions**. [Dillon (2021)](https://forum.effectivealtruism.org/posts/hqkyaHLQhzuREcXSX/data-on-forecasting-accuracy-across-different-time-horizons#Background) notes *“There is some evidence that forecasting skill generalises across topics (see Superforecasting, Tetlock, 2015 and for a brief overview see*[*here*](https://www.cardrates.com/news/good-judgment-helps-organizations-quantify-risks/)*) and this might inform a prior that good forecasters in the short term will also be good over the long term, but there may be specific adjustments which are worth emphasising when forecasting in different temporal domains.”* I have not found any evidence either way on whether good forecasters in the short term will also be good over the long term, but this does seem possible to analyse from the data that [Dillon](https://forum.effectivealtruism.org/posts/hqkyaHLQhzuREcXSX/data-on-forecasting-accuracy-across-different-time-horizons#PredictionBook_Analysis) and [niplav](https://www.lesswrong.com/posts/MquvZCGWyYinsN49c/range-and-forecasting-accuracy#comments) collect.8
**Finally, there are caveats in the original survey worth noting here, too**. For example, how the question is framed makes a difference to forecasts, even when the meaning is the same. To illustrate this, the authors note
>
> “**People consistently give later forecasts if you ask them for the probability in N years instead of the year that the probability is M**. We saw this in the straightforward HLMI (high-level machine intelligence) question and most of the tasks and occupations, and also in most of these things when we tested them on mturk people earlier. For HLMI for instance, if you ask when there will be a 50% chance of HLMI you get a median answer of 40 years, yet if you ask what the probability of HLMI is in 40 years, you get a median answer of 30%.”
>
>
>
This is commonly true of the ‘Narrow tasks’ forecasts (although I disagree with the authors that it is *consistently* so).9 For example, when asked when there is a 50% chance AI can write a top forty hit, respondents gave a median of 10 years. Yet when asked about the probability of this milestone being reached in 10 years, respondents gave a median of 27.5%.
What does this all mean for us?
-------------------------------
Maybe not a huge amount at this point. It is probably a little too early to get a good picture of the experts’ accuracy, and there are a few important caveats. But this should update you slightly towards the experts’ timelines if you were sceptical of their forecasts. Within another five years, we will have ~twice the data and a good sense of how the experts performed across their 50% estimates.
It is also limiting to have only one comprehensive survey of AI experts which includes both long-term and shorter-term timelines. What would be excellent for assessing accuracy is detailed forecasts from various different groups, including political pundits, technical experts, and professional forecasters, with which we can compare accuracy between groups. It would be easier to analyse the forecasting accuracy of the questions focused on what developments have *happened*, rather than what developments are *feasible*. We could try closer to home, maybe the average EA would be better at forecasting developments than the average AI expert – it seems worth testing now to give us some more data in ten years!
[](https://aiimpacts.org/wp-content/uploads/2023/03/rethinklogo.png)
*This is a blog post, not a research report, meaning it was produced quickly and is not to our typical standards of substantiveness and careful checking for accuracy. I’m grateful to Alex Lintz, Amanda El-Dakhakhni, Ben Cottier, Charlie Harrison, Oliver Guest, Michael Aird, Rick Korzekwa, and Zach Stein-Perlman for comments on an earlier draft.*
*If you are interested in RP’s work, please visit our*[*research database*](https://www.rethinkpriorities.org/research)*and subscribe to our*[*newsletter*](https://www.rethinkpriorities.org/newsletter)*.*
*Cross-posted to*[*EA Forum,*](https://forum.effectivealtruism.org/posts/tCkBsT6cAw6LEKAbm/scoring-forecasts-from-the-2016-expert-survey-on-progress-in)*[Lesswrong](https://www.lesswrong.com/posts/tQwjkFT8s2uf2arFN/scoring-forecasts-from-the-2016-expert-survey-on-progress-in), and*[*this google doc*](https://docs.google.com/document/d/1CzFaNBnUhN0KIG0GU8RjozdV0S4CsdQlJ8f474HdHXk/edit)*.*
Footnotes
---------
1. I only analysed this ‘fixed probabilities’ question and not the alternative ‘fixed years’ question, which asked:
“How likely do you think it is that the following AI tasks will be feasible within the next:
– 10 years?
– 20 years?
– 50 years?”
We are not yet at any of these dates, so the analysis would be much more unclear.
2. 9 = 4\*5% + 14\*15% + 6\*30% + 5\*55% + 2\*80% + 1\*90%
3. A*precise* number as a Brier score does not imply an *accurate* assessment of forecasting ability – ideally, we could work with a larger dataset (i.e. more surveys, with more questions) to get more accuracy.
4. My methodology for the Brier score calculations is based on rounding down to the nearest given forecast, or rounding up to the 10% mark. For example, if a 10% chance was given at 3 years, and a 50% chance at 10 years, the forecast was taken to be 10%, rather than estimating a full probability distribution and finding the 5.5 years point. This skews the expert forecasts towards being more conservative and unfairly penalises them. If the experts gave a 10% chance of X happening in 3 years, I didn’t check whether it had happened in 3 years, but instead checked if it had happened by now. I estimate these two factors (the first skewing the forecasts to be more begives a roughly balance 5-10% increase to the Brier score, given most milestones included a probability at the 5 year mark. A better analysis would estimate the probability distributions implied by each 10, 50, 90% point probability, then assess the probability implied at 5.5 years.
5. For more detail, see [Brier score – Wikipedia](https://en.wikipedia.org/wiki/Brier_score).
6. By ‘bearish’ and ‘bullish’ I mean expecting AI milestones to be met later or sooner, respectively.
7. The score breakdown and method for these calculations is also [here](https://docs.google.com/spreadsheets/d/175mCZwcZcrFQENcjUL3bd5ksC8ioCo9EZAYdYl8zZjk/edit?usp=sharing).
8. This seems valuable, and I’m not sure why it hasn’t been analysed yet.
Somewhat relevant sources:<https://forum.effectivealtruism.org/posts/hqkyaHLQhzuREcXSX/data-on-forecasting-accuracy-across-different-time-horizons><https://www.lesswrong.com/posts/MquvZCGWyYinsN49c/range-and-forecasting-accuracy><https://www.openphilanthropy.org/research/how-feasible-is-long-range-forecasting/><https://forum.effectivealtruism.org/topics/long-range-forecasting>
9. I sampled ten forecasts where probabilities were given on a 10 year timescale, and five of them (Subtitles, Transcribe, Top forty, Random game, Explain) gave later forecasts when asked with a ‘probability in N years’ framing rather than a ‘year that the probability is M’ framing, three of them (Video scene, Read aloud, Atari) gave the same forecasts, and two of them (Rosetta, Taylor) gave an earlier forecast. This is why I disagree it leads to *consistently*later forecasts. |
78f2965d-c3ff-42b2-8332-7397f7b6705b | trentmkelly/LessWrong-43k | LessWrong | Covid Canada Jan25: low & slow
🇨🇦 People liked my Canada comment on Zvi's post on Jan 14th, so here's another update as a top-level post. I thought I wouldn't have much to say but apparently I wrote some stuff!
(I want to underscore that this is a rambly summary from someone who does not have the same thorough researchy energy or rigorous models as Zvi or many other LWers in many situations. If you have major decisions to make, use this summary as at most a jumping off point. Slightly BC-heavy because I moved to BC a few months ago and have been getting more news here. Also some of my rambles involve info that is probably common-knowledge to most Canadians who are informed whatsoever, I guess because I'm imagining people from other countries finding this of some interest as a contrast or something.)
So.
It continues to be true that various Canadian authorities are talking about their plan to gradually get everyone gradually vaccinated by September as if it's just a reasonable plan and there's no reason to try do anything faster. Like how someone very conscientious might say "yeah, I'll do a quarter of my xmas shopping each weekend in November and be totally ready by December" which is a reasonable safety buffer for xmas but that is just not the situation here. A weird tone thing.
Maybe things will go faster if we can get some AstraZeneca, or one of the 4 other companies we've got contracts with. We can hope—we've purchased >400M doses for our 38M people. Assuming we haven't cancelled those now that Pfizer has promised us 80M doses by September (enough for everyone).
One conservative MP snarkily summarized this many-company situation as:
> "It's like saying that I have negotiated a contract with six fire departments to respond to my fire, but they won't respond for six hours when I do have a fire. And my neighbour has negotiated one contract with a single fire department to respond in five minutes," Chong told host Chris Hall.
>
> "Personally, I'll take the single contract with the fire d |
135678d5-6c4c-49fc-9b25-1cef200d44e3 | trentmkelly/LessWrong-43k | LessWrong | Ilya: The AI scientist shaping the world
Recently (2 Nov), The Guardian posted what I thought was an extremely well-made video with Ilya's thoughts. I didn't think to repost it at the time but given the OpenAI developments over the last couple of days, and the complete Twitter and media meltdown surrounding that, I thought this video gives a strong vibey insight into Ilya's thoughts on AGI and safety and it's a useful reference point for how general public may perceive Ilya (had 221k views thus far).
* * *
Transcript (bold highlights mine):
Now AI is a great thing, because AI will solve all the problems that we have today.
It will solve employment, it will solve disease, it will solve poverty, but it will also create new problems.
The problem of fake news is going to be a million times worse, cyber attacks will become much more extreme, we will have totally automated AI weapons. I think AI has the potential to create infinitely stable dictatorships. This morning a warning about the power of artificial intelligence, more than 1,300 tech industry leaders, researchers and others are now asking for a pause in the development of artificial intelligence to consider the risks.
Playing God, scientists have been accused of playing God for a while, but there is a real sense in which we are creating something very different from anything we've created so far. Yeah, I mean, we definitely will be able to create completely autonomous beings with their own goals.
And it will be very important, especially as these beings become much smarter than humans, it's going to be important to have these beings, the goals of these beings be aligned with our goals.
What inspires me? I like thinking about the very fundamentals, the basics. What can our systems not do, that humans definitely do? Almost approach it philosophically.
Questions like, what is learning?
What is experience?
What is thinking?
How does the brain work?
I feel that technology is a force of nature. I feel like there is a lot of similarity between te |
ae370b2f-aaf1-4416-8b12-cb4de1578fbf | trentmkelly/LessWrong-43k | LessWrong | Voting Results for the 2022 Review
The 5th Annual LessWrong Review has come to a close!
Review Facts
There were 5330 posts published in 2022.
Here's how many posts passed through the different review phases.
PhaseNo. of postsEligibilityNominations Phase579Any 2022 post could be given preliminary votesReview Phase363 Posts with 2+ votes could be reviewedVoting Phase168Posts with 1+ reviews could be voted on
Here how many votes and voters there were by karma bracket.
Karma BucketNo. of VotersNo. of Votes Cast Any3335007 1+3074944 10+2984902 100+2454538 1,000+1212801 10,000+24816
To give some context on this annual tradition, here are the absolute numbers compared to last year and to the first year of the LessWrong Review.
201820212022 Voters59238333 Nominations75452579 Reviews120209227 Votes127228705007 Total LW Posts170345065330
Review Prizes
There were lots of great reviews this year! Here's a link to all of them
Of 227 reviews we're giving 31 of them prizes.
This follows up on Habryka who gave out about half of these prizes 2 months ago.
Note that two users were paid to produce reviews and so will not be receiving the prize money. They're still here because I wanted to indicate that they wrote some really great reviews.
Click below to expand and see who won prizes.
Excellent ($200) (7 reviews)
* ambigram for their review of Meadow Theory
* Buck for his self-review of Causal Scrubbing: a method for rigorously testing interpretability hypotheses
* DirectedEvolution for their paid review of How satisfied should you expect to be with your partner?
* LawrenceC for their paid review of Some Lessons Learned from Studying Indirect Object Identification in GPT-2 small
* LawrenceC for their paid review of How "Discovering Latent Knowledge in Language Models Without Supervision" Fits Into a Broader Alignment Scheme
* LoganStrohl for their self-review of the Intro to Naturalism sequence
* porby for their self-review of Why I think strong general AI is coming soon
Great |
6c65ea50-994b-4826-b042-402cb10e355e | trentmkelly/LessWrong-43k | LessWrong | Infinite tower of meta-probability
Suppose that I have a coin with probability of heads p. I certainly know that p is fixed and does not change as I toss the coin. I would like to express my degree of belief in p and then update it as I toss the coin.
Using a constant pdf to model my initial belief, the problem becomes a classic one and it turns out that my belief in p should be expressed with the pdf f(x)=(nh)xh(1−x)n−h after observing h heads out of n tosses. That's fine.
But let's say I'm a super-skeptic guy that avoids accepting any statement with certainty, and I am aware of the issue of parametrization dependence too. So I dislike this solution and instead choose to attach beliefs to statements of the form S(f)= "my initial degree of belief is represented with probability density function f."
Well this is not quite possible since the set of all such f is uncountable. However something similar to the probability density trick we use for continuous variables should do the job here as well. After observing some heads and tails, each initial belief function will be updated just as we did before, which will create a new uneven "density" distribution over S(f). When I want to express my belief that p is in between numbers a and b, now I have a probability density function instead of a definite number, which is a collection of all definite numbers from each (updated) prior. Now I can use the mean of this function to express my guess and I can even be skeptic about my own belief!
This first meta level is still somewhat manageable, as I computed the Var(μ) = 1/12 for the initial uniform density over S(f) where μ is the mean of a particular f. I am not sure whether my approach is correct, though. Since the domain of each f is finite, I discretize this domain and represent the uniform density over S(f) as a finite collection of continuous random variables whose joint density is constant. Then taking the limit to infinity.
The whole thing may not make sense at all. I'm just curious what would happen |
d9529475-d2e2-422a-8b40-e4010e6b698c | trentmkelly/LessWrong-43k | LessWrong | Categorizing Love: How having more words for love might make it less scary
When discussing the idea of loving more than just our spouses and families, the phrase "love thy neighbor" often comes to mind. A quote I tend to prefer was said by Thomas Aquinas: "The person who truly understands love could love anyone". He believed that true love was unspecific, and open to all humanity. When we speak of falling in love with someone, we tend to talk of the person as if they're flawless (as one does in the honeymoon period of a relationship). Aquinas instead preferred a less romantic, more modern view of love: where you love someone, flaws and all.
That's not to say you have to love strangers equally to family and friends. A popular children's poem goes "I love you, I love you, I love you, I do. But don't get excited; I love monkeys too!". Love gets underused with people because we want to save it for someone special, and overused with things and experiences. I might say that I love peanut butter, but feel shy telling my partner I love them, even though I have given up peanut butter due to their allergy. This is because we don't tend to quantify love, even though it is something that waxes and wanes with time. I might microlove peanut putter, but decalove my partner. Or maybe, I refuse to even say "I love you" to my partner until I feel that I megalove them -- even though they've already said it to me. I may have milliloved my husband at first sight, but now feel that I gigalove them. Someone who participates in hierarchical polyamory might kilolove their secondary partners and teralove their primary.
You'll note that these different examples imply different models of what love even is. A monogamous person may see jealousy as part of a normal, functioning romantic relationship, while a polyamorous person may do all in their power to process jealousy until they don't feel it anymore. Different cultures have different ideas of what kinds of closeness and affection are appropriate in couples, families, and friendships. Some people feel that love is |
feff894e-4bb9-4ff8-af25-25982dfc61d3 | StampyAI/alignment-research-dataset/arbital | Arbital | Lattice: Exercises
Try these exercises to test your knowledge of lattices.
## Distributivity
Does the lattice meet operator distribute over joins? In other words, for all lattices $L$ and all $p, q, r \in L$, is it necessarily true that $p \wedge (q \vee r) = (p \wedge q) \vee (p \wedge r)$? Prove your answer.
%%hidden(Solution):
The following counterexample shows that lattice meets do not necessarily distribute over joins.

%%%comment:
dot source:
digraph G {
node [= 0.1, height = 0.1](https://arbital.com/p/width)
edge [= "none"](https://arbital.com/p/arrowhead)
rankdir = BT;
t -> p
t -> q
t -> r
p -> s
q -> s
r -> s
}
%%%
In the above lattice, $p \wedge (q \vee r) = p \neq t = (p \wedge q) \vee (p \wedge r)$.
%%
## Common elements
Let $L$ be a lattice, and let $J$ and $K$ be two finite subsets of $L$ with a non-empty intersection. Prove that $\bigwedge J \leq \bigvee K$.
%%hidden(Solution):
If $J$ and $K$ have a non-empty intersection, then there exists some lattice element $p$ such that $p \in J$ and $p \in K$. Since $\bigwedge J$ is a lower bound of $J$, we have $\bigwedge J \leq p$. Since $\bigvee K$ is an upper bound of $K$, we have $p \leq \bigvee K$. By transitivity, we have $\bigwedge J \leq p \leq \bigvee K$.
%%
## Another inequality
Let $L$ be a lattice, and let $J$ and $K$ be two finite subsets of $L$ such that for all $j \in J$ and $k \in K$, $j \leq k$. Prove that $\bigvee J \leq \bigwedge K$.
%%hidden(Solution):
Rephrasing the problem statement, we have that every element of $J$ is a lower bound of $K$ and that every element of $K$ is an upper bound of $J$. It the follows that for $j \in J$, $j \leq \bigwedge K$. Hence, $\bigwedge K$ is an upper bound of $J$, and therefore it is greater than or equal to the *least* upper bound of $J$: $\bigvee J \leq \bigwedge K$.
%%
## The minimax theorem
Let $L$ be a lattice and $A$ an $m \times n$ matrix of elements of $L$. Prove the following inequality: $$\bigvee_{i=1}^m \bigwedge_{j=1}^n A_{ij} \leq \bigwedge_{j=1}^n \bigvee_{i=1}^m A_{ij}$$.
%%hidden(Solution):
To get an intuitive feel for this theorem, it helps to first consider a small concrete instantiation. Consider the $3 \times 3$ matrix depicted below, with elements $a,b,c,d,e,f,g,h$, and $i$. The inequality instantiates to $(a \wedge b \wedge c) \vee (d \wedge e \wedge f) \vee (g \wedge h \wedge i) \leq (a \vee d \vee g) \wedge (b \vee e \vee h) \wedge (c \vee f \vee i)$. Why would this inequality hold?
$$\left[\begin{array}{ccc}
a & b & c \\
d & e & f \\
g & h & i \\
\end{array} \right](https://arbital.com/p/)$$
Notice that each parenthesized expression on the left hand side of the inequality shares an element with each parenthesized expression on the right hand side of the inequality.This is true because the parenthesized expressions on the left hand side correspond to rows and the parenthesized expressions on the right hand side correspond to columns; each row of a matrix shares an element with each of its columns. The theorem proven in the *Common elements* exercise above then tells us that each parenthesized expression on the left hand side is less than or equal to each parenthesized expression on the right hand side.
Let $J = \{ a \wedge b \wedge c, d \wedge e \wedge f, g \wedge h \wedge i \}$ and $K = \{ a \vee d \vee g, b \vee e \vee h, c \vee f \vee i \}$. Then the hypothesis for the theorem proven in the *Another inequality* exercise holds, giving us $\bigvee J \leq \bigwedge K$, which is exactly what we wanted to prove. Extending this approach to the general case is straightforward.
%% |
4915cf36-8c10-48b3-a150-ba851c69b694 | trentmkelly/LessWrong-43k | LessWrong | Missing the Trees for the Forest
Politics is the mind-killer. A while back, I gave an example: the government's request that Kelloggs [EDIT: General Mills, thanks CronoDAS] top making false claims about Cheerios. By the time the right-wing and left-wing blogospheres had finished with it, this became everything from part of the deliberate strangulation of the American entrepreneurial spirit by a conspiracy of bureaucrats, to a symbol of the radicalization of the political right into a fringe group obsessed with Communism, to a prelude to Obama's plan to commit genocide against all citizens who disagree with him. All because of Cheerios!
Why? What drives someone to hear about a reasonable change in cereal advertising policy and immediately think of a second Holocaust?
This reminds me of something I used to notice when reading about politics. Sometimes there would be a seemingly good idea to deregulate something that clearly needed deregulation. The idea's proponents would go on TV and say that, hey, this was obviously a good idea. Whoever by the vagary of politics had to oppose the idea would go on TV and talk about industry's plot to emasculate government safeguards. Predatory corporations! Class solidarity! Consumer safety!
Then the next day, there would be seemingly good idea to regulate something that clearly needed regulating. The idea's proponents would go on TV and say that, hey, this was obviously a good idea. Its opponents would go on TV and say that all government regulation was inherently bad. Small government! Freedom! Capitalism!
I have found a pattern: when people consider an idea in isolation, they tend to make good decisions. When they consider an idea a symbol of a vast overarching narrative, they tend to make very bad decisions.
Let me offer another example.
A white man is accused of a violent attack on a black woman. In isolation, well, either he did it or he didn't, and without any more facts there's no use discussing it.
But what if this accusation is viewed as a symbol |
c5ffcdbb-6fa8-4048-a2ab-def3fb6a305c | trentmkelly/LessWrong-43k | LessWrong | Frontier AI Labs: the Call Option to AGI
This is a cross post from my Substack, East Wind.
Since the launch of ChatGPT less than three years ago, the pace of AI development has only accelerated. Over the past six months, the intensity of research, funding, and product announcements has seemingly gone parabolic. OpenAI's recent $40 billion funding round, DeepSeek’s disruptive R1 model, Google’s formidable Gemini 2.5 Pro, and, hot off the press, Meta poaching Scale AI Co-Founder Alexandr Wang for $14B to run its superintelligence lab, all serve to highlight this relentless pace. At the foundational model layer, startups, investors, and tech incumbents are clearly going all in.
The critical questions now are: what’s the endgame for this layer of the stack, and where will value accrue? Will it be the Goliaths like Google, who already own the entire technology stack and have existing distribution, or will it be the Davids (frontier AI labs like OpenAI and Anthropic)? In this post, I argue that for AI labs to justify their valuations (OpenAI at $300B, Anthropic at $61.5B, and xAI selling secondaries at a $113B), they must execute a multi-pronged strategy: capture advertising revenue from incumbents, build a defensible enterprise business, and invest in moonshot endeavors.
In this post, I cover the following:
* The current state of VC investing at the foundation model layer, and why large fund sizes and frontier AI labs are a match made in heaven
* A general framework for evaluating the revenue drivers for frontier AI labs, from consumer, to API, to service revenues. I present this as a war waged on three fronts
* Front #1 (Consumer): I highlight that while paid subscriptions for apps like ChatGPT currently drive the bulk of revenue, frontier AI labs will ultimately need to monetize their free users and take incumbents’ market share
* Front #2 (API): On the enterprise side of things, API revenue growth will plateau in the medium term
* Front #3 (Service Revenues): therefore, AI labs have to move to the a |
020f0850-dff0-4537-94b5-146a880239e8 | trentmkelly/LessWrong-43k | LessWrong | Could the simulation argument also apply to dreams?
> We know that a dream can be real, but who ever thought that reality could be a dream? We exist, of course, but how, in what way? As we believe, as flesh-and-blood human beings, or are we simply parts of someone's feverish, complicated nightmare?
>
> * Charles Beaumont
In reading about the summary of Bostrom's Simulation Argument, it seems to speculate on the realization of future technology which may or may not ever exist. That is, computer technology that is capable of making simulations that are not only vividly accurate to the behavior of people from the distant past, but also contain a consciousness that are convinced they are the very people they are imitating. And as long as there are many such self-conscious simulations, and only one reality (i.e. a "high ratio scenario"), then the odds of a self-conscious agent being in reality and not a simulation are pretty low.
But until such technology exists, we can do some empirical investigation on simulation technology we already have, using the most advanced computer ever developed in the natural world: the human brain.
Dreams as Simulations
When we dream, our brain is effectively creating a fully-detailed simulation using our organic hardware. This can be simulations based on our normal lives, or variations of our lives, or possible future scenarios such as in stress-induced dreams. Or alternatively our dreams can simulate other people's lives, either real or fictional, based on our personal experiences, or perfectly replicate how we might imagine those people would interact with us or each other.
I've never been one for lucid dreaming myself, but in my personal experience my dreams can be quite vivid. My dream-self can hold conversations with people, go outside and see large crowds going about their day, or even look out a balcony to an entire landscape of city life. The details and experiences of an entire world can be simulated by the subconscious imagination of ones own mind.
So the simulation argumen |
b8fd88ee-5d83-48fd-b7ef-de9082620265 | trentmkelly/LessWrong-43k | LessWrong | Agents, Simulators and Interpretability
We have already spoken about the differences between tools, agents and simulators and the differences in their safety properties. Given the practical difference between them, it would be nice to predict which properties an AI system has. One way to do this is to consider the process used to train the AI system.
The Training process
Predicting an AI’s properties based on its training process assumes that inner misalignment is negligible and that the model will develop properties compatible with the training goal given to it.
An example would be comparing a system such as AlphaZero, which was given no instructions in its training other than “win the game”, to an LLM with the task “predict the next token”. As AlphaZero is given a terminal goal which is some distance in time away, it seems likely that it will engage in agentic behaviour by:
* Only caring about the end result
* Setting instrumental goals which will help it move towards a win (such as having the goal of taking pieces)
An LLM is given next token prediction as its task, and is therefore more likely to:
* Predict the next token with little consideration[1] for what might come after.
* Allocate all resources to the current moment, as there are no instrumental steps to perform before predicting the next token.
This change in behaviour depending on training objective should come as no surprise to anyone who has read the original simulator post.
The more interesting question is what happens once you add extra bells and whistles to this basic training process - what happens once the LLM has been fine-tuned, RLHFed and had some chain-of-thought added before it is trained on the results of the chain-of-thought, it's gone through a divorce, lost custody of its children, etc, etc. For this it might be useful to think a little more carefully about what happens within the network when it goes through multiple stages of training.
Mechanistic understanding
To preface: this is a speculative picture of what |
8c74a1d9-b00a-487b-ba9c-7e8b3acc6a08 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Mixed-Strategy Ratifiability Implies CDT=EDT
*([Cross-posted from IAFF](https://agentfoundations.org/item?id=1690).)*
I provide conditions under which CDT=EDT in Bayes-net causal models.
[Previously](https://agentfoundations.org/item?id=1629), I discussed conditions under which LICDT=LIEDT. That case was fairly difficult to analyse, although it looks fairly difficult to get LICDT and LIEDT to differ. It’s much easier to analyze the case of CDT and EDT ignoring logical uncertainty.
As I argued in that post, it seems to me that a lot of informal reasoning about the differences between CDT and EDT doesn’t actually give the same problem representation to both decision theories. One can easily imagine handing a causal model to CDT and a joint probability distribution to EDT, without checking that the probability distribution could possibly be consistent with the causal model. Representing problems in Bayes nets seems like a good choice for comparing the behavior of CDT and EDT. CDT takes the network to encode causal information, while EDT ignores that and just uses the probability distribution encoded by the network.
It’s easy to see that CDT=EDT if all the causal parents of an agent’s decision are observed. CDT makes decisions by first cutting the links to parents, and then conditioning on alternative actions. EDT conditions on the alternatives without cutting links. So, EDT differs from CDT insofar as actions provide evidence about causal parents. If all parents are known, then it’s not possible for CDT and EDT to differ.
So, any argument for CDT over EDT or vice versa must rely on the possibility of unobserved parents.
The most obvious parents to any decision node are the observations themselves. These are, of course, observed. But, it’s possible that there are other significant causal parents which can’t be observed so easily. For example, to recover the usual results in the classical thought experiments, it’s common to add a node representing “the agent’s abstract algorithm” which is a parent to the agent and any simulations of the agent. This abstract algorithm node captures the correlation which allows EDT to cooperate in the prisoner’s dilemma and one-box in Newcomb, for example.
Here, I argue that sufficient introspection still implies that CDT=EDT. Essentially, the agent may not have direct access to all its causal parents, but if it has enough self-knowledge (unlike the setup in [Smoking Lesion Steelman](https://agentfoundations.org/item?id=1525)), the same screening-off phenomenon occurs. This is somewhat like saying that the output of the abstract algorithm node is known. Under this condition, EDT and CDT both two-box in Newcomb and defect in the prisoner’s dilemma.
Case 1: Mixed-Strategy Ratifiability
------------------------------------
Suppose that CDT and EDT agents are given the same decision problem in the form of a Bayesian network. Actions are represented by a variable node in the network, ***A***, with values ***a***. Agents select mixed strategies somehow, under the constraint that their choice is maximal with respect to the expectations which they compute for their actions; IE:
1. (*EDT maximization constraint.*) The EDT agent must choose a mixed strategy in which ***P(a)>ϵ*** only if the action is among those which maximize expected utility.
2. (*CDT maximization constraint.*) The CDT agent is under the same restriction, but with respect to the causal expectation.
(*Exploration constraint.*) I further restrict all action probabilities to be at *least* epsilon, to ensure that the conditional expectations are well-defined.
(*Ratifiability constraint.*) I’ll also assume ratifiability of mixed strategies: the belief state from which CDT and EDT make their decision is one in which they know which mixed strategy they select. Put another way, the decision is required to be stable under knowledge of the decision. I discuss ratifiability more [here](https://agentfoundations.org/item?id=1663).
We can imagine the agent getting this kind of self-knowledge in several ways. Perhaps it knows its own source code and can reason about what it would do in situations like this. Perhaps it knows “how these things go” from experience. Or perhaps the decision rule which picks out the mixed strategies explicitly looks for a choice consistent with mixed-strategy ratifiability.
How this gets represented in the Bayes net is by a node representing the selection of mixed strategy, which I’ll call ***D*** (the “decision” node) which is the direct parent of ***A*** (our action node). ***D*** gives the probability of ***A***.
(*Mixed-strategy implementability.*) I also assume that ***A*** has no other direct parents, representing the assumption that the choice of mixed strategy is the *only* thing determining the action. This is like the assumption that the environment doesn’t contain anything which correlates itself with our random number generator to mess with our experimentation, which I discussed in the [LICDT=LIEDT conditions](https://agentfoundations.org/item?id=1629) post. It’s allowable for things to be correlated with our randomness, but if so, they must be *downstream* of it. Hence, it’s also a form of my “law of logical causality” from [earlier](https://agentfoundations.org/item?id=1663).
**Theorem 1.** Under the above assumptions, the consistent choices of mixed strategy are the same for CDT and EDT.
*Proof.* The CDT and EDT expected utility calculations become the same under the mixed-strategy ratifiability condition, since ***D*** screens ***A*** off from any un-observed parents of ***D***. Besides that, all the rest of the constraints are already the same for CDT and EDT. So, the consistent choices of mixed strategies will be the same. ◻
It’s natural to think of these possible choices as equilibria in the game-theoretic sense. My constraints on the decision procedures for EDT and CDT don’t force any particular choice of mixed strategy in cases where several options have maximal utility; but, the condition that that choice must be self-consistent forces it into a few possibilities.
The important observation for my purposes is that this argument for CDT=EDT doesn’t require any introspection beyond knowing which mixed strategy you’re going to choose in the situation you’re in. Perhaps this still seems like a lot to assume. I would contend that it’s easier than you may think. As we saw in the logical inductor post, it just seems to happen naturally for LIDT agents. It would also seem to happen for agents who can reason about themselves, or simply know themselves well enough due to experience.
Furthermore, the ratifiability constraint is something which CDTers have argued for independent reasons, to fix problems which otherwise arise for CDT. So denial of this assumption seems to be an unavailable response for CDTers.
The way I’ve defined CDT and EDT may seem a bit unnatural, since I’ve constrained them based on max-expectation choice of *actions*, but stated that they are choosing *mixed strategies*. Shouldn’t I be selecting from the possible probability distributions on actions, based on the expected utility of those? This would invalidate my conclusion, since the CDT expectation of different choices of ***D*** can differ from the EDT expectation. But, it is impossible to enforce ratifiability while also ensuring that conditioning on different choices of ***D*** is well-defined. So, I think this way of doing it is the natural way when a ratifiability constraint is in play.[1]
Case 2: Approximate Ratifiability
---------------------------------
More concerning, perhaps, is the way my argument takes under-specified decision procedures (only giving constraints under which a decision procedure is fit to be called CDT or EDT) and concludes a thing about what happens in the under-specified cases (effectively, any necessary tie-breaking between actions with equal expected utility must choose action probabilities consistent with the agent’s beliefs about the probabilities of its actions). Wouldn’t the argument just be invalid if we started with fully-specified versions of CDT and EDT, which already use some particular tie-breaking procedure? Shouldn’t we, then, take this as an argument against ratifiability as opposed to an argument for CDT=EDT?
Certainly the conclusion doesn’t follow without the assumption of ratifiability. I can address the concern to some extent, however, by making a version of the argument for fixed (but continuous) decision procedures under an approximate ratifiability condition. This will also get rid of the (perhaps annoying) exploration constraint.
(*Continuous EDT*) The EDT agent chooses mixed strategies according to some fixed way which is a continuous function of the belief-state (regarded as a function from worlds to probabilities). This function (the “selection function”) is required to agree with maximum-expected-utility choices when the expectations are well-defined and the differences in utilities between options are greater than some ***ϵ>0***.
(*Continuous CDT*) The same, but taking CDT-style expectations.
(*Approximate Ratifiability*) Let the true mixed strategy which will be chosen by the agent’s decision rule be ***d∗***. For any other ***d∈D*** such that ***|ln(d(a))−ln(d∗(a)))|>ϵ*** for any ***a∈A***, we have ***P(D=d)=0***.
(We still assume mixed-strategy implementability, too.)
Approximate ratifiability doesn’t perfectly block evidence from flowing backward from the action to the parents of the decision, like perfect ratifiability did. It does bound the amount of evidence, though: since the alternate ***d*** must be very close to ***d∗***, the likelihood ratio cannot be large. Now, as we make epsilon arbitrarily small, there is some delta which bounds the differences in action utilities assigned by CDT and EDT which gets arbitrarily small as well. Hence, the EDT and CDT selection functions must agree on more and more.
By Brouwer’s fixed-point theorem, there will be equilibria for the CDT and EDT selection functions. Although there’s no guarantee these equilibria are close to each other the way I’ve spelled things out, we could construct selection functions for both CDT and EDT which get within epsilon of any of the equilibria from theorem 1.
Case 3: Abandoning Mixed Strategies
-----------------------------------
There's one more objection I'd like to deal with. Mixed-strategy implementability is required for both arguments above. It might be claimed that this smuggles CDT-like reasoning into EDT.
Informally, I would argue that if mixed-strategy implementability fails, then CDT will learn the wrong causal network. A failure of mixed-strategy implementability basically says that we cannot perform independent experiments. What we thought was a random choice was actually influenced by something. It seems plausible that CDT agents will have constructed incorrect causal networks in such a world, where the extra parents of ***A*** are mistakenly treated as children.
To put it a different way: mixed-strategy implementability might be a feature of causal networks that agents can form by their own experimentation in the world. In that case, considering thought experiments where the assumption fails would not be relevant to actual performance of decision procedures.
However, this reply is not very strong. The truth is that "mixed strategies" are an ontological artifact: you actually take one action or another. Only some agent-architectures will first choose a mixed strategy and then randomize according to the chosen probabilities. Even if so, mixed-strategy implementability implies an absurd degree of trust in that randomization.
So to address the problem formally, we replace "mixed strategies" with *the agent's own estimate of its action probabilities*.
For example, consider rock-paper-scissors between Alice and Bob, who are "reasonably" good at predicting each other. If Alice can predict her own choice at any point, she is concerned that Bob will pick up on the same pattern and predict her. Suppose that Alice decides to play Rock. She will become concerned that Bob has predicted this, and will play Paper. So Alice will shift to play Scissors. And so on. This process will iterate until it is too late to change decisions.
In other words, "mixed strategies" can emerge naturally from following incentives against predictability. The agent just takes whichever action has the highest expected utility; but in doing so, the agent pushes its own beliefs away from certainty, since if it were certain that it would take some specific action, then a different action would look more appealing.
This idea can be formalized by representing everything with Bayesian networks, as before, but now we make the ***D🡒A*** link *deterministic;* the decision procedure of the agent *completely* determines the action from the beliefs of the agent. ***D*** should now be thought of as *the agents beliefs about which action it will take,* and nothing else -- so what we're doing here is saying that given a belief about its own action probabilities, the agent has some decision it makes. This link is also assumed to be *rational* (choosing the maximum-expectation action, by either the CDT notion of expectation, or the EDT notion).
(Since we're back to discontinuous functions, we can no longer magic away the division-by-zero problem by invoking continuity, like in the previous section; but we can do other things, which I'll leave to reader imagination for now.)
However, the agent's self-knowledge must be approximate: the agent's probabilities about ***D*** are zero outside some epsilon of its true distribution on ***A*** at the time of making its decision. (If we required perfection, Alice might get stuck in an infinite loop when trying to play rock-paper-scissors with Bob.)
We now make a similar argument as before: our approximate knowledge of ***D*** screens off any correlations between ***A*** and parents of ***D,*** as epsilon shrinks to zero. Notably, this requires that the relationship between ***D*** and its parents is continuous, since the screen-off phenomenon might not occur if the uncertainty is shrinking to zero around a discontinuity.
Consequences for Counterfactuals
--------------------------------
The arguments above are fairly rudimentary. The point I’m trying to drive at is more radical: there is basically one notion of counterfactual available. It is the one which both CDT and EDT arrive at, if they have very much introspection. It isn’t particularly good for the kinds of decision-theory problems we’d like to solve: it tends to two-box in realistic Newcomb’s problems (where the predictor is imperfect), defect in prisoner’s dilemma, et cetera. My conclusion is that these are not problems to try and solve by counterfactual reasoning. They are problems to solve with updateless reasoning, bargaining, [cooperative oracles](https://agentfoundations.org/item?id=1468), [predictable exploration](https://agentfoundations.org/item?id=1683), and so on.
I don’t think any of this is very new in terms of the arguments between CDT and EDT in the literature. Philosophers seem to have a fairly good understanding of how CDT equals EDT when introspection is possible; see SEP on [objections to CDT](https://plato.stanford.edu/entries/decision-causal/#Obje). The proofs above are just versions of the tickle defense for EDT. However, I think the AI alignment community may not be so aware of the extent to which EDT and CDT coincide. Philosophers continue to distinguish between EDT and CDT, while knowing that they wouldn’t differ for ideal introspective agents, on the grounds that decision theories should provide notions of rationality even under failure of introspection. It’s worth asking whether advanced AIs may still have some fundamental introspection barriers which lead to different results for CDT and EDT. From where we stand now, looking at positive introspection results over the years, from [probabilistic truth](http://intelligence.org/files/DefinabilityTruthDraft.pdf) to [reflective oracles](https://arxiv.org/abs/1508.04145) to [logical induction](https://intelligence.org/2016/09/12/new-paper-logical-induction/), I think the answer is no.
It’s possible that a solution to AI alignment will be some kind of tool AI, designed to be highly intelligent in a restricted domain but incapable of thinking about other agent, including itself, on a strategic level. Perhaps there is a useful distinction between CDT and EDT in that case. Yet, such an AI hardly seems to need a decision theory at all, much less the kind of reflective decision theory which MIRI tends to think about.
The meagre reasons in the post above hardly seem to suffice to support this broad view, however. Perhaps my Smoking Lesion Steelman series gives some intuition for it ([I](https://agentfoundations.org/item?id=1525), [II](https://agentfoundations.org/item?id=1662), [III](https://agentfoundations.org/item?id=1663)). Perhaps I’ll be able to make more of a case as time goes on.
[1]: Really, I think the reasoning in this paragraph is much too fast, but there's a lot to be said on the subject and it would overcomplicate this post. |
f30a75ed-516f-405e-8170-a37b9864f541 | trentmkelly/LessWrong-43k | LessWrong | Antiantinatalism
Cross posted from Putanumonit.com
----------------------------------------
Does life suck? I think it does, somewhat. Others would say it sucks even worse than that. David Benatar thinks that life sucks so profoundly that bestowing it on anyone, like your child, is a grave crime. The antinatalist philosopher is having a moment: a profile in the New Yorker, an appearance on Sam Harris’ podcast, and a reader emailing to ask me what I think of the case against being born.
I tried to make sense of antinatalism, and I think it’s bad philosophy. But I also think it’s bad economics, and plays on the widely held intuition that an extra person makes the rest of humanity worse off by taking up some space, some resources, some piece of the pie that would have gone to others. I hold that this zero-sum view is ignorant of the reality of the modern economy. Having children is good for the children, good for you, and good for the world.
Like a pirate cow, the philosophy of antinatalism stands on three legs:
1. Some conception of negative utilitarianism, i.e. the view that reducing suffering is the principal (or only) thing that matters morally, and that moderate pain weighs more than great joy.
2. The observation that life contains more bad things than good things.
3. A divide between existing and non-existing agents, and the assertion that the latter (i.e. unborn babies) have only an absolute preference to avoid the risk of any suffering, and no preference for enjoying anything at all.
I’ll address these in order.
NEGATIVE UTILITARIANISM
Negative utilitarianism isn’t strictly necessary for the antinatalist argument, which is lucky for them because it’s a pretty incoherent philosophy. However, antinatalists sometimes sneak it in by implication. For example, the reader asked me if I’ll take 5 minutes of the worst pain imaginable for an hour of the greatest pleasure. Benatar presented Harris with a similar trade-off: would Sam be willing to have children and grandchildren |
96db9663-03b7-4044-b7c3-622a045ad2d9 | StampyAI/alignment-research-dataset/blogs | Blogs | Precedents for economic n-year doubling before 4n-year doubling
The only times gross world product appears to have doubled in *n* years without having doubled previously in 4*n* years were between 4,000 BC and 3,000 BC, and most likely between 10,000 BC and 4,000 BC.
Details
-------
### Background
A key open question regarding AI risk is how quickly advanced artificial intelligence will ‘take off’, which is to say something like ‘go from being a small source of influence in the world to an overwhelming one’.
In *Superintelligence*[1](https://aiimpacts.org/precedents-for-economic-n-year-doubling-before-4n-year-doubling/#easy-footnote-bottom-1-2406 " Bostrom, Nick. <em>Superintelligence: Paths, Dangers, Strategies</em>. 1 edition. Oxford: Oxford University Press, 2014. </p>
"), Nick Bostrom defines the following answers, seemingly in line with common usage:
* **Slow takeoff** takes decades or centuries
* **Moderate takeoff** takes months or years
* **Fast takeoff** takes minutes to days
However the specific criteria for takeoff having occurred are generally ambiguous.
Paul Christiano has suggested[2](https://aiimpacts.org/precedents-for-economic-n-year-doubling-before-4n-year-doubling/#easy-footnote-bottom-2-2406 "paulfchristiano. “Takeoff Speeds.” <em>The Sideways View</em> (blog), February 24, 2018. <a href=\"https://sideways-view.com/2018/02/24/takeoff-speeds/\">https://sideways-view.com/2018/02/24/takeoff-speeds/</a>. ") operationalizing ‘slow takeoff’ as,
> There will be a complete 4 year interval in which world output doubles, before the first 1 year interval in which world output doubles. (Similarly, we’ll see an 8 year doubling before a 2 year doubling, etc.)
>
>
### Historic precedents
We were interested in whether anything faster than a ‘slow takeoff’ by this definition would be historically unprecedented. That is, we wanted to know whether whenever the economy has doubled in *n* years, it has always completed a doubling in 4*n* years or less before the beginning of the *n* year doubling.
We took historic gross world product (GWP) estimates from Wikipedia[3](https://aiimpacts.org/precedents-for-economic-n-year-doubling-before-4n-year-doubling/#easy-footnote-bottom-3-2406 "“Gross World Product.” In <em>Wikipedia</em>, August 14, 2019. <a href=\"https://en.wikipedia.org/w/index.php?title=Gross_world_product&oldid=910796857\">https://en.wikipedia.org/w/index.php?title=Gross_world_product&oldid=910796857</a>. <br><br>The page notes that most of their data comes from J Bradford de Long’s dataset: <br><br>J. Bradford DeLong (24 May 1998). <a href=\"http://holtz.org/Library/Social%20Science/Economics/Estimating%20World%20GDP%20by%20DeLong/Estimating%20World%20GDP.htm\">“Estimating World GDP, One Million B.C. – Present”</a>. Retrieved 5 February 2013.") and checked at each date how long it had taken for the economy to double, and whether it had always at some point doubled in as few as four times as many years prior to the start of that doubling.[4](https://aiimpacts.org/precedents-for-economic-n-year-doubling-before-4n-year-doubling/#easy-footnote-bottom-4-2406 "[Note May 13 2020: This sheet is temporarily wrong.]<s>Instances coincide with <a href=\"https://docs.google.com/spreadsheets/d/1Muz2ftyDUUewMTZPxYxeXF-uj6lBKYP-O3-IvdtHhCo/edit?ts=5e95f280#gid=0&range=G:G\">Column G in this spreadsheet</a> giving a number higher than 4, when <a href=\"https://docs.google.com/spreadsheets/d/1Muz2ftyDUUewMTZPxYxeXF-uj6lBKYP-O3-IvdtHhCo/edit?ts=5e95f280#gid=0&range=E2\">E2</a> is set to 2.</s>")
We found two apparent examples of faster takeoffs, so defined:
* Between 4,000 BC and 3,000 BC, GWP doubled in 1,000 years, yet it had never before doubled in as few as 4000 years
* Between 10,000 BC and 4,000 BC, GWP doubled in 6,000 years, yet there is no record of it doubling earlier in as few as 24,000 years. The records at that point are fairly sparse, so this is less clear, but it seems unlikely that there was a doubling in 24,000 years.[5](https://aiimpacts.org/precedents-for-economic-n-year-doubling-before-4n-year-doubling/#easy-footnote-bottom-5-2406 "Toward the end of the period it took 15,000 years to grow by $0.6Bn, and growth of $1.8Bn would have been needed for a doubling. So assuming linear growth at the end-of-period rate, this would have taken around 45,000 years, whereas in if growth was speeding up, it should have taken longer.") This appears to coincide with the beginning of agriculture, in around 9000BC.[6](https://aiimpacts.org/precedents-for-economic-n-year-doubling-before-4n-year-doubling/#easy-footnote-bottom-6-2406 " Khan Academy. “The Dawn of Agriculture (Article).” Accessed April 14, 2020. <a href=\"https://www.khanacademy.org/humanities/world-history/world-history-beginnings/birth-agriculture-neolithic-revolution/a/where-did-agriculture-come-from\">https://www.khanacademy.org/humanities/world-history/world-history-beginnings/birth-agriculture-neolithic-revolution/a/where-did-agriculture-come-from</a>. ")
The 300 year period immediately after 1300 saw a doubling of GWP growth, and the 1200 years beforehand did not see a doubling, however there was an earlier doubling within the 1200 years ending at 1200AD. So this is not technically an instance, but was a case of briefly accelerating growth. GWP between 1100 and 1300 actually declined though, so this is perhaps a different kind of case to the ones we are interested in.
*Corresponding author: Daniel Kokotajlo*
Notes
----- |
df052bcf-e245-48bc-97b3-0d8aadc2bf06 | trentmkelly/LessWrong-43k | LessWrong | Preface to a Proposal for a New Mode of Inquiry
Summary: The problem of AI has turned out to be a lot harder than was originally thought. One hypothesis is that the obstacle is not a shortcoming of mathematics or theory, but limitations in the philosophy of science. This article is a preview of a series of posts that will describe how, by making a minor revision in our understanding of the scientific method, further progress can be achieved by establishing AI as an empirical science.
The field of artificial intelligence has been around for more than fifty years. If one takes an optimistic view of things, its possible to believe that a lot of progress has been made. A chess program defeated the top-ranked human grandmaster. Robotic cars drove autonomously across 132 miles of Mojave desert. And Google seems to have made great strides in machine translation, apparently by feeding massive quantities of data to a statistical learning algorithm.
But even as the field has advanced, the horizon has seemed to recede. In some sense the field's successes make its failures all the more conspicuous. The best chess programs are better than any human, but go is still challenging for computers. Robotic cars can drive across the desert, but they're not ready to share the road with human drivers. And Google is pretty good at translating Spanish to English, but still produces howlers when translating Japanese to English. The failures indicate that, instead of being threads in a majestic general theory, the successes were just narrow, isolated solutions to problems that turned out to be easier than they originally appeared.
So what went wrong, and how to move forward? Most mainstream AI researchers are reluctant to provide clear answers to this question, so instead one must read behind the lines in the literature. Every new paper in AI implicitly suggests that the research subfield of which it is a part will, if vigorously pursued, lead to dramatic progress towards intelligence. People who study reinforcement learning think |
e54841b2-25ba-4dba-bdfc-b2224e595ca0 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Applications open for AI Safety Fundamentals: Governance Course
[**Apply**](https://apply.aisafetyfundamentals.com/governance?prefill_%5Ba%5Dsource=EA%20Forum%20launch%20post&utm_campaign=launch&utm_source=eaforum) **to participate or facilitate, before 25th June 2023**.
We are excited to support participants who are curious about working in AI governance, or who already do so. If you have networks that might be interested, we would appreciate you sharing this course with them.
Full announcement
-----------------
There has been increasing interest in how AI governance can mitigate extreme risks from AI, but it can be difficult to get up to speed on research and ideas in this area.
The [*AI Safety Fundamentals (AISF)*](https://www.aisafetyfundamentals.com/?utm_source=EA+Forum&utm_medium=launch+post&utm_campaign=AISF)*: Governance Course* is a **completely free online class designed to efficiently introduce key ideas in AI governance**, with a focus on risks from future AI systems. We offer:
* [**A**](https://80000hours.org/problem-profiles/artificial-intelligence/)[**widely**](https://aisafetyfundamentals.com/)[**recommended**](https://hearthisidea.com/episodes/garfinkel) **curriculum** that provides a structured guide to the field
+ The course is designed with input from a wide range of relevant experts. The [curriculum](https://www.aisafetyfundamentals.com/ai-governance-curriculum) will be updated before the course launches in mid-July.
* Weekly facilitated **small-group discussions**, for accountability and sharing ideas
* Our [**course community**](https://aisafetyfundamentals.com/our-community)—opportunities to engage in relevant online discussions, learn about professional opportunities, and attend Q&A sessions with experts
The course is run by [BlueDot Impact](https://bluedotimpact.org), a nonprofit project founded by members of the organising team behind the course's previous iteration.
Note that we have renamed the website from "AGI Safety Fundamentals" to "AI Safety Fundamentals". We'll release another post within the next week to explain our reasoning, and we'll respond to any discussion about the rebrand there.
[**Apply here**](https://apply.aisafetyfundamentals.com/governance?prefill_%5Ba%5Dsource=EA%20Forum%20launch%20post&utm_campaign=launch&utm_source=eaforum)**, by 25th June 2023.**
### **Time commitment**
The course will run for 12 weeks from **July-September 2023**. It comprises 8 weeks of reading and virtual small-group discussions, followed by a 4-week project.
The time commitment is around **5 hours per week**. The split will be ~1.5-2 hours of reading, ~1.5 hours of discussion, and a ~1-hour expert Q&A session.
### **Course structure**
Participants will be grouped depending on their current policy expertise. Discussion facilitators will be knowledgeable about AI governance; they can help answer participants’ questions and point them to further resources.
Participants can use project time to synthesise their views on the field and how they can put these ideas into practice, and/or to start building knowledge or writing samples that will help them with their career.
### **Target audience**
Due to capacity constraints, we don't expect to be able to accept all applicants. We think this course will particularly be able to help you if any of the following apply to you:
* **You have policy experience**, and are keen to apply your skills to reducing risk from AI.
* **You have a technical background**, and want to learn about how you can use your skills to contribute to AI Governance agenda.
* **You are early in your career or a student who is interested in exploring a career in governance** to reduce risks from advanced AI.
**We expect at least 25% of the participants will not fit any of these descriptions.** There are many skills, backgrounds and approaches to AI Governance we haven’t captured here, and we will consider all applications accordingly.
If we don’t have the capacity to have you in the organized course, you can still read through our public curriculum .
### **Apply now!**
If you would like to be considered for the next round of the courses, starting in July 2023, **please**[**apply here**](https://apply.aisafetyfundamentals.com/governance?prefill_%5Ba%5Dsource=EA%20Forum%20launch%20post&utm_campaign=launch&utm_source=eaforum) **by 25th June 2023**. More details can be found [here](https://www.aisafetyfundamentals.com/governance-course-details). We aim to let you know the outcome of your application by late June 2023.
If you already have experience working on AI Governance or feel well-versed in the content, we’d be excited for you to join our community of facilitators. Please [apply to facilitate](https://apply.aisafetyfundamentals.com/governance?prefill_%5Ba%5Dsource=EA%20Forum%20launch%20post&utm_campaign=launch&utm_source=eaforum) here. (This is the same form; you will be offered an option to select “facilitator”.) |
3d1ec4be-4592-43c7-bddc-f18e78fa5d0b | trentmkelly/LessWrong-43k | LessWrong | Misspecification in Inverse Reinforcement Learning - Part II
In this post, I will provide a summary of the paper Quantifying the Sensitivity of Inverse Reinforcement Learning to Misspecification, and explain some of its results. I will assume basic familiarity with reinforcement learning. This is the fifth post in the theoretical reward learning sequence, which starts in this post. This post is somewhat self-contained, but I will largely assume that you have read this post and this post before reading this one.
In Misspecification in Inverse Reinforcement Learning (also discussed in this post), I attempt to analyse how sensitive IRL is to misspecification of the behavioural model. The main limitation of this analysis is that it is based on equivalence relations – that is, it only distinguishes between the case where the learnt reward function is equivalent or nonequivalent to the ground truth reward (for some specific ways of defining this equivalence). This means that it cannot distinguish between small and large errors in the learnt reward. Quantifying the differences between reward functions is nontrivial — to solve this, I developed STARC metrics, which are described in this post. In Quantifying the Sensitivity of Inverse Reinforcement Learning to Misspecification, which I’m summarising in this post, I extend the analysis in Misspecification in Inverse Reinforcement Learning using STARC metrics.
Formalism
We must first modify the definition in Misspecification in Inverse Reinforcement Learning to make use of pseudometrics on R. This is straightforward:
> Definition: Given a pseudometric d on R, and two behavioural models f,g:R→Π, we say that f is ϵ-robust to misspecification with g if
>
> 1. If f(R1)=g(R2), then d(R1,R2)≤ϵ.
> 2. If f(R1)=f(R2), then d(R1,R2)≤ϵ.
> 3. Im(g)⊆Im(f).
> 4. f≠g.
This definition is directly analogous to that given in Misspecification in Inverse Reinforcement Learning (and in this post).
Some of the results in this paper apply to any pseudometric on R, but sometimes, we will have to |
055fc9af-a430-4405-b2b6-deeab3351da0 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Long-Term Trends in the Public Perception of Artificial Intelligence
Introduction
------------
>
> Artificial intelligence will spur innovation and create opportunities, both for individuals and entrepreneurial companies, just as the Internet has led to new businesses like Google and new forms of communication like blogs and social networking. Smart machines, experts predict, will someday tutor students, assist surgeons and safely drive cars.
>
>
>
> Computers Learn to Listen, and Some Talk Back. NYT, 2010
>
>
>
> In the wake of recent technological advances in computer vision, speech recognition and robotics, scientists say they are increasingly concerned that artificial intelligence technologies may permanently displace human workers, roboticize warfare and make Orwellian surveillance techniques easier to develop, among other disastrous effects.
>
>
>
> Study to Examine Effects of Artificial Intelligence. NYT, 2014
>
>
>
>
>
>
These two excerpts from articles in the New York Times lay out competing visions for the future of artificial intelligence (AI) in our society. The first excerpt is optimistic about the future of AI—the field will “spur innovation,” creating machines that tutor students or assist surgeons—while the second is pessimistic, raising concerns about displaced workers and dystopian surveillance technologies. But which vision is more common in the public imagination, and how have these visions evolved over time?
Understanding public concerns about AI is important, as these concerns can translate into regulatory activity with potentially serious repercussions [[Stone, P. et al.2016](#bib.bibx19)]. For example, some have recently suggested that the government should regulate AI development to prevent existential threats to humanity [[Guardian2014](#bib.bibx9)]. Others have argued that racial profiling is implicit in some machine learning algorithms, in violation of current law [[ProPublica2016](#bib.bibx13)]. More broadly, if public expectations diverge too far from what is possible, we may court the smashed hopes that often follow from intense enthusiasm and high expectations.
AI presents a difficult case for studies of topic sentiment over time because the term is not precisely defined. Lay people and experts alike have varied understandings of what “artificial intelligence” means [[Stone, P. et al.2016](#bib.bibx19)]. Even in the narrowest, engineering-centric definitions, AI refers to a broad constellation of computing technologies.
We present a characterization of impressions expressed about AI in the news over 30 years. First, we define a set of indicators that capture levels of engagement, general sentiment, and hopes and concerns about AI. We then apply and study these indicators across 30 years of articles from the New York Times. As a proxy for public opinion and engagement, no other corpus extends so far into the past to capture how a general audience thinks about AI. Moving forward, we can apply these indicators to present day articles in an ongoing effort to track public perception.
Our study relies on a combination of crowdsourcing and natural language processing. For each article under analysis, we extract all mentions of artificial intelligence and use paid crowdsourcing to annotate these mentions with measures of relevance, their levels of pessimism or optimism about AI, and the presence of specific hopes and concerns, such as “losing control of AI” or “AI will improve healthcare.” These annotations form the basis of the indicators and allow us to bootstrap a classifier that can automatically extract impressions about AI, with applications to tracking trends in new articles as they are generated.
To study how public perception of AI has changed over time, we analyze the set of indicators for articles published in the New York Times between January 1986 and June 2016. We address four research questions:
R1: How prominent is AI in the public discussion today, as compared to the past?
R2: Have news articles become generally more optimistic or more pessimistic about AI over time?
R3: What ideas are most associated with AI over time?
R4: What specific ideas were the public concerned about in the past, which are no longer concerns today? Likewise, what new ideas have arisen as concerns?
When we examine the impression indicators across historical data, we find that AI has generally taken on a stronger role in public discussion over time—with a few notable blips, such as the so-called AI winter in 1987. Further, we find that the mood of discussion has generally remained more optimistic over time, although this trend is not common across all concerns (e.g., AI’s impact on work). Finally, we discover that some ideas, such as “AI for healthcare” or “losing control of AI,” are more common today than in the past. Other ideas, for example, that “AI is not making enough progress” or that “AI will have a positive impact on work,” were more common in the past than they are today.
Indicators of Impressions about AI
----------------------------------
We capture the intensity of engagement on AI in the news as well as the prevalence of a diverse set of hopes and concerns about the future of AI. We took inspiration from the Asilomar Study of 2008-09 [[Horvitz and Selman2009](#bib.bibx10)] and the One Hundred Year Study on Artificial Intelligence [[Stanford University2014](#bib.bibx18)] to create measures that capture a long-term perspective for how AI impacts society.
### General Measures
We have included the following general measures:
Engagement. This measure serves as a proxy for public interest and engagement around AI, capturing how much AI is discussed in the news over time.
Optimism vs. Pessimism. This measure captures the attitude of a discussion—the degree to which it implies a sense of optimism or pessimism about the future of AI. This attitude can stem from technological progress, such as optimistic reporting on new breakthroughs in deep learning. But it can also be influenced by the impact of new technologies on society: for example, the time-saving benefits of a self-driving car (a form of optimism); or the dangers of surveillance as data is collected and mined to track our leanings, locations, and daily habits (a form of pessimism). We include such attitudinal leanings as an indicator to track these high-level trends. Notably, traditional sentiment analysis does not capture optimism versus pessimism.
The remainder of our indicators capture common hopes and concerns about the future of AI.
### Hopes for Artificial Intelligence
We have included the following hopes for AI as indicators:
Impact on work (positive): AI makes human work easier or frees us from needing to work at all, e.g., by managing our schedules, automating chores via robots.
Education: AI improves how students learn, e.g., through automatic tutoring or grading, or providing other kinds of personalized analytics.
Transportation: AI enables new forms of transportation, e.g., self-driving cars, or advanced space travel.
Healthcare: AI enhances the health and well-being of people, e.g., by assisting with diagnosis, drug discovery, or enabling personalized medicine.
Decision making: AI or expert systems help us make better decisions, e.g., when to take a meeting, or case-based reasoning for business executives.
Entertainment: AI brings us joy through entertainment, e.g., though smarter enemies in video games.
Singularity (positive): A potential singularity will bring positive benefits to humanity, e.g., immortality.
Merging of human and AI (positive): Humans merge with AI in a positive way, e.g., robotic limbs for the disabled, positive discussions about potential rise of transhumanism.
### Concerns for Artificial Intelligence
We have also considered the following concerns for AI:
Loss of control: Humans lose control of powerful AI systems, e.g., Skynet or “Ex Machina” scenarios.
Impact on work (negative): AI displaces human jobs, e.g., large-scale loss of jobs by blue collar workers.
Military applications: AI kills people or leads to instabilities and warfare through military applications, e.g., robotic soldiers, killer drones.
Absence of Appropriate Ethics: AI lacks ethical reasoning, leading to negative outcomes, e.g., loss of human life.
Lack of progress: The field of AI is advancing more slowly than expected, e.g., unmet expectations like those that led to an AI Winter.
Singularity (negative): The singularity harms humanity, e.g., humans are replaced or killed.
Merging of human and AI (negative): Humans merge with AI in a negative way, e.g., cyborg soldiers.
Data: Thirty Years of News Articles
-----------------------------------
We conduct our analysis over the full set of articles published by the New York Times between January 1986 and May 2016—more than 3 million articles in total.
We have created this dataset by querying the New York Times public API for metadata (e.g., title of article, section of paper, current URL) associated with articles published on each individual day within the scope of our analysis. For each article, we then scrape the full text from its URL using the BeautifulSoup python package.
Next, we annotate articles on AI. Unfortunately, crowdsourcing annotations for full news articles is a complex task, requiring a large time expenditure for workers. For this reason we segment our data into paragraphs. In news articles, paragraphs tend to be self-contained enough that workers can annotate them accurately without reading the rest of the article. This makes them a good middle ground between full documents and individual sentences. For example:
>
> Artificial intelligence “has great potential to benefit humanity in many ways.” An association with weaponry, though, could set off a backlash that curtails its advancement.
>
>
>
While the above paragraph clearly discusses AI for military applications, annotating the same text at the sentence or document level might not produce that annotation. For example, sentence level annotations would not connect “its” with AI, and document level annotations would too often result in workers missing the relevant passage, but paragraph level annotations easily capture this relationship.
It is expensive to crowdsource annotations the tens of millions of paragraphs in the dataset, so we filter these paragraphs to the set that contain “artificial intelligence”, “AI”, or “robot”. (We include “robot” to increase coverage—we are not concerned with false positives at this stage, as we will later filter for relevance.) In total, we retrieve more than 8000 paragraphs that mention AI over a thirty year period.
Crowdsourcing to Annotate Indicators
------------------------------------
Crowdsourcing provides an efficient way to gather annotations for our dataset of AI-related paragraphs. In this section, we present the details of the approach.
### Task Setup
We used Amazon Mechanical Turk (AMT) to collect annotations for the more than 8000 AI-related paragraphs in our dataset. We assigned each paragraph to a task with multiple components. First, we collected annotations for attitude about the future of AI (from pessimistic to optimistic) on a 5-point Likert scale. We then collected low level annotations for all of the specific hopes and concerns developed. We requested binary labels that indicate whether the hope or concern is present in the paragraph (e.g., AI will have a negative impact on work).
Finally, to ensure that unrelated paragraphs do not bias our results, we collected high-level annotations for AI relevance (from strongly unrelated to strongly related) on a 5-point Likert scale.
We assigned each AMT task to three independent workers in pursuit of reliable labels [[Sheng, Provost, and
Ipeirotis2008](#bib.bibx17)]. We provided examples to better ground the task [[Doroudi et al.2016](#bib.bibx5)], and recruited Masters workers to ensure quality results. We paid $0.15 per task in line with guidelines for ethical research [[Salehi, Irani, and Bernstein2015](#bib.bibx15)], for a total cost of $3825. In Supplementary Material, we include a template for the task we used.
In general, workers show high rates of agreement over labels for AI relevance and mood. Across paragraphs, 97% of workers agreed that they were either at least somewhat related to AI or else unrelated. 70% of workers agreed when distinguishing between optimistic and pessimistic articles. When interpreting ratings for AI relevance and attitude, we take the average across workers.
### Interpreting annotations for hopes and concerns
One decision we must make is how to interpret the crowd annotations for hopes and concerns. Should we require that all three workers mark a paragraph with a hope or concern to include it in our data? Or trust the majority vote of two workers? Or require only one worker’s vote? Requiring a larger number of votes will reduce the rate of false positives (i.e., labeling a paragraph with a hope or concern it does not exhibit), but may increase the rate of false negatives.
To determine the best approach, we established a ground truth dataset for one example concern, military applications for AI. We examined each paragraph associated with this concern by at least one worker and determined whether it in fact expressed that concern. This allowed us to calculate precision and
a proxy for recall111This number will be higher than true recall, but describes how many true positives we miss in the subset of ground truth data. across voting schemes.
We find a trade-off between precision and recall (Table [1](#Sx4.T1 "Table 1 ‣ Interpreting annotations for hopes and concerns ‣ Crowdsourcing to Annotate Indicators ‣ Long-Term Trends in the Public Perception of Artificial Intelligence")). Requiring two or more votes results in precision of 100%, but recall of 59%. Alternatively, only requiring one worker vote results in precision of 80% and recall of 100%. In light of these numbers and the fact that many of our hopes and concerns are covered sparsely in the dataset (for example, we see only 231 mentions of “loss of control of AI” across the thirty year corpus), we require only one worker vote to label a paragraph with a given hope or concern.
| # worker votes | 1 | 2 | 3 |
| --- | --- | --- | --- |
| precision | 0.81 | 1.00 | 1.00 |
| recall | 1.00 | 0.59 | 0.18 |
| | | | |
Table 1: How voting schemes impact a paragraph’s association with military applications in terms of precision and a proxy for recall on ground truth data.
Trends in the Public Perception of AI
-------------------------------------
Using our crowdsourced annotations, we now analyze trends in public impressions of AI over 30 years of news articles. We conduct this analysis through four research questions.

Figure 1: Articles that discuss AI over time, as a percentage of the total number of articles published per year. The green line plots optimistic articles and the yellow line plots pessimistic articles. AI discussion has exploded since 2009, but levels of pessimism and optimism have remained balanced.
### R1: How prominent is discussion of AI?
A natural starting point for understanding the public perception of AI is to examine how frequently it is discussed over time, and what events influence this discussion.
We capture this idea through an engagement measure. To compute this, we first filter the data to include only paragraphs with an average AI relevance rating of more than 3.0, as determined by our crowdsourcing pipeline. We then aggregate these paragraphs by the news article they appear in, and further aggregate articles by their year of publication. This leaves us with data that count how many articles that mention AI are published every year from 1986 to 2016. Finally, we normalize these counts by the total volume of articles published each year.
We present a graph of AI engagement in Figure [1](#Sx5.F1 "Figure 1 ‣ Trends in the Public Perception of AI ‣ Long-Term Trends in the Public Perception of Artificial Intelligence"). Most strikingly, we observe a dramatic rise in articles that mention AI beginning in late 2009. While the cause of this rise is unclear, it occurs following a renaissance in the use of neural nets (”deep learning”) in natural language and perceptual applications, and after a front page story discussed the Asilomar meeting [[Horvitz and Selman2009](#bib.bibx10)]. We also observe a fall in AI discussion that corresponds with the start of the 1987 AI winter—reaching its lowest level in 1995.
### R2: Have impressions reported in the news become more optimistic or pessimistic about AI?
In addition to engagement, we studied indicators for levels of pessimism and optimism in the coverage of AI. How have these levels changed over time? While it is easy to imagine a public celebration of AI technology as it becomes more common, it is also possible to imagine greater levels of concern, as people worry about changes they cannot control.
To track public sentiment over time, we draw on the dataset of AI-related news articles, aggregated by year, that we created for R1. We divide each year into counts of optimistic and pessimistic articles, as determined by the attitude rating in our crowdsourcing pipeline (considering an article optimistic if it has an average rating greater than 3, and pessimistic if it has an average rating of less than three).
We present the resulting trends in Figure [1](#Sx5.F1 "Figure 1 ‣ Trends in the Public Perception of AI ‣ Long-Term Trends in the Public Perception of Artificial Intelligence"). In general, AI has had consistently more optimistic than pessimistic coverage over time, roughly 2-3 times more over the 30 year period. Since 2009, both optimistic and pessimistic coverage have exploded along with general interest in AI.

Figure 2: New York Times keywords associated with articles that mention AI over time. For example, chess emerges most strongly in the late 1990s, after Deep Blue beats Kasparov.
### R3: What kinds of ideas are associated with AI, and how have they changed?
The field of AI has changed enormously since 1986. What kinds of ideas did people associate with AI in the past, and how have these ideas changed in the present?
To find out, we investigate the keywords most associated with AI-related articles from different time periods. We gather these keywords—for example, “space” or “world politics” or “driverless vehicles”—from the New York Times API. We then group all New York Times articles into six five-year intervals between 1986 and 2016, and compute the mutual information (MI) between keyword counts and AI articles within each time period. For example, the keyword “space” might appear 80 times across all articles and 25 times in association with AI-related articles between 1986 and 1990, producing high MI with AI for that time period. This gives us a measure of the keywords most associated with AI articles over time. We then look across time periods and record themes in how these keywords change.
We present a sample of the keywords most strongly associated with AI for each time period in Figure [2](#Sx5.F2 "Figure 2 ‣ R2: Have impressions reported in the news become more optimistic or pessimistic about AI? ‣ Trends in the Public Perception of AI ‣ Long-Term Trends in the Public Perception of Artificial Intelligence"). Each keyword in the sample is among the 50 most related for that period and applies to at least two AI articles in the corpus. Some keywords (e.g., “robot”) are common across all periods, and we did not include these in the sample. Other keywords (e.g., “computer games”) remain strongly related to AI after the first time period in which they appear.
The change in AI-associated keywords across time is revealing. From the concept of space weapons in 1986:
>
> Real-time parallel processing may be the computational key to the creation of artificial intelligence, and conceivably to such functions as the control of President Reagan’s Strategic Defensive Initiative, or Star Wars, program.
>
>
>
To chess in 1997:
>
> Even before the world chess champion Garry Kasparov faced the computer Deep Blue yesterday, pundits were calling the rematch another milestone in the inexorable advance of artificial intelligence.
>
>
>
To search engines in 2006:
>
> Accoona is a search engine that uses a heavy dose of artificial intelligence to find results that Google may miss.
>
>
>
To driverless vehicles in 2016:
>
> United States vehicle safety regulators have said the artificial intelligence system piloting a self-driving Google car could be considered the driver under federal law.
>
>
>
We also observe how the association of AI with individual keywords changes across time. For example, the association between AI and science fiction, while present across all periods, peaks in the early 1990s.

Figure 3: Hopes and concerns from 1986 to 2016. In recent years, we see an increase in concern that humanity will lose of control of AI, and hope for the beneficial impact of AI on healthcare. The y-axis measures the percentage of AI articles that mention a specific hope or concern.
### R4: How have public hopes and concerns about AI changed over time?
Beyond keywords, we studied indicators for fine-grained set of hopes and concerns related to AI. Here we examine how these ideas have evolved over time.
To this end, we examine all paragraphs tagged with AI hopes and concerns. We aggregate each of these paragraphs by article, and then by year. We consider an article as expressing a given hope or concern if it contains at least one paragraph that the crowd labeled with that concept. This gives us data that count the total number of times each AI hope and concern is expressed per article per year. We normalize these data by the total number of AI-related articles published per year, to arrive at a yearly percentage of AI-related articles that discuss each hope and concern.
We present the resulting trends in Figure [3](#Sx5.F3 "Figure 3 ‣ R3: What kinds of ideas are associated with AI, and how have they changed? ‣ Trends in the Public Perception of AI ‣ Long-Term Trends in the Public Perception of Artificial Intelligence"). While some data are sparse, we observe several clear upward trends. The fear of loss of control, for example, has become far more common in recent years—more than triple what it was as a percentage of AI articles in the 1980s (Figure 3M). For example, in one article from 2009:
>
> Impressed and alarmed by advances in artificial intelligence, a group of computer scientists is debating whether there should be limits on research that might lead to loss of human control over computer-based systems that carry a growing share of society’s workload, from waging war to chatting with customers on the phone.
>
>
>
Ethical concerns for AI have also become more common, driven in part by similar existential worries (Figure 3L). For example, in an article from 2015:
>
> Two main problems with artificial intelligence lead people like Mr. Musk and Mr. Hawking to worry. The first, more near-future fear, is that we are starting to create machines that can make decisions like humans, but these machines don’t have morality and likely never will.
>
>
>
These trends suggest an increase in public belief that we may soon be capable of building dangerous AI systems.
From a more positive standpoint, AI hopes for healthcare have also trended upwards (Figure 3G). One strong theme is AI systems that care for patients. From 2003:
>
> For patients with more advanced cases, the researchers held out the possibility of systems that use artificial intelligence techniques to determine whether a person has remembered to drink fluids during the day.
>
>
>
Another driver of this trend is systems that can diagnose patients, or bioinformatics to cure disease. From 2013:
>
> After Watson beat the best human Jeopardy champions in 2011, its artificial intelligence technology was directed toward new challenges, like assisting doctors in making diagnoses in a research project at the Cleveland Clinic.
>
>
>
In contrast, concerns over lack of progress have decreased over time, despite a recent uptick (Figure 3P). This concern reached its high in 1988, at the start of the AI winter:
>
> The artificial intelligence industry in general has been going through a retrenchment, with setbacks stemming from its failure to live up to its promises of making machines that can recognize objects or reason like a human.
>
>
>
>
Intriguingly, many articles labeled with this concern in recent years draw reference to the past—a kind of meta-discussion about the lack of progress concern itself.
Among the remainder of the trends, a positive view of the impact of AI on human work has become less common, while a negative view has increased sharply in recent years (Figure 3E-F). AI for education has grown over time (Figure 3D), as has a positive view of merging with AI (Figure 3I) and the role of AI in fiction (Figure 3N).

Figure 4: We validated the increasing concern in loss of control on Reddit data. The y-axis measures the percentage of AI-related comments that mention loss of control of AI.
News Articles from 1956 to 1986
-------------------------------
The New York Times provides full text for articles published after 1986, but article abstracts (short descriptions of article content) are available over a much longer time period. To extend our results, we collected a dataset of all abstracts published between 1956 (the year of the first AI workshop at Dartmouth) and 1986.
Articles that mention AI are less common over this earlier period, with only 40 abstracts that reference AI (the first appears in 1977) and 247 that mention robots. These data are too sparse to extend our earlier analyses to 1956, but we have manually annotated each abstract with topic keywords to observe themes over time.
In the 1950s, robots are most associated with military applications and especially missiles, e.g., “the guided missile—the almost human robot of the skies.” The 1960s and 70s strongly emphasize space, as in “a ten-pound robot was shot into orbit today.” Interest in AI picks up considerably in the early 1980s, where we see the first article that worries AI will negatively impact human jobs, the first reported death via robot, “a factory worker killed by a robot arm,” and the first mention of AI in healthcare, “a robot to prepare meals and perform other chores for quadriplegics.”
External validity
-----------------
Do the trends we have discovered in the New York Times generalize to the public at large? While this question is difficult to answer directly, we have replicated one of our primary findings on 5 years of public posts from Reddit, a popular online community with a diverse set of users.
Concretely, we train a classifier to predict the presence of loss of control in paragraphs about AI using our annotated data from the New York Times. We then apply this classifier to posts made by Reddit users. We use a logistic regression model based on TF-IDF features and threshold the positive class probability at 0.9. In validation, we observe precision of 0.8 on a sample of 100 Reddit posts annotated with ground truth. Finally, we apply this classifier to every post that mentioned “artificial intelligence” from 2010 to 2015.
We present the resulting trend in Figure [4](#Sx5.F4 "Figure 4 ‣ R4: How have public hopes and concerns about AI changed over time? ‣ Trends in the Public Perception of AI ‣ Long-Term Trends in the Public Perception of Artificial Intelligence"), which mirrors Figure 3M over the same time period. Broadly, this replication suggests that attitudes among Reddit users shift in line with what we see in the New York Times, providing some evidence for the external validity of our findings.
Related Work
------------
Others have discussed the impact of artificial intelligence on society and the range of future outcomes [[Dietterich and Horvitz2015](#bib.bibx4)]. These discussions are in part driven by a need to address public concerns about AI—our work is the first to quantify such concerns through direct analysis. The set of indicators we have introduced will be useful in framing future discussions, such as those ongoing in the One Hundred Year Study of Artificial Intelligence [[Stanford University2014](#bib.bibx18)].
Public opinion polls have similarly measured topics relevant to AI. While such polls are recent (and not conducted over time), they support our findings, showing greater levels of optimism than pessimism about AI, but increasing existential fear and worry about jobs [[BSA2015](#bib.bibx2), [60 Minutes2016](#bib.bibx1)]. Future polls might allow us to directly measure public opinion on the set of measures we have studied.
Beyond artificial intelligence, other work has mined cultural perspectives from text corpora over long time periods. For example, by analyzing 200 years of data from Google Books, it is possible to quantify the adoption of new technologies or changes in psychological attitudes through linguistic patterns [[Michel et al.2011](#bib.bibx12), [Greenfield2013](#bib.bibx8)]. Using music, others have quantified changes in artistic style over a 40 year period [[Serrà et al.2012](#bib.bibx16)]. We use crowdsourced annotations to extend the limits of what is possible under these kinds of quantitative analyses.
News and social media offer a powerful reflection of public attitudes over time. For example, by analyzing such data, it is possible to predict cultural events such as revolutions [[Radinsky and Horvitz2013](#bib.bibx14), [Leetaru2011](#bib.bibx11)], or examine public opinion on same-sex marriage [[Zhang and Counts2015](#bib.bibx20)]. Here we use such data to discover and validate similar trends in the public perception of artificial intelligence.
Finally, crowdsourcing is a powerful tool for enabling new kinds of quantitative analyses. For example, it is possible to crowdsource lexicons of words to answer novel research questions [[Fast, Chen, and Bernstein2016](#bib.bibx7)], or leverage crowds to bootstrap classifiers that can then be applied to much larger corpora [[Danescu-Niculescu-Mizil et
al.2013](#bib.bibx3), [Fast and Horvitz2016](#bib.bibx6)]. Here we use crowds to identify themes in articles that would be difficult to analyze under fully automated approaches.
Conclusion
----------
We present a set of indicators that capture levels of engagement, general sentiment, and hopes and concerns for the future of artificial intelligence over time. We then validate these impression indicators by studying trends in 30 years of articles from the New York Times. We find that discussion of AI has increased sharply since 2009 and has been consistently more optimistic than pessimistic. However, many specific concerns, such as the fear of loss of control of AI, have been increasing in recent years. |
647803ec-1f7b-48ff-b710-9a3feb5d2b2b | trentmkelly/LessWrong-43k | LessWrong | Yudkowsky on The Trajectory podcast
Edit: TLDR: EY focuses on the clearest and IMO most important part of his argument:
* Before building an entity smarter than you, you should probably be really sure its goals align with yours.
* Humans are historically really bad at being really sure of anything nontrivial on the first real try.
I found this interview notable as the most useful public statement yet of Yudkowsky's views. I congratulate both him and the host, Dan Fagella, for strategically improving how they're communicating their ideas.
Dan is to be commended for asking the right questions and taking the right tone to get a concise statement of Yudkowsky's views on what we might do to survive, and why. It also seemed likely that Yudkowsky has thought hard about his messaging after having his views both deliberately and accidentally misunderstood and panned. Despite having followed his thinking over the last 20 years, I gained new perspective on his current thinking from this interview.
Takeaways:
* Humans will probably fail to align the first takeover-capable AGI and all die
* Not because alignment is impossible
* But because humans are empirically foolish
* And historically rarely get hard projects right on the first real try
* Here he distinguishes first real try from getting some practice -
* Metaphor: launching a space probe vs. testing components
* Therefore, we should not build general AI
* This ban could be enforced by international treaties
* And monitoring the use of GPUs, which would legally all be run in data centers
* Yudkowsky emphasizes that governance is not within his expertise.
* We can probably get away with building some narrow tool AI to improve life
* Then maybe we should enhance human intelligence before trying to build aligned AGI
* Key enhancement level: get smart enough to quit being overoptimistic about stuff working
* History is just rife with people being surprised their projects and approaches don't work
I find mys |
adffb4d0-9cbc-4695-a6ee-d507ab94fe36 | trentmkelly/LessWrong-43k | LessWrong | Attention! Financial scam targeting Less Wrong users
Recently, multiple suspicious user accounts were created on Less Wrong. These accounts don't post any content in the forum. Instead, they are used only to send private messages to the existing users.
Many users have received a copy of the same message, but different variants exist, too. Here are the examples I know about. If you have received a different variant, please post it in a comment below this article:
> Hi good day. My boss is interested on donating to MIRI's project and he is wondering if he could send money through you and you donate to miri through your company and thus accelertaing the value created. He wants to use "match donations" as a way of donating thats why he is looking for people in companies like you. I want to discuss more about this so if you could see this message please give me a reply. Thank you!
> hi. ive made 500k+ the last half year on esport betting and i can show proof. i was a great poker player before that so i have reason to believe i am good and wellsuited at this. i want to offer free education to one of the efw people that have their priorities straight in this world and will work towards minimising existential risk. the higher intelligence the better. ultimately i would like to offload some work to someone because currently i am gettin gquite a bit burnt out and i would like to study finance, and having someone take advantage of the incredible ineffeciencies in this area is of huge importance. i would like to discuss this with someone and how to make it real, and have exchange of thoughts on all of the aspects on how to best do it. i can post proof and make donations to miri to show im serious so that we or someone else could have a discussion about it
I don't know yet about anyone who replied and got scammed, so this is all based on indirect evidence. If you got scammed, please tell me. If you are ashamed, I can publish your story anonymously. Your story could help other potential victims.
Most likely, the schem |
45621af8-1b91-443d-bd36-ff51900e9719 | trentmkelly/LessWrong-43k | LessWrong | Some conditional independence (Bayes Network) exercises from ai-class.com
If you'd like to see some visual representations of conditional independence is neither necessary or sufficient for independence, confounding causes, explaining away, etc. you should be able to view these videos from ai-class.com.
Working the exercises gave me a better understanding than the "I understand this and so don't need to actually apply it" feeling that almost satisfied me. |
c84fd337-4447-4a01-ad7b-bd646c25bdb5 | trentmkelly/LessWrong-43k | LessWrong | A Very Mathematical Explanation of Derivatives
This post is meant for readers familiar with algebra and derivatives, but want to deepen their understanding and/or need a refresh.
Linear functions
Let's start with a family of very basic functions: the linear functions, expressed as f(x)=ax+b. You might remember its derivative is f′(x)=a, because x is multiplied by a and the constant b "disappears" when taking the derivative. This is correct, but let's actually calculate the derivative. Since f(x) is a linear function, f′(x) is the same for all x. That is, a linear function "goes up" with the same "speed" everywhere, as can be seen in the following graph for g(x)=2x+5:
For example, between x=0 and x=1, f(x) increases with 2, just like it does between e.g. x=2 and x=3. Therefore, determining the average slope between x and x+d will do. The average slope between x and x+d is how much f(x) increases between x and x+d, divided by the difference between x and x+d (which is d). Let d=1, in which case we don't have to do the division, as f′(x)=f(x+1)−f(x)1=f(x+1)−f(x). Filling in ax+b for f(x) and a(x+1)+b for f(x+1), we get:
f′(x)=f(x+1)−f(x)=(a(x+1)+b)−(ax+b)=ax+a+b−ax−b=a
There it is! f′(x)=a. So for g(x)=2x+5, where a=2, this means g′(x)=2.
Polynomials (and more)
Polynomials are functions with the following form:
f(x)=a0xn+a1xn−1+...+an−1x+an
Determining their derivative is a bit more tricky than determining the derivative of a linear function, because now, the derivative isn't necessarily the same everywhere. After all, take g(x)=x2:
We can see this is a curved line, and so the derivative is constantly changing. We can sill do something like the "trick" we did with linear functions, but we can't determine f′(x)by looking how f(x) changes between x and x+1: that would assume f′(x) is the same between x and x+1, which isn't true. For x and x+0.001, we would have a better estimate of f′(x), but we'd still assume f′(x) to be constant between these values. We need to determine how f(x) changes between x and |
13d43265-4d67-43e2-a2a2-bc404539b306 | trentmkelly/LessWrong-43k | LessWrong | Defaulting to not noticing the meetup list
I just registered that I'm not looking at the meetup list to see whether there's anything in my area-- the letters are too small and faint.
Are other people skimming past the meetup list, too?
If it's a general problem, I recommend bolding the city names. |
bd346431-0040-4117-82a5-644bf415e44d | trentmkelly/LessWrong-43k | LessWrong | [LINK] Common fallacies in probability (when numbers aren't used)
Too many people attempt to use logic when they should be using probabilities - in fact, when they are using probabilities, but don't mention it. Here are some of the major fallacies caused by misusing logic and probabilities this way:
1. "It's not certain" does not mean "It's impossible" (and vice versa).
2. "We don't know" absolutely does not imply "It's impossible".
3. "There is evidence against it" doesn't mean much on its own.
4. Being impossible *in a certain model*, does not mean being impossible: it changes the issue to the probability of the model.
Common fallacies in probability |
23b2b277-aa3f-4dbe-b816-8276ffda7ed9 | trentmkelly/LessWrong-43k | LessWrong | Introducing myself: Henry Lieberman, MIT CSAIL, whycantwe.org
I'm Henry Lieberman, Research Scientist at the MIT Computer Science and AI Lab. I'm interested in long-term thinking about the future of humanity, technology and society, and have developed some new ideas, together with my colleague Christopher Fry, about how AI and other technologies can ensure a positive future for humanity. For the full story, see my Web site, https://www.whycantwe.org, where you'll find a 12-minute TED talk; other videos, and writing based on our book, "Why Can't We All Just Get Along?".
For specific thoughts on the Alignment question, here's an abstract (maybe a future paper and/or talk at an appropriate venue):
AI Alignment Depends on Human Alignment
Henry Lieberman – MIT CSAIL
The problem of whether the goals and values of an artificially intelligent agent will align with human goals and values, can be reduced to this problem: Will the goals and values of different human agents ever align with each other?
Regardless of what you believe about the problem for humans, we're likely to get the same answer when we think about intelligent machines. We can only program AI "in our own image", so both the features and bugs of humanity will reappear in AI. Thus, whether AI turns out to be a good thing or a bad thing in the future, depends critically on this question: Will humans cooperate with each other, or will they compete with one another?
Right now, our society is schizophrenic -- some of our institutions are oriented towards cooperation (like science), others (like business and politics) seem to be primarily oriented towards competing. Many of the social problems caused by AI are a result of this schizophrenia. If AI becomes a tool of warring human factions, we're doomed. But it doesn't have to be like that.
With all the evident conflict and disagreement in the world, some despair of the prospect of ever getting people to align their values, substantially, if not perfectly. Yet the technology itself will provide unprecedented opportuni |
100ba000-247e-4768-8804-92677d80a9a7 | trentmkelly/LessWrong-43k | LessWrong | The next decades might be wild
I’d like to thank Simon Grimm and Tamay Besiroglu for feedback and discussions.
Update (early April 2023): I now think the timelines in this post are too long and expect the world to get crazy faster than described here. For example, I expect many of the things suggested for 2030-2040 to already happen before 2030. Concretely, in my median world the CEO of a large multinational company like Google is an AI. This might not be the case legally but effectively an AI makes most major decisions.
This post is inspired by What 2026 looks like and an AI vignette workshop guided by Tamay Besiroglu. I think of this post as “what would I expect the world to look like if these timelines (median compute for transformative AI ~2036) were true” or “what short-to-medium timelines feel like” since I find it hard to translate a statement like “median TAI year is 20XX” into a coherent imaginable world.
I expect some readers to think that the post sounds wild and crazy but that doesn’t mean its content couldn’t be true. If you had told someone in 1990 or 2000 that there would be more smartphones and computers than humans in 2020, that probably would have sounded wild to them. The same could be true for AIs, i.e. that in 2050 there are more human-level AIs than humans. The fact that this sounds as ridiculous as ubiquitous smartphones sounded to the 1990/2000 person, might just mean that we are bad at predicting exponential growth and disruptive technology.
Update: titotal points out in the comments that the correct timeframe for computers is probably 1980 to 2020. So the correct time span is probably 40 years instead of 30. For mobile phones, it's probably 1993 to 2020 if you can trust this statistic.
I’m obviously not confident (see confidence and takeaways section) in this particular prediction but many of the things I describe seem like relatively direct consequences of more and more powerful and ubiquitous AI mixed with basic social dynamics and incentives.
Taking stock of |
944bc698-3ce6-4f95-a8e8-e4b0d1131ea4 | StampyAI/alignment-research-dataset/blogs | Blogs | “Technological unemployment” AI vs. “most important century” AI: how far apart?
In casual conversations about the future of AI - particularly among people who don’t go in for [wild](https://www.cold-takes.com/all-possible-views-about-humanitys-future-are-wild/), sci-fi stuff - there seems to be a lot of attention given to the problem of **technological unemployment**: AI systems outcompeting humans at enough jobs to create a drastic, sustained rise in the unemployment rate.
This tends to be seen as a “near-term” problem, whereas the [world-transforming impacts of AI I’ve laid out](https://www.cold-takes.com/most-important-century/) tend to be seen as more “long-term.”
This *could* be right. But here I’ll try to convey an intuition that it’s overstated: that the kind of AI that could [power a massive productivity explosion and threaten humanity’s very existence](https://www.cold-takes.com/transformative-ai-timelines-part-1-of-4-what-kind-of-ai/#impacts-of-pasta) could come pretty soon after - or even before! - the kind of AI that could lead to significant, long-lasting technological unemployment.
“Technological unemployment” AI would need to be extraordinarily powerful and versatile
---------------------------------------------------------------------------------------
The first key point is that I think people **underestimate how powerful and versatile AI would have to be to create significant, long-lasting technological unemployment.**
For example, imagine that AI advances to the point where truck drivers are no longer needed. Would this add over [3 million Americans](https://www.alltrucking.com/faq/truck-drivers-in-the-usa/#:~:text=There%20are%20approximately%203.6%20million,American%20Trucking%20Associations%20(ATA).) to the ranks of the unemployed? Of course not - they’d get other jobs. We’ve had centuries of progress in automation, yet today’s unemployment rate [is similar to where it was 50 years ago](https://fred.stlouisfed.org/series/UNRATE), around 5-6%.
(Temporary unemployment/displacement is a potential issue as well. But I don't think it is usually what people are picturing when they talk about technological unemployment, and I don't see a case that there's anything in that category that would be importantly different from the daily job destruction and creation that has been part of the economy for a long time.)
In order to leave these 3 million people *durably* unemployed, AI systems would have to outperform them at essentially **every economically valuable task.**
When imagining a world of increasing automation, it’s not hard to picture a lot of job options for relatively low-skilled workers that seem very hard to automate away. Examples might include:
* Caregiver roles, where it’s important for people to feel that they’re connecting with other humans (so it’s hard for AI to fully fill in).
* Roles doing intricate physical tasks that are well-suited to human hands, and/or unusually challenging for robots. (My general sense is that AI software is improving more rapidly than robot hardware.)
* Providing training data for AIs, focused on cases where they struggle.
* Surveying and interviewing neighbors and community members, in order to collect data that would otherwise be hard to get.
* Perhaps a return to [agricultural employment](https://ourworldindata.org/employment-in-agriculture#employment-in-agriculture-1300-to-today), if rising wealth leads to increasing demand for food from small, humane and/or picturesque farms (and if it turns out that AI-driven robots have trouble with all the tasks these farms require - or it turns out that AI-run farms are just hard to market).
* Many more possibilities that I’m not immediately thinking of.
And these roles could end up paying quite well, if automation elsewhere in the economy greatly raises productivity (leading to more total wealth chasing the people in these roles).
In my view, **a world where automation has made low-skill workers *fully unemployable* is a world with *extremely powerful, well-developed, versatile AI systems and robots*** - capable of doing *everything* that, say, 10% of humans can do. This could require AI with human-level capabilities at language, logic, fine motor control, interpersonal interaction, and more.
Powerful, versatile AI could quickly become transformative ("most important century") AI
----------------------------------------------------------------------------------------
And then the question is, how far is that from a world with AI systems that can make *higher-skilled* workers fully unemployable? For example, AI systems that could do absolutely everything that today’s successful scientists and engineers can do? Because that sounds to me like [PASTA](https://www.cold-takes.com/transformative-ai-timelines-part-1-of-4-what-kind-of-ai/) (my term for a type of AI that I've argued could make this century the [most important of all time for humanity](https://www.cold-takes.com/most-important-century/)), and at that point I think we have [bigger things to worry about](https://www.cold-takes.com/transformative-ai-timelines-part-1-of-4-what-kind-of-ai/#impacts-of-pasta).
In fact, I think there’s a solid chance that PASTA will come *before* the kind of AI that can make lower-skilled workers unemployable. This is because PASTA might not have to match humans at certain kinds of motor control and social interaction. So it might not make anyone totally unemployable (in the sense of having zero skills with economic value), even as it leads to a productivity explosion, wild technologies like [digital people](https://www.cold-takes.com/how-digital-people-could-change-the-world/), and maybe even human extinction.
**The idea that we might see AIs *fully outcompete* low-skill humans in the next few decades, but not fully outcompete higher-skill humans until decades after that, seems intuitively a bit weird to me.** It could certainly end up being right, but I worry that it is fundamentally coming from a place of anthropomorphizing AI and assuming it will find the same things easy and challenging that we do.
**Bottom line:** I think it’s too quick to think of technological unemployment as the next problem we’ll be dealing with, and wilder issues as being much further down the line. By the time (or even before) we have AI that can truly replace every facet of what low-skill humans do, the “wild sci-fi” AI impacts could be the bigger concern.
For email filter: florpschmop |
c464bedd-8f9a-4b05-aca1-22c035160887 | trentmkelly/LessWrong-43k | LessWrong | Empirical vs. Mathematical Joints of Nature
We (Alex and Elizabeth) are thinking about doing this project where we figure out how paradigm formation happened in chaos theory. Alex has also been thinking about paradigm formation for agent foundations (which people often talk about as being pre-paradigmatic). These are some thoughts on what paradigm formation means.
Alex_Altair
There's an issue which is something like, agent foundations is more like math than like science, and so it's unclear to me exactly what it means to have a paradigm. And I think this is similar to chaos theory, so it might be useful to talk it through and compare them.
Alex_Altair
On one hand, you could say that a paradigm is just a set of methods that people generally agree successfully solve problems. And in that sense, domains of math could totally have paradigms.
But in the sciences, there's another standard of whether a problem was solved, which is that reality was successfully predicted. Domains of math don't exactly try to "predict" phenomena, and so whether some problems were solved feels more subjective.
Alex_Altair
And I feel like both chaos theory and agent foundations are more like fields where people will just generally agree whether or not their confusion was resolved by certain frameworks, rather than fields where empirical phenomena are predicted.
Elizabeth
One definition I have been using of a paradigm is that it is a single solution to problems people believed were disparate. Newtonian physics predicted the rate of a falling apple and the orbit of the moon. Plate tectonics explained magnetic striping on the ocean floor, mountains, and the Wallace line (and let you use information about one to make predictions about the other that were born out).
Alex_Altair
Ah, interesting. That sounds related to something I've been thinking about which I might call paradigm shifts vs paradigm formation. I think Kuhn mostly talks about shifts, where there exists a previous strong paradigm. But if a field has no paradigm at all, t |
ad8b42a6-4faa-4017-a4a0-9d1e9a07c3a2 | trentmkelly/LessWrong-43k | LessWrong | Money Circulation in Games
I recently heard that they regulate the amount of money circulating in certain MMO games, which seems to me like a far fetched thing. Let us assume that you are a player in a game where you can kill monsters and gold is the currency. Each monster drops a set amount of gold each time you kill it, assuming that the monsters re-spawn, you could continue to pick up the gold dropped by each monster until you had an X amount of money.
Take Runescape for example. In your inventory you have 24 32-bit slots, each slot can hold 2,147,483,647 (or 231-1)gold pieces, but there is no limit to how many stacks of 231-1 gold pieces you can have. The only limit to the amount of gold you can have hear is the size of your banking account, and how many slots it can hold. In a member banking account, there are 516 spaces, which can each hold 2,147,483,647 gold, limiting you to 1,108,101,561,852 gold.
In another game, let us assume that monsters drop not just money, but also items. Let us also assume that there are shops you can sell the items too. If you kill monsters for said items and sell them to said shops, would you place limits on the amount of money said shops had in stock? What would happen when you wanted to sell and the shop had no money left to give you? In Fallout 3 (Which wasn't an MMO game but an XBox 360 game) each shop only had a set amount of "bottlecaps," the currency, and you supplied it to them by buying things from them. If they ran out of gold and you sold your items, then you would just give them away for free. If you were to incorporate this feature into an MMO game, then the result would probably be outrage from many players.
What if a game company were to add a feature which was more lifelike, where all jobs in the world were done by people. If you choose to run a shop, then you buy supplies from a warehouse, which is owned by the game company, and you cannot sell back to them. Assuming you made this game, this would be one way to help regulate money. Anot |
a3216ae1-1f12-40fb-a133-2f088b3074db | trentmkelly/LessWrong-43k | LessWrong | Lifehack Ideas December 2014
> Life hacking refers to any trick, shortcut, skill, or novelty method that increases productivity and efficiency, in all walks of life.
— Wikipedia
This thread is for posting any promising or interesting ideas for lifehacks you've come up with or heard of. If you've implemented your idea, please share the results. You are also encouraged to post lifehack ideas you've tried out that have not been successful, and why you think they weren't. If you can, please give credit for ideas that you got from other people.
To any future posters of Lifehack Ideas threads, please remember to add the "lifehacks_thread" tag. |
32b67486-0d61-454c-a997-74fa98d5d3b8 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Contrastive Code Representation Learning.
1 Introduction
---------------
Programmers increasingly rely on machine-aided programming tools such as automated refactoring and autocompletion refactoring\_kim2012field.
However, the wide diversity of programs encountered in practice limits the generalization of handmade rules. Large classes of program behaviors, such as naming errors or semantic bugs, prove difficult to encode in rules and require deeper language understanding. As a consequence, learning based approaches are attractive.
Recent work uses machine learning for bug detection pradel2018deepbugs, refactoring refactoring\_Kurbatova2020RecommendationOM; refactoring\_Yonai2019MercemMN, autocompletion karpathy\_2015; gpt3\_codegen and optimization adams2019learning; kaufman2019learned; mendis2019ithemal; mirhoseini2017device.
Due to the difficulty of annotating supervised training datasets over code, state-of-the-art approaches rely either on (1) synthetic supervised datasets or (2) self-supervised pre-training. Synthetic datasets with auto-generated labels have been applied to method naming alon2018code2seq; alon2019code2vec, documentation generation wiseman2017challenges and bug detection benton2019defexts; ferenc2018public. However, auto-generated synthetic datasets suffer from subtle duplication issues 10.1145/3359591.3359735 and biases shin2019synthetic which degrade generalization performance. Moreover, autogenerated data is less diverse than real data and does not cover all program behaviors encountered in the wild.
In contrast, self-supervised pre-training enables the use of large open-source repositories such as GitHub with limited or no annotations without artificially generating labels. Prior work has explored context-based token embeddings ben2018neural, prediction of specific attributes allamanis2016convolutional, and masked language modeling feng2020codebert; cuBERT.
These efforts focus on reconstructing the textual content of a program given surrounding tokens.
However, these pretext tasks focus on superficial language reasoning and do not explicitly address the underlying program functionality.
The resulting models attend to particularities of each program implementation such as variable names.
We hypothesize that *programs with the same functionality should have the same underlying representation* for downstream code understanding tasks, a principle illustrated in Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Contrastive Code Representation Learning").
While it is time intensive to identify equivalent programs in a large corpus, it is cheap to leverage static compiler transformations to automatically generate many equivalent versions of a particular source program.
In this work, we develop ContraCode, a self-supervised representation learning algorithm that uses source-to-source compiler transformation techniques (e.g.,
dead code elimination, obfuscation and constant folding) to generate syntactically diverse but functionally equivalent programs.
ContraCode uses these equivalent programs to construct a challenging discriminative pretext task that requires the model to identify equivalent programs out of a large dataset of distractors.
In doing so, it has to embed the functionality, not the form, of the code.
In essence, the domain knowledge from our code transformations induces the knowledge of the structure of programs onto learned representations.
The contributions of our work include:
1. the concept of program representation learning based on functional equivalence, independent of the underlying encoder model architecture,
2. an instantiation of this based on a novel application of compiler transformations to generate equivalent, textually divergent batches of programs, and
3. an evaluation of several model architectures demonstrating that Contrastive Code Representation Learning results in a 10.2% relative accuracy improvement over supervised baselines for the code summarization task and up to 4.5% improvement for the type inference task.

Figure 1: Programs with the same functionality should have the same underlying representation. ContraCode learns such representations with contrastive learning: the network is trained to find equivalent programs among many distractors, thereby distilling compiler invariants into the representation.
2 Related Work
---------------
#### Self-supervised learning
Self-supervised learning is a general representation learning strategy where some dimensions or attributes of a datapoint are predicted from the remaining parts. These methods are unsupervised in the sense that they do not rely on labels. However, self-supervised tasks are often solved using losses and architectures designed for supervised learning.
Self-supervised pre-training has yielded large improvements in both natural-language processing devlin2018bert; nlp\_howard2018universal; nlp\_radford2018improving; nlp\_radford2019language and computer vision weaksupervision\_mahajan2018exploring; chen2020improved; chen2020simple; he2019momentum; henaff2019data; oord2018representation by improving generalization erhan2010does.
Early work in self-supervised learning for computer vision found that weak features, such as the orientation rotnet\_gidaris2018unsupervised, color zhang2016colorful and context pathak2016context of an image, are meaningful signals for representation learning weaksupervision\_mahajan2018exploring.
#### Contrastive learning
Recently, contrastive learning has emerged as a simple framework unifying many past approaches to self-supervised learning based on comparing pairs or collections of similar and dissimilar items hadsell2006dimensionality. Rather than training the network to predict labels or generate data, contrastive methods directly minimize a distance between the representations of similar data (positives) and maximize the distance between dissimilar data (negatives). Approaches that use few negatives include Siamese networks bromley1994signature and triplet losses schroff2015facenet. Contrastive predictive coding cpcv1\_oord2018representation; henaff2019data learns to encode pieces of sequential data such as audio so that the representations are predictive of representations of future pieces of the data using the InfoNCE loss oord2018representation, a variational lower bound on mutual information between views of the data wu2020mutual inspired by noise-constrastive estimation gutmann2010noise. By framing the problem as classification, the model need not generate all the fine details of the data, but must extract its identity. In instance discrimination tasks, rather than comparing pieces of data such as timeslices, variants (data augmentations) of an entire image are compared to different images. Momentum Contrast he2019momentum is a memory-efficient method for contrastive learning that caches representations of negative samples and only computes gradients for the positive query encoder. SimCLR chen2020simple evaluated an InfoNCE-like loss over exceptionally large batch sizes, thereby providing a dense loss signal between positive and negative pairs. SimCLR demonstrated state-of-the-art results without the momentum queue in MoCo. However, it requires considerable computational resources to train over such large batch sizes. A recent extension of MoCo chen2020improved added the projection head and additional augmentations from SimCLR. In computer vision, simple augmentations such as rotating, cropping, blurring or jittering an image can generate diverse variants of a base image. However, text-based domains like code lack such simple transformations. The InfoNCE pre-training objective has been applied to natural language cpcv1\_oord2018representation; chuang2020debiased, but is outperformed by baselines or requires auxiliary supervised models for data augmentation Fang\_2020.
#### Code representation learning
There has been substantial work on architectures and tasks for machine learning on code allamanis2018survey. The tree or graph structure of code can be exploited to encode invariances into the representation learning method. Inst2vec ben2018neural locally embeds individual statements in LLVM IR by processing a contextual flow graph with a context prediction objective mikolov2013distributed.
Tree-Based CNN embeds the Abstract Syntax Tree (AST) nodes of high-level source code.
Code2seq alon2018code2seq embeds paths in the AST with a specialized attention-based encoder and an LSTM decoder for supervised sequence-to-sequence tasks. These architectures are orthogonal to the training objective. Transformer vaswani2017attention architectures have been pre-trained on unlabeled code cuBERT; feng2020codebert using the masked language modeling objective devlin2018bert; liu2019roberta, an instance of the cloze task taylor1953cloze where hidden tokens predicted by the model. Recurrent networks have also been pre-trained for code tasks Hussain\_2020 e.g. through language modeling Peters:2018; karampatsis2020scelmo. These models do not use contrastive learning, though semi-automated program transformations have been used to assess the stability of the predictions of program classifiers under refactoring and optimization wang2019coset; wang2019learning. Our framework differs from previous work in that it learns contextual embeddings of program tokens in an unsupervised fashion via contrastive learning and transfers knowledge to tasks.
We adopt the extreme code summarization (method naming) task from alon2018code2seq to verify the performance and the semantic meaning of the representation learned by the encoder, and the variable type inference task of DeepTyper hellendoorn2018deep. Other authors have explored summarization movshovitz2013natural; allamanis2016convolutional; iyer2016summarizing and type inference bielik2020adversarial; p2020opttyper; Wei2020LambdaNet; allamanis2020typilus; pradel2019typewriter with different languages and datasets.

Figure 2: ContraCode extends the MoCo training framework he2019momentum to learn an encoder of programs using a database of unlabeled programs and a suite of semantics-preserving transformations.
3 Method: Contrastive Code Representation Learning
---------------------------------------------------
Learned code representations should be similar for functionally equivalent programs and dissimilar for non-equivalent programs (Figure [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Contrastive Code Representation Learning")). Program structure encodes the global information about programs necessary for code understanding tasks such as code summarization allamanis2016convolutional and algorithm classification wang2019coset. The principle of contrastive learning offers a simple objective for learning such representations if data can be organized into pairs of positives and negatives. The objective uses each pair to shape representation space, drawing positives together and pushing negatives apart. However, a major question remains: given an unlabeled corpus of programs, how do we identify equivalent programs? We address this question in Sec. [3.1](#S3.SS1 "3.1 Equivalence by construction ‣ 3 Method: Contrastive Code Representation Learning ‣ Contrastive Code Representation Learning"), then introduce the learning framework in Sec. [3.2](#S3.SS2 "3.2 Contrastive pre-training ‣ 3 Method: Contrastive Code Representation Learning ‣ Contrastive Code Representation Learning").
###
3.1 Equivalence by construction
Modern programming languages afford great flexibility to software developers, allowing them to implement the same desired functionality through different implementation choices. Crowdsourced datasets mined from developers, such as GitHub repositories, have many near-duplicates in terms of textual similarity 10.1145/3359591.3359735, and are bound to contain even more functional equivalences for common tasks. Satisfiability solvers can identify these equivalent programs 10.1145/512529.512566; 10.1145/1168857.1168906, though are slow and require formal documentation of semantics. Programs can instead be compared using test-cases massalin1987superoptimizer, but this is also costly and requires dependencies and execution environments to run the code.
Instead of searching for equivalences, we propose equivalent by construction data generation. Our insight is to apply source-to-source compiler transformations to unlabeled code to generate many variants with the same functionality.
For example, dead-code elimination (DCE) is a common compiler optimization that removes operations that leave the output of a function unchanged. While the functionality of the program is the same after DCE, wang2019coset finds that up to 12.7% of the predictions of current code understanding models change after the transformation.

Figure 3: A JavaScript method from the unlabeled training set with two automatically generated semantically-equivalent programs. The original method from the StackEdit Markdown editor.

Figure 4: Per-example variants
A particular source code sequence, e.g. “W\*x + b” can be parsed unambiguously into a tree-structured representation ‘‘(+ (\* W x) b)’’.
This structure opens the possibility of performing automated code transformations.
A rich body of prior programming language work explores transformations of Abstract Syntax Trees that parse and optimize a program prior to machine code generation.
We leverage compiler infrastructure tools for JavaScript babel\_github; terser\_github and perform the following source-to-source transformations on JavaScript method bodies:
#### Variable renaming, identifier mangling:
Arguments can be renamed with random word sequences and identifiers can be replaced with short tokens to learn naming invariance. Program behavior is preserved despite obfuscation.
#### Reformatting, beautification, compression:
Personal coding conventions do not affect the semantics of code; autoformatting normalizes style conventions.
#### Dead-code insertion:
Commonly used no-ops such as comments and log statements that do not affect program behavior are inserted.
#### Dead-code elimination:
In this pass, all unused code with no side effects are removed. Various statements can be inlined or removed as stale or unneeded functionality.
#### Constant folding:
During constant folding, all expressions that can be pre-computed at compilation time can be inlined. As an example, an expression (2 + 3) \* 4 is replaced with 20.
#### Type upconversion:
In Javascript, some types are polymorphic and can be converted between each other. As an example, booleans can be represented as true or as 1.
#### Subword regularization kudo2018subword:
With an appropriate vocabulary, text can be tokenized in several different ways, with a single word (\_function) versus many subtokens sequences (\_func tion).
#### Line subsampling:
We randomly select a subset (p=0.9) of lines from a method body. This transformation is not semantics-preserving. However, it serves as a valuable regularization.
###
3.2 Contrastive pre-training
Augmentations discussed in Section [3.1](#S3.SS1 "3.1 Equivalence by construction ‣ 3 Method: Contrastive Code Representation Learning ‣ Contrastive Code Representation Learning") can be used to adapt several contrastive learning frameworks to code representation learning. We adapt the Momentum Contrast he2019momentum method that was designed for vision model pre-training. Our training procedure is depicted in Figure [2](#S2.F2 "Figure 2 ‣ Code representation learning ‣ 2 Related Work ‣ Contrastive Code Representation Learning"). In each iteration of training, a batch of programs is sampled from a large database of programs. Each program in the batch is transformed in two different ways using a random subset of transformations to derive functionally equivalent query programs and key programs. The query programs are embedded with an encoder trained via SGD, while key programs are embedded with an architecturally identical momentum encoder trained slowly via an exponential moving average (EMA) of the query encoder parameters.
While equivalent query and key programs define positive pairs, we exploit past programs to generate a very large set of negatives. Past embeddings of the key programs are stored in a queue. As there are few identical programs in a varied dataset, these programs will largely be functionally different from the positives and define the negatives. This approach allows us to use a very large set of negatives, over 100\textscK, with minimal additional computational cost.
Our method is independent to the choice of underlying encoder architecture. We evaluate contrastive pre-training over a Transformer vaswani2017attention and BiLSTM huang2015bidirectional architecture, with specific details in Sec. [4.1](#S4.SS1 "4.1 Dataset and tasks ‣ 4 Experiments ‣ Contrastive Code Representation Learning").
#### Pre-training objective
To pre-train, we minimize the InfoNCE loss by formulating a contrastive objective that measures similarity between programs by the inner product of their embeddings. Equation ([1](#S3.E1 "(1) ‣ Pre-training objective ‣ 3.2 Contrastive pre-training ‣ 3 Method: Contrastive Code Representation Learning ‣ Contrastive Code Representation Learning")) shows the InfoNCE loss for instance discrimination, a function whose value is low when q is similar to its positive key k+ and dissimilar to all other keys (considered negative keys for q):
| | | | |
| --- | --- | --- | --- |
| | Lq,k+,k−=−logexp(q⋅k+/τ)exp(q⋅k+/τ)+∑k−exp(q⋅k−/τ) | | (1) |
In general, the query representation is q=fq(xq) where fq is an encoder network and xq is a query sample (likewise, k=fk(xk) using the EMA key encoder). Views xq,xk depend on the specific domain and pretext task. In our case, the views are tokenized representations of the program with appropriate data augmentation via code transformation.
This loss can be seen as pre-training fq to classify the positive xk+ among all xk, using the normalizing denominator to define possible labels.
#### Transfer
After pre-training converges, the encoder fq is transferred to downstream tasks. As the output space of the task can differ from the encoder, we add a task-specific MLP, LSTM or Transformer decoder after fq, then train the resulting network end-to-end on task data.
4 Experiments
--------------
In this section, we explore the following experimental questions: (1) Can neural network text encoders learn program representations that are predictive of equivalent programs? and (2) Does contrastive pre-training improve downstream task performance? We also perform ablations to understand partial transfer of the model. To answer these questions, we compare models from the extreme code summarization and type inference literature to versions pre-trained with ContraCode.
###
4.1 Dataset and tasks
| | |
| --- | --- |
| Character length per code sample
(a) Character length per code sample
| Character length per identifier
(b) Character length per identifier
|
Figure 5: CodeSearchNet code summarization dataset statistics: (a) The majority of code sequences are under 2000 characters, but there is long tail of programs that span up to 15000 characters long, (b) JavaScript identifiers are relatively short compared to languages like C♯ and Java.
For pre-training, we use the CodeSearchNet dataset husain2019codesearchnet, a large corpus of methods extracted from popular Github repositories across 6 programming languages. We train models on the JavaScript programming language. CodeSearchNet includes 1,843,099 JavaScript training programs, 81,487 of which have an extracted documentation string and method name.
The asymmetry in labeled and unlabeled dataset sizes stems from JavaScript coding practices: anonymous functions with no name and often no documentation are widespread.
These labeled programs are used for a downstream extreme code summarization task, method prediction allamanis2016convolutional; alon2019code2vec; alon2018code2seq.
In addition, we use the Github dataset from DeepTyper hellendoorn2018deep for a type inference task.
Some repositories used by DeepTyper have been deleted or made private since publication, so we regenerate a subset of the dataset using the same procedure. Dataset statistics are included in the supplement.
We precompute up to 21 equivalent forms of each training method by applying 20 random subsets of the transformations from Section [3.1](#S3.SS1 "3.1 Equivalence by construction ‣ 3 Method: Contrastive Code Representation Learning ‣ Contrastive Code Representation Learning"), keeping the original method, and removing exact duplicates. The statistics are shown in Figure [4](#S3.F4 "Figure 4 ‣ 3.1 Equivalence by construction ‣ 3 Method: Contrastive Code Representation Learning ‣ Contrastive Code Representation Learning"). 11% of the methods have no alternatives after our compiler transforms, such as one-line functions that are already obfuscated. However, we apply subword regularization kudo2018subword during pre-training to derive random, different tokenizations for each batch, so pairs will still differ. After pre-training, we fine-tune the network’s encoder for downstream tasks.

Figure 6: t-SNE tsne2008 plot of ContraCode representations

Figure 7: Pre-training quickly converges if non-equivalent programs frequently change.
#### Extreme code summarization by method name prediction
The CodeSearchNet dataset used for pre-training includes method name labels where available. We extract 81,487 methods that have a documentation string and method name. The asymmetry in labeled and unlabeled dataset sizes stems from JavaScript coding practices; anonymous functions with no name nor docstring are widespread. These labeled programs are used for a downstream extreme code summarization task, where the method name is masked in the input function and predicted by the neural network allamanis2016convolutional; alon2019code2vec; alon2018code2seq. Method names are generally informative and summarize the method when tokenized, such as reverseString.
Our downstream method name prediction task is a sequence-to-sequence generation problem, so we implement a Transformer model vaswani2017attention with 6 encoder layers and 4 decoder layers. The encoder and decoder share the same token embedding, which is weight-tied with the output projection in the decoder.
We use subword tokenization based on fitting a unigram language model, with a top-down EM procedure to iteratively reduce the size of the vocabulary to 8,000 tokens following kudo2018subword. Unlike bottom-up byte-pair encoding sennrich2015neural, the unigram LM allows multiple decodings to be sampled. While the dataset has a long-tail of rare symbols, the vocabulary covers 99.95% of characters in the text.
#### Type inference
Type inference or hinting tools can generate type annotations for untyped JavaScript programs, which can help programmers find bugs and serve as documentation. We regenerate the DeepTyper dataset using the subset that is still available on GitHub using the original procedure. The training set consists of 15,570 TypeScript files from 187 projects with 6,902,642 total tokens, and the validation and test sets are from held-out repositories. For training, additional types are inferred by static analysis to augment user-defined types; all types are removed from the input to the model. We generate contextual embeddings of each token using a 2-layer Bidirectional LSTM, as used by DeepTyper, and a 6-layer Transformer, modified from RoBERTa to be parameter equivalent to the LSTM. A 2-layer MLP head is used to predict types from the predicted embedding of each token.
###
4.2 Can ContraCode program representations match equivalent programs?
In Figure [7](#S4.F7 "Figure 7 ‣ 4.1 Dataset and tasks ‣ 4 Experiments ‣ Contrastive Code Representation Learning"), we compare two strategies of refreshing the MoCo queue of key embeddings (i.e., the set of negative, non-equivalent programs).
In the first strategy, we add 8 items out of the batch to the queue (1×), while in the second we add 96 items (12×). In addition, we use a larger queue (65k versus 125k keys) and a slightly larger batch size (64 versus 96).
We observe that for the baseline queue fill rate, the accuracy decreases for the first 8125 iterations as the queue fills. This decrease in accuracy is expected as the task becomes more difficult due to the increasing number of negatives during queue warmup. However, it is surprising that accuracy grows so slowly once the queue is filled.
We suspect this is because the key encoder changes significantly over thousands of iterations: with a momentum term m=0.999, the original key encoder parameters are decayed by a factor of 2.9×10−4 by the moving average. If the queue is rapidly refreshed, queue embeddings are predicted by recent key encoders, not old parameters. This also indicates that a large diversity of negative, non-equivalent programs are helpful for rapid convergence of the ContraCode pre-training task.
We qualitatively inspect the quality of learned representations by visualizing ContraCode representations using t-SNE tsne2008. We annotate each method with a tag derived from the method name. While there is some overlap, each method class is clustered with other similarly tagged methods. We found that the representations learned by BERT showed more overlap between different algorithm tags; contrastive features may therefore learn better global representations of programs.
###
4.3 Does contrastive pre-training improve downstream task performance?
After contrastive pre-training, we fine-tune the model on the downstream task of code summarization (method name prediction). In Table [1](#S4.T1 "Table 1 ‣ 4.3 Does contrastive pre-training improve downstream task performance? ‣ 4 Experiments ‣ Contrastive Code Representation Learning"), we tested 3 different settings: (1) supervised training with the 81k labeled programs using baseline AST-based architectures (code2vec, code2seq), (2) pre-training on all 1.84M programs using the masked language model objective followed by fine-tuning on the labeled programs (RoBERTa liu2019roberta), (3) supervised training with a Transformer architecture using ContraCode augmentations and (4) contrastive pre-training with all 1.84M programs followed by pre-training (ContraCode). We find that all models overfit during supervised training, so we use early stopping according to the validation loss.
Contrastive pre-training with fine-tuning outperforms the prior code2seq model, a competitive supervised baseline, by 8.2% in test precision and 7.9% in test F1 score. ContraCode outperforms a model fine-tuned after RoBERTa pre-training by 4.8% F1. Representations learned via masked language modeling appear to learn poor structural representations of code. Surprisingly, ContraCode augmentations improve supervised learning performance; a simple Transformer model with our augmentations (described in Sec. [3.1](#S3.SS1 "3.1 Equivalence by construction ‣ 3 Method: Contrastive Code Representation Learning ‣ Contrastive Code Representation Learning")) obtains a higher F1 score than RoBERTa pre-training.
| | | | | |
| --- | --- | --- | --- | --- |
| Method | Pre-training | Precision | Recall | F1 |
| (1.8M programs) |
| code2vec alon2019code2vec | - | 10.78% | 8.24% | 9.34% |
| code2seq alon2018code2seq | - | 12.17% | 7.65% | 9.39% |
| RoBERTa-6 liu2019roberta | MLM devlin2018bert, 90k | 15.13% | 11.47% | 12.45% |
| Transformer vaswani2017attention + ContraCode augmentations | - | 18.01% | 13.84% | 15.65% |
| Transformer vaswani2017attention + ContraCode pre-training | MoCo, 20k steps | 20.34% | 14.96% | 17.24% |
Table 1: Results for different settings of the code summarization task: supervised training with 81k functions, masked language model pre-training and contrastive pre-training with fine-tuning.
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| Method | Pretraining | Acc@1 | Acc@5 | Acc@1 | Acc@5 |
| (1.8M programs) | (all types) | (all types) | (- any) | (- any) |
| any type | - | 41.82% | 41.82% | 0.00% | 0.00% |
| TypeScript CheckJS bierman2014understanding | - | 45.11% | 45.11% | 16.32% | 16.32% |
| Name only hellendoorn2018deep | - | 28.94% | 70.07% | - | - |
| Transformer vaswani2017attention | - | 45.66% | 80.08% | 51.87% | 71.95% |
| Transformer + ContraCode | MoCo, 240k steps | 46.86% | 81.85% | 52.54% | 71.56% |
| RoBERTa-6 liu2019roberta | MLM, 90k steps devlin2018bert | 40.85% | 75.76% | 48.37% | 68.00% |
| RoBERTa-6 + ContraCode | MLM + MoCo, 240k steps | 47.16% | 81.44% | 51.32% | 71.93% |
| DeepTyper hellendoorn2018deep (d=512) | - | 51.73% | 82.71% | 60.60% | 78.20% |
| DeepTyper (d=512) + RoBERTa-6 | MLM, 10k steps devlin2018bert | 50.24% | 82.85% | 59.45% | 78.42% |
| DeepTyper (d=512) + ContraCode | MoCo (mean) + MLP, 10k | 49.15% | 82.58% | 60.88% | 79.41% |
| DeepTyper (d=512) + ContraCode | MoCo (hidden), 10k | 51.70% | 83.03% | 62.16% | 79.56% |
| DeepTyper (d=512) + ContraCode | MoCo (hidden), 20k | 52.65% | 84.60% | 63.35% | 79.69% |
Table 2: Results for different settings of the type inference task, supervised with 15.6k files.
Table [2](#S4.T2 "Table 2 ‣ 4.3 Does contrastive pre-training improve downstream task performance? ‣ 4 Experiments ‣ Contrastive Code Representation Learning") shows the improvements that ContraCode offers on the type inference task in terms of accuracy averaged over all typed variables and averaged over all typed variables with a type other than the catch-all any type. We use early stopping based on validation set top-1 accuracy across all types. All learning-based approaches outperform static-analysis baselines.
In addition, learned models rank multiple type annotations that can be displayed to users, allowing us to compute top-5 accuracy. ContraCode significantly improves accuracy across three representative baseline models: Transformer, pre-trained RoBERTa with a masked language modeling objective, and the BiLSTM used by DeepTyper. In particular, we outperform the supervised Transformer by up to 1.77% in top-5 accuracy and the supervised DeepTyper model by up to 2.75% in top-1 accuracy (4.5% relative increase), simply by pre-training for global representations with ContraCode.
The model pretrained with masked language modeling performs poorly due to the superficial local reconstruction objective. We enrich the MLM objective with ContraCode via an auxiliary loss. This hybrid local-global representation achieves between 2.95% and 6.31% increases in top-1 accuracy over RoBERTa.
###
4.4 Qualitative results
Figure [9](#S4.F9 "Figure 9 ‣ 4.4 Qualitative results ‣ 4 Experiments ‣ Contrastive Code Representation Learning") shows a qualitative example of predictions for the code summarization task. The JavaScript method is not seen during training. A Transformer pretrained with ContraCode predicts the correct method name as the most likely decoding through beam search. The next four predictions are reasonable, capturing that the method processes an image. The 2nd and 3rd most likely decodings, getImageItem and createImage, use get and create as synonyms for load, though the final two unlikely decodings include terms not mentioned in the method body.
We can also visualize outputs of the type inference model. Figure [8](#S4.F8 "Figure 8 ‣ 4.4 Qualitative results ‣ 4 Experiments ‣ Contrastive Code Representation Learning") shows two TypeScript programs from the held-out test set. User-provided type annotations are removed from the programs, and the model is provided with a tokenized form without access to dependencies. We visualize predictions from a variant of DeepTyper (a bidirectional LSTM) pretrained with ContraCode, the best-performing model in Table [2](#S4.T2 "Table 2 ‣ 4.3 Does contrastive pre-training improve downstream task performance? ‣ 4 Experiments ‣ Contrastive Code Representation Learning"). In the first program, our model consistently predicts the correct return and parameter type. While a tool based on static analysis could infer the void return types, the type of the message argument is ambiguous without access to the imported write method signature. Still, the model correctly predicts with high confidence that the variable message is a string.
In the second program, ContraCode correctly predicts 4 of 8 types including the ViewContainerRef and ChangeDetectorRef types, each imported from the AngularJS library. As this sample is held-out from the training set, these predictions show generalization from other repositories using AngularJS.

Figure 8: Our model, a variant of DeepTyper pretrained with ContraCode, generates type annotations for two programs in the held-out set. The model consistently predicts the correct return type of functions, and even predicts project-specific types imported at the top of the file. The model corresponds to the bottom row of Table [2](#S4.T2 "Table 2 ‣ 4.3 Does contrastive pre-training improve downstream task performance? ‣ 4 Experiments ‣ Contrastive Code Representation Learning").
[⬇](http://data:text/plain;base64,ZnVuY3Rpb24geCh1cmwsIGNhbGxiYWNrLCBlcnJvcikgewogIHZhciBpbWcgPSBuZXcgSW1hZ2UoKTsKICBpbWcuc3JjID0gdXJsOwogIGlmKGltZy5jb21wbGV0ZSl7CiAgICByZXR1cm4gY2FsbGJhY2soaW1nKTsKICB9CiAgaW1nLm9ubG9hZCA9IGZ1bmN0aW9uKCl7CiAgICBpbWcub25sb2FkID0gbnVsbDsKICAgIGNhbGxiYWNrKGltZyk7CiAgfTsKICBpbWcub25lcnJvciA9IGZ1bmN0aW9uKGUpewogICAgaW1nLm9uZXJyb3IgPSBudWxsOwogICAgZXJyb3IoZSk7CiAgfTsKfQ==)
function x(url, callback, error) {
var img = new Image();
img.src = url;
if(img.complete){
return callback(img);
}
img.onload = function(){
img.onload = null;
callback(img);
};
img.onerror = function(e){
img.onerror = null;
error(e);
};
}
Ground truth: loadImage
Prediction: loadImage
Other predictions:
getImageItem
createImage
loadImageForBreakpoint
getImageSrcCSS
Figure 9: A JavaScript program from the CodeSearchNet dataset not seen during training and the predicted method names from a Transformer pre-trained with ContraCode. ContraCode predicts the correct method name as its most likely decoding.
###
4.5 Ablations
#### Should we pre-train global or local representations?
We compare pre-training DeepTyper with two variants of ContraCode. We either use the mean of token hidden states across the program (averaging local features), or the terminal hidden states as input to the MLP used to extract the contrastive representation q=fq(x) (global features). Using the global features for pre-training yields significantly improved performance (bottom two rows, Table [2](#S4.T2 "Table 2 ‣ 4.3 Does contrastive pre-training improve downstream task performance? ‣ 4 Experiments ‣ Contrastive Code Representation Learning")).
#### Do pre-trained encoders help more with shallow decoders?
In Table [3](#S4.T3 "Table 3 ‣ Do pre-trained encoders help more with shallow decoders? ‣ 4.5 Ablations ‣ 4 Experiments ‣ Contrastive Code Representation Learning"), we ablate the size of the decoder erhan2010does to understand whether large untrained decoders limit the improvements from contrastive encoder pre-training. We tested 1-layer and 4-layer Transformers. We can conclude that 4-layer Transformer achieves higher performance using all 3 criteria. With 45k pre-training steps, the 4-layer decoder achieves 0.50% higher precision, 0.64% higher recall and 0.77% higher F1 score than the 1-layer model. The 1-layer decoder models benefit significantly from longer pre-training, with a 6.3% increase in F1 from 10k to 45k iterations. We hope to see similarly large gains in downstream tasks with small decoders like code classification, the setting considered by self-supervised vision models.
| Decoder | Pre-training | Supervision | Precision | Recall | F1 |
| --- | --- | --- | --- | --- | --- |
| (1.8M programs) | (81k programs) |
| Transformer, 1 layer | MoCo, 10k steps | Original set | 11.91% | 5.96% | 7.49% |
| Transformer, 1 layer | MoCo, 45k steps | Original set | 17.71% | 12.57% | 13.79% |
| Transformer, 4 layers | MoCo, 45k steps | Original set | 18.21% | 13.21% | 14.56% |
Table 3: Training time and decoder depth ablation on the method name prediction task. Longer pre-training significantly improves downstream performance when a shallow, 1 layer decoder is used.
| Method | Pre-training | Acc@1 | Acc@5 | Acc@1 | Acc@5 |
| --- | --- | --- | --- | --- | --- |
| (1.8M programs) | (all) | (all) | (- any) | (- any) |
| Transfer BiLSTM | MoCo (mean), 10k steps | 49.32% | 80.03% | 59.75% | 77.98% |
| Transfer BiLSTM, 1 layer of MLP | MoCo (mean), 10k steps | 49.15% | 82.58% | 60.88% | 79.41% |
Table 4: Transferring part of the Contrastive MLP head improves type inference. The encoder is a 2-layer BiLSTM (d=512), with a 2-layer MLP head for both pre-training purposes and type inference.
#### Which part of the model should be transferred?
SimCLR chen2020simple proposed using a small MLP head to reduce the dimensionality of the representation used in the InfoNCE loss during pre-training, and did not transfer the MLP to the downstream image-classification task. In contrast, we find it beneficial to transfer part of the contrastive MLP head to type inference, showing a 2% improvement in top-5 accuracy over transferring the encoder only (Table [4](#S4.T4 "Table 4 ‣ Do pre-trained encoders help more with shallow decoders? ‣ 4.5 Ablations ‣ 4 Experiments ‣ Contrastive Code Representation Learning")). We believe the improvement stems from fine-tuning both the encoder and MLP, while SimCLR did not fine-tune. We only transferred the MLP when pre-training with the mean of token embeddings, not the terminal hidden states, as the dimensionality of the MLP head differs.
5 Conclusions
--------------
A key challenge when applying machine learning to machine-aided programming tools is how to leverage large-scale unannotated repositories of code like GitHub.
We propose ContraCode, a pre-training task that learns global representations of the functionality of code based on the hypothesis that good representations of functionally equivalent programs should be similar. We leverage contrastive learning to induce this invariance via automatically applying equivalence preserving transformations to the source code.
We find application of ContraCode pre-training significantly improves accuracy on two downstream tasks. Our approach is complementary to model architecture and consistently improves performance when combined with baseline approaches.
Broader Impact
--------------
Complex software systems are deployed in safety-critical applications. Software bugs impact end-user safety; tragic examples include unintended acceleration toyota\_unintended\_acc and radiation therapy overdoses leveson1993investigation. Machine-aided programming tools such as type checkers have improved end-user safety by preventing bugs before code deployment.
We believe these tools also improve the equity of programming by making it more accessible to novice programmers. Developer tools have significantly improved developer productivity by providing insights on large code bases during development. Machine learning methods like ContraCode have the potential to further these benefits through summarization and semantic code understanding.
Still, machine-aided programming tools have the potential to introduce software bugs via false positives or mss bugs via false negatives that a user may not notice. Such errors should be characterized prior to deploying a tool pre-trained by ContraCode, and may be mitigated by surfacing several possible predictions to the user with associated confidence scores. It is important that learned machine-aided programming tools do not provide a false sense of security.
Acknowledgements
----------------
We thank Koushik Sen, Jonathan Ho and Aravind Srinivas for their insightful feedback. In addition to NSF CISE Expeditions Award CCF-1730628, the NSF GRFP under Grant No. DGE-1752814, and ONR PECASE N000141612723, this research is supported by gifts from Alibaba, Amazon Web Services, Ant Financial, Ericsson, Facebook, Futurewei, Google, Intel, Microsoft, NVIDIA, Scotiabank, Splunk and VMware. Opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of funding agencies. |
a457bcf0-3607-4b2d-9d24-3c7f8bb70b18 | StampyAI/alignment-research-dataset/aisafety.info | AI Safety Info | Won't humans be able to beat an unaligned AI since we have a huge advantage in numbers?
Humans likely won’t have an advantage in effective numbers, for three main reasons:
1. The AI will likely work much more quickly than humans can (transistors are millions of times faster than neurons).
1. The AI might create copies of itself, or cooperate with copies created by other people (as it takes much more compute to train an AI than to run it, it is reasonable to predict that any computer you can train one AGI on you can run several million AGIs on).
1. Human numbers only help if there is cooperation and coordination. It’s much harder to get humans with diverse motives to act together than an AI which can duplicate itself and inspect the thoughts of copies.
#### The AI will likely work much quicker than humans can
[In the words of Dr. Andrew Critch](https://www.lesswrong.com/posts/Ccsx339LE9Jhoii9K/slow-motion-videos-as-ai-risk-intuition-pumps): "...plenty of risks arise just from the fact that humans are extremely slow. Transistors can fire about 10 million times faster than human brain cells, so it's possible we'll eventually have digital minds operating 10 million times faster than us, meaning from a decision-making perspective we'd look to them like stationary objects, like plants or rocks."
To give an example of how a digital mind might view humans, Dr. Critch shows [this](https://vimeo.com/83664407) video of humans in a subway slowed to one one-hundredth of their original speed.
Science fiction has many examples of beings that think much faster than humans; these are almost always unrealistic in one way or another, but can still be useful for understanding what fast enough thinking can do: [Frame By Frame](https://qntm.org/frame) by qntm (short and funny), [That Alien Message](https://www.lesswrong.com/posts/5wMcKNAwB6X4mp9og/that-alien-message) by Eliezer Yudkowsky (longer and excellent).
#### The AI will likely create copies of itself and effectively cooperate with copies
Unlike humans who can’t easily create identical copies of themselves, an AGI could create perfect clones of its mind by copying the software to another location.
[Holden Karnofsky](https://en.wikipedia.org/wiki/Holden_Karnofsky) (co-founder of [Open Philanthropy](https://www.openphilanthropy.org/)) estimates [here](https://www.cold-takes.com/ai-could-defeat-all-of-us-combined/]) that, based on Ajeya Cotra's [biological anchors](https://www.alignmentforum.org/posts/KrJfoZzpSDpnrv9va/draft-report-on-ai-timelines) model for forecasting AI, if a human level AI is created through gradient descent one could subsequently use the computer it was trained on to run several hundred million copies of that AI - about 5-10% of Earth's working age population.
They could then run more copies on other computers.
These copies might be capable of [superrational](https://en.wikipedia.org/wiki/Superrationality) cooperation. (As copies of each other they know that the other AIs will think all the same things they do, improving trust and allowing them to make plans and coordinate without communicating.) This would allow for a unified intelligence distributed across a very wide geographical space.
Karnofsky describes what effect minds being implementable on cheap hardware might have in the essays: [The Duplicator: Instant Cloning Would Make the World Economy Explode](https://www.cold-takes.com/the-duplicator/) and [Digital People Would Be An Even Bigger Deal](https://www.cold-takes.com/how-digital-people-could-change-the-world/).
|
922fd9f0-b8e7-4563-8474-f9aa18bbcd99 | trentmkelly/LessWrong-43k | LessWrong | Introducing Effective Altruist Profiles
We’re excited to announce EA Profiles, a new community platform for effective altruists. There are already hundreds of profiles for you to browse from members of the community such as Peter Singer and Jeff Kaufman, full of interesting information like people’s favoured causes and charities, and the actions they’re taking to make the world a better place. And you can create your own right now!
The Profiles should serve as a virtual “Who’s Who” of EA - a place to see information about those who identify with effective altruism, and share what we’re doing to inspire and motivate others. They enable applications such as a map of EAs and a cause-neutral registry of past and planned donations, which we'll cover in a separate announcement.
Your EA Profile provides a natural, standard way to share your identification with the ideas of effective altruism and the ways in which you and people you know can do enormous amounts of good, from spreading these ideas to donating to highly efficient charities. We know that people can be slow or cautious about sharing this, but for familiar reasons think that doing so is highly valuable, spreading and normalising a focus on effectiveness and high impact donations. And making a Profile is a great excuse to do so: you’re sharing this information because we asked for it! You can then point people to it, potentially triggering interesting conversations with friends who might like to hear about the ways they can do the most good.
Many of the Profiles come from answers which people opted to make public in the first annual survey of effective altruists this year (still open if you haven’t taken it yet - it provides another way to create a full or partial Profile). Peter Hurford is currently working on analysing the survey results and will share them and the raw data from the survey soon, but for now the EA Profiles provide some of the most interesting results: public information on the inspiring actions that individuals are taking.
If |
584762d8-062b-4def-847b-24e1f32345d6 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Boston / Cambridge - The future of life: a cosmic perspective (Max Tegmark), Dec 1
Discussion article for the meetup : Boston / Cambridge - The future of life: a cosmic perspective (Max Tegmark), Dec 1
WHEN: 01 December 2013 02:00:00PM (-0500)
WHERE: Citadel, 98 Elm St, Apt 1, Somerville, MA
Max Tegmark will be giving a talk, "The future of life: a cosmic perspective", at 3pm.
We may need a larger venue depending on the turnout, so please RSVP on the meetup page: http://www.meetup.com/Cambridge-Less-Wrong-Meetup/events/151129022/
Cambridge/Boston-area Less Wrong meetups are every Sunday at 2pm at Citadel (98 Elm St Apt 1 Somerville, near Porter Square).
Our default schedule is as follows:
—Phase 1: Arrival, greetings, unstructured conversation.
—Phase 2: The headline event. This starts promptly at 3pm, and lasts 30-60 minutes.
—Phase 3: Further discussion. We'll explore the ideas raised in phase 2, often in smaller groups.
—Phase 4: Dinner.
Discussion article for the meetup : Boston / Cambridge - The future of life: a cosmic perspective (Max Tegmark), Dec 1 |
35c53d6d-27b9-4605-922e-b49cdea2a850 | trentmkelly/LessWrong-43k | LessWrong | Confession Thread: Mistakes as an aspiring rationalist
We looked at the cloudy night sky and thought it would be interesting to share the ways in which, in the past, we made mistakes we would have been able to overcome, if only we had been stronger as rationalists. The experience felt valuable and humbling. So why not do some more of it on Lesswrong?
An antithesis to the Bragging Thread, this is a thread to share where we made mistakes. Where we knew we could, but didn't. Where we felt we were wrong, but carried on anyway.
As with the recent group bragging thread, anything you've done wrong since the comet killed the dinosaurs is fair game, and if it happens to be a systematic mistake that over long periods of time systematically curtailed your potential, that others can try to learn avoiding, better.
This thread is an attempt to see if there are exceptions to the cached thought that life experience cannot be learned but has to be lived. Let's test this belief together! |
e461542e-2fde-43fe-9ae0-cc1b0034a033 | trentmkelly/LessWrong-43k | LessWrong | New Alignment Research Agenda: Massive Multiplayer Organism Oversight
[Metadata: crossposted from https://tsvibt.blogspot.com/2023/04/new-alignment-research-agenda-massive.html.]
When there's an AGI that's smarter than a human, how will we make sure it's not trying to kill us? The answer, in outline, is clear: we will watch the AGI's thoughts, and if it starts thinking about how to kill us, we will turn it off and then fix it so that it stops trying to kill us.
Limits of AI transparency
There is a serious obstacle to this plan. Namely, the AGI will be very big and complicated, so it will be very difficult for us to watch all of its many thoughts. We don't know how to build structures made of large groups of humans that can process that much information to make good decisions.
How can we overcome this obstacle?
ML systems
Current AI transparency methods are fundamentally limited by the size and richness of their model systems. To gain practical empirical experience today with modeling very large systems, we have to look to systems that are big and complex enough, with the full range of abstractions, to be analogous to future AGI systems.
Evolution
Too weak, too slow.
Brains
Too small, too fast.
Solution: Organism Oversight
Organisms have multi-level complexity (cells, gene regulatory networks, intercellular signaling, epigenetic state, flows, tissues, long-range signaling, homeostasis, etc.). Organisms come in a wide range of sizes, from unicellular to whale, providing a natural curriculum.
Thus, the Massive Multiplayer Organism Oversight research program proposes to empirically develop systems for aggregrating human expertise in modeling components of large complex systems into accurate and useful gestalt predictions about real-world behavior, by empirically testing the predictive power of groups of humans each specialize to monitor, understand, predict, and explain one aspect or component of a biological organism.
Concretely, each multi-level component of a model organism will be assign to one person. For example, there |
d48b095f-f292-4bf8-bc3f-e9df7e218049 | StampyAI/alignment-research-dataset/blogs | Blogs | The Wicked Problem Experience
*Click lower right to download or find on Apple Podcasts, Spotify, Stitcher, etc.*
I’ve spent a lot of my career working on [wicked problems](https://en.wikipedia.org/wiki/Wicked_problem): problems that are vaguely defined, where there’s no clear goal for exactly what I’m trying to do or how I’ll know when or whether I’ve done it.
In particular, [minimal-trust investigations](https://www.cold-takes.com/minimal-trust-investigations/) - trying to understand some topic or argument myself ([what charity to donate to](https://www.givewell.org), [whether civilization is declining](https://www.cold-takes.com/cost-disease-and-civilizational-decline/), [whether AI could make this the most important century of all time for humanity](https://www.cold-takes.com/most-important-century/)), with little reliance on what “the experts” think - tend to have this “wicked” quality:
* I could spend my whole life learning about any subtopic of a subtopic of a subtopic, so learning about a topic is often mostly about deciding how deep I want to go (and what to skip) on each branch.
* There aren’t any stable rules for how to make that kind of decision, and I’m constantly changing my mind about what the goal and scope of the project even is.
This piece will narrate an example of what it’s like to work on this kind of problem, and why I [say](https://www.cold-takes.com/learning-by-writing/) it is “hard, taxing, exhausting and a bit of a mental health gauntlet.”
My example is from the 2007 edition of [GiveWell](https://www.givewell.org). It’s an adaptation from a private doc that some other people who work on wicked problems have found cathartic and validating.
It’s particularly focused on what I call the **hypothesis rearticulation** part of investigating a topic (steps 3 and 6 in my [learning by writing](https://www.cold-takes.com/learning-by-writing/) process), which is when:
* I have a hypothesis about the topic I’m investigating.
* I realize it doesn’t seem right, and I need a new one.
* Most of the things I can come up with are either “too strong” (it would take too much work to examine them satisfyingly) or “too weak” (they just aren’t that interesting/worth investigating).
* I need to navigate that balance and find a new hypothesis that is (a) coherent; (b) important if true; (c) maybe something I can argue for.
After this piece tries to give a sense for what the challenge is like, a future piece will give accumulated tips for navigating it.
Flashback to 2007 GiveWell
--------------------------
*Context for those unfamiliar with GiveWell:*
* *In 2007, I co-founded (with [Elie Hassenfeld](https://www.givewell.org/about/people)) an organization that recommends evidence-backed, cost-effective charities to help people do as much good as possible with their donations.** *When we started the project, we initially asked charities to apply for $25,000 grants, and to agree (as part of the process) that we could publish their application materials. This was our strategy for trying to find charities that could provide evidence about how much they were helping people (per dollar).** *This example is from after we had collected information from charities and determined which one we wanted to rank #1, and were now trying to write it all up for our website. Since then, [GiveWell](https://www.givewell.org) has evolved a great deal and is much better than the 2007 edition I’ll be describing here.* * *(This example is reconstructed from my memory a long time later, so it’s probably not literally accurate.)*
**Initial “too strong” hypothesis.** [Elie](https://www.givewell.org/about/people) (my co-founder at GiveWell) and I met this morning and I was like “I’m going to write a page explaining what GiveWell’s recommendations are and aren’t. Basically, they aren’t trying to evaluate every charity in the world. Instead they’re saying which ones are the most cost-effective.” He nodded and was like “Yeah, that’s cool and helpful, write it.”
Now I’m sitting at my computer trying to write down what I just said in a way that an outsider can read - the “hypothesis articulation” phase.
I write, “GiveWell doesn’t evaluate every charity in the world. Our goal is to save the most lives possible per dollar, not to create a complete ranking or catalogue of charities. Accordingly, our research is oriented around identifying the single charity that can save the most lives per dollar spent,”
Hmm. Did we identify the “single charity that can save the most lives per dollar spent?” Certainly not. For example, I have no idea how to compare these charities to cancer research organizations, which are out of scope. Let me try again:
“GiveWell doesn’t evaluate every charity in the world. Our goal is to save the most lives possible per dollar, not to create a complete ranking or catalogue of charities. Accordingly, our research is oriented around identifying the single charity with the highest *demonstrated lives saved per dollar spent* - the charity that can prove rigorously that it saved the most” - no, it can’t prove it saved the *most* lives - “the charity that can prove rigorously that ” - uh -
Do any of our charities prove *anything* rigorously? Now I’m looking at the page we wrote for our #1 charity and ugh. I mean [here](https://web.archive.org/web/20080914003505/http://www.givewell.net/psi#Weighingtheevidence) are some quotes from our summary on the case for their impact: “All of the reports we've seen are internal reports (i.e., [the charity] - not an external evaluator - conducted them) … Neither [the charity]’s sales figures nor its survey results conclusively demonstrate an impact … It is possible that [the charity] simply uses its subsidized prices to outcompete more expensive sellers of similar materials, and ends up reducing people's costs but not increasing their ownership or utilization of these materials … We cannot have as much confidence in our understanding of [the charity] as in our understanding of [two other charities], whose activities are simpler and more straightforward.”
That’s our #1 charity! We have less confidence in it than our lower-ranked charities … but we ranked it higher anyway because it’s more cost-effective … but it’s not the most cost-effective charity in the world, it’s probably not even the most cost-effective charity we looked at …
**Hitting a wall.** Well I have no idea what I want to say here.

*This image represents me literally playing some video game like Super Meat Boy while failing to articulate what I want to say. I am not actually this bad at Super Meat Boy (certainly not after all the time I’ve spent playing it while failing to articulate a hypothesis), but I thought all the deaths would give a better sense for how the whole situation feels.*
**Rearticulating the hypothesis and going “too weak.”** Okay, screw this. I know what the problem was - I was writing based on wishful thinking. We haven’t found the most cost-effective charity, we haven’t found the most proven charity. Let’s just lay it out, no overselling, just the real situation.
“GiveWell doesn’t evaluate every charity in the world, because we didn’t have time to do that this year. Instead, we made a completely arbitrary choice to focus on ‘saving lives in Africa’; then we emailed 107 organizations that seemed relevant to this goal, of which 59 responded; we did a really quick first-round application process in which we asked them to provide evidence of their impact; we chose 12 finalists, analyzed those further, and were most impressed with Population Services International. There is no reason to think that the best charities are the ones that did best in our process, and significant reasons to think the opposite, that the best charities are not the ones putting lots of time into a cold-emailed application from an unfamiliar funder for $25k. Like every other donor in the world, we ended up making an arbitrary, largely aesthetic judgment that we were impressed with Population Services International. Readers who share our aesthetics may wish to donate similarly, and can also purchase photos of Elie and Holden at the following link:”
OK wow. This is what we’ve been working on for a year? Why would anyone want this? Why are we writing this up? I should keep writing this so it’s just DONE but ugh, the thought of finishing this website is almost as bad as the thought of not finishing it.
**Hitting a wall.**

What do I do, what do I do, what do I do.
**Rearticulating the hypothesis and assigning myself more work.** OK. I gave up, went to sleep, thought about other stuff for a while, went on a vision quest, etc. I’ve now realized that we can put it this way: our top charities are the ones with verifiable, demonstrated impact and room for more funding, and we rank them by estimated cost-effectiveness. “Verifiable, demonstrated” is something appealing we can say about our top charities and not about others, even though it’s driven by the fact that they responded to our emails and others didn’t. And then we rank the best charities within that. Great.
So I’m sitting down to write this, but I’m kind of thinking to myself: “Is that really quite true? That ‘the charities that participated in our process and did well’ and ‘The charities with verifiable, demonstrated impact’ are the same set? I mean … it seems like it could be true. For years we looked for charities that had evidence of impact and we couldn’t find any. Now we have 2-3. But wouldn’t it be better if I could verify none of these charities that ignored us have good evidence of impact just sitting around on their website? I mean, we definitely looked at a lot of websites before but we gave up on it, and didn’t scan the eligible charities comprehensively. Let me try it.”
I take the list of charities that didn’t participate in round 1. That’s not all the charities in the world, but if none of them have a good impact section on their website, we’ve got a pretty plausible claim that the best stuff we saw in the application process is the best that is (now) publicly available, for the “eligible” charities in the cause. (This assumes that if one of the applicants had good stuff sitting around on their website, they would have sent it.)
I start looking at their websites. There are 48 charities, and in the first hour I get through 6, verifying that there’s nothing good on any of those websites. This is looking good: in 8 work hours I’ll be able to defend the claim I’ve decided to make.
Hmm. This water charity has some kind of map of all the wells they’ve built, and some references to academic literature arguing that wells save lives. Does that count? I guess it depends on exactly what the academic literature establishes. Let’s check out some of these papers … huh, a lot of these aren’t papers per se so much as big colorful reports with giant bibliographies. Well, I’ll keep going through these looking for the best evidence I can …
**“This will never end.”** Did I just spend two weeks reading terrible papers about wells, iron supplementation and community health workers? Ugh and I’ve only gotten through 10 more charities, so I’m only about ⅓ of the way through the list as a whole. I was supposed to be just writing up what we found, I can’t take a 6-week detour!
**The over-ambitious deadline.** All right, I’ll sprint and get it done in a week. [1 week later] Well, now I’m 60% way through the whole list. !@#$
**“This is garbage.”** What am I even doing anyway? I’m reading all this literature on wells and unilaterally deciding that it doesn’t count as “proof of impact” the way that Population Services International’s surveys count as “proof of impact.” I’m the zillionth person to read these papers; why are we creating a website out of these amateur judgments? Who will, or SHOULD, care what I think? I’m going to spend another who knows how long writing up this stupid page on what our recommendations do and don’t mean, and then another I don’t even want to think about it finishing up all the other pages we said we’d write, and then we’ll put it online and literally no one will read it. Donors won’t care - they will keep going to charities that have lots of nice pictures. Global health professionals will just be like “Well this is amateur hour.”[1](https://www.cold-takes.com/p/45a0d976-2f23-4aab-a587-7a54cff07459/#fn1)
This is just way out of whack. Every time I try to add enough meat to what we’re doing that it’s worth publishing at all, the timeline expands another 2 months, AND we still aren’t close to having a path to a quality product that will mean something to someone.

What’s going wrong here?
------------------------
* I have a deep sense that I have something to say that is worth arguing for, **but I don’t actually know *what* I am trying to say.** I can express it in conversation to Elie, but every time I start writing it down for a broad audience, I realize that Elie and I had a lot of shared premises that won’t be shared by others. Then I need to decide between arguing the premises (often a huge amount of extra work), weakening my case (often leads to a depressing sense that I haven’t done anything worthwhile), or somehow reframing the exercise (the right answer more often than one would think).
* It often feels like I know what I need to say and now the work is just “writing it down.” But “writing it down” often reveals a lot of missing steps and thus explodes into more tasks - and/or involves long periods of playing Super Meat Boy while I try to figure out whether there’s some version of what I was trying to say that wouldn’t have this property.
* I’m approaching a well-established literature with an idiosyncratic angle, giving me constant impostor syndrome. On any given narrow point, there are a hundred people who each have a hundred times as much knowledge as I do; it’s easy to lose sight of the fact that despite this, I have *some* sort of value-added to offer (I just need to not overplay what this is, and often I don’t have a really crisp sense of what it is).
* Because of the idiosyncratic angle, I lack a helpful ecosystem of peer reviewers, mentors, etc.
+ There’s nothing to stop me from sinking weeks into some impossible and ill-conceived version of my project that I could’ve avoided just by, like, rephrasing one of my sentences. (The above GiveWell example has me trying to do extra work to establish a bunch of points that I ultimately just needed to sidestep, as you can see from the [final product](https://web.archive.org/web/20080901145132/http://www.givewell.net/developing-world-summary). This definitely isn’t always the answer, but it can happen.)
+ **I’m simultaneously trying to pose my question and answer it.** This creates a dizzying feeling of constantly creating work for myself that was actually useless, or skipping work that I needed to do, and never knowing which I’m doing because I can’t even tell you who’s going to be reading this and what they’re going to be looking for.
+ There aren’t any well-recognized standards I can make sure I’m meeting, and the scope of the question I’m trying to answer is so large that I generally have a creeping sense that I’m producing something way too shot through with guesswork and subjective judgment to cause anyone to actually change their mind.
All of these things are true, and they’re all part of the picture. But nothing really changes the fact that I’m on my way to **having (and publishing) an unusually thoughtful take on an important question.** If I can keep my eye on that prize, avoid steps that don’t help with it (though not to an extreme, i.e., it’s good for me to have basic contextual knowledge), and keep reframing my arguments until I capture (without overstating) what’s new about what I’m doing, I will create something valuable, both for my own learning and potentially for others’.
“Valuable” doesn’t at all mean “final.” We’re trying to push the conversation forward a step, not end it. One of the fun things about the GiveWell example is that the final product that came out at the end of that process was actually pretty bad! It had essentially nothing in common with the version of GiveWell that first started feeling satisfying to donors and moving serious money, a few years later. (No overlap in top charities, very little overlap in methodology.)
For me, a huge part of the challenge of working on this kind of problem is just continuing to come back to that. As I bounce between “too weak” hypotheses and “too strong” ones, I need to keep re-aiming at something I can argue that’s worth arguing, and remember that getting there is just one step in my and others’ learning process. A future piece will go through some accumulated tips on pulling that off.
**Next in series:** [Useful Vices for Wicked Problems](https://www.cold-takes.com/useful-vices-for-wicked-problems/)
---
Footnotes
---------
1. I really enjoyed the “What qualifies you to do this work?” [FAQ](https://web.archive.org/web/20080901190245/http://www.givewell.net/faq#Whatqualifiesyoutodothiswork) on the old GiveWell site that I ran into while writing this. [↩](https://www.cold-takes.com/p/45a0d976-2f23-4aab-a587-7a54cff07459/#fnref1) |
bdd3cdbb-89d0-48af-955b-e882320fd046 | trentmkelly/LessWrong-43k | LessWrong | Slow corporations as an intuition pump for AI R&D automation
How much should we expect AI progress to speed up after fully automating AI R&D? This post presents an intuition pump for reasoning about the level of acceleration by talking about different hypothetical companies with different labor forces, amounts of serial time, and compute. Essentially, if you'd expect an AI research lab with substantially less serial time and fewer researchers than current labs (but the same cumulative compute) to make substantially less algorithmic progress, you should also expect a research lab with an army of automated researchers running at much higher serial speed to get correspondingly more done. (And if you'd expect the company with less serial time to make similar amounts of progress, the same reasoning would also imply limited acceleration.) We also discuss potential sources of asymmetry which could break this correspondence and implications of this intuition pump.
The intuition pump
Imagine theoretical AI companies with the following properties:
SlowCorp NormalCorp Analog to NormalCorp with 50x slower, 5x less numerous employees, and lower ceiling on employee quality Future frontier AI company Time to work on AI R&D 1 week 1 year Number of AI researchers and engineers 800 4,000 Researcher/engineer quality Median frontier AI company researcher/engineer Similar to current frontier AI companies if they expanded rapidly[1] H100s 500 million 10 million Cumulative H100-years 10 million 10 million
NormalCorp is similar to a future frontier AI company. SlowCorp is like NormalCorp except with 50x less serial time, a 5x smaller workforce, and lacking above median researchers/engineers.[2] How much less would SlowCorp accomplish than NormalCorp, i.e. what fraction of NormalCorp's time does it take to achieve the amount of algorithmic progress that SlowCorp would get in a week?
SlowCorp has 50x less serial labor, 5x less parallel labor, as well as reduced labor quality. Intuitively, it seems like it should make much less progress than Norma |
a3988c77-e2fc-44ae-a066-6a997b91a495 | trentmkelly/LessWrong-43k | LessWrong | Notes on the Psychology of Power
Luke/SI asked me to look into what the academic literature might have to say about people in positions of power. This is a summary of some of the recent psychology results.
The powerful or elite are: fast-planning abstract thinkers who take action (1) in order to pursue single/minimal objectives, are in favor of strict rules for their stereotyped out-group underlings (2) but are rationalizing (3) & hypocritical when it serves their interests (4), especially when they feel secure in their power. They break social norms (5, 6) or ignore context (1) which turns out to be worsened by disclosure of conflicts of interest (7), and lie fluently without mental or physiological stress (6).
What are powerful members good for? They can help in shifting among equilibria: solving coordination problems or inducing contributions towards public goods (8), and their abstracted Far perspective can be better than the concrete Near of the weak (9).
1. Galinsky et al 2003; Guinote, 2007; Lammers et al 2008; Smith & Bargh, 2008
2. Eyal & Liberman
3. Rustichini & Villeval 2012
4. Lammers et al 2010
5. Kleef et al 2011
6. Carney et al 2010
7. Cain et al 2005; Cain et al 2011
8. Eckel et al 2010
9. Slabu et al; Smith & Trope 2006; Smith et al 2008
These benefits may not exceed the costs (is inducing contributions all that useful with improved market mechanisms like assurance contracts - made increasingly famous thanks to Kickstarter?) Now, to forestall objections from someone like Robin Hanson that these traits - if negative - can be ameliorated by improved technology and organizations and the rest just represents our egalitarian forager prejudice against the elites and corporations who gave us the wealthy modern world, I would point out that these traits look like they would be quite effective at maximizing utility and some selected for in future settings…
(Additional cautions include that, in order to control for all sorts of confounds, these are generally small WEIRD sa |
04969f6a-886c-4fd0-95a4-031b04102706 | trentmkelly/LessWrong-43k | LessWrong | We Live in an Era of Unprecedented World Peace
[Edit: This data seems to underestimate the violent death tolls in state societies. I think the general thesis is still valid but the data I used in this article should be taken very skeptically.]
Beside not dying of infectious disease my favorite thing about living in the 21st century is the fact I live in an era of unprecedented world peace. For most of human history, people didn't live in civilizations. For 90% of Homo sapiens existence, everyone lived as hunter-gatherers, pastoralists, or just small-scale farmers. Primitive societies are violent.
A few of primitive societies stand out as having relatively less violence, particularly the Eskimos and the !Kung. The Eskimos live in the Arctic tundra. The !Kung live in the Kalahari desert. They have so little violence because there is so little to fight over.
Most people live in places with high population densities. Places with lots of food can support larger populations. I suspect that, prior to civilization, most people lived in the most plentiful regions like modern New Guinea. In The World Until Yesterday, Jared Diamond writes about how in New Guinea, entire tribes would commit regular genocide against each other.
The !Kung and the Eskimos were paragons of nonviolence by the standards of primitive societies. Yet the 20th century (which included the Russo-Japanese War, World War I, World War II, the Armenian Genocide, the Chinese Civil War, the Korean War, the Vietnam War, the Soviet-Afghan War and many other conflicts) had a fraction of the per capita violent deaths of the !Kung and the Eskimos.
I was surprised to discover that conflict death rate went up by an order of magnitude between the Colombian Exchange and the modern era. (The chart uses a log scale.) But even at its height, civilization's per capita violent death rate was a fraction of the most peaceful primitive societies we have numbers for.
If we lived with the violent death rate of the early 20th century then we would be fortunate. Global |
b26eff9d-6fa2-489d-a946-04f4a8d93ff2 | trentmkelly/LessWrong-43k | LessWrong | A Guide to Forecasting AI Science Capabilities
The following contains resources that I (Eleni) curated to help the AI Science team of AI Safety Camp 2023 prepare for the second half of the project, i.e., forecasting science capabilities. Suggestions for improvement of this guide are welcome.
Key points and readings
for forecasting in general:
* What is a vignette?: https://www.lesswrong.com/posts/jusSrXEAsiqehBsmh/vignettes-workshop-ai-impacts
* Start using Metaculus and Manifold (if you haven’t already)
* Book review of Superforecasting
* Actually possible: thoughts on Utopia
for forecasting AI in particular:
* What is a hard take off?: “A hard takeoff (or an AI going "FOOM"[2]) refers to AGI expansion in a matter of minutes, days, or months. It is a fast, abruptly, local increase in capability. This scenario is widely considered much more precarious, as this involves an AGI rapidly ascending in power without human control. This may result in unexpected or undesired behavior (i.e. Unfriendly AI). It is one of the main ideas supporting the Intelligence explosion hypothesis.
* Read more:https://www.lesswrong.com/posts/tjH8XPxAnr6JRbh7k/hard-takeoff
* What is a soft take off?: “A soft takeoff refers to an AGI that would self-improve over a period of years or decades. This could be due to either the learning algorithm being too demanding for the hardware or because the AI relies on experiencing feedback from the real-world that would have to be played out in real time.”
* What is a sharp left turn?: the transition from a slower to a faster scaling regime as defined here (6:27 to 7:50).
* Pivotal acts: acts that we, humans, take that make a big difference in terms of making x-risk less likely.
* Pivotal acts from Math AIs: use AI to solve alignment at the formal/mathematical level.
* Objection: AI alignment doesn’t seem like a purely mathematical problem - it requires knowledge about different aspects of reality that we haven’t been able to formalize (yet) e.g., how do agents (both hum |
f401f081-6f85-4eb9-83f7-1a6778ca90d8 | trentmkelly/LessWrong-43k | LessWrong | Decision Theory but also Ghosts
Spoiler Warning: The Sixth Sense (1999) is a good movie. Watch it before reading this.
A much smaller eva once heard of Descartes' Cogito ergo sum as being the pinnacle of skepticism, and disagreed. "Why couldn't I doubt that? Maybe I just think 'I think' → 'I am' and actually it doesn't and I'm not." This might be relevant later.
----------------------------------------
FDT has some problems. It needs logical counterfactuals, including answers to questions that sound like "what would happen if these logically contradictory events co-occurred?" and there is in fact no such concept to point to. It needs logical causality, and logic does not actually have causality. It thinks it can control the past, despite admitting that the past has already happened and believing its own observations of the past even when these contradict its claimed control over the past.
It ends up asking things like "but what would you want someone in your current epistemic state to do if you were in some other totally contradictory epistemic state" and then acting like that proves you should follow some decision policy. Yes, in a game of Counterfactual Mugging, someone who didn't know which branch they were going to be in would want that they pay the mugger, but you do know what branch you are in. Why should some other less informed version of yourself get such veto power over your actions, and why should you be taking actions that you don't expect to profit from given the beliefs that you actually have?
I have an alternative and much less spooky solution to all of this: ghosts.
Ghosts
In contrast to Philosophical Zombies, which are physically real but have no conscious experience, I define a Philosophical Ghost to be something that has an experience but is not physically instantiated into reality, although it may experience the belief that it is physically instantiated into reality. Examples include story characters, simulacra inside of hypothetical or counterfactual predictions, |
b25bd626-42ee-49ce-9625-11cd2bef7193 | trentmkelly/LessWrong-43k | LessWrong | Draft report on AI timelines
Hi all, I've been working on some AI forecasting research and have prepared a draft report on timelines to transformative AI. I would love feedback from this community, so I've made the report viewable in a Google Drive folder here.
With that said, most of my focus so far has been on the high-level structure of the framework, so the particular quantitative estimates are very much in flux and many input parameters aren't pinned down well -- I wrote the bulk of this report before July and have received feedback since then that I haven't fully incorporated yet. I'd prefer if people didn't share it widely in a low-bandwidth way (e.g., just posting key graphics on Facebook or Twitter) since the conclusions don't reflect Open Phil's "institutional view" yet, and there may well be some errors in the report.
The report includes a quantitative model written in Python. Ought has worked with me to integrate their forecasting platform Elicit into the model so that you can see other people's forecasts for various parameters. If you have questions or feedback about the Elicit integration, feel free to reach out to elicit@ought.org.
Looking forward to hearing people's thoughts! |
a4e77fa0-bef9-407c-a741-d8f7cef5568d | trentmkelly/LessWrong-43k | LessWrong | Rohin Shah on reasons for AI optimism
Rohin Shah
I along with several AI Impacts researchers recently talked to talked to Rohin Shah about why he is relatively optimistic about AI systems being developed safely. Rohin Shah is a 5th year PhD student at the Center for Human-Compatible AI (CHAI) at Berkeley, and a prominent member of the Effective Altruism community.
Rohin reported an unusually large (90%) chance that AI systems will be safe without additional intervention. His optimism was largely based on his belief that AI development will be relatively gradual and AI researchers will correct safety issues that come up.
He reported two other beliefs that I found unusual: He thinks that as AI systems get more powerful, they will actually become more interpretable because they will use features that humans also tend to use. He also said that intuitions from AI/ML make him skeptical of claims that evolution baked a lot into the human brain, and he thinks there’s a ~50% chance that we will get AGI within two decades via a broad training process that mimics the way human babies learn.
A full transcript of our conversation, lightly edited for concision and clarity, can be found here.
By Asya Bergal |
7682c133-848d-45f3-a61f-9e7dd8a25984 | trentmkelly/LessWrong-43k | LessWrong | Counterfactual self-defense
Let's imagine these following dialogues between Omega and an agent implementing TDT. Usual standard assumptions on Omega applies: the agent knows Omega is real, trustworthy and reliable, and Omega knows that the agent knows that, and the agent knows that Omega knows that the agent knows, etc. (that is, Omega's trustworthiness is common knowledge, à la Aumann).
Dialogue 1.
Omega: "Would you accept a bet where I pay you 1000$ if a fair coin flip comes out tail and you pay me 100$ if it comes out head?"
TDT: "Sure I would."
Omega: "I flipped the coin. It came out head."
TDT: "Doh! Here's your 100$."
I hope there's no controversy here.
Dialogue 2.
Omega: "I flipped a fair coin and it came out head."
TDT: "Yes...?"
Omega: "Would you accept a bet where I pay you 1000$ if the coin flip came out tail and you pay me 100$ if it came out head?"
TDT: "No way!"
I also hope no controversy arises: if the agent would answer yes, then there's no reason he wouldn't accept all kinds of losing bets conditioned on information it already knows.
The two bets are equal, but the information is presented in different order: in the second dialogue, the agent has the time to change its knowledge about the world and should not accept bets that it already knows are losing.
But then...
Dialogue 3.
Omega: "I flipped a coin and it came out head. I offer you a bet where I pay you 1000$ if the coin flip comes out tail, but only if you agree to pay me 100$ if the coin flip comes out head."
TDT: "...?"
In the original counterfactual discussion, apparently the answer of the TDT implementing agent should have been yes, but I'm not entirely clear on what is the difference between the second and the third case.
Thinking about it, it seems that the case is muddled because the outcome and the bet are presented at the same time. On one hand, it appears correct to think that an agent should act exactly how it should if it had pre-committed, but on the other hand, an agent should not ignore any info |
43fc5e95-098e-4bdf-86b1-5112124d0f08 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Acausal trade: conclusion: theory vs practice
.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
When I [started](https://agentfoundations.org/item?id=1465) this dive into acausal trade, I expected to find subtle and interesting theoretical considerations. Instead, most of the issues are practical.
---
Theory
------
The big two theoretical questions are whether we model [infinite worlds](https://agentfoundations.org/item?id=1455) with infinitely many agents, and whether we should agree to some '[pre-existence](https://agentfoundations.org/item?id=1471)' deal with all agents, including those that don't and cannot exist. We lay aside the infinite case for the time being; pre-existence deals simply lead to all agents maximising a single utility joint function. There are many issues with that - why would the agents accept a deal that gives them nothing at the moment they accept it, how can the agents share a common prior, how much effort are they required to make to not deal with logically impossible agents, and so on - but it's a possible option.
Practice
--------
Without prexistence deals, then the situation is not hard to [model](https://agentfoundations.org/item?id=1465), and though practical issues seems to dominate acausal trade. There is the perennial issue of how to divide gains from trade and how to [avoid extortion](http://lesswrong.com/lw/obb/extortion_and_trade_negotiations). There is a "[Double decrease](https://agentfoundations.org/item?id=1463)": when an acausal trade network has fewer contributors, then those contributors also contribute less (since they derive lower advantage from doing so), compounding the decrease (and a converse result for larger trade networks).
There are many reasons an acausal trade network could be smaller. All agents could be [unusual](https://agentfoundations.org/item?id=1404) and distinct, making it almost impossible to figure out what agents actually exist. The different utilities could [fail to be compatible](https://agentfoundations.org/item?id=1464) in various ways. The agent's [decision algorithms](https://agentfoundations.org/item?id=1466) and [concepts of fairness](https://agentfoundations.org/item?id=1469) could be incompatible. And many agents could be [deliberately designed](https://agentfoundations.org/item?id=1480) to not engage in acausal trade.
Against that all, the number N of potential agents could be so absurdly high that a lot of acausal trade happens anyway. This is probably necessary, to compensate for the extreme guesswork that goes into acausal trade: all the other agents exist only in our heads. Trade is still possible with such agents, but we shouldn't forget our potential biases and errors when we attempt that estimation.
Scott's example
===============
The only major detailed example I know of that illustrates acausal trade, is Scott's example [here](http://slatestarcodex.com/2017/03/21/repost-the-demiurges-older-brother/). There an AI that realises it's likely not the first AI, and attempts to surrender by simulating the reaction of a potential earlier AI.
Note that this is not acausal, it's an acausal-like approach to estimate the reaction of other AIs during future causal interactions.
In any case, the AI ends up tapping into an acausal network of AIs with the joint agreement of non-interference for current and future AIs that might be brought into existence - a weaker version of the "universal utility" that exists for pre-existence deals. |
49a46408-fd35-4d96-871a-684887ee1e16 | trentmkelly/LessWrong-43k | LessWrong | Roger Williams (Author of Metamorphosis of Prime Intellect) on Singularity
This is Roger's article on Singularity issues, connecting his MOPI novel to how things might/should happen.
http://localroger.com/prime-intellect/mopising.html
(Roger is clearly aware of SIAI ideas and has referenced Eliezer in some of his posts)
|
6ae086f5-3585-4ead-b8c9-85bdfcf6b652 | trentmkelly/LessWrong-43k | LessWrong | High level climate intervention considerations
I’ve lately helped Giving What We Can extend their charity evaluation to climate change mitigation charities. This is a less abridged draft of a more polished post up on their blog.
Suppose you wanted to prevent climate change. What methods would get you the most emissions reduction for your money?
GWWC research has recently tried to answer this question, with a preliminary investigation of a number of climate change mitigation charities. Another time, I’ll discuss our investigation and its results in more detail. This time I’m going to tell you about some of the high level arguments and considerations we encountered for focusing on some kinds of mitigation methods over others.
The binding budget consideration
The world’s nations have been trying to negotiate agreements, limiting their future emissions in concert. The emissions targets chosen in such agreements are intended to sum up to meet a level deemed ‘safe’. Suppose some day such agreements are achieved. It seems then that any emissions you have reduced in advance will just be extra that someone will be allowed to emit after that agreement.
This argument implies political strategies are better than more direct means of reducing emissions. In particular, political strategies directed at causing such an agreement to come about.
This argument may sound plausible, but note that it relies on the following assumptions:
1. the probability of such an agreement being formed is not substantially altered by prior emissions reductions
2. the emissions targets set in such an agreement are not sensitive to the cost of achieving them
3. such targets will be met, or we will fail to meet them by a similar margin regardless of how far we begin from them.
None of these is very plausible. Agreement seems more likely if it will be cheaper for the parties to uphold, or if it is more expensive to have no agreement. These are both altered by prior emissions reductions. There is no threshold of danger at which targets wil |
32b1ba93-9692-4771-957f-f6687b04b741 | StampyAI/alignment-research-dataset/youtube | Youtube Transcripts | Reinforcement Learning 5: Function Approximation and Deep Reinforcement Learning
so I've alluded to the topic of today's
lecture quite a bit already in earlier
lectures this is quite natural as well
because we're doing both these parts of
the course for one part is focusing on
deep learning and the other part is
focusing on reinforced learning but all
the other hands may be before the course
you would have expected it may be more
tight integration of these two but turns
out there's a lot to be said about
reinforcement learning without even
talking about how to approximate the
functions so that's what we've been
doing so far we've been talking about
how to do these things maybe even when
you do them tabular ly and the
assignments also reflect that where you
haven't been doing much tensor flow or
deep learning in terms of the
reinforcement learning assignment but of
course many of you will know and have
known before this course started that
there is such a thing as deep
reinforcement learning and today I'll
touch upon what that means what that
means as a term but also what it means
in practice more generally we'll talk
about function proximation which is the
term that rich also uses in the region
and in the southern embargo book more
generally to talk about approximating
functions so again just to recap quickly
this is the setting reinforcement
learning and agents can learn a policy a
value function or a model and we'll
focus on that how to learn and
especially the value function in this
lecture and in general we're just in a
general problem including consequences
time and how to deal with that but
specifically I now want to highlight the
fact that all of these things are
functions I did that is in the first
lecture as well but I want to re
highlight that again so each each of
these a policy of value function or
model is basically a mapping from
Francis for the value function from a
state to a value or a state action pair
in the case of action values to a value
in the case of a model it's a mapping
from estates to for instance a next
state or maybe an expected next state
and in the case of a policy it's a
mapping from States to actions now what
we want to do essentially is learn these
from experience
and if there are too many states which
is often the case we will need to
approximate and in general this is
called reinforce including with for
approximation which is a bit of a long
term but when you use deep neural nets
people typically refer to this as deep
reinforcement learning to just basically
merge the terms deep learning and
reinforcement learning now this term is
fairly new it came to prominence
basically a few years ago but the idea
of combining neural networks worth
reinforcement learning is actually quite
old decades old
we just gotta may be better at it and of
course in addition we have the same
benefits that deep learning has
exploited quite successfully in recent
years which is the fact that we not only
do not only do we understand the methods
better we also now have the computer
resources to train these things for
fairly long amounts of time with fairly
large amounts of data and it turns out
if you do that then certain things just
work that we're not sure we were not
sure would work say in the 90s or
earlier that said many of the algorithms
the base algorithms that we use are
essentially that old q-learning for
instance is from 1989 by chris watkins
and it has it basically was immediately
extended to also be used with neural
networks but that doesn't mean that we
really understood what was going on back
then I say we but I wasn't researching
my them but we as a field that we really
understood what was going on back then
or that we were very effective at it but
it didn't work if you were a little bit
careful if you were a little bit of
aware of the properties of the function
approximator
of the neural network in that case but
all basically first I'll step up a bit a
little bit and not go immediately into
the deep Nets and just to be clear for
this lecture are we talking about
learning value functions in the next
lecture I'll talk about learning
policies explicitly so we'll return to
policy gradients which got covered in
the lecture and exploration and
exploitation when we were discussing the
single state immediate reward case and
next extra I'll talk about policy
gradients in the deep reinforced
building
where we work offering the fool
sequential problem and in addition we're
covering the case where we have
arbitrary nonlinear function
approximation but for this lecture we'll
stick to the value functions just for
clarity mostly now the motivation is
quite clear we want to use reinforcement
learning and turns out we can use
reinforcement learning to solve large
problems one of the earlier examples was
backgammon this is something that Jerry
Tercero did where he basically used TD
learning with neural network and then
use this in the game of backgammon which
is a tricky game but turns are actually
not that tricky for reinforced planning
because you can play many of these
things against yourself essentially
because the rules of the games are
fairly well-defined so you know exactly
you can you can program it program that
in into a computer you can have an agent
play against itself and it can learn to
become better and of course more
recently this was applied this
methodology not the exact algorithm but
the methodology of applying
reinforcement learning was applied to go
which is much much bigger than
backgammon and you could never hope to
learn this if you were going to try to
store every value that you could
possibly find for every state
individually in addition there are some
problems which are may be easier thought
of as having an infinite continuous
space so in example here is helicopter
helicopter control was done several
years ago go several years ago as well
and there's many similar control
problems that have been tackled with
reinforcement learning and here the
state space is basically infinite
although it's bounded typically and then
again the problem is to find a mapping
from that state space to either a policy
or a value function and of course again
it's good to keep in mind this example
of the robot just whenever you think
about reinforcing I find it quite
helpful when I think about algorithms or
what not to think about the case would
this learn or would this be able to
learn at all when it would be embodied
on the robot right if this robot has a
limited brain and it needs to do some
approximation because it has a limited
view of the world but the world is big
then somehow you need to be able to
cover that case so the main question
here is how can we scale up our methods
for prediction and control and so recap
not fully but which mostly considered
look-up tables so far at points i've
pointed towards hey this equation is for
the lookup table but you can extend it
to the function proximation case by just
replacing from some stuff but we haven't
really almost depth of what that means
or how that work and obviously whenever
we can apply this to a state value you
can typically also apply this to state
action value so I'll be trading these
these cases more or less indifferently
now there's a few problems with large
MVPs that we it's good to be explicit
about that we want to tackle so the one
is quite obviously that if there are so
many states you cannot even fit it in
memory in a computer you cannot build a
table that is that big to cover all the
states in a game like go for instance in
like in a typical big so especially the
robots are clear examples if the robot
is in the real world you might want to
put universe on the machine but that
doesn't fit so you need to do something
else there additionally and sometimes
even more importantly it's too slow to
try to learn the value for each state
individually and this is essentially the
problem of generalization when every
cease state we want to learn about that
state but we also want to learn about
all the similar states because if it's a
really big problem you're never going to
see the exact same state twice so that
means that if you would learn about each
state individually you would never learn
anything or you would never learn
anything that you can use in the later
States because they will all look like
brand-new states so obviously you want
to generalize this will come as no
surprise and another thing that often
pops up and I'll come back to is that
individual states are often not fully
observable again it's useful to think of
a robot which maybe has a camera to view
the world and it only sees whatever it
sees through its camera but it can't
look through walls it can't look maybe
behind itself the sensors are in that
sense limited and you want to somehow
deal with that
so the solution that we're proposing
here is just to estimate these things
with some function and notation that
I'll be using as I did before is that
there are some theta parameter I should
say here that the book these days uses W
for the parameters for the value
functions just to prevent confusion but
doesn't really matter it's just a name
variable name for the parameters and you
can think of this as all the weights of
your neural network and the idea is for
Institute in a prediction case to
approximate the true value of a policy
this also immediately kind of points
towards a means to do control because as
you may remember we've discussed policy
iteration at some point and generalized
policy iteration means you first
estimate the value of your current
policy and then you improve that policy
and you don't have to fully improve it
you can just improve it a little bit and
then you could do the estimation again
and the improvement and you can
interleave these steps quite fine-grain
e that's generalized policy iteration
which as an intermediate step has this
step of approximating the value of a
policy so if we can approximate the
values of policy this already gives us a
way to do control of course we can also
immediately try to estimate the optimal
values which is on the right there you
could or V star or Q star which
essentially means is we can do sarsa or
we can do Q learning we could do the on
policy thing of learning about the
current policy or we could try
immediately to learn about the greedy
policy which basically means we're
interleaving the steps of policy
evaluation and improvement very fine on
each step were kind of doing both at the
same time now the hope is if we have
such a function if it's a well defined
function on the full state space we can
plug in any state and we can get an
answer immediately and if your learning
algorithm is well designed in some sense
and if your function isn't too weird
you'll probably get a reasonable answer
if the state looks a little bit like
states you've seen before that's the
hope of course there's many ways to do
that and I'll talk about a few of them
in this lecture and the high-level idea
that we're talking about mostly here is
to update these parameters theta using
either Montecarlo or temporal difference
learning and in the end I'll talk about
how to unify these but the other thing
that I wanted to say which I won't
touch upon that much in this lecture but
I'll get to back back to a little bit
also in the next lecture is that the
environment States might not be fully
observable as I mentioned the robot
example when you just have your vision
from the camera which means you might
want to learn a state update function
and state up the functions is to remind
you is something that takes the previous
agent state and the current observation
and it outputs a new agent state so now
I'm using s here to do to refer to the
agent state which is essentially state
internal to the agents which might not
coincide with the environment State
which might be much much bigger so in
the slides that will come mostly I won't
talk about this too much and one way to
think about this is that whenever you
see a state you could just think about
the observation which is a simple way to
construct an agent state you just take
your observation you just ignore the
previous agent state and you're done
right this is an agent says but if you
only look at that your potential
solution might be limited the robot can
only ever do you can learn only ever
learn a function that is a direct
function from these observations which
might not always lead you to the optimal
policy so I just want you to keep this
in mind you can maybe forget about it
for most of the lecture but whenever you
then want to apply something like this
in the real world and I will get back to
this again this is something that is a
that is potentially important okay now
you might think I might merely go and
talk about deep neural networks now as
plugging those in but there's actually
many potential choices that I do want to
mention so the obvious first curve a
choice here says put into the artificial
neural network as a function parameter
alternatively one thing that has been
done in the past is to put a decision
tree in there which has maybe somewhat
harder boundaries in terms of
generalization but they're fairly well
understood and you can use them
effectively if you if your problem is
well suited for them you could also do
something nonparametric their nearest
neighbors just store a few samples find
the nearest one use that one and this is
actually something that is sometimes
pops back up again the people re
investigating turns out it works quite
well in certain problems or you
construct certain features I'll touch
upon that more so here it says free a
wavelet basis
one potential choice there's many ways
you can construct features course coding
is essentially a different way to
construct features don't worry if you
don't know what any of these two mean
I'll talk more about especially the
course coding in a moment but just think
of it as a way to construct features
which you then later use to maybe do a
simple linear function rather than to
try to learn a whole deep neural network
and these were very popular in the past
also because they're quite
computationally efficient and they tend
to be quite data efficient because it's
easier to learn a linear function then
it is to learn a deep neural network of
course you're limited in the type of
functions you can learn you need very
good features if all you're ever going
to do with it is construct a linear
function of your features now in
principle in terms of the generic
updates you can use any function
approximation but of course reinforced
learning has some specific properties
which might make it harder there are
some listed here this is not meant to be
an exhaustive list but one important
difference with the standard supervised
case is that the experience is not iid
typically successive time steps and
therefore successive updates if you
update your value function online will
be correlated which may or may not be a
problem that is good to be aware of also
as I mentioned in the first lecture and
after a couple of times the agent policy
affects the data it receives which
affects the nature of the function
you're learning so these things are
tightly integrated in basically highly
non-trivial ways and the learning
dynamics of the full system is something
that is not that well understood and
there's a related note the value
functions can be non stationary now the
policy iteration case is a very clear
example of that there we're not plugging
in one specific policy but we're going
to change the policy repeatedly because
we want to find something that works
really well which means each time we're
kind of trying to estimate a different
value function but turns out depending
on your learning algorithm the value
function might be non stationary or the
targets that you're trying to
approximate can be non stationary for
other reasons for instance when you're
doing bootstrapping as in TD learning
because then I'll show you the examples
later again on later slides but just to
remind you what does that mean to deal
earning it means that you're updating
the value of the states towards the
reward and then the value at the next
state add it together but the value at
the next state itself is part of the
function that you're updating which
means that in total your update is
non-stationary which may cause problems
for certain types of function
proximation or it may invalidate certain
algorithms that might assume that this
is not the case and it might actually
break them in practice as well another
property of reinforced learning is that
feedbacks delayed which means especially
in the online case you might do
something you might immediately update
using say TD learning but it's not
always clear that this is the best thing
to do sometimes you want to wait a few
updates as in Montecarlo learning but
then this it creates overhead you need
to do the bookkeeping if you if you
program this and it's not always true if
you'll to do this know that that part
might be easier than some of the others
so here's some some potential choices
like generic choices I would say for a
function proximation we started off with
the table right just store for every
state you can possibly see just think of
every observation you can possibly see
store these in a exact value in a table
somewhere which you can an update maybe
you still update it only slightly for
each observation because maybe sorry for
each transition because maybe your data
is noisy as we discussed in earlier
lectures but this is a fairly well
understood thing now an easy thing you
can do especially when you're sailors
say continuous spaces which are still
not that high dimensional you could
think of just cutting this up so if you
think about your state space as being
Sprint's as a two dimensional space it's
just a plane and its bounded well one
thing you could do is you could just cut
that up into pieces and then call each
of these pieces of state that's a valid
thing to do and then you're basically
back to the tabular version right we've
just manually created something that is
essentially a tabular MVP however one
thing that you should note then is that
we've actually aggregated States
together which means you might not be
able to observe exactly in which state
you are so you've made the problem
partially observable when you do that
slightly more generically or slightly
more generally you could do a linear
function approximation this basically
subsumes both the seller and the state
aggregation case
where we say we have some features to
cutting up the safe space was one
example but you could think of many
other features that you could construct
and then we hope that we can learn a
function that is accurate enough as a
linear combination of these features the
benefit of this is that it's very well
understood and we can say much more
about where does their duty algorithms
go when you run them for a long time do
they converge in it so where do they
converge it also tends to learn faster
than if you do arbitrary nonlinear
function approximation but of course
it's very much dependent on the nature
of the features and it might be very
tricky for a certain problem to define
good features but if you can this is
definitely something that you could
consider in the most general case and
one that we happen to like a lot these
days is to use differential nonlinear
functions such as neural networks the
benefit of this is that we can just toss
a raw signal in like pixels from a
camera and you can still hope to learn
and that is a big benefit because you no
longer have to create features you don't
longer have to actually understand your
problem that well for instance on these
Atari games I've run algorithms on Atari
games which I don't even understand I've
never played I don't know how to play
like the algorithms will be much better
at these games than I am and I can do
that because I don't need to understand
the game which is quite a nice benefit
so which you use I assume most of you
will be tempted to use the deep neural
networks which is fine and they tend to
give you best performance these days
depending on the setup but just to point
it out this list up there basically from
the top to the bottom starts off with
things that we understand really well
but might have a little bit more weak
performance and then they go to things
that we know work well because we've
seen it in practice but we can't really
say much with confidence about in in the
theory so we can't necessarily guarantee
you that it will work well it just
happens to be the case that we know when
we actually run this and you're a little
bit careful with how you do this that
you can make them work really well by
the way as always feel free to stop me
whenever when you have a question
because you're likely not to be the only
one with that question
okay so this is just this is very
generic you kept this might be a little
bit boring even considering you've seen
all this stuff in the other part of
course as well but just to be clear
we're going to define some
differentiable function denoted here J
just think of this as a loss which is a
function of your parameters and then
we're going to take its gradient which
is just a vector with all the partial
derivatives and then the goal is to say
find a minimum if you think of it as
loss actually in the policy gradient
case we might define things that we want
to optimize find the maximum rather than
the minimum but of course that's easy to
do just by putting a minus sign in front
but Denari we want to move the
parameters in the direction of the
negative gradients to do gradient
descent and this gives you one valid way
to update of course there's other
optimizers but this is a good one to
keep in mind and most of the concrete
algorithms are giving this lecture I'll
give you the stochastic gradient descent
version so actually maybe let me go to
the next slide which gives the
stochastic gradient descent for value
functions that doesn't mean that of
course you can only use that you can
apply different optimizers you can apply
rmsprop atom things you might other
optimized you might have heard of from
deep learning essentially anything you
can toss the gradient into and that
results into an update you can apply to
the deep reinforcement learning case but
for clarity I will only show you the
vanilla stochastic gradient descent
versions of the update so then to apply
this to value functions we define some
expectation and this is actually
important now something to touch upon a
little bit so I subscript this
expectation with Pi which is the current
policy and the thing that is random in
is expectation is actually the state
because note that we've put the true
value of that state on the left and then
the current estimate of that states V
theta on the right and then there's a
squared error but the only thing that's
random there is a state so what I mean
with the expectation under the policy of
this thing is I mean there are some
distribution over states which in this
case
is the thing that isn't used by the
policy that you're following so this is
a non policy loss function essentially
and this is important when we do
function approximation because we have
to somehow decide where to spend our
resources where you're going to fit a
function it's going to fit basically the
best it possibly can where you have the
most data so this ties into the question
of how do you then select your data
which is important for the control
problem and if you pick a certain policy
that never goes to a certain portion of
your state space you'll only get a
little bit of function approximation
resources allocated there and your
generalization there might not be that
good v theta yes sir good question V
theta is basically our current estimate
with any function approximation of the V
Pi in this case so this loss is when you
do the on policy policy evaluation case
I use VT so just generically as this is
some value function which is
parametrized by theta one way to think
about that is two it could be for
instance a neural network which takes
the agency this input which could just
be your observation and then the output
is the current estimate for the value of
that state under the policy so I'll give
you actual I'll give you the TD
algorithm in a moment so then you can
see exactly what the TD algorithm in
this case is so I should have preface
this by saying this is again me
basically just first defining things
because this loss is not something that
is actually available you will not have
access to V PI particularly so we need
somehow to instantiate this to turn this
into an algorithm we can actually run
and I'll do that in a moment this is
first just basically define what would
be an ideal updates if you want to do
stochastic gradient descent to learn
this value function yes
see the policies around attention for
today is gonna end up so the question is
why is so the random variable I said the
only random variable is the state and
the reason that is the case is because
I've actually used the true value for
that state so I'm not rolling out
anything - I'm don't have a Monte Carlo
return there in particular I will have
in a later slide because you have to
instantiate this and then that will also
be random in this particular formulation
the only thing that's random is the
state because I'm using I'm plugging in
the true value function which of course
is something you can't do in practice
but it's just for the for defining the
loss essentially and then of course we
can derive a stochastic sorry the
stochastic gradient descent update which
is on the bottom there I use this delta
theta notation here which basically
means this is the thing that I'm going
to add to theta to the parameters
instead of each time writing the next
theta is the previous theta plus
something
I'll just only write that letter that
letter thing the thing that we're going
to add which in this case is just a step
size times the sampled gradient of the
loss that we defined now in this case
this sampled gradient as it is given on
this slide is still not something that
is available because although we've
instantiated the states
I still haven't instantiated the true
value which we don't have I'll return to
this in a later slide where I will
instantiate it with both TD learning and
with Monte Carlo learning but this is
just first talking about what the goal
is and to make it concrete we can talk
about a specific function which is much
easier to show explicitly which will be
a linear function of some features
there's a question
yeah so the question is do we use while
do we assume we're out a policy we all
need assuming that it's fixed as you say
so this is the policy evaluation case so
this doesn't cover policy iteration
doesn't cover control this is just one
thing you might do and it might not be
the only thing you want to do or it
might not be enough for what you want to
do if you want to do control this is not
enough by itself it's a good question
Thanks oh sorry it's a very good
question so theta is the parameters of
the policy are not given here so the
policy is fixed we're assuming it's
basically something that might not even
be under your control there's just some
sequence of mapping from States to
actions theta here refers only to the
parameters of the value function so only
to that mapping from the states to the
value later on and especially in the
next lecture I will talk about
parametric policies where you also have
a function with its own parameters that
will output an action and then these
parameters we somehow have to think
about how to update but I'll defer that
to the next lecture it's good question
Thanks okay so to make this concrete
let's instantiate a function let's pick
a simple one a linear function to do
that first we have to define some
features because typically we don't want
to do a linear function of say the
pixels that come in so in this case
there's just some mapping from the
states to some features and one there's
a few examples here on the slide for
instance if you're if you have a robot
this could be the distance from certain
landmarks let's say sprinkle landmarks
all across some map and then this could
just be a vector with all the numbers
that correspond to the distances from
all these landmarks and if you have
enough of these landmarks you can
basically exactly determine where the
robot is from these features and you
could maybe hope to have some
predictions that also are linear
functions of these features it really
depends on what your prediction is
though really depends on the reward
signal whether that's enough whether
those features are rich enough in that
sense there's some other example things
that have
done in the past such as configuring
somehow picking out peace and palm
configurations and chests rather than
trying to map each configuration to a
specific state value to a specific
cassell in a table you could basically
aggregate many of them together and say
oh if it if your palms are roughly like
this this feature will be um it will be
equal to one and if they're not like
that it will be off it will be equal to
zero
oftentimes these features are by owner
Eenie don't have to be the distances for
instance iron bar in your binary but
many people have done things in the past
where they've basically defined binary
features which give you indicators of
whether certain things are true or not
and then your your way that some of
these things is just your estimate of
the value yeah it is how they used to do
chess ai so I think a lot of chess I'm
not actually that familiar with what was
done in a chess ai but I believe most of
it was actually based more on search and
nearest exert and there was very little
reinforcement learning applied to chess
so these days you can write apply
reinforcement learning to chess
obviously but it turns out especially in
these type of problems it's actually
quite easy to leverage a lot of human
knowledge if you have a lot of human
knowledge it's much easier to start
features that are quite informative but
you could also immediately construct
evaluation functions like oh if you have
this many palms and this many pieces
then you should be better off than the
other one who has fewer and then you can
just search through a big space do smart
search you don't search everywhere and
then you could use use these evaluations
directly so you don't have to construct
features and then learn a value of that
you can combine these things you can
learn these evaluations okay
so now the value function has a fairly
simple form the theta the parameters of
our value function is now just also a
vector with the same size or the same
number of elements as our features so we
have a number per feature and I already
said this a number a number of times on
the previous slide but essentially value
function will just be a weighted sum of
the features so we're multiplying each
of these features these Phi J at state s
with the corresponding number theta J
which is just a real number and this
will then constitute our value function
this is just a simple function in some
sense and this actually helps understand
it better as well so talk about this
function quite a bit in this lecture and
of course our loss function that we had
before we can now Stan she ate by just
replacing the V theta at a more generic
way of writing it down with this
specific choice where we multiply this
theta vector with the feature vector the
Thetas are global they're shared across
all states because we're learning this
one weight vector that you to define our
whole function and then the features
depend on the state now if we would if
we would have labels if we will have
these true values at each states then
this would just amount to regression
linear regression and we could find the
global optimum which means we could find
least square solution and the update
rule for the stochastic grade in the
same case is very simple what I'll do on
this slide and later often is a whenever
I take the feature of the state at s T
just to reduce to the notation a little
bit I'll just say features T so there's
just a Phi with the subscript T which is
the features you see at that point in
time so that means we don't have to
reason about States there's just a lot
of features coming at you and rewards
coming at you and this is where your
algorithm is done based on the update is
very simple it's a step size times the
prediction error where again I'm still
using the true value there so this is
the difference between the true value
and your current estimate
time's the feature vector in the case of
linear functions because it just happens
to be the case that the gradients of a
linear function with respect to your
parameter is just only the feature
vector that's not the case for deep
neural networks or more generally for
linear of or for nonlinear function
proximation a special case of this is we
can still do tabular using this exact
same formulation by considering a
feature vector that's basically one hot
which means that exactly one of the
values is 1 and each time and all the
other values are 0 of our feature vector
and then we just make sure that we have
one such feature for every state which
means that the linear function
proximation case that I just showed you
basically generalizes the tabular case
of course this also merely shows the
problem with this a Buehler case because
there will be many many states in those
in those cases when you have a large
problem that you want to solve which
means that this is a very large vector
potentially so this is just basically to
show you that these things are the same
in some sense or that the linear one
generalizes the tabular one now to give
a concrete example for how could you
potentially build features this is a
very simple example called course coding
and the idea is quite simple that you
have you overlay over it's let's say you
have a two-dimensional space over the
two-dimensional space you overlay some
basically location indicators and in
this case there's not a single feature
that will turn on
it doesn't say oh what is the nearest
thing but it will actually say when
you're near certain locations the
features will be on for those locations
which means you can actually in this
case there might be three features on
because we're near enough three of these
centers of these circles which means
that the combination of these three
features actually tells you fairly
precisely where you are and then we can
use that as a feature representation
just to do the way that some
and things like this have been tried
quite a bit in the past and it tends to
be quite effective but it's also quite
easy to consider failure mode so when
wood is fill well one clear way when it
would fail is when you have a very high
dimensional space if it's a continuous
space but it's not two dimensions but
it's like maybe 100 dimensions or maybe
if you think about pixels if you have a
hundred by 100 pixels that's already
10000 dimensions if each of these can
have a real value then maybe something
like this doesn't scale that well but
for a low dimensional space is sorry low
dimensional problems with low
dimensional state spaces this might be a
very appropriate way to first model it
and then try if you can find a simple
solution that that exploits these
features there's some generalization
here which means that whenever he
updates any of these weights associated
with the features we basically will
update the weight for the whole circle
for each of these circles so we're not
just updating the value within that
small almost triangle in the middle but
in fact we will be updating the value a
little bit for all of the other shaded
regions there as well because we're
updating essentially in this case three
different values corresponding to the
each of these three features and that
means that whenever we change one of
these values the whole value function
within that region gets updated a little
bit and this is nice because it means
that if you end up somewhere which is
close but not exactly at the same point
you will already get a well-defined
value there which is probably fairly
accurate if the true value is fairly
smooth there of course if there's large
discontinuities which sometimes happens
sometimes the true value really has a
sharp edge somewhere it depends how you
space these things whether you can
capture that and it could be that you
generalize over that cliff and that
maybe this might cause problems with
your approximation which is basically
just another way of saying if you have a
linear function of some features it's
probably going to be not that flexible
so you might not be able to capture all
of the rich functions that you might
need to solve a certain problem
[Applause]
also note and I mentioned this before
that when we do something like this
we're actually aggregating states so
even if you only consider like the small
little track triangle in the middle on
the left hand side there there's
multiple states that fall into this
triangle potentially you could end up in
this place near this place multiple
times but you can't actually distinguish
them if these are binary features
especially then all of them will have
the exact same feature representation
all of these all of these situations
where you're near enough which means
they cannot have different values what
this also means is that the problem
becomes non Markovian because the fact
that you cannot tell exactly where you
are means you could potentially also
move exactly not exactly determine what
the next reward distribution or state
distribution would be without taking
into account where you were before and
this is exactly violating the definite
definition of the Markov decision
process and in fact this is the common
case when you do function approximation
because we're going to generalize we're
going to want to generalize because
otherwise learning is in is incredibly
slow but when you generalize this does
mean that you lose the Markov property a
little bit which is something to take
into account to be aware of and you
might want to correct for that in
various ways one way that I'll just
mention here in passing but I'll get
back to in the next lecture is that you
might want to build up an agent state
that is very rich and it has a lot of
information you might want to think
about memory for instance yeah it's a
very good question so how what would
ease what would these features mean if
you for instance you do have a 2d input
but it's not spatial and essentially the
answer to that is it's unclear and it
might be fully inappropriate and this is
also why this slide actually shows three
examples one like on the Left we're
doing not that much generalization in
some sense the the circles are fairly
small which means we're fairly precise
and in that case you might still be okay
because near might still be well-defined
but but maybe you want to do more
general generalization
in the middle plot but maybe section
more appropriate to have something that
is very differently shaped and it might
be need fully inappropriate to
generalize in such a way across your
input space so this ties back to the
question of how do you define your
features and in general you really need
to understand your problem a little bit
in order to even define useful features
you cannot just hope to have a one
solution for all all problems in terms
of feature feature definitions it's a
very good question yeah yeah so why is
it non-markovian
I guess the the situation that may be
clearest is if you think about think
about a robot that can be in many
different rooms and let's say we have
features per room so this is kind of
like this where we have like a location
indicator right but well I'm just making
it very very large-scale in some sense
because rooms we can think of has
basically fairly large things now the
definition of the Markov property is
that you cannot essentially improve your
let me say let me say it more clearly
the distribution of the next reward and
States so the state stabilization
distribution if you will depends on your
current state but if you add previous
states you cannot make it it doesn't
depend of your previous state given your
current state so the shorthand that we
use for that was the the future
conditioned on the presence is
independent of the past so when you have
features saved per room for a robot
that's no longer the case because you
might have transitioned just into that
room on the previous step and if you
only look at the feature right now which
is in the room you might be anywhere in
the room but if you would take into
account that the previous feature was I
was just outside of the room in this
other room this will go if it gave you a
lot more information so the distribution
of your reward might might be quite
different when you add previous
observations in that case
it also has very concrete consequences
because it means that your value
function might be a lot more accurate if
you take into account a few previous
observations because it's much easy to
predict the actual value of being where
you are which might not be anywhere in
the room but it might actually be in the
northwest corner of the room or
something like that and taking previous
observations into a kind might allow you
to basically know that whereas just
looking at the current observation might
not now it's a good question so what is
the underlying dynamics this is saying
she did a question so you could imagine
doing something where where each time a
robot transition somewhere you reset it
to the center of that region say and
then it only then it can transition
somewhere else in that case it would be
Markovian again well that's not
typically the case the underlying
dynamics typically use the actual
location rather than the features that
the robot sees yeah oh yeah sorry this
is just this is not necessarily better
than a grid which is the question in
fact most people use grids this is
basically just to depict that it doesn't
have to be a grid it can be arbitrarily
shaped you could do arbitrary things
here this is actually also fairly often
done as I as I said with the example of
the robot with distances it's a little
bit like that and maybe you could have
instead of just using the distances
themselves as features you could have
thresholds on the distances and then you
get exactly this you could say if you're
within 10 meters of this locator then in
the feature ISM and then you basically
get exactly this and this has been used
as well in the past
okay so now we get back to that question
that was asked before very rightfully so
so we don't actually have the true value
function which we've been using as a
placeholder basically up till now so we
need to construct some targets some
valid target for that well one obvious
choice for that is just to use the full
mark of sorry full Montecarlo return
which actually is an unbiased estimate
for that true value we just run the
policy until termination of an episode
say and then we just take that return
which we've denoted G in the past just
to remind you GT is the reward of the
next step our t plus one plus the
discount reward after that plus the
discount it's double discounted reward
after that and so on all the way until
termination or indefinitely in the
continuing case so as mentioned when we
discuss differences between Montecarlo
and TD in previous lectures I've already
alluded to a problem with that a
potential problem with that is that they
could take very long before you actually
have this return which is one of the
reasons why you might want to prefer to
do something more like TV where we
essentially do the same thing we just
replace this true value with an estimate
and in this case that estimate is the
one step reward plus the discounted
approximated value at the next state so
now you can see V theta showing up in
more than one place it is the thing that
we're updating but it's also used as the
constructed targets for our update this
is very similar to the tabular update
the only difference is now that there's
this gradient there at the end
so we're basically multiplying the step
size with the temporal difference error
in this case or the Monte Carlo error in
the Monte Carlo case and then
multiplying that with your gradients of
the value function with respect to your
current parameters and this will then
give you an update
now to go a little bit more depth of the
Montecarlo version so the return as I
said is an unbiased noisy sample which
means we're almost exactly in the
supervise case we have something that
you could call a data set which is
inputs States say s 0 up to St say say
we have data up to s T right now and for
each of these say we have a Monte Carlo
return so let's assume we've actually
we're in a situation where we actually
have that final Montecarlo return as
well maybe the problem terminated after
time step T maybe it also terminated a
couple of times before them we don't
care but maybe this final a Monte Carlo
return is just as one step reward and s
T is the last state you've seen and then
you can use this training data to do the
normal supervised learning thing which
you've done many times I I assume and
this would be the linear case do you
know their first there's actually the
generic case and then the linear case is
given there where I've instantiated the
gradient of the value function with
respect to the parameters as the current
feature vector which is the case for the
linear function approximation which
gives us linear Montecarlo policy
evaluation this is just regression right
so in the bottom case it's a linear
regression in the top case it could
actually be nonlinear regression this
could still be a neural network if you
want but especially for the linear case
this converges to a local optimum
because it's a it's a complex loss
function and stochastic gradient descent
can find the minimum there and in the
general case it will find a local
optimum in the sorry nonlinear case you
can find a local optimum in the linear
case it can only find the global optimum
because there is only one optimum there
are no local optima but this does also
work for nonlinear functions so you
could plug in a neural network you could
just do regression with that you've
you've done that before
and this in that sense should just work
but we might want to do TD instead where
we instead of using a Monte Carlo return
we use this one-step return and we
bootstrap so we use the one step reward
and we have used this
counted value at the next states and we
plug that in into place of the true
value function which again allows you to
construct a training set and in this
case we construct this we can construct
this anytime immediately after taking a
step because it's immediately available
we don't have to wait indefinitely until
an episode ends and then we can
construction update looks very similar
to the Montecarlo case and this would be
in the the bottom equation it would be
linear because again I've instantiated
the the gradient there with the current
feature vector the top top one is more
generic where I still have the gradient
symbol in there which could also be
applied to neural networks and one thing
I did is the notational thing here of
replacing the TD error with this Delta
which is used often in literature so I
wanted to put it on a few slides as well
so you're familiar with that notation
which means we can write the update very
concisely this is again step size alpha
times the temporal difference error in
this case Delta times the feature Phi I
didn't subscribe subscript the step size
here with a wither T you could also have
a time varying step size in which case
all of these would be subscript it with
T and this gives you valid updates both
of these the Montecarlo case in the
temporal difference case and then we can
talk about where do these things go
where do they converge especially for
the linear case this is quite easy to
look at so this is why we focus on that
one a little bit and it turns out to
converge to this quantity there at the
top there's a small proofer on the slide
which is not as tricky it's something
you've probably seen many times before
because it's essentially just the normal
regression case but because we're using
the return G we can later replace that
again with the true value because it's
in an expectation
it's an unbiased sample so this is
normal regression you come you get the
normal least square solution essentially
that you would expect by doing so
category in the sense another
interesting question is this is
basically unsurprising because it's
normal regression again the question is
does TD find the same solution and it
turns out
does not the solution is slightly
different and the reason is essentially
the fact that we can't reuse this thing
this error all the way to zero and then
the question is so where shoot you
allocate your function approximation
resources and in the Montecarlo case
this only basically depends on your
state distribution so the error there at
the top that we're minimizing the
squared difference between the samples
return and the estimated value at each
of the states this is a random quantity
because of the value and the return but
how well we'll estimate each state value
basically depends on how often we visit
them and/or how often we update them so
if we assume your policy case I didn't
actually put a PI there so I'm not
saying anything about which policy but
let's assume we're doing the on policy
case where there's a whether it's a
policy that is the same one that was
used to generate the return it's also
the one that basically waits which
states we care about then this will
essentially weigh the importance of each
of the states by how often you are there
and it will make your function more
accurate in the states that you are
often compared to states where you are
less often you cannot hope to have a
function that is completely accurate
everywhere so there will be some
trade-off and depending on where you go
more the function will be better and in
the TD case something similar happens
but in addition there's this
bootstrapping that happens we're also
updating towards the guests so at some
point you'll stop updating because your
average gradient of the loss will become
zero at some point you've reached a
local optimum but this is not
necessarily at the same point as the
Montecarlo return which opens a question
which one should you use so typically
the asymptotic Montecarlo return is
preferred because it's essentially the
same thing as the true loss that we care
about for the policy evaluation case the
return is a noisy sample for the true
value but it doesn't actually matter for
the convergence because in the
convergence we can replace that because
it's in an expectation with the true
value which means it ends up in the same
place as if we would have used the true
value and regress towards that there's
just
the case 40d which ends up in a
different place and it can be quite a
bit different depending on the function
approximation that you use used
essentially because we're learning a
guess from a guess which means that the
value that we're bootstrapping on might
indefinitely be a little bit wrong for
the same reasons that the value that
we're loading with Montecarlo is a
little bit wrong we're doing function
proximation we cannot hope to have truly
accurate values everywhere but if we're
using these estimates indefinitely as in
our targets that means that we're going
to estimate something that is a little
bit different from the thing that we
actually care about
so asymptotically you might want to
prefer a monte carlo solution if you
have enough time you might just want to
run that indefinitely long and you'll
find the solution however temporal
difference methods typically converge
faster they learn faster in practice
which is why you might so prefer them
even if they'll go to exactly place you
want they still go to a well-defined
place which is still a good solution
typically and they might reach it apart
quite a bit faster so the trade-off
there might be quite quite good yeah
[Music]
yeah sorry I should I should clarify
that it's a very good question so
previously I discussed something where I
showed that TD found indeed basically
the solution to assuming there's a
Markov model and then solving that
whereas Monte Carlo found the solution
for basically the regression solution
which are difference that was in the
batch case where you basically learn
indefinitely on finite data so the Monte
Carlo sorry the the mark of problem that
TD soules is the one that best fits the
data up to that point and then if you
run over and over all the data again
it'll basically solve for that one in
the limits they go to the same place in
the limit of data all right so that
example was in basically the limit of
time of updates considering fixed data
so that's a need a little bit confusing
so thanks for helping to clarify and
this does mean this is
tights to the question of what why this
did he learn faster because it might
we'll learn something that is actually
more well suited to learn quickly um but
in the limit in this case it actually
ends up somewhere else altogether which
has nothing to do with that building the
Markov model in some sense it's just a
different solution
now I just wanted to there's another
potential source of confusion that I
want to preempt because if you're doing
the bootstrapping there's a lost at the
fact that just dependent now your
parameters and there's a fairly natural
thing you could do there which is just
to take it's in the middle of the slide
there to take a loss that is just your
square TD error and just to take the
gradient of that
so essentially what I've done here to
achieve that loss to get get that loss I
have replaced the true value with the
estimate that we're going to use the
reward plus discounted next state value
before I took the gradient previously I
first took the gradient I still had the
true value there I got my gradients and
then I replaced that true value with
something we can actually have for
instance the one-step TD target or the
Montecarlo return in this case I first
replace it with a target actually had
and then I take the gradients and turns
out that leads to a different algorithm
because if you don't take the gradient
you're also going to take the gradient
of the value at the next state which is
a little bit of an odd thing to do if
you think about it because what does
that mean it means we were in a certain
state st we did a transition we saw a
reward and we end up in a new state and
now we're going to update both of those
values so that the error on this
transition is lower but that kind of
violates causality because why would you
change the value of the next state which
the semantics of which are about the
future to make the updates for this
state better and indeed it turns out
this works a little bit less well in
practice this is called bellman
residuals for historical reasons there
there was a paper by Barrett who in
which he proposes this as maybe a
meaningful way to do things
the update is a little bit similar to
what we saw before but instead of having
the gradient of the sorry in the middle
on the right update the delta theta the
update to our parameters theta is now
step size times temporal difference
error that part is the same times the
gradients of the value function
at st- the discounted value function at
st plus one this is what you would get
if you define your square TD error to be
the loss and you just take the gradients
and this is also I felt it important to
mention this because it's a common
mistake I mean this isn't valid
algorithm it just happens to be
typically worse than TD but it's a
mistake people often make when they
implement these things especially in
current day auto differentiating
software packages like tensor flow so
what I propose to do instead is if you
implement something like this that you
put the targets the reward plus
discounted next eight value in a stop
gradients what that means is when you
define your loss what this means is
basically you're saying this is a proxy
for the real thing
but I don't want you to update this
proxy just to make the value at this
state better because it won't actually
make that value better necessarily in
fact you're changing your value at a
different state so it's kind of a
practical point but there's also a
fundamental point here that this
algorithm is actually doesn't work that
well and that was a little bit of a
surprise to some people because they
expect as well you can just define this
as a loss it seems to be a valid loss
and then we have a true gradient
algorithm on that loss and everything
seems fine but I think the reason for
that is less I just mentioned that
basically violating causality by the
weight a fixed point of these things is
in many cases the same so in the end
you'll find maybe the same solution but
it might take you long
so as I said I'd like to talk about
control and the easiest way to do that
like the small steps that we can take
from what we did just now is just to
replace the value the state value
estimates with state action estimates so
we're essentially just replacing a V
with a Q and then we can do policy
iteration where we do the generalized
policy iteration where we don't consider
fully evaluating policy and we don't
consider maybe fully improving policy so
for instance one thing we could do is we
could approximate the action value
function for the current policy with a
parametric function G sorry Q theta and
then maybe we will just follow an
epsilon greedy policy which is a form of
policy improvement of course there's a
difference here from the previous case
because we're not actually guaranteed if
we do these approximations with
functions that might depend a lot on how
you sample and where you sample and
there's noise and in addition there's
function approximation error
you're not actually guaranteed that your
value function has monotonically
increase or what sorry moment sonically
improved during an evaluation step
that's kind of okay if you in general it
improves you're still good but it's it
does mean that some theoretical results
get invalidated by just doing function
approximation in this case but we could
still probably method and in many cases
it's still completely valid which in
practice means for instance we could do
the linear function again for clarity we
could define state action features now
for instance we could just do the same
thing we did before we could split up a
state space by just discretizing into
two little cells or whatnot
and then maybe we have a feature for
each action which is one way to do this
this is especially useful if you have a
very small action space maybe you can
only move up down left right or
something like that and you're in a two
dimensional space then it's fairly easy
to find such features you could still
hope to have a good function if you have
a linear function of those features this
is so exactly the same as before all I
did is replace States with state action
pairs and V values with
values okay we can apply this
immediately for control and this is
linear salsa which is I I will remind
you the state action value version of
temporal difference learning so will
bootstrap on the value of the next state
and the next action as selected under
your current policy we'll use that as
the value to bootstrap on to construct
our target that's sarsa and then we just
apply that with a linear function in
this case using the course coding that
you seen before and mountain pukar is a
very simple problem that often shows up
in in examples and in older older papers
and it's nice for various reasons one is
that it's very easy to implement it's
fast to run and has some nice properties
for instance the state space can be
considered to be continuous and it
consists of a location where is this car
on the x-axis and the velocity of the
car
we're not encoding say the height
because it's a fixed setting so the
height is actually implicitly given by
the location of the car and then the
goal is to accelerate your car out of
this valley essentially and up to the
goal and the tricky thing about this
domain is that you can't actually if you
just push forward you won't reach it
what you have to do is first push back
so you climb the hill a little bit on
the left hand side and then you push
forward and you use the momentum from
first going down to go up and then reach
the goal and the reason that that's
interesting isn't because it's a
slightly tricky exploration problem
because you first have to go the wrong
way in order to go the right way you
just get a reward when you reach to go
and otherwise maybe you don't get any
rewards so it's also for that reason it
can be a hard exploration problem
because this may be sparse rewards so
you don't even know what you should be
doing but if you explore enough if you
have you have only two actions basic he
left and right sometimes there's three
sometimes there's also the coast action
which basically doesn't apply it in any
acceleration one way or the other but
you can solve this with just
accelerating or accelerating the other
direction which amounts to braking if
you're already
thing so then there would only be two
actions so if you can you can fairly
exhaustively explore if there's only two
actions even if it's a tricky
exploration problem and what these
figures then show is basically how the
the value function evolves if you do
something like course coding in this
two-dimensional space so here the axes
are the position and the velocity and
then the height of this function is the
value at that position and this must be
for one of the actions but I don't know
which one but what's something
interesting is happening around the
later episodes if you look at the
episodes down there a thousand and nine
thousand there's actually quite a bit of
structure there there's a ridge there's
a peak somewhere and the reason for that
is that this value function the optimal
value function actually has something
that is very it's basically
discontinuity because if you have a
certain velocity if you're say close to
the goal you will reach the goal if you
press accelerate further but if your
velocity is a little bit lower at some
point it's too low and there's like a
strict cutoff somewhere where your
velocity can be just a little bit lower
and then you might accelerate but you
won't reach it so then the optimal
policy all of a sudden is to go the
other way and then go back again which
means that there's this Ridge and it
shows up in the value function here and
the only reason this can show up is that
the course coding here is not to coarse
because otherwise we smoothing over this
and it might not learn to represent the
value there accurately whether that's a
problem really depends you could have a
value function that is fairly inaccurate
but it still tells you the right actions
to do because to pick your policy may be
only that you care about is the ordering
of the action values and not having each
action value to be completely accurate
that's another thing to keep in mind
sometimes it's okay if your function is
not that good as long as it represents
the right ordering of the actions or
roughly the right ordering of the
actions and if you have a smoother
function if you generalize more you do
have the opportunity potentially to
learn faster which is a bed of
now this has also been tried by the way
with other ways to discretize as I said
this is a a well well used toy problem
that's been used by many people in many
instances and also cutting this up into
rectangles or little squares rather than
Mugen chorus coding all of that just
works doing it more coarse less coarse
it typically just works but there's very
big differences in how quickly it learns
and how robust your solution is and how
optimally your solution is if you cut it
too coarse the car won't know whether it
can accelerate in a certain region or it
cannot and it might choose to do
something that is maybe safer and in
some cases where it could actually reach
to go it might actually decide to go
first the other way because then it's
sure that it will reach the goal if you
have this very rough function
approximation in this case it's
fine-grained enough to not have to do
that but that's something that also
again in general to keep in mind okay so
this is another view with radial basis
functions which is pretty much the same
thing as the coarse coding and here you
can see this ridge quite clearly which
is a it's an interesting structure to
value function not trivial not something
that I could have predicted immediately
okay
so some convergence considerations so
when do these incremental prediction
algorithms converge for instance when
using bootstrapping I already said it
confers you somewhere else when doing
the linear thing then the Montecarlo but
does it converge always when does it
converge what are the conditions doesn't
matter which function approximation we
use doesn't matter whether we use
function approximation in the tabular
case we know some of these things
converged do these results transfer and
what about off policy learning this
turns out to be an interesting and
important one because that's actually
quite tricky so ideally you want because
algorithms are converging all these
cases but turns out we we kind of happen
these days but it's not that trivial to
do that and this is one of the earlier
examples the example it's not the
simplest one you could think of but it's
for historical reasons I still use this
one here it's still a fairly simple MEP
-
MVP's in MRP and we're just doing
prediction we're trying to predict the
value of this process which is
completely defined by if you're in any
of the states at the top you will
deterministically go to that state at
the bottom if you're in that state at
the bottom you will go to that same
state 99% of the time and 1% of the time
you will terminate and which means
you'll go back to one of those states at
the top and a new episode starts you
always start in one of the states at the
top I think or maybe you start
uniforming in all six of them I don't
think that actually matters for the for
the purpose of this problem there's a
specific function defined here which is
a little bit old it's like it's manually
constructed to have a certain property
which is why it's a little bit old and
essentially there are seven features
here six states but seven features and
in the first state I there at the top
left what you see there is there
something feed at seven which is the
seventh feature sorry it says theta
seven which means that the seventh
feature is equal to one my value
function is a weighted sum of the
features and the weights are theta 1 up
to 7 but the features themselves in this
case the seventh feature is 1 and the
first feature is 2 in that state that's
what it means that's why the value
function is now defined as theta 7 plus
2 times theta 1 just means the feature
vector is 2 0 0 0 0 0 and N 1 I don't
know whether I said the right amount of
zeros there the second state is very
similarly defined but it has a number 2
on the second elements rather than the
first the seventh feature still equal to
1 now you don't have to fully understand
why specifically this but it turns out
that if you construct your function like
this and then you can start that bottom
state to have a 2x position 7 and a 1
position 6 then something weird happens
if you update all of these states
equally so what we'll do is well
essentially take all of these states and
we'll update all of them using this
function approximation at the same
time and then these parameters diverge I
didn't talk about rewards there are none
they're all zero so there's clearly a
solution here which is to put your
feature vector so your parameter vector
equal to zero but if it doesn't start
off at zero this is a log scale they can
oscillate out-of-control and this is
because we're doing the bootstrapping
we're doing TD and we're not updating
the state values in proportion to how
often they would be visited if you would
actually follow this MVP sorry MRP
marker for our process because if you
would actually step through this you
would spend a whole lot more time in the
bottom State then you were would in any
of the top states and turns out if you
would do that
then everything's fine for updating on
policy as it is called but if you change
your state distribution to be off policy
so you're predicting something else
you're predicting the value under
something that you're not following
right now then turns out you can get
these things these these things might
all say it out of control now there's
been lots of follow-up work by the way I
encourage you to try this out of you if
you want just to implement this it's
very simple to implement it's a simple
problem and then you could try it out
that these things actually do get out of
control the paper by bears which I'll
put a resource on Moodle it's point to
that paper he lists like specific
initializations that you could try out
and you should be able to replicate
exactly if you want to try that there
are other simpler examples of this as
well and there's been lots of follow-up
work later for people trying to fix this
trying to find algorithms that are not
linear temporal difference learning but
maybe slight extension slight variations
thereof that don't have this property
that do converge and they do exist there
are ways to do that to have guarantees
converge you with linear temporal
difference learning but it's already
quite tricky to get these things right
let alone if you do normally near
function proximation
that said this is a problem mostly I
would I would argue of theoretical
importance because it turns out if you
do linear time for different learning in
practice
it quite often works really well in
addition if you learn online using the
current policy this problem doesn't
occur it's only a problem because we
weren't updating proportional to how
often the policy would actually end up
there
but it does mean this so as I said
Montecarlo is basically regression which
means that we know what it does
roughly and the check mark here
especially so check mark means it's
converges for certain conditions so the
top row there means multi-car to
converge is when you do tell it's able
lookup well you do a linear function
proximation or when you do nonlinear
function approximation the load linear
function foxman comes first with the
caveat that it's only guaranteed to
converge to a local optimum as typically
the case when you do any nonlinear
regression temporal difference learning
on policy is not guaranteed to converge
the vanilla version of it when you do
nonlinear function proximation that said
it typically does work well in practice
when you go off policy and with this I
mean that you update the states not
proportional to how often the policy
that you're trying to estimate would
visit them then we also lose the
convergence property of temporal
difference learning although as I said
there are more advanced methods that
correct for this and that day they
basically turn that one cross into a
check as well nonlinear is still kind of
all bets are off
so basically in short tabular control
learning algorithms such as q-learning
and sarsa can be extended to function
proximation an example of that is DQ n
DQ Network I'll get back to that in a
moment the theory with function
proximation is not fully developed
although a lots a lots of work has been
done and we understand these things way
better than we did many years ago but it
is additionally another thing that I
wants to call out tracking is often
prefer refers to convergence anyway your
problem might be non stationary there
might be other agents in there that
might be changing there might be other
reasons why you want to prefer tracking
so it's actually unclear that you even
want to converge in the first place so
that's another thing to consider however
it's very hard to reason about what is
the appropriate tracking rate then or
it's a little bit less well-defined
which is why most Theory actually
focuses on the convergence rather than
the tracking which is still important
because what's convergence tells you
even if you don't necessarily care it
also tells you what the algorithm is
doing in the interim where is it headed
right if you know say for linear
temporal difference learning we know
what the fixed point is we know what the
eventual solution is that it would find
if it was run indefinitely long but this
also means that on any step it's roughly
going in that direction and this might
be informed if even if you want to track
and not not run anything to convergence
with tracking I mean for instance using
this fixed step size so that you never
actually hope to converge to a single
solution but instead you hope to track
this the data that comes at you this is
essentially related to the points I made
about the data are not being iid and not
being stationary necessarily in
reinforcement learning so for instance
if your policy changes you want to track
the values rather than trying to
converge to some value for the mixture
whole policies that you've ever seen you
would rather learn the value for the
policy that is right now that that's
what I mean when I say tracking thanks
okay so so far we considered mostly
online updates basically go through your
data and just update whenever you see
something you could also do something
that is a bit more deficient by batching
things as discussed before where we
talked about this more in a theoretical
sense of okay let's see there like a
small batch of data and train this all
the way until the end here I'm talking
about a little bit more general let's
say you just store the data you've seen
so far and you want to use that to be
more data efficient by updating on each
data point maybe more than once so one
way to do that is to have an approximate
value function as before right could be
a poor approximation to start off with
it's just a linear function or a
nonlinear function with some parameters
and we collect some data sets where I
use the generic notation here V hats of
Pi where this could be instantiated with
the TD targets reward plus discounted
next value or it could be instantiated
with the Monte Carlo targets whichever
you want and then the question is which
parameters would best fit this data in a
sense and now of course we could just
apply the same algorithm we did before
but just keep on applying it to this
data maybe we keep on collecting new
data store it into the replay sorry this
this big batch of data in reinforcement
learning terminology is typically called
a replay buffer because we're replaying
past experiences but you could also
consider for understanding just
basically collect this data once and
then keep on replaying on it and see
what you would learn if you do that now
it turns out if you do that if you keep
on learning on this batch of data you
will find the least square solution
which depends on your choice of V hats
and I'll go a little bit let's see yes
I'll go a little bit more concretely
into that but it's important to note so
the experience replay indefinitely like
if you run it indefinitely it's not
really really that surprising this case
is not specific to the linear version
but like the notational split the linear
version but
you just think about this as converging
in the linear case where it actually
finds the least square solution in
linear cases well-defined it's a single
thing right it's the only optimum and
then it will converge that that solution
of course this might take many
iterations not something to maybe do in
practice at least for a fixed data set
but it does make you a lot more simply
efficient because for any data you will
find the solution that best fits that
data up to now and especially if you're
in control this might be quite a
valuable trade-off because then you can
choose your next action really carefully
and if interaction with the world is
expensive and that's the expensive part
of your whole system then you want to be
very careful about which actually
selects so you might be better off
spending lots of compute replaying your
data many many times before you actually
choose a new action now using a linear
value function we can actually solve the
least square solution directly and oh
sorry one thing to point out let me go
back here I called the data there that
curly D which you could think of as a
distribution over data but it's in this
case an empirical distribution it's just
a fixed data set and then I also
subscript my expectations with that D
which basically means there's this
empirical distribution that I'm sampling
from the expectation is not a true
expectation across a continuous
distribution that might happen
it's just conditioned on the data for
this data and I'm using that notation
here again and yeah the expected when
you've converts this means that you're
expected update is zero this basically
just means you're you're there you're
done nothing happens anymore that's
quite simple to reason about but then we
can instantiate that by just thinking
about what that means in this case and
then we can find the solution here with
some simple algebraic manipulation which
looks of a great deal like a Monte Carlo
solution that I've shown before if you
just think of this V hats right now as
using a Monte Carlo return there the
difference is there's no expectations
we're using the actual data before I was
talking about where does Monte Carlo
converge in the long run and then there
were expectations which are under your
current policy where would it go and in
this case we're basically looking at
what
for the data you've seen so far what we
what would be the least square solution
now as you will probably know like
there's an inverse matrix here this is a
summation of outer products of your
feature vectors in this case for the
linear case let's assume that that thing
exists the inverse if you can if you can
compute that it would be cubic to
compute it on the fly right now but if
you build this thing up iteratively
which you can do using something that's
called the shermann morrison update then
you can do this in quadratic time
essentially it is just boils down to the
fact that we can add each of these outer
products one by one in critic time this
is still more expensive than central
difference learning algorithm and it
really depends on how big your feature
vector is whether this is a good thing
to do if your feature vector is saying
in say the hundreds or thousands then
this might be quite feasible if it's in
the millions it becomes quite unwieldy
and you might prefer to do the the TD
case instead of this but the nice thing
about this is that we can incrementally
build up these things both the inverse
matrix and the other parts for each new
data data a sample that comes in and we
basically get the batch solution so we
basically get the answer that you would
get if you would indefinitely keep an
updating on your data set so you don't
have to actually revisit the old data
you don't have to keep on replaying it
in the linear case you could also just
update these things immediately and you
get the exact same solution this only
applies for the linear case again so
this this is good to keep in mind but
then it's quite an efficient algorithm
so we don't know the true values so we
have these estimates V hat that I had on
the previous slide which we can now see
ate in both of these common ways we
could do a Monte Carlo where you could
do TD and we could solve directly for
the fixed point and we call this least
squares Monte Carlo or least squares
temporal difference learning and one
thing that happens is in the New York
Policy case the cross turns into a check
mark for LS TD least squares time for
different learning but there's little -
is there for the nonlinear case because
these things are simply just not defined
for nonlinear case at least in the
vanilla form
now let's move on so now we're going to
step away from the linear case the least
squares TV is efficient in terms of data
slightly more computation expensive but
it doesn't actually scale to nonlinear
functions which you might sometimes need
and the main reason you need them as I
said before us that sometimes is really
hard to construct good features and it
could be much more efficient and much
better not to do that just to rely on
the raw data and to have a function
during its own features essentially or
in other words to use normally near
function of the observations or off your
agent state so many of the ideas that we
talked about so far in this whole
process energy transfer basically
immediately to that case we just plug in
the nonlinear stochastic gradient update
for say temporal difference learning and
it just works essentially not completely
you have to tune things a little bit you
have to pick appropriate step sizes you
have to do the things you normally have
to do in deep learning construct a good
network find a good optimizer things
like that but then the idea is they
transfer so if you do these things
carefully you can get these things to
work so examples of that is temporal
difference earning monte carlo double Q
learning transfers experience replay
transfers very well actually
somebody's don't and I list two examples
here there are more but just to make you
where you see B which we discussed in
the second lecture is a means to explore
very efficiently in multi armed bandits
you could imagine trying to transfer
that algorithm and people have attempted
that to the sequential case one easy way
to do that is to do the Montecarlo
version where you just replace reward
with monte carlo and then you do UCB
with that there's other ways you can
transfer this to supplant your problems
there something called Monte Carlo tree
search where you could use ideas like
this but it's not a natural fit for a
nonlinear function approximation and the
reason is count
you see we kept track of counts of state
visits or state action visits how many
times have you selected a certain action
and if you do function approximation
it's actually hard to come up with these
counts and people have attempted this
and if there's been some progress on
that actually to basically preempt that
somehow Isildur in these counts but the
reason why it's hard is quite intuitive
because what we want is generalization
we want value functions that generalize
well so if you enter a say that you've
never seen before did you get a fairly
good estimate of what the value areas
but how uncertain you are about that
value depends on how often you've been
there according to do you see beeg
formulation which means you have to
count how often you've seen it but then
learning account across a stage space
you basically don't want to generalize
too much you want maybe you want to
generalize a little bit in as far as
these states are similar but it's very
hard to define what it means for them to
be similar and if you do this naively
turns out not to work that well and as a
similar thing so maybe you want to be
more data efficient maybe you want to do
something like an STD I'll remind you
Alice Lee basically souls the replay
setting where you could do you could
think about replaying your experience
indefinitely you can get the same
solution with LSD but you can get it
analytically the analytically part falls
apart when you do nonlinear function
approximation you can't solve this
analytically anymore you don't get the
exact solution immediately out of out of
the box you can still do it iteratively
using experience replay and that turns
out to be in practice much more often
used efficiently with deep reinforcement
learning so here is a concrete example
now for what what would that meant that
mean so one thing we can do is we could
try to do neural cue learning let's call
it so what does that mean we'll have a
network that maps observations to action
values this is sometimes called an
action out Network because we'll
basically just have a network that has
multiple outputs as many as you have
actions
so obviously this only works if you have
a discrete action set next lecture I'll
talk about what you can do when you have
a continuous action set and this
function can then just be a deep neural
network and this has been done for
instance or Atari
I put observation here you could also
put agent state there in this case maybe
you could say let's just consider the
case where the observations are your
agencies and these are the same we could
do an epsilon really exploration policy
where these Q values basically merely
turn it into a policy with Epsilon
greedy exploration so you take the
highest Q value current Q value with one
minus Epsilon and we take a random one
with Epsilon
and this can then lead to an action you
sample from that policy then we define a
loss
sorry I'll use slightly different
notation for the stop gradients here in
the previous slides they used double
brackets here are you single brackets
but it's again the brackets do you know
to stop gradients and it's on the slide
so I'm not that sad about that so we
define a loss and then we can just take
the gradient of that loss heating the
stop gradients which gives us this this
gradients which doesn't actually exactly
give us the update because you still
have to multiply it in with a step size
but instead what we typically do we toss
this gradient into an optimizer say if
you do tensor flow there's actually
predefined optimizers which take a step
size as an arguments or potential other
hyper parameters as arguments and you
could you could toss this gradient into
stochastic gradient descent with a
certain step size then we get exactly
the same thing we had before there's
just alpha times this thing is the
update to your weights but you can also
just take this gradient and plug it into
our mess prop or plug it into atom and
that the same she just works you can
just do that and it'll learn hopefully
if you tune your step sizes so here's a
little bit of pseudocode in tensor flow
there's some abstraction happening here
right there so magic there's this Q net
function that I haven't defined but
you've constructed some Network you
throw some observation and you get an
action value there's another magic
function or epsilon greedy that takes
these action action values and gives you
a sampled action these things are not
hard to implement but they're hidden
from the slide you don't index to get
your your action value for the action
that you've just selected hidden from
the notation it is Q there at the top is
of course for that current observation
so this is like a Q s but not yet for a
and then later on QA is also
when you select the action this is the
thing that we're going to update as it
says in the commentary we're going to
compute Q of s dat and we're going to
want to update that so to do that we
take the action we put it into the
environment we step through the
environment to get a reward discount in
the next observation and because we're
doing Q learning what we'll do is we
take the next observation we'll put it
through our approximation again over
here where we say Q net of the next
observation and then we do a max on that
which intensive first called TF not
reduce max this gives us the maximum
action value in the next state and then
we can build our target by saying
rewards plus discount times stop
gradients that thing max Q next and then
our temporal difference error which I've
here called Delta to construct that you
also have to deduct the current action
value this is our error
we're basically comparing this QA the
value of the state indicate the currents
action in the current state with this
target which is a one step Q learning
target and then we can define a loss in
this case squared loss on the central
difference error divided by two and this
is not a residual algorithm because we
had these stop gradients on the next
state value so this will implement TD
and then you can just toss this loss
into your optimizer it could be
stochastic gradient descent could be
Adam and then it should hopefully turn
now you can extend this slightly by by
using some tricks that were found to be
very useful in deep reinforcement
learning for instance you could make it
more like dqn which is essentially the
same algorithm but it has these two
additional components a replay buffer so
it stores all these transitions
observation action reward next
observation tuples it stores some
summary in a buffer and then instead of
updating on the online data that is
coming in DQ n samples mini-batches from
that buffer this also means that each
sample is typically looked at more than
once in a typical DQ anime
implementation you might look at each
transition four times or eight times or
something like that and then the
additional novelty of the
when is that there's also a target
Network which is typically denoted with
it's the same network but it has a
different parameter which is theta - and
the idea here is to keep the target that
we're going to bootstrap on fixed a
little bit more to make the updates more
stationary more like the supervised case
because we hope that would then improve
stability of the algorithm and it turns
out it does and the way this is
constructed is that we just take the
parameters that you're updating on each
after each mini batch and every one so
often say every 10,000 steps or
something like that you would copy them
over into the target Network but then
you keep them fixed in the interim and
this stabilizes the updates a little bit
and it's turned out to be important
important for performance back then not
all current algorithms use that anymore
for some algorithms it turns out to be
important for stability for other
algorithms turns out to be less
important so not that well understood
when you need is when you don't but it's
something that can help stability so it
can be useful to try which means the
loss function is not defined slightly
differently because now there's two
Thetas I still put to stop gradients
around the value at the next states but
maybe I didn't even have to anymore
because if you think of this thing and
then take up the Grady with respect to
theta there is actually no gradient with
respect to theta - if you just think of
this as an independent thing just for
symmetry and clarity I did put stop
Grady in there again and you could think
about theater - as a function of theta
in a slightly contrived way so maybe
it's a little bit safer to think about
it this way and then we can do exactly
the same as we did before we can toss
that into an optimizer we can minimize
this loss over time which is still non
stationary because the sargan our
network will still change your policy
will still change so it still has some
other benefits sorry some of the
disadvantages of reinforced learning if
you're used to supervised learning but
you can't apply this and it has been
successfully applied to things like
Atari where you couldn't basically just
take this algorithm run it and it can
learn these games of course there's a
lot of hidden magic now right there's
some pre-processing that was done there
some tuning of hyper parameters that is
importance certain discount factors
picks in SR it's typically point 99
which means you have a certain horizon
over which you're trying to act
optimally but given that there's this is
a fairly simple algorithm that can then
be applied to all of these different
video games without needing retuning per
game which was the interesting feat
there so there are some generality that
was achieved which is important the
replay and the target networks which are
the additional bits over what you might
call maybe more vanilla neural cue
learning algorithm they essentially and
one way to think about it is is that
they make the reinforced room setup look
a little bit more like supervised
learning the targets are a little bit
more stationary the sampling is a little
bit more iid if you sample uniformly
random from this replay buffer and that
may be for those reasons helped
stability it's unclear whether they're
vital as it says on the slide and I
mentioned already for the target network
but they helped in that case and one way
to think about this is this is deep
learning aware reinforcement learning
we've changed the update slightly we've
changed the things we're putting into
our updates the data in terms of replay
but also the actual update targets to
the algorithm we're applying we've
changed them a little bit to be to be
aware of the function approximation that
we're using and this helps you could
also do the opposite you could also have
reinforcement learning where deep
learning where maybe you construct a
network in such a way that it's well
geared to do reinforcement learning
which I won't talk about right now but
it's important to maybe think about
these things somewhat holistically think
about the whole system rather than just
trying to plug these things together and
hope for the best but that said if you
do plug them together you can actually
make them work yeah
so why why this is our Gannett we're
help essentially is the question or yeah
so so why do we need them it's unclear
that we do actually so more recent
algorithms sometimes don't use target
networks and they work just as well
without depending on what you do so the
the intuition behind it was that it just
makes the updates a little bit less
non-stationary because if you don't have
a target network each time you update
your network the values will change
everywhere and one observation that Vlad
who originally worked on the QM one
observation that he had was actually if
you make these networks bigger you
increase their capacity the target
network becomes less important and one
reason for that is probably or at least
this is one hypothesis if you have a
fairly small network then whenever you
update a state action pair value you
will basically update many values there
will be a lot of generalization which
means you're additionally changing the
targets which means you're tracking
something that is moving quite wildly
and this might be hard if you have a
bigger network you have more capacity
it's as if you're doing course course
coding or something but you've made it
more fine-grained which brings it closer
to the tabular case in a sense which
means that if you update this value that
you're trying to updates the target file
you might not change that much the value
at the next states because the network
has more capacity it generalizes maybe
less and that if you've generalized less
maybe this target networks become less
necessary and maybe you become less
important so that's one intuition but
the truth is we kind of really don't
know exactly why and how they help but
yeah sorry yeah typically what is done
is that these networks are exactly the
same except for the weights so the
weights in the target network are just
an old copy of the weights of your
online network and otherwise they're
exactly the same so every once in a
while they will be exactly the same
network because you've just copied the
parameters for your online networking
Zargon Network at which points they're
exactly the same but then you just keep
the target Network fixed and the online
network keeps updating and keeps
changing and then sometime later the
parameter values are not somewhere else
you just copy it over again and you make
them the same again
this is just one thing you could do not
necessarily the best or the only thing
but that's how it was implemented in dqn
okay so one thing I quickly wanted to
touch upon before we do run out of time
is to unify Monte Carlo in central
difference learning and this is
important as well when doing function
approximation for multiple regions
actually so the first one on the slide
is that when we bootstrap updates might
use old estimates which means that
information in a sense propagates slowly
I'll show you an example of that is even
holds in the tabular case in Monte Carlo
the information progresses propagates
much faster because the first time you
see reward if you just think of that
case the first time you ever see a
reward in a Monte Carlo case you might
be updating many state values that came
before all of them within the current
episode will be updated a little bit
towards that reward now when the episode
ends in a temporal difference learning
case if you do TD with a single step you
actually only update this value exactly
before getting that reward and the other
ones they were already updated they're
using the old values so they don't know
about this reward yet it's only when you
return back to a state and then that one
transitions to that say you've just
updated that the information can
propagate back further maybe let me
quickly show you the picture that
corresponds to that this is a trajectory
that you've taken on the left hand side
there where there was some winding path
that in the end ended up at the goal
let's say the agent didn't know where
the goal was so it just did some random
stuff and then the action values has
updated by one step Saoirse will only
update the action going up straight into
the goal the action before that that led
to that state has already been updated
using the previous estimates now if
instead you would propagate you would do
Monte Carlo you would propagate the
information all the way back to all the
is that you've did this might also not
be fully appropriate because you might
be assigning credits for this reward for
this reaching this goal to action say
that he stepped away now there's an
intermediate thing that you can do which
is n step returns and one way to depict
that is is this where temporal
difference learning just takes one step
then bootstraps Montecarlo takes all the
steps until the termination and uses
that but of course you could do
intermediate things where you just take
two steps and then your boot trip or you
take three and then you bootstrap and
you could do any of those so you could
make this a parameter and the updates
then look like this where and in this
one it's the on the top that's just CD
so we can now basically augment our
notation by putting a little one in
brackets over the return which means
we're doing a one step return in every
bootstrapping and then the infinite step
return is equal to Monte Carlo we can
just use this as a targets everything
else stays exactly the same
so it's in between Monte Carlo in
temporal difference learning where we're
just picking a certain number of how
many steps do we do and in this example
here on the right hand side this is the
update that you got for ten steps our
sir which doesn't propagate the
information all the way back to the
beginning but that might also be
inappropriate because some of these
actions earlier on they stepped up where
they shouldn't have and maybe you don't
want to propagate the information that
you've ended up in to go all the way
there because you don't want to
encourage these actions so this gives
you a way to go a little bit
intermediate and update the recent
actions to give them credit for the
reward
this is called the credit assignment
problem that this is referring to to
give them credit for the rewarded you
eventually obtained but the actions that
were too far in the past you don't give
them credit immediately if then they
later on turn out to go to good places
they will still learn right as TD did
but they won't immediately get credit
for everything this also makes the
update less noisy than for Monte Carlo
clearly the least variance you get for
TD and then the most varies you get from
Carlo these things are in between in
terms of bias and in terms of variance
this is an example where there's a
random walk you've seen the random walk
before the only difference is now
there's nineteen states instead of five
the picture depicts five but just
imagine this thing as being bigger
with 19 states and there's a reward of
one at one end and there's a reward of
zero at the other end the policy is just
moving randomly and we're just trying to
predict what the values for each of
these states and then there's these very
colorful plot down there what this shows
is you can basically just look at the
left hand side here you could look for
more diesel in the book this is on
umberto but what this shows here is
essentially four different step sizes it
shows you the curve for the error in
your prediction for each of these n
steps so the red line which is the one
over here is 4 td and is 1 and it shows
that you can use a fairly high step size
if you do that because the variance is
low but the best you can do in terms of
error for a certain amount of data this
is for the first 10 episodes of doing
this for a certain amount of data the
best you can do is not brilliant in
terms of error if you use a 2 step or a
4 step which you're down here you have
to tune your step size appropriately but
then you can get much lower error so
this shows there's some intermediate
gain here if you use two rollers they're
too far those are all the way bunched up
at the top there that's getting close to
Montecarlo again then you basically have
too much variance and you'll suffer from
that so the error will be fairly high
again just because of the variance yeah
yeah
this is prediction error sorry yeah this
is not control this is just prediction
error there isn't even control the
policy's always uniformly random in
terms of going left and right thanks ok
so it's almost 4 so we have to wrap up
this is just me stating again that these
have the benefits of both temporal
difference learning in Monte Carlo
I only have two more slices you can look
at at your leisure one I'll actually get
back to the next lecture so don't worry
too much about this I'll actually
basically somewhere in the beginning of
next lectures explain this one again I
just wanted to flash it up because it
uses multi-step returns and the other
thing is just basically saying there's
lots of research here this is an example
of combining many different advances
recent advances in
reinforcement learning and show that
these things can actually all help
together and we get much faster learning
these days than we did only a couple of
years ago so the research field is
moving quite fast and there's lots of
interesting stuff happening but there's
still many unsolved questions as well
and that was basically I had so thank
you |
b446836d-710c-4a78-a24f-a1eb087476ef | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | [AN #91]: Concepts, implementations, problems, and a benchmark for impact measurement
Alignment Newsletter is a weekly publication with recent content relevant to AI alignment around the world. Find all Alignment Newsletter **[resources here](http://rohinshah.com/alignment-newsletter/)**. In particular, you can look through **[this spreadsheet](https://docs.google.com/spreadsheets/d/1PwWbWZ6FPqAgZWOoOcXM8N_tUCuxpEyMbN1NYYC02aM/edit?usp=sharing)** of all summaries that have ever been in the newsletter.
Audio version **[here](http://alignment-newsletter.libsyn.com/alignment-newsletter-91)** (may not be up yet).
HIGHLIGHTS
==========
**[Reframing Impact - Part 2](https://www.alignmentforum.org/s/7CdoznhJaLEKHwvJW)** *(Alex Turner)* (summarized by Rohin): In **[part 1](https://www.alignmentforum.org/s/7CdoznhJaLEKHwvJW)** (**[AN #68](https://mailchi.mp/87c0d944c461/an-68-the-attainable-utility-theory-of-impact)**) of this sequence, we saw that an event is *impactful* if it *changes our ability to get what we want*. This part takes this understanding and applies it to AI alignment.
In the real world, there are many events that cause *objective* negative impacts: they reduce your ability to pursue nearly any goal. An asteroid impact that destroys the Earth is going to be pretty bad for you, whether you want to promote human flourishing or to make paperclips. Conversely, there are many plans that produce objective positive impacts: for many potential goals, it's probably a good idea to earn a bunch of money, or to learn a lot about the world, or to command a perfectly loyal army. This is particularly exacerbated when the environment contains multiple agents: for goals that benefit from having more resources, it is objectively bad for you if a different agent seizes your resources, and objectively good for you if you seize other agents' resources.
Based on this intuitive (but certainly not ironclad) argument, we get the **Catastrophic Convergence Conjecture (CCC)**: "Unaligned goals tend to have catastrophe-inducing optimal policies because of power-seeking incentives".
Let's now consider a *conceptual* version of **[Attainable Utility Preservation (AUP)](https://www.alignmentforum.org/posts/yEa7kwoMpsBgaBCgb/towards-a-new-impact-measure)** (**[AN #25](https://mailchi.mp/0c5eeec28f75/alignment-newsletter-25)**): the agent optimizes a primary (possibly unaligned) goal, but is penalized for changing its "power" (in the intuitive sense). Intuitively, such an agent no longer has power-seeking incentives, and so (by the **[contrapositive](https://en.wikipedia.org/wiki/Contraposition)** of the CCC) it will not have a catastrophe-inducing optimal policy -- exactly what we want! This conceptual version of AUP also avoids thorny problems such as ontology identification and butterfly effects, because the agent need only reason about its own beliefs, rather than having to reason directly about the external world.
**Rohin's opinion:** This was my favorite part of the sequence, as it explains the conceptual case for AUP clearly and concisely. I especially liked the CCC: I believe that we should be primarily aiming to prevent an AI system "intentionally" causing catastrophe, while not attempting to guarantee an absence of "accidental" mistakes (**[1](https://www.alignmentforum.org/posts/ZeE7EKHTFMBs8eMxn/clarifying-ai-alignment)** (**[AN #33](https://mailchi.mp/b6dc636f6a1b/alignment-newsletter-33)**), **[2](https://www.alignmentforum.org/posts/E2aZ9Xwdz3i2ghPtn/techniques-for-optimizing-worst-case-performance)** (**[AN #43](https://mailchi.mp/768a8130013f/alignment-newsletter-43)**)), and the CCC is one way of cashing out this intuition. It's a more crisp version of the idea that **[convergent instrumental subgoals](https://selfawaresystems.files.wordpress.com/2008/01/ai_drives_final.pdf)** are in some sense the "source" of AI accident risk, and if we can avoid instrumental subgoals we will probably have solved AI safety.
**[Reframing Impact - Part 3](https://www.alignmentforum.org/s/7CdoznhJaLEKHwvJW)** *(Alex Turner)* (summarized by Rohin): The final section of the sequence turns to an actual implementation of AUP, and deals with problems in how the implementation deviates from the conceptual version of AUP. We measure power by considering a set of auxiliary rewards, and measuring the change in attainable utilities of this auxiliary set as impact, and penalizing the agent for that. The first post presents some empirical results, many of which **[we've covered before](https://www.alignmentforum.org/posts/mDTded2Dn7BKRBEPX/penalizing-impact-via-attainable-utility-preservation)** (**[AN #39](https://mailchi.mp/036ba834bcaf/alignment-newsletter-39)**), but I wanted to note the new results on **[SafeLife](https://www.partnershiponai.org/safelife/)** (summarized below). On the high-dimensional world of SafeLife, the authors train a VAE to find a good latent representation, and choose a single linear reward function on the latent representation as their auxiliary reward function: it turns out this is enough to avoid side effects in at least some cases of SafeLife.
We then look at some improvements that can be made to the original AUP implementation. First, according to CCC, we only need to penalize *power*, not *impact*: as a result we can just penalize *increases* in attainable utilities, rather than both increases and decreases as in the original version. Second, the auxiliary set of rewards only provides a *proxy* for impact / power, which an optimal agent could game (for example, by **[creating subagents](https://www.alignmentforum.org/posts/mdQEraEZQLg7jtozn/subagents-and-impact-measures-full-and-fully-illustrated)**, summarized below). So instead, we can penalize increases in attainable utility for the *primary* goal, rather than using auxiliary rewards. There are some other improvements that I won't go into here.
**Rohin's opinion:** I think the plan "ensure that the AI systems we build don't seek power" is pretty reasonable and plausibly will be an important part of AI alignment. However, the implementation of AUP is trying to do this under the threat model of optimal agents with potentially unaligned primary goals. I think this is probably going to do something quite different from the conceptual version of AUP, because impact (as defined in this sequence) occurs only when the agent's beliefs *change*, which doesn't happen for optimal agents in deterministic environments. The current implementation of AUP tries to get around this using proxies for power (but these can be gamed) or by defining "dumber" beliefs against which power is measured (but this fails to leverage the AI system's understanding of the world). See **[this comment](https://www.alignmentforum.org/posts/wAAvP8RG6EwzCvHJy/reasons-for-excitement-about-impact-of-impact-measure?commentId=s48grPhMbuBEXNtyc)** for more details.
Note that the author himself is more **[excited](https://www.alignmentforum.org/s/7CdoznhJaLEKHwvJW/p/wAAvP8RG6EwzCvHJy)** about AUP as deconfusion, rather than as a solution to AI alignment, though he is more optimistic about the implementation of AUP than I am.
**[Subagents and impact measures, full and fully illustrated](https://www.alignmentforum.org/posts/mdQEraEZQLg7jtozn/subagents-and-impact-measures-full-and-fully-illustrated)** *(Stuart Armstrong)* (summarized by Flo): Impact measures reduce the reward an agent **A** receives for reaching a state **s** by the distance between **s** and some baseline state **s'**. This article clarifies the interaction of **[impact measures and subagents](https://www.alignmentforum.org/posts/sYjCeZTwA84pHkhBJ/attainable-utility-has-a-subagent-problem)** (**[AN #86](https://mailchi.mp/598f425b1533/an-86-improving-debate-and-factored-cognition-through-human-experiments)**).
In the **[attainable utility framework](https://www.alignmentforum.org/posts/mDTded2Dn7BKRBEPX/penalizing-impact-via-attainable-utility-preservation)** (**[AN #39](https://mailchi.mp/036ba834bcaf/alignment-newsletter-39)**) the distance metric measures changes in **A**'s power, its ability to optimize a set of auxiliary rewards **R**, relative to doing nothing. This means that **A** is never penalized for doing nothing. Thus, if **A** manages to construct a subagent **SA** without getting penalized for that, **A** can just stop doing anything afterwards without getting a penalty, no matter what **SA** does.
For the *stepwise inaction baseline*, where **s'** is the state that **A** would have reached had it done nothing in the last time step, **A** can completely avoid the penalty by building an **SA** that commits to balance out the change in **A**'s ability to optimize the auxiliary reward **R** if **A** decided to optimize **R**, but instead becomes an optimizer for **A**'s real reward when **A** does nothing in the next step.
For the *inaction baseline*, where **s'** is the state reached if **A** had not done anything for the whole episode, it gets more complicated. When only gains in power are penalized, **SA** has to be built such that it does not cause a significant increase in **R**, even if **A** decided to optimize for **R** later on. If **SA** is constructed in a way such that **A** cannot control its behaviour after some time has passed, the penalty **A** receives for the construction only depends on the *actual* effect of **SA** on **R**. This is a lot weaker than the original penalty, which was about the *possible* effects of **A**'s actions on **R**.
In the case where decreases in power are also penalized, **A** needs to make sure that building **SA** does not reduce its ability to optimize **R**. This is not always possible without **A** retaining some control over **SA**, but giving up control was only necessary to prevent the construction of **SA** from increasing **A**'s potential to optimize **R**. It seems like it is often possible for **A** to finetune the amount of control it retains over **SA** such that **A**'s ability to optimize **R** barely changes while **SA** is able to do things **A** could not do unpenalized.
In the most extreme example, **A** boxes itself into **SA** and does nothing in reality, but is counterfactually able to intervene on **SA**'s policy. If **A** is able to cleverly put constraints on its own future actions in other ways, no subagents are needed to avoid the penalty. While other impact penalties like **[relative reachability](https://arxiv.org/abs/1806.01186)** (**[AN #10](https://mailchi.mp/d1a19c140226/alignment-newsletter-10)**) do allow for subagents to be constructed, they do not undermine the penalty for these.
**Flo's opinion:** The article contains many useful examples in a grid world and I recommend reading it for a deeper understanding of the problem. The main problem with the attainable utility penalty seems to be the definition of power. While this has proven to be quite useful in simple examples, it seems like agents in more complex environments would be able to disentangle their ability to optimize their own reward and the auxiliary rewards, for example by essentially committing to never optimize the auxiliary rewards beyond a certain threshold. Such an agent would still look very powerful from the outside and I don't see why power-reducing commitments would diminish the agent's incentive to take away power from others. So while the **[catastrophic convergence conjecture](https://www.lesswrong.com/posts/w6BtMqKRLxG9bNLMr/the-catastrophic-convergence-conjecture)**, which states that unaligned goals tend to lead to catastrophic optimal policies because of power-seeking incentives, still rings true, it seems like we need to look at power from our perspective instead of the agent's.
**Rohin's opinion:** I agree with Flo above: the issue is that AUP is measuring a proxy for our intuitive notion of power that falls apart under adversarial optimization. In particular, while it is normally reasonable to measure power by looking at the ability to optimize a set of auxiliary reward functions, this characterization no longer works when the agent can ensure that it won't be able to optimize those specific rewards, while still being able to optimize its primary reward. Subagents are a particularly clean way of demonstrating the problem.
**[Introducing SafeLife: Safety Benchmarks for Reinforcement Learning](https://www.partnershiponai.org/safelife/)** *(Carroll Wainwright et al)* (summarized by Rohin): So far, techniques to avoid negative side effects have only been tested on **[simple](https://arxiv.org/abs/1806.01186)** (**[AN #10](https://mailchi.mp/d1a19c140226/alignment-newsletter-10)**) **[gridworlds](https://www.alignmentforum.org/posts/mDTded2Dn7BKRBEPX/penalizing-impact-via-attainable-utility-preservation)** (**[AN #39](https://mailchi.mp/036ba834bcaf/alignment-newsletter-39)**) **[or](https://bair.berkeley.edu/blog/2019/02/11/learning_preferences/)** (**[AN #45](https://mailchi.mp/35b451cb4d70/alignment-newsletter-45)**) **[hypotheticals](https://www.alignmentforum.org/posts/wzPzPmAsG3BwrBrwy/test-cases-for-impact-regularisation-methods)** (**[AN #45](https://mailchi.mp/35b451cb4d70/alignment-newsletter-45)**). SafeLife aims to provide a high-dimensional environment in which negative side effects are likely. It is based on Conway's Game of Life, which allows for complex effects arising out of relatively simple rules. An agent is given the ability to move, create life in an adjacent cell, or destroy life in an adjacent cell. With the specified reward function, the agent must build desired patterns, remove undesired patterns, and navigate to the exit.
The challenge comes when there are additional "neutral" patterns in the environment. In this case, we want the agent to leave those patterns alone, and not disrupt them, even if doing so would allow it to complete the main task faster. The post shows several examples of agents attempting these levels. Vanilla RL agents don't avoid side effects at all, and so unsurprisingly they do quite badly. An agent with a naive impact measure that simply says to preserve the initial state can correctly solve levels where all of the "neutral" patterns are static, but has much more trouble when the existing patterns are dynamic (i.e. they oscillate over time).
**Read more:** **[Paper: SafeLife 1.0: Exploring Side Effects in Complex Environments](http://arxiv.org/abs/1912.01217)**
**Rohin's opinion:** I am a big fan of benchmarks; they seem to be a prerequisite to making a lot of quantitative progress (as opposed to more conceptual progress, which seems more possible to do without benchmarks). This benchmark seems particularly nice to me because the "side effects" which need to be avoided haven't been handcoded into the benchmark, but instead arise from some simple rules that produce complex effects.
TECHNICAL AI ALIGNMENT
======================
HANDLING GROUPS OF AGENTS
-------------------------
**[TanksWorld: A Multi-Agent Environment for AI Safety Research](http://arxiv.org/abs/2002.11174)** *(Corban G. Rivera et al)* (summarized by Asya): This paper presents TanksWorld, a simulation environment that attempts to illustrate three important aspects of real-world AI safety challenges: competing performance objectives, human-machine learning, and multi-agent competition. TanksWorld consists of two teams of N vs. N tanks. Tanks move and shoot while navigating in a closed arena with obstacles. Tanks are rewarded for killing opponent tanks and penalized for killing neutral and allied tanks according to a specified reward function. Each tank is controlled by either its own AI or a special policy meant to mimic a 'human' teammate. Each individual tank can only see a small portion of its environment, and must communicate with other teammates to gain more information. The following parameters can be varied to emphasize different research challenges:
- The communication range between tanks -- meant to represent environmental uncertainty.
- The number of neutral tanks and obstacles -- meant to represent the extent to which tanks must care about 'safety', i.e. avoid collateral damage.
- The control policies of teammates -- meant to represent the variability of human-machine teams.
**Asya's opinion:** I am generally excited about more work on demonstrating safety challenges; I think it helps to seed and grow the field in concrete directions. I am particularly excited about the possibility for TanksWorld to demonstrate multi-agent safety problems with agents in direct competition. I feel unsure about whether TanksWorld will be a good demonstration of general problems with human-machine interaction-- intuitively, that seems to me like it would be very difficult to capture and require more complex real-world modeling.
FORECASTING
-----------
**[Distinguishing definitions of takeoff](https://www.alignmentforum.org/posts/YgNYA6pj2hPSDQiTE/distinguishing-definitions-of-takeoff)** *(Matthew Barnett)* (summarized by Rohin): This post lists and explains several different "types" of AI takeoff that people talk about. Rather than summarize all the definitions (which would only be slightly shorter than the post itself), I'll try to name the main axes that definitions vary on (but as a result this is less of a summary and more of an analysis):
1. *Locality*. It could be the case that a single AI project far outpaces the rest of the world (e.g. via recursive self-improvement), or that there will never be extreme variations amongst AI projects across all tasks, in which case the "cognitive effort" will be distributed across multiple actors. This roughly corresponds to the Yudkowsky-Hanson FOOM debate, and the latter position also seems to be that taken by **[CAIS](https://www.fhi.ox.ac.uk/reframing/)** (**[AN #40](https://mailchi.mp/b649f32b07da/alignment-newsletter-40)**).
2. *Wall clock time*. In **[Superintelligence](https://www.amazon.com/Superintelligence-Dangers-Strategies-Nick-Bostrom/dp/1501227742)**, takeoffs are defined based on how long it takes for a human-level AI system to become strongly superintelligent, with "slow" being decades to centuries, and "fast" being minutes to days.
3. *GDP trend extrapolation*. Here, a continuation of an exponential trend would mean there is no takeoff (even if we some day get superintelligent AI), a hyperbolic trend where the doubling time of GDP decreases in a relatively continuous / gradual manner counts as continuous / gradual / slow takeoff, and a curve which shows a discontinuity would be a discontinuous / hard takeoff.
**Rohin's opinion:** I found this post useful for clarifying exactly which axes of takeoff people disagree about, and also for introducing me to some notions of takeoff I hadn't seen before (though I haven't summarized them here).
**[Will AI undergo discontinuous progress?](https://www.alignmentforum.org/posts/5WECpYABCT62TJrhY/will-ai-undergo-discontinuous-progress)** *(Sammy Martin)* (summarized by Rohin): This post argues that the debate over takeoff speeds is over a smaller issue than you might otherwise think: people seem to be arguing for either discontinuous progress, or continuous but fast progress. Both camps agree that once AI reaches human-level intelligence, progress will be extremely rapid; the disagreement is primarily about whether there is already quite a lot of progress *before* that point. As a result, these differences don't constitute a "shift in arguments on AI safety", as some have claimed.
The post also goes through some of the arguments and claims that people have made in the past, which I'm not going to summarize here.
**Rohin's opinion:** While I agree that the debate about takeoff speeds is primarily about the path by which we get to powerful AI systems, that seems like a pretty important question to me with **[many ramifications](https://alignmentforum.org/posts/mJ5oNYnkYrd4sD5uE/clarifying-some-key-hypotheses-in-ai-alignment)** (**[AN #62](https://mailchi.mp/4a1b3c4249ae/an-62are-adversarial-examples-caused-by-real-but-imperceptible-features)**).
OTHER PROGRESS IN AI
====================
REINFORCEMENT LEARNING
----------------------
**[On Catastrophic Interference in Atari 2600 Games](http://arxiv.org/abs/2002.12499)** *(William Fedus, Dibya Ghosh et al)* (summarized by Rohin): One common worry with deep learning is the possibility of *catastrophic interference*: as the model uses gradients to learn a new behaviour, those same gradients cause it to forget past behaviours. In model-free deep RL, this would be particularly harmful in long, sequential tasks as in hard exploration problems like Montezuma’s Revenge: after the model learns how to do the first few subtasks, as it is trying to learn the next subtask, it would “forget” the first subtasks, degrading performance. The authors set out to test this hypothesis.
If this hypothesis were true, there would be an easy way to improve performance: once you have learned to perform the first subtask, just create a brand new neural net for the next subtask, so that training for this next subtask doesn’t interfere with past learning. Since the new agent has no information about what happened in the past, and must just “pick up” from wherever the previous agent left off, it is called the Memento agent (a reference to the movie of the same name). One can then solve the entire task by executing each agent in sequence.
In practice, they train an agent until its reward plateaus. They train a new Memento agent starting from the states that the previous agent reached, and note that it reliably makes further progress in hard exploration games like Montezuma’s Revenge, and not in “steady-state” games like Pong (where you wouldn’t expect as much catastrophic interference). Of course, with the Memento agent, you get both twice the training time and twice the model size, which could explain the improvement. They compare against giving the original agent twice the compute and model capacity, and find that Memento still does significantly better. They also present some fine-grained experiments which show that for a typical agent, training on specific contexts adversely affects performance on other contexts that are qualitatively different.
**Rohin's opinion:** I think this is pretty strong evidence that catastrophic interference is in fact a problem with the Atari games. On the other hand, **[OpenAI Five](https://blog.openai.com/openai-five/)** (**[AN #13](https://mailchi.mp/8234356e4b7f/alignment-newsletter-13)**) also has many, many subtasks, that in theory should interfere with each other, and it still seems to train well. Some guesses at how to reconcile these facts:
1) the tasks in Dota are more correlated than in (say) Montezuma’s Revenge, and so interference is less of a problem (seems plausible)
2) the policy in OpenAI Five was large enough that it could easily allocate separate capacity for various subtasks (seems unlikely, I believe the policy was relatively small), or
3) with sufficiently large-scale training, there is more “exploration” in weight-space until a configuration is found where interference doesn’t happen (seems unlikely given that large batch sizes help, since they tend to reduce weight-space exploration).
DEEP LEARNING
-------------
**[A new model and dataset for long-range memory](https://deepmind.com/blog/article/A_new_model_and_dataset_for_long-range_memory)** *(Jack W. Rae et al)* (summarized by Nicholas): A central challenge in language modeling is capturing long-range dependencies. For example, a model needs to be able to identify the antecedent of a pronoun even if it is much earlier in the text. Existing datasets consist of news and Wikipedia articles, where articles have average lengths ranging from 27 to 3,600 words. This paper introduces a dataset of Project Gutenberg books, PG-19, where each book has a much longer average length of 69,000 words. This benchmark enables comparison of how well algorithms can make use of information that is spread out across a much larger context.
They then introduce the *Compressive Transformer*, which builds on the ***[TransformerXL](http://ai.googleblog.com/2019/01/transformer-xl-unleashing-potential-of.html)*** (**[AN #44](https://mailchi.mp/6bfac400a0c3/alignment-newsletter-44)**). The *TransformerXL* saves old activations into a FIFO queue, discarding them when the queue is full. The *Compressive Transformer* instead has two FIFO queues: the first stores the activations just like *TransformerXL*, but when activations are ejected, they are compressed and added to the second queue. This functions as a sort of long-term memory, storing information from a longer period of time but in a compressed format.
They try a number of types of compression function and find that it is best to use a 1D convolutional compression function with an auxiliary loss that leads to lossy compression, where information that is not attended to can be removed. The compression network and the Transformer optimize independent losses without any mixing.
They find that the *Compressive Transformer* improves on *TransformerXL* on their new PG-19 dataset and is state of the art on the already existing WikiText-103 and Enwik8 benchmarks. They also inspect where the network attends to and find that more attention is paid to the compressed memory than the oldest activations in regular memory, showing that the network is preserving some valuable information.
**Read more:** **[Paper: Compressive Transformers for Long-Range Sequence Modelling](https://arxiv.org/abs/1911.05507)**
**Nicholas's opinion:** I like the idea of saving long-term memory in a more efficient but lower-dimensional format than short-term memory. The current **[trend](https://arxiv.org/abs/2001.08361)** (**[AN #87](https://mailchi.mp/c29b3247da6f/4da2bu7tjd)**) in language modelling is that more computation leads to better results, so I think that algorithms that target computation on the most relevant information are promising. I’d be interested to see (and curious if the authors tried) more continuous variants of this where older information is compressed at a higher rate than newer information, since it seems rather arbitrary to split into two FIFO queues where one has a fixed compression rate.
I’m not well calibrated on the meaning of the evaluation metrics for NLP, so I don’t have a sense of how much of an improvement this is over the *TransformerXL*. I looked through some of the example text they gave in the blog post and thought it was impressive but has clear room for improvement.
MACHINE LEARNING
----------------
**[Quantifying Independently Reproducible Machine Learning](https://thegradient.pub/independently-reproducible-machine-learning/)** *(Edward Raff)* (summarized by Flo): While reproducibility refers to our ability to obtain results that are similar to the results presented in a paper, **independent reproducibility** requires us to be able to reproduce similar results using *only* what is written in the paper. Crucially, this excludes using the author's code. This is important, as a paper should distill insights rather than just report results. If minor technical details in a reimplementation can lead to vastly different results, this suggests that the paper did not accurately capture all important aspects. The distinction between reproducibility and independent reproducibility is similar to the previously suggested distinctions between **[reproducibility of methods and reproducibility of conclusions](http://proceedings.mlr.press/v97/bouthillier19a.html)** (**[AN #66](https://mailchi.mp/c8ea4a5e842f/an-66-decomposing-robustness-into-capability-robustness-and-alignment-robustness)**) and **[replicability and reproducibility](http://cogprints.org/7691/7/ICMLws09.pdf)**.
The author attempted to replicate 255 machine learning papers, of which 162 were successfully replicated and ran a statistical analysis on the results. Factors that helped with independent reproduction included specified hyperparameters, ease of reading and authors answering emails. Meanwhile, neither shared code nor the inclusion of pseudo-code robustly increased the rate of reproduction. Interestingly, papers with a strong focus on theory performed worse than mostly empirical or mixed ones. While more rigour can certainly be valuable in the long term, including learning bounds or complicated math just for the sake of it should thus be avoided. Most of the data is **[publically available](https://github.com/EdwardRaff/Quantifying-Independently-Reproducible-ML)** and the author encourages further analysis.
**Read more:** **[Paper: A Step Toward Quantifying Independently Reproducible Machine Learning Research](https://arxiv.org/abs/1909.06674)**
**Flo's opinion:** I appreciate this hands-on approach to evaluating reproducibility and think that independent reproducibility is important if we want to draw robust conclusions about the general properties of different ML systems. I am a bit confused about the bad reproducibility of theory-heavy papers: One hypothesis would be that there is little incentive to provide theoretical justification for approaches that work robustly, as empirical evidence for their merits is generated more easily than theoretical results. This relationship might then flip, as results get more brittle.
**Rohin's opinion:** My explanation for the theoretical results is different: most theory tends to make at least a few assumptions that don't actually hold in order to obtain interesting guarantees. A paper will typically only include empirical results that confirm the theory, which will tend to select for environments in which the assumptions are minimally violated. If you then try to reproduce the paper in a new setting, it is more likely that the assumption is violated more strongly, and so the theoretical results don't show up any more.
#### **FEEDBACK**
I'm always happy to hear feedback; you can send it to me, **[Rohin Shah](https://rohinshah.com/)**, by **replying to this email**.
#### **PODCAST**
An audio podcast version of the **Alignment Newsletter** is available. This podcast is an audio version of the newsletter, recorded by **[Robert Miles](http://robertskmiles.com/)**. |
03d13960-ce9f-4d0a-969f-45f18475e04b | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | I'm Interviewing Kat Woods, EA Powerhouse. What Should I Ask?
### **If You've Never Heard of Kat Woods (But Really, Who in EA Hasn't?), Here's a List of Projects She Has Cofounded:**
- [Charity Entrepreneurship](https://www.charityentrepreneurship.com/), an incubator that has launched 18 Charities so far
-Charity Science Health, now [Suvita](https://www.suvita.org/), which has helped vaccinate over 200,000 children
- [Nonlinear](https://www.nonlinear.org/), a longtermist EA incubator
-[Superlinear](https://www.super-linear.org/about), a platform which hosts competitions to solve X-Risk problems (with some pretty huge prizes)
As if that isn't enough, she's also a prolific contributor to the intellectual sphere of the community - just look at her [post history](https://forum.effectivealtruism.org/users/katherinesavoie?fbclid=IwAR23BIm38L5HKKp9GfIkLakC8d3YMaZ2MlfCTP2NUgiae7hwKHcmNbxRpiY).
### **So What should I ask her?**
I'm planning on asking her about her plans to grow the AI Safety community and what the biggest issues are in the AI community.
I'm also very interested in asking questions about her mindset; Kat mentioned to me that she was able to overcome imposter syndrome, which I know many of us suffer with. We'll also talk about concrete ways to become happier, and I'm really keen on figuring out how she manages to stay so productive.
Send more questions! I interview her in 22 hours.
Also, if you're interested in my podcast, [here's an episode](https://youtu.be/4AmgvuKXbbY) I filmed with Jack Rafferty, co founder of the Lead Exposure Elimination Project (also funded by Charity Entrepreneurship. Thanks Kat!) |
3ae76a9c-d25c-4a84-9b5d-9ee99151b601 | trentmkelly/LessWrong-43k | LessWrong | Polling Thread - Tutorial
After some hiatus another installment of the Polling Thread.
This is your chance to ask your multiple choice question you always wanted to throw in. Get qualified numeric feedback to your comments. Post fun polls.
Additionally this is your chance to learn to write polls. This installment is devoted to try out polls for the cautious and curious.
These are the rules:
1. Each poll goes into its own top level comment and may be commented there.
2. You must at least vote all polls that were posted earlier than you own. This ensures participation in all polls and also limits the total number of polls. You may of course vote without posting a poll.
3. Your poll should include a 'don't know' option (to avoid conflict with 2). I don't know whether we need to add a troll catch option here but we will see.
If you don't know how to make a poll in a comment look at the Poll Markup Help.
----------------------------------------
This is a somewhat regular thread. If it is successful I may post again. Or you may. In that case do the following :
* Use "Polling Thread" in the title.
* Copy the rules.
* Add the tag "poll".
* Link to this Thread or a previous Thread.
* Create a top-level comment saying 'Discussion of this thread goes here; all other top-level comments should be polls or similar'
* Add a second top-level comment with an initial poll to start participation. |
4091ca86-b7d0-4853-b3da-c7eb0f7c26bd | trentmkelly/LessWrong-43k | LessWrong | AI #119: Goodbye AISI?
AISI is being rebranded highly non-confusingly as CAISI. Is it the end of AISI and a huge disaster, or a tactical renaming to calm certain people down? Hard to tell. It could go either way. Sometimes you need to target the people who call things ‘big beautiful bill,’ and hey, the bill in question is indeed big. It contains multitudes.
The AI world also contains multitudes. We got Cursor 1.0, time to get coding.
On a personal note, this was the week of LessOnline, which was predictably great. I am sad that I could not stay longer, but as we all know, duty calls. Back to the grind.
TABLE OF CONTENTS
1. Language Models Offer Mundane Utility. The white whale.
2. Language Models Don’t Offer Mundane Utility. You need a system prompt.
3. Language Models Could Offer More Mundane Utility. A good set of asks.
4. Huh, Upgrades. The highlight is Cursor 1.0, with memory and more.
5. Fun With Media Generation. Video is high bandwidth. But also low bandwidth.
6. Choose Your Fighter. Opinions differ, I continue to mostly be on Team Claude.
7. Deepfaketown and Botpocalypse Soon. Fake is not a natural category. Whoops.
8. Get My Agent On The Line. We all know they’re not secure, but how bad is this?
9. They Took Our Jobs. Economists respond to Dario’s warning.
10. The Art of the Jailbreak. Why not jailbreak AI overviews?
11. Unprompted Attention. More prompts to try out.
12. Get Involved. SFCompute, Speculative Technologies.
13. Introducing. Anthropic open sources interpretability tools, better AR glasses.
14. In Other AI News. FDA launches their AI tool called Elsa.
15. Show Me the Money. Delaware hires bank to value OpenAI’s nonprofit.
16. Quiet Speculations. People don’t get what is coming, but hey, could be worse.
17. Taking Off. AI beats humans in a test of predicting the results of ML experiments.
18. Goodbye AISI? They’re rebranding as CAISI. It’s unclear how much this matters.
19. The Quest for Sane Regulations. The bill is, at least, definit |
86363af3-12ca-4918-95c1-d4592801c5de | trentmkelly/LessWrong-43k | LessWrong | Is the coronavirus the most important thing to be focusing on right now?
LessWrong has been and is planning to devote a significant amount of attention to the coronavirus. But is that what we should be focused on? Is it more important than things like existential risk reduction and malaria treatments? |
02c9539f-b768-42c3-9978-9dc78c57e7d1 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | (Ir)rationality of Pascal's wager
During the last few weeks I’ve spent a lot of time thinking about ,,Pascalian” themes, like the paradoxes generated by introducing infinities in ethics or decision theory. In this post I want to focus on Pascal’s wager (Hajek, 2018), and why it is (ir)rational to accept it.
Firstly, it seems to me that a huge part of responses to Pascal’s wager are just unsuccessful rationalizations, which people create to avoid the conclusion. It is common to see people who (a) claim that this conclusion is plainly absurd and just dismiss it without argument, or (b) people who try to give an argument which at first glance seems to work, but at the second glance it backfires and leads to even worse absurdities than the wager.
In fact it is not very surprising if we take into account the psychological studies showing how motivated reasoning and unconscious processes leading to cognitive biases are common (Haidt, 2001; Greene, 2007). Arguably, accepting the Pascal’s wager goes against at least a few of those biases (like scope insensitivity, risk aversion when dealing with small probabilities, even not to mention that the conclusion is rather uncomfortable).
Nevertheless, although I think that the arguments typically advanced against Pascal’s wager are not successful, it still may be rational not to accept the wager.
Here is why I think so.
I regard the expected utility theory as the right approach to making choices under uncertainty, even when dealing with tiny probabilities of the large outcomes. This is simply because it can be shown, that over long series of such choices following such strategy would pay off. However, this argument holds only over the long series of choices, when there is enough time for such improbable scenarios to occur.
For example, imagine a person, let’s call her Sue, who knows with absolute certainty that she has only one decision to make in her life, and after that she will magically disappear. She has a choice between two options.
Option A: 0,0000000000000000001 % probability of creating infinite value.
Option B: 99 % probability of creating of a huge, but finite amount of value.
I think that in this case, option B is the right choice.
However, if instead of having this one choice in her life Sue had to face infinitely many such choices over an infinitely long time, then I think the option A is the right choice, because it gives the best results in expectation.
Of course our lives are, in some sense, the long series of choices, so we ought to follow the expected utility theory. But, what if someone decides to make just one decision, which is worse in expectation but very improbable to have any negative consequences? Of course, if this person would start to make such decisions repeatedly, then she will predictably end worse off, but if she is able to reliably restrict herself to making just this single decision solely on the basis of its small probability, and following the expected utility otherwise, then for me it seems to be rational.
I’ll illustrate what I mean by an example. Imagine three people: Bob, John and Sam. They all think that the acceptance of the Pascal’s wager is unlikely to result in salvation/avoidance of hell. However, they also think that they should maximize the expected utility, and that expected utility in the case of Pascal’s wager is infinite.
Confronted with that difficult dilemma, Bob abandons the expected utility theory and decides to rely more on his ,,intuitive’’ assessment of the choiceworthiness of actions. In other words, he just goes with his gut feelings.
John takes a different strategy, and decides to follow the expected utility theory, so he devotes the rest of his live to researching which religion is most likely to be true. (Since he is not sure which religion is true and he thinks that information value is extremely high in this case)
Sam adopts a mixed strategy. He decides to follow the expected utility theory, but in this one case he decides to make an exception and to not accept the wager, because he thinks it is unlikely to pay off. But he doesn’t want to abandon the expected utility approach either.
It seems to me that the Sam’s strategy achieve the best result at the end. Bob’s strategy is a nonstarter for me, since it predictably will lead to a bad outcomes. On the other hand, John’s strategy commits him to devote whole his life to something, what in the end gives no effects.
Meanwhile, it is unlikely that this one decision to not accept the wager will harm Sam, and following the expected utility theory in other decisions will predictably lead to the most desirable results.
For me it seems to work. Nevertheless, I have to admit that my solution also may seem as an ad hoc rationalization designed to avoid the uncomfortable conclusion.
This argument has also some important limitations, which I won’t address in detail here in order not to make this post too long. However I want to highlight them quickly.
1. How can you be sure that you will stick with your decision not to make any more such exceptions from the expected utility theory?
2. Why making the exception for this particular decision and not any other?
3. The problem posed by tiny probabilities of infinite value, the so called *fanaticism* problem, is not resolved by this trick, since the existence of God is not the only possible source of the infinite value (Beckstead, 2013; Bostrom, 2011).
4. What if taking that kind of approach would popularise it, causing more people to adopt it, but in different decisions than this concerning Pascal’s wager (or give the evidence that infinitely many copies of you has adopted it, if the universe is infinite (Bostrom, 2011))?
I don’t think that any of this objections is fatal, but I think they are worth considering. Of course, it is possible, and indeed quite probable, that I may have missed something important, fall prey to my bias or made some other kind of error. This is why I decided to write this post. I want to ask anyone who has some thoughts about this topic to comment about my argument, whether the conclusion is right, wrong, or right from wrong reasons. The whole issue may seem abstract, but I think it is really important, so I would appreciate giving it a serious thought.
Thanks in advance for all your comments! :)
Sources:
1. Beckstead, N. (2013). *On the Overwhelming Importance of* *Shaping the Far Future*
Bostrom, N. (2011). Infinite Ethics. *Analysis and Metaphysics*, Vol. 10 (2011): pp. 9-59
Greene, J. D. (2007). The secret joke of Kant's soul. In W. Sinnott-Armstrong (Ed.), *Moral psychology, Vol. 3. The neuroscience of morality: Emotion, brain disorders, and development* (pp. 35-80). Cambridge, MA, US: MIT Press.
Haidt, J. (2001). The Emotional Dog and it’s Rational Tail: A Social Intuitionist Approach to Moral Judgement. *Psychological Review* 108: 814-834
Hájek, A. "Pascal's Wager", *The Stanford Encyclopedia of Philosophy* (Summer 2018 Edition), Edward N. Zalta (ed.), URL = <https://plato.stanford.edu/archives/sum2018/entries/pascal-wager/>.
All of the above sources can be found online. |
ef2723c0-1743-46e1-81fb-35dbacee4122 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | In Defense of the Arms Races… that End Arms Races
All else being equal, arms races are a waste of resources and often an example of the defection equilibrium in the [prisoner’s dilemma](https://en.wikipedia.org/wiki/Prisoner's_dilemma). However, in some cases, such capacity races may actually be the globally optimal strategy. Below I try to explain this with some examples.
1: If the U.S. kept racing in its military capacity after WW2, the U.S. may have been able to use its negotiating leverage to stop the Soviet Union from becoming a nuclear power: halting proliferation and preventing the build up of world threatening numbers of high yield weapons. Basically, the earlier you win an arms race, the less nasty it may be later. If the U.S. had won the cold war earlier, global development may have taken a very different course, with decades of cooperative growth instead of immense amounts of Soviet GDP being spent on defense, and ultimately causing its collapse. The principle: it may make sense to start an arms race if you think you are going to win if you start now, provided that a nastier arms race is inevitable later.

2: If neither the U.S. nor Russia developed nuclear weapons at a quick pace, many more factions could have developed them later at a similar time, and this would be much more destabilizing and potentially violent than cases where there is a monopolar or a bipolar power situation. Principle: it is easier to generate stable coordination with small groups of actors than large groups. The more actors there are, the less likely [MAD](https://en.wikipedia.org/wiki/Mutual_assured_destruction) and treaties are to work, the earlier an arms race starts, the more prohibitively expensive it is for new groups to join the race.
3: If hardware design is a bottleneck on the development of far more powerful artificial intelligence systems, then racing to figure out good algorithms now will let us test a lot more things before we get to the point a relatively bad set of algorithms can create an immense amount of harm due to the hardware it has at its disposal (improbable example: imagine a Hitler emulation with the ability to think 1000x faster). Principle: the earlier you start an arms race, the more constrained you are by technological limits.[1](#bottom)
I do not necessarily think these arguments are decisive, but I do think it is worth figuring out what the likely alternatives are before deciding if engaging in a particular capacity race is a bad idea. In general:
* It’s nice for there to not be tons of violence and death from many factions fighting for power (multipolar situation)
* It is nice to not have the future locked into a horrible direction by the first country/company/group/AI/etc. to effectively take over the world due some advantage derived from racing toward a technological advantage (singleton/monopolar power)
* It’s nice for there to not be the constant risk of overwhelming suffering and death from a massive arms build up between two factions (bipolar situation)
So if an arms race is good or not basically depends on if the “good guys” are going to win (and remain good guys). If not, racing just makes everyone spend more on potentially risky tech and less on helping people. [While some concerns about autonomous drones are legitimate](https://futureoflife.org/2019/04/02/fli-podcast-why-ban-lethal-autonomous-weapons/?cn-reloaded=1) and they may make individuals much more powerful, I am unsure it is good to stop investment races now unless they can also be stopped from happening later. Likewise, the consequences of U.S. leadership in such a race are likely to shape how lethal autonomous weapons proliferate in a more ethical direction, with lower probabilities of civilian deaths than the weapons that states would otherwise purchase. It is also probably better to start figuring out what goes wrong while humans will still be controlling mostly autonomous drones than to wait for a bunch of countries to defect on unenforceable arms control agreements later in conflict and start deploying riskier/less well vetted systems.
If one thinks decision agencies will be better governed in the future, delaying technologies that centralize power may make sense to avoid locking in bad governments/companies/AI systems. However, to the degree competent bureaucracies can gain advantage from making risky tech investments regardless of their alignment with the general population, the more aligned systems must keep a lead to prevent others from locking in poor institutions.
Overall, arms races are wasteful and unsafe, but they may mitigate other even less safe races if they happen at the right time under the right conditions. In general, [by suppressing the incentive for violence between individuals and building up larger societies](https://www.amazon.com/War-What-Good-Conflict-Civilization/dp/0374286000), states pursuing power in zero-sum power races ultimately created positive sum economic spillovers from peace and innovation.
---
**Notes:**
1. As opposed to tech research continuing outside the military, and when an arms race begins there is a sudden destabilizing leap in attack capacity for one side or another. *[Return to Article](#1)*
2. You can see other related arguments in the debate on nuclear modernization [here](https://www.csis.org/events/debate-modernization-nuclear-missiles). |
0dafc483-0d82-41dd-a48e-d7d71e1698e1 | trentmkelly/LessWrong-43k | LessWrong | Hacker-AI and Digital Ghosts – Pre-AGI
Software vulnerabilities are mainly found by chance. We all know hacking is labor-intensive. This will invite and thrive the use of AI. It is assumed that it is just a matter of time until attackers create tools with advanced “Hacker-AI” to accelerate the detection and understanding of hard-/software vulnerabilities in complex/unknown technical systems.
This post suggests that Hacker-AI will become a dangerous consequential cyberwar weapon - capable of decapitating governments and establishing persistent global supremacy for its operator. Two features amplify the motivation for creating and deploying this Hacker-AI: stealth distribution/deployment as an undetectable digital ghost and that it could be irremovable, i.e., the first Hacker-AI could be the only one.
Here we focus solely on significant problems related to attacks or threats. These threats we define as actual or potential harm or damage to humans and/or their property. Threats and attacks are intentional and significant for their victims immediately or in the future. We give every significant problem a headline that catches the gist of the underlying issues so we can refer to these problems easily later.
We don’t assume extraordinary abilities from an AGI. The drivers for this development are technically skilled humans/organizations who seek AI tools to accomplish their goals faster and less labor-intensive.
Problems/ Vulnerabilities in our IT ecosystem
The following 10 problems, issues, or vulnerabilities do not follow a particular order. It is assumed that they all contribute to the danger of Hacker-AI. Preventing Hacker-AI implies confronting these issues technically.
“Software is invisible”. Software consists of (compiled) instructions that run directly or via an intermediary layer on CPUs. It’s stored in files invisible in strict practical or operational terms. We can only make it visible indirectly with assumptions on other software, i.e., that their complex interplay of instructions is reliabl |
33d48121-e208-4b55-83bb-8505bce578e1 | trentmkelly/LessWrong-43k | LessWrong | In search of benevolence (or: what should you get Clippy for Christmas?)
(Cross-posted from Hands and Cities)
Suppose that you aspire to promote the welfare of others in a roughly impartial way, at least in some parts of your life. This post examines a dilemma that such an aspiration creates, especially given subjectivism about meta-ethics. If you don’t use idealized preference-satisfaction as your theory of welfare, your “helping someone” often ends up “imposing your will” on them (albeit, in a way they generally prefer over nothing) — and for subjectivists, there’s no higher normative authority that says whose will is right. But if you do use idealized preference satisfaction as your theory of welfare, then you end up with a host of unappealing implications — notably, for example, you can end up randomizing the universe, turning it into an ocean of office supplies, and causing suffering to one agent that a sufficient number of others prefer (even if they never find out).
I don’t like either horn of this dilemma. But I think that the first horn (e.g., accepting some aspect of “imposing your will,” though some of the connotations here may not ultimately apply) is less bad, especially on further scrutiny and with further conditions.
I. “Wants” vs. “Good for”
Consider two ontologies — superficially similar, but importantly distinct. The first, which I’ll call the “preference ontology,” begins with a set of agents, who are each assigned preferences about possible worlds, indicating how much an idealized version of the agent would prefer that world to others. The second, which I’ll call the “welfare ontology,” begins with a set of patients, who are each assigned “welfare levels” in possible worlds, indicating how “good for” the patient each world is.
On a whiteboard, and in the mind’s eye, these can look the same. You draw slots, representing person-like things; you write numbers in the slots, representing some kind of person-relative “score” for a given world. Indeed, the ontologies look so similar that it’s tempting to equate them, an |
19ffa2ad-157b-4546-9265-138923ce3010 | trentmkelly/LessWrong-43k | LessWrong | How Likely Is Cryonics To Work?
If an American signs up for cryonics and pays their ~$300/year, what are their odds of being revived? Talking to people at LessWrong meetups I've heard estimates of 1 in 2. My friend George Dahl, whose opinion I respect a lot, guesses "less than 1 in 10^6". Niether has given me reasons, those numbers are opaque. My estimate of these odds pretty much determines whether I should sign up. I could afford $300/year, and I would if I thought the odds were 1:2, but not if they were 1:10^6. [1]
In order to see how likely this is to work, we should look at the process. I would sign up with a cryonics company and for life insurance. I'd go on living, enjoying my life and the people around me, paying my annual fees, until some point when I died. After death they would drain my blood, replace it with something that doesn't rupture cell walls when it freezes, freeze me in liquid nitrogen, and leave me there for a long time. At some point, probably after the development of nanotechnology, people would revive me, probably as a computer program.
There's a lot of steps there, and it's easy to see ways they could go wrong. [3] Let's consider some cases and try to get probabilities [4]:
Update: the probabilities below are out of date, and only useful for understanding the comments. I've made a spreadsheet listing both my updated probabilities and those for as many other people as I can find: https://docs.google.com/spreadsheet/...
0.03 You mess up the paperwork, either for cryonics or life insurance 0.10 Something happens to you financially where you can no longer afford this 0.06 You die suddenly or in a circumstance where you would not be able to be frozen in time (see leading causes of death) 0.04 You die of something like Altzheimers where the brain is degraded at death (Altzheimers is much more common than brain cancer) 0.01 The cryonics company is temporarily out of capacity and cannot actually take you, perhaps because lots of people died at once 0.02 The life insurance |
eabf3294-61ef-4ad7-8d58-40f3cbab5abf | trentmkelly/LessWrong-43k | LessWrong | Playing with Aerial Photos
Flying in a window seat offers opportunities for serendipitous aerial photography. You don't get to choose what is going to be within view of the window, but when there's something interesting it can be fun to try and get a good picture. There are a few I've taken that I like:
Our neighborhood, with Powderhouse Park in the lower right, Davis in the middle right, Porter in the middle top, Trum Field in the lower left, and the bike path running horizontally across the middle:
Did you know that after taking a boat up to the top of the Chesapeake you can keep going, all the way to Philly? Here's the Chesapeake & Delaware Canal:
Porter, looking East toward Kendall and Back Bay:
Downtown Boston:
Manhattan:
Singing Beach, Manchester by-the-sea:
Castle Island, right next to the East end of the container port::
More recently I've been playing around with a cheap telescope attachment. Pictures are generally pretty blurry, but occasionally I get something nice. Here's Atlantic City from about 70mi NW:
Comment via: facebook, mastodon |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.