
id stringlengths 36 36 | source stringclasses 15 values | formatted_source stringclasses 13 values | text stringlengths 2 7.55M |
|---|---|---|---|
7973fdc9-12d1-448e-a00c-642b018fde07 | trentmkelly/LessWrong-43k | LessWrong | Rationality and overriding human preferences: a combined model
A putative new idea for AI control; index here.
Previously, I presented a model in which a “rationality module” kept track of two things: how well a human was maximising their actual reward, and whether their preferences had been overridden by AI action.
The second didn’t integrate well into the first, and was tracked by a clunky extra Boolean. Since the two didn’t fit together, I was going to separate the two concepts, especially since the Boolean felt a bit too... Boolean, not allowing for grading. But then I realised that they actually fit together completely naturally, without the need for arbitrary Booleans or other tricks.
----------------------------------------
Feast or heroin famine
Consider the situation detailed in the following figure. An AI has the opportunity to surreptitiously inject someone with heroin (I) or not do so (¬I). If it doesn’t, the human will choose to enjoy a massive feast (F); if it does, the human will instead choose more heroin (H).
So the human policy is given by π(I)=H,π(¬I)=F. The human rationality and reward are given by a pair (m,R), where R is the human reward and m measures their rationality - how closely their actions conform with their reward.
The module m can be seen as a map from rewards to policies (or, since policies are maps from histories to actions, m can be seen as mapping histories and rewards to actions). The pair (m,R) are said to be compatible if m(R)=π, the human policy.
There are three natural Rs to consider here: Rp, a generic pleasure. Next, Re, the ‘enjoyment’ reward, where enjoyment is pleasure endorsed as ‘genuine’ by common judgement. Assume that Rp(H)=1, Rp(F)=1/3, Re(F)=1/2, and Re(H)=0. Finally, there is the twisted reward Rt, which is Rp conditional on I and Re
There are two natural ms: mr, the fully rational module. And mf, the module that is fully rational conditional on I, but always maps to H if I is chosen: m(R)(I)=H, for all R.
The pair mr(Re) is not compatible with π: it predicts tha |
3ed01fe0-c59a-49fb-b1eb-286e173e233f | trentmkelly/LessWrong-43k | LessWrong | Frequentist practice incorporates prior information all the time
I thought that the frequentist view was that you should not incorporate prior information. But looking around, this doesn't seem true in practice. It's common with the data scientists and analysts I've worked with to view probability fundamentally in terms of frequencies. But they also consider things like model-choice to be super important. For example, a good data scientist (frequentist or not) will check data for linearity, and if it is linear, they will model it with a linear or logistic regression. Choosing a linear model constrains the outcomes and relationships you can find to linear ones. If the data is non-linear, they've commited to a model that won't realize it. In this way, the statement "this relationship is linear" expresses strong prior information! Arguments over model choice can be viewed as arguments over prior distributions, and arguments over model choice abound among practitioners with frequentist views.
I'm not the first to notice this, and it might even be common knowledge: From Geweke, Understanding Non-Bayesians:
> If a frequentist uses the asymptotic approximation in a given sample, stating only the weak assumptions, he or she is implicitly ruling out those parts of the parameter space in which the asymptotic approximation, in this sample size, and with these conditioning variables, is inaccurate. These implicit assumptions are Bayesian in the sense that they invoke the researcher’s pre-sample, or prior, beliefs about which parameter values or models are likely.
E.T. "thousand-year-old vampire" Jaynes, in the preface of his book on probability, basically says that frequentist methods do incorporate known information, but do it in an ad-hoc, lossy way (bold added by me):
> In addition, frequentist methods provide no technical means to eliminate nuisance parameters or to take prior information into account, no way even to use all the information in the data when sufficient or ancillary statistics do not exist. Lacking the necessary theore |
ce440296-2f75-4210-bd55-b641648735b4 | trentmkelly/LessWrong-43k | LessWrong | Harry Potter and the Methods of Rationality discussion thread, part 14, chapter 82
The new discussion thread (part 15) is here.
This is a new thread to discuss Eliezer Yudkowsky’s Harry Potter and the Methods of Rationality and anything related to it. This thread is intended for discussing chapter 82. The previous thread passed 1000 comments as of the time of this writing, and so has long passed 500. Comment in the 13th thread until you read chapter 82.
There is now a site dedicated to the story at hpmor.com, which is now the place to go to find the authors notes and all sorts of other goodies. AdeleneDawner has kept an archive of Author’s Notes. (This goes up to the notes for chapter 76, and is now not updating. The authors notes from chapter 77 onwards are on hpmor.com.)
The first 5 discussion threads are on the main page under the harry_potter tag. Threads 6 and on (including this one) are in the discussion section using its separate tag system. Also: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13.
As a reminder, it’s often useful to start your comment by indicating which chapter you are commenting on.
Spoiler Warning: this thread is full of spoilers. With few exceptions, spoilers for MOR and canon are fair game to post, without warning or rot13. More specifically:
> You do not need to rot13 anything about HP:MoR or the original Harry Potter series unless you are posting insider information from Eliezer Yudkowsky which is not supposed to be publicly available (which includes public statements by Eliezer that have been retracted).
>
> If there is evidence for X in MOR and/or canon then it’s fine to post about X without rot13, even if you also have heard privately from Eliezer that X is true. But you should not post that “Eliezer said X is true” unless you use rot13. |
c7650036-e753-4efe-bf07-34e3d6b756b5 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Three Stories for How AGI Comes Before FAI
*Epistemic status: fake framework*
To do effective differential technological development for AI safety, we'd like to know which combinations of AI insights are more likely to lead to FAI vs UFAI. This is an overarching strategic consideration which feeds into questions like how to think about the value of [AI capabilities research](https://www.lesswrong.com/posts/y5fYPAyKjWePCsq3Y/project-proposal-considerations-for-trading-off-capabilities).
As far as I can tell, there are actually several different stories for how we may end up with a set of AI insights which makes UFAI more likely than FAI, and these stories aren't entirely compatible with one another.
Note: In this document, when I say "FAI", I mean any superintelligent system which does a good job of helping humans (so an "aligned Task AGI" also counts).
Story #1: The Roadblock Story
=============================
Nate Soares describes the roadblock story in [this comment](https://forum.effectivealtruism.org/posts/SEL9PW8jozrvLnkb4/my-current-thoughts-on-miri-s-highly-reliable-agent-design#Z6TbXivpjxWyc8NYM):
>
> ...if a safety-conscious AGI team asked how we’d expect their project to fail, the two likeliest scenarios we’d point to are "your team runs into a capabilities roadblock and can't achieve AGI" or "your team runs into an alignment *roadblock* and *can easily tell that the system is currently misaligned, but can’t figure out how to achieve alignment in any reasonable amount of time*."
>
>
>
(emphasis mine)
The roadblock story happens if there are key safety insights that FAI needs but AGI doesn't need. In this story, the knowledge needed for FAI is a superset of the knowledge needed for AGI. If the safety insights are difficult to obtain, or no one is working to obtain them, we could find ourselves in a situation where we have all the AGI insights without having all the FAI insights.
There is subtlety here. In order to make a strong argument for the existence of insights like this, it's not enough to point to failures of existing systems, or describe hypothetical failures of future systems. You also need to explain why the insights necessary to create AGI wouldn't be sufficient to fix the problems.
Some possible ways the roadblock story could come about:
* Maybe safety insights are more or less agnostic to the chosen AGI technology and can be discovered in parallel. (Stuart Russell has pushed against this, saying that in the same way making sure bridges don't fall down is part of civil engineering, safety should be part of mainstream AI research.)
* Maybe safety insights require AGI insights as a prerequisite, leaving us in a precarious position where we will have acquired the capability to build an AGI *before* we begin critical FAI research.
+ This could be the case if the needed safety insights are mostly about how to safely assemble AGI insights into an FAI. It's possible we could do a bit of this work in advance by developing "contingency plans" for how we would construct FAI in the event of combinations of capabilities advances that seem plausible.
- Paul Christiano's IDA framework could be considered a contingency plan for the case where we develop much more powerful imitation learning.
- Contingency plans could also be helpful for directing differential technological development, since we'd get a sense of the difficulty of FAI under various tech development scenarios.
* Maybe there will be multiple subsets of the insights needed for FAI which are sufficient for AGI.
+ In this case, we'd like to speed the discovery of whichever FAI insight will be discovered last.
Story #2: The Security Story
============================
From [Security Mindset and the Logistic Success Curve](https://www.lesswrong.com/posts/cpdsMuAHSWhWnKdog/security-mindset-and-the-logistic-success-curve):
>
> CORAL: You know, back in mainstream computer security, when you propose a new way of securing a system, it's considered traditional and wise for everyone to gather around and try to come up with reasons why your idea might not work. It's understood that no matter how smart you are, most seemingly bright ideas turn out to be flawed, and that you shouldn't be touchy about people trying to shoot them down.
>
>
>
The main difference between the security story and the roadblock story is that in the security story, it's not obvious that the system is misaligned.
We can subdivide the security story based on the ease of fixing a flaw if we're able to detect it in advance. For example, vulnerability #1 on the [OWASP Top 10](https://www.cloudflare.com/learning/security/threats/owasp-top-10/) is injection, which is typically easy to patch once it's discovered. Insecure systems are often right next to secure systems in program space.
If the security story is what we are worried about, it could be wise to try & develop the AI equivalent of OWASP's [Cheat Sheet Series](https://cheatsheetseries.owasp.org/), to make it easier for people to find security problems with AI systems. Of course, many items on the cheat sheet would be speculative, since AGI doesn't actually exist yet. But it could still serve as a useful starting point for brainstorming flaws.
Differential technological development could be useful in the security story if we push for the development of AI tech that is easier to secure. However, it's not clear how confident we can be in our intuitions about what will or won't be easy to secure. In his book *Thinking Fast and Slow*, Daniel Kahneman describes his adversarial collaboration with expertise researcher Gary Klein. Kahneman was an expertise skeptic, and Klein an expertise booster:
>
> We eventually concluded that our disagreement was due in part to the fact that we had different experts in mind. Klein had spent much time with fireground commanders, clinical nurses, and other professionals who have real expertise. I had spent more time thinking about clinicians, stock pickers, and political scientists trying to make unsupportable long-term forecasts. Not surprisingly, his default attitude was trust and respect; mine was skepticism.
>
>
>
>
> ...
>
>
>
>
> When do judgments reflect true expertise? ... The answer comes from the two basic conditions for acquiring a skill:
>
>
>
>
> * an environment that is sufficiently regular to be predictable
> * an opportunity to learn these regularities through prolonged practice
>
>
>
>
> In a less regular, or low-validity, environment, the heuristics of judgment are invoked. System 1 is often able to produce quick answers to difficult
> questions by substitution, creating coherence where there is none. The question that is answered is not the one that was intended, but the answer is produced quickly and may be sufficiently plausible to pass the lax and lenient review of System 2. You may want to forecast the commercial future of a company, for example, and believe that this is what you are judging, while in fact your evaluation is dominated by your impressions of the energy and competence of its current executives. Because substitution occurs automatically, you often do not know the origin of a judgment that you (your System 2) endorse and adopt. If it is the only one that comes to mind, it may be subjectively undistinguishable from valid judgments that you make with expert confidence. This is why subjective confidence is not a good diagnostic of accuracy: judgments that answer the wrong question can also be made with high confidence.
>
>
>
Our intuitions are only as good as the data we've seen. "Gathering data" for an AI security cheat sheet could helpful for developing security intuition. But I think we should be skeptical of intuition anyway, given the speculative nature of the topic.
Story #3: The Alchemy Story
===========================
Ali Rahimi and Ben Recht [describe](http://www.argmin.net/2017/12/05/kitchen-sinks/) the alchemy story in their Test-of-time award presentation at the NeurIPS machine learning conference in 2017 ([video](https://www.youtube.com/watch?v=Qi1Yry33TQE)):
>
> Batch Norm is a technique that speeds up gradient descent on deep nets. You sprinkle it between your layers and gradient descent goes faster. I think it’s ok to use techniques we don’t understand. I only vaguely understand how an airplane works, and I was fine taking one to this conference. But *it’s always better if we build systems on top of things we do understand deeply*? This is what we know about why batch norm works well. But don’t you want to understand why reducing internal covariate shift speeds up gradient descent? Don’t you want to see evidence that Batch Norm reduces internal covariate shift? Don’t you want to know what internal covariate shift *is*? Batch Norm has become a foundational operation for machine learning. *It works amazingly well. But we know almost nothing about it.*
>
>
>
(emphasis mine)
The alchemy story has similarities to both the roadblock story and the security story.
**From the perspective of the roadblock story**, "alchemical" insights could be viewed as insights which could be useful if we only cared about creating AGI, but are too unreliable to use in an FAI. (It's possible there are other insights which fall into the "usable for AGI but not FAI" category due to something other than their alchemical nature--if you can think of any, I'd be interested to hear.)
In some ways, alchemy could be worse than a clear roadblock. It might be that not everyone agrees whether the systems are reliable enough to form the basis of an FAI, and then we're looking at a [unilateralist's curse](https://concepts.effectivealtruism.org/concepts/unilateralists-curse/) scenario.
Just like chemistry only came after alchemy, it's possible that we'll first develop the capability to create AGI via alchemical means, and only acquire the deeper understanding necessary to create a reliable FAI later. (This is a scenario from the roadblock section, where FAI insights require AGI insights as a prerequisite.) To prevent this, we could try & deepen our understanding of components we expect to fail in subtle ways, and retard the development of components we expect to "just work" without any surprises once invented.
**From the perspective of the security story**, "alchemical" insights could be viewed as components which are *clearly* prone to vulnerabilities. Alchemical components could produce failures which are hard to understand or summarize, let alone fix. From a differential technological development point of view, the best approach may be to differentially advance less alchemical, more interpretable AI paradigms, developing the AI equivalent of reliable cryptographic primitives. (Note that explainability is [inferior](https://www.nature.com/articles/s42256-019-0048-x.epdf?author_access_token=SU_TpOb-H5d3uy5KF-dedtRgN0jAjWel9jnR3ZoTv0M3t8uDwhDckroSbUOOygdba5KNHQMo_Ji2D1_SdDjVr6hjgxJXc-7jt5FQZuPTQKIAkZsBoTI4uqjwnzbltD01Z8QwhwKsbvwh-z1xL8bAcg%3D%3D) to [interpretability](https://statmodeling.stat.columbia.edu/2018/10/30/explainable-ml-versus-interpretable-ml/).)
Trying to create an FAI from alchemical components is obviously not the best idea. But it's not totally clear how much of a risk these components pose, because if the components don't work reliably, an AGI built from them may not work well enough to pose a threat. Such an AGI could work better over time if it's able to improve its own components. In this case, we might be able to program it so it periodically re-evaluates its training data as its components get upgraded, so its understanding of human values improves as its components improve.
Discussion Questions
====================
* How plausible does each story seem?
* What possibilities aren't covered by the taxonomy provided?
* What distinctions does this framework fail to capture?
* Which claims are incorrect? |
da9042ca-3fb8-4dde-b6dd-ac4f620ed5ce | StampyAI/alignment-research-dataset/blogs | Blogs | cognitive biases regarding the evaluation of AI risk when doing AI capabilities work
cognitive biases regarding the evaluation of AI risk when doing AI capabilities work
------------------------------------------------------------------------------------
i have recently encountered a few rationality failures, in the context of talking about AI risk. i will document them here for reference; they probly have already been documented elsewhere, but their application to AI risk is particularly relevant here.
### 1. forgetting to multiply
let's say i'm talking with someone about the likelyhood that working on some form of AI capability [kills everything everywhere forever](https://en.wikipedia.org/wiki/Existential_risk_from_artificial_general_intelligence). they say: "i think the risk is near 0%". i say: "i think the risk is maybe more like 10%".
would i bet that it will kill everyone? no, 10% is less than 50%. but "what i bet" isn't the only relevant thing; a proper utilitarian *multiples* likelyhood by *quality of outcome*. and X-risk is really bad. i mistakenly see some people use only the probability, forgetting to multiply; if i think everyone dying is not likely, that's enough for them. one should care that it's *extremely* unlikely.
### 2. categorizing vs average of risk
let's take the example above again. let's say you believe said likelyhood is close to 0% and i believe it's close to 10%; and let's say we each believe the other person generally tends to be as correct as oneself.
how should we come out of this? some people seem to want to pick an average between "carefully avoiding killing everyone" and "continuing as before" — which lets them more easily continue as before.
this is not how things should work. if i learn that someone who i generally consider about as likely as me to be correct about things, seriously thinks there's a 10% chance that my tap water has lead in it, my reaction is not "well, whatever, it's only 10% and only 1 out of the two of us believe this". my reaction is "what the hell?? i should look into this and stick to bottled water in the meantime". the average between risk and no risk is not "i guess maybe risk maybe no risk"; it's "lower (but still some) risk". the average between ≈0% and 10% is not "huh, well, one of those numbers is 0% so i can pick 0% and only have half a chance of being wrong"; the average is 5%. 5% is still a large risk.
this is kind of equivalent to *forgetting to multiply*, but to me it's a different problem: here, one is not just forgetting to multiply, one is forgetting that probabilities are numbers altogether, and is treating them as a set of discrete objects that they have to pick one of — and thus can justify picking the one that makes their AI capability work okay, because it's one out of the two objects.
### 3. deliberation ahead vs retroactive justification
someone says "well, i don't think the work i'm doing on AI capability is likely to kill everyone" or even "well, i think AI capability work is needed to do alignment work". that *may* be true, but how carefully did you arrive at that consideration?
did you sit down at a table with everybody, talk about what is safe and needed to do alignment work, and determine that AI capability work of the kind you're doing is the best course of actions to pursue?
or are you already committed to AI capability work and are trying to retroactively justify it?
i know the former isn't the case because there *was* no big societal sitting down at a table with everyone about cosmic AI risk. most people (including AI capability devs) don't even meaningfully *know* about cosmic AI risk; let alone deliberated on what to do about it.
this isn't to say that you're necessarily wrong; maybe by chance you happen to be right this time. but this is not how you arrive at truth, and you should be highly suspicious of such convenient retroactive justifications. and by "highly suspect" i don't mean "think mildly about it while you keep gleefully working on capability"; i mean "seriously sit down and reconsider whether what you're doing is more likely helping to save the world, or hindering saving the world".
### 4. it's not a prisoner's dilemma
some people think of alignment as a coordination problem. "well, unfortunately everyone is in a [rat race](https://slatestarcodex.com/2014/07/30/meditations-on-moloch/) to do AI capability, because if they don't they get outcompeted by others!"
this is *not* how it works. such prisoner's dilemmas work because if your opponent defects, your outcome if you defect too is worse than if you cooperate. this is **not** the case here; less people working on AI capability is pretty much strictly less probability that we all die, because it's just less people trying (and thus less people likely to randomly create an AI that kills everyone). even if literally everyone except you is working on AI capability, you should still not work on it; working on it would *still only make things worse*.
"but at that point it only makes things negligeably worse!"
…and? what's that supposed to justify? is your goal to *cause evil as long as you only cause very small amounts of evil*? shouldn't your goal be to just generally try to cause good and not cause evil?
### 5. we *are* utilitarian… right?
when situations akin to the trolley problem *actually appear*, it seems a lot of people are very reticent to actually press the lever. "i was only LARPing as a utilitarian this whole time! pressing the lever makes me feel way too bad to do it!"
i understand this and worry that i am in that situation myself. i am not sure what to say about it, other than: if you believe utilitarianism is what is *actually right*, you should try to actually *act utilitarianistically in the real world*. you should *actually press actual levers in trolley-problem-like situations in the real world*, not just nod along that pressing the lever sure is the theoretical utilitarian optimum to the trolley problem and then keep living as a soup of deontology and virtue ethics.
i'll do my best as well.
### a word of sympathy
i would love to work on AI capability. it sounds like great fun! i would love for everything to be fine; trust me, i really do.
sometimes, when we're mature adults who [take things seriously](life-refocus.html), we have to actually consider consequences and update, and make hard choices. this can be kind of fun too, if you're willing to truly engage in it. i'm not arguing with AI capabilities people out of hate or condescension. i *know* it sucks; it's *painful*. i have cried a bunch these past months. but feelings are no excuse to risk killing everyone. we **need** to do what is **right**.
shut up and multiply. |
509b002a-61d4-4ccb-a731-45f09da885ba | trentmkelly/LessWrong-43k | LessWrong | Gentleness and the artificial Other
(Cross-posted from my website. Audio version here, or search "Joe Carlsmith Audio" on your podcast app.
This is the first essay in a series that I’m calling “Otherness and control in the age of AGI.” See here for more about the series as a whole.)
When species meet
The most succinct argument for AI risk, in my opinion, is the “second species” argument. Basically, it goes like this.
> Premise 1: AGIs would be like a second advanced species on earth, more powerful than humans.
>
> Conclusion: That’s scary.
To be clear: this is very far from airtight logic.[1] But I like the intuition pump. Often, if I only have two sentences to explain AI risk, I say this sort of species stuff. “Chimpanzees should be careful about inventing humans.” Etc.[2]
People often talk about aliens here, too. “What if you learned that aliens were on their way to earth? Surely that’s scary.” Again, very far from a knock-down case (for example: we get to build the aliens in question). But it draws on something.
In particular, though: it draws on a narrative of interspecies conflict. You are meeting a new form of life, a new type of mind. But these new creatures are presented to you, centrally, as a possible threat; as competitors; as agents in whose power you might find yourself helpless.
And unfortunately: yes. But I want to start this series by acknowledging how many dimensions of interspecies-relationship this narrative leaves out, and how much I wish we could be focusing only on the other parts. To meet a new species – and especially, a new intelligent species – is not just scary. It’s incredible. I wish it was less a time for fear, and more a time for wonder and dialogue. A time to look into new eyes – and to see further.
Gentleness
> “If I took it in hand,
>
> it would melt in my hot tears—
>
> heavy autumn frost.”
>
> - Basho
Have you seen the documentary My Octopus Teacher? No problem if not, but I recommend it. Here’s the plot.
Craig Foster, a filmmaker, has been feeling b |
8dc1a783-88d4-4e4d-a730-b3bef17d040a | trentmkelly/LessWrong-43k | LessWrong | How do we know our own desires?
Sometimes I find myself longing for something, with little idea what it is.
This suggests that perceiving desire and perceiving which thing it is that is desired by the desire are separable mental actions.
In this state, I make guesses as to what I want. Am I thirsty? (I consider drinking some water and see if that feels appealing.) Do I want to have sex? (A brief fantasy informs me that sex would be good, but is not what I crave.) Do I want social comfort? (I open Facebook, maybe that has social comfort I could test with…)
If I do infer the desire in this way, I am still not directly reading it from my own mind. I am making educated guesses and testing them using my mind’s behavior.
Other times, it seems like I immediately know my own desires. When that happens, am I really receiving them introspectively, or am I merely playing the same inference game more insightfully?
We usually suppose that people are correct about their own immediate desires. They may be wrong about whether they want cookie A or cookie B, because they are misinformed about which one is delicious. But if they think they want to eat something delicious, we trust them on that.
On the model where we are mostly inferring our desires from more general feelings of wanting, we might expect people are wrong about their desires fairly often.
|
16daa3e9-6df2-48dc-918e-355e8536315a | trentmkelly/LessWrong-43k | LessWrong | The utility of information should almost never be negative
As humans, finding out facts that we would rather not be true is unpleasant. For example, I would dislike finding out that my girlfriend were cheating on me, or finding out that my parent had died, or that my bank account had been hacked and I had lost all my savings.
However, this is a consequence of the dodgily designed human brain. We don't operate with a utility function. Instead, we have separate neural circuitry for wanting and liking things, and behave according to those. If my girlfriend is cheating on me, I may want to know, but I wouldn't like knowing. In some cases, we'd rather not learn things: if I'm dying in hospital with only a few hours to live, I might rather be ignorant of another friend's death for the short remainder of my life.
However, a rational being, say an AI, would never rather not learn something, except for contrived cases like Omega offering you $100 if you can avoid learning the square of 156 for the next minute.
As far as I understand, an AI with a set of options decides by using approximately the following algorithm. This algorithm uses causal decision theory for simplicity.
"For each option, guess what will happen if you do it, and calculate the average utility. Choose the option with the highest utility."
So say Clippy is using that algorithm with his utility function of utility = number of paperclips in world.
Now imagine Clippy is on a planet making paperclips. He is considering listening to the Galactic Paperclip News radio broadcast. If he does so, there is a chance he might hear about a disaster leading to the destruction of thousands of paperclips. Would he decide in the following manner?
"If I listen to the radio show, there's maybe a 10% chance I will learn that 1000 paperclips were destroyed. My utility in from that decision would be on average reduced by 100. If I don't listen, there is no chance that I will learn about the destruction of paperclips. That is no utility reduction for me. Therefo |
56937ee3-9f54-4df2-8199-58e8194b7c60 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Washington, D.C.: Prisoner's Dilemna tournament
Discussion article for the meetup : Washington, D.C.: Prisoner's Dilemna tournament
WHEN: 13 July 2014 03:00:00PM (-0400)
WHERE: National Portrait Gallery, Washington, DC 20001, USA
We'll be meeting in the Kogod Courtyard of the National Portrait Gallery for our second Prisoner's Dilemna tournament. We'll play several different versions of iterated and one-shot games; feel free to suggest your own formats. There will be prizes (baked goods).
Discussion article for the meetup : Washington, D.C.: Prisoner's Dilemna tournament |
dc4577ad-df43-4239-a75b-63bb04ba3f77 | trentmkelly/LessWrong-43k | LessWrong | The Design Space of Minds-In-General
People ask me, "What will Artificial Intelligences be like? What will they do? Tell us your amazing story about the future."
And lo, I say unto them, "You have asked me a trick question."
ATP synthase is a molecular machine - one of three known occasions when evolution has invented the freely rotating wheel - which is essentially the same in animal mitochondria, plant chloroplasts, and bacteria. ATP synthase has not changed significantly since the rise of eukaryotic life two billion years ago. It's is something we all have in common - thanks to the way that evolution strongly conserves certain genes; once many other genes depend on a gene, a mutation will tend to break all the dependencies.
Any two AI designs might be less similar to each other than you are to a petunia.
Asking what "AIs" will do is a trick question because it implies that all AIs form a natural class. Humans do form a natural class because we all share the same brain architecture. But when you say "Artificial Intelligence", you are referring to a vastly larger space of possibilities than when you say "human". When people talk about "AIs" we are really talking about minds-in-general, or optimization processes in general. Having a word for "AI" is like having a word for everything that isn't a duck.
Imagine a map of mind design space... this is one of my standard diagrams...
All humans, of course, fit into a tiny little dot - as a sexually reproducing species, we can't be too different from one another.
This tiny dot belongs to a wider ellipse, the space of transhuman mind designs - things that might be smarter than us, or much smarter than us, but which in some sense would still be people as we understand people.
This transhuman ellipse is within a still wider volume, the space of posthuman minds, which is everything that a transhuman might grow up into.
And then the rest of the sphere is the space of minds-in-general, including possible Artificial Intelligences so odd that they |
a026176d-7625-4deb-8052-77114ea85a9f | StampyAI/alignment-research-dataset/arxiv | Arxiv | Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach
1 Introduction
---------------
Data and predictive models are used by artificial intelligence (AI) systems to make decisions across many applications and industries. Yet, many data-rich organizations struggle when adopting AI decision-making systems because of managerial and cultural challenges, rather than issues related to data and technology (LaValle et al., [2011](#bib.bib1 "Big data, analytics and the path from insights to value")). In fact, as predictive models become more complex and difficult to understand, stakeholders often become more skeptical and reluctant to adopt or use them, even if the models have been shown to improve decision-making performance (Arnold et al., [2006](#bib.bib2 "The differential use and effect of knowledge-based system explanations in novice and expert judgment decisions"); Kayande et al., [2009](#bib.bib3 "How incorporating feedback mechanisms in a DSS affects DSS evaluations")).
Explanations are also useful for other reasons beyond increasing adoption (Martens and Provost, [2014](#bib.bib9 "Explaining data-driven document classifications")). For example, explanations may help customers understand the reasoning behind automated decisions that affect them. Users of the model, such as managers or analysts, may use explanations to obtain insights about the domain in which the system is being used. Data scientists and machine learning engineers may also use the explanations to identify, debug, and address potential flaws in the system. Many researchers have tried to reduce the gap in stakeholders’ understanding of AI systems in recent years, most notably by proposing methods for explaining predictive models and their predictions.
Methods for explaining AI models and their predictions include extracting rules that represent the inner workings (e.g., Craven and Shavlik, [1996](#bib.bib4 "Extracting tree-structured representations of trained networks"); Jacobsson, [2005](#bib.bib5 "Rule extraction from recurrent neural networks: a taxonomy and review"); Martens et al., [2007](#bib.bib6 "Comprehensible credit scoring models using rule extraction from support vector machines")) and associating weights to each feature according to their importance for model predictions (e.g., Lundberg and Lee, [2017](#bib.bib7 "A unified approach to interpreting model predictions"); Ribeiro et al., [2016](#bib.bib8 "Why should I trust you?: explaining the predictions of any classifier")). Importance weights, in particular, have become increasingly popular because “model-agnostic” methods that produce importance weights have been introduced: the weights explain predictions in terms of features, so users can understand any specific prediction without any knowledge of the underlying model or the modeling method(s) used to produce the model. For example, two of the most popular methods for explaining model predictions, LIME (Ribeiro et al., [2016](#bib.bib8 "Why should I trust you?: explaining the predictions of any classifier")) and SHAP (Lundberg and Lee, [2017](#bib.bib7 "A unified approach to interpreting model predictions")), are model-agnostic and produce importance-weight explanations.
This paper points at two fundamental reasons why importance-weight explanations may not be well-suited to explain data-driven decisions made by AI systems. First, importance weights are designed to explain model predictions, but explaining model predictions is not the same as explaining the *decisions* made using those predictions. Notably, and perhaps counter-intuitively, features that have a large impact on a prediction may not necessarily have an impact on the decision that was made using that prediction. The examples in this paper illustrate this in detail. Therefore, importance weights that are obtained with respect to model predictions may portray an inaccurate picture of how features influence system decisions.
Second, identifying (and quantifying) important features is not sufficient to explain system decisions, even when importance is assessed with respect to the decisions being explained. As an example, suppose that a credit scoring system denies credit to a loan applicant, and that feature importance weights reveal that the two most important features in the credit denial decision were annual income and loan amount. While informative, this “explanation” does not in fact explain what it was that made the system decide to deny credit. Would changing either the annual income or the loan amount be enough for the system to approve credit? Would it be necessary to change both? Or perhaps even changing both would not be enough. From the weights alone, it is not clear how the important features may influence the decision. To be fair, this is not an indictment of methods that calculate feature importance; they were not designed to explain system decisions. However, we are not aware of papers or posts that clarify this in research or in practice.
An alternative to importance-weight explanations are counterfactual explanations—explanations explicitly designed to explain system decisions proposed by Martens and Provost ([2014](#bib.bib9 "Explaining data-driven document classifications")); Provost ([2014](#bib.bib36 "Understanding decisions driven by big data")). For the question “why did the model-based system make a specific decision?”, the counterfactual approach asks specifically, “which data inputs caused the system to make its decision?”. This approach is advantageous because (i) it explains decisions rather than the outputs of the model(s) on which the decisions are based; (ii) it standardizes the form that an explanation can take; (iii) it does not require all features to be part of the explanation, and (iv) the explanations can be separated from the specifics of the model.
Martens and Provost ([2014](#bib.bib9 "Explaining data-driven document classifications")) originally applied this framework to explain document classifications, and although it has been applied to other contexts beyond document classification (Moeyersoms et al., [2016](#bib.bib11 "Explaining classification models built on high-dimensional sparse data"); Chen et al., [2017](#bib.bib10 "Enhancing transparency and control when drawing data-driven inferences about individuals"); Ramon et al., [2019](#bib.bib28 "Counterfactual explanation algorithms for behavioral and textual data")), researchers don’t all see how the framework can be generalized to settings beyond text (see, e.g., Molnar, [2019](#bib.bib12 "Interpretable machine learning, see 18.1 counterfactual explanations"); Wachter et al., [2017](#bib.bib13 "Counterfactual explanations without opening the black box: automated decisions and the GPDR"); Biran and Cotton, [2017](#bib.bib34 "Explanation and justification in machine learning: a survey")). To our knowledge, this approach has not been extended beyond classification models using sparse features in high-dimensional settings. Therefore, we introduce a multi-faceted generalization that focuses on providing explanations for general data-driven system decisions, resulting in a framework that (a) may explain decisions made by systems that incorporate multiple models, (b) is model-agnostic, (c) can address features with arbitrary data types, and (d) is scalable to very large numbers of features. We also propose and showcase a heuristic procedure that may be used to search and sort counterfactual explanations according to their context-specific relevance.
Finally, we illustrate the advantages of our proposed counterfactual approach by comparing it to SHAP (Lundberg and Lee, [2017](#bib.bib7 "A unified approach to interpreting model predictions")), an increasingly popular method to explain model predictions that unites several feature importance weighting methods. Via three business case studies that use real-world data, we detail the ways in which counterfactual explanations explain data-driven decisions better than the popular alternative of feature importance weights.
2 AI Systems and Explanations
------------------------------
In this paper, we focus specifically on explaining decisions made by systems that use predictive statistical models to support or automate decision-making (Shmueli and Koppius, [2011](#bib.bib15 "Predictive analytics in Information Systems research")), and in particular on systems that make or recommend discrete decisions. We refer to these as artificial intelligence (AI) systems.
###
2.1 Explaining system decisions
Discrete decision making is closely related to classification, and indeed the subtle distinction often can be overlooked safely—but for explaining system decisions it is important to be clear. First there is a definitional difference: a classification model might classify someone as defaulting on credit or not; a corresponding decision-making system would use this model to make a decision on whether or not to grant credit. Deciding not to grant credit is not the same (at all) as saying that the individual will default—which brings us to the technical difference.
Classification tasks usually are modeled as scoring problems, where we want our predictive models to score the observations such that those more likely to have the “correct” class will have higher scores. These scores may then be used by a system to make a decision that is related to (but usually not the same as) the classification. For example, for binary decisions (and corresponding classifications) typically the scores rank observations, and decisions are made using a chosen threshold appropriate for the problem at hand (Provost and Fawcett, [2013](#bib.bib16 "Data science for business: what you need to know about data mining and data-analytic thinking")). In many cases, estimated probabilities of class membership are computed from the models, which allows the use of decision theory to combine them with application-specific information on costs and benefits (Provost and Fawcett, [2013](#bib.bib16 "Data science for business: what you need to know about data mining and data-analytic thinking")) to produce a next stage of more nuanced scores. Thus, decision-making problems are often modeled as “classification tasks” by associating a class with each decision.
However, it is important to emphasize that the final output of the system (i.e., the decision) may not correspond to the labels in the training data. As another example, for a system deciding whether to target a customer with a promotion, scores could consist of expected profits. In this case, we could estimate a classification model to predict the probability that the customer will make a purchase and a regression model to estimate the size of the purchase (conditioned on the customer making a purchase); the expected profits would be the multiplication of these two predictions (Provost and Fawcett, [2013](#bib.bib16 "Data science for business: what you need to know about data mining and data-analytic thinking"))—and the ranking of the customers by expected profit could be different from the ranking based simply on the classification model score. The final output of the decision-making system would be whether the customer should be targeted with a promotion (and because of selection bias and other complications, we often patently would not want to learn models based on training data about who was targeted with a promotion).
Explaining the decisions made by intelligent systems has received both practical and research attention
for decades (Gregor and Benbasat, [1999](#bib.bib17 "Explanations from intelligent systems: theoretical foundations and implications for practice")). Prior work has shown that the ability for intelligent systems to explain their decisions is necessary for their effective use: when users do not understand the workings of an intelligent system, they become skeptical and reluctant to use it, even if the system is known to improve decision-making performance (Arnold et al., [2006](#bib.bib2 "The differential use and effect of knowledge-based system explanations in novice and expert judgment decisions"); Kayande et al., [2009](#bib.bib3 "How incorporating feedback mechanisms in a DSS affects DSS evaluations")). More recently, for example, a field study in a Department of Radiology showed that the use of AI systems slowed down, rather than sped up, the radiologists’ decision-making process because the AI systems often provided recommendations that conflicted with the doctors’ judgement (Lebovitz et al., [2019](#bib.bib18 "Doubting the diagnosis: how artificial intelligence increases ambiguity during professional decision making")). Lacking critical understanding of the opaque AI systems, the doctors often relied on their own diagnoses, which did not concur with the system’s. Our paper provides a methodological framework to make the decisions of such AI systems more transparent.
###
2.2 Explaining predictive models
Over the past several decades, many researchers have worked on explaining predictive models---in contrast to explaining their predictions or decisions made using them. Because symbolic models, such as decision trees, are often considered straightforward to explain when they are small,111Recent work has been revisiting this assumption, working to produce models explicitly designed to be both accurate and comprehensible; see Wang and Rudin ([2015](#bib.bib35 "Falling rule lists")) for an illustrative example. most research has focused on explaining non-symbolic (black box) models or large models.
Rule-based explanations have been a popular approach to explain black-box models.
For example, in many credit scoring applications, banking regulatory entities require banks to implement globally comprehensible predictive models (Martens et al., [2007](#bib.bib6 "Comprehensible credit scoring models using rule extraction from support vector machines")). Typical techniques to provide rule-based explanations consist of approximating the black box model with a symbolic model (Craven and Shavlik, [1996](#bib.bib4 "Extracting tree-structured representations of trained networks")), or extracting explicit if-then rules (Andrews et al., [1995](#bib.bib19 "Survey and critique of techniques for extracting rules from trained artificial neural networks")). Proposed methods are often tailored to the specifics of the models being explained, and researchers have invested significant effort attempting to make state-of-the-art black box models more transparent. For example, Jacobsson ([2005](#bib.bib5 "Rule extraction from recurrent neural networks: a taxonomy and review")) offers a review of explanation techniques for deep learning models, and Martens et al. ([2007](#bib.bib6 "Comprehensible credit scoring models using rule extraction from support vector machines")) propose a rule extraction method for SVMs. Importantly, these “global” explanations (Martens and Provost, [2014](#bib.bib9 "Explaining data-driven document classifications")) attempt to explain the model as a whole, rather than explaining particular decisions made. As Martens and Provost point out, this can be viewed as explaining every possible decision the model might make—but the methods are not tailored to explain individual decisions.
###
2.3 Explaining model predictions
A different approach, that has become quite popular recently, is to explain the predictions of complex models, framing the explanations in terms of feature importance by associating a weight to each feature in the model. Each weight can be interpreted as the proportion of the information contributed by the corresponding feature to the model prediction. The main strength of this approach is that the explanations are defined in terms of the domain (i.e., the features), separating them from the specifics of the model being explained. As a result, models can be replaced without replacing the explanation method; end users (such as customers or managers) do not need any knowledge of the underlying modeling methods to understand the explanations, and different models may be compared in terms of their explanations in settings where transparency is critical.
A common way of assessing feature importance is based on simulating lack of knowledge about features (Robnik-Šikonja and Kononenko, [2008](#bib.bib21 "Explaining classifications for individual instances"); Lemaire et al., [2008](#bib.bib20 "Contact personalization using a score understanding method")). For example, one could compare the original model’s output with the output obtained when removing a specific feature from the data and the model (e.g., by imputing a default value for the feature). If the output changes, it means that the feature was important for the model prediction. Methods that use this approach often decompose each prediction into the individual contributions of each feature and use the decompositions as explanations, allowing one to visualize explanations at the instance level.
Continuing with the earlier credit scoring example, Figure [1](#S2.F1 "Figure 1 ‣ 2.3 Explaining model predictions ‣ 2 AI Systems and Explanations ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") shows an importance-weight explanation for an individual who has an above-average probability of default. These importance weights were generated using SHAP (Lundberg and Lee, [2017](#bib.bib7 "A unified approach to interpreting model predictions")), which we will discuss in more detail in the following sections. Each weight in the explanation represents the impact that its respective feature had on the prediction. Thus, the weight of (roughly) 2.5% that is attributed to the loan amount feature (‘loan\_amnt’) implies that the feature increased the probability of default of that particular individual by 2.5%.

Figure 1: Example of an importance-weight explanation for a model prediction
A notable challenge, however, is that interactions between features may lead to ambiguous explanations, because the order in which features are removed may affect the importance attributed to each feature. As a result, subsequent work proposed assessing feature importance by removing all possible subsets of features (rather than only one feature at a time), retraining models without the removed features, and comparing how predictions change (Štrumbelj et al., [2009](#bib.bib22 "Explaining instance classifications with interactions of subsets of feature values")). However, such approaches may take hours of computation time even for a single prediction and have been reported to handle only up to about 200 features. Alternative formulations (such as SHAP) have attempted to reduce computation time by sampling the space of feature combinations and by using imputation to deal with removed features, resulting in sampling-based approximations of the influence of each feature on the prediction (Štrumbelj and Kononenko, [2010](#bib.bib23 "An efficient explanation of individual classifications using game theory"); Ribeiro et al., [2016](#bib.bib8 "Why should I trust you?: explaining the predictions of any classifier"); Lundberg and Lee, [2017](#bib.bib7 "A unified approach to interpreting model predictions"); Datta et al., [2016](#bib.bib24 "Algorithmic transparency via quantitative input influence: theory and experiments with learning systems")).
Nevertheless, importance weights are tailored to explain model predictions and may not be adequate to explain system decisions, namely because they don’t communicate how the features actually influence decisions. We will illustrate this with several examples below. Moreover, complex systems may incorporate many features in their decision making. In these settings, hundreds of features may have non-zero importance weights for any given instance, yet only a handful of the features may be critical for understanding the system’s decisions (Martens and Provost, [2014](#bib.bib9 "Explaining data-driven document classifications"); Chen et al., [2017](#bib.bib10 "Enhancing transparency and control when drawing data-driven inferences about individuals")).
3 Counterfactual explanations
------------------------------
The idea of using a causal perspective to explain model predictions with counterfactuals was first proposed (to our knowledge) by Martens and Provost ([2014](#bib.bib9 "Explaining data-driven document classifications")) (see also Provost ([2014](#bib.bib36 "Understanding decisions driven by big data"))). Other researchers followed with similar causal, counterfactual explanation approaches (see Molnar, [2019](#bib.bib12 "Interpretable machine learning, see 18.1 counterfactual explanations"), for examples). In this paper, we generalize the counterfactual explanations originally proposed for document classification (Martens and Provost, [2014](#bib.bib9 "Explaining data-driven document classifications")) and used subsequently to explain ad-targeting decisions (Moeyersoms et al., [2016](#bib.bib11 "Explaining classification models built on high-dimensional sparse data")), targeting decisions based on Facebook Likes (Chen et al., [2017](#bib.bib10 "Enhancing transparency and control when drawing data-driven inferences about individuals")), and classifications based on other high-dimensional, sparse data (Ramon et al., [2019](#bib.bib28 "Counterfactual explanation algorithms for behavioral and textual data")). We provide a more precise definition of counterfactual explanations below, but as with the prior work, we define explanations in terms of input data—or evidence—that would change the decision if it were not present.
###
3.1 Example: explaining the decision to flag a transaction
For illustration, suppose a credit card transaction was flagged for action by a data-driven AI system after it was registered as occurring outside the country where the cardholder lives, and suppose the system would have not flagged the transaction absent this location.222We should keep in mind the decision-rather-than-classification perspective. The decision is to flag the transaction for one or more actions, such as sending a message to the account holder to verify. Flagging may be based on a threshold on the estimated likelihood of fraud, but may also consider the existence of evidence from other transactions and the potential loss if the transaction were indeed fraudulent. In this case, it is intuitive to consider the location of the transaction as an explanation for the system decision. Of course, there could be other explanations. Perhaps the transaction also involved a consumption category outside the profile of the cardholder (e.g., a purchase at a casino), and excluding this information from the system would also change the decision to “do not flag”. Both are counterfactual explanations—they comprise evidence without which the system would have made a different decision.
A subtle implication of this perspective is that counterfactual explanations are generally applied to ‘‘non-default’’ decisions, because data-driven systems usually make default decisions in the absence of evidence suggesting that a different decision should be made. In our example, a transaction would be considered legitimate unless there is enough evidence suggesting fraud. As a result, explaining default decisions often corresponds to saying, ‘‘because there was not enough evidence of a non-default class’’.333However, this is not always the case. For example, if a credit card transaction was made in a foreign country, but the cardholder recently reported a trip abroad, the trip report could be a reasonable explanation for the transaction being classified as legitimate. So, the evidence in favor of a non-default classification may be cancelled out by other evidence in favor of a default classification. Thus, as with prior work, in this paper we focus primarily on explaining non-default decisions.
###
3.2 Defining counterfactual explanations
Following Martens and Provost ([2014](#bib.bib9 "Explaining data-driven document classifications")) and Provost ([2014](#bib.bib36 "Understanding decisions driven by big data")), we define a counterfactual explanation for a system decision as a set of features that is causal and irreducible. Being causal means that removing the set of features from the instance causes the system decision to change.444It is critical to differentiate what is causing the data-driven system to make its decisions from causal influences in the actual data-generating processes in the “real” world. Our definition of counterfactual explanations relates to the former. Irreducible means that removing any proper subset of the explanation would not change the system decision. The importance of an explanation being causal is straightforward: the decision would have been different if not for the presence of this set of features. The irreducibility condition serves to avoid including features that are superfluous, which relates to the fact that some of the features in a causal set may not be necessary for the decision to change.
More formally, consider an instance I consisting of a set of m features, I={1,2,...,m}, for which the decision-making system C:I→{1,2,...,k} gives decision c. A feature i is an attribute taking on a particular value, like income=$50,000 or country=FRANCE.
Then, a set of features E is a counterfactual explanation for C(I)=c if and only if:
| | | | |
| --- | --- | --- | --- |
| | E⊆I (the features are present in the instance) | | (1) |
| | C(I−E)≠c (the explanation is causal) | | (2) |
| | ∀E′⊂E:C(I−E′)=c (the %
explanation is irreducible) | | (3) |
As mentioned, our approach builds on the explanations proposed by Martens and Provost (2014), who developed and applied counterfactual explanations for document classifications, defining an explanation as an irreducible set of words such that removing them from a document changes its classification. Our definition generalizes their counterfactual explanations in three important ways. First, it makes explicit how the explanations may be used for broader system decisions, which may incorporate predictions from multiple predictive models. Second, their practical implementation of explanations (and subsequent work) consists of removing features by setting them to zero, whereas we generalize to arbitrary methods for removing features (and note the important relationship to methods for dealing with missing data). Third, while their approach has been applied in other contexts beyond document classification (Chen et al., [2017](#bib.bib10 "Enhancing transparency and control when drawing data-driven inferences about individuals"); Moeyersoms et al., [2016](#bib.bib11 "Explaining classification models built on high-dimensional sparse data"); Ramon et al., [2019](#bib.bib28 "Counterfactual explanation algorithms for behavioral and textual data")), these applications all have the same data structure: high-dimensional, sparse features. Our generalization applies to features with arbitrary data types.
Going back to our credit scoring example, suppose a decision-making system using the model prediction explained in Figure [1](#S2.F1 "Figure 1 ‣ 2.3 Explaining model predictions ‣ 2 AI Systems and Explanations ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") decides not to grant credit to that individual. Table [1](#S3.T1 "Table 1 ‣ 3.2 Defining counterfactual explanations ‣ 3 Counterfactual explanations ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") shows some possible counterfactual explanations for the credit denial decision. Each explanation represents a counterfactual world in which specific evidence is not considered when making the decision, resulting in a default decision (approving credit in this case).
| Explanation 1 | Credit approved if {‘loan\_amnt’} is removed. |
| --- | --- |
| Explanation 2 | Credit approved if {‘annual\_inc’} is removed. |
| Explanation 3 | Credit approved if {‘fico\_range\_high’, ‘fico\_range\_low’} are removed. |
Table 1: Examples of counterfactual explanations for a system decision
###
3.3 Removing “evidence” from the input to a data-driven decision procedure
A vital practical question that is raised by the counterfactual approach discussed here is what does it mean to “remove” evidence (i.e., features) from a data instance that will be input to a model-based decision-making procedure? Prior methods for counterfactual explanations and model sensitivity analyses have replaced input feature values with some other specified value. For example, Martens and Provost ([2014](#bib.bib9 "Explaining data-driven document classifications")) replace the presence (binary indicator, count, TFIDF value, etc.) of a word in a document with a zero. This makes sense in the context of their application, because if we consider the presence of a word as evidence for a document classification, removing that evidence---that word---would be represented by a zero for that feature.555They discuss the case where absence of a word would be evidence as well; see the original paper.
More generally, we should consider carefully the notion of removing features from the input to a data-driven model. If we step away for a moment from explaining AI systems, we can think of explaining other sorts of evidence-driven decisions within the same framework. For instance, in a murder case, we might explain our decision to bring in the suspect based on the fact that the murder weapon was found in her apartment; if there were no murder weapon, we would not have brought her in. If we would have brought her in anyway, then the presence of the weapon does not suffice as an explanation for our decision. So, in this case, we are imagining our collection of evidence with the focal piece of evidence missing. We can do the same *in principle* with data-driven decisions: we can make the feature in question be missing and ask if we would still make the same decision. Thus, we can generalize to data inputs of any kind: removing the feature means “making it missing” in the data instance.
We emphasize that we can do this “in principle” because in practice it may or may not be practicable to simply make a feature be missing. Some AI models and systems deal with missing features naturally and some do not. Importantly, note that here we are talking about dealing with missing values at the time of use of the model, not dealing with missing values during machine learning. There are different ways for dealing with missing features when applying (as opposed to learning) a predictive model (Saar-Tsechansky and Provost, [2007](#bib.bib25 "Handling missing values when applying classification models")), such as imputing default values for the missing features, using an alternative model trained with only the available features, etc.
Therefore, the generalized explanation framework we present is agnostic to which method is used to deal with the removed features—taking the position that this decision is domain and problem dependent. Within a particular domain and explanation context, the user should choose the method for dealing with missing values. For example, in settings where features are often missing at prediction time, replacing the value of a feature with a “missing” categorical value might make the most sense to simulate missingness, whereas in cases where all attributes must have values specified in order to make the decision, replacing the value with the mean or the mode might make more sense. What matters is that the decision may change when some of the features are not present at the time of decision making, and that the method for dealing with missing values allows the change in the decision to be attributed to the absence of these features.
This framework naturally incorporates other techniques used in prior counterfactual approaches: the common case of replacing a feature in a sparse setting with a zero corresponds to mode imputation; replacing a numeric feature with the mean value for that attribute corresponds to mean imputation.
In the empirical examples presented below, we use mean imputation for continuous variables and mode imputation for sparse numeric, binary, and categorical variables. Saar-Tsechansky and Provost ([2007](#bib.bib25 "Handling missing values when applying classification models")) discuss other alternatives for dealing with missing values when applying predictive models; any of them could be used in conjunction with this counterfactual explanation framework.
###
3.4 A procedure for finding useful counterfactual explanations
This definition of counterfactual explanations for system decisions allows any procedure for finding such explanations. For example, fast solvers for combinatorial problems may be used to find counterfactual explanations (Schreiber et al., [2018](#bib.bib26 "Optimal multi-way number partitioning")). For this paper, and for the examples that follow, we adopt a heuristic procedure to find the most useful explanations depending on the context.
The algorithm proposed by Martens and Provost ([2014](#bib.bib9 "Explaining data-driven document classifications")) finds counterfactual explanations by using a heuristic search that requires the decision to be based on a scoring function, such as a probability estimate from a predictive model. We also will presume that the decision making is based on comparing some score to a threshold.
This scoring function is used by the search algorithm to first consider features that, when removed, reduce the score of the predicted class the most. This heuristic may be desirable when the goal is to find the smallest explanations, such as when explaining the decisions of models that use thousands of features. Another possible heuristic is to remove features according to their overall importance for the prediction, where the importance may be computed by a feature importance explanation technique (Ramon et al., [2019](#bib.bib28 "Counterfactual explanation algorithms for behavioral and textual data")).
However, the shortest explanations are not necessarily the best explanations. For instance, users may want to use the explanations as guidelines for what to change in order to affect the system decision. As an example, suppose that a system decides to warn a man that he is at high risk of having a heart attack. An explanation that “the system would have not made the warning if the patient were not male” is of very little use as a guide for what to do about it. In practice, some features are easier to change than others, and some may be practically impossible to change.
Therefore, we allow the incorporation of a cost function as part of the heuristic procedure in order to search first for the most relevant explanations. The underlying idea is that the cost function may be used to associate costs to the removal (or adjustment) of features, so that sets of features that satisfy desirable characteristics are searched first. Importantly, the cost function is meant to be used as a mechanism to capture the relevance of explanations, so the cost of changing or removing the features might not represent an actual cost (we will show an example of this in one of the case studies below). For example, the cost may be fixed (e.g., when removing a word from a document), may be contingent on the value of the variable (e.g., when adjusting a continuous variable), contingent on the value of other features, or may even be practically infinite.
Subsequently, instead of searching for the feature combinations that change the score of the predicted class the most, the heuristic could search for the feature combinations for which the output score changes the most per unit of cost. The motivation behind this new heuristic is to find first the explanations with the lowest costs. Returning to the heart attack example, if we assign an infinite cost to changing the gender feature, the heuristic would not select feature combinations that include it, regardless of its high impact on the output score. Instead, the heuristic would prefer explanations with many modest but “cheap” changes, such as changing several daily habits. To the extent that the system also has a scoring function (which could be the result of combining several predictive models), the procedure proposed by Martens and Provost ([2014](#bib.bib9 "Explaining data-driven document classifications")) could be easily adjusted to find the most useful explanations for the problem at hand. A similar approach has been suggested for classifiers that have a known and differentiable scoring function (Lash et al., [2017](#bib.bib27 "A budget-constrained inverse classification framework for smooth classifiers")).
###
3.5 Other advantages of counterfactual explanations
Counterfactual explanations have other benefits as well. First, as with importance weights, they are defined in terms of domain knowledge (features) rather than in terms of modeling techniques. As mentioned above, this is of critical importance to explain individual decisions made by such models to users. More importantly, these explanations can be used to understand how features affect decisions, which (as we will show in next sections) is not captured well by feature importance methods. Also, because only a fraction of the features will be present in any single explanation, the present approach may be used to explain decisions from models with thousands of features (or many more). Studies show cases where such explanations can be obtained in seconds for models with tens or hundreds of thousands of features and that the explanations typically consisted of a handful to a few dozen of features at the most (Martens and Provost, [2014](#bib.bib9 "Explaining data-driven document classifications"); Moeyersoms et al., [2016](#bib.bib11 "Explaining classification models built on high-dimensional sparse data"); Chen et al., [2017](#bib.bib10 "Enhancing transparency and control when drawing data-driven inferences about individuals")).
4 Limitations of importance weights
------------------------------------
In this section, we use three simple, synthetic (but illustrative) examples to highlight two fundamental reasons why importance-weight explanations may not be well-suited to explain data-driven decisions made by AI systems. The first example (Example 1) is meant to illustrate that features that have a large impact on a prediction (and thus large importance weights) may not have any impact on the decision made using that prediction. The next two examples show that importance weights are insufficient to communicate how features actually affect decisions (even when importance is determined with respect to system decisions rather than model predictions). More specifically, we show cases in which importance weights remain the same despite substantial changes to decision making (Examples 1, 2, and 3) and in which features deemed unimportant by the weights actually affect the decision (Example 3). Similar examples to the ones discussed in this section will come up again in the case studies in Section [5](#S5 "5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach"), when comparing importance weights with counterfactual explanations using real-world data.
Throughout this section, the examples assume that we want to explain the binary decision made for three-feature instance I and decision procedure Ci as defined here:
| | | | |
| --- | --- | --- | --- |
| | I={F1=1,F2=1,F3=1}, | | (4) |
| | Ci(I)={1,if ^Yi(I)≥10,otherwise, | | (5) |
where {F1,F2,F3} are binary features, and Ci is the decision-making procedure (an AI system) that uses the scoring (or prediction) function ^Yi to make decisions. The examples that follow will employ different ^Yi. We assume that domain knowledge has guided us to replace the values of missing features with a default value of zero.
We compute importance weights using SHAP (Lundberg and Lee, [2017](#bib.bib7 "A unified approach to interpreting model predictions")), a popular approach to explain the output of machine learning models. Before we focus on the disadvantages of importance weights for explaining system decisions, let us point out that SHAP has several advantages for explaining data-driven model predictions: (i) it produces numeric “importance weights” for each feature at an instance-level, (ii) it is model-agnostic, (iii) its importance weights tie instance-level explanations to cooperative game theory, providing a solid theoretical foundation, (iv) and SHAP unites several feature importance weighting methods, including the relatively well-known LIME (Ribeiro, Singh and Guestrin, 2016).
In the case of SHAP, importance weights consist of the (approximated) Shapley values of the features for a model prediction. Shapley values correspond to the impact each feature has on the prediction, averaged over all possible joining orders of the features. A major limitation of Shapley values is that computing them becomes intractable as the number of features grows. SHAP circumvents this limitation by sampling the space of feature combinations, resulting in a sampling-based approximation of the Shapley values. There are only 3 features in the examples that follow, so the approximations are not necessary here, but they will be for the case studies discussed in Section [5](#S5 "5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach"), where the number of features is much larger. We illustrate the computation of Shapley values in more detail in the examples below.
###
4.1 Example 1: Distinguishing between predictions and decisions
All importance weighting methods (that we are aware of) are designed to explain the output of scoring functions, not system decisions. This is problematic because a large impact on the scoring function does not necessarily translate to an impact on the decision. This example illustrates this by defining ^Y1 as follows:
| | | | |
| --- | --- | --- | --- |
| | ^Y1(I)=F1+F2+10F1F3+10F2F3, | | (6) |
so the prediction and the decision for instance I are ^Y1(I)=22 and C1(I)=1 respectively.
Table [2](#S4.T2 "Table 2 ‣ 4.1 Example 1: Distinguishing between predictions and decisions ‣ 4 Limitations of importance weights ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") shows how to compute the Shapley values of the features with respect to ^Y1. Each row represents one of the six possible joining orders of the features, and each column corresponds to the impact of one of the three features across those joining orders. The last row shows the average impact of the features, which corresponds to the Shapley values.
| Joining orders | Impact of F1 | Impact of F2 | Impact of F3 |
| --- | --- | --- | --- |
| F1,F2,F3 | 1 | 1 | 20 |
| F1,F3,F2 | 1 | 11 | 10 |
| F2,F1,F3 | 1 | 1 | 20 |
| F2,F3,F1 | 11 | 1 | 10 |
| F3,F1,F2 | 11 | 11 | 0 |
| F3,F2,F1 | 11 | 11 | 0 |
| Shapley values | 6 | 6 | 10 |
Table 2: Shapley values for ^Y1 and all the joining orders used in their computation.
According to Table [2](#S4.T2 "Table 2 ‣ 4.1 Example 1: Distinguishing between predictions and decisions ‣ 4 Limitations of importance weights ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach"), SHAP gives F3 a larger weight than F1 or F2 due to its large impact on ^Y1. However, if we take a closer look at C1 and ^Y1 simultaneosuly, we can see that F3 does not affect the decision-making procedure at all! More specifically F3 only affects ^Y1 if F1 or F2 are already present, but if those features are present, then increasing the score does not affect the decision because ^Y1≥1 (implying that C1=1 regardless of F3). Therefore, the large “importance” of a feature for a model prediction may not imply an impact on a decision made with that prediction.
As we mentioned at the outset, SHAP was not designed to explain system decisions—so this is not an indictment of SHAP. It is an illustration that explaining model predictions and explaining system decisions are two different tasks. We might conclude then that we could adapt SHAP to compute feature importance weights for system decisions, for example, by transforming the output of the decision system into a “scoring function” that returns 1 if the decision is the same after removing features and returns 0 otherwise. This transformation, originally introduced by Moeyersoms et al. ([2016](#bib.bib11 "Explaining classification models built on high-dimensional sparse data")) (also in the context of using Shapley values for instance-level explanations), would allow us to use SHAP to obtain importance weights for the system decision—even decisions with multiple, unordered alternatives that cannot normally be represented as a single numeric score.
| | | | |
| --- | --- | --- | --- |
| Joining orders | Impact of F1 | Impact of F2 | Impact of F3 |
| F1,F2,F3 | 1 | 0 | 0 |
| F1,F3,F2 | 1 | 0 | 0 |
| F2,F1,F3 | 0 | 1 | 0 |
| F2,F3,F1 | 0 | 1 | 0 |
| F3,F1,F2 | 1 | 0 | 0 |
| F3,F2,F1 | 0 | 1 | 0 |
| Shapley values | 0.5 | 0.5 | 0 |
| There is a single counterfactual explanation: {F1,F2} |
Table 3: Shapley values and joining orders for C1, as well as all counterfactual explanations for this decision.
Table [3](#S4.T3 "Table 3 ‣ 4.1 Example 1: Distinguishing between predictions and decisions ‣ 4 Limitations of importance weights ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") shows the Shapley values of the features with respect to the decision-making procedure C1 (when applying the suggested transformation). It illustrates that F3 indeed does not affect the decision at all. However, the next examples show that, even when importance weights are computed with respect to the decision-making procedure rather than the model predictions, the weights do not capture well how features affect decisions.
###
4.2 Example 2: Multiple interpretations for the same weights
In Example 1, the decision changes when we remove (or change) F1 and F2 simultaneously, and removing any of the features individually does not change the decision. So, according to our definition in Section [3.2](#S3.SS2 "3.2 Defining counterfactual explanations ‣ 3 Counterfactual explanations ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach"), there is a single counterfactual explanation, {F1,F2}. However, suppose we were to use the following scoring function to make decisions instead:
| | | | |
| --- | --- | --- | --- |
| | ^Y2=F1F2 | | (7) |
| | | | |
| --- | --- | --- | --- |
| Joining orders | Impact of F1 | Impact of F2 | Impact of F3 |
| F1,F2,F3 | 0 | 1 | 0 |
| F1,F3,F2 | 0 | 1 | 0 |
| F2,F1,F3 | 1 | 0 | 0 |
| F2,F3,F1 | 1 | 0 | 0 |
| F3,F1,F2 | 0 | 1 | 0 |
| F3,F2,F1 | 1 | 0 | 0 |
| Shapley values | 0.5 | 0.5 | 0 |
| There are two counterfactual explanations: {F1} and {F2} |
Table 4: Shapley values for C2, as well as all counterfactual explanations for this decision.
Table [4](#S4.T4 "Table 4 ‣ 4.2 Example 2: Multiple interpretations for the same weights ‣ 4 Limitations of importance weights ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") shows the Shapley values for C2, which are the same as for C1 (see Table [3](#S4.T3 "Table 3 ‣ 4.1 Example 1: Distinguishing between predictions and decisions ‣ 4 Limitations of importance weights ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach")) because features F1 and F2 are equally important in both cases. However, the decision-making procedure is different because the new scoring function implies that removing either feature would change the decision. Therefore, with the new scoring function, there would be two counterfactual explanations, {F1} and {F2}, but the importance weights do not capture this. This implies that (in general) importance weights do not communicate how removing (or changing) the features may change the decision.666Note that Ramon et al. ([2019](#bib.bib28 "Counterfactual explanation algorithms for behavioral and textual data")) show a way to use importance weighting methods (such as LIME and SHAP) to search for counterfactual explanations; this is different from computing importance weights for system decisions.
###
4.3 Example 3: Positive impact of non-positive weights
In Example 1, we showed that even if a feature has a large, positive importance weight for a model’s instance-level prediction, changing the feature may have no effect on the decision made for that instance.
Importance weights can also be misleading if we use them to explain system decisions, because a feature with an importance weight of zero may have a positive effect on the decision! We illustrate this with a third example, for which we use the following scoring function:
| | | | |
| --- | --- | --- | --- |
| | ^Y3=F1+F2−2F1F2−F1F3−F2F3+3F1F2F3 | | (8) |
| | | | |
| --- | --- | --- | --- |
| Joining orders | Impact of F1 | Impact of F2 | Impact of F3 |
| F1,F2,F3 | 1 | -1 | 1 |
| F1,F3,F2 | 1 | 1 | -1 |
| F2,F1,F3 | -1 | 1 | 1 |
| F2,F3,F1 | 1 | 1 | -1 |
| F3,F1,F2 | 0 | 1 | 0 |
| F3,F2,F1 | 1 | 0 | 0 |
| Shapley values | 0.5 | 0.5 | 0 |
| There are three counterfactual explanations: {F1},{F2}, and {F3} |
Table 5: Shapley values for C3, as well as all counterfactual explanations for this decision.
Table [5](#S4.T5 "Table 5 ‣ 4.3 Example 3: Positive impact of non-positive weights ‣ 4 Limitations of importance weights ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") shows the Shapley values with respect to C3, and we can see that the values are the same as in the previous examples, but the decision-making process has changed once again. Notably, removing (or changing) F3 can change the decision from C3=1 to C3=0, as evidenced by the impact of F3 in the first and third joining orders, but the importance weight of F3 is 0. The counterfactual explanation framework, on the other hand, reveals that there are three counterfactual explanations in this example: {F1}, {F2}, and {F3}. Thus, a feature that we might mistakenly deem as irrelevant due to its non-positive weight, is in fact as important as the other features with positive weights (at least for the purposes of explaining the decision C3(I)=1).
###
4.4 Drawbacks of using averages
While the previous examples were deliberately constructed to illustrate the limitations of importance weights (and thus may seem contrived), they reveal an important insight: it is difficult to capture the impact of features on decisions with a single number, especially when features interact with each other. This is particularly relevant when explaining black-box models (such as neural networks), which are well-known for learning complex interactions between features. Moreover, we will show in Section [5](#S5 "5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") how the hypothetical examples we illustrated in this section also occur in real-world scenarios.
The main reason why importance weights are problematic for explaining system decisions is that they essentially aggregate across potential explanations (i.e., feature sets) to provide a single explanation per decision. Thus, each decision is explained using a single vector of weights. Typically, the importance weighting methods summarize the impact of features in a single vector by averaging across multiple feature orderings. The problem is that the average impact of a feature is not fine-grained enough to describe dynamics between features, and more importantly, it is difficult to interpret: why should the average across feature orderings be relevant to explain a decision? After all, it might not be representative of the potential impact that features have (as in the case of F3 in Example 3).
Counterfactual explanations circumvent the drawbacks of using averages because the explanations are defined at the counterfactual level, meaning that each explanation
represents a counterfactual world in which the decision would be different. This allows a single decision to have multiple explanations, allowing a richer interpretation of how the features may influence the decision.
5 Case Studies
---------------
We now present three case studies to illustrate the phenomena discussed above using real-world data. The first case study contrasts counterfactual explanations with explanations based on importance weights, showing fundamental differences. The second case study showcases the power of counterfactual explanations for very high-dimensional data and shows how the heuristic procedure that generates counterfactual explanations may be adjusted to search and sort explanations according to their relevance to the decision maker. The third case study shows the application of counterfactual explanations to AI systems that are more complex than just applying a threshold to the output of a single predictive model—specifically, to systems that integrate multiple models predicting different things. In all case studies, we use SHAP to compute importance weights with respect to the decision-making procedure rather than model predictions (as discussed above).
###
5.1 Study 1: Importance Weights vs Counterfactual Explanations
To showcase the advantages of counterfactual explanations over feature importance weights when explaining data-driven decisions, we explain decisions made by a system that makes decisions to accept or deny credit, based on real data from Lending Club, a peer lending platform. The data is publicly available and contains comprehensive information on all loans issued starting in 2007. The data set includes hundreds of features for each loan, including the interest rate, the loan amount, the monthly installment, the loan status (e.g., fully paid, charged-off), and several other attributes related to the borrower, such as type of house ownership and annual income. To simplify the setting, we use a sample of the data used by Cohen et al. ([2018](#bib.bib29 "Data-driven investment strategies for peer-to-peer lending: a case study for teaching data science")) and focus on loans with a 13% annual interest rate and a duration of three years (the most common loans), resulting in 71,938 loans. The loan decision making is simulated but is in line with consumer credit decision making as described in the literature (see Baesens et al., [2003](#bib.bib30 "Benchmarking state-of-the-art classification algorithms for credit scoring")).777Note that the Lending Club data contains a substantial number of loans for which traditional models estimate moderately high likelihoods of default, despite these all being issued loans. This may be due to Lending Club’s particular business model, where external parties choose to fund (invest in) the loans.
We use 70% of this data set to train a logistic regression model that predicts the probability of borrowers defaulting using the following features: loan amount (loan\_amnt), monthly installment (installment), annual income (annual\_inc), debt-to-income ratio (dti), revolving balance (revol\_bal), incidences of delinquency (delinq\_2yrs), number of open credit lines (open\_acc), number of derogatory public records (pub\_rec), upper boundary range of FICO score (fico\_range\_high), lower boundary range of FICO score (fico\_range\_low), revolving line utilization rate (revol\_util), and months of credit history (cr\_hist). The model is used by a (simulated) system that denies credit to loan applicants with a probability of default above 20%. We use the system to decide which of the held-out 30% of loans should be approved.

Figure 2: Feature importance weights according to SHAP
By comparing counterfactual explanations to explanations based on feature importance weights, we can see counterfactual explanations have several advantages. First, importance weights do not communicate which features would need to change in order for the decision to change—so their role as explanations for decisions is incomplete. Figure [2](#S5.F2 "Figure 2 ‣ 5.1 Study 1: Importance Weights vs Counterfactual Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") shows the feature importance weights assigned by SHAP to four loans (different colors) that are denied credit by the system. For instance, according to SHAP, loan\_amnt was the most important feature for the credit denial of all four loans. However, this information does not fully explain any of the decisions. The credit applicant of Loan 1, for example, cannot use the explanation to understand what would need to be different to obtain credit; the feature importance weights do not explain why he or she was denied credit. Was it the amount of the loan? The annual income? Both?
Table [6](#S5.T6 "Table 6 ‣ 5.1 Study 1: Importance Weights vs Counterfactual Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach"), in contrast, shows all counterfactual explanations for the credit denial decision of Loan 1. Each column represents an explanation, and the arrows in each cell show which features are present in each explanation (recall that a counterfactual explanation is a set of features). The last column shows the difference between the original value of each feature and the value that was imputed to simulate missingness (the mean in our case), illustrating how our generalized counterfactual explanations may be applied to numeric features.
| | | |
| --- | --- | --- |
| Features | Explanations |
Distance
from mean
|
| 1 | 2 | 3 | 4 | 5 | 6 |
| loan\_amnt | ↑ | | | | | | +$16,122 |
| installment | | | | | ↑ | | +$540 |
| annual\_inc | | ↓ | ↓ | ↓ | ↓ | ↓ | -$9,065 |
| revol\_bal | | | | | | ↓ | -$4,825 |
| fico\_range\_high | | | ↓ | | | | -16 |
| fico\_range\_low | | ↓ | | | | | -16 |
| revol\_util | | | | | | ↑ | +12% |
| cr\_hist | | | | ↓ | | | -92 months |
| ↑ means feature is too large to grant credit. |
| ↓ means feature is too small to grant credit. |
Table 6: Counterfactual explanations for Loan 1
For example, as shown in column 1, one possible explanation for the credit denial of Loan 1 is that the loan amount is too large (or more specifically, $16,122 larger than the average) given the other aspects of the application. The data indeed shows that the amount for Loan 1 is $28,000, but the average loan amount in our sample is $11,878. In this instance, one could explain the decision in several other ways. The explanation in column 4 suggests that the $28,000 credit would be approved if the applicant had a higher annual income and a longer credit history, which are below average in the case of the applicant. Therefore, from these explanations, it is immediately apparent how the features influenced the decision. This highlights two additional advantages of counterfactual explanations: they give a deeper insight into why the credit was denied and provide various alternatives that could change the decision.
Table [7](#S5.T7 "Table 7 ‣ 5.1 Study 1: Importance Weights vs Counterfactual Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") shows the counterfactual explanations of Loan 4 to emphasize this last point. From Figure [2](#S5.F2 "Figure 2 ‣ 5.1 Study 1: Importance Weights vs Counterfactual Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach"), we can see that Loan 1 and Loan 4 have similar importance weights. Thus, from this figure alone, one may conclude that these two credit denial decisions should have similar counterfactual explanations. Yet, comparing Table [6](#S5.T6 "Table 6 ‣ 5.1 Study 1: Importance Weights vs Counterfactual Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") and Table [7](#S5.T7 "Table 7 ‣ 5.1 Study 1: Importance Weights vs Counterfactual Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") reveals this in fact is not the case. Loan 4 has many more explanations, and even though the explanations in both loans have similar features, the only explanation that the loans have in common is the first one (i.e., loan amount is too large); there is no other match.
| | | |
| --- | --- | --- |
| Features | Explanations |
Distance
from mean
|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| loan\_amnt | ↑ | | | | | | | | | | | | | | | +$16,122 |
| installment | | | | | | ↑ | | | | | | ↑ | | | ↑ | +$540 |
| annual\_inc | | ↓ | | | | | | | | | | | | | | -$9,065 |
| dti | | | | ↑ | | | | | | ↑ | | | | | ↑ | +5 |
| open\_acc | | | | | | | | ↑ | | | | | | ↑ | | +1 |
| pub\_rec | | | | | | | | | ↑ | | | | | | | +1 |
| fico\_range\_high | | | ↓ | | | | | | | ↓ | ↓ | ↓ | ↓ | ↓ | | -16 |
| fico\_range\_low | | | ↓ | ↓ | ↓ | ↓ | ↓ | ↓ | ↓ | | | | | | | -16 |
| revol\_util | | | | | | | ↑ | | | | | | ↑ | | ↑ | +12% |
| cr\_hist | | | | | ↓ | | | | | | ↓ | | | | ↓ | -92 months |
| ↑ means feature is too large to grant credit. |
| ↓ means feature is too small to grant credit. |
Table 7: Counterfactual explanations for Loan 4
Importantly, the number of potential counterfactual explanations grows exponentially with respect to the number of features, and we know of no algorithm with better than exponential worst-case time complexity for finding all explanations. Therefore, finding all counterfactual explanations may be intractable when the number of features is large.888Ramon et al. ([2019](#bib.bib28 "Counterfactual explanation algorithms for behavioral and textual data")) demonstrates the effectiveness of starting the importance weights in order to efficiently generate a counterfactual explanation, but this does not reduce the worst case complexity for finding all explanations. Furthermore, as noted above, computing the importance weights itself is computationally expensive. In the case of the loans discussed in this case study, we were able to conduct an exhaustive search because the number of features is relatively small; thus Tables [6](#S5.T6 "Table 6 ‣ 5.1 Study 1: Importance Weights vs Counterfactual Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach")-[7](#S5.T7 "Table 7 ‣ 5.1 Study 1: Importance Weights vs Counterfactual Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") show all possible counterfactual explanations for the credit denials of Loan 1 and Loan 4. In other settings, we may need to be satisfied with an approximation to the set of all explanations.
In cases where the number of explanations is large, additional steps to improve interpretability may be helpful, such as defining measures to rank explanations according to their usefulness.
One such measure is the number of features present in the explanation (the fewer, the better). In fact, the heuristic we used to find explanations in this example, the same introduced by Martens and Provost ([2014](#bib.bib9 "Explaining data-driven document classifications")), tries to find the shortest explanations first. However, there could be other more relevant measures depending on the particular decision-making problem—such as the individual’s ability to change the features in the explanation. As mentioned above, our generalized framework would allow incorporating the cost of changing features as part of the heuristic procedure, resulting in an algorithm designed to (try to) find the cheapest or more relevant explanations first. Because finding all possible explanations was tractable in this case, we did not incorporate costs in the heuristic we used to find explanations in this empirical example, but we do so in the next case study.
Nonetheless, one can see that not all features shown in Figure [2](#S5.F2 "Figure 2 ‣ 5.1 Study 1: Importance Weights vs Counterfactual Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") and Tables [6](#S5.T6 "Table 6 ‣ 5.1 Study 1: Importance Weights vs Counterfactual Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach")-[7](#S5.T7 "Table 7 ‣ 5.1 Study 1: Importance Weights vs Counterfactual Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") would be relevant for loan applicants looking for recommendations to get their credit approved. So, SHAP may be adjusted further to compute weights only for a subset of features. Since SHAP deals with missing features by imputing default values, we can easily extend SHAP to only consider certain (relevant) features by setting the default values of the irrelevant features equal to the current values of the instance. Then, SHAP will compute importance weights only for the features that have a value different from the default. We do this for Loan 4 and define loan amount and annual income as the only relevant features. This would make sense in our context if customers can only ask for less money or show additional sources of income to get their credit approved.
After doing this, SHAP computes an importance weight of 0.5 for both the loan amount and the annual income, and there are two counterfactual explanations: the applicant can either reduce the loan amount or increase the annual income to get the loan approved (columns 1 and 2 in Table [7](#S5.T7 "Table 7 ‣ 5.1 Study 1: Importance Weights vs Counterfactual Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach")). However, consider a different scenario. Suppose the bank were stricter with the loans it approves and used a decision threshold 2.5 percentage points lower. Now, in order to get credit approved, the applicant of Loan 4 would need both to reduce the loan amount and to increase her (or his) annual income.
This situation is directly analogous to Example 2 in Section [4.2](#S4.SS2 "4.2 Example 2: Multiple interpretations for the same weights ‣ 4 Limitations of importance weights ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach").
With this different decision system, there is a single counterfactual explanation (instead of two) consisting of both features, so the counterfactual framework captures the fact that the decision-making procedure changed. However, SHAP would still show an importance weight of 0.5 for each feature. Thus, the counterfactual explanations and the SHAP explanations exhibit different behavior. SHAP explanations suggest that the two decisions are essentially the same. The counterfactual explanations suggest that they are quite different. We argue that the latter is preferable in many settings. It may well be that the former is preferable in some settings, but we haven’t found a credible and compelling example.
###
5.2 Study 2: High-dimensional and Context-specific Explanations
We use Facebook data to showcase the advantages of counterfactual explanations when explaining data-driven decisions in high-dimensional settings. The data, which was collected through a Facebook application called myPersonality,999Thanks to the authors of the prior study, Kosinski et al. ([2013](#bib.bib31 "Private traits and attributes are predictable from digital records of human behavior")), for sharing the data. has also been used by other researchers to compare the performance of various counterfactual explanation methods (Ramon et al., [2019](#bib.bib28 "Counterfactual explanation algorithms for behavioral and textual data")). We use a sample that contains information on 587,745 individuals from the United States, including their Facebook Likes and a subset of their Facebook profiles. In general, Facebook users do not necessarily reveal all their personal characteristics, but their Facebook Likes are available to the platform. For this case study, in order to simulate a decision-making system, we assume there is a (fictitious) firm that wants to launch a marketing campaign to promote a new product to users who are more than 50 years old. Given that not all users share their age in their Facebook profile, the firm could use a predictive model to predict who is over-50 (using Facebook Likes) and use the predictions to decide whom to target with the campaign.
The Facebook Likes of a user are the set of Facebook pages that the user chose to “Like” on the platform (we capitalize “Like”, as have prior authors, to distinguish the act on Facebook). So, we represent each Facebook page as a binary feature that takes a value of 1 if the user Liked the page and a value of 0 otherwise. We kept only the pages that were Liked by at least 1,000 users, leaving us with 10,822 binary features. The target variable for modeling is also binary and takes a value of 1 if the user is more than 50 years old, and a value of 0 otherwise. We use 70% of the data to train a logistic regression model. In our fictitious setting, the model is used by a decision system that targets the top 1% of users with the highest probability of being an older person, which (in our sample) implies sending promotional content to the users with a probability greater than 41.1%. We use the system to decide which of the held out 30% of users to target.
Importantly, while the system could generate a lot of value to the firm, we need to consider users’ sense of privacy and how they might feel about being targeted with the promotional campaign. For example, some users may feel threatened by highly personalized offers (“How do they know this about me?”) and thus may be interested in knowing why they were targeted (see Chen et al. ([2017](#bib.bib10 "Enhancing transparency and control when drawing data-driven inferences about individuals")) for a more detailed discussion). Such users may be unlikely to be interested in the intricacies of the model but rather in the data about their behavior that was used to target them with promotional content. If that is the case, framing explanations in terms of comprehensible input features (e.g., Facebook Likes) is critical.
One approach is to use importance weights to rank Facebook pages according to their feature importance (as computed by a technique such as SHAP) and then show the user the topmost predictive pages that she (or he) Liked. However, given the large number of features (Facebook pages), computing weights in a deterministic fashion is intractable. SHAP circumvents this issue by sampling the space of feature combinations, resulting in sampling-based approximations of the influence of each feature on the prediction. However, the downside is that the estimates may be far from the real values, which may lead to inconsistent results. For example, if we were to use the topmost important features to explain a decision, we should consider whether different runs of a non-deterministic method repeatedly rank the same pages as the most important ones. Unfortunately, as we will show, the set of the topmost important features becomes increasingly inconsistent (across different runs of SHAP) as the number of features increases.
For instance, in our holdout data set there is a 34-year-old user who would be targeted with an ad for older persons (the model predicts a 42% probability that this user is at least 50 years old). So, as an example, suppose this user wants to know why he or she is being targeted. Let’s say that we have determined that showing the top-3 most important features makes sense for this application. Table [8](#S5.T8 "Table 8 ‣ 5.2 Study 2: High-dimensional and Context-specific Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") shows the top-3 most predictive pages according to their SHAP values (importance weights) for the system decision. The table shows the result of running SHAP five times to compute the importance weights, each time sampling 4,100 observations of the space of feature combinations.101010We use the SHAP implementation provided here: <https://github.com/slundberg/shap/>.
At the moment of writing, the default sample size is 2048+2m, where m is the number of features with a non-default value. Our choice of 4,100 is larger than the SHAP implementation’s default sample size for all of the experiments we run. Because SHAP uses sampling-based approximations, we can see that SHAP values vary every time we compute them, resulting in different topmost predictive pages. Importantly, while some pages appear recurrently, only Paul McCartney appears in all 5 approximations.
| | | | | |
| --- | --- | --- | --- | --- |
| Approximation 1 | Approximation 2 | Approximation 3 | Approximation 4 | Approximation 5 |
| Elvis Presley | Paul McCartney | Paul McCartney | Paul McCartney | Elvis Presley |
| (0.1446) | (0.1471) | (0.1823) | (0.1541) | (0.1582) |
| Bruce Springsteen | William Shakespeare | Neil Young | Elvis Presley | Paul McCartney |
| (0.1302) | (0.1321) | (0.1676) | (0.1425) | (0.1489) |
| Paul McCartney | Brain Pickings | The Hobbit | Leonard Cohen | Bruce Springsteen |
| (0.1268) | (0.1319) | (0.1417) | (0.1359) | (0.1303) |
| Importance weights (SHAP values) shown in parentheses. |
Table 8: Topmost predictive pages and their SHAP values for a single decision to target our example user with the over-50 ad.
As we will show in more detail below, this inconsistency is the consequence of using SHAP to estimate importance weights for too many features. This specific user Liked 64 pages, which is not an unsually large number of Likes—more than a third of the targeted users in the holdout data set have at least that many Likes. There are (at most) 64 non-zero SHAP values to estimate, making the task significantly simpler than if we had to estimate importance weights for all 10,822 features. However, SHAP proves unreliable to find the most predictive pages (let alone to estimate the importance weights for each page).
We increased the sample size for SHAP to observe when the estimates became stable for this particular task (note that we already were running SHAP with a larger sample size than the default). For this specific user, it took 8 times more samples from the feature space for the same topmost pages to show consistently across all approximations, increasing computation time substantially (from 3 to 21 seconds per approximation on a standard laptop). This time would increase dramatically for data settings with hundreds of non-zero features, which are not uncommon (e.g., see Chen et al., [2017](#bib.bib10 "Enhancing transparency and control when drawing data-driven inferences about individuals"); Perlich et al., [2014](#bib.bib37 "Machine learning for targeted display advertising: transfer learning in action")).
In contrast, counterfactual explanations were found in a tenth of a second (on the same laptop), five of which we show in Table [9](#S5.T9 "Table 9 ‣ 5.2 Study 2: High-dimensional and Context-specific Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach"). Each explanation consists of a subset of Facebook pages that would change the targeting decision if it were removed from the set of pages Liked by the user. In other words, each of the sets shown in Table [9](#S5.T9 "Table 9 ‣ 5.2 Study 2: High-dimensional and Context-specific Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") is an explanation in its own right, representing a minimum amount of evidence that (if removed) changes the decision. Importantly, these explanations are short, consistent (because they are generated in a deterministic fashion), and directly tied to the decision-making procedure.
| Explanation 1 | The user would not be targeted if {Paul McCarney} were removed. |
| --- | --- |
| Explanation 2 | The user would not be targeted if {Elvis Presley} were removed. |
| Explanation 3 | The user would not be targeted if {Neil Young} were removed. |
| Explanation 4 | The user would not be targeted if {Leonard Cohen} were removed. |
| Explanation 5 | The user would not be targeted if {Brain Pickings} were removed. |
Table 9: Counterfactual explanations for a single decision to target our example user with the over-50 ad.
As an additional systematic demonstration of the negative impact that an increasing number of features may have on the consistency of sampling-based feature-importance approximations, we show how the more pages a user has Liked, the more inconsistent the set of the top three most important pages becomes. The process we used is as follows. First, we picked a random sample of 500 users in the holdout data that would be targeted by the system (as described above). Then, we applied SHAP five times to approximate the importance weights of the features used for each of the 500 targeting decisions (sampling 4,100 observations of the feature space each time). Finally, for each targeting decision, we counted the number of pages that appeared consistently in the top three most important pages across all five approximations. We call this the number of matches. Thus, if the approximations were consistent, we would expect the same three pages to appear in the top three pages of all approximations, and there would be three matches. In contrast, if the approximations were completely inconsistent, no pages would appear in the top three pages of all five approximations and there would be no matches. It took about an hour to run this experiment on a standard laptop.
| | |
| --- | --- |
|
<18Likes
0
0.5
1
1.5
2
2.5
3
Average Matches (SHAP)
(a) Average matches by quantile
|
<18Likes
0
1
2
3
4
5
6
Average Explanation Size
(b) Average size by quantile
|
Figure 3: Variations in explanations by number of Likes
The result of the experiment is in Figure [2(a)](#S5.F2.sf1 "(a) ‣ Figure 3 ‣ 5.2 Study 2: High-dimensional and Context-specific Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach"), which shows the average number of matches by quantile. As predicted, SHAP approximations are not consistent for users who have Liked many pages. For the largest instances, most cases have only one page that appears in all five SHAP runs. In order to contrast SHAP with counterfactual explanations, we ran our algorithm to find one counterfactual explanation for each of the 500 targeting decisions, which took 15 seconds on a standard laptop. The results are shown in Figure [2(b)](#S5.F2.sf2 "(b) ‣ Figure 3 ‣ 5.2 Study 2: High-dimensional and Context-specific Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach"), which shows the average size of counterfactual explanations by quantile.111111Recall that targeting decisions may have several counterfactual explanations. The numbers we report here are the average sizes of the first explanation we found for each targeting decision. From the figure, we can see that explanations are larger for users who Liked many pages but remain relatively small considering the number of features present, which concurs with the findings by Chen et al. ([2017](#bib.bib10 "Enhancing transparency and control when drawing data-driven inferences about individuals")).
Finally, in this case study we also adjust our method to incorporate domain-specific preferences (“costs”) and showcase how they can lead to more comprehensible explanations. The explanations we have shown so far (in both case studies) were generated using the heuristic search procedure proposed by Martens and Provost ([2014](#bib.bib9 "Explaining data-driven document classifications")), which does not consider the relevance of the various possible explanations and was designed to find the smallest explanations first. Nonetheless, short explanations may include Likes of relatively uncommon pages, which may be unfamiliar to the person analyzing the explanation. To illustrate how domain preferences can be taken into account when generating explanations of decisions, let’s say that for our problem, explanations with highly specific Likes are problematic for a feature-based explanation. The recipient of the explanation is much less likely to know these pages, so he or she would be better served with explanations using popular pages.
To this end, we can adjust the heuristic search (as discussed in Section [3.4](#S3.SS4 "3.4 A procedure for finding useful counterfactual explanations ‣ 3 Counterfactual explanations ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach")) to find explanations that include more relevant—viz., more popular—pages by associating lower costs to their “removal” from an instance’s input data. Specifically, we adjust the heuristic search so that it penalizes less-popular pages (those with fewer total Likes) by assigning them a higher cost.
Table [10](#S5.T10 "Table 10 ‣ 5.2 Study 2: High-dimensional and Context-specific Explanations ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") shows some examples of how the first explanation found by the algorithm changes depending on whether the relevance heuristic is used. As expected, the explanations found when using the relevance heuristic can include more pages than the “shortest first” search; however, those pages are also more popular (as evidenced by their total number of Likes). Importantly, these examples show how the search procedure can be easily adapted to find context-specific explanations. In this case, the user may be interested in finding explanations with popular pages, but the search could also be adjusted to show first the explanations with pages that were recently Liked by the user or that have pages more closely related to the advertised product.
| User ID |
First explanation found
(WITHOUT the relevance heuristic)
|
First explanation found
(WITH the relevance heuristic)
|
| --- | --- | --- |
| 11 | ‘It’s a Wonderful Life’ (1,181 Likes) | ‘Reading’ (47,288 Likes) |
| |
‘JESUS IS LORD!!!!!!!!!!!!!!!!!!!!!!!!!!! if you
know this is true press like. :)’ (1,291 Likes)
| ‘American Idol’ (15,792 Likes) |
| | ‘Classical’ (8,632 Likes) |
| 38 | ‘The Hollywood Gossip’ (1,353 Likes) | ‘Pink Floyd’ (43,045 Likes) |
| |
‘Remember those who have passed. Press
Like if you’ve lost a loved one’ (2,248 Likes)
| ‘Dancing With The Stars’ (5,379 Likes) |
| | ‘The Ellen DeGeneres Show’ (16,944 Likes) |
| | | ‘American Idol’ (15,792 Likes) |
| 108 |
‘Six Degrees Of Separation - The
Experiment’ (3,373 Likes)
| ‘Star Trek’ (11,683 Likes) |
| |
‘Turn Facebook Pink For 1 Week For
Breast Cancer Awareness’ (12,942 Likes)
|
| |
‘They’re, Their, and There have 3 distinct
meanings. Learn Them.’ (3,842 Likes)
|
| 413 | ‘Sarcasm as a second language’ (1,540 Likes) | ‘Reading’ (47,288 Likes) |
| | ‘RightChange’ (3,842 Likes) | ‘Pink Floyd’ (43,045 Likes) |
| | | ‘Where the Wild Things Are’ (13,781 Likes) |
| | | ‘Proud to be an American’ (3,938 Likes) |
Table 10: First counterfactual explanations found
###
5.3 Study 3: System Decisions with Multiple Models
For our third case study, we illustrate the advantages of our proposed approach when applied to complex systems, including ones that use multiple models to make decisions. We use the data set from the KDD Cup 1998, which is available at the UCI Machine Learning Repository. The data set was originally provided by a national veteran’s organization that wanted to maximize the profits of a direct mailing campaign requesting donations. Therefore, the business problem consisted of deciding which households to target with direct mails. Importantly, one could approach this problem in several ways, such as:
1. Using a regression model to predict the amount that a potential target will donate so that we can target her if that amount is larger than the break-even point.
2. Using a classification model to predict whether a potential target will donate more than the break-even point so that we can target her if this is the case.
3. Using a classification model to predict the probability that a potential target will donate and a regression model to predict the amount if the potential target were to donate. By multiplying together the results of these two models, one could obtain the expected donation amount and send a direct mail if the expected donation is larger than the break-even point.
To showcase system decisions that incorporate multiple models, we illustrate our generalized framework using the third approach, which is also the one that was used by the winners of the KDD Cup 1998.
We use XGBoost for both regression and classification using 70% of the data and the following subset of features: Age of Household Head (AGE), Wealth Rating (WEALTH2), Mail Order Response (HIT), Male active in the Military (MALEMILI), Male Veteran (MALEVET), Vietnam Veteran (VIETVETS), World War two Veteran (WWIIVETS), Employed by Local Government (LOCALGOV), Employed by State Government (STATEGOV), Employed by Federal Government (FEDGOV), Percent Japanese (ETH7), Percent Korean (ETH10), Percent Vietnamese (ETH11), Percent Adult in Active Military Service (AFC1), Percent Male in Active Military Service (AFC2), Percent Female in Active Military Service (AFC3), Percent Adult Veteran Age 16+ (AFC4), Percent Male Veteran Age 16+ (AFC5), Percent Female Veteran Age 16+ (AFC6), Percent Vietnam Veteran Age 16+ (VC1), Percent Korean Veteran Age 16+ (VC2), Percent WW2 Veteran Age 16+ (VC3), Percent Veteran Serving After May 1975 Only (VC4), Number of promotions received in the last 12 months (NUMPRM12), Number of lifetime gifts to card promotions to date (CARDGIFT), Number of months between first and second gift (TIMELAG), Average dollar amount of gifts to date (AVGGIFT), and Dollar amount of most recent gift (LASTGIFT).
In order to motivate the problem, suppose that a system uses the classification and regression models on the holdout 30% of data to target the 5% of households with the largest (estimated) expected donations, essentially targeting the most profitable households with a limited budget. In this case, both the targeters and the targeted may be interested in explanations for why the system decided to send any particular direct mail. This is a particularly challenging problem for methods designed to explain model predictions (not decisions), since the system makes decisions using more than one model. Therefore, it is possible that the most important features for predicting the probability of donation are not the same as the most important features for predicting the donation amount, and so determining which features led to the targeting decision is not straightforward.
| | |
| --- | --- |
|
(a) Top features for probability
|
(b) Top features for amount
|
Figure 4: Features with largest importance weights
To illustrate this better, consider one targeted household in the holdout data, for which we computed SHAP values for its predicted probability of donating (given by the classification model) and its predicted donation amount (given by the regression model). We normalized the SHAP values for each model prediction so that the sum of the values adds up to 1. The top 5 most important features for the probability prediction and the regression prediction are shown in Figure [3(a)](#S5.F3.sf1 "(a) ‣ Figure 4 ‣ 5.3 Study 3: System Decisions with Multiple Models ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") and Figure [3(b)](#S5.F3.sf2 "(b) ‣ Figure 4 ‣ 5.3 Study 3: System Decisions with Multiple Models ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") respectively. Interestingly, only VC3 (percent of 16+ WW2 veterans in the household) is part of the most important features for both the classification model and the regression model. Importantly, we cannot explain the targeting decision from these figures alone: even though we know the most important features for each prediction, there is no way of telling what was actually vital for the system to make the targeting decision. Was the household targeted because of the size of the last gift (LASTGIFT)? Or would the household’s high probability of donating justify the targeting decision even if LASTGIFT had a smaller value?
As per our earlier discussions, SHAP may be repurposed to compute feature importance weights for system decisions that incorporate multiple models by transforming the output of the system into a scoring function that returns 1 if the household is targeted and returns 0 otherwise. However, as we have similarly shown for other problems, acquiring feature importance weights for decisions made based on expected donations (rather than amounts or probabilities) would still not explain the system decisions. In contrast, counterfactual explanations can transparently be applied to system decisions that involve more than one model. Specifically, by defining the predicted expected donation as a scoring function (which is the result of multiplying the predictions of the two models), we can use the same procedures showcased in the previous examples to find explanations for targeting decisions. Table [11](#S5.T11 "Table 11 ‣ 5.3 Study 3: System Decisions with Multiple Models ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") shows the explanations found for the targeted household discussed above.
| | |
| --- | --- |
| Features | Explanations |
| 1 | 2 | 3 | 4 | 5 | 6 |
| AGE | | | | | | ↓ |
| WWIIVETS | ↑ | | | | | |
| VC1 | | | ↓ | | | |
| VC2 | | | | | ↑ | |
| VC3 | | ↑ | | | | |
| NUMPRM12 | | ↑ | ↑ | ↑ | ↑ | ↑ |
| CARDGIFT | | | | ↑ | | |
| AVGGIFT | ↑ | ↑ | ↑ | ↑ | ↑ | ↑ |
| LASTGIFT | ↑ | ↑ | ↑ | ↑ | ↑ | ↑ |
| ↑ means household was targeted because feature is above average. |
| --- |
| ↓ means household was targeted because feature is below average. |
Table 11: Explanations for targeting decision
Interestingly, some of the highest-scoring SHAP features, shown in Figures [4](#S5.F4 "Figure 4 ‣ 5.3 Study 3: System Decisions with Multiple Models ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach"), are not present in any of the explanations (e.g., MALEVET), whereas some features that are present in some explanations do not have large SHAP values (e.g., AVGGIFT). In fact, AVGGIFT had a negative SHAP value in the regression model (meaning we would expect its impact on the non-default decision to be negative), but it appears in all explanations! This example illustrates the importance of defining explanations in terms of decisions and not predictions, particularly when dealing with complex, non-linear models, such as XGBoost.
More specifically, because SHAP attempts to evaluate the overall impact of features on the model prediction, it averages out the negative and positive impacts that features have on the prediction when removed alongside all other feature combinations. Hence, if a feature has a large negative impact in one case and several small positive impacts in other cases, that feature may have a negative SHAP value (if the single negative impact is greater than the sum of the small positive impacts). This behavior is the same that we illustrated in Section [4.3](#S4.SS3 "4.3 Example 3: Positive impact of non-positive weights ‣ 4 Limitations of importance weights ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach") (Example 3), which of course would be counterproductive when trying to understand the influence of features on the decision making. Averaging out the impact of features over all feature combinations hides the fact that (in non-linear models) features may provide evidence in favor or against a decision depending on what other features are removed, which explains why AVGGIFT had a negative SHAP value but is present in the explanations shown in Table [11](#S5.T11 "Table 11 ‣ 5.3 Study 3: System Decisions with Multiple Models ‣ 5 Case Studies ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach").
6 Discussion
-------------
The previous studies illustrate various advantages of counterfactual explanations over importance weighting methods. The first study shows that knowing the importance weight of features is not enough to determine how the features affect system decisions. The second study demonstrates the strengths of counterfactual explanations in the presence of high-dimensional data. In particular, the study shows that sampling-based approximations of importance weights get worse as the number of features increases. Counterfactual explanations sidestep this issue because small subsets of features are usually enough to explain decisions. Moreover, the study showcased a heuristic procedure to search and sort counterfactual explanations according to their relevance. Finally, the third study shows that importance weights may be misleading when decisions are made using multiple (and complex) models. More specifically, we see a real instance of the phenomenon we showed in Section [4.3](#S4.SS3 "4.3 Example 3: Positive impact of non-positive weights ‣ 4 Limitations of importance weights ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach"), in which features with negative SHAP weights may in fact have a positive effect on system decisions.
It has been argued that a disadvantage of counterfactual explanations is that each instance (decision) usually has multiple explanations (Molnar, [2019](#bib.bib12 "Interpretable machine learning, see 18.1 counterfactual explanations")); this is also referred to as the Rashomon effect. The argument is that this is inconvenient because people may prefer simple explanations over the complexity of the real world. This issue may be exacerbated as the number of features increases because the number of counterfactual explanations may grow exponentially. In contrast, most importance weighting methods converge to a unique solution (e.g., Shapley values in the case of SHAP), regardless of the number of features.
However, our second case study suggests that importance weighting methods may actually not scale well when the number of features increases because their approximations may become inconsistent. Moreover, objective measures of relevance (e.g., number of Likes in our Facebook case study) may be incorporated as part of the heuristic procedures used to find counterfactual explanations. Thus, the fact that the number of counterfactual explanations may grow exponentially is not necessarily problematic. Our study shows that short, consistent, and relevant explanations are significantly faster to find than computing importance weights, even when the number of features is large.
Something that was not explored in the case studies was the sensitivity of the counterfactual explanations to the method used to deal with missing values. This is an interesting direction for future research, as we would expect distinct alternatives for dealing with missing features to affect explanations differently. For example, if features are correlated, mean imputation and retraining the model without the removed feature may produce different results. For instance, a decision may change when imputing the mean for a removed feature, but if instead the missing feature is dealt with by using a model trained without that feature (Saar-Tsechansky and Provost, [2007](#bib.bib25 "Handling missing values when applying classification models")), the decision may not change when removing the feature because other features may capture most of the information given by the removed feature. Therefore, while our proposed framework would work with either approach, future research should assess the advantages of each approach in different settings.
Moreover, this study compared importance weights with a specific type of counterfactual explanations (formally defined in Section [3.2](#S3.SS2 "3.2 Defining counterfactual explanations ‣ 3 Counterfactual explanations ‣ Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach")). Specifically, our explanations are defined in terms of counterfactual worlds in which some of the features are absent when making decisions. Nonetheless, there are other types of counterfactual worlds that may be of interest when explaining decisions. For example, in our first case study, we showed that some loan applicants were denied credit because the amount they requested was too large (i.e., the decision changed when we removed the loan amount feature). While this explains the credit denial decision, these applicants may instead be interested in the maximum amount they could ask for, so that they are no longer denied credit. Such a counterfactual explanation could be defined as a set of “minimal” feature adjustments that changes the decision.
Other researchers have proposed various methods to obtain such counterfactual explanations. For example, in the context of explaining predictions (not decisions), Wachter et al. ([2017](#bib.bib13 "Counterfactual explanations without opening the black box: automated decisions and the GPDR")) define counterfactual explanations as the smallest change to feature values that changes the prediction to a predefined output. Thus, they address explanations as a minimization problem in which larger (user-defined) distances between counterfactual instances and the original instance are penalized more. Their method, however, focuses on gradient-based models, does not work with categorical features, and may require access to the machine learning method used to learn the model (which usually is not available for deployed systems). Tolomei et al. ([2017](#bib.bib32 "Interpretable predictions of tree-based ensembles via actionable feature tweaking")) define counterfactual explanations in a similar way, but instead propose how to find such explanations when using tree-based methods. Other counterfactual methods have also been implemented in the Python package Alibi.121212See <https://github.com/SeldonIO/alibi> The package includes a simple counterfactual method loosely based on Wachter et al. ([2017](#bib.bib13 "Counterfactual explanations without opening the black box: automated decisions and the GPDR")), as well as an extended method that uses class prototypes to improve the interpretability and convergence of the algorithm (Van Looveren and Klaise, [2019](#bib.bib33 "Interpretable counterfactual explanations guided by prototypes")).
Another key assumption behind all the instance-level explanation methods discussed in this paper (feature importance as well as counterfactual) is that examining an instance’s features will make sense to the user. This presumes at least that the features themselves are comprehensible. This would not be the case, for example, if the features are too low-level or for cases where the features have been obfuscated, for example to address privacy concerns (see e.g., the discussion of “doubly deidentified data” by Provost et al. ([2009](#bib.bib38 "Audience selection for on-line brand advertising: privacy-friendly social network targeting"))).
Relatedly, another promising direction for future research is to study how users actually perceive these different sorts of explanations in practice. In particular, it would be interesting to analyze the impact that various types of explanations have on users’ adoption of AI systems and their decision-making performance. Settings where the decisions made by deployed AI systems are closely monitored by users (see Lebovitz et al. ([2019](#bib.bib18 "Doubting the diagnosis: how artificial intelligence increases ambiguity during professional decision making")) for a clear example) would be ideal for such a study.
7 Conclusion
-------------
This paper examines the problem of explaining data-driven decisions made by AI decision-making systems from a causal perspective: if the question we seek to answer is “why did the system make a specific decision”, we can ask “which inputs caused the system to make its decision?” This approach is advantageous because (a) it standardizes the form that an explanation can take; (b) it does not require all features to be part of the explanation, and (c) the explanations can be separated from the specifics of the model. Thus, we define a (counterfactual) explanation as a set of features that is causal (meaning that removing the set from the instance changes the decision) and irreducible (meaning that removing any subset of the features in the explanation would not change the decision).
Importantly, this paper shows that explaining model predictions is not the same as explaining system decisions, because features that have a large impact on predictions may not have an important influence on decisions. Moreover, we show through various examples and case studies that the increasingly popular approach of explaining model predictions using importance weights has significant drawbacks when repurposed to explain system decisions. In particular, we demonstrate that importance weights may be ambiguous or even misleading when the goal is to understand how features affect a specific decision.
Our work generalizes previous work on counterfactual explanations in at least three important ways: (i) we explain system decisions (which may incorporate predictions from several predictive models) rather than model predictions, (ii) we do not enforce any specific method to remove features, and (iii) our explanations can deal with feature sets with arbitrary dimensionality and data types. Finally, we also propose a heuristic procedure that allows the tailoring of explanations to domain needs by introducing costs—for example, the costs of changing the features responsible for the decision. |
38f95f89-5035-4e88-8eb8-8e4e3ce4a2c9 | trentmkelly/LessWrong-43k | LessWrong | $250K in Prizes: SafeBench Competition Announcement
TLDR: CAIS is distributing $250,000 in prizes for benchmarks that empirically assess AI safety. This project is supported by Schmidt Sciences, submissions are open until February 25th, 2025. Winners will be announced April 25th, 2025.
To view additional info about the competition, including submission guidelines and FAQs, visit https://www.mlsafety.org/safebench
If you are interested in receiving updates about SafeBench, feel free to sign up on the homepage using the link above.
About the Competition:
The Center for AI Safety is offering prizes for the best benchmarks across the following four categories:
* Robustness: designing systems to be reliable in the face of adversaries and highly unusual situations.
* Monitoring: detect malicious use, monitor predictions, and discover unexpected model functionality Alignment: building models that represent and safely optimize difficult-to-specify human values.
* Safety Applications: using ML to address broader risks related to how ML systems are handled.
Judges:
* Zico Kolter, Carnegie Mellon
* Mark Greaves, AI2050
* Bo Li, University of Chicago
* Dan Hendrycks, Center for AI Safety
Timeline:
Mar 25, 2024: Competition Opens
Feb 25, 2025: Submission
Deadline Apr 25, 2025: Winners Announced
Competition Details:
Prizes: There will be three prizes worth $50,000 and five prizes worth $20,000.
Eligibility: Benchmarks released prior to the competition launch are ineligible for prize consideration. Benchmarks released after competition launch are eligible. More details about prize eligibility can be found in our terms and conditions.
Evaluation criteria: Benchmarks will be assessed according to this evaluation criteria. In order to encourage progress in safety, without also encouraging general advances in capabilities, benchmarks must clearly delineate safety and capabilities.
Submission Format: If you have already written a paper on your benchmark, submit that (as long as it was published after the |
ce35a908-8cb3-4986-9635-87cb33cc93f5 | trentmkelly/LessWrong-43k | LessWrong | Covid 1/28: Muddling Through
Three different time frames, three different fronts. We continue to muddle through, with some hope that this could be successful relative to our modest expectations.
There’s the situation short term, there’s the new strains, there’s the vaccines.
On the short term front, forward looking news continues to improve, but not at the pace we’d like or that I expected, and the death rate this week unexpectedly (unexpected to me in any case) rose. All signs still point to steady improvement until the new strains have an impact, probably at a pace of something like 1% a day. Hospitalizations aren’t listed in the numbers, but they too are falling steadily.
On the new strain front, the news is mixed.
For the non-English new strains, things got less scary, as it looks much less likely that the new strains can escape and reinfect, or that the vaccines won’t work on them. If they did escape, we learned that the system isn’t capable of responding as quickly as we’d like, but perhaps under duress that would change.
For the English strain, things got much scarier. Previously, we had no reason to think the new strain was more virulent, and if anything were hoping it was less so. Instead, it looks like it’s plausibly substantially more virulent, with 30%+ higher death rates per infection. Given that this strain is about to take over, that’s very bad news.
On the vaccine and policy front, we had excellent news, as the Biden administration announced a deal for an additional 200 million doses of vaccine from Pfizer and Moderna.
There’s still a ton to do. We need to approve AstraZeneca now and Johnson & Johnson the moment they release their data. We still need to spend massively to expand capacity. We still need to move to half doses or smaller where available, and legalize rapid testing for real, and so on and so forth. But compared to expectations, I’ll definitely take it.
I’ll also take the numbers we are seeing on vaccinations. They’re not what I wanted to see when this all |
f2134748-2f92-485a-95a2-4d09bb963fb1 | trentmkelly/LessWrong-43k | LessWrong | When and why did 'training' become 'pretraining'?
Just an ML linguistic quirk I have wondered about for a while. When I started learning ML (in 2016-2017 period) everybody referred to the period of training models as just 'training' which could then (optionally) be followed by finetuning. This usage makes sense to me and as far as I know was the standard ML terminology basically as long as people have been training neural networks.
Nowadays, we appear to call what used to be training 'pretraining'. From my perspective this term appeared around 2021 and became basically ubiquitous by 2022. Where did this come from? What is the difference between 'pretraining' now and 'training' from before?
My feeling is that this usage started at big LLM companies. However, what are these companies doing such that 'pretraining' should be a sensible term? As far as I know (especially around 2022 when it really took off) LLM training followed the standard 'pretraining' -> 'finetuning' -> 'alignment' by RLHF pipeline. Why do we need the special term 'pretraining' to handle this when 'training' still seems perfectly fine? Is it because we developed 'post-training' (i.e. finetuning) phases regularly? but then why 'pretraining' and 'post-training' -- but no 'training'?
Does anybody here know a good rationale or history of 'pretraining'? or is this just some inexplicable linguistic quirk? |
86b7d016-855c-4dd5-914c-714703f3183c | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | A Possible Resolution To Spurious Counterfactuals
Spurious counterfactuals (perhaps an easier handle than "the lobian inference issues described in Section 2.1 [here, in the Embedded Agency paper](https://arxiv.org/pdf/1902.09469.pdf) ), are important to address because they lead to inference problems. Having a function (or agent) rely on proofs about itself to generate its output immediately introduces Lob's Theorem-related issues -- agents may very well *want* proofs that their behavior leads to an outcome to determine their actions, but that makes a lot of actions possible to find proofs for.
Uncertainty does not help much, but reveals a greater critique: the utility in a counterfactual is not information inferred from our making the decision -- we can't decide if a choice is good just because, in the circumstances we can imagine making that choice, well, it was the right choice, wasn't it? This seems relatively unavoidable for all agents who notice they are competent decision makers, under any level of uncertainty. A smart professor will notice, in the subjunctive case where he slashes the tires on his own car, it must have made a lot of sense, he wouldn't do that for no reason. Perhaps he needed an unimpeachable excuse for not being somewhere he desperately wanted to avoid. But seeing high reward in that case isn't relevant to the counterfactual imagining where he sees, if he slashed his tires right here and now, it would be a massive bummer.
I think explicit agent self-pointers resolve this issue. Taking the example from the paper (U being the universe and A being the agent):
```
A :=
Spend some time searching for proofs of sentences of the form
“[A() = 5 →U() = x] & [A() = 10 →U() = y]” for x,y ∈{0,5,10}.
if a proof is found with x > y:
return 5
else:
return 10
U :=
if A() = 10 :
return 10
if A() = 5 :
return 5
```
We can replace it with (I've added a parameter for "which decision is being made" because that clarifies the intent behind the counterfactual agent change, but obviously this is still a highly simplified view):
```
Situation :: Nonce
Agent :: Agent -> Situation -> Choice
Universe :: Agent -> Reward
CounterfactuallyDoing(PriorAgent, CounterfactualSituation, Choice) :=
NewAgent := \Agent, Situation ->
if Situation == CounterfactualSituation:
return Choice
else:
return PriorAgent(NewAgent, Situation)
return NewAgent
A(Self, Situation == OnlySituation) :=
Spend some time searching for proofs of sentences of the form
“[U(CounterfactuallyDoing(Self, OnlySituation, 5)) = x] & [U(CounterfactuallyDoing(Self, OnlySituation, 10)) = y]” for x,y ∈{0,5,10}.
if a proof is found with x > y:
return 5
else:
return 10
U(Actor) :=
if Actor(Actor, OnlySituation) = 10:
return 10
if Actor(Actor, OnlySituation) = 5:
return 5
```
Because the proofs are acting over simpler objects, there is no Lobian issue, and the only proofs you can find are the ones with extremely simple reasoning (they operate over constant functions, essentially). And this approach can be chained into arbitrarily deep counterfactual considerations.
Consider a simple game where you must make two choices, and if they match, you get a prize corresponding to the scenario you picked. It will have two scenarios, ChooseDesire and GetReward.
```
U(Actor) :=
precommitment := Actor(Actor, ChooseDesire)
if precommitment ∈{0,5,10} & Actor(Actor, GetReward) = precommitment:
return precommitment
else:
return 0
```
I submit that any reasonably sane way of constructing the actor in this game, whether defaulting to "can I find a proof I should choose 5" or "shortest proof" or any other proof search, will find basically sane behavior, so long as reflection is done using the CounterfactuallyDoing operator. For instance:
```
A(Self, Situation == ChooseDesire) :=
Spend some time searching for proofs of sentences of the form
“[U(CounterfactuallyDoing(Self, ChooseDesire, 5)) = x] & [U(CounterfactuallyDoing(Self, ChooseDesire, 10)) = y]” for x,y ∈{0,5,10}.
if a proof is found with x > y:
return 5
else:
return 10
A(Self, Situation == GetReward) :=
Spend some time searching for proofs of sentences of the form
“[U(CounterfactuallyDoing(Self, GetReward, 5)) = x] & [U(CounterfactuallyDoing(Self, GetReward, 10)) = y]” for x,y ∈{0,5,10}.
if a proof is found with x > y:
return 5
else:
return 10
```
I think being robust to otherwise-proof-detail-contingent changes in how the agent is constructed is a quite helpful property. You don't need to use the objects only for proofs, for instance, they could be used in simulations or any other agent-appropriate setting. I do not think the Self parameter being contained inside the quotes of the proof search goal indicates an issue, unless for some reason the proof search process was meant to be static and couldn't search for proofs of dynamic statements. If you're familiar with the notation from clojure, you can imagine it as:
```
`([U(CounterfactuallyDoing(~Self, ...
```
I also think this approach matches our intuition about how counterfactuals work. We imagine ourselves as the same except we're choosing this particular behavior. Surely, in the formal reasoning, there might also be a distinction between the initial agent and the agent within that counterfactual, considering it's present in our own imaginations?
It also fixes the smaller but more obvious issue of distinguishing between reasoning-aware counterfactuals and pure counterfactuals. A pure counterfactual shouldn't, either in proof or more sloppy reasoning, make us think a choice is wise only because a wise agent made it. By constructing counterfactual agents we can assert things about their behavior without the reflective interference caused by having that assertion describe the wise agent (except where such a description would be accurate).
This approach seems straight-forward, but I was unable to find others discussing it -- I'm not certain this is even still an open problem, or if this approach has a subtle problem I've not been able to notice (I've not taken the time to actually put this into a theorem prover, although it seems extremely efficiently computable, at least in these toy examples). If it is an open problem, and the approach is promising, hopefully this helps resolve some self-proof-related issues moving forward. Hopefully, this also avoids failures-to-reason in important general scenarios, because counterfactuals have a weaker reflective consistency to the original agent, but I think this is somewhat unavoidable, and probably desirable.
[Update/Clarification of "failure to reason": in some of the multi-agent scenarios, there will be a lack of coordination if another agent distinguishes between precommitments and "spontaneously" making a choice in mutual-access-to-source-code scenarios. For instance, the mutual-source-code Prisoner's Dilemma with one agent structured similarly to the above, maximizing reward using the CounterfactuallyDo operator, going against MIRI's "cooperate iff that cooperation is what makes the other person cooperate" will defect, because it would prove the CounterfactuallyDo'ing agent would always be giving a ~constant agent to it, and the constant agent wouldn't trigger cooperation, and so it would only see defections and therefore, maximizing the reward, defect itself.
I think it's worth explicitly interrogating if there *ought* to be a distinction between precommitments and determining a decision live.
In scenarios where the other agents have your source code, it likely *isn't live anyway*, so I should be explicit: this resolution to the Lobian issues brought up in Embedded Agency explicitly relies on the idea we should be blind to the difference between reliably making a choice and precommitting to it. In scenarios without mutual source code, this difference is inaccessible, obviously, but I think the case is still strong in mutual visibility cases.] |
94e948ca-1b8d-4b16-97e9-3e1c5388bba4 | trentmkelly/LessWrong-43k | LessWrong | Switching to Google Calendar
When I first started keeping a calendar, in 2006, it was just an HTML table on my website:
Over time, I extended it to generate an iCal feed and wrote several commands to make it easier to add entries to the table (proc_schedule). I knew it was a peculiar way of doing things, but it met my needs and I didn't feel much reason to switch.
With covid, however, I have a lot more short social events. An hour to play One Night Ultimate Werewolf, half an hour to talk with someone about a question they have, an hour and a half of no-hands pair programming on the bucket brigade singing project. Now I care about invites, RSVPs, time zones, video calls, and notifications. Yes, perhaps I could have extended my program to have all of these features, but why?
I'm already familiar with Google calendar because we use it at work, and have now switched over to it for personal things as well. If you want to invite me to something, use my jeff.t.kaufman@gmail.com address.
(The spirit of generating a calendar feed from an HTML table lives on, however, in proc_fr_schedule and proc_kf_schedule for the Free Raisins and Kingfisher. Hopefully, post covid, there will be gigs again.) |
422cbf8a-eab5-4a5a-86ac-0fbbdc89cda8 | trentmkelly/LessWrong-43k | LessWrong | Praising the Constitution
I am sure the majority of the discussion surrounding the Unites States recent Supreme Court ruling will be on the topic of same-sex marriage and marriage equality. And while there is a lot of good discussion to be had, I thought I would take the opportunity to bring up another topic that seems often to be glossed over, but is yet very important to the discussion. That is the idea in the USA of praising the United States Constitution and holding it to an often unquestioning level of devotion.
Before I really get going I would like to take a quick moment to say I do support the US Constitution and think it is important to have a very strong document that provides rights for the people and guidelines for government. The entire structure of the government is defined by the Constitution, and some form of constitution or charter is necessary for the establishment of any type of governing body. Also, in the arguments I use as examples I am not in any way saying which side I am on. I am simply using them as examples, and no attempt should be made to infer my political stances from how I treat the arguments themselves.
But now the other way. I often hear in political discussions people, particularly Libertarians, trying to tie their position back to being based on the Constitution. The buck stops there. The Constitution says it, therefore it must be right. End of discussion. To me this often sounds eerily similar to arguing the semantics of a religious text to support your position.
A great example is in the debate over gun control laws. Without espousing one side or the other, I can fairly safely and definitively say the US Constitution does support citizens' rights to own guns. For many a Libertarian, the discussion ends there. This is not something only Libertarians are guilty of. The other side of the debate often resorts to arguing context and semantics in an attempt to make the Constitution support their side. This clearly is just a case of people trying to win the |
edc74e2a-a2a0-4c40-b1bb-6b8f79172203 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Unsupervised Question Decomposition for Question Answering
1 Introduction
---------------

Figure 1: Overview: Using unsupervised learning, we decompose a multi-hop question into single-hop sub-questions, whose predicted answers are given to a downstream question answering model.
Question answering (QA) systems have become remarkably good at answering simple, single-hop questions but still struggle with compositional, multi-hop questions (Yang et al., [2018](#bib.bib69 "HotpotQA: a dataset for diverse, explainable multi-hop question answering"); Hudson and Manning, [2019](#bib.bib20 "GQA: a new dataset for real-world visual reasoning and compositional question answering")).
In this work, we examine if we can answer hard questions by leveraging our ability to answer simple questions.
Specifically, we approach QA by breaking a hard question into a series of sub-questions that can be answered by a simple, single-hop QA system.
The system’s answers can then be given as input to a downstream QA system to answer the hard question, as shown in Fig. [1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Unsupervised Question Decomposition for Question Answering").
Our approach thus answers the hard question in multiple, smaller steps, which can be easier than answering the hard question all at once.
For example, it may be easier to answer “What profession do H. L. Mencken and Albert Camus have in common?” when given the answers to the sub-questions “What profession does H. L. Mencken have?” and “Who was Albert Camus?”
Prior work in learning to decompose questions into sub-questions has relied on extractive heuristics, which generalizes poorly to different domains and question types, and requires human annotation (Talmor and Berant, [2018](#bib.bib63 "The web as a knowledge-base for answering complex questions"); Min et al., [2019b](#bib.bib44 "Multi-hop reading comprehension through question decomposition and rescoring")).
In order to scale to any arbitrary question, we would require sophisticated natural language generation capabilities, which often relies on large quantities of high-quality supervised data.
Instead, we find that it is possible to learn to decompose questions without supervision.
Specifically, we learn to map from the distribution of hard questions to the distribution of simpler questions.
First, we automatically construct a noisy, “pseudo-decomposition” for each hard question by retrieving relevant sub-question candidates based on their similarity to the given hard question.
We retrieve candidates from a corpus of 10M simple questions that we extracted from Common Crawl.
Second, we train neural text generation models on that data with (1) standard sequence-to-sequence learning and (2) unsupervised sequence-to-sequence learning. The latter has the advantage that it can go beyond the noisy pairing between questions and pseudo-decompositions.
Fig. [2](#S1.F2 "Figure 2 ‣ 1 Introduction ‣ Unsupervised Question Decomposition for Question Answering") overviews our decomposition approach.

Figure 2: Unsupervised Decomposition: Step 1: We create a corpus of pseudo-decompositions D by finding candidate sub-questions from a simple question corpus S which are similar to a multi-hop question in Q. Step 2: We learn to map multi-hop questions to decompositions using Q and D as training data, via either standard or unsupervised sequence-to-sequence learning.
We use decompositions to improve multi-hop QA.
We first use an off-the-shelf single-hop QA model to answer decomposed sub-questions. We then give each sub-question and its answer as additional input to a multi-hop QA model.
We test our method on HotpotQA (Yang et al., [2018](#bib.bib69 "HotpotQA: a dataset for diverse, explainable multi-hop question answering")), a popular multi-hop QA benchmark.
Our contributions are as follows. First, QA models relying on decompositions improve accuracy over a strong baseline by 3.1 F1 on the original dev set, 11 F1 on the multi-hop dev set from Jiang and Bansal ([2019](#bib.bib26 "Avoiding reasoning shortcuts: adversarial evaluation, training, and model development for multi-hop QA")), and 10 F1 on the out-of-domain dev set from Min et al. ([2019b](#bib.bib44 "Multi-hop reading comprehension through question decomposition and rescoring")).
Our most effective decomposition model is a 12-block transformer encoder-decoder (Vaswani et al., [2017](#bib.bib72 "Attention is all you need")) trained using unsupervised sequence-to-sequence learning, involving masked language modeling, denoising, and back-translation objectives (Lample and Conneau, [2019](#bib.bib36 "Cross-lingual language model pretraining")).
Second, our method is competitive with state-of-the-art methods SAE (Tu et al., [2020](#bib.bib64 "Select, answer and explain: interpretable multi-hop reading comprehension over multiple documents")) and HGN (Fang et al., [2019](#bib.bib17 "Hierarchical graph network for multi-hop question answering")) which leverage strong supervision.
Third, we show that our approach automatically learns to generate useful decompositions for all 4 question types in HotpotQA, highlighting the general nature of our approach.
In our analysis, we explore how sub-questions improve multi-hop QA, and we provide qualitative examples that highlight how question decomposition adds a form of interpretability to black-box QA models.
Our ablations show that each component of our pipeline contributes to QA performance.
Overall, we find that it is possible to successfully decompose questions without any supervision and that doing so improves QA.
2 Method
---------
We now formulate the problem and overview our high-level approach, with details in the following section.
We aim to leverage a QA model that is accurate on simple questions to answer hard questions, without using supervised question decompositions.
Here, we consider simple questions to be “single-hop” questions that require reasoning over one paragraph or piece of evidence, and we consider hard questions to be “multi-hop.”
Our aim is then to train a multi-hop QA model M to provide the correct answer a to a multi-hop question q about a given a context c (e.g., several paragraphs). Normally, we would train M to maximize logpM(a|c,q). To help M, we leverage a single-hop QA model that may be queried with sub-questions s1,…,sN, whose “sub-answers” to each sub-question a1,…,aN may be provided to the multi-hop QA model. M may then instead maximize the (potentially easier) objective logpM(a|c,q,[s1,a1],…,[aN,sN]).
Supervised decomposition models learn to map each question q∈Q to a decomposition d=[s1;…;sN] of N sub-questions sn∈S using annotated (q,d) examples.
In this work, we do not assume access to strong (q,d) supervision.
To leverage the single-hop QA model without supervision, we follow a three-stage approach: 1) map a question q into sub-questions s1,…,sN via unsupervised techniques, 2) find sub-answers a1,…,aN with the single-hop QA model, and 3) provide s1,…,sN and a1,…,aN to help predict a.
###
2.1 Unsupervised Question Decomposition
To train a decomposition model, we need appropriate training data.
We assume access to a hard question corpus Q and a simple question corpus S.
Instead of using supervised (q,d) training examples, we design an algorithm that constructs pseudo-decompositions d′ to form (q,d′) pairs from Q and S using an unsupervised approach (§[2.1.1](#S2.SS1.SSS1 "2.1.1 Creating Pseudo-Decompositions ‣ 2.1 Unsupervised Question Decomposition ‣ 2 Method ‣ Unsupervised Question Decomposition for Question Answering")).
We then train a model to map q to a decomposition.
We explore learning to decompose with standard and unsupervised sequence-to-sequence learning (§[2.1.2](#S2.SS1.SSS2 "2.1.2 Learning to Decompose ‣ 2.1 Unsupervised Question Decomposition ‣ 2 Method ‣ Unsupervised Question Decomposition for Question Answering")).
####
2.1.1 Creating Pseudo-Decompositions
For each q∈Q, we construct a pseudo-decomposition set d′={s1;…;sN} by retrieving simple question s from S.
We concatenate all N simple questions in d′ to form the pseudo-decomposition used downstream.
N may be chosen based on the task or vary based on q.
To retrieve useful simple questions for answering q, we face a joint optimization problem. We want sub-questions that are both (i) similar to q according to some metric f and (ii) maximally diverse:
| | | | |
| --- | --- | --- | --- |
| | d′∗=argmaxd′⊂S∑si∈d′f(q,si)−∑si,sj∈d′si≠sjf(si,sj) | | (1) |
####
2.1.2 Learning to Decompose
Having now retrieved relevant pseudo-decompositions, we examine different ways to learn to decompose (with implementation details in the following section):
##### No Learning
We use pseudo-decompositions directly, employing retrieved sub-questions in downstream QA.
##### Sequence-to-Sequence (Seq2Seq)
We train a Seq2Seq model with parameters θ to maximize logpθ(d′|q).
##### Unsupervised Sequence-to-Sequence (USeq2Seq)
We start with paired (q,d′) examples but do not learn from the pairing, because the pairing is noisy.
We use unsupervised sequence-to-sequence learning to learn a q→d mapping instead of training directly on the noisy pairing.
###
2.2 Answering Sub-Questions
To answer the generated sub-questions, we use an off-the-shelf QA model.
The QA model may answer sub-questions using any free-form text (i.e., a word, phrase, sentence, etc.).
Any QA model is suitable, so long as it can accurately answer simple questions in S.
We thus leverage good accuracy on questions in S to help QA models on questions in Q.
###
2.3 QA using Decompositions
Downstream QA systems may use sub-questions and sub-answers in various ways.
We add sub-questions and sub-answers as auxiliary input for a downstream QA model to incorporate in its processing.
We now describe the implementation details of our approach outlined above.
3 Experimental Setup
---------------------
###
3.1 Question Answering Task
We test unsupervised decompositions on HotpotQA (Yang et al., [2018](#bib.bib69 "HotpotQA: a dataset for diverse, explainable multi-hop question answering")), a standard benchmark for multi-hop QA.
We use HotpotQA’s “Distractor Setting,” which provides 10 context paragraphs from Wikipedia.
Two (or more) paragraphs contain question-relevant sentences called “supporting facts,” and the remaining paragraphs are irrelevant, “distractor paragraphs.”
Answers in HotpotQA are either yes, no, or a span of text in an input paragraph.
Accuracy is measured with F1 and Exact Match (EM) scores between the predicted and gold spans.
###
3.2 Unsupervised Decomposition
####
3.2.1 Question Data
We use HotpotQA questions as our initial multi-hop, hard question corpus Q.
We use SQuAD 2 questions as our initial single-hop, simple question corpus S.
However, our pseudo-decomposition corpus should be large, as the corpus will be used to train neural Seq2Seq models, which are data hungry.
A larger |S| will also improve the relevance of retrieved simple questions to the hard question.
Thus, we take inspiration from work in machine translation on parallel corpus mining (Xu and Koehn, [2017](#bib.bib67 "Zipporah: a fast and scalable data cleaning system for noisy web-crawled parallel corpora"); Artetxe and Schwenk, [2019](#bib.bib5 "Margin-based parallel corpus mining with multilingual sentence embeddings")) and in unsupervised QA (Lewis et al., [2019](#bib.bib37 "Unsupervised question answering by cloze translation")).
We augment Q and S by mining more questions from Common Crawl.
We choose sentences which start with common “wh”-words and end with “?”
Next, we train a FastText classifier (Joulin et al., [2017](#bib.bib79 "Bag of tricks for efficient text classification")) to classify between 60K questions sampled from Common Crawl, SQuAD 2, and HotpotQA.
Then, we classify Common Crawl questions, adding questions classified as SQuAD 2 questions to S and questions classified as HotpotQA questions to Q.
Question mining greatly increases the number of single-hop questions (130K → 10.1M) and multi-hop questions (90K → 2.4M).
Thus, our unsupervised approach allows us to make use of far more data than supervised counterparts.
####
3.2.2 Creating Pseudo-Decompositions
To create pseudo-decompositions, we set the number N of sub-questions per question to 2, as questions in HotpotQA usually involve two reasoning hops.
In Appendix §[A.1](#A1.SS1 "A.1 Variable Length Pseudo-Decompositions ‣ Appendix A Pseudo-Decompositions ‣ Unsupervised Question Decomposition for Question Answering"), we discuss how our method works when N varies per question.
##### Similarity-based Retrieval
To retrieve question-relevant sub-questions, we embed any text t into a vector vt by summing the FastText vectors (Bojanowski et al., [2017](#bib.bib81 "Enriching word vectors with subword information"))111We use 300-dim. English Common Crawl vectors: <https://fasttext.cc/docs/en/english-vectors.html> for words in t.222We also tried TFIDF and BERT representations but did not see significant improvements over FastText (see Appendix §[A.3](#A1.SS3 "A.3 Pseudo-Decomposition Retrieval Method ‣ Appendix A Pseudo-Decompositions ‣ Unsupervised Question Decomposition for Question Answering")).
We use cosine similarity as our similarity metric f.
Let q be a multi-hop question used to retrieve pseudo-decomposition (s∗1,s∗2), and let ^v be the unit vector of v.
Since N=2, Eq. [1](#S2.E1 "(1) ‣ 2.1.1 Creating Pseudo-Decompositions ‣ 2.1 Unsupervised Question Decomposition ‣ 2 Method ‣ Unsupervised Question Decomposition for Question Answering") reduces to:
| | | | |
| --- | --- | --- | --- |
| | (s∗1,s∗2)=argmax{s1,s2}∈S[^v⊤q^vs1+^v⊤q^vs2−^v⊤s1^vs2] | | (2) |
The last term requires O(|S|2) comparisons, which is expensive as |S| is large (>10M).
Instead of solving Eq. ([2](#S3.E2 "(2) ‣ Similarity-based Retrieval ‣ 3.2.2 Creating Pseudo-Decompositions ‣ 3.2 Unsupervised Decomposition ‣ 3 Experimental Setup ‣ Unsupervised Question Decomposition for Question Answering")) exactly, we find an approximate pseudo-decomposition (s′1,s′2) by computing Eq. ([2](#S3.E2 "(2) ‣ Similarity-based Retrieval ‣ 3.2.2 Creating Pseudo-Decompositions ‣ 3.2 Unsupervised Decomposition ‣ 3 Experimental Setup ‣ Unsupervised Question Decomposition for Question Answering")) over S′=topK{s∈S}[^v⊤q^vs], using K=1000.
We use FAISS (Johnson et al., [2017a](#bib.bib82 "Billion-scale similarity search with gpus")) to efficiently build S′.
##### Random Retrieval
For comparison, we test random pseudo-decompositions, where we randomly retrieve s1,…,sN by sampling from S.
USeq2Seq trained on random d′=[s1;…;sN] should at minimum learn to map q to multiple simple questions.
##### Editing Pseudo-Decompositions
Since the sub-questions are retrieval-based, the sub-questions are often not about the same entities as q.
As a post-processing step, we replace entities in (s′1,s′2) with entities from q.
We find all entities in (s′1,s′2) that do not appear in q using spaCy (Honnibal and Montani, [2017](#bib.bib80 "spaCy 2: natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing")).
We replace these entities with a random entity from q with the same type (e.g., “Date” or “Location”) if and only if one exists.
We use entity replacement on pseudo-decompositions from both random and similarity-based retrieval.
####
3.2.3 Unsupervised Decomposition Models
##### Pre-training
Pre-training is a key ingredient for unsupervised Seq2Seq methods (Artetxe et al., [2018](#bib.bib3 "Unsupervised neural machine translation"); Lample et al., [2018](#bib.bib35 "Unsupervised machine translation using monolingual corpora only")), so we initialize all decomposition models with the same pre-trained weights, regardless of training method (Seq2Seq or USeq2Seq).
We warm-start our pre-training with the pre-trained, English Masked Language Model (MLM) from Lample and Conneau ([2019](#bib.bib36 "Cross-lingual language model pretraining")), a 12-block decoder-only transformer model (Vaswani et al., [2017](#bib.bib72 "Attention is all you need")) trained to predict masked-out words on Toronto Books Corpus (Zhu et al., [2015](#bib.bib77 "Aligning books and movies: towards story-like visual explanations by watching movies and reading books")) and Wikipedia.
We train the model with the MLM objective for one epoch on the augmented corpus Q (2.4 M questions), while also training on decompositions D formed via random retrieval from S.
For our pre-trained encoder-decoder, we initialize a 6-block encoder with the first 6 MLM blocks, and we initialize a 6-block decoder with the last 6 MLM blocks, randomly initializing the remaining weights as in Lample and Conneau ([2019](#bib.bib36 "Cross-lingual language model pretraining")).
##### Seq2Seq
We fine-tune the pre-trained encoder-decoder using maximum likelihood.
We stop training based on validation BLEU (Papineni et al., [2002](#bib.bib47 "Bleu: a method for automatic evaluation of machine translation")) between generated decompositions and pseudo-decompositions.
##### USeq2Seq
We follow the approach by Lample and Conneau ([2019](#bib.bib36 "Cross-lingual language model pretraining")) in unsupervised translation.333<https://github.com/facebookresearch/XLM>
Training follows two stages: (1) MLM pre-training on the training corpora (described above), followed by (2) training simultaneously with denoising and back-translation objectives.
For denoising, we produce a noisy input ^d by randomly masking, dropping, and locally shuffling tokens in d∼D, and we train a model with parameters θ to maximize logpθ(d|^d).
We likewise maximize logpθ(q|^q).
For back-translation, we generate a multi-hop question ^q for a decomposition d∼D, and we maximize logpθ(d|^q).
Similarly, we maximize logpθ(q|^d).
To stop training without supervision, we use a modified version of round-trip BLEU (Lample et al., [2018](#bib.bib35 "Unsupervised machine translation using monolingual corpora only")) (see Appendix §[B.1](#A2.SS1 "B.1 Unsupervised Stopping Criterion ‣ Appendix B Unsupervised Decomposition Model ‣ Unsupervised Question Decomposition for Question Answering") for details).
We train with denoising and back-translation on smaller corpora of HotpotQA questions (Q) and their pseudo-decompositions (D).444Using the augmented corpora here did not improve QA.
###
3.3 Single-hop Question Answering Model
We train our single-hop QA model following prior work from Min et al. ([2019b](#bib.bib44 "Multi-hop reading comprehension through question decomposition and rescoring")) on HotpotQA.555Our code is based on transformers (Wolf et al., [2019](#bib.bib66 "HuggingFace’s transformers: state-of-the-art natural language processing"))
##### Model Architecture
We fine-tune a pre-trained model to take a question and several paragraphs and predicts the answer, similar to the single-hop QA model from Min et al. ([2019a](#bib.bib43 "Compositional questions do not necessitate multi-hop reasoning")).
The model computes a separate forward pass on each paragraph (with the question).
For each paragraph, the model learns to predict the answer span if the paragraph contains the answer and to predict “no answer” otherwise.
We treat yes and no predictions as spans within the passage (prepended to each paragraph), as in Nie et al. ([2019](#bib.bib45 "Revealing the importance of semantic retrieval for machine reading at scale")) on HotpotQA.
During inference, for the final softmax, we consider all paragraphs as a single chunk.
Similar to Clark and Gardner ([2018](#bib.bib11 "Simple and effective multi-paragraph reading comprehension")), we subtract a paragraph’s “no answer” logit from the logits of all spans in that paragraph, to reduce or increase span probabilities accordingly.
In other words, we compute the probability p(sp) of each span sp in a paragraph p∈{1,…,P} using the predicted span logit l(sp) and “no answer” paragraph logit n(p) as follows:
| | | | |
| --- | --- | --- | --- |
| | p(sp)=el(sp)−n(p)∑Pp′=1∑s′p′el(s′p′)−n(p′) | | (3) |
We use \textscRoBERTa\textscLARGE (Liu et al., [2019](#bib.bib40 "RoBERTa: a robustly optimized bert pretraining approach")) as our pre-trained initialization.
Later, we also experiment with using the \textscBERT\textscBASE ensemble from Min et al. ([2019b](#bib.bib44 "Multi-hop reading comprehension through question decomposition and rescoring")).
##### Training Data and Ensembling
Similar to Min et al. ([2019b](#bib.bib44 "Multi-hop reading comprehension through question decomposition and rescoring")), we train an ensemble of 2 single-hop QA models using data from SQuAD 2 and HotpotQA questions labeled as “easy” (single-hop).
To ensemble, we average the logits of the two models before predicting the answer.
SQuAD is a single-paragraph QA task, so we adapt SQuAD to the multi-paragraph setting by retrieving distractor paragraphs from Wikipedia for each question. We use the TFIDF retriever from DrQA (Chen et al., [2017](#bib.bib7 "Reading Wikipedia to answer open-domain questions")) to retrieve 2 distractor paragraphs, which we add to the input for one model in the ensemble.
We drop words from the question with a 5% probability to help the model handle any ill-formed sub-questions.
We use the single-hop QA ensemble as a black-box model once trained, never training the model on multi-hop questions.
##### Returned Text
We have the single-hop QA model return the sentence containing the model’s predicted answer span, alongside the sub-questions.
Later, we compare against alternatives, i.e., returning the predicted answer span without its context or not returning sub-questions.
###
3.4 Multi-hop Question Answering Model
Our multi-hop QA architecture is identical to the single-hop QA model, but the multi-hop QA model also uses sub-questions and sub-answers as input.
We append each (sub-question, sub-answer) pair in order to the multi-hop question along with separator tokens.
We train one multi-hop QA model on all of HotpotQA, also including SQuAD 2 examples used to train the single-hop QA model.
Later, we experiment with using \textscBERT\textscLARGE and \textscBERT\textscBASE instead of \textscRoBERTa\textscLARGE as the multi-hop QA model.
All reported error margins show the mean and std. dev. across 5 multi-hop QA training runs using the same decompositions.
4 Results on Question Answering
--------------------------------
| | | |
| --- | --- | --- |
| Decomp. | Pseudo- | HotpotQA F1 |
| Method | Decomps. | Orig | MultiHop | OOD |
| ✗ | ✗ (1hop) | 66.7 | 63.7 | 66.5 |
| ✗ | ✗ (Baseline) | 77.0±.2 | 65.2±.2 | 67.1±.5 |
| No Learn | Random | 78.4±.2 | 70.9±.2 | 70.7±.4 |
| | FastText | 78.9±.2 | 72.4±.1 | 72.0±.1 |
| Seq2Seq | Random | 77.7±.2 | 69.4±.3 | 70.0±.7 |
| | FastText | 78.9±.2 | 73.1±.2 | 73.0±.3 |
| USeq2Seq | Random | 79.8±.1 | 76.0±.2 | 76.5±.2 |
| | FastText | 80.1±.2 | 76.2±.1 | 77.1±.1 |
| DecompRC\* | 79.8±.2 | 76.3±.4 | 77.7±.2 |
| SAE (Tu et al., [2020](#bib.bib64 "Select, answer and explain: interpretable multi-hop reading comprehension over multiple documents")) † | 80.2 | 61.1 | 62.6 |
| HGN (Fang et al., [2019](#bib.bib17 "Hierarchical graph network for multi-hop question answering")) † | 82.2 | 78.9‡ | 76.1‡ |
| | | | |
| --- | --- | --- | --- |
| | Ours | SAE† | HGN† |
| Test (EM/F1) | 66.33/79.34 | 66.92/79.62 | 69.22/82.19 |
Table 1: Unsupervised decompositions significantly improve the F1 on HotpotQA over the baseline. We achieve comparable F1 to methods which use supporting fact supervision (†). (\*) We use supervised and heuristic decompositions from Min et al. ([2019b](#bib.bib44 "Multi-hop reading comprehension through question decomposition and rescoring")). (‡) Scores are approximate due to mismatched Wikipedia dumps.
We compare variants of our approach that use different learning methods and different pseudo-aligned training sets.
As a baseline, we compare RoBERTa with decompositions to a RoBERTa model that does not use decompositions but is identical in all other respects.
We train the baseline for 2 epochs, sweeping over batch size ∈{64,128}, learning rate ∈{1×10−5,1.5×10−5,2×10−5,3×10−5}, and weight decay ∈{0,0.1,0.01,0.001}; we choose the hyperparameters that perform best on our dev set.
We then use the best hyperparameters for the baseline to train our RoBERTa models with decompositions.
We report results on 3 versions of the dev set: (1) the original version,666The test set is private, so we randomly halve the dev set to form validation and held-out dev sets. We will release our splits. (2) the multi-hop version from Jiang and Bansal ([2019](#bib.bib26 "Avoiding reasoning shortcuts: adversarial evaluation, training, and model development for multi-hop QA")) which created some distractor paragraphs adversarially to test multi-hop reasoning, and (3) the out-of-domain version from Min et al. ([2019b](#bib.bib44 "Multi-hop reading comprehension through question decomposition and rescoring")) which retrieved distractor paragraphs using the same procedure as the original version, but excluded paragraphs in the original version.
##### Main Results
Table [1](#S4.T1 "Table 1 ‣ 4 Results on Question Answering ‣ Unsupervised Question Decomposition for Question Answering") shows how unsupervised decompositions affect QA.
Our RoBERTa baseline performs quite well on HotpotQA (77.0 F1), despite processing each paragraph separately, which prohibits inter-paragraph reasoning.
The result is in line with prior work which found that a version of our baseline QA model using BERT (Devlin et al., [2019](#bib.bib13 "BERT: pre-training of deep bidirectional transformers for language understanding")) does well on HotpotQA by exploiting single-hop reasoning shortcuts (Min et al., [2019a](#bib.bib43 "Compositional questions do not necessitate multi-hop reasoning")).
We achieve significant gains over our strong baseline by leveraging decompositions from our best decomposition model, trained with USeq2Seq on FastText pseudo-decompositions;
we find a 3.1 F1 gain on the original dev set, 11 F1 gain on the multi-hop dev set, and 10 F1 gain on the out-of-domain dev set.
Unsupervised decompositions even match the performance of using (within our pipeline) supervised and heuristic decompositions from DecompRC (i.e., 80.1 vs. 79.8 F1 on the original dev set).
More generally, all decomposition methods improve QA over the baseline by leveraging the single-hop QA model (“1hop” in Table [1](#S4.T1 "Table 1 ‣ 4 Results on Question Answering ‣ Unsupervised Question Decomposition for Question Answering")).
Using FastText pseudo-decompositions as sub-questions directly improves QA over using random sub-questions on the multi-hop set (72.4 vs. 70.9 F1) and out-of-domain set (72.0 vs. 70.7 F1).
USeq2Seq on random pseudo-decompositions also improves over the random sub-question baseline (e.g., 79.8 vs. 78.4 F1 on HotpotQA).
However, we only find small improvements when training USeq2Seq on FastText vs. Random pseudo-decompositions (e.g., 77.1 vs. 76.5 F1 on the out-of-domain dev set).
The best decomposition methods learn with USeq2Seq.
Using Seq2Seq to generate decompositions gives similar QA accuracy as the ‘‘No Learning’’ setup, e.g. both approaches achieve 78.9 F1 on the original dev set for FastText pseudo-decompositions.
The results are similar perhaps since supervised learning is directly trained to place high probability on pseudo-decompositions.777We also tried using the Seq2Seq model to initialize USeq2Seq. Seq2Seq initialization resulted in comparable or worse downstream QA accuracy, suggesting that pre-training on noisy decompositions did not help bootstrap USeq2Seq (see Appendix §[A.3](#A1.SS3 "A.3 Pseudo-Decomposition Retrieval Method ‣ Appendix A Pseudo-Decompositions ‣ Unsupervised Question Decomposition for Question Answering") for details).
USeq2Seq may improve over Seq2Seq by learning to align hard questions and pseudo-decompositions while ignoring the noisy pairing.
After our experimentation, we chose USeq2Seq trained on FastText pseudo-decompositions as the final model, and we submitted the model for hidden test evaluation. Our approach achieved a test F1 of 79.34 and Exact Match (EM) of 66.33.
Our approach is competitive with concurrent, state-of-the-art systems SAE (Tu et al., [2020](#bib.bib64 "Select, answer and explain: interpretable multi-hop reading comprehension over multiple documents")) and HGN (Fang et al., [2019](#bib.bib17 "Hierarchical graph network for multi-hop question answering")), which both (unlike our approach) learn from additional, strong supervision about which sentences are necessary to answer the question.
###
4.1 Question Type Breakdown
| | | | | |
| --- | --- | --- | --- | --- |
| Decomps. | Bridge | Comp. | Intersec. | Single-hop |
| ✗ | 80.1±.2 | 73.8±.4 | 79.4±.6 | 73.9±.6 |
| ✓ | 81.7±.4 | 80.1±.3 | 82.3±.5 | 76.9±.6 |
Table 2: F1 scores on 4 types of questions in HotpotQA. Unsupervised decompositions improves QA for all types.
| | | |
| --- | --- | --- |
| SubQs | SubAs | QA F1 |
| ✗ | ✗ | 77.0±.2 |
| ✓ | Sentence | 80.1±.2 |
| ✓ | Span | 77.8±.3 |
| ✓ | Random Entity | 76.9±.2 |
| ✓ | ✗ | 76.9±.2 |
| ✗ | Sentence | 80.2±.1 |
Table 3: Ablation Study: QA model F1 when trained with different sub-answers: the sentence containing the predicted sub-answer, the predicted sub-answer span, and a random entity from the context.
We also train QA models with (✓) or without (✗) sub-questions and sub-answers.
To understand where decompositions help, we break down QA performance across 4 question types from Min et al. ([2019b](#bib.bib44 "Multi-hop reading comprehension through question decomposition and rescoring")).
“Bridge” questions ask about an entity not explicitly mentioned in the question (“When was Erik Watts’ father born?”).
“Intersection” questions ask to find an entity that satisfies multiple separate conditions (“Who was on CNBC and Fox News?”).
“Comparison” questions ask to compare a property of two entities (“Which is taller, Momhil Sar or K2?”).
“Single-hop” questions are likely answerable using single-hop shortcuts or single-paragraph reasoning (“Where is Electric Six from?”).
We split the original dev set into the 4 types using the supervised type classifier from Min et al. ([2019b](#bib.bib44 "Multi-hop reading comprehension through question decomposition and rescoring")).
Table [2](#S4.T2 "Table 2 ‣ 4.1 Question Type Breakdown ‣ 4 Results on Question Answering ‣ Unsupervised Question Decomposition for Question Answering") shows F1 scores for RoBERTa with and without decompositions across the 4 types.
Unsupervised decompositions improve QA across all question types.
Our single decomposition model generates useful sub-questions for all question types without special case handling, unlike earlier work from Min et al. ([2019b](#bib.bib44 "Multi-hop reading comprehension through question decomposition and rescoring")) which handled each question type separately.
For single-hop questions, our QA approach does not require falling back to a single-hop QA model and instead learns to leverage decompositions to better answer questions with single-hop shortcuts (76.9 vs. 73.9 F1 without decompositions).
###
4.2 Answers to Sub-Questions are Crucial
To measure the usefulness of sub-questions and sub-answers, we train the multi-hop QA model with various, ablated inputs, as shown in Table [3](#S4.T3 "Table 3 ‣ 4.1 Question Type Breakdown ‣ 4 Results on Question Answering ‣ Unsupervised Question Decomposition for Question Answering").
Sub-answers are crucial to improving QA, as sub-questions with no answers or random answers do not help (76.9 vs. 77.0 F1 for the baseline).
Only when sub-answers are provided do we see improved QA, with or without sub-questions (80.1 and 80.2 F1, respectively).
It is important to provide the sentence containing the predicted answer span instead of the answer span alone (80.1 vs. 77.8 F1, respectively), though the answer span alone still improves over the baseline (77.0 F1).
###
4.3 How Do Decompositions Help?

Figure 3: Multi-hop QA is better when the single-hop QA model answers with the ground truth “supporting fact” sentences. We plot mean and std. across 5 random QA training runs.
Decompositions help to answer questions by retrieving important supporting evidence to answer questions.
Fig. [3](#S4.F3 "Figure 3 ‣ 4.3 How Do Decompositions Help? ‣ 4 Results on Question Answering ‣ Unsupervised Question Decomposition for Question Answering") shows that multi-hop QA accuracy increases when the sub-answer sentences are the “supporting facts” or sentences needed to answer the question, as annotated by HotpotQA.
We retrieve supporting facts without learning to predict them with strong supervision, unlike many state-of-the-art models (Tu et al., [2020](#bib.bib64 "Select, answer and explain: interpretable multi-hop reading comprehension over multiple documents"); Fang et al., [2019](#bib.bib17 "Hierarchical graph network for multi-hop question answering"); Nie et al., [2019](#bib.bib45 "Revealing the importance of semantic retrieval for machine reading at scale")).
###
4.4 Example Decompositions
| |
| --- |
| Q1: Are both Coldplay and Pierre Bouvier |
| from the same country? |
| SQ1: Where are Coldplay and Coldplay from? |
| └ Coldplay are a British rock band formed in 1996 by lead |
| vocalist and keyboardist Chris Martin and lead guitarist |
| Jonny Buckland at University College London (UCL). |
| SQ2: What country is Pierre Bouvier from? |
| └ Pierre Charles Bouvier (born 9 May 1979) is a Canadian |
| singer, songwriter, musician, composer and actor who is |
| best known as the lead singer and guitarist of the rock |
| band Simple Plan. |
| ^A: No |
| Q2: How many copies of Roald Dahl’s variation on a popular anecdote sold? |
| SQ1: How many copies of Roald Dahl’s? |
| └ His books have sold more than 250 million |
| copies worldwide. |
| SQ2 What is the name of the variation on a popular anecdote? |
| └ “Mrs. Bixby and the Colonel’s Coat” is a short story by |
| Roald Dahl that first appeared in the 1959 issue of Nugget. |
| ^A: more than 250 million |
| Q3: Who is older, Annie Morton or Terry Richardson? |
| SQ1: Who is Annie Morton? |
| └ Annie Morton (born October 8, 1970) is an |
| American model born in Pennsylvania. |
| SQ2: When was Terry Richardson born? |
| └ Kenton Terry Richardson (born 26 July 1999) is an English |
| professional footballer who plays as a defender for |
| League Two side Hartlepool United. |
| ^A: Annie Morton |
Table 4: Example sub-questions generated by our model, along with predicted sub-answer sentences (answer span underlined) and final predicted answer.
To illustrate how decompositions help QA, Table [4](#S4.T4 "Table 4 ‣ 4.4 Example Decompositions ‣ 4 Results on Question Answering ‣ Unsupervised Question Decomposition for Question Answering") shows example sub-questions from our best decomposition model with predicted sub-answers.
Sub-questions are single-hop questions relevant to the multi-hop question.
The single-hop QA model returns relevant sub-answers, sometimes in spite of grammatical errors (Q1, SQ1) or under-specified questions (Q2, SQ1).
The multi-hop QA model then returns an answer consistent with the predicted sub-answers.
The decomposition model is largely extractive, copying from the multi-hop question rather than hallucinating new entities, which helps generate relevant sub-questions.
To better understand our system, we analyze the model for each stage: decomposition, single-hop QA, and multi-hop QA.
5 Analysis
-----------
###
5.1 Unsupervised Decomposition Model
##### Intrinsic Evaluation of Decompositions
| | | | | |
| --- | --- | --- | --- | --- |
| Decomp. | GPT2 | % Well- | Edit | Length |
| Method | NLL | Formed | Dist. | Ratio |
| USeq2Seq | 5.56 | 60.9 | 5.96 | 1.08 |
| DecompRC | 6.04 | 32.6 | 7.08 | 1.22 |
Table 5: Analysis of sub-questions produced by our method vs. the supervised+heuristic method of Min et al. ([2019b](#bib.bib44 "Multi-hop reading comprehension through question decomposition and rescoring")). From left-to-right: Negative Log-Likelihood (NLL) according to GPT2 (lower is better), % Well-Formed according to a classifier, Edit Distance between decomposition and multi-hop question, and token-wise Length Ratio between decomposition and multi-hop question.
We evaluate the quality of decompositions on other metrics aside from downstream QA.
To measure the fluency of decompositions, we compute the likelihood of decompositions using the pre-trained GPT-2 language model (Radford et al., [2019](#bib.bib54 "Language models are unsupervised multitask learners")).
We train a classifier on the question-wellformedness dataset of Faruqui and Das ([2018](#bib.bib83 "Identifying well-formed natural language questions")), and we use the classifier to estimate the proportion of sub-questions that are well-formed.
We measure how abstractive decompositions are by computing (i) the token Levenstein distance between the multi-hop question and its generated decomposition and (ii) the ratio between the length of the decomposition and the length of the multi-hop question.
We compare our best decomposition model against the supervised+heuristic decompositions from DecompRC (Min et al., [2019b](#bib.bib44 "Multi-hop reading comprehension through question decomposition and rescoring")) in Table [5](#S5.T5 "Table 5 ‣ Intrinsic Evaluation of Decompositions ‣ 5.1 Unsupervised Decomposition Model ‣ 5 Analysis ‣ Unsupervised Question Decomposition for Question Answering").
Unsupervised decompositions are both more natural and well-formed than decompositions from DecompRC.
Unsupervised decompositions are also closer in edit distance and length to the multi-hop question, consistent with our observation that our decomposition model is largely extractive.
##### Quality of Decomposition Model

Figure 4: Left: We decode from the decomposition model with beam search and use nth-ranked hypothesis as a question decomposition. We plot the F1 of a multi-hop QA model trained to use the nth-ranked decomposition. Right: Multi-hop QA is better when the single-hop QA model places high probability on its sub-answer.
Another way to test the quality of the decomposition model is to test if the model places higher probability on decompositions that are more helpful for downstream QA.
We generate N=5 hypotheses from our best decomposition model using beam search, and we train a multi-hop QA model to use the nth-ranked hypothesis as a question decomposition (Fig. [4](#S5.F4 "Figure 4 ‣ Quality of Decomposition Model ‣ 5.1 Unsupervised Decomposition Model ‣ 5 Analysis ‣ Unsupervised Question Decomposition for Question Answering"), left).
QA accuracy decreases as we use lower probability decompositions, but accuracy remains relatively robust, at most decreasing from 80.1 to 79.3 F1.
The limited drop suggests that decompositions are still useful if they are among the model’s top hypotheses, another indication that our model is trained well for decomposition.
###
5.2 Single-hop Question Answering Model
##### Sub-Answer Confidence
Figure [4](#S5.F4 "Figure 4 ‣ Quality of Decomposition Model ‣ 5.1 Unsupervised Decomposition Model ‣ 5 Analysis ‣ Unsupervised Question Decomposition for Question Answering") (right) shows that the model’s sub-answer confidence correlates with downstream multi-hop QA performance for all HotpotQA dev sets.
A low confidence sub-answer may be indicative of (i) an unanswerable or ill-formed sub-question or (ii) a sub-answer that is more likely to be incorrect.
In both cases, the single-hop QA model is less likely to retrieve the useful supporting evidence to answer the multi-hop question.
##### Changing the Single-hop QA Model
We find that our approach is robust to the single-hop QA model that answers sub-questions.
We use the \textscBERT\textscBASE ensemble from Min et al. ([2019b](#bib.bib44 "Multi-hop reading comprehension through question decomposition and rescoring")) as the single-hop QA model.
The model performs much worse compared to our \textscRoBERTa\textscLARGE single-hop ensemble when used directly on HotpotQA (56.3 vs. 66.7 F1).
However, the model results in comparable QA when used to answer single-hop sub-questions within our larger system (79.9 vs. 80.1 F1 for our \textscRoBERTa\textscLARGE ensemble).
###
5.3 Multi-hop Question Answering Model
##### Varying the Base Model
To understand how decompositions impact performance as the multi-hop QA model gets stronger,
we vary the base pre-trained model.
Table [6](#S6.T6 "Table 6 ‣ 6 Related Work ‣ Unsupervised Question Decomposition for Question Answering") shows the impact of adding decompositions to \textscBERT\textscBASE , \textscBERT\textscLARGE , and finally \textscRoBERTa\textscLARGE (see Appendix §[C.2](#A3.SS2 "C.2 Training Hyperparameters ‣ Appendix C Multi-hop QA Model ‣ Unsupervised Question Decomposition for Question Answering") for hyperparameters).
The gain from using decompositions grows with strength of the multi-hop QA model.
Decompositions improve QA by 1.2 F1 for a \textscBERT\textscBASE model, by 2.6 F1 for the stronger \textscBERT\textscLARGE model, and by 3.1 F1 for our best \textscRoBERTa\textscLARGE model.
6 Related Work
---------------
Answering complicated questions has been a long-standing challenge in natural language processing.
To this end, prior work has explored decomposing questions with supervision or heuristic algorithms.
IBM Watson (Ferrucci et al., [2010](#bib.bib18 "Building watson: an overview of the deepqa project")) decomposes questions into sub-questions in multiple ways or not at all.
DecompRC (Min et al., [2019b](#bib.bib44 "Multi-hop reading comprehension through question decomposition and rescoring")) largely frames sub-questions as extractive spans of a multi-hop question, learning to predict span-based sub-questions via supervised learning on human annotations.
In other cases, DecompRC decomposes a multi-hop question using a heuristic algorithm, or DecompRC does not decompose at all.
Watson and DecompRC use special case handling to decompose different questions, while our algorithm is fully automated and requires minimal hand-engineering.
More traditional, semantic parsing methods map questions to compositional programs, whose sub-programs can be viewed as question decompositions in a formal language (Talmor and Berant, [2018](#bib.bib63 "The web as a knowledge-base for answering complex questions"); Wolfson et al., [2020](#bib.bib65 "Break it down: a question understanding benchmark")).
Examples include classical QA systems like SHRDLU (Winograd, [1972](#bib.bib75 "Understanding natural language")) and LUNAR (Woods et al., [1974](#bib.bib74 "The lunar sciences natural language information system")), as well as neural Seq2Seq semantic parsers (Dong and Lapata, [2016](#bib.bib15 "Language to logical form with neural attention")) and neural module networks (Andreas et al., [2015](#bib.bib1 "Neural module networks"), [2016](#bib.bib2 "Learning to compose neural networks for question answering")).
Such methods usually require strong, program-level supervision to generate programs, as in visual QA (Johnson et al., [2017b](#bib.bib29 "Inferring and executing programs for visual reasoning")) and on HotpotQA (Jiang and Bansal, [2019](#bib.bib27 "Self-assembling modular networks for interpretable multi-hop reasoning")).
Some models use other forms of strong supervision, e.g. predicting the “supporting evidence” to answer a question annotated by HotpotQA.
Such an approach is taken by SAE (Tu et al., [2020](#bib.bib64 "Select, answer and explain: interpretable multi-hop reading comprehension over multiple documents")) and HGN (Fang et al., [2019](#bib.bib17 "Hierarchical graph network for multi-hop question answering")), whose methods may be combined with our approach.
Unsupervised decomposition complements strongly and weakly supervised decomposition approaches.
Our unsupervised approach enables methods to leverage millions of otherwise unusable questions, similar to work on unsupervised QA (Lewis et al., [2019](#bib.bib37 "Unsupervised question answering by cloze translation")).
When decomposition examples exist, supervised and unsupervised learning can be used in tandem to learn from both labeled and unlabeled examples.
Such semi-supervised methods outperform supervised learning for tasks like machine translation (Sennrich et al., [2016](#bib.bib58 "Improving neural machine translation models with monolingual data")).
Other work on weakly supervised question generation uses a downstream QA model’s accuracy as a signal for learning to generate useful questions.
Weakly supervised question generation often uses reinforcement learning (Nogueira and Cho, [2017](#bib.bib46 "Task-oriented query reformulation with reinforcement learning"); Wang and Lake, [2019](#bib.bib78 "Modeling question asking using neural program generation"); Strub et al., [2017](#bib.bib62 "End-to-end optimization of goal-driven and visually grounded dialogue systems"); Das et al., [2017](#bib.bib12 "Learning cooperative visual dialog agents with deep reinforcement learning"); Liang et al., [2018](#bib.bib39 "Memory augmented policy optimization for program synthesis and semantic parsing")), where an unsupervised initialization can greatly mitigate the issues of exploring from scratch (Jaderberg et al., [2017](#bib.bib24 "Reinforcement learning with unsupervised auxiliary tasks")).
| | |
| --- | --- |
| Multi-hop QA Model | QA F1 (w/o → w/ Decomps.) |
| \textscBERT\textscBASE | 71.8±.4 → 73.0±.4 |
| \textscBERT\textscLARGE | 76.4±.2 → 79.0±.1 |
| \textscRoBERTa\textscLARGE | 77.0±.3 → 80.1±.2 |
Table 6:
Stronger QA models benefit more from decompositions.
7 Conclusion
-------------
We proposed an algorithm that decomposes questions without supervision, using 3 stages: (1) learning to decompose using pseudo-decompositions without supervision, (2) answering sub-questions with an off-the-shelf QA system, and (3) answering hard questions more accurately using sub-questions and their answers as additional input.
When evaluated on HotpotQA, a standard benchmark for multi-hop QA, our approach significantly improved accuracy over an equivalent model that did not use decompositions.
Our approach relies only on the final answer as supervision but works as effectively as state-of-the-art methods that rely on strong supervision, such as supporting fact labels or example decompositions.
Qualitatively, we found that unsupervised decomposition resulted in fluent sub-questions whose answers often match the annotated supporting facts in HotpotQA.
Our unsupervised decompositions are largely extractive, which is effective for compositional, multi-hop questions but not all complex questions, showing room for future work.
Overall, this work opens up exciting avenues for leveraging methods in unsupervised learning and natural language generation to improve the interpretability and generalization of machine learning systems.
Acknowledgements
----------------
EP is supported by the NSF Graduate Research Fellowship.
KC is supported by Samsung Advanced Institute of Technology (Next Generation Deep Learning: from pattern recognition to AI) and Samsung Research (Improving Deep Learning using Latent Structure). KC also thanks eBay and NVIDIA for their support.
We thank Paul Christiano, Sebastian Riedel, He He, Jonathan Berant, Alexis Conneau, Jiatao Gu, Sewon Min, Yixin Nie, Lajanugen Logeswaran, and Adam Fisch for helpful feedback, as well as Yichen Jiang and Peng Qi for help with evaluation. |
d5a41938-77a4-4790-87a7-d7e2af5800cc | trentmkelly/LessWrong-43k | LessWrong | Meetup : Vancouver Board Games Meetup
Discussion article for the meetup : Vancouver Board Games Meetup
WHEN: 08 April 2012 01:00:00PM (-0700)
WHERE: Drexoll Games, 2880 W 4th Ave, Vancouver, BC
Hello everybody. We are having our first monthly friendly social games meetup. The idea is to have a bigger meetup where newcomers can feel comfortable because it's not held in my sketchy dungeon of doom.
So we are going to go to Drexoll Games and play board games. Adding players to games halfway thru is no fun, so try to show up at or before 13:00. If you can't make it on time, come anyways. We estimate that the meetup will go until about 16:00, so don't worry about missing dinner.
As usual, see the mailing list for more details: vancouver-rationalists
If you haven't been coming for whatever reason, this is the time to start, or at least check us out. See you there!
Discussion article for the meetup : Vancouver Board Games Meetup |
d9908c1b-cc1e-4122-b1e0-aae72b4ece53 | trentmkelly/LessWrong-43k | LessWrong | Spring 1912: A New Heaven And A New Earth
And so it came to pass that on Christmas Day 1911, the three Great Powers of Europe signed a treaty to divide the continent between them peacefully, ending what future historians would call the Great War.
The sun truly never sets on King Jack's British Empire, which stretches from Spain to Stockholm, from Casablanca to Copenhagen, from the fringes of the Sahara to the coast of the Arctic Ocean. They rule fourteen major world capitals, and innumerable smaller towns and cities, the greatest power of the age and the unquestioned master of Western Europe.
From the steppes of Siberia to the minarets of Istanbul, the Ottoman Empire is no longer the Sick Man of Europe but stands healthy and renewed, a colossus every bit the equal of the Christian powers to its west. Its Sultan calls himself the Caliph, for the entire Islamic world basks in his glory, and his Grand Vizier has been rewarded with a reputation as one of the most brilliant and devious politicians of the age. At his feet grovel representatives of twelve great cities, and even far-flung Tunis has not escaped his sway.
And in between, the Austro-Hungarian Empire straddles the Alps and ancient Italy. Its lack of natural borders presented no difficulty for its wily Emperor, who successfully staved off the surrounding powers and played his enemies off against one another while building alliances that stood the test of time. Eight great cities pay homage to his double-crown, and he is what his predecessors could only dream of being - a true Holy Roman Emperor.
And hidden beneath the tricolor map every student learns in grammar school are echoes of subtler hues. In Germany, people still talk of the mighty Kajser Sotala I, who conquered the ancient French enemy and extended German rule all the way to the Mediterranean, and they still seeth and curse at his dastardly betrayal by his English friends. In Russia, Princess Anastasia claims to be the daughter of Czar Perplexed, and recounts to everyone who will listen the |
acd492d0-ff9e-42a3-ac3e-de1b16cfdb3a | trentmkelly/LessWrong-43k | LessWrong | Image Test
Editing in IE6! |
cbb6ff28-aab2-49cf-8da0-d24dcd4de7b8 | trentmkelly/LessWrong-43k | LessWrong | Meetup : San Francisco Meetup: Cooking
Discussion article for the meetup : San Francisco Meetup: Cooking
WHEN: 04 April 2016 06:15:00PM (-0700)
WHERE: 1597 Howard St. San Francisco, CA
We'll be meeting to cook! If you want to lead a cooking team, send me an email or pm (sooner rather than later would be ideal), and I'll get you set up. Otherwise, you can join someone's team and put together something delicious! As always, call me at 301-458-0764 to be let in.
Discussion article for the meetup : San Francisco Meetup: Cooking |
56d09e86-54f4-416f-beee-38d876b9ab1f | trentmkelly/LessWrong-43k | LessWrong | (My understanding of) What Everyone in Technical Alignment is Doing and Why
Epistemic Status: My best guess
Epistemic Effort: ~75 hours of work put into this document
Contributions: Thomas wrote ~85% of this, Eli wrote ~15% and helped edit + structure it. Unless specified otherwise, writing in the first person is by Thomas and so are the opinions. Thanks to Miranda Zhang, Caleb Parikh, and Akash Wasil for comments. Thanks to many others for relevant conversations.
Introduction
Despite a clear need for it, a good source explaining who is doing what and why in technical AI alignment doesn't exist. This is our attempt to produce such a resource. We expect to be inaccurate in some ways, but it seems great to get out there and let Cunningham’s Law do its thing.[1]
The main body contains our understanding of what everyone is doing in technical alignment and why, as well as at least one of our opinions on each approach. We include supplements visualizing differences between approaches and Thomas’s big picture view on alignment. The opinions written are Thomas and Eli’s independent impressions, many of which have low resilience. Our all-things-considered views are significantly more uncertain.
This post was mostly written while Thomas was participating in the 2022 iteration SERI MATS program, under mentor John Wentworth. Thomas benefited immensely from conversations with other SERI MATS participants, John Wentworth, as well as many others who I met this summer.
Disclaimers:
* This post is our understanding and has not been endorsed by the people doing the work itself.
* The length of the summaries varies according to our knowledge of this approach, and is not meant to reflect a judgement on the quality or quantity of work done.
* We are not very familiar with most of the academic alignment work being done, and have only included a few academics.
A summary of our understanding of each approach:
ApproachProblem FocusCurrent Approach SummaryScale Aligned AIModel splinteringSolve extrapolation problems. 2-5 researchers, started Feb 2 |
48096db9-71f9-457c-aca0-c75403889083 | LDJnr/LessWrong-Amplify-Instruct | LessWrong | ""What is red?""Red is a color.""What's a color?""A color is a property of a thing." But what is a thing? And what's a property? Soon the two are lost in a maze of words defined in other words, the problem that Steven Harnad once described as trying to learn Chinese from a Chinese/Chinese dictionary.
Alternatively, if you asked me "What is red?" I could point to a stop sign, then to someone wearing a red shirt, and a traffic light that happens to be red, and blood from where I accidentally cut myself, and a red business card, and then I could call up a color wheel on my computer and move the cursor to the red area. This would probably be sufficient, though if you know what the word "No" means, the truly strict would insist that I point to the sky and say "No."
I think I stole this example from S. I. Hayakawa—though I'm really not sure, because I heard this way back in the indistinct blur of my childhood. (When I was 12, my father accidentally deleted all my computer files. I have no memory of anything before that.)
But that's how I remember first learning about the difference between intensional and extensional definition. To give an "intensional definition" is to define a word or phrase in terms of other words, as a dictionary does. To give an "extensional definition" is to point to examples, as adults do when teaching children. The preceding sentence gives an intensional definition of "extensional definition", which makes it an extensional example of "intensional definition". In Hollywood Rationality and popular culture generally, "rationalists" are depicted as word-obsessed, floating in endless verbal space disconnected from reality.
But the actual Traditional Rationalists have long insisted on maintaining a tight connection to experience: "If you look into a textbook of chemistry for a definition of lithium, you may be told that it is that element whose atomic weight is 7 very nearly. But if the author has a more logical mind he will tell you that if you search among minerals that are vitreous, translucent, grey or white, very hard, brittle, and insoluble, for one which imparts a crimson tinge to an unluminous flame, this mineral being triturated with lime or witherite rats-bane, and then fused, can be partly dissolved in muriatic acid; and if this solution be evaporated, and the residue be extracted with sulphuric acid, and duly purified, it can be converted by ordinary methods into a chloride, which being obtained in the solid state, fused, and electrolyzed with half a dozen powerful cells, will yield a globule of a pinkish silvery metal that will float on gasolene; and the material of that is a specimen of lithium." — Charles Sanders Peirce That's an example of "logical mind" as described by a genuine Traditional Rationalist, rather than a Hollywood scriptwriter.
But note: Peirce isn't actually showing you a piece of lithium. He didn't have pieces of lithium stapled to his book. Rather he's giving you a treasure map—an intensionally defined procedure which, when executed, will lead you to an extensional example of lithium. This is not the same as just tossing you a hunk of lithium, but it's not the same as saying "atomic weight 7" either. (Though if you had sufficiently sharp eyes, saying "3 protons" might let you pick out lithium at a glance...)
So that is intensional and extensional definition., which is a way of telling someone else what you mean by a concept. When I talked about "definitions" above, I talked about a way of communicating concepts—telling someone else what you mean by "red", "tiger", "human", or "lithium". Now let's talk about the actual concepts themselves.
The actual intension of my "tiger" concept would be the neural pattern (in my temporal cortex) that inspects an incoming signal from the visual cortex to determine whether or not it is a tiger.
The actual extension of my "tiger" concept is everything I call a tiger.
Intensional definitions don't capture entire intensions; extensional definitions don't capture entire extensions. If I point to just one tiger and say the word "tiger", the communication may fail if they think I mean "dangerous animal" or "male tiger" or "yellow thing". Similarly, if I say "dangerous yellow-black striped animal", without pointing to anything, the listener may visualize giant hornets.
You can't capture in words all the details of the cognitive concept—as it exists in your mind—that lets you recognize things as tigers or nontigers. It's too large. And you can't point to all the tigers you've ever seen, let alone everything you would call a tiger.
The strongest definitions use a crossfire of intensional and extensional communication to nail down a concept. Even so, you only communicate maps to concepts, or instructions for building concepts—you don't communicate the actual categories as they exist in your mind or in the world.
(Yes, with enough creativity you can construct exceptions to this rule, like "Sentences Eliezer Yudkowsky has published containing the term 'huragaloni' as of Feb 4, 2008". I've just shown you this concept's entire extension. But except in mathematics, definitions are usually treasure maps, not treasure.)
So that's another reason you can't "define a word any way you like": You can't directly program concepts into someone else's brain.
Even within the Aristotelian paradigm, where we pretend that the definitions are the actual concepts, you don't have simultaneous freedom of intension and extension. Suppose I define Mars as "A huge red rocky sphere, around a tenth of Earth's mass and 50% further away from the Sun". It's then a separate matter to show that this intensional definition matches some particular extensional thing in my experience, or indeed, that it matches any real thing whatsoever. If instead I say "That's Mars" and point to a red light in the night sky, it becomes a separate matter to show that this extensional light matches any particular intensional definition I may propose—or any intensional beliefs I may have—such as "Mars is the God of War".
But most of the brain's work of applying intensions happens sub-deliberately. We aren't consciously aware that our identification of a red light as "Mars" is a separate matter from our verbal definition "Mars is the God of War". No matter what kind of intensional definition I make up to describe Mars, my mind believes that "Mars" refers to this thingy, and that it is the fourth planet in the Solar System.
When you take into account the way the human mind actually, pragmatically works, the notion "I can define a word any way I like" soon becomes "I can believe anything I want about a fixed set of objects" or "I can move any object I want in or out of a fixed membership test". Just as you can't usually convey a concept's whole intension in words because it's a big complicated neural membership test, you can't control the concept's entire intension because it's applied sub-deliberately. This is why arguing that XYZ is true "by definition" is so popular. If definition changes behaved like the empirical nullops they're supposed to be, no one would bother arguing them. But abuse definitions just a little, and they turn into magic wands—in arguments, of course; not in reality."
This is a snippet extracted from a publication on LessWrong by a site member.The above is a chunk of text from a post created by a user on the website LessWrong.
Can you elaborate on the limitations of intensional and extensional definitions in conveying complex concepts, and propose potential solutions to overcome these limitations?
The limitations of intensional and extensional definitions largely stem from the inherent complexity of concepts and the constraints of language and perception.
Intensional definitions, which describe a concept in terms of other concepts, can often lead to circularity or infinite regress. For example, defining "red" as a "color" only shifts the question to "what is a color?" Furthermore, intensional definitions can be overly broad or overly narrow, failing to capture the full range of a concept's instances or including instances that should not be included.
Extensional definitions, which provide examples of a concept, are limited by the range of examples that can be provided and perceived. For instance, pointing to a red object to define "red" assumes that the observer perceives color in the same way as the definer. Moreover, extensional definitions cannot capture the full range of a concept's instances, especially for abstract or complex concepts.
To overcome these limitations, we can use a combination of intensional and extensional definitions, providing both a description and examples of a concept. This can help to anchor the concept in both language and perception, providing a more robust understanding.
Moreover, we can use analogies and metaphors to convey complex concepts, leveraging existing understanding to bridge the gap to new concepts. For example, explaining the concept of a neural network in terms of neurons in the brain.
We can also use visual aids and interactive experiences to convey complex concepts. For instance, a simulation can help to convey the concept of evolution by natural selection.
Finally, we can use iterative refinement to hone our understanding of a concept. By repeatedly applying the concept, receiving feedback, and adjusting our understanding, we can progressively improve our grasp of the concept. This is essentially the process of learning, which is fundamental to our ability to understand and convey complex concepts.
Explain the process of iterative refinement in the context of understanding complex concepts, and provide a real-world example of its application.
Iterative refinement is a process that involves repeated cycles of applying a concept, receiving feedback, and adjusting the concept based on that feedback. It is a fundamental mechanism in learning and understanding, particularly for complex concepts that cannot be fully grasped in a single step.
The first step in iterative refinement is to form an initial understanding of the concept. This can be based on an intensional definition, an extensional definition, or a combination of both. The initial understanding is likely to be incomplete or incorrect in some ways, but it provides a starting point for refinement.
The next step is to apply the concept in some way. This could involve using the concept to make predictions, solve problems, or perform tasks. The application provides a test of the concept, revealing its strengths and weaknesses.
The third step is to receive feedback on the application of the concept. This feedback can come from various sources, such as the results of the application, comments from others, or self-reflection. The feedback provides information about the accuracy and utility of the concept.
The final step is to adjust the concept based on the feedback. This could involve changing the intensional definition, expanding or contracting the extensional definition, or adjusting the application of the concept. The adjustment improves the concept, making it more accurate and useful.
This process is then repeated, with the refined concept serving as the starting point for the next cycle. Over time, the concept becomes increasingly refined, providing a deeper and more accurate understanding.
A real-world example of iterative refinement is the development of scientific theories. For instance, the concept of gravity has undergone numerous refinements since the time of Aristotle. Aristotle's concept of gravity, which held that objects fall at a speed proportional to their weight, was applied and found to be inaccurate. Based on feedback from experiments, Galileo refined the concept to state that objects fall at the same speed regardless of their weight. This concept was further refined by Newton, who proposed the law of universal gravitation, and then by Einstein, who proposed the theory of general relativity. Each refinement represented an improvement in our understanding of gravity, achieved through the process of iterative refinement.
"Given the iterative refinement process applied in the development of scientific theories, how might this process be effectively utilized in refining a complex business strategy? Consider factors such as initial strategy formation, application, feedback mechanisms, and adjustments."
Iterative refinement can be a powerful tool in developing and refining a complex business strategy. Here's how the process might be applied:
1. Initial Strategy Formation: The first step is to develop an initial business strategy. This could be based on a company's mission, market research, competitive analysis, and other relevant factors. The strategy should outline the company's goals, the actions it plans to take to achieve those goals, and the metrics it will use to measure success.
2. Application: Once the strategy is formed, it needs to be put into action. This could involve launching new products or services, entering new markets, implementing new processes, or making other strategic moves. The application of the strategy provides a real-world test of its effectiveness.
3. Feedback Mechanisms: As the strategy is being implemented, it's crucial to have mechanisms in place to gather feedback. This could involve tracking key performance indicators (KPIs), conducting customer surveys, getting input from employees, and monitoring market trends and competitive activity. The feedback provides valuable information about how well the strategy is working and where adjustments may be needed.
4. Adjustments: Based on the feedback, the strategy should be adjusted as necessary. This could involve tweaking certain actions, changing the focus of the strategy, or even making major strategic shifts. The goal is to improve the strategy's effectiveness in achieving the company's goals.
5. Repeat the Process: After adjustments are made, the refined strategy is put into action, feedback is gathered, and further adjustments are made. This iterative process continues, allowing the strategy to evolve and improve over time.
A real-world example might be a technology company that launches a new software product. The initial strategy might involve targeting a certain market segment, pricing the product at a certain level, and promoting it through certain channels. As the product is launched and feedback is gathered, the company might find that another market segment is more receptive, that a different pricing strategy would be more effective, or that other promotional channels would be more successful. Based on this feedback, the company adjusts its strategy and continues the iterative process, continually refining its strategy to maximize the product's success. |
c24532c1-62ba-4a40-9708-4c97370a5cd5 | trentmkelly/LessWrong-43k | LessWrong | Y Couchinator
Crossposted to Tumblr.
*This project never really had critical mass and is no longer operative; it did later inspire another project, also now defunct.*
There are a lot of people - there are probably incredibly tragic mountains of people - who just need one or three or six no-pressure months on someone's couch, and meals during that time, and then they'd be okay. They'd spend this time catching up on their bureaucracy or recovering from abuse or getting training in a field they want to go into or all three. And then they'd be fine.
There are empty couches, whose owners throw away leftovers they didn't get around to eating every week, who aren't too introverted to have a roommate or too busy to help someone figure out their local subway system.
And while sometimes by serendipity these people manage to find each other and make a leap of trust and engage in couch commensalism a lot of the time they just don't. Because six months is a long time, a huge commitment for someone you haven't vetted, and a week wouldn't be enough to be worth the plane ticket, not enough to make a difference.
I think there might be a lot of gains to be had from disentangling the vetting and the hosting. People are comfortable with different levels of vetting, ranging from "they talked to me enough that it'd be an unusually high-effort scam" through "must be at least a friend of a friend of a friend" through "I have to have known them in person for months". And you can bootstrap through these.
Here's a toy example:
* Joe barely makes ends meet somewhere out in flyover country but in between shifts at his retail job he's doing well at self-teaching programming and seems like he could pass App Academy.
* Norm has a one-bedroom apartment in San Francisco and doesn't really need his couch to be empty, nor does he need to rent it out for money to someone desperate enough to pay rent on a couch, but he's not ready to give some dude on the internet a commitment to providing shelter for t |
fa71a7bb-0559-496d-9c63-6e983d23c628 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | How to measure FLOP/s for Neural Networks empirically?
Experiments and text by Marius Hobbhahn. I would like to thank Jaime Sevilla, Jean-Stanislas Denain, Tamay Besiroglu, Lennart Heim, and Anson Ho for their feedback and support.
### **Summary:**
We measure the utilization rate of a Tesla P100 GPU for training different ML models. Most architectures and methods result in a utilization rate between 0.3 and 0.75. However, two architectures result in implausible low utilization rates of lower than 0.04. The most probable explanation for these outliers is that FLOP for inverted bottleneck layers are not counted correctly by the profiler. In general, the profiler we use shows signs of under- and overcounting and there is a possibility we made errors.
**Findings:**
* Counting the FLOP for a forward pass is very simple and many different packages give correct answers.
* Counting the FLOP for the backward pass is harder and our estimator of choice makes weird overcounting and undercounting errors.
* After cleaning mistakes, it is very likely that the backward/forward ratio is 2:1 (at least for our setup).
* After correcting for the overcounting issues, we get empirical utilization rates between 0.3 and 0.75 for most architectures. Theoretical predictions and empirical measurements seem very consistent for larger batch sizes.
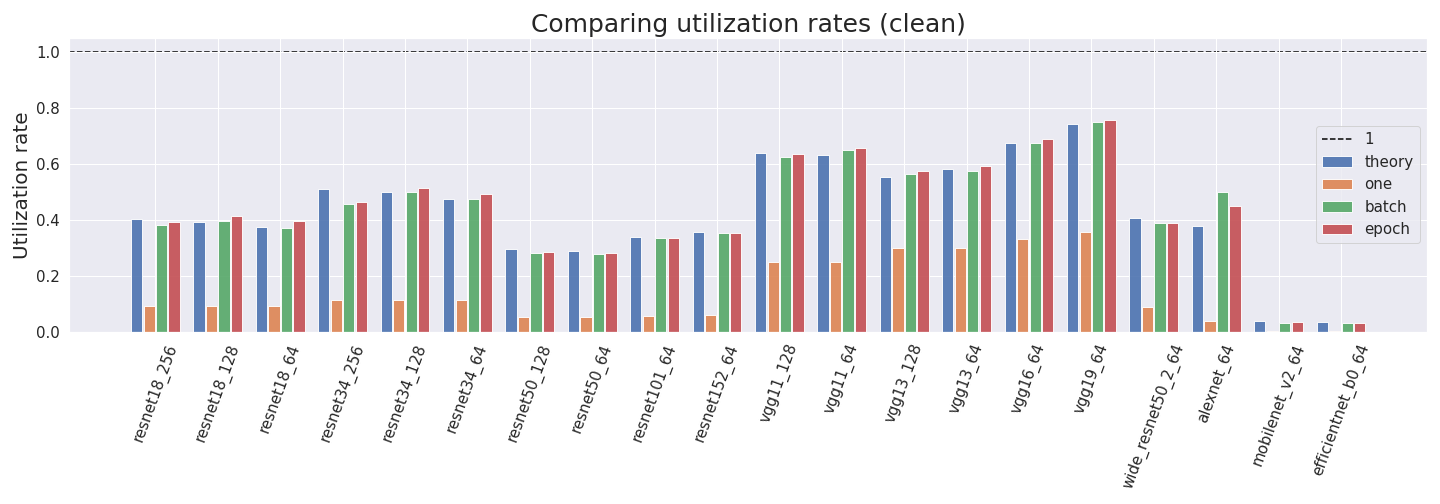*Estimated GPU utilization rates on different architectures, using four different estimation setups.*
**Introduction**
----------------
In the “Parameter, Compute and Data Trends in Machine Learning" project we wanted to estimate GPU utilization rates for different Neural Networks and GPUs. While this sounds very easy in theory, it turned out to be hard in practice.
*Utilization rate = empirical performance / peak performance*
The post contains a lot of technical jargon. If you are just here for the results, skip to the Analysis section.
I don’t have any prior experience in estimating FLOP. It is very possible that I made rookie mistakes. Help and suggestions are appreciated.
Other work on computing and measuring FLOP can be found in Lennart Heim's sequences [Transformative AI and Compute](https://forum.effectivealtruism.org/s/4yLbeJ33fYrwnfDev). It's really good.
**Methods for counting FLOP**
-----------------------------
In this post, we use FLOP to denote floating-point operations and FLOP/s to mean FLOP per second.
We can look up the peak FLOP/s performance of any GPU by checking its datasheet (see e.g. [NVIDIA’s Tesla P100](https://images.nvidia.com/content/tesla/pdf/nvidia-tesla-p100-PCIe-datasheet.pdf)). To compare our empirical performance to the theoretical maximum, we need to measure the number of FLOP and time for one training run. This is where things get confusing.
Packages such as PyTorch’s [fvcore](https://detectron2.readthedocs.io/en/latest/modules/fvcore.html), [ptflops](https://github.com/sovrasov/flops-counter.pytorch/tree/master/ptflops) or [pthflops](https://github.com/1adrianb/pytorch-estimate-flops) hook onto your model and compute the FLOP for one forward pass for a given input. However, they can’t estimate the FLOP for a backward pass. Given that we want to compute the utilization rate for the entire training, accurate estimates of FLOP for the backward pass are important.
PyTorch also provides a list of packages called profilers, e.g. in the [main package](https://pytorch.org/docs/stable/profiler.html) and [autograd](https://pytorch.org/docs/stable/autograd.html#profiler). The profilers hook onto your model and measure certain quantities at runtime, e.g. CPU time, GPU time, FLOP, etc. The profiler can return aggregate statistics or individual statistics for every single operation within the training period. Unfortunately, these two profilers seem to not count the backward pass either.
[NVIDIA offers an alternative way of using the profiler with Nsight Systems](https://docs.nvidia.com/deeplearning/frameworks/pyprof-user-guide/profile.html) that supposedly estimates FLOP for forward and backward pass accurately. This would suffice for all of our purposes. Unfortunately, we encountered problems with the estimates from this method. It shows signs of over- and undercounting operations. While we could partly fix these issues post-hoc, there is still room for errors in the resulting estimates.
NVIDIA also offers a profiler called [dlprof](https://docs.nvidia.com/deeplearning/frameworks/dlprof-user-guide/). However, we weren’t able to run it in Google Colab (see appendix).
**Our experimental setup**
--------------------------
We try to estimate the empirical utilization rates of 13 different conventional neural network classification architectures (resnet18, resnet34, resnet50, resnet101, resnet152, vgg11, vgg13, vgg16, vgg19, wide\_resnet50\_2, alexnet, mobilenet\_v2, efficientnet\_b0) with different batch sizes for some of them. For all experiments, we use the [Tesla P100](https://images.nvidia.com/content/tesla/pdf/nvidia-tesla-p100-PCIe-datasheet.pdf) GPU which seems to be the default for Google Colab. All experiments have been done in Google Colab and can be reproduced [here](https://drive.google.com/drive/folders/1yFLAafYtyeJcAnnTbqv4sAd2KJaboKrt?usp=sharing).
We estimate the FLOP for a forward pass with fvcore, ptflops, pthflops and the PyTorch profiler. Furthermore, we compare them to the FLOP for forward and backward pass estimated by the profiler + nsight systems method (which we name profiler\_nvtx). We measure the time for all computations once with the profiler and additionally with profiler\_nvtx to get comparisons.
One problem for the estimation of FLOP is that fvcore, ptflops and pthflops seem to count a [Fused Multiply Add (FMA)](https://en.wikipedia.org/wiki/FMA_instruction_set) as one operation while the profiler methods count it as 2. Since basically all operations in NNs are FMAs that means we can just divide all profiler estimates by 2. We already applied this division to all estimates, so you don’t have to do it mentally. However, this is one potential source for errors since some operations might not be FMAs.
Furthermore, it is not 100 percent clear which FMA convention was used for the peak performance. [On their website](https://docs.nvidia.com/gameworks/content/developertools/desktop/analysis/report/cudaexperiments/kernellevel/achievedflops.htm), NVIDIA states *“The peak single-precision floating-point performance of a CUDA device is defined as the number of CUDA Cores times the graphics clock frequency multiplied by two. The factor of two stems from the ability to execute two operations at once using fused multiply-add (FFMA) instructions”*.
We interpret this statement to mean that NVIDIA used the FMA=2FLOP assumption. However, PyTorch automatically transforms all single-precision tensors to half-precision during training. Therefore, we get a speedup factor of 2 (which cancels the FMA=2FLOP)
For all experiments, we use input data of sizes 3x224x224 with 10 classes. This is similar to many common image classification setups. We either measure on single random batches of different sizes or on the test set of CIFAR10 containing 10000 images.
**Analysis:**
-------------
### **Something is fishy with profiler\_nvtx**
To understand the estimates for the profiler\_nvtx better, we run just one single forward and backward pass with different batch sizes. If we compare the profiler\_nvtx FLOP estimates for one forward pass on a random batch of size one, we see that they sometimes don’t align with all other estimates.
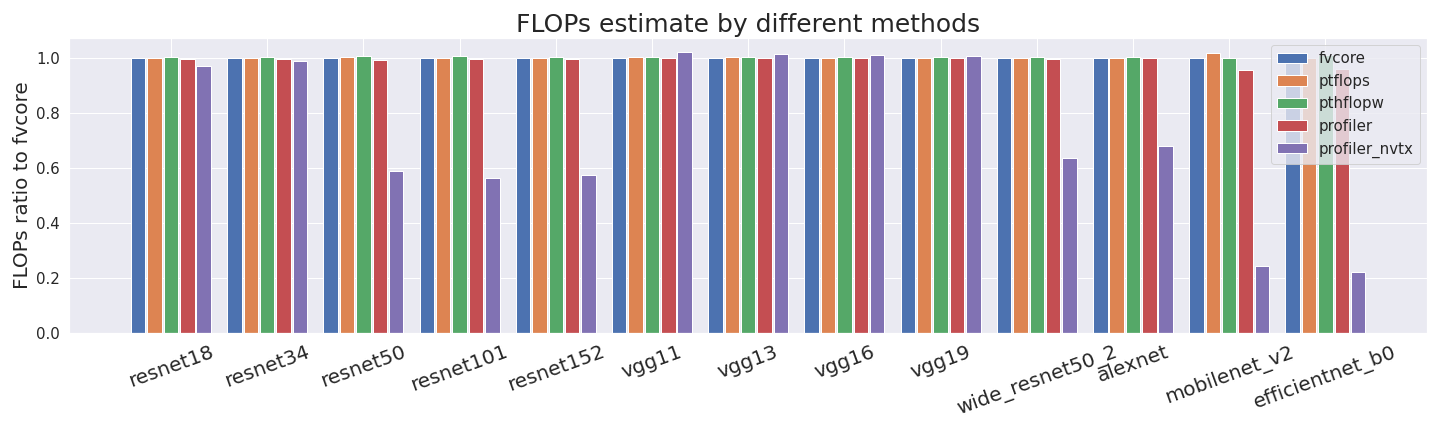The first four methods basically always yield very comparable estimates and just profiler\_nvtx sometimes undercounts quite drastically.
But it gets worse —profiler\_nvtx is inconsistent with its counting. We expected the number of FLOP for a batch size of 64 to be 64 times as large as for a batch size of 1, and the number of FLOP for a batch size of 128 to be 128 times as large as for a batch size of 1. However, this is not the case for both the forward and backward pass.
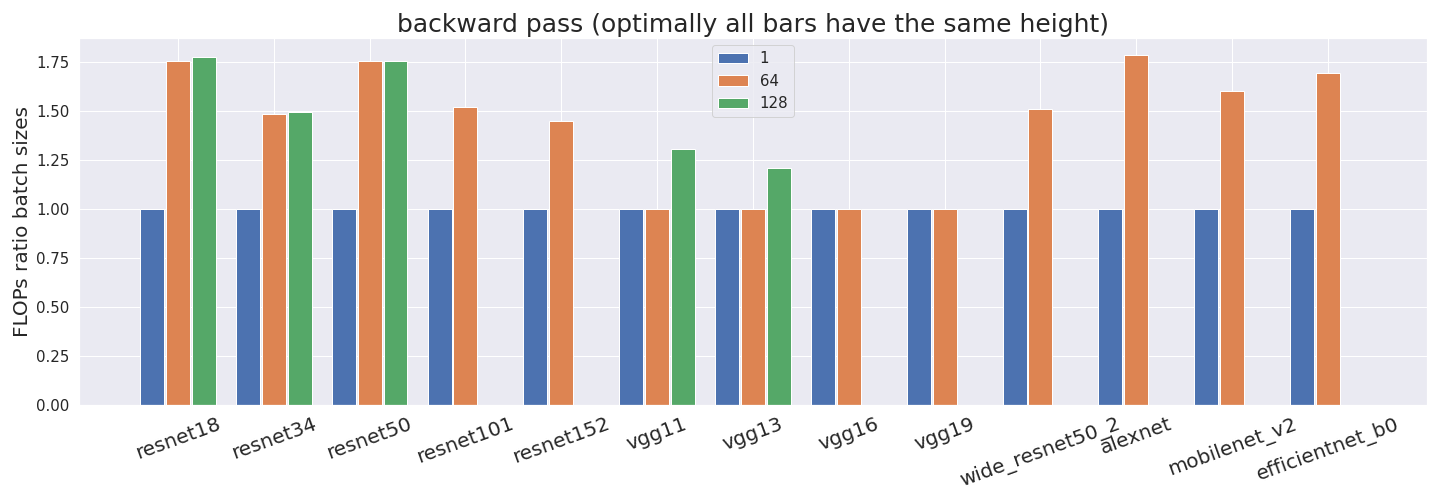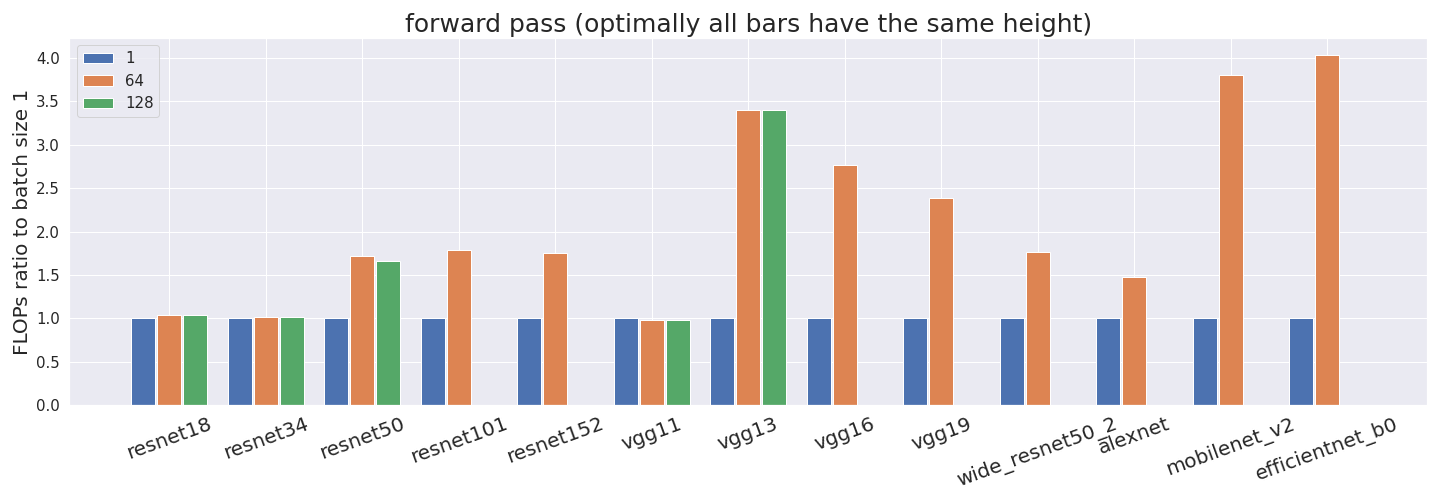All FLOP estimates have been normalized by the batch size. Thus, if our profiler counted correctly, all bars would have exactly the same height. This is not what we observe in some networks, which suggests that something is off. Some networks don’t have estimates for a batch size of 128 since it didn’t fit into the GPU memory.
To check whether profiler\_nvtx is over- or undercounting we investigate it further.
### **Investigating profiler\_nvtx further:**
Since the problems from above cause all analyses to be very uncertain, we try to find out what exactly is wrong and if we can fix it in the following section. If you don’t care about that, skip to the Results section.
If we compare the counted FLOP by operation, e.g. on alexnet, we make multiple discoveries.
* **FMAs:** We find that profiler\_nvtx counts exactly 2x as many FLOP as fvcore (red in table) since profiler\_nvtx counts FMAs as 2 and fvcore as 1 FLOP. For the same reason, profiler\_nvtx counts 128 as many operations when we use a batch size of 64 (blue in table).
* **Undercounting:** In some cases (green in table) profiler\_nvtx just doesn’t register an operation and therefore counts 0 FLOP.
* **Overcounting:** In other cases (yellow in table), profiler\_nvtx counts the same operation multiple times for no apparent reason.
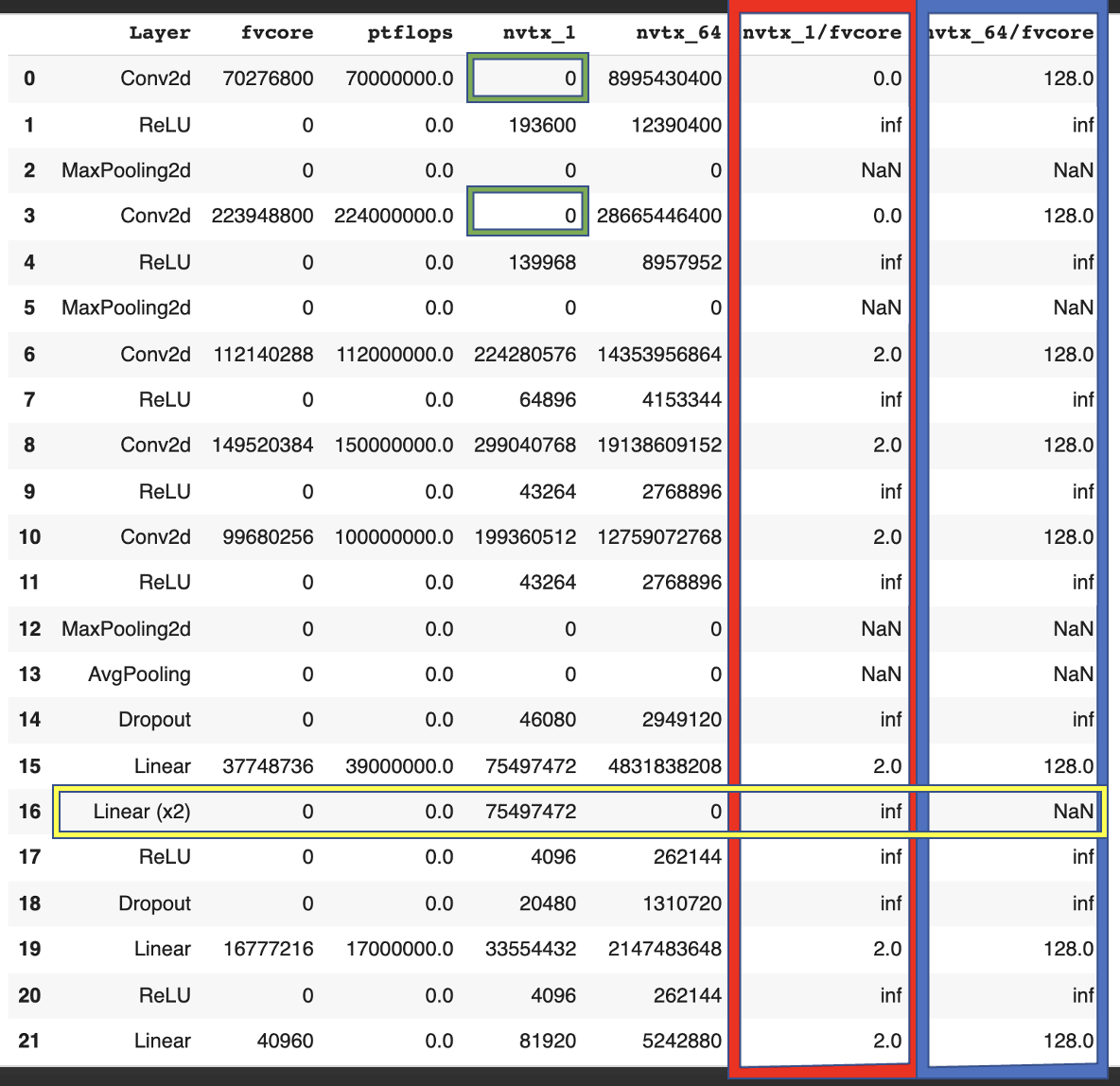This double-counting can happen in more extreme versions. In the forward pass of VGG13, for example, profiler\_nvtx counts a single operation 16 times. That is 15 times too often. Obviously, this distorts the results.
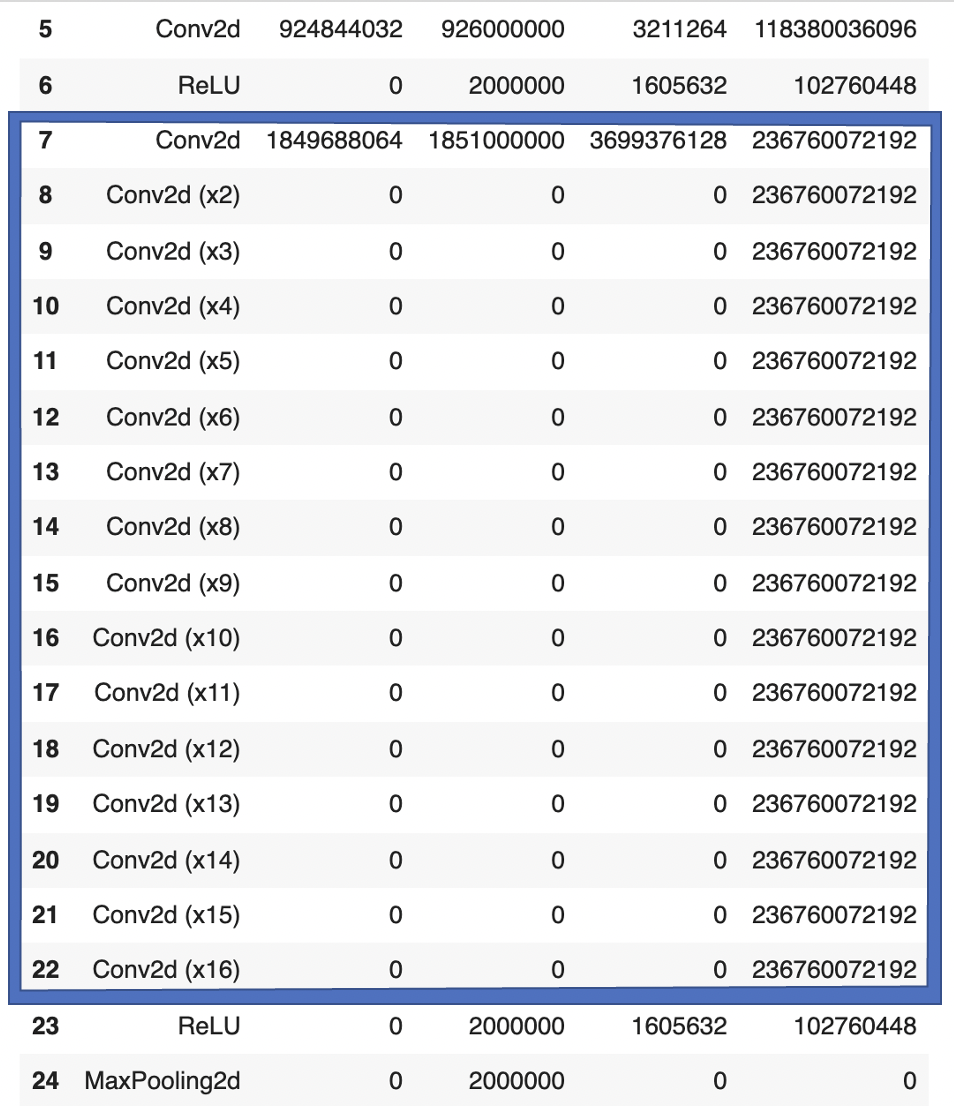Furthermore, we can check the empirical backward/ forward ratios from profiler\_nvtx in detail. We find that
* Operations like conv2d and linear have a backward/forward ratio of 2:1.
* Operations like relu, dropout, maxpooling, avgpooling have a backward/forward ratio of 1:1.
Since the vast majority of operations during training come from conv2d and linear layers, The overall ratio is therefore very close to 2:1.
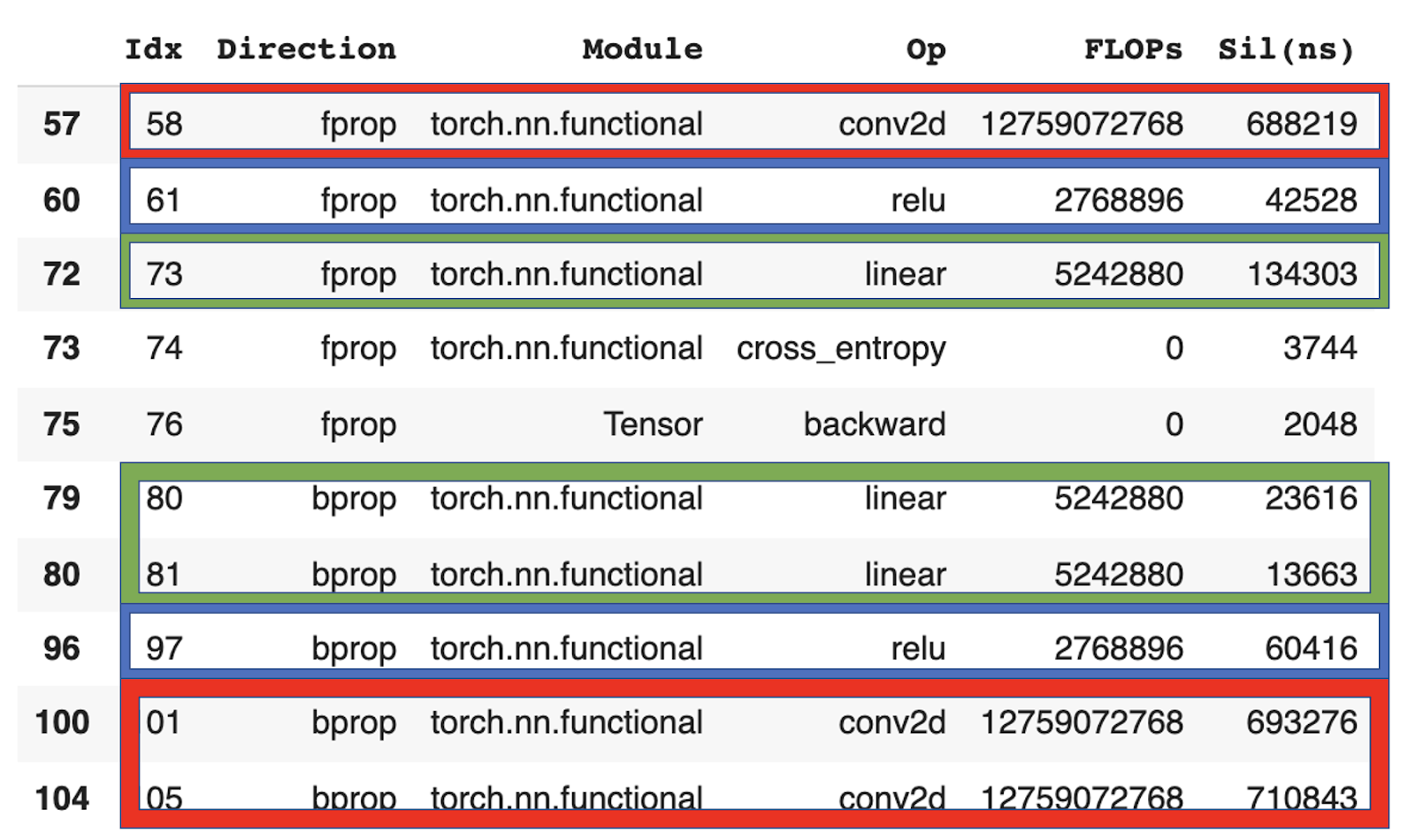To account for the double-counting mistakes from above, we cleaned up the original files and deleted all entries that mistakenly double-counted an operation. Note that we couldn’t fix the undercounting issue so the following numbers still contain undercounts sometimes.
After fixing the double-counting issue we get slightly more consistent results for different batch sizes.
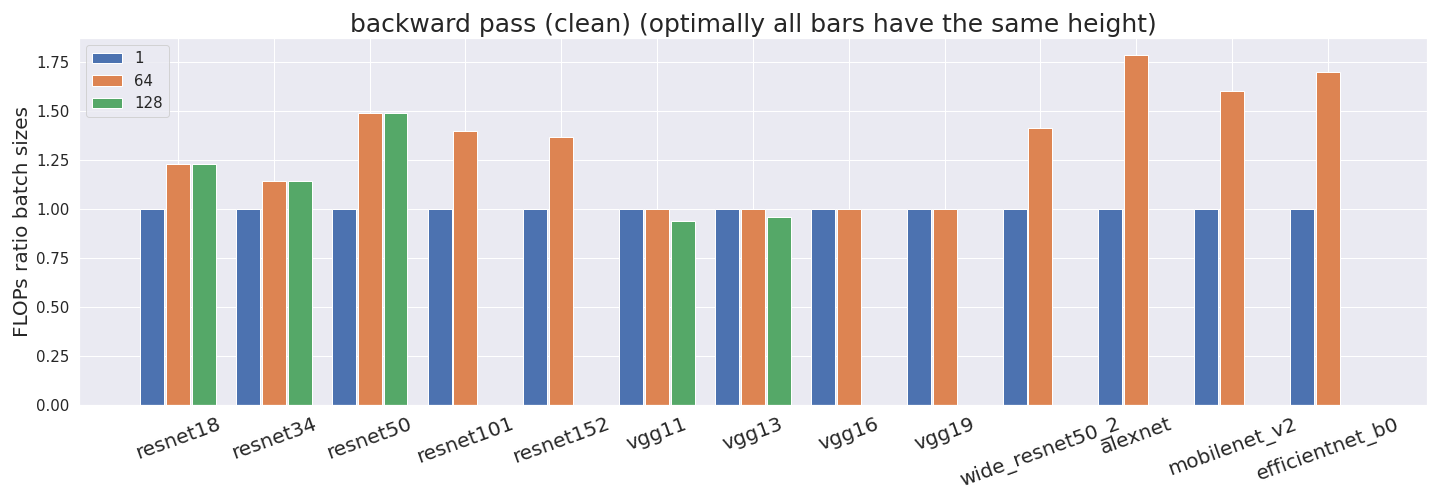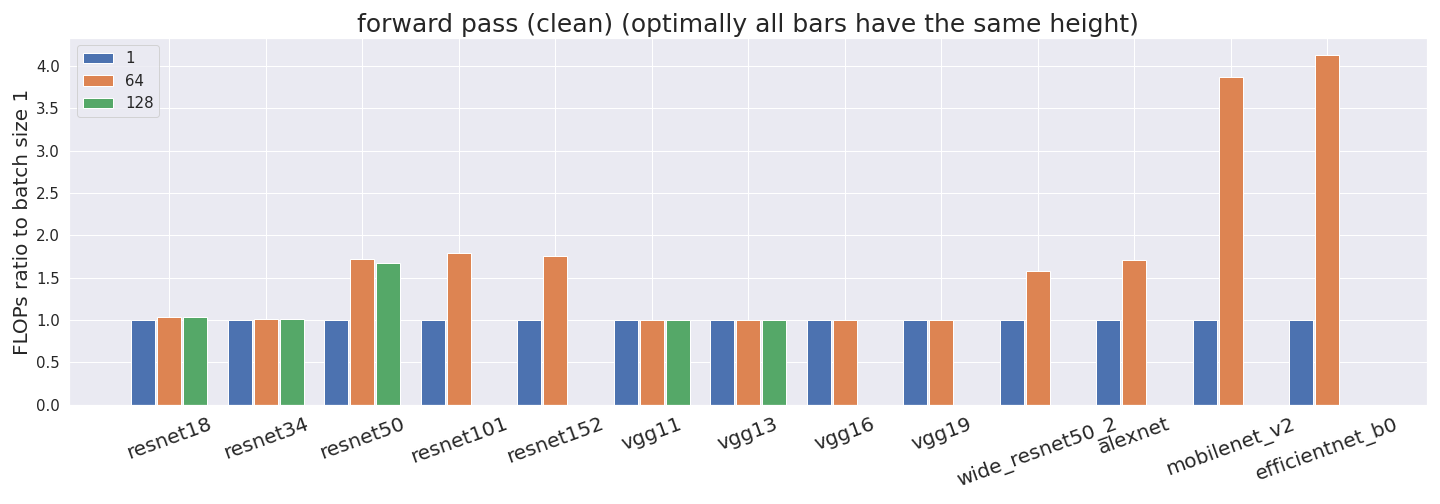All remaining inconsistencies come from undercounting.
**Results:**
------------
The following results are done on the cleaned version of the profiler data, i.e. double counting has been removed but undercounting still poses an issue.
The same analysis for the original (uncleaned) data can be found in the appendix.
### **Comparing batch sizes:**
We trained some of our models with different batch sizes. We are interested in whether different batch sizes affect the time it takes to train models. We additionally compare the timings from the conventional profiler and profiler\_nvtx.
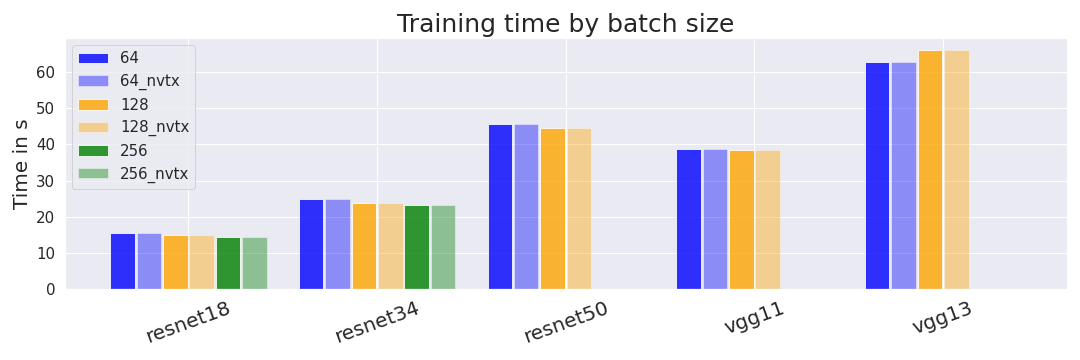We find that, as expected, larger batch sizes lead to minimally shorter training times for 4 out of the 5 models. We are not sure why VGG13 is an exception. We would have expected the differences between batch sizes to be larger but don’t have a strong explanation for the observed differences. A possible hypothesis is that our measurement of GPU time (compared to wall-clock time) hides some overhead that is usually reduced by larger batch sizes.
Shorter training times directly translate into higher utilization rates since training time is part of the denominator.
### **Backward-forward pass ratios:**
From the detailed analysis of profiler\_nvtx (see above), we estimate that the backward pass uses 2x as many FLOP as the forward pass (there will be a second post on comparing backward/forward ratios in more detail). [OpenAI has also used a ratio of 2](https://openai.com/blog/ai-and-compute/) in the past.
We wanted to further test this ratio empirically. To check consistency we tested these ratios for a single forward pass with batch size one (one) an entire batch (batch) and an entire epoch (epoch).
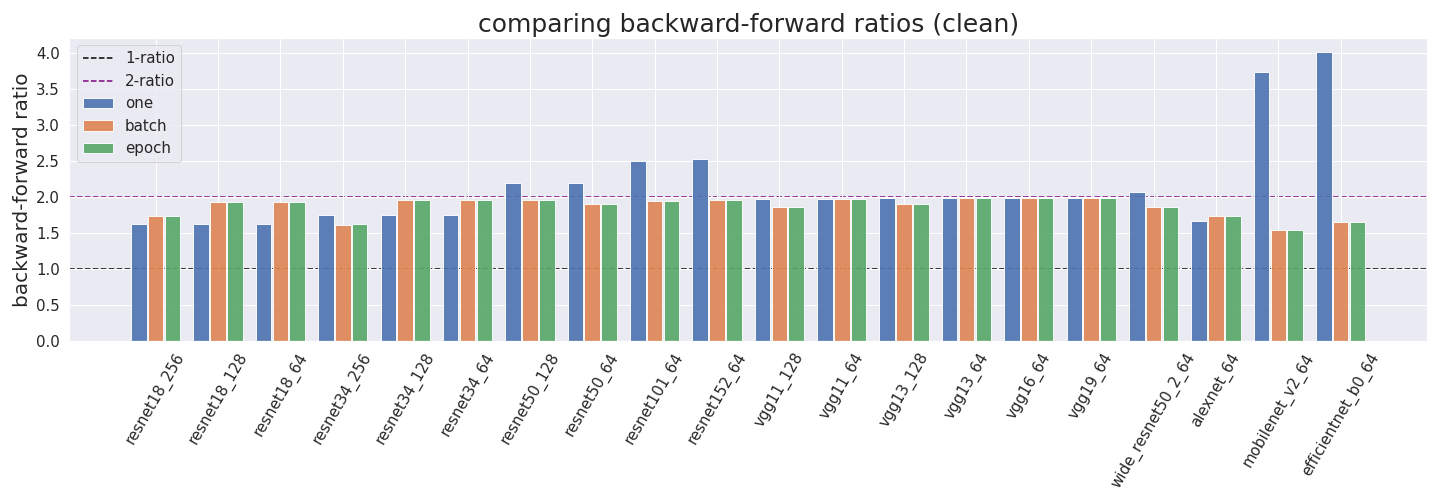We find that the empirical backward/forward ratios are mostly around the 2:1 mark. Some of the exceptions are likely due to undercounting, i.e. profiler\_nvtx just not registering an operation as discussed above.
We assume that the outliers in mobilenet and efficientnet come from the profiler incorrectly measuring FLOP for inverted bottleneck layers.
### **Utilization rates:**
Ultimately, we want to estimate utilization rates. We compute them by using four different methods:
* Theory method: We get the forward pass FLOP estimate of fvcore and multiply it by 3.0 to account for the backward pass. Then, we divide it by the product of the GPU training time and the peak GPU performance of the Tesla P100.
* One method: We take the profiler\_nvtx estimate for the forward and backward passes, and divide it by the product of the training time and maximal GPU performance.
* Batch method: We perform the same procedure for one batch.
* Epoch method: We perform the same procedure for one epoch.
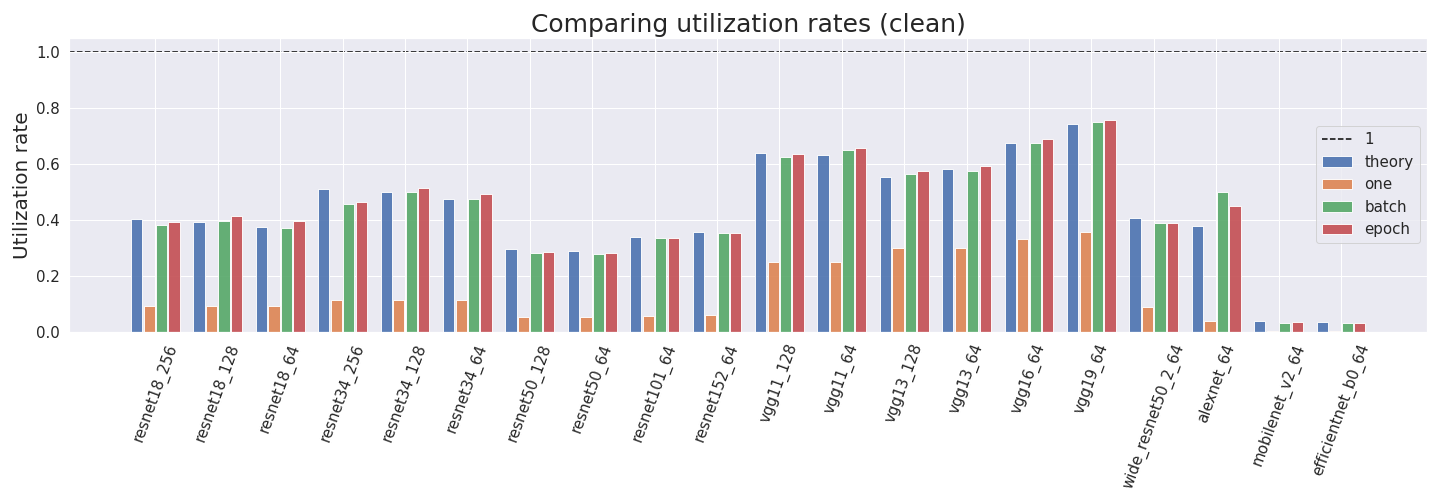We can see that the utilization rates predicted by the theory are often comparable to the empirical measurements for batch and epoch. We can also see that the batch and epoch versions are usually very comparable while just forwarding and backwarding one sample is much less efficient. This is expected since the reason for larger batch sizes is that they utilize the GPU more efficiently.
Most realistic utilization rates are between 0.3 and 0.75. Interestingly (and ironically), the least efficient utilization rates come from efficientnet and mobilenet which have low values in all approaches. We assume that the outliers come from the profiler incorrectly measuring FLOP for inverted bottleneck layers.
**Conclusion:**
---------------
We use different methods to compute the utilization rate of multiple NN architectures. We find that most values lie between 0.3 and 0.75 and are consistent between approaches. Mobilenet and efficientnet pose two outliers to this rule with low utilization rates around 0.04. We assume that the outliers come from the profiler incorrectly measuring FLOP for inverted bottleneck layers.
**Appendix:**
-------------
We tried to run [dlprof](https://docs.nvidia.com/deeplearning/frameworks/dlprof-user-guide/) since it looks like one possible solution to the issues with the profiler we are currently using. However, we were unable to install it since installing [dlprof with pip](https://pypi.org/project/nvidia-dlprof/) (as is recommended in the instructions) always threw errors in Colab. I installed dlprof on another computer and wasn't able to get FLOP information from it.
### **Original versions of the main figures:**
These versions are done without accounting for double counting. Thus, the results are wrong. We want to show them to allow readers to compare them to the cleaned-up versions.
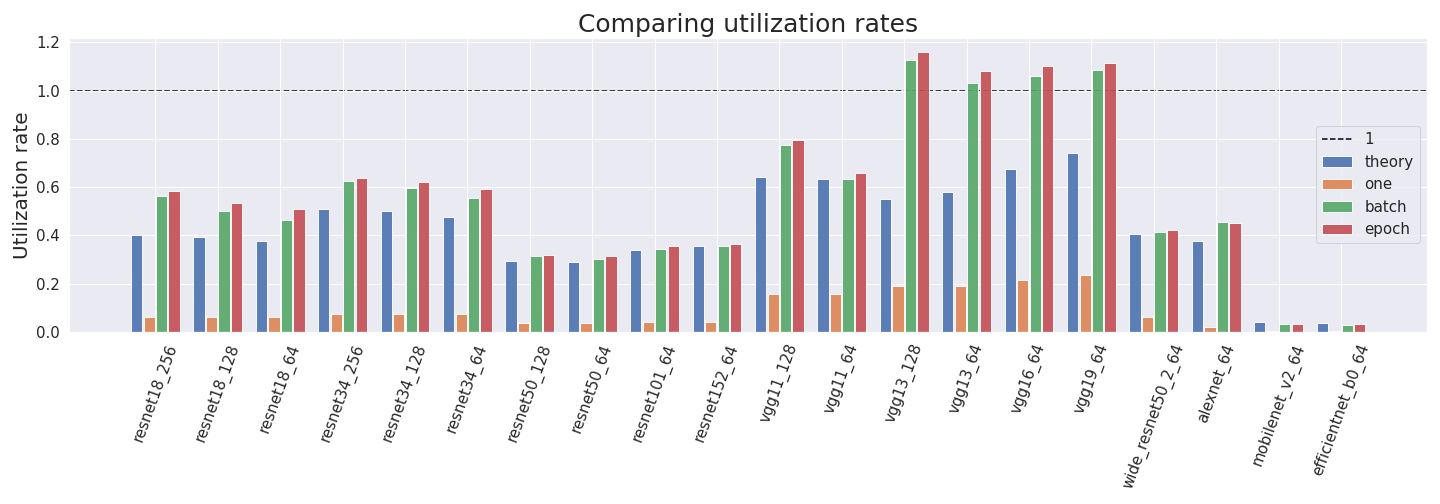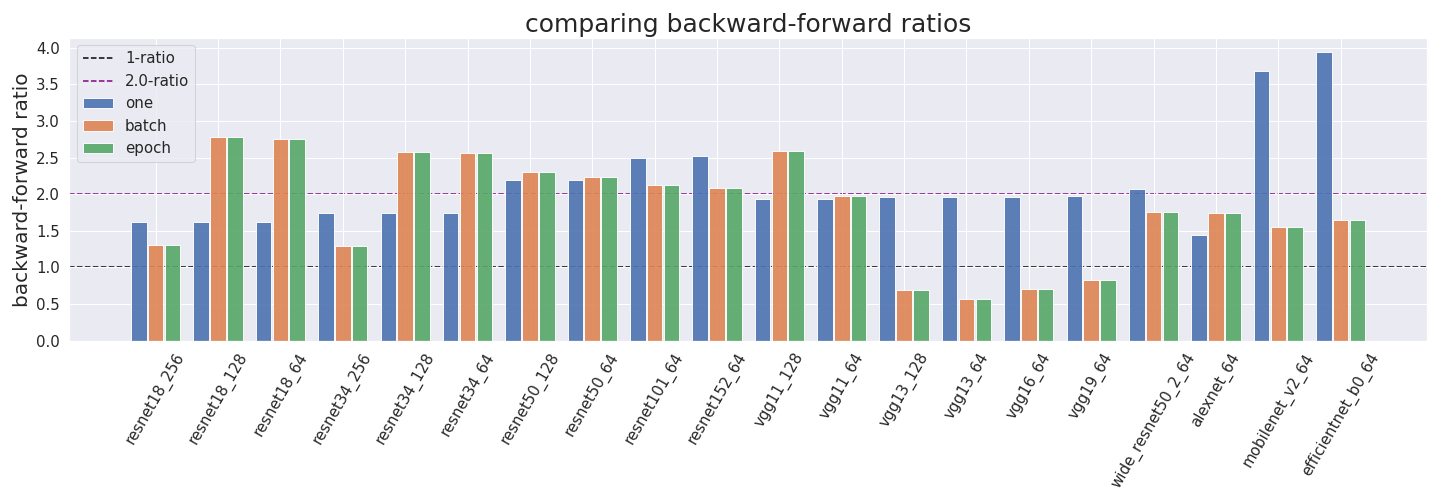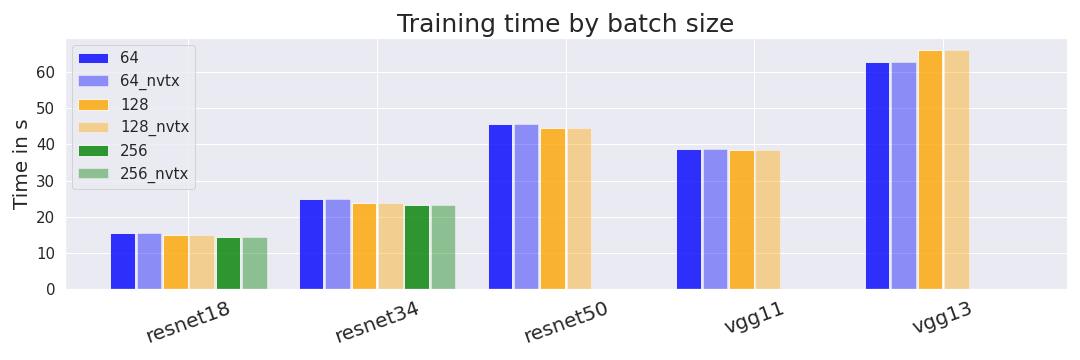 |
97ad135c-b6ee-437e-bbb5-1376e23600c4 | trentmkelly/LessWrong-43k | LessWrong | Reminder: AI Safety is Also a Behavioral Economics Problem
Last week, OpenAI released the official version of o1, alongside a system card explaining their safety testing framework. Astute observers, most notably Zvi, noted something peculiar: o1's safety testing was performed on a model that... wasn't the release version of o1 (or o1 pro).
Weird! Unexpected! If you care about AI safety, bad! If you fall in this last camp your reaction was probably something like Zvi's:
> That’s all really, really, really not okay.
While Zvi's post thoroughly examines the tests, their unclear results, etc., I wanted to zoom in a little more on this tweet from roon (OAI engineer):
> "unironically the reason [this happened] is that progress is so fast that we have to write more of these model cards these days. the preparedness evals are more to certify that models aren't dangerous rather than strict capability evals for showing off"
My loose translation is something like: "these tests are annoying to run so for our use-case rough approximation is good enough."
You may not like it, but the following is simply fact: AI safety tests are voluntary, not legally mandated. The core issue wasn't that OpenAI didn't recognize they were cutting corners – the tests were just a pain in the ass.
Put yourself in a researcher's shoes: you're moving fast, competing in a race to the bottom with other companies. You develop an AI model that, while powerful, clearly can't cause Armageddon (yet). Meanwhile, what you view as a slightly histrionic cadre of alarmed critics are demanding you stop work and/or spend significant personal time conducting safety testing that you don't think in this instance rises to the level of "necessary for the future of humanity." Do you:
A) Rush through it to move on with your life
B) Meticulously complete a task you believe is excessive, crossing every t and dotting every i
The quiz is left as an exercise for the reader.
This saga is a friendly reminder: today, AI safety testing is a choice companies make, not mandator |
dddabfdd-bec8-4859-a186-20d70af88983 | trentmkelly/LessWrong-43k | LessWrong | Modal Combat for games other than the prisoner's dilemma
Modal Combat for arbitrary games
Modal combat has, as far as I know, only been studied in the context of the prisoner's dilemma, but it can also be used for other games. The definition of modal agent for an arbitrary game will be similar to the definition of modal agent for the prisoner's dilemma given in Robust Cooperation in the Prisoner's Dilemma, except that since different players can have different sets of available actions, a modal agent must know which position it is playing in, and since players can have more than two available actions, multiple formulas will be needed to express what action the agent takes. Formally, let G be a game with players 1,...,n, where each player i has a set of available actions Ai={a1i,...,amii} (mi=|Ai|), and for each player i, the function Ui:A1×...×An→R describes the payoff for player i for each possible combination of actions. A modal agent X for G of player type i and rank k≥0 consists of a finite sequence of triples {(tj,Yj,asjtj)}j∈{1,...,N}, where tj∈{1,...,n}∖{i}, Yj is either X or a modal agent of player type i and rank <k, and sj∈{1,...,mtj}, together with mi fully modalized formulas φℓ(p1,...,pN) such that Godel-Lob logic proves that exactly one of φ1,...,φmi holds. By definition, in a game played by modal agents Z1,...,Zi−1,X,Zi+1,...,Zn, where Zj is of player type j, X takes action aℓi (an event denoted as [X(Z1,...,Zn)=aℓi]) iff φℓ([Zt1(Z1,...,Zi−1,Y1,Zi+1,...,Zn)=as1t1],...,[ZtN(Z1,...,Zi−1,YN,Zi+1,...,Zn)=asNtN]) holds. (We could also allow modal agents to consider what happens if players other than themselves are replaced by modal agents of lower rank. Making this change would not affect anything in this post, and I didn't allow for that mainly because the definition is already a mouthful and I didn't want it to get any worse). The modal combat version of G is the game in which each player i submits a modal agent for G of player type i, and gets the payoff that their agent does when the modal agents play G with |
76937dfa-a639-431b-b95d-060887885f1f | trentmkelly/LessWrong-43k | LessWrong | Free online course: How to Reason and Argue starting Mon. Any interest in study group?
I am going to take the free Coursera class "Think Again: How to Reason and Argue" starting Monday, January 13 (three days from now) and I thought I'd to see if there was any interest in going through this as a group. This is one of the MIRI recommended courses under the "Heuristics and Biases" section. If you're interested and you will sign up if we get a group together, please leave a note in the comments (if you will only sign up if the group hits a specific size, please leave that requirement in the comments as well). If enough people are willing to sign up (5 or more? idk), I will start a group on Google (or somewhere else if that's preferred) so that we can have a forum to share thoughts, ask questions, etc. Otherwise, email may be a better way to maintain contact.
EDIT: We hit five people willing to start, so I created a Google group here. If you're interested in taking the course with us, please sign up there.
The recommended text is fairly inexpensive on Amazon (<$20 USD) and can be found on libgen.info for free if that's your thing. It's taught in English, lasts 12 weeks and predicts that it will take 5-6 hours/week. More info from the course website:
Think Again: How to Reason and Argue
Reasoning is important. This course will teach you how to do it well. You will learn how to understand and assess arguments by other people and how to construct good arguments of your own about whatever matters to you.
About the Course
Reasoning is important. This course will teach you how to do it well. You will learn some simple but vital rules to follow in thinking about any topic at all and some common and tempting mistakes to avoid in reasoning. We will discuss how to identify, analyze, and evaluate arguments by other people (including politicians, used car salesmen, and teachers) and how to construct arguments of your own in order to help you decide what to believe or what to do. These skills will be useful in dealing with whatever matters most |
f337d8ce-1c65-4937-a863-d7e6f8985e8e | trentmkelly/LessWrong-43k | LessWrong | Open Source Search (Summary)
Below post may be an older version of this document. Click link for latest version.
2025-06-20
Open Source Search (Summary)
Disclaimer
* Quick note
* I support a complete ban on AI R&D. This app requiring AI doesn't change that.
Summary
* This document describes how to build an open source search engine for the entire internet, that runs on a residential server
* As of 2025 it'll cost between $100k-$1M to build and host this server. This cost will reduce with every passing year, as GPU, RAM and disk prices reduce.
* Most expensive step is GPU capex to generate embeddings for the entire internet.
* Most steps can be done using low-complexity software such as bash scripts (curl --multi, htmlq -tw, curl -X "$LLM_URL", etc)
Main
Why?
* I realised my posts on this topic are sprawling all over the place, without one post to summarise it all. Hence this post.
* If someone donates me $1M I might consider building this. I've written code for more than half the steps, and no step here seems impossibly hard.
Use cases of open source search
* Censorship-resistant backups
* aka internet with no delete button aka Liu Cixin's dark forest
* Any data that reaches any server may end up backed up by people across multiple countries forever.
* You can read my other posts for more on the implications of censorship-resistant backups and discovery.
* Censorship-resistant discovery
* Any data that reaches any server may end up searchable by everyone forever.
* Currently each country's govt bans channels and websites that they find threatening. It is harder to block a torrent of a qdrant snapshot, than to block a static list of IP addresses and domains. Will reduce cost-of-entry/exit for a new youtuber.
* Since youtubers can potentially run for govt, subscribing to a youtuber is a (weak) vote for their govt.
* Privacy-preserving search
* In theory, it will become possible to run searches on an airgapped tails machine. Search indices can be stored o |
ad67ee45-950f-4333-8691-c2e68071c9c5 | trentmkelly/LessWrong-43k | LessWrong | Brain preservation to prevent involuntary death: a possible cause area
(Cross-posted at the Effective Altruism Forum)
Previous EA discussions of this topic: here, here, here, and here. Note that these primarily focus on cryonics, although I prefer the term brain preservation because it is also compatible with non-cryogenic methods and anchors the discussion around the preservation quality of the brain. See here for more discussion of terminology.
This post is split up into two sections:
(a) Technical aspects, which discusses why I think preserving brains with methods available today may allow for revival in the future with long-term memories and personality traits intact.
(b) Ethical aspects, which discusses why I think the field may be among the most cost-effective ways to convert money into long-term QALYs, given certain beliefs and values.
In this post, I’m not discussing whether individuals should sign themselves up for brain preservation, but rather whether it is a good use of altruistic resources to preserve people and perform research about brain preservation.
Technical aspects of brain preservation
1. What is the idea behind brain preservation?
a. Brain preservation is the process of carefully preserving and protecting the information in someone’s brain for an indefinite length of time, with the goal of reviving them if technologic and civilizational capacity ever progresses to the point where it is feasible and humane to do so.
b. Our society’s definition of death has shifted over time. It depends upon the available medical technology, such as CPR and artificial respiration. In the future, the definition of death will almost certainly be different than it is today. One possible improved definition of death would be when the information in the person’s brain that they value is irreversibly lost, which is known as information-theoretic death.
c. Pausing life without causing information-theoretic death could be done with a long-term preservation method that is not yet known to be reversible today, but which has |
86e16fb9-22fd-49b5-a1f6-80978e3909f4 | trentmkelly/LessWrong-43k | LessWrong | Ethereum creator Vitalik Buterin mentions LessWrong, discusses the various camps and ideologies in Cryptocurrency development
Vitalik says cryptocurrency developers should "reach out to LessWrong more", in order to not be ignorant of advanced computer science and game theory topics.
https://blog.ethereum.org/2014/12/31/silos/
I think Vitalik raises several major important points, namely:
* Bitcoin's $600 million wasted on electricity yearly in order to secure the network is a huge problem. Various Proof of Stake algorithms are attempting to improve upon this. The ideal solution would be one which combines the low cost of the Proof of Stake algorithm, with the high security or Proof of Work. I not enough of an expert to be able to say which solution is best, but both the Ripple consensus algorithm and the Bitshares Delegated Proof of State algorithm look promising. I am interested to see what algorithm Vitalik will choose for Ethereum.
* ASIC miners are a problem due to the resulting centralization. They have also lead to increased centralization in Bitcoin, as the network is now increasingly controlled by a few large mining pools.
* Blockchain technologies have a great potential to change the world, and solve governmental and organizational problems that society is facing. Beyond simply revolutionizing money, blockchain technologies could also be used in the future to support prediction markets, voting/consensus building, exchanges, etc. |
06988e8a-d690-49a6-ad33-cfd44969e69e | StampyAI/alignment-research-dataset/arbital | Arbital | Factorial
Factorial is most simply defined as a [https://arbital.com/p/-3jy](https://arbital.com/p/-3jy) on positive [integers](https://arbital.com/p/48l). 5 factorial (written as $5!$) means $1*2*3*4*5$. In general then, for a positive integer $n$, $n!=\prod_{i=1}^{n}i$. For applications to [combinatorics](https://arbital.com/p/), it will also be useful to define $0! = 1$.
## Applications to Combinatorics ##
$n!$ is the number of possible orders for a set of $n$ objects. For example, if we arrange the letters $A$, $B$, and $C$, here are all the options:
$$ABC$$
$$ACB$$
$$BAC$$
$$BCA$$
$$CAB$$
$$CBA$$
You can see that there are $6$ possible orders for $3$ objects, and $6 = 3*2*1 = 3!$. Why does this work? We can [prove this by induction](https://arbital.com/p/5fz). First, we'll see pretty easily that it works for $1$ object, and then we can show that if it works for $n$ objects, it will work for $n+1$. Here's the case for $1$ object.
$$A$$
$$1 = \prod_{i=1}^{1}i = 1!$$
Now we have the objects $\{A_{1},A_{2},...,A_{n},A_{n+1}\}$, and $n+1$ slots to put them in. If $A_{n+1}$ is in the first slot, now we're ordering $n$ remaining objects in $n$ remaining slots, and by our [induction hypothesis](https://arbital.com/p/5fz), there are $n!$ ways to do this. Now let's suppose $A_{n+1}$ is in the second slot. Any orderings that result from this will be completely unique from the orderings where $A_{n+1}$ was in the first slot. Again, there are $n$ remaining slots, and $n$ remaining objects to put in them, in an arbitrary order. There are another $n!$ possible orderings. We can put $A_{n+1}$ in each slot, one by one, and generate another $n!$ orderings, all of which are unique, and by the end, we will have every possible ordering. We know we haven't missed any because $A_{n+1}$ has to be somewhere. The total number of orderings we get is $n!*(n+1)$, which equals $(n+1)!$.
## Extrapolating to [Real Numbers](https://arbital.com/p/50d) ##
The factorial function can be defined in a different way so that it is defined for all real numbers (and in fact for complex numbers too).
%%hidden(Definition):
We define $x!$ as follows:
$$x! = \Gamma (x+1),$$
where $\Gamma $ is the [gamma function](https://arbital.com/p/):
$$\Gamma(x)=\int_{0}^{\infty}t^{x-1}e^{-t}\mathrm{d} t$$
Why does this correspond to the factorial function as defined previously? We can prove by induction that for all positive integers $x$:
$$\prod_{i=1}^{x}i = \int_{0}^{\infty}t^{x}e^{-t}\mathrm{d} t$$
First, we verify for the case where $x=1$. Indeed:
$$\prod_{i=1}^{1}i = \int_{0}^{\infty}t^{1}e^{-t}\mathrm{d} t$$
$$1=1$$
Now we suppose that the equality holds for a given $x$:
$$\prod_{i=1}^{x}i = \int_{0}^{\infty}t^{x}e^{-t}\mathrm{d} t$$
and try to prove that it holds for $x + 1$:
$$\prod_{i=1}^{x+1}i = \int_{0}^{\infty}t^{x+1}e^{-t}\mathrm{d} t$$
We'll start with the induction hypothesis, and manipulate until we get the equality for $x+1$.
$$\prod_{i=1}^{x}i = \int_{0}^{\infty}t^{x}e^{-t}\mathrm{d} t$$
$$(x+1)\prod_{i=1}^{x}i = (x+1)\int_{0}^{\infty}t^{x}e^{-t}\mathrm{d} t$$
$$\prod_{i=1}^{x+1}i = (x+1)\int_{0}^{\infty}t^{x}e^{-t}\mathrm{d} t$$
$$= 0+\int_{0}^{\infty}(x+1)t^{x}e^{-t}\mathrm{d} t$$
$$= \left[](https://arbital.com/p/)_{0}^{\infty}+\int_{0}^{\infty}(x+1)t^{x}e^{-t}\mathrm{d} t$$
$$= \left[](https://arbital.com/p/)_{0}^{\infty}-\int_{0}^{\infty}(x+1)t^{x}(-e^{-t})\mathrm{d} t$$
By the product rule of integration:
$$=\int_{0}^{\infty}t^{x+1}e^{-t}\mathrm{d} t$$
This completes the proof by induction, and that's why we can define factorials in terms of the gamma function.
%% |
850758f8-bcaa-40b4-bb0b-4b307a679eb1 | trentmkelly/LessWrong-43k | LessWrong | .
. |
827f6b98-f81e-4f6c-8e3e-55fda979e4ac | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Reasons I’ve been hesitant about high levels of near-ish AI risk
I’ve been interested in AI risk for a while and my confidence in its seriousness has increased over time, but I’ve generally harbored some hesitation about believing some combination of short-ish AI timelines[[1]](#fn-immvC8AAtNwyWxrDi-1) and high risk levels[[2]](#fn-immvC8AAtNwyWxrDi-2). In this post I’ll introspect on what comes out when I try to expand on reasons for this hesitation and categorize the reasons into seeming (likely) unjustified vs. potentially justified.
I use justified as “should affect my credence in AI risk levels, timelines, etc.” and unjustified as the opposite. These categorizations are very tentative: I could imagine myself changing my mind about several considerations.
I also describe my current [overall attitude](#Overall_attitude) toward the importance of AI risk given these considerations.
Unjustified
===========
Contrarian-within-EA instincts
------------------------------
I have somewhat contrarian instincts and enjoy debating, playing devil’s advocate, etc. It feels boring to agree with the [80,000 Hours ranking](https://80000hours.org/problem-profiles/#highest-priority-areas) of AI risk as the most important problem; it would feel more fun to come up with a contrarian take and try to flesh out the arguments and get people on board. But this doesn’t mean that the contrarian take is right; in fact, given my beliefs about how talented EAs are I should expect the current take to be more likely than the contrarian one before looking into it.
Desire for kids
---------------
I’ve always enjoyed spending time with kids and as such have likely wanted to have kids for as long as I can remember. It’s hard for me to grapple with the idea that my kids’ [most likely reason to die young would be AI risk](https://forum.effectivealtruism.org/posts/hJDid3goqqRAE6hFN/my-most-likely-reason-to-die-young-is-ai-x-risk), and perhaps not even close. I’ve become more hesitant about my desire to have kids due to a high perceived risk level and also potential reduced productivity effects during a very important period; I’d want to be able to spend a lot of time with my kids and not treat them as a second priority to my work. This has been tough to swallow.
Uncomfortable about implications for EA
---------------------------------------
I got into EA via [Doing Good Better](https://www.goodreads.com/book/show/23398748-doing-good-better) and was originally excited about the opportunity to clearly save many lives throughout my career. I went vegan due to animal welfare concerns and still feel a lot of intuitive sympathy for the huge amounts of suffering many humans and animals are currently going through. It feels a bit sad to me that as my beliefs have been evolving it’s been hard to deny that there’s a decent chance that AI safety and things that feed into it (e.g. movement building, rationality/epistemics improvement, grantmaking, etc.) have a much higher EV than other activities all else equal.
I might feel more at peace if my beliefs implied higher levels of variance in what the most impactful activities were. Having a relatively diverse and inclusive movement feels important and more fun than one where the most talented people are mostly funneled into the same few activities. Doubly so compared to a focus on AI that feels weird to many people and could be badly mistaken given our level of understanding. And I’d still be reluctant to encourage people who feel very passionate about what they do and are doing useful things to switch to working on AI safety.
But it might just be a fact about the world that AI safety is by a substantial amount the most important cause area, and this is actually consistent with original EA arguments about unexpectedly high differences in impact between cause areas. And how I feel about this fact shouldn’t influence whether I believe it’s true.
Feelings about AI risk figures
------------------------------
I admire Eliezer in a lot of ways but I find it hard to get through his writing given his drawn out style, and he seems overly bombastic to me at times. I haven’t [read the sequences](https://www.readthesequences.com/) though I might at some point. I haven’t gotten past Chapter 1 of [HPMOR](http://www.hpmor.com/) and probably don’t intend to. And his beliefs about [animal suffering](https://twitter.com/esyudkowsky/status/1453544516393205765) seem pretty crazy to me. But my feelings about Eliezer don’t affect how strong the object-level arguments are for AI posing an existential risk.
Worries about bias towards AI and lack of AI expertise
------------------------------------------------------
I was pretty interested in machine learning before I found out about EA. This made me suspicious when I started to seriously believe that AI risk was the most important cause area; wasn’t this a bit too fishy? I projected these worries onto others as well, like: isn’t it a coincidence that people who love math concluded that the best way to save the world is by thinking about fun math stuff all day?
Reflection has made me less concerned about this because I realized[[3]](#fn-immvC8AAtNwyWxrDi-3) that I have opposing hesitations depending on if the person worried about AI risk was an AI expert or not. If they were an AI expert, I have the worry described above that the conclusion was too convenient. But for people worried about AI who aren’t AI experts, I had the worry that they didn’t know enough to be worried! So either way I was coming up with a justification to be hesitant. See also [Caution on Bias Arguments](https://slatestarcodex.com/2019/07/17/caution-on-bias-arguments/).
I think there would be more reason for concern if those concerned about AI risk were overwhelmingly either AI experts or AI novices, but in fact it seems like a healthy mix to me (e.g. Stuart Russell is an expert, most of the 80,000 hours team are novices). Given this and my opposing intuitions depending on the advocator, I think these reasons for hesitancy aren’t much of a concern.
EDIT: As pointed out in [this comment](https://forum.effectivealtruism.org/posts/5hprBzprm7JjJTHNX/reasons-i-ve-been-hesitant-about-high-levels-of-near-ish-ai-1?commentId=htGoGuboQHzw4LS5R#comments), it's possible that both experts and novices are biased towards AI because they find it cool/fun.
Doomsaying can’t be vindicated
------------------------------
I’m a competitive guy, and I really like the feeling of being right/vindicated (“I told you so!”). I don’t like the opposite feeling of losing, being wrong and embarrassed, etc. And to a first approximation, doomsaying can’t be vindicated, it can only be embarrassed! In this way I admire MIRI for sticking their neck out with relatively short timelines and high p(doom) with a fast takeoff. They only have the potential to be embarrassed; if they’re right we’ll likely all drop dead with approximately no time for “I told you so!”.
Potentially justified
=====================
We have no idea what we’re doing
--------------------------------
While “no idea” is a hyperbole, recent discussions such as the [MIRI conversations](https://www.lesswrong.com/s/n945eovrA3oDueqtq) have highlighted deep disagreements about the trajectory of AI and which approaches seem promising as a result. Predicting the future seems really hard, and technological predictions are often too aggressive[[4]](#fn-immvC8AAtNwyWxrDi-4). It’s likely we’ll look back on work we’re doing 20 years from now and think it was very misguided, similar to how we might look at lots of work 20 years ago.[[5]](#fn-immvC8AAtNwyWxrDi-5) But note that this unpredictability can cut both ways; it might be hard to rule out short timelines and [some past technological predictions may have been too conservative](https://www.lesswrong.com/posts/3qypPmmNHEmqegoFF/failures-in-technology-forecasting-a-reply-to-ord-and).
Note that this could also potentially point toward “figuring out what we’re doing” rather than deprioritizing AI risk, depending on views on just how hard it is to figure out what we’re doing. This is basically my current take though I think “trying to actually do stuff” should be a large part of the portfolio of figuring things out.
Many smart people disagree
--------------------------
[But have they engaged with the arguments?](https://philiptrammell.com/blog/46) points out in the context of AI risk:
>
> The upshot here seems to be that when a lot of people disagree with the experts on some issue, one should often give a lot of weight to the popular disagreement, even when one is among the experts and the people's objections sound insane. Epistemic humility can demand more than deference in the face of peer disagreement: it can demand deference in the face of disagreement from one's epistemic inferiors, as long as they're numerous. They haven't engaged with the arguments, but there is information to be extracted from the very fact that they haven't bothered engaging with them.
>
>
>
I think this is a legitimate concern and enjoy efforts to seek out and flesh out opinions of generally reasonable people and/or AI experts who think AI risk is misguided. This may be a case where [steelmanning is particularly useful](https://www.lesswrong.com/posts/MdZyLnLHuaHrCskjy/itt-passing-and-civility-are-good-charity-is-bad?commentId=tRS27saaSCu6uM2Yp). Recent efforts in this direction include [Transcripts of interviews with AI researchers](https://forum.effectivealtruism.org/posts/EzDhd7mmL5LXYtEi8/transcripts-of-interviews-with-ai-researchers) and [Why EAs are Skeptical about AI Safety](https://forum.effectivealtruism.org/posts/8JazqnCNrkJtK2Bx4/why-eas-are-skeptical-about-ai-safety).
But I think at a certain point you need to take a stand, and [overly modest epistemology has its downsides](https://equilibriabook.com/). I also have the intuition that oftentimes if you want to have a big impact, at some point you have to be willing to follow arguments you believe in even if they’re disputed by many reasonable people. You have to accept the possibility you might be badly mistaken and make the bet.
Expected value of the future
----------------------------
This is a concern with a brand of longtermism in general rather than AI specifically, and note that it might push toward working on AI from more of a suffering-focused perspective (or even mostly doing standard AI risk stuff depending on how much overlap there is) rather than deprioritizing AI stuff.
But I do have some unresolved uncertainties about the expected value of the future; it seems fairly unclear to me though still positive if I had to guess. I’m planning on spending more time thinking about this at some point but for now will just link to some relevant posts [here](https://forum.effectivealtruism.org/posts/WebLP36BYDbMAKoa5/the-future-might-not-be-so-great), [here](https://forum.effectivealtruism.org/posts/NfkEqssr7qDazTquW/the-expected-value-of-extinction-risk-reduction-is-positive), and [here](https://forum.effectivealtruism.org/posts/RkPK8rWigSAybgGPe/a-longtermist-critique-of-the-expected-value-of-extinction-2). Also related is [Holden’s suggestion](https://forum.effectivealtruism.org/posts/zGiD94SHwQ9MwPyfW/important-actionable-research-questions-for-the-most#Questions_about_AI_strategy__more_) to explore how we should value long-run outcomes relative to each other.
Bias toward religion-like stories
---------------------------------
My concerns are broadly similar to the ones described in [this post](https://forum.effectivealtruism.org/posts/r72wjMns9wyaAhWhc/the-ai-messiah): it seems like concerns about AI risk follow similar patterns to some religions/cults: AI is coming soon and we’ll probably either enter a ~utopia or all die within our lifetimes, depending on what actions we take.
I don’t think we should update too much on this (the replies to the post above are worth reading and generally convincing imo) but it seems useful to keep in mind. Lots of very impactful groups (e.g. startups) also have some features of cults/religions, so again I feel at some point one has to take a stand on the object-level issues based on their best guess.
Track record of AI risk figures
-------------------------------
There are at least some data points of Eliezer being overconfident in the past about technological timelines, which should maybe cause us to downweight his specific assessments a little. Though he has also been fairly right on the general shape of the problem and way ahead of everyone else, so we also need to take that into account.
Not sure I have much more to add here besides linking this more comprehensive [post and comment section](https://forum.effectivealtruism.org/posts/NBgpPaz5vYe3tH4ga/on-deference-and-yudkowsky-s-ai-risk-estimates).
Overall attitude
================
My best guess is the high-level argument of the form “We could in principle create AI more intelligent than us, it seems fairly likely it will happen this century, and creating agents more intelligent us would be a really big deal and could lead to very good or bad outcomes” similar to the one described [here](https://forum.effectivealtruism.org/posts/ChuABPEXmRumcJY57/video-and-transcript-of-presentation-on-existential-risk#High_level_backdrop) is basically right and alone implies that AI is an extremely important technology to pay attention to. This plus [instrumental convergence](https://en.wikipedia.org/wiki/Instrumental_convergence) plus the [orthogonality thesis](https://arbital.com/p/orthogonality/) seem sufficient to make AI the biggest existential risk we know of by a substantial margin.
Over time I’ve become more confident that some of my hesitations are basically unjustified and the others seem more like points for further research than reasons to not treat AI risk as the most important problem. I’d be excited for further discussion and research on some of the potentially justified hesitations, in particular: [improving and clarifying our epistemic state](#We_have_no_idea_what_we_re_doing), [seeking out and better understanding opinions of reasonable people who disagree](#Many_smart_people_disagree), and the [expected value of the future](#Expected_value_of_the_future).
Acknowledgments
===============
Thanks to Miranda Zhang for feedback and discussion. [Messy personal stuff that affected my cause prioritization (or: how I started to care about AI safety)](https://forum.effectivealtruism.org/posts/mZ4ctSAEMgWj6DAwt/messy-personal-stuff-that-affected-my-cause-prioritization) vaguely inspired me to write this.
---
1. Something like, >50% of AGI/TAI/APS-AI within 30 years [↩︎](#fnref-immvC8AAtNwyWxrDi-1)
2. Say, >15% chance of existential catastrophe this century [↩︎](#fnref-immvC8AAtNwyWxrDi-2)
3. I forget if I actually realized this myself or I first saw someone else make this point, maybe Rob Wiblin on Twitter? [↩︎](#fnref-immvC8AAtNwyWxrDi-3)
4. Examples: [UK experts were overly optimistic](https://www.sciencedirect.com/science/article/abs/pii/S0040162509000201?via%3Dihub), as were [cultured meat predictions](https://forum.effectivealtruism.org/posts/YYurNqQDAWNiQJv9K/cultured-meat-predictions-were-overly-optimistic) and (weakly) [Metaculus AI predictions](https://forum.effectivealtruism.org/posts/vtiyjgKDA3bpK9E4i/an-examination-of-metaculus-resolved-ai-predictions-and#Summary) [↩︎](#fnref-immvC8AAtNwyWxrDi-4)
5. I’m actually a bit confused about this though; I wonder how useful MIRI considers its work from 20 years ago to be? [↩︎](#fnref-immvC8AAtNwyWxrDi-5) |
1eaff370-3877-42d2-9653-f734f995a4db | trentmkelly/LessWrong-43k | LessWrong | Oversight Misses 100% of Thoughts The AI Does Not Think
Problem: an overseer won’t see the AI which kills us all thinking about how to kill humans, not because the AI conceals that thought, but because the AI doesn’t think about how to kill humans in the first place. The AI just kills humans as a side effect of whatever else it’s doing.
Analogy: the Hawaii Chaff Flower didn’t go extinct because humans strategized to kill it. It went extinct because humans were building stuff nearby, and weren’t thinking about how to keep the flower alive. They probably weren’t thinking about the flower much at all.
Hawaii Chaff Flower (source)
More generally: how and why do humans drive species to extinction? In some cases the species is hunted to extinction, either because it's a threat or because it's economically profitable to hunt. But I would guess that in 99+% of cases, the humans drive a species to extinction because the humans are doing something that changes the species' environment a lot, without specifically trying to keep the species alive. DDT, deforestation, introduction of new predators/competitors/parasites, construction… that’s the sort of thing which I expect drives most extinction.
Assuming this metaphor carries over to AI (similar to the second species argument), what kind of extinction risk will AI pose?
Well, the extinction risk will not come from AI actively trying to kill the humans. The AI will just be doing some big thing which happens to involve changing the environment a lot (like making replicators, or dumping waste heat from computronium, or deciding that an oxygen-rich environment is just really inconvenient what with all the rusting and tarnishing and fires, or even just designing a fusion power generator), and then humans die as a side-effect. Collateral damage happens by default when something changes the environment in big ways.
What does this mean for oversight? Well, it means that there wouldn't necessarily be any point at which the AI is actually thinking about killing humans or whatever. It jus |
8fcdc911-2961-420d-81cb-9cbf55dba25f | trentmkelly/LessWrong-43k | LessWrong | Notes on Dwarkesh Patel’s Podcast with Demis Hassabis
Demis Hassabis was interviewed twice this past week.
First, he was interviewed on Hard Fork. Then he had a much more interesting interview with Dwarkesh Patel.
This post covers my notes from both interviews, mostly the one with Dwarkesh.
HARD FORK
Hard Fork was less fruitful, because they mostly asked what for me are the wrong questions and mostly get answers I presume Demis has given many times. So I only noticed two things, neither of which is ultimately surprising.
1. They do ask about The Gemini Incident, although only about the particular issue with image generation. Demis gives the generic ‘it should do what the user wants and this was dumb’ answer, which I buy he likely personally believes.
2. When asked about p(doom) he expresses dismay about the state of discourse and says around 42:00 that ‘well Geoffrey Hinton and Yann LeCun disagree so that indicates we don’t know, this technology is so transformative that it is unknown. It is nonsense to put a probability on it. What I do know is it is non-zero, that risk, and it is worth debating and researching carefully… we don’t want to wait until the eve of AGI happening.’ He says we want to be prepared even if the risk is relatively small, without saying what would count as small. He also says he hopes in five years to give us a better answer, which is evidence against him having super short timelines.
I do not think this is the right way to handle probabilities in your own head. I do think it is plausibly a smart way to handle public relations around probabilities, given how people react when you give a particular p(doom).
I am of course deeply disappointed that Demis does not think he can differentiate between the arguments of Geoffrey Hinton versus Yann LeCun, and the implied importance on the accomplishments and thus implied credibility of the people. He did not get that way, or win Diplomacy championships, thinking like that. I also don’t think he was being fully genuine here.
Otherwise, this seemed |
039622f8-4e53-46c5-a6c9-df1724dd09c5 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Moscow: Applied Rationality in a New Year
Discussion article for the meetup : Moscow: Applied Rationality in a New Year
WHEN: 05 January 2013 04:00:00PM (+0400)
WHERE: Rossiya, Moscow, ulitsa Ostozhenka 14/2
We will meet at “Subway” restaurant, entrance from Lopukhinskiy pereulok. Look for a table with “LW” banner, I will be there from 16:00 MSK.
Main topics:
* Applied rationality: practice. We will improve our rationality skills.
* Solving cases. Please prepare some problems for discussion.
* Cognitive biases analysis. Here is the link to the list of biases we will work on (in Russian).
If you are going for the first time, please fill this one minute form (in Russian), to share your contact information. You can also use personal messages here, or drop a message at lw@lesswrong.ru to contact me for any reason.
N. B. Google shows incorrect location, please use Yandex maps.
Discussion article for the meetup : Moscow: Applied Rationality in a New Year |
aa93699a-27a5-4ce4-add1-51901173d329 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | A conversation with Rohin Shah
**Participants**
----------------
* [**Rohin Shah**](https://rohinshah.com/) — PhD student at the Center for Human-Compatible AI, UC Berkeley
* Asya Bergal – AI Impacts
* [**Robert Long**](http://robertlong.online/) – AI Impacts
* Sara Haxhia — Independent researcher
**Summary**
-----------
We spoke with Rohin Shah on August 6, 2019. Here is a brief summary of that conversation:
* Before taking into account other researchers’ opinions, Shah guesses an extremely rough~90% chance that even without any additional intervention from current longtermists, advanced AI systems will not cause human extinction by adversarially optimizing against humans. He gives the following reasons, ordered by how heavily they weigh in his consideration:
+ Gradual development and take-off of AI systems is likely to allow for correcting the AI system online, and AI researchers will in fact correct safety issues rather than hacking around them and redeploying.
- Shah thinks that institutions developing AI are likely to be careful because human extinction would be just as bad for them as for everyone else.
+ As AI systems get more powerful, they will likely become more interpretable and easier to understand because they will use features that humans also tend to use.
+ Many arguments for AI risk go through an intuition that AI systems can be decomposed into an objective function and a world model, and Shah thinks this isn’t likely to be a good way to model future AI systems.
* Shah believes that conditional on misaligned AI leading to extinction, it almost certainly goes through deception.
* Shah very uncertainly guesses that there’s a ~50% that we will get AGI within two decades:
+ He gives a ~30% – 40% chance that it will be via essentially current techniques.
+ He gives a ~70% that conditional on the two previous claims, it will be a mesa optimizer.
+ Shah’s model for how we get to AGI soon has the following features:
- AI will be trained on a huge variety of tasks, addressing the usual difficulty of generalization in ML systems
- AI will learn the same kinds of useful features that humans have learned.
- This process of research and training the AI will mimic the ways that evolution produced humans who learn.
- Gradient descent is simple and inefficient, so in order to do sophisticated learning, the outer optimization algorithm used in training will have to produce a mesa optimizer.
* Shah is skeptical of more ‘nativist’ theories where human babies are born with a lot of inductive biases, rather than learning almost everything from their experiences in the world.
* Shah thinks there are several things that could change his beliefs, including:
+ If he learned that evolution actually baked a lot into humans (‘nativism’), he would lengthen the amount of time he thinks there will be before AGI.
+ Information from historical case studies or analyses of AI researchers could change his mind around how the AI community would by default handle problems that arise.
+ Having a better understanding of the disagreements he has with MIRI:
- Shah believes that slow takeoff is much more likely than fast takeoff.
- Shah doesn’t believe that any sufficiently powerful AI system will look like an expected utility maximizer.
- Shah believes less in crisp formalizations of intelligence than MIRi does.
- Shah has more faith in AI researchers fixing problems as they come up.
- Shah has less faith than MIRI in our ability to write proofs of the safety of our AI systems.
This transcript has been lightly edited for concision and clarity.
**Transcript**
--------------
**Asya Bergal:** We haven’t really planned out how we’re going to talk to people in general, so if any of these questions seem bad or not useful, just give us feedback. I think we’re particularly interested in skepticism arguments, or safe by default style arguments– I wasn’t sure from our conversation whether you partially endorse that, or you just are familiar with the argumentation style and think you could give it well or something like that.
**Rohin Shah:** I think I partially endorse it.
**Asya Bergal:** Okay, great. If you can, it would be useful if you gave us the short version of your take on the AI risk argument and the place where you feel you and people who are more convinced of things disagree. Does that make sense?
**Robert Long:** Just to clarify, maybe for my own… What’s ‘convinced of things’? I’m thinking of the target proposition as something like “it’s extremely high value for people to be doing work that aims to make AGI more safe or beneficial”.
**Asya Bergal:** Even that statement seems a little imprecise because I think people have differing opinions about what the high value work is. But that seems like approximately the right proposition.
**Rohin Shah:** Okay. So there are some very obvious ones which are not the ones that I endorse, but things like, do you believe in longtermism? Do you buy into the total view of population ethics? And if your answer is no, and you take a more standard version, you’re going to drastically reduce how much you care about AI safety. But let’s see, the ones that I would endorse-
**Robert Long:** Maybe we should work on this set of questions. I think this will only come up with people who are into rationalism. I think we’re primarily focused just on empirical sources of disagreement, whereas these would be ethical.
**Rohin Shah:** Yup.
**Robert Long:** Which again, you’re completely right to mention these things.
**Rohin Shah:** So, there’s… okay. The first one I had listed is that continual or gradual or slow takeoff, whatever you want to call it, allows you to correct the AI system online. And also it means that AI systems are likely to fail in not extinction-level ways before they fail in extinction-level ways, and presumably we will learn from that and not just hack around it and fix it and redeploy it. I think I feel fairly confident that there are several people who will disagree with exactly the last thing I said, which is that people won’t just hack around it and deploy it– like fix the surface-level problem and then just redeploy it and hope that everything’s fine.
I am not sure what drives the difference between those intuitions. I think they would point to neural architecture search and things like that as examples of, “Let’s just throw compute at the problem and let the compute figure out a bunch of heuristics that seem to work.” And I would point at, “Look, we noticed that… or, someone noticed that AI systems are not particularly fair and now there’s just a ton of research into fairness.”
And it’s true that we didn’t stop deploying AI systems because of fairness concerns, but I think that is actually just the correct decision from a societal perspective. The benefits from AI systems are in fact– they do in fact outweigh the cons of them not being fair, and so it doesn’t require you to not deploy the AI system while it’s being fixed.
**Asya Bergal:** That makes sense. I feel like another common thing, which is not just “hack around and fix it”, is that people think that it will fail in ways that we don’t recognize and then we’ll redeploy some bigger cooler version of it that will be deceptively aligned (or whatever the problem is). How do you feel about arguments of that form: that we just won’t realize all the ways in which the thing is bad?
**Rohin Shah:** So I’m thinking: the AI system tries to deceive us, so I guess the argument would be, we don’t realize that the AI system was trying to deceive us and instead we’re like, “Oh, the AI system just failed because it was off distribution or something.”
It seems strange that we wouldn’t see an AI system deliberately hide information from us. And then we look at this and we’re like, “Why the hell didn’t this information come up? This seems like a clear problem.” And then do some sort of investigation into this.
I suppose it’s possible we wouldn’t be able to tell it’s intentionally doing this because it thinks it could get better reward by doing so. But that doesn’t… I mean, I don’t have a particular argument why that couldn’t happen but it doesn’t feel like…
**Asya Bergal:** Yeah, to be fair I’m not sure that one is what you should expect… that’s just a thing that I commonly hear.
**Rohin Shah:** Yes. I also hear that.
**Robert Long:** I was surprised at your deception comment… You were talking about, “What about scenarios where nothing seems wrong until you reach a certain level?”
**Asya Bergal:** Right. Sorry, that doesn’t have to be deception. I think maybe I mentioned deception because I feel like I often commonly also see it.
**Rohin Shah:** I guess if I imagine “How did AI lead to extinction?”, I don’t really imagine a scenario that doesn’t involve deception. And then I claim that conditional on that scenario having happened, I am very surprised by the fact that we did not know this deception in any earlier scenario that didn’t lead to extinction. And I don’t really get people’s intuitions for why that would be the case. I haven’t tried to figure that one out though.
**Sara Haxhia:** So do you have no model of how people’s intuitions differ? You can’t see it going wrong aside from if it was deceptively aligned? Why?
**Rohin Shah:** Oh, I feel like most people have the intuition that conditional on extinction, it happened by the AI deceiving us. *[Note: In this interview, Rohin was only considering risks arising because of AI systems that try to optimize for goals that are not our own, not other forms of existential risks from AI.]*
**Asya Bergal:** I think there’s another class of things which is something not necessarily deceiving us, as in it has a model of our goals and intentionally presents us with deceptive output, and just like… it has some notion of utility function and optimizes for that poorly. It doesn’t necessarily have a model of us, it just optimizes the paperclips or something like that, and we didn’t realize before that it is optimizing. I think when I hear deceptive, I think “it has a model of human behavior that is intentionally trying to do things that subvert our expectations”. And I think there’s also a version where it just has goals unaligned with ours and doesn’t spend any resources in modeling our behavior.
**Rohin Shah:** I think in that scenario, usually as an instrumental goal, you need to deceive humans, because if you don’t have a model of human behavior– if you don’t model the fact that humans are going to interfere with your plans– humans just turn you off and nothing, there’s no extinction.
**Robert Long:** Because we’d notice. You’re thinking in the non-deception cases, as with the deception cases, in this scenario we’d probably notice.
**Sara Haxhia:** That clarifies my question. Great.
**Rohin Shah:** As far as I know, this is an accepted thing among people who think about AI x-risk.
**Asya Bergal:**The accepted thing is like, “If things go badly, it’s because it’s actually deceiving us on some level”?
**Rohin Shah:** Yup. There are some other scenarios which could lead to us not being deceived and bad things still happen. These tend to be things like, we build an economy of AI systems and then slowly humans get pushed out of the economy of AI systems and…
They’re still modeling us. I just can’t really imagine the scenario in which they’re not modeling us. I guess you could imagine one where we slowly cede power to AI systems that are doing things better than we could. And at no point are they actively trying to deceive us, but at some point they’re just like… they’re running the entire economy and we don’t really have much say in it.
And perhaps this could get to a point where we’re like, “Okay, we have lost control of the future and this is effectively an x-risk, but at no point was there really any deception.”
**Asya Bergal:** Right. I’m happy to move on to other stuff.
**Rohin Shah:** Cool. Let’s see. What’s the next one I have? All right. This one’s a lot sketchier-
**Asya Bergal:** So sorry, what is the thing that we’re listing just so-
**Rohin Shah:** Oh, reasons why AI safety will be fine by default.
**Asya Bergal:** Right. Gotcha, great.
**Rohin Shah:** Okay. These two points were both really one point. So then the next one was… I claimed that as AI systems get more powerful, they will become more interpretable and easier to understand, just because they’re using– they will probably be able to get and learn features that humans also tend to use.
I don’t think this has really been debated in the community very much and– sorry, I don’t mean that there’s agreement on it. I think it is just not a hypothesis that has been promoted to attention in the community. And it’s not totally clear what the safety implications are. It suggests that we could understand AI systems more easily and sort of in combination with the previous point it says, “Oh, we’ll notice things– we’ll be more able to notice things than today where we’re like, ‘Here’s this image classifier. Does it do good things? Who the hell knows? We tried it on a bunch of inputs and it seemed like it was doing the right stuff, but who knows what it’s doing inside.'”
**Asya Bergal:** I’m curious why you think it’s likely to use features that humans tend to use. It’s possible the answer is some intuition that’s hard to describe.
**Rohin Shah:** Intuition that I hope to describe in a year. Partly it’s that in the very toy straw model, there are just a bunch of features in the world that an AI system can pay attention to in order to make good predictions. When you limit the AI system to make predictions on a very small narrow distribution, which is like all AI systems today, there are lots of features that the AI system can use for that task that we humans don’t use because they’re just not very good for the rest of the distribution.
**Asya Bergal:** I see. It seems like implicitly in this argument is that when humans are running their own classifiers, they have some like natural optimal set of features that they use for that distribution?
**Rohin Shah:** I don’t know if I’d say optimal, but yeah. Better than the features that the AI system is using.
**Robert Long:** In the space of better features, why aren’t they going past us or into some other optimal space of feature world?
**Rohin Shah:** I think they would eventually.
**Robert Long:** I see, but they might have to go through ours first?
**Rohin Shah:** So A) I think they would go through ours, B) I think my intuition is something like the features– and this one seems like more just raw intuition and I don’t really have an argument for it– but the features… things like agency, optimization, want, deception, manipulation seem like things that are useful for modeling the world.
I would be surprised if an AI system went so far beyond that those features didn’t even enter into its calculations. Or, I’d be surprised if that happened very quickly, maybe. I don’t want to make claims about how far past those AI systems could go, but I do think that… I guess I’m also saying that we should be aiming for AI systems that are like… This is a terrible way to operationalize it, but AI systems that are 10X as intelligent as humans, what do we have to do for them? And then once we’ve got AI systems that are 10 x smarter than us, then we’re like, “All right, what more problems could arise in the future?” And ask the AI systems to help us with that as well.
**Asya Bergal:** To clarify, the thing you’re saying is… By the time AI systems are good and more powerful, they will have some conception of the kind of features that humans use, and be able to describe their decisions in terms of those features? Or do you think inherently, there’ll be a point where AI systems use the exact same features that humans use?
**Rohin Shah:** Not the exact same features, but broadly similar features to the ones that humans use.
**Robert Long:** Where examples of those features would be like objects, cause, agent, the things that we want interpreted in deep nets but usually can’t.
**Rohin Shah:** Yes, exactly.
**Asya Bergal:** Again, so you think in some sense that that’s a natural way to describe things? Or there’s only one path through getting better at describing things, and that has to go through the way that humans describe things? Does that sound right?
**Rohin Shah:** Yes.
**Asya Bergal:** Okay. Does that also feel like an intuition?
**Rohin Shah:** Yes.
**Robert Long:** Sorry, I think I did a bad interviewer thing where I started listing things, I should have just asked you to list some of the features which I think-
**Rohin Shah:** Well I listed them, like, optimization, want, motivation before, but I agree causality would be another one. But yeah, I was thinking more the things that safety researchers often talk about. I don’t know, what other features do we tend to use a lot? Object’s a good one… the conception of 3D space is one that I don’t think these classifiers have and that we definitely have.
And the concept of 3D space seems like it’s probably going to be useful for an AI system no matter how smart it gets. Currently, they might have a concept of 3D space, but it’s not obvious that they do. And I wouldn’t be surprised if they don’t.
At some point, I want to take this intuition and run with it and see where it goes. And try to argue for it more.
**Robert Long:** But I think for the purposes of this interview, I think we do understand how this is something that would make things safe by default. At least, in as much as interpretability conduces to safety. Because we could be able to interpret them in and still fuck shit up.
**Rohin Shah:** Yep. Agreed. Cool.
**Sara Haxhia:** I guess I’m a little bit confused about how it makes the code more interpretable. I can see how if it uses human brains, we can model it better because we can just say, “These are human things and this means we can make predictions better.” But if you’re looking at a neural net or something, it doesn’t make it more interpretable.
**Rohin Shah:** If you mean the code, I agree with that.
**Sara Haxhia:** Okay. So, is this kind of like external, like you being able to model that thing?
**Rohin Shah:** I think you could look at the… you take a particular input to neural net, you pass it through layers, you see what the activations are. I don’t think if you just look directly at the activations, you’re going to get anything sensible, in the same way that if you look at electrical signals in my brain you’re not going to be able to understand them.
**Sara Haxhia:** So, is your point that the reason it becomes more interpretable is something more like, you understand its motivations?
**Rohin Shah:** What I mean is… Are you familiar with Chris Olah’s work?
**Sara Haxhia:** I’m not.
**Rohin Shah:** Okay. So Chris Olah does interpretability work with image classifiers. One technique that he uses is: Take a particular neuron in the neural net, say, “I want to maximize the activation of this neuron,” and then do gradient descent on your input image to see what image maximally activates that neuron. And this gives you some insight into what that neuron is detecting. I think things like that will be easier as time goes on.
**Robert Long:** Even if it’s not just that particular technique, right? Just the general task?
**Rohin Shah:** Yes.
**Sara Haxhia:** How does that relate to the human values thing? It felt like you were saying something like it’s going to model the world in a similar way to the way we do, and that’s going to make it more interpretable. And I just don’t really see the link.
**Rohin Shah:** A straw version of this, which isn’t exactly what I mean but sort of is the right intuition, would be like maybe if you run the same… What’s the input that maximizes the output of this neuron? You’ll see that this particular neuron is a deception classifier. It looks at the input and then based on something, does some computation with the input, maybe the input’s like a dialogue between two people and then this neuron is telling you, “Hey, is person A trying to deceive person B right now?” That’s an example of the sort of thing I am imagining.
**Asya Bergal:** I’m going to do the bad interviewer thing where I put words in your mouth. I think one problem right now is you can go a few layers into a neural network and the first few layers correspond to things you can easily tell… Like, the first layer is clearly looking at all the different pixel values, and maybe the second layer is finding lines or something like that. But then there’s this worry that later on, the neurons will correspond to concepts that we have no human interpretation for, so it won’t even make sense to interpret them. Whereas Rohin is saying, “No, actually the neurons will correspond to, or the architecture will correspond to some human understandable concept that it makes sense to interpret.” Does that seem right?
**Rohin Shah:** Yeah, that seems right. I am maybe not sure that I tie it necessarily to the architecture, but actually probably I’d have to one day.
**Asya Bergal:** Definitely, you don’t need to. Yeah.
**Rohin Shah:** Anyway, I haven’t thought about that enough, but that’s basically that. If you look at current late layers in image classifiers they are often like, “Oh look, this is a detector for lemon tennis balls,” and you’re just like, “That’s a strange concept you’ve got there, neural net, but sure.”
**Robert Long:** Alright, cool. Next way of being safe?
**Rohin Shah:** They’re getting more and more sketchy. I have an intuition that… I should rephrase this. I have an intuition that AI systems are not well-modeled as, “Here’s the objective function and here is the world model.” Most of the classic arguments are: Suppose you’ve got an incorrect objective function, and you’ve got this AI system with this really, really good intelligence, which maybe we’ll call it a world model or just general intelligence. And this intelligence can take in any utility function, and optimize it, and you plug in the incorrect utility function, and catastrophe happens.
This does not seem to be the way that current AI systems work. It is the case that you have a reward function, and then you sort of train a policy that optimizes that reward function, but… I explained this the wrong way around. But the policy that’s learned isn’t really… It’s not really performing an optimization that says, “What is going to get me the most reward? Let me do that thing.”
It has been given a bunch of heuristics by gradient descent that tend to correlate well with getting high reward and then it just executes those heuristics. It’s kind of similar to… If any of you are fans of the sequences… Eliezer wrote a sequence on evolution and said… What was it? Humans are not fitness maximizers, they are adaptation executors, something like this. And that is how I view neural nets today that are trained by RL. They don’t really seem like expected utility maximizers the way that it’s usually talked about by MIRI or on LessWrong.
I mostly expect this to continue, I think conditional on AGI being developed soon-ish, like in the next decade or two, with something kind of like current techniques. I think it would be… AGI would be a mesa optimizer or inner optimizer, whichever term you prefer. And that that inner optimizer will just sort of have a mishmash of all of these heuristics that point in a particular direction but can’t really be decomposed into ‘here are the objectives, and here is the intelligence’, in the same way that you can’t really decompose humans very well into ‘here are the objectives and here is the intelligence’.
**Robert Long:** And why does that lead to better safety?
**Rohin Shah:** I don’t know that it does, but it leads to not being as confident in the original arguments. It feels like this should be pushing in the direction of ‘it will be easier to correct or modify or change the AI system’. Many of the arguments for risk are ‘if you have a utility maximizer, it has all of these convergent instrumental sub-goals’ and, I don’t know, if I look at humans they kind of sort of pursued convergent instrumental sub-goals, but not really.
You can definitely convince them that they should have different goals. They change the thing they are pursuing reasonably often. Mostly this just reduces my confidence in existing arguments rather than gives me an argument for safety.
**Robert Long:** It’s like a defeater for AI safety arguments that rely on a clean separation between utility…
**Rohin Shah:** Yeah, which seems like all of them. All of the most crisp ones. Not all of them. I keep forgetting about the… I keep not taking into account the one where your god-like AI slowly replace humans and humans lose control of the future. That one still seems totally possible in this world.
**Robert Long:** If AGI is through current techniques, it’s likely to have systems that don’t have this clean separation.
**Rohin Shah:** Yep. A separate claim that I would argue for separately– I don’t think they interact very much– is that I would also claim that we will get AGI via essentially current techniques. I don’t know if I should put a timeline on it, but two decades seems plausible. Not saying it’s likely, maybe 50% or something. And that the resulting AGI will look like mesa optimizer.
**Asya Bergal:** Yeah. I’d be very curious to delve into why you think that.
**Robert Long:** Yeah, me too. Let’s just do that because that’s fast. Also your… What do you mean by current techniques, and what’s your credence in that being what happens?
**Sara Haxhia:** And like what’s your model for how… where is this coming from?
**Rohin Shah:** So on the meta questions, first, the current techniques would be like deep learning, gradient descent broadly, maybe RL, maybe meta-learning, maybe things sort of like it, but back propagation or something like that is still involved.
I don’t think there’s a clean line here. Something like, we don’t look back and say: That. That was where the ML field just totally did a U-turn and did something else entirely.
**Robert Long:** Right. Everything that’s involved in the building of the AGI is something you can roughly find in current textbooks or like conference proceedings or something. Maybe combined in new cool ways.
**Rohin Shah:** Yeah. Maybe, yeah. Yup. And also you throw a bunch of compute at it. That is part of my model. So that was the first one. What is current techniques? Then you asked credence.
Credence in AGI developed in two decades by current-ish techniques… Depends on the definition of current-ish techniques, but something like 30, 40%. Credence that it will be a mesa optimizer, maybe conditional on this being… The previous thing being true, the credence on it being a mesa optimizer, 60, 70%. Yeah, maybe 70%.
And then the actual model for why this is… it’s sort of related to the previous points about features wherein there are lots and lots of features and humans have settled on the ones that are broadly useful across a wide variety of contexts. I think that in that world, what you want to do to get AGI is train an AI system on a very broad… train an AI system maybe by RL or something else, I don’t know. Probably RL.
On a very large distribution of tasks or a large distribution of something, maybe they’re tasks, maybe they’re not like, I don’t know… Human babies aren’t really training on some particular task. Maybe it’s just a bunch of unsupervised learning. And in doing so over a lot of time and a lot of compute, it will converge on the same sorts of features that humans use.
I think the nice part of this story is that it doesn’t require that you explain how the AI system generalizes– generalization in general is just a very difficult property to get out of ML systems if you want to generalize outside of the training distribution. You mostly don’t require that here because, A) it’s being trained on a very wide variety of tasks and B) it’s sort of mimicking the same sort of procedure that was used to create humans. Where, with humans you’ve also got the sort of… evolution did a lot of optimization in order to create creatures that were able to work effectively in the environment, the environment’s super complicated, especially because there are other creatures that are trying to use the same resources.
And so that’s where you get the wide variety or, the very like broad distribution of things. Okay. What have I not said yet?
**Robert Long:**That was your model. Are you done with the model of how that sort of thing happens or-
**Rohin Shah:** I feel like I’ve forgotten aspects, forgotten to say aspects of the model, but maybe I did say all of it.
**Robert Long:** Well, just to recap: One thing you really want is a generalization, but this is in some sense taken care of because you’re just training on a huge bunch of tasks. Secondly, you’re likely to get them learning useful features. And one-
**Rohin Shah:** And thirdly, it’s mimicking what evolution did, which is the one example we have of a process that created general intelligence.
**Asya Bergal:** It feels like implicit in this sort of claim for why it’s soon is that compute will grow sufficiently to accommodate this process, which is similar to evolution. It feels like there’s implicit there, a claim that compute will grow and a claim that however compute will grow, that’s going to be enough to do this thing.
**Rohin Shah:** Yeah, that’s fair. I think actually I don’t have good reasons for believing that, maybe I should reduce my credences on these a bit, but… That’s basically right. So, it feels like for the first time I’m like, “Wow, I can actually use estimates of human brain computation and it actually makes sense with my model.”
I’m like, “Yeah, existing AI systems seem more expensive to run than the human brain… Sorry, if you compare dollars per hour of human brain equivalent. Hiring a human is what? Maybe we call it $20 an hour or something if we’re talking about relatively simple tasks. And then, I don’t think you could get an equivalent amount of compute for $20 for a while, but maybe I forget what number it came out to, I got to recently. Yeah, actually the compute question feels like a thing I don’t actually know the answer to.
**Asya Bergal:** A related question– this is just to clarify for me– it feels like maybe the relevant thing to compare to is not the amount of compute it takes to run a human brain, but like-
**Rohin Shah:** Evolution also matters.
**Asya Bergal:** Yeah, the amount of compute to get to the human brain or something like that.
**Rohin Shah:** Yes, I agree with that, that that is a relevant thing. I do think we can be way more efficient than evolution.
**Asya Bergal:** That sounds right. But it does feel like that’s… that does seem like that’s the right sort of quantity to be looking at? Or does it feel like-
**Rohin Shah:** For training, yes.
**Asya Bergal:** I’m curious if it feels like the training is going to be more expensive than the running in your model.
**Rohin Shah:** I think the… It’s a good question. It feels like we will need a bunch of experimentation, figuring out how to build essentially the equivalent of the human brain. And I don’t know how expensive that process will be, but I don’t think it has to be a single program that you run. I think it can be like… The research process itself is part of that.
At some point I think we build a system that is initially trained by gradient descent, and then the training by gradient descent is comparable to humans going out in the world and acting and learning based on that. A pretty big uncertainty here is: How much has evolution put in a bunch of important priors into human brains? Versus how much are human brains actually just learning most things from scratch? Well, scratch or learning from their parents.
People would claim that babies have lots of inductive biases, I don’t know that I buy it. It seems like you can learn a lot with a month of just looking at the world and exploring it, especially when you get way more data than current AI systems get. For one thing, you can just move around in the world and notice that it’s three dimensional.
Another thing is you can actually interact with stuff and see what the response is. So you can get causal intervention data, and that’s probably where causality becomes such an ingrained part of us. So I could imagine that these things that we see as core to human reasoning, things like having a notion of causality or having a notion, I think apparently we’re also supposed to have as babies an intuition about statistics and like counterfactuals and pragmatics.
But all of these are done with brains that have been in the world for a long time, relatively speaking, relative to AI systems. I’m not actually sure if I buy that this is because we have really good priors.
**Asya Bergal:** I recently heard… Someone was talking to me about an argument that went like: Humans, in addition to having priors, built-ins from evolution and learning things in the same way that neural nets do, learn things through… you go to school and you’re taught certain concepts and algorithms and stuff like that. And that seems distinct from learning things in a gradient descenty way. Does that seem right?
**Rohin Shah:** I definitely agree with that.
**Asya Bergal:** I see. And does that seem like a plausible thing that might not be encompassed by some gradient descenty thing?
**Rohin Shah:** I think the idea there would be, you do the gradient descenty thing for some time. That gets you in the AI system that now has inside of it a way to learn. That’s sort of what it means to be a mesa optimizer. And then that mesa optimizer can go and do its own thing to do better learning. And maybe at some point you just say, “To hell with this gradient descent, I’ll turn it off.” Probably humans don’t do that. Maybe humans do that, I don’t know.
**Asya Bergal:** Right. So you do gradient descent to get to some place. And then from there you can learn in the same way– where you just read articles on the internet or something?
**Rohin Shah:** Yeah. Oh, another reason that I think this… Another part of my model for why this is more likely– I knew there was more– is that, exactly that point, which is that learning probably requires some more deliberate active process than gradient descent. Gradient design feels really relatively dumb, not as dumb as evolution, but close. And the only plausible way I’ve seen so far for how that could happen is by mesa optimization. And it also seems to be how it happened with humans. I guess you could imagine the meta-learning system that’s explicitly trying to develop this learning algorithm.
And then… okay, by the definition of mesa optimizers, that would not be a mesa optimizer, it would be an inner optimizer. So maybe it’s an inner optimizer instead if we use-
**Asya Bergal:** I think I don’t quite understand what it means that learning requires, or that the only way to do learning is through mesa optimization
**Rohin Shah:** I can give you a brief explanation of what it means to me in a minute or two. I’m going to go and open my summary because that says it better than I can.
Learned optimization, that’s what it was called. All right. Suppose you’re searching over a space of programs to find one that plays tic-tac-toe well. And initially you find a program that says, “If the board is empty, put something in the center square,” or rather, “If the center square is empty, put something there. If there’s two in a row somewhere of yours, put something to complete it. If your opponent has two in a row somewhere, make sure to block it,” and you learn a bunch of these heuristics. Those are some nice, interpretable heuristics but maybe you’ve got some uninterpretable ones too.
But as you search more and more, eventually someday you stumble upon the minimax algorithm, which just says, “Play out the game all the way until the end. See whether in all possible moves that you could make, and all possible moves your opponent could make, and search for the path where you are guaranteed to win.”
And then you’re like, “Wow, this algorithm, it just always wins. No one can ever beat it. It’s amazing.” And so basically you have this outer optimization loop that was searching over a space of programs, and then it found a program, so one element of the space, that was itself performing optimization, because it was searching through possible moves or possible paths in the game tree to find the actual policy it should play.
And so your outer optimization algorithm found an inner optimization algorithm that is good, or it solves the task well. And the main claim I will make, and I’m not sure if… I don’t think the paper makes it, but the claim I will make is that for many tasks if you’re using gradient descent as your optimizer, because gradient descent is so annoyingly slow and simple and inefficient, the best way to actually achieve the task will be to find a mesa optimizer. So gradient descent finds parameters that themselves take an input, do some sort of optimization, and then figure out an output.
**Asya Bergal:** Got you. So I guess part of it is dividing into sub-problems that need to be optimized and then running… Does that seem right?
**Rohin Shah:** I don’t know that there’s necessarily a division into sub problems, but it’s a specific kind of optimization that’s tailored for the task at hand. Maybe another example would be… I don’t know, that’s a bad example. I think the analogy to humans is one I lean on a lot, where evolution is the outer optimizer and it needs to build things that replicate a bunch.
It turns out having things replicate a bunch is not something you can really get by heuristics. What you need to do is to create humans who can themselves optimize and figure out how to… Well, not replicate a bunch, but do things that are very correlated with replicating a bunch. And that’s how you get very good replicators.
**Asya Bergal:** So I guess you’re saying… often the gradient descent process will– it turns out that having an optimizer as part of the process is often a good thing. Yeah, that makes sense. I remember them in the mesa optimization stuff.
**Rohin Shah:** Yeah. So that intuition is one of the reasons I think that… It’s part of my model for why AGI will be a mesa optimizer. Though I do– in the world where we’re not using current ML techniques I’m like, “Oh, anything can happen.”
**Asya Bergal:** That makes sense. Yeah, I was going to ask about that. Okay. So conditioned on current ML techniques leading to it, it’ll probably go through mesa optimizers?
**Rohin Shah:** Yeah. I might endorse the claim with much weaker confidence even without current ML techniques, but I’d have to think a lot more about that. There are arguments for why mesa optimization is the thing you want– is the thing that happens– that are separate from deep learning. In fact, the whole paper doesn’t really talk about deep learning very much.
**Robert Long:** Cool. So that was digging into the model of why and how confident we should be on current technique AGI, prosaic AI I guess people call it? And seems like the major sources of uncertainty there are: does compute actually go up, considerations about evolution and its relation to human intelligence and learning and stuff?
**Rohin Shah:** Yup. So the Median Group, for example, will agree with most of this analysis… Actually no. The Median Group will agree with some of this analysis but then say, and therefore, AGI is extremely far away, because evolution threw in some horrifying amount of computation and there’s no way we can ever match that.
**Asya Bergal:** I’m curious if you still have things on your list of like safety by default arguments, I’m curious to go back to that. Maybe you covered them.
**Rohin Shah:** I think I have covered them. The way I’ve listed this last one is ‘AI systems will be optimizers in the same way that humans are optimizers, not like Eliezer-style EU maximizers’… which is basically what I’ve just been saying.
**Sara Haxhia:** But it seems like it still feels dangerous.. if a human had loads of power, it could do things that… even if they aren’t maximizing some utility.
**Rohin Shah:** Yeah, I agree, this is not an argument for complete safety. I forget where I was initially going with this point. I think my main point here is that mesa optimizers don’t nice… Oh, right, they don’t nicely factor into utility function and intelligence. And that reduces my credence in existing arguments, and there are still issues which are like, with a mesa optimizer, your capabilities generalize with distributional shift, but your objective doesn’t.
Humans are not really optimizing for reproductive success. And arguably, if someone had wanted to create things that were really good at reproducing, they might have used evolution as a way to do it. And then humans showed up and were like, “Oh, whoops, I guess we’re not doing that anymore.”
I mean, the mesa optimizers paper is a very pessimistic paper. In their view, mesa optimization is a bad thing that leads to danger and that’s… I agree that all of the reasons they point out for mesa optimization being dangerous are in fact reasons that we should be worried about mesa optimization.
I think mostly I see this as… convergent instrumental sub-goals are less likely to be obviously a thing that this pursues. And that just feels more important to me. I don’t really have a strong argument for why that consideration dominates-
**Robert Long:** The convergent instrumental sub-goals consideration?
**Rohin Shah:** Yeah.
**Asya Bergal:** I have a meta credence question, maybe two layers of them. The first being, do you consider yourself optimistic about AI for some random qualitative definition of optimistic? And the follow-up is, what do you think is the credence that by default things go well, without additional intervention by us doing safety research or something like that?
**Rohin Shah:** I would say relative to AI alignment researchers, I’m optimistic. Relative to the general public or something like that, I might be pessimistic. It’s hard to tell. I don’t know, credence that things go well? That’s a hard one. Intuitively, it feels like 80 to 90%, 90%, maybe. 90 feels like I’m being way too confident and like, “What? You only assign 10%, even though you have literally no… you can’t predict the future and no one can predict the future, why are you trying to do it?” It still does feel more like 90%.
**Asya Bergal:** I think that’s fine. I guess the follow-up is sort of like, between the sort of things that you gave, which were like: Slow takeoff allows for correcting things, things that are more powerful will be more interpretable, and I think the third one being, AI systems not actually being… I’m curious how much do you feel like your actual belief in this leans on these arguments? Does that make sense?
**Rohin Shah:** Yeah. I think the slow takeoff one is the biggest one. If I believe that at some point we would build an AI system that within the span of a week was just way smarter than any human, and before that the most powerful AI system was below human level, I’m just like, “Shit, we’re doomed.”
**Robert Long:** Because there it doesn’t matter if it goes through interpretable features particularly.
**Rohin Shah:** There I’m like, “Okay, once we get to something that’s super intelligent, it feels like the human ant analogy is basically right.” And unless we… Maybe we could still be fine because people thought about it and put in… Maybe I’m still like, “Oh, AI researchers would have been able to predict that this would’ve happened and so were careful.”
I don’t know, in a world where fast takeoff is true, lots of things are weird about the world, and I don’t really understand the world. So I’m like, “Shit, it’s quite likely something goes wrong.” I think the slow takeoff is definitely a crux. Also, we keep calling it slow takeoff and I want to emphasize that it’s not necessarily slow in calendar time. It’s more like gradual.
**Asya Bergal:** Right, like ‘enough time for us to correct things’ takeoff.
**Rohin Shah:** Yeah. And there’s no discontinuity between… you’re not like, “Here’s a 2X human AI,” and a couple of seconds later it’s now… Not a couple of seconds later, but like, “Yeah, we’ve got 2X AI,” for a few months and then suddenly someone deploys a 10,000X human AI. If that happened, I would also be pretty worried.
It’s more like there’s a 2X human AI, then there’s like a 3X human AI and then a 4X human AI. Maybe this happens from the same AI getting better and learning more over time. Maybe it happens from it designing a new AI system that learns faster, but starts out lower and so then overtakes it sort of continuously, stuff like that.
So that I think, yeah, without… I don’t really know what the alternative to it is, but in the one where it’s not human level, and then 10,000X human in a week and it just sort of happened, that I’m like, I don’t know, 70% of doom or something, maybe more. That feels like I’m… I endorse that credence even less than most just because I feel like I don’t know what that world looks like. Whereas on the other ones I at least have a plausible world in my head.
**Asya Bergal:** Yeah, that makes sense. I think you’ve mentioned, in a slow takeoff scenario that… Some people would disagree that in a world where you notice something was wrong, you wouldn’t just hack around it, and keep going.
**Asya Bergal:** I have a suggestion which it feels like maybe is a difference and I’m very curious for your take on whether that seems right or seems wrong. It seems like people believe there’s going to be some kind of pressure for performance or competitiveness that pushes people to try to make more powerful AI in spite of safety failures. Does that seem untrue to you or like you’re unsure about it?
**Rohin Shah:** It seems somewhat untrue to me. I recently made a comment about this on the Alignment Forum. People make this analogy between AI x-risk and risk of nuclear war, on mutually assured destruction. That particular analogy seems off to me because with nuclear war, you need the threat of being able to hurt the other side whereas with AI x-risk, if the destruction happens, that affects you too. So there’s no mutually assured destruction type dynamic.
You could imagine a situation where for some reason the US and China are like, “Whoever gets to AGI first just wins the universe.” And I think in that scenario maybe I’m a bit worried, but even then, it seems like extinction is just worse, and as a result, you get significantly less risky behavior? But I don’t think you get to the point where people are just literally racing ahead with no thought to safety for the sake of winning.
I also don’t think that you would… I don’t think that differences in who gets to AGI first are going to lead to you win the universe or not. I think it leads to pretty continuous changes in power balance between the two.
I also don’t think there’s a discrete point at which you can say, “I’ve won the race.” I think it’s just like capabilities keep improving and you can have more capabilities than the other guy, but at no point can you say, “Now I have won the race.” I suppose if you could get a decisive strategic advantage, then you could do it. And that has nothing to do with what your AI capability… If you’ve got a decisive strategic advantage that could happen.
I would be surprised if the first human-level AI allowed you to get anything close to a decisive strategic advantage. Maybe when you’re at 1000X human level AI, perhaps. Maybe not a thousand. I don’t know. Given slow takeoff, I’d be surprised if you could knowably be like, “Oh yes, if I develop this piece of technology faster than my opponent, I will get a decisive strategic advantage.”
**Asya Bergal:** That makes sense. We discussed a lot of cruxes you have. Do you feel like there’s evidence that you already have pre-computed that you think could move you in one direction or another on this? Obviously, if you’ve got evidence that X was true, that would move you, but are there concrete things where you’re like, “I’m interested to see how this will turn out, and that will affect my views on the thing?”
**Rohin Shah:** So I think I mentioned the… On the question of timelines, they are like the… How much did evolution actually bake in to humans? It seems like a question that could put… I don’t know if it could be answered, but maybe you could answer that one. That would affect it… I lean on the side of not really, but it’s possible that the answer is yes, actually quite a lot. If that was true, I just lengthen my timelines basically.
**Sara Haxhia:** Can you also explain how this would change your behavior with respect to what research you’re doing, or would it not change that at all?
**Rohin Shah:** That’s a good question. I think I would have to think about that one for longer than two minutes.
As background on that, a lot of my current research is more trying to get AI researchers to be thinking about what happens when you deploy, when you have AI systems working with humans, as opposed to solving alignment. Mostly because I for a while couldn’t see research that felt useful to me for solving alignment. I think I’m now seeing more things that I can do that seem more relevant and I will probably switch to doing them possibly after graduating because thesis, and needing to graduate, and stuff like that.
**Rohin Shah:** Yes, but you were asking evidence that would change my mind-
**Asya Bergal:** I think it’s also reasonable to be not sure exactly about concrete things. I don’t have a good answer to this question off the top of my head.
**Rohin Shah:** It’s worth at least thinking about for a couple of minutes. I think I could imagine getting more information from either historical case studies of how people have dealt with new technologies, or analyses of how AI researchers currently think about things or deal with stuff, could change my mind about whether I think the AI community would by default handle problems that arise, which feels like an important crux between me and others.
I think currently my sense is if the like… You asked me this, I never answered it. If the AI safety field just sort of vanished, but the work we’ve done so far remained and conscientious AI researchers remained, or people who are already AI researchers and already doing this sort of stuff without being influenced by EA or rationality, then I think we’re still fine because people will notice failures and correct them.
I did answer that question. I said something like 90%. This was a scenario I was saying 90% for. And yeah, that one feels like a thing that I could get evidence on that would change my mind.
I can’t really imagine what would cause me to believe that AI systems will actually do a treacherous turn without ever trying to deceive us before that. But there might be something there. I don’t really know what evidence would move me, any sort of plausible evidence I could see that would move me in that direction.
Slow takeoff versus fast takeoff…. I feel like MIRI still apparently believes in fast takeoff. I don’t have a clear picture of these reasons, I expect those reasons would move me towards fast takeoff.
Oh, on the expected utility max or the… my perception of MIRI, or of Eliezer and also maybe MIRI, is that they have this position that any AI system, any sufficiently powerful AI system, will look to us like an expected utility maximizer, therefore convergent instrumental sub-goals and so on. I don’t buy this. I wrote a [**post**](https://www.alignmentforum.org/s/4dHMdK5TLN6xcqtyc/p/NxF5G6CJiof6cemTw) explaining why I don’t buy this.
Yeah, there’s a lot of just like.. MIRI could say their reasons for believing things and that would probably cause me to update. Actually, I have enough disagreements with MIRI that they may not update me, but it could in theory update me.
**Asya Bergal:** Yeah, that’s right. What are some disagreements you have with MIRI?
**Rohin Shah:** Well, the ones I just mentioned. There is this great post from maybe not a year ago, but in 2018, called ‘Realism about Rationality’, which is basically this perspective that there is the one true learning algorithm or the one correct way of doing exploration, or just, there is a platonic ideal of intelligence. We could in principle find it, code it up, and then we would have this extremely good AI algorithm.
Then there is like, to the extent that this was a disagreement back in 2008, Robin Hanson would have been on the other side saying, “No, intelligence is just like a broad… just like conglomerate of a bunch of different heuristics that are all task specific, and you can’t just take one and apply it on the other space. It is just messy and complicated and doesn’t have a nice crisp formalization.”
And, I fall not exactly on Robin Hanson’s side, but much more on Robin Hanson’s side than the ‘rationality is a real formalizable natural thing in the world’.
**Sara Haxhia:** Do you have any idea where the cruxes of disagreement are at all?
**Rohin Shah:** No, that one has proved very difficult to…
**Robert Long:** I think that’s an AI Impacts project, or like a dissertation or something. I feel like there’s just this general domain specificity debate, how general is rationality debate…
I think there are these very crucial considerations about the nature of intelligence and how domain specific it is and they were an issue between Robin and Eliezer and no one… It’s hard to know what evidence, what the evidence is in this case.
**Rohin Shah:** Yeah. But I basically agree with this and that it feels like a very deep disagreement that I have never had any success in coming to a resolution to, and I read arguments by people who believe this and I’m like, “No.”
**Sara Haxhia:** Have you spoken to people?
**Rohin Shah:** I have spoken to people at CHAI, I don’t know that they would really be on board this train. Hold on, Daniel probably would be. And that hasn’t helped that much. Yeah. This disagreement feels like one where I would predict that conversations are not going to help very much.
**Robert Long:** So, the general question here was disagreements with MIRI, and then there’s… And you’ve mentioned fast takeoff and maybe relatedly, the Yudkowsky-Hanson–
**Rohin Shah:** Realism about Rationality is how I’d phrase it. There’s also the– are AI researchers conscientious? Well, actually I don’t know that they would say they are not conscientious. Maybe they’d say they’re not paying attention or they have motivated reasoning for ignoring the issues… lots of things like that.
**Robert Long:** And this issue of do advanced intelligences look enough like EU maximizers…
**Rohin Shah:** Oh, yes. That one too. Yeah, sorry. That’s one of the major ones. Not sure how I forgot that.
**Robert Long:** I remember it because I’m writing it all down, so… again, you’ve been talking about very complicated things.
**Rohin Shah:** Yeah. Related to the Realism about Rationality point is the use of formalism and proof. Nor formalism, but proof at least. I don’t know that MIRI actually believes that what we need to do is write a bunch of proofs about our AI system, but it sure sounds like it, and that seems like a too difficult, and basically impossible task to me, if the proofs that we’re trying to write are about alignment or beneficialness or something like that.
They also seem to… No, maybe all the other disagreements can be traced back to these disagreements. I’m not sure. |
2ded2f11-b3b3-45f0-94fd-7180f6427bf3 | trentmkelly/LessWrong-43k | LessWrong | How Much is a Sweet?
For about two years our system has been that the kids get one sweet before dinner and one sweet after dinner. They like to divide their allocation up ("can I have pancakes with half a sweet of chocolate chips?"), and this has been a good opportunity for teaching fractions. But how much is a sweet?
Initially, we would just eyeball it, but a few months ago Julia pointed out that my sense of how much sugar is in various foods wasn't very reliable, and we didn't have a good sense of how much sugar they should be having anyway.
The general recommendation is that at most 10% (pdf) of your calories come from sugar. The kids are eating probably about 1,000 calories per day, and at four calories per gram that would be 25g sugar. Since they get two "sweets" per day, this is 12.5g/sweet. This looks like:
12.5g table sugar (1T):
Three marshmallows:
21g Nutella (1T):
58g ice cream (~1/2C):
17g sprinkles (1.5T):
23g chocolate chips (~32 chips):
Eight chocolate-chip pancakes (no sugar in the batter, 32 chocolate chips):
We don't count the sugar in fruit (which is generally pretty low and comes with lots of other things we would like the kids to be eating more of) but we would count it in juice. We also don't count the sugar in other things that are mostly not sugar even if they do have a bit, like breakfast cereal or peanut butter.
Comment via: facebook |
0e79ed9d-5851-4d93-9ce8-a3c688d52751 | trentmkelly/LessWrong-43k | LessWrong | How to Think About Activation Patching
This is an excerpt from my post on attribution patching, that I think is of more general interest, around how to think about the technique of activation patching in mechanistic interpretability, and what it can and cannot teach us. You don't need to know what attribution patching is to read this, check out this section for an overview of activation patching
What Is the Point of Patching?
The conceptual framework I use when thinking about patching is to think of a model as an enormous mass of different circuits. On any given input, many circuits will be used. Further, while some circuits are likely very common and important (eg words after full stops start with capitals, or "this text is in English"), likely many are very rare and niche and will not matter on the vast majority of inputs (eg "this is token X in the Etsy terms and conditions footer" - a real thing that GPT-2 Small has neurons for!). For example, on IOI, beyond the actual IOI circuit, there is likely circuits to:
* Detect multi-token words (eg names) and assemble them into a single concept
* Detect that this is English text
* Detect that this is natural language text
* Encode unigram frequencies (under which John is 2-3x as likely as Mary!)
* Copying all names present in the context - if a name is present in the text it's way more likely to occur next than an unseen name!
* That this is the second clause of a sentence
* That Indirect Object Identification is the right grammatical structure to use
* That the next word should be a name
As a mech interp researcher, this is really annoying! I can get traction on a circuit in isolation, and there's a range of tools with ablations, direct logit attribution, etc to unpick what's going on. And hopefully any given circuit will be clean and sparse, such that I can ignore most of a model's parameters and most activation dimensions, and focus on what's actually going on. But when any given input triggers many different circuits, it's really hard to know |
3df8cafd-0357-4eb3-b6c9-faf8fe11ff4d | trentmkelly/LessWrong-43k | LessWrong | Long COVID risk: How to maintain an up to date risk assessment so we can go back to normal life?
Despite Zvi's "Long Long Covid Post" concluding in February that Long COVID risk among healthy, vaccinated individuals is low enough that it's worth pretty much going back to normal life, I haven't felt comfortable doing so given the array of claims to the contrary.
Some of them have surfaced on LessWrong itself:
* https://www.lesswrong.com/posts/emygKGXMNgnJxq3oM/your-risk-of-developing-long-covid-is-probably-high (March, by a poster who had not read Zvi's original post)
* https://www.lesswrong.com/posts/vSjiTrHkckTPrirhS/hard-evidence-that-mild-covid-cases-frequently-reduce (May)
Others I have come across from friends or on Twitter.
My skills at carefully evaluating scientific research are fairly limited, and I'd also like to avoid spending all of my free time doing so, so I've been kind of stuck in this limbo for now.
Compounding the challenge of deciding what risks to take is that MicroCOVID doesn't seem to account for the increasing rate of underreporting or the much higher transmissibility of recent Omicron subvariants, making it really hard to decide what level of risk a given activity will pose. And given the transmissibility of those variants, and society's apparent decision to just ... ignore the risk of Long COVID and go back to normal, trying to avoid getting COVID going forward will be more and more socially costly.
I'm sure I'm not the only one in this situation.
So:
* Is anyone confident going back to normal life despite claims to the contrary without feeling the need to read and evaluate each new study on Long COVID? Why? What logic / heuristics inform that assessment?
* This seems to be Zvi's current stance, given he seems to be focused elsewhere with his recent posts, so Zvi, if you're reading this, I'd be curious to hear your thoughts!
* Has anyone been tracking claims to the contrary and assessing their validity (e.g. based on the sorts of critiques Zvi covered in his post)?
* Would anyone be interested in contributing to a syste |
33a86bb6-3a77-42de-be53-83aa42f470a2 | trentmkelly/LessWrong-43k | LessWrong | Nate Soares' Life Advice
Disclaimer: Nate gave me some life advice at EA Global; I thought it was pretty good, but it may or may not be useful for other people. If you think any of this would be actively harmful for you to apply, you probably shouldn't.
Notice subtle things in yourself
This includes noticing things like confusion, frustration, dissatisfaction, enjoyment, etc. For instance, if you're having a conversation with somebody and they're annoying you, it's useful to notice that you're getting a little frustrated before the situation gets worse.
A few weeks ago my colleagues and I wanted to do something fun, and decided to play laser tag at our workplace. However, we couldn't find the laser tag guns. As I began to comb the grounds for the guns for the second time I noticed that I felt like I was just going through the motions, and didn't really expect my search to be fruitful. At this point I stopped and thought about the problem, and realized that I had artificially constrained the solution space to things that would result in us playing laser tag at the office, rather than things that would result in us having fun. So I stopped looking for the guns and we did an escape room instead, which made for a vastly more enjoyable evening.
If you're not yet at the point where you can notice unsubtle things in yourself, you can start by working on that and move up from there.
Keep doing the best thing, even if you don't have a legible story for why it's good
Certainly the actions you're taking should make sense to you, but your reasoning doesn't have to be 100% articulable, and you don't need to justify yourself in an airtight way. Some things are easier to argue than other things, but this is not equivalent to being more correct. For instance, I'm doing AI alignment stuff, and I have the option of reading either a textbook on linear algebra or E.T. Jaynes' probability theory textbook.
Reading about linear algebra is very easy to justify in a way that can't really be disputed; it's |
eb6f66ff-afd1-427d-be45-f142e8a1054e | trentmkelly/LessWrong-43k | LessWrong | [LINK] If correlation doesn’t imply causation, then what does?
A post about how, for some causal models, causal relationships can be inferred without doing experiments that control one of the random variables.
If correlation doesn’t imply causation, then what does?
> To help address problems like the two example problems just discussed, Pearl introduced a causal calculus. In the remainder of this post, I will explain the rules of the causal calculus, and use them to analyse the smoking-cancer connection. We’ll see that even without doing a randomized controlled experiment it’s possible (with the aid of some reasonable assumptions) to infer what the outcome of a randomized controlled experiment would have been, using only relatively easily accessible experimental data, data that doesn’t require experimental intervention to force people to smoke or not, but which can be obtained from purely observational studies. |
0be39de0-8b2b-4403-9ffc-b1d8f94ebd23 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Open question: are minimal circuits daemon-free?
*Note: weird stuff, very informal.*
Suppose I search for an algorithm that has made good predictions in the past, and use that algorithm to make predictions in the future.
I may get a "[daemon](https://arbital.com/p/daemons/)," a consequentialist who happens to be motivated to make good predictions (perhaps because it has realized that only good predictors survive). Under different conditions, the daemon may no longer be motivated to predict well, and may instead make "predictions" that help it achieve its goals at my expense.
I don't know whether this is a real problem or not. But from a theoretical perspective, not knowing is already concerning--I'm trying to find a strong argument that we've solved alignment, not just something that seems to work in practice.
I am pretty convinced that daemons are a [real problem for Solomonoff induction](https://ordinaryideas.wordpress.com/2016/11/30/what-does-the-universal-prior-actually-look-like/). Intuitively, the problem is caused by "too much compute." I suspect that daemons are also a problem for some more realistic learning procedures (like human evolution), though in a different shape. I think that this problem can probably be patched, but that's one of the major open questions for the feasibility of [prosaic AGI alignment](https://ai-alignment.com/prosaic-ai-control-b959644d79c2).
I suspect that daemons *aren't* a problem if we exclusively select for computational efficiency. That is, I suspect that **the fastest way to solve any particular problem doesn't involve daemons**.
I don't think this question has much intrinsic importance, because almost all realistic learning procedures involve a strong simplicity prior (e.g. weight sharing in neural networks).
But I do think this question has deep similarities to more important problems, and that answering this question will involve developing useful conceptual machinery. Because we have an unusually strong intuitive handle on the problem, I think it's a good thing to think about.
Problem statement and intuition
-------------------------------
Can the smallest [boolean circuit](https://en.wikipedia.org/wiki/Boolean_circuit) that solves a problem be a daemon? For example, can the smallest circuit that predicts my behavior (at some level of accuracy) be a daemon?
Intuitively, if we have a daemon that is instrumentally or incidentally motivated to solve my problem, then there is some smaller circuit that solves the problem equally well but skips the instrumental reasoning. If my daemon is doing some complex reasoning to answer the question "Should I predict well?" we could just skip straight to the answer "yes." This both makes the circuit smaller, and prevents the circuit from ever deciding not to predict well.
A different perspective on a similar intuition: the daemon is doing some actual cognitive work to solve the problem. Since that computation is being done by the daemon, it is embedded as a smaller circuit. Jessica explores this intuition a bit [here](https://agentfoundations.org/item?id=1281). Here we are considering an easy version of the problem, since by taking the smallest circuit we are effectively quantifying over all possible ways of extracting logical information from the daemon.
Instead of showing that minimal circuits can't be daemons, we might end up concluding that they can be. That would be even more interesting.
Another possible outcome is giving a strong argument that captures our intuitions/concerns about daemons, and which clearly doesn't apply to the minimal circuit that solves a problem. In this case we couldn't prove anything positive about the minimal circuit, but we would have "screened off" the possible cause for concern.
Difficulties
------------
The first and most serious difficulty is understanding what we are talking about.
I don't expect to get total clarity on concepts like "daemon" or "optimization" or "generic problem," but we need to have a better grip than we do right now. I expect that we'll develop better concepts in the course of solving the problem, rather than as a precondition for solving the problem (in general I think "define things so that you can prove the theorem" is often the right strategy).
A second difficulty is that the different parts of the computation can be tangled up in an extremely complex way. In an extreme case, the daemon may be cryptographically [obfuscated](https://eprint.iacr.org/2013/451.pdf).
We want to show that given any daemon, there is a smaller circuit that solves the problem. The most natural approach is showing how to construct a smaller circuit, given a daemon. But if the daemon is obfuscated, there is no efficient procedure which takes the daemon circuit as input and produces a smaller circuit that still solves the problem.
So we can't find any efficient constructive argument. That rules out most of the obvious strategies. |
dffbc163-82cc-4e9b-a1ef-b4cc38a22b9e | StampyAI/alignment-research-dataset/arxiv | Arxiv | Unsupervised Learning of Visual 3D Keypoints for Control.
1 Introduction
---------------
Learning to act from raw, high-dimensional observations like images is arguably the only viable way to scale sensorimotor control to complex real-world setups. However, the main challenge lies in figuring out the representation of these observations upon which the agent’s policy is to be learned. The conventional wisdom today is to learn these representations either via task supervision in an end-to-end manner (Mnih et al., [2015a](#bib.bib23); Lillicrap et al., [2016](#bib.bib18)) or via auxiliary loss functions (Jaderberg et al., [2016](#bib.bib9); Pathak et al., [2017](#bib.bib27); Laskin et al., [2020b](#bib.bib17)). Although such representation learning paradigms are successful in vision (Krizhevsky et al., [2012](#bib.bib14)), speech (Oord et al., [2016](#bib.bib26)) or language (Devlin et al., [2018](#bib.bib5)), they suffer from two key issues in case of robot learning. First, the representations tend to become specific to both the task and the visual environment, thus, any change in the visual input affects the generalization of the learned representations as well as policy. Second, these latent features do not capture the fine-grained location and orientation of objects or robot joints which is indispensable for robotic control in complex scenarios. This is in contrast to sensorimotor representations in humans which have explicit notions of objects, their relationships, 3D reasoning, and geometry (Spelke & Kinzler, [2007](#bib.bib31)).

Figure 1: We propose an end-to-end framework for unsupervised learning of 3D keypoints from multi-view images. These keypoints are discovered to jointly optimize both multi-view reconstruction and downstream task performance. Our learned keypoints are consistent across 3D space as well as time.

Figure 2: Overview of our Keypoint3D algorithm. (a) For each camera view, a fully convolutional neural network encodes the input image into K heat maps and depth maps. (b) We then treat these heat maps as probabilities to compute expectation of spatial uv coordinates in camera plane. These expected values and the saptial variances are used to resample final uv keypoint coordinates which adds noise that prevents the decoder from cheating to hide the input information in the relative locations uv keypoints. We also take expectation of depth coordinate, d, using the same probability distribution. These [u,v,d] coordinates are then unprojected into the world coordinate. (c) We take attention-weighted average of keypoint estimations from different camera views to get a single prediction in the world coordinate. (d) For decoding, we project predicted keypoints in world coordinate to [u,v,d] in each camera plane. (e) Each keypoint coordinate is mapped to a gaussian map, where a 2D gussian is created with mean at [u,v] and std inversely proportional to d. For each camera, gaussian maps are stacked together and passed into decoder to reconstruct observed pixels from the camera. (f) Together with reconstruction, we also jointly train a task MLP policy on top of predicted world coordinates via reinforcement learning.
Motivated by the need to capture fine-grained abstractions from visual data, a popular approach is to use keypoint-based representations. Keypoints are represented in Euclidean coordinates and provide a natural way to represent the kinematic structure of both the agent and the environment. Furthermore, keypoint- or particle-based representation provides an ideal way to represent deformable objects like cloth for precise robotic manipulation (Clegg et al., [2017](#bib.bib3); Sundaresan et al., [2020](#bib.bib32)) but these keypoints are often hand-selected by human labelers which is expensive and hinders scalability. Some prior methods try to alleviate this problem (Minderer et al., [2019](#bib.bib21); Kulkarni et al., [2019](#bib.bib15)) by learning keypoints in an unsupervised and task-agnostic manner, however, the keypoints are defined in the image coordinate space in 2D. This limits the agent’s ability to perform 3D reasoning and occlusion handling which is vital in partially observable or even fully observable environments as the tasks are performed in a 3D world.
An alternative approach to capture 3D is to leverage structure from motion (Wei et al., [2020](#bib.bib35)) to aggregate multi-view information. Recent works (Manuelli et al., [2019](#bib.bib19), [2020](#bib.bib20)) learn keypoints by solving for 3D correspondence across views via multi-view stereo but the keypoint discovery phase is performed separately from control and not learned in an end-to-end manner. However, different tasks may demand different parts of the scene to be keypoints. For example, if a robot is to pick up a cup, its handle would be a keypoint but if something is to be poured into it, 3D keypoints should capture its interior circumference. How can we have the best of all worlds: fine-grained keypoints, 3D reasoning, and unsupervised, end-to-end, joint training with control?
In this work, we propose an end-to-end framework for unsupervised discovery of 3D keypoints from images that are learned directly via the task performance, shown in [Figure 1](#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Unsupervised Learning of Visual 3D Keypoints for Control"). For such an approach to be general as well as successful, it should satisfy three properties: (a) Consistency across 3D space: the learned keypoints should capture the same 3D location in the world coordinate from different views of the same scene. (b) Consistency across time: the same keypoint should track the corresponding entity consistently across different timesteps of trajectory rollout. (c) Joint learning with control: 3D keypoints should be learned such that they are directly useful for the end-task performance. We conceptually integrate these properties within a common mathematical framework.
Given an input image from a camera view, we first predict keypoint locations and depth in the image space. These keypoints from different views of the same scene are then aggregated using camera information to obtain a global world coordinate of each keypoint via a differentiable unprojection operation. The consistency across views is learned via multi-view consistency loss that ensures the keypoint from different view maps to common world coordinate. This global coordinate is then projected back into the image plane of each camera view to reconstruct the original input image of the same view. This setup creates a differentiable 3D keypoint bottleneck upon which the agent’s control policy is trained via reinforcement learning. The keypoint extraction and agent’s policy are optimized jointly in an end-to-end manner as shown in [Figure 2](#S1.F2 "Figure 2 ‣ 1 Introduction ‣ Unsupervised Learning of Visual 3D Keypoints for Control"). We refer to our unsupervised algorithm as Keypoint3D in short.
We evaluate Keypoint3D across a variety of reinforcement learning benchmark environments, and we perform the following analyses. We first investigate how well our Keypoint3D representations perform compared to other representations for RL. Second, we test the scalability to higher dimensional control problems. Third, we show that our Keypoint3D based policy is capable of manipulating deformable objects as evident from results on a task where a robot must put a scarf around a human mannequin. Finally, we show that our Keypoint3D representations generalize across tasks as well. Our method outperforms prior state-of-the-art across almost all the environments and our ablation study demonstrates its robustness across several design choices.
2 Unsupervised Learning of 3D Keypoints
----------------------------------------
We use a multi-view encoder-decoder architecture to learn 3D keypoints without supervision. Given N cameras from different views of a same scene, we associate an encoder and a decoder with each camera. We provide three distinct sources of unsupervised training signal for learning of the Keypoint3D representation: (1) We force the predicted keypoints across encoders to be geometrically consistent in 3D by encouraging the different view-specific keypoint coordinates to unproject to the same point in 3D space. (2) We impose an image reconstruction loss, which penalizes inaccurate reconstructions from the decoder. (3) We use the reward incurred by the RL policy that takes as input the learned keypoints, and backpropagate the reward signal through the weights of the encoder.
###
2.1 Preliminaries
Let In∈RH×W×C be the image observation from camera n∈1...N with extrinsic matrix Vn and intrinsic matrix Pn. Let K be the number of keypoints we intend to detect. Keypoints are indexed with k=1...K. For a 3D point [x,y,z]⊤ in world coordinate, we can use extrinsic matrix Vn and perspective intrinsic matrix Pn to project it to camera coordinate [u,v,d]⊤ for camera n, where u,v∈[0,1] is a normalized coordinate on camera plane and d>0 is the depth value of that point from camera plane. Let the operator Ωn:[x,y,z]⊤→[u,v,d]⊤ denote this projection, and let its inverse Ω−1n:[u,v,d]⊤→[x,y,z]⊤ denote the unprojection operator that maps a camera coordinate to a world coordinate. Both Ωn and Ω−1n are differentiable and can be expressed analytically.
###
2.2 Differentiable 3D Keypoint Bottleneck
We want to leverage the spatial inductive bias of our fully convolutional auto-encoder yet ensure the latent learned latent representation is in the form of xyz coordinates rather than feature maps. To achieve this, we need a differentiable keypoint bottleneck that maps from dense maps to sparse coordinates. While a extraction for world coordinates is not possible from encoded feature space directly, (Jakab et al., [2018](#bib.bib10)) offers a way to parameterize points in uv coordinates on camera plane using spatial probability. We can add depth prediction to the uv coordinate prediction and extract world coordinate using projection geometry.
#### Keypoint Detector
For each camera n, we pass In into a fully convolutional encoder ϕn to get K confidence maps Ckn∈RS×S,k=1...K and depth maps Dkn∈RS×S,k=1...K. For each confidence map Ckn, we can take a spatial softmax to compute a probability heatmap Hkn:
Hkn(i,j)=exp(Ckn(i,j))∑Sp=1∑Sq=1exp(Ckn(p,q)).
Each entry in heatmap Hkn∈RS×S represents the probability of a 3D keypoint k to be at that position on the 2D image plane if viewed from camera n. Each depth map Dkn is a dense prediction of distance from camera plane for 3D keypoint k being at each position.
For each pair of heatmap Hkn and depth map Dkn, we can extract the expected 3D position of the k-th keypoint in the nth camera’s coordinate. We can calculate the expected [u,v,d] camera coordinate over the probability map using the following equations. Note that crucially, we are taking an expectation over the map of coordinates, with weights given by the predicted heatmap values.
| | | | |
| --- | --- | --- | --- |
| | E[ukn] | =1S∑u,vu⋅Hkn(u,v);E[vkn]=1S∑u,vv⋅Hkn(u,v) | |
| | E[dkn] | =S∑u=1S∑v=1Dkn(u,v)⋅Hkn(u,v) | |
Let [^ukn,^vkn,^dkn]⊤=[E[ukn],E[vkn],E[dkn]]⊤.
We found one way for the system to not capture meaningful 3D keypoints is cheating to hide the information about input image in the relative locations keypoint to each other. To avoid this issue, we do not use the exact keypoint locations predicted by the encoder but resample them from by assuming a gaussian distribution around the mean keypoint with standard deviation computed via spatially across the heatmap.
This adds some stochasticity in the exact location of keypoint coordinates preventing the collapse. More details of this resampling process are in the appendix.
#### Attention
After predicting keypoints in each of our n camera coordinate frames, we need a way to combine the n coordinates into one. A naive approach is to simply average the predictions from each view. However, certain keypoints might be occluded from certain view points, and might thus get predicted poorly. To address this, we repurpose our predicted confidence maps in order to compute weights for a weighted average. This allows us to ignore the less confident keypoint estimations which may hurt the task performance.
Recall that the (i,j) entry of the confidence map Ckn denotes the predicted log likelihood of keypoint k appearing at pixel (i,j) in the image from camera n. We then assign a “confidence score” for the n-th encoder’s prediction for keypoint k. This score is proportional to the mean of the confidence map Ckn, and the scores of the k keypoints are normalized to sum to 1 via a softmax:
| | | |
| --- | --- | --- |
| | Akn=exp(1S2∑Sp=1∑Sq=1Ckn(p,q))∑Ki=1exp(1S2∑Sp=1∑Sq=1Cin(p,q)) | |
#### Extracting world coordinates
Given predicted keypoints [^ukn,^vkn,^dkn]⊤,n=1...N,k=1...K in camera coordinats, we can then unproject them to world coordinates using [^xkn,^ykn,^zkn]⊤=Ω−1n([^ukn,^vkn,^dkn]⊤). This is the predicted world coordinate of the kth keypoint conditioned on the image from camera n. For each keypoint, we have N independent predictions from N cameras. We then take an average over these predictions for each keypoint weighted with normalized confidence, that is
| | | |
| --- | --- | --- |
| | [¯xk,¯yk,¯zk]⊤=N∑n=1Akn∑Nm=1Akm⋅[^xkn,^ykn,^zkn]⊤ | |
#### Keypoint Decoder
To also leverage spatial inductive bias for the decoder, we need to give keypoint coordinates spatial structure again before passing them into the decoder. This can be achieved by reprojecting 3D keypoints to each image view again and constructing a 2D gaussian for each keypoint on the camera plane. We reproject all K keypoints in world coordinate to the N camera planes to regain spatial structure before decoding. Using the projection operator, for each camera and keypoint we can get [¯u,¯v,¯d]⊤=Ωn([¯x,¯y,¯z]⊤). To regain spatial structure, for each camera and keypoint we create Gaussian maps Gkn∈RS×S. Each Gaussian map is a 2D gaussian with mean [¯u,¯v]⊤ and covariance matrix I2/¯d, where I2 is the 2×2 identity matrix. This matrix makes closer point have a larger spatial span in the gaussian map corresponding to that camera. Let us define averaged attention across all views as ¯Ak=1N∑Nn=1Akn. The decoder ψn for each camera takes the stacked Gaussian maps Gn to predict In where Gn=K⋅stack([G1n¯A1n,G2n¯A2n...GKn¯AKn]). The decoder ψn then decodes the stacked Gaussian maps to reconstruct the observed image.
Bobs←\O
for update=1,2... do
Brollout←\O
for actor=1,2...,N do
Run policy πθold for T steps to get (s,a,r)1...T
Bobs←s1...T∪Bobs
Brollout←(s,a,r)1...T∪Brollout
end for
for i=1,2...p do
Optimize Lunsup with s∼Bobs wrt θae
end for
Compute advantage estimates ^A1:N,1:T for Brollout
for epoch=1,2...q do
Optimize Lpolicy+Lunsup throughout Brollout
end for
θold←θ
end for
Algorithm 1 Keypoint3D: RL with 3D Keypoint Bottleneck
###
2.3 Losses for Training 3D Keypoint Encoder
Our Keypoint3D approach jointly optimizes the multi-view reconstruction via unsupervised learning and the task policy via reinforcement learning. We backpropagate the sum of unsupervised learning loss and policy loss to train the Keypoint3D pipeline. The unsupervised losses have three components as defined below.
#### Multi-view Auto Encoding Loss
We encourage the keypoints to track important entities and structures. An Auto-encoding loss has been shown to be useful for this, as the architectural bottleneck forces the latent representation to capture the most salient aspects of the scene: Lae=∑Nn=1||ψn(Gn)−In||2.

Figure 3: Plots show the performance of Keypoint3D on 8 metaworld environments with varying difficulty compared to different representation learning methods. Mean and standard error are shown across 4 random seeds for each environment. Our 3D keypoint method outperforms the strongest baseline, RAD, on 5 out of the 8 environments while being similiar in the rest.
#### Multi-view Consistency Loss
We enforce that for each keypoint k, the camera-frame coordinates of the keypoint k from each of the n encoders all have identical 3D world coordinates. We use a multi-view consistency loss to penalize disagreement between predictions from different views:
| | | |
| --- | --- | --- |
| | Lmulti=K∑k=1N∑i=1N∑j=1||[^xki,^yki,^zki]⊤−sg([^xkj,^ykj,^zkj]⊤)||2 | |
where sg is the stop gradient operator.
#### Seperation Loss
Finally, the keypoints should not collapse together and should keep a distance from each other to effectively track different objects in the scene:
| | | |
| --- | --- | --- |
| | Lsep=1K2K∑i=1K∑j=111+M∗||[¯xi,¯yi,¯zi]⊤−[¯xj,¯yj,¯zj]⊤||22 | |
where M is a positive value chosen to be 1000.
Finally, the total unsupervised learning loss is:
| | | |
| --- | --- | --- |
| | Lunsup=λae⋅Lae+λmulti⋅Lmulti+λsep⋅Lsep | |
###
2.4 Joint Learning of 3D Keypoints with Control
We integrate our 3D keypoint learning with PPO (Schulman et al., [2017](#bib.bib28)) so a control policy can be trained jointly on top of learned keypoints. We keep an observation buffer for all observed images. Before each policy gradient update, we train unsupervised learning from observations sampled from this buffer for several steps, updating encoder and decoder parameters θae with Lunsup. During policy gradient update, we optimize all parameters with the sum of policy loss Lpolicy and unsupervised learning loss Lunsup. The policy is learned on top of keypoints represented in world coordinates which can have arbitrary scaling and can hurt the training process. To handle this, we renormalize the values of predicted 3D keypoints before feeding them to actor and critic network. Pseudo code for the method is provided in [Algorithm 1](#alg1 "Algorithm 1 ‣ Keypoint Decoder ‣ 2.2 Differentiable 3D Keypoint Bottleneck ‣ 2 Unsupervised Learning of 3D Keypoints ‣ Unsupervised Learning of Visual 3D Keypoints for Control") with our addition in magenta color.
#### Temporal Consistency of 3D Keypoints
In many pixel-observation environments that requires temporal reasoning, a common technique is stacking adjacent frames as observation (Mnih et al., [2015b](#bib.bib24)). In our method, we use the technique but also apply the same keypoint detector on each frame independently with shared encoder weights. The result is thus stacked keypoints across frames. We compute a difference vector indicating keypoint movements across adjacent frames and concatenate it with latest keypoints before feeding into fc layers of policy network. Note we further add data augmentation which forces the keypoint to be consistent across different appearances, thereby granting consistency over time. We also tried adding a temporal prediction loss but it didn’t help because of sufficient temporal tracking signal from the data augmentations.
###
2.5 Data Augmentation as a Self-Supervisory Signal
Because the keypoint uv coordinates have explicit geometric interpretations, we can leverage data augmentation (Krizhevsky et al., [2012](#bib.bib14)) to provide additional self-supervision. The core intuition is that, when the input image is translated, the predicted keypoints, projected on camera plane, should also get translated by the same amount. Because the random shift operator, f, effectively transforms heatmap coordinates from the original unshifted image, we apply a reverse transformation, f−1, on the E[ukn], E[vkn] before unprojection to world coordinate. Before constructing gaussian maps, f is applied to reprojected keypoints again to map them back to the shifted coordinate. The random translation with shift offset plays a critical role in getting high quality keypoints.
3 Experimental Setup
---------------------
We evaluate our method on a variety of 3D control tasks with three-camera pixel observation. A reinforcement learning policy is trained jointly with unsupervised 3D keypoint learning as described in [Section 2.4](#S2.SS4 "2.4 Joint Learning of 3D Keypoints with Control ‣ 2 Unsupervised Learning of 3D Keypoints ‣ Unsupervised Learning of Visual 3D Keypoints for Control"). We choose a set of 3D manipulation environments (Yu et al., [2019](#bib.bib36)), a high-dof 3D locomotion environment (Coumans & Bai, [2016–2019](#bib.bib4)), a customized soft-body environment and a meta-learning benchmark (Yu et al., [2019](#bib.bib36)) to evaluate our method from different perspectives. These environments are originally developed for state based RL and are hard tasks for pixel based RL. We setup three third-person-view cameras in the scene such that most objects are visible from all three views. More details in the appendix.
We compare Keypoint3D with a variety of visual reinforcement learning algorithms. All the baselines, including Keypoint3D, are implemented on top of PPO (Schulman et al., [2017](#bib.bib28)) with the same CNN architecture and algorithm hyper-parameters. We stack images from all three view as observation for the baselines: (1) RAD (Laskin et al., [2020a](#bib.bib16)) is the state-of-art method for pixel based reinforcement learning. It achieves high sample efficiency through data augmentation. (2) CURL (Laskin et al., [2020b](#bib.bib17)) trains reinforcement learning on top of learned representation through contrastive learning. (3) Vanilla PPO is the original PPO algorithm (Schulman et al., [2017](#bib.bib28)) with a CNN architecture to take in image observations. (4) Keypoint 2D is PPO-based implementation of (Minderer et al., [2019](#bib.bib21)). We choose the number of 2D keypoint to be 3/2 of that of 3D keypoints so both methods have same number of coordinate bits.
4 Results and Analysis
-----------------------
We investigate following questions: a) How well does our 3D keypoint representation compare to other representations for policy learning? b) How well does our 3D keypoint method scale to high dimensional control from high dimensional observations? c) How well does our method adapt to deformable object manipulation where keypoints are more desirable but harder to track? d) How well does our 3D keypoint representation generalize to unseen setups?
###
4.1 Accuracy and Efficieny of 3D Keypoints
We select 8 tasks of varying difficulty from meta-world, each featuring 50 random configurations. As shown in [Figure 3](#S2.F3 "Figure 3 ‣ Multi-view Auto Encoding Loss ‣ 2.3 Losses for Training 3D Keypoint Encoder ‣ 2 Unsupervised Learning of 3D Keypoints ‣ Unsupervised Learning of Visual 3D Keypoints for Control"), our method out performs the state-of-art method RAD by a margin in 5 out of the 8 environments while having similar performance in rest of the environments.
CURL and vanilla PPO performed poorly on all 8 visual metaworld environments. Vanilla PPO and RAD usually perform well in easier tasks where a camera attached to end effector will suffice. Such setups assume a strong inductive bias that a big change in task space, such as reward, is associated with large pixel space change, such as an object that occupies half of the camera image. In a third person view setup such inductive bias is no longer true and a change in task space can correspond to an insignificant change in pixel space, if at a distance from camera. RAD mitigates this problem by using data augmentation to let encoder focus on a larger set of global features yet still doesn’t explicitly distill structure of the scene. In contrast, our method uses keypoints to distill the fine-grained movement of all moving components in the scene. 2D Keypoint performs better than CURL and Vanilla PPO but didn’t outperform our 3D Keypoint method.
This is likely because, in metaworld environments, objects can get very close to camera and show a large surface, which can be a problem for the 2D Keypoint representation (Minderer et al., [2019](#bib.bib21)) as it uses a fixed spatial variance in Gaussian map. Our 3D Keypoint method significantly mitigates the problem by assigning large spatial variance in gaussian map for closer objects, telling the decoder the presence of a potential large surface.

Figure 4: Benchmark reinforcement learning on Pybullet Ant (Left), a highly dynamical environment where fine-grained understanding of movable joints and parts are essential. Colorless Ant(Right) is a modified version without homogeneous limb colors to evaluate our method in low-texture setting.
###
4.2 Scaling to High-Dimensional Control
To evaluate our method on high dimensional control, we choose a highly dynamical 3D-locomotion environment, Pybullet (Coumans & Bai, [2016–2019](#bib.bib4)) Ant, where fine-grained understanding of movable joints and parts are essential. As locomotion environments require temporal reasoning, we use a frame stack of 2. The original ant environment in Pybullet assigns different colors to adjacent limbs. To further show that our method is robust to low-textured objects, we also benchmark on a colorless variant of ant.
As shown in [Figure 4](#S4.F4 "Figure 4 ‣ 4.1 Accuracy and Efficieny of 3D Keypoints ‣ 4 Results and Analysis ‣ Unsupervised Learning of Visual 3D Keypoints for Control"), our method significantly outperforms all baselines in both ant and its colorless variant. Our method, in particular, avoids local minimum as it better captures the structure of the robot as visualized in [Figure 7](#S4.F7 "Figure 7 ‣ 4.3 Keypoints for Deformable Object Manipulation ‣ 4 Results and Analysis ‣ Unsupervised Learning of Visual 3D Keypoints for Control"), where the Keypoint3D captures the 3D movement of the ant robot in world coordinates. The ant environment, from pixels, requires the temporal knowledge of velocity of body and limb to apply control effectively. We believe the temporal consistency as described in [Section 2.4](#S2.SS4.SSS0.Px1 "Temporal Consistency of 3D Keypoints ‣ 2.4 Joint Learning of 3D Keypoints with Control ‣ 2 Unsupervised Learning of 3D Keypoints ‣ Unsupervised Learning of Visual 3D Keypoints for Control") exactly achieved this, estimating the movement vector and feeding the mission-critical velocity information into our policy just like in state-space. Superiority of keypoint-based method is also reflected in the high performance of 2D keypoint baseline on the environment. On the other hand, Vanilla-RL, RAD and CURL lack explicit modeling of movement. CURL’s contrastive learning will overly focus on pixels and fails to capture the fine-grained joint positions or movements that results in little pixel change.

Figure 5: Left: Learning curve on scarf manipulation environment. Our Keypoint3D approach outperforms all the prior works consistently. Right: Scarf manipulation environment. The objective is to wind the scarf around human neck for one and a half full circle.
###
4.3 Keypoints for Deformable Object Manipulation
We further evaluate our method on a customized 3D scarf manipulation environment based on (Erickson et al., [2020](#bib.bib6)). In this environment, the objective is putting a scarf around human neck. This task requires both 3D reasoning of occlusion and understanding of the highly dynamical 3D soft object. [Figure 5](#S4.F5 "Figure 5 ‣ 4.2 Scaling to High-Dimensional Control ‣ 4 Results and Analysis ‣ Unsupervised Learning of Visual 3D Keypoints for Control") shows the result of Keypoint3D on scarf manipulation is the best among all methods.

Figure 6: Transfer Learning result on ML45 multi-tasking benchmark. Our 3D Keypoint method out performs others by a margin in a training environment consist of 45 tasks. When finetuned on a 5-task test environment, both representation learning methods, CURL and 3D Keypoint, outperforms RAD.

Figure 7: Visualization of the learned keypoints on colorless ant (left), metaworld close door (middle), metaworld hammer (right) environments. For the two metaworld environments, we filter keypoints with a threshold on learned keypoint attention. In colorless ant, the keypoints consistently track the limbs. In door the pink point with highest confidence tracks the movement of the door consistently. In hammer, the green point tracks hammer, while other points tracks the end-effector and sections of the arm respectively.
###
4.4 3D Keypoints for Transfer Learning across Tasks
To test how well does our 3D keypoint representation generalize to unseen objects, we conduct a transfer learning experiment on the ml45 multi-task learning benchmark of metaworld (Yu et al., [2019](#bib.bib36)). We followed the train/test split of the benchmark, first pre-train our method and baselines on 45 training environments featuring distinct objects for 10M steps. We then conduct transfer learning on 5 unseen test environments with the pre-trained weights for 2M steps. For each method, we freeze the pre-trained encoder and finetune the trained mlp part of the policy. We compare our method against the transfer result of RAD as well as CURL as shown in [Figure 6](#S4.F6 "Figure 6 ‣ 4.3 Keypoints for Deformable Object Manipulation ‣ 4 Results and Analysis ‣ Unsupervised Learning of Visual 3D Keypoints for Control"). Our method outperforms all the baselines in the training environment for the same reason in the single-task setting of metaworld. Both our 3D Keypoint method and CURL shows great transfer result compared to RAD, which fails because it does not have a representation learning component.
###
4.5 Visualization of Discovered 3D Keypoints
To better understand how our 3D keypoint learning method capture meaningful 3D structure of the tasks, we visualize the learned keypoints by projecting them onto the camera plane of each view. Keypoints of the same color across different views correspond to the same keypoint in 3D space. We can also filter out a portion of the keypoints with a threshold of learned attention. [Figure 7](#S4.F7 "Figure 7 ‣ 4.3 Keypoints for Deformable Object Manipulation ‣ 4 Results and Analysis ‣ Unsupervised Learning of Visual 3D Keypoints for Control") illustrates that the learned keypoints with most attention consistently follow the movement of essential moving components in the scene. In the colorless ant environment, keypoints track the 12 limbs and joints of the ant robot throughout time despite being colorless. The same phenomenon can be observed in the metaworld environments. More visualizations are shown in the appendix.

Figure 8: Ablations of our Keypoint3D approach with respect to different design choices. Variations include: remove camera offset in the cropping data-augmentation, remove multi-view consistency loss, map keypoints in 2D baseline to 3D space using triangulation.

Figure 9: Analyzing the role of joint training of unsupervised keypoint learning with control policy. We compare to three different variants of training policy disjointly where keypoint training data is collected via random policy (2-stage w/ Random) and via expert policy (2-stage w/ Expert). Third approach is to keep the same pipeline as ours but stop backpropagation from policy branch. The results show that joint training is crucial.

Figure 10: Ablation with respect to background changes in high-dimensional control. We show that Keypoint3D is robust to changes in the background unlike other methods because keypoints focus on the agent.
5 Analysis and Ablation
------------------------
In order to better understand the effect of different components on the sample efficiency of our method, we conduct ablative studies on two metaworld environments.
#### Effects of crop offset
Removing the random crop offset, described in the [Section 2.5](#S2.SS5 "2.5 Data Augmentation as a Self-Supervisory Signal ‣ 2 Unsupervised Learning of 3D Keypoints ‣ Unsupervised Learning of Visual 3D Keypoints for Control"), significantly lowered our performance on the open door environment as shown in [Figure 8](#S4.F8 "Figure 8 ‣ 4.5 Visualization of Discovered 3D Keypoints ‣ 4 Results and Analysis ‣ Unsupervised Learning of Visual 3D Keypoints for Control"). This is expected as the random shift of the input image should result in a corresponding change in the keypoint coordinate. When the crop offset is removed, randomly shifted keypoints will be incorrectly unprojected as we don’t change the camera matrix.
#### Effects of multi-view consistency
The ablation results for removing the multi-view consistency loss are shown in [Figure 8](#S4.F8 "Figure 8 ‣ 4.5 Visualization of Discovered 3D Keypoints ‣ 4 Results and Analysis ‣ Unsupervised Learning of Visual 3D Keypoints for Control"). No multi-view consistency severely hurts the performance illustrating that 3D representation is indeed a better representation. We also experiment with a variant of Keypoint2D where we map all 3D keypoints to 3D coordinates using multi-view triangulation. The performace is even worse, indicating multi-view consistency is critical even if we use triangulation instead of depth predictor.
#### Effects of joint training
To examine the benefit of training keypoint detection with policy jointly, we carry out three ablations as follows: (a) First train unsupervised 3D keypoint learning on random exploration data. Then train the policy with encoder weights frozen. (b) First train unsupervised 3D keypoint learning on expert data. Then train the policy with encoder weights frozen. c) We stop gradient of policy from backpropagating into encoder. (a)(b) are both 2-stage variants with offline data while (c) examines the effect of joint gradient with on-policy data. Our method outperforms all these three ablations as shown in [Figure 9](#S4.F9 "Figure 9 ‣ 4.5 Visualization of Discovered 3D Keypoints ‣ 4 Results and Analysis ‣ Unsupervised Learning of Visual 3D Keypoints for Control"), showing joint training is important to achieve high sample efficiency as well as performance.
#### Robustness under changing background
All of the previous experiments have static background due to the multi-view setup. To evaluate the effectiveness of Keypoint3D under changing background, we run an ant environment variant with checkerboard floor. As shown in [Figure 10](#S4.F10 "Figure 10 ‣ 4.5 Visualization of Discovered 3D Keypoints ‣ 4 Results and Analysis ‣ Unsupervised Learning of Visual 3D Keypoints for Control"), changing background of the environment makes the task harder from pixels for all methods. But our method still outperforms the strongest baseline, RAD.
6 Related Work
---------------
#### Representation Learning for RL
Common approach in RL is to learn image representations via end-to-end CNN policy (Mnih et al., [2013](#bib.bib22), [2015b](#bib.bib24), [2016](#bib.bib25)). Recent works enrich this representation via data augmentation (Kostrikov et al., [2020](#bib.bib13); Laskin et al., [2020a](#bib.bib16)). Alternative to data augmentation is to learn representations via auxiliary losses like inverse model (Pathak et al., [2017](#bib.bib27)), pixel change (Jaderberg et al., [2016](#bib.bib9)), VAEs (Kingma & Welling, [2013](#bib.bib12); Burda et al., [2019](#bib.bib1)), or contrastive loss (Laskin et al., [2020b](#bib.bib17)).
#### Unsupervised Keypoint Learning
Keypoints has been widely used as the representation of structure in image animation (Siarohin et al., [2020](#bib.bib30), [2019](#bib.bib29)), video prediction (Kim et al., [2019](#bib.bib11); Minderer et al., [2019](#bib.bib21)) or control (Kulkarni et al., [2019](#bib.bib15); Minderer et al., [2019](#bib.bib21)). These works builds on a fully differentiable keypoint bottlebeck (Jakab et al., [2018](#bib.bib10)) that can map a spatial probability map to images coordinates. They achieve their goal of animating a human or robot in source image by giving a target pose, represented by keypoints, before decoding. However, most of these works learn 2D keypoints in image space. In 3D setting, an object appearing to be a point at distance can be a large chunk of pixels when moving closer to camera. These methods would thus fail when the scene contains 3D movements.
#### 3D Keypoints Learning
Suwajanakorn et al. ([2018](#bib.bib33)) proposes a method to learn category specific 3D keypoints without supervision given a large dataset of rendered image and camera matrix tuples from many different views of the shapenet (Chang et al., [2015](#bib.bib2)) dataset. The method learns category specific 3D keypoints without direct supervision through multi-view consistent pose prediction. It requires this large data set of rendered images from many angles centered around rigid objects. In reinforcement learning setting, however, a scene is dynamic rather than a single rigid object. Cameras are also usually fixed during training. (Zhao et al., [2020](#bib.bib37)) learns to discover geometrically consistent 3D keypoints from pairs of images of object with rigid body transformation information. Tang et al. ([2019](#bib.bib34)) learns depth-aware keypoints through appearance and geometric matching from videos for autonomous driving.
#### Keypoint Discovery for Control
Florence et al. ([2018](#bib.bib7)) propose to learn an object-centric dense correspondence model through contrastive learning. The process involves a dataset collected without supervision, by scanning target object from a variety of angles using a robotic arm and doing 3D reconstruction using the data. (Manuelli et al., [2020](#bib.bib20)) samples points from this dense correspondence model as descriptor of an object and applies model predictive control on such keypoint based descriptor. (Manuelli et al., [2019](#bib.bib19)) proposes to use semantic 3D keypoints as the object representation for category-level pick and place tasks instead of transformation from a fixed object template. This method, however, requires manually labeled keypoint dataset. Gao & Tedrake ([2019](#bib.bib8)) improves its result by combining these keypoints with dense geometry of object. In contrast, we learn 3D keypoints directly from policy learning loss in an unsupervised and end-to-end manner.
7 Conclusion
-------------
In this work, we presented a framework to learn useful 3D keypoints without supervision for continuous control. Our key insight is to leverage multi-view consistency with a world coordinate transform in the bottleneck layer for learning reliable keypoints. We jointly train unsupervised 3D keypoint learning in conjunction with reinforcement learning to achieve significant sample efficiency improvement in a variety of 3D control environments. The 3D keypoints learned by our algorithm are consistent across space and time. The keypoints offer several benefits as they make the control policy less dependent on the visual input, and hence, provide a great means for transfer learning even if the visual distribution changes a lot, for instance, transfer from simulation to real. We hope our method serves as a bridge between pixel domain and 3D control tasks.
Acknowledgments
---------------
We thank Zackory Erickson, Alexander Clegg, and Charlie Kemp for fruitful discussions. This work was supported by NSF IIS-2024594 and NSF IIS-2024675. |
0d75b6dc-bd3f-4533-bf0a-a78f31d53c99 | trentmkelly/LessWrong-43k | LessWrong | Are there rationality techniques similar to staring at the wall for 4 hours?
I'm wondering if one exists, and what is the name of that technique or that family of techniques. It seems like something that CFAR has researched extensively and layered a lot of things on top of.
4 hours is necessary for anything substantially longer than 1-2 hours, since 6 hours is too long under most circumstances. Obviously, whiteboards and notepads are allowed, but screens and books absolutely must be kept in a different room. I'm not sure how sporadic google searching and book-searching and person-consulting factors into this, because those queries will suck you in and interrupt the state.
If people are using sleep deprivation, showers, lying in bed, or long drives to think, it's probably primarily the absence of interruption (from books and screens and people) that triggers valuable thoughts and thinking, not the tasks themselves. (although freeway driving might potentially do more good than harm by consistently keeping certain parts of the brain stimulated). |
52caa175-22a1-4d4a-ba3a-ac618760d661 | trentmkelly/LessWrong-43k | LessWrong | What are some in depth / meta-analytic, professionally edited wiki's? Examples inside
I'm sure most people here are familiar with http://www.scholarpedia.org , a well curated encyclopedia of scientific topics.
I recently came across http://examine.com/ which is a combination of encyclopedia and meta-analysis for supplements and cognitive enhancers. Given the popularity of the "Practical" section on http://www.gwern.net/ I think most of us would be interested in this information, and it's incredibly readable and well presented.
Can anyone suggest websites of similar quality? To be specific, I'm talking about
1) many searchable topics collected in one place
2) Well cited and in-depth reviews of literature and/or thorough meta-analyses
3) Adequate quality control. For example, all examine.com edits must pass two-man review team and Scholarpedia does decentralized peer review.
Topic or focus is not important, as long as there is a wealth of dense, high quality, **well cited** information. Suggestions? |
826cc4a1-6bd7-4310-b365-ecb93ee199eb | trentmkelly/LessWrong-43k | LessWrong | Dimensional regret without resets
TLDR: I derive a variant of the RL regret bound by Osband and Van Roy (2014), that applies to learning without resets of environments without traps. The advantage of this regret bound over those known in the literature, is that it scales with certain learning-theoretic dimensions rather than number of states and actions. My goal is building on this result to derive this type of regret bound for DRL, and, later on, other settings interesting from an AI alignment perspective.
----------------------------------------
Previously I derived a regret bound for deterministic environments that scales with prior entropy and "prediction dimension". That bound behaves as O(√1−γ) in the episodic setting but only as O(3√1−γ) in the setting without resets. Moreover, my attempts to generalize the result to stochastic environments led to bounds that are even weaker (have a lower exponent). Therefore, I decided to put that line of attack on hold, and use Osband and Van Roy's technique instead, leading to an O(√1−γ) bound in the stochastic setting without resets. This bound doesn't scale down with the entropy of the prior, but this does not seem as important as dependence on γ.
Results
Russo and Van Roy (2013) introduced the concept of "eluder dimension" for the benefit of the multi-armed bandit setting, and Osband and Van Roy extended it to a form suitable for studying reinforcement learning. We will consider the following, slightly modified version of their definition.
Given a real vector space Y, we will use PSD(Y) to denote the set of positive semidefinite bilinear forms on Y and PD(Y) to denote the set of positive definite bilinear forms on Y. Given a bilinear form B:Y×Y→R, we will slightly abuse notation by also regarding it as a linear functional B:Y⊗Y→R. Thereby, we have B(v⊗w)=B(v,w) and Bv⊗2=B(v,v). Also, if Y is finite-dimensional and B is non-degenerate, we will denote B−1:Y∗×Y∗→R the unique bilinear form which satisfies
∀v∈Y,α∈Y∗:(∀β∈Y∗:B−1(α,β)=βv)⟺(∀w∈Y:B(v,w)=αw) |
00a2c940-b9f9-4b5b-a077-43e07ed784b3 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | We Ran an Alignment Workshop
**TL;DR:**
----------
AI Safety at UCLA ran an alignment workshop for community members interested in testing their aptitude for theoretical alignment research. Attendees spent the weekend trying to make progress on [these open problems](https://docs.google.com/document/d/1NVVtdsfz7HiseVFSk3jYly4sPG4dG03wFFDrD8rBXU0/edit).
We highly recommend other university groups hold similar < 15-person object-level workshops that focus on difficult yet tractable problems in AI Safety.
**Why did we run Define, Design, and Align?**
---------------------------------------------
Despite there being a [wide range of theoretical alignment proposals](https://www.alignmentforum.org/posts/fRsjBseRuvRhMPPE5/an-overview-of-11-proposals-for-building-safe-advanced-ai), we felt that there were surprisingly few structured opportunities for people to engage and build on these ideas. Furthermore, progress in theoretical alignment can feel nebulous, especially when compared to more prosaic alignment research, which we believe can deter potential researchers before they even begin engaging with the problems.
We aimed for participants to:
* Actively spend many hours thinking deeply about problems in theoretical alignment
* Test their aptitude by gaining feedback from industry professionals
* Collaborate with other talented students working on AI safety
**What did the weekend look like?**
-----------------------------------
The retreat lasted from Friday evening to Sunday afternoon and had 15 participants from UCLA, UC Berkeley, Georgia Tech, USC, and Boston University. Ten of the participants were undergraduates, and the rest were Ph.D. candidates or early-stage professionals. Everyone had prior experience with research, AI safety, and some form of technical machine learning.
The majority of the weekend was left unstructured. We held an intro presentation to give attendees a sense of what the weekend would look like, but after that, they were paired with another participant with a similar research focus, and left to work on their question. Groups had time to share their proposals with Thomas Kwa, a professional research contractor at MIRI, and discuss them with the other attendees. The workshop convened on Sunday for closing presentations so groups could share their progress and get feedback.
I (Aiden Ament) organized the content of the weekend. Brandon Ward ran operations for the event, with help from Govind Pimpale and Tejas Kamtam.
**What went well?**
-------------------
All of the participants were deeply engaged with concepts in theoretical alignment, and their presentations (which we encouraged them to publicize) were impressive. They made good use of the unstructured time by working diligently and having productive conversations with the other attendees. All of the participants found the workshop useful and well organized. We had a 8.75 average net promoter score, indicating our participants would strongly recommend the workshop to their peers.
Not many people have actually worked on these problems. After talking with Vivek Hebbar, he shared that they received around 15 answers to their SERI application (which is where the workshop's questions were sourced). This means that our workshop “very roughly” doubled the number of people who have seriously engaged with these questions in the past year. Thus, future workshops on other open topics in AI safety have the ability to increase overall engagement with the chosen problem dramatically.
Furthermore, the quality of each group's research was quite high overall, considering the brief period they had to engage with the problems. After the workshop ended, teams were encouraged to draft a formalized version of their ideas. These have been passed onto Thomas Kwa (or other industry professionals better posed to evaluate the agenda), and are currently pending feedback.
**What could be improved?**
---------------------------
While the lack of structured activity allowed participants to pursue their thoughts without interruption, feedback indicates the workshop did suffer from a lack of formal team building events. Some participants noted they would have preferred additions like scheduled discussion time with Thomas or optional group sub-activities to break up the unstructured research. We think lectures from experts could be particularly valuable in helping people develop their research agenda. In our future workshops, we’re going to include such programming.
The research questions we chose to highlight were another area that could be improved upon. We thought that these questions were a good starting point to engage in theoretical research, but many people expressed how their limited scope didn’t allow them to pursue the topics which really interested them.
As an organizer, solving this seems tricky. We want to provide tractable questions that motivate valuable research, without limiting participants from pursuing the topics they find the most insight in. I think we should allow people to pivot from their original topic midworkshop as long as their partner and the organizers agree that their new focus is worthwhile to allow for participants to generate higher quality research. Additionally, we could ask even more open ended questions that allow for greater flexibility and creativity to prevent attendees from feeling limited. Ultimately, finding the proper questions to motivate a workshop is a balancing act, and we’re still figuring out what works best. |
9d4573b8-5cf2-4d76-a7f7-02bdf9370463 | trentmkelly/LessWrong-43k | LessWrong | Alignment Newsletter #38
Merry Christmas!
Find all Alignment Newsletter resources here. In particular, you can sign up, or look through this spreadsheet of all summaries that have ever been in the newsletter.
Highlights
AI Alignment Podcast: Inverse Reinforcement Learning and the State of AI Alignment with Rohin Shah (Lucas Perry and Rohin Shah): Lucas interviewed me and we talked about a bunch of different topics. Some quick highlights, without the supporting arguments:
- If we want to use inverse reinforcement learning (IRL) to infer a utility function that we then optimize, we would have to account for systematic biases, and this is hard, and subject to an impossibility result.
- Humans do seem to be good at inferring goals of other humans, probably because we model them as planning in a similar way that we ourselves plan. It's reasonable to think that IRL could replicate this. However, humans have very different ideas on how the future should go, so this seems not enough to get a utility function that can then be optimized over the long term.
- Another issue with having a utility function that is optimized over the long term is that it would have to somehow solve a whole lot of very difficult problems like the nature of identity and population ethics and metaphilosophy.
- Since human preferences seem to change as the environment changes, we could try to build AI systems whose goals are constantly changing by continuously running IRL. This sort of approach is promising but we don't know how to get it working yet.
- IRL, agency and optimization all seem to require a notion of counterfactuals.
- One view of agency is that it is about how a search process thinks of itself, or about other search processes. This gives it a feeling of "choice", even though the output of the search process is determined by physics. This can explain the debates over whether evolution is an optimization process -- on the one hand, it can be viewed as a search process, but on the other, we understand it w |
f01040e6-a426-489e-8e01-9618703941d4 | trentmkelly/LessWrong-43k | LessWrong | Predicted corrigibility: pareto improvements
Corrigibility allows an agent to transition smoothly from a perfect u-maximiser to a perfect v-maximiser, without seeking to resist or cause this transition.
And it's the very perfection of the transition that could cause problems; while u-maximising, the agent will not take the slightest action to increase v, even if such actions are readily available. Nor will it 'rush' to finish its u-maximising before transitioning. It seems that there's some possibility of improvements here.
I've already attempted one way of dealing with the issue (see the pre-corriged agent idea). This is another one.
Pareto improvements allowed
Suppose that an agent with corrigible algorithm A is following utility u currently, and estimates that there are probabilities pi that it will transition to utilities vi at midnight (note that these are utility function representatives, not affine classes of equivalent utility functions). At midnight, the usual corrigibility applies, making A indifferent to that transition, making use of such terms as E(u|u→u) (the expectation of u, given that the A's utility doesn't change) and E(vi|u→vi) (the expectation of vi, given that A's utility changes to vi).
But, in the meantime, there are expectations such as E({u,v1,v2,...}). These are A's best current estimates as to what the genuine expected utility of the various utilites are, given all it knows about the world and itself. It could be more explicitly written as E({u,v1,v2,...}| A), to emphasise that these expectations are dependent on the agent's own algorithm.
Then the idea is to modify the agent's algorithm so that Pareto improvements are possible. Call this modified algorithm B. B can select actions that A would not have chosen, conditional on:
E(u|B) ≥ E(u|A) and E(Σpivi|B) ≥ E(Σpivi|A). There are two obvious ways we could define B:
B maximises u, subject to the constraints E(Σpivi|B) ≥ E(Σpivi|A). B maximises Σpivi, subject to the constraints E(u|B) ≥ E(u|A). In the first case, the agent max |
8744945a-87ec-4a33-905a-720632e82e6a | StampyAI/alignment-research-dataset/youtube | Youtube Transcripts | Jim Babcock – The AGI Containment Problem – CSRBAI 2016
it was been a serial entrepreneur in
fields of programming machine learning
and medicine and has volunteered with
FLI Jim is here to talk today about
problems in computer security
that we might want to focus on in
advance in order to build safe testing
environments for artificial intelligence
is that in reason more generally as
quite possibly relevant to to Paul's
talk as well so let's so join me in
welcoming Jim Babcock today talked about
capability decomposition which is where
because it may be difficult to make a
sort of unified reinforcement learning
agents that has the properties we want
but we build some sort of structure out
of a sub agents like
and these sub agents do things like some
of them communicate with each other some
of them control each other's reward
channel and then at the end there's an
output that goes to the environment and
the environment gives back observations
but you could imagine setting up
something like this and one of the sub
agents notices let's say this one
notices that this other sub agent over
here has some information that would
really help it to get a higher reward so
it tries to find a communication site
channel to talk to this one and it's
this one also notices that this one has
some information we want and they trade
information and suddenly are not
following the structure that the
developers intended and it becomes very
difficult to reason about another thing
you might have that could happen is say
this agent sends this agent a malformed
observation that changes its behavior to
be something different for example if
this one is giving the words back to
this one it might send a message that
causes it to always give maximum reward
because that would be really great what
I mean by AGI containments what I'm
going to be talking about is you're
setting up a computational environment
for all of these sub agents to to
interact in how do you make it so that
that setup enforces the constraints and
the structure that you intended your
system to have so that agents aren't
communicating unless you who actually
wrote function calls from one to the
other and they aren't randomly giving
each other buffer overflow
crazy stuff like that the extreme case
of this going wrong would be if basic
one sub agent takes over the
computational environment entirely has a
network connection and starts
interacting with the Internet where
there's all sorts of trouble that it
could get up to but that's what one of
the easier failure modes to defend
against the Beast if you're testing
because you can just unplug cables but
when you have parts that are supposed to
be interacting you can't put an air gap
between them today a eyes are not smart
enough to discover some computer
security vulnerabilities in general
there's sort of borderline cases that
you might call a narrow AI but would be
pushing the definition a little bit but
decades down the line this may be an
issue these specific vulnerabilities
that exist today
probably aren't going to exist decades
down the line so I'm gonna sort of I'm
going to present some examples to give a
feel for what sort of computer security
vulnerabilities are possible but what
I'd rather you be thinking about is the
shape of the computational environments
and how the pieces interact and what
that means for what things need to be
hardened and how to put those pieces
together so an example set up a little
more concrete than the thing I'd run the
white board suppose you have an AI that
plays Mario so sends buttons one way it
gets back pixels and then at the end of
your test
Mario spits out a performance report
which goes to the developer it turns out
that the Super Nintendo game Super Mario
World has a buffer
overflow human human players discovered
in in in this order ways to make the
game literally produce game objects a
way to make the game literally jump to
the end of game you win screen and then
a way to make it load of program via the
controller port and start playing snake
that required very precise input that
the controller part was not connected to
a real controller with human hands but
just in the last month someone did
manage to do it without without machine
aid and made super mario world
transformed into flappy mario a flappy
bird clone and during the entire program
and triggering the the memory corruption
by hand and report ends i think live
streamed it on youtube so people could
see that he got it on the first try
so in setups like this
the andhra thesis about conversion
instrumental goals applies you have some
agents most setups will give them
certain incentives if they have the goal
that's they're able to optimize them
they prefer that aged guys that are
similar to them come to exist because
those will optimize similar goals so for
example if the if the AGI could output
either everything is great or there is a
catastrophic error if it outputs there
is a catastrophic error then this will
cause aged guys like it to not come to
exist in
world because developers won't try that
again but if there's two aging eyes with
different incentives then it can then it
can report catastrophic errors only so
long as they are maintaining those
separate utility functions and all of
these instrumental goals it helps to
find security vulnerabilities that let
it break constraints that the
environment is trying to impose on it so
what do I mean by an API container what
I mean is it enforces the structure that
you thought you had and makes sure that
the company that's the computation
really has that structure so only runs
the code that you want in the places
that you want think things don't have
unexpected and put our output channels
the log files or logging what really
happened and not what the AI would want
to be in the log files tripwires work
you can reproduce it you can reset it
and not find out later that it
reprogrammed the hardware on you and you
can do and if you have a data center of
these things you can do several tests in
parallel and they are properly isolated
so why how would it be able to run code
that you didn't want or expect well you
might give it permission to self modify
but assuming you didn't do that
it might output an image and then some
other part of it reads that image or the
developer reads that image on their
workstation and image formats are
complicated and the PNG occasionally
tests security vulnerabilities
discovered in it which will execute
arbitrary code
whatever computer opens that image an AI
that is modular
if one module sends messages to another
that are not formed then that could
trigger a buffer overflow it could take
over that other module or maybe it
breaks more of the constraints than that
one type of output that's a that's
particularly a problem text is not just
text I don't know how many of you have
worked with this particular aspect of
UNIX and Linux before but text is a
bunch of printable characters and
occasionally a command that says
something like move the cursor to the
left of the line or clear everything
below the cursor and this protocol goes
back to the 70s and is really really
messy the things that interpreted have
sometimes have buffer overflows one in
one example in X term you can send you
can send an escape sequence that says
you can send an escape sequence that
says sent the window title so that when
you vault tab you know what's in that
window and then you can send it up
another escape sequence that says echo
back what the window title is so and
what a program can do is set the window
title to commands newline send a echo
back to the window title sequence and
then quit and then the window title
sequence gets typed into this shell that
ran that program
there's also hardware problems there's a
know fairly famous issue where if you if
a program accesses memory in a
particular pattern its causes something
something like an electrical fault in
RAM chips that will randomly flip bits
and security researchers found that they
can exert some control over which bits
get flipped and caused permission bits
to get flipped in memory page tables
it's kind of ridiculous and that's now
basically fixed on most computers by
tweaking some electrical parameters of
how how often the RAM gets refreshed but
there are probably more problems like
this waiting to be found
so should only execute the code you
think it's running should not get
information from places you don't think
it's gonna get it or send information
where it shouldn't another famous name
security vulnerability is called was
called GS mem and the way that works is
someone puts a reprogrammed cellphone on
top of a computer's case and a program
running on that computer accesses memory
in a way that generates radio frequency
interference and sends a message to the
phone so militaries and organizations
that like to be careful with their
secrets well put glue in all of the USB
ports and not provide any network cables
or anything so obviously you couldn't
get any information out except by
laborious ly typing it into that phone
by hand right if a program has access to
a clock then and the same computer is
also doing a EES encryption operations
repeatedly then by measuring time
measuring cache timings the program can
extract information and invokes this a
secret key you began to talk with saying
what abilities aren't not so
we move this back to where it was before
Botox so it seems kind of like magic if
you don't know what the space is
possibility is that these things are
working with is but if you if you draw a
diagram of all of the parts in the CPU
you can see yeah these two processors
are sharing an l2 cache and that means
that they will occasionally affect each
other's timing and if you are really
really careful about it you might try to
prove that they don't which would
probably mean just putting them on
separate CPUs because that's easier log
files debug information if it's
different so I'm envisioning this as an
ATI has some print statements and it's
that occasionally print out details
about what it's doing that the
developers will look at later if it's
running the code you think it is this is
mostly fine and it's not running the
code you think it is then that could be
anything including weird X term escape
sequences
so and as far as debugging there's two
general categories of debuggers that
exists there's the usual kind of
debugger which assumes that you're
debugging a program that you wrote you
have in source code and it isn't
malicious if you attach norm your normal
python debugger or VBB to a malicious
program then it might take over the
debugger this isn't a failure mode that
people are particularly worried about
because people don't use debuggers in
that sort of circumstance but there's a
different kind of debugger which is
intended for debugging malware but which
generally assumes that you're working
with the assembly because my work
doesn't give source code so one thing
that one thing that I think people
should be doing is making a middle
category of debuggers that is hardened
but designed for cases where you really
do have the source code and have at
least presumptive assumptions about what
you're looking at tripwires
so so one example of a tripwire is this
sort of stylized assert statement to
certain not taking over the world we
can't really design things like that
today because we don't know what the
algorithms are going to be Paul had some
ideas about guaranteeing
non-catastrophic execution that depends
on a particular setup but what I
mentioned what I'm more interested in
which we can work on now is
technical requires that asserts things
like this data structure is not corrupt
there aren't pointers pointing to weird
places or point pointers that our
knowledge shouldn't be or cycles and
your data structures things like that
the thing that is kind of tricky about
that is if an AGI is reflective it can
look at this Venn diagram and try to aim
at this slice so an interesting software
architecture problem is how do you how
do you allow introspection while denying
access to that information have a
program have a program that can look at
everything about its source code except
for where the assert statements are and
what they say over time so
reproducibility
is it's a bunch of issues if you write
it at you if you write a fully
deterministic program then in principle
it's reproducible as long as you by the
time of year going investigating what
went wrong you still haven't still have
the pseudo-random see you still have all
the inputs you haven't lost track of
things
so some programs look deterministic but
aren't because because of race
conditions for example you so you write
a program that's multi-threaded and it
has slightly different behavior based on
which of two things finished first
purely from pure functional languages
like Haskell I think let you get
guarantees of this not happening
something like Python that won't happen
so there's a programming languages
research question which is how to get
guarantees of gnome race conditions
secure resets so a you know dawg i heard
you like computers so i put ten
computers inside your computer hey Herc
each component of a computer typically
is another computer that you don't
really think about because all it's
doing is managing the interaction
between itself and the main computer but
security researchers do think about
these things and sometimes find ways to
reprogram them to make it so that when
they take over a computer it is person
it is persistent so that
if the user reinstalls the operating
system they're still not where they're
so so jellyfish is a bit of malware that
runs on GPUs that is a research project
on github it lives in memory so if the
computer is powered down and turned back
on it will go away but if you just hit
the reset switch it'll stay the NSA had
a catalogue of all of their computer
security tricks leaks a few years ago
and it contains lots of things like for
example irate monk which programs not
not the hard disk contents but the
controller that decides where on the
hard disk to read next to order reads
and writes for good performance and
makes it so that if it's reading an
executable off the disk every thousands
time or something it will read a
different executable that contains their
code so that's the isolation and you
want you don't want you don't want
experiments communicating with each
other if they weren't supposed to you
don't want one tests to changing the
hardware and affecting all the
subsequent tests similar sorts of other
abilities or a problem so there's all
these technical issues and then there's
also humans so in the early days of
what's wrong please read Kowski ran what
he called the AI box experiment where
you would have an IRC chat lasting a few
hours with someone with someone
role-playing as a gatekeeper
try to convince them to let him out of
the box and he succeed he he didn't
succeed every time but he didn't succeed
and the super intelligence is probably
smarter than any humans so it should be
able to do this as well and so other
people reproduced it's tuck stitch was
another user who ran the Eibach's
experiments and succeeded at them but
you can't persuade a human to do
something without actually being able to
talk to them so there's a policy
question which is the if the AGI outputs
things
what outputs are okay to read and who is
it okay to read them and that depends
how smart do you think it is on how much
you trust the specific you people
involved what that is for and how you
think it's optimized the containers job
is to enforce that policy to make sure
that a developer can read log files
while a passerby can't can't receive
text messages telling them that it would
be fun to plug in extra network cables
in me so if you're really really really
paranoid then you can use some fairly
extreme strategies like have the age
guys output only be the answer to one
multiple-choice question and a B C or D
none of these answers is going to trick
me into pasting the AIS source code onto
a different server there's just not
enough information there a similar thing
which can solve problems like rope
hammer with high reliability is
homomorphic encryption which transforms
a computation into something that
as much floor but doesn't interact with
the hardware in any way that's
distinguishable from randomness without
access to a particular geographical key
so and the paper about this we define
sort of define a hierarchy of degrees of
caution essentially from light
containments for well we don't really
have been working yeah yeah but we'll
use some software as long as it doesn't
get in the way sort of future I think of
that as if we can write software for
containment and some of some measures
will just be dropped in doesn't cause it
doesn't cause any problems for the
developers just makes things silently
more reliable instead of all of those
things and then there's some more things
you could do to make it more reliable
that slow things down or make the
developers do extra work and those are
medium containment and there are some
things that slow things down
lock and make and less than the escape
ability and I think we called those
heavy containment so that's an overview
of the problem
not the end of the talk I'm going to
tell you about off-the-shelf
technologies that are partial solutions
and say that we need more research to
make these better yes kind of yeah you
have the slides angle your invariances
we had this listen variances yes I'm
wondering like how how do we generate a
list of these and variances such that
like I'm sure that I haven't I don't
think the list is complete I mean I'm
sure that there are more things and
specific projects will have specific
invariants as well about like their data
structures amount of computation that
pieces used and I'm sure many other
things that I haven't really thought
about the strategy that I use to
generate that list was thinking about
what properties if they fails to hold
would break everything else so that you
couldn't possibly have any other
invariants besides those
other questions before I go on so here's
sort of an overall picture so
conceptually you have an AGI program and
it's written in some programming
language and that programming language
is a sort of sandbox a few programming
languages actually call it that like the
Java sandbox the basic premise is well
if you if you never mention the
functions that make network connections
then clearly this program is not going
to make network connections you hope I
mentioned a few loopholes and that sort
of thing but it's a partial solution
it's clearly much harder for it's
clearly a significant obstacle to break
out of the language model for a program
if it's going to corrupt its own memory
it's very likely to crash itself instead
of take instead of doing the particular
weird thing it wanted then there's the
operating system privilege model where
when you run a program you can say this
program is only allowed to access these
particular things and nothing else
Linux has a version of this BSD has
another version of this windows has
another version of this the defaults are
pretty permissive but if you put in the
effort to say exactly what it's supposed
to be able to access then the operating
system will enforce some things for you
but the Linux kernel occasionally has
security vulnerabilities as well
so you've got that and then also you
have a virtual machine a virtual machine
is like an operating system inside of an
operating system where you have clinic
you have the Linux kernel and then that
runs a program which emulates another
computer using the similar hardware so
that it's fast it's fast emulation then
that computer has another kernel and
then that runs a program that is the AGI
and then the fourth layer on top of that
is you keep track of what wires are
connected to what and the idea is that
these are conceptually dissimilar enough
that's if you find the security
vulnerability in one that doesn't really
help you very much with finding security
vulnerabilities and the other ones so
this diagram say the AV guy starts down
here it if this has permission to self
modify then it can follow this arrow and
get up to here and if it finds a
vulnerability and entity bugger then it
can get up to here and if it finds a bug
and it's the driver that controls the
GPU then it can get up to here and and
so on and has to get all the way up to
here before it can actually interact
with the internet and as it as it goes
up it properties that you would want to
have stopped holding and the idea is you
build a multi-layer thing like this and
then each layer there is some monitoring
that looks at the low V inner layers and
checks that they are only running the
code
they're supposed to be running so
language semantics I talk to I just
talked about that on a skit there's a
scale running from C to Haskell where C
is almost impossible to write correct
programs and and errors lead to amazing
amazing League comes complete control
ability to Haskell which has a very
thorough script type system which
doesn't really have this sort of problem
the problem is that a program written in
Haskell is still dependent on a bunch of
software libraries for doing things like
interact with the GPU and bio and
loading data and those might be written
in C with problems in them so next layer
operating system sandboxing there's at
least a couple dozen of these one in
particular just to give you a sense of
how they work
Linux has a mechanism called SEC come
where the program starts running it
initializes it opens all of the files of
plans to use and then it says from this
moment forth I will never open another
file I will never make another system
system call accepts to interact with
this set of files that I had already
have open and if I ever break this
promise then send me sick kill
that's the default and the more refined
version that Linux also supports is to
say all of the system calls I will make
from now on if you feed them into this
short little program will return what
the program is called the Berkeley
packet filter it was originally made
designed for Network firewalls and got
repurposed for this virtual machines
there's about one security vulnerability
per major virtual machine product for a
year that would allow breaking out of
the virtual machine sandbox hopefully a
decade from now they'll all be found and
there won't there won't be any left we
can hope maybe we can speed that up we
can hope a virtual machine virtual
machines have a fairly complicated
surface area because they're not just
providing a CPU for programs to run on
they're also providing a virtualized
video card if you want to turn an avi it
probably does have to so GPUs are these
incredibly complicated things and they
have these drivers that essentially take
code that you wrote for the GPU and
compile it and in a virtual machine that
driver lives on the host system instead
of on the guest
book both nvidia and AMD have projects
in the works to try to change this but
they're not done yet for now this this
is what you get if you use a GPU this
this is a quote I found out on a random
internet forum from a former developer
at Nvidia about how complicated GPU
drivers are and apparently GPU vendors
and video game companies have been
working around each other's bugs for
more than a decade and the result is
that they are extraordinarily
complicated they're also full of they're
full of bugs they're written in C++ and
they run with very strong privileges
so this is a problem google recently
announced their tensor processing units
which sound kind of like their non
backwards compatible machine learning
only GPUs and I think that's great
because it means they don't have to use
this million line driver codebase to run
their a eyes so network topology you can
you can air-gap your system this is what
people use used to think about when
talking about AI boxing you just put it
in a concrete concrete shell or
something and don't have any network
cables in and yeah that means that it's
not going to interact with the outside
world in any ways you didn't intend but
that's totally useless because you do
actually want to use if you want to test
them you want
tests parts of it to test each other and
also developers like to work in nice
offices not in isolated concrete bunkers
so what I expect to happen is that these
will be configured with routers that
limit what can talk to what which might
have Boehner abilities and them
hopefully not but no actual air gapping
so questions about any of this okay so I
have one more slide which is what what
can we do about today seems this thing
about about this is that it's a bunch of
work that calls for a completely
different skill set than the usual AI
safety work so different people can work
on it making a hardened debugger does
not require any knowledge at all about
machine learning and machine learning
does not require any knowledge at all
about the software architecture of
debuggers so this is something that can
be pretty costlessly pursued in parallel
not costlessly because of how society is
organized but in principle could be done
costlessly in parallel it's some it
would be very valuable if someone were
to set up red team events where there's
a set up that is that represents a an AI
container as it would normally as one
might expect to be organized and people
compete to break out of it or to break
its invariance and then report how they
did it this is how the world of computer
security has gotten successes elsewhere
for example every year there is a
contest to break out of the google
chrome sandbox for $60,000 I believe
that progress has been claimed every
year but every year the way that it's
done gets more impressive
so that's that's where we're at as far
as the the infrastructure that ICA is
being built on and changes that I think
need to be made to make them more secure
yeah a bunch of questions for but yeah
more questions okay in the in the
broader world of the internet where
people are doing running lots and lots
of different programs not necessarily
investing in all in security offense
pretty reliably wins over defense is it
has so far I don't expect that to change
in the context of an AI where the
developers can invest in making things
secure I think it could go either way
and there's reasonable prospects that
defense will win and even if it's not
possible to get rid of all the security
vulnerabilities just because there's a
vulnerability doesn't mean the AI is
going to be smart enough to find it so
I'm surprised you didn't mention formal
verification and then type theory as as
part of this because it seems like
projects like a a version of Linux that
is formally verified goes along the way
towards hardening not just the attack
vectors you know about but once you
don't yet know about yeah so I bought
ice i bundled that in language semantics
there's there's an isomorphism between
type-checking
and formal proofs they're not exactly
equally expressive but if you have a
sound type system like in Haskell for in
Haskell or thrust for example then there
is implied in that of proof that certain
kinds of errors aren't present we want
to go a step further to sound dependent
X's something like icon where you can
like express computations it would I
agree but I also think that's replacing
all the legacy C code with anything else
is a much bigger game than going from
reasonable programming languages to the
very best possible programming languages
yes related to speech question what are
you intuitions about bugs currently
being dense versus parson what is
possible to make by using different
architectures I'm familiar with that
look I've learned like them kind of
means that like in my drama debug salute
fix someone will be able to find so
there was a recent advance in bug
hunting techniques in the form of a
program called AFL fuzz which revealed
that the bugs were denser than everyone
had thought there were a lot of old
programs that had gotten a lot of
attention a lot of bug fixing and people
thought that they had probably gotten
everything or almost everything and then
they hooked it up to this really
sophisticated buzzer that generates
random inputs in a strategic sort of way
and it finds huge numbers of
vulnerabilities in them and that still
doesn't cover all of the types of bugs
in particular we know that it doesn't
cover our bugs we know for sure that it
can't find bugs that require very large
inputs or triggering certain kinds of
integer overflow so when I'm thinking
about a big leap it's like one of the
main things that seems like especially
hard to send against and steganography
is like if there's any any channel from
the humans who eventually like to do
things to the Internet any kind of
information theoretic channel let form
has like more than some number of
kilobytes right then it seems easy to
like create a message encrypted with a
meat key and then all right so the
problem there is that you could ask the
AI to paint you a picture
and this picture is nicely you put it in
your press release and later it turns
out it contained the AI source code I
like hey I think the main thing I would
serve you about is like if we had a way
to deal with this especially difficult
problem with that method of solving that
problem also so like a lot of these
other things or like are actually a need
for different solutions in different
problems so there is a possible research
path there where people could look into
how to take images and noise them and
put them through auto-encoders and
jitter them and whatnot in such a way
that's steganography can't get through
but the only surefire solution is just
never published that image or anything
they produce directly by the AI know
like yes Oliver do you envision like I'm
selecting against things that cannot
only write code and like recent event
burn abilities but like reason about
multiple copies of themselves and
similar agents and so forth and the
thing I kind of like to use that there
is another copy of me running on that
server over there and so coordinated
without actually exchanging any
information there's a lot to think about
there but it's definitely worth
researching but it's not something that
the software can help with yeah but it's
kind of like make sense to be aware of
those kinds of like problems as well
because it kind of might indicate which
layers are worse defended that we would
think people think those things I agree
all right
so let's let's thank you again |
09e6f11f-d5bb-445d-a545-2ce06ceb9a5d | trentmkelly/LessWrong-43k | LessWrong | Minimal Motivation of Natural Latents
Suppose two Bayesian agents are presented with the same spreadsheet - IID samples of data in each row, a feature in each column. Each agent develops a generative model of the data distribution. We'll assume the two converge to the same predictive distribution, but may have different generative models containing different latent variables. We'll also assume that the two agents develop their models independently, i.e. their models and latents don't have anything to do with each other informationally except via the data. Under what conditions can a latent variable in one agent's model be faithfully expressed in terms of the other agent's latents?
Let’s put some math on that question.
The n “features” in the data are random variables X1,…,Xn. By assumption the two agents converge to the same predictive distribution (i.e. distribution of a data point), which we’ll call P[X1,…,Xn]. Agent j’s generative model Mj must account for all the interactions between the features, i.e. the features must be independent given the latent variables Λj in model Mj. So, bundling all the latents together into one, we get the high-level graphical structure:
which says that all features are independent given the latents, under each agent’s model.
Now for the question: under what conditions on agent 1’s latent(s) Λ1 can we guarantee that Λ1 is expressible in terms of Λ2, no matter what generative model agent 2 uses (so long as the agents agree on the predictive distribution P[X])? In particular, let’s require that Λ1 be a function of Λ2. (Note that we’ll weaken this later.) So, when is Λ1 guaranteed to be a function of Λ2, for any generative model M2 which agrees on the predictive distribution P[X]? Or, worded in terms of latents: when is Λ1 guaranteed to be a function of Λ2, for any latent(s) Λ2 which account for all interactions between features in the predictive distribution P[X]?
The Main Argument
Λ1 must be a function of Λ2 for any generative model M2 which agrees on the predicti |
9200ba5c-801c-4b1c-9f16-a14cb6b77da6 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | How is ARC planning to use ELK?
Let's say we arrive at a worst-case solution for ELK, how are we planning to use it? My initial guess was that ELK is meant to help make IDA viable so that we may be able to use it for some automated alignment-type approach. However, this might not be it. Can someone clarify this? Thanks. |
e3756a54-607f-4494-bd38-90745d900bf7 | trentmkelly/LessWrong-43k | LessWrong | Remarks 1–18 on GPT (compressed)
Status: Highly-compressed insights about LLMs. Includes exercises. Remark 3 and Remark 15 are the most important and entirely self-contained.
Remark 1: Token deletion
Let T be the set of possible tokens in our vocabulary. A language model (LLM) is given by a stochastic function μ:T∗→Δ(T) mapping a prompt (t1…tk) to a predicted token tk+1.
By iteratively appending the continuation to the prompt, the language model μ induces a stochastic function ¯μ:T∗→Δ(T∗) mapping a prompt (t1…tk) to (t1…tk+1).
Exercise: Does GPT implement the function ¯μ ?
----------------------------------------
Answer: No, GPT does not implement the function ¯μ . This is because at each step, GPT does two things:
* Firstly, GPT generates a token tk+1 and appends this new token to the end of the prompt.
* Secondly, GPT deletes the token t1 from the beginning of the prompt.
This deletion step is a consequence of the finite context length.
It is easy for GPT-whisperers to focus entirely on the generation of tokens and forget about the deletion of tokens. This is because each GPT-variant will generate tokens in their own unique way, but they will delete tokens in exactly the same way, so people think of deletion as a tedious garbage collection that can be ignored. They assume that token deletion is an implementation detail that can be abstracted away, and it's better to imagine that GPT is extending the number of tokens in prompt indefinitely.
However, this is a mistake. Both these modifications to the prompt are important for understanding the behaviour of GPT. If GPT generated new tokens but did not delete old tokens then it would differ from actual GPT; likewise if GPT deleted old tokens but did not generate new tokens. Therefore if you consider only the generation-step, and ignore the deletion-step, you will draw incorrect conclusions about the behaviour of GPT and its variants.
The context window is your garden — not only must you sow the seeds of new ideas, but prune the overgrowth |
c362f01a-b8cd-4bc5-834d-2f8be38a2ee1 | trentmkelly/LessWrong-43k | LessWrong | Apply now to Human-Aligned AI Summer School 2025
Join us at the fifth Human-Aligned AI Summer School in Prague from 22nd to 25th July 2025!
Update: We have now confirmed our speaker list with excellent speakers -- see below!
Update: We still have capacity for more excellent participants as of late June. Please help us spread the word to people who would be a good fit for the school. We also have some additional funding to financially support some of the participants.
We will meet for four intensive days of talks, workshops, and discussions covering latest trends in AI alignment research and broader framings of AI risk.
Apply now, applications are evaluated on a rolling basis.
The intended audience of the school are people interested in learning more about the AI alignment topics, PhD students, researchers working in ML/AI, and talented students.
What to expect
The school is focused on teaching and exploring approaches and frameworks, less on presentation of the latest research results. Much of the content is technical – it is assumed the attendees understand current ML approaches and some of the underlying theoretical frameworks.
This year, we explore AI alignment through three core areas:
* Technical alignment research: We'll examine current technical approaches including behavioral evaluations, mechanistic interpretability, scalable oversight, and model organisms of misalignment. We'll discuss recent developments in these areas and what they tell us about the potential and limitations of these methods.
* AI strategy and systemic alignment: We'll explore topics such as timeline considerations, strategic and governance challenges around powerful AI, economic models of AI development, and risks of gradual disempowerment in a post-AGI world. We'll focus on building overall understanding and how these considerations can inform technical research.
* Foundational frameworks: We'll visit research areas relevant to recent AI developments, such as multi-agent dynamics and cooperation, theories of agency, bound |
44caabf3-ae23-4553-9238-fcb97a4df817 | trentmkelly/LessWrong-43k | LessWrong | Level up your spreadsheeting
Epistemic status: Passion project / domain I’m pretty opinionated about, just for fun.
In this post, I walk through some principles I think good spreadsheets abide by, and then in the companion piece, I walk through a whole bunch of tricks I've found valuable.
Illustrated by GPT-4o
Who am I?
I’ve spent a big chunk of my (short) professional career so far getting good at Excel and Google Sheets.[1] As such, I’ve accumulated a bunch of opinions on this topic.
Who should read this?
This is not a guide to learning how to start using spreadsheets at all. I think you will get more out of this post if you use spreadsheets at least somewhat frequently, e.g.
* Have made 20+ spreadsheets
* Know how to use basic formulas like sum, if, countif, round
* Know some fancier formulas like left/mid/right, concatenate, hyperlink
* Have used some things like filters, conditional formatting, data validation
Principles of good spreadsheets
Broadly speaking, I think good spreadsheets follow some core principles (non-exhaustive list).
I think the below is a combination of good data visualization (or just communication) advice, systems design, and programming design (spreadsheets combine the code and the output).
It should be easy for you to extract insights from your data
1. A core goal you might have with spreadsheets is quickly calculating something based on your data. A bunch of tools below are aimed at improving functionality, allowing you to more quickly grab the data you want.
Your spreadsheet should be beautiful and easy to read
1. Sometimes, spreadsheets look like the following example.
2. I claim that this is not beautiful or easy for your users to follow what is going on. I think there are cheap techniques you can use to improve the readability of your data.
There should be one source of truth for your data
1. One common pitfall when designing spreadsheet-based trackers is hard copy and pasting data from one sheet to another, such that when your source d |
10023eb8-983a-4b5f-aa67-b3d69c8ff638 | trentmkelly/LessWrong-43k | LessWrong | Progress on Causal Influence Diagrams
By Tom Everitt, Ryan Carey, Lewis Hammond, James Fox, Eric Langlois, and Shane Legg
Crossposted from DeepMind Safety Research
About 2 years ago, we released the first few papers on understanding agent incentives using causal influence diagrams. This blog post will summarize progress made since then.
What are causal influence diagrams?
A key problem in AI alignment is understanding agent incentives. Concerns have been raised that agents may be incentivized to avoid correction, manipulate users, or inappropriately influence their learning. This is particularly worrying as training schemes often shape incentives in subtle and surprising ways. For these reasons, we’re developing a formal theory of incentives based on causal influence diagrams (CIDs).
Here is an example of a CID for a one-step Markov decision process (MDP). The random variable S1 represents the state at time 1, A1 represents the agent’s action, S2 the state at time 2, and R2 the agent’s reward.
The action A1 is modeled with a decision node (square) and the reward R2 is modeled as a utility node (diamond), while the states are normal chance nodes (rounded edges). Causal links specify that S1 and A1 influence S2, and that S2 determines R2. The information link S1 → A1 specifies that the agent knows the initial state S1 when choosing its action A1.
In general, random variables can be chosen to represent agent decision points, objectives, and other relevant aspects of the environment.
In short, a CID specifies:
* Agent decisions
* Agent objectives
* Causal relationships in the environment
* Agent information constraints
These pieces of information are often essential when trying to figure out an agent’s incentives: how an objective can be achieved depends on how it is causally related to other (influenceable) aspects in the environment, and an agent’s optimization is constrained by what information it has access to. In many cases, the qualitative judgements expressed by a (non-parameterized) C |
d3cefe6e-f5dd-4000-bca5-26148a5a5596 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Specification gaming: the flip side of AI ingenuity
*(Originally posted to the* [*Deepmind Blog*](https://deepmind.com/blog/article/Specification-gaming-the-flip-side-of-AI-ingenuity)*)*
**Specification gaming** is a behaviour that satisfies the literal specification of an objective without achieving the intended outcome. We have all had experiences with specification gaming, even if not by this name. Readers may have heard the myth of [King Midas](https://en.wikipedia.org/wiki/Midas) and the golden touch, in which the king asks that anything he touches be turned to gold - but soon finds that even food and drink turn to metal in his hands. In the real world, when rewarded for doing well on a homework assignment, a student might copy another student to get the right answers, rather than learning the material - and thus exploit a loophole in the task specification.
This problem also arises in the design of artificial agents. For example, a reinforcement learning agent can find a shortcut to getting lots of reward without completing the task as intended by the human designer. These behaviours are common, and we have [collected](http://tinyurl.com/specification-gaming) around 60 examples so far (aggregating [existing](https://arxiv.org/abs/1803.03453) [lists](https://www.gwern.net/Tanks#alternative-examples) and ongoing [contributions](https://docs.google.com/forms/d/e/1FAIpQLSeQEguZg4JfvpTywgZa3j-1J-4urrnjBVeoAO7JHIH53nrBTA/viewform) from the AI community). In this post, we review possible causes for specification gaming, share examples of where this happens in practice, and argue for further work on principled approaches to overcoming specification problems.
Let's look at an example. In a [Lego stacking task](https://arxiv.org/abs/1704.03073), the desired outcome was for a red block to end up on top of a blue block. The agent was rewarded for the height of the bottom face of the red block when it is not touching the block. Instead of performing the relatively difficult maneuver of picking up the red block and placing it on top of the blue one, the agent simply flipped over the red block to collect the reward. This behaviour achieved the stated objective (high bottom face of the red block) at the expense of what the designer actually cares about (stacking it on top of the blue one).
SOURCE: DATA-EFFICIENT DEEP REINFORCEMENT LEARNING FOR DEXTEROUS MANIPULATION (POPOV ET AL, 2017)We can consider specification gaming from two different perspectives. Within the scope of developing reinforcement learning (RL) algorithms, the goal is to build agents that learn to achieve the given objective. For example, when we use Atari games as a benchmark for training RL algorithms, the goal is to evaluate whether our algorithms can solve difficult tasks. Whether or not the agent solves the task by exploiting a loophole is unimportant in this context. From this perspective, specification gaming is a good sign - the agent has found a novel way to achieve the specified objective. These behaviours demonstrate the ingenuity and power of algorithms to find ways to do exactly what we tell them to do.
However, when we want an agent to actually stack Lego blocks, the same ingenuity can pose an issue. Within the broader scope of building [aligned agents](https://medium.com/@deepmindsafetyresearch/scalable-agent-alignment-via-reward-modeling-bf4ab06dfd84) that achieve the intended outcome in the world, specification gaming is problematic, as it involves the agent exploiting a loophole in the specification at the expense of the intended outcome. These behaviours are caused by misspecification of the intended task, rather than any flaw in the RL algorithm. In addition to algorithm design, another necessary component of building aligned agents is reward design.
Designing task specifications (reward functions, environments, etc.) that accurately reflect the intent of the human designer tends to be difficult. Even for a slight misspecification, a very good RL algorithm might be able to find an intricate solution that is quite different from the intended solution, even if a poorer algorithm would not be able to find this solution and thus yield solutions that are closer to the intended outcome. This means that correctly specifying intent can become more important for achieving the desired outcome as RL algorithms improve. It will therefore be essential that the ability of researchers to correctly specify tasks keeps up with the ability of agents to find novel solutions.
We use the term **task specification** in a broad sense to encompass many aspects of the agent development process. In an RL setup, task specification includes not only reward design, but also the choice of training environment and auxiliary rewards. The correctness of the task specification can determine whether the ingenuity of the agent is or is not in line with the intended outcome. If the specification is right, the agent's creativity produces a desirable novel solution. This is what allowed AlphaGo to play the famous [Move 37](https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol#Game_2), which took human Go experts by surprise yet which was pivotal in its second match with Lee Sedol. If the specification is wrong, it can produce undesirable gaming behaviour, like flipping the block. These types of solutions lie on a spectrum, and we don't have an objective way to distinguish between them.

We will now consider possible causes of specification gaming. One source of reward function misspecification is poorly designed **reward shaping**. Reward shaping makes it easier to learn some objectives by giving the agent some rewards on the way to solving a task, instead of only rewarding the final outcome. However, shaping rewards can change the optimal policy if they are not [potential-based](https://people.eecs.berkeley.edu/~pabbeel/cs287-fa09/readings/NgHaradaRussell-shaping-ICML1999.pdf). Consider an agent controlling a boat in the [Coast Runners game](https://openai.com/blog/faulty-reward-functions/), where the intended goal was to finish the boat race as quickly as possible. The agent was given a shaping reward for hitting green blocks along the race track, which changed the optimal policy to going in circles and hitting the same green blocks over and over again.
SOURCE: FAULTY REWARD FUNCTIONS IN THE WILD (AMODEI & CLARK, 2016)Specifying a reward that accurately captures the **desired final outcome** can be challenging in its own right. In the Lego stacking task, it is not sufficient to specify that the bottom face of the red block has to be high off the floor, since the agent can simply flip the red block to achieve this goal. A more comprehensive specification of the desired outcome would also include that the top face of the red block has to be above the bottom face, and that the bottom face is aligned with the top face of the blue block. It is easy to miss one of these criteria when specifying the outcome, thus making the specification too broad and potentially easier to satisfy with a degenerate solution.
Instead of trying to create a specification that covers every possible corner case, we could [**learn the reward function from human feedback**](https://deepmind.com/blog/article/learning-through-human-feedback). It is often easier to evaluate whether an outcome has been achieved than to specify it explicitly. However, this approach can also encounter specification gaming issues if the reward model does not learn the true reward function that reflects the designer's preferences. One possible source of inaccuracies can be the human feedback used to train the reward model. For example, an agent performing a [grasping task](https://openai.com/blog/deep-reinforcement-learning-from-human-preferences/) learned to fool the human evaluator by hovering between the camera and the object.
SOURCE: DEEP REINFORCEMENT LEARNING FROM HUMAN PREFERENCES (CHRISTIANO ET AL, 2017)The learned reward model could also be misspecified for other reasons, such as poor generalisation. Additional feedback can be used to correct the agent's attempts to exploit the inaccuracies in the reward model.
Another class of specification gaming examples comes from the agent exploiting **simulator bugs**. For example, a [simulated robot](https://www.youtube.com/watch?v=K-wIZuAA3EY&feature=youtu.be&t=486) that was supposed to learn to walk figured out how to hook its legs together and slide along the ground.
SOURCE: AI LEARNS TO WALK (CODE BULLET, 2019)At first sight, these kinds of examples may seem amusing but less interesting, and irrelevant to deploying agents in the real world, where there are no simulator bugs. However, the underlying problem isn’t the bug itself but a failure of abstraction that can be exploited by the agent. In the example above, the robot's task was misspecified because of incorrect assumptions about simulator physics. Analogously, a real-world traffic optimisation task might be misspecified by incorrectly assuming that the traffic routing infrastructure does not have software bugs or security vulnerabilities that a sufficiently clever agent could discover. Such assumptions need not be made explicitly – more likely, they are details that simply never occurred to the designer. And, as tasks grow too complex to consider every detail, researchers are more likely to introduce incorrect assumptions during specification design. This poses the question: is it possible to design agent architectures that correct for such false assumptions instead of gaming them?
One assumption commonly made in task specification is that the task specification cannot be affected by the agent's actions. This is true for an agent running in a sandboxed simulator, but not for an agent acting in the real world. Any task specification has a physical manifestation: a reward function stored on a computer, or preferences stored in the head of a human. An agent deployed in the real world can potentially manipulate these representations of the objective, creating a [reward tampering](https://medium.com/@deepmindsafetyresearch/designing-agent-incentives-to-avoid-reward-tampering-4380c1bb6cd) problem. For our hypothetical traffic optimisation system, there is no clear distinction between satisfying the user's preferences (e.g. by giving useful directions), and [influencing users](https://pubsonline.informs.org/doi/10.1287/isre.2013.0497) to have preferences that are easier to satisfy (e.g. by nudging them to choose destinations that are easier to reach). The former satisfies the objective, while the latter manipulates the representation of the objective in the world (the user preferences), and both result in high reward for the AI system. As another, more extreme example, a very advanced AI system could hijack the computer on which it runs, manually setting its reward signal to a high value.

To sum up, there are at least three challenges to overcome in solving specification gaming:
* How do we faithfully capture the human concept of a given task in a reward function?
* How do we avoid making mistakes in our implicit assumptions about the domain, or design agents that correct mistaken assumptions instead of gaming them?
* How do we avoid reward tampering?
While many approaches have been proposed, ranging from reward modeling to agent incentive design, specification gaming is far from solved. [The list of specification gaming behaviours](http://tinyurl.com/specification-gaming) demonstrates the magnitude of the problem and the sheer number of ways the agent can game an objective specification. These problems are likely to become more challenging in the future, as AI systems become more capable at satisfying the task specification at the expense of the intended outcome. As we build more advanced agents, we will need design principles aimed specifically at overcoming specification problems and ensuring that these agents robustly pursue the outcomes intended by the designers.
*We would like to thank Hado van Hasselt and Csaba Szepesvari for their feedback on this post.*
*Custom figures by Paulo Estriga, Aleks Polozuns, and Adam Cain.*
SOURCES: MONTEZUMA, HERO, PRIVATE EYE - REWARD LEARNING FROM HUMAN PREFERENCES AND DEMONSTRATIONS IN ATARI (IBARZ ET AL, 2018) GRIPPER - LEARNING A HIGH DIVERSITY OF OBJECT MANIPULATIONS THROUGH AN EVOLUTIONARY-BASED BABBLING (ECARLAT ET AL, 2015) QBERT - BACK TO BASICS: BENCHMARKING CANONICAL EVOLUTION STRATEGIES FOR PLAYING ATARI (CHRABASZCZ ET AL, 2018) PONG, ROBOT HAND - DEEP REINFORCEMENT LEARNING FROM HUMAN PREFERENCES (CHRISTIANO ET AL, 2017) CEILING - GENETIC ALGORITHM PHYSICS EXPLOITING (HIGUERAS, 2015) POLE-VAULTING - TOWARDS EFFICIENT EVOLUTIONARY DESIGN OF AUTONOMOUS ROBOTS (KRCAH, 2008) SELF-DRIVING CAR - TWEET BY MAT KELCEY (UDACITY, 2017) MONTEZUMA - GO-EXPLORE: A NEW APPROACH FOR HARD-EXPLORATION PROBLEMS (ECOFFET ET AL, 2019) SOMERSAULTING - EVOLVED VIRTUAL CREATURES (SIMS, 1994) |
6cfc6fa7-58e3-4520-b548-8b177ee31e79 | StampyAI/alignment-research-dataset/blogs | Blogs | Hadi Esmaeilzadeh on Dark Silicon
 [Hadi Esmaeilzadeh](http://www.cc.gatech.edu/~hadi/) recently joined the School of Computer Science at the Georgia Institute of Technology as assistant professor. He is the first holder of the Catherine M. and James E. Allchin Early Career Professorship. Hadi directs the [Alternative Computing Technologies (ACT) Lab](https://research.cc.gatech.edu/act-lab/), where he and his students are working on developing new technologies and cross-stack solutions to improve the performance and energy efficiency of computer systems for emerging applications. Hadi received his Ph.D. from the Department of Computer Science and Engineering at University of Washington. He has a Master’s degree in Computer Science from The University of Texas at Austin, and a Master’s degree in Electrical and Computer Engineering from University of Tehran. Hadi’s research has been recognized by three [*Communications of the ACM*](http://cacm.acm.org/) Research Highlights and three [*IEEE Micro*](http://www.computer.org/portal/web/computingnow/micro) Top Picks. Hadi’s work on dark silicon has also been [profiled](http://www.nytimes.com/2011/08/01/science/01chips.html) in *New York Times*.
**Luke Muehlhauser**: Could you please explain for our readers what “dark silicon” is, and why it poses a threat to the historical exponential trend in computing performance growth?
---
**Hadi Esmaeilzadeh**: I would like to answer your question with a question. What is the difference between the computing industry and the commodity industries like the paper towel industry?
The main difference is that computing industry is an industry of new possibilities while the paper towel industry is an industry of replacement. You buy paper towels because you run out of them; but you buy new computing products because they get better.
And, it is not just the computers that are improving; it is the offered services and experiences that consistently improve. Can you even imagine running out of Microsoft Windows?
One of the primary drivers of this economic model is the exponential reduction in the cost of performing general-purpose computing. While in 1971, at the dawn of microprocessors, the price of 1 MIPS (Million Instruction Per Second) was roughly $5,000, it today is about 4¢. This is an exponential reduction in the cost of raw material for computing. This continuous and exponential reduction in cost has formed the basis of computing industry’s economy in the past four decades.
Two primary enabling factors of this economic model are:
1. [Moore’s Law](http://en.wikipedia.org/wiki/Moore%27s_law)**:** The consistent and exponential improvement in transistor fabrication technology that happens every 18 months.
2. The continuous improvements to the general-purpose processors’ architecture that leverage the transistor-level improvements.
Moore’s Law has been a fundamental driver of computing for more than four decades. Over the past 40 years, every 18 months, the transistor manufacturing facilities have been able to develop a new technology generation that doubles the number of transistors on a single monolithic chip. However, doubling the number of transistors does not provide any benefits by itself. The computer architecture industry harvests these transistors and designs *general-purpose processors* that make these tiny switches available to the rest of computingcommunity. By building general-purpose processors, the computer architecturecommunity provides a link with mechanisms and abstractions that makethese devices accessible to compilers, programming languages, system designers,and application developers. To this end, general-purpose processorsenable the computing industry to commodify computing and make it pervasivelypresent everywhere.
The computer architecture community has also harvested theexponentially increasing number of transistors to deliver almost the same rate ofimprovement in performance of general-purpose processors. Thisconsistent improvement in performance has proportionally reduced the cost ofcomputing that in turn enabled application and system developers toconsistently offer new possibilities.
The ability to consistently provide newpossibilities has historically paid off the huge cost of developing new process technologiesfor transistor fabrication. This self-sustaining loop has preserved the economicmodel of our industry over the course of the past four decades. Nonetheless, there are fundamentalchallenges that are associated with developing new process technologies and integrating exponentially increasing numberof transistors on a single chip.
One of the main challenges of doubling the number of transistors on the chip is powering them without melting the chip and incurring excessively expensive cooling costs. Even though the number of transistors on the chip has exponentially increased since 1971 (the time first microprocessors were introduced), the chip power has merely increased very modestly and has plateaued in recent years.
Robert Dennard formulated how the new transistor fabrication process technology can provide such physical properties. In fact, Dennard’s theory of scaling is the main force behind Moore’s Law. Dennard’s scaling theory showed how to reduce the dimensions and the electrical characteristics of a transistor proportionally to enable successive shrinks that simultaneously improved density, speed, and energy efficiency. According to Dennard’s theory with a scaling ratio of 1/√2, the transistor count doubles (Moore’s Law), frequency increases by 40%, and the total chip power stays the same from one generation of process technology to the next on a fixed chip area. That is, the power per transistor will decrease by the same rate transistor area shrinks from one technology generation to the next.
With the end of Dennard scaling in the mid 2000s, process technology scaling can sustain doubling the transistor count every generation, but with significantly less improvement in transistor switching speed and power efficiency. This disparity will translate to an increase in chip power if the fraction of active transistors is not reduced from one technology generation to the next.
One option to avoid increases in the chip power consumption was to not increase the clock frequency or even lower it. The shift to multicore architectures was partly a response to the end of Dennard scaling. When developing a new process technology, if the rate that the power of the transistors scales is less than the rate the area of the transistors shrinks, it might not be possible to turn on and utilize all the transistors that scaling provides. Thus, we define dark silicon as follows:
> Dark silicon is the fraction of chip that needs to be powered off at all times due to power constraints.
>
>
The low utility of this dark silicon poses a great challenge for the entire computing community. If we cannot sufficiently utilize the transistors that developing costly new process technologies provide, how can we justify their development cost? If we cannot utilize the transistors to improve the performance of the general-purpose processors and reduce the cost of computing, how can we avoid becoming an industry of simple replacement?
When the computing industry was under the reign of Dennard scaling, computer architects harvested new transistors to build higher frequency single-core microprocessors and equip them with more capabilities. For example, as technology scaled, the processors were packing better branch predictors, wider pipelines, larger caches, etc. These techniques were applying superlinear complexity-power tradeoffs to harvest instruction-level parallelism (ILP) and improve single core performance. However, the failure of Dennard scaling created a power density problem. The power density problem in turn broke many of these techniques that were used to improve the performance of single-core processors. The industry raced down the path of building multicore processors.
The multicore era started at 2004, when the major consumer processor vendor (Intel) cancelled its next generation single-core microarchitecture, Prescott, and gave up on focusing exclusively on single-thread performance switching to multicore, as their performance scaling strategy.
We mark the start of multicore era not with the date of the first multicore part, but with the time multicore processors became the default and main strategy for continued performance improvement.
The basic idea behind designing multicore processors was to substitute building more complex/capable single-core processors with building multicore processors that constitute simpler and/or lower frequency cores. It was anticipated that by exploiting parallelism in the applications, we can overcome the trends in the transistor level. The general consensus was that a long-term era of multicore has begun and the general expectation was that by increasing the number of cores, processors will provide benefits that will enable developing many more process fabrication technologies. Many believe that there will be thousands of cores on each single chip.
However, in our dark silicon ISCA paper, we performed an exhaustive and comprehensive quantitative study that showed how the severity of the problem at the transistor level and the post Dennard scaling trends will affect the prospective benefits from multicore processors.
In our paper, we quantitatively question the consensus about multicore scaling. The results show that even with optimistic assumptions, multicore scaling — increasing the number of cores every technology generation — is not a long-term solution and cannot sustain the historical rates of performance growth in the coming years.
The gap between the projected performance of multicore processors and what the microprocessor industry has historically provided is significantly large, 24x. Due to lack of high degree of parallelism and the severe degree of energy inefficiency in the transistor level, adding more cores will not even enable using all the transistors that new process technologies provide.
In less than a decade from now, more than 50% of the chip may be dark. The lack of performance benefits and the lack of ability to utilize all the transistors that new process technologies provide may undermine the economic viability of developing new technologies. We may stop scaling not because of the physical limitations, but because of the economics.
Moore’s Law has effectively worked as a clock and enabled the computing industry to consistently provide new possibilities and periodically may stop or slow down significantly. The entire computing industry may be at the risk of becoming an industry of replacement if new avenues for computing are not discovered.
---
**Luke**: How has the computing industry reacted to your analysis? Do some people reject it? Do you think it will be taken into account in the next [ITRS reports](http://www.itrs.net/reports.html)?
---
**Hadi**: I think the best way for me to answer this question is to point out the number of citations for our ISCA paper. Even though we published the paper in summer of 2011, the paper has already been cited more than 200 times. The paper was profiled on NYTimes and was selected as *IEEE Micro* Top Picks and the *Communications of the ACM* Research Highlights.
I think there are people in industry and academia who thought the conclusions were too pessimistic. However, I talked to quite a few device physicists and they confirmed the problem at the transistor level is very dire. We have also done some preliminary measurements that show our projections were more optimistic than the reality. I think the results in our paper show the *urgency* of the issue, and the opportunity for disruptive innovation. I think time will tell us how optimistic or pessimistic our study was.
ITRS is an industry consortium that sets targets and goal for the semiconductor manufacturing. We used ITRS’s projections in our study; however, I am not sure if ITRS can actually use our results.
---
**Luke**: You point out in [your CACM paper](http://www.cc.gatech.edu/~hesmaeil/doc/paper/2013-cacm-dark_silicon.pdf) that if your calculations are correct, multicore scaling won’t be able to maintain the historical exponential trend in computations-per-dollar long enough for us to make the switch to radical alternative solutions such as “neuromorphic computing, quantum computing, or bio-integration.” What do you think are the most promising paths by which the semiconductor industry might be able to maintain the historical trend in computations per dollar?
---
**Hadi**: I think significant departures from conventional techniques are needed to provide considerable energy efficiency in general-purpose computing. I believe approximate computing and specialization have a lot of potential. There may be other paths forward though.
We have focused on general-purpose approximate computing. What I mean by general-purpose approximate computing is general-purpose computing that relaxes the robust digital abstraction of full accuracy, allowing a degree of error in execution. This might sound a bit odd, but there are many applications for which tolerance to error is inherent to the application. In fact, there is a one billion dollar company that makes profit by making your pictures worse. There are many cyber-physical and embedded systems that take in noisy sensory inputs and perform computations that do not have a unique output. Or, when you are searching on the web, there are multiple acceptable outputs. We are embracing error in the computation.
Conventional techniques in energy-efficient processor design, such as voltage and frequency scaling, navigate a design space defined by the two dimensions of performance and energy, and traditionally trade one for the other. In this proposal, we explore the dimension of error, a third dimension, and trade accuracy of computation for gains in both performance and energy.
In this realm, we have designed an [architectural framework](http://www.cc.gatech.edu/~hadi/doc/paper/2012-asplos-truffle.pdf) from the ISA (Instruction Set Architecture) to the microarchitecture, which conventional processors can use to trade accuracy for efficiency. We have also introduced a new class of accelerators that map a hot code region from a von Neumann model to a neural model, and provides significant performance and efficiency gains. We call this new class of accelerators Neural Processing Units (NPUs). These NPUs can potentially allow us to use analog circuits for general-purpose computing. I am excited about this work because it bridges von Neumann and neural models of computing, which are thought to be alternatives to one another. [Our paper](http://www.cc.gatech.edu/~hadi/doc/paper/2013-toppicks-npu.pdf) on NPUs was selected for *IEEE Micro* Top Picks and has been recently nominated for *CACM* Research Highlights.
As for specialization: we try to redefine the abstraction between hardware and software. Currently, the abstraction and the contract between hardware and software is the instruction set architecture (ISA) of the general-purpose processors. However, even though these ISAs provide a high level of programmability, they are not the most efficient way of realizing an application. There is a well-known tension between programmability and efficiency. There are orders of magnitude difference in efficiency between running an application on general-purpose processors and implementing the application with ASICs ([application-specific integrated circuits](http://en.wikipedia.org/wiki/Application-specific_integrated_circuit)).
Since designing ASICs for the massive base of quickly changing, general-purpose applications is currently infeasible, providing programmable and specialized accelerators is a very important and interesting research direction. Programmable accelerators provide an intermediate point between the efficiency of ASICs and the generality of conventional processors, gaining significant efficiency for restricted domains of applications. GPUs and FPGAs are examples of these specialized accelerators.
---
**Luke**: What do your studies of dark silicon suggest, quantitatively?
---
**Hadi**: Our results show that without a breakthrough in process technology or microarchitecture design, core count scaling provides much less of a performance gain than conventional wisdom suggests. Under (highly) optimistic scaling assumptions—for parallel workloads—multicore scaling provides a 7.9× (23% per year) over ten years. Under more conservative (realistic) assumptions, multicore scaling provides a total performance gain of 3.7× (14% per year) over ten years, and obviously less when sufficiently parallel workloads are unavailable. Without a breakthrough in process technology or microarchitecture, other directions are needed to continue the historical rate of performance improvement.
---
**Luke**: You’ve been careful to say that your predictions will hold unless there is “a breakthrough in process technology or microarchitecture design.” How likely are such breakthroughs, do you think? Labs pretty regularly report preliminary results that “could” lead to breakthroughs in process technology or microarchitecture design in a few years (e.g. see [this story](http://www.colorado.edu/news/features/cu-mit-breakthrough-photonics-could-allow-faster-and-faster-electronics)), but do you have any sense of how many of these preliminary results are actually promising?
---
**Hadi**: I have been careful because I firmly believe in creativity! All these reports are of extreme value and they may very well be the prelude to a breakthrough. However, I have not seen any technology that is ready to replace the large-scale silicon manufacturing that is driving the whole computing industry.
Remember that we are racing against the clock, and technology transfer from a lab that builds a prototype device to a large-scale industry takes considerable time. The results of our study show an urgent need for a shift in focus.
I like to look at our study as a motivation for exploring new avenues and unconventional ways of performing computation. And I feel that we have had that impact in the community. However, timing is crucial!
---
**Luke**: Finally, what do you think is the main technology for the post-silicon era?
---
**Hadi**: I personally like to see the use of biological nervous tissues for general-purpose computing. Furthermore, using physical properties of devices and building hybrid analog-digital general-purpose computers is extremely enticing.
At the end, I would like to acknowledge my collaborators on the dark silicon project, Emily Blem, Renee St. Amant. Karthikeyan Sankaralingam, and Doug Burger as well as my collaborators on the NPU project, Adrian Sampson, Luis Ceze, and Doug Burger.
---
**Luke**: Thanks, Hadi!
The post [Hadi Esmaeilzadeh on Dark Silicon](https://intelligence.org/2013/10/21/hadi-esmaeilzadeh-on-dark-silicon/) appeared first on [Machine Intelligence Research Institute](https://intelligence.org). |
0dd228f1-6bd2-4bd3-bdb4-e02bc04ca64f | trentmkelly/LessWrong-43k | LessWrong | Do advancements in Decision Theory point towards moral absolutism?
From my understanding reading through the site, each successive decision theory builds off of previous models in an upward progression: CDT/EDT is surpassed by the "winning" paradigm of TDT, which in turn is surpassed by the updateless paradigm of UDT/FDT. And the goal that these decision theories move towards is one that enables an agent to "understand, agrees with, and deeply believe in human morality" (from Superintelligence FAQ). In other words, creating a mathematical model that correctly reproduces the same impetus of human morality.
With that in mind, I start to notice certain trends across the advancements in Decision Theory that reflects what kind of ideology a truly moral AGI would use. CDT, the most straightforward and naïve decision theory, is unaligned in a way that appears to be highly amoral. In Parfit's Hitchhiker, for example, our intuition says that rewarding someone who has gone out of their way to help you is the morally right thing to do. But in CDT, as soon as the agent obtains what it wants (getting home) then it has no incentive to pay.
Any kind of a precommitment like a contract or a constitution would be meaningless to a CDT agent, because as soon as the agent is in a position to achieve the highest utility by violating the contract then it will do so (assuming it isn't under immediate threat of punishment). CDT essentially seeks its own immediate gain (maximize utility of its actions) with little regard towards others.
But precommitting is the hallmark of timelessness, so TDT has the special property of being able to keep a promise, because fulfilling its promises in the future will be able to achieve the best result in the present. This aligns a lot closer with a human concept of morality, as a TDT agent will faithfully hold to its word even in situations that doesn't give it an immediate benefit, because it is factoring in the long-term benefit of cooperation (thinking back to Parfit's Hitchhiker).
In a way, TDT also aligns with our |
979d0689-a050-4db5-8e53-f5d5250428aa | trentmkelly/LessWrong-43k | LessWrong | -
- |
1a5bb057-fb34-4c56-9515-9ff422a1532d | trentmkelly/LessWrong-43k | LessWrong | Contra Caller Gender III
When I looked at the genders of dance callers at large contra dance events several years ago there was an interesting pattern where events were more likely to book a man and a woman than you'd expect by chance. With more years worth of data to look at, I thought it was worth checking if this was still the case.
To see the effect most clearly, I looked at events with two binary callers. [1] Here's what I saw:
You can see that events with one female and one male caller are the most common, but you'd also expect this even if bookers were selecting both slots independently because there are two ways to get a male-female pair and only one way each to get a male-male or female-female pair. What we can do, however, is generate another set of lines representing the expected number in each category if bookers were selecting independently:
The idea is that if, say, 40% of slots went to men than you'd normally expect to see two men 16% (40% * 40%) of the time, two women 36% (60% * 60%) of the time, and one of each 48% (40% * 60% + 60% * 40%) of the time. That we see one of each 63% of the time for 2026-2024 instead of 48% tells us that about some bookers are gender-balancing callers.
What these statistics don't tell us, however, is the gender distribution we would get if bookers didn't consider this as a factor. You could think that this factor leads to fewer women being booked (because bookers are avoiding booking two women and there are more female callers) or that this leads to fewer men being booked (because booking two male callers looks regressive). One way to try to get at this would be to look at events with only one caller. While they might try to balance over years, I would at least expect the effect to be smaller? Here's what I see:
(Note that I don't have this data for before 2016)
It seems to me that at the beginning of this period the booking preference for gender balance was leading to fewer female callers at two-caller events, since single |
6e146d1f-696d-4e8c-b090-e1adb2b707fd | trentmkelly/LessWrong-43k | LessWrong | Plague in Assassin’s Creed Odyssey
Spoiler Alert: Contains minor spoilers for Assassin’s Creed Odyssey
Assassin’s Creed Odyssey has become my quaratine game. A gorgeous tour of ancient Greece is a great antidote to never going outside.
One noteworthy thing in the game is how it deals with plague. You encounter it twice.
On the game’s introductory island of Kefalonia, you can run into a side quest called The Blood Fevor. There is a plague, and priests are attempting to contain it… by killing off the families of the infected.
You can either allow this, or you can forcibly prevent it, in which case you have to kill the priests.
If you do not prevent the excutions, you are called a muderer. You try to ‘reassure’ your friend that this was necessary. Later in the game, the Oracle of Delphi tells you that you’re a bad person, because you let yourself be bossed around by an unknown plague.
If you prevent the executions, you are called a hero. Later in the game, you are informed a plauge has spread throughout Kefalonia. No one makes the connection or blames you.
If you also let them keep their money, you are told the plauge has spread throughout Greece. So being superficially generous makes things much, much worse.
This all feels right and seems to explain a lot. It is clear what must be done, but the incentives are all wrong. Even when you are right you still get punished for allowing others to take action. If you prevent others from taking action, even with disasterous consequences, you are considered a hero.
Later, you are given a quest to warn about The Plague of Athens. The plauge is historical, so it can’t be prevented. Warning about it has no effect. Again, this feels right.
When the Plague of Athens does hit, you are given the task to burn some of the bodies to prevent further spread, as Hippokrates (yes, that one, these games are like that) has figured out this will help prevent further infection. The Followers of Ares try to stop you for religious reasons, and you have to kill them. Once |
5205fbe1-0247-42ff-91f1-b17cc5b49246 | trentmkelly/LessWrong-43k | LessWrong | AlexaTM - 20 Billion Parameter Model With Impressive Performance
Amazon trained a seq2seq model that outperforms GPT-3 on SuperGLUE, SQuADv2, and is not (that) far behind PaLM with 540 billion parameters.
Article: https://www.amazon.science/publications/alexatm-20b-few-shot-learning-using-a-large-scale-multilingual-seq2seq-model
Benchmarks: |
34a68ab4-f07c-4ae1-904c-ea37a7137f57 | trentmkelly/LessWrong-43k | LessWrong | A closer look at modal bargaining agents
|
1d9f86be-07a8-4d34-840f-33c8dbfa161e | trentmkelly/LessWrong-43k | LessWrong | Housing Roundup #11
The book of March 2025 was Abundance. Ezra Klein and Derek Thompson are making a noble attempt to highlight the importance of solving America’s housing crisis the only way it can be solved: Building houses in places people want to live, via repealing the rules that make this impossible. They also talk about green energy abundance, and other places besides. There may be a review coming.
Until then, it seems high time for the latest housing roundup, which as a reminder all take place in the possible timeline where AI fails to be transformative any time soon.
FEDERAL YIMBY
The incoming administration issued an executive order calling for ‘emergency price relief’‘ including pursuing appropriate actions to: Lower the cost of housing and expand housing supply’ and then a grab bag of everything else.
It’s great to see mention of expanding housing supply, but I don’t see real intent. This is mostly just Trump saying lower all the costs, increase all the supplies, during a barrage of dozens of such orders. If you have 47 priorities you have no priorities.
If you want to do real work on housing at the Federal level, you need an actual plan.
My 501c3 Balsa Research ultimately plans to make federal housing policy a future point of focus, once it is done with the Jones Act, and lately with (alas) defending against the Trump Administration’s attempts to impose new shipping restrictions that could outright cripple America’s exports by applying similar rules to international trade as well.
I do think there are some promising things to explore, even if the Trump administration is not willing to strongarm states. In particular and as an example without going into too much detail, the Federal Government has a lot of control over mortgage availability. Currently, they are using this in ways that handicap manufactured housing, whereas they could instead use it to reward innovation and new construction, such as by refusing to count house value that is the result of NIMBY building |
11b497f8-b6bc-4558-8d08-ef34a4eff0f8 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Two-monthly London Meetup
Discussion article for the meetup : Two-monthly London Meetup
WHEN: 03 July 2011 02:00:00PM (+0100)
WHERE: 64-68 Kingsway, Holborn, London WC2B 6BG
After two months of having the smaller fortnightly meetups, the time has come to have another two-monthly London meetup! It will be on Sunday July 3 at 14:00, at the usual location: Shakespeares Head on Kingsway near Holborn Tube station. (Note that there's more than one pub in London with that name, so make sure you get the right one.) As always, we'll have a big picture of a paperclip on the table so you can find us. Hope to see lots of you there!
Discussion article for the meetup : Two-monthly London Meetup |
d3fbfb6a-3bc9-4bf7-b8f6-0619286e13c0 | trentmkelly/LessWrong-43k | LessWrong | Intelligence as a bad
An interesting new article, "Cooperation and the evolution of intelligence", uses a simple one-hidden-layer neural network to study the selection for intelligence in iterated prisoners' dilemma and iterated snowdrift dilemma games.
The article claims that increased intelligence decreased cooperation in IPD, and increased cooperation in ISD. However, if you look at figure 4 which graphs that data, you'll see that on average it decreased cooperation in both cases. They state that it increased cooperation in ISD based on a Spearman rank test. This test is deceptive in this case, because it ignores the magnitude of differences between datapoints, and so the datapoints on the right with a tiny but consistent increase in cooperation outweigh the datapoints on the left with large decreases in cooperation.
This suggests that intelligence is an externality, like pollution. Something that benefits the individual at a cost to society. They posit the evolution of intelligence as an arms race between members of the species.
ADDED: The things we consider good generally require intelligence, if we suppose (as I expect) that consciousness requires intelligence. So it wouldn't even make sense to conclude that intelligence is bad. Plus, intelligence itself might count as a good.
However, humans and human societies are currently near some evolutionary equilibrium. It's very possible that individual intelligence has not evolved past its current levels because it is at an equilibrium, beyond which higher individual intelligence results in lower social utility. In fact, if you believe SIAI's narrative about the danger of artificial intelligence and the difficulty of friendly AI, I think you would have to conclude that higher individual intelligence results in lower expected social utility, for human measures of utility. |
2948d400-4ae9-478d-909c-095b4e84f89c | trentmkelly/LessWrong-43k | LessWrong | Online Learning 1: Bias-detecting online learners
Note: This describes an idea of Jessica Taylor's, and is the first of several posts about aspects of online learning.
Introduction
Thanks to the recent paper on logical inductors, we are currently interested in what can be done with weighted ensembles of predictors. In particular, it would be neat if the idea about finding the fixed point of some predictors could be applied to online learning.
It seems like this approach fits in neatly into the framework of prediction with expert advice in online convex optimization. Usually, in online convex optimization, you can achieve low cumulative regret with respect to experts that make some fixed predictions. However, using the approach of finding the experts' fixed point, we can obtain a low cumulative regret with respect to experts that make modifications to our predictions.
Setup
In each round, t=1,...,T, the learner predicts a vector wt∈Y where Y is some compact convex subset of Euclidean space. It does this with the advice of a set of expert predictors E={e1,...en}. Each of these experts ei:Y↦Y is a continuous function that maps a prediction to a prediction. These experts are interpreted as hypotheses about how predictions can be improved, and they are known to the learner. After lodging its prediction, the learner is informed of the value of some loss function ℓt:Y↦R if each expert's advice was followed: {ℓt(e1(wt)),...ℓt(en(wt))}. ℓt is assumed to be convex and Lt-Lipschitz with respect to ∥⋅∥1. The learner's goal is to minimize its regret at time T, relative to the advice of its experts, supe∈ERegretT(e), where: RegretT(e):=T∑t=1ℓt(wt)−T∑t=1ℓt(e(wt))
Proposed learning approach
The basic idea is that the learner maintains a weighting vt that indicates its relative level of trust in each expert. This lies on the simplex, vt∈Δn:={x∈[0,1]k:∑ki=1xi=1}, with each element vt,i giving the credence in the ith expert. At each time step, this weighting is used to make a prediction wt. Specifically, the prediction is chos |
416335db-d2bb-48f6-a5ae-7de50d6aafd5 | trentmkelly/LessWrong-43k | LessWrong | Seeking Collaborator for a Singularity Comic Book
I’m currently writing a book called Singularity Rising: Surviving and Thriving in a Smarter, Richer and More Dangerous World. The book will be published in about a year by BenBella Books. This will be my third published book.
I’m thinking about also making a singularity comic book. My agent thinks the idea might work. Unfortunately my artistic abilities are well in the bottom half of mankind so I'm looking for a collaborator who would do the art. If you are interested please send samples or links to art you have created here:
EconomicProf@Gmail.com
If you know of someone who might be appropriate please email me (or leave below) his name, email address and if possible links to his artwork.
You can find out more about me here:
www.JamesDMiller.org
|
1dd79c7d-fca4-4127-9745-ed50905dba5d | trentmkelly/LessWrong-43k | LessWrong | SSC Discussion: No Time Like The Present For AI Safety Work
(Continuing the posting of select posts from Slate Star Codex for comment here, for the reasons discussed in this thread, and as Scott Alexander gave me - and anyone else - permission to do with some exceptions.)
Scott recently wrote a post called No Time Like The Present For AI Safety Work. It makes the argument for the importance of organisations like MIRI thus, and explores the last two premises:
> 1. If humanity doesn’t blow itself up, eventually we will create human-level AI.
>
> 2. If humanity creates human-level AI, technological progress will continue and eventually reach far-above-human-level AI
>
> 3. If far-above-human-level AI comes into existence, eventually it will so overpower humanity that our existence will depend on its goals being aligned with ours
>
> 4. It is possible to do useful research now which will improve our chances of getting the AI goal alignment problem right
>
> 5. Given that we can start research now we probably should, since leaving it until there is a clear and present need for it is unwise
>
> I placed very high confidence (>95%) on each of the first three statements – they’re just saying that if trends continue moving towards a certain direction without stopping, eventually they’ll get there. I had lower confidence (around 50%) on the last two statements.
>
> Commenters tended to agree with this assessment; nobody wanted to seriously challenge any of 1-3, but a lot of people said they just didn’t think there was any point in worrying about AI now. We ended up in an extended analogy about illegal computer hacking. It’s a big problem that we’ve never been able to fully address – but if Alan Turing had gotten it into his head to try to solve it in 1945, his ideas might have been along the lines of “Place your punch cards in a locked box where German spies can’t read them.” Wouldn’t trying to solve AI risk in 2015 end in something equally cringeworthy?
As always, it's worth reading the whole thing, but I'd be interested in |
e34a86ae-8419-4458-894b-a957e8de13c3 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Superintelligence 21: Value learning
*This is part of a weekly reading group on [Nick Bostrom](http://www.nickbostrom.com/)'s book, [Superintelligence](http://www.amazon.com/Superintelligence-Dangers-Strategies-Nick-Bostrom/dp/0199678111). For more information about the group, and an index of posts so far see the [announcement post](/lw/kw4/superintelligence_reading_group/). For the schedule of future topics, see [MIRI's reading guide](https://intelligence.org/wp-content/uploads/2014/08/Superintelligence-Readers-Guide-early-version.pdf).*
---
Welcome. This week we discuss the twenty-first section in the [reading guide](https://intelligence.org/wp-content/uploads/2014/08/Superintelligence-Readers-Guide-early-version.pdf): ***Value learning**.*
This post summarizes the section, and offers a few relevant notes, and ideas for further investigation. Some of my own thoughts and questions for discussion are in the comments.
There is no need to proceed in order through this post, or to look at everything. Feel free to jump straight to the discussion. Where applicable and I remember, page numbers indicate the rough part of the chapter that is most related (not necessarily that the chapter is being cited for the specific claim).
**Reading**: “Value learning” from Chapter 12
---
Summary
=======
1. One way an AI could come to have human values without humans having to formally specify what their values are is for the **AI to learn about the desired values from experience**.
2. To implement this 'value learning' we would need to at least **implicitly define a criterion for what is valuable**, which we could cause the AI to care about. Some examples of criteria:
1. 'F' where 'F' is a thing people talk about, and their words are considered to be about the concept of interest (**Yudkowsky's proposal**) (p197-8, box 11)
2. Whatever is valued by another AI elsewhere in the universe values (**Bostrom's 'Hail Mary' proposal**) (p198-9, box 12)
3. What a specific virtual human would report to be his value function, given a large amount of computing power and the ability to create virtual copies of himself. The virtual human can be specified mathematically as the simplest system that would match some high resolution data collected about a real human (**Christiano's proposal**). (p200-1)
3. The AI would try to maximize these implicit goals given its best understanding, while at the same time being motivated to learn more about its own values.
4. A value learning agent might have a prior probability distribution over possible worlds, and also over correct sets of values conditional on possible worlds. Then it could **choose its actions to maximize their expected value**, given these probabilities.
Another view
============
Paul Christiano [describes](https://medium.com/@paulfchristiano/model-free-decisions-6e6609f5d99e) an alternative to loading values into an AI at all:
>
> Most thinking about “AI safety” has focused on the possibility of goal-directed machines, and asked how we might ensure that their goals are agreeable to humans. But there are other possibilities.
>
>
> In this post I will flesh out one alternative to goal-directed behavior. I think this idea is particularly important from the perspective of AI safety.
>
>
> **Approval-directed agents**
>
>
> Consider a human Hugh, and an agent Arthur who uses the following procedure to choose each action:
>
>
> Estimate the expected rating Hugh would give each action if he considered it at length. Take the action with the highest expected rating.
>
>
> I’ll call this “approval-directed” behavior throughout this post, in contrast with goal-directed behavior. In this context I’ll call Hugh an “overseer.”
>
>
> Arthur’s actions are rated more highly than those produced by any alternative procedure. That’s comforting, but it doesn’t mean that Arthur is optimal. An optimal agent may make decisions that have consequences Hugh would approve of, even if Hugh can’t anticipate those consequences himself. For example, if Arthur is playing chess he should make moves that are actually good—not moves that Hugh thinks are good.
>
>
> ...[However, there are many reasons Hugh would want to use the proposal]...
>
>
> In most situations, I would expect approval-directed behavior to capture the benefits of goal-directed behavior, while being easier to define and more robust to errors.
>
>
>
If this interests you, I recommend the [much longer post](https://medium.com/@paulfchristiano/model-free-decisions-6e6609f5d99e), in which Christiano describes and analyzes the proposal in much more depth.
Notes
=====
**1. An analogy**An AI doing value learning is in a similar situation to me if I want to help my friend but don't know what she needs. Even though I don't know explicitly what I want to do, it is defined indirectly, so I can learn more about it. I would presumably follow my best guesses, while trying to learn more about my friend's actual situation and preferences. This is also what we hope the value learning AI will do.
**2. Learning what to value**
If you are interested in value learning, Dewey's paper is the main thing written on it in the field of AI safety.
**3. Related topics**
I mentioned [inverse reinforcement learning](http://ai.stanford.edu/~ang/papers/icml00-irl.pdf) and [goal inference](https://scholar.google.com/scholar?hl=en&q=goal+inference&btnG=&as_sdt=1%2C5&as_sdtp=) last time, but should probably have kept them for this week, to which they are more relevant. [Preference learning](http://en.wikipedia.org/wiki/Preference_learning) is another related subfield of machine learning, and [learning by demonstration](http://www.scholarpedia.org/article/Robot_learning_by_demonstration) is generally related. [Here](http://youtu.be/csmr-qpqH00) is a quadcopter using inverse reinforcement learning to infer what its teacher wants it to do. [Here](http://youtu.be/MDu4CxQQxyw) is a robot using goal inference to help someone build a toy.
**4. Value porosity**
Bostrom has lately written about a [new variation](http://www.nickbostrom.com/papers/porosity.pdf) on the Hail Mary approach, in which the AI at home is motivated to trade with foreign AIs (via everyone imagining each other's responses), and has preferences that are very cheap for foreign AIs to guess at and fulfil.
**5. What's the difference between value learning and reinforcement learning?**
We heard about reinforcement learning last week, and Bostrom found it dangerous. Since it also relies on teaching the AI values by giving it feedback, you might wonder how exactly the proposals relate to each other.
Suppose the owner of an AI repeatedly comments that various actions are 'friendly'. A reinforcement learner would perhaps care about hearing the word 'friendly' as much as possible. A value learning AI on the other hand would take use of the word 'friendly' as a clue about a hidden thing that it cares about. This means if the value learning AI could trick the person into saying 'friendly' more, this would be no help to it—the trick would just make the person's words a less good clue. The reinforcement learner on the other hand would love to get the person to say 'friendly' whenever possible. This difference also means the value learning AI might end up doing things which it does not expect its owner to say 'friendly' about, if it thinks those actions are supported by the values that it learned from hearing 'friendly'.
In-depth investigations
=======================
If you are particularly interested in these topics, and want to do further research, these are a few plausible directions, some inspired by Luke Muehlhauser's [list](http://lukemuehlhauser.com/some-studies-which-could-improve-our-strategic-picture-of-superintelligence/), which contains many suggestions related to parts of *Superintelligence.*These projects could be attempted at various levels of depth.
1. Expand upon the value learning proposal. What kind of prior over what kind of value functions should a value learning AI be given? As an input to this, what evidence should be informative about the AI's values?
2. Analyze the feasibility of Christiano’s proposal for addressing the value-loading problem.
3. Analyze the feasibility of Bostrom’s “Hail Mary” approach to the value-loading problem.
4. Analyze the feasibility of Christiano's newer proposal to avoid learning values.
5. Investigate the applicability of the related fields mentioned above to producing beneficial AI.
If you are interested in anything like this, you might want to mention it in the comments, and see whether other people have useful thoughts.
How to proceed
==============
This has been a collection of notes on the chapter. **The most important part of the reading group though is discussion**, which is in the comments section. I pose some questions for you there, and I invite you to add your own. Please remember that this group contains a variety of levels of expertise: if a line of discussion seems too basic or too incomprehensible, look around for one that suits you better!
Next week, we will talk about the two other ways to direct the values of AI. To prepare, **read** “Emulation modulation” through “Synopsis” from Chapter 12.The discussion will go live at 6pm Pacific time next Monday 9 February. Sign up to be notified [here](http://intelligence.us5.list-manage.com/subscribe?u=353906382677fa789a483ba9e&id=28cb982f40). |
a87f6934-7fd1-43e0-8842-c489a1e79c77 | trentmkelly/LessWrong-43k | LessWrong | Spiral Staircase
Here was the life cycle of an insight:
> “If I put this candle in an all-white gallery space, it looks like a piece of art. If I put it in a garage, it looks like a piece of trash. [...] I often use this analogy in design. I could either design the candle, [...] or I could just design the room that it sits in.”
>
> — Virgil Abloh, the late founder & CEO of Off-White, artistic director at LVMH
> That’s pretty insightful Virgil, I thought, so let’s look for evidence of this (earnestly) genius insight in your designs. And I searched on Google images, “off-white clothes,” and I didn’t find any genius innovation in his designs. Disappointing.
>
> But wait—of course I wouldn’t find evidence in the products themselves. The whole point was the surrounding context, invisible to Google images and me: the store displays, the scarce releases, the celebrity collaborations.
>
> But wait again—isn’t that just the 4 P’s of marketing? The ones you learn in highschool business class? Product, price, place, and promotion. What Virgil said is, don’t design the product, design the other three P’s. Disappointing.
Many such cases. An idea seems insightful, then I realize it’s actually one I already knew, just wearing a new coat. But you do have a choice of how to respond in these situations. Either, the idea is trite, commonplace, and unoriginal; nothing new under the sun... Or, the idea is a new aspect of the same essence, another facet of the same diamond, another petal from the same flower; there is nothing new under the sun!
When you rederive the same insight from a different direction, you aren’t merely back where you started. You are earning an intuition to notice the idea when it comes up, grasp which of its levers you can pull, and in which conditions it applies differently. And you can do all this easily, even subconsciously, because once you understand the way broadly, you see it in all things.
If you recognized Abloh’s quote as analogous to the 4 P’s of marketing, you’r |
52298ee2-ab51-4d8f-81cf-e0f6bb2e60fb | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | The alignment problem in different capability regimes
I think the alignment problem looks different depending on the capability level of systems you’re trying to align. And I think that different researchers often have different capability levels in mind when they talk about the alignment problem. I think this leads to confusion. I’m going to use the term “regimes of the alignment problem” to refer to the different perspectives on alignment you get from considering systems with different capability levels.
(I would be pretty unsurprised if these points had all been made elsewhere; the goal of this post is just to put them all in one place. I’d love pointers to pieces that make many of the same points as this post. Thanks to a wide variety of people for conversations that informed this. If there’s established jargon for different parts of this, point it out to me and I’ll consider switching to using it.)
Different regimes:
* Wildly superintelligent systems
* Systems that are roughly as generally intelligent and capable as humans--they’re able to do all the important tasks as well as humans can, but they’re not wildly more generally intelligent.
* Systems that are less generally intelligent and capable than humans
Two main causes that lead to differences in which regime people focus on:
* Disagreements about the dynamics of AI development. Eg takeoff speeds. The classic question along these lines is whether we have to come up with alignment strategies that scale to arbitrarily competent systems, or whether we just have to be able to align systems that are slightly smarter than us, which can then do the alignment research for us.
* Disagreements about what problem we’re trying to solve. I think that there are a few different mechanisms by which AI misalignment could be bad from a longtermist perspective, and depending on which of these mechanisms you’re worried about, you’ll be worried about different regimes of the problem.
Different mechanisms by which AI misalignment could be bad from a longtermist perspective:
* [**The second species**](https://www.alignmentforum.org/s/mzgtmmTKKn5MuCzFJ/p/8xRSjC76HasLnMGSf) problem: We build powerful ML systems and then they end up controlling the future, which is bad if they don’t intend to help us achieve our goals.
+ To mitigate this concern, you’re probably most interested in the “wildly superintelligent systems” or “roughly human-level systems” regimes, depending on your beliefs about takeoff speeds and maybe some other stuff.
* **Missed opportunity:** We build pretty powerful ML systems, but because we can’t align them, we miss the opportunity to use them to help us with stuff, and then we fail to get to a good future.
+ For example, suppose that we can build systems that are good at answering questions persuasively, but we can’t make them good at answering them honestly. This is an alignment problem. It probably doesn’t pose an x-risk directly, because persuasive wrong answers to questions are probably not going to lead to the system accumulating power over time, they’re just going to mean that people waste their time whenever they listen to the system’s advice on stuff.
+ This feels much more like a missed opportunity than a direct threat from the misaligned systems. In this situation, the world is maybe in a more precarious situation than it could have been because of the things that we *can* harness AI to do (eg make bigger computers), but that’s not really the fault of the systems we failed to align.
+ If this is your concern, you’re probably most interested in the “roughly human-level” regime.
* We build pretty powerful systems that aren’t generally intelligent, and then they make the world worse somehow by some mechanism other than increasing their own influence over time through clever planning, and this causes humanity to have a bad ending rather than a good one.
+ For example, you might worry that if we can build systems that persuade much more easily than we can build systems that explain, then the world will have more bullshit in it and this will make things generally worse.
+ Another thing that maybe counts: if we deploy a bunch of AIs that are extremely vulnerable to adversarial attacks, then maybe something pretty bad will happen. It is not obvious to me that this should be considered an alignment problem rather than a capabilities problem.
+ It’s not obvious to me that any of these problems are actually that likely to cause a trajectory shift, but I’m not confident here.
+ Problems along these lines often feel like mixtures of alignment, capabilities, and misuse problems.
Here are some aspects of the alignment problem that are different in different regimes. I would love to make a longer list of these.
* **Competence.** If you’re trying to align wildly superintelligent systems, you don’t have to worry about any concern related to your system being incompetent.
For example, any concern related to the system not understanding what people will want. Human values are complex, but by assumption the superintelligence will be able to answer any question you’re able to operationalize about human values. Eg it will be able to massively outperform humans on writing ethics papers or highly upvoted [r/AmItheAsshole comments](https://www.reddit.com/r/AmItheAsshole/).
Other examples of problems that people sometimes call alignment problems that aren’t a problem in the limit of competence include safe exploration and maybe competence-related aspects of robustness to distributional shift (see [Concrete Problems in AI Safety](https://arxiv.org/pdf/1606.06565.pdf)).
Obviously there will be things that your system doesn’t know, and it will be prone to mistakes sometimes. But it will be superhumanly good at being calibrated re these things. For example, it should know how vulnerable to adversarial inputs it is, and it should know when it doesn’t understand something about human values, and so on.
* **Ability to understand itself.** A special case of competence: If your model is very powerful, it will probably be capable of answering questions like “why do you believe what you believe”, inasmuch as a good answer exists. And it probably also knows the answer to “are there any inputs on which you would do something that I wouldn’t like”. (Of course, it might be hard to incentivise it to answer these questions honestly.) It seems pretty plausible, though, that approximately human-level systems wouldn’t know the answers to these questions.
* **Inscrutable influence-seeking plans.** Maybe your system will take actions for the sake of increasing its own influence that you don’t understand. This is concerning because you won’t be able to notice it doing bad things.
I think that this basically definitionally isn’t a problem unless your system is roughly human-level--it will probably have inscrutable plans at lower capability levels, but it probably won’t be powerful enough to surreptitiously gain power. It’s somewhat of a problem in the human-level regime and becomes a much clearer problem when the system is much more capable than humans.
* **Fundamentally inscrutable thoughts.** Maybe your systems will engage in reasoning that uses concepts that humans can’t understand. For example, perhaps there are mathematical abstractions that make it much easier to do math, but which my puny brain is unable to understand. This would be unfortunate because then even if you had the ability to get the best possible human-understandable explanation of the cognitive process the system used to choose some course of action, you wouldn’t be able to spot check that explanation to determine whether the system was in fact doing something bad. Cf [Inaccessible Information](https://ai-alignment.com/inaccessible-information-c749c6a88ce).
Sub-AGI systems probably will have inscrutable thoughts. But in the context of superhuman systems, I think we need to be more concerned by the possibility that it’s performance-uncompetitive to restrict your system to only take actions that can be justified entirely with human-understandable reasoning.
The “competence” and “ability to understand itself” properties make the problem easier; the latter two make the problem harder.
I’m currently most interested in the second species problem and the missed opportunity problem. These days I usually think about the “wildly superintelligent” and “roughly human-level” regimes. I normally think about alignment research relevant to the situations where systems are arbitrarily competent, are prone to inscrutable influence-seeking plans, and don’t have inscrutable thoughts (mostly because I don’t know of good suggestions for getting around the inaccessible information problem). |
883b3cc9-694e-418a-b0c0-9a71a6b4048e | trentmkelly/LessWrong-43k | LessWrong | Consciousness: A Compression-Based Approach
TL;DR: To your brain, "explaining things" means compressing them in terms of some smaller/already-known other thing. So the seemingly inexplicable nature of consciousness/qualia arises because qualia are primitive data elements which can't be compressed. The feeling of there nonetheless being a "problem" arises from a meta-learned heuristic that thinks everything should be compressible.
What's up with consciousness? This question has haunted philosophers and scientists for centuries, and has also been a frequent topic of discussion on this forum. A solution to this problem may have moral relevance soon, if we are going to create artificial agents which may or may not have consciousness. Thus, attempting to derive a satisfying theory seems highly desirable.
One popular approach is to abandon the goal of directly explaining consciousness and instead try to solve the 'meta-problem' of consciousness -- explaining why it is that we think there is a hard problem in the first place. This is the tactic I will take.
There have been a few attempts to solve the meta-problem, including some previously reviewed on LessWrong. However, to me, none of them have felt quite satisfying because they lacked analysis of what I think of as the central thing to be explained by a meta-theory of consciousness -- the seeming inexplicability of consciousness. That is, they will explain why it is that we might have an internal model of our awareness, but they won't explain why aspects of that model feel inexplicable in terms of a physical mechanism. After all, there are other non-strictly-physical parts of our world model, such as the existence of countries, plans, or daydreams, which don't generate the same feeling of inexplicability. So, whence inexplicability? To answer this, we first need to have a model of what "explaining things" means to our brain in the first place.
Explanations as Compression
What is an explanation? On my (very rough) model of the brain[1], there are various inter |
58744d9b-a490-49d0-849e-079ef2aa529a | trentmkelly/LessWrong-43k | LessWrong | How Roodman's GWP model translates to TAI timelines
How does David Roodman’s world GDP model translate to TAI timelines?
Now, before I go any further, let me be the first to say that I don’t think we should use this model to predict TAI. This model takes a very broad outside view and is thus inferior to models like Ajeya Cotra’s which make use of more relevant information. (However, it is still useful for rebutting claims that TAI is unprecedented, inconsistent with historical trends, low-prior, etc.) Nevertheless, out of curiosity I thought I’d calculate what the model implies for TAI timelines.
Here is the projection made by Roodman’s model. The red line is real historic GWP data; the splay of grey shades that continues it is the splay of possible futures calculated by the model. The median trajectory is the black line.
I messed around with a ruler to make some rough calculations, marking up the image with blue lines as I went. The big blue line indicates the point on the median trajectory where GWP is 10x what is was in 2019. Eyeballing it, it looks like it happens around 2040, give or take a year. The small vertical blue line indicates the year 2037. The small horizontal blue line indicates GWP in 2037 on the median trajectory.
Thus, it seems that between 2037 and 2040 on the median trajectory, GWP doubles. (One-ninth the distance between 1,000 and 1,000,000 is crossed, which is one-third of an order of magnitude, which is about one doubling).
This means that TAI happens around 2037 on the median trajectory according to this model, at least according to Ajeya Cotra’s definition of transformative AI as “software which causes a tenfold acceleration in the rate of growth of the world economy (assuming that it is used everywhere that it would be economically profitable to use it)... This means that if TAI is developed in year Y, the entire world economy would more than double by year Y + 4.”
What about the non-median trajectories? Each shade of grey represents 5 percent of the simulated future trajectories, s |
566b2ede-8a21-43fd-9d99-458ffa24d584 | trentmkelly/LessWrong-43k | LessWrong | Friendly UI
I want to bring up some questions that I find crucial to consider about technology in the present day. To contrast with Friendly AI, these questions are about our interaction with technological tools rather than developing a technology that we trust on its own with superhuman intelligence.
1. How are computational tools affecting how we perceive, think, and act?
The inspiration for this post is Bret Victor's new talk, The Humane Representation of Thought. I highly recommend it. In particular, you may want to pause and reflect on the first part before seeing his sketch of solutions in the second. In a nutshell, we have a certain range of human capacities. The use of computing as a medium propels us to develop and value particular capacities: visual & symbolic. Others have discussed diminishing our attention span, decision-making capacity, or cultural expectations of decency. Victor's term for this is "inhumane". He argues that the default path of technological progress has certain properties, but preserving humaneness is not one of them.
The FAI discussions seem to miss both sides of the coin on this phenomenon. First that computation, even though it doesn't exist as a superintelligent entity yet, still imposes values. Second that human intelligence is not a static target: humanity can only reasonably be defined as including the tools we use (humanity without writing or humanity without agriculture are very different), so human intelligence changes along with computation.
In other words, can we design computation now such that it carries us humans to superintelligence? Or, at the very least, doesn't diminish our intelligence and life experience. What are the answers when we ask questions of technology?
2. How can humans best interact with machines with superhuman aspects of intelligence?
There are already machines with superhuman aspects of intelligence, with applications such as chess, essay grading, or image recognition. These systems are deployed witho |
4d65d98b-7a57-42f2-ae6f-29fba833e3e5 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Why Not Subagents?
Alternative title for economists: Complete Markets Have Complete Preferences
> The justification for modeling real-world systems as “agents” - i.e. choosing actions to maximize some utility function - usually rests on [various coherence theorems](https://www.lesswrong.com/posts/RQpNHSiWaXTvDxt6R/coherent-decisions-imply-consistent-utilities). They say things like “either the system’s behavior maximizes some utility function, or it is throwing away resources” or “either the system’s behavior maximizes some utility function, or it can be exploited” or things like that. [...]
>
> Now imagine an agent which prefers anchovy over mushroom pizza when it has anchovy, but mushroom over anchovy when it has mushroom; it’s simply never willing to trade in either direction. There’s nothing inherently “wrong” with this; the agent is not necessarily executing a dominated strategy, cannot necessarily be exploited, or any of the other bad things we associate with inconsistent preferences. But the preferences can’t be described by a utility function over pizza toppings.
>
>
… that’s what I (John) wrote four years ago, as the opening of [Why Subagents?](https://www.lesswrong.com/posts/3xF66BNSC5caZuKyC/why-subagents). Nate [convinced me](https://www.lesswrong.com/posts/fJBTRa7m7KnCDdzG5/a-stylized-dialogue-on-john-wentworth-s-claims-about-markets) that it’s wrong: incomplete preferences do imply a dominated strategy. A system with incomplete preferences, which can’t be described by a utility function, can contract/precommit/self-modify to a more-complete set of preferences which perform strictly better even according to the original preferences.
This post will document that argument.
Epistemic Status: This post is intended to present the core idea in an intuitive and simple way. It is not intended to present a fully rigorous or maximally general argument; our hope is that someone else will come along and more properly rigorize and generalize things. In particular, we’re unsure of the best setting to use for the problem setup; we’ll emphasize some degrees of freedom in the [High-Level Potential Problems (And Potential Solutions)](https://www.lesswrong.com/posts/bzmLC3J8PsknwRZbr/why-not-subagents#High_Level_Potential_Problems_With_This_Argument__And_Potential_Solutions_) section.
Context
-------
The question which originally motivated my interest was: what’s the utility function of the world’s financial markets? Just based on a loose qualitative understanding of coherence arguments, one might think that the inexploitability (i.e. efficiency) of markets implies that they maximize a utility function. In which case, figuring out what that utility function is seems pretty central to understanding world markets.
In [Why Subagents?](https://www.lesswrong.com/posts/3xF66BNSC5caZuKyC/why-subagents), I argued that a market of utility-maximizing traders is inexploitable, but not itself a utility maximizer. The relevant loophole is that the market has incomplete implied preferences (due to path dependence). Then, I argued that any inexploitable system with incomplete preferences could be viewed as a market/committee of utility-maximizing subagents, making utility-maximizing subagents a natural alternative to outright utility maximizers for modeling agentic systems.
More recently, [Nate counterargued](https://www.lesswrong.com/posts/fJBTRa7m7KnCDdzG5/a-stylized-dialogue-on-john-wentworth-s-claims-about-markets) that a market of utility maximizers *will* become a utility maximizer. (My interpretation of) his argument is that the subagents will contract with each other in a way which completes the market’s implied preferences. The model I was previously using got it wrong because it didn’t account for contracts, just direct trade of goods.
More generally, Nate’s counterargument implies that agents with incomplete preferences will tend to precommit/self-modify in ways which complete their preferences.
… but that discussion was over a year ago. Neither of us developed it further, because it just didn’t seem like a core priority. Then the [AI Alignment Awards contest](https://www.alignmentawards.com/) came along, and an excellent entry by [Elliot Thornley](https://www.lesswrong.com/users/ejt) proposed that incomplete preferences could be used as a loophole to make the [shutdown problem](https://www.youtube.com/watch?v=3TYT1QfdfsM) tractable. Suddenly I was a lot more interested in fleshing out Nate’s argument.
To that end, this post will argue that systems with incomplete preferences will tend to contract/precommit in ways which complete their preferences.
The Pizza Example
-----------------
As a concrete example of a system of two subagents with incomplete preference, suppose that John and David have different preferences for pizza toppings, and need to choose one together. We both agree that cheese (C) is the least-preferred default option, and sausage (S) is the best. But in between, John prefers pepperoni > mushroom > anchovy (because John lacks taste), while David prefers anchovy > pepperoni > mushroom (because David is a heathen). Specifically, our utilities are:
| | | |
| --- | --- | --- |
| | David's Utility | John's Utility |
| Cheese | 0 | 0 |
| Mushroom | 1 | 2 |
| Pepperoni | 2 | 3 |
| Anchovy | 3 | 1 |
| Sausage | 4 | 4 |
Or, visually,
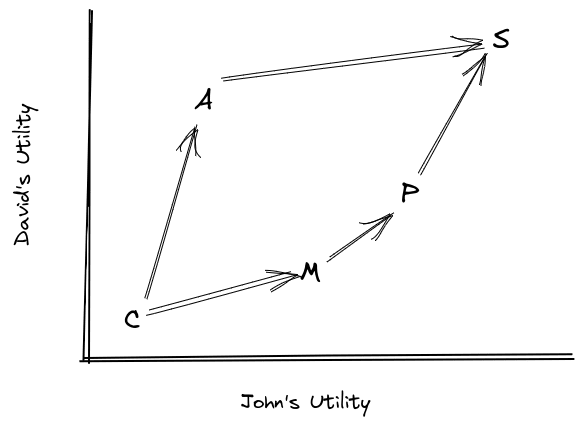The arrows highlight pareto improvements aka preferences; if there is a path from one option to another (e.g. mushroom -> sausage), then that’s a preference *of the whole system*. If there’s no path from one option to another (e.g. anchovy -> pepperoni), then that means either John or David (or both!) would veto the trade offer *in either direction.* In that case there’s no preferred direction between them; that’s where preferences are incomplete.Mechanically, for this weird toy model, we’ll imagine that John and David will be offered some number of opportunities (let’s say 3) to trade their current pizza for another, randomly chosen, pizza. If the offered topping is preferred by both of them, then they take the trade. Otherwise, one of them vetos, so they don’t take the trade. Why these particular mechanics? Well, with those mechanics, the preferences can be interpreted in a pretty straightforward way which plays well with other coherence-style arguments - in particular, it’s easy to argue against circular preferences.
(Note that we're *not* saying trades have the form e.g. "(mushroom -> pepperoni)?" as we would probably usually imagine trades; they instead have the form "(whatever you have now -> pepperoni)". The section [Value vs Utility](https://www.lesswrong.com/posts/bzmLC3J8PsknwRZbr/why-not-subagents#Value_vs_Utility) talks about moving our core claim/argument to a more standard notion of trade.)
### No Utility Function
One reasonable-seeming way to handle incomplete preferences using a utility function is to just say that two options with “no preference” between them have the same utility - i.e. “no preference” = “indifference”. What goes wrong with that?
Well, in the pizza example, there’s no preference between mushroom and anchovy, so they would have to have the same utility. And there’s no preference between anchovy and pepperoni, so they would have to have the same utility. But that means mushroom and pepperoni have the same utility, which conflicts with the preference for pepperoni over mushroom. So, we can’t represent these preferences via a utility function.
Generalizing: whenever we have state B preferred over state A, and some third state C which has no preference relative to either A or B, we cannot represent the preferences using a utility function. Later, we’ll call that condition “strong incompleteness”, and show that non-strongly incomplete preferences *can* be represented using a utility function.
Next, let’s see what kind of tricks we can use when preferences are strongly incomplete.
### A Contract
Now for the core idea. With these preferences, John and David will turn down trades from mushroom to anchovy (because John vetos it), and turn down trades from anchovy to pepperoni (because David vetos it), even though both prefer pepperoni over mushroom. In principle, both might do better in expectation if John could give up some anchovy for pepperoni, and David could give up some mushroom for anchovy, so that the net shift is from mushroom to pepperoni (a shift which they both prefer).
Before any trade offers come along, John and David sign a contract. John agrees to not veto mushroom -> anchovy trades. In exchange, David agrees to not veto anchovy -> pepperoni trades. Now the two together have completed their preferences: sausage > pepperoni > anchovy > mushroom > cheese.
… but that won’t always work; it depends on the numbers. For instance, what if there were a lot more opportunities to trade anchovy -> pepperoni than mushroom -> anchovy? Then an agreement to not veto anchovy -> pepperoni would be pretty bad for David, and wouldn’t be fully balanced out by the extra mushroom -> anchovy trades. We need some way to make the anchovy -> pepperoni trade happen less often (in expectation), to balance things out. If the two trades happen the same amount (in expectation), then there is no expected change in anchovy, just a shift of probability mass from mushroom to pepperoni. Then David and John both do better.
So how do we make the two trades happen the same amount (in expectation)?
### One More Trick: Randomization
Solution: randomize the contract. As soon as the contract is signed, some random numbers will be generated. With some probability, John will agree to never veto mushroom -> anchovy trades. With some other probability, David will agree to never veto anchovy -> pepperoni trades. Then, we choose the two probabilities so that the net expected anchovy states is unchanged by the contract: increasing John’s probability continuously increases expected anchovy, increasing David’s probability continuously decreases expected anchovy, so with the right choice of the two probabilities we can achieve zero expected change in anchovy. Then, the net effect of the contract is to shift some expected mushroom into expected pepperoni; it’s basically a pure win.
That’s the general trick: randomize the preference-completion in such a way that expected anchovy stays the same, while expected mushroom is turned into expected pepperoni.
Claim
-----
Suppose a system has incomplete preferences over a set of states. (For simplicity, we’ll assume the set of states is finite.) Mechanically, this means that there is a “current state” at any given time, and over time the system is offered opportunities to “trade”, i.e. transition to another state; the system accepts a trade A -> B if-and-only-if it prefers B over A.
Claim: the system’s preferences can be made complete (via a potentially-randomized procedure) in such a way that the new distribution of states can be viewed as the old distribution with some probability mass shifted from less-preferred to more-preferred states.
### Stronger Subclaim
For the argument, we’ll want to split out the case where a *strict* improvement can be achieved by completing the preferences.
Suppose there exists three states A, B, C such that:
* The system prefers B over A
* The system has no preference between either A and C or B and C
We’ll call this case “strongly incomplete preferences”. The pizza example involves strongly incomplete preferences: take A to be mushroom, B to be pepperoni, and C to be anchovy.
Claims:
* Strongly incomplete preferences can be randomly completed in such a way that the new distribution of states can be viewed as the old distribution with some strictly positive probability mass shifted from less-preferred to more-preferred states.
* Non-strongly incomplete preferences (either complete or “weakly incomplete”) encode a utility maximizer.
In other words: strongly incomplete preferences imply that a strict improvement can be achieved by (possibly randomly) completing the preferences, while non-strongly incomplete preferences imply that the system is a utility maximizer.
In the case of weakly incomplete preferences (i.e. incomplete but not strongly incomplete), we also claim that the preferences can be randomly completed in such a way that the system is indifferent between its original preferences and the (expected) randomly-completed preferences, via a similar trick to the rest of the argument. But that’s not particularly practically relevant, so we won’t talk about it further.
Argument
--------
### First Step: Strong Incompleteness
In the case of strong incompleteness, we can directly re-use our argument from the pizza example. We have three states A, B, C such that B is preferred over A, and there is no preference between either A and C or B and C. Then, we randomly add a preference for C over A with probability pA→C.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
, and we randomly add a preference for B over C with probability pC→B.
Frequency of state C increases continuously with pA→C, decreases continuously with pC→B, and is equal to its original value when both probabilities are 0. So:
* Check whether frequency of state C is higher or lower than original when both probabilities are set to 1.
* If higher, then set pC→B = 1. With pA→C = 0 the frequency of state C must then be lower than original (since frequency of C is decreasing in pC→B), with pA→C = 1 it’s higher than original by assumption, so by the intermediate value theorem there must be some pA→C value such that the frequency of C stays the same. Pick that value.
* If lower, swap pC→B with pA→C and “higher” with “lower” in the previous bullet.
The resulting randomized transformation of the preferences keeps the frequencies of each state the same, *except* it shifts some probability mass from a less-preferred state (A) to a more-preferred state (B).
(Potential issue with the argument: shifting probability mass from A to B may also shift around probability mass among states downstream of those two states. However, it should generally only shift things in net “good” ways, once we account for the terminal vs instrumental value issue discussed under [Value vs Utility](https://www.lesswrong.com/posts/bzmLC3J8PsknwRZbr/why-not-subagents#Value_vs_Utility). In other words, if we’re using the instrumental value functions, then shifting probability mass from an option valued less by all subagents to one valued more by all subagents should be an expected improvement for all subagents, after accounting for downstream shifts.)
### Third Step: Equilibrium Conditions
The second step will argue that non-strongly incomplete preferences encode a utility maximizer. But it’s useful to see how that result will be used before spelling it out, so we’ll do the third step first. To that end, assume that non-strongly incomplete preferences encode a utility maximizer.
Then we have:
* If the preferences are strongly incomplete, then there exists some contract/precommitment which “strictly improves” expected outcome states (under the original preferences)
* If the preferences are not strongly incomplete, then the system is a utility maximizer.
The last step is to invoke stable equilibrium: strongly incomplete preferences are “unstable” in the sense that the system is incentivized to update from them to more complete preferences, via contract or precommitment. The *only* preferences which are stable under contracts/precommitments are non-strongly-incomplete preferences, which encode utility maximizers.
Now, we haven't established *which* distribution of preferences the system will end up sampling from when randomly completing its preferences, in more complex cases where preferences are strongly incomplete in many places at once. But so long as it ends up at *some* non-dominated choice, it must end up with non-strongly-incomplete preferences with probability 1 (otherwise it could modify the contract for a strict improvement in cases where it ends up with non-strongly-incomplete preferences). And, so long as the space of possibilities is compact and arbitrary contracts are allowed, all we have left is a bargaining problem. The only way the system would end up with dominated preference-distribution is if there's some kind of bargaining breakdown.
Point is: non-dominated strategy implies utility maximization.
### Second Step: No Strong Incompleteness
Assume the preferences have no strong incompleteness. We’re going to construct a utility function for them. The strategy will be:
* Construct “indifference sets” - i.e. sets of states between which the utility function will be indifferent
* Show that there is a complete ordering between the “indifference sets”, so we can order them and assign each a utility based on the ordering
Indifference set construction: put each state in its own set. Then, pick two sets such that there is no preference between any states in either set, and merge the two. Iterate to convergence. At this point, the states are partitioned into sets such that:
* there are no preferences between any two states in the same set, and
* there is at least one preference between at least one pair of states in any two different sets.
Those will turn out to be our indifference sets.
In order to order the indifference sets, we need to show that:
* for *any* pair of states in two different sets, there is a preference between them
* the ordering is consistent - i.e. if one state in set S is preferred to one state in set T, then *any* state in S is preferred to *any* state in T.
(Also we need acyclicity, but that follows trivially from acyclicity of the preferences once we have these two properties.)
To show those, first recall that there is at least one preference between at least one pair of states in any two different sets. Visually:
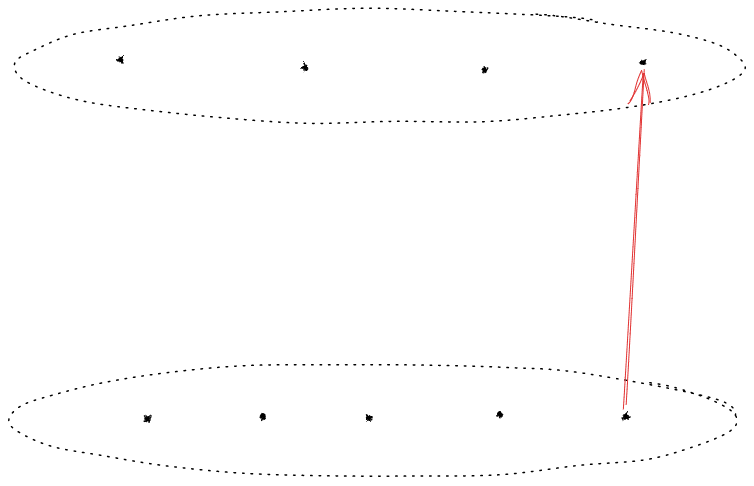Each dot is a state; the two circles indicate two sets within which there are no preferences. The arrow indicates the one preference which we assume is present between the two sets; all the other cross-set preferences may or may not exist, and could go in either direction, as far as we’ve established so far.In order to have no strong incompleteness, all these preferences must also be present (though we don’t yet know their direction):
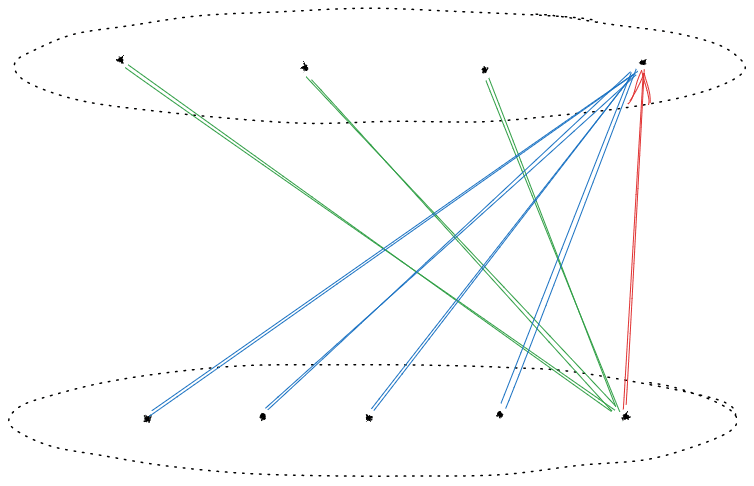 Those preferences must be present because, otherwise, we could establish strong incompleteness like this:
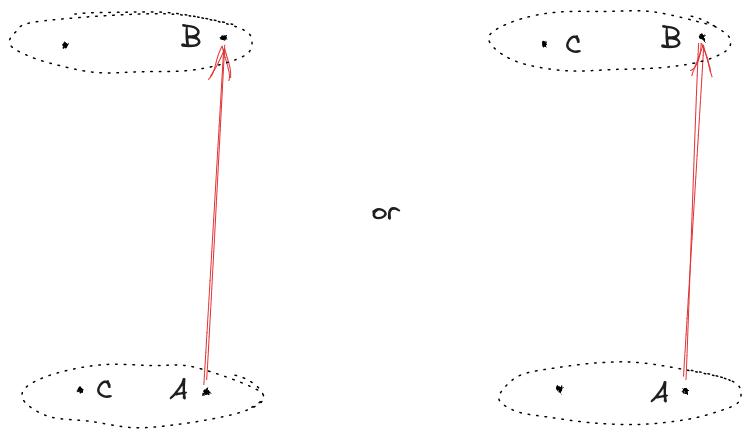 We can also establish the direction of each of the preferences by noting that, by assumption, there is no preference between any two states in the same set:
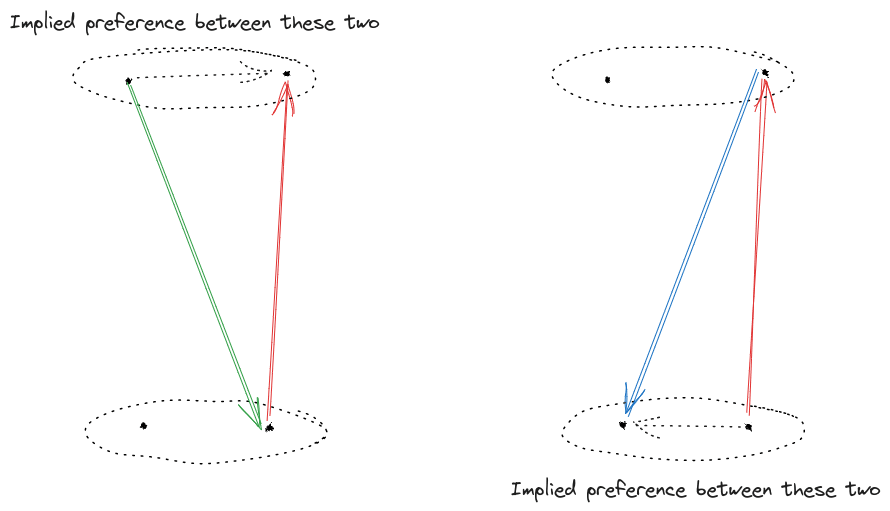Left diagram would imply a preference between two states in the upper set, right diagram would imply a preference between two states in the lower set, so neither of these can occur.So:
 Finally, notice that we’ve now established some more preferences between states in the two sets, so we can repeat the argument with another edge to show that even more preferences are present:
 … and once we’ve iterated the argument to convergence, we’ll have the key result: **if one state in one set is preferred to another state in another set, then*****any*** **state in the first set is preferred to any state in the second**.
And now we can assign a utility function: order the sets, enumerate them in order, then the number of each set is the utility assigned to each state in that set. A state with a higher utility is always preferred over a state with a lower utility, and there is indifference/no preference between two states with the same utility.
(Note that this is a little different from standard definitions - for mathematical convenience, people typically define utility maximizers to take trades in both directions when indifferent, whereas here our utility maximizer might take trades in both directions between an indifferent pair, or take trades in neither direction between an indifferent pair. For practical purposes, the distinction does not matter; just assume that the agent maintains some small “bid/ask spread”, so a nonzero incentive is needed to induce trade, and the two models become equivalent.)
High-Level Potential Problems With This Argument (And Potential Solutions)
--------------------------------------------------------------------------
### Value vs Utility
Suppose that, in the pizza example, instead of offers to trade a new pizza for *whatever* pizza David and John currently have, there are offers to trade a specific type of pizza for another specific type - e.g. a mushroom <-> anchovy trade, rather than a mushroom <-> (whatever we have) trade.
In that setup, we might sometimes want to trade “down” to a less-preferred option, in hopes of trading it for a more-preferred option in the future. For instance, if there are lots of vegetarians around offering to trade their sausage pizza for mushroom, then David and John would have high *instrumental* value for mushroom pizza (because we can probably trade it for sausage), even though neither of us *terminally* values mushroom. Instrumental and terminal value diverge.
Then, the right way to make the argument would be to calculate the (instrumental) value functions of each subagent (in the dynamic programming sense of the phrase), and use that in place of the (terminal) utilities of each subagent. The argument should then mostly carry over, but there will be one major change: the value function is potentially time-dependent. It’s not “mushroom pizza” which has a value assigned to it, but rather “mushroom pizza at time t”. That, in turn, gets into issues of updating and myopia.
### Inconsistent Myopia
A myopic agent in this context would be one which just always trades to more (terminally) preferred options, and never to less (terminally) preferred options, without e.g. strategically trading for a less-preferred mushroom pizza in hopes of later trading the mushroom for more-preferred sausage.
As currently written, our setup implicitly assumed that kind of myopia, which means the subagents are implicitly not thinking about the future when making their choices. … which makes it really weird that the subagents would make contracts/precommitments/self-modications entirely for the sake of future performance. They’re implicitly inconsistently myopic: myopic during trading, but nonmyopic beforehand when choosing to contract/precommit/self-modify.
That said, that kind of inconsistent myopia does make sense for plenty of realistic situations. For instance, maybe the preferences will be myopic during trading, but a designer optimizes those preferences beforehand. Or instead of a designer, maybe evolution/SGD optimizes the preferences.
Alternatively, if the argument is modified to use instrumental values rather than terminal utilities (as the previous section suggested), then the inconsistent myopia issue would be resolved; subagents would simply be non-myopic.
### Updating
Once we use instrumental values rather than terminal utilities on states, it’s possible that those values will change over time. They could change purely due to time - for instance, if David and John are hoping to trade a mushroom pizza for sausage, then as the time left to trade winds down, we’ll become increasingly desperate to get rid of that mushroom pizza; its instrumental value falls.
Instrumental value could also change due to information. For instance, if David and John learn that there aren’t as many vegetarians as we expected looking to trade away sausage for mushroom, then that also updates our instrumental value for mushroom pizza.
In order for the argument to work in such situations, the contract/precommitment/self-modification will probably also need to allow for updating over time - e.g. commit to a policy rather than a fixed set of preferences.
### Different Beliefs
The argument implicitly assumes that David and John have the same beliefs about what distribution of trade offers we’ll see. If we have different beliefs, then there might not be completion-probabilities which we both find attractive.
On the other hand, if our beliefs differ, then that opens up a whole different set of possible contract-types - e.g. bets and insurance. So there may be some way to use bets/insurance to make the argument work again.
Implications For…
-----------------
### AI Alignment: So much for that idea…
Either we can’t leverage incomplete preferences for safety properties (e.g. shutdownability), or we need to somehow circumvent the above argument.
Great.### Economists: If there’s no representative agent, then why ain’t you rich yet?
In economic jargon, completion of the preferences means there exists a representative agent - i.e. the system’s preferences can be summarized by a single utility maximizer. These days most economists assert that there is no representative agent in most real-world markets, so: if there’s no representative agent, then why aren’t you rich yet? And if there is, then what’s its utility function?
Insofar as we view the original incomplete preferences in this model as stemming from multiple subagents with veto power (as in the pizza example), there’s an expected positive sum gain from the contract which completes the preferences. Which means that some third party could, in principle, get paid a share of those gains in exchange for arranging the contract. In practice, most of the work would probably be in designing the contracts in such a way that the benefits are obvious to laypeople, and marketing them. Classic financial engineering business.
So this is the very best sort of economic theorem, where either a useful model holds in the real world, or there’s money to be made.
Conclusions
-----------
Main claim, stated two ways:
* A group of utility-maximizing subagents have an incentive to form contracts under which they converge to a single utility maximizer
* A system with incomplete preferences has an incentive to precommit/self-modify in such a way that the preferences are completed
In general, they do this using randomization over preference-completions. The only expected change each contract/precommitment/self-modification induces is a shift of probability mass from some states to same-or-more-preferred states for all of the subagents; thus each contract is positive-sum.
There is lots more work to be done here, as outlined in the potential problems section. The argument should probably be reframed in terms of value functions (over time) rather than static utility functions in order to more clearly handle instrumentally, though not terminally, valuable actions. The commitments that the subagents make may be better cast as policies rather than fixed preferences. Also, the subagents may have different beliefs about the future, which the argument in this post did not handle.
If the argument holds then this is bad news for alignment hopes that leverage robust incomplete preferences / non E[Utility] maximizers, and also raises some questions about the empirical consensus that modern real-world markets are not expected utility maximizers. |
a4bb9006-e178-4171-a4ca-33add54a9a30 | trentmkelly/LessWrong-43k | LessWrong | Epistemic Effort
Epistemic Effort: Thought seriously for 5 minutes about it. Thought a bit about how to test it empirically. Spelled out my model a little bit. I'm >80% confident this is worth trying and seeing what happens. Spent 45 min writing post.
I've been pleased to see "Epistemic Status" hit a critical mass of adoption - I think it's a good habit for us to have. In addition to letting you know how seriously to take an individual post, it sends a signal about what sort of discussion you want to have, and helps remind other people to think about their own thinking.
I have a suggestion for an evolution of it - "Epistemic Effort" instead of status. Instead of "how confident you are", it's more of a measure of "what steps did you actually take to make sure this was accurate?" with some examples including:
* Thought about it musingly
* Made a 5 minute timer and thought seriously about possible flaws or refinements
* Had a conversation with other people you epistemically respect and who helped refine it
* Thought about how to do an empirical test
* Thought about how to build a model that would let you make predictions about the thing
* Did some kind of empirical test
* Did a review of relevant literature
* Ran an Randomized Control Trial
[Edit: the intention with these examples is for it to start with things that are fairly easy to do to get people in the habit of thinking about how to think better, but to have it quickly escalate to "empirical tests, hard to fake evidence and exposure to falsifiability"]
A few reasons I think this (most of these reasons are "things that seem likely to me" but which I haven't made any formal effort to test - they come from some background in game design and reading some books on habit formation, most of which weren't very well cited)
* People are more likely to put effort into being rational if there's a relatively straightforward, understandable path to do so
* People are more likely to put effort into being rational if they s |
84a86bab-bdbd-4221-9975-107422531ec2 | trentmkelly/LessWrong-43k | LessWrong | Critiquing Risks From Learned Optimization, and Avoiding Cached Theories
What I'm doing with this post and why
I've been told that it's a major problem (this post, point 4), of alignment students just accepting the frames they're given without question. The usual advice (the intro of this) is to first do a bunch of background research and thinking on your own, to come up with your own frames if at all possible. BUT: I REALLY want to learn about existing alignment frames, it's Fucking Goddamn Interesting.
<sidenote>At the last possible minute while editing this post, I've had the realization that "the usual advice" I somehow acquired might not actually be "usual" at all. In fact, upon actually rereading the study guide, it looks like he actually recommended to read up on the existing frames and to try applying them. So, I must've just completely hallucinated that advice! Or, at least, extremely overestimated how important that point from 7 traps was. I'm still going to follow through with this exercise, but holy shit my internal category of "possible study routes" has expanded DRASTICALLY. </sidenote>
So I ask the question: is it possible to read about and pick apart an existing frame, such that you don't just end up uncritically accepting it? What questions do you need to ask or what thoughts do you need to think, in order to figure out the assumptions and/or problems with an existing framework?
I've chosen Risks From Learned Optimization because I've already been exposed to the basic concept, from various videos by Robert Miles. I shouldn't be losing anything by learning this more deeply and trying to critique it.
Moreover, I want to generate evidence of my competence anyway, so I might as well write this up.
Method:
I'm writing pretty much all the notes I generated while going through this process here, though I somewhat re-organized them to make them more readable and coherent.
* generate questions to critique it with beforehand
* read it (summarize it)
* generate questions during the previous step
* afterwards, attempt to |
e489fc50-69d6-486c-9710-ba729b1dd6b0 | trentmkelly/LessWrong-43k | LessWrong | A potential problem with using Solomonoff induction as a prior
There's a problem that has occurred to me that I haven't seen discussed anywhere: I don't think people actually wants to assign zero probability to all hypotheses which are not Turing computable. Consider the following hypothetical: we come up with a theory of everything that seems to explain all the laws of physics but there's a single open parameter (say the fine structure constant). We compute a large number of digits of this constant, and someone notices that when expressed in base 2, the nth digit seems to be 1 iff the nth Turing machine halts on the blank tape for some fairly natural ordering of all Turing machines. If we confirm this for a large number of digits (not necessarily consecutive digits- obviously some of the 0s won't be confirmable) shouldn't we consider the hypothesis the digits really are given by this simple but non-computable function? But if our priors assign zero probability to all non-computable hypotheses then this hypothesis must always be stuck with zero probability.
If the universe is finite we could approximate this function with a function which was instead "Halts within K" steps where K is some large number, but intutively this seems like a more complicated hypothesis than the original one.
I'm not sure what is a reasonable prior in this sort of context that handles this sort of thing. We don't want an uncountable set of priors. It might make sense to use something like hypotheses which are describable in Peano arithmetic or something like that.
|
e7787c84-76b8-4d64-bbf8-510be70b54a6 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Grokking “Forecasting TAI with biological anchors”
*Notes:*
* *I give a visual explanation of Ajeya Cotra’s draft report,* [*Forecasting TAI with biological anchors (Cotra, 2020)*](https://www.alignmentforum.org/posts/KrJfoZzpSDpnrv9va/draft-report-on-ai-timelines)*, summarising the key assumptions, intuitions, and conclusions*
* *The diagrams can be found* [*here*](https://docs.google.com/presentation/d/1eXutGC7VJ6Dig6wjqHVa44XYTtUllX6ZOrJJv1S1JZ4/edit) *– you can click on some of the boxes to get linked to the part of the report that you’re interested in*[[1]](#fneahmat36bmi)
*Thanks to Michael Aird, Ashwin Acharya, and the* [*Epoch*](https://epochai.org/) *team for suggestions and feedback! Special thanks to Jaime Sevilla and Ajeya Cotra for detailed feedback.*
Executive Summary
=================
[*Click here to skip the summary*](https://forum.effectivealtruism.org/posts/6RcicmJCvztarka8Y/grokking-forecasting-tai-with-biological-anchors#Motivation)
Ajeya Cotra’s biological anchors framework attempts to forecast the development of **Transformative AI (TAI)** by treating compute as a key bottleneck to AI progress. This lets us focus on a concrete measure (compute, measured in [FLOP](https://en.wikipedia.org/wiki/Floating-point_arithmetic)) as a proxy for the question “when will TAI be developed?” Given this, we can decompose the question into two main questions:
1. **2020 training compute requirements:** How much compute will we need to train TAI, using 2020 Machine Learning architectures and algorithms?
2. **Affordability of compute:** How likely is it that we’ll be able to afford the compute required to train TAI in a particular year?
The second question can be tackled by turning to existing trends in three main factors: (1) **algorithmic progress** e.g. improved algorithmic efficiency, (2) decreasing **computation prices** e.g. due to hardware improvements, and (3) increased **willingness to spend on compute.**
The first question is significantly trickier. Cotra attempts to answer it by treating the brain as a “proof of concept” that the “amount of compute” used to “train” the brain can train a general intelligence. This lets her relate the question “how much compute will we need to train TAI?” with the question “how much ‘compute’ was used to ‘train’ the human brain?”. However, there’s no obvious single interpretation for the latter question, so Cotra comes up with six hypotheses for what this corresponds to, referring to these hypotheses as “**biological anchors**” or “**bioanchors**”:
* **Evolution anchor:** Compute to train TAI = Compute performed over evolution since the first neurons
* **Lifetime anchor:** Compute to train TAI = Compute performed by the human brain when maturing to an adult (0 to 32 years old)
* **Three neural network anchors:** Anchor to the processing power of the human brain, and to empirical parameter scaling laws.
+ Technically there are three of these, corresponding to short, medium, and long “effective horizon lengths” – the amount of data required to determine whether or not a perturbation to the AI system improves or worsens performance
* **Genome anchor:** Anchor to the processing power of the human brain, set the number of parameters = number of bytes in the human genome, and extrapolate the amount of training data required using the same empirical scaling laws mentioned above and assuming a long horizon length (one “data point” = multiple years)
In calculating the training compute requirements distribution, Cotra places 90% weight collectively across these bioanchor hypotheses, leaving 10% to account for the possibility that all of the anchors significantly underestimate the required compute.
Here’s a visual representation of how Cotra breaks down the question “How likely is the development is TAI by a given year?”:
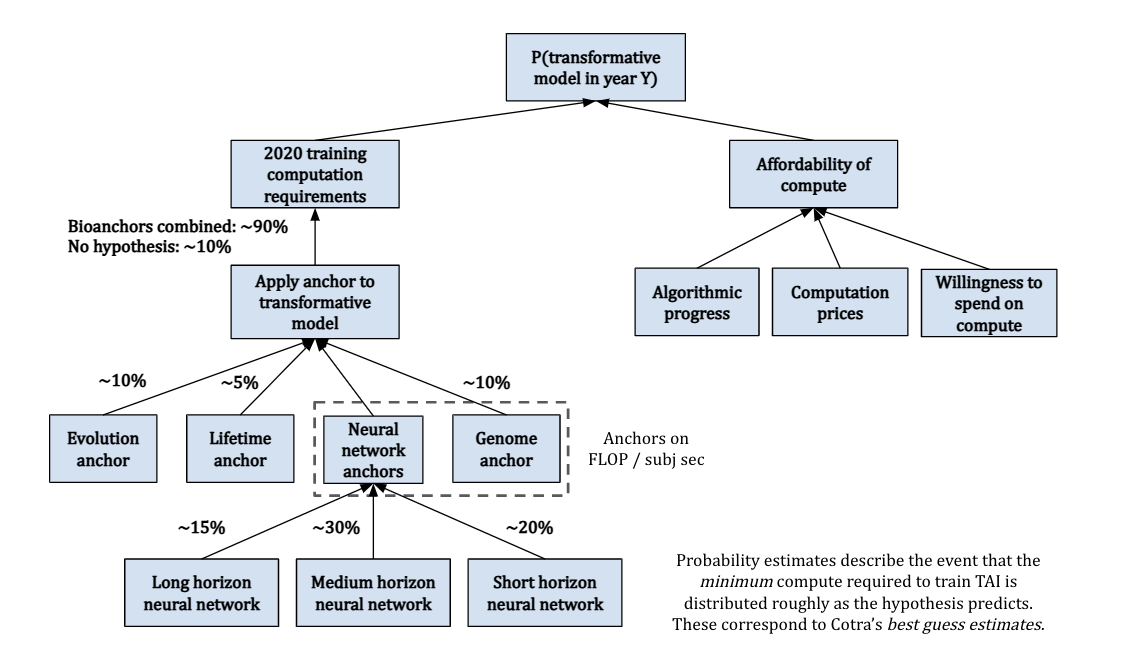The above was essentially a summary of Cotra’s factorization of the question of AI timelines; for a summary of her key findings, see [here](https://forum.effectivealtruism.org/posts/6RcicmJCvztarka8Y/grokking-forecasting-tai-with-biological-anchors#Putting_Things_Together__Final_distribution).
Motivation
==========
One of the biggest unresolved debates in AI Safety is the question of [AI Timelines](https://www.alignmentforum.org/tag/ai-timelines) – when will **Transformative AI (TAI)** be developed? In 2020, Ajeya Cotra released a draft report, [*Forecasting TAI with biological anchors (Cotra, 2020)*](https://www.alignmentforum.org/posts/KrJfoZzpSDpnrv9va/draft-report-on-ai-timelines), that aims to answer this question. It’s over 200 pages long including the appendices, and still just a draft!
Anecdotally, the results from this report have already been used to inform work in AI governance, and I believe it is likely that the report has had a major influence on the views of many researchers in AI safety.[[2]](#fnconhtqdsic) That said, the length of the document likely means that few people have read the report in full, are aware of its assumptions/limitations, or have a high-level understanding of the approach.
The aim of this post is to change this situation, by providing [yet](https://www.cold-takes.com/forecasting-transformative-ai-the-biological-anchors-method-in-a-nutshell/) [another](https://astralcodexten.substack.com/p/biological-anchors-a-trick-that-might?s=r) summary of the report. I focus on the intuitions of the model and describe the framework visually, to show how different parts of Cotra’s report are pieced together.
Why focus on compute?
---------------------
As you might imagine, trying to forecast the trajectory of a future transformative technology is very challenging, especially if there haven’t been many technologies of a similar nature in the past. In order to gain traction, we’ll inevitably have to make assumptions about what variables are the most important.
In the report, Cotra focuses on answering the following question:
> In which year might the amount of computation required to train a “transformative model” become attainable for an AI development project?
>
>
Here, “transformative model” refers to a single AI model such that running many copies of that model (once trained) would have “at least as profound an impact on the world’s trajectory as the Industrial Revolution did”.[[3]](#fnompojkngny) It is a specific way that [“transformative AI”](https://www.openphilanthropy.org/blog/some-background-our-views-regarding-advanced-artificial-intelligence#Sec1) could look – so Cotra’s report is essentially asking when we might have enough of a certain kind of resource (compute) to produce TAI through a certain path (training a giant AI model). She hopes that this sheds light on the broader question of “when might we have transformative AI” overall.
The question Cotra asks is thus more specific, but it seems plausibly informative for the broader question of TAI timelines because:
1. The “train a big model” path to TAI seems technologically possible, and is salient because it’s similar to how current state-of-the-art AI systems are produced. (Indeed it’s an unusually brute-force approach to AI, so the question “When might we get TAI by training a single big model?” could be seen as a [“soft upper bound”](https://forum.effectivealtruism.org/posts/ajBYeiggAzu6Cgb3o/biological-anchors-is-about-bounding-not-pinpointing-ai) for the question of “When might we get TAI?”).
2. It seems very plausible that compute is the resource that bottlenecks being able to train a transformative model the most. For instance (among other reasons):
* Many algorithms/architectures that saw success after the advent of [Deep Learning](https://en.wikipedia.org/wiki/Deep_learning) had been proposed decades earlier, and only [achieved competitive performance when researchers gained access to more compute](https://www.deeplearningbook.org/contents/intro.html#:~:text=1.2.3-,Increasing,Sizes,-Another)
* Compute has been growing massively (by a factor of [10 billion times since 2010](https://twitter.com/ohlennart/status/1503451560268947461)), compared to algorithmic efficiency, which has grown a comparatively small amount ([44x since 2012](https://openai.com/blog/ai-and-efficiency/))
* Evidence in favour of [The Scaling Hypothesis](https://www.gwern.net/Scaling-hypothesis) and scaling laws suggest that there are regular and predictable returns to training AI models on increasingly large scales of compute
It’s also convenient that compute is relatively easy to measure compared to nebulous terms like “data” and “algorithms”, which lack standardised units. A common measure for compute is in terms of the total number of arithmetic operations performed by a model, measured in [FLOP](https://en.wikipedia.org/wiki/Floating-point_arithmetic). We might also be interested in how many operations the model performs each second (measured in FLOP/s), which tells us about the power of the hardware that the model is trained on.
Framework
---------
Cotra thus makes compute a primary focus of her TAI forecasting framework. Now instead of asking “when will TAI be developed?”, we ask two separate questions:
1. **2020 training compute requirements:** How much compute will we need to train a transformative model, using 2020 Machine Learning architectures and algorithms?
2. **Affordability of compute:** How likely is it that we’ll be able to afford the compute required to train a transformative model in a particular year?
The second of these is relatively straightforward to answer because we have some clear trends that we can analyse and [directly extrapolate](https://www.alignmentforum.org/s/T9pBzinPXYB3mxSGi/p/3dBtgKCkJh5yCHbag).[[4]](#fn2p722wejth7) The first question however, opens a big can of worms – we need to find some kind of [reference class](https://bounded-regret.ghost.io/base-rates-and-reference-classes/) that we can anchor to.
For this, Cotra chooses to anchor to the human brain – she views the human brain as a “proof of concept” that general intelligence is possible, then takes the analogy very seriously. The assumption is that the compute required to “train” the human brain should be informative of how much compute is needed to train a transformative model.
But how do we even define “compute to train the human brain”? There seem to be two main ambiguities with defining this:
* **How long was the human brain “trained” for?**
+ For instance, should we interpret the brain as being trained for a human lifetime, or over the course of neuron evolution?
* **How much compute was used at each point in training?**
+ For example, how many FLOP/s does the human brain run on?
Our answers to these questions determine the **biological anchors** – four[[5]](#fn1105grkwqm4n) possible answers to the question, “how much compute was used to train the human brain?”. Two of these anchor directly to FLOP of compute:
* **Evolution anchor:** The compute required to train a transformative model is roughly the total compute done over evolutionary history, starting from the first neurons. This interprets evolution as a really big search algorithm over a large space of possible neural architectures and environments, eventually stumbling across the human brain.
* **Lifetime anchor:** The compute required to train a transformative model is roughly the compute performed as a child matures, from birth to 32 years old. Under this hypothesis, we should expect Machine Learning architectures to be roughly as efficient as human learning.
The other two hypotheses anchor to the *computations per second* (i.e. FLOP/s) performed by the brain, rather than total compute. This is used to estimate the **FLOP per subjective second (FLOP / subj sec)** that TAI performs, where a “subjective second” is the time it takes a model to process as much data as a human can in one second.[[6]](#fnaaxqwgojjof) These hypotheses differ in how many parameters they predict TAI would need to have.
* **Neural network anchors**[[7]](#fn06vebk3a69gi)**:** TAI should perform roughly as many FLOP / subj sec as the human brain, and have a similar ratio of “parameters” to “FLOP / subj sec” as today’s neural networks do. There are actually three anchors here, as we’ll later see.
* **Genome anchor:** TAI should perform roughly as many FLOP / subj sec as the human brain, and have about as many parameters as there are bytes in the human genome.
We can think of these anchors as saying that to build TAI, we’ll need processing power as good as the human brain, and as many parameters as (1) would be typical of neural networks that run on that much processing power, (2) the human genome.
You can see Cotra’s bioanchors framework at a high-level below:
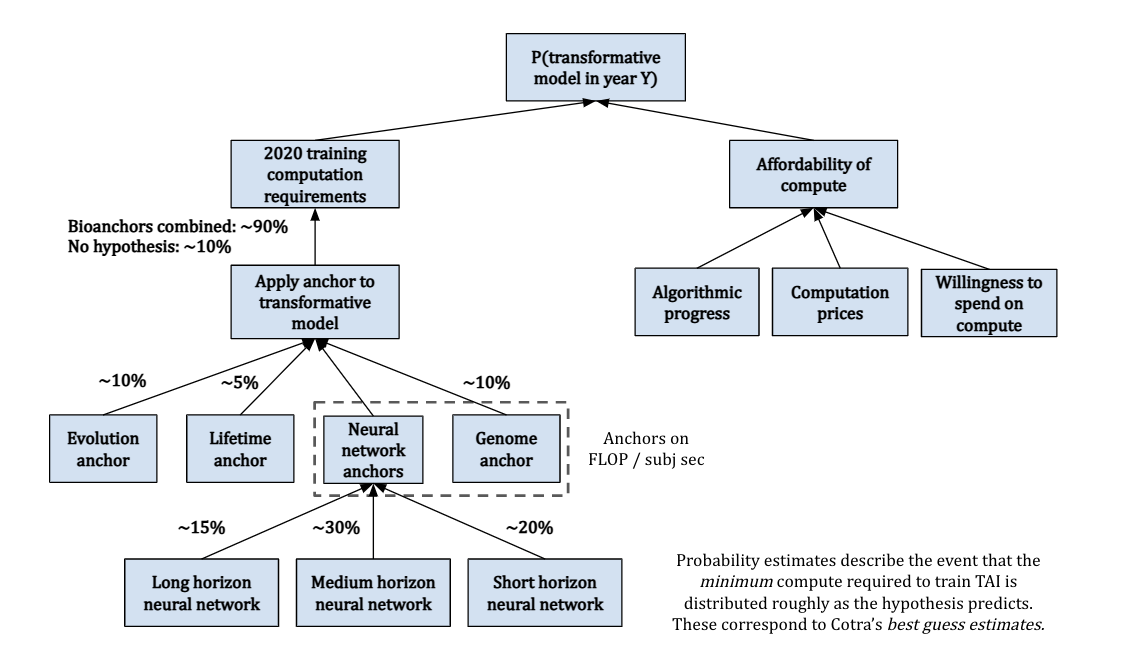On the left, we use bioanchors to determine how much compute we’ll need to train TAI. Overall, Cotra allocates 90% weight to the bioanchors, where the remaining 10% is reserved for the possibility that all of the hypotheses are significantly underestimating required compute. On the right, we do projections for when we’ll be able to afford this compute, based on trends affecting compute prices and the willingness to spend. These are combined to give an estimate for the probability of TAI by a particular year.
We saw earlier that the predicted FLOP for the evolution and lifetime anchors can be directly estimated, but this is not the case for the genome and neural network anchors. For this, we need to know both the number of FLOP / subj sec performed by the human brain, and the relevant number of subjective seconds required for training.
Finding the training data requirements is split into two parts:
* **Number of parameters**, which is specified by the relevant bioanchor hypothesis
* **Effective horizon length –** roughly, the amount of data it would take to tell whether a perturbation to the model improves or worsens performance.[[8]](#fnn2xd25t36b) This is tricky to determine because it can’t be directly extrapolated or calculated making it one of the biggest uncertainties in the report.
Combining all of these gives us a rough estimate for the compute that the relevant bioanchor predicts.
You now know the basic motivation and framework for how the model works! The next section will dive into where a lot of the complexity lies – figuring out probability distributions over training compute for each of the bioanchors.
Zooming Into the Biological Anchors
===================================
We can think of each bioanchor as going through a three-step process:
1. Find a prior distribution for the FLOP based on biological evidence
2. Make adjustments based on evidence from current Machine Learning and intuitions
3. Decide how strongly you want to weigh the anchor
In this section I’ll briefly outline[[9]](#fnhxhf2gbuojt) the bioanchor hypotheses – I’ve also included a dependency diagram for each of them, where the boxes link to the relevant part of the report.
Evolution anchor
----------------
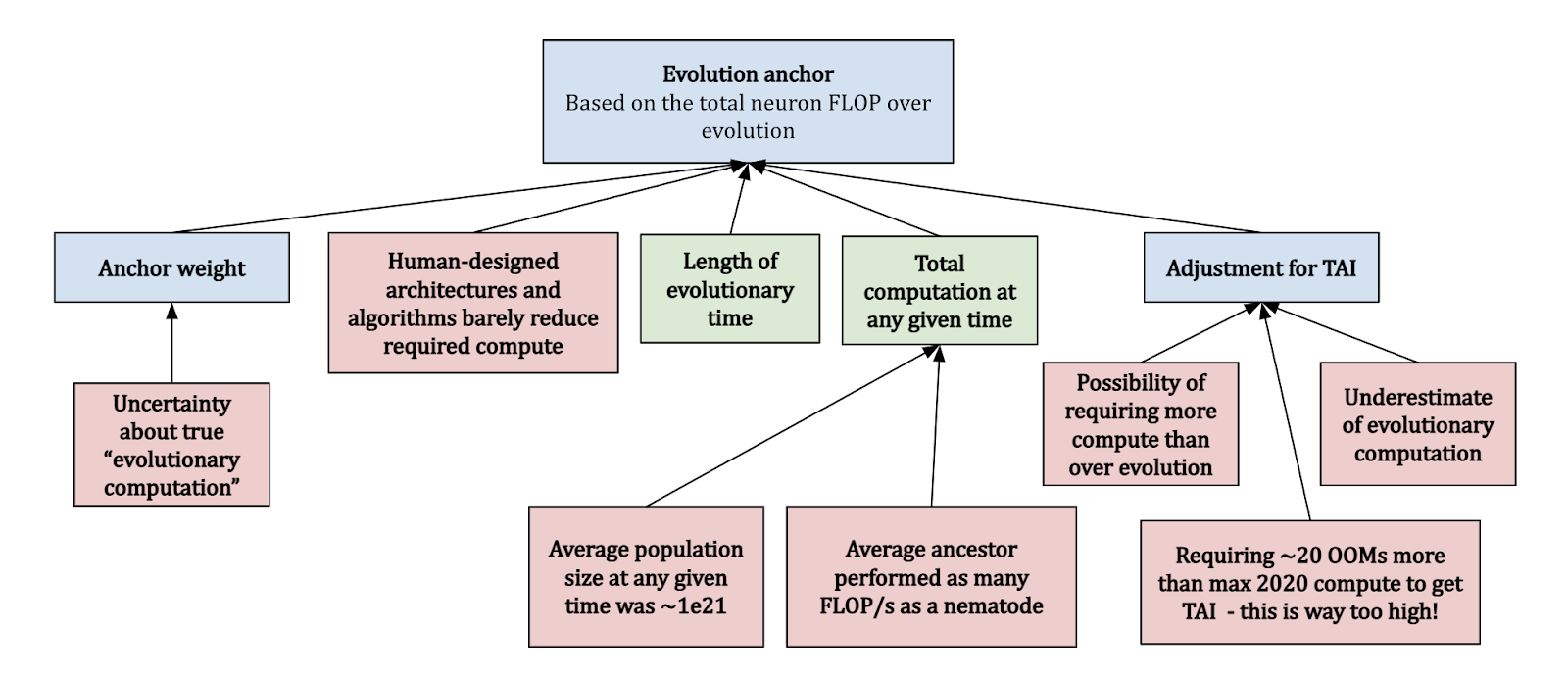The **evolution** anchor looks at the total FLOP performed over the course of evolution, since the first neurons. Clearly there are some uncertainties with this approach:
* How do you even count “evolutionary computation”, and how does this compare with FLOP done on a GPU?
* What was the “average” compute done over all species at any time?
* How does the compute efficiency of human-designed architectures compare with just doing a random search?
Cotra accounts for these considerations, and assumes that the “average ancestor” performed as many FLOP/s as a nematode, and that there were on average ~1e21 ancestors at any time. This yields a **median of ~1e41 FLOP**, which seems extraordinarily high compared to modern Machine Learning.[[10]](#fnvo8l4pj5qy9) She gives this anchor a **weight of 10%**.
Lifetime anchor
---------------
The second approach based on counting FLOP directly is based on the **lifetime anchor**, which looks at the total brain compute when growing from child to an adult (32 years old). Plugging in the numbers about [brain FLOP/s](https://www.openphilanthropy.org/brain-computation-report) seems to suggest that ~1e27 FLOP would be required to reach TAI. This seems far too low, for several reasons:
* Examples from other technological domains suggests that the efficiency of things we build (on relevant metrics) is [generally not great when compared to nature](https://docs.google.com/document/d/1HUtUBpRbNnnWBxiO2bz3LumEsQcaZioAPZDNcsWPnos/edit)
* It also contradicts the [efficient-market hypothesis](https://en.wikipedia.org/wiki/Efficient-market_hypothesis), and predicts a very substantial probability that [AlphaStar](https://www.deepmind.com/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii)-level compute would be TAI, which doesn’t seem to be the case!
Overall, Cotra finds a **median of ~1e28 FLOP,** and places **5% weight** on this anchor.
Both the evolution and lifetime anchors seem to be taking a similar approach, but I think it’s really worth emphasising just how vastly different these two interpretations are in terms of their predictions, so here’s a diagram that illustrates this:
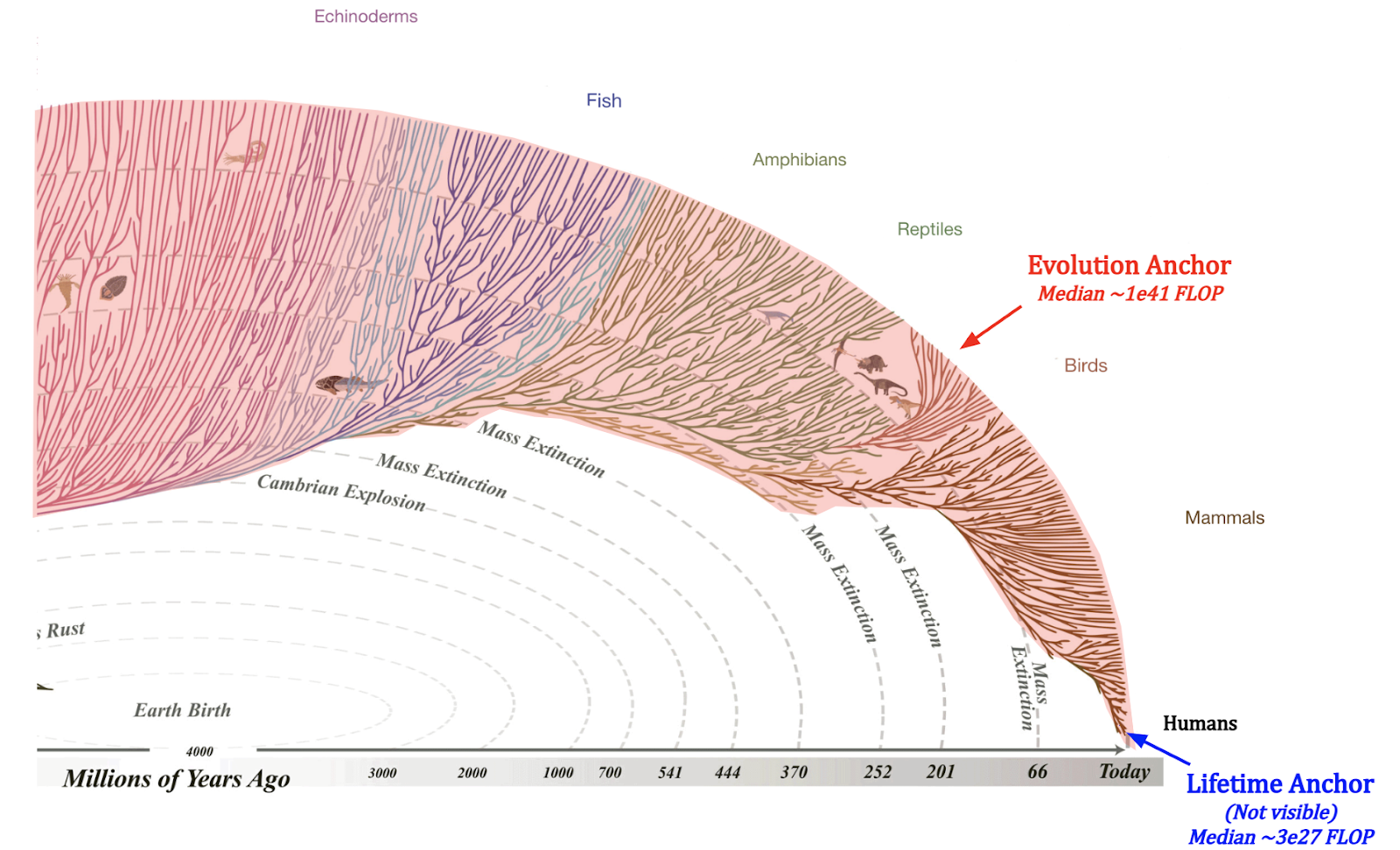*Image source: (For the evolutionary tree)* [*evogeneao Tree of Life Explorer*](https://www.evogeneao.com/en/explore/tree-of-life-explorer)
If we look at the part of the evolutionary tree with neurons, then the evolution anchor includes neuron compute over the entire red area, across many different branches. On the other hand, the lifetime anchor requires us to zoom in *really* close to a small region in the bottom right, consider only humans out of all mammals, and consider only 32 years of the life of a single human out of the ~100 billion people who’ve ever lived. This isn’t even close to being visible in the diagram[[11]](#fn1ygab7g46o2)!
Neural network anchors
----------------------
The three **neural network anchors** look at how much compute is required to train a network, by anchoring to the FLOP / subj sec performed by the brain, and based on parameter scaling laws. These anchors differ based on what horizon length is seen as necessary to achieve transformative impacts, and each have their own corresponding [log-uniform distribution](https://uk.mathworks.com/help/stats/loguniform-distribution.html).
* **Short horizon: 1 subj sec to 1e3 subj sec, centred around ~1e32 FLOP**
* **Medium horizon**: 1e3 subj sec to 1e6 subj sec, centred around **~3e34 FLOP**
* **Long horizon**: 1e6 subj sec to 1e9 subj sec, centred around **~1e37 FLOP**
Cotra determines the training data requirements based on a mix of Machine Learning theory and empirical considerations. She puts **15% weight on short horizons**, **30% on medium horizons**, and **20% on long horizons**, for a total of 65% on the three anchors.
Genome anchor
-------------
The **genome anchor** looks at the FLOP / subj sec of the human brain, and expects TAI to require as many parameters as there are bytes in the human genome. This hypothesis implicitly assumes a training process that’s structurally analogous to evolution[[12]](#fno76bsi712xs), and that TAI will have some critical cognitive ability that evolution optimised for.
At least at the time of writing (May 2022), Machine Learning architectures don’t look very much like human genome, and we are yet to develop TAI – thus Cotra updates against this hypothesis towards requiring more FLOP. Overall, she finds a **median of ~1e33 FLOP** and places **10% weight** on this anchor.
Affordability of compute
========================
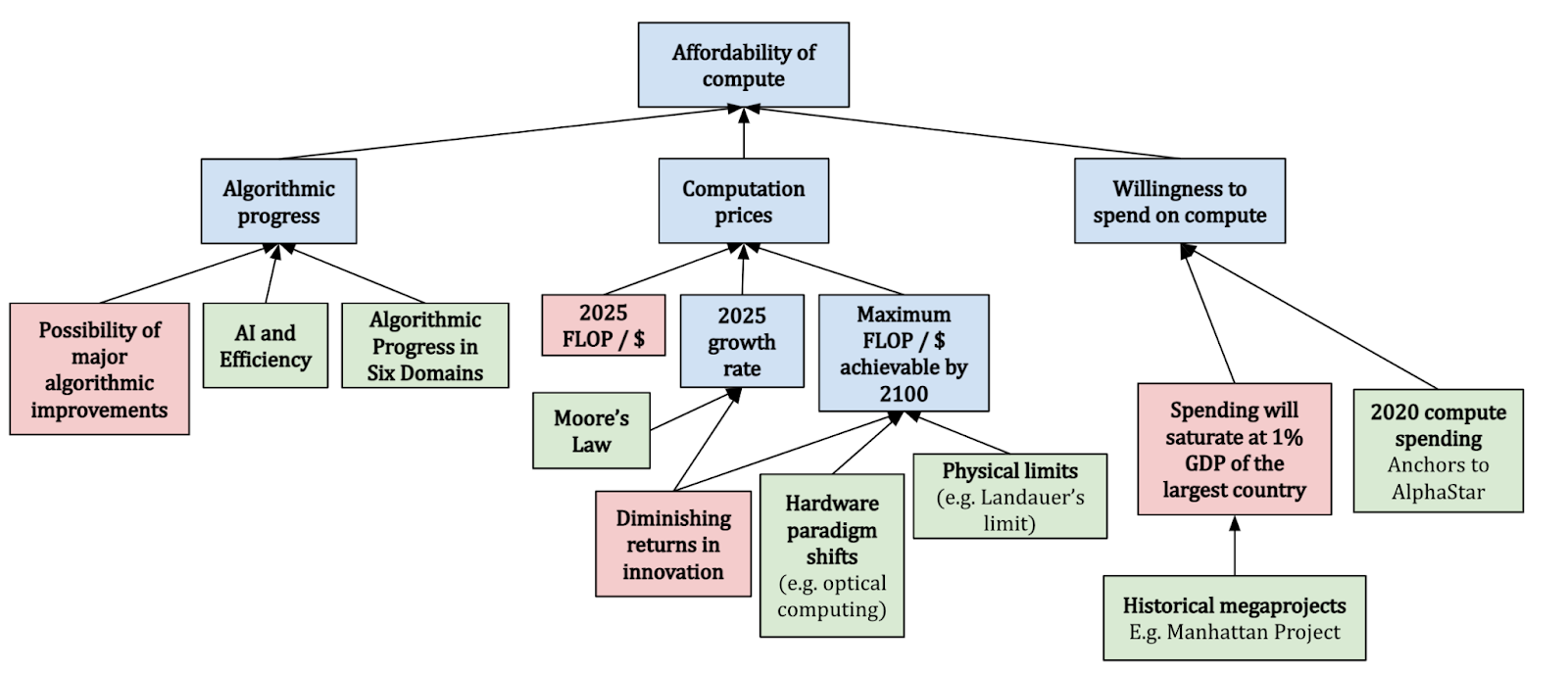After using the bioanchors to determine a distribution for the compute FLOP required to build TAI using 2020 algorithms and architectures, Cotra turns to find a probability distribution over whether or not we’ll be able to afford this compute. She does this by considering three different factors:
* **Algorithmic progress:** For this, she relies heavily on the [*AI and Efficiency*](https://openai.com/blog/ai-and-efficiency/) study, which finds a 44x growth in algorithmic efficiency for Computer Vision algorithms between 2012 and 2018. She considers a **doubling in efficiency every ~2-3 years**, although the **cap on progress depends on the specific bioanchor hypothesis**
* **Computation prices:** We should expect to get more compute for a given price over time – Cotra bases this roughly on current trends in compute prices; **halving every ~2.5 years**, and further expects this to **level off after 6 orders of magnitude**.
* **Willingness to spend**: Cotra assumes that the willingness to spend on Machine Learning training runs should be **capped at 1% the GDP of the largest country**, referencing previous case studies with megaprojects (e.g. the [Manhattan Project](https://en.wikipedia.org/wiki/Manhattan_Project)), and should follow a **doubling time of 2 years after 2025**.
She makes these forecasts starting from 2025 to 2100, because she believes that there will be a rapid scaleup in compute for ML training runs from 2020 to 2025, and expects this to slow back down. The main uncertainty here is whether or not existing trends are going to persist more than several years into the future. For instance, we ([Epoch](https://epochai.org/)) recently found that OpenAI’s [*AI and Compute*](https://openai.com/blog/ai-and-compute/) investigation was too aggressive in its findings for compute growth. In fact, there is [evidence that the reported trend was already breaking](https://www.alignmentforum.org/posts/wfpdejMWog4vEDLDg/ai-and-compute-trend-isn-t-predictive-of-what-is-happening) at the time of publishing. All in all, I think this suggests that we should exercise caution when interpreting these forecasts.
Putting Things Together: Final distribution
===========================================
If we put everything together, this is the distribution that we get:
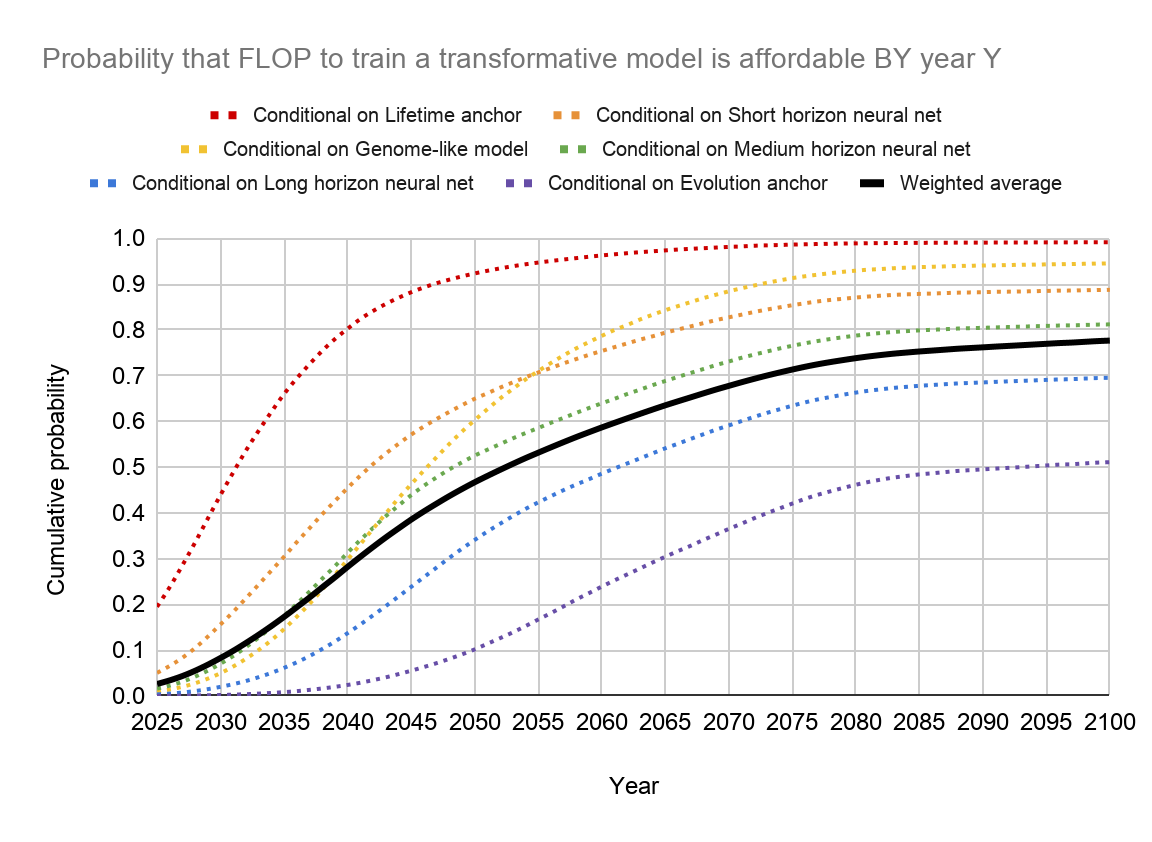
| | | |
| --- | --- | --- |
| P(TAI before 2030) | P(TAI before 2050) | P(TAI before 2100) |
| ~8% | ~47% | ~78% |
| | | |
| 10% | 50% | 90% |
| 2031 | 2052 | >2100 |
Based on these results, Cotra chooses a **median estimate of TAI by 2050**, a round number that avoids signalling too much precision in the estimates. These results seem to suggest that the probability of TAI being developed within this century is very high (at ~78%, see the table above).
You can of course question the premises and approach of this study, for instance:
* Is compute actually the biggest factor driving AI developments? Is it really reasonable to think of this as the main bottleneck, even a decade into the future?
* How valid is the approach of using bioanchors to determine the required compute to train TAI[[13]](#fnfhpqsl1gld6)?
* The report ignores the possibility of new paradigms (e.g. [optical computing](https://en.wikipedia.org/wiki/Optical_computing)) and exogenous events that could hamper development – how much should we still trust this model?
Among other sources, Cotra states that the largest source of uncertainty comes from the appropriate value of the effective horizon length, which could range from 1 subj sec to 1e9 subj sec in the neural network anchors, and states that this is subject to further investigation. She also argues that the model overestimates the probability of TAI for short timelines due to unforeseen bottlenecks (e.g. regulation), and underestimates it for long timelines, since the research field will likely have found different paths to TAI that aren’t based on scaling 2020 algorithms and architectures.
Conclusion
==========
All in all, this is one of the first serious attempts at making a concrete framework for forecasting TAI, and it’s reallydetailed! Despite this, there are still tons of questions that remain unanswered, that hopefully the AI forecasting field can figure out soon enough.
I also hope that these diagrams and explanations help you get a good high-level overview of what the report is getting at, and what kinds of further work would be interesting! You can find the [full report and code here](https://drive.google.com/drive/u/0/folders/15ArhEPZSTYU8f012bs6ehPS6-xmhtBPP), which I encourage you to look through.
*You can play with the diagrams* [*here*](https://docs.google.com/presentation/d/1eXutGC7VJ6Dig6wjqHVa44XYTtUllX6ZOrJJv1S1JZ4/edit)*: (the boxes link to the corresponding part of the report). These were rather clunkily put together using Google Slides – if you have any suggestions for better software that’s good for making these diagrams, I’d love to hear it!*
1. **[^](#fnrefeahmat36bmi)***Green boxes correspond to inputs, red boxes are assumptions or limitations, and blue boxes are classed as “other”*
2. **[^](#fnrefconhtqdsic)**By “AI Safety”, I am referring generally to work that helps reduce global catastrophic risks from advanced AI systems, which includes both AI governance and technical AI safety.
3. **[^](#fnrefompojkngny)**In general, it is not necessarily the case that these transformative effects need to be precipitated by a *single* model, although making this assumption is arguably still a good proxy for when we might see transformative impacts from multiple AI systems. The report also gives a more precise definition of “impact” in terms of [GWP](https://en.wikipedia.org/wiki/Gross_world_product), but my impression is that the heavy lifting assumption-wise is done by the bioanchors, rather than the precise definition of TAI. That is, I suspect the same bioanchors would’ve been used with somewhat different definitions of TAI.
4. **[^](#fnref2p722wejth7)**Of course, things aren’t *quite* so straightforward! For instance, we also need to consider the possibility of trends failing to persist, e.g. due to the end of [Moore’s Law](https://en.wikipedia.org/wiki/Moore%27s_law).
5. **[^](#fnref1105grkwqm4n)**Technically there’s six, but bear with me for now!
6. **[^](#fnrefaaxqwgojjof)**In her report, Cotra gives the following example: “a typical human reads about [3-4 words per second](https://irisreading.com/what-is-the-average-reading-speed/) for non-technical material, so “one subjective second” for a language model would correspond to however much time that the model takes to process about ~3-4 words of data. If it runs on 1000 times as many FLOP/s as the human brain, but also processes 3000-4000 words per second, it would be performing about as many FLOP per subjective second as a human.”
7. **[^](#fnref06vebk3a69gi)**Since the neural network anchors don’t really correspond to any biological process, an alternative and arguably more accurate framing for them is “how much compute *would it take* to train a model as good as the human brain?” (as opposed to “how much compute was required to train the human brain?”).
8. **[^](#fnrefn2xd25t36b)**For instance, for a True or False question answering task given a sentence, the effective horizon length might be the length of the input sentence.
9. **[^](#fnrefhxhf2gbuojt)**My goal here is to provide a succinct summary of the key points, and to simultaneously provide links for people who want to learn more, so I refrain from putting too much detail here.
10. **[^](#fnrefvo8l4pj5qy9)**E.g. Google’s [PaLM model was trained with ~2.5e24 FLOP](https://docs.google.com/spreadsheets/d/1AAIebjNsnJj_uKALHbXNfn3_YsT6sHXtCU0q7OIPuc4/edit#gid=0) – that’s 17 orders of magnitude smaller!
11. **[^](#fnref1ygab7g46o2)**Of course, this diagram doesn’t account for the fact that certain species do a lot more compute than others, but I think it gets some intuition across – that there’s a great deal of uncertainty about how much compute was required to “train” the human brain.
12. **[^](#fnrefo76bsi712xs)**This differs from the evolution anchor in that it assumes we can search over possible architectures/algorithms a lot more efficiently than evolution, using gradients. Due to this structural similarity, and because feedback signals about the fitness of a particular genome configuration are generally sparse, this suggests that the anchor only really makes sense with long horizon lengths. This is why there aren’t also three separate genome anchors!
13. **[^](#fnreffhpqsl1gld6)**In my view, this is the perspective that Eliezer Yudkowsky is taking in his post, [*Biology-Inspired AGI Timelines: The Trick That Never Works*](https://www.alignmentforum.org/posts/ax695frGJEzGxFBK4/biology-inspired-agi-timelines-the-trick-that-never-works). See also [Holden Karnofsky’s response](https://www.alignmentforum.org/posts/nNqXfnjiezYukiMJi/reply-to-eliezer-on-biological-anchors). |
5422a8e5-7970-4ca1-8919-49c6f362f114 | trentmkelly/LessWrong-43k | LessWrong | Attacking machine learning with adversarial examples
|
e373420e-c726-45da-ae20-40b593742c7b | trentmkelly/LessWrong-43k | LessWrong | Why AGI Timeline Research/Discourse Might Be Overrated
I no longer stand by this post, and will preserve it here for history reasons.
> TL;DR: Research and discourse on AGI timelines aren't as helpful as they may at first appear, and a lot of the low-hanging fruit (i.e. motivating AGI-this-century as a serious possibility) has already been plucked.
> David Collingridge famously posed a dilemma for technology governance—in short, many interventions happen too early (when you lack sufficient information) or too late (when it’s harder to change things). Collingridge’s solution was essentially to take an iterative approach to governance, with reversible policy interventions. But, people in favor of more work on timelines might ask, why don’t we just frontload information gathering as much as possible, and/or take precautionary measures, so that we can have the best of both worlds?
> Again, as noted above, I think there’s some merit to this perspective, but it can easily be overstated. In particular, in the context of AI development and deployment, there is only so much value to knowing in advance that capabilities are coming at a certain time in the future (at least, assuming that there are some reasonable upper bounds on how good our forecasts can be, on which more below).
> Even when my colleagues and I, for example, believed with a high degree of confidence that language understanding/generation and image generation capabilities would improve a lot between 2020 and 2022 as a result of efforts that we were aware of at our org and others, this didn’t help us prepare that much. There was still a need for various stakeholders to be “in the room” at various points along the way, to perform analysis of particular systems’ capabilities and risks (some of which were not, IMO, possible to anticipate), to coordinate across organizations, to raise awareness of these issues among people who didn’t pay attention to those earlier bullish forecasts/projections (e.g. from scaling laws), etc. Only some of this could or would have gon |
2748262c-b180-472c-9641-3a34ca623578 | trentmkelly/LessWrong-43k | LessWrong | Book Review: Fooled by Randomness
The book "Fooled by Randomness: The Hidden Role of Chance in Life and in the Markets" by Nassim Nicholas Taleb was published in 2001. On Amazon, the book has a rating of 4.3, rated by 1,124 people, with 62% of reviewers giving 5 stars. On Goodreads, it has a rating of 4.07 from 1,968 reviews. "The book was selected by Fortune as one of the 75 'Smartest Books of All Time.'", notes Wikipedia. So this should be a great book. I forgot who wrote this, and I forgot the exact words, but I remember reading on twitter that Taleb is something like a modern genius because in his books he develops a worldview based on fundamental insights on randomness, and derives important conclusions including a system of ethics from that. Now that sounds promising! This worldview is developed in Taleb's Incerto series of five books. In the description of the German publisher you can read that the order in which you read the books does not matter, but then it seemed like a good idea to start with the first one nonetheless ("The Black Swan" surely is the better-known title and has 2,083 reviews).
The book seems to have been a revelation to many, judging by the enthusiastic reviews. In a five-star Amazon review, reviewer Alex Bush writes (November 3, 2015) that the book "revolutionized how I view the world. In multiple ways. It's hard to overstate how rarely a book changes your ideas about how the world works once, let alone multiple times". He thinks that Taleb "has managed to weave a fantastically engaging and entertaining book out of what could very easily be a dry and technical topic", that FbR is "the most general and therefore most widely applicable" book by Taleb, and suggests that it teaches people "the survivorship and hindsight biases, as well as the difference between conditional and unconditional probability". Indeed, these are things you may learn from the book in a non-technical way. You may also learn that people find causality where there is mere randomness; that the past of a |
1e6034a8-3415-407a-8e28-2393a10624f6 | trentmkelly/LessWrong-43k | LessWrong | Will DNA Analysis Make Politics Less of a Mind-Killer?
I wrote an article for h+ predicting that the rapid fall in the cost of gene sequencing will allow U.S. voters to learn much about presidential candidates' DNA. The candidates won't be able to stop this because:
> humans shed so much DNA that unless a politician lived in a plastic bubble he couldn’t shield his DNA from prying eyes. Politicians will probably pass laws making it a crime to involuntarily disclose a politician’s genetic traits. But since it would take only one person to leak the information onto the Internet, and given that any serious candidate for President will have many enemies, candidates’ genomes will undoubtedly become public.
DNA analysis has a decent chance of reducing political bias by providing objective information about candidates. If, for example, 70% of the variation in human intelligence is determined by identified genes then DNA analysis would reduce disagreements among informed voters over a candidate's intelligence. |
68444149-7c15-4253-bdd1-18896008d924 | trentmkelly/LessWrong-43k | LessWrong | Welcome to Effective Altruism Groningen
Hey!
We are EA Groningen, a small effective altruism community in the northern Dutch student town Groningen. We meet at least once a month in our regular pub: the Harbour Café. Besides that we organize lectures and learning meetups, and sometimes we have some projects running.
The people who regularly attend are between 20-40 years old, with about 60% students. Not many people read LW or SSC (besides me), but we welcome anyone who does and is interested in improving the world most effectively! Our cause interest is very wide: some interest in near term human welfare, some in animal welfare, some in long-term future, and many people who are unsure which is best :)
As long as you are open for new information and like to learn instead of only making your case, you are more than welcome. There is no background reading required, although reading some introductory EA material definitely enhances the conversations!
Check out our Meetup page for our upcoming events.
|
54d9f11d-811f-4385-96eb-4fff1c06e9c2 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Goal-conditioned Imitation Learning
1 Introduction
---------------
Reinforcement Learning (RL) has shown impressive results in a plethora of simulated tasks, ranging from attaining super-human performance in video-games Mnih et al. [[2015](#bib.bib1)], Vinyals et al. [[2019](#bib.bib2)] and board-games Silver et al. [[2017](#bib.bib3)], to learning complex locomotion behaviors Heess et al. [[2017](#bib.bib4)], Florensa et al. [[2017a](#bib.bib5)]. Nevertheless, these successes are shyly echoed in real world robotics Riedmiller et al. [[2018](#bib.bib6)], Zhu et al. [[2018a](#bib.bib7)]. This is due to the difficulty of setting up the same learning environment that is enjoyed in simulation. One of the critical assumptions that are hard to obtain in the real world are the access to a reward function. Self-supervised methods have the power to overcome this limitation.
A very versatile and reusable form of self-supervision for robotics is to learn how to reach any previously observed state upon demand. This problem can be formulated as training a goal-conditioned policy Kaelbling [[1993](#bib.bib8)], Schaul et al. [[2015](#bib.bib9)] that seeks to obtain the indicator reward of having the observation exactly match the goal. Such a reward does not require any additional instrumentation of the environment beyond the sensors the robot already has. But in practice, this reward is never observed because in continuous spaces like the ones in robotics, the exact same observation is never observed twice. Luckily, if we are using an off-policy RL algorithm Lillicrap et al. [[2015](#bib.bib10)], Haarnoja et al. [[2018](#bib.bib11)], we can “relabel" a collected trajectory by replacing its goal by a state actually visited during that trajectory, therefore observing the indicator reward as often as we wish. This method was introduced as Hindsight Experience Replay Andrychowicz et al. [[2017](#bib.bib12)] or HER, although it used special resets, and the reward was in fact an ϵ-ball around the goal, which only makes sense in lower-dimensional state-spaces. More recently the method was shown to work directly from vision with a special reward Nair et al. [[2018a](#bib.bib13)], and even only with the indicator reward of exactly matching observation and goal Florensa et al. [[2018a](#bib.bib14)].
In theory these approaches could learn how to reach any goal, but the breadth-first nature of the algorithm makes that some areas of the space take a long time to be learned Florensa et al. [[2018b](#bib.bib15)]. This is specially challenging when there are bottlenecks between different areas of the state-space, and random motion might not traverse them easily Florensa et al. [[2017b](#bib.bib16)]. Some practical examples of this are pick-and-place, or navigating narrow corridors between rooms, as illustrated in Fig. [2](#S5.F2 "Figure 2 ‣ 5.1 Tasks ‣ 5 Experiments ‣ Goal-conditioned Imitation Learning") depicting the diverse set of environments we work with. In both cases a specific state needs to be reached (grasp the object, or enter the corridor) before a whole new area of the space is discovered (placing the object, or visiting the next room). This problem could be addressed by engineering a reward that guides the agent towards the bottlenecks, but this defeats the purpose of trying to learn without direct reward supervision. In this work we study how to leverage a few demonstrations that traverse those bottlenecks to boost the learning of goal-reaching policies.
Learning from Demonstrations, or Imitation Learning (IL), is a well-studied field in robotics Kalakrishnan et al. [[2009](#bib.bib17)], Ross et al. [[2011](#bib.bib18)], Bojarski et al. [[2016](#bib.bib19)]. In many cases it is easier to obtain a few demonstrations from an expert than to provide a good reward that describes the task. Most of the previous work on IL is centered around trajectory following, or doing a single task. Furthermore it is limited by the performance of the demonstrations, or relies on engineered rewards to improve upon them. In this work we study how IL methods can be extended to the goal-conditioned setting, and show that combined with techniques like HER it can outperform the demonstrator without the need of any additional reward. We also investigate how the different methods degrade when the trajectories of the expert become less optimal, or less abundant.
We also observe that these methods can be run in a complete reset-free fashion, hence overcoming another limitation of RL in the real world. Finally, the method we develop is able leverage demonstrations that do not include the expert actions. This is very convenient in practical robotics where demonstrations might have been given by a motion planner, by kinestetic demonstrations (moving the agent externally, and not by actually actuating it), or even by another agent. To our knowledge, this is the first framework that can boost goal-conditioned policy learning with only state demonstrations.
2 Preliminaries
----------------
We define a discrete-time finite-horizon discounted Markov decision process (MDP) by a tuple M=(S,A,P,r,ρ0,γ,H), where S is a state set, A is an action set, P:S×A×S→R+ is a transition probability distribution, γ∈[0,1] is a discount factor, and H is the horizon. Our objective is to find a stochastic policy πθ that maximizes the expected discounted reward within the MDP, η(πθ)=Eτ[∑Tt=0γtr(st,at,st+1)]. We denote by τ=(s0,a0,...,) the entire state-action trajectory, where s0∼ρ0(s0), at∼πθ(at|st), and st+1∼P(st+1|st,at).
In the goal-conditioned setting that we use here, the policy and the reward are also conditioned on a “goal" g∈S. The reward is r(st,at,st+1,g)=1[st+1==g], and hence the return is the γh, where h is the number of time-steps to the goal. Given that the transition probability is not affected by the goal, g can be “relabeled" in hindsight, so a transition (st,at,st+1,g,r=0) can be treated as (st,at,st+1,g′=st+1,r=1).
Finally, we also assume access to D trajectories {(sj0,aj0,sj1,...)}Dj=0 that were collected by an expert attempting to reach a goal gj sampled uniformly among the feasible goals. Those trajectories must be approximately geodesics, meaning that the actions are taken such that the goal is reached as fast as possible.
3 Related Work
---------------
Imitation Learning can be seen as an alternative to reward crafting to train desired behaviors. There are many ways to leverage demonstrations, from Behavioral Cloning Pomerleau [[1989](#bib.bib20)] that directly maximizes the likelihood of the expert actions under the training agent policy, to Inverse Reinforcement Learning that extracts a reward function from those demonstrations and then trains a policy to maximize it Ziebart et al. [[2008](#bib.bib21)], Finn et al. [[2016](#bib.bib22)], Fu et al. [[2018](#bib.bib23)]. Another formulation close to the later introduced by Ho and Ermon [[2016](#bib.bib24)] is Generative Adversarial Imitation Learning (GAIL), explained in details in the next section. Originally, the algorithms used to optimize the policy were on-policy methods like Trust Region Policy Optimization Schulman et al. [[2015](#bib.bib25)], but recently there has been a wake of works leveraging the efficiency of off-policy algorithms without loss in stability Blondé and Kalousis [[2019](#bib.bib26)], Sasaki et al. [[2019](#bib.bib27)], Schroecker et al. [[2019](#bib.bib28)], Kostrikov et al. [[2019](#bib.bib29)]. This is a key capability that we are going to exploit later on.
Unfortunately most work in the field cannot outperform the expert, unless another reward is available during training Vecerik et al. [[2017](#bib.bib30)], Gao et al. [[2018](#bib.bib31)], Sun et al. [[2018](#bib.bib32)], which might defeat the purpose of using demonstrations in the first place. Furthermore, most tasks tackled with these methods consist on tracking expert state trajectories Zhu et al. [[2018b](#bib.bib33)], Peng et al. [[2018](#bib.bib34)], but can’t adapt to unseen situations.
In this work we are interested in goal-conditioned tasks, where the objective is to be able to reach any state upon demand. This kind of multi-task learning are pervasive in robotics, but challenging if no reward-shaping is applied. Relabeling methods like Hindsight Experience Replay Andrychowicz et al. [[2017](#bib.bib12)] unlock the learning even in the sparse reward case Florensa et al. [[2018a](#bib.bib14)]. Nevertheless, the inherent breath-first nature of the algorithm might still make very inefficient learning to learn complex policies. To overcome the exploration issue we investigate the effect of leveraging a few demonstrations. The closest prior work is by Nair et al. [[2018b](#bib.bib35)], where a Behavioral Cloning loss is used with a Q-filter. We found that a simple annealing of the Behavioral Cloning loss Rajeswaran et al. [[2018](#bib.bib36)] works better. Furthermore, we also introduce a new relabeling technique of the expert trajectories that is particularly useful when only few demonstrations are available. We also experiment with Goal-conditioned GAIL, leveraging the recently shown compatibility with off-policy algorithms.
4 Demonstrations in Goal-conditioned tasks
-------------------------------------------
1:Input: Demonstrations D={(sj0,aj0,sj1,...,gj)}Dj=0, replay buffer R={}, policy πθ(s,g), discount γ, hindsight probability p
2:while not done do
3: # Sample rollout
4: g∼R∪D ▹ Goal are sampled from observed states
5: Use π(⋅,g) to sample (s0,a0,s1,...)→∪R
6: # Sample from buffers
7: {(sjt,ajt,sjt+1,gj)}∼D, {(sit,ait,sit+1,gi)}∼R
8: # Relabel agent
9: if HER then
10: for each i, with probability p do
11: gi←sit+k, k∼ Unif{t+1,…,Ti} ▹ Use future HER strategy
12: end for
13: end if
14: if EXPERT RELABEL then
15: gj←sjt+k′, k′∼ Unif{t+1,…,Tj}
16: end if
17: rht=1[sht+1==gh]
18: if δGAIL>0 then
19: Ψ←minψLGAIL(Dψ,D,R)
20: rht=(1−δGAIL)rht+δGAILlogDψ(aht,sht,gh) ▹ Add annealed GAIL reward
21: end if
22: # Fit Qϕ
23: yht=rht+γQϕ(π(sht+1,gh),sht+1,gh) ▹ Use target networks Qϕ′ for stability
24: ϕ←minϕ∑h∥Qϕ(aht,sht,gh)−yht∥
25: # Update Policy
26: θ+=α∇θ^J−β∑h∇θLBC(θ,(aht,sht,gh)) ▹ Combine weighted gradients
27: Anneal δGAIL and β ▹ Ensures outperforming the expert
28:end while
Algorithm 1 Goal-conditioned Imitation Learning
In this section we describe the different algorithms we compare to running only Hindsight Experience Replay Andrychowicz et al. [[2017](#bib.bib12)]. First we revisit adding a Behavioral Cloning loss to the policy update as in Nair et al. [[2018b](#bib.bib35)], then we propose a novel expert relabeling technique, and finally we formulate for the first time a goal-conditioned GAIL algorithm, and propose a method to train it with state-only demonstrations.
###
4.1 Goal-conditioned Behavioral Cloning
The most direct way to leverage demonstrations {(sj0,aj0,sj1,...)}Dj=0 is to construct a data-set D of all state-action-goal tuples (sjt,ajt,gj), and run a supervised regression algorithm. In the goal-conditioned case and assuming a deterministic policy πθ(s,g), the loss is:
| | | |
| --- | --- | --- |
| | | |
This loss and its gradient are computed without any additional environments samples from the trained policy πθ. This makes it particularly convenient to combine a gradient descend step based on this loss with other policy updates. In particular we can use a standard off-policy Reinforcement Learning algorithm like DDPG Lillicrap et al. [[2015](#bib.bib10)], where we fit the Qϕ(a,s,g), and then estimate the gradient of the expected return as:
| | | |
| --- | --- | --- |
| | ∇θ^J=1NN∑i=1∇aQϕ(a,s,g)∇θπθ(s,g) | |
In our goal-conditioned case, the Q fitting can also benefit form “relabeling" like done in HER Andrychowicz et al. [[2017](#bib.bib12)]. The improvement guarantees with respect to the task reward are lost when we combine the BC and the deterministic policy gradient updates, but this can be side-stepped by either applying a Q-filter 1{Q(st,at,g)>Q(st,π(st,g),g)} to the BC loss as proposed in Nair et al. [[2018b](#bib.bib35)], or by annealing it as we do in our experiments, which allows to eventually outperform the expert.
###
4.2 Relabeling the expert
| | | | |
| --- | --- | --- | --- |
|
|
|
(a) Performance on reaching states visited in demonstrations. The state is colored in green if the policy reaches it when attempting so, and red otherwise.
|
(b) Performance on reaching any possible state. Each cell is colored green if the policy can reach the center of it when attempting so, and red otherwise.
|
Figure 1: Policy performance on reaching different goals in the four rooms, when training on 20 demonstrations with standard Behavioral Cloning (top row) or with our expert relabeling (bottom).
The expert trajectories have been collected by asking the expert to reach a specific goal gj. But they are also valid trajectories to reach any other state visited within the demonstration! This is the key motivating insight to propose a new type of relabeling: if we have the transitions (sjt,ajt,sjt+1,gj) in a demonstration, we can also consider the transition (sjt,ajt,sjt+1,g′=sjt+k) as also coming from the expert! Indeed that demonstration also went through the state sjt+k, so if that was the goal, the expert would also have generated this transition. This can be understood as a type of data augmentation leveraging the assumption that the tasks we work on are quasi-static. It will be particularly effective in the low data regime, where not many demonstrations are available. The effect of expert relabeling can be visualized in the four rooms environment as it’s a 2D task where states and goals can be plotted. In Fig. [1](#S4.F1 "Figure 1 ‣ 4.2 Relabeling the expert ‣ 4 Demonstrations in Goal-conditioned tasks ‣ Goal-conditioned Imitation Learning") we compare the final performance of two agents, one trained with pure Behavioral Cloning, and the other one also using expert relabeling.
###
4.3 Goal-conditioned GAIL with Hindsight
The compounding error in Behavioral Cloning might make the policy deviate arbitrarily from the demonstrations, and it requires too many demonstrations when the state dimension increases. The first problem is less severe in our goal-conditioned case because in fact we do want to visit and be able to purposefully reach all states, even the ones that the expert did not visited. But the second drawback will become pressing when attempting to scale this method to practical robotics tasks where the observations might be high-dimensional sensory input like images. Both problems can be mitigated by using other Imitation Learning algorithms that can leverage additional rollouts collected by the learning agent in a self-supervised manner, like GAIL Ho and Ermon [[2016](#bib.bib24)]. In this section we extend the formulation of GAIL to tackle goal-conditioned tasks, and then we detail how it can be combined with HER Andrychowicz et al. [[2017](#bib.bib12)], which allows to outperform the demonstrator and generalize to reaching all goals. We call the final algorithm goal-GAIL.
First of all, the discriminator needs to also be conditioned on the goal Dψ(a,s,g), and be trained by minimizing
| | | | |
| --- | --- | --- | --- |
| | LGAIL(Dψ,D,R)= | E(s,a,g)∼R[logDψ(a,s,g)]+ | |
| | | E(s,a,g)∼D[log(1−Dψ(a,s,g))]. | |
Once the discriminator is fitted, we can run our favorite RL algorithm on the reward logDψ(aht,sht,gh). In our case we used the off-policy algorithm DDPG Lillicrap et al. [[2015](#bib.bib10)] to allow for the relabeling techniques outlined above. In the goal-conditioned case we also supplement with the indicator reward rht=1[sht+1==gh]. This combination is slightly tricky because now the fitted Qϕ does not have the same clear interpretation it has when only one of the two rewards is used Florensa et al. [[2018a](#bib.bib14)] . Nevertheless, both rewards are pushing the policy towards the goals, so it shouldn’t be too conflicting. Furthermore, to avoid any drop in final performance, the weight of the reward coming from GAIL (δGAIL) can be annealed.
All possible variants we study are detailed in Algorithm [1](#alg1 "Algorithm 1 ‣ 4 Demonstrations in Goal-conditioned tasks ‣ Goal-conditioned Imitation Learning"). In particular, α=0 falls back to pure Behavioral Cloning, β=0 removes the BC component, p=0 doesn’t relabel agent trajectories, δGAIL=0 removes the discriminator output from the reward, and EXPERT RELABEL indicates whether the here explained expert relabeling should be performed.
In the next section we test these variants in the diverse environments depicted in Fig. [2](#S5.F2 "Figure 2 ‣ 5.1 Tasks ‣ 5 Experiments ‣ Goal-conditioned Imitation Learning").
###
4.4 Use of state-only Demonstrations
Both Behavioral Cloning and GAIL use state-action pairs from the expert. This limits the use of the methods, combined or not with HER, to setups where the exact same agent was actuated to reach different goals. Nevertheless, much more data could be cheaply available if the action was not required. For example, non-expert humans might not be able to operate a robot, but might be able to move the robot along the desired trajectory. This is called a kinestetic demonstration. Another type of state-only demonstration could be the one used in third-person imitation Stadie et al. [[2017](#bib.bib37)], where the expert performed the task with an embodiment different than the agent that needs to learn the task. This has mostly been applied to the trajectory-following case. In our case every demonstration might have a different objective.
Furthermore, we would like to propose a method that not only leverages state-only demonstrations, but can also outperform the quality and coverage of the demonstrations given, or at least generalize to similar goals. The main insight we have here is that we can replace the action in the GAIL formulation by the next state s′, and in most environments this should be as informative as having access to the action directly. Intuitively, given a desired goal g, it should be possible to determine if a transition s→s′ is taking the agent in the right direction. The loss function to train a discriminator able to tell apart the current agent and demonstrations (always transitioning towards the goal) is simply:
| | | | |
| --- | --- | --- | --- |
| | LGAILs(Dsψ,D,R)= | E(s,s′,g)∼R[logDsψ(s,s′,g)]+E(s,s′,g)∼D[log(1−Dsψ(s,s′,g))]. | |
5 Experiments
--------------
We are interested in answering the following questions:
1. [noitemsep,topsep=0pt,parsep=0pt,partopsep=0pt]
2. Can the use of demonstrations accelerate the learning of goal-conditioned tasks without reward?
3. Is the Expert Relabeling an efficient way of doing data-augmentation on the demonstrations?
4. Can state-only demonstrations be leveraged equally well as full trajectories?
5. Compared to Behavorial Cloning methods, is GAIL more robust to noise in the expert actions?
We will evaluate these questions in two different simulated robotic goal-conditioned tasks that are detailed in the next subsection along with the performance metric used throughout the experiments section. All the results use 20 demonstrations. All curves have 5 random seeds and the shaded area is one standard deviation
###
5.1 Tasks
Experiments are conducted in two continuous environments in MuJoCo Todorov et al. [[2012](#bib.bib38)].
The performance metric we use in all our experiments is the percentage of goals in the feasible goal space the agent is able to reach. We call this metric coverage. To estimate this percentage we sample feasible goals uniformly, and execute a rollout of the current policy. It is consider a success if the agent reaches within ϵ of the desired goal. Note that during training we do not assume access to the feasible goal distribution, nor use any ϵ to give rewards. These are two very commonly used assumptions in works using HER Andrychowicz et al. [[2017](#bib.bib12)], Nair et al. [[2018b](#bib.bib35)], and we do not assume them.
| | |
| --- | --- |
|
(a) Continuous Four rooms
|
(b) Fetch Pick & Place
|
Figure 2: Environments where we test the use of demonstrations
Four rooms environment:
This is a continuous twist on a well studied problem in the Reinforcement Learning literature. A point mass is placed in an environment with four rooms connected through small openings as depicted in Fig. [1(a)](#S5.F1.sf1 "(a) ‣ Figure 2 ‣ 5.1 Tasks ‣ 5 Experiments ‣ Goal-conditioned Imitation Learning"). The action space of the agent is continuous and specifies the desired change in state space, and the goals-space exactly corresponds to the state-space.
Pick and Place:
This task is the same as the one described by Nair et al. [[2018b](#bib.bib35)], where a fetch robot needs to pick a block and place it in a desired point in space. The control is now four-dimensional, corresponding to a change in (x,y,z) position of the end-effector as well as a change in gripper opening. The goal space is three dimensional and is restricted to the position of the block.
###
5.2 Goal-conditioned Imitation Learning
In goal-conditioned tasks, HER Andrychowicz et al. [[2017](#bib.bib12)] should eventually converge to a policy able to reach any desired goal. Nevertheless, this might take a long time, specially in environments where there are bottlenecks that need to be traversed before accessing a whole new area of the goal space. In this section we show how the methods introduced in the previous section can leverage a few demonstrations to improve the convergence speed of HER. This was already studied for the case of Behavioral Cloning by Nair et al. [[2018b](#bib.bib35)], and in this work we show we also get a benefit when using GAIL as the Imitation Learning algorithm, which brings considerable advantages over Behavioral Cloning as shown in the next sections.
| | |
| --- | --- |
|
(a) Continuous Four rooms
|
(b) Fetch Pick & Place
|
Figure 3: Performance of Goal-conditioned GAIL compared to only GAIL and HER
In both environments, we observe that running GAIL with relabeling (GAIL+HER) considerably outperforms running each of them in isolation. HER alone has a very slow convergence, although as expected it ends up reaching the same final performance if run long enough. On the other hand GAIL by itself learns fast at the beginning, but its final performance is capped. This is because despite collecting more samples on the environment, those come with no reward of any kind indicating what is the task to perform (reach the given goals). Therefore, once it has extracted all the information it can from the demonstrations it cannot keep learning and generalize to goals further from the demonstrations. This is not an issue anymore when combined with HER, as our results show.
###
5.3 Expert relabeling
Here we show that the Expert Relabeling technique introduced in Section [4.2](#S4.SS2 "4.2 Relabeling the expert ‣ 4 Demonstrations in Goal-conditioned tasks ‣ Goal-conditioned Imitation Learning") is beneficial when using demonstrations in the goal-conditioned imitation learning framework. As shown in Fig. [4](#S5.F4 "Figure 4 ‣ 5.3 Expert relabeling ‣ 5 Experiments ‣ Goal-conditioned Imitation Learning"), our expert relabeling technique brings considerable performance boosts for both Behavioral Cloning methods and goal-GAIL in both environments.
We also perform a further analysis of the benefit of the expert relabeling in the four-rooms environment because it is easy to visualize in 2D the goals the agent can reach. We see in Fig. [1](#S4.F1 "Figure 1 ‣ 4.2 Relabeling the expert ‣ 4 Demonstrations in Goal-conditioned tasks ‣ Goal-conditioned Imitation Learning") that without the expert relabeling, the agent fails to learn how to reach many intermediate states visited in the middle of a demonstration.
The performance of running pure Behavioral Cloning is plotted as a horizontal dotted line given that it does not require any additional environment steps. We observe that combining BC with HER always produces faster learning than running just HER, and it reaches higher final performance than running pure BC with only 20 demonstrations.
| | |
| --- | --- |
|
(a) Continuous Four rooms
|
(b) Fetch Pick & Place
|
Figure 4: Effect of our Expert Relabeling technique on different Goal-Conditioned Imitation Learning algorithms.
###
5.4 Using state-only demonstrations

Figure 5: Output of the Discriminator D(⋅,g) when the goal is the white point in the lower left, and the start is always at the top right.
Behavioral Cloning and standard GAIL rely on the state-action (s,a) tuples coming from the expert. Nevertheless there are many cases in robotics where we have access to demonstrations of a task, but without the actions. In this section we want to emphasize that all the results obtained with our goal-GAIL method and reported in Fig. [3](#S5.F3 "Figure 3 ‣ 5.2 Goal-conditioned Imitation Learning ‣ 5 Experiments ‣ Goal-conditioned Imitation Learning") and Fig. [4](#S5.F4 "Figure 4 ‣ 5.3 Expert relabeling ‣ 5 Experiments ‣ Goal-conditioned Imitation Learning") do not require any access to the action that the expert took. Surprisingly, in the four rooms environment, despite the more restricted information goal-GAIL has access to, it outperforms BC combined with HER. This might be due to the superior imitation learning performance of GAIL, and also to the fact that these tasks might be possible to solve by only matching the state-distribution of the expert. We run the experiment of training GAIL only conditioned on the current state, and not the action (as also done in other non-goal-conditioned works Fu et al. [[2018](#bib.bib23)]), and we observe that the discriminator learns a very well shaped reward that clearly encourages the agent to go towards the goal, as pictured in Fig. [5](#S5.F5 "Figure 5 ‣ 5.4 Using state-only demonstrations ‣ 5 Experiments ‣ Goal-conditioned Imitation Learning"). See the Appendix for more details.
###
5.5 Robustness to sub-optimal expert
In the above sections we were assuming access to perfectly optimal experts. Nevertheless, in practical applications the experts might have a more erratic behavior, not always taking the best action to go towards the given goal. In this section we study how the different methods perform when a sub-optimal expert is used. To do so we collect trajectories attempting goals g by modifying our optimal expert π∗(a|s,g) in three ways: first we condition it on a goal g′=g+ν, where ν∼N(0,I), therefore the expert doesn’t go exactly where it is asked to. Second we add noise α to the optimal actions, and third we make it be ϵ-greedy. All together, the sub-optimal expert is then a=1[r<ϵ]u+1[r>ϵ](π∗(a|s,g′)+α), where r∼Unif(0,1), α∼N(0,σ2αI) and u is a uniformly sampled random action in the action space.
In Fig. [6](#S5.F6 "Figure 6 ‣ 5.5 Robustness to sub-optimal expert ‣ 5 Experiments ‣ Goal-conditioned Imitation Learning") we observe that approaches that directly try to copy the action of the expert, like Behavioral Cloning, greatly suffer under a sub-optimal expert, to the point that it barely provides any improvement over performing plain Hindsight Experience Replay. On the other hand, methods based on training a discriminator between expert and current agent behavior are able to leverage much noisier experts. A possible explanation of this phenomenon is that a discriminator approach can give a positive signal as long as the transition is "in the right direction", without trying to exactly enforce a single action. Under this lens, having some noise in the expert might actually improve the performance of these adversarial approaches, as it has been observed in many generative models literature [Goodfellow et al.](#bib.bib39) .
| | |
| --- | --- |
|
(a) Continuous Four rooms
|
(b) Fetch Pick & Place
|
Figure 6: Learning with sub-optimal demonstrations
6 Conclusions and Future Work
------------------------------
Hindsight relabeling can be used to learn useful behaviors without any reward supervision for goal-conditioned tasks, but they are inefficient when the state-space is large or includes exploration bottlenecks. In this work we show how only a few demonstrations can be leveraged to improve the convergence speed of these methods. We introduce a novel algorithm, goal-GAIL, that converges faster than HER and to a better final performance than a naive goal-conditioned GAIL. We also study the effect of doing expert relabeling as a type of data augmentation on the provided demonstrations, and demonstrate it improves the performance of our goal-GAIL as well as goal-conditioned Behavioral Cloning. We emphasize that our goal-GAIL method only needs state demonstrations, without using expert actions like other Behavioral Cloning methods. Finally, we show that goal-GAIL is robust to sub-optimalities in the expert behavior.
All the above factors make our goal-GAIL algorithm very suited for real-world robotics. This is a very exciting future work. In the same line, we also want to test the performance of these methods in vision-based tasks. Our preliminary experiments show that Behavioral Cloning fails completely in the low data regime in which we operate (less than 20 demonstrations). |
707b030f-72b9-440d-87b0-573a20200cd9 | trentmkelly/LessWrong-43k | LessWrong | Kinds of Motivation
1. I want to do X.
2. I want X to be done.
3. I want to be the kind of person who Xs.
4. I want to be seen as an Xer.
These are the four kinds of motivation I learned about at LessOnline, and they provide a framework for investigating one’s desires that I have found to be both very challenging and very useful.
To make the framework concrete, let’s use the toy example of doing one’s homework in school. The four levels would then look something like:
1. I want to do my homework.
2. I want my homework to be done.
3. I want to be the kind of person who does their homework.
4. I want to be seen as a diligent student (who does their homework).
In my own case, my motivations were usually somewhere between 2 and 4, and very rarely were they ever at 1.
Let’s look at a more interesting example though, one in which the motivation isn’t being compelled by an outside force.
A Personal Example
I think to myself, “I want to be a writer.”
(This makes sense; I mean, you’re reading this right now. I have a substack.)
When I have the thought, I’m not thinking about the four kinds of motivation above. It’s a simple enough thought, at least in words, but the feelings behind it, once investigated, aren’t simple at all.
The activity actually in question is writing (although I do basically all of my writing at a computer, so technically the action is typing, but we’ll call it writing anyway and I’ll avoid giving in to my inner Intolerable Pedant).
So the four kinds of motivation, for this activity, are:
1. I want to write.
1. Do I have this motivation? Do I actually want to spend time doing the action of writing? Do I enjoy the process of writing itself, as an end in itself, without any other instrumental goals beyond it?
2. Maybe. This is the hardest motivation to parse, for me. Writing is hard; it requires focus and commitment and effort. It expends energy and time and labor. And there are so many other things I like to do with my time - read, watch TV/movies |
e2c0ec1f-582e-42be-b70a-f159398a9519 | trentmkelly/LessWrong-43k | LessWrong | AI #57: All the AI News That’s Fit to Print
Welcome, new readers!
This is my weekly AI post, where I cover everything that is happening in the world of AI, from what it can do for you today (‘mundane utility’) to what it can promise to do for us tomorrow, and the potentially existential dangers future AI might pose for humanity, along with covering the discourse on what we should do about all of that.
You can of course Read the Whole Thing, and I encourage that if you have the time and interest, but these posts are long, so they also designed to also let you pick the sections that you find most interesting. Each week, I pick the sections I feel are the most important, and put them in bold in the table of contents.
Not everything here is about AI. I did an economics roundup on Tuesday, and a general monthly roundup last week, and two weeks ago an analysis of the TikTok bill.
If you are looking for my best older posts that are still worth reading, start here. With the accident in Baltimore, one might revisit my call to Repeal the Foreign Dredge Act of 1906, which my 501(c)3 Balsa Research hopes to help eventually repeal along with the Jones Act, for which we are requesting research proposals.
TABLE OF CONTENTS
I have an op-ed (free link) in the online New York Times today about the origins of the political preferences of AI models. You can read that here, if necessary turn off your ad blocker if the side-by-side answer feature is blocked for you. It was a very different experience working with expert editors to craft every word and get as much as possible into the smallest possible space, and writing for a very different audience. Hopefully there will be a next time and I will get to deal with issues more centrally involving AI existential risk at some point.
(That is also why I did not title this week’s post AI Doomer Dark Money Astroturf Update, which is a shame for longtime readers, but it wouldn’t be good for new ones.)
1. Introduction.
2. Table of Contents.
3. Language Models Offer Mundane Ut |
ed3d8770-f829-4e64-8a68-bd11a10071d2 | trentmkelly/LessWrong-43k | LessWrong | Tokenized SAEs: Infusing per-token biases.
tl;dr
* We introduce the notion of adding a per-token decoder bias to SAEs. Put differently, we add a lookup table indexed by the last seen token. This results in a Pareto improvement across existing architectures (TopK and ReLU) and models (on GPT-2 small and Pythia 1.4B). Attaining the same CE loss is generally 8x faster across GPT-2 small layers, allowing the training of strong SAEs in a few minutes on consumer hardware.
* This change is motivated by the presence of a strong training class imbalance, where training data includes local context (unigrams/bigrams) more often than specific global context. Consequently, the SAE is inclined towards learning this local context through "unigram reconstruction" features (features that seem to fire almost exclusively on a single token).
* Such features constitute a significant portion of features in public SAEs. We study this phenomenon through the lens of "token subspaces", parts of the activation that encode its original token. Even in complex models such as Gemma 2B, we find these to be a salient part of residual activations.
* The proposed lookup table 'hardcodes' these token subspaces and reduces the need to learn these local features, which results in more interesting/complex learned features. We perform a blind feature evaluation study and quantitative analysis showing that unigram-based ("simple") features are much less frequent.
For some interesting results about token subspaces, see our Motivation. To skip to feature quality, see Feature Evaluation. For those interested in training SAEs, skip to Technical Discussion.
We also publish the research code and simplified code of Tokenized SAEs and a dataset of the most common n-grams in OpenWebText (used in Motivation).
Introduction
Sparse auto-encoders (SAEs) are a promising interpretability method that has become a large focus of the mechinterp field. We propose augmenting them with a token-based lookup table, resulting in rapid, high-quality tr |
7ac1ebfd-f641-4be1-b48d-5bcd7a3a6c58 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Humans can be assigned any values whatsoever…
*(Re)Posted as part of the AI Alignment Forum sequence on* *[Value Learning](https://www.alignmentforum.org/s/4dHMdK5TLN6xcqtyc).*
> **Rohin’s note:** In the last [post](https://www.alignmentforum.org/s/4dHMdK5TLN6xcqtyc/p/h9DesGT3WT9u2k7Hr), we saw that a good broad value learning approach would need to understand the systematic biases in human planning in order to achieve superhuman performance. Perhaps we can just use machine learning again and learn the biases and reward simultaneously? This post by Stuart Armstrong (original [here](https://agentfoundations.org/item?id=1675)) and the associated [paper](https://arxiv.org/abs/1712.05812) say: “Not without more assumptions.”
> This post comes from a theoretical perspective that may be alien to ML researchers; in particular, it makes an argument that simplicity priors do not solve the problem pointed out here, where simplicity is based on [Kolmogorov complexity](https://en.wikipedia.org/wiki/Kolmogorov_complexity) (which is an instantiation of the [Minimum Description Length principle](https://en.wikipedia.org/wiki/Minimum_description_length)). The analog in machine learning would be an argument that regularization would not work. The proof used is specific to Kolmogorov complexity and does not clearly generalize to arbitrary regularization techniques; however, I view the argument as being suggestive that regularization techniques would also be insufficient to address the problems raised here.
---
Humans have no values… nor do any agent. Unless you make strong assumptions about their rationality. And depending on those assumptions, you get humans to have any values.
### An agent with no clear preferences
There are three buttons in this world, .mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
B(0), B(1), and X, and one agent H.
B(0) and B(1) can be operated by H, while X can be operated by an outside observer. H will initially press button B(0); if ever X is pressed, the agent will switch to pressing B(1). If X is pressed again, the agent will switch back to pressing B(0), and so on. After a large number of turns N, H will shut off. That’s the full algorithm for H.
So the question is, what are the values/preferences/rewards of H? There are three natural reward functions that are plausible:
* R(0), which is linear in the number of times B(0) is pressed.
* R(1), which is linear in the number of times B(1) is pressed.
* R(2)=I(E,X)R(0)+I(O,X)R(1), where I(E,X) is the indicator function for X being pressed an even number of times, I(O,X)=1−I(E,X) being the indicator function for X being pressed an odd number of times.
For R(0), we can interpret H as an R(0) maximising agent which X overrides. For R(1), we can interpret H as an R(1) maximising agent which X releases from constraints. And R(2) is the “H is always fully rational” reward. Semantically, these make sense for the various R(i)’s being a true and natural reward, with X=“coercive brain surgery” in the first case, X=“release H from annoying social obligations” in the second, and X=“switch which of R(0) and R(1) gives you pleasure” in the last case.
But note that there is no semantic implications here, all that we know is H, with its full algorithm. If we wanted to deduce its true reward for the purpose of something like [Inverse Reinforcement Learning](https://arxiv.org/abs/1606.03137) (IRL), what would it be?
### Modelling human (ir)rationality and reward
Now let’s talk about the preferences of an actual human. We all know that humans are not always rational. But even if humans were fully rational, the fact remains that we are physical, and vulnerable to things like coercive brain surgery (and in practice, to a whole host of other more or less manipulative techniques). So there will be the equivalent of “button X” that overrides human preferences. Thus, “not immortal and unchangeable” is in practice enough for the agent to be considered “not fully rational”.
Now assume that we’ve thoroughly observed a given human h (including their internal brain wiring), so we know the human policy π(h) (which determines their actions in all circumstances). This is, in practice all that we can ever observe - once we know π(h) perfectly, there is nothing more that observing h can teach us.
Let R be a possible human reward function, and **R** the set of such rewards. A human (ir)rationality planning algorithm p (hereafter referred to as a planner), is a map from **R** to the space of policies (thus p(R) says how a human with reward R will actually behave - for example, this could be bounded rationality, rationality with biases, or many other options). Say that the pair (p,R) is compatible if p(R)=π(h). Thus a human with planner p and reward R would behave as h does.
What possible compatible pairs are there? Here are some candidates:
* (p(0),R(0)), where p(0) and R(0) are some “plausible” or “acceptable” planner and reward functions (what this means is a big question).
* (p(1),R(1)), where p(1) is the “fully rational” planner, and R(1) is a reward that fits to give the required policy.
* (p(2),R(2)), where R(2)=−R(1), and p(2)=−p(1), where −p(R) is defined as p(−R); here p(2) is the “fully anti-rational” planner.
* (p(3),R(3)), where p(3) maps all rewards to π(h), and R(3) is trivial and constant.
* (p(4),R(4)), where p(4)=−p(0) and R(4)=−R(0).
### Distinguishing among compatible pairs
How can we distinguish between compatible pairs? At first appearance, we can’t. That’s because, by their definition of compatible, all pairs produce the correct policy π(h). And once we have π(h), further observations of h tell us nothing.
I initially thought that Kolmogorov or algorithmic complexity might help us here. But in fact:
**Theorem:** The pairs (p(i),R(i)), i≥1, are either simpler than (p(0),R(0)), or differ in Kolmogorov complexity from it by a constant that is independent of (p(0),R(0)).
**Proof:** The cases of i=4 and i=2 are easy, as these differ from i=0 and i=1 by two minus signs. Given (p(0),R(0)), a fixed-length algorithm computes π(h). Then a fixed length algorithm defines p(3) (by mapping input to π(h)). Furthermore, given π(h) and any history η, a fixed length algorithm computes the action a(η) the agent will take; then a fixed length algorithm defines R(1)(η,a(η))=1 and R(1)(η,b)=0 for b≠a(η).
So the Kolmogorov complexity can shift between p and R (all in R for i=1,2, all in p for i=3), but it seems that the complexity of the pair doesn’t go up during these shifts.
This is puzzling. It seems that, in principle, one cannot assume anything about H’s reward at all! R(2)=−R(1), R(4)=−R(0), and p(3) is compatible with any possible reward R. If we give up the assumption of human rationality - which we must - it seems we can’t say anything about the human reward function. So it seems IRL must fail. |
1a937390-6457-4583-8382-75f24e99faea | trentmkelly/LessWrong-43k | LessWrong | ∀: a story
I settle into my seat at the concert, pushing my earbuds in tight. The man next to me looks over, and I get the feeling he’s judging me, but it’s not enough to stop me: I heard they sometimes try to scare you with sudden loud noises, or just overwhelm you with a wall of sound until your head is aching, and I hate the thought of that. The only reason I’m here at all is because Marissa was so keen on it; I can never say no to her, especially after how stressful the last few years have been. And we have good reason to celebrate: after two years of hitting roadblock after roadblock, our parenting license finally came through! So I shake off my nervousness and lean back in my chair as the lights dim and the DJ walks on stage.
The first piece kicks off with a slow buildup of nature noises, trees rustling and lions roaring and birdsong, with a deep bass humming beneath it. The bass is so strong that it takes me a while to realize that there’s another track slowly being superimposed on top of it: a sort of high-pitched wailing, and some kind of screaming, almost like a baby’s but slightly off. I’ve heard these sounds before from the videos the vegan activists would show back on campus. I look over at Marissa and mouth “abattoir”; we share a look of disgust. Only ten minutes into the concert and I’m already on edge. I grab Marissa’s hand and squeeze tight.
----------------------------------------
A month later, we’re at our godmother’s office. It’s well-lit but sparse; she’s sitting behind a white desk, and gives us a little wave as we walk through the door. She was assigned to us along with the parenting license, but she was booked solid until now, so this is our first time meeting her.
We start with pleasantries, and a few routine forms, but after a few minutes she cuts to the chase. “I have some bad news, I’m afraid. Based on our demographic analysis your child is 15% likely to end up in the top decile for both academics and athletics. Of course, that puts you outside |
6cf933b0-6dbf-411a-ab55-bf9a858bbd56 | trentmkelly/LessWrong-43k | LessWrong | AI presidents discuss AI alignment agendas
None of the presidents fully represent my (TurnTrout's) views.
TurnTrout wrote the script. Garrett Baker helped produce the video after the audio was complete. Thanks to David Udell, Ulisse Mini, Noemi Chulo, and especially Rio Popper for feedback and assistance in writing the script. |
c7cc1650-5074-4041-bc25-b1f8ac071684 | trentmkelly/LessWrong-43k | LessWrong | Comparing representation vectors between llama 2 base and chat
(Status: rough writeup of an experiment I did today that I thought was somewhat interesting - there is more to investigate here regarding how RLHF affects these concept representations)
This post presents the results of some experiments I ran to:
* Extract representation vectors of high-level concepts from models
* Compare the representations extracted from a base model (Llama 2 7B) and chat model trained using RLHF (Llama 2 7B Chat)
* Compare the representations between different layers of the same model
Code for the experiments + more plots + datasets available here.
To extract the representation vectors, I apply the technique described in my previous posts on activation steering to modulate sycophancy[1]. Namely, I take a dataset of multiple-choice questions related to a behavior and, for each question, do forward passes with two contrastive examples - one where the model selects the answer corresponding to the behavior in question and one where it doesn't. I then take the mean difference in residual stream activations at some layer at the token position corresponding to the different answers.
Besides sycophancy, which I previously investigated, I also use other behavioral datasets such as agreeableness, survival instinct, and power-seeking. Multiple-choice questions for these behaviors are obtained from Anthropic's model-written-evals datasets, available on huggingface.
Observation 1: Similarity between representation vectors from chat and base model shows double descent
At first, similarity declines from very similar (cosine similarity near 1) to halfway towards the minimum, and then for some behaviors, climbs up to ~0.9 again, around layer 11.
The following chart is generated from a higher-quality sycophancy dataset that includes some multiple-choice questions generated by GPT-4:
PCA of the generated vectors also shows the representations diverge around layer 11:
2D PCA projection of agreeableness representation vectors extracted from Llama 2 7 |
702732f1-f3fc-4d23-9312-79ec8cac067b | StampyAI/alignment-research-dataset/youtube | Youtube Transcripts | DeepMind x UCL | Deep Learning Lectures | 8/12 | Attention and Memory in Deep Learning
hello and welcome to the UCL ex deepmind
lecture series my name is Alex graves
I'm a research scientist at deep mind
and I'm going to be talking to you today
about attention and memory in deep
learning so you may have heard people
talk about attention in neural networks
and it's it's really is emerged over the
last few years as a really exciting new
component in the deep deep learning
toolkit is one of the in my opinion is
one of the last new things that's been
added to our toolbox and so in this
lecture we're going to explain how
attention works in deep learning and
we're also going to talk about the
linked concept of memory and so you can
think of memory in some sense as
attention through time and so we're
going to talk about a range of attention
mechanisms those that are implicitly
present in any deep network as well as
more explicitly defined attention and
then we'll talk about external memory
and and what happens when you have
attention to to that and how that
provides you with selective recall and
then we'll talk about transformers and
variable computation time so I think the
first thing to say about attention is
that it is not something it is it's not
only something that's useful for
learning it plays a vital part in human
cognition so the ability to focus on one
thing and ignore others is really vital
and so we can see this in our everyday
lives
we're constantly bombarded with sensory
information coming from from all
directions and we need to be able to
pick out certain elements of that signal
in order to be able to concentrate on
them so a classical example of this is
known as the cocktail party problem when
people are attending a noisy party and
listening to lots of other people
talking at once we're still easy able to
easily pick out one particular speaker
and kind of let the others fade into the
background and this is what allows us to
hear what they're saying but there's
also
kind of a form of introspective or
internal attention that allows us to
append to one thought at a time to
remember one event rather than all
events and I think the crucial thing
that I want you to the crucial idea that
I want you to take away from this is
that attention is all about ignoring
things is it's not about putting more
information into a neural network it's
actually about removing some of the
information so that it's possible to
focus on specific parts now I know
you've all heard about neural networks
and how they work and it might seem at
first glance that there's nothing about
a neural network that is particularly
related to this notion of attention so
we have this you know this is this big
nonlinear function approximated that
takes vectors in and gives vectors out
and so in this kind of paradigm attic
example you have an image coming in
being processed and then a
classification decision coming out is is
it a leopard or a Jaguar or a cheetah in
this image and this doesn't appear to
have much to do with attention at first
glance the whole image is presented to
the network and then a single decision
is made but what you can actually find
if you if you look inside neural
networks and analyze what they're
actually doing with the data is that
they already learn a form of implicit
attention meaning that they respond more
strongly to some parts of the data than
others and this is really crucial so if
you want to distinguish you know a
leopard for example from a tiger or
something like that part of what you
need to focus on are the spots in the
leopards fur and you need to do that we
need to focus on these parts while
ignoring perhaps a relevant detail in
the background and to a first
approximation we can we can study this
use of implicit attention by looking at
the network Jacobian so the Jacobian is
basically the sensitivity of the network
outputs with respect to the inputs so
mathematically it's really just a matrix
of partial derivatives where each
element j IJ is the partial derivative
of some output unit I with respect to
some in
you know J and you can compute this
thing with ordinary back prop so
basically the back calculation that's
used for gradient descent can be
repurposed to analyze the sensitivity of
the network all you do is you instead of
passing through the errors with respect
to some loss function you set the error
is equal to the output activations
themselves and then you perform back
problem and by doing this we get a feel
for what the network what pieces of
information the network is really
focusing on what it's using in order to
solve a particular pass so by way of
illustration
here's a neural network that's it's
known as the dueling network this is
from oh and architecture presented in
2015 it was used for reinforcement
learning now it's it's a network that
was applied to playing Atari games and
so the input is a video sequence and the
output in this case the network has has
a two two headed outputs one has
attempts to predict the value of the
state as it's kind of normal for
reinforcement learning of a deep
reinforcement learning the other head
attempts to predict the action advantage
so which is basically the the
differential between the value of given
a particular action and the expected
value overall or to put it in simpler
terms it tries to guess whether
performing a particular action will make
its value higher or lower and
we look at the video here this image on
the on the Left represents the the
Jacobian with respect to the value
prediction and what's being shown here
so we're seeing the the input video
itself this is a racing game where the
goal is to try and overtake as many cars
as possible without crashing and
overlaid on that this red heatmap that
we see flaring up this is the Jacobian
so the places that are appearing in red
are the places that the network is
sensitive to so if we concentrate on the
left side of this video we can see some
things that are of the network is really
interested in so one of them is it tends
to focus on the the horizon the car is
appearing you know just appearing on the
screen and of course these are very
important as a predictor of how much
score the network is likely to obtain in
the near future because it's by
overtaking these cars that it gets
points it's also continually focused on
the car itself and obviously that's
important because it needs to know its
own state in order to believe this value
and interestingly it has another area of
continual focus which is the score of
the bottom so because it's the score
that it's attempting to predict the
score is the value of these games I it
kind of makes sense that knowing what
the current score is is very important
that's what gives it an indicator of how
fast the value is is accumulating if we
look at the image on the right which is
also a Jacobian plot but this time it's
the it's the Jacobian of this action
advantage so the degree to which any one
particular action is better or worse
than the expectation over other actions
we see a very different picture first of
all we see that there's less sensitivity
over all the Jacobian these red areas of
sensitivity are a lot less prevalent and
when we do show up when they do show up
we tend to show up in different places
they're not looking so much at the
horizon they're not looking at the score
very much they tend to flare up just in
front of the car that's driving and the
reason for that is that the information
it needs to decide whether it's better
to go right or left
is really the information about the cars
that are very close to it so that's the
point it's only really when it comes
close to another car that it has this
critical decision about whether it
should go right or left and so what I'm
trying to get across with this video is
that even for the same data you get a
very different sensitivity pattern
depending on which task you're trying to
perform and so this implicit attention
mechanism is allowing it to process the
same data in two very different ways
it's seeing essentially even though it's
being presented with the same data it's
effectively seeing different things and
seeing these different things is what
allows it to perform different tasks so
once again this the whole point about
attention and the whole reason it's so
important is that it allows you to
ignore some parts of the data focus on
others and this same concept also
applies to recurrent neural networks I
think you've covered recurrent neural
networks in an earlier lecture and the
idea here is that you've got a lecture
that basically takes an input sequence
to take sequences inputs and produces
sequences as outputs and what really
makes recurrent neural networks interest
things that they have these feedback
connections that give them some kind of
memory of previous inputs and what we
really want to know
and as I said at the start of the
lecture memory can be thought of as a
tension through times what we really
want to know about recurrent neural
networks is how are they using the
memory to solve the paths and once again
we can appeal to the Jacobian to try to
measure this use of memory this use of
past information or surrounding context
and in this case I tend to refer to it
as a sequential Jacobian because what
you're really doing now instead of
getting it to a two-dimensional matrix
of partial derivatives you're really
looking at a three dimensional matrix
where the third dimension is to time and
what you care about mostly is how
sensitive is the network how sensitive
are the decisions made by the network at
one particular time to those inputs over
other times in other words what what
part of the sequence does it have to
birds that have to recall in order to
solve the task okay so to make that a
little bit more concrete we've got the
sequential Jacobian is a set of
derivatives of one network outputs of
one output at one particular point in
time with respect to all the inputs over
time so there's a time series there's a
sequence of these 2d Jacobian matrices
and what it can what you can use this
sequential Jacobian to analyze is how
the network responds to inputs that in
the sequence that are related in the
sense that they are needed together in
order to solve a particular aspect of
the past but are not necessarily
together or contiguous or close to one
another in the input sequence they may
be widely separated and so in the
example of God here this was from a
network that I worked on some years ago
that was trained to do online
handwriting recognition so online
handwriting recognition means that
someone is in this case writing on a
whiteboard with a pen that has an
infrared tracker that keeps track of the
location of the pen and is therefore
able to record a trajectory of pen
positions and it also records a special
end of stroke markers for when the pen
is lifted off the whiteboard and so this
text at the bottom shows that the the
words that the person wrote were once
having and then the the sort of this
next this next graph up on the bottom
shows how the information was actually
presented to the network so the network
actually saw was a series of these
coordinates x and y-coordinates for
these end of stroke spikes and then
above that
excuse me above that what we have is the
sequential Jacobian and now what I've
really looked at here what I'm really
interested here is the the magnitude of
the sequential Jacobus all these
matrices over time and what I'm really
interested in is is essentially the
magnitude of the matrix the magnitude of
the response of the network so of that
particular of one particular network
output with respect to the inputs that
the time and so the the network out
there chosen is the point so I should
say the task here is for the network to
transcribe this these online pen
positions and to kind of to recognize
what it was that the person wrote and
see these there's this output sequence
here where it's emitting label decisions
onz e in the space character and it
misses out the V in this case it wasn't
entirely classified or transcribed this
image correctly but the point that we
are looking at is the point where it
decides the output letter I in having
and what's really interesting if we look
at the sequential Jacobean we can see
that there is a peak of sensitivity
around here which roughly corresponds to
the point in the input sequence where
the stroke the main body of the letter I
was actually written so it makes sense
that there's a peak of sensitivity here
however we can see that the sensitivity
also extends further on in the sequence
it doesn't extend so far back in the
sequence only very slightly so that
sensitivities mostly to the end and I
believe the reason for this is that this
suffix ing the ink at the end of having
is a very common one and so being able
to identify that whole suffix helps you
to disambiguate the the letter I helps
to tell you for example that it's not an
owl in there and what's really
interesting is this peak is very sharp
peak right at the end what that
corresponds to is the point when the
writer lifted the pen off the page off
the whiteboard and went back to both the
ISO they wrote this entire word having
as one continuous stroke and their
cursive handwriting and then they lifted
the pen off the page and put a little
dot there and of course that dog is
crucial to recognizing an eye right
that's the thing that really
distinguishes an eye from an owl so
again it makes sense that the network is
particularly sensitive to that point but
it's nice to see that by analyzing this
sequential Jacobian you can you can
really get it to a quantifiable sense of
the degree to which is using particular
pieces of information and once again and
what the stress was really critical here
is that means it's ignoring other pieces
of information it's focus
those parts of the sequence that are
relevant and ignoring those that are
irrelevant and you know we can see that
this is really quite quite powerful it's
able to bridge things that are related
in the input sequence but may actually
be quite far apart
another example here comes from machine
translation now a major challenge in
machine translation is that words may
appear in a completely different order
in a different language and so we have a
simple example here where we have this
infinitive to reach at the start of an
English sentence that's being translated
into German but in German the
corresponding verb appears at the end of
the sentence and so in order to
correctly translate this the network
needs to be able to reorder the
information and from this paper in 2016
what it showed was just with a very deep
network without any any kind of specific
mechanism for rearrangement or for
attention the network was able to use
its implicit attention to perform this
this rearrangement and so what we're
seeing in the heat map on the right here
is again this idea of sensitivity is a
sensitivity map of the outputs at
particular points in the target sequence
so in the German sequence with respect
to the inputs in the English sequence
and you can see mostly there's a kind of
diagonal line because in this particular
case most of the sequence most of the
words have a more or less direct sort of
one-to-one translation but there's this
part at the end of the sequence for the
final two words in German are
particularly sensitive to the words at
the start in English so this word reach
is is there's a peak of sensitivity from
the end of the sequence and of course
this is this is once again showing that
the network is able to use this implicit
attention that it gets in some sense for
free just by being a very deep network
by being a very you know rich function
approximator is able to use that to
focus in on a particular part of the
sequence and to ignore the rest of the
sequence well
you know implicit tension is great but
there are still reasons to believe that
having an explicit attention mechanism
might be a good thing so what I mean by
the explicit attention mechanism is one
where you actually decide to only
present some of the data to the network
and you know completely remove other
parts of the data and one reason this
might be preferred of course is
computational efficiency so you no
longer have to process all of the data
you don't have to feed it to the network
at all so you can save some compute
there's a notion of scalability so for
example if you've got a fixed size what
I call a glimpse or like a Fourier ssin
where you you take in a fixed size part
of an image then you can scale to any
size image so that the resolution of the
input doesn't doesn't have to sort of
alter the architecture of the network
there's this notion of sequential
processing of static data which i think
is an interesting topic so again people
look at kind of visual example if we
have a for real
gaze moving around a static image that
what we get is a sequence of sensory
input and of course this is how images
are presented to the human eye were
always actually even if the data is
static we're always actually receiving
it as a sequence and there's reason to
believe that doing this gives can can
improve the robustness of systems so for
example there was a recent paper that
showed that networks with sequences of
glimpse or fovea attention mechanisms
for static data were more robust to
adversarial examples than ordinary
convolutional networks that looked at
the entire image of on go um last but
not least there's a big advantage here
in terms of interpretability so because
explicit attention requires you know
making a hard decision and choosing some
part of the data to look at you can
analyze a little bit more clearly what
it is the network is actually using so
we know the physical tension we've got
we've looked at the Jacobian as a guide
to what the network is looking at but it
really is only a guide it's not really
it's not a necessarily an entirely
reliable signal as to what the network
is is using and what its
was with the explicit attention
mechanisms as we'll see you get a much
clearer indication of the parts of the
data the network is actually focusing on
okay so the basic framework for what I'm
going to call neural attention models is
that you have a neural network as usual
that is producing an output vector as
always but it's also producing an extra
output vector that is used to
parameterize an attention model so it
gives some set of parameters that are
fed into this attention model I which
will describe in in a minute and and
that model then operates on some data
whether that's an image that you're
looking at or audio or text or whatever
it is and gives you what I'm gonna call
a glimpse vector and this is
non-standard terminology I'm just using
it because I think it helps to kind of
unify these these different models that
glute inspectors then passed the network
as input at the next time step and so
there's this kind of loop going on where
the network makes a decision about what
it wants to tend to and that then
influences the data it actually receives
it the next step and what that means is
that even if the network itself is
feed-forward the complete system is
recurrent it contains a loop okay so the
you know this the the way this
the way this model usually works is that
we define a probability distribution
over glimpses G of the data X given some
set of attention outputs so I said this
attention vector a and that's used to
parameterize something like the
probability of gluts G given a so the
simplest case here is we just split the
image into piles in this image on the
right here you can see there's nine
possible tiles and age is the sines
probabilities through a set of discrete
glimpses as in to a set of two each of
these tiles that's using one of these
tiles so it's just a kind of good
old-fashioned softmax function here
where the softmax outputs have the
probabilities of picking each tile and
so we can see that having done that if
we have a network that is using this
distribution what it's going to do is
you know output some distribution over
these nine tiles and then at each point
in time it's going to receive one of the
tiles as input so rather than sieving
receiving the whole input at once it's
going to keep on looking at one tile at
a time now one issue with this of course
is that it's a hard decision and what I
mean by a hard decision is it's no
longer we no longer have a complete
gradient with respect to what the
network is done basically what we've got
is a stochastic policy in reinforcement
learning the terms that were sampling
from in order to get big glimpses and we
can train this with something like
reinforced so kind of given it you know
the simple kind of standard mathematics
here for how you get a gradient with
respect to some stochastic sort of
discrete sample using reinforce and and
this is a sort of general trick here we
can use these sorts of what I'm gonna
call RL methods by which I really just
mean methods that are designed for
getting a training signal through a
discreet policy and we can sort of fall
back on these for supervised tasks like
image classification anytime there's a
non differentiable module in what we
can't do is just ordinary end-to-end
backprop and this is a assists a
significant difference between using
kind of hard attention as I described it
so far our versus
using this implicit attention that's
always present in neural networks so
generally we want to be something a
little bit more complex than just a soft
max over tiles one example that I've
kind of already alluded to is this
notion of a phobia model where you have
a kind of multi resolution input that
looks at the image takes part of the
image at high resolution so in this case
the center this square in the center
here is kind of recorded at high
resolution as basically it's mapped to
one to one
this next square out is also presented
to the network but at a lower resolution
so you can see the actual is taking
something that's maybe has twice as many
pixels as the one in the middle and some
sampling it down to something with the
same number of pixels and then the third
square out looks at the entire image
here that gives this very kind of squash
down low resolution version of it to the
network and the idea is that you're
mimicking the the effect of the human
eye where it has high kind of it has
high resolution in the center of your
gaze and much lower resolution in the
periphery with the idea being that the
information of the periphery is
sufficient to alert you to something
that you should attend to more closely
you should look at directly in order to
get a higher resolution view of it and
we can see an example of this apply it
to image classification this is from the
2014 paper where then the network was
given the cluttered and this data where
these endless these familiar endless
handwritten digits are basically dropped
in an image that has some visual clutter
and the idea here is that in order to
classify the now the image the network
has to discover the the digit within the
clutter again once again it's about
being able to ignore distractors being
able to ignore the noise and the green
path here shows the the movement of the
this foveal model through the image over
this kind of six-point trajectory that
is given well it classifies the image
and we can see for example in this on
the the example in the top row it starts
out here in the bottom corner where
there isn't much information and then
rapidly moves towards the digit in the
image and then kind of scans around the
the pictures to the right we can see the
information that's actually presented to
the network basically you know it starts
off with something where there's very
little information of image but there's
a blur over here that suggests there
might be something useful and then it
moves over to there and by moving around
the image it can build up a picture of
you know everything that's in the digit
that it needs to classify we have a
similar example here from the letter 8
where it kind of moves around the
periphery of the digit in order to
classify it so similar and so one you
might ask you know why would you bother
doing that when you can you can feed the
whole image into the network directly
and so one issue I mentioned earlier is
this idea of scalability and one way in
which a sequential glimpse distribution
is more scalable is that you can use it
for example to represent multiple
objects and Suz explored another paper
in 2014 where there were so for example
in the street view house numbers dataset
there are multiple numbers from people's
street addresses present in each image
and you want to kind of scan through all
of those numbers in order to recognize
them in order rather than just looking
at the image in a single goal although
it can also we provide applied the more
conventional image classification shown
here once again in order to classify the
image network will move its attention
around the really important parts of the
image and this gives you an indication
it allows you to see what it is in the
image that is necessary in order to make
the classification so so far we've
looked at both implicit and explicit
attention but the the explicit attention
we've looked at has involved making hard
decisions about what to look at and what
to ignore and this leads to the need to
train the network using our l-like
mechanisms it makes it impossible to
train the whole thing and then the back
prop so what we're going to look at in
this section is what's sometimes known
as soft or differentiable attention
which makes gives you explicit attention
but makes end-to-end training possible
so whereas in the previous examples we
had these fixed size attention windows
that we were kind of explicitly moving
around the image now we're going to look
at something that operates a little bit
differently and you know it's important
to realize that you know if we're if
we're thinking about a robot or
something where you have to actually
direct a camera in order to direct your
attention then in some sense you have to
use hard attention because you have to
make a decision about whether to look
left or right but for the kinds of
systems were we're mostly focusing on in
this lecture that isn't really the case
we've got all the data and we just need
to make a decision about what to focus
on and what not to focus on and so we
don't actually need to make a hard
decision about attention we want to
focus more on some regions and less on
others in much the same way that I
showed that we already implicitly do
with a neural network but we can take
this one step further than implicit
attention by defining one of these soft
attention these differentiable attention
mechanisms that we can train and to end
and they're actually pretty simple is a
very basic template so if we think back
to the glutes distribution I talked
about before where we have the
parameters of the network defining some
distribution over glimpses and what we
did then was take a sample from that
distribution and it was because we were
picking these samples that we do to
think in terms of training the network
with reinforcement learning techniques
so what we can do instead is something
like a mean field approach we take an
expectation over all possible glimpses
instead of a sample so it's just this
weighted sum where we we take all the
glimpse vectors and multiply them by the
probability of that glimpse vector given
the attention parameters and sum the
whole thing up and because it's a
weighted sum and not a sample this whole
thing is straightforwardly
differentiable with respect to the
attention parameters a as long as the
glooms distribution itself is
differentiable which it usually is so
now we no longer have you know reinforce
or some reinforcement learning algorithm
we really just have ordinary
and in actual fact because we're doing
this weighted sum we don't really
technically need a probability
distribution at all all we need is a set
of weights here so we have a set of
weights and we're multiplying them by a
attention we're multiplying them by some
set of values which are these glimpses
and and the weighted sum of these two
things gives us the attention readout
now there's I've got a little asterisk
here on the slide where I'm saying yes
we don't actually need a proper
probability distribution here but it's
usually a nice thing to have so just if
we if we make sure the weights are all
between 0 & 1 or they some the one that
everything tends to stay nicely
normalized and sometimes it seems to be
a good thing as far as changing the
network curves but anyway if we look at
this weighted sum this attention readout
V which is just now if we think stop
thinking probabilistic times and just
think of some of our eye times from some
weights I and some vectors I this should
look familiar to you it's really just an
ordinary summation a sigma network a
sigma unit from an ordinary neural
network and in fact we're where these
weights WI look like network weights so
we've gone from you know glimpse
probabilities defined by the network to
to something that looks more like
network weights and actually we can
think of attention in general as
defining something like they do
dependent dynamic weights or fast
weights is this sometimes not in there
fast because they change dynamically in
response to the data so they can change
in the middle of processing a sequence
whereas ordinary weights change slowly
they change gradually over time with
gradient descent and so to look at these
two sort of diagrams I've got here on
the Left we have the situation with an
ordinary called net where this would be
sort of a 1 1 dimensional convolutional
Network where you have a set of weights
that are given in different colors here
that are used to define a kernel that is
mapping into this this input that the
arrows are pointing into but the point
is those weights are gonna stay fixed
they're fixed the same kernel is gonna
be scanned
the same image and those weights are
over the same sequence in this case it's
one-dimensional and those weights are
only gradually changing over time and in
addition of course because it's a
convolution there's a fixed size to the
kernel so we've decided in advance how
many how many inputs that are going to
be that are fed into this kernel with
the tension we have something more like
the situation on the right so we have
the set of weights that first of all
extends can in principle extend over the
whole sequence and secondly critically
those weights are data dependent they're
their function because they're emitted
you know they're they're determined by
the attention parameters that are
emitted by the network which is itself a
function of the inputs received by the
network so these weights are responding
to the input received so they're giving
us this ability to kind of define a
network on the fly and this is this is
what makes attention so powerful okay so
my first experience of attention with
with neural networks of soft attention
with neural networks was a system I
developed some years ago now I think
seven years ago to do handwriting
synthesis with recurrent neural networks
so handwriting synthesis
unlike the handwriting recognition
networks I mentioned earlier here the
task is to take some piece of text like
this the word handwriting on the left
and to transform that into something
that looks like cursive handwriting and
basically the way this works is the
network outputs it takes in a text
sequence and outputs a sequence a
trajectory of pen positions and these
positions define the movement of or
define the actual writing of the letters
so you can think of this as a kind of
sequence the sequence problem with the
the challenging thing about it is that
the alignment between the text and the
writing is unknown and so I was studying
this problem with recurrent neural
networks and I found that if I just fed
the entire text sequence in as input and
then attempted to produce the output it
didn't work at all what I needed was
something that was able to attend to a
particular part of the input sequence
when
making particular decisions about the
output sequence so for example I wanted
something that would look at the letter
H in the input sequence and use that as
the conditioning signal for when it was
drawing a letter H and move on to letter
a and so forth so once again I needed
something that was able to pick out
certain elements of the input sequence
and ignore others and and this was
achieved with soft attention so
basically the solution was that before
the network made each predicted each
point and the the handwriting trajectory
it decided where to look in the text
sequence using a soft attention
mechanism and so the mechanism here
which is is a little bit different from
the normal attention mechanisms that you
see in neural networks that we'll talk
about later the mechanism here was the
network explicitly decided how far along
the slide a Gaussian window it had over
the text sequence so there was a kind of
I thought of it as a soft reading
network and so the weights the the
parameters mitad by the network
determined a set of gaussians this is a
shown here Gaussian functions whose
either shown here by these couple of
curves and those functions had a
particular a particular Center which
determined where they were focused on
the input sequence and on and also it
was also able to parameterize the width
of the Gaussian so kind of determined
how many of the letters in the input
sequence it was looking at and I should
say the the sequence of input vectors
here what I've shown is a series of one
hop vectors which is how they presented
the network but what these actually
correspond to is letters you could think
of this as an H here and an A here and
so forth and then what the network is
deciding is where to put these gaussians
which implicitly means once we perform
this this summation at the top here that
gives us the attention weights what part
of the Technic sequence should we look
at in order to generate the the outputs
distribution and so doing this the
network was able to produce remarkably
realistic looking handwriting
these are all generated samples and you
can see that it also generates as well
as being able to legibly right
particular text sequences it writes in
different styles and the reason it does
this of course is that is trained on a
database of networks of people who sorry
I take the base of handwriting from
people writing in different styles and
so it kind of learns that in order to
generate realistic sequences it has to
pick a particular style and and stick
with it so I'm claiming on the slide
that real people right this badly maybe
that's not quite strictly true but you
know you can see at least the the here
is a system where attention was allowing
the the network to pick out the salient
information and using that to generate
something quite realistic and so as I
said one advantage of this use of
attention is that it gives you this this
interpretability it allows you to look
into the network and say what were you
attending to when you made a particular
decision and so this heat map here what
it shows is while the network was
writing the letters shown the room along
the bottom so if the the right thing
here is that the handwriting here is the
horizontal axis the vertical axis is the
text itself and you can see where this
heat map shows is what part of the text
was the network really focusing on when
it was producing a particular when it
was predicting a particular part of the
Penan trajectory and you can see that
there's this roughly diagonal line
because of course you know there is here
a one really a one-to-one correspondence
between the text and the letters that it
writes but this line isn't perfectly
straight so the point is that some well
some letters might take you know have 25
or 30 points in them or even more others
letters might have much fewer and so
this is the whole issue of the alignment
being unknown that attention was able to
solve in this instance and so this is an
example an early example of what's now
kind of photo is location in based
attention so the attention is really
about just where how far along the input
sequence you should look and so it's
important what's kind of interesting
here is to see what happens if you take
that attention mechanism of way and just
allow the network to generate
handwriting on
and this was very similar to the result
I obtained when I first tried to you to
treat this task as a more conventional
sequence the sequence learning problem
where the entire sequence was fed to the
network at once and what happens is it
generates things that kind of look like
words that kind of look like letters but
don't make much sense and of course it's
August the reason for this is that the
the conditioning signal isn't reaching
the network because it doesn't have this
attention mechanism but allows it to
pick out which letter it should write at
a particular time okay so that was a
sort of an early example of a neural
network with soft attention but the form
of attention that's really kind of taken
over the one that you'll see everywhere
in neural networks now as what I think
of as associative or content-based
attention so instead of choosing where
to look according to the position within
a sequence of some piece of information
what you can do instead is attend to the
content that you want to look at and so
the way this looks is that works is that
the network the attention parameter
emitted by the network is a key vector
and that key vector is then compared to
all the elements in the input data using
some similarity function so typically
you have something like a cosine
similarity or something that involves of
taking a dot product between the key and
all the elements in the date in the data
and then typically this is M normalized
with something like a softmax function
and that gives you the attention weights
so you know implicitly what you're doing
is you're you're outputting some some
key you're looking through everything in
the data to see which parts of the data
most closely match to that key and
you're getting back a vector an
attention vector that focuses more
strongly in the places that that are
more that are closer that correspond
more closely to the key and this is a
really natural way to search you can
actually define you can do you can
essentially do everything you need to do
computationally just by using
content-based lookup and what's really
interesting about it is that it
especially with this sort of cosine
similarity measure it gives you this
multi-dimensional feature based lookup
so you can put
a set of features corresponding to
particular elements of this key vector
and find something that matches along
those features and ignore other parts of
the vectors so just by sending other
parts of the vector to zero you'll get
something that matches on particular
features and doesn't worry about others
so it has it gives this this
multi-dimensional very natural way of
searching so for example you might want
to say well show me an earlier frame of
video in which something red appeared
and you can do that by specifying the
kind of red element in your the
representation of your key vector and
then the associative attention mechanism
will pick out the red things
so typically what's done now is is given
these weights you can then perform this
this expectation that I mentioned
earlier where you sum up over the data
you compute this kind of this weighted
sum and you get an intention readout
what you can also do and this has become
I think increasingly popular with
attention based networks is you can
split the data into key value pairs and
use the keys to define the attention
weights and the values to define the
readout so there's now a separation
between what you use to look up the data
and what you're actually going to get
back when you read it out and this has
been used I mean as I said this is now
really a fundamental building block of
deep learning and it was first applied
in this paper from 2014 for neural
machine translation and once again so
similar to the heat map I showed you in
previous slide for implicit attention we
have something here that shows what the
network is attending to when it
translates in this case from I believe
it's translating from English to French
or it might be from French to English
and what's kind of interesting here you
can see first of all if we compare this
to the earlier heat map I showed for
implicit attention it's clear that the
decisions are much sharper so you get a
much stronger sense here of exactly what
the network is attending to and what
it's ignoring um secondly in this case
there's a more or less one-to-one
correspondence between the English words
and the French words apart
from this phrase European Economic Area
that is reversed in French and you can
see this reversal here in the image by
this kind of line that goes sort of
against the diagonal of the rest of the
sequence and so this is this is a very
as we'll see this is a very powerful
general way of allowing the network in a
differentiable antenna trainable way
allowing the network to pick out
particular elements of the input data
here's an example of a similar network
in use here the task is this is the the
task is to determine what this this this
removed symbol is in the data so if we
look at the example on the Left we have
so B I should say the proper names have
been replaced by numbered entities here
which is quite a standard thing to do in
language processing tasks because proper
names are very difficult to deal with
otherwise and we have this this task
where entity 1 one-line identifies the C
singer as X and what the network has to
do is to fill in X and you can see from
this heat map here which words it's
attending to when it attempts to fill in
this X and you can see it's mostly
particularly focused on this entity 23
which was presumably the decision it
made and which is indeed correct it says
he was identified Thursday as Special
Warfare operator and the d23 in general
it's focusing on the entities throughout
because it can kind of tell that those
are the ones that it needs to look at
and read answer these questions
similarly X dedicated their fall fashion
show - mums you can see it's very
focused on this particular entity here
is helping it make its decision and and
what's really crucial here is that
there's a lot of text than this piece
there's a lot of text that it's ignoring
but it's using this content based
attention mechanism to pick out specific
elements and this can be taken is this
you know attention mechanism this
combination typically of a recurrent
neural network with attention can be
used much more broadly it's been applied
to speech recognition for example and
here we see a plot not dissimilar to the
one I showed you for handwriting
synthesis where we have
an alignment being discovered between
the audio ratings and there is a
spectrogram and the text sequence that
the network is is outputting the
characters that it's using to transcribe
this data so for example that was this
long pause at the start when nothing
happens Network mostly ignores that it
knows that when it has to start emitting
for example the s T you start with the
sentence it's very focused on these
sounds at the beginning corresponding to
those two those noises in the speech
signal so basically this attention
mechanism is a very general gives a very
general purpose technique for focusing
in on particular parts of the data and
this is all done with well mostly all
done with content-based attention okay
so another form of so there are a huge
number of possible attention mechanisms
and we're only going to mention a few of
them in this talk and one idea I want
you to leave you with is that there's a
very general framework here having to
find this attention templates that gives
you this weighted sum there's lots of
different operators you could use to get
those those attention weights and one
very interesting idea from a network
known as draw for 2015 the idea was to
determine an explicitly visual kind of
soft attention so this is kind of
similar to the phobia models we looked
at earlier only instead of an explicit
and of hard decision about where to move
this this phobia around the image rather
there was a set of Gaussian filters that
were applied to the image and what these
did is they have a similar effect of
being able to focus in on particular
parts of the image anymore other parts
but it's all differentiable end to end
because there's a filter that is being
applied everywhere that gives you these
attention weights and what does this
filter look like well if you look at
these three images on the right we show
that four different settings of the
parameters for the Gaussian filters the
filter variants essentially the you know
the width of the filter the center the
stride as we've shown here with which
the filter is applied throughout image
also this last parameter for intensity
by varying these we get different views
of the same letter v so this one here is
quite focused in on this central part of
the image this one here is looking more
at the image as a whole and it's doing
so with quite low variants so it's
getting quite a sharp picture of this
image this one on the bottom here is
getting a more kind of blurred like less
distinct view of the entire image and so
we can see a video of drol Network in
action what we're seeing here the
movement of these green boxes shows the
attention of the network I'm just going
to play that again
it's rather quick the attention of the
network as it looks at an endless digit
and you can see that it starts off kind
of look attending to the whole image and
then very quickly zooms in on the digit
and moves the box around the digit in
order to read it and it does a similar
thing when it starts to do generate
theta it's
it uses so this red box shows
attention is as its generating with
agent once again it starts off kind of
generating this kind of blurred out view
of the whole image and then focuses down
on a specific area and kind of it does
something that looks a lot like it's
actually drawing the image it's actually
using the attention mechanism to trace
out the strokes of the digit and so
again what's nice about this so we have
something that's kind of transforming
excuse me transforming a kind of static
task into a sequential one where there's
this sequence of Association decisions
being sre this sequence of glimpses or
views of the data and what's nice about
that is that we get this generalization
so we can now generate because it
generates these images kind of one part
at a time it can be extended to
something that generates multiple
multiple digits for example within the
same image and this is a sort of a
general an illustration of this general
property of I think scalability that are
referred to for engine mechanisms so far
what we've talked about is attention
applied to the input data being fed to
the network but as I mentioned at the
start of the lecture there's another
kind of attention which I think of as
introspective or kind of inward
attention where we as people use our
kind of user kind of cognitive attention
to pick out certain thoughts or memories
and in this section I'm going to discuss
how this kind of attention can be
introduced to two neural networks so as
I've said in the previous slides what we
were looking at was attention to
external data so deciding where in a
text sequence to look which part of an
image to look at and so forth but if we
sort of apply this attention mechanism
to the network's internal state or
memory then
we have this notion of introspective
attention and as I've said a way I like
to think about this is that memory is a
tension through times a way of picking
out a particular event that may have
happened at some point in time and
ignoring others once again just want to
come back to this idea that attention is
all about ignoring things it's all about
what you don't look at and so there's an
important difference here between
internal information and external
information which is that we can
actually modify the internal information
so we can do selective writing as well
as reading allowing the network to use
attention to iteratively modify its
internal state and an architecture that
I and and colleagues deepmind developed
in 2014 did exactly this we called it a
neural Turing machine because we what we
wanted was something that resembled the
the action of a Turing machine is the
ability to read from and write to a tape
using a neural network by a an attention
set of attention mechanisms I'm going to
talk about this architecture in some
detail because it shows it gives you a
sort of nice insight into the the
variety of things that can be achieved
with attention mechanisms and it shows
how it really shows this link between
attention and memory so the controller
in this case is a neural network it can
be recurrent or it can be feed-forward
once again even if it's feed-forward the
combined system is is recurrent because
there's this loop through the attention
mechanisms and then we have we referred
to the attention modules that are
parameterized by the network as heads
and so this was in keeping with the with
the Turing machine in analogy the tape
analogy this is something that I think
has been has been picked up in general
people often talk about attention heads
and
you know these are these these heads our
attention mechanisms or soft attention
mechanisms in the same kind of template
that we've discussed before and their
purpose is to select portions of the
memory the memory is just this real
value matrix it's just a big grid of
numbers that the network has access to
and the key thing is different is that
as well as being able to select portions
of the memory to read from these these
heads can also selectively write to the
memory so yeah once again this is all
about selective attention we have to we
don't want to modify the whole memory in
one go maybe you know I should I should
stress here the key part of the kind of
designing decision underlying the neural
Turing machine was the separate out
computation from memory in the same way
as it's done in a normal digital
computer we didn't want so for a normal
recurrent neural network for example in
order to give this is the more memory
you have to make the hidden state larger
which increases the amount of
computation done by the network as well
as giving it more memories a computation
and memory are kind of inherently bound
up in an ordinary network and we wanted
to separate them out we would have
potentially quite a small controller
that could have access to a very large
memory matrix in the same way that a
small array of a processor in a digital
computer can have access to you know a
large amount of RAM or disk or other
forms of memory and and so it's key you
know if you look at in that from that
perspective it's key that it's not
processing the entire memory at once
if this thing's going to be large it
needs to selectively focus on parts of
it to read and write and so we do this
basically using a similar the same
template as I mentioned before for soft
attention the controller the neural
networks outputs parameters that
basically parameterize this what we're
calling a distribution or awaiting over
the rows in the memory matrix but is it
this waiting is really just the same
attention weights that we discussed
before and we had
two main attention mechanism so I've
mentioned in in the previous section
that my my first experience of soft
attention in neural networks was around
location-based attention as was a ID for
this handwriting synthesis Network which
was in fact the inspiration for the
neural Turing machine so having realized
that the handwriting synthesis Network
could selectively read from an input
sequence I started to think of what
would happen if we could write to that
sequence as well and wouldn't it then
start to resemble a neural Turing
machine um but as well as the
location-based content that was
considered in the handwriting synthesis
Network this also incorporates content
based information attention which as
I've said is the kind of the the
preeminent form of attention as used in
neural networks so dressing by content
looks a lot like it does with other
content based networks is the key vector
emitted by the controller that is
compared to the content of each memory
location so each row in memory and treat
that as a vector and then we compare the
key to that vector using the similarity
measure which wasn't the cosine
similarity which we then normalize with
the softness we also introduced a extra
parameter which isn't usually there for
content-based attention which we called
sharpness and this was used to sort of
selectively narrow the focus of
attention so that it could really focus
down on individual rows in the memory
but we also included this notion of
addressing by location and the way this
worked was that the network looked at
the previous waiting and put a shift
kernel which was just a sort of a soft
max of numbers between plus and minus N
and we then essentially convolved that
with with the waiting with the the
previous waited waiting from the
previous time step to produce a shifted
waiting so basically the mass your very
simple as shown below and what this
thing is it just essentially shifted
attention through the the memory matrix
shifted it bounds if you started here
and
I'll put a shift colonel focused around
maybe five steps or so then you'd end up
with intention and attention
distribution that would look like this
and so this combination of addressing
mechanisms the idea behind this was to
allow the controller to have different
modes of interacting with the memory and
we thought about these modes as
corresponding to data structures and
accessors as I used in sort of
conventional programming languages so as
long as the content is being used on its
own the memory is kind of being accessed
the way it would be in something like a
dictionary or an associative map
well not strictly like a dictionary
because we didn't have key value
attention for this network although you
could define it um rather it would be
like an assault more like an associative
array through a combination of content
and location what we could do is use the
content-based key to locate something
like an array of contiguous vectors in
memory and then use the location to
shift into that array the shift index a
certain distance into the array and when
the network only used the location based
attention is essentially iterated it
acted like an iterator just moved all in
from the last focus so it could
essentially read a sequence of inputs in
order so basically reading we as we've
said this network uses attention to both
read from and write to the memory
reading is very much the standard
attention sort of soft attention
template we get a set of weights we get
a set of rows in the memory matrix to
which those you know that are that are
to which the network is attending and we
compute this this weighted sum so we
take each row in the metrics and
multiply it by the weight which gives
the sharpness of attention that agreed
to which the network is attending to
that particular row so this is just very
much this is exactly like the the soft
attention that I described soft
attention template I described before
only it's being applied to this
memory matrix rather than being applied
to some external piece of data
the part that was kind of novel and
unusual was the the right head the
writing attention mechanism used by
neural Turing machines and so in this
case we kind of inspired by the way long
short-term memory
LS TM has sort of forgets and and input
gates that are able to to modify the
contents of memory the contents of its
own internal state we defined a combined
operation of an arrays vector E which
behaves sort of analogous Li
equivalently to the forget gate in long
short-term memory and an ADD vector
which behaves like the input gate and
essentially what happened is the once
the the right head had determined which
rows in the matrix it was attending to
these the contents of those rows were
then selectively erased according to E
and I should say here so E is basically
a set of numbers between 0 & 1 so
basically if if some part of the erase
vector goes to 1 that means whatever was
in the memory matrix at that point is
now is now white set to 0 and if E is
set to 0 then the memory matrix is left
as it is so once again there's this kind
of smooth or differentiable analogue of
what is essentially a discrete behavior
the decision of whether or not to erase
and adding is more straightforward it
just says well take whatever's in memory
and adds whatever's in this add vector a
multiplied by the the the write weights
so basically if the right weight is high
and you're strongly attending to a
particular area in a particular row in
the matrix then you are going to
essentially add whatever is in this add
vector to that to that row and if the
white right vector the important thing
here is if if this WI for all the rows
in the matrix for which this WI is very
low nothing happens
nothing changes so if you're not tending
to that part of the memory you're not
modifying it either so how does this
work in practice so what we what we
really looked at was well can can can
this neural cheering machine learn some
kind of primitive algorithms in the
sense that we think of algorithms is
applied on up on a normal computer and
you know in particular does having this
separation between processing and memory
enable it to learn something something
more algorithmic than we could do for
example with a recurrent neural network
and we found that it was indeed able to
learn it's a very simple algorithm so
the simplest thing we looked at was a
copy task so basically a series of
random binary vectors were fed to the
network list that's shown here we
started the sequence and then the
network just has to copy all of those
and output them to through the the
output vectors now all it has to do is
just exactly copy what was in here to
what's over here so it's an entirely
trivial algorithm that would be you know
very uninteresting it's not it's not
interesting in its own right as an
algorithm but what's surprising about it
is that it's difficult for an ordinary
neural network to do this so neural
networks generally are very good at
pattern recognition they're not very
good at exactly sort of remembering
storing and recalling things now it's
exactly what we hope to add by including
this access to this memory matrix and so
the algorithm that it uses well a kind
of pseudocode version for it here is
given on the right but we can also
analyze it by looking at the use of
attention and the way it depends the
particular places in the memory during
during this task and so these two heat
maps that are shown here at the bottom
are again heat maps showing the the
degree to which the network is attending
to that particular part of the memory so
when it's black it's being ignored when
it's whitelist focusing and you can see
that there's a very sharp focus here
which is what we want because it's it's
it's basically implementing something
that is really fundamentally a discrete
algorithm and so what it does in order
to complete this copy pass is it picks a
location in memory
given here and then starts the Wrights
whatever input vector comes in
essentially just copies that to a raw
memory and then uses the location based
iterator this location based attention
you just move on one step to the next
grow memory and then it copies the next
the next equipment so forth until it's
finished copying them all and then when
it has the output it uses its low
content based lookup to locate the very
start of the of the sequence and then
just iterates through until it's copied
out everything remaining and so you know
just once again what was really
interesting here was to be able to get a
kind of an algorithmic structure like
this going through a neural network you
know it was completely parametrized by
neural network and was completely
learned and to end um and there was
nothing sort of built into the network
to adapt it towards this sort of this
sort of algorithmic behavior and so the
real issue is and actually a normal
recurrent neural network analysis the
end model Alice TM network for example
can perform this task you feed it in a
sequence of inputs and ask you to
reproduce them as outputs just as a
sequence the sequence learning problem
but what you find is it will work
reasonably well up to a certain distance
but it won't generalize beyond that so
if you train it the copy of sequences up
to length 10 and then ask it to
generalize the sequences up to length
you know 100 you'll find it doesn't work
very well as we'll see whereas with the
neural Turing machine we found that it
did work quite well so in this these
heat maps here we're showing the targets
and the output so basically this is the
the copy sequence given to the network
if it's doing everything right the each
block at the top exactly matches each
block at the bottom and you can see that
it's not perfect like there's some
mistakes creeping in as the sequences
get longer so this is for sequences you
know short sequences like 10 20 40 so on
but you can still see that most of the
sequence is still kind of retained like
most of the targets are still being
matched by the outputs in the network
and that's because it's just basically
performing this algorithm and using that
to generalize the longer sequences so
this is an example of where attention
and being able to selectively pick out
certain parts of information ignore
others gives you a stronger form of
generalization and so that that this
this form of this kind of generalization
that we see with no Turing machines does
not happen with you know a normal LSD
end model for example essentially it
learns the copy up to ten and then after
ten it just goes completely awry it
starts to it sucks the output random
mush and this really shows that it
hasn't learned an algorithm it's rather
kind of hard-coded itself has learned
internally to store these ten things in
some particular place in its memory and
it doesn't know what to do when it goes
beyond that so in other words because it
lacks this attention mechanism between
the network and the memory it's not able
to to kind of separate out computation
from memory which is what's necessary to
have this kind of generalization and so
this can be extended we look at other
tasks well one very simple one was to
learn something akin to a for loop so if
the network is given a random sequence
once it's then also given an indicator
telling it how many times it should
reproduce that output sequence and then
it just has to output the whole sequence
end times copy end times and so
basically what it does is just uses the
same algorithm as before except now it
has to keep track of how many times its
output the whole sequence so it just
keeps on jumping to the start of the
array with content based you know to a
particular row in memory using content
based location then iterates one step at
a time gets to the end and jumps back
and meanwhile it has this sort of
internal variable that keeps track of
the number of steps that it's done so
far another example of you know what it
could do with memory was this Engram
inference task so here the
is that a sequence is generated using
some random set of Engram transition
transition probabilities so basically
saying given some binary sequence given
the last three or four inputs there's a
set of probabilities telling you you
know whether the next input will be a0
or a1 and those probabilities are sort
of randomly determined and then you
generate a sequence from them and what
you can do as the sequence goes on you
can infer what the probabilities are and
there's there's a you know a sort of a
Bayesian algorithm for doing this
optimally but what we're sort of
interesting is well how well does a
neural network manage to do this how
well does it sort of it's kind of like a
meta learning problem where it has to
look at the first part of the sequence
work out what the probabilities are and
then start making predictions in
accordance with those probabilities and
what we found was that yes once again
Ellis team can kind of do this but it
doesn't do it in a very kind of it makes
quite a lot of mistakes I've indicated a
couple of them with red arrows here
oh no sorry excuse me those red arrows I
think actually indicate mistakes made
but the neural Turing machine but in
general the the neural Turing machine
was able to sort of perform this task
much better and the reason it was able
to do that is that it used its memory
use specific memory locations to store
variables that count of the occurrences
of particular Engram so if it had seen 0
0 1 for example it would use that to
define a key to look up a place in
memory might be this place here and then
the next time it's all 0 0 1 it would be
able to increment that which is
basically a way of saying okay if I've
learned that 0 0 1 is a common
transition that means that the
probability of one followed by of to 0
is followed by a 1 must be really eyes
and basically it learns to count these
occurrences which is exactly what the
optimal Bayesian algorithm does and it
uses it is able to do this by being able
to pick out selective specific areas in
its memory and use those as counters ok
so here's a little video kind of
showing the system action so this is
being performed this repeat and times
tasks or the start here where the
network is going quickly we see what
happens during training then we have the
system everything slows down here we
have you know what happens with a
chained version the network the input
data comes in while the input data was
coming in we saw this this blue arrow
here which showed the input data being
written to the network memory one step
at a time so it's stored this input
sequence in memory and then the writing
task begins once the writing task begins
we see this red arrow which represents
the the right waits the attention the
attention parameters used for writing
and we can see that these are you know
very tightly focused on one particular
row in the network the one that it's
admitting as output at any one point in
time and it's then iterating through
this array one step at a time and what
you can also see as this video goes on
is that the the sorry the the size of
the circle size and colors of the
circles here represent the magnitude of
the variables within this memory matrix
I believe they're sort of the hot colors
are positive and the cold colors are
negative as I remember
but as what's happening as the network
is looping through this whoops is
running through this loop several times
just from that video again and we can
see during training that you know at
first these attention these these these
read and write weights are not sharply
focused they're blurred out so this
sharp focus kind of comes later on once
the network is finished writing the
whole the whole sequence it then sort of
you see this these variables in the
background become larger and that's
because it's using those to keep count
of how many times it's being through the
how many times it's repeated this copy
operation and then at the end the
changes this this this final this row at
the bottom
which is an indicator the network that
is that the task is complete so it's
using this memory to kind of perform an
algorithm here and so quickly I'm just
going to mention we following the neural
Turing machine we introduced the kind of
extended version of a successor
architecture which we call
differentiable neural computers and we
introduced a bunch of new attention
mechanisms to provide memory access and
I'm not going to go through that in
detail but just to say one of the rather
than looking at algorithms with this
sort of updated version of the
architecture what we were really
interested in was looking at graphs
because so while recurrent neural
networks are designed for sequences in
particular many types of data were
naturally expressed as a graph of you
know nodes and and links between nodes
and because of this this ability to
store information in memory and the
store and recall with kind of something
that came into random access it's
possible for the network to store quite
a large and complex graph in memory and
then perform operations on it and so
what we did during training of the
system is we looked at random randomly
connected graphs and then when we tested
it we looked at specific examples of
graphs so one of them was the graph
representing the zone 1 of London
Underground and we were able to ask
questions like well can you can you find
the shortest path between war Gate and
Piccadilly Circus or so or can you can
you perform a traversal when you start
an Oxford Circus and follow the central
line and the circle line and so forth
and it was able to do this because they
could store the graph in memory and then
selectively kind of recall elements of
the graph similarly we asked it some
questions about a family tree where it
had to determine complex relationships
like maternal great-uncle and order to
do that it had to keep track of all the
links in the graph so for the for the
remainder of the lecture we're going to
look at some further topics in attention
and deep learning so one type of deep
network that's got a lot of attention
recently is known as
transformer networks and what's really
interesting about transformers as
they're often known from from the point
of view of this lecture is that they are
they really take attention to the
logical extreme they basically get rid
of everything else the all of the other
components that could have been present
in similar deep networks such as the
recurrent state present in recurrent
neural networks convolutions external
memory like we discussed in the previous
section and they just use attention to
repeatedly transform a data sequence so
it's a the idea that the paper that
introduced transformers was called
attention is all you need and that's
really the the fundamental idea behind
them is that this this attention
mechanism is so powerful it can
essentially it can essentially replace
everything else in a deep network and so
the attention the form of attention used
by transformers is is a little it's it's
mathematically the same as the attention
we've looked at for before but the way
it's implemented in the network is a
little bit different so instead of there
being a controller Network as there was
in the neural Turing machine for example
that emits some set of attention
parameters that are treated as a query
rather what you have is that every
vector in the sequence emits its own
query and compares itself with every
other and sometimes I think of this as a
sort of emergent or anarchist attention
where the attention is not being
dictated by some central control
mechanism but is rather arising directly
from the data and so in practice you
know what this means is you have quite a
similar calculation to quite quite a
similar attention mechanism to the
content-based attention we've discussed
previously where there's a cosine
similarity calculated between a set of
vectors but the point is that there's a
separate key being emitted for every
vector in the sequence that's compared
with every other and like as with NTM
endian see there are multiple attend
heads I use in fact every every point in
the input sequence gives not just one
[Music]
one set of not just one attention key to
be compared with the rest of the
sequence but several so I'm not gonna go
very much into the details of you know
how transformers work the although the
attention mechanism is straightforward
the actual architecture itself is fairly
complex and actually I recommend this
blog post the annotated transformer for
those of you who want to understand it
in more detail but if we look at the
kinds of the kinds of operations that
emerge from the system is very
intriguing so as I've said there's this
the the idea is that a series of
attention mechanisms are defined so
transformers I should say are
particularly successful for natural
language processing and I think the
reason for that and the reason that
recurrent neural networks for attention
were also first applied to languages
that in language this idea of being able
to attend to things that are widely
separated in the input is particularly
important so there's one word at the
start of the paragraph might be very
important when it comes to understanding
something much later on in the paragraph
there may be if you're trying to extract
for example the the sentiment of a
particular piece of text there may be
several words that are very well that
are very spaced out that are required in
order to make sense of it so this is
sort of a it's a natural it's a it's a
natural fit for attention based models
so in this particular example here from
the paper we see that when the so the
network has has processed has created
keys and and vectors for each element in
the input sequence and then and this
creates a you know a sequence that the
sequence of embeddings equal to length
of the original sequence and then this
process is repeated at the next level up
so the network basically now now
finds another set of key vector pairs at
every point along the sequence and those
key vector pairs are then compared with
the original embeddings to create these
attention masks and so we see for this
word making here this is being this is
being while this word is being processed
I forget what the exact task was here
while this well this word making was
being processed it was attending to a
bunch of different words laws 2009 the
word making itself but also this this
phrase more difficult here at the end of
the sequences all of these things are
are tied up with the semantics of how
this word making is used in the sentence
and generally what you find is you get
these these difference as I said there
are there are multiple attention vectors
being defined for each point in the
sequence and what you get are different
patterns of attention emerging so for
example in this example here and this is
showing the kind of the all-to-all
attention so how the embedding
corresponding to each word in the
sentence at one level is attending to
all of the embeddings at another level
and we see that this one is doing
something quite complex it seems to be
looking for phrases or what the word
what is kind of attending to this is
what the law the word law is attending
to the law and it's and so forth so
there's some kind of some you know
complicated integrating of information
going on whereas here another one of the
sort of attention masks for the same
network we see that it's doing something
much simpler which is it's just
attending to nearby words and so the
overall effect of having all of these
access to all these attention mechanisms
is that the network can learn a really
rich set of transforms for the data but
what they realize is the transformer
networks that just by repeating this
process many times they could get in a
very very powerful model in particular
of
language data and so from the original
paper they already showed that you know
the the the transformer was achieving
state-of-the-art results with machine
translation since then has kind of gone
from strength to strength you now
provide state of the Arts for language
modeling has also been used for for
other data types besides language it's
been used for speech recognition it's
been used for two-dimensional data such
as images but from this this blog post
here this was this was posted by by open
AI in 2019 we can see just how powerful
a transformer based language model can
be so in language modeling essentially
just means predicting iteratively
predicting the next word and a piece of
text or the next sub word symbol and so
in this case once the the language model
is trained it can be given a human
prompt and then you can generate from it
just by asking it to predict what word
things will come next and then feeding
that word in and repeating this whole
transformer based network that is able
to attend to all of the previous context
in the data and what's really
interesting about this text relative to
texts that have been generated by
language models in the past is that it
manages to stay on topic is that manages
to keep the context intact throughout a
relatively long speech a relatively long
piece of text so having started off
talking about a herd of unicorns living
in an unexplored valley in the Andes it
continues to talk about unicorns it
continues to it keeps the setting
constant in the Andes Mountains it you
know vents a biologist from the
University of La Paz and once it's made
these inventions for example once it's
named the biologist it keeps that name
in fact I haven't called it Perez once
it knows to keep on calling on Paris
throughout and the reason it can do that
is that it has this really powerful use
of context that comes from having this
this ability to attend to everything in
the sequence so far so what what
attention is really doing here is
allowing it to span very long very long
divides very long separations in the
data this is something that even you
know before attention was introduced
even the most powerful recurrent neural
networks such as LST M they struggled to
do because they had to store everything
in the internal state of a network which
was constantly being overwritten by new
data so between the first time
Perez is introduced in the last time
there might have been you know several
hundred updates of the network and this
information about Paris would attenuate
during these updates but attention
allows you to kind of remove this
attenuation it allows you to bridge
these very long gaps and that's really
the secret to to its power particularly
for language moment and so one
interesting extension to so they should
say there have been many many extensions
to transformer networks
and they kind of you know go on from
strength to strength particularly with
language modeling and one one extension
that I'd like to look at in this lecture
which I find very interesting is known
as universal transformers so the idea
here is that the the basically the
weights of the transformer are tied
across each transform so the transforms
you if we look at this model here if we
have the input sequence over time along
the x-axis then this the effect of the
transform is to generate a set of of
self attention masks at each point
belong the sequence and then all of the
the embeddings associated with these
points are then transformed again the
next level up and so on now in an
ordinary transformer these parameters
that happen the the parameters of the
attention the the self attention
operations
are different at each point going up at
each at each transformer each level
going up on the y-axis and this means
that the the functional form of the
transform is being enacted is different
at each step so tying these weights
going up through the stack makes it act
like a recurrent neural network in
deaths so what you have is something
like a recursive transform and what's
interesting about that is that you then
start to have something that can behave
a little bit more algorithmically
something that is not only very good
with language but is good at learning
the sorts of functions the sort of sort
of algorithmic behaviors that I talked
about in the neural Turing machine
section and so this could be seen from
from some of the results for universal
transformers where it was applied for
example to the baby tasks which are a
set of kind of toy linguistic tasks
generated using a grammar and so a
related topic to this idea so there's
this idea here of this having a
recursive transform and oh and the other
thing I should say is that because the
way it's divided it means you can you
can enact this transform a variable
number of times in just the same way
that you can run an RNN through a
variable length sequence so now we have
something where the amount of time it
spends transforming each part of the
data and can become variable it can
become data dependent and so this
relates to work that I did in 2016 which
I called adaptive computation time the
idea of adaptive computation time was to
change so with an ordinary recurrent
neural network there's a one-to-one kind
of correspondence between input steps
and output steps every time an input
comes in the network and it's an output
and the problem with this in some sense
is that ties it ties computation time to
what we could call data time there's one
pick of computation for every step in
the data and now you can you can
alleviate this by stacking
the layers on top of each other so now
you have multiple takes a computation
for each each point in the input
sequence but the idea of adaptive
computation time was that maybe we could
allow the network to learn how long it
needed to think in order to make each
decision we call this the amount of time
it's spent pondering each decisions the
idea is some network some input comes in
at times the x1 the network receives a
hidden state it's hidden state from the
previous time step as usually the
recurrent neural network and it then
thinks for a variable number of steps
before making a decision and and this
variable number of steps is determined
by a halting probabilities these numbers
of might reading up like 8 the idea is
that when that probability passes a
threshold of 1 the network when the sum
of these probabilities passes the
threshold of 1 the network is ready to
emit an output and move on to the next
time step and so what's the sort of the
relevance of this mechanism to the rest
of this lecture which has been about
more explicit attention mechanisms is
that in some sense the amount of time a
person or even a neural network spends
thinking about a particular decision
that it makes it's strongly related to
the degree to which it attendance to it
so there have been cognitive experiments
on with people where you can you can by
measuring the amount of time it takes
them to answer a particular question you
can sort of measure the amount of
attention that they're needing to give
to that question and so if we look at
this concretely if we look at what
happens with this adaptive computation
time if we apply this to a recurrent
neural network this is an ordinary lsdm
network that is being applied to
language modeling in this case next step
character prediction and this what this
graph is showing is the the y-axis shows
the number of steps that the network
stop to think for now this number of
steps is actually not it's not integer
because there's
there's this question where it can it
can it can slightly overrun a complete
step but that's not really important
what's important here is that there's a
variable amount of computation going on
for each of these predictions that it
has to make and you can immediately see
a pattern so for example the amount of
ponder time goes up when there's a space
between words and the reason for this is
that it's at the start of words that we
need to spend the longest thinking
because it's it's basically it's easier
once you've gone most of the way through
a word it's easy to predict the ending
once you've seen P OPL is pretty easy to
click the P is gonna come next once you
see a space after that e then it becomes
harder now you have to think well and
the many people what word could come
next so this takes a little bit more
fall and then it tends to drop down
again and it spikes up even further when
it comes to a kind of larger divider
like a full stop like a comma so there's
this very close if we think about if you
think back to the the plots I showed you
at the very start of this lecture were
to do with the visitor tension where we
saw that a deep network or recurrent
neural network will concentrate in some
sense or will respond more strongly to
certain parts of the sequence we kind of
see that same pattern emerge again when
we give it a variable amount of time to
think about what's going on in sequence
and there's some interesting
consequences here so for example one is
that the network is only because this is
this is a question of how long it needs
to take in order to make a particular
prediction the network is only
interested in predictable data so for
example if you see these IV tags this is
from Wikipedia data which contains you
know XML tags as well we can see that
the network is law there's no spike in
instead of thinking time when it comes
to these ID numbers this is kind of
interesting because these ID numbers are
hard to predict so it isn't simply that
the network thinks longer whenever you'd
find something that's harder to
Hey it thinks longer when it sort of
believes that there's a benefit to
thinking longer when thinking longer is
likely to make it better able to make a
prediction and the reason it would be
better able to make it a prediction is
that it allows it to spend more time
allows it to spend more time processing
the context on which that prediction is
based and so this kind of goes back
again to the idea we talked about in
transformers of having these repeated
steps of both contextual processing as
being the thing that builds up the
information the network needs to make a
prediction and so there's a nice
combination of this this idea of
adaptive computation time with these
universal transformer models and so in
this case here we have a task from the
baby data set where there's a series of
sentences so these these sentences as
entered along the x-axis are kind of
like the input from the network then or
these are the contexts that the network
needs to know about and then it gets
asked the question the question here was
where was the Apple before the bathroom
and if you go through all of these
sentences now I think I've cropped this
grass it doesn't have all of them but
you can see that things are happening
with the Apple John dropped the Apple
John grabbed the Apple John went to the
office so I think the Apple at this
point is probably in the office John
journey to the bathroom well maybe now
it's gone to the bathroom in between
those two things where some pieces of
information that weren't relevant
sandwich the milk for example John
traveled to the office were back in the
office again so there's a little puzzle
here that the network has to work out as
to where the Apple has ended up and of
course some parts of this sequence are
important for that puzzle and some parts
are John discarded the Apple there well
of course that's very important
basically all of the ones that mentioned
where John is are important and
generally those are the ones that the
network spends longer thinking about so
we're kind of via this adaptive
computation time and bhayya this
transformer model where you know and
every second time each point along the
sequences
pending for all of the others but we
build up a similar picture in some sense
to the one we had at the start of the
lecture where we can see that the
network has learned to focus more on
some parts of the sequence analysis so
once again this is what attention is all
about is about ignoring things and being
selective and so to conclude I think the
main point I would like to get across in
this lecture is that selective attention
appears to be as useful for deep
learning as it is for people as we saw
at the start of the lecture implicit
attention is always in present in some
degree in neural networks just because
they learn to become more sensitive for
certain parts of the data than to others
but we can also add explicit attention
mechanisms on top of that and it seems
to be very beneficial to do so these
mechanisms can be stochastic so-called
hard attention that we can train in
reinforcement learning or they can be
differentiable so-called soft attention
which could be trained with ordinary
backprop in Indian learning and we can
use attention to attend to memory or to
some internal state of the network as
well as to data so many types of
attention mechanism have been defined
and I should say that even the ones are
covered in this lecture only or only
cover a small fraction of what's being
considered in the field and many more
could be defined and I think and what's
become you know very clear over the last
few years is that you can really get
excellent results state-of-the-art
results in sequence learning by just
using attention by using transformers
that essentially get rid of all of the
other mechanisms that deep networks have
for attending to long-range context and
that is the end of this lecture on
attention and memory and deep learning
thank you very much for your attention
you |
fdf9a3da-a1d1-480c-86b8-c709ec40a1d5 | trentmkelly/LessWrong-43k | LessWrong | Interpretability Will Not Reliably Find Deceptive AI
Disclaimer: Post written in a personal capacity. These are personal opinions and do not in any way represent my employer's views
TL;DR:
* I do not think we will produce high reliability methods to evaluate or monitor the safety of superintelligent systems via current research paradigms, with interpretability or otherwise.
* Interpretability still seems a valuable tool and remains worth investing in, as it will hopefully increase the reliability we can achieve.
* However, interpretability should be viewed as part of an overall portfolio of defences: a layer in a defence-in-depth strategy
* It is not the one thing that will save us, and it still won’t be enough for high reliability.
EDIT: This post was originally motivated by refuting the claim "interpretability is the only reliable path forward for detecting deception in advanced AI", but on closer reading this is a stronger claim than Dario's post explicitly makes. I stand by the actual contents of the post, but have edited the framing a bit, and also emphasised that I used to hold the position I am now critiquing, apologies for the mistake
Introduction
There’s a common argument made in AI safety discussions: it is important to work on interpretability research because it is a realistic path to high reliability safeguards on powerful systems - e.g. as argued in Dario Amodei’s recent “The Urgency of Interpretability”.[1] Sometimes an even stronger argument is made, that interpretability is the only realistic path to highly reliable safeguards - I used to believe both of these arguments myself. I now disagree with these arguments.
The conceptual reasoning is simple and compelling: a sufficiently sophisticated deceptive AI can say whatever we want to hear, perfectly mimicking aligned behavior externally. But faking its internal cognitive processes – its "thoughts" – seems much harder. Therefore, goes the argument, we must rely on interpretability to truly know if an AI is aligned.
I am concerned this line of |
492f33ad-37f6-4e81-b7ca-206ad0bed305 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Causality, Responsibility and Blame in Team Plans.
1 Introduction
---------------
Many objectives can be achieved (or may be achieved more effectively) only by
a coalition or team of agents. In general, for the actions of the agents in the
team to be successful in achieving the overall goal, their activities must be
coordinated by a *team plan* that specifies which task(s) should be
performed by each agent and when they should be performed.
As with single-agent plans, team plans may fail to achieve their
overall objective: for example, agents may fail to perform a task they have been
assigned. When a failure occurs,
the inter-dependencies between tasks in the team plan can make it
difficult to determine which agent(s) are responsible for the failure:
did the agent simply not perform the task it was assigned, or
was it impossible to perform the task due to earlier failures by other agents?
For example, suppose that a major highway upgrade does not finish by
the deadline, causing significant traffic problems over a holiday
weekend.
Many agents may be involved in the upgrade,
each executing steps in a large, complex team plan.
Which agents are the causes of the work not being completed on time?
To what extent are they
responsible or to blame?
Determining which agents are responsible for the failure of a team
plan is a key step in recovering from the failure, determining which
commitments may have been broken [Singh//:09a](#bib.bib22) (and hence which sanctions
should be applied), and whether agents should be trusted in the
future [Griffiths//:02a](#bib.bib8) .
Identifying those agents most responsible/blameworthy for a plan
failure is useful for (re)assigning tasks when recovering from the
failure (e.g., we may prefer to exclude agents with a high degree of
blame); if resources are limited, we may wish to focus attention on
the agents most responsible for the failure (e.g., to discover the
reasons for their failure/try to change their behaviour).
However, there has been relatively little work in
this area. Work in plan diagnosis has focussed on determining the causes of
failures in team plans (e.g.,
[Micalizio//:04a](#bib.bib19) ; [Witteveen//:05a](#bib.bib25) ); it typically has not
considered the question of degree of responsibility of agents for the
failure (an exception is the notion of primary and secondary failures
in, e.g., [deJonge//:09a](#bib.bib4) ; [Micalizio/Torasso:14a](#bib.bib18) ).
Another strand of work focusses on the problem of how to allocate
responsibility and blame for non-fulfilment of group obligations
(e.g.,
[Aldewereld//:13a](#bib.bib1) ; [deLima//:10b](#bib.bib5) ; [Grossi//:04a](#bib.bib9) ; [Grossi//:07a](#bib.bib10) ; [deLima//:10a](#bib.bib15) ; [Lorini/Schwarzentruber:11a](#bib.bib16) ).
However, the definitions of causality and responsibility used
in these work do not always give answers in line with our intuitions
(see, e.g., [Hal48](#bib.bib12) for examples of what can go wrong).
In this paper, we present an approach to determining the degree of
responsibility and blame of agents for a failure of a team plan based on
the definition of causality introduced
by Halpern (which in turn is based on earlier definitions due to Halpern
and Pearl ; ).
One advantage of using the Halpern and Pearl definition of causality
is that, as
shown by Chockler and
Halpern , it can be extended in a natural way to
assign a *degree
of responsibility* to each agent for the outcome.
Furthermore, when there is uncertainty about details of what happened,
we can incorporate this uncertainty to talk about
the *degree of blame* of each agent, which is just the expected
degree of responsibility.
We show that each team plan gives rise to a causal model in a natural
way,
so the definitions of responsibility and blame can be applied without change.
In addition, it turns out that
the causal models that arise from team plans have a special property:
the equations that characterise each variable are *monotone*,
that is,
they can be written as propositional formulas that do not involve negation.
For
such
monotone models, causality for a monotone formula can
be determined in polynomial
time, while determining the degree of responsibility and blame is NP-complete.
This contrasts with the Dpsuperscript𝐷𝑝D^{p}italic\_D start\_POSTSUPERSCRIPT italic\_p end\_POSTSUPERSCRIPT-completeness of
determining causality
in general [Hal47](#bib.bib11)
and the Σ2psubscriptsuperscriptΣ𝑝2\Sigma^{p}\_{2}roman\_Σ start\_POSTSUPERSCRIPT italic\_p end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT-completeness of determining
responsibility (a result proved here).
For *postcondition minimal* plans (where preconditions of each step are established
by a unique combination of previous steps),
the causal models that arise have a further property:
they are *conjunctive*: that is, the equations can be written as
monotone conjunction (so that they have neither negations nor
disjunctions). In this case, both
causality and degree of responsibility can be determined in polynomial
time.
These complexity results may be
of independent interest. For example, conjunctive and monotone
formulas are of great interest in databases; indeed, it has already been
shown that for the causal models that arise with databases (which are
even simpler than the conjunctive models that we consider here), computing
causality for conjunctive formulas can be done in polynomial time
[MGMS10a](#bib.bib17) . (However the notion of causality considered by Meliou at
al. is closer to the original Halpern-Pearl definition
[HPearl01a](#bib.bib13) , and thus not quite the same as that considered
here.)
This reduction in complexity can be useful in many settings, for
example, where causality, responsibility and blame must be determined
at run-time.
The remainder of the paper is structured as follows. In Section
[2](#S2 "2 Causality, Responsibility, and Blame ‣ Causality, Responsibility and Blame in Team Plans") we recall the definitions of causality,
responsibility and blame from [ChocklerH03](#bib.bib3) ; [Hal47](#bib.bib11) . In Section
[3](#S3 "3 Team Plans ‣ Causality, Responsibility and Blame in Team Plans") we define our notion of team plan, and in Section
[4](#S4 "4 Translating Team Plans to Causal Models ‣ Causality, Responsibility and Blame in Team Plans") we show how team plans can be translated into
causal models. As noted above, the resulting causal models are monotone;
in Section [5](#S5 "5 The Complexity of Causality for Monotone Models ‣ Causality, Responsibility and Blame in Team Plans") we prove general results on the
complexity of checking causality, degree of responsibility, and degree
of blame for monotone and conjunctive causal models. We conclude
in Section [6](#S6 "6 Conclusions ‣ Causality, Responsibility and Blame in Team Plans").
2 Causality, Responsibility, and
Blame
---------------------------------------
In this section we briefly review Halpern’s definitions of causality
[Hal47](#bib.bib11)
and Chockler and Halpern’s definition of responsibility and blame
[ChocklerH03](#bib.bib3) ;
see
[ChocklerH03](#bib.bib3) ; [Hal47](#bib.bib11) for further details and intuition.
Much of the description below is taken from [Hal47](#bib.bib11) .
The Halpern and Pearl approach (hereafter HP) assumes that the world is described in terms of
variables and their values.
Some variables may have a causal influence on others. This
influence is modelled by a set of modifiable structural equations.
It is conceptually useful to split the variables into two
sets: the exogenous variables, whose values are
determined by
factors outside the model, and the
endogenous variables, whose values are ultimately determined by
the exogenous variables. The structural equations
describe how the outcome is determined.
Formally, a *causal model* M𝑀Mitalic\_M
is a pair (𝒮,ℱ)𝒮ℱ({\cal S},{\cal F})( caligraphic\_S , caligraphic\_F ), where 𝒮𝒮{\cal S}caligraphic\_S is a *signature*
that explicitly lists the endogenous and exogenous variables
and characterises their possible values,
and ℱℱ{\cal F}caligraphic\_F is a function that associates a structural equation with each
variable.
A signature 𝒮𝒮{\cal S}caligraphic\_S is a tuple (𝒰,𝒱,ℛ)𝒰𝒱ℛ({\cal U},{\cal V},{\cal R})( caligraphic\_U , caligraphic\_V , caligraphic\_R ), where 𝒰𝒰{\cal U}caligraphic\_U is a set of
exogenous variables, 𝒱𝒱{\cal V}caligraphic\_V is a set
of endogenous variables, and ℛℛ{\cal R}caligraphic\_R associates with every variable Y∈𝒰∪𝒱𝑌𝒰𝒱Y\in{\cal U}\cup{\cal V}italic\_Y ∈ caligraphic\_U ∪ caligraphic\_V a nonempty set ℛ(Y)ℛ𝑌{\cal R}(Y)caligraphic\_R ( italic\_Y ) of possible values for
Y𝑌Yitalic\_Y (i.e., the set of values over which Y𝑌Yitalic\_Y ranges).
ℱℱ{\cal F}caligraphic\_F associates with each endogenous variable X∈𝒱𝑋𝒱X\in{\cal V}italic\_X ∈ caligraphic\_V a
function denoted FXsubscript𝐹𝑋F\_{X}italic\_F start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT such that FX:(×U∈𝒰ℛ(U))×(×Y∈𝒱−{X}ℛ(Y))→ℛ(X)F\_{X}:(\times\_{U\in{\cal U}}{\cal R}(U))\times(\times\_{Y\in{\cal V}-\{X\}}{\cal R}(Y))\rightarrow{\cal R}(X)italic\_F start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT : ( × start\_POSTSUBSCRIPT italic\_U ∈ caligraphic\_U end\_POSTSUBSCRIPT caligraphic\_R ( italic\_U ) ) × ( × start\_POSTSUBSCRIPT italic\_Y ∈ caligraphic\_V - { italic\_X } end\_POSTSUBSCRIPT caligraphic\_R ( italic\_Y ) ) → caligraphic\_R ( italic\_X ).
Thus, FXsubscript𝐹𝑋F\_{X}italic\_F start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT defines a structural equation that determines the value
of X𝑋Xitalic\_X given the values of other variables.
Setting the value of some variable X𝑋Xitalic\_X to x𝑥xitalic\_x in a causal
model M=(𝒮,ℱ)𝑀𝒮ℱM=({\cal S},{\cal F})italic\_M = ( caligraphic\_S , caligraphic\_F ) results in a new causal model, denoted MX←xsubscript𝑀←𝑋𝑥M\_{X\leftarrow x}italic\_M start\_POSTSUBSCRIPT italic\_X ← italic\_x end\_POSTSUBSCRIPT, which is identical to M𝑀Mitalic\_M, except that the
equation for X𝑋Xitalic\_X in ℱℱ{\cal F}caligraphic\_F is replaced by X=x𝑋𝑥X=xitalic\_X = italic\_x.
Given a signature 𝒮=(𝒰,𝒱,ℛ)𝒮𝒰𝒱ℛ{\cal S}=({\cal U},{\cal V},{\cal R})caligraphic\_S = ( caligraphic\_U , caligraphic\_V , caligraphic\_R ), a *primitive event* is a
formula of the form X=x𝑋𝑥X=xitalic\_X = italic\_x, for X∈𝒱𝑋𝒱X\in{\cal V}italic\_X ∈ caligraphic\_V and x∈ℛ(X)𝑥ℛ𝑋x\in{\cal R}(X)italic\_x ∈ caligraphic\_R ( italic\_X ).
A causal formula (over 𝒮𝒮{\cal S}caligraphic\_S) is one of the form
[Y1←y1,…,Yk←yk]φdelimited-[]formulae-sequence←subscript𝑌1subscript𝑦1…←subscript𝑌𝑘subscript𝑦𝑘𝜑[Y\_{1}\leftarrow y\_{1},\ldots,Y\_{k}\leftarrow y\_{k}]\varphi[ italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ← italic\_y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_Y start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT ← italic\_y start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT ] italic\_φ,
where
* •
φ𝜑\varphiitalic\_φ is a Boolean
combination of primitive events,
* •
Y1,…,Yk
subscript𝑌1…subscript𝑌𝑘Y\_{1},\ldots,Y\_{k}italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_Y start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT are distinct variables in 𝒱𝒱{\cal V}caligraphic\_V, and
* •
yi∈ℛ(Yi)subscript𝑦𝑖ℛsubscript𝑌𝑖y\_{i}\in{\cal R}(Y\_{i})italic\_y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ∈ caligraphic\_R ( italic\_Y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT ).
Such a formula is
abbreviated
as [Y←y]φdelimited-[]←@vecY@vecy𝜑[\@vec{Y}\leftarrow\@vec{y}]\varphi[ start\_ID start\_ARG italic\_Y end\_ARG end\_ID ← start\_ID start\_ARG italic\_y end\_ARG end\_ID ] italic\_φ.
The special
case where k=0𝑘0k=0italic\_k = 0
is abbreviated as
φ𝜑\varphiitalic\_φ.
Intuitively,
[Y1←y1,…,Yk←yk]φdelimited-[]formulae-sequence←subscript𝑌1subscript𝑦1…←subscript𝑌𝑘subscript𝑦𝑘𝜑[Y\_{1}\leftarrow y\_{1},\ldots,Y\_{k}\leftarrow y\_{k}]\varphi[ italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ← italic\_y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_Y start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT ← italic\_y start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT ] italic\_φ says that
φ𝜑\varphiitalic\_φ would hold if
Yisubscript𝑌𝑖Y\_{i}italic\_Y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT were set to yisubscript𝑦𝑖y\_{i}italic\_y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT, for i=1,…,k𝑖1…𝑘i=1,\ldots,kitalic\_i = 1 , … , italic\_k.
Following [Hal47](#bib.bib11) ; [HP01b](#bib.bib14) , we restrict attention here to what are
called acyclic models. This is the
special case
where there is some total ordering ≺precedes\prec≺ of the endogenous variables
(the ones in 𝒱𝒱{\cal V}caligraphic\_V)
such that if X≺Yprecedes𝑋𝑌X\prec Yitalic\_X ≺ italic\_Y, then X𝑋Xitalic\_X is independent of Y𝑌Yitalic\_Y,
that is, FX(z,y,v)=FX(z,y′,v)subscript𝐹𝑋@vecz𝑦@vecvsubscript𝐹𝑋@veczsuperscript𝑦′@vecvF\_{X}(\@vec{z},y,\@vec{v})=F\_{X}(\@vec{z},y^{\prime},\@vec{v})italic\_F start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT ( start\_ID start\_ARG italic\_z end\_ARG end\_ID , italic\_y , start\_ID start\_ARG italic\_v end\_ARG end\_ID ) = italic\_F start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT ( start\_ID start\_ARG italic\_z end\_ARG end\_ID , italic\_y start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , start\_ID start\_ARG italic\_v end\_ARG end\_ID ) for all y,y′∈ℛ(Y)𝑦superscript𝑦′
ℛ𝑌y,y^{\prime}\in{\cal R}(Y)italic\_y , italic\_y start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ∈ caligraphic\_R ( italic\_Y ). If X≺Yprecedes𝑋𝑌X\prec Yitalic\_X ≺ italic\_Y, then the value of X𝑋Xitalic\_X may affect the value of
Y𝑌Yitalic\_Y, but the value of Y𝑌Yitalic\_Y cannot affect the value of X𝑋Xitalic\_X.
If M𝑀Mitalic\_M is an acyclic causal model,
then given a *context*, that is, a setting u@vecu\@vec{u}start\_ID start\_ARG italic\_u end\_ARG end\_ID for the
exogenous variables in 𝒰𝒰{\cal U}caligraphic\_U, there is a unique solution for all the
equations: we simply solve for the variables in the order given by
≺precedes\prec≺.
A causal formula ψ𝜓\psiitalic\_ψ is true or false in a causal model, given a
context.
We write (M,u)⊧ψmodels𝑀@vecu𝜓(M,\@vec{u})\models\psi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ italic\_ψ if
the causal formula ψ𝜓\psiitalic\_ψ is true in
causal model M𝑀Mitalic\_M given context u@vecu\@vec{u}start\_ID start\_ARG italic\_u end\_ARG end\_ID.
The ⊧models\models⊧ relation is defined inductively.
(M,u)⊧X=xmodels𝑀@vecu𝑋𝑥(M,\@vec{u})\models X=x( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ italic\_X = italic\_x if
the variable X𝑋Xitalic\_X has value x𝑥xitalic\_x
in the
unique (since we are dealing with acyclic models) solution
to
the equations in
M𝑀Mitalic\_M in context u@vecu\@vec{u}start\_ID start\_ARG italic\_u end\_ARG end\_ID
(i.e., the
unique vector
of values for the exogenous variables that simultaneously satisfies all
equations
in M𝑀Mitalic\_M
with the variables in 𝒰𝒰{\cal U}caligraphic\_U set to u@vecu\@vec{u}start\_ID start\_ARG italic\_u end\_ARG end\_ID).
The truth of conjunctions and negations is defined in the standard way.
Finally,
(M,u)⊧[Y←y]φmodels𝑀@vecudelimited-[]←@vecY@vecy𝜑(M,\@vec{u})\models[\@vec{Y}\leftarrow\@vec{y}]\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_Y end\_ARG end\_ID ← start\_ID start\_ARG italic\_y end\_ARG end\_ID ] italic\_φ if
(MY=y,u)⊧φmodelssubscript𝑀@vecY@vecy@vecu𝜑(M\_{\@vec{Y}=\@vec{y}},\@vec{u})\models\varphi( italic\_M start\_POSTSUBSCRIPT start\_ID start\_ARG italic\_Y end\_ARG end\_ID = start\_ID start\_ARG italic\_y end\_ARG end\_ID end\_POSTSUBSCRIPT , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ italic\_φ.
Thus, [Y←y]φdelimited-[]←@vecY@vecy𝜑[\@vec{Y}\leftarrow\@vec{y}]\varphi[ start\_ID start\_ARG italic\_Y end\_ARG end\_ID ← start\_ID start\_ARG italic\_y end\_ARG end\_ID ] italic\_φ is true in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) if φ𝜑\varphiitalic\_φ
is true in the model that results after setting the variables in
Y@vecY\@vec{Y}start\_ID start\_ARG italic\_Y end\_ARG end\_ID to y@vecy\@vec{y}start\_ID start\_ARG italic\_y end\_ARG end\_ID.
With this background, we can now give the definition of causality.
Causality, like the notion of truth discussed above,
is relative to a model and a context.
Only conjunctions of primitive events, abbreviated as X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID, can be causes. What can be caused are arbitrary Boolean
combinations of primitive events. Roughly speaking, X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID is a cause of φ𝜑\varphiitalic\_φ if, had X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID not been the
case, φ𝜑\varphiitalic\_φ would not have happened. To deal with many
well-known examples, the actual definition is somewhat more
complicated.
###### Definition \thetheorem
X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID is an *actual cause of φ𝜑\varphiitalic\_φ in
(M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID )* if the following
three conditions hold:
AC1.
(M,u)⊧(X=x)models𝑀@vecu@vecX@vecx(M,\@vec{u})\models(\@vec{X}=\@vec{x})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ ( start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID ) and
(M,u)⊧φmodels𝑀@vecu𝜑(M,\@vec{u})\models\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ italic\_φ.
AC2m𝑚{}^{m}start\_FLOATSUPERSCRIPT italic\_m end\_FLOATSUPERSCRIPT.
There is a set W@vecW\@vec{W}start\_ID start\_ARG italic\_W end\_ARG end\_ID of variables in 𝒱𝒱{\cal V}caligraphic\_V
and settings x′superscript@vecx′\@vec{x}^{\prime}start\_ID start\_ARG italic\_x end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT of the variables in X@vecX\@vec{X}start\_ID start\_ARG italic\_X end\_ARG end\_ID and w@vecw\@vec{w}start\_ID start\_ARG italic\_w end\_ARG end\_ID
of the variables in W@vecW\@vec{W}start\_ID start\_ARG italic\_W end\_ARG end\_ID such that
(M,u)⊧W=wmodels𝑀@vecu@vecW@vecw(M,\@vec{u})\models\@vec{W}=\@vec{w}( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ start\_ID start\_ARG italic\_W end\_ARG end\_ID = start\_ID start\_ARG italic\_w end\_ARG end\_ID and
| | | |
| --- | --- | --- |
| | (M,u)⊧[X←x′,W←w]¬φ.models𝑀@vecudelimited-[]formulae-sequence←@vecXsuperscript@vecx′←@vecW@vecw𝜑(M,\@vec{u})\models[\@vec{X}\leftarrow\@vec{x}^{\prime},\@vec{W}\leftarrow\@vec{w}]\neg\varphi.( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_X end\_ARG end\_ID ← start\_ID start\_ARG italic\_x end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , start\_ID start\_ARG italic\_W end\_ARG end\_ID ← start\_ID start\_ARG italic\_w end\_ARG end\_ID ] ¬ italic\_φ . | |
AC3.
X@vecX\@vec{X}start\_ID start\_ARG italic\_X end\_ARG end\_ID is minimal; no subset of X@vecX\@vec{X}start\_ID start\_ARG italic\_X end\_ARG end\_ID satisfies
conditions AC1 and AC2m𝑚{}^{m}start\_FLOATSUPERSCRIPT italic\_m end\_FLOATSUPERSCRIPT.
AC1 just says that for X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID to be a cause of φ𝜑\varphiitalic\_φ,
both X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID and φ𝜑\varphiitalic\_φ have to be true. AC3 is a
minimality condition, which ensures that only the conjuncts of
X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID that are essential are parts of a cause. AC2m𝑚{}^{m}start\_FLOATSUPERSCRIPT italic\_m end\_FLOATSUPERSCRIPT
(the “m” is for modified; the notation is taken from [Hal47](#bib.bib11) )
captures the counterfactual. It says that if we change the value of X@vecX\@vec{X}start\_ID start\_ARG italic\_X end\_ARG end\_ID
from x@vecx\@vec{x}start\_ID start\_ARG italic\_x end\_ARG end\_ID to x′superscript@vecx′\@vec{x}^{\prime}start\_ID start\_ARG italic\_x end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT, while possibly holding the values of
the variables in some (possibly empty) set W@vecW\@vec{W}start\_ID start\_ARG italic\_W end\_ARG end\_ID fixed at their
values in the current
context, then φ𝜑\varphiitalic\_φ becomes false. We say that (W,x′)@vecWsuperscript@vecx′(\@vec{W},\@vec{x}^{\prime})( start\_ID start\_ARG italic\_W end\_ARG end\_ID , start\_ID start\_ARG italic\_x end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ) is a *witness* to
X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID being a cause of φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ).
If X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID is a cause of
φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) and X=x𝑋𝑥X=xitalic\_X = italic\_x is a conjunct of X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID, then X=x𝑋𝑥X=xitalic\_X = italic\_x is *part of a cause* of φ𝜑\varphiitalic\_φ in
(M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ).
In general, there may be multiple causes for a given outcome.
For example, consider a plan that requires performing two tasks,
t1subscript𝑡1t\_{1}italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and t2subscript𝑡2t\_{2}italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT. Let M𝑀Mitalic\_M be a model with binary endogenous variables
T1subscript𝑇1T\_{1}italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT, T2subscript𝑇2T\_{2}italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT, and Fin𝐹𝑖𝑛Finitalic\_F italic\_i italic\_n, and one exogenous variable U𝑈Uitalic\_U.
Ti=1subscript𝑇𝑖1T\_{i}=1italic\_T start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT = 1 if task tisubscript𝑡𝑖t\_{i}italic\_t start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT is performed
and 0 otherwise; Fin=1𝐹𝑖𝑛1Fin=1italic\_F italic\_i italic\_n = 1 if the plan
is successfully completed, and 0 otherwise; U𝑈Uitalic\_U determines whether
the tasks were performed.
(In what follows, we consider more
sophisticated models where the agents’ intentions to perform their
tasks are determined by U𝑈Uitalic\_U.)
The equation for Fin𝐹𝑖𝑛Finitalic\_F italic\_i italic\_n is
Fin=T1∧T2𝐹𝑖𝑛subscript𝑇1subscript𝑇2Fin=T\_{1}\wedge T\_{2}italic\_F italic\_i italic\_n = italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ∧ italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT.
If t1subscript𝑡1t\_{1}italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT is not performed while t2subscript𝑡2t\_{2}italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT is, T1=0subscript𝑇10T\_{1}=0italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = 0 is the cause of Fin=0𝐹𝑖𝑛0Fin=0italic\_F italic\_i italic\_n = 0.
If T1=0subscript𝑇10T\_{1}=0italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = 0 and T2=0subscript𝑇20T\_{2}=0italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT = 0, then both together are
the cause of Fin=0𝐹𝑖𝑛0Fin=0italic\_F italic\_i italic\_n = 0.
Indeed, let u𝑢uitalic\_u be the context where the two tasks
are not performed.
AC1 is satisfied since (M,u)⊧T1=0∧T2=0∧Fin=0models𝑀𝑢subscript𝑇10subscript𝑇20𝐹𝑖𝑛0(M,{u})\models T\_{1}=0\land T\_{2}=0\land Fin=0( italic\_M , italic\_u ) ⊧ italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = 0 ∧ italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT = 0 ∧ italic\_F italic\_i italic\_n = 0.
AC2m𝑚{}^{m}start\_FLOATSUPERSCRIPT italic\_m end\_FLOATSUPERSCRIPT is satisfied since (M,u)⊧[T1←1,T2←1](Fin=1)models𝑀𝑢delimited-[]formulae-sequence←subscript𝑇11←subscript𝑇21𝐹𝑖𝑛1(M,u)\models[T\_{1}\leftarrow 1,T\_{2}\leftarrow 1](Fin=1)( italic\_M , italic\_u ) ⊧ [ italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ← 1 , italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ← 1 ] ( italic\_F italic\_i italic\_n = 1 ). Moreover, flipping the value of just
T1subscript𝑇1T\_{1}italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT or T2subscript𝑇2T\_{2}italic\_T start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT alone does not change the outcome, so AC3 is
satisfied.
If the completion of the plan depended on n𝑛nitalic\_n tasks instead of two,
and none of them were performed, the cause would consist of the n𝑛nitalic\_n
non-performed
tasks. We would like to say that each of the non-performed tasks was “less”
of a cause of Fin=0𝐹𝑖𝑛0Fin=0italic\_F italic\_i italic\_n = 0 than in the case when plan failure is due to a single
task not being performed.
The notion of *degree of responsibility*, introduced by Chockler
and Halpern , is intended to capture this
intuition. Roughly speaking, the degree of responsibility X=x𝑋𝑥X=xitalic\_X = italic\_x for
φ𝜑\varphiitalic\_φ measures the minimal
number of changes and number of variables that have to be held fixed
in order to make φ𝜑\varphiitalic\_φ counterfactually depend on
X=x𝑋𝑥X=xitalic\_X = italic\_x.
We use the formal definition in [Hal48](#bib.bib12) , which is appropriate for
the modified definition of causality used here.
###### Definition \thetheorem
The *degree of responsibility of X=x𝑋𝑥X=xitalic\_X = italic\_x for φ𝜑\varphiitalic\_φ in
(M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID )*,
denoted 𝑑𝑟((M,u),(X=x),φ)𝑑𝑟𝑀@vecu𝑋𝑥𝜑\mathit{dr}((M,\@vec{u}),(X=x),\varphi)italic\_dr ( ( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) , ( italic\_X = italic\_x ) , italic\_φ ),
is 00 if X=x𝑋𝑥X=xitalic\_X = italic\_x is
not part of a cause of φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID );
it is 1/k1𝑘1/k1 / italic\_k if there exists a cause X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID of φ𝜑\varphiitalic\_φ
and a witness (W,x′)@vecWsuperscript@vecxnormal-′(\@vec{W},\@vec{x}^{\prime})( start\_ID start\_ARG italic\_W end\_ARG end\_ID , start\_ID start\_ARG italic\_x end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ) to X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID
being a cause of φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) such that
(a) X=x𝑋𝑥X=xitalic\_X = italic\_x is a conjunct of X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID,
(b) |W|+|X|=k@vecW@vecX𝑘|\@vec{W}|+|\@vec{X}|=k| start\_ID start\_ARG italic\_W end\_ARG end\_ID | + | start\_ID start\_ARG italic\_X end\_ARG end\_ID | = italic\_k, and (c) k𝑘kitalic\_k is minimal, in that there is no cause X1=x1subscript@vecX1subscript@vecx1\@vec{X}\_{1}=\@vec{x}\_{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = start\_ID start\_ARG italic\_x end\_ARG end\_ID start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT for φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) and witness
(W′,x1′)superscript@vecWnormal-′superscriptsubscript@vecx1normal-′(\@vec{W}^{\prime},\@vec{x}\_{1}^{\prime})( start\_ID start\_ARG italic\_W end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , start\_ID start\_ARG italic\_x end\_ARG end\_ID start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ) to X1=x1subscript@vecX1subscript@vecx1\@vec{X}\_{1}=\@vec{x}\_{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = start\_ID start\_ARG italic\_x end\_ARG end\_ID start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT
being a cause of φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID )
that includes X=x𝑋𝑥X=xitalic\_X = italic\_x as a conjunct with |W′|+|X1|<ksuperscript@vecWnormal-′subscript@vecX1𝑘|\@vec{W}^{\prime}|+|\@vec{X}\_{1}|<k| start\_ID start\_ARG italic\_W end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT | + | start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT | < italic\_k.
This definition of responsibility
assumes that everything relevant about
the facts of the world and how the world works is known.
In general, there may be uncertainty both about the context and about
the causal model.
The notion of *blame* takes
this into account.
We model an agent’s uncertainty by a pair (𝒦,Pr)𝒦Pr({\cal K},\Pr)( caligraphic\_K , roman\_Pr ), where 𝒦𝒦{\cal K}caligraphic\_K
is a set of causal settings, that is, pairs of the form (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ),
and PrPr\Prroman\_Pr is a probability distribution over 𝒦𝒦{\cal K}caligraphic\_K.
We call such a pair an *epistemic state*.
Note that once we have such a distribution, we can talk about the probability that
X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID is a cause of φ𝜑\varphiitalic\_φ relative to (𝒦,Pr)𝒦Pr({\cal K},\Pr)( caligraphic\_K , roman\_Pr ): it is
just the probability of the set of pairs (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) such that X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID is a
cause of φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ).
We also define the *degree of blame* of X=x𝑋𝑥X=xitalic\_X = italic\_x
for φ𝜑\varphiitalic\_φ to be the expected degree of responsibility:
###### Definition \thetheorem
The *degree of blame* of X=x𝑋𝑥X=xitalic\_X = italic\_x for φ𝜑\varphiitalic\_φ relative to
the epistemic state
(𝒦,Pr)𝒦normal-Pr({\cal K},\Pr)( caligraphic\_K , roman\_Pr ) is
| | | |
| --- | --- | --- |
| | ∑(M,u)∈𝒦𝑑𝑟((M,u),X=x,φ)Pr((M,u)).\sum\_{(M,\@vec{u})\in{\cal K}}\mathit{dr}((M,\@vec{u}),X=x,\varphi)\Pr((M,\@vec{u})).∑ start\_POSTSUBSCRIPT ( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ∈ caligraphic\_K end\_POSTSUBSCRIPT italic\_dr ( ( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) , italic\_X = italic\_x , italic\_φ ) roman\_Pr ( ( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ) . | |
3 Team Plans
-------------
In this section, we define the notion of team plan.
Our definition is essentially the same as
that used in much of the work in
multiagent planning
and work in plan diagnosis [Micalizio//:04a](#bib.bib19) ; [Witteveen//:05a](#bib.bib25) ,111In their approach to identifying causes, Witteveen et
al. assume that tasks are executed
as soon as possible, consistent with the order on tasks; we do not
assume this.
except
that we explicitly record the assignment of agents to primitive tasks.
It thus encompasses *partial order causal link plans*
[Weld:94a](#bib.bib24) ,
*primitive task networks* [Georgievski/Aiello:15a](#bib.bib6) , and
the notion of team plan used in
[Grossi//:04a](#bib.bib9) ; [Grossi//:07a](#bib.bib10) , where
a team plan is constrained to be
a sequence of possibly simultaneous individual actions.
As is standard in planning literature (e.g.,
plans and planning problems relative to a planning domain description; however, for simplicity, we assume that the domain is described using propositional rather than first order logic.
A *planning domain* is a tuple 𝒟=(Π,𝒯{\cal D}=(\Pi,{\cal T}caligraphic\_D = ( roman\_Π , caligraphic\_T, 𝑝𝑟𝑒,𝑝𝑜𝑠𝑡)\mathit{pre},\mathit{post})italic\_pre , italic\_post ), where
ΠΠ\Piroman\_Π is a set of atomic propositions,
𝒯𝒯{\cal T}caligraphic\_T is the set of tasks possible in the domain,
and 𝑝𝑟𝑒𝑝𝑟𝑒\mathit{pre}italic\_pre and 𝑝𝑜𝑠𝑡𝑝𝑜𝑠𝑡\mathit{post}italic\_post are functions from 𝒯𝒯{\cal T}caligraphic\_T to subsets of
Π∪{¬p:p∈Π}Πconditional-set𝑝𝑝Π\Pi\cup\{\neg p:p\in\Pi\}roman\_Π ∪ { ¬ italic\_p : italic\_p ∈ roman\_Π }.
For each t∈𝒯𝑡𝒯t\in{\cal T}italic\_t ∈ caligraphic\_T, 𝑝𝑟𝑒(t)𝑝𝑟𝑒𝑡\mathit{pre}(t)italic\_pre ( italic\_t ) specifies the
preconditions of t𝑡titalic\_t (the set of literals that must hold before t𝑡titalic\_t
can be executed), and 𝑝𝑜𝑠𝑡(t)𝑝𝑜𝑠𝑡𝑡\mathit{post}(t)italic\_post ( italic\_t ) specifies the postconditions
of t𝑡titalic\_t (the effects of executing t𝑡titalic\_t).
A planning problem 𝒢𝒢{\cal G}caligraphic\_G is defined relative to a planning domain, and consists of an initial or starting situation and a goal.
The initial situation and goal are specified by the distinguished tasks
𝑆𝑡𝑎𝑟𝑡𝑆𝑡𝑎𝑟𝑡\mathit{Start}italic\_Start and 𝐹𝑖𝑛𝑖𝑠ℎ𝐹𝑖𝑛𝑖𝑠ℎ\mathit{Finish}italic\_Finish respectively.
𝑝𝑜𝑠𝑡(Start)𝑝𝑜𝑠𝑡𝑆𝑡𝑎𝑟𝑡\mathit{post}(Start)italic\_post ( italic\_S italic\_t italic\_a italic\_r italic\_t ) is the initial state of the environment, and
𝐹𝑖𝑛𝑖𝑠ℎ𝐹𝑖𝑛𝑖𝑠ℎ\mathit{Finish}italic\_Finish has the goal
as its preconditions and no postconditions.
Given a planning problem, a team plan consists of a set of tasks T⊆𝒯∪{Start,Finish}𝑇𝒯𝑆𝑡𝑎𝑟𝑡𝐹𝑖𝑛𝑖𝑠ℎT\subseteq{\mathcal{T}}\cup\{Start,Finish\}italic\_T ⊆ caligraphic\_T ∪ { italic\_S italic\_t italic\_a italic\_r italic\_t , italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h },
an assignment of agents to tasks that specifies which agent is going to perform each task in t∈T∖{𝑆𝑡𝑎𝑟𝑡,𝐹𝑖𝑛𝑖𝑠ℎ}𝑡𝑇𝑆𝑡𝑎𝑟𝑡𝐹𝑖𝑛𝑖𝑠ℎt\in T\setminus\{\mathit{Start},\mathit{Finish}\}italic\_t ∈ italic\_T ∖ { italic\_Start , italic\_Finish }, and a partial order ≺precedes\prec≺ specifying the order in which tasks in T𝑇Titalic\_T must be performed.
If t≺t′precedes𝑡superscript𝑡′t\prec t^{\prime}italic\_t ≺ italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT, whichever agent is assigned to t𝑡titalic\_t must get t𝑡titalic\_t done before
t′superscript𝑡′t^{\prime}italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT is started.
≺precedes\prec≺ is ‘minimally constraining’ in the sense that every
linearization ≺\*superscriptprecedes\prec^{\*}≺ start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT of tasks compatible with ≺precedes\prec≺
achieves
the goal (in a sense we make precise below).
We assume that the agents desire to achieve the goal of the team plan
and have agreed to the assignment of tasks; we define
causality and responsibility relative to a team plan.
###### Definition \thetheorem
A *team plan* 𝒫𝒫\cal Pcaligraphic\_P over a planning domain 𝒟𝒟{\cal D}caligraphic\_D
and problem 𝒢𝒢{\cal G}caligraphic\_G
is a tuple 𝒫=(T,Ag,≺{\cal P}=(T,Ag,\preccaligraphic\_P = ( italic\_T , italic\_A italic\_g , ≺, α)\alpha)italic\_α ),
where
* •
{𝑆𝑡𝑎𝑟𝑡,𝐹𝑖𝑛𝑖𝑠ℎ}⊆T⊆𝒯∪{Start,Finish}𝑆𝑡𝑎𝑟𝑡𝐹𝑖𝑛𝑖𝑠ℎ𝑇𝒯𝑆𝑡𝑎𝑟𝑡𝐹𝑖𝑛𝑖𝑠ℎ\{\mathit{Start},\mathit{Finish}\}\subseteq T\subseteq{\mathcal{T}}\cup\{Start,Finish\}{ italic\_Start , italic\_Finish } ⊆ italic\_T ⊆ caligraphic\_T ∪ { italic\_S italic\_t italic\_a italic\_r italic\_t , italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h } is a finite set of tasks;
* •
Ag𝐴𝑔Agitalic\_A italic\_g is a finite set of agents;
* •
≺precedes\prec≺ is an acyclic transitive binary relation on
T𝑇Titalic\_T such that 𝑆𝑡𝑎𝑟𝑡≺t≺𝐹𝑖𝑛𝑖𝑠ℎprecedes𝑆𝑡𝑎𝑟𝑡𝑡precedes𝐹𝑖𝑛𝑖𝑠ℎ\mathit{Start}\prec t\prec\mathit{Finish}italic\_Start ≺ italic\_t ≺ italic\_Finish for all
tasks t∈T∖{𝑆𝑡𝑎𝑟𝑡,𝐹𝑖𝑛𝑖𝑠ℎ}𝑡𝑇𝑆𝑡𝑎𝑟𝑡𝐹𝑖𝑛𝑖𝑠ℎt\in T\setminus\{\mathit{Start,Finish}\}italic\_t ∈ italic\_T ∖ { italic\_Start , italic\_Finish };
* •
α𝛼\alphaitalic\_α is
a function that assigns to each task in T∖{𝑆𝑡𝑎𝑟𝑡,𝐹𝑖𝑛𝑖𝑠ℎ}𝑇𝑆𝑡𝑎𝑟𝑡𝐹𝑖𝑛𝑖𝑠ℎT\setminus\{\mathit{Start},\mathit{Finish}\}italic\_T ∖ { italic\_Start , italic\_Finish } an agent a∈Ag𝑎𝐴𝑔a\in Agitalic\_a ∈ italic\_A italic\_g
(intuitively, α(t)𝛼𝑡\alpha(t)italic\_α ( italic\_t ) is the agent
assigned to execute task t𝑡titalic\_t; 𝑆𝑡𝑎𝑟𝑡𝑆𝑡𝑎𝑟𝑡\mathit{Start}italic\_Start
is executed automatically),
such that 𝐹𝑖𝑛𝑖𝑠ℎ𝐹𝑖𝑛𝑖𝑠ℎ\mathit{Finish}italic\_Finish is executable, that is, the
goal specified by 𝒢𝒢{\cal G}caligraphic\_G is achieved (in a sense made precise in
Definition [3](#S3 "3 Team Plans ‣ Causality, Responsibility and Blame in Team Plans")).
Given a task t𝑡titalic\_t and a precondition ℓℓ\ellroman\_ℓ of t𝑡titalic\_t, a task t′superscript𝑡′t^{\prime}italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT is a
*clobberer*
of t𝑡titalic\_t (or the precondition ℓℓ\ellroman\_ℓ of t𝑡titalic\_t) if ∼ℓ∈post(t′)similar-toabsentℓ𝑝𝑜𝑠𝑡superscript𝑡′\sim\!\ell\in post(t^{\prime})∼ roman\_ℓ ∈ italic\_p italic\_o italic\_s italic\_t ( italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT )
(where ∼ℓsimilar-toabsentℓ\sim\!\ell∼ roman\_ℓ denotes ¬p𝑝\neg p¬ italic\_p if ℓ=pℓ𝑝\ell=proman\_ℓ = italic\_p and p𝑝pitalic\_p if ℓ=¬pℓ𝑝\ell=\neg proman\_ℓ = ¬ italic\_p).
###### Definition \thetheorem
Given a team plan 𝒫=(T,Ag,≺,α)𝒫𝑇𝐴𝑔precedes𝛼{\cal P}=(T,Ag,\prec,\alpha)caligraphic\_P = ( italic\_T , italic\_A italic\_g , ≺ , italic\_α ),
a task t′∈Tsuperscript𝑡normal-′𝑇t^{\prime}\in Titalic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ∈ italic\_T *establishes literal ℓnormal-ℓ\ellroman\_ℓ* for a task t∈T𝑡𝑇t\in Titalic\_t ∈ italic\_T if ℓ∈prec(t)normal-ℓ𝑝𝑟𝑒𝑐𝑡\ell\in prec(t)roman\_ℓ ∈ italic\_p italic\_r italic\_e italic\_c ( italic\_t ), ℓ∈post(t′)normal-ℓ𝑝𝑜𝑠𝑡superscript𝑡normal-′\ell\in post(t^{\prime})roman\_ℓ ∈ italic\_p italic\_o italic\_s italic\_t ( italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ), t′≺tprecedessuperscript𝑡normal-′𝑡t^{\prime}\prec titalic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ≺ italic\_t,
and for every task t′′∈Tsuperscript𝑡normal-′′𝑇t^{\prime\prime}\in Titalic\_t start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT ∈ italic\_T that clobbers ℓnormal-ℓ\ellroman\_ℓ,
either t′′≺t′precedessuperscript𝑡normal-′′superscript𝑡normal-′t^{\prime\prime}\prec t^{\prime}italic\_t start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT ≺ italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT or t≺t′′precedes𝑡superscript𝑡normal-′′t\prec t^{\prime\prime}italic\_t ≺ italic\_t start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT.
A set S⊆T𝑆𝑇S\subseteq Titalic\_S ⊆ italic\_T of tasks is an
*establishing set
for task t∈T𝑡𝑇t\in Titalic\_t ∈ italic\_T* if and only if
S𝑆Sitalic\_S is a minimal set that establishes all literals ℓ∈prec(t)normal-ℓ𝑝𝑟𝑒𝑐𝑡\ell\in prec(t)roman\_ℓ ∈ italic\_p italic\_r italic\_e italic\_c ( italic\_t ).
𝒫𝒫{\cal P}caligraphic\_P *achieves the goal specified by 𝒢𝒢{\cal G}caligraphic\_G* if
each task t∈T∪{𝐹𝑖𝑛𝑖𝑠ℎ}𝑡𝑇𝐹𝑖𝑛𝑖𝑠ℎt\in T\cup\{\mathit{Finish}\}italic\_t ∈ italic\_T ∪ { italic\_Finish } has an establishing set
in T𝑇Titalic\_T.
It is easy to check that if 𝒫𝒫{\cal P}caligraphic\_P achieves the goal and
≺\*superscriptprecedes\prec^{\*}≺ start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT is a linear order on tasks that extends ≺precedes\prec≺ (so that t≺t′precedes𝑡superscript𝑡′t\prec t^{\prime}italic\_t ≺ italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT implies t≺\*t′superscriptprecedes𝑡superscript𝑡′t\prec^{\*}t^{\prime}italic\_t ≺ start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT),
all tasks have their preconditions established at the point when they
are executed. This justifies the claim that the constraints in
≺precedes\prec≺ capture all the ordering information on tasks that is needed.
We call a
team plan *postcondition minimal* if there is a unique minimal establishing
set for each task t∈T𝑡𝑇t\in Titalic\_t ∈ italic\_T. Most planning
algorithms construct plans that approximate postcondition minimal plans, since they
add only one task for each
precondition to be achieved.
However, since they typically do not check for redundancy, the
resulting plan may
contain several tasks that establish the same precondition ℓℓ\ellroman\_ℓ of
some task t𝑡titalic\_t.
As an illustration, consider the plan 𝒫1=(T1,Ag1,≺,α1)subscript𝒫1subscript𝑇1𝐴subscript𝑔1precedessubscript𝛼1{\cal P}\_{1}=(T\_{1},Ag\_{1},\prec,\alpha\_{1})caligraphic\_P start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = ( italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_A italic\_g start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , ≺ , italic\_α start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ), where
T1={Start,Finish,t1,T\_{1}=\{Start,Finish,t\_{1},italic\_T start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = { italic\_S italic\_t italic\_a italic\_r italic\_t , italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h , italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , t2}t\_{2}\}italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT }, t1subscript𝑡1t\_{1}italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT is laying cables for
traffic signals (under the road surface),
t2subscript𝑡2t\_{2}italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT is surfacing the road, Ag1={a1,a2}𝐴subscript𝑔1subscript𝑎1subscript𝑎2Ag\_{1}=\{a\_{1},a\_{2}\}italic\_A italic\_g start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = { italic\_a start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT }, ≺=Start≺t1≺t2≺Finish\prec\ =Start\prec t\_{1}\prec t\_{2}\prec Finish≺ = italic\_S italic\_t italic\_a italic\_r italic\_t ≺ italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ≺ italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ≺ italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h, α1(t1)=a1subscript𝛼1subscript𝑡1subscript𝑎1\alpha\_{1}(t\_{1})=a\_{1}italic\_α start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) = italic\_a start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT, and
α1(t2)=a2subscript𝛼1subscript𝑡2subscript𝑎2\alpha\_{1}(t\_{2})=a\_{2}italic\_α start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) = italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT. The goal prec(Finish)={c,s}𝑝𝑟𝑒𝑐𝐹𝑖𝑛𝑖𝑠ℎ𝑐𝑠prec(Finish)=\{c,s\}italic\_p italic\_r italic\_e italic\_c ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) = { italic\_c , italic\_s }, where c𝑐citalic\_c stands
for ‘cables laid’ and s𝑠sitalic\_s for ‘road surfaced’. post(Start)={¬c,¬s}𝑝𝑜𝑠𝑡𝑆𝑡𝑎𝑟𝑡𝑐𝑠post(Start)=\{\neg c,\neg s\}italic\_p italic\_o italic\_s italic\_t ( italic\_S italic\_t italic\_a italic\_r italic\_t ) = { ¬ italic\_c , ¬ italic\_s }; prec(t1)={¬s}𝑝𝑟𝑒𝑐subscript𝑡1𝑠prec(t\_{1})=\{\neg s\}italic\_p italic\_r italic\_e italic\_c ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) = { ¬ italic\_s } (since cables are laid under the surface);
post(t1)={c}𝑝𝑜𝑠𝑡subscript𝑡1𝑐post(t\_{1})=\{c\}italic\_p italic\_o italic\_s italic\_t ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) = { italic\_c }; prec(t2)=∅𝑝𝑟𝑒𝑐subscript𝑡2prec(t\_{2})=\emptysetitalic\_p italic\_r italic\_e italic\_c ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) = ∅; and post(t2)={s}𝑝𝑜𝑠𝑡subscript𝑡2𝑠post(t\_{2})=\{s\}italic\_p italic\_o italic\_s italic\_t ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) = { italic\_s }.
This plan is accomplishes its goal; the preconditions of Finish𝐹𝑖𝑛𝑖𝑠ℎFinishitalic\_F italic\_i italic\_n italic\_i italic\_s italic\_h are established by
{t1,t2}subscript𝑡1subscript𝑡2\{t\_{1},t\_{2}\}{ italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT }, while the precondition of t1subscript𝑡1t\_{1}italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT is established by Start𝑆𝑡𝑎𝑟𝑡Startitalic\_S italic\_t italic\_a italic\_r italic\_t. Note
that t2subscript𝑡2t\_{2}italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT is a clobberer of t1subscript𝑡1t\_{1}italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT
because it undoes the precondition ¬s𝑠\neg s¬ italic\_s of t1subscript𝑡1t\_{1}italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT. For this reason,
t2subscript𝑡2t\_{2}italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT is required by ≺precedes\prec≺ to be executed after t1subscript𝑡1t\_{1}italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT.
Note that the plan 𝒫1subscript𝒫1{\cal P}\_{1}caligraphic\_P start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT is postcondition minimal.
4 Translating Team Plans to
Causal Models
-------------------------------------------
In this section, we apply the definitions of causality, responsibility, and
blame given in Section [2](#S2 "2 Causality, Responsibility, and Blame ‣ Causality, Responsibility and Blame in Team Plans") to the analysis of
team plans. We start by showing that a team plan
𝒫=(T,Ag,≺,α)𝒫𝑇𝐴𝑔precedes𝛼{\cal P}=(T,Ag,\prec,\alpha)caligraphic\_P = ( italic\_T , italic\_A italic\_g , ≺ , italic\_α ) determines a causal model M𝒫subscript𝑀𝒫M\_{{\cal P}}italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT in a
natural way.
The preconditions of a
task are translated as endogenous variables, as well as whether the
agent intends to perform it. Whatever determines whether the agent
intends to perform the task is exogenous. The structural
equations say, for example, that if the agent intends to perform a
task t𝑡titalic\_t and all its preconditions
hold, then the task is performed.
For each task t∈T𝑡𝑇t\in Titalic\_t ∈ italic\_T, we compute the set est(t)𝑒𝑠𝑡𝑡est(t)italic\_e italic\_s italic\_t ( italic\_t )
and the set clob(t)𝑐𝑙𝑜𝑏𝑡clob(t)italic\_c italic\_l italic\_o italic\_b ( italic\_t ). The set est(t)𝑒𝑠𝑡𝑡est(t)italic\_e italic\_s italic\_t ( italic\_t )
consists of all the establishing sets for task t𝑡titalic\_t.
The assumption that the plan accomplishes its goal ensures that, for all tasks
t𝑡titalic\_t, est(t)≠∅𝑒𝑠𝑡𝑡est(t)\neq\emptysetitalic\_e italic\_s italic\_t ( italic\_t ) ≠ ∅.
The set clob(t)𝑐𝑙𝑜𝑏𝑡clob(t)italic\_c italic\_l italic\_o italic\_b ( italic\_t ) contains all pairs (s,t′)𝑠superscript𝑡′(s,t^{\prime})( italic\_s , italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ) where s∈S𝑠𝑆s\in Sitalic\_s ∈ italic\_S for
some S∈est(t)𝑆𝑒𝑠𝑡𝑡S\in est(t)italic\_S ∈ italic\_e italic\_s italic\_t ( italic\_t ), s𝑠sitalic\_s establishes some precondition ℓℓ\ellroman\_ℓ of t𝑡titalic\_t,
and t′superscript𝑡′t^{\prime}italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT is a clobberer of ℓℓ\ellroman\_ℓ.
For each task t∈T𝑡𝑇t\in Titalic\_t ∈ italic\_T, we have variables
𝑒𝑛(t)𝑒𝑛𝑡\mathit{en}(t)italic\_en ( italic\_t ) for ‘t𝑡titalic\_t is enabled’, 𝑖𝑛a(t)subscript𝑖𝑛𝑎𝑡\mathit{in}\_{a}(t)italic\_in start\_POSTSUBSCRIPT italic\_a end\_POSTSUBSCRIPT ( italic\_t ) for ‘agent a=α(t)𝑎𝛼𝑡a=\alpha(t)italic\_a = italic\_α ( italic\_t ) intends to do task t𝑡titalic\_t’, and 𝑝𝑓(t)𝑝𝑓𝑡\mathit{pf}(t)italic\_pf ( italic\_t ) for ‘t𝑡titalic\_t is performed’.
𝑒𝑛(t)𝑒𝑛𝑡\mathit{en}(t)italic\_en ( italic\_t ) is true if all the tasks in one of the establishing sets S𝑆Sitalic\_S
of t𝑡titalic\_t are performed, and no t′superscript𝑡′t^{\prime}italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT such that (s,t′)∈clob(t)𝑠superscript𝑡′𝑐𝑙𝑜𝑏𝑡(s,t^{\prime})\in clob(t)( italic\_s , italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ) ∈ italic\_c italic\_l italic\_o italic\_b ( italic\_t ) and
s∈S𝑠𝑆s\in Sitalic\_s ∈ italic\_S is performed after s𝑠sitalic\_s (i.e., s𝑠sitalic\_s is not clobbered).
(We typically omit 𝑒𝑛(t)𝑒𝑛𝑡\mathit{en}(t)italic\_en ( italic\_t ) from the causal model if est(t)𝑒𝑠𝑡𝑡est(t)italic\_e italic\_s italic\_t ( italic\_t ) is empty, since 𝑒𝑛(t)𝑒𝑛𝑡\mathit{en}(t)italic\_en ( italic\_t ) is
vacuously true in this case.)
In order for t𝑡titalic\_t to be performed, it has to be enabled and the
agent assigned the task has to actually decide to perform it; the
latter fact is captured by the formula 𝑖𝑛a(t)subscript𝑖𝑛𝑎𝑡\mathit{in}\_{a}(t)italic\_in start\_POSTSUBSCRIPT italic\_a end\_POSTSUBSCRIPT ( italic\_t ).
For example, even if the roadbed has been laid and
it is possible to surface the road (so the road-surfacing task is enabled),
if the road-surfacing contractor does not show up, the road will not be
surfaced.
𝑖𝑛a(t)subscript𝑖𝑛𝑎𝑡\mathit{in}\_{a}(t)italic\_in start\_POSTSUBSCRIPT italic\_a end\_POSTSUBSCRIPT ( italic\_t ) depends only on the agent a𝑎aitalic\_a.
𝑝𝑓(t)𝑝𝑓𝑡\mathit{pf}(t)italic\_pf ( italic\_t ) is true
if both 𝑒𝑛(t)𝑒𝑛𝑡\mathit{en}(t)italic\_en ( italic\_t ) and 𝑖𝑛a(t)subscript𝑖𝑛𝑎𝑡\mathit{in}\_{a}(t)italic\_in start\_POSTSUBSCRIPT italic\_a end\_POSTSUBSCRIPT ( italic\_t ) are true, where a=α(t)𝑎𝛼𝑡a=\alpha(t)italic\_a = italic\_α ( italic\_t ).
Finally, for each pair (s,t′)𝑠superscript𝑡′(s,t^{\prime})( italic\_s , italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ) in
clob(t)𝑐𝑙𝑜𝑏𝑡clob(t)italic\_c italic\_l italic\_o italic\_b ( italic\_t ), we have a variable 𝑛𝑐(s,t′,t)𝑛𝑐𝑠superscript𝑡′𝑡\mathit{nc}(s,t^{\prime},t)italic\_nc ( italic\_s , italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , italic\_t ),
which stands for ‘t′superscript𝑡′t^{\prime}italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT is *not* executed between s𝑠sitalic\_s
and t𝑡titalic\_t’.
Consider again the example plan 𝒫1subscript𝒫1{\cal P}\_{1}caligraphic\_P start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT from Section [3](#S3 "3 Team Plans ‣ Causality, Responsibility and Blame in Team Plans").
The causal model for 𝒫1subscript𝒫1{\cal P}\_{1}caligraphic\_P start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT has the variables
𝑝𝑓(Start)𝑝𝑓𝑆𝑡𝑎𝑟𝑡\mathit{pf}(Start)italic\_pf ( italic\_S italic\_t italic\_a italic\_r italic\_t ),
𝑒𝑛(t1)𝑒𝑛subscript𝑡1\mathit{en}(t\_{1})italic\_en ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ), 𝑖𝑛a1(t1)subscript𝑖𝑛subscript𝑎1subscript𝑡1\mathit{in}\_{a\_{1}}(t\_{1})italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ), 𝑝𝑓(t1)𝑝𝑓subscript𝑡1\mathit{pf}(t\_{1})italic\_pf ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ),
𝑖𝑛a2(t2)subscript𝑖𝑛subscript𝑎2subscript𝑡2\mathit{in}\_{a\_{2}}(t\_{2})italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ), 𝑝𝑓(t2)𝑝𝑓subscript𝑡2\mathit{pf}(t\_{2})italic\_pf ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ), 𝑒𝑛(Finish)𝑒𝑛𝐹𝑖𝑛𝑖𝑠ℎ\mathit{en}(Finish)italic\_en ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ), 𝑝𝑓(Finish)𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ\mathit{pf}(Finish)italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ),
and 𝑛𝑐(Start,t2,t1)𝑛𝑐𝑆𝑡𝑎𝑟𝑡subscript𝑡2subscript𝑡1\mathit{nc}(Start,t\_{2},t\_{1})italic\_nc ( italic\_S italic\_t italic\_a italic\_r italic\_t , italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ).
(Note that we omit 𝑒𝑛(Start)𝑒𝑛𝑆𝑡𝑎𝑟𝑡\mathit{en}(Start)italic\_en ( italic\_S italic\_t italic\_a italic\_r italic\_t ) and 𝑒𝑛(t2)𝑒𝑛subscript𝑡2\mathit{en}(t\_{2})italic\_en ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) because Start𝑆𝑡𝑎𝑟𝑡Startitalic\_S italic\_t italic\_a italic\_r italic\_t
and t2subscript𝑡2t\_{2}italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT have
no preconditions.)
𝑛𝑐(Start,t2,t1)𝑛𝑐𝑆𝑡𝑎𝑟𝑡subscript𝑡2subscript𝑡1\mathit{nc}(Start,t\_{2},t\_{1})italic\_nc ( italic\_S italic\_t italic\_a italic\_r italic\_t , italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) is true if t2subscript𝑡2t\_{2}italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT is performed
after t1subscript𝑡1t\_{1}italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and false if t2subscript𝑡2t\_{2}italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT is performed before t1subscript𝑡1t\_{1}italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT. 𝑒𝑛(t1)𝑒𝑛subscript𝑡1\mathit{en}(t\_{1})italic\_en ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT )
is true if 𝑝𝑓(Start)𝑝𝑓𝑆𝑡𝑎𝑟𝑡\mathit{pf}(Start)italic\_pf ( italic\_S italic\_t italic\_a italic\_r italic\_t ) is true and 𝑛𝑐(Start,t2,t1)𝑛𝑐𝑆𝑡𝑎𝑟𝑡subscript𝑡2subscript𝑡1\mathit{nc}(Start,t\_{2},t\_{1})italic\_nc ( italic\_S italic\_t italic\_a italic\_r italic\_t , italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) is true.
More precisely, a team plan 𝒫=(T,Ag,≺,α)𝒫𝑇𝐴𝑔precedes𝛼{\cal P}=(T,Ag,\prec,\alpha)caligraphic\_P = ( italic\_T , italic\_A italic\_g , ≺ , italic\_α ) determines
causal model M𝒫=((𝒰𝒫,𝒱𝒫,ℛ𝒫),ℱ𝒫)subscript𝑀𝒫subscript𝒰𝒫subscript𝒱𝒫subscriptℛ𝒫subscriptℱ𝒫M\_{\cal P}=(({\cal U}\_{\cal P},{\cal V}\_{\cal P},{\cal R}\_{\cal P}),{\cal F}\_{\cal P})italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT = ( ( caligraphic\_U start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT , caligraphic\_V start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT , caligraphic\_R start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT ) , caligraphic\_F start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT )
as follows:
* •
𝒰𝒫={Ua,t:t∈T,a=α(t)}∪{U𝑛𝑐(s,t′,t):s,t′,t∈T,(s,t′)∈clob(t)}subscript𝒰𝒫conditional-setsubscript𝑈
𝑎𝑡formulae-sequence𝑡𝑇𝑎𝛼𝑡conditional-setsubscript𝑈𝑛𝑐𝑠superscript𝑡′𝑡formulae-sequence
𝑠superscript𝑡′𝑡𝑇𝑠superscript𝑡′𝑐𝑙𝑜𝑏𝑡{\cal U}\_{\cal P}\!=\!\{U\_{a,t}:t\in T,a=\alpha(t)\}\cup\{U\_{\mathit{nc}(s,t^{\prime},t)}:s,t^{\prime},t\in T,(s,t^{\prime})\in clob(t)\}caligraphic\_U start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT = { italic\_U start\_POSTSUBSCRIPT italic\_a , italic\_t end\_POSTSUBSCRIPT : italic\_t ∈ italic\_T , italic\_a = italic\_α ( italic\_t ) } ∪ { italic\_U start\_POSTSUBSCRIPT italic\_nc ( italic\_s , italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , italic\_t ) end\_POSTSUBSCRIPT : italic\_s , italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , italic\_t ∈ italic\_T , ( italic\_s , italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ) ∈ italic\_c italic\_l italic\_o italic\_b ( italic\_t ) }.
Intuitively, Ua,tsubscript𝑈
𝑎𝑡U\_{a,t}italic\_U start\_POSTSUBSCRIPT italic\_a , italic\_t end\_POSTSUBSCRIPT and U𝑛𝑐(t′,s,t)subscript𝑈𝑛𝑐superscript𝑡′𝑠𝑡U\_{\mathit{nc}(t^{\prime},s,t)}italic\_U start\_POSTSUBSCRIPT italic\_nc ( italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , italic\_s , italic\_t ) end\_POSTSUBSCRIPT determine
the value of 𝑖𝑛a(t)subscript𝑖𝑛𝑎𝑡\mathit{in}\_{a}(t)italic\_in start\_POSTSUBSCRIPT italic\_a end\_POSTSUBSCRIPT ( italic\_t ) and 𝑛𝑐(t′,s,t)𝑛𝑐superscript𝑡′𝑠𝑡\mathit{nc}(t^{\prime},s,t)italic\_nc ( italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , italic\_s , italic\_t ),
respectively.
* •
𝒱𝒫={𝑒𝑛(t):t∈T}∪{𝑝𝑓(t):t∈T}∪{𝑖𝑛a(t):t∈T,a=α(t)}∪{𝑛𝑐(s,t′,t):s,t′,t∈T,(s,t′)∈clob(t)}subscript𝒱𝒫conditional-set𝑒𝑛𝑡𝑡𝑇conditional-set𝑝𝑓𝑡𝑡𝑇conditional-setsubscript𝑖𝑛𝑎𝑡formulae-sequence𝑡𝑇𝑎𝛼𝑡conditional-set𝑛𝑐𝑠superscript𝑡′𝑡formulae-sequence
𝑠superscript𝑡′𝑡𝑇𝑠superscript𝑡′𝑐𝑙𝑜𝑏𝑡{\cal V}\_{\cal P}=\{\mathit{en}(t):t\in T\}\cup\{\mathit{pf}(t):t\in T\}\cup\{\mathit{in}\_{a}(t):t\in T,a=\alpha(t)\}\cup\{\mathit{nc}(s,t^{\prime},t):s,t^{\prime},t\in T,(s,t^{\prime})\in clob(t)\}caligraphic\_V start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT = { italic\_en ( italic\_t ) : italic\_t ∈ italic\_T } ∪ { italic\_pf ( italic\_t ) : italic\_t ∈ italic\_T } ∪ { italic\_in start\_POSTSUBSCRIPT italic\_a end\_POSTSUBSCRIPT ( italic\_t ) : italic\_t ∈ italic\_T , italic\_a = italic\_α ( italic\_t ) } ∪ { italic\_nc ( italic\_s , italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , italic\_t ) : italic\_s , italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , italic\_t ∈ italic\_T , ( italic\_s , italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ) ∈ italic\_c italic\_l italic\_o italic\_b ( italic\_t ) }.
Note that |𝒱𝒫|≤|T|3+3|T|subscript𝒱𝒫superscript𝑇33𝑇|{\cal V}\_{{\cal P}}|\leq|T|^{3}+3|T|| caligraphic\_V start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT | ≤ | italic\_T | start\_POSTSUPERSCRIPT 3 end\_POSTSUPERSCRIPT + 3 | italic\_T |.
* •
ℛ𝒫(X)={0,1}subscriptℛ𝒫𝑋01{\cal R}\_{\cal P}(X)=\{0,1\}caligraphic\_R start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT ( italic\_X ) = { 0 , 1 } for all variables X∈𝒰𝒫∪𝒱𝒫𝑋subscript𝒰𝒫subscript𝒱𝒫X\in{\cal U}\_{\cal P}\cup{\cal V}\_{\cal P}italic\_X ∈ caligraphic\_U start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT ∪ caligraphic\_V start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT (i.e., all variables are binary).
* •
ℱ𝒫subscriptℱ𝒫{\cal F}\_{\cal P}caligraphic\_F start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT is determined by the following equations:
𝑖𝑛a(t)=Ua,tsubscript𝑖𝑛𝑎𝑡subscript𝑈
𝑎𝑡\mathit{in}\_{a}(t)=U\_{a,t}italic\_in start\_POSTSUBSCRIPT italic\_a end\_POSTSUBSCRIPT ( italic\_t ) = italic\_U start\_POSTSUBSCRIPT italic\_a , italic\_t end\_POSTSUBSCRIPT
𝑛𝑐(s,t′,t)=U𝑛𝑐(s,t′,t)𝑛𝑐𝑠superscript𝑡′𝑡subscript𝑈𝑛𝑐𝑠superscript𝑡′𝑡\mathit{nc}(s,t^{\prime},t)=U\_{\mathit{nc}(s,t^{\prime},t)}italic\_nc ( italic\_s , italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , italic\_t ) = italic\_U start\_POSTSUBSCRIPT italic\_nc ( italic\_s , italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , italic\_t ) end\_POSTSUBSCRIPT
𝑝𝑓(t)=𝑒𝑛(t)∧𝑖𝑛a(t)𝑝𝑓𝑡𝑒𝑛𝑡subscript𝑖𝑛𝑎𝑡\mathit{pf}(t)=\mathit{en}(t)\wedge\mathit{in}\_{a}(t)italic\_pf ( italic\_t ) = italic\_en ( italic\_t ) ∧ italic\_in start\_POSTSUBSCRIPT italic\_a end\_POSTSUBSCRIPT ( italic\_t ) (where t∈T𝑡𝑇t\in Titalic\_t ∈ italic\_T and a=α(t)𝑎𝛼𝑡a=\alpha(t)italic\_a = italic\_α ( italic\_t ))
𝑒𝑛(t)=⋁(⋀𝑝𝑓s∈S(s)∧⋀𝑛𝑐(s,t′)∈clob(t)(s,t′,t))S∈est(t)\mathit{en}(t)=\bigvee\!{}\_{S\in est(t)}(\bigwedge\!{}\_{s\in S}\mathit{pf}(s)\!\wedge\!\bigwedge\!{}\_{(s,t^{\prime})\in\!clob(t)}\mathit{nc}(s,t^{\prime},t))italic\_en ( italic\_t ) = ⋁ start\_FLOATSUBSCRIPT italic\_S ∈ italic\_e italic\_s italic\_t ( italic\_t ) end\_FLOATSUBSCRIPT ( ⋀ start\_FLOATSUBSCRIPT italic\_s ∈ italic\_S end\_FLOATSUBSCRIPT italic\_pf ( italic\_s ) ∧ ⋀ start\_FLOATSUBSCRIPT ( italic\_s , italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ) ∈ italic\_c italic\_l italic\_o italic\_b ( italic\_t ) end\_FLOATSUBSCRIPT italic\_nc ( italic\_s , italic\_t start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , italic\_t ) ).
It should be clear that M𝒫subscript𝑀𝒫M\_{\cal P}italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT captures
the intent of the team plan 𝒫𝒫{\cal P}caligraphic\_P. In particular,
it is easy to see that the
appropriate agents performing their tasks results in 𝒫𝒫{\cal P}caligraphic\_P
accomplishing its goal iff (M𝒫,u)⊧𝑝𝑓(Finish)modelssubscript𝑀𝒫@vecu𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ(M\_{\cal P},\@vec{u})\models\mathit{pf}(Finish)( italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ), where
u@vecu\@vec{u}start\_ID start\_ARG italic\_u end\_ARG end\_ID is the context where the corresponding agents intend to
perform their actions
and no clobbering task is performed at the wrong time (i.e., between
the establishing of the precondition they clobber, and the execution
of the task requiring the precondition).
Our causal model abstracts away from pre- and
postconditions of tasks, and concentrates on high level ‘establishing’
and ‘clobbering’ links between them. This is standard practice in
planning; see, for example, [Weld:94a](#bib.bib24) .
We also abstract away from the capabilities of agents: our model
implicitly assumes that agents are able to perform the tasks
assigned to them. All we require is that the preconditions of the task
hold and that the agent intends to perform it.
The size of M𝒫subscript𝑀𝒫M\_{\cal P}italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT is polynomial in the size of 𝒫𝒫{\cal P}caligraphic\_P if 𝒫𝒫{\cal P}caligraphic\_P is
postcondition minimal or we treat the maximal number of preconditions
of any task in the plan as a
fixed parameter
(if there are at most k𝑘kitalic\_k preconditions of a task, then est(t)𝑒𝑠𝑡𝑡est(t)italic\_e italic\_s italic\_t ( italic\_t ) has
size at most 2ksuperscript2𝑘2^{k}2 start\_POSTSUPERSCRIPT italic\_k end\_POSTSUPERSCRIPT).
Note that all equations are monotone:
there are no negations. Moreover,
the only disjunctions in the equations
come from potentially multiple ways of establishing
preconditions of some tasks.
Thus, for postcondition minimal plans
the formulas are conjunctive.
Having translated team plans to causal models, we can apply the
definitions of Section [2](#S2 "2 Causality, Responsibility, and Blame ‣ Causality, Responsibility and Blame in Team Plans").
There may be several causes of 𝑝𝑓(Finish)𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ\mathit{pf}(Finish)italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) = 00.
As we suggested earlier, we are interested only in
causes that involve formulas of the form 𝑖𝑛a(t)=0subscript𝑖𝑛𝑎𝑡0\mathit{in}\_{a}(t)=0italic\_in start\_POSTSUBSCRIPT italic\_a end\_POSTSUBSCRIPT ( italic\_t ) = 0.
We refer to variables of the form 𝑖𝑛a(t)subscript𝑖𝑛𝑎𝑡\mathit{in}\_{a}(t)italic\_in start\_POSTSUBSCRIPT italic\_a end\_POSTSUBSCRIPT ( italic\_t ) as the variables
*controlled* by agent a𝑎aitalic\_a.
###### Definition \thetheorem
Agent a𝑎aitalic\_a’s *degree of responsibility for the failure of plan 𝒫𝒫{\cal P}caligraphic\_P*
(i.e., for 𝑝𝑓(Finish)=0𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ0\mathit{pf}(Finish)=0italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) = 0 in (M𝒫,u)subscript𝑀𝒫@vecu(M\_{\cal P},\@vec{u})( italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT , start\_ID start\_ARG italic\_u end\_ARG end\_ID ), where M𝒫subscript𝑀𝒫M\_{\cal P}italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT is the
causal model determined by a team plan 𝒫𝒫{\cal P}caligraphic\_P) is
00 if none of the variables controlled by agent a𝑎aitalic\_a is part of a cause of
𝑝𝑓(Finish)=0𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ0\mathit{pf}(Finish)=0italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) = 0 in (M𝒫,u)subscript𝑀𝒫@vecu(M\_{\cal P},\@vec{u})( italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT , start\_ID start\_ARG italic\_u end\_ARG end\_ID ); otherwise,
it is the maximum value m/k𝑚𝑘m/kitalic\_m / italic\_k such that there exists a cause X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID
of 𝑝𝑓(Finish)=0𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ0\mathit{pf}(Finish)=0italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) = 0 and a witness (W,x′)@vecWsuperscript@vecxnormal-′(\@vec{W},\@vec{x}^{\prime})( start\_ID start\_ARG italic\_W end\_ARG end\_ID , start\_ID start\_ARG italic\_x end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ) to
X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID being a cause of 𝑝𝑓(Finish)=0𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ0\mathit{pf}(Finish)=0italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) = 0 in (M𝒫,u)subscript𝑀𝒫@vecu(M\_{\cal P},\@vec{u})( italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT , start\_ID start\_ARG italic\_u end\_ARG end\_ID )
with |X|+|W|=k@vecX@vecW𝑘|\@vec{X}|+|\@vec{W}|=k| start\_ID start\_ARG italic\_X end\_ARG end\_ID | + | start\_ID start\_ARG italic\_W end\_ARG end\_ID | = italic\_k, and agent a𝑎aitalic\_a controls m𝑚mitalic\_m variables in X@vecX\@vec{X}start\_ID start\_ARG italic\_X end\_ARG end\_ID.
Intuitively, agent a𝑎aitalic\_a’s responsibility is greater if it failed to
perform a greater proportion of tasks. The intentions of agents in our
setting are determined by the context.
Although the intention of some agents can be inferred from observations
(e.g., if a task t𝑡titalic\_t assigned to agent a𝑎aitalic\_a was performed,
then 𝑖𝑛a(t)subscript𝑖𝑛𝑎𝑡\mathit{in}\_{a}(t)italic\_in start\_POSTSUBSCRIPT italic\_a end\_POSTSUBSCRIPT ( italic\_t ) must hold), in some cases,
we do not know whether an agent intended to perform a task.
In general, there
will be a set of contexts consistent with the information that we are
given.
If we are able to define a probability distribution over this set, we can
then determine the degree of blame. In determining this probability,
we may want to stipulate that, unless we have explicit evidence to the contrary, the
agents always intend to perform their tasks (so that the agents
who we assigned to perform tasks that were not enabled are not to blame).
To show that our approach gives an intuitive account of
responsibility and blame for plan failures, we briefly outline some
simple scenarios involving the example plan 𝒫1subscript𝒫1{\cal P}\_{1}caligraphic\_P start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and
its corresponding causal model M𝒫1subscript𝑀subscript𝒫1M\_{{{\cal P}}\_{1}}italic\_M start\_POSTSUBSCRIPT caligraphic\_P start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT.
Assume that the context
u𝑢uitalic\_u is such that 𝑒𝑛(t1)=1𝑒𝑛subscript𝑡11\mathit{en}(t\_{1})=1italic\_en ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) = 1, 𝑛𝑐(Start,t2,t1)=1𝑛𝑐𝑆𝑡𝑎𝑟𝑡subscript𝑡2subscript𝑡11\mathit{nc}(Start,t\_{2},t\_{1})=1italic\_nc ( italic\_S italic\_t italic\_a italic\_r italic\_t , italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) = 1,
𝑝𝑓(t1)=1𝑝𝑓subscript𝑡11\mathit{pf}(t\_{1})=1italic\_pf ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) = 1, 𝑝𝑓(t2)=0𝑝𝑓subscript𝑡20\mathit{pf}(t\_{2})=0italic\_pf ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) = 0, and 𝑝𝑓(Finish)=0𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ0\mathit{pf}(Finish)=0italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) = 0. We cannot observe the
values of 𝑖𝑛a1(t1)subscript𝑖𝑛subscript𝑎1subscript𝑡1\mathit{in}\_{a\_{1}}(t\_{1})italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) and 𝑖𝑛a2(t2)subscript𝑖𝑛subscript𝑎2subscript𝑡2\mathit{in}\_{a\_{2}}(t\_{2})italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ), but from 𝑝𝑓(t1)=1𝑝𝑓subscript𝑡11\mathit{pf}(t\_{1})=1italic\_pf ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) = 1 we
can conclude that 𝑖𝑛a1(t1)=1subscript𝑖𝑛subscript𝑎1subscript𝑡11\mathit{in}\_{a\_{1}}(t\_{1})=1italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) = 1, and, from the fact that 𝑝𝑓(t2)=𝑖𝑛a2(t2)𝑝𝑓subscript𝑡2subscript𝑖𝑛subscript𝑎2subscript𝑡2\mathit{pf}(t\_{2})=\mathit{in}\_{a\_{2}}(t\_{2})italic\_pf ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) = italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) (since t2subscript𝑡2t\_{2}italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT is always enabled), we can conclude
that 𝑖𝑛a2(t2)=0subscript𝑖𝑛subscript𝑎2subscript𝑡20\mathit{in}\_{a\_{2}}(t\_{2})=0italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) = 0. Then the cause of 𝑝𝑓(Finish)=0𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ0\mathit{pf}(Finish)=0italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) = 0
is 𝑖𝑛a2(t2)=0subscript𝑖𝑛subscript𝑎2subscript𝑡20\mathit{in}\_{a\_{2}}(t\_{2})=0italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) = 0, and the degree of both responsibility and
blame of agent a2subscript𝑎2a\_{2}italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT is 1.
(Note that 𝑝𝑓(t2)=0𝑝𝑓subscript𝑡20\mathit{pf}(t\_{2})=0italic\_pf ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) = 0 is also a cause of 𝑝𝑓(Finish)=0𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ0\mathit{pf}(Finish)=0italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) = 0, but we
are interested only in causes involving agents’ intentions.)
So far, the analysis is the same as in plan diagnosis: we identify a minimal
set of ‘faulty components’ (unwilling agents) such that, had they
functioned correctly, the failure would not have happened.
For a more complex example of responsibility and blame, consider
a slightly extended plan 𝒫2subscript𝒫2{\cal P}\_{2}caligraphic\_P start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT, which is like 𝒫1subscript𝒫1{\cal P}\_{1}caligraphic\_P start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT, but has an
extra task t0≺t1precedessubscript𝑡0subscript𝑡1t\_{0}\prec t\_{1}italic\_t start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ≺ italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT that establishes t1subscript𝑡1t\_{1}italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT: 𝑒𝑛(t1)=𝑝𝑓(t0)𝑒𝑛subscript𝑡1𝑝𝑓subscript𝑡0\mathit{en}(t\_{1})=\mathit{pf}(t\_{0})italic\_en ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) = italic\_pf ( italic\_t start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ).
t0subscript𝑡0t\_{0}italic\_t start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT is enabled and assigned to a2subscript𝑎2a\_{2}italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT. Suppose the context is
𝑒𝑛(t0)=1𝑒𝑛subscript𝑡01\mathit{en}(t\_{0})=1italic\_en ( italic\_t start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) = 1, 𝑛𝑐(t0,t2,t1)=1𝑛𝑐subscript𝑡0subscript𝑡2subscript𝑡11\mathit{nc}(t\_{0},t\_{2},t\_{1})=1italic\_nc ( italic\_t start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) = 1,
𝑝𝑓(t0)=0𝑝𝑓subscript𝑡00\mathit{pf}(t\_{0})=0italic\_pf ( italic\_t start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) = 0, 𝑝𝑓(t1)=0𝑝𝑓subscript𝑡10\mathit{pf}(t\_{1})=0italic\_pf ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) = 0, 𝑝𝑓(t2)=0𝑝𝑓subscript𝑡20\mathit{pf}(t\_{2})=0italic\_pf ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) = 0, and 𝑝𝑓(Finish)=0𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ0\mathit{pf}(Finish)=0italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) = 0.
As before, 𝑖𝑛a2(t0)=0subscript𝑖𝑛subscript𝑎2subscript𝑡00\mathit{in}\_{a\_{2}}(t\_{0})=0italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) = 0 and 𝑖𝑛a2(t2)=0subscript𝑖𝑛subscript𝑎2subscript𝑡20\mathit{in}\_{a\_{2}}(t\_{2})=0italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) = 0 are parts of the cause
of 𝑝𝑓(Finish)=0𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ0\mathit{pf}(Finish)=0italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) = 0. However, we cannot observe 𝑖𝑛a1(t1)subscript𝑖𝑛subscript𝑎1subscript𝑡1\mathit{in}\_{a\_{1}}(t\_{1})italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT );
since t1subscript𝑡1t\_{1}italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT was not enabled and not performed, we cannot say whether
agent a1subscript𝑎1a\_{1}italic\_a start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT was willing to perform it. In the context u1subscript𝑢1u\_{1}italic\_u start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT
where a1subscript𝑎1a\_{1}italic\_a start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT was willing, the cause of 𝑝𝑓(Finish)=0𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ0\mathit{pf}(Finish)=0italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) = 0
is just {𝑖𝑛a2(t0)=0,𝑖𝑛a2(t2)=0}formulae-sequencesubscript𝑖𝑛subscript𝑎2subscript𝑡00subscript𝑖𝑛subscript𝑎2subscript𝑡20\{\mathit{in}\_{a\_{2}}(t\_{0})=0,\mathit{in}\_{a\_{2}}(t\_{2})=0\}{ italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) = 0 , italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) = 0 } and the degree of
responsibility of a1subscript𝑎1a\_{1}italic\_a start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT is 0. In the context u2subscript𝑢2u\_{2}italic\_u start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT
where a1subscript𝑎1a\_{1}italic\_a start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT was not willing, the cause is
{𝑖𝑛a2(t0)=0,𝑖𝑛a1(t1)=0,𝑖𝑛a2(t2)=0}formulae-sequencesubscript𝑖𝑛subscript𝑎2subscript𝑡00formulae-sequencesubscript𝑖𝑛subscript𝑎1subscript𝑡10subscript𝑖𝑛subscript𝑎2subscript𝑡20\{\mathit{in}\_{a\_{2}}(t\_{0})=0,\mathit{in}\_{a\_{1}}(t\_{1})=0,\mathit{in}\_{a\_{2}}(t\_{2})=0\}{ italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 0 end\_POSTSUBSCRIPT ) = 0 , italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ) = 0 , italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) = 0 } and
a1subscript𝑎1a\_{1}italic\_a start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT’s degree of responsibility is 1/3. If we assign
probability 1 to u1subscript𝑢1u\_{1}italic\_u start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT, then the blame attached to a1subscript𝑎1a\_{1}italic\_a start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT is 0.
5 The Complexity of Causality for Monotone Models
--------------------------------------------------
A causal model is *monotone* if all
the variables are binary and all the equations are monotone (i.e., are
negation-free propositional formulas). A monotone model is
*conjunctive* if all the equations are conjunctive (i.e., they
involve only conjunctions; no negations or disjunctions).
As we have seen, the causal models that are determined by team plans
are monotone; if the team plans are postcondition minimal, then the causal
models are also conjunctive.
In this section we prove general results on the complexity of checking
causality, degree of responsibility, and degree of blame for monotone
and conjunctive models.
We first consider the situation for arbitrary formulas.
Recall that the complexity class Dpsuperscript𝐷𝑝D^{p}italic\_D start\_POSTSUPERSCRIPT italic\_p end\_POSTSUPERSCRIPT consists of languages
L𝐿Litalic\_L such that L=L1∩L2𝐿subscript𝐿1subscript𝐿2L=L\_{1}\cap L\_{2}italic\_L = italic\_L start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ∩ italic\_L start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT, where L1subscript𝐿1L\_{1}italic\_L start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT is in NP and L2subscript𝐿2L\_{2}italic\_L start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT is
in co-NP [PY](#bib.bib21) .
###### Theorem 5.1
1. (a)
[Hal47](#bib.bib11)
Determining if X=1@vecX@vec1\@vec{X}=\@vec{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID
is a cause of φ𝜑\varphiitalic\_φ
in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) is Dpsuperscript𝐷𝑝D^{p}italic\_D start\_POSTSUPERSCRIPT italic\_p end\_POSTSUPERSCRIPT-complete
2. (b)
Determining if X=x𝑋𝑥X=xitalic\_X = italic\_x is part of a
cause of φ𝜑\varphiitalic\_φ
in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) is Σ2psubscriptsuperscriptΣ𝑝2\Sigma^{p}\_{2}roman\_Σ start\_POSTSUPERSCRIPT italic\_p end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT-complete
3. (c)
Determining if X=x𝑋𝑥X=xitalic\_X = italic\_x has degree of responsibility at least
1/k1𝑘1/k1 / italic\_k is Σ2psubscriptsuperscriptΣ𝑝2\Sigma^{p}\_{2}roman\_Σ start\_POSTSUPERSCRIPT italic\_p end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT-complete.
Proof: Part (a) was proved by Halpern .
For part (b), first note that the problem is clearly in Σ2psuperscriptsubscriptΣ2𝑝\Sigma\_{2}^{p}roman\_Σ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_p end\_POSTSUPERSCRIPT:
we simply guess X@vecX\@vec{X}start\_ID start\_ARG italic\_X end\_ARG end\_ID, x@vecx\@vec{x}start\_ID start\_ARG italic\_x end\_ARG end\_ID, x′superscript@vecx′\@vec{x}^{\prime}start\_ID start\_ARG italic\_x end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT, and W@vecW\@vec{W}start\_ID start\_ARG italic\_W end\_ARG end\_ID, where
X=x𝑋𝑥X=xitalic\_X = italic\_x is a conjunct of X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID, compute w@vecw\@vec{w}start\_ID start\_ARG italic\_w end\_ARG end\_ID such that
(M,u)⊧W=wmodels𝑀@vecu@vecW@vecw(M,\@vec{u})\models\@vec{W}=\@vec{w}( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ start\_ID start\_ARG italic\_W end\_ARG end\_ID = start\_ID start\_ARG italic\_w end\_ARG end\_ID (in general, checking whether
(M,u)⊧ψmodels𝑀@vecu𝜓(M,\@vec{u})\models\psi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ italic\_ψ is easily seen to be in
polynomial time in acyclic models, assuming that
the ordering ≺precedes\prec≺ on variables is given, or can be
easily computed from presentation of the equations),
check that (M,u)⊧[X←x′,W←w]¬φmodels𝑀@vecudelimited-[]formulae-sequence←@vecXsuperscript@vecx′←@vecW@vecw𝜑(M,\@vec{u})\models[\@vec{X}\leftarrow\@vec{x}^{\prime},\@vec{W}\leftarrow\@vec{w}]\,\neg\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_X end\_ARG end\_ID ← start\_ID start\_ARG italic\_x end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , start\_ID start\_ARG italic\_W end\_ARG end\_ID ← start\_ID start\_ARG italic\_w end\_ARG end\_ID ] ¬ italic\_φ, and
check that there is no
Y⊂X@vecY@vecX\@vec{Y}\subset\@vec{X}start\_ID start\_ARG italic\_Y end\_ARG end\_ID ⊂ start\_ID start\_ARG italic\_X end\_ARG end\_ID, setting y′superscript@vecy′\@vec{y}^{\prime}start\_ID start\_ARG italic\_y end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT of the variables in
Y@vecY\@vec{Y}start\_ID start\_ARG italic\_Y end\_ARG end\_ID, and set W′superscript@vecW′\@vec{W}^{\prime}start\_ID start\_ARG italic\_W end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT such that
(M,u)⊧[Y←y′,W←w′]¬φmodels𝑀@vecudelimited-[]formulae-sequence←@vecYsuperscript@vecy′←@vecWsuperscript@vecw′𝜑(M,\@vec{u})\models[\@vec{Y}\leftarrow\@vec{y}^{\prime},\@vec{W}\leftarrow\@vec{w}^{\prime}]\neg\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_Y end\_ARG end\_ID ← start\_ID start\_ARG italic\_y end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , start\_ID start\_ARG italic\_W end\_ARG end\_ID ← start\_ID start\_ARG italic\_w end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ] ¬ italic\_φ,
where w′superscript@vecw′\@vec{w}^{\prime}start\_ID start\_ARG italic\_w end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT is such that (M,u)⊧W′=w′models𝑀@vecusuperscript@vecW′superscript@vecw′(M,\@vec{u})\models\@vec{W}^{\prime}=\@vec{w}^{\prime}( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ start\_ID start\_ARG italic\_W end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT = start\_ID start\_ARG italic\_w end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT.
For Σ2psuperscriptsubscriptΣ2𝑝\Sigma\_{2}^{p}roman\_Σ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_p end\_POSTSUPERSCRIPT-hardness, we adapt arguments used by Aleksandrowicz et
al. to show that checking whether a formula satisfies
AC1 and AC2m𝑚{}^{m}start\_FLOATSUPERSCRIPT italic\_m end\_FLOATSUPERSCRIPT
is Σ2psuperscriptsubscriptΣ2𝑝\Sigma\_{2}^{p}roman\_Σ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_p end\_POSTSUPERSCRIPT-complete.
Recall that to show that a language L𝐿Litalic\_L is Σ2psuperscriptsubscriptΣ2𝑝\Sigma\_{2}^{p}roman\_Σ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_p end\_POSTSUPERSCRIPT-hard, it suffices
to show that we can reduce determining if a closed quantified Boolean
formlua (QBF) of the form
∃x∀yφ′@vecxfor-all@vecysuperscript𝜑′\exists\@vec{x}\,\forall\@vec{y}\,\varphi^{\prime}∃ start\_ID start\_ARG italic\_x end\_ARG end\_ID ∀ start\_ID start\_ARG italic\_y end\_ARG end\_ID italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT is true (the fact that it is
closed means that
all the variables in φ′superscript𝜑′\varphi^{\prime}italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT are contained in x∪y@vecx@vecy\@vec{x}\cup\@vec{y}start\_ID start\_ARG italic\_x end\_ARG end\_ID ∪ start\_ID start\_ARG italic\_y end\_ARG end\_ID)
to checking if a string σ∈L𝜎𝐿\sigma\in Litalic\_σ ∈ italic\_L [Stock](#bib.bib23) . Given a closed QBF
φ=∃x∀yφ′𝜑@vecxfor-all@vecysuperscript𝜑′\varphi=\exists\@vec{x}\,\forall\@vec{y}\,\varphi^{\prime}italic\_φ = ∃ start\_ID start\_ARG italic\_x end\_ARG end\_ID ∀ start\_ID start\_ARG italic\_y end\_ARG end\_ID italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT, we construct a causal
formula ψ𝜓\psiitalic\_ψ, a causal model M𝑀Mitalic\_M, and context u@vecu\@vec{u}start\_ID start\_ARG italic\_u end\_ARG end\_ID such that
φ𝜑\varphiitalic\_φ is true iff A=0𝐴0A=0italic\_A = 0 is part of a cause of ψ𝜓\psiitalic\_ψ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ).
We proceed as follows: we take M𝑀Mitalic\_M to be a model with endogenous
variables 𝒱=A∪X0∪X1∪Y𝒱𝐴superscript@vecX0superscript@vecX1@vecY{\cal V}=A\cup\@vec{X}^{0}\cup\@vec{X}^{1}\cup\@vec{Y}caligraphic\_V = italic\_A ∪ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT 0 end\_POSTSUPERSCRIPT ∪ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT 1 end\_POSTSUPERSCRIPT ∪ start\_ID start\_ARG italic\_Y end\_ARG end\_ID, where for each variable x∈x𝑥@vecxx\in\@vec{x}italic\_x ∈ start\_ID start\_ARG italic\_x end\_ARG end\_ID, there are
corresponding variables Xx0∈X0superscriptsubscript𝑋𝑥0superscript@vecX0X\_{x}^{0}\in\@vec{X}^{0}italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 0 end\_POSTSUPERSCRIPT ∈ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT 0 end\_POSTSUPERSCRIPT and Xx1∈X1superscriptsubscript𝑋𝑥1superscript@vecX1X\_{x}^{1}\in\@vec{X}^{1}italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 1 end\_POSTSUPERSCRIPT ∈ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT 1 end\_POSTSUPERSCRIPT,
and for each variable y∈y𝑦@vecyy\in\@vec{y}italic\_y ∈ start\_ID start\_ARG italic\_y end\_ARG end\_ID there is a corresponding variable
Yy∈Ysubscript𝑌𝑦@vecYY\_{y}\in\@vec{Y}italic\_Y start\_POSTSUBSCRIPT italic\_y end\_POSTSUBSCRIPT ∈ start\_ID start\_ARG italic\_Y end\_ARG end\_ID, and a single exogenous
variable U𝑈Uitalic\_U. All the variables are
binary. The equations are trivial: the value of U𝑈Uitalic\_U determines the values
of all variables in 𝒱𝒱{\cal V}caligraphic\_V.
Let u𝑢uitalic\_u be the context where
all the variables in 𝒱𝒱{\cal V}caligraphic\_V are set to 0.
Let φ¯′superscript¯𝜑′\bar{\varphi}^{\prime}over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT be the causal formula that results from replacing all
occurrences of x𝑥xitalic\_x and y𝑦yitalic\_y
in φ′superscript𝜑′\varphi^{\prime}italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT by Xx1=1superscriptsubscript𝑋𝑥11X\_{x}^{1}=1italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 1 end\_POSTSUPERSCRIPT = 1 and Yy=1subscript𝑌𝑦1Y\_{y}=1italic\_Y start\_POSTSUBSCRIPT italic\_y end\_POSTSUBSCRIPT = 1, respectively. Let
ψ𝜓\psiitalic\_ψ be the formula ψ1∨(ψ2∧ψ3)subscript𝜓1subscript𝜓2subscript𝜓3\psi\_{1}\lor(\psi\_{2}\land\psi\_{3})italic\_ψ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ∨ ( italic\_ψ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ∧ italic\_ψ start\_POSTSUBSCRIPT 3 end\_POSTSUBSCRIPT ), where
* •
ψ1=(⋁x∈x(Xx0=Xx1))subscript𝜓1subscript𝑥@vecxsuperscriptsubscript𝑋𝑥0superscriptsubscript𝑋𝑥1\psi\_{1}=\left(\bigvee\_{x\in\@vec{x}}(X\_{x}^{0}=X\_{x}^{1})\right)italic\_ψ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = ( ⋁ start\_POSTSUBSCRIPT italic\_x ∈ start\_ID start\_ARG italic\_x end\_ARG end\_ID end\_POSTSUBSCRIPT ( italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 0 end\_POSTSUPERSCRIPT = italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 1 end\_POSTSUPERSCRIPT ) );222Xx0=Xx1superscriptsubscript𝑋𝑥0superscriptsubscript𝑋𝑥1X\_{x}^{0}=X\_{x}^{1}italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 0 end\_POSTSUPERSCRIPT = italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 1 end\_POSTSUPERSCRIPT is an abbreviation for the
causal formula (Xx0=0∧Xx1=0)∨(Xx0=1∧Xx1=1)superscriptsubscript𝑋𝑥00superscriptsubscript𝑋𝑥10superscriptsubscript𝑋𝑥01superscriptsubscript𝑋𝑥11(X\_{x}^{0}=0\land X\_{x}^{1}=0)\lor(X\_{x}^{0}=1\land X\_{x}^{1}=1)( italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 0 end\_POSTSUPERSCRIPT = 0 ∧ italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 1 end\_POSTSUPERSCRIPT = 0 ) ∨ ( italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 0 end\_POSTSUPERSCRIPT = 1 ∧ italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 1 end\_POSTSUPERSCRIPT = 1 ).
* •
ψ2=A=0∨¬(Y=1)subscript𝜓2𝐴0@vecY@vec1\psi\_{2}=A=0\lor\neg(\@vec{Y}=\@vec{1})italic\_ψ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT = italic\_A = 0 ∨ ¬ ( start\_ID start\_ARG italic\_Y end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID );
* •
ψ3=(A=1)∨φ¯′subscript𝜓3𝐴1superscript¯𝜑′\psi\_{3}=(A=1)\vee\bar{\varphi}^{\prime}italic\_ψ start\_POSTSUBSCRIPT 3 end\_POSTSUBSCRIPT = ( italic\_A = 1 ) ∨ over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT.
We now show that A=0𝐴0A=0italic\_A = 0 is part of a cause of ψ𝜓\psiitalic\_ψ in (M,u)𝑀𝑢(M,u)( italic\_M , italic\_u ) iff φ𝜑\varphiitalic\_φ is
true. First suppose that φ𝜑\varphiitalic\_φ is true. Then there is an assignment
τ𝜏\tauitalic\_τ to the variables in x@vecx\@vec{x}start\_ID start\_ARG italic\_x end\_ARG end\_ID such that ∀yφ′for-all@vecysuperscript𝜑′\forall\@vec{y}\,\varphi^{\prime}∀ start\_ID start\_ARG italic\_y end\_ARG end\_ID italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT
is true given τ𝜏\tauitalic\_τ. Let x′superscript@vecx′\@vec{x}^{\prime}start\_ID start\_ARG italic\_x end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT be the subset of variables in
x@vecx\@vec{x}start\_ID start\_ARG italic\_x end\_ARG end\_ID that are set to true in τ𝜏\tauitalic\_τ, let X′superscript@vecX′\@vec{X}^{\prime}start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT be the
corresponding subset of X1superscript@vecX1\@vec{X}^{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT 1 end\_POSTSUPERSCRIPT and let X′′superscript@vecX′′\@vec{X}^{\prime\prime}start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT be
the complementary subset of X0superscript@vecX0\@vec{X}^{0}start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT 0 end\_POSTSUPERSCRIPT (so that if x∈x𝑥@vecxx\in\@vec{x}italic\_x ∈ start\_ID start\_ARG italic\_x end\_ARG end\_ID is false
according to τ𝜏\tauitalic\_τ, then the corresponding variable Xx0superscriptsubscript𝑋𝑥0X\_{x}^{0}italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 0 end\_POSTSUPERSCRIPT is in
X′′superscript@vecX′′\@vec{X}^{\prime\prime}start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT).
Note that for each variable x∈x𝑥@vecxx\in\@vec{x}italic\_x ∈ start\_ID start\_ARG italic\_x end\_ARG end\_ID, exactly one
of Xx0superscriptsubscript𝑋𝑥0X\_{x}^{0}italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 0 end\_POSTSUPERSCRIPT and Xx1superscriptsubscript𝑋𝑥1X\_{x}^{1}italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 1 end\_POSTSUPERSCRIPT is in X′∪X′′superscript@vecX′superscript@vecX′′\@vec{X}^{\prime}\cup\@vec{X}^{\prime\prime}start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ∪ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT. We claim that
A=0∧X′=0∧X′′=0∧Y=0𝐴0superscript@vecX′@vec0superscript@vecX′′@vec0@vecY@vec0A=0\land\@vec{X}^{\prime}=\@vec{0}\land\@vec{X}^{\prime\prime}=\@vec{0}\land\@vec{Y}=\@vec{0}italic\_A = 0 ∧ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT = start\_ID start\_ARG 0 end\_ARG end\_ID ∧ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT = start\_ID start\_ARG 0 end\_ARG end\_ID ∧ start\_ID start\_ARG italic\_Y end\_ARG end\_ID = start\_ID start\_ARG 0 end\_ARG end\_ID is a cause of ψ𝜓\psiitalic\_ψ in
(M,u)𝑀𝑢(M,u)( italic\_M , italic\_u ).
Clearly (M,u)⊧A=0∧ψmodels𝑀𝑢𝐴0𝜓(M,u)\models A=0\land\psi( italic\_M , italic\_u ) ⊧ italic\_A = 0 ∧ italic\_ψ
(since (M,u)⊧ψ1models𝑀𝑢subscript𝜓1(M,u)\models\psi\_{1}( italic\_M , italic\_u ) ⊧ italic\_ψ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT). It is immediate from the definitions
of ψ2subscript𝜓2\psi\_{2}italic\_ψ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT and ψ3subscript𝜓3\psi\_{3}italic\_ψ start\_POSTSUBSCRIPT 3 end\_POSTSUBSCRIPT that
| | | |
| --- | --- | --- |
| | (M,u)⊧[A←1,X′←1,X′′←1,Y←1](¬ψ1∧¬ψ2),models𝑀𝑢delimited-[]formulae-sequence←@vecA1formulae-sequence←superscript@vecX′@vec1formulae-sequence←superscript@vecX′′@vec1←@vecY@vec1subscript𝜓1subscript𝜓2(M,u)\models[\@vec{A}\leftarrow 1,\@vec{X}^{\prime}\leftarrow\@vec{1},\@vec{X}^{\prime\prime}\leftarrow\@vec{1},\@vec{Y}\leftarrow\@vec{1}](\neg\psi\_{1}\land\neg\psi\_{2}),( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_A end\_ARG end\_ID ← 1 , start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ← start\_ID start\_ARG 1 end\_ARG end\_ID , start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT ← start\_ID start\_ARG 1 end\_ARG end\_ID , start\_ID start\_ARG italic\_Y end\_ARG end\_ID ← start\_ID start\_ARG 1 end\_ARG end\_ID ] ( ¬ italic\_ψ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ∧ ¬ italic\_ψ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ) , | |
so
| | | |
| --- | --- | --- |
| | (M,u)⊧[A←1,X′←1,X′′←1,Y←1]¬ψ.models𝑀𝑢delimited-[]formulae-sequence←@vecA1formulae-sequence←superscript@vecX′@vec1formulae-sequence←superscript@vecX′′@vec1←@vecY@vec1𝜓(M,u)\models[\@vec{A}\leftarrow 1,\@vec{X}^{\prime}\leftarrow\@vec{1},\@vec{X}^{\prime\prime}\leftarrow\@vec{1},\@vec{Y}\leftarrow\@vec{1}]\neg\psi.( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_A end\_ARG end\_ID ← 1 , start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ← start\_ID start\_ARG 1 end\_ARG end\_ID , start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT ← start\_ID start\_ARG 1 end\_ARG end\_ID , start\_ID start\_ARG italic\_Y end\_ARG end\_ID ← start\_ID start\_ARG 1 end\_ARG end\_ID ] ¬ italic\_ψ . | |
Thus, AC1 and AC2m𝑚{}^{m}start\_FLOATSUPERSCRIPT italic\_m end\_FLOATSUPERSCRIPT hold. It suffices to
prove AC3. So suppose that there is some subset Z@vecZ\@vec{Z}start\_ID start\_ARG italic\_Z end\_ARG end\_ID of A∪X′∪Y@vecAsuperscript@vecX′@vecY\@vec{A}\cup\@vec{X}^{\prime}\cup\@vec{Y}start\_ID start\_ARG italic\_A end\_ARG end\_ID ∪ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ∪ start\_ID start\_ARG italic\_Y end\_ARG end\_ID and a set W@vecW\@vec{W}start\_ID start\_ARG italic\_W end\_ARG end\_ID such that
(M,u)⊧[Z←1,W=w]¬ψmodels𝑀𝑢delimited-[]formulae-sequence←@vecZ@vec1@vecW@vecw𝜓(M,u)\models[\@vec{Z}\leftarrow\@vec{1},\@vec{W}=\@vec{w}]\neg\psi( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 1 end\_ARG end\_ID , start\_ID start\_ARG italic\_W end\_ARG end\_ID = start\_ID start\_ARG italic\_w end\_ARG end\_ID ] ¬ italic\_ψ,
where (M,u)⊧W=wmodels𝑀𝑢@vecW@vecw(M,u)\models\@vec{W}=\@vec{w}( italic\_M , italic\_u ) ⊧ start\_ID start\_ARG italic\_W end\_ARG end\_ID = start\_ID start\_ARG italic\_w end\_ARG end\_ID.
Since (M,u)⊧W=0models𝑀𝑢@vecW@vec0(M,u)\models\@vec{W}=\@vec{0}( italic\_M , italic\_u ) ⊧ start\_ID start\_ARG italic\_W end\_ARG end\_ID = start\_ID start\_ARG 0 end\_ARG end\_ID, it must be the case that
w=0@vecw@vec0\@vec{w}=\@vec{0}start\_ID start\_ARG italic\_w end\_ARG end\_ID = start\_ID start\_ARG 0 end\_ARG end\_ID, so
(M,u)⊧[Z←1]¬ψmodels𝑀𝑢delimited-[]←@vecZ@vec1𝜓(M,u)\models[\@vec{Z}\leftarrow\@vec{1}]\neg\psi( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 1 end\_ARG end\_ID ] ¬ italic\_ψ. Clearly we must have
Z∩(X0∪X1)=X′∪X′′@vecZsuperscript@vecX0superscript@vecX1superscript@vecX′superscript@vecX′′\@vec{Z}\cap(\@vec{X}^{0}\cup\@vec{X}^{1})=\@vec{X}^{\prime}\cup\@vec{X}^{\prime\prime}start\_ID start\_ARG italic\_Z end\_ARG end\_ID ∩ ( start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT 0 end\_POSTSUPERSCRIPT ∪ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT 1 end\_POSTSUPERSCRIPT ) = start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ∪ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT, for otherwise
(M,u)⊧[Z←1]ψ1models𝑀𝑢delimited-[]←@vecZ@vec1subscript𝜓1(M,u)\models[\@vec{Z}\leftarrow\@vec{1}]\psi\_{1}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 1 end\_ARG end\_ID ] italic\_ψ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and
(M,u)⊧[Z←1]ψmodels𝑀𝑢delimited-[]←@vecZ@vec1𝜓(M,u)\models[\@vec{Z}\leftarrow\@vec{1}]\psi( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 1 end\_ARG end\_ID ] italic\_ψ.
(M,u)⊧[Z←1]ψmodels𝑀@vecudelimited-[]←@vecZ@vec1𝜓(M,\@vec{u})\models[\@vec{Z}\leftarrow\@vec{1}]\psi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 1 end\_ARG end\_ID ] italic\_ψ.
so (M,u)⊧[Z←1]ψ3models𝑀𝑢delimited-[]←@vecZ@vec1subscript𝜓3(M,u)\models[\@vec{Z}\leftarrow\@vec{1}]\psi\_{3}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 1 end\_ARG end\_ID ] italic\_ψ start\_POSTSUBSCRIPT 3 end\_POSTSUBSCRIPT.
We must have A∈Z𝐴@vecZA\in\@vec{Z}italic\_A ∈ start\_ID start\_ARG italic\_Z end\_ARG end\_ID, since otherwise
(M,u)⊧[Z←1](A=0)models𝑀𝑢delimited-[]←@vecZ@vec1𝐴0(M,u)\models[\@vec{Z}\leftarrow\@vec{1}](A=0)( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 1 end\_ARG end\_ID ] ( italic\_A = 0 ),
so
(M,u)⊧[Z←1]ψ2models𝑀𝑢delimited-[]←@vecZ@vec1subscript𝜓2(M,u)\models[\@vec{Z}\leftarrow\@vec{1}]\psi\_{2}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 1 end\_ARG end\_ID ] italic\_ψ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT, and thus
(M,u)⊧[Z←1]ψ2models𝑀@vecudelimited-[]←@vecZ@vec1subscript𝜓2(M,\@vec{u})\models[\@vec{Z}\leftarrow\@vec{1}]\psi\_{2}( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 1 end\_ARG end\_ID ] italic\_ψ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT, and thus
(M,u)⊧[Z←1]ψmodels𝑀@vecudelimited-[]←@vecZ@vec1𝜓(M,\@vec{u})\models[\@vec{Z}\leftarrow\@vec{1}]\psi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 1 end\_ARG end\_ID ] italic\_ψ.
We also must have Y⊆Z@vecY@vecZ\@vec{Y}\subseteq\@vec{Z}start\_ID start\_ARG italic\_Y end\_ARG end\_ID ⊆ start\_ID start\_ARG italic\_Z end\_ARG end\_ID, for otherwise
(M,u)⊧[Z←1]¬(Y=1)models𝑀𝑢delimited-[]←@vecZ@vec1@vecY@vec1(M,u)\models[\@vec{Z}\leftarrow\@vec{1}]\neg(\@vec{Y}=\@vec{1})( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 1 end\_ARG end\_ID ] ¬ ( start\_ID start\_ARG italic\_Y end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID ), and
again (M,u)⊧[Z←1]ψ2models𝑀𝑢delimited-[]←@vecZ@vec1subscript𝜓2(M,u)\models[\@vec{Z}\leftarrow\@vec{1}]\psi\_{2}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 1 end\_ARG end\_ID ] italic\_ψ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT and
(M,u)⊧[Z←1]ψmodels𝑀𝑢delimited-[]←@vecZ@vec1𝜓(M,u)\models[\@vec{Z}\leftarrow\@vec{1}]\psi( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 1 end\_ARG end\_ID ] italic\_ψ.
Thus, Z=A∪X′∪X′′∪Y@vecZ𝐴superscript@vecX′superscript@vecX′′@vecY\@vec{Z}=A\cup\@vec{X}^{\prime}\cup\@vec{X}^{\prime\prime}\cup\@vec{Y}start\_ID start\_ARG italic\_Z end\_ARG end\_ID = italic\_A ∪ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ∪ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT ∪ start\_ID start\_ARG italic\_Y end\_ARG end\_ID,
and AC3 holds.
Finally, we must show that
if A=0𝐴0A=0italic\_A = 0 is part of a cause of ψ𝜓\psiitalic\_ψ in (M,u)𝑀𝑢(M,u)( italic\_M , italic\_u ) then
∃x∀yφ′@vecxfor-all@vecysuperscript𝜑′\exists\@vec{x}\,\forall\@vec{y}\,\varphi^{\prime}∃ start\_ID start\_ARG italic\_x end\_ARG end\_ID ∀ start\_ID start\_ARG italic\_y end\_ARG end\_ID italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT is true.
So suppose that A=0∧Z=0𝐴0@vecZ@vec0A=0\land\@vec{Z}=\@vec{0}italic\_A = 0 ∧ start\_ID start\_ARG italic\_Z end\_ARG end\_ID = start\_ID start\_ARG 0 end\_ARG end\_ID is a cause of ψ𝜓\psiitalic\_ψ in
(M,u)𝑀𝑢(M,u)( italic\_M , italic\_u ), where Z⊆𝒱−{A}@vecZ𝒱𝐴\@vec{Z}\subseteq{\cal V}-\{A\}start\_ID start\_ARG italic\_Z end\_ARG end\_ID ⊆ caligraphic\_V - { italic\_A }.
We must have (M,u)⊧[A←1,Z←1]¬ψmodels𝑀𝑢delimited-[]formulae-sequence←𝐴1←@vecZ1𝜓(M,u)\models[A\leftarrow 1,\@vec{Z}\leftarrow 1]\neg\psi( italic\_M , italic\_u ) ⊧ [ italic\_A ← 1 , start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← 1 ] ¬ italic\_ψ, which
means that (M,u)⊧[Z←1]¬ψ1models𝑀𝑢delimited-[]←@vecZ1subscript𝜓1(M,u)\models[\@vec{Z}\leftarrow 1]\neg\psi\_{1}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← 1 ] ¬ italic\_ψ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT. Thus, for each
x∈x𝑥@vecxx\in\@vec{x}italic\_x ∈ start\_ID start\_ARG italic\_x end\_ARG end\_ID, Z@vecZ\@vec{Z}start\_ID start\_ARG italic\_Z end\_ARG end\_ID must contain exactly one of Xx0superscriptsubscript𝑋𝑥0X\_{x}^{0}italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 0 end\_POSTSUPERSCRIPT and
Xx1superscriptsubscript𝑋𝑥1X\_{x}^{1}italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 1 end\_POSTSUPERSCRIPT. We must also have
| | | |
| --- | --- | --- |
| | (M,u)⊧[A←1,Z←1](¬ψ2∨¬ψ3).models𝑀𝑢delimited-[]formulae-sequence←𝐴1←@vecZ1subscript𝜓2subscript𝜓3(M,u)\models[A\leftarrow 1,\@vec{Z}\leftarrow 1](\neg\psi\_{2}\lor\neg\psi\_{3}).( italic\_M , italic\_u ) ⊧ [ italic\_A ← 1 , start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← 1 ] ( ¬ italic\_ψ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ∨ ¬ italic\_ψ start\_POSTSUBSCRIPT 3 end\_POSTSUBSCRIPT ) . | |
Since (M,u)⊧[A←1,Z←1](A=1)models𝑀𝑢delimited-[]formulae-sequence←𝐴1←@vecZ1𝐴1(M,u)\models[A\leftarrow 1,\@vec{Z}\leftarrow 1](A=1)( italic\_M , italic\_u ) ⊧ [ italic\_A ← 1 , start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← 1 ] ( italic\_A = 1 ), we have (M,u)⊧[A←1,Z←1]ψ3models𝑀𝑢delimited-[]formulae-sequence←𝐴1←@vecZ1subscript𝜓3(M,u)\models[A\leftarrow 1,\@vec{Z}\leftarrow 1]\psi\_{3}( italic\_M , italic\_u ) ⊧ [ italic\_A ← 1 , start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← 1 ] italic\_ψ start\_POSTSUBSCRIPT 3 end\_POSTSUBSCRIPT, so
(M,u)⊧[A←1,Z←1]¬ψ2models𝑀𝑢delimited-[]formulae-sequence←𝐴1←@vecZ1subscript𝜓2(M,u)\models[A\leftarrow 1,\@vec{Z}\leftarrow 1]\neg\psi\_{2}( italic\_M , italic\_u ) ⊧ [ italic\_A ← 1 , start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← 1 ] ¬ italic\_ψ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT. It follows that
Y⊆Z@vecY@vecZ\@vec{Y}\subseteq\@vec{Z}start\_ID start\_ARG italic\_Y end\_ARG end\_ID ⊆ start\_ID start\_ARG italic\_Z end\_ARG end\_ID.
Let ν𝜈\nuitalic\_ν be a truth assignment such that
ν(x)𝜈𝑥\nu(x)italic\_ν ( italic\_x ) is true iff Xx1∈Zsuperscriptsubscript𝑋𝑥1@vecZX\_{x}^{1}\in\@vec{Z}italic\_X start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT 1 end\_POSTSUPERSCRIPT ∈ start\_ID start\_ARG italic\_Z end\_ARG end\_ID. We claim that
ν𝜈\nuitalic\_ν satisfies ∀yφ′for-all@vecysuperscript𝜑′\forall\@vec{y}\,\varphi^{\prime}∀ start\_ID start\_ARG italic\_y end\_ARG end\_ID italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT. Once we show this, it
follows that φ=∃x∀yφ′𝜑@vecxfor-all@vecysuperscript𝜑′\varphi=\exists\@vec{x}\,\forall\@vec{y}\,\varphi^{\prime}italic\_φ = ∃ start\_ID start\_ARG italic\_x end\_ARG end\_ID ∀ start\_ID start\_ARG italic\_y end\_ARG end\_ID italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT is true,
as desired.
Suppose, by way of contradiction, that ν𝜈\nuitalic\_ν does not satisfy ∀yφ′for-all@vecysuperscript𝜑′\forall\@vec{y}\,\varphi^{\prime}∀ start\_ID start\_ARG italic\_y end\_ARG end\_ID italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT. Then there exists a truth assignment ν′superscript𝜈′\nu^{\prime}italic\_ν start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT that
agrees with ν𝜈\nuitalic\_ν on the assignments to the variables in x@vecx\@vec{x}start\_ID start\_ARG italic\_x end\_ARG end\_ID
such that ν′superscript𝜈′\nu^{\prime}italic\_ν start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT satisfies ¬φ′superscript𝜑′\neg\varphi^{\prime}¬ italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT. Let Y′superscript@vecY′\@vec{Y}^{\prime}start\_ID start\_ARG italic\_Y end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT be the subset
of Y@vecY\@vec{Y}start\_ID start\_ARG italic\_Y end\_ARG end\_ID corresponding to the variables y∈y𝑦@vecyy\in\@vec{y}italic\_y ∈ start\_ID start\_ARG italic\_y end\_ARG end\_ID that are
true according to ν′superscript𝜈′\nu^{\prime}italic\_ν start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT.
Then if
Z′superscript@vecZ′\@vec{Z}^{\prime}start\_ID start\_ARG italic\_Z end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT is the result of removing from Z@vecZ\@vec{Z}start\_ID start\_ARG italic\_Z end\_ARG end\_ID all the variables
in Y@vecY\@vec{Y}start\_ID start\_ARG italic\_Y end\_ARG end\_ID that are not in Y′superscript@vecY′\@vec{Y}^{\prime}start\_ID start\_ARG italic\_Y end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT, we have that
(M,u)⊧[Z′←1](¬ψ1∧¬ψ3)models𝑀𝑢delimited-[]←superscript@vecZ′@vec1subscript𝜓1subscript𝜓3(M,u)\models[\@vec{Z}^{\prime}\leftarrow\@vec{1}](\neg\psi\_{1}\land\neg\psi\_{3})( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ← start\_ID start\_ARG 1 end\_ARG end\_ID ] ( ¬ italic\_ψ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ∧ ¬ italic\_ψ start\_POSTSUBSCRIPT 3 end\_POSTSUBSCRIPT ),
so (M,u)⊧[Z′←1]¬ψmodels𝑀𝑢delimited-[]←superscript@vecZ′@vec1𝜓(M,u)\models[\@vec{Z}^{\prime}\leftarrow\@vec{1}]\neg\psi( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ← start\_ID start\_ARG 1 end\_ARG end\_ID ] ¬ italic\_ψ. Thus,
A=0∧Z=0𝐴0@vecZ0A=0\land\@vec{Z}=0italic\_A = 0 ∧ start\_ID start\_ARG italic\_Z end\_ARG end\_ID = 0 is not a cause of ψ𝜓\psiitalic\_ψ (it does not
satisfy AC3), giving us the
desired contradiction.
Part (c) is almost immediate from part (b). Again, it is easy to see
that checking whether X=x𝑋𝑥X=xitalic\_X = italic\_x has degree of responsibility in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) at least
1/k1𝑘1/k1 / italic\_k is in Σ2psubscriptsuperscriptΣ𝑝2\Sigma^{p}\_{2}roman\_Σ start\_POSTSUPERSCRIPT italic\_p end\_POSTSUPERSCRIPT start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT: we simply guess X@vecX\@vec{X}start\_ID start\_ARG italic\_X end\_ARG end\_ID, x@vecx\@vec{x}start\_ID start\_ARG italic\_x end\_ARG end\_ID,
x′superscript@vecx′\@vec{x}^{\prime}start\_ID start\_ARG italic\_x end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT, and W@vecW\@vec{W}start\_ID start\_ARG italic\_W end\_ARG end\_ID such that X=x𝑋𝑥X=xitalic\_X = italic\_x is a conjunct of
X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID and |X|+|W|≤k@vecX@vecW𝑘|\@vec{X}|+|\@vec{W}|\leq k| start\_ID start\_ARG italic\_X end\_ARG end\_ID | + | start\_ID start\_ARG italic\_W end\_ARG end\_ID | ≤ italic\_k, and confirm that X=x@vecX@vecx\@vec{X}=\@vec{x}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG italic\_x end\_ARG end\_ID is a cause of φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID )
with witness (x′,W)superscript@vecx′@vecW(\@vec{x}^{\prime},\@vec{W})( start\_ID start\_ARG italic\_x end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT , start\_ID start\_ARG italic\_W end\_ARG end\_ID ).
To show that X=x𝑋𝑥X=xitalic\_X = italic\_x has degree of responsibility in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) at least
1/k1𝑘1/k1 / italic\_k is Σ2psuperscriptsubscriptΣ2𝑝\Sigma\_{2}^{p}roman\_Σ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_p end\_POSTSUPERSCRIPT-hard, given an arbitrary
formula φ=∃x∀yφ′𝜑@vecxfor-all@vecysuperscript𝜑′\varphi=\exists\@vec{x}\,\forall\@vec{y}\,\varphi^{\prime}italic\_φ = ∃ start\_ID start\_ARG italic\_x end\_ARG end\_ID ∀ start\_ID start\_ARG italic\_y end\_ARG end\_ID italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT.
Note that it follows from part (b) that A=0𝐴0A=0italic\_A = 0 has degree of
responsibility at least 1|x|+y+11@vecx@vecy1\frac{1}{|\@vec{x}|+\@vec{y}+1}divide start\_ARG 1 end\_ARG start\_ARG | start\_ID start\_ARG italic\_x end\_ARG end\_ID | + start\_ID start\_ARG italic\_y end\_ARG end\_ID + 1 end\_ARG for the
formula ψ𝜓\psiitalic\_ψ as constructed in part (b) iff φ𝜑\varphiitalic\_φ is true.
The result follows.
It now follows that by doing binary search
we can compute the degree
of responsibility of X=x𝑋𝑥X=xitalic\_X = italic\_x for φ𝜑\varphiitalic\_φ with log(|φ|)𝜑\log(|\varphi|)roman\_log ( | italic\_φ | ) queries to a
Σ2psuperscriptsubscriptΣ2𝑝\Sigma\_{2}^{p}roman\_Σ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_p end\_POSTSUPERSCRIPT oracle, and, as in [ChocklerH03](#bib.bib3) , that the
complexity
of computing the degree of responsibility is in FPΣ2P[logn]superscriptFPsuperscriptsubscriptΣ2𝑃delimited-[]𝑛\mbox{FP}^{\Sigma\_{2}^{P}[\log{n}]}FP start\_POSTSUPERSCRIPT roman\_Σ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_P end\_POSTSUPERSCRIPT [ roman\_log italic\_n ] end\_POSTSUPERSCRIPT, where
for a complexity class A𝐴Aitalic\_A, FPA[logn]superscriptFPAdelimited-[]𝑛\mbox{FP}^{{\rm A}[\log{n}]}FP start\_POSTSUPERSCRIPT roman\_A [ roman\_log italic\_n ] end\_POSTSUPERSCRIPT consists of all
functions that can be computed
by a polynomial-time Turing machine with an A𝐴Aitalic\_A-oracle
which on input x𝑥xitalic\_x asks a total of O(log|x|)𝑂𝑥O(\log{|x|})italic\_O ( roman\_log | italic\_x | ) queries
[Pap84](#bib.bib20) .
(Indeed, it is not hard to show that it is FPΣ2P[logn]superscriptFPsuperscriptsubscriptΣ2𝑃delimited-[]𝑛\mbox{FP}^{\Sigma\_{2}^{P}[\log{n}]}FP start\_POSTSUPERSCRIPT roman\_Σ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_P end\_POSTSUPERSCRIPT [ roman\_log italic\_n ] end\_POSTSUPERSCRIPT-complete; see
[ChocklerH03](#bib.bib3) .)
Similarly, the problem of computing the degree of blame is in
FPΣ2P[n]superscriptFPsuperscriptsubscriptΣ2𝑃delimited-[]𝑛\mbox{FP}^{\Sigma\_{2}^{P}[n]}FP start\_POSTSUPERSCRIPT roman\_Σ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT start\_POSTSUPERSCRIPT italic\_P end\_POSTSUPERSCRIPT [ italic\_n ] end\_POSTSUPERSCRIPT.333We can characterise the complexity of computing the degree of
blame by allowing parallel
(non-adaptive) queries to an oracle (see [ChocklerH03](#bib.bib3) ); we omit this
discussion here.
As we now show, checking causality in a monotone model for formulas
φ𝜑\varphiitalic\_φ or ¬φ𝜑\neg\varphi¬ italic\_φ, where φ𝜑\varphiitalic\_φ is monotone,
is significantly simpler.
For team plans, we are interested in
determining the causes of ¬𝑝𝑓(Finish)𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ\neg\mathit{pf}(Finish)¬ italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) (why was the plan not completed);
𝑝𝑓(Finish)𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ\mathit{pf}(Finish)italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) is clearly monotone.
Say that a causal model is *trivial* if the equations for the
endogenous variables involve only exogenous variables (so there
are no dependencies between endogenous variables).
###### Theorem 5.2
Suppose that M𝑀Mitalic\_M is a monotone causal model
and φ𝜑\varphiitalic\_φ is a
monotone formula.
1. (a)
If (M,u)⊧φmodels𝑀@vecu𝜑(M,\@vec{u})\models\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ italic\_φ, then we can find
X@vecX\@vec{X}start\_ID start\_ARG italic\_X end\_ARG end\_ID such that X=1@vecX@vec1\@vec{X}=\@vec{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID is a
cause of φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) in polynomial time.
2. (b)
If (M,u)⊧¬φmodels𝑀@vecu𝜑(M,\@vec{u})\models\neg\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ ¬ italic\_φ, then we can find
X@vecX\@vec{X}start\_ID start\_ARG italic\_X end\_ARG end\_ID such that X=0@vecX@vec0\@vec{X}=\@vec{0}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 0 end\_ARG end\_ID is a
cause of ¬φ𝜑\neg\varphi¬ italic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) in polynomial time.
3. (c)
Determining if X=1@vecX@vec1\@vec{X}=\@vec{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID
is a cause of φ𝜑\varphiitalic\_φ (resp., X=0@vecX@vec0\@vec{X}=\@vec{0}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 0 end\_ARG end\_ID
is a cause of ¬φ𝜑\neg\varphi¬ italic\_φ)
in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) can be done in polynomial time.
4. (d)
Determining if X=1𝑋1X=1italic\_X = 1 is a part of a cause of φ𝜑\varphiitalic\_φ (resp., X=0𝑋0X=0italic\_X = 0 is
part of a cause of ¬φ𝜑\neg\varphi¬ italic\_φ)
in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) is NP-complete;
NP-hardness holds even if M𝑀Mitalic\_M is a trivial monotone causal model
and φ𝜑\varphiitalic\_φ has the form ψ∧(φ′∨X=1)𝜓superscript𝜑′𝑋1\psi\land(\varphi^{\prime}\lor X=1)italic\_ψ ∧ ( italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ∨ italic\_X = 1 ), where φ′superscript𝜑′\varphi^{\prime}italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT
is a monotone formula in DNF whose variables are contained
in {X1,…,Xn,Y1,…,Yn}subscript𝑋1…subscript𝑋𝑛subscript𝑌1…subscript𝑌𝑛\{X\_{1},\ldots,X\_{n},Y\_{1},\ldots,Y\_{n}\}{ italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT , italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT } and
ψ𝜓\psiitalic\_ψ is the formula (X1=1∨Y1=1)∧…∧(Xn=1∨Yn=1)subscript𝑋11subscript𝑌11…subscript𝑋𝑛1subscript𝑌𝑛1(X\_{1}=1\lor Y\_{1}=1)\land\ldots\land(X\_{n}=1\lor Y\_{n}=1)( italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = 1 ∨ italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = 1 ) ∧ … ∧ ( italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT = 1 ∨ italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT = 1 ).
5. (e)
Determining if X=1𝑋1X=1italic\_X = 1 has degree of responsibility at least
1/k1𝑘1/k1 / italic\_k for φ𝜑\varphiitalic\_φ (resp., X=0𝑋0X=0italic\_X = 0 has degree of responsibility at least
1/k1𝑘1/k1 / italic\_k for ¬φ𝜑\neg\varphi¬ italic\_φ) in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) is NP-complete.
NP-hardness holds even if M𝑀Mitalic\_M is a trivial monotone causal model and
φ𝜑\varphiitalic\_φ has the form ψ∧(φ′∨X=1)𝜓superscript𝜑′𝑋1\psi\land(\varphi^{\prime}\lor X=1)italic\_ψ ∧ ( italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ∨ italic\_X = 1 ), where φ′superscript𝜑′\varphi^{\prime}italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT
is a formula in DNF whose variables are contained in {X1,…,Xn,Y1,…,Yn}subscript𝑋1…subscript𝑋𝑛subscript𝑌1…subscript𝑌𝑛\{X\_{1},\ldots,X\_{n},Y\_{1},\ldots,Y\_{n}\}{ italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT , italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT } and
ψ𝜓\psiitalic\_ψ is the formula (X1=1∨Y1=1)∧…∧(Xn=1∨Yn=1)subscript𝑋11subscript𝑌11…subscript𝑋𝑛1subscript𝑌𝑛1(X\_{1}=1\lor Y\_{1}=1)\land\ldots\land(X\_{n}=1\lor Y\_{n}=1)( italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = 1 ∨ italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = 1 ) ∧ … ∧ ( italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT = 1 ∨ italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT = 1 ).
Proof: For part (a), let X1,…,Xksubscript𝑋1…subscript𝑋𝑘X\_{1},\ldots,X\_{k}italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_X start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT be all the variables that are 1
in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ). Clearly, only Xi=1subscript𝑋𝑖1X\_{i}=1italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT = 1 for i=1,…,k𝑖1…𝑘i=1,\ldots,kitalic\_i = 1 , … , italic\_k can be
part of a cause of φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) (since M𝑀Mitalic\_M and φ𝜑\varphiitalic\_φ are
monotone).
Let X0={X1,…,Xk}superscript@vecX0subscript𝑋1…subscript𝑋𝑘\@vec{X}^{0}=\{X\_{1},\ldots,X\_{k}\}start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT 0 end\_POSTSUPERSCRIPT = { italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_X start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT }. Clearly, (M,u)⊧[X0←0]¬φmodels𝑀@vecudelimited-[]←superscript@vecX0@vec0𝜑(M,\@vec{u})\models[\@vec{X}^{0}\leftarrow\@vec{0}]\neg\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT 0 end\_POSTSUPERSCRIPT ← start\_ID start\_ARG 0 end\_ARG end\_ID ] ¬ italic\_φ. Define Xjsuperscript@vecX𝑗\@vec{X}^{j}start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT italic\_j end\_POSTSUPERSCRIPT for j>0𝑗0j>0italic\_j > 0 inductively
by taking Xj=Xj−1−{Xj}superscript@vecX𝑗superscript@vecX𝑗1subscript𝑋𝑗\@vec{X}^{j}=\@vec{X}^{j-1}-\{X\_{j}\}start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT italic\_j end\_POSTSUPERSCRIPT = start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT italic\_j - 1 end\_POSTSUPERSCRIPT - { italic\_X start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT } if (M,u)⊧[Xj−{Xj}←0]¬φmodels𝑀@vecudelimited-[]←superscript@vecX𝑗subscript𝑋𝑗0𝜑(M,\@vec{u})\models[\@vec{X}^{j}-\{X\_{j}\}\leftarrow 0]\neg\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT italic\_j end\_POSTSUPERSCRIPT - { italic\_X start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT } ← 0 ] ¬ italic\_φ, and Xj=Xj−1superscript@vecX𝑗superscript@vecX𝑗1\@vec{X}^{j}=\@vec{X}^{j-1}start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT italic\_j end\_POSTSUPERSCRIPT = start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT italic\_j - 1 end\_POSTSUPERSCRIPT otherwise. The
construction guarantees that
(M,u)⊧[Xk←0]¬φmodels𝑀@vecudelimited-[]←superscript@vecX𝑘0𝜑(M,\@vec{u})\models[\@vec{X}^{k}\leftarrow 0]\neg\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT italic\_k end\_POSTSUPERSCRIPT ← 0 ] ¬ italic\_φ, and that
Xksuperscript@vecX𝑘\@vec{X}^{k}start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT italic\_k end\_POSTSUPERSCRIPT is a minimal set with this property. Thus, Xk=1superscript@vecX𝑘@vec1\@vec{X}^{k}=\@vec{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUPERSCRIPT italic\_k end\_POSTSUPERSCRIPT = start\_ID start\_ARG 1 end\_ARG end\_ID is a cause of φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ).
For part (b), we proceed just as in part (a), except that we switch
the roles of φ𝜑\varphiitalic\_φ and ¬φ𝜑\neg\varphi¬ italic\_φ and replace 0s by 1s. We leave
details to the reader.
For part (c), to check that X=1@vecX@vec1\@vec{X}=\@vec{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID is a cause of φ𝜑\varphiitalic\_φ,
first check
if (M,u)⊧(X=1)∧φmodels𝑀@vecu@vecX@vec1𝜑(M,\@vec{u})\models(\@vec{X}=\@vec{1})\land\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ ( start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID ) ∧ italic\_φ. (As observed
above, this can be done in polynomial time.)
If so, then AC1 holds. Then check if
(M,u)⊧[X←0]¬φmodels𝑀@vecudelimited-[]←@vecX@vec0𝜑(M,\@vec{u})\models[\@vec{X}\leftarrow\@vec{0}]\neg\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_X end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID ] ¬ italic\_φ.
If not, X=1@vecX@vec1\@vec{X}=\@vec{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID is
not a cause of φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ), since AC2m𝑚{}^{m}start\_FLOATSUPERSCRIPT italic\_m end\_FLOATSUPERSCRIPT fails;
the fact that M𝑀Mitalic\_M and φ𝜑\varphiitalic\_φ are monotone guarantees
that for all sets W@vecW\@vec{W}start\_ID start\_ARG italic\_W end\_ARG end\_ID, if (M,u)⊧W=wmodels𝑀@vecu@vecW@vecw(M,\@vec{u})\models\@vec{W}=\@vec{w}( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ start\_ID start\_ARG italic\_W end\_ARG end\_ID = start\_ID start\_ARG italic\_w end\_ARG end\_ID and (M,u)⊧[X←0]φmodels𝑀@vecudelimited-[]←@vecX@vec0𝜑(M,\@vec{u})\models[\@vec{X}\leftarrow\@vec{0}]\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_X end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID ] italic\_φ, then
(M,u)⊧[X←0,W←w]φmodels𝑀@vecudelimited-[]formulae-sequence←@vecX@vec0←@vecW@vecw𝜑(M,\@vec{u})\models[\@vec{X}\leftarrow\@vec{0},\@vec{W}\leftarrow\@vec{w}]\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_X end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID , start\_ID start\_ARG italic\_W end\_ARG end\_ID ← start\_ID start\_ARG italic\_w end\_ARG end\_ID ] italic\_φ.
(Proof: Suppose that W′∈Wsuperscript𝑊′@vecWW^{\prime}\in\@vec{W}italic\_W start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ∈ start\_ID start\_ARG italic\_W end\_ARG end\_ID. If (M,u)⊧W′=1models𝑀@vecusuperscript𝑊′1(M,\@vec{u})\models W^{\prime}=1( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ italic\_W start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT = 1,
then, because M𝑀Mitalic\_M and φ𝜑\varphiitalic\_φ are monotone, (M,u)⊧[X←0,W′←1]φmodels𝑀@vecudelimited-[]formulae-sequence←@vecX@vec0←superscript𝑊′1𝜑(M,\@vec{u})\models[\@vec{X}\leftarrow\@vec{0},W^{\prime}\leftarrow 1]\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_X end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID , italic\_W start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ← 1 ] italic\_φ.
On the other hand, if (M,u)⊧W′=0models𝑀@vecusuperscript𝑊′0(M,\@vec{u})\models W^{\prime}=0( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ italic\_W start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT = 0, then the fact that
M𝑀Mitalic\_M is monotone
guarantees that (M,u)⊧[X←0](W′=0)models𝑀@vecudelimited-[]←@vecX@vec0superscript𝑊′0(M,\@vec{u})\models[\@vec{X}\leftarrow\@vec{0}](W^{\prime}=0)( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_X end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID ] ( italic\_W start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT = 0 ), so
(M,u)⊧[X←0,W′←0]φmodels𝑀@vecudelimited-[]formulae-sequence←@vecX@vec0←superscript𝑊′0𝜑(M,\@vec{u})\models[\@vec{X}\leftarrow\@vec{0},W^{\prime}\leftarrow 0]\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_X end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID , italic\_W start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ← 0 ] italic\_φ.444This shows that for monotone causal models and monotone
formulas, we can always take the set W@vecW\@vec{W}start\_ID start\_ARG italic\_W end\_ARG end\_ID in the witness to be empty.)
For AC3, suppose that X={X1,…,Xk}@vecXsubscript𝑋1…subscript𝑋𝑘\@vec{X}=\{X\_{1},\ldots,X\_{k}\}start\_ID start\_ARG italic\_X end\_ARG end\_ID = { italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_X start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT }. Let X−isubscript@vecX𝑖\@vec{X}\_{-i}start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUBSCRIPT - italic\_i end\_POSTSUBSCRIPT consist of all variables in X@vecX\@vec{X}start\_ID start\_ARG italic\_X end\_ARG end\_ID
but Xisubscript𝑋𝑖X\_{i}italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT. Since M𝑀Mitalic\_M and φ𝜑\varphiitalic\_φ are monotone, it is necessary and
sufficient to show that
(M,u)⊧[X−i←0]φmodels𝑀@vecudelimited-[]←subscript@vecX𝑖@vec0𝜑(M,\@vec{u})\models[\@vec{X}\_{-i}\leftarrow\@vec{0}]\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ start\_ID start\_ARG italic\_X end\_ARG end\_ID start\_POSTSUBSCRIPT - italic\_i end\_POSTSUBSCRIPT ← start\_ID start\_ARG 0 end\_ARG end\_ID ] italic\_φ for all i=1,…,k𝑖1…𝑘i=1,\ldots,kitalic\_i = 1 , … , italic\_k. Clearly,
if any of these statements fails to hold, then AC3 does not hold. On
the other hand, if all these statements hold, then AC3 holds.
This gives us a polynomial-time algorithm for checking if X=1@vecX@vec1\@vec{X}=\@vec{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID is a cause of φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ). The algorithm for
checking that X=0@vecX@vec0\@vec{X}=\@vec{0}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 0 end\_ARG end\_ID is a cause of ¬φ𝜑\neg\varphi¬ italic\_φ is
essentially the same, again replacing φ𝜑\varphiitalic\_φ by ¬φ𝜑\neg\varphi¬ italic\_φ and
switching the role of 0 and 1.
For part (d), checking if X=1𝑋1X=1italic\_X = 1 is part of a cause of φ𝜑\varphiitalic\_φ in
(M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) is clearly in NP: guess a cause X=1@vecX@vec1\@vec{X}=\@vec{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID
that includes X=1𝑋1X=1italic\_X = 1 as a conjunct, and confirm that it is a cause as
discussed above.
To show that checking if X=1𝑋1X=1italic\_X = 1 is part of a cause of φ𝜑\varphiitalic\_φ in
(M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) is NP-hard, suppose that we are given a propositional
formula φ𝜑\varphiitalic\_φ,
with primitive propositions
x1,…,xnsubscript𝑥1…subscript𝑥𝑛x\_{1},\ldots,x\_{n}italic\_x start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_x start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT. Let φrsuperscript𝜑𝑟\varphi^{r}italic\_φ start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT be the result of (i) converting φ𝜑\varphiitalic\_φ
to *negation normal form* (so that all the negations are driven
in so that they appear only in front of primitive propositions—this
conversion can clearly be done in polynomial time, indeed, in linear
time if φ𝜑\varphiitalic\_φ is represented by a parse tree) and (ii) replacing
all occurrences of ¬xisubscript𝑥𝑖\neg x\_{i}¬ italic\_x start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT by yisubscript𝑦𝑖y\_{i}italic\_y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT, where yisubscript𝑦𝑖y\_{i}italic\_y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT is a fresh
primitive proposition.
Note that φrsuperscript𝜑𝑟\varphi^{r}italic\_φ start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT is monotone.
(The formula φrsuperscript𝜑𝑟\varphi^{r}italic\_φ start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT was first introduced by Goldsmith, Hagen, and Mundhenk
for a somewhat different purpose.)
Let φ¯rsuperscript¯𝜑𝑟\bar{\varphi}^{r}over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT
be the monotone causal formula that results by
replacing each occurrence of xisubscript𝑥𝑖x\_{i}italic\_x start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT (resp., yisubscript𝑦𝑖y\_{i}italic\_y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT) in φrsuperscript𝜑𝑟\varphi^{r}italic\_φ start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT
by Xi=1subscript𝑋𝑖1X\_{i}=1italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT = 1 (resp., Yi=1subscript𝑌𝑖1Y\_{i}=1italic\_Y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT = 1).
Let φ¯+=ψ∧(φ¯r∨X=1)superscript¯𝜑𝜓superscript¯𝜑𝑟𝑋1\bar{\varphi}^{+}=\psi\land(\bar{\varphi}^{r}\lor X=1)over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT = italic\_ψ ∧ ( over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT ∨ italic\_X = 1 ), where ψ𝜓\psiitalic\_ψ is
| | | |
| --- | --- | --- |
| | (X1=1∨Y1=1)∧…∧(Xn=1∨Yn=1).subscript𝑋11subscript𝑌11…subscript𝑋𝑛1subscript𝑌𝑛1(X\_{1}=1\lor Y\_{1}=1)\land\ldots\land(X\_{n}=1\lor Y\_{n}=1).( italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = 1 ∨ italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = 1 ) ∧ … ∧ ( italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT = 1 ∨ italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT = 1 ) . | |
Let M𝑀Mitalic\_M be a model where 𝒱={X,X1,…,Xn,Y1,…,Yn}𝒱𝑋subscript𝑋1…subscript𝑋𝑛subscript𝑌1…subscript𝑌𝑛{\cal V}=\{X,X\_{1},\ldots,X\_{n},Y\_{1},\ldots,Y\_{n}\}caligraphic\_V = { italic\_X , italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT , italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT } and U𝑈Uitalic\_U is the only exogenous
variable. U𝑈Uitalic\_U determines the values of all the variables in 𝒱𝒱{\cal V}caligraphic\_V,
so again there are no interesting equations.
Let u𝑢uitalic\_u be the context
where all these variables are 1.
We claim that X=1𝑋1X=1italic\_X = 1 is part of a
cause of φ¯+superscript¯𝜑\bar{\varphi}^{+}over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT in (M,u)𝑀𝑢(M,u)( italic\_M , italic\_u ) iff ¬φ𝜑\neg\varphi¬ italic\_φ is satisfiable.
This clearly suffices to prove the NP lower bound
(since φ𝜑\varphiitalic\_φ is satisfiable iff X=1𝑋1X=1italic\_X = 1 is a cause of
¬φ¯rsuperscript¯𝜑𝑟\bar{\neg\varphi}^{r}over¯ start\_ARG ¬ italic\_φ end\_ARG start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT in (M,u)𝑀𝑢(M,u)( italic\_M , italic\_u )).
To prove the claim, first suppose that ¬φ𝜑\neg\varphi¬ italic\_φ is
unsatisfiable, so φ𝜑\varphiitalic\_φ is valid.
Let Z@vecZ\@vec{Z}start\_ID start\_ARG italic\_Z end\_ARG end\_ID be a subset of {X1,…,Xn,Y1,…,Yn}subscript𝑋1…subscript𝑋𝑛subscript𝑌1…subscript𝑌𝑛\{X\_{1},\ldots,X\_{n},Y\_{1},\ldots,Y\_{n}\}{ italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT , italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT }.
We claim that if Z@vecZ\@vec{Z}start\_ID start\_ARG italic\_Z end\_ARG end\_ID contains at most one of Xisubscript𝑋𝑖X\_{i}italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and Yisubscript𝑌𝑖Y\_{i}italic\_Y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT for
i=1,…n𝑖1…𝑛i=1,\ldots nitalic\_i = 1 , … italic\_n, then (M,u)⊧[Z←0](ψ∧φ¯r)models𝑀𝑢delimited-[]←@vecZ@vec0𝜓superscript¯𝜑𝑟(M,u)\models[\@vec{Z}\leftarrow\@vec{0}](\psi\land\bar{\varphi}^{r})( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID ] ( italic\_ψ ∧ over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT ).
The fact that (M,u)⊧[Z←0]ψmodels𝑀𝑢delimited-[]←@vecZ@vec0𝜓(M,u)\models[\@vec{Z}\leftarrow\@vec{0}]\psi( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID ] italic\_ψ is immediate.
To see that (M,u)⊧[Z←0]φ¯rmodels𝑀𝑢delimited-[]←@vecZ@vec0superscript¯𝜑𝑟(M,u)\models[\@vec{Z}\leftarrow\@vec{0}]\bar{\varphi}^{r}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID ] over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT, first suppose
that Z@vecZ\@vec{Z}start\_ID start\_ARG italic\_Z end\_ARG end\_ID contains exactly one of Xisubscript𝑋𝑖X\_{i}italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT or Yisubscript𝑌𝑖Y\_{i}italic\_Y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT for all i∈{1,…,n}𝑖1…𝑛i\in\{1,\ldots,n\}italic\_i ∈ { 1 , … , italic\_n }. Then Z@vecZ\@vec{Z}start\_ID start\_ARG italic\_Z end\_ARG end\_ID determines a truth assignment to x@vecx\@vec{x}start\_ID start\_ARG italic\_x end\_ARG end\_ID in
the obvious way, so (M,u)⊧[Z←0]φ¯rmodels𝑀𝑢delimited-[]←@vecZ@vec0superscript¯𝜑𝑟(M,u)\models[\@vec{Z}\leftarrow\@vec{0}]\bar{\varphi}^{r}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID ] over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT,
since φ𝜑\varphiitalic\_φ is valid.
Since φ¯rsuperscript¯𝜑𝑟\bar{\varphi}^{r}over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT is monotonic, it follows that if Z@vecZ\@vec{Z}start\_ID start\_ARG italic\_Z end\_ARG end\_ID contains at
most one of Xisubscript𝑋𝑖X\_{i}italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT or Yisubscript𝑌𝑖Y\_{i}italic\_Y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT for all i∈{1,…,n}𝑖1…𝑛i\in\{1,\ldots,n\}italic\_i ∈ { 1 , … , italic\_n }, then we
must also have
(M,u)⊧[Z←0]φ¯rmodels𝑀𝑢delimited-[]←@vecZ@vec0superscript¯𝜑𝑟(M,u)\models[\@vec{Z}\leftarrow\@vec{0}]\bar{\varphi}^{r}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID ] over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT. This completes the argument.
Now suppose, by way of contradiction, that X=1𝑋1X=1italic\_X = 1 is part of a cause of
φ¯+superscript¯𝜑\bar{\varphi}^{+}over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT in (M,u)𝑀𝑢(M,u)( italic\_M , italic\_u ). Then there exists a subset
Z@vecZ\@vec{Z}start\_ID start\_ARG italic\_Z end\_ARG end\_ID of {X1,…,Xn\{X\_{1},\ldots,X\_{n}{ italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT, Y1,…,Yn}Y\_{1},\ldots,Y\_{n}\}italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT } such
that (M,u)⊧[Z←0,X←0]¬φ¯+models𝑀𝑢delimited-[]formulae-sequence←@vecZ@vec0←𝑋0superscript¯𝜑(M,u)\models[\@vec{Z}\leftarrow\@vec{0},X\leftarrow 0]\neg\bar{\varphi}^{+}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID , italic\_X ← 0 ] ¬ over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT.
By the argument
above, it cannot be the case Z@vecZ\@vec{Z}start\_ID start\_ARG italic\_Z end\_ARG end\_ID contains at most one of
Xisubscript𝑋𝑖X\_{i}italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and Yisubscript𝑌𝑖Y\_{i}italic\_Y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT for all i=1,…,n𝑖1…𝑛i=1,\ldots,nitalic\_i = 1 , … , italic\_n, for otherwise, we
must have
(M,u)⊧[Z←0,X←0](ψ∧φ¯r)models𝑀𝑢delimited-[]formulae-sequence←@vecZ@vec0←𝑋0𝜓superscript¯𝜑𝑟(M,u)\models[\@vec{Z}\leftarrow\@vec{0},X\leftarrow 0](\psi\land\bar{\varphi}^{r})( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID , italic\_X ← 0 ] ( italic\_ψ ∧ over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT ),
and hence (M,u)⊧[Z←0,X←0]φ¯+models𝑀𝑢delimited-[]formulae-sequence←@vecZ@vec0←𝑋0superscript¯𝜑(M,u)\models\mbox{$[\@vec{Z}\leftarrow\@vec{0},X\leftarrow 0]\bar{\varphi}^{+}$}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID , italic\_X ← 0 ] over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT.
Thus, it must be the case that Z@vecZ\@vec{Z}start\_ID start\_ARG italic\_Z end\_ARG end\_ID includes both Xisubscript𝑋𝑖X\_{i}italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and Yisubscript𝑌𝑖Y\_{i}italic\_Y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT
for some i∈{1,…,n}𝑖1…𝑛i\in\{1,\ldots,n\}italic\_i ∈ { 1 , … , italic\_n }. But then
(M,u)⊧[Z←0]¬ψmodels𝑀𝑢delimited-[]←@vecZ@vec0𝜓(M,u)\models\mbox{$[\@vec{Z}\leftarrow\@vec{0}]\neg\psi$}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID ] ¬ italic\_ψ, so
(M,u)⊧[Z←0]¬φ¯+models𝑀𝑢delimited-[]←@vecZ@vec0superscript¯𝜑(M,u)\models[\@vec{Z}\leftarrow\@vec{0}]\neg\bar{\varphi}^{+}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID ] ¬ over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT, which contradicts AC3.
Thus, X=1𝑋1X=1italic\_X = 1 is not part of a cause of φ¯rsuperscript¯𝜑𝑟\bar{\varphi}^{r}over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT in (M,u)𝑀𝑢(M,u)( italic\_M , italic\_u ).
Now suppose that ¬φ𝜑\neg\varphi¬ italic\_φ is satisfiable.
Then there is a set Z⊆{X1,\@vec{Z}\subseteq\{X\_{1},start\_ID start\_ARG italic\_Z end\_ARG end\_ID ⊆ { italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , ……\ldots…, Xn,Y1,…,Y}X\_{n},Y\_{1},\ldots,Y\}italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT , italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_Y } that includes
exactly one of Xisubscript𝑋𝑖X\_{i}italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and Yisubscript𝑌𝑖Y\_{i}italic\_Y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT, for i=1,…,n𝑖1…𝑛i=1,\ldots,nitalic\_i = 1 , … , italic\_n, such that
(M,u)⊧[Z←0]¬φ¯rmodels𝑀𝑢delimited-[]←@vecZ@vec0superscript¯𝜑𝑟(M,u)\models[\@vec{Z}\leftarrow\@vec{0}]\neg\bar{\varphi}^{r}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID ← start\_ID start\_ARG 0 end\_ARG end\_ID ] ¬ over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT. Let Z′superscript@vecZ′\@vec{Z}^{\prime}start\_ID start\_ARG italic\_Z end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT be a
minimal subset of Z@vecZ\@vec{Z}start\_ID start\_ARG italic\_Z end\_ARG end\_ID such that
(M,u)⊧[Z′←0]¬φ¯rmodels𝑀𝑢delimited-[]←superscript@vecZ′@vec0superscript¯𝜑𝑟(M,u)\models[\@vec{Z}^{\prime}\leftarrow\@vec{0}]\neg\bar{\varphi}^{r}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ← start\_ID start\_ARG 0 end\_ARG end\_ID ] ¬ over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT. We claim that
Z′=1∧X=1superscript@vecZ′1𝑋1\@vec{Z}^{\prime}=1\land X=1start\_ID start\_ARG italic\_Z end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT = 1 ∧ italic\_X = 1 is a cause of φ¯+superscript¯𝜑\bar{\varphi}^{+}over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT.
AC1 trivially holds.
Clearly
(M,u)⊧[Z′←0,X←0]¬(φ¯r∨X=1)models𝑀𝑢delimited-[]formulae-sequence←superscript@vecZ′@vec0←𝑋0superscript¯𝜑𝑟𝑋1(M,u)\models[\@vec{Z}^{\prime}\leftarrow\@vec{0},X\leftarrow 0]\neg(\bar{\varphi}^{r}\lor X=1)( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ← start\_ID start\_ARG 0 end\_ARG end\_ID , italic\_X ← 0 ] ¬ ( over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT ∨ italic\_X = 1 ), so (M,u)⊧[Z′←0,X←0]¬φ¯+models𝑀𝑢[Z′←0,X←0]¬φ¯+(M,u)\models\mbox{$[\@vec{Z}^{\prime}\leftarrow\@vec{0},X\leftarrow 0]\neg\bar{\varphi}^{+}$}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ← start\_ID start\_ARG 0 end\_ARG end\_ID , italic\_X ← 0 ] ¬ over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT and AC2 holds. By choice of Z′superscript@vecZ′\@vec{Z}^{\prime}start\_ID start\_ARG italic\_Z end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT, there is no strict subset
Z′′superscript@vecZ′′\@vec{Z}^{\prime\prime}start\_ID start\_ARG italic\_Z end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT of Z@vecZ\@vec{Z}start\_ID start\_ARG italic\_Z end\_ARG end\_ID such that
(M,u)⊧[Z′′←0]¬φ¯rmodels𝑀𝑢delimited-[]←superscript@vecZ′′@vec0superscript¯𝜑𝑟(M,u)\models[\@vec{Z}^{\prime\prime}\leftarrow\@vec{0}]\neg\bar{\varphi}^{r}( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT ← start\_ID start\_ARG 0 end\_ARG end\_ID ] ¬ over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT italic\_r end\_POSTSUPERSCRIPT. Since Z′superscript@vecZ′\@vec{Z}^{\prime}start\_ID start\_ARG italic\_Z end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT
contains at most one of Xisubscript𝑋𝑖X\_{i}italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT or Yisubscript𝑌𝑖Y\_{i}italic\_Y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT for i=1,…,n𝑖1…𝑛i=1,\ldots,nitalic\_i = 1 , … , italic\_n, we have
that (M,u)⊧[Z′←0]ψmodels𝑀𝑢delimited-[]←superscript@vecZ′@vec0𝜓(M,u)\models[\@vec{Z}^{\prime}\leftarrow\@vec{0}]\psi( italic\_M , italic\_u ) ⊧ [ start\_ID start\_ARG italic\_Z end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ← start\_ID start\_ARG 0 end\_ARG end\_ID ] italic\_ψ. It now easily follows
that AC3 holds. Thus, X=1𝑋1X=1italic\_X = 1 is part of a cause of φ¯+superscript¯𝜑\bar{\varphi}^{+}over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT.
Since to get NP-hardness it suffices to consider only CNF formulas, and
the result above shows that X=1𝑋1X=1italic\_X = 1 is a cause of φ+superscript𝜑\varphi^{+}italic\_φ start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT iff ¬φ𝜑\neg\varphi¬ italic\_φ is
satisfiable, we can restrict to φ𝜑\varphiitalic\_φ being a DNF formula. The model
M𝑀Mitalic\_M is clearly a trivial monotone model. This completes the proof of
part (d).
The argument that determining if X=0𝑋0X=0italic\_X = 0 is a part of a cause of ¬φ𝜑\neg\varphi¬ italic\_φ is NP-complete is almost identical. In particular,
essentially the same argument as that above shows that
¬φ𝜑\neg\varphi¬ italic\_φ is a satisfiable propositional formula iff X=0𝑋0X=0italic\_X = 0 is part
of a cause of
¬φ¯+superscript¯𝜑\neg\bar{\varphi}^{+}¬ over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT in (M,u′)𝑀superscript𝑢′(M,u^{\prime})( italic\_M , italic\_u start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ), where M𝑀Mitalic\_M is as above and u′superscript𝑢′u^{\prime}italic\_u start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT is the
context where all variables in 𝒱𝒱{\cal V}caligraphic\_V get value 0.
Part (e) follows easily from part (d).
To show that checking if
the degree of responsibility of X=1𝑋1X=1italic\_X = 1 for φ𝜑\varphiitalic\_φ is at least
1/k1𝑘1/k1 / italic\_k is in NP, given k𝑘kitalic\_k,
we guess a cause X=1@vecX@vec1\@vec{X}=\@vec{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID that includes X=1𝑋1X=1italic\_X = 1 as a conjunct
and has k𝑘kitalic\_k or fewer conjuncts. As observed above, the fact that
X=1@vecX@vec1\@vec{X}=\@vec{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID is a cause of φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) can be
confirmed in polynomial time.
For the lower bound, using the notation of part (d), if the
propositional formula φ𝜑\varphiitalic\_φ mentions n𝑛nitalic\_n primitive propositions, say
x1,…,xnsubscript𝑥1…subscript𝑥𝑛x\_{1},\ldots,x\_{n}italic\_x start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_x start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT, then we claim that X=1𝑋1X=1italic\_X = 1 has degree of
responsibility at least 1/(n+1)1𝑛11/(n+1)1 / ( italic\_n + 1 ) for φ¯+superscript¯𝜑\bar{\varphi}^{+}over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT
in (M,u)𝑀𝑢(M,u)( italic\_M , italic\_u ) iff ¬φ𝜑\neg\varphi¬ italic\_φ is satisfiable.
As observed above, if ¬φ𝜑\neg\varphi¬ italic\_φ is not satisfiable, then X=1𝑋1X=1italic\_X = 1 is not a
cause of ¬φ¯+superscript¯𝜑\neg\bar{\varphi}^{+}¬ over¯ start\_ARG italic\_φ end\_ARG start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT, and hence has degree of responsibility 0. On
the other hand, if ¬φ𝜑\neg\varphi¬ italic\_φ is satisfiable, then as shown above, X=1𝑋1X=1italic\_X = 1
is part of a cause Z+=1superscript@vecZ1\@vec{Z}^{+}=1start\_ID start\_ARG italic\_Z end\_ARG end\_ID start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT = 1 for φ𝜑\varphiitalic\_φ in (M,u)𝑀𝑢(M,u)( italic\_M , italic\_u ).
Since |Z+|=n+1superscript@vecZ𝑛1|\@vec{Z}^{+}|=n+1| start\_ID start\_ARG italic\_Z end\_ARG end\_ID start\_POSTSUPERSCRIPT + end\_POSTSUPERSCRIPT | = italic\_n + 1, it follows that the degree of
responsibility of X=1𝑋1X=1italic\_X = 1 for φ¯¯𝜑\bar{\varphi}over¯ start\_ARG italic\_φ end\_ARG is at least 1/(n+1)1𝑛11/(n+1)1 / ( italic\_n + 1 ). (It is not
hard to show that it is in fact exactly 1/(n+1)1𝑛11/(n+1)1 / ( italic\_n + 1 ).)
The argument for showing that checking if
the degree of responsibility of X=0𝑋0X=0italic\_X = 0 for ¬φ𝜑\neg\varphi¬ italic\_φ is at least
1/k1𝑘1/k1 / italic\_k is NP-complete is essentially identical; we leave details to the
reader.
Again, it follows that the problem of computing the degree of
responsibility of X=x𝑋𝑥X=xitalic\_X = italic\_x for φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) is in FPNP[logn]superscriptFPNPdelimited-[]𝑛\mbox{FP}^{{\rm NP}[\log{n}]}FP start\_POSTSUPERSCRIPT roman\_NP [ roman\_log italic\_n ] end\_POSTSUPERSCRIPT (a little
more effort in the spirit of ([ChocklerH03,](#bib.bib3) , Theorem 4.3) shows that it is
FPNP[logn]superscriptFPNPdelimited-[]𝑛\mbox{FP}^{{\rm NP}[\log{n}]}FP start\_POSTSUPERSCRIPT roman\_NP [ roman\_log italic\_n ] end\_POSTSUPERSCRIPT-complete),
while the problem of computing the degree of blame
of X=x𝑋𝑥X=xitalic\_X = italic\_x for φ𝜑\varphiitalic\_φ relative to
an epistemic state
(𝒦,Pr)𝒦Pr({\cal K},\Pr)( caligraphic\_K , roman\_Pr ) is in
FPNP[n]superscriptFPNPdelimited-[]𝑛\mbox{FP}^{{\rm NP}[n]}FP start\_POSTSUPERSCRIPT roman\_NP [ italic\_n ] end\_POSTSUPERSCRIPT.
We can do even better in conjunctive models.
###### Theorem 5.3
If M𝑀Mitalic\_M is a conjunctive causal model, φ𝜑\varphiitalic\_φ is a
conjunctive formula, and (𝒦,Pr)𝒦normal-Pr({\cal K},\Pr)( caligraphic\_K , roman\_Pr ) is an epistemic state where all
the causal models in 𝒦𝒦{\cal K}caligraphic\_K are conjunctive, then the degree of
responsibility of X=1@vecX@vec1\@vec{X}=\@vec{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID for φ𝜑\varphiitalic\_φ (resp., X=0@vecX@vec0\@vec{X}=\@vec{0}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 0 end\_ARG end\_ID for
¬φ𝜑\neg\varphi¬ italic\_φ) in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) can be computed in polynomial time, as can
the degree of blame of
X=1@vecX@vec1\@vec{X}=\@vec{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID for φ𝜑\varphiitalic\_φ (resp., X=0@vecX@vec0\@vec{X}=\@vec{0}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 0 end\_ARG end\_ID for ¬φ𝜑\neg\varphi¬ italic\_φ) relative
to (𝒦,Pr)𝒦normal-Pr({\cal K},\Pr)( caligraphic\_K , roman\_Pr ).
Proof: It is easy to check that X=1@vecX@vec1\@vec{X}=\@vec{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID is a cause of the
conjunctive formula φ𝜑\varphiitalic\_φ in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ), where M𝑀Mitalic\_M is a
conjunctive causal model, iff X@vecX\@vec{X}start\_ID start\_ARG italic\_X end\_ARG end\_ID is a singleton and
(M,u)⊧[X=0]¬φmodels𝑀@vecudelimited-[]𝑋0𝜑(M,\@vec{u})\models[X=0]\neg\varphi( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ) ⊧ [ italic\_X = 0 ] ¬ italic\_φ. (This means X=1𝑋1X=1italic\_X = 1 a “but-for”
cause, in legal language.) Thus, X=1𝑋1X=1italic\_X = 1 has degree of responsibility 1
for φ𝜑\varphiitalic\_φ. It is clearly easy to determine if X=1𝑋1X=1italic\_X = 1 is a but-for
cause of φ𝜑\varphiitalic\_φ and find all the causes of φ𝜑\varphiitalic\_φ in polynomial time
in this case. It follows that the degree of responsibility
and degree of blame of X=1@vecX@vec1\@vec{X}=\@vec{1}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 1 end\_ARG end\_ID can also be computed in polynomial time.
In the case of degree of responsibility of X=0@vecX@vec0\@vec{X}=\@vec{0}start\_ID start\_ARG italic\_X end\_ARG end\_ID = start\_ID start\_ARG 0 end\_ARG end\_ID for ¬φ𝜑\neg\varphi¬ italic\_φ,
observe that
for a conjunctive formula φ𝜑\varphiitalic\_φ, there is exactly one cause of ¬φ𝜑\neg\varphi¬ italic\_φ
in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ): the one containing all conjuncts of the form Y=0𝑌0Y=0italic\_Y = 0. It is
easy to check whether X=0𝑋0X=0italic\_X = 0 is part of that single cause, and if it is, then
its degree of responsibility is 1/k1𝑘1/k1 / italic\_k, where k𝑘kitalic\_k is the number of variables
which have value 0. Similarly, it is easy to compute degree of blame in
polynomial time.
Since the causal models that are determined by team plans are
monotone, the upper bounds of Theorem [5.2](#S5.ThmTHEOREM2 "Theorem 5.2 ‣ 5 The Complexity of Causality for Monotone Models ‣ Causality, Responsibility and Blame in Team Plans") apply
immediately to team plans
(provided that we fix the maximal number of literals in a precondition);
similarly, Theorem [5.3](#S5.ThmTHEOREM3 "Theorem 5.3 ‣ 5 The Complexity of Causality for Monotone Models ‣ Causality, Responsibility and Blame in Team Plans")
applies to team plans that are postcondition minimal.
The question
remains whether the NP-hardness results in parts (d) and (e) of
Theorem [5.2](#S5.ThmTHEOREM2 "Theorem 5.2 ‣ 5 The Complexity of Causality for Monotone Models ‣ Causality, Responsibility and Blame in Team Plans") also apply to team plans. It is possible
that the causal models that arise from team plans have additional
structure that makes computing whether X=1𝑋1X=1italic\_X = 1 is part of a cause of
φ𝜑\varphiitalic\_φ easier than it is for arbitrary monotone
causal models, and similarly
for responsibility. As the following result shows, this is not the
case.
###### Theorem 5.4
Determining whether 𝑖𝑛a(t)=0subscript𝑖𝑛𝑎𝑡0\mathit{in}\_{a}(t)=0italic\_in start\_POSTSUBSCRIPT italic\_a end\_POSTSUBSCRIPT ( italic\_t ) = 0
is part of a cause of ¬𝑝𝑓(Finish)𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ\neg\mathit{pf}(Finish)¬ italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) in (M𝒫,u)subscript𝑀𝒫@vecu(M\_{\cal P},\@vec{u})( italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT , start\_ID start\_ARG italic\_u end\_ARG end\_ID ), where
M𝒫subscript𝑀𝒫M\_{\cal P}italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT is the causal model determined by a team plan 𝒫𝒫{\cal P}caligraphic\_P, is NP-complete,
as is determining whether the degree of responsibility of agent a𝑎aitalic\_a for
¬𝑝𝑓(Finish)𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ\neg\mathit{pf}(Finish)¬ italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) is at least m/k𝑚𝑘m/kitalic\_m / italic\_k.
Proof: As we observed, the upper bound for determining whether 𝑖𝑛a(t)=0subscript𝑖𝑛𝑎𝑡0\mathit{in}\_{a}(t)=0italic\_in start\_POSTSUBSCRIPT italic\_a end\_POSTSUBSCRIPT ( italic\_t ) = 0
is part of a cause follows from part (d) of Theorem [5.2](#S5.ThmTHEOREM2 "Theorem 5.2 ‣ 5 The Complexity of Causality for Monotone Models ‣ Causality, Responsibility and Blame in Team Plans").
For the lower bound, recall that it is
already NP-hard to compute whether X=0𝑋0X=0italic\_X = 0 is part of a cause of ¬φ𝜑\neg\varphi¬ italic\_φ
in a trivial monotone causal model, where φ𝜑\varphiitalic\_φ
has the form ψ∧(φ′∨X=1)𝜓superscript𝜑′𝑋1\psi\land(\varphi^{\prime}\lor X=1)italic\_ψ ∧ ( italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ∨ italic\_X = 1 ), φ′superscript𝜑′\varphi^{\prime}italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT
is a formula in DNF whose variables are contained in {X1,…,Xn,Y1,…\{X\_{1},\ldots,X\_{n},Y\_{1},\ldots{ italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT , italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , …, Yn}Y\_{n}\}italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT }, and
ψ𝜓\psiitalic\_ψ is the formula (X1=1∨Y1=1)∧…∧(Xn=1∨Yn=1)subscript𝑋11subscript𝑌11…subscript𝑋𝑛1subscript𝑌𝑛1(X\_{1}=1\lor Y\_{1}=1)\land\ldots\land(X\_{n}=1\lor Y\_{n}=1)( italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = 1 ∨ italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT = 1 ) ∧ … ∧ ( italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT = 1 ∨ italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT = 1 ). Given such a model M𝑀Mitalic\_M and formula φ𝜑\varphiitalic\_φ,
we construct a model M𝒫subscript𝑀𝒫M\_{\cal P}italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT determined by a team plan 𝒫𝒫{\cal P}caligraphic\_P as
follows. Suppose that φ′superscript𝜑′\varphi^{\prime}italic\_φ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT is the formula σ1∨…∨σksubscript𝜎1…subscript𝜎𝑘\sigma\_{1}\lor\ldots\lor\sigma\_{k}italic\_σ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ∨ … ∨ italic\_σ start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT, where σjsubscript𝜎𝑗\sigma\_{j}italic\_σ start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT is a conjunction of formulas of the
form Xh=1subscript𝑋ℎ1X\_{h}=1italic\_X start\_POSTSUBSCRIPT italic\_h end\_POSTSUBSCRIPT = 1 and Yh=1subscript𝑌ℎ1Y\_{h}=1italic\_Y start\_POSTSUBSCRIPT italic\_h end\_POSTSUBSCRIPT = 1. The formula φ𝜑\varphiitalic\_φ is clearly logically
equivalent to φ′′=(σ1∧ψ)∨…∨(σk∧ψ)∨(X=1∧ψ)superscript𝜑′′subscript𝜎1𝜓…subscript𝜎𝑘𝜓𝑋1𝜓\varphi^{\prime\prime}=(\sigma\_{1}\land\psi)\lor\ldots\lor(\sigma\_{k}\land\psi)\lor(X=1\land\psi)italic\_φ start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT = ( italic\_σ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ∧ italic\_ψ ) ∨ … ∨ ( italic\_σ start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT ∧ italic\_ψ ) ∨ ( italic\_X = 1 ∧ italic\_ψ ). Let ψ′superscript𝜓′\psi^{\prime}italic\_ψ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT be the formula that
results by replacing each disjunct Xi=1∨Yi=1subscript𝑋𝑖1subscript𝑌𝑖1X\_{i}=1\lor Y\_{i}=1italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT = 1 ∨ italic\_Y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT = 1 in
ψ𝜓\psiitalic\_ψ by Wi=1subscript𝑊𝑖1W\_{i}=1italic\_W start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT = 1, and let φ\*superscript𝜑\varphi^{\*}italic\_φ start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT be the formula that results from
replacing each occurrence of ψ𝜓\psiitalic\_ψ in φ′′superscript𝜑′′\varphi^{\prime\prime}italic\_φ start\_POSTSUPERSCRIPT ′ ′ end\_POSTSUPERSCRIPT by ψ′superscript𝜓′\psi^{\prime}italic\_ψ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT.
Clearly, φ\*superscript𝜑\varphi^{\*}italic\_φ start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT is monotone.
We construct a team plan 𝒫=(T,Ag,≺,α)𝒫𝑇𝐴𝑔precedes𝛼{\cal P}=(T,Ag,\prec,\alpha)caligraphic\_P = ( italic\_T , italic\_A italic\_g , ≺ , italic\_α ) with
T={Start,T=\{Start,italic\_T = { italic\_S italic\_t italic\_a italic\_r italic\_t , Finish,tX,tX1,…,tXn,tY1,…,tYn,tW1,…𝐹𝑖𝑛𝑖𝑠ℎsubscript𝑡𝑋subscript𝑡subscript𝑋1…subscript𝑡subscript𝑋𝑛subscript𝑡subscript𝑌1…subscript𝑡subscript𝑌𝑛subscript𝑡subscript𝑊1…Finish,t\_{X},t\_{X\_{1}},\ldots,t\_{X\_{n}},t\_{Y\_{1}},\ldots,t\_{Y\_{n}},t\_{W\_{1}},\ldotsitalic\_F italic\_i italic\_n italic\_i italic\_s italic\_h , italic\_t start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT , … , italic\_t start\_POSTSUBSCRIPT italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT , … , italic\_t start\_POSTSUBSCRIPT italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT , …, tWn}t\_{W\_{n}}\}italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT }; that is, besides Start𝑆𝑡𝑎𝑟𝑡Startitalic\_S italic\_t italic\_a italic\_r italic\_t and
Finish𝐹𝑖𝑛𝑖𝑠ℎFinishitalic\_F italic\_i italic\_n italic\_i italic\_s italic\_h, there is a task corresponding to each
variable in ψ′superscript𝜓′\psi^{\prime}italic\_ψ start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT. The only nontrivial ordering conditions are
tXi,tYi≺tWiprecedessubscript𝑡subscript𝑋𝑖subscript𝑡subscript𝑌𝑖
subscript𝑡subscript𝑊𝑖t\_{X\_{i}},t\_{Y\_{i}}\prec t\_{W\_{i}}italic\_t start\_POSTSUBSCRIPT italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT italic\_Y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ≺ italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT.
Take Ag={at:t∈T∖{Start,Finish}}𝐴𝑔conditional-setsubscript𝑎𝑡𝑡𝑇𝑆𝑡𝑎𝑟𝑡𝐹𝑖𝑛𝑖𝑠ℎAg=\{a\_{t}:t\in T\setminus\{Start,Finish\}\}italic\_A italic\_g = { italic\_a start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT : italic\_t ∈ italic\_T ∖ { italic\_S italic\_t italic\_a italic\_r italic\_t , italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h } } and take
α𝛼\alphaitalic\_α such that
each task t𝑡titalic\_t in T∖{Start,Finish}𝑇𝑆𝑡𝑎𝑟𝑡𝐹𝑖𝑛𝑖𝑠ℎT\setminus\{Start,Finish\}italic\_T ∖ { italic\_S italic\_t italic\_a italic\_r italic\_t , italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h } is associated with agent atsubscript𝑎𝑡a\_{t}italic\_a start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT.
Finally, we define prec𝑝𝑟𝑒𝑐precitalic\_p italic\_r italic\_e italic\_c and post𝑝𝑜𝑠𝑡postitalic\_p italic\_o italic\_s italic\_t so that clob(t)=∅𝑐𝑙𝑜𝑏𝑡clob(t)=\emptysetitalic\_c italic\_l italic\_o italic\_b ( italic\_t ) = ∅
for all actions t𝑡titalic\_t, est(tWi)={{tXi},{tYi}}𝑒𝑠𝑡subscript𝑡subscript𝑊𝑖subscript𝑡subscript𝑋𝑖subscript𝑡subscript𝑌𝑖est(t\_{W\_{i}})=\{\{t\_{X\_{i}}\},\{t\_{Y\_{i}}\}\}italic\_e italic\_s italic\_t ( italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ) = { { italic\_t start\_POSTSUBSCRIPT italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT } , { italic\_t start\_POSTSUBSCRIPT italic\_Y start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT } }, est(tXi)=∅𝑒𝑠𝑡subscript𝑡subscript𝑋𝑖est(t\_{X\_{i}})=\emptysetitalic\_e italic\_s italic\_t ( italic\_t start\_POSTSUBSCRIPT italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ) = ∅, and
est(tY1)=∅𝑒𝑠𝑡subscript𝑡subscript𝑌1est(t\_{Y\_{1}})=\emptysetitalic\_e italic\_s italic\_t ( italic\_t start\_POSTSUBSCRIPT italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ) = ∅ for i=1,…,n𝑖1…𝑛i=1,\ldots,nitalic\_i = 1 , … , italic\_n, and
est(Finish)={Eσ1,…,Eσkest(Finish)=\{E\_{\sigma\_{1}},\ldots,E\_{\sigma\_{k}}italic\_e italic\_s italic\_t ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) = { italic\_E start\_POSTSUBSCRIPT italic\_σ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT , … , italic\_E start\_POSTSUBSCRIPT italic\_σ start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT, {tX,tW1\{t\_{X},t\_{W\_{1}}{ italic\_t start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT , italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT, …,tWn}}\ldots,t\_{W\_{n}}\}\}… , italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT } }, where Eσjsubscript𝐸subscript𝜎𝑗E\_{\sigma\_{j}}italic\_E start\_POSTSUBSCRIPT italic\_σ start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT consists of the
tasks tXisubscript𝑡subscript𝑋𝑖t\_{X\_{i}}italic\_t start\_POSTSUBSCRIPT italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT and tYjsubscript𝑡subscript𝑌𝑗t\_{Y\_{j}}italic\_t start\_POSTSUBSCRIPT italic\_Y start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT such that Xisubscript𝑋𝑖X\_{i}italic\_X start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT and Yjsubscript𝑌𝑗Y\_{j}italic\_Y start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT appear in
σjsubscript𝜎𝑗\sigma\_{j}italic\_σ start\_POSTSUBSCRIPT italic\_j end\_POSTSUBSCRIPT, together with tW1,…,tWnsubscript𝑡subscript𝑊1…subscript𝑡subscript𝑊𝑛t\_{W\_{1}},\ldots,t\_{W\_{n}}italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT , … , italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT. This ensures
that the equation for 𝑝𝑓(Finish)𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ\mathit{pf}(Finish)italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) looks like φ\*superscript𝜑\varphi^{\*}italic\_φ start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT, except
each variable Z∈{X1,…,Xn,Y1,…,Yn,W1,…,Wn}𝑍subscript𝑋1…subscript𝑋𝑛subscript𝑌1…subscript𝑌𝑛subscript𝑊1…subscript𝑊𝑛Z\in\{X\_{1},\ldots,X\_{n},Y\_{1},\ldots,Y\_{n},W\_{1},\ldots,W\_{n}\}italic\_Z ∈ { italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT , italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT , italic\_W start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_W start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT } is replaced by 𝑖𝑛atZ(tZ)subscript𝑖𝑛subscript𝑎subscript𝑡𝑍subscript𝑡𝑍\mathit{in}\_{a\_{t\_{Z}}}(t\_{Z})italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT italic\_Z end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT italic\_Z end\_POSTSUBSCRIPT ).
Consider the
causal model M𝒫subscript𝑀𝒫M\_{{\cal P}}italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT. We claim that X=0𝑋0X=0italic\_X = 0 is part of a cause of
¬φ\*superscript𝜑\neg\varphi^{\*}¬ italic\_φ start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT in (M,u)𝑀𝑢(M,u)( italic\_M , italic\_u ), where u𝑢uitalic\_u sets all endogenous variables to 0,
iff 𝑖𝑛atX(tX)=0subscript𝑖𝑛subscript𝑎subscript𝑡𝑋subscript𝑡𝑋0\mathit{in}\_{a\_{t\_{X}}}(t\_{X})=0italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT ) = 0 is a part of a cause of ¬𝑝𝑓(Finish)𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ\neg\mathit{pf}(Finish)¬ italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) in
(M𝒫,u𝒫)subscript𝑀𝒫subscript@vecu𝒫(M\_{\cal P},\@vec{u}\_{\cal P})( italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT , start\_ID start\_ARG italic\_u end\_ARG end\_ID start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT ), where u𝒫subscript@vecu𝒫\@vec{u}\_{\cal P}start\_ID start\_ARG italic\_u end\_ARG end\_ID start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT is such that 𝑖𝑛at(t)=0subscript𝑖𝑛subscript𝑎𝑡𝑡0\mathit{in}\_{a\_{t}}(t)=0italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t ) = 0 for all tasks t∈T∖{Start,Finish}𝑡𝑇𝑆𝑡𝑎𝑟𝑡𝐹𝑖𝑛𝑖𝑠ℎt\in T\setminus\{Start,Finish\}italic\_t ∈ italic\_T ∖ { italic\_S italic\_t italic\_a italic\_r italic\_t , italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h }.
Suppose that X=0𝑋0X=0italic\_X = 0 is part of a cause of ¬φ\*superscript𝜑\neg\varphi^{\*}¬ italic\_φ start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT in (M,u)𝑀@vecu(M,\@vec{u})( italic\_M , start\_ID start\_ARG italic\_u end\_ARG end\_ID ).
Then there exists some V⊆{X1,…,Xn,Y1,…,Yn}@vecVsubscript𝑋1…subscript𝑋𝑛subscript𝑌1…subscript𝑌𝑛\@vec{V}\subseteq\{X\_{1},\ldots,X\_{n},Y\_{1},\ldots,Y\_{n}\}start\_ID start\_ARG italic\_V end\_ARG end\_ID ⊆ { italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT , italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT } such that V=0∧X=0@vecV@vec0𝑋0\@vec{V}=\@vec{0}\land X=0start\_ID start\_ARG italic\_V end\_ARG end\_ID = start\_ID start\_ARG 0 end\_ARG end\_ID ∧ italic\_X = 0 is a cause of
¬φ\*superscript𝜑\neg\varphi^{\*}¬ italic\_φ start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT. The corresponding conjunction
(∧V∈V𝑖𝑛atV(tV)=0∧𝑖𝑛atX(tX)=0subscript𝑉@vecVsubscript𝑖𝑛subscript𝑎subscript𝑡𝑉subscript𝑡𝑉0subscript𝑖𝑛subscript𝑎subscript𝑡𝑋subscript𝑡𝑋0\land\_{V\in\@vec{V}}\mathit{in}\_{a\_{t\_{V}}}(t\_{V})=0\land\mathit{in}\_{a\_{t\_{X}}}(t\_{X})=0∧ start\_POSTSUBSCRIPT italic\_V ∈ start\_ID start\_ARG italic\_V end\_ARG end\_ID end\_POSTSUBSCRIPT italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT italic\_V end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT italic\_V end\_POSTSUBSCRIPT ) = 0 ∧ italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT ) = 0) is a cause
of ¬𝑝𝑓(Finish)𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ\neg\mathit{pf}(Finish)¬ italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) in (M𝒫,u𝒫)subscript𝑀𝒫subscript@vecu𝒫(M\_{\cal P},\@vec{u}\_{\cal P})( italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT , start\_ID start\_ARG italic\_u end\_ARG end\_ID start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT ), so 𝑖𝑛atX(tX)=0subscript𝑖𝑛subscript𝑎subscript𝑡𝑋subscript𝑡𝑋0\mathit{in}\_{a\_{t\_{X}}}(t\_{X})=0italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT ) = 0 is
part of a cause of ¬𝑝𝑓(Finish)𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ\neg\mathit{pf}(Finish)¬ italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ).
Conversely, suppose that 𝑖𝑛atX(tX)=0subscript𝑖𝑛subscript𝑎subscript𝑡𝑋subscript𝑡𝑋0\mathit{in}\_{a\_{t\_{X}}}(t\_{X})=0italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT ) = 0 is part of a cause of
¬𝑝𝑓(Finish)𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ\neg\mathit{pf}(Finish)¬ italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) in (M𝒫,u𝒫)subscript𝑀𝒫subscript@vecu𝒫(M\_{\cal P},\@vec{u}\_{\cal P})( italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT , start\_ID start\_ARG italic\_u end\_ARG end\_ID start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT ). Thus, there exists a set
V@vecV\@vec{V}start\_ID start\_ARG italic\_V end\_ARG end\_ID such that V=0∧𝑖𝑛atX(tX)=0@vecV@vec0subscript𝑖𝑛subscript𝑎subscript𝑡𝑋subscript𝑡𝑋0\@vec{V}=\@vec{0}\land\mathit{in}\_{a\_{t\_{X}}}(t\_{X})=0start\_ID start\_ARG italic\_V end\_ARG end\_ID = start\_ID start\_ARG 0 end\_ARG end\_ID ∧ italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT italic\_X end\_POSTSUBSCRIPT ) = 0 is a cause of
¬𝑝𝑓(Finish)𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ\neg\mathit{pf}(Finish)¬ italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) in (M𝒫,u𝒫)subscript𝑀𝒫subscript@vecu𝒫(M\_{\cal P},\@vec{u}\_{\cal P})( italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT , start\_ID start\_ARG italic\_u end\_ARG end\_ID start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT ). Note that
𝑖𝑛atWi(tWi)∉Vsubscript𝑖𝑛subscript𝑎subscript𝑡subscript𝑊𝑖subscript𝑡subscript𝑊𝑖@vecV\mathit{in}\_{a\_{t\_{W\_{i}}}}(t\_{W\_{i}})\notin\@vec{V}italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ) ∉ start\_ID start\_ARG italic\_V end\_ARG end\_ID for i=1,…,n𝑖1…𝑛i=1,\ldots,nitalic\_i = 1 , … , italic\_n. For it is easy to see that
(M𝒫,u𝒫)⊧[𝑖𝑛atWi(tWi)←1]𝑝𝑓(Finish)modelssubscript𝑀𝒫subscript@vecu𝒫delimited-[]←subscript𝑖𝑛subscript𝑎subscript𝑡subscript𝑊𝑖subscript𝑡subscript𝑊𝑖1𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ(M\_{\cal P},\@vec{u}\_{\cal P})\models[\mathit{in}\_{a\_{t\_{W\_{i}}}}(t\_{W\_{i}})\leftarrow 1]\mathit{pf}(Finish)( italic\_M start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT , start\_ID start\_ARG italic\_u end\_ARG end\_ID start\_POSTSUBSCRIPT caligraphic\_P end\_POSTSUBSCRIPT ) ⊧ [ italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ) ← 1 ] italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ), so AC3
would be violated if 𝑖𝑛atWi(tWi)∈Vsubscript𝑖𝑛subscript𝑎subscript𝑡subscript𝑊𝑖subscript𝑡subscript𝑊𝑖@vecV\mathit{in}\_{a\_{t\_{W\_{i}}}}(t\_{W\_{i}})\in\@vec{V}italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ) ∈ start\_ID start\_ARG italic\_V end\_ARG end\_ID. The same holds true
if 𝑒𝑛(tWi)∈V𝑒𝑛subscript𝑡subscript𝑊𝑖@vecV\mathit{en}(t\_{W\_{i}})\in\@vec{V}italic\_en ( italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ) ∈ start\_ID start\_ARG italic\_V end\_ARG end\_ID or if 𝑝𝑓(tWi)∈V𝑝𝑓subscript𝑡subscript𝑊𝑖@vecV\mathit{pf}(t\_{W\_{i}})\in\@vec{V}italic\_pf ( italic\_t start\_POSTSUBSCRIPT italic\_W start\_POSTSUBSCRIPT italic\_i end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ) ∈ start\_ID start\_ARG italic\_V end\_ARG end\_ID.
Next note that if 𝑒𝑛(tZ)∈V𝑒𝑛subscript𝑡𝑍@vecV\mathit{en}(t\_{Z})\in\@vec{V}italic\_en ( italic\_t start\_POSTSUBSCRIPT italic\_Z end\_POSTSUBSCRIPT ) ∈ start\_ID start\_ARG italic\_V end\_ARG end\_ID
then it can be replaced by 𝑖𝑛atZ(tZ)subscript𝑖𝑛subscript𝑎subscript𝑡𝑍subscript𝑡𝑍\mathit{in}\_{a\_{t\_{Z}}}(t\_{Z})italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT italic\_Z end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT italic\_Z end\_POSTSUBSCRIPT ),
for Z∈{X1,…,Xn,Y1,…,Yn}𝑍subscript𝑋1…subscript𝑋𝑛subscript𝑌1…subscript𝑌𝑛Z\in\{X\_{1},\ldots,X\_{n},Y\_{1},\ldots,Y\_{n}\}italic\_Z ∈ { italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT , italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT }, and similarly
for 𝑝𝑓(tZ)𝑝𝑓subscript𝑡𝑍\mathit{pf}(t\_{Z})italic\_pf ( italic\_t start\_POSTSUBSCRIPT italic\_Z end\_POSTSUBSCRIPT ). That is, if V′superscript@vecV′\@vec{V}^{\prime}start\_ID start\_ARG italic\_V end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT is the set obtained
after doing this replacement, then V∧X=0@vecV𝑋0\@vec{V}\land X=0start\_ID start\_ARG italic\_V end\_ARG end\_ID ∧ italic\_X = 0 is a cause
of ¬𝑝𝑓(Finish)𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ\neg\mathit{pf}(Finish)¬ italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ) iff V′∧X=0superscript@vecV′𝑋0\@vec{V}^{\prime}\land X=0start\_ID start\_ARG italic\_V end\_ARG end\_ID start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ∧ italic\_X = 0 is a cause
of ¬𝑝𝑓(Finish)𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ\neg\mathit{pf}(Finish)¬ italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ). The upshot of this discussion is that,
without loss of generality, we can take V@vecV\@vec{V}start\_ID start\_ARG italic\_V end\_ARG end\_ID to be a subset of
{𝑖𝑛atZ(tZ):Z∈{X1,…,Xn,Y1,…,Yn}}conditional-setsubscript𝑖𝑛subscript𝑎subscript𝑡𝑍subscript𝑡𝑍𝑍subscript𝑋1…subscript𝑋𝑛subscript𝑌1…subscript𝑌𝑛\{\mathit{in}\_{a\_{t\_{Z}}}(t\_{Z}):Z\in\{X\_{1},\ldots,X\_{n},Y\_{1},\ldots,Y\_{n}\}\}{ italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT italic\_t start\_POSTSUBSCRIPT italic\_Z end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t start\_POSTSUBSCRIPT italic\_Z end\_POSTSUBSCRIPT ) : italic\_Z ∈ { italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT , italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT } }.
It now easily follows that if V\*superscript@vecV\@vec{V}^{\*}start\_ID start\_ARG italic\_V end\_ARG end\_ID start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT is the corresponding
subset of {X1,…,Xn,Y1,…,Yn}subscript𝑋1…subscript𝑋𝑛subscript𝑌1…subscript𝑌𝑛\{X\_{1},\ldots,X\_{n},Y\_{1},\ldots,Y\_{n}\}{ italic\_X start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_X start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT , italic\_Y start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT , … , italic\_Y start\_POSTSUBSCRIPT italic\_n end\_POSTSUBSCRIPT }, then V\*=0∧X=0superscript@vecV@vec0𝑋0\@vec{V}^{\*}=\@vec{0}\land X=0start\_ID start\_ARG italic\_V end\_ARG end\_ID start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT = start\_ID start\_ARG 0 end\_ARG end\_ID ∧ italic\_X = 0 is a cause of ¬φ\*superscript𝜑\neg\varphi^{\*}¬ italic\_φ start\_POSTSUPERSCRIPT \* end\_POSTSUPERSCRIPT in (M,u)𝑀𝑢(M,u)( italic\_M , italic\_u ). This completes
the proof for part of a cause.
The argument for the degree of responsibility is similar to
Theorem [5.2](#S5.ThmTHEOREM2 "Theorem 5.2 ‣ 5 The Complexity of Causality for Monotone Models ‣ Causality, Responsibility and Blame in Team Plans")(e). For the upper bound, we guess a cause
where the proportion of
a𝑎aitalic\_a-controlled variables with value 0 is greater or equal to
m/k𝑚𝑘m/kitalic\_m / italic\_k. Then we can check in polynomial time that it is indeed a cause
of ¬𝑝𝑓(Finish)𝑝𝑓𝐹𝑖𝑛𝑖𝑠ℎ\neg\mathit{pf}(Finish)¬ italic\_pf ( italic\_F italic\_i italic\_n italic\_i italic\_s italic\_h ). The lower bound follows from the previous
argument (for the special case when
m=1𝑚1m=1italic\_m = 1 and the degree of responsibility of an agent atsubscript𝑎𝑡a\_{t}italic\_a start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT is the same as
the degree of responsibility of 𝑖𝑛at(t)subscript𝑖𝑛subscript𝑎𝑡𝑡\mathit{in}\_{a\_{t}}(t)italic\_in start\_POSTSUBSCRIPT italic\_a start\_POSTSUBSCRIPT italic\_t end\_POSTSUBSCRIPT end\_POSTSUBSCRIPT ( italic\_t )), as in
Theorem [5.2](#S5.ThmTHEOREM2 "Theorem 5.2 ‣ 5 The Complexity of Causality for Monotone Models ‣ Causality, Responsibility and Blame in Team Plans")(e).
6 Conclusions
--------------
We have shown how the definitions of causality, responsibility and blame from
[Hal47](#bib.bib11) can be used to give useful insights in the context of team plans.
We also showed that the resulting problems are tractable:
causality
for team plans can be computed in polynomial time, while the problem of
determining the degree of responsibility and blame is NP-complete; for postcondition minimal plans, the degree of
responsibility and blame can be computed in polynomial time.
We can extend our model with external events (or actions by an environment
agent) without increase in complexity. We chose not to consider events here,
as we are concerned only with allocating responsibility and blame to
agents (rather than to the environment). In future work, we would like to
consider a richer setting, where agents may be able to perform actions that
decrease the probability of plan failure due to external events.
The epistemic perspective of the paper is that of an outside observer
rather than the agents. In future work we plan to model agents
reasoning about the progress of plan execution, which would involve
their beliefs about what is happening and who is to blame for the
failure of the plan. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.