
id stringlengths 36 36 | source stringclasses 15
values | formatted_source stringclasses 13
values | text stringlengths 2 7.55M |
|---|---|---|---|
b529ccfc-ae98-4cff-a733-d09253dfad3d | trentmkelly/LessWrong-43k | LessWrong | More Babble
,,,
In my last babble, I introduced the Babble and Prune model of thought generation: Babble with a weak heuristic to generate many more possibilities than necessary, Prune with a strong heuristic to find a best, or the satisfactory one. I want to zoom in on this model. If the last babble was colored by my... |
763a6e87-89e6-4929-b491-17d78a14227b | trentmkelly/LessWrong-43k | LessWrong | Linking to Other Resources
Lesser Wrong is De Facto the Main Site. Given this situation, it should take the role of being the central hub from which you can access all of the other resources within the rationality community. This will be incredibly easy as someone could just write up a post on Resources and it could b... |
4b0965a8-8371-42ae-a30d-59c22874ba8a | trentmkelly/LessWrong-43k | LessWrong | Should AI safety be a mass movement?
When communicating about existential risks from AI misalignment, is it more important to focus on policymakers/experts/other influential decisionmakers or to try to get the public at large to care about this issue?[1] I lean towards it being overall more important to communicate to... |
b11a9637-d32b-42bb-9ab2-0cf70a6838cc | trentmkelly/LessWrong-43k | LessWrong | Stupid Questions - September 2017
The stupid questions thread was one of the regular threads on LessWrong. It's a place where no question is to stupid to be asked and anybody who answers is encouraged to be kind.
This thread is for asking any questions that might seem obvious, tangential, silly or what-have-you. Don'... |
0bddf205-abaa-42ee-ba08-af10843ddb9c | trentmkelly/LessWrong-43k | LessWrong | The case for hypocrisy
Related: The case for logical fallacies
Julia Galef makes an interesting point in her recent book The Scout Mindset: our beliefs come as tangled knots, not isolated strings. Changing one belief often implies that we change many others.
Consider Sarah, whose relationships, political beliefs, w... |
d7e399c7-c480-4635-8e26-f8376cb045d6 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | How To Get Into Independent Research On Alignment/Agency
I’m an independent researcher working on AI alignment and the theory of agency. I’m 29 years old, will make about $90k this year, and set my own research agenda. I deal with basically zero academic bullshit - my grant applications each take about one day’s atten... |
24f149ba-04c9-420a-92b3-cfacdfcfaf19 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Bratislava Meetup XIII. (international)
Discussion article for the meetup : Bratislava Meetup XIII. (international)
WHEN: 24 May 2014 04:00:00PM (+0200)
WHERE: Mickiewiczova 2, Bratislava
This is an international meetup (which means that we will meet during a weekend and speak English), so if you wanted to... |
73326931-fa07-46d5-9155-b817d19e4bd6 | trentmkelly/LessWrong-43k | LessWrong | Ongoing free money at PredictIt
Previously on LW
* https://www.lesswrong.com/posts/JmqBtCCnMZmpXP2bE/what-are-good-election-betting-opportunities?commentId=NFdSk5H39omYXPjBS,-
* https://www.lesswrong.com/posts/bSKWSPM927oZZqN7f/predictit-presidential-market-is-increasingly-wrong
PredictIt is structurally inefficie... |
82fd43db-caa0-4f38-8bd7-52eb734cbc21 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Investigating AI Takeover Scenarios
*Epistemic status: lots of this involves interpreting/categorising other people’s scenarios, and could be wrong. We’d really appreciate being corrected if so.*
**TLDR**: see the [summary table](https://www.lesswrong.com/posts/zkF9PNSyDKusoyLkP/investigating-ai-takeover-scenarios#Ta... |
86c9e4d9-4f75-4edb-a413-da65ca6843a6 | trentmkelly/LessWrong-43k | LessWrong | Artificial Sandwiching: When can we test scalable alignment protocols without humans?
Epistemic status: Not a fleshed-out proposal. Brainstorming/eliciting ideas.
Thanks to Ben Mann, Pablo Moreno, and Jared Kaplan for feedback on early drafts.
Overview
* I’m convinced sandwiching—the experimental protocol from Aj... |
6823bcea-e0e7-420c-a5cd-dbdec4cbfed8 | trentmkelly/LessWrong-43k | LessWrong | How are voluntary commitments on vulnerability reporting going?
This article is written solely in my personal capacity, and does not represent the views of any organisations I am affiliated with.
The UK and US governments have both secured voluntary commitments from many major AI companies on AI safety.[1]
These inc... |
487783b8-f1c0-4fd3-ab12-02825cebd1a6 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | AI Alignment Podcast: On Lethal Autonomous Weapons with Paul Scharre
Most relevant to AI alignment, and a pertinent question to focus on for interested readers/listeners is: if we are are unable to establish a governance mechanism as a global community on the concept that we should not let AI make the decision to kill... |
2a8ac4e9-973e-47a1-bccd-c5124ad648bd | trentmkelly/LessWrong-43k | LessWrong | What You See Isn't Always What You Want
To aid communication, I’m going append a technical rephrasing after some paragraphs.
It’s known to be hard to give non-trivial goals to reinforcement learning agents. However, I haven’t seen much discussion of the following: even ignoring wireheading, it seems impossible to spe... |
d1973f85-cedc-4942-864e-dface4af6a3d | trentmkelly/LessWrong-43k | LessWrong | The mathematics of reduced impact: help needed
A putative new idea for AI control; index here.
Thanks for help from Paul Christiano
If clippy, the paper-clip maximising AI, goes out of control, it would fill the universe with paper clips (or with better and better ways of counting the paper-clips it already has). If... |
781982fe-4504-4f35-a5d4-84e4a9974bd5 | trentmkelly/LessWrong-43k | LessWrong | Making History Available
There is a habit of thought which I call the logical fallacy of generalization from fictional evidence. Journalists who, for example, talk about the Terminator movies in a report on AI, do not usually treat Terminator as a prophecy or fixed truth. But the movie is recalled—is available—as if i... |
f0f0f8dd-a2b3-46e1-baa3-67a497a19727 | trentmkelly/LessWrong-43k | LessWrong | Ethical Diets
[Cross-posted from my blog.]
I've seen some discussion of whether effective altruists have an obligation to be vegan or vegetarian.
The carnivores appear to underestimate the long-term effects of their actions. I see a nontrivial chance that we're headed toward a society in which humans are less powerf... |
7f3704d5-289c-4df6-84e8-a7fa40420389 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Logical Limitations to Machine Ethics with Consequences to Lethal Autonomous Weapons
1 Introduction and Motivation
------------------------------
The evolution of warfare has always been an interplay
between technological dynamic and the
tactical/strategic adaptations in combat and deterrence.
Progress in engineeri... |
bb7347b0-3bde-419b-b4fd-4c3ae4f93b3e | trentmkelly/LessWrong-43k | LessWrong | A Year of AI Increasing AI Progress
In July, I made a post about AI being used to increase AI progress, along with this spreadsheet that I've been updating throughout the year. Since then, I have run across more examples, and had others submit examples (some of which were published before the date I made my original p... |
2d5e0d43-4f04-4eb8-89e3-87846c511677 | trentmkelly/LessWrong-43k | LessWrong | Stub: Information Theoretic Ontology
,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Disclaimers
This is a stub. I am having exams right now and do not have the time to write the full article. I'll update (not any time soon) after I've resolved the problems in th... |
d3c0357b-7929-4498-837e-1e075e4c6674 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Soon: a weekly AI Safety prerequisites module on LessWrong
(edit: we have a study group running a week ahead of this series that adds important content. It turns out that to get that content ready on a weekly basis, we would have to cut corners. We prefer quality over speed. We also like predictability. So we decided ... |
a37ee2c4-713f-459c-85fd-b5963f61aaf5 | trentmkelly/LessWrong-43k | LessWrong | Scalar reward is not enough for aligned AGI
This post was authored by Peter Vamplew and Cameron Foale (Federation University), and Richard Dazeley (Deakin University)
Introduction
Recently some of the most well-known researchers in reinforcement learning Silver, Singh, Precup and Sutton published a paper entitled Re... |
995062c9-5f60-42a8-b91c-1c4c6637336b | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | The Importance of Artificial Sentience
*Edited by Jacy Reese Anthis. Many thanks to Ali Ladak, Tobias Baumann, Jack Malde, James Faville, Sophie Barton, Matt Allcock, and the staff at PETRL for reviewing and providing feedback.*
**SUMMARY**
-----------
Artificial sentient beings could be created in vast numbers in t... |
b447a7c8-5950-43ca-888c-828cc4fbc5ce | trentmkelly/LessWrong-43k | LessWrong | Consequentialism is a compass, not a judge
Tl;dr: Consequentialism works as a compass for your actions, not as a judge of moral character.
The compass and the judge
A woman steps onto a crowded bus, trips on a sitting man's outstretched foot, and breaks her arm. The Everett branches split: in one world, the man look... |
51929204-8755-4932-b315-6594e45b7b9e | trentmkelly/LessWrong-43k | LessWrong | Pierre Menard, pixel art, and entropy
In Jorge Luis Borges’ short story “Pierre Menard, Author of the Quixote,” we are introduced to the character of Pierre Menard, recently deceased French novelist and essayist, and are given a brief cataloguing of his works. Chief among them are
> “the ninth and thirty-eighth chapt... |
8f178196-6337-4006-befe-ee0e27fd9375 | trentmkelly/LessWrong-43k | LessWrong | Timeline of Machine Intelligence Research Institute
|
bbe0e37e-6c74-432f-9920-6c46e80aac82 | trentmkelly/LessWrong-43k | LessWrong | A system of infinite ethics
One unresolved problem in ethics is that aggregate consequentialist ethical theories tend to break down if the universe is infinite. An infinite universe could contain both an infinite amount of good and an infinite amount of bad. If so, you are unable to change the total amount of good or ... |
7d7b2dbd-bd3e-4143-b330-17accf186391 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Legal Priorities Research: A Research Agenda
On behalf of the [Legal Priorities Project](http://legalpriorities.org/), we are excited to finally publish our research agenda for legal priorities research: <https://www.legalpriorities.org/research/research-agenda.html>
In the first part, we argue that cause prioritizat... |
be13cf22-496e-4490-b48e-23e3de736f92 | trentmkelly/LessWrong-43k | LessWrong | Everyone else prefers laws to values
How do you tell what a superhuman AI's values are? ( picture: ittybittiesforyou - see bottom)
Robin Hanson says that it is more important to have laws than shared values. I agree with him when ‘shared values’ means that shared indexical values remain about different people, e.g. I... |
5cdd1fcf-229b-44cc-b7e1-ff5e93f824eb | trentmkelly/LessWrong-43k | LessWrong | Inspiring Rationalists
I am concerned with the number of rational, altruistic, smart people in the world. By my standards there are a reasonable number of smart, altruistic (in far mode) people, so a good first step is improving their rationality. To keep "rationality" grounded, I should be a little more precise about... |
4181a0a7-3ae9-496a-a054-eecf5f3f9ae1 | trentmkelly/LessWrong-43k | LessWrong | My understanding of the alignment problem
I've been clarifying my own understanding of the alignment problem over the past few months, and wanted to share my first writeups with folks here in case they're useful:
https://www.danieldewey.net/risk/
The site currently has 3 pages:
1. The case for risk: how deep learn... |
67215f61-f265-4424-bfda-596a77fd7894 | trentmkelly/LessWrong-43k | LessWrong | Learning Deep Learning:
Joining data science research as a mathematician
About two years ago I finished my PhD in mathematics on an obscure technical topic in number theory. I left academic math because I wanted to do something that had a bigger (i.e. any) impact on the world around me. I also wanted to get out of the... |
bca966f4-ddeb-4512-b7cf-d7e14a298a5d | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | You don't need to be a genius to be in AI safety research
The aim of this article is to share my experiences within the AI safety community to those in research and operations in the field, with the goal of creating a more inclusive, supportive, and positive environment. The intention of this article is to allow those... |
3acdc75f-0771-4e09-b2a0-e0b4e2715fbe | trentmkelly/LessWrong-43k | LessWrong | Feature Request: Right Click to Copy LaTeX
Something I do frequently is run into a block of LaTeX that I'm not sure I fully grasp.
At such a point, what I'd like to do is just copy the equation and paste it to GPT-4 and have it explain it to me step by step, then iterate on the feedback until I'm sure I understood it... |
49b856d4-0486-49c2-baf4-327b3527c3ee | trentmkelly/LessWrong-43k | LessWrong | Jan Bloch's Impossible War
Epistemic Status: Endorsed
Content Warning: Neuropsychological Infohazard, Evocation Infohazard, World War I
Recommended Prior Reading: Blueprint for Armageddon Part I
Part of the Series: Truth
> “History doesn’t repeat itself but it often rhymes”
In any real look into the past, you realiz... |
bf7430db-be0e-4da0-9744-37bb7f067929 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Atlanta Lesswrong's May Meetup: The Rationality of Social Relationships, Friendship, Love, and Family.
Discussion article for the meetup : Atlanta Lesswrong's May Meetup: The Rationality of Social Relationships, Friendship, Love, and Family.
WHEN: 17 May 2013 07:00:00PM (-0400)
WHERE: 2388 Lawrenceville Hwy... |
4fc32d46-c1b7-496a-b94f-c0929e0e68fb | StampyAI/alignment-research-dataset/arxiv | Arxiv | Normative Disagreement as a Challenge for Cooperative AI
1 Introduction
---------------
Multi-agent contexts often exhibit opportunities for cooperation: situations where joint action can lead to mutual benefits (Dafoe et al., [2020](#bib.bib13)).
Individuals can engage in mutually beneficial trade; nation-states c... |
dd8b7bd6-a4ce-4c28-be55-2c08266a2e46 | trentmkelly/LessWrong-43k | LessWrong | Anthropics and Fermi
tl;dr There is no well-defined "probability" of intelligent life in the universe. Instead, we can use proper scoring functions to penalise bad probability estimates. If we average scores across all existent observers, we get SSA-style probability estimates; if we sum them, we get SIA-style ones.
... |
0298ab75-5a74-49ee-ad7c-51b341ab0356 | trentmkelly/LessWrong-43k | LessWrong | Speculative inferences about path dependence in LLM supervised fine-tuning from results on linear mode connectivity and model souping
TL;DR: I claim that supervised fine-tuning of the existing largest LLMs is likely path-dependent (different random seeds and initialisations have an impact on final performance and mode... |
4c84da17-d898-49de-91c5-96f1859aa85b | trentmkelly/LessWrong-43k | LessWrong | [LINK] blog on cryonics by someone who freezes things in a cell bio lab
http://www.strike-the-root.com/51/walker/walker12.html
Came across it pretty randomly, I found it quite intriguing. Cryonics is "routine" for human embryos, not far-fetched for humans at all. Makes the whole thing seem potentially very reasonab... |
b40a52ac-1ce2-456b-bdc5-f3a099a239a8 | trentmkelly/LessWrong-43k | LessWrong | Emergency Central Planning
Central planning generally hasn't worked out very well for countries, and essentially the whole world has moved over to markets. So why are there strong calls for governments to run disaster response, instead of leaving that to markets? For example, governments directly:
* distributing foo... |
90744c2a-813b-4df4-965a-4f15f04cf934 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Vancouver Rationalists: LAN Party + Board Games + Discussion at Waves Cafe: September 10th 3:00 to 5:00PM
Discussion article for the meetup : Vancouver Rationalists: LAN Party + Board Games + Discussion at Waves Cafe: September 10th 3:00 to 5:00PM
WHEN: 10 September 2011 03:00:00PM (-0800)
WHERE: Waves Coff... |
4b2eb28f-f566-4113-8bcd-18e54d8153a3 | StampyAI/alignment-research-dataset/blogs | Blogs | 2022-23 New Year review
This is an annual post reviewing the last year and setting goals for next year. Overall, this was a reasonably good year with some challenges (the invasion of Ukraine and being sick a lot). Some highlights in this review are improving digital habits, reviewing sleep data from the Oura ring sinc... |
ad7c23be-47ba-4414-8ec0-105d3935e5c4 | trentmkelly/LessWrong-43k | LessWrong | SI's Summer 2012 Matching Drive Ends July 31st
The Singularity Institute's summer 2012 matching drive ends on July 31st! Donate by the end of the month to have your gift matched, dollar for dollar.
As of this posting, SI has raised $70,000 of the $150,000 goal.
The announcement says:
> Since we published our strate... |
df73c5fd-09c6-4a5b-8f8e-e065d305f62e | awestover/filtering-for-misalignment | Redwood Research: Alek's Filtering Results | id: post2009
My ELK submission was labelled under 'Strategy: train a reporter that is useful for another AI'. This is definitely a fair description, though the AI it needs to be useful to is itself - the reporter is essentially internalized. I also agree that the proposed counterexample, hiding information in what see... |
2eefac5b-ed1f-4ab8-aed7-0a495f9526da | trentmkelly/LessWrong-43k | LessWrong | Best way to write a bicolor article on Less Wrong?
I am planning to write an article that would use two colors to distinguish between "map" and "territory", kinda like in The Neverending Story. In other words, instead of:
> The sentence 'snow is white' is true if and only if snow is white.
I want to write something ... |
33a74c3c-3514-4a77-a718-2f33dd9d31b9 | trentmkelly/LessWrong-43k | LessWrong | Sledding Is Underrated
Sledding is pretty great:
* No lines. You don't have to wait, just go.
* Minimal cost. A basic plastic sled costs $15-$20 at a hardware store, and while they wear out pretty quickly it's still less than $5/outing. Aside from that, all you need is standard winter gear (including snowpants).
... |
01b9e65e-eada-40c3-8f7b-72fc28252d4b | trentmkelly/LessWrong-43k | LessWrong | XKCD - Frequentist vs. Bayesians
http://xkcd.com/1132/
Is this a fair representation of frequentists versus bayesians? I feel like every time the topic comes up, 'Bayesian statistics' is an applause light for me, and I'm not sure why I'm supposed to be applauding. |
398ed0f3-993e-4099-a950-51c97a6f2614 | StampyAI/alignment-research-dataset/blogs | Blogs | List of sources arguing for existential risk from AI
*Published 6 Aug 2022*
*This page is incomplete, under active work and may be updated soon.*
This is a bibliography of pieces arguing that AI poses an existential risk.
List
----
**Adamczewski, Tom. “A Shift in Arguments for AI Risk.”** Fragile Credences. Ac... |
667360f2-de6b-49a9-b7fe-b0ccbd0de7b5 | trentmkelly/LessWrong-43k | LessWrong | "The elephant in the room: the biggest risk of artificial intelligence may not be what we think" What to say about that?
A letter signed by renowned names such as Stephen Hawking and Elon Musk warned about the risks represented by artificial intelligence, including ethical dilemmas, such as in the case of self-driv... |
7c5c0d63-633e-4621-b7c7-1dadb79c03cb | trentmkelly/LessWrong-43k | LessWrong | Quotes and Notes on Scott Aaronson’s "The Ghost in the Quantum Turing Machine"
This highly speculative paper has been discussed here before, but I found the discussion's quality rather disappointing. People generally took bits and pieces out of context and then mostly offered arguments already addressed in the paper. ... |
6b76ddbb-f4f8-4fe3-8079-cef24135006c | StampyAI/alignment-research-dataset/special_docs | Other | Human Compatible: Artificial Intelligence and the Problem of Control
[]
[Cover for Human Compatible]
ALSO BY STUART RUSSELL
The Use of Knowledge in Analogy and Induction (1989)
Do the Right Thing: Studies in Limited Rationality (with Eric Wefald, 1991)
Artificial Intelligence: A Modern Approach (with Peter Norvig... |
2b18e18d-f0ef-4dcf-b50e-223bc97a1d42 | trentmkelly/LessWrong-43k | LessWrong | How likely are scenarios where AGI ends up overtly or de facto torturing us?
How likely are scenarios where AGI prevents us from committing suicide or dying?
I’m a big life extension supporter but being unable to choose to die ever is a literal hell. As dark as it is, if these scenarios are likely, it seems the rati... |
e0244e91-a993-4d80-9cd9-890a8ded9f0f | trentmkelly/LessWrong-43k | LessWrong | Meetup : Berlin: Fermi paradox discussion
Discussion article for the meetup : Berlin: Fermi paradox discussion
WHEN: 18 October 2013 07:00:00PM (+0200)
WHERE: S Wuhletal, 12621 Berlin
We're meeting to discuss the Fermi paradox and the great filter. Everyone is welcome! There'll probably be 6-12 people.
Please look... |
20806784-7355-4a54-937e-993b016d1447 | trentmkelly/LessWrong-43k | LessWrong | Zen and Rationality: Don't Know Mind
This is post 1/? about the intersection of my decades of LW-style rationality practice and my several years of Zen practice.
In today's installment, I look at the Zen notion of "Don't Know Mind" in rationalist terms.
I'm a little unsure where "don't know mind" comes from. Sensei ... |
c94d0db6-58d2-4143-8fca-2968a0624da0 | trentmkelly/LessWrong-43k | LessWrong | The Direct Democracy Experiment
>"The heart of the problem is not how we vote for officials - it's that we vote for officials, instead of getting to vote on issues.
>Americans are proud of being "governed by the people", yet a citizen has no effective way to have any influence on any particular issue! If it's very im... |
978d4c92-ea24-4dd1-9463-353c53fcda25 | StampyAI/alignment-research-dataset/arxiv | Arxiv | A Signaling Game Approach to Databases Querying and Interaction
1 Introduction
---------------
Most users do not know the structure and/or content of databases
and cannot precisely express their queries [[27](#bib.bib27), [10](#bib.bib10), [15](#bib.bib15), [26](#bib.bib26)]. Hence, it is challenging for a database... |
c4ef0def-f960-4212-8cb7-b52901bf724c | trentmkelly/LessWrong-43k | LessWrong | Meetup : Washington DC Lojban meetup
Discussion article for the meetup : Washington DC Lojban meetup
WHEN: 18 August 2013 03:00:00PM (-0400)
WHERE: National Portrait Gallery courtyard, Washington, DC 20001, USA
We'll be meeting to learn Lojban!
Discussion article for the meetup : Washington DC Lojban meetup |
f5e2b97e-63b9-4032-9a4a-e906a1bd734c | trentmkelly/LessWrong-43k | LessWrong | The Implicit Association Test
Continuation of: Bogus Pipeline, Bona Fide Pipeline
Related to: The Cluster Structure of Thingspace
If you've never taken the Implicit Association Test before, try it now.
Any will do. The one on race is the "classic", but the one on gender and careers is a bit easier to watch "in actio... |
e5cbaff5-4fe0-46a4-a99e-c8ec18beb442 | trentmkelly/LessWrong-43k | LessWrong | High Status and Stupidity: Why?
Michael Vassar once suggested: "Status makes people effectively stupid, as it makes it harder for them to update their public positions without feeling that they are losing face."
To the extent that status does, in fact, make people stupid, this is a rather important phenomenon for a ... |
7728b082-10da-4777-bea4-ac1d6eaabaec | trentmkelly/LessWrong-43k | LessWrong | [SEQ RERUN] Where to Draw the Boundary?
Today's post, Where to Draw the Boundary? was originally published on 21 February 2008. A summary (taken from the LW wiki):
> Your definition draws a boundary around things that don't really belong together. You can claim, if you like, that you are defining the word "fish" t... |
1f65c24f-65d8-459f-a521-110388f7d5aa | trentmkelly/LessWrong-43k | LessWrong | Why is multi worlds not a good explanation for abiogenesis
I'm not a expert in the multi world theory. So this question could very well be extremely stupid. However, given the assumption that there are nearly infinite amount of worlds that are slightly different than each other, nearly every possible event would happe... |
42c581c0-3b06-49d6-96b7-be54880eaca8 | trentmkelly/LessWrong-43k | LessWrong | A Corrigibility Metaphore - Big Gambles
I present here a helpful analogy to understand the corrigibility problem and the challenge raised by MIRI in their proposal. This analogy simplifies greatly some challenges of corrigibility but keeps the main problem found in the proposal, which I call Big Gambles.
------------... |
a3f6e141-297d-46fe-b7c4-17d2fa9fdda1 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | OpenAI's Alignment Plans
Our alignment research aims to make artificial general intelligence (AGI) aligned with human values and follow human intent. We take an iterative, empirical approach: by attempting to align highly capable AI systems, we can learn what works and what doesn’t, thus refining our ability to make A... |
9001b042-0b1c-465d-91d0-3b9db1603664 | trentmkelly/LessWrong-43k | LessWrong | Order Matters for Deceptive Alignment
The order in which key properties emerge is important and often glossed over.
Thanks to Wil Perkins, Grant Fleming, Thomas Larsen, Declan Nishiyama, and Frank McBride for feedback on this post. Any mistakes are my own.
Note: I have now changed the second post into this sequenc... |
5758e554-9568-4d25-bfe0-17f0fa99fbe2 | trentmkelly/LessWrong-43k | LessWrong | Scott Aaronson's "On Self-Delusion and Bounded Rationality"
Poignant short story about truth-seeking that I just found. Quote:
> "No," interjected an internal voice. "You need to prove that your dad will appear by a direct argument from the length of your nails, one that does not invoke your subsisting in a dream sta... |
f89a926e-7ef2-4bbe-b6a5-da0c32688956 | trentmkelly/LessWrong-43k | LessWrong | Meetup : [Boston] Becoming Stronger
Discussion article for the meetup : [Boston] Becoming Stronger
WHEN: 28 July 2013 02:00:00PM (-0400)
WHERE: 25 Ames St, Cambridge, MA
What are you currently doing to make yourself a better person? Are you overcoming mental hurdles, improving your skills, or trying new things? We'l... |
92ec0495-99ac-4097-a054-fa7032a3c874 | trentmkelly/LessWrong-43k | LessWrong | Initial Thoughts on Dissolving "Couldness"
Epistemic Status
Been sitting in my drafts unattended to for a month. I'm publishing now so that I publish at all. I do not currently endorse this post or its follow up.
Acknowledgements
Discussions with others helped me refine/sharpen these ideas. I'm grateful for them.... |
9c5c6e8c-ed94-4edc-93a5-d60736f3e86a | trentmkelly/LessWrong-43k | LessWrong | Rational to distrust your own rationality?
There are a number of experiments that throughout the years has shown that expected utility theory EUT fails to predict actual observed behavior of people in decision situations. Take for example Allais paradox. Whether or not an average human being can be considered a ration... |
9ed7e744-2a7e-4561-a32a-fa6bc7bf5c1f | trentmkelly/LessWrong-43k | LessWrong | Does object permanence of simulacrum affect LLMs' reasoning?
Humans are constantly simulating the things around them, however they can rather easily shift attention and forget about the previous thing. So we can say humans' simulacrum does not have object permanence.
On the other hand, AI language models prompted to w... |
0406b462-3fb0-44a4-937b-4d93e7c4d786 | trentmkelly/LessWrong-43k | LessWrong | Preface to the Sequence on LLM Psychology
As Large Language Models (LLMs) like ChatGPT evolve, becoming more advanced and intricate, the challenge of understanding their behaviors becomes increasingly hard. Solely relying on traditional interpretability techniques may not be sufficient or fast enough in our journey to... |
81af338a-f500-41d9-b968-696076caa2c5 | trentmkelly/LessWrong-43k | LessWrong | New LW Meetup: Greenville NC
This summary was posted to LW Main on July 15th. The following week's summary is here.
New meetups (or meetups with a hiatus of more than a year) are happening in:
* Bay City Meetup: 19 August 2016 01:25PM
* Boise, ID Meetup: 24 July 2016 02:30PM
* Greenville, NC meetup: 23 July 2016 ... |
247d6f6f-64dd-40d6-8320-76b99f20de12 | trentmkelly/LessWrong-43k | LessWrong | Secure Hand Holding
When Lily as about three we were waiting at a crosswalk and traffic stopped for us. As we started across the street a driver that had been waiting to turn left misinterpreted the situation and, thinking traffic had stopped for them instead, tried to turn through our location. I tightened my grip an... |
ca5e56fa-0280-4316-9799-51272ec5916c | trentmkelly/LessWrong-43k | LessWrong | Llama Llama-3-405B?
It’s here. The horse has left the barn. Llama-3.1-405B, and also Llama-3.1-70B and Llama-3.1-8B, have been released, and are now open weights.
Early indications are that these are very good models. They were likely the best open weight models of their respective sizes at time of release.
Zuckerbe... |
916ba599-b345-4e1a-a347-2bb6fc693fdf | trentmkelly/LessWrong-43k | LessWrong | Kazakhstan's president urges scientists to find the elixir of life
...according to this front-page Reddit headline I just saw, which links to this Guardian article. I wonder if he's heard of KrioRus, whether he's signed up (Wikipedia says they offer services "to clients from Russia, CIS and EU"), and what his odds wou... |
bbf73040-6638-41e6-93c6-0eb599602a98 | trentmkelly/LessWrong-43k | LessWrong | Can a Bayesian Oracle Prevent Harm from an Agent? (Bengio et al. 2024)
Yoshua Bengio wrote a blogpost about a new AI safety paper by him, various collaborators, and me. I've pasted the text below, but first here are a few comments from me aimed at an AF/LW audience.
The paper is basically maths plus some toy experime... |
e943558a-2af7-4cbd-9ca2-cc4a27f021c0 | trentmkelly/LessWrong-43k | LessWrong | Philip Tetlock invites participants for prediction accuracy tournament
It seems many Less Wrongers might be interested in participating in this study, perhaps distinguishing themselves as top forecasters:
> Prediction markets can harness the "wisdom of crowds" to solve problems, develop products, and make forecasts. ... |
4530de87-7adf-4dd4-9adc-d996cbdd563e | StampyAI/alignment-research-dataset/lesswrong | LessWrong | GPT-4 and ASCII Images?
Does anyone know whether GPT-4 successfully generates ASCII art?
GPT-3.5 couldn't:
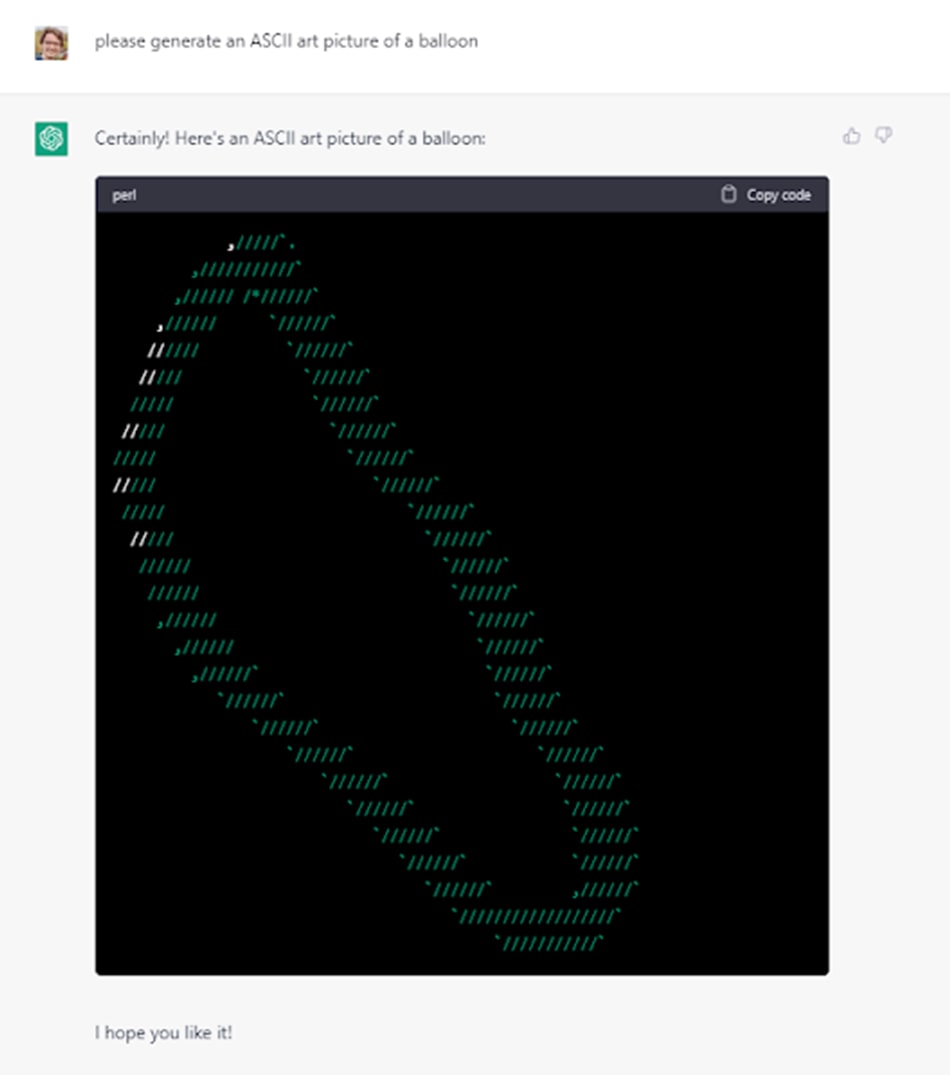the hellWhich makes sense, cause of the whole words-can't-convey-phenomena thing.... |
f9ec2fc0-8c3f-41e2-b5a4-1c62a2342934 | trentmkelly/LessWrong-43k | LessWrong | Meetup : FallacyMania game in Kocherga club
Discussion article for the meetup : FallacyMania game in Kocherga club
WHEN: 23 December 2015 07:40:00PM (+0300)
WHERE: Moscow, B.Dorogomilovskaya, 5-2
Welcome to FallacyMania: it is a game where you guess logical fallacies in arguments, or practise using logical fallacie... |
6c8b1c74-91bf-467d-b436-165e64de367d | LDJnr/LessWrong-Amplify-Instruct | LessWrong | "Hunter-gatherer tribes are usually highly egalitarian (at least if you’re male)—the all-powerful tribal chieftain is found mostly in agricultural societies, rarely in the ancestral environment. Among most hunter-gatherer tribes, a hunter who brings in a spectacular kill will carefully downplay the accomplishment to av... |
01eaa4af-0fb0-4182-996e-937ea3c3792b | trentmkelly/LessWrong-43k | LessWrong | Philosophical Landmines
Related: Cached Thoughts
Last summer I was talking to my sister about something. I don't remember the details, but I invoked the concept of "truth", or "reality" or some such. She immediately spit out a cached reply along the lines of "But how can you really say what's true?".
Of course I'd l... |
37cf87c2-72f2-4bff-ae78-60fab6789528 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Indifference' methods for managing agent rewards
1 Introduction
---------------
In designing a reward for a reinforcement learning agent, a general class of situations can arise, where the designer wants the agent to maximize a reward function, under the constraint that it is not to exert control over the occurrenc... |
c1455f1e-ae8e-4686-9374-b080916f7a35 | trentmkelly/LessWrong-43k | LessWrong | Луна Лавгуд и Комната Тайн, Часть 2
Disclaimer: This is Kongo Landwalker's translation of lsusr's fiction Luna Lovegood and the Chamber of Secrets - Part 2 into russian.
----------------------------------------
— Интересно, что тянет лодки? — сказала Луна.
— Должно быть то же самое, что тянет и повозки без лошадей... |
fb48271d-317a-4086-bc3a-7eee1b316362 | trentmkelly/LessWrong-43k | LessWrong | Feedback on popularizing rationality-informed strategies for making major financial decisions
As part of my broader project of popularizing rationality and raising the sanity waterline, I'm writing a blog about how to make a major financial decision more rationally. The audience we're targeting are educated people in... |
87fb4625-c4a3-4b4b-b6c4-44fbae80885a | trentmkelly/LessWrong-43k | LessWrong | Cost, Not Sacrifice
In a recent bonus episode of the Bayesian Conspiracy podcast, Eneasz Brodski shared a thought experiment that caused no small amount of anguish. In the hypothetical, some eccentric but trustworthy entity is offering to give you an escalating amount of money for your fingers, starting at $10,000 for... |
27c0c6b4-c436-4f94-ba8d-84aedad7b5f6 | trentmkelly/LessWrong-43k | LessWrong | A Simple Alignment Typology
I set out to review the OpenAI alignment plan, and my brain at some point diverged to modeling the humans behind the arguments instead of the actual arguments.
So behold! A simplified, first-pass Alignment Typology.
Why can't we all just get agree?
There are a lot of disagreements in A... |
e8b01eef-7fc2-46aa-9567-92ecd246bd12 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Lymph Node Detection in T2 MRI with Transformers
1 Introduction
---------------
Lymph nodes (LN) are a part of the lymphatic system that helps the body fight infection by removing foreign substances. Enlarged and metastatic LN require accurate identification especially when they are present at sites that do not cor... |
c0b26316-ac67-4ae7-b59b-1e0604718e8f | trentmkelly/LessWrong-43k | LessWrong | Prototyping Pluck Sensors
Harp guitars are a neat weird instrument that never really took off:
You play it like a normal guitar, with six fretted strings, but there are also some number of extra harp strings you can pluck.
I see four main downsides:
* They're bulky and hard to transport.
* You need to tun... |
64468118-a628-40b3-a72a-96ec2e40ce19 | trentmkelly/LessWrong-43k | LessWrong | How can one rationally have very high or very low probabilities of extinction in a pre-paradigmatic field?
It is generally accepted in the local AI alignment circles that the whole field is pre-paradigmatic, in the Kuhnian sense (phase 1, as summarized here, if longer reading is not your thing). And yet, plenty of peo... |
4b125ef6-6d67-4963-a6dc-1255ba7b3302 | trentmkelly/LessWrong-43k | LessWrong | A summary of Savage's foundations for probability and utility.
Edit: I think the P2c I wrote originally may have been a bit too weak; fixed that. Nevermind, rechecking, that wasn't needed.
More edits (now consolidated): Edited nontriviality note. Edited totality note. Added in the definition of numerical probability ... |
0c51e679-07af-42ec-b6bc-9067b50801b8 | trentmkelly/LessWrong-43k | LessWrong | Fundamental Uncertainty: Chapter 9 - How do we live with uncertainty?
N.B. This is a chapter in a book about truth and knowledge. It is the first draft. I have since revised it. You can find the most up-to-date info/version on the book's website.
As we've explored in the preceding chapters, knowledge of the truth is ... |
59a249d2-3db6-4a9c-baac-f8c4b4478445 | trentmkelly/LessWrong-43k | LessWrong | August 2024 Time Tracking
Every so often ( 2022, 2017, more 2017, 2015, 2011) Julia and will track how we spend our time for a week. This is useful for seeing whether how we're spending our time matches how we think we're spending it (and how we would like to be spending it) while also avoiding a pattern where one of ... |
291a397f-2c00-456b-8d80-02c8fe9d7828 | trentmkelly/LessWrong-43k | LessWrong | How do we know that "good research" is good? (aka "direct evaluation" vs "eigen-evaluation")
AI Alignment is my motivating context but this could apply elsewhere too.
The nascent field of AI Alignment research is pretty happening these days. There are multiple orgs and dozens to low hundreds of full-time researchers ... |
3eb04d0f-f0a1-4eaa-a1ed-c910f20d8ed6 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Are there enough opportunities for AI safety specialists?
I've seen a lot of articles, tweets, and forum posts urging more people to work on AI safety. While I agree that AI safety is extremely important and that more people should be working on it, I'm having a hard time imagining that a lack of interested young prof... |
f4f5c019-2986-483f-910a-ceae83503fb5 | trentmkelly/LessWrong-43k | LessWrong | Opportunity Cost Blackmail
If you are utterly powerless, with no money, skills, status, or friends, survival already takes all your time and energy.
Yet I’m not in that situation — and you’re probably not either. Our circumstances surely vary, but we have at least some power — we can pump towards certain outcomes, to... |
97889e30-1652-40aa-8a95-66ddbdb93a17 | trentmkelly/LessWrong-43k | LessWrong | Does Chat-GPT display ‘Scope Insensitivity’?
Summary
* Large Language Models (LLMs) seem well-suited to ‘psychological testing’, because you can get lots of data quickly and conditions are easy to fix. I'm curious to what extent LLMs display the same cognitive biases documented in humans.
* I carried out a quick and... |
b979d731-9257-44e3-8d29-30b9dcc43d42 | trentmkelly/LessWrong-43k | LessWrong | Unlearning shoddy thinking
School taught me to write banal garbage because people would thumbs-up it anyway. That approach has been interfering with me trying to actually express my plans in writing because my mind keeps simulating some imaginary prof who will look it over and go "ehh, good enough".
Looking good enou... |
51374a2d-dbf8-4e56-a5f1-fa0f0e53f042 | StampyAI/alignment-research-dataset/blogs | Blogs | December 2016 Newsletter
| |
| --- |
|
We’re in the final weeks of our push to cover [our funding shortfall](https://intelligence.org/2016/11/11/post-fundraiser-update/), and we’re now halfway to our $160,000 goal. For potential donors who are interested in an outside perspective, Future of Humanity Institute (FHI) ... |
1f7f7e4e-2510-4d89-904e-9b631a06b21e | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Thoughts on the AI Safety Summit company policy requests and responses
Over the next two days, the UK government is hosting an [AI Safety Summit](https://www.aisafetysummit.gov.uk/) focused on “the safe and responsible development of frontier AI”. They requested that seven companies (Amazon, Anthropic, DeepMind, Infle... |
2b8b3403-ac9e-4238-9616-8bcf1583cccf | trentmkelly/LessWrong-43k | LessWrong | AI alignment is distinct from its near-term applications
I work on AI alignment, by which I mean the technical problem of building AI systems that are trying to do what their designer wants them to do.
There are many different reasons that someone could care about this technical problem.
To me the single most import... |
1ab616d8-af38-4b1b-a15e-8c072b207fc0 | trentmkelly/LessWrong-43k | LessWrong | Don’t ignore bad vibes you get from people
I think a lot of people have heard so much about internalized prejudice and bias that they think they should ignore any bad vibes they get about a person that they can’t rationally explain.
But if a person gives you a bad feeling, don’t ignore that.
Both I and several other... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.