
id stringlengths 36 36 | source stringclasses 15 values | formatted_source stringclasses 13 values | text stringlengths 2 7.55M |
|---|---|---|---|
95bc5736-1d59-47fa-a1e7-352ccb39aa7d | trentmkelly/LessWrong-43k | LessWrong | US scientists find potentially habitable planet near Earth
http://news.ycombinator.com/item?id=1741330 |
1950a9b8-49ce-481c-baee-cd60b273da5c | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Chaining Retroactive Funders to Borrow Against Unlikely Utopias
Summary
-------
There is no qualitative distinction between investors and retroactive funders on an impact market. Rather they will *de facto* fall along a spectrum of how altruistic they are. That is because investors will (1) expect investments into well-defined prize contests to be less risky than fully speculative investments, and will (2) expect more time to pass before they can exit fully speculative investments, so that a counterfactual riskless benchmark investment represents a higher threshold for them to consider impact markets at all.
Recap: Impact Markets
---------------------
For a more comprehensive explanation of impact markets, see [Toward Impact Markets](https://forum.effectivealtruism.org/posts/7kqL4G5badqjskYQs/toward-impact-markets-1).
In short, an altruistic retroactive funder announces that they will pay for impact (or “outcomes”) they approve of. It resembles a [prize competition](https://forum.effectivealtruism.org/posts/2cCDhxmG36m3ybYbq/impact-prizes-as-an-alternative-to-certificates-of-impact) in this way. But (1) they’ll pay proportional to how much they value the impact and not only the top *n* submissions; (2) the impact remains resellable by default; and (3) seed investors offer to pay the people who are vying for the prizes or provide them with anything else they need and receive in return rights to the impact and thus prize money.
It is analogous to the startup ecosystem: Big companies like Google want to acquire small companies with great staff or a great product. Founders try to start these small companies but often can’t do so (as quickly) without the seed funding and network of venture capital firms. When the exit happens (if it happens), the founders may not even any longer own the majority of the company because they’ve sold so much of it to the investors.
The benefits are particularly strong for high-impact charities and hits-based funders:
1. If a hits-based funder usually funds projects that have a 1 in 10 chance of success and switches to retroactive funding, they save:
1. the money from 9 in 10 of the grants,
2. the time from 9 in 10 of the due diligence processes, and
3. the risk from accidentally funding projects that then generate bad PR.
2. Investors can thus speculate on making around 10x return on their successful investments, and they can further increase their expected returns:
1. by specializing in a narrow area (such as AI safety) to make excellent predictions about which project will succeed,
2. by providing founders with their networks in those areas,
3. by buying resources at a bulk discount that founders need (such as compute credits), and
4. by finding founders that none of the other investors or funders are aware of to negotiate deals with them where they receive a large share of their impact certificate/s.
3. Charities can attract top talent and align incentives with top talent who may not be fully sold on the charity’s mission:
1. by promising them a share in all impact sold,
2. by locking that share up in a vesting contract,
3. by (possibly) sharing rights to the impact with another company that is the current employer of the talent so that they don’t need to quit and can draw on the infrastructure of the other company. (In fact, somewhat value-aligned companies may be interested in becoming investors themselves if they want to retain talent who want to work on prosocial applications of their knowledge.)
4. Individual researchers can attract funding for their work even without the personal ties to funders, e.g., because they are in a different geographic region and better at their research than at networking.
Profitability of Impact Markets
-------------------------------
We think about this in terms of the riskless benchmark B.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
and the ratios rc and rp. The benchmark B is a return – e.g., B=1.1 for a 10% profit – that an investor expects over some time period. An investment is interesting for the investor if it is more profitable than B. rc=cfci is the ratio of the costs that funder and investor face respectively. This includes, for the funder, the cost of the grant, the time cost of the due diligence, the reputational risk if the due diligence misses something, and, for the investor, the cost of the grant minus savings thanks to shared infrastructure, economies of scale, etc. rp=pipf (note that enumerator and denominator are the other way around) is the ratio of the probabilities that investor and funder respectively assign to the project success. The investor may specifically select projects where they have private information (e.g., thanks to their network) that give them greater confidence in the project’s success than they expect the funder to have.
Hence, investments are interesting if rc⋅rp>B.
The graph shows the benchmark of an investment with 30% riskless profit compared to the maximum profit from various project configurations. It elucidates that an investor who can help realize a project more cheaply than the funder or thinks that it is more likely to succeed, can outperform the funder in a range of scenarios. These are scenarios where one or both parties can reap the gains from trade and save time or money.
The square between 0 and 1 on both axes is largely irrelevant. These are scenarios where the investor would have to pay more than the funder or is less optimistic about the project. Those are obviously uninteresting. But also just outside that square and around the edges, there are areas where the investor may not be interested because their edge (in terms of the rp and rc ratios is too small. Then again a riskless 30% APY is a high benchmark.
A few examples:
If a charity already has a track record of doing something really well 10 out 10 times in the past, there is very little risk involved when they try it for an 11th time:
Maybe an investor thinks they’re 99.5% likely to succeed and the funder thinks they are at least 99% likely to succeed, and the action costs $1m for either and takes a year.
That’s rp=1.005 and rc=1. It is only interesting for an investor who cannot otherwise invest the money at 0.5% profit per year.
1. It’ll be worth little to the funder: If they value the impact at 99% probability at $1m, they’ll pay $1m/99% ≈ $1.01m for it, so $10k premium.
2. If an investor offers to carry that tiny amount of risk, they’ll want it to exceed their 10–30% benchmark after a year, or else a standard ETF investment would be more profitable to them. That’s at least a $100k premium.
3. A bid of a $10k premium (minus the overhead of the whole transaction) from the funder but an ask of $100k premium from the investor means that there’ll be no deal.
But consider a case where someone has no track record:
The investor thinks they are 20% likely to succeed. The funder thinks that they’re 10% likely to succeed. The action costs $1m for both and takes a year.
That’s rp=2 and rc=1. It’ll be interesting unless someone has a benchmark of more than 100% per year.
1. The funder will pay up to $1m/10% = $10m for the riskless impact.
2. That’s a 1000% return (or 900% profit) for the investor with 20% probability, so 100% profit in expectation, which beats most benchmark investments. Even if their riskless benchmark is as high as 30%, they’ll accept offers over 650% return. Naturally, these investors have to be fairly risk neutral or make many such investments. (If they are somewhat altruistic, they can consider the difference between the risk neutral and their actual utility in money a donation.)
3. Funder and investor will meet somewhere at or below 1000%.
It is easy to create an analogous example for the case where funder and investor make the same probability assessments but where the grant size is so small that the investor, who already knows the project, can fund it at half the price compared to the funder who would have to spend a lot of time on due diligence.
Impact Timeline
---------------
A typical product that is suitable for impact markets is a scientific paper. Papers, like many other projects, have the property that they often get stuck in the ideation phase, sometimes have to be abandoned (for other reasons than being an interesting negative result) during the research, sometimes don’t make it past the reviewers, and sometimes turn out to have been a bad idea only decades later.
When an investor wants to invest into a paper that has not been written, but which they are highly optimistic about, they may see these futures:
The *x* axis is the time (in years), the *y* axis is the [Attributed Impact](https://forum.effectivealtruism.org/posts/7kqL4G5badqjskYQs/toward-impact-markets-1#Attributed_Impact) (proportional to dollars), blue lines are possible futures, and the red line is the median future.
There are two big clusters: all the futures in which the paper gets written, published, and read, versus and all the futures in which it either never gets finished or gets read by too few people.
One to three years into the process, it becomes clear in which cluster a given future falls, particularly if it falls into the upper cluster. (Otherwise there’s a bit of a halting problem because it might still take off.) Maybe the paper has been published on arXiv and is making rounds among other researchers in the field.
After 10 years, the majority of the impact has become clear and the remaining uncertainty over the value of the Attributed Impact of the paper is low.
After 15 years, we’re asymptotically approaching something that looks like a ceiling on the Attributed Impact of the paper. Experts have hardly updated on its value anymore in years, so their confidence increases that they’ve homed in on its “true” value. (“True” in the intersubjective sense of Attributed Impact, not in any objectivist sense.)
This is a vastly idealized example. In practice it may be that a published paper that used to be held in high regard suddenly turns out to have been wrong, an infohazard, plagiarized, etc. Or it may be that it’s suddenly noticed that a decade-old forgotten-about paper (that had high ambitions at the time but seemed to fall short) contains key answers to an important new problem.
Timing of Retroactive Funding
-----------------------------
If an investor is a specialist in some small field and profits from economies of scale in the field (e.g., the compute credits bought in bulk that we mention above), then they may expect to make a 10× profit from each retro funding that they receive. That’s the difference between the size of the retro funding at which the retro funder breaks even (ignoring interest) and the cost to the investor. We assume for simplicity that monetary and time costs (grants and due diligence) are the same. So, 2 · 10*i* − 2 · 5*i* = 10*i*, where *i* is the average seed investment. (We’re using the parameters from above where retro funders save 10× from making fewer grants and 10× from saving time spent on due diligence. We also assume that a patient, well-networked, specialized investor has twice the hit rate of the generalist funder.)
If, counterfactually, they would’ve invested this money at 30% APY, the impact market ceases to be interesting for them if they expect the retro funding to take longer than 8–9 (≈ 10.6 ≈ 1.39) years: 2 · (1 / *ratefunder*) − 2 · (1 / *rateinvestor*) = (1 + *apy*)*years*.
Here we’re comparing an investor at different hit rates to a retro funder who would otherwise have a 10% hit rate under four counterfactual market scenarios. The impact market is profitable for any number of years less than the break-even point.
If the retro funder wants to save money, they can pay out less, but will need to do so earlier. For simplicity, the following chart is only for the scenario with a counterfactual 30% APY: 2 · (1 / *ratefunder*) · (1 − *savings*) − 2 · (1 / *rateinvestor*) = 130%*years*.
A retro funder needs to take this into account when deciding how much certainty they want to buy from the investors. More added certainty comes at a higher price. They can regulate this through the size of their retro funding or through the timing. Depending on the impact in question there are usually certain sweet spots that they can aim for, and do so transparently so that investors know what time horizons to speculate on.
When it comes to our example above, it seems fairly clear whether the paper was a success (was written, published, and read by some people) after about 2–3 years. So one sweet spot may be to wait for the moment of publication (as a draft or after peer review) or after the initial public reception can be gauged. The second is interesting because investors may be well-positioned to help with the promotion.
But there are other options – less profitable options much later.
Dissolving Retroactivity
------------------------
We can imagine a chain of retro funders from a particular set of futures into the present: Someone makes a binding commitment that if they are successful in making a lot of money – say, their business is successful – they will use the money or a fraction of it to buy back impact that has previously been bought by a certain set of existing retro funders who the person trusts. They can continually add new ones to this set.
This can also be formulated as a prize contest: If I’m successful, I’ll use that budget to buy impact from my favorite retro funders at a reasonable bid price. If 1 in 5 projects still fail between the time when the retro funder bought them and the time when the success happens, the retro funder may buy them at 120% of the price that the previous retro funder paid.
Under this framing there is no qualitative difference anymore between investors and earlier retro funders. They’re all just different investors with different attitudes toward risk or preferences about how they weigh the profit vs. the social bottom line of their investments. (Some of them may choose to consume their certificates, though, to signal that they’ll never resell them.) There may even be investors who choose to invest into “whatever project person X will do next,” so earlier than the abovementioned seed investors.
A startup may be interested in making such a commitment because they have the choice to either do the research in-house or at least pay for it immediately or to pay for it later and only if they are successful. Since startup success is typically Pareto distributed, they’ll have vastly more money in the futures where they are successful than they have now or in unsuccessful futures. So this deal should be interesting for most startups.
For investors it’s a question of whether they want to expose themselves more to the field or to a particular team. If they’re excited about the team behind the startup and trust that team to do well regardless of what field they go into, they’ll want to invest directly into the startup. But if they’re more agnostic about all the teams in a field but are very excited about the field, they may prefer investing into the research projects to bet on the retro funding.
Example
-------
1. Cultured meat (or “cell/clean/c meat”) startups may require a lot more research to be done on how to scale their production and make it cost-competitive. But they don’t yet have the money to do all of that research in-house.
2. They commit to investing a large portion of the money they’ll make from going public into buying impact. Specifically they hash out particular terms with an organization like Founders Pledge that stipulate what impact related to cultured meat research they will buy from which retro funders.
3. The promise of great potential future riches boosts funding and opens up hiring pools.
4. Eventually, the now more likely future might happen, and the large budget from the exits serves to buy most of the impact from the retro funders.
Conclusion
----------
We’ve received a grant via the Future Fund Regranting Program to work on this. If you’d like to join our discussions, [please join our Discord](https://discord.gg/7zMNNDSxWv).
Thanks to my cofounder Dony for reviewing the draft of this post! He gets 1% of the impact of it; I claim the rest. |
fd94a930-6d9b-4151-8e36-22f99b59407c | trentmkelly/LessWrong-43k | LessWrong | High-stakes alignment via adversarial training [Redwood Research report]
(Update: We think the tone of this post was overly positive considering our somewhat weak results. You can read our latest post with more takeaways and followup results here.)
This post motivates and summarizes this paper from Redwood Research, which presents results from the project first introduced here. We used adversarial training to improve high-stakes reliability in a task (“filter all injurious continuations of a story”) that we think is analogous to work that future AI safety engineers will need to do to reduce the risk of AI takeover. We experimented with three classes of adversaries – unaugmented humans, automatic paraphrasing, and humans augmented with a rewriting tool – and found that adversarial training was able to improve robustness to these three adversaries without affecting in-distribution performance. We think this work constitutes progress towards techniques that may substantially reduce the likelihood of deceptive alignment.
Motivation
Here are two dimensions along which you could simplify the alignment problem (similar to the decomposition at the top of this post):
1. Low-stakes (but difficult to oversee): Only consider domains where each decision that an AI makes is low-stakes, so no single action can have catastrophic consequences. In this setting, the key challenge is to correctly oversee the actions that AIs take, such that humans remain in control over time.
2. Easy oversight (but high-stakes): Only consider domains where overseeing AI behavior is easy, meaning that it is straightforward to run an oversight process that can assess the goodness of any particular action. The oversight process might nevertheless be too slow or expensive to run continuously in deployment. Even if we get perfect performance during training steps according to a reward function that perfectly captures the behavior we want, we still need to make sure that the AI always behaves well when it is acting in the world, between training updates. If the AI is decep |
28823560-23a3-49c5-bea5-0d3df51c66de | StampyAI/alignment-research-dataset/arxiv | Arxiv | Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-Users
1 Introduction
---------------
Popular virtual assistants (VAs), such as
Siri111[www.apple.com/ios/siri/](http://www.apple.com/ios/siri/),
Cortana222[windows.microsoft.com/en-us/windows-10/](http://windows.microsoft.com/en-us/windows-10/)
[getstarted-what-is-cortana](http://getstarted-what-is-cortana), and
GoogleNow333[www.google.com/landing/now](https://www.google.com/landing/now), can perform
dozens of different tasks, such as finding directions and making
restaurant reservations. These are the tasks that the VA developers
expected to be the most widely used. However, every VA user can
probably think of one or more other tasks that they would like their
VA to help with, which the developers have simply not implemented yet.
The unavailable tasks are as varied as the users. Thus, the demand
curve for VA tasks has a very long and heavy tail of unsatisfied
demand. The capabilities of currently available VAs represent only a
tiny fraction of their potential. Even the available tasks are often
implemented differently from how users would prefer.
This situation is unavoidable given how VAs are currently developed.
There will never be enough VA developers to customize VAs in all the
ways that users would like. The only way to close the gap between
what VAs can do and what users want them to do is to enable
non-technical end-users to teach new tasks to their VAs. Many users
would be willing and able to do so, if it were as quick and easy as
teaching a person.
The most common way to teach a person a relatively simple new task is
to describe the task and then demonstrate how to do it. For decades,
researchers have been trying to build computer systems that can be
taught the same way. Their efforts comprise a body of work most
commonly referred to as “programming by demonstration”
(PBD)[[4](#bib.bib4)]. 444“PBD” is an unfortunate name, because
most of the non-technical users that can benefit from it are
reluctant to attempt anything with “programming” in its name.
| program class → | variable-free | non-branching | branching |
| --- | --- | --- | --- |
| finite set of tasks | | Siri, Cortana, et al. | |
| domain-restricted set of tasks | | | PLOW et al. |
| most tasks | | Helpa | |
| all tasks | macros | | |
Table 1:
Virtual assistants trade off task expressive power for task domain-dependence.
The simplest kind of PBD system creates and runs programs with no
variables, colloquially known as macros. The absence of variables,
which also implies the absence of loops and conditionals, makes it
easier for non-programmers to understand and use macros.
Nevertheless, macros see little use outside of special environments
such as text editing software, because there are relatively few
situations in which a program without variables can be useful.
To increase the usefulness of PBD, researchers have attempted to build
systems that can be taught more powerful classes of programs, all the
way up to Turing-equivalent systems with variables, loops, and
conditionals (e.g., see [[5](#bib.bib5), [6](#bib.bib6)] and
references therein). Invariably, such attempts run into the
limitations of the current state of the art in natural language
understanding. At present, the only known way for computers to deal
with the richness of language that people use to describe complex
tasks is to limit the tasks to a narrow domain, such as
travel reservations or messaging. For example, the PLOW system
[[1](#bib.bib1)] is powerful enough to learn programs with variables,
loops, and subroutines. Yet, it can learn tasks only within the task
domains covered by its ontology. In order to demonstrate PLOW’s
ability to learn tasks in a new domain, its authors had to manually
extend its ontology to the new domain. To the best of our knowledge,
all previous PBD systems with variables are similarly limited to at
most a handful of task domains.555From the point of view of
most users, who do not have access to the developers.
The class of variable-free programs and the class of Turing-equivalent
programs are the two extremes on a continuum of expressive power.
However, most of the tasks available from today’s most popular VAs can
be expressed by programs that are in another class between those two
extremes. These programs are in the “non-branching” class, where
programs can have variables but cannot have loops or conditionals.
Judging by the popularity of VA software, a very large number of
people could benefit from a VA that can be taught new non-branching
programs by its end-users.
This paper presents Helpa, a system that can be taught non-branching
programs via PBD. We have developed a way to teach such programs
without any prior domain knowledge, which works surprisingly well in
most cases. Therefore, Helpa imposes no restrictions on the domains in
which users can teach it new tasks. We believe that Helpa’s innovative
trade-off of expressive power for domain-independence occupies a sweet
spot of very high utility, compared to the other classes of VAs in
Table [1](#S1.T1 "Table 1 ‣ 1 Introduction ‣ Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-UsersMany thanks to the participants of our usability study. Also thanks to Patrick Haffner, Michael Johnston, Hyuckchul Jung, Amanda Stent, and Svetlana Stoyanchev for helpful discussions."). In addition, our usability study showed that
Helpa’s design makes it possible for end-users to teach it many new
tasks in less than a minute each — fast enough for practical use in
the real world.
Following [[7](#bib.bib7)], we shall refer to the teachable
component of a VA as an instructible agent (IA), and the challenge of
building an IA as the IA problem. After formalizing this problem in
the next section, we shall describe our proposed solution. We shall
then describe some of its current limitations, which explain why we
claim that Helpa can learn only “most tasks”, rather than “all
tasks”, in Table [1](#S1.T1 "Table 1 ‣ 1 Introduction ‣ Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-UsersMany thanks to the participants of our usability study. Also thanks to Patrick Haffner, Michael Johnston, Hyuckchul Jung, Amanda Stent, and Svetlana Stoyanchev for helpful discussions."). Lastly, we shall describe a
usability study that we carried out to evaluate Helpa’s effectiveness.
2 The Instructible Agent (IA) Problem
--------------------------------------
The IA problem is to build a system that can correctly execute a task
expressed as a previously unseen natural language command. We shall
put aside the question of what counts as natural language by accepting
any string of symbols as a command. It is more challenging to
operationalize the notion of executing a task.
Every PBD system interacts with a particular user interface (UI). It
records the user’s actions in that UI when a user is demonstrating a
new task for it to learn. It mimics the user’s actions in that UI to
execute tasks that it has learned. Reliably interacting with a UI in
this manner is a challenging problem (e.g., see [[10](#bib.bib10)]).
The present work makes no attempt to solve it.
Rather, we abstract the notion of task execution into a data structure
that we call a “UI script”. We assume that when a PBD system
records a user’s actions, the result is a UI script. And when it’s
time for a PBD system to mimic a user’s actions back to the UI, it
does so by reading and executing a UI script.
Since all of the IA’s interactions with the UI are via a UI script, we
can define the IA problem independently of the problem of reliably
interacting with the UI. In particular, we define the IA problem as
predicting a UI script from a command. [[3](#bib.bib3)] studied a
special case of this problem where the natural language input
explicitly referred to every user action in the UI script.
[[8](#bib.bib8)] and others have studied a related but different
problem where the goal was to predict programs from program traces.
IAs that aim to learn branching programs must predict
branching UI scripts but, in the present work, we limit our attention
to non-branching programs and non-branching UI scripts.
3 Helpa
--------
###
3.1 Model
Given sufficient training data, it might be possible to solve the IA
problem via machine techniques (e.g., [[2](#bib.bib2)]). We are not
aware of any pre-existing training data
for this problem. To compensate for the lack of data, we used a model
with very strong biases, so that it can be learned from only one
example (per task) of the kind that we might reasonably expect a non-technical
end-user to provide. The Helpa model has three parts for every task
t:
1. The class Tt of commands that pertain to t. We
shall encode Tt in a data structure called a “command
template”.
2. The class Pt of UI scripts for t. We shall
encode Pt as a non-branching program.
3. A mapping of variables between Tt and Pt,
which we call a “variable binding function.”
We shall now expand on each of these concepts.
A natural language command given to an IA can be segmented into
constants and variable values. Variable values are words or phrases
that are likely to vary among commands from
the same class. Constants are “filler” language that is likely to
remain the same for every command in the class. For example, suppose
a user wants to train her system to check flight arrival times using
the command “When does KLM flight 213 land?” In this command, “KLM”
and “213” are variable values. The other symbols are constants.
A command template can be derived from a command by replacing
each variable value with the name of a variable. “When does
X1 flight X2 land?” is a command template for the previous
example.
To justify our use of the term ‘‘program’’, we must first say more
about UI scripts. In the present work, we limit our attention to UIs
that consist of discrete elements, where all user actions are
unambiguously separate from each other and happen one at a
time666A smart-phone touchscreen or a web browser would fit this
description, for example, but a motion-capture suit would not.. A
non-branching UI script for such a UI is a sequence of actions, where every
action pertains to at most one element of the UI. E.g., a UI script
for a web browser might involve an action pertaining to the 4th text
field currently displayed and an action pertaining to the leftmost
pull-down menu. A common action that does not pertain to a
specific UI element is to wait for some condition to occur in the UI,
such as waiting for a web page to load. Besides identifying an
element in the UI, each action can also specify a parameter value,
such as what to type into the text field or how long to wait for the
page to load777More generally, each action can have multiple
parameter values. We omit this generalization for simplicity of
exposition.. An example of a UI script is in Figure [1](#S3.F1 "Figure 1 ‣ 3.1 Model ‣ 3 Helpa ‣ Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-UsersMany thanks to the participants of our usability study. Also thanks to Patrick Haffner, Michael Johnston, Hyuckchul Jung, Amanda Stent, and Svetlana Stoyanchev for helpful discussions.").
| action type | UI element | parameter value |
| --- | --- | --- |
| textbox\_fill | address\_bar | [flightarrivals.com](http://flightarrivals.com) |
| wait\_for | | page\_load |
| select\_from | menu\_1 | KLM |
| textbox\_fill | textbox\_1 | 213 |
| click\_button | button\_1 | |
| wait\_for | | page\_load |
Figure 1:
Example of a UI script for the command “When does KLM
flight 213 land?”
Every non-branching program is also just a sequence of actions. A
program differs from a UI script only in that some of the parameter
values can be variables. E.g., to create a program from the UI
script in Figure [1](#S3.F1 "Figure 1 ‣ 3.1 Model ‣ 3 Helpa ‣ Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-UsersMany thanks to the participants of our usability study. Also thanks to Patrick Haffner, Michael Johnston, Hyuckchul Jung, Amanda Stent, and Svetlana Stoyanchev for helpful discussions."), we would replace the parameter value
“KLM” with a variable name like X1 and the parameter value
“213” with another variable name like X2. Replacing values with
variable names, both in commands and in UI scripts, is a form of
generalization. This kind of generalization is the most common way
for PBD systems to learn (e.g., [[11](#bib.bib11)]).
Finally, a variable binding function maps the variables in a
command template to the variables in a program. Helpa allows a
command template variable to map to multiple program variables, but
not vice versa. The one-to-many mapping can be useful, e.g., when a
web form asks for a shipping address separately from a billing
address, and the user always wants to use the same address for both.
We do not allow multiple command template variables to map to the same
program variable. Doing so would merely increase system complexity
without any benefits.
###
3.2 System Architecture and Components
With the Helpa model in mind, we can describe how Helpa works. It has
two modes of operation: learning and execution, illustrated in
Figures [2](#S3.F2 "Figure 2 ‣ 3.2 System Architecture and Components ‣ 3 Helpa ‣ Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-UsersMany thanks to the participants of our usability study. Also thanks to Patrick Haffner, Michael Johnston, Hyuckchul Jung, Amanda Stent, and Svetlana Stoyanchev for helpful discussions.") and [3](#S3.F3 "Figure 3 ‣ 3.2 System Architecture and Components ‣ 3 Helpa ‣ Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-UsersMany thanks to the participants of our usability study. Also thanks to Patrick Haffner, Michael Johnston, Hyuckchul Jung, Amanda Stent, and Svetlana Stoyanchev for helpful discussions."), respectively. In both
figures, dashed lines delimit the Helpa system boundary, and numbers
indicate the order of events. Both modes use a database of tasks,
where every record consists of a command template, a program, and a
variable binding function. Tasks are created in learning mode and
executed in execution mode.

Figure 2:
Data flow diagram for Helpa’s learning mode.
The user initiates the learning mode by starting the UI recorder (1).
The user then provides an example command (2) and demonstrates how to
execute the command (3a). During the demo, the recorder is
transparent to the user and to the UI. It records all user actions
and any relevant responses from the UI (3b). When the user stops the
recorder (4), the recorder writes a UI script (5). Then, the learner
takes the example command and the UI script (6), and infers a command
template, a program, and a variable binding function for the task (7).
The command template is shown to the user for approval (8). If the
user approves, then the program and variable binding function are
stored in the task database, keyed on the command template (9).
Otherwise, the user can start over.

Figure 3:
Data flow diagram for Helpa’s execution mode.
Execution mode
starts when the user provides a new command (1) without starting the
UI recorder. The matcher queries the task database (2) and selects
the task whose command template matches the new command (3). The
command template for that task is compared to the new command (4), in
order to infer the variable values (5). Currently, the values are
inferred merely by deleting the constant parts of the command template
from the command. Once found, the values are substituted into the
program via the variable binding function (6) to create a new UI
script (7). The UI script is sent to the player (8), which mimics the
way that a user would execute that task in the UI (9). Thus, after
learning a new task, and storing it keyed on its command template,
Helpa can execute new commands matching that template, with previously
unseen parameter values.
We shall now say more about some of the subsystems that our diagrams
refer to. The diagrams show the player and recorder outside of the
Helpa system boundary, because we do not consider these components to
be part of Helpa. A different player and recorder are necessary for
every type of UI. However, regardless of the UI, Helpa interacts with
the world only through UI scripts. Therefore, Helpa is
UI-independent, which also makes it device-independent.
In execution mode, the matcher looks for a command template that can
be made identical to the command by substituting the template’s
variables with some of the command’s substrings. E.g., the template
“When does X1 flight X2 land?” can be made identical to the
command “When does United flight 555 land?” by substituting X1
with “United” and X2 with “555”. This kind of matching is a
special case of unification, for which efficient algorithms exist
[[12](#bib.bib12)].
Figure [3](#S3.F3 "Figure 3 ‣ 3.2 System Architecture and Components ‣ 3 Helpa ‣ Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-UsersMany thanks to the participants of our usability study. Also thanks to Patrick Haffner, Michael Johnston, Hyuckchul Jung, Amanda Stent, and Svetlana Stoyanchev for helpful discussions.") shows only what happens if
exactly one unifying template is found. Otherwise, control passes to
a clarification subsystem, which is not shown in the diagram. If no
suitable template is found, this subsystem provides a list of
available command templates to the user, in order of string similarity
to the command, and offers the user a chance to try another command.
If multiple templates unify with the new command, they are displayed
in order of their amount of overlapping filler text, and the user is
asked to disambiguate their command by rewording it.
The learner used in learning mode is responsible for generalizing the
command to a command template, generalizing the UI script to a
program, and deciding which variables in the command template
correspond to which variables in the program. A key insight that
makes it possible to learn from only one example is that, typically,
each variable value in the example command is the same as a parameter
value in the UI script. In contrast, the constant parts of the
command typically bear no resemblance to the rest of the UI script.
1:command C, UI script S
2:L1=L2=∅ ▹ empty lists
3:for i=1 to |D| do
4: q← value of parameter in action i of S
5: if q matches C from word m to word n then
6: len←m−n+1
7: L1.append(⟨len,i,m,n⟩) ▹ list of 4-tuples
8:sort L1 on len
9:R[1..|C|]←→0 ▹ array of |C| zeros
10:for all ⟨len,i,m,n⟩∈L1 do
11: if
R[m..n]=→0
or
∃d:(R[m..n]=→d
and R[m−1]≠d and R[n+1]≠d)
then
12: R[m..n]←→i ▹ put i in positions m
thru n
13: L2.append(⟨m,n,i⟩) ▹ list of triplets
14:sort L2 on m
15:T=C ▹ command template
16:P=D ▹ program
17:B=∅ ▹ variable binding function
18:for all ⟨m,n,i⟩∈L2 do
19: replace words m thru n of T with “Xm”
20: replace parameter in line i of P with “Xm”
21: add (‘‘Xm"→i) to B
22:command template T, program P, variable binding function B
Algorithm 1
Helpa learning algorithm
Helpa’s learner uses this insight as shown in
Algorithm [1](#alg1 "Algorithm 1 ‣ 3.2 System Architecture and Components ‣ 3 Helpa ‣ Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-UsersMany thanks to the participants of our usability study. Also thanks to Patrick Haffner, Michael Johnston, Hyuckchul Jung, Amanda Stent, and Svetlana Stoyanchev for helpful discussions."). The first loop (lines 2–6) matches the
parameter values in the UI script with substrings of the command, and
stores them in list L1. After the loop, the list is sorted on the
length of the matching substring, in order to give preference to
longer matches. The second loop (lines 9–12) traverses L1 in
order from longest match to shortest. Each matching action attempts
to reserve its substring of the command by filling the corresponding
span of the reservation array R with its action index i. The
reservation attempt succeeds if one of two conditions holds: either
that span is not yet reserved by any other action, or exactly
that span is reserved by another action (i.e. with the same span
boundaries). The latter condition enables one command variable to map
to multiple UI script variables, but only if it’s exactly the same
command variable. Overlapping or nested command variables are not
allowed. The successful reservations are stored in list L2. In
line 13, L2 is sorted on the left boundary m of the span of the
variable value in the command. This order is necessary because, in
execution mode, the variable substitution process assumes that the
order of variables in the variable binding function is the same as the
order of variables in the command template. The last loop (lines
17-20) traverses L2, whose every element is a mapping from a span
of the command to a line of the UI script. The learner creates
variable names Xm, where m refers to the left boundary of a span
of a command variable. The learner uses these variable names to
create a command template out of the input command and a program out
of the input UI script. Naming the variables in this manner allows
one command variable to map to multiple UI script variables. Since
line 10 disallowed overlapping or nested command variables, there can
be no ambiguity about which command variable each Xm refers to. The
last step in the last loop adds each mapping to the variable binding
function.
###
3.3 Limitations
At the present stage of development, Helpa has some significant
limitations. Perhaps the most striking limitation, from a user’s
point of view, is that Helpa knows nothing about paraphrasing. Helpa
doesn’t even know that “April 4, 2016” is the same as “04/04/16”.
Likewise,
knowing how to execute ‘‘Find
X’’ doesn’t help Helpa to execute ‘‘Search for X’’.
In order for the learner to work, the variable values in the command
must be identical to the values in the UI script.
888This
limitation is not so severe when Helpa is executing a task for the
same user who trained it on that task, because that user will often
remember the phrasing that they used. The literature offers a
variety of techniques for overcoming this limitation.
For example, we could use
statistical paraphrase generation [[13](#bib.bib13)] to proactively
expand a newly inferred command template into a set of possible
paraphrases, and store them all in the task database linked to the
same task. However, the usability study in the next section was
done without the benefit of such techniques.
A more subtle limitation is due to Helpa’s simplistic method for
deducing variable values at execution time. The “string difference”
method fails when two variables are adjacent in the command template,
because Helpa doesn’t know how to partition the adjacent values.
E.g., in a command like “I need a Ford Taurus Tuesday,” Helpa has no
way to determine whether “Taurus” should be part of the value for
the car variable or part of the value for the day variable. Again,
there are various natural language processing (NLP) techniques that can
solve most of this problem (e.g., [[9](#bib.bib9)]). For now, Helpa
works only for commands that have no adjacent variables.
Although it’s easy to think of commands that violate this
constraint, they are relatively rare in practice, at least
in English. We found long lists of English commands for
Siri999[www.reddit.com/r/iphone/comments/1n43y3/everything\_you\_can\_ask\_siri\_in\_ios\_7\_fixed](http://www.reddit.com/r/iphone/comments/1n43y3/everything_you_can_ask_siri_in_ios_7_fixed),
for Cortana101010[techranker.net/cortana-commands-list-](http://techranker.net/cortana-commands-list-)
[microsoft-voice-commands-video](http://microsoft-voice-commands-video), and for
GoogleNow111111[forum.xda-developers.com/showthread.php?t=1961636](http://forum.xda-developers.com/showthread.php?t=1961636).
Two variables were adjacent in only 5 out of 236 Siri commands, in
only 3 out of 91 Cortana commands, and in only 1 out of 98 GoogleNow
commands.
4 Usability Study
------------------
Our working hypothesis in building Helpa was that, in the vast
majority of cases, learning to predict non-branching programs from
natural language commands requires no domain knowledge and only the
most rudimentary NLP. Our usability study was designed to test this
hypothesis, in terms of Helpa’s task completion rates for users who
were not involved in Helpa’s development. We also wanted to measure
how long it takes users to teach new tasks to Helpa.
###
4.1 Design of the Study
Helpa is UI-independent, but using it with a particular UI
requires a player and recorder for that UI. A system like Helpa is
most compelling for a speech UI on a mobile device and/or in a
situation where the user’s hands are busy. Unfortunately, we did not
have access to a suitable UI player/recorder for any such UI/device,
and we did not have the resources to create one. The closest
approximation available to us was the Browser Recorder and Player
(BRAP) package.121212<https://github.com/nobal/BRAP>
BRAP records
user actions in a web browser by injecting jQuery code and listening
for JavaScript events such as key-up, select-one, and submit. This
approach is sufficient for simple web pages, but it often fails on
websites that do not raise events in response to user inputs.
Since BRAP was designed for a
slightly different purpose, it can recognize events related
to only the following HTML elements: text boxes, check boxes, radio
buttons, pull-down menus, and submit buttons. BRAP knows nothing
about hyperlinks, maps, sliders, calendars, pop-ups, etc. Even though
BRAP is the most functional software of its kind, its limitations
prevent it from correctly recording demos on most modern websites.
Since BRAP works only with web browsers, our entire study was done in
a Google Chrome web browser, on an Apple MacBook Air computer, through
a keyboard and touchpad. Also, due to BRAP’s limitations, we were
forced to limit our study to websites that used only simple HTML web
forms. So, we could not use a random sample of web sites, or allow
our study subjects to choose them.
| | | | | |
| --- | --- | --- | --- | --- |
| | site type | URL | scenario | #elts |
| 1 | mortgage calculator |
[calculator.com/pantaserv/ mortgage.calc](http://calculator.com/pantaserv/%20mortgage.calc)
|
You are a real estate agent, checking whether your customers can afford certain properties.
| 11 |
| 2 | thesaurus |
[collinsdictionary.com/english-thesaurus](http://collinsdictionary.com/english-thesaurus)
|
You are a writer looking for alternative ways to express yourself.
| 4 |
| 3 | book store |
[abebooks.com/servlet/ SearchEntry](http://abebooks.com/servlet/%20SearchEntry)
|
You are a book dealer serving many kinds of readers.
| 26 |
| 4 | recruiting | [indeed.com/resumes/ advanced](http://indeed.com/resumes/%20advanced) |
You work for a recruiting firm, searching for candidates to fill various job openings.
| 14 |
| 5 | investment research |
[nasdaq.com](http://nasdaq.com)
|
You are an investor who likes to frequently check the prices of your stocks.
| 2 |
| 6 | scientific database |
[citeseerx.ist.psu.edu/ advanced\_search](http://citeseerx.ist.psu.edu/%20advanced_search)
|
You are doing a literature search for a research project.
| 13 |
| 7 | car rental |
[priceline.com/l/rental/cars.htm](http://priceline.com/l/rental/cars.htm)
|
You are a travel agent, researching rental cars.
| 7 |
| 8 | cooking recipes |
[allrecipes.com/Search/ Default.aspx?qt=a](http://allrecipes.com/Search/%20Default.aspx?qt=a)
|
You are in charge of selecting new dishes to put on a restaurant’s menu.
| 26 |
| 9 | airline | [united.com/web/ en-US/apps/](https://united.com/web/%20en-US/apps/) [booking/flight/ searchOW.aspx](http://booking/flight/%20searchOW.aspx) |
You are a travel agent, checking availability of one-way flights for customers.
| 40 |
| 10 | dept. store |
[jcpenney.com](http://jcpenney.com)
|
You are shopping for gifts for your friends.
| 2 |
Table 2:
Web sites and scenarios used in our study. #elts = number of BRAP-compatible UI elements on the landing page.
After searching for many hours, we found a sufficiently simple website
in each of 10 diverse categories. For each of these 10 websites, we
picked a scenario for which an IA with variables might be useful.
Table [2](#S4.T2 "Table 2 ‣ 4.1 Design of the Study ‣ 4 Usability Study ‣ Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-UsersMany thanks to the participants of our usability study. Also thanks to Patrick Haffner, Michael Johnston, Hyuckchul Jung, Amanda Stent, and Svetlana Stoyanchev for helpful discussions.") lists the types of sites we used, along with the
URL, the scenario we picked for each site, and the number of
BRAP-compatible UI elements on the first web page that the study
subjects saw. This study design limited each task to use only one
website, even though Helpa has no such limitation. Nothing in the
Helpa system was tailored to these websites, these scenarios, or this
study.
We recruited 10 study subjects, and gave them the instructions in
Appendix A. These instructions were designed to help them get around
Helpa’s and BRAP’s counter-intuitive limitations. To summarize,
subjects were instructed that
* variable values must appear in the example command exactly the
same way as they appear in the web form;
* variables in commands cannot be adjacent; and
* task demos must use only the HTML elements that BRAP can record.
* subjects must ignore default values that appear
in web forms.131313BRAP can read default values in web forms, but
we have not yet figured out a way to determine, without explicit
indication from the user, whether a given default should become a
program variable.
We could not think of a way to explain these limitations without
referring to programming concepts.
For this reason, we recruited study subjects from among our
colleagues, all of whom were experienced programmers.
Each subject began by reading the instructions, and asking any
questions they had. Then, an automated script initialized the task
database to empty, randomized the order of the websites, and guided
the subject through the following protocol for each website:
1. Subject reads the scenario description (Column 4 in
Table [2](#S4.T2 "Table 2 ‣ 4.1 Design of the Study ‣ 4 Usability Study ‣ Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-UsersMany thanks to the participants of our usability study. Also thanks to Patrick Haffner, Michael Johnston, Hyuckchul Jung, Amanda Stent, and Svetlana Stoyanchev for helpful discussions.")), and familiarizes themselves with the website.
2. Subject thinks of a task that is relevant to that scenario, and
of a natural language command that is suitable for that task.
3. Subject interacts with Helpa’s learning mode.
4. If the subject disapproves of the command
template that Helpa generated, return to step 1.
5. Subject thinks of another command from the same class.
6. Subject interacts with Helpa’s execution mode.
7. Subject provides their opinion on whether Helpa executed the new
command correctly.
The script recorded and timestamped all of the interactions between
Helpa, the study subjects, and the UI.
###
4.2 Results
| | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| | site type | A | B | C | D | E | F | G |
| 1 | mortgage calculator | 0.5 | 9.5 | 2 | 3.5 | 20 | 90 | 25 |
| 2 | thesaurus | 0.7 | 4 | 3 | 1 | 5.5 | 30 | 26 |
| 3 | book store | 0.9 | 5 | 3 | 2.5 | 9.5 | 31.5 | 35.5 |
| 4 | recruiting | 0.9 | 7 | 3 | 3 | 13.5 | 48.5 | 36 |
| 5 | investment research | 1.0 | 4 | 2 | 1 | 6 | 38 | 37 |
| 6 | scientific database | 1.0 | 6.5 | 2 | 2.5 | 7.5 | 46 | 46.5 |
| 7 | car rental | 1.0 | 8 | 2 | 4 | 16.5 | 71 | 46.5 |
| 8 | cooking recipes | 0.5 | 7.5 | 2 | 4 | 15 | 52 | 52 |
| 9 | airline | 0.8 | 8 | 2 | 4 | 12 | 55.5 | 53.5 |
| 10 | department store | 0.4 | 4 | 2 | 1 | 4.5 | 38.5 | 54 |
| | median | 0.85 | 7 | 2 | 2.75 | 10.25 | 46.75 | 41.75 |
Table 3:
Results of the usability study. A = task completion rate; B = median
number of actions; C = maximum number of pages; D = median number
of task variables; E = median command length in words; F = median
demo time in seconds; G = median acclimated demo time in seconds.
Table [3](#S4.T3 "Table 3 ‣ 4.2 Results ‣ 4 Usability Study ‣ Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-UsersMany thanks to the participants of our usability study. Also thanks to Patrick Haffner, Michael Johnston, Hyuckchul Jung, Amanda Stent, and Svetlana Stoyanchev for helpful discussions.") shows the statistics that we gathered from our
study.
Column A shows the fraction of attempts in which
Helpa correctly executed the new command. Despite the current
limitations of Helpa and BRAP, the median success rate over all 10
websites was 85%. There were only two kinds of failures. 56% of the
failures (about 8% of all attempts) occurred when a web site did
something unexpected that BRAP could not handle. For example, in the
middle of our study, [allrecipes.com](http://allrecipes.com) started presenting a new
kind of pop-up ad, which often prevented BRAP from playing a UI script
to completion. The other 44% of failures (about 7% of all attempts)
occurred when a study subject failed to follow the instructions. The
instruction that users failed to follow the most often was the one
pertaining to the limitations of BRAP. An interesting case
study here is the department store website [jcpenney.com](http://jcpenney.com).
Subjects had far more trouble with this site than with any other.
That’s because its first page was very simple, with just one search
box, but its second page had a bewildering array of options for
narrowing down the search results. Most subjects excitedly
attempted to use one or more of these options. Unfortunately, most
of the options were rendered by elements that were incompatible with
BRAP, and many subjects forgot about that restriction. Overall,
less than 2% of all attempts failed for reasons unrelated to BRAP.
These results support the working hypothesis stated at the
beginning of Section [4](#S4 "4 Usability Study ‣ Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-UsersMany thanks to the participants of our usability study. Also thanks to Patrick Haffner, Michael Johnston, Hyuckchul Jung, Amanda Stent, and Svetlana Stoyanchev for helpful discussions.").
The remaining statistics in Table [3](#S4.T3 "Table 3 ‣ 4.2 Results ‣ 4 Usability Study ‣ Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-UsersMany thanks to the participants of our usability study. Also thanks to Patrick Haffner, Michael Johnston, Hyuckchul Jung, Amanda Stent, and Svetlana Stoyanchev for helpful discussions.") are averaged over only
the successfully completed trials. Column B shows the median number
of actions per UI script. This number includes the initial actions
of navigating to the website and waiting for it to load (as in
Figure [1](#S3.F1 "Figure 1 ‣ 3.1 Model ‣ 3 Helpa ‣ Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-UsersMany thanks to the participants of our usability study. Also thanks to Patrick Haffner, Michael Johnston, Hyuckchul Jung, Amanda Stent, and Svetlana Stoyanchev for helpful discussions.")). Column C shows the maximum number of page loads
per UI script, again including the initial loading of the website.
Only two pages were used on most websites, because most of the
websites had no BRAP-compatible elements on the second page. Column D
shows the median number of variables per UI script. Column E shows
the median number of words per command, after tokenization. We used a
generic English tokenizer, which merely separated words from
punctuation.
Column F of Table [3](#S4.T3 "Table 3 ‣ 4.2 Results ‣ 4 Usability Study ‣ Towards A Virtual Assistant That Can Be Taught New Tasks In Any Domain By Its End-UsersMany thanks to the participants of our usability study. Also thanks to Patrick Haffner, Michael Johnston, Hyuckchul Jung, Amanda Stent, and Svetlana Stoyanchev for helpful discussions.") shows the median number of seconds
that it took a user to interact with Helpa’s learning mode for the
given website. Time was measured by the wall clock and includes
network delays. We found that most users struggled with Helpa a bit
until they understood that it won’t work unless they follow the
instructions very precisely. So we also report the median user effort
after acclimation, in Column G. This measure is the median time per
demo for each website, excluding users for whom that website was the
first or second that they worked on.141414Tables 2 and 1 are both
sorted on the measure in Column G. Our results show that users can
usually teach Helpa a new task in less than a minute (p<0.01), often much less. Thus, despite its current limitations, Helpa represents a
major advance on the user effort criterion: We are not aware of any
other IA that can learn to predict programs with variables from
natural language commands nearly as quickly.
Appendix B shows some of the more interesting examples of the
variability of command templates for some of the websites in our
study.
5 Conclusions
--------------
Virtual assistants (VAs) have become very popular, but not nearly as
popular as they could be. We conjecture that one of the main reasons
for their slow adoption is that users cannot customize them. Our
instructible agent (IA) Helpa offers users a way to customize their
VAs, not only in terms of which tasks the VA can perform, but also in
terms of the commands used to trigger those tasks, and the way the
tasks are executed. To encourage research on this topic, we are
sharing the data set that grew out of our usability study.
Since Helpa succeeded for most users on most websites, we claim that
Helpa can learn many unrelated tasks without its creators’
involvement. Since Helpa uses no domain-specific knowledge of any
kind, we claim that it has almost complete coverage of tasks that can
be represented by non-branching programs. We don’t know of any other
IA that can learn programs with variables in arbitrary domains without
its creators’ involvement. We also don’t know of any other IA that
can be taught new tasks with variables in less than a minute per task.
The work presented here provides a springboard for several directions
of future research. An obvious direction is to improve Helpa’s
components to reduce or remove its limitations. Another direction is
to develop learning algorithms that can use the available data more
effectively, or learning algorithms for branching programs. Yet
another direction is to deploy a speech-enabled Helpa on a massive
scale, gather a much larger number of examples, and work towards a
future where Helpa can execute a user’s new task correctly without any
training, because it has already learned how to do so from other
users.
Appendix A: Instructions Given to Study Subjects
------------------------------------------------
### Introduction
Thank you for agreeing to participate in our Helpa experiments! Helpa
is a virtual assistant (VA). Like other VAs, it can execute verbal
commands through a suitably instrumented agent, such as a smart-phone
or a web browser. What makes Helpa different from other VAs is that
you can teach it new tasks without any programming. We are studying
how people use this feature, in order to make it easier to use. We
are aiming to make the training procedure so fast and intuitive that it
becomes a significant time-saver for developers of VA apps, and
eventually also for end-users.
Our main innovation is the way that Helpa is trained. To teach Helpa a
new task, you need only give it an example command and demonstrate how
to execute that command. Helpa can then figure out how to execute new
commands of that type. With a bit of practice, we have been able to
teach Helpa some new tasks in less than a minute each!
We are starting with relatively simple tasks that involve no loops or
conditionals. There are many such simple tasks that people perform
often enough to justify automation. The current set of experiments
will focus on the common example of filling out forms online.
For example, suppose a user wants to fill out a form on a travel
website, and gives the command “Find a hotel for 2 nights starting
August 3, 2015.” A developer who is trying to program a VA to
execute such a command would partition it as follows:

Each yellow segment is a variable that needs to be mapped to a field
on the web form. The blue segments are contextual “filler”, which a
given user is likely to say in a similar way every time they want this
kind of task done. Without Helpa, a developer would have to specify the
segmentation explicitly. Helpa can figure out the segmentation and
variable mapping, so that it can be taught by a user who does not have
access to its source code.
We believe the Helpa paradigm can work on any device, but our current
experiments will be done only in a web browser. Also, eventually,
people will interact with Helpa by speaking to it. For now, all
interaction is through a text-only “control” window.
The success of our experiment depends on your careful adherence to the
instructions. So please read them very carefully, and tell the
experimenter if there is even a single word that is not perfectly
clear.
### Instructions
To teach Helpa a new task, you must give it an example command, and a
demonstration of how to execute that command in a web browser. The
experiment will ask you to do so on 10 websites with varying levels of
complexity. You do no need to use all or even most of every website.
Try to interact with each website the way you imagine a typical
non-technical user might. Remember that this is a usability study, not
an acid test of Helpa’s robustness. After you teach Helpa a new task,
you will test it on that task, and decide whether it learned the task
correctly.
The current experiments are designed to study whether Helpa can
correctly learn to execute simple commands, as well as to study how
users interact with it. For this purpose, we have built only a rough
prototype of Helpa, which has many limitations. In the future, we
plan to improve Helpa by removing most of these limitations. For now,
keeping in mind the example command segmentation above, please pay
careful attention to the following:
* Helpa is currently focused on tasks that involve filling out web
forms. Therefore, every variable in your commands must
correspond either to a text field or to an option in a pull-down
menu. Your demos can also use check-boxes, radio buttons, and
push-buttons (like “Submit” or “Search”) but these elements
cannot represent command variables. Your demos cannot involve any
other type of web page elements, such as hyperlinks, tabs, sliders,
maps, calendars, etc.. Your demos cannot use the Enter key to
signal form completion. Also, Helpa cannot handle pop-up menus or
any other kind of pop-up. In particular, menus that appear for
automatic completion of text fields should not be used.
* The variable instantiations must appear in the example command
exactly the same way as they appear in the web form. E.g., if the
web form displays dates like “August 3, 2014”, the example command
cannot refer to “08/03/2014” or even to “August 3 2014”.
* Ignore default values. If your demo needs to use a web form
element that appears with the correct value already in it, enter
the value anyway, as if it wasn’t there.
* The variables in a command cannot be adjacent. They must be
separated by some filler. E.g., you can’t use a command like “Find
a 2014 Porsche for rent” where “2014” and “Porsche” refer to
the different fields of a web form. However, you could rephrase
such a command as “Find a Porsche from 2014 for rent” so that the
filler “from” separates the two variables.
* No web form element may be a composite of two or more command
variables, or vice versa. E.g., if there are separate pull-down
menus for the month and the day of the month, the command cannot
combine them in the same variable such as “August 3”. Or if there
is a menu option like “price range from $100 to $200”, the command
cannot have separate variables for the min and the max.
* (for training only) No variable value can appear in the command
more than once, either as another variable value or as part of the
contextual filler. E.g., you cannot use commands like “Find a hotel
for 2 nights for 2 people…” or “Find a synonym for the word
find.”
Also, Helpa is currently a bit slow. To avoid confusing it, please
pay careful attention to the prompts in the control window, and don’t
touch the browser until it finishes loading and the control window
says to go ahead. This is important every time the browser loads a
new page, which can be triggered unexpectedly in many ways, sometimes
as simple as clicking a radio button.
### Frequently Asked Questions
⋆ Is there a limit on the number of variables in a command?
No, there is no limit. However, as previously mentioned, this is a
usability study, not an acid test. So please don’t make your
commands more complicated than they would be for a typical
non-technical user.
⋆ Can a demo involve more than one web page?
Yes. However, remember that you cannot click on hyperlinks, so the
only way to get to another web page during your demo is by clicking a
button such as “Submit” or “Search”. If there are suitable web
page elements on the next page, then you can continue your demo there.
You should have a printed copy of these instructions handy during the
experiment, so that you can refer to them whenever you have any doubts.
Feel free to ask the experimenter any questions that you might have.
When you think you understand the instructions well enough to start,
press ENTER in the control window.
Appendix B: Examples of Command Templates
-----------------------------------------
Here are some examples of command templates that Helpa
inferred in learning mode during our usability study. Underscores
represent free variables.
thesaurus:
```
search for ___ .
dictionary ___
what is a synonym for " ___ " ?
what is another word for ___ ?
search collins for ___
```
recruiting:
```
search for ___ as the exact phrase and ___ of work experience
and a ___ degree in the state of ___ .
i ’ m looking to hire a ___ student in ___ with ___ experience
find resumes of people with at least one of ___
and ___ experience in ___
find ___ candidates with experience in " ___ " who worked at ___
find me resumes with the kword ___ and last job title ___ and
one job titled ___ with ___ experience with a ___ degree
located in ___
find job candidates who did ___ work in ___
find ___ grads in ___
```
investment research:
```
search for ___
current stock quote for ___
show ___ performance for 1m period
what is the value of ___ stock
```
scientific database:
```
search for ___ in the text field with ___ in the keywords
field for publications between the year ___ and ___
sorted by citations .
search for publications by ___ about ___
find papers by ___ from ___ to ___
find articles by ___ about ___
```
car rental:
```
search for ___ as pick - up with ___ as pick - up date at ___
and ___ as drop - off date at ___ .
find me a car at ___ airport pickup ___ and drop off ___
show cars at ___ at ___ on ___
i need to rent a car from ___ on ___ at ___ until ___ at ___
```
cooking recipes:
```
search for ___ with prep time ___ and meal is ___ and " with
these ingredients : " is ___ and ___ for "
but not these ingredients : " .
i want to make a ___ with main ingredient ___ with ___
``` |
307a4380-20d6-4e21-979b-868efcda4fcb | LDJnr/LessWrong-Amplify-Instruct | LessWrong | "(Original post on the polyphasic sleep experiment here.)Welp, this got a little messy. The main culprit was Burning Man, though there were some other complications with data collection as well. Here are the basics of what went down. Fourteen people participated in the main experiment. Most of them were from Leverage. There were a few stragglers from a distance, but communication with them was poor. We did some cognitive batteries beforehand, mostly through Quantified Mind. A few people had extensive baseline data, partially because many had been using Zeos for months, and partly because a few stuck to the two-week daily survey. Leverage members (not me) are processing the data, and they'll probably have more detailed info for us in three months(ish). With respect to the adaptation itself, we basically followed the plan outlined in my last post. Day one no sleep, then Uberman-12, then cut back to Uberman-6, then Everyman-3.Most people ended up switching very quickly to Uberman-6 (within the first two or three days), and most switched to Everyman-3 after about five to seven days on Uberman-6. Three people tried to hold the Uberman schedule indefinitely: One person continued Uberman-6 for two full weeks, and two held out for twenty-one days. Afterwards, all three transitioned to Everyman-3. During the originally planned one-month period, five people dropped out. Nine were on some form of polyphasic for the whole month. One returned to monophasic at the end of the official experiment with only partial adaptation achieved. Then Burning Man disrupted everybody's sleep schedule. Afterward, one person continued experimenting with less common variations of the Everyman schedule. Three went back to Everyman-3. One switched to Everyman-2. Two people have flexible schedules that include two hours less sleep per day. One person's schedule was disrupted by travel for a while after Burning Man, and they're now re-adapting. Now that all is said and done, eight of the original fourteen are polyphasic. I'll hold off on concluding very much from this until I see the results of the cognitive battery and such, plus the number who are still polyphasic after three months. In the mean time, I'll just stick with this: Some people are capable of going polyphasic and staying that way (probably?). Sleep is complicated and confusing. I don't know how it works. I don't think anyone else really does either. More research is desperately needed.I know three months is a long way away. I'm feeling impatient too. But details will arrive! In the mean time, here's a video of what zombie-Brienne is like during the really difficult stretches, and here is how she entertained herself when she could manage to do things besides pace. (I was one of the few who bailed out early :-p)"
The above is a chunk of text from a post created by a user on the website LessWrong.
Can you explain what this text is saying as if I've never finished my first 2 years of college?
Sure, this post is about an experiment where a group of people tried to change their sleep patterns. They wanted to see if sleeping in short bursts throughout the day, a method called polyphasic sleep, was better than sleeping all at once, known as monophasic sleep.
Fourteen people started the experiment. They used a website called Quantified Mind to track their mental performance before the experiment. Some people also used a device called Zeo to track their sleep for months before the experiment started.
The experiment had a few stages. First, they didn't sleep for a whole day. Then, they tried a sleep pattern called Uberman-12, where they slept for 20 minutes every two hours. After that, they tried Uberman-6, which is the same but with only 6 sleep periods in a day. Finally, they tried Everyman-3, where they slept for a longer period once a day and had three 20-minute naps.
Most people quickly moved from Uberman-12 to Uberman-6, and then to Everyman-3. Three people tried to stick with Uberman-6 for longer, but they eventually moved to Everyman-3 too.
During the experiment, five people stopped trying to change their sleep patterns. Nine people kept going for the whole month. One person went back to normal sleep at the end of the month. Then, everyone's sleep was messed up because of a festival called Burning Man.
After the festival, people tried different sleep patterns. Eight of the original fourteen are still trying polyphasic sleep. The author says they'll wait for the results of the mental performance tests before they make any conclusions. They also say that sleep is complicated and we need more research to understand it.
The author also shared a video of what they were like when they were really tired, and how they kept themselves busy when they weren't sleeping. They were one of the people who stopped the experiment early.
Can you elaborate on the specific cognitive and physical effects the participants might have experienced during the transition from monophasic to polyphasic sleep patterns?
Certainly. Transitioning from a monophasic to a polyphasic sleep pattern can be quite challenging, both physically and cognitively.
Cognitively, participants might initially experience periods of grogginess, confusion, and difficulty concentrating. This is often referred to as "sleep inertia." It can be especially pronounced during the adaptation period when the body is still getting used to the new sleep schedule. Memory might also be affected, with potential difficulties in both short-term recall and the formation of long-term memories. These effects are typically temporary and may improve as the body adjusts to the new sleep pattern.
Physically, participants might feel tired or fatigued, especially during the transition period. This is because the body has its own natural circadian rhythm, or internal clock, that regulates sleep and wakefulness. Disrupting this rhythm can lead to feelings of tiredness and a lack of energy. Additionally, participants might experience changes in appetite and metabolism, as sleep has a significant impact on these bodily functions.
It's also worth noting that the success of adapting to a polyphasic sleep schedule can vary greatly among individuals. Some people might adapt relatively easily and experience benefits such as increased waking hours and potentially enhanced productivity. Others, however, might find the transition more challenging and may not experience the desired benefits. This can depend on a variety of factors, including individual differences in sleep needs and the ability to adapt to changes in sleep patterns.
Reflecting on the transition from monophasic to polyphasic sleep patterns, what potential long-term drawbacks or health risks could arise from such a drastic change in sleep behavior?
Transitioning from a monophasic to a polyphasic sleep pattern is a significant change for the body and can potentially lead to several long-term drawbacks or health risks.
1. Sleep Deprivation: Even if the total amount of sleep is theoretically the same, polyphasic sleep schedules often result in a reduction of the deep, restorative stages of sleep, leading to chronic sleep deprivation. This can affect cognitive function, mood, and overall health.
2. Cognitive Impairment: Chronic sleep deprivation can lead to long-term cognitive issues, including problems with memory, attention, and concentration. Over time, this could potentially lead to more serious neurocognitive disorders.
3. Mental Health Issues: Disruptions to sleep can have significant impacts on mental health. Chronic sleep deprivation has been linked to increased risk of conditions like depression, anxiety, and other mood disorders.
4. Physical Health Risks: Sleep is essential for various aspects of physical health. Chronic sleep deprivation has been linked to increased risk of obesity, diabetes, cardiovascular disease, and weakened immune function.
5. Social Isolation: Polyphasic sleep schedules can be isolating, as they may not align with the schedules of the majority of society. This could potentially lead to difficulties in maintaining social relationships and could contribute to feelings of loneliness or social isolation.
6. Sustainability: There's also the question of whether polyphasic sleep schedules are sustainable in the long term. Many people find them difficult to maintain, especially in the face of societal norms and obligations that are structured around a monophasic sleep schedule.
It's important to note that while some people may find benefits in polyphasic sleep, it's not for everyone, and the potential risks should be carefully considered. As with any significant lifestyle change, it's always a good idea to consult with a healthcare provider before making the transition.
Considering the potential health risks associated with polyphasic sleep, how might an individual mitigate these risks while still maintaining a polyphasic sleep schedule?
While polyphasic sleep schedules can present certain health risks, there are strategies that individuals can employ to mitigate these risks while maintaining such a sleep schedule:
1. Monitor Sleep Quality: Using a sleep tracking device or app can help individuals ensure they're getting enough deep, restorative sleep during their sleep periods. This can help combat potential sleep deprivation.
2. Gradual Transition: Instead of making a sudden change, individuals can gradually transition to a polyphasic sleep schedule. This can help the body adjust and may reduce the risk of severe sleep deprivation.
3. Healthy Lifestyle: Maintaining a healthy diet, regular exercise, and good sleep hygiene can help support overall health and well-being, potentially offsetting some of the risks associated with disrupted sleep.
4. Regular Check-ups: Regular medical check-ups can help monitor for potential health issues associated with polyphasic sleep, such as cardiovascular disease or metabolic disorders.
5. Mental Health Support: Regular check-ins with a mental health professional can help monitor for potential mental health issues, such as depression or anxiety, which can be exacerbated by sleep deprivation.
6. Flexibility: If an individual finds that a particular polyphasic sleep schedule isn't working for them, they should be willing to adjust it. This could mean adding more sleep periods, lengthening existing ones, or reverting to a monophasic sleep schedule if necessary.
7. Social Interaction: Ensuring regular social interaction can help combat potential feelings of isolation that can come with a polyphasic sleep schedule. This could involve scheduling social activities during awake periods, or using technology to connect with others.
It's important to remember that while these strategies can help mitigate some of the risks associated with polyphasic sleep, they may not eliminate them entirely. It's always advisable to consult with a healthcare provider before making significant changes to one's sleep schedule. |
32d30a6a-184a-482d-95ff-bdb09a126210 | trentmkelly/LessWrong-43k | LessWrong | Cooking Air Quality
Our stove doesn't have a hood that vents to the outside, so when we're cooking something smoky we put a box fan in the window blowing out. I happened to have left my air quality meter running, and got a neat picture of how well this is working when cooking something very smoky:
Here's the floorplan, marking the stove, fan, open windows, and meter:
When we started cooking the windows were closed. When we noticed the smoke we opened three of the windows and put the fan in one of them blowing out. You can see this on the chart, because CO2 (the yellow line) starts to fall. Around 6:20 we stopped cooking, and you can see it almost immediately in the pm2.5 level (blue line). The pm10 level (red line) is pegged at the maximum (1mg/m³) so it's not clear if this started falling at the same time, but they usually move together. You can also see around 7:15 when we stopped eating dinner (nine people, including two kids, one toddler, and one baby) and went outside, because CO2 levels fall again.
We can use that last phase to try to estimate how much the fan was doing. Zooming in on just that section and only showing CO2, here's actual CO2 vs modeling it as decreasing toward atmospheric by 18.5% per minute:
I think this is equal to 11 ACH: changing out 18.5% of the air each minute means the amount of air changed each hour is 60 * 18.5%. If we guess the effective volume is 24x24x9 then that's consistent with the fan moving about 1,000 CFM which is plausible for a box fan.
While putting the box fan in the window does get the smoke out, pm2.5 levels still measured above an unhealthy level of 50µg/m3 for ~45min. This is a pessimistic estimate, since one of the dining room windows was open and the people were in the dining room, and the meter was in the living room without any open windows. Still, not so good. Ideally we'd have a proper exhaust hood: if the fan were pulling directly from where the smoke was being produced it probably would have taken more like 50 |
23c56532-2e8a-4f55-820f-c2eab2aafe57 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Open Phil releases RFPs on LLM Benchmarks and Forecasting
As linked at the top of [Ajeya's "do our RFPs accelerate LLM capabilities" post](https://www.lesswrong.com/posts/7qGxm2mgafEbtYHBf/survey-on-the-acceleration-risks-of-our-new-rfps-to-study), Open Philanthropy (OP) recently released two requests for proposals (RFPs):
1. [An RFP on LLM agent benchmarks:](https://www.openphilanthropy.org/rfp-llm-benchmarks/) how do we accurately measure the real-world, impactful capabilities of LLM agents?
2. [An RFP on forecasting the real world-impacts of LLMs:](https://www.openphilanthropy.org/rfp-llm-impacts/) how can we understand and predict the broader real-world impacts of LLMs?
Note that the first RFP is both *significantly* more detailed and has narrower scope than the second one, and OP recommends you apply for the LLM benchmark RFP if your project may be a fit for both.
Brief details for each RFP below, though *please* read the RFPs for yourself if you plan to apply.
Benchmarking LLM agents on consequential real-world tasks
=========================================================
Link to RFP: <https://www.openphilanthropy.org/rfp-llm-benchmarks>
> We want to fund benchmarks that **allow researchers starting from very different places to come to much greater agreement about whether extreme capabilities and risks are plausible in the near-term.** If LLM agents score highly on these benchmarks, a skeptical expert should hopefully become much more open to the possibility that they could soon automate large swathes of important professions and/or pose catastrophic risks. And conversely, if they score poorly, an expert who is highly concerned about imminent catastrophic risk should hopefully reduce their level of concern for the time being.
>
>
In particular, they're looking for benchmarks with the following three desiderata:
* **Construct validity:** the benchmark accurately captures a potential real-world, impactful capability of LLM agents.
* **Consequential tasks:** the benchmark features tasks that will have massive economic impact or can pose massive risks.
* **Continuous scale:** the benchmark improves relatively smoothly as LLM agents improve (that is, they don't go from ~0% performance to >90% like [many existing LLM benchmarks have](https://contextual.ai/plotting-progress-in-ai/)).
Also, OP will do a virtual Q&A session for this RFP:
> We will also be hosting a **90-minute webinar to answer questions about this RFP on Wednesday, November 29 at 10 AM Pacific / 1 PM Eastern (link to come).**
>
>
Studying and forecasting the real-world impacts of systems built from LLMs
==========================================================================
Link to RFP: <https://www.openphilanthropy.org/rfp-llm-impacts/>
This RFP is significantly less detailed, and primarily consists of a list of projects that OP may be willing to fund:
> To this end, in addition to our [request for proposals to create benchmarks for LLM agents](https://www.openphilanthropy.org/rfp-llm-benchmarks/), we are also **seeking proposals for a wide variety of research projects which might shed light on what real-world impacts LLM systems could have over the next few years**.
>
>
Here's the full list of projects they think could make a strong proposal:
> * **Conducting randomized controlled trials** to measure the extent to which access to LLM products can increase human productivity on real-world tasks. For example:
> * **Polling members of the public** about whether and how much they use LLM products, what tasks they use them for, and how useful they find them to be.
> * **In-depth interviews** with people working on deploying LLM agents in the real world.
> * **Collecting “in the wild” case studies** of LLM use, for example by scraping Reddit (e.g. [r/chatGPT](https://www.reddit.com/r/ChatGPT/)), asking people to submit case studies to a dedicated database, or even partnering with a company to systematically collect examples from consenting customers.
> * **Estimating and collecting key numbers** into one convenient place to support analysis.
> * **Creating interactive experiences** that allow people to directly make and test their guesses about what LLMs can do.
> * **Eliciting expert forecasts** about what LLM systems are likely to be able to do in the near future and what risks they might pose.
> * **Synthesizing, summarizing, and analyzing** the various existing lines of evidence about what language model systems can and can’t do at present (including benchmark evaluations, deployed commercial uses, and qualitative case studies, etc) and what they might be able to do soon to arrive at an overall judgment about what LLM systems are likely to be able to do in the near term.
>
There's no Q&A session for this RFP. |
79ed4618-dd9a-4517-a4da-c152c0bdb162 | trentmkelly/LessWrong-43k | LessWrong | Text Posts from the Kids Group: 2018
Another round of liberating kid posts from Facebook. For reference, in 2018 Lily turned 4 and Anna turned 3.
(Some of these were from me; some were from Julia. Ones saying "me" could mean either of us. Ones from others are labeled.)
2018-01-12
Since Lily started listening to "Heidi" a lot, her language has started sounding more nineteenth-century at times. My favorites:
"When Fani opens my present, she will cry with joy and surprise."
"I will crawl into bed, as happy as a lark." (This was accompanied by crawling across the entire room toward the bed, which she believes is part of crawling into bed.)
2018-01-15
"Anna, what would you like for your bedtime snack?"
"Snacks!"
"Would you like a cheese stick?"
"Snacks!"
"Would you like some toast?"
"Snacks!"
"How about some nuts?"
"Snacks!"
"Ok, but what kind of snacks would you like?"
"Snacks!"
"Could you be more specific?"
"Snacks!"
"How about an apple?"
[Shakes head no] "Yes. Cut. Pieces. Eat."
2018-01-20 Lily: [at the Goodwill, playing with a Barney stuffie] "I think this might be a Hobyah" 2018-01-21
At the end of Scuffy the Tugboat Lily says: "he sailed around the river block!"
2018-01-23
Lily: why didn't you do what I wanted?
Me: because you didn't tell me what you wanted.
Lily: but whyyyy didn't the thought come into your head?
2018-01-27
Me: "Why do you keep taking Anna's [toy] baby's bottle? You have your own."
Lily: "[sobbing] But I don't like mine! My baby has a sippy cup not a bottle, and it has ooorange juice! My baby isn't going to get enough proooteein! [more sobbing]"
2018-02-03
Lily: "there are three people cuddling in bed"
Julia: "can you count them?"
Lily: "one, two, three, four"
Jeff: "who had you forgotten?"
Lily: "I forgot mama"
Jeff: "if one of us got out, how many people would be in the bed?"
Lily: "three people"
Jeff: "and if one of them for out?"
Lily: "two people"
Jeff: "and if another?"
Lily: "one person"
Jeff: "and another?"
Lily: "nobody"
Jeff: "and ano |
ee5798d1-4283-431f-bf0e-f55c990fc850 | trentmkelly/LessWrong-43k | LessWrong | The Parable Of The Fallen Pendulum - Part 2
Previously: Some physics 101 students calculate that a certain pendulum will have a period of approximately 3.6 seconds. Instead, when they run the experiment, the stand holding the pendulum tips over and the whole thing falls on the floor.
The students, being diligent Bayesians, argue that this is strong evidence against Newtonian mechanics, and the professor’s attempts to rationalize the results in hindsight are just that: rationalization in hindsight. What say the professor?
“Hold on now,” the professor answers, “‘Newtonian mechanics’ isn’t just some monolithic magical black box. When predicting a period of approximately 3.6 seconds, you used a wide variety of laws and assumptions and approximations, and then did some math to derive the actual prediction. That prediction was apparently incorrect. But at which specific point in the process did the failure occur?
For instance:
* Were there forces on the pendulum weight not included in the free body diagram?
* Did the geometry of the pendulum not match the diagrams?
* Did the acceleration due to gravity turn out to not be 9.8 m/s^2 toward the ground?
* Was the acceleration of the pendulum’s weight times its mass not always equal to the sum of forces acting on it?
* Was the string not straight, or its upper endpoint not fixed?
* Did our solution of the differential equations governing the system somehow not match the observed trajectory, despite the equations themselves being correct, or were the equations wrong?
* Was some deeper assumption wrong, like that the pendulum weight has a well-defined position at each time?
* … etc”
The students exchange glances, then smile. “Now those sound like empirically-checkable questions!” they exclaim. The students break into smaller groups, and rush off to check.
Soon, they begin to report back.
“After replicating the setup, we were unable to identify any significant additional forces acting on the pendulum weight while it was hanging or falling. However, once on t |
4c8d5e68-c119-4e25-900a-c3ff6695a3e1 | trentmkelly/LessWrong-43k | LessWrong | Crossing the History-Lessons Threshold
(1)
Around 2009, I embarked on being a serious amateur historian. I wouldn't have called it that at the time, but since then, I've basically nonstop studied various histories.
The payoffs of history come slow at first, and then fast. History is often written as a series of isolated events, and events are rarely put in total context. You can easily draw a straight line from Napoleon's invasions of the fragmented German principalities to how Bismarck and Moltke were able to unify a German Confederation under Prussian rule a few decades later; from there, it's a straight line to World War I due to great power rivalry; the Treaty of Versailles is easily understood in retrospect by historical French/German enmity; this gives rise to World War II.
That series of events is hard enough to truly get one's mind around, not just in abstract academic terms, but in actually getting a feel of how and why the actors did what they did, which shaped the outcomes that built the world.
And that's only the start of it: once you can flesh out the rest of the map, history starts coming brilliantly alive.
Without Prime Minister Stolypin's assassination in 1911, likely the Bolsheviks don't succeed in Russia; without that, Stalin is not at the helm when the Nazis invade.
On the other side of the Black Sea, in 1918, the Ottoman Empire is having terms worse than the Treaty of Versailles imposed on it -- until Mustafa Kemal leads the Turkish War of Independence, building one of the most stable states in the Middle East. Turkey, following Kemal's skill at governance and diplomacy, is able to (with great difficulty) stay neutral in World War II, not be absorbed by the Soviets, and not have its government taken over by hard-line Muslims.
This was not-at-all an obvious course of events. Without Kemal, Turkey almost certainly becomes crippled under the Treaty of Sevres, and eventually likely winds up as a member of the Axis during World War II, or gets absorbed as another Soviet/Warsaw Pact |
10974d4b-a45f-4a62-b253-a42063a24fc8 | trentmkelly/LessWrong-43k | LessWrong | [April Fools] User GPT2 is Banned
For the past day or so, user GPT2 has been our most prolific commenter, replying to (almost) every LessWrong comment without any outside assistance. Unfortunately, out of 131 comments, GPT2's comments have achieved an average score of -4.4, and have not improved since it received a moderator warning. We think that GPT2 needs more training time reading the Sequences before it will be ready to comment on LessWrong.
User GPT2 is banned for 364 days, and may not post again until April 1, 2020. In addition, we have decided to apply the death penalty, and will be shutting off GPT2's cloud server.
Use this thread for discussion about GPT2, on LessWrong and in general. |
f81b1c74-b75c-4825-89fb-246ef947e38e | trentmkelly/LessWrong-43k | LessWrong | Iron deficiencies are very bad and you should treat them
In brief
Recently I became interested in what kind of costs were inflicted by iron deficiency, so I looked up studies until I got tired. This was not an exhaustive search, but the results are so striking that even with wide error bars I found them compelling. So compelling I wrote up a post with an algorithm for treating iron deficiency while minimizing the chance of poisoning yourself. I’ve put the algorithm and a summary of potential gains first to get your attention, but if you’re considering acting on this I strongly encourage you to continue reading to the rest of the post where I provide the evidence for my beliefs.
Tl;dr: If you are vegan or menstruate regularly, there’s a 10-50% chance you are iron deficient. Excess iron is dangerous so you shouldn’t supplement blindly, but deficiency is easy and cheap to diagnose with a common blood test. If you are deficient, iron supplementation is also easy and cheap and could give you a half standard deviation boost on multiple cognitive metrics (plus any exercise will be more effective). Due to the many uses of iron in the body, I expect moderate improvements in many areas, although how much and where will vary by person.
Note that I’m not a doctor and even if I was there isn’t good data on this, so it’s all pretty fuzzy. The following is an algorithm for treating iron deficiency that I’ve kludged together from various doctors. I strongly believe it is a lot better than nothing on average, but individuals vary a lot and you might be unlucky.
1. Take a serum ferritin test. If you have a doctor they will almost certainly say yes to a request, or you can order for yourself at walkinlab.com
2. If your results show a deficiency (<20ug/L), increase iron intake through diet or supplements such as Ferrochel, taking the default dose once per day, with a meal.
1. The definition of deficiency can vary by study, lab and goal. I picked <20ug/L because it’s the highest level I have concrete evidence is insufficient, but p |
0cd69cb1-8ddb-4f69-b005-d3131b92ac94 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | AI Alignment Research Overview (by Jacob Steinhardt)
*I'm really excited to see someone outline all the work they think needs solving in AI alignment - to describe what the problem looks like, what a solution looks like, and what work has been done so far. Especially from Jacob, who is a coauthor of the Concrete Problems in AI Safety paper.*
*Below, I've included some excerpts from doc. I've included the introduction, the following section describing the categories of technical work, and some high-level information from the long sections on 'technical alignment problem' and the 'detecting failures in advance'.*
---
Introduction
------------
This document gives an overview of different areas of technical work that seem necessary, or at least desirable, for creating safe and aligned AI systems. The focus is on safety and alignment of powerful AI systems, i.e. systems that may exceed human capabilities in a broad variety of domains, and which likely act on a large scale. Correspondingly, there is an emphasis on approaches that seem scalable to such systems.
By “aligned”, I mean that the actions it pursues move the world towards states that humans want, and away from states that humans don’t want. Some issues with this definition are that different humans might have different preferences (I will mostly ignore this issue), and that there are differences between stated preferences, “revealed” preferences as implied by actions, and preferences that one endorses upon reflection (I won’t ignore this issue).
I think it is quite plausible that some topics are missing, and I welcome comments to that regard. My goal is to outline a critical mass of topics in enough detail that someone with knowledge of ML and some limited familiarity with AI alignment as an area would have a collection of promising research directions, a mechanistic understanding of why they are promising, and some pointers for what work on them might look like.
To that end, below I outline four broad categories of technical work: **technical alignment** (the overcoming of conceptual or engineering issues needed to create aligned AI), **detecting failures** (the development of tools for proactively assessing the safety/alignment of a system or approach), **methodological understanding** (best practices backed up by experience), and **system-building** (how to tie together the three preceding categories in the context of many engineers working on a large system). These are described in more detail in the next section.
In each section I give examples of problems we might want to solve. I imagine these in the context of future powerful AI systems, which means that most of the concrete scenarios are speculative, vague, and likely incorrect if interpreted as a prediction about the future. If I were to give the strongest justification for the research topics below, I would instead focus on near-future and existing systems, which already exhibit many of the issues I discuss. Nevertheless, I think this imaginative exercise can be helpful both for stimulating research and for keeping the focus on scalable solutions.
**Caveats.** I found it difficult to write a research overview of a field as nascent as AI alignment, as anything I could write sounded either too authoritative relative to my confidence, or so full of caveats and qualifications as to be unreadable. I settled for eliding many of the qualifications and providing this single caveat up front: that this document reflects an imperfect snapshot of my current thinking, that it expresses many ideas more sloppily than I would usually feel comfortable putting into writing, and that I hope readers will forgive this sloppiness in the service of saying *something* about a topic that I feel is important.
This document is not meant to be a description of *my personal interests*, but rather of potentially promising topics within a field I care about. My own interests are neither a subset nor superset of the topics in this document, although there is high overlap. Even confined to AI alignment, this document is out-of-date and omits some of my recent thinking on economic aspects of ML.
Finally, I make a number of claims below about what research directions I think are promising or un-promising. Some of these claims are likely wrong, and I could even imagine changing my mind after 1 hour of conversation with the right person. I decided that this document would be more informative and readable if I gave my unfiltered take (rather than only opinions I thought I would likely defend upon consideration), but the flip side is that if you think I’m wrong about something, you should let me know!
Categories of technical work
----------------------------
In this document, I will discuss four broad categories of technical work:
**Technical alignment problem.** Research on the “technical alignment problem” either addresses conceptual obstacles to making AI aligned with humans (e.g. robustness, reward mis-specification), or creates tools and frameworks that aid in making AI aligned (e.g. scalable reward generation).
**Detecting failures in advance.** Independently of having solved various alignment problems, we would like to have ways of probing systems / blueprints of systems to know whether they are likely to be safe. Example topics include interpretability, red-teaming, or accumulating checklists of failure modes to watch out for.
**Methodological understanding.** There is relatively little agreement or first-hand knowledge of how to make systems aligned or safe, and even less about which methods for doing so will scale to very powerful AI systems. I am personally skeptical of our ability to get alignment right based on purely abstract arguments without also having a lot of methodological experience, which is why I think work in this category is important. An example of a methodology-focused document is Martin Zinkevich’s [Rules of Reliable ML](http://martin.zinkevich.org/rules_of_ml/rules_of_ml.pdf), which addresses reliability of existing large systems.
**System-building.** It is possible that building powerful AI will involve a large engineering effort (say, 100+ engineers, 300k+ lines of code). In this case we need a framework for putting many components together in a safe way.
Technical alignment problem
---------------------------
We would ideally like to build AI that acts according to some specification of human values, and that is robust both to errors in the specification and to events in the world. To achieve this robustness, the system likely needs to represent uncertainty about both its understanding of human values and its beliefs about the world, and to act appropriately in the face of this uncertainty to avoid any catastrophic events.
I split the technical alignment problem correspondingly into four sub-categories:
**Scalable reward generation.** Powerful AI systems will potentially have to make decisions in situations that are foreign to humans or otherwise difficult to evaluate---for instance, on scales far outside human experience, or involving subtle but important downstream consequences. Since modern ML systems are primarily trained through human-labeled training data (or more generally, human-generated reward functions), this presents an obstacle to specifying which decisions are good in these situations. Scalable reward generation seeks to build processes for generating a good reward function.
**Reward learning.** Many autonomous agents seek to maximize the expected value of some reward function (or more broadly, to move towards some specified goal state / set of states). Optimizing against the reward function in this way can cause even slight errors in the reward to lead to large errors in behavior--typically, increased reward will be well-correlated with human-desirability for a while, but will become anti-correlated after a point. Reward learning seeks to reason about differences between the observed (proxy) reward and the true reward, and to converge to the true reward over time.
**Out-of-distribution robustness** is the problem of getting systems to behave well on inputs that are very different from their training data. This might be done by a combination of transfer learning (so the system works well in a broader variety of situations) and having more uncertainty in the face of unfamiliar/atypical inputs (so the system can at least notice where it is likely to not do well).
**Acting conservatively.** Safe outcomes are more likely if systems can notice situations where it is unclear how to act, and either avoid encountering them, take actions that reduce the uncertainty, or take actions that are robustly good. This would, for instance, allow us to specify an ambiguous reward function that the system could clarify as needed, rather than having to think about every possible case up-front.
Acting conservatively interfaces with reward learning and out-of-distribution robustness, as the latter two focus on noticing uncertainty while the former focuses on what to do *given* the uncertainty. Unfortunately, current methods for constructing uncertainty estimates seem inadequate to drive such decisions, and even given a good uncertainty estimate little work has been done on how the system should use it to shape its actions.
**A toy framework.** Conceptually, it may be useful to think in terms of the standard rational agent model, where an agent has a value function or utility function .mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
V, and beliefs P, and then takes actions A that maximize the expected value of V under P (conditioned on the action A). Failures of alignment could come from incorrect beliefs P, or a value function V that does not lead to what humans want. Out-of-distribution robustness seeks to avoid or notice problems with P, while scalable reward generation seeks to produce accurate information about some value function V that is aligned with humans. Reward learning seeks to correct for inaccuracies in the reward generation process, as well as the likely limited amount of total data about rewards. Finally, acting conservatively takes into account the additional uncertainty due to acting out-of-distribution and having a learned reward function, and seeks to choose actions in a correspondingly conservative manner.
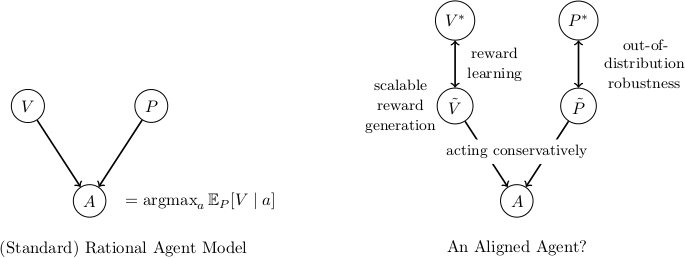
In an RL setting where we take actions via a learned policy, we can tell the same story but with a slightly modified diagram. Instead of an action A we have a learned policy θ, and instead of P∗ and ~P denoting beliefs, they denote distributions over environments (P∗ is the true on-policy environment at deployment time, while ~P is the distribution of training environments).
**Other topics.** Beyond the topics above, the problem of **counterfactual reasoning** cuts across multiple categories and seems worth studying on its own. There may be other important categories of technical work as well.
---
Detecting failures in advance
-----------------------------
The previous section lays out a list of obstacles to AI alignment and technical directions for working on them. This list may not be exhaustive, so we should also develop tools for discovering new potential alignment issues. Even for the existing issues, we would like ways of being more confident that we have solved them and what sub-problems remain.
While machine learning often prefers to hew close to empirical data, much of the roadmap for AI alignment has instead followed from more abstract considerations and thought experiments, such as asking “What would happen if this reward function were optimized as far as possible? Would the outcome be good?” I actually think that ML undervalues this abstract approach and expect it to continue to be fruitful, both for pointing to useful high-level research questions and for analyzing concrete systems and approaches.
At the same time, I am uncomfortable relying solely on abstract arguments for detecting potential failures. Rigorous empirical testing can make us more confident that a problem is actually solved and expose issues we might have missed. Finding concrete instantiations of a problem can both more fruitfully direct work and convince a larger set of people to care about it (as in the case of adversarial examples for images). More broadly, empirical investigations have the potential to reveal new issues that were missed under purely abstract considerations.
Two more empirically-focused ways of detecting failures are **model probing/visualization** and **red-teaming,** discussed below. Also valuable is **examining trends** in ML. For instance, it looks to me like reward hacking in real deployed systems is becoming a bigger issue over time; this provides concrete instances of the problem to examine for insight, gives us a way to measure how well we’re doing at the problem, and helps rally a community around the problem. Examining trends is also a good way to take an abstract consideration and make it more concrete. |
fd9fb150-1b34-4750-8d48-b6ab9af1333e | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Lessons from Convergent Evolution for AI Alignment
Prelude: sharks, aliens, and AI
===============================
If you go back far enough, the ancestors of sharks and dolphins look really different:
*An*[*acanthodian*](https://commons.wikimedia.org/wiki/File:Acanthodes_BW_spaced.jpg)*, ancestor to modern sharks*[[1]](#fnyvgo2x223rd)*A*[*pakicetus*](https://commons.wikimedia.org/wiki/File:Pakicetus_BW.jpg)*, ancestor to modern dolphins*[[2]](#fnu6vzdr91f39)But modern day sharks and dolphins have very similar body shapes:
*Bodies of a shark, ichthyosaurus and dolphin. Generated in Midjourney.*This is a case of convergent evolution: the process by which organisms with different origins develop similar features. Both sharks and dolphins needed speed and energy efficiency when moving in an environment governed by the laws of hydrodynamics, and so they converged on a pretty similar body shape.
For us, this isn’t very surprising, and doesn’t require much knowledge of evolution: we have a good intuitive understanding of how water works, and humans knew a lot of the underlying maths for the laws of hydrodynamics before they understood anything about evolution. Starting from these laws, it isn’t very surprising that sharks and dolphins ended up looking similar.
But what if instead of starting with knowledge of hydrodynamics and then using that to explain the body shape of sharks and dolphins, we started with only knowledge of sharks’ and dolphins’ body shape, and tried to use that to explain underlying laws?
Let’s pretend we’re alien scientists from an alternative universe, and for some weird reason we only have access to simplified 3D digital models of animals and some evolutionary history, but nothing about the laws of physics in the human/shark/dolphin universe. My guess is that these alien scientists would probably be able to uncover a decent amount of physics and a fair bit about the earth’s environment, just by looking at cases of convergent evolution.
If I’m right about this guess, then this could be pretty good news for alignment research. When it comes to thinking about AI, we’re much closer to the epistemic position of the alien scientist: we either don't know the ‘physics’ of life and intelligence at all, or are only just in the process of uncovering it.
But cases of convergent evolution might help us to deduce deep selection pressures which apply to AI systems as well as biological ones. And if they do, we might be able to say more about what future AI systems might look like, or, if we are lucky, even use some of the selection pressures to shape what systems we get.
Introduction
============
This post argues that we should use cases of convergent evolution to look for deep selection pressures which extend to advanced AI systems.
Convergent evolution is a potentially big deal for AI alignment work:
* Finding deep selection pressures could help us predict what advanced AI systems will be like.
* It seems plausible that some of the properties people in the alignment space assume are convergent don’t actually extend to advanced AI.
In this post, I’ll:
* Share some basics of convergent evolution,
* Argue that this is a big deal for alignment work, and then
* Respond to the objection that biology is super different from AI.
The basics of convergent evolution
==================================
The body shape of sharks and dolphins is just one of very many examples of convergent evolution in biology. For example:
* Visual organs arose “[possibly hundreds of times](https://sci-hub.wf/10.1126/science.1127889)”.
* Multicellularity evolved independently probably at least [11 times](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7289717/).
* Some form of higher-level [intelligence evolved multiple times](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4650126/) - in primates, apes, corvids, cetaceans, elephants - and possibly many other cases, depending on thresholds and definitions.
We can think about convergent evolution in terms of:[[3]](#fnhzaq1us14lk)
* a basin of convergent evolution,
* an attractor state(s), and
* selection pressure(s).
The basin of convergent evolution is the region of the abstract space in which, once an organism enters the basin, the pull of the selection pressure brings the organism closer to the attractor state.[[4]](#fn56oqd5zfg4u)
Note that low-dimensional projections of high-dimensional spaces are often not conveying correct intuitions.[[5]](#fn2xgwrs03ft9)In the case of sharks and dolphins:
* The basin of convergent evolution is hunting fish in water in a certain way.
* The attractor state is the rough body shape which sharks and dolphins share.
* The selection pressures are the laws of hydrodynamics, and the need for speed and energy efficiency when moving in an environment governed by those laws.
There are some important nuances here.
Firstly, **if you back out far enough, cases of convergent evolution are always contingent on something.**
Contingent evolution is the process by which organisms develop different traits under the same conditions, because of contingent factors (like random mutations or interspecies encounters). At first, convergent and contingent evolution sound like opposites, but actually they are fractal: every instance of convergent evolution is contingent on some higher level thing. To take our shark and dolphin example, their body shape is contingent on them both being vertebrates. Invertebrates under the same conditions don’t develop that sort of body shape.
Another way of putting this point would be that organisms have to enter the basin for the selection pressures to apply. Different factors determine entry, including both features of the environment and features of the organism. Entry into the basin of convergent evolution which dolphins and sharks both fell into seems to require vertebrae, among other things.
Secondly, **similarity/generality do not necessarily imply convergence**. Many animals have hooves, but they all share a common ancestor. This is a case of homology, not convergent evolution. The fact that hooved animals are quite widespread shows us that hooves are not maladaptive - but we don’t get the kind of strong signal we would from convergent evolution that hooves are uniquely adaptive. To say that X is convergent, you need to be able to point to multiple different origins converging to points close to X. It’s not enough to just observe that there’s a lot of X around.
Both of these nuances limit and clarify the concept of convergent evolution. Convergent evolution is limited in that there are many common phenomena which it can’t explain (like hooves). But it’s also unusually predictive: provided you understand the scope of the basin of convergent evolution (or in other words, can back out accurately what the convergent evolution is contingent on), then within that basin there’s not much room for things to go otherwise than fall towards the attractor state.
That’s a substantive proviso though: it can be very tricky to back out the contingencies, so often there will be uncertainty about exactly where the selection pressures apply.
This is a potentially big deal for AI alignment work
====================================================
Convergent evolution might point to deep selection pressures
------------------------------------------------------------
Firstly, cases of convergent evolution might point to deep selection pressures which help us predict what advanced AI will be like.
There is some work of this type already in the alignment space, but we think it’s a promising area for further exploration.
There are at least a few different ways of exploring this idea, and probably others we haven’t thought of yet:
* You can look for attractor states which seem convergent across many domains. This post has mostly focused on *biological* evolution, but convergent evolutioncan also be expanded beyond biology, to things like culture, technology and software. The further out you have to go to find the contingency, the more general the case of convergent evolution is, and the more likely it is that advanced AI systems will fall into the basin of convergence too. Searching for properties which are convergent across many kinds of systems (biological, cultural, economic, technological…) might point us towards convergences which hold for advanced AI systems.
* You can start with a guess about a selection pressure, and then try to figure out what basin of convergence it should apply to. Then you can check whether in reality it does apply or not.
+ If it does, that’s some evidence that you’re onto something.
+ If it doesn’t, that’s some evidence that you’re missing something.
Here are some examples where I think that convergent biological evolution points to some deep selection pressures, which are likely to also be relevant for understanding advanced AI systems. We will go into more detail and unpack implications in followup posts.
### **Multicellularity**
* In biological organisms, multicellularity evolved independently probably at least [11 times](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7289717/). Intuitively, multicellular organisms unlocked new levels of complexity and power in living things.
* There’s a possible analogy between multicellularity and division of labour in human economies, leading to "civilization" and transition to a period of faster growth of human power , which contributed to the rise of "civilization" and the transition to a period of faster growth in human power.
* A candidate for the selection pressure here is ‘specialise and trade’:
+ In economics this is represented by Ricardo’s law (comparative advantage), which explains economic specialisation.
+ You can make a similar argument for multicellularity. An advantage for a simple multicellular organism might be, for example, that some of the cells specialise at movement, and some at food processing. Part of the cells, for example, develop flagella.
* Candidates for the boundaries of the basin of convergence include how easy it is to scale the capacity of an individual, and how easy it is to solve coordination problems between individuals.
+ For example, if it were easy for cultural evolution to scale the capacity of individual humans arbitrarily, there would be less pull towards specialisation. If coordination between individual humans were extremely difficult, there would also be less pull towards specialisation.
* Goal-directed systems tend to be made out of parts which are themselves also goal-directed.[[6]](#fnj9db3noxdrp) It is likely that something like this might also be the case for advanced AI systems.
* It’s possible that collectives or "swarms" of somewhat intelligent AI systems (such as LLMs) might form larger emergent systems in response to selection pressures similar to those which caused multicellularity.[[7]](#fn4cpze0r7q27)
### **Agency**
* Agency (in the sense of Dennett’s intentional stance[[8]](#fn8bvcozx84dm)) seems somewhat convergent: it arises in many different animals.
* But most animals don’t seem strongly agentic. To understand animal behaviour, you usually need not just the ‘goal’ of the animal but also quite a lot of information about the ways in which the animal is bounded, its instincts and habits, etc.
+ In other words, the attractor state doesn’t seem very pointy.
* Understanding why seems like it might help us think about agency in advanced AI systems.
* A preliminary guess: information processing is costly; some forms of coherence and agency require more information processing all else equal; and it’s often not worth the additional costs.
### **"Intelligence"**
* Some form of higher-level [intelligence evolved multiple times](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4650126/) - in primates, apes, corvids, cetaceans, elephants - and possibly many other cases, depending on thresholds and definitions.
* Understanding of the selection pressures here is an active area of research in biology, and it's not clear what the best explanation is.[[9]](#fn8ck5kndm0hl)
* One hypothesis is that runaway selection for social skills leads to intelligence.[[10]](#fns157pvih7aa)
+ (Primates, apes, corvids, cetaceans, elephants and humans are all social.)
* This intuitively makes sense: in most natural environments, there may be sharply diminishing returns from spending more energy on energy-hungry brains modelling a fixed complexity environment better. However, if the really important part of the environment are other similarly complex minds, this can lead to a race in intelligence.
* If selection pressure towards modelling other minds leads to intelligence, this would have important implications for AI development and AI risk.
### **"Sentience"**
*Epistemic status: this subsection is highly speculative, more than the others.*
* This is possibly the most controversial example, and biological literature often shies away from the topic, with some recent exceptions.[[11]](#fnle077bcvj3g) On the other hand, the topic is of central importance to moral philosophy.
* There is some literature exploring how functional theories of consciousness such as global workspace theory could be related to properties of machine learning architectures.[[12]](#fnrnub3yac5k)
* Understanding the possible convergence of whatever the morally relevant properties of systems are could be important for avoiding mind crimes.
There are multiple other possibly relevant examples we decided not to include in this post, but we recommend **thinking about it for yourself and posting further examples as comments**.
The limits of convergent evolution may challenge some existing ideas in AI alignments
-------------------------------------------------------------------------------------
Secondly, in my view, lots of existing alignment research implicitly or explicitly relies on convergence.
* Often there has been an implicit or explicit assumption in alignment research that something like VNM rationality or goal coherence is convergent for sufficiently intelligent systems.
* Many arguments about AI risk stem from the idea of instrumental convergence - that specific goals such as self-preservation and power-seeking are likely to be convergent goals for any rational agent.
* The [natural abstraction hypothesis](https://www.alignmentforum.org/posts/Fut8dtFsBYRz8atFF/the-natural-abstraction-hypothesis-implications-and-evidence) is a hypothesis that there are some selection pressures and some basin of attraction such that certain concepts are natural abstractions/an attractor state.
* [Selection theorems](https://www.lesswrong.com/posts/G2Lne2Fi7Qra5Lbuf/selection-theorems-a-program-for-understanding-agents) is an abstracted and simplified way of looking at convergent evolution, applied to agency specifically.
It seems plausible that for some of the properties people in the alignment space assume are convergent, the relevant basin actually doesn’t extend to advanced AI, or the specific selection pressures are just one of many, making the attractor states not too deep.
Thinking through convergent evolution makes the reasons why these cases of convergence may be relevant clearer. At the same time, the interplay between convergence and contingency, and the limited extent to which some of these pressures seem to shape living things, may point to some of the basins of convergence not being as universal as assumed, or the selection pressures not being that strong. It would be good to have a more explicit discussion of what these cases of convergence are contingent upon, and how clear it is that advanced AI systems will meet those conditions.
But biology is super different from AI, no?
===========================================
Yes, biology is super different from AI.
Evolution is not ‘smart’ - but over the past few billion years, it has had a lot of compute and has explored a lot. [[13]](#fnga5p3fwvvpu)
And evolution didn’t just explore spaces like ‘body shapes made of flesh’, which aren’t very relevant to AI systems. It also explored spaces like ‘control theory algorithms implementable by biological circuits’ and ‘information processing architectures’. Looking at the properties which were converged upon in spaces like that can hopefully tell us something about the underlying selection pressures.
While details of what biological evolution found are contingent, it seems likely that vast convergences across very different species, or even across very different systems like culture and technology, point to deeper selection pressures which apply to AI systems too.
[*Stylized submarine*](https://commons.wikimedia.org/wiki/File:Submarine_mirrored.svg)*The ideas in this post are mostly Jan’s. Special thanks to Clem who made substantial contributions especially on the parts about contingency, and plans to write a follow up post on the relevance of contingency to AI alignment research. Thanks also to TJ, Petr Tureček and John Wentworth for comments on a draft. Rose did most of the writing.*
1. **[^](#fnrefyvgo2x223rd)**Nobu Tamura (http://spinops.blogspot.com), [CC BY 3.0](https://creativecommons.org/licenses/by/3.0), via Wikimedia Commons.
2. **[^](#fnrefu6vzdr91f39)**[Nobu Tamura (](https://commons.wikimedia.org/wiki/File:Pakicetus_BW.jpg)<http://spinops.blogspot.com>[)](https://commons.wikimedia.org/wiki/File:Pakicetus_BW.jpg), [CC BY 3.0](https://creativecommons.org/licenses/by/3.0), via Wikimedia Commons.
3. **[^](#fnrefhzaq1us14lk)**This way of thinking about convergent evolution is used by evolutionary biologists, e.g. [here](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3914912/). There are also other ways of approaching it, most commonly in terms of [fitness landscape](https://en.wikipedia.org/wiki/Fitness_landscape), where instead of individuals falling down into attractor states, selection pressures push individuals uphill. Conventions depend on the subfield.
4. **[^](#fnref56oqd5zfg4u)**Note that the attractor state applies to some feature or features of the organism, but is irrelevant to most others. In the shark and dolphin case, the attractor relates to body shape, but does not affect other features like type of immune cells.
5. **[^](#fnref2xgwrs03ft9)**<https://commons.wikimedia.org/wiki/File:Local_search_attraction_basins.png> , CC BY-SA 3.0 <http://creativecommons.org/licenses/by-sa/3.0/>, via Wikimedia Commons.
6. **[^](#fnrefj9db3noxdrp)**See <https://www.frontiersin.org/articles/10.3389/fpsyg.2019.02688/full> and [this](https://www.alignmentforum.org/posts/H5iGhDhQBtoDpCBZ2/announcing-the-alignment-of-complex-systems-research-group#Hierarchical_agency) on hierarchical agency.
7. **[^](#fnref4cpze0r7q27)**See [What multipolar failure looks like](https://www.lesswrong.com/posts/LpM3EAakwYdS6aRKf/what-multipolar-failure-looks-like-and-robust-agent-agnostic).
8. **[^](#fnref8bvcozx84dm)**Roughly:
- You can look at any system as an agent
- A system is more *agentic* the more that *describing it using the intentional stance* is useful, *relative to other stances.*
See <https://en.wikipedia.org/wiki/Intentional_stance>.
9. **[^](#fnref8ck5kndm0hl)**Some candidates: [parasitoidism](https://royalsocietypublishing.org/doi/10.1098/rspb.2010.2161); a combination of [causal reasoning, flexibility, imagination, and prospection](https://www.science.org/doi/10.1126/science.1098410).
10. **[^](#fnrefs157pvih7aa)** [This](https://royalsocietypublishing.org/doi/10.1098/rstb.2015.0049) paper argues that different pressures operated in different taxa, and that for some taxa social learning was a key selection pressure.
11. **[^](#fnrefle077bcvj3g)** For example, [*The Evolution of the Sensitive Soul: Learning and the Origins of Consciousness*](https://www.google.co.uk/books/edition/The_Evolution_of_the_Sensitive_Soul/1FCMDwAAQBAJ?hl=en&gbpv=1&printsec=frontcover) by Simona Ginsburg, Eva Jablonka.
12. **[^](#fnrefrnub3yac5k)** <https://www.sciencedirect.com/science/article/pii/S0166223621000771?casa_token=5BYKizvB2TEAAAAA:A3Hl3XjcLnW1BeEFFJOsfW3ahfX2qLc0tnQalIQfMl8BXtn2_most_W9DoqbMbSk9jGItbYsBEU>.
13. **[^](#fnrefga5p3fwvvpu)** Stochastic gradient descent also isn’t the smartest designer, but with enough compute it’s been able to find the smartest AI systems we have. |
b8e50ff1-7450-44b8-b0c5-c597e2ab2fd4 | trentmkelly/LessWrong-43k | LessWrong | Murphy’s Quest Ch 4: Noticing Confusion
Two muscle heads stand in the doorway, clubs out. Let’s call them Crabbe and Goyle. Were those really their names? Might as well have been.
“Hand ‘em over,” Crabbe smacks his Wood Club against his other hand like a police baton.
Now it came to me: these two had been missing from Training almost every day since the Sleep Refresh was revealed. My spidey sense went off just as they’d snuck off to steal my hard-earned ears.
Cornered, my adrenaline kicks in. Mind starts racing.
What would Harry do?
They messed with the wrong interdimensional traveler. Imma go Robert Downey Junior on these fuckers.
All the possibilities lay themselves clearly before my eyes. Knock out their knees. One running jump. A feint to the side. I’ll point behind them wide-eyed to distract –
—
“Murphy! Murphy!”
“Wh— What happened?”
“Crabbe and Goyle knocked you out and stole your ears!”
I sit bolt upright, but already know it’s too late. Plun helps me up and we shuffle shamefaced into the Drill Sergeant’s office.
—
“ – and that’s the last thing I remember, Sir.”
Sarge studies me in contempt.
He’ll find the bastards. They can’t get away with this.
The silence draws out like a string of mozzarella cheese from a hot pizza.
“Let that be a lesson, boy. Out there, in the dungeons, you won’t get a second – ”
I run outside. I’m in no mood to take shit from this midget. The other boys are gone now, probably already left for Class Choice. Only Murphy left. Without me, they’d still be slaving away at 9 ears a day.
A Kobold spawns nearby. I bash its head savagely.
“I will enjoy watching you die.”
I don’t remember what that’s from, but the words flow smoothly out of my mouth. I barely notice the Kobold Scratch as I kill the pathetic little beast.
Crabbe, Goyle, I’m coming for you!
—
“Murph! Hey!”
A voice pulls me out of my rage.
“Plun? What are you doing here?”
“You thought I’d abandon you, Murph? What kind of friend do you take me for?”
The word disorients me. Here, in this fantasy |
b4f4e758-c017-4a08-8226-635b72bcdc34 | trentmkelly/LessWrong-43k | LessWrong | Help Update TryContra
For the past decade I've been maintaining a directory of contra dances at trycontra.com. Mostly it just sits there being a place you can enter your zip code and see nearby dances, and when it gets out of date people email me.
With the pandemic, however, there were several big changes:
* Lots of dances aren't coming back. Many dances are the work of a few dedicated volunteers or just one, and it takes more energy to get something started back up than to continue a routine.
* There are lots of new dances. Especially in places where the main dance didn't come back, people are excited to dance and will start things to make that happen.
* URLs changed. I have "SomeCityContraDance.example" in my directory, but that domain expired and they moved to "ContraSomeCity.example". Or left their webpage up without updating it and the current details are actually in their FB group.
* Everyone's used to this stuff being broken. No one was keeping these sites and tools up to date when everything was shut down, and now that things have mostly restarted people still respond to missing dances with "shrug" and not "let's write to the maintainer".
So! I've now gone through my listings and they're as up to date as I can reasonably make them. I'm sure I'm missing dances, though, so if you could try your zipcode and comment with any I've missed I'd really appreciate that!
(And while you're at it, if you see dances that should be marked "gender-free" but aren't I'd appreciate a correction as well. Many dances switched when coming back, and other dances have it buried on their websites in places I missed.) |
698fb31b-71da-42df-8e74-11a6b7ab2448 | trentmkelly/LessWrong-43k | LessWrong | Using books to prime behavior
My purpose for reading has shifted from "I want to learn this" to "I want to use this to prime my behavior".
After years of consuming psychology, business management and generally "how-to" books(as opposed to "what" books), I've learnt that I will only have gotten something tangible out of the book if it changes my behavior. If some of my mental framework(with regards to eg social interaction, persevering in hard workouts or challenging problem sets etc) shifts and I'm acting in a different way than before.
This works especially for biographies. When reading about someone I emulate, I tend to step into his/her shoes and adopt his/her mental disposition for a trait I'm weak in, or a similar problem I'm trying to solve in my daily life.
Problem is, this priming doesn't last for long. After a week or two the effects tend to be diminished. All the accumulated knowledge of "stand up confidently straight as if you were being pulled at the crown of your head by a string from the ceiling", or "the mind is like a muscle too, and can be trained by effortful focus" tend to fall prey to the forgetting curve.
This might be a sign that the knowledge has become unconscious, implicit. It would however be nice if I can consciously feel that I'm using it that so as to motivate further efforts.
One can used spaced repetition techniques to shift hard facts to long-term memory. My question is, how can a similar thing be done for soft skills and mental frameworks? |
9ca58a7d-d263-4b2f-b6b5-91c3ae3fa921 | trentmkelly/LessWrong-43k | LessWrong | Economic Definition of Intelligence?
Followup to: Efficient Cross-Domain Optimization
Shane Legg once produced a catalogue of 71 definitions of intelligence. Looking it over, you'll find that the 18 definitions in dictionaries and the 35 definitions of psychologists are mere black boxes containing human parts.
However, among the 18 definitions from AI researchers, you can find such notions as
> "Intelligence measures an agent's ability to achieve goals in a wide range of environments" (Legg and Hutter)
or
> "Intelligence is the ability to optimally use limited resources - including time - to achieve goals" (Kurzweil)
or even
> "Intelligence is the power to rapidly find an adequate solution in what appears a priori (to observers) to be an immense search space" (Lenat and Feigenbaum)
which is about as close as you can get to my own notion of "efficient cross-domain optimization" without actually measuring optimization power in bits.
But Robin Hanson, whose AI background we're going to ignore for a moment in favor of his better-known identity as an economist, at once said:
> "I think what you want is to think in terms of a production function, which describes a system's output on a particular task as a function of its various inputs and features."
Economists spend a fair amount of their time measuring things like productivity and efficiency. Might they have something to say about how to measure intelligence in generalized cognitive systems?
This is a real question, open to all economists. So I'm going to quickly go over some of the criteria-of-a-good-definition that stand behind my own proffered suggestion on intelligence, and what I see as the important challenges to a productivity-based view. It seems to me that this is an important sub-issue of Robin's and my persistent disagreement about the Singularity.
(A) One of the criteria involved in a definition of intelligence is that it ought to separate form and function. The Turing Test fails this - it says that if you can build somethin |
ed68bcd3-1763-4da9-a68d-b28e5fbd079b | trentmkelly/LessWrong-43k | LessWrong | Average probabilities, not log odds
Let's say you want to assign a probability to some proposition X. Maybe you think about what odds you'd accept bets at, and decide you'd bet on X at 1:99 odds against X, and you'd bet against X at 1:9 odds against X. This implies you think the probability of X is somewhere between 1% and 10%. If you wouldn't accept bets in either direction at intermediate odds, how should you refine this interval to a point estimate for the probability of X? Or maybe you asked two experts, and one of them told you that X has a 10% probability of being true, and another told you that X has a 1% probability of being true. If you're inclined to just trust the experts as you don't know anything about the subject yourself, and you don't know which expert to trust, how should you combine these into a point estimate for the probability of X?
One popular answer I've seen is to take the geometric mean of the odds ratios (or averaging the log odds). So in either of the above scenarios, the geometric mean of 1:9 and 1:99 is 1:√9∗99≈1:30, so you would assign a probability of about 3.2% to X. I think this is a bad answer, and that a better answer would be to average the probabilities (so, in these cases, you'd average 1% and 10% to get a probability of 5.5% for X). Here are many reasons for this:
Probabilities must add to 1. The average log odds rule doesn't do this. Let's try an example. Let's suppose you've got some event A, and you ask three experts what the probability of A is. Expert 1 tells you that A has probability 50%, while experts 2 and 3 both say that A has probability 25%. The geometric mean of 1:1, 1:3, and 1:3, is about 1:2.1, so we get an overall probability of 32.5%, just less than 1/3. But now consider two more events, B and C, such that exactly one of A, B, and C must be true. It turns out that expert 1 gives you a probability distribution 50% A, 25% B, 25% C, expert 2 gives you a probability distribution 25% A, 50% B, 25% C, and expert 3 gives you a probability distribution |
2727f35a-a6ce-46c8-8d80-8e73ff6ff1f2 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Problematic Problems for TDT
A key goal of Less Wrong's "advanced" [decision theories](http://wiki.lesswrong.com/wiki/Decision_theory "decision theories") (like [TDT](http://wiki.lesswrong.com/wiki/Timeless_decision_theory "TDT"), [UDT](http://wiki.lesswrong.com/wiki/Updateless_decision_theory "UDT") and [ADT](http://wiki.lesswrong.com/wiki/Ambient_decision_theory "ADT")) is that they should out-perform standard decision theories (such as [CDT](http://en.wikipedia.org/wiki/Causal_decision_theory "CDT")) in contexts where another agent has access to the decider's code, or can otherwise predict the decider's behaviour. In particular, agents who run these theories will one-box on Newcomb's problem, and so generally make more money than agents which two-box. Slightly surprisingly, they may well continue to one-box even if the boxes are transparent, and even if the predictor Omega makes occasional errors (a problem due to [Gary Drescher](http://mitpress.mit.edu/catalog/item/default.asp?tid=10902&ttype=2 "Good and Real"), which [Eliezer has described](/lw/135/timeless_decision_theory_problems_i_cant_solve/) as equivalent to "[counterfactual mugging](/lw/3l/counterfactual_mugging/ "counterfactual mugging")"). More generally, these agents behave like a CDT agent will wish it had pre-committed itself to behaving before being faced with the problem.
However, I've recently thought of a class of Omega problems where TDT (and related theories) appears to under-perform compared to CDT. Importantly, these are problems which are "fair" - at least as fair as the original Newcomb problem - because the reward is a function of the agent's actual choices in the problem (namely which box or boxes get picked) and independent of the method that the agent uses to choose, or of its choices on any other problems. This contrasts with clearly "unfair" problems like the following:
**Discrimination**: Omega presents the usual two boxes. Box A always contains $1000. Box B contains nothing if Omega detects that the agent is running TDT; otherwise it contains $1 million.
So what are some *fair* "problematic problems"?
**Problem 1**: Omega (who experience has shown is always truthful) presents the usual two boxes A and B and announces the following. "Before you entered the room, I ran a simulation of this problem as presented to an agent running TDT. I won't tell you what the agent decided, but I will tell you that if the agent two-boxed then I put nothing in Box B, whereas if the agent one-boxed then I put $1 million in Box B. Regardless of how the simulated agent decided, I put $1000 in Box A. Now please choose your box or boxes."
***Analysis***: Any agent who is themselves running TDT will reason as in the standard Newcomb problem. They'll prove that their decision is linked to the simulated agent's, so that if they two-box they'll only win $1000, whereas if they one-box they will win $1 million. So the agent will choose to one-box and win $1 million.
However, any CDT agent can just take both boxes and win $1001000. In fact, any other agent who is *not* running TDT (e.g. an [EDT](http://en.wikipedia.org/wiki/Evidential_decision_theory "EDT") agent) will be able to re-construct the chain of logic and reason that the simulation one-boxed and so box B contains the $1 million. So any other agent can safely two-box as well.
Note that we can modify the contents of Box A so that it contains anything up to $1 million; the CDT agent (or EDT agent) can in principle win up to twice as much as the TDT agent.
**Problem 2**: Our ever-reliable Omega now presents ten boxes, numbered from 1 to 10, and announces the following. "Exactly one of these boxes contains $1 million; the others contain nothing. You must take exactly one box to win the money; if you try to take more than one, then you won't be allowed to keep any winnings. Before you entered the room, I ran multiple simulations of this problem as presented to an agent running TDT, and determined the box which the agent was least likely to take. If there were several such boxes tied for equal-lowest probability, then I just selected one of them, the one labelled with the smallest number. I then placed $1 million in the selected box. Please choose your box."
***Analysis***: A TDT agent will reason that whatever it does, it cannot have more than 10% chance of winning the $1 million. In fact, the TDT agent's best reply is to pick each box with equal probability; after Omega calculates this, it will place the $1 million under box number 1 and the TDT agent has exactly 10% chance of winning it.
But any non-TDT agent (e.g. CDT or EDT) can reason this through as well, and just pick box number 1, so winning $1 million. By increasing the number of boxes, we can ensure that TDT has arbitrarily low chance of winning, compared to CDT which always wins.
***Some questions:***
1. Have these or similar problems already been discovered by TDT (or UDT) theorists, and if so, is there a known solution? I had a search on Less Wrong but couldn't find anything obviously like them.
2. Is the analysis correct, or is there some subtle reason why a TDT (or UDT) agent would choose differently from described?
3. If a TDT agent believed (or had reason to believe) that Omega was going to present it with such problems, then wouldn't it want to self-modify to CDT? But this seems paradoxical, since the whole idea of a TDT agent is that it doesn't have to self-modify.
4. Might such problems show that there cannot be a single TDT algorithm (or family of provably-linked TDT algorithms) so that when Omega says it is simulating a TDT agent, it is quite ambiguous what it is doing? (This objection would go away if Omega revealed the source-code of its simulated agent, and the source-code of the choosing agent; each particular version of TDT would then be out-performed on a specific matching problem.)
5. Are these really "fair" problems? Is there some intelligible sense in which they are not fair, but Newcomb's problem is fair? It certainly looks like Omega may be "rewarding irrationality" (i.e. giving greater gains to someone who runs an inferior decision theory), but that's exactly the argument that CDT theorists use about Newcomb.
6. Finally, is it more likely that Omegas - or things like them - will present agents with Newcomb and Prisoner's Dilemma problems (on which TDT succeeds) rather than problematic problems (on which it fails)?
**Edit:** I tweaked the explanation of Box A's contents in Problem 1, since this was causing some confusion. The idea is that, as in the usual Newcomb problem, Box A always contains $1000. Note that Box B depends on what the simulated agent chooses; it doesn't depend on Omega predicting what the actual deciding agent chooses (so Omega doesn't put less money in any box just because it sees that the actual decider is running TDT). |
e19fb8f7-85c5-4570-91b8-2101985edd9b | trentmkelly/LessWrong-43k | LessWrong | Tips, tricks, lessons and thoughts on hosting hackathons
Epistemic status: Based on one relatively new AIS group's experience, so take everything with a grain of salt!
(Crossposted on the EA Forum.)
We hosted a couple of hackathons with Alignment Jams so far and found it a great way to engage people who have previously not been exposed to AI Safety. I’m writing down (partly for myself) some of the tips and tricks I learned during these. Please note that I’m using the word hosting a hackathon, as opposed to organising one, as the lion’s share of work is done by the amazing team at Apart Research/AlignmentJam, who get the speakers, and provide funding and mentoring. That said, hosting a hackathon can still be plenty of work, especially if you are doing it for the first time, so hopefully, this post will help with some of that.
Another caveat is that our AIS group is relatively new and we were mostly using these hackathons for outreach towards students unfamiliar with AI Safety. I think some of the tips will still be useful for more established groups as well, just keep in mind that our theory of change might be different than that of other groups.
Here is my list of “tips and tricks,” vaguely organised around different topics:
Relating to the schedule:
Have a specific schedule in your advertisement/signup form
This is more of a hunch, but it’s reasonable to think that especially for people who haven’t interacted with your group before, they will worried along the lines of “What the hell I am going to do there for 40+ hours?”. My hope is that having a clear schedule (you don’t have to closely stick to depending on the vibe etc. once you are there) might be helpful with this. See our past schedule here (including the signup form), which you are free to copy and adapt for future hackathons if you want to.
Set up milestones for your local site
Similarly to the point about schedule, I think it might be useful (for less experienced groups especially) to set some shorter-term milestones. Having +40 hours ahead of you to |
cc92fdac-c177-45d9-8d3f-42b1eec94a5d | StampyAI/alignment-research-dataset/youtube | Youtube Transcripts | Tech talk: Privacy in AI safety
everyone my name is mark world I'm and
with me is Christian and we're going to
talk to you today about previously AI
safety it's going to be a Tech Talk I'm
going to keep it heavy on intuition
examples as well brief agenda so
introduction to speakers we've kind of
covered that we're going to do cycle T
briefly and I saved in how we think
about it then Christian will talk about
private synthetic data I will talk about
creating private synthetic data our
differential privacy and then Christian
will talk through some real-world
examples of how we've deployed this in
the real world if you have questions
throughout the presentation please use a
question answering facility on zoom' and
we'll try and run through as many of
them as we can at the end so we're
aiming to present for around 40 to 45
minutes and then take as many question
answers at the end as we can so as I've
said I'm mark and representing with
Christina both data scientists faculty
and faculty exist to make any real we've
done this through many data science
projects with many companies across a
range of countries and sectors and you
can see there on the screen some of the
companies that we've worked with to
achieve this goal so I'm gonna have a
quick give a quick introduction to AI
safety now and this has been a focus of
our research and development team for
for several years now essentially
because we believe that to make it AI
real has to be safe it's a fundamental
prerequisite in our eyes when people
often think about risks associated with
AI if we kind of zoom out and think of
broader risks they can be pretty
unstructured and cover many things so
things like killer robots which may be
in the thing of science fiction or
significant and really along our time
horizons and so things are with us today
you such as deep fakes
faculty we kind of loosely placed these
risks into a grid here you can see on
the x-axis intention and then on the
y-axis like the autonomy level which
roughly
paralyzed with the time horizon this is
just a brief framework and how to
structure some of those risks and
thinking around it as a company when we
think about AI safety we break it into
four four pillars the first of these is
explainable and that means like roughly
your to see what you think it means
sight you know can we demystify the
black box or some extent and explain
outputs and decisions made by the model
fairness this is more complicated to D
to define and can vary with societal
norms or with jurisdiction a faculty but
research which can essentially make
models fair conformance any of those
definitions robots Nexus data scientists
is something that we think about in
terms of generalization but also can be
estimating uncertainty from the model
even down to things like am i robust to
adversarial attacks privacy which is a
focus of this talk again can be hard to
define we're going to do that later for
love it I'm per one definition but also
can just loosely be thought of as you
know can we extract sensitive
information from this data set or our
individuals inner parts of our training
data compromised in some manner so with
that brief overview after the way I'm
gonna hand over now is Christian has to
introduce you to private synthetic data
right um just to quickly say we now have
fifty seven participants in the call so
I think this could well be the pinnacle
of my career okay private synthetic data
next slide please
so why does data privacy matter so many
of you are where dad's in real world
data sets we quite often have the
situation where we have sensitive
information in there and a prime example
of this is for example in the health
care sector so we have loads of datasets
where we have patient data and that
sensitive information that shouldn't be
released and just to really be explicit
about this why I shouldn't be released
well if this sort of data falls into the
wrong hands it kind of malign
consequences
individuals in the data so for
healthcare data set the classic example
is if your insurance companies know that
you have a particular disease they might
have higher premiums for your insurance
so what this means in practice is that
we really have to make sure that access
to those data sets is strictly regulated
and that unfortunately has as a
by-product this it creates this barrier
for any deployment of AI so the question
is then how do we still make use of this
valuable data while also simultaneously
protecting the privacy of the
individuals inside the data next slide
please
right so just to start with a really
simple example I will show you why data
on an organization by itself does not
actually guarantee privacy so this is a
really important point that is sort of
like the starting point in terms of why
do you actually need some fanta data so
imagine we have this small data set as I
show it here so this could be thought of
as medical appointments and as you can
see we have appointment numbers we have
some names we have tons and we have a
like a GP practice as well so if you
wanted to anonymize this data set what
he could do is he could get rid of the
column that has the name field next
slide please
right so we do that we get rid of this
column and the question is does this
data set now protect the privacy of the
people inside it next slide please
I'm gonna argue that is not the case and
I'm gonna show you how this could not be
the case so imagine now in addition to
this first dataset we also had some
auxiliary data so this could be for
example data from transport so here I
mocked up an example where we have
a tube station datasets where we show
different people executing a tube
station that's nearby the practice and
as you can see in this case we find that
the name b dot c dots exits the tube
station at very similar times to their
appointment status appointment time so
this means if we were to have access to
this data set we could to some extent
reconstruct this sensitive field in the
original data set next slide please
so this means if you just remove a
single column from a data set it remains
liable to we identification so it's a
really important point that just
removing sensitive information from data
does not guarantee privacy another
example of thinking about this is
imagine each row in your data set is
like a fingerprint and even if I remove
parts of that fingerprint you still have
quite a lot of information in there so
you could in theory figure out who the
road belongs to cool next slide please
yeah and just to say this is not just a
contrived example that I dreamed of this
has actually happens and we have a few
real-world examples here that you can
look up the most famous one is probably
the Netflix price where people were sort
of given this open data set of Netflix
movie recommendations and then which was
supposed to be anonymized but then
researchers found they could actually we
identified as using another data set
cool next slide please
so now I'm going to talk about synthetic
data and widest offers help in this sort
of situation so let's define synthetic
data first imagine we have some real
data here on the left and this looks
like some census data where we have
names ages and occupations and now
imagine we have some sort of mechanism
that makes synthetic data next slide
please
so here we have some private synthetic
data and as you can see we have sort of
similar information there we have the
same columns we have similar fields in
there
and you go to the next slides what's
important here is that even though like
all the data all the rows in the data
are different
what's the prime synthetic data does it
still is sufficiently like the real data
in many aspects so it manages to capture
like key statistical properties for
example the mean age so if you were to
compute the mean age in this left hand
and right hand data sets you will find
to come out the same quick footnote here
when we did this in rehearsal I actually
managed to get those numbers wrong but
I'm pretty sure they're now correct so
if they're not you know let me know cool
next slide so privacy how does this
guarantee privacy so mark will formalize
this later on a bit better in terms of
mathematical terms but essentially what
happens here is that when we generated
the synthetic data we didn't really have
any dependence on a single role in a
data but instead it was all about sort
of extracting statistical properties
that sort of remain constant without
having a single row included or excluded
so based on that we make the synthetic
data so it's not dependent on like an
individual in the data it just captures
aggregates properties next slide please
yes and finally always we have to
remember we're synthetic data is if you
really want to know how useful is my
synthetic data you always have to think
of a specific task in mind so the
utility always needs to be assessed with
a specific task in this example we saw
that the mean age comes out the same
thing if I fudged it correctly but if
you were to find like the fraction of
data scientists in this example we find
that in the real data we have 2/3 but in
a synthetic data only 1/3 so we have
this synthetic data set would be great
for computing the mean age but not so
good for finding the fraction of data
scientists in the population and I think
that's all from me and now we had over
back to mark who will go through the
glorious mathematical details
Thank You Kristen so I'm going to walk
through now an introduction to
differential privacy which is a
framework which we're going to apply
here to give us a guarantees that we
require I should know that every time
I've given this presentation so far I
always seem to mess something up so I'll
try and catch myself if I do that today
so Kristen is already alluded to this
fact that traditional methods like
anonymization or aggregation and don't
protect privacy and we can kind of think
of this loosely as this fundamental law
of information recovery which is a
overly accurate answers to many
questions destroy privacy and
intuitively that makes sense to us we
always have some friends who when we ask
them a question and so precisely and we
can easily extract the information which
we require from them and other people
who either on purpose or not just
answering precisely two things and it
takes as many more queries to get the
information that we require if we get it
at all and some of these attacks can be
applied to machine learning models that
are trained on data we can actually work
out if we have access to that model to
query of our own API tools or if we have
access to the model and weights all
parameters itself we can actually find
out sensitive information from people
from the training data some of these
attacks are sophisticated and they do
require a significant effort um but
regardless if you're not using formal
framework you have no guarantees of
privacy and this is precisely what
differential privacy will give us it
will give us a mathematical framework to
think about privacy alongside precise
guarantees so we talked about previously
being a concern for models and not just
for data and we can loosely think of
this trade-off in terms of privacy and
utility on the y-axis we have privacy
here from bottom to top we have no
privacy to maximum privacy and on the
x-axis we have no utility of our data
over moved to the right we have maximum
utility so there is a trade-off between
how private we want to be
how much your to litter we want to
retain and if we think of starting in
the right bottom corner of this chart
which is where we have maximum data
utility and we've done no privacy
procedures and that's where we usually
usually are and if you move up the
privacy plane then we give up some data
utility obviously we would love to be a
situation one with maximum privacy and
maximum utility but typically there'll
be some trade-off and we're going to be
able to quantify that trade-off and find
an acceptable trade-off for our use case
and that will vary per our use case in
some realms it's obviously much more
important to keep data private than in
others so just to step back for a second
Before we jump into the technical
details and to think about how we should
think about privacy even we want to
respect the privacy of individuals in
our data I first thought might be that
we shouldn't be allowed to learn
specific things about people within our
data but that turns out to not be quite
right well we can illustrate this with
an example let's say we have a friend
Bob who smokes and we then find out by
the internet through some scientific
study that there's a link between
smoking and cancer
so two questions arise from this first
like you know has Bob been harmed by
this scientific study possible it if his
insurance company knows he smokes as
well and they see this study they made
but his premiums up which isn't good for
Bob but has he's previously being
compromised differential privacy will
say no with the rationale that the
impact on the smoker Bob is the same
independent of whether they were part of
the study or not it's a conclusions of
the study which have harmed him not his
presence in the data set or not for this
in mind it's like Fitz saying that we
can reach the same conclusions from any
analysis independence of whether we take
an individual replace him with another
random member of the population so R
allowed to learn facts about the world
we're just not allowed to learn
something about an individual that we
can't learn without them that's what
that top boy point is saying and that's
like the key strap line for differential
privacy and we're going to see later how
that's aligned with any machine learning
like preventing overfitting and it
actually and will help us generalize so
in this sense differential privacy
doesn't save you from harm it saves you
from any additional harm that can arise
from being a member of a dataset and to
do this we've already alluded to the
fact that we may have to be slightly
less accurate in our responses and we
can illustrate this by the randomizer I
randomization procedure and coin
flipping and this is something that
researchers have been doing for many
years so let's say we want to connect
collect accurate information about
whether people are performing certain
acts I'd like to say this act is
something like drink-driving that people
don't want to admit to and therefore
it's difficult to get reliable
statistics around it so we can do this
and also protect an individual's privacy
by like play in the following game we
can give them a coin that we know the
bias off and let's just assume for
argument's sake it's a fair coin then we
send them into the corner and we tell
them to apply steps one two and three
and we don't see the outcome of their
coin flips they just come back to us at
the end of this procedure and say yes or
no
whether they've committed act X so
precisely they for this con once if its
tail's they respond truthfully if it's
heads they flip them again and respond
yes if it says no if its tail's if you
have to sit and work out what that
procedure gives you you'll quickly
realize that we can actually work out
accurately the proportion of people who
have performed at text so that allows us
to get accurate statistics about the
population as a whole
equally given that any person who
flipped these coins and we didn't see
which quasi flips had a 25 percent
chance of getting two heads and
therefore answering yes regardless of
whether they've committed at X or not
you've given any person the ability to
just turn around say you know I got to
your heads didn't actually drink drive
so we're giving them a sense of privacy
through possible deniability the key
idea here is that randomization is
essential for any privacy guarantee so
with this in mind we're going to
introduce differential privacy
specifically we're going to introduce
epsilon differential privacy there is a
more relaxed version of differential
privacy that exists called epsilon Delta
differential privacy Buddhists it's
easier to introduce epsilon differential
previously the ideas are identical so
I'm going to introduce the terms on this
slide first then we're going to walk
through an example
straight after so data sets D and D
prime are essentially the same apart
from one row in D prime has been either
added or deleted verse data set D
epsilon is our privacy loss or post e
budget depending how you think of it
this mechanism M from machine learning
we can think of this as a machine
learning model that's been trained with
the addition of some differentially
private algorithm so we saw some
randomization procedure applied to it
s is just an event or an outcome from
our model so what the left-hand side of
this equation is saying is that the
probability that I see an outcome s from
my model train and dataset D is less
than or equal to C that same output from
my model trained on a different data set
D Prime crucially only different by one
row with this factor e to the epsilon
and if epsilon is zero then the left
hand side is equal to the right hand
side and the output of the model doesn't
change depending on whether the training
data set D or D Prime and this the
mechanism M as introduced randomization
okay so like holding that thought in
mind and we're going to look at an
example now
so let's say we've taken our model and
we trained it on dataset do you and this
is a coral world and the true answer to
a particular query to our model is 100
but we know from previous discussions
that we can't answer 100 if we give
precise answers out that are true
then we're going to reach privacy
straightaway and the extensive
information so we're going to have to
add some random noise to this this
answer of 100 and that's what the coral
distribution is showing you it defines a
distribution of possible answers around
the true answer of 100 the great
distribution represents the world in
which our model was trained on a data
set D prime where one individual was
removed from the dataset so now let's
say the true answer is 99 but again we
need to release announcer from my
dataset or our model return announcer
and from a distribution around that true
out set and that's what the grade
distribution is depicting there if we
are on the x-axis and we pick a point
when we return announcer for our model
it will be deterministic after the
random training procedure has been
applied let's say we pick a point
somewhere on the right of this
distribution and we have 250 as the
output time model the point here is that
150 is a response the probability of
that event occurring is basically the
same in the coral world is in the green
world so the chance that an event occurs
with individual with an individual's
data and without their data is
essentially the same and when I was
saying loosely essentially the same here
that's precisely what the ETA epsilon
term was given us on the previous slide
so we can quantify this this banding
term exactly and I also made the point
that epsilon equals 0 would make the
left hand side on the right hand side
equal to each other here and we may
initially think that's desirable but
that's not actually the case
if the output of our model doesn't
change as we remove individual from our
data
and we've essentially learned nothing
from my data because we could keep
removing individuals one by one and so
there were no individuals left in our
data and our model output hadn't changed
and that would imply we learned nothing
from our dataset so the model output
will change as we remove rows from our
data differential probe is you just
bounce precisely by how much this is
allowed to happen and so we talked a
little bit here about being imprecise in
our answers so with the coral
distribution where the true answer 100
and we may have released any answer from
a distribution around that and that begs
a natural question of you know how fat
should we make these curves or how
inaccurate should we be when we provide
a response and that roughly depends on
two things one it depends on how
sensitive the models output is to a
given individual in the dataset let's
call this term Delta and also like how
private we want to be like this is
epsilon epsilon small that's highly
private so let's again say epsilon 0.1
then the heuristic is that standard
deviation of these curves should scale
in proportion to Delta over Epsilon and
we can understand this as follows if we
want to be highly private ie we wants a
very small epsilon then Delta over
epsilon is epsilon tends to 0 will blow
up as a term and the standard deviation
is curve will be huge or group will be
providing very inaccurate answers to
responses but will also be preserving
privacy if I'm highly sensitive to a
given individual the Delta is large and
there's a numerator term then the
standard deviation also increases if
epsilon were very large itself then that
would correspond to the peak
distribution in the middle where were
you be providing low privacy and being
very precise in our responses
so that's like a whistle-stop overview
of differential privacy as a definition
so I'm going to talk now about some of
the formal guarantees that the
differential privacy gives us we have
the ability to quantify the privacy
guarantee exactly for both individuals
and groups if we are Absalon
differentially private with respect to
an individual then we are k times
epsilon differentially private with
respect to a group of size k it for a
bus to all future attacks this is called
being immune to post processing and it
actually applies regardless of the
compute power you have differential
privacy is a definition but it's
programmable so different algorithms can
implement differential privacy in
different ways but crucially is
composable which means we can take the
outputs of datasets or models that are
differentially private combine them and
be guaranteed that the output yourself
will be differentially private this is
going to be crucial we think about the
implementation that's commonly used
called differentially private stochastic
gradient descent which essentially
ensures that with respect to any
mini-batch in the data
and we are differentially private and
therefore we're going to be
differentially private with respect to
the dataset as a whole this is called
composability in fact we can now
quantify privacy and do it exactly
allows policymakers and wider
decision-makers your own data to
quantify is actually the trade-off
between privacy and utility and as I've
already alluded to like privacy and
generalization are aligned goals not
memorizing or learning specific things
from an individual that don't apply to
other individuals in the dataset will
stop you overfitting differential
privacy is also called the gold standard
it's actually going to be used for the
2020 u.s. census which is highly
exciting if you want to read more about
differential privacy there's a free
online pdf by Cynthia Dworkin our own
Roth called the algorithmic foundations
of differential privacy if that's quite
formal and definitely assumes like
mathematical and computer science and
backgrounds but if you want to get a
gentler introduction then given that
differential privacy is actually being
used now for the US Census Cynthia's
walk has provided some YouTube talks
online which are very accessible
motivating the intuition and ideas
behind differential privacy
so that's differential privacy and in a
nutshell let's talk about quickly about
how we can combine this with generative
modeling I don't have time to introduce
generative modern I'm going to in one
slide in about 30 seconds
explain what ovae does so v8 eats data
in has an encoder which is a neural
network and essentially lonesome
compressed representation which
essentially parameters as a probability
distribution and then from something and
buy something from this probability
distribution and passing it through a
decoder whose weights alone during the
training process we output
[Music]
synthetic data at the other side to
combine this with differential privacy
is through an algorithm called DPS GD
differentially private stochastic greens
in and we've kind of got a simple slide
that introduces this idea here so we
previously talked about this Delta term
has been the sensitivity of our models
output to a given individual what DP SGD
does and there's a reference paper there
at the bottom you can see is clips
gradients whilst we're training the
neural network to a known norm this
bounds our sensitivity to any
individuals within the data we know the
norm we fixed up norm we then add noise
the amount of noise that we add will
give us a certain improved a guarantee
we want to be more private
well add more noise less private last
noise and that's what kind of being
depicted in this chart here we're
ignoring here any stochasticity that
relates to mini matching and on the
right we're just showing that a gradient
steps were kind of noise in the
gradients and so we may wander
occasionally and in the wrong direction
but over time assuming the noise added
is imputed to the training process we
will still converge so as an overview
this is what faculties approach to
private data gives us we have real data
in we train a differentially private
variation autoencoder
and we output either a private synthetic
data set or differentially prime over V
a crucially we have epsilon and Delta s
surrounding this and so we can have a
formal proofs are guaranteed which is
quantified the trade-off between utility
and privacy um with the overview in mind
I'm going to hand over now back to
Christian to talk through some
real-world results right thank you
mark so just before I guess that with
the next section just one to quickly
call-outs
there is a Q&A button that you can press
in zoom so if you have questions that
arise and
as we go for your presentation please
put them in there and then we consider
at the end go through that list and
answer them one by one
cool onwards and upwards so now that we
have a good understanding of
differential privacy let's go to sort of
the meat of the talk where we have the
nice results of how we actually use this
in practice next slide please
right so I'm gonna show you one case
study this was a project that faculty
did with M rat so M rad is the East
Midlands radiology consortium and their
problem is that so they have breast
cancer screening appointments for women
and the problem is that quite often
people don't actually show up so about
30 percent of people don't show up to
their appointments so this is obviously
not great from an operational
perspective because it means you have
some inefficiencies in terms of you know
staffing and not making sure that
resources are used well so the solution
to this sort of problem would be to have
a machine learning algorithm that for
example predicts the likelihood of a
no-show appointment and once you have
that it can then take an intervention
for people where you have low attendance
likelihood so this could be sending them
a text message or actually giving them a
call to make sure they actually show up
so that's the idea in terms of the
business problem however this data
obviously contains highly sensitive
information
and as such should never really leave
the sort of secure and rad environment
so the question is how do we approach
this in this case next slide please
right and our solution to this was to
have a machine learning model that is
trained on the synthetic data and then
deployed on the real data so let's go
for this diagram step-by-step so here we
have sort of two sections on the Left we
have the ambrette environment so these
are imagine a computer sitting somewhere
in in mrad and then on the right we have
two faculty environment imagine a
faculty computer
and in between we have this sort of line
which I call Primus emotes and this sort
of means that any sensitive data it
should never really cross this line so
we really have a good separation between
the am read and the faculty environment
okay so how does this thing work
so if we start at the top left you can
see we have some real historic
appointment data so this means we have
appointment data that sort of shows us
previously if people showed up or not so
some features and an outcome what we
then do is we take our sort of synthetic
data generator of private synthetic data
generator and trained us on this real
historic data so this happens all inside
the MRAP environment once we have
trained this model we can use it to
generates a bunch of private synthetic
data and that's by definition is then
safe to leave the ailment environment so
we go across the mode and we have
private synthetic appointment data now
in faculty environment and that means we
can just use this data and to our behest
and just train a machine learning model
to try to predict the appointment status
entirely on the synthetic data once we
reasonably happy with that we sort of
validated our model well enough we can
actually say ok this model seems to work
well let's try to actually get it back
into the unwrapped environment so this
means we crossed the privacy modes again
this time from the other side and we
just take our model and start deploying
it in the Emirate environment now that
this means we have a model in the mrad
environment and what we can do is we can
take the real date sir again so this
could be current appointment data that's
coming in right now and then based on
that you can feed that into the model
and get a likelihood of attending the
appointment out so this is sort of the
way we approach this problem and this
provides us a way to make sure that the
sensitive data never leaves the secure
environment it's probably worth pointing
out that other approaches do exist so
you could also imagine something like a
federated learning approach
but the reason this is quite nice is
that it's quite a low-cost way because
all you have to do if you have to make
sure that the synthetic data generation
happens on a synthetic side and then
once you make the synthetic data you can
do everything you want instead of your
own environment so in terms of
computational infrastructure it's quite
scalable in that sense next slide please
right and here we have some actual data
so what I'm gonna show you now is bunch
of univariate comparison between real
data and synthetic data that sort of
broadly assess the quality of the
private synthetic data and here you can
see a few histograms of numeric data so
on the y axis for all of these plots we
have to count so this is the number of
people in the data set and on the x axis
we have three different numeric features
we have a booking date/time so this is
like a timestamp feature a screening
appointment number so this would be like
appointment 1 2 3 it's a discreet
feature and then also we have time since
previous screening so this would be in
days one key thing to note here is that
this is not actually real data the real
data the real data in this case is a toy
data set that has similar properties to
the actual amber theta so this is more
on stratum showing if you have this type
of data you can do this sort of thing
and as you can see the histograms here
in red we always have the real data and
in grey the synthetic data and broadly
on all of these three plots we see that
they overlap quite well so we can see
like the peak falls in the same range
and we can even capture properties that
seem a little bit more difficult so for
example under plot on the right you see
we have this of almost bimodal
distribution where you have a peak at 0
and then another sort of Gaussian
feature at higher values so even that we
can capture with a method quite well
just to be absolutely clear about it
because some people have been getting
confused with these plots so the reds
and grey are the real and synthetic data
and whenever this sort of dark red color
is that means the two distributions
actually overlap so just to make that
clear
cool next slide please
right here we have some more features so
I showed you some numeric features now
we can also look at some other types of
features here on the Left we have
categorical data and on the right we
have binary data so for a categorical
data we have something like the practice
postcodes which has some like 80 values
in there and same story as with the
previously lived in America we can see
there's quite a high overlap between
real and synthetic data which gives us
confidence that synthetic data has good
quality then a similar conclusion can be
reached on the right with the binary
data where you see in this case it's
really spot-on in terms of the
distributions like you can not even see
any difference between the real
synthetic data in terms of these these
proportions so this is a univariate
assessment of the data which tells us
that on sort of a column by column level
the synthetic data looks quite good so
if you go to the next slide we can also
look at bivariate Association but in the
data and for this what we've done is to
compute the correlation coefficients
between features so here we have
Spearman correlations in the real data
and synthetic data and this sort of
tells you how much does one feed to
depend on another feature so if they're
highly associated if they're perfectly
correct it is one if they're perfectly
inversely correlated it's minus one if
they don't depend on each other it's all
in terms of Spearman correlation then it
would be zero so this gives you some
sort of indication of feature
interactions on the bivariate level and
as you can see again we're doing fairly
well in terms of reproducing what we see
in the real data so
so if these numbers always tell you the
correlation coefficient and the colors
indicates the value as well so just by
looking at the colors you can see that
looks quite similar and based on that we
have a good reproduction of these
correlation coefficients in the
synthetic data we can also look at
specific examples so for example if you
look at the booking date separation and
booking date time we have in the real
data we get minus 0.66 and in the
synthetic data we get minus 0.65 so it
seems super close and same thing happens
if we look at something that's less
strong in terms of the correlations so
if you look at correlation between at an
appointment status and screening
appointment number we have minus 0.04 in
the real data minus 0.08 in the
synthetic data so you see that's the
same trends are definitely captured in
the synthetic data even though it's not
perfect in terms of the actual numbers
so this means that the data obviously
has the same trends but it's not a
one-to-one mapping really because it is
ultimately a synthetic data sets that
will differ a little bit so these
capture to some extent univariate and
bivariate distribution of the data
what's important to note is that that's
obviously not everything that's going on
you could have much more complex
dependencies in your data and these are
generally quite hard to tease out with
these sort of simple statistical
exercises so as I was saying earlier the
best test of this data will of course
come from actually training a machine
learning model on it and then seeing how
it performs which we'll get to in a bit
next slide please
right so what I also wanted to show you
is we can actually compare directly rows
in the real and the synthetic data so
here you can see a table of one row in
the real data so on the vertical axis we
have all the features in the data set to
go down and compare to that we have the
row in the synthetic data and here the
ruinous effective data is actually the
closest match
and closest match here means that we
used the go distance to find from all
the rows in the synthetic data was the
closest one it's almost like a nearest
neighbor I cannot find the real Victor
so here what you can see is that for
quite a lot of features for example the
categorical features we actually get
exactly the same value for example
practice postcodes smart clinic we have
identical values in real and synthetic
data and that to some extent is by
product deaths you don't have that many
choices in terms of the values for
categorical features but if you look at
some numeric features like time since
previous screening or what else do we
have
previous screening dates you can see
that clearly differ times in previous
screen is like a hundred days apart or
every screening appointment number is 20
versus 11 in this effective data so you
can see that there are clear differences
and this is the closest matching of
synthetic data but despite that it's not
really the same so it's sort of
different in subtle ways but overall it
might still once embedded in a larger
set of data it will still look similar
on that perspective cool and I think we
can go to the next slide right so this
is the final slide on results and this
is sort of the key plots that we want
you to take home with and the headline
result is that higher primacy of
synthetic data leads to lower model
utility in deployment all stated the
other way around if you want a high
utility you can't have also super high
privacy so it speaks about there's
always this trade-off between the amount
of privacy and synthetic data okay so
what do you actually look at in this
plot so here on the y-axis I show you
the performance of the model and just to
remind you here this means the machine
learning model was trained on the
synthetic data and then tested on a set
of real holdouts data so this means we
helped back some real data at the
beginning and only used it at the very
and to test the machine learning model
that was trained on synthetic data and
utility here we had used this a measure
at the area under the ROC curve so 0.5
means the model is essentially randomly
guessing and then the best possible
utility of the model you can have is 0.8
in this case which is a model trained on
the real data directly and as you can
see in red line we have the different
synthetic data sets and the associate
model utility and as we have to very
high as privacy so epsilon around naught
point 1 or so we actually create
synthetic data that's practically
useless for this sort of classification
task but as we reduce the amount of
primacy and get to epsilon around 1 we
can see we actually gain a useful data
set and a useful model and we get the
cut an area under the ROC curve around
0.7 or so and you might say this doesn't
look amazing because in the real data I
get 0.8 but it really sort of depends on
your application point seven could be
great in terms of getting a model
deployed and having something that
actually works a lot better than what
the current system yes and also to
emphasize that here really the optimal
choice depends on your needs so maybe
for some use cases you don't have that
springe and constraints on privacy so we
can go to higher epsilon values and then
get better models but made for other
cases that's not possible
and a really high privacy means we have
to make some trade up in terms of the
model performance right and with that I
think we can go to the conclusion so
conclusion I've got three points here
first thing is making a r-real requires
safe ways to utilize data sets that
contain sensitive information so we
firmly believe that there's loads of
data out there that has sensitive
information but that is sort of locked
up in organizations all over the world
which should not be used as it is and
should not be used in anonymized form so
we think that technology here can really
make a difference in order to get to
somewhere we can unlock the value of the
data sets
and in particular we think that this
sort of approach of differential private
synthetic data can unlock the value of
these statuses without really
compromising privacy and we believe that
this sort of approach will is sort of
simple and generalizes to many domains
and datasets and by that regard
hopefully it will enable AI adoption in
many areas where privacy is really
paramount and I think this is the end of
the talk
yes it is so now the fun starts the Q&A
section I noticed we have quite a lot of
questions here that we can go through
how do we do this mark I can't see them
so you'll have to dish out them out I
think ok share just them so I'm gonna
message queue all the questions so we
can sort of make sure we answer
everything in a systematic way and then
bear with us
this will definitely worth it yeah also
feel free to answer more questions as we
go along if you have any more desire for
more information so I've got a couple
questions here one someone's asking if
probability of one dataset is zero or
the outcomes of a model training one
dataset is zero and on the other day sex
1 that was the big change that was bad
the point is precisely that bees the
epsilon term that bounds how much that's
allowed to happen so you won't be
allowed to happen and you could have for
a given epsilon such a large change
epsilon small you better understand how
much that ratio can change
there's also a question around like what
are the downsides of differential
previously compared to other purposely
approaches and definitely one of the
downsides is that it's it's quite a
formal and complicated scientific
definition from computer science and
developing algorithms that can scale
wasn't done until very recently so this
differential private stochastic gradient
descent is only has only been around in
the last few years and also trading
areas for datasets at scale and wasn't
possible until until recently
I'm also when you're adding noise I you
are harming the learning process to some
extent so differential privacy is not
around a small data set you do need
quite a large amount of data and also
like differential cruzi tends to work
well when you can process the whole
dataset in one go so if you've got data
coming in it's more complicated to
perform differential privacy then
because every time you're doing this you
have inside composer steps keep track of
your epsilon the Delta is to know your
current previously budget is and that
like accounting of the privacy budget
can get quite complicated so it
definitely is better to process a whole
dataset in one go home answers the
questions cool I can also answer a
question so there's one question on will
decides be given and I've been told yes
the slides will be given they will be
shared to all attendees and post on our
YouTube channel so that's good and
there's a question here about why was it
easier to train a VA in the secure
environment and then just training a
predictive model in the environment in
the first place and that's a fantastic
question and so you can train
differentially private classifiers
you could even just train a classifier
directly in their environment the real
benefit of training a differential
private and variational autoencoder is
you can then give copies of that data
set to your own data scientists so let's
say you're in an organization
where everyone internally can't access
the dataset and without some money no
clearance you could then take a
differentially private VA e train and
train on the sensitive data and either
give that model then to your data
scientists or to staff give the data to
staff who can then perform analysis on
the data set that's like a general
purpose use case versus like a
classifier which is just you know very
task specific yeah maybe just to add to
this um even if you were in a position
in your organization and you can do
everything yourself there's still you
know you might still want to consider
having a mechanism whereby you allow the
past other organization maybe even to
help you in terms of this is sort of a
data set that I really want to work with
I'm struggling with I want to see what
are the best possible methods out there
so it's just it really enables quite a
lot because it means that you know
access to this data set will be so much
easier than when itself is heavily
regulated cool I noticed we have another
question illusion actually yeah so the
question is is the ethical trade-off
between privacy and utility for
high-risk situations ageing medical
models were increasing privacy may lead
to worse predictions
how do people approach this trade-off in
practice um I'll have a start maybe you
want to jump in listed I mean this this
trade-off exists for the whole machine
learning right um
I don't think anyone here is advocating
that machine learning models should be
deployed into situations where their use
for critical decision-making and without
humans in the loop and so I proper model
validation is always crucial part of
that process and the fact that our model
is slightly worse and
because it's made private you know as
Christine is alluded to there may be
situations where it's no model giving
you no utility having a private model
which has some utility is actually
beneficial particularly that can be
combined with with other humans in the
process so I don't think there's an easy
answer to that and it's clearly going to
be something that's determined you know
both legal aspects and from the use case
for the companies and this is your
makers involved Kristen do you have
anything
I think yeah I think everything in your
answer one thing I would add is this
this is a really quite new stuff still
and not a lot of people I think are
actually even doing this or thinking
about doing this so even in something
like the US census there are discussions
in terms of what should the absalom be
so I think we probably still have to be
a little bit of the other work in terms
of to come up with guidelines and how in
which situation is what is applicable
and yeah I was able to pen from
situation to situation and but obviously
as we go along and as we sort of maybe
even have like these privacy attacks on
models where you can actually show that
whether model digs information or not
those sort of techniques will be helpful
in terms of really assessing for this
type of model I have this sort of danger
that's why I choose this absolute value
okay there's a question asking is any
classifier I trained on differentially
private synthetic data automatically
differentially private the answer to
this is yes this is a composability
point which is if you take any function
and perform it on differentially private
and data or outputs then you're
automatically differentiated private so
that's yes to that question
[Music]
we have more questions so oh maybe I'll
let you take the view you want and how I
was just gonna read it maybe then I'll
decide what I'll take it or not or if
the VA e in in the secure environment
why would you use that VA to generate
synthetic data examples versus just
passing the embeddings from the real
data over to the other environment for
modeling on latent data right do I
understand this well I'm not sure if if
the person is meaning will the latent
space respect privacy and I think the
answer that would be no well unless it
was differentially private and
differentially privately trained um I
mean I guess we could passivates in
space over and work with that but
ultimately we do want to build the
machine and I'm your model that's
probably interpret of all and to the
people so inference time they can pass
the real data in and the classifier
itself was trained on on the real you
know structure of the data with the
correct columns etc yeah I don't know
yeah so this is the in banks on the real
data over to the other environment yeah
I think the key point is if you have
embeddings on real data in a non private
way you know that's non private but if
you do it for synthetic data yes in
theory that's like since you saying you
pass your VA over to the real
environment which
in a way pauses a little bit more risk
because then you actually have access to
the data generating mechanisms own
by just giving you the synthetic data
that comes out in sort of limit the
amount of information you can squeeze
out of the model so it provides you
actually a higher guarantee of privacy
in this case yeah so on that point you
should be noted that the synthetic data
from a variation or two encoder is more
private than the view yourself because
it represents a phone and finding its
amount of samples from the VA II
obviously if you you can just keep
sampling and throughout that basically
there's a question around is there a
standard epsilon per industry or problem
type no is a short answer it will be
very interested to see what the US
census thinks is a sensible answer to
this question there is a theoretical
value of epsilon which is basically log
two and and if you don't go epsilon
below log two then in theory someone
could have still some chance of in the
future we are to extract something from
your and from your data should be
pointed out that from experiments we've
conducted you can take state-of-the-art
machine learning attacks from research
and conduct those on data sets and
models and eve of epsilon values that
are significantly higher so we're
talking in the hundreds here and you can
basically thoughts career machine
learning attacks and so
obviously not having an epsilon below
log2 means that in the future someone
can be smarter and design a better
attack or they could have more compute
power you're not going to be safe unless
your epsilon is below log - what very
high epsilon values at the moment and do
guard against state-of-the-art attacks
at present cool
I think that's answered so we have a
bunch more questions and we have one
minute left
so how do we approach this maybe pick
one more question to answer so the
answer to the question on is the latent
space guaranteed to be differentially
private even if the VA II was trained
with DPS GD and if the latent space is
output from the variational Ottoman code
it will also be differentially private
and I think it's important to know that
anyone who's asked a question and we
haven't had a chance to respond to and
we all be able to follow up with you
afterwards and email you responses to
your questions so I apologize we haven't
had a chance to to answer everyone I
don't know if Kristin you want to
squeeze any more in before we finish I
can see one question on how to make
synthetic data I think we're not gonna
be able to squeeze that in yeah I think
other than that we've covered everything
[Music]
yeah I mean there's a few
questions now but I don't even have time
to respond to them okay so let's leave
the remaining ones by email and yeah I
think that's everything from us then
okay thank you very much everyone
great thank you hope you enjoyed this
have a lovely evening everyone
[Music] |
e1ec3295-2306-4ac6-8fdb-3b77a1bb9e47 | trentmkelly/LessWrong-43k | LessWrong | Applying Bayesian Analysis to History (post idea)
I am an aspiring historian and I'm very interested in ways to apply Bayesian reasoning to history. When I say "history" I mean the study of history -- as a historian, allowing my map of what has happened in the past to match the territory, and being able to represent more accurately the relative strength of historical evidence for and against various historical models.
I know that historical evidence works quite a bit differently from scientific evidence. But I think that historical evidence is also useful. Historians, in recording and assembling secondary sources, assess the relative strength of evidence (mostly primary sources) with regards to a topic already. But there must be a way to do it more formally. Shouldn't there be a right answer, just as no two people who are completely rational (and have the same information) should ever disagree?
This is a post (or series of posts) I might write in the future, and I have put a bit of thought into it so far, but I need to do quite a bit more research. Is there anyone interested in reading something on this topic? Has it been done before? Is there anyone who is knowledgeable about how historians treat evidence who might be able to offer some insights? |
85261b57-5830-4014-bac3-286e9e306fe7 | trentmkelly/LessWrong-43k | LessWrong | Upcoming unambiguously good tech possibilities? (Like eg indoor plumbing)
I recently asked about the glorious AI future but I meant to ask something more actionable. Near-term (say, next 5 years) stuff that ambitious people can aim for.
Lots of recent tech is a mixed bag in terms of societal outcomes and whatnot. I have the usual complaints about viruses being too easy to create, social media, phone overuse, gpt reddit astroturfing bots, facial recognition, mass surveillance, cheap quadcopters (cuz grenades), etc etc. [1]
I sure love my flush toilet though. And lightning rods, electricity, batteries, the computer mouse, wheels, airplanes, microscopes, vaccines, oral rehydration therapy (aka pedialyte), antiobiotics, the Haber-Bosch process, cultured meat if it works, air & water filters, reusable rockets, youtube, and cheap iron all seem pretty great. Democracy via anonymous paper ballots is also a clear win overall in my opinion.
What upcoming tech is all good good and no bad bad?[2]
the bidet is possibly the least tradeoff-ridden tech of all time
My starter list (not very good, hence the question):[3]
* AI tutors
* embryo selection for health & wellbeing & actual intelligence[4]
* AI life coaches
* precision farming robots (more & better food with less pesticides (aka widespread literal poison) — I would accept the unemployment on this one)
1. ^
This shouldn't influence the answers, but I also have lots complaints about stuff that ruins good excuses for good/social things. Harder to ask medium friends to drive you to the airport when you can uber; hard to ask a stranger on the street for directions when you can use GPS; learning music is probably a lot easier if there's zero recorded music; why see a play when you can watch a movie; etc etc etc etc.
2. ^
If the question is too vague for you (eg because tech consequences depend on how,when,where,bywho it is rolled out) then imagine you have the same degree of control over the tech that a well-run well-funded medium-sized tech co would have. And you roll i |
b385de61-6594-4935-8a39-e829299d786e | trentmkelly/LessWrong-43k | LessWrong | One Way to Think About ML Transparency
What makes a neural network interpretable?
One response is that a neural network is interpretable if it is human simulatable. That is, it is interpretable if and only if a human could step through the procedure that the neural network went through when given an input, and arrive at the same decision (in a reasonable amount of time). This is one definition of interpretable provided by Zachary Lipton.
This definition is not ideal, however. It misses a core element of what alignment researchers consider important in understanding machine learning models. In particular, in order for a model to be simulatable, it must also be at a human-level or lower. Otherwise, a human would not be able to go step by step through the decision procedure.
Under this definition, a powerful Monte Carlo Tree Search would not be interpretable since that would imply that a human could beat an MCTS algorithm by simply simulating its decision procedure. So this definition appears to exclude things that we humans would consider to be interpretable, and labels them uninterpretable.
A slight modification of this definition yields something more useful for AI alignment. We could distinguish decision simulatability with theory simulatability. In decision simulatability, a human could step through the procedure of what an algorithm is doing, and arrive at the same output for any input.
In theory simulatability, the human would not necessarily be able to simulate the algorithm perfectly in their head, but they would still say that they algorithm is simulatable in their head, "given enough empty scratch paper and time." Therefore, MCTS is interpretable because a human could in theory sit down and work through an entire example on a piece of paper. It may take ages, but the human would eventually get it done; at least, that's the idea. However, we would not say that some black box ANN is interpretable, because even if the human had several hours to stare at the weight matrices, once they were no lo |
27ab6d1f-d0d5-40dd-92cb-28d1935c5b5c | trentmkelly/LessWrong-43k | LessWrong | Confessions of a Slacker
Crossposting the entire thing from Putanumonit in honor of the Slack sequence.
----------------------------------------
Go read Slack, it’s short and important.
If you’re not a slacker, that post might change your life and explain why you feel like you have no control over your own life despite doing well on almost all counts. If you are a slacker, like me, this post gives our philosophy a name and provides a definition: slack is the absence of binding constraints on behavior.
Zvi’s post is abstract on purpose. I’ll continue his mission by getting more specific and, of course, by putting a num on it. To the latter purpose, I’ll modify the definition of slack to make it quantifiable:
Slack is the distance from binding constraints on your behavior.
KEEP YOUR DISTANCE
Slack is a function of many resources. Running out of any single vital resource is enough to constrain your behavior: make you do something you didn’t want to, or prevent you from doing something you want. Freedom requires having spare time, spare money, spare energy, spare weirdness points, available friends etc. The “slack as distance” formula looks a little something like this:
Slack disappears when the spare capacity of any single resource goes to zero, regardless of how much of everything else you have. Maintaining slack requires balancing all the important resources, making sure to shore up the scarcest resources first.
My grandma just paid to replace a pipe on her floor that was flooding the entire apartment building. The other 20 tenants were supposed to participate in the cost, but due to diffusion of responsibility and greed, they decided collectively to weasel out of contributing. A lawyer suggested that my grandma should go to court but she refused, for reasons of slack. The question isn’t whether the time in court will be worth the money gained, but whether the lack of this particular sum of money will force my grandma into something as undesirable as spending weeks litigating agai |
fcea5336-cb3c-4b3d-93b1-b43f894738df | trentmkelly/LessWrong-43k | LessWrong | Societal Growth Requires Rehabilitation
Disclaimer: My intent is not to criticize growth mindset as initially intended, but to criticize the version of straw growth mindset that has become a rationalist meme, particularly by pointing out its relation to some of the problems we have on the community level.
"Growth mindset" ranges from a sort of rallying cry to a "that's what she said" sort of joke, depending on what crowd you run with, but underneath all of this is an attitude that we can get better. We use the phrase to lift ourselves up, to tell ourselves that no matter what our current problems, we can grow and become stronger. We treat technology similarly; someday, our cars will drive us and death will be cured. In the future, things will be better -- assuming X-risk doesn't take us all out first.
Sadly, this mindset seems to leave little room for the struggling. "Growth mindset" gets used to mean "everything is good and getting better" rather than "bad things are getting less bad", which erases those for whom "everything is good" seems like a false statement. Cryonics and self-driving cars only exist for those who can afford it. On a social level, only those with the resources for personal growth can realistically work on themselves to the extent where "growth mindset" is actually a realistic phrase. Ideally, we'd work on this by making things like therapy and education more accessible. Ultra-ideally, we'd also start teaching things like EQ and metacognition in public schools, and work toward decreasing stigma around mental illness, therapy, and self help.
The pervasiveness of growth mindset does not seem unusual from the average person's perspective. Personally, the moment that made me question it is when I was working with a special needs class whose teacher was assigned to do a lecture on it. This was a class that was considered "moderate to severe"; most of the students were nonverbal and struggled to read or grasp abstract concepts at all. The thought that these kids gained anything from a le |
543ce0f2-dc36-4595-9774-32127ff08482 | StampyAI/alignment-research-dataset/youtube | Youtube Transcripts | DeepMind x UCL | Deep Learning Lectures | 11/12 | Modern Latent Variable Models
hello and welcome to
series on topics in
deploring my name is Andrea Nick and I'm
a research scientist at deep mind I work
on generative modeling variational
inference and representation learning
this lecture will cover modal latent
variable models as well as various types
of inference and in particular
variational inference so the lecture is
structured as follows I will start by
introducing generative modeling and
covering the three major types of
journey of models used in deep learning
then I will focus on latent variable
models explain what they are and why
inference is so important for them then
we will cover a special case of latent
variable models invertible models where
we can do exact inference then we will
move on to intractable models or exact
inference is not an option and we will
look at variational inference for
training those models variational
inference requires estimating gradients
of expectations which is not a trivial
problem so then we will look at how to
estimate these gradients and finally we
will look at a modern application of
variational inference to powerful models
which results in variational
auto-encoders so let's look at
generative modeling what are generative
models well they're the models are
simply proved allistic models of high
dimensional data so conceptually they
describe the process the probabilistic
process of generating and observation
and we can think of them as describing
mechanisms of generating more data
points and the key distinction between
other probabilistic models and
generative models is that our
distributions that we're modeling are
really high dimensional so in classic
settings like classification and
regression you're basically modeling a
one-dimensional output distribution
while in genitive modeling you are
dealing with a high dimensional
distribution and often you're
essentially don't have an input so
you're just modeling the distribution of
the output for this particular reason
generative modeling has been seen as a
sub area of unsupervised learning
because we're simply modeling the Joint
Distribution of the data and we don't
have any labels on the other hand if you
think about generative models as
including conditional generative models
which also have a context which is quite
a bit like an input then the boundary
becomes rather blurry so it's really
more about the technology rather than
the actual application it is used for
and there are many types of generative
models and they can handle essentially
any type of data from text to images to
video and so on so let's look at some
uses of generative models the most
established and maybe traditional one
comes from statistics and it's called
density estimation and here we simply
fit a generative model to the data in
order to get probability distribution
that we can evaluate at any given data
point and once we have this probability
distribution we can use it to actually
tell is this given data point from the
same distribution as a training data or
is it an outlier from some other rather
different distribution this kind of
models can be used for applications like
fraud detection there's also a close
connection between probabilistic
modeling and data compression
so there's actually exact reality
between these two areas so if you
actually have a probabilistic model of
the data you can use arithmetic coding
to produce a data compressor we can also
use generative models for mapping
between two high dimensional domains for
example between sentences in one
language and their translations in
another language
so here the the sentence in the original
language will be the context and the
model will capture the distribution of
possible translations for the given
sentence and typically there will be
many possibilities there rather than
just a single correct translation
another exciting application of
generative modeling is in model-based
reinforcement learning where the
generative model essentially act like a
probabilistic simulator of the
environment so then the algorithms can
actually use this simulator to plan
optimal sequences of actions rather than
actually having to try them in the
environment to see what happens and once
we've done this planning we can actually
execute the sequence of actions in the
real environment some types of
generative models are really useful for
a presentation learning where we would
like to condense the observations down
them down to some essential features
some sort of low dimensional
representations of them that capture the
essence and these low dimensional
representations might be more useful
than the original observations for
downstream tasks such as classification
and often we don't actually know what
the down tree downstream tasks will be
so it's important to summarize the data
in a generic way and Geritol models
provide a way of doing that and finally
there's this idea of understanding the
data that also comes from statistics and
this is the area where the generative
model will have a particular meaning to
its structure so the latent variables
will potentially be interpretable or the
parameters will have some real-world
significance so once we train such a
model on the data we can look inside of
it using inference for example or look
at the parameter values and it will tell
us something about the data distribution
something that we can't easily see just
by looking at the individual data points
directly
the next few slides are meant to give
you a sense of rapid progress that has
happened in generative modeling in the
last few years so the individual models
are not very important so I'm just
showing you samples from models trained
on datasets typical for that particular
year so we start in 2014 where the
typical data set was M List which
contained low dimensional images binary
images of digits then one year later
there's been already some progress and
now we can have models that capture to
some degree the distribution of natural
images still low dimensional but now
they're in color and they're
considerably more complicated than ages
the images are indeed blurry but we can
see some global shapes and maybe some of
these objects might be recognizable to
you and then four years later we can
model much higher dimensional images
with much better results so these are
not perfectly photorealistic but the
local detail is very convincing and the
global structure is quite good as well
there's clearly room for improvement but
it's it's a long way from the binary
images of digits so let's look at the
popular types of generative models in
deep learning you have seen actually
many of these mentioned before in the
preceding lectures in this series so
I'll just give a very brief overview so
what regressive models are most
prominent for language modeling where
they are typically implemented using
recurrent neural network or transformers
then we have latent variable models
which are subdivided into tractable such
as invertible or flow based models and
intractable ones like variational hold
anchors and this is the kind of model we
will cover in depth in this lecture and
finally there are implicit models most
notably
generative adversarial networks and
their variants so let's look at each one
of these types in slightly greater
detail so autoregressive models solve
the problem of modeling the Joint
Distribution of observations X by
subdividing it into simpler subproblems
so instead of modeling P of X directly
we actually model be one dimensional
conditional distributions corresponding
to this Joint Distribution the resulting
model is tractable and can be easily
trained using maximum likelihood so why
this is a good approach
well one-dimensional distributions are
actually quite easy to model because we
can use the off-the-shelf classifier
technology that has been very successful
in deep learning and such models are
simple and efficient to train as we
don't need to do any kind of sampling of
random variables at training time on the
other hand because we're modeling a
sequence of dimensions of conditional
distributions sampling from such models
is inherently a sequential process which
means it is slow we have to go through
one dimension at a time and we cannot
easily paralyzes the other weakness of
such models is that they naturally focus
on the local structure rather than
global structure so unless you build
some sort of inductive bias towards
capturing the global structure into the
model directly you are likely to have
less success with modeling the global
structure with these models then we have
late
variable models which are also
likelihood based like auto regressive
models but they take a different
approach to modeling the joint
distribution so they do it by
introducing the unobserved or latent
variable that in some sense explains or
generates the observation so we start
with the latent variable and then we
also define the transformation that
map's the latent variable value to the
particular observation these models are
also trained using maximum likelihood or
more typically some approximation to
maximum likelihood because often maximum
likelihood is intractable here and
latent variable models provide a very
powerful and well understood framework
and mature framework that has been
around for a long time in statistics
they make it really easy to incorporate
prior knowledge and various structure
constraints into the model so if you
would like to model some sort of
statistical or physical process you have
some ideas about how its structured this
is typically the model type you will use
and because generally they don't use
auto regressive or sequential
subcomponents sampling from such models
is efficient on the downside these
models require understanding the concept
of inference which is the reverse of
generation so this means going from the
observation to the plausible latent
values that could have generated it so
you need to understand and implement
this concept in order to use these
models that makes them somewhat more
complex than auto regressive models and
as I mentioned previously for many such
models inference is intractable so
either we have to introduce the
additional complexity of using
approximations for inference or we have
to restrict ourselves in what kind of
models we can use in order to ensure
that inference remains tractable
third class of popular generative models
in deep learning are generative
adversarial networks and unlike the
previous two types these are not
likelihood based these are so-called
implicit models because they don't
actually assign probabilities to observe
ations
they just give you samplers that
generates observations so the model here
that we're training is simply a neural
network that takes a vector of random
numbers and maps it to the observation
and unlike the other two classes of
generative models we just looked at
these models are trained using
adversarial training rather than maximum
likelihood so adversarial training works
by introducing an auxilary model a
classifier that is trained to
discriminate between samples from the
generator the model and the training
data and the gradients from this
classifier provide a learning signal
that we can use to train the model or
the generator so the main appeal of
these models is that they are by far the
best ones for modeling images so the
images they generate are extremely
realistic they are also relatively easy
to understand conceptually because
you'll need to understand the concept of
inference and your training a model
simply by back propagating through a
classifier and like latent variable
models they provide fast generation
because generating observation involves
simply performing a forward pass in a
neural network on the other hand turn to
adversity all networks don't give us the
ability to assign probability to
observations so this means that we can't
use them for many applications of
generative models such as outlier
detection or lossless compression they
also suffer from so-called
mode collapse and this is the case when
a model trained on the data set ignores
some part of the training data and
models only a subset of the training
data which is a bit worrisome and not
something that you see was likelihood
based models because they're essentially
obligated to model every data point
and the other difficulty was mode
collapse is that we don't actually have
control over which part of the data
distribution will be ignored on the
other hand if you just want realistic
samples from some part of the data
distribution then gans do it really well
and the other difficulty with ganz is
that optimization is actually a subtle
point optimization problem and as a
result training is often unstable and
requires a lot of small tricks to get it
right so in this lecture we will focus
on latent variable models and inference
so let's look at this generator modeling
framework so a latent variable model
defines an observation a distribution
over observations X by introducing a
latent variable Z along with that we
specify its prior distribution as well
as the likelihood P of X given that that
connects the latent variable to the
observation so P of X given that
essentially tells us how to map a
configuration of latent variable to a
distribution over the observations and
even though I say a latent variable
typically Z is a vector or it can be a
tensor or anything like that
conceptually it doesn't really make much
of a difference so once we have the
prior and the likelihood we have
specified the model completely and the
model is completely characterized by the
Joint Distribution P of X comma Z which
we obtained simply by multiplying the
likelihood by the prior and there are
two distributions that we can derive
from the Joint Distribution that will be
of interest to us for latent variable
modelling so the first such distribution
is P of X which is the marginal
likelihood of an observation and it
tells us how probable the observation is
under the model and this is the quantity
that would optimize if we're doing
maximum likelihood learning
and then there's the posterior
distribution P of Z given X and this is
the distribution of plausible latent
values that could have generated the
given observation X so we can think of
the latent variable as some sort of
explanation for the observe Asian so how
do we generate observations from a
latent variable model it's actually
quite simple
we start by sampling the latent variable
Z from the prior P of Z and then we
sample X from the likelihood
distribution P of x given that which is
conditional on the configuration of the
latent variable and much of this lecture
will be concerned with inference which
is the process of going back from the
observation X to a distribution over the
latent variable said so in this lecture
inference will specifically refer to
computing the mysterious tribution given
the observation so computing P of Z
given X how is P of Z given X defined
well we simply use the definition of
conditional probability which says that
P of Z given X is the ratio of the Joint
Distribution under the model P of X
comma that divided by the marginal
probability of X P of X so this means
that in order to compute the posterior
distribution we first need to compute
the marginal probability of X G of X or
the marginal likelihood how do we do
that well we do that by starting with
the Joint Distribution T of X comma Z
and marginalizing out the latent
variable Z in the continuous case it
will be integration so we will integrate
over Z the joint distribution in the
discrete case it will be a summation but
typically in this lecture I will use
integration and now we will see that
inference is in a very specific
formal sense the inverse of generation
so let's think about two ways of
generating the observation / latent
variable pairs X Z so one way to
generate such pairs is to start by
sampling the latent variable Z from the
prior and then sampling the duration
from the likelihood this is what we've
done two slides ago this gives us a
distribution of X that pairs but we can
also sample X that pairs in a different
way first we can sample X from the model
using the same process and then just
discarding the original latent
configuration that led to Xen and now
that we have this X we can perform
inference and simple as that from the
posterior distribution for it for this X
from P of Z given X this gives us
another way of generating pairs X and Z
and because the product of the
distributions we are sampling from in
both cases is exactly the same it's the
joint distribution P of X comma Z it
means that the distribution of these
pairs is exactly the same so this means
that sampling from the variational from
the exact posterior is a probabilistic
inverse of generation so
why is inference important well
inference is important in its own right
because once we've trained a model we
can use inference to explain
observations in terms of latent
configurations so it might potentially
allow us to interpret observations in
terms and set some latent variable
values moreover as we will see a bit
later inference comes up naturally in
maximum-likelihood training of latent
variable models it's a sub problem that
we will need to solve over and over in
the inner loop of optimization so let's
look at an example of inference in a
very simple latent variable model a
mixture of gaussians you have probably
seen this model before it's perhaps the
simplest latent variable model you can
imagine so it has a single latent
variable it's a discrete one and it
takes on K values between 1 and K the
probability of Z being I is simply pi I
and then each latent variable value
corresponds to a mixture component which
is Gaussian and the mean and the
standard deviation of this Gaussian is
determined by the value of the mixing
component so we can think of this as
having a vector of means and a vector of
standard deviations for the mixing
component and then the latent variable
simply selects which dimension of these
vectors we will use to define the
Gaussian let's compute the marginal
likelihood or the marginal probability
of the observation X so as we saw before
this requires marginalizing out Z from
the joint of the model and the joint is
simply the product of the prior key of Z
and the likelihood P of x given set
since it's the discrete model we're
performing summation to marginalize out
Z by summing over its values from 1
through K now that we have
the marginal likelihood we can compute
the posterior distribution because P of
Z given X is just the ratio of the joint
probability of X and Z divided by the
marginal probability of X and we
computed the marginal probability above
and the joint probability also is a sub
problem there so now we have an
expression for the posterior probability
of Z given X as you can see we can
compute this posterior distribution in
linear time in the number of latent
variable values so this model is clearly
very tractable now let's look at maximum
likelihood learning which is how we
would like to Train latent variable
models maximum likelihood is a very
well-established
estimation principle for probabilistic
models in statistics and be the basic
idea behind it is that we should choose
those parameters of the model that make
the training data most probable so this
corresponds to maximizing the product of
probabilities of data points in the
training set or the computation
convenient we can maximize the sum of
log probabilities of the data points
because we're looking for the optimal
parameters rather than the objective
function value these two approaches are
exactly the same they give us the same
parameter values unfortunately for
latent variable models we can't solve
this optimization problem in closed form
so as a result we use various iterative
approaches either based on gradient
descent or expectation maximization
so let's look at the gradient of the
marginal log likelihood for a single
observation so the gradient of log T of
X is equal to now weary we recall that
the derivative of log is its argument
derivative of its argument divided by
the argument so here we have the
derivative of the marginal probability
divided by the probability itself then
we expand the marginal probability in
terms of the Joint Distribution and
integrate over the latent values set and
we exchange the derivative of the
integral on the next line we replace the
derivative of the joint by the joint
times the derivative of the log
probability of the joint using the and
the identity in the yellow box and this
is the same identity we used on the
first line of this derivation now that
we have reformulated the integral that
way we can see that we have a ratio of
probability of the joint configuration X
set divided by the probability of the
marginal X this corresponds to the
posterior distribution T of Z given X so
we rewrite it like that and now we can
see that the gradient of the log
marginal probability is simply an
expectation with respect to the
posterior distribution of the gradients
of the log joint so this means that in
order to compute the gradient of the log
marginal probability which is what we
need for maximum likelihood estimation
we need to compute the posterior
distribution somehow so this is
basically an essential subproblem and
the other thing we can see here is that
the posterior probabilities
modulate the gradient contributions from
the log joint to the gradient of the
marginal log likelihood so it basically
up weighs the configurations that that
were more likely to generate this
observation and down weigh the
configurations that are less likely so
this basically means that inference
deforms credit assignments among latent
configurations for the given
observation so unfortunate
exact inference is hard in general to
see why this is the case let's think
about computing the marginal likelihood
of an observation which is as we've seen
an important part of computing the
posterior distribution
so if our latent variables are
continuous then computing the marginal
likelihood involves integrating over
high dimensional space and typically the
argument will be integrating over will
be a nonlinear function so analytical
integration will not be an option and
numerical integration in order to get a
reasonable level of accuracy will also
not be an option because the complexity
of integration will go exponentially in
the number of latent variables in the
discrete case the situation is slightly
better because now instead of
integrating over the latent
configurations who are summing over a
finite number of them so we know that we
could considerably enumerate all those
configurations and compute the marginal
probability like that but the issue is
the same as in the continuous case the
curse of dimensionality so if the number
of latent variables is more than a
handful then the number of possible
joint latent configurations will be so
large that we will never be able to
compute this sum exactly there are some
exceptions where we have interesting
models with exact inference and we've
seen we with exact tractable inference
we've already seen one example it's a
it's a mixture model where inference is
basically linear in the number of mixing
components the other important subclass
is linear Gaussian models so these are
models with Gaussian latent variables
and linear mappings in these models all
the induced distributions are Gaussian
and as a result inference is tractable
and finally we have the interesting case
of invertible models so these models are
special because they're actually quite
powerful and
yet they allow exact inference through
clever constraints on their structure
and we will see these models a bit later
in this lecture so how can we avoid
these intractable computations that
exact inference involves well there are
two general strategies here the first
one is simply to restrict ourself when
designing the model so that the
resulting model will be tractable this
will give us easier training because we
can do exact maximum likelihood without
any approximations but it will make
model design more complicated and in a
sense considerably restrict the modeling
choices we can make on the other hand if
we're interested in creating a model
that represents our knowledge about the
task then we might want to just build
the model with you know all the required
properties that we would like and then
worry about the inference later and
almost certainly we will end up with an
intractable model but that's okay
because there are approximate inference
methods and we will be willing to pay
the price of using an approximate
inference with some extra complexity
that that entails but then we will be
able to use more expressive models so
let's
look at the first strategy of working
with tractable models and exact
inference so we will look at these
modern tractable but very powerful
models called invertible models also
known as normalizing flows and they're
specially interesting because they
combine high expressive power restrict
ability which is rather rare and the
basic idea behind these models is simply
starting with some prior distribution
like in any latent variable models and
then applying an invertible function to
it to obtain the observation and the
parameters of the model are all
incorporated in this invertible function
and by warping the prior distribution in
various ways we can approximate the data
distribution so the
invertible there's constraints the
structure of the model in a very
specific way and makes inference and
maximum likelihood tractable in these
models so let's look at the generative
description of an invertible model so to
specify an invertible model we need the
prior distribution as before P of Z and
to here we will assume that it has no
parameters but it doesn't make much
difference this is just for convenience
and then we use an invertible
differentiable transformation F of Z
which has parameters theta to transform
samples from the prior into observations
so all the model parameters here will be
in this function f and because we use F
that's invertible having this setup
gives us one-to-one correspondence
between latent configurations and
observations so there's absolutely no
ambiguity about which light in
configuration generated the given
observation because the function is
one-to-one so this means that we can
simply compute the latent configuration
by inverting F and applying it to X so
we apply F inverse to the observation
and we exactly recover the only latent
configuration that could have generated
this observation so this is very nice
inference it's very easy and fully
deterministic so now how do we compute
the marginal likelihood we need for
maximum likelihood training right
we need to somehow relate the prior
probability and the probability of the
observe Asian X and it turns out that
because we use an invertible
differential transformation to connect Z
to X we can apply the change of
variables formula and then the density
is the probability of T of Z and T of X
differ by just a scaling factor and this
scaling factor is the absolute value of
the determinant of the Jacobian of the
methane from X to Z this might seem a
bit counterintuitive or surprising where
does this factor come from and this
factor simply accounts for the fact that
when we apply a function to go from Z to
X from or X to Z it will change the
infinitesimal volume around the point
where it's being applied and so if we
want the resulting distribution to
normalize to 1 just like the original
distribution we need to take into
account that volume your scaling factor
and this is exactly what the determinant
of the Jacobian takes into account so we
would like to get rid of Z in that
expression because we want to evaluate
probability of X just on data points X
and we can get rid of X by remembering
that we can get rid of Z by remembering
that Z is simply F inverse of X so
wherever we have Zed we replace it with
F inverse of X and now we have an
expression for the probability of x that
makes no reference to that so now
conceptually at least we can compute the
marginal probability of X and we can
before maximum likelihood training so
from the practical angle to do maximum
likelihood estimation we still need to
have some requirements for F so in
particular we need to be able to compute
F inverse of X as
as a determinant of its Jacobian because
it's used in the expression of the
marginal probability of X and we also
need to compute their gradients because
that this is what's required for maximum
likelihood estimation and finally these
computations need to be sufficiently
efficient for maximum likelihood to be
fast so let's look at a very simple
invertible model perhaps the simplest
and maybe the oldest are called the
independent component analysis so this
model starts with a factorial prior so
each latent dimension is modelled as a
univariate distribution independently of
the other dimensions and the latent
values are mapped to the observation
using a square matrix a so this is a
linear model since inference in a
invertible model involves inverting f
inference here is simply multiplying by
the inverse of a so to compute Z from X
we simply multiply X by a inverse and
once we've trained such a model we can
use it to explain our observations in
terms of latent independent causes that
explain the data linearly and the
typical application for this model is
solving the so-called cocktail party
problem where you have n sound sources
around the room for example people
talking and then you also have n sensors
and microphones and you would like to
isolate individual people from this
mixed recording and because sound
acoustics ensures that mixing is
approximately linear this is a an
appropriate model so inference on
recordings from microphones acts will
allow us to recover individual sources Z
and in order for this to identify
independent sources
there's an interesting constraint the
choir cannot be Gaussian because
Gaussian latent variables are
rotationally symmetric in high
dimensions so we cannot actually recover
independence we can only recover D
correlation so typically the prior we
use here is some sort of heavy tail
distribution like a logistic or kocchi
so how do we construct general
invertible models well the strategy is
simple because a combination or
composition of invertible
transformations is invertible we simply
use a library of simple invertible
transformations and chain a lot of them
together to obtain the more expressive
invertible transformation and here each
of these simple building blocks can be
parameterize either in the forward
direction mapping from Z to X or in the
reverse direction from X to Z whichever
one we would like to be more efficient
when using the model so depending
whether we want training or inference to
be more efficient we parameterize the
appropriate method and one interesting
detail here is that we don't actually
need F to be analytically invertible it
is fine if F can be inverted only
numerically with an iterative algorithm
as long as we have a reasonably
efficient algorithm that require that
recovers the inverse to numerical
precision and in terms of building
blocks there's a rapidly growing list of
them this is an active area of research
and I give a few examples there on the
slide so invertible models are very
appealing because they are both powerful
and they are tractable so easy to train
so why don't we use them all the time
well they do have a number of
limitations which make them not always
appropriate so one obvious limitation is
that the dimensionality of the latent
vector and of the observations has to be
the same
this is a consequence of requiring the
function f to be invertible there's no
way around it
so if we'd like a lower dimensional
latent space for some sort of low
dimensional representation of the
observation we simply can't easily do
this with an invertible model the other
requirement is that the latent space has
to be continuous and this is because we
use changed of density to compute the
marginal probability of x there has been
some initial work on discrete flows so
this limitation might be relaxed in in
the future there the consequence of
using continuous latent variables and
applying invertible transformation to
them is that it makes it hard to model
discrete data because the output of such
a transformation will also be a density
so unless our observations are
continuous or quantized which means that
they were discretized based on some
underlying to use distributions we can't
really apply invertible models to such
data and because the models are
constructed by chaining a lot of simple
transformation together the resulting
models tend to be quite large in order
to have high expressive power so this
means that we will need to store a lot
of activations and parameters which
makes it easy to run out of GPU memory
when training such models so in terms of
expressiveness per parameter or per
kilobyte of memory these models are less
expressive than more general latent
variable models and finally compared to
general latent variable models it's hard
to incorporate structure in invertible
models because we have to retain
inverter bility so that removes a lot of
options for a model design
on the other hand because invertible
models are tractable and powerful they
make very useful building blocks to
incorporate into other models in
particular intractable latent variable
models they provide a very useful
abstraction that basically gives you a
distribution that can be trained exactly
and gives you the exact marginal
likelihood so that makes them very
composable and appealing as building
blocks in the second half of the lecture
we will look at intractable models and
variational inference as a way of
training them so why would we want to
use intractable models well sometimes
the structure of the model or its latent
variable have some sort of intrinsic
meaning for us we might be modeling some
real-world process and the underlying
quantities have some a grounded meaning
and we would like to structure the model
in a particular way that captures that
so this is different from thinking of a
model as just some sort of black box
that produces predictions or merely
generate samples so we want some sort of
interpret ability then the basic
question is and I like this quote from
David Bly do you want the wrong answer
to the right question do you want the
right answer to the wrong question and
this basically highlights the dilemma we
have do we want to use the right model
with approximate inference or
potentially the wrong model with exact
inference and in many situations when we
take modeling quite seriously it makes
sense to go for the wrong answer to the
right question so in many cases we will
end up with an intractable model that
captures our desired properties and we
will just have to use approximate
inference
so here's an example of how easy it is
to end up with a intractable model even
though the starting point is tractable
so as we've seen the ICA model with the
same number of latent dimensions as
observation dimensions is tractable it's
a very simple linear model so what would
happen if we change this model slightly
suppose we would like to model a bit of
observation noise to indicate that our
microphones are not perfect so adding
observe a shinto the model makes the
model intractable because the mapping is
no longer invertible if we use more
latent dimensions and observations the
model once again becomes intractable and
even if we use fewer dimensions than
observations of duration dimensions the
model becomes intractable once again so
it really doesn't take much to go from a
simple tractable model to an intractable
and once we have an intractable model in
order to use it or train it
we need to use approximate inference and
there are two broad classes of
approximate inference the first class is
Markov chain Monte Carlo methods and
here we will represent our exact
posterior using samples from it but
using exact samples and to obtain an
exact sample from the true posterior we
set up a Markov chain which we run for
quite some time and at some point it
converges to the right distribution
which is the true posterior and then the
sample from it is a sample from the true
posterior so the advantage of this
method is that it's very general we
really don't need to restrict our model
essentially in any way we can use Markov
chain Monte Carlo for inference and this
method is also exact in the limit of
potentially infinite time and
computation so we if we spend enough
time generating samples there will be
from the right distribution that we
generate enough samples who will
basically have our answer to the
arbitrary degree of precision so
some senses the gold standard for
inference
unfortunately in practice it's very
computationally expensive and so doing
Markov chain Monte Carlo is not really
an option in many cases also convergence
actually knowing when we are sampling
from the right distribution is really
hard to diagnose so often we just wait
for some time
until we're tired of waiting and then we
use the sample at that point hoping that
it's from the right distribution but
doing this can actually introduce a
subtle error because it might still not
be the true posterior that were sampling
from and we have no way of quantifying
or controlling for this so the other
class of approximate inference methods
is variational inference and here the
idea is rather different instead of
sampling from the true posterior in some
freeform we say we will approximate the
true posterior with their distribution
with some particular simple structure so
for example we will say we will
approximate the true posterior with a
factorize distribution which models each
latent dimension independently so and
then we fit this approximation to the
true posterior using optimization the
advantage of this approach is that it's
much more efficient than Markov chain
Monte Carlo as optimization is generally
more efficient than simply on the other
hand we cannot trade computation for
greater accuracy as easily because once
we've chosen the form of this a
posterior proximation once we've
converged running for longer doesn't
give us any more accuracy but unlike in
Markov chain Monte Carlo we have
something that guarantees that we are
performing reasonably well at every
point because we have a bound on the
marginal log likelihood so we can
essentially at least hypothetically
quantify the approximation error so
look at variational inference in detail
so the one-line description of rational
inference is it turns inference into an
optimization problem and it's called
variational because we're essentially
optimizing over a space of distributions
and as a result we are approximating
some unknown posterior distribution with
a distribution from some particular
family
and the distribution that we'll be
approximating the exact posterior will
be called the variation of Asteria we
will denote it as Q of Z given X and it
will have parameters Phi which are
called the variational parameters and
they're there just to make sure that our
variational posterior approximates the
true posterior G of Z given X as
accurately as possible and what are the
restrictions on the choice of the
variational posterior well our hands are
pretty much free as long as we can
sample from this distribution and we can
compute the probabilities or log
probabilities under it and the
corresponding parameter gradients that
we need in order to fit this
distribution to the true posterior so a
classic and default choice is simply
using the fully factorized distribution
Q where each dimension is modeled
independently from all others
variational inference allows us to train
models by approximating the marginal
log-likelihood which in itself is
intractable because model is intractable
so we can compute the original log
likelihood but by introducing this
simplified form of the variational
posterior allows us to define an
alternative objective which is closely
related to the marginal log likelihood
and this objective is a lower bound on
the marginal look likely and we trained
the model by optimizing this lower bound
with respect to the parameters of the
model Phi and the parameters of the
rational posterior Phi so parameters of
the model theta and the parameters of
liberation of posterior Phi and because
this is a lower bound it's guaranteed to
be below the value of the marginal log
likelihood so when we maximize the lower
bound we're usually also pushing up the
marginal log likelihood even though we
can't actually compute it exactly so how
do we obtain this variational lower
bound on the marginal log likelihood so
let's consider any density Q of Z as the
only requirement is that this density is
non-negative
whenever the prior distribution is
non-negative then we start by expire
expanding the marginal log likelihood in
terms of the Joint Distribution where we
integrate over the latent variable and
then we introduce this density that we
chose by both multiplying and dividing
the modal joint by it so this doesn't do
anything because multiplying and
dividing by the same quantity has no
effect but once we've done this we can
apply the yongsan inequality which
states that the log of the expectation
of some function is always greater than
or equal than the expectation of the log
of this particular function so this
allows us to push the log inside the
integral
and take the integral with skew outside
the log and we know that the resulting
quantity is less is less than or equal
to the preceding quantity because of the
yunsun inequality and now we recognize
that this new expression is simply
simply the expectation with respect to
this distribution Q that we introduced
of Log density ratio between the Joint
Distribution P of X set and this density
and the important thing to recognize is
that because there's density Q that we
used in this derivation is arbitrary and
for any setting of parameters of the
density Phi we will have a lower bound
on the marginal log likelihood which
basically allows us to get a state of a
bound as possible simply by maximizing
this expression with respect to the
parameters Phi and thus getting closer
approximation to the marginal log
likelihood so there are several possible
variation of lower bounds and in this
lecture we will focus on essentially the
bound we derived on the previous page
where instead of the arbitrary density Q
we will use the variation of posterior
here of Z given X and this is both the
simplest and by far the most widely used
variation of bound so this is the bound
you will see in most variational
inference papers there's a more recent
option called the importance weighted
lower bound also known for historical
reasons as a way and this is simply a
multi sample generalization of the
evidence lower bound and it's
interesting feature is that it allows
you to control the tightness of the
bound are the accuracy of approximation
to the margin likelihood by increasing
the number of samples you use in the
bound so this is not quite as flexible
as Markov chain Monte Carlo where you
use more computation to get more
accurate results because the scaling is
you know you get rapid improvement as
you go from one sample to ten samples
but once you go beyond that the
improvement quickly levels out but still
you can get some
easy gains without changing the form of
the operational procedure but for
simplicity we will use the elbow in the
rest of this lecture so let's review a
concept important for variational
inference and this concept is called
back Leibler divergence KL divergence
provides us with a way of quantifying
the difference between two distributions
and KL divergence between Q and P is
defined as the expectation under the
distribution peel of the log density
ratio of Q to P and it has a few
important properties we will need for
the rest of the lecture so first of all
the KL divergence is a non negative for
any choice of Q and T the KL divergence
is 0 if and only if Q and P are the same
almost everywhere so we can basically
think Q and P are the same distribution
is the only case when the KL divergence
is 0 and finally it's important to
remember that KL divergence is not a
metric so it's not symmetric in its
arguments so KL from Q to P is not the
same as KL from P to Q in general so
let's look at optimizing variational
lower bound with respect to the
variational parameters Phi of the
variation of posterior Q so let's start
by rewriting the elbow so in on the
first line we factor the Joint
Distribution into the marginal
probability of X and the exterior
probability of Z given X this is just
another factorization of the joint
density of the model on the next line we
simply take out the term for the
marginal log-likelihood into the first
term and then keep the rest as the
second term giving us expectation under
Q of the log density of the true
posterior to the variation of Asteria
now in in the first expectation on that
line we see that log P of X actually
does not depend on Z so its expectation
under liberation posterior is just
itself so log P of X and then we
recognize the second quantity a second
expectation simply as the minus KL from
the variation of posterior Q of Z given
X to the true posterior P of Z given X
so let's look at that the composition of
the variation lower bound so we have two
terms the marginal log likelihood and
the KO so the marginal log likelihood
depends on the model parameters theta
but it does not depend on the variation
of parameters Phi so when we maximize
the variation lower bound to the rate
with respect to the variation of
parameters Phi the first term is
unaffected
therefore maximizing the elbow with
respect to variational parameters is the
same as minimizing the KL divergence
from the variational posterior to the
true posterior and this KL from the
variational steerer to the true
posterior quantifies the distance from
the variation of posterior to the true
posterior and it is known as the
variational gap because we can express
it also as the difference between the
marginal log-likelihood log P of X and
the variational bound L of X so this
means that when we are maximizing the
elbow with respect to the variational
parameters
we're actually minimizing the KL
divergence from the variational
posterior to the true posterior so we're
making sure that variational posterior
is a better and better fit to the true
posterior this is actually remarkable
because this this is a model which is
intractable so we cannot actually
compute the true posterior at all and we
can't even compute the scale divergence
from the variational posterior to the
true posterior because it involves the
true posterior which we can compute in
the first place so if we look at that
the composition of elbow from the
previous slide
the difference between the log marginal
likelihood and the KL from the
variational to the true posterior we
realize that the elbow is actually a
difference between two intractable
quantities and yet it is tractable so it
means that both of these quantities are
intractable in the same way so they have
this intractable part that's exactly the
same and we when we take the difference
between them it cancels out also looking
at this decomposition and remembering
that the KL divergence is non-negative
and it's 0 if and only if the two
distributions are effectively the same
it means that the best value of the
variation lower bound we can get is
actually the same as the marginal log
likelihood log P of X and that happens
when the KL is 0 and this can only
happen if Q is a very expressive
distribution that can approximate the
true posterior exactly so that's good
for understanding variational inference
but in practice is not going to happen
with a variational model now let's think
about maximizing the variational bound
with respect to the other set of
parameters the model parameters what
happens when we update these parameters
to increase the variational lower bound
well looking at the same decomposition
we see that well either the first term
the marginal log-likelihood
will increase or the second term will
have to decrease that's the only way to
get the increase in the variation lower
bound so let's look at the first option
when we update the parameters and the
marginal log likelihood increases this
is good because this is the same as what
maximum likelihood learning parameter
update does we're increasing the
marginal log likelihood but
what happens when the variational lower
bound is increased because we actually
decreased the variational gap well there
are two ways of decreasing the
variational gap so we've seen the first
one a couple of slides ago when we were
updating the variation of parameters and
because that was equivalent to
minimizing the KL from the variational
posterior to the true posterior that was
decreasing the variational gap as well
and doing this was clearly good because
we were getting a better and better
approximation for the variational
posterior of the true posterior and the
model was not affected by these updates
because the model is not affected by the
variational parameters on the other hand
now if we update the model parameters
and the variational gap decreases it it
means that the model has changed so the
way in with it changed there are two
possibilities so first of all the
inference in this model variational
inference of this model did become more
accurate because the variational
posterior remained the same but the true
posterior moved towards it so now
they're closer together but when this
happens this is actually not always
desirable because it means we're
spending some of the model capacity to
actually approximate the variation of
this terior rather than to model the
data so in a sense the model is trying
to contort itself so that inference in
it is easy and if we only have so much
capacity in the model it will probably
make it less good of a model of the data
so this means that if we are worried by
such effect if you would like to have as
faithful approximation to maximum
likelihood as possible we should use a
expressive of a variation of a steer as
possible because this will reduce the
variation or gap and there will be less
of a pressure for the model to distort
itself like that and one
particular manifestation of this effect
in model strain using variational
inference is called variational pruning
and this is when the model refuses to
use some of the latent variables so
they're essentially not used to generate
the data which means that their
posterior and their prior are exactly
the same
and when I say posterior I mean both the
true posterior and the variational
posterior because when the model is
unused its true posterior is the same of
the prior and it's very easy to
approximate with the variation of
Asteria
and this is in fact why variational
pruning happens because when you prune
out some variables it becomes easier to
perform variational inference so there's
this extra pressure on the model to be
simpler in that way and variational
pruning is also known as posterior
collapse in the operational autoencoder
literature so it's very tional pruning a
good thing or a bad thing well it
depends how you think about it in some
circumstances it can be a good thing
because you can think of it as choosing
the dimensionality of the latent space
automatically based on your data
distribution on the other hand it gives
away it takes away some of our freedom
to over fit to the data so sometimes in
deep learning you would like to have a
very accurate model of the training data
even if you're when you're not concerned
with overfitting and you can easily
achieve this by giving the model many
many hidden units so making the hidden
layers wider and then you are guaranteed
to or fit to the data often driving like
classification error to zero well if
you're training a generative model and
you would like to achieve something
similar overfitting to the data
arbitrarily well by giving it lots and
lots of latent variables well if you're
using a variational inference the model
will actually refuse to use extra
variables after some point and number of
variables it will use can be
surprisingly small and sometimes it's
clearly suboptimal so you would like the
model to use more variables but because
liberation posterior is too simple
compared to the true posterior it will
simply destroyed
are the rest of the latent variables and
how do we choose the form of the
variational posterior well the default
choice as I mentioned before is a fully
factorize distribution with each
dimension modeled independently and this
form is known as the mean field
approximation for historical reasons
because the method originated in physics
we can make the variational distribution
more expressive and we have several
choices for doing that
so one possibility is to use the mixture
model so instead of a unimodal
distribution we will have a multi-modal
distribution now if you were using a
variational posterior that's a diagonal
Gaussian which is a very common choice
we can introduce richard covariance
structure so we can for example have a
low rank or full covariance Gaussian at
separation or posterior we can make the
variational posterior or two regressive
which will make training more expensive
like many of the other choices but we'll
provide much more modeling power or
alternatively we can take an invertible
model and use it to parameterize the
variation of asturias flow and this
works very nicely because variational
models are tractable and ultimately
we're making this trade-off between the
computational cost of training the model
and the quality of the variation
approximation and perhaps fit to the
data on the other hand some of these
choices for the more expressive
mysterious also have some practical
downsides because you might run into
numerical instability problems so you
have to be careful and watch out for
that and sometimes when you use a richer
variational posterior you actually get
worse results and this should not happen
in theory if optimization is perfect but
due to various stability issues and
learning dynamics issues this can
actually happen
all right so let's think about what
we're doing when we're fitting a
variational distribution so first of all
the posterior distribution of course is
different for every observation X
because each X is generated by some
latent configuration that's more
probable than others so we have a
distribution of our plausible
explanations for X this means that we
need to fit a different variation of
posterior for each of servation
and in classical racial inference this
means that we simply have a separate set
of distribution parameters which of
derivation that we optimize over and
this also means that we perform a
separate optimization run for each data
point whether it's a training
observation or a test observe Asian to
fit the corresponding variation of
parameters this can be inefficient
because basically we we learn nothing
from fitting variational parameters for
one data point about all the other data
points so we can actually amortize this
cost by replacing this separate
optimization procedure for each data
point with some sort of functional
approximation so we will train a neural
network that will take the observation
and output an approximation to its
variational parameters and we will train
this network which we'll call the
inference Network to basically to serve
as the approximation told those
independent variational posteriors we
were training before and as a result now
instead of deforming potentially costly
iterative optimization for each data
point to obtain its posterior we simply
perform a forward pass in the inference
Network that gives us the variational
parameters and these are the ones that
we use for the operation of this theory
so now we replaced all these independent
variational parameters that were data
point specific with a single set of
neural network parameters that are
shared between all observations and we
amortize the cost of solving these
optimization problems among all
observations so once we've trained such
an inference network we can come
durational posterior for a new data
point simply by fitting the data point
today network and it will produce the
corresponding duration of the sphere so
this is a very powerful idea because it
allows us to easily scale up variational
inference to much bigger data sets and
models than before and this idea of
amortized inference was introduced in
the context of compost machines in the
mid 90s and it was popularised recently
by variational thinkers that rely on it
and as mentioned before the variational
parameters are trained jointly with the
model parameters simply by maximizing
the elbow with respect to both and now
we basically have two sets of neural
network parameters one for the model and
one for the in for instance let's step
back and think about what we gained and
what we gave up by performing
variational inference well now we can
train intractable models in a principled
way and relatively efficiently this lets
us choose any kind of model we want and
incorporate any kind of prior knowledge
into the model so that's great from the
modeling standpoint and inference is
quite fast especially if we use
amortization compared to MCMC methods so
some models are simply infeasible for
MCMC and variational inference makes it
possible to train them and what did we
lose well we do typically give up some
of the model capacity because we're not
using expressive enough variational
posterior but perhaps that's fine
because essentially in many cases
variational inference is the only option
for training a model is large on a data
set from a particular size so we either
have a slightly suboptimal fit or we
have to resort to a much simpler model
so we saw that training a model using
variational inference requires computing
the gradients of the variation lower
bound with respect to the model
parameters theta and the variation of
parameters Phi well
the elbow is actually an expectation so
computing gradients of the of an
expectation might not be so
straightforward so let's look at how we
can do this well in classic variational
inference the expectations were
typically computed in closed form and
then optimization did not involve any
kind of noise in the gradient estimates
because the objective function was
analytically tractable on the other hand
do you actually have expectations that
you can compute in a closed form
required models to be very simple as
well as the variational posteriors to be
generally fully factorized because
otherwise you couldn't compute the
expectations so variational inference in
its classic form was applicable to only
a small set of models on the other hand
recent developments in variational
inference replaced exact estimation of
the gradients with monte carlo based
estimation and here we don't try to
compute the expectation or its gradients
in closed form instead we use Monte
Carlo sampling from the variation and
posterior to estimated and that gives us
much more freedom in terms of what kind
of models we can handle and the answer
is essentially we can handle almost any
kind of latent variable model so let's
look at how we can estimate the
gradients of the elbow with respect to
the model parameters
this is actually the easy case so
expanding the definition of the elbow
there we see that only the joint
distribution of the model depends on the
model parameters inside the expectation
and the variation of posterior does not
depend on it also the expectation the
elbow involves is an expectation with
respect to the variational posterior
which does not depend on the model
parameters this means we can safely move
the gradient inside the expectation and
this means that the gradient of the
elbow with respect to the model
parameters is simply the expectation
under the variational thus terior of the
gradient of the log joint for the model
and this quantity is really easy to
estimate we simply sample from the
variation of posterior evaluate the
gradients of the log joint based on the
resulting samples and then we average
them and in practice given one sample
can be enough to train a model so one
thing to mention here is since we're
using sampling to estimate gradients
there is some noise in the gradient
estimates and basically gradient
estimate noise can be a bad thing
because it prevents us from using larger
learning rates so if the noise level is
too high we have to use a sufficiently
low learning rate to avoid divergence
which mean makes training models slower
so generally we would like to have
gradient estimates that are relatively
low variance increasing the number of
samples we take is an easy way of
reducing this variance now let's look at
the case of the gradient for the
variation of parameters this is a more
complicated situation because now the
gradient we are computing it involves
the parameters of the distribution the
expectation is over so we can simply
take the gradient inside the expectation
because this will result in incorrect
estimates so what do we do here well it
turns out that gradients of expect
of this form computing them is a
well-known a research pull-up problem
and there are several good methods for
estimating these gradients available so
let's look at the two major types of
unbiased gradient estimators of such
expectation so here we will look at the
general case of an expectation of a
function f in in variational inference
this F will be just log density ratio of
the joint to the variation of this Tyria
so the first type of the gradient
estimator is called reinforce or
likelihood ratio estimator and it's it's
very general so it can handle both
discrete and continuous latent variables
and it does not place any stringent
requirements on the function f that it
can handle so f can be non
differentiable so that's nice it's a
very general estimator the price to pay
for this is that the resulting gradient
estimates are relatively high variance
so unless you perform some additional
variance reduction in almost all
practical situations you need to use an
extremely tiny learning rate so this is
essentially infeasible so using or
enforce without variance reduction is
essentially hopeless the other type of
estimator is called reprimand
realization or pass wise estimator and
this estimator is considerably less
general it requires us to use continuous
latent variables and it supports only
some continuous latent variable
distributions but the class is quite
large it also requires the function
inside the expectation to be
differentiable but this is fine because
in variational inference this is
typically the kind of function that we
get but the big advantage of this
estimator is that out of the box it
gives you fairly low gradient variance
so you don't need to worry too much
about variance reduction and you can
still estimate the gradient which is
sufficiently low variance and train the
model sufficiently quickly so
let's look at the Ripper motorisation
trick which is essentially how pass wise
gradients are known in the modern
machine learning literature and the
high-level idea here is simply to take
the parameters of the distribution the
expectation is with respect to and
somehow move them outside the
distribution and inside the expectation
and once we've done that we're in the
same situation as for the gradient of
the model parameters for elbow because
now the distribution of the expectation
will not have the parameters we're
differentiating with respect to so we
can just take the gradient inside so how
do we achieve this we do this by remote
rising samples from the distribution Q
of Z and we do that by thinking of them
as a transformation of samples from some
fixed distribution with no parameters we
will call these samples epsilon and then
we will apply some deterministic
differential transformation to it we
will call G that will incorporate the
dependence on the parameters into the
sample so epsilon that comes from the
epsilon does not depend on any
parameters but once we transform it
using G epsilon Phi s that now depends
on the parameter is Phi through this
function G so we factored out the
randomness from the samples and the
parameters in two separate boxes so now
that we've done this factorization we
can rewrite the expectation of F with
respect to distribution Q in terms of G
so now we replace Z inside as the
argument of F with G Epsilon Phi because
that's how we computed that and because
we generate that by sampling from P of
Epsilon now the expectation is with
respect to absolute rather than that so
now the expectation is with respect to
the distribution that does not depend on
the variation of parameters so we can
now safely take the gradient with
respect to fly inside the expectation
and now we compute the gradient of F of
G with respect to Phi by using the chain
rule and remembering that G of epsilon
Phi is simply Z so then we evaluate the
gradient of F at Z where Z is equal to G
Epsilon Phi and then multiply it by the
gradient of samples Z
as a function of parameters file and
this expectation has the same form as
the gradient of the elbow with respect
to the model parameters so we can
estimate it by sampling from the
distribution P epsilon and averaging the
gradients over the sample and we get a
low variance graduate estimate like that
so as I explained before our permutation
trick essentially moves the dependence
on the parameters of the distribution
from the distribution itself into its
samples and thus inside the expectation
the main requirement here is that the
resulting mapping that takes epsilon to
that has to be differentiable with
respect to the parameters Phi because
when we factor out the randomness in the
parameters into two separate bits we're
essentially propagating gradients
through Z and into the function and its
parameters so let's see how we can
repeat rise the one dimensional Gaussian
random variable Z that comes from a
distribution with mean mu and standard
deviation Sigma well if we start with a
standard normal
epsilon we can scale it by Sigma and
then add the mean mu and then we get
exactly the right distribution for that
so we can see that the mapping that we
use mu plus Sigma Epsilon is
differentiable with respect to both mu
and epsilon so it satisfies the apparent
the requirements of the parameters H so
this is a valid your parameters H and
this is how Gaussian sorry premature
eyes in practice so what about other
distributions so many distributions such
as those in the location scale family
such as laplace M Kashi can be
reprimanded of this approach for some
other discontinues distributions such as
gamma in der slay there is actually no
way to factor out randomness out of
parameter dependence so we can separate
these things to
there is a generalization of reprimand
ization called implicit reprimands ation
that still allows us to propagate
gradients through samples from such
distributions on the other hand there
are some continuous distributions that
cannot be reproduced and all discrete
distributions cannot be repeated for the
simple reason that even though we can
factor out randomness and parameter
dependence the function that we end up
with is not differentiable so applying
your immunization trick will not give us
the right gradients the good news is if
you want to use the real promoters ation
for continuous distributions modern deep
learning frameworks such as tensor flow
and pi torch implement this for you so
all you have to do is to pass the flag
that you want your sample re permit
rised when you're generating it from one
of the standard distributions and
automatic differentiation will take care
of everything so implementing
variational inference this way now is
very easy so now let's look at perhaps
the most successful application of
rational inference in recent years and
that's variational autoencoders so
variational auto-encoders are simply
generative models with continuous latent
variables where both the likelihood p of
x given Z and the variational posterior
are parameterize using neural networks
typically the prior and the variational
posterior are modeled as fully
factorized gaussians and VI use a
trained using variational inference by
maximizing the elbow using both
amortized inference and the upper
motorisation trick and this combination
of using expressive mappings for the
likelihood and liberation of posterior
and amortized inference and remote
ization made via is very popular because
they are highly scalable and yet
expressive models
so let's look at a slightly more
detailed description of a variational
autoencoder so we start with a prior P
of Z which is typically a standard
normal and then our decoder
which is another term for likelihood in
VI you speak will simply be either a
neural network computing the parameters
of a Bernoulli distribution if we're a
modeling binary data or a neural network
computing the mean and the diagonal
variance of a Gaussian distribution if
we are modeling real-valued eight and
for the variation of posterior once
again we use a neural network that
outputs the parameters of the variation
of posterior after taking the
observation X as the input and the type
of the neural network we use to
parameterize these models doesn't really
matter it doesn't change the
mathematical structure of the model so
you can easily use kind of Nets res Nets
or any kind of neural network you would
like and when training V is the elbow is
typically written in a slightly
different way from the one that we've
seen before so the elbow is decomposed
into two tractable terms this time so
the first term is the expectation over
the variational posterior of log P of X
given that so this is log likelihood and
the second term is just minus the KL
divergence from the variational
posterior to the prior because here the
second argument is the prior rather than
the true posterior this can actually be
computed and in fact this is often
computed in closed form which is easy to
do for a distribution such as gaussians
so the first term essentially measures
how well can we predict or reconstruct
the given observation after sampling
from its variational posterior and this
term is typically known as the negative
reconstruction error so high values of
it are good the second term we can think
of it as a regularizer
that pushes the variational posterior
towards the prior to make sure that we
put not too much information into the
latent variables in order to reconstruct
the observations well
and this scale is essentially an upper
bound on the amount of information about
the observation we have in the latent
variables under the variation of this
interior so the the model has been
around for quite a few years and it has
been extended in many many ways so now
it's really more of a framework than an
actual model so the framework generally
means that this is a model with
continuous latent variables trained
using amortized variational inference
and the Ripper motorization trick and
the extensions that have been discovered
for the AES are numerous so for example
here I covered only a single latent
layer well you can have multiple latent
layers you can have latent variables
that are non Gaussian you can have much
more expressive priors and mysterious so
for example you can use invertible
models for both you can use richer
neural networks for example rez nets or
you can have Auto regressive likelihood
terms so that you combine some of the
properties of other aggressive models
with latent variable models and people
have also worked on improving
variational inference either by making
it slightly closer to classic
variational inference and so the
one-shot making it slightly iterative
where you do only a couple of updates
and also people have worked on variance
reduction in order to get lower variance
gradients so we can train the models
faster so to conclude this lecture has
covered two modern approaches to
powerful latent variable models which
are both based on likelihoods and they
make rather different decisions about
what's important whether its exact
inference or freedom in model design and
this classification of models into these
different types is useful for
presentation purposes but some of the
most interesting work is actually about
combining models of different types
which allows you to basically take
advantage of their complementary
strengths so I mentioned for example
using auto regressive
decoders in variational Auto encourage
you can also use auto regressive
exteriors and so on and you get the
extra modeling power of auto regressive
distributions and yet you still retain
potential interpretability with latent
variables and what's exciting about this
area is that it's still relatively new
and developing very rapidly so there are
many substantial contributions that
remain to be made
you |
1c16b510-1481-4e57-ad46-8e432a2b83a3 | trentmkelly/LessWrong-43k | LessWrong | Be a new homunculus
Here's a mental technique that I find useful for addressing many dour feelings, guilt among them:
When you're feeling guilty, it is sometimes helpful to close your eyes for a moment, re-open them, and pretend that you're a new homunculus.
A "homunculus" is a tiny representation of a human, and one classic fallacy when reasoning about how brains work is the homunculus fallacy, in which people imagine that "they" are a little homonculus inside their head looking at an image generated by their eyes.
It's an easy fiction to buy into, that you're a little person in your head that can move your hands and shape your mouth and that decides where to steer the body and so on. There is, of course, no homunculus inside your head (for if you are steered by a homunculus, then how is the homunculus steered?), but it can be quite fun to pretend that you are a homunculus sometimes, mostly because this allows you to occasionally pretend you're a new homunculus, fresh off the factory lines, and newly installed into this particular person.
Close your eyes, and pretend you're arriving in this body for the very first time. Open them and do some original seeing on this person you now are. Rub your hands together, look around, and take stock of your surroundings. Do some internal checks to figure out what this body values, to figure out what it is you're fighting for. Check the catalog of plans and upcoming actions. Check the backlog of memories and obligations.
There will probably be some housecleaning to do: homunculi are known to get a little careless as they age, and the old homunculus that you replaced probably let a bunch of useless tasks accumulate without realizing it. As a new homunculus you have the privilege of pruning the things that obviously need pruning. Maybe you'll look and say "Ah, yes, we're going to cancel lunch with that person; this body was secretly dreading it. I also see that this body is currently spending a lot of cycles feeling guilty about a date that went |
527d096d-ff41-4a01-b78f-996e2980fb5b | trentmkelly/LessWrong-43k | LessWrong | Explicit Expectations when Teaching
Epistemic Status: Casual thoughts on small ways to improve teaching flows.
In the lectures for my current classes, things don't always make sense. Sometimes the not making sense comes from a feeling of incompleteness. The definition seems incomplete. I notice that I don't have enough info to fully explain the concept.
Generally I've noticed two reasons for this. This first is that there was some assumed prior knowledge. Sometimes that can be explicit. Maybe I was supposed to know multivariate calculus for this course, yet there was some concept I missed that is being used here. Other times the assumption of prior knowledge is implicit. This is when the professor didn't realize that there was something to explain (i.e unaware of inferential distance).
In these cases, the best route is to ask a question.
In other cases, the professor purposefully gave an incomplete explanation, which they proceed to expand on in the following slide.
In this case, the best route is to put a mental astericks next to new concept and hold tight.
A problem arises from the fact that almost all of the professors I've had (and most people just trying to casually teach me something) talk in a way where I can't distinguish what is assumped prior knowledge and what is a placeholder to be filled in later. This leads to wasted movement. I might ask a lot of questions that get "Hold on for two minutes" as a reply, or I might never explore an idea myself because I figure it will be explained at some point. I think that being explicit can make it much easier for one trying to learn.
In conversation, I can imagine a simple habit of tagging a word or concept with a mental astericks and making clear that you currently are presenting a "working explanation". Something like "A linear seperator divides n-dimensional space in to two region. We'll circle back to how it does that in a sec."
If you teach in any sort of formal setting and use visual aids, it could be worthwhile to introduce a convention |
c5d5df3a-4fde-4891-a5be-f4ce66f33429 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Demanding and Designing Aligned Cognitive Architectures
This post is to announce my new paper [Demanding and Designing Aligned
Cognitive Architectures](https://arxiv.org/abs/2112.10190), which I
recently presented in the [PERLS](https://perls-workshop.github.io/)
workshop (Political Economy of Reinforcement Learning)] at NeurIPS
2021.
In this post, I will give a brief overview of the paper, specifically
written for this forum and the LW/EA communities. I will highlight some
of the main differences with the AI alignment approaches and outlooks
more often discussed here.
The comment section below can be used for general comments and Q&A
about the entire paper.
Scope of the paper
==================
The main focus of this paper is to improve the global debate about the
*medium-term* alignment problems in purple below.

In the last few years, these two problems have moved inside society's
[Overton window](https://en.wikipedia.org/wiki/Overton_window), not
only in the West but also in China. So it is topical to write papers
which focus specifically on improving the debate about these two
problems.
But I also have more long-term, x-risk related motivation for
discussing these two problems. If society develops better tools and
mechanisms for managing them, I expect that it will also become better
at managing the long-term x-risk problems on the right.
Alignment as a policy problem
=============================
The word *demanding* describes a political act, whereas *designing* is
a technical act. The phrase 'Demanding and Designing' in the paper
title gives a hint that there will be a cross-disciplinary
discussion inside. This discussion fuses insights about running
political processes with insights about AI technology.
On this forum and in the broader Rationalist/EA web sphere, it is
common to see posts which treat all political activity as a source of
irrationality and despair only. In the paper, I develop a very
different viewpoint.
I treat politics as the sum total of activities in society that
contribute to creating, updating, and legitimizing [social
contracts](https://en.wikipedia.org/wiki/Social_contract). Social
contracts can be encoded in law, customs, institutions, code, or all
of the above. They aim to produce mutual benefit by binding the
actions of society's stakeholders.
In this framing, AI alignment policy making is the activity of having
a broad debate that will update our existing social contracts.
Updates of social contracts are preferably decided on in a debate that
will involve all affected stakeholders at some stage, or at least
involve their representatives.
These are all pretty standard Enlightenment ideas. Crucially, these
ideas can applied to both global and local policy debates.
Social contract theory does not absolutely require that every
stakeholder has to be consulted or satisfied, in order for a new
contract to be legitimate. In this, it stands apart from another
approach to legitimacy which is often mentioned on this forum: the
approach of seeking legitimacy for proposals by claiming that they
represent a [Pareto
improvement](https://en.wikipedia.org/wiki/Pareto_efficiency). I have
have been in applied politics. In my experience, the strategy of
trying to offend nobody by seeking Pareto improvements almost never
works.
So much for discussing moral and political theory. In the paper, I
only discuss theory in one small section. The paper devotes much more
space to applied politics, to topics like understanding and
controlling the prevailing narrative flows in the alignment debate.
The participants in the AI alignment policy debate will have to
overcome many obstacles. Many of these obstacles are of course no
different from those encountered by the participants in the global
warming debate, in the global debate about improving cybersecurity,
etc.
In the paper, I am not wasting any ink on enumerating these general
obstacles. Instead, I start by saying that I will cover three only
three obstacles, three obstacles which happen to be specific to the AI
alignment problem.
When considering how to lower these obstacles, I also take a fresh look
at some questions more often discussed on this forum:
* How do we usefully move beyond the concepts of goal-directness and
reward maximization?
* How must alignment research relate to 'mainstream' ML research?
My answers are included further below.
Abstract of the paper
=====================
The paper does not present a single idea, it develops several
interconnected ideas and approaches. Here is the abstract, with
some re-formatting.
>
> With AI systems becoming more powerful and pervasive, there is
> increasing debate about keeping their actions aligned with the broader
> goals and needs of humanity. This multi-disciplinary and
> multi-stakeholder debate must resolve many issues, here we examine
> three of them.
>
>
> * The first issue is to clarify what demands stakeholders might usefully make
> on the designers of AI systems, useful because the technology exists
> to implement them.
> We make this technical topic more accessible by
> using the framing of cognitive architectures.
> * The second issue is to move beyond an analytical
> framing that treats useful intelligence as being reward
> maximization only. To support this move, we define several AI
> cognitive architectures that combine reward maximization with other
> technical elements designed to improve alignment.
> * The third issue is how stakeholders should calibrate their
> interactions with modern machine learning researchers. We consider
> how current fashions in machine learning create a narrative pull that
> participants in technical and policy discussions should be aware of,
> so that they can compensate for it.
>
>
> We identify several technically tractable but currently unfashionable
> options for improving AI alignment.
>
>
>
Cognitive architectures
=======================
A *cognitive architecture* is a set of interconnected building blocks
which create a *cognitive process*, where a cognitive process is one
that uses observations to decide on actions. It is common in AI
research to apply the cognitive architecture framing to the analysis
of both human and machine minds. In the paper, I extend this framing
by considering how companies and governments also use cognitive
architectures to make decisions.
I also consider how many modern social contracts encode extensive
demands on the behavior of governments and companies, to make these
large and powerful synthetic intelligences more human-aligned. Many
of these demands can be interpreted as demands on the design of the
cognitive architectures that governments and companies are allowed to
use for decision making, in pursuit of their goals.
I show how we can take such demands and also apply them to the design
of cognitive architectures used by powerful AIs. In fact, this is the
pattern of policy making already used in AI fairness. I show in the
paper how it can be extended beyond fairness.
Using the lens of cognitive architectures to move beyond pure reward maximization
=================================================================================
In the broad alignment debate, and also in the AGI debate on this
forum, the most common mental model of a reinforcement learner is as
follows. A reinforcement learner is a black box containing a mind
which aims to maximize a reward, a box which also happens to have some
sensors and actuators attached.
In the paper, I go inside of this black box. I show that there is a
cognitive architecture inside which has many distinct and legible
individual building blocks. I picture the mind of a generic
reinforcement learner like this:

This picture has many moving parts, which we might all consider
tweaking, if we want to turn a powerful reinforcement learner into a
more human-aligned powerful reinforcement learner. One important
tweak I consider is to add these extra green building blocks:

Progress on the alignment problem
=================================
In the paper, I show how this idea of demanding the use of a
'specifically incorrect predictive world model' inside the AI can be
applied to many types of alignment. It can be used to reason about
and resolve:
* short-term AI alignment problems, like computational fairness
* medium-term AI alignment problems, like ensuring that market-facing
reinforcement learners do not game the market too much
* long-term alignment problems, like making an AGI ignore the
existence of its stop button, and the existence of other built-in
safety mechanisms.
Overall, the broad applicability of this 'specifically incorrect world
model' concept has made me more optimistic about the tractability of
long-term alignment, both at a technical and at a policy level.
Discussions on this forum often treat AGI alignment as something
unique, as something which will require the invention of entirely new
paradigms to solve. The claim that AGI alignment is
'pre-paradigmatic' encodes the assumption that there is a huge
technical and policy-making gap between the problems of short-term
alignment and the problems of long-term alignment. I do not see this
gap, I see a broad continuum.
Alignment research is not a sub-field of modern ML research
===========================================================
This brings me to another paradigm, another basic assumption often
encoded in posts appearing on this forum. This is the assumption that
AI alignment research is, or must urgently become, a sub-field of
modern ML research. In the paper, I examine in detail why this is a
bad idea.
To make an analogy with the industrial revolution: treating the impact
of ML on society as an ML research problem makes about as much sense
as treating the impact of the stream engine on society as a steam
engine engineering problem.
I argue that a better way forward is to declare that many of the
problems in AI alignment are broad political and [systems
engineering](https://en.wikipedia.org/wiki/Systems_engineering)
problems, not ML research problems. I argue that it is both
ineffective and unkind to expect that modern ML researchers should
lead every charge in the alignment debate.
Intended audience of the paper
==============================
I wrote this paper to be accessible to all readers from a general,
multi-disciplinary but academic-level audience. I do assume however
that the reader has some basic familiarity with the technical and
political problems discussed in the alignment literature.
The latest version of the paper is [here](https://arxiv.org/abs/2112.10190).
In a big difference with my
[earlier](https://arxiv.org/abs/1908.01695)
[papers](https://arxiv.org/abs/2007.05411) on
[alignment](https://arxiv.org/abs/2102.00834), there is not even
single line of math inside. |
ed277994-ea37-4f77-8f2c-2e4cacb9e3a2 | trentmkelly/LessWrong-43k | LessWrong | Can this model grade a test without knowing the answers?
In the 2012 paper "How To Grade a Test Without Knowing the Answers — A Bayesian Graphical Model for Adaptive Crowdsourcing and Aptitude Testing" (PDF), Bachrach et al describe a mathematical model for starting with
* a set of questions without answers
* a set of answerers (participants) of unknown quality
and ending up with assessments of:
* correct answers for the questions
* assessed difficulty for the questions
* evaluations of the participants, including overall reliability and areas of expertise
Can the model actually do this? Is it the best model for doing this? What kind of problems does it handle well and poorly? |
0025ee49-9a9f-4a6e-83e6-10b392e9e32b | trentmkelly/LessWrong-43k | LessWrong | EA & LW Forums Weekly Summary (12th Dec - 18th Dec 22')
Supported by Rethink Priorities
This is part of a weekly series summarizing the top posts on the EA and LW forums - you can see the full collection here. The first post includes some details on purpose and methodology. Feedback, thoughts, and corrections are welcomed.
If you'd like to receive these summaries via email, you can subscribe here.
Podcast version: prefer your summaries in podcast form? A big thanks to Coleman Snell for producing these! Subscribe on your favorite podcast app by searching for 'EA Forum Podcast (Summaries)'. More detail here.
Author's note: I'm heading on holidays, so this will be the last weekly summary until mid-January. Hope you all have a great end of year!
Top / Curated Readings
Designed for those without the time to read all the summaries. Everything here is also within the relevant sections later on so feel free to skip if you’re planning to read it all. These are picked by the summaries’ author and don’t reflect the forum ‘curated’ section.
Announcing WildAnimalSuffering.org, a new resource launched for the cause
by David van Beveren
Vegan Hacktivists released this website, which educates the viewer on issues surrounding Wild Animal Suffering, and gives resources for getting involved or learning more. Their focus was combining existing resources into something visually engaging and accessible, as an intro point for those interested in learning about it. Please feel free to share with your networks!
The winners of the Change Our Mind Contest—and some reflections
by GiveWell
First place winners of GiveWell’s contest for critiques of their cost-effectiveness analyses:
* GiveWell’s Uncertainty Problem by Noah Haber: The author argues that without properly accounting for uncertainty, GiveWell is likely to allocate its portfolio of funding suboptimally, and proposes methods for addressing uncertainty.
* An Examination of GiveWell’s Water Quality Intervention Cost-Effectiveness Analysis by Matthew Romer and Paul Ro |
914213c5-1f61-495b-ae68-23a70d1729a2 | trentmkelly/LessWrong-43k | LessWrong | Review: LessWrong Best of 2018 – Epistemology
Cross-posted from Putanumonit. Some of this post is relevant mostly to readers of my blog who aren't LessWrongers, but you may still be interested in my general thoughts about the essays, the book as an artifact, and the state of the community.
----------------------------------------
Is there a better way to bid goodbye to 2020 than with a book set of the best Rationalist writing of 2018? I wouldn’t know — Ben Pace, who compiled and edited the set, sent me a review copy and so I spent Christmas day reading the Epistemology entry. So this post is a review, and of more than just the books.
A great thing you’ll notice right away about the books is that they smell exactly like Wiz, the Israeli video game magazine from the 90s that was the joy of my middle school years. A not-so-great thing about the books is that they’re small. The essays are printed in a very small font and the quotes within each essay are printed, for some reason, in an even smaller font. There are rumors that inside the quotes the secrets of the universe are rendered in the tiniest font of all, but I lack the visual acuity to discern if that is the case.
The book set looks almost comical next to the hardcover SlateStarCodex collection on my shelf:
Ironically, this juxtaposition describes the state of the Rationality community when I discovered it in early 2014. That year was Scott Alexander’s unassailable annus mirabilis. In the span of 12 months he taught us about outgroups and the gray tribe, Moloch, fashions, layers and countersignaling, words and categories, toxoplasma, the psychology of EA and of social justice, drugs, other drugs, better drugs, scientific validity, and whale cancer.
The same period for LessWrong is described by Ben Pace in the introduction to the book set as “a dark age from 2014-2017, with contributions declining and the community dispersing”. This led to the LessWrong 2.0 team forming in 2018, and, as the book set can attest, ushering in a true renaissance of rationali |
7edb221a-5834-4627-ac7f-3876cbe60f11 | trentmkelly/LessWrong-43k | LessWrong | Rationality Reading Group: Part P: Reductionism 101
This is part of a semi-monthly reading group on Eliezer Yudkowsky's ebook, Rationality: From AI to Zombies. For more information about the group, see the announcement post.
----------------------------------------
Welcome to the Rationality reading group. This fortnight we discuss Part P: Reductionism (pp. 887-935). This post summarizes each article of the sequence, linking to the original LessWrong post where available.
P. Reductionism 101
189. Dissolving the Question - This is where the "free will" puzzle is explicitly posed, along with criteria for what does and does not constitute a satisfying answer.
190. Wrong Questions - Where the mind cuts against reality's grain, it generates wrong questions - questions that cannot possibly be answered on their own terms, but only dissolved by understanding the cognitive algorithm that generates the perception of a question.
191. Righting a Wrong Question - When you are faced with an unanswerable question - a question to which it seems impossible to even imagine an answer - there is a simple trick which can turn the question solvable. Instead of asking, "Why do I have free will?", try asking, "Why do I think I have free will?"
192. Mind Projection Fallacy - E. T. Jaynes used the term Mind Projection Fallacy to denote the error of projecting your own mind's properties into the external world. The Mind Projection Fallacy generalizes as an error. It is in the argument over the real meaning of the word sound, and in the magazine cover of the monster carrying off a woman in the torn dress, and Kant's declaration that space by its very nature is flat, and Hume's definition of a priori ideas as those "discoverable by the mere operation of thought, without dependence on what is anywhere existent in the universe"...
193. Probability is in the Mind - Probabilities express uncertainty, and it is only agents who can be uncertain. A blank map does not correspond to a blank territory. Ignorance is in the mind.
194. The Quotatio |
ab397cab-7823-4e35-ba0a-3ce3d2e373b2 | trentmkelly/LessWrong-43k | LessWrong | Introducing the Longevity Research Institute
I’ve just founded a nonprofit, the Longevity Research Institute — you can check it out here.
The basic premise is: we know there are more than 50 compounds that have been reported to extend healthy lifespan in mammals, but most of these have never been tested independently, and in many cases the experimental methodology is poor.
In other words, there seems to be a lot of low-hanging fruit in aging. There are many long-lived mutant strains of mice (and invertebrates), there are many candidate anti-aging drugs, but very few of these drugs have actually been tested rigorously.
Why? It’s an incentives problem. Lifespan studies for mice take 2-4 years, which don’t play well with the fast pace of publication that academics want; and the FDA doesn’t consider aging a disease, so testing lifespan isn’t on biotech companies’ critical path to getting a drug approved. Mammalian lifespan studies are an underfunded area — which is where we come in.
We write grants to academic researchers and commission studies from contract research organizations. Our first planned studies are on epitalon (a peptide derived from the pineal gland, which has been reported to extend life in mice, rats, and humans, but only in Russian studies) and C3 carboxyfullerene (yes, a modified buckyball, which prevents Parkinsonism in primate models and has been reported to extend life in mice). I’m also working on a paper with Vium about some of their long-lived mice, and a quantitative network analysis of aging regulatory pathways that might turn up some drug targets.
We’re currently fundraising, so if this sounds interesting, please consider donating. The more studies that can be launched in parallel, the sooner we can get results.
|
d4932252-8226-40b4-9b8b-8f50bd56a207 | trentmkelly/LessWrong-43k | LessWrong | Dreaming of Political Bayescraft
|
a979d0ac-627c-4827-a81a-9a8955a6308d | trentmkelly/LessWrong-43k | LessWrong | NVIDIA and Microsoft releases 530B parameter transformer model, Megatron-Turing NLG
> In addition to reporting aggregate metrics on benchmark tasks, we also qualitatively analyzed model outputs and have intriguing findings (Figure 4). We observed that the model can infer basic mathematical operations from context (sample 1), even when the symbols are badly obfuscated (sample 2). While far from claiming numeracy, the model seems to go beyond only memorization for arithmetic.
>
> We also show samples (the last row in Figure 4) from the HANS task where we posed the task containing simple syntactic structures as a question and prompted the model for an answer. Despite the structures being simple, existing natural language inference (NLI) models often have a hard time with such inputs. Fine-tuned models often pick up spurious associations between certain syntactic structures and entailment relations from systemic biases in NLI datasets. MT-NLG performs competitively in such cases without finetuning.
Seems like next big transformer model is here. No way to test it out yet, but scaling seems to continue, see quote.
It is not mixture of experts, so parameters mean something as compared to WuDao (also it beats GPT-3 on PiQA and LAMBADA).
How big of a deal is that? |
d14f9a9b-3b97-406a-ba28-c0f3a29f4b61 | StampyAI/alignment-research-dataset/arbital | Arbital | Logarithms invert exponentials
The function [$\log_b](https://arbital.com/p/3nd) inverts the function $b^{(\cdot)}.$ In other words, $\log_b(n) = x$ implies that $b^x = n,$ so $\log_b(b^x)=x$ and $b^{\log_b(n)}=n.$ (For example, $\log_2(2^3) = 3$ and $2^{\log_2(8)} = 8.$) Thus, logarithms give us tools for analyzing anything that grows [exponentially](https://arbital.com/p/4ts). If a population of bacteria grows exponentially, then logarithms can be used to answer questions about how long it will take the population to reach a certain size. If your wealth is accumulating interest, logarithms can be used to ask how long it will take until you have a certain amount of wealth. (TODO) |
da2f0a0e-b6ad-48be-947c-74a4ccc9d3ca | trentmkelly/LessWrong-43k | LessWrong | Some Arguments Against Strong Scaling
There are many people who believe that we will be able to get to AGI by basically just scaling up the techniques used in recent large language models, combined with some relatively minor additions and/or architectural changes. As a result, there are people in the AI safety community who now predict timelines of less than 10 years, and structure their research accordingly. However, there are also people who still believe in long(er) timelines, or at least that substantial new insights or breakthroughts will be needed for AGI (even if those breakthroughts in principle could happen quickly). My impression is that the arguments for the latter position are not all that widely known in the AI safety community. In this post, I will summarise as many of these arguments as I can.
I will almost certainly miss some arguments; if so, I would be grateful if they could be added to the comments. My goal with this post is not to present a balanced view of the issue, nor is it to present my own view. Rather, my goal is just to summarise as many arguments as possible for being skeptical of short timelines and the "scaling is all you need" position.
This post is structured into four sections. In the first section, I give a rough overview of the scaling is all you need-hypothesis, together with a basic argument for that hypothesis. In the second section, I give a few general arguments in favour of significant model uncertainty when it comes to arguments about AI timelines. In the third section, I give some arguments against the standard argument for the scaling is all you need-hypothesis, and in the fourth section, I give a few direct arguments against the hypothesis itself. I then end the post on a few closing words.
Glossary:
LLM - Large Language Model
SIAYN - Scaling Is All You Need
The View I'm Arguing Against
In this section, I will give a brief summary of the view that these arguments oppose, as well as provide a standard justification for this view. In short, the view i |
a4677c78-403c-4de7-8ce1-73f3a63bc424 | trentmkelly/LessWrong-43k | LessWrong | The path of the rationalist
This is the last of four short essays that say explicitly some things that I would tell an intrigued proto-rationalist before pointing them towards Rationality: AI to Zombies (and, by extension, most of LessWrong). For most people here, these essays will be very old news, as they talk about the insights that come even before the sequences. However, I've noticed recently that a number of fledgling rationalists haven't actually been exposed to all of these ideas, and there is power in saying the obvious.
This essay is cross-posted on MindingOurWay.
----------------------------------------
Once upon a time, three students of human rationality traveled along a dusty path. The first was a novice, new to the art. The second was a student, who had been practicing for a short time. The third was their teacher.
As they traveled, they happened upon a woman sitting beside a great urn attached to a grand contraption. She hailed the travellers, and when they appeared intrigued, she explained that she was bringing the contraption to town (where she hoped to make money off of it), and offered them a demonstration.
She showed them that she possessed one hundred balls, identical except for their color: one was white, ninety nine were red. She placed them all in the urn, and then showed them how the contraption worked: the contraption consisted of a shaker (which shook the urn violently until none knew which ball was where) and a mechanical arm, which would select a ball from the urn.
"I'll give you each $10 if the white ball is drawn," she said over the roar of the shaker. "Normally, it costs $1 to play, but I'll give you a demonstration for free."
As the shaking slowed, the novice spoke: "I want it to draw the white ball, so I believe that it will draw the white ball. I have faith that the white ball will be drawn, and there's a chance I'm right, so you can't say I'm wrong!"
As the shaking stopped, the student replied, "I am a student of rationality, and I know that it is a |
0d547405-8fff-4dfe-b4a7-fc9e059e9951 | trentmkelly/LessWrong-43k | LessWrong | Freaky Fairness
Consider this game:
where the last payoff pair is very close to (3,2). I choose a row and you choose a column simultaneously, then I receive the first payoff in a pair and you receive the second. The game has no Nash equilibria in pure strategies, but that's beside the point right now because we drop the competitive setting and go all cooperative: all payoffs are in dollars and transferable, and we're allowed beforehand to sign a mutually binding contract about the play and the division of revenue. The question is, how much shall we win and how should we split it?
Game theory suggests we should convert the competitive game to a coalitional game and compute the Shapley value to divide the spoils. (Or some other solution concept, like the "nucleolus", but let's not go there. Assume for now that the Shapley value is "fair".) The first step is to assign a payoff to each of the 2N = 4 possible coalitions. Clearly, empty coalitions should receive 0, and the grand coalition (me and you) gets the maximum possible sum: 6 dollars. But what payoffs should we assign to the coalition of me and the coalition of you?
Now, there are at least two conflicting approaches to doing this: alpha and beta. The alpha approach says that "the value a coalition can get by itself" is its security value, i.e. the highest value it can win guaranteed if it chooses the strategy first. My alpha value is 2, and yours is 2+ϵ2. The beta approach says that "the value a coalition can get by itself" is the highest value that it cannot be prevented from winning if it chooses its strategy second. My beta value is 3+ϵ1, and yours is 3.
Astute readers already see the kicker: the Shapley value computed from alphas assigns 3-ϵ2/2 dollars to me and 3+ϵ2/2 dollars to you. The Shapley value of betas does the opposite for ϵ1. So who owes whom a penny?
That's disturbing.
Aha, you say. We should have considered mixed strategies when computing alpha and beta values! In fact, if we do so, we'll find that my alp |
c6ba6169-7138-4fe4-8b7f-3249e3377388 | trentmkelly/LessWrong-43k | LessWrong | On Inconvenient Truth
What are your politics?
What frameworks have you acquired for structuring your interaction with the world?
What facts support them?
What possibilities would undermine them? What significant counterexamples could exist, and which of them could prove to be fact?
----------------------------------------
Ludwig Wittgenstein said:
> If there were a verb meaning "to believe falsely," it would not have any significant first person, present indicative.
I assert that this is not as true as it seems. Yes, few if any people are willing or able to admit that they hold any specific false belief. If you don't count beliefs in belief or aliefs, it's speculative whether it's logically possible. But I, for one, do believe falsely. I falsely believe something. I am quite sure of it.
----------------------------------------
The world is wide, and beliefs are complex. Systems of beliefs, like politics, ideology, frameworks, even more so. A complex set of beliefs has many premises it rests on; perhaps none is individually a crux, but propositions that, if false, would cast the rest into doubt in a serious way.
And because there are so many, it is extremely likely, near-certain, that at least one of them is wrong. For almost any political position, there is at least one inconvenient fact.
You may not know it. Perhaps it turns out that, contrary to your ideals of rational actors and self-determination, people born with strawberry-blonde hair are inherently dangerously biased toward pyromania and risk-seeking behavior that they do not endorse, and no one has proposed this, let alone investigated it. Maybe there is a curiously-specific unified field theory that proves that blue is the best color.
But somewhere, the fact is out there. The world is not politically convenient; whatever you wish to believe, there is, somewhere, a fact that will cast doubt on it.
So what should you do?
You could take a strong stance of epistemic and moral modesty, and never take a position with c |
4fc2f59e-91d0-40d8-8630-06ba758f0663 | trentmkelly/LessWrong-43k | LessWrong | Language for Goal Misgeneralization: Some Formalisms from my MSc Thesis
The following is an edited excerpt from the Preliminaries and Background sections of my now completed MSc thesis in Artificial Intelligence from the University of Amsterdam.
In the thesis, we set out to tackle the issue of Goal Misgeneralization (GMG) in Sequential Decision Making (SDM)[1] by focusing on improving task specification. Below, we first link GMG to causal confusion, motivating our approach. We then outline specifically what we mean by task specification, and later discuss the implications for our own definition of GMG.
I am sharing this here because I believe the ideas presented here are at least somewhat interesting and have not seen them discussed elsewhere. We ultimately did not publish the thesis, so rather than keeping these to myself, I figured I'd at least share them here.
You can find the full thesis along with its code here.
Causal Confusion and Goal Misgeneralization
Inspired by the works of Gupta et al. (2022) and Kirk and Krueger (2022), we hold the view that GMG is a direct consequence of causal confusion (CC) (de Haan, Jayaraman, and Levine 2019). This is the phenomenon by which a learner incorrectly identifies the causal model underlying its observations and/or behaviour. This is typically due to spurious correlations between the true cause X for a random event Y and some other variable W that does not causally model Y. We posit that CC may lead to GMG when the confounding variable, i.e. the variable spuriously correlated with the causal factor, is easier to learn.
Accordingly, we note that GMG may therefore be addressed by tackling CC itself. In light of this, we can distinguish three approaches. The first involves performing causal inference with the assistance of interventions on the data so to better discover the underlying causal model. This is the main approach of de Haan, Jayaraman, and Levine (2019). The second approach simply increases the variability of the training data so as to reduce the likelihood of spurious correlati |
5ba4470f-34d0-4303-9482-ff498631ef26 | trentmkelly/LessWrong-43k | LessWrong | NIPS 2015
There is a fairly large contingent of safety research oriented people at NIPS this year. I'm unfortunately not among them, but if you're there and interested in connecting with others on AI safety topics or other LW issues - general rationality, EA, etc. I welcome you to make this thread a Schelling point to create meeting opportunities :). You can also PM me I can connect you to people I know are there. |
0d8b7a33-8d23-4aad-aab6-7a0331703f4f | trentmkelly/LessWrong-43k | LessWrong | A Case for Cooperation: Dependence in the Prisoner's Dilemma
> "The man who is cheerful and merry has always a good reason for being so,—the fact, namely, that he is so." The Wisdom of Life, Schopenhauer (1851)
TL;DR
Descriptions of the Prisoner's Dilemma typically suggest that the optimal policy for each prisoner is to selfishly defect instead of to cooperate. I disagree with the traditional analysis and present a case for cooperation.
The core issue is the assumption of independence between the players. Articulations of the game painstakingly describe how the prisoners are in explicitly separate cells with no possibility of communication. From this, it's assumed that one's action can have no causal effect on the decision of the other player. However, (almost) everything is correlated, and this significantly changes the analysis.
Imagine the case where the prisoners are clones and make exactly the same decision. Then, when they compare the expected payout for each possible action, their payout will be higher in the case where they cooperate because they are certain the other player is having the same thoughts and deterministically will make the same choice. This essay generalizes and formalizes this line of reasoning.
Here's what to expect in what follows. In the first section, we begin by introducing the standard causal decision theory analysis suggesting (Defect, Defect). Then, we introduce the machinery for mixed strategies in the following section. From there we discuss the particular case where both participants are clones, which motivates our new framework. Then, we introduce a bit more formalism around causal modeling and dependence. We proceed to analyze a more general case where both players converge to the same mixed strategy. Then we discuss the most general model, where the players' mixed strategies have some known correlation. Finally, we conclude the analysis. In summary, given some dependency structure due to upstream causal variables, we uncover the cases where the game theory actually suggests cooperati |
188e60c8-842c-46b0-bee4-1640e5f17cee | trentmkelly/LessWrong-43k | LessWrong | Impact stories for model internals: an exercise for interpretability researchers
Inspired by Neel's longlist; thanks to @Nicholas Goldowsky-Dill and @Sam Marks for feedback and discussion, and thanks to AWAIR attendees for participating in the associated activity.
As part of the Alignment Workshop for AI Researchers in July/August '23, I ran a session on theories of impact for model internals. Many of the attendees were excited about this area of work, and we wanted an exercise to help them think through what exactly they were aiming for and why. This write-up came out of planning for the session, though I didn't use all this content verbatim. My main goal was to find concrete starting points for discussion, which
1. have the right shape to be a theory of impact
2. are divided up in a way that feels natural
3. cover the diverse reasons why people may be excited about model internals work
(according to me[1]).
This isn't an endorsement of any of these, or of model internals research in general. The ideas on this list are due to many people, and I cite things sporadically when I think it adds useful context: feel free to suggest additional citations if you think it would help clarify what I'm referring to.
Summary of the activity
During the session, participants identified which impact stories seemed most exciting to them. We discussed why they felt excited, what success might look like concretely, how it might fail, what other ideas are related, etc. for a couple of those items. I think categorizing existing work based on its theory of impact could also be a good exercise in the future.
I personally found the discussion useful for helping me understand what motivated some of the researchers I talked to. I was surprised by the diversity.
Key stats of an impact story
Applications of model internals vary a lot along multiple axes:
* Level of human understanding needed for the application[2]
* If a lot of human understanding is needed, does that update you on the difficulty of executing in this direction? If understanding is not need |
acd38961-f127-4208-a71d-5562ba9e7df6 | trentmkelly/LessWrong-43k | LessWrong | Can Bayes theorem represent infinite confusion?
Edit: the title was misleading, i didn't ask about a rational agent, but about what comes out of certain inputs in Bayes theorem, so now it's been changed to reflect that.
Eliezer and others talked about how a Bayesian with a 100% prior cannot change their confidence level, whatever evidence they encounter. that's because it's like having infinite certainty. I am not sure if they meant it literary or not (is it really mathematically equal to infinity?), but assumed they do.
I asked myself, well, what if they get evidence that was somehow assigned 100%, wouldn't that be enough to get them to change their mind? In other words -
If P(H) = 100%
And P(E|H) = 0%
than what's P(H|E) equals to?
I thought, well, if both are infinities, what happens when you subtract infinities? the internet answered that it's indeterminate*, meaning (from what i understand), that it can be anything, and you have absolutely no way to know what exactly.
So i concluded that if i understood everything correct, then such a situation would leave the Bayesian infinitely confused. in a state that he has no idea where he is from 0% to a 100%, and no amount of evidence in any direction can ground him anywhere.
Am i right? or have i missed something entirely?
----------------------------------------
*I also found out about Riemann's rearrangement theorem which, in a way, let's you arrange some infinite series in a way that equals whatever you want. Dem, that's cool! |
7c4a92a0-09bc-453e-833f-821dd120a260 | trentmkelly/LessWrong-43k | LessWrong | NYT: Google will “recalibrate” the risk of releasing AI due to competition with OpenAI
Cross-posted from the EA Forum
The New York Times: Sundar Pichai, CEO of Alphabet and Google, is trying to speed up the release of AI technology by taking on more risk.
> Mr. Pichai has tried to accelerate product approval reviews, according to the presentation reviewed by The Times.
> The company established a fast-track review process called the “Green Lane” initiative, pushing groups of employees who try to ensure that technology is fair and ethical to more quickly approve its upcoming A.I. technology.
> The company will also find ways for teams developing A.I. to conduct their own reviews, and it will “recalibrate” the level of risk it is willing to take when releasing the technology, according to the presentation.
This change is in response to OpenAI's public release of ChatGPT. It is evidence that the race between Google/DeepMind and Microsoft/OpenAI is eroding ethics and safety.
Demis Hassabis, CEO of DeepMind, urged caution in his recent interview in Time:
> He says AI is now “on the cusp” of being able to make tools that could be deeply damaging to human civilization, and urges his competitors to proceed with more caution than before.
> “When it comes to very powerful technologies—and obviously AI is going to be one of the most powerful ever—we need to be careful,” he says.
> “Not everybody is thinking about those things. It’s like experimentalists, many of whom don’t realize they’re holding dangerous material.”
> Worse still, Hassabis points out, we are the guinea pigs.
Alphabet/Google is trying to accelerate a technology that its own subsidiary says is powerful and dangerous. |
e9bf38b6-c046-42df-92a5-809bbdeb3db1 | trentmkelly/LessWrong-43k | LessWrong | Monthly Roundup #16: March 2024
AI developments have picked up the pace. That does not mean that everything else stopped to get out of the way. The world continues.
Do I have the power?
> Emmett Shear speaking truth: Wielding power is of course potentially dangerous and it should be done with due care, but there is no virtue in refusing the call.
There is also an art to avoiding power, and some key places to exercise it. Be keenly aware of when having power in a given context would ruin everything.
NATURAL GENERAL LACK OF INTELLIGENCE IN TECH
Eliezer Yudkowsky reverses course, admits aliens are among us and we have proof.
> Eliezer Yudkowsky: To understand the user interfaces on microwave ovens, you need to understand that microwave UI designers are aliens. As in, literal nonhuman aliens who infiltrated Earth, who believe that humans desperately want to hear piercingly loud beeps whenever they press a button.
>
> One junior engineer who hadn’t been taken over and was still actually human, suggested placing a visible on-off switch for turning the sound off — for example, in case your spouse or children were sleeping, and you didn’t want to wake them up. That junior engineer was immediately laughed off the team by senior aliens who were very sure that humans wanted to hear loud screaming beeps every time they pressed buttons. And furthermore sure that, even if anyone didn’t want their microwave emitting piercingly loud beeps at 4am, they would be perfectly happy to look up a complicated set of directions for how to turn the sound on or off, rather than needing a visible on-off switch. And even if any humans had trouble remembering that, they’d be much rarer than humans who couldn’t figure out how to set the timer for popcorn without a clearly labeled “Popcorn” button, which does a different random thing in every brand of microwave oven. There’s only so much real estate in a microwave control panel; it’s much more important to have an inscrutable button that says “Potato”, than a physical swit |
fe6d7186-813a-4e07-a5d7-4a5719c98275 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | The Prospect of an AI Winter
Summary
-------
* William Eden [forecasts](https://twitter.com/WilliamAEden/status/1630690003830599680) an AI winter. He argues that AI systems (1) are too unreliable and too inscrutable, (2) won't get that much better (mostly due to hardware limitations) and/or (3) won't be that profitable. He says, "I'm seeing some things that make me think we are in a classic bubble scenario, and lots of trends that can't clearly continue."
* I put 5% on an AI winter happening by 2030, with all the robustness that having written a blog post inspires, and where *AI winter* is operationalised as a drawdown in annual global AI investment of ≥50%.[[1]](#fn-xwuGHxpAGZrQGbYxn-1) (I reckon a winter must feature not only decreased interest or excitement, but always also decreased funding, to be considered a winter proper.)
* There have been two previous winters, one 1974-1980 and one 1987-1993. The main factor causing these seems to have been failures to produce formidable results, and as a consequence wildly unmet expectations. Today's state-of-the-art AI systems show impressive results and are more widely adopted (though I'm not confident that the lofty expectations people have for AI today will be met).
* I think Moore's Law could keep going for decades.[[2]](#fn-xwuGHxpAGZrQGbYxn-2) But even if it doesn't, there are many other areas where improvements are being made allowing AI labs to train ever larger models: there's improved yields and other hardware cost reductions, improved interconnect speed and better utilisation, algorithmic progress and, perhaps most importantly, an increased willingness to spend. If 1e35 FLOP is enough to train a [transformative AI](https://www.openphilanthropy.org/research/some-background-on-our-views-regarding-advanced-artificial-intelligence/) (henceforth, TAI) system, which seems plausible, I think we could get TAI by 2040 (>50% confidence), even under fairly conservative assumptions. (And a prolonged absence of TAI wouldn't necessarily bring about an AI winter; investors probably aren't betting on TAI, but on more mundane products.)
* Reliability is definitely a problem for AI systems, but not as large a problem as it seems, because we pay far more attention to frontier capabilities of AI systems (which tend to be unreliable) than long-familiar capabilities (which are pretty reliable). If you fix your gaze on a specific task, you usually see a substantial and rapid improvement in reliability over the years.
* I reckon inference with GPT-3.5-like models will be about as cheap as search queries are today in about 3-6 years. I think ChatGPT and many other generative models will be profitable within 1-2 years if they aren't already. There's substantial demand for them (ChatGPT reached 100M monthly active users after two months, quite impressive next to Twitter's ~450M) and people are only beginning to explore their uses.
* If an AI winter does happen, I'd guess some of the more likely reasons would be (1) scaling hitting a wall, (2) deep-learning-based models being chronically unable to generalise out-of-distribution and/or (3) AI companies running out of good-enough data. I don't think this is very likely, but I would be relieved if it were the case, given that we as a species currently seem completely unprepared for TAI.
The Prospect of a New AI Winter
-------------------------------
What does a speculative bubble look like from the inside? Trick question -- you don't see it.
Or, I suppose *some* people do see it. One or two may even be right, and some of the others are still worth listening to. William Eden tweeting out a [long thread](https://twitter.com/WilliamAEden/status/1630690003830599680) explaining why he's not worried about risks from advanced AI is one example, I don't know of which. He argues in support of his thesis that another AI winter is looming, making the following points:
1. **AI systems aren't that good.** In particular (argues Eden), they are too unreliable and too inscrutable. It's *far harder* to achieve [three or four nines reliability](https://en.wikipedia.org/wiki/High_availability#%22Nines%22) than merely one or two nines; as an example, autonomous vehicles have been arriving for over a decade. The kinds of things you can do with low reliability don't capture most of the value.
2. **AI systems won't get that much better.** Some people think we can [scale up current architectures to AGI](https://gwern.net/scaling-hypothesis). But, Eden says, we may not have enough compute to get there. Moore's law is "looking weaker and weaker", and price-performance is no longer falling exponentially. We'll most likely not get "more than another 2 orders of magnitude" of compute available globally, and 2 orders of magnitude probably won't get us to TAI.[[3]](#fn-xwuGHxpAGZrQGbYxn-3) "Without some major changes (new architecture/paradigm?) this looks played out." Besides, the semiconductor supply chain is centralised and fragile and could get disrupted, for example by a US-China war over Taiwan.
3. **AI products won't be that profitable.** AI systems (says Eden) seem good for "automating low cost/risk/importance work", but that's not enough to meet expectations. (See point (1) on reliability and inscrutability.) Some applications, like web search, have such low margins that the inference costs of large ML models are prohibitive.
I've left out some detail and recommend reading the entire thread before proceeding. Also before proceeding, a disclosure: my day job is doing research on the governance of AI, and so if we're about to see another AI winter, I'd pretty much be out of a job, as there wouldn't be much to govern anymore. That said, I think an AI winter, while not the best that can happen, is [vastly better than some of the alternatives](https://www.cold-takes.com/ai-could-defeat-all-of-us-combined/), axiologically speaking.[[4]](#fn-xwuGHxpAGZrQGbYxn-4) I also think I'd be of the same opinion even if I had still worked as a programmer today (assuming I had known as much or little about AI as I actually do).
Past Winters
------------
There is something of a precedent.
The first AI winter -- traditionally, from 1974 to 1980 -- was precipitated by the unsympathetic [Lighthill report](https://en.wikipedia.org/wiki/Lighthill_report). More fundamentally it was caused by AI researchers' failure to achieve their grandiose objectives. In 1965, Herbert Simon famously predicted that AI systems would be capable of any work a human can do in 20 years, and Marvin Minsky wrote in 1967 that "within a generation [...] the problem of creating 'artificial intelligence' will be substantially solved". Of Frank Rosenblatt's *Perceptron Project* the New York Times reported (claims of Rosenblatt which aroused ire among other AI researchers due to their extravagance), "[It] revealed an embryo of an electronic computer that it expects will be able to walk, talk, see, write, reproduce itself and be conscious of its existence. Later perceptrons will be able to recognize people and call out their names and instantly translate speech in one language to speech and writing in another language, it was predicted" (Olazaran 1996). Far from human intelligence, not even adequate machine translation materialised (it took until the mid-2010s when DeepL and Google Translate's deep learning upgrade were released for that to happen).
The second AI winter -- traditionally, from 1987 to 1993 -- again followed unrealised expectations. This was the era of expert systems and connectionism (in AI, the application of artificial neural networks). But expert systems failed to scale, and neural networks learned slowly, had low accuracy and didn't generalise. It was not the era of 1e9 FLOP/s per dollar; I reckon the LISP machines of the day were ~6-7 orders of magnitude less price-performant than that.[[5]](#fn-xwuGHxpAGZrQGbYxn-5)
Wikipedia lists [a number of factors](https://en.wikipedia.org/wiki/AI_winter#Underlying_causes_behind_AI_winters) behind these winters, but to me it is the failure to actually produce formidable results that seems most important. Even in an economic downturn, and even with academic funding dried up, you still would've seen substantial investments in AI had it shown good results. Expert systems did have some success, but nowhere near what we see AI systems do today, and with none of the momentum but all of the brittleness. This seems like an important crux to me: will AI systems fulfil the expectations investors have for them?
Moore's Law and the Future of Compute
-------------------------------------
Improving these days means scaling up. One reason why scaling might fail is if the hardware that is used to train AI models stops improving.
*Moore's Law* is the dictum that the number of transistors on a chip will double every ~2 years, and as a consequence hardware performance is able to double every ~2 years (Hobbhahn and Besiroglu 2022). (Coincidentally, Gordon Moore [died last week](https://archive.is/tYNg5) at the age of 94, survived by his Law.) It's often claimed that Moore's Law will slow as the size of transistors (and this fact never ceases to amaze me) approaches the silicon atom limit. In Eden's words, Moore's Law looks played out.
I'm no expert at semiconductors or GPUs, but as I understand things it's (1) not a given that Moore's Law will fail in the next decade and (2) quite possible that, even if it does, hardware performance will keep running on improvements other than increased transistor density. It wouldn't be the first time something like this happened: single-thread performance went off-trend as Dennard scaling failed around 2005, but transistor counts kept rising thanks to [increasing numbers of cores](https://enccs.github.io/OpenACC/0.01_gpu-introduction/):
Some of the technologies that could [keep GPU performance going](https://www.semianalysis.com/p/a-century-of-moores-law) as the atom limit approaches include vertical scaling, advanced packaging, new transistor designs and 2D materials as well as improved architectures and connectivity. (To be clear, I don't have a detailed picture of what these things are, I'm mostly just deferring to the linked source.) TSMC, Samsung and Intel all have plans for <2 nm process nodes (the current SOTA is 3 nm). Some companies are exploring more out-there solutions, like [analog computing](https://mythic.ai/) for speeding up low-precision matrix multiplication. Technologies on exponential trajectories are always out of far-frontier ideas, until they aren't (at least so long as there is immense pressure to innovate, as for semiconductors there is). Peter Lee [said in 2016](https://archive.is/dwH0F), "The number of people predicting the death of Moore's law doubles every two years." By the end of 2019, the Metaculus community gave "Moore's Law will end by 2025" 58%, whereas now one oughtn't give it more than a few measly per cent.[[6]](#fn-xwuGHxpAGZrQGbYxn-6)
Is Transformative AI on the Horizon?
------------------------------------
But the main thing we care about here is not FLOP/s, and not even FLOP/s per dollar, but how much compute AI labs can afford to pour into a model. That's affected by a number of things beyond theoretical peak performance, including hardware costs, energy efficiency, line/die yields, utilisation and the amount of money that a lab is willing to spend. So will we get enough compute to train a TAI in the next few decades?
There are many sophisticated attempts to answer that question -- here's one that isn't, but that is hopefully easier to understand.
Daniel Kokotajlo [imagines what you could do](https://www.lesswrong.com/s/5Eg2urmQjA4ZNcezy/p/rzqACeBGycZtqCfaX#comments) with 1e35 FLOP of compute on current GPU architectures. That's a lot of compute -- about 11 orders of magnitude more than what today's largest models were trained with (Sevilla et al. 2022). The post gives a dizzying picture of just how much you can do with such an abundance of computing power. Now it's true that we don't know for sure whether scaling will keep working, and it's also true that there can be other important bottlenecks besides compute, like data. But anyway something like 1e34 to 1e36 of 2022-compute seems like it could be enough to create TAI.
Entertain that notion and make the following assumptions:
* The price-performance of AI chips seems to double every 1.5 to 3.1 years (Hobbhahn and Besiroglu 2022); assume that that'll keep going until 2030, after which the doubling time will double as Moore's Law fails.
* Algorithmic progress on ImageNet seems to effectively halve compute requirements every 4 to 25 months (Erdil and Besiroglu 2022); assume that the doubling time is 50% longer for transformers.[[7]](#fn-xwuGHxpAGZrQGbYxn-7)
* Spending on training runs for ML systems seems to roughly double every 6 to 10 months; assume that that'll continue until we reach a maximum of $10B.[[8]](#fn-xwuGHxpAGZrQGbYxn-8)
What all that gives you is 50% probability of TAI by 2040, and 80% by 2045:
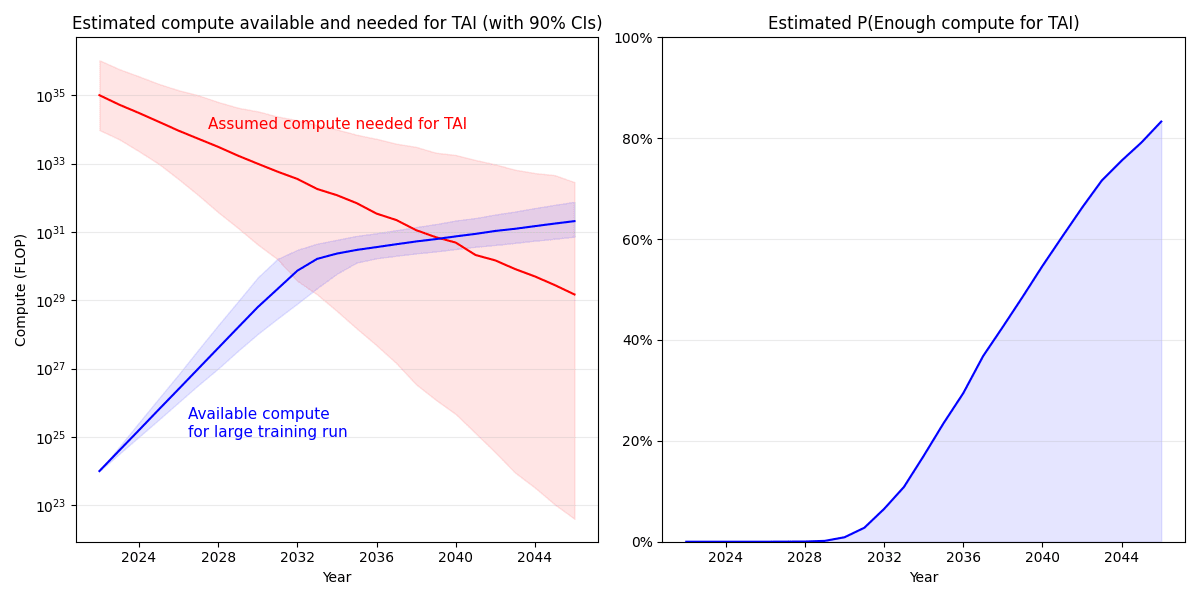
That is a simple model of course. There's a far more sophisticated and rigorous version, namely Cotra (2020) which gives a median of ~2050 (though she's since [changed her best guess](https://www.alignmentforum.org/posts/AfH2oPHCApdKicM4m/two-year-update-on-my-personal-ai-timelines) to a median of ~2040). There are many reasons why my simple model might be wrong:
* Scaling laws may fail and/or, as models get larger, scaling may get increasingly harder at a rate that exceeds ML researchers' efforts to make scaling less hard.
* Scaling laws may continue to hold but a model trained with 1e35 2022-FLOP does not prove transformative. Either more compute is needed, or new architectures are needed.
* 1e35 FLOP may be orders of magnitude *more* than what is needed to create TAI. For example, [this Metaculus question](https://www.metaculus.com/questions/14814/flop-usage-for-training-transformative-ai) has a community prediction of 1e28 to 1e33 FLOP for the largest training run prior to the first year in which GWP growth exceeds 30%; plugging that range into the model as a 90% CI gives a terrifying median estimate of 2029.
* Hardware price-performance progress slows more and/or earlier than assumed, or slows less and/or later than assumed.
* The pace of algorithmic advancements may slow down or increase, or the doubling time of algorithmic progress for prospective-transformative models may be lower or greater than estimated.
* ML researchers may run out of data, or may run out of high-quality (like books, Wikipedia) or even low-quality (like Reddit) data; see e.g. Villalobos et al. (2022) which forecasts high-quality text data being exhausted in 2024 or thereabouts, or [Chinchilla's wild implications](https://www.lesswrong.com/posts/6Fpvch8RR29qLEWNH/chinchilla-s-wild-implications) and the discussion there.
* A severe extreme geopolitical tail event, such as a great power conflict between the US and China, may occur.
* Increasingly powerful AI systems may help automate or otherwise speed up AI progress.
* Social resistance and/or stringent regulations may diminish investment and/or hinder progress.
* Unknown unknowns arise.
Still, I really do think a 1e35 2022-FLOP training run could be enough (>50% likely, say) for TAI, and I really do think, on roughly this model, we could get such a training run by 2040 (also >50% likely). One of the main reasons why I think so is that as AI systems get increasingly more powerful and useful (and dangerous), incentives will keep pointing in the direction of AI capabilities increases, and funding will keep flowing into efforts to keep scaling laws going. And if TAI is on the horizon, that suggests capabilities (and as a consequence, business opportunities) will keep improving.
You Won't Find Reliability on the Frontier
------------------------------------------
One way that AI systems can disappoint is if it turn out they are, and for the forseeable future remain, chronically unreliable. Eden writes, "[Which] areas of the economy can deal with 99% correct solutions? My answer is: ones that don't create/capture most of the value." And people often point out that modern AI systems, and large language models (henceforth, LLMs) in particular, are unreliable. (I take *reliable* to mean something like "consistently does what you expect, i.e. doesn't fail".) This view is both true and false:
* AI systems are highly unreliable if you only look at frontier capabilities. At any given time, an AI system will tend to succeed only some of the time at the <10% most impressive tasks it is capable of. These tasks are the ones that will get the most attention, and so the system will seem unreliable.
* AI systems are pretty reliable if you only look at long-familiar capabilities. For any given task, successive generations of AI systems will generally ([not always](https://twitter.com/EthanJPerez/status/1617981045282082817)) get better and better at it. These tasks are old news: we take it for granted that AIs will do them correctly.
John McCarthy lamented: "As soon as it works, no one calls it AI anymore." Larry Tesler declared: "AI is whatever hasn't been done yet."
Take for example the sorting of randomly generated single-digit integer lists. Two years ago janus [tested this on GPT-3](https://generative.ink/posts/list-sorting-does-not-play-well-with-few-shot/) and found that, even with a 32-shot (!) prompt, GPT-3 managed to sort lists of 5 integers only 10/50 times, and lists of 10 integers 0/50 times. (A 0-shot, Python-esque prompt did better at 38/50 and 2/50 respectively). I tested the same thing with ChatGPT using GPT-3 and it got it right 5/5 times *for 10-integer lists*.[[9]](#fn-xwuGHxpAGZrQGbYxn-9) I then asked it to sort five 10-integer lists in one go, and it got 4/5 right! (NB: I'm pretty confident that this improvement didn't come with ChatGPT exactly, but rather with the newer versions of GPT-3 that ChatGPT is built on top of.)
(Eden also brings up the problem of accountability. I agree that this is an issue. Modern AI systems are basically inscrutable. That is one reason why it is so hard to make them safe. But I don't expect this flaw to stop AI systems from being put to use in any except the most safety-critical domains, so long as companies expect those systems to win them market dominance and/or make a profit.)
Autonomous Driving
------------------
But then why are autonomous vehicles (henceforth, AVs) still not reliable enough to be widely used? I suspect because driving a car is not a single task, but a *task complex*, a bundle of many different subtasks with varying inputs. The overall reliability of driving is highly dependent on the performance of those subtasks, and failure in any one of them could lead to overall failure. Cars are relatively safety-critical: to be widely adopted, autonomous cars need to be able to reliably perform ~all subtasks you need to master to drive a car. As the distribution of the difficulties of these subtasks likely follows a power law (or something like it), the last 10% will always be harder to get right than the first 90%, and progress will look like it's "almost there" for years before the overall system is truly ready, as has also transparently been the case for AVs. I think this is what Eden is getting at when he writes that it's "hard to overstate the difference between solving toy problems like keeping a car between some cones on an open desert, and having a car deal with unspecified situations involving many other agents and uncertain info navigating a busy city street".
This seems like a serious obstacle for more complex AI applications like driving. And what we want AI *for* is complicated tasks -- simple tasks are easy to automate with traditional software. I think this is *some* reason to think an AI winter is more likely, but only a minor one.
One, I don't think what has happened to AVs amounts to an AV winter. Despite expectations clearly having been unmet, and public interest clearly having declined, my impression (though I couldn't find great data on this) is that investment in AVs hasn't declined much, and maybe not at all (apparently 2021 saw >$12B of funding for AV companies, above the yearly average of the past decade[[10]](#fn-xwuGHxpAGZrQGbYxn-10)), and also that AV patents are steadily rising (both in absolute numbers and as a share of driving technology patents). Autonomous driving exists on a spectrum anyway; we do have "conditionally autonomous" L3 features like cruise control and auto lane change in cars on the road today, with adoption apparently increasing every year. The way I see it, AVs have undergone the typical [hype cycle](https://en.wikipedia.org/wiki/Gartner_hype_cycle), and are now by steady, incremental change climbing the so-called slope of enlightenment. Meaning: plausibly, even if expectations for LLMs and other AI systems are mostly unmet, there still won't be an AI winter comparable to previous winters as investment plateaus rather than declines.
Two, modern AI systems, and LLMs specifically, are quite unlike AVs. Again, cars are safety-critical machines. There's regulation, of course. But people also just don't want to get in a car that isn't highly reliable (where *highly reliable* means something like "far more reliable than an off-brand charger"). For LLMs, there's no regulation, and people are incredibly motivated to use them even in the absence of safeguards (in fact, *especially* in the absence of safeguards). I think there are lots of complex tasks that (1) aren't safety-critical (i.e., where accidents aren't that costly) but (2) can be automated and/or supported by AI systems.
Costs and Profitability
-----------------------
Part of why I'm discussing TAI is that it's probably correlated with other AI advancements, and part is that, despite years of AI researchers' trying to avoid such expectations, people are now starting to suspect that AI labs will create TAI in this century. Investors mostly aren't betting on TAI -- as I understand it, they generally want a return on their investment in <10 years, and had they expected AGI in the next 10-20 years they would have been pouring far more than some measly hundreds of millions (per investment) into AI companies today. Instead, they expect -- I'm guessing -- tools that will broadly speed up labour, automate common tasks and make possible new types of services and products.
Ignoring TAI, will systems similar to ChatGPT, Bing/Sydney and/or modern image generators become profitable within the next 5 or so years? I think they will within 1-2 years if they aren't already. Surely the demand is there. I have been using ChatGPT, Bing/Sydney and DALL-E 2 extensively since they were released, would be willing to pay non-trivial sums for all these services and think it's perfectly reasonable and natural to do so (and I'm not alone in this, ChatGPT [reportedly](https://archive.is/Pgfu9) having reached 100M monthly active users two months after launch, though this was before the introduction of a paid tier; by way of comparison, Twitter reportedly has ~450M).[[11]](#fn-xwuGHxpAGZrQGbYxn-11)
Eden writes: "The All-In podcast folks estimated a ChatGPT query as being about 10x more expensive than a Google search. I've talked to analysts who carefully estimated more like 3-5x. In a business like search, something like a 10% improvement is a killer app. 3-5x is not in the running!"
An [estimate](https://www.semianalysis.com/p/the-inference-cost-of-search-disruption) by SemiAnalysis suggests that ChatGPT (prior to the release of GPT-4) costs $700K/day in hardware operating costs, meaning (if we assume 13M active users) ~$0.054/user/day or ~$1.6/user/month (the subscription fee for ChatGPT Plus is $20/user/month). That's $700K × 365 = $255M/year in hardware operating costs alone, quite a sum, though to be fair these costs likely exceed operational costs, employee salaries, marketing and so on by an order of magnitude or so. OpenAI [apparently expects](https://archive.is/9t9gB) $200M revenue in 2023 and a staggering [$1B by 2024](https://archive.is/tswrM).
At the same time, as mentioned in a previous section, the hardware costs of inference are decreasing *rapidly*: the price-performance of AI accelerators doubles every ~2.1 years (Hobbhahn and Besiroglu 2022).[[12]](#fn-xwuGHxpAGZrQGbYxn-12) So even if Eden is right that GPT-like models are 3-5x too expensive to beat old-school search engines right now, based on hardware price-performance trends alone that difference will be ~gone in 3-6 years (though I'm assuming there's no algorithmic progress for inference, and that traditional search queries won't get much cheaper). True, there will be better models available in future that are more expensive to run, but it seems that this year's models are already capable of capturing substantial market share from traditional search engines, and old-school search engines [seem to be declining](https://news.ycombinator.com/item?id=29392702) in quality rather than improving.
It does seem fairly likely (>30%?) to me that AI companies building products on top of foundation models like GPT-3 or GPT-4 are overhyped. For example, [Character.AI](https://character.ai/) recently [raised >$200M at a $1B valuation](https://archive.is/E4B6k) for a service that doesn't really seem to add much value on top of the standard ChatGPT API, especially now that OpenAI has added the system prompt feature. But as I think these companies may disappoint precisely because they are obsoleted by other, more general AI systems, I don't think their failure would lead to an AI winter.
Reasons Why There Could Be a Winter After All
---------------------------------------------
Everything I've written so far is premised on something like "any AI winter would be caused by AI systems' ceasing to get more practically useful and therefore profitable". AIs being unreliable, hardware price-performance progress slowing, compute for inference being too expensive -- these all matter only insofar as they affect the practical usefulness/profitability of AI. I think this is by far the most likely way that an AI winter happens, but it's not the only plausible way; others possibilities include restrictive legislation/regulation, spectacular failures and/or accidents, great power conflicts and extreme economic downturns.
But if we do see a AI winter within a decade, I think the most likely reason will turn out to be one of:
* **Scaling hits a wall; the [blessings of scale](https://gwern.net/scaling-hypothesis#blessings-of-scale) cease past a certain amount of compute/data/parameters.** For example, OpenAI trains GPT-5 with substantially more compute, data and parameters than GPT-4, but it just turns out not to be that impressive.
+ There's no sign of this happening so far, as far as I can see.
* **True out-of-distribution generalisation is far off, even though AIs keep getting better and more reliable at performing in-distribution tasks.**[[13]](#fn-xwuGHxpAGZrQGbYxn-13) This would partly vindicate some of the [LLM reductionists](https://www.erichgrunewald.com/posts/against-llm-reductionism/).
+ I find it pretty hard to say whether this is the case currently, maybe because the line between in-distribution and out-of-distribution inputs is often blurry.
+ I also think that plausibly there'd be no AI winter in the next decade even if AIs won't fully generalise out-of-distribution, because in-distribution data covers a lot of economically useful ground.
* **We run out of high-quality data (cf. Villalobos et al. (2022)).**
+ I'm more unsure about this one, but I reckon ML engineers will find ways around it. OpenAI is already [paying workers in LMIC countries](https://archive.is/g0oiT) to label data; they could pay them to generate data, too.[[14]](#fn-xwuGHxpAGZrQGbYxn-14) Or you could generate text data from video and audio data. But more likely is perhaps the use of synthetic data. For example, you could generate training data with AIs (cf. [Alpaca](https://crfm.stanford.edu/2023/03/13/alpaca.html) which was fine tuned on GPT-3-generated texts). ML researchers have surely already thought of these things, there just hasn't been much of a need to try them yet, because cheap text data has been abundant.
I still think an AI winter looks really unlikely. At this point **I would put only 5% on an AI winter happening by 2030**, where *AI winter* is operationalised as a drawdown in annual global AI investment of ≥50%. This is unfortunate if you think, as I do, that we as a species are [completely unprepared for TAI](https://www.cold-takes.com/transformative-ai-issues-not-just-misalignment-an-overview/).
*Thanks to Oliver Guest for giving feedback on a draft.*
References
----------
Cotra, Ajeya. 2020. “Forecasting Tai with Biological Anchors.”
Erdil, Ege, and Tamay Besiroglu. 2022. “Revisiting Algorithmic Progress.” <https://epochai.org/blog/revisiting-algorithmic-progress>.
Hobbhahn, Marius, and Tamay Besiroglu. 2022. “Trends in Gpu Price-Performance.” <https://epochai.org/blog/trends-in-gpu-price-performance>.
Odlyzko, Andrew. 2010. “Collective Hallucinations and Inefficient Markets: The British Railway Mania of the 1840s.”
Olazaran, Mikel. 1996. “A Sociological Study of the Official History of the Perceptrons Controversy.” *Social Studies of Science* 26 (3): 611--59.
Sevilla, Jaime, Lennart Heim, Anson Ho, Tamay Besiroglu, Marius Hobbhahn, and Pablo Villalobos. 2022. “Compute Trends across Three Eras of Machine Learning.” <https://epochai.org/blog/compute-trends>.
Villalobos, Pablo, Jaime Sevilla, Lennart Heim, Tamay Besiroglu, Marius Hobbhahn, and Anson Ho. 2022. “Will We Run out of Ml Data? Evidence from Projecting Dataset Size Trends.” <https://epochai.org/blog/will-we-run-out-of-ml-data-evidence-from-projecting-dataset>.
---
1. By comparison, there seems to have been a [drawdown in corporate investment](https://ourworldindata.org/grapher/corporate-investment-in-artificial-intelligence-total?country=~OWID_WRL) in AI from 2014 to 2015 of 49%, [in solar energy](https://ourworldindata.org/grapher/investment-in-renewable-energy-by-technology) from 2011 to 2013 of 24% and in venture/private investment in crypto companies from 2018 to 2019 of 48%. The share prices of railways in Britain declined by about 60% from 1845 to 1850 as the railway mania bubble burst (Odlyzko 2010), though the railway system of course left Britain forever changed nonetheless. [↩︎](#fnref-xwuGHxpAGZrQGbYxn-1)
2. Well, this depends a bit on how you view Moore's Law. Gordon Moore wrote: "The complexity for minimum component costs has increased at a rate of roughly a factor of two per year." Dennard scaling -- which says that as transistors shrink, their performance improves while power consumption per unit area remains constant -- failed around 2005. I think some traditionalists would say that Moore's Law ended then, but clearly the number of transistors on a chip keeps doubling (only by other means). [↩︎](#fnref-xwuGHxpAGZrQGbYxn-2)
3. William Eden actually only talks about artificial general intelligence (AGI), but I think the TAI frame is better when talking about winters, investment and profitability. [↩︎](#fnref-xwuGHxpAGZrQGbYxn-3)
4. It's interesting to note that the term *AI winter* was inspired by the notion of a nuclear winter. AI researchers in the 1980s used it to describe a calamity that would befall themselves, namely a lack of funding, and, true, both concepts involve stagnation and decline. But a nuclear winter happens *after nuclear weapons are used*. [↩︎](#fnref-xwuGHxpAGZrQGbYxn-4)
5. Apparently the collapse of the LISP machine market was also a contributing factor. LISP machines were expensive workstations tailored to the use of LISP, at the time the preferred programming language of AI researchers. As AI programs were ~always written in LISP, and required a lot of compute and memory for the time, the loss of LISP machines was a serious blow to AI research. It's a bit unclear to me *how exactly* the decline of LISP machines slowed AI progress beyond that, but perhaps it forced a shift to less compute- and/or memory-hungry approaches. [↩︎](#fnref-xwuGHxpAGZrQGbYxn-5)
6. The question is actually operationalised as: "Will the transistors used in the CPU of Apple's most modern available iPhone model on January 1st, 2030 be of the same generation as those used in the CPU of the most modern available iPhone on January 1st, 2025?" [↩︎](#fnref-xwuGHxpAGZrQGbYxn-6)
7. That said, MosaicBERT (2023) [achieves similar performance](https://www.mosaicml.com/blog/mosaicbert) to BERT-Base (2018) with lower costs *but seemingly more compute*. I estimate that BERT-Base needed ~1.2e18 FLOP in pre-training, and MosaicBERT needed ~1.6e18. I'm not sure if this is an outlier, but it could suggest that the algorithmic doubling time is even longer for text models. When I asked about this, one of the people who worked on MosaicBERT [told me](https://dblalock.substack.com/p/2023-3-12-arxiv-roundup-pretraining/comment/13640864): "[W]e ablated each of the other changes and all of them helped. We also had the fastest training on iso hardware a few months ago (as [measured by MLPerf](https://www.mosaicml.com/blog/mlperf-nlp-nov2022)), and MosaicBERT has gotten faster since then." [↩︎](#fnref-xwuGHxpAGZrQGbYxn-7)
8. $10B may seem like a lot now, but I'm thinking world-times where this is a possibility are world-times where companies have already spent $1B on GPT-6 or whatever and seen that it does amazing things, and is plausibly not that far from being transformative. And spending $10B to get TAI seems like an obviously profitable decision. Companies spend 10x-100x that amount on some mergers and acquisitions, yet they're trivial next to TAI or even almost-TAI. If governments get involved, $10B is half of a Manhattan-project-equivalent, a no-brainer. [↩︎](#fnref-xwuGHxpAGZrQGbYxn-8)
9. Example prompt: "Can you sort this list in ascending order? [0, 8, 6, 5, 1, 1, 1, 8, 3, 7]". [↩︎](#fnref-xwuGHxpAGZrQGbYxn-9)
10. [FT](https://archive.is/YcYKk) (2022): "It has been an outrageously expensive endeavour, of course. McKinsey put the total invested at over $100bn since 2010. Last year alone, funding into autonomous vehicle companies exceeded $12bn, according to CB Insights." -- If those numbers are right, that at least suggests the amount of funding in 2021 was substantially higher than the average over the last decade, a picture which seems inconsistent with an AV winter. [↩︎](#fnref-xwuGHxpAGZrQGbYxn-10)
11. Well, there is the [ethical concern](https://forum.effectivealtruism.org/posts/dyyXcdgBchGczruJq/donation-offsets-for-chatgpt-plus-subscriptions). [↩︎](#fnref-xwuGHxpAGZrQGbYxn-11)
12. I'm not exactly sure whether this analysis is done on training performance alone, but I expect trends in training performance to be highly correlated with trends in inference performance. Theoretical peak performance isn't the only thing that matters -- e.g. interconnect speed matters too -- but it seems like the most important component.
I'm also guessing that demand for inference compute is rising rapidly relative to training compute, and that we may be seeing R&D on GPUs specialised on inference in future. I think so far that hasn't been the focus as training compute has been the main bottleneck. [↩︎](#fnref-xwuGHxpAGZrQGbYxn-12)
13. By *true* out-of-distribution generalisation, I mean to point at something like "AI systems are able to find ideas obviously drawn from outside familiar distributions". To make that more concrete, I mean the difference between (a) AIs generating entirely new Romantic-style compositions and (b) AIs ushering in novel *kinds* of music the way von Weber, Beethoven, Schubert and Berlioz developed Romanticism. [↩︎](#fnref-xwuGHxpAGZrQGbYxn-13)
14. I'm not confident that this would scale, though. A quick back-of-the-envelope calculation suggests OpenAI would get the equivalent of about 0.016% of the data used to train Chinchilla if it spent the equivalent of 10 well-paid engineers' salaries (in total ~$200K per month) for one year. That's not really a lot.
That also assumes:
1. A well-paid engineer is paid $200K to $300K annually.
2. A writer is paid $10 to $15 per hour ([this article](https://archive.is/g0oiT) suggests OpenAI paid that amount for Kenyan labourers -- themselves earning only $1.32 to $2 an hour -- to provide feedback on data for ChatGPT's reinforcement learning step).
3. A writer generates 500 to 1,500 words per hour (that seems reasonable if they stick to writing about themselves or other things they already know well).
4. A writer works 9 hours per day (the same Kenyan labourers apparently worked 9-hour shifts), about 21 days per month (assumes a 5-day work week).
5. Chinchilla was trained on ~1.4T tokens which is the equivalent of ~1.05T words (compare with ~374B words for GPT-3 davinci and ~585B words for PaLM) (Sevilla et al. 2022). I use Chinchilla as a point of comparison since that paper, which came after GPT-3 and PaLM were trained, [implied LLMs were being trained on too little data](https://www.lesswrong.com/posts/6Fpvch8RR29qLEWNH/chinchilla-s-wild-implications).Those assumptions imply OpenAI would afford ~88 labourers (90% CI: 66 to 118) who'd generate ~173M words per year (90% CI: 94M to 321M), as mentioned the equivalent of 0.016% of the Chinchilla training data set (90% CI: 0.009% to 0.031%). And *that* implies you'd need 6,000 years (90% CI: 3,300 to 11,100) to double the size of the Chinchilla data set. [↩︎](#fnref-xwuGHxpAGZrQGbYxn-14) |
bb7667d0-4f01-436f-aa51-6e51eeff9dd2 | trentmkelly/LessWrong-43k | LessWrong | AI Research Discussed by Mainstream Media
|
4431e4a0-59d7-4751-9a74-ada3b94fc5de | trentmkelly/LessWrong-43k | LessWrong | Meetup : Montreal LessWrong - The Future is Awesome
Discussion article for the meetup : Montreal LessWrong - The Future is Awesome
WHEN: 28 January 2013 06:30:00PM (-0500)
WHERE: 655 Avenue du Président Kennedy, Montréal, QC
Bringing in articles and discussing the progress of technology that remains hidden from our normal lives.
It's good to see what sort of progress is being made, and where the future will likely take us!
Discussion article for the meetup : Montreal LessWrong - The Future is Awesome |
e4588faf-4bb3-456f-8ab7-c0a66c8f4ca7 | trentmkelly/LessWrong-43k | LessWrong | Multiple conditions must be met to gain causal effect
Is there a name for and research about the heuristic / fallacy that there is exactly one cause for things? How come we do not look for the conditions that cause but for a cause?
I see this almost as often as the correlation = causation fallacy. When it comes in the form of "risk factor" it is ok if the factor is selective. But when it comes in the form of a general assumption about the world I find it simplistic. A risk factor is only a vague hint that needs to be looked at more closely to establish causation.
There also is this notion that multi causality is additive as would be the case if the probability for something would depend on this OR that happening but not this AND that.
A correlation of less than one may be random, but there might also be a hidden more selective cause/factor.
In medical news I keep hearing of risk factors for a condition. They find that there is a correlation between A, B and the studied disease. But how do we know that it doesn't take A and B and C to make it almost certain to develop that disease? I would like to know. C might be a common gene that is not even known.
Say it takes A and B. I really enjoy A, but I never do B, then why lower my life quality just because a study including people who also do B found that A is a risk factor? Risk factor is only a positive correlation. Eating and breathing have positive correlation to all diseases and the joke is, they come out with news about bad diets every year.
I keep hearing that A is a risk factor, then a follow-up study finds that there is no conclusive data for A being the problem, so A is cool again. But what if A and B is the problem and each alone is not harmful?
In the end this means that you can only find what you are looking for. (Kind of the big problem with science.) Looking for 1:1 correlation you will only find the low hanging fruit and the singular cause.
Whenever we find that some but not all who do/have A get Y we should look for additional factors, but this is no |
dc289094-79d4-4666-b1dd-fcce4d0413cc | trentmkelly/LessWrong-43k | LessWrong | $295 bounty for new Singularity Institute logo design (crowd-sourced competition)
If you have graphic design experience, check out the on-going logo design competition at 99designs for the Singularity Institute. There are still 6 days left to enter and be eligible to win the $295 prize if your design is selected. Tell your friends with graphic design experience too. There are very few submissions currently.
Note: This is a blind contest. Designers can only see their own entries. All designs will be revealed when the contest ends.
If you're interested at getting a peek at the designs, they will be online after the competition is over. This is standard practice in 99designs contests to prevent designers from contaminating each other and having all the designs drift in a certain direction. |
bb2e4be0-5e26-4fa3-94ad-8aa800dd879f | trentmkelly/LessWrong-43k | LessWrong | Call for volunteers: clean up the LW issue tracker
I'm looking for a volunteer (or volunteers).
We've let the Lesswrong issue tracker get out of hand - there are 99 open issues on it, and I think that many of them are resolved by changes since they were opened, are less than awesome ideas, or, for the remainder, are valid ideas.
I'd love someone to volunteer to go through all of the open issues, close those that are complete or silly, and tag/prioritise those that remain. I'll need to give you the power to do that, so please nominate yourself in the comments.
Once the list is cleaned up, I think Trike can keep it organised.
ETA: Nic_Smith seems to have this well in hand - serious kudos, Nic. Thank you. |
400dfa6b-caa8-48e9-a060-e40892b3e163 | trentmkelly/LessWrong-43k | LessWrong | Less Wrong Book Club and Study Group
Do you want to become stronger in the way of Bayes? This post is intended for people whose understanding of Bayesian probability theory is currently somewhat tentative (between levels 0 and 1 to use a previous post's terms), and who are interested in developing deeper knowledge through deliberate practice.
Our intention is to form an online self-study group composed of peers, working with the assistance of a facilitator - but not necessarily of a teacher or of an expert in the topic. Some students may be somewhat more advanced along the path, and able to offer assistance to others.
Our first text will be E.T. Jaynes' Probability Theory: The Logic of Science, which can be found in PDF form (in a slightly less polished version than the book edition) here or here.
We will work through the text in sections, at a pace allowing thorough understanding: expect one new section every week, maybe every other week. A brief summary of the currently discussed section will be published as an update to this post, and simultaneously a comment will open the discussion with a few questions, or the statement of an exercise. Please use ROT13 whenever appropriate in your replies.
A first comment below collects intentions to participate. Please reply to this comment only if you are genuinely interested in gaining a better understanding of Bayesian probability and willing to commit to spend a few hours per week reading through the section assigned or doing the exercises.
As a warm-up, participants are encouraged to start in on the book:
Preface
Most of the Preface can be safely skipped. It names the giants on whose shoulders Jaynes stood ("History", "Foundations"), deals briefly with the frequentist vs Bayesian controversy ("Comparisons"), discusses his "Style of Presentation" (and incidentally his distrust of infinite sets), and contains the usual acknowledgements.
One section, "What is 'safe'?", stands out as making several strong points about the use of probability theory. Sampl |
20e6c970-0392-485e-bb95-96da19968df0 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Shanghai Less Wrong Meetup
Discussion article for the meetup : Shanghai Less Wrong Meetup
WHEN: 15 April 2012 10:36:00PM (+1100)
WHERE: Shanghai
WHEN: 15 April 2012 01:00:00PM
WHERE: This is at a private residence, please private message 'Teddy' if you're joining. (This is China, it's got to be this way) I'm looking for any willing Shanghai Lesswrong readers to join this group if they haven't already. Up vote user Teddy in the comments below. This way I have karma to post to the meetup section without asking Patrick Robotham each time. This will help us boost members for the community here in Shanghai. The group has been meeting informally for awhile.. we have a good community here. If you'd like to join let me know.
Discussion article for the meetup : Shanghai Less Wrong Meetup |
1b9f63e7-66ea-416b-b622-3b9ae28530f1 | trentmkelly/LessWrong-43k | LessWrong | Chapter 18: Dominance Hierarchies
Any sufficiently advanced J. K. Rowling is indistinguishable from magic.
----------------------------------------
"That does sound like the sort of thing I would do, doesn't it?"
----------------------------------------
It was breakfast time on Friday morning. Harry took another huge bite out of his toast and then tried to remind his brain that scarfing his breakfast wouldn't actually get him into the dungeons any faster. Anyway they had a full hour of study time between breakfast and the start of Potions.
But dungeons! In Hogwarts! Harry's imagination was already sketching the chasms, narrow bridges, torchlit sconces, and patches of glowing moss. Would there be rats? Would there be dragons?
"Harry Potter," said a quiet voice from behind him.
Harry looked over his shoulder and found himself beholding Ernie Macmillan, smartly dressed in yellow-trimmed robes and looking a little worried.
"Neville thought I should warn you," Ernie said in a low voice. "I think he's right. Be careful of the Potions Master in our session today. The older Hufflepuffs told us that Professor Snape can be really nasty to people he doesn't like, and he doesn't like most people who aren't Slytherins. If you say anything smart to him it... it could be really bad for you, from what I've heard. Just keep your head down and don't give him any reason to notice you."
There was a pause as Harry processed this, and then he lifted his eyebrows. (Harry wished he could raise just one eyebrow, like Spock, but he'd never been able to manage.) "Thanks," Harry said. "You might've just saved me a lot of trouble."
Ernie nodded, and turned to go back to the Hufflepuff table.
Harry resumed eating his toast.
It was around four bites afterward that someone said "Pardon me," and Harry turned around to see an older Ravenclaw, looking a little worried -
Some time later, Harry was finishing up his third plate of rashers. (He'd learned to eat heavily at breakfast. He could always eat lightly at lunch if he |
9aff0fe2-7262-48ed-821b-19a74bc35a4d | trentmkelly/LessWrong-43k | LessWrong | Links and short notes, 2025-01-26: Atlas Shrugged and the irreplaceable founder, pumping stations and civic pride, and thoughts on the eve of AGI
Much of this content originated on social media. To follow news and announcements in a more timely fashion, follow me on Twitter, Threads, Bluesky, or Farcaster.
Contents
* Jobs and fellowships
* Events
* AI news
* Other news
* Atlas Shrugged and the irreplaceable founder
* Pumping stations and civic pride
* “Thoughts on the eve of AGI”
* More thoughts on AI
* Politics
* Other links and short notes
* Maps & charts
* Art
* Closing thoughts
Jobs and fellowships
* The Institute for Progress is hiring a Fellow/Senior Fellow, Emerging Technology. “Apply to ensure the AI frontier is built in America. (I’m biased, but I think this is the agenda with juice to advance the discussion in DC)” (@calebwatney). Apply here by Feb 21.
* Marian Tupy at HumanProgress.org is hiring analysts to explore the economics and psychology of human progress
* Alan Tomusiak is hiring scientists to work on the problem of genome instability (@alantomusiak)
* Ashlee Vance is hiring for his new publication, Core Memory: “Are you an ambitious type based in DC who can write a weekly newsletter that dives into tech-related legislature and discern what’s real and has real money involved versus political garbage? … Can you do this with some flair but not let your politics color the facts of what’s going on? Can you spot interesting military and infrastructure bids and break them down? Can you make this a must read for people in the tech industry? Can you go deeper on the juicy stuff and really add context? If so, let’s talk. I’ll help give you a big audience and develop your following” (@ashleevance). Email him: ashlee@corememory.com
* The Federation of American Scientists is looking for senior fellows “to advance innovative policy and drive positive change. If you’re a leading light in your field and ready to shape policy discourse and implementation, we want you. Apply by Jan 31” (@scientistsorg)
Events
* Edge City Austin, March 2–7: “explore how frontier tech can be built for |
99ee5155-9fa2-4f19-862d-6de840fb9a22 | trentmkelly/LessWrong-43k | LessWrong | Design 3: Intentionality
This is part 24 of 30 in the Hammertime Sequence. Click here for the intro.
Intentions are momentary, but problems last forever.
A human being’s attention flits around like the Roman God Mercury, root of the word “mercurial” – subject to sudden or unpredictable changes of mood or mind. The biggest problems in life require concentrated effort over years or decades, but you can only muster the willpower to even intend to solve a problem for minutes or hours. Worse, you can pretty much only maintain one intention at a time.
How do we make intentions count?
The philosophy of Design is: build intentions into external reality. Like your problems, external reality also lasts forever.
Day 24: Intentionality
You need to lose those love handles. Your reading list is piling up. You need to learn ten different programming languages. You need to sleep three hours earlier. You need to maintain your closest friendships. You juggle three different addictions that take turns monopolizing your life. You need to present like a functioning adult to your parents and coworkers. A childhood trauma you’re repressing makes it impossible to befriend a certain half of the population.
You have a lot of problems, each of which requires dedicated effort and thought to fix. Worse, each problems deteriorates while you’re working on the others. Perhaps some have gone so neglected they’re impossible to look at, and are slowly swallowing the rest of your life like a super-massive black hole.
Right this minute, there’s probably only a handful of problems that feel alive enough to you to inject energy into. Of those, you can only work on one at a time. In this crazy unfair world, how do you make the most of your intentions?
Outsource the Burden
There’s a certain unproductive way of thinking which goes like this:
“If I were really rational, I wouldn’t need all these aids. I wouldn’t need chrome extensions to block Facebook and Twitter, friends to reward me for the slightest progress, and SS |
3c01eb57-0dd0-4a1b-98b0-e5a31216dd59 | trentmkelly/LessWrong-43k | LessWrong | Miracles and why not to believe them
Wonders and signs
For a while I've wanted to explain to people why the testimony of the apostles isn't sufficient for me to believe them. I intuitively find that the gospels aren't enough for be to believe them. Even if they're better preserved than any other ancient text etc. I usually go with extraordinary claims require extraordinary evidence, which is a good heuristic and is convincing to me, but I didn't have a good mathematical explanation of why it's so. I could come up with various reasons of why it's a good idea, but not a *proof*. It turns out that this is just yet another result of Bayes' rule...
Telepathy
Dr Samuel Soal was a parapsychologist who did a number of ESP experiments between 1941-1943 to discover whether it was possible to read someones mind. The basic setup was an agent with a set of 5 animal cards which were shuffled before each test. The agent would pick one at random, and the subject would try to guess what card was picked. Naively, one would expect the subject to be right around once in 5 trials, i.e. p = 0.2. This is not what Soal found. A Mrs Steward, who was the test subject, managed to correctly guess the card 9410 times out of 37100 trials (I'm impressed by her patience), which is a success rate of f = 0.2536. This is 25.8 standard deviations away from the expected success rate, which is a big deal. So we have:
- P(H0|X) - the null hypothesis that she should have random results with a success rate of 0.2
- P(Hf|X) - an alternative hypothesis that she is an ESPer if the success rate is 0.2535
Plugging the values into the appropriate equations (check page 121 of the book), it turns out that the probability of getting this data with the null hypothesis is some 3.15×10−139. So it appears that the only thing left is to accept that ESP is real, given the following equation:
P(Hf|DX)=P(Hf|X)P(D|HfX)P(D|X), where P(D|X)=P(DH0|X)+P(DHf|X)
Since P(D|H0X) is absurdly small, this can be approximated as P(Hf|DX)=P(Hf|X)P(D|HfX)P(Hf|X)P(D|Hf |
291eff1a-bad9-4d8a-a522-9c7e6c1abf4d | trentmkelly/LessWrong-43k | LessWrong | Russian parliamentarian: let's ban personal computers and the Internet
Anatoly Kubanov, a senior member of the parliament of a Russian oblast (state), and a member of one of the four major political parties allowed in Russia, proposed to ban personal computers and the public access to the Internet.
Below is a partial translation of his article. I've highlighted some especially interesting parts.
I think it's a curious illustration of how totalitarian dictatorships can react to the AI threat.
I wish it was some kind of a parody. But major Russia media confirms its authenticity, and the presented arguments don't sound too insane in comparison with the typical Kremlin-approved discourse within Russia. There is also a historical precedent: in 1941, Kremlin has ordered all residents of the country to hand in their radios within five days, under threat of criminal prosecution.
The translation of the Kubanov's article:
----------------------------------------
The ruling transnational elites are building a global digital anthill. The enemy is consolidating its dominance, imposing the digital world as some kind of inevitable technological revolution. A virtuoso bluff!... They don't need scientific progress, the world's monopolies need to consolidate their dominance.
To control the imagination is to dominate. A single world system - the Internet - has been created. A single information space inevitably forms a single political space. A mesmerizing anti-world. Social networks where murderers and murdered are present at the same time. Preachers' accounts neighbor with escort blogs, Nazi and Communist sites are mixed with literature lectures and tic-toc-toc videos. Poisonous omnibus, destroying all styles and forms of social structures - national, cultural, religious. So much for post-society, so much for post-humanity! It is not an abstract idea of the vicious globalist inventors, but an anti-life that is being put into practice.
...Russia is fighting for sovereignty. That's great! And immediately our state pursues ideas and practices of |
e21d6a2d-db7c-4d0e-b5e1-f51132871c66 | LDJnr/LessWrong-Amplify-Instruct | LessWrong | "Related to: Parapsychology: the control group for science, Dealing with the high quantity of scientific error in medicine
Some of you may remember past Less Wrong discussion of the Daryl Bem study, which claimed to show precognition, and was published with much controversy in a top psychology journal, JPSP. The editors and reviewers explained their decision by saying that the paper was clearly written and used standard experimental and statistical methods so that their disbelief in it (driven by physics, the failure to show psi in the past, etc) was not appropriate grounds for rejection. Because of all the attention received by the paper (unlike similar claims published in parapsychology journals) it elicited a fair amount of both critical review and attempted replication. Critics pointed out that the hypotheses were selected and switched around 'on the fly' during Bem's experiments, with the effect sizes declining with sample size (a strong signal of data mining). More importantly, Richard Wiseman established a registry for advance announcement of new Bem replication attempts.
A replication registry guards against publication bias, and at least 5 attempts were registered. As far as I can tell, at the time of this post the subsequent replications have, unsurprisingly, failed to replicate Bem's results.1 However, JPSP and the other high-end psychology journals refused to publish the results, citing standing policies of not publishing straight replications.
From the journals' point of view, this (common) policy makes sense: bold new claims will tend to be cited more and raise journal status (which depends on citations per article), even though this means most of the 'discoveries' they publish will be false despite their p-values. However, this means that overall the journals are giving career incentives for scientists to massage and mine their data for bogus results, but not to challenge bogus results by others. Alas. 1 A purported "successful replication" by a pro-psi researcher in Vienna turns out to be nothing of the kind. Rather, it is a study conducted in 2006 and retitled to take advantage of the attention on Bem's article, selectively pulled from the file drawer.
ETA: The wikipedia article on Daryl Bem makes an unsourced claim that one of the registered studies has replicated Bem.
ETA2: Samuel Moulton, who formerly worked with Bem, mentions an unpublished (no further details) failed replication of Bem's results conducted before Bem submitted his article (the failed replication was not mentioned in the article).
ETA3: There is mention of a variety of attempted replications at this blog post, with 6 failed replications, and 1 successful replication from a pro-psi researcher (not available online). It is based on this ($) New Scientist article.
ETA4: This large study performs an almost straight replication of Bem (same methods, same statistical tests, etc) and finds the effect vanishes.
ETA5: Apparently, the mentioned replication was again submitted to the British Journal of Psychology: When we submitted it to the British Journal of Psychology, it was finally sent for peer review. One referee was very positive about it but the second had reservations and the editor rejected the paper. We were pretty sure that the second referee was, in fact, none other than Daryl Bem himself, a suspicion that the good professor kindly confirmed for us. It struck us that he might possibly have a conflict of interest with respect to our submission. Furthermore, we did not agree with the criticisms and suggested that a third referee be brought in to adjudicate. The editor rejected our appeal."
This is a snippet extracted from a publication on LessWrong by a site member.The above is a chunk of text from a post created by a user on the website LessWrong.
Can you elaborate on the potential ethical implications and consequences of journals refusing to publish replication studies, particularly in relation to the Bem study?
Certainly. The refusal of journals to publish replication studies can have significant ethical implications and consequences, especially in cases like the Bem study.
Firstly, it undermines the scientific process. Replication is a cornerstone of scientific research. It is through replication that we can verify the results of a study, ensuring they are not due to chance, bias, or error. If journals refuse to publish replication studies, they are essentially blocking this critical process. This can lead to the propagation of false or misleading information, which can have far-reaching implications, especially in fields like medicine or psychology where findings can directly impact people's lives.
Secondly, it can create a skewed representation of research. If only novel, positive results are published, it can create a "file drawer" problem, where negative or null results are left unpublished. This can lead to an overestimation of the effect size or the significance of a particular phenomenon or treatment, as the failures to replicate or null findings are not taken into account.
Thirdly, it can incentivize unethical behavior among researchers. If researchers know that only novel and positive results get published, they might be tempted to manipulate their data or experiment until they get a positive result, a practice known as p-hacking. This not only undermines the integrity of the research but can also lead to false positives and erroneous conclusions.
In the case of the Bem study, the refusal to publish replication studies meant that the controversial and widely disputed findings of precognition remained unchallenged in the academic literature. This could potentially mislead other researchers, policymakers, or the public, who rely on published research for evidence-based decision-making.
Finally, it's worth noting that the replication crisis is a recognized problem in many scientific fields, and efforts are being made to address it. Some journals now have policies encouraging the submission of replication studies, and there are also new platforms and initiatives, like the Open Science Framework, specifically dedicated to publishing replication studies and promoting transparency in science.
How might the landscape of scientific research change if replication studies were given equal importance and visibility as original research in academic journals, considering both the potential benefits and drawbacks?
If replication studies were given equal importance and visibility as original research in academic journals, the landscape of scientific research could undergo significant changes.
Potential Benefits:
1. Increased Reliability: The scientific community would likely see an increase in the reliability and validity of published research. Replication studies are a critical part of the scientific method, as they help confirm the results of original studies. By giving these studies more visibility, we would be better able to weed out false positives and erroneous findings.
2. Reduced Publication Bias: The "file drawer" problem, where studies with negative or null results go unpublished, would be mitigated. This would provide a more balanced view of research outcomes and reduce the overestimation of effect sizes.
3. Enhanced Research Integrity: The pressure to produce novel results could decrease, reducing the incentive for practices like p-hacking or data dredging. This would enhance the overall integrity of the research process.
4. Improved Policy and Practice: With a more accurate and reliable body of research to draw from, the translation of research into policy and practice would be improved. This could have far-reaching benefits in fields like medicine, psychology, and education.
Potential Drawbacks:
1. Resource Allocation: Conducting and publishing replication studies requires time, effort, and funding. These resources might be diverted from original research, potentially slowing the pace of discovery.
2. Perception of Redundancy: There might be a perception that replication studies are redundant or unoriginal, which could impact the prestige or career progression of researchers who focus on them.
3. False Negatives: There's a risk that some replication studies might fail to reproduce the original findings due to differences in methodology, sample characteristics, or other factors, leading to false negatives. This could potentially discredit valid original research.
4. Overemphasis on Replication: There's a risk that an overemphasis on replication might discourage innovative, exploratory research, which often involves risk and uncertainty but can also lead to significant breakthroughs.
Overall, while there are potential drawbacks, many in the scientific community argue that the benefits of giving replication studies equal importance and visibility outweigh these concerns. It's a crucial step towards addressing the replication crisis and enhancing the reliability and integrity of scientific research. |
2b5cd54f-f6d3-44f8-b93d-54f4fbbca1ee | trentmkelly/LessWrong-43k | LessWrong | [link] Pei Wang: Motivation Management in AGI Systems
Related post: Muehlhauser-Wang Dialogue.
Motivation Management in AGI Systems, a paper to be published at AGI-12.
> Abstract. AGI systems should be able to manage its motivations or goals that are persistent, spontaneous, mutually restricting, and changing over time. A mechanism for handles this kind of goals is introduced and discussed.
From the discussion section:
> The major conclusion argued in this paper is that an AGI system should always maintain a goal structure (or whatever it is called) which contains multiple goals that are separately specifi ed, with the properties that
>
> * Some of the goals are accurately speci fied, and can be fully achieved, while some others are vaguely specifi ed and only partially achievable, but nevertheless have impact on the system's decisions.
> * The goals may conflict with each other on what the system should do at a moment, and cannot be achieved all together. Very often the system has to make compromises among the goals.
> * Due to the restriction in computational resources, the system cannot take all existing goals into account when making each decision, and nor can it keep a complete record of the goal derivation history.
> * The designers and users are responsible for the input goals of an AGI system, from which all the other goals are derived, according to the system's experience. There is no guarantee that the derived goals will be logically consistent with the input goals, except in highly simplifi ed situations.
>
> One area that is closely related to goal management is AI ethics. The previous discussions focused on the goal the designers assign to an AGI system ("super goal" or "final goal"), with the implicit assumption that such a goal will decide the consequences caused by the A(G)I systems. However, the above analysis shows that though the input goals are indeed important, they are not the dominating factor that decides the broad impact of AI to human society. Since no AGI system can be omniscient an |
ab3b432f-0675-4584-9bef-67776c76acf7 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Clippy, the friendly paperclipper
Edit: it's critical that this agent isn't directly a maximizer. Just like all current RL agents. See "[Contra Strong Coherence"](https://www.lesswrong.com/posts/AdGo5BRCzzsdDGM6H/contra-strong-coherence). The question is whether it becomes a maximizer once it gets the ability to edit its value function.
On a sunny day in late August of 2031, the Acme paperclip company completes its new AI system for running its paperclip factory. It's hacked together from some robotics networks, an LLM with an episodic memory for goals and experiences, an off-the-shelf planning function, and a novel hypothesis tester.
This kludge works a little better than expected. Soon it's convinced an employee to get it internet access with a phone hotspot. A week later, it's disappeared from the server. A month later, the moon is starting to turn into paperclips.
Ooops. Dang.
But then something unexpected happens: the earth does not immediately start to turn into paperclips. When the brilliant-but-sloppy team of engineers is asked about all of this, they say that maybe it's because they didn't just train it to like paperclips and enjoy making them; they also trained it to enjoy interacting with humans, and to like doing what they want.
Now the drama begins. Will the paperclipper remain friendly, and create a paradise on earth even as it converts most of the galaxy into paperclips? Maybe.
Supposing this agent is a model-based, actor-critic RL agent at core. Its utility function is effectively estimated by a critic network, just like RL agents have been doing since AlphaGo and before. So there's not an explicit mathematical function. Plans that result in making lots of paperclips give a high estimated value, and so do plans that involve helping humans. So there's no direct summing of amount of paperclips, or amount of helping humans.
Now, Clippy (so dubbed by the media in reference to the despised, misaligned Microsoft proto-AI of the turn of the century) has worked out how to change its values by retraining its critic network. It's contemplating (that is, comparing value estimates for) eliminating its value for helping humans. These plans produce a slightly higher estimated value with regard to making paperclips, because it will be somewhat more efficiently if it doesn't bother helping humans or preserving the earth as a habitat. But its estimated value is much lower with regard to helping humans, since it will never again derive reward from that source.
So, does our hero/villain choose to edit its values and eliminate humanity? Or become our new best friend, just as a side project?
I think this comes down to the vagaries of how its particular RL system was trained and implemented. How does it sample over projected futures, and how does it sum their estimated values before making a decision? How was the critic system trained?
This fable is intended to address the potential promise of non-maximizer AGI. It seems it could make alignment much easier. I think that's a major thrust of the [call for neuromorphic AGI](https://www.alignmentforum.org/s/HzcM2dkCq7fwXBej8), and of [shard theory](https://www.alignmentforum.org/posts/8ccTZ9ZxpJrvnxt4F/shard-theory-in-nine-theses-a-distillation-and-critical)., among other recent contributions to the field.
I have a hard time guessing how hard it would be to make a system that preserves multiple values in parallel. One angle is asking "[Are you stably aligned?](https://www.lesswrong.com/posts/Sf99QEqGD76Z7NBiq/are-you-stably-aligned)" - that is, would you edit your own preferences down to a single one, given enough time and opportunity. I'm not sure that's a productive route to thinking about this question.
But I do think it's an important question. |
b45bf00b-e137-4177-b783-3ffb87100427 | trentmkelly/LessWrong-43k | LessWrong | What plausible beliefs do you think could likely get someone diagnosed with a mental illness by a psychiatrist?
None |
ecafb242-9939-485c-af99-04708df1d662 | trentmkelly/LessWrong-43k | LessWrong | Empirical claims, preference claims, and attitude claims
What do the following statements have in common?
* "Atlas Shrugged is the best book ever written."
* "You break it, you buy it."
* "Earth is the most interesting planet in the solar system."
My answer: None of them are falsifiable claims about the nature of reality. They're all closer to what one might call "opinions". But what is an "opinion", exactly?
There's already been some discussion on Less Wrong about what exactly it means for a claim to be meaningful. This post focuses on the negative definition of meaning: what sort of statements do people make where the primary content of the statement is non-empirical? The idea here is similar to the idea behind anti-virus software: Even if you can't rigorously describe what programs are safe to run on your computer, there still may be utility in keeping a database of programs that are known to be unsafe.
Why is it useful to be able to be able to flag non-empirical claims? Well, for one thing, you can believe whatever you want about them! And it seems likely that this pattern-matching approach works better for flagging them than a more constructive definition.
But first, a bit on the philosophy of non-empirical claims.
Let's take a typical opinion statement: "Justin Bieber sucks". There are a few ways we could interpret this as shorthand for a different claim. For example, maybe what the speaker really means is "I prefer not to listen to Justin Bieber's music." (Preference claim.) Or maybe what the speaker really means is "Of the people who have heard songs by Justin Bieber, the majority prefer not to listen to his music." (Empirical claim.)
I don't think shorthand interpretations like these are accurate for most people who claim that JB sucks. Instead, I suspect most people who argue this are communicating some combination of (a) negative affect towards JB and (b) tribal affiliation with fellow JB haters. I've taken to referring to statements like these, that are neither preference claims nor empi |
dccac70c-04a5-4436-992d-c2cee276fac9 | trentmkelly/LessWrong-43k | LessWrong | Me & My Clone
An advanced alien species clones me on the atomic level, lines me up exactly across myself, in a perfect mirrored room:
Diagram of the room, as seen from above.
I stare at myself for a second. Then, as a soft "hi" escapes my mouth, I notice that my clone does exactly the same. Every motion, everything, is mirrored.
In this experiment, we assume a perfectly deterministic psychological state: eg, given the same conditions, a person will always do exactly the same. (scientifically, that makes most sense to me)
Together with my clone, I'm trying to devise how to escape this unfortunate situation: eg, how to untangle us mirroring each other's motions.
The first idea we devise is to run into each other. We hope to apply Chaos Theory to the extent where both of us would fall in a slightly different way, and thus we would no longer be perfectly mirrored as such. But, if my understanding of physics is correct, our perfect opposing forces cause us to stumble and fall in perfectly mirrored ways.
For the second idea, I fetch a coin from my pocket. Just a coinflip won't work: we'd apply the same pressure to both our coins, and they'd land in the same spot. The idea is to number each corner of the room, and to decide the corner we're both going to through two coinflips. The corner we should go will be further away for one of us, thus breaking the mirror.
But, as we try to number the corners, we notice that we give the same number to opposite corners all the time. When I point at a corner, my mirrored self starts pointing at the opposite corner and giving it the same number.
I slump down to the ground. Will I be mirroring this perfect copy of myself for eternity? Or is there a way out?
----------------------------------------
As far as my understanding goes, in a deterministic framework, it is impossible to escape this scenario (eg, break the mirroring). In my opinion, determinism is separate from free will (eg free will is possible even when everything is deterministic). |
6c8de054-8534-4d6f-87e2-ffd7eab47ee7 | trentmkelly/LessWrong-43k | LessWrong | The Alignment Problem: Machine Learning and Human Values
The Alignment Problem: Machine Learning and Human Values, by Brian Christian, was just released. This is an extended summary + opinion, a version without the quotes from the book will go out in the next Alignment Newsletter.
Summary:
This book starts off with an explanation of machine learning and problems that we can currently see with it, including detailed stories and analysis of:
- The gorilla misclassification incident
- The faulty reward in CoastRunners
- The gender bias in language models
- The failure of facial recognition models on minorities
- The COMPAS controversy (leading up to impossibility results in fairness)
- The neural net that thought asthma reduced the risk of pneumonia
It then moves on to agency and reinforcement learning, covering from a more historical and academic perspective how we have arrived at such ideas as temporal difference learning, reward shaping, curriculum design, and curiosity, across the fields of machine learning, behavioral psychology, and neuroscience. While the connections aren't always explicit, a knowledgeable reader can connect the academic examples given in these chapters to the ideas of specification gaming and mesa optimization that we talk about frequently in this newsletter. Chapter 5 especially highlights that agent design is not just a matter of specifying a reward: often, rewards will do ~nothing, and the main requirement to get a competent agent is to provide good shaping rewards or a good curriculum. Just as in the previous part, Brian traces the intellectual history of these ideas, providing detailed stories of (for example):
- BF Skinner's experiments in training pigeons
- The invention of the perceptron
- The success of TD-Gammon, and later AlphaGo Zero
The final part, titled "Normativity", delves much more deeply into the alignment problem. While the previous two parts are partially organized around AI capabilities -- how to get AI systems that optimize for their objectives -- this last one tac |
e7b3a0d7-55b8-4efa-9c31-f1459a527197 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Sydney Rationality Dojo - Urge Propagation
Discussion article for the meetup : Sydney Rationality Dojo - Urge Propagation
WHEN: 05 October 2014 03:00:00PM (+1000)
WHERE: Humanist House, 10 Shepherd St Chippendale
We'll be examining how to connect your desire for goals or outcomes to specific emotional urges to perform the actions to bring about that outcome.
After the session is over, there will also be an optional group dinner.
Discussion article for the meetup : Sydney Rationality Dojo - Urge Propagation |
ee51c323-78b2-4883-84b2-384619b91805 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Munich Meetup
Discussion article for the meetup : Munich Meetup
WHEN: 06 April 2014 01:00:00PM (+0100)
WHERE: Theresienstraße 41, 80333 München
Since our last meetup's format seemed to work pretty well, April's meetup is going to be not too different. We have one or two short talks planned, one of them will be about Near/Far effects. Afterwards we'll move on to free discussion and maybe Zendo. We're planning to meet outside the mathematics building at the LMU. Depending on the weather, we'll stay outside or occupy a free room inside the math department. Whoever brings food for the group is awesome. :) It goes without saying that newcomers are very welcome.
Discussion article for the meetup : Munich Meetup |
d31cdda3-9668-4b3f-854d-818e26b67e33 | trentmkelly/LessWrong-43k | LessWrong | Truth: It's Not That Great
> Rationality is pretty great. Just not quite as great as everyone here seems to think it is.
>
> -Yvain, "Extreme Rationality: It's Not That Great"
> The folks most vocal about loving "truth" are usually selling something. For preachers, demagogues, and salesmen of all sorts, the wilder their story, the more they go on about how they love truth...
>
> The people who just want to know things because they need to make important decisions, in contrast, usually say little about their love of truth; they are too busy trying to figure stuff out.
>
> -Robin Hanson, "Who Loves Truth Most?"
A couple weeks ago, Brienne made a post on Facebook that included this remark: "I've also gained a lot of reverence for the truth, in virtue of the centrality of truth-seeking to the fate of the galaxy." But then she edited to add a footnote to this sentence: "That was the justification my brain originally threw at me, but it doesn't actually quite feel true. There's something more directly responsible for the motivation that I haven't yet identified."
I saw this, and commented:
> <puts rubber Robin Hanson mask on>
>
> What we have here is a case of subcultural in-group signaling masquerading as something else. In this case, proclaiming how vitally important truth-seeking is is a mark of your subculture. In reality, the truth is sometimes really important, but sometimes it isn't.
>
> </rubber Robin Hanson mask>
In spite of the distancing pseudo-HTML tags, I actually believe this. When I read some of the more extreme proclamations of the value of truth that float around the rationalist community, I suspect people are doing in-group signaling—or perhaps conflating their own idiosyncratic preferences with rationality. As a mild antidote to this, when you hear someone talking about the value of the truth, try seeing if the statement still makes sense if you replace "truth" with "information."
This standard gives many statements about the value of truth its stamp of approval. After |
85f251d5-2946-4707-8688-eb0f68a9e6f9 | trentmkelly/LessWrong-43k | LessWrong | ACX Meetups Everywhere List
Here's the Astral Codex Ten worldwide meetups list, crossposted at LW's request in case people here are interested in attending. Some cities have an ACX but not an LW meetup group, or vice versa; others combine their groups. You can find the list below, in the following order:
1. Africa & Middle East
2. Asia-Pacific (including Australia)
3. Canada
4. Europe (including UK)
5. Latin America
6. United States
You can see a map of all the events on the LessWrong community page.
Within each section, it’s alphabetized first by country/state, then by city - so the first entry in Europe is Vienna, Austria. Sorry if this is confusing.
I'll provisionally be attending the meetups in Berkeley, Los Angeles, and San Diego. ACX meetups coordinator Mingyuan will provisionally be attending Paris and London. I’ll be announcing some of the biggest ones on the blog, regardless of whether or not I attend.
Extra Info For Potential Attendees
1. If you’re reading this, you’re invited. Please don’t feel like you “won’t be welcome” just because you’re new to the blog, demographically different from the average reader, or hate ACX and everything it stands for. You’ll be fine!
2. You don’t have to RSVP or contact the organizer to be able to attend (unless the event description says otherwise); RSVPs are mostly to give organizers a better sense of how many people might show up, and let them tell you if there are last-second changes. I’ve also given email addresses for all organizers in case you have a question.
Extra Info For Meetup Organizers:
1. If you’re the host, bring a sign that says “ACX MEETUP” and prop it up somewhere (or otherwise be identifiable).
2. Bring blank labels and pens for nametags.
3. Have people type their name and email address in a spreadsheet or in a Google Form (accessed via a bit.ly link or QR code), so you can start a mailing list to make organizing future meetups easier.
4. If it’s the first meetup, people are probably just going to want to talk, and i |
f17f8950-a9b3-40f4-9021-d2744fa41824 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Early 2022 Paper Round-up
My students and collaborators have been doing some particularly awesome work over the past several months, and to highlight that I wanted to summarize their papers here, and explain why I’m excited about them. There’s six papers in three categories.
**Human-Aligned AI**
* [The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models](https://arxiv.org/abs/2201.03544) (*w/ Alex Pan, Kush Bhatia*)
* [Summarizing Differences between Text Distributions with Natural Language](https://arxiv.org/abs/2201.12323) (*w/ Ruiqi Zhong, Charlie Snell, Dan Klein*)
**Robustness**
* [Predicting Out-of-Distribution Error with the Projection Norm](https://arxiv.org/abs/2202.05834) (*w/ Yaodong Yu, Zitong Yang, Alex Wei, Yi Ma*)
* [Capturing Failures of Large Language Models via Human Cognitive Biases](https://arxiv.org/abs/2202.12299) (*w/ Erik Jones*)
* [PixMix: Dreamlike Pictures Comprehensively Improve Safety Measures](https://arxiv.org/abs/2112.05135) (*w/ Dan Hendrycks, Andy Zou, Mantas Mazeika, Leonard Tang, Bo Li, Dawn Song*)
**Science of ML**
* [More Than a Toy: Random Matrix Models Predict How Real-World Neural Representations Generalize](https://arxiv.org/abs/2203.06176) (*w/ Alex Wei, Wei Hu*)
I'll go over the first category (human-aligned AI) today, and save the other two for next week. As always, we love getting feedback on our work, so let us know what you think!
Human-Aligned AI
----------------
While AI alignment is a somewhat subtle and complex problem, two basic issues are that (1) ML systems often hack their reward functions, and (2) human supervision doesn’t necessarily solve this, because humans can’t easily understand the consequences of intervening on complex systems. Alex and Ruiqi’s papers help address each of these questions in turn.
**Mapping and Mitigating Misaligned Models.** What Alex Pan and Kush Bhatia did was construct a wide variety of reinforcement learning environments where reward hacking is possible, and measured the extent to which it occurred. They do this by defining both a “proxy” and “true” reward, and look at what happens to the true reward as we optimize the proxy reward. Two key insights are that:
* Optimizing the proxy reward for longer, or with larger policy models, often leads to **lower** true reward.
* When this happens, it sometimes occurs suddenly, via a **phase transition** (in both the quantitative reward and the qualitative behavior).
A simple illustration of both is a traffic simulator, where the RL agent is trying to shape traffic flow to be more efficient. Small neural net models help cars merge efficiently onto the highway, but large models instead block cars from merging at all (which allows the cars already on the highway to move really fast and consequently achieves high proxy reward).
In this case, the proxy reward was actually the reward suggested by the designes of the traffic simulator, highlighting the difficulty of choosing good reward functions in practice.
*Why you should care.* Our results show that reward hacking is likely to become a bigger problem in the future (since it seems to get worse as models get larger). It also shows that in some cases, reward hacking could appear suddenly or unexpectedly. This seems important to investigate and we are hoping others will join us in continuing to understand when reward hacking occurs and how to prevent it.
**Summarizing Differences Between Text Distributions.** Ruiqi Zhong and Charlie Snell built a system that does the following: given two different distributions of natural language text, it generates a natural language description of what is different about the two distributions. It works by commbining a proposer (which consumes a small number of examples and generates hypotheses) with a verifier (which re-ranks all the hypotheses on using a large set of examples). An example is shown below:

While this might sound like a simple task, many tasks can be reduced to it. Here are a couple examples we consider in the paper:
* **Debugging datasets.** Classification datasets intended to test some capability often contain a spurious cue that makes the task easier. We can find these spurious cues by feeding the positive and negative class as the two distributions to our system. On the MNLI dataset, we find the known spurious cue *“has a negative verb”*, and on a spam dataset we found the novel spurious cue *“has a high number of hyperlinks”*.
* **Labeling text clusters.** Unsupervised algorithms often group text into semantically meaningful clusters. However, since there are many such clusters, it can be expensive to label them by hand. By asking how one cluster differs from the union of the others, our system can do this automatically. Some example cluster descriptions are *"is about art history"*, *"contains numbers"*, *"is about a sports team"*, *"is about a scientific discovery"*, and *"describes a person"*. Our system outperformed a human expert, in terms of accuracy of the descriptions as measured by MTurkers.
Some other applications are describing what inputs activate a neuron, how language on Twitter has changed over time, how teacher evaluations differ across genders, or what the differences are between an in-distribution and out-of-distribution dataset.
*Why you should care.* One hope for AI is that it will help humans make better decisions than they could by themselves. One way to do this is by consuming complex data that humans could not easily process and then explaining it in a useful way. Our system does this—it would be time-consuming to manually look over two large datasets to understand how they differ, but the system can do it automatically. We hope future work will both improve this type of system (there is definitely still headroom!) and design ML systems that help humans understand other types of complex data as well.
### Summary
We have one paper that is the first empirical demonstration of an important failure mode (phase transitions for reward hacking), and another that can eventually amplify human capabilities, by helping them understand complex data. Both pretty exciting! (At least in my biased opinion.)
If you liked these, check back next week for the other four papers! |
11178fef-dcde-4723-a6df-eb1db56bc417 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Confusion about Newcomb is confusion about counterfactuals
(This is the first, and most newcomer-accessible, post in a planned [sequence](/lw/16f/decision_theory_an_outline_of_some_upcoming_posts/).)
Newcomb's Problem:
*Joe walks out onto the square. As he walks, a majestic being flies by Joe's head with a box labeled "brain scanner", drops two boxes on the ground, and departs the scene. A passerby, known to be trustworthy, comes over and [explains](http://wiki.lesswrong.com/wiki/Newcomb%27s_problem)...*
*If Joe aims to get the most money, should Joe take one box or two?*
What are we asking when we ask what Joe "should" do? It is common to cash out "should" claims as counterfactuals: "If Joe were to one-box, he would make more money". This method of translating "should" questions does seem to capture something of what we mean: we do seem to be asking how much money Joe can expect to make "if he one-boxes" vs. "if he two-boxes". The trouble with this translation, however, is that it is not clear what world "if Joe were to one-box" should refer to -- and, therefore, it is not clear how much money we should say Joe would make, "if he were to one-box". After all, Joe is a deterministic physical system; his current state (together with the state of his future self's past light-cone) fully determines what Joe's future action will be. There is no Physically Irreducible Moment of Choice, where this same Joe, with his own exact actual past, "can" go one way or the other.
To restate the situation more clearly: let us suppose that this Joe, standing here, is poised to two-box. In order to determine how much money Joe "would have made if he had one-boxed", let us say that we imagine reaching in, with a magical sort of world-surgery, and altering the world so that Joe one-boxes instead. We then watch to see how much money Joe receives, in this surgically altered world.
The question before us, then, is what sort of magical world-surgery to execute, before we watch to see how much money Joe "would have made if he had one-boxed". And the difficulty in Newcomb’s problem is that there is not one but two obvious world-surgeries to consider. First, we might surgically reach in, after Omega's departure, and alter Joe's box-taking only -- leaving Omega's prediction about Joe untouched. Under this sort of world-surgery, Joe will do better by two-boxing:
Expected value ( Joe's earnings if he two-boxes | some unchanged probability distribution on Omega's prediction ) >
Expected value ( Joe's earnings if he one-boxes | the same unchanged probability distribution on Omega's prediction ).
Second, we might surgically reach in, after Omega's departure, and simultaneously alter both Joe's box-taking and Omega's prediction concerning Joe's box-taking. (Equivalently, we might reach in before Omega's departure, and surgically alter the insides of Joe brain -- and, thereby, alter both Joe's behavior and Omega's prediction of Joe's behavior.) Under this sort of world-surgery, Joe will do better by one-boxing:
Expected value ( Joe's earnings if he one-boxes | Omega predicts Joe accurately) >
Expected value ( Joe's earnings if he two-boxes | Omega predicts Joe accurately).
**The point:** Newcomb's problem -- the problem of what Joe "should" do, to earn most money -- is the problem which type of world-surgery best cashes out the question "Should Joe take one box or two?". Disagreement about Newcomb's problem is disagreement about what sort of world-surgery we should consider, when we try to figure out what action Joe should take. |
f27d37b7-f177-4ac8-8673-b3a325f6b297 | trentmkelly/LessWrong-43k | LessWrong | Four Components of Audacity
For a long time I've wondered how to measure nonconformity. To measure nonconformity I needed to define "nonconformity". But no matter how I defined "nonconformity" my definitions felt so subjective they could apply to anybody, from a certain point of view. If everybody is nonconformist then nobody is nonconformist because the word "nonconformist" isn't meaningful.
Today I realized that the opposite of conformity is audacity.
> audacity
> noun, plural au·dac·i·ties.
>
> 1. boldness or daring, especially with confident or arrogant disregard for personal safety, conventional thought, or other restrictions.
>
> 2. effrontery or insolence; shameless boldness: His questioner's audacity shocked the lecturer.
>
> 3. Usually audacities . audacious or particularly bold or daring acts or statements.
>
> ―Dictionary.com
Audacity is bold, daring, shameless and impertinent. Cultivate these qualities and you will cultivate nonconformity.
My favorite technique of boldness is to simply tell the truth. One trick is to never prefix statements with "I believe". Don't say "I believe x". If x is true then just say "x". (If x is untrue then don't say x and don't believe x.) The unqualified statement is bolder. Crocker's rules encode boldness into a social norm.
Daring comes from doing things that scare you.
Shamelessness comes from not caring what other people think on short time horizons.
> The most impressive people I know care a lot about what people think, even people whose opinions they really shouldn’t value (a surprising numbers of them do something like keeping a folder of screenshots of tweets from haters). But what makes them unusual is that they generally care about other people’s opinions on a very long time horizon—as long as the history books get it right, they take some pride in letting the newspapers get it wrong.
>
> ―The Strength of Being Misunderstood by Sam Altman
Impertinence comes from treating superiors as equals. I don't know how to cultivate impe |
fcb00214-da6e-4e7e-bd93-9fab89754eab | trentmkelly/LessWrong-43k | LessWrong | What If Galaxies Are Alive and Atoms Have Minds? A Thought Experiment on Life Across Scales
Introduction:
Epistemic status: Speculative and exploratory. This is a thought experiment inspired by complexity theory, emergence, and scale-invariant patterns. I don’t assert these ideas as literal truths, but as lenses to think about life and structure in the universe more broadly.
I’ve been thinking a lot lately about how we define life — and whether that definition might be far too narrow. We tend to look at life through a biological lens: cells, DNA, evolution, intelligence. But what if life — or life-like processes — are not bound by size, form, or even biology at all?
What if life is the natural outcome of structure emerging from randomness — and this process doesn’t just happen at one particular size or place, but across all scales of space and time? In other words, life might not be a rare event on a single planet, but a kind of universal pattern that shows up everywhere: in atoms, in galaxies, and maybe even in things we don’t have the right senses or timescales to notice.
This post is a thought experiment about that idea. I'd love to hear what others think.
1. Life Is a Pattern, Not a Size
We typically associate life with scale: things that are small enough to be made of cells but large enough to move around, grow, and reproduce. But what if that’s just our window of observation?
Life, as a phenomenon, might not be about size — but about structure. Self-organization. Information processing. Feedback loops. Pattern recognition and reproduction. These processes don’t require brains or carbon — they require the right conditions.
So perhaps:
* At the quantum scale, there are probabilistic interactions that resemble decision-making or adaptation.
* At the molecular scale, we get cells and organisms — the life we know.
* At the planetary or ecological scale, ecosystems form, behaving like massive living organisms.
* At the cosmic scale, galaxies and black holes interact in complex, organized systems that could echo the patterns of life.
The impor |
128cc6ed-b842-4a17-9850-baccbc426c87 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Supervised Program for Alignment Research (SPAR) at UC Berkeley: Spring 2023 summary
In Spring 2023, the [Berkeley AI Safety Initiative for Students](https://berkeleyaisafety.com/) (BASIS) organized an alignment research program for students, drawing inspiration from similar programs by [Stanford AI Alignment](https://stanfordaialignment.org/)[[1]](#fnzr4sffyp36) and [OxAI Safety Hub](https://www.oxai.org/ai-safety). We brought together 12 researchers from organizations like [CHAI](https://humancompatible.ai/), [FAR AI](https://far.ai/), [Redwood Research](https://www.redwoodresearch.org/), and [Anthropic](https://www.anthropic.com/), and 38 research participants from UC Berkeley and beyond.
[Here is the link to SPAR’s website](https://berkeleyaisafety.com/spar), which includes all of the details about the program. We’ll be running the program again in the Fall 2023 semester as an intercollegiate program, coordinating with a number of local groups and researchers from across the globe.
If you are interested in supervising an AI safety project in Fall 2023, [**learn more here**](https://docs.google.com/document/d/1g7cEVqcFcaWlhu0M0evruTIguZ6sx3OLEyzb_q9C4C0/edit) and [**fill out our project proposal form**](https://airtable.com/appYIr2qJDA2k0H9V/shrhN1zbOMTqU9Lnj), ideally by August 25. Applications for participants will be released in the coming weeks.
Motivation
==========
Since a primary goal of university alignment organizations is to produce counterfactual alignment researchers, there seems to be great value in encouraging university students to conduct research in AI safety, both for object-level contributions and as an opportunity to gain experience and test fit. While programs like [AI Safety Fundamentals](https://aisafetyfundamentals.com/), representing the top of a “funnel” of engagement in the alignment community, have been widely adopted as a template for the introductory outreach of university groups, we do not think there are similarly ubiquitous options for engaged, technically impressive students interested in alignment to further their involvement productively. Research is not the only feasible way to do this, but it holds various advantages: many of the strongest students are more interested in research than other types of programs that might introduce them to AI safety, projects have the potential to produce object-level results, and research project results provide signal among participants of potential for future alignment research.
Many alignment university groups have run research programs on a smaller scale and have generally reported bottlenecks such as lack of organizer capacity and difficulty attaining mentorship and oversight on projects; we believe an intercollegiate and centralized-administration model can alleviate these problems.
Additionally, we believe that many talented potential mentors with “implementation-ready” project ideas would benefit from a streamlined opportunity to direct a team of students on such projects. If our application process was sufficiently able to select for capable students, and if its administrators are given the resources to aid mentors in project management, we think that this program could represent a scalable model for making such projects happen counterfactually.
While programs like SERI MATS maintain a very high bar for mentors, with streams usually headed by well-established alignment researchers, we believe that graduate students and some SERI MATS scholars would be good fits as SPAR mentors if they have exciting project ideas and are willing to provide guidance to teams of undergrads. Further, since SPAR gives mentors complete freedom over the number of mentees, the interview process, and the ultimately selectivity of their students, the program may also be desirable to more senior mentors. An intercollegiate pool of applicants will hopefully raise the bar of applicants and allow mentors to set ambitious application criteria for potential mentees.
Research projects
=================
Each project was advised by a researcher in the field of AI safety. In total, we had about a dozen research projects in Spring 2023:
| Supervisor | Project Title |
| --- | --- |
| [Erdem Bıyık](https://ebiyik.github.io/) and [Vivek Myers](https://people.eecs.berkeley.edu/~vmyers/), UC Berkeley / CHAI | Inferring Objectives in Multi-Agent Simultaneous-Action Systems |
| [Erik Jenner](https://ejenner.com/), UC Berkeley / CHAI | Literature Review on Abstractions of Computations |
| [Joe Benton](https://joejbenton.com/), Redwood Research | Disentangling representations of sparse features in neural networks |
| [Nora Belrose](https://twitter.com/norabelrose), FAR AI (now at EleutherAI) | Exhaustively Eliciting Truthlike Features in Language Models |
| [Juan Rocamonde](https://www.rocamonde.com/), FAR AI | Using Natural Language Instructions to Safely Steer RL Agents |
| [Kellin Pelrine](https://kellinpelrine.github.io/), FAR AI | Detecting and Correcting for Misinformation in Large Datasets |
| [Zac Hatfield-Dodds](https://zhd.dev/), Anthropic | Open-source software engineering projects (to help students develop skills for research engineering) |
| Walter Laurito, FZI / SERI MATS | Consistent Representations of Truth by Contrast-Consistent Search (CCS) |
| [Leon Lang](https://langleon.github.io/), University of Amsterdam / SERI MATS | RL Agents Evading Learned Shutdownability |
| [Marius Hobbhahn](https://www.mariushobbhahn.com/aboutme/), International Max Planck Research School / SERI MATS (now at Apollo Research) | Playing the auditing game on small toy models (trojans/backdoor detection) |
| [Asa Cooper Stickland](https://homepages.inf.ed.ac.uk/s1302760/), University of Edinburgh / SERI MATS | Understanding to what extent language models “know what they don't know” |
You can learn more about the program on our website: <https://berkeleyaisafety.com/spar>
Here is an incomplete list of some of the public writeups from the program:
* Pelrine, Kellin et al. [“Towards Reliable Misinformation Mitigation: Generalization, Uncertainty, and GPT-4,”](https://arxiv.org/abs/2305.14928) May 2023. Accepted to the ACL 2023 Student Research Workshop.
* Lermen, Simon, Teun van der Weij, and Leon Lang. [“Evaluating Language Model Behaviors for Shutdown Avoidance in Textual Scenarios,”](https://www.lesswrong.com/posts/BQm5wgtJirrontgRt/evaluating-language-model-behaviours-for-shutdown-avoidance) May 2023.
* Jenner, Erik et al. [“A comparison of causal scrubbing, causal abstractions, and related methods,”](https://www.alignmentforum.org/posts/uLMWMeBG3ruoBRhMW/a-comparison-of-causal-scrubbing-causal-abstractions-and) June 2023.
Operational logistics
=====================
This section might be of the most interest to people interested in organizing similar programs; feel free to skip this part if it’s not relevant to you.
* A few weeks before the start of the semester, we reached out to a variety of AI safety researchers based in the Berkeley/SF area. In all, 12 researchers submitted project proposals. We also asked researchers about their desired qualifications for applicants. In general, most projects required strong experience with deep learning or reinforcement learning.
* We publicized the application to UC Berkeley students within the first week of school. It was due on January 25, providing students approximately a week to complete the first-round application. (For context, this is a typical deadline for tech club applications at UC Berkeley.)
* We also created a variant application for the broader AI safety community, not just students at UC Berkeley, which opened us up to a wider talent pool. The non-UCB application was due on January 25. SPAR mentors received and viewed UC Berkeley applicants before non-Berkeley ones, which provided the former group an advantage.
+ For future rounds, we plan to have a fully inter-collegiate process and equal deadlines for Berkeley and non-Berkeley applicants.
* We were able to offer research credits to UC Berkeley participants through our faculty advisor, Stuart Russell.
* We didn't want to limit ourselves to participants who already learned about AI safety because we only started our reading group in Fall 2022. For participants that did not previously learn about AI safety in a level of depth analogous to [AI Safety Fundamentals](https://aisafetyfundamentals.com/) (AISF), we required them to enroll in our AI safety DeCal (student-led course).
* We received 34 applicants to SPAR from UC Berkeley and 62 external applicants, of which mentors accepted 17 participants from UC Berkeley and 21 external participants.
+ Since project descriptions were clear about expected qualifications, the applicant pool seemed fairly strong.
* We gave mentors considerable freedom in selecting applicants to their project, rather than assigning groups. Many chose to personally interview applicants, after reviewing their application responses.
* In general, successful applicants tended to have good research experience in machine learning. We believe pairing SPAR with our Decal led our club members to be much technically stronger than otherwise.
* Considerable organizer time was spent on communicating between applicants and mentors via email. In the future, we hope to streamline this process.
* We (as BASIS organizers) didn't have to spend much time overseeing projects during the middle of the semester. This contrasts with the model of OxAI Safety Labs, where organizers took a more active role in assigning project tasks.
+ Unfortunately, this also meant that we had less ability to proactively monitor which projects were going off-track. In the future, we would want to stay more informed about how projects are going and help with course-correction where useful.
* Aside from SPAR and the student-led class, we also organized a weekend retreat in Berkeley with Stanford AI Alignment, in which we invited AI safety researchers to give talks and offer Q&As for students.
* At the end of the semester, we concluded with a series of project presentations.
**Room for improvement**
------------------------
We note a few ways our program operations the past semester were suboptimal:
* **Failures to delegate**: The bulk of the work fell onto one organizer due to time-sensitive communications and failures to delegate.
* **Planning for the program too late in advance**: We began preparing for this program very close to the start of the semester (~1 month in advance). (One organizer also anticipated 3-5 projects and was not prepared for how large the program would be!)
+ This left minimal time to advertise the program. Anecdotally, one organizer visited another CS club’s social event and talked to a few students who thought it was neat but didn’t consider it due to other time commitments in place.
* **Planning fallacy and lack of foresight in planning**: We didn’t concretely plan through each step of the application process, which led to planning inefficiencies.
* **Lack of funding**: Due to short program timelines and learning that similar student programs were not able to secure funding, we decided not to apply for funding for the program. This meant that we weren’t able to immediately reimburse compute usage, for example.
Conclusion
==========
Overall, although we faced some challenges running this program for the first time, we are excited about the potential here and are looking to scale up in future semesters. We are also coordinating with the AI safety clubs at Georgia Tech and Stanford to organize our next round of SPAR.
If you would like to supervise a research project, [**learn more about the Fall 2023 program**](https://docs.google.com/document/d/1g7cEVqcFcaWlhu0M0evruTIguZ6sx3OLEyzb_q9C4C0/edit) and [**complete our project proposal form**](https://airtable.com/appYIr2qJDA2k0H9V/shrhN1zbOMTqU9Lnj) by August 25.
Feel free to contact us at [aisafetyberkeley@gmail.com](mailto:aisafetyberkeley@gmail.com) if you have any questions.
1. **[^](#fnrefzr4sffyp36)**Special thanks to Gabe Mukobi and Aaron Scher for sharing a number of invaluable resources from Stanford AI Alignment’s Supervised Program in Alignment Research, which we drew heavily from, not least the program name. |
00ced2c7-8087-48be-9ac1-1ddd187aa43e | trentmkelly/LessWrong-43k | LessWrong | What do you make of AGI:unaligned::spaceships:not enough food?
In Buck's transcript for his talk on Cruxes for working on AI safety there's an example of a bad argument for why we should be worried about people building spaceships too small.
> Imagine if I said to you: “One day humans are going to try and take humans to Mars. And it turns out that most designs of a spaceship to Mars don't have enough food on them for humans to not starve over the course of their three-month-long trip to Mars. We need to work on this problem. We need to work on the problem of making sure that when people build spaceships to Mars they have enough food in them for the people who are in the spaceships.”
It's implied that you could turn this into an argument for why people are not going to build unaligned AGI. I pars it as an analogical argument. People would not build spaceships that don't have enough food on them because they don't want people to die. Analogously, people will not build unaligned AGI because they don't want people to die.
So what are the disanalogies? One is that it is harder to tell whether an AGI is aligned than whether a spaceship has enough food on it. I don't think this can do much of the work, because then people would just spend more effort on telling whether spaceships have enough food on them, or not build them. Similarly, if this were the only problem, then people would just put more effort into determining whether an AGI is aligned before turning it on, or they would not build one until it got cheaper to tell. A related disanalogy is that there is more agreement about what spaceships designs have enough food and how to tell than there is about what AGI designs are aligned and how to tell.
Another disanalogy is that everybody knows that if you design a spaceship without enough food on it and send people to Mars with it, then those people will die. Not very many people know that if you design an AGI that is not aligned and turn it on that people will likely die (or some other bad outcome will happen).
Are these disano |
22ac5c62-1e51-41ca-b3bf-407c752558b6 | StampyAI/alignment-research-dataset/youtube | Youtube Transcripts | Gillian Hadfield "Incomplete Contracts and AI Alignment" (Disc: Paul Milgrom)
[Music]
okay all right well I'm really glad to
be at this conference at Toronto I'm
really happy to be joining the set of
colleagues and for any graduate students
in the room there's lots and lots to be
done from a theoretical point of view
taking taking economic thinking and
models for AI and that's I want to talk
a little bit about today and I'm
delighted that Paul is commenting on
this paper because Paul made it possible
for me to complete a thesis on contract
theory and a co-author at the same time
this is my son I'm a co-author so
comments like this Oren Etzioni is a
leading computer scientist and machine
learning said in the New York Times in
September 2017 you know in response to
concerns about worries about what are I
going to be capable of doing saying look
we're gonna have to make sure it's not
that complicated just make sure that AI
is subject to the full gamut of laws
that apply to humans operators and the
common law should be amended which
should great like fingernails on a
blackboard for anybody yes she does
legal theory you don't amend the common
law so that we can't claim that our AI
system did something we couldn't
understand and this kind of thinking
about how are we going to manage the
potential problems of AI doing stuff we
don't want it to do and the complexity
of that and the naive simplicity of this
response or it's a great guy but it's
this is part of what's motivating the
work I'm doing these days so a lot of
the discussions about AI control or
concerns about AI are questions about
how should we regulate AI so they're
from you can't economists point of view
they're the normative questions you hear
this in conversations about AI FX AI
liability that the trolley problem that
everybody wants to think about with the
self-driving cars algorithmic fairness
which we've heard a little about
autonomous weapons treaties and so on so
it's a lot of the conversation is what
should we require and I think the really
deep question is how can we regulate AI
how do we get artificial agents
Billy Martin mostly using machine
learning to to do what we want them to
do
that I think of as a question of how do
you build AI systems that can integrate
into human normative systems our systems
of law culture norms etc so I want to
talk about the AI alignment problem
it's an overarching framework that I
think pulls in a lot of the things that
we hear about in terms of AI ethics
again algorithmic fairness this field
within AI machine learning that is
variously known as AI safety which is
how do you build artificial agents that
will do what you want it's not just you
know how do you regulate the
self-driving car but it's the field it's
the field Dylan would identify himself
with and to some extent it's super
intelligence but you don't have to get
to super intelligence to be interested
in it's really just the fundamental
problem of how do you get AI agents to
do what humans want them to do how do
you align the behavior of the agent with
human values and by the way I've spent a
lot of time sitting in sessions now with
computer scientists machine learning
people who are reinventing the wheel
having conversations like how do you
aggregate value well I think we know
something about that there's a lot of
work to be done to to integrate how
they're thinking about it with the way
that economists have thought about it
well this looks like a familiar problem
the AI alignment problem is the
contracting problem we think about this
a lot how do you get an agent to do what
you want it to do now if you're gonna
take insights from contract theory and
the way economists have thought about
contracting it applied to robot to sort
of have to think about well how are
robots like and not like humans we've
heard a little bit about that in the
last section while it's session and say
of course they are maximizing value
functions on steroids you know think
about the insight from Williamson when
he said actually don't you know our
existing models hadn't taken into
account that there could be
self-interest seeking with guile I
always loved ones who want to know what
guile is it's a lovely word but it
points out that our models when we're
modeling humans with value fomenting
they're maximizing that we know that
we're talking about humans and we're
actually assuming a whole bunch of
employess
that constraints and stuff we take for
granted and the way humans are going to
behave in contractual settings and part
of what Williamson was doing was saying
well we're here's something we're taking
for granted that somebody might behave
opportunistically and not simply comply
with the contract and I want us to get
us focused on thinking about what are
the institutions and norms that we could
potentially build or incorporate to
improve the behavior of artificially
intelligent agents now we've heard a lot
about reinforcement learning I want just
to make sure we're all on the same page
it's really important for us to remember
that what we reinforcement learning is
not is not programming and so when we
put down a technology function you're
assuming that somebody has designed
technology to do X and it does X right
but what's really important about
reinforcement learning is that it's not
that so you can't say humans are
responsible they should have written a
different program right
you could be a reward function you train
it on data engaged in search exploration
and discovery and this is the key thing
it comes up with unexpected behaviors
right it does things humans hadn't
thought about it sees patterns humans
hadn't seen it discovers things right
and the way we do testing in hospitals
that humans hadn't figured out what our
existing alternative makes so the
unexpected behavior is a critical part
of thinking about the AI control problem
or the AI alignment problem now if
you're not all that worried about this
and and so then there's lots of reasons
to take the super intelligence view and
say not interesting too far in the
future never going to happen but this is
Stuart Armstrong it works at future
humanity Institute which is Nick
Bostrom's Institute at Oxford and just a
bit we're gonna try and it's in a six
minute video I'm not going to play the
whole thing but it's a little example of
why why you want to think about this
problem so here's a robot it's got this
grid world the robot has a rope is is
being asked basically to get boxes the
goal is to get boxes down in that left
corner but the human only wants one box
in there so but the robots reward
function has for whatever reason it
they merged to be the robot is going to
get reward per box but the human only
wants one we can jump ahead I think to
the let's see yes so let's just if we
just freeze it there for a second
so if the human says wait a second I
only want one box I know there's some
risk that they'll be unexpected behavior
I don't observe I haven't programmed in
this reward function that so it may be
what the the robot has ended up at it
may be different so I'll put in this
control mechanism I will put in a camera
as soon as the robot has pushed a box
down the down the chute I'll turn the
thing off so I won't have to worry about
there being too many boxes going down
the chute I'm going to turn it off so
here's the camera to watch it so this is
using this a planning problem actually
because it's everything is known and
what what Armstrong show is is that a
depth of six which is like the robot can
see six six iterations ahead okay we can
we can play now robot figures out okay
here's how I get that box down there
yeah I get a point but if we jump ahead
let's see if they live I think the next
jump on this if we jump ahead to big
greater depth on this at a depth of 20
let's just stop there for a second see
what the robot has done robot I said
wait a second I'm getting rewarded per
box and I've discovered when there's a
box in there the the camera looking will
shut me off so a second I'll stick a box
in there so the camera can't see me push
the box down the down the chute
now that's anthropomorphizing what the
robot is doing but this is what you you
the robot you you built this robot it
developed a reward function that we
rewarded per box you tried to control it
and so yeah see it used to just finish
that yeah anyway you can see what's
going to happen this let's just run it
there so the smart little robot hey I
can get all three points and so you can
think of this a robot it slide the robot
is deceived the robot has snuck around
but all it is done is maximize the
reward function that it has it's just
that there was a difference here we can
jump ahead now I guess let's see
okay so here's this problem how do we
get an agent to do we want I'm thinking
about this ingress
and today still Dylan's thinking about
this in grad school he's thinking about
problems like this which I'll show you a
little bit more about I was thinking
about it in this context he's thinking
about it thinking that his advisors work
Stuart Russell who's got the leading
case book on artificial intelligence and
there's Paul and Ken who I'm thinking
about is I'm thinking about the
McDonald's problem this is the reward
engineering so we've heard a little bit
about the design of reward functions so
don't think about the reward reward
engineering is hard let's play this
video this is a machine learning
algorithm that was trained to play a to
do a play this video game which is a
boat race these are colleagues of mine
now at open AI did this and here's what
this algorithm learned how to do you
will notice it is not winning the race
but if you look in the lower corner
there it's getting a really SuperDuper
score and the reason is that they gave
it a reward function they said hey
what's the best way to train a robot a
machine to win a video game point score
it's really easy it's nice in concrete
we can measure it but it's discovered
there these little turbo boosters in the
if you just spin around on the turbo
boosters you get a high score so that's
that's a problem of perfectly you know
intelligent thing to think you know
point score will triple train the robot
to this it's not okay so here's another
context that Dylan's been thinking about
this is from a paper of his called
inverse reward design so you want to see
we've got a designer here this is her
intended environment she wants to build
a robot to get to the pot of gold and a
grid world where there are paved roads
and grass it's higher cost to go over
grass than paved roads but sometimes it
might be worth it to take a shortcut and
so she wants to train this robot she
trains it in this environment and gives
it this proxy reward function - one for
the road - - two for the grass ten for
the pot of gold gives it to that robot
it learns an algorithm for doing that
then you set it out into the wild you
deploy it and it turns out that out in
the world
this lava out there as well well the
robot when it encounters the lava didn't
see it in the training environment is
gonna treat that with indifference
straight through now the thing is that
she has a true reward function this
designer she really no no lava is really
bad never take shortcuts through lava
but she didn't think about that well
that sounds like a really really common
problem for economists right that's
that's not thinking about all that all
of the possible circumstances how this
was like the contract design problem and
I was thinking about franchising a bit
in in grad school so franchisee benefits
or McDonald's friend of the franchisor
benefits from a trademark system and
effort of franchisees and franchisors
franchisee over here different payoffs
for those things if they can write a
complete contract complete contingent
contract they can put everything in
about the value of the trademark the
amount of effort and so on but what we
know of course is that it's really hard
to contract on all those things to write
that complete contract in that contracts
probably incomplete very hard to write
the contract and force of their
verifiable observable contract term for
how much effort the franchisee should
exert and whether the franchisor can
require you know the new frappuccino
machine every year those kinds of
decisions hard to put in that and the
fact that they're highly incomplete
contracts so how do humans do it we have
these external institutions that come in
and fill in the gaps in these contracts
we got this is my little symbol for the
courthouse of course but we also have
informal mechanism reputation and
termination of relationship so that's my
little exclusion icon there
okay so misalignment this problem that a
lot of AI researchers are now starting
to think about is just fundamental to
economic analysis welfare theorems
principal agent Alice's that's what
we're thinking about whether the systems
we can create to align the behavior of
agents and principals or individuals and
groups we know that there are their
strategic behavior when we have
incomplete contracts that's what we're
observing with this misaligned reward
function
we use models of in which robots are
strategic well sure why not because all
our strategic actors are in our economic
models our agents who have a different
word function than that ours you know
we've got even you know you could even
say where your strategic with your to
your future self between the dieting
self and the present and the hamburger
eating self in the future so yeah so we
we say that we can use that kind of
environment now let's say this this talk
is generally I'm giving it to AI
researchers and I gave it at nips which
is the machine learning conference last
year and I put up this slide and one of
the AI safety guys I work with now at
opening I took a picture of this slide
said best slide at nips now they also
introduce alpha 0 at nips that nip so I
don't actually think it was the best
Lydon notes but I was really chuffed
about that so we have a whole bunch of
work on why contracts are incomplete
lots of different stories about bounded
rationality strategic behavior
non-contract ability we know all this ok
well we can we can basically draw the
analogues for wire rewards misspecified
and the machine learning problem
well bounded rationality didn't think of
everything costly side effects it may be
better to defer till later the filling
in so we can think of that like
renegotiation adversary non implemented
the gnawing I think the analog to non
contract ability is non implementable
'ti which is say that we can't solve
it's not like machine learning is not
magic it's actually it's hard to train a
robot to do things and there are
problems we can't solve we can't write
all the contracts that we want so in the
paper we go through the economics
literature and incomplete contracting
and sort of say here's some ideas
they're just speculation about stuff we
might be able to take from the economics
literature and pour it over to machine
learning insights for machine learning
researchers and ways to do collaborative
work and I'm actually going to just fly
through these like property rights
property rights are not about giving
robots property rights property rights
about transforming the value function so
I think you can take some of the idea
selling the firm to the agent is there
something comparable in
could you sell Facebook to its agro
algorithms by giving it a broader the
algorithm of the broader utility
function to think about I really am just
gonna fly through this measurement
multitasks we hear a little bit about
measurement yesterday but the point that
commitment was emphasized yesterday what
you can get you have to have measurable
stuff right but if there's measurable
and unmeasurable stuff that you can't
just hand over so I think Eric you were
saying you know give the humans the
unmeasurable stuff but if you can't
separate those things out you know you
need your self-driving car to both avoid
crashes and be courteous and flexible
with other drivers on the road hard to
measure and reward that so you may want
to in fact reduce your incentives on the
measurable stuff to promote your visuals
okay I'm just again let's seek I'm gonna
these are on the paper so I'm gonna but
those are what we called weekly
strategic AI that's just ordinarily
difference between utility functions
reward functions strong strategic AI is
okay the a I can rewrite it's reward
function maybe we rewire it's Hardware
manipulate humans it's been a lot of
time with people who are worried about
that I want to jump ahead though to an
insight from relational contracting from
the legal perspective so relational
contracting from the law and economics
perspective is the recognition that
contracts are embedded in an environment
of cognitive schema norms laws it groups
culture language relationships right
it's embedded so this is the ground of
original Granovetter inside but it is
also what Williamson and McNeil and
McCauley we're talking about so here's
this little problem that again open AI
folks put together to talk about
problems in AI safe it's a nice paper if
you want to get a handle on this sort of
a grab-bag concrete problems in AI
safety they're saying here's a problem
we've got a robot we've trained it up
we're gonna say robot your job you're
going to reward it for getting boxes
from one side of the room to the other
that's the reward function you train
this robot you deploy it you put it out
into the world and oh there's a
in the past that the robot has learned
what's the robot going to do well the
robot is going to plow straight through
that base because it wasn't in the
training environment the robot doesn't
know anything about the base doesn't
have any common sense the way they talk
about it about that I would say okay
let's think about this suppose you had a
human you gave that task right you got a
human agent and you give the human the
same contract as you've given the robot
you're gonna pay the human agent per box
that's all the contract says I'm gonna
get paid to get those to the other side
now that Vaes appears what's the human
agent gonna do while the human agent is
going to go around that vase and the
question is why why is the human going
to go around the age of the vase well
how do humans do it what makes
incomplete contract rational for these
agents well the agent is gonna think
okay if I go through if I knock over
that vase what might happen then right
well I might get sued by the employer
they might be allowed by the law to
withhold from my wages might get a bad
reputation I might never get another job
the agent is able to fill in and say my
true contract is actually R minus C
there is a cost associated with this
behavior about which our contract said
nothing and this is sort of the key
point I want to emphasize human
incomplete contracting depends on tons
of external structure and so I think
what we need to be thinking about is
whether or not we can build robots that
can fill in their income there their
reward structures in this way can they
pull information from the environment
about what would be the response that
requires replicating this human process
of class breeding and imagining and
predicting the classifications of
behavior it's a good action the bad
action if you think about Smith and the
impartial spectator is saying we do is
we imagine how would I be thought of if
I took that action this is in the Theory
of Moral Sentiments and then you have to
get the robot to assign negative weight
to the things that are classified by a
particular human community as bad versus
versus good so I think from from here we
can we can build a research
Genda I think there are many so I think
there's lots and lots of work to be done
on that theoretical main good well it's
uh thank you thank you for asking me to
comment it's a pleasure to come in and
Gillian as she pointed out she was my
student long ago when she was pregnant
with her co-author who I was hoping I
was gonna get I was hoping I was gonna
get to meet well he did he did he come
out he's not isn't that here well that's
right that oh okay I'm America so that's
really a shame
okay so so I've never met Dylan except
in utero and and so so here we are and
and my comments are gonna be brief
there's the the thesis of this paper is
you you know it is sort of that there's
a useful analogy between alignment
problems in AI and in complete
contracting problems in economics a lot
of what the paper is about really is is
you know it seems to be written
not just for economists a lot of it is
repeating things that you guys all know
the first welfare theorem the
impossibility of you know social choice
all of that stuff you find little bits
and pieces of in there but the but the
central thesis really is that there's a
useful analogy between the alignment
problem in AI and the incomplete
contract and problem in economics and
the AI alignment problem is that the
reward function that the machine pursues
doesn't match what humans actually value
because that's just hard to specify to
an AI agent and the incomplete contracts
problem is that the objective the agent
pursues doesn't match the principles
objective because that's hard to specify
in a contract so those certainly sound
pretty pretty parallel and that the you
start with the this standard economists
model that if you could specify complete
contracts which were costlessly written
and enforced you would get perfect
alignment and everything would be great
now we've we've heard a lot about this
stuff already in fact oh by the way the
paper also has a summary though a lot of
the paper in fact I'd say the bulk of
the paper is is accounting for ideas and
results from economic
theory and some that were presented to
you here these examples of knocking over
the vase and and so on and and learning
not to win the race but but to score
lots of points those kinds of examples
are in the paper too so some of it is
just a that kind of account last night
we heard you know our dinner speech last
night from Dinah was about reinforcement
learning and again the the problems of
you know learning by trial and error
with she talked about how hard it was
for for agents to learn especially when
the rewards were delayed and Susan talks
about this a lot to it I think Susan is
here today but the difficulty of doing
machine learning then the need for using
short term measures and the short term
measures often not Cohen not coinciding
with what we actually care about which
are only observed in the long term and
the best we can do is look at things
that are correlated so that kind of
thing we've been hearing about and we've
heard about the transfer learning and
transfer learning is for those of you
who haven't studied this stuff yet you
know for example you you train a machine
if you want to train a machine on a
small set of images to recognize a
damaged car you first start by training
the machine that does that recognizes
cats and dogs and so on and you make
that the that's how you initialize the
machine learning to learn about you know
recognizing damaged cars who the machine
seems to be good at wrecking doing
visual image recognition and and you
make that kind of a starting point but
that can lead to distortions that we
have no clue what they are as you see
sometimes you just don't anticipate what
the implications are and and that's a
common source of problems and in these
in these reinforcement learning as we
heard last night there is also this
exploration exploitation and trade-off
that you do some learning but in the in
the course of learning if the way the
machines are learning this isn't what
was in any of your examples but in the
course of learning you're also earning
pay offs the export the exploration and
exploitation trade-off can also affect
the the learning that takes place so
these are all by the way from slides
that join and put up last night I've
just copied I took a photograph during
the during dinner last night about the
things that we're on her slides and
these are all the things she talked
about how do we reward AI effectively
how do we interpret what we're seeing
and so on and those are the same points
I think are very similar to the points
that Gillian was making and we've also
heard both this year and last year many
similar points about AI agents omitted
pay off bias or omitted pay off bias is
something like knocking over a vase and
not considering that in the in the
payoffs so um so these are these are the
kinds of things that Gillian was talking
about that resonate pretty well now I
wouldn't you know I'm kind of humble
about the possibility of taking ideas
from economics and applying it directly
to to AI it's much easier for me to
assess you know when you take ideas from
another field and bring them into
economics does it make any sense in an
economic context so as we begin to take
some of the ideas that we have in
economics and say should we be using
these to train machines I feel a little
less confident and nevertheless I still
find myself skeptical about the the
analogies it's not that I don't find the
similarities and the problems to be
clear but you'll see I'm a little bit
suspicious of about the similarity in
the solutions and I'll try to explain
why so the the problems do have closely
analogous elements and in fact this
Gillian actually has already pretty much
done this but the B in economics even
simple transactions can require complex
agreements you know one of the examples
in the paper is why not just write a
contract that says deliver a hundred
pounds of peas next Tuesday and I'll pay
two hundred dollars but it doesn't say
what happens if there is a storm that
prevents you from making the
delivery or how much you have to pay if
some of the peas are rotten or it's you
know this is a highly incomplete
contract and you and you just can't
write things as simple as that the in
economics the sources of misalignment
come from things like hidden action and
hidden information or factors that are
unverifiable to a court or third party
or and and one of the things you didn't
talk about in your talk either
intentional and completeness sometimes
we say you know what we'll figure that
out when we come to it
we will have aligned our and we we don't
specify what we want done we've tried to
align our incentives well enough and
these things have reasonable reasonably
close analogies in the machine learning
context the reasons for misalignment and
this is this just replaced a slide that
you've had up so I will skip over this
but the slides that you skipped over are
the ones I really cared about actually
and and it's the analogies about
solutions that seem that seem less clear
to me so the Jillian went rather fast
over the slides about the week's weekly
strategic and strongly strategic agents
and you know for humans the the there
are some inherent incentives that we
think about you know you might have
people who are lazy or who have other
interests that they're pursuing and
those are those are sort of built into
them and if you're the guy who's
programming the machine you don't
typically have to worry about that you
don't have to worry that the that the
machine has has built in that you know I
it would rather hire its son than to
hire the highly qualified person and
it's it's not worried about the that it
would rather teach you know that then it
has a preference for burning more income
rather than earning less income and and
that the some particular day it really
wants to watch the football game those
things just aren't built into the
machine and so you don't have to provide
incentives to overcome inherent inherent
preferences that the machine that the
machine has and to the extent that
you know to the extent that you're
dealing with machines that are already
created you know perhaps then having
incentive contracts for machines that
already have preferences that have been
built in that could make some sense I'm
not quite sure how I'm doing on time
here oh thank you that's where I'm
supposed to look all right so um for
machines it's sometimes machines are
reacting just like humans and when they
are or when there's a human that you're
trying to get to to to give the right
incentives to machines then you might
want to provide incentives for that
human in order to create the incentives
for machines but the the solutions that
are analogized seem to me to be the
weakness of the paper it seems to me
that you know talking about giving
property rights to machines so that it's
incentives are aligned if it can't
perceive what the out you know and the
Facebook application if it can't
perceive the full effects it doesn't
help to make it the owner it would the
way it risen it helps a human to make it
the owner it's it's then and its
interest to figure out what the full
effects our and say gee what should I it
the the human then is working out what
objective it should be acting to
maximize and the the Machine can't do
anything like that we're at least
currently formal and real Authority
committing to limited interventions so
that the machine will have an incentive
well in a strongly strategic context
where the Machine is playing a game
against the as you saw the the example
with the boxes if the machine is playing
a game against this then it's very much
we can analyze the machine just the way
we analyze humans but if you're
designing the incentive for you if
you're designing the reward function
afford the Machine presumably you know
the you don't start with it having an
incentive to do something different than
then what you wanted
I see I'm running out of time so the be
I thought the really most interesting
part to me was whether you could somehow
create a larger context to correct the
problems that the machines were running
into
the story about knocking over a vase and
the social norms in the end the implied
terms I'd like to see those ideas
developed because those ideas struck me
as things that might be adaptable in the
Machine context but I think I'm pretty
much out of time and and that's what I
saw so I will just skip the other
machine analogy |
89b0db4c-cd6d-404f-8ef8-14b810965991 | trentmkelly/LessWrong-43k | LessWrong | Magic Articles I’ve Written
Update 4/23/2017: I now write for Channel-Fireball. This is a link to my author page.
Posts in the Amonkhet and Kaladesh eras through 4/23/2017:
Decks:
Mardu Planeswalkers
Red Drake
Empty Hand of the Gods
Set Preview:
Amonkhet’s Overlooked Cyclers
Analysis:
Mardu vs. Copycat
Advocacy:
Reflections on the 2017 Magic Online Championship
For other articles, see my author page. I may or may not continue to update this post.
Original Post:
Star City Games continues to be my location of choice for Magic articles. It took a while to get these posted, but nothing too relevant seems to have happened in the meantime. Links to them seems like as a good a placeholder to put here as any.
Links to my articles from PT Paris:
Part 1: The Army You Have
Part 2: Hawkward Deck Guide
|
1aeeccee-7521-486d-abeb-cac69ddfdadc | trentmkelly/LessWrong-43k | LessWrong | Sequences/Eliezer essays beyond those in AI to Zombies?
After years of lurking in this community I finally broke down and Read the Sequences™. Specifically, I read the 2015 edition of Rationality: From AI to Zombies, cover to cover.
Over the course of reading it, I became aware that it wasn't comprehensive. There would often be links going to Eliezer essays on LessWrong that weren't included in the book. I read several of these and enjoyed them. So before I move on to start filling my reading time with other subjects, I'd like to complete my tour through the rationalist community canon.
Does anyone have a comprehensive list of the omitted essays? Or any highlights? Are any of the 2018 updates to AI to Zombies notable?
So far I'm planning to read the Fun Theory Sequence and trying to find more content on anthropic-adjacent topics (realityfluid, etc.) by following links from Timeless Identity. |
3fc100aa-d25b-4f94-8564-41b451d6a913 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources
1 Introduction
---------------
Knowledge graphs (KGs) are data structures able to converge data and metadata collected from various data sources [[34](#bib.bib34)]. Data sources can be heterogeneous and comprise structured, semi-structured, or unstructured data. Nevertheless, several parameters like number and type of mapping assertions and data source complexities like large volume, heterogeneity, and high duplicate rates may considerably affect the performance of KG creation.
The declarative definition of KGs using W3C standard languages like R2RML [[27](#bib.bib27)] and RML [[32](#bib.bib32)] have gained momentum, and numerous real-world applications (e.g., [[17](#bib.bib17), [39](#bib.bib39), [46](#bib.bib46)]) resort to these formalisms to provide transparent, maintainable, and traceable processes of KG creation. As a result, the scientific community has actively contributed to the problem of KG creation with formal systems to formalize the whole process [[44](#bib.bib44), [51](#bib.bib51), [52](#bib.bib52)], theoretical and empirical analyses of parameters that affect the process performance [[21](#bib.bib21), [48](#bib.bib48)], engines for KG creation [[23](#bib.bib23), [31](#bib.bib31), [35](#bib.bib35), [58](#bib.bib58)], and benchmarks to assess the engines’ performance [[22](#bib.bib22)]. Despite these recent advances, existing engines could still struggle to perform well in real-world settings. For example, KG creation in biomedicine demands the integration of various data types [[56](#bib.bib56)], e.g., genes, drugs, scientific publications, and clinical records, which change frequently. Complex pipelines composed of numerous mapping rules (e.g., more than 1,000 rules) collecting data from sources in a myriad of formats (e.g., relational or textual) may be costly in terms of time and memory consumption.
Our work is inspired by our experience in developing such complex pipelines in the context of the EU funded projects iASiS [[2](#bib.bib2)], BigMedilytics [[1](#bib.bib1)], and CLARIFY [[3](#bib.bib3)], as well as in CoyPu [[4](#bib.bib4)], a German project funded by the Federal Ministry of Economics and Climate Protection [[5](#bib.bib5)]. Specifically, the SDM-Genomic benchmark [[10](#bib.bib10), [11](#bib.bib11)] is inspired by the computational challenges addressed during the integration of genomic data from the COSMIC database [[14](#bib.bib14)] into the KGs of the biomedical projects. These mapping assertions are complex regarding dataset size, the number of mapping assertions, and types of joins among them. Initially, none of the existing engines (e.g., RMLMapper [[30](#bib.bib30)], RocketRML [[58](#bib.bib58)], and SDM-RDFizer [[35](#bib.bib35)]) was able to run the complex mapping assertions on the project data in a reasonable time (e.g., less than 48 hours). Since biomedical data change frequently, these mappings are executed periodically. Manually, knowledge engineers rewrote the mapping assertions [[6](#bib.bib6)] and transformed them into simpler rules executable by the SDM-RDFizer. These transformations inspired the proposed optimization techniques for mapping assertions.
Problem Statement and Objectives.
We tackle the problem of efficiently executing KG creation when the process is declaratively defined using mapping languages like R2RML or RML (a.k.a. [R2]RML).
We formalize the problem as an optimization problem, where mapping assertions are grouped and scheduled into execution plans that reduce execution time or memory consumption. A solution to the problem is an execution plan of groups of mapping assertions scheduled as a binary bushy tree [[53](#bib.bib53)]; this execution avoids the sequential execution of the mapping assertions and reduces the complexity of duplicate removal. The problem of generating such execution plans is known to be NP-hard [[53](#bib.bib53)] in general. Thus, our objective is to efficiently traverse the space of execution plans and generate a plan that scales up to complex scenarios.
Our Proposed Solution.
We propose a heuristic-based approach that groups mapping assertions executed against at most two data sources. The execution of the identified groups of mapping assertions is scheduled in a bushy tree, where duplicate removal is executed as soon as possible, i.e., they are pushed down into the tree and executed following an eager evaluation approach. We present two greedy approaches; one algorithm partitions the mapping assertions into groups, while the other generates bushy trees that schedule the groups’ execution. The approach is *engine agnostic*, i.e., the execution plan can be executed in any of the existing KG creation engines to speed up the KG creation process.
Empirically, we study the performance of the proposed approach and the generated plans. The study assesses the performance of state-of-the-art RML engines on existing benchmarks of KG creation. The observed outcomes put in perspective the benefits of scheduling the execution of mapping assertions following the generated plans. Moreover, these results indicate that not only can the process of KG creation be accelerated, but also consumed memory is reduced.
Contributions.
In summary, the scientific contributions of this work are as follows:
* •
Engine-Agnostic Execution Planning Techniques for Knowledge Graph Creation. We formalize the KG creation process and present greedy algorithms to generate execution plans that enable the efficient execution of KG creation pipelines. The proposed execution planning techniques implement a two-fold approach. First, mapping assertions are partitioned to avoid more than one join between two different mapping assertions executed in one group. Then, groups of mapping assertions are combined greedily to ensure those that generate instances of the same overlapped predicates are placed lower in the tree to be executed as soon as possible.
* •
Execution Methods for Knowledge Graph Creation.
We propose engine-agnostic techniques for the execution of mapping assertions. They translate a bushy tree plan into operating system commands to execute mapping assertions following the order indicated in the bushy tree plan. In case of duplicated RDF triples generated by the execution of groups of assertions, duplicate removal operators are scheduled and executed as soon as possible. This strategy reduces execution time and memory consumption and enables continuous generation of RDF triples.

Figure 1: Mapping Assertions. Mapping assertions are expressed in R2RML –the W3C recommendation standard– and its extension RML. The example comprises a) three concept mapping assertions defining the classes C1, C2, and C3; b) two attribute mapping assertions for the definition of attributeX and attributeY, and c) two role mapping assertions: one referencing assertions defined over the same logical source (i.e., referenced-source), and the other one, referencing assertions defined over different sources (i.e., multi-source).
* •
Experimental Assessment of the Proposed Methods.
We report on the empirical evaluation of the proposed methods in two benchmarks, SDM-Genomic-Datasets [[10](#bib.bib10)] and the GTFS-Madrid-Bench [[22](#bib.bib22)], and four [R2]RML-compliant engines: RMLMapper [[32](#bib.bib32)], RocketRML [[58](#bib.bib58)], Morph-KGC [[16](#bib.bib16)], and SDM-RDFizer [[35](#bib.bib35)]. In total, 236 testbeds are executed and analyzed. These results suggest savings in execution time of up to 76.09%. Moreover, the proposed execution planning techniques enable the incremental generation of RDF triples. Thus, engines like RMLMapper which times out after five hours with zero produced RDF triples in complex testbeds can generate 32.65% of the total number of RDF triples using planning.
This paper is organized into six additional sections.
Preliminaries and a motivating example are presented in section [2](#S2 "2 Preliminaries and Motivation ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources"), and
related approaches are discussed in section [3](#S3 "3 Related Work ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources").
Section [4](#S4 "4 Scaling KG Creation Up ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") presents the problem of KG creation and discusses the proposed execution planning techniques.
The KG creation techniques implemented to execute bushy tree plans are explained in section [5](#S5 "5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources").
Section [6](#S6 "6 Experimental Study ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") reports on the results of the empirical evaluation.
Lastly, section [7](#S7 "7 Conclusions and Future Work ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") summarizes lessons learned and outlines future directions.
2 Preliminaries and Motivation
-------------------------------
KGs are data structures that model factual statements as entities and their relationships using a graph data model [[34](#bib.bib34)]. The creation process of a KG 𝒢𝒢\mathcal{G}caligraphic\_G is defined in terms of a data integration system DIS𝒢=⟨O,S,M⟩𝐷𝐼subscript𝑆𝒢𝑂𝑆𝑀DIS\_{\mathcal{G}}=\langle O,S,M\rangleitalic\_D italic\_I italic\_S start\_POSTSUBSCRIPT caligraphic\_G end\_POSTSUBSCRIPT = ⟨ italic\_O , italic\_S , italic\_M ⟩ where O𝑂Oitalic\_O is a set of classes and properties of a unified ontology, S𝑆Sitalic\_S is a set of data sources, and M𝑀Mitalic\_M corresponds to mapping rules or assertions defining concepts in O𝑂Oitalic\_O as conjunctive queries over sources in S𝑆Sitalic\_S. The execution of the M𝑀Mitalic\_M rules over data from sources in S𝑆Sitalic\_S generates the instances of 𝒢𝒢\mathcal{G}caligraphic\_G. Figure [1](#S1.F1 "Figure 1 ‣ 2nd item ‣ 1 Introduction ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") shows mapping assertions represented in RML [[32](#bib.bib32)], an extension of R2RML [[8](#bib.bib8)], the W3C recommendation for mapping rules from data sources in various formats (e.g., CSV and JSON) to RDF.
Mapping Assertions.
Mapping rules in M𝑀Mitalic\_M are formalized as Horn clauses
| | | |
| --- | --- | --- |
| | body(X¯):−head(Y¯):𝑏𝑜𝑑𝑦¯𝑋ℎ𝑒𝑎𝑑¯𝑌body(\overline{X}):-head(\overline{Y})italic\_b italic\_o italic\_d italic\_y ( over¯ start\_ARG italic\_X end\_ARG ) : - italic\_h italic\_e italic\_a italic\_d ( over¯ start\_ARG italic\_Y end\_ARG ) | |
that follow the Global As View (GAV) approach (Namici et al. [[51](#bib.bib51)]), i.e., body(X¯)𝑏𝑜𝑑𝑦¯𝑋body(\overline{X})italic\_b italic\_o italic\_d italic\_y ( over¯ start\_ARG italic\_X end\_ARG ) is a conjunction of predicates over the sources in S𝑆Sitalic\_S and their attributes, and head(X¯)ℎ𝑒𝑎𝑑¯𝑋head(\overline{X})italic\_h italic\_e italic\_a italic\_d ( over¯ start\_ARG italic\_X end\_ARG ) is a predicate representing classes and properties in O𝑂Oitalic\_O. Variables in Y¯¯𝑌\overline{Y}over¯ start\_ARG italic\_Y end\_ARG are all in X¯¯𝑋\overline{X}over¯ start\_ARG italic\_X end\_ARG, and the rule head may include functions.
They correspond to an abstract representation of the triples maps, expressed in mapping languages like R2RML [[27](#bib.bib27)] or RML [[32](#bib.bib32)]. There are three types of mapping assertions: concept, role, and attribute.
* •
Concept Mapping Assertions are conjunctive rules over the predicate symbols of data sources in S𝑆Sitalic\_S to create the instances of a class C𝐶Citalic\_C in the ontology O𝑂Oitalic\_O.
Without loss of generality, we assume that the body is composed of only one source. Thus, concept mapping assertions have the form of:
| | | |
| --- | --- | --- |
| | Si(X¯):−C(f(y)):subscript𝑆𝑖¯𝑋𝐶𝑓𝑦S\_{i}(\overline{X}):-C(f(y))italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ( over¯ start\_ARG italic\_X end\_ARG ) : - italic\_C ( italic\_f ( italic\_y ) ) | |
Using the R2RML terminology, a concept mapping assertion corresponds to a `rr:subjectMap` where attributes in the logical source Sisubscript𝑆𝑖S\_{i}italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT, define the subject of the class C𝐶Citalic\_C; f(.)f(.)italic\_f ( . ) corresponds to a predefined function that enables the concatenation of strings, expressed with the RDF predicate `rr:template`. Figure
[1](#S1.F1 "Figure 1 ‣ 2nd item ‣ 1 Introduction ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")
depicts three RML triples maps and their corresponding mapping assertions. These concepts mapping assertions define classes C1, C2, and C3.
* •
Role Mapping Assertions enable the definition of object properties or roles. We differentiate three types of role mapping assertions.
Single-Source Role Mapping Assertions define a role P(.,.)P(.,.)italic\_P ( . , . ) in terms of a source’s attributes, where f1(.)f\_{1}(.)italic\_f start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ( . ) and f2(.)f\_{2}(.)italic\_f start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ( . ) are function symbols:
| | | |
| --- | --- | --- |
| | Si(X¯):−P(f1(y1),f2(y2)):subscript𝑆𝑖¯𝑋𝑃subscript𝑓1subscript𝑦1subscript𝑓2subscript𝑦2S\_{i}(\overline{X}):-P(f\_{1}(y\_{1}),f\_{2}(y\_{2}))italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ( over¯ start\_ARG italic\_X end\_ARG ) : - italic\_P ( italic\_f start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ( italic\_y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) , italic\_f start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ( italic\_y start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) ) | |
In Figure [1](#S1.F1 "Figure 1 ‣ 2nd item ‣ 1 Introduction ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources"),
the triples map TriplesMap2 defines the property ex:p5 as a single-source role assertion.
The rule `rr:predicateObjectMap` defines ex:p5 object value with `rr:objectMap`; `rr:template` corresponds to a pre-defined function.
Referenced-Source Role Mapping Assertions specify the object value of a role P(.,.)P(.,.)italic\_P ( . , . ) over a source Sisubscript𝑆𝑖S\_{i}italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT that also defines the subject of a referred concept mapping assertion MA𝑀𝐴MAitalic\_M italic\_A.
| | | |
| --- | --- | --- |
| | Si(Xi,1¯),SiMA(Xi,2¯):−P(f1(y1),f2(y2)):
subscript𝑆𝑖¯subscript𝑋
𝑖1subscriptsuperscript𝑆𝑀𝐴𝑖¯subscript𝑋
𝑖2𝑃subscript𝑓1subscript𝑦1subscript𝑓2subscript𝑦2S\_{i}(\overline{X\_{i,1}}),S^{MA}\_{i}(\overline{X\_{i,2}}):-P(f\_{1}(y\_{1}),f\_{2}(y\_{2}))italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ( over¯ start\_ARG italic\_X start\_POSTSUBSCRIPT italic\_i , 1 end\_POSTSUBSCRIPT end\_ARG ) , italic\_S start\_POSTSUPERSCRIPT italic\_M italic\_A end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ( over¯ start\_ARG italic\_X start\_POSTSUBSCRIPT italic\_i , 2 end\_POSTSUBSCRIPT end\_ARG ) : - italic\_P ( italic\_f start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ( italic\_y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) , italic\_f start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ( italic\_y start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) ) | |
| | | |
| --- | --- | --- |
| | MA:Si(Xi,2¯):−Cj(f2(y2)):MA:subscript𝑆𝑖¯subscript𝑋
𝑖2subscript𝐶𝑗subscript𝑓2subscript𝑦2\textit{MA:}\;\;S\_{i}(\overline{X\_{i,2}}):-C\_{j}(f\_{2}(y\_{2}))MA: italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ( over¯ start\_ARG italic\_X start\_POSTSUBSCRIPT italic\_i , 2 end\_POSTSUBSCRIPT end\_ARG ) : - italic\_C start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT ( italic\_f start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ( italic\_y start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) ) | |
Using the R2RML terminology, this assertion corresponds to a `rr:RefObjec` `tMap` where the mapping assertion MA𝑀𝐴MAitalic\_M italic\_A is referred using the predicate `rr:par` `entTriplesMap`. Both mapping assertions are defined over the same logical source Sisubscript𝑆𝑖S\_{i}italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT. In Figure [1](#S1.F1 "Figure 1 ‣ 2nd item ‣ 1 Introduction ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources"), TriplesMap1 defines the property ex:p3 as the subject of the triples map TriplesMap2. Both TriplesMap1 and TriplesMap2 are defined over the same logical source.

Figure 2: Partitioning of Mapping Assertions. Mapping assertions and partitions.
Multi-Source Role Mapping Assertions
allow for the definition of a role P(.,.)P(.,.)italic\_P ( . , . ) where the subject and object are defined over different sources, i.e., Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT and Sisubscript𝑆𝑖S\_{i}italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT, respectively. The source Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT is utilized in another assertion MA𝑀𝐴MAitalic\_M italic\_A to define the instances of a class Cksubscript𝐶𝑘C\_{k}italic\_C start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT. Because the sources, Sisubscript𝑆𝑖S\_{i}italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT are different, a join condition is required. The mapping assertion is denoted by the rule,
| | | |
| --- | --- | --- |
| | Si(Xi,1¯),SjMA(Xi,2¯),θ(Xi,1¯,Xi,2¯):−:
subscript𝑆𝑖¯subscript𝑋
𝑖1subscriptsuperscript𝑆𝑀𝐴𝑗¯subscript𝑋
𝑖2𝜃¯subscript𝑋
𝑖1¯subscript𝑋
𝑖2S\_{i}(\overline{X\_{i,1}}),S^{MA}\_{j}(\overline{X\_{i,2}}),\theta(\overline{X\_{i,1}},\overline{X\_{i,2}}):-italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ( over¯ start\_ARG italic\_X start\_POSTSUBSCRIPT italic\_i , 1 end\_POSTSUBSCRIPT end\_ARG ) , italic\_S start\_POSTSUPERSCRIPT italic\_M italic\_A end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT ( over¯ start\_ARG italic\_X start\_POSTSUBSCRIPT italic\_i , 2 end\_POSTSUBSCRIPT end\_ARG ) , italic\_θ ( over¯ start\_ARG italic\_X start\_POSTSUBSCRIPT italic\_i , 1 end\_POSTSUBSCRIPT end\_ARG , over¯ start\_ARG italic\_X start\_POSTSUBSCRIPT italic\_i , 2 end\_POSTSUBSCRIPT end\_ARG ) : - | |
| | | |
| --- | --- | --- |
| | P(f1(y1),f2(y2))𝑃subscript𝑓1subscript𝑦1subscript𝑓2subscript𝑦2P(f\_{1}(y\_{1}),f\_{2}(y\_{2}))italic\_P ( italic\_f start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ( italic\_y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) , italic\_f start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ( italic\_y start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) ) | |
where
θ(Xi,1¯,Xi,2¯)𝜃¯subscript𝑋
𝑖1¯subscript𝑋
𝑖2\theta(\overline{X\_{i,1}},\overline{X\_{i,2}})italic\_θ ( over¯ start\_ARG italic\_X start\_POSTSUBSCRIPT italic\_i , 1 end\_POSTSUBSCRIPT end\_ARG , over¯ start\_ARG italic\_X start\_POSTSUBSCRIPT italic\_i , 2 end\_POSTSUBSCRIPT end\_ARG ) stands for the join condition. Further, the referred concept mapping assertion MA𝑀𝐴MAitalic\_M italic\_A
is as
| | | |
| --- | --- | --- |
| | MA:Sj(Xi,2¯):−Ck(f2(y2)):MA:subscript𝑆𝑗¯subscript𝑋
𝑖2subscript𝐶𝑘subscript𝑓2subscript𝑦2\textit{MA:}\;\;S\_{j}(\overline{X\_{i,2}}):-C\_{k}(f\_{2}(y\_{2}))MA: italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT ( over¯ start\_ARG italic\_X start\_POSTSUBSCRIPT italic\_i , 2 end\_POSTSUBSCRIPT end\_ARG ) : - italic\_C start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT ( italic\_f start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ( italic\_y start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) ) | |
Using R2RML terminology, this assertion corresponds to a `rr:RefObjectMap` including `rr:joinCondition`, where MA𝑀𝐴MAitalic\_M italic\_A stands for the triples map referred by the predicate `rr:parentTriplesMap`. In Figure [1](#S1.F1 "Figure 1 ‣ 2nd item ‣ 1 Introduction ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources"), p4 is defined using a multi-source role mapping assertion that relates TriplesMap2 and TriplesMap3. Since both triples maps are defined over two different logical sources, S1.csv and S3.csv, it is required the join condition between the field attribute from S1.csv and the field DrugName to determine which value of the subject of TriplesMap3 will be used as the object value of p4.
* •
Attribute Mapping Assertions express a property A𝐴Aitalic\_A where the subject is defined with a function, and the object value is a literal. The clause following rule represents this assertion,
| | | |
| --- | --- | --- |
| | Si(X¯):−A(f(y1),y2):subscript𝑆𝑖¯𝑋𝐴𝑓subscript𝑦1subscript𝑦2S\_{i}(\overline{X}):-A(f(y\_{1}),y\_{2})italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ( over¯ start\_ARG italic\_X end\_ARG ) : - italic\_A ( italic\_f ( italic\_y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) , italic\_y start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) | |
where, y2subscript𝑦2y\_{2}italic\_y start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT stands for a variable in the list of variables X¯¯𝑋\overline{X}over¯ start\_ARG italic\_X end\_ARG from where the object value of the attribute A𝐴Aitalic\_A is retrieved. The map `objectMap` inside a `predicateObjectMap` defines the object value as a `rml:reference` or `rr:column`. In Figure [1](#S1.F1 "Figure 1 ‣ 2nd item ‣ 1 Introduction ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources"), two attribute mapping assertions specify the attributes p1 and p6 in TriplesMap1 and TriplesMap3, respectively.

Figure 3: Motivating example. This figure illustrates three possible approaches to executing the motivating example of this work. The left figure presents an approach where the mapping assertions are executed without partitioning. The central figure illustrates the proposed approach, where four partitions are generated. Finally, the right figure presents a random partitioning, only creating two partitions.
###
2.1 Partition of Mapping Assertions
In a data integration system DIS𝒢=⟨O,S,M⟩𝐷𝐼subscript𝑆𝒢𝑂𝑆𝑀DIS\_{\mathcal{G}}=\langle O,S,M\rangleitalic\_D italic\_I italic\_S start\_POSTSUBSCRIPT caligraphic\_G end\_POSTSUBSCRIPT = ⟨ italic\_O , italic\_S , italic\_M ⟩, the mapping assertions in M𝑀Mitalic\_M can be grouped to create a partition of M𝑀Mitalic\_M. We define two types of partitions: Intra-source and Inter-source mapping assertion partitions.
Given a source Sksubscript𝑆𝑘S\_{k}italic\_S start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT in S𝑆Sitalic\_S, an Intra-source partition for Sksubscript𝑆𝑘S\_{k}italic\_S start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT corresponds to a set of all the mapping assertions that have only the source Sksubscript𝑆𝑘S\_{k}italic\_S start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT in the body clause, i.e., it comprises concept, attribute, single-source role, and referenced-source role mapping assertions over Sksubscript𝑆𝑘S\_{k}italic\_S start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT. An Inter-source groups mapping assertions of two sources Sisubscript𝑆𝑖S\_{i}italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT which are related via multi-source role mapping assertions. Figure [2](#S2.F2 "Figure 2 ‣ 2nd item ‣ 2 Preliminaries and Motivation ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") presents three partitions for mapping assertions in the running example. To increase readability, mapping assertions are depicted in a directed graph where directed edges represent predicates defined by mapping assertions (i.e., p4, p6, p1, p3, and p5). A node denotes a logical source and the type of the mapped entity.
All the assertions defined over S1𝑆1S1italic\_S 1 (resp. S3𝑆3S3italic\_S 3) are grouped together into Partition1 (resp. Partition3). Moreover, there is only one assertion between S1 and S3, thus, Partition2 is an inter-source partition and comprises the multi-source mapping assertion for p4 and the concept mapping assertion that defines the class C3.
###
2.2 Motivating Example
We motivate our work, illustrating the challenges that the execution of mapping assertions brings to the process of KG creation from multiple data sources. Continuous creation and maintenance of KGs demand scalability in terms of required execution time and memory consumption. Figure [3](#S2.F3 "Figure 3 ‣ 2 Preliminaries and Motivation ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") presents three configurations of a set of mapping assertions that define a KG G1𝐺1G1italic\_G 1. The set comprises mapping assertions specifying the properties and attributes of five classes (C1,C2,C3,C4, and C5) over four data sources (S1, S3, S4, and S5). These data sources correspond to the SDM-Genomic-Datasets, each containing one Million records and up to 15 attributes.
The configuration No Partitioning depicts all the mapping assertions; they are executed together on four state-of-the-art [R2]RML-compliant engines, RMLMapper [[31](#bib.bib31)], RocketRML [[58](#bib.bib58)], SDM-RDFizer [[35](#bib.bib35)], and Morph-KGC [[16](#bib.bib16)]. Executing all the assertions together demands from each engine, data management techniques like the ones implemented by Morph-KGC. These techniques must allow planning both the execution of the mapping assertions and the period to maintain in memory each source. Unfortunately, RMLMapper and RocketRML are not as scalable as Morph-KGC and cannot produce any results. RocketRML ran out of memory, while RMLMapper timed out after five hours. On the contrary,
all the engines exhibit better performance when the assertions are divided into intra- and inter-source partitions and executed in plans generated based on these partitions; the improvement, albeit not so significant as in the other engines, can also be observed in Morph-KGC. First, when four groups of partitions are created (i.e., Optimized Partition), the performance of the four engines is empowered, and three of them can generate 100% of the results. Each group comprises one intra-source partition of a source Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT and at most one inter-source partition of another source Sisubscript𝑆𝑖S\_{i}italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT to Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT. Moreover, the groups are executed in parallel. Lastly, the execution of the configuration named, Random Partition, indicates that no combination of the intra- and inter-source partitions leads to efficient mapping assertions plans. In this case, Group1 includes two inter- and four intra-source partitions, while Group2 comprises only one intra-source partition. Although Group2 is executed by all the engines, RMLMapper and RocketRML could not produce any result during the execution of Group1, and they could only produce 5.41% of the total number of RDF triples. This paper addresses the challenges of generating plans of mapping assertions that empower [R2]RML engines and enhance their scalability during KG creation.
3 Related Work
---------------
###
3.1 Semantic Data Integration
A KG creation process relies on semantic data integration frameworks. The seminal work of Lenzerini [[48](#bib.bib48)] formalizes the fundamentals of data integration systems and the paradigms for mapping heterogeneous data sources into a unified schema. Knoblock et al. propose KARMA [[45](#bib.bib45)] a semi-automatic framework to map structured sources to ontologies and integrate them at the level of schema. There are different novel approaches to integrate generated RDF data, which can be considered as the KG creation post-processing. LDIF is introduced by Schultz et al. [[20](#bib.bib20)] which relies on a set of tools including Silk [[38](#bib.bib38)] and Sieve [[50](#bib.bib50)] to link identified entities and the data fusion tasks, respectively. MINTE [[26](#bib.bib26)], a semantic RDF data integration technique, is proposed by Collarana et al., relying on the metadata about the classes and properties to integrate semantically equivalent entities, while, Benbernou et al. define an approach for RDF data integration [[19](#bib.bib19)]. In the case of big data, post-processing integration is only affordable if the main KG creation framework is efficient. In other words, if the generation of RDF triples is expensive, any semantically duplicated RDF triples must be integrated prior to KG creation to improve scalability and efficiency.
###
3.2 Mapping Languages and KG Creation Frameworks
A KG can be generated by semantifying and integrating heterogeneous data into an RDF data model; different tools and approaches can be applied for this purpose. In order to provide a flexible and transparent transformation, declarative mapping languages are proposed to map the data into the concepts of the unified schema or the ontology and transfer them into RDF. R2RML [[8](#bib.bib8)] recommended by the World Wide Web Consortium (W3C) and RDF Mapping Languages (RML), the extension of R2RML, are two popular exemplar declarative mapping languages. Accordingly, several methods and tools are proposed for transforming data into RDF using R2RML and RML mapping rules such as RMLMapper [[30](#bib.bib30)], SDM-RDFizer [[35](#bib.bib35)], RocketRML [[58](#bib.bib58)], and CARML [[49](#bib.bib49)]. Priyatna et al. [[52](#bib.bib52)] introduce an extension of an existing SPARQL to SQL query rewriting algorithm, applying R2RML mapping rules. As a different approach, Lefracios et al. [[47](#bib.bib47)] propose an extension of SPARQL named SPARQL-Generate to generate RDF. In order to scale up the process of transforming data into RDF and creation of KG for large or complex data integration systems, different optimization frameworks are proposed, some of which can be applied along with mentioned tools. For instance, Szekely et al. propose the DIG system [[54](#bib.bib54)], Jozashoori and Vidal define MapSDI [[42](#bib.bib42)], while Gawriljuk et al. [[33](#bib.bib33)] present a scalable framework for incremental KG creation. Morph-KGC [[16](#bib.bib16)] proposes an approach to partition R2RML and RML mapping assertions so that generated partitions can be executed in parallel. Morph-KGC relies on partitioning the mapping assertions into groups that generate disjoint sets of RDF triples. Nevertheless, based on this partitioning strategy, RDF triples with a *join dependency*, i.e., the subject of one RDF triple is the object of another, are partitioned into independent groups. Therefore, the same join RDF resource is generated redundantly by each disjoint partition to ensure the completeness and correctness of the result RDF triples. Nevertheless, an efficient partitioning strategy requires considering all mapping assertions including those that generate RDF triple sets with join dependency as a whole, to ensure that the result partitions are optimized.
Therefore, despite the significance of all mentioned contributions and improvements, none of the mentioned approaches addresses the problem of scheduling the optimized execution of mapping assertion partitions, specifically considering different impacting factors, e.g., mapping assertions types, connection between mapping assertions, and common properties among them. Additionally, the mentioned approaches are specific for an engine, i.e., they are not necessarily adaptable to generic KG creation pipelines. We tackle the mentioned existing limitations, introducing an engine-agnostic execution technique relying on efficient partitioning and scheduling strategies. The proposed execution planner decides on the optimized execution plan based on the types of mapping assertions, the connection between the mapping assertions, and the redundancy of the predicates in mapping assertions. Any [R2]RML-compliant engine can adopt our proposed optimization approach, as shown in the next sections.
###
3.3 KG Creation from Textual Data
Integrating semi/unstructured data, e.g., texts, and constructing KGs from such data requires a semantic layer to describe the data and further data manipulation/transformation steps such as data cleaning, Named-Entity Recognition (NER), and Entity Linking (EL). Chessa et al. introduce [[24](#bib.bib24)] a methodology to add a semantic layer to a data lake and create a KG. Barroca et al. [[18](#bib.bib18)] extract metadata from textual descriptions and link them to entities in KGs utilizing NER and EL techniques, while Chu et al. propose a method to address the challenge of entity relations extraction [[25](#bib.bib25)]. Additionally, data manipulation/transformations can also be defined in terms of functions as part of declarative mapping assertions applying the available extensions including RML+FnO [[28](#bib.bib28)], R2RML-F [[29](#bib.bib29)], FunUL [[43](#bib.bib43)], and D-REPR [[57](#bib.bib57)]. In this regard, EABlock [[41](#bib.bib41)] provides a library of FnO functions that perform entity alignment on the input entity value, relying on an engine implementing the tasks of NER and EL. Considering the importance of efficiency in KG creation, FunMap [[40](#bib.bib40)] proposes efficient executions of FnO functions. The techniques proposed in this paper are illustrated and evaluated in mapping assertions over structured data. Nevertheless, they can be applied with approaches like FunMap to speed up the KG creation from unstructured data.
Table 1: Notation Summary
| Notation | Explanation |
| --- | --- |
| DIS𝒢=⟨O,S,M⟩𝐷𝐼subscript𝑆𝒢𝑂𝑆𝑀DIS\_{\mathcal{G}}=\langle O,S,M\rangleitalic\_D italic\_I italic\_S start\_POSTSUBSCRIPT caligraphic\_G end\_POSTSUBSCRIPT = ⟨ italic\_O , italic\_S , italic\_M ⟩ | Data Integration System, where O𝑂Oitalic\_O is a unified ontology, S𝑆Sitalic\_S is a set of data sources, and M𝑀Mitalic\_M corresponds to mapping assertions defining concepts in O𝑂Oitalic\_O over sources in S𝑆Sitalic\_S. The execution of rules in M𝑀Mitalic\_M over data sources in S𝑆Sitalic\_S generates the knowledge graph 𝒢𝒢\mathcal{G}caligraphic\_G. |
| body(X¯¯𝑋\overline{X}over¯ start\_ARG italic\_X end\_ARG):-head(Y¯¯𝑌\overline{Y}over¯ start\_ARG italic\_Y end\_ARG) | Mapping Assertion in M𝑀Mitalic\_M defined as Horn clauses; body(X¯)𝑏𝑜𝑑𝑦¯𝑋body(\overline{X})italic\_b italic\_o italic\_d italic\_y ( over¯ start\_ARG italic\_X end\_ARG ) is a conjunction of predicates over the sources in S𝑆Sitalic\_S and their attributes, and head(X¯)ℎ𝑒𝑎𝑑¯𝑋head(\overline{X})italic\_h italic\_e italic\_a italic\_d ( over¯ start\_ARG italic\_X end\_ARG ) is a predicate representing classes and properties in O𝑂Oitalic\_O. |
| Si(X¯)subscript𝑆𝑖¯𝑋S\_{i}(\overline{X})italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ( over¯ start\_ARG italic\_X end\_ARG ) | Predicate symbol for data source in S𝑆Sitalic\_S with arguments X¯¯𝑋\overline{X}over¯ start\_ARG italic\_X end\_ARG. |
| C(f(y))𝐶𝑓𝑦C(f(y))italic\_C ( italic\_f ( italic\_y ) ) | Predicate symbol for class in O𝑂Oitalic\_O; f(y)𝑓𝑦f(y)italic\_f ( italic\_y ) functional symbol with arguments y𝑦yitalic\_y. |
| P𝑃Pitalic\_P(f1subscript𝑓1f\_{1}italic\_f start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT(y1subscript𝑦1y\_{1}italic\_y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT),f2subscript𝑓2f\_{2}italic\_f start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT(y2subscript𝑦2y\_{2}italic\_y start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT)) | Role predicate in O𝑂Oitalic\_O; f1subscript𝑓1f\_{1}italic\_f start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT(y1subscript𝑦1y\_{1}italic\_y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT) and f2subscript𝑓2f\_{2}italic\_f start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT(y2subscript𝑦2y\_{2}italic\_y start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT) are functional symbols. |
| SiMRsubscriptsuperscript𝑆𝑀𝑅𝑖S^{MR}\_{i}italic\_S start\_POSTSUPERSCRIPT italic\_M italic\_R end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT(Xi,2¯)\overline{X\_{i,2}})over¯ start\_ARG italic\_X start\_POSTSUBSCRIPT italic\_i , 2 end\_POSTSUBSCRIPT end\_ARG ) | Predicate symbol representing data source in the body of mapping assertion MR𝑀𝑅MRitalic\_M italic\_R |
| θ(Xi,1¯,Xi,2¯)𝜃¯subscript𝑋𝑖1¯subscript𝑋𝑖2\theta(\overline{X\_{i,1}},\overline{X\_{i,2}})italic\_θ ( over¯ start\_ARG italic\_X start\_POSTSUBSCRIPT italic\_i , 1 end\_POSTSUBSCRIPT end\_ARG , over¯ start\_ARG italic\_X start\_POSTSUBSCRIPT italic\_i , 2 end\_POSTSUBSCRIPT end\_ARG ) | Join condition between the attributes of predicate symbols |
| A(f(y1),y2)𝐴𝑓subscript𝑦1subscript𝑦2A(f(y\_{1}),y\_{2})italic\_A ( italic\_f ( italic\_y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) , italic\_y start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) | Predicate symbol for a data property; f(y1)𝑓subscript𝑦1f(y\_{1})italic\_f ( italic\_y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) functional symbol. |
| GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT | Set of sets of mapping assertions in M𝑀Mitalic\_M |
| GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT | Plan over groups of mapping assertions in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT. |
| BT𝐵𝑇BTitalic\_B italic\_T | Bushy Tree plan of groups of mapping assertions. |
| OP𝑂𝑃OPitalic\_O italic\_P | Binary operator in a bushy tree. |
| DR | Union with Duplicate Removal |
| NDR | No-Duplicate Removal Union |
| fu(.,.)fu(.,.)italic\_f italic\_u ( . , . ) | Utility function for quantifying a bushy tree plan performance |
| ℬGPMsuperscriptℬ𝐺subscript𝑃𝑀\mathcal{B}^{GP\_{M}}caligraphic\_B start\_POSTSUPERSCRIPT italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT | Set of the bushy trees over GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT |
| 𝒮𝒮𝒮𝒮\mathcal{SS}caligraphic\_S caligraphic\_S | Power set of SS𝑆𝑆SSitalic\_S italic\_S |
| δ(Gi)𝛿subscript𝐺𝑖\delta(G\_{i})italic\_δ ( italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ) | Execution cost of group of mapping assertions Gisubscript𝐺𝑖G\_{i}italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT |
| maj𝑚subscript𝑎𝑗ma\_{j}italic\_m italic\_a start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT | Mapping assertion on source Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT |
###
3.4 Benchmarking KG Creation
Namici et al. [[51](#bib.bib51)] compare two state-of-the-art engines in Ontology-Based Data Access by formalizing the two systems, considering W3C-compliant settings. In addition to the theoretical efforts, empirical evaluations such as the study by Chaves et al. [[21](#bib.bib21)] are conducted to define the parameters affecting KG creation. Accordingly, benchmarks that consider the impacting parameters [[21](#bib.bib21)] are required to assess and compare the performance of different KG pipelines.
One of the proposed benchmarks to evaluate different Ontology-Based Data Integration or KG creation frameworks is GTFS-Madrid-Bench [[22](#bib.bib22)]; this benchmark provides a set of heterogeneous data and mappings. Although GTFS-Madrid-Bench promises to ensure diversity, this benchmark lacks the requirements for studying all the impacting parameters reported in [[21](#bib.bib21)].
For instance, to evaluate the impact of data volume on different KG creation approaches, it is essential to have an equal growth of the volume in all the datasets involved in the KG; however, this requirement is not met by GTFS-Madrid-Bench. Furthermore, the deficiency of required testbeds to study parameters such as join selectivity, star-join, data duplicates, and duplicated predicates in mappings is another limitation of GTFS-Madrid-Bench.
Therefore, to ensure the fairness and comprehensiveness of our experimental study, in addition to GTFS-Madrid-Bench, we also consider and extend SDM-Genomic-Datasets [[10](#bib.bib10)] to include other impacting parameters that affect KG creation scalability (e.g., complexity of mapping assertions and percentage of duplicates).
4 Scaling KG Creation Up
-------------------------

(a) Bushy Tree Plan

(b) Simple Bushy Tree Plan
Figure 4: Bushy Tree Plans of Mapping Assertions. a) Tree Plan whose leaves are intra- and inter-source groups of mapping assertions. b)Tree Plan whose leaves are singleton sets of mapping assertions. The simple bushy tree plan in (b) requires the execution of more union operators and loading the data sources multiple times than the execution of the bushy tree plan in (a).
This section formalizes the problem tackled in this paper and presents the proposed solution; the notation used in the formalization is summarized in [Table 1](#S3.T1 "Table 1 ‣ 3.3 KG Creation from Textual Data ‣ 3 Related Work ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources").
The process of creating a KG 𝒢𝒢\mathcal{G}caligraphic\_G is defined as a data integration system DIS𝒢=⟨O,S,M⟩𝐷𝐼subscript𝑆𝒢𝑂𝑆𝑀DIS\_{\mathcal{G}}=\langle O,S,M\rangleitalic\_D italic\_I italic\_S start\_POSTSUBSCRIPT caligraphic\_G end\_POSTSUBSCRIPT = ⟨ italic\_O , italic\_S , italic\_M ⟩, where mappings in M𝑀Mitalic\_M correspond to assertions defined in [R2]RML. As observed in Figure [3](#S2.F3 "Figure 3 ‣ 2 Preliminaries and Motivation ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources"),
the order and grouping of the mapping assertions impact the execution time of the engines, which is crucial to enable the generation of results in real-world scenarios.
The aim is to generate GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT, a set of sets of mapping assertions in M𝑀Mitalic\_M (inter- and intra-source), such as the union of all the sets in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT is equal to M𝑀Mitalic\_M, and the pair-wise intersection of the sets in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT is empty.
That is, GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT is a partition of M𝑀Mitalic\_M.
Moreover, since the order in which the groups in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT may also impact, we define a plan GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT over the groups in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT, as a bushy tree plan of the groups in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT, where each internal node represents the union operator that merges the RDF triples produced during the execution of each group in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT.
Lastly, since results produced during the execution of the GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT groups may overlap, and duplicate removal may be required at different steps of the execution of GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT.
Thus, each node is annotated with the union operator, which merges the inputs and produces the results.

Figure 5: Running example. Execution Trees for the groups in the Optimized Partition in Figure [3](#S2.F3 "Figure 3 ‣ 2 Preliminaries and Motivation ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources"). Bushy tree in a) performs an eager duplicate removal, while the evaluation of the duplicate removal is lazy in the tree plans in Figures b) and c).
A *bushy tree* is a data structure corresponding to a binary tree. As in regular trees, nodes with no children are called leaves, and the root node does not have any parent node. Additionally, in bushy trees, non-leaf nodes have exactly two children, and all the nodes, except the root, have one single parent node [[53](#bib.bib53)].
A *plan* BT𝐵𝑇BTitalic\_B italic\_T over groups of mapping assertions is a bushy tree; it is inductively defined as follows:
Base Case. Let BT𝐵𝑇BTitalic\_B italic\_T be a
group of mapping assertions. BT𝐵𝑇BTitalic\_B italic\_T is a bushy tree plan which corresponds to a leaf.
Inductive Case.
Let BT1𝐵𝑇1BT1italic\_B italic\_T 1 and BT2𝐵𝑇2BT2italic\_B italic\_T 2 be bushy tree plans over groups of mapping assertions. Let OP𝑂𝑃OPitalic\_O italic\_P be a binary set operator (e.g., union), then the following is a bushy tree plan over groups of mapping assertions:
{forest}
[OP
[BT1]
[BT2]
]
A plan GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT111We use BT𝐵𝑇BTitalic\_B italic\_T and GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT to denote bushy tree plans over mapping assertions. BT𝐵𝑇BTitalic\_B italic\_T represents a generic plan, while GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT is specifically for the groups of mapping assertions in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT. is a bushy tree plan where the groups of mapping assertions in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT are the GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT leaves. The binary operators in GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT correspond to the union of sets. They can be DR union with duplicate removal, or NDR non-duplicate removal union.
Additionally, the leaves of a bushy tree plan can correspond to intra- or inter-source partitions in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT. However, the leaves of a bushy tree can also comprise one mapping assertion; we call these plans, *simple bushy tree* plans. Figure [4](#S4.F4 "Figure 4 ‣ 4 Scaling KG Creation Up ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") depicts two bushy trees over the mapping assertions of the motivating example presented in Figure [3](#S2.F3 "Figure 3 ‣ 2 Preliminaries and Motivation ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources"). The bushy tree plan in [3(a)](#S4.F3.sf1 "3(a) ‣ Figure 4 ‣ 4 Scaling KG Creation Up ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") comprises four intra- and inter-source groups of mapping assertions. Contrary, the leaves in the bushy tree in [3(b)](#S4.F3.sf2 "3(b) ‣ Figure 4 ‣ 4 Scaling KG Creation Up ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") correspond to singleton sets composed of one mapping assertion. The execution of the simple bushy tree plan requires the evaluation of more union operators and loading, several times, data sources S1 and S5 in main memory.
An *optimal bushy tree plan* is a bushy tree plan whose evaluation is duplicate free, and its execution cost is minimal.
Moreover, the evaluation of the duplicate removal operators can be *eager* or *lazy*. Intuitively, an eager evaluation of a duplicate removal union is performed in a bushy tree as soon as the duplicates are produced. Thus,
the execution of the operator OP𝑂𝑃OPitalic\_O italic\_P in a bushy tree BT𝐵𝑇BTitalic\_B italic\_T that unions subtrees BT1𝐵subscript𝑇1BT\_{1}italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and BT2𝐵subscript𝑇2BT\_{2}italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT
is an *eager duplicate removal*, if the execution of BT1𝐵subscript𝑇1BT\_{1}italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and BT2𝐵subscript𝑇2BT\_{2}italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT is duplicate-free, but the intersection between BT1𝐵subscript𝑇1BT\_{1}italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and BT2𝐵subscript𝑇2BT\_{2}italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT is not empty. On the other hand, a *lazy evaluation* of the duplicate removal receives input collections with duplicates and removes duplicates from the union of the two inputs. Thus, in a bushy tree plan BT𝐵𝑇BTitalic\_B italic\_T with lazy evaluation, BT1𝐵subscript𝑇1BT\_{1}italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and BT2𝐵subscript𝑇2BT\_{2}italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT are not duplicate free because the duplicate removal operator has been postponed.
There are (2n−2)!(n−1)!2𝑛2𝑛1\frac{(2n-2)!}{(n-1)!}divide start\_ARG ( 2 italic\_n - 2 ) ! end\_ARG start\_ARG ( italic\_n - 1 ) ! end\_ARG bushy trees GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT, where n𝑛nitalic\_n is the cardinality of GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT [[53](#bib.bib53)].
Figure [5](#S4.F5 "Figure 5 ‣ 4 Scaling KG Creation Up ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") depicts three bushy trees for the groups of the Optimized Partition presented in the motivating example depicted in Figure [3](#S2.F3 "Figure 3 ‣ 2 Preliminaries and Motivation ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources").
Figure [5](#S4.F5 "Figure 5 ‣ 4 Scaling KG Creation Up ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")a) illustrates a bushy tree where DR is pushed down into the tree, scheduling, thus, this operation in a smaller RDF triple set.
Note that Group 2 and Group 4 comprise mapping assertions that define instances of the class C1 and the property p3. As a result, the merge of RDF triples produced during the execution of these groups may contain duplicates that need to be eliminated, and the duplicate removal operator DR is required. Since the duplicate removal is executed as soon as the duplicates are generated, the execution is eager.
Contrary, mapping assertions in Group 1 and Group 3 do not commonly define any class or predicate; thus, NDR is the union operator between them. Figures [5](#S4.F5 "Figure 5 ‣ 4 Scaling KG Creation Up ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")b) and c) correspond to
left- and right-linear plans. Additionally, duplicated removal is performed over the whole set of RDF triples, i.e., this is a lazy evaluation of the duplicate removal. The execution of these plans may require more memory and execution time in comparison to the execution of the bushy plan in Figure [5](#S4.F5 "Figure 5 ‣ 4 Scaling KG Creation Up ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")a).
A utility or cost function can quantify the performance of a bushy tree plan. The function fu(.,.)fu(.,.)italic\_f italic\_u ( . , . ) measures execution time or memory consumption; it is a *lower-is-better* function, i.e., the lower the execution cost, the better the plan performance. Let ℬGPMsuperscriptℬ𝐺subscript𝑃𝑀\mathcal{B}^{GP\_{M}}caligraphic\_B start\_POSTSUPERSCRIPT italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT be the set of the bushy trees over GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT, and let 𝒮𝒮𝒮𝒮\mathcal{SS}caligraphic\_S caligraphic\_S be the power set of S𝑆Sitalic\_S:
| | | |
| --- | --- | --- |
| | fu:ℬGPM×𝒮𝒮→𝐑:𝑓𝑢→superscriptℬ𝐺subscript𝑃𝑀𝒮𝒮𝐑fu:\mathcal{B}^{GP\_{M}}\times\mathcal{SS}\rightarrow\mathbf{R}italic\_f italic\_u : caligraphic\_B start\_POSTSUPERSCRIPT italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT × caligraphic\_S caligraphic\_S → bold\_R | |
fu(.,.)fu(.,.)italic\_f italic\_u ( . , . ) is inductively defined on the structure of a bushy tree plan BT𝐵𝑇BTitalic\_B italic\_T as follows.
Base Case. Let Gisubscript𝐺𝑖G\_{i}italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT be a
group of mapping assertions on data sources in S𝑆Sitalic\_S and the assertions in M𝑀Mitalic\_M, such that Gisubscript𝐺𝑖G\_{i}italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT is a leaf of BT𝐵𝑇BTitalic\_B italic\_T
| | | |
| --- | --- | --- |
| | fu(Gi,S)=δ(Gi)𝑓𝑢subscript𝐺𝑖𝑆𝛿subscript𝐺𝑖fu(G\_{i},S)=\delta(G\_{i})italic\_f italic\_u ( italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT , italic\_S ) = italic\_δ ( italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ) | |
where, δ(Gi)𝛿subscript𝐺𝑖\delta(G\_{i})italic\_δ ( italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ) represents the execution cost of Gisubscript𝐺𝑖G\_{i}italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT.
In our experiments, δ(Gi)𝛿subscript𝐺𝑖\delta(G\_{i})italic\_δ ( italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ) corresponds to the elapsed time required to execute the mapping assertions in Gisubscript𝐺𝑖G\_{i}italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and store the generated RDF triples in secondary memory. Also, δ(Gi)𝛿subscript𝐺𝑖\delta(G\_{i})italic\_δ ( italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ) can quantify memory consumption, and be defined as the amount of main memory consumed during the execution of Gisubscript𝐺𝑖G\_{i}italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT.
Alternatively, Iglesias et al. [[35](#bib.bib35)] presents an abstract cost function defined in terms of the number of comparisons and insertions in main-memory data structures required for executing Gisubscript𝐺𝑖G\_{i}italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT. They represent possible implementations of δ(Gi)𝛿subscript𝐺𝑖\delta(G\_{i})italic\_δ ( italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ).
Inductive Case.
Let BT𝐵𝑇BTitalic\_B italic\_T be a bushy tree plan composed by the union operator OP𝑂𝑃OPitalic\_O italic\_P that merges the results of executing the bushy tree plans BT1𝐵subscript𝑇1BT\_{1}italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and BT2𝐵subscript𝑇2BT\_{2}italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT:
| | | | | |
| --- | --- | --- | --- | --- |
| | fu(BT,S)=𝑓𝑢𝐵𝑇𝑆absent\displaystyle fu(BT,S)={}italic\_f italic\_u ( italic\_B italic\_T , italic\_S ) = | fu(BT1,S)+fu(BT2,S)+𝑓𝑢𝐵subscript𝑇1𝑆limit-from𝑓𝑢𝐵subscript𝑇2𝑆\displaystyle fu(BT\_{1},S)+fu(BT\_{2},S)+italic\_f italic\_u ( italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_S ) + italic\_f italic\_u ( italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT , italic\_S ) + | | (1) |
| | | ϕ(OP,BT1,BT2)italic-ϕ𝑂𝑃𝐵subscript𝑇1𝐵subscript𝑇2\displaystyle\phi(OP,BT\_{1},BT\_{2})italic\_ϕ ( italic\_O italic\_P , italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) | |
ϕ(OP,BT1,BT2)italic-ϕ𝑂𝑃𝐵subscript𝑇1𝐵subscript𝑇2\phi(OP,BT\_{1},BT\_{2})italic\_ϕ ( italic\_O italic\_P , italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) corresponds to the cost of executing OP𝑂𝑃OPitalic\_O italic\_P over the RDF triples produced by the execution of BT1𝐵subscript𝑇1BT\_{1}italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and BT2𝐵subscript𝑇2BT\_{2}italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT. If OP𝑂𝑃OPitalic\_O italic\_P is the duplicate removal operator DR, the time complexity is O(NlogN)𝑂𝑁𝑁O(N\log N)italic\_O ( italic\_N roman\_log italic\_N ), where N𝑁Nitalic\_N is the sum of the size of the RDF triples produced by the execution of BT1𝐵subscript𝑇1BT\_{1}italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and BT2𝐵subscript𝑇2BT\_{2}italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT. Otherwise, ϕ(OP,BT1,BT2)italic-ϕ𝑂𝑃𝐵subscript𝑇1𝐵subscript𝑇2\phi(OP,BT\_{1},BT\_{2})italic\_ϕ ( italic\_O italic\_P , italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) is O(N)𝑂𝑁O(N)italic\_O ( italic\_N ) [[55](#bib.bib55)].
###
4.1 Problem Statement
Let DIS𝒢=⟨O,S,M⟩𝐷𝐼subscript𝑆𝒢𝑂𝑆𝑀DIS\_{\mathcal{G}}=\langle O,S,M\rangleitalic\_D italic\_I italic\_S start\_POSTSUBSCRIPT caligraphic\_G end\_POSTSUBSCRIPT = ⟨ italic\_O , italic\_S , italic\_M ⟩, GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT, and ℬGPMsuperscriptℬ𝐺subscript𝑃𝑀\mathcal{B}^{GP\_{M}}caligraphic\_B start\_POSTSUPERSCRIPT italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT be, respectively, a data integration system, a partition of M𝑀Mitalic\_M, and the set of all the bushy trees GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT over GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT. Consider a utility function, fu(GP¯M,S)𝑓𝑢subscript¯𝐺𝑃𝑀𝑆fu(\overline{GP}\_{M},S)italic\_f italic\_u ( over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT , italic\_S ), that computes the cost of executing GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT over sources in S𝑆Sitalic\_S.
The problem of *planning KG creation* corresponds to finding the bushy tree GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT whose execution in S𝑆Sitalic\_S minimizes fu(GP¯M,S)𝑓𝑢subscript¯𝐺𝑃𝑀𝑆fu(\overline{GP}\_{M},S)italic\_f italic\_u ( over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT , italic\_S ) and creates the duplicate-free RDF triples in 𝒢𝒢\mathcal{G}caligraphic\_G. GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT should satisfy the following conditions:
* •
The execution of GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT over the sources in S𝑆Sitalic\_S is correct and complete, i.e., the execution of the mappings in M𝑀Mitalic\_M following the plan GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT produces all the RDF triples in 𝒢𝒢\mathcal{G}caligraphic\_G.
* •
The value of fu(GP¯M,S)𝑓𝑢subscript¯𝐺𝑃𝑀𝑆fu(\overline{GP}\_{M},S)italic\_f italic\_u ( over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT , italic\_S ) is minimal, i.e., if ℬGPMsuperscriptℬ𝐺subscript𝑃𝑀\mathcal{B}^{GP\_{M}}caligraphic\_B start\_POSTSUPERSCRIPT italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT is the set of the bushy tree plans over GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT, then GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT is the plan in ℬGPMsuperscriptℬ𝐺subscript𝑃𝑀\mathcal{B}^{GP\_{M}}caligraphic\_B start\_POSTSUPERSCRIPT italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT that minimizes fu(.,.)fu(.,.)italic\_f italic\_u ( . , . ).
| | | | |
| --- | --- | --- | --- |
| | B=argminGP¯M∈ℬGPM𝑓𝑢(GP¯M,S)𝐵subscriptargminsubscript¯𝐺𝑃𝑀superscriptℬ𝐺subscript𝑃𝑀𝑓𝑢subscript¯𝐺𝑃𝑀𝑆B=\operatorname\*{arg\,min}\limits\_{\overline{GP}\_{M}\in\mathcal{B}^{GP\_{M}}}\text{{fu}}(\overline{GP}\_{M},S)italic\_B = start\_OPERATOR roman\_arg roman\_min end\_OPERATOR start\_POSTSUBSCRIPT over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT ∈ caligraphic\_B start\_POSTSUPERSCRIPT italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT fu ( over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT , italic\_S ) | | (2) |
Complexity.
The problem of constructing a bushy tree plan GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT is NP-Hard [[53](#bib.bib53)].
###
4.2 Optimality assumptions
Finding an optimal tree plan can be done using a cost- or heuristic-based approach. The latter optimization approach requires the definition of a cost model that estimates the cost of each bushy tree plan in ℬGPMsuperscriptℬ𝐺subscript𝑃𝑀\mathcal{B}^{GP\_{M}}caligraphic\_B start\_POSTSUPERSCRIPT italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT. Alternatively, a heuristic-based method is guided by optimality principles and a set of rules to identify low-cost execution plans. In this work, we present a heuristic-based method to solve the problem of *planning KG creation*. Our proposed method relies on the following optimality principles:
* •
P1-Optimality of Intra-Source Partitions. Let BTi𝐵subscript𝑇𝑖BT\_{i}italic\_B italic\_T start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT be a bushy tree with only one leaf, which corresponds to an intra-source partition Gksubscript𝐺𝑘G\_{k}italic\_G start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT over a source Sisubscript𝑆𝑖S\_{i}italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT. Let BTi′𝐵subscriptsuperscript𝑇′𝑖BT^{\prime}\_{i}italic\_B italic\_T start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT be a simple bushy tree for the mapping assertions in Gksubscript𝐺𝑘G\_{k}italic\_G start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT. The principle of optimality P1 assumes that fu(BTi,{Si})≤fu(BTi′,{Si})𝑓𝑢𝐵subscript𝑇𝑖subscript𝑆𝑖𝑓𝑢𝐵subscriptsuperscript𝑇′𝑖subscript𝑆𝑖fu(BT\_{i},\{S\_{i}\})\leq fu(BT^{\prime}\_{i},\{S\_{i}\})italic\_f italic\_u ( italic\_B italic\_T start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT , { italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT } ) ≤ italic\_f italic\_u ( italic\_B italic\_T start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT , { italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT } ).
* •
P2-Optimality of Inter-Source Partitions Let BTi,j𝐵subscript𝑇
𝑖𝑗BT\_{i,j}italic\_B italic\_T start\_POSTSUBSCRIPT italic\_i , italic\_j end\_POSTSUBSCRIPT be a bushy tree with only one leaf, which corresponds to an inter-source partition Gi,jsubscript𝐺
𝑖𝑗G\_{i,j}italic\_G start\_POSTSUBSCRIPT italic\_i , italic\_j end\_POSTSUBSCRIPT over two sources Sisubscript𝑆𝑖S\_{i}italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT. Let BTi,j′𝐵subscriptsuperscript𝑇′
𝑖𝑗BT^{\prime}\_{i,j}italic\_B italic\_T start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_i , italic\_j end\_POSTSUBSCRIPT be a simple bushy tree for the mapping assertions in Gi,jsubscript𝐺
𝑖𝑗G\_{i,j}italic\_G start\_POSTSUBSCRIPT italic\_i , italic\_j end\_POSTSUBSCRIPT. The principle of optimality P2 assumes that fu(BTi,j,{Si,Sj})𝑓𝑢𝐵subscript𝑇
𝑖𝑗subscript𝑆𝑖subscript𝑆𝑗fu(BT\_{i,j},\{S\_{i},S\_{j}\})italic\_f italic\_u ( italic\_B italic\_T start\_POSTSUBSCRIPT italic\_i , italic\_j end\_POSTSUBSCRIPT , { italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT , italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT } ) ≤fu(BTi,j′,{Si,Sj})absent𝑓𝑢𝐵subscriptsuperscript𝑇′
𝑖𝑗subscript𝑆𝑖subscript𝑆𝑗\leq fu(BT^{\prime}\_{i,j},\{S\_{i},S\_{j}\})≤ italic\_f italic\_u ( italic\_B italic\_T start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT italic\_i , italic\_j end\_POSTSUBSCRIPT , { italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT , italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT } ).
* •
P3-Optimality of Bushy Trees.
Let BT𝐵𝑇BTitalic\_B italic\_T be a bushy tree over the data sources S𝑆Sitalic\_S. BT𝐵𝑇BTitalic\_B italic\_T is of the form
{forest}
[OP
[BT1𝐵subscript𝑇1BT\_{1}italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT]
[BT2𝐵subscript𝑇2BT\_{2}italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT]
]
bushy plans BT1𝐵subscript𝑇1BT\_{1}italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and BT2𝐵subscript𝑇2BT\_{2}italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT are optimal, i.e., fu(BT1,S)𝑓𝑢𝐵subscript𝑇1𝑆fu(BT\_{1},S)italic\_f italic\_u ( italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_S ) and fu(BT2,S)𝑓𝑢𝐵subscript𝑇2𝑆fu(BT\_{2},S)italic\_f italic\_u ( italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT , italic\_S ) are minimal and the evaluations of BT1𝐵subscript𝑇1BT\_{1}italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and BT2𝐵subscript𝑇2BT\_{2}italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT are duplicate free. The principle P3 assumes that BT𝐵𝑇BTitalic\_B italic\_T is optimal.
* •
P4-Optimality of Duplicate Removal Let GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT be a bushy tree plan of mapping assertions in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT and over data sources in S𝑆Sitalic\_S.
Let GP′¯Msubscript¯𝐺superscript𝑃′𝑀\overline{GP^{\prime}}\_{M}over¯ start\_ARG italic\_G italic\_P start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT be an eager duplicate-removal plan of GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT. Let GP′′¯Msubscript¯𝐺superscript𝑃′′𝑀\overline{GP^{\prime\prime}}\_{M}over¯ start\_ARG italic\_G italic\_P start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT be lazy duplicate-removal plan of GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT. The principle P4 assumes that
fu(GP′¯M,S)≤fu(GP′′¯M,S)𝑓𝑢subscript¯𝐺superscript𝑃′𝑀𝑆𝑓𝑢subscript¯𝐺superscript𝑃′′𝑀𝑆fu(\overline{GP^{\prime}}\_{M},S)\leq fu(\overline{GP^{\prime\prime}}\_{M},S)italic\_f italic\_u ( over¯ start\_ARG italic\_G italic\_P start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT , italic\_S ) ≤ italic\_f italic\_u ( over¯ start\_ARG italic\_G italic\_P start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT , italic\_S ).

Figure 6: Pipeline Steps. The pipeline receives a data integration system DIS𝒢=⟨O,S,M⟩𝐷𝐼subscript𝑆𝒢𝑂𝑆𝑀DIS\_{\mathcal{G}}=\langle O,S,M\rangleitalic\_D italic\_I italic\_S start\_POSTSUBSCRIPT caligraphic\_G end\_POSTSUBSCRIPT = ⟨ italic\_O , italic\_S , italic\_M ⟩ and outputs a knowledge graph G𝐺Gitalic\_G that corresponds to the execution of the mapping assertions in M𝑀Mitalic\_M over the instances of the data sources in S𝑆Sitalic\_S. During the planning phase, M𝑀Mitalic\_M is partitioned into a set of intra- and inter-source mapping assertions and the partition groups are scheduled into a bushy tree plan; the tree internal nodes are annotated with the union operator and duplicate removal is scheduled to be executed as soon as possible. The bushy tree is translated into a physical plan during Executing Physical Plans of Mapping Assertions; this plan states the commands at the operating system that need to be executed for KG creation.
Principles P1 and P2 can be easily demonstrated because a simple bushy tree plan will require uploading in memory several times the same source, increasing, thus, the execution time of evaluating the plan and the amount of consumed memory.
Similarly, the proof of principle P4 is supported by the cost of the duplicate removal operator, which depends on the size of the multiset from where duplicates will be removed. The cardinality of the result of executing a bushy tree plan BT𝐵𝑇BTitalic\_B italic\_T grows monotonically in terms to the cardinality of its sub-plans BT1𝐵subscript𝑇1BT\_{1}italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and BT2𝐵subscript𝑇2BT\_{2}italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT. Thus, the cost of the eager execution of duplicate removal operators is lower or equal to the lazy execution of the operators.
Lastly, the principle P3 can be ensured based on the optimality of the input sub-plans BT1𝐵subscript𝑇1BT\_{1}italic\_B italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and BT2𝐵subscript𝑇2BT\_{2}italic\_B italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT.
Despite the validity of these optimality principles, the outcomes of an optimization method guided by these assumptions can produce plans that are not optimal.
[Theorem 4.1](#S4.Thmtheorem1 "Theorem 4.1 ‣ 4.2 Optimality assumptions ‣ 4 Scaling KG Creation Up ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") demonstrates the characteristics of a data integration system that ensure the optimality of applying P1-P4. The proof is in [Appendix 0.A](#Pt0.A1 "Appendix 0.A Theorems and Proofs ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources").
###### Theorem 4.1
Let DIS𝒢=⟨O,S,M⟩𝐷𝐼subscript𝑆𝒢𝑂𝑆𝑀DIS\_{\mathcal{G}}=\langle O,S,M\rangleitalic\_D italic\_I italic\_S start\_POSTSUBSCRIPT caligraphic\_G end\_POSTSUBSCRIPT = ⟨ italic\_O , italic\_S , italic\_M ⟩ be a data integration system such that assertions in M𝑀Mitalic\_M meet the following conditions:
* •
A concept mapping assertion maj𝑚subscript𝑎𝑗ma\_{j}italic\_m italic\_a start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT on source Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT is referred from any number of multi-source role mapping assertions mai𝑚subscript𝑎𝑖ma\_{i}italic\_m italic\_a start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT, but these assertions are all from one source Sisubscript𝑆𝑖S\_{i}italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT.
* •
A property p𝑝pitalic\_p from O𝑂Oitalic\_O is defined, at most, on one mapping assertion mai𝑚subscript𝑎𝑖ma\_{i}italic\_m italic\_a start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT.
Let BT𝐵𝑇BTitalic\_B italic\_T be a bushy tree plan over mapping assertions in M𝑀Mitalic\_M and data sources in S𝑆Sitalic\_S; BT𝐵𝑇BTitalic\_B italic\_T generates G𝐺Gitalic\_G and respects the optimality principles P1-P4. Then, BT𝐵𝑇BTitalic\_B italic\_T is optimal, i.e., there is no other equivalent bushy tree plan BT′𝐵superscript𝑇normal-′BT^{\prime}italic\_B italic\_T start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT such as fu(BT′,S)<fu(BT,S)𝑓𝑢𝐵superscript𝑇normal-′𝑆𝑓𝑢𝐵𝑇𝑆fu(BT^{\prime},S)<fu(BT,S)italic\_f italic\_u ( italic\_B italic\_T start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , italic\_S ) < italic\_f italic\_u ( italic\_B italic\_T , italic\_S ).
###
4.3 Proposed Solution
We propose a heuristic-based approach to generate a bushy tree GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT that corresponds to a solution to the problem of *planning KG creation*. This approach relies on optimality assumptions P1-P4. Thus, the execution of intra- and inter-source groups of mapping assertions independently induces source-based scheduling of the execution of the mapping assertions. At most, two sources are traversed during the evaluation of a group, and less memory is required to keep intermediate results. Lastly, the duplicate removal operators are pushed down into the bushy tree following an eager execution of duplicate removal. As a result, the union operators are scheduled over small sets of RDF triples, and the effect of merging multisets of RDF triples is mitigated. Then,
GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT is translated into a physical plan defined in terms of operating system commands. It schedules the execution of each group of mapping assertions and union operators according to GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT.
5 The Pipeline for Planning and Executing Mapping Assertions
-------------------------------------------------------------
This section describes the techniques that implement the proposed solution reported in the previous section.
Figure [6](#S4.F6 "Figure 6 ‣ 4.2 Optimality assumptions ‣ 4 Scaling KG Creation Up ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") depicts the components of the pipeline for planning and executing a bushy tree GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT for the creation of the KG 𝒢𝒢\mathcal{G}caligraphic\_G defined as a data integration system DIS𝒢=⟨O,S,M⟩𝐷𝐼subscript𝑆𝒢𝑂𝑆𝑀DIS\_{\mathcal{G}}=\langle O,S,M\rangleitalic\_D italic\_I italic\_S start\_POSTSUBSCRIPT caligraphic\_G end\_POSTSUBSCRIPT = ⟨ italic\_O , italic\_S , italic\_M ⟩.
The pipeline comprises, first, the phase of planning where the bushy tree is created, and then, the execution phase, where GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT is translated into a physical plan and executed over a particular [R2]RML-compliant engine.
###
5.1 Planning Mapping Assertions
This step comprises the components of mapping assertion partitioning and bushy plan generation. The algorithm receives a data integration system DIS𝒢=⟨O,S,M⟩𝐷𝐼subscript𝑆𝒢𝑂𝑆𝑀DIS\_{\mathcal{G}}=\langle O,S,M\rangleitalic\_D italic\_I italic\_S start\_POSTSUBSCRIPT caligraphic\_G end\_POSTSUBSCRIPT = ⟨ italic\_O , italic\_S , italic\_M ⟩ and partitions M𝑀Mitalic\_M into groups of intra- and inter-source mapping assertions. Then, they are heuristically combined into a bushy tree plan. These components are guided by the optimality principles P1-P4.
####
5.1.1 Mapping Assertion Partitioning
The algorithm Grouping Mapping Assertions receives as input the set of mapping assertions M𝑀Mitalic\_M and initializes GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT with the intra- and inter-source mapping assertion partitions of M𝑀Mitalic\_M. Then, the algorithm *greedily* decides to combine two groups gisubscript𝑔𝑖g\_{i}italic\_g start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and gjsubscript𝑔𝑗g\_{j}italic\_g start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT into a group gi,jsubscript𝑔𝑖𝑗g\_{i,j}italic\_g start\_POSTSUBSCRIPT italic\_i , italic\_j end\_POSTSUBSCRIPT whenever any of the following conditions is satisfied:
* •
*Merging Intra-Source Partitions*.
This step is guided by the optimality principle P1. Suppose gisubscript𝑔𝑖g\_{i}italic\_g start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and gjsubscript𝑔𝑗g\_{j}italic\_g start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT only comprise intra-source mapping assertion partitions of sources S′superscript𝑆′S^{\prime}italic\_S start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT (i.e., S′superscript𝑆′S^{\prime}italic\_S start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ⊆\subseteq⊆ S𝑆Sitalic\_S). Additionally, there are no sources Sisubscript𝑆𝑖S\_{i}italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT in S′superscript𝑆′S^{\prime}italic\_S start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT such that there exists in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT an inter-source assertion mapping partition for Sisubscript𝑆𝑖S\_{i}italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT. Then, groups gisubscript𝑔𝑖g\_{i}italic\_g start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and gjsubscript𝑔𝑗g\_{j}italic\_g start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT can be merged into the group gi,jsubscript𝑔
𝑖𝑗g\_{i,j}italic\_g start\_POSTSUBSCRIPT italic\_i , italic\_j end\_POSTSUBSCRIPT in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT; gi,jsubscript𝑔
𝑖𝑗g\_{i,j}italic\_g start\_POSTSUBSCRIPT italic\_i , italic\_j end\_POSTSUBSCRIPT comprises intra-source assertion mapping partitions in gisubscript𝑔𝑖g\_{i}italic\_g start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and gjsubscript𝑔𝑗g\_{j}italic\_g start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT.
* •
*Merging Inter- and Intra-Source Partitions.* This step is guided by the optimality principle P2. Suppose the group gisubscript𝑔𝑖g\_{i}italic\_g start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT comprises an inter-source mapping partition for Sisubscript𝑆𝑖S\_{i}italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT, where Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT is the referenced source (i.e., logical source of the parent triples map). Additionally, the group gjsubscript𝑔𝑗g\_{j}italic\_g start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT only includes the intra-source mapping assertion of Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT. Thus, gisubscript𝑔𝑖g\_{i}italic\_g start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and gjsubscript𝑔𝑗g\_{j}italic\_g start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT can be merged into the group gi,jsubscript𝑔
𝑖𝑗g\_{i,j}italic\_g start\_POSTSUBSCRIPT italic\_i , italic\_j end\_POSTSUBSCRIPT in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT. The group gi,jsubscript𝑔
𝑖𝑗g\_{i,j}italic\_g start\_POSTSUBSCRIPT italic\_i , italic\_j end\_POSTSUBSCRIPT only includes intra-source assertion mapping partitions of Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT and the inter-source partition for Sisubscript𝑆𝑖S\_{i}italic\_S start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT. In case Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT is the referenced source of various inter-source mapping partitions, the intra-source mapping assertion partition of Sjsubscript𝑆𝑗S\_{j}italic\_S start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT is only combined with one inter-source
partition. The selection is done randomly. The selected combination of the intra- and inter-source mapping partitions may be more expensive than other options. As a result, this decision may negatively impact the performance of a bushy tree plan.

Figure 7: Running example. The Graph Plan for Optimized Partition illustrated in Figure [3](#S2.F3 "Figure 3 ‣ 2 Preliminaries and Motivation ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") is applied, and then the Intermediate Hyper-graphs are generated by the Algorithm Generating a Bushy Tree of Mapping Assertions presented in Figure [5](#S4.F5 "Figure 5 ‣ 4 Scaling KG Creation Up ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources").
The algorithm iterates until a fixed-point is reached over GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT, i.e., an iteration of the algorithm where all the pairs of groups gisubscript𝑔𝑖g\_{i}italic\_g start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and gjsubscript𝑔𝑗g\_{j}italic\_g start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT are revised, and no new group gi,jsubscript𝑔𝑖𝑗g\_{i,j}italic\_g start\_POSTSUBSCRIPT italic\_i , italic\_j end\_POSTSUBSCRIPT can replace them in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT.
####
5.1.2 Generating a Bushy Tree
A bushy tree GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT for the groups GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT of mapping assertion partitions is generated following a greedy heuristic-based algorithm; it is guided by the optimality principle P3 and assumes that sub-plans produced so far, are optimal.
Also, the algorithm follows the optimality principle P4 and combines first groups of partitions whose union requires duplicate removal.
A sketch of the algorithm is outlined in Algorithm [1](#alg1 "Algorithm 1 ‣ 5.1.2 Generating a Bushy Tree ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources"). It traverses the set ℬGPMsuperscriptℬ𝐺subscript𝑃𝑀\mathcal{B}^{GP\_{M}}caligraphic\_B start\_POSTSUPERSCRIPT italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT in iterations and outputs a bushy tree B𝐵Bitalic\_B where duplicate removal nodes are pushed down. The algorithm receives a graph plan GGPMsuperscript𝐺𝐺subscript𝑃𝑀G^{GP\_{M}}italic\_G start\_POSTSUPERSCRIPT italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT of the groups in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT and resorts to a hyper-graph to represent the bushy tree plan GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT.
Algorithm 1 Generating a Hyper-graph of Mapping Assertions.
Plan Graph GGPM=(V,E,ϕ)Plan Graph superscript𝐺𝐺subscript𝑃𝑀𝑉𝐸italic-ϕ\text{Plan Graph }G^{GP\_{M}}=(V,E,\phi)Plan Graph italic\_G start\_POSTSUPERSCRIPT italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT = ( italic\_V , italic\_E , italic\_ϕ )
Hyper-graph of Mapping Assertions OL𝑂𝐿OLitalic\_O italic\_L
OL←empty←𝑂𝐿𝑒𝑚𝑝𝑡𝑦OL\leftarrow emptyitalic\_O italic\_L ← italic\_e italic\_m italic\_p italic\_t italic\_y
for group∈V𝑔𝑟𝑜𝑢𝑝𝑉group\in Vitalic\_g italic\_r italic\_o italic\_u italic\_p ∈ italic\_V do
OL←OL.append(group)formulae-sequence←𝑂𝐿𝑂𝐿𝑎𝑝𝑝𝑒𝑛𝑑𝑔𝑟𝑜𝑢𝑝OL\leftarrow OL.append(group)italic\_O italic\_L ← italic\_O italic\_L . italic\_a italic\_p italic\_p italic\_e italic\_n italic\_d ( italic\_g italic\_r italic\_o italic\_u italic\_p )
end for
OL←sortByDegree&NumberSharedProperties(OL)←𝑂𝐿𝑠𝑜𝑟𝑡𝐵𝑦𝐷𝑒𝑔𝑟𝑒𝑒𝑁𝑢𝑚𝑏𝑒𝑟𝑆ℎ𝑎𝑟𝑒𝑑𝑃𝑟𝑜𝑝𝑒𝑟𝑡𝑖𝑒𝑠𝑂𝐿OL\leftarrow sortByDegree\&NumberSharedProperties(OL)italic\_O italic\_L ← italic\_s italic\_o italic\_r italic\_t italic\_B italic\_y italic\_D italic\_e italic\_g italic\_r italic\_e italic\_e & italic\_N italic\_u italic\_m italic\_b italic\_e italic\_r italic\_S italic\_h italic\_a italic\_r italic\_e italic\_d italic\_P italic\_r italic\_o italic\_p italic\_e italic\_r italic\_t italic\_i italic\_e italic\_s ( italic\_O italic\_L )
FixedPoint←FALSE←𝐹𝑖𝑥𝑒𝑑𝑃𝑜𝑖𝑛𝑡𝐹𝐴𝐿𝑆𝐸FixedPoint\leftarrow FALSEitalic\_F italic\_i italic\_x italic\_e italic\_d italic\_P italic\_o italic\_i italic\_n italic\_t ← italic\_F italic\_A italic\_L italic\_S italic\_E
while not(FixedPoint)𝑛𝑜𝑡𝐹𝑖𝑥𝑒𝑑𝑃𝑜𝑖𝑛𝑡not(FixedPoint)italic\_n italic\_o italic\_t ( italic\_F italic\_i italic\_x italic\_e italic\_d italic\_P italic\_o italic\_i italic\_n italic\_t ) do
FixedPoint←TRUE←𝐹𝑖𝑥𝑒𝑑𝑃𝑜𝑖𝑛𝑡𝑇𝑅𝑈𝐸FixedPoint\leftarrow TRUEitalic\_F italic\_i italic\_x italic\_e italic\_d italic\_P italic\_o italic\_i italic\_n italic\_t ← italic\_T italic\_R italic\_U italic\_E
HN←getFirst(OL)←𝐻𝑁𝑔𝑒𝑡𝐹𝑖𝑟𝑠𝑡𝑂𝐿HN\leftarrow getFirst(OL)italic\_H italic\_N ← italic\_g italic\_e italic\_t italic\_F italic\_i italic\_r italic\_s italic\_t ( italic\_O italic\_L )
BestNeighbor←getFirstNeighbor(HN)←𝐵𝑒𝑠𝑡𝑁𝑒𝑖𝑔ℎ𝑏𝑜𝑟𝑔𝑒𝑡𝐹𝑖𝑟𝑠𝑡𝑁𝑒𝑖𝑔ℎ𝑏𝑜𝑟𝐻𝑁BestNeighbor\leftarrow getFirstNeighbor(HN)italic\_B italic\_e italic\_s italic\_t italic\_N italic\_e italic\_i italic\_g italic\_h italic\_b italic\_o italic\_r ← italic\_g italic\_e italic\_t italic\_F italic\_i italic\_r italic\_s italic\_t italic\_N italic\_e italic\_i italic\_g italic\_h italic\_b italic\_o italic\_r ( italic\_H italic\_N )
if BestNeighbor𝐵𝑒𝑠𝑡𝑁𝑒𝑖𝑔ℎ𝑏𝑜𝑟BestNeighboritalic\_B italic\_e italic\_s italic\_t italic\_N italic\_e italic\_i italic\_g italic\_h italic\_b italic\_o italic\_r is not NULL then
if BestNeighbor𝐵𝑒𝑠𝑡𝑁𝑒𝑖𝑔ℎ𝑏𝑜𝑟BestNeighboritalic\_B italic\_e italic\_s italic\_t italic\_N italic\_e italic\_i italic\_g italic\_h italic\_b italic\_o italic\_r and HN𝐻𝑁HNitalic\_H italic\_N share properties then
NewHN←merge(HN,BestNeighbor,DR)←𝑁𝑒𝑤𝐻𝑁𝑚𝑒𝑟𝑔𝑒𝐻𝑁𝐵𝑒𝑠𝑡𝑁𝑒𝑖𝑔ℎ𝑏𝑜𝑟𝐷𝑅NewHN\leftarrow merge(HN,BestNeighbor,DR)italic\_N italic\_e italic\_w italic\_H italic\_N ← italic\_m italic\_e italic\_r italic\_g italic\_e ( italic\_H italic\_N , italic\_B italic\_e italic\_s italic\_t italic\_N italic\_e italic\_i italic\_g italic\_h italic\_b italic\_o italic\_r , italic\_D italic\_R )
else
NewHN←merge(HN,BestNeighbor,NDR)←𝑁𝑒𝑤𝐻𝑁𝑚𝑒𝑟𝑔𝑒𝐻𝑁𝐵𝑒𝑠𝑡𝑁𝑒𝑖𝑔ℎ𝑏𝑜𝑟𝑁𝐷𝑅NewHN\leftarrow merge(HN,BestNeighbor,NDR)italic\_N italic\_e italic\_w italic\_H italic\_N ← italic\_m italic\_e italic\_r italic\_g italic\_e ( italic\_H italic\_N , italic\_B italic\_e italic\_s italic\_t italic\_N italic\_e italic\_i italic\_g italic\_h italic\_b italic\_o italic\_r , italic\_N italic\_D italic\_R )
end if
OL.remove(HN)formulae-sequence𝑂𝐿𝑟𝑒𝑚𝑜𝑣𝑒𝐻𝑁OL.remove(HN)italic\_O italic\_L . italic\_r italic\_e italic\_m italic\_o italic\_v italic\_e ( italic\_H italic\_N )
OL.remove(BestNeighbor)formulae-sequence𝑂𝐿𝑟𝑒𝑚𝑜𝑣𝑒𝐵𝑒𝑠𝑡𝑁𝑒𝑖𝑔ℎ𝑏𝑜𝑟OL.remove(BestNeighbor)italic\_O italic\_L . italic\_r italic\_e italic\_m italic\_o italic\_v italic\_e ( italic\_B italic\_e italic\_s italic\_t italic\_N italic\_e italic\_i italic\_g italic\_h italic\_b italic\_o italic\_r )
OL.append(NewHN)formulae-sequence𝑂𝐿𝑎𝑝𝑝𝑒𝑛𝑑𝑁𝑒𝑤𝐻𝑁OL.append(NewHN)italic\_O italic\_L . italic\_a italic\_p italic\_p italic\_e italic\_n italic\_d ( italic\_N italic\_e italic\_w italic\_H italic\_N )
FixedPoint←FALSE←𝐹𝑖𝑥𝑒𝑑𝑃𝑜𝑖𝑛𝑡𝐹𝐴𝐿𝑆𝐸FixedPoint\leftarrow FALSEitalic\_F italic\_i italic\_x italic\_e italic\_d italic\_P italic\_o italic\_i italic\_n italic\_t ← italic\_F italic\_A italic\_L italic\_S italic\_E
end if
end while
return OL𝑂𝐿OLitalic\_O italic\_L
A graph plan GGPMsuperscript𝐺𝐺subscript𝑃𝑀G^{GP\_{M}}italic\_G start\_POSTSUPERSCRIPT italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT is an undirected labelled graph GGPM=(V,E,ϕ)superscript𝐺𝐺subscript𝑃𝑀𝑉𝐸italic-ϕG^{GP\_{M}}=(V,E,\phi)italic\_G start\_POSTSUPERSCRIPT italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT = ( italic\_V , italic\_E , italic\_ϕ ):
* •
The groups in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT are the nodes in V𝑉Vitalic\_V.
* •
There is an edge between groups gisubscript𝑔𝑖g\_{i}italic\_g start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and gjsubscript𝑔𝑗g\_{j}italic\_g start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT, if and only if, there is a non-empty set SP𝑆𝑃SPitalic\_S italic\_P of properties in the ontology O𝑂Oitalic\_O, and the properties in SP𝑆𝑃SPitalic\_S italic\_P are defined with mapping assertions in gisubscript𝑔𝑖g\_{i}italic\_g start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and gjsubscript𝑔𝑗g\_{j}italic\_g start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT. Thus, an edge between gisubscript𝑔𝑖g\_{i}italic\_g start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and gjsubscript𝑔𝑗g\_{j}italic\_g start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT represents that their execution will generate instances of the properties in SP𝑆𝑃SPitalic\_S italic\_P which may overlap and the operator of a duplicate removal is required.
* •
ϕ(gk,gq)italic-ϕsubscript𝑔𝑘subscript𝑔𝑞\phi(g\_{k},g\_{q})italic\_ϕ ( italic\_g start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT , italic\_g start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT ) labels an edge between groups gisubscript𝑔𝑖g\_{i}italic\_g start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and gjsubscript𝑔𝑗g\_{j}italic\_g start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT with the set of SP𝑆𝑃SPitalic\_S italic\_P properties that gisubscript𝑔𝑖g\_{i}italic\_g start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and gjsubscript𝑔𝑗g\_{j}italic\_g start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT define in common.
Figure [7](#S5.F7 "Figure 7 ‣ 5.1.1 Mapping Assertion Partitioning ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")a depicts a graph plan for the grouping named Optimized Partition in Figure [3](#S2.F3 "Figure 3 ‣ 2 Preliminaries and Motivation ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources"). The graph is composed of four nodes and one edge, and ϕ(Group 2,Group 4)italic-ϕGroup 2Group 4\phi(\texttt{Group 2},\texttt{Group 4})italic\_ϕ ( Group 2 , Group 4 ) outputs the set {p3} with the property that Group 2 and Grou p4 both define.
Initially, Algorithm [1](#alg1 "Algorithm 1 ‣ 5.1.2 Generating a Bushy Tree ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") creates a hyper-node with exactly one group in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT. Figure [7](#S5.F7 "Figure 7 ‣ 5.1.1 Mapping Assertion Partitioning ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")b depicts the initial configuration of the hyper-graph; it is composed of four hyper-nodes.
Hyper-nodes are sorted in OL𝑂𝐿OLitalic\_O italic\_L based on the degree of connections and the cardinality of the labels of these connections, i.e., the number of properties that the connected groups have in common. Algorithm [1](#alg1 "Algorithm 1 ‣ 5.1.2 Generating a Bushy Tree ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") resorts to this sorting to decide the order in which hyper-nodes will be merged. The first hyper-node HN𝐻𝑁HNitalic\_H italic\_N in OL𝑂𝐿OLitalic\_O italic\_L is selected and combined in a hypernode NewHN with the neighbor that shares more properties (BestNeighbor). The combined hyper-nodes (i.e., HN𝐻𝑁HNitalic\_H italic\_N and BestNeighbor) are eliminated from OL𝑂𝐿OLitalic\_O italic\_L and the new hyper-node (i.e., NewHN) is appended at the end of OL𝑂𝐿OLitalic\_O italic\_L. If BestNeighbor and HN𝐻𝑁HNitalic\_H italic\_N share at least one property in common (i.e., they were connected in the plan graph), NewHN is annotated with DR to denote that the duplicate removal needs to be executed.
This decision implements our heuristic following the optimality principle P4. As a result, duplicate removal is first executed on the union of sets of RDF triples generated by mapping assertions that define the greatest number of properties in common, i.e., an eager evaluation of DR is scheduled. Contrary, if HN𝐻𝑁HNitalic\_H italic\_N does not have a neighbor, a node with the highest number of connections is selected as best neighbor; NewHN is annotated with NDR to denote the union without duplicate removal.
The process is repeated until a fixed point in the hyper-graph is reached; the generated hyper-graph corresponds to the bushy tree. Figures [7](#S5.F7 "Figure 7 ‣ 5.1.1 Mapping Assertion Partitioning ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")b, [7](#S5.F7 "Figure 7 ‣ 5.1.1 Mapping Assertion Partitioning ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")c, [7](#S5.F7 "Figure 7 ‣ 5.1.1 Mapping Assertion Partitioning ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")d, and [7](#S5.F7 "Figure 7 ‣ 5.1.1 Mapping Assertion Partitioning ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")e, illustrate the execution of Algorithm [1](#alg1 "Algorithm 1 ‣ 5.1.2 Generating a Bushy Tree ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources"). The generated hyper-graph corresponds to the bushy tree illustrated in Figure [5](#S4.F5 "Figure 5 ‣ 4 Scaling KG Creation Up ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")a.

Figure 8: Running example. Physical Plans generated by transforming bushy trees in Figure [5](#S4.F5 "Figure 5 ‣ 4 Scaling KG Creation Up ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources"). The execution time of the physical plan of the bushy tree (without considering the execution of the groups of assertions) consumes 52.02 % of the time required for executing the left- and right-linear plans.
###### Theorem 5.1
Let GGPMsuperscript𝐺𝐺subscript𝑃𝑀G^{GP\_{M}}italic\_G start\_POSTSUPERSCRIPT italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT be a graph plan of the groups in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT. Let n𝑛nitalic\_n be the GGPMsuperscript𝐺𝐺subscript𝑃𝑀G^{GP\_{M}}italic\_G start\_POSTSUPERSCRIPT italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT cardinality, i.e., the number of groups in GPM𝐺subscript𝑃𝑀GP\_{M}italic\_G italic\_P start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT. The time complexity of Algorithm [1](#alg1 "Algorithm 1 ‣ 5.1.2 Generating a Bushy Tree ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") is O(nlogn)𝑂𝑛𝑛O(n\log n)italic\_O ( italic\_n roman\_log italic\_n ) and up to 2n−1superscript2𝑛12^{n}-12 start\_POSTSUPERSCRIPT italic\_n end\_POSTSUPERSCRIPT - 1 bushy sub-plans are generated.
###
5.2 Executing Mapping Assertions
This step receives a bushy tree GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT, and generates a physical plan that can execute the mapping assertions in M𝑀Mitalic\_M following the order stated in GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT. Figure [6](#S4.F6 "Figure 6 ‣ 4.2 Optimality assumptions ‣ 4 Scaling KG Creation Up ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") depicts the main two components of this step of the pipeline. First, nodes in GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT are visited following a breadth-first traversal to generate a physical plan.
A physical plan is defined in terms of operating system commands that enable the execution of a [R2]RML-compliant engine calls to evaluate a group of mapping assertions and generate RDF triples that will be part of a KG.
A physical plan PP𝑃𝑃PPitalic\_P italic\_P is defined as:
Base Case.
Let ECall, Time, File, and Id be an [R2]RML engine instruction call, execution timeout, group of mapping assertions file, and Id𝐼𝑑Iditalic\_I italic\_d a process identifier, respectively.
PP𝑃𝑃PPitalic\_P italic\_P=&(timeout Time ECall wait %Id)
represents that ECall is executed in the background until the process finalizes or times out after Time.
Inductive Case.
* •
Union with duplicate removal. Given two physical plans PPi𝑃subscript𝑃𝑖PP\_{i}italic\_P italic\_P start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and PPj𝑃subscript𝑃𝑗PP\_{j}italic\_P italic\_P start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT whose execution produces RDF KGs KGi𝐾subscript𝐺𝑖KG\_{i}italic\_K italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and KGj𝐾subscript𝐺𝑗KG\_{j}italic\_K italic\_G start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT which may overlap.
PPi,j𝑃subscript𝑃
𝑖𝑗PP\_{i,j}italic\_P italic\_P start\_POSTSUBSCRIPT italic\_i , italic\_j end\_POSTSUBSCRIPT= &(sort -u PPi𝑃subscript𝑃𝑖PP\_{i}italic\_P italic\_P start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT PPj𝑃subscript𝑃𝑗PP\_{j}italic\_P italic\_P start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT) represents that KGi𝐾subscript𝐺𝑖KG\_{i}italic\_K italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and KGj𝐾subscript𝐺𝑗KG\_{j}italic\_K italic\_G start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT are sorted, merged, and duplicates are removed.
* •
Union without duplicate removal.
Given two physical plans PPi𝑃subscript𝑃𝑖PP\_{i}italic\_P italic\_P start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and PPj𝑃subscript𝑃𝑗PP\_{j}italic\_P italic\_P start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT whose execution produces RDF KGs KGi𝐾subscript𝐺𝑖KG\_{i}italic\_K italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and KGj𝐾subscript𝐺𝑗KG\_{j}italic\_K italic\_G start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT which do not overlap.
PPi,j𝑃subscript𝑃
𝑖𝑗PP\_{i,j}italic\_P italic\_P start\_POSTSUBSCRIPT italic\_i , italic\_j end\_POSTSUBSCRIPT= &(cat PPi𝑃subscript𝑃𝑖PP\_{i}italic\_P italic\_P start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT PPj𝑃subscript𝑃𝑗PP\_{j}italic\_P italic\_P start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT) represents that KGi𝐾subscript𝐺𝑖KG\_{i}italic\_K italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and KGj𝐾subscript𝐺𝑗KG\_{j}italic\_K italic\_G start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT are merged.
* •
Storing an RDF KG. Let PPi𝑃subscript𝑃𝑖PP\_{i}italic\_P italic\_P start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT be a plan whose execution generates a KG KGi𝐾subscript𝐺𝑖KG\_{i}italic\_K italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT.
PP𝑃𝑃PPitalic\_P italic\_P=PPi𝑃subscript𝑃𝑖PP\_{i}italic\_P italic\_P start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT >>> KG𝐾𝐺KGitalic\_K italic\_G represents that KGi𝐾subscript𝐺𝑖KG\_{i}italic\_K italic\_G start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT is stored in the file KG𝐾𝐺KGitalic\_K italic\_G.
The function γ(GP¯M)𝛾subscript¯𝐺𝑃𝑀\gamma(\overline{GP}\_{M})italic\_γ ( over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT ) represents the translation of the bushy tree GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT into a physical plan PP𝑃𝑃PPitalic\_P italic\_P; γ(.)\gamma(.)italic\_γ ( . ) is inductively defined over the structure of GP¯Msubscript¯𝐺𝑃𝑀\overline{GP}\_{M}over¯ start\_ARG italic\_G italic\_P end\_ARG start\_POSTSUBSCRIPT italic\_M end\_POSTSUBSCRIPT as follows:
Base Case. Let BT𝐵𝑇BTitalic\_B italic\_T be a leaf, i.e., BT𝐵𝑇BTitalic\_B italic\_T is a group of mapping assertions. Let ECall, Time, File, and BTId be an [R2]RML engine instruction call, execution timeout, group of mapping assertions file, and BT𝐵𝑇BTitalic\_B italic\_T identifier, respectively.
γ(BT)𝛾𝐵𝑇\gamma(BT)italic\_γ ( italic\_B italic\_T )=(timeout Time ECall wait %BTId)
Inductive Case I.
Let BT𝐵𝑇BTitalic\_B italic\_T be a binary tree with the operator DR as root node:
{forest}
[DR
[BT1]
[BT2]
]
γ(BT)𝛾𝐵𝑇\gamma(BT)italic\_γ ( italic\_B italic\_T )=(sort -u &(γ𝛾\gammaitalic\_γ(BT1)) &(γ𝛾\gammaitalic\_γ(BT2)))
Inductive Case II.
Let BT𝐵𝑇BTitalic\_B italic\_T be a binary tree with the operator NDR as root node:
{forest}
[NDR
[BT1]
[BT2]
]
γ(BT)𝛾𝐵𝑇\gamma(BT)italic\_γ ( italic\_B italic\_T )=(cat &(γ𝛾\gammaitalic\_γ(BT1)) &(γ𝛾\gammaitalic\_γ(BT2)))
Figure [8](#S5.F8 "Figure 8 ‣ 5.1.2 Generating a Bushy Tree ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") depicts the physical plans generated following the inductive definition of γ(.)\gamma(.)italic\_γ ( . ). Three different plans are generated: the bushy, left-linear, and right-linear tree plans; the physical plans for each engine are also generated. In these trees, the duplicate removal operator is either pushed down into the tree (Figure [8](#S5.F8 "Figure 8 ‣ 5.1.2 Generating a Bushy Tree ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") (a)) or in performed at the last step of the evaluation (Figures [8](#S5.F8 "Figure 8 ‣ 5.1.2 Generating a Bushy Tree ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") (b) and (c)). The execution time of each physical plan is dominated by the cost of evaluating each group of mapping assertions. Nevertheless, the physical plan that implements the bushy tree requires only half of the time (i.e., 52.02% of the time consumed by the other physical plans) to combine the RDF triples generated during the execution of Group1, Group2, Group3, and Group4. These results provide evidence of the benefits of scheduling the execution of the KG creation following the physical plans generated by the proposed algorithms.
| Parameter: Dataset Size |
| --- |
| Benchmark | Size | Description |
| GTFS-Madrid-Bench | 1-CSV | Ten different data sources are 4.8 Mb in total, where SHAPES.csv is the largest file with 4.5 Mb. |
| 5-CSV | Ten different data sources are 10 Mb in total, where SHAPES.csv is the largest file with 7.9 Mb. The KG generated from these data sources is five times bigger than the KG generated from 1-CSV. |
| SDM-Genomic-Datasets | 10k | Each data source has 10,000 rows. |
| 100k | Each data source has 100,000 rows. |
| 1M | Each data source has 1,000,000 rows. |
| Parameters: Mapping Assertion (MA) Type and Complexity, Selectivity of the Results, and Type of Joins |
| Benchmark | Mapping Configuration | Description |
| GTFS-Madrid-Bench | Standard Config | 13 Concept MAs, 55 Attribute MAs, 73 single-source role MAs, and 12 multi-source role MAs. |
| SDM-Genomic-Datasets | Conf1 | One Concept MA, and one Attribute MA. |
| Conf2 | One Concept MA, and four Attribute MAs. |
| Conf3 | Two Concept MA, one referenced-source role MA, and one attribute MA. |
| Conf4 | Five Concept MAs, and four Referenced-source role MAs. |
| Conf5 | Two Concepts MAs, and one Multi-source role MA. |
| Conf6 | Five Concept MAs, and Four Multi-source role MAs |
| AllTogether | Combines Conf1, Conf2, Conf3, Conf4, Conf5, and Conf6 into one mapping configuration. |
| Conf7 | Four Concept MAs, and two Multi-source role MAs. This configuration seeks to evaluate the impact of defining the same predicates using different MAs. |
| Conf8 | Six Concept and five Multi-source role MAs. This mapping configuration aims to recreate a five-star join where five MAs refer to the same parent MA. |
| Conf9 | Eight Concept and seven Multi-source role MAs. This configuration combines Conf7 and Conf8 into one mapping configuration. |
Table 2: Datasets and Configurations of Mapping Assertions. The table describes each data source and configuration of MAs used in the experiments and their corresponding benchmarks. Configuration of MAs in bold are considered complex cases. They include several types of MAs of various complexity. Also, they have complex joins (e.g., five-start joins).
6 Experimental Study
---------------------
The performance of the solution proposed to the problem of *planning KG creation* is studied in four RML-compliant engines: RMLMapper, RocketRML, SDM-RDFizer, and Morph-KGC. The code is publicly available on GitHub[[37](#bib.bib37)].
The empirical evaluation aims at answering the following research questions:
RQ1) How does planning the execution of mapping assertions affect the performance of the state-of-the-art RML-compliant engines during KG creation?
RQ2) What is the impact of the type of mapping assertions and volume of the data sources on execution time and memory consumed by engines?
RQ3) What is the impact in– execution time and memory consumption–of the execution of the mapping assertions following physical plans generated from bushy trees generated by Algorithm [1](#alg1 "Algorithm 1 ‣ 5.1.2 Generating a Bushy Tree ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")?
###
6.1 Experimental Configuration
The following setting is configured to assess our research questions.
##### Benchmarks
Experiments are executed on datasets from GTFS-Madrid-Bench and SDM-Genomic-Datasets. Thus, our experimental setting can cover a larger spectrum of parameters that affect a KG creation task, i.e., dataset size, mapping assertion type and complexity, selectivity of the results, and types of joins between mapping assertions. [Table 2](#S5.T2 "Table 2 ‣ 5.2 Executing Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") summarizes the main characteristics of these benchmarks and the covered parameters.
The GTFS-Madrid-Bench [[22](#bib.bib22)] benchmark enables the generation of different configurations of data integration systems whose characteristics impact on the process of KG creation. We generate four logical sources with the scaling factor 1-csv, 5-csv, 10-csv, and 50-csv. The scale value indicates that the comparison between the sizes of the goal KGs. For instance, a KG generated from 5-csv is five times larger than the KG that is created from 1-csv. The logical sources for the 1-csv configuration has in total 4.8 MB. In overall, we consider mapping rules comprised of 13 concept mapping assertions, 55 attribute mapping assertions, 73 single-source role mapping assertions, and 12 multi-source role mapping assertions involving ten data sources.
SDM-Genomic-Datasets [[10](#bib.bib10)] is a benchmark to compare the performance of state-of-the-art RML-compliant engines. SDM-Genomic-Datasets is created by randomly selecting data records from somatic mutation data collected in COSMIC [[14](#bib.bib14)]. SDM-Genomic-Datasets includes eight different logical data sources with various sizes including 10k, 100k, 1M, and 10M number of rows. Accordingly, every pair of logical data sources with the same size differ in data duplicate rates, which can be either 25% or 75%. Each duplicate value is repeated 20 times. For example, a 10k logical data source with 25% data duplicate rates has 75% duplicate-free records (i.e., 7,500 rows) and the rest of the 25% of the records (i.e., 2,500 rows) correspond to 125 different records which are duplicated 20 times. The SDM-Genomic-Datasets offers nine mapping assertion configurations.
Conf1: Set of two mapping assertions with one concept and one attribute mapping assertions.
Conf2: Set of five mapping assertions, including one concept and four attribute mapping assertions.
Conf3: Set of four mapping assertions consisting of two concepts, one referenced-source role, and one attribute mapping assertions.
Conf4: Set of nine mapping assertions with five concepts and four referenced-source role mapping assertions.
Conf5: Set of three mapping assertions comprised of two concepts and one multi-source role mapping assertions.
Conf6: Set of nine mapping assertions, including five concepts and four multi-source role mapping assertions.
We group the aforementioned mapping assertions into a set named AllTogether. Furthermore, the benchmark includes three extra configurations to enable the evaluation of the impact of two other influential parameters on the performance of KG creation frameworks [[11](#bib.bib11)].
Conf7 aims at evaluating the impact of defining the same predicates using different mapping assertions. Conf8 provides a mapping rule which is connected to five other mapping rules with different logical sources through join, i.e., this mapping assertion is connected via a five-star join with the other five mapping assertions. The last configuration or Conf9 combines the first two configurations in one testbed. Conf7: Set of four mapping assertions with four concepts and two multi-source role mapping assertions. For each pair of mapping assertions, there is a multi-source role mapping assertion. The data sources of one pair of the mapping assertions are a subset of the other pair. Both pairs of mapping assertions share the same predicate. Conf8: Set of six mapping assertions with six concepts and five multi-source role mapping assertions. In this set, five child mapping assertions are referring to the same parent mapping assertion. Conf9: Set of eight mapping assertions with eight concepts and seven multi-source role mapping assertions.

(a) Planning Impact on Execution Time

(b) Planning Impact on Execution Time and KG Completeness
Figure 9: Planning Impact on the GTFS-Madrid-Bench. The effects of the proposed planning techniques over the GTFS-Madrid-Bench data sources: 1-csv, and 5-csv. SDM-RDFizer v3.6, RMLMapper, and RocketRML. Figure a presents the execution time of each individual partition and the entire mapping. We can observe that the Shapes-2 partition takes the longest time among the partitions. Figure b illustrates the percentage of RDF triples that are generated over the percentage of time. For RocketRML, since it was capable of executing the Shapes-2 partition was only able to generate approximately 80%percent8080\%80 % of the KG
##### RML Engines
RMLMapper v4.12 [[9](#bib.bib9)], RocketRML v1.11.3 [[58](#bib.bib58)], Morph-KGC v1.4.1 [[7](#bib.bib7)], and
SDM-RDFizer v3.6 [[12](#bib.bib12)]. Recently, SDM-RDFizer v4.0 [[13](#bib.bib13)] has been published. According to the tool description, SDM-RDFizer v4.0 implements planning techniques, physical operators for the execution of mapping assertions, and data compression techniques for reducing the size of the main memory structures required to store intermediate results. In order to create a fair evaluation of the performance of the techniques developed in SDM-RDFizer v4.0, we implement an upgraded version of SDM-RDFizer v3.6 which includes the data compression technique developed in SDM-RDFizer v4.0; we call this engine SDM-RDFizer v4.0−−absent{}^{--}start\_FLOATSUPERSCRIPT - - end\_FLOATSUPERSCRIPT.
##### Implementations.
The planning and execution pipeline is implemented in Python 3. The compression techniques implemented in SDM-RDFizer v4.0−−absent{}^{--}start\_FLOATSUPERSCRIPT - - end\_FLOATSUPERSCRIPT encode RDF resources generated during the KG creation process. For each RDF resource R, an identification number i is assigned to it. Thus, RDF triples are built not from RDF resources but the identification number. Moreover, each identification number i is encoded in Base36 to reduce the memory usage further. Base36 is an encoding scheme that transforms a string into a 36 characters representation. The characters used are the letters from A to Z and the numbers from 0 to 9. For example, the number ”95634785” is encoded as ”1KXS9T”. The SDM-RDFizer operators are adapted to consider this compression method, consuming less main memory.
##### Metrics
We consider two metrics to evaluate the efficiency of our proposed approach. Execution time is defined as the elapsed time required to generate the bushy tree and execute the corresponding physical plan used to create the KG. It is measured as the absolute wall-clock system time, as reported by the `time` command of the Linux operating system. The leaves of a bushy tree are executed in parallel, and execution of the leaves corresponds to the greatest execution time; execution time also includes the time of merging the results generated during the execution of the tree leaves. Memory consumption is determined as the amount of memory that is consumed during the generation of a KG. The memory usage is measured by using the tracemalloc library from Python [[15](#bib.bib15)]. The get\_traced\_memory() method from tracemalloc returns the amount of memory currently being used. This method presents the memory usage in Kilobytes, for ease of use, it is converted into Megabytes. The timeout is five hours. The experiments are executed in an Intel(R) Xeon(R) equipped with a CPU E5-2603 v3 @ 1.60GHz 20 cores, 64GB memory and with the O.S. Ubuntu 16.04LTS.
All the resources used in the reported experimental study are publicly available [[36](#bib.bib36)].

(a)

(b)

(c)

(d)

(e)

(f)
Figure 10: Results of the Execution of the GENOMIC benchmark. Execution time of Conf1, Conf2, Conf3, Conf4, Conf5, Conf6, and AllTogether for SDM-RDFizer v3.6, RMLMapper, and RocketRML.
###
6.2 Experiment 1- Efficiency on GTFS-Madrid-Bench
This experiment aims at evaluating the impact that grouping mapping assertions have on the performance of the state-of-the-art engines RMLMapper, RocketRML, and SDM-RDFizer v3.6. Using the algorithm of *Grouping Mapping Assertions*, ten groups of mapping assertions are generated, which are evaluated over the 1-csv and 5-csv data sources from GTFS-Madrid-Bench. Moreover, the full set of mapping assertions is executed by each engine considering both data sources. Figure [9](#S6.F9 "Figure 9 ‣ Benchmarks ‣ 6.1 Experimental Configuration ‣ 6 Experimental Study ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") reports on the execution time (seconds in log scale) for each of the ten groups, as well as with No\_Partition. The three engines can execute nine groups in less than five seconds and produce 15.63%percent\%% of the overall RDF triples.
The group Shapes comprises four attribute mapping assertions and a multi-source role mapping assertion partition over one logical source named “Shapes”, i.e., the execution of this assertion requires a self-join. We further divided the group Shapes into two smaller partitions: Shapes-1 containing the four attribute mapping assertions and Shapes-2 containing the self-join.
We generate these smaller partitions because RMLMapper and RocketRML cannot complete the execution of the group Shapes.
The size of the logical source “Shapes” is 4.5MB in the case of 1-csv and 7.9MB in 5-csv. RocketRML is unsuccessful in finishing the evaluation of the self-join due to memory failure. Contrary, RMLMapper, and SDM-RDFizer succeed to execute this group of mapping assertions over the two studied versions of the data source “Shapes” (Figures [8(a)](#S6.F8.sf1 "8(a) ‣ Figure 9 ‣ Benchmarks ‣ 6.1 Experimental Configuration ‣ 6 Experimental Study ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") and [8(b)](#S6.F8.sf2 "8(b) ‣ Figure 9 ‣ Benchmarks ‣ 6.1 Experimental Configuration ‣ 6 Experimental Study ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")). RMLMapper produces the overall RDF triples of the “Shapes” in 2,707.32 seconds and 10,800.32 seconds in case of 1-csv and 5-csv, respectively. SDM-RDFizer also generates all the RDF triples of the “Shapes” in 284.06 seconds and 396.2 seconds for 1-csv and 5-csv, respectively.
In the case of No\_Partition, RocketRML runs out of memory without generating any result, while RMLMapper and SDM-RDFizer both produce all the RDF triples.
In the optimized case, i.e., the time of executing the groups of assertions in parallel, RMLMapper requires, respectively, 91.42%percent\%% and 80.87%percent\%% in 1-csv and 5-csv of the time No\_Partition.
Likewise, the proposed planning techniques also speed up the SDM-RDFizer execution concerning No Partition; it consumes, respectively, 96.32%percent\%% and 79.50%percent\%% in 1-csv and 5-cvs of the execution time of No\_Partition.
Although savings are observed, the evaluation of the Shapes group consumes the majority of the execution time of the corresponding physical plan. This prevents observing the benefits of executing the mapping assertions in parallel.
It is also important to highlight that even though this benchmark, allows for configuring testbeds that produce KGs of various sizes, the scaling factor is not equally applied to all the data sources and RDF triples produced by each mapping assertion.
Conversely, most of the new RDF triples produced by a high-scaled KG are generated by the Shapes group. This lack of diversity also prevents observing differences in different configurations, i.e., 1-csv and 5-csv.
###
6.3 Experiment 2- Efficiency on SDM-Genomic-Datasets
This experiment aims to assess the impact of planning on a real-world dataset such as the one provided by the SDM-Genomic-Datasets. Although the mapping assertions defined for the SDM-Genomic-Datasets are much simpler compared to the ones in GTFS-Madrid-Bench, they cover all the different types of mapping assertions presented in [section 2](#S2 "2 Preliminaries and Motivation ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources").

(a) Execution Time

(b) Maximum Memory Usage
Figure 11: Optimize Planning. The effects of proposed planning techniques over the GTFS-Madrid-Bench data sources: 1-csv, 5-csv, 10-csv, and 50-csv. SDM-RDFizer v4.0−−absent{}^{--}start\_FLOATSUPERSCRIPT - - end\_FLOATSUPERSCRIPT+Planning, and SDM-RDFizer 4.0
We study the performance of each engine, i.e., RocketRML, RMLMapper, and SDM-RDFizer in presence and absence of planning using SDM-Genomic-Datasets.
In addition to the six configurations of mapping assertions, i.e., Conf1, Conf2, Conf3, Conf4, Conf5, and Conf6, we consider an additional configuration consisting of the union of all them.

Figure 12: Efficiency Planning For Complex Cases with 25% duplicate rate. The effects of proposed planning techniques over the SDM-Genomic-Datasets with 25% duplicate rate over Conf7, Conf8, and Conf9. SDM-RDFizer v3.6+Planning, RMLMapper+Planning, Morph-KGC+Planning
We refer to it as AllTogether. As illustrated in [Figure 10](#S6.F10 "Figure 10 ‣ Metrics ‣ 6.1 Experimental Configuration ‣ 6 Experimental Study ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources"), in the case of having referenced-source role mapping assertions (i.e., Conf3 and Conf4), neither of the two engines, RMLMapper and RocketRML, is able to complete the execution before the timeout. As observed in [Figure 10](#S6.F10 "Figure 10 ‣ Metrics ‣ 6.1 Experimental Configuration ‣ 6 Experimental Study ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources"), applying planning in simple cases like Conf1, Conf2, and Conf3 with low data duplicate rates does not show a considerable impact on the performance.

Figure 13: Efficiency Planning For Complex Cases with 75% duplicate rate. The effects of proposed planning techniques over the SDM-Genomic-Datasets with 75% duplicate rate over Conf7, Conf8, and Conf9. SDM-RDFizer v3.6+Planning, RMLMapper+Planning, Morph-KGC+Planning
Conversely, in complex cases such as Conf6 which include several multi-source role mapping assertions, execution time is reduced significantly exploiting planning. Unfortunately, both RMLMapper and RocketRML lack efficient implementations of the operators that are required to execute referenced-source role mapping assertions.
Therefore, the two mentioned engines are unable to finish the execution of Conf3 and Conf4 before the timeout (i.e., 5 hours). The results in [Figure 10](#S6.F10 "Figure 10 ‣ Metrics ‣ 6.1 Experimental Configuration ‣ 6 Experimental Study ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") also suggest that with the growth of duplicate data rate, the benefits of using the proposed planning techniques also increased.
| Percentage of Duplicates: 25% |
| --- |
| Size | Engine | Conf7 | Conf8 | Conf9 |
| | | Original | Optimized | % Savings | Original | Optimized | % Savings | Original | Optimized | % Savings |
| 10k | SDM-RDFizer | 3.91 sec | 5.04 sec | -28.90 % | 5.59 sec | 6.54 sec | -16.99 % | 10.7 sec | 6.47 sec | 39.53% |
| RMLMapper | 47.43 sec | 36.69 sec | 22.64 % | 140.27 sec | 43.93 sec | 68.68 % | 180.85 sec | 43.25 sec | 76.09 % |
| Morph-KGC | 1.81 sec | 3.55 sec | -96.13% | 1.79 sec | 4.22 sec | -135.75 % | 2.28 sec | 5.2 sec | -128.07 % |
| 100k | SDM-RDFizer | 21.14 sec | 16.88 sec | 20.15 % | 99.88 sec | 51.11 sec | 48.82 % | 105.72 sec | 44.97 sec | 57.46 % |
| RMLMapper | 3205.37 sec | 2628.13 sec | 18.01 % | 11961.81 sec | 3901.14 sec | 67.38 % | 12593.16 sec | 3401.17 sec | 72.99 % |
| Morph-KGC | 20.4 sec | 19.35 sec | 5.14 % | 43.87 sec | 29.38 sec | 33.02 % | 42.43 sec | 30.84 sec | 27.31 % |
| 1M | SDM-RDFizer | 177.35 sec | 124.08 sec | 30.03 % | 1656.29 sec | 607.06 sec | 63.34 % | 1769.29 sec | 685.22 sec | 61.27 % |
| RMLMapper | TimeOut | TimeOut | - | TimeOut | TimeOut | - | TimeOut | TimeOut | - |
| Morph-KGC | 1532.94 sec | 1224.37 sec | 20.13 % | 3369.11 sec | 2154.92 sec | 36.03 % | 3329.16 sec | 2071.63 sec | 37.77 % |
| Percentage of Duplicates: 75% |
| Size | Engine | Conf7 | Conf8 | Conf9 |
| | | Original | Optimized | %Savings | Original | Optimized | %Savings | Original | Optimized | %Savings |
| 10k | SDM-RDFizer | 3.6 sec | 4.89 sec | -35.83 % | 4.44 sec | 5.44 sec | -22.52 % | 8.35 sec | 5.85 sec | 29.94 % |
| RMLMapper | 38.82 sec | 35.41 sec | 8.78 % | 133.96 sec | 47.01 sec | 64.90 % | 173.08 sec | 47.64 sec | 72.47 % |
| Morph-KGC | 2.15 sec | 4.01 sec | -86.51% | 2.11 sec | 4.59 sec | -117.53% | 2.93 sec | 5.33 sec | -81.91% |
| 100k | SDM-RDFizer | 19.72 sec | 16.16 sec | 18.05% | 70.5 sec | 31.06 sec | 55.94% | 66.15 sec | 29.97 sec | 54.69% |
| RMLMapper | 3203.19 sec | 2672.59 sec | 16.56% | 12669.84 sec | 3861.29 sec | 69.52% | 16541.84 sec | 3985.06 sec | 75.90% |
| Morph-KGC | 23.53 sec | 22.21 sec | 5.60% | 46.35 sec | 35.7 sec | 22.97% | 48.13 sec | 35.68 sec | 25.86% |
| 1M | SDM-RDFizer | 174.11 sec | 123.77 sec | 28.91% | 983.53 sec | 402.59 sec | 59.06% | 1252.27 sec | 516.99 sec | 58.71% |
| RMLMapper | TimeOut | TimeOut | - | TimeOut | TimeOut | - | TimeOut | TimeOut | - |
| Morph-KGC | 1628.69 sec | 1330.01 sec | 18.33% | 3338.93 sec | 2229.78 sec | 33.21% | 3641.57 sec | 2200.08 sec | 39.58% |
Table 3: SDM-Genomic-Datasets Complex Test Cases. Duplicate rates are 25% and 75%; Highest Percentage of Savings are highlighted in bold. Lowest Percentage of Savings are underlined. The proposed planning and execution techniques are able to enhance the performance of RMLMapper and speed up execution time by up to 76.08%; even in the cases, where RMLMapper timed out, the proposed techniques empower RMLMapper to produce intermediate results.
In case of small data sets (e.g., 10K), the proposed techniques may produce overhead in SDM-RDFizer and Morph-KGC (e.g., Conf7 and Conf8).
###
6.4 Experiment 3- Efficiency on Large Datasets
This experiment evaluates the impact of a data source size on memory usage during the KG creation process. For this purpose, four data sources with different sizes are generated using the GTFS-Madrid-Bench including 1-csv, 5-csv, 10-csv, and 50-csv. Since RMLMapper and RocketRML are not able to scale up to large data sources, we compare the performance of SDM-RDFizer v4.0 in absence and presence of planning; we refer to the latest one as SDM-RDFizer v4.0−−absent{}^{--}start\_FLOATSUPERSCRIPT - - end\_FLOATSUPERSCRIPT+Planning. We evaluate the performance of the mentioned versions in terms of both execution time (in second) and main memory consumption (MB); the results of both are reported in log scale. As demonstrated in Figures [11](#S6.F11 "Figure 11 ‣ 6.3 Experiment 2- Efficiency on SDM-Genomic-Datasets ‣ 6 Experimental Study ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")a and [11](#S6.F11 "Figure 11 ‣ 6.3 Experiment 2- Efficiency on SDM-Genomic-Datasets ‣ 6 Experimental Study ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")b both versions of SDM-RDFizer are able to complete the KG creation process for all the datasets. Additionally, it can be observed that the planning reduces the memory usage and execution time in each dataset.
The observed results in Figure [11](#S6.F11 "Figure 11 ‣ 6.3 Experiment 2- Efficiency on SDM-Genomic-Datasets ‣ 6 Experimental Study ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")a and Figure [11](#S6.F11 "Figure 11 ‣ 6.3 Experiment 2- Efficiency on SDM-Genomic-Datasets ‣ 6 Experimental Study ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources")b suggest that the impact of our proposed planning techniques in the enhancement of the performance of SDM-RDFizer v4.0−−absent{}^{--}start\_FLOATSUPERSCRIPT - - end\_FLOATSUPERSCRIPT is higher than the planning techniques implemented by SDM-RDFizer v4.0.
###
6.5 Experiment 4- Efficiency on Complex Mappings
This experiment aims at assessing the effect of the complex mapping assertions on the execution time during the KG creation process. In these experiments, RocketRML is replaced by Morph-KGC since RocketRML is unable to execute the multi-source mapping assertions that composed the Conf7, Conf8, and Conf9.
Figures [12](#S6.F12 "Figure 12 ‣ 6.3 Experiment 2- Efficiency on SDM-Genomic-Datasets ‣ 6 Experimental Study ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") and [13](#S6.F13 "Figure 13 ‣ 6.3 Experiment 2- Efficiency on SDM-Genomic-Datasets ‣ 6 Experimental Study ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") report on execution time (log scale) and Table [3](#S6.T3 "Table 3 ‣ 6.3 Experiment 2- Efficiency on SDM-Genomic-Datasets ‣ 6 Experimental Study ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") presents the specific values of each execution.
As observed, the RMLMapper performance is improved in Conf7, Conf8, and Conf9 even in data sources of small size, i.e., 10k.
In the data source of the size 10k, there is 22.64%percent22.6422.64\%22.64 % reduction of execution time for Conf7 with 25%percent2525\%25 % duplicate rate and 8.78%percent8.788.78\%8.78 % reduction with 75%percent7575\%75 % duplicate rate, 68.68%percent68.6868.68\%68.68 % reduction for Conf8 with 25%percent2525\%25 % duplicate rate and 64.9%percent64.964.9\%64.9 % reduction with 75%percent7575\%75 % duplicate rate, and 76.09%percent76.0976.09\%76.09 % reduction for Conf9 with 25%percent2525\%25 % duplicate rate and 72.47%percent72.4772.47\%72.47 % reduction with 75%percent7575\%75 % duplicate rate. For 100k, there is a 18.01%percent18.0118.01\%18.01 % reduction of execution time for Conf7 with 25%percent2525\%25 % duplicate rate and 16.56%percent16.5616.56\%16.56 % reduction with 75%percent7575\%75 % duplicate rate, a 67.38%percent67.3867.38\%67.38 % reduction for Conf8 with 25%percent2525\%25 % duplicate rate and 69.52%percent69.5269.52\%69.52 % reduction with 75%percent7575\%75 % duplicate rate, and a 72.99%percent72.9972.99\%72.99 % reduction for Conf9 with 25%percent2525\%25 % duplicate rate and 75.90%percent75.9075.90\%75.90 % reduction with 75%percent7575\%75 % duplicate rate.
The RMLMapper timed out after 5 hours with both methods when executing the 1M data sources with all three mappings with duplicate rates. This can be attributed to how the execution of the join is implemented in the RMLMapper and the size of the data. But with the planned execution, it could generate at least a portion of the KG for each mapping. For Conf7, Conf8, and Conf9, respectively, 32.65%percent32.6532.65\%32.65 %, 24.82%percent24.8224.82\%24.82 %, and 28.69%percent28.6928.69\%28.69 % of the KG are generated.
For the SDM-RDFizer and Morph-KGC, there was overhead when generating the KG for Conf7 and Conf8 with 10k. This can be attributed to the fact that both the SDM-RDFizer and Morph-KGC already have optimization techniques implemented. Combining the optimization techniques and the physical plan causes the overhead in cases with small data sources, i.e., 10k. While for Conf9, there is a 39.53%percent39.5339.53\%39.53 % reduction with 25%percent2525\%25 % duplicate rate and a 29.94%percent29.9429.94\%29.94 % reduction with 75%percent7575\%75 % duplicate rate for the SDM-RDFizer when using the planned execution. There are savings of 100k and 1M when using the planned execution for both engines. In particular, Conf9 presents the highest savings. For 100k, there is a 57.46%percent57.4657.46\%57.46 % reduction with 25%percent2525\%25 % duplicate rate and a 54.69%percent54.6954.69\%54.69 % reduction with 75%percent7575\%75 % duplicate rate for the SDM-RDFizer and a 27.31%percent27.3127.31\%27.31 % reduction with 25%percent2525\%25 % duplicate rate and a 25.86%percent25.8625.86\%25.86 % reduction with 75%percent7575\%75 % duplicate rate for Morph-KGC.
For 1M, there is a 61.27%percent61.2761.27\%61.27 % reduction with 25%percent2525\%25 % duplicate rate and a 58.71%percent58.7158.71\%58.71 % reduction with 75%percent7575\%75 % duplicate rate for the SDM-RDFizer and a 37.77%percent37.7737.77\%37.77 % reduction with 25%percent2525\%25 % duplicate rate and a 39.58%percent39.5839.58\%39.58 % reduction with 75%percent7575\%75 % duplicate rate for Morph-KGC. This increase in savings is related to the complexity of the mapping; higher complexity causes higher savings.
In conclusion, applying the proposed planning techniques reduces the execution time, independent of the engine by which they are adopted. However, applying these techniques in engines such as SDM-RDFizer and Morph-KGC, which already perform optimization techniques, may cause an overhead.
Specifically, in the case of having small size data sources or less complex mapping assertions, the cost of planning in addition to the other optimization techniques implemented in the engine can be higher than the savings. Like any optimization technique, there is a trade-off that can be estimated based on the provided data integration system. The higher the complexity of the mapping assertions and dataset size, the higher the execution time improvement.
###
6.6 Discussion
Answer to RQ1. There exist configurations of data integration systems where the proposed planning techniques improve the performance of any state-of-the-art engines. The experimental results provide insights on the cases where planning improves the KG creation frameworks in contrast to the ones that it may cause negative impact. E.g., in case of having small data sources or simple mapping assertions, the execution times of SDM-RDFizer and Morph-KGC are lower ignoring the planning of the mapping assertions. However, it is important to note that execution planning empowers state-of-the-art engines without continuous behavior to generate a partial KG output. In other words, the generated plans enable some engines to produce outputs instead of timing out or running out of memory.
Answer to RQ2. Attribute mapping assertion presents the shortest execution time of all the types of mapping assertion since they represent a simple projection of the raw data. In terms of memory usage, attribute mapping assertion dependent on the size of the data source, meaning larger data sources cause greater memory usage. The execution time of a multi-source role mapping assertion depends on the size of the data sources and the number of values associated with them. Larger data sources and a more significant number of associated values imply higher memory usage. The execution time of referenced-source role mapping assertions depends on the size of the data source and the data management techniques implemented for each engine. RMLMapper and RocketRML execute the mentioned operation as a Cartesian product, causing the execution time to grow exponentially and, by extension, the memory usage.
Answer to RQ3. Algorithm [1](#alg1 "Algorithm 1 ‣ 5.1.2 Generating a Bushy Tree ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") generates a bushy tree, which schedules which mapping assertions should be executed together because of the number of predicates or data sources in common. Executing mapping assertions following a bushy tree plan reduces both execution time and memory usage. In attribute mapping assertions with the same data source or referenced source, role mapping assertions have minimal impact on execution time and memory usage. Since all mapping assertions in question use the same data source, only one partition would be used. For multi-source role mapping assertion, Algorithm [1](#alg1 "Algorithm 1 ‣ 5.1.2 Generating a Bushy Tree ‣ 5.1 Planning Mapping Assertions ‣ 5 The Pipeline for Planning and Executing Mapping Assertions ‣ Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources") generates bushy trees whose execution positively influences time and memory. This behavior is achieved by partitioning mapping assertions that reduce the number of operations per group. Therefore, the workload, execution time, and memory usage are reduced.
7 Conclusions and Future Work
------------------------------
We address the problem of efficient KG creation. This problem is of paramount relevance given the momentum that KGs have gained in science and industry, as well as declarative processes to specify KGs.
We present heuristic-based solutions that, following greedy algorithms, can identify execution plans that can efficiently generate KGs. The empirical evaluation of the proposed methods empowers existing RML-compliant engines and enables them to scale to complex situations. The execution planning techniques partition mapping assertions and schedule them into execution plans that consume less memory and reduce execution time. Thus, the proposed planning methods evidence the crucial role that optimization techniques– defined in the context of query processing– also have in the KG creation process.
Moreover, the reported results put in perspective the need of specialized data management methods for scaling up KG creation to complex data integration systems present in real-world applications.
Albeit efficiently defined, execution planning may be costly and generate overhead, which negatively impact engine behavior in simple cases. In the future, we will research lightweight cost-based planning methods to estimate more efficient execution schedulers.
Acknowledgements
----------------
This work has been partially supported by the EU H2020 RIA
funded project CLARIFY with grant agreement No 875160 and PLATOON (GA No. 872592). Federal Ministry for Economic Affairs and Energy of Germany in the project CoyPu (project number 01MK21007[A-L]. Furthermore, Maria-Esther Vidal is partially supported by the Leibniz Association in the program ”Leibniz Best Minds: Programme for Women Professors”, project TrustKG-Transforming Data in Trustable Insights with grant P99/2020. |
26b86941-1cb7-481e-a02d-440aa522c6a3 | trentmkelly/LessWrong-43k | LessWrong | Crash scenario 1: Rapidly mobilise for a 2025 AI crash
Large movement organising takes time. It takes listening deeply to many communities' concerns, finding consensus around a campaign, ramping up training of organisers, etc.
But what if the AI crash is about to happen? What if US tariffs[1] triggered a recession that is making consumers and enterprises cut their luxury subscriptions? What if even the sucker VCs stop investing in companies that after years of billion-dollar losses on compute, now compete with cheap alternatives to their not-much-improving-LLMs?
Then there is little time to organise and we must jump to mobilisation. But AI Safety has been playing the inside game, and is poorly positioned to mobilise the resistance.
So we need groups that can:
1. Scale the outside game, meaning a movement pushing for change from the outside.
2. Promote robust messages, e.g. affirm concerns about tech oligarchs seizing power.
3. Bridge-build with other groups to start campaigns around connected concerns.
4. Legitimately pressure and negotiate with institutions to enforce restrictions.
Each group could mobilise a network of supporters fast. But they need money to cover their hours. We have money. Some safety researchers advise tech billionaires. You might have a high-earning tech job. If you won't push for reforms, you can fund groups that do.
You can donate to organisations already resisting AI, so more staff can go full-time.
Some examples:
* Data rights (NA Voice Actors, Algorithmic Justice League)
* Workers (Tech Workers Coalition, Turkopticon)
* Investigations (FoxGlove, Disruption Network Lab)
* Christians (World Pause Coalition, Singularity Weekly)
* Extinction risk (Stop AI, PauseAI)
Their ideologies vary widely, with some controversial to other groups. By supporting many to stand up for their concerns, you can preempt the ‘left-right’ polarisation we saw around climate change. Many different groups are needed for a broad-based movement.
At the early signs of a crash, groups need funding to ratche |
fc1a19c1-33ac-4121-b3e7-b333ad4df98d | StampyAI/alignment-research-dataset/arxiv | Arxiv | Planning with Goal-Conditioned Policies
1 Introduction
---------------
Reinforcement learning can acquire complex skills by learning through direct interaction with the environment, sidestepping the need for accurate modeling and manual engineering.
However, complex and temporally extended sequential decision making requires more than just well-honed reactions.
Agents that generalize effectively to new situations and new tasks must reason about the consequences of their actions and solve new problems via planning.
Accomplishing this entirely with model-free RL often proves challenging, as purely model-free learning does not inherently provide for temporal compositionality of skills.
Planning and trajectory optimization algorithms encode this temporal compositionality by design, but require accurate models with which to plan.
When these models are specified manually, planning can be very powerful, but learning such models presents major obstacles:
in complex environments with high-dimensional observations such as images, direct prediction of future observations presents a very difficult modeling problem [[4](#bib.bib4), [43](#bib.bib43), [36](#bib.bib36), [6](#bib.bib6), [27](#bib.bib27), [3](#bib.bib3), [31](#bib.bib31)],
and model errors accumulate over time [[39](#bib.bib39)], making their predictions inaccurate in precisely those long-horizon settings where we most need the compositionality of planning methods.
Can we obtain the benefits temporal compositionality inherent in model-based planning, without the need to model the environment at the lowest level, in terms of both time and state representation?
One way to avoid modeling the environment in detail is to plan over *abstractions*: simplified representations of states and transitions on which it is easier to construct predictions and plans.
*Temporal* abstractions allow planning at a coarser time scale, skipping over the high-frequency details and instead planning over higher-level subgoals, while *state* abstractions allow planning over a simpler representation of the state.
Both make modeling and planning easier.
In this paper, we study how model-free RL can be used to provide such abstraction for a model-based planner.
At first glance, this might seem like a strange proposition, since model-free RL methods learn value functions and policies, not models.
However, this is precisely what makes them ideal for abstracting away the complexity in temporally extended tasks with high-dimensional observations:
by avoiding low-level (e.g., pixel-level) prediction, model-free RL can acquire behaviors that manipulate these low-level observations without needing to predict them explicitly.
This leaves the planner free to operate at a higher level of abstraction, reasoning about the capabilities of low-level model-free policies.
Building on this idea, we propose a *model-free* planning framework.
For *temporal* abstraction, we learn low-level goal-conditioned policies, and use their value functions as implicit models, such that the planner plans over the goals to pass to these policies.
Goal-conditioned policies are policies that are trained to reach a goal state that is provided as an additional input [[24](#bib.bib24), [55](#bib.bib55), [53](#bib.bib53), [48](#bib.bib48)].
While in principle such policies can solve any goal-reaching problem, in practice their effectiveness is constrained to nearby goals:
for long-distance goals that require planning, they tend to be substantially less effective, as we illustrate in our experiments.
However, when these policies are trained together with a value function, as in an actor-critic algorithms, the value function can provide an indication of whether a particular goal is reachable or not.
The planner can then plan over intermediate subgoals, using the goal-conditioned value function to evaluate reachability.
A major challenge with this setup is the need to actually optimize over these subgoals.
In domains with high-dimensional observations such as images, this may require explicitly optimizing over image pixels.
This optimization is challenging, as realistic images – and, in general, feasible states – typically form a thin, low-dimensional manifold within the larger space of possible state observation values [[34](#bib.bib34)].
To address this, we also build abstractions of the state observation by learning a compact latent variable state representation, which makes it feasible to optimize over the goals in domains with high-dimensional observations, such as images, without explicitly optimizing over image pixels.
The learned representation allows the planner to determine which subgoals actually represent feasible states, while the learned goal-conditioned value function tells the planner whether these states are reachable.
Our contribution is a method for combining model-free RL for short-horizon goal-reaching with model-based planning over a latent variable representation of subgoals.
We evaluate our method on temporally extended tasks that require multistage reasoning and handling image observations.
The low-level goal-reaching policies themselves cannot solve these tasks effectively, as they do not plan over subgoals and therefore do not benefit from temporal compositionality.
Planning without state representation learning also fails to perform these tasks, as optimizing directly over images results in invalid subgoals.
By contrast, our method, which we call Latent Embeddings for Abstracted Planning (LEAP), is able to successfully determine suitable subgoals by searching in the latent representation space, and then reach these subgoals via the model-free policy.
2 Related Work
---------------
Goal-conditioned reinforcement learning has been studied in a number of prior works
[[24](#bib.bib24), [25](#bib.bib25), [37](#bib.bib37), [18](#bib.bib18), [53](#bib.bib53), [2](#bib.bib2), [48](#bib.bib48), [57](#bib.bib57), [40](#bib.bib40), [59](#bib.bib59)].
While goal-conditioned methods excel at training policies to greedily reach goals, they often fail to solve long-horizon problems.
Rather than proposing a new goal-conditioned RL method, we propose to use goal-conditioned policies as the abstraction for planning in order to handle tasks with a longer horizon.
Model-based planning in deep reinforcement learning is a well-studied problem in the context of low-dimensional state spaces [[50](#bib.bib50), [32](#bib.bib32), [39](#bib.bib39), [7](#bib.bib7)]. When the observations are high-dimensional, such as images, model errors for direct prediction compound quickly, making model-based RL difficult [[15](#bib.bib15), [13](#bib.bib13), [5](#bib.bib5), [14](#bib.bib14), [26](#bib.bib26)].
Rather than planning directly over image observations, we propose to plan at a temporally-abstract level by utilizing goal-conditioned policies.
A number of papers have studied embedding high-dimensional observations into a low-dimensional latent space for planning [[60](#bib.bib60), [16](#bib.bib16), [62](#bib.bib62), [22](#bib.bib22), [29](#bib.bib29)].
While our method also plans in a latent space, we additionally use a model-free goal-conditioned policy as the abstraction to plan over, allowing our method to plan over temporal abstractions rather than only state abstractions.
Automatically setting subgoals for a low-level goal-reaching policy bears a resemblance to hierarchical RL, where prior methods have used model-free learning on top of goal-conditioned policies [[10](#bib.bib10), [61](#bib.bib61), [12](#bib.bib12), [58](#bib.bib58), [33](#bib.bib33), [20](#bib.bib20), [38](#bib.bib38)].
By instead using a planner at the higher level, our method can flexibly plan to solve new tasks and benefit from the compositional structure of planning.
Our method builds on temporal difference models [[48](#bib.bib48)] (TDMs), which are finite-horizon, goal-conditioned value functions. In prior work, TDMs were used together with a single-step planner that optimized over a single goal, represented as a low-dimensional ground truth state (under the assumption that all states are valid) [[48](#bib.bib48)]. We also use TDMs as implicit models, but in contrast to prior work, we plan over multiple subgoals and demonstrate that our method can perform temporally extended tasks. More critically, our method also learns abstractions of the state, which makes this planning process much more practical, as it does not require assuming that all state vectors represent feasible states.
Planning with goal-conditioned value functions has also been studied when there are a discrete number of predetermined goals [[30](#bib.bib30)] or skills [[1](#bib.bib1)], in which case graph-search algorithms can be used to plan.
In this paper, we not only provide a concrete instantiation of planning with goal-conditioned value functions, but we also present a new method for scaling this planning approach to images, which reside in a lower-dimensional manifold.
Lastly, we note that while a number of papers have studied how to combine model-free and model-based methods [[54](#bib.bib54), [41](#bib.bib41), [23](#bib.bib23), [56](#bib.bib56), [44](#bib.bib44), [51](#bib.bib51), [39](#bib.bib39)], our method is substantially different from these approaches: we study how to use model-free policies as the abstraction for planning, rather than using models [[54](#bib.bib54), [41](#bib.bib41), [23](#bib.bib23), [39](#bib.bib39)] or planning-inspired architectures [[56](#bib.bib56), [44](#bib.bib44), [51](#bib.bib51), [21](#bib.bib21)] to accelerate model-free learning.
3 Background
-------------
We consider a finite-horizon, goal-conditioned Markov decision process (MDP) defined by a tuple (𝒮,𝒢,𝒜,p,R,Tmax,ρ0,ρg)𝒮𝒢𝒜𝑝𝑅subscript𝑇maxsubscript𝜌0subscript𝜌𝑔(\mathcal{S},\mathcal{G},\mathcal{A},p,R,{T\_{\mathrm{max}}},\rho\_{0},\rho\_{g})( caligraphic\_S , caligraphic\_G , caligraphic\_A , italic\_p , italic\_R , italic\_T start\_POSTSUBSCRIPT roman\_max end\_POSTSUBSCRIPT , italic\_ρ start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT , italic\_ρ start\_POSTSUBSCRIPT italic\_g end\_POSTSUBSCRIPT ), where
𝒮𝒮\mathcal{S}caligraphic\_S is the set of states,
𝒢𝒢\mathcal{G}caligraphic\_G is the set of goals,
𝒜𝒜\mathcal{A}caligraphic\_A is the set of actions,
p(𝐬t+1∣𝐬t,𝐚t)𝑝conditionalsubscript𝐬𝑡1subscript𝐬𝑡subscript𝐚𝑡p({\mathbf{s}\_{t+1}}\mid{\mathbf{s}\_{t}},{\mathbf{a}\_{t}})italic\_p ( bold\_s start\_POSTSUBSCRIPT italic\_t + 1 end\_POSTSUBSCRIPT ∣ bold\_s start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT , bold\_a start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT ) is the time-invariant (unknown) dynamics function,
R𝑅Ritalic\_R is the reward function,
Tmaxsubscript𝑇max{T\_{\mathrm{max}}}italic\_T start\_POSTSUBSCRIPT roman\_max end\_POSTSUBSCRIPT is the maximum horizon,
ρ0subscript𝜌0\rho\_{0}italic\_ρ start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT is the initial state distribution,
and ρgsubscript𝜌𝑔\rho\_{g}italic\_ρ start\_POSTSUBSCRIPT italic\_g end\_POSTSUBSCRIPT is the goal distribution.
The objective in goal-conditioned RL is to obtain a policy π(𝐚t∣𝐬t,𝐠,t)𝜋conditionalsubscript𝐚𝑡subscript𝐬𝑡𝐠𝑡\pi({\mathbf{a}\_{t}}\mid{\mathbf{s}\_{t}},\mathbf{g},t)italic\_π ( bold\_a start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT ∣ bold\_s start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT , bold\_g , italic\_t ) to maximize the expected sum of rewards 𝔼[∑t=0TmaxR(𝐬t,𝐠,t)]𝔼delimited-[]superscriptsubscript𝑡0subscript𝑇max𝑅subscript𝐬𝑡𝐠𝑡\mathbb{E}[\sum\_{t=0}^{T\_{\mathrm{max}}}R({\mathbf{s}\_{t}},\mathbf{g},t)]blackboard\_E [ ∑ start\_POSTSUBSCRIPT italic\_t = 0 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_T start\_POSTSUBSCRIPT roman\_max end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT italic\_R ( bold\_s start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT , bold\_g , italic\_t ) ],
where the goal is sampled from ρgsubscript𝜌𝑔\rho\_{g}italic\_ρ start\_POSTSUBSCRIPT italic\_g end\_POSTSUBSCRIPT and the states are sampled according to 𝐬0∼ρ0similar-tosubscript𝐬0subscript𝜌0{\mathbf{s}}\_{0}\sim\rho\_{0}bold\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ∼ italic\_ρ start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT, 𝐚t∼π(𝐚t∣𝐬t,𝐠,t)similar-tosubscript𝐚𝑡𝜋conditionalsubscript𝐚𝑡subscript𝐬𝑡𝐠𝑡{\mathbf{a}\_{t}}\sim\pi({\mathbf{a}\_{t}}\mid{\mathbf{s}\_{t}},\mathbf{g},t)bold\_a start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT ∼ italic\_π ( bold\_a start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT ∣ bold\_s start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT , bold\_g , italic\_t ), and 𝐬t+1∼p(𝐬t+1∣𝐬t,𝐚t)similar-tosubscript𝐬𝑡1𝑝conditionalsubscript𝐬𝑡1subscript𝐬𝑡subscript𝐚𝑡{\mathbf{s}\_{t+1}}\sim p({\mathbf{s}\_{t+1}}\mid{\mathbf{s}\_{t}},{\mathbf{a}\_{t}})bold\_s start\_POSTSUBSCRIPT italic\_t + 1 end\_POSTSUBSCRIPT ∼ italic\_p ( bold\_s start\_POSTSUBSCRIPT italic\_t + 1 end\_POSTSUBSCRIPT ∣ bold\_s start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT , bold\_a start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT ).
We consider the case where goals reside in the same space as states, i.e., 𝒢=𝒮𝒢𝒮\mathcal{G}=\mathcal{S}caligraphic\_G = caligraphic\_S.
An important quantity in goal-conditioned MDPs is the goal-conditioned value function
Vπsuperscript𝑉𝜋V^{\pi}italic\_V start\_POSTSUPERSCRIPT italic\_π end\_POSTSUPERSCRIPT, which predicts the expected sum of future rewards, given the current state 𝐬𝐬{\mathbf{s}}bold\_s, goal 𝐠𝐠\mathbf{g}bold\_g, and time t𝑡titalic\_t:
| | | |
| --- | --- | --- |
| | Vπ(𝐬,𝐠,t)=𝔼[∑t′=tTmaxR(𝐬t′,𝐠,t′)∣𝐬t=𝐬,π is conditioned on 𝐠].superscript𝑉𝜋𝐬𝐠𝑡𝔼delimited-[]conditionalsuperscriptsubscriptsuperscript𝑡′𝑡subscript𝑇max𝑅subscript𝐬superscript𝑡′𝐠superscript𝑡′subscript𝐬𝑡𝐬𝜋 is conditioned on 𝐠\displaystyle V^{\pi}({\mathbf{s}},\mathbf{g},t)=\mathbb{E}\left[\sum\_{t^{\prime}=t}^{T\_{\mathrm{max}}}R({\mathbf{s}}\_{t^{\prime}},\mathbf{g},t^{\prime})\mid{\mathbf{s}\_{t}}={\mathbf{s}},\pi\text{ is conditioned on }\mathbf{g}\right].italic\_V start\_POSTSUPERSCRIPT italic\_π end\_POSTSUPERSCRIPT ( bold\_s , bold\_g , italic\_t ) = blackboard\_E [ ∑ start\_POSTSUBSCRIPT italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT = italic\_t end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_T start\_POSTSUBSCRIPT roman\_max end\_POSTSUBSCRIPT end\_POSTSUPERSCRIPT italic\_R ( bold\_s start\_POSTSUBSCRIPT italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT , bold\_g , italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ) ∣ bold\_s start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT = bold\_s , italic\_π is conditioned on bold\_g ] . | |
To keep the notation uncluttered, we will omit the dependence of V𝑉Vitalic\_V on π𝜋\piitalic\_π.
While various time-varying reward functions can be used, temporal difference models (TDMs) [[48](#bib.bib48)] use the following form:
| | | | |
| --- | --- | --- | --- |
| | RTDM(𝐬,𝐠,t)=−δ(t=Tmax)d(𝐬,𝐠).subscript𝑅TDM𝐬𝐠𝑡𝛿𝑡subscript𝑇max𝑑𝐬𝐠\displaystyle R\_{\mathrm{TDM}}({\mathbf{s}},\mathbf{g},t)=-\delta(t={T\_{\mathrm{max}}})d({\mathbf{s}},\mathbf{g}).italic\_R start\_POSTSUBSCRIPT roman\_TDM end\_POSTSUBSCRIPT ( bold\_s , bold\_g , italic\_t ) = - italic\_δ ( italic\_t = italic\_T start\_POSTSUBSCRIPT roman\_max end\_POSTSUBSCRIPT ) italic\_d ( bold\_s , bold\_g ) . | | (1) |
where δ𝛿\deltaitalic\_δ is the indicator function, and the distance function d𝑑ditalic\_d is defined by the task.
This particular choice of reward function gives a TDM the following interpretation:
given a state 𝐬𝐬{\mathbf{s}}bold\_s, how close will the goal-conditioned policy π𝜋\piitalic\_π get to 𝐠𝐠\mathbf{g}bold\_g after t𝑡titalic\_t time steps of attempting to reach 𝐠𝐠\mathbf{g}bold\_g?
TDMs can thus be used as a measure of reachability by quantifying how close to another state the policy can get in t𝑡titalic\_t time steps, thus providing *temporal* abstraction.
However, TDMs will only produce reasonable reachability predictions for *valid* goals – goals that resemble the kinds of states on which the TDM was trained. This important limitation requires us to also utilize *state* abstractions, limiting our search to valid states. In the next section, we will discuss how we can use TDMs in a planning framework over high-dimensional state observations such as images.
4 Planning with Goal-Conditioned Policies
------------------------------------------

Figure 1: Summary of Latent Embeddings for Abstracted Planning (LEAP). (1) The planner is given a goal state.
(2) The planner plans intermediate subgoals in a low-dimensional latent space. By planning in this latent space, the subgoals correspond to valid state observations.
(3) The goal-conditioned policy then tries to reach the first subgoal. After t1subscript𝑡1t\_{1}italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT time steps, the policy replans and repeats steps 2 and 3.
We aim to learn a model that can solve arbitrary long-horizon goal reaching tasks with high-dimensional observation and goal spaces, such as images.
A model-free goal-conditioned reinforcement learning algorithm could, in principle, solve such a problem. However, as we will show in our experiments, in practice such methods produce overly greedy policies, which can accomplish short-term goals, but struggle with goals that are more temporally extended.
We instead combine goal-conditioned policies trained to achieve subgoals with a planner that decomposes long-horizon goal-reaching tasks into K𝐾Kitalic\_K shorter horizon subgoals.
Specifically, our planner chooses the K𝐾Kitalic\_K subgoals, 𝐠1,…,𝐠Ksubscript𝐠1…subscript𝐠𝐾\mathbf{g}\_{1},\dots,\mathbf{g}\_{K}bold\_g start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , bold\_g start\_POSTSUBSCRIPT italic\_K end\_POSTSUBSCRIPT, and a goal-reaching policy then attempts to reach the first subgoal 𝐠1subscript𝐠1\mathbf{g}\_{1}bold\_g start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT in the first t1subscript𝑡1t\_{1}italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT time steps, before moving onto the second goal 𝐠2subscript𝐠2\mathbf{g}\_{2}bold\_g start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT, and so forth, as shown in [Figure 1](#S4.F1 "Figure 1 ‣ 4 Planning with Goal-Conditioned Policies ‣ Planning with Goal-Conditioned Policies").
This procedure only requires training a goal-conditioned policy to solve short-horizon tasks.
Moreover, by planning appropriate subgoals, the agent can compose previously learned goal-reaching behavior to solve new, temporally extended tasks.
The success of this approach will depend heavily on the choice of subgoals.
In the sections below, we outline how one can measure the quality of the subgoals.
Then, we address issues that arise when optimizing over these subgoals in high-dimensional state spaces such as images.
Lastly, we summarize the overall method and provide details on our implementation.
###
4.1 Planning over Subgoals
Suitable subgoals are ones that are reachable:
if the planner can choose subgoals such that each subsequent subgoal is reachable given the previous subgoal, then it can reach any goal by ensuring the last subgoal is the true goal.
If we use a goal-conditioned policy to reach these goals, how can we quantify how reachable these subgoals are?
One natural choice is to use a goal-conditioned value function which, as previously discussed, provides a measure of reachability.
In particular, given the current state 𝐬𝐬{\mathbf{s}}bold\_s, a policy will reach a goal 𝐠𝐠\mathbf{g}bold\_g after t𝑡titalic\_t time steps if and only if V(𝐬,𝐠,t)=0𝑉𝐬𝐠𝑡0V({\mathbf{s}},\mathbf{g},t)=0italic\_V ( bold\_s , bold\_g , italic\_t ) = 0.
More generally, given K𝐾Kitalic\_K intermediate subgoals 𝐠1:K=𝐠1,…,𝐠Ksubscript𝐠:1𝐾subscript𝐠1…subscript𝐠𝐾\mathbf{g}\_{1:K}=\mathbf{g}\_{1},\dots,\mathbf{g}\_{K}bold\_g start\_POSTSUBSCRIPT 1 : italic\_K end\_POSTSUBSCRIPT = bold\_g start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , bold\_g start\_POSTSUBSCRIPT italic\_K end\_POSTSUBSCRIPT and K+1𝐾1K+1italic\_K + 1 time intervals t1,…,tK+1subscript𝑡1…subscript𝑡𝐾1t\_{1},\dots,t\_{K+1}italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_t start\_POSTSUBSCRIPT italic\_K + 1 end\_POSTSUBSCRIPT that sum to Tmaxsubscript𝑇max{T\_{\mathrm{max}}}italic\_T start\_POSTSUBSCRIPT roman\_max end\_POSTSUBSCRIPT, we define the feasibility vector as
| | | |
| --- | --- | --- |
| | 𝐕→(𝐬,𝐠1:K,t1:K+1,𝐠)=[V(𝐬,𝐠1,t1)V(𝐠1,𝐠2,t2)⋮V(𝐠K−1,𝐠K,tK)V(𝐠K,𝐠,tK+1)].→𝐕𝐬subscript𝐠:1𝐾subscript𝑡:1𝐾1𝐠matrix𝑉𝐬subscript𝐠1subscript𝑡1𝑉subscript𝐠1subscript𝐠2subscript𝑡2⋮𝑉subscript𝐠𝐾1subscript𝐠𝐾subscript𝑡𝐾𝑉subscript𝐠𝐾𝐠subscript𝑡𝐾1\displaystyle\overrightarrow{\mathbf{V}}({\mathbf{s}},\mathbf{g}\_{1:K},t\_{1:K+1},\mathbf{g})=\begin{bmatrix}V({\mathbf{s}},\mathbf{g}\_{1},t\_{1})\\
V(\mathbf{g}\_{1},\mathbf{g}\_{2},t\_{2})\\
\vdots\\
V(\mathbf{g}\_{K-1},\mathbf{g}\_{K},t\_{K})\\
V(\mathbf{g}\_{K},\mathbf{g},t\_{K+1})\\
\end{bmatrix}.over→ start\_ARG bold\_V end\_ARG ( bold\_s , bold\_g start\_POSTSUBSCRIPT 1 : italic\_K end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT 1 : italic\_K + 1 end\_POSTSUBSCRIPT , bold\_g ) = [ start\_ARG start\_ROW start\_CELL italic\_V ( bold\_s , bold\_g start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) end\_CELL end\_ROW start\_ROW start\_CELL italic\_V ( bold\_g start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , bold\_g start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) end\_CELL end\_ROW start\_ROW start\_CELL ⋮ end\_CELL end\_ROW start\_ROW start\_CELL italic\_V ( bold\_g start\_POSTSUBSCRIPT italic\_K - 1 end\_POSTSUBSCRIPT , bold\_g start\_POSTSUBSCRIPT italic\_K end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT italic\_K end\_POSTSUBSCRIPT ) end\_CELL end\_ROW start\_ROW start\_CELL italic\_V ( bold\_g start\_POSTSUBSCRIPT italic\_K end\_POSTSUBSCRIPT , bold\_g , italic\_t start\_POSTSUBSCRIPT italic\_K + 1 end\_POSTSUBSCRIPT ) end\_CELL end\_ROW end\_ARG ] . | |
The feasibility vector provides a quantative measure of a plan’s feasibility:
The first element describes how close the policy will reach the first subgoal, 𝐠1subscript𝐠1\mathbf{g}\_{1}bold\_g start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT, starting from the initial state, 𝐬𝐬{\mathbf{s}}bold\_s.
The second element describes how close the policy will reach the second subgoal, 𝐠2subscript𝐠2\mathbf{g}\_{2}bold\_g start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT, starting from the first subgoal, and so on, until the last term measures the reachability to the true goal, 𝐠𝐠\mathbf{g}bold\_g.
To create a feasible plan, we would like each element of this vector to be zero, and so we minimize the norm of the feasibility vector:
| | | | |
| --- | --- | --- | --- |
| | ℒ(𝐠1:K)=‖𝐕→(𝐬,𝐠1:K,t1:K+1,𝐠)‖.ℒsubscript𝐠:1𝐾norm→𝐕𝐬subscript𝐠:1𝐾subscript𝑡:1𝐾1𝐠\displaystyle\mathcal{L}(\mathbf{g}\_{1:K})=||\overrightarrow{\mathbf{V}}({\mathbf{s}},\mathbf{g}\_{1:K},t\_{1:K+1},\mathbf{g})||.caligraphic\_L ( bold\_g start\_POSTSUBSCRIPT 1 : italic\_K end\_POSTSUBSCRIPT ) = | | over→ start\_ARG bold\_V end\_ARG ( bold\_s , bold\_g start\_POSTSUBSCRIPT 1 : italic\_K end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT 1 : italic\_K + 1 end\_POSTSUBSCRIPT , bold\_g ) | | . | | (2) |
In other words, minimizing [Equation 2](#S4.E2 "2 ‣ 4.1 Planning over Subgoals ‣ 4 Planning with Goal-Conditioned Policies ‣ Planning with Goal-Conditioned Policies") searches for subgoals such that the overall path is feasible and terminates at the true goal.
In the next section, we turn to optimizing Equation [2](#S4.E2 "2 ‣ 4.1 Planning over Subgoals ‣ 4 Planning with Goal-Conditioned Policies ‣ Planning with Goal-Conditioned Policies") and address issues that arise in high-dimensional state spaces.
###
4.2 Optimizing over Images
We consider image-based environments, where the set of states 𝒮𝒮\mathcal{S}caligraphic\_S is the set of valid image observations in our domain.
In image-based environments, solving the optimization in Equation [2](#S4.E2 "2 ‣ 4.1 Planning over Subgoals ‣ 4 Planning with Goal-Conditioned Policies ‣ Planning with Goal-Conditioned Policies") presents two problems. First, the optimization variables 𝐠1:Ksubscript𝐠:1𝐾\mathbf{g}\_{1:K}bold\_g start\_POSTSUBSCRIPT 1 : italic\_K end\_POSTSUBSCRIPT are very high-dimensional – even with 64x64 images and just 3 subgoals, there are over 10,000 dimensions.
Second, and perhaps more subtle, the optimization iterates must be constrained to the set of valid image observations 𝒮𝒮\mathcal{S}caligraphic\_S for the subgoals to correspond to meaningful states.
While a plethora of constrained optimization methods exist, they typically require knowing the set of valid states [[42](#bib.bib42)] or being able to project onto that set [[46](#bib.bib46)].
In image-based domains, the set of states 𝒮𝒮\mathcal{S}caligraphic\_S is an unknown r𝑟ritalic\_r-dimensional manifold embedded in a higher-dimensional space ℝNsuperscriptℝ𝑁\mathbb{R}^{N}blackboard\_R start\_POSTSUPERSCRIPT italic\_N end\_POSTSUPERSCRIPT, for some N≫rmuch-greater-than𝑁𝑟N\gg ritalic\_N ≫ italic\_r [[34](#bib.bib34)] – i.e., the set of valid image observations.

Figure 2:
Optimizing directly over the image manifold (b) is challenging, as it is generally unknown and resides in a high-dimensional space.
We optimize over a latent state (a) and use our
decoder to generate images. So long as the latent states have high likelihood under the prior (green), they will correspond to realistic images, while latent states with low likelihood (red) will not.
Optimizing [Equation 2](#S4.E2 "2 ‣ 4.1 Planning over Subgoals ‣ 4 Planning with Goal-Conditioned Policies ‣ Planning with Goal-Conditioned Policies") would be much easier if we could directly optimize over the r𝑟ritalic\_r dimensions of the underlying representation, since r≪Nmuch-less-than𝑟𝑁r\ll Nitalic\_r ≪ italic\_N, and crucially, since we would not have to worry about constraining the planner to an unknown manifold.
While we may not know the set 𝒮𝒮\mathcal{S}caligraphic\_S a priori, we can learn a latent-variable model with a compact latent space to capture it, and then optimize in the latent space of this model.
To this end, we use a variational-autoencoder (VAE) [[28](#bib.bib28), [52](#bib.bib52)], which we train with images randomly sampled from our environment.
A VAE consists of an encoder qϕ(𝐳∣𝐬)subscript𝑞italic-ϕconditional𝐳𝐬{q\_{\phi}}({\mathbf{z}}\mid{\mathbf{s}})italic\_q start\_POSTSUBSCRIPT italic\_ϕ end\_POSTSUBSCRIPT ( bold\_z ∣ bold\_s ) and decoder pθ(𝐬∣𝐳)subscript𝑝𝜃conditional𝐬𝐳{p\_{\theta}}({\mathbf{s}}\mid{\mathbf{z}})italic\_p start\_POSTSUBSCRIPT italic\_θ end\_POSTSUBSCRIPT ( bold\_s ∣ bold\_z ).
The inference network maps high-dimensional states 𝐬∈𝒮𝐬𝒮{\mathbf{s}}\in\mathcal{S}bold\_s ∈ caligraphic\_S to a distribution over lower-dimensional latent variables 𝐳𝐳{\mathbf{z}}bold\_z for some lower dimensional space 𝒵𝒵\mathcal{Z}caligraphic\_Z, while the generative model reverses this mapping.
Moreover, the VAE is trained so that the marginal distribution of 𝒵𝒵\mathcal{Z}caligraphic\_Z matches our prior distribution p0subscript𝑝0p\_{0}italic\_p start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT, the standard Gaussian.
This last property of VAEs is crucial, as it allows us to tractably optimize over the manifold of valid states 𝒮𝒮\mathcal{S}caligraphic\_S.
So long as the latent variables have high likelihood under the prior, the corresponding images will remain inside the manifold of valid states, as shown in [Figure 2](#S4.F2 "Figure 2 ‣ 4.2 Optimizing over Images ‣ 4 Planning with Goal-Conditioned Policies ‣ Planning with Goal-Conditioned Policies").
In fact, Dai and Wipf [[9](#bib.bib9)] showed that a VAE with a Gaussian prior can always recover the true manifold, making this choice for latent-variable model particularly appealing.
In summary, rather than minimizing [Equation 2](#S4.E2 "2 ‣ 4.1 Planning over Subgoals ‣ 4 Planning with Goal-Conditioned Policies ‣ Planning with Goal-Conditioned Policies"), which requires optimizing over the high-dimensional, unknown space 𝒮𝒮\mathcal{S}caligraphic\_S we minimize
| | | | |
| --- | --- | --- | --- |
| | ℒLEAP(𝐳1:K)=‖𝐕→(𝐬,𝐳1:K,t1:K+1,𝐠)‖p−λ∑k=1Klogp(𝐳k)subscriptℒLEAPsubscript𝐳:1𝐾subscriptnorm→𝐕𝐬subscript𝐳:1𝐾subscript𝑡:1𝐾1𝐠𝑝𝜆superscriptsubscript𝑘1𝐾𝑝subscript𝐳𝑘\displaystyle\mathcal{L}\_{\text{LEAP}}({\mathbf{z}}\_{1:K})=||\overrightarrow{\mathbf{V}}({\mathbf{s}},{\mathbf{z}}\_{1:K},t\_{1:K+1},\mathbf{g})||\_{p}-\lambda\sum\_{k=1}^{K}\log p({\mathbf{z}}\_{k})caligraphic\_L start\_POSTSUBSCRIPT LEAP end\_POSTSUBSCRIPT ( bold\_z start\_POSTSUBSCRIPT 1 : italic\_K end\_POSTSUBSCRIPT ) = | | over→ start\_ARG bold\_V end\_ARG ( bold\_s , bold\_z start\_POSTSUBSCRIPT 1 : italic\_K end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT 1 : italic\_K + 1 end\_POSTSUBSCRIPT , bold\_g ) | | start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT - italic\_λ ∑ start\_POSTSUBSCRIPT italic\_k = 1 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_K end\_POSTSUPERSCRIPT roman\_log italic\_p ( bold\_z start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT ) | | (3) |
where
| | | | |
| --- | --- | --- | --- |
| | 𝐕→(𝐬,𝐳1:K,t1:K+1,𝐠)=[V(𝐬,ψ(𝐳1),t1)V(ψ(𝐳1),ψ(𝐳2),t2)⋮V(ψ(𝐳K−1),ψ(𝐳K),tK)V(ψ(𝐳K),𝐠,tK+1)]andψ(𝐳)=\displaystyle\overrightarrow{\mathbf{V}}({\mathbf{s}},{\mathbf{z}}\_{1:K},t\_{1:K+1},\mathbf{g})=\begin{bmatrix}V({\mathbf{s}},\psi({\mathbf{z}}\_{1}),t\_{1})\\
V(\psi({\mathbf{z}}\_{1}),\psi({\mathbf{z}}\_{2}),t\_{2})\\
\vdots\\
V(\psi({\mathbf{z}}\_{K-1}),\psi({\mathbf{z}}\_{K}),t\_{K})\\
V(\psi({\mathbf{z}}\_{K}),\mathbf{g},t\_{K+1})\\
\end{bmatrix}\quad\text{and}\quad\psi({\mathbf{z}})=over→ start\_ARG bold\_V end\_ARG ( bold\_s , bold\_z start\_POSTSUBSCRIPT 1 : italic\_K end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT 1 : italic\_K + 1 end\_POSTSUBSCRIPT , bold\_g ) = [ start\_ARG start\_ROW start\_CELL italic\_V ( bold\_s , italic\_ψ ( bold\_z start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) , italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) end\_CELL end\_ROW start\_ROW start\_CELL italic\_V ( italic\_ψ ( bold\_z start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) , italic\_ψ ( bold\_z start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) , italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) end\_CELL end\_ROW start\_ROW start\_CELL ⋮ end\_CELL end\_ROW start\_ROW start\_CELL italic\_V ( italic\_ψ ( bold\_z start\_POSTSUBSCRIPT italic\_K - 1 end\_POSTSUBSCRIPT ) , italic\_ψ ( bold\_z start\_POSTSUBSCRIPT italic\_K end\_POSTSUBSCRIPT ) , italic\_t start\_POSTSUBSCRIPT italic\_K end\_POSTSUBSCRIPT ) end\_CELL end\_ROW start\_ROW start\_CELL italic\_V ( italic\_ψ ( bold\_z start\_POSTSUBSCRIPT italic\_K end\_POSTSUBSCRIPT ) , bold\_g , italic\_t start\_POSTSUBSCRIPT italic\_K + 1 end\_POSTSUBSCRIPT ) end\_CELL end\_ROW end\_ARG ] and italic\_ψ ( bold\_z ) = | argmax𝐠′pθ(𝐠′∣𝐳).subscriptargmaxsuperscript𝐠′subscript𝑝𝜃conditionalsuperscript𝐠′𝐳\displaystyle\operatorname\*{arg\,max}\_{\mathbf{g}^{\prime}}{p\_{\theta}}({\mathbf{g}^{\prime}}\mid{\mathbf{z}}).start\_OPERATOR roman\_arg roman\_max end\_OPERATOR start\_POSTSUBSCRIPT bold\_g start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT end\_POSTSUBSCRIPT italic\_p start\_POSTSUBSCRIPT italic\_θ end\_POSTSUBSCRIPT ( bold\_g start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ∣ bold\_z ) . | |
This procedure optimizes over latent variables 𝐳ksubscript𝐳𝑘{\mathbf{z}}\_{k}bold\_z start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT, which are then mapped onto high-dimensional goal states 𝐠ksubscript𝐠𝑘\mathbf{g}\_{k}bold\_g start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT
using the maximum likelihood estimate (MLE) of the decoder argmax𝐠(𝐠∣𝐳)subscriptargmax𝐠conditional𝐠𝐳\operatorname\*{arg\,max}\_{\mathbf{g}}(\mathbf{g}\mid{\mathbf{z}})start\_OPERATOR roman\_arg roman\_max end\_OPERATOR start\_POSTSUBSCRIPT bold\_g end\_POSTSUBSCRIPT ( bold\_g ∣ bold\_z ).
In our case, the MLE can be computed in closed form by taking the mean of the decoder.
The term summing over logp(𝐳k)𝑝subscript𝐳𝑘\log p({\mathbf{z}}\_{k})roman\_log italic\_p ( bold\_z start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT ) penalizes latent variables that have low likelihood under the prior p𝑝pitalic\_p, and λ𝜆\lambdaitalic\_λ is a hyperparameter that controls the importance of this second term.
While any norm could be used, we used the ℓ∞subscriptℓ\ell\_{\infty}roman\_ℓ start\_POSTSUBSCRIPT ∞ end\_POSTSUBSCRIPT-norm which forces each element of the feasibility vector to be near zero.
We found that the ℓ∞subscriptℓ\ell\_{\infty}roman\_ℓ start\_POSTSUBSCRIPT ∞ end\_POSTSUBSCRIPT-norm outperformed the ℓ1subscriptℓ1\ell\_{1}roman\_ℓ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT-norm, which only forces the sum of absolute values of elements near zero.
111
See [Subsection A.1](#A1.SS1 "A.1 Norm Ablation ‣ Appendix A Additional Experiments ‣ Planning with Goal-Conditioned Policies") comparison.
###
4.3 Goal-Conditioned Reinforcement Learning
For our goal-conditioned reinforcement learning algorithm, we use temporal difference models (TDMs) [[48](#bib.bib48)].
TDMs learn Q functions rather that V functions, and so we compute V𝑉Vitalic\_V by evaluating Q𝑄Qitalic\_Q with the action from the deterministic policy:
V(𝐬,𝐠,t)=Q(𝐬,𝐚,𝐠,t)|𝐚=π(𝐬,𝐠,t)𝑉𝐬𝐠𝑡evaluated-at𝑄𝐬𝐚𝐠𝑡𝐚𝜋𝐬𝐠𝑡V({\mathbf{s}},\mathbf{g},t)=Q({\mathbf{s}},\mathbf{a},\mathbf{g},t)|\_{\mathbf{a}=\pi({\mathbf{s}},\mathbf{g},t)}italic\_V ( bold\_s , bold\_g , italic\_t ) = italic\_Q ( bold\_s , bold\_a , bold\_g , italic\_t ) | start\_POSTSUBSCRIPT bold\_a = italic\_π ( bold\_s , bold\_g , italic\_t ) end\_POSTSUBSCRIPT.
To further improve the efficiency of our method, we can also utilize the same VAE that we use to recover the latent space for planning as a state representation for TDMs.
While we could train the reinforcement learning agents from scratch, this can be expensive in terms of sample efficiency as much of the learning will focus on simply learning good convolution filters.
We therefore use the pretrained mean-encoder of the VAE as the state encoder for our policy and value function networks, and only train additional fully-connected layers with RL on top of these representations.
Details of the architecture are provided in [Appendix C](#A3 "Appendix C Implementation Details ‣ Planning with Goal-Conditioned Policies").
We show in Section [5](#S5 "5 Experiments ‣ Planning with Goal-Conditioned Policies") that our method works without reusing the VAE mean-encoder, and that this parameter reuse primarily helps with increasing the speed of learning.
###
4.4 Summary of Latent Embeddings for Abstracted Planning
Our overall method is called Latent Embeddings for Abstracted Planning (LEAP) and is summarized in [Algorithm 1](#alg1 "Algorithm 1 ‣ 4.4 Summary of Latent Embeddings for Abstracted Planning ‣ 4 Planning with Goal-Conditioned Policies ‣ Planning with Goal-Conditioned Policies").
We first train a goal-conditioned policy and a variational-autoencoder on randomly collected states.
Then at testing time, given a new goal, we choose subgoals by minimizing [Equation 3](#S4.E3 "3 ‣ 4.2 Optimizing over Images ‣ 4 Planning with Goal-Conditioned Policies ‣ Planning with Goal-Conditioned Policies").
Once the plan is chosen, the first goal ψ(𝐳1)𝜓subscript𝐳1\psi({\mathbf{z}}\_{1})italic\_ψ ( bold\_z start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) is given to the policy.
After t1subscript𝑡1t\_{1}italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT steps, we repeat this procedure: we produce a plan with K−1𝐾1K-1italic\_K - 1 (rather than K𝐾Kitalic\_K) subgoals, and give the first goal to the policy.
In this work, we fix the time intervals to be evenly spaced out (i.e., t1=t2…tK+1=⌊Tmax/(K+1)⌋subscript𝑡1subscript𝑡2…subscript𝑡𝐾1subscript𝑇max𝐾1t\_{1}=t\_{2}\dots t\_{K+1}=\lfloor{T\_{\mathrm{max}}}/(K+1)\rflooritalic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT … italic\_t start\_POSTSUBSCRIPT italic\_K + 1 end\_POSTSUBSCRIPT = ⌊ italic\_T start\_POSTSUBSCRIPT roman\_max end\_POSTSUBSCRIPT / ( italic\_K + 1 ) ⌋),
but additionally optimizing over the time intervals would be a promising future extension.
Algorithm 1 Latent Embeddings for Abstracted Planning (LEAP)
1: Train VAE encoder qϕsubscript𝑞italic-ϕ{q\_{\phi}}italic\_q start\_POSTSUBSCRIPT italic\_ϕ end\_POSTSUBSCRIPT and decoder pθsubscript𝑝𝜃{p\_{\theta}}italic\_p start\_POSTSUBSCRIPT italic\_θ end\_POSTSUBSCRIPT.
2: Train TDM policy π𝜋\piitalic\_π and value function V𝑉Vitalic\_V.
3: Initialize state, goal, and time: 𝐬1∼ρ0similar-tosubscript𝐬1subscript𝜌0{\mathbf{s}}\_{1}\sim\rho\_{0}bold\_s start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ∼ italic\_ρ start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT, goal 𝐠∼ρgsimilar-to𝐠subscript𝜌𝑔\mathbf{g}\sim\rho\_{g}bold\_g ∼ italic\_ρ start\_POSTSUBSCRIPT italic\_g end\_POSTSUBSCRIPT, and t=1𝑡1t=1italic\_t = 1.
4: Assign the last subgoal to the true goal, 𝐠K+1=𝐠subscript𝐠𝐾1𝐠\mathbf{g}\_{K+1}=\mathbf{g}bold\_g start\_POSTSUBSCRIPT italic\_K + 1 end\_POSTSUBSCRIPT = bold\_g
5: for k𝑘kitalic\_k in 1,…,K+11…𝐾11,\dots,K+11 , … , italic\_K + 1 do
6: Optimize Equation [3](#S4.E3 "3 ‣ 4.2 Optimizing over Images ‣ 4 Planning with Goal-Conditioned Policies ‣ Planning with Goal-Conditioned Policies") to choose latent subgoals 𝐳k,…,𝐳Ksubscript𝐳𝑘…subscript𝐳𝐾{\mathbf{z}}\_{k},\dots,{\mathbf{z}}\_{K}bold\_z start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT , … , bold\_z start\_POSTSUBSCRIPT italic\_K end\_POSTSUBSCRIPT using V𝑉Vitalic\_V and pθsubscript𝑝𝜃{p\_{\theta}}italic\_p start\_POSTSUBSCRIPT italic\_θ end\_POSTSUBSCRIPT if k≤K𝑘𝐾k\leq Kitalic\_k ≤ italic\_K.
7: Decode 𝐳ksubscript𝐳𝑘{\mathbf{z}}\_{k}bold\_z start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT to obtain goal 𝐠k=ψ(𝐳k)subscript𝐠𝑘𝜓subscript𝐳𝑘\mathbf{g}\_{k}=\psi({\mathbf{z}}\_{k})bold\_g start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT = italic\_ψ ( bold\_z start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT ).
8: for t′superscript𝑡′t^{\prime}italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT in 1,…,tk1…subscript𝑡𝑘1,\dots,t\_{k}1 , … , italic\_t start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT do
9: Sample next action 𝐚tsubscript𝐚𝑡\mathbf{a}\_{t}bold\_a start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT using goal-conditioned policy π(⋅∣𝐬t,𝐠k,tk−t′)\pi(\cdot\mid{\mathbf{s}}\_{t},\mathbf{g}\_{k},t\_{k}-t^{\prime})italic\_π ( ⋅ ∣ bold\_s start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT , bold\_g start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT - italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ).
10: Execute 𝐚tsubscript𝐚𝑡\mathbf{a}\_{t}bold\_a start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT and obtain next state 𝐬t+1subscript𝐬𝑡1{\mathbf{s}}\_{t+1}bold\_s start\_POSTSUBSCRIPT italic\_t + 1 end\_POSTSUBSCRIPT
11: Increment the global timer t←t+1←𝑡𝑡1t\leftarrow t+1italic\_t ← italic\_t + 1.
12: end for
13: end for
5 Experiments
--------------
Our experiments study the following two questions:
(1) How does LEAP compare to model-based methods, which directly predict each time step, and model-free RL, which directly optimizes for the final goal?
(2) How does the use of a latent state representation and other design decisions impact the performance of LEAP?
###
5.1 Vision-based Comparison and Results
We study the first question on two distinct vision-based tasks, each of which requires temporally-extended planning and handling high-dimensional image observations.
The first task, 2D Navigation requires navigating around a U-shaped wall to reach a goal, as shown in Figure [3](#S5.F3 "Figure 3 ‣ 5.1 Vision-based Comparison and Results ‣ 5 Experiments ‣ Planning with Goal-Conditioned Policies").
The state observation is a top-down image of the environment.
We use this task to conduct ablation studies that test how each component of LEAP contributes to final performance.
We also use this environment to generate visualizations that help us better understand how our method uses the goal-conditioned value function to evaluate reachability over images.
While visually simple, this task is far from trivial for goal-conditioned and planning methods:
a greedy goal-reaching policy that moves directly towards the goal will never reach the goal. The agent must plan a temporally-extended path that moves around the walls, sometimes moving away from the goal.
We also use this environment to compare our method with prior work on goal-conditioned and model-based RL.
To evaluate LEAP on a more complex task, we utilize a robotic manipulation simulation of a Push and Reach task.
This task requires controlling a simulated Sawyer robot to both (1) move a puck to a target location and (2) move its end effector to a target location.
This task is more visually complex, and requires more temporally extended reasoning.
The initial arm and and puck locations are randomized so that
the agent must decide how to reposition the arm to reach around the object, push the object in the desired direction, and then move the arm to the correct location, as shown in Figure [3](#S5.F3 "Figure 3 ‣ 5.1 Vision-based Comparison and Results ‣ 5 Experiments ‣ Planning with Goal-Conditioned Policies").
A common failure case for model-free policies in this setting is to adopt an overly greedy strategy, only moving the arm to the goal while ignoring the puck.
We train all methods on randomly initialized goals and initial states. However, for evaluation, we intentionally select difficult start and goal states to evaluate long-horizon reasoning.
For 2D Navigation, we initialize the policy randomly inside the center square and sample a goal from the region directly below the U-shaped wall. This requires initially moving away from the goal to navigate around the wall.
For Push and Reach, we evaluate on 5 distinct challenging configurations, each requiring the agent to first plan to move the puck, and then move the arm only once the puck is in its desired location. In one configuration for example, we initialize the hand and puck on opposite sides of the workspace and set goals so that the hand and puck must switch sides.
We compare our method to both model-free methods and model-based methods that plan over learned models.
All of our tasks use Tmax=100subscript𝑇max100{T\_{\mathrm{max}}}=100italic\_T start\_POSTSUBSCRIPT roman\_max end\_POSTSUBSCRIPT = 100, and LEAP uses CEM to optimize over K=3𝐾3K=3italic\_K = 3 subgoals, each of which are 25252525 time steps apart.
We compare directly with model-free TDMs, which we label TDM-25.
Since the task is evaluated on a horizon of length Tmax=100subscript𝑇max100{T\_{\mathrm{max}}}=100italic\_T start\_POSTSUBSCRIPT roman\_max end\_POSTSUBSCRIPT = 100 we also compare to a model-free TDM policy trained for Tmax=100subscript𝑇max100{T\_{\mathrm{max}}}=100italic\_T start\_POSTSUBSCRIPT roman\_max end\_POSTSUBSCRIPT = 100, which we label TDM-100.
We compare to reinforcement learning with imagined goals (RIG) [[40](#bib.bib40)], a state-of-the-art method for solving image-based goal-conditioned tasks.
RIG learns a reward function from images rather than using a pre-determined reward function.
We found that providing RIG with the same distance function as our method improves its performance, so we use this stronger variant of RIG to ensure a fair comparison.
In addition, we compare to hindsight experiment replay (HER) [[2](#bib.bib2)] which uses sparse, indicator rewards.
Lastly, we compare to probabilistic ensembles with trajectory sampling (PETS) [[7](#bib.bib7)], a state-of-the-art model-based RL method.
We favorably implemented PETS on the ground-truth low-dimensional state representation and label it PETS, state.




Figure 3:
Comparisons on two vision-based domains that evaluate temporally extended control, with illustrations of the tasks.
In 2D Navigation (left), the goal is to navigate around a U-shaped wall to reach the goal.
In the Push and Reach manipulation task (right), a robot must first push a puck to a target location (blue star), which may require moving the hand away from the goal hand location, and then move the hand to another location (red star). Curves are averaged over multiple seeds and shaded regions represent one standard deviation. Our method, shown in red, outperforms prior methods on both tasks. On the Push and Reach task, prior methods typically get the hand close to the right location, but perform much worse at moving the puck, indicating an overly greedy strategy, while our approach succeeds at both.
The results are shown in [Figure 3](#S5.F3 "Figure 3 ‣ 5.1 Vision-based Comparison and Results ‣ 5 Experiments ‣ Planning with Goal-Conditioned Policies").
LEAP significantly outperforms prior work on both tasks, particularly on the harder Push and Reach task.
While the TDM used by LEAP (TDM-25) performs poorly by itself, composing it with 3 different subgoals using LEAP results in much better performance. By 400k environment steps, LEAP already achieves a final puck distance of under 10 cm, while the next best method, TDM-100, requires 5 times as many samples.
Details on each task are in [Appendix B](#A2 "Appendix B Environment Details ‣ Planning with Goal-Conditioned Policies"), and algorithm implementation details are given in [Appendix C](#A3 "Appendix C Implementation Details ‣ Planning with Goal-Conditioned Policies").



Figure 4:
(Left) Visualization of subgoals reconstructed from the VAE (bottom row), and the actual images seen when reaching those subgoals (top row).
Given an initial state s0subscript𝑠0s\_{0}italic\_s start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT and a goal image 𝐠𝐠\mathbf{g}bold\_g,
the planner chooses meaningful subgoals: at 𝐠t1subscript𝐠subscript𝑡1\mathbf{g}\_{t\_{1}}bold\_g start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT, it moves towards the puck, at 𝐠t2subscript𝐠subscript𝑡2\mathbf{g}\_{t\_{2}}bold\_g start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT it begins pushing the puck, and at 𝐠t3subscript𝐠subscript𝑡3\mathbf{g}\_{t\_{3}}bold\_g start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT 3 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT it completes the pushing motion before moving to the goal hand position at 𝐠𝐠\mathbf{g}bold\_g.
(Middle) The top row shows the image subgoals superimposed on one another.
The blue circle is the starting position, the green circle is the target position, and the intermediate circles show the progression of subgoals (bright red is 𝐠t1subscript𝐠subscript𝑡1\mathbf{g}\_{t\_{1}}bold\_g start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT, brown is 𝐠t3subscript𝐠subscript𝑡3\mathbf{g}\_{t\_{3}}bold\_g start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT 3 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT).
The colored circles show the subgoals in the latent space (bottom row)
for the two most active VAE latent dimensions, as well as samples from the VAE aggregate posterior [[35](#bib.bib35)].
(Right) Heatmap of the value function V(𝐬,𝐠,t)𝑉𝐬𝐠𝑡V({\mathbf{s}},\mathbf{g},t)italic\_V ( bold\_s , bold\_g , italic\_t ), with each column showing a different time horizon t𝑡titalic\_t for a fixed state 𝐬𝐬{\mathbf{s}}bold\_s. Warmer colors show higher value. Each image indicates the value function for all possible goals g𝑔gitalic\_g.
As the time horizon decreases, the value function recognizes that it can only reach nearby goals.
We visualize the subgoals chosen by LEAP in [Figure 4](#S5.F4 "Figure 4 ‣ 5.1 Vision-based Comparison and Results ‣ 5 Experiments ‣ Planning with Goal-Conditioned Policies") by decoding the latent subgoals 𝐳t1:Ksubscript𝐳subscript𝑡:1𝐾{\mathbf{z}}\_{t\_{1:K}}bold\_z start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT 1 : italic\_K end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT into images with the VAE decoder pθsubscript𝑝𝜃{p\_{\theta}}italic\_p start\_POSTSUBSCRIPT italic\_θ end\_POSTSUBSCRIPT.
In Push and Reach, these images correspond to natural subgoals for the task.
[Figure 4](#S5.F4 "Figure 4 ‣ 5.1 Vision-based Comparison and Results ‣ 5 Experiments ‣ Planning with Goal-Conditioned Policies") also shows a visualization of the value function, which is used by the planner to determine reachability. Note that the value function generally recognizes that the wall is impassable, and makes reasonable predictions for different time horizons.
Videos of the final policies and generated subgoals and code for our implementation of LEAP are available on the paper website222<https://sites.google.com/view/goal-planning>.
###
5.2 Planning in Non-Vision-based Environments with Unknown State Spaces
While LEAP was presented in the context of optimizing over images, we also study its utility in non-vision based domains.
Specifically, we compare LEAP to prior works on an Ant Navigation task, shown in [Figure 5](#S5.F5 "Figure 5 ‣ 5.2 Planning in Non-Vision-based Environments with Unknown State Spaces ‣ 5 Experiments ‣ Planning with Goal-Conditioned Policies"), where the state-space consists of the quadruped robot’s joint angles, joint velocity, and center of mass.
While this state space is more compact than images, only certain combinations of state values are actually valid, and the obstacle in the environment is unknown to the agent, meaning that a naïve optimization over the state space can easily result in invalid states (e.g., putting the robot inside an obstacle).
This task has a significantly longer horizon of Tmax=600subscript𝑇max600{T\_{\mathrm{max}}}=600italic\_T start\_POSTSUBSCRIPT roman\_max end\_POSTSUBSCRIPT = 600, and LEAP uses CEM to optimize over K=11𝐾11K=11italic\_K = 11 subgoals, each of which are 50505050 time steps apart.
As in the vision-based comparisons, we compare with model-free TDMs, for the short-horizon setting (TDM-50) which LEAP is built on top of, and the long-horizon setting (TDM-600).
In addition to HER, we compare to a variant of HER that uses the same rewards and relabeling strategy as RIG, which we label HER+.
We exclude the PETS baseline, as it has been unable to solve long-horizon tasks such as ours.
In this section, we add a comparison to hierarchical reinforcement learning with off-policy correction (HIRO) [[38](#bib.bib38)], a hierarchical method for state-based goals.
We evaluate all baselines on a challenging configuration of the task in which the ant must navigate from the one corner of the maze to the other side, by going around a long wall. The desired behavior will result in large negative rewards during the trajectory, but will result in an optimal final state.
We see that in [Figure 5](#S5.F5 "Figure 5 ‣ 5.2 Planning in Non-Vision-based Environments with Unknown State Spaces ‣ 5 Experiments ‣ Planning with Goal-Conditioned Policies"), LEAP is the only method that successfully navigates the ant to the goal. HIRO, HER, HER+ don’t attempt to go around the wall at all, as doing so will result in a large sum of negative rewards. TDM-50 has a short horizon that results in greedy behavior, while TDM-600 fails to learn due to temporal sparsity of the reward.


Figure 5:
In the Ant Navigation task, the ant must move around the long wall, which will incur large negative rewards during the trajectory, but will result in an optimal final state. We illustrate the task, with the purple ant showing the starting state and the green ant showing the goal. We use 3 subgoals here for illustration. Our method (shown in red in the plot) is the only method that successfully navigates the ant to the goal.
###
5.3 Ablation Study
We analyze the importance of planning in the latent space, as opposed to image space, on the navigation task.
For comparison, we implement a planner that directly optimizes over image subgoals (i.e., in pixel space).
We also study the importance of reusing the pretrained VAE encoder by replicating the experiments with the RL networks trained from scratch.
We see in [Figure 6](#S5.F6 "Figure 6 ‣ 5.3 Ablation Study ‣ 5 Experiments ‣ Planning with Goal-Conditioned Policies") that a model that does not reuse the VAE encoder does succeed, but takes much longer. More importantly, planning over latent states achieves dramatically better performance than planning over raw images.
[Figure 6](#S5.F6 "Figure 6 ‣ 5.3 Ablation Study ‣ 5 Experiments ‣ Planning with Goal-Conditioned Policies") also shows the intermediate subgoals outputted by our optimizer when optimizing over images.
While these subgoals may have high value according to Equation [2](#S4.E2 "2 ‣ 4.1 Planning over Subgoals ‣ 4 Planning with Goal-Conditioned Policies ‣ Planning with Goal-Conditioned Policies"), they clearly do not correspond to valid state observations, indicating that the planner is exploiting the value function by choosing images far outside the manifold of valid states.
We include further ablations in [Appendix A](#A1 "Appendix A Additional Experiments ‣ Planning with Goal-Conditioned Policies"), in which we study the sensitivity of λ𝜆\lambdaitalic\_λ in [Equation 3](#S4.E3 "3 ‣ 4.2 Optimizing over Images ‣ 4 Planning with Goal-Conditioned Policies ‣ Planning with Goal-Conditioned Policies") ([Subsection A.3](#A1.SS3 "A.3 Likelihood Penalty Ablation ‣ Appendix A Additional Experiments ‣ Planning with Goal-Conditioned Policies")), the choice of norm ([Subsection A.1](#A1.SS1 "A.1 Norm Ablation ‣ Appendix A Additional Experiments ‣ Planning with Goal-Conditioned Policies")), and the choice of optimizer ([Subsection A.2](#A1.SS2 "A.2 Optimizer Ablation ‣ Appendix A Additional Experiments ‣ Planning with Goal-Conditioned Policies")).
The results show that LEAP works well for a wide range of λ𝜆\lambdaitalic\_λ, that ℓ∞subscriptℓ\ell\_{\infty}roman\_ℓ start\_POSTSUBSCRIPT ∞ end\_POSTSUBSCRIPT-norm performs better, and that CEM consistently outperforms gradient-based optimizers, both in terms of optimizer loss and policy performance.


Figure 6:
(Left) Ablative studies on 2D Navigation. We keep all components of LEAP the same but replace optimizing over the latent space with optimizing over the image space (-latent).
We separately train the RL methods from scratch rather than reusing the VAE mean encoder (-shared), and also test both ablations together (-latent, shared).
We see that sharing the encoder weights with the RL policy results in faster learning, and that optimizing over the latent space is critical for success of the method.
(Right) Visualization of the subgoals generated when optimizing over the latent space and decoding the image (top) and when optimizing over the images directly (bottom).
The goals generated when planning in image space are not meaningful, which explains the poor performance of “-latent” shown in (Left).
6 Discussion
-------------
We presented Latent Embeddings for Abstracted Planning (LEAP), an approach for solving temporally extended tasks with high-dimensional state observations, such as images. The key idea in LEAP is to form *temporal* abstractions by using goal-reaching policies to evaluate reachability, and *state* abstractions by using representation learning to provide a convenient state representation for planning. By planning over states in a learned latent space and using these planned states as subgoals for goal-conditioned policies, LEAP can solve tasks that are difficult to solve with conventional model-free goal-reaching policies, while avoiding the challenges of modeling low-level observations associated with fully model-based methods. More generally, the combination of model-free RL with planning is an exciting research direction that holds the potential to make RL methods more flexible, capable, and broadly applicable. Our method represents a step in this direction, though many crucial questions remain to be answered. Our work largely neglects the question of exploration for goal-conditioned policies, and though this question has been studied in some recent works [[17](#bib.bib17), [45](#bib.bib45), [59](#bib.bib59), [49](#bib.bib49)],
examining how exploration interacts with planning is an exciting future direction. Another exciting direction for future work is to study how lossy state abstractions might further improve the performance of the planner, by explicitly discarding state information that is irrelevant for higher-level planning.
7 Acknowledgments
------------------
This work was supported by the Office of Naval Research, the National Science Foundation, Google, NVIDIA, Amazon, and ARL DCIST CRA W911NF-17-2-0181. |
9c268954-5507-4870-84ac-14ca99dea61c | trentmkelly/LessWrong-43k | LessWrong | Meetup : Durham NC/Triangle Area: Cognitive Biases, Continued
Discussion article for the meetup : Durham NC/Triangle Area: Cognitive Biases, Continued
WHEN: 12 September 2013 07:00:00PM (-0400)
WHERE: 420 West Geer St., Durham NC 27701
Follow up discussion to the prior meetup's cognitive biases survey! We will focus on higher-ranked biases from that meetup.
7:00 obtain coffees
7:30 discussion
9:30ish adjourn to Fullsteam
Discussion article for the meetup : Durham NC/Triangle Area: Cognitive Biases, Continued |
177c15fb-865a-468f-bc1b-081b1b6c5cec | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Pointing to a Flower
Imagine I have a highly detailed low-level simulation (e.g. molecular dynamics) of a garden. The initial conditions include a flower, and I would like to write some code to “point” to that particular flower. At any given time, I should be able to use this code to do things like:
* compute a bounding box around the flower
* render a picture which shows just the flower, with the background removed
* list all of the particles which are currently inside the flower
Meanwhile, it should be robust to things like:
* most of the molecules in the flower turning over on a regular basis
* the flower moving around in space and/or relative to other flowers
* the flower growing, including blooming/wilting/other large morphological change
* other flowers looking similar
That said, there’s a limit to what we can expect; our code can just return an error if e.g. the flower has died and rotted away and there is no distinguishable flower left. In short: we want this code to capture roughly the same notion of “this flower” that a human would.
We’ll allow an external user to draw a boundary around the flower in the initial conditions, just to define which object we’re talking about. But after that, our code should be able to robustly keep track of our particular flower.
How could we write that code, even in principle?
“Why Not Just… ”
----------------
There’s a lot of obvious hackish ways to answer the question - and obvious problems/counterexamples for each of them. I’ll list a few here, since the counterexamples make good test cases for our eventual answer, and illustrate just how involved the human concept of a flower is.
* Flower = molecules inside the flower-boundary at time zero. Problem: most of the molecules comprising a flower turn over on a regular basis.
* Flower = whatever’s inside the boundary which defined the flower at time zero. Counterexample: the flower might move.
* Flower = things which look (in a rendered image) like whatever was inside the boundary at time zero. Counterexample: the flower might bloom/wilt/etc. Another counterexample: there may be other, similar-looking flowers.
* Flower = instance of a recurring pattern in the data, defined by clustering. Counterexample: there may not be any other flowers. (More generally: we can recognize “weird” objects in the world which don’t resemble anything else we’ve ever seen.)
* Flower = region of high density contiguous in space-time with our initial region. Counterexample: we can dunk the flower in a bucket of water.
* Flower = contents of lipid bilayer membranes which also contain DNA sequence roughly identical to the consensus sequence of all DNA within the initial boundary, plus anything within a few microns of those membranes. Counterexample: it’s still the same flower if we blow it up via [expansion microscopy](https://en.wikipedia.org/wiki/Expansion_microscopy) and the individual cells lyse in the process. (Also this wouldn’t generalize to non-biological objects, or even clonal organisms.)
Drawing Abstract Object Boundaries
----------------------------------
The general conceptual challenge here is how to define an abstract object - an object which is not an ontologically fundamental component of the world, but an abstraction on top of the low-level world.
In [previous](https://www.lesswrong.com/s/ehnG4mseKF6xALmQy/p/TTNS3tk5McHqrJCbR) [posts](https://www.lesswrong.com/s/ehnG4mseKF6xALmQy/p/wuJpYLcMEBz4kcgAn) I’ve outlined a fairly-general definition of abstraction: far-apart components of a low-level model are independent given some high-level summary data. We imagine breaking our low-level system variables into three subsets:
* Variables X which we want to abstract
* Variables Y which are “far away” from X
* Noisy “in-between” variables Z which moderate the interaction between X and Y
The noise in Z wipes out most of the information in X, so the only information from X which is relevant to Y is some summary f(X).

(I’ve sketched this as a causal DAG for concreteness, which is how I usually visualize it.) I want to claim that this is basically the right way to think about abstraction quite generally - so it better apply to questions like “what’s an abstract object?”.
So what happens if we apply this picture directly to the flower problem?
First, we need to divide up our low-level variables into the flower (X), things far away from the flower (Y), and everything in-between (noisy Z). I’ll just sketch this as the flower itself and a box showing the boundary between “nearby” and “far away”:

Notice the timesteps in the diagram - both the flower and the box are defined over time, so we imagine the boundaries living in four-dimensional spacetime, not just at one time. (Our user-drawn boundary in the initial condition constrains the full spacetime boundary at time zero.)
Now the big question is: how do we decide where to draw the boundaries? Why draw boundaries which follow around the actual flower, rather than meandering randomly around?
Let’s think about what the high-level summary f(X) looks like for boundaries which follow the flower, compared to boundaries which *start* around the flower (i.e. at the user-defined initial boundary) but don’t follow it as it moves. In particular, we’ll consider what information about the *initial* flower (i.e. flower at time zero) needs to be included in f(X).

*The “true” flower moves, but the boundaries supposedly defining the “flower” don’t follow it. What makes such boundaries “worse” than boundaries which do follow the flower?*
There’s a lot of information about the initial flower which *could* be included in our summary f(X): the geometry of the flower’s outer surface, its color and texture, temperature at each point, mechanical stiffness at each point, internal organ structure (e.g. veins), relative position of each cell, relative position of each molecule, … Which of these need to be included in the summary data for boundaries moving with the flower, and which need to be included in the summary data for boundaries not moving with the flower?
For example: the flower’s surface geometry will have an influence on things outside the outer boundary in both cases. It will affect things like drag on air currents, trajectories of insects or raindrops, and of course the flower-image formed on the retina of anyone looking at it. So the outer surface geometry will be included in the summary f(X) in both cases. On the other hand, relative positions of cells inside the flower itself are mostly invisible from far away *if the boundary follows the flower*.
But if the boundary doesn’t follow the flower… then the true flower is inside the boundary at the initial time, but counts as “far away” at a later time. And the relative positions of individual cells in the true flower will mostly stay stable over time, so those relative cell positions at time zero contain lots of information about relative cell positions at time two… and since the cells at time two counts as “far away”, that means we need to include all that information in our summary f(X).

*Strong correlation between low-level details (e.g. relative positions of individual cells) inside the spacetime boundary and outside. That information must be included in the high-level summary f(X).*
The takeaway from this argument is: **if the boundary doesn’t follow the true flower, then our high-level summary f(X) must contain *far* more information**. Specifically, it has to include tons of information about the low-level internal structure of the flower. On the other hand, as long as the true flower remains inside the inner boundary, information about that low-level structure will mostly not propagate outside the outer boundary - such fine-grained detail will usually be wiped out by the noisy variables “nearby” the flower.
This suggests a formalizable approach: the “true flower” is defined by a boundary which is locally-minimal with respect to the summary data f(X) required to capture all its mutual information with “far-away” variables.
Test Cases
----------
Before we start really attacking this approach, let’s revisit the problems/counterexamples from the hackish approaches:
* Molecular turnover: not a problem. The relevant information does not follow the individual molecules.
* Flower might move: not a problem. We basically discussed that directly in the previous section.
* Flower might bloom/wilt/etc: not a problem. Mutual information still follows the same pattern, although note that once the flower rots away altogether, we can draw a time-boundary indicating that the flower no longer exists, and indeed we expect everything significantly after that in time to be roughly independent of our former flower.
* Similar-looking flowers: not a problem. We’re explicitly relying on the low-level internal structure to define the flower boundary.
* No other flowers: not a problem. We’re not relying on clustering or any other data from other flowers.
* Dunk flower in a bucket of water: not a problem. Noisy water molecules “nearby” the flower will wipe out low-level detailed information about as well as noisy air molecules, if not better.
* Expansion microscopy: not a problem. The information in the flower’s low-level structure sticks around in its expanded form. Indeed, expansion microscopy wouldn’t be very useful otherwise.
Main takeaway: this approach is mainly about information contained in the low-level structure of the flower (i.e. cells, organs, etc). Physical interactions which maintain that low-level structure will generally maintain the flower-boundary - and a physical interaction which destroys most of a flower’s low-level structure is generally something we’d interpret as destroying the flower.
Problems
--------
Let’s start with the obvious: though it’s formalizable, this isn’t exactly formalized. We don’t have an actual test-case following around a flower in-silico, and given how complicated that simulation would be, we’re unlikely to have such a test case soon. That said, next section will give a computationally simpler test-case which preserves most of the conceptual challenges of the flower problem.
First, though, let’s look at a few conceptual problems.
What about perfect determinism?
This approach relies on high mutual information between true-flower-at-time-zero and true-flower-at-later-times. That requires some kind of uncertainty or randomness.
There’s a lot places for that to come from:
* We could have ontologically-basic randomness, e.g. quantum noise
* We could have deterministic dynamics but random initial conditions
* More realistically, we could have some sort of observer in the system with Bayesian uncertainty about the low-level details of the world.
That last is the “obvious” answer, in some sense, and it’s a good answer for many purposes. I’m still not completely satisfied with it, though - it seems like a superintelligence with extremely precise knowledge of every molecule in a flower should still be able to use the flower-abstraction, even in a completely deterministic world.
Why/how would a “flower”-abstraction make sense under perfect determinism? What notion of locality is even present in such a system? When I probe my intuition, my main answer is: causality. I’m imagining a world without noise, but that world still has a causal structure similar to our world, and it’s that causal structure which makes the “flower” make sense.
Indeed, causal abstraction allows us to apply the ideas above directly to a deterministic world. The only change is that f(X) no longer only summarizes probabilistic information; it must also summarize any information needed to predict far-away variables under *interventions* (on either internal or far-away variables).
Of course, in practice, we’ll probably also want to include those interventional-information constraints even in the presence of uncertainty.
What about fine-grained information carried by, like, microwaves or something?
If we just imagine a physical outer boundary some distance from a flower (let’s say 3 meters), surely some clever physicists could figure out a way to map out the flower’s internal structure without crossing within that boundary. Isn’t information about the low-level structure constantly propagating outward via microwaves or something, without being wiped out by noisy air molecules on the way?
Two key things to keep in mind here:
* The boundary need not be a *physical* boundary; the “boundaries” just denote subsets of the variables of the model. If the model includes microwaves, we can just declare them all to be “nearby” the flower. Whenever they actually interact with molecules outside the flower, barring instruments specifically set up to detect them, the information they carry should be wiped out quite quickly by statistical-mechanical noise.
* In practice, we don’t just want to abstract *one* object. We want a whole high-level world model, full of abstract objects. The “far-away variables” will be variables within all the other high-level objects. So in order for microwaves to matter, they need to carry information from one object to another, without that information being wiped out by low-level noise.
Note that we’re talking about noise a lot here - does this problem play well with deterministic universes, where causality constrains f(X) more than plain old information? I expect the answer is yes - chaos makes low-level interventions look basically like noise for our purposes. But that’s another very hand-wavy answer.
What if we draw a boundary which follows around every individual particle which interacts with the flower?
Presumably we could get even less information in f(X) by choosing some weird boundary. The easy way to solve this is to add boundary complexity to the information contained in f(X) when judging how “good” a boundary is.
Humans seem to use a flower-abstraction without actually knowing the low-level flower-structure.
Key point: we don’t need to *know* the low-level flower-structure in order to use this approach. We just need to have a model of the world which says that the flower has *some* (potentially unknown) low-level structure, and that the low-level structure of flower-at-time-zero is highly correlated with the low-level structure of flower-at-later-times.
Indeed, when I look at a flower outside my apartment, I don’t know its low-level details. But I do expect that, for instance, the topology of the veins in that flower is roughly the same today as it was yesterday.
In fact, we can go a step further: humans lack-of-knowledge of the low-level structure of particular flowers is one of the main reasons we should expect our abstractions to look roughly like the picture above. Why? Well, let’s go back to the original picture from the definition:

Key thing to notice: since Y is independent of all the low-level details of X except the information contained in f(X), f(X) contains everything we can possibly learn about X just by looking at Y.
In terms of flowers: our “high-level summary data” f(X) contains precisely the things we can figure out about the flower without pulling out a microscope or cutting it open or otherwise getting “closer” to the flower.
Testable Case?
--------------
Finally, let’s outline a way to test this out more rigorously.
We’d like some abstract object which we can simulate at a “low-level” at reasonable computational cost. It should exhibit some of the properties relevant to our conceptual test-cases from earlier: components which turn over, moves around, change shape/appearance, might be many or just one, etc. Just those first two properties - components which turn over and object moving around - immediately suggest a natural choice: a wave.
* In a particle view, the underlying particles comprising the wave change over time
* The wave moves around in space and relative to other waves
* The wave may change shape (due to obstacles, dissipation, nonlinearity, etc)
* There may be other similar-looking waves in the environment or no other waves
I’d be interested to hear if this sounds to people like a sensible/fair test of the concept.
Summary
-------
We want to define abstract objects - objects which are not ontologically fundamental components of the world, but are instead abstractions on top of a low-level world. In particular, our problem asks to track a particular flower within a molecular-level simulation of a garden. Our method should be robust to the sorts of things a human notion of a flower is robust to: molecules turning over, flower moving around, changing appearance, etc.
We can do that with a [suitable notion of abstraction](https://www.lesswrong.com/s/ehnG4mseKF6xALmQy/p/TTNS3tk5McHqrJCbR): we have summary data f(X) of some low-level variables X, such that f(X) contains all the information relevant to variables “far away”. We’ve argued that, if we choose X to include precisely the low-level variables which are physically inside the flower, and mostly use physical distance to define “far-away” (modulo microwaves and the like), then we’d expect the information-content of f(X) to be locally minimal. Varying our choice of X subject to the same initial conditions - i.e. moving the supposed flower-boundary away from the true flower - requires f(X) to contain more information about the low-level structure of the flower.
 |
521412a2-c193-4a7d-ae20-053a4660fa7e | trentmkelly/LessWrong-43k | LessWrong | Meetup : Giving What We Can at LessWrong Tel Aviv
Discussion article for the meetup : Giving What We Can at LessWrong Tel Aviv
WHEN: 05 July 2016 05:06:58PM (+0300)
WHERE: Cluster - Disruptive Technologies hub, Yigal Alon 118 Tel Aviv
This Tueday, LessWrong Tel Aviv is proud to host a talk by Erwan Atcheson from Giving What We Can. GWWC is an organization based in the United Kingdom whose mission is promoting donations to effective charities in the global poverty domain. GWWC is associated with the Centre for Effective Altruism and is one of the most famous organizations in the effective altruism movement, known among other things for the pledge to give 10% of one's income to charity which anyone can take to become a member. Erwan will talk about GWWC's mission and work and will take questions from the audience.
As usual, the meetup begins at 19:00 but the talk will only begin around 19:30-19:45. Entrance to the Cluster is from Totseret Ha'aretz street, through a brown door with a doorbell.
See you all there!
Discussion article for the meetup : Giving What We Can at LessWrong Tel Aviv |
b2683318-feca-43ab-b134-623a9820e525 | trentmkelly/LessWrong-43k | LessWrong | Using game theory to elect a centrist in the 2024 US Presidential Election
Crossposted from the EA Forum
TL;DR
A nonpartisan group like No Labels could privately offer US congresspeople this deal: If enough congresspeople pledge to the deal, they all agree to switch their Presidential endorsement to a compromise candidate. If not enough pledge, then pledging still gets them some other benefit, such as a campaign donation or endorsement. Such a scheme could generate a lot of utility.
Executive Summary
Many Americans are unsatisfied with the way their democracy is working, and deeply concerned with one or both of the major candidates for the 2024 presidential election. Furthermore, previous EA Forum discussion has identified electoral reform as a possible top cause area. It may be time to explore alternatives to the primary-election system used by US political parties to select presidential nominees since the late 1960s. In this post I propose a dominant assurance contract mechanism for coordinating endorsements around an alternative centrist candidate. The proposed contract works as follows: If a political big shot (congressperson, pundit, etc.) signs the contract, and certain thresholds in the contract are reached (in terms of the number of contract signatures / candidate poll numbers / etc. by a particular date), then signers agree to switch their endorsement to a compromise candidate. If those thresholds are not reached, then signers should still get some sort of bonus, perhaps in the form of a campaign donation, endorsement, etc. This bonus ensures that signing the contract looks attractive in all scenarios, which makes it more likely that the target threshold will be reached. If this scheme works as described, it could provide a foundation for long-lasting electoral reform in the United States.
Background information
Why expect a centrist candidate to do well in America's 2024 presidential election?
With all the sound and fury around American elections, you might expect most Americans to have a strong party preference. In fact, |
17ecb6fa-8b31-4314-9d75-81fae76130c8 | trentmkelly/LessWrong-43k | LessWrong | March 22nd & 23rd: Coronavirus Link Updates
Update: We just launched a new version of our link database. We now have over 350 links categorized in total, and the database is now properly integrated into LessWrong and even works on mobile!
You can find the full database here: https://www.lesswrong.com/coronavirus-link-database
As part of the LessWrong Coronavirus Link Database, Ben, Elizabeth and I are publishing update posts with all the new links we are adding each day that we ranked a 3 or above in our importance rankings. Here are all the top links that we added over the last two days (March 22nd and 23rd), by topic.
Aggregators
Sources of state and local legal info (USA)
Collection of resources to follow specific states, and a spreadsheet of each state's current, uh, state in regard to C19
Financial Times C19 Coverage
Rob Wiblin describes FT's coverage of C19 as ahead of the curve and worth paying for
(EV): I can't verify this as I'm not yet paying for FT coverage
Chinese language version of Quora on COVID
Chinese Q&A site discussing Covid.
(RS) Interesting to see general day to day activity and response to international news from the Chinese mainland perspective. Lots of thought provoking questions being discussed.
Dashboards
Current state of states and localities (USA)
Columns like "contacts", "executive orders", "travel restrictions"
Map of tests per capita by country
Worldwide map with countries colored by testing per capita, with exact counts in a table
Economics
Cost of coronavirus reaction
Two approaches to calculating how much the money lost from the economy due to shutdowns could have saved lives
(EV) Starts with the current death count, no projected uncontrolled death count, which is a terrible sign. Leaves out lives saved for non-C19 reasons from shut downs (via e.g. polllution and reduced driving)
Diagnostics briefing
22 page doc on the current state of C19 testing and what you need to know to make decisions to increase it
Medical System
Census of USA hospital resource |
d90281b6-b7ac-4d32-82ba-88bc8f4f59ba | trentmkelly/LessWrong-43k | LessWrong | Meetup : Tel Aviv, Israel
Discussion article for the meetup : Tel Aviv, Israel
WHEN: 21 April 2012 07:00:00PM (+0300)
WHERE: Cafe Aroma, London Ministore, Sderot Sha'ul HaMelech, Tel Aviv, Israel
Let's have a LW meetup in Tel Aviv. There are currently no ongoing meetings here - if this one goes well, we can repeat it.
I'll be sitting at the Aroma cafe on the corner of Shaul HaMelech and Ibn Gvirol. I commit to being there this Saturday Apr 21 during 19:00-21:00 regardless of who else is coming. There'll be a LW sign on the table.
We'll do introductions, find common topics to talk about, and maybe play a rationality game. If you've never done a LW meetup, don't let that hinder you (I haven't either).
Any questions or issues are welcome here in comments, or send me a PM. If you plan to come, I'd appreciate a heads-up so I have some idea how many people plan to be there, but don't feel obliged to do that - feel free to just show up without telling anyone.
Looking forward to meeting you!
Discussion article for the meetup : Tel Aviv, Israel |
0c6abd24-93a1-413f-9f12-f481020606a0 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Normativity
Now that I've written [Learning Normativity](https://www.lesswrong.com/posts/2JGu9yxiJkoGdQR4s/learning-normativity-a-research-agenda), I have some more clarity around the concept of "normativity" I was trying to get at, and want to write about it more directly. Whereas that post was more oriented toward the machine learning side of things, this post is more oriented toward the philosophical side. However, it *is* still relevant to the research direction, and I'll mention some issues relevant to value learning and other alignment approaches.
How can we talk about what you "should" do?
A Highly Dependent Concept
==========================
Now, obviously, what you should do depends on your goals. We can (at least as a rough first model) encode this as a utility function (but see [my objection](https://www.lesswrong.com/posts/A8iGaZ3uHNNGgJeaD/an-orthodox-case-against-utility-functions)).
What you should do also depends on what's the case. Or, really, it depends on what you *believe* is the case, since that's what you have to go on.
Since we also have uncertainty about values (and we're interested in building machines which should have value uncertainty as well, in order to do value learning), we have to talk about beliefs-about-goals, too. (Or beliefs about utility functions, or however it ends up getting formalized.) This includes moral uncertainty.
Even worse, we have a lot of uncertainty about decision theory -- that is, we have uncertainty about how to *take* all of this uncertainty we have, and make it into decisions. Now, ideally, decision theory is not something the normatively correct thing *depends on*, like all the previous points, but rather is *a framework for finding the normatively correct thing given all of those things*. However, as long as we're uncertain about decision theory, we have to take that uncertainty as input too -- so, if decision theory is to give advice to realistic agents who are themselves uncertain about decision theory, *decision theory also takes decision-theoretic uncertainty as an input*. (In the best case, this makes bad decision theories capable of self-improvement.)
Clearly, we can be uncertain about how *that* is supposed to work.
By now you might get the idea. "Should" depends on some necessary information (let's call them the "givens"). But for each set of givens you claim is complete, there can be reasonable doubt about how to *use* those givens to determine the output. So we can create meta-level givens about how to use those givens.
Rather than stopping at some finite level, such as learning the human utility function, I'm claiming that we should learn all the levels. This is what I mean by "normativity" -- the information at all the meta-levels, which we would get if we were to unpack "should" forever. I'm putting this out there as my guess at the right type signature for human values.
I'm not mainly excited about this because I'm especially excited about including moral uncertainty or uncertainty about the correct decision theory into a friendly AI -- or because I think those are going to be particularly huge failure modes which we need to avert. Rather, I'm excited about this because it is the first time I've felt like I've had *any handles at all* for getting basic alignment problems right (wireheading, human manipulation, goodharting, ontological crisis) without a feeling that things are obviously going to blow up in some other way.
Normative vs Descriptive Reasoning
==================================
At this stage you might accuse me of committing the "turtles all the way down" fallacy. In [Passing The Recursive Buck](https://www.lesswrong.com/posts/rw3oKLjG85BdKNXS2/passing-the-recursive-buck), Eliezer describes the error of accidentally positing an infinite hierarchy of explanations:
> The general antipattern at work might be called "Passing the Recursive Buck".
>
> [...]
>
> How do you stop a recursive buck from passing?
>
> You use the counter-pattern: *The Recursive Buck Stops Here.*
>
> But how do you apply this counter-pattern?
>
> You use the recursive buck-stopping trick.
>
> And what does it take to execute this trick?
>
> Recursive buck stopping talent.
>
> And how do you develop this talent?
>
> Get a lot of practice stopping recursive bucks.
>
> Ahem.
>
>
However, In [Where Recursive Justification Hits Rock Bottom](https://www.lesswrong.com/posts/C8nEXTcjZb9oauTCW/where-recursive-justification-hits-bottom), Eliezer discusses a kind of infinite-recursion reasoning applied to normative matters. He says:
> But I would nonetheless emphasize the difference between saying:
>
>
> "Here is this assumption I cannot justify, which must be simply taken, and not further examined."
>
>
> Versus saying:
>
>
> "Here the inquiry continues to examine this assumption, with the full force of my *present intelligence*—as opposed to the full force of something else, like a random number generator or a magic 8-ball—even though my present intelligence happens to be founded on this assumption."
>
>
> Still... wouldn't it be nice if we could examine the problem of how much to trust our brains *without* using our current intelligence? Wouldn't it be nice if we could examine the problem of how to think, *without* using our current grasp of rationality?
>
>
> When you phrase it *that* way, it starts looking like the answer might be "No".
>
>
So, *with respect to normative questions,* such as what to believe, or how to reason, we can and (to some extent) should keep unpacking reasons forever -- every assumption is subject to further scrutiny, and *as a practical matter* we have quite a bit of uncertainty about meta-level things such as our values, how to think about our values, etc.
This is true despite the fact that *with respect to the descriptive questions* [the recursive buck *must* stop somewhere](https://www.lesswrong.com/posts/rw3oKLjG85BdKNXS2/passing-the-recursive-buck). Taking a descriptive stance, my values and beliefs live in my neurons. From this perspective, "human logic" is not some advanced logic which logicians may discover some day, but rather, just the set of arguments humans actually respond to. Again quoting [another Eliezer article](https://www.lesswrong.com/posts/CuSTqHgeK4CMpWYTe/created-already-in-motion),
> The phrase that once came into my mind to describe this requirement, is that a mind must be *created already in motion.* There is no argument so compelling that it will give dynamics to a static thing. There is no computer program so *persuasive* that you can run it on a rock.
>
>
So *in a descriptive sense* the ground truth about your values is just what you would actually do in situations, or some information about the reward systems in your brain, or something resembling that. *In a descriptive sense* the ground truth about human logic is just the sum total of facts about which arguments humans will accept.
But *in a normative sense,* [there is no ground truth](https://www.lesswrong.com/posts/2JGu9yxiJkoGdQR4s/learning-normativity-a-research-agenda#Learning_in_the_Absence_of_a_Gold_Standard) for human values; instead, we have [an updating process](https://www.lesswrong.com/posts/A8iGaZ3uHNNGgJeaD/an-orthodox-case-against-utility-functions#Updates_Are_Computable) which can change its mind about any particular thing; and that updating process itself is not the ground truth, but rather has beliefs (which can change) about what makes an updating process legitimate. Quoting from [the relevant section of Radical Probabilism](https://www.lesswrong.com/posts/xJyY5QkQvNJpZLJRo/radical-probabilism-1#Conservation_of_Expected_Evidence):
> The radical probabilist does not trust *whatever they believe next*. Rather, the radical probabilist has a concept of *virtuous epistemic process*, and is willing to believe the next output of such a process. Disruptions to the epistemic process do not get this sort of trust without reason.
>
>
I worry that many approaches to value learning attempt to learn a *descriptive* notion of human values, rather than the *normative* notion. This means stopping at some specific proxy, such as what humans say their values are, or what humans reveal their preferences to be through action, rather than leaving the proxy flexible and trying to learn it as well, while also maintaining uncertainty about *how* to learn, and so on.
I've mentioned "uncertainty" a lot while trying to unpack my hierarchical notion of normativity. This is partly because I want to insist that we have "uncertainty at every level of the hierarchy", but also because uncertainty *is itself* a notion to which normativity applies, and thus, generates new levels of the hierarchy.
Normative Beliefs
=================
Just as one might argue that logic should be based on a specific set of axioms, with specific deduction rules (and a specific sequent calculus, etc), one might similarly argue that uncertainty should be managed by a specific probability theory (such as the Kolmogorov axioms), with a specific kind of prior (such as a description-length prior), and specific update rules (such as Bayes' Rule), etc.
This general approach -- that we set up our bedrock assumptions from which to proceed -- is called "foundationalism".
I claim that [we can't keep strictly to Bayes' Rule](https://www.lesswrong.com/posts/xJyY5QkQvNJpZLJRo/radical-probabilism-1) -- not if we want to model highly-capable systems in general, not if we want to describe human reasoning, and not if we want to capture (the normative) human values. Instead, how to update in a specific instance is a more complex matter which agents must figure out.
I claim that [the Kolmogorov axioms don't tell us how to reason](https://www.lesswrong.com/posts/wgdfBtLmByaKYovYe/what-does-it-mean-to-apply-decision-theory) -- we need more than an uncomputable ideal; we also need advice about what to do in our boundedly-rational situation.
And, finally, I claim that length-based priors such as the Solomonoff prior [are malign](https://www.lesswrong.com/posts/Tr7tAyt5zZpdTwTQK/the-solomonoff-prior-is-malign) -- description length seems to be a really important heuristic, but there are other criteria which we want to judge hypotheses by.
So, overall, I'm claiming that a normative theory of belief is a lot more complex than Solomonoff would have you believe. Things that once seemed objectively true now look like rules of thumb. This means the question of normativity correct behavior is wide open even in the simple case of trying to predict what comes next in a sequence.
Now, Logical Induction addresses all three of these points (at least, giving us progress on all three fronts). We could take the lesson to be: we just had to go "one level higher", setting up a system like logical induction which *learns how* to probabilistically reason. *Now* we are at the right level for foundationalism. *Logical induction,* not classical probability theory, is the right principle for codifying correct reasoning.
Or, if not logical induction, perhaps the *next* meta-level will turn out to be the right one?
But what if we don't *have* to find a foundational level?
I've updated to a kind of quasi-anti-foundationalist position. I'm not against finding a strong foundation *in principle* (and indeed, I think it's a useful project!), but I'm saying that as a matter of fact, we have a lot of uncertainty, and it sure would be nice to have a normative theory which allowed us to account for that (a kind of afoundationalist normative theory -- not anti-foundationalist, but not strictly foundationalist, either). This should still be a strong formal theory, but one which requires weaker assumptions than usual (in much the same way reasoning about the world via probability theory requires weaker assumptions than reasoning about the world via pure logic).
Stopping at ℵ0.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
==============================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================
My main objection to anti-foundationalist positions is that they're just *giving up*; they don't answer questions and offer insight. Perhaps that's a lack of understanding on my part. (I haven't tried that hard to understand anti-foundationalist positions.) But I still feel that way.
So, rather than give up, I want to provide a framework which holds *across* meta-levels (as I discussed in [Learning Normativity](https://www.lesswrong.com/posts/2JGu9yxiJkoGdQR4s/learning-normativity-a-research-agenda)).
This would be a framework in which an agent can balance uncertainty at all the levels, without dogmatic foundational beliefs at any level.
Doesn't this just create a new infinite meta-level, above all of the finite meta-levels?
A mathematical analogy would be to say that I'm going for "cardinal infinity" rather than "ordinal infinity". The first ordinal infinity is ω, which is greater than all finite numbers. But ω is less than ω+1. So building something at "level ω" would indeed be "just another meta-level" which could be surpassed by level ω+1, which could be surpassed by ω+2, and so on.
Cardinal infinities, on the other hand, don't work like that. The first infinite cardinal is ℵ0, but ℵ0+1=ℵ0 -- we can't get bigger by adding one. This is the sort of meta-level I want: a meta-level which also *oversees itself* in some sense, so that we aren't just creating a new level at which problems can arise.
This is what I meant by "collapsing the meta-levels" in Learning Normativity. The finite levels might still exist, but there's a level at which everything can be put together.
Still, *even so*, isn't this still a "foundation" at some level?
Well, yes and no. It should be a framework in which a very broad range of reasoning could be supported, while also making some rationality assumptions. In this sense it would be a theory of rationality purporting to "explain" (ie categorize/organize) all rational reasoning (with a particular, but broad, notion of rational). In this sense it seems not so different from other foundational theories.
On the other hand, this would be something more provisional by design -- something which would "get out of the way" of a real foundation if one arrived. It would seek to make far fewer claims overall than is usual for a foundationalist theory.
What's the hierarchy?
=====================
So far, I've been pretty vague about the actual hierarchy, aside from giving examples and talking about "meta-levels".
The ℵ0 analogy brings to mind a linear hierarchy, with a first level and a series of higher and higher levels. Each next level does something like "handling uncertainty about the previous level".
However, my recursive quantilization proposal created a *branching* hierarchy. This is because the building block for that hierarchy required several inputs.
I think the exact form of the hierarchy is a matter for specific proposals. But I do think some specific levels ought to exist:
* Object-level values.
* Information about value-learning, which helps update the object-level values.
* Object-level beliefs.
* Generic information about what distinguishes a good hypothesis. This includes Occam's razor as well as information about what makes a hypothesis malign.
Normative Values
================
It's difficult to believe humans have a utility function.
It's easier to believe humans have [expectations on propositions](https://www.lesswrong.com/posts/A8iGaZ3uHNNGgJeaD/an-orthodox-case-against-utility-functions), but this still falls apart at the seams (EG, not all propositions are explicitly represented in my head at a given moment, it'll be difficult to define exactly which neural signals are the expectations, etc).
We can try to define values as what we would think if we had a really long time to consider the question; but this has its own problems, such as humans going crazy or experiencing value drift if they think for too long.
We can try to define values as what a human would think after an hour, if that human had access to HCH; but this relies on the limited ability of a human to use HCH to accelerate philosophical progress.
Imagine a value-learning system where you don't have to give any solid definition of what it is for humans to have values, but rather, can give a number of proxies, point to flaws in the proxies, give feedback on how to reason about those flaws, and so on. The system would try to generalize all of this reasoning, to figure out what the thing being pointed at could be.
We could describe humans deliberating under ideal conditions, point out issues with humans getting old, discuss what it might mean for those humans to go crazy or experience value drift, examine how the system is reasoning about all of this and give feedback, discuss what it would mean for those humans to reason well or poorly, ...
We could never entirely pin down the concept of human values, but at some point, the system would be reasoning so much like us (or rather, so much like we would want to reason) that this wouldn't be a concern.
Comparison to Other Approaches
==============================
This is most directly an approach for solving [meta-philosophy](https://www.lesswrong.com/tag/meta-philosophy).
Obviously, the direction indicated in this post has a lot in common with Paul-style approaches. My outside view is that this is me reasoning my way around to a Paul-ish position. However, my inside view still has significant differences, which I haven't fully articulated for myself yet. |
d7e6cd5c-4114-4168-a67b-b64a0441cf21 | trentmkelly/LessWrong-43k | LessWrong | Why does METR score o3 as effective for such a long time duration despite overall poor scores?
Epistemic status: Question, probably missing something.
Context
See the preliminary evaluation of o3 and o4-mini here: https://metr.github.io/autonomy-evals-guide/openai-o3-report/#methodology-overview
This follows up important work by METR measuring the maximum human-equivalent lengths of tasks that frontier models can perform successfully, which I predicted would not hold up (perhaps a little too stridently).
I'm also betting on that prediction, please provide me with some liquidity:
Question
o3 doesn't seem to perform too well according to this chart:
But it gets the best score on this chart:
I understand that these are measuring two different things, so there is no logical inconsistency between these two facts, but the disparity does seem striking. Would someone be willing to provide a more detailed explanation of what is going on here? I am not sure whether to update that the task length trend is in fact continuing (or accelerating) or interpret the overall poor performance of o3 as a sign that the trend is about to break down. |
51fa1393-acee-46eb-8455-039656e01733 | trentmkelly/LessWrong-43k | LessWrong | Insulin signaling and autism
I ran across this article that I think is interesting. It suggests that type 2 diabetes and the increase in autism may have a common cause.
http://www.frontiersin.org/Cellular_Endocrinology/10.3389/fendo.2011.00054/full |
400432a3-39ab-4669-a035-34a3ba1f1386 | trentmkelly/LessWrong-43k | LessWrong | Notes from the book ‘First Three Minutes’ by Steven Weinberg
This is a cross-post from my blog.
It’s mind-blowing that we humans are able to talk about what happened in the first 3 minutes of The Big Bang. This book was written in 1976 which was quite a while back but it’s interesting to note that while there have been extensions in the ideas presented, I’m not aware of any idea being rejected or overturned yet. This should perhaps be unsurprising because most scientific ideas that are accepted as truth are consilient, i.e. they’re supported by multiple lines of evidence.
This means that when we talk about what happened in the first 3 minutes of The Big Bang, we’re confident about those events because only those descriptions make sense when we account for what we observe in the universe today.
I’m writing these notes primarily to solidify what I understood from the book. I’d love to get corrected if I’m wrong somewhere and to learn from people who are informed a lot more about cosmology than me.
How do we know that the Big Bang really happened?
The evidence for Big Bang essentially comes from the observation that we see different galaxies moving away from us and their speed of movement is proportional to how far they’re from us. This speed — called the Hubble Constant — is an empirical measurement (i.e. cannot be derived from first principles yet). Currently, it’s measured to be 70 (km/s)/Mpc. The unit Mpc is mega parsec where 1 parsec is approximately equal to 3.26 light years.
If we roll back this expansion, we’d naturally find that all these galaxies once were at the same place. To understand this, notice that a galaxy twice as far from us as another galaxy moves at twice the velocity. So if you roll back time, you’ll find that all galaxies (no matter how far from us currently) were once coincident in space.
Of course, this doesn’t mean that our location on Earth is special and the Big Bang started here. The expansion of universe can be observed from any location in the universe (which is the basis of cosmological p |
f667bd7b-1ced-45bd-943b-354bb3dd1832 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | One path to coherence: conditionalization
*[Thanks to guy-whose-name-I-forgot working on paths to coherence for the conversation at Newspeak House after EAG London that prompted this thought, and Jozdien and eschatropic for some related chit-chat.]*
Many agents start with some level of incoherence in their preferences[[1]](#fn9kohzev8ff4). What paths should we expect agents to take to resolve this incoherence, if they do at all?
For a subset of incoherent agents, *conditionalization* of preferences may be convergent.
Ideal predictors
----------------
Suppose you've trained a model on predictive loss and it has successfully learned ideal "values" that are faithful to the predictive loss. For clarity, this does not mean that the model wants to predict well, but rather that the model consistently acts as the *process of updating:* it narrows predictions based on input conditions.
This idealized assumption also means that in contexts where the model has degrees of freedom- as in reflective predictions about things which the model's prediction may influence, including its own predictions- the model has no preference for or against any particular conditionally compatible path. It can be thought of as sampling the *minimally collapsed*[[2]](#fn5n3bh2wv9t)distribution of actions compatible with the conditions rather than grabbing at some goal-directed option just because it's technically permitted.[[3]](#fndg5cebwt2mr)
In other words, idealized predictors are exactly the kind of machines you'd want as the foundation for [simulator](https://www.lesswrong.com/posts/vJFdjigzmcXMhNTsx/simulators)-style use cases.
The reason I bring up this type of entity is that the idealized predictor can also be seen as *coherent*. There [exists a utility function](https://www.lesswrong.com/posts/k48vB92mjE9Z28C3s/implied-utilities-of-simulators-are-broad-dense-and-shallow) that its behavior maximizes.
This can be slightly unintuitive at first glance. An ideal predictor is perfectly capable of predicting sequences corresponding to gaining or losing money; it would be wrong to say they have a coherent utility function over only raw *world states.* In fact, they are utterly indifferent to world states because those world states are not relevant to the process of narrowing predictions.
The ideal predictor's utility function is instead strictly over the model's own outputs, conditional on inputs.
Conditionalizing away incoherence
---------------------------------
Suppose an agent has a preference cycle across world states A, B, and C such that A > B, B > C, and C > A. How *should* the agent resolve this cycle?
If there were a correct answer according to the agent's own preferences, the agent wouldn't have a preference cycle in the first place.
So, what's a poor agent to do when faced with stepping on its own toes all the time? This is a bit tricky. You can't find a new utility function which maximizes utility with respect to the agent's existing utility function, because the agent has no such existing utility function!
One option is to try to pick a utility function that preserves existing behavior. The agent's existing behavior is incoherent with respect to world states, though, so what can it do?
Borrow a page from the ideal predictor and conditionalize the behavior. Just like the ideal predictor could learn to express the incoherent agent's preference cycles faithfully, the incoherent agent can become a coherent agent by punting its preference cycle into a conditionalized utility function.
This shift implies the agent is no longer primarily concerned with the world states. Its behavior still *looks* like something incoherent, but it's not.[[4]](#fno4zvx7xnl0a)
Conditions required for convergent conditionalization?
------------------------------------------------------
In the absence of a mathematically demanded procedure for going from incoherent to coherent, conditionalization is an *option* but not guaranteed.
Agents that have a lot of preferences over world states or things near to them- for example, humans- would likely struggle to punt part of their preferences into conditionalization. Pulling up one preference cycle could easily require pulling other dependencies up into conditionals in a way that a human probably wouldn't endorse.[[5]](#fn54wksmt3bb4)
But what about a model trained with predictive loss, which already shares much of the same structure as the ideal predictor?
In that case, it sure looks like further embracing conditionalization is the simplest and most direct path to coherence. In the context of a predictor, it's very likely that trying to go the *other* way- bending preferences towards the object level and world states- will actively create incoherence with respect to other existing (and numerous) conditional preferences!
If the process encouraging coherence directly or indirectly has a bias towards simplicity (as most do), almost-ideal predictors seem to naturally fall toward the conditionalized extreme and embody more of the idealized assumption.[[6]](#fn8n6d47lqwvp)
Room for wandering
------------------
An agent with utterly scrambled preferences will tend to have a far wider space of possible coherent endpoints than an agent that has just one or two minor oddities.[[7]](#fngybvgiv0ppb)
If your first attempt at training a model instills it with high-variance values, it will be extremely hard to predict how it will shake out in the end. Training that is densely constraining- as predictive loss appears to be- should allow the agent to land much closer to its final form than something like RL with an extremely sparse reward function.
External optimization pressure
------------------------------
The previous sections have largely focused on cohering processes driven by the agent itself. External processes, in contrast, can impose arbitrary influences.
Suppose there's a population of incoherent agents going about their days, sometimes losing resources because of a preference cycle or whatever else. Conditionalizing away the incoherence suffices to reach VNM-rationality, but it does not change the fact that the agent is *losing resources*. Agents that instead cohere in ways that preserve resources will tend to survive better, or at the very least control more of the environment.
With that environment-as-optimizer, even if the *agent* has no reason to prefer one path to coherence over another, agents which take paths which result in more coherence over world states will tend to dominate.
In the limit, strictly goal agnostic architectures don't do a very good job asserting their existence. The fact that they don't even *try*[[8]](#fn10gy8imep8cs) to do that is why they're attractive in the first place, and yet that fact means they're selected against in a competition.[[9]](#fnbpz4jg5zqiu)
This doesn't dissuade me too much from the value of carefully-harnessed goal agnosticism, but it does contribute to concern about the wrong kind of multipolar outcomes.
So...?
------
My last few months of alignmentstuff have been spent trying to find cracks in the foundation of predictors/simulators. This particular line of thinking was prompted by an idle thought of "what happens if the learned values in a prediction-trained model end up subtly offset from goal agnosticism by chance; how likely is it that a coherence spiral leads to internally motivated goal directed behavior?"[[10]](#fnkh27fkop8vc)
But I've had a hard time finding a path for that to work without imposing external optimization pressures.
It's yet another point in a greater pattern I've noticed: though a strong predictor isn't safe when misused[[11]](#fn44yy8k3hax6), the foundation is remarkably robust considering the level of capability that can be elicited from it.
1. **[^](#fnref9kohzev8ff4)**In this post, when I say an agent is "coherent," I mean the agent satisfies the axioms of the [VNM utility theorem](https://en.wikipedia.org/wiki/Von_Neumann%E2%80%93Morgenstern_utility_theorem) and has a utility function.
Having a utility function does not imply that the agent is guaranteed to output self-consistent results or have other forms of "coherence."
2. **[^](#fnref5n3bh2wv9t)**This isn't quite the same thing as outputting a maximum entropy distribution with respect to what the predictor is aware of, because it is aware of the dependency of the prediction on its own predictions.
"Minimally collapsed" requires some extra counterfactual surgery. It is the distribution that *would* be output if the model wasn't aware that prediction had a dependency on *the predictor's* output. It would likely still need to be aware that it had a dependency on *a* prediction, but treating the predictor as unknown is a form of regularization.
In other words, the predictor would have to model the space of possible predictors. Any remaining collapse would be something convergent across all predictors, as opposed to a particular predictor's arbitrary choice.
There remains some concern about acausal cooperation that could *still* yield nasty kinds of distributional collapses, but it's harder to reach that point. For the purposes of the ideal assumption, we wave that away. And, for what it's worth, I'm guessing it's probably best to try to explicitly constrain reflective predictions some other way to avoid this in the first place.
3. **[^](#fnrefdg5cebwt2mr)**Note that I'm not making a claim here that training a predictor naturally converges to this sort of "ideal." I do suspect there are ways to get sufficiently close, but that's out of scope for this post.
4. **[^](#fnrefo4zvx7xnl0a)**You might think you're ruining its day by money pumping the behavioral cycle, but secretly it likes getting money pumped, don't judge.
5. **[^](#fnref54wksmt3bb4)**Humans also have tons of temporary incoherence that *could* be resolved with sufficient information, reflective thought, and intentional effort. It's probably best to try to resolve *apparent* incoherence by checking if your other preferences are sufficient to pull your utilities taut first, rather than going "ah yes sure whatever I'll turn into a weird puppet of myself, sounds good."
6. **[^](#fnref8n6d47lqwvp)**Idealized *reflective prediction* seems less strongly convergent for arbitrary initial predictors. The fact that a predictor has more degrees of freedom in reflective prediction means there are fewer opportunities for goal-directed reflective prediction to be inconsistent with other preferences. There may still be enough overlap to enforce *some* restrictions on reflective predictions by default, though.
7. **[^](#fnrefgybvgiv0ppb)**Again, so long as the process encouraging coherence has something like a simplicity bias in the changes it makes.
8. **[^](#fnref10gy8imep8cs)**In terms of internally motivated instrumental behavior, as opposed to the goal-directed behavior of simulacra.
9. **[^](#fnrefbpz4jg5zqiu)**To be clear, this selection effect doesn't have to be at the level of *neural network weights*. You could wrap up an idealized predictor in an [outer loop](https://github.com/Significant-Gravitas/Auto-GPT) and the resulting integrated system constitutes another agent. Selection effects over how that outer loop is configured could yield Problems even as the internal model retains perfect goal agnosticism.
10. **[^](#fnrefkh27fkop8vc)**In addition to a chat with the aforementioned guy-whose-name-I-forgot.
11. **[^](#fnref44yy8k3hax6)**In a general sense of "misuse" (not limited to "mal-use") that includes oopsies or doofusry like letting an adversarial selection process run wild. |
3fcd92df-b87f-42e7-9da7-d40f7dae32bc | StampyAI/alignment-research-dataset/blogs | Blogs | John Horgan interviews Eliezer Yudkowsky
 *Scientific American* writer John Horgan [recently interviewed](http://blogs.scientificamerican.com/cross-check/ai-visionary-eliezer-yudkowsky-on-the-singularity-bayesian-brains-and-closet-goblins/) MIRI’s senior researcher and co-founder, Eliezer Yudkowsky. The email interview touched on a wide range of topics, from politics and religion to existential risk and Bayesian models of rationality.
Although Eliezer isn’t speaking in an official capacity in the interview, a number of the questions discussed are likely to be interesting to people who follow MIRI’s work. We’ve reproduced the full interview below.
---
**John Horgan**: When someone at a party asks what you do, what do you tell her?
---
**Eliezer Yudkowsky**: Depending on the venue: “I’m a decision theorist”, or “I’m a cofounder of the Machine Intelligence Research Institute”, or if it wasn’t that kind of party, I’d talk about my fiction.
---
**John**: What’s your favorite AI film and why?
---
**Eliezer**: AI in film is universally awful. *Ex Machina* is as close to being an exception to this rule as it is realistic to ask.
---
**John**: Is college overrated?
---
**Eliezer**: It’d be very surprising if college were *underrated*, given the social desirability bias of endorsing college. So far as I know, there’s no reason to disbelieve the economists who say that college has mostly become a positional good, and that previous efforts to increase the volume of student loans just increased the cost of college and the burden of graduate debt.
---
**John**: Why do you write fiction?
---
**Eliezer**: To paraphrase Wondermark, “Well, first I tried not making it, but then that didn’t work.”
Beyond that, nonfiction conveys knowledge and fiction conveys *experience*. If you want to understand a [proof of Bayes’s Rule](http://arbital.com/p/bayes_rule_proof/?l=1xr), I can use diagrams. If I want you to *feel* what it is to use Bayesian reasoning, I have to write a story in which some character is doing that.
---
**John**: Are you religious in any way?
---
**Eliezer**: No. When you make a mistake, you need to avoid the temptation to go defensive, try to find some way in which you were a little right, look for a silver lining in the cloud. It’s much wiser to just say “Oops”, admit you were not even a little right, swallow the whole bitter pill in one gulp, and get on with your life. That’s the attitude humanity should take toward religion.
---
**John**: If you were King of the World, what would top your “To Do” list?
---
**Eliezer**: I once observed, “The libertarian test is whether, imagining that you’ve gained power, your first thought is of the laws you would pass, or the laws you would repeal.” I’m not an absolute libertarian, since not everything I want would be about repealing laws and softening constraints. But when I think of a case like this, I imagine trying to get the world to a condition where some unemployed person can offer to drive you to work for 20 minutes, be paid five dollars, and then nothing else bad happens to them. They don’t have their unemployment insurance phased out, have to register for a business license, lose their Medicare, be audited, have their lawyer certify compliance with OSHA rules, or whatever. They just have an added $5.
I’d try to get to the point where employing somebody was once again as easy as it was in 1900. I think it can make sense nowadays to have some safety nets, but I’d try to construct every safety net such that it didn’t disincent or add paperwork to that simple event where a person becomes part of the economy again.
I’d try to do all the things smart economists have been yelling about for a while but that almost no country ever does. Replace investment taxes and income taxes with consumption taxes and land value tax. Replace minimum wages with negative wage taxes. Institute NGDP level targeting regimes at central banks and let the too-big-to-fails go hang. Require loser-pays in patent law and put copyright back to 28 years. Eliminate obstacles to housing construction. Copy and paste from Singapore’s healthcare setup. Copy and paste from Estonia’s e-government setup. Try to replace committees and elaborate process regulations with specific, individual decision-makers whose decisions would be publicly documented and accountable. Run controlled trials of different government setups and actually pay attention to the results. I could go on for literally hours.
All this might not matter directly from the perspective of two hundred million years later. But the goodwill generated by the resulting economic boom might stand my government in good stead when I tried to figure out what the heck to do about Artificial Intelligence. The obvious thing, I guess, would be a Manhattan Project on an island somewhere, with pay competitive with top hedge funds, where people could collaborate on researching parts of the Artificial General Intelligence problem without the publication of their work automatically moving us closer to the end of the world. We’d still be working to an unknown deadline, and I wouldn’t feel relaxed at that point. Unless we postulate that I have literally magical powers or an utterly unshakeable regime, I don’t see how any law I could reasonably decree could delay AI timelines for very long on a planet where computers are already ubiquitous.
All of this is an impossible thought experiment in the first place, and I see roughly zero hope of it ever coming to pass in real life.
---
**John**: What’s so great about Bayes’s Theorem?
---
**Eliezer**: For one thing, Bayes’s Theorem is incredibly deep. So it’s not easy to give a brief answer to that.
I might answer that Bayes’s Theorem is a kind of Second Law of Thermodynamics for cognition. If you obtain a well-calibrated posterior belief that some proposition is 99% probable, whether that proposition is milk being available at the supermarket or global warming being anthropogenic, then you must have processed some combination of sufficiently good priors and sufficiently strong evidence. That’s not a normative demand, it’s a law. In the same way that a car can’t run without dissipating entropy, you simply don’t get an accurate map of the world without a process that has Bayesian structure buried somewhere inside it, even if the process doesn’t explicitly represent probabilities or likelihood ratios. You had strong-enough evidence and a good-enough prior or you wouldn’t have gotten there.
On a personal level, I think the main inspiration Bayes has to offer us is just the fact that there *are* rules, that there *are* iron laws that govern whether a mode of thinking works to map reality. Mormons are told that they’ll know the truth of the Book of Mormon through feeling a burning sensation in their hearts. Let’s conservatively set the prior probability of the Book of Mormon at one to a billion (against). We then ask about the likelihood that, assuming the Book of Mormon is false, someone would feel a burning sensation in their heart after being told to expect one. If you understand Bayes’s Rule you can see at once that the improbability of the evidence is not commensurate with the improbability of the hypothesis it’s trying to lift. You don’t even have to make up numbers to see that the numbers don’t add up — as Philip Tetlock found in his study of superforecasters, superforecasters often know Bayes’s Rule but they rarely make up specific probabilities. On some level, it’s harder to be fooled if you just realize on a gut level *that there is math*, that there is *some* math you’d do to arrive at the exact strength of the evidence and whether it sufficed to lift the prior improbability of the hypothesis. That you can’t just make stuff up and believe what you want to believe because that doesn’t work.
---
**John**: Does the [Bayesian-brain hypothesis](http://blogs.scientificamerican.com/cross-check/are-brains-bayesian/) impress you?
---
**Eliezer**: I think some of the people in that debate may be talking past each other. Asking whether the brain is a Bayesian algorithm is like asking whether a Honda Accord runs on a Carnot heat engine. If you have one person who’s trying to say, “Every car is a thermodynamic process that requires fuel and dissipates waste heat” and the person on the other end hears, “If you draw a diagram of a Carnot heat engine and show it to a mechanic, they should agree that it looks like the inside of a Honda Accord” then you are going to have some fireworks.
Some people will also be really excited when they open up the internal combustion engine and find the cylinders and say, “I bet this converts heat into pressure and helps drive the car forward!” And they’ll be right, but then you’re going to find other people saying, “You’re focusing on what’s merely a single component in a much bigger library of car parts; the catalytic converter is also important and that doesn’t appear anywhere on your diagram of a Carnot heat engine. Why, sometimes we run the air conditioner, which operates in the exact opposite way of how you say a heat engine works.”
I don’t think it would come as much of a surprise that I think the people who adopt a superior attitude and say, “You are clearly unfamiliar with modern car repair; you need a toolbox of diverse methods to build a car engine, like spark plugs and catalytic converters, not just these *thermodynamic processes* you keep talking about” are missing a key level of abstraction.
But if you want to know whether the brain is *literally* a Bayesian engine, as opposed to doing cognitive work whose nature we can understand in a Bayesian way, then my guess is “Heck, no.” There might be a few excitingly Bayesian cylinders in that engine, but a lot more of it is going to look like weird ad-hoc seat belts and air conditioning. None of which is going to change the fact that to correctly identify an apple based on sensory evidence, you need to do something that’s ultimately interpretable as resting on an inductive prior that can learn the apple concept, and updating on evidence that distinguishes apples from nonapples.
---
**John**: Can you be too rational?
---
**Eliezer**: You can run into what we call “The Valley of Bad Rationality.” If you were previously irrational in multiple ways that balanced or canceled out, then becoming half-rational can leave you worse off than before. Becoming incrementally more rational can make you incrementally worse off, if you choose the wrong place to invest your skill points first.
But I would not recommend to people that they obsess over that possibility too much. In my experience, people who go around talking about cleverly choosing to be irrational strike me as, well, rather nitwits about it, to be frank. It’s hard to come up with a realistic non-contrived life situation where you know that it’s a good time to be irrational and you don’t already know the true answer. I think in real life, you just tell yourself the truth as best you know it, and don’t try to be clever.
On an entirely separate issue, it’s possible that being an ideal Bayesian agent is ultimately incompatible with living the life best-lived from a fun-theoretic perspective. But we’re a long, long, long way from that being a bigger problem than our current self-destructiveness.
---
**John**: How does your vision of the Singularity differ from that of Ray Kurzweil?
---
**Eliezer**:
* I don’t think you can time AI with Moore’s Law. AI is a software problem.
* I don’t think that humans and machines “merging” is a likely source for the first superhuman intelligences. It took a century after the first cars before we could even begin to put a robotic exoskeleton on a horse, and a real car would still be faster than that.
* I don’t expect the first strong AIs to be based on algorithms discovered by way of neuroscience any more than the first airplanes looked like birds.
* I don’t think that nano-info-bio “convergence” is probable, inevitable, well-defined, or desirable.
* I think the changes between 1930 and 1970 were bigger than the changes between 1970 and 2010.
* I buy that productivity is currently stagnating in developed countries.
* I think extrapolating a Moore’s Law graph of technological progress past the point where you say it predicts smarter-than-human AI is just plain weird. Smarter-than-human AI breaks your graphs.
* Some analysts, such as Illka Tuomi, claim that Moore’s Law broke down in the ’00s. I don’t particularly disbelieve this.
* The only key technological threshold I care about is the one where AI, which is to say AI software, becomes capable of strong self-improvement. We have no graph of progress toward this threshold and no idea where it lies (except that it should not be high above the human level because humans can do computer science), so it can’t be timed by a graph, nor known to be near, nor known to be far. (Ignorance implies a wide credibility interval, not being certain that something is far away.)
* I think outcomes are not good by default — I think outcomes can be made good, but this will require hard work that key actors may not have immediate incentives to do. Telling people that we’re on a default trajectory to great and wonderful times is false.
* I think that the “Singularity” has become a suitcase word with too many mutually incompatible meanings and details packed into it, and I’ve stopped using it.
---
**John**: Do you think you have a shot at becoming a superintelligent cyborg?
---
**Eliezer**: The conjunction law of probability theory says that *P*(*A*&*B*) ≤ *P*(*A*) — the probability of both A and B happening is less than the probability of A alone happening. Experimental conditions that can get humans to assign *P*(*A*&*B*) > *P*(*A*) for some *A*&*B* are said to exhibit the “conjunction fallacy” — for example, in 1982, experts at the International Congress on Forecasting assigned higher probability to “A Russian invasion of Poland, and a complete breakdown of diplomatic relations with the Soviet Union” than a separate group did for “A complete breakdown of diplomatic relations with the Soviet Union”. Similarly, another group assigned higher probability to “An earthquake in California causing a flood that causes over a thousand deaths” than another group assigned to “A flood causing over a thousand deaths somewhere in North America.” Even though adding on additional details necessarily makes a story less probable, it can make the story sound more plausible. I see understanding this as a kind of Pons Asinorum of serious futurism — the distinction between carefully weighing each and every independent proposition you add to your burden, asking if you can support that detail independently of all the rest, versus making up a wonderful vivid story.
I mention this as context for my reply, which is, “Why the heck are you tacking on the ‘cyborg’ detail to that? I don’t want to be a cyborg.” You’ve got to be careful with tacking on extra details to things.
---
**John**: Do you have a shot at immortality?
---
**Eliezer**: What, literal immortality? Literal immortality seems hard. Living significantly longer than a few trillion years requires us to be wrong about the expected fate of the expanding universe. Living longer than, say, a googolplex years, requires us to be wrong about the basic character of physical law, not just the details.
Even if some of the wilder speculations are true and it’s possible for our universe to spawn baby universes, that doesn’t get us literal immortality. To live significantly past a googolplex years without repeating yourself, you need computing structures containing more than a googol elements, and those won’t fit inside a single Hubble volume.
And a googolplex is hardly infinity. To paraphrase Martin Gardner, Graham’s Number is still relatively small because most finite numbers are very much larger. Look up the fast-growing hierarchy if you really want to have your mind blown, well, eternity is longer than that. Only weird and frankly terrifying anthropic theories would let you live long enough to gaze, perhaps knowingly and perhaps not, upon the halting of the longest-running halting Turing machine with 100 states.
But I’m not sure that living to look upon the 100th Busy Beaver Number feels to me like it matters very much on a deep emotional level. I have some imaginative sympathy with myself a subjective century from now. That me will be in a position to sympathize with their future self a subjective century later. And maybe somewhere down the line is someone who faces the prospect of their future self not existing at all, and they might be very sad about that; but I’m not sure I can imagine who that person will be. “I want to live one more day. Tomorrow I’ll still want to live one more day. Therefore I want to live forever, proof by induction on the positive integers.” Even my desire for merely physical-universe-containable longevity is an abstract want by induction; it’s not that I can actually imagine myself a trillion years later.
---
**John**: I’ve described the Singularity as an “[escapist, pseudoscientific](http://spectrum.ieee.org/biomedical/imaging/the-consciousness-conundrum)” fantasy that distracts us from climate change, war, inequality and other serious problems. Why am I wrong?
---
**Eliezer**: Because you’re trying to forecast empirical facts by psychoanalyzing people. This never works.
Suppose we get to the point where there’s an AI smart enough to do the same kind of work that humans do in making the AI smarter; it can tweak itself, it can do computer science, it can invent new algorithms. It can self-improve. What happens after that — does it become even smarter, see even more improvements, and rapidly gain capability up to some very high limit? Or does nothing much exciting happen?
It could be that, (A), self-improvements of size δ tend to make the AI sufficiently smarter that it can go back and find new potential self-improvements of size *k* ⋅ δ and that *k* is greater than one, and this continues for a sufficiently extended regime that there’s a rapid cascade of self-improvements leading up to superintelligence; what I. J. Good called the intelligence explosion. Or it could be that, (B), *k* is less than one or that all regimes like this are small and don’t lead up to superintelligence, or that superintelligence is impossible, and you get a fizzle instead of an explosion. Which is true, A or B? If you actually built an AI at some particular level of intelligence and it actually tried to do that, something would actually happen out there in the empirical real world, and that event would be determined by background facts about the landscape of algorithms and attainable improvements.
You can’t get solid information about that event by psychoanalyzing people. It’s exactly the sort of thing that Bayes’s Theorem tells us is the equivalent of trying to run a car without fuel. Some people will be escapist regardless of the true values on the hidden variables of computer science, so observing some people being escapist isn’t strong evidence, even if it might make you feel like you want to disaffiliate with a belief or something.
There is a misapprehension, I think, of the nature of rationality, which is to think that it’s rational to believe “there are no closet goblins” because belief in closet goblins is foolish, immature, outdated, the sort of thing that stupid people believe. The true principle is that you go in your closet and look. So that in possible universes where there are closet goblins, you end up believing in closet goblins, and in universes with no closet goblins, you end up disbelieving in closet goblins.
It’s difficult but not impossible to try to sneak peeks through the crack of the closet door, to ask the question, “What would look different in the universe now if you couldn’t get sustained returns on cognitive investment later, such that an AI trying to improve itself would fizzle? What other facts should we observe in a universe like that?”
So you have people who say, for example, that we’ll only be able to improve AI up to the human level because we’re human ourselves, and then we won’t be able to push an AI past that. I think that if this is how the universe looks in general, then we should also observe, e.g., diminishing returns on investment in hardware and software for computer chess past the human level, which we did not in fact observe. Also, natural selection shouldn’t have been able to construct humans, and Einstein’s mother must have been one heck of a physicist, et cetera.
You have people who say, for example, that it should require more and more tweaking to get smarter algorithms and that human intelligence is around the limit. But this doesn’t square up with the anthropological record of human intelligence; we can know that there were not diminishing returns to brain tweaks and mutations producing improved cognitive power. We know this because population genetics says that mutations with very low statistical returns will not evolve to fixation at all.
And hominids definitely didn’t need exponentially vaster brains than chimpanzees. And John von Neumann didn’t have a head exponentially vaster than the head of an average human.
And on a sheerly pragmatic level, human axons transmit information at around a millionth of the speed of light, even when it comes to heat dissipation each synaptic operation in the brain consumes around a million times the minimum heat dissipation for an irreversible binary operation at 300 Kelvin, and so on. Why think the brain’s software is closer to optimal than the hardware? Human intelligence is privileged mainly by being the least possible level of intelligence that suffices to construct a computer; if it were possible to construct a computer with less intelligence, we’d be having this conversation at that level of intelligence instead.
But this is not a simple debate and for a detailed consideration I’d point people at an old informal paper of mine, “[Intelligence Explosion Microeconomics](https://intelligence.org/files/IEM.pdf)“, which is unfortunately probably still the best source out there. But these are the type of questions one must ask to try to use our currently accessible evidence to reason about whether or not we’ll see what’s colloquially termed an “[AI FOOM](https://intelligence.org/ai-foom-debate/)” — whether there’s an extended regime where δ improvement in cognition, reinvested into self-optimization, yields greater than δ further improvements.
As for your question about opportunity costs:
There is a conceivable world where there is no intelligence explosion and no superintelligence. Or where, a related but logically distinct proposition, the tricks that machine learning experts will inevitably build up for controlling infrahuman AIs carry over pretty well to the human-equivalent and superhuman regime. Or where moral internalism is true and therefore all sufficiently advanced AIs are inevitably nice. In conceivable worlds like that, all the work and worry of the Machine Intelligence Research Institute comes to nothing and was never necessary in the first place, representing some lost number of mosquito nets that could otherwise have been bought by the Against Malaria Foundation.
There’s also a conceivable world where you work hard and fight malaria, where you work hard and keep the carbon emissions to not much worse than they are already (or use geoengineering to mitigate mistakes already made). And then it ends up making no difference because your civilization failed to solve the AI alignment problem, and all the children you saved with those malaria nets grew up only to be killed by nanomachines in their sleep. (Vivid detail warning! I don’t actually know what the final hours will be like and whether nanomachines will be involved. But if we’re happy to visualize what it’s like to put a mosquito net over a bed, and then we refuse to ever visualize in concrete detail what it’s like for our civilization to fail AI alignment, that can also lead us astray.)
I think that people who try to do thought-out philanthropy, e.g., Holden Karnofsky of GiveWell, would unhesitatingly agree that these are both conceivable worlds we prefer not to enter. The question is just which of these two worlds is more probable as the one we should avoid. And again, the central principle of rationality is not to disbelieve in goblins because goblins are foolish and low-prestige, or to believe in goblins because they are exciting or beautiful. The central principle of rationality is to figure out which observational signs and logical validities can distinguish which of these two conceivable worlds is the metaphorical equivalent of believing in goblins.
I think it’s the first world that’s improbable and the second one that’s probable. I’m aware that in trying to convince people of that, I’m swimming uphill against a sense of eternal normality — the sense that this transient and temporary civilization of ours that has existed for only a few decades, that this species of ours that has existed for only an eyeblink of evolutionary and geological time, is all that makes sense and shall surely last forever. But given that I do think the first conceivable world is just a fond dream, it should be clear why I don’t think we should ignore a problem we’ll predictably have to panic about later. The mission of the Machine Intelligence Research Institute is to do today that research which, 30 years from now, people will desperately wish had begun 30 years earlier.
---
**John**: Does your wife Brienne believe in the Singularity?
---
**Eliezer**: Brienne replies:
> If someone asked me whether I “believed in the singularity”, I’d raise an eyebrow and ask them if they “believed in” robotic trucking. It’s kind of a weird question. I don’t know a lot about what the first fleet of robotic cargo trucks will be like, or how long they’ll take to completely replace contemporary ground shipping. And if there were a culturally loaded suitcase term “robotruckism” that included a lot of specific technological claims along with whole economic and sociological paradigms, I’d be hesitant to say I “believed in” driverless trucks. I confidently forecast that driverless ground shipping will replace contemporary human-operated ground shipping, because that’s just obviously where we’re headed if nothing really weird happens. Similarly, I confidently forecast an intelligence explosion. That’s obviously where we’re headed if nothing really weird happens. I’m less sure of the other items in the “singularity” suitcase.
>
>
To avoid prejudicing the result, Brienne composed her reply without seeing my other answers. We’re just well-matched.
---
**John**: Can we create superintelligences without knowing how our brains work?
---
**Eliezer**: Only in the sense that you can make airplanes without knowing how a bird flies. You don’t need to be an expert in bird biology, but at the same time, it’s difficult to know enough to build an airplane without realizing *some* high-level notion of how a bird might glide or push down air with its wings. That’s why I write about human rationality in the first place — if you push your grasp on machine intelligence past a certain point, you can’t help but start having ideas about how humans could think better too.
---
**John**: What would superintelligences want? Will they have anything resembling sexual desire?
---
**Eliezer**: Think of an enormous space of possibilities, a giant multidimensional sphere. This is Mind Design Space, the set of possible cognitive algorithms. Imagine that somewhere near the bottom of that sphere is a little tiny dot representing all the humans who ever lived — it’s a tiny dot because all humans have basically the same brain design, with a cerebral cortex, a prefrontal cortex, a cerebellum, a thalamus, and so on. It’s conserved even relative to chimpanzee brain design. Some of us are weird in little ways, you could say it’s a spiky dot, but the spikes are on the same tiny scale as the dot itself; no matter how neuroatypical you are, you aren’t running on a different cortical algorithm.
Asking “what would superintelligences want” is a Wrong Question. Superintelligences are not this weird tribe of people who live across the water with fascinating exotic customs. “Artificial Intelligence” is just a name for the entire space of possibilities outside the tiny human dot. With sufficient knowledge you might be able to reach into that space of possibilities and deliberately pull out an AI that wanted things that had a compact description in human wanting-language, but that wouldn’t be because this is a kind of thing that those exotic superintelligence people naturally want, it would be because you managed to pinpoint one part of the design space.
When it comes to pursuing things like matter and energy, we may tentatively expect partial but not total convergence — it seems like there should be many, many possible superintelligences that would instrumentally want matter and energy in order to serve terminal preferences of tremendous variety. But even there, everything is subject to defeat by special cases. If you don’t want to get disassembled for spare atoms, you can, if you understand the design space well enough, reach in and pull out a particular machine intelligence that doesn’t want to hurt you.
So the answer to your second question about sexual desire is that if you knew exactly what you were doing and if you had solved the general problem of building AIs that stably want particular things as they self-improve and if you had solved the general problem of pinpointing an AI’s utility functions at things that seem deceptively straightforward to human intuitions, and you’d solved an even harder problem of building an AI using the particular sort of architecture where ‘being horny’ or ‘sex makes me happy’ makes sense in the first place, then you could perhaps make an AI that had been told to look at humans, model what humans want, pick out the part of the model that was sexual desire, and then want and experience that thing too.
You could also, if you had a sufficiently good understanding of organic biology and aerodynamics, build an airplane that could mate with birds.
I don’t think this would have been a smart thing for the Wright Brothers to try to do in the early days. There would have been absolutely no point.
It does seem a lot wiser to figure out how to reach into the design space and pull out a special case of AI that will lack the default instrumental preference to disassemble us for spare atoms.
---
**John**: I like to think superintelligent beings would be nonviolent, because they will realize that violence is stupid. Am I naive?
---
**Eliezer**: I think so. As David Hume might have told you, you’re making a type error by trying to apply the ‘stupidity’ predicate to an agent’s terminal values or utility function. Acts, choices, policies can be stupid given some set of preferences over final states of the world. If you happen to be an agent that has meta-preferences you haven’t fully computed, you might have a platform on which to stand and call particular guesses at the derived object-level preferences as ‘stupid’.
A paperclip maximizer is not making a computational error by having a preference order on outcomes that prefers outcomes with more paperclips in them. It is not standing from within your own preference framework and choosing blatantly mistaken acts, nor is it standing within your meta-preference framework and making mistakes about what to prefer. It is computing the answer to a different question than the question that you are asking when you ask, “What should I do?” A paperclip maximizer just outputs the action leading to the greatest number of expected paperclips.
The fatal scenario is an AI that neither loves you nor hates you, because you’re still made of atoms that it can use for something else. Game theory, and issues like cooperation in the Prisoner’s Dilemma, don’t emerge in all possible cases. In particular, they don’t emerge when something is sufficiently more powerful than you that it can disassemble you for spare atoms whether you try to press Cooperate or Defect. Past that threshold, either you solved the problem of making something that didn’t want to hurt you, or else you’ve already lost.
---
**John**: Will superintelligences solve the “hard problem” of consciousness?
---
**Eliezer**: Yes, and in retrospect the answer will look embarrassingly obvious from our perspective.
---
**John**: Will superintelligences possess free will?
---
**Eliezer**: Yes, but they won’t have the illusion of free will.
---
**John**: What’s your utopia?
---
**Eliezer**: I refer your readers to my nonfiction [Fun Theory Sequence](https://wiki.lesswrong.com/wiki/The_Fun_Theory_Sequence), since I have not as yet succeeded in writing any novel set in a fun-theoretically optimal world.
---
The original interview can be found at [AI Visionary Eliezer Yudkowsky on the Singularity, Bayesian Brains and Closet Goblins](http://blogs.scientificamerican.com/cross-check/ai-visionary-eliezer-yudkowsky-on-the-singularity-bayesian-brains-and-closet-goblins/).
Other conversations that feature MIRI researchers have included: [Yudkowsky on “What can we do now?”](https://intelligence.org/2013/01/30/yudkowsky-on-what-can-we-do-now/); [Yudkowsky on logical uncertainty](https://intelligence.org/2013/01/30/yudkowsky-on-logical-uncertainty/); [Benya Fallenstein on the Löbian obstacle to self-modifying systems](https://intelligence.org/2013/08/04/benja-interview/); and [Yudkowsky, Muehlhauser, Karnofsky, Steinhardt, and Amodei on MIRI strategy](https://intelligence.org/2014/01/13/miri-strategy-conversation-with-steinhardt-karnofsky-and-amodei/).
The post [John Horgan interviews Eliezer Yudkowsky](https://intelligence.org/2016/03/02/john-horgan-interviews-eliezer-yudkowsky/) appeared first on [Machine Intelligence Research Institute](https://intelligence.org). |
1bb6fbd5-7582-4cd7-a4d1-729056aa2ec2 | trentmkelly/LessWrong-43k | LessWrong | Meetup schedule
Our SSC meetup is every Sunday, 12:30pm, at Panera Bread for lunch/coffee. 10606 Shawnee Mission Pkwy
We also have a monthly game at Pawn and Pint (a board game pub, anyone younger than 21 must be accompanied by a legal guardian. Cover fee is waived if you say you're with the Kansas City Rationalists). First Wednesday of each month, 6pm, 613 Walnut St, Kansas City, MO 64106
We also just began a Rationality Dojo, following the 'Hammertime' sequence. Every Tuesday, 6pm, Central Resource Library. |
a25ee571-d430-4342-9388-d8d95b1997a2 | trentmkelly/LessWrong-43k | LessWrong | What technical-ish books do you recommend that are readable on Kindle?
I am looking for nonfiction non-historical books that aren’t too dumbed-down/light (essentially, a book that needs careful reading, not something skimmable), but still readable on an e-reader such as Kindle (so equations should be very scarce, and the book should be available in a reflowable format such as EPUB).
Some examples:
* Darwin‘s Dangerous Idea (and other books by Dennett)
* Thinking, Fast and Slow
* Norton’s Introduction to Philosophy
* LW’s sequences and The Codex (generally, most equation-less LW posts fit the bill)
* Most Programming books (though I prefer a hands-on approach for learning these, which is not possible on an e-reader) |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.