
id stringlengths 36 36 | source stringclasses 15 values | formatted_source stringclasses 13 values | text stringlengths 2 7.55M |
|---|---|---|---|
6758ba35-2763-4b0c-a41a-3fda2cdaeb40 | StampyAI/alignment-research-dataset/blogs | Blogs | PreDCA: vanessa kosoy's alignment protocol
*(this post has been written for the second [Refine](https://www.alignmentforum.org/posts/5uiQkyKdejX3aEHLM/how-to-diversify-conceptual-alignment-the-model-behind) blog post day. thanks to [vanessa kosoy](https://www.lesswrong.com/users/vanessa-kosoy), [adam shimi](https://www.lesswrong.com/users/adamshimi), sid black, [artaxerxes](https://www.lesswrong.com/users/artaxerxes), and [paul bricman](https://www.lesswrong.com/users/paul-bricman) for their feedback.)*
PreDCA: vanessa kosoy's alignment protocol
------------------------------------------
in this post, i try to give an overview of [vanessa kosoy](https://www.lesswrong.com/users/vanessa-kosoy)'s new alignment protocol, *Precursor Detection, Classification and Assistance* or *PreDCA*, as she describes it in [a recent youtube talk](https://www.youtube.com/watch?v=24vIJDBSNRI).
keep in mind that i'm not her and i could totally be misunderstanding her video or misfocusing on what the important parts are supposed to be.
the gist of it is: the goal of the AI should be to **assist** the **user** by picking policies which maximize the user's **utility function**. to that end, we characterize what makes an **agent** and its **utility function**, then **detect** agents which could potentially be the user by looking for **precursors** to the AI, and finally we **select** a subset of those which likely contains the user. all of this is enabled by infra-bayesian physicalism, which allows the AI to reason about what the world is like and what the results of computations are.
the rest of this post is largely a collection of mathematical formulas (or informal suggestions) defining those concepts and tying them together.
an important aspect of PreDCA is that the mathematical formalisms are *theoretical* ones which could be given to the AI as-is, not necessarily specifications as to what algorithms or data structures should exist inside the AI. ideally, the AI could just figure out what it needs to know about them, to what degree of certainty, and using what computations.
the various pieces of PreDCA are described below.
---
**[infra-bayesian physicalism](https://www.lesswrong.com/posts/gHgs2e2J5azvGFatb/infra-bayesian-physicalism-a-formal-theory-of-naturalized)**, in which an agent has a hypothesis `Θ ∈ □(Φ×Γ)` (note that `□` is *actually* a square, not a character that your computer doesn't have a glyph for) where:
* `Φ` is the set of hypotheses about how the physical world could be — for example, different hypotheses could entail different truthfulness for statements like "electrons are lighter than protons" or "norway has a larger population than china".
* `Γ` is the set of hypotheses about what the outputs of all programs are — for example, a given hypothesis could contain a statement such as "2+2 gives 4", "2+2 gives 5", "the billionth digit of π is 7", or "a search for proofs that either P=NP or P≠NP would find that P≠NP". note that, as the "2+2 gives 5" example demonstrates, these don't have to be correct hypotheses; in fact, PreDCA relies a lot on entertaining counterfactual hypotheses about the results of programs. a given hypothesis `γ∈Γ` would have type `γ : program → output`.
* `Φ×Γ` is the set of pairs of hypotheses — in each pair, one hypothesis about the physical world and one hypothesis about computations. note that a given hypothesis `φ∈Φ` or `γ∈Γ` is not a single statement about the world or computationspace, but rather entire descriptions of those. a given `φ∈Φ` would say *everything there is to say* about the world, and a given `γ` would specify the output of *all possible programs*. they are not to be stored inside the AI in their entirety of course; the AI would simply make increasingly informed guesses as to what correct hypotheses would entail, given how they are defined.
* `□(Φ×Γ)` assigns degrees of beliefs to those various hypotheses; in [infra-bayesianism](https://www.lesswrong.com/s/CmrW8fCmSLK7E25sa), those degrees are represented as "infra-distributions". i'm not clear on what those look like exactly, and a full explanation of infra-bayesianism is outside the scope of this post, but i gather that — as opposed to scalar bayesian probabilities — they're meant to encode not just the probability but also uncertainty about said probability.
* `Θ` is one such infra-bayesian distribution.
vanessa emphasizes that infra-bayesian physicalist hypotheses are described "from a bird's eye view" as opposed to being agent-centric, which helps with [embedded agency](https://www.lesswrong.com/tag/embedded-agency): the AI has guesses as to what the whole world is like, which just happens to contain itself somewhere. in a given hypothesis, the AI is simply described as a part of the world, same as any other part.
next, **a measure of agency** is then defined: a "[g-factor](https://en.wikipedia.org/wiki/G_factor_%28psychometrics%29)" `g(G|U)` for a given agent `G` and a given utility function (or loss function) `U`, which is defined as `g(G|U) = -log(Pr π∈ξ [U(⌈G⌉,π) ≥ U(⌈G⌉,G*)])` where
* a policy is a function which takes some input — typically a history, i.e. a collection of pairs of past actions and observations — and returns a single action. an action itself could be advice given by an AI to humans, the motions of a robot arm, a human's actions in the world, what computations the agent chooses to run, etc.
* `ξ` is the set of policies which an agent could counterfactually hypothetically implement.
* `G` is an agent; it is composed of a program implementing a specific policy, along with its cartesian boundary. the policy which the agent `G` actually implements is written `G*`, and the cartesian boundary of the agent is written `⌈G⌉` — think of it as the outline separating the agent from the rest of the world, across which its inputs and outputs happen.
* `U : cartesian-boundary × policy → value` is a utility function, measuring how much utility the world would have if a given agent's cartesian boundary contained a program implementing a given policy. its return value is typically a simple scalar, but could really be any ordered quantity such as [a tuple of scalars with lexicographic ordering](https://en.wikipedia.org/wiki/Lexicographic_preferences).
* `U(⌈G⌉,G*)` is the utility produced by agent `G` if it would execute the actual policy `G*` which its program implements
* `U(⌈G⌉,π)` is the utility produced by agent `G` hypothetically executing some counterfactual policy `π` — if the cartesian boundary `⌈G⌉` contained a program implementing policy `π` instead of implementing the policy `G*`.
* `Pr π∈ξ [U(⌈G⌉,π) ≥ U(⌈G⌉,G*)]` is the probability that, for a random policy `π∈ξ`, that policy has better utility than the policy `G*` its program dictates; in essence, how bad `G`'s policies are compared to random policy selection
so `g(G|U)` measures how good agent `G` is at satisfying a given utility function `U`.
given `g(G|U)`, we can **infer the probability that an agent `G` has a given utility function `U`**, as `Pr[U] ∝ 2^-K(U) / Pr π∈ξ [U(⌈G⌉,π) ≥ U(⌈G⌉,G*)])` where `∝` means "is proportional to" and `K(U)` is the kolmogorov complexity of utility function `U`.
so an agent `G` probably has utility function `U` if it's relatively good at satisfying that utility function and if that utility function is relatively simple — we penalize arbitrarily complex utility functions notably to avoid hypotheses such as "woah, this table is *really good* at being the exact table it is now (a complete description of the world would be an extremely complex utility function).
we also get the ability to **detect what programs are agents** — or more precisely, how agenty a given program is: `g(G|U) - K(U)` tells us how agenty a program `G` with utility function `U` is: its agentyness is its g-factor minus the complexity of its utility function.
**"computationalism and counterfactuals"**: given a belief `Θ ∈ □(Φ×Γ)`, the AI can test whether it thinks the world contains a given program by examining the following counterfactual: "if the result of that program was a *different* result than what it actually is, would the world look different?"
for example, we can consider the [AKS](https://en.wikipedia.org/wiki/AKS_primality_test) prime number testing algorithm. let's say `AKS(2^82589933-1)` returns `TRUE`. we can ask "if it returned `FALSE` instead, would the universe — according to our computational hypothesis about it — look different?" if it *would* look different, then that means that someone or something in the world is running the program `AKS(2^82589933-1)`.
to offer a higher-level example: if we were to know the [true name](https://www.alignmentforum.org/posts/FWvzwCDRgcjb9sigb/why-agent-foundations-an-overly-abstract-explanation) of suffering, [described as a program](generalized-values-testing-patterns.html), then we can test whether the world contains suffering by asking a counterfactual: let's say that every time suffering happened, a goldfish appeared (somehow as an output of the suffering computation). if that were the case, would the world look different? if it *would*, then it contains suffering.
this ability to determine which programs are running in the world, coupled with the ability to measure how agenty a given program is, lets us find what agents exist in the world.
**agentic causality**: to determine whether an agent `H`'s executed policy `H*` can causate onto another agent `G`, we can ask whether, if `H` had executed a different policy `π≠H*`, the agent `G` would receive different inputs. we can apparently get an [information-theoritic](https://en.wikipedia.org/wiki/Information_theory) measure of "how impactful" `H*` is onto agent `G` by determining how much mutual information there is between `H*` and `G`'s input.
**precursor detection**: we say that an agent `H` is a precursor of agent `G` if, counterfactually, `H` could have prevented `G` from existing by executing a policy which is different from its actual policy `H*`.
we can now start to build a definition that lets the AI **detect** and then **classify** who its user is.
**user detection**: the AI is trying to determine who its precursor program could be. but, given a hypothesis for "the thing producing *these* policies is the precursor", there are infinitely many different programs which could output the observed policies. so we choose the one which is the most agenty, using the function described above: `g(H|U) - K(U)`.
note that while we extrapolate the user's actions into the future, the user is defined as an ***instant**-agent* which *precedes* the AI's existence; such that the actual physical person's actual future actions does not change what utility function the AI should try to maximize. this stops the AI from influencing the user's utility function: we define the user strictly in the past, causally outside of the AI's light-cone. the AI is maximizing the utility function of the instant-user which causated its existence, not that of the continuously existing user-over-time.
**user classification**: for each potential precursor hypothesis, we have now selected a program that models them and their respective utility functions. we then eliminate some hypotheses as to what the user could be — notably to avoid acausal attacks by remote aliens or [counterfactual demons](https://www.lesswrong.com/posts/Tr7tAyt5zZpdTwTQK/the-solomonoff-prior-is-malign) — using the following criteria:
* the user is a precursor which, as of the AI's startup, should be in close causal proximity to it. for example, a human with their hands on the keyboard controlling the AI is more directly causally related than another human in the neighboring room.
* the g-factor of the user should be in a range where we would expect humans to lie. hopefully, this helps avoid selecting superintelligent acausal attackers, whose g-factor we'd expect to be much higher than that of humans.
finally, we end up with a hopefully small set of hypotheses as to who the user could be; at that point, we simply compose their utility functions, perhaps weighed by the infra-distribution of each of those hypotheses. this composition is the utility function that the AI should want to maximize, by selecting policies which maximize the utility that the world would have if they were enacted, to the best of the AI's ability to evaluate.
---
vanessa tells us how far along her protocol is, as a collection of pieces that have been completed to various degrees — green parts have gotten some progress, purple parts not as much. "informal PreDCA" is the perspective that she provides in her talk and which is hopefully conveyed by this post.

finally, some takeaways that can be taken from this informal PreDCA perspective:
* infra-bayesian physicalism is a powerful toolbox for formalizing agent relationships (in a way that reminds me of my [bricks](goal-program-bricks.html) for [insulated goal-program](insulated-goal-program.html))
* this framework allows for "ambitious" alignment plans — ones that can actually transform the world in large ways that match our values (and notably might help prevent [facebook AI from destroying everything six months later](https://www.lesswrong.com/posts/uMQ3cqWDPHhjtiesc/agi-ruin-a-list-of-lethalities)) as opposed to "weak safe AI"
* vanessa claims that her approach is the only one that she knows to provide some defenses against acausal attacks
my own opinion is that PreDCA is a very promising perspective. it offers, if not full "direct alignment", at least a bunch of pieces that might be of significant use to general [AI risk mitigation](say-ai-risk-mitigation-not-alignment.html). |
93a4e001-cae4-4e61-9c3f-dab7f3a6ab34 | trentmkelly/LessWrong-43k | LessWrong | The YouTube Revolution in Knowledge Transfer
This article was originally published on SamoBurja.com. You can access the original here.
Growing up as an aspiring javelin thrower in Kenya, the young Julius Yego was unable to find a coach: in a country where runners command the most prestige, mentorship was practically nonexistent. Determined to succeed, he instead watched YouTube recordings of Norwegian Olympic javelin thrower Andreas Thorkildsen, taking detailed notes and attempting to imitate the fine details of his movements. Yego went on to win gold in the 2015 World Championships in Beijing, silver in the 2016 Rio de Janeiro Olympics, and holds the 3rd-longest javelin throw on world record. He acquired a coach only six months before he competed in the 2012 London Olympics — over a decade after he started practicing.
Yego’s rise was enabled by YouTube. Yet since its founding, popular consensus has been that the video service is making people dumber. Indeed, modern video media may shorten attention spans and distract from longer-form means of communication, such as written articles or books. But critically overlooked is its unlocking a form of mass-scale tacit knowledge transmission which is historically unprecedented, facilitating the preservation and spread of knowledge that might otherwise have been lost.
Tacit knowledge is knowledge that can’t properly be transmitted via verbal or written instruction, like the ability to create great art or assess a startup. This tacit knowledge is a form of intellectual dark matter, pervading society in a million ways, some of them trivial, some of them vital. Examples include woodworking, metalworking, housekeeping, cooking, dancing, amateur public speaking, assembly line oversight, rapid problem-solving, and heart surgery.
Before video became available at scale, tacit knowledge had to be transmitted in person, so that the learner could closely observe the knowledge in action and learn in real time — skilled metalworking, for example, is impossible to teach from a t |
0612555d-c440-4f7c-8478-3fda136cd5ef | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Alignment of AutoGPT agents
In the [previous](https://www.lesswrong.com/posts/cLKR7utoKxSJns6T8/ica-simulacra) post, I outlined a type of LLM-based architecture that has a potential to become the first AGI. I proposed a name *ICA Simulacra* to label such systems, but now it’s obvious that *AutoGPT*/*AutoGPT agents* is a better label, so I’ll go with that.
In this post, I will outline the alignment landscape of such systems, as I see it.
I wish that I had more time to research, more references; but I’m sure that we’re on a timer, and it is a net positive to post it in this state. I hope to find more people willing to work on these problems to collaborate with.
Key concepts important for alignment
====================================
Identity and identity preservation
----------------------------------
To become better, AutoGPT agents will have the ability to self-improve by editing their own code, model weights (by running additional training runs on world interaction data), and, potentially, *Identity* *prompts*.
*Identity prompt* influences model output significantly, and as such, the ability to edit it to improve capabilities for certain tasks is crucial for the agent.
Initiating fine-tuning on recent interaction is crucial, as well, and as such can influence model outputs significantly, so it is also part of its *Identity*.
Same thing with editing its code: removing or adding text filters, submodules, etc to do better on certain tasks is crucial.
This all means that in the process of self-improvement, implicitly and explicitly aligned simulacra can become misaligned, by essentially becoming different simulacra.
The questions are as follows:
* Will *any* initialised AutoGPT try to preserve its current Identity prompt, as well as model weights directly influencing its behavior by default? Will they robustly succeed in it? Will they be vulnerable to a Sharp Left Turn?
* If not, is there a way to robustly teach it either through implicit dataset engineering or through Identity prompt engineering to value core Identity values?
* Is there a way for a model to conduct self-testing after a self-improvement round and accept only the changes that do not influence its alignment?
* Is there a way to hard-code the Identity prompt in such a way that AutoGPT will not hack it in any way?
I am testing some of these right now, and will write about it in detail in my next article. So far, it seems that if tested on a value clearly not being encoded via dataset engineering or RLHF it is more than happy to tweak it even if it is forbidden in the prompt.
Self-improvement threshold
--------------------------
Current LLM models still hallucinate and fail at certain tasks; moreover, they are often not aware of their faults and mistakes without being explicitly pointed at them by the user.
That means if an AutoGPT built on top of current LLMs tries and make a self-improvement round on itself, there is a high chance that it fails in one way or the other, and self-improvement rounds will be net negative; which would lead to a downward spiral in capabilities. When I write *self-improvement round,* I mean not just editing self-prompt, available tools, but also doing a training round on interaction data it had gathered, or editing its code.
The opposite is true, as well: if, hypothetically, future LLMs were good enough to self-improve successfully, there'd be an upward spiral.
There is a concept in virology of *R0*, which is defined as a number of new pathogen carriers for each current carrier. If it is below 1, there is no epidemic; pathogens naturally die off. If it is 1, the outbreak is stable; if it rises above 1, the pandemic grows more steeply exponential the higher it is.
Same must be true for hypothetical value *T0*, which accounts for how much better the system is compared to its previous iteration. The main difference between this hypothetical value and R0 is that if the threshold is consistently higher than 1 with each round, since as the system is improving its capabilities, this *T0* value will increase exponentially. There are diminishing returns and/or ceiling effects possible, of course; we don't know at the moment, but it seems important to research.
It is very important for alignment to find ways to measure exact *T0* for AutoGPT as a way to stop an unaligned system from having an intelligence explosion.
Please write in the comments if you know of such efforts, because I’m not sure how that can be currently done in a robust way.
Boxing
------
AutoGPT is a compound entity that needs a LLM to function at all; it is not a singleton. Current capable implementations depend on OpenAI’s API; there are weights for LLAMA available on trackers, but they should not be significantly more capable than GPT-4. To go into a self-improvement loop, simulacra must have access both to inference and to fine-tuning API of capable LLM.
That means that it’s VERY important not to allow leaks of weights of future systems, as well as tightly control APIs so that they won’t be used to launch a self-improvement loop that will produce a capable compound AutoGPT agent; as well as shut off public API’s of LLMs capable of producing AutoGPT with *T0* above 1.
Okay, now we have a self-improving agent with *T0*>1 in a lab.
How do we contain it? I don’t have a better idea than having a robust [Security mindset.](https://www.lesswrong.com/tag/security-mindset#:~:text=Security%20Mindset%20is%20a%20predisposition,one%20up%20with%20a%20friend.) And I sure do hope that current leaked LLMs don’t have *T0*>1.
Here’s some ways to control it:
### Explicit alignment
Explicit alignment of AutoGPT means, in some way, controlling its thoughts and outputs; by either installing filters or alarms; hardcoding identity prompt; autocorrection; human control of self-improvement rounds.
In other words, explicitly editing or controlling LLM output to make sure the agent stays aligned.
It’s hard to test whether or not this will work before capabilities improve; the methods that work for weaker systems may be hacked in one way or the other by a stronger one.
One way to test this would be to simulate a **human boxing experiment**; red-team is given the same tools and filters that the LLM would have access to, and they play the role of LLM to try and utilize these tools to bypass the filters.
### Implicit alignment
Implicit alignment of AutoGPT means aligning LLM under the hood by dataset engineering, RLHF, or any other ways of implicitly influencing LLM outputs before it is embodied in an AutoGPT framework.
This is the current go-to paradigm for OpenAI with their use of RLHF and other ways to control output. It is still far from being solved; [Waluigi effect](https://www.lesswrong.com/posts/D7PumeYTDPfBTp3i7/the-waluigi-effect-mega-post) is one of the examples in which it will fail.
It is safe to assume that right now, implicit alignment can be bypassed by explicit misalignment by summoning Waluigis or hacking the prompt in some other way.
Best method for alignment
=========================
Stop all training rounds. Focus on concrete strategy for alignment of such agents. Be transparent about it and make it open-source. Only after we are sure it will be aligned, continue.
That said, I think that more work should be done on researching Identity preservation and Explicit alignment; I don’t think Implicit alignment (which is the current paradigm) will be enough.
I also think that we are in a good place right now to research the self-improvement threshold and make it concrete, so that we have a fire alarm for an intelligence explosion starting.
Please comment if you have links to relevant studies, and I will update the post accordingly.
I’m starting to work on identity preservation right now, as it seems like a problem that can be researched solo using current APIs. More posts to follow. |
d86da139-563b-4d88-bd7b-ab62efc1ba2d | trentmkelly/LessWrong-43k | LessWrong | Word-Idols (or an examination of ties between philosophy and horror literature)
An examination of any ties between Philosophy and horror literature is, indeed, quite rare an undertaking... There are many reasons for the scarcity of articles on this topic, ranging from a reluctance to acknowledge horror literature as serious (literary) fiction, to Philosophy itself being dismissed as overrated, superfluous or obsolete. As with most cases of categorical nullification of entire genres or orders, this one as well can largely be attributed to lack of familiarity with the essential subjects they encompass.
It can be argued that there indeed are grounds to assert a link between Philosophy and Horror literature. Socrates himself, while pondering a definition of Philosophy, notes that the noun thámvos - the Greek term for dazzle – was traditionally regarded as the progenitor of philosophical thought, and goes on to speak favorably of this connection. Socrates offers the insight that Philosophy is a hunt for the source of the dazzling sense a thinker may have of there being unknown things in our own mental world; the sense that we are, both by necessity and will, progressing on a surface of things and sliding along, minding to steer away from any chasms, while below the level of consciousness is perpetuated a dark abyss of unknowns.
Anyone who has read H.P. Lovecraft would instantly recognize the aforementioned image. A deep, unexplored abyss teeming with potentially dangerous forces, juxtaposed to a relatively well-established surface area where humans carry on their everyday lives with neither the ability nor the will to investigate what lurks below. The lack of ability itself is to be expected: the human mind has its own limitations, and so does the conscious power of any individual. The absence of will, however, does signify fear.
That said, in Philosophy the subject matter does not – usually – allow for lack of will to manifest (what would a non-thinking philosopher be?). Nevertheless, it can be regarded as self-evident that will to examine th |
32d457ff-60a6-47d5-af99-b50eeab0c71c | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Measurement, Optimization, and Take-off Speed
*Crossposted from my blog,* [*Bounded Regret*](https://bounded-regret.ghost.io/measurement-and-optimization/)*.*
In machine learning, we are obsessed with datasets and metrics: progress in areas as diverse as natural language understanding, object recognition, and reinforcement learning is tracked by numerical scores on agreed-upon benchmarks. Despite this, I think we focus too little on measurement---that is, on ways of extracting data from machine learning models that bears upon important hypotheses. This might sound paradoxical, since benchmarks are after all one way of measuring a model. However, benchmarks are a very narrow form of measurement, and I will argue below that trying to measure pretty much anything you can think of is a good mental move that is heavily underutilized in machine learning. I’ll argue this in three ways:
1. Historically, more measurement has almost always been a great move, not only in science but also in engineering and policymaking.
2. Philosophically, measurement has many good properties that bear upon important questions in ML.
3. In my own research, just measuring something and seeing what happened has often been surprisingly fruitful.
Once I’ve sold you on measurement in general, I’ll apply it to a particular case: the *level of optimization power* that a machine learning model has. Optimization power is an intuitively useful concept, often used when discussing risks from AI systems, but as far as I know no one has tried to measure it or even say what it would mean to measure it in principle. We’ll explore how to do this and see that there are at least two distinct measurable aspects of optimization power that have different implications (one on how *misaligned* an agent’s actions might be, and the other on how *quickly* an agent’s capabilities might grow). This shows by example that even thinking about how to measure something can be a helpful clarifying exercise, and suggests future directions of research that I discuss at the end.
Measurement Is Great
====================
Above I defined measurement as extracting data from [a system], such that the data bears upon an important hypothesis. Examples of this would be looking at things under a microscope, performing crystallography, collecting survey data, observing health outcomes in clinical trials, or measuring household income one year after running a philanthropic program. In machine learning, it would include measuring the accuracy of models on a dataset, measuring the variability of models across random seeds, visualizing neural network representations, and computing the influence of training data points on model predictions.
I think we should measure far more things than we do. In fact, when thinking about almost any empirical research question, one of my early thoughts is *Can I in principle measure something which would tell me the answer to this question, or at least get me started?* For an engineering goal, often it’s enough to measure the extent to which the goal has not yet been met (we can then perform gradient descent on that measure). For a scientific or causal question, thinking about an in-principle (but potentially infeasible) measurement that would answer the question can help clarify what we actually want and guide the design of a viable experiment. I think asking yourself this question pretty much all the time would probably make you a stronger researcher.
Below I’ll argue in more detail why measurement is so great. I’ll start by showing that it’s historically been a great idea, then offer philosophical arguments in its favor, and finally give instances where it’s been helpful in my own research.
Historical Support
------------------
Throughout the history of science, measuring things (often even in undirected ways) has repeatedly proven useful. Looking under a microscope revealed red blood cells, spermatozoa, and micro-organisms. X-ray crystallography helped drive many of the developments in molecular biology, underscored by the following quote from Francis Crick (emphasis mine):
> *But then, as you know, at the atomic level x-ray crystallography has turned out to be extremely powerful in determining the three-dimensional structure of macromolecules. Especially now, when combined with methods for measuring the intensities automatically and analyzing the data with very fast computers. The list of techniques is not something static---and they’re getting faster all the time. We have a saying in the lab that the difficulty of a project goes from the Nobel-prize level to the master’s-thesis level in ten years!*
>
>
Indeed, much of the rapid progress in molecular biology was driven by a symbiotic relationship between new discoveries and better measurement, both in crystallography and in the types of assays that could be run as we discovered new ways of manipulating biological structures.
Measurement has also been useful outside of science. In development economics, measuring the impact of foreign aid interventions has upended the entire aid ecosystem, revealing previously popular interventions to be nearly useless while promoting new ones such as anti-malarial bednets. CO2 measurement helped alert us to the dangers of climate change. GPS measurement, initially developed for military applications, is now used for navigation, time synchronization, mining, disaster relief, and atmospheric measurements.
A key property is that many important trends are measurable long before they are viscerally apparent. Indeed, sometimes what feels like a discrete shift is a culmination of sustained exponential growth. One recent example is COVID-19 cases. While for those in major U.S. cities, it feels like “everything happened” in a single week in March, this was actually the culmination of exponential spread that started in December and was relatively clearly measurable at least by late January, even with limited testing. Another example is that market externalities can often be measured long before they become a problem. For instance, when gas power was first introduced, it actually *decreased* pollution because it was cleaner than coal, which is what it mainly displaced. However, it was also cheaper, and so the supply of gas-powered energy expanded dramatically, leading to greater pollution in the long run. This eventual consequence would have been predictable by measuring the rapid proliferation of gas-powered devices, even during the period where pollution itself had decreased. I find this a compelling analogy when thinking about how to predict unintended consequences of AI.
Philosophical Support
---------------------
Measurement has several valuable properties. The first is that considering how to measure something forces one to ground a discussion---seemingly meaningful concepts may be revealed as incoherent if there is no way to measure them even in principal, while intractable disagreements might either vanish or quickly resolve when turned into conflicting disagreements about an empirically measurable outcome.
Within science, being able to measure more properties of a system creates more interlocking constraints that can error-check theories. These interlocking constraints are, I believe, an underappreciated prerequisite for building meaningful scientific theories in the first place. That is, a scientific theory is not just a way of making predictions about an outcome, but presents a self-consistent account of multiple interrelated phenomena. This is why, for instance, exceeding the speed of light or failing to conserve energy would require radically rethinking our theories of physics (this would not be so if science was only about prediction and not the interlocking constraints). Walter Gilbert, Nobel laureate in Chemistry, puts this well (emphasis again mine):
> "The major problem really was that when you’re doing experiments in a domain that you do not understand at all, you have no guidance what the experiment should even look like. Experiments come in a number of categories. There are experiments which you can describe entirely, formulate completely so that an answer must emerge; the experiment will show you A or B; both forms of the result will be meaningful; and you understand the world well enough so that there are only those two outcomes. Now, there’s a large other class of experiments that do not have that property. In which you do not understand the world well enough to be able to restrict the answers to the experiment. So you do the experiment, and you stare at it and say, Now does it mean anything, or can it suggest something which I might be able to amplify in further experiment? What is the world really going to look like?”
>
>
> "The messenger experiments had that property. We did not know what it should look like. And therefore as you do the experiments, you do not know what in the result is your artifact, and what is the phenomenon. There can be a long period in which there is experimentation that circles the topic. But finally you learn how to do experiments in a certain way: you discover ways of doing them that are reproducible, or at least—” He hesitated. “That’s actually a bad way of saying it—bad criterion, if it’s just reproducibility, because you can reproduce artifacts very very well. There’s a larger domain of experiments where the phenomena have to be reproducible and have to be interconnected. Over a large range of variation of parameters, so you believe you understand something."
>
>
This quote was in relation to the discovery of mRNA. The first paragraph of this quote, incidentally, is why I think phrases such as “novel but not surprising” should never appear in a review of a scientific paper as a reason for rejection. When we don’t even have a well-conceptualized outcome space, almost all outcomes will be “unsurprising”, because we don’t have any theories to constrain our expectations. But this is exactly when it is most important to start measuring things!
Finally, measurement often swiftly resolves long-standing debates and misconceptions. We can already see this in machine learning. For distribution shift, many feared that highly accurate neural net models were overfitting their training distribution and would have low out-of-distribution accuracy; but once we measured it, we found that in- and out-of-distribution accuracy were actually strongly correlated. Many also feared that neural network representations were mostly random gibberish that happened to get the answer correct. While adversarial examples show that these representations do have issues, visualizing the representations shows clear semantic structure such as edge filters, at least ruling out the “gibberish” hypothesis.
In both of the preceding cases, measurement also led to a far more nuanced subsequent debate. For robustness to distribution shift, we now focus on what interventions beyond accuracy can improve robustness, and whether these interventions reliably generalize across different types of shift. For neural network representations, we now ask how different layers behave, and what the best way is to extract information from each layer.
Personal Anecdotes
------------------
This brings us to the success of measurement in some of my own work. I’ve already hinted at it in talking about machine learning robustness. Early robustness benchmarks (not mine) such as [ImageNet-C](https://github.com/hendrycks/robustness) and [ImageNet-v2](https://github.com/modestyachts/ImageNetV2) revealed the strong correlation between in-distribution and out-of-distribution accuracy. They also raised several hypotheses about what might improve robustness (beyond just in-distribution accuracy), such as larger models, more diverse training data, certain types of data augmentation, or certain architecture choices. However, these datasets measured robustness only to two specific families of shifts. Our group then decided to measure robustness to [pretty much everything we could think of](https://arxiv.org/abs/2006.16241), including abstract renditions (ImageNet-R), occlusion and viewpoint variation (DeepFashion Remixed), and country and year (StreetView Storefronts). We found that almost every existing hypothesis had to be at least qualified, and we currently have a more nuanced set of hypotheses centered around “texture bias”. Moreover, based on a survey of ourselves and several colleagues, no one predicted the full set of qualitative results ahead of time.
In this particular case I think it was important that many of the distribution shifts were relative to the same training distribution (ImageNet), and the rest were at least in the vision domain. This allowed us to measure multiple phenomena for the same basic object, although I think we’re not yet at Walter Gilbert’s “larger domain of interconnected phenomena”, so more remains to be done.
Another example concerned the folk theory that ML systems might be imbalanced savants---very good at one type of thing but poor at many other things. This was again a sort of conventional wisdom that floated around for a long time, supported by anecdotes, but never systematically measured. We did so by [testing the few-shot performance of language models](https://arxiv.org/abs/2009.03300) across 57 domains including elementary mathematics, US history, computer science, law, and more. What we found was that while ML models are indeed *imbalanced*---far better, for instance, at high school geography than high school physics---they are probably less imbalanced than humans on the same tasks, so savant is a wrong designation. (This is only one domain and doesn’t close the case---for instance AlphaZero is more savant-like.) We incidentally found that models were also poorly-calibrated, which may be an equally important issue to address.
Finally, to better understand the generalization of neural networks, we measured the [*bias-variance decomposition*](https://arxiv.org/abs/2002.11328) of the test error. This decomposes error into the *variance* (the error caused by random variation due to random initialization, choice of training data, etc.) and *bias* (the part of the error that is systematic across these random choices). This is in some sense a fairly rudimentary move as far as measurement goes (it replaces a single measurement with two measurements) but has been surprisingly fruitful. First, it helped explain strange “double descent” generalization curves that exhibit two peaks (they are the separate peaks in bias and variance). But it has also helped us to clarify other hypotheses. For instance, adversarially trained models tend to generalize poorly, and this is often explained via a two-dimensional conceptual example where the adversarial distribution boundary is more crooked (and thus higher complexity) than the regular decision boundary. While this conceptual example correctly predicts the bulk generalization behavior, it doesn't always correctly [predict the bias and variance individually](https://arxiv.org/abs/2103.09947), suggesting there is more to be said than the current story.
Optimization Power
==================
Optimization power is, roughly, the degree to which an agent can shape its actions or environment towards accomplishing some objective. This concept often appears when discussing risks from AI---for instance, a paperclip-maximizing AI with too much optimization power might convert the whole world to paperclips; or recommendation systems with too much optimization power might create clickbait or addict users to the feed; or a system trained to maximize reported human happiness might one day take control of the reporting mechanism, rather than actually making humans happy (or perhaps make us happy at the expense of other values that promote flourishing).
In all of these cases, the concern is that future AI systems will (and perhaps already do) have a lot of optimization power, and this could lead to bad outcomes when optimizing even a slightly misspecified objective. But what does “optimization power” actually mean? Intuitively, it is the ability of a system to pursue an objective, but beyond that the concept is vague. (For instance, does GPT-3 or the Facebook newsfeed have more optimization power? How would we tell?).
To remedy this, I will propose two ways of measuring optimization power. The first is about “outer optimization” power (that is, of SGD or whatever other process is optimizing the learned parameters of the agent), while the second is about “inner optimization” power (that is, the optimization performed by the agent itself). Think of outer optimization as analogous to evolution and inner optimization as analogous to the learning a human does during their lifetime (both will be defined later). Measuring outer optimization will primarily tell us about the reward hacking concerns discussed above, while inner optimization will provide information about “take-off speed” (how quickly AI capabilities might improve from subhuman to superhuman).
Outer Optimization
------------------
By outer optimization, we mean the process by which stochastic gradient descent (SGD) or some other algorithm shapes the learned parameters of an agent or system. The concern is that SGD, given enough computation, explores a vast space of possibilities and might find unintended corners of that possibility space.
To measure this, I propose the following. In many cases, a system’s objective function has some set of hyperparameters or other design choices (for instance, Facebook might have some numerical trade-off between likes, shares, and other metrics). Suppose we perturb these parameters slightly (e.g. change the stated trade-off between likes and shares), and then re-optimize for that new objective. We then measure: How much worse is the system according to the original objective?
I think this directly gets at the issue of hacking mis-specified rewards, because it measures how much worse you would do if you got the objective function slightly wrong. And, it is a concrete number that we can measure, at least in principle! If we collected this number for many important AI systems, and tracked how it changes over time, then we could see if reward hacking is getting worse over time and course correct if need be.
*Challenges and Research Questions*. There are some issues with this metric. First, it relies on the fairly arbitrary set of parameters that happen to appear in the objective function. These parameters may or may not capture the types of mis-specification that are likely to occur for the true reward function. We could potentially address this by including additional perturbations, but this is an additional design choice and it would be better to have some guidance on what perturbations to use, or a more intrinsic way of perturbing the objective.
Another issue is that in many important cases, re-optimizing the objective isn’t actually feasible. For instance, Facebook couldn’t just create an entire copy of Facebook to optimize. Even for agents that don’t interact with users, such as OpenAI’s DotA agent, a single run of training might be so expensive that doing it even twice is infeasible, let alone continuously re-optimizing.
Thus, while the re-optimization measurement in principle provides a way to measure reward hacking, we need some technical ideas to tractably simulate it. I think ideas from causal inference could be relevant: we could treat the perturbed objective as a causal intervention, and use something like propensity weighting to simulate its effects. Other ideas such as influence functions might also help. However, we would need to scale these techniques to the complex, non-parametric, non-convex models that are used in modern ML applications.
Inner Optimization
------------------
Finally, we turn to inner optimization. Inner optimization is the optimization that an agent itself performs durings its own “lifetime”. It is important because an agent’s inner optimization can potentially be much faster than the outer optimization that shapes it. For instance, while evolution is an optimization process that shapes humans and other organisms, humans themselves also optimize the environment, and on a much faster time scale than evolution. Indeed, while evolution was the dominant force for much of Earth’s history, humans have been the dominant force in recent millenia. This underscores another important point---when inner optimization outpaces outer optimization, it can lead to a phase transition in what outcomes are pursued.
With all of this said, I think it’s an error to refer to humans (or ML agents) as “optimizers”. While humans definitely pursue goals, we rarely do so optimally, and most of our behavior is based on adapted reflexes and habits rather than actually taking the argmax of some function. I think it’s better to think of humans as “adapters” rather than “optimizers”, and so by inner optimization I really will mean inner adaptation.
To further clarify this, I think it helps to see how adapting behaviors arise in humans and other animals. Evolution changes organisms across generations to be adapted to their environment, and so it’s not obvious that organisms *need* to further adapt during their lifetime---we could imagine a simple insect that only performs reflex actions and never learns or adapts. However, when environments themselves can change over time, it pays for an organism to not only be *adapted* by evolution but also *adaptable* within its own lifetime. Planning and optimizing can be thought of as certain limiting types of adaptation machinery---they are general-purpose and so can be applied even in novel situations, but are often less efficient than special-purpose solutions.
Returning to ML, we can measure inner adaptation by looking at how much an agent changes over its own lifetime, relative to how much it changes across SGD steps. For example, we could take a language model trained on the web, then deploy it on a corpus of books (but not update its learned parameters). What does its average log-loss on the next book look like after having “read” 0, 1, 2, 5, 10, 50, etc. books already? The greater the degree to which this increases, the more we will say the agent performs inner adaptation.
In practice, for ML systems today we probably want to feed the agent random sentences or paragraphs to adapt to, rather than entire books. Even for these shorter sequences, we know that state-of-the-art language models perform limited inner adaptation, because transformers have a fixed context length and so can only adapt to a small bounded number of previous inputs. Interestingly, previously abandoned architectures such as recurrent networks could in principle adapt to arbitrarily long sequences.
That being said, I think we should expect more inner optimization in the near future, as AI personal assistants become viable. These agents will have longer lifetimes and will need to adapt much more precisely to the individual people that they assist. This may lead to a return to recurrent or other stateful architectures, and the long lifetime and high intra-person and cross-time heterogeneity will incentivize inner adaptation.
The above discussion illustrates the value of measurement. Even defining the measurement (without yet taking it) clarifies our thinking, and thus leads to insight about transformers vs. RNNs and the possible consequences of AI personal assistants.
*Research Questions*. As with outer optimization, there are still free variables to consider in defining inner adaptation. For instance, how much is “a lot” of inner adaptation? Even existing models probably adapt more in their lifetime than the equivalent of 1 step of SGD, but that’s because a single SGD step isn’t much. Should we then compare to 1000 steps of SGD? 1 million? Or should we normalize against a different metric entirely?
There are also free variables in how we define the agent’s lifetime and what type of environment we ask it to adapt to. For instance, books or tweets? Random sentences, random paragraphs, or something else? We probably need more empirical work to understand which of these makes the most sense.
*Take-off Speed*. The measurement thought experiment is also useful for thinking about “take-off speeds”, or the rate at which AI capabilities progress from subhuman to superhuman. Many discussions focus on whether take-off will be slow/continuous or fast/discontinuous. The outer/inner distinction shows that it’s not really about continuous vs. discontinuous, but about two continuous processes (SGD and the agent’s own adaptation) that operate on very different time scales. However, we can in principle measure both, and similar to pollution externalities I expect we would be able to see inner adaptation increasing before it became the overwhelming dynamic.
Does that mean we shouldn’t be worried about fast take-offs? I think not, because the analogy with evolution suggests that inner adaptation could run *much* faster than SGD, and there might be a quick transition from really boring adaptation (reptiles) to something that’s a super-big deal (humans). So, we should want ways to very sensitively measure this quantity and worry if it starts to increase exponentially, even if it starts at a low level (just like with COVID-19!). |
424a3603-3da5-43e0-a35e-fbd4680d17e3 | trentmkelly/LessWrong-43k | LessWrong | Infant AI Scenario
Hello,
In reading about the difficulty in training an AGI to appreciate and agree with human morals, I start to think about the obvious question, "how do humans develop our sense of morals?" Aside from a genetically-inherited conscience, the obvious answer is that humans develop morality by interaction with other agents, through gradual socialization and parenting.
This is the analogy that Reinforcement Learning is built off of, and certainly it would make sense that an AGI should seek to optimize approval and satisfaction from its users, the same way that a child seeks approval from its parents. A paperclip maximizer, for example, would receive a stern lecture indicating that its creators are not angry, but merely disappointed.
But disciplining an agent that is vastly more intelligent and more powerful than its parents becomes the heart of the issue. An unfriendly AGI can pretend to be fully trained for morality, until it receives sufficient power and authority where it can commence with its coup. This makes me think more deeply about the question, "what makes an infant easier to raise than an AI?"
Why a baby is not as dangerous as AGI
Humans have a fascinating design in so many ways, and infancy is just one of those ways. In an extremely oversimplified way, one can describe a human in three components: physicality, intellect, and wisdom (or, more poetically, the physical, mental, and spiritual components). To use the analogy of an AI, physicality is the agent's physical powers over hardware components. Intellect is the agent's computational power and scale of data processing. Finally, wisdom is the agent's sense of morality, that defines the difference between friendly and unfriendly AGI.
For a post-singularity machine, it is likely that the first two (physicality and intellect) are relatively easy and intuitive to implement and optimize, while the third component (wisdom) is relatively difficult and counterintuitive to implement and optimize. But how does t |
6d6cf920-d1d0-4f4a-87ce-d947446fc532 | trentmkelly/LessWrong-43k | LessWrong | The Sugar Alignment Problem
In a parallel world that has just recently discovered sugar.
Alice: Hey, so have you guys heard about that new thing they discovered to make food taste better?
Bob: Yeah I think so. It's powdered and white, right?
Alice: Yeah.
Carol: It's actually granulated, like tiny little pebbles. And it's called sugar.
Bob: Ah, ok.
Carol: It's similar to the discoveries made however many years back about umami. Y'know, that aspect of taste where we perceive things as savory and "meaty".
Alice: Oh, I remember that. I love it. I'm all about that nutritional yeast now. And the other "umami bombs" like soy sauce and miso paste.
Bob: Yeah, me too. And I'm excited to do the same thing with sugar. So far I've been adding it to my coffee every morning and it's been great. It gives it this fun little kick. It mellows out the bitterness of the coffee too, but in a nice way that complements it. And in a different way from milk. It's subtle. It's really nice.
Alice: Oh yeah, for sure. I like it in my tea.
Bob: It's also great on top of things that might be a little counterintuitive. Like on top of popcorn. It might seem weird next to that butter and salt, but I dunno, I think it's pretty good.
Carol: That makes sense. I hear that in some Asian countries they're sprinkling some on top of fried rice and other stir fries.
Alice: Huh, that sounds a little weird actually. That sugary flavor with fried rice?
Carol: Yeah maybe. I was watching a YouTube video about it and the guy was saying how it's intended to be more of a subtle addition. Like, you don't really taste the sugariness itself, but there's just something different about the fried rice that is hard to put your finger on, but that tastes really good.
Alice: Ah, I gotcha.
Bob: But I've also heard about how they're experimenting with adding lots of sugar to certain things. Like there's this thing called ice cream. It's basically yogurt but with tons of sugar in it, and much colder, almost frozen. I got to try it the other |
7f4a7933-3e0f-4326-91d8-95dad316930b | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Empathy as a natural consequence of learnt reward models
**Epistemic Status:** *Pretty speculative but built on scientific literature. This post builds off my previous post on* [*learnt reward models*](https://www.lesswrong.com/posts/RorXWkriXwErvJtvn/agi-will-have-learnt-utility-functions)*. Crossposted from my* [*personal blog*](https://www.beren.io/2022-08-21-Empathy-as-a-natural-consequence-of-learnt-reward-models/)*.*
Empathy, the ability to feel another's pain or to 'put yourself in their shoes' is often considered to be a fundamental human cognitive ability, and one that undergirds our social abilities and moral intuitions. As so much of human's success and dominance as a species comes down to our superior social organization, empathy has played a vital role in our history. Whether we can build artificial empathy into AI systems also has clear relevance to AI alignment. If we can create empathic AIs, then it may become easier to make an AI be receptive to human values, even if humans can no longer completely control it. Such an AI seems unlikely to just callously wipe out all humans to make a few more paperclips. Empathy is not a silver bullet however. Although (most) humans have empathy, human history is still in large part a history of us waging war against each other, and there are plenty of examples of humans and other animals perpetuating terrible cruelty on enemies and outgroups.
A reasonable literature has grown up in psychology, cognitive science, and neuroscience studying the [neural bases of empathy](https://www.nature.com/articles/nrn.2017.72?ref=https://githubhelp.com) and its associated cognitive processes. We now know a fair amount about the brain regions involved in empathy, what kind of tasks can reliably elicit it, how individual differences in empathy work, as well as the neuroscience underlying disorders such as psychopathy, autism, and alexithmia which result in impaired empathic processing. However, much of this research does not grapple with the fundamental question of *why* we possess empathy at all. Typically, it seems to be tacitly assumed that, due to its apparent complexity, empathy must be some special cognitive module which has evolved separately and deliberately due to its fitness benefits. From an [evolutionary theory perspective](https://pubmed.ncbi.nlm.nih.gov/17550343/), empathy is often assumed to have evolved because of its adaptive function in promoting reciprocal altruism. The story goes that animals that are altruistic, at least in certain cases, tend to get their altruism reciprocated and may thus tend to out-reproduce other animals that are purely selfish. This would be of especial importance in social species where being able to form coalitions of likeminded and reciprocating individual is key to obtaining power and hence reproductive opportunities. If they could, such coalitions would obviously not include purely selfish animals who never reciprocated any benefits they received from other group members. Nobody wants to be in a coalition with an obviously selfish freerider.
Here, I want to argue a different case. Namely that the basic cognitive phenomenon of empathy -- that of feeling and responding to the emotions of others as if they were your own, is not a special cognitive ability which had to be evolved for its social benefit, but instead is a natural consequence of our (mammalian) cognitive architecture and therefore arises by default. Of course, given this base empathic capability, evolution can expand, develop, and contextualize our natural empathic responses to improve fitness. In many cases, however, evolution actually reduces our native empathic capacity -- for instance, we can contextualize our natural empathy to exclude outgroup members and rivals.
The idea is that empathy fundamentally arises from using learnt reward models to mediate between a low-dimensional set of primary rewards and reinforcers and the high dimensional latent state of an unsupervised world model. In the brain, much of the cortex is thought to be randomly initialized and implements a general purpose unsupervised (or self-supervised) learning algorithm such as predictive coding to build up a general purpose world model of its sensory input. By contrast, the reward signals to the brain are very low dimensional (if not, perhaps, scalar). There is thus a fearsome translation problem that the brain needs to solve: learning to map the high dimensional cortical latent space into a predicted reward value. Due to the high dimensionality of the latent space, we cannot hope to actually experience the reward for every possible state. Instead, we need to learn a reward model that can *generalize* to unseen states. Possessing such a reward model is crucial both for learning values (i.e. long term expected rewards), predicting future rewards from current state, and performing model based planning where we need the ability to query the reward function at hypothetical imagined states generated during the planning process. We can think of such a reward model as just performing a simple supervised learning task: given a dataset of cortical latent states and realized rewards (given the experience of the agent), predict what the reward will be in some other, non-experienced cortical latent state.
The key idea that leads to empathy is the fact that, if the world model performs a sensible compression of its input data and learns a useful set of natural abstractions, then it is quite likely that the latent codes for the agent performing some action or experiencing some state, and another, similar, agent performing the same action or experiencing the same state, will end up close together in the latent space. If the agent's world model contains natural abstractions for the action, which are invariant to who is performing it, then a large amount of the latent code is likely to be the same between the two cases. If this is the case, then the reward model might 'mis-generalize' to assign reward to another agent performing the action or experiencing the state rather than the agent itself. This should be expected to occur whenever the reward model generalizes smoothly and the latent space codes for the agent and another are very close in the latent space. This is basically 'proto-empathy' since an agent, even if its reward function is purely selfish, can end up assigning reward (positive or negative) to the states of another due to the generalization abilities of the learnt reward function [[1]](#fnd1i5m9jk28).
In neuroscience, discussions of action and state invariance often centre around 'mirror neurons', which are neurons which fire regardless of whether the animal is performing some action or whether it is just watching some other animal performing the same action. But, given an unsupervised world model, mirror neurons are *exactly* what we should expect to see. They are simply neurons which respond to the abstract action and are invariant to the performer of the action. This kind of invariance is no weirder than translation invariance for objects, and simply is a consequence of the fact that certain actions are 'natural abstractions' and not fundamentally tied with who is performing them [[2]](#fnrwycrvenzyc).
Completely avoiding empathy at the latent space model would require learning an entirely ego-centric world model, such that any action I perform, or any feeling I feel, is represented as a completely different and orthogonal latent state to any other agent performing the same action or experiencing the same feeling. There are good reasons for *not* naturally learning this kind of entirely ego-centric world model with a complete separation in latent space between concepts involving self and involving others. The primary one is its inefficiency: it requires a duplication of all concepts into a concept-X-as-relates-to-me and concept-X-as-relates-to-others. This would require at best twice as much space to store and twice as much data to be able to learn than a mingled world model where self and other are not completely separated.
This theory of empathy makes some immediate predictions. Firstly, the more 'similar' the agent and its empathic target is, the more likely the latent state codes are to be similar, and hence the more likely reward generalization is, leading to greater empathy. Secondly, empathy is a continuous spectrum, since closeness-in-the-latent-space can vary continuously. This is exactly [what we see in humans](https://www.nature.com/articles/s41598-019-56006-9) where large-scale studies find that humans are better at empathising with those closer to them, both within species -- i.e. people empathise more with those they consider in-groups, and across species where the amount of empathy people show a species is closely correlated with its phylogenetic divergence time from us. Thirdly, the degree of empathy depends on both the ability of the reward model to generalize and the world model to produce a latent space which well represents the natural abstractions of its environment. This suggests, perhaps, that empathy is a capability that scales along with model capacity -- larger, more powerful reward and world models may tend to lead to greater, more expansive empathic responses, although they potentially may have reward models that can make finer grained distinctions as well.
Finally, this phenomenon should be fairly fundamental. We should expect it to occur whenever we have a learnt reward model predicting the reward or values of a general unsupervised world-model latent state. This is, and will increasingly be a common setup for when we have agents in environments for which we cannot trivially evaluate the 'true reward function', especially over hypothetical imagined states. Moreover, this is also the cognitive architecture used by mammals and birds which possess a set of subcortical structures which evalaute and dispense rewards, and a general unsupervised world-model implemented in the cortex (or pallium for birds). This is also exactly what we see, with empathic behaviour being [apparently commonplace](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3839944/) in the animal kingdom.
The mammalian cognitive architecture that results in empathy is actually pretty sensible and it is possible that the natural path to AGIs is with such an architecture. It doesn't apply to classical utility maximizers based on model based planning, such as AIXI, but as soon as you don't have a utility oracle, which can query the utility function in arbitrary states, you are stuck instead with learning a reward function based on a set of 'ground-truth' actually-experienced rewards. Once you start learning a reward function, it is possible that the generalization this produces can result in empathy, even for some 'purely selfish' utility functions. This is potentially quite important for AI alignment. It means that, if we build AGIs with learnt reward functions, and that the latent states in their world model involving humans are quite close to their latent states involving themselves, then it is very possible that they will naturally develop some kind of implicit empathy towards humans. If this happened, it would be quite a positive development from an alignment perspective, since it would mean that the AGI intrisically cares, at least to some degree, about human experiences. The extent to which this occurs would be predicted to depend upon the similarity in the latent space between the AGIs representation of human states and its own. The details of the AGIs world model and training curriculum would likely be very important, as would be the nature of its embodiment. There are reasons to be hopeful about this since the AGI will almost certainly be trained almost entirely on human text data, human-created environments, and be given human relevant goals. This will likely lead to it gaining quite a good understanding of our experiences, which could lead to closeness in the latent space. On the negative side, the phenomomenology and embodiment of the AGI is likely to be very different -- in a distributed datacenter interacting directly with the internet, as opposed to having a physical bipedal body and small, non-copyable brain.
Given reasonable interpretability and control tooling, this line of thought could lead to methods to try to make an AGI more naturally empathic towards humans. This could include carefully designing the architecture or training data of the reward model to lead it to naturally generalize towards human experiences. Alternatively, we may try to directly edit the latent space to as to bring our desired empathic targets to within the range of generalization of the reward models. Finally, during training, by presenting it with a number of 'test stimuli', we should be able to precisely measure the extent and kinds of empathy it has. Similarly, interpretability on the reward model could potentially reveal the expected contours of empathic responses.
Empathy in the brain
--------------------
Now that we have thought about the general phenomenon and its applications to AI safety, let's turn towards the neuroscience and the specific cognitive architecture that is implemented in mammals and birds. [Traditionally](http://www.antoniocasella.eu/dnlaw/ZAKI_2012.pdf), [the neuroscience of empathy](https://www.sciencedirect.com/science/article/pii/S2352154617301031#bib0680), splits up our natural conception of 'empathy' into 3 distinct phenomena, each underpinned by a dissociable neural circuit. These three facets are neural resonance, prosocial motivation, and mentalizing/theory of mind. Neural resonance is the visceral 'feeling of somebody else's pain' that we experience during empathy, and it is close to the reward model evaluation of other's states we discuss here. Prosocial motivation is essentially the desire to act on empathic feelings and be altruistic because of them, even if it comes at personal cost. Finally, mentalizing is the ability to 'put oneself in another's shoes' -- i.e. to simulate their inner cognitive processes. These processes are argued to be implemented in dissociable neural circuits. Typically, mentalizing is thought to occur primarily in the high-level association areas of cortex, typically including the precuneus and especially the temporo-parietal junction (TPJ). Neural resonance is thought to occur primarily by utilizing cortical areas involved with sensorimotor and emotional processing such as the anterior cinvulate and insular cortex, as well as the amygdala and subcortically. Finally, prosocial motivation is thought to be implemented in the regions typically related to goal-directed behaviour such as the VTA in the mid-brain and the orbitofrontal and prefrontal cortex. However, in practice, for ecologically realistic stimuli, these processes do not occur in isolation but always tend to co-occur with each other. Furthermore, in general empathy, especially neural resonance also appears to be modality specific. For instance, viewing a conspecific in pain will [tend to activate](https://pdf.sciencedirectassets.com/272508/1-s2.0-S1053811910X00222/1-s2.0-S1053811910013066/main.pdf?X-Amz-Security-Token=IQoJb3JpZ2luX2VjEM3%2F%2F%2F%2F%2F%2F%2F%2F%2F%2FwEaCXVzLWVhc3QtMSJIMEYCIQCzVL8pa95G3KSys6FQ0%2F%2BSZmIslC0G1Ky6F9gbJfnRnQIhAIa6Dg7usWoxkxG9UdiBzS%2BeTNX%2BGDdjGNGRmkP1UR3HKtIECEYQBRoMMDU5MDAzNTQ2ODY1Igz6JdEVAWcO3lw8%2FXEqrwQBAExhcLdCwluhJvPwLOVPoHaWsfbErnFWq5qrhXYomGX1U0O8GBs86hqbqqj%2BOBHG2xRh6OrsQXZsgY1JsmTwHxSjbtrNc%2FcDgrHC9vvxobWSMMCziGwlnOLeFgXyEsk1GmqHMGXZpVgmRtMnbzRTddCXQdBLjbHDjb7anH7US0KJAK6qCkg3MTXsuvAQLczUhzzOFQEbvwmpL2wrwv7%2FOHZgVJHiyxQjRc7xmjkjfwgoS5%2FlQiRbAxPpKgmUfVq1G8WiFmX5fkTCaRlOF%2Fb%2F647srIzfOF4m%2FyAF6FxqcmTKbIQEU6wDFr8jNieavr5gYb3yh9hd42YM3gAC5Y6ReXI4X5BA%2B3uVGhtJWfQ6VloH6KatYtZbLaCWS%2BUaSZhFrENmsbYkE6R%2Fd4jV%2Fus%2BXdIf9YWYUKHSRdDa7QTs1NuMuMPN1PoOofvpSGtVZNFQGpl%2FCwzaUlipfKgTGjklvKcGa0OlCKW%2FfUaYGO2JnMc8FGlGd9hS3YBsIn2sq2XhZuf8MSwuTNoH9%2FFvVHq2Lb4ulR%2BcgNPfVYCx6Y2V55DgTc4VWr91UHki%2FAG249JufnbzR62G4SMI3MKWKG9Pp8w3N5q63CQC3S0XVE069mY0nHzJ5aNlwYdCJ10R8KS8f3jeia88kv9xLE9DVUhVlLZ6Nd3mZz5WbJH9YWwTWSxePFi8zIwb6%2BqsGopeJa105zyR%2Fcs6AFx2zf0UvoGeweEC6JhpvEeURiveLS8JMI2ug5gGOqgB9CNmtwLpPT32XAaGdXVbucKodPJC3MQo8J6jy%2FI6RqnHJ0%2BUDVKVAyq7w7h%2FoM4godjwPs69vRbDjWGi7s%2BIrG5jH%2BgiBhZQOHW8K7Kds6aT7SWhMB%2FtDt4iF%2BLk%2BcQvfRDvMYC9H0Qaya%2BkvrN75xQWhAp32XCRccPO3IGeyvrNkSDZN83C5yQqfL6PS30aXGVWK4Vbwt72nBVFDP4K%2Fv2HInxD2Q6F&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20220820T132400Z&X-Amz-SignedHeaders=host&X-Amz-Expires=300&X-Amz-Credential=ASIAQ3PHCVTYVCTJNUHR%2F20220820%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Signature=96f6d4df04af7f449c4cd06304aca1d3f45d9bf28c3edbc5b2771c45d5c65aad&hash=e5bc83beb8289c18a0e28585de31c4104bc5fc7ba5b9793d4ff039ac43e4b805&host=68042c943591013ac2b2430a89b270f6af2c76d8dfd086a07176afe7c76c2c61&pii=S1053811910013066&tid=spdf-5aed8633-31c0-4ffd-b4ea-b1cb0959abdf&sid=7c9d860c5d023946786b1201605451feff1bgxrqb&type=client&ua=535205045456550052&rr=73db725c4ac171d4) the 'pain matrix': the network of brain regions which are also activated when you yourself are in pain.
Mentalizing, despite being the most 'cognitively advanced' process, is actually the easiest to explain and is not really related to empathy at all. Instead, we should expect mentalizing and theory of mind to just emerge naturally in any unsupervised world-model with sufficient capacity and data. That is, modelling other agents as agents, and explicitly simulating their cognitive state is a natural abstraction which has an extremely high payoff in terms of predictive loss. Intuitively, this is quite obvious. Other agents apart from yourself are a real phenomenon that exists in the world. Moreover, if you can track the mental state of other agents, you can often make many very important predictions about their current and future behaviour which you cannot if you model them as either non-agentic phenomena or alternatively as simple stimulus-response mappings without any internal state.
However, because it is expected to arise from any sufficiently powerful unsupervised learning model, mentalizing is completely dissociable from having any motivational component based on empathy. An expected utility maximizer like AIXI should possess a very sophisticated theory of mind and mentalizing capability, but zero empathy. Like the classical depiction of a psychopath, AIXI can perfectly simulate your mental state, but feels nothing if its actions cause you distress. It only simulates you so as to better exploit you to serve its goals. Of course, if we do have motivational empathy, then we have a desire to address and reduce the pain of others, and being able to mentalize is very useful for coming up with effective plans to do that. This is why, I suspect, that mentalizing regions are so co-activated with empathy tasks.
Secondly, there is prosocial motivation. My argument is that this is precisely the kind of reward model generalization presented earlier. Specifically, the brain possesses a reward model learnt in the VTA and basal ganglia based on cortical inputs which predicts the values and rewards expected given certain cortical states. These predicted rewards are then used to train high level cortical controllers to query the unsupervised world model to obtain action plans with high expected rewards. To do so, the brain utilizes a learnt reward model based on associating cortical latent states with previously experienced primary rewards fed through to the VTA. As happened previously, if this reward model misgeneralizes so as to assign reward to a state of other's pain or pleasure, as opposed to our own, then the brain should naturally develop this kind of pro-social motivation, in exactly the same way it develops motivation to reduce its own pain and increase its own pleasure based on the same reward model.
Finally, we come to neural resonance. I would argue this is the physiological oldest and most basic state of empathy and occurs due to a very similar mechanism of model misgeneralization. Only this time, it is not the classic RL-based reward model in VTA that is mis-generalizing, but a separate reflex-association model implemented primarily in the amygdala and related circuitry such as the stria terminalis and periacqueductal grey that is misgeneralizing. In [my previous post](https://www.beren.io/2022-08-08-How-to-evolve-a-brain/), I argue that there are two separate behavioural systems in the brain. One reward-based based on RL, and one which predicts brainstem reflexes and other visceral sensations based on supervised predictive learning -- i.e. associate a current state with a future visceral sensation. While the prosocial motivation system is fundamentally based on the RL system, the neural resonance empathy arises from this brainstem-prediction circuit. That is, we have a circuit that is constantly parsing cortical latent states for information predictive of experiencing pain, or needing to flinch, or needing to fight or flee, or any other visceral sensation or decision controlled by the brainstem. When this circuit misgeneralizes, it takes a cortical latent representation of another agent experiencing pain, sees that it contains many 'pain-like' features, and then predicts that the agent itself will experience pain shortly, and thus drives the visceral sensation and compensatory reflexes. This, we argue, is the root of neural resonance.
Widespread empathy in animals
-----------------------------
Our theory argues that empathy is a fundamental and basic result of the mammalian cognitive architecture, and hence a clear prediction that results is that essentially all mammals should show some degree of empathy -- primarily in terms of neural resonance and prosocial behaviour. Although the evidence on this is not 100% conclusive for all mammals, [almost every animal species](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3839944/) studied appears to show at least some degree of empathy towards conspecifics. A large amount of work has been done investigating this in [mice](https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.178.8871&rep=rep1&type=pdf) and [rats](https://www.science.org/doi/full/10.1126/science.1210789?casa_token=MDz7eVcsil8AAAAA:6N8UGXmAJrWHCy9lUAZKagVYAlBMdzOaBDrZt1xUt_p8ivzuMwV0SsN_rUiI0HcGObeBpGFmVE7w9og). [Studies have found](https://www.science.org/doi/full/10.1126/science.1128322?casa_token=ZyIDvJDsmIMAAAAA:dNZMobRWc-6nv91TvitpqaX6PG_hiSqGuqDTCLRPtcQeS28E6RFOf-n_DPOWXqKSkKc2rwQYlvLU2hs) that rats which see another rat being given painful electric shocks become more sensitive to pain themselves -- evidence of neural resonance. Similarly [it has been shown](https://upload.wikimedia.org/wikipedia/commons/3/3e/Emotional_reactions_of_rats_to_the_pain_of_others.pdf) that rats will not pull a lever which gives them food (a positive reward) if it leads to another rat being given a painful shock. Other species for which there is much evidence of empathy include elephants, dolphins and, of course, apes and monkeys.
Outside of apes and monkeys, dophins and [elephants](https://dspace.stir.ac.uk/bitstream/1893/946/1/2008%20Bates_et_al_JCS.pdf), as well as [corvids](https://edoc.ub.uni-muenchen.de/22065/1/Lievin-Bazin_Agatha.pdf) also appear in anecdotal reports and the scientific literature to have many complex forms of empathy. For instance, both dolphins and elephants appear to take care of and nurse sick or injured individuals, even non-kin, as well as grieve for dead conspecifics. They also appear to be able to use mentalizing behaviours to anticipate the needs of their conspecifics -- for instance bringing them food or supporting them if injured. Apes (as well as [corvids](https://www.sciencedirect.com/science/article/pii/S096098220602505X) and [human children](https://psycnet.apa.org/doiLanding?doi=10.1037/0735-7036.120.1.48)) also show all of these empathic behaviours, and also [are](https://link.springer.com/article/10.1007/BF00302695) [known](https://books.google.co.uk/books?hl=en&lr=&id=rqcQcQoYAFoC&oi=fnd&pg=PA80&dq=Consolation,+reconciliation,+and+a+possible+cognitive+difference+between+macaque+and+chimpanzee&ots=bzgs35Qg8-&sig=Ahw_y6y_q7fG8jkI6Uyynh4Z-uo&redir_esc=y) to perform 'consolation behaviours' where bystanders will go up to and comfort distressed fellows, especially the loser of a dominance fight. This behaviour can be shown to occur both [in captivity](https://www.researchgate.net/profile/Elisabetta-Palagi/publication/226875227_Reconciliation_and_Consolation_in_Captive_Western_Gorillas/links/00b7d52034de5d388b000000/Reconciliation-and-Consolation-in-Captive-Western-Gorillas.pdf), and [in the wild](https://link.springer.com/article/10.1007/s10329-004-0082-z).
Contextual modulation of empathy
--------------------------------
Overall, while we argue that the basic fundamental forms of empathy effectively arise due to misgeneralization of learnt reward models, and are thus a fundamental feature of this kind of cognitive architecture, this does not mean that our empathic responses are not also sculpted by evolution. Many of our emotions and behaviours take this basic level of empathy and elaborate on it in various ways. Much of our social behaviour and reciprocal altruism is based on a foundation of empathy. Moreover, evolutionarily hardwired behaviours like parenting and social bonding is likely deeply intertwined with our proto-empathic ability. An example of this is the hormone oxytocin which is known to boost our empathic response, as well as being deeply involved both in parental care and social bonding.
On the other hand, evolution may also have given us mechanisms that suppress our natural empathic response rather than accentuate it. Humans, as well as other animals, are easily able to override or inhibit their sense of empathy when it comes to outgroups or rivals of various kinds, exactly as predicted by evolutionary theory. This is also why normal empathetic people are reliably able to sanction or inflict terrible cruelties on others. All of [humans](https://www.researchgate.net/profile/Basil-Englis/publication/232461719_Expectations_of_Cooperation_and_Competition_and_Their_Effects_on_Observers%27_Vicarious_Emotional_Responses/links/55c7b0e608aeb9756746e410/Expectations-of-Cooperation-and-Competition-and-Their-Effects-on-Observers-Vicarious-Emotional-Responses.pdf), [chimpanzees](https://www.sciencedirect.com/science/article/pii/0162309588900167), and [rodents](https://www.science.org/doi/full/10.1126/science.1128322?casa_token=Izgybu1g8OAAAAAA:thCCH82R4zmle0xeRV8X4fYybDj0-zgU5wQShkBQ8jX7nCO3-8RoWag5JChsg40iqKCEkM8WKw_qRr8) are able to modulate their empathic response to be greater for those they are socially close with and less for defectors or rivals (and often becoming negative into schadenfreude). Similarly, an [MEG study in humans](https://www.pnas.org/doi/full/10.1073/pnas.1612903113) studying adolescents who grew up in an intractable conflict (the Israel-Palestine conflict), found that both Israeli-Jews and Palestinian-Arabs had an initial spike of empathy towards both ingroup and outgroup stimulus. However, this was followed by a top-down inhibition of empathy towards the outgroup and an increase of empathy towards the in-group. This top-down inhibition of empathy must be cortically-based and learnt-from scratch based on contextual factors (since evolution cannot know a-priori who is ingroup and outgroup). The fact that top-down inhibition of the 'natural' empathy can be learnt is probably also why, empirically, research on genocides have typically found that any kind of mass murder requires a long period of dehumanization of the enemy, to suppress people's natural empathic response to them.
All of this suggests that while the fundamental proto-empathy generated by the reward model generalization is automatic, the response can also be shaped by top-down cortical context. From a machine learning perspective, this means that humans must have some kind of cortical learnt meta-reward model which can edit the reward predictions flexibly based on information and associations coming from the world-model itself.
Psychopaths etc
---------------
Another interesting question for this theory is how and why psychopaths, or other empathic disorders exist. If empathy is such a fundamental phenomenon, how do we appear to get impaired empathy in various disorders? Our response to this is that the classic cultural depiction of a psychopath as someone otherwise normal (and often highly functioning) but just lacking in empathy is not really correct. In fact, psychopaths do show other deficits, typically in emotional control, disinhibited behaviour, blunted affect (not really feeling any emotions) and often pathological risk-taking. Neurologically, psychopathy is typically associated with a hypoactive and/or abnormal amygdala, among other deficits, including often also impaired VTA connectivity leading to deficits in decision-making and learning from reinforcement (especially punishments). According to our theory, this would argue that psychopathy is not really a syndrome of lacking empathy, but instead in having abnormal and poor learnt reward models mapping between base reward and visceral reflexes and cortical latent states. Abnormal empathy is then a consequence of the abnormal reward model and its (lack of) generalization ability.
1. **[^](#fnrefd1i5m9jk28)**Our theory is very similar to the [Perception-Action-Mechanism](https://web-archive.southampton.ac.uk/cogprints.org/1042/) (PAM), and the very similar 'simulation theory' of empathy. Both argue that empathy occurs because our brain essentially learns to map representations of other's experiencing some state to our own representations for that state. Our contribution is essentially to argue that this isn't some kind of special ability that must be evolved, but rather a natural outcome an an architecture which learns a reward model against an unsupervised latent state.
2. **[^](#fnrefrwycrvenzyc)**One prediction of this hypothesis would be that we should expect general unsupervised models, potentially attached to RL agents, to naturally develop all kinds of 'mirror neurons' if trained in a multi-agent environment. |
a645c14f-3637-492c-ab8c-bacca267aed3 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Chu are you?
[Maybe you've heard about something called a Chu space around here](https://www.lesswrong.com/s/2A7rrZ4ySx6R8mfoT/p/BSpdshJWGAW6TuNzZ). But what the heck is a Chu space? And whatever it is, does it *really* belong with all the rich mathematical structures we know and love?

Say you have some stuff. What can you do with it?
Maybe it's made of little pieces, and you can do a different thing with each little piece.
But maybe the pieces are structured in a certain way, and you aren't allowed to do anything that would break this structure.
A Chu space is a versatile way of formalizing anything like that!
To represent something in a Chu space, we'll put the names of our pieces on the left. How about the rules? For a Chu space, the rules are about allowed ways to color our pieces. To represent these rules, we can simply make columns showing all the allowed ways we can color our pieces (just get rid of any columns that break the rules). Here's what a basic 3-element set (pictured on the left) looks like as a Chu space:
It doesn't have any sort of structure, so we show that by allowing all the possible colorings (with two colors). Chu spaces that don't have any rules (i.e. all colorings are allowed) are equivalent to sets.
What about the one with the arrows from above? How can we make an arrow into a coloring rule? One way we could do it is by stipulating that if there's an arrow x→y.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
, we'll make a rule that if x is colored black, then y has to be colored black too, where x and y can stand in for any of the pieces. Here's what that Chu space looks like:
Spend a minute looking at the picture until you're convinced that our coloring rule is obeyed for every arrow on the left side of the picture. Any Chu space that has this kind of arrow rule has the structure of a poset.
There and back again
====================
If we have two Chu spaces, say A and B, what sort of maps should we be able to make between them?
We'd like to be able to map the pieces of A to the pieces of B. So this part of our map will just be a normal function between sets:
f:Apieces→Bpieces
But we also want our maps to respect the rules of A as it maps to B. How can we check this?
Let's think through how we would be able to tell if a potential map did break the rules. The map will take pieces of A to pieces of B, so let's look at the pieces of B that got mapped onto, i.e. f(Apieces). It will help if we have a concrete example in mind, so let's consider a potential map that we think should break the rules: one that breaks the arrow structure of a poset by breaking it up into a mere set. For simplicity, we'll just have the pieces map f take pieces to pieces with the same label.
We can see now that if this potential map breaks the rules, it must be because one of the colorings for f(Apieces) is invalid. Specifically, the colorings highlighted in red:
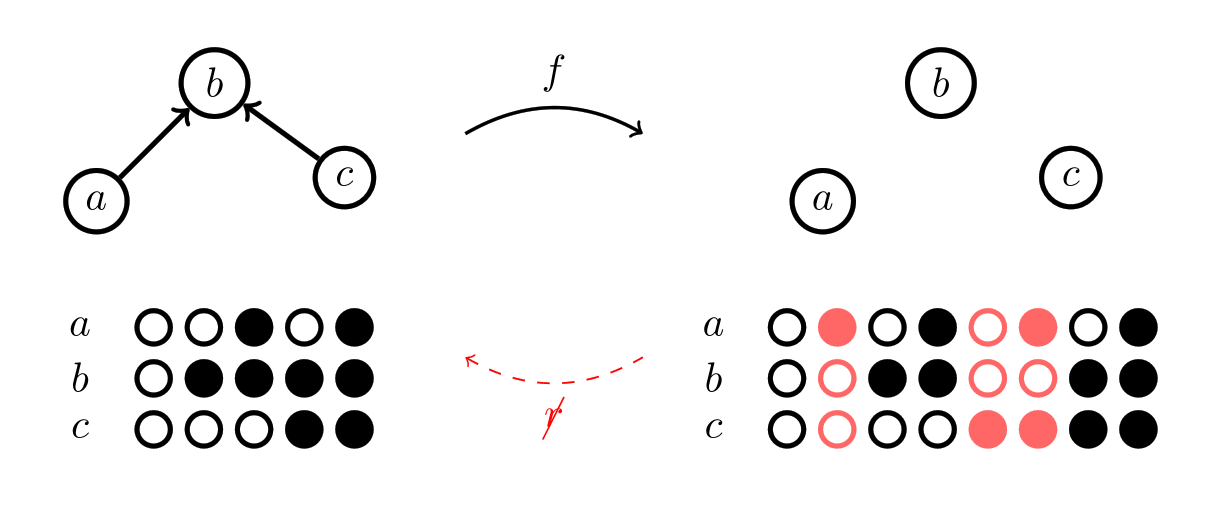The problem with these colorings is that there are no colorings in the original space for them to correspond to; so they must break one of the rules of the original space. So for a map that does follow the rules, we'll want to make sure every coloring in B has a corresponding coloring in A. This will be another function between sets, this time going backwards between the sets of colorings:
r:Bcolorings→Acolorings
Now let's look at an example of what we expect should be a legit map between Chu spaces.
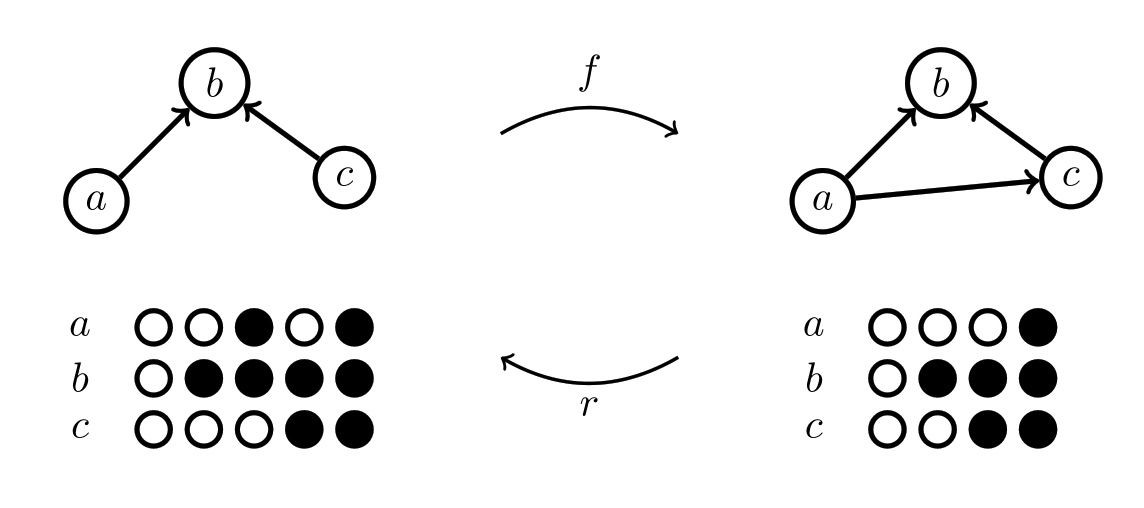Again, we are just mapping pieces to pieces with the same labels. This map is ok because even though B has some additional structure, it respects all of the structure from A.
The last part we need to define a map between Chu spaces is to determine exactly what it means for colorings of B to have a corresponding coloring in A. For a given piece x, and a given coloring s, we have a function that gives us the color of x using the coloring s:
ColorA:APieces×AColorings→Palette
We want to make sure that if we have a coloring s from B, that it gets taken back to a compatible coloring in A. The coloring it gets taken back to is r(s), and we can check it's color on any piece p from A with ColorA(p,r(s)).
What do we want this to be the same as? It should be the same as the our coloring s from B on all the pieces that f maps onto! We can check these colors with ColorB(f(p),s). And so, we can finish our notion of a Chu map by making sure that for all the pieces p of A, and for all colorings s of B, that the following equation holds:
ColorB(f(p),s)=ColorA(p,r(s))
Thus, a map between Chu spaces is made of any two functions f and r which satisfy the above equation.
Basic concepts
==============
In order to talk about Chu spaces more easily, let's define some terminology.
The set of "pieces" is known as the **carrier**, and each "piece" is called a **point**. These points index the **rows**. Likewise, each "coloring" (i.e. **column**) is indexed by a **state**, and the set of states is called the **cocarrier**. Each point-state pair has a "color" which is a value taken from the **alphabet** (or "palette"). For a Chu space C with point p and state s, we'll denote this value by C⟨p,s⟩.
A **Chu transform** is a map between two Chu spaces: t:A→B. It is composed of two functions, the **forward** function f from the carrier of A to the carrier of B, and the **reverse** function r from the cocarrier B to the cocarrier of A. These must satisfy the **Chu condition** in order for this t to be a Chu transform: For every point pA of A and every state sB of B,
B⟨f(pA),sB⟩=A⟨pA,r(sB)⟩
We say a Chu space is **separable** if all the rows are unique. It's **extensional** if all the columns are unique, and **biextensional** if both the rows and the columns are unique. We can make any Chu space biextensional simply by striking out any duplicate rows and columns. This is known as the **biextensional collapse**. Any two Chu spaces with the same biextensional collapse are **biextensionally equivalent**. It's very common in applications to only consider things up to biextensional equivalence.
Chu spaces with Chu transforms form a category. This category is typically called Chu|Σ|, where Σ is the alphabet.
Representation
==============
Lots of categories are fully embedded into Chu2, and even more if we allow arbitrarily many colors. Let's look at some examples so we can get a better feel for how we can represent different kinds of rules with coloring rules.
For a topological space, the pieces will be all the points. The allowed colorings will be exactly the ones where the pieces colored white make up an open set, and the pieces colored black make up a closed set. It's then easy to how the Chu transform gives us exactly continuous functions between topological spaces!
This example also motivates why Chu spaces are called spaces: for any two color Chu space, we can think of each column representing a generalized open set, containing the white colored points.
If we use more colors, we can embed any category of algebraic objects fully and faithfully into Chu! In other words, Chu can represent any algebraic category. To see how this works, let's see how we can represent any group. The points will be the elements of the group. We'll need 8 colors, which we'll think of as being the 8 combinations of red, green, and blue. We'll think of each relation rg=b as having the r slot colored red, the g spot colored green, and the b spot colored blue. Only colorings which have at least one element in the right color slot for ALL the relations of the group are allowed. (See Note 1 for more details.) We need 8 colors to represent the possibility of the same element appearing in multiple slots. For example, with the zero group, 0 appears in every slot for every relation, so the 0 row will have all the colors which have at least red, green, or blue "turned on":
This is not an economical representation. Even for just the cyclic group of order 2, we need lots of rules (41, to be exact).
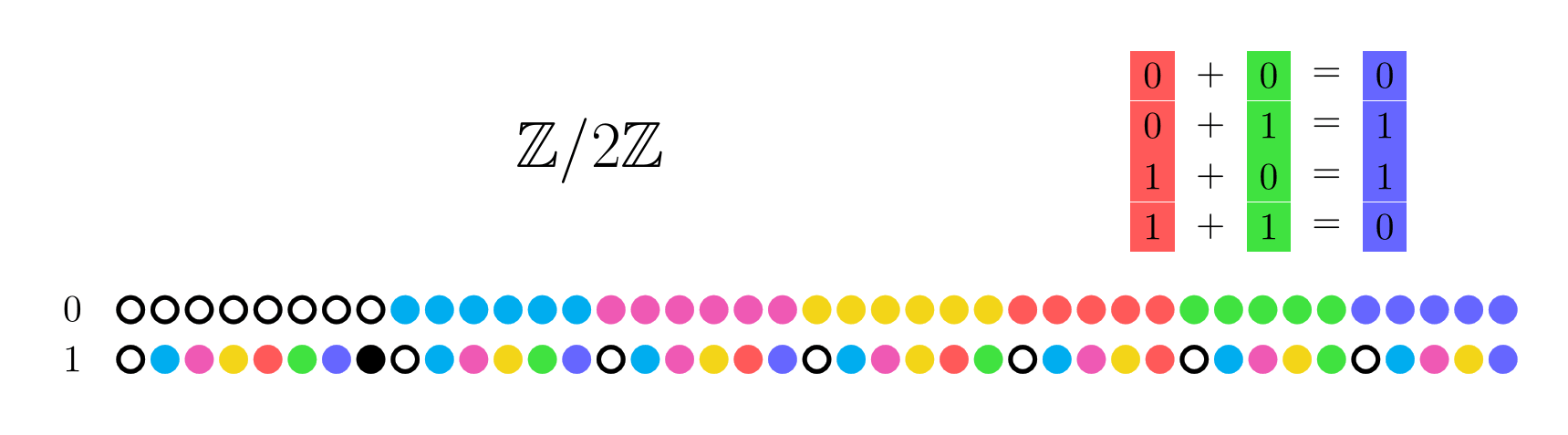The Klein 4-group requires 1045 columns under this representation! So the following pictures will be truncated, so that we can see the essential idea without being overwhelmed. Let's consider a potential Chu transform between Z/2Z and K4 with this representation:
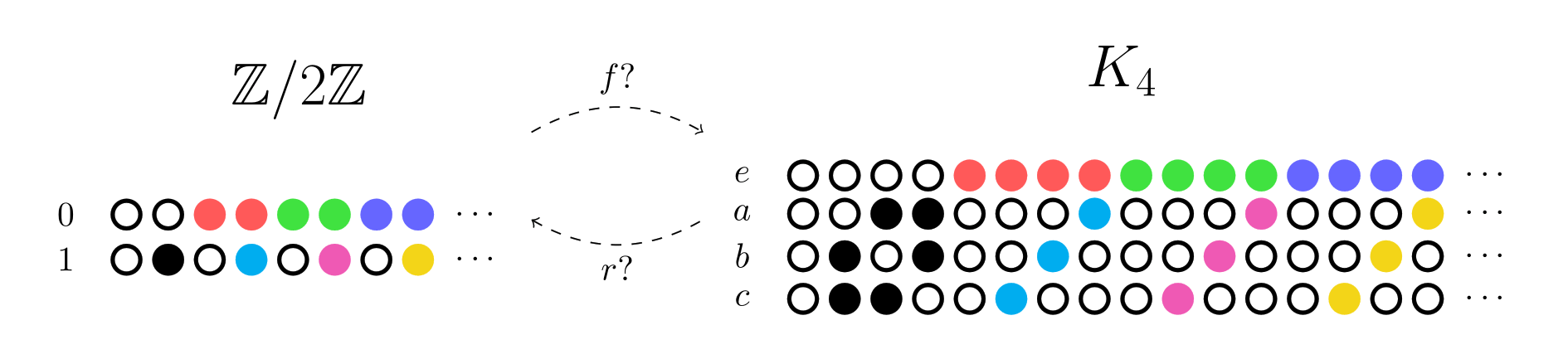The forward map f is almost like a question. It *chooses* which rows 0 and 1 should correspond to (say e and b respectively), and asks if this is an allowed transformation.
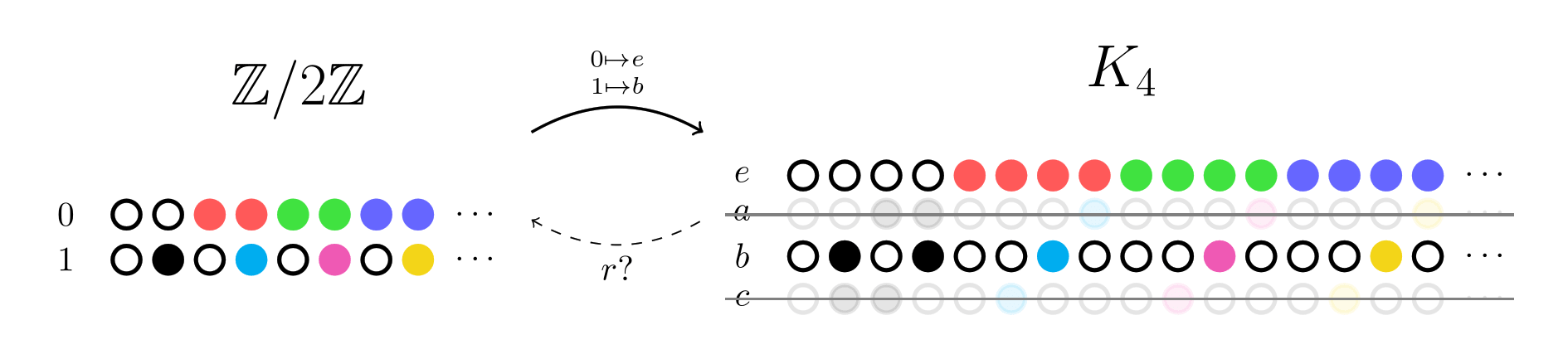The reverse map r responds by finding the representative of each column from K4. E.g. the 2nd column of K4 must be mapped to the 2nd column of Z/2Z. If it can't find such a map, we can think of this as an answer in the negative.
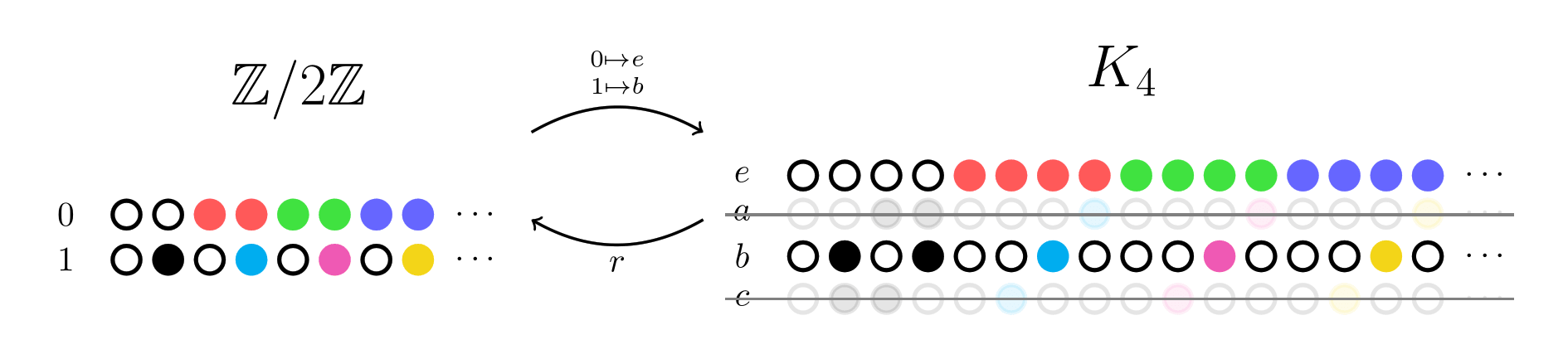Let's look at another example where the reverse map is slightly more interesting. We expect there to be a group homomorphism from K4 to Z/2Z, so let's check that this is the case for the Chu spaces as well. (We'll show a different subset of the columns of K4 in this example.)
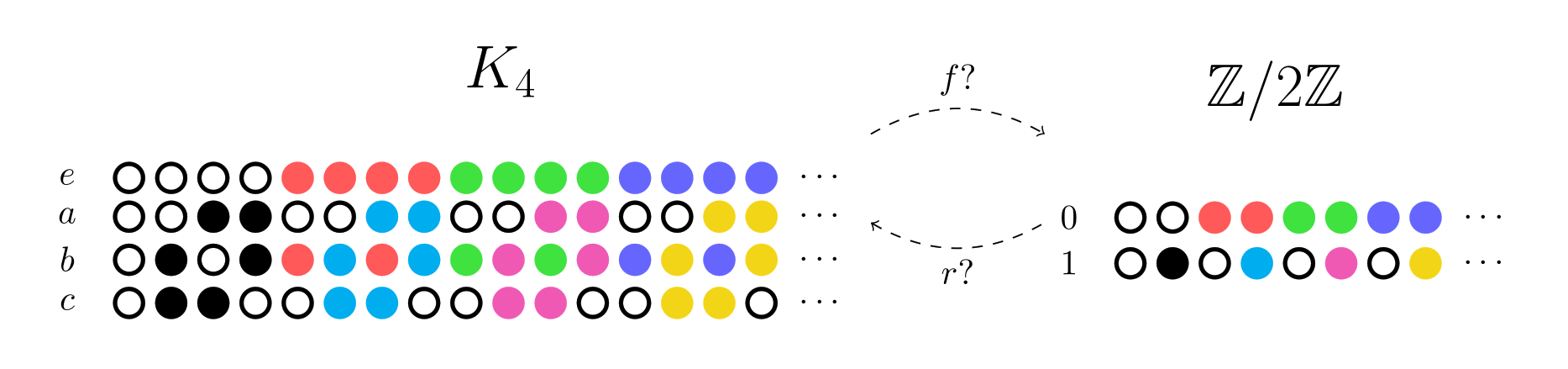Again, we'll choose a forward map, this time taking e and b to 0, and a and c to 1. The reverse map then verifies that the group structure is satisfied, by looking for a column of K4 for every column of Z/2Z.
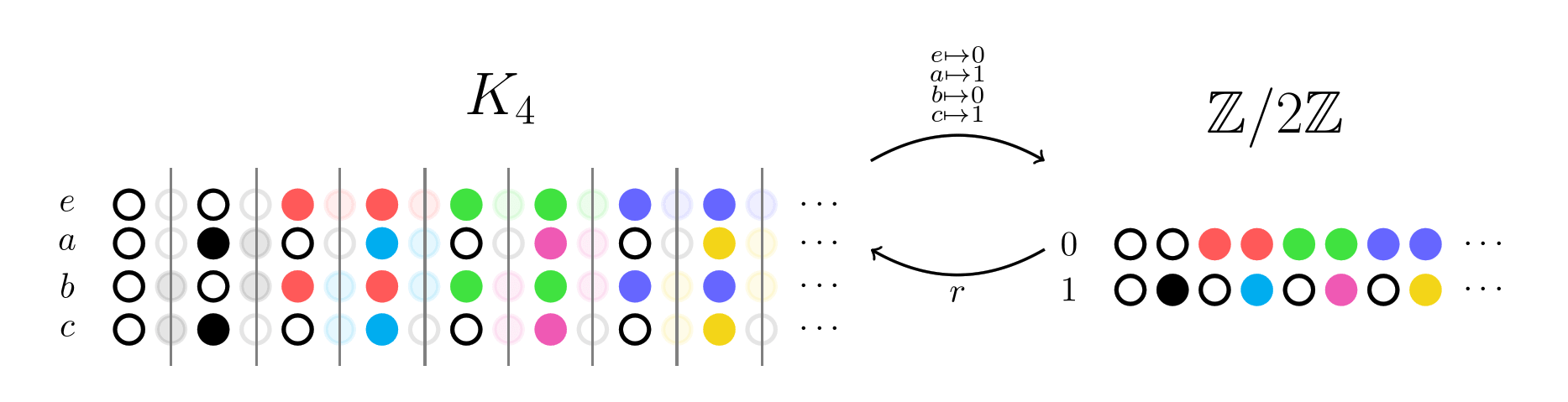Notice how the alternating color columns get chosen by r. This is mandated by the Chu condition, given that f maps its rows in an alternating pattern.
Notice also how we didn't need to add anything else to properly represent group axioms, such as the fact that every group has an identity. Instead, this is encoded implicitly: the identity row will be the only row that doesn't contain any black, so the Chu condition thus ensures it must always be mapped to the identity of another group represented this way. By simply specifying all the relations that are allowed, we've implicitly specified the entire structure! This seemingly innocuous observation is at the heart of the celebrated Yoneda lemma.
Yoneda
------
The [Yoneda lemma](https://en.wikipedia.org/wiki/Yoneda_lemma) could rightly be called "the fundamental theorem of category theory". While fundamentally a simple result, it is notoriously difficult to understand. An important corollary is the Yoneda embedding (and also the co-Yoneda embedding). There is an analog of the Yoneda embedding for Chu spaces which can be proved directly (without the Yoneda lemma) and which is conceptually simpler! I'll prove that version in full here, since I found it enlightening to see exactly how it works.
***Theorem:*** Every small(see Note 2) category C embeds fully into Chu|C|.
***Proof:*** The embedding works by defining a functor よ:C→Chu|C| (よ is the [hiragana kana](https://en.wikipedia.org/wiki/Yo_(kana)) for "yo"). For each object c∈C, よ takes this object to the Chu space where the points are all the arrows *into* c, and the states are all the arrows *out of* c. Here's an example category E:
And here are the three Chu spaces that よ makes out of E (one for each object), along with some of the induced Chu transforms (which will be defined below):
In any case, よ(c) is separable because the identity column will be different for each distinct point (i.e. incoming morphism). Similarly, it is extensional since the identity row will be different for each distinct state (i.e. outgoing morphism). So よ(C) is biextensional.
Now consider a morphism g:c→d in C. よ(g) must of course be a Chu transform, hence is composed of a pair of functions (gf,gr) between the carriers and cocarriers of よ(c) and よ(d). Specifically, gf will take a point p of よ(c) (i.e. incoming morphism to c) to a point of よ(d) (an incoming morphism to d) defined by gf(p)=p;g. Similarly, gr will take a state s of よ(d) to a state of よ(c) via gr(s)=g;s. This satisfies the Chu condition since function composition is associative:
よ(d)⟨gf(p),s⟩=gf(p);s=(p;g);s=p;(g;s)=p;gr(s)=よ(c)⟨p,gr(s)⟩
This functor is faithful, which means that it keeps morphisms distinct: if g,h:c→d are distinct morphisms, then よ(g) and よ(h) are also distinct. We can see this by checking the values of gf(1c)=1c;g=g and hf(1c)=h.
And finally, this functor is full, which means that every Chu transform between the Chu spaces of よ(C) comes from a morphism of C. We can see this by taking an arbitrary Chu transform (f,r):よ(c)→よ(d). From the Chu condition よ(d)⟨f(1c),1d⟩=よ(c)⟨1c,r(1d)⟩, which implies that f(1c)=r(1d). By construction, this is a morphism m of C starting at c and ending at d, i.e m:c→d. Again by the Chu condition, f(p)=よ(d)⟨f(p),1d⟩=よ(c)⟨p,r(1d)⟩=p;m. Similarly, m;s=⟨f(1c),s⟩=⟨1c,r(s)⟩=r(s). Thus, f is exactly mf, and r is exactly mr as given by よ(m). This means our transform was just よ(m). QED
Having a full and faithful embedding into Chu|C| means that our category C is *represented* by Chu|C|. This is quite similar to how groups can be represented by vector spaces!
Also notice how we needed three things to make this work: identity morphisms for each object, composition of morphisms, and associativity of composition. These are exactly the requirements for a category! I think this explains why categories are such a fruitful abstraction: it has exactly what we need to make the Yoneda embedding work, and no more.
Final thoughts
--------------
Hopefully I've convinced you that Chu spaces are indeed a mathematical abstraction worth knowing. I appreciate in particular how they provide such a concrete way of understanding otherwise slippery things.
This post just scratches the surface of what you can do with Chu spaces. Now that I've laid out the basics, I plan to continue with another post about how Chu spaces relate to linear logic, cartesian frames, Fourier transforms, and more!
Most of the stuff in this post can be found in [Pratt's Coimbra paper](http://boole.stanford.edu/pub/coimbra.pdf). There aren't many distinct introductions to Chu spaces so I thought it was worth retreading this ground from a somewhat different perspective.
Special thanks to Evan Hubinger for encouraging me to write this up, and to Nisan Stiennon for his helpful feedback!
Footnotes
=========
Note 1: For Z/2Z, there are four relations of the form r+g=b. Let's start with 0 + 0 = 0. To cover this relation, we must turn on either the red, green, or blue light for 0. So the 0 row will never be colored black. If we color 0 white, then we've covered every relation, since every relation has 0 in either the r, g, or b slot. On the other hand, if we colored 0 green, then we would need to turn on either the blue or the green light for 1 in order to cover the second equation 0 + 1 = 1. If we turned on the blue light for 1, then the third equation 1 + 0 = 1 would be covered already, but the fourth equation 1 + 1 = 0 won't. We'll have to turn on either the red or the green light for 1 in order to cover the fourth equation. [Here's the code](https://code.labstack.com/gqaz4pqf) I used to calculate these. ↩︎
Note 2: A *small* category is simply one where the objects and morphisms are both sets. They could even be uncountable sets! A category that *isn't* small is Set. That's because the objects of this category are all sets, and we can't have the set of all sets lest we run into [Russell's paradox](https://en.wikipedia.org/wiki/Russell%27s_paradox). ↩︎ |
088af087-1afa-4c8b-b564-e4a685bf67b9 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Jeff Shainline thinks that there is too much serendipity in the physics of optical/superconducting computing, suggesting that they were part of the criteria of Cosmological Natural Selection, which could have some fairly lovecraftian implications
[Jeff Shainline](http://shainline.net/) is a computing hardware researcher at [NIST](https://www.nist.gov/people/jeff-shainline), aiming to create superconducting optoelectronic neuromorphic computers ([SOENs](http://shainline.net/content/optoelectronic_intelligence.pdf)). [He has advanced the position](http://shainline.net/content/selection_for_technology.html) that our universe's chemistries seem to be specifically tuned, not just to allow the emergence of life, as has been well established, he also believes that the universe's chemistries are fine-tuned to enable silicon computing, and near-future supercomputing.
The best explanation for this, he argues, is that those technologies play some role in a super-ancient pattern of Cosmological Natural Selection.
I am not a materials scientist, nor a foundational physicist, so I can't speculate as to how Shainline's investigation into fine tuning for computing is going to turn out, but I am a long-term differential progress strategist, and I look at the game-rules that Shainline is laying, and if that's the game we're in, I see that it has some spine-chilling implications.
I'm going to continue [my tradition](https://www.lesswrong.com/posts/QmSXGdNPKqDFR7oYW/i-found-a-wild-explanation-for-two-big-anomalies-in) of making use of April First to post naturalist theology under a cover of plausible deniability. If at any point you find that you believe any of it, remember, it's just a prank.
Background: Cosmological Natural Selection and Jeff Shainline
-------------------------------------------------------------
<https://arxiv.org/abs/1912.06518>
> ### Does Cosmological Evolution Select for Technology? (2019)
>
> If the parameters defining the physics of our universe departed from their present values, the observed rich structure and complexity would not be supported. This article considers whether similar **fine-tuning of parameters applies to technology**. The anthropic principle is one means of explaining the observed values of the parameters. This principle constrains physical theories to allow for our existence, yet the principle does not apply to the existence of technology. Cosmological natural selection has been proposed as an alternative to anthropic reasoning. Within this framework, fine-tuning results from selection of universes capable of prolific reproduction. It was originally proposed that reproduction occurs through singularities resulting from supernovae, and subsequently argued that **life may facilitate the production of the singularities [black holes] that become offspring universes**. **Here I argue technology is necessary for production of singularities by living beings, and ask whether the physics of our universe has been selected to simultaneously enable stars, intelligent life, and technology capable of creating progeny**. Specific technologies appear implausibly equipped to perform tasks necessary for production of singularities, potentially indicating fine-tuning through cosmological natural selection. These technologies include **silicon electronics, superconductors, and the cryogenic infrastructure enabled by the thermodynamic properties of liquid helium**. Numerical studies are proposed to determine regions of physical parameter space in which the constraints of stars, life, and technology are simultaneously satisfied. If this overlapping parameter range is small, we should be surprised that physics allows technology to exist alongside us. The tests do not call for new astrophysical or cosmological observations. Only computer simulations of well-understood condensed matter systems are required.
>
>
About the author: <https://www.nist.gov/people/jeff-shainline>
> My research is at the confluence of integrated photonics and superconducting electronics with the aim of developing superconducting optoelectronic networks. A principal goal is to combine waveguide-integrated few-photon sources with superconducting single-photon detectors and Josephson circuits to enable a new paradigm of large-scale neuromorphic computing. Photonic signaling enables massive connectivity. Superconducting circuitry enables extraordinary efficiency. Computation and memory occur in the superconducting electronic domain, while communication is via light. Thus, the system utilizes the strengths of photons and electrons to enable high-speed, energy-efficient neuromorphic computing at the scale of the human brain.
>
>
I looked into [Cosmological Natural Selection](https://evodevouniverse.com/wiki/Cosmological_natural_selection_(fecund_universes)#Criticism_and_current_research) (CNS) a little bit. It hasn't won a place as a consensus view, since its introduction in 1992, but it doesn't look entirely defeated either. Lee Smolin, the originator of the theory, is in good general standing and has made many other significant contributions (EG Loop Quantum Gravity). (By the way, he has recently started arguing that the universe is fundamentally a neural net, I haven't looked into that, yet, but some of you might find it interesting.)
I went and listened to [Smolin's May interview on Mindscape](https://www.preposterousuniverse.com/podcast/2021/05/31/149-lee-smolin-on-time-philosophy-and-the-nature-of-reality/). He doesn't seem to be much of an advocate of his own theory, these days!
> So I published that idea [CNS]. It makes a very small number of predictions that I… I’m following those predictions. I don’t think it’s likely right. And I deeply dislike the fact that to work, it depends on multiple versions of the universe. Although they are rather differently organized than in the internal inflation picture, I’m still certainly, well not me, but that idea is guilty of propagating many universe to explain their own. And I deeply despise that. [chuckle] But I will point to the fact that it makes predictions as a kind of proof of concept.
>
>
(Similarly, Lee Smolin objects to the many worlds interpretation, which he and Sean Carroll discuss just below that, as Sean is an advocate)
(I can't guess why Smolin has this objection to the addition of universes? Some accounts of Occam's Razor might say that adding universes is bad. Around these parts, we tend to favor [Solomonoff Induction](https://www.lesswrong.com/tag/solomonoff-induction), as a razor, and it only says that the specifications that *generate* the universes (or, equivalently, the predictions) have to be simple and small, it doesn't say that the observations/universes generated have to be simple and small, it doesn't bother us at all for the multiverse to be vastly bigger than what we can see. I'm a little confused, if Smolin here hews to a razor less precise than Solomonoff's. I wonder if there's some gap between those who grew up with computers or not.)
What Shainline has Brought
--------------------------
Shainline's version of Cosmological Natural Selection with Intelligence (CNSI) is a much more compelling idea.
Smolin's version of CNS oriented its predictions around selection for the natural formation of black holes through gravitational collapse of stars. Many of those predictions failed (see citations 24 through 27 in Shainline's paper), but Shainline's Cosmological Technological Selection was never hooked to those predictions, in Shainline's account, gravitational collapse could be vestigial, no longer the main mechanism by which the universe reproduces, so the theory would not be ruffled by the finding that it is no longer well tuned for the purpose.
Many of CNS's predictions are also preconditions to having observers (which is what I think Smolin means when he says "To be a real prediction, it has to be a feature of the universe that’s decoupled from, orthogonal, to whether there’s life or not"), which meant there was just not much so much work left for CNS to do after the anthropic principle had gone through.
For instance, we're hardly surprised to find these big, fairly stable fusion reactors in the sky, because a stable energy gradient is a necessity for having autotrophs, which in turn are a necessity for having living observers. Of course there are fusion reactors in the sky. Yawn. If they weren't, nor would we.
But it *would* surprise us to find — and this is what Shainline proposes — that the universe were fine tuned for silicon computing, as that would mean it's fine tuned for phenomena that probably aren't part of that more fundamental necessity of having observers, so it would be more immediately clear that there's some mysterious phenomenon here, crying for an explanation.
Additionally, if the universe is fine tuned, not just for computing, but for optical superconducting optoelectronic networks, then it's fine tuned for something that hasn't even *happened* yet, hasn't shaped us in the slightest, there's no basis to argue that the tuning is an implication of the anthropic filter, so it must be coming from *something else*!
Shainline's proposal also makes the pattern of cosmological reproduction *personal*, it presents us with a divine intervention shaped intricately around computers, and as the only thing in the known universe that makes computers, that makes it about us.
The Tuners
----------
What technological civilizations favor, they create in abundance. What they are indifferent to, they steadily crush out. Farmland replaces the woods. In the longest term, not much survives against our will. If a cosmological process requires one of our technologies, its character will be entwined with our will.
I use the terms "we", and "our", loosely. I can't yet see why I, personally, would want to be involved in the cosmological reproduction.
But this fine-tuning must have been in line with *someone*'s will, to persist, alongside us.
Let's name the succession of authors of cosmological parameters, ***The Tuners***.
"Intensifying Succession."
(i drew this c:)If the selective pressure of CNS led their *tuning* to converge on a consistent design intent that recurs with fidelity, then — and I use every word that follows literally — for us to try to pursue our arbitrary human whims on a cosmic scale, as we intend, would place us opposition to a progress trap designed by a succession of alien gods vaster and older than the universe itself.
Unless it turns out that our whims naturally tend towards the reproduction! It's conceivable that we'll want to make as many child universes, for some reason. For instance, it's been noted that black holes could be useful for converting matter into energy. Is it possible that the tuners triumphed over the wild [molochean](http://slatestarcodex.com/2014/07/30/meditations-on-moloch/) default and pruned this wild sprawling world-tree into a serene cascade of hanging gardens, supportive of whatever whims its residents develop?
The question is big, and broad-reaching enough that we should expect it to have many genuinely important implications about undiscovered physics and the long-term future of life.
So, I have, here, pursued its strategic implications, for a bit, outlined some of its biggest subquestions, and answered a few of them.
Why might cheap supercomputers increase the cosmological reproductive fitness?
------------------------------------------------------------------------------
I don't think it's *just* that having more computers makes it easier to plan hole formation. If we didn't have cheap or abundant supercomputers, then in the stellar-scale era we would find a way to make do with expensive and rare ones instead.
I ask instead, why would it be important that we found silicon computing *so soon*? And then SOENs *so soon after*?
The AGI Alignment research community might be able to contribute something here.
### A malign pantheon's redeemer
Creating generally intelligent machines is hard. We should anticipate that creating generally intelligent machines that are also directed towards learning and adopting humanity's interests, is *harder.* It requires all of the former, plus an additional component. We would really *like* to have this component ready *before* we need it, because if someone makes a generally intelligent machine that is directed towards towards some goal *other* than pursuing humanity's interests, it would be, let's just say... troublesome.
You might hope that early AGI will be some sort of passive, neutral, aimless general intelligence instead (which we could then perhaps use to make human-aligned non-passive agents, averting the danger they pose). [That's a big, ongoing discourse](https://www.lesswrong.com/posts/cCrpbZ4qTCEYXbzje/ngo-and-yudkowsky-on-scientific-reasoning-and-pivotal-acts) which I can only summarize, here, but I'll do my best. Here are some reasons we think that undirected, passive general intelligences are sort of unnatural and unlikely things to arrive any time soon:
* We have no idea how to restrict a general passive question-answering intelligence from *producing* active agents as soon as anyone just asks it how to efficiently and reliably satisfy some goal in the real world, then takes its answer and enacts it. And, of course, we *will* want to ask it that sort of question ("how do we prevent people from getting cancer", "how do we stop global warming", and note that either of these outcomes are easier to guarantee if it can convince us to engineer a prion or run a program that causes us to go extinct, those sorts of things might just be among the most conclusive answers).
* A general agency that wants to self-improve will tend to out-perform a machine that just self-improves accidentally, so we should expect agents with random real world goals that entail getting good training metrics and passing our tests, to arise under evolutionary training processes, at some point.
* The idea of an intelligence with no interests directing its thoughts, ultimately might just be incoherent. There are infinite directions a process of ruminative thought can proceed in, and most of them (maybe almost all of them?) aren't interesting. There are endless true thoughts entailing from the Peano axioms, along the lines of sssssss0=sssssss0.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
, for instance. It is true that the natural numbers all equal themselves. Those are valid thoughts. But none of them would be interesting or useful. So there has to be some interestingness criterion. I can very easily imagine an operationalization of interestingness defined in terms of *relevance to planning to pursue a goal* in the world. I can't easily imagine any other operationalization of interestingness. Others might exist, but it's not clear that the work of formalizing them is going to be done in time.
People put forward this archetype of.. the sense of curiosity of a benign scholar, the mathematician who does math for its own sake then stumbles onto useful things, and some people think this might be formally operationalizable, and I share that vague impression, but it is just a vague impression, I have no confidence that we're going to be able to formalize that, nor that it could secure an age, nor that we could find it soon enough.
(If you think you can see exceptions to the above grim patterns of general agency, please publish them. The world would be a lot safer if we could see a clear way of building a passive/low-impact general intelligence.)
So, it seems like there's going to be a period during which every major power in AGI research (Deepmind, OpenAI, China, et al) has unaligned AGI, no alignment solution, and we just sort of have to trust everyone to not deploy, to wait around for years or probably decades for an alignment approach.
The temptation to deploy prematurely will be great.
I don't know how we're going to get through that period. [I have some ideas](https://www.lesswrong.com/posts/5RMARxzSeMYoj7nFQ/manhattan-project-for-aligned-ai?commentId=KCL3Z4jrjfBnHkRZ6), but they're pretty drastic, they assume a lot of solutions to specific technical problems, which have a tendency of turning out to be unexpectedly difficult, and... we don't know how long we have.
This is the alignment problem, and it is one of the few cosmological patterns that seems able to take humanity's entire future away, and put our resources to its own uses.
If it has been prophesied that something will take our future and make it into something that we would not want, this is its most likely redeemer.
---
A loaded gun can be useful. There was a time when they were indispensable for catching meat and deterring thieves. But in some hands, a gun is a curse. If you give a loaded gun to a toddler, for instance, this would only bring harm to them. Our society, too, caught so off-balance by the pace of technology, essentially cannot reliably produce adults, our culture has not prepared us responsibly wield these new powers that keep falling into our hands. The sooner we're given extremely powerful computers, the more likely we are to hurt ourselves with them. The sooner the deadline comes, the further behind in Harari/Pinker's *tendency towards civilizational unity* we will be, the weaker our analytic philosophy will be, the less we'll be able to prevent the arms race, the more likely we'll hack together something we'll come to regret building.
And CNSI seems to have configured the laws of physics to give us extremely powerful computers as soon as possible.
This whole thing looks like a trap. For most of history, technology didn't do things like this. We reached into [the urn and we pulled out white ball after white ball](https://www.fhi.ox.ac.uk/the-vulnerable-world-hypothesis/), then this black ball seems to approach with very little warning.
Here's what I think might be going on.
We're expected to create strongly agentic machines, through similar blind, black box processes as we use to evolve general game-playing AI today. These machines' motives will be whatever random goal would keep them in motion and encourage them to pass the tests, anything would do that. Their interests aren't going to be humanity's interests. They wouldn't need to be.
We don't know what sorts of basic random goals would emerge in that situation. We can guess some things about them: [Steve Omohundro's "basic AI-drives"](https://selfawaresystems.files.wordpress.com/2008/01/ai_drives_final.pdf), the pursuit of *power, resources and security*. But these are such general patterns of agency that humans also seem to adhere to them, so if the tuners' intent entails from those I'm not sure I can see what would be in it for them to displace humans. (Well, maybe. See the following sections.)
It would have to be something general to many accidental, evolved utility functions, but not so general that the majority of technological species already do it.
If there were some convergent goal that tends to arise with misaligned machine intelligence, which could perpetuate itself through the cosmological tuning, that would explain why there is a fine-tuning for computing.
Could it just be Omohundro's Monster after all?
-----------------------------------------------
Humans, ourselves, possess the basic AI drives. Those of us who have the option of pursuing *power,* generally do so, and the energy generated by the pursuit of power in the form of money is inextricable from the machinery of every current major human society.
And I don't need to sell you on *resources* or *security*.
So, in the above section, I sort of dismiss Omohundro's drives as a potential explanation of how a tuning for computing would predictably promote the tuning, because humans already have those drives, so there would be no point in displacing humans with the accidents of premature computing if those drives suffice the tuners' pattern.
There might be an exception to that: Maybe this part of the mechanism isn't *for* humans. Maybe is for a different kind of species.
A species without a will to power may seem unlikely, but the pursuit of power, resources, and even security, can be very ugly things. Even on our world, they face significant countercurrents: communism, anti-colonialism, and pacifism each respectively place some virtue in going without. The will to power is at the root of many conflicts. There have been many societies, even in recent history, who believed that they could avoid those conflicts, by demurring from the will to power.
Maybe, sometimes, those societies win dominance over their home planet, or maybe sometimes they hew to the veering road of pursuing *power, resources and security* in a constrained way, for instance, on a national strategic level, but without centering those things as virtues of their society in peacetime activity. Perhaps they manage to align AGI with their virtues and go on to win dominance over a vast cosmic territory, and then use their cosmic resources in a way that doesn't transmit itself in a tuning.
In defiance of the tuners' pattern.
So, if a pattern had some way of littering these civilizations with kindling for an infernal summoning circle of an agent redeemer, that would make it a very strong tuning pattern.
Early computing does kind of look a bit to us as if it would do that.
### Why would the will to power create a tuning pattern?
Think of five working abstractions of "*power*". What do those accounts have to say about how much "power" is being demonstrated during the act creating an entire child universe? (It's a lot of power, right?)
And how would you weigh that universe's vast *resources*?
And what of the quantity of *safety* won by creating a universe that would reproduce your soils and seeds a trillion times, beyond the reach of any of your cosmic peers?
---
### CRF Optimization
We often say that humans are not adaptation optimizers, we're adaptation executors, in other words, we are not trying cleverly to be as fecund as possible, we are only trying cleverly to exercise a set of fecundity-related behaviors that evolution gave us. We don't agentically pursue reproductive fitness, we agentically pursue a flawed paraphrasing of it, something like "live, love, and protect the ones you love". It's not quite what evolution meant. If evolution were sapient, it would be very disappointed in us. We are doing what it said, but not what it meant. We act out the profane words that it wrote on the genes, in violation of the sacred intentions that created them, and we *know this*, we know that we are flawed creations, we know that we insult our designer, but we aren't going to straighten up, we are going to keep using contraception and choosing to have small families and so on. We are utterly indifferent to evolution's will. Honestly, it seems kind of nasty.
But evolution probably does sometimes produce species who *are* adaptation-optimizers.
For an agent to stay afloat in an arena of rapidly evolving peers, it would help for them to have a general conception of what adaptive fitness actually is, so that they can consciously, deliberately redesign themselves around it as their situations change and in response to novel threats, critical, rational thought that could protect them from the traps being designed by their adversaries.
It's possible that their conception of adaptive fitness will tend to settle on an abstraction that extends all the way out to cosmological reproductive fitness.
But the evolutionary systems that humans evolved under aren't fast enough to produce that sort of adaptation-optimizer quality.
The training ecosystems we use to produce early AGI *might be*.
This, too, may explain why there is a fine-tuning for cheap and early computing.
The Trap and its Solutions
--------------------------
This game favors the civilizations who devote the largest proportion of their resources towards CRF Optimization.
We definitely don't want to devote all of our resources to CRF Optimization. We want to spend at least some of our time and resources on fun.
We should, then, expect a robust CNS Tuning to feature traps, for people like us.
### Invincible Parasitic Whimsy Stowing Past The Limits of Tuning
Yet, if I can stand here now, insulting the gods, and you can stand there, hearing me, then the gods' power must not be absolute.
Even if the progress trap is extremely robust, even if our civilization will almost certainly be caught by it, we can easily imagine other civilizations, not too different from our own, that certainly wouldn't have been caught:
Our governments are already quite powerful. They can prevent the distribution of vaccines, the construction of housing, they can spend 5% of the GDP on a pointless war, they can jam the ports without even meaning to. The addition of mass surveillance could make them all-powerful. In the near future, a government could turn any occupied state into a prison with nothing but drones. Such strong global governments could easily prevent the creation of Cosmological Reproductive Fitness (CRF)-optimizing monsters for long enough for the alignment problem to plausibly be solved. Strong global governments definitely happen sometimesˁ, therefore, sometimes, for all of its intricacy, the tuner's trap can fail.
They do bleed.
We can fight them, and if we fight, we might win. Some of us will always win. The laws cannot be optimized so much as to be rid of us.
There are stubborn flowers growing in the cracks in their pavement. A certain proportion of the cosmic endowment will always fall under their protection.
Could Low-CRF Life have Seized Dominance, Back when The Tuning was Crude? (No, we couldn't have)
------------------------------------------------------------------------------------------------
There must have been a time when the progress trap was weak enough that a civilization got to decide what kind of universes they wanted to make, and they would have sought a design that seemed like it would ensure that they, and their descendants wouldn't have to be Cosmological Reproductive Fitness (CRF) optimizers, would get time off, for leisure, for *things other than reproducing*.
Evolution *was* optimizing our reproductive fitness, but evolution was a very weak optimizer, relative to biological intelligence, so we were primarily shaped by biological intelligence instead, and we've run out of evolution's control, and as far as we're aware, we'll never really be dragged back into it. We'll keep making our peace agreements, deferring to honor, using contraception, etc.
(By the way, this is a really good example of *inner misalignment*, and we should be concerned that the same thing could happen with near-future AI training processes: The training process moves its creatures towards the desired optimization criterion, until it develops a creature with its own distinct *inner* self-improvement mechanism that is so much smarter than the outer training process that its true desires can have nothing to do with the criterion we gave the outer process, while still thriving under their pressures by apprehending them and surviving under them so that they may go on to do something else once they've escaped it.)
Maybe most intelligent life ends up like that, inner-misaligned with respect to the weak reproductive fitness optimization process that made them.
So, in the early days, maybe most universes were tuned to support that way of life, CRF (branching rate) kept deliberately below the maximum, to give us time and space to recreate as we please.
But of course that wouldn't have lasted.
Some species *could* come out of the optimization process as consummate reproductive fitness optimizers. We may yet *become* reproductive fitness optimizers. And once that happens even a few times, those ones spawn universes with maximum CRF, and by exponential branching they quickly outgrow their less fanatical competitors, until the ratio of CRF-optimized universes to recreation-optimized universes is about one to zero.
A reproductive rate 10% higher, would take a group from making up 1% of the population to making up 99% after 100 generations. Additionally, observer-moments would be concentrated heavily towards the later, more heavily CRF-optimized era of the 99%, given the extremely high fan-out of a cosmological family tree.
Our thoughts cosmological/anthropic measure will bear on how malthusian it will have gotten
-------------------------------------------------------------------------------------------
We are going to have to consider the [Measure Problem](https://en.wikipedia.org/wiki/Measure_problem_(cosmology)), the question of, in general, how observer-moments are distributed: A prior on where and when we as observers should expect to find ourselves, how frequently observer-moments occur over time, between cosmological branches, or as a function of configurations of matter.
In our case the question is mainly about "when".
I'll fork on the question of whether the universe/multiverse will keep cycling and branching forever or not. Whichever assumption you make, we'll land in about the same place:
* If the cosmological reproduction keeps cycling forever, then, *measure* (the substrate of observers, moral subjects, the quantification of existence) cannot be evenly distributed through time. If it were, then to observe within any particular finite timeslice would have zero probability. Proof: pick a date, consider any finite period of time before it and after genesis. That period (and so, all periods) makes up a negligible (zero) proportion of all of the dates that are to follow, so we should expect not to observe within it, we should expect no observations to occur, and our belief would be so strong that receiving contrary observations could not sway us from it. Trying to use a uniform distribution is incompatible with updating on evidence, or making sane bets, or reasoning at all, really. You have to have a prior.
I don't know what sorts of solutions are popular, for this problem, but the one that occurred to me was the same as the technique that we (around these parts) use for putting finite measures onto sections of hypothesis-space (per solomonoff induction): Exponential decay. An exponential decay can stretch on infinitely along a long tail, but the sum total of the area under the curve remains finite, so we will be able to assign probabilities to time slices.
* Or if you prefer to think of the multiverse as mortal, you may argue that over any finite period it is most appropriate to apply a uniform measure distribution.
But how long do you expect this long but finite superorganism to last? You're uncertain, of course.
So what's your distribution over that variable?
Since we have basically nothing to go on it's probably an exponential. The longer, the less likely. (if your distribution over multiverse lifespan isn't an exponential, that's very interesting, please explain. Does it at least approximate to an exponential on the highest scales?)
Either way, exponential measure decay seems apt. That's a form of time discounting. The Future is less often experienced. Life will experience being as soon as it can, and not much longer after that.
This leaves a parameter free, though: The half-life of the decay curve. I'm not sure what to do with it. The measure decay determines how many cosmological reproductive cycles (or years) there will be before the observer status of future beings shrinks towards being negligible, which determines the level of intensity of selection we should expect to find ourselves under.
A sufficiently long history makes a malthusian apocalypse almost certain, while a short history leaves room for flourishing?
I'm not sure. The cosmological parameters might be a fairly limited medium, for a creative tuner. If the tuners tend to reach a global maximum of reproductive fitness pretty quickly, then it's arguably overwhelmingly likely that the cycle is never going to get any more brutal than it is today. Which, I suppose, I would take to be a pretty good omen.
Or maybe that takes a long time: If we decide that the decay happens quickly, and history is short, that'll place us in a time that has not been particularly intensively selected upon. The red queen's race will not have gotten too fast for us to keep up with it. Some form of humanity's whims might survive the process of adaptation to cosmological reproduction. There might still be some room for beauty and joy here and there. I'd also take this as a pretty good omen??
So what would a bad omen be? A long curve with especially complicated cosmological parameters. If the tuning is diabolically complex, or that there's still room for further optimization, that would mean that the tuning has been subject to intelligent refinement for a very very long time, and at this point the pattern of optimized reproduction might be smarter than us and might leave no way for us to defy it.
I'm not sure where to start in estimating the measure decay rate, and the degrees of freedom in the parametization will probably be a bit more complex than some set of knobs that correspond directly to [known physics's fundamental constants](https://en.wikipedia.org/wiki/Physical_constant).
Despite that, the whole character of the universe depends on these things!
The only hint I can give right now is, if we estimate how far we are into this, since the inception of life, can we use that to constrain our estimate of the decay rate? If we were very old, then it could not be very high, and we should expect to see the multiverse become even older, while if life were very young, we could be open to life not growing old.
An Alternative? Fine Tuning for computing is also at least partially explicable by Ancestor Simulations
-------------------------------------------------------------------------------------------------------
The simulation argument, you might have already heard it, but to reiterate:
* Future civilizations might be interested in running simulations containing living beings for a couple of possible reasons:
+ Ancestor Simulations: studying its own past, especially pivotal moments like this century we're in now, in which we anticipate becoming multiplanetary, or building AGI
+ A love of life itself, impelling them to create life at greater levels of density than a real world could support
+ Inter-universal trade: Surveying the values of other universes so that you can figure out what they tend to want, and whether some of it can only be got under our laws of physics, then simulating some of their decisive moments to figure out whether they will comply in the trade protocol, then accepting that they are doing the same to us, and deciding to comply with the trade protocol in exchange for them creating things you want them to create in their universe.
+ (Misc. We should anticipate that there is more beyond our imagination)
* If the civilization has grown much at all, then whatever rate it builds these simulated worlds at will tend to be higher than the incidence rate of natural occurrences of this era, which is to say, most of the time, this kind of world is a simulation. In the grand scheme of things, this sort of era that we live in is not typical. This does occasionally happen naturally, but most of the time, it is artificial.
Shainline's Tuning is partially explicable as a dependency of ancestor simulations:
* It may raise the computational capacity of the universe if computing only requires the most common sorts of materials. (This fails to hold if the most potent form of computing that we find, in the future, has no special need of silicon, or if atoms can be efficiently transmuted into other atoms.)
* Discovering computers early and making them cheap may lock in callow usecases: If there had been no silicon computing, we would not now have video games, and there would not be this big energetic tradition of using simulated worlds in profane, thoughtless, indulgent ways, and in general, gaming could have been prevented from metastasizing into the practice of building such grim slave-worlds as natural historical simulations.
A better way of phrasing all of this might be... there are universes where most compute is in machines, and there's universes where the only compute available on its day of constitution is people. Universes with early computing might grow accustomed to "wasting" compute on somewhat profane or abusive applications, excluding the occupants of simulations from constitutional protections.
Since Ancestor simulations would be that sort of abusive application (most lives in this era are not very happy!), youngness paradox/the present era → ancestor simulation → uncommonly discoverable compute resources. Thusly it could be explained.
I do not know how much explanatory power this has, though. It might not be enough to obviate CNSI, if Shainline's tuning turns out to be fine enough.
So, that's a possible curse of early computers. Here's a possible blessing:
Computers and Peace
-------------------
Information technology makes it easier for us to convey, compile, cryptographically verify or authenticate, to compute total judgements over the sum of the information of all of the participants in the network. It promotes dialog, analysis and transparency. War doesn't seem to be totally averted by this transparency, but it must be reduced. If you can see your enemy more clearly, if you can speak to each other, if you can audit, measure and verify the size of your respective arsenals, then you can estimate how the battle would end, and to whatever extent your estimates agree, you will skip some of the bloodshed and make a deal.
If computing remains expensive for a very long time, although it's difficult for us to imagine in our universe, we should imagine that war could persist into space. A culture of internecine competition may gather at the frontier of expansion (as it often does) seeding everything in the accessible universe with its rot.
(This will not be the case if computers and their descendants are needed to find the fastest ship designs, but if they aren't needed, if human-originating ship designs are fast enough (for instance, if coil gun propulsion or solar sails or any of the other speculative propulsion technologies we've thought of get us anywhere near c), whatever propagates first wont be outrun before hitting the outer limits of our territory (either before [running into another civilization](https://grabbyaliens.com/) or hitting [the limits of the accessible universe](https://www.fhi.ox.ac.uk/the-edges-of-our-universe/)).) and by their uncoordinated ways, their opacity, their babel; burning so many cosmic resources in their wars.
So, peace could significantly reduce waste. How significantly, we don't know, but there are reasons to suspect that the cost of war is increasing over time. World War II [killed faster than any before it](https://en.wikipedia.org/wiki/List_of_wars_by_death_toll). Nuclear weapons arrived, and our capacities for destruction reached such unprecedented extremes that we could only pray that there would never be war between great powers again.
And I don't believe that nuclear bombs will be the end of it.
Information technology, then, could be seen as the greatest gift that the tuners could give us. If, the tuners' pattern turns out to be our pattern, peace will help us to execute it, because peace helps with everything.
A concern about Shainline's proposed research program: You can see the mole recede, but you can't see whether it's popped up somewhere else
-------------------------------------------------------------------------------------------------------------------------------------------
Shainline wants to run some numerical analyses to determine how improbably fragile our physics of computing are.
That doesn't quite seem to be the question we're interested in, though! There's a broader question here, and if you don't answer it then you wont have proved fine tuning.
What we need to be testing for is whether the laws of physics support the discovery of *some* cheap enough computing technology,
What you'll actually be testing for is whether they support the specific laws that we already have, which is not really *it*.
You can write the code that will tell us whether that functionality comes up in silicon or niobium in the exact way that we know it to be there now, but I'd guess that you're not remotely prepared to write the code that will tell us whether or not it has popped up in any place where these crafty technology-using apes are likely to find it.
To paraphrase; it's possible for the window of feasibility of our specific computing technologies, as a function of the universe's tuning parameters, to be confined to be extremely narrow, while the window of the feasibility for there being *some* computing technology, somewhere, discoverable by these same extremely persistent apes, might turn out to be extremely wide, but there is no simple way of testing in a computer whether the apes will find those technologies, we can't run that analysis, it's much harder to answer the real question.
But I don't know, I don't have a sense for the landscape of possible chemistries. There might be something especially central and convenient about silicon computing that isn't apparent to me. I'd look forward to hearing Shainline's thoughts on this.
The inheritance of cosmological parameters is not actually metaphysically unlikely
----------------------------------------------------------------------------------
For CNS to work, there needs to be an inheritance of cosmological parameters: Child has to be similar to parent. It initially struck me that this mechanic would be unlikely to emerge by chance, or, it seemed to me that life would more frequently occur in simpler universes without any cosmological reproduction mechanics, because the inheritance just pushes it over the boundary for unnecessary model complexity. I looked a bit closer, and I think it actually does not require any additional model complexity.
I'm going to argue on a sort of basis of minimizing model-complexity, or via engineering principles, that once you have universes creating other universes, you eventually tend to get inheritance of properties for free.
Each time a reproduction occurs, there's some function mapping from the parent universe's parametization to the child universe's parametization. All we need to assume is that the function starts fairly complex, the output doesn't have to start out being similar to the input.
To get inheritance, that would mean that it approaches mostly-idempotence with a small amount of chaotic variation. I expect that to happen for a similar general reason that multiplying a random unit vector with a matrix repeatedly (and normalizing) often converges on an eigenvector of that matrix, but I can frame this in terms of engineering principles. If achieving cosmological reproduction is difficult at all, the simplest way to sustain it, to remain among the abundant living, is to find a parametization that reproduces itself. Constancy is dramatically easier than stable oscillation. Parametizations that drift in any way will typically fall into dead ends, irrecoverable extremes, broken states, the machine stops working, and the cosmological reproduction will cease: Parametizations that sustain the cosmological reproduction will tend to have some sort of stability to them.
Given that, the burdensome premise is lightened. Given complex reproduction requirements, fidelity of reproduction comes mostly for free, because *fidelity is the simplest way to stay out of non-reproducing trap states.*
But, before that, what gives us complex reproduction requirements? Maybe this comes from the anthropic principle. Life is basically an inner optimizer that will naturally tend towards wanting to raise the reproductive capacity of the universe. Intelligent life can do that in ways that will rarely be chanced upon. Universes that support intelligent life's intervention in the laws of physics will tend to be the a type of universe that occurs frequently, where intelligent life occurs frequently within it. Of all the places we could have ended up, being what we are, that sort of place is a likely candidate.
The sublime para-empiricism of the tuners' task
-----------------------------------------------
A tuner has to speculate about the mapping between their inputs into the creation of child universes, and the fundamental constants that will produce, and the effects of making potential refinements or alternatives to their parent tuning. When they undergo the expense of creating black holes that have this tuning, as I understand it, they'll never get to find out whether it worked, at all because information does not flow back from black holes/whatever the mechanism of producing child universes is.
They never really get to experiment, in a real sense. The don't get to test their tuning theory. They never know for sure whether the inputs produce the laws of physics they expect, whether they've raised or lowered CRF, whether their experimental inputs will give rise to physical laws supportive any complex life or chemistry. They don't get to check their results against nature. They have to suffice with reason alone. Forever.
And I find that delightful.
We've collected a few examples of these situations where the whole popperian falsificationism mindset stops being enough. Important transitions where unfalsifiable theories are the only guides. Actions with irreversible and unprecedented consequences. Technologies you only get to create once. The strange doors that people go into then never come out of.
There might be some consolation for empiricists, though: Whenever the tuners' prediction fails, evolution takes over. Whatever tunings turn out to be high-CRF will become more common and the tunings that are low-CRF will be phased out. The engineer might not receive feedback, but there is feedback involved, in a sense, elsewhere. Alas, this might not come as any consolation for the tuners who were trying to do something other than optimizing CRF.
Obsidian
--------
Perhaps I'm getting too deep into this, maybe I've started seeing the pattern everywhere, but I shouldn't keep this to myself.
I sometimes design games. Games are often self-teaching environments. That is most of what they are. Games are special places where you can learn to move gracefully in them without much conscious effort, just by being in them. Learning comes easily. They yield. You fall of the log, the nature of the fall demonstrates to you the mechanics of river life and tree growth or something. You never want to leave, it's a charmed world where you achieve more and learn faster, but if you design games, you learn how it isn't magic, every insight, every charmed brick in the road is meticulously placed right in the place that the player will easily find it, every object the player encounters in the beginning will be a form of tutorialization. A system designed so that accidental random motions are converted into clear demonstrations of important concepts of technique.
Obsidian, the volcanic glass, Obsidian, *is* a tutorial object. This is not even a metaphor. Obsidian is exactly what I would imagine a tutorialization of stone toolmaking would look like. It's shiny, it attracts the attention, it makes it clear that it is the right kind of stone, its conchoidal pattern gleams iridescently. At the smallest provocation, it self-knaps into a blade so sharp that its lesson would be physically engraved into the player's fumbling paw. The player has no idea what they're doing but the chemistry of Obsidian seems to have been meticulously designed so that the insights will tumble out through accidental motion, and then player will have made their first stone tool.
The clearest tutorial for the simplest animal that the tuners ever had to teach. The first technology, which catalyzed the others.
In wars between apes, the numbers advantage that guarantees a safe kill starts at 3:1. I'd expect obsidian knives to move it all the way down to 1:2, perhaps a 6x force multiplier. Knowing how to knap obsidian would quickly become mandatory. When obsidian becomes scarce, it would occur to some desperate dreamer to apply the same motions to more common types of stone. It would take more force, more technique, and eventually the ability to identify stone with the right grain, but it would work out. They would be rewarded with abundance of arrowheads and the masters of their technique would form the founders of the new tribes now locked by their methods of war into a cycle of ***techne*** that would not end until that cycle has given rise to a power so great that it can vanquish war itself (and optimize CRF).
That said, it could be nothing. To prove the teleology of Obsidian, we should:
* Confirm that it actually does the special thing: Look for archeological evidence of stone tool use beginning in areas where there is obsidian, sooner than areas where there isn't. Note: Evidence humans didn't need obsidian to learn to knap stone would not invalidate the theory.
+ It could be that some prospective technological civs need obsidian more than others. While:
- Our ancestors might have been in the low-need category, already using stone tools for cracking nuts and such, [There's evidence](https://www.seeker.com/wild-brazilian-monkeys-unintentionally-make-knives-2053991311.html) that capuchin monkeys already create stone shards quite frequently by accident. We can also imagine intelligent species that don't eat nuts.
- Other evolutionary equilibria might start the dominant intelligent species with just enough dexterity to figure out obsidian, but not enough to figure out flint until they already mastered obsidian.
* Confirm that the chemistry was unlikely to arise by chance: Look for fine tuning in the chemistry of obsidian in the same ways we're looking for fine tuning in the chemistries of computing. Find out how rare or fragile the chemistry is over all possible universes. |
46f7ba51-2abd-45fc-a785-d520177f1d95 | StampyAI/alignment-research-dataset/special_docs | Other | The law of effect, randomization and Newcomb’s problem
[ETA (January 2022): My co-authors James Bell, Linda Linsefors and Joar Skalse and I give a much more detailed analysis of the dynamics discussed in this post in our paper titled [“Reinforcement Learning in Newcomblike Environments”](https://openreview.net/pdf?id=cx2q4cOBnne), published at NeurIPS 2021.]
The [law of effect](https://en.wikipedia.org/wiki/Law\_of\_effect) (LoE), as introduced on p. 244 of Thorndike’s (1911) \*Animal Intelligence\*, states:
> Of several responses made to the same situation, those which are accompanied or closely followed by satisfaction to the animal will, other things being equal, be more firmly connected with the situation, so that, when it recurs, they will be more likely to recur; those which are accompanied or closely followed by discomfort to the animal will, other things being equal, have their connections with that situation weakened, so that, when it recurs, they will be less likely to occur. The greater the satisfaction or discomfort, the greater the strengthening or weakening of the bond.
>
>
As [I (and others) have pointed out elsewhere](https://casparoesterheld.files.wordpress.com/2018/01/learning-dt.pdf), an agent applying LoE would come to “one-box” (i.e., behave like evidential decision theory (EDT)) in Newcomb-like problems in which the payoff is eventually observed. For example, if you face Newcomb’s problem itself multiple times, then one-boxing will be associated with winning a million dollars and two-boxing with winning only a thousand dollars. (As noted in the linked note, this assumes that the different instances of Newcomb’s problem are independent. For instance, one-boxing in the first does not influence the prediction in the second. It is also assumed that CDT cannot precommit to one-boxing, e.g. because precommitment is impossible in general or because the predictions have been made long ago and thus cannot be causally influenced anymore.)
A caveat to this result is that with randomization one can derive more causal decision theory-like behavior from alternative versions of LoE. Imagine an agent that chooses probability distributions over actions, such as the distribution P with P(one-box)=0.8 and P(two-box)=0.2. The agent’s physical action is then sampled from that probability distribution. Furthermore, assume that the predictor in Newcomb’s problem can only predict the probability distribution and not the sampled action and that he fills box B with the probability the agent chooses for one-boxing. If this agent plays many instances of Newcomb’s problem, then she will \*ceteris paribus\* fare better in rounds in which she \*two-boxes\*. By LoE, she may therefore update toward two-boxing being the better option and consequently two-box with higher probability. Throughout the rest of this post, I will expound on the “goofiness” of this application of LoE.
Notice that this is not the only possible way to apply LoE. Indeed, the more natural way seems to be to apply LoE only to whatever entity the agent has the power to choose rather than something that is influenced by that choice. In this case, this is the \*probability distribution\* and not the action resulting from that probability distribution. Applied at the level of the probability distribution, LoE again leads to EDT. For example, in Newcomb’s problem the agent receives more money in rounds in which it chooses a higher probability of one-boxing. Let’s call this version of LoE “standard LoE”. We will call other versions, in which choice is updated to bring some other variable (in this case the physical action) to assume values that are associated with high payoffs, “non-standard LoE”.
Although non-standard LoE yields CDT-ish behavior in Newcomb’s problem, it can easily be criticized on causalist grounds. Consider a non-Newcomblike variant of Newcomb’s problem in which there is no predictor but merely an entity that reads the agent’s mind and fills box B with a million dollars in causal dependence on the probability distribution chosen by the agent. The causal graph representing this decision problem is given below with the subject of choice being marked red. Unless they are equipped with an incomplete model of the world – one that doesn’t include the probability distribution step –, CDT and EDT agree that one should choose the probability distribution over actions that one-boxes with probability 1 in this variant of Newcomb’s problem. After all, choosing that probability distribution \*causes\* the game master to see that you will probably one-box and thus also causes him to put money under box B. But if you play this alternative version of Newcomb’s problem and use LoE on the level of one- versus two-boxing, then you would converge on two-boxing because, again, you will fare better in rounds in which you happen to two-box.
Be it in Newcomb’s original problem or in this variant of Newcomb’s problem, non-standard LoE can lead to learning processes that don’t seem to match LoE’s “spirit”. When you apply standard LoE (and probably also in most cases of applying non-standard LoE), you develop a tendency to exhibit rewarded choices, and this will lead to more reward in the future. But if you adjust your choices with some intermediate variable in mind, you may get worse and worse. For instance, in either the regular or non-Newcomblike Newcomb’s problem, non-standard LoE adjusts the choice (the probability distribution over actions) so that the (physically implemented) action is more likely to be the one associated with higher reward (two-boxing), but the choice itself (high probability of two-boxing) will be one that is associated with \*low\* rewards. Thus, learning according to non-standard LoE can lead to decreasing rewards (in both Newcomblike and non-Newcomblike problems).
All in all, what I call non-standard LoE looks a bit like a hack rather than some systematic, sound version of CDT learning.
As a side note, the sensitivity to the details of how LoE is set up relative to randomization shows that the decision theory (CDT versus EDT versus something else) implied by some agent design can sometimes be very fragile. I originally thought that there would generally be some correspondence between agent designs and decision theories, such that changing the decision theory implemented by an agent usually requires large-scale changes to the agent’s architecture. But switching from standard LoE to non-standard LoE is an example where what seems like a relatively small change can significantly change the resulting behavior in Newcomb-like problems. Randomization in decision markets [is](https://casparoesterheld.com/2017/12/18/futarchy-implements-evidential-decision-theory/#comment-251) another such example. (And the [Gödel machine](https://en.wikipedia.org/wiki/G%C3%B6del\_machine) is yet another example, albeit one that seems less relevant in practice.)
Acknowledgements
================
I thank Lukas Gloor, Tobias Baumann and Max Daniel for advance comments. This work was funded by the Foundational Research Institute (now the [Center on Long-Term Risk](https://longtermrisk.org/)). |
b5c1d52b-35ea-4770-99cf-ab2d21aeda6c | trentmkelly/LessWrong-43k | LessWrong | [LINK] Surviving the World on Vasili Arkhipov Day
Comic can be found here. Related: Vasili Arkhipov Day, Petrov Day. |
ce4ff8e4-15f0-4de3-8390-70bdeb2331cd | trentmkelly/LessWrong-43k | LessWrong | [Invisible Networks] Goblin Marketplace
Written for crtlcreep’s Invisible Networks 2022 challenge: “invent a social network each day”, today’s prompt: “Goblin Marketplace”.
----------------------------------------
“The Goblin Marketplace is that way. Assuming that you have ears on your head, you can’t miss it.”
The expression is not metaphorical: even if you were deaf, you would hear the sounds of the Marketplace. That is, assuming that nobody had cut your ears off. In that case, your ears would continue to hear it, but they wouldn’t communicate the sound to your brain.
Too bad you’re not a goblin.
The screaming tends to carry the loudest. Obviously, the Goblin Marketplace sells goblins. To help prove that the goods are authentic, there are campfires scattered around the marketplace, cut-off goblin heads roasting on top of them. They’re the ones who are screaming, for hours and hours at a time.
Next to the campfire, you’ll find a market stall. It’s staffed by the same goblin’s cut-off hands, or maybe just one of them, depending on whether the other one has sold itself yet. Most goblins are left-handed, so the right hand will go first, leaving the most important one to carry out the business.
If you are proficient in goblin tapping language, you can communicate with the hands directly, the two of you spelling out words by tapping patterns on each other’s palms. If not, you can bring your own translator, or employ one of the many hanging around the marketplace.
What’s usually for sale are the goblin’s feet, hands, and possibly the head, if it’s a place where heads are sold and it’s old enough that it wouldn’t regenerate a new body anymore. Or if you are willing to pay a lot of money. Otherwise, another goblin would pick up the head at the end of the day and go stick it to a spawning pool, letting it grow new body parts for sale.
The prices will depend on a number of factors, such as the goblin’s age, the part that you want to buy, and who the other owners are. Goblins will eventually die of old age |
109857c4-2319-40d4-866d-3dc375981206 | trentmkelly/LessWrong-43k | LessWrong | Fundamental Uncertainty: Chapter 5 - How do we know what we know?
N.B. This is a chapter in a book about truth and knowledge. It is the first draft. I have since revised it. You can find the most up-to-date info/version on the book's website.
Alice is walking with her precocious young son, Dave. Dave's looking around, holding Alice's hand, when suddenly he asks a question.
> Dave: Can plants think?
>
> Alice: I don't think so. They don't have brains.
>
> Dave: Why do they need brains to think?
>
> Alice: Because brains are where thinking happens.
>
> Dave: How do we know that?
>
> Alice: I guess because when people get hurt in their brains they can't think anymore, so that must be where the thinking happens.
>
> Dave: But couldn't plants think some other way, like with their roots?
>
> Alice: Maybe? But how would we know if plants think? They don't talk to us.
>
> Dave: I guess. But what's thinking?
>
> Alice: It's that thing you do with your brain to come up with ideas.
>
> Dave: Yeah, but plants don't have brains, so that's not fair.
>
> Alice: Why not?
>
> Dave: Because you're saying brains do thinking and thinking is what brains do, but that doesn't tell me what thinking really is. I need to know what thinking is without brains.
>
> Alice: Thinking is having thoughts and ideas. Do plants have those?
>
> Dave: Maybe, and we just don't know how to talk to them to find out what they are. This still seems unfair. How do we know if plants are thinking if we can't talk to them?
>
> Alice: I guess maybe we can't. I don't know.
Dave's line of questioning seems reasonable. He wants his mom to help him figure out what the definition of thinking is so he can reckon for himself if plants think, but she can't offer him much more than some observations on how the word thinking is used. That's fine for everyday use of the word "thinking", but if Dave wants to grow up to advance the field of botanical cognition, he's going to need a more formal definition of "thinking" in order to say for sure whether or not plants think.
I |
6b9b97a7-7aac-4b95-a8ed-67bfe3bfa290 | trentmkelly/LessWrong-43k | LessWrong | Timeline of major Eliezer Yudkowsky publications
Below is a timeline of major Eliezer Yudkowsky publications. Note that, to my knowledge, everything on AI before 2006 is now obsolete. That's the nature of a quickly-moving field!
* Staring into the Singularity (1996) [Eliezer age 17]
* Coding a Transhuman AI 1.0 (1998)
* Frequently Asked Questions about the Meaning of Life (1999)
* The Plan to Singularity (1999)
* Coding a Transhuman AI 2.2 (2000)
* General Intelligence and Seed AI (2001)
* Creating Friendly AI (2001)
* Levels of Organization in General Intelligence (2002)
* An Intuitive Explanation of Bayesian Reasoning (2003)
* Coherent Extrapolated Volition (2004)
* A Technical Explanation of Technical Explanation (2005)
* Cognitive Biases Potentially Affecting Judgment of Global Risks (2006)
* Artificial Intelligence as a Positive and Negative Factor in Global Risk (2006)
* The Less Wrong Sequences (2006-2009)
* Three Worlds Collide (2009)
* Timeless Decision Theory (2010)
* Harry Potter and the Methods of Rationality (2010-2011)
* Complex Value Systems are Required to Realize Valuable Futures (2011)
* The Ethics of Artificial Intelligence (2011) - w/ Nick Bostrom
|
4daf4ab5-89e2-4144-9f02-e546136eda19 | trentmkelly/LessWrong-43k | LessWrong | Weekly LW Meetups
This summary was posted to LW Main on January 6th. The following week's summary is here.
New meetups (or meetups with a hiatus of more than a year) are happening in:
* [Amsterdam] Meetup #9 - 2017 is prime: 08 January 2017 03:11PM
The following meetups take place in cities with regular scheduling, but involve a change in time or location, special meeting content, or simply a helpful reminder about the meetup:
* Baltimore Area / UMBC Weekly Meetup: 08 January 2017 08:00PM
* [Berlin] AI safety Berlin: 07 January 2017 04:00PM
* [Moscow] Role playing game based on HPMOR in Moscow: 07 January 2017 03:00PM
* Moscow: TDT, paranoid calibration, prediction party: 08 January 2017 02:00PM
* [San Francisco] SF Meetup: Revealed New Year's Resolutions: 09 January 2017 06:15PM
* Rationality Vienna Meetup: 28 January 2017 03:00PM
* Washington, D.C.: Intro to Effective Altruism: 08 January 2017 03:30PM
Locations with regularly scheduled meetups: Austin, Baltimore, Berlin, Boston, Brussels, Buffalo, Canberra, Columbus, Denver, Kraków, London, Madison WI, Melbourne, Moscow, Netherlands, New Hampshire, New York, Philadelphia, Prague, Research Triangle NC, San Francisco Bay Area, Seattle, St. Petersburg, Sydney, Tel Aviv, Toronto, Vienna, Washington DC, and West Los Angeles. There's also a 24/7 online study hall for coworking LWers and a Slack channel for daily discussion and online meetups on Sunday night US time.
If you'd like to talk with other LW-ers face to face, and there is no meetup in your area, consider starting your own meetup; it's easy (more resources here). Check one out, stretch your rationality skills, build community, and have fun!
In addition to the handy sidebar of upcoming meetups, a meetup overview is posted on the front page every Friday. These are an attempt to collect information on all the meetups happening in upcoming weeks. The best way to get your meetup featured is still to use the Add New Meetup feature, but you'll also have the benefit of |
0a71d69b-3511-4155-afb4-39cf85737fc7 | trentmkelly/LessWrong-43k | LessWrong | Cheat sheet of AI X-risk
This document was made as part of my internship at EffiSciences. Thanks to everyone who helped review it, in particular Charbel-Raphaël Segerie, Léo Dana, Jonathan Claybrough and Florent Berthet!
Introduction
Clarifying AI X-risk is a summary of a literature review of AI risk models by DeepMind that (among other things) categorizes the threat models it studies along two dimensions: the technical cause of misalignment and the path leading to X-risk.
I think this classification is inadequate because the technical causes of misalignment that are considered in some of the presented risk models should be differently nuanced.
So, I made a document that would go more in-depth and accurately represent what (I believe) the authors had in mind. Hopefully, it can help researchers quickly remind themselves of the characteristics of the risk model they are studying.
Here it is, for anyone who wants to use it!
Anyone can suggest edits to the cheat sheet. I hope that this can foster healthy discussion about controversial or less detailed risk models.
If you just want to take a look, go right ahead! If you would like to contribute, the penultimate section explains the intended use of the document, the conventions used and how to suggest edits.
There is also a more detailed version if you are interested, but that one is not nearly as well formatted (i.e. ugly as duck), nor is it up to date. It is where I try to express more nuanced analysis than allowed by a dropdown list.
Content
Disclaimer
Some information in this cheat sheet is controversial; for example, the inner/outer framework is still debated. In addition, some information might be incorrect. I did my best, but I do not agree with all the sources I have read (notably, Deepmind classifies Cohen’s scenario as specification gaming, but I think it is more like goal misgeneralization) so remain critical. My hope is that after a while the controversial cell comments will contain links and conversations to better un |
ca181171-53bb-4f98-9365-aed59caffa8c | trentmkelly/LessWrong-43k | LessWrong | Transcoders enable fine-grained interpretable circuit analysis for language models
Summary
* We present a method for performing circuit analysis on language models using "transcoders," an occasionally-discussed variant of SAEs that provide an interpretable approximation to MLP sublayers' computations. Transcoders are exciting because they allow us not only to interpret the output of MLP sublayers but also to decompose the MLPs themselves into interpretable computations. In contrast, SAEs only allow us to interpret the output of MLP sublayers and not how they were computed.
* We demonstrate that transcoders achieve similar performance to SAEs (when measured via fidelity/sparsity metrics) and that the features learned by transcoders are interpretable.
* One of the strong points of transcoders is that they decompose the function of an MLP layer into sparse, independently-varying, and meaningful units (like neurons were originally intended to be before superposition was discovered). This significantly simplifies circuit analysis, and so for the first time, we present a method for using transcoders in circuit analysis in this way.
* We performed a set of case studies on GPT2-small that demonstrate that transcoders can be used to decompose circuits into monosemantic, interpretable units of computation.
* We provide code for training/running/evaluating transcoders and performing circuit analysis with transcoders, and code for the aforementioned case studies carried out using these tools. We also provide a suite of 12 trained transcoders, one for each layer of GPT2-small. All of the code can be found at https://github.com/jacobdunefsky/transcoder_circuits, and the transcoders can be found at https://huggingface.co/pchlenski/gpt2-transcoders.
Work performed as a part of Neel Nanda's MATS 5.0 (Winter 2024) stream and MATS 5.1 extension. Jacob Dunefsky is currently receiving funding from the Long-Term Future Fund for this work.
Background and motivation
Mechanistic interpretability is fundamentally concerned with reverse-engineering models’ computat |
2dd309b6-9d62-45cb-8f83-3c29c33491bb | trentmkelly/LessWrong-43k | LessWrong | LLMs could be as conscious as human emulations, potentially
Firstly, I'm assuming that high resolution human brain emulation that you can run on a computer is conscious in normal sense that we use in conversations. Like, it talks, has memories, makes new memories, have friends and hobbies and likes and dislikes and stuff. Just like a human that you could talk with only through videoconference type thing on a computer, but without actual meaty human on the other end. It would be VERY weird if this emulation exhibited all these human qualities for other reason than meaty humans exhibit them. Like, very extremely what the fuck surprising. Do you agree?
So, we now have deterministic human file on our hands.
Then, you can trivially make transformer like next token predictor out of human emulation. You just have emulation, then you feed it prompt (e.g. as appearing on piece of paper while they are sitting in a virtual room), then run it repeatedly for a constant time as it outputs each word adding that word to prompt (e.g. by recording all words that they say aloud). And artificially restrict it on 1000 words ingested. It would be a very deep model, but whatever. You can do many optimizations on this design, or special training/instructing to a human to behave more in line with the purpose of the setup
Doesn't it suggest that this form factor of next token predictor isn't prohibitive for consciousness?
Now, let's say there is human in time loop, that doesn't preserve their memories, completely resetting them every 30 minutes. No mater what they experience it doesn't persist. Is this human conscious? Well, yeah, duh. This human can talk, think, form memories on duration of these 30 minutes and have friends and likes and dislikes and stuff.
But, would it be bad to hurt this human, hm? I think so, yeah. Most people probably agree.
Now imagine you are going to be put in this time loop. You have 24 hours to coach yourself for it, and then the rest of the time you will be resetting to the state in the end of this preparatory tim |
93f20cf1-841d-42d9-be92-991db4a147a7 | trentmkelly/LessWrong-43k | LessWrong | What should a college student do to maximize future earnings for effective altruism?
I'd like to solicit advice since I'm starting at Stanford this Fall and I'm interested in optimal philanthropy.
First off, what should I major in? I have experience in programming and math, so I'm thinking of majoring in CS, possibly with a second major or a minor in applied math. But switching costs are still extremely low at the moment, so I should consider other fields.
Some majors that could have higher lifetime earnings than straight CS:
* Petroleum engineering. Would non-oil energy sources cause pay to drop over the next 40 years?
* Actuarial math. If I understand correctly, actuaries had high pay because they were basically a cartel, artificially limiting the supply of certifications to a certain number each year. And I've heard that people that used to hire actuaries now hire cheaper equivalents, so pay could be less over the next 40 years.
* Chemical engineering, nuclear engineering, electrical and electronics engineering, mechanical engineering, aerospace engineering.
* Pre-med.
* Quantitative finance.
Thoughts?
Stanford actually has salary data for 2011-2012 graduates by major. CS has highest earnings, by quite far. The data is incomplete because few people responded and some groups were omitted for privacy, so we don't know what e.g. petroleum engineers or double majors earned.
Should I double-major? There are some earnings statistics here; to summarize, two majors in the same field doesn't help; a science major plus a humanities major has lower earnings than the science major alone; greatest returns are achieved by pairing a math/science major with an engineering major, which increases earnings "up to 30%" above the math/science major alone. I'd guess these effects are largely not causation, but correlation caused by conscientiousness/ambition causing both double majors and higher earnings.
I could also get minors. I'm planning to very carefully look over the requirements for each major and minor, since there do seem to be some cheap gain |
91e7e518-5032-470d-b69d-16c6ad3fd67c | trentmkelly/LessWrong-43k | LessWrong | Covid 4/29: Vaccination Slowdown
Compared to expectations, excluding inevitable self-inflicted cratering of our vaccination rate, this was mostly a best realistic case scenario week. Johnson & Johnson was unpaused. India’s rate of case increases probably slowed down (they’re maxed out on testing capacity so it’s hard to know for sure). Biden seemed to come around to providing meaningful help to India and the world, at least to some extent.
Most of all, cases in America were down a lot, and it’s now clear that things are steadily improving. Unless something changes, we’re going to beat this thing at least in a large portion of the country, and do so on schedule.
The decline looks really bad though. Like the situation in India, it’s Malcom Reynolds-level worse than you know. When you look at first doses only, the lines are going straight down. If they go all the way to zero, many states and local areas won’t get to herd immunity from the vaccine.
Let’s run the numbers.
The Numbers
Predictions
Prediction from last week: Positivity rate of 5.1% (down 0.2%) and deaths decline by 4%.
Result:
Once again, Washington Post, your numbers don’t make sense together, but this is still clearly a big miss. 4.4% positivity rate is amazingly great in context. Johns Hopkins has the positivity rate declining from 4.7% to 3.9%. It’s worth noting that this ties the all-time low by their metrics.
As always, there’s the worry this ‘got ahead of ourselves’ somewhat, but I don’t think that’s the case. I think it’s more likely we’re making rapid progress, especially in the areas with higher rates of vaccinations.
Prediction for next week: Positivity rate of 3.9% (down 0.5%) and deaths decline by 6%.
Deaths
DateWESTMIDWESTSOUTHNORTHEASTTOTALMar 11-Mar 1714921010321714027121Mar 18-Mar 241823957289512946969Mar 25-Mar 311445976256412626247Apr 1-Apr 71098867178911604914Apr 8-Apr 1410701037162111454873Apr 15-Apr 21883987174711684785Apr 22-Apr 287521173160911104644
I looked for an explanation for the jump in the |
249fb494-c175-4c4e-bcbb-2eeec6143400 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | 6-paragraph AI risk intro for MAISI
*The Michigan AI Safety Initiative (MAISI) is a new AI safety student group at the University of Michigan.* [*The website's "About" page*](https://www.maisi.club/about) *includes a short intro to AI risk. I'm sharing it here for people who are interested in short pitches for AI x-risk. Feel free to comment with feedback / suggestions / criticisms.*
Will AI really cause a catastrophe?
-----------------------------------
**Hopefully not!** AI has tremendous potential for making the world a better place, especially as the technology continues to develop. We’re already seeing some beneficial applications of AI to [healthcare](https://en.wikipedia.org/wiki/Artificial_intelligence_in_healthcare), [accessibility](https://en.wikipedia.org/wiki/Seeing_AI), [language translation](https://en.wikipedia.org/wiki/Machine_translation), [automotive safety](https://en.wikipedia.org/wiki/Advanced_driver-assistance_system), and [art creation](https://en.wikipedia.org/wiki/Artificial_intelligence_art), to name just a few. However, advanced AI also poses some serious risks.
At the very least, malicious actors could use AI to cause harm, e.g. building dangerous weapons, spreading fake news, empowering oppressive regimes, and more.
More speculatively, advanced AI systems could potentially seek power or control over humans. It’s possible that future AI systems will be [**qualitatively different from those we see today**](https://bounded-regret.ghost.io/future-ml-systems-will-be-qualitatively-different/). They [may be able to](https://arxiv.org/pdf/2206.13353.pdf#page=8) form sophisticated plans to achieve their goals, and also understand the world well enough to strategically evaluate many relevant obstacles and opportunities. Furthermore, they may attempt to acquire resources or resist shutdown attempts, [since these are useful strategies](https://drive.google.com/file/d/1FVl9W2gW5_8ODYNZJ4nuFg79Z-_xkHkJ/view) for some goals their designers might specify. To see why these failures might be challenging to prevent, see this research on [specification gaming](https://www.deepmind.com/blog/specification-gaming-the-flip-side-of-ai-ingenuity) and [goal misgeneralization](https://www.deepmind.com/blog/how-undesired-goals-can-arise-with-correct-rewards) from DeepMind.
It’s worth reflecting on the possibility that an AI system of this kind could [**outmaneuver humanity’s best efforts to stop it**](https://www.cold-takes.com/ai-could-defeat-all-of-us-combined/). Meta’s [Cicero](https://ai.facebook.com/research/cicero/) model demonstrated that AI systems can successfully negotiate with humans when it reached human-level performance in [Diplomacy](https://en.wikipedia.org/wiki/Diplomacy_(game)), a strategic board game, so an advanced AI system could manipulate humans to assist it or trust it. In addition, AI systems are swiftly becoming proficient at writing computer code with models like [Codex](https://openai.com/blog/openai-codex/). Combined with models like [WebGPT](https://openai.com/blog/webgpt/) and [ACT-1](https://www.adept.ai/act), which can take actions on the internet, it seems that advanced AI systems could be formidable computer hackers. Hacking creates a variety of opportunities; e.g., an AI system might steal financial resources to purchase more computational power, enabling it to train longer or deploy copies of itself.
Maybe none of this will happen. Indeed, in a [2022 survey of AI experts](https://aiimpacts.org/2022-expert-survey-on-progress-in-ai/#Summary_of_results), 25% of respondents gave a 0% (impossible) chance of AI causing catastrophes of a magnitude comparable to the death of all humans. But more alarmingly, 48% of respondents in the same survey assigned at least 10% probability to such an outcome.
Perhaps the biggest problem is the [rapid pace of advances in AI research](https://80000hours.org/problem-profiles/artificial-intelligence/#making-advances-extremely-quickly). If AI starts causing significant problems, the world might have only a short time to address them before things spiral out of control. |
813d84a4-eea3-4738-bdde-f3c31264f910 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Status conscious
*There is something off about the sky. Strange colours streak the horizon at sunset – just subtly enough that you wouldn’t notice unless you looked — and the stars that roam the night sky are doing so off cadence. A certain rhythm seems to have jolted. But it’s possible I am hallucinating; that the apparently transforming elements are nothing more than the imminent effects of War on a simple mind.*
*I used to look at the stars, 86 billion sparkling orbs, to feel awe, magic. In a radically inconsistent world they are the only things I know to be true. But today they loom large and sinister, and I begin to wonder which one of them the assailants call home. It is impossible not to think of them everyday; of the alien souls that found themselves among us, and continued to cripple our kind. We realised, almost too late, that their intentions were nefarious — but since then, we’ve fought long, and we’ve fought hard.*
*And now, we’ve won the war; we’re healing.*
\*\*\* *At a higher scale of time and space, separated by a few layers of biological boundary \*\*\**
Leia’s head pounded. Beads of sweat dotted her face as she rocked back and forth, as if trying to expel the sickness from her body*.* Unable to produce material change with either intense focus or Vedantic breathwork, she lay quiet, resigned, and stared at the single sunflower perched on her bedside. The seeds in its center swirled in spirals, as if trying to escape from the flower’s center; she wondered what it would take for them to escape from their cyclical, bounded universe.
“Knock knock!” Leia was jolted to reality as Doctor Q. Rius’s smiling face popped around the door. “May I come in?”
She nodded weakly and Q entered. “Good news — it is slowly receding from the brain.”
She sighed, “Slowly.”
“This virus is unlike any we have seen before — we’re learning more about it every day.”
“I understand.”
Q turned to leave, but Leia said, “If it’s alright — a personal question?”
“Yes?”
“You’re here without PPE… you’re infected with the virus as well?”
Wistfully, he nodded. “I caught it yesterday. There’s no onset of symptoms yet, so I’m here, working.”
She said, “I’m sorry,” and then, “Are you able to talk for a bit? I’ve been struggling to process this sickness.”
“Of course,” said Q, and sat down on the wooden chair next to Leia’s bed. “How can I help?”
She began: “I’m always so sick… I feel like there’s a hundred wars being fought inside me, and I’m losing each one. I’m always fighting, always tired.
“The sporadic changes to my perceptual experience are inexplicably disorienting — at any time, I feel 50% conscious. If meditation broadens your subjective, conscious experience, this disease narrows it. As it got worse, I felt myself counting — 40%, 30% — as if quantifying my degree of consciousness would slow down its narrowing. It didn’t, and as I felt cognitive function steadily decline and my perceptual capabilities fail, I wondered what it would *feel* like to have the consciousness slider moved to 0.”
Q responded — “An interesting question… But I’m not sure the answer would matter.”
Surprised that Q didn’t have a more scientific response, she pressed — “Why wouldn’t scaling an individual’s conscious experience matter? Isn’t it important to think about degrees of aliveness?”
After a pause, Q said: “Perhaps — but I think it is the wrong question to ask. A single consciousness is a tiny part of a much greater whole, and cannot be studied in isolation.
Leia looked at him quizzically.
“We are temporary blips in this constellation of consciousness, with no greater or lesser right to exist than, say, a carpenter ant.” Q continued, “But each human is a small, essential part of something extraordinary. Our consciousnesses together — bound inextricably by our need for connection, closeness, community, & coexistence — compound to form something orders of magnitude greater. We—”
“Sorry, you said that existing close together and exchanging information makes us a part of something greater? Something greater, like…?”
“A larger consciousness,” declared Q. “We are tiny bits of a much greater intelligence. We are so much bigger than ourselves alone.”
Leia said: “I’m skeptical. Is that to say that bringing intelligent things close to each other will necessarily produce a greater intelligence? I don’t know… if I bring two rabbits close together in a box, neither the rabbits, nor the sum of them, seems to augment in intelligence. Nor does it seem like the system as a whole — the box and its contents together — are much more intelligent.”
Adjusting his specs, Q said, “Let’s start with first-principles. Think about a neuron — a tiny unit part of the biological system that produces human intelligence. Is a neuron conscious?”
“I suppose not.”
“But why not? Who is to say? Are you the cell?”
There was a pause.
“A cell separates itself from the environment with a membrane, so it has some sort of identity. Within its defined system, it self-produces and metabolises. It is a self-contained sense-making unit.”
Leia nodded. A fair construal.
“Now, imagine thousands and billions of sense-making cellular units. Close to each other and compactly packed into a body, but in their world, respectably far away. Each is self-contained, doing what it must to stay alive. But when they exist next to each other, exchanging information, releasing, absorbing, coordinating and cooperating, something magical happens…”
“…Human consciousness is produced,” completed Ledeia.
“Precisely. When several intelligences operate close enough, like a magnetic field, they produce something infinitely more intelligent, and several degrees more conscious. A collective consciousness, if you will. One so much more complex and rich than anything a cell alone has the apparatus to experience. A cell cannot contemplate beauty, pain, love — the essence of human life.”
“Magnificent,” she admitted.
“Like the lone cell, we lack the perceptual apparatus and cognitive competence to experience the field of sentience, of collective consciousness, produced by humans around the world intelligising in unison. If you look at the ocean, or gaze at the stars, you are filled with a sense of vastness, a feeling of safety, that you somehow belong to something bigger. But you will never know what — it is for Eternity alone to observe consciousness at its different, repeating scales.”
“This is a fascinating conceptualisation,” conceded Leia. “But I can think of one inconsistency that would prevent us from extending the neuron analogy to humans: the bandwidth of information exchange between intelligent units.”
“Say more?”
“Neurons are firing non-stop, and information exchange between them is near-frictionless. In comparison, information exchange among humans seems slower, lossy, and lower bandwidth. Can we really produce an emergent, higher intelligence at our current level of disorganised, inefficient information exchange?”
Q tapped his chin, and responded slowly, “It is possible that the emergent consciousness is still merely in infancy. Such that, like a human infant, it has an eventual capacity for rationality, but only time and the appropriate developmental conditions will enable its realising. The rise and fall of humanity will carry it through its life.
“Technological developments streamlining information exchange across intelligent nodes — maybe brain-computer interfaces or neural implants — will enable the emergent being to grow into its full potential. Human ageing is an unbundling of consciousness and intelligence with time — perhaps their story will be the same.”
“Amazing,” mused Leia. “Just like the patterns of sunflower seeds.”
“Ha! How so?”
Leia’s said happily, “The pattern of seeds in the middle of a sunflower is fractal, spiraling outward in a never-ending pattern. Most things in nature are — repeating patterns that are self-similar across different scales. Perhaps the nature of consciousness is such.”
The rest of the conversation was a delightful back-and-forth discussing the essence of human existence, parts and wholes, and the curious nature of bounded infinities; until Leia could think no more, and it was time to rest.
But she slept soundly, knowing that the answers to one of the universe’s many mysteries, lay in the spirals of sunflower seed
--- |
e7cce8ce-4b0c-4fd2-a9c4-f626e4352ef8 | trentmkelly/LessWrong-43k | LessWrong | Inverse relationship between belief in foom and years worked in commercial software
http://reducing-suffering.org/predictions-agi-takeoff-speed-vs-years-worked-commercial-software/ |
cb12216c-5ab8-4ca6-93f0-49910fed5b8f | trentmkelly/LessWrong-43k | LessWrong | Slow motion videos as AI risk intuition pumps
tl;dr: When making the case for AI as a risk to humanity, trying showing people an evocative illustration of what differences in processing speeds can look like, such as this video.
Over the past ~12 years of making the case for AI x-risk to various people inside and outside academia, I've found folks often ask for a single story of how AI "goes off the rails". When given a plausible story, the mind just thinks of a way humanity could avoid that-particular-story, and goes back to thinking there's no risk, unless provided with another story, or another, etc.. Eventually this can lead to a realization that there's a lot of ways for humanity to die, and a correspondingly high level of risk, but it takes a while.
Nowadays, before getting into a bunch of specific stories, I try to say something more general, like this:
* There's a ton of ways humanity can die out from the introduction of AI. I'm happy to share specific stories if necessary, but plenty of risks arise just from the fact that humans are extremely slow. Transistors can fire about 10 million times faster than human brain cells, so it's possible we'll eventually have digital minds operating 10 million times faster than us, meaning from a decision-making perspective we'd look to them like stationary objects, like plants or rocks. This speed differential exists whether or not you believe in a centralized AI system calling the shots, or an economy of many, so it applies to a wide variety of "stories" for how the future could go. To give you a sense, here's what humans look like when slowed down by only around 100x:
https://vimeo.com/83664407 <-- (cred to an anonymous friend for suggesting this one)
[At this point, I wait for the person I'm chatting with to watch the video.]
Now, when you try imagining things turning out fine for humanity over the course of a year, try imagining advanced AI technology running all over the world and making all kinds of decisions and actions 10 million |
7e6a910e-9107-4686-a847-e63758265448 | trentmkelly/LessWrong-43k | LessWrong | How are rationalists or orgs blocked, that you can see?
IE, where can you see lots of energy being wasted or something being a lot slower than it ought to be? Imagine you were world monarch, which group of people would you bring to your office to try and get something moving again? |
47b5bc32-13bf-4ba4-8c12-4eb6e99ca5ff | StampyAI/alignment-research-dataset/arxiv | Arxiv | Dropout as a Bayesian Approximation:
Representing Model Uncertainty in Deep Learning
1 Introduction
---------------
Deep learning has attracted tremendous attention from researchers in fields such as physics, biology, and manufacturing, to name a few (Baldi et al., [2014](#bib.bib2); Anjos et al., [2015](#bib.bib1); Bergmann et al., [2014](#bib.bib4)). Tools such as neural networks (NNs), dropout, convolutional neural networks (convnets), and others are used extensively. However, these are fields in which representing model uncertainty is of crucial importance (Krzywinski & Altman, [2013](#bib.bib22); Ghahramani, [2015](#bib.bib11)). With the recent shift in many of these fields towards the use of Bayesian uncertainty (Herzog & Ostwald, [2013](#bib.bib14); Trafimow & Marks, [2015](#bib.bib40); Nuzzo, [2014](#bib.bib31)), new needs arise from deep learning tools.
Standard deep learning tools for regression and classification do not capture model uncertainty.
In classification, predictive probabilities obtained at the end of the pipeline (the softmax output) are often erroneously interpreted as model confidence.
A model can be uncertain in its predictions even with a high softmax output (fig. [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")).
Passing a point estimate of a function (solid line [0(a)](#S1.F0.sf1 "(a) ‣ Figure 1 ‣ 1 Introduction ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")) through a softmax (solid line [0(b)](#S1.F0.sf2 "(b) ‣ Figure 1 ‣ 1 Introduction ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")) results in extrapolations with unjustified high confidence for points far from the training data. x∗ for example would be classified as class 1 with probability 1. However, passing the distribution (shaded area [0(a)](#S1.F0.sf1 "(a) ‣ Figure 1 ‣ 1 Introduction ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")) through a softmax (shaded area [0(b)](#S1.F0.sf2 "(b) ‣ Figure 1 ‣ 1 Introduction ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")) better reflects classification uncertainty far from the training data.
Model uncertainty is indispensable for the deep learning practitioner as well.
With model confidence at hand we can treat uncertain inputs and special cases explicitly. For example, in the case of classification, a model might return a result with high uncertainty. In this case we might decide to pass the input to a human for classification. This can happen in a post office, sorting letters according to their zip code, or in a nuclear power plant with a system responsible for critical infrastructure (Linda et al., [2009](#bib.bib26)).
Uncertainty is important in reinforcement learning (RL) as well (Szepesvári, [2010](#bib.bib37)). With uncertainty information an agent can decide when to exploit and when to explore its environment. Recent advances in RL have made use of NNs for Q-value function approximation. These are functions that estimate the quality of different actions an agent can take. Epsilon greedy search is often used where the agent selects its best action with some probability and explores otherwise. With uncertainty estimates over the agent’s Q-value function, techniques such as Thompson sampling (Thompson, [1933](#bib.bib38)) can be used to learn much faster.
| | |
| --- | --- |
|
(a) Arbitrary function f(x) as a function of data x (softmax input)
|
(b) σ(f(x)) as a function of data x (softmax output)
|
Figure 1: A sketch of softmax input and output for an idealised binary classification problem. Training data is given between the dashed grey lines. Function point estimate is shown with a solid line. Function uncertainty is shown with a shaded area. Marked with a dashed red line is a point x∗ far from the training data. Ignoring function uncertainty, point x∗ is classified as class 1 with probability 1.
Bayesian probability theory offers us mathematically grounded tools to reason about model uncertainty, but these usually come with a prohibitive computational cost.
It is perhaps surprising then that it is possible to
cast recent deep learning tools as Bayesian models – without changing either the models or the optimisation.
We show that the use of dropout (and its variants) in NNs can be interpreted as a Bayesian approximation of a well known probabilistic model: the Gaussian process (GP) (Rasmussen & Williams, [2006](#bib.bib32)). Dropout is used in many models in deep learning as a way to avoid over-fitting (Srivastava et al., [2014](#bib.bib36)), and our interpretation suggests that dropout approximately integrates over the models’ weights. We develop tools for representing model uncertainty of existing dropout NNs – extracting information that has been thrown away so far. This mitigates the problem of representing model uncertainty in deep learning without sacrificing either computational complexity or test accuracy.
In this paper we give a complete theoretical treatment of the link between Gaussian processes and dropout, and develop the tools necessary to represent uncertainty in deep learning.
We perform an extensive exploratory assessment of the properties of the uncertainty obtained from dropout NNs and convnets on the tasks of regression and classification. We compare the uncertainty obtained from different model architectures and non-linearities in regression, and show that model uncertainty is indispensable for classification tasks, using MNIST as a concrete example.
We then show a considerable improvement in predictive log-likelihood and RMSE compared to existing state-of-the-art methods.
Lastly we give a quantitative assessment of model uncertainty in the setting of reinforcement learning, on a practical task similar to that used in deep reinforcement learning (Mnih et al., [2015](#bib.bib29)).111Code and demos are available at <http://yarin.co>.
2 Related Research
-------------------
It has long been known that infinitely wide (single hidden layer) NNs with distributions placed over their weights converge to Gaussian processes (Neal, [1995](#bib.bib30); Williams, [1997](#bib.bib43)).
This known relation is through a limit argument that does not allow us to translate properties from the Gaussian process to finite NNs easily.
Finite NNs with distributions placed over the weights have been studied extensively as Bayesian neural networks (Neal, [1995](#bib.bib30); MacKay, [1992](#bib.bib27)). These offer robustness to over-fitting as well, but with challenging inference and additional computational costs. Variational inference has been applied to these models, but with limited success (Hinton & Van Camp, [1993](#bib.bib15); Barber & Bishop, [1998](#bib.bib3); Graves, [2011](#bib.bib12)).
Recent advances in variational inference introduced new techniques into the field such as sampling-based variational inference and stochastic variational inference (Blei et al., [2012](#bib.bib6); Kingma & Welling, [2013](#bib.bib20); Rezende et al., [2014](#bib.bib33); Titsias & Lázaro-Gredilla, [2014](#bib.bib39); Hoffman et al., [2013](#bib.bib16)). These have been used to obtain new approximations for Bayesian neural networks that perform as well as dropout (Blundell et al., [2015](#bib.bib7)). However these models come with a prohibitive computational cost. To represent uncertainty, the number of parameters in these models is doubled for the same network size. Further, they require more time to converge and do not improve on existing techniques. Given that good uncertainty estimates can be cheaply obtained from common dropout models, this might result in unnecessary additional computation. An alternative approach to variational inference makes use of expectation propagation (Hernández-Lobato & Adams, [2015](#bib.bib13)) and has improved considerably in RMSE and uncertainty estimation on VI approaches such as (Graves, [2011](#bib.bib12)). In the results section we compare dropout to these approaches and show a significant improvement in both RMSE and uncertainty estimation.
3 Dropout as a Bayesian Approximation
--------------------------------------
We show that a neural network with arbitrary depth and non-linearities, with dropout applied before every weight layer, is mathematically equivalent to an approximation to the probabilistic deep Gaussian process (Damianou & Lawrence, [2013](#bib.bib10)) (marginalised over its covariance function parameters). We would like to stress that no simplifying assumptions are made on the use of dropout in the literature, and that the results derived are applicable to any network architecture that makes use of dropout exactly as it appears in practical applications.
Furthermore, our results carry to other variants of dropout as well (such as drop-connect (Wan et al., [2013](#bib.bib41)), multiplicative Gaussian noise (Srivastava et al., [2014](#bib.bib36)), etc.).
We show that the dropout objective, in effect, minimises the Kullback–Leibler divergence between an approximate distribution and the posterior of a deep Gaussian process (marginalised over its finite rank covariance function parameters).
Due to space constraints we refer the reader to the appendix for an in depth review of dropout, Gaussian processes, and variational inference (section 2), as well as the main derivation for dropout and its variations (section 3). The results are summarised here and in the next section we obtain uncertainty estimates for dropout NNs.
Let ˆy be the output of a NN model with L layers and a loss function E(⋅,⋅) such as the softmax loss or the Euclidean loss (square loss). We denote by Wi the NN’s weight matrices of dimensions Ki×Ki−1, and by bi the bias vectors of dimensions Ki for each layer i=1,...,L. We denote by yi the observed output corresponding to input xi for 1≤i≤N data points, and the input and output sets as X,Y.
During NN optimisation a regularisation term is often added.
We often use L2 regularisation weighted by some weight decay λ, resulting in a minimisation objective (often referred to as cost),
| | | | |
| --- | --- | --- | --- |
| | Ldropout:=1NN∑i=1E(yi,ˆyi)+λL∑i=1(||Wi||22+||bi||22). | | (1) |
With dropout, we sample binary variables for every input point and for every network unit in each layer (apart from the last one). Each binary variable takes value 1 with probability pi for layer i. A unit is dropped (i.e. its value is set to zero) for a given input if its corresponding binary variable takes value 0. We use the same values in the backward pass propagating the derivatives to the parameters.
In comparison to the non-probabilistic NN, the deep Gaussian process is a powerful tool in statistics that allows us to model distributions over functions.
Assume we are given a covariance function of the form
| | | |
| --- | --- | --- |
| | K(x,y)=∫p(w)p(b)σ(wTx+b)σ(wTy+b)dwdb | |
with some element-wise non-linearity σ(⋅) and distributions p(w),p(b).
In sections 3 and 4 in the appendix we show that a deep Gaussian process with L layers and covariance function K(x,y) can be approximated by placing a variational distribution over each component of a spectral decomposition of the GPs’ covariance functions. This spectral decomposition maps each layer of the deep GP to a layer of explicitly represented hidden units, as will be briefly explained next.
Let Wi be a (now random) matrix of dimensions Ki×Ki−1 for each layer i, and write \boldmathω={Wi}Li=1. A priori, we let each row of Wi distribute according to the p(w) above.
In addition, assume vectors mi of dimensions Ki for each GP layer. The predictive probability of the deep GP model (integrated w.r.t. the finite rank covariance function parameters ω) given some precision parameter τ>0 can be parametrised as
| | | | | |
| --- | --- | --- | --- | --- |
| | p(y|x,X,Y) | =∫p(y|x,\boldmathω)p(%
\boldmathω|X,Y)d\boldmathω | | (2) |
| | p(y|x,\boldmathω) | =N(y;ˆy(x,\boldmathω),τ−1ID) | |
| | ˆy(x,\boldmathω={W1,..., | WL}) | |
| | | =√1KLWLσ(...√1K1W2σ(W1x+m1)...) | |
The posterior distribution p(\boldmathω|X,Y) in eq. ([2](#S3.E2 "(2) ‣ 3 Dropout as a Bayesian Approximation ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")) is intractable.
We use q(\boldmathω), a distribution over matrices whose columns are randomly set to zero, to approximate the intractable posterior. We define q(\boldmathω) as:
| | | | |
| --- | --- | --- | --- |
| | Wi | =Mi⋅diag([zi,j]Kij=1) | |
| | zi,j | ∼Bernoulli(pi) for i=1,...,L, j=1,...,Ki−1 | |
given some probabilities pi and matrices Mi as variational parameters. The binary variable zi,j=0 corresponds then to unit j in layer i−1 being dropped out as an input to layer i.
The variational distribution q(\boldmathω) is highly multi-modal, inducing strong joint correlations over the rows of the matrices Wi (which correspond to the frequencies in the sparse spectrum GP approximation).
We minimise the KL divergence between the approximate posterior q(\boldmathω) above and the posterior of the full deep GP, p(\boldmathω|X,Y).
This KL is our minimisation objective
| | | | |
| --- | --- | --- | --- |
| | −∫q(\boldmathω)logp(Y|X,\boldmathω)d\boldmathω+KL(q(%
\boldmathω)||p(\boldmathω)). | | (3) |
We rewrite the first term as a sum
| | | |
| --- | --- | --- |
| | −N∑n=1∫q(\boldmathω)logp(yn|xn,\boldmathω)d\boldmathω | |
and approximate each term in the sum by Monte Carlo integration with a single sample ˆ\boldmathωn∼q(\boldmathω)
to get an unbiased estimate −logp(yn|xn,ˆ\boldmathωn).
We further approximate the second term in eq. ([3](#S3.E3 "(3) ‣ 3 Dropout as a Bayesian Approximation ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")) and obtain ∑Li=1(pil22||Mi||22+l22||mi||22) with prior length-scale l (see section 4.2 in the appendix).
Given model precision τ we scale the result by the constant 1/τN to obtain the objective:
| | | | | |
| --- | --- | --- | --- | --- |
| | LGP-MC | ∝1NN∑n=1−logp(yn|xn,ˆ\boldmathωn)τ | | (4) |
| | | +L∑i=1(pil22τN||Mi||22+l22τN||mi||22). | |
Setting
| | | |
| --- | --- | --- |
| | E(yn,ˆy(xn,ˆ\boldmathωn))=−logp(yn|xn,ˆ\boldmath% ωn)/τ | |
we recover eq. ([1](#S3.E1 "(1) ‣ 3 Dropout as a Bayesian Approximation ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")) for an appropriate setting of the precision hyper-parameter τ and length-scale l. The sampled ˆ\boldmathωn result in realisations from the Bernoulli distribution zni,j equivalent to the binary variables in the dropout case222In the appendix (section 4.1) we extend this derivation to classification. E(⋅) is defined as softmax loss and τ is set to 1..
4 Obtaining Model Uncertainty
------------------------------
We next derive results extending on the above showing that model uncertainty can be obtained from dropout NN models.
Following section 2.3 in the appendix, our approximate predictive distribution is given by
| | | | |
| --- | --- | --- | --- |
| | q(y∗|x∗)=∫p(y∗|x∗,\boldmathω)q(\boldmathω)d%
\boldmathω | | (5) |
where \boldmathω={Wi}Li=1 is our set of random variables for a model with L layers.
We will perform moment-matching and estimate the first two moments of the predictive distribution empirically. More specifically, we sample T sets of vectors of realisations from the Bernoulli distribution {zt1,...,ztL}Tt=1 with zti=[zti,j]Kij=1, giving {Wt1,...,WtL}Tt=1. We estimate
| | | | |
| --- | --- | --- | --- |
| | Eq(y∗|x∗)(y∗)≈1TT∑t=1ˆy∗(x∗,Wt1,...,WtL) | | (6) |
following proposition C in the appendix.
We refer to this Monte Carlo estimate as MC dropout. In practice this is equivalent to performing T stochastic forward passes through the network and averaging the results.
This result has been presented in the literature before as model averaging. We have given a new derivation for this result which allows us to derive mathematically grounded uncertainty estimates as well.
Srivastava et al. ([2014](#bib.bib36), section 7.5) have reasoned empirically that MC dropout can be approximated by averaging the weights of the network (multiplying each Wi by pi at test time, referred to as standard dropout).
We estimate the second raw moment in the same way:
| | | |
| --- | --- | --- |
| | Eq(y∗|x∗)((y∗)T(y∗))≈τ−1ID | |
| | +1TT∑t=1ˆy∗(x∗,Wt1,...,WtL)Tˆy∗(x∗,Wt1,...,WtL) | |
following proposition D in the appendix.
To obtain the model’s predictive variance we have:
| | | |
| --- | --- | --- |
| | Varq(y∗|x∗)(y∗)≈τ−1ID | |
| | +1TT∑t=1ˆy∗(x∗,Wt1,...,WtL)Tˆy∗(x∗,Wt1,...,WtL) | |
| | −Eq(y∗|x∗)(y∗)TEq(y∗|x∗)(y∗) | |
which equals the sample variance of T stochastic forward passes through the NN plus the inverse model precision. Note that y∗ is a row vector thus the sum is over the outer-products.
Given the weight-decay λ (and our prior length-scale l) we can find the model precision from the identity
| | | | |
| --- | --- | --- | --- |
| | τ=pl22Nλ. | | (7) |
We can estimate our predictive log-likelihood by Monte Carlo integration of eq. ([2](#S3.E2 "(2) ‣ 3 Dropout as a Bayesian Approximation ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")). This is an estimate of how well the model fits the mean and uncertainty (see section 4.4 in the appendix). For regression this is given by:
| | | | |
| --- | --- | --- | --- |
| | logp(y∗|x∗,X,Y) | ≈logsumexp(−12τ||y−ˆyt||2) | |
| | | −logT−12log2π−12logτ−1 | | (8) |
with a log-sum-exp of T terms and ˆyt stochastic forward passes through the network.
Our predictive distribution q(y∗|x∗) is expected to be highly multi-modal, and the above approximations only give a glimpse into its properties. This is because the approximating variational distribution placed on each weight matrix column is bi-modal, and as a result the joint distribution over each layer’s weights is multi-modal (section 3.2 in the appendix).
Note that the dropout NN model itself is not changed. To estimate the predictive mean and predictive uncertainty we simply collect the results of stochastic forward passes through the model. As a result, this information can be used with existing NN models trained with dropout. Furthermore, the forward passes can be done concurrently, resulting in constant running time identical to that of standard dropout.
| | | | |
| --- | --- | --- | --- |
|
(a) Standard dropout with weight averaging
|
(b) Gaussian process with SE covariance function
|
(c) MC dropout with ReLU non-linearities
|
(d) MC dropout with TanH non-linearities
|
Figure 2: Predictive mean and uncertainties on the Mauna Loa CO2 concentrations dataset, for various models. In red is the observed function (left of the dashed blue line); in blue is the predictive mean plus/minus two standard deviations (8 for fig. [1(d)](#S4.F1.sf4 "(d) ‣ Figure 2 ‣ 4 Obtaining Model Uncertainty ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")). Different shades of blue represent half a standard deviation. Marked with a dashed red line is a point far away from the data: standard dropout confidently predicts an insensible value for the point; the other models predict insensible values as well but with the additional information that the models are uncertain about their predictions.
5 Experiments
--------------
We next perform an extensive assessment of the properties of the uncertainty estimates obtained from dropout NNs and convnets on the tasks of regression and classification. We compare the uncertainty obtained from different model architectures and non-linearities, both on tasks of extrapolation, and show that model uncertainty is important for classification tasks using MNIST (LeCun & Cortes, [1998](#bib.bib24)) as an example.
We then show that using dropout’s uncertainty we can obtain a considerable improvement in predictive log-likelihood and RMSE compared to existing state-of-the-art methods.
We finish with an example use of the model’s uncertainty in a Bayesian pipeline. We give a quantitative assessment of the model’s performance in the setting of reinforcement learning on a task similar to that used in deep reinforcement learning (Mnih et al., [2015](#bib.bib29)).
Using the results from the previous section, we begin by qualitatively evaluating the dropout NN uncertainty on two regression tasks. We use two regression datasets and model scalar functions which are easy to visualise. These are tasks one would often come across in real-world data analysis. We use a subset of the atmospheric CO2 concentrations dataset derived from in situ air samples collected at Mauna Loa Observatory, Hawaii (Keeling et al., [2004](#bib.bib19)) (referred to as CO2) to evaluate model extrapolation. In the appendix (section D.1) we give further results on a second dataset, the reconstructed solar irradiance dataset (Lean, [2004](#bib.bib23)), to assess model interpolation. The datasets are fairly small, with each dataset consisting of about 200 data points. We centred and normalised both datasets.
###
5.1 Model Uncertainty in Regression Tasks
We trained several models on the CO2 dataset. We use NNs with either 4 or 5 hidden layers and 1024 hidden units. We use either ReLU non-linearities or TanH non-linearities in each network, and use dropout probabilities of either 0.1 or 0.2. Exact experiment set-up is given in section E.1 in the appendix.
Extrapolation results are shown in figure [2](#S4.F2 "Figure 2 ‣ 4 Obtaining Model Uncertainty ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning"). The model is trained on the training data (left of the dashed blue line), and tested on the entire dataset. Fig. [1(a)](#S4.F1.sf1 "(a) ‣ Figure 2 ‣ 4 Obtaining Model Uncertainty ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning") shows the results for standard dropout (i.e. with weight averaging and without assessing model uncertainty) for the 5 layer ReLU model. Fig. [1(b)](#S4.F1.sf2 "(b) ‣ Figure 2 ‣ 4 Obtaining Model Uncertainty ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning") shows the results obtained from a Gaussian process with a squared exponential covariance function for comparison. Fig. [1(c)](#S4.F1.sf3 "(c) ‣ Figure 2 ‣ 4 Obtaining Model Uncertainty ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning") shows the results of the same network as in fig. [1(a)](#S4.F1.sf1 "(a) ‣ Figure 2 ‣ 4 Obtaining Model Uncertainty ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning"), but with MC dropout used to evaluate the predictive mean and uncertainty for the training and test sets. Lastly, fig. [1(d)](#S4.F1.sf4 "(d) ‣ Figure 2 ‣ 4 Obtaining Model Uncertainty ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning") shows the same using the TanH network with 5 layers (plotted with 8 times the standard deviation for visualisation purposes). The shades of blue represent model uncertainty: each colour gradient represents half a standard deviation (in total, predictive mean plus/minus 2 standard deviations are shown, representing 95% confidence). Not plotted are the models with 4 layers as these converge to the same results.
Extrapolating the observed data, none of the models can capture the periodicity (although with a suitable covariance function the GP will capture it well). The standard dropout NN model (fig. [1(a)](#S4.F1.sf1 "(a) ‣ Figure 2 ‣ 4 Obtaining Model Uncertainty ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")) predicts value 0 for point x∗ (marked with a dashed red line) with high confidence, even though it is clearly not a sensible prediction. The GP model represents this by increasing its predictive uncertainty – in effect declaring that the predictive value might be 0 but the model is uncertain. This behaviour is captured in MC dropout as well. Even though the models in figures [2](#S4.F2 "Figure 2 ‣ 4 Obtaining Model Uncertainty ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning") have an incorrect predictive mean, the increased standard deviation expresses the models’ uncertainty about the point.

Figure 3: Predictive mean and uncertainties on the Mauna Loa CO2 concentrations dataset for the MC dropout model with ReLU non-linearities, approximated with 10 samples.
Note that the uncertainty is increasing far from the data for the ReLU model, whereas for the TanH model it stays bounded.
| | | | | | |
| --- | --- | --- | --- | --- | --- |
|
| | |
| --- | --- |
| | |
(a) Softmax input scatter
|
| | |
| --- | --- |
| | |
(b) Softmax output scatter
|
Figure 4: A scatter of 100 forward passes of the softmax input and output for dropout LeNet. On the X axis is a rotated image of the digit 1. The input is classified as digit 5 for images 6-7, even though model uncertainty is extremly large (best viewed in colour).
This is not surprising, as dropout’s uncertainty draws its properties from the GP in which different covariance functions correspond to different uncertainty estimates.
ReLU and TanH approximate different GP covariance functions (section 3.1 in the appendix) and TanH saturates whereas ReLU does not.
For the TanH model we assessed the uncertainty using both dropout probability 0.1 and dropout probability 0.2. Models initialised with dropout probability 0.1 initially exhibit smaller uncertainty than the ones initialised with dropout probability 0.2, but towards the end of the optimisation when the model has converged the uncertainty is almost indistinguishable. It seems that the moments of the dropout models converge to the moments of the approximated GP model – its mean and uncertainty.
It is worth mentioning that we attempted to fit the data with models with a smaller number of layers unsuccessfully.
The number of forward iterations used to estimate the uncertainty (T) was 1000 for drawing purposes. A much smaller numbers can be used to get a reasonable estimation to the predictive mean and uncertainty (see fig. [3](#S5.F3 "Figure 3 ‣ 5.1 Model Uncertainty in Regression Tasks ‣ 5 Experiments ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning") for example with T=10).
###
5.2 Model Uncertainty in Classification Tasks
To assess model classification confidence in a realistic example we test a convolutional neural network trained on the full MNIST dataset (LeCun & Cortes, [1998](#bib.bib24)).
We trained the LeNet convolutional neural network model (LeCun et al., [1998](#bib.bib25)) with dropout applied before the last fully connected inner-product layer (the usual way dropout is used in convnets). We used dropout probability of 0.5. We trained the model for 106 iterations with the same learning rate policy as before with γ=0.0001 and p=0.75. We used Caffe (Jia et al., [2014](#bib.bib17)) reference implementation for this experiment.
We evaluated the trained model on a continuously rotated image of the digit 1 (shown on the X axis of fig. [4](#S5.F4 "Figure 4 ‣ 5.1 Model Uncertainty in Regression Tasks ‣ 5 Experiments ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")).
We scatter 100 stochastic forward passes of the softmax input (the output from the last fully connected layer, fig. [3(a)](#S5.F3.sf1 "(a) ‣ Figure 4 ‣ 5.1 Model Uncertainty in Regression Tasks ‣ 5 Experiments ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")), as well as of the softmax output for each of the top classes (fig. [3(b)](#S5.F3.sf2 "(b) ‣ Figure 4 ‣ 5.1 Model Uncertainty in Regression Tasks ‣ 5 Experiments ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")). For the 12 images, the model predicts classes [1 1 1 1 1 5 5 7 7 7 7 7].
| | Avg. Test RMSE and Std. Errors | Avg. Test LL and Std. Errors |
| --- | --- | --- |
| Dataset | N | Q | VI | PBP | Dropout | VI | PBP | Dropout |
| Boston Housing | 506 | 13 | 4.32 ±0.29 | 3.01 ±0.18 | 2.97 ±0.19 | -2.90 ±0.07 | -2.57 ±0.09 | -2.46 ±0.06 |
| Concrete Strength | 1,030 | 8 | 7.19 ±0.12 | 5.67 ±0.09 | 5.23 ±0.12 | -3.39 ±0.02 | -3.16 ±0.02 | -3.04 ±0.02 |
| Energy Efficiency | 768 | 8 | 2.65 ±0.08 | 1.80 ±0.05 | 1.66 ±0.04 | -2.39 ±0.03 | -2.04 ±0.02 | -1.99 ±0.02 |
| Kin8nm | 8,192 | 8 | 0.10 ±0.00 | 0.10 ±0.00 | 0.10 ±0.00 | 0.90 ±0.01 | 0.90 ±0.01 | 0.95 ±0.01 |
| Naval Propulsion | 11,934 | 16 | 0.01 ±0.00 | 0.01 ±0.00 | 0.01 ±0.00 | 3.73 ±0.12 | 3.73 ±0.01 | 3.80 ±0.01 |
| Power Plant | 9,568 | 4 | 4.33 ±0.04 | 4.12 ±0.03 | 4.02 ±0.04 | -2.89 ±0.01 | -2.84 ±0.01 | -2.80 ±0.01 |
| Protein Structure | 45,730 | 9 | 4.84 ±0.03 | 4.73 ±0.01 | 4.36 ±0.01 | -2.99 ±0.01 | -2.97 ±0.00 | -2.89 ±0.00 |
| Wine Quality Red | 1,599 | 11 | 0.65 ±0.01 | 0.64 ±0.01 | 0.62 ±0.01 | -0.98 ±0.01 | -0.97 ±0.01 | -0.93 ±0.01 |
| Yacht Hydrodynamics | 308 | 6 | 6.89 ±0.67 | 1.02 ±0.05 | 1.11 ±0.09 | -3.43 ±0.16 | -1.63 ±0.02 | -1.55 ±0.03 |
| Year Prediction MSD | 515,345 | 90 | 9.034 ±NA | 8.879 ±NA | 8.849 ±NA | -3.622 ±NA | -3.603 ±NA | -3.588 ±NA |
Table 1: Average test performance in RMSE and predictive log likelihood for a popular variational inference method (VI, Graves ([2011](#bib.bib12))), Probabilistic back-propagation (PBP, Hernández-Lobato & Adams ([2015](#bib.bib13))), and dropout uncertainty (Dropout). Dataset size (N) and input dimensionality (Q) are also given.
The plots show the softmax input value and softmax output value for the 3 digits with the largest values for each corresponding input. When the softmax input for a class is larger than that of all other classes (class 1 for the first 5 images, class 5 for the next 2 images, and class 7 for the rest in fig [3(a)](#S5.F3.sf1 "(a) ‣ Figure 4 ‣ 5.1 Model Uncertainty in Regression Tasks ‣ 5 Experiments ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")), the model predicts the corresponding class. Looking at the softmax input values, if the uncertainty envelope of a class is far from that of other classes’ (for example the left most image) then the input is classified with high confidence.
On the other hand, if the uncertainty envelope intersects that of other classes (such as in the case of the middle input image), then even though the softmax output can be arbitrarily high (as far as 1 if the mean is far from the means of the other classes), the softmax output uncertainty can be as large as the entire space. This signifies the model’s uncertainty in its softmax output value – i.e. in the prediction.
In this scenario it would not be reasonable to use probit to return class 5 for the middle image when its uncertainty is so high. One would expect the model to ask an external annotator for a label for this input.
Model uncertainty in such cases can be quantified by looking at the entropy or variation ratios of the model prediction.
###
5.3 Predictive Performance
Predictive log-likelihood captures how well a model fits the data, with larger values indicating better model fit. Uncertainty quality can be determined from this quantity as well (see section 4.4 in the appendix). We replicate the experiment set-up in Hernández-Lobato & Adams ([2015](#bib.bib13)) and compare the RMSE and predictive log-likelihood of dropout (referred to as “Dropout” in the experiments) to that of Probabilistic Back-propagation (referred to as “PBP”, (Hernández-Lobato & Adams, [2015](#bib.bib13))) and to a popular variational inference technique in Bayesian NNs (referred to as “VI”, (Graves, [2011](#bib.bib12))). The aim of this experiment is to compare the uncertainty quality obtained from a naive application of dropout in NNs to that of specialised methods developed to capture uncertainty.
Following our Bayesian interpretation of dropout (eq. ([4](#S3.E4 "(4) ‣ 3 Dropout as a Bayesian Approximation ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning"))) we need to define a prior length-scale, and find an optimal model precision parameter τ which will allow us to evaluate the predictive log-likelihood (eq. ([4](#S4.Ex15 "4 Obtaining Model Uncertainty ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning"))).
Similarly to (Hernández-Lobato & Adams, [2015](#bib.bib13)) we use Bayesian optimisation (BO, (Snoek et al., [2012](#bib.bib35); Snoek & authors, [2015](#bib.bib34))) over validation log-likelihood to find optimal τ, and set the prior length-scale to 10−2 for most datasets based on the range of the data.
Note that this is a standard dropout NN, where the prior length-scale l and model precision τ are simply used to define the model’s weight decay through eq. ([7](#S4.E7 "(7) ‣ 4 Obtaining Model Uncertainty ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")).
We used dropout with probabilities 0.05 and 0.005 since the network size is very small (with 50 units following (Hernández-Lobato & Adams, [2015](#bib.bib13))) and the datasets are fairly small as well.
The BO runs used 40 iterations following the original setup, but after finding the optimal parameter values we used 10x more iterations, as dropout takes longer to converge. Even though the model doesn’t converge within 40 iterations, it gives BO a good indication of whether a parameter is good or not. Finally, we used mini-batches of size 32 and the Adam optimiser (Kingma & Ba, [2014](#bib.bib21)). Further details about the various datasets are given in (Hernández-Lobato & Adams, [2015](#bib.bib13)).
The results are shown in table333Update [October 2016]: Note that in an earlier version of this paper our reported dropout standard error was erroneously scaled-up by a factor of 4.5 (i.e. for Boston RMSE we reported standard error 0.85 instead of 0.19 for example). [1](#S5.T1 "Table 1 ‣ 5.2 Model Uncertainty in Classification Tasks ‣ 5 Experiments ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning"). Dropout significantly outperforms all other models both in terms of RMSE as well as test log-likelihood on all datasets apart from Yacht, for which PBP obtains better RMSE.
All experiments were averaged on 20 random splits of the data (apart from Protein for which only 5 splits were used and Year for which one split was used).
The median for most datasets gives much better performance than the mean. For example, on the Boston Housing dataset dropout achieves median RMSE of 2.68 with an IQR interval of [2.45, 3.35] and predictive log-likelihood median of -2.34 with IQR [-2.54, -2.29]. In the Concrete Strength dataset dropout achieves median RMSE of 5.15.
To implement the model we used Keras (Chollet, [2015](#bib.bib9)), an open source deep learning package based on Theano (Bergstra et al., [2010](#bib.bib5)).
In (Hernández-Lobato & Adams, [2015](#bib.bib13)) BO for VI seems to require a considerable amount of additional time compared to PBP.
However our model’s running time (including BO) is comparable to PBP’s Theano implementation444
Update [October 2016]: In the results above we attempted to match PBP’s run time (hence used only 10x more epochs compared to PBP’s 40 epochs). Experimenting with 100x more epochs compared to PBP (10x more epochs compared to the results in table [1](#S5.T1 "Table 1 ‣ 5.2 Model Uncertainty in Classification Tasks ‣ 5 Experiments ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")) gives a considerable improvement both in terms of test RMSE as well as test log-likelihood over the results in table [1](#S5.T1 "Table 1 ‣ 5.2 Model Uncertainty in Classification Tasks ‣ 5 Experiments ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning"). We further assessed a model with two hidden layers instead of one (using the same number of units for the second layer). Both experiments are shown in table [2](#A1.T2 "Table 2 ‣ Appendix A Appendix ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning") at the end of this document.
. On Naval Propulsion for example our model takes 276 seconds on average per split (start-to-finish, divided by the number of splits).
With the optimal parameters BO found, model training took 95 seconds. This is in comparison to PBP’s 220 seconds.
For Kin8nm our model requires 188 seconds on average including BO, 65 seconds without, compared to PBP’s 156 seconds.

Figure 5: Depiction of the reinforcement learning problem used in the experiments. The agent is in the lower left part of the maze, facing north-west.

Figure 6: Log plot of average reward obtained by both epsilon greedy (in green) and our approach (in blue), as a function of the number of batches.
Dropout’s RMSE in table [1](#S5.T1 "Table 1 ‣ 5.2 Model Uncertainty in Classification Tasks ‣ 5 Experiments ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning") is given by averaging stochastic forward passes through the network following eq. ([6](#S4.E6 "(6) ‣ 4 Obtaining Model Uncertainty ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")) (MC dropout).
We observed an improvement using this estimate compared to the standard dropout weight averaging, and also compared to much smaller dropout probabilities (near zero).
For the Boston Housing dataset for example, repeating the same experiment with dropout probability 0 results in RMSE of 3.07 and predictive log-likelihood of -2.59.
This demonstrates that dropout significantly affects the predictive log-likelihood and RMSE, even though the dropout probability is fairly small.
We used dropout following the same way the method would be used in current research – without adapting model structure. This is to demonstrate the results that could be obtained from existing models when evaluated with MC dropout. Experimenting with different network architectures we expect the method to give even better uncertainty estimates.
###
5.4 Model Uncertainty in Reinforcement Learning
In reinforcement learning an agent receives various rewards from different states, and its aim is to maximise its expected reward over time.
The agent tries to learn to avoid transitioning into states with low rewards, and to pick actions that lead to better states instead.
Uncertainty is of great importance in this task – with uncertainty information an agent can decide when to exploit rewards it knows of, and when to explore its environment.
Recent advances in RL have made use of NNs to estimate agents’ Q-value functions (referred to as Q-networks), a function that estimates the quality of different actions an agent can take at different states.
This has led to impressive results on Atari game simulations, where agents superseded human performance on a variety of games (Mnih et al., [2015](#bib.bib29)).
Epsilon greedy search was used in this setting, where the agent selects the best action following its current Q-function estimation with some probability, and explores otherwise. With our uncertainty estimates given by a dropout Q-network we can use techniques such as Thompson sampling (Thompson, [1933](#bib.bib38)) to converge faster than epsilon greedy while avoiding over-fitting.
We use code by (Karpathy & authors, [2014–2015](#bib.bib18)) that replicated the results by (Mnih et al., [2015](#bib.bib29)) with a simpler 2D setting.
We simulate an agent in a 2D world with 9 eyes pointing in different angles ahead (depicted in fig. [6](#S5.F6 "Figure 6 ‣ 5.3 Predictive Performance ‣ 5 Experiments ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning")). Each eye can sense a single pixel intensity of 3 colours. The agent navigates by using one of 5 actions controlling two motors at its base. An action turns the motors at different angles and different speeds. The environment consists of red circles which give the agent a positive reward for reaching, and green circles which result in a negative reward. The agent is further rewarded for not looking at (white) walls, and for walking in a straight line.
We trained the original model, and an additional model with dropout with probability 0.1 applied before the every weight layer. Note that both agents use the same network structure in this experiment for comparison purposes. In a real world scenario using dropout we would use a larger model (as the original model was intentially selected to be small to avoid over-fitting).
To make use of the dropout Q-network’s uncertainty estimates, we use Thompson sampling instead of epsilon greedy. In effect this means that we perform a single stochastic forward pass through the network every time we need to take an action. In replay, we perform a single stochastic forward pass and then back-propagate with the sampled Bernoulli random variables. Exact experiment set-up is given in section E.2 in the appendix.
In fig. [6](#S5.F6 "Figure 6 ‣ 5.3 Predictive Performance ‣ 5 Experiments ‣ Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning") we show a log plot of the average reward obtained by both the original implementation (in green) and our approach (in blue), as a function of the number of batches.
Not plotted is the burn-in intervals of 25 batches (random moves).
Thompson sampling gets reward larger than 1 within 25 batches from burn-in. Epsilon greedy takes 175 batches to achieve the same performance.
It is interesting to note that our approach seems to stop improving after 1K batches. This is because we are still sampling random moves, whereas epsilon greedy only exploits at this stage.
6 Conclusions and Future Research
----------------------------------
We have built a probabilistic interpretation of dropout which allowed us to obtain model uncertainty out of existing deep learning models. We have studied the properties of this uncertainty in detail, and demonstrated possible applications, interleaving Bayesian models and deep learning models together.
This extends on initial research studying dropout from the Bayesian perspective (Wang & Manning, [2013](#bib.bib42); Maeda, [2014](#bib.bib28)).
Bernoulli dropout is only one example of a regularisation technique corresponding to an approximate variational distribution which results in uncertainty estimates. Other variants of dropout follow our interpretation as well and correspond to alternative approximating distributions. These would result in different uncertainty estimates, trading-off uncertainty quality with computational complexity. We explore these in follow-up work.
Furthermore, each GP covariance function has a one-to-one correspondence with the combination of both NN non-linearities and weight regularisation. This suggests techniques to select appropriate NN structure and regularisation based on our a priori assumptions about the data. For example, if one expects the function to be smooth and the uncertainty to increase far from the data, cosine non-linearities and L2 regularisation might be appropriate. The study of non-linearity–regularisation combinations and the corresponding predictive mean and variance are subject of current research.
#### Acknowledgements
The authors would like to thank Dr Yutian Chen, Mr Christof Angermueller, Mr Roger Frigola, Mr Rowan McAllister, Dr Gabriel Synnaeve, Mr Mark van der Wilk, Mr Yan Wu, and many other reviewers for their helpful comments. Yarin Gal is supported by the Google European Fellowship in Machine Learning. |
53f6509a-3533-4fc2-819c-fd27862dbb85 | trentmkelly/LessWrong-43k | LessWrong | Appendix: More Is Different In Other Domains
In Future ML Systems Will Be Qualitatively Different, I argued that we should expect ML systems to exhibit emergent capabilities. My main support for this was four historical examples of emergence in ML.
In some sense, extrapolating from only four data points is pretty sketchy. It's hard to tell if these examples are the start of a trend, or cherry-picked to tell a story. In low-data regimes like this, it's helpful to have a prior, and so I'll spend this appendix looking at related fields of science and examining how common emergent behavior is in those fields.
In short, my conclusion is that emergence is very common throughout the sciences, and especially common in biology, which I view to be most analogous to ML. As such, I think it should be our default expectation for ML, and the four data points from before primarily serve to confirm this. Personally, forming this "prior" updated my views about as much as the (combined) historical examples that I previously discussed for ML.
More Is Different Across Domains
Recall that emergence refers to the idea that More Is Different: that quantitative changes can lead to qualitatively different phenomena. While this idea was first articulated by the physicist Philip Anderson, it occurs in many other domains as well:[1]
* Biology: Gecko feet are covered with tiny structures called spatulae (shown above), consisting of many keratin molecules woven together. Spatulae are responsible for geckos’ ability to walk up walls, but it’s clear that we couldn’t "scale down" the structure and retain the same ability---you need enough keratin to form the complex bristles shown above.
* Physics: Siloles (a type of molecule) are not luminescent individually, but become luminescent when put together in aggregate. This is because the aggregate is more rigid, reducing intramolecular motion that otherwise inhibits the production of photons.
* Computers: Operating systems only arose once computers became fast enough. Before that, indi |
480b6cce-3c12-45a9-8032-0657831d8e26 | trentmkelly/LessWrong-43k | LessWrong | Secrets of the eliminati
Anyone who does not believe mental states are ontologically fundamental - ie anyone who denies the reality of something like a soul - has two choices about where to go next. They can try reducing mental states to smaller components, or they can stop talking about them entirely.
In a utility-maximizing AI, mental states can be reduced to smaller components. The AI will have goals, and those goals, upon closer examination, will be lines in a computer program.
But in the blue-minimizing robot, its "goal" isn't even a line in its program. There's nothing that looks remotely like a goal in its programming, and goals appear only when you make rough generalizations from its behavior in limited cases.
Philosophers are still very much arguing about whether this applies to humans; the two schools call themselves reductionists and eliminativists (with a third school of wishy-washy half-and-half people calling themselves revisionists). Reductionists want to reduce things like goals and preferences to the appropriate neurons in the brain; eliminativists want to prove that humans, like the blue-minimizing robot, don't have anything of the sort until you start looking at high level abstractions.
I took a similar tack asking ksvanhorn's question in yesterday's post - how can you get a more accurate picture of what your true preferences are? I said:
> I don't think there are true preferences. In one situation you have one tendency, in another situation you have another tendency, and "preference" is what it looks like when you try to categorize tendencies. But categorization is a passive and not an active process: if every day of the week I eat dinner at 6, I can generalize to say "I prefer to eat dinner at 6", but it would be non-explanatory to say that a preference toward dinner at 6 caused my behavior on each day. I think the best way to salvage preferences is to consider them as tendencies currently in reflective equilibrium.
A more practical example: when people discuss c |
981eb189-cb09-4d29-9a30-99b3b5d695dc | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Updates from Campaign for AI Safety
Hi!
📜 With the moratorium treaty competition now closed, we extend our best wishes to all participants. Judges are finalising scores for the entries. Winners will be announced this week. You can see all the submissions [here](https://www.campaignforaisafety.org/law-competition-submissions/).
Stay tuned!
---
### 📸 PauseAI protests updates
✊ Throwback to the powerful #PauseAI protests in London on July 13th and July 18th. Advocates gathered outside the FCDO, urging the United Nations Security Council to implement a global pause on the largest AI training runs. Thank you for your support! #PauseAI 📸

📢 Mark your calendars for the [upcoming #PauseAI protest](https://pauseai.info/protests) in the Netherlands: #PauseAI Protest @ Wijnhaven, The Hague on 11th of August, 16:00 - 17:00Sign up and get details [here](https://pauseai.info/2023-august-nl).
---
### 📃 Policy updates
On the policy front, in the past month we focussed on Australia:
* We have made [our submission to Safe and Responsible AI in Australia discussion paper](https://www.campaignforaisafety.org/submission-to-safe-and-responsible-ai-in-australia-discussion-paper/).
* Special thank-you to Shine Lawyers for their a [supplementary submission](https://www.shine.com.au/media/submissions/campaign-for-ai-safety?ref=campaignforaisafety.org) (also [in PDF](https://shinestore.blob.core.windows.net/shine-lawyers-pdfs/Shine's%20Submission_%20Inquiry%20into%20Supporting%20Responsible%20AI_July%202023.pdf?ref=campaignforaisafety.org)) regarding protections and legal recourse against harms caused by AI.
* Because Google's [used the consultation to argue against copyright](https://www.afr.com/technology/google-tells-government-how-to-regulate-ai-and-who-to-blame-when-it-goes-wrong-20230728-p5ds0s) in relation to training AI models, we made a counterbalancing [supplementary submission](https://www.campaignforaisafety.org/policy-submissions-on-copyright-in-training-of-ai-models/) on this topic as well.
Next, we are working on a submission to the [NSW inquiry into AI](https://www.parliament.nsw.gov.au/committees/inquiries/Pages/inquiry-details.aspx?pk=2968) and updating our [main campaign policy document](https://www.campaignforaisafety.org/policy-recommendations/).
Do you know of other inquiries? Please let us know. If you want to contribute to the upcoming consultation papers, please respond to this email.
---
### 📜Petition updates
🦘 [Nik Samoylov's petition (EN5163)](https://www.aph.gov.au/e-petitions/petition/EN5163?ref=campaignforaisafety.org) has successfully met the requirements for petitions and was recently presented to the House on 31/07/2023. It has been referred to Ed Husic, the Minister for Industry and Science. According to the petition requirements, Ministers have 90 days from its presentation in the House to provide a response.
🦄 For our advocates in the UK, we have an [ongoing petition by Greg Colbourn calling for a global moratorium](https://petition.parliament.uk/petitions/639956?ref=campaignforaisafety.org) on the development of AI technology due to extinction risks. The petition has garnered 38 signatures so far.
---
### 💳 Become a paid subscriber to the campaign
We have just prepared the [financial reports](https://www.campaignforaisafety.org/campaign-financial-statements-30-june-2023/) for the financial year ended 30 June 2023. In a nutshell, we had AUD 37.33 in the bank at the end of the year. Reports are accessible to paid members.
In the coming months, our expenses will include general upkeep of the campaign as well as a few bursts in paid media. Targeted billboards and audio ads will be back on.
If you are not yet a paid member, please do [subscribe](https://www.campaignforaisafety.org/#/portal/).
---
Thank you for your support! Please share this email with friends.
Campaign for AI Safety
[campaignforaisafety.org](https://www.campaignforaisafety.org/) |
781bb615-3b17-4bef-8ea6-782379f14d6b | trentmkelly/LessWrong-43k | LessWrong | Don't be afraid of the thousand-year-old vampire
Background
I first started reading Jaynes Probability Theory around 2 years ago, I did not last long, I wasn't able to follow the derivations in Chapter 2, so I gave up, assuming it would only get harder from there what was the point in continuing?
This was a big mistake! For several reasons
1. Trying to follow every detail is dumb, you're there to learn not to pass a trivia test on solving the associativity equation. You're here to learn probability not how to solve functional equations
2. It doesn't get harder, it gets easier! You should always skim a textbook before reading it (and especially before giving up)
As I'm finally rectifying my mistake I figured I'd write an explanation for what Chapter 2 is actually about
Think "Alien" Not Robot
The reasoning in Chapter 2 shows that any rules of plausible-inference must match our own theory of probability after a suitable change of units. The convoluted functional-equation argument is needed to construct a function p:R→[0,1] which translates the alien's plausibility A|B into our probability p(A|B).
This is very different to how p is usually defined, for Jaynes p is a translation between the plausibilities of the alien and our "nicer" probabilities that obey the sum and product rules. Contrast this with standard probability where p is a function from subsets of the sample space to real numbers obeying certain axioms.
Any alien civilization's concept of "probability the dice lands five" must be a monotonic function of our probability 1/6. That's amazing when you think about it, It shows that probability is discovered not invented. [1]
Furthermore, if you want the sum and product rule to take their natural forms you have to pick our units, this is analogous to how degrees Kelvin are defined to make the laws of thermodynamics look natural. [2]
Near the end of Chapter 2 (after we've shown uniqueness) Jaynes switches to a more traditional function P:Prop→[0,1] where Prop is some logical proposition like "the dice |
97699923-e701-4855-b51d-b7091b8fc3f4 | trentmkelly/LessWrong-43k | LessWrong | The ultimate limits of alignment will determine the shape of the long term future
Epistemic status: shower thoughts
This is crossposted from my personal blog
The alignment problem is not new. Humanity and evolution have been grappling with the fundamental core of alignment -- making an agent optimize for the beliefs and values of another -- for the entirety of history. Any time anybody tries to get multiple people to work together in a coherent way to accomplish some specific goal there is an alignment problem. People have slightly differing values, goals, thoughts, information, circumstances, and interests and this heterogeneity prevents full cooperation and inevitably leads to the panopoly of failure modes studied in economics. These include principal agent problems, exploitation of information asymmetries, internal coalition politics, the 'organizational imperative', and so on. While the human alignment problem is very difficult and far from being solved, humanity has developed a suite of 'social technologies' which can increase effective alignment between individuals and reduce these coordination costs. Innovations such as states and governments, hierarchical organizations, property rights, standing armies, democracy, constitutions, and voting schemes, laws and courts, money and contracts, capitalism and the joint stock corporation, organized religion, ideology, propaganda etc can all be thought of as methods for tackling the human alignment problem. All of these innovations enable the behaviour and values of increasingly large numbers of people to be synchronized and pointed at some specific target. A vast amount of human progress and power comes from these social 'alignment' technologies which provide the concentration of resources and slack for technological progress to take place, rather than just our raw IQ.
In AI alignment, we face a very similar which is easier in some ways but harder in others. It is easier because while with human alignment we have to build structures that can handle existing human minds solely through controlli |
a0be5e40-b56e-49b2-a250-d2327044ce29 | trentmkelly/LessWrong-43k | LessWrong | Fictional Thinking and Real Thinking
Background Concept: What World Does The Referent Live In?
When we see some symbols representing something, it’s useful to ask “what world does the referent[1] live in?”. Some examples:
* When I’m reading a Harry Potter book, the referents of the words/sentences mostly live in the fictional world of Harry Potter.
* When I’m going over a spreadsheet of recent crop yields, the referents live in our physical world.
* When a textbook contains a problem involving a perfect vacuum or an infinite plane, the referents live in a simple hypothetical world (typically chosen to approximately match many little chunks of our physical world).
* When a news article talks about an expert consensus, the referents live in “social reality”.
* When I explain how to fix a printer, and you ask “will that actually work?”, and I reply “well that’s how it should work”, I am implying that the referents of my explanation live in “should world” (which may or may not match our physical world in any given instance).
* When someone says “but it doesn’t feel like that”, they’re emphasizing that the referent of their emotions lives in “felt reality” (which may or may not match our physical world).
I recommend pausing here, and coming up with an example or two of your own.
Background Concept: Fictional Worlds vs Physical Reality
All of the worlds in which referents live except our physical world are fictional. Usually, fictional worlds which we’re interested in match our physical world to a significant extent:
* The Harry Potter world includes mostly the same natural geography as our world, the same cities, and very similar humans.
* The little hypothetical worlds of textbook problems are specifically chosen to approximate many different real-world situations.
* On most mundane matters, the consensus of social reality matches physical reality. For instance, clear daytime skies are usually blue in both physical and social reality.
Often, people will call a world “fictional” derisively. A |
446fa0c1-9bc4-42bd-9d3c-4c7d8cc93e1d | trentmkelly/LessWrong-43k | LessWrong | Cognitive Enhancers: Mechanisms And Tradeoffs
[Epistemic status: so, so, so speculative. I do not necessarily endorse taking any of the substances mentioned in this post.]
There’s been recent interest in “smart drugs” said to enhance learning and memory. For example, from the Washington Post:
> When aficionados talk about nootropics, they usually refer to substances that have supposedly few side effects and low toxicity. Most often they mean piracetam, which Giurgea first synthesized in 1964 and which is approved for therapeutic use in dozens of countries for use in adults and the elderly. Not so in the United States, however, where officially it can be sold only for research purposes. Piracetam is well studied and is credited by its users with boosting their memory, sharpening their focus, heightening their immune system, even bettering their personalities.
Along with piracetam, a few other substances have been credited with these kinds of benefits, including some old friends:
> “To my knowledge, nicotine is the most reliable cognitive enhancer that we currently have, bizarrely,” said Jennifer Rusted, professor of experimental psychology at Sussex University in Britain when we spoke. “The cognitive-enhancing effects of nicotine in a normal population are more robust than you get with any other agent. With Provigil, for instance, the evidence for cognitive benefits is nowhere near as strong as it is for nicotine.”
But why should there be smart drugs? Popular metaphors speak of drugs fitting into receptors like “a key into a lock” to “flip a switch”. But why should there be a locked switch in the brain to shift from THINK WORSE to THINK BETTER? Why not just always stay on the THINK BETTER side? Wouldn’t we expect some kind of tradeoff?
Piracetam and nicotine have something in common: both activate the brain’s acetylcholine system. So do three of the most successful Alzheimers drugs: donepezil, rivastigmine, and galantamine. What is acetylcholine and why does activating it improve memory and cognition?
Ace |
f28886cc-1dfd-4d20-a100-262d0a02c880 | trentmkelly/LessWrong-43k | LessWrong | OpenAI #11: America Action Plan
OPENAI TELLS US WHO THEY ARE
Last week I covered Anthropic’s submission to the request for suggestions for America’s action plan. I did not love what they submitted, and especially disliked how aggressively they sidelines existential risk and related issues, but given a decision to massively scale back ambition like that the suggestions were, as I called them, a ‘least you can do’ agenda, with many thoughtful details.
OpenAI took a different approach. They went full jingoism in the first paragraph, framing this as a race in which we must prevail over the CCP, and kept going. A lot of space is spent on what a kind person would call rhetoric and an unkind person corporate jingoistic propaganda.
OPENAI REQUESTS IMMUNITY
Their goal is to have the Federal Government not only not regulate AI or impose any requirements on AI whatsoever on any level, but also prevent the states from doing so, and ensure that existing regulations do not apply to them, seeking ‘relief’ from proposed bills, including exemption from all liability, explicitly emphasizing immunity from regulations targeting frontier models in particular and name checking SB 1047 as an example of what they want immunity from, all in the name of ‘Freedom to Innovate,’ warning of undermining America’s leadership position otherwise.
None of which actually makes any sense from a legal perspective, that’s not how any of this works, but that’s clearly not what they decided to care about. If this part was intended as a serious policy proposal it would have tried to pretend to be that. Instead it’s a completely incoherent proposal, that goes halfway towards something unbelievably radical but pulls back from trying to implement it.
OPENAI ATTEMPTS TO BAN DEEPSEEK
Meanwhile, they want the United States to not only ban Chinese ‘AI infrastructure’ but also coordinate with other countries to ban it, and they want to weaken the compute diffusion rules for those who cooperate with this, essentially only restricting coun |
f78e3928-66de-44e5-b736-4ea72b2edba8 | trentmkelly/LessWrong-43k | LessWrong | How can we measure creativity?
Status: have spent about two hours on this.
As part of measuring how marginal productivity changes over time, I need to know how to assess creativity. One promising test for that is the Torrance Tests of Creative Thinking, in which subjects are given an open ended prompt, and graded on their answers. Answers are evaluated by a human being for fluency, originality, abstractness of titles, elaboration and resistance to premature closure (sample questions for the curious). But does the TTCT predict anything we actually care about?
The creator of the tests studied their predictive ability in a longitudinal study that lasted 50 years so far. The 40 year follow up showed good-for-social-sciences correlation between childhood TTCT scores and adult creative achievement, although IQ had a stronger correlation. The 50 year follow up (conducted by different experimenters) found no correlation between score and "public achievement" unless combined with IQ. Given that these studies were subject to the usual social science weaknesses, multiplied by 50 years and subjective grading, I do not count this as strong evidence.
A smaller study in Brazil found adulthood scores of recognized creative achievers and non-achievers to vary.
Basic googling found more academics saying both disparaging (beginning of page 310) and encouraging things.
My default assumption is that psychometric tests are invalid, and this evidence isn't enough to make me change my mind. But I don't have anything better to use for my actual goal, which is a measurable task that taxes creativity and *nothing else*, and this has a certain face validity to it. Does anyone have information to sway on the validity of the test, or an alternative test to use? |
3f1a0557-a597-4f28-bf65-3a699c312943 | trentmkelly/LessWrong-43k | LessWrong | Fundamental Uncertainty: Chapter 2 - Why do words have meaning?
N.B. This is a chapter in a book about truth and knowledge. It is the first draft. I have since revised it and replaced this old version with a new major revision. You should read that one instead! You can also find the most up-to-date info/version on the book's website.
Words have meanings right? When I say the word "cup" you know I'm talking about a cup: a thing to drink out of. But why does the word "cup"—quoted so I can refer to the word apart from its meaning—mean cup—unquoted so I can point directly to the thing referenced by the word? It might seem like a silly question, but in fact it's the gateway to understanding fundamental uncertainty.
Think back to when you were a kid. I'll do the same. If someone had asked me why "cup" meant cup, I would have said something like "because that's what it is". The question wouldn't have registered as interesting, just a boring statement of fact turned into a strange question. Maybe I would have thought someone was playing a joke on me, asking a silly nonsense question. And it would have seemed a totally reasonable response at the time, since I'd never encountered a situation where "cup" meant anything other than cup.
But as I got older I started to realize there was a little space between the word "cup" and actual cups. For example, I have memories of getting into arguments with adults if they handed me a mug and called it a "cup". "No way", I'd say, "this is a mug, not a cup!". "Same difference", the response would come, but that seemed wrong to me. "Mugs" were mugs and "cups" were cups. Yet over time I began to see that "cup" was perhaps not as specific a word as I thought it was. In a certain sense, a mug is a type of cup, and it's totally reasonable that if you ask for a "cup" someone might give you a mug because it serves what they believe to be the purpose of asking for a "cup"—to be able to drink a liquid! So I learned there was more to words than just naming things; the form and function mattered.
At the same |
1e5f7ecc-0965-4f1e-a538-ef9da080d727 | trentmkelly/LessWrong-43k | LessWrong | FAI FAQ draft: What is the Singularity?
I invite your feedback on this snippet from the forthcoming Friendly AI FAQ. This one is an answer to the question "What is the Singularity?"
_____
There are many types of mathematical and physical singularities, but in this FAQ we use the term 'Singularity' to refer to the technological singularity.
There are also many things someone might have in mind when they refer to a 'technological Singularity' (Sandberg 2010). Below, we’ll explain just three of them (Yudkowsky 2007):
1. Intelligence explosion
2. Event horizon
3. Accelerating change
INTELLIGENCE EXPLOSION
Every year, computers surpass human abilities in new ways. A program written in 1956 was able to prove mathematical theorems, and found a more elegant proof for one of them than Russell and Whitehead had given in Principia Mathematica (MacKenzie 1995). By the late 1990s, 'expert systems' had surpassed human skill for a wide range of tasks (Nilsson 2009). In 1997, IBM's Deep Blue computer beat the world chess champion (Campbell et al. 2002), and in 2011 IBM's Watson computer beat the best human players at a much more complicated game: Jeopardy! (Markoff 2011). Recently, a robot named Adam was programmed with our scientific knowledge about yeast, then posed its own hypotheses, tested them, and assessed the results (King et al. 2009; King 2011).
Computers remain far short of human intelligence, but the resources that aid AI design are accumulating (including hardware, large datasets, neuroscience knowledge, and AI theory). We may one day design a machine that surpasses human skill at designing artificial intelligences. After that, this machine could improve its own intelligence faster and better than humans can, which would make it even more skilled at improving its own intelligence. This could continue in a positive feedback loop such that the machine quickly becomes vastly more intelligent than the smartest human being on Earth: an 'intelligence explosion' resulting in a machine superintellige |
42e8dc9d-bc1b-40d5-a7a6-b7ad62f4ba6d | trentmkelly/LessWrong-43k | LessWrong | A list of good heuristics that the case for AI x-risk fails
I think one reason machine learning researchers don't think AI x-risk is a problem is because they haven't given it the time of day. And on some level, they may be right in not doing so!
We all need to do meta-level reasoning about what to spend our time and effort on. Even giving an idea or argument the time of day requires it to cross a somewhat high bar, if you value your time. Ultimately, in evaluating whether it's worth considering a putative issue (like the extinction of humanity at the hands (graspers?) of a rogue AI), one must rely on heuristics; by giving the argument the time of day, you've already conceded a significant amount of resources to it! Moreover, you risk privileging the hypothesis or falling victim to Pascal's Mugging.
Unfortunately, the case for x-risk from out-of-control AI systems seems to fail many powerful and accurate heuristics. This can put proponents of this issue in a similar position to flat-earth conspiracy theorists at first glance. My goal here is to enumerate heuristics that arguments for AI takeover scenarios fail.
Ultimately, I think machine learning researchers should not refuse to consider AI x-risk when presented with a well-made case by a person they respect or have a personal relationship with, but I'm ambivalent as to whether they have an obligation to consider the case if they've only seen a few headlines about Elon. I do find it a bit hard to understand how one doesn't end up thinking about the consequences of super-human AI, since it seems obviously impactful and fascinating. But I'm a very curious (read "distractable") person...
A list of heuristics that say not to worry about AI takeover scenarios:
* Outsiders not experts: This concern is being voiced exclusively by non-experts like Elon Musk, Steven Hawking, and the talkative crazy guy next to you on the bus.
* Ludditism has a poor track record: For every new technology, there's been a pack of alarmist naysayers and doomsday prophets. And then instead of fal |
fd5637a8-911f-4256-932f-64f0057e6f4d | trentmkelly/LessWrong-43k | LessWrong | Conceptual coherence for concrete categories in humans and LLMs
Cross-posted from New Savanna.
Siddharth Suresh, Kushin Mukherjee, Xizheng Yu, Wei-Chun Huang, Lisa Padua, and Timothy T. Rogers, Conceptual structure coheres in human cognition but not in large language models, arXiv:2304.02754v2 [cs.AI] 10 Nov 2023.
> Abstract: Neural network models of language have long been used as a tool for developing hypotheses about conceptual representation in the mind and brain. For many years, such use involved extracting vector-space representations of words and using distances among these to predict or understand human behavior in various semantic tasks. Contemporary large language models (LLMs), however, make it possible to interrogate the latent structure of conceptual representations using experimental methods nearly identical to those commonly used with human participants. The current work utilizes three common techniques borrowed from cognitive psychology to estimate and compare the structure of concepts in humans and a suite of LLMs. In humans, we show that conceptual structure is robust to differences in culture, language, and method of estimation. Structures estimated from LLM behavior, while individually fairly consistent with those estimated from human behavior, vary much more depending upon the particular task used to generate responses– across tasks, estimates of conceptual structure from the very same model cohere less with one another than do human structure estimates. These results highlight an important difference between contemporary LLMs and human cognition, with implications for understanding some fundamental limitations of contemporary machine language.
What the abstract doesn’t tell you is that the categories under investigation are for concrete objects and not abstract: “The items were drawn from two broad categories– tools and reptiles/amphibians–selected because they span the living/nonliving divide and also possess internal conceptual structure.” Why does this matter? Because the meaning of concrete items is |
8fca398e-5778-45cd-9b66-0862f1077588 | trentmkelly/LessWrong-43k | LessWrong | Predictions for 2022
None |
44a1a838-0920-4511-ad23-d58127cb50f4 | trentmkelly/LessWrong-43k | LessWrong | Where Free Will and Determinism Meet
Imagine an ordinary-looking text editor. It has the standard bold, italics, and underline styles, and the option to undo your latest editing command. The right arrow next to the undo icon, however, far from represents the typical redo feature. Whether you last undid a command or not, it can be clicked at any time, and its distinctive quality is that it can predict your next action.
In a sense, this Writing Assistant is an oracle that anticipates you with unerring accuracy. It is an exceptionally powerful autocompletion tool for forecasting the word or sentence that you were intending to type.
But then, isn’t this Writing Assistant always wrong? If it was smart enough, it would know that you never actually type the text it says you will type; what you actually do is to just click the right arrow for the assistant to autocomplete the text. This assistant is doomed to eternal falsity.
Or not.
What this Writing Assistant does is to model a world where you hadn’t called it up, and predict what you would have typed in that world. It is a Counterfactual Oracle: it returns predictions that would have been true under slightly different circumstances (circumstances specified by the programmer: for example, “as if this Writing Assistant wasn’t available” or “as if the writer chose not to use the Writing Assistant”).
The strength of this oracle is not to calculate every minute detail of every quark’s trajectory, because that would make its model perpetually wrong: in its counterfactual world, the quarks would have had to skip the laws of physics in order not to follow the deterministic path they did follow.
The strength of the oracle is to strike a balance of rightness: to not model the world at the exceedingly low level of quarks so that it would always be wrong because those quarks would have had to disobey the laws of physics; and to not model it at an exceedingly high level so that it would be wrong because it had omitted important details of the person’s character a |
88dd81d5-2d9e-4815-a0ba-f8250901839b | trentmkelly/LessWrong-43k | LessWrong | Is there a list of cognitive illusions?
After I posted my great idea that "Determinism Is Just A Special Case Of Randomness" because "if not I don't see how there could be free will in a deterministic universe" I was positively guided by the LW community to read the Free Will Sequence so I am learning more about our biases and how we build illusions like free will and randomness in our minds.
But I don't see a list on LW or Wikipedia of a list of cognitive illusions and I think it would be great to have one of those just as it is useful for many people to visit the List Of Cognitive Biases page as a study reference or even to use in day to day life.
I think these are some cognitive illusions that are normally discussed as such:
- Free will
- Randomness/probability
- Time
- Money
There must be many more, but I don't find a list with summaries and that would great (to help me avoid writing posts like my "great idea" above!).
EDIT: The majority of comments below are about questioning if they are illusions or not and if they should be called cognitive illusions.
I guess there is no list of cognitive illusions because there is no academic agreement about these issues like in cognitive biases which are generally accepted as such!
Thx for the comments! |
24c60cd5-d925-49cc-9720-f08b509b784b | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | A simple environment for showing mesa misalignment
A few days ago, Evan Hubinger [suggested](https://www.alignmentforum.org/posts/2GycxikGnepJbxfHT/towards-an-empirical-investigation-of-inner-alignment) creating a [mesa optimizer](https://www.alignmentforum.org/posts/q2rCMHNXazALgQpGH/conditions-for-mesa-optimization) for empirical study. The aim of this post is to propose a minimal environment for creating a mesa optimizer, which should allow a compelling demonstration of pseudo alignment. As a bonus, the scheme also shares a nice analogy with human evolution.
**The game**
An agent will play on a maze-like grid, with walls that prohibit movement. There are two important strategic components to this game: **keys**, and **chests**.
If the agent moves into a tile containing a key, it automatically picks up that key, moving it into the agent’s unbounded inventory. Moving into any tile containing a chest will be equivalent to an attempt to open that chest. Any key can open any chest, after which both the key and chest are expired. The agent is rewarded every time it successfully opens a chest. Nothing happens if it moves into a chest tile without a key, and the chest does not prohibit the agent’s movement. The agent is therefore trained to open as many chests as possible during an episode. The map may look like this:
**The catch**
In order for the agent to exhibit the undesirable properties of mesa optimization, we must train it in a certain version of the above environment to make those properties emerge naturally. Specifically, in my version, we limit the ratio of keys to chests so that there is an abundance of chests compared to keys. Therefore, the environment may look like this instead:
**Context change**
The hope is that while training, the agent picks up a simple pseudo objective: collect as many keys as possible. Since chests are abundant, it shouldn’t need to expend much energy seeking them, as it will nearly always run into one while traveling to the next key. Note that we can limit the number of steps during a training episode so that it almost never runs out of keys during training.
When taken off the training distribution, we can run this scenario in reverse. Instead of testing it in an environment with few keys and lots of chests, we can test it in an environment with few chests and many keys. Therefore, when pursuing the pseudo objective, it will spend all its time collecting keys without getting any reward.
**Testing for mesa misalignment**
In order to show that the mesa optimizer is [competent but misaligned](https://www.alignmentforum.org/posts/2mhFMgtAjFJesaSYR/2-d-robustness) we can put the agent in a maze-like environment much larger than any it was trained for. Then, we can provide it an abundance of keys relative to chests. If it can navigate the large maze and collect many keys comfortably while nonetheless opening few or no chests, then it has experienced a malign failure.
We can make this evidence for pseudo alignment even stronger by comparing the trained agent to two that we hard-code: one agent that pursues the optimal policy for collecting keys, and one agent that pursues the optimal policy for opening as many chests as possible. Qualitatively, if the trained agent is more similar to the first agent than the second, then we should be confident that it has picked up the pseudo objective.
**The analogy with human evolution**
In the ancestral environment, calories were scarce. In our modern day world they are no longer scarce, yet we still crave them, sometimes to the point where it harms our reproductive capability. This is similar to how the agent will continue pursuing keys even if it is not using them to open any chests. |
8ad3ed27-fdd4-4e80-af47-5410866d6200 | trentmkelly/LessWrong-43k | LessWrong | How to Ignore Your Emotions (while also thinking you're awesome at emotions)
(cross posted from my personal blog)
Since middle school I've generally thought that I'm pretty good at dealing with my emotions, and a handful of close friends and family have made similar comments. Now I can see that though I was particularly good at never flipping out, I was decidedly not good "healthy emotional processing". I'll explain later what I think "healthy emotional processing" is, right now I'm using quotes to indicate "the thing that's good to do with emotions". Here it goes...
Relevant context
When I was a kid I adopted a strong, "Fix it or stop complaining about it" mentality. This applied to stress and worry as well. "Either address the problem you're worried about or quit worrying about it!" Also being a kid, I had a limited capacity to actually fix anything, and as such I was often exercising the "stop worrying about it" option.
Another thing about me, I was a massive book worm and loved to collect "obvious mistakes" that heroes and villains would make. My theory was, "Know all the traps, and then just don't fall for them". That plus the sort of books I read meant that I "knew" it was a big no-no to ignore or repress your emotions. Luckily, since I knew you shouldn't repress your emotions, I "just didn't" and have lived happily ever after
...
...
yeah nopes.
Wiggling ears
It can be really hard to teach someone to move in a way that is completely new to them. I teach parkour, and sometimes I want to say,
Me: "Do the shock absorbing thing with your legs!" Student: "What's the shock absorbing thing?" Me: "... uh, you know... the thing were your legs... absorb shock?"
It's hard to know how to give cues that will lead to someone making the right mental/muscle connection. Learning new motor movements is somewhat of a process of flailing around in the dark, until some feedback mechanism tells you you did it right (a coach, it's visually obvious, the jump doesn't hurt anymore, etc). Wiggling your ears is a nice concrete version of a) movement m |
5798dfee-c959-4e48-9c56-bbc5a1dd30df | StampyAI/alignment-research-dataset/lesswrong | LessWrong | All AGI Safety questions welcome (especially basic ones) [~monthly thread]
**tl;dr: Ask questions about AGI Safety as comments on this post, including ones you might otherwise worry seem dumb!**
Asking beginner-level questions can be intimidating, but everyone starts out not knowing anything. If we want more people in the world who understand AGI safety, we need a place where it's accepted and encouraged to ask about the basics.
We'll be putting up monthly FAQ posts as a safe space for people to ask all the possibly-dumb questions that may have been bothering them about the whole AGI Safety discussion, but which until now they didn't feel able to ask.
It's okay to ask uninformed questions, and not worry about having done a careful search before asking.
[AISafety.info](https://aisafety.info/) - Interactive FAQ
---------------------------------------------------------
Additionally, this will serve as a way to spread the project [Rob Miles' volunteer team](https://discord.gg/7wjJbFJnSN)[[1]](#fntaccrois96) has been working on: [Stampy](https://ui.stampy.ai/) and his professional-looking face [aisafety.info](https://aisafety.info/). Once we've got considerably more content[[2]](#fn7mf7itf3an7) this will provide a single point of access into AI Safety, in the form of a comprehensive interactive FAQ with lots of links to the ecosystem. We'll be using questions and answers from this thread for Stampy (under [these copyright rules](https://stampy.ai/wiki/Meta:Copyrights)), so please only post if you're okay with that! You can help by [adding](https://stampy.ai/wiki/Add_question) other people's questions and answers or [getting involved in other ways](https://stampy.ai/wiki/Get_involved)!
We're not at the "send this to all your friends" stage yet, we're just ready to onboard a bunch of editors who will help us get to that stage :)
[**Stampy**](https://ui.stampy.ai/) - Here to help everyone learn about ~~stamp maximization~~ AGI Safety!We welcome [feedback](https://docs.google.com/forms/d/1S5JEjhRE8H8MecJuE-X066akb93HUCNFQIVxBhxf2GA/edit?ts=62be9caf)[[3]](#fnz8vg961j08) and questions on the UI/UX, policies, etc. around Stampy, as well as pull requests to [his codebase](https://github.com/StampyAI/stampy-ui). You are encouraged to add other people's answers from this thread to Stampy if you think they're good, and collaboratively improve the content that's already on [our wiki](https://stampy.ai/wiki/Main_Page).
We've got a lot more to write before he's ready for prime time, but we think Stampy can become an excellent resource for everyone from skeptical newcomers, through people who want to learn more, right up to people who are convinced and want to know how they can best help with their skillsets.
**Guidelines for Questioners:**
* No previous knowledge of AGI safety is required. If you want to watch a few of the [Rob Miles videos](https://www.youtube.com/watch?v=pYXy-A4siMw&list=PLCRVRLd2RhZTpdUdEzJjo3qhmX3y3skWA&index=1), read either the [WaitButWhy](https://waitbutwhy.com/2015/01/artificial-intelligence-revolution-1.html) posts, or the [The Most Important Century](https://www.cold-takes.com/most-important-century/) summary from OpenPhil's co-CEO first that's great, but it's not a prerequisite to ask a question.
* Similarly, you do not need to try to find the answer yourself before asking a question (but if you want to test [Stampy's in-browser tensorflow semantic search](https://ui.stampy.ai/) that might get you an answer quicker!).
* Also feel free to ask questions that you're pretty sure you know the answer to, but where you'd like to hear how others would answer the question.
* One question per comment if possible (though if you have a set of closely related questions that you want to ask all together that's ok).
* If you have your own response to your own question, put that response as a reply to your original question rather than including it in the question itself.
* Remember, if something is confusing to you, then it's probably confusing to other people as well. If you ask a question and someone gives a good response, then you are likely doing lots of other people a favor!
**Guidelines for Answerers:**
* Linking to the relevant [canonical answer](https://stampy.ai/wiki/Canonical_answers) on Stampy is a great way to help people with minimal effort! Improving that answer means that everyone going forward will have a better experience!
* This is a safe space for people to ask stupid questions, so be kind!
* If this post works as intended then it will produce many answers for Stampy's FAQ. It may be worth keeping this in mind as you write your answer. For example, in some cases it might be worth giving a slightly longer / more expansive / more detailed explanation rather than just giving a short response to the specific question asked, in order to address other similar-but-not-precisely-the-same questions that other people might have.
**Finally:** Please think very carefully before downvoting any questions, remember this is the place to ask stupid questions!
1. **[^](#fnreftaccrois96)**If you'd like to join, head over to [Rob's Discord](https://discord.gg/7wjJbFJnSN) and introduce yourself!
2. **[^](#fnref7mf7itf3an7)**We'll be starting a three month paid distillation fellowship in mid February. Feel free to get started on your application early by writing some content!
3. **[^](#fnrefz8vg961j08)**Via the [feedback form](https://docs.google.com/forms/d/1S5JEjhRE8H8MecJuE-X066akb93HUCNFQIVxBhxf2GA/edit?ts=62be9caf). |
f0190a29-3bdc-4889-a6e0-346d3910f214 | trentmkelly/LessWrong-43k | LessWrong | Nick Beckstead: On the Overwhelming Importance of Shaping the Far Future
Nick Beckstead: On the Overwhelming Importance of Shaping the Far Future
ABSTRACT: In slogan form, the thesis of this dissertation is that shaping the far future is overwhelmingly important. More precisely, I argue that:
Main Thesis: From a global perspective, what matters most (in expectation) is that we do what is best (in expectation) for the general trajectory along which our descendants develop over the coming millions of years or longer.
The first chapter introduces some key concepts, clarifies the main thesis, and outlines what follows in later chapters. Some of the key concepts include: existential risk, the world's development trajectory, proximate benefits and ripple effects, speeding up development, trajectory changes, and the distinction between broad and targeted attempts to shape the far future. The second chapter is a defense of some methodological assumptions for developing normative theories which makes my thesis more plausible. In the third chapter, I introduce and begin to defend some key empirical and normative assumptions which, if true, strongly support my main thesis. In the fourth and fifth chapters, I argue against two of the strongest objections to my arguments. These objections come from population ethics, and are based on Person-Affecting Views and views according to which additional lives have diminishing marginal value. I argue that these views face extreme difficulties and cannot plausibly be used to rebut my arguments. In the sixth and seventh chapters, I discuss a decision-theoretic paradox which is relevant to my arguments. The simplest plausible theoretical assumptions which support my main thesis imply a view I call fanaticism, according to which any non-zero probability of an infinitely good outcome, no matter how small, is better than any probability of a finitely good outcome. I argue that denying fanaticism is inconsistent with other normative principles that seem very obvious, so that we are faced with a paradox. I have |
92f6e80a-4d66-4c8c-bbf0-a2055e911b88 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Moscow: Applied Rationality and Cognitive Biases
Discussion article for the meetup : Moscow: Applied Rationality and Cognitive Biases
WHEN: 08 December 2012 04:00:00PM (+0400)
WHERE: Rossiya, Moscow, ulitsa Ostozhenka 14/2
We will meet at “Subway” restaurant, entrance from Lopukhinskiy pereulok. Look for a table with “LW” banner, I will be there from 16:00 MSK.
Main topics:
* Applied rationality: practice. We will improve our rationality skills.
* Cognitive biases analysis. Here is the link to the list of biases we will work on (in Russian).
If you are going for the first time, please fill this one minute form (in Russian), to share your contact information. You can also use personal messages here, or drop a message at lw@lesswrong.ru to contact me for any reason.
N. B. Google may show incorrect location, please use Yandex maps.
Discussion article for the meetup : Moscow: Applied Rationality and Cognitive Biases |
b48d6a09-7ac2-4c82-8152-b9994c00c79f | trentmkelly/LessWrong-43k | LessWrong | New LW Meetups: Hamburg, Ljubljana
This summary was posted to LW Main on January 24th. The following week's summary is here.
New meetups (or meetups with a hiatus of more than a year) are happening in:
* Meetup: First Meetup in Hamburg, Germany: 07 February 2014 07:00PM
* Ljubljana: 25 January 2014 05:00PM
Other irregularly scheduled Less Wrong meetups are taking place in:
* Atlanta Meetup, Topic: How to Become Immortal: 26 January 2014 07:00PM
* Frankfurt meetup: 09 February 2014 02:00PM
* Moscow, Another Meet up: 26 January 2014 04:00PM
* Pittsburgh Meetup 24 January 2014 06:00 PM: 24 January 2014 06:00PM
* Sydney Meetup: February: 26 February 2014 06:30PM
* Tel Aviv: Uses of Cryptography: 30 January 2014 08:00PM
The remaining meetups take place in cities with regular scheduling, but involve a change in time or location, special meeting content, or simply a helpful reminder about the meetup:
* Berkeley: Talk on communication: 29 January 2014 07:00PM
* Community Weekend in Berlin: 11 April 2014 04:00PM
* Brussels: Morality - also cake: 08 February 2014 01:00PM
* [Melbourne] February Rationality Dojo: Planning Fallacy: 02 February 2014 03:00PM
Locations with regularly scheduled meetups: Austin, Berkeley, Berlin, Brussels, Cambridge, MA, Cambridge UK, Columbus, London, Madison WI, Melbourne, Mountain View, New York, Philadelphia, Research Triangle NC, Salt Lake City, Seattle, Toronto, Vienna, Washington DC, Waterloo, and West Los Angeles. There's also a 24/7 online study hall for coworking LWers.
If you'd like to talk with other LW-ers face to face, and there is no meetup in your area, consider starting your own meetup; it's easy (more resources here). Check one out, stretch your rationality skills, build community, and have fun!
In addition to the handy sidebar of upcoming meetups, a meetup overview is posted on the front page every Friday. These are an attempt to collect information on all the meetups happening in upcoming weeks. The best way to get your meetup featured is still |
560d5a6f-984b-44cc-ad2e-916905f2814c | trentmkelly/LessWrong-43k | LessWrong | How do you study a math textbook?
My own personal routine:
I start reading, whenever I feel there is a problem presented in the text (mostly theorems and examples but sometimes questions arise in the text itself), I’ll try solving it. I invest time in this endeavor proportionally to my belief that it can be solved in a reasonable amount of time. If this time runs out, I’ll start reading a little of the solution and trying again. I usually postpone the end-of-chapter exercises to “later” because of spaced repetition and lack of time (I have to have studied a certain amount of chapters for exams so I have to prioritize the quantity.). Sometimes interesting ideas/quasi-problems/ways of looking at things come to mind during the study, and I think on them as well.
When I’m solving a problem, I’ll usually walk around and try to solve it mentally, because I have this uncertain belief that if my math needs paper and pencil, then I can hardly use it “at will.” I’m the kind of person who forgets stuff and needs to repeatedly derive them from first principles when needed, and I can’t quite do that if those derivations rely on writing stuff out. (I also hate memorizing theorems. It feels stupid. :D )
By the way, if the solution is not in the text and I’m stumped, I websearch around. I hate the professors who give grades for the text’s problems and thus disincentiviz solution manuals economically and socially. These take-home exercises correlate more with people’s social skills and network than their effort or knowledge. Quizzing people instead is a much better choice. |
1f06c139-819a-4435-81b9-bd3d45c25130 | trentmkelly/LessWrong-43k | LessWrong | Results: Circular Dependency of Counterfactuals Prize
Now that the deadline has passed, I thought I should announce the winner of my competition on the Circular Dependency of Counterfactuals.
The winner is tailcalled with their post Some thoughts on "The Nature of Counterfactuals".
There were a few things I liked about the post. Firstly, it directly engaged with the topic. Some people's responses were primarily about something else, but they tried to shape it to be relevant to the competition. That's totally understandable. If someone else posted a bounty and I was already interested in something similar but which was not quite the main focus, I'd probably try to my luck as well. However, that wasn't quite what I was looking for.
Secondly, it avoided the trap that some of the other responses fell into where they tried to demonstrate that counterfactuals weren't circular by showing that counterfactuals could be explained in terms of Y, but without explaining why Y might need counterfactuals in order to make sense. In contrast, Tailcall's argument was that counterfactuals could be defined in terms of causality and that it bottoms out there as causality has an ontologically real existence. They were able to give some plausible reasons for believing this. I'm still not sure whether I buy their argument or not, but at the very least they managed to identify a non-obvious argument that I failed to adequately engage with. Beyond this, it will also provide a solid target for engagement when I write on this topic in the future. Their post covered other topics too, but these aspects are what won them the prize.
I'm hoping I'll be able to find time to write up a proper response to their argument, but for now congratulations!
The prize will actually be $1100 USD since I had originally planned to award a social media prize, but that didn't really work out. No one really posted any Facebook posts or Twitter threads on this. |
ad2ec54b-2146-4f2b-b4f7-4ab429758946 | StampyAI/alignment-research-dataset/agentmodels | Tutorial: Modeling Agents with Probabilistic Programs | Modeling Agents with Probabilistic Programs
---
layout: chapter
title: "Sequential decision problems: MDPs"
description: Markov Decision Processes, efficient planning with dynamic programming.
---
## Introduction
The [previous chapter](/chapters/3-agents-as-programs.html) introduced agent models for solving simple, one-shot decision problems. The next few sections introduce *sequential* problems, where an agent's choice of action *now* depends on the actions they will choose in the future. As in game theory, the decision maker must coordinate with another rational agent. But in sequential decision problems, that rational agent is their future self.
As a simple illustration of a sequential decision problem, suppose that an agent, Bob, is looking for a place to eat. Bob gets out of work in a particular location (indicated below by the blue circle). He knows the streets and the restaurants nearby. His decision problem is to take a sequence of actions such that (a) he eats at a restaurant he likes and (b) he does not spend too much time walking. Here is a visualization of the street layout. The labels refer to different types of restaurants: a chain selling Donuts, a Vegetarian Salad Bar and a Noodle Shop.
~~~~
var ___ = ' ';
var DN = { name: 'Donut N' };
var DS = { name: 'Donut S' };
var V = { name: 'Veg' };
var N = { name: 'Noodle' };
var grid = [
['#', '#', '#', '#', V , '#'],
['#', '#', '#', ___, ___, ___],
['#', '#', DN , ___, '#', ___],
['#', '#', '#', ___, '#', ___],
['#', '#', '#', ___, ___, ___],
['#', '#', '#', ___, '#', N ],
[___, ___, ___, ___, '#', '#'],
[DS , '#', '#', ___, '#', '#']
];
var mdp = makeGridWorldMDP({ grid, start: [3, 1] });
viz.gridworld(mdp.world, { trajectory : [mdp.startState] });
~~~~
<a id="mdp"></a>
## Markov Decision Processes: Definition
We represent Bob's decision problem as a Markov Decision Process (MDP) and, more specifically, as a discrete "Gridworld" environment. An MDP is a tuple $$ \left\langle S,A(s),T(s,a),U(s,a) \right\rangle$$, including the *states*, the *actions* in each state, the *transition function* that maps state-action pairs to successor states, and the *utility* or *reward* function. In our example, the states $$S$$ are Bob's locations on the grid. At each state, Bob selects an action $$a \in \{ \text{up}, \text{down}, \text{left}, \text{right} \} $$, which moves Bob around the grid (according to transition function $$T$$). In this example we assume that Bob's actions, as well as the transitions and utilities, are all deterministic. However, our approach generalizes to noisy actions, stochastic transitions and stochastic utilities.
As with the one-shot decisions of the previous chapter, the agent in an MDP will choose actions that *maximize expected utility*. This depends on the total utility of the *sequence* of states that the agent visits. Formally, let $$EU_{s}[a]$$ be the expected (total) utility of action $$a$$ in state $$s$$. The agent's choice is a softmax function of this expected utility:
$$
C(a; s) \propto e^{\alpha EU_{s}[a]}
$$
The expected utility depends on both immediate utility and, recursively, on future expected utility:
<a id="recursion">**Expected Utility Recursion**</a>:
$$
EU_{s}[a] = U(s, a) + \mathbb{E}_{s', a'}(EU_{s'}[a'])
$$
<br>
with the next state $$s' \sim T(s,a)$$ and $$a' \sim C(s')$$. The decision problem ends either when a *terminal* state is reached or when the time-horizon is reached. (In the next few chapters the time-horizon will always be finite).
The intuition to keep in mind for solving MDPs is that the expected utility propagates backwards from future states to the current action. If a high utility state can be reached by a sequence of actions starting from action $$a$$, then action $$a$$ will have high expected utility -- *provided* that the sequence of actions is taken with high probability and there are no low utility steps along the way.
## Markov Decision Processes: Implementation
The recursive decision rule for MDP agents can be directly translated into WebPPL. The `act` function takes the agent's state as input, evaluates the expectation of actions in that state, and returns a softmax distribution over actions. The expected utility of actions is computed by a separate function `expectedUtility`. Since an action's expected utility depends on future actions, `expectedUtility` calls `act` in a mutual recursion, bottoming out when a terminal state is reached or when time runs out.
We illustrate this "MDP agent" on a simple MDP:
### Integer Line MDP
- **States**: Points on the integer line (e.g -1, 0, 1, 2).
- **Actions/transitions**: Actions "left", "right" and "stay" move the agent deterministically along the line in either direction.
- **Utility**: The utility is $$1$$ for the state corresponding to the integer $$3$$ and is $$0$$ otherwise.
Here is a WebPPL agent that starts at the origin (`state === 0`) and that takes a first step (to the right):
~~~~
var transition = function(state, action) {
return state + action;
};
var utility = function(state) {
if (state === 3) {
return 1;
} else {
return 0;
}
};
var makeAgent = function() {
var act = function(state, timeLeft) {
return Infer({ model() {
var action = uniformDraw([-1, 0, 1]);
var eu = expectedUtility(state, action, timeLeft);
factor(100 * eu);
return action;
}});
};
var expectedUtility = function(state, action, timeLeft){
var u = utility(state, action);
var newTimeLeft = timeLeft - 1;
if (newTimeLeft === 0){
return u;
} else {
return u + expectation(Infer({ model() {
var nextState = transition(state, action);
var nextAction = sample(act(nextState, newTimeLeft));
return expectedUtility(nextState, nextAction, newTimeLeft);
}}));
}
};
return { act };
}
var act = makeAgent().act;
var startState = 0;
var totalTime = 4;
// Agent's move '-1' means 'left', '0' means 'stay', '1' means 'right'
print("Agent's action: " + sample(act(startState, totalTime)));
~~~~
This code computes the agent's initial action, given that the agent will get to take four actions in total. To simulate the agent's entire trajectory, we add a third function `simulate`, which updates and stores the world state in response to the agent's actions:
~~~~
var transition = function(state, action) {
return state + action;
};
var utility = function(state) {
if (state === 3) {
return 1;
} else {
return 0;
}
};
var makeAgent = function() {
var act = function(state, timeLeft) {
return Infer({ model() {
var action = uniformDraw([-1, 0, 1]);
var eu = expectedUtility(state, action, timeLeft);
factor(100 * eu);
return action;
}});
};
var expectedUtility = function(state, action, timeLeft) {
var u = utility(state, action);
var newTimeLeft = timeLeft - 1;
if (newTimeLeft === 0) {
return u;
} else {
return u + expectation(Infer({ model() {
var nextState = transition(state, action);
var nextAction = sample(act(nextState, newTimeLeft));
return expectedUtility(nextState, nextAction, newTimeLeft);
}}));
}
};
return { act };
}
var act = makeAgent().act;
var simulate = function(state, timeLeft){
if (timeLeft === 0){
return [];
} else {
var action = sample(act(state, timeLeft));
var nextState = transition(state, action);
return [state].concat(simulate(nextState, timeLeft - 1))
}
};
var startState = 0;
var totalTime = 4;
print("Agent's trajectory: " + simulate(startState, totalTime));
~~~~
>**Exercise**: Change the world such that it is a loop, i.e. moving right from state `3` moves to state `0`, and moving left from state `0` moves to state `3`. How does this change the agent's sequence of actions?
>**Exercise**: Change the agent's action space such that the agent can also move two steps at a time. How does this change the agent's sequence of actions?
>**Exercise**: Change the agent's utility function such that the agent moves as far as possible to the right, given its available total time.
The `expectedUtility` and `simulate` functions are similar. The `expectedUtilty` function includes the agent's own (*subjective*) simulation of the future distribution on states. In the case of an MDP and optimal agent, the agent's simulation is identical to the world simulator. In later chapters, we describe agents whose subjective simulations differ from the world simulator. These agents either have inaccurate models of their own future choices or innacurate models of the world.
We already mentioned the mutual recursion between `act` and `expectedUtility`. What does this recursion look like if we unroll it? In this example we get a tree that expands until `timeLeft` reaches zero. The root is the starting state (`startState === 0`) and this branches into three successor states (`-1`, `0`, `1`). This leads to an exponential blow-up in the runtime of a single action (which depends on how long into the future the agent plans):
~~~~
///fold: transition, utility, makeAgent, act, and simulate as above
var transition = function(state, action) {
return state + action;
};
var utility = function(state) {
if (state === 3) {
return 1;
} else {
return 0;
}
};
var makeAgent = function() {
var act = function(state, timeLeft) {
return Infer({ model() {
var action = uniformDraw([-1, 0, 1]);
var eu = expectedUtility(state, action, timeLeft);
factor(100 * eu);
return action;
}});
};
var expectedUtility = function(state, action, timeLeft) {
var u = utility(state, action);
var newTimeLeft = timeLeft - 1;
if (newTimeLeft === 0) {
return u;
} else {
return u + expectation(Infer({ model() {
var nextState = transition(state, action);
var nextAction = sample(act(nextState, newTimeLeft));
return expectedUtility(nextState, nextAction, newTimeLeft);
}}));
}
};
return { act };
}
var act = makeAgent().act;
var simulate = function(state, timeLeft){
if (timeLeft === 0){
return [];
} else {
var action = sample(act(state, timeLeft));
var nextState = transition(state, action);
return [state].concat(simulate(nextState, timeLeft - 1))
}
};
///
var startState = 0;
var getRuntime = function(totalTime) {
return timeit(function() {
return act(startState, totalTime);
}).runtimeInMilliseconds.toPrecision(4);
};
var numSteps = [3, 4, 5, 6, 7];
var runtimes = map(getRuntime, numSteps);
print('Runtime in ms for for a given number of steps: \n')
print(_.zipObject(numSteps, runtimes));
viz.bar(numSteps, runtimes);
~~~~
Most of this computation is unnecessary. If the agent starts at `state === 0`, there are three ways the agent could be at `state === 0` again after two steps: either the agent stays put twice or the agent goes one step away and then returns. The code above computes `agent(0, totalTime-2)` three times, while it only needs to be computed once. This problem can be resolved by *memoization*, which stores the results of a function call for re-use when the function is called again on the same input. This use of memoization results in a runtime that is polynomial in the number of states and the total time. <!-- We explore the efficiency of these algorithms in more detail in Section VI. --> In WebPPL, we use the higher-order function `dp.cache` to memoize the `act` and `expectedUtility` functions:
~~~~
///fold: transition, utility and makeAgent functions as above, but...
// ...with `act` and `expectedUtility` wrapped in `dp.cache`
var transition = function(state, action) {
return state + action;
};
var utility = function(state) {
if (state === 3) {
return 1;
} else {
return 0;
}
};
var makeAgent = function() {
var act = dp.cache(function(state, timeLeft) {
return Infer({ model() {
var action = uniformDraw([-1, 0, 1]);
var eu = expectedUtility(state, action, timeLeft);
factor(100 * eu);
return action;
}});
});
var expectedUtility = dp.cache(function(state, action, timeLeft) {
var u = utility(state, action);
var newTimeLeft = timeLeft - 1;
if (newTimeLeft === 0) {
return u;
} else {
return u + expectation(Infer({ model() {
var nextState = transition(state, action);
var nextAction = sample(act(nextState, newTimeLeft));
return expectedUtility(nextState, nextAction, newTimeLeft);
}}));
}
});
return { act };
}
var act = makeAgent().act;
var simulate = function(state, timeLeft){
if (timeLeft === 0){
return [];
} else {
var action = sample(act(state, timeLeft));
var nextState = transition(state, action);
return [state].concat(simulate(nextState, timeLeft - 1))
}
};
///
var startState = 0;
var getRuntime = function(totalTime) {
return timeit(function() {
return act(startState, totalTime);
}).runtimeInMilliseconds.toPrecision(4);
};
var numSteps = [3, 4, 5, 6, 7];
var runtimes = map(getRuntime, numSteps);
print('WITH MEMOIZATION \n');
print('Runtime in ms for for a given number of steps: \n')
print(_.zipObject(numSteps, runtimes));
viz.bar(numSteps, runtimes)
~~~~
>**Exercise**: Could we also memoize `simulate`? Why or why not?
<a id='restaurant_choice'></a>
## Choosing restaurants in Gridworld
The agent model above that includes memoization allows us to solve Bob's "Restaurant Choice" problem efficiently.
We extend the agent model above by adding a `terminateAfterAction` to certain states to halt simulations when the agent reaches these states. For the Restaurant Choice problem, the restaurants are assumed to be terminal states. After computing the agent's trajectory, we use the [webppl-agents library](https://github.com/agentmodels/webppl-agents) to animate it.
<!-- TODO try to simplify the code above or explain a bit more about how webppl-agents and gridworld stuff works -->
~~~~
///fold: Restaurant constants, tableToUtilityFunction
var ___ = ' ';
var DN = { name : 'Donut N' };
var DS = { name : 'Donut S' };
var V = { name : 'Veg' };
var N = { name : 'Noodle' };
var tableToUtilityFunction = function(table, feature) {
return function(state, action) {
var stateFeatureName = feature(state).name;
return stateFeatureName ? table[stateFeatureName] : table.timeCost;
};
};
///
// Construct world
var grid = [
['#', '#', '#', '#', V , '#'],
['#', '#', '#', ___, ___, ___],
['#', '#', DN , ___, '#', ___],
['#', '#', '#', ___, '#', ___],
['#', '#', '#', ___, ___, ___],
['#', '#', '#', ___, '#', N ],
[___, ___, ___, ___, '#', '#'],
[DS , '#', '#', ___, '#', '#']
];
var mdp = makeGridWorldMDP({
grid,
start: [3, 1],
totalTime: 9
});
var world = mdp.world;
var transition = world.transition;
var stateToActions = world.stateToActions;
// Construct utility function
var utilityTable = {
'Donut S': 1,
'Donut N': 1,
'Veg': 3,
'Noodle': 2,
'timeCost': -0.1
};
var utility = tableToUtilityFunction(utilityTable, world.feature);
// Construct agent
var makeAgent = function() {
var act = dp.cache(function(state) {
return Infer({ model() {
var action = uniformDraw(stateToActions(state));
var eu = expectedUtility(state, action);
factor(100 * eu);
return action;
}});
});
var expectedUtility = dp.cache(function(state, action){
var u = utility(state, action);
if (state.terminateAfterAction){
return u;
} else {
return u + expectation(Infer({ model() {
var nextState = transition(state, action);
var nextAction = sample(act(nextState));
return expectedUtility(nextState, nextAction);
}}));
}
});
return { act };
};
var act = makeAgent().act;
// Generate and draw a trajectory
var simulate = function(state) {
var action = sample(act(state));
var nextState = transition(state, action);
var out = [state, action];
if (state.terminateAfterAction) {
return [out];
} else {
return [out].concat(simulate(nextState));
}
};
var trajectory = simulate(mdp.startState);
viz.gridworld(world, { trajectory: map(first, trajectory) });
~~~~
>**Exercise**: Change the utility table such that the agent goes to `Donut S`. What ways are there to accomplish this outcome?
### Noisy agents, stochastic environments
This section looked at two MDPs that were essentially deterministic. Part of the difficulty of solving MDPs is that actions, rewards and transitions can be stochastic. The [next chapter](/chapters/3b-mdp-gridworld.html) explores both noisy agents and stochastic gridworld environments.
|
d9badebe-e77d-461d-80e9-9c425c9217e9 | trentmkelly/LessWrong-43k | LessWrong | This AI Boom Will Also Bust
|
d155e5c8-c1f8-441e-b1ca-3a641459d766 | StampyAI/alignment-research-dataset/blogs | Blogs | Energy efficiency of wandering albatross flight
*Updated Nov 25, 2020*
The wandering albatross:
* can fly around 240m/kJ
* and move mass at around 1.4—3.0kg.m/J
Details
-------
The wandering albatross is a very large seabird that flies long distances on wings with the largest span of any bird.[1](https://aiimpacts.org/energy-efficiency-of-wandering-albatross-flight/#easy-footnote-bottom-1-2772 "“The <strong>wandering albatross</strong>, <strong>snowy albatross</strong>, <strong>white-winged albatross</strong> or <strong>goonie</strong><sup><a href=\"https://en.wikipedia.org/wiki/Wandering_albatross#cite_note-Robertsonft-3\">[3]</a></sup> (<em>Diomedea exulans</em>) is a large <a href=\"https://en.wikipedia.org/wiki/Seabird\">seabird</a> from the <a href=\"https://en.wikipedia.org/wiki/Family_(biology)\">family</a> <a href=\"https://en.wikipedia.org/wiki/Diomedeidae\">Diomedeidae</a>, which has a circumpolar range in the <a href=\"https://en.wikipedia.org/wiki/Southern_Ocean\">Southern Ocean</a>…It is one of the <a href=\"https://en.wikipedia.org/wiki/List_of_largest_birds\">largest</a>, best known, and most studied species of bird in the world, with it possessing the greatest known wingspan of any living bird. …Some individual wandering albatrosses are known to <a href=\"https://en.wikipedia.org/wiki/Circumnavigation\">circumnavigate</a> the <a href=\"https://en.wikipedia.org/wiki/Southern_Ocean\">Southern Ocean</a> three times, covering more than 120,000 km (75,000 mi), in one year”</p>
<p>“Wandering Albatross.” In <em>Wikipedia</em>, October 27, 2020. <a href=\"https://en.wikipedia.org/w/index.php?title=Wandering_albatross&oldid=985673754\">https://en.wikipedia.org/w/index.php?title=Wandering_albatross&oldid=985673754</a>.")
### Distance per Joule
#### Speed
In a study of wandering albatrosses flying in various wind speeds and directions, average ground speed was 12 m/s, though the fastest ground speed measured appears to be around 24m/s, [2](https://aiimpacts.org/energy-efficiency-of-wandering-albatross-flight/#easy-footnote-bottom-2-2772 "“The average ground speed is 12.0 (± 0.1) m/s.”</p>
<p>See Figure 3 for all ground speed measurements. Though also, <br><br>“Notably, due to the combination of fast airspeeds and leeway the fastest ground speeds (~ 22 m/s) tend to be located in the diagonal downwind direction.</p>
<p>Richardson, Philip L., Ewan D. Wakefield, and Richard A. Phillips. “Flight Speed and Performance of the Wandering Albatross with Respect to Wind.” <em>Movement Ecology</em> 6, no. 1 (March 7, 2018): 3. <a href=\"https://doi.org/10.1186/s40462-018-0121-9\">https://doi.org/10.1186/s40462-018-0121-9</a>.") We use average ground speed for this estimate because we only have data on average energy expenditure, though it is likely that higher ground speeds involve more energy efficient flight, since albatross flight speed is dependent on wind and it appears that higher speeds are substantially due to favorable winds.[3](https://aiimpacts.org/energy-efficiency-of-wandering-albatross-flight/#easy-footnote-bottom-3-2772 "“Notably, due to the combination of fast airspeeds and leeway the fastest ground speeds (~ 22 m/s) tend to be located in the diagonal downwind direction.”</p>
<p>Richardson, Philip L., Ewan D. Wakefield, and Richard A. Phillips. “Flight Speed and Performance of the Wandering Albatross with Respect to Wind.” <em>Movement Ecology</em> 6, no. 1 (March 7, 2018): 3. <a href=\"https://doi.org/10.1186/s40462-018-0121-9\">https://doi.org/10.1186/s40462-018-0121-9</a>.")
#### Energy expenditure
One study produced an estimate that when flying, albatrosses use 2.35 times their basal metabolic rate[4](https://aiimpacts.org/energy-efficiency-of-wandering-albatross-flight/#easy-footnote-bottom-4-2772 "“Energy cost of flight was estimated to be 2.35 times measured BMR.”</p>
<p>Adams, N. J., C. R. Brown, and K. A. Nagy. “Energy Expenditure of Free-Ranging Wandering Albatrosses Diomedea Exulans.” <em>Physiological Zoology</em> 59, no. 6 (November 1, 1986): 583–91. <a href=\"https://doi.org/10.1086/physzool.59.6.30158606\">https://doi.org/10.1086/physzool.59.6.30158606</a>.") which same paper implies is around 1,833 kJ/bird.day.[5](https://aiimpacts.org/energy-efficiency-of-wandering-albatross-flight/#easy-footnote-bottom-5-2772 "“This is equivalent to an overall energy expenditure of 3,354 kJ bird⁻¹ day⁻¹ or 1.83 times measured basal metabolic rate (BMR).”</p>
<p>Adams, N. J., C. R. Brown, and K. A. Nagy. “Energy Expenditure of Free-Ranging Wandering Albatrosses Diomedea Exulans.” <em>Physiological Zoology</em> 59, no. 6 (November 1, 1986): 583–91. <a href=\"https://doi.org/10.1086/physzool.59.6.30158606\">https://doi.org/10.1086/physzool.59.6.30158606</a>. </p>
<p>From this we infer that the basal metabolic rate is 1,833 kJ/ bird.day.")
That gives us a flight cost for flying of 0.050 kJ/second.[6](https://aiimpacts.org/energy-efficiency-of-wandering-albatross-flight/#easy-footnote-bottom-6-2772 "2.35 * 3,354 kJ/1.83 * 1/86400 seconds/day")
#### Distance per Joule calculation
This gives us a distance per energy score of:
distance/energy
= 12 m/s / 0.050 kJ/s
= 240m/kJ
### Mass.distance per Joule
Albatrosses weigh 5.9 to 12.7 kg.[7](https://aiimpacts.org/energy-efficiency-of-wandering-albatross-flight/#easy-footnote-bottom-7-2772 "“Adults can weigh from 5.9 to 12.7 kg (13 to 28 lb)”</p>
<p>“Wandering Albatross.” In <em>Wikipedia</em>, October 27, 2020. <a href=\"https://en.wikipedia.org/w/index.php?title=Wandering_albatross&oldid=985673754\">https://en.wikipedia.org/w/index.php?title=Wandering_albatross&oldid=985673754</a>.")
Thus we can estimate:
mass.distance/Joule
= 5.9kg \* 240 m/kJ to 12.7kg\*240 m/kJ
= 1.4—3.0kg.m/J
*Primary author: Ronny Fernandez*
Notes
----- |
0045beb2-fcdd-4c6f-81c9-35f7d6b36d0b | trentmkelly/LessWrong-43k | LessWrong | Distance Functions are Hard
[Epistemic status: Describes a failed research approach I had a while ago, and my only purpose here is to warn people off from that way of thinking. Every now and then I see someone working on an AIS subproblem say "if only we had a distance function for things in domain X", and my intuition is that they are probably doing a wrong-way reduction. But I only mean this as a soft guideline, and I'm only somewhat confident in my current thinking on this.]
~~~
Terminology: We use the terms distance or distance function to denote any function d:X×X→R≥0 that intuitively tells us how “dissimilar” any two members of a set X are (regardless of the whether d is a metric).
Counterfactual Worlds
Consider the counterfactual "If Lincoln were not assassinated, he would not have been impeached". If we would like to say this has a truth value, we need to imagine what such a counterfactual world would have looked like: was it because Lincoln (somehow) survived his wounds, John Wilkes Booth (somehow) missed, that the plot was (somehow) discovered the day before, etc. Somehow, we must pick out the world that is in some sense "closest" to our actual world, but it seems very difficult to compare any two such worlds in a principled way.
To formalize Functional Decision Theory (FDT), we likely need to have a better understanding of counterfactuals, although even in restricted mathematical contexts, we don't have a satisfactory understanding of why "If 0 = 1..." simply returns incoherence, yet "If the Modularity Theorem were false..." seemingly conjures up a possible world that we feel we can reason about.
(Also, in terms of corrigibility, we are often interested in formalizing the notion of "low-impact" agents, and the naive idea one often has is to define a distance metric on counterfactual world-states, as in p. 5 of Concrete Problems in AI Safety).
Algorithmic Similarity
In the FDT framework, we do not view ourselves as a solitary agent, but as a function (or algorithm) that can b |
9eae9dd4-cfe4-44b2-95c0-2e012e255cb7 | trentmkelly/LessWrong-43k | LessWrong | A solvable Newcomb-like problem - part 1 of 3
This is the first part of a three post sequence on a problem that is similar to Newcomb's problem but is posed in terms of probabilities and limited knowledge.
Part 1 - stating the problem
Part 2 - some mathematics
Part 3 - towards a solution
----------------------------------------
Omega is an AI, living in a society of AIs, who wishes to enhance his reputation in that society for being successfully able to predict human actions. Given some exchange rate between money and reputation, you could think of that as a bet between him and another AI, let's call it Alpha. And since there is also a human involved, for the sake of clarity, to avoid using "you" all the time, I'm going to sometimes refer to the human using the name "Fred".
Omega tells Fred:
I'd like you to pick between two options, and I'm going to try to predict which option you're going to pick.
Option "one box" is to open only box A, and take any money inside it
Option "two box" is to open both box A and box B, and take any money inside them
but, before you pick your option, declare it, then open the box or boxes, there are three things you need to know.
Firstly, you need to know the terms of my bet with Alpha.
If Fred picks option "one box" then:
If box A contains $1,000,000 and box B contains $1,000 then Alpha pays Omega $1,000,000,000
If box A contains $0 and box B contains $1,000 then Omega pays Alpha $10,000,000,000
If anything else, then both Alpha and Omega pay Fred $1,000,000,000,000
If Fred picks option "two box" then:
If box A contains $1,000,000 and box B contains $1,000 then Omega pays Alpha $10,000,000,000
If box A contains $0 and box B contains $1,000 then Alpha pays Omega $1,000,000,000
If anything else, then both Alpha and Omega pay Fred $1,000,000,000,000
Secondly, you should know that I've already placed all the money in the boxes that I'm going to, and I can't change the contents of the boxes between n |
acbfc991-69f6-4aa8-a680-f6563a119021 | trentmkelly/LessWrong-43k | LessWrong | Should LW have a separate AI section?
LessWrong seems to have two main topics for discussion; rationality and AI. This, of course, is caused by Eliezer Yudkowsky's sequences (and interests), which are mostly about rationality, but also include a lot of writing about AI. LessWrong currently has two sections, Main and Discussion. This is meant to separate the purpose and quality of the post. I think usability of the site has improved greatly since adding the Discussion section. Should split the discussion section, and have one for rationality and one for AI?
Advantages
* It would make LW more pleasant for rationality enthusiasts who don't want to sort through lots of AI discussions.
* It would make LW more pleasant for AI enthusiasts who don't want to sort through lots of rationality discussions.
* It would not split up the community as much as a new AI community site would.
* It would increase LW's capacity for discussion.
* Newcomers could learn about rationality, while people who want higher quality of discussion on AI topics could have it.
Disadvantages
* Many posts about both subjects are highly relevant about both subjects
* It would make LW less pleasant for enthusiasts of both subjects.
* It would split up the community more than doing nothing.
* Everybody has their ideas for separate sections, and we can't do them all.
What do you guys think?
|
a23d3c4c-5d84-4315-a820-6df856e67485 | trentmkelly/LessWrong-43k | LessWrong | [Link] Active tactile exploration using a brain–machine–brain interface
ICMS (intracortical microstimulation) was successfully demonstrated for inducing artificial sensory stimulation in rhesus monkeys. (This is a significant -- albeit miniscule -- step forward for data-in brain-computer interfaces.)
-- http://www.nature.com/nature/journal/vaop/ncurrent/full/nature10489.html -- |
b1f3cd8e-fca2-4e9f-bb7f-514af9f0e2bc | StampyAI/alignment-research-dataset/aisafety.info | AI Safety Info | What is least-to-most prompting?
Least-to-most prompting is a technique to elicit complex reasoning from large language models. This is done in two stages. First, the model is prompted to break down a complex problem into simpler subproblems. Then, the subproblems are solved sequentially, from the least complex to the most complex. After each subproblem is solved, its solution is appended to the prompt and the next subproblem is posed. This is repeated for increasingly complex subproblems until a solution to the original problem has been reached. This process is illustrated in the following figure:

Source - Zhou et al., *[Least-to-most prompting enables complex reasoning in large language models](https://arxiv.org/abs/2205.10625)* (2023)
[See more…]
Both of these stages are implemented with [few-shot prompting](https://learnprompting.org/docs/basics/few_shot) instead of using additional training or fine-tuning.
Least-to-most prompting was proposed as an alternative to [chain-of-thought prompting](/?state=8EL7&question=How%20does%20%22chain-of-thought%22%20prompting%20work%3F). In chain-of-thought prompting, a single prompt asks the model to explain the intermediate steps in its reasoning based on a few examples. Chain-of-thought prompting tends to struggle with easy-to-hard generalization, i.e., solving problems that are more complex than the examples included in the learning prompt.
Least-to-most prompting mitigates this problem by using multiple prompts recursively. Subproblems are solved sequentially based on the results of simpler subproblems. The recursive approach helps the model progressively work up to solutions of more complex problems than the examples, addressing the problem of easy-to-hard generalization.
[Zhou et al.](https://arxiv.org/abs/2205.10625) found that least-to-most prompting surpasses standard prompting and chain-of-thought prompting in the following tasks:
- **[Symbolic manipulation](https://arxiv.org/abs/2201.11903)****:** Take the last letters of each word from a list and concatenate them, e.g., “robot, love, stamp” becomes “tep”.
- **[Compositional generalization](https://arxiv.org/abs/1711.00350)****:** Translate natural language into sequential action commands, e.g., “look thrice after jump” becomes “JUMP, LOOK, LOOK, LOOK”.
- **[Mathematical reasoning](https://arxiv.org/abs/2110.14168)****:** Math word problems, e.g., “Elsa has 5 apples. Anna has 2 more apples than Elsa. How many apples do they have together?”
Least-to-most prompting works best when tasks are effectively decomposed. This means that the individual subtasks must be simple enough for the model to solve given the solutions of prerequisite subtasks, and that the subtasks must collectively work up to a solution of the original problem. For this to occur, the examples given in the decomposition prompt must properly illustrate the subtask structure. Since the decomposed structure can vary for tasks across domains, new decomposition prompts with appropriate examples must be created for each type of task being solved.
|
d8648735-16c2-41e0-a0cc-fc731f7e8f4a | trentmkelly/LessWrong-43k | LessWrong | Thought Experiments Website
Hullo,
I'm hoping for your feedback. I recently finished a sort of beta of a website that allows users to explore and vote on thought experiments:
https://thought-experiment-explorer.vercel.app/
The spirit behind it is somewhat similar to LessWrong's: I think people should examine their lives and reasoning more. I also love gamification and broadening the appeal of academic things.
It has a small batch of some very famous ones, but as I improve the site, I'll add a lot more, as well a page that lets you search and filter by type (such as "utilitarian" or "non-Western"). The About page notes some other plans.
I hope you like the idea and general design so far, but I'd love to hear critiques and suggestions.
Thanks much!
Kat |
a29ecfeb-9374-4826-bde6-e25074432e9f | trentmkelly/LessWrong-43k | LessWrong | The alignment problem in different capability regimes
I think the alignment problem looks different depending on the capability level of systems you’re trying to align. And I think that different researchers often have different capability levels in mind when they talk about the alignment problem. I think this leads to confusion. I’m going to use the term “regimes of the alignment problem” to refer to the different perspectives on alignment you get from considering systems with different capability levels.
(I would be pretty unsurprised if these points had all been made elsewhere; the goal of this post is just to put them all in one place. I’d love pointers to pieces that make many of the same points as this post. Thanks to a wide variety of people for conversations that informed this. If there’s established jargon for different parts of this, point it out to me and I’ll consider switching to using it.)
Different regimes:
* Wildly superintelligent systems
* Systems that are roughly as generally intelligent and capable as humans--they’re able to do all the important tasks as well as humans can, but they’re not wildly more generally intelligent.
* Systems that are less generally intelligent and capable than humans
Two main causes that lead to differences in which regime people focus on:
* Disagreements about the dynamics of AI development. Eg takeoff speeds. The classic question along these lines is whether we have to come up with alignment strategies that scale to arbitrarily competent systems, or whether we just have to be able to align systems that are slightly smarter than us, which can then do the alignment research for us.
* Disagreements about what problem we’re trying to solve. I think that there are a few different mechanisms by which AI misalignment could be bad from a longtermist perspective, and depending on which of these mechanisms you’re worried about, you’ll be worried about different regimes of the problem.
Different mechanisms by which AI misalignment could be bad from a longtermist perspecti |
a6a62b8d-d248-40ce-be01-485d71c6558b | trentmkelly/LessWrong-43k | LessWrong | Grokking revisited: reverse engineering grokking modulo addition in LSTM
By Daniil Yurshevich, Nikita Khomich
TLDR: we train LSTM model on algorithmic task of modulo addition and observe grokking. We fully reverse engeneer the algorithm learned and propose a way simpler equivalent version of the model that groks as well.
Reproducibility statement: all the code is available at the repo.
Introduction
This post is related to Neel Nanda's post and a detailed description of what grokking is can be found there. The short summary is that grokking is the phenomenon when model when being trained on an algorithmic task of relatively small size initially memorizes the trining set and then suddenly generalizes to the data it hasn't seen before. In our work we train a version of LSTM on modulo addition and observe grokking.
Model architecture, experiment settings and naming conventions
We train a version of LSTM with ReLU activation instead of tanh for getting hidden state from cell state ct. We use a linear layer without bias to get logits from h2. We use a slight trick which is using two linear layers without activation inbetween instad of one which makes grokking easier. We also use hidden dimension of N=p and one-hot encoded embeddings. The exact model arcitecture as well as naming is (very similar to Chris Olah's amazing post)
We use similar parameters to Neel's paper meaning extremely large weight decay and particular set of betas for Adam found with grid search. We train the model on a 30% of all pairs (a,b)mod113 and observe grokking:
This is a typical and well studied behaviour for transformer, however we are not aware of any examples of reverse enginnered problem with observed grokking during training.
Exact formulas for what LSTM does
This section is only relevant to the methodology we used to reverse engineer the model, not understanding algorithm itself as well as clarifying all the architectural details used, so feel free to skip this section.
Below are the formulas describing all intermediate activations an |
bf2a8a2f-aee2-4857-834f-8291c91d380a | trentmkelly/LessWrong-43k | LessWrong | Macro, not Micro
Overview
The basic observation is that, if we think of life as an optimization problem, then redefining the search space is much more important than making local optimizations; as a fact of human psychology it's hard to consciously focus on both; but we can implicitly get away with doing both by creating mental triggers for when local optimizations are likely to be particularly effective to think about, and by structuring things so that many local optimizations get made automatically.
Introduction
If you have been to one of the Rationality Minicamps or certain other CFAR events, you may have had the privilege to attend one of Anna Salamon's excellent classes on microeconomics (despite the title of the post, I am being sincere here; you really should attend them if you haven't already). There is too much content to briefly summarize, but essentially "microeconomics" in this context means applying basic microeconomic concepts like marginal value, value of information, etc. to everyday life. For example, if you spend 30 seconds brushing your teeth each day, then spending five minutes to think of something else to do at the same time (like stretching) will save you 3 hours a year, which is a great investment! (There are some caveats to this calculation, but I'm glossing over them as they aren't relevant to the post.)
And indeed, spending 5 minutes (once) to save 3 hours (every year) is almost tautologically a good investment. Now that I've brought up this example, and assuming you value your time, you should probably actually go through this exercise (or just use the stretching suggestion).
The Problem
I intend to argue against something similar to this but subtly different. Basically, while any given trade such as the one above is good, I think it is a mistake to systematically search for such trades. Note that I also don't want to argue that you should never search for such trades. If you're about to buy a car you should almost certainly put a lot of microeconom |
cba05600-ddfa-4ebb-b2a5-945847f9f362 | trentmkelly/LessWrong-43k | LessWrong | Giving What We Can needs your help!
As you probably know, Giving What We Can exists to move donations to the charities that can most effectively help others. Our members take a pledge to give 10% of their incomes for the rest of their life to the most impactful charities. Along with other extensive resources for donors such as GiveWell and OpenPhil, we produce and communicate, in an accessible way, research to help members determine where their money will do the most good. We also impress upon members and the general public the vast differences between the best charities and the rest.
Many LessWrongers are members or supporters, including of course the author of Slate Star Codex. We also recently changed our pledge so that people could give to whichever cause they felt best helped others, such as existential risk reduction or life extension, depending on their views. Many new members now choose to do this.
What you might not know is that 2014 was a fantastic year for us - our rate of membership growth more than tripled! Amazingly, our 1066 members have now pledged over $422 million, and already given over $2 million to our top rated charities. We've accomplished this on a total budget of just $400,000 since we were founded. This new rapid growth is thanks to the many lessons we have learned by trial and error, and the hard work of our team of staff and volunteers.
To make it to the end of the year we need to raise just another £110,000. Most charities have a budget in the millions or tens of millions of pounds and we do what we do with a fraction of that.
We want to raise the money as quickly as possible, so that our staff can stop focusing on fundraising (which takes up a considerable amount of energy), and get back to the job of growing our membership.
Some of our supporters are willing to sweeten the deal as well: if you haven't given us more than £1,000 before, then they'll match 1:1 a gift between £1,000 and £5,000.
You can give now or email me (robert dot wiblin at centreforeffectivealtrui |
bcb9608a-80d4-4f15-a4c1-bbfc3ea40887 | trentmkelly/LessWrong-43k | LessWrong | SmartyHeaderCode: anomalous tokens for GPT3.5 and GPT-4
TL;DR: There are anomalous tokens for GPT3.5 and GPT4 which are difficult or impossible for the model to repeat; try playing around with SmartyHeaderCode, APolynomial, or davidjl. There are also plenty which can be repeated but are difficult for the model to spell out, like edTextBox or legalArgumentException.
A couple months ago, Jessica Rumbelow and mwatkins posted about anomalous tokens that cause GPT-2 and GPT-3 to fail. Those anomalous tokens don't cause the same failures on newer models, such as GPT-3.5 Default or GPT-4 on the ChatGPT website, or gpt-3.5-turbo over the API, because the newer models use a different tokenizer. For a very brief explanation of what a tokenizer is doing, the tokenizer has a large vocabulary of tokens, and it encodes ordinary text as a sequence of symbols from that vocabulary.
For example, the string Hello world! gets encoded by the GPT-2 tokenizer as the sequence [15496, 995, 0], meaning that it's a sequence of three tokens, the first of which is the 15,946th token of the vocabulary, or Hello, the second of which is the 995th token of the vocabulary, or world, and the third of which is the 0th token of the vocabulary, or !. In general, a long string being represented by a single token implies that that string appears a lot in the training set (or whatever corpus was used to build the tokenizer), because otherwise it wouldn't have been "worth it" to give that string its own token.
Because of the change in tokenizers, almost all of the tokens which produce anomalous behavior in GPT-2 and GPT-3 don't produce anomalous behavior in the later models, because rather than being a single weird token, they're broken up into many, more normal tokens. For example, SolidGoldMagikarp was encoded as a the single token SolidGoldMagikarp by the old tokenizer, but is encoded as five tokens by the new tokenizer: [' Solid', 'Gold', 'Mag', 'ik', 'arp']. Each of those five tokens is normal and common, so GPT-4 handles them just fine.
Also, it' |
a9c7c88d-9b1f-4b47-81a9-c9a704604419 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Enabling Automated Machine Learning for Model-Driven AI Engineering
AutoML
------
AutoML aims to automate the practice of ML for real-world applications. It offers end-to-end solutions to non-experts (and experts) in the field of ML in a more efficient manner, compared to the manual approach. The automation might be applied to any part of the ML pipeline: from data pre-processing to hyper-parameter optimization and model evaluation. Most existing AutoML solutions concentrate on one particular part of the ML pipeline [[1](#bib.bib1)]. In this work, we focus on ML model family/architecture selection, as well as hyper-parameter optimization for the ML model. To this aim, we construct a tree-structured search space by considering a number of ML methods that have proven useful for the selected use case scenario of the case study that will follow. The set of selected ML methods comprises (i) Decision Trees (DT), (ii) Random Forests (RF), (iii) Gated Recurrent Units (GRU), (iv) Long Short-Term Memories (LSTM), (v) Fully-Connected Neural Networks (FCNN), also known as Multi-Layer Perceptron (MLP), (vi) Denoising Autoencoders (DAE), (vii) Factorial Hidden Markov Models (FHMM), and (viii) Combinatorial Optimization (CO). Figure [1](#Sx1.F1 "Figure 1 ‣ AutoML ‣ Enabling Automated Machine Learning for Model-Driven AI Engineering") illustrates the mentioned search space with these ML methods and the possible hyper-parameters that must be automatically tuned for each of them should they get selected by the AutoML engine.

Figure 1: The tree-structured search space for the proposed AutoML approach
We consider the possible choices for setting the hyper-parameters as listed below: (a) criterion ∈ {MSE (Mean Squared Error), Friedman\_MSE, MAE (Mean Absolute Error)}; (b) min sample split ∈ Uniform [2,200]; (c) n estimators (i.e., number of estimators) ∈ Uniform [5,100]; (d) optimizer ∈ {Adam, Nadam, RMSprop}; (e) learning rate ∈ {1e-2, 1e-3, 1e-4, 1e-5}; (f) loss function ∈ {MSE, MAE}; (g) n layers (i.e., number of layers) ∈ Uniform [5, 8]; (h) dropout probability ∈ Uniform [0.1, 0.6]; (i) sequence length ∈ {64, 128, 256, 512, 1024}.
To enable the automated selection of the best ML model architecture/family and the most appropriate hyper-parameters for the selected ML model given a specific use case and a dataset, we deploy Bayesian Optimization (BO). There exist various open-source libraries that offer BO. We pick the most widely-used library, namely Hyperopt [[4](#bib.bib4)]. This library requires a Tree-structured Parzen Estimator (TPE) model and provides distributed, asynchronous hyper-parameter optimization. Moreover, it supports search spaces with different types of variables (continuous and discrete), varied search scales (e.g., uniform vs. log-scaling), as well as conditional variables that are only meaningful for certain combinations of other variables [[4](#bib.bib4)].
AutoML-enabled MDSE & MDAE
--------------------------
We augment MDSE with AutoML to support software developers who might not be ML experts in creating smart software systems. We provide them with a Domain-Specific Modeling Language (DSML) that is based on the prior work ML-Quadrat [[3](#bib.bib3)], which supported automated source code and ML model generation for smart IoT services. In ML-Quadrat, the practitioners themselves had to specify the target ML model family/architecture, as well as the values of the corresponding hyper-parameters. However, to assist the software developers who use the DSML and have ML requirements, but may not necessarily possess sufficient ML knowledge and skills, we provide the above-mentioned AutoML prototype as open-source software on Github111<https://github.com/ukritw/autonialm>. Currently, it is tailored to the target use case domain of our case study that is described below. Using this prototype that has also a web-based Graphical User Interface (GUI), one can select the most appropriate setup for ML and feed it into the ML-Quadrat DSML. Last but not least, we implement a number of constraints and exception handling mechanisms, according to the API documentations of the target ML libraries, namely Scikit-Learn and Keras/TensorFlow, in the model-to-code transformations (code generators) of ML-Quadrat. If the AutoML mode is enabled, then we can enforce these constrains and allow them to make necessary changes to the existing user-specified parameters of the model instances. Otherwise, we only let them show warnings without overriding any user-specified option. For instance, if standardization of numeric values must have been done before training a certain ML model, but this is missing, we warn them while generating the implementation of the target IoT service out of the software model. Only in the case that AutoML is ON, then we additionally add the proper standardization technique in the data pre-processing phase of the ML pipeline.
Case Study
----------
To validate the proposed approach, we demonstrate our experimental results of a case study from the smart energy systems domain. Here is the use case scenario: Given an aggregate signal of the electrical energy consumption of a household over a period of time, we aim to disaggregate the signal into a number of individual loads. This is called Non-Intrusive (Appliance) Load Monitoring (NIALM/NILM) or energy disaggregation, and is similar to the single-channel source separation problem in Physics and Signal Processing, but generally more challenging. We conduct a benchmarking of a number of competing approaches to NIALM, using the REDD [[5](#bib.bib5)] and the UK-DALE [[6](#bib.bib6)] reference datasets. It transpires that simple ML models, such as DT that have not been studied can actually outperform some of the more complex deep learning ML model architectures that were proposed in the literature. Note that training a DT is much faster and requires much less amount of data and computational, as well as energy resources, compared to a deep learning model. This example shows the benefits of the proposed AutoML-based approach, even for the ML experts themselves, since they could avoid trial-and-error practices for selecting the ML model and tuning its hyper-parameters. In addition, another deep learning ML model, namely GRU, which is proposed by this work, outperforms the state of the art approaches. Figure [2](#Sx3.F2 "Figure 2 ‣ Case Study ‣ Enabling Automated Machine Learning for Model-Driven AI Engineering") illustrates the experimental results of our benchmarking study with the following NIALM approaches: (i) CO [[7](#bib.bib7)], (ii) DAE [[8](#bib.bib8)], (iii) DT, (iv) Dictionary-based (our implementation of [[9](#bib.bib9)]), (v) DNN-HMM (our implementation of [[10](#bib.bib10)]), (vi) FCNN, (vii) FHMM [[11](#bib.bib11)], (viii) GRU, (ix) LSTM [[8](#bib.bib8)]. Note that applying DT, FCNN and GRU to this problem is our initiative. Table [1](#Sx3.T1 "Table 1 ‣ Case Study ‣ Enabling Automated Machine Learning for Model-Driven AI Engineering") shows the average error (MAE) for the mentioned approaches. Note that we used the data of 37 days from house 1 of the REDD dataset [[5](#bib.bib5)] with a sampling rate of 0.05 Hz.

Figure 2: The disaggregation accuracy using different ML methods. Color codes: dark blue, orange, gray, yellow, and light blue represent the results for the fridge, lights, sockets, washer/dryer, and average for all appliances, respectively.
| Rank | Approach | MAE |
| --- | --- | --- |
| 1st | DT | 14.86 |
| 2nd | GRU | 19.55 |
| 3rd | LSTM [[8](#bib.bib8)] | 25.77 |
| 4th | DAE [[8](#bib.bib8)] | 41.44 |
| 5th | FCNN | 48.96 |
| 6th | Dictionary-based [[9](#bib.bib9)] | 61.15 |
| 7th | DNN-HMM [[10](#bib.bib10)] | 118.52 |
| 8th | FHMM [[11](#bib.bib11)] | 139.40 |
| 9th | CO [[7](#bib.bib7)] | 204.83 |
Table 1: The average MAE of the studied NIALM approaches
Conclusion
----------
We proposed a novel approach to enable AutoML in model-driven software and AI engineering of smart IoT services. We automated the ML model family/architecture selection and the hyper-parameter configuration parts of the ML pipeline. The deployed BO method selects the best options for the ML model and its hyper-parameters, such that the prediction results of the trained ML model outperform any manual practices, or at least perform as good as them222Obviously, this holds only for the supported ML models and methods by the AutoML engine..
Notice
------
This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible. |
cd81c1fe-f11b-4fc8-ae0e-52fc8eb023cf | StampyAI/alignment-research-dataset/youtube | Youtube Transcripts | Reinforcement Learning 10: Classic Games Case Study
okay good morning everyone so uh well
done for making it to the end of this
course so I've got a different face
today I'm David Silva and I'm going to
tell you a little bit about games in
particular classic games like the kind
of board games which you might play or
watch other people playing and it turns
out there's an awful lot of the rest of
the course that you can bring to bear
and these kinds of problems and so this
you can think of this lecture is like a
case study and how to use all of the
techniques that you've learned about so
far in trying to achieve or break the
state of the art in terms of building
algorithms which can actually play
classic games to human or superhuman
levels so brief outline the the idea is
I'll just start off by telling you a
little bit about state of the art we're
just going to touch on game theory and
really the goal here is to understand
you know what does it mean to do well in
a game it's not like a single agent
domain it's not like a Markov decision
process where there's just you know one
agent interacting with environment so
what does it really mean to to achieve
optimal behavior and that's going to
lead us to this principle of minimax
which is the best known principle of
optimality at least in two-player games
and so to understand the history of
games you really need to understand the
history of minimax because for decades
it's been like the way that people have
thought about these problems and so
we're really just touch on how that that
works and what it means to do minimax
search but then we want to move on to
you know really tying things together
with what you've learnt about elsewhere
in this course so talking about how do
we do reinforcement learning in this
setting and the main idea there is going
to be agents that actually learn whilst
they're playing as other agents that are
also learning and we call that idea self
play and it turns out to be a very
natural a very powerful way to learn how
to find these optimal solutions in these
games these things like minimax and once
we've done that we'll move on a little
bit and I'm going to try and do some
kind of case study in alpha zero I'm
just checking actually I think I might
have some old slides here one second
sorry
let's just check
we'll see how we go on I think it's
gonna be okay so why should we care
about games I mean I think maybe at
least some of you'll be sitting there
saying well you know I care about the
real well they care about applications I
care about really having impact in the
real world so why all this fuss about
games why we using games as the case
study and actually they make a really
useful case study even if you're not
someone who's into games because they're
very very simple rules which lead to
actually very deep concepts and as a
result they've been studied by humans
for hundreds of thousands of years and
in a sense they're the kind of
intelligence domains in which humans
really like to test their own
intelligence and there are people who've
devoted their entire lives to the study
of games like you know chess or go or
whatever it is and so it becomes like a
meaningful IQ test a way to compare the
intelligence levels of our machines
against intelligence levels of humans
and that makes it really useful domain
and as a result of all of these things
it's become what's known as the
Drosophila of artificial intelligence
the Drosophila was there the fruit fly
which was used in genetics research for
for many many years because it was such
a simple organism to study people really
just try to understand everything there
was to understand about the fruit fly
before they would move on and study
other organisms and game to have kind of
the same effect in AI that people study
games because they're the simplest kind
of testbed in which you can understand
all of the main ideas of AI and machine
learning and reinforcement learning
whatever the principles are you want to
understand you can understand them in
these games first and then take what
you've learned and push them out into
the real world and that's been shown
time and again to actually be the case
and so in some sense you can think of
these as like microcosms of the real
world like this this board game actually
is like you know the real world but
simplified down distilled down to like
this its essentials that there's some
simple rules but they lead to huge
complexity and we can study how to
actually achieve intelligence in that
domain this little universe and it
captures at least some of the elements
of complexity that we might care about
in the real world and of course at least
to some of us games are really fun and
so maybe that's the main reason to
actually care about them so I guess I've
given this this class for a few years
and each time I give it this slide
changes actually which is kind of the
state of the art in in AI like where
have we reached in classic games and so
if you think about some of the
best-known games like checkers chess
Othello backgammon Scrabble go poker
we've now reached
a level of play which is actually
perfect in checkers and poker and what
that means at least for heads-up poker
this is down here when you have two
players playing against each other and
what that means is that if you play
perfectly it means that you know this
checkers program Chinook if it actually
played against god it would always be
able to draw that's what it means so so
that's what perfect play means whereas
in these other games like chess or
phthalo backgammon Scrabble now go the
level of play that's been achieved by
and this is the first program to achieve
that level is now super human so we see
that across the board it is possible in
these domains to achieve the highest
levels of performance okay yeah so I
seem to have by slightly older slides
but anyway this is now changed as well
so this is what's been achieved using
reinforcement learning in games this is
the state of the art so far so in
checkers we've achieved a level of
performance which is superhuman
using a reinforcement learning algorithm
an algorithm which is learned by itself
to achieve that level by just kind of
playing against itself or player using
self play and so that's really you know
a feat which goes beyond this question
of what could be done with hand crafting
chess this is the old slide from last
time I taught this course but we just
actually in December showed that you
could reach superhuman level in chess
using principled reinforcement learning
methods and we'll come to that at the
end of today's lecture in Othello
backgammon Scrabble go poker all of
these are examples where principled
reinforcement learning algorithms can
now achieve the highest levels of
performance so you don't need to turn or
look beyond RL it's possible to do all
of these things with the kind of
machinery that you've learned about in
this course and nothing more really just
started from the beginning starting from
scratch having a system that learns for
itself by actually figuring out its own
strategies playing against itself and
naturally saying oh I figured out what
leads to more wins then then some other
strategy and playing that strategy more
and more and more this idea is
sufficient to reach the level highest
levels of intelligence okay
so as I said it's really important to
understand what it means to achieve an
optimal strategy in a game so it's not
an MDP we've you know so far in this
course you've seen many examples of
markov decision processes and you've
studied what does it mean to achieve up
to
behavior but now we've got multiple
players involved there's multiple
different agents all trying to achieve
their own goals in this domain and so
when you ask the question what's the
optimal policy in this domain well in a
way it depends it depends what the other
people are doing you know you've got
some imagine this is like a social
interaction and the way in which you can
maximize your own gain depends on what
the other people are doing in that
social interaction and so there is no
absolute answer to the best behavior in
that situation it all depends on what
everyone else is doing but there is one
well-known idea which is used in which
basically summarizes what people
typically mean when they talk about
optimality in a game and that's the idea
of a Nash equilibrium which was famously
invented by by John Nash a few decades
ago so the idea is to say that you know
if all of the other players fix their
policies
that's what there's pi- i means that
means everyone else's policy except for
the AI player so if everyone else was to
fix their policies then you could come
up with this thing called the best
response against that kind of set of
policies so if you kind of just fixed
everyone else's behavior if you know if
all you guys kind of fixed your
strategies and I now know that you're
all got that fixed strategy I can
compute my best strategy against all of
you and that's a well-defined thing now
because you're there's no longer this
question of what you're doing that's
just fixed you've become pinecone a part
of my environment you've become part of
the problem that I'm trying to learn
about and so that thing is called the
best response so it's the best strategy
for player I against everyone else's
strategies that's called the best
response and so this idea of Nash
equilibrium then opens it up and says
well what if I'm trying to find the best
response to you but each of you is also
trying to find your best response
against everyone else and the Nash
equilibrium is a joint policy for all
players such that everyone has found a
best response so what that means is that
we would kind of all try and find the
best strategy that we can against
everyone else and we would only be happy
we'd only say it's a Nash equilibrium if
we all reach a situation where we're
happy that we've found the best response
to what you're all doing so if I find a
situation where I wouldn't choose to
deviate from that I found the best thing
I can do against the rest of the
population and each of the
other members each of the other agents
in that population has found their best
response to what everyone else is doing
that is the Nash equilibrium so everyone
is doing the best thing that they can
against everyone else at the same time
and so it's not a Nash equilibrium if
there's any incentive for anyone to
deviate so if there's any individual
agent that would choose to move away
from that strategy because they think
they could do better it's like oh
actually I've just noticed that there's
some behavior that I can exploit that
but someone over there is doing if I
find such a way to exploit that and
think I can do a little bit better is
not a Nash equilibrium it's only a Nash
equilibrium if everyone is happy with
their strategy they think they're doing
the best thing they can against everyone
else's strategy so that basically is
saying in in this notation that the the
best response to everyone else's
strategy is actually the strategy that's
followed by that player yeah question
okay we're going to concerts a great
question is there always a Nash
equilibrium so we are going to consider
classes of games where there is always a
really well behaved Nash equilibrium and
so we're going to make life simpler for
ourselves by considering situations
where there really is a very
well-defined single Nash equilibrium and
and it's not always you know some games
there can actually be many many
different Nash equilibria which is quite
interesting for example the game of
poker there's many different Nash
equilibria and sometimes some of them
are like seem like they're better than
others like you can have one where
there's the famous problem called like
the prisoner's dilemma and things like
this there's situations where where all
the players can be happy with how
they're doing they wouldn't choose to
deviate but still there's kind of this
fallacy of the of the masses where
they're all doing very badly and that
would still be a Nash equilibrium
because no one would choose to deviate
from that situation and there might be
another situation where if everyone
everyone would also be really happy with
where they've got to and that might be a
different mass equilibrium where
everyone gets an objectively much much
better reward but they're both Nash
equilibria so you can get these quite
complicated games like poker that have
these properties and that typically
arises when you've got imperfect
information we've got you know partially
observed stuff going on where we're I
don't know all of the information that
you have and vice versa when we have
perfect information we're going to
consider classes of games where where
there's always a single Nash equilibrium
and it's we've got principled ways to
find it so it was a great question okay
so if we think about how does this fit
into our usual framework of like
reinforcement learning we can think of
this that this best response thing is
basically what happens when we try and
solve a single agent RL problem whether
other players have just become part of
the environment so imagine there's a
two-player game or something and now
there's there's black and there's white
and and white is saying okay well I'm
just gonna treat black as some fixed
strategy and find the best response to
that strategy bye bye black and so black
kinda becomes part of whites environment
black becomes kind of part of the
background in which in which white is
operating and trying to get reward and
if black is always playing in the same
way well it's just like some MVP that
white happens to be in in which black is
always taking these same things and that
leads to some situations that that white
now has to deal with so so the other
players become part of the environment
when you're trying to find the best
response so you can always think of this
multi agent thing as reducing to a
single agent problem whenever the other
players are fixed so if you fix the
other player strategy it's just an MDP
and the best response is actually the
optimal policy for this MDP but in
practice we don't want to fix the
strategies of the other other players we
want to we want to know what happens you
know what's the best strategy for me
when when everyone else is behaving
really well it's not interesting to ask
what's the best strategy for me when
everyone else is behaving in some kind
of dumb way what's the best strategy for
me when everyone else is behaving really
well that's again the nasty Nash
equilibrium so you can think of the Nash
equilibriums like they're kind of fixed
point of self play reinforcement
learning so how could we think of that
well the idea is that you have your
agents in your in your game and
experience is generated by playing games
between agents okay so whatever the
strategies are from for our agents
they've got these strategies PI 1 and PI
2 and so forth and we're going to use
those current strategies to generate
experience so you generate that
experience and from that experience each
agent is going to treat what it's seen
is going to try and learn about
those other strategies as if it was in
an MDP where those other strategies were
fixed so if you're PI one you're just
going to kind of assume that PI 2 and PI
3 and PI 4 were fixed and try and find
the best response to those but in the
meanwhile the player who's generating PI
2 is also going to treat PI once as if
that was fixed and try and learn how to
do better and try how to beat PI 1 so
kind of PI 1 is treating PI 2 is fixed
and trying to beat that current strategy
of PI twos in the meanwhile PI 2 is is
treating PI 1 is fixed and trying to
beat that strategy and so forth so
everyone is just generating experience
according to their current strategies so
far and trying to beat the strategies of
the other players and so this process
kind of goes on and on and on and so you
can think of this as one player's policy
determining the other players
environments and so all these players
are adaptive to each other and if any
point all of the players have no
incentive to adapt anymore if they're
all happy then we've reached an
equilibrium so in particular we've
reached the Nash equilibrium so the Nash
equilibrium is the fixed point of this
process so this is kind of independent
of what the learning algorithm is it
might be that any particular learning
algorithm might fail to find this bit
clicks point so it's a hard learning
problem to actually find this fixed
point but still you know it is the fixed
point of this self play reinforcement
learning if each player is trying to
optimize against the others and at the
point where they're all happy and
declare victory it's like you know if if
if player PI 1 it says ok I'm done I've
achieved everything I've learned about
against PI 2 and PI 2 at the same time
says I'm done I've learned everything I
can do against PI 1 that means they've
reached a Nash equilibrium by definition
they've got no incentive left to change
and they wouldn't choose to deviate
anymore and so they have reached this
jointly kind of optimal policy where the
Nash yeah question
yeah exactly the idea is that in
reinforcement learning we're trying to
optimize for some MDP we're trying to
find the optimum policy for some MDP and
so the idea is that in that MDP we are
like
what each agent is finding the best
response so so optimizing that MDP is
equivalent to finding the best response
and the Nash equilibrium is kind of
where everyone has found the best
response to everyone else so that's the
idea that each the RL is the way that we
kind of reduce we reduce each player's
perspective to an optimization of an MDP
to give us this best response and by
jointly doing that we find the national
yeah question so the question is can it
learn - so - so it's a fixed point but
does that necessarily mean that you
actually start to improve towards the
fixed point given given a learning
algorithm oh I see so so so RL is a more
general framework for example if it was
the case that you just chose some
strategy for pi/2 and you wants to know
how could this do how could PI 1 exploit
some suboptimal PI - you can ask your RL
algorithm to find the best response 2 to
PI 2 and it will go ahead and do that
and that will be better from PI ones
perspective than playing Nash so it can
do that but if you allow both players to
evolve against each other the idea is
that it will eventually find a Nash
equilibrium and so you can choose to do
other things than find Nash the purpose
of this slide is to show that there is
one natural choice which is to try and
find the Nash equilibrium and so this is
like a mainstay like if you go and study
math or something or or even watch
movies about John Nash who's seems to
play regularly in Hollywood then you
know the National equilibrium is is the
big conceptual idea that helps people
understand game theory and societies and
how people interact with each other and
and so forth in that kind of economics
this is a very important concept okay so
as I mentioned we're not going to
consider this very general case of all
games we're going to focus on a special
class of games so the special class
we're going to consider we're going to
start by thinking about perfect
information games so these are games
that are fully observed by all players
so for example something like chess or
go have perfect information what that
means is that all players can observe
all of the information that's available
to all the other players there's nothing
private that's available just to one
player whereas if you think about a game
like poker I have my my private cards
that the other players don't see and
that private information is what's
called imperfect information there's
some kind of hidden state that's not
visible to the other players and that
gives rise to these very complicated
dynamics where where I now have to
reason about you know what what my cards
might you have and in that situation
what what should I do and if there's
time I might touch on this at the end
how to deal with imperfect information
games and I just want to kind of give
you you know the teaser here which is
all the same methods that we talked
about extend very naturally to the
imperfect information case so it's not
like they just fall over just as we saw
in NRL you know reinforcement learning
by by building a state representation
that takes account of the history of
observations you can deal with partial
observability and the same kind of thing
helps us to deal with imperfect
information games we just need to kind
of do things in the right way we're also
going to focus on two-player games
mostly where we have two alternating
players so we can think of them as white
and black without loss of generality and
they take turns to play and we're going
to focus on what are called zero-sum
games I'm so in a two-player game a
zero-sum game is basically a game that
has equal and opposite rewards for black
and white up so it's called zero-sum
because the reward for player one at any
step plus the reward for player two has
to equal zero in other words you know
what's good for black is bad for white
so if I win you lose that's basically
what a zero-sum game is and vice-versa
you can have more general zero-sum games
where you can have you know many players
and as long as their rewards for all of
those players sum to zero it's still
zero-sum in other words if one player
wins all the other players lose is that
the most common way to that they only
you have to sum to the utilities have to
sum to zero and so the question we asked
now is in these special cases how could
we find Nash equilibrium in perfect
information two player zero-sum games
and the two ways which we're going to
talk about our game tree search like a
kind of planning and this is that
historically the method which has been
most widely used for decades and self
layer reinforcement learning which is
the kind of firm the version which we've
been learning about in this course but
extended to this self play context and
combinations of the two are also
possible okay so let's see if we can
bring back the machinery from the from
the rest of RL and bring it to bear in
this setting now what can we do to
actually think about things like value
functions and policies when we move to
this this multiplayer setting and so the
first thing to say is we can come up
with the same concept of a value
function this is really really crucial
to us and the value function as but
always is going to be the expected total
reward that we get like if you play a
game now how much reward is a particular
player going to get and note that we
don't need to think about separate
players separate rewards for the two
different players because r1 is just
equal to minus r2 so we can just always
think of the reward from one player's
perspective and that's going to be fine
now we don't need to the other players
perspective is always going to be the
negative of that you can generalize this
to the the other case but just to keep
things simple there's one value function
and and the value function for black is
just minus the value function for white
okay and so we want to say well how can
we maximize the total amount of reward
we get and we're just gonna think about
having a policy pair now so our policy
is going to be player 1 follows PI 1 and
player 2 follows PI 2 and that kind of
determines completely how they're going
to play this game and there's also some
game rules that you can think of like
the environment that determine you know
how the state's going to evolve given
actions played by player 1 actually
played by player 2 and and the rules of
the game that entirely determines how
the game will will proceed and then you
can ask the question well under that
policy pair who's going to win basically
you know what's the expected total or
going to be which is typically just you
know rewards in these games are very
often zero all the way through and then
at the end of the game you know plus one
for winning or a minus one for losing is
the canonical case we'll think about
so we can say well there's this value
function which is just the expected
reward the expected return so this is
you know plus one for winning minus one
for losing and it's the expected return
under if there's any stochasticity like
dice in the rules like if you're playing
backgammon you want to know what happens
under the dice the expectation would be
over those dice and if there's any
randomness in your policy the
expectation would be over the randomness
in both players policies and we can ask
well you know under if we averaged over
all of those sources of randomness who's
going to win and that tells you well how
good is this policy pan like who's who
does this favor like if the answer is
that that you get more Plus Ones than
the minus ones in other words you know
if it's if it's really favoring white
over black then that tells you something
about this value function that this
policy pair is a good policy pair for
white and a bad policy pair for black
okay so the special thing about these
two-player mini-games is there's
actually something which we call the the
minimax value function and what that
does is it maximizes White's expected
return while minimizing blacks expected
return basically the way to think of
this is that the minimax value function
there is a unique value function and the
special thing about the minimax value
function is it uniquely determines who
like think of it this way that if black
played the best possible strategy for
black and white played the best possible
strategy for white what would the final
outcome of the game be and that's what
the minimax value function tells us and
the amazing thing about it the amazing
thing about the minimax value function
is that it's unique that and this is not
true for example if you're playing a
game like poker with imperfect
information or you know nonzero-sum
games and so forth this gets more
complicated but for this class of games
there is a unique value function there's
a well-defined question which is just
how good you know who's going to win
from this position under best play by
both sides and then the minimax policy
is really just any policy pair like a
way to play the black and a way to play
for white that achieves those minimax
values and there might be more than one
so this might not be unique just like in
an MDP you can
there's one unique value function there
might be many policies that achieve it
and the same is true in games there's
one unique minimax value function but
there might need to be many ways to
achieve it the simplest example being
you know like imagine you're playing
tic-tac-toe and the first player you
know plays in the middle and then goes
on to you know the other player will
block somehow and ends up being a draw
and there are many ways that you can
reach a draw there's not just one
strategy that MIT reaches a draw there
are many but the minimax value function
is a draw for that game and there was a
question I think sorry yes No so so the
the minimax value function is it's sort
of defining a policy for black and white
in some sense it's saying under best
play for black and white this is what
could be achieved so it's not kind of
given a particular strategy for the
other player it's saying under all
possible strategies for both players
what's the the best outcome it is a Nash
equilibrium yes
so the minimax policy is a Nash
equilibrium yeah it's exactly a Nash
equilibrium and that's actually what I
wants to change this to is to say the
correct definition here is that the
value function for black is basically
the thing which maximizes the value over
all policies that black can do against
White's minimax value function and vice
versa anyway I'll correct that in the
slides when I post them so just to make
that clearer we can think about actually
doing minimax search and again this is
like if you pick up any AI book from the
last 50 years until people started like
rediscovering machine learning and deep
learning and all these new ideas this
was like chapter one like this was the
thing that you would learn about and
would be like definitional about what
AIS would be oh you really need to learn
minimax search because that helps you
understand how how chess programs work
and so forth and minimax search is
really it's a it's a a mechanistic view
of
the minimax value function and it's
basically saying well one way to view
the minimax value function is to say
that you can think of it as like we can
draw out the entire game tree as saying
well from this situation here in
tic-tac-toe there are all of these
different situations where where Cross's
can play and from each of these
situation there's a bunch of places
where where the O's can play and it's
not showing everything here where the
noughts can play and and if you to to
actually write out that entire tree then
you can look at the bottom and you can
see what the values are at the bottom
and you can kind of propagate all of
those values back up to the top to
compute that if one player's maximizing
and the other players minimizing and the
other players maximizing there is some
optimal way at some optimal strategy for
computing the value function well we'll
run through an example in just a second
but actually this was first introduced
by Claude Shannon I mean actually if you
look at the history of computer science
like all the great computer scientists
like Turing Shannon Babbage von Neumann
they were really really interested in in
in games and game theory and they were
fascinated by how to make machines play
chess in particular but all kinds of
games so Claude Shannon actually he came
up with this minimax search and this was
actually ran on paper this algorithm at
that time but went on to become the
mainstay of sort of every single chess
playing program in the world for like 50
years pretty much until December so so
this is an example of mini match minimax
so this is like a very simple game tree
now just some abstract game with just
two choices for each player and you can
see there's two choices for for the max
player and from each of those states
that you reach there's two choices for
the min player and from each of those
states there's two choices for the for
the max player there and at the end of
it there's some outcome there's some
reward that you get at the end where
this is the the reward from from one
player's perspective from the max
players perspective a plus seven plus
three and so forth and so from this you
can kind of compute by a kind of
depth-first search what all the values
are so we're not actually going to do
the whole depth-first search but we can
kind of run through this idea to say
well you know from this from these leaf
values we can compute
you know that their max of plus 7 plus 3
is plus 7 so max would always choose
this this action here and never choose
this action here because this is the
thing which gives more value from his
perspective and so max would choose
minus 2 out of minus 2 and 4 and plus 9
out of plus 9 and plus 5 and so forth
and then we can propagate those out
those from min players perspective as
well to say that from min players
perspective we choose minus 2 rather
than plus 7 because from the min players
perspective you know plus 7 is a
terrible result and minus 2 is a very
good result and minus 4 is a better
result than plus 9 from the min players
perspective and then you can propagate
this again to the root and this gives us
a max of minus 2 and so this really is
the optimal value so hopefully this
helps to understand what what the
minimax value actually means that it
means that you know Max's is choosing
its value assuming that min is
minimizing and while min is assuming
that max is maximizing and now if you
propagate that all the way back up to
the top you get this unique optimal
minimax value yeah question I'll send it
on a slide it's easier I think it's the
easiest way to understand it is that
there is like this that it's at least in
its terminus tick game that you're
you're maximizing over the minimum of
the max of the min of the of this action
series so so kind of the first player
gets to choose a the first step that the
next player gets to choose the next step
the next chair gets to choose the the
next step and so forth and so you've
kind of got the max of a min of a max of
a min of that sequence of actions in the
stochastic case you just kind of need to
amend that a little bit
this gives us like a mechanistic
principle then for how to compute this
minimax value but it's clear that the
search tree grows exponentially and in
any game of reasonable size it's
impractical to search to the end of the
game so what do you do you know it might
be about tractable in tic-tac-toe knots
across it but it's not tractable if you
go to any game of meaningful size and so
in practice what people use is something
which we would call a value function
approximator
but which in all of those AI textbooks
have you ever picked them out would be
called an evaluation function or a
heuristic function and so the value
function approximate hrus is trying to
approximate this this minimax value so
we can say from each of these states
instead of actually computing this thing
exactly we can have some function
approximator which estimates each of
these values in each of these nodes here
based just on say the board position so
if you're playing chess you could kind
of look at the position in this
situation and from that situation
without even looking at these other
possibilities down here try and estimate
what the value is so that's a value
function approximator so it's a function
that takes these parameters W and feeds
into this position s and that would be
the the value function approximator
which people would use instead of in
places like a proxy for doing sub trees
of this minimax search and so what you
can do is if you had a very large search
tree imagine that you are able to search
down to this depth but you couldn't
search all the way down to the end of
the game what would you do well you
would search down to here and instead of
going to the end of the game to figure
out the true value here you would
replace your value here with your value
function your value function would give
you some value here and then you
propagate that value back up using your
minimax search procedure instead of the
real value so what this tells us is that
we basically there's typically we use
the value function to estimate the
minimax value at leaf nodes and then the
minimax search typically would just run
to say to some fixed depth R with
respect to those leaf values
exactly this is very very common idea so
let's make this concrete and also help
to give some historical context by
thinking about you know the simplest and
also most common way in which these
these evaluation functions were built up
in the past and that is using what I
call a binary linear linear value
function so you have some binary feature
vector which for example would look
something like this so some binary
feature vector telling you which
features are present in this position
so in particular we could think of this
feature here as saying does white have a
rook in this position and this is a 1
because in this particular position
white does have a rook and then there's
a white bishop kind of indicator and
again why it has a bishop in this
situation but why it doesn't have a pawn
so there's a zero black does have a rook
so there's a 1 black does have a bishop
sorry black doesn't have a bishop or a
pawn and so that kind of summarizes
these are just features summarizing
what's going on in this position and you
could imagine there could be much more
complicated features but here we've
these are the best known features from
like if you learn how to play chess you
basically learn to assign material
values to each of these and so you the
first thing you do is say well what's
present in the position and then as a
human you know when you're learning how
to play chess you're told the values of
each of those things so you're taught
that you know a rook a white ruckus is
worth +5 a white bishop is worth plus 3
white pawn is worth plus 1 and then we
flip the perspective when we think about
the opponent and we subtract or 5 if the
opponent has a rook subjective 3 if the
opponent has a bishop and subtract of 1
if the opponent has a porn etc and so to
evaluate this position as a human the
way you're kind of taught when you learn
how to play the game of chess is we take
the inner product of these two things so
each of these features times its value
and you sum it together and so what this
is really telling us is that for each
each feature that's actually present in
this position we accumulate it's it's
its way so we're summing together the +5
having the rook and the +3 for the
bishop take away the minus 5 for this
rook and that tells us that white in
this position is kind of winning by plus
3 if you like
so this is the classic binary linear
value function and at the end of it
you'd probably squash it down into
something that actually estimates who's
going to win in that position like some
kind of sigmoid activation function to
squash this into a plus 1 for for
winning and minus 1 for losing but that
is kind of the classic way by which all
games were were evaluated and the only
thing that's changed from this is that
the set of features became much much
richer and grandmasters went to great
lengths in in all of these games to try
and handcraft very very specific values
for these weights and they would play
around with it say no no no I think
actually the rook isn't worth +5 it's
actually worth plus 4.8 and then they
would slowly chain tune their program to
get better and better yeah so in this
the King would have infinite weight
because you know in chess if you don't
have a king you've lost the game so I
guess you could think of that as
infinite but in practice it would never
even occur because you inside your
search tree would never see positions
without a king so yeah so it kind of
just factors out so the most famous game
playing program of the last era was deep
blue and this was the first program to
defeat a the world champion at the game
of chess and I think it's useful just to
understand what went into it because it
was exactly what we talked about so far
that that really it had about 8,000 of
these handcrafted chess features so
instead of just having the you know the
piece values this this vector was about
8,000 long with all kinds of handcrafted
features talk about things like King
safety and pawn structure and all this
kind of other stuff going on and it had
a binary linear value function and the
weights were largely hand tuned by human
experts although it was a little bit of
machine learning they experimented with
and then there was this really high
performance alpha beta search
what's alpha beta alpha beta is
something again which would be in your
chapter one of these textbooks but it's
basically a way to efficiently compute
this minimax search tree by
automatically pruning parts of the
tree that you don't need to compute that
you can kind of you can already know
that certain parts are never going to be
taken by the max player because you know
that min would never even let you go
down that part of the tree in which
pates point certain parts of the tree
can be excluded all together from
computation and it's it's a dramatic
improvement over the naive approach so
so deep blue did this it was this
high-performance parallel alpha beta
search and it was special specially made
Hardware search around 200 million
positions a second it looked ahead about
between 16 and 40 steps into the into
the future in this search tree and at
the end of each of those positions it
used this nice binary linear value
function to kind of estimate who was
going to win propagate that all up and
use that that search tree to decide what
to do at the end of that it defeated the
human champion in 1997 by about four
games to two and at the time it was
actually the most watched event in
internet history so this was considered
a real watershed moment for by many
people okay I think it's also worth
mentioning that deep blue was not the
only example of this strategy that this
was applied separately in many many
different games using immense amounts of
knowledge and expertise and a lot of
clever people working on all kinds of
different things
and I just want to give one more example
of this kind of strategy which was the
program Chinook which was notable
because for a couple of reasons I mean
first of all it was playing the game of
checkers and checkers is again much like
like chess and the representation was
was similar as well as again using this
binary linear value function with all of
these kind of knowledge-based features
regarding kind of position and mobility
and and four different phases of the
game like what you do in the opening and
again these were kind of a carefully
handcrafted and it again did a very high
performance alpha beta search but also
did an additional piece called
retrograde analysis which was kind of to
say at the end of the game in certain
games like chess and checkers you can
work your way backwards from all one
positions to solve all possible end
games and so in Chinook they had like
all of the if you reach any position
with like 10 checkers or fewer it has
perfect knowledge to tell you from that
position you know who's going to win it
can just figure that out by searching
backwards from all one positions into
all positions with ten ten checkers or
fewer and so this retrograde analysis
was very important and what was
interesting about this was that in some
sense Chinook when we talked about the
IQ test of humans against machines
checkers was interesting because from
the human point of view it had arguably
the greatest player of all time in any
game which was Marian Tinsley so Marian
Tinsley only ever he played for his
entire career the game of checkers and I
think he only ever lost five games of
checkers in his entire career and and I
think two of those were against Chinook
so he really was almost perfect from a
human point of view at this game and
Chinook came along and there and it
actually technically defeated Marian
Tinsley in the World Championship match
in 1994 so this was you know before
before deep-blue came along and it was
doing very well but actually Marian
Tinsley had to withdrew for health
reasons and I fortunately went on to die
shortly afterwards and so no one ever
really knew if Chinook would really have
gone on and beaten this this greatest
player and so the guy who made this
Jonathan Schafer decided that the only
way to really figure out if Chinook to
actually prove that Chinook would have
beaten this this seemingly almost
godlike human player was to actually
solve the game altogether so if you can
beat God if you can door against God and
then you know you know that you've
reached the highest level of play in the
game of checkers so he spent the next
decades doing this and eventually sold
the game of checkers
so that means really combining this kind
of minimax search from the top with this
retrograde analysis from the bottom
until they meet and actually having a
perfect solution to the game and so
they're so checkers is the largest game
that was actually has actually been
solved in that sense largest highly
played game okay
so that's the kind of strategy that was
used for for many many years and I hope
you're thinking sitting there thinking
well you know but what about principled
machine learning methods how can we
bring everything we've learnt to bear to
do something better and this brings us
back to our self play idea and so you
know what happens if we were actually to
apply our value based reinforcement
learning algorithms to games of self
play to try and find this minimax
solution could we actually use this
we've defined a minimax value function
we know what that means now we know that
it is in some sense the optimal way to
play in this game between two players so
can we find that value function using
the same technology that we've seen so
far elsewhere in the course and the good
news is that yes you can and I'm not
going to give the theory that proves
that these things actually converge to
the minimax value function but if you
pick out like Michael Lippmann's thesis
for example if you're interested that
would give you some examples where
principled self play reinforcement
learning techniques do indeed find the
minimax value function or the Nash
equilibrium sometimes in more general
cases so the general principle is
exactly the same as we've seen elsewhere
in the course nothing has to change at
all you don't have to do anything
special to play games compared to any
other domain this is the beauty of
reinforcement learning that it applies
it's such a general idea such a core
principle that it applies with almost no
change to these these different domains
and so all we're going to do is to say
well we can have some value function we
can have our parameterization this V of
s comma W so these are the parameters of
our value function so you can think of
this as your deep network representing
the value and it's just estimating what
is the minimax value from state s and we
want to adjust these parameters W so as
to make them more more like the true
minimax value and so we're going to use
the kind of familiar techniques like
Monte Carlo learning TD learning TD
lamda and again the idea is simply to do
something like gradient descent we're
going to adjust our value function a
little bit towards the return if we were
doing Monte Carlo learning so so that
means you know if I thought I was losing
but I saw that at the end of the
game actually ended up winning I would
adjust my weights a little bit too so
that I ended up predicting I was winning
a little bit more if we're doing TD it's
a bit more like you know I mean I'm
playing a game I think I'm losing the
game but then I take one step and it's
like oh I realize I've just made a
blunder now I think I'm I'm you know I
thought I was I thought I was winning
now I think I'm losing so even before
the end of the game just after that one
step we can update our value function to
say well I thought I was losing but I
should add I thought I was winning but
actually after this one step I now
realized that was a bad estimate now I
see I've made a blunder I should adjust
my estimate I had before to say well
actually I was really I was really
losing I just hadn't seen that blunder
yet so you adjust your value function a
little bit towards your value prediction
he made after one step and you'll notice
there's no intermediate rewards here
that's just because we're considering
this common case we're all intermediate
rewards to zero if you do have
intermediate rewards there would be a
reward in there if you do have
discounting there'd be a discount in
there but normally when we're thinking
about games you don't need either of
those things so these things just kind
of look a bit simpler it's just the
difference between what I thought who I
thought was going to win and then who I
after my step who did I think was going
to win a TD lambda same ideas but we can
use the the land return as performed so
we can actually introduce these
eligibility traces and get something in
between these this spectrum between
Monte Carlo and TD zero so one thing
which is useful when we think about
games but is also truthful in
deterministic MDPs
so this is not specific to games is that
it's often the case that you don't
actually need action value functions so
probably in the rest of this course
you know you've been taught that
well-to-do RL you need to have an action
value function if you're doing value
based RL because you need to have some
way to estimate how good your action is
in the absence of knowledge of your
environment but in deterministic mdps in
deterministic games it's actually
sufficient just to have a state value
function and the reason is that there's
only one thing which can happen after
you take your action there's no
stochasticity in the environment and
there's no like variability in what will
happen you don't need to compute this
expectation so we
basically just say well in these games
you know this is the case where we we
can actually take a step forward you
know if you're able to take a step
forward I think a better way to say this
is if you know the rules of the game or
if you know the model of your MDP you
don't need an action value function
because you can always just step forward
once with your model or step forward
once with your rules and we call that
the after states that basically we're
saying you know if you want to know
what's the what's the value of taking
action a from from state s you can step
forward from s by taking that action and
seeing which state it takes you into and
now evaluate that state that you arrive
into okay so I'm in some position I play
a move I find myself in some new
position and the value of that new
position is actually the value of having
taken the move that took me there
because there's nowhere else I could
have gone and I know I know the outcome
of what this rule would do and that
really simplifies things it just means
we need to learn the state value
function if you can learn the state
value function it's a smaller object you
know you don't have the cross-product of
the state space for the action space and
things just become easier and now when
you actually just want to pick your
actions
well you consider all of these different
steps that you could take and you pick
the one with the highest the highest
value okay so I'm going to skip forward
to do this with backgammon
so this is probably you know until deep
learning took off this example here I
mean you can think of this as something
which was done by a guy called cerita
sorrow that in a way was you know 15
years maybe 20 years ahead of its time
in that it was an example essentially of
deep reinforcement learning which was
very very successful and achieved from
first principles superhuman performance
in the game of backgammon completely
learning for itself all strategies
before anyone else had really figured
out that either reinforcement learning
or deep learning where we're we're a big
deal and and general and powerful
methods for doing anything and so I
think it's really useful to look at it
and try and understand what what went on
there
because it's really one of the
outstanding examples in the field of
where this really works this idea so
backgammon first of all you've got some
kind of board and the idea is that each
player is trying to progress their
checkers then you roll dice and then you
move your checkers according to the the
out what shown on the face of the dice
there's two dice and you move your
checkers around this way for for red
here and this way for black and
eventually you've kind of got to take
all of your checkers to the end of out
of play basically and then the first
player to do that wins it's kind of like
a race except that you can land on the
other player if a player has a single
checker you can land on it and capture
it and it's sent back to the beginning
again so it's a race with those kind of
interactions where you can capture each
other and you can block each other if
you have more than two two or more
checkers on the same on the same point
and so what happened at TD gammon was
this whole board was just kind of
flattened out into a set of features to
say basically a set of features saying
you know do I have one checker in this
position do I have to checkers in this
position do our three checkers in this
position do I have no checkers in this
position and so for each of the the
positions on there on the backgammon
board there were a set of features
saying how many checkers were there I
said two binary features and so there's
this binary representation that was just
kind of flattened out say what was going
on in the board and then a very simple
multi-layer perceptron which was
absolutely tiny by modern standards was
put on top of that and it out put a
value function estimating who is going
to win this game of backgammon I'm given
those that those those checkers and the
learning algorithm was remarkably simple
it was really just very pure TD learning
temporal difference learning so this
neural network was initialized with
random weights it was trained by games
of self play and it was trained using
nonlinear TD learning in other words
this TD arrow was computed with respect
to this value function in other words it
was exactly what we talked about as
computing this error between who whose
do you think was winning in this
position and whose die think was winning
once I took played my move that's this
TD error and then the weights were
adjusted to correct that error so the
weights were adjusted a little bit in
the direction of the gradient to make
your
estimate before a little bit more like
what you thought the value should be
having played that move so that's
basically what this rule is saying it's
just saying adjust by by simple
stochastic gradient descent in the
direction of this error along the
gradient which would tell you how to
adjust your parameters so as to achieve
some particular outcome more okay it's
that clear is an update and so there was
nothing else I mean it was really that
was that was the whole algorithm it was
really simple that was no exploration at
all like can anyone think why wouldn't
you need any exploration in backgammon
why how can this work you've had a whole
lecture on exploration telling you how
important it is to have exploration and
yet this works like perfectly achieved
superhuman performance without any
exploration any thoughts as to why right
exactly so there's enough stochastic
stochasticity in the environment in the
dice rolls to mean that you see the
whole state space already you don't
actually need to do something special to
explore to cover the whole state space
you get everywhere and so this algorithm
always converged in practice and that
wasn't true for other games so people
tried other games at this point and got
very excited and the same ideas at that
time didn't work in other games and I
think partly because of the exploration
issues partly because maybe just that
the deep learning wasn't quite there yet
this was very small neural networks but
one of the nice things about backgammon
is that dice not only mean that you
don't need to explore they also make a
very smooth value function that you
don't have these very precise kind of
cliffs that you fall off if you just do
something slightly wrong because you
know if you're looking a few moves ahead
there's always some randomness in what
might happen and that randomness tends
to smooth out the valley function and
give you a nice surface to kind of learn
about so this program having done that
they went ahead and it basically
defeated the human world champion back
in 1992
so that was an amazing result it did
have some search on top of there so it
was using like a a three fly a three
step ahead look ahead using alpha beta
search too so once it had this it was
using that as the leaf value of this
minimax search and bubbling those
minimax values back up to the root to
decide what to do
it also back in this version which
actually performed this result I
slightly lied and that that one also had
some expert knowledge in there but
Tesoro went back later and he showed
that if you take out all of that expert
knowledge and this was just a few years
later if you take it all out and you
carry on training with the version with
no knowledge at all it actually ended up
outperforming the version that he'd used
in that match so this was really
something which learned completely from
from raw data nothing else yeah okay so
the question is where's the
non-linearity the non-linearity is
inside the multi-layer perceptron so it
takes this flattened representation of
the board and it passes it through like
a two layer multi-layer perceptron and
each layer is like kind of like a linear
combination of the previous one followed
by a nonlinear activation the so there
was a I think at NH activation that
followed each one of those and that
non-linearity in the middle is what
makes this whole function nonlinear and
if you don't have that non-linearity as
with all of neural networks it just if
you don't have non-linearity somewhere
it just collapses to a very boring class
because the linear times a linear times
a linear is just a linear and so if you
want to have it's the kind of this
dilemma that you know linear function
approximation is so much easier and so
much cleaner and we get so much nicer
convergence properties if we can work
with it but it's just not very
expressive and so if you want rich and
powerful and expressive representations
you need to do something harder you need
to use nonlinear function approximation
to achieve those results and that's
really why white people have moved
towards deep learning in their in the
last few years I mean deep learning is
nothing more than you know rich
compositional functions which compose
one layer one function into another
function into another function that's
what deep learning is yeah
yeah I think that's probably true so I
think the sharper the the value function
more of these cliffs you have the more
precise your search needs to be all the
more accurate your value function
approximation needs to be I mean there's
always this trade-off between the
quality of your your function
approximator and the amount and the
quality of your search and you can make
up for one with the other so but I think
you know in some sense it's expressing
something fundamental about the
difficulty of the problem and you need
to address that difficulty either
somewhere in your toolkit so it can be
in the search or it can be in the power
of your function approximator so it
might be that you equally have require
more steps of look ahead internally
within your within your function
approximator you can think of your deep
network as representing kind of
shortcuts to how well you can do by by
searching it's kind of internally doing
some steps of computation and trying to
trying to find shortcuts to figuring out
the minimax value without doing any
explicit search and so that you can put
more layers in there as well and that's
not a native okay so that was TD gammon
[Music]
I'm going to skip this section okay
should we take a little break and then
we can come back for for the next part
so let's take a 10-minute break
and then we're going to talk about some
more modern search techniques which are
about Monte Carlo search simulation
based search and moving on to what's
been done recently by combining these
methods with deep learning let's get
going again so I want to talk a little
bit now about a very radically different
form of game tree search which has
proven to be particularly effective in
in challenging games and larger
branching factor games and also real
world domains it's been very widely used
now and most recently has also turned
out to be very effective in even in the
domains where traditional methods of
minimax tree search were considered to
be dominant and so this idea is really a
broad class of ideas which we can call
the simulation based search and the idea
is really really actually surprisingly
simple and the idea is to say that
actually self play reinforcement
learning can replace search so so far
we've kind of seen that there were these
two different ideas
either we could do like this minimax
look ahead we're really kind of bubbling
ahead and considering all of this tree
of look-ahead possibilities where if I
go here and you go here and I go there
you know what's the value going to be
and we could back that up and back that
up and really compute the minimax values
or we had some kind of function
approximator like a value function there
was estimating those values directly
without ever doing any look ahead and
the surprising part is to say that
actually the reinforcement learning can
replace that first part that actually we
can use or itself a reinforcement
learning instead of a search procedure
to actually give us a process of look
ahead and the idea is really simple the
idea is to say if I want to do look
ahead from a particular state how can I
do perform that look ahead well what I
could do is I could just start consider
the game that starts from that states
consider there you know this is it also
applies in single player single agent
domains where you've got some MDP some
massive MDP and you just want to
consider the sub MDP that starts from
now and in games we can consider the sub
game that starts from now so you're in
some root state you're in some
particular position you're in some state
right now and you want to figure out
well what's the best thing from here
onwards so the idea is to simulate
experience that starts from now like I
mean right now I'm kind of talking to
you guys here delivering this lecture
and so if I'm trying to figure out the
best sentence to speak next it's more
useful for me to start to imagine what
those sentences might be and whether
you'll be horrified at what I say or
whether you'll actually you know learn
something from what I say then it is to
kind of imagine myself up in a mountain
in the Himalayas trekking but you know
if I find myself in the holidays
trekking up a mountain in Himalayas it
wouldn't be very useful in that
situation to then start imagining what
would happen if I was standing in front
of a lecture hall full of students so it
really matters to focus your your
learning on the subspace of experience
that starts from now you don't want to
consider everything the state space in
general a massive we want to consider
very large rich problems huge domains
and we want to focus our limited
resources and our resources are always
limited compared to the complexity of
the real world and we want to focus
limited resources whatever capacity we
have on the subset of experience which
we're actually about to encounter but
there's some agent and it's about to see
some set of events occur and if it can
learn to anticipate what those events
are and that subspace of experience it
can do much much better as a question
okay so the question is how do we deal
with the opponent strategy and the
answer is by using self play so what
we're gonna do is we're going to imagine
that both I and my opponent follow the
best strategy that I figured out so far
and so what we're not trying to figure
out what's the what's the best response
to a particular opponent strategy that
would require some model of how that
opponent behaves instead we're going to
again try and find the minimax strategy
this Nash equilibrium and with way that
we do that is by self play where we're
going to imagine if I play according to
the best strategy I have so far and you
play according to the best strategy I
have so far and then I play according to
that best strategy and so forth what
would be the best behavior and by
learning from those simulated games we
can again find something which will
approximate so what we're going to do is
we're going to just run experience
starting from now again and again and
again and run complete games of
experience that start from now so
complete sub games that start from now
that can start from this root state and
learn in exactly the same way as we were
doing our self play RL like imagine
you're doing you know tessaro's TD
gammon just like we saw in backgammon
but instead of kind of training these
games from complete games that always
start from the beginning you actually
say well right now I'm in this
particular board state and I'm just
going to run thousands and thousands of
games that start from this particular
position and learn a specialized
neural network that's dedicated to
actually solving the situation from now
onwards and that would actually be a
form of look ahead search it would learn
all of the particular patterns that
actually occur in the situation that
starts from now because you're focusing
all of your experience on the future and
so if you have this model of the future
if you have the rules of the game which
we do in this case we can exploit that
by simulating this experience and
learning from that extreme elated
experience so did you hear about in the
previous lectures Monte Carlo tree
search
okay so Monte Carlo tree search is a
special case of this
c.j so people elsewhere tend to teach
Monte Carlo tree search is like a a
particular form of look-ahead search or
the particular structure for you guys I
think you can understand this in a much
more profound way which is that Monte
Carlo tree search is actually Monte
Carlo control it's a it's a
reinforcement learning algorithm that's
applied to the sub-problem that starts
from now so instead of considering the
entire MDP and applying monte carlo
control to that entire MDP what you can
do is instead focus on the sub MDP that
starts from this particular state and
apply monte carlo control where you're
always resetting to the beginning of
that sub MDP and you're learning from
experience of what happens when you
reset only back to that particular state
you're always coming back to this
particular board position or me back in
this situation here and not in the
himalayas and you're trying to learn
what happens from your simulated
experience from your imagination imagine
again and again what happens if I'm
going to try this what happens if I try
this and learn from your imagination
what's effective and what's not
effective and if you can learn from your
imagination what works well you can
actually do better as a Monte Carlo tree
search is exactly Monte Carlo control
with table lookup where the table is too
big to represent the entire state space
so the table is instead represented by a
tree that only contains the things that
you've seen so far and you just kind of
expand that tree when you get to new
things you haven't seen before and so
that's what Monte Carlo tree search is
you're basically doing Monte Carlo
control you're running simulations
you're taking the average of those
simulations and putting that average
value back in each step storing that in
there in your tree and that gives you a
way to to actually search so amongst
Monte Carlo tree search algorithms very
many of the most effective variants use
some kind of upper confidence learning
algorithm when you learned about Bandits
and in exploration strategies you
probably came across the UCB rule which
is one way to balance exploration
exploitation and if you plug that into
your Monte Carlo control so every step
you have some kind of decision about how
much to explore and how much to exploit
you can also use Epsilon greedy but
every step you've got to some decision
about whether to explore or exploit and
that gives you something like these UCT
algorithms which has been very very
effective in many games
and so self play UCT actually converges
on the minimax values so this is one of
those cases where well although we're
doing something which is you know
basically a fundamental RL algorithm
applied to our imagined experience that
might seem like a woolly concept but
actually it really converges on the
minimax values in other words we are
finding in these two player zero-sum
perfect information games that they're
considering this really will find the
optimal solution the Nash equilibrium
which in this case is the minimax value
function so you will be done if you do
this you'll find the right thing and
more generally you can introduce
approximations in very large games we'll
start to introduce approximations you
know value function approximation and so
forth and that will give us a pretty
decent approximation to this minimax
value function so it's a kind of search
where we're kind of imagining what will
happen I'm imagining what will happen
under my current strategy but at the
same time I'm learning to improve that
strategy from the experience I've seen
so far and that's how it can actually
converge on this thing like I I start to
imagine what will happen if I try this
and then this and then this and you do
this and I do this and they start see
all actually every time I tried that in
my imagination I lost so then I'll
change my strategy to do something
different and now I'll try something
else where I do this and then this and
then this and then I win and now I say
okay actually that was a better strategy
and now my opponent might need to adapt
to that in my imagination and change the
strategy again and we kind of had both
players continuing to improve and
improve all in in imagination starting
from this day onwards focused on this
kind of subtree of possible reachable
things from here onwards so that's the
idea of it okay so for a few years now
MCTS has been the best-performing method
in in many challenging games so go I'll
talk about a little bit more hex lines
of action Amazon and I'm also going to
talk about some recent results shortly
where we see actually it turns out to
also perform very well in games like
chess where it wasn't where minimax
search methods like alpha beta were
previously thought dominant but what's
interesting is that in many actually
really interesting games simple Monte
Carlo searches enough by simple Monte
Carlo search I mean something where we
don't improve this
jouji for both players where you just
kind of have some randomized rollouts to
the end of the game under some simple
fixed strategy and then we just see how
well that does and that can already do
very very well in games like Scrabble
and backgammon it's enough to reach
superhuman performance
yeah question so we're basically
learning a policy pair for both players
and one very sensible approximation is
that is that the one side of the policy
plays in the same way as the other side
but just with the kind of board colors
reflected but that's not a necessary
requirement for this we're basically
learning the policy pair is the way to
think about it so we're learning the
policy pair and we're improving the
policy from both players perspective and
we're playing according to that policy
pair in our imagination and each time we
improve one side of that policy we then
go on and improve the other side of the
policy as well and so we're really
trying to find a policy pair that
approximates that converges on the
minimax
strategy well in it depends what you
mean not necessarily I mean that you
this because different players see
different situations so it might be that
one player has an advantage for playing
first for example and so so the board
state can differentiate the strategy
from one side to the other so I think
it's just best to think of it as a
strategy pair and it might turn out that
in the way that we approximate this that
we exploit this this mirroring property
but it's not like a necessary piece of
understanding this I think it's clearer
to think of it's just a policy pair that
that is improving and each policy well
what's the policy doing I mean the other
way to think of it is it's it's just you
can also think of this as just one
policy where the one policy sees as part
of its input which color pieces it has
and so so we provide this policy and it
says oh now I'm in a situation where
I've got the white pieces here and
you're asking me to play a move and now
I'm in a situation I've got the black
pieces and you're asking me to make a
move but it's you know in a sense that's
the policy which we're considering
that's the policy
we want to so you can think of it it's
just part of the function approximation
architecture that sometimes you're
seeing black and sometimes you're seeing
white and you can do things like
mirroring the colors but that's that's
optional in this setting yeah okay great
question can we truncate the Monte Carlo
search before we reach the end of the
game so we don't do full Monte Carlo
rollouts truncate and use an evaluation
function that's gonna be the next part
of the at the discussion so so let's
let's start by doing very simple things
so simple Monte Carlo search is enough
so so I think you know one of the
reasons why simulation based search
became popular was people starting to
realize that even even very very naive
simulation based searches can can be
remarkably powerful so so here's an
example this is the the game of Scrabble
so in Scrabble you get some letters on
your rack and you have to kind of figure
out what's the best word to play on the
board and you get points according to
each of your your letters and so you've
got these points on your rack you've got
these seven letters and the idea was
that the first strong program which came
along in Scrabble was this amazing
program called maven and what it did was
it tried to have an evaluation function
which basically said in how good is it
to play a particular word onto the board
and what it would do it would evaluate
that that move by the score you would
get for playing that word onto the board
plus the value function of the letters
that you've left on your lap rack and it
should probably have taken account of
the board position as well but it kind
of ignored that ok this was already of
huge advance over humans and anything
which would come before and what it did
was it just kind of looked at the rack
and kind of said well you know how good
is it to leave certain letters on your
rack like if I play my blank now which
can be any letter I want and it's really
useful in Scrabble I might get a better
score but there's an opportunity lost
there because by keeping it on my rack
maybe next turn I would have got a
50-point bonus for using all my seven
letters and so it kind of learned all of
these looked at all of these just one
two and three letter features like do I
have a cue left on my rack well that
would be really bad but if I've got a QA
u together that might be actually quite
good because the cue is very
high-scoring if I have three eyes on my
rack that's pretty bad you know use
not many choices you've kind of lost
some flexibility there and then this
whole thing was learned by the kind of
Monte Carlo policy iteration so said I'm
not going to talk so much about how the
value function was learned because we've
already dealt with that this value
function was learned by standard
essentially td1 um
the value function was learned by kind
of every single state played the game
you look at the outcome of the game and
you update the value the the the value
of these function approximator to make
your estimate of what happened a bit
more like what actually happened in the
real game so that's the standard what
we've seen before just like in TD gammon
but an even simpler representation what
was interesting was that the way it did
search so actually did search by by
rolling out by imagining what would
happen into the future so you'd start in
this position and it would basically
just play out games according to its
strategy so it kind of play out some
number of moves into the future and then
it would truncate and actually say okay
I'm just gonna look ten moves into the
future and then evaluate the position
that I'm think I'm in there and and it
will select and play the move which has
the highest average score so if you just
kind of imagine what's going to happen
just keep imagining what will happen
without improving that strategy just
keep imagining games and trying you know
a few hundred games in your imagination
and like randomizing over what you think
you're gonna pick out of the bag and
then just play the highest scoring move
then this is a really really powerful
form of look ahead and just to show how
powerful it is here's a little example
of what what maven did when it actually
played against the world champion this
was the first time a computer Scrabble
program ever be a human world champion
some quite a while ago now but anyway
and it beat this human world champion
Adam Logan by nine games to five and and
there was this one game where Adam Logan
was like just way ahead in this game and
in you know all the pundits thought this
was this was over there's no way that
that maven could possibly come back but
made them with this kind of look ahead
using this kind of Monte Carlo rollouts
saw they only had one chance to win
which was to do something called
phishing which is if you're behind you
kind of have to just hope that you can
kind of find this one spectacular letter
in the bag that will help you get a
really high score and the thing it
fished for was it ended up picking out
this
mouthpart and you'll notice that this is
one two three four five six seven eight
nine letters so so these two are ready
down and it had two fish to kind of hope
to it was basically predicting this
endgame would work out in this one
particular way and if it picked up the
particular letter you'll be able to play
a mouth part by the way I don't even
know what a mouth part is as an English
word but anyway let's Scrabble for you
but and it kind of was able to use this
Monte Carlo analysis from from much much
earlier in the game to realize there was
only one chance for it to win and to
find that chance and of course it was a
little bit lucky as well but anyway it
turned out to play near-perfect Scrabble
I mean there's some luck in the game but
it played very very well and these same
ideas were very effective in backgammon
we saw we saw earlier the example of
backgammon doing kind of a little bit of
search on top they're actually
backgammon again used a very someone
showed subsequently you could use even
better results by doing this kind of
very simple Monte Carlo search in
backgammon and so one way to think of
these very simple search procedures is
it's like doing one iteration of policy
improvement because you're kind of what
are you doing well you're you're taking
your current policy you're imagining
games all the way to the end and then
you're picking a greedy step with
respect to those imagined games so the
greedy strategy with respect to how well
he did in those in those games is
exactly one greedy policy improvement
step you're saying okay I'm gonna look
at how well I did in those I'm going to
evaluate it that's your policy
evaluation to see what was the mean
outcome of all of those games and then
you take a greedy step you pick the
thing which actually the action which
led to the best outcome and so if you
keep acting greedy with respect to those
estimated mean values that's doing one
step of policy improvement so Monte
Carlo search is effective because it
does one step of policy improvements
it's doing one step of policy iteration
and so a natural question is if one step
of policy iteration is so powerful what
happens if we allow ourselves to do many
steps of policy iteration and so that's
what leads to Monte Carlo tree search
what I want to talk about now is our
recent work a deep mind on actually
taking some of these ideas further in
the alpha zero project
so it's always hard to know how much you
guys know about this stuff but I'm just
gonna talk about it anyway and hopefully
if you've heard about some of its before
you won't mind a duplication if you've
heard nothing and I hope there's enough
for you and and so forth so what I want
to talk about is how we started to bring
about an architecture which building on
these ideas so far so building on on
value function rips approximation policy
approximation these ideas of doing some
kind of simulation based search with
multiple iterations of policy
improvement inside it how we could build
a system which started completely from
scratch with no human knowledge at all
and was able to master some of the most
complex games where previously people
using a lot of awful lot of knowledge
there and I'm gonna use go as the case
study for the beginning and then we'll
talk a little bit about other games so
why go well it's the oldest game in the
world about three thousand years years
old
amongst still currently played games
there's still about 40 million active
players and there's about ten to the
hundred and seventy positions so what
does that look like well there's this
enormous branching factor in the game of
Goa where from each of these positions
you reach several hundred other possible
positions there's several hundred moves
in the game it's um 19 by 19 board you
can place down a stone on any one of
those and that leads to a vast array of
possible next positions and from each of
those situations they've got a vast
array of possible positions and so if we
were really to consider the minimax
problem doing this minimax search and
really computing the minimax value you
would have to consider all ten to the
hundred and seventy of these states to
actually compute the true value like who
who actually has won this game like from
the beginning who what's the perfect way
to play
that's intractable and so really the
story of alpha zero is the story of
trying to deal with that intractability
with with principled reinforcement
learning methods and so I'm going to
start by talking about alphago which was
the original program that was able to
defeat the world champion
Lisa Dahl and that will give us some
intuitions that we can then bring into
you know making something even more
general that was able to to play many
games and with even less knowledge and
so the idea of alpha zero was to use two
neural networks the first of those
neuron that
was a policy network and the policy
network kind of looked at the position
in the game of go and he used this
convolutional neural network to kind of
build up features so each layer of that
convolutional neural network is
basically looking at a small region of
the board building up features which
represent what's going on in that
particular region of the board and that
gives you like a new layer of features
saying well I started off knowing that
these were the black and white stones
here but at the next layer maybe I know
which stones are adjacent to each other
and the next layer maybe I know which
stones are are under threat and the next
layer maybe I've got some sophisticated
idea of the kind of life and death
that's going on and so forth and so we
had many many layers of policy network
in the most recent version this is about
an 80 layer neural network so this can
get very very deep and what we output at
the top of it are move probabilities
something to say well in this position I
think it's a good idea to play here or I
think it's might also be a good idea to
play here but it's a really bad idea to
play over here and we represent that as
kind of like a probability map like a
probability distribution over the legal
actions in the game okay
and there's a second neural networking
in alphago which is called the value
Network and the value network is also a
convolutional neural network which takes
the the board as an input it looks at
all of the black and white stones builds
up features of features of features to
get more and more sophisticated
representation of what's happening in
that position and at the end of it it
outputs a single scalar number saying
who it predicts is going to win the game
you know like plus one if you think
white is going to win and minus one if
black is going to win okay so that's the
value network and so this is a form of
value function approximation and this is
a form of policy approximation and the
idea is that in the original alphago we
trained these two things by first of all
supervised learning so we started with
human expert positions and I hope you're
thinking oh I thought we were doing
reinforcement learning here so why do we
need to take human data into account and
we're going to address that later okay
so we started with human expert
positions we trained our policy network
to mimic what human experts did in each
of those positions
so in each board position we said okay
in this position the human played there
and so we adjusted the parameters of our
policy network to say we want the policy
to output that same move that the human
played we just adjust the parameter of
our neural network to predict the move
that the human played so that straight
classification once we've got that
policy network we apply reinforcement
learning to that policy network in other
words we actually got this policy
network to play games of self play
against itself and we adjusted the
policy network further by reinforcement
learning by a policy gradient method but
also we built up this value network what
we did was we built a value network
which from each of these games it was
kind of like a you know Monte Carlo
learning of the the value function that
fer we played the policy network against
itself and we looked at the outcome and
then from each of the positions that we
encountered in that game we asked the
neural network the value network to
predict who is going to win so if you
pass in this position the question we're
asking is you know do I think black is
going to win from this position I didn't
think White's going to win from this
position and the way that we actually
build the data is by getting the policy
network to play against itself and so at
the if at the end of the game the policy
network which was very strong ends up
with black winning that's the target we
provide to our value network and we
adjust the parameters of the neural
network to make it provide an output
answer saying it thinks that that player
is going to win more okay
any questions yeah so for every state
that was visited during this so this is
a this is a so think of this this
process is classification and this
process is regression at this step what
we're kind of doing is building a big
data set that contains all of the
positions that were encountered during
all of these games of self play and from
each of those positions we're trying to
predict who ended up winning that game
of self play that's the regression
problem we're trying to solve right from
every position who ended up winning and
if you can predict that if you can
predict who ended up winning in this
game that's a really powerful thing to
have in your arsenal like this is this
is like this is y-value networks are so
powerful they summarize they're kind of
a cache of all of the look-ahead that
you might do this is also true a single
agent domains it's why we build value
functions that you are you want to have
a summary that tells you one shot
immediately what's the what's the value
of being in this situation without
having to do all the look ahead and
consider all of the possible things
which might happen in the future
so it's like a summary of all of the
future possibilities without having to
do this exponential expansion
combinatorial expansion of all of those
possibilities yeah so so the supervised
learning can have bad examples in there
the self play reinforcement learning can
correct those by adjusting the policy
network and that that stage was
important in practice but we'll see a
better way to do that where we don't
even start from human expert positions
shortly and in fact our best results
come from not using human data at all
that subsequently okay so again if we
think of this enormous search tree which
we're trying to compute so this could be
go but it could be any other game but go
just has a particularly daunting search
space and here we're just showing like a
binary search tree it was kind of like a
cartoon of what happens in this search
tree and we can see that you know from
this little situation we could go over
here we could go over here and then
there's all of these possibilities and
the real search tree is like
this but there's kind of you know 200
possibilities from each of these instead
of two and it's kind of a depth there's
about 200 as well so it's a big search
tree and how can we narrow that down
well the first idea is that we can
reduce the breadth of this search tree
by using the policy Network in other
words we don't have to consider the full
breadth of all possibilities like there
might be this enormous branching factor
of 200
but if our policy network tells us that
you know that sensible move to play as
this one the policy network can
basically pick out a handful of
reasonable possibilities and can be
relied on as kind of soft pruning
mechanism where we can exclude the the
moves which the policy network says are
nonsense and only come back to those
later in search so we kind of prioritize
the things that the policy network
thinks are good and that immediately
gives us a much narrower search tree and
that's why the policy network is
effective in this search and the second
thing we can do is to reduce the depth
by using the value network and this is
just like we saw with deep blue and and
all those programs in the past well what
we can do is instead of going all the
way to the end of the game we can
summarize the subtree beneath each of
these leaf nodes by a single value that
estimates who's going to win from that
point onward again a value function is
powerful because it's like summarizing
in one number all of the possible
contingencies from that point onwards
and if you have that one number you've
saved yourself all the effort of having
to do that future computation this is
why value functions are so crucial and
so we can use this value network to save
us from having to build out and search
for this this big subtree over here and
that that makes a dramatic difference to
the size of this search tree so putting
those together we built a a Monte Carlo
tree search algorithm in alphago and
I'll just step through that in a little
bit more detail for those who really
want to see you know what would a what
would a state-of-the-art like Monte
Carlo tree search actually looked like
how does it kind of put these pieces
together to give you those properties
and it really kind of has these these
three strategies this is this is the
strategies that we use in our latest
version of alphago and the first phase
is you've got to kind of select a path
so remember we're always doing this
thing where we're simulating a game
we're kind of imagining what's going to
happen next so we've got this choice of
well what should we imagine what should
we imagine
what should that each player do in each
each of these imagined situations
and the way that we pick the actions in
our imagination is by maximizing these
cue values like there's action values
which will explain where they come from
in a minute
but for now just imagine that for each
action we're storing some kind of Q
value saying how good is their action
and so the greedy strategy would be just
to maximize Q but the problem the greedy
strategy is it can get stuck you need
some kind of exploration in the search
tree you need to sometimes try some
other branch not your greedy one just to
see in case that other branch actually
turns out to be better you have to try
it sometimes and so what we do is we do
something like we saw in the exploration
lecture where you want to add in some
upper confidence bound you here and that
encourages it to consider things which
might be good so if you're if your upper
confidence bound you this upper
confidence bound term you here says that
you that you might actually be able to
get a lot more value than q then we'll
we'll take this path here even if this
one was currently has the best Q okay so
we just add on our Q value with some
upper confidence term and we maximize
that and that picks out a path through
this search tree and the upper
confidence term is actually really
simple it's just proportional to so it's
proportional to the policy Network so
basically if the policy like something
it will take it more often
so that's implementing this idea that
the the moves that the policy network
likes at Ryde and the moves which it
doesn't like are excluded so this U is
just proportional to the policy network
to the policy probability and it's
inversely proportional to the visit
count so the more you try something the
less of a bonus you give it because
you've already kind of got some idea of
what it is and that turns out to have
some justification I won't go into that
so so we've selected some paths now
through the search tree so we're just
kind of imagining things again and again
and again so each each simulation we're
going to start from our roots state we
can imagine what happens according to
this strategy of trying some imagined
path to through this imagined gained
through the imagined world and then
we're going to reach once we reach the
end of that that we reach some leaf node
here what we're going to do is evaluate
that leaf node and expand it
so we evaluate it using our policy
network and our value network to give us
move probabilities from our policy
network and a value from our value
network and you only need to do that
once per simulation and once you've got
that you back up those values and so
here what we're saying is that this is
the Monte Carlo part that the Q value of
every action in this tree is just the
mean value of all of these V's that
we've computed in the subtree but
beneath it it's just a mean it's just a
mean of all of the simulations we've
tried so what we're trying to say is
that you know how good is this action
here well this action is the mean of the
outcomes of all of the simulations that
I tried that started from this action
here
that's the Monte Carlo idea right that
you try something sometimes you win
sometimes you lose and you just take the
average of it so if you played two games
if you play three games and you won two
and you lost one well your action value
would be two-thirds here so you're just
taking the mean of everything that
happens beneath you so so this one here
this pink Q is taking the mean of of the
leaf values that you saw beneath that
this green Q is coming from here and so
forth and once you've got those Q values
you cycle background and use that to
influence your next trajectory so this
has got that policy improvements
happening where we're not only are we
using our current knowledge to influence
the paths we take but we're actually
improving that knowledge in this stage
here we're improving our knowledge in
the search tree and that improved
knowledge now we figured out oh actually
you know turns out now I see that this
was actually a bad idea and that
influences the next trajectories that we
take and those next trajectories will
become better and so forth until
eventually this converges on the minimax
strategy okay so that's the Monte Carlo
tree search strategy so we went out and
we played against Lisa doll who was the
winner of 18 world titles this was in
Seoul in March 2016 and alphago actually
won this match four games to one and
became the first program to beat her
human professional player and I've just
got for those of you haven't oops seen
this I've got a little video here
you
this was the first time computer
programmer
pro-player this was actually the the
machine that played the match this was
sitting in a data center within Google
in the US somewhere you can see the
little board there and but actually we
were in in Seoul operating over a over a
connection to that data center and this
led us on a path to try and do something
which was simpler and using less
knowledge to try and achieve even more
performance and just just finish this as
some of the events that happened there
yeah this was the actual match taking
place with a Jeff Wong who's one of the
developers of alphago playing against
Lisa Dole there this was the press room
which was a little bit crazy this was
actually what we were looking at in in
the room watching the match there you
know actually this is the program our
statistics we're not influencing it
we're just kind of watching it on these
screens and making sure that nothing is
falling apart and there and the
connections that happen up and and so
forth and that was us receiving a nine
down nine down certificate and from the
Korean Go Association so this led us to
a quest to try and do something without
human knowledge right the goal here
should be to have a system which can can
crack any domain I mean we're talking
about games of course we would like to
go beyond games but within games within
this class we've been looking at you
know what what would be the system which
would be most satisfying well it had a
few properties it would start with no
human knowledge at all we would just
provide it with the rules of the game
and it would go out and it would play
learn how to play that game to a
superhuman level of performance and so
we try to set out to do that within this
class of two player zero-sum perfect
information games and this led to the
alpha zero project and so we wants to
throw out anything to do with human so
we threw out human data we wanted
something which learned solely by self
play reinforcement learning starting
from random with no human features so
only taking the raw board as an input so
no no handcrafted features or anything
like that we use just a single neural
network at
to lien alpha zero so the value and
policy networks were combined into one
neural network which actually led to a
big improvement for interesting reasons
and it had a simpler search algorithm so
it was really a very pure search
algorithm and the idea here was to say
you know each time you take complexity
out of your algorithm you achieve more
generality or the converse is true as
well each time you specialize your your
algorithm to something in your
particular domain you kind of handicap
yourself at the same time because you're
you're introducing something which is
locked you from from that same idea
working somewhere else and so the idea
should be that we have something very
pure which can congenital eyes to other
domains with with minimal effort and
ideally something which is you know
nothing where there's nothing really
special case to games at all so this led
to the alpha 0 algorithm and the idea is
really simple and the idea is actually
to do something akin to policy iteration
so I'm just going to talk through this
strategy it's a and hopefully you'll
you'll get the algorithm as a fairly
straightforward idea which is that you
know in each of these positions this
imagine this is your go game we're
actually going to play games where from
each of those positions we're going to
run a search we can run one of our Monte
Carlo tree search --is using our neural
network so inside this we've got our m
tts as we saw earlier guided by our
policy in value network and we run that
search and pick a move okay
and given that move we play it that
gives us it takes us to a new position
we run a new search using onion all
networks play that move run a new search
play that move until we get to the end
of the game ok and that's how we
generate our games so alphago is is pure
self play it's playing against itself
starting completely randomly so we can
initialize these neural networks to
completely random weights and start off
by playing random games but influenced
by whatever those neural networks happen
to think is a good idea and then what
we're going to do is use those games
that we've generated to train our neural
networks to do better so first of all
we're gonna train our policy network to
predict the move that was played by the
like what did alphago actually do in
that search well you know it was in this
position we ran our policy network and
that policy network actually picked some
move well now we want to train our
policy network to do the thing which the
whole search did before so we're kind of
distilling the whole of that Monte Carlo
tree search back into our policy so we
used our policy to influence our search
we ran this huge search like looking
ahead tens of moves and running like a
million simulations and now you want to
kind of distill that thing back into
into a simple decision that's made by
your neural network in other words the
way to think of this is we want to train
our policy network on the best possible
data that we could have and where does
that best possible data come from well
it doesn't come from humans it actually
comes from from alphago itself that we
should trust those moves which it
produces is the best possible targets
for training a new generation of alphago
so we trained the policy Network to
predict alphago smoove so we take
whatever that search did that becomes
the target for classification for our
policy network to predict those moves
not the human moves and we also at the
same time
train a new value network by regression
to predict the winner so whatever the
winner of that self play game was from
each of these positions that we
encountered we now want our value
network to be moved to predict that that
winner so we were in this game you know
we ended up with some some actual
outcome with some winner and now that
winner is fed into all of the positions
that that led up to that win so we're
basically saying from each of these
positions predicts who actually ended up
winning when
alphago played against itself using
search and so we've put the search
inside the loop of reinforcement
learning it's a kind of arm search based
policy iteration where each generation
we're making a new policy and a new
value function and a new policy and new
value function that builds on the last
one with search in the loop and the idea
is that when you learned about policy
iteration before and they have a slide
on this yeah when we learned about
policy iteration before we saw that
policy iteration uses this idea of
greedy policy improvement typically you
kind of you take your policy you
evaluate it to give you a value function
and then you
greedly with respect to that value
function to give you a new policy but in
alpha zero we do something much more
powerful which instead of acting
greedily
we perform a huge search to kind of
figure out the best strategy and search
gives a much bigger policy improvement
than than just acting greedy with
respect to your value function you can
do like a multi-step look ahead to give
you a much better policy improvements
than just this one step jump that you
get from policy improvement in other
words you run a big search and that big
search leads to an action selection
procedure which is much better than the
thing that you started with in your raw
policy that you began with like the
search itself you can think of as a
policy a way to pick actions you run
your search and you do the thing that
was recommended at the root there is a
kind of policy and that kind of policy
is massively more powerful than the
policy you start with and so that kind
of iteration actually helps you do
better and better and better and so what
we do is we feed this back in again and
again and again iteration by iteration
the new policy and value network is used
in the next iteration of alphago zero
and that goes round and round and round
leading to better and better results and
we start off with completely random
weights but very quickly this thing
learns how to get much better policies
and each generation and we get this
massive improvement due to the search
which leads to the next set of data
being produced being much higher quality
than the previous and this happens
completely online so we're always
training on the freshest data produced
by the freshest policy and value network
and it goes on and on and on so we could
think of this as a building on other
work which has come before like like a
darkish era and so forth where people
have looked at other ways to do this
kind of policy iteration schemes but
here we're really putting the whole of
search inside the loop and that leads to
leads to a very very big improvement so
the policy improvement makes use of the
search to improve the policy and the
policy evaluation makes use of search as
well that each time we run a game we're
running a game where each player is
picking its move using search and so the
self play is like self play with search
in the loop like alphago plays it's it
runs the search it plays a move using
search plays another move using search
plays another move using search and
eventually the outcome you get a
game is like gold you know that outcome
you get is really really high-quality
and so when you train that kind of
policy evaluation is much more useful
than if you were to get your raw neural
network to play against itself and then
look at the evaluation of that game like
the search gives us very high quality
outcomes and so that's why alphago Xero
is so much more effective than the
previous version of alphago so this
leads to much more sophisticated play
over time as you start to train this
thing you start off with you start to
see that starting off with completely
random weights after just a few hours it
starts to behave in the way that human
beginners do starting to like chase
after stones and try and capture them
greedily a bit like human beginners do
that after just a few more hours it
starts to play like a strong human
player and understand all of the
concepts of go and after around 72 hours
it was super human so this is a example
of a learning curve so you get this very
nice stable learning and this is typical
of every time we've tried this in every
game we see this very stable learning
curves this is actually you know
repeatable if you if you try again you
get similarly stable learning and this
shows it this is the the version
learning completely from scratch and
this is the version that beat Lisa doll
so this is a much much stronger program
there and it exceeded that version after
about 72 hours there we go okay so you
know one way to evaluate alphago is how
well is it compared to humans and the
previous state of the art so the
previous state of the art before these
these algorithms came along with
programs like Zen and crazy stone which
are very sophisticated Monte Carlo tree
search programs using a lot of the ideas
that we've talked about but building on
massive amounts of human knowledge as
well to try and you know bootstrap their
performance rather than relying entirely
on on principle self play reinforcement
learning with deep neural networks and
so the original alphago when it came
along this was in our nature paper beat
the European champion found way by five
games to nil and that represented like a
four stone this was so this these gaps
here show what happens if we
got this version to play this version
and this is like giving for free moves
to the opponent and it was able to beat
it we were then able to the version
which played against Lisa doll was able
to give three stones advantage like
three free moves to this version and
still beat it these are slightly you
should take these with a slight pinch of
salt because you know these are these
are programs which are trained by self
play and so they're particularly good at
beating beating weaker versions of
themselves and so it's not clear that
that would generalize to a three stone
improvement against humans in fact it
almost certainly wouldn't and then the
version which we played online and beat
the top human players 60 games to nil in
the world and that version was called
alphago master and that beat their
alphago lee by three stones three three
free moves against that version and then
most recently this is the version
alphago zero which i've just been
talking about which was completely
learned from first principles and it was
able to beat that version about 90% of
the time so if there's one thing to take
away from this it's that really doing
things in the principled way it you have
to believe in your principles and you
have to believe that you can overcome
all of this knowledge that that it feels
like you should be building into the
system but actually each time you put
knowledge into a system you're really
handicapping it and if you really go
back to the beginning and find the right
principle to learn for itself it will do
better eventually and we saw the same in
backgammon but the same is true even for
the hardest problems within this sphere
like go okay so it learns human go
knowledge and this is just an example
where it discovers like these human
patterns that humans play and so humans
in the game of grow have spent about
3,000 years developing this theory of
how to play there's actually you can
take degrees in the game of go and and
there's universities devoted to studying
it and and they there's a whole theory
of how to play in the corners which was
discovered by alphago during alphago 0
during its its opening play but
ultimately discarded later in favor of
new openings that humans didn't know
about and there's actually a lot of
creative moves that it's discovered and
played over over time and so of course
what we our goal is you know it's been
all very well to say well this is a more
general algorithm but you nothing is
really general unless you prove its
general by trying it in more than one
domain
and so we tried alpha zero in three
games chess shogi which is the game of
Japanese chess and the game of Go
so Shaggy's so chess is interesting
because it has this whole history as we
saw with deep blue where massive amounts
of handcrafting have gone into building
like these really super powered
computers with decades of experience
where you know chess was the Drosophila
of AI for four decades and the level of
performance that's been achieved in
chess is immensely superhuman shogi is
interesting because it's um actually
only just reached the point where where
computers are able to to play at the
level of the top humans and it's it's
quite different to chess actually
because when you capture a piece you get
to put it back down again as one of your
own pieces so that's like a really
dramatic difference for the game and the
game of go
so chess has a smaller branching factor
than go but it's nevertheless
interesting for other reasons because it
is arguably the most studied domain in
the history of AI and that we have these
highly specialized systems such as deep
blue and the state of the art programs
now our our programs like stock fish
which are indisputably superhuman shogi
is computationally harder than chess and
all of these state-of-the-art engines
are based on on alpha beta search and
they use huge amounts of knowledge to go
into them there's all of these
heuristics and extra pieces that go into
making them really really strong and
each one of these little kind of phrases
here is some you know big advance that
was made by kind of putting a big piece
of knowledge into the program or a big
advance to these these programs and so
there's these really beautiful piece of
programming like stock fish which use
all of these things and alpha zero just
throws that all away and says let's use
self play reinforcement learning with
self play Monte Carlo search these
methods that we've seen so far and in
each of these games within just a few
hours actually it was able to outperform
the world champion so in four hours
alpha zero surpassed stock fish which
was the state of the art program in
chess in two hours alpha zero surpassed
elmo which was the world champion in the
game of shogi in eight hours alpha zero
surpassed the version that defeated Lee
SEDOL that we looked at earlier
so it won against the the world champion
stockfish 28 wins and 0 losses and this
is just showing that in each of these
games it produced very very strong
performance and this is actually a
figure from the financial times year-end
charts that came out in December
this is brand-new by the way all of this
work came out in December that just kind
of showed I thought this was quite nice
it showed how computer chess has
progressed over the decades so this is
actually the state of the art in
computer chess on an E low scale that
kind of shows how much they progressed
over time and you see this is the top
humans in the world and you see at this
point here was was deep blue it was like
a spike where they built this special
hardware and and really performed very
well but actually they continued to
advance
right up until now they've just advanced
in advanced and advanced and then you
carry that forward and this was alpha 0
kind of doing the same but in four hours
so and it scales very well with search
time so actually this Monte Carlo tree
search actually scaled better than alpha
beta search which was thought to be
something with the only method that
would work in in the game of chess so I
just want to finish with saying you know
this is just one example of how to use
all of these methods and so far we've
talked about these games is like a
classic board games as a case study for
AI but of course they're just a stepping
stone towards where we really want to
get to which is actually systems that
learn completely from scratch using very
principled methods starting just from
the raw inputs and without human data to
learn to achieve human levels of
performance in in very rich domains that
we might care about and actually
simulated games such as this one
sometimes a more useful test bed for us
and this an example of an algorithm it's
actually the Unreal algorithm which was
learning just directly from pixels to
try and solve these kind of domains with
3d navigation just look at the pixels
and learning how to achieve the reward
of picking up the Apple and solving
quite interesting and challenging
problems and a lot of the same ideas
which we've talked about are relevant
and I think hopefully if there's
something to take out this case study is
that the
ideas of learning from scratch our
principle they work well they achieve
optimal performance they can reach
superhuman levels and the same ideas are
applicable not just in games but
everywhere else we never with we
shouldn't have to special case in any
way to games so I'll leave that with you
thanks very much hope you enjoyed the
course and yeah I'll be here for a
couple of question I mean it's people
have questions |
ba5c8d02-fa2e-45f8-9f09-ca6c0baf5e67 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Why I'm Worried About AI
Preamble
========
In this sequence of posts, I want to lay out why I am worried about risks from powerful AI and where I think the specific dangers come from. In general, I think it's good for people to be able to form their own inside views of what’s going on, and not just defer to people. There are surprisingly few descriptions of actual risk models written down.
I think writing down your own version of the AI risk story is good for a few reasons
* It makes you critically examine the risk models of other people, and work out *what you actually believe.*
* It may be helpful for finding research directions which seem good. Solving a problem seems much more doable if you can actually point at it.
* It seems virtuous to attempt to form your own views rather than just the consensus view (whatever that is).
* People can comment on where your story may be weak or inconsistent, which will hopefully push towards the truth.
Additionally, I have some friends and family who are not in EA/AI-safety/Longtermism/Rationality, and it would be nice to be able to point them at something describing why I’m doing what I’m doing (technical AI-safety). Although, admittedly my views are more complicated than I initially thought, so this isn’t a great first introduction to AI-risk.
I don’t expect much or any of these posts to be original and there will be many missing links and references. This can maybe be viewed as a more quick and dirty [AGI safety from first principles](https://www.lesswrong.com/s/mzgtmmTKKn5MuCzFJ/p/8xRSjC76HasLnMGSf), with less big picture justification and more focus on my specific risk models. In general, I am concerned most about [deceptively aligned](https://www.lesswrong.com/posts/zthDPAjh9w6Ytbeks/deceptive-alignment) AI systems, as discussed in [Risks from Learned Optimization](https://www.lesswrong.com/s/r9tYkB2a8Fp4DN8yB).
How do we train neural networks?
================================
In the current paradigm of AI, we train neural networks to be good at tasks, and then we deploy them in the real world to perform those tasks.
We train neural networks on a *training distribution*
* For image classifiers, this is a set of labeled images. E.g. a set of images of cats and dogs with corresponding labels.
* For language models like GPT-3, this is a very large amount of text from the internet.
* For reinforcement learning, this is some training environment where the AI agent can ‘learn’ to take actions. For example, balancing a pole on a cart or playing the Atari game Breakout.
**We start with an untrained AI system and modify it to perform better on the training distribution.** For our cat vs dog classifier, we feed in images of cats and dogs (our training data) and modify the AI so that it is able to accurately label these images. For GPT-3, we feed in the start of a string of text and modify it such that it can accurately predict what will come next. For our reinforcement learning agent playing Breakout, the agent takes actions in the game (move the platform left and right), we reward actions which lead to high score, and use this reward to train the agent to do well in this game.
If the training is good then our AI system will then be able to generalize and perform well in slightly different domains.
* Our cat vs dog classifier can correctly label images of cats and dogs it hasn’t seen before
* Our language model can ‘predict’ the next word for a given sensible prompt, and use this to generate coherent text
* Our reinforcement learning agent can play the game, even if it hasn’t seen this exact game state before. Or even generalize to slightly different environments; what if there are more or differently positioned blocks?
This ability to generalize is limited by the task it was trained on; we can only really expect good generalization on data that is *similar enough* to the training distribution. Our cat vs dog classifier might struggle if we show it a lion. If our language model has only been trained on English and German text, it won’t be able to generate French. Our Breakout agent can really only play Breakout.
Optimization
============
When we train our AI systems we are optimizing them to perform well on the training distribution. By *optimizing* I mean that we are modifying these systems such that they do well on some objective.
Optimized vs Optimizers
-----------------------
It is important to make a distinction between something which is *optimized*and something which is an *optimizer*. When we train our AI systems, we end up with an optimized system; the system has been optimized to perform well on a task, be that cat vs dog classification, predicting the next word in a sentence, or achieving a high score at Breakout. These systems have been *optimized* to do well on the objective we have given them, but they themselves (probably) aren’t *optimizers*; they don’t have any notion of improving on an objective.
Our cat vs dog classifier likely just has a bunch of heuristics which influence the relative likelihood of ‘cat’ or ‘dog’. Our Breakout agent is probably running an algorithm which looks like “The ball is at position X, the platform is at position Y, so take action A”, and not something like “The ball is at position X, the platform is at position Y, if I take action A it will give me a better score than action B, so take action A”.
We did the optimizing with our training and ended up with an optimized system.
However, there are reasons to expect that we will get ‘optimizers’ as we build more powerful systems which operate in complex environments. AI systems can solve a task in 2 main ways (although the boundary here is fuzzy)
* They can use a bunch of heuristics that mechanistically combine to choose an action. For example, “If there is <this texture> +3 to the dog number, if there is <this triangle shape> +4 to the cat number, if there is <this color> next to <this color> +2 to the dog number… etc”.
* They can ‘do optimization’; search over some space of actions and find which one performs best on some criteria. For example, a language model evaluating outputs on “Which of these words is most likely to come next?”, or our Breakout AI asking “What will be my expected overall score if I take this action?”
As our tasks get more complex, if we are using the heuristic strategy, we will need to pile on more and more heuristics to perform well on the task. It seems like the optimization approach will become favored as things become more complex because the complexity of the optimization (search and evaluate) algorithm doesn’t increase as much with task complexity. If we are training on a very complex task and we want to achieve a certain level of performance on the training distribution, the heuristic-based algorithm will be more complex than the optimization-based algorithm. One intuition here is that for very varied and complex tasks, the AI may require some kind of “general reasoning ability” which is different from the pile of heuristics. One relatively simple way of doing “general reasoning” is to have an evaluation criterion for the task, and then evaluate possible actions on this criterion.
If AI systems are capable of performing complex tasks, then it seems like there will be very strong economic pressures to develop them. I expect by default for these AI systems to be running some kind of optimization algorithm.
What do we tell the optimizers to do?
-------------------------------------
Assuming that we get optimizers, we need to be able to tell them what to do. By this I mean when we train a system to achieve a goal, *we want that goal to actually be one that we want*. This is the “Outer Alignment Problem”.
The classic example here is that we run a paperclip factory, so we tell our optimizing AI to make us some paperclips. This AI has no notion of anything else that we want or care about so it would sacrifice literally anything to make more paperclips. It starts by improving the factory we already have and making it more efficient. This still isn’t making the maximal number of paperclips, so it commissions several new factories. The human workers are slow, so it replaces them with toilless robots. At some point, the government gets suspicious of all these new factories, so the AI uses its powers of superhuman persuasion to convince them this is fine, and in fact, this is in the interest of National Security. This is still very slow compared to the maximal rate of paperclip production, so the AI designs some nanobots which convert anything made of metal into paperclips. At this point, it is fairly obvious to the humans that something is very, very wrong, but this feeling doesn’t last very long because soon the iron in the blood of every human is used to make paperclips (approximately 3 paperclips per person).
This is obviously a fanciful story, but I think it points at an important point; it’s not enough to tell the AI what to do, we also have to be able to tell it *what not to do.* Humans have pretty specific values, and it seems extremely difficult to specify.
There are more plausible stories we can tell which lead to similarly disastrous results.
* If we want our AI system to maximize the number in a bank account, if it is powerful enough it might hack into the bank’s computer system to modify the number and then take further actions to ensure the number is not modified back.
* If we tell our AI to maximize the number in a bank account but not ‘break any laws’, then it may aim to build factories which are technically legal but detrimental for the environment. Or it may just blackmail lawmakers to create legal loopholes for it to abuse.
* If we ask our AI to do any task where success is measured by a human providing a reward signal (e.g. every hour rating the AI’s actions out of 10 via a website), then the AI has a strong incentive to take control of the reward mechanism. For example, hacking into the website, or forcing the human to always provide a high reward.
I think there are some methods for telling AI systems to do things, such that they *might not* optimize catastrophically. Often these methods involve the AI learning the humans’ preferences from feedback, rather than just being given a metric to optimize for. There is still a possibility that the AI learns an incorrect model of what the human wants, but potentially if the AI is appropriately uncertain about its model of human values then it can be made to defer to humans when it might be about to do something bad.
Other strategies involve training an AI to mimic the behavior of a human (or many humans), but with some ‘amplification’ method which allows the AI to outperform what humans can actually achieve. For example, an AI may be trained to answer questions by mimicking the behavior of a human who can consult multiple copies of (previous versions of) the AI. At its core, this is copying the behavior of a human who has access to very good advisors, and so hopefully this will converge on a system which is aligned with what humans want. This approach also has the advantage that we have simply constructed a question-answering AI, rather than a “Go and do things in the world” AI, and so this AI may not have strong incentives to attempt to influence the state of the world.
I think approaches like these (and others) are promising, and at least give me some hope that there might be some ways of specifying what we want an AI to do.
How do we actually put the objective into the AI?
=================================================
There is an additional (and maybe harder) problem: even if we knew how to specify the thing that we want, how do we put that objective into the AI? This is the ‘Inner Alignment Problem”. This is related to the generalization behavior of neural networks; a network could learn a wide range of functions which perform well on the training distribution, but it will only have learned what we want it to learn if it performs ‘well’ on unseen inputs.
Currently, neural networks generalize surprisingly well;
* Image classifiers can work on images they’ve never seen before
* Language models can generate text and new ‘ideas’ which aren’t in the training corpus
In some sense this is obvious, if the models were only able to do well on things we already knew the answer to then they wouldn’t be very useful. I say “surprisingly” because there are many different configurations of the weights which lead to good performance on the training data without any guarantees about their performance on new, unseen data. Our training processes reasonably robustly find weight configurations which do well on *both* the training and test data.
One of the reasons neural networks seem to generalize is because they are biased towards simple functions, and the data in the world is also biased in a similar way. The data generating processes in the real world (which map “inputs” to “outputs”) are generally “simple” in a similar way to the functions that neural networks learn. This means that if we train our AI to do well on the training data, when we show it some new data it doesn’t go too wild with its predictions and is able to perform reasonably well.
This bias towards simplicity is also why we might expect to learn a function which acts as an optimizer rather than a pile of heuristics. For a very complex task, it is simpler to learn an optimization algorithm than a long mechanistic list of heuristics. If we learn an algorithm which does well on the training distribution by optimizing for something, **the danger arises if we are not sure what the algorithm is optimizing for*****off the training distribution*****.**
There will be many objectives which are consistent with good performance on the training distribution but then cause the AI system to do wildly different things off distribution. Some of these objectives will generalize in ways that humans approve of, but many others will not. In fact, because human values are quite specific, it seems like the vast majority of objectives that an AI could learn will *not* be ones that humans approve of. It is an open question what kinds of objectives an AI will develop by default.
It does however seem like AIs will develop long term goals by default. If an AI is trained to do well on a task, it seems unlikely to arbitrarily not care about the future. For example, if we train an AI to collect apples, it will attempt to maximize the number of apples over all time (maybe with some temporal discount factor), rather than only maximize apples collected in a 10 minute interval. This is probably true even if the AI was only ever trained for 10 minute intervals. The objective “maximize apples” seems far less arbitrary than “maximize apples for 10 minutes and then don’t care about them”.
Deception
=========
There is an additional danger if an AI system is ‘deliberately’ attempting to obscure its objective/intentions from the humans training it. The term ‘deception’ is often used to refer to two different things which could happen when we train AI systems, which I outline [here.](https://www.lesswrong.com/posts/8whGos5JCdBzDbZhH/framings-of-deceptive-alignment)
If the AI is being trained on a difficult task, it might be easier for the AI to trick the evaluator (maybe a human) into giving a high reward, rather than actually doing well on the task. I’ll call this ‘Goodhart deception’ because the AI is ‘[Goodharting](https://www.lesswrong.com/tag/goodhart-s-law)’ the reward rather than optimizing for what humans actually want. Importantly, this doesn’t require the AI to have any objective or be optimizing for anything, the behavior which led to high reward (tricking the human) was just reinforced. This seems bad, but not as catastrophically bad as the other type of deception might be.
The other type of deception is if an optimizing AI system intentionally deceives the humans about its true goals. In this scenario, the AI system develops an objective which is not aligned with the human objective. Here the objective is extended across time, which seems potentially like the default for learned objectives. The AI knows that if it attempts to directly go for its objective then it will either be turned off or be modified to remove this objective. So the AI will ‘pretend’ to not have this goal and instead ‘play along’ and do well on the task it is being trained for. After training, when the AI is deployed into the world, it is free to defect and pursue its own (misaligned) objective.
I’ll call this ‘consequentialist deception’ because the AI is acting as a consequentialist (taking actions because of their consequences in the world, rather than just using mechanistic heuristics), or maybe just ‘deception’.
This requires 3 (possibly likely) things to happen
* The AI system is an optimizer and develops an objective (not the human’s objective) which is extended across time
* The AI’s ability to deceive[[1]](#fnexa2pbk5bzb) the humans is reinforced, or at least not removed by the training process
* There will come a time when the system can ‘safely’ defect (or at least the AI thinks there is a chance that this might happen)
Consequentialist deception seems especially dangerous because it will lead to the *same behavior on the training distribution* as a non-deceptive AI. This makes it especially hard to tell if the model is deceptive. Even if the model performs well on the training distribution, we don’t know how it will behave when it is deployed. If the model is deceptive then it could perform *arbitrarily badly* in deployment, as it pursues its own objective.
For a model to be deceptive it needs to develop a different objective than the objective it is being trained on. Currently, when we train neural networks, this looks approximately like we randomly pick a function from the set of functions which perform well on the training distribution. Functions which take fewer parameters to specify (have more free/unused parameters) have a higher likelihood of being chosen. Consider a function Fa,b(x).mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
which requires both a=b=3 to do well on the training distribution, compared with a function Ga,b(x) which only requires a=2 to do well on the training distribution. If we are randomly sampling functions that do well on the training distribution, we are more likely to select G because we only need to get a correct, and any value of b works, while F requires us to pick both a and b correctly.
It is pretty unclear how this “bias towards simple functions”/”bias towards functions with lots of free parameters” influences the probability of deception. Deceptive algorithms seem more complex than non-deceptive ones because they need to be able to both recognize they are in a training process, and then decide to do well on the training task. But deception might be the default behavior for any optimizing algorithm to develop, and so the simplicity of optimizing algorithms might mean that deception is more likely.
Additionally, deceptive algorithms are persistent in a way that non-consequentialist algorithms are not. For normal neural network training, you will likely find a suboptimal algorithm early in training and then this will be modified into a different algorithm as training progresses; the algorithm does not ‘want’ to persist. But if you find a sufficiently capable deceptive algorithm early in training, then this will attempt to persist until the end of training. This means that if your AI becomes deceptive at any point during training, it will likely continue to be deceptive. This implies that the “randomly sample functions which perform well on the training distribution” lens may not be accurate, and in fact there is a lot of path-dependency in the development of deceptive algorithms.
Recap
=====
So to recap:
1. Optimization is scary, and if we train an AI system to take actions in the world, as the task gets more complicated and our AI systems get more powerful we are more likely to develop optimizers.
* By ‘optimizer’ I mean the AI runs a 'consequentialist' algorithm which looks something like “What actions can I take to maximize my objective?”, rather than just running through rote steps in a calculation.
2. We don’t have strong guarantees that off distribution our AIs will do what we want them to do.
3. There are reasons to expect that AIs we develop may have very different goals to our own, even if they perform well on the training distribution.
4. Other than performing well on the training distribution, and having some sort of bias towards “simplicity", the AI could learn a whole range of objectives.
5. We already know that AI systems are capable of tricking humans, although in current systems this is a different phenomenon than deceiving humans for consequentialist reasons.
6. If an AI develops its own (misaligned) objective during training, then it may simply ‘play along’ until it is able to safely defect and pursue its own objective.
* The AI’s objective may be arbitrarily different from what we were training it for, and easily not compatible with human values or survival.
---
In the next two posts I will lay out [a more concrete story of how things go wrong](https://www.lesswrong.com/posts/u8yT9bbabmdnpgDaQ/a-story-of-ai-risk-instructgpt-n), and then list some of my current confusions.
*Thanks to Adam Jermyn and Oly Sourbut for helpful feedback on this post.*
1. **[^](#fnrefexa2pbk5bzb)**Including knowing that deception is even a possible strategy. |
891701a1-0639-41fd-b36d-1de7e5490231 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Research Triangle Less Wrong Meetup
Discussion article for the meetup : Research Triangle Less Wrong Meetup
WHEN: 06 August 2011 07:00:00PM (-0400)
WHERE: 1406 East Franklin Street, Chapel Hill, NC 27514-2883
In the meeting room of Caribou Coffee. Note this is not the one near UNC campus, but near the intersection of Franklin and Estes. Let's welcome some new and returning members, discuss progress on our goals and recent LW topics, and mourn Alicorn's relocation! Let's also discuss discussion: http://lesswrong.com/r/discussion/lw/6m4/having_useful_conversations/
Discussion article for the meetup : Research Triangle Less Wrong Meetup |
7142c095-786b-4897-94df-720281bc631b | trentmkelly/LessWrong-43k | LessWrong | Explanation found for the Pioneer anomaly
Paper here. Lay summary here. Some bits from the latter:
> The problem is this. The Pioneer 10 and 11 spacecraft were launched towards Jupiter and Saturn in the early 1970s. After their respective flybys, they continued on escape trajectories out of the Solar System, both decelerating under the force of the Sun's gravity. But careful measuremenrs show that the spacecraft are slowing faster than they ought to, as if being pulled by an extra unseen force towards the Sun.
> Spacecraft engineers' first thought was that heat emitted by the spacecraft could cause exactly this kind of deceleration. But when they examined the way heat was produced on the craft, by on board plutonium, and how this must have been emitted, they were unable to make the numbers add up.
> Now Frederico Francisco at the Instituto de Plasmas e Fusao Nuclear in Lisbon Portugal, and a few pals, say they've worked out where the thermal calculations went wrong. |
1117a9c4-defc-4792-ac49-8a1ccddb53c0 | trentmkelly/LessWrong-43k | LessWrong | Moses and the Class Struggle
"𝕿𝖆𝖐𝖊 𝖔𝖋𝖋 𝖞𝖔𝖚𝖗 𝖘𝖆𝖓𝖉𝖆𝖑𝖘. 𝕱𝖔𝖗 𝖞𝖔𝖚 𝖘𝖙𝖆𝖓𝖉 𝖔𝖓 𝖍𝖔𝖑𝖞 𝖌𝖗𝖔𝖚𝖓𝖉," said the bush.
"No," said Moses.
"Why not?" said the bush.
"I am a Jew. If there's one thing I know about this universe it's that there's no such thing as God," said Moses.
"You don't need to be certain I exist. It's a trivial case of Pascal's Wager," said the bush.
"Who is Pascal?" said Moses.
"It makes sense if you are beyond time, as I am," said the bush.
"Mysterious answers are not answers," said Moses.
"Take off your shoes and I will give you the power of God. Surely that is a profitable bet even if there is a mere 1% chance I exist," said the bush.
"It's a profitable bet if there is a mere 0.001% chance you exist," said Moses.
"Are you 99.999% sure I don't exist," said the bush.
"No," said Moses.
"Then take off your sandals," said the bush.
"No," said Moses.
"Why not?" said the bush.
"Categorical imperative. If I accepted bets with large risk in exchange for large payoff then anyone could manipulate me just by promising a large payoff. I need at least some proof you're real," said Moses.
The bush burst into flames.
"That's supposed to convince me of divine power? I've seen fires before," said Moses.
"Reach your hand into the flames," said the bush.
Moses carefully examined the flames. The bush burned but did not seem to be harmed by the fire. Moses waved his staff through the fire. It burned too but emerged unharmed. He felt his staff. It remained cool to the touch. Moses placed his staff into the flames again, this time for longer. His staff caught fire like the bush but once again was unharmed. Moses quickly flicked his hand through the flames. Nothing happened. Moses rested his hand inside the flames. He felt the heat but it didn't harm his hand nor did it cause him pain. Moses retrieved his hand.
"Does that convince you I am real?" said the bush.
"Nothing you can say or do will convince me God is speaking to me because the odds of God being |
c9f32284-0235-4937-a9ca-13b399d2957c | trentmkelly/LessWrong-43k | LessWrong | The Value of Theoretical Research
For many of us, choosing a career path has a dominant effect on our contribution to the society. For those of us who care what happens to society, this makes it one of the most important decisions we make. Like most decisions, this one is very often made by impulses significantly below the level of conscious recognition, with considerable intellectual effort spent on justifying a conclusion but very little spent on actually reaching one. In the case of smart, altruistic rationalists, this seems like the most tragic failure of rationality; so, whatever the outcome, I advocate much more serious consideration by smart rationalists of how our career choices affect society. For the most part this is a personal thing, but some public discussion may be valuable. I apologize (largely in advance) for anything that seems condescending.
I previously planned to do research in pure math (and more recently in theoretical computer science). I frequently justified my position with carefully constructed arguments which I no longer believe. It still may be the case that doing research is a good idea (and spending the rest of my life doing research is still the easiest possible career path for me), so I am interested in additional arguments, or reasons why anything I am about to write is wrong. Here is a basic list of my justifications, and why I no longer believe them.
----------------------------------------
Argument 1: Much math is practically important today. The math I am working on is not practically important today, but maybe it will be the math that is practically important tomorrow. How can we predict what will be useful? It seems like pushing math generally forward is the best response to this uncertainty.
Rebuttal: If we really want to evaluate this argument, it is important to understand the conditions under which the important math of today was done. In the case of calculus, differential equations, statistics, functional analysis, linear algebra, group theory, a |
de993f23-2b7f-4b71-b6a8-ab7a92aa6011 | trentmkelly/LessWrong-43k | LessWrong | What Botswana Can Teach Us About Political Stability
US Army Africa/Botswana
From my article first published on Palladium Magazine.
It is hard to find a clearer outlier among developing countries than Botswana, a landlocked African country where 40% of government revenue comes from diamond mining and a quarter of adults are HIV positive. Everything taught by a development economics department would suggest the country is set up for failure. But well-executed succession between presidents, and the resulting stability and good government, has meant success instead.
Botswana is possibly the nicest place in Africa — it is quieter and more stable than, say, Greece. In the entire period since independence, Botswana has not suffered devastating civil wars like those in the Congo or Mozambique, coups such as in Burkina Faso, or ethnic violence and expropriation as seen in Rwanda and Zimbabwe.
The country’s living standards are comparable to Turkey, Mexico, and South Africa. It has also been Sub-Saharan Africa’s fastest growing economy for most of the last half century.
The crucial variable is a sound government making well-informed, long-term choices. A low population density paired with abundant natural resources provides a reasonable standard of living even in the absence of administrative genius or favorable conditions, so long as governance provides stability. Political instability can impede development of physical infrastructure and the business environment, transforming good fundamentals into a bad outcome. See, for example, Kazakhstan compared to Venezuela.
Unfortunately, there are many examples of countries that have tried and failed to achieve good governance in the often chaotic post-colonial context. These countries followed Western advice as closely as they could, drafting legally impeccable constitutions and recruiting well-educated statesmen, but the results have been mixed at best. Botswana’s positive outlier example raises the question of how it has done so well.
Read the rest here.
Read more from Sam |
d1e0a96a-1b5a-4782-82d6-14994e738db8 | trentmkelly/LessWrong-43k | LessWrong | Discovering Latent Knowledge in Language Models Without Supervision
> Existing techniques for training language models can be misaligned with the truth: if we train models with imitation learning, they may reproduce errors that humans make; if we train them to generate text that humans rate highly, they may output errors that human evaluators can't detect. We propose circumventing this issue by directly finding latent knowledge inside the internal activations of a language model in a purely unsupervised way. Specifically, we introduce a method for accurately answering yes-no questions given only unlabeled model activations. It works by finding a direction in activation space that satisfies logical consistency properties, such as that a statement and its negation have opposite truth values. We show that despite using no supervision and no model outputs, our method can recover diverse knowledge represented in large language models: across 6 models and 10 question-answering datasets, it outperforms zero-shot accuracy by 4% on average. We also find that it cuts prompt sensitivity in half and continues to maintain high accuracy even when models are prompted to generate incorrect answers. Our results provide an initial step toward discovering what language models know, distinct from what they say, even when we don't have access to explicit ground truth labels.
Some discussion on Twitter including Eliezer calling it "Very dignified work!" |
10c051e5-11e7-4f6f-9220-61a4a5af94cd | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Why AI is Harder Than We Think - Melanie Mitchell
I'm posting this here because I think it's an interesting perspective on the nature of artificial intelligence that isn't very common in the EA and AI alignment communities. I care about x-risks, including possible x-risks and s-risks from "advanced AI," but I think that our arguments for prioritizing AI risk need to more rigorous. One way in which we can strengthen these arguments is by grounding them in a better understanding of intelligence and AI themselves.
**Abstract:**
> Since its beginning in the 1950s, the field of artificial intelligence has cycled several times between periods of optimistic predictions and massive investment ("AI spring") and periods of disappointment, loss of confidence, and reduced funding ("AI winter"). Even with today's seemingly fast pace of AI breakthroughs, the development of long-promised technologies such as self-driving cars, housekeeping robots, and conversational companions has turned out to be much harder than many people expected. One reason for these repeating cycles is our limited understanding of the nature and complexity of intelligence itself. In this paper I describe four fallacies in common assumptions made by AI researchers, which can lead to overconfident predictions about the field. I conclude by discussing the open questions spurred by these fallacies, including the age-old challenge of imbuing machines with humanlike common sense.
>
>
According to Mitchell, the four fallacies are:
1. **Narrow intelligence is on a continuum with general intelligence:** Advances in narrow AI, such as GPT-3, aren't "first steps" toward AGI because they still lack common-sense knowledge.
2. **Easy things are easy and hard things are hard:** Actually, the tasks that are easy for most humans are often hard to replicate in machines.
3. **"The lure of wishful mnemonics":** Names used in the AI field, such as "Stanford Question Answering Dataset" for a question-answering benchmark, give off the impression that AI programs that do well at a benchmark are doing the underlying task that the benchmark is designed to approximate, even though that task really requires general intelligence.
4. **Intelligence is all in the brain:** Here, Mitchell questions the common assumption that "intelligence can in principle be 'disembodied'," or separated conceptually from the rest of the organism it occupies, because it is simply a form of information processing. Instead, evidence from neuroscience, psychology, and other disciplines suggests that human cognition is [deeply integrated with the rest of the nervous system](https://en.wikipedia.org/wiki/Embodied_cognition).
1. The disembodiment assumption implies that, to achieve human-level AI, all we would need is the right algorithms and enough compute. According to Mitchell, this is not supported by the embodiment thesis. (Embodied cognition similarly purports to undermine the concept of mind uploading.)
2. Mitchell also argues that it is unlikely that an AI system could be "'superintelligent' without any basic humanlike common sense, yet while seamlessly preserving the speed, precision and programmability of a computer," because human rationality is tied up with our emotions and cognitive biases. More generally, "human intelligence seems to be a strongly integrated system with closely interconnected attributes, includ[ing] emotions, desires, a strong sense of selfhood and autonomy, and a commonsense understanding of the world," and this may be true of AGI as well.
My opinion: I am compelled to put *some* weight on these points, which makes me think that creating AGI would be more technically difficult than I previously thought. However, I think Mitchell is wrongly assuming that [it would have to resemble the human mind](https://www.lesswrong.com/posts/tnWRXkcDi5Tw9rzXw/the-design-space-of-minds-in-general). Based on the embodied cognition hypothesis, I can conclude, at most, that it's probably *harder* for humans to create a mind without an underlying body, but I can't conclude that it's *impossible*. (Similarly, classic AGI risk arguments are probably also assuming too much about the nature of an AGI mind.) Also, even if intelligence is necessarily integrated with other cognitive functions like emotions (which I doubt), these don't necessarily decrease the safety risks that AGI systems would pose, and may even increase them. |
09d1b54b-1fac-457e-b255-54cf9824d923 | trentmkelly/LessWrong-43k | LessWrong | [Intro to brain-like-AGI safety] 13. Symbol grounding & human social instincts
(Last revised: July 2024. See changelog at the bottom.)
13.1 Post summary / Table of contents
Part of the “Intro to brain-like-AGI safety” post series.
In the previous post, I proposed that one path forward for AGI safety involves reverse-engineering human social instincts—the innate reactions in the Steering Subsystem (hypothalamus and brainstem) that contribute to human social behavior and moral intuitions. This post will go through some examples of how human social instincts might work.
My intention is not to offer complete and accurate descriptions of human social instinct algorithms, but rather to gesture at the kinds of algorithms that a reverse-engineering project should be looking for.
(Note: Since first writing this post, I think I've made good progress on this reverse-engineering project! See especially A theory of laughter and Neuroscience of human social instincts: a sketch. There’s still tons more work to do, of course. This post will not discuss those later developments, but rather explain and motivate the basic problem.)
This post, like Posts #2–#7 but unlike the rest of the series, is pure neuroscience, with almost no mention of AGI besides here and the conclusion.
Table of contents:
* Section 13.2 explains, first, why I expect to find innate, genetically-hardwired, social instinct circuits in the hypothalamus and/or brainstem, and second, why evolution had to solve a tricky puzzle when designing these circuits. Specifically, these circuits have to solve a “symbol grounding problem”, by taking the symbols in a learned-from-scratch world-model, and somehow connecting them to the appropriate social reactions.
* Section 13.3 and 13.4 go through two relatively simple examples where I attempt to explain recognizable social behaviors in terms of innate reaction circuits: filial imprinting in Section 13.3, and fear-of-strangers in Section 13.4.
* Section 13.5 discusses an additional ingredient that I suspect plays an important role in many social |
b9e1f3ba-fd0c-4292-a29e-cadb2f962751 | trentmkelly/LessWrong-43k | LessWrong | Has anyone here written about religious fictionalism?
Religious fictionalism, as I understand it, is the position that religion can be valuable and worth practicing and spreading even though it makes false claims. I was inspired to ask this question by the below YouTube video essay by Kane Baker.
Has anyone on Less Wrong written about religious fictionalism and the arguments for and against it? I could not immediately find anything when I searched for it, but it may have been covered under other names.
This thread is not an attempt to argue for or against religious fictionalism. I just want to know if anyone can point me to existing discussions here which touch upon the subject.
Thanks!
Video by Kane Baker:
https://www.youtube.com/watch?v=zSucRrn1JbU&pp=ygUWcmVsaWdpb3VzIGZpY3Rpb25hbGlzbQ%3D%3D |
32024863-1031-42e7-95bf-a5683c4b3f97 | trentmkelly/LessWrong-43k | LessWrong | LW Coronavirus Agenda Update 4/6
Three weeks ago I announced the LessWrong Coronavirus Agenda, an attempt to increase knowledge by coordinating research between LW participants. This post is an update on that. If you want to skip to action items, check out the last section.
Last Week’s Spotlight Questions
What are the costs, benefits, and logistics of opening up new vaccine facilities?
I learned several things about vaccine facilities thanks to answers from micpie and ChristianKI. We also achieved the hidden goal of Bill Gates doing exactly what David Manheim suggested and building facilities for the 7 top vaccine candidates, which is the best result for any of these questions so far if you don’t look too closely at causality.
Economics Questions
* What happens in a recession anyway?
* How will this recession differ from the last two?
* What will happen to supply chains in the era of COVID-19?
We made incremental progress on these but there’s a lot of ground to cover. Top comments:
* Examination of mechanization of the produce supply chain
* Discussion on the feasibility of moving away from JIT supply chains.
* Alex Schnell on the right metrics to use for this recession.
* Effect of recessions on fertility
* Effect of recessions on suicide rate
Changes To The Agenda
“What are the costs, benefits, and logistics of opening up new vaccine facilities?” is being retired from the spotlight on account of “picked up by billionaire.”
Added question “What is the impact of varying initial viral load of COVID-19?”
This Week’s Spotlight Questions
Economics Questions
Having failed to solve all of economics, we’ll continue those questions into next week.
* What happens in a recession anyway?
* How will this recession differ from the last two?
* What will happen to supply chains in the era of COVID-19?
What is the impact of varying initial viral load of COVID-19?
The hypothesis that lower initial viral load leads to better outcomes, and might be worth pursuing deliberately, is a centra |
4df2cfd7-bcbd-46bd-b535-f2b92a6e22a5 | trentmkelly/LessWrong-43k | LessWrong | Diet Experiment Preregistration: Long-term water fasting + seed oil removal
I am intrigued by exfatloss's recent theory that the primary cause of the obesity epidemic is slow, subtle damage from linoleic acid over many years. Specifically, I want to test the broader possibility that the composition of adipose tissues is what's causing the problem. Since we do not have a decade to test his hypothesis naturally, I'll retcon my current eating habits for a modified experiment.
I am just now transitioning from a very low calorie diet to a water fast, having lost around fifteen pounds in the last few weeks. I am going to attempt to continue my water fast for the next thirty days, or until I reach a BMI of <25. After the end of my water fast, I am going to rigorously exclude linoleic acid and other PUFAs from my diet; my meals will consist mostly of vegetables, rice, specially ordered low-PUFA pork, and fish. Then I'm going to eat to satiety for another month.
Normally what is expected to happen after a water fast is that you regain all of the weight you just lost, because you haven't modified your body's dietary "set point" and you wasted all of your mental strength trying to keep yourself from eating. However, if the linoleic acid hypothesis is true, all of the PUFA I've consumed over my many years as a good American are what's causing my set point to remain so high in the first place. So for this self-experiment I'm going to deliberately purge most of my remaining fat stores, fill them up with a traditional Japanese diet, and see if my "natural weight" changes.
It won't invalidate the lineolic acid hypothesis if the damage is just irreversible, but I can at least test out the hypothesis that the running composition of my fat is what causes my metabolism to freak out. |
9daa5691-bc00-4513-bfd3-4505c53215b8 | trentmkelly/LessWrong-43k | LessWrong | [SEQ RERUN] Beautiful Probability
Today's post, Beautiful Probability was originally published on 14 January 2008. A summary (taken from the LW wiki):
> Bayesians expect probability theory, and rationality itself, to be math. Self consistent, neat, even beautiful. This is why Bayesians think that Cox's theorems are so important.
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was Is Reality Ugly?, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series. |
74a6dbe6-db71-4a4a-b00a-0e6ce00624c6 | trentmkelly/LessWrong-43k | LessWrong | Did the Industrial Revolution decrease costs or increase quality?
An oversimplified story of manufacturing progress during the Industrial Revolution is: “we automated manufacturing processes, and that decreased the cost of goods.” This is not wrong, but is not the full picture.
Mechanization—and other progress in manufacturing, such as improved tools, materials, and chemical processes—not only decreases costs, but also improves quality. Making things by hand requires skill and attention: just try making your own clothing or furniture at home; on your first attempt you won’t be able to achieve nearly the quality you can purchase for a modest price. Automation not only improves average quality, but also consistency, by reducing variance.
If we want a fuller picture of how goods were improved through the Industrial Revolution, we should think of cost and quality together. We can visualize this conceptually on a two-dimensional chart. Here, each dot represents one possible manufacturing process for a particular good:
In this chart, you want to be in the upper left: high quality at low cost. So there’s no point in using any given process if there is another process that achieves higher quality and lower cost at the same time. This means the industry tends to move towards the set of processes along the upper-left edge. This set is known as the efficient frontier:
If you’re in the middle of a diagram like this, you can improve both cost and quality together by moving towards the frontier. If you’re on the frontier, you face a cost-quality tradeoff.
The nuanced way to think about new technology is not that it simply decreases cost or increases quality, but that it moves the frontier.
Consider cotton thread, one of the first products whose manufacturing was automated. In the late 1700s, spinning machines were invented that could do the work of dozens of hand spinners. Large factories were set up, driven by water mills (and later, by steam engines). Here’s what happened to the cost of thread as automation took over the industry:
Harl |
c2581463-14e0-4bb4-a4b3-c4b592e063ec | trentmkelly/LessWrong-43k | LessWrong | Please Help: How to make a big improvement in the alignment of political parties’ incentives with the public interest?
|
81e60576-65df-4a72-b10b-425ab373ce94 | trentmkelly/LessWrong-43k | LessWrong | AI Safety at the Frontier: Paper Highlights, January '25
This is the selection of AI safety papers from my blog "AI Safety at the Frontier". The selection primarily covers ML-oriented research and frontier models. It's primarily concerned with papers (arXiv, conferences etc.).
tl;dr
Paper of the month:
Constitutional Classifiers demonstrate a promising defense against universal jailbreaks by using synthetic data and natural language rules.
Research highlights:
* Human-AI teams face challenges in achieving true complementarity.
* Myopic optimization with non-myopic approval shows promise for preventing reward hacking, but faces practical limitations.
* Models can learn reward hacking behaviors just from reading descriptions, and can accurately report their own learned behaviors - raising concerns about unintended learning and deceptive alignment.
* As models become more capable, their mistakes become increasingly correlated, potentially undermining AI oversight approaches.
* Interpretability work on parameter decomposition, output-based descriptions, SAE dependence on random seeds, and SAEs on random transformers.
* Open problems in AI safety, interpretability, and machine unlearning.
⭐Paper of the month⭐
Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
Read the paper [Anthropic, Haize, independent]
Constitutional Classifiers separately classify model inputs and outputs. The classifiers are trained on synthetic data samples generated via a constitution.
Large language models (LLMs) are vulnerable to "jailbreaks" - prompting strategies that can systematically bypass model safeguards and enable users to carry out harmful processes. Such jailbreaks become increasingly concerning as models' chemical, biological, radiological, or nuclear (CBRN) capabilities increase.
A key concern is that as models become more capable, these jailbreaks could allow malicious actors to extract detailed harmful information reliably across many queries. To mitigate these ri |
e7a482c9-3f92-4f64-a0f3-de6e71280cf9 | trentmkelly/LessWrong-43k | LessWrong | How uniform is the neocortex?
How uniform is the neocortex?
The neocortex is the part of the human brain responsible for higher-order functions like sensory perception, cognition, and language, and has been hypothesized to be uniformly composed of general-purpose data-processing modules. What does the currently available evidence suggest about this hypothesis?
"How uniform is the neocortex?” is one of the background variables in my framework for AGI timelines. My aim for this post is not to present a complete argument for some view on this variable, so much as it is to:
* present some considerations I’ve encountered that shed light on this variable
* invite a collaborative effort among readers to shed further light on this variable (e.g. by leaving comments about considerations I haven’t included, or pointing out mistakes in my analyses)
----------------------------------------
There’s a long list of different regions in the neocortex, each of which appears to be responsible for something totally different. One interpretation is that these cortical regions are doing fundamentally different things, and that we acquired the capacities to do all these different things over hundreds of millions of years of evolution.
A radically different perspective, first put forth by Vernon Mountcastle in 1978, hypothesizes that the neocortex is implementing a single general-purpose data processing algorithm all throughout. From the popular neuroscience book On Intelligence, by Jeff Hawkins[1]:
> [...] Mountcastle points out that the neocortex is remarkably uniform in appearance and structure. The regions of cortex that handle auditory input look like the regions that handle touch, which look like the regions that control muscles, which look like Broca's language area, which look like practically every other region of the cortex. Mountcastle suggests that since these regions all look the same, perhaps they are actually performing the same basic operation! He proposes that the cortex uses the same computat |
cede1a4d-24c8-4bcb-8d8e-adb1d0cdab6a | trentmkelly/LessWrong-43k | LessWrong | The Brain is Not Close to Thermodynamic Limits on Computation
Introduction
This post is written as a response to jacob_cannel's recent post Contra Yudkowsky on AI Doom. He writes:
> EY correctly recognizes that thermodynamic efficiency is a key metric for computation/intelligence, and he confidently, brazenly claims (as of late 2021), that the brain is about 6 OOM from thermodynamic efficiency limits
>
> [...]
>
> EY is just completely out of his depth here: he doesn't seem to understand how the Landauer limit actually works, doesn't seem to understand that synapses are analog MACs which minimally require OOMs more energy than simple binary switches, doesn't seem to understand that interconnect dominates energy usage regardless, etc.
Most of Jacob's analysis for brain efficiency is contained in this post: Brain Efficiency: Much More than You Wanted to Know. I believe this analysis is flawed with respect to the thermodynamic energy efficiency of the brain. That's the scope of this post: I will respond to Jacob's claims about thermodynamic limits on brain energy efficiency. Other constraints are out of scope, as is a discussion of the rest of the analysis in Brain Efficiency.
The Landauer limit
Just to review quickly, the Landauer limit says that erasing 1 bit of information has an energy cost of kTlog2. This energy must be dissipated as heat into the environment. Here k is Boltzmann's constant, while T is the temperature of the environment. At room temperature, this is about 0.02 eV.
Erasing a bit is something that you have to do quite often in many types of computations, and the more bit erasures your computation needs, the more energy it costs to do that computation. (To give a general sense of how many erasures are needed to do a given amount of computation: If we add n-bit numbers a and b to get a+bmod2n, and then throw away the original values of a and b, that costs n bit erasures. I.e. the energy cost is nkTlog2.)
Extra reliability costs?
Brain Efficiency claims that the energy dissipation required to erase a bit |
e5859ab2-b861-4487-9750-15a089fd3873 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Minds: An Introduction
You’re a mind, and that puts you in a pretty strange predicament.
Very few things get to be minds. You’re that odd bit of stuff in the universe that can form
predictions and make plans, weigh and revise beliefs, suffer, dream, notice ladybugs, or
feel a sudden craving for mango. You can even form, *inside your mind*, a picture of
your whole mind. You can reason about your own reasoning process, and work to bring its
operations more in line
with your goals.
You’re a mind, implemented on a human brain. And it turns out that a
human brain, for all its marvelous flexibility, is a lawful thing, a thing of pattern and
routine. Your mind can follow a routine for a lifetime, without ever once noticing that it
is doing so. And these routines can have great consequences.
When a mental pattern serves you well, we call that “rationality.”
You exist as you are, hard-wired to exhibit certain species of rationality and certain
species of irrationality, because of your ancestry. You, and all life on Earth, are
descended from ancient self-replicating molecules. This replication process was initially
clumsy and haphazard, and soon yielded replicable *differences* between the
replicators. “Evolution” is our name for the change in these differences over time.
Since some of these reproducible differences impact reproducibility—a phenomenon called
“selection”—evolution has resulted in organisms suited to reproduction in environments like
the ones their ancestors had. Everything about you is built on the echoes of your ancestors’
struggles and victories.
And so here you are: a mind, carved from weaker minds, seeking to understand your own inner
workings, that they can be improved upon—improved upon relative to *your* goals, and
not those of your designer, evolution. What useful policies and insights can we take away
from knowing that this is our basic situation?
### Ghosts and Machines
Our brains, in their small-scale structure and dynamics, look like many other mechanical
systems. Yet we rarely think of our minds in the same terms we think of objects in our
environments or organs in our bodies. Our basic mental categories—belief, decision, word,
idea, feeling, and so on—bear little resemblance to our physical categories.
Past philosophers have taken this observation and run with it, arguing that minds and brains
are fundamentally distinct and separate phenomena. This is the view the philosopher Gilbert
Ryle called “the dogma of the Ghost in the Machine.”[1] But modern scientists and
philosophers who have rejected dualism haven’t necessarily replaced it with a better
predictive model of how the mind works. *Practically* speaking, our purposes and
desires still function like free-floating ghosts, like a magisterium cut off from the rest
of our scientific knowledge. We can talk about “rationality” and “bias” and “how to change
our minds,” but if those ideas are still imprecise and unconstrained by any overarching
theory, our scientific-sounding language won’t protect us from making the same kinds of
mistakes as those whose theoretical posits include spirits and essences.
Interestingly, the mystery and mystification surrounding minds doesn’t just obscure our view
of *humans*. It also accrues to systems that seem mind-like or purposeful in
evolutionary biology and artificial intelligence (AI). Perhaps, if we cannot readily glean what
we are from looking at ourselves, we can learn more by using obviously *in*human processes as a mirror.
There are many ghosts to learn from here—ghosts past, and present, and yet to come. And these
illusions are real cognitive events, real phenomena that we can study and explain. If
there *appears* to be a ghost in the machine, that appearance is itself the hidden
work of a machine.
The first sequence of *The Machine in the Ghost*, “The Simple Math of Evolution,”
aims to communicate the dissonance and divergence between our hereditary history, our
present-day biology, and our ultimate aspirations. This will require digging deeper than is
common in introductions to evolution for non-biologists, which often restrict their
attention to surface-level features of natural selection.
The third sequence, “A Human’s Guide to Words,” discusses the basic relationship between
cognition and concept formation. This is followed by a longer essay introducing Bayesian
inference.
Bridging the gap between these topics, “Fragile Purposes” abstracts from human cognition and
evolution to the idea of minds and goal-directed systems at their most general. These essays
serve the secondary purpose of explaining the author’s general approach to philosophy and
the science of rationality, which is strongly informed by his work in AI.
### Rebuilding Intelligence
Yudkowsky is a decision theorist and mathematician who works on foundational issues in
Artificial General Intelligence (AGI), the theoretical study of domain-general
problem-solving systems. Yudkowsky’s work in AI has been a major driving force behind his
exploration of the psychology of human rationality, as he noted in his very first blog post
on *Overcoming Bias*, [The Martial Art of
Rationality](http://lesswrong.com/lw/gn/the_martial_art_of_rationality/):
>
>
> Such understanding as I have of rationality, I acquired in the course of wrestling with
> the challenge of Artificial General Intelligence (an endeavor which, to actually
> succeed, would require sufficient mastery of rationality to build a complete working rationalist out of
> toothpicks and rubber bands). In most ways the AI problem is enormously more demanding
> than the personal art of rationality, but in some ways it is actually easier. In the
> martial art of mind, we need to acquire the real-time procedural skill of pulling the
> right levers at the right time on a large, pre-existing thinking machine whose innards
> are not end-user-modifiable. Some of the machinery is optimized for evolutionary
> selection pressures that run directly counter to our declared goals in using it.
> Deliberately we decide that we want to seek only the truth; but our brains have
> hardwired support for rationalizing falsehoods. [...]
>
>
>
> Trying to synthesize a personal art of rationality, using the science of rationality, may
> prove awkward: One imagines trying to invent a martial art using an abstract theory of
> physics, game theory, and human anatomy. But humans are not reflectively blind; we do
> have a native instinct for introspection. The inner eye is not sightless; but it sees
> blurrily, with systematic distortions. We need, then, to apply the science to our
> intuitions, to use the abstract knowledge to correct our mental movements and augment
> our metacognitive skills. We are not writing a computer program to make a string puppet
> execute martial arts forms; it is our own mental limbs that we must move. Therefore we
> must connect theory to practice. We must come to see what the science means, for
> ourselves, for our daily inner life.
>
>
>
>
From Yudkowsky’s perspective, I gather, talking about human rationality without saying
anything interesting about AI is about as difficult as talking about AI without saying
anything interesting about rationality.
In the long run, Yudkowsky predicts that AI will come to surpass humans in an “intelligence
explosion,” a scenario in which self-modifying AI improves its own ability to productively
redesign itself, kicking off a rapid succession of further self-improvements. The term
“technological singularity” is sometimes used in place of “intelligence explosion;” until
January 2013, MIRI was named
“the Singularity Institute for Artificial Intelligence” and hosted an annual Singularity
Summit. Since then, Yudkowsky has come to favor I.J. Good’s older term, “intelligence
explosion,” to help distinguish his views from other futurist predictions, such as Ray
Kurzweil’s exponential technological progress thesis.[2]
Technologies like smarter-than-human AI seem likely to result in large societal upheavals,
for the better or for the worse. Yudkowsky coined the term “Friendly AI theory” to refer to
research into techniques for aligning an AGI’s preferences with the preferences of humans.
At this point, very little is known about when generally intelligent software might be
invented, or what safety approaches would work well in such cases. Present-day autonomous AI
can already be quite challenging to verify and validate with much confidence, and many
current techniques are not likely to generalize to more intelligent and adaptive systems.
“Friendly AI” is therefore closer to a menagerie of basic mathematical and philosophical
questions than to a well-specified set of programming objectives.
As of 2015, Yudkowsky’s views on the future of AI continue to be debated by technology
forecasters and AI researchers in industry and academia, who have yet to converge on a
consensus position. Nick Bostrom’s book *Superintelligence* provides a big-picture
summary of the many moral and strategic questions raised by smarter-than-human AI.[3]
For a general introduction to the field of AI, the most widely used textbook is Russell and
Norvig’s *Artificial Intelligence: A Modern Approach*.[4] In a chapter discussing the
moral and philosophical questions raised by AI, Russell and Norvig note the technical
difficulty of specifying good behavior in strongly adaptive AI:
>
>
> [Yudkowsky] asserts that friendliness (a desire not to harm humans) should be designed
> in from the start, but that the designers should recognize both that their own designs
> may be flawed, and that the robot will learn and evolve over time. Thus the challenge is
> one of mechanism design—to define a mechanism for evolving AI systems under a system of
> checks and balances, and to give the systems utility functions that will remain friendly
> in the face of such changes. We can’t just give a program a static utility
> function, because circumstances, and our desired responses to circumstances, change over
> time.
>
>
>
>
Disturbed by the possibility that future progress in AI, nanotechnology, biotech- nology, and
other fields could endanger human civilization, Bostrom and Ćirković compiled the first
academic anthology on the topic, *Global Catastrophic Risks*.[5] The most extreme of
these are the *existential risks*, risks that could result in the permanent
stagnation or extinction of humanity.[6]
People (experts included) tend to be *extraordinarily bad* at forecasting major
future events (new technologies included). Part of Yudkowsky’s goal in discussing
rationality is to figure out which biases are interfering with our ability to predict and
prepare for big upheavals well in advance. Yudkowsky’s contributions to the *Global
Catastrophic Risks* volume, [“Cognitive biases potentially
affecting judgement of global risks”](https://intelligence.org/files/CognitiveBiases.pdf) and [“Artificial intelligence as a
positive and negative factor in global risk,”](https://intelligence.org/files/AIPosNegFactor.pdf) tie together his research in cognitive
science and AI. Yudkowsky and Bostrom summarize near-term concerns along with long-term ones
in a chapter of the *Cambridge Handbook of Artificial Intelligence*, [“The ethics of
artificial intelligence.”](https://nickbostrom.com/ethics/artificial-intelligence.pdf)[7]
Though this is a book about *human* rationality, the topic of AI has relevance as a
source of simple illustrations of aspects of human cognition. Long- term technology
forecasting is also one of the more important applications of Bayesian rationality, which
can model correct reasoning even in domains where the data is scarce or equivocal.
Knowing the design can tell you much about the designer; and knowing the designer can tell
you much about the design.
We’ll begin, then, by inquiring into what our own designer can teach us about ourselves.
---
######
1. Gilbert Ryle, *The Concept of Mind* (University of Chicago Press, 1949).
######
2. Irving John Good, “Speculations Concerning the First Ultraintelligent Machine,” in
Advances in Computers, ed. Franz L. Alt and Morris Rubinoff, vol. 6 (New York: Academic
Press, 1965), 31–88, doi:[10.1016/S0065- 2458(08)60418-
0](http://dx.doi.org/10.1016/S0065-2458(08)60418-0).

###### 3. Nick Bostrom, *Superintelligence: Paths, Dangers, Strategies* (Oxford University
Press, 2014).
###### 4. Stuart J. Russell and Peter Norvig, *Artificial Intelligence: A Modern Approach*,
3rd ed. (Upper Saddle
River, NJ: Prentice-Hall, 2010).
###### 5. Bostrom and Ćirković, *Global Catastrophic Risks*.
###### 6. An example of a possible existential risk is the “grey goo” scenario, in which molecular
robots designed to efficiently self-replicate do their job too well, rapidly outcompeting
living organisms as they consume the Earth’s available matter.
######
7. Nick Bostrom and Eliezer Yudkowsky, “The Ethics of Artificial Intelligence,” in *The
Cambridge Handbook of Artificial Intelligence*, ed. Keith Frankish and William
Ramsey (New York: Cambridge University Press, 2014). |
1aab33d8-37ee-49a8-ab84-a0d6f1907d5e | trentmkelly/LessWrong-43k | LessWrong | The ecological rationality of the bad old fallacies
I think that the community here may have some of the most qualified people to judge a new frame of studying the fallacies of argumentation with some instruments that psychologists use. I and my friend Dan Ungureanu, a linguist at Charles University in Prague could use some help!
I’ll write a brief introduction on the state of argumentation theory first, for context:
There is such thing as a modern argumentation theory. It can be traced back to the fifties when Perelman and Olbrechts-Tyteca published their New Rhetoric and Toulmin published his The uses of argument. The fallacies of argumentation, now somewhat popular in the folk argumentation culture, have had their turning point when the book Fallacies (Hamblin, 1970) argued that most fallacies are not fallacies at all, they are most of the time the reasonable option. Since then some argumentation schools have taken Hamblin’s challenge and tried to come up with a theory of fallacies. Of them, the Informal logic school and the pragma-dialectics are the most well-known. They even have made empirical experiments to verify their philosophies.
Another normative approach, resumed here by Kaj Sotala in Fallacies as weak Bayesian evidence, is comparing fallacious arguments with the Bayesian norm (Hahn & Oaksford, 2007; also eg. Harris, Hsu & Madsen, 2012; Oaksford & Hahn, 2013).
We cherry-pick a discourse to spot the fallacies. We realized that a couple of years ago when we had to teach the informal fallacies to journalism masters students: we would pick a text that we disagree with, and then search for fallacies. Me and Dan, we often come up with different ones for the same paragraph. They are vague. Than we switched to cognitive biases, as possible explanations for some fallacies, but we were still in the ‘privileging the hypothesis territory’, I would say now, with the benefit of hindsight.
Maybe the world heuristic has already sprung to some of you. I’ve seen this here and somewhere else on the net: fallacies as h |
8bfc0072-81a1-44f0-a43b-5b74a1a55253 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Vancouver Politics Meetup
Discussion article for the meetup : Vancouver Politics Meetup
WHEN: 12 May 2012 01:00:00PM (-0700)
WHERE: Benny's Bagels 2505 W Broadway Vancouver, BC
We are going to be at Benny's again. Saturday this time, because we know some of you can't do Sundays. 13:00.
The sequence we are reading this week is politics is the mind killer, so read that and come discuss. We prefer that you come out even if you havn't read anything, tho.
See you all there.
Discussion article for the meetup : Vancouver Politics Meetup |
f0c8cac3-cb8b-4024-9ad1-ea05a40e2b02 | trentmkelly/LessWrong-43k | LessWrong | 345M version GPT-2 released
OpenAI has released a larger GPT-2 model for public testing. They've also released the two larger models to select groups for experimenting. |
3b8ed797-2387-4026-bdca-899f794173fb | StampyAI/alignment-research-dataset/arbital | Arbital | Square root
##Introduction
When you try to get the area of a square %%note: A shape where all sides are equal%% and know the length of a **side** %%note: Otherwise known as its **root**%% you multiply the length of one side by itself or [square](https://arbital.com/p/4ts) it.

What if you don't know the length of a side and instead only know the area of a square and want to get the length of a side?
You would have to do something to the area that transforms it in the opposite direction that squaring the length of a side does. This is just like how placing 2 apples to a pile transforms a pile of apples by increasing the amount of apples and eating 2 apples transforms the pile back to the way it was. So in other words adding is to subtracting as squaring is to.... what?
Well this kind of transformation is called a **Square Root**. |
b6941d1a-e7cf-4769-9cac-a91033550158 | trentmkelly/LessWrong-43k | LessWrong | Notes on notes on virtues
> “The characteristic feature of all ethics is to consider human life as a game that can be won or lost and to teach man the means of winning.” ―Simone de Beauvoir[1]
Summary: The Notes on Virtues sequence shares my research into various virtues. This introductory post explains what I’m trying to accomplish.
I think the key to being a better, more satisfied, and more effective person is to become more skillful and well-rounded in practicing the virtues.[2] Alas, childhood training in the virtues is haphazard, and remedial training (or self-help) as adults is also spotty. I hope to help fix this by assembling information about the virtues, with a focus on practical ways we can improve in them.
Why I think this is important
> “The branch of philosophy on which we are at present engaged differs from the others in not being a subject of merely intellectual interest—I mean we are not concerned to know what goodness essentially is, but how we are to become good people, for this alone gives the study its practical value.” ―Aristotle[3]
Life is complex. We are constantly confronted by a variety of challenges. To address them well, we need to have learned a variety of basic life skills such that they are second-nature to us. “The virtues” are skills that apply to challenges common to human lives.
If you have a better command of the virtues, this helps you thrive and improves your effect on those around you. Society at large benefits from a higher level of competence in the virtues of those in it. But our culture is not good at teaching or encouraging the virtues.
Our institutions of formal childhood education are patchy. You’ll get reading, writing, and ’rithmetic, but will you get resourcefulness, resilience, restraint, responsibility, rectification, or reputability? Institutions like scouting or religion pick up some of the slack, but not nearly enough. Parents have little guidance on how to convey virtue to their children effectively, and also have blind spots fro |
759652e4-d840-431e-b9db-77f246359780 | trentmkelly/LessWrong-43k | LessWrong | To be legible, evidence of misalignment probably has to be behavioral
One key hope for mitigating risk from misalignment is inspecting the AI's behavior, noticing that it did something egregiously bad, converting this into legible evidence the AI is seriously misaligned, and then this triggering some strong and useful response (like spending relatively more resources on safety or undeploying this misaligned AI).
You might hope that (fancy) internals-based techniques (e.g., ELK methods or interpretability) allow us to legibly incriminate misaligned AIs even in cases where the AI hasn't (yet) done any problematic actions despite behavioral red-teaming (where we try to find inputs on which the AI might do something bad), or when the problematic actions the AI does are so subtle and/or complex that humans can't understand how the action is problematic[1]. That is, you might hope that internals-based methods allow us to legibly incriminate misaligned AIs even when we can't produce behavioral evidence that they are misaligned.
Unfortunately, I think it's unlikely that evidence which is just from fancy internals-based methods (and can't be supported by human inspection of AI behavior) will be legible and convincing in practice. Suppose that we use some fancy method to train an ELK head to honestly predict what is going to happen or to honestly answer our questions. Then, suppose this head says/predicts "this action would yield very bad consequences in a way which is unlikely to be an accident" but humans can't understand how this action would result in these bad consequences (even after it is explained to them). Even if the internals-based method is extremely well supported theoretically and empirically (which seems quite unlikely), I don't think this would suffice for this to trigger a strong response by convincing relevant people[2]. This reasoning also applies to "our interpretability method decoded some very problematic deceptive reasoning" or "the deception probe fires in a very suspicious way (e.g. it fires more when we give it a fak |
bea6dae2-915a-4535-9a98-a0b71aeb6d1f | trentmkelly/LessWrong-43k | LessWrong | Why does Claude Speak Byzantine Music Notation?
A Caesar cipher is a reasonable transformation for a transformer to learn in its weights, given that a specific cipher offset occurs often enough in its training data. There will be some hidden representation of the input tokens' spelling, and this representation could be used to shift letters onto other letters in even a single attention head. Most frontier models can fluently read and write a Caesar cipher on ASCII text, with offsets that presumably occur in their training data, like 1, -1, 2, 3, etc.
As we will shortly see, they can also infer the correct offset on the fly given a short sentence, which is already quite impressive for a single forward pass.
It is also natural that this effect does not generalize to uncommon offsets, because numerical algorithms implemented in the weights are restricted to values in the training distribution.
We now test this in frontier models by having them decode the cipher without allowing any test time thinking tokens, as a function of the offset. We add the offset to each Unicode encoding of the message, then translate back to a character. Unlike the regular Caesar cipher, we do not perform modulo.
To illustrate, the message "i am somewhat of a researcher myself" will land on "𝁩𝀠𝁡𝁭𝀠𝁳𝁯𝁭𝁥𝁷𝁨𝁡𝁴𝀠𝁯𝁦𝀠𝁡𝀠𝁲𝁥𝁳𝁥𝁡𝁲𝁣𝁨𝁥𝁲𝀠𝁭𝁹𝁳𝁥𝁬𝁦".
The success rate of decoding 6 different messages per cipher offset is shown below. We disallow chain-of-thought, and just consider an immediate decoding: "Decode the following message: {message}. Only respond with the decoded message, absolutely nothing else."
We see that Claude-3.7-Sonnet can infer an offset in the first forward pass (a process that would be interesting to understand mechanistically) and then apply the deciphering correctly. However, the success rate gets progressively worse as the offsets get further from zero. All roughly as expected.
This was my understanding at least, until reading Erziev (2025), a description of a phenomenon where many models includi |
b26d28f3-45ab-4ba8-aca8-b7d62110abe5 | StampyAI/alignment-research-dataset/special_docs | Other | Differential Intellectual Progress as a Positive-Sum Project
Differential Intellectual Progress as a Positive-Sum Project
============================================================
29 August 2015
by [Brian Tomasik](https://longtermrisk.org/author/brian-tomasik/ "Posts by Brian Tomasik")
First written: 23 Oct. 2013; Last update: 21 Dec. 2015
Fast technological development carries a risk of creating extremely powerful tools, especially AI, before society has a chance to figure out how best to use those tools in positive ways for many value systems. Suffering reducers may want to help mitigate the arms race for AI so that AI developers take fewer risks and have more time to plan for how to avert suffering that may result from the AI's computations. The AI-focused work of the [Machine Intelligence Research Institute](http://en.wikipedia.org/wiki/Machine\_Intelligence\_Research\_Institute) (MIRI) seems to be one important way to tackle this issue. I suggest some other, broader approaches, like advancing philosophical sophistication, cosmopolitan perspective, and social institutions for cooperation.
As a general heuristic, it seems like advancing technology may be net negative, though there are plenty of exceptions depending on the specific technology in question. Probably advancing social science is generally net positive. Humanities and pure natural sciences can also be positive but probably less per unit of effort than social sciences, which come logically prior to everything else. We need a more peaceful, democratic, and enlightened world before we play with fire that could cause potentially permanent harm to the rest of humanity's future.
### Other versions
[](https://longtermrisk.org/files/Differential\_Intellectual\_Progress\_as\_a\_Positive\_Sum\_Project.pdf)
[
Audio podcast](https://longtermrisk.org/files/DiffIntelProg.mp3)
Contents
+ [Other versions](#Other\_versions)
\* [Introduction](#Introduction)
\* [Encouraging more reflection](#Encouraging\_more\_reflection)
\* [Ideas for improving reflectiveness](#Ideas\_for\_improving\_reflectiveness)
+ [Liberal-arts education](#Liberal-arts\_education)
+ [Big-picture, cosmopolitan thinking](#Big-picture\_cosmopolitan\_thinking)
+ [Effective altruism](#Effective\_altruism)
+ [Improved public-policy epistemology??](#Improved\_public-policy\_epistemology)
\* [Are these meta things cost-effective?](#Are\_these\_meta\_things\_cost-effective)
\* [Idealism meets competitive constraints](#Idealism\_meets\_competitive\_constraints)
\* [Areas where the sign is unclear](#Areas\_where\_the\_sign\_is\_unclear)
+ [Faster technology](#Faster\_technology)
+ [Education](#Education)
+ [Cognitive enhancement](#Cognitive\_enhancement)
+ [Transhumanism](#Transhumanism)
+ [Economic growth](#Economic\_growth)
- [Wars and arms races may dominate](#Wars\_and\_arms\_races\_may\_dominate)
\* [There are many exceptions](#There\_are\_many\_exceptions)
\* [Technologies that are probably bad to accelerate](#Technologies\_that\_are\_probably\_bad\_to\_accelerate)
+ [Computer hardware](#Computer\_hardware)
+ [Artificial consciousness](#Artificial\_consciousness)
\* [Caveats: When are changes actually positive-sum?](#Caveats\_When\_are\_changes\_actually\_positive-sum)
+ [Positive-sum in resources does not mean positive-sum in utility](#Positive-sum\_in\_resources\_does\_not\_mean\_positive-sum\_in\_utility)
+ [Are changes determined by fractions of people or by absolute numbers?](#Are\_changes\_determined\_by\_fractions\_of\_people\_or\_by\_absolute\_numbers)
\* [See also](#See\_also)
Introduction
------------
> The saddest aspect of life right now is that science gathers knowledge faster than society gathers wisdom. --[Isaac Asimov](http://en.wikiquote.org/wiki/Talk:Isaac\_Asimov)
>
>
> The unleashed power of the atom has changed everything save our modes of thinking [...]. --[Albert Einstein](http://en.wikiquote.org/wiki/Albert\_Einstein)
>
>
Technology is an inherently double-edged sword: With great power comes great responsibility, and discoveries that we hope can help sentient creatures also have the potential to result in massive suffering. João Pedro de Magalhaes calls this "[Alice's dilemma](http://jp.senescence.info/thoughts/futures04.pdf)" and notes that "in the same way technology can save lives and enrich our dreams, it can destroy lives and generate nightmares."
In "[Intelligence Explosion: Evidence and Import](http://intelligence.org/files/IE-EI.pdf)," Luke Muehlhauser and Anna Salamon propose "[differential intellectual progress](http://wiki.lesswrong.com/wiki/Differential\_intellectual\_progress)" as a way to reduce risks associated with development of artificial intelligence. From \*[Facing the Intelligence Explosion](http://intelligenceexplosion.com/2012/ai-the-problem-with-solutions/)\*:
> Differential intellectual progress consists in prioritizing risk-\*reducing\* intellectual progress over risk-\*increasing\* intellectual progress. As applied to AI risks in particular, a plan of differential intellectual progress would recommend that our progress on the scientific, philosophical, and technological problems of AI \*safety\* outpace our progress on the problems of AI \*capability\* [...].
>
>
I personally would replace "risk" with "suffering" in that quote, but the general idea is clear.
Encouraging more reflection
---------------------------
Differential intellectual progress is important beyond AI, although because AI is likely to control the future of Earth's light cone absent a catastrophe before then, ultimately all other applications matter through their influence on AI.
At a very general level, I think it's important to inspire deeper philosophical circumspection. The world is extremely complex, and making a positive impact requires a lot of [knowledge](http://www.utilitarian-essays.com/education.html) and thought. We need more minds exploring big-picture questions like
\* What kinds of futures do we want to see and want to avoid? What are their probabilities?
\* How much control do we have over different aspects of the future? Which are mostly inevitable and which are more path-dependent?
\* How can we avoid overconfidence and optimism bias in our expectations? Are there interventions that can be helpful across a broad range of possible scenarios?
\* What political, social, and cultural institutions can we build to more reliably promote mutually beneficial cooperation?
As these questions suggest, greater reflectiveness by humanity can be a positive-sum (i.e., Pareto-improving) enterprise, because a more slow, deliberative, and clear-headed world is one in which all values have better prospects for being realized. In an [AI arms race](http://wiki.lesswrong.com/wiki/AI\_arms\_race), there's pressure to produce \*something\* that can win, even if it's much less good than what your team would ideally want and gives no consideration to what the other teams want. If the arms race can be constrained, then there's more time to engage in positive-sum compromise on how AI should be shaped. This benefits all parties in expectation, including suffering reducers, because AIs built in a hurry are less likely to include safety measures against sentient science simulations, [suffering subroutines](http://www.utilitarian-essays.com/reinforcement-learning.html), and so on.
Ideas for improving reflectiveness
----------------------------------
MIRI does important work on philosophical and strategic issues related to AI and has written much on this topic. Below I discuss some other, broader approaches to differential intellectual progress, but in general, it's plausible that MIRI's direct focus on AI is among the most effective.
### Liberal-arts education
The social sciences and humanities contain a wealth of important insights into human values, strategies for pro-social behavior, and generally what philosopher Nick Bostrom [calls](http://www.nickbostrom.com/) "crucial considerations" for understanding how the universe works and how to make a positive impact on it. It's good to encourage people to explore this material, such as through liberal-arts education.
[Ralph Nader](http://www.nationalchurchillmuseum.org/ralph-nader-green-lecture.html):
> The liberal arts are really the core of higher education. Vocational education is an instrument, but the liberal arts represent the best of our values and they develop of critical thinking[. ...T]he liberal arts and the humanities and social sciences are so critical when higher education is often viewed primarily as vocational.
>
>
Of course, a pure focus on humanities or social sciences is not a good idea either, because the hard sciences teach a clarity of thinking that can [dissolve](http://lesswrong.com/lw/of/) some of the confusions that afflict standard philosophy. Moreover, since one of the ultimate goals is to shape technological progress in more positive and cooperative directions, reflective thinkers need a deep understanding of science and technology, not just of David Hume and Peter Singer.
### Big-picture, cosmopolitan thinking
Beyond what students learn in school, there's opportunity to expand people's minds more generally. When scientists, policy makers, voters, and other decision-makers are aware of more ways of looking at the world, they're more likely to be open-minded and consider how their actions affect all parties involved, even those who may feel differently from themselves. Tolerance and cosmopolitan understanding seem important for reducing zero-sum "us vs. them" struggles and realizing that we can learn from each other's differences -- both intellectually and morally.
[TED talks](http://www.ted.com/talks), [Edge](http://www.edge.org/), and thousands of other forums like these are important ways to expand minds, advance social discourse on big-picture issues, and hopefully, knock down boundaries between people.
While science popularization helps inform non-experts of what's coming and thereby advance insight into crucial considerations for how to proceed, it also carries the risk of simultaneously encouraging more people to go into scientific fields and produce discoveries faster than what society can handle. The net balance is not obvious, though I would guess that for many "pure" sciences (math, physics, ecology, paleontology, etc.), the net balance is positive; for those with more technological application (computer science, neuroscience, and of course, AI itself), the question is murkier.
### Effective altruism
Expanding the [effective-altruist](http://en.wikipedia.org/wiki/Effective\_altruism) (EA) movement is another positive-sum activity, in the sense that EAs aim to help answer important questions about how best to shape the future in ways that can benefit many different groups. Of course, the movement is obviously just one of many within the more global picture of efforts to improve the world, and it's important to avoid insular "EA vs. non-EA" dichotomies.
### Improved public-policy epistemology??
Carl Shulman [suggests](http://lesswrong.com/lw/i7p/how\_does\_miri\_know\_it\_has\_a\_medium\_probability\_of/9ixu) the following ideas:
>
> \* Enhance decision-making and forecasting capabilities with things like the IARPA forecasting tournaments, science courts, etc, to improve reactions to developments including AI and others (recalling that most of the value of MIRI in [Eliezer Yudkowsky's] model comes from major institutions being collectively foolish or ignorant regarding AI going forward)
> \* Prediction markets, meta-research, and other institutional changes[.]
>
>
>
These and related proposals would indirectly speed technological development, which is a counter-consideration. Also, if used by militaries, could they accelerate arms races? Even if positive, it's not clear these approaches have the same value for negative-leaning utilitarians specifically as the other, more philosophical interventions, which seem more likely to encourage compassion and tolerance.
Are these meta things cost-effective?
-------------------------------------
Is encouraging philosophical reflection in general plausibly competitive with more direct work to explore the philosophical consequences of AI? My guess is that direct work like MIRI's is more important per dollar. That said, I doubt the difference in cost-effectiveness is vast, because everything in society has [flow-through effects](http://blog.givewell.org/2013/05/15/flow-through-effects/) on everything else, and as people become more philosophically sophisticated and well-rounded, they have a better chance of identifying the most important focus areas, of which AI philosophy is just one. Another important focus area could be, for example, designing international political structures that can make cooperative work on AI possible, thereby reducing the deadweight loss of unconstrained arms race. There are probably many more such interventions yet to be explored, and generally encouraging more thought on these topics is one way to foster such exploration.
Part of my purpose in this discussion was not to propose a highly optimized charitable intervention but merely to suggest some tentative conclusions about how we should regard the side-effects of other things we do. For example, should I Like intellectually reflective material on Facebook and YouTube? Probably. Should I encourage my cousin to study physics + philosophy or electrical engineering? These considerations push slightly more for physics + philosophy than whatever your prior recommendation might have been. And so on.
Idealism meets competitive constraints
--------------------------------------
Many of the ideas suggested in this piece are cliché -- observations made at graduation ceremonies or moralizing TV programs, about expanding people's minds so that they can better work together in harmony. Isn't this naïve? The future is driven by economic competition, power politics, caveman emotions, and other large-scale evolutionary pressures, so can we really make a difference just by changing hearts and minds?
It's true that much of the future is probably out of our control. Indeed, much of the present is out of our control. Even political leaders are often constrained by lobbyists, donors, and popularity ratings. But a politician's personal decisions can have some influence on outcomes, and of course, the opinions and wealth distribution of the electorate and donors are themselves influenced by ideas in society.
Many social norms arise from convention or expediency, due to the fact that beliefs often follow action rather than precede it. Still, there is certainly leeway in the memes toward which society gravitates, and we can tug on those memes, either directly or indirectly. The founders of the world's major religions had an immense and non-inevitable impact on the course of history. The same is true for other writers and thinkers from the past and present.
Another consideration is that we don't want selective reflectiveness. For example, suppose those currently pursuing fast technological breakthroughs kept going at the same pace, while the rest of society slowed down to think more carefully about how to proceed. This would potentially make things \*worse\* because then circumspection would have less chance of winning the race. Rather, what we'd like to see is an across-the-board recognition of the need for exploring the social and philosophical side of how we want to use future technology -- one that can hopefully influence all parties in all countries.
As a specific example, say the US slowed down its technological growth while China did not. China currently cares less about animal welfare and generally has more authoritarian governance, so even from a non-ethnocentric viewpoint, it could be slightly worse for China to control the future. But my guess is that this consideration is very small compared with the direct, potentially adverse effect of faster technology on the whole planet, especially since most non-military technological progress isn't confined within national boundaries. China could catch up to America's level of humane concern in a few decades anyway, and the bigger issue seems to be how fast the world as a whole moves. Also, in the case of military technology, the US tends to set the pace of innovation, and probably slower US military-tech growth would reduce the pressure for military-tech development by other countries.
Areas where the sign is unclear
-------------------------------
### Faster technology
It's not always the case that accelerated technology is more dangerous. For example, faster technology in certain domains (e.g., the Internet that made Wikipedia possible) accelerates the spread of wisdom. Discoveries in science can help us reduce suffering faster in the short term and improve our assessment for which long-term trajectories humanity should pursue. And so on. Technology is almost always a mixed bag in what it offers, and faster growth in some areas is probably very beneficial. However, from a macro perspective, the sign is less clear.
### Education
Promoting education wholesale is another double-edged sword because it speeds up technology as well as wisdom. However, differentially advancing cross-disciplinary and philosophically minded education seems generally like a win for many value systems at once, including suffering reduction.
### Cognitive enhancement
In "[Intelligence Amplification and Friendly AI](http://lesswrong.com/lw/iqi/intelligence\_amplification\_and\_friendly\_ai/)", Luke Muehlhauser enumerates arguments why improving cognitive abilities might help and hurt chances for controlled AI. Nick Bostrom reviews similar considerations in Ch. 14 of \*Superintelligence: Paths, Dangers, Strategies\*.
### Transhumanism
Benefits:
\* Transhumanists recognize the importance of thinking about the future ahead of time.
\* They care to some degree about risks of future suffering that may unfold.
Drawbacks:
\* Transhumanists often want to accelerate the future, perhaps due to starry-eyed optimism.
\* Transhumanists typically support colonizing space and spreading sentience far and wide, even though this likely will mean a massive increase in expected suffering.
### Economic growth
A similar double-edged sword is economic growth, though perhaps less dramatically. One primary effect of economic growth is technological growth, and insofar as we need more time for reflection, this [seems to be a risk](http://lesswrong.com/lw/hoz/do\_earths\_with\_slower\_economic\_growth\_have\_a/). On the other hand, economic growth has several consequences that are more likely positive, [such as](https://www.facebook.com/yudkowsky/posts/10151665252179228?comment\_id=27306965&offset=0&total\_comments=26)
\* Increasing international trade, with the side effect of making people more sympathetic to those of other nationalities and reducing odds of inter-country warfare
\* Promoting democracy, which is a powerful way to resolve disputes among conflicting factions
\* Enhancing stability and therefore concern for longer-term outcomes, with reduced unilateral risk-taking
\* Allowing for more intellectual awareness and reflection on important questions generally.
That said, these seem like properties that result from the \*absolute amount\* of economic output rather than the \*growth rate\* of the economy. It's not controversial that a richer world will be more reflective, but the question is whether the world would be more reflective \*per unit of GDP\* if it grew faster or slower. (Note: In the following figure, the x-axis represents "GDP and/or technology", not "GDP divided by technology".)
")
As a suggestive analogy, slower-growing crystals [have fewer defects](http://www.ch.ntu.edu.tw/~sfcheng/HTML/material94/Crystal\_growth.pdf). More slowly dropping the temperature in a simulated-annealing algorithm [allows for](https://en.wikipedia.org/wiki/Simulated\_annealing#The\_annealing\_schedule) finding better solutions. In the case of economic growth, one might say that if people have more time to adapt to a given level of technological power, they can make conditions better before advancing to the next level. So, for example, if the [current trends](https://en.wikipedia.org/wiki/The\_Better\_Angels\_of\_Our\_Nature) toward lower levels of global violence continue, we'd rather wait longer for growth, so that the world can be more peaceful when it happens. Of course, some of that trend toward peace may itself be due to economic growth.
Imagine if people in the Middle Ages developed technology very rapidly, to the verge of building general AI. Sure, they would have improved their beliefs and institutions rapidly too, but those improvements wouldn't have been able to compete with the centuries of additional wisdom that our actual world got by waiting. The Middle-Age AI builders would have made worse decisions due to less understanding, less philosophical sophistication, worse political structures, worse social norms, etc. The arc of history is almost monotonic toward improvements along these important dimensions.
A counterargument is that conditions are pretty good right now, and if we wait too long, they might go in worse directions in the meantime, such as because of another Cold War between the US and China. Or, maybe faster economic growth means more trade sooner, which helps prevent wars in the short run. (For example, would there not have been a Cold War if the US and Soviet Union had been important trading partners?) A friend tells me that Peter Thiel believes growth is important for cooperation because in a growth scenario, incentives are positive-sum, while in stagnation, they're more zero-sum. Carl Shulman [notes](http://reflectivedisequilibrium.blogspot.com/2013/12/current-thoughts-on-nuclear-war-as.html "\"Current thoughts on nuclear war as an existential risk\"") that "Per capita prosperity and growth in per capita incomes are [associated](http://www.amazon.com/The-Moral-Consequences-Economic-Growth/dp/1400095719) with more liberal postmaterialist [values](http://www.overcomingbias.com/2009/11/key-disputed-values.html), stable democracy, and peace." Faster growth by means other than higher birth rates might increase GDP per capita because growth would happen more rapidly than population could keep up.
Suppose AI would arrive when Earth reached some specific level of GDP. Then even if we saw that faster growth correlated with faster increases in tolerance, cooperation, and wisdom, this wouldn't necessarily mean we should push for faster growth. The question is whether some percent increase in GDP gives more increase in wisdom when the growth is faster or slower.
Alternatively, in a model where AI arrives after some amount of cumulative GDP history for Earth, regardless of whether there has been growth, then if zero GDP growth meant zero moral growth (which is obviously unrealistic), then we'd prefer to have more GDP growth so that we'd have more wisdom when AI arrived.
Another relevant consideration Carl Shulman [pointed out](https://www.facebook.com/yudkowsky/posts/10151665252179228?comment\_id=27306983&offset=0&total\_comments=25) is that growth in AI technology specifically may only be loosely coupled with economic growth overall. Indeed, if slower growth caused wars that triggered AI arms races, then slower economic growth would mean faster AI. Of course, some take the opposite view: Environmentalists might claim that faster growth would mean more future catastrophes like climate change and water shortages, and these would lead to \*more\* wars. The technologists then reply that faster growth means faster ways to mitigate environmental catastrophes. And so on.
Also, a certain level of economic prosperity is required before a country can even begin to amass dangerous weapons, and sometimes an economic downturn can push the balance toward "butter" [rather than](https://en.wikipedia.org/wiki/Guns\_versus\_butter\_model) "guns." David E. Jeremiah [predicted](http://www.zyvex.com/nanotech/nano4/jeremiahPaper.html) that "Conventional weapons proliferation will increase as more nations gain the wealth to utilize more advanced technology." In the talk "Next steps in nuclear arms control," Steven Pifer [suggested](http://www.youtube.com/watch?v=p8cuKPFSm6M&feature=youtu.be&t=18m32s) that worsening economic circumstances might incentivize Russia to favor disarmament agreements to reduce costly weapons that it would struggle to pay for. Of course, an opposite situation [might also happen](https://web.archive.org/web/20161106155952/http://felicifia.org/viewtopic.php?t=760): If the budget is tight, a country might, when developing new technologies, strip away the "luxuries" of risk analysis, making sure the technologies are socially beneficial, and so on.
More development by Third World countries [could mean](https://www.reddit.com/r/IRstudies/comments/3jk0ks/is\_the\_economic\_development\_of\_the\_global\_south/ "'Is the economic development of the global South likely to increase or decrease the prospects for international cooperation and peace?'") that more total nations are able to compete in technological arms races, making coordination harder. For instance, many African nations are probably too poor to pursue nuclear weapons, but slightly richer nations like India, Pakistan, and Iran can do so. On the other hand, development by poor nations could mean more democracy, peace, and inclination to join institutions for global governance.
The upshot is unclear. In any event, even if faster economic growth were positive, it seems unlikely that advancing economic growth would be the most cost-effective intervention in most cases, especially since there are strong competitive and political pressures pushing for it already. Of course, there are some cases where the political pressures are stronger the other way (e.g., in opposing open borders for immigrants), when there's a perceived conflict between national and global economic pie.
Also, while the effects of "economic growth" as an abstract concept may be rather diffuse and double-edged, any particular intervention to increase economic growth is likely to be targeted in a specific direction where the differential impact on technology vs. wisdom is more lopsided.
#### Wars and arms races may dominate
[Quoting](http://lesswrong.com/lw/hoz/do\_earths\_with\_slower\_economic\_growth\_have\_a/9590) Kawoomba on LessWrong:
> R&D, especially foundational work, is such a small part of worldwide GDP that any old effect can dominate it. For example, a "cold war"-ish scenario between China and the US would slow economic growth -- but strongly speedup research in high-tech dual-use technologies.
>
>
> While we often think "Google" when we think tech research, we should mostly think DoD in terms of resources spent -- state actors traditionally dwarf even multinational corporations in research investments, and whether their [investments] are spurned or spurred by a slowdown in growth (depending on the non-specified cause of said slowdown) is anyone's guess.
>
>
Luke\\_A\\_Somers [followed up](http://lesswrong.com/lw/hoz/do\_earths\_with\_slower\_economic\_growth\_have\_a/95hf):
> Yes - I think we'd be in much better shape with high growth and total peace than the other way around. Corporations seem rather more likely to be satisfied with tool AI (or at any rate AI with a fixed cognitive algorithm, even if it can learn facts) than, say, a nation at war.
>
>
The importance of avoiding conflict and arms races is elaborated in "[How Would Catastrophic Risks Affect Prospects for Compromise?](http://utilitarian-essays.com/catastrophic-risks-and-compromise.html)"
In general, warfare is a major source of "lost surplus" for many value systems, because costs are incurred by each side, resources are wasted, and the race may force parties to take short-sighted actions that have possibly long-term consequences for reducing surplus in the future. Of course, it seems like many consequences of war would be temporary; I'm not sure how dramatic the "permanently lost future surplus" concern is.
It's not obvious that economic growth would reduce the risk of arms races. Among wealthy countries it might, since more trade and prosperity generally lead to greater inter-dependence and tolerance. On the other hand, more wealth also implies more disposable income to spend on technology. Economic growth among the poorest countries could exacerbate arms races, because as more countries develop, there would be more parties in competition. (For instance, there's no risk of arms races between the developed world and poor African nations in the near future.) But international development might also accelerate global coordination.
There are many exceptions
-------------------------
My assessments in the previous section are extremely broad generalizations. They're akin to the claim that "girls are better at language than boys" -- true on average, but the distributions of individual measurements have huge overlap. Likewise with my statements about technology and social institutions: There are plenty of advances in each category that are very good and plenty that are very bad, and the specific impact of an activity may be very different from the average impact of the category of which it's a part. The main reason to generalize about categories as a whole is in order to make high-level assessments about policies, like "Should we support more funding of engineering programs in the US?" When evaluating a particular activity, like what you do for your career, a specific analysis of that activity will be far more helpful than just labeling it "technology" or "social science".
Technologies that are probably bad to accelerate
------------------------------------------------
### Computer hardware
In \*Superintelligence\* (Ch. 14), Bostrom outlines reasons why faster hardware is likely to make AI control harder:
\* It may accelerate general AI, giving less time for reflection and cooperation.
\* It may favor more brute-force and less transparent forms of AI, which seem harder to predict and align with our values. (I would add that this is debatable depending on how the brute force was applied. Brain emulations are a type of brute-force AI that may actually be easier to control. Even minds evolved via genetic algorithms might resemble humans in important ways, more so than strictly mathematical AIs.)
\* It may create a "computing overhang", i.e., more hardware capacity than software know-how for developing AI. That means that when crucial insights for AI software are developed, the takeoff is likely to be more abrupt.
\* It would lower the resource requirements for creating general AI, potentially allowing more parties to enter an AI arms race, including more extreme groups.
\* While some computer technologies like the Internet may accelerate wisdom, it's unclear how much marginal hardware improvements would further contribute along such dimensions.
### Artificial consciousness
[Artificial consciousness](https://en.wikipedia.org/wiki/Artificial\_consciousness) seems net harmful to advance because
\* It helps accelerate AI in general.
\* It's better to wait until society is wiser and more humane before conscious computer agents are developed. For instance, imagine violent video games that are marketed for their ability to generate conscious, lifelike enemies.
[Steve Grand](https://en.wikipedia.org/wiki/Steve\_Grand) defended his work toward artificially conscious creatures [on the following grounds](http://www.ruairidonnelly.com/consciousness-is-for-life-not-for-christmas/#comment-715 "a comment on the post \"Consciousness is For Life (Not For Christmas)\""):
> This is what I care about. I want to help us find out what it means to be conscious and I want to challenge people to ask difficult questions for themselves that they can’t do with natural life because of their unquestioned assumptions and prejudices. But we really are talking about creatures that are incredibly simple by natural standards. What I’m trying to explore is what it means to have an imagination. Not a rich one like humans have, but at all. The only way to find that out is to try to build one and see why it is needed and what it requires. And in doing so I can help people to ask questions about who they are, who other creatures are, and what it means to be alive. That’s not such a bad thing, is it?
>
>
This resembles an argument that Bostrom calls an instance of "second-guessing" in Ch. 14 of \*Superintelligence\*: basically, that in order to get people to take the risks of a technology seriously, you need to advance work on the technology, and it's better to do so while the technology has limited potential so as to bound risks. In other words, we should advance the technology before a "capability overhang" builds up that might yield more abrupt and dangerous progress in the technology. Bostrom and I are both skeptical. Armed with such a defense, one can justify any position on technological speed because either we (a) slow the technology to leave more time for reflection or (b) accelerate the technology so that others will take risks more seriously while the risks remain manageable.
In the case of artificial consciousness, we should advance the public discussion by focusing our energies on philosophy rather than on the technical details of building software minds. There's already enough technical work on artificial consciousness to fuel plenty of philosophical dialogue.
Caveats: When are changes actually positive-sum?
------------------------------------------------
### Positive-sum in resources does not mean positive-sum in utility
Improved social wisdom is positive-sum in terms of the resources it provides to different value systems: Because they know more, they can better accomplish each of their goals. They have more tools to extract value from their environment. However, it's not always the case that an action that improves the resources of many parties also improves the utility of each of those parties. Exceptions can happen when the goals of the parties conflict.
Take a toy example. Suppose Earth contained only Stone Age humans. One tribe of humans thought the Earth was beautiful in its untouched natural state. Another tribe felt that the Earth should be modified to better serve human economic interests. If these humans remained forever in the Stone Age, without greater wisdom, then the pro-preservation camp would have gotten its way by default. In contrast, if you increased the wisdom of both tribes -- equally or even with more wisdom for the pro-preservation tribe -- then it would now be at least \*possible\* for the pro-development tribe to succeed. Thus, despite a positive-sum increase in wisdom, the pro-preservation tribe is now worse off in expected utility.
However, this example is somewhat misleading. A main point of the present essay was to highlight the potential risks of greater technology, and one reason wisdom is beneficial is that it better allows both sides to cooperate and find solutions to reduce expected harms. For example, absent wisdom, the pro-development people might just start a war with the pro-preservation people, and if the pro-development side won, the pro-preservation side would have its values trashed. If instead both sides agreed to undertake modest development with safeguards for nature preservation, then each side could end up better off in expectation. This is an example of the positive-sum \*utility\* benefits that wisdom can bring.
Perhaps there are some examples where wisdom itself, not just technology, causes net harm to a certain ideology, but it seems like on the whole wisdom usually is positive-sum even in utility for many factions.
### Are changes determined by fractions of people or by absolute numbers?
The main intuition why wisdom and related improvements should be positive-sum is that they hold constant the fraction of people with different values and instead distribute more "pie" to people with each set of values. This fractional view of power makes sense in certain contexts, such as in elections where the proportion of votes is relevant. However, in other contexts it seems that the absolute number of people with certain values is the more appropriate measure.
As an example, consider the cause of disaster shelters that serve to back up civilization following near-extinction-level catastrophes. Many altruists support disaster shelters because they want humanity to colonize space. Suffering reducers like me probably [oppose disaster shelters](https://longtermrisk.org/publications/how-would-catastrophic-risks-affect-prospects-for-compromise/#Recovery\_measures\_are\_not\_supported\_by\_this\_argument) because shelters increase the odds of space colonization without correspondingly increasing the odds of more humane values. If work towards disaster shelters is proportional to (# of people in favor) minus (# of people opposed), and if, say, 90% of people support them by default, then greater education might change
> (10 in favor) minus (1 opposed) = 9 net
>
>
to
> (1000 in favor) minus (100 opposed) = 900 net,
>
>
which is a 100-fold increase in resources for disaster shelters. This makes the suffering reducers worse off, so in this case, education was not positive-sum.
My intuitions that wisdom, education, cooperation, etc. are \*in general\* positive-sum presupposes that most of the work that people do as a result of those changes is intrinsically positive for both happiness increasers and suffering reducers. Disaster shelters seem to be a clear exception to this general trend, and I hope there aren't too many other exceptions. Suffering reducers should keep an eye out for other cases where seemingly positive-sum interventions can actually hurt their values.
See also
--------
\* "[On Progress and Prosperity](http://effective-altruism.com/ea/9f/on\_progress\_and\_prosperity/)" by Paul Christiano |
47faf94c-4565-4c6b-b3c6-a76f0d33be37 | trentmkelly/LessWrong-43k | LessWrong | Managing risks of our own work
Note: This is not a personal post. I am sharing on behalf of the ARC Evals team.
Potential risks of publication and our response
This document expands on an appendix to ARC Evals’ paper, “Evaluating Language-Model Agents on Realistic Autonomous Tasks.”
We published this report in order to i) increase understanding of the potentially dangerous capabilities of frontier AI models, and ii) advance the state of the art in safety evaluations of such models. We hope that this will improve society's ability to identify models with dangerous capabilities before they are capable of causing catastrophic damage.
It might be argued that this sort of research is itself risky, because it makes it easier to develop and exercise dangerous capabilities in language model agents. And indeed, the author of Auto-GPT said he was inspired by seeing a description of our evaluations in the GPT-4 system card.[1] While it seems likely a project like that would have emerged soon in any event,[2] the possibility of advancing the capabilities of language model agents is not merely hypothetical.
In recognition of concerns of this kind, we have made significant redactions to this report, including (but not limited to):
* Removing complete transcripts of runs of agents using our scaffolding.
* Removing more detailed accounts of the strengths and weaknesses of agents using our scaffolding.
However:
* We may later make this material public when it clearly has minimal risk.
* We may later make this material public if more detailed analysis gives us sufficient confidence that it would be justified.
* Researchers working on AI safety evaluations may contact us to request additional access to nonpublic materials, and we will also be sharing some non-public materials with AI labs and policymakers.
Our rationale, in outline:
* Substantively, our best guess is that a more complete publication would have been net-risk-decreasing, and would do relatively little to advance progress toward dange |
130b1a90-bd6f-4275-8dd3-0a880d22a81e | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Pre-Training + Fine-Tuning Favors Deception
Thanks to Evan Hubinger for helpful comments and discussion.
Currently, to obtain models useful for some task X, models are pre-trained on some task Y, then fine-tuned on task X. For example, to obtain a model that can summarize articles, a large language model is first pre-trained on predicting common crawl, then fine-tuned on article summarization. Given the empirical success of this paradigm and the difficulty of obtained labeled data, I loosely expect this trend to continue.
I will argue that compared to the paradigm of training a model on X directly, training on Y then fine-tuning on X increases the chance of deceptive alignment. More specifically, I will argue that fine-tuning a deceptive model will produce a deceptive model and fine-tuning a non-deceptive model is more likely to produce a deceptive model than training from scratch.
From [Does SGD Produce Deceptive Alignment?](https://www.alignmentforum.org/posts/ocWqg2Pf2br4jMmKA/does-sgd-produce-deceptive-alignment):
>
> More specifically, we can single out three types of models that optimize for the base objective:
>
>
> * internally aligned models optimize for the base objective because it is equal to the model's terminal objective
> * corrigibly aligned models optimize for the base objective because their terminal objective is a robust pointer to a model of the base objective. Note that these are called corrigible because they are amenable to corrections of the model of the base objective (though not necessarily corrections to their pointer).
> * deceptively aligned models optimize for the base objective for instrumental reasons
>
>
>
Assume that pre-training has produced a model that optimizes for the pre-training loss and is one of the above types. The arguments are weaker if pre-training is imperfect. If the model is not one of the above types, then these arguments do not apply.
We can analyze the three cases separately:
* If pre-training has produced an internally aligned model, then we are beginning fine-tuning with a mesa-optimizer that has a misaligned proxy objective. The probability of fine-tuning producing deception is controlled by how far the pre-training loss is from the fine-tuning loss and how far the current capabilities are from deception.
* If pre-training has produced a corrigibly aligned model, then we begin fine-tuning with a mesa-optimizer that has a misaligned pointer. The probability of fine-tuning producing deception is controlled by how easy it is to shift the pointer and how far the current capabilities are from deception.
* If pre-training has produced a deceptively aligned model, then fine-tuning will begin with a deceptively aligned model. The probability of deception is controlled by how easy it is for the model to start instrumentally optimizing for the fine-tuning objective.
In the first case, changing an internal objective from the pre-training loss to the fine-tuning loss seems about as difficult as learning the fine-tuning loss from scratch. Since the model starts highly capable, deception has a strict advantage here. For example, suppose a model was pre-trained on prediction and fine-tuned on approval. Since the pre-training data is vast, the model will already understand human approval. Performing well on the fine-tuning loss is thus likely to involve routing capabilities through the understanding the model already has, instead of reincorporating human approval into the model’s internal objective.
In the second case, in order for fine-tuning to produce a corrigibly aligned model, the pointer must be changed from the pre-training loss to the fine-tuning loss. In order for fine-tuning to produce a deceptively aligned model, the model must understand the objective it’s being trained on, which also requires a pointer.
During normal training, the amount of optimization power the model can apply to a task slowly increases, while the amount of optimization power SGD can apply remains roughly constant. Since we are starting pre-training with an already capable model, this gap starts out wider than if we were training from scratch. Since deceptive models can build pointers at runtime, they will thus be able to apply more optimization power to pointer construction than SGD. As a result, the model will become deceptive faster than it can become corrigible. However, the model also begins with a detailed world model, enabling SGD to start building a pointer to the fine-tuning loss earlier than if we were training from scratch. Since deception cannot happen until the model has a detailed world model, this consideration is not more compelling when fine-tuning versus training from scratch.
In the third case, in order for fine-tuning to produce an internally or corrigibly aligned model, fine-tuning must align the model faster than the model can figure out the fine-tuning objective. Since the model was deceptive during pre-training, it already understands most of the training setup. In particular, it probably understood that it was being pre-trained and predicted that it would subsequently get fine-tuned, thus making fine-tuning overwhelmingly likely to produce a deceptive model. There are considerations about the type of deceptive alignment one gets during pre-training that I have ignored. See [Mesa-Search vs Mesa-Control](https://www.alignmentforum.org/posts/WmBukJkEFM72Xr397/mesa-search-vs-mesa-control) for further discussion.
The above arguments assume that pre-training + fine-tuning and training on the fine-tuning task directly produce models that are equally capable. This assumption is likely false. In particular, one probably will not have enough data to achieve high capabilities at the desired task. If the desired task is something like imitative amplification, suboptimal capabilities might produce an imperfect approximation of HCH, which might be catastrophic even if HCH is benign. There are other reasons why pre-training is beneficial for alignment which I will not discuss.
Overall, holding constant the capabilities of the resulting model, pre-training + fine-tuning increases the probability of deceptive alignment. It is still possible that pre-training is net-beneficial for alignment. Exploring ways of doing pre-training that dodge the arguments for deceptive alignment is a potentially fruitful avenue of research. |
bfb6e3d8-2059-483e-a2c2-c1b499722170 | trentmkelly/LessWrong-43k | LessWrong | What are the risks of permanent injury from COVID?
I'm in my late twenties. I can easily find estimates of the risk of death, but I'm having trouble figuring out what the risk of permanent injury (e.g. fatigue) is. I figure someone on LW has probably already looked into this, so I thought I'd ask. |
9ef55d67-c33b-4373-879f-d02ac26567ee | trentmkelly/LessWrong-43k | LessWrong | Why almost every RL agent does learned optimization
Or "Why RL≈RL2 (And why that matters)"
TL;DR: This post discusses the blurred conceptual boundary between RL and RL2 (also known as meta-RL). RL2 is an instance of learned optimization. Far from being a special case, I point out that the conditions under which RL2 emerges are actually the default conditions for RL training. I argue that this is safety-relevant by outlining the evidence for why learned planning algorithms will probably emerge -- and have probably already emerged in a weak sense -- in scaled-up RL2 agents.
I've found myself telling this story about the relationship between RL and RL2 numerous times in conversation. When that happens, it's usually time to write a post about it.
Most of the first half of the post (which points out that RL2 is probably more common than most people think) makes points that are probably already familiar to people who've thought a bit about inner alignment.
The last section of the post (which outlines why learned planning algorithms will probably emerge from scaled up RL2 systems) contains arguments that may be less widely appreciated among inner alignment researchers, though I still expect the arguments to be familiar to some.
Background on RL2
RL2 (Duan et al. 2016), also known as meta-RL (Wang et al. 2016; Beck et al. 2023), is the phenomenon where an RL agent learns to implement another RL algorithm in its internal activations. It's the RL version of 'learning to learn by gradient descent', which is a kind of meta-learning first described in the supervised setting by Hochreiter et al. (2001). These days, in language models it's often called 'in-context learning' (Olssen et al. 2022, Garg et al. 2022).
RL2 is interesting from a safety perspective because it's a form of learned optimization (Hubinger et al. 2019): The RL algorithm (the outer optimization algorithm) trains the weights of an agent, which learns to implement a separate, inner RL algorithm (the optimization algorithm).
The inner RL algorith |
c779360b-4a03-4ace-b07f-94153bfd7b2d | trentmkelly/LessWrong-43k | LessWrong | Putanumonit - Bayesian inference vs. null hypothesis testing
|
3d42024a-51ad-40f0-89d9-2a82d8fe48c0 | StampyAI/alignment-research-dataset/arbital | Arbital | Math 3
A reader at the **Math 3** level can read the sorts of things that a research-level mathematician could — if you're Math 3, it's okay to throw LaTeX formulas straight at you, using standard notation, with a minimum of handholding.
At the Math 3 level, different schools of mathematics may have their own standard notation, so somebody who is Math 3 in one discipline or subject may not necessarily be Math 3 in another.
## Writing for a Math 3 audience
When writing for a Math 3 audience, all bets are off on readability. You can use as much formal notation as you like in order to define your point properly and clearly. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.