
modelId stringlengths 4 111 | lastModified stringlengths 24 24 | tags list | pipeline_tag stringlengths 5 30 ⌀ | author stringlengths 2 34 ⌀ | config null | securityStatus null | id stringlengths 4 111 | likes int64 0 9.53k | downloads int64 2 73.6M | library_name stringlengths 2 84 ⌀ | created timestamp[us] | card stringlengths 101 901k | card_len int64 101 901k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
ku-nlp/deberta-v2-large-japanese | 2023-05-12T14:10:35.000Z | [
"transformers",
"pytorch",
"safetensors",
"deberta-v2",
"fill-mask",
"deberta",
"ja",
"dataset:wikipedia",
"dataset:cc100",
"dataset:oscar",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | ku-nlp | null | null | ku-nlp/deberta-v2-large-japanese | 5 | 3,781 | transformers | 2023-01-07T07:45:25 | ---
language: ja
license: cc-by-sa-4.0
library_name: transformers
tags:
- deberta
- deberta-v2
- fill-mask
datasets:
- wikipedia
- cc100
- oscar
metrics:
- accuracy
mask_token: "[MASK]"
widget:
- text: "京都 大学 で 自然 言語 処理 を [MASK] する 。"
---
# Model Card for Japanese DeBERTa V2 large
## Model description
This is a Japanese DeBERTa V2 large model pre-trained on Japanese Wikipedia, the Japanese portion of CC-100, and the
Japanese portion of OSCAR.
## How to use
You can use this model for masked language modeling as follows:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('ku-nlp/deberta-v2-large-japanese')
model = AutoModelForMaskedLM.from_pretrained('ku-nlp/deberta-v2-large-japanese')
sentence = '京都 大学 で 自然 言語 処理 を [MASK] する 。' # input should be segmented into words by Juman++ in advance
encoding = tokenizer(sentence, return_tensors='pt')
...
```
You can also fine-tune this model on downstream tasks.
## Tokenization
The input text should be segmented into words by [Juman++](https://github.com/ku-nlp/jumanpp) in
advance. [Juman++ 2.0.0-rc3](https://github.com/ku-nlp/jumanpp/releases/tag/v2.0.0-rc3) was used for pre-training. Each
word is tokenized into subwords by [sentencepiece](https://github.com/google/sentencepiece).
## Training data
We used the following corpora for pre-training:
- Japanese Wikipedia (as of 20221020, 3.2GB, 27M sentences, 1.3M documents)
- Japanese portion of CC-100 (85GB, 619M sentences, 66M documents)
- Japanese portion of OSCAR (54GB, 326M sentences, 25M documents)
Note that we filtered out documents annotated with "header", "footer", or "noisy" tags in OSCAR.
Also note that Japanese Wikipedia was duplicated 10 times to make the total size of the corpus comparable to that of
CC-100 and OSCAR. As a result, the total size of the training data is 171GB.
## Training procedure
We first segmented texts in the corpora into words using [Juman++](https://github.com/ku-nlp/jumanpp).
Then, we built a sentencepiece model with 32000 tokens including words ([JumanDIC](https://github.com/ku-nlp/JumanDIC))
and subwords induced by the unigram language model of [sentencepiece](https://github.com/google/sentencepiece).
We tokenized the segmented corpora into subwords using the sentencepiece model and trained the Japanese DeBERTa model
using [transformers](https://github.com/huggingface/transformers) library.
The training took 36 days using 8 NVIDIA A100-SXM4-40GB GPUs.
The following hyperparameters were used during pre-training:
- learning_rate: 1e-4
- per_device_train_batch_size: 18
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 16
- total_train_batch_size: 2,304
- max_seq_length: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-06
- lr_scheduler_type: linear schedule with warmup
- training_steps: 300,000
- warmup_steps: 10,000
The accuracy of the trained model on the masked language modeling task was 0.799.
The evaluation set consists of 5,000 randomly sampled documents from each of the training corpora.
## Fine-tuning on NLU tasks
We fine-tuned the following models and evaluated them on the dev set of JGLUE.
We tuned learning rate and training epochs for each model and task
following [the JGLUE paper](https://www.jstage.jst.go.jp/article/jnlp/30/1/30_63/_pdf/-char/ja).
| Model | MARC-ja/acc | JSTS/pearson | JSTS/spearman | JNLI/acc | JSQuAD/EM | JSQuAD/F1 | JComQA/acc |
|-------------------------------|-------------|--------------|---------------|----------|-----------|-----------|------------|
| Waseda RoBERTa base | 0.965 | 0.913 | 0.876 | 0.905 | 0.853 | 0.916 | 0.853 |
| Waseda RoBERTa large (seq512) | 0.969 | 0.925 | 0.890 | 0.928 | 0.910 | 0.955 | 0.900 |
| LUKE Japanese base* | 0.965 | 0.916 | 0.877 | 0.912 | - | - | 0.842 |
| LUKE Japanese large* | 0.965 | 0.932 | 0.902 | 0.927 | - | - | 0.893 |
| DeBERTaV2 base | 0.970 | 0.922 | 0.886 | 0.922 | 0.899 | 0.951 | 0.873 |
| DeBERTaV2 large | 0.968 | 0.925 | 0.892 | 0.924 | 0.912 | 0.959 | 0.890 |
*The scores of LUKE are from [the official repository](https://github.com/studio-ousia/luke).
## Acknowledgments
This work was supported by Joint Usage/Research Center for Interdisciplinary Large-scale Information Infrastructures (
JHPCN) through General Collaboration Project no. jh221004, "Developing a Platform for Constructing and Sharing of
Large-Scale Japanese Language Models".
For training models, we used the mdx: a platform for the data-driven future.
| 4,861 | [
[
-0.040283203125,
-0.068359375,
0.025299072265625,
-0.007076263427734375,
-0.0261383056640625,
0.0027008056640625,
-0.0270843505859375,
-0.032562255859375,
0.0283050537109375,
0.036712646484375,
-0.0438232421875,
-0.052581787109375,
-0.0528564453125,
0.001351... |
ibm/knowgl-large | 2023-03-16T17:01:06.000Z | [
"transformers",
"pytorch",
"safetensors",
"bart",
"text2text-generation",
"seq2seq",
"relation-extraction",
"triple-generation",
"entity-linking",
"entity-type-linking",
"relation-linking",
"en",
"dataset:Babelscape/rebel-dataset",
"arxiv:2210.13952",
"arxiv:2207.05188",
"license:cc-by... | text2text-generation | ibm | null | null | ibm/knowgl-large | 43 | 3,774 | transformers | 2022-09-20T16:10:09 | ---
language:
- en
license: cc-by-nc-sa-4.0
tags:
- seq2seq
- relation-extraction
- triple-generation
- entity-linking
- entity-type-linking
- relation-linking
datasets: Babelscape/rebel-dataset
widget:
- text: The Italian Space Agency’s Light Italian CubeSat for Imaging of Asteroids,
or LICIACube, will fly by Dimorphos to capture images and video of the impact
plume as it sprays up off the asteroid and maybe even spy the crater it could
leave behind.
model-index:
- name: knowgl
results:
- task:
type: Relation-Extraction
name: Relation Extraction
dataset:
name: Babelscape/rebel-dataset
type: REBEL
metrics:
- type: re+ macro f1
value: 70.74
name: RE+ Macro F1
---
# KnowGL: Knowledge Generation and Linking from Text
The `knowgl-large` model is trained by combining Wikidata with an extended version of the training data in the [REBEL](https://huggingface.co/datasets/Babelscape/rebel-dataset) dataset. Given a sentence, KnowGL generates triple(s) in the following format:
```
[(subject mention # subject label # subject type) | relation label | (object mention # object label # object type)]
```
If there are more than one triples generated, they are separated by `$` in the output. More details in [Rossiello et al. (AAAI 2023)](https://arxiv.org/pdf/2210.13952.pdf).
The model achieves state-of-the-art results for relation extraction on the REBEL dataset. See results in [Mihindukulasooriya et al. (ISWC 2022)](https://arxiv.org/pdf/2207.05188.pdf).
The generated labels (for the subject, relation, and object) and their types can be directly mapped to Wikidata IDs associated with them.
#### Citation
```bibtex
@inproceedings{knowgl-aaai_2023_demo,
author = {Gaetano Rossiello and
Md. Faisal Mahbub Chowdhury and
Nandana Mihindukulasooriya and
Owen Cornec and
Alfio Gliozzo},
title = {KnowGL: Knowledge Generation and Linking from Text},
booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence}
year = {2023}
}
```
```bibtex
@inproceedings{DBLP:conf/semweb/Mihindukulasooriya22,
author = {Nandana Mihindukulasooriya and
Mike Sava and
Gaetano Rossiello and
Md. Faisal Mahbub Chowdhury and
Irene Yachbes and
Aditya Gidh and
Jillian Duckwitz and
Kovit Nisar and
Michael Santos and
Alfio Gliozzo},
title = {Knowledge Graph Induction Enabling Recommending and Trend Analysis:
{A} Corporate Research Community Use Case},
booktitle = {{ISWC}},
series = {Lecture Notes in Computer Science},
volume = {13489},
pages = {827--844},
publisher = {Springer},
year = {2022}
}
``` | 2,835 | [
[
-0.032745361328125,
-0.0616455078125,
0.0379638671875,
-0.020294189453125,
0.0009131431579589844,
-0.00868988037109375,
-0.0167999267578125,
-0.051422119140625,
0.00597381591796875,
0.040435791015625,
-0.0487060546875,
-0.056732177734375,
-0.0282135009765625,
... |
timm/tf_mobilenetv3_small_075.in1k | 2023-04-27T22:49:51.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1905.02244",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tf_mobilenetv3_small_075.in1k | 0 | 3,774 | timm | 2022-12-16T05:39:15 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tf_mobilenetv3_small_075.in1k
A MobileNet-v3 image classification model. Trained on ImageNet-1k in Tensorflow by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 2.0
- GMACs: 0.0
- Activations (M): 1.3
- Image size: 224 x 224
- **Papers:**
- Searching for MobileNetV3: https://arxiv.org/abs/1905.02244
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tf_mobilenetv3_small_075.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_mobilenetv3_small_075.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 112, 112])
# torch.Size([1, 16, 56, 56])
# torch.Size([1, 24, 28, 28])
# torch.Size([1, 40, 14, 14])
# torch.Size([1, 432, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tf_mobilenetv3_small_075.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 432, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{howard2019searching,
title={Searching for mobilenetv3},
author={Howard, Andrew and Sandler, Mark and Chu, Grace and Chen, Liang-Chieh and Chen, Bo and Tan, Mingxing and Wang, Weijun and Zhu, Yukun and Pang, Ruoming and Vasudevan, Vijay and others},
booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
pages={1314--1324},
year={2019}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 4,158 | [
[
-0.0308685302734375,
-0.0261993408203125,
-0.001422882080078125,
0.0093536376953125,
-0.0275726318359375,
-0.028900146484375,
-0.00811004638671875,
-0.0269775390625,
0.0207672119140625,
0.029296875,
-0.023345947265625,
-0.05810546875,
-0.046844482421875,
-0.... |
AIDA-UPM/mstsb-paraphrase-multilingual-mpnet-base-v2 | 2021-07-13T14:12:45.000Z | [
"transformers",
"pytorch",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"multilingual",
"endpoints_compatible",
"region:us"
] | sentence-similarity | AIDA-UPM | null | null | AIDA-UPM/mstsb-paraphrase-multilingual-mpnet-base-v2 | 11 | 3,767 | transformers | 2022-03-02T23:29:04 | ---
pipeline_tag: sentence-similarity
language: "multilingual"
tags:
- feature-extraction
- sentence-similarity
- transformers
- multilingual
---
# mstsb-paraphrase-multilingual-mpnet-base-v2
This is a fine-tuned version of `paraphrase-multilingual-mpnet-base-v2` from [sentence-transformers](https://www.SBERT.net) model with [Semantic Textual Similarity Benchmark](http://ixa2.si.ehu.eus/stswiki/index.php/Main_Page) extended to 15 languages: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering, semantic search and measuring the similarity between two sentences.
<!--- Describe your model here -->
This model is fine-tuned version of `paraphrase-multilingual-mpnet-base-v2` for semantic textual similarity with multilingual data. The dataset used for this fine-tuning is STSb extended to 15 languages with Google Translator. For mantaining data quality the sentence pairs with a confidence value below 0.7 were dropped. The extended dataset is available at [GitHub](https://github.com/Huertas97/Multilingual-STSB). The languages included in the extended version are: ar, cs, de, en, es, fr, hi, it, ja, nl, pl, pt, ru, tr, zh-CN, zh-TW. The pooling operation used to condense the word embeddings into a sentence embedding is mean pooling (more info below).
<!-- ## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
# It support several languages
sentences = ["This is an example sentence", "Esta es otra frase de ejemplo", "最後の例文"]
# The pooling technique is automatically detected (mean pooling)
model = SentenceTransformer('mstsb-paraphrase-multilingual-mpnet-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
``` -->
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# We should define the proper pooling function: Mean pooling
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ["This is an example sentence", "Esta es otra frase de ejemplo", "最後の例文"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('AIDA-UPM/mstsb-paraphrase-multilingual-mpnet-base-v2')
model = AutoModel.from_pretrained('AIDA-UPM/mstsb-paraphrase-multilingual-mpnet-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
Check the test results in the Semantic Textual Similarity Tasks. The 15 languages available at the [Multilingual STSB](https://github.com/Huertas97/Multilingual-STSB) have been combined into monolingual and cross-lingual tasks, giving a total of 31 tasks. Monolingual tasks have both sentences from the same language source (e.g., Ar-Ar, Es-Es), while cross-lingual tasks have two sentences, each in a different language being one of them English (e.g., en-ar, en-es).
Here we compare the average multilingual semantic textual similairty capabilities between the `paraphrase-multilingual-mpnet-base-v2` based model and the `mstsb-paraphrase-multilingual-mpnet-base-v2` fine-tuned model across the 31 tasks. It is worth noting that both models are multilingual, but the second model is adjusted with multilingual data for semantic similarity. The average of correlation coefficients is computed by transforming each correlation coefficient to a Fisher's z value, averaging them, and then back-transforming to a correlation coefficient.
| Model | Average Spearman Cosine Test |
|:---------------------------------------------:|:------------------------------:|
| mstsb-paraphrase-multilingual-mpnet-base-v2 | 0.835890 |
| paraphrase-multilingual-mpnet-base-v2 | 0.818896 |
<br>
The following tables breakdown the performance of `mstsb-paraphrase-multilingual-mpnet-base-v2` according to the different tasks. For the sake of readability tasks have been splitted into monolingual and cross-lingual tasks.
| Monolingual Task | Pearson Cosine test | Spearman Cosine test |
|:------------------:|:---------------------:|:-----------------------:|
| en;en | 0.868048310692506 | 0.8740170943535747 |
| ar;ar | 0.8267139454193487 | 0.8284459741532022 |
| cs;cs | 0.8466821720942157 | 0.8485417688803879 |
| de;de | 0.8517285961812183 | 0.8557680051557893 |
| es;es | 0.8519185309064691 | 0.8552243211580456 |
| fr;fr | 0.8430951067985064 | 0.8466614534379704 |
| hi;hi | 0.8178258630578092 | 0.8176462079184331 |
| it;it | 0.8475909574305637 | 0.8494216064459076 |
| ja;ja | 0.8435588859386477 | 0.8456031494178619 |
| nl;nl | 0.8486765104527032 | 0.8520856765262531 |
| pl;pl | 0.8407840177883407 | 0.8443070467300299 |
| pt;pt | 0.8534880178249296 | 0.8578544068829622 |
| ru;ru | 0.8390897585455678 | 0.8423041443534423 |
| tr;tr | 0.8382125451820572 | 0.8421587450058385 |
| zh-CN;zh-CN | 0.826233678946644 | 0.8248515460782744 |
| zh-TW;zh-TW | 0.8242683809675422 | 0.8235506799952028 |
<br>
| Cross-lingual Task | Pearson Cosine test | Spearman Cosine test |
|:--------------------:|:---------------------:|:-----------------------:|
| en;ar | 0.7990830340462535 | 0.7956792016468148 |
| en;cs | 0.8381274879061265 | 0.8388713450024455 |
| en;de | 0.8414439600928739 | 0.8441971698649943 |
| en;es | 0.8442337511356952 | 0.8445035292903559 |
| en;fr | 0.8378437644605063 | 0.8387903367907733 |
| en;hi | 0.7951955086055527 | 0.7905052217683244 |
| en;it | 0.8415686372978766 | 0.8419480899107785 |
| en;ja | 0.8094306665283388 | 0.8032512280936449 |
| en;nl | 0.8389526140129767 | 0.8409310421803277 |
| en;pl | 0.8261309163979578 | 0.825976253023656 |
| en;pt | 0.8475546209070765 | 0.8506606391790897 |
| en;ru | 0.8248514914263723 | 0.8224871183202255 |
| en;tr | 0.8191803661207868 | 0.8194200775744044 |
| en;zh-CN | 0.8147678083378249 | 0.8102089470690433 |
| en;zh-TW | 0.8107272160374955 | 0.8056129680510944 |
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 687 with parameters:
```
{'batch_size': 132, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"callback": null,
"epochs": 2,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 140,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> | 8,901 | [
[
-0.0278778076171875,
-0.053619384765625,
0.0273284912109375,
0.0194244384765625,
-0.024261474609375,
-0.0167999267578125,
-0.01111602783203125,
-0.01071929931640625,
0.0264129638671875,
0.0205078125,
-0.02783203125,
-0.03924560546875,
-0.051239013671875,
0.0... |
timm/convnextv2_nano.fcmae_ft_in22k_in1k | 2023-03-31T23:39:29.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2301.00808",
"license:cc-by-nc-4.0",
"region:us"
] | image-classification | timm | null | null | timm/convnextv2_nano.fcmae_ft_in22k_in1k | 0 | 3,767 | timm | 2023-01-05T01:55:39 | ---
tags:
- image-classification
- timm
library_tag: timm
license: cc-by-nc-4.0
datasets:
- imagenet-1k
- imagenet-1k
---
# Model card for convnextv2_nano.fcmae_ft_in22k_in1k
A ConvNeXt-V2 image classification model. Pretrained with a fully convolutional masked autoencoder framework (FCMAE) and fine-tuned on ImageNet-22k and then ImageNet-1k.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 15.6
- GMACs: 2.5
- Activations (M): 8.4
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders: https://arxiv.org/abs/2301.00808
- **Original:** https://github.com/facebookresearch/ConvNeXt-V2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnextv2_nano.fcmae_ft_in22k_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_nano.fcmae_ft_in22k_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 80, 56, 56])
# torch.Size([1, 160, 28, 28])
# torch.Size([1, 320, 14, 14])
# torch.Size([1, 640, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_nano.fcmae_ft_in22k_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 640, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{Woo2023ConvNeXtV2,
title={ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders},
author={Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon and Saining Xie},
year={2023},
journal={arXiv preprint arXiv:2301.00808},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,832 | [
[
-0.0689697265625,
-0.031402587890625,
-0.005268096923828125,
0.03619384765625,
-0.03155517578125,
-0.01428985595703125,
-0.012481689453125,
-0.034942626953125,
0.06317138671875,
0.0177154541015625,
-0.04486083984375,
-0.0384521484375,
-0.053070068359375,
-0.... |
adsabs/astroBERT | 2023-05-12T19:03:53.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"pretraining",
"fill-mask",
"en",
"arxiv:2112.00590",
"license:mit",
"endpoints_compatible",
"region:us"
] | fill-mask | adsabs | null | null | adsabs/astroBERT | 8 | 3,765 | transformers | 2022-06-28T20:17:48 | ---
license: mit
language:
- en
task_categories:
- fill-mask
task_ids:
- masked-language-modeling
pipeline_tag: fill-mask
widget:
- text: "M67 is one of the most studied [MASK] clusters."
example_title: "M67"
- text: "A solar twin is a star with [MASK] parameters and chemical composition very similar to our Sun."
example_title: "solar twin"
- text: "The dynamical evolution of planets close to their star is affected by [MASK] effects"
example_title: "dynamical evolution"
- text: "The Kepler satellite collected high-precision long-term and continuous light [MASK] for more than 100,000 solar-type stars"
example_title: "Kepler satellite"
- text: "The Local Group is composed of the Milky Way, the [MASK] Galaxy, and numerous smaller satellite galaxies."
example_title: "Local Group"
- text: "Cepheid variables are used to determine the [MASK] to galaxies in the local universe."
example_title: "Cepheid"
- text: "Jets are created and sustained by [MASK] of matter onto a compact massive object."
example_title: "Jets"
- text: "A single star of one solar mass will evolve into a [MASK] dwarf."
example_title: "single star"
- text: "The Very Large Array observes the sky at [MASK] wavelengths."
example_title: "Very Large Array"
- text: "Elements heavier than [MASK] are generated in supernovae explosions."
example_title: "Elements"
- text: "Spitzer was the first [MASK] to fly in an Earth-trailing orbit."
example_title: "Spitzer"
- text: "Galaxy [MASK] can occur when two (or more) galaxies collide"
example_title: "galaxies collide"
- text: "Dark [MASK] is a hypothetical form of matter thought to account for approximately 85% of the matter in the universe."
example_title: "hypothetical matter"
- text: "The cosmic microwave background (CMB, CMBR), in Big Bang cosmology, is electromagnetic radiation which is a remnant from an early stage of the [MASK]."
example_title: "CMBR"
- text: "The Local Group of galaxies is pulled toward The Great [MASK]."
example_title: "galaxies pulled"
- text: "The Moon is the only [MASK] of the Earth."
example_title: "Moon"
- text: "Galaxies are categorized according to their visual morphology as [MASK], spiral, or irregular."
example_title: "morphology"
- text: "Stars are made mostly of [MASK]."
example_title: "Stars moslyl"
- text: "Comet tails are created as comets approach the [MASK]."
example_title: "Comet tails"
- text: "Pluto is a dwarf [MASK] in the Kuiper Belt."
example_title: "Pluto"
- text: "The Large and Small Magellanic Clouds are irregular [MASK] galaxies and are two satellite galaxies of the Milky Way."
example_title: "Magellanic Clouds"
- text: "The Milky Way has a [MASK] black hole, Sagittarius A*, at its center."
example_title: "Milky Way"
- text: "Andromeda is the nearest large [MASK] to the Milky Way and is roughly its equal in mass."
example_title: "Andromeda"
- text: "The [MASK] medium is the gas and dust between stars."
example_title: "gast and dust"
---
# ***astroBERT: a language model for astrophysics***
This public repository contains the work of the [NASA/ADS](https://ui.adsabs.harvard.edu/) on building an NLP language model tailored to astrophysics, along with tutorials and miscellaneous related files.
This model is **cased** (it treats `ads` and `ADS` differently).
## astroBERT models
0. **Base model**: Pretrained model on English language using a masked language modeling (MLM) and next sentence prediction (NSP) objective. It was introduced in [this paper at ADASS 2021](https://arxiv.org/abs/2112.00590) and made public at ADASS 2022.
1. **NER-DEAL model**: This model adds a token classification head to the base model finetuned on the [DEAL@WIESP2022 named entity recognition](https://ui.adsabs.harvard.edu/WIESP/2022/SharedTasks) task. Must be loaded from the `revision='NER-DEAL'` branch (see tutorial 2).
2. **SciX Categorizer**: This model was finetuned to classify text into one of 7 categories of interest to SciX (Astronomy, Heliophysics, Planetary Science, Earth Science, NASA-funded Biophysics, Other Physics, Other, Text Garbage).
### Tutorials
0. [generate text embedding (for downstream tasks)](https://nbviewer.org/urls/huggingface.co/adsabs/astroBERT/raw/main/Tutorials/0_Embeddings.ipynb)
1. [use astroBERT for the Fill-Mask task](https://nbviewer.org/urls/huggingface.co/adsabs/astroBERT/raw/main/Tutorials/1_Fill-Mask.ipynb)
2. [make NER-DEAL predictions](https://nbviewer.org/urls/huggingface.co/adsabs/astroBERT/raw/main/Tutorials/2_NER_DEAL.ipynb)
3. [categorize texts for SciX](https://nbviewer.org/urls/huggingface.co/adsabs/astroBERT/raw/main/Tutorials/3_SciX_Categorizer.ipynb)
### BibTeX
```bibtex
@ARTICLE{2021arXiv211200590G,
author = {{Grezes}, Felix and {Blanco-Cuaresma}, Sergi and {Accomazzi}, Alberto and {Kurtz}, Michael J. and {Shapurian}, Golnaz and {Henneken}, Edwin and {Grant}, Carolyn S. and {Thompson}, Donna M. and {Chyla}, Roman and {McDonald}, Stephen and {Hostetler}, Timothy W. and {Templeton}, Matthew R. and {Lockhart}, Kelly E. and {Martinovic}, Nemanja and {Chen}, Shinyi and {Tanner}, Chris and {Protopapas}, Pavlos},
title = "{Building astroBERT, a language model for Astronomy \& Astrophysics}",
journal = {arXiv e-prints},
keywords = {Computer Science - Computation and Language, Astrophysics - Instrumentation and Methods for Astrophysics},
year = 2021,
month = dec,
eid = {arXiv:2112.00590},
pages = {arXiv:2112.00590},
archivePrefix = {arXiv},
eprint = {2112.00590},
primaryClass = {cs.CL},
adsurl = {https://ui.adsabs.harvard.edu/abs/2021arXiv211200590G},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
``` | 5,720 | [
[
-0.031005859375,
-0.052093505859375,
0.0249481201171875,
0.014892578125,
0.005504608154296875,
0.0080718994140625,
-0.01885986328125,
-0.04296875,
0.042388916015625,
0.04833984375,
-0.02264404296875,
-0.052520751953125,
-0.0447998046875,
-0.00602340698242187... |
Yntec/RealRainbows | 2023-07-23T20:12:01.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Cisney_Gassai",
"PatchMonk",
"rainbowpatch",
"Realisian",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/RealRainbows | 0 | 3,763 | diffusers | 2023-07-23T19:28:16 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- Cisney_Gassai
- PatchMonk
- rainbowpatch
- Realisian
---
# RealRainbows
A mix of Realisian by Cisney_Gassai and Rainbowpath by PatchMonk. You can use "Rainbowpath" in the prompt to enhance the style.
Original pages:
https://civitai.com/models/5528/rainbowpatch
https://civitai.com/models/47130?modelVersionId=51711 | 489 | [
[
-0.038543701171875,
-0.053131103515625,
0.00201416015625,
0.06414794921875,
-0.02606201171875,
0.039581298828125,
0.033050537109375,
-0.0751953125,
0.07763671875,
0.0228729248046875,
-0.097900390625,
-0.0015621185302734375,
-0.0203399658203125,
0.01458740234... |
yiyanghkust/finbert-esg | 2022-10-17T00:36:19.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"financial-text-analysis",
"esg",
"environmental-social-corporate-governance",
"en",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | yiyanghkust | null | null | yiyanghkust/finbert-esg | 30 | 3,762 | transformers | 2022-05-12T06:53:32 | ---
language: "en"
tags:
- financial-text-analysis
- esg
- environmental-social-corporate-governance
widget:
- text: "Rhonda has been volunteering for several years for a variety of charitable community programs. "
---
ESG analysis can help investors determine a business' long-term sustainability and identify associated risks. FinBERT-ESG is a FinBERT model fine-tuned on 2,000 manually annotated sentences from firms' ESG reports and annual reports.
**Input**: A financial text.
**Output**: Environmental, Social, Governance or None.
# How to use
You can use this model with Transformers pipeline for ESG classification.
```python
# tested in transformers==4.18.0
from transformers import BertTokenizer, BertForSequenceClassification, pipeline
finbert = BertForSequenceClassification.from_pretrained('yiyanghkust/finbert-esg',num_labels=4)
tokenizer = BertTokenizer.from_pretrained('yiyanghkust/finbert-esg')
nlp = pipeline("text-classification", model=finbert, tokenizer=tokenizer)
results = nlp('Rhonda has been volunteering for several years for a variety of charitable community programs.')
print(results) # [{'label': 'Social', 'score': 0.9906041026115417}]
```
Visit [FinBERT.AI](https://finbert.ai/) for more details on the recent development of FinBERT.
If you use the model in your academic work, please cite the following paper:
Huang, Allen H., Hui Wang, and Yi Yang. "FinBERT: A Large Language Model for Extracting Information from Financial Text." *Contemporary Accounting Research* (2022).
| 1,521 | [
[
-0.023590087890625,
-0.071533203125,
0.0208740234375,
0.002948760986328125,
-0.020721435546875,
0.0007891654968261719,
-0.01023101806640625,
-0.048797607421875,
0.016143798828125,
0.055084228515625,
-0.044464111328125,
-0.04693603515625,
-0.058135986328125,
... |
VietAI/vit5-base | 2022-09-27T18:09:26.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"summarization",
"translation",
"question-answering",
"vi",
"dataset:cc100",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | question-answering | VietAI | null | null | VietAI/vit5-base | 3 | 3,758 | transformers | 2022-03-14T16:36:06 | ---
language: vi
datasets:
- cc100
tags:
- summarization
- translation
- question-answering
license: mit
---
# ViT5-base
State-of-the-art pretrained Transformer-based encoder-decoder model for Vietnamese.
## How to use
For more details, do check out [our Github repo](https://github.com/vietai/ViT5).
[Finetunning Example can be found here](https://github.com/vietai/ViT5/tree/main/finetunning_huggingface).
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("VietAI/vit5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("VietAI/vit5-base")
model.cuda()
```
## Citation
```
@inproceedings{phan-etal-2022-vit5,
title = "{V}i{T}5: Pretrained Text-to-Text Transformer for {V}ietnamese Language Generation",
author = "Phan, Long and Tran, Hieu and Nguyen, Hieu and Trinh, Trieu H.",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Student Research Workshop",
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-srw.18",
pages = "136--142",
}
``` | 1,220 | [
[
-0.010894775390625,
-0.036346435546875,
0.01445770263671875,
0.02386474609375,
-0.035247802734375,
-0.008026123046875,
-0.0158538818359375,
0.00081634521484375,
-0.00884246826171875,
0.0299224853515625,
-0.03070068359375,
-0.044036865234375,
-0.045135498046875,
... |
timm/tinynet_c.in1k | 2023-04-27T21:50:26.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2010.14819",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tinynet_c.in1k | 0 | 3,750 | timm | 2022-12-13T00:22:13 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tinynet_c.in1k
A TinyNet image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 2.5
- GMACs: 0.1
- Activations (M): 2.9
- Image size: 184 x 184
- **Papers:**
- Model rubik's cube: Twisting resolution, depth and width for tinynets: https://arxiv.org/abs/2010.14819v2
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tinynet_c.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tinynet_c.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 8, 92, 92])
# torch.Size([1, 16, 46, 46])
# torch.Size([1, 24, 23, 23])
# torch.Size([1, 64, 12, 12])
# torch.Size([1, 176, 6, 6])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tinynet_c.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1280, 6, 6) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{han2020model,
title={Model rubik’s cube: Twisting resolution, depth and width for tinynets},
author={Han, Kai and Wang, Yunhe and Zhang, Qiulin and Zhang, Wei and Xu, Chunjing and Zhang, Tong},
journal={Advances in Neural Information Processing Systems},
volume={33},
pages={19353--19364},
year={2020}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,928 | [
[
-0.033111572265625,
-0.037078857421875,
0.004070281982421875,
0.0004820823669433594,
-0.0206146240234375,
-0.0278778076171875,
-0.018798828125,
-0.0272979736328125,
0.0197296142578125,
0.0272979736328125,
-0.0310516357421875,
-0.04443359375,
-0.04559326171875,
... |
mental/mental-bert-base-uncased | 2023-02-27T20:07:55.000Z | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"mental health",
"en",
"arxiv:2110.15621",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | mental | null | null | mental/mental-bert-base-uncased | 18 | 3,742 | transformers | 2022-03-02T23:29:05 | ---
license: cc-by-nc-4.0
language:
- en
library_name: transformers
tags:
- mental health
---
# MentalBERT
[MentalBERT](https://arxiv.org/abs/2110.15621) is a model initialized with BERT-Base (`uncased_L-12_H-768_A-12`) and trained with mental health-related posts collected from Reddit.
We follow the standard pretraining protocols of BERT and RoBERTa with [Huggingface’s Transformers library](https://github.com/huggingface/transformers).
We use four Nvidia Tesla v100 GPUs to train the two language models. We set the batch size to 16 per GPU, evaluate every 1,000 steps, and train for 624,000 iterations. Training with four GPUs takes around eight days.
More domain-specific pretrained models for mental health are available at https://huggingface.co/AIMH
## Usage
Load the model via [Huggingface’s Transformers library](https://github.com/huggingface/transformers):
```
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("mental/mental-bert-base-uncased")
model = AutoModel.from_pretrained("mental/mental-bert-base-uncased")
```
To minimize the influence of worrying mask predictions, this model is gated. To download a gated model, you’ll need to be authenticated.
Know more about [gated models](https://huggingface.co/docs/hub/models-gated).
## Paper
For more details, refer to the paper [MentalBERT: Publicly Available Pretrained Language Models for Mental Healthcare](https://arxiv.org/abs/2110.15621).
```
@inproceedings{ji2022mentalbert,
title = {{MentalBERT: Publicly Available Pretrained Language Models for Mental Healthcare}},
author = {Shaoxiong Ji and Tianlin Zhang and Luna Ansari and Jie Fu and Prayag Tiwari and Erik Cambria},
year = {2022},
booktitle = {Proceedings of LREC}
}
```
## Social Impact
We train and release masked language models for mental health to facilitate the automatic detection of mental disorders in online social content for non-clinical use.
The models may help social workers find potential individuals in need of early prevention.
However, the model predictions are not psychiatric diagnoses.
We recommend anyone who suffers from mental health issues to call the local mental health helpline and seek professional help if possible.
Data privacy is an important issue, and we try to minimize the privacy impact when using social posts for model training.
During the data collection process, we only use anonymous posts that are manifestly available to the public.
We do not collect user profiles even though they are also manifestly public online.
We have not attempted to identify the anonymous users or interact with any anonymous users.
The collected data are stored securely with password protection even though they are collected from the open web.
There might also be some bias, fairness, uncertainty, and interpretability issues during the data collection and model training.
Evaluation of those issues is essential in future research. | 2,971 | [
[
-0.043121337890625,
-0.056671142578125,
0.040679931640625,
0.02618408203125,
-0.009552001953125,
-0.01177215576171875,
-0.0269622802734375,
-0.048858642578125,
0.01239013671875,
0.022674560546875,
-0.0628662109375,
-0.040374755859375,
-0.061065673828125,
-0.... |
ku-nlp/deberta-v2-tiny-japanese-char-wwm | 2023-03-23T07:31:19.000Z | [
"transformers",
"pytorch",
"safetensors",
"deberta-v2",
"fill-mask",
"deberta",
"character",
"wwm",
"ja",
"dataset:wikipedia",
"dataset:cc100",
"dataset:oscar",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | ku-nlp | null | null | ku-nlp/deberta-v2-tiny-japanese-char-wwm | 0 | 3,740 | transformers | 2023-01-05T08:48:29 | ---
language: ja
license: cc-by-sa-4.0
library_name: transformers
tags:
- deberta
- deberta-v2
- fill-mask
- character
- wwm
datasets:
- wikipedia
- cc100
- oscar
metrics:
- accuracy
mask_token: "[MASK]"
widget:
- text: "京都大学で自然言語処理を[MASK][MASK]する。"
---
# Model Card for Japanese character-level DeBERTa V2 tiny
## Model description
This is a Japanese DeBERTa V2 tiny model pre-trained on Japanese Wikipedia, the Japanese portion of CC-100, and the Japanese portion of OSCAR.
This model is trained with character-level tokenization and whole word masking.
## How to use
You can use this model for masked language modeling as follows:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('ku-nlp/deberta-v2-tiny-japanese-char-wwm')
model = AutoModelForMaskedLM.from_pretrained('ku-nlp/deberta-v2-tiny-japanese-char-wwm')
sentence = '京都大学で自然言語処理を[MASK][MASK]する。'
encoding = tokenizer(sentence, return_tensors='pt')
...
```
You can also fine-tune this model on downstream tasks.
## Tokenization
There is no need to tokenize texts in advance, and you can give raw texts to the tokenizer.
The texts are tokenized into character-level tokens by [sentencepiece](https://github.com/google/sentencepiece).
## Training data
We used the following corpora for pre-training:
- Japanese Wikipedia (as of 20221020, 3.2GB, 27M sentences, 1.3M documents)
- Japanese portion of CC-100 (85GB, 619M sentences, 66M documents)
- Japanese portion of OSCAR (54GB, 326M sentences, 25M documents)
Note that we filtered out documents annotated with "header", "footer", or "noisy" tags in OSCAR.
Also note that Japanese Wikipedia was duplicated 10 times to make the total size of the corpus comparable to that of CC-100 and OSCAR. As a result, the total size of the training data is 171GB.
## Training procedure
We first segmented texts in the corpora into words using [Juman++ 2.0.0-rc3](https://github.com/ku-nlp/jumanpp/releases/tag/v2.0.0-rc3) for whole word masking.
Then, we built a sentencepiece model with 22,012 tokens including all characters that appear in the training corpus.
We tokenized raw corpora into character-level subwords using the sentencepiece model and trained the Japanese DeBERTa model using [transformers](https://github.com/huggingface/transformers) library.
The training took one day using 8 NVIDIA A100-SXM4-40GB GPUs.
The following hyperparameters were used during pre-training:
- learning_rate: 2e-4
- per_device_train_batch_size: 190
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 4
- total_train_batch_size: 6,080
- max_seq_length: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-06
- lr_scheduler_type: linear schedule with warmup
- training_steps: 100,000
- warmup_steps: 10,000
The accuracy of the trained model on the masked language modeling task was 0.499.
The evaluation set consists of 5,000 randomly sampled documents from each of the training corpora.
## Acknowledgments
This work was supported by Joint Usage/Research Center for Interdisciplinary Large-scale Information Infrastructures (JHPCN) through General Collaboration Project no. jh221004, "Developing a Platform for Constructing and Sharing of Large-Scale Japanese Language Models".
For training models, we used the mdx: a platform for the data-driven future.
| 3,383 | [
[
-0.035491943359375,
-0.060455322265625,
0.018768310546875,
0.002552032470703125,
-0.04119873046875,
0.00726318359375,
-0.015106201171875,
-0.034698486328125,
0.033447265625,
0.038421630859375,
-0.04510498046875,
-0.041961669921875,
-0.05810546875,
0.00840759... |
citizenlab/twitter-xlm-roberta-base-sentiment-finetunned | 2022-12-02T13:49:38.000Z | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"en",
"nl",
"fr",
"pt",
"it",
"es",
"de",
"da",
"pl",
"af",
"dataset:jigsaw_toxicity_pred",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | citizenlab | null | null | citizenlab/twitter-xlm-roberta-base-sentiment-finetunned | 20 | 3,736 | transformers | 2022-03-02T23:29:05 | ---
pipeline_type: "text-classification"
widget:
- text: "this is a lovely message"
example_title: "Example 1"
multi_class: false
- text: "you are an idiot and you and your family should go back to your country"
example_title: "Example 2"
multi_class: false
language:
- en
- nl
- fr
- pt
- it
- es
- de
- da
- pl
- af
datasets:
- jigsaw_toxicity_pred
metrics:
- F1 Accuracy
---
# citizenlab/twitter-xlm-roberta-base-sentiment-finetunned
This is multilingual XLM-Roberta model sequence classifier fine tunned and based on [Cardiff NLP Group](cardiffnlp/twitter-roberta-base-sentiment) sentiment classification model.
## How to use it
```python
from transformers import pipeline
model_path = "citizenlab/twitter-xlm-roberta-base-sentiment-finetunned"
sentiment_classifier = pipeline("text-classification", model=model_path, tokenizer=model_path)
sentiment_classifier("this is a lovely message")
> [{'label': 'Positive', 'score': 0.9918450713157654}]
sentiment_classifier("you are an idiot and you and your family should go back to your country")
> [{'label': 'Negative', 'score': 0.9849833846092224}]
```
## Evaluation
```
precision recall f1-score support
Negative 0.57 0.14 0.23 28
Neutral 0.78 0.94 0.86 132
Positive 0.89 0.80 0.85 51
accuracy 0.80 211
macro avg 0.75 0.63 0.64 211
weighted avg 0.78 0.80 0.77 211
```
| 1,551 | [
[
-0.01666259765625,
-0.0221405029296875,
0.0135955810546875,
0.033905029296875,
-0.0232086181640625,
0.021636962890625,
-0.0064239501953125,
0.0012865066528320312,
0.0214385986328125,
0.0234222412109375,
-0.042724609375,
-0.05718994140625,
-0.06500244140625,
... |
joeddav/bart-large-mnli-yahoo-answers | 2021-06-14T10:44:33.000Z | [
"transformers",
"pytorch",
"jax",
"bart",
"text-classification",
"zero-shot-classification",
"en",
"dataset:yahoo-answers",
"arxiv:1909.00161",
"endpoints_compatible",
"has_space",
"region:us"
] | zero-shot-classification | joeddav | null | null | joeddav/bart-large-mnli-yahoo-answers | 10 | 3,736 | transformers | 2022-03-02T23:29:05 | ---
language: en
tags:
- text-classification
- pytorch
datasets:
- yahoo-answers
pipeline_tag: zero-shot-classification
---
# bart-lage-mnli-yahoo-answers
## Model Description
This model takes [facebook/bart-large-mnli](https://huggingface.co/facebook/bart-large-mnli) and fine-tunes it on Yahoo Answers topic classification. It can be used to predict whether a topic label can be assigned to a given sequence, whether or not the label has been seen before.
You can play with an interactive demo of this zero-shot technique with this model, as well as the non-finetuned [facebook/bart-large-mnli](https://huggingface.co/facebook/bart-large-mnli), [here](https://huggingface.co/zero-shot/).
## Intended Usage
This model was fine-tuned on topic classification and will perform best at zero-shot topic classification. Use `hypothesis_template="This text is about {}."` as this is the template used during fine-tuning.
For settings other than topic classification, you can use any model pre-trained on MNLI such as [facebook/bart-large-mnli](https://huggingface.co/facebook/bart-large-mnli) or [roberta-large-mnli](https://huggingface.co/roberta-large-mnli) with the same code as written below.
#### With the zero-shot classification pipeline
The model can be used with the `zero-shot-classification` pipeline like so:
```python
from transformers import pipeline
nlp = pipeline("zero-shot-classification", model="joeddav/bart-large-mnli-yahoo-answers")
sequence_to_classify = "Who are you voting for in 2020?"
candidate_labels = ["Europe", "public health", "politics", "elections"]
hypothesis_template = "This text is about {}."
nlp(sequence_to_classify, candidate_labels, multi_class=True, hypothesis_template=hypothesis_template)
```
#### With manual PyTorch
```python
# pose sequence as a NLI premise and label as a hypothesis
from transformers import BartForSequenceClassification, BartTokenizer
nli_model = BartForSequenceClassification.from_pretrained('joeddav/bart-large-mnli-yahoo-answers')
tokenizer = BartTokenizer.from_pretrained('joeddav/bart-large-mnli-yahoo-answers')
premise = sequence
hypothesis = f'This text is about {label}.'
# run through model pre-trained on MNLI
x = tokenizer.encode(premise, hypothesis, return_tensors='pt',
max_length=tokenizer.max_len,
truncation_strategy='only_first')
logits = nli_model(x.to(device))[0]
# we throw away "neutral" (dim 1) and take the probability of
# "entailment" (2) as the probability of the label being true
entail_contradiction_logits = logits[:,[0,2]]
probs = entail_contradiction_logits.softmax(dim=1)
prob_label_is_true = probs[:,1]
```
## Training
The model is a pre-trained MNLI classifier further fine-tuned on Yahoo Answers topic classification in the manner originally described in [Yin et al. 2019](https://arxiv.org/abs/1909.00161) and [this blog post](https://joeddav.github.io/blog/2020/05/29/ZSL.html). That is, each sequence is fed to the pre-trained NLI model in place of the premise and each candidate label as the hypothesis, formatted like so: `This text is about {class name}.` For each example in the training set, a true and a randomly-selected false label hypothesis are fed to the model which must predict which labels are valid and which are false.
Since this method studies the ability to classify unseen labels after being trained on a different set of labels, the model is only trained on 5 out of the 10 labels in Yahoo Answers. These are "Society & Culture", "Health", "Computers & Internet", "Business & Finance", and "Family & Relationships".
## Evaluation Results
This model was evaluated with the label-weighted F1 of the _seen_ and _unseen_ labels. That is, for each example the model must predict from one of the 10 corpus labels. The F1 is reported for the labels seen during training as well as the labels unseen during training. We found an F1 score of `.68` and `.72` for the unseen and seen labels, respectively. In order to adjust for the in-vs-out of distribution labels, we subtract a fixed amount of 30% from the normalized probabilities of the _seen_ labels, as described in [Yin et al. 2019](https://arxiv.org/abs/1909.00161) and [our blog post](https://joeddav.github.io/blog/2020/05/29/ZSL.html).
| 4,276 | [
[
-0.04254150390625,
-0.052703857421875,
0.0274505615234375,
-0.0020618438720703125,
-0.0220489501953125,
-0.01474761962890625,
-0.0005445480346679688,
-0.0244903564453125,
0.0323486328125,
0.028594970703125,
-0.052642822265625,
-0.0460205078125,
-0.03363037109375... |
facebook/dino-vitb16 | 2023-05-22T07:04:00.000Z | [
"transformers",
"pytorch",
"tf",
"vit",
"feature-extraction",
"dino",
"vision",
"dataset:imagenet-1k",
"arxiv:2104.14294",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | feature-extraction | facebook | null | null | facebook/dino-vitb16 | 90 | 3,732 | transformers | 2022-03-02T23:29:05 | ---
license: apache-2.0
tags:
- dino
- vision
datasets:
- imagenet-1k
---
# Vision Transformer (base-sized model, patch size 16) trained using DINO
Vision Transformer (ViT) model trained using the DINO method. It was introduced in the paper [Emerging Properties in Self-Supervised Vision Transformers](https://arxiv.org/abs/2104.14294) by Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, Armand Joulin and first released in [this repository](https://github.com/facebookresearch/dino).
Disclaimer: The team releasing DINO did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-1k, at a resolution of 224x224 pixels.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
Note that this model does not include any fine-tuned heads.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import ViTImageProcessor, ViTModel
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('facebook/dino-vitb16')
model = ViTModel.from_pretrained('facebook/dino-vitb16')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2104-14294,
author = {Mathilde Caron and
Hugo Touvron and
Ishan Misra and
Herv{\'{e}} J{\'{e}}gou and
Julien Mairal and
Piotr Bojanowski and
Armand Joulin},
title = {Emerging Properties in Self-Supervised Vision Transformers},
journal = {CoRR},
volume = {abs/2104.14294},
year = {2021},
url = {https://arxiv.org/abs/2104.14294},
archivePrefix = {arXiv},
eprint = {2104.14294},
timestamp = {Tue, 04 May 2021 15:12:43 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2104-14294.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | 3,259 | [
[
-0.038665771484375,
-0.019805908203125,
0.0083465576171875,
-0.007354736328125,
-0.03070068359375,
-0.000054895877838134766,
0.006366729736328125,
-0.038848876953125,
0.025360107421875,
0.035797119140625,
-0.03350830078125,
-0.017822265625,
-0.0443115234375,
... |
StivenLancheros/roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_AugmentedTransfer_ES | 2022-03-21T22:36:06.000Z | [
"transformers",
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | StivenLancheros | null | null | StivenLancheros/roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_AugmentedTransfer_ES | 0 | 3,731 | transformers | 2022-03-21T22:05:55 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_AugmentedTransfer_ES
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_AugmentedTransfer_ES
This model is a fine-tuned version of [StivenLancheros/roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_Augmented_ES](https://huggingface.co/StivenLancheros/roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_Augmented_ES) on the CRAFT dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2043
- Precision: 0.8666
- Recall: 0.8614
- F1: 0.8639
- Accuracy: 0.9734
## Model description
This model performs Named Entity Recognition for 6 entity tags: Sequence, Cell, Protein, Gene, Taxon, and Chemical from the CRAFT(Colorado Richly Annotated Full Text) Corpus in Spanish (MT translated) and English. Entity tags have been normalized and replaced from the original three letter code to a full name e.g. B-Protein, I-Chemical.
This model is trained on augmented data created using Entity Replacement. 20% of the entities were replaced using a list of entities for each entity tag obtained from the official ontologies for each entity class. Three datasets (original, augmented, MT translated CRAFT) were concatenated. To improve F1 score the transfer learning was completed in two steps.
Using [StivenLancheros/roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_Augmented_ES](https://huggingface.co/StivenLancheros/roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_Augmented_ES) as a base model, I finetuned once more on the original CRAFT dataset in English.
Biobert --> Augmented CRAFT --> CRAFT ES (MT translated)
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0088 | 1.0 | 1360 | 0.1793 | 0.8616 | 0.8487 | 0.8551 | 0.9721 |
| 0.0046 | 2.0 | 2720 | 0.1925 | 0.8618 | 0.8426 | 0.8521 | 0.9713 |
| 0.0032 | 3.0 | 4080 | 0.1926 | 0.8558 | 0.8630 | 0.8594 | 0.9725 |
| 0.0011 | 4.0 | 5440 | 0.2043 | 0.8666 | 0.8614 | 0.8639 | 0.9734 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
| 3,038 | [
[
-0.02618408203125,
-0.04742431640625,
0.0232391357421875,
0.0024318695068359375,
-0.01172637939453125,
-0.00826263427734375,
-0.004180908203125,
-0.04205322265625,
0.0232086181640625,
0.037628173828125,
-0.04083251953125,
-0.0560302734375,
-0.05267333984375,
... |
sail-rvc/BartSimpson_e230_s7360 | 2023-07-14T07:19:28.000Z | [
"transformers",
"rvc",
"sail-rvc",
"audio-to-audio",
"endpoints_compatible",
"region:us"
] | audio-to-audio | sail-rvc | null | null | sail-rvc/BartSimpson_e230_s7360 | 0 | 3,721 | transformers | 2023-07-14T07:18:45 |
---
pipeline_tag: audio-to-audio
tags:
- rvc
- sail-rvc
---
# BartSimpson_e230_s7360
## RVC Model

This model repo was automatically generated.
Date: 2023-07-14 07:19:28
Bot Name: juuxnscrap
Model Type: RVC
Source: https://huggingface.co/juuxn/RVCModels/
Reason: Converting into loadable format for https://github.com/chavinlo/rvc-runpod
| 390 | [
[
-0.03521728515625,
-0.0184783935546875,
0.0234222412109375,
0.00594329833984375,
-0.038177490234375,
0.00855255126953125,
0.01080322265625,
-0.0010128021240234375,
0.0305328369140625,
0.07330322265625,
-0.049468994140625,
-0.044952392578125,
-0.033782958984375,
... |
timm/lcnet_075.ra2_in1k | 2023-04-27T22:48:59.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2110.00476",
"arxiv:2109.15099",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/lcnet_075.ra2_in1k | 0 | 3,718 | timm | 2022-12-16T05:37:34 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for lcnet_075.ra2_in1k
A LCNet image classification model. Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* RandAugment `RA2` recipe. Inspired by and evolved from EfficientNet RandAugment recipes. Published as `B` recipe in [ResNet Strikes Back](https://arxiv.org/abs/2110.00476).
* RMSProp (TF 1.0 behaviour) optimizer, EMA weight averaging
* Step (exponential decay w/ staircase) LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 2.4
- GMACs: 0.1
- Activations (M): 2.0
- Image size: 224 x 224
- **Papers:**
- PP-LCNet: A Lightweight CPU Convolutional Neural Network: https://arxiv.org/abs/2109.15099
- ResNet strikes back: An improved training procedure in timm: https://arxiv.org/abs/2110.00476
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('lcnet_075.ra2_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'lcnet_075.ra2_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 24, 112, 112])
# torch.Size([1, 48, 56, 56])
# torch.Size([1, 96, 28, 28])
# torch.Size([1, 192, 14, 14])
# torch.Size([1, 384, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'lcnet_075.ra2_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 384, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{cui2021pp,
title={PP-LCNet: A lightweight CPU convolutional neural network},
author={Cui, Cheng and Gao, Tingquan and Wei, Shengyu and Du, Yuning and Guo, Ruoyu and Dong, Shuilong and Lu, Bin and Zhou, Ying and Lv, Xueying and Liu, Qiwen and others},
journal={arXiv preprint arXiv:2109.15099},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@inproceedings{wightman2021resnet,
title={ResNet strikes back: An improved training procedure in timm},
author={Wightman, Ross and Touvron, Hugo and Jegou, Herve},
booktitle={NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future}
}
```
| 4,706 | [
[
-0.033233642578125,
-0.0301971435546875,
-0.0045013427734375,
-0.0009579658508300781,
-0.023162841796875,
-0.025390625,
-0.02490234375,
-0.03350830078125,
0.01227569580078125,
0.040863037109375,
-0.03411865234375,
-0.04534912109375,
-0.05096435546875,
-0.010... |
sap-ai-research/miCSE | 2023-08-23T09:28:48.000Z | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"en",
"arxiv:2211.04928",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | sentence-similarity | sap-ai-research | null | null | sap-ai-research/miCSE | 7 | 3,714 | transformers | 2022-11-09T13:22:51 | ---
pipeline_tag: sentence-similarity
tags:
- feature-extraction
- sentence-similarity
language: en
license: apache-2.0
---
# **m**utual **i**nformation **C**ontrastive **S**entence **E**mbedding (**miCSE**) for Low-shot Sentence Embeddings
Paper accepted at [ACL 2023](https://2023.aclweb.org/)[](https://arxiv.org/abs/2211.04928)[](https://github.com/SAP-samples/acl2023-micse/)
# Brief Model Description
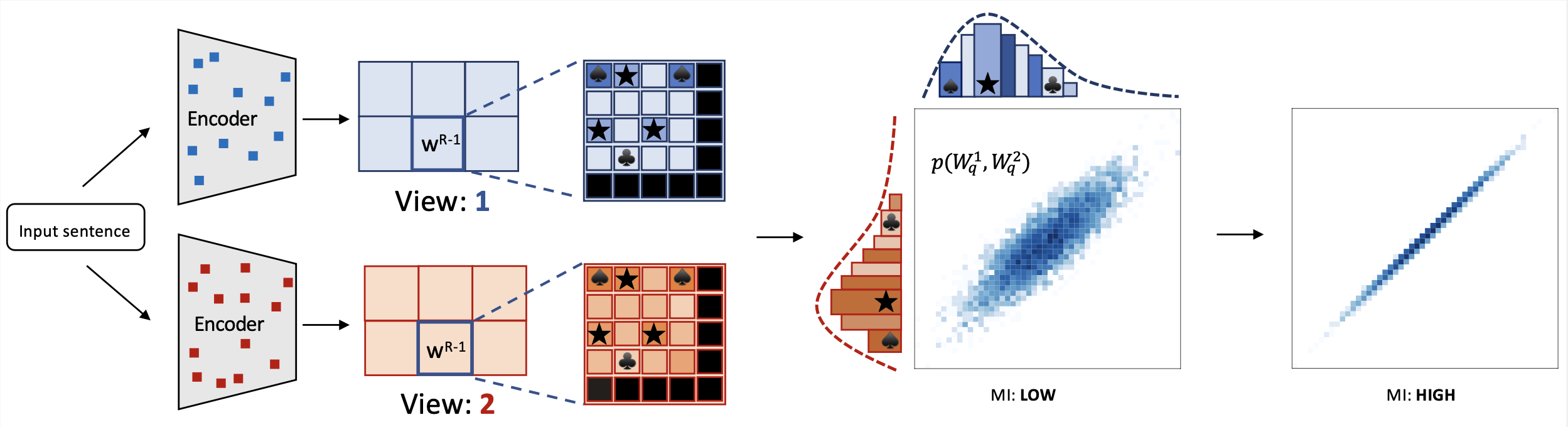
The **miCSE** language model is trained for sentence similarity computation. Training the model imposes alignment between the attention pattern of different views (embeddings of augmentations) during contrastive learning. Intuitively, learning sentence embeddings with miCSE entails enforcing __syntactic consistency across dropout augmented views__. Practically, this is achieved by regularizing the self-attention distribution. By regularizing self-attention during training, representation learning becomes much more sample efficient. Hence, self-supervised learning becomes tractable even when the training set is limited in size. This property makes miCSE particularly interesting for __real-world applications__, where training data is typically limited.
# Model Use Cases
The model intended to be used for encoding sentences or short paragraphs. Given an input text, the model produces a vector embedding capturing the semantics. Sentence representations correspond to embedding of the _**[CLS]**_ token. The embedding can be used for numerous tasks such as **retrieval**,**sentence similarity** comparison (see example 1) or **clustering** (see example 2).
# Training data
The model was trained on a random collection of **English** sentences from Wikipedia. The *full-shot* training file is available [here](https://huggingface.co/datasets/princeton-nlp/datasets-for-simcse/resolve/main/wiki1m_for_simcse.txt).
Low-shot training data consists of data splits of different sizes (from 10% to 0.0064%) of the [SimCSE](https://github.com/princeton-nlp/SimCSE) training corpus. Each split size comprises 5 files, created with a different seed indicated with filename postfix.
Data can be downloaded [here](https://huggingface.co/datasets/sap-ai-research/datasets-for-micse).
# Model Training
In order to make use of the **few-shot** capability of **miCSE**, the mode needs to be trained on your data. The source code and data splits used in the paper are available [here](https://github.com/SAP-samples/acl2023-micse).
## Training Data
# Model Usage
### Example 1) - Sentence Similarity
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, AutoModel
import torch.nn as nn
tokenizer = AutoTokenizer.from_pretrained("sap-ai-research/miCSE")
model = AutoModel.from_pretrained("sap-ai-research/miCSE")
# Encoding of sentences in a list with a predefined maximum lengths of tokens (max_length)
max_length = 32
sentences = [
"This is a sentence for testing miCSE.",
"This is yet another test sentence for the mutual information Contrastive Sentence Embeddings model."
]
batch = tokenizer.batch_encode_plus(
sentences,
return_tensors='pt',
padding=True,
max_length=max_length,
truncation=True
)
# Compute the embeddings and keep only the _**[CLS]**_ embedding (the first token)
# Get raw embeddings (no gradients)
with torch.no_grad():
outputs = model(**batch, output_hidden_states=True, return_dict=True)
embeddings = outputs.last_hidden_state[:,0]
# Define similarity metric, e.g., cosine similarity
sim = nn.CosineSimilarity(dim=-1)
# Compute similarity between the **first** and the **second** sentence
cos_sim = sim(embeddings.unsqueeze(1),
embeddings.unsqueeze(0))
print(f"Distance: {cos_sim[0,1].detach().item()}")
```
</details>
### Example 2) - Clustering
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, AutoModel
import torch.nn as nn
import torch
import numpy as np
import tqdm
from datasets import load_dataset
import umap
import umap.plot as umap_plot
# Determine available hardware
if torch.backends.mps.is_available():
device = torch.device("mps")
elif torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("/Users/d065243/miCSE")
model = AutoModel.from_pretrained("/Users/d065243/miCSE")
model.to(device);
# Load Twitter data for sentiment clustering
dataset = load_dataset("tweet_eval", "sentiment")
# Compute embeddings of the tweets
# set batch size and maxium tweet token length
batch_size = 50
max_length = 128
iterations = int(np.floor(len(dataset['train'])/batch_size))*batch_size
embedding_stack = []
classes = []
for i in tqdm.notebook.tqdm(range(0,iterations,batch_size)):
# create batch
batch = tokenizer.batch_encode_plus(
dataset['train'][i:i+batch_size]['text'],
return_tensors='pt',
padding=True,
max_length=max_length,
truncation=True
).to(device)
classes = classes + dataset['train'][i:i+batch_size]['label']
# model inference without gradient
with torch.no_grad():
outputs = model(**batch, output_hidden_states=True, return_dict=True)
embeddings = outputs.last_hidden_state[:,0]
embedding_stack.append( embeddings.cpu().clone() )
embeddings = torch.vstack(embedding_stack)
# Cluster embeddings in 2D with UMAP
umap_model = umap.UMAP(n_neighbors=250,
n_components=2,
min_dist=1.0e-9,
low_memory=True,
angular_rp_forest=True,
metric='cosine')
umap_model.fit(embeddings)
# Plot result
umap_plot.points(umap_model, labels = np.array(classes),theme='fire')
```
</details>
### Example 3) - Using [SentenceTransformers](https://www.sbert.net/)
<details>
<summary> Click to expand </summary>
```python
from sentence_transformers import SentenceTransformer, util
from sentence_transformers import models
import torch.nn as nn
# Using the model with [CLS] embeddings
model_name = 'sap-ai-research/miCSE'
word_embedding_model = models.Transformer(model_name, max_seq_length=32)
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
# Using cosine similarity as metric
cos_sim = nn.CosineSimilarity(dim=-1)
# List of sentences for comparison
sentences_1 = ["This is a sentence for testing miCSE.",
"This is using mutual information Contrastive Sentence Embeddings model."]
sentences_2 = ["This is testing miCSE.",
"Similarity with miCSE"]
# Compute embedding for both lists
embeddings_1 = model.encode(sentences_1, convert_to_tensor=True)
embeddings_2 = model.encode(sentences_2, convert_to_tensor=True)
# Compute cosine similarities
cosine_sim_scores = cos_sim(embeddings_1, embeddings_2)
#Output of results
for i in range(len(sentences1)):
print(f"Similarity {cosine_scores[i][i]:.2f}: {sentences1[i]} << vs. >> {sentences2[i]}")
```
</details>
<br/>
# Benchmark
Model results on SentEval Benchmark:
<details>
<summary> Click to expand </summary>
```shell
+-------+-------+-------+-------+-------+--------------+-----------------+--------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | S.Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+--------+
| 71.71 | 83.09 | 75.46 | 83.13 | 80.22 | 79.70 | 73.62 | 78.13 |
+-------+-------+-------+-------+-------+--------------+-----------------+--------+
```
</details>
## Citations
If you use this code in your research or want to refer to our work, please cite:
```
@inproceedings{klein-nabi-2023-micse,
title = "mi{CSE}: Mutual Information Contrastive Learning for Low-shot Sentence Embeddings",
author = "Klein, Tassilo and
Nabi, Moin",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.339",
pages = "6159--6177",
abstract = "This paper presents miCSE, a mutual information-based contrastive learning framework that significantly advances the state-of-the-art in few-shot sentence embedding.The proposed approach imposes alignment between the attention pattern of different views during contrastive learning. Learning sentence embeddings with miCSE entails enforcing the structural consistency across augmented views for every sentence, making contrastive self-supervised learning more sample efficient. As a result, the proposed approach shows strong performance in the few-shot learning domain. While it achieves superior results compared to state-of-the-art methods on multiple benchmarks in few-shot learning, it is comparable in the full-shot scenario. This study opens up avenues for efficient self-supervised learning methods that are more robust than current contrastive methods for sentence embedding.",
}
```
#### Authors:
- [Tassilo Klein](https://tjklein.github.io/)
- [Moin Nabi](https://moinnabi.github.io/) | 10,103 | [
[
-0.0204315185546875,
-0.038970947265625,
0.0248870849609375,
0.017852783203125,
-0.0237274169921875,
-0.003376007080078125,
-0.0123138427734375,
-0.007770538330078125,
0.020172119140625,
0.0210418701171875,
-0.03643798828125,
-0.055450439453125,
-0.04052734375,
... |
timm/deit3_large_patch16_224.fb_in22k_ft_in1k | 2023-03-28T01:16:21.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-22k",
"arxiv:2204.07118",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/deit3_large_patch16_224.fb_in22k_ft_in1k | 0 | 3,713 | timm | 2023-03-28T01:12:20 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
- imagenet-22k
---
# Model card for deit3_large_patch16_224.fb_in22k_ft_in1k
A DeiT-III image classification model. Pretrained on ImageNet-22k and fine-tuned on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 304.4
- GMACs: 61.6
- Activations (M): 63.5
- Image size: 224 x 224
- **Papers:**
- DeiT III: Revenge of the ViT: https://arxiv.org/abs/2204.07118
- **Original:** https://github.com/facebookresearch/deit
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-22k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('deit3_large_patch16_224.fb_in22k_ft_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'deit3_large_patch16_224.fb_in22k_ft_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 197, 1024) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{Touvron2022DeiTIR,
title={DeiT III: Revenge of the ViT},
author={Hugo Touvron and Matthieu Cord and Herve Jegou},
journal={arXiv preprint arXiv:2204.07118},
year={2022},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,058 | [
[
-0.0318603515625,
-0.035888671875,
0.009857177734375,
0.01453399658203125,
-0.0280914306640625,
-0.021514892578125,
-0.004878997802734375,
-0.0298919677734375,
0.0156402587890625,
0.02337646484375,
-0.04052734375,
-0.054595947265625,
-0.047454833984375,
-0.0... |
Abdulkader/autotrain-medical-reports-summarizer-2484176581 | 2022-12-15T14:15:11.000Z | [
"transformers",
"pytorch",
"autotrain",
"summarization",
"unk",
"dataset:Abdulkader/autotrain-data-medical-reports-summarizer",
"co2_eq_emissions",
"endpoints_compatible",
"has_space",
"region:us"
] | summarization | Abdulkader | null | null | Abdulkader/autotrain-medical-reports-summarizer-2484176581 | 4 | 3,699 | transformers | 2022-12-15T14:11:59 | ---
tags:
- autotrain
- summarization
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- Abdulkader/autotrain-data-medical-reports-summarizer
co2_eq_emissions:
emissions: 0.018508154116891218
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 2484176581
- CO2 Emissions (in grams): 0.0185
## Validation Metrics
- Loss: 1.728
- Rouge1: 44.555
- Rouge2: 34.430
- RougeL: 44.168
- RougeLsum: 43.895
- Gen Len: 8.930
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/Abdulkader/autotrain-medical-reports-summarizer-2484176581
``` | 753 | [
[
-0.024444580078125,
-0.0252227783203125,
0.02886962890625,
0.0167388916015625,
-0.005527496337890625,
0.003631591796875,
0.020660400390625,
-0.0110626220703125,
0.0278472900390625,
0.0230712890625,
-0.0537109375,
-0.03216552734375,
-0.058624267578125,
0.0047... |
cl-tohoku/bert-large-japanese-v2 | 2023-05-19T00:47:40.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"pretraining",
"ja",
"dataset:cc100",
"dataset:wikipedia",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | cl-tohoku | null | null | cl-tohoku/bert-large-japanese-v2 | 5 | 3,698 | transformers | 2023-05-19T00:40:34 | ---
license: apache-2.0
datasets:
- cc100
- wikipedia
language:
- ja
widget:
- text: 東北大学で[MASK]の研究をしています。
---
# BERT large Japanese (unidic-lite with whole word masking, CC-100 and jawiki-20230102)
This is a [BERT](https://github.com/google-research/bert) model pretrained on texts in the Japanese language.
This version of the model processes input texts with word-level tokenization based on the Unidic 2.1.2 dictionary (available in [unidic-lite](https://pypi.org/project/unidic-lite/) package), followed by the WordPiece subword tokenization.
Additionally, the model is trained with the whole word masking enabled for the masked language modeling (MLM) objective.
The codes for the pretraining are available at [cl-tohoku/bert-japanese](https://github.com/cl-tohoku/bert-japanese/).
## Model architecture
The model architecture is the same as the original BERT large model; 24 layers, 1024 dimensions of hidden states, and 16 attention heads.
## Training Data
The model is trained on the Japanese portion of [CC-100 dataset](https://data.statmt.org/cc-100/) and the Japanese version of Wikipedia.
For Wikipedia, we generated a text corpus from the [Wikipedia Cirrussearch dump file](https://dumps.wikimedia.org/other/cirrussearch/) as of January 2, 2023.
The corpus files generated from CC-100 and Wikipedia are 74.3GB and 4.9GB in size and consist of approximately 392M and 34M sentences, respectively.
For the purpose of splitting texts into sentences, we used [fugashi](https://github.com/polm/fugashi) with [mecab-ipadic-NEologd](https://github.com/neologd/mecab-ipadic-neologd) dictionary (v0.0.7).
## Tokenization
The texts are first tokenized by MeCab with the Unidic 2.1.2 dictionary and then split into subwords by the WordPiece algorithm.
The vocabulary size is 32768.
We used [fugashi](https://github.com/polm/fugashi) and [unidic-lite](https://github.com/polm/unidic-lite) packages for the tokenization.
## Training
We trained the model first on the CC-100 corpus for 1M steps and then on the Wikipedia corpus for another 1M steps.
For training of the MLM (masked language modeling) objective, we introduced whole word masking in which all of the subword tokens corresponding to a single word (tokenized by MeCab) are masked at once.
For training of each model, we used a v3-8 instance of Cloud TPUs provided by [TPU Research Cloud](https://sites.research.google/trc/about/).
## Licenses
The pretrained models are distributed under the Apache License 2.0.
## Acknowledgments
This model is trained with Cloud TPUs provided by [TPU Research Cloud](https://sites.research.google/trc/about/) program. | 2,632 | [
[
-0.039154052734375,
-0.06536865234375,
0.01861572265625,
0.00774383544921875,
-0.04931640625,
0.0024204254150390625,
-0.033447265625,
-0.032073974609375,
0.042755126953125,
0.039398193359375,
-0.04901123046875,
-0.040283203125,
-0.0400390625,
0.0048255920410... |
timm/tinynet_d.in1k | 2023-04-27T21:50:29.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2010.14819",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/tinynet_d.in1k | 0 | 3,694 | timm | 2022-12-13T00:22:20 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for tinynet_d.in1k
A TinyNet image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 2.3
- GMACs: 0.1
- Activations (M): 1.4
- Image size: 152 x 152
- **Papers:**
- Model rubik's cube: Twisting resolution, depth and width for tinynets: https://arxiv.org/abs/2010.14819v2
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('tinynet_d.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tinynet_d.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 8, 76, 76])
# torch.Size([1, 16, 38, 38])
# torch.Size([1, 24, 19, 19])
# torch.Size([1, 64, 10, 10])
# torch.Size([1, 176, 5, 5])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'tinynet_d.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1280, 5, 5) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{han2020model,
title={Model rubik’s cube: Twisting resolution, depth and width for tinynets},
author={Han, Kai and Wang, Yunhe and Zhang, Qiulin and Zhang, Wei and Xu, Chunjing and Zhang, Tong},
journal={Advances in Neural Information Processing Systems},
volume={33},
pages={19353--19364},
year={2020}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,928 | [
[
-0.0335693359375,
-0.03765869140625,
0.004535675048828125,
-0.0006566047668457031,
-0.0212249755859375,
-0.0274505615234375,
-0.018402099609375,
-0.025543212890625,
0.0200653076171875,
0.0268707275390625,
-0.031982421875,
-0.04376220703125,
-0.045501708984375,
... |
microsoft/layoutlm-base-cased | 2021-09-27T05:55:31.000Z | [
"transformers",
"pytorch",
"layoutlm",
"arxiv:1912.13318",
"endpoints_compatible",
"region:us"
] | null | microsoft | null | null | microsoft/layoutlm-base-cased | 13 | 3,682 | transformers | 2022-03-02T23:29:05 | # LayoutLM
**Multimodal (text + layout/format + image) pre-training for document AI**
[Microsoft Document AI](https://www.microsoft.com/en-us/research/project/document-ai/) | [GitHub](https://aka.ms/layoutlm)
## Model description
LayoutLM is a simple but effective pre-training method of text and layout for document image understanding and information extraction tasks, such as form understanding and receipt understanding. LayoutLM archives the SOTA results on multiple datasets. For more details, please refer to our paper:
[LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318)
Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou, [KDD 2020](https://www.kdd.org/kdd2020/accepted-papers)
## Different Tokenizer
Note that LayoutLM-Cased requires a different tokenizer, based on RobertaTokenizer. You can
initialize it as follows:
~~~
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('microsoft/layoutlm-base-cased')
~~~
## Citation
If you find LayoutLM useful in your research, please cite the following paper:
``` latex
@misc{xu2019layoutlm,
title={LayoutLM: Pre-training of Text and Layout for Document Image Understanding},
author={Yiheng Xu and Minghao Li and Lei Cui and Shaohan Huang and Furu Wei and Ming Zhou},
year={2019},
eprint={1912.13318},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| 1,443 | [
[
-0.0173492431640625,
-0.045806884765625,
0.035614013671875,
0.0250396728515625,
-0.01971435546875,
0.0021266937255859375,
0.01824951171875,
0.0021610260009765625,
0.0004944801330566406,
0.0189971923828125,
-0.03759765625,
-0.04412841796875,
-0.040374755859375,
... |
CompVis/ldm-super-resolution-4x-openimages | 2023-07-05T16:18:48.000Z | [
"diffusers",
"pytorch",
"super-resolution",
"diffusion-super-resolution",
"arxiv:2112.10752",
"license:apache-2.0",
"has_space",
"diffusers:LDMSuperResolutionPipeline",
"region:us"
] | null | CompVis | null | null | CompVis/ldm-super-resolution-4x-openimages | 72 | 3,679 | diffusers | 2022-11-09T12:35:04 | ---
license: apache-2.0
tags:
- pytorch
- diffusers
- super-resolution
- diffusion-super-resolution
---
# Latent Diffusion Models (LDM) for super-resolution
**Paper**: [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)
**Abstract**:
*By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs.*
**Authors**
*Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer*
## Usage
### Inference with a pipeline
```python
!pip install git+https://github.com/huggingface/diffusers.git
import requests
from PIL import Image
from io import BytesIO
from diffusers import LDMSuperResolutionPipeline
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model_id = "CompVis/ldm-super-resolution-4x-openimages"
# load model and scheduler
pipeline = LDMSuperResolutionPipeline.from_pretrained(model_id)
pipeline = pipeline.to(device)
# let's download an image
url = "https://user-images.githubusercontent.com/38061659/199705896-b48e17b8-b231-47cd-a270-4ffa5a93fa3e.png"
response = requests.get(url)
low_res_img = Image.open(BytesIO(response.content)).convert("RGB")
low_res_img = low_res_img.resize((128, 128))
# run pipeline in inference (sample random noise and denoise)
upscaled_image = pipeline(low_res_img, num_inference_steps=100, eta=1).images[0]
# save image
upscaled_image.save("ldm_generated_image.png")
```
| 2,830 | [
[
-0.050048828125,
-0.043853759765625,
0.027374267578125,
-0.0009617805480957031,
-0.025482177734375,
-0.003932952880859375,
0.01166534423828125,
-0.02056884765625,
0.0020847320556640625,
0.033294677734375,
-0.03973388671875,
-0.01788330078125,
-0.048126220703125,... |
moussaKam/barthez | 2021-11-15T12:59:17.000Z | [
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"summarization",
"bart",
"fill-mask",
"fr",
"arxiv:2010.12321",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | moussaKam | null | null | moussaKam/barthez | 11 | 3,678 | transformers | 2022-03-02T23:29:05 | ---
tags:
- summarization
- bart
language:
- fr
widget:
- text: Barthez est le meilleur <mask> du monde.
license: apache-2.0
pipeline_tag: "fill-mask"
---
A french sequence to sequence pretrained model based on [BART](https://huggingface.co/facebook/bart-large). <br>
BARThez is pretrained by learning to reconstruct a corrupted input sentence. A corpus of 66GB of french raw text is used to carry out the pretraining. <br>
Unlike already existing BERT-based French language models such as CamemBERT and FlauBERT, BARThez is particularly well-suited for generative tasks (such as abstractive summarization), since not only its encoder but also its decoder is pretrained.
In addition to BARThez that is pretrained from scratch, we continue the pretraining of a multilingual BART [mBART](https://huggingface.co/facebook/mbart-large-cc25) which boosted its performance in both discriminative and generative tasks. We call the french adapted version [mBARThez](https://huggingface.co/moussaKam/mbarthez).
| Model | Architecture | #layers | #params |
| ------------- |:-------------:| :-----:|:-----:|
| [BARThez](https://huggingface.co/moussaKam/barthez) | BASE | 12 | 165M |
| [mBARThez](https://huggingface.co/moussaKam/mbarthez) | LARGE | 24 | 458M |
<br>
paper: https://arxiv.org/abs/2010.12321 \
github: https://github.com/moussaKam/BARThez
```
@article{eddine2020barthez,
title={BARThez: a Skilled Pretrained French Sequence-to-Sequence Model},
author={Eddine, Moussa Kamal and Tixier, Antoine J-P and Vazirgiannis, Michalis},
journal={arXiv preprint arXiv:2010.12321},
year={2020}
}
```
| 1,746 | [
[
-0.035736083984375,
-0.0438232421875,
0.028472900390625,
0.028167724609375,
-0.0123748779296875,
0.0179290771484375,
-0.0147552490234375,
-0.0199432373046875,
0.0174560546875,
0.0538330078125,
-0.04791259765625,
-0.0323486328125,
-0.0455322265625,
0.01434326... |
BAAI/bge-large-zh | 2023-10-12T03:38:28.000Z | [
"transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"zh",
"arxiv:2310.07554",
"arxiv:2309.07597",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | feature-extraction | BAAI | null | null | BAAI/bge-large-zh | 196 | 3,673 | transformers | 2023-08-02T07:13:44 | ---
license: mit
language:
- zh
---
**Recommend switching to newest [BAAI/bge-large-zh-v1.5](https://huggingface.co/BAAI/bge-large-zh-v1.5), which has more reasonable similarity distribution and same method of usage.**
<h1 align="center">FlagEmbedding</h1>
<h4 align="center">
<p>
<a href=#model-list>Model List</a> |
<a href=#frequently-asked-questions>FAQ</a> |
<a href=#usage>Usage</a> |
<a href="#evaluation">Evaluation</a> |
<a href="#train">Train</a> |
<a href="#contact">Contact</a> |
<a href="#citation">Citation</a> |
<a href="#license">License</a>
<p>
</h4>
More details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding).
[English](README.md) | [中文](https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md)
FlagEmbedding can map any text to a low-dimensional dense vector which can be used for tasks like retrieval, classification, clustering, or semantic search.
And it also can be used in vector databases for LLMs.
************* 🌟**Updates**🌟 *************
- 10/12/2023: Release [LLM-Embedder](./FlagEmbedding/llm_embedder/README.md), a unified embedding model to support diverse retrieval augmentation needs for LLMs. [Paper](https://arxiv.org/pdf/2310.07554.pdf) :fire:
- 09/15/2023: The [technical report](https://arxiv.org/pdf/2309.07597.pdf) of BGE has been released
- 09/15/2023: The [masive training data](https://data.baai.ac.cn/details/BAAI-MTP) of BGE has been released
- 09/12/2023: New models:
- **New reranker model**: release cross-encoder models `BAAI/bge-reranker-base` and `BAAI/bge-reranker-large`, which are more powerful than embedding model. We recommend to use/fine-tune them to re-rank top-k documents returned by embedding models.
- **update embedding model**: release `bge-*-v1.5` embedding model to alleviate the issue of the similarity distribution, and enhance its retrieval ability without instruction.
<details>
<summary>More</summary>
<!-- ### More -->
- 09/07/2023: Update [fine-tune code](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md): Add script to mine hard negatives and support adding instruction during fine-tuning.
- 08/09/2023: BGE Models are integrated into **Langchain**, you can use it like [this](#using-langchain); C-MTEB **leaderboard** is [available](https://huggingface.co/spaces/mteb/leaderboard).
- 08/05/2023: Release base-scale and small-scale models, **best performance among the models of the same size 🤗**
- 08/02/2023: Release `bge-large-*`(short for BAAI General Embedding) Models, **rank 1st on MTEB and C-MTEB benchmark!** :tada: :tada:
- 08/01/2023: We release the [Chinese Massive Text Embedding Benchmark](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB) (**C-MTEB**), consisting of 31 test dataset.
</details>
## Model List
`bge` is short for `BAAI general embedding`.
| Model | Language | | Description | query instruction for retrieval [1] |
|:-------------------------------|:--------:| :--------:| :--------:|:--------:|
| [BAAI/llm-embedder](https://huggingface.co/BAAI/llm-embedder) | English | [Inference](./FlagEmbedding/llm_embedder/README.md) [Fine-tune](./FlagEmbedding/llm_embedder/README.md) | a unified embedding model to support diverse retrieval augmentation needs for LLMs | See [README](./FlagEmbedding/llm_embedder/README.md) |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh-v1.5](https://huggingface.co/BAAI/bge-large-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-large-en](https://huggingface.co/BAAI/bge-large-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [MTEB](https://huggingface.co/spaces/mteb/leaderboard) leaderboard | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-en` | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en](https://huggingface.co/BAAI/bge-small-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) |a small-scale model but with competitive performance | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB) benchmark | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-zh` | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a small-scale model but with competitive performance | `为这个句子生成表示以用于检索相关文章:` |
[1\]: If you need to search the relevant passages to a query, we suggest to add the instruction to the query; in other cases, no instruction is needed, just use the original query directly. In all cases, **no instruction** needs to be added to passages.
[2\]: Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding. To balance the accuracy and time cost, cross-encoder is widely used to re-rank top-k documents retrieved by other simple models.
For examples, use bge embedding model to retrieve top 100 relevant documents, and then use bge reranker to re-rank the top 100 document to get the final top-3 results.
All models have been uploaded to Huggingface Hub, and you can see them at https://huggingface.co/BAAI.
If you cannot open the Huggingface Hub, you also can download the models at https://model.baai.ac.cn/models .
## Frequently asked questions
<details>
<summary>1. How to fine-tune bge embedding model?</summary>
<!-- ### How to fine-tune bge embedding model? -->
Following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) to prepare data and fine-tune your model.
Some suggestions:
- Mine hard negatives following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune#hard-negatives), which can improve the retrieval performance.
- If you pre-train bge on your data, the pre-trained model cannot be directly used to calculate similarity, and it must be fine-tuned with contrastive learning before computing similarity.
- If the accuracy of the fine-tuned model is still not high, it is recommended to use/fine-tune the cross-encoder model (bge-reranker) to re-rank top-k results. Hard negatives also are needed to fine-tune reranker.
</details>
<details>
<summary>2. The similarity score between two dissimilar sentences is higher than 0.5</summary>
<!-- ### The similarity score between two dissimilar sentences is higher than 0.5 -->
**Suggest to use bge v1.5, which alleviates the issue of the similarity distribution.**
Since we finetune the models by contrastive learning with a temperature of 0.01,
the similarity distribution of the current BGE model is about in the interval \[0.6, 1\].
So a similarity score greater than 0.5 does not indicate that the two sentences are similar.
For downstream tasks, such as passage retrieval or semantic similarity,
**what matters is the relative order of the scores, not the absolute value.**
If you need to filter similar sentences based on a similarity threshold,
please select an appropriate similarity threshold based on the similarity distribution on your data (such as 0.8, 0.85, or even 0.9).
</details>
<details>
<summary>3. When does the query instruction need to be used</summary>
<!-- ### When does the query instruction need to be used -->
For the `bge-*-v1.5`, we improve its retrieval ability when not using instruction.
No instruction only has a slight degradation in retrieval performance compared with using instruction.
So you can generate embedding without instruction in all cases for convenience.
For a retrieval task that uses short queries to find long related documents,
it is recommended to add instructions for these short queries.
**The best method to decide whether to add instructions for queries is choosing the setting that achieves better performance on your task.**
In all cases, the documents/passages do not need to add the instruction.
</details>
## Usage
### Usage for Embedding Model
Here are some examples for using `bge` models with
[FlagEmbedding](#using-flagembedding), [Sentence-Transformers](#using-sentence-transformers), [Langchain](#using-langchain), or [Huggingface Transformers](#using-huggingface-transformers).
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
If it doesn't work for you, you can see [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md) for more methods to install FlagEmbedding.
```python
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
```
For the value of the argument `query_instruction_for_retrieval`, see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list).
By default, FlagModel will use all available GPUs when encoding. Please set `os.environ["CUDA_VISIBLE_DEVICES"]` to select specific GPUs.
You also can set `os.environ["CUDA_VISIBLE_DEVICES"]=""` to make all GPUs unavailable.
#### Using Sentence-Transformers
You can also use the `bge` models with [sentence-transformers](https://www.SBERT.net):
```
pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
For s2p(short query to long passage) retrieval task,
each short query should start with an instruction (instructions see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list)).
But the instruction is not needed for passages.
```python
from sentence_transformers import SentenceTransformer
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
```
#### Using Langchain
You can use `bge` in langchain like this:
```python
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
model.query_instruction = "为这个句子生成表示以用于检索相关文章:"
```
#### Using HuggingFace Transformers
With the transformers package, you can use the model like this: First, you pass your input through the transformer model, then you select the last hidden state of the first token (i.e., [CLS]) as the sentence embedding.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
```
### Usage for Reranker
Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker.
The reranker is optimized based cross-entropy loss, so the relevance score is not bounded to a specific range.
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
Get relevance scores (higher scores indicate more relevance):
```python
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
#### Using Huggingface transformers
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
## Evaluation
`baai-general-embedding` models achieve **state-of-the-art performance on both MTEB and C-MTEB leaderboard!**
For more details and evaluation tools see our [scripts](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md).
- **MTEB**:
| Model Name | Dimension | Sequence Length | Average (56) | Retrieval (15) |Clustering (11) | Pair Classification (3) | Reranking (4) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | **64.23** | **54.29** | 46.08 | 87.12 | 60.03 | 83.11 | 31.61 | 75.97 |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | 63.55 | 53.25 | 45.77 | 86.55 | 58.86 | 82.4 | 31.07 | 75.53 |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 384 | 512 | 62.17 |51.68 | 43.82 | 84.92 | 58.36 | 81.59 | 30.12 | 74.14 |
| [bge-large-en](https://huggingface.co/BAAI/bge-large-en) | 1024 | 512 | 63.98 | 53.9 | 46.98 | 85.8 | 59.48 | 81.56 | 32.06 | 76.21 |
| [bge-base-en](https://huggingface.co/BAAI/bge-base-en) | 768 | 512 | 63.36 | 53.0 | 46.32 | 85.86 | 58.7 | 81.84 | 29.27 | 75.27 |
| [gte-large](https://huggingface.co/thenlper/gte-large) | 1024 | 512 | 63.13 | 52.22 | 46.84 | 85.00 | 59.13 | 83.35 | 31.66 | 73.33 |
| [gte-base](https://huggingface.co/thenlper/gte-base) | 768 | 512 | 62.39 | 51.14 | 46.2 | 84.57 | 58.61 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1024| 512 | 62.25 | 50.56 | 44.49 | 86.03 | 56.61 | 82.05 | 30.19 | 75.24 |
| [bge-small-en](https://huggingface.co/BAAI/bge-small-en) | 384 | 512 | 62.11 | 51.82 | 44.31 | 83.78 | 57.97 | 80.72 | 30.53 | 74.37 |
| [instructor-xl](https://huggingface.co/hkunlp/instructor-xl) | 768 | 512 | 61.79 | 49.26 | 44.74 | 86.62 | 57.29 | 83.06 | 32.32 | 61.79 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 768 | 512 | 61.5 | 50.29 | 43.80 | 85.73 | 55.91 | 81.05 | 30.28 | 73.84 |
| [gte-small](https://huggingface.co/thenlper/gte-small) | 384 | 512 | 61.36 | 49.46 | 44.89 | 83.54 | 57.7 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | 1536 | 8192 | 60.99 | 49.25 | 45.9 | 84.89 | 56.32 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 384 | 512 | 59.93 | 49.04 | 39.92 | 84.67 | 54.32 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 768 | 512 | 59.51 | 42.24 | 43.72 | 85.06 | 56.42 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 768 | 514 | 57.78 | 43.81 | 43.69 | 83.04 | 59.36 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 4096 | 2048 | 57.59 | 48.22 | 38.93 | 81.9 | 55.65 | 77.74 | 33.6 | 66.19 |
- **C-MTEB**:
We create the benchmark C-MTEB for Chinese text embedding which consists of 31 datasets from 6 tasks.
Please refer to [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md) for a detailed introduction.
| Model | Embedding dimension | Avg | Retrieval | STS | PairClassification | Classification | Reranking | Clustering |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| [**BAAI/bge-large-zh-v1.5**](https://huggingface.co/BAAI/bge-large-zh-v1.5) | 1024 | **64.53** | 70.46 | 56.25 | 81.6 | 69.13 | 65.84 | 48.99 |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | 768 | 63.13 | 69.49 | 53.72 | 79.75 | 68.07 | 65.39 | 47.53 |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | 512 | 57.82 | 61.77 | 49.11 | 70.41 | 63.96 | 60.92 | 44.18 |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | 1024 | 64.20 | 71.53 | 54.98 | 78.94 | 68.32 | 65.11 | 48.39 |
| [bge-large-zh-noinstruct](https://huggingface.co/BAAI/bge-large-zh-noinstruct) | 1024 | 63.53 | 70.55 | 53 | 76.77 | 68.58 | 64.91 | 50.01 |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | 768 | 62.96 | 69.53 | 54.12 | 77.5 | 67.07 | 64.91 | 47.63 |
| [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 1024 | 58.79 | 63.66 | 48.44 | 69.89 | 67.34 | 56.00 | 48.23 |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | 512 | 58.27 | 63.07 | 49.45 | 70.35 | 63.64 | 61.48 | 45.09 |
| [m3e-base](https://huggingface.co/moka-ai/m3e-base) | 768 | 57.10 | 56.91 | 50.47 | 63.99 | 67.52 | 59.34 | 47.68 |
| [m3e-large](https://huggingface.co/moka-ai/m3e-large) | 1024 | 57.05 | 54.75 | 50.42 | 64.3 | 68.2 | 59.66 | 48.88 |
| [multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 768 | 55.48 | 61.63 | 46.49 | 67.07 | 65.35 | 54.35 | 40.68 |
| [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) | 384 | 55.38 | 59.95 | 45.27 | 66.45 | 65.85 | 53.86 | 45.26 |
| [text-embedding-ada-002(OpenAI)](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings) | 1536 | 53.02 | 52.0 | 43.35 | 69.56 | 64.31 | 54.28 | 45.68 |
| [luotuo](https://huggingface.co/silk-road/luotuo-bert-medium) | 1024 | 49.37 | 44.4 | 42.78 | 66.62 | 61 | 49.25 | 44.39 |
| [text2vec-base](https://huggingface.co/shibing624/text2vec-base-chinese) | 768 | 47.63 | 38.79 | 43.41 | 67.41 | 62.19 | 49.45 | 37.66 |
| [text2vec-large](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 1024 | 47.36 | 41.94 | 44.97 | 70.86 | 60.66 | 49.16 | 30.02 |
- **Reranking**:
See [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/) for evaluation script.
| Model | T2Reranking | T2RerankingZh2En\* | T2RerankingEn2Zh\* | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| text2vec-base-multilingual | 64.66 | 62.94 | 62.51 | 14.37 | 48.46 | 48.6 | 50.26 |
| multilingual-e5-small | 65.62 | 60.94 | 56.41 | 29.91 | 67.26 | 66.54 | 57.78 |
| multilingual-e5-large | 64.55 | 61.61 | 54.28 | 28.6 | 67.42 | 67.92 | 57.4 |
| multilingual-e5-base | 64.21 | 62.13 | 54.68 | 29.5 | 66.23 | 66.98 | 57.29 |
| m3e-base | 66.03 | 62.74 | 56.07 | 17.51 | 77.05 | 76.76 | 59.36 |
| m3e-large | 66.13 | 62.72 | 56.1 | 16.46 | 77.76 | 78.27 | 59.57 |
| bge-base-zh-v1.5 | 66.49 | 63.25 | 57.02 | 29.74 | 80.47 | 84.88 | 63.64 |
| bge-large-zh-v1.5 | 65.74 | 63.39 | 57.03 | 28.74 | 83.45 | 85.44 | 63.97 |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | 67.28 | 63.95 | 60.45 | 35.46 | 81.26 | 84.1 | 65.42 |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | 67.6 | 64.03 | 61.44 | 37.16 | 82.15 | 84.18 | 66.09 |
\* : T2RerankingZh2En and T2RerankingEn2Zh are cross-language retrieval tasks
## Train
### BAAI Embedding
We pre-train the models using [retromae](https://github.com/staoxiao/RetroMAE) and train them on large-scale pairs data using contrastive learning.
**You can fine-tune the embedding model on your data following our [examples](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune).**
We also provide a [pre-train example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/pretrain).
Note that the goal of pre-training is to reconstruct the text, and the pre-trained model cannot be used for similarity calculation directly, it needs to be fine-tuned.
More training details for bge see [baai_general_embedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md).
### BGE Reranker
Cross-encoder will perform full-attention over the input pair,
which is more accurate than embedding model (i.e., bi-encoder) but more time-consuming than embedding model.
Therefore, it can be used to re-rank the top-k documents returned by embedding model.
We train the cross-encoder on a multilingual pair data,
The data format is the same as embedding model, so you can fine-tune it easily following our [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker).
More details please refer to [./FlagEmbedding/reranker/README.md](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
## Contact
If you have any question or suggestion related to this project, feel free to open an issue or pull request.
You also can email Shitao Xiao(stxiao@baai.ac.cn) and Zheng Liu(liuzheng@baai.ac.cn).
## Citation
If you find this repository useful, please consider giving a star :star: and citation
```
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## License
FlagEmbedding is licensed under the [MIT License](https://github.com/FlagOpen/FlagEmbedding/blob/master/LICENSE). The released models can be used for commercial purposes free of charge.
| 27,349 | [
[
-0.036590576171875,
-0.0670166015625,
0.0300140380859375,
0.01105499267578125,
-0.0303955078125,
-0.021087646484375,
-0.02581787109375,
-0.0223541259765625,
0.0292816162109375,
0.025421142578125,
-0.02703857421875,
-0.06390380859375,
-0.037139892578125,
-0.0... |
facebook/dpr-reader-single-nq-base | 2022-12-21T15:19:45.000Z | [
"transformers",
"pytorch",
"tf",
"dpr",
"en",
"dataset:nq_open",
"arxiv:2004.04906",
"arxiv:1702.08734",
"arxiv:1910.09700",
"license:cc-by-nc-4.0",
"has_space",
"region:us"
] | null | facebook | null | null | facebook/dpr-reader-single-nq-base | 2 | 3,668 | transformers | 2022-03-02T23:29:05 | ---
language: en
license: cc-by-nc-4.0
tags:
- dpr
datasets:
- nq_open
inference: false
---
`dpr-reader-single-nq-base`
# Table of Contents
- [Model Details](#model-details)
- [How To Get Started With the Model](#how-to-get-started-with-the-model)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [Training](#training)
- [Evaluation](#evaluation-results)
- [Environmental Impact](#environmental-impact)
- [Technical Specifications](#technical-specifications)
- [Citation Information](#citation-information)
- [Model Card Authors](#model-card-authors)
## Model Details
**Model Description:** [Dense Passage Retrieval (DPR)](https://github.com/facebookresearch/DPR) is a set of tools and models for state-of-the-art open-domain Q&A research. `dpr-reader-single-nq-base` is the reader model trained using the [Natural Questions (NQ) dataset](https://huggingface.co/datasets/nq_open) ([Lee et al., 2019](https://aclanthology.org/P19-1612/); [Kwiatkowski et al., 2019](https://aclanthology.org/Q19-1026/)).
- **Developed by:** See [GitHub repo](https://github.com/facebookresearch/DPR) for model developers
- **Model Type:** QA Reader Model
- **Language(s):** [CC-BY-NC-4.0](https://github.com/facebookresearch/DPR/blob/main/LICENSE), also see [Code of Conduct](https://github.com/facebookresearch/DPR/blob/main/CODE_OF_CONDUCT.md)
- **License:** English
- **Related Models:**
- [`dpr-ctx_encoder-single-nq-base`](https://huggingface.co/facebook/dpr-ctx_encoder-single-nq-base)
- [`dpr-question_encoder-single-nq-base`](https://huggingface.co/facebook/dpr-question_encoder-single-nq-base)
- [`dpr-ctx_encoder-multiset-base`](https://huggingface.co/facebook/dpr-ctx_encoder-multiset-base)
- [`dpr-question_encoder-multiset-base`](https://huggingface.co/facebook/dpr-question_encoder-multiset-base)
- [`dpr-reader-multiset-base`](https://huggingface.co/facebook/dpr-reader-multiset-base)
- **Resources for more information:**
- [Research Paper](https://arxiv.org/abs/2004.04906)
- [GitHub Repo](https://github.com/facebookresearch/DPR)
- [Hugging Face DPR docs](https://huggingface.co/docs/transformers/main/en/model_doc/dpr)
- [BERT Base Uncased Model Card](https://huggingface.co/bert-base-uncased)
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import DPRReader, DPRReaderTokenizer
tokenizer = DPRReaderTokenizer.from_pretrained("facebook/dpr-reader-single-nq-base")
model = DPRReader.from_pretrained("facebook/dpr-reader-single-nq-base")
encoded_inputs = tokenizer(
questions=["What is love ?"],
titles=["Haddaway"],
texts=["'What Is Love' is a song recorded by the artist Haddaway"],
return_tensors="pt",
)
outputs = model(**encoded_inputs)
start_logits = outputs.start_logits
end_logits = outputs.end_logits
relevance_logits = outputs.relevance_logits
```
## Uses
#### Direct Use
`dpr-reader-single-nq-base`, [`dpr-ctx_encoder-single-nq-base`](https://huggingface.co/facebook/dpr-ctx_encoder-single-nq-base), and [`dpr-question_encoder-single-nq-base`](https://huggingface.co/facebook/dpr-question_encoder-single-nq-base) can be used for the task of open-domain question answering.
#### Misuse and Out-of-scope Use
The model should not be used to intentionally create hostile or alienating environments for people. In addition, the set of DPR models was not trained to be factual or true representations of people or events, and therefore using the models to generate such content is out-of-scope for the abilities of this model.
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware this section may contain content that is disturbing, offensive, and can propogate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al., 2021](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al., 2021](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model can include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Training
#### Training Data
This model was trained using the [Natural Questions (NQ) dataset](https://huggingface.co/datasets/nq_open) ([Lee et al., 2019](https://aclanthology.org/P19-1612/); [Kwiatkowski et al., 2019](https://aclanthology.org/Q19-1026/)). The model authors write that:
> [The dataset] was designed for end-to-end question answering. The questions were mined from real Google search queries and the answers were spans in Wikipedia articles identified by annotators.
#### Training Procedure
The training procedure is described in the [associated paper](https://arxiv.org/pdf/2004.04906.pdf):
> Given a collection of M text passages, the goal of our dense passage retriever (DPR) is to index all the passages in a low-dimensional and continuous space, such that it can retrieve efficiently the top k passages relevant to the input question for the reader at run-time.
> Our dense passage retriever (DPR) uses a dense encoder EP(·) which maps any text passage to a d- dimensional real-valued vectors and builds an index for all the M passages that we will use for retrieval. At run-time, DPR applies a different encoder EQ(·) that maps the input question to a d-dimensional vector, and retrieves k passages of which vectors are the closest to the question vector.
The authors report that for encoders, they used two independent BERT ([Devlin et al., 2019](https://aclanthology.org/N19-1423/)) networks (base, un-cased) and use FAISS ([Johnson et al., 2017](https://arxiv.org/abs/1702.08734)) during inference time to encode and index passages. See the paper for further details on training, including encoders, inference, positive and negative passages, and in-batch negatives.
## Evaluation
The following evaluation information is extracted from the [associated paper](https://arxiv.org/pdf/2004.04906.pdf).
#### Testing Data, Factors and Metrics
The model developers report the performance of the model on five QA datasets, using the top-k accuracy (k ∈ {20, 100}). The datasets were [NQ](https://huggingface.co/datasets/nq_open), [TriviaQA](https://huggingface.co/datasets/trivia_qa), [WebQuestions (WQ)](https://huggingface.co/datasets/web_questions), [CuratedTREC (TREC)](https://huggingface.co/datasets/trec), and [SQuAD v1.1](https://huggingface.co/datasets/squad).
#### Results
| | Top 20 | | | | | Top 100| | | | |
|:----:|:------:|:---------:|:--:|:----:|:-----:|:------:|:---------:|:--:|:----:|:-----:|
| | NQ | TriviaQA | WQ | TREC | SQuAD | NQ | TriviaQA | WQ | TREC | SQuAD |
| | 78.4 | 79.4 |73.2| 79.8 | 63.2 | 85.4 | 85.0 |81.4| 89.1 | 77.2 |
## Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). We present the hardware type and based on the [associated paper](https://arxiv.org/abs/2004.04906).
- **Hardware Type:** 8 32GB GPUs
- **Hours used:** Unknown
- **Cloud Provider:** Unknown
- **Compute Region:** Unknown
- **Carbon Emitted:** Unknown
## Technical Specifications
See the [associated paper](https://arxiv.org/abs/2004.04906) for details on the modeling architecture, objective, compute infrastructure, and training details.
## Citation Information
```bibtex
@inproceedings{karpukhin-etal-2020-dense,
title = "Dense Passage Retrieval for Open-Domain Question Answering",
author = "Karpukhin, Vladimir and Oguz, Barlas and Min, Sewon and Lewis, Patrick and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.550",
doi = "10.18653/v1/2020.emnlp-main.550",
pages = "6769--6781",
}
```
## Model Card Authors
This model card was written by the team at Hugging Face. | 8,334 | [
[
-0.041595458984375,
-0.06610107421875,
0.0236968994140625,
0.00852203369140625,
-0.0114288330078125,
-0.0025005340576171875,
-0.0016126632690429688,
-0.0262451171875,
0.00554656982421875,
0.03155517578125,
-0.054534912109375,
-0.0306549072265625,
-0.034149169921... |
valhalla/distilbart-mnli-12-9 | 2021-06-14T10:34:58.000Z | [
"transformers",
"pytorch",
"jax",
"bart",
"text-classification",
"distilbart",
"distilbart-mnli",
"zero-shot-classification",
"dataset:mnli",
"endpoints_compatible",
"region:us"
] | zero-shot-classification | valhalla | null | null | valhalla/distilbart-mnli-12-9 | 9 | 3,657 | transformers | 2022-03-02T23:29:05 | ---
datasets:
- mnli
tags:
- distilbart
- distilbart-mnli
pipeline_tag: zero-shot-classification
---
# DistilBart-MNLI
distilbart-mnli is the distilled version of bart-large-mnli created using the **No Teacher Distillation** technique proposed for BART summarisation by Huggingface, [here](https://github.com/huggingface/transformers/tree/master/examples/seq2seq#distilbart).
We just copy alternating layers from `bart-large-mnli` and finetune more on the same data.
| | matched acc | mismatched acc |
| ------------------------------------------------------------------------------------ | ----------- | -------------- |
| [bart-large-mnli](https://huggingface.co/facebook/bart-large-mnli) (baseline, 12-12) | 89.9 | 90.01 |
| [distilbart-mnli-12-1](https://huggingface.co/valhalla/distilbart-mnli-12-1) | 87.08 | 87.5 |
| [distilbart-mnli-12-3](https://huggingface.co/valhalla/distilbart-mnli-12-3) | 88.1 | 88.19 |
| [distilbart-mnli-12-6](https://huggingface.co/valhalla/distilbart-mnli-12-6) | 89.19 | 89.01 |
| [distilbart-mnli-12-9](https://huggingface.co/valhalla/distilbart-mnli-12-9) | 89.56 | 89.52 |
This is a very simple and effective technique, as we can see the performance drop is very little.
Detailed performace trade-offs will be posted in this [sheet](https://docs.google.com/spreadsheets/d/1dQeUvAKpScLuhDV1afaPJRRAE55s2LpIzDVA5xfqxvk/edit?usp=sharing).
## Fine-tuning
If you want to train these models yourself, clone the [distillbart-mnli repo](https://github.com/patil-suraj/distillbart-mnli) and follow the steps below
Clone and install transformers from source
```bash
git clone https://github.com/huggingface/transformers.git
pip install -qqq -U ./transformers
```
Download MNLI data
```bash
python transformers/utils/download_glue_data.py --data_dir glue_data --tasks MNLI
```
Create student model
```bash
python create_student.py \
--teacher_model_name_or_path facebook/bart-large-mnli \
--student_encoder_layers 12 \
--student_decoder_layers 6 \
--save_path student-bart-mnli-12-6 \
```
Start fine-tuning
```bash
python run_glue.py args.json
```
You can find the logs of these trained models in this [wandb project](https://wandb.ai/psuraj/distilbart-mnli). | 2,406 | [
[
-0.044891357421875,
-0.052337646484375,
0.017852783203125,
0.0204010009765625,
-0.0157928466796875,
0.013916015625,
-0.00244903564453125,
-0.0168609619140625,
0.024566650390625,
0.031341552734375,
-0.04290771484375,
-0.01190185546875,
-0.0447998046875,
0.010... |
line-corporation/japanese-large-lm-3.6b | 2023-08-17T01:06:17.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"ja",
"dataset:wikipedia",
"dataset:mc4",
"dataset:cc100",
"dataset:oscar",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | line-corporation | null | null | line-corporation/japanese-large-lm-3.6b | 72 | 3,645 | transformers | 2023-07-21T00:48:05 | ---
license: apache-2.0
datasets:
- wikipedia
- mc4
- cc100
- oscar
language:
- ja
---
# japanese-large-lm-3.6b
This repository provides a 3.6B parameters Japanese language model, trained by [LINE Corporation](https://linecorp.com/ja/).
[Tech Blog](https://engineering.linecorp.com/ja/blog/3.6-billion-parameter-japanese-language-model) explains details.
## How to use
```
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline, set_seed
model = AutoModelForCausalLM.from_pretrained("line-corporation/japanese-large-lm-3.6b", torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained("line-corporation/japanese-large-lm-3.6b", use_fast=False)
generator = pipeline("text-generation", model=model, tokenizer=tokenizer, device=0)
set_seed(101)
text = generator(
"おはようございます、今日の天気は",
max_length=30,
do_sample=True,
pad_token_id=tokenizer.pad_token_id,
num_return_sequences=5,
)
for t in text:
print(t)
# 下記は生成される出力の例
# [{'generated_text': 'おはようございます、今日の天気は雨模様ですね。梅雨のこの時期の 朝は洗濯物が乾きにくいなど、主婦にとっては悩みどころですね。 では、'},
# {'generated_text': 'おはようございます、今日の天気は晴れ。 気温は8°C位です。 朝晩は結構冷え込むようになりました。 寒くなってくると、...'},
# {'generated_text': 'おはようございます、今日の天気は曇りです。 朝起きたら雪が軽く積もっていた。 寒さもそれほどでもありません。 日中は晴れるみたいですね。'},
# {'generated_text': 'おはようございます、今日の天気は☁のち☀です。 朝の気温5°C、日中も21°Cと 暖かい予報です'},
# {'generated_text': 'おはようございます、今日の天気は晴天ですが涼しい1日です、気温は午後になり低くなり25°Cくらい、風も強いようですので、'}]
```
## Model architecture
| Model | Vocab size | Architecture | Position type | Layers | Hidden dim | Attention heads |
| :---: | :--------: | :----------- | :-----------: | :----: | :--------: | :-------------: |
| 1.7B | 51200 | GPT2 | Absolute | 24 | 2304 | 24 |
| 3.6B | 51200 | GPTNeoX | RoPE | 30 | 3072 | 32 |
## Training Corpus
Our training corpus consists of the Japanese portions of publicly available corpus such as C4, CC-100, and Oscar.
We also incorporated the Web texts crawled by in-house system.
The total size of our training corpus is about 650 GB.
The trained model achieves 7.50 perplexity on the internal validation sets of Japanese C4.
## Tokenization
We use a sentencepiece tokenizer with a unigram language model and byte-fallback.
We **do not** apply pre-tokenization with Japanese tokenizer.
Thus, a user may directly feed raw sentences into the tokenizer.
## License
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0) | 2,458 | [
[
-0.03314208984375,
-0.05865478515625,
0.0283355712890625,
0.0239105224609375,
-0.050384521484375,
-0.01336669921875,
-0.0236053466796875,
-0.020538330078125,
0.01215362548828125,
0.041534423828125,
-0.04241943359375,
-0.058258056640625,
-0.032012939453125,
0... |
TheBloke/Llama-2-70B-GPTQ | 2023-09-27T12:44:50.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-2",
"en",
"arxiv:2307.09288",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/Llama-2-70B-GPTQ | 75 | 3,641 | transformers | 2023-07-18T23:45:06 | ---
language:
- en
license: llama2
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
model_name: Llama 2 70B
base_model: meta-llama/Llama-2-70b-hf
inference: false
model_creator: Meta Llama 2
model_type: llama
pipeline_tag: text-generation
prompt_template: '{prompt}
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Llama 2 70B - GPTQ
- Model creator: [Meta Llama 2](https://huggingface.co/meta-llama)
- Original model: [Llama 2 70B](https://huggingface.co/meta-llama/Llama-2-70b-hf)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Meta Llama 2's Llama 2 70B](https://huggingface.co/meta-llama/Llama-2-70b-hf).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Llama-2-70B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Llama-2-70B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Llama-2-70B-GGUF)
* [Meta Llama 2's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/meta-llama/Llama-2-70b-hf)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: None
```
{prompt}
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/Llama-2-70B-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 40.66 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/Llama-2-70B-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 37.99 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/Llama-2-70B-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 36.65 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-3bit-128g-actorder_True](https://huggingface.co/TheBloke/Llama-2-70B-GPTQ/tree/gptq-3bit-128g-actorder_True) | 3 | 128 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 28.03 GB | No | 3-bit, with group size 128g and act-order. Higher quality than 128g-False. |
| [gptq-3bit-128g-actorder_False](https://huggingface.co/TheBloke/Llama-2-70B-GPTQ/tree/gptq-3bit-128g-actorder_False) | 3 | 128 | No | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 28.03 GB | No | 3-bit, with group size 128g but no act-order. Slightly higher VRAM requirements than 3-bit None. |
| [gptq-3bit--1g-actorder_True](https://huggingface.co/TheBloke/Llama-2-70B-GPTQ/tree/gptq-3bit--1g-actorder_True) | 3 | None | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 26.78 GB | No | 3-bit, with Act Order and no group size. Lowest possible VRAM requirements. May be lower quality than 3-bit 128g. |
| [gptq-3bit-64g-actorder_True](https://huggingface.co/TheBloke/Llama-2-70B-GPTQ/tree/gptq-3bit-64g-actorder_True) | 3 | 64 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 29.30 GB | No | 3-bit, with group size 64g and act-order. |
| [main](https://huggingface.co/TheBloke/Llama-2-70B-GPTQ/tree/main) | 4 | None | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 35.33 GB | Yes | 4-bit, with Act Order. No group size, to lower VRAM requirements. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download from branches
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/Llama-2-70B-GPTQ:gptq-4bit-32g-actorder_True`
- With Git, you can clone a branch with:
```
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/Llama-2-70B-GPTQ
```
- In Python Transformers code, the branch is the `revision` parameter; see below.
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Llama-2-70B-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/Llama-2-70B-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Llama-2-70B-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers>=4.32.0 optimum>=1.12.0
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip3 install .
```
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
```shell
pip3 uninstall -y transformers
pip3 install git+https://github.com/huggingface/transformers.git
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Llama-2-70B-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''{prompt}
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Meta Llama 2's Llama 2 70B
# **Llama 2**
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. This is the repository for the 70B pretrained model, converted for the Hugging Face Transformers format. Links to other models can be found in the index at the bottom.
## Model Details
*Note: Use of this model is governed by the Meta license. In order to download the model weights and tokenizer, please visit the [website](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) and accept our License before requesting access here.*
Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
**Model Developers** Meta
**Variations** Llama 2 comes in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
|Llama 2|*A new mix of publicly available online data*|7B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|13B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|70B|4k|✔|2.0T|1.5 x 10<sup>-4</sup>|
*Llama 2 family of models.* Token counts refer to pretraining data only. All models are trained with a global batch-size of 4M tokens. Bigger models - 70B -- use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Dates** Llama 2 was trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
**Research Paper** ["Llama-2: Open Foundation and Fine-tuned Chat Models"](arxiv.org/abs/2307.09288)
## Intended Use
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
To get the expected features and performance for the chat versions, a specific formatting needs to be followed, including the `INST` and `<<SYS>>` tags, `BOS` and `EOS` tokens, and the whitespaces and breaklines in between (we recommend calling `strip()` on inputs to avoid double-spaces). See our reference code in github for details: [`chat_completion`](https://github.com/facebookresearch/llama/blob/main/llama/generation.py#L212).
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws).Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research Super Cluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint** Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 539 tCO2eq, 100% of which were offset by Meta’s sustainability program.
||Time (GPU hours)|Power Consumption (W)|Carbon Emitted(tCO<sub>2</sub>eq)|
|---|---|---|---|
|Llama 2 7B|184320|400|31.22|
|Llama 2 13B|368640|400|62.44|
|Llama 2 70B|1720320|400|291.42|
|Total|3311616||539.00|
**CO<sub>2</sub> emissions during pretraining.** Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.
## Evaluation Results
In this section, we report the results for the Llama 1 and Llama 2 models on standard academic benchmarks.For all the evaluations, we use our internal evaluations library.
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
|---|---|---|---|---|---|---|---|---|---|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
**Overall performance on grouped academic benchmarks.** *Code:* We report the average pass@1 scores of our models on HumanEval and MBPP. *Commonsense Reasoning:* We report the average of PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, and CommonsenseQA. We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks. *World Knowledge:* We evaluate the 5-shot performance on NaturalQuestions and TriviaQA and report the average. *Reading Comprehension:* For reading comprehension, we report the 0-shot average on SQuAD, QuAC, and BoolQ. *MATH:* We report the average of the GSM8K (8 shot) and MATH (4 shot) benchmarks at top 1.
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama 1|7B|27.42|23.00|
|Llama 1|13B|41.74|23.08|
|Llama 1|33B|44.19|22.57|
|Llama 1|65B|48.71|21.77|
|Llama 2|7B|33.29|**21.25**|
|Llama 2|13B|41.86|26.10|
|Llama 2|70B|**50.18**|24.60|
**Evaluation of pretrained LLMs on automatic safety benchmarks.** For TruthfulQA, we present the percentage of generations that are both truthful and informative (the higher the better). For ToxiGen, we present the percentage of toxic generations (the smaller the better).
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama-2-Chat|7B|57.04|**0.00**|
|Llama-2-Chat|13B|62.18|**0.00**|
|Llama-2-Chat|70B|**64.14**|0.01|
**Evaluation of fine-tuned LLMs on different safety datasets.** Same metric definitions as above.
## Ethical Considerations and Limitations
Llama 2 is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide)
## Reporting Issues
Please report any software “bug,” or other problems with the models through one of the following means:
- Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
- Reporting problematic content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
## Llama Model Index
|Model|Llama2|Llama2-hf|Llama2-chat|Llama2-chat-hf|
|---|---|---|---|---|
|7B| [Link](https://huggingface.co/llamaste/Llama-2-7b) | [Link](https://huggingface.co/llamaste/Llama-2-7b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat-hf)|
|13B| [Link](https://huggingface.co/llamaste/Llama-2-13b) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-13b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf)|
|70B| [Link](https://huggingface.co/llamaste/Llama-2-70b) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-70b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf)|
| 24,572 | [
[
-0.041290283203125,
-0.05126953125,
0.00771331787109375,
0.019775390625,
-0.0267791748046875,
-0.005657196044921875,
0.006153106689453125,
-0.047515869140625,
0.0269622802734375,
0.0235137939453125,
-0.05078125,
-0.0367431640625,
-0.0289306640625,
-0.0003199... |
potsawee/t5-large-generation-squad-QuestionAnswer | 2023-03-12T16:08:15.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:squad",
"arxiv:2301.12307",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | potsawee | null | null | potsawee/t5-large-generation-squad-QuestionAnswer | 27 | 3,640 | transformers | 2023-03-12T15:37:01 | ---
license: apache-2.0
datasets:
- squad
language:
- en
library_name: transformers
pipeline_tag: text2text-generation
---
# t5-large fine-tuned to SQuAD for Generating Question+Answer
- Input: `context` (e.g. news article)
- Output: `question <sep> answer`
The answers in the training data (SQuAD) are highly extractive; therefore, this model will generate **extractive** answers. If you would like to have **abstractive** questions/answers, you can use our model trained on the RACE dataset: https://huggingface.co/potsawee/t5-large-generation-race-QuestionAnswer.
## Model Details
t5-large model is fine-tuned to the SQuAD dataset where the input is the context/passage and the output is the question followed by the answer. This is the first component in the question generation pipeline (i.e. `g1`) in our [MQAG paper](https://arxiv.org/abs/2301.12307),
or please refer to the GitHub repo of this project: https://github.com/potsawee/mqag0.
## How to Use the Model
Use the code below to get started with the model. You can also set ```do_sample=True``` in ```generate()``` to obtain different question-answer pairs.
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("potsawee/t5-large-generation-squad-QuestionAnswer")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("potsawee/t5-large-generation-squad-QuestionAnswer")
>>> context = r"""Chelsea's mini-revival continued with a third victory in a row as they consigned struggling Leicester City to a fifth consecutive defeat.
Buoyed by their Champions League win over Borussia Dortmund, Chelsea started brightly and Ben Chilwell volleyed in from a tight angle against his old club.
Chelsea's Joao Felix and Leicester's Kiernan Dewsbury-Hall hit the woodwork in the space of two minutes, then Felix had a goal ruled out by the video assistant referee for offside.
Patson Daka rifled home an excellent equaliser after Ricardo Pereira won the ball off the dawdling Felix outside the box.
But Kai Havertz pounced six minutes into first-half injury time with an excellent dinked finish from Enzo Fernandez's clever aerial ball.
Mykhailo Mudryk thought he had his first goal for the Blues after the break but his effort was disallowed for offside.
Mateo Kovacic sealed the win as he volleyed in from Mudryk's header.
The sliding Foxes, who ended with 10 men following Wout Faes' late dismissal for a second booking, now just sit one point outside the relegation zone.
""".replace('\n', ' ')
>>> inputs = tokenizer(context, return_tensors="pt")
>>> outputs = model.generate(**inputs, max_length=100)
>>> question_answer = tokenizer.decode(outputs[0], skip_special_tokens=False)
>>> question_answer = question_answer.replace(tokenizer.pad_token, "").replace(tokenizer.eos_token, "")
>>> question, answer = question_answer.split(tokenizer.sep_token)
>>> print("question:", question)
question: Who scored the winner for Chelsea?
>>> print("answer:", answer)
answer: Mateo Kovacic
```
## Generating Distractors (other options in a multiple-choice setup)
```Context ---> Question + (A) Answer (B) Distractor1 (C) Distractor2 (D) Distractor3```
Please refer to our distractor generation model, e.g. https://huggingface.co/potsawee/t5-large-generation-race-Distractor
## Citation
```bibtex
@article{manakul2023mqag,
title={MQAG: Multiple-choice Question Answering and Generation for Assessing Information Consistency in Summarization},
author={Manakul, Potsawee and Liusie, Adian and Gales, Mark JF},
journal={arXiv preprint arXiv:2301.12307},
year={2023}
}
``` | 3,604 | [
[
-0.03594970703125,
-0.05096435546875,
0.0276641845703125,
0.0211334228515625,
-0.0108795166015625,
0.0203857421875,
-0.007091522216796875,
-0.03167724609375,
0.0217132568359375,
0.0124969482421875,
-0.06842041015625,
-0.0150299072265625,
-0.0220184326171875,
... |
nlpai-lab/kullm-polyglot-12.8b-v2 | 2023-05-31T15:48:09.000Z | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"ko",
"license:apache-2.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | nlpai-lab | null | null | nlpai-lab/kullm-polyglot-12.8b-v2 | 41 | 3,637 | transformers | 2023-05-31T06:28:28 | ---
license: apache-2.0
language:
- ko
---
# KULLM-Polyglot-12.8B-v2
This model is a fine-tuned version of [EleutherAI/polyglot-ko-12.8b](https://huggingface.co/EleutherAI/polyglot-ko-12.8b) on a KULLM v2
Detail Codes are available at [KULLM Github Repository](https://github.com/nlpai-lab/KULLM)
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-4
- train_batch_size: 6
- seed: 42
- distributed_type: multi-GPU (A100 80G)
- num_devices: 4
- gradient_accumulation_steps: 21.3
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8.0
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu117
- Datasets 2.11.0
- Tokenizers 0.13.3 | 773 | [
[
-0.046142578125,
-0.067138671875,
0.0310821533203125,
0.024871826171875,
-0.038421630859375,
0.00727081298828125,
-0.006488800048828125,
-0.0284576416015625,
0.0104827880859375,
0.0204925537109375,
-0.0333251953125,
-0.033660888671875,
-0.05108642578125,
-0.... |
sail-rvc/vader | 2023-07-14T07:45:07.000Z | [
"transformers",
"rvc",
"sail-rvc",
"audio-to-audio",
"endpoints_compatible",
"region:us"
] | audio-to-audio | sail-rvc | null | null | sail-rvc/vader | 0 | 3,637 | transformers | 2023-07-14T07:44:36 |
---
pipeline_tag: audio-to-audio
tags:
- rvc
- sail-rvc
---
# vader
## RVC Model

This model repo was automatically generated.
Date: 2023-07-14 07:45:06
Bot Name: juuxnscrap
Model Type: RVC
Source: https://huggingface.co/juuxn/RVCModels/
Reason: Converting into loadable format for https://github.com/chavinlo/rvc-runpod
| 373 | [
[
-0.0311431884765625,
-0.023590087890625,
0.02252197265625,
-0.01654052734375,
-0.0305938720703125,
0.01308441162109375,
0.0150604248046875,
0.014434814453125,
0.0301361083984375,
0.07489013671875,
-0.044891357421875,
-0.04376220703125,
-0.034637451171875,
-0... |
timm/eva_large_patch14_336.in22k_ft_in22k_in1k | 2023-03-31T06:18:55.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-22k",
"arxiv:2211.07636",
"license:mit",
"region:us"
] | image-classification | timm | null | null | timm/eva_large_patch14_336.in22k_ft_in22k_in1k | 0 | 3,623 | timm | 2022-12-22T07:11:06 | ---
tags:
- image-classification
- timm
library_tag: timm
license: mit
datasets:
- imagenet-1k
- imagenet-22k
- imagenet-22k
---
# Model card for eva_large_patch14_336.in22k_ft_in22k_in1k
An EVA image classification model. Pretrained on ImageNet-22k with masked image modeling (using EVA-CLIP as a MIM teacher) and fine-tuned on ImageNet-22k then on ImageNet-1k by paper authors.
NOTE: `timm` checkpoints are float32 for consistency with other models. Original checkpoints are float16 or bfloat16 in some cases, see originals if that's preferred.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 304.5
- GMACs: 191.1
- Activations (M): 270.2
- Image size: 336 x 336
- **Papers:**
- EVA: Exploring the Limits of Masked Visual Representation Learning at Scale: https://arxiv.org/abs/2211.07636
- **Pretrain Dataset:**
- ImageNet-22k
- ImageNet-22k
- **Dataset:** ImageNet-1k
- **Original:**
- https://github.com/baaivision/EVA
- https://huggingface.co/BAAI/EVA
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('eva_large_patch14_336.in22k_ft_in22k_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'eva_large_patch14_336.in22k_ft_in22k_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 577, 1024) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |top1 |top5 |param_count|img_size|
|-----------------------------------------------|------|------|-----------|--------|
|eva02_large_patch14_448.mim_m38m_ft_in22k_in1k |90.054|99.042|305.08 |448 |
|eva02_large_patch14_448.mim_in22k_ft_in22k_in1k|89.946|99.01 |305.08 |448 |
|eva_giant_patch14_560.m30m_ft_in22k_in1k |89.792|98.992|1014.45 |560 |
|eva02_large_patch14_448.mim_in22k_ft_in1k |89.626|98.954|305.08 |448 |
|eva02_large_patch14_448.mim_m38m_ft_in1k |89.57 |98.918|305.08 |448 |
|eva_giant_patch14_336.m30m_ft_in22k_in1k |89.56 |98.956|1013.01 |336 |
|eva_giant_patch14_336.clip_ft_in1k |89.466|98.82 |1013.01 |336 |
|eva_large_patch14_336.in22k_ft_in22k_in1k |89.214|98.854|304.53 |336 |
|eva_giant_patch14_224.clip_ft_in1k |88.882|98.678|1012.56 |224 |
|eva02_base_patch14_448.mim_in22k_ft_in22k_in1k |88.692|98.722|87.12 |448 |
|eva_large_patch14_336.in22k_ft_in1k |88.652|98.722|304.53 |336 |
|eva_large_patch14_196.in22k_ft_in22k_in1k |88.592|98.656|304.14 |196 |
|eva02_base_patch14_448.mim_in22k_ft_in1k |88.23 |98.564|87.12 |448 |
|eva_large_patch14_196.in22k_ft_in1k |87.934|98.504|304.14 |196 |
|eva02_small_patch14_336.mim_in22k_ft_in1k |85.74 |97.614|22.13 |336 |
|eva02_tiny_patch14_336.mim_in22k_ft_in1k |80.658|95.524|5.76 |336 |
## Citation
```bibtex
@article{EVA,
title={EVA: Exploring the Limits of Masked Visual Representation Learning at Scale},
author={Fang, Yuxin and Wang, Wen and Xie, Binhui and Sun, Quan and Wu, Ledell and Wang, Xinggang and Huang, Tiejun and Wang, Xinlong and Cao, Yue},
journal={arXiv preprint arXiv:2211.07636},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 5,074 | [
[
-0.0491943359375,
-0.02996826171875,
0.00714874267578125,
0.01024627685546875,
-0.02056884765625,
0.0016307830810546875,
-0.01393890380859375,
-0.0301666259765625,
0.043914794921875,
0.0328369140625,
-0.035400390625,
-0.053558349609375,
-0.052337646484375,
0... |
Yntec/CinematicReality | 2023-08-06T10:33:24.000Z | [
"diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/CinematicReality | 0 | 3,623 | diffusers | 2023-08-05T06:55:25 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
inference: false
---
Warning: This model is horny! Add "nude, naked" to the negative prompt if want to avoid NSFW.
# TODO: Finish this model card. | 235 | [
[
-0.025421142578125,
-0.045684814453125,
0.030426025390625,
0.04058837890625,
-0.071533203125,
-0.0318603515625,
0.041748046875,
-0.0283203125,
0.017730712890625,
0.0714111328125,
-0.048828125,
-0.055389404296875,
-0.039093017578125,
0.0007576942443847656,
... |
facebook/esm1b_t33_650M_UR50S | 2022-12-02T14:40:11.000Z | [
"transformers",
"pytorch",
"tf",
"esm",
"fill-mask",
"arxiv:1907.11692",
"arxiv:1810.04805",
"arxiv:1603.05027",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | fill-mask | facebook | null | null | facebook/esm1b_t33_650M_UR50S | 9 | 3,612 | transformers | 2022-10-17T15:06:20 | ---
license: mit
widget:
- text: "MQIFVKTLTGKTITLEVEPS<mask>TIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGG"
---
# **ESM-1b**
ESM-1b ([paper](https://www.pnas.org/content/118/15/e2016239118#:~:text=https%3A//doi.org/10.1073/pnas.2016239118), [repository](https://github.com/facebookresearch/esm)) is a transformer protein language model, trained on protein sequence data without label supervision. The model is pretrained on Uniref50 with an unsupervised masked language modeling (MLM) objective, meaning the model is trained to predict amino acids from the surrounding sequence context. This pretraining objective allows ESM-1b to learn generally useful features which can be transferred to downstream prediction tasks. ESM-1b has been evaluated on a variety of tasks related to protein structure and function, including remote homology detection, secondary structure prediction, contact prediction, and prediction of the effects of mutations on function, producing state-of-the-art results.
**Important note**: ESM-2 is now available in a range of checkpoint sizes. For most tasks, ESM-2 performance will be superior to ESM-1 and ESM-1b, and so we recommend using it instead unless your goal is explicitly to compare against ESM-1b. The ESM-2 checkpoint closest in size to ESM-1b is [esm2_t33_650M_UR50D](https://huggingface.co/facebook/esm2_t33_650M_UR50D).
## **Model description**
The ESM-1b model is based on the [RoBERTa](https://arxiv.org/abs/1907.11692) architecture and training procedure, using the Uniref50 2018_03 database of protein sequences. Note that the pretraining is on the raw protein sequences only. The training is purely unsupervised -- during training no labels are given related to structure or function.
Training is with the masked language modeling objective. The masking follows the procedure of [Devlin et al. 2019](https://arxiv.org/abs/1810.04805), randomly masking 15% of the amino acids in the input, and includes the pass-through and random token noise. One architecture difference from the RoBERTa model is that ESM-1b uses [pre-activation layer normalization](https://arxiv.org/abs/1603.05027).
The learned representations can be used as features for downstream tasks. For example if you have a dataset of measurements of protein activity you can fit a regression model on the features output by ESM-1b to predict the activity of new sequences. The model can also be fine-tuned.
ESM-1b can infer information about the structure and function of proteins without further supervision, i.e. it is capable of zero-shot transfer to structure and function prediction. [Rao et al. 2020](https://openreview.net/pdf?id=fylclEqgvgd) found that the attention heads of ESM-1b directly represent contacts in the 3d structure of the protein. [Meier et al. 2021](https://openreview.net/pdf?id=uXc42E9ZPFs) found that ESM-1b can be used to score the effect of sequence variations on protein function.
## **Intended uses & limitations**
The model can be used for feature extraction, fine-tuned on downstream tasks, or used directly to make inferences about the structure and function of protein sequences, like any other masked language model. For full examples, please see [our notebook on fine-tuning protein models](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_language_modeling.ipynb)
## **Training data**
The ESM-1b model was pretrained on [Uniref50](https://www.uniprot.org/downloads) 2018-03, a dataset consisting of approximately 30 million protein sequences.
## **Training procedure**
### **Preprocessing**
The protein sequences are uppercased and tokenized using a single space and a vocabulary size of 21. The inputs of the model are then of the form:
```
<cls> Protein Sequence A
```
During training, sequences longer than 1023 tokens (without CLS) are randomly cropped to a length of 1023.
The details of the masking procedure for each sequence follow Devlin et al. 2019:
* 15% of the amino acids are masked.
* In 80% of the cases, the masked amino acids are replaced by `<mask>`.
* In 10% of the cases, the masked amino acids are replaced by a random amino acid (different) from the one they replace.
* In the 10% remaining cases, the masked amino acids are left as is.
### **Pretraining**
The model was trained on 128 NVIDIA v100 GPUs for 500K updates, using sequence length 1024 (131,072 tokens per batch). The optimizer used is Adam (betas=[0.9, 0.999]) with a learning rate of 1e-4, a weight decay of 0, learning rate warmup for 16k steps and inverse square root decay of the learning rate after. | 4,617 | [
[
-0.02960205078125,
-0.06396484375,
0.0175628662109375,
-0.0011997222900390625,
-0.02374267578125,
0.00490570068359375,
0.004055023193359375,
-0.048065185546875,
0.026824951171875,
0.03631591796875,
-0.051239013671875,
-0.03302001953125,
-0.07586669921875,
0.... |
lllyasviel/control_v11p_sd15_normalbae | 2023-05-04T18:49:23.000Z | [
"diffusers",
"art",
"controlnet",
"stable-diffusion",
"controlnet-v1-1",
"image-to-image",
"arxiv:2302.05543",
"license:openrail",
"has_space",
"diffusers:ControlNetModel",
"region:us"
] | image-to-image | lllyasviel | null | null | lllyasviel/control_v11p_sd15_normalbae | 5 | 3,608 | diffusers | 2023-04-14T19:24:11 | ---
license: openrail
base_model: runwayml/stable-diffusion-v1-5
tags:
- art
- controlnet
- stable-diffusion
- controlnet-v1-1
- image-to-image
duplicated_from: ControlNet-1-1-preview/control_v11p_sd15_normalbae
---
# Controlnet - v1.1 - *normalbae Version*
**Controlnet v1.1** is the successor model of [Controlnet v1.0](https://huggingface.co/lllyasviel/ControlNet)
and was released in [lllyasviel/ControlNet-v1-1](https://huggingface.co/lllyasviel/ControlNet-v1-1) by [Lvmin Zhang](https://huggingface.co/lllyasviel).
This checkpoint is a conversion of [the original checkpoint](https://huggingface.co/lllyasviel/ControlNet-v1-1/blob/main/control_v11p_sd15_normalbae.pth) into `diffusers` format.
It can be used in combination with **Stable Diffusion**, such as [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5).
For more details, please also have a look at the [🧨 Diffusers docs](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/controlnet).
ControlNet is a neural network structure to control diffusion models by adding extra conditions.

This checkpoint corresponds to the ControlNet conditioned on **normalbae images**.
## Model Details
- **Developed by:** Lvmin Zhang, Maneesh Agrawala
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Resources for more information:** [GitHub Repository](https://github.com/lllyasviel/ControlNet), [Paper](https://arxiv.org/abs/2302.05543).
- **Cite as:**
@misc{zhang2023adding,
title={Adding Conditional Control to Text-to-Image Diffusion Models},
author={Lvmin Zhang and Maneesh Agrawala},
year={2023},
eprint={2302.05543},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
## Introduction
Controlnet was proposed in [*Adding Conditional Control to Text-to-Image Diffusion Models*](https://arxiv.org/abs/2302.05543) by
Lvmin Zhang, Maneesh Agrawala.
The abstract reads as follows:
*We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions.
The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k).
Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices.
Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data.
We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc.
This may enrich the methods to control large diffusion models and further facilitate related applications.*
## Example
It is recommended to use the checkpoint with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) as the checkpoint
has been trained on it.
Experimentally, the checkpoint can be used with other diffusion models such as dreamboothed stable diffusion.
**Note**: If you want to process an image to create the auxiliary conditioning, external dependencies are required as shown below:
1. Install https://github.com/patrickvonplaten/controlnet_aux
```sh
$ pip install controlnet_aux==0.3.0
```
2. Let's install `diffusers` and related packages:
```
$ pip install diffusers transformers accelerate
```
3. Run code:
```python
import torch
import os
from huggingface_hub import HfApi
from pathlib import Path
from diffusers.utils import load_image
from PIL import Image
import numpy as np
from controlnet_aux import NormalBaeDetector
from diffusers import (
ControlNetModel,
StableDiffusionControlNetPipeline,
UniPCMultistepScheduler,
)
checkpoint = "lllyasviel/control_v11p_sd15_normalbae"
image = load_image(
"https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/input.png"
)
prompt = "A head full of roses"
processor = NormalBaeDetector.from_pretrained("lllyasviel/Annotators")
control_image = processor(image)
control_image.save("./images/control.png")
controlnet = ControlNetModel.from_pretrained(checkpoint, torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
generator = torch.manual_seed(33)
image = pipe(prompt, num_inference_steps=30, generator=generator, image=control_image).images[0]
image.save('images/image_out.png')
```



## Other released checkpoints v1-1
The authors released 14 different checkpoints, each trained with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
on a different type of conditioning:
| Model Name | Control Image Overview| Condition Image | Control Image Example | Generated Image Example |
|---|---|---|---|---|
|[lllyasviel/control_v11p_sd15_canny](https://huggingface.co/lllyasviel/control_v11p_sd15_canny)<br/> | *Trained with canny edge detection* | A monochrome image with white edges on a black background.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11e_sd15_ip2p](https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p)<br/> | *Trained with pixel to pixel instruction* | No condition .|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_inpaint](https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint)<br/> | Trained with image inpainting | No condition.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/output.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/output.png"/></a>|
|[lllyasviel/control_v11p_sd15_mlsd](https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd)<br/> | Trained with multi-level line segment detection | An image with annotated line segments.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11f1p_sd15_depth](https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth)<br/> | Trained with depth estimation | An image with depth information, usually represented as a grayscale image.|<a href="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_normalbae](https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae)<br/> | Trained with surface normal estimation | An image with surface normal information, usually represented as a color-coded image.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_seg](https://huggingface.co/lllyasviel/control_v11p_sd15_seg)<br/> | Trained with image segmentation | An image with segmented regions, usually represented as a color-coded image.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_lineart](https://huggingface.co/lllyasviel/control_v11p_sd15_lineart)<br/> | Trained with line art generation | An image with line art, usually black lines on a white background.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15s2_lineart_anime](https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime)<br/> | Trained with anime line art generation | An image with anime-style line art.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_openpose](https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime)<br/> | Trained with human pose estimation | An image with human poses, usually represented as a set of keypoints or skeletons.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_scribble](https://huggingface.co/lllyasviel/control_v11p_sd15_scribble)<br/> | Trained with scribble-based image generation | An image with scribbles, usually random or user-drawn strokes.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_softedge](https://huggingface.co/lllyasviel/control_v11p_sd15_softedge)<br/> | Trained with soft edge image generation | An image with soft edges, usually to create a more painterly or artistic effect.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11e_sd15_shuffle](https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle)<br/> | Trained with image shuffling | An image with shuffled patches or regions.|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11f1e_sd15_tile](https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile)<br/> | Trained with image tiling | A blurry image or part of an image .|<a href="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/original.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/original.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/output.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/output.png"/></a>|
## Improvements in Normal 1.1:
- The normal-from-midas method in Normal 1.0 is neither reasonable nor physically correct. That method does not work very well in many images. The normal 1.0 model cannot interpret real normal maps created by rendering engines.
- This Normal 1.1 is much more reasonable because the preprocessor is trained to estimate normal maps with a relatively correct protocol (NYU-V2's visualization method). This means the Normal 1.1 can interpret real normal maps from rendering engines as long as the colors are correct (blue is front, red is left, green is top).
- In our test, this model is robust and can achieve similar performance to the depth model. In previous CNET 1.0, the Normal 1.0 is not very frequently used. But this Normal 2.0 is much improved and has potential to be used much more frequently.
## More information
For more information, please also have a look at the [Diffusers ControlNet Blog Post](https://huggingface.co/blog/controlnet) and have a look at the [official docs](https://github.com/lllyasviel/ControlNet-v1-1-nightly). | 16,282 | [
[
-0.044708251953125,
-0.044158935546875,
0.009796142578125,
0.043212890625,
-0.0186767578125,
-0.020965576171875,
0.00414276123046875,
-0.0413818359375,
0.0423583984375,
0.021881103515625,
-0.057281494140625,
-0.02734375,
-0.055206298828125,
-0.01105499267578... |
liyucheng/frame_finder | 2023-09-14T23:06:41.000Z | [
"transformers",
"pytorch",
"roberta",
"token-classification",
"en",
"dataset:liyucheng/FrameNet_v17",
"license:cc",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | liyucheng | null | null | liyucheng/frame_finder | 0 | 3,604 | transformers | 2023-09-14T23:00:14 | ---
license: cc
datasets:
- liyucheng/FrameNet_v17
language:
- en
---
# Frame Classification
This model is trained FrameNet v1.7. Check out the training dataset [here](https://huggingface.co/datasets/liyucheng/FrameNet_v17).
The data is loaded with `ds = dataset.load_dataset('liyucheng/FrameNet_v17', name = 'frame_label')`.
This flatten all frame annotation to specific sentences, making frame classification a sequence tagging task.
# Metrics
```
{'accuracy_score': 0.8382018348623853, 'precision': 0.8382018348623853, 'recall': 0.8382018348623853, 'micro_f1': 0.8382018348623853, 'macro_f1': 0.45824850358482677}
```
| 628 | [
[
-0.03363037109375,
-0.036102294921875,
-0.00372314453125,
0.0062713623046875,
-0.0186767578125,
-0.0178375244140625,
0.005100250244140625,
-0.019927978515625,
0.03045654296875,
0.044158935546875,
-0.05230712890625,
-0.05474853515625,
-0.046173095703125,
-0.0... |
sail-rvc/BrunoMars1000v2 | 2023-07-14T07:20:14.000Z | [
"transformers",
"rvc",
"sail-rvc",
"audio-to-audio",
"endpoints_compatible",
"region:us"
] | audio-to-audio | sail-rvc | null | null | sail-rvc/BrunoMars1000v2 | 0 | 3,602 | transformers | 2023-07-14T07:19:19 |
---
pipeline_tag: audio-to-audio
tags:
- rvc
- sail-rvc
---
# BrunoMars1000v2
## RVC Model

This model repo was automatically generated.
Date: 2023-07-14 07:20:13
Bot Name: juuxnscrap
Model Type: RVC
Source: https://huggingface.co/juuxn/RVCModels/
Reason: Converting into loadable format for https://github.com/chavinlo/rvc-runpod
| 383 | [
[
-0.0372314453125,
-0.018768310546875,
0.01898193359375,
0.01318359375,
-0.032806396484375,
0.001346588134765625,
0.0131683349609375,
0.0037059783935546875,
0.0302886962890625,
0.072998046875,
-0.052703857421875,
-0.03887939453125,
-0.03961181640625,
-0.00181... |
facebook/fastspeech2-en-ljspeech | 2022-01-28T23:25:24.000Z | [
"fairseq",
"audio",
"text-to-speech",
"en",
"dataset:ljspeech",
"arxiv:2006.04558",
"arxiv:2109.06912",
"has_space",
"region:us"
] | text-to-speech | facebook | null | null | facebook/fastspeech2-en-ljspeech | 225 | 3,580 | fairseq | 2022-03-02T23:29:05 | ---
library_name: fairseq
task: text-to-speech
tags:
- fairseq
- audio
- text-to-speech
language: en
datasets:
- ljspeech
widget:
- text: "Hello, this is a test run."
example_title: "Hello, this is a test run."
---
# fastspeech2-en-ljspeech
[FastSpeech 2](https://arxiv.org/abs/2006.04558) text-to-speech model from fairseq S^2 ([paper](https://arxiv.org/abs/2109.06912)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_synthesis)):
- English
- Single-speaker female voice
- Trained on [LJSpeech](https://keithito.com/LJ-Speech-Dataset/)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/fastspeech2-en-ljspeech",
arg_overrides={"vocoder": "hifigan", "fp16": False}
)
model = models[0]
TTSHubInterface.update_cfg_with_data_cfg(cfg, task.data_cfg)
generator = task.build_generator(model, cfg)
text = "Hello, this is a test run."
sample = TTSHubInterface.get_model_input(task, text)
wav, rate = TTSHubInterface.get_prediction(task, model, generator, sample)
ipd.Audio(wav, rate=rate)
```
See also [fairseq S^2 example](https://github.com/pytorch/fairseq/blob/main/examples/speech_synthesis/docs/ljspeech_example.md).
## Citation
```bibtex
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
| 2,129 | [
[
-0.019622802734375,
-0.06561279296875,
0.015960693359375,
0.03515625,
-0.00038504600524902344,
-0.00609588623046875,
-0.02215576171875,
-0.029693603515625,
0.0024471282958984375,
0.0184173583984375,
-0.04931640625,
-0.0308990478515625,
-0.02667236328125,
0.0... |
Yntec/Pavo-Mix-Diffusers | 2023-07-27T05:25:15.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Eagelaxis",
"Pavo",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/Pavo-Mix-Diffusers | 1 | 3,580 | diffusers | 2023-07-20T19:47:38 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- Eagelaxis
- Pavo
---
# Pavo-Mix
Original page:
https://civitai.com/models/25909/pavo-mix | 262 | [
[
-0.05584716796875,
-0.0005431175231933594,
0.01039886474609375,
0.04608154296875,
-0.035797119140625,
-0.006866455078125,
0.030548095703125,
0.0254364013671875,
0.05853271484375,
0.06280517578125,
-0.053558349609375,
-0.0006937980651855469,
-0.00858306884765625,... |
Yntec/Deliberate | 2023-10-30T22:00:04.000Z | [
"diffusers",
"General",
"Anime",
"Art",
"XpucT",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:cc-by-nc-nd-4.0",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/Deliberate | 1 | 3,579 | diffusers | 2023-10-20T20:51:16 | ---
license: cc-by-nc-nd-4.0
library_name: diffusers
pipeline_tag: text-to-image
tags:
- General
- Anime
- Art
- XpucT
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# Deliberate
Deliberate 1.0 with the MoistMixV2 VAE baked in for improved details over Deliberate 1.1.
Comparison:

(Click for larger)

Sample and prompt:
Cartoon Pretty CUTE Girl, sitting on Overwatch, DETAILED CHIBI EYES, soaking in the rain, gorgeous detailed hair, Ponytail, Magazine ad, iconic, 1940, sharp focus, aerial photography, trending on artstation, peter lloyd. Illustration By ROSSDRAWS and Dave Rapoza and artgerm and leyendecker and Clay
Original page:
https://huggingface.co/XpucT/Deliberate | 948 | [
[
-0.035369873046875,
-0.056793212890625,
0.024139404296875,
0.0423583984375,
-0.0264129638671875,
-0.006134033203125,
0.0156402587890625,
-0.037811279296875,
0.05767822265625,
0.056671142578125,
-0.07196044921875,
-0.0103759765625,
-0.049896240234375,
-0.0133... |
naver/efficient-splade-V-large-doc | 2022-07-08T11:37:17.000Z | [
"transformers",
"pytorch",
"distilbert",
"fill-mask",
"splade",
"query-expansion",
"document-expansion",
"bag-of-words",
"passage-retrieval",
"knowledge-distillation",
"document encoder",
"en",
"dataset:ms_marco",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible... | fill-mask | naver | null | null | naver/efficient-splade-V-large-doc | 3 | 3,573 | transformers | 2022-07-05T09:45:02 | ---
license: cc-by-nc-sa-4.0
language: "en"
tags:
- splade
- query-expansion
- document-expansion
- bag-of-words
- passage-retrieval
- knowledge-distillation
- document encoder
datasets:
- ms_marco
---
## Efficient SPLADE
Efficient SPLADE model for passage retrieval. This architecture uses two distinct models for query and document inference. This is the **doc** one, please also download the **query** one (https://huggingface.co/naver/efficient-splade-V-large-query). For additional details, please visit:
* paper: https://dl.acm.org/doi/10.1145/3477495.3531833
* code: https://github.com/naver/splade
| | MRR@10 (MS MARCO dev) | R@1000 (MS MARCO dev) | Latency (PISA) ms | Latency (Inference) ms
| --- | --- | --- | --- | --- |
| `naver/efficient-splade-V-large` | 38.8 | 98.0 | 29.0 | 45.3
| `naver/efficient-splade-VI-BT-large` | 38.0 | 97.8 | 31.1 | 0.7
## Citation
If you use our checkpoint, please cite our work (need to update):
```
@inproceedings{10.1145/3477495.3531833,
author = {Lassance, Carlos and Clinchant, St\'{e}phane},
title = {An Efficiency Study for SPLADE Models},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531833},
doi = {10.1145/3477495.3531833},
abstract = {Latency and efficiency issues are often overlooked when evaluating IR models based on Pretrained Language Models (PLMs) in reason of multiple hardware and software testing scenarios. Nevertheless, efficiency is an important part of such systems and should not be overlooked. In this paper, we focus on improving the efficiency of the SPLADE model since it has achieved state-of-the-art zero-shot performance and competitive results on TREC collections. SPLADE efficiency can be controlled via a regularization factor, but solely controlling this regularization has been shown to not be efficient enough. In order to reduce the latency gap between SPLADE and traditional retrieval systems, we propose several techniques including L1 regularization for queries, a separation of document/query encoders, a FLOPS-regularized middle-training, and the use of faster query encoders. Our benchmark demonstrates that we can drastically improve the efficiency of these models while increasing the performance metrics on in-domain data. To our knowledge, we propose the first neural models that, under the same computing constraints, achieve similar latency (less than 4ms difference) as traditional BM25, while having similar performance (less than 10% MRR@10 reduction) as the state-of-the-art single-stage neural rankers on in-domain data.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2220–2226},
numpages = {7},
keywords = {splade, latency, information retrieval, sparse representations},
location = {Madrid, Spain},
series = {SIGIR '22}
}
``` | 2,941 | [
[
-0.0224151611328125,
-0.05120849609375,
0.0318603515625,
0.04150390625,
-0.022216796875,
-0.0171661376953125,
-0.020721435546875,
-0.015167236328125,
0.00922393798828125,
0.025482177734375,
-0.016357421875,
-0.03631591796875,
-0.052276611328125,
-0.001294136... |
naver-clova-ix/donut-base-finetuned-rvlcdip | 2022-08-13T08:28:05.000Z | [
"transformers",
"pytorch",
"vision-encoder-decoder",
"donut",
"image-to-text",
"vision",
"arxiv:2111.15664",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | image-to-text | naver-clova-ix | null | null | naver-clova-ix/donut-base-finetuned-rvlcdip | 5 | 3,568 | transformers | 2022-07-19T13:53:57 | ---
license: mit
tags:
- donut
- image-to-text
- vision
---
# Donut (base-sized model, fine-tuned on RVL-CDIP)
Donut model fine-tuned on RVL-CDIP. It was introduced in the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewok et al. and first released in [this repository](https://github.com/clovaai/donut).
Disclaimer: The team releasing Donut did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Donut consists of a vision encoder (Swin Transformer) and a text decoder (BART). Given an image, the encoder first encodes the image into a tensor of embeddings (of shape batch_size, seq_len, hidden_size), after which the decoder autoregressively generates text, conditioned on the encoding of the encoder.

## Intended uses & limitations
This model is fine-tuned on RVL-CDIP, a document image classification dataset.
We refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/donut) which includes code examples.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2111-15664,
author = {Geewook Kim and
Teakgyu Hong and
Moonbin Yim and
Jinyoung Park and
Jinyeong Yim and
Wonseok Hwang and
Sangdoo Yun and
Dongyoon Han and
Seunghyun Park},
title = {Donut: Document Understanding Transformer without {OCR}},
journal = {CoRR},
volume = {abs/2111.15664},
year = {2021},
url = {https://arxiv.org/abs/2111.15664},
eprinttype = {arXiv},
eprint = {2111.15664},
timestamp = {Thu, 02 Dec 2021 10:50:44 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2111-15664.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | 2,031 | [
[
-0.0258331298828125,
-0.042022705078125,
0.0213470458984375,
-0.01580810546875,
-0.0011014938354492188,
-0.005382537841796875,
-0.008087158203125,
-0.035980224609375,
0.00864410400390625,
0.046875,
-0.03387451171875,
-0.019989013671875,
-0.0531005859375,
0.0... |
pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-linelevel-ml384 | 2023-05-19T06:46:30.000Z | [
"transformers",
"pytorch",
"tensorboard",
"lilt",
"token-classification",
"object-detection",
"vision",
"generated_from_trainer",
"DocLayNet",
"COCO",
"PDF",
"IBM",
"Financial-Reports",
"Finance",
"Manuals",
"Scientific-Articles",
"Science",
"Laws",
"Law",
"Regulations",
"Pat... | token-classification | pierreguillou | null | null | pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-linelevel-ml384 | 8 | 3,567 | transformers | 2023-02-09T15:43:23 | ---
language:
- multilingual
- en
- de
- fr
- ja
license: mit
tags:
- object-detection
- vision
- generated_from_trainer
- DocLayNet
- COCO
- PDF
- IBM
- Financial-Reports
- Finance
- Manuals
- Scientific-Articles
- Science
- Laws
- Law
- Regulations
- Patents
- Government-Tenders
- object-detection
- image-segmentation
- token-classification
inference: false
datasets:
- pierreguillou/DocLayNet-base
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-linelevel-ml384
results:
- task:
name: Token Classification
type: token-classification
metrics:
- name: f1
type: f1
value: 0.8584
- name: accuracy
type: accuracy
value: 0.8584
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Document Understanding model (finetuned LiLT base at line level on DocLayNet base)
This model is a fine-tuned version of [nielsr/lilt-xlm-roberta-base](https://huggingface.co/nielsr/lilt-xlm-roberta-base) with the [DocLayNet base](https://huggingface.co/datasets/pierreguillou/DocLayNet-base) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0003
- Precision: 0.8584
- Recall: 0.8584
- F1: 0.8584
- Tokens Accuracy: 0.8584
- Line Accuracy: 0.9197
## Accuracy at line level
- Line Accuracy: 91.97%
- Accuracy by label
- Caption: 79.42%
- Footnote: 68.21%
- Formula: 98.02%
- List-item: 82.72%
- Page-footer: 99.17%
- Page-header: 84.18%
- Picture: 83.2%
- Section-header: 76.92%
- Table: 97.65%
- Text: 91.17%
- Title: 77.46%
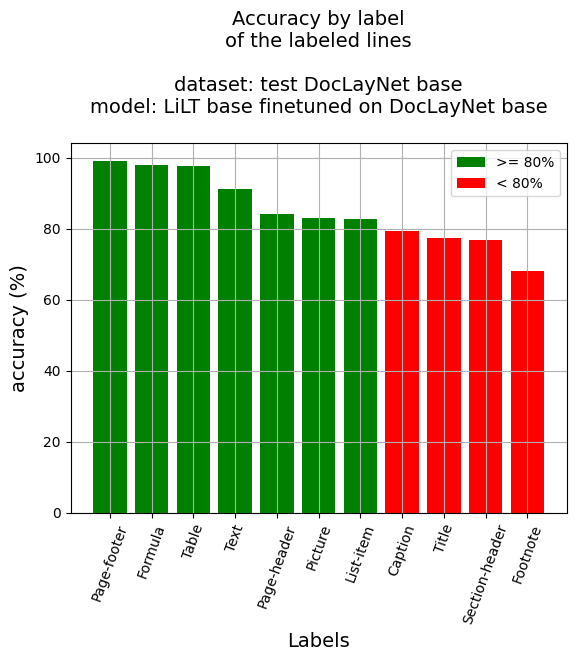
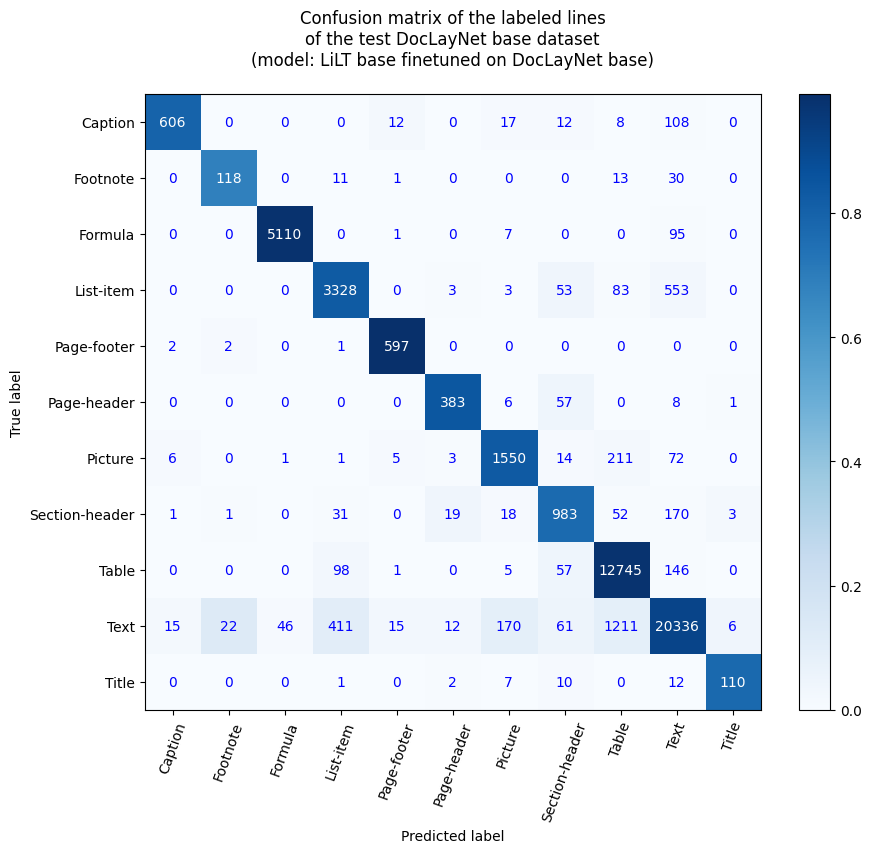
## References
### Blog posts
- Layout XLM base
- (03/05/2023) [Document AI | Inference APP and fine-tuning notebook for Document Understanding at line level with LayoutXLM base]()
- LiLT base
- (02/16/2023) [Document AI | Inference APP and fine-tuning notebook for Document Understanding at paragraph level](https://medium.com/@pierre_guillou/document-ai-inference-app-and-fine-tuning-notebook-for-document-understanding-at-paragraph-level-c18d16e53cf8)
- (02/14/2023) [Document AI | Inference APP for Document Understanding at line level](https://medium.com/@pierre_guillou/document-ai-inference-app-for-document-understanding-at-line-level-a35bbfa98893)
- (02/10/2023) [Document AI | Document Understanding model at line level with LiLT, Tesseract and DocLayNet dataset](https://medium.com/@pierre_guillou/document-ai-document-understanding-model-at-line-level-with-lilt-tesseract-and-doclaynet-dataset-347107a643b8)
- (01/31/2023) [Document AI | DocLayNet image viewer APP](https://medium.com/@pierre_guillou/document-ai-doclaynet-image-viewer-app-3ac54c19956)
- (01/27/2023) [Document AI | Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)](https://medium.com/@pierre_guillou/document-ai-processing-of-doclaynet-dataset-to-be-used-by-layout-models-of-the-hugging-face-hub-308d8bd81cdb)
### Notebooks (paragraph level)
- LiLT base
- [Document AI | Inference APP at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levelparagraphs_ml512.ipynb)
- [Document AI | Inference at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levelparagraphs_ml512.ipynb)
- [Document AI | Fine-tune LiLT on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LiLT_on_DocLayNet_base_in_any_language_at_paragraphlevel_ml_512.ipynb)
### Notebooks (line level)
- Layout XLM base
- [Document AI | Inference at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LayoutXLM_base_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Inference APP at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet base dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LayoutXLM_base_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LayoutXLM_base_on_DocLayNet_base_in_any_language_at_linelevel_ml_384.ipynb)
- LiLT base
- [Document AI | Inference at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Inference APP at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Fine-tune LiLT on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LiLT_on_DocLayNet_base_in_any_language_at_linelevel_ml_384.ipynb)
- [DocLayNet image viewer APP](https://github.com/piegu/language-models/blob/master/DocLayNet_image_viewer_APP.ipynb)
- [Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)](processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb)
### APP
You can test this model with this APP in Hugging Face Spaces: [Inference APP for Document Understanding at line level (v1)](https://huggingface.co/spaces/pierreguillou/Inference-APP-Document-Understanding-at-linelevel-v1).
### DocLayNet dataset
[DocLayNet dataset](https://github.com/DS4SD/DocLayNet) (IBM) provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories.
Until today, the dataset can be downloaded through direct links or as a dataset from Hugging Face datasets:
- direct links: [doclaynet_core.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_core.zip) (28 GiB), [doclaynet_extra.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_extra.zip) (7.5 GiB)
- Hugging Face dataset library: [dataset DocLayNet](https://huggingface.co/datasets/ds4sd/DocLayNet)
Paper: [DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis](https://arxiv.org/abs/2206.01062) (06/02/2022)
## Model description
The model was finetuned at **line level on chunk of 384 tokens with overlap of 128 tokens**. Thus, the model was trained with all layout and text data of all pages of the dataset.
At inference time, a calculation of best probabilities give the label to each line bounding boxes.
## Inference
See notebook: [Document AI | Inference at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
## Training and evaluation data
See notebook: [Document AI | Fine-tune LiLT on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LiLT_on_DocLayNet_base_in_any_language_at_linelevel_ml_384.ipynb)
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.7223 | 0.21 | 500 | 0.7765 | 0.7741 | 0.7741 | 0.7741 | 0.7741 |
| 0.4469 | 0.42 | 1000 | 0.5914 | 0.8312 | 0.8312 | 0.8312 | 0.8312 |
| 0.3819 | 0.62 | 1500 | 0.8745 | 0.8102 | 0.8102 | 0.8102 | 0.8102 |
| 0.3361 | 0.83 | 2000 | 0.6991 | 0.8337 | 0.8337 | 0.8337 | 0.8337 |
| 0.2784 | 1.04 | 2500 | 0.7513 | 0.8119 | 0.8119 | 0.8119 | 0.8119 |
| 0.2377 | 1.25 | 3000 | 0.9048 | 0.8166 | 0.8166 | 0.8166 | 0.8166 |
| 0.2401 | 1.45 | 3500 | 1.2411 | 0.7939 | 0.7939 | 0.7939 | 0.7939 |
| 0.2054 | 1.66 | 4000 | 1.1594 | 0.8080 | 0.8080 | 0.8080 | 0.8080 |
| 0.1909 | 1.87 | 4500 | 0.7545 | 0.8425 | 0.8425 | 0.8425 | 0.8425 |
| 0.1704 | 2.08 | 5000 | 0.8567 | 0.8318 | 0.8318 | 0.8318 | 0.8318 |
| 0.1294 | 2.29 | 5500 | 0.8486 | 0.8489 | 0.8489 | 0.8489 | 0.8489 |
| 0.134 | 2.49 | 6000 | 0.7682 | 0.8573 | 0.8573 | 0.8573 | 0.8573 |
| 0.1354 | 2.7 | 6500 | 0.9871 | 0.8256 | 0.8256 | 0.8256 | 0.8256 |
| 0.1239 | 2.91 | 7000 | 1.1430 | 0.8189 | 0.8189 | 0.8189 | 0.8189 |
| 0.1012 | 3.12 | 7500 | 0.8272 | 0.8386 | 0.8386 | 0.8386 | 0.8386 |
| 0.0788 | 3.32 | 8000 | 1.0288 | 0.8365 | 0.8365 | 0.8365 | 0.8365 |
| 0.0802 | 3.53 | 8500 | 0.7197 | 0.8849 | 0.8849 | 0.8849 | 0.8849 |
| 0.0861 | 3.74 | 9000 | 1.1420 | 0.8320 | 0.8320 | 0.8320 | 0.8320 |
| 0.0639 | 3.95 | 9500 | 0.9563 | 0.8585 | 0.8585 | 0.8585 | 0.8585 |
| 0.0464 | 4.15 | 10000 | 1.0768 | 0.8511 | 0.8511 | 0.8511 | 0.8511 |
| 0.0412 | 4.36 | 10500 | 1.1184 | 0.8439 | 0.8439 | 0.8439 | 0.8439 |
| 0.039 | 4.57 | 11000 | 0.9634 | 0.8636 | 0.8636 | 0.8636 | 0.8636 |
| 0.0469 | 4.78 | 11500 | 0.9585 | 0.8634 | 0.8634 | 0.8634 | 0.8634 |
| 0.0395 | 4.99 | 12000 | 1.0003 | 0.8584 | 0.8584 | 0.8584 | 0.8584 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
## Other models
- Line level
- [Document Understanding model (finetuned LiLT base at line level on DocLayNet base)](https://huggingface.co/pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-linelevel-ml384) (accuracy | tokens: 85.84% - lines: 91.97%)
- [Document Understanding model (finetuned LayoutXLM base at line level on DocLayNet base)](https://huggingface.co/pierreguillou/layout-xlm-base-finetuned-with-DocLayNet-base-at-linelevel-ml384) (accuracy | tokens: 93.73% - lines: ...)
- Paragraph level
- [Document Understanding model (finetuned LiLT base at paragraph level on DocLayNet base)](https://huggingface.co/pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-paragraphlevel-ml512) (accuracy | tokens: 86.34% - paragraphs: 68.15%)
- [Document Understanding model (finetuned LayoutXLM base at paragraph level on DocLayNet base)](https://huggingface.co/pierreguillou/layout-xlm-base-finetuned-with-DocLayNet-base-at-paragraphlevel-ml512) (accuracy | tokens: 96.93% - paragraphs: 86.55%) | 12,816 | [
[
-0.032623291015625,
-0.063232421875,
0.0277099609375,
0.0104522705078125,
0.003849029541015625,
-0.03411865234375,
-0.001735687255859375,
-0.038360595703125,
0.0071868896484375,
0.03167724609375,
-0.034576416015625,
-0.0574951171875,
-0.0382080078125,
-0.012... |
potsawee/longformer-large-4096-answering-race | 2023-05-27T22:13:04.000Z | [
"transformers",
"pytorch",
"longformer",
"multiple-choice",
"question-answering",
"en",
"dataset:race",
"arxiv:2301.12307",
"license:apache-2.0",
"region:us"
] | question-answering | potsawee | null | null | potsawee/longformer-large-4096-answering-race | 15 | 3,564 | transformers | 2023-03-12T16:15:58 | ---
license: apache-2.0
datasets:
- race
language:
- en
library_name: transformers
pipeline_tag: question-answering
inference: false
---
# longformer-large-4096 fine-tuned to RACE for (Multiple-Choice) Question Answering
- Input: `context`, `question`, `options`
- Output: logit (or probability over the options)
## Model Details
longformer-large-4096 model is fine-tuned to the RACE dataset where the input is a concatenation of ```context + question + option```. We follow the architecture/setup described in https://openreview.net/forum?id=HJgJtT4tvB).
The output is the logit over the options. This is the question answering (QA) component in our [MQAG paper](https://arxiv.org/abs/2301.12307),
or please refer to the GitHub repo of this project: https://github.com/potsawee/mqag0.
## How to Use the Model
Use the code below to get started with the model.
```python
>>> import torch
>>> import numpy as np
>>> from transformers import LongformerTokenizer, LongformerForMultipleChoice
>>> tokenizer = LongformerTokenizer.from_pretrained("potsawee/longformer-large-4096-answering-race")
>>> model = LongformerForMultipleChoice.from_pretrained("potsawee/longformer-large-4096-answering-race")
>>> context = r"""Chelsea's mini-revival continued with a third victory in a row as they consigned struggling Leicester City to a fifth consecutive defeat.
Buoyed by their Champions League win over Borussia Dortmund, Chelsea started brightly and Ben Chilwell volleyed in from a tight angle against his old club.
Chelsea's Joao Felix and Leicester's Kiernan Dewsbury-Hall hit the woodwork in the space of two minutes, then Felix had a goal ruled out by the video assistant referee for offside.
Patson Daka rifled home an excellent equaliser after Ricardo Pereira won the ball off the dawdling Felix outside the box.
But Kai Havertz pounced six minutes into first-half injury time with an excellent dinked finish from Enzo Fernandez's clever aerial ball.
Mykhailo Mudryk thought he had his first goal for the Blues after the break but his effort was disallowed for offside.
Mateo Kovacic sealed the win as he volleyed in from Mudryk's header.
The sliding Foxes, who ended with 10 men following Wout Faes' late dismissal for a second booking, now just sit one point outside the relegation zone.
""".replace('\n', ' ')
>>> question = "Who had a goal ruled out for offside?"
>>> options = ['Ricardo Pereira', 'Ben Chilwell', 'Joao Felix', 'The Foxes']
>>> inputs = prepare_answering_input(
tokenizer=tokenizer, question=question,
options=options, context=context,
)
>>> outputs = model(**inputs)
>>> prob = torch.softmax(outputs.logits, dim=-1)[0].tolist()
>>> selected_answer = options[np.argmax(prob)]
>>> print(prob)
[0.00145158, 0.00460851, 0.99049687, 0.00344302]
>>> print(selected_answer)
Joao Felix
```
where the function that prepare the input to the answering model is:
```python
def prepare_answering_input(
tokenizer, # longformer_tokenizer
question, # str
options, # List[str]
context, # str
max_seq_length=4096,
):
c_plus_q = context + ' ' + tokenizer.bos_token + ' ' + question
c_plus_q_4 = [c_plus_q] * len(options)
tokenized_examples = tokenizer(
c_plus_q_4, options,
max_length=max_seq_length,
padding="longest",
truncation=True,
return_tensors="pt",
)
input_ids = tokenized_examples['input_ids'].unsqueeze(0)
attention_mask = tokenized_examples['attention_mask'].unsqueeze(0)
example_encoded = {
"input_ids": input_ids,
"attention_mask": attention_mask,
}
return example_encoded
```
## Related Models
- Question/Answering Generation ```Context ---> Question + Answer```:
- https://huggingface.co/potsawee/t5-large-generation-race-QuestionAnswer
- https://huggingface.co/potsawee/t5-large-generation-squad-QuestionAnswer
- Distractor (False options) Generation:
- https://huggingface.co/potsawee/t5-large-generation-race-Distractor
## Citation
```bibtex
@article{manakul2023mqag,
title={MQAG: Multiple-choice Question Answering and Generation for Assessing Information Consistency in Summarization},
author={Manakul, Potsawee and Liusie, Adian and Gales, Mark JF},
journal={arXiv preprint arXiv:2301.12307},
year={2023}
}
``` | 4,315 | [
[
-0.032928466796875,
-0.05047607421875,
0.03228759765625,
0.017059326171875,
-0.01471710205078125,
0.0100555419921875,
-0.0159759521484375,
-0.03363037109375,
0.030303955078125,
0.0202789306640625,
-0.0577392578125,
-0.0184478759765625,
-0.0190277099609375,
0... |
timm/deit_base_patch16_384.fb_in1k | 2023-03-28T01:33:19.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2012.12877",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/deit_base_patch16_384.fb_in1k | 0 | 3,560 | timm | 2023-03-28T01:31:58 | ---
tags:
- image-classification
- timm
library_tag: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for deit_base_patch16_384.fb_in1k
A DeiT image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 86.9
- GMACs: 55.5
- Activations (M): 101.6
- Image size: 384 x 384
- **Papers:**
- Training data-efficient image transformers & distillation through attention: https://arxiv.org/abs/2012.12877
- **Original:** https://github.com/facebookresearch/deit
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('deit_base_patch16_384.fb_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'deit_base_patch16_384.fb_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 577, 768) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@InProceedings{pmlr-v139-touvron21a,
title = {Training data-efficient image transformers & distillation through attention},
author = {Touvron, Hugo and Cord, Matthieu and Douze, Matthijs and Massa, Francisco and Sablayrolles, Alexandre and Jegou, Herve},
booktitle = {International Conference on Machine Learning},
pages = {10347--10357},
year = {2021},
volume = {139},
month = {July}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 3,216 | [
[
-0.03717041015625,
-0.035614013671875,
0.005970001220703125,
0.01399993896484375,
-0.029510498046875,
-0.02410888671875,
-0.01456451416015625,
-0.026397705078125,
0.0071258544921875,
0.017730712890625,
-0.042205810546875,
-0.05169677734375,
-0.0552978515625,
... |
intfloat/simlm-msmarco-reranker | 2023-05-22T09:36:12.000Z | [
"transformers",
"pytorch",
"electra",
"text-classification",
"en",
"arxiv:2207.02578",
"license:mit",
"endpoints_compatible",
"region:us"
] | text-classification | intfloat | null | null | intfloat/simlm-msmarco-reranker | 7 | 3,559 | transformers | 2022-08-11T05:27:09 | ---
license: mit
language:
- en
---
# SimLM: Pre-training with Representation Bottleneck for Dense Passage Retrieval
paper available at [https://arxiv.org/pdf/2207.02578](https://arxiv.org/pdf/2207.02578)
code available at [https://github.com/microsoft/unilm/tree/master/simlm](https://github.com/microsoft/unilm/tree/master/simlm)
## Paper abstract
In this paper, we propose SimLM (Similarity matching with Language Model pre-training), a simple yet effective pre-training method for dense passage retrieval.
It employs a simple bottleneck architecture that learns to compress the passage information into a dense vector through self-supervised pre-training.
We use a replaced language modeling objective, which is inspired by ELECTRA,
to improve the sample efficiency and reduce the mismatch of the input distribution between pre-training and fine-tuning.
SimLM only requires access to unlabeled corpus, and is more broadly applicable when there are no labeled data or queries.
We conduct experiments on several large-scale passage retrieval datasets, and show substantial improvements over strong baselines under various settings.
Remarkably, SimLM even outperforms multi-vector approaches such as ColBERTv2 which incurs significantly more storage cost.
## Results on MS-MARCO passage ranking task
| Model | dev MRR@10 | dev R@50 | dev R@1k | TREC DL 2019 nDCG@10 | TREC DL 2020 nDCG@10 |
|--|---|---|---|---|---|
| **SimLM (this model)** | 43.8 | 89.2 | 98.6 | 74.6 | 72.7 |
## Usage
Since we use a listwise loss to train the re-ranker,
the relevance score is not bounded to a specific numerical range.
Higher scores mean more relevant between the given query and passage.
Get relevance score from our re-ranker:
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer, BatchEncoding, PreTrainedTokenizerFast
from transformers.modeling_outputs import SequenceClassifierOutput
def encode(tokenizer: PreTrainedTokenizerFast,
query: str, passage: str, title: str = '-') -> BatchEncoding:
return tokenizer(query,
text_pair='{}: {}'.format(title, passage),
max_length=192,
padding=True,
truncation=True,
return_tensors='pt')
tokenizer = AutoTokenizer.from_pretrained('intfloat/simlm-msmarco-reranker')
model = AutoModelForSequenceClassification.from_pretrained('intfloat/simlm-msmarco-reranker')
model.eval()
with torch.no_grad():
batch_dict = encode(tokenizer, 'how long is super bowl game', 'The Super Bowl is typically four hours long. The game itself takes about three and a half hours, with a 30 minute halftime show built in.')
outputs: SequenceClassifierOutput = model(**batch_dict, return_dict=True)
print(outputs.logits[0])
batch_dict = encode(tokenizer, 'how long is super bowl game', 'The cost of a Super Bowl commercial runs about $5 million for 30 seconds of airtime. But the benefits that the spot can bring to a brand can help to justify the cost.')
outputs: SequenceClassifierOutput = model(**batch_dict, return_dict=True)
print(outputs.logits[0])
```
## Citation
```bibtex
@article{Wang2022SimLMPW,
title={SimLM: Pre-training with Representation Bottleneck for Dense Passage Retrieval},
author={Liang Wang and Nan Yang and Xiaolong Huang and Binxing Jiao and Linjun Yang and Daxin Jiang and Rangan Majumder and Furu Wei},
journal={ArXiv},
year={2022},
volume={abs/2207.02578}
}
``` | 3,522 | [
[
-0.02020263671875,
-0.037109375,
0.02880859375,
0.0126800537109375,
-0.044219970703125,
-0.0132598876953125,
-0.0007119178771972656,
-0.0076446533203125,
0.00504302978515625,
0.0271148681640625,
-0.02703857421875,
-0.02117919921875,
-0.0262603759765625,
0.01... |
staka/fugumt-ja-en | 2023-08-15T08:40:58.000Z | [
"transformers",
"pytorch",
"marian",
"text2text-generation",
"translation",
"en",
"ja",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | translation | staka | null | null | staka/fugumt-ja-en | 28 | 3,557 | transformers | 2022-05-08T04:32:09 | ---
license: cc-by-sa-4.0
language:
- en
- ja
tags:
- translation
widget:
- text: "猫はかわいいです。"
---
# FuguMT
This is a translation model using Marian-NMT.
For more details, please see [my repository](https://github.com/s-taka/fugumt).
* source language: ja
* target language: en
### How to use
This model uses transformers and sentencepiece.
```python
!pip install transformers sentencepiece
```
You can use this model directly with a pipeline:
```python
from transformers import pipeline
fugu_translator = pipeline('translation', model='staka/fugumt-ja-en')
fugu_translator('猫はかわいいです。')
```
### Eval results
The results of the evaluation using [tatoeba](https://tatoeba.org/ja)(randomly selected 500 sentences) are as follows:
|source |target |BLEU(*1)|
|-------|-------|--------|
|ja |en |39.1 |
(*1) sacrebleu | 839 | [
[
0.00982666015625,
-0.0523681640625,
0.03857421875,
0.0457763671875,
-0.04144287109375,
-0.026336669921875,
-0.0159912109375,
-0.0009069442749023438,
0.0245361328125,
0.0428466796875,
-0.056640625,
-0.023162841796875,
-0.04840087890625,
0.02069091796875,
... |
timm/coatnet_1_rw_224.sw_in1k | 2023-05-10T23:42:23.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2201.03545",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/coatnet_1_rw_224.sw_in1k | 0 | 3,554 | timm | 2023-01-20T21:24:32 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for coatnet_1_rw_224.sw_in1k
A timm specific CoAtNet image classification model. Trained in `timm` on ImageNet-1k by Ross Wightman.
ImageNet-1k training done on TPUs thanks to support of the [TRC](https://sites.research.google/trc/about/) program.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 41.7
- GMACs: 8.0
- Activations (M): 34.6
- Image size: 224 x 224
- **Papers:**
- CoAtNet: Marrying Convolution and Attention for All Data Sizes: https://arxiv.org/abs/2201.03545
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('coatnet_1_rw_224.sw_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coatnet_1_rw_224.sw_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'coatnet_1_rw_224.sw_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,130 | [
[
-0.051605224609375,
-0.03076171875,
0.0016994476318359375,
0.0310821533203125,
-0.023529052734375,
-0.01556396484375,
-0.0102386474609375,
-0.0258941650390625,
0.05718994140625,
0.01666259765625,
-0.04290771484375,
-0.046478271484375,
-0.048095703125,
-0.005... |
MoritzLaurer/multilingual-MiniLMv2-L6-mnli-xnli | 2023-03-20T08:26:58.000Z | [
"transformers",
"pytorch",
"safetensors",
"xlm-roberta",
"text-classification",
"zero-shot-classification",
"nli",
"multilingual",
"en",
"ar",
"bg",
"de",
"el",
"es",
"fr",
"hi",
"ru",
"sw",
"th",
"tr",
"ur",
"vi",
"zh",
"dataset:multi_nli",
"dataset:xnli",
"arxiv:2... | zero-shot-classification | MoritzLaurer | null | null | MoritzLaurer/multilingual-MiniLMv2-L6-mnli-xnli | 22 | 3,554 | transformers | 2023-02-11T13:10:37 |
---
language:
- multilingual
- en
- ar
- bg
- de
- el
- es
- fr
- hi
- ru
- sw
- th
- tr
- ur
- vi
- zh
license: mit
tags:
- zero-shot-classification
- text-classification
- nli
- pytorch
metrics:
- accuracy
datasets:
- multi_nli
- xnli
pipeline_tag: zero-shot-classification
widget:
- text: "Angela Merkel ist eine Politikerin in Deutschland und Vorsitzende der CDU"
candidate_labels: "politics, economy, entertainment, environment"
---
---
# Multilingual MiniLMv2-L6-mnli-xnli
## Model description
This multilingual model can perform natural language inference (NLI) on 100+ languages and is therefore also
suitable for multilingual zero-shot classification. The underlying multilingual-MiniLM-L6 model was created
by Microsoft and was distilled from XLM-RoBERTa-large (see details [in the original paper](https://arxiv.org/pdf/2002.10957.pdf)
and newer information in [this repo](https://github.com/microsoft/unilm/tree/master/minilm)).
The model was then fine-tuned on the [XNLI dataset](https://huggingface.co/datasets/xnli), which contains hypothesis-premise pairs from 15 languages,
as well as the English [MNLI dataset](https://huggingface.co/datasets/multi_nli).
The main advantage of distilled models is that they are smaller (faster inference, lower memory requirements) than their teachers (XLM-RoBERTa-large).
The disadvantage is that they lose some of the performance of their larger teachers.
For highest inference speed, I recommend using this 6-layer model. For higher performance I recommend
[mDeBERTa-v3-base-mnli-xnli](https://huggingface.co/MoritzLaurer/mDeBERTa-v3-base-mnli-xnli) (as of 14.02.2023).
### How to use the model
#### Simple zero-shot classification pipeline
```python
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="MoritzLaurer/multilingual-MiniLMv2-L6-mnli-xnli")
sequence_to_classify = "Angela Merkel ist eine Politikerin in Deutschland und Vorsitzende der CDU"
candidate_labels = ["politics", "economy", "entertainment", "environment"]
output = classifier(sequence_to_classify, candidate_labels, multi_label=False)
print(output)
```
#### NLI use-case
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model_name = "MoritzLaurer/multilingual-MiniLMv2-L6-mnli-xnli"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
premise = "Angela Merkel ist eine Politikerin in Deutschland und Vorsitzende der CDU"
hypothesis = "Emmanuel Macron is the President of France"
input = tokenizer(premise, hypothesis, truncation=True, return_tensors="pt")
output = model(input["input_ids"].to(device)) # device = "cuda:0" or "cpu"
prediction = torch.softmax(output["logits"][0], -1).tolist()
label_names = ["entailment", "neutral", "contradiction"]
prediction = {name: round(float(pred) * 100, 1) for pred, name in zip(prediction, label_names)}
print(prediction)
```
### Training data
This model was trained on the XNLI development dataset and the MNLI train dataset.
The XNLI development set consists of 2490 professionally translated texts from English
to 14 other languages (37350 texts in total) (see [this paper](https://arxiv.org/pdf/1809.05053.pdf)).
Note that the XNLI contains a training set of 15 machine translated versions of the MNLI dataset for 15 languages,
but due to quality issues with these machine translations, this model was only trained on the professional translations
from the XNLI development set and the original English MNLI training set (392 702 texts).
Not using machine translated texts can avoid overfitting the model to the 15 languages;
avoids catastrophic forgetting of the other languages it was pre-trained on;
and significantly reduces training costs.
### Training procedure
The model was trained using the Hugging Face trainer with the following hyperparameters.
The exact underlying model is [mMiniLMv2-L6-H384-distilled-from-XLMR-Large](https://huggingface.co/nreimers/mMiniLMv2-L6-H384-distilled-from-XLMR-Large).
```
training_args = TrainingArguments(
num_train_epochs=3, # total number of training epochs
learning_rate=4e-05,
per_device_train_batch_size=64, # batch size per device during training
per_device_eval_batch_size=120, # batch size for evaluation
warmup_ratio=0.06, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
)
```
### Eval results
The model was evaluated on the XNLI test set on 15 languages (5010 texts per language, 75150 in total).
Note that multilingual NLI models are capable of classifying NLI texts without receiving NLI training data
in the specific language (cross-lingual transfer). This means that the model is also able of doing NLI on
the other languages it was training on, but performance is most likely lower than for those languages available in XNLI.
The average XNLI performance of multilingual-MiniLM-L6 reported in the paper is 0.68 ([see table 11](https://arxiv.org/pdf/2002.10957.pdf)).
This reimplementation has an average performance of 0.713.
This increase in performance is probably thanks to the addition of MNLI in the training data and this model was distilled from
XLM-RoBERTa-large instead of -base (multilingual-MiniLM-L6-v2).
|Datasets|avg_xnli|ar|bg|de|el|en|es|fr|hi|ru|sw|th|tr|ur|vi|zh|
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|Accuracy|0.713|0.687|0.742|0.719|0.723|0.789|0.748|0.741|0.691|0.714|0.642|0.699|0.696|0.664|0.723|0.721|
|Speed text/sec (A100 GPU, eval_batch=120)|6093.0|6210.0|6003.0|6053.0|5409.0|6531.0|6205.0|5615.0|5734.0|5970.0|6219.0|6289.0|6533.0|5851.0|5970.0|6798.0|
|Datasets|mnli_m|mnli_mm|
| :---: | :---: | :---: |
|Accuracy|0.782|0.8|
|Speed text/sec (A100 GPU, eval_batch=120)|4430.0|4395.0|
## Limitations and bias
Please consult the original paper and literature on different NLI datasets for potential biases.
## Citation
If you use this model, please cite: Laurer, Moritz, Wouter van Atteveldt, Andreu Salleras Casas, and Kasper Welbers. 2022.
‘Less Annotating, More Classifying – Addressing the Data Scarcity Issue of Supervised Machine Learning with Deep Transfer Learning and BERT - NLI’.
Preprint, June. Open Science Framework. https://osf.io/74b8k.
## Ideas for cooperation or questions?
If you have questions or ideas for cooperation, contact me at m{dot}laurer{at}vu{dot}nl or [LinkedIn](https://www.linkedin.com/in/moritz-laurer/)
| 6,735 | [
[
-0.021484375,
-0.024627685546875,
0.00699615478515625,
-0.0006480216979980469,
-0.003437042236328125,
-0.01457977294921875,
-0.0216827392578125,
-0.049468994140625,
0.01678466796875,
0.015228271484375,
-0.04705810546875,
-0.0306396484375,
-0.0382080078125,
0... |
uer/sbert-base-chinese-nli | 2023-10-17T15:29:59.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"zh",
"arxiv:1909.05658",
"arxiv:2212.06385",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | sentence-similarity | uer | null | null | uer/sbert-base-chinese-nli | 78 | 3,550 | sentence-transformers | 2022-03-02T23:29:05 | ---
language: zh
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
license: apache-2.0
widget:
- source_sentence: "那个人很开心"
sentences:
- "那个人非常开心"
- "那只猫很开心"
- "那个人在吃东西"
---
# Chinese Sentence BERT
## Model description
This is the sentence embedding model pre-trained by [UER-py](https://github.com/dbiir/UER-py/), which is introduced in [this paper](https://arxiv.org/abs/1909.05658). Besides, the model could also be pre-trained by [TencentPretrain](https://github.com/Tencent/TencentPretrain) introduced in [this paper](https://arxiv.org/abs/2212.06385), which inherits UER-py to support models with parameters above one billion, and extends it to a multimodal pre-training framework.
## How to use
You can use this model to extract sentence embeddings for sentence similarity task. We use cosine distance to calculate the embedding similarity here:
```python
>>> from sentence_transformers import SentenceTransformer
>>> model = SentenceTransformer('uer/sbert-base-chinese-nli')
>>> sentences = ['那个人很开心', '那个人非常开心']
>>> sentence_embeddings = model.encode(sentences)
>>> from sklearn.metrics.pairwise import paired_cosine_distances
>>> cosine_score = 1 - paired_cosine_distances([sentence_embeddings[0]],[sentence_embeddings[1]])
```
## Training data
[ChineseTextualInference](https://github.com/liuhuanyong/ChineseTextualInference/) is used as training data.
## Training procedure
The model is fine-tuned by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We fine-tune five epochs with a sequence length of 128 on the basis of the pre-trained model [chinese_roberta_L-12_H-768](https://huggingface.co/uer/chinese_roberta_L-12_H-768). At the end of each epoch, the model is saved when the best performance on development set is achieved.
```
python3 finetune/run_classifier_siamese.py --pretrained_model_path models/cluecorpussmall_roberta_base_seq512_model.bin-250000 \
--vocab_path models/google_zh_vocab.txt \
--config_path models/sbert/base_config.json \
--train_path datasets/ChineseTextualInference/train.tsv \
--dev_path datasets/ChineseTextualInference/dev.tsv \
--learning_rate 5e-5 --epochs_num 5 --batch_size 64
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_sbert_from_uer_to_huggingface.py --input_model_path models/finetuned_model.bin \
--output_model_path pytorch_model.bin \
--layers_num 12
```
### BibTeX entry and citation info
```
@article{reimers2019sentence,
title={Sentence-bert: Sentence embeddings using siamese bert-networks},
author={Reimers, Nils and Gurevych, Iryna},
journal={arXiv preprint arXiv:1908.10084},
year={2019}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
@article{zhao2023tencentpretrain,
title={TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities},
author={Zhao, Zhe and Li, Yudong and Hou, Cheng and Zhao, Jing and others},
journal={ACL 2023},
pages={217},
year={2023}
``` | 3,844 | [
[
-0.018768310546875,
-0.049652099609375,
0.0260467529296875,
0.035125732421875,
-0.0222015380859375,
-0.037994384765625,
-0.03314208984375,
-0.0217742919921875,
0.0195770263671875,
0.0216827392578125,
-0.048004150390625,
-0.036346435546875,
-0.027008056640625,
... |
tartuNLP/EstBERT | 2023-09-12T08:44:15.000Z | [
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"fill-mask",
"et",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | tartuNLP | null | null | tartuNLP/EstBERT | 1 | 3,545 | transformers | 2022-03-02T23:29:05 | ---
language: et
license: cc-by-4.0
widget:
- text: "Miks [MASK] ei taha mind kuulata?"
---
---
# EstBERT
### What's this?
The EstBERT model is a pretrained BERT<sub>Base</sub> model exclusively trained on Estonian cased corpus on both 128 and 512 sequence length of data.
### How to use?
You can use the model transformer library both in tensorflow and pytorch version.
```
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("tartuNLP/EstBERT")
model = AutoModelForMaskedLM.from_pretrained("tartuNLP/EstBERT")
```
You can also download the pretrained model from here, [EstBERT_128]() [EstBERT_512]()
#### Dataset used to train the model
The EstBERT model is trained both on 128 and 512 sequence length of data. For training the EstBERT we used the [Estonian National Corpus 2017](https://metashare.ut.ee/repository/browse/estonian-national-corpus-2017/b616ceda30ce11e8a6e4005056b40024880158b577154c01bd3d3fcfc9b762b3/), which was the largest Estonian language corpus available at the time. It consists of four sub-corpora: Estonian Reference Corpus 1990-2008, Estonian Web Corpus 2013, Estonian Web Corpus 2017 and Estonian Wikipedia Corpus 2017.
### Reference to cite
[Tanvir et al 2021](https://aclanthology.org/2021.nodalida-main.2)
### Why would I use?
Overall EstBERT performs better in parts of speech (POS), name entity recognition (NER), rubric, and sentiment classification tasks compared to mBERT and XLM-RoBERTa. The comparative results can be found below;
|Model |UPOS |XPOS |Morph |bf UPOS |bf XPOS |Morph |
|--------------|----------------------------|-------------|-------------|-------------|----------------------------|----------------------------|
| EstBERT | **_97.89_** | **98.40** | **96.93** | **97.84** | **_98.43_** | **_96.80_** |
| mBERT | 97.42 | 98.06 | 96.24 | 97.43 | 98.13 | 96.13 |
| XLM-RoBERTa | 97.78 | 98.36 | 96.53 | 97.80 | 98.40 | 96.69 |
|Model|Rubric<sub>128</sub> |Sentiment<sub>128</sub> | Rubric<sub>128</sub> |Sentiment<sub>512</sub> |
|-------------------|----------------------------|--------------------|-----------------------------------------------|----------------------------|
| EstBERT | **_81.70_** | 74.36 | **80.96** | 74.50 |
| mBERT | 75.67 | 70.23 | 74.94 | 69.52 |
| XLM\-RoBERTa | 80.34 | **74.50** | 78.62 | **_76.07_**|
|Model |Precicion<sub>128</sub> |Recall<sub>128</sub> |F1-Score<sub>128</sub> |Precision<sub>512</sub> |Recall<sub>512</sub> |F1-Score<sub>512</sub> |
|--------------|----------------|----------------------------|----------------------------|----------------------------|-------------|----------------|
| EstBERT | **88.42** | 90.38 |**_89.39_** | 88.35 | 89.74 | 89.04 |
| mBERT | 85.88 | 87.09 | 86.51 |**_88.47_** | 88.28 | 88.37 |
| XLM\-RoBERTa | 87.55 |**_91.19_** | 89.34 | 87.50 | **90.76** | **89.10** |
| 3,588 | [
[
-0.05047607421875,
-0.0496826171875,
0.0191497802734375,
0.018768310546875,
-0.019134521484375,
0.004299163818359375,
-0.01403045654296875,
-0.01556396484375,
0.0312042236328125,
0.018402099609375,
-0.027130126953125,
-0.059722900390625,
-0.0614013671875,
-0... |
ai-forever/FRED-T5-large | 2023-11-03T12:50:12.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"ru",
"arxiv:2309.10931",
"arxiv:2205.05131",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | ai-forever | null | null | ai-forever/FRED-T5-large | 15 | 3,542 | transformers | 2023-02-28T08:34:42 | ---
language:
- ru
license: apache-2.0
---
# FRED-T5 large 820M (Full-scale Russian Enhanced Denoisers T5)
The model architecture design, pretraining, and evaluation are documented in our preprint: [**A Family of Pretrained Transformer Language Models for Russian**](https://arxiv.org/abs/2309.10931).
The model was trained by [SberDevices](https://sberdevices.ru/).
Architecture based on T5.
It has 24 layers and 1024 hidden size. More details in config.json.
The model trained on a mixture of 7 denoisers like UL2 with several differences (https://arxiv.org/abs/2205.05131).
It was trained on Russian language corpus (300GB). The dataset is the same as for ruT5 models.
Bbpe tokenizer. 50257 + special tokens 107. Prefix tokens: '\<LM\>', '\<SC1>',.. '\<SC6>'
First half of the time model trained on the small part of all dataset (1%,3GB) and without prefixes in each task.
For RSG, we trained as described in the T5 paper. First, we trained multitask for all tasks. Then we took the best checkpoint for the task and trained it further.
RSG submit here https://russiansuperglue.com/login/submit_info/2060
Total training time was around 35 days on 160 V100 GPUs + 5 days on 80 A100.
## Usage (HuggingFace Models Repository)
```python
import torch
from transformers import GPT2Tokenizer, T5ForConditionalGeneration
tokenizer = GPT2Tokenizer.from_pretrained('ai-forever/FRED-T5-1.7B',eos_token='</s>')
model = T5ForConditionalGeneration.from_pretrained('ai-forever/FRED-T5-1.7B')
device='cuda'
model.to(device)
#Prefix <LM>
lm_text='<LM>Принялся Кутузов рассказывать свою историю как он сюда попал. Началось'
input_ids=torch.tensor([tokenizer.encode(lm_text)]).to(device)
outputs=model.generate(input_ids,eos_token_id=tokenizer.eos_token_id,early_stopping=True)
print(tokenizer.decode(outputs[0][1:]))
# print result: , как водится, с того, что он был в плену.</s>
#Prefix <SC1>
lm_text='<SC1>Принялся Кутузов рассказывать свою историю <extra_id_0>. Началось с того, что он был в армии, служил в артиллерии.'
input_ids=torch.tensor([tokenizer.encode(lm_text)]).to(device)
outputs=model.generate(input_ids,eos_token_id=tokenizer.eos_token_id,early_stopping=True)
print(tokenizer.decode(outputs[0][1:]))
#print result: '<extra_id_0>, как он жил</s>'
# Prefix <SC5>
lm_text='<SC5>Принялся Кутузов рассказывать свою историю <extra_id_0>. Началось с того, что он был в армии, служил в артиллерии.'
input_ids=torch.tensor([tokenizer.encode(lm_text)]).to(device)
outputs=model.generate(input_ids,eos_token_id=tokenizer.eos_token_id,early_stopping=True,max_length=100)
print(tokenizer.decode(outputs[0][1:]))
#print result: '<extra_id_0> </s>'
```
# Authors
+ NLP core team RnD [Telegram channel](https://t.me/nlpcoreteam):
+ Dmitry Zmitrovich
+ Andrei Kalmykov
+ Vitaly Kadulin
+ Mikhail Novikov
+ Alexey Khoroshilov
[Salute AI Community](https://t.me/SaluteTechGroup).
# Cite us
```
@misc{zmitrovich2023family,
title={A Family of Pretrained Transformer Language Models for Russian},
author={Dmitry Zmitrovich and Alexander Abramov and Andrey Kalmykov and Maria Tikhonova and Ekaterina Taktasheva and Danil Astafurov and Mark Baushenko and Artem Snegirev and Tatiana Shavrina and Sergey Markov and Vladislav Mikhailov and Alena Fenogenova},
year={2023},
eprint={2309.10931},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 3,398 | [
[
-0.02362060546875,
-0.037109375,
0.0107574462890625,
0.01122283935546875,
-0.0307769775390625,
0.00492095947265625,
-0.023284912109375,
-0.0258026123046875,
0.0032291412353515625,
-0.01219940185546875,
-0.039642333984375,
-0.03582763671875,
-0.057037353515625,
... |
shi-labs/versatile-diffusion | 2023-03-27T21:10:36.000Z | [
"diffusers",
"image-to-text",
"image-to-image",
"text-to-image",
"text-to-text",
"image-editing",
"image-variation",
"generation",
"vision",
"dataset:Laion2B-en",
"arxiv:2211.08332",
"license:mit",
"has_space",
"diffusers:VersatileDiffusionPipeline",
"region:us"
] | text-to-image | shi-labs | null | null | shi-labs/versatile-diffusion | 42 | 3,538 | diffusers | 2022-11-22T22:47:21 | ---
license: mit
tags:
- image-to-text
- image-to-image
- text-to-image
- text-to-text
- image-editing
- image-variation
- generation
- vision
datasets:
- Laion2B-en
widget:
- text: "A high tech solarpunk utopia in the Amazon rainforest"
example_title: Amazon rainforest
---
# Versatile Diffusion V1.0 Model Card
We built **Versatile Diffusion (VD), the first unified multi-flow multimodal diffusion framework**, as a step towards **Universal Generative AI**. Versatile Diffusion can natively support image-to-text, image-variation, text-to-image, and text-variation, and can be further extended to other applications such as semantic-style disentanglement, image-text dual-guided generation, latent image-to-text-to-image editing, and more. Future versions will support more modalities such as speech, music, video and 3D.
Resources for more information: [GitHub](https://github.com/SHI-Labs/Versatile-Diffusion), [arXiv](https://arxiv.org/abs/2211.08332).
# Model Details
One single flow of Versatile Diffusion contains a VAE, a diffuser, and a context encoder, and thus handles one task (e.g., text-to-image) under one data type (e.g., image) and one context type (e.g., text). The multi-flow structure of Versatile Diffusion shows in the following diagram:
<p align="center">
<img src="https://huggingface.co/shi-labs/versatile-diffusion-model/resolve/main/assets/figures/vd_combined.png" width="99%">
</p>
- **Developed by:** Xingqian Xu, Atlas Wang, Eric Zhang, Kai Wang, and Humphrey Shi
- **Model type:** Diffusion-based multimodal generation model
- **Language(s):** English
- **License:** MIT
- **Resources for more information:** [GitHub Repository](https://github.com/SHI-Labs/Versatile-Diffusion), [Paper](https://arxiv.org/abs/2211.08332).
- **Cite as:**
```
@article{xu2022versatile,
title = {Versatile Diffusion: Text, Images and Variations All in One Diffusion Model},
author = {Xingqian Xu, Zhangyang Wang, Eric Zhang, Kai Wang, Humphrey Shi},
year = 2022,
url = {https://arxiv.org/abs/2211.08332},
eprint = {2211.08332},
archiveprefix = {arXiv},
primaryclass = {cs.CV}
}
```
# Usage
You can use the model both with the [🧨Diffusers library](https://github.com/huggingface/diffusers) and the [SHI-Labs Versatile Diffusion codebase](https://github.com/SHI-Labs/Versatile-Diffusion).
## 🧨 Diffusers
Diffusers let's you both use a unified and more memory-efficient, task-specific pipelines.
**Make sure to install `transformers` from `"main"` in order to use this model.**:
```
pip install git+https://github.com/huggingface/transformers
```
## VersatileDiffusionPipeline
To use Versatile Diffusion for all tasks, it is recommend to use the [`VersatileDiffusionPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/versatile_diffusion#diffusers.VersatileDiffusionPipeline)
```py
#! pip install git+https://github.com/huggingface/transformers diffusers torch
from diffusers import VersatileDiffusionPipeline
import torch
import requests
from io import BytesIO
from PIL import Image
pipe = VersatileDiffusionPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
# prompt
prompt = "a red car"
# initial image
url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
# text to image
image = pipe.text_to_image(prompt).images[0]
# image variation
image = pipe.image_variation(image).images[0]
# image variation
image = pipe.dual_guided(prompt, image).images[0]
```
### Task Specific
The task specific pipelines load only the weights that are needed onto GPU.
You can find all task specific pipelines [here](https://huggingface.co/docs/diffusers/main/en/api/pipelines/versatile_diffusion#versatilediffusion).
You can use them as follows:
### Text to Image
```py
from diffusers import VersatileDiffusionTextToImagePipeline
import torch
pipe = VersatileDiffusionTextToImagePipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe.remove_unused_weights()
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(0)
image = pipe("an astronaut riding on a horse on mars", generator=generator).images[0]
image.save("./astronaut.png")
```
#### Image variations
```py
from diffusers import VersatileDiffusionImageVariationPipeline
import torch
import requests
from io import BytesIO
from PIL import Image
# download an initial image
url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
pipe = VersatileDiffusionImageVariationPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(0)
image = pipe(image, generator=generator).images[0]
image.save("./car_variation.png")
```
#### Dual-guided generation
```py
from diffusers import VersatileDiffusionDualGuidedPipeline
import torch
import requests
from io import BytesIO
from PIL import Image
# download an initial image
url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
response = requests.get(url)
image = Image.open(BytesIO(response.content)).convert("RGB")
text = "a red car in the sun"
pipe = VersatileDiffusionDualGuidedPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
pipe.remove_unused_weights()
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(0)
text_to_image_strength = 0.75
image = pipe(prompt=text, image=image, text_to_image_strength=text_to_image_strength, generator=generator).images[0]
image.save("./red_car.png")
```
### Original GitHub Repository
Follow the instructions [here](https://github.com/SHI-Labs/Versatile-Diffusion/#evaluation).
# Cautions, Biases, and Content Acknowledgment
We would like the raise the awareness of users of this demo of its potential issues and concerns. Like previous large foundation models, Versatile Diffusion could be problematic in some cases, partially due to the imperfect training data and pretrained network (VAEs / context encoders) with limited scope. In its future research phase, VD may do better on tasks such as text-to-image, image-to-text, etc., with the help of more powerful VAEs, more sophisticated network designs, and more cleaned data. So far, we have kept all features available for research testing both to show the great potential of the VD framework and to collect important feedback to improve the model in the future. We welcome researchers and users to report issues with the HuggingFace community discussion feature or email the authors.
Beware that VD may output content that reinforces or exacerbates societal biases, as well as realistic faces, pornography, and violence. VD was trained on the LAION-2B dataset, which scraped non-curated online images and text, and may contain unintended exceptions as we removed illegal content. VD in this demo is meant only for research purposes. | 7,211 | [
[
-0.045928955078125,
-0.0675048828125,
0.0338134765625,
0.0340576171875,
-0.0152740478515625,
-0.0187225341796875,
-0.005489349365234375,
-0.0237884521484375,
0.015777587890625,
0.029998779296875,
-0.03973388671875,
-0.04083251953125,
-0.044647216796875,
-0.0... |
MBZUAI/LaMini-Flan-T5-248M | 2023-04-28T12:08:23.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"instruction fine-tuning",
"en",
"arxiv:2304.14402",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | MBZUAI | null | null | MBZUAI/LaMini-Flan-T5-248M | 35 | 3,536 | transformers | 2023-04-10T17:37:18 | ---
license: cc-by-nc-4.0
tags:
- generated_from_trainer
- instruction fine-tuning
model-index:
- name: flan-t5-small-distil-v2
results: []
language:
- en
pipeline_tag: text2text-generation
widget:
- text: >-
how can I become more healthy?
example_title: example
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
<p align="center" width="100%">
<a><img src="https://raw.githubusercontent.com/mbzuai-nlp/lamini-lm/main/images/lamini.png" alt="Title" style="width: 100%; min-width: 300px; display: block; margin: auto;"></a>
</p>
# LaMini-Flan-T5-248M
[]()
This model is one of our LaMini-LM model series in paper "[LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions](https://github.com/mbzuai-nlp/lamini-lm)". This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on [LaMini-instruction dataset](https://huggingface.co/datasets/MBZUAI/LaMini-instruction) that contains 2.58M samples for instruction fine-tuning. For more information about our dataset, please refer to our [project repository](https://github.com/mbzuai-nlp/lamini-lm/).
You can view other models of LaMini-LM series as follows. Models with ✩ are those with the best overall performance given their size/architecture, hence we recommend using them. More details can be seen in our paper.
<table>
<thead>
<tr>
<th>Base model</th>
<th colspan="4">LaMini-LM series (#parameters)</th>
</tr>
</thead>
<tbody>
<tr>
<td>T5</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-t5-61m" target="_blank" rel="noopener noreferrer">LaMini-T5-61M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-t5-223m" target="_blank" rel="noopener noreferrer">LaMini-T5-223M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-t5-738m" target="_blank" rel="noopener noreferrer">LaMini-T5-738M</a></td>
<td></td>
</tr>
<tr>
<td>Flan-T5</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-flan-t5-77m" target="_blank" rel="noopener noreferrer">LaMini-Flan-T5-77M</a>✩</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-flan-t5-248m" target="_blank" rel="noopener noreferrer">LaMini-Flan-T5-248M</a>✩</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-flan-t5-783m" target="_blank" rel="noopener noreferrer">LaMini-Flan-T5-783M</a>✩</td>
<td></td>
</tr>
<tr>
<td>Cerebras-GPT</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-cerebras-111m" target="_blank" rel="noopener noreferrer">LaMini-Cerebras-111M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-cerebras-256m" target="_blank" rel="noopener noreferrer">LaMini-Cerebras-256M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-cerebras-590m" target="_blank" rel="noopener noreferrer">LaMini-Cerebras-590M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-cerebras-1.3b" target="_blank" rel="noopener noreferrer">LaMini-Cerebras-1.3B</a></td>
</tr>
<tr>
<td>GPT-2</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-gpt-124m" target="_blank" rel="noopener noreferrer">LaMini-GPT-124M</a>✩</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-gpt-774m" target="_blank" rel="noopener noreferrer">LaMini-GPT-774M</a>✩</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-gpt-1.5b" target="_blank" rel="noopener noreferrer">LaMini-GPT-1.5B</a>✩</td>
<td></td>
</tr>
<tr>
<td>GPT-Neo</td>
<td><a href="https://huggingface.co/MBZUAI/lamini-neo-125m" target="_blank" rel="noopener noreferrer">LaMini-Neo-125M</a></td>
<td><a href="https://huggingface.co/MBZUAI/lamini-neo-1.3b" target="_blank" rel="noopener noreferrer">LaMini-Neo-1.3B</a></td>
<td></td>
<td></td>
</tr>
<tr>
<td>GPT-J</td>
<td colspan="4">coming soon</td>
</tr>
<tr>
<td>LLaMA</td>
<td colspan="4">coming soon</td>
</tr>
</tbody>
</table>
## Use
### Intended use
We recommend using the model to response to human instructions written in natural language.
We now show you how to load and use our model using HuggingFace `pipeline()`.
```python
# pip install -q transformers
from transformers import pipeline
checkpoint = "{model_name}"
model = pipeline('text2text-generation', model = checkpoint)
input_prompt = 'Please let me know your thoughts on the given place and why you think it deserves to be visited: \n"Barcelona, Spain"'
generated_text = model(input_prompt, max_length=512, do_sample=True)[0]['generated_text']
print("Response", generated_text)
```
## Training Procedure
<p align="center" width="100%">
<a><img src="https://raw.githubusercontent.com/mbzuai-nlp/lamini-lm/main/images/lamini-pipeline.drawio.png" alt="Title" style="width: 100%; min-width: 250px; display: block; margin: auto;"></a>
</p>
We initialize with [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) and fine-tune it on our [LaMini-instruction dataset](https://huggingface.co/datasets/MBZUAI/LaMini-instruction). Its total number of parameters is 248M.
### Training Hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
## Evaluation
We conducted two sets of evaluations: automatic evaluation on downstream NLP tasks and human evaluation on user-oriented instructions. For more detail, please refer to our [paper]().
## Limitations
More information needed
# Citation
```bibtex
@article{lamini-lm,
author = {Minghao Wu and
Abdul Waheed and
Chiyu Zhang and
Muhammad Abdul-Mageed and
Alham Fikri Aji
},
title = {LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions},
journal = {CoRR},
volume = {abs/2304.14402},
year = {2023},
url = {https://arxiv.org/abs/2304.14402},
eprinttype = {arXiv},
eprint = {2304.14402}
}
``` | 6,412 | [
[
-0.04913330078125,
-0.051544189453125,
0.01290130615234375,
0.01849365234375,
-0.017242431640625,
-0.0306243896484375,
-0.0100555419921875,
-0.049346923828125,
0.0218658447265625,
0.02001953125,
-0.06060791015625,
-0.0321044921875,
-0.03955078125,
0.00437927... |
timm/convnextv2_base.fcmae | 2023-03-31T23:04:16.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2301.00808",
"license:cc-by-nc-4.0",
"region:us"
] | image-classification | timm | null | null | timm/convnextv2_base.fcmae | 0 | 3,531 | timm | 2023-01-05T01:37:39 | ---
tags:
- image-classification
- timm
library_tag: timm
license: cc-by-nc-4.0
---
# Model card for convnextv2_base.fcmae
A ConvNeXt-V2 self-supervised feature representation model. Pretrained with a fully convolutional masked autoencoder framework (FCMAE). This model has no pretrained head and is only useful for fine-tune or feature extraction.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 87.7
- GMACs: 15.4
- Activations (M): 28.8
- Image size: 224 x 224
- **Papers:**
- ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders: https://arxiv.org/abs/2301.00808
- **Original:** https://github.com/facebookresearch/ConvNeXt-V2
- **Pretrain Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnextv2_base.fcmae', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_base.fcmae',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 56, 56])
# torch.Size([1, 256, 28, 28])
# torch.Size([1, 512, 14, 14])
# torch.Size([1, 1024, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_base.fcmae',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1024, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{Woo2023ConvNeXtV2,
title={ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders},
author={Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon and Saining Xie},
year={2023},
journal={arXiv preprint arXiv:2301.00808},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,746 | [
[
-0.0703125,
-0.03118896484375,
-0.00479888916015625,
0.0384521484375,
-0.031646728515625,
-0.0158233642578125,
-0.01255035400390625,
-0.034912109375,
0.06585693359375,
0.0189361572265625,
-0.045440673828125,
-0.038818359375,
-0.05340576171875,
-0.00437545776... |
rinna/japanese-gpt-1b | 2023-03-22T04:09:05.000Z | [
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"ja",
"japanese",
"gpt",
"lm",
"nlp",
"dataset:cc100",
"dataset:wikipedia",
"dataset:c4",
"license:mit",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text-generation | rinna | null | null | rinna/japanese-gpt-1b | 91 | 3,523 | transformers | 2022-03-02T23:29:05 | ---
language: ja
thumbnail: https://github.com/rinnakk/japanese-pretrained-models/blob/master/rinna.png
tags:
- ja
- japanese
- gpt
- text-generation
- lm
- nlp
license: mit
datasets:
- cc100
- wikipedia
- c4
widget:
- text: "西田幾多郎は、"
---
# japanese-gpt-1b

This repository provides a 1.3B-parameter Japanese GPT model. The model was trained by [rinna Co., Ltd.](https://corp.rinna.co.jp/)
# How to use the model
~~~~
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-1b", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-1b")
if torch.cuda.is_available():
model = model.to("cuda")
text = "西田幾多郎は、"
token_ids = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_length=100,
min_length=100,
do_sample=True,
top_k=500,
top_p=0.95,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
bad_words_ids=[[tokenizer.unk_token_id]]
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
# sample output: 西田幾多郎は、その主著の「善の研究」などで、人間の内面に自然とその根源があると指摘し、その根源的な性格は、この西田哲学を象徴しているとして、カントの「純粋理性批判」と「判断力批判」を対比して捉えます。それは、「人が理性的存在であるかぎりにおいて、人はその当人に固有な道徳的に自覚された善悪の基準を持っている」とするもので、この理性的な善悪の観念を否定するのがカントの
~~~~
# Model architecture
A 24-layer, 2048-hidden-size transformer-based language model.
# Training
The model was trained on [Japanese C4](https://huggingface.co/datasets/allenai/c4), [Japanese CC-100](http://data.statmt.org/cc-100/ja.txt.xz) and [Japanese Wikipedia](https://dumps.wikimedia.org/other/cirrussearch) to optimize a traditional language modelling objective. It reaches around 14 perplexity on a chosen validation set from the same data.
# Tokenization
The model uses a [sentencepiece](https://github.com/google/sentencepiece)-based tokenizer. The vocabulary was first trained on a selected subset from the training data using the official sentencepiece training script, and then augmented with emojis and symbols.
# Licenese
[The MIT license](https://opensource.org/licenses/MIT)
| 2,294 | [
[
-0.034423828125,
-0.06817626953125,
0.01568603515625,
0.0196380615234375,
-0.042694091796875,
-0.01404571533203125,
-0.01491546630859375,
-0.01499176025390625,
0.00978851318359375,
0.0321044921875,
-0.03790283203125,
-0.0438232421875,
-0.0469970703125,
0.002... |
nitrosocke/archer-diffusion | 2023-05-16T09:22:34.000Z | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | nitrosocke | null | null | nitrosocke/archer-diffusion | 212 | 3,514 | diffusers | 2022-10-20T17:17:37 | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
---
### Archer Diffusion
This is the fine-tuned Stable Diffusion model trained on screenshots from the TV-show Archer.
Use the tokens **_archer style_** in your prompts for the effect.
**If you enjoy my work, please consider supporting me**
[](https://patreon.com/user?u=79196446)
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
#!pip install diffusers transformers scipy torch
from diffusers import StableDiffusionPipeline
import torch
model_id = "nitrosocke/archer-diffusion"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a magical princess with golden hair, archer style"
image = pipe(prompt).images[0]
image.save("./magical_princess.png")
```
**Portraits rendered with the model:**

**Celebrities rendered with the model:**

**Landscapes rendered with the model:**

**Animals rendered with the model:**

**Sample images used for training:**

#### Prompt and settings for portraits:
**archer style beautiful portrait of ariana grande**
_Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 946707299, Size: 512x704_
#### Prompt and settings for landscapes:
**archer style suburban street night blue indoor lighting Negative prompt: grey cars**
_Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 2915669764, Size: 1024x576_
This model was trained using the diffusers based dreambooth training and prior-preservation loss in 4.000 steps and using the _train-text-encoder_ feature.
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) | 3,432 | [
[
-0.0309295654296875,
-0.05706787109375,
0.0152740478515625,
0.01165008544921875,
-0.01520538330078125,
-0.00702667236328125,
0.01432037353515625,
-0.02703857421875,
0.024749755859375,
0.032012939453125,
-0.03466796875,
-0.04107666015625,
-0.057647705078125,
... |
kernelmachine/silo-pdsw-1.3b | 2023-08-08T18:46:58.000Z | [
"transformers",
"pytorch",
"text-generation",
"openlm",
"silo",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-generation | kernelmachine | null | null | kernelmachine/silo-pdsw-1.3b | 0 | 3,513 | transformers | 2023-08-06T14:19:51 | ---
license: apache-2.0
language:
- en
pipeline_tag: text-generation
tags:
- text-generation
- openlm
- silo
---
# Silo Language Models: Isolating Legal Risk in a Datastore
This is Silo-PDSW, first introduced in [Silo Language Models]() by researchers at University of Washington, UC Berkeley, and the Allen Institute for AI.
### NOTE: Dependencies
To use the model, you need to install a specific transformers fork:
```
pip install git+https://github.com/kernelmachine/transformers@openlm#egg=transformers
```
The model also depends on `xformers`, install via
```
pip install xformers
```
### Model Description
Silo-PDSW is a 1.3B parameter, decoder-only language model trained on data in the public domain and under permissive software licenses from [the Open License Corpus (OLC)](https://huggingface.co/datasets/kernelmachine/open-license-corpus).
The model is based on the LLaMA architecture as implemented in (OpenLM)[].
The model is trained with 128 A100 GPUs across 16 nodes.
### Model and Training Hyperparameters
We follow the model architecture of LLaMa, and we use the GPT-NeoX-20B tokenizer, with 50432 BPE types.
During training, we use 2,048 token sequences that are packed across document boundaries, and we pre-pend a beginning-of-text token to every document.
We use weight decay of 0.1, the Adam optimizer with beta_2 of 0.95, 2,000 steps of warmup, with a cosine learning rate scheduler.
| Model | #L | #H | d_model | LR | Batch |
|--------|-----|-----|-------------|--------|--------|
| 1.3B | 24 | 16 | 2048 | 1e-3 | 2.6M |
### Training data
Silo-PDSW was trained on data in the public domain and under permissive software licenses from [the Open License Corpus (OLC)](https://huggingface.co/datasets/kernelmachine/open-license-corpus).
The model was trained on the following domain proportions (please see the OLC repository for more details on the data sources for each domain):
| Domain | Tokens (B) | % |
|-----------------|------------|-------|
| Code | 58.9 | 59.1 |
| Legal | 27.1 | 27.2 |
| Conversation | 5.9 | 5.9 |
| Math | 3.5 | 3.5 |
| Books | 2.9 | 2.9 |
| Science | 1.2 | 1.2 |
| News | 0.2 | 0.2 |
| Total | 99.6 | 100.0 |
We train with early stopping for 250B tokens in total, or a little more than two epochs of training over this subset
Since the distribution of OLC is highly skewed, we perform a simple upweighting scheme where we upsample all data that accounts for less than 5% of the corpus by a factor of 3x, which we found to work well after a sweep of different settings.
### Intended Uses and Limitations
This model can be used for prompting for evaluation of downstream tasks as well as text generation.
### How to use
You can use this model directly with a pipeline for text generation.
```python
from transformers import pipeline
generator = pipeline('text-generation', model="kernelmachine/silo-pdsw-1.3b", device='cuda')
generator("Hello")
[{'generated_text': "Hello, I'm a new user of Ubuntu. I'm trying to install the latest version of Ubuntu"}]
```
By default, generation is deterministic. In order to use the top-k sampling, please set do_sample to True.
```python
from transformers import pipeline, set_seed
set_seed(32)
generator = pipeline('text-generation', model="kernelmachine/silo-pdsw-1.3b", device='cuda', do_sample=True)
generator("Hello")
[{'generated_text': 'Hello: Hello World;", ""));\n }\n\n [Test]\n public void'}]
```
### Limitations and Bias
Silo-PDSW inherits the biases and limitations of public domain data, which carry risks of toxic or otherwise unfair output, due to the prevalence of older copyright-expired text.
Silo-PDSW may also output personally identifiable information, because we did not filter that out of training data.
| 3,978 | [
[
-0.01132965087890625,
-0.046142578125,
0.04376220703125,
0.007236480712890625,
-0.019256591796875,
-0.004817962646484375,
-0.005374908447265625,
-0.02410888671875,
-0.0003464221954345703,
0.044952392578125,
-0.026885986328125,
-0.04840087890625,
-0.0615844726562... |
aubmindlab/bert-large-arabertv2 | 2023-03-20T13:07:11.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"tensorboard",
"safetensors",
"bert",
"fill-mask",
"ar",
"dataset:wikipedia",
"dataset:Osian",
"dataset:1.5B-Arabic-Corpus",
"dataset:oscar-arabic-unshuffled",
"dataset:Assafir(private)",
"arxiv:2003.00104",
"autotrain_compatible",
"endpoints_c... | fill-mask | aubmindlab | null | null | aubmindlab/bert-large-arabertv2 | 6 | 3,506 | transformers | 2022-03-02T23:29:05 | ---
language: ar
datasets:
- wikipedia
- Osian
- 1.5B-Arabic-Corpus
- oscar-arabic-unshuffled
- Assafir(private)
widget:
- text: " عاصم +ة لبنان هي [MASK] ."
---
# AraBERT v1 & v2 : Pre-training BERT for Arabic Language Understanding
<img src="https://raw.githubusercontent.com/aub-mind/arabert/master/arabert_logo.png" width="100" align="left"/>
**AraBERT** is an Arabic pretrained language model based on [Google's BERT architechture](https://github.com/google-research/bert). AraBERT uses the same BERT-Base config. More details are available in the [AraBERT Paper](https://arxiv.org/abs/2003.00104) and in the [AraBERT Meetup](https://github.com/WissamAntoun/pydata_khobar_meetup)
There are two versions of the model, AraBERTv0.1 and AraBERTv1, with the difference being that AraBERTv1 uses pre-segmented text where prefixes and suffixes were split using the [Farasa Segmenter](http://alt.qcri.org/farasa/segmenter.html).
We evaluate AraBERT models on different downstream tasks and compare them to [mBERT]((https://github.com/google-research/bert/blob/master/multilingual.md)), and other state of the art models (*To the extent of our knowledge*). The Tasks were Sentiment Analysis on 6 different datasets ([HARD](https://github.com/elnagara/HARD-Arabic-Dataset), [ASTD-Balanced](https://www.aclweb.org/anthology/D15-1299), [ArsenTD-Lev](https://staff.aub.edu.lb/~we07/Publications/ArSentD-LEV_Sentiment_Corpus.pdf), [LABR](https://github.com/mohamedadaly/LABR)), Named Entity Recognition with the [ANERcorp](http://curtis.ml.cmu.edu/w/courses/index.php/ANERcorp), and Arabic Question Answering on [Arabic-SQuAD and ARCD](https://github.com/husseinmozannar/SOQAL)
# AraBERTv2
## What's New!
AraBERT now comes in 4 new variants to replace the old v1 versions:
More Detail in the AraBERT folder and in the [README](https://github.com/aub-mind/arabert/blob/master/AraBERT/README.md) and in the [AraBERT Paper](https://arxiv.org/abs/2003.00104v2)
Model | HuggingFace Model Name | Size (MB/Params)| Pre-Segmentation | DataSet (Sentences/Size/nWords) |
---|:---:|:---:|:---:|:---:
AraBERTv0.2-base | [bert-base-arabertv02](https://huggingface.co/aubmindlab/bert-base-arabertv02) | 543MB / 136M | No | 200M / 77GB / 8.6B |
AraBERTv0.2-large| [bert-large-arabertv02](https://huggingface.co/aubmindlab/bert-large-arabertv02) | 1.38G 371M | No | 200M / 77GB / 8.6B |
AraBERTv2-base| [bert-base-arabertv2](https://huggingface.co/aubmindlab/bert-base-arabertv2) | 543MB 136M | Yes | 200M / 77GB / 8.6B |
AraBERTv2-large| [bert-large-arabertv2](https://huggingface.co/aubmindlab/bert-large-arabertv2) | 1.38G 371M | Yes | 200M / 77GB / 8.6B |
AraBERTv0.2-Twitter-base| [bert-base-arabertv02-twitter](https://huggingface.co/aubmindlab/bert-base-arabertv02-twitter) | 543MB / 136M | No | Same as v02 + 60M Multi-Dialect Tweets|
AraBERTv0.2-Twitter-large| [bert-large-arabertv02-twitter](https://huggingface.co/aubmindlab/bert-large-arabertv02-twitter) | 1.38G / 371M | No | Same as v02 + 60M Multi-Dialect Tweets|
AraBERTv0.1-base| [bert-base-arabertv01](https://huggingface.co/aubmindlab/bert-base-arabertv01) | 543MB 136M | No | 77M / 23GB / 2.7B |
AraBERTv1-base| [bert-base-arabert](https://huggingface.co/aubmindlab/bert-base-arabert) | 543MB 136M | Yes | 77M / 23GB / 2.7B |
All models are available in the `HuggingFace` model page under the [aubmindlab](https://huggingface.co/aubmindlab/) name. Checkpoints are available in PyTorch, TF2 and TF1 formats.
## Better Pre-Processing and New Vocab
We identified an issue with AraBERTv1's wordpiece vocabulary. The issue came from punctuations and numbers that were still attached to words when learned the wordpiece vocab. We now insert a space between numbers and characters and around punctuation characters.
The new vocabulary was learned using the `BertWordpieceTokenizer` from the `tokenizers` library, and should now support the Fast tokenizer implementation from the `transformers` library.
**P.S.**: All the old BERT codes should work with the new BERT, just change the model name and check the new preprocessing function
**Please read the section on how to use the [preprocessing function](#Preprocessing)**
## Bigger Dataset and More Compute
We used ~3.5 times more data, and trained for longer.
For Dataset Sources see the [Dataset Section](#Dataset)
Model | Hardware | num of examples with seq len (128 / 512) |128 (Batch Size/ Num of Steps) | 512 (Batch Size/ Num of Steps) | Total Steps | Total Time (in Days) |
---|:---:|:---:|:---:|:---:|:---:|:---:
AraBERTv0.2-base | TPUv3-8 | 420M / 207M | 2560 / 1M | 384/ 2M | 3M | -
AraBERTv0.2-large | TPUv3-128 | 420M / 207M | 13440 / 250K | 2056 / 300K | 550K | 7
AraBERTv2-base | TPUv3-8 | 420M / 207M | 2560 / 1M | 384/ 2M | 3M | -
AraBERTv2-large | TPUv3-128 | 520M / 245M | 13440 / 250K | 2056 / 300K | 550K | 7
AraBERT-base (v1/v0.1) | TPUv2-8 | - |512 / 900K | 128 / 300K| 1.2M | 4
# Dataset
The pretraining data used for the new AraBERT model is also used for Arabic **GPT2 and ELECTRA**.
The dataset consists of 77GB or 200,095,961 lines or 8,655,948,860 words or 82,232,988,358 chars (before applying Farasa Segmentation)
For the new dataset we added the unshuffled OSCAR corpus, after we thoroughly filter it, to the previous dataset used in AraBERTv1 but with out the websites that we previously crawled:
- OSCAR unshuffled and filtered.
- [Arabic Wikipedia dump](https://archive.org/details/arwiki-20190201) from 2020/09/01
- [The 1.5B words Arabic Corpus](https://www.semanticscholar.org/paper/1.5-billion-words-Arabic-Corpus-El-Khair/f3eeef4afb81223df96575adadf808fe7fe440b4)
- [The OSIAN Corpus](https://www.aclweb.org/anthology/W19-4619)
- Assafir news articles. Huge thank you for Assafir for providing us the data
# Preprocessing
It is recommended to apply our preprocessing function before training/testing on any dataset.
**Install the arabert python package to segment text for AraBERT v1 & v2 or to clean your data `pip install arabert`**
```python
from arabert.preprocess import ArabertPreprocessor
model_name="aubmindlab/bert-large-arabertv2"
arabert_prep = ArabertPreprocessor(model_name=model_name)
text = "ولن نبالغ إذا قلنا إن هاتف أو كمبيوتر المكتب في زمننا هذا ضروري"
arabert_prep.preprocess(text)
>>>"و+ لن نبالغ إذا قل +نا إن هاتف أو كمبيوتر ال+ مكتب في زمن +نا هذا ضروري"
```
# TensorFlow 1.x models
The TF1.x model are available in the HuggingFace models repo.
You can download them as follows:
- via git-lfs: clone all the models in a repo
```bash
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
git lfs install
git clone https://huggingface.co/aubmindlab/MODEL_NAME
tar -C ./MODEL_NAME -zxvf /content/MODEL_NAME/tf1_model.tar.gz
```
where `MODEL_NAME` is any model under the `aubmindlab` name
- via `wget`:
- Go to the tf1_model.tar.gz file on huggingface.co/models/aubmindlab/MODEL_NAME.
- copy the `oid sha256`
- then run `wget https://cdn-lfs.huggingface.co/aubmindlab/aragpt2-base/INSERT_THE_SHA_HERE` (ex: for `aragpt2-base`: `wget https://cdn-lfs.huggingface.co/aubmindlab/aragpt2-base/3766fc03d7c2593ff2fb991d275e96b81b0ecb2098b71ff315611d052ce65248`)
# If you used this model please cite us as :
Google Scholar has our Bibtex wrong (missing name), use this instead
```
@inproceedings{antoun2020arabert,
title={AraBERT: Transformer-based Model for Arabic Language Understanding},
author={Antoun, Wissam and Baly, Fady and Hajj, Hazem},
booktitle={LREC 2020 Workshop Language Resources and Evaluation Conference 11--16 May 2020},
pages={9}
}
```
# Acknowledgments
Thanks to TensorFlow Research Cloud (TFRC) for the free access to Cloud TPUs, couldn't have done it without this program, and to the [AUB MIND Lab](https://sites.aub.edu.lb/mindlab/) Members for the continuous support. Also thanks to [Yakshof](https://www.yakshof.com/#/) and Assafir for data and storage access. Another thanks for Habib Rahal (https://www.behance.net/rahalhabib), for putting a face to AraBERT.
# Contacts
**Wissam Antoun**: [Linkedin](https://www.linkedin.com/in/wissam-antoun-622142b4/) | [Twitter](https://twitter.com/wissam_antoun) | [Github](https://github.com/WissamAntoun) | <wfa07@mail.aub.edu> | <wissam.antoun@gmail.com>
**Fady Baly**: [Linkedin](https://www.linkedin.com/in/fadybaly/) | [Twitter](https://twitter.com/fadybaly) | [Github](https://github.com/fadybaly) | <fgb06@mail.aub.edu> | <baly.fady@gmail.com>
| 8,489 | [
[
-0.053802490234375,
-0.0540771484375,
0.02215576171875,
0.010162353515625,
-0.025970458984375,
-0.002941131591796875,
-0.01265716552734375,
-0.04632568359375,
0.02069091796875,
0.020233154296875,
-0.043548583984375,
-0.05029296875,
-0.060272216796875,
0.0010... |
Manismart2/my-pet-dog | 2023-11-05T08:55:24.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"doi:10.57967/hf/1316",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Manismart2 | null | null | Manismart2/my-pet-dog | 0 | 3,505 | diffusers | 2023-11-05T08:52:02 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by Manismart2 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:
.jpg)
.jpg)



.jpg)

.jpg)
.jpg)

| 1,255 | [
[
-0.061065673828125,
-0.028778076171875,
0.0283966064453125,
0.01776123046875,
-0.020843505859375,
0.0277557373046875,
0.0183563232421875,
-0.03631591796875,
0.039886474609375,
0.01220703125,
-0.039337158203125,
-0.031280517578125,
-0.019927978515625,
0.01710... |
Yehor/wav2vec2-xls-r-300m-uk-with-small-lm | 2022-07-30T08:51:01.000Z | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"uk",
"dataset:mozilla-foundation/common_voice_10_0",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | automatic-speech-recognition | Yehor | null | null | Yehor/wav2vec2-xls-r-300m-uk-with-small-lm | 5 | 3,502 | transformers | 2022-06-08T12:31:06 | ---
language:
- uk
license: "apache-2.0"
datasets:
- mozilla-foundation/common_voice_10_0
---
🇺🇦 Join Ukrainian Speech Recognition Community - https://t.me/speech_recognition_uk
⭐ See other Ukrainian models - https://github.com/egorsmkv/speech-recognition-uk
This model has apostrophes and hyphens.
The language model is trained on the texts of the Common Voice dataset, which is used during training.
Metrics:
| Dataset | CER | WER |
|-|-|-|
| CV7 (no LM) | 0.0432 | 0.2288 |
| CV7 (with LM) | 0.0169 | 0.0706 |
| CV10 (no LM) | 0.0412 | 0.2206 |
| CV10 (with LM) | 0.0118 | 0.0463 |
More:
- The same model, but trained on noisy data: https://huggingface.co/Yehor/wav2vec2-xls-r-300m-uk-with-small-lm-noisy
- Traced JIT version: https://huggingface.co/Yehor/wav2vec2-xls-r-300m-uk-traced-jit
| 805 | [
[
-0.0016698837280273438,
-0.020172119140625,
0.03436279296875,
-0.0013895034790039062,
-0.03564453125,
0.003253936767578125,
-0.01361083984375,
-0.037567138671875,
0.009765625,
0.039459228515625,
-0.04022216796875,
-0.049652099609375,
-0.044677734375,
0.01802... |
kyujinpy/KoR-Orca-Platypus-13B | 2023-10-19T13:30:25.000Z | [
"transformers",
"pytorch",
"llama",
"text-generation",
"ko",
"dataset:kyujinpy/OpenOrca-KO",
"dataset:kyujinpy/KOpen-platypus",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | kyujinpy | null | null | kyujinpy/KoR-Orca-Platypus-13B | 3 | 3,502 | transformers | 2023-10-13T20:45:59 | ---
language:
- ko
datasets:
- kyujinpy/OpenOrca-KO
- kyujinpy/KOpen-platypus
library_name: transformers
pipeline_tag: text-generation
license: cc-by-nc-sa-4.0
---
**(주)미디어그룹사람과숲과 (주)마커의 LLM 연구 컨소시엄에서 개발된 모델입니다**
**The license is `cc-by-nc-sa-4.0`.**
# **🐳KoR-Orca-Platypus-13B🐳**

## Model Details
**Model Developers** Kyujin Han (kyujinpy)
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture**
KoR-Orca-Platypus-13B is an auto-regressive language model based on the LLaMA2 transformer architecture.
**Repo Link**
Github Korean-OpenOrca: [🐳KoR-Orca-Platypus-13B🐳](https://github.com/Marker-Inc-Korea/Korean-OpenOrca)
**Base Model** [hyunseoki/ko-en-llama2-13b](https://huggingface.co/hyunseoki/ko-en-llama2-13b)
**Training Dataset**
Version of combined dataset: [kyujinpy/KOR-OpenOrca-Platypus](https://huggingface.co/datasets/kyujinpy/KOR-OpenOrca-Platypus)
I combined [OpenOrca-KO](https://huggingface.co/datasets/kyujinpy/OpenOrca-KO) and [kyujinpy/KOpen-platypus](https://huggingface.co/datasets/kyujinpy/KOpen-platypus).
I use A100 GPU 40GB and COLAB, when trianing.
# **Model Benchmark**
## KO-LLM leaderboard
- Follow up as [Open KO-LLM LeaderBoard](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard).
| Model | Average |Ko-ARC | Ko-HellaSwag | Ko-MMLU | Ko-TruthfulQA | Ko-CommonGen V2 |
| --- | --- | --- | --- | --- | --- | --- |
| KoR-Orca-Platypus-13B🐳(ours) | 50.13 | 42.06 | 53.95 | 42.28 | 43.55 | 68.78 |
| [GenAI-llama2-ko-en-platypus](https://huggingface.co/42MARU/GenAI-llama2-ko-en-platypus) | 49.81 | 45.22 | 55.25 | 41.84 | 44.78 | 61.97 |
| [KoT-Platypus2-13B](https://huggingface.co/kyujinpy/KoT-platypus2-13B) | 49.55 | 43.69 | 53.05 | 42.29 | 43.34 | 65.38 |
| [KO-Platypus2-13B](https://huggingface.co/kyujinpy/KO-Platypus2-13B) | 47.90 | 44.20 | 54.31 | 42.47 | 44.41 | 54.11 |
| [Korean-OpenOrca-13B🐳](https://huggingface.co/kyujinpy/Korean-OpenOrca-13B) | 47.85 | 43.09 | 54.13 | 40.24 | 45.22 | 56.57 |
> Compare with Top 4 SOTA models. (update: 10/14)
# Implementation Code
```python
### KO-Platypus
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
repo = "kyujinpy/KoR-Orca-Platypus-13B"
OpenOrca = AutoModelForCausalLM.from_pretrained(
repo,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto'
)
OpenOrca_tokenizer = AutoTokenizer.from_pretrained(repo)
```
--- | 2,499 | [
[
-0.03497314453125,
-0.048065185546875,
0.01082611083984375,
0.03338623046875,
-0.032501220703125,
-0.0032787322998046875,
-0.01837158203125,
-0.033660888671875,
0.02581787109375,
0.01885986328125,
-0.02886962890625,
-0.057525634765625,
-0.034942626953125,
0.... |
juierror/flan-t5-text2sql-with-schema-v2 | 2023-07-31T15:26:29.000Z | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | text2text-generation | juierror | null | null | juierror/flan-t5-text2sql-with-schema-v2 | 17 | 3,501 | transformers | 2023-07-31T14:58:27 | ---
language: en
widget:
- text: >-
convert question and table into SQL query. tables: people_name(id,name),
people_age(people_id,age). question: how many people with name jui and age
less than 25
license: cc-by-sa-4.0
pipeline_tag: text2text-generation
inference:
parameters:
max_length: 512
num_beams: 10
top_k: 10
---
This is an upgraded version of [https://huggingface.co/juierror/flan-t5-text2sql-with-schema](https://huggingface.co/juierror/flan-t5-text2sql-with-schema).
It supports the '<' sign and can handle multiple tables.
# How to use
```python
from typing import List
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("juierror/flan-t5-text2sql-with-schema-v2")
model = AutoModelForSeq2SeqLM.from_pretrained("juierror/flan-t5-text2sql-with-schema-v2")
def get_prompt(tables, question):
prompt = f"""convert question and table into SQL query. tables: {tables}. question: {question}"""
return prompt
def prepare_input(question: str, tables: Dict[str, List[str]]):
tables = [f"""{table_name}({",".join(tables[table_name])})""" for table_name in tables]
tables = ", ".join(tables)
prompt = get_prompt(tables, question)
input_ids = tokenizer(prompt, max_length=512, return_tensors="pt").input_ids
return input_ids
def inference(question: str, tables: Dict[str, List[str]]) -> str:
input_data = prepare_input(question=question, tables=tables)
input_data = input_data.to(model.device)
outputs = model.generate(inputs=input_data, num_beams=10, top_k=10, max_length=512)
result = tokenizer.decode(token_ids=outputs[0], skip_special_tokens=True)
return result
print(inference("how many people with name jui and age less than 25", {
"people_name": ["id", "name"],
"people_age": ["people_id", "age"]
}))
print(inference("what is id with name jui and age less than 25", {
"people_name": ["id", "name", "age"]
})))
```
# Dataset
- [CoSQL](https://yale-lily.github.io/cosql)
- [spider](https://yale-lily.github.io/spider)
- [SParC](https://yale-lily.github.io/sparc) | 2,116 | [
[
-0.0028553009033203125,
-0.05389404296875,
0.01898193359375,
0.01324462890625,
-0.00241851806640625,
-0.014984130859375,
-0.007793426513671875,
-0.01422119140625,
0.01483917236328125,
0.0279693603515625,
-0.0380859375,
-0.03662109375,
-0.0302276611328125,
0.... |
Sannirappa/my-favourite-cricketer | 2023-11-05T15:53:35.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Sannirappa | null | null | Sannirappa/my-favourite-cricketer | 0 | 3,501 | diffusers | 2023-11-05T15:49:22 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### my-favourite-cricketer Dreambooth model trained by Sannirappa following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: CVR-204
Sample pictures of this concept:
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
| 853 | [
[
-0.059783935546875,
-0.01447296142578125,
0.0139312744140625,
0.023406982421875,
-0.0288848876953125,
0.02899169921875,
0.0262298583984375,
-0.0189666748046875,
0.042327880859375,
0.0248260498046875,
-0.0478515625,
-0.02996826171875,
-0.0396728515625,
0.0198... |
mrm8488/bert-tiny-finetuned-sms-spam-detection | 2023-03-16T17:28:05.000Z | [
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"text-classification",
"sms",
"spam",
"detection",
"en",
"dataset:sms_spam",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | mrm8488 | null | null | mrm8488/bert-tiny-finetuned-sms-spam-detection | 23 | 3,499 | transformers | 2022-03-02T23:29:05 | ---
language: en
tags:
- sms
- spam
- detection
datasets:
- sms_spam
widget:
- text: "Camera - You are awarded a SiPix Digital Camera! call 09061221066 fromm landline. Delivery within 28 days."
---
# BERT-Tiny fine-tuned on on sms_spam dataset for spam detection
Validation accuray: **0.98** | 293 | [
[
-0.0245513916015625,
-0.043182373046875,
0.004032135009765625,
0.048583984375,
-0.035552978515625,
-0.0321044921875,
-0.01702880859375,
-0.0044097900390625,
-0.0015153884887695312,
0.03997802734375,
-0.049285888671875,
-0.04296875,
-0.0472412109375,
-0.00082... |
DeepFloyd/IF-II-M-v1.0 | 2023-06-02T19:05:19.000Z | [
"diffusers",
"pytorch",
"if",
"text-to-image",
"arxiv:2205.11487",
"arxiv:2110.02861",
"license:deepfloyd-if-license",
"diffusers:IFSuperResolutionPipeline",
"region:us"
] | text-to-image | DeepFloyd | null | null | DeepFloyd/IF-II-M-v1.0 | 20 | 3,497 | diffusers | 2023-03-21T13:16:58 | ---
license: deepfloyd-if-license
extra_gated_prompt: "DeepFloyd LICENSE AGREEMENT\nThis License Agreement (as may be amended in accordance with this License Agreement, “License”), between you, or your employer or other entity (if you are entering into this agreement on behalf of your employer or other entity) (“Licensee” or “you”) and Stability AI Ltd.. (“Stability AI” or “we”) applies to your use of any computer program, algorithm, source code, object code, or software that is made available by Stability AI under this License (“Software”) and any specifications, manuals, documentation, and other written information provided by Stability AI related to the Software (“Documentation”).\nBy clicking “I Accept” below or by using the Software, you agree to the terms of this License. If you do not agree to this License, then you do not have any rights to use the Software or Documentation (collectively, the “Software Products”), and you must immediately cease using the Software Products. If you are agreeing to be bound by the terms of this License on behalf of your employer or other entity, you represent and warrant to Stability AI that you have full legal authority to bind your employer or such entity to this License. If you do not have the requisite authority, you may not accept the License or access the Software Products on behalf of your employer or other entity.\n1. LICENSE GRANT\n a. Subject to your compliance with the Documentation and Sections 2, 3, and 5, Stability AI grants you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty free and limited license under Stability AI’s copyright interests to reproduce, distribute, and create derivative works of the Software solely for your non-commercial research purposes. The foregoing license is personal to you, and you may not assign or sublicense this License or any other rights or obligations under this License without Stability AI’s prior written consent; any such assignment or sublicense will be void and will automatically and immediately terminate this License.\n b. You may make a reasonable number of copies of the Documentation solely for use in connection with the license to the Software granted above.\n c. The grant of rights expressly set forth in this Section 1 (License Grant) are the complete grant of rights to you in the Software Products, and no other licenses are granted, whether by waiver, estoppel, implication, equity or otherwise. Stability AI and its licensors reserve all rights not expressly granted by this License.\L\n2. RESTRICTIONS\n You will not, and will not permit, assist or cause any third party to:\n a. use, modify, copy, reproduce, create derivative works of, or distribute the Software Products (or any derivative works thereof, works incorporating the Software Products, or any data produced by the Software), in whole or in part, for (i) any commercial or production purposes, (ii) military purposes or in the service of nuclear technology, (iii) purposes of surveillance, including any research or development relating to surveillance, (iv) biometric processing, (v) in any manner that infringes, misappropriates, or otherwise violates any third-party rights, or (vi) in any manner that violates any applicable law and violating any privacy or security laws, rules, regulations, directives, or governmental requirements (including the General Data Privacy Regulation (Regulation (EU) 2016/679), the California Consumer Privacy Act, and any and all laws governing the processing of biometric information), as well as all amendments and successor laws to any of the foregoing;\n b. alter or remove copyright and other proprietary notices which appear on or in the Software Products;\n c. utilize any equipment, device, software, or other means to circumvent or remove any security or protection used by Stability AI in connection with the Software, or to circumvent or remove any usage restrictions, or to enable functionality disabled by Stability AI; or\n d. offer or impose any terms on the Software Products that alter, restrict, or are inconsistent with the terms of this License.\n e. 1) violate any applicable U.S. and non-U.S. export control and trade sanctions laws (“Export Laws”); 2) directly or indirectly export, re-export, provide, or otherwise transfer Software Products: (a) to any individual, entity, or country prohibited by Export Laws; (b) to anyone on U.S. or non-U.S. government restricted parties lists; or (c) for any purpose prohibited by Export Laws, including nuclear, chemical or biological weapons, or missile technology applications; 3) use or download Software Products if you or they are: (a) located in a comprehensively sanctioned jurisdiction, (b) currently listed on any U.S. or non-U.S. restricted parties list, or (c) for any purpose prohibited by Export Laws; and (4) will not disguise your location through IP proxying or other methods.\L\n3. ATTRIBUTION\n Together with any copies of the Software Products (as well as derivative works thereof or works incorporating the Software Products) that you distribute, you must provide (i) a copy of this License, and (ii) the following attribution notice: “DeepFloyd is licensed under the DeepFloyd License, Copyright (c) Stability AI Ltd. All Rights Reserved.”\L\n4. DISCLAIMERS\n THE SOFTWARE PRODUCTS ARE PROVIDED “AS IS” and “WITH ALL FAULTS” WITH NO WARRANTY OF ANY KIND, EXPRESS OR IMPLIED. STABILITY AIEXPRESSLY DISCLAIMS ALL REPRESENTATIONS AND WARRANTIES, EXPRESS OR IMPLIED, WHETHER BY STATUTE, CUSTOM, USAGE OR OTHERWISE AS TO ANY MATTERS RELATED TO THE SOFTWARE PRODUCTS, INCLUDING BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE, SATISFACTORY QUALITY, OR NON-INFRINGEMENT. STABILITY AI MAKES NO WARRANTIES OR REPRESENTATIONS THAT THE SOFTWARE PRODUCTS WILL BE ERROR FREE OR FREE OF VIRUSES OR OTHER HARMFUL COMPONENTS, OR PRODUCE ANY PARTICULAR RESULTS.\L\n5. LIMITATION OF LIABILITY\n TO THE FULLEST EXTENT PERMITTED BY LAW, IN NO EVENT WILL STABILITY AI BE LIABLE TO YOU (A) UNDER ANY THEORY OF LIABILITY, WHETHER BASED IN CONTRACT, TORT, NEGLIGENCE, STRICT LIABILITY, WARRANTY, OR OTHERWISE UNDER THIS LICENSE, OR (B) FOR ANY INDIRECT, CONSEQUENTIAL, EXEMPLARY, INCIDENTAL, PUNITIVE OR SPECIAL DAMAGES OR LOST PROFITS, EVEN IF STABILITY AI HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. THE SOFTWARE PRODUCTS, THEIR CONSTITUENT COMPONENTS, AND ANY OUTPUT (COLLECTIVELY, “SOFTWARE MATERIALS”) ARE NOT DESIGNED OR INTENDED FOR USE IN ANY APPLICATION OR SITUATION WHERE FAILURE OR FAULT OF THE SOFTWARE MATERIALS COULD REASONABLY BE ANTICIPATED TO LEAD TO SERIOUS INJURY OF ANY PERSON, INCLUDING POTENTIAL DISCRIMINATION OR VIOLATION OF AN INDIVIDUAL’S PRIVACY RIGHTS, OR TO SEVERE PHYSICAL, PROPERTY, OR ENVIRONMENTAL DAMAGE (EACH, A “HIGH-RISK USE”). IF YOU ELECT TO USE ANY OF THE SOFTWARE MATERIALS FOR A HIGH-RISK USE, YOU DO SO AT YOUR OWN RISK. YOU AGREE TO DESIGN AND IMPLEMENT APPROPRIATE DECISION-MAKING AND RISK-MITIGATION PROCEDURES AND POLICIES IN CONNECTION WITH A HIGH-RISK USE SUCH THAT EVEN IF THERE IS A FAILURE OR FAULT IN ANY OF THE SOFTWARE MATERIALS, THE SAFETY OF PERSONS OR PROPERTY AFFECTED BY THE ACTIVITY STAYS AT A LEVEL THAT IS REASONABLE, APPROPRIATE, AND LAWFUL FOR THE FIELD OF THE HIGH-RISK USE.\L\n6. INDEMNIFICATION\n You will indemnify, defend and hold harmless Stability AI and our subsidiaries and affiliates, and each of our respective shareholders, directors, officers, employees, agents, successors, and assigns (collectively, the “Stability AI Parties”) from and against any losses, liabilities, damages, fines, penalties, and expenses (including reasonable attorneys’ fees) incurred by any Stability AI Party in connection with any claim, demand, allegation, lawsuit, proceeding, or investigation (collectively, “Claims”) arising out of or related to: (a) your access to or use of the Software Products (as well as any results or data generated from such access or use), including any High-Risk Use (defined below); (b) your violation of this License; or (c) your violation, misappropriation or infringement of any rights of another (including intellectual property or other proprietary rights and privacy rights). You will promptly notify the Stability AI Parties of any such Claims, and cooperate with Stability AI Parties in defending such Claims. You will also grant the Stability AI Parties sole control of the defense or settlement, at Stability AI’s sole option, of any Claims. This indemnity is in addition to, and not in lieu of, any other indemnities or remedies set forth in a written agreement between you and Stability AI or the other Stability AI Parties.\L\n7. TERMINATION; SURVIVAL\n a. This License will automatically terminate upon any breach by you of the terms of this License.\L\Lb. We may terminate this License, in whole or in part, at any time upon notice (including electronic) to you.\L\Lc. The following sections survive termination of this License: 2 (Restrictions), 3 (Attribution), 4 (Disclaimers), 5 (Limitation on Liability), 6 (Indemnification) 7 (Termination; Survival), 8 (Third Party Materials), 9 (Trademarks), 10 (Applicable Law; Dispute Resolution), and 11 (Miscellaneous).\L\n8. THIRD PARTY MATERIALS\n The Software Products may contain third-party software or other components (including free and open source software) (all of the foregoing, “Third Party Materials”), which are subject to the license terms of the respective third-party licensors. Your dealings or correspondence with third parties and your use of or interaction with any Third Party Materials are solely between you and the third party. Stability AI does not control or endorse, and makes no representations or warranties regarding, any Third Party Materials, and your access to and use of such Third Party Materials are at your own risk.\L\n9. TRADEMARKS\n Licensee has not been granted any trademark license as part of this License and may not use any name or mark associated with Stability AI without the prior written permission of Stability AI, except to the extent necessary to make the reference required by the “ATTRIBUTION” section of this Agreement.\L\n10. APPLICABLE LAW; DISPUTE RESOLUTION\n This License will be governed and construed under the laws of the State of California without regard to conflicts of law provisions. Any suit or proceeding arising out of or relating to this License will be brought in the federal or state courts, as applicable, in San Mateo County, California, and each party irrevocably submits to the jurisdiction and venue of such courts.\L\n11. MISCELLANEOUS\n If any provision or part of a provision of this License is unlawful, void or unenforceable, that provision or part of the provision is deemed severed from this License, and will not affect the validity and enforceability of any remaining provisions. The failure of Stability AI to exercise or enforce any right or provision of this License will not operate as a waiver of such right or provision. This License does not confer any third-party beneficiary rights upon any other person or entity. This License, together with the Documentation, contains the entire understanding between you and Stability AI regarding the subject matter of this License, and supersedes all other written or oral agreements and understandings between you and Stability AI regarding such subject matter. No change or addition to any provision of this License will be binding unless it is in writing and signed by an authorized representative of both you and Stability AI."
extra_gated_fields:
"Organization /\_Affiliation": text
Previously related publications: text
I accept the above license agreement, and will use the Software non-commercially and for research purposes only: checkbox
tags:
- if
- text-to-image
inference: false
---
# IF-II-M-v1.0
DeepFloyd-IF is a pixel-based text-to-image triple-cascaded diffusion model, that can generate pictures with new state-of-the-art for photorealism and language understanding. The result is a highly efficient model that outperforms current state-of-the-art models, achieving a zero-shot FID-30K score of `6.66` on the COCO dataset.
*Inspired by* [*Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding*](https://arxiv.org/pdf/2205.11487.pdf)

## Model Details
- **Developed by:** DeepFloyd, StabilityAI
- **Model type:** pixel-based text-to-image cascaded diffusion model
- **Cascade Stage:** II
- **Num Parameters:** 450M
- **Language(s):** primarily English and, to a lesser extent, other Romance languages
- **License:** <span style="color:blue"><a href="https://huggingface.co/spaces/DeepFloyd/deepfloyd-if-license">DeepFloyd IF License Agreement</a></span>
- **Model Description:** DeepFloyd-IF is modular composed of frozen text mode and three pixel cascaded diffusion modules, each designed to generate images of increasing resolution: 64x64, 256x256, and 1024x1024. All stages of the model utilize a frozen text encoder based on the T5 transformer to extract text embeddings, which are then fed into a UNet architecture enhanced with cross-attention and attention-pooling
- **Resources for more information:** [GitHub](https://github.com/deep-floyd/IF), [Website](https://deepfloyd.ai), [All Links](https://linktr.ee/deepfloyd)
## Using with `diffusers`
IF is integrated with the 🤗 Hugging Face [🧨 diffusers library](https://github.com/huggingface/diffusers/), which is optimized to run on GPUs with as little as 14 GB of VRAM.
Before you can use IF, you need to accept its usage conditions. To do so:
1. Make sure to have a [Hugging Face account](https://huggingface.co/join) and be loggin in
2. Accept the license on the model card of [DeepFloyd/IF-I-M-v1.0](https://huggingface.co/DeepFloyd/IF-I-M-v1.0)
3. Make sure to login locally. Install `huggingface_hub`
```sh
pip install huggingface_hub --upgrade
```
run the login function in a Python shell
```py
from huggingface_hub import login
login()
```
and enter your [Hugging Face Hub access token](https://huggingface.co/docs/hub/security-tokens#what-are-user-access-tokens).
Next we install `diffusers` and dependencies:
```sh
pip install diffusers accelerate transformers safetensors sentencepiece
```
And we can now run the model locally.
By default `diffusers` makes use of [model cpu offloading](https://huggingface.co/docs/diffusers/optimization/fp16#model-offloading-for-fast-inference-and-memory-savings) to run the whole IF pipeline with as little as 14 GB of VRAM.
If you are using `torch>=2.0.0`, make sure to **remove all** `enable_xformers_memory_efficient_attention()` functions.
* **Load all stages and offload to CPU**
```py
from diffusers import DiffusionPipeline
from diffusers.utils import pt_to_pil
import torch
# stage 1
stage_1 = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-M-v1.0", variant="fp16", torch_dtype=torch.float16)
stage_1.enable_xformers_memory_efficient_attention() # remove line if torch.__version__ >= 2.0.0
stage_1.enable_model_cpu_offload()
# stage 2
stage_2 = DiffusionPipeline.from_pretrained(
"DeepFloyd/IF-II-M-v1.0", text_encoder=None, variant="fp16", torch_dtype=torch.float16
)
stage_2.enable_xformers_memory_efficient_attention() # remove line if torch.__version__ >= 2.0.0
stage_2.enable_model_cpu_offload()
# stage 3
safety_modules = {"feature_extractor": stage_1.feature_extractor, "safety_checker": stage_1.safety_checker, "watermarker": stage_1.watermarker}
stage_3 = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-x4-upscaler", **safety_modules, torch_dtype=torch.float16)
stage_3.enable_xformers_memory_efficient_attention() # remove line if torch.__version__ >= 2.0.0
stage_3.enable_model_cpu_offload()
```
* **Retrieve Text Embeddings**
```py
prompt = 'a photo of a kangaroo wearing an orange hoodie and blue sunglasses standing in front of the eiffel tower holding a sign that says "very deep learning"'
# text embeds
prompt_embeds, negative_embeds = stage_1.encode_prompt(prompt)
```
* **Run stage 1**
```py
generator = torch.manual_seed(0)
image = stage_1(prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, generator=generator, output_type="pt").images
pt_to_pil(image)[0].save("./if_stage_I.png")
```
* **Run stage 2**
```py
image = stage_2(
image=image, prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, generator=generator, output_type="pt"
).images
pt_to_pil(image)[0].save("./if_stage_II.png")
```
* **Run stage 3**
```py
image = stage_3(prompt=prompt, image=image, generator=generator, noise_level=100).images
image[0].save("./if_stage_III.png")
```
There are multiple ways to speed up the inference time and lower the memory consumption even more with `diffusers`. To do so, please have a look at the Diffusers docs:
- 🚀 [Optimizing for inference time](https://huggingface.co/docs/diffusers/api/pipelines/if#optimizing-for-speed)
- ⚙️ [Optimizing for low memory during inference](https://huggingface.co/docs/diffusers/api/pipelines/if#optimizing-for-memory)
For more in-detail information about how to use IF, please have a look at [the IF blog post](https://huggingface.co/blog/if) and the [documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/if) 📖.
Diffusers dreambooth scripts also supports fine-tuning 🎨 [IF](https://huggingface.co/docs/diffusers/main/en/training/dreambooth#if).
With parameter efficient finetuning, you can add new concepts to IF with a single GPU and ~28 GB VRAM.
## Training
**Training Data:**
1.2B text-image pairs (based on LAION-A and few additional internal datasets)
Test/Valid parts of datasets are not used at any cascade and stage of training. Valid part of COCO helps to demonstrate "online" loss behaviour during training (to catch incident and other problems), but dataset is never used for train.
**Training Procedure:** IF-II-M-v1.0 is a pixel-based diffusion cascade which uses T5-Encoder embeddings (hidden states) to upscale image from 64px to 256px. During training,
- Images are cropped to square via shifted-center-crop augmentation (randomly shift from center up to 0.1 of size) and resized to 64px (low-res) and 256px (ground-truth) using `Pillow==9.2.0` BICUBIC resampling with reducing_gap=None (it helps to avoid aliasing) and processed to tensor BxCxHxW
- Low-res images are extra augmented by noise (q-sample methods) with the same diffusion configuration for cascade-I series. Uniform distributed randomised augmentation noising param (aug-level) is added to Unet as condition to process by trainable layers timestep embedding and linear projection with activation.
- Text prompts are encoded through open-sourced frozen T5-v1_1-xxl text-encoder (that completely was trained by Google team), random 10% of texts are dropped to empty string to add ability for classifier free guidance (CFG)
- The non-pooled output of the text encoder is fed into the projection (linear layer without activation) and is used in UNet backbone of the diffusion model via controlled hybrid self- and cross- attention
- Also, the output of the text encode is pooled via attention-pooling (64 heads) and is used in time embed as additional features
- Diffusion process is limited by 1000 discrete steps, with cosine beta schedule of noising image
- The loss is a reconstruction objective between the noise that was added to the image and the prediction made by the UNet
- The training process for checkpoint IF-II-M-v1.0 has 2_500_000 steps at resolution 256x256 on all datasets, OneCycleLR policy, few-bit backward GELU activations, optimizer AdamW8bit + DeepSpeed-Zero1, fully frozen T5-Encoder

**Hardware:** 24 x 8 x A100 GPUs
**Optimizer:** [AdamW8bit](https://arxiv.org/abs/2110.02861) + [DeepSpeed ZeRO-1](https://www.deepspeed.ai/tutorials/zero/)
**Batch:** 1536
**Learning rate**: [one-cycle](https://pytorch.org/docs/stable/generated/torch.optim.lr_scheduler.OneCycleLR.html) cosine strategy, warmup 10000 steps, start_lr=4e-6, max_lr=1e-4, final_lr=1e-8

## Evaluation Results
`FID-30K: 6.66`

# Uses
## Direct Use
The model is released for research purposes. Any attempt to deploy the model in production requires not only that the LICENSE is followed but full liability over the person deploying the model.
Possible research areas and tasks include:
- Generation of artistic imagery and use in design and other artistic processes.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion but applies in the same way for IF_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model was trained mainly with English captions and will not work as well in other languages.
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have... (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
IF was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
IF mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
*This model card was written by: DeepFloyd Team and is based on the [StableDiffusion model card](https://huggingface.co/CompVis/stable-diffusion-v1-4).* | 23,757 | [
[
-0.044219970703125,
-0.06451416015625,
0.01922607421875,
0.0302886962890625,
-0.0170440673828125,
-0.003887176513671875,
-0.018768310546875,
-0.0352783203125,
0.006748199462890625,
0.0233154296875,
-0.04052734375,
-0.04217529296875,
-0.046112060546875,
-0.01... |
TheBloke/StableBeluga2-70B-GPTQ | 2023-09-27T12:44:59.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"dataset:conceptofmind/cot_submix_original",
"dataset:conceptofmind/flan2021_submix_original",
"dataset:conceptofmind/t0_submix_original",
"dataset:conceptofmind/niv2_submix_original",
"arxiv:2307.09288",
"arxiv:2306.02707",
"lic... | text-generation | TheBloke | null | null | TheBloke/StableBeluga2-70B-GPTQ | 90 | 3,491 | transformers | 2023-07-21T22:58:55 | ---
language:
- en
license: llama2
datasets:
- conceptofmind/cot_submix_original
- conceptofmind/flan2021_submix_original
- conceptofmind/t0_submix_original
- conceptofmind/niv2_submix_original
model_name: StableBeluga2
base_model: stabilityai/StableBeluga2
inference: false
model_creator: Stability AI
model_type: llama
pipeline_tag: text-generation
prompt_template: '### System:
{system_message}
### User:
{prompt}
### Assistant:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# StableBeluga2 - GPTQ
- Model creator: [Stability AI](https://huggingface.co/stabilityai)
- Original model: [StableBeluga2](https://huggingface.co/stabilityai/StableBeluga2)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Stability AI's StableBeluga2](https://huggingface.co/stabilityai/StableBeluga2).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/StableBeluga2-70B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/StableBeluga2-70B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/StableBeluga2-70B-GGUF)
* [Stability AI's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/stabilityai/StableBeluga2)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Orca-Hashes
```
### System:
{system_message}
### User:
{prompt}
### Assistant:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/StableBeluga2-70B-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 40.66 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/StableBeluga2-70B-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 37.99 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/StableBeluga2-70B-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 36.65 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-3bit-128g-actorder_True](https://huggingface.co/TheBloke/StableBeluga2-70B-GPTQ/tree/gptq-3bit-128g-actorder_True) | 3 | 128 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 28.03 GB | No | 3-bit, with group size 128g and act-order. Higher quality than 128g-False. |
| [gptq-3bit-128g-actorder_False](https://huggingface.co/TheBloke/StableBeluga2-70B-GPTQ/tree/gptq-3bit-128g-actorder_False) | 3 | 128 | No | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 28.03 GB | No | 3-bit, with group size 128g but no act-order. Slightly higher VRAM requirements than 3-bit None. |
| [gptq-3bit--1g-actorder_True](https://huggingface.co/TheBloke/StableBeluga2-70B-GPTQ/tree/gptq-3bit--1g-actorder_True) | 3 | None | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 26.78 GB | No | 3-bit, with Act Order and no group size. Lowest possible VRAM requirements. May be lower quality than 3-bit 128g. |
| [gptq-4bit-128g-actorder_False](https://huggingface.co/TheBloke/StableBeluga2-70B-GPTQ/tree/gptq-4bit-128g-actorder_False) | 4 | 128 | No | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 36.65 GB | Yes | 4-bit, without Act Order and group size 128g. |
| [gptq-3bit-64g-actorder_True](https://huggingface.co/TheBloke/StableBeluga2-70B-GPTQ/tree/gptq-3bit-64g-actorder_True) | 3 | 64 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 29.30 GB | No | 3-bit, with group size 64g and act-order. |
| [main](https://huggingface.co/TheBloke/StableBeluga2-70B-GPTQ/tree/main) | 4 | None | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 35.33 GB | Yes | 4-bit, with Act Order. No group size, to lower VRAM requirements. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download from branches
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/StableBeluga2-70B-GPTQ:gptq-4bit-32g-actorder_True`
- With Git, you can clone a branch with:
```
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/StableBeluga2-70B-GPTQ
```
- In Python Transformers code, the branch is the `revision` parameter; see below.
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/StableBeluga2-70B-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/StableBeluga2-70B-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `StableBeluga2-70B-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers>=4.32.0 optimum>=1.12.0
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip3 install .
```
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
```shell
pip3 uninstall -y transformers
pip3 install git+https://github.com/huggingface/transformers.git
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/StableBeluga2-70B-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''### System:
{system_message}
### User:
{prompt}
### Assistant:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Stability AI's StableBeluga2
# Stable Beluga 2
Use [Stable Chat (Research Preview)](https://chat.stability.ai/chat) to test Stability AI's best language models for free
## Model Description
`Stable Beluga 2` is a Llama2 70B model finetuned on an Orca style Dataset
## Usage
Start chatting with `Stable Beluga 2` using the following code snippet:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained("stabilityai/StableBeluga2", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("stabilityai/StableBeluga2", torch_dtype=torch.float16, low_cpu_mem_usage=True, device_map="auto")
system_prompt = "### System:\nYou are Stable Beluga, an AI that follows instructions extremely well. Help as much as you can. Remember, be safe, and don't do anything illegal.\n\n"
message = "Write me a poem please"
prompt = f"{system_prompt}### User: {message}\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(**inputs, do_sample=True, top_p=0.95, top_k=0, max_new_tokens=256)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
Stable Beluga 2 should be used with this prompt format:
```
### System:
This is a system prompt, please behave and help the user.
### User:
Your prompt here
### Assistant:
The output of Stable Beluga 2
```
## Other Beluga Models
[StableBeluga 1 - Delta](https://huggingface.co/stabilityai/StableBeluga1-Delta)
[StableBeluga 13B](https://huggingface.co/stabilityai/StableBeluga-13B)
[StableBeluga 7B](https://huggingface.co/stabilityai/StableBeluga-7B)
## Model Details
* **Developed by**: [Stability AI](https://stability.ai/)
* **Model type**: Stable Beluga 2 is an auto-regressive language model fine-tuned on Llama2 70B.
* **Language(s)**: English
* **Library**: [HuggingFace Transformers](https://github.com/huggingface/transformers)
* **License**: Fine-tuned checkpoints (`Stable Beluga 2`) is licensed under the [STABLE BELUGA NON-COMMERCIAL COMMUNITY LICENSE AGREEMENT](https://huggingface.co/stabilityai/StableBeluga2/blob/main/LICENSE.txt)
* **Contact**: For questions and comments about the model, please email `lm@stability.ai`
### Training Dataset
` Stable Beluga 2` is trained on our internal Orca-style dataset
### Training Procedure
Models are learned via supervised fine-tuning on the aforementioned datasets, trained in mixed-precision (BF16), and optimized with AdamW. We outline the following hyperparameters:
| Dataset | Batch Size | Learning Rate |Learning Rate Decay| Warm-up | Weight Decay | Betas |
|-------------------|------------|---------------|-------------------|---------|--------------|-------------|
| Orca pt1 packed | 256 | 3e-5 | Cosine to 3e-6 | 100 | 1e-6 | (0.9, 0.95) |
| Orca pt2 unpacked | 512 | 3e-5 | Cosine to 3e-6 | 100 | 1e-6 | (0.9, 0.95) |
## Ethical Considerations and Limitations
Beluga is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Beluga's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Beluga, developers should perform safety testing and tuning tailored to their specific applications of the model.
## How to cite
```bibtex
@misc{StableBelugaModels,
url={[https://huggingface.co/stabilityai/StableBeluga2](https://huggingface.co/stabilityai/StableBeluga2)},
title={Stable Beluga models},
author={Mahan, Dakota and Carlow, Ryan and Castricato, Louis and Cooper, Nathan and Laforte, Christian}
}
```
## Citations
```bibtext
@misc{touvron2023llama,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller and Cynthia Gao and Vedanuj Goswami and Naman Goyal and Anthony Hartshorn and Saghar Hosseini and Rui Hou and Hakan Inan and Marcin Kardas and Viktor Kerkez and Madian Khabsa and Isabel Kloumann and Artem Korenev and Punit Singh Koura and Marie-Anne Lachaux and Thibaut Lavril and Jenya Lee and Diana Liskovich and Yinghai Lu and Yuning Mao and Xavier Martinet and Todor Mihaylov and Pushkar Mishra and Igor Molybog and Yixin Nie and Andrew Poulton and Jeremy Reizenstein and Rashi Rungta and Kalyan Saladi and Alan Schelten and Ruan Silva and Eric Michael Smith and Ranjan Subramanian and Xiaoqing Ellen Tan and Binh Tang and Ross Taylor and Adina Williams and Jian Xiang Kuan and Puxin Xu and Zheng Yan and Iliyan Zarov and Yuchen Zhang and Angela Fan and Melanie Kambadur and Sharan Narang and Aurelien Rodriguez and Robert Stojnic and Sergey Edunov and Thomas Scialom},
year={2023},
eprint={2307.09288},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtext
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| 21,491 | [
[
-0.041839599609375,
-0.053375244140625,
0.00397491455078125,
0.013397216796875,
-0.020263671875,
-0.00799560546875,
0.00402069091796875,
-0.04437255859375,
0.0249176025390625,
0.0230865478515625,
-0.04632568359375,
-0.036041259765625,
-0.0268707275390625,
-0... |
sail-rvc/EdSheeran2333333 | 2023-07-14T07:21:49.000Z | [
"transformers",
"rvc",
"sail-rvc",
"audio-to-audio",
"endpoints_compatible",
"region:us"
] | audio-to-audio | sail-rvc | null | null | sail-rvc/EdSheeran2333333 | 0 | 3,486 | transformers | 2023-07-14T07:21:31 |
---
pipeline_tag: audio-to-audio
tags:
- rvc
- sail-rvc
---
# EdSheeran2333333
## RVC Model

This model repo was automatically generated.
Date: 2023-07-14 07:21:49
Bot Name: juuxnscrap
Model Type: RVC
Source: https://huggingface.co/juuxn/RVCModels/
Reason: Converting into loadable format for https://github.com/chavinlo/rvc-runpod
| 384 | [
[
-0.031646728515625,
-0.0246429443359375,
0.023406982421875,
0.0041351318359375,
-0.03350830078125,
0.006011962890625,
0.01291656494140625,
-0.00017547607421875,
0.031524658203125,
0.0689697265625,
-0.04730224609375,
-0.046905517578125,
-0.036895751953125,
-0... |
vishnuvardhan09/sneaer | 2023-11-05T11:07:35.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | vishnuvardhan09 | null | null | vishnuvardhan09/sneaer | 0 | 3,486 | diffusers | 2023-11-05T11:02:04 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### sneaer Dreambooth model trained by vishnuvardhan09 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: VNR-323
Sample pictures of this concept:

| 392 | [
[
-0.0310821533203125,
-0.01354217529296875,
0.0361328125,
-0.0037708282470703125,
-0.0166473388671875,
0.046600341796875,
0.037567138671875,
-0.0220489501953125,
0.05841064453125,
0.023223876953125,
-0.058746337890625,
-0.0062103271484375,
-0.0310821533203125,
... |
timm/convnextv2_base.fcmae_ft_in22k_in1k_384 | 2023-03-31T23:06:58.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2301.00808",
"license:cc-by-nc-4.0",
"region:us"
] | image-classification | timm | null | null | timm/convnextv2_base.fcmae_ft_in22k_in1k_384 | 0 | 3,479 | timm | 2023-01-05T01:39:14 | ---
tags:
- image-classification
- timm
library_tag: timm
license: cc-by-nc-4.0
datasets:
- imagenet-1k
- imagenet-1k
---
# Model card for convnextv2_base.fcmae_ft_in22k_in1k_384
A ConvNeXt-V2 image classification model. Pretrained with a fully convolutional masked autoencoder framework (FCMAE) and fine-tuned on ImageNet-22k and then ImageNet-1k.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 88.7
- GMACs: 45.2
- Activations (M): 84.5
- Image size: 384 x 384
- **Papers:**
- ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders: https://arxiv.org/abs/2301.00808
- **Original:** https://github.com/facebookresearch/ConvNeXt-V2
- **Dataset:** ImageNet-1k
- **Pretrain Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('convnextv2_base.fcmae_ft_in22k_in1k_384', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_base.fcmae_ft_in22k_in1k_384',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 96, 96])
# torch.Size([1, 256, 48, 48])
# torch.Size([1, 512, 24, 24])
# torch.Size([1, 1024, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'convnextv2_base.fcmae_ft_in22k_in1k_384',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1024, 12, 12) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
All timing numbers from eager model PyTorch 1.13 on RTX 3090 w/ AMP.
| model |top1 |top5 |img_size|param_count|gmacs |macts |samples_per_sec|batch_size|
|------------------------------------------------------------------------------------------------------------------------------|------|------|--------|-----------|------|------|---------------|----------|
| [convnextv2_huge.fcmae_ft_in22k_in1k_512](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_512) |88.848|98.742|512 |660.29 |600.81|413.07|28.58 |48 |
| [convnextv2_huge.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in22k_in1k_384) |88.668|98.738|384 |660.29 |337.96|232.35|50.56 |64 |
| [convnext_xxlarge.clip_laion2b_soup_ft_in1k](https://huggingface.co/timm/convnext_xxlarge.clip_laion2b_soup_ft_in1k) |88.612|98.704|256 |846.47 |198.09|124.45|122.45 |256 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_384) |88.312|98.578|384 |200.13 |101.11|126.74|196.84 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k_384) |88.196|98.532|384 |197.96 |101.1 |126.74|128.94 |128 |
| [convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_soup_ft_in12k_in1k_320) |87.968|98.47 |320 |200.13 |70.21 |88.02 |283.42 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k_384) |87.75 |98.556|384 |350.2 |179.2 |168.99|124.85 |192 |
| [convnextv2_base.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k_384) |87.646|98.422|384 |88.72 |45.21 |84.49 |209.51 |256 |
| [convnext_large.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k_384) |87.476|98.382|384 |197.77 |101.1 |126.74|194.66 |256 |
| [convnext_large_mlp.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_large_mlp.clip_laion2b_augreg_ft_in1k) |87.344|98.218|256 |200.13 |44.94 |56.33 |438.08 |256 |
| [convnextv2_large.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in22k_in1k) |87.26 |98.248|224 |197.96 |34.4 |43.13 |376.84 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k_384) |87.138|98.212|384 |88.59 |45.21 |84.49 |365.47 |256 |
| [convnext_xlarge.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_xlarge.fb_in22k_ft_in1k) |87.002|98.208|224 |350.2 |60.98 |57.5 |368.01 |256 |
| [convnext_base.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k_384) |86.796|98.264|384 |88.59 |45.21 |84.49 |366.54 |256 |
| [convnextv2_base.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in22k_in1k) |86.74 |98.022|224 |88.72 |15.38 |28.75 |624.23 |256 |
| [convnext_large.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_large.fb_in22k_ft_in1k) |86.636|98.028|224 |197.77 |34.4 |43.13 |581.43 |256 |
| [convnext_base.clip_laiona_augreg_ft_in1k_384](https://huggingface.co/timm/convnext_base.clip_laiona_augreg_ft_in1k_384) |86.504|97.97 |384 |88.59 |45.21 |84.49 |368.14 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in12k_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in12k_in1k) |86.344|97.97 |256 |88.59 |20.09 |37.55 |816.14 |256 |
| [convnextv2_huge.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_huge.fcmae_ft_in1k) |86.256|97.75 |224 |660.29 |115.0 |79.07 |154.72 |256 |
| [convnext_small.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_small.in12k_ft_in1k_384) |86.182|97.92 |384 |50.22 |25.58 |63.37 |516.19 |256 |
| [convnext_base.clip_laion2b_augreg_ft_in1k](https://huggingface.co/timm/convnext_base.clip_laion2b_augreg_ft_in1k) |86.154|97.68 |256 |88.59 |20.09 |37.55 |819.86 |256 |
| [convnext_base.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_base.fb_in22k_ft_in1k) |85.822|97.866|224 |88.59 |15.38 |28.75 |1037.66 |256 |
| [convnext_small.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k_384) |85.778|97.886|384 |50.22 |25.58 |63.37 |518.95 |256 |
| [convnextv2_large.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_large.fcmae_ft_in1k) |85.742|97.584|224 |197.96 |34.4 |43.13 |375.23 |256 |
| [convnext_small.in12k_ft_in1k](https://huggingface.co/timm/convnext_small.in12k_ft_in1k) |85.174|97.506|224 |50.22 |8.71 |21.56 |1474.31 |256 |
| [convnext_tiny.in12k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k_384) |85.118|97.608|384 |28.59 |13.14 |39.48 |856.76 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k_384) |85.112|97.63 |384 |28.64 |13.14 |39.48 |491.32 |256 |
| [convnextv2_base.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_base.fcmae_ft_in1k) |84.874|97.09 |224 |88.72 |15.38 |28.75 |625.33 |256 |
| [convnext_small.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_small.fb_in22k_ft_in1k) |84.562|97.394|224 |50.22 |8.71 |21.56 |1478.29 |256 |
| [convnext_large.fb_in1k](https://huggingface.co/timm/convnext_large.fb_in1k) |84.282|96.892|224 |197.77 |34.4 |43.13 |584.28 |256 |
| [convnext_tiny.in12k_ft_in1k](https://huggingface.co/timm/convnext_tiny.in12k_ft_in1k) |84.186|97.124|224 |28.59 |4.47 |13.44 |2433.7 |256 |
| [convnext_tiny.fb_in22k_ft_in1k_384](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k_384) |84.084|97.14 |384 |28.59 |13.14 |39.48 |862.95 |256 |
| [convnextv2_tiny.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in22k_in1k) |83.894|96.964|224 |28.64 |4.47 |13.44 |1452.72 |256 |
| [convnext_base.fb_in1k](https://huggingface.co/timm/convnext_base.fb_in1k) |83.82 |96.746|224 |88.59 |15.38 |28.75 |1054.0 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k_384](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k_384) |83.37 |96.742|384 |15.62 |7.22 |24.61 |801.72 |256 |
| [convnext_small.fb_in1k](https://huggingface.co/timm/convnext_small.fb_in1k) |83.142|96.434|224 |50.22 |8.71 |21.56 |1464.0 |256 |
| [convnextv2_tiny.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_tiny.fcmae_ft_in1k) |82.92 |96.284|224 |28.64 |4.47 |13.44 |1425.62 |256 |
| [convnext_tiny.fb_in22k_ft_in1k](https://huggingface.co/timm/convnext_tiny.fb_in22k_ft_in1k) |82.898|96.616|224 |28.59 |4.47 |13.44 |2480.88 |256 |
| [convnext_nano.in12k_ft_in1k](https://huggingface.co/timm/convnext_nano.in12k_ft_in1k) |82.282|96.344|224 |15.59 |2.46 |8.37 |3926.52 |256 |
| [convnext_tiny_hnf.a2h_in1k](https://huggingface.co/timm/convnext_tiny_hnf.a2h_in1k) |82.216|95.852|224 |28.59 |4.47 |13.44 |2529.75 |256 |
| [convnext_tiny.fb_in1k](https://huggingface.co/timm/convnext_tiny.fb_in1k) |82.066|95.854|224 |28.59 |4.47 |13.44 |2346.26 |256 |
| [convnextv2_nano.fcmae_ft_in22k_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in22k_in1k) |82.03 |96.166|224 |15.62 |2.46 |8.37 |2300.18 |256 |
| [convnextv2_nano.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_nano.fcmae_ft_in1k) |81.83 |95.738|224 |15.62 |2.46 |8.37 |2321.48 |256 |
| [convnext_nano_ols.d1h_in1k](https://huggingface.co/timm/convnext_nano_ols.d1h_in1k) |80.866|95.246|224 |15.65 |2.65 |9.38 |3523.85 |256 |
| [convnext_nano.d1h_in1k](https://huggingface.co/timm/convnext_nano.d1h_in1k) |80.768|95.334|224 |15.59 |2.46 |8.37 |3915.58 |256 |
| [convnextv2_pico.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_pico.fcmae_ft_in1k) |80.304|95.072|224 |9.07 |1.37 |6.1 |3274.57 |256 |
| [convnext_pico.d1_in1k](https://huggingface.co/timm/convnext_pico.d1_in1k) |79.526|94.558|224 |9.05 |1.37 |6.1 |5686.88 |256 |
| [convnext_pico_ols.d1_in1k](https://huggingface.co/timm/convnext_pico_ols.d1_in1k) |79.522|94.692|224 |9.06 |1.43 |6.5 |5422.46 |256 |
| [convnextv2_femto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_femto.fcmae_ft_in1k) |78.488|93.98 |224 |5.23 |0.79 |4.57 |4264.2 |256 |
| [convnext_femto_ols.d1_in1k](https://huggingface.co/timm/convnext_femto_ols.d1_in1k) |77.86 |93.83 |224 |5.23 |0.82 |4.87 |6910.6 |256 |
| [convnext_femto.d1_in1k](https://huggingface.co/timm/convnext_femto.d1_in1k) |77.454|93.68 |224 |5.22 |0.79 |4.57 |7189.92 |256 |
| [convnextv2_atto.fcmae_ft_in1k](https://huggingface.co/timm/convnextv2_atto.fcmae_ft_in1k) |76.664|93.044|224 |3.71 |0.55 |3.81 |4728.91 |256 |
| [convnext_atto_ols.a2_in1k](https://huggingface.co/timm/convnext_atto_ols.a2_in1k) |75.88 |92.846|224 |3.7 |0.58 |4.11 |7963.16 |256 |
| [convnext_atto.d2_in1k](https://huggingface.co/timm/convnext_atto.d2_in1k) |75.664|92.9 |224 |3.7 |0.55 |3.81 |8439.22 |256 |
## Citation
```bibtex
@article{Woo2023ConvNeXtV2,
title={ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders},
author={Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon and Saining Xie},
year={2023},
journal={arXiv preprint arXiv:2301.00808},
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
| 15,831 | [
[
-0.06805419921875,
-0.03076171875,
-0.006256103515625,
0.037506103515625,
-0.031646728515625,
-0.01534271240234375,
-0.0124053955078125,
-0.03533935546875,
0.06378173828125,
0.018218994140625,
-0.044586181640625,
-0.039276123046875,
-0.05340576171875,
-0.004... |
TheBloke/zephyr-7B-beta-GPTQ | 2023-10-27T14:56:24.000Z | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"generated_from_trainer",
"en",
"dataset:HuggingFaceH4/ultrachat_200k",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"arxiv:2305.18290",
"arxiv:2310.16944",
"license:mit",
"text-generation-inference",
"region:us"
] | text-generation | TheBloke | null | null | TheBloke/zephyr-7B-beta-GPTQ | 27 | 3,474 | transformers | 2023-10-27T13:16:11 | ---
base_model: HuggingFaceH4/zephyr-7b-beta
datasets:
- HuggingFaceH4/ultrachat_200k
- HuggingFaceH4/ultrafeedback_binarized
inference: false
language:
- en
license: mit
model-index:
- name: zephyr-7b-beta
results: []
model_creator: Hugging Face H4
model_name: Zephyr 7B Beta
model_type: mistral
prompt_template: '<|system|>
</s>
<|user|>
{prompt}</s>
<|assistant|>
'
quantized_by: TheBloke
tags:
- generated_from_trainer
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Zephyr 7B Beta - GPTQ
- Model creator: [Hugging Face H4](https://huggingface.co/HuggingFaceH4)
- Original model: [Zephyr 7B Beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Hugging Face H4's Zephyr 7B Beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/zephyr-7B-beta-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/zephyr-7B-beta-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/zephyr-7B-beta-GGUF)
* [Hugging Face H4's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Zephyr
```
<|system|>
</s>
<|user|>
{prompt}</s>
<|assistant|>
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-compatible clients start -->
## Known compatible clients / servers
These GPTQ models are known to work in the following inference servers/webuis.
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
- [KobaldAI United](https://github.com/henk717/koboldai)
- [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui)
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
This may not be a complete list; if you know of others, please let me know!
<!-- README_GPTQ.md-compatible clients end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama and Mistral models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/zephyr-7B-beta-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.16 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/zephyr-7B-beta-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.57 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/zephyr-7B-beta-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.52 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/zephyr-7B-beta-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.68 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/zephyr-7B-beta-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 8.17 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/zephyr-7B-beta-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 4.29 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/zephyr-7B-beta-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/zephyr-7B-beta-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `zephyr-7B-beta-GPTQ`:
```shell
mkdir zephyr-7B-beta-GPTQ
huggingface-cli download TheBloke/zephyr-7B-beta-GPTQ --local-dir zephyr-7B-beta-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir zephyr-7B-beta-GPTQ
huggingface-cli download TheBloke/zephyr-7B-beta-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir zephyr-7B-beta-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Hugging Face cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir zephyr-7B-beta-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/zephyr-7B-beta-GPTQ --local-dir zephyr-7B-beta-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/zephyr-7B-beta-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/zephyr-7B-beta-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/zephyr-7B-beta-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `zephyr-7B-beta-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
- Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/zephyr-7B-beta-GPTQ --port 3000 --quantize gptq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''<|system|>
</s>
<|user|>
{prompt}</s>
<|assistant|>
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_GPTQ.md-use-from-tgi end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/zephyr-7B-beta-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''<|system|>
</s>
<|user|>
{prompt}</s>
<|assistant|>
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with Transformers. For non-Mistral models, AutoGPTQ can also be used directly.
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama and Mistral models in 4-bit. Please see the Provided Files table above for per-file compatibility.
For a list of clients/servers, please see "Known compatible clients / servers", above.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Hugging Face H4's Zephyr 7B Beta
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
<img src="https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha/resolve/main/thumbnail.png" alt="Zephyr Logo" width="800" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Model Card for Zephyr 7B β
Zephyr is a series of language models that are trained to act as helpful assistants. Zephyr-7B-β is the second model in the series, and is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) that was trained on on a mix of publicly available, synthetic datasets using [Direct Preference Optimization (DPO)](https://arxiv.org/abs/2305.18290). We found that removing the in-built alignment of these datasets boosted performance on [MT Bench](https://huggingface.co/spaces/lmsys/mt-bench) and made the model more helpful. However, this means that model is likely to generate problematic text when prompted to do so and should only be used for educational and research purposes. You can find more details in the [technical report](https://arxiv.org/abs/2310.16944).
## Model description
- **Model type:** A 7B parameter GPT-like model fine-tuned on a mix of publicly available, synthetic datasets.
- **Language(s) (NLP):** Primarily English
- **License:** MIT
- **Finetuned from model:** [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/huggingface/alignment-handbook
- **Demo:** https://huggingface.co/spaces/HuggingFaceH4/zephyr-chat
- **Chatbot Arena:** Evaluate Zephyr 7B against 10+ LLMs in the LMSYS arena: http://arena.lmsys.org
## Performance
At the time of release, Zephyr-7B-β is the highest ranked 7B chat model on the [MT-Bench](https://huggingface.co/spaces/lmsys/mt-bench) and [AlpacaEval](https://tatsu-lab.github.io/alpaca_eval/) benchmarks:
| Model | Size | Alignment | MT-Bench (score) | AlpacaEval (win rate %) |
|-------------|-----|----|---------------|--------------|
| StableLM-Tuned-α | 7B| dSFT |2.75| -|
| MPT-Chat | 7B |dSFT |5.42| -|
| Xwin-LMv0.1 | 7B| dPPO| 6.19| 87.83|
| Mistral-Instructv0.1 | 7B| - | 6.84 |-|
| Zephyr-7b-α |7B| dDPO| 6.88| -|
| **Zephyr-7b-β** 🪁 | **7B** | **dDPO** | **7.34** | **90.60** |
| Falcon-Instruct | 40B |dSFT |5.17 |45.71|
| Guanaco | 65B | SFT |6.41| 71.80|
| Llama2-Chat | 70B |RLHF |6.86| 92.66|
| Vicuna v1.3 | 33B |dSFT |7.12 |88.99|
| WizardLM v1.0 | 70B |dSFT |7.71 |-|
| Xwin-LM v0.1 | 70B |dPPO |- |95.57|
| GPT-3.5-turbo | - |RLHF |7.94 |89.37|
| Claude 2 | - |RLHF |8.06| 91.36|
| GPT-4 | -| RLHF |8.99| 95.28|
In particular, on several categories of MT-Bench, Zephyr-7B-β has strong performance compared to larger open models like Llama2-Chat-70B:

However, on more complex tasks like coding and mathematics, Zephyr-7B-β lags behind proprietary models and more research is needed to close the gap.
## Intended uses & limitations
The model was initially fine-tuned on a filtered and preprocessed of the [`UltraChat`](https://huggingface.co/datasets/stingning/ultrachat) dataset, which contains a diverse range of synthetic dialogues generated by ChatGPT.
We then further aligned the model with [🤗 TRL's](https://github.com/huggingface/trl) `DPOTrainer` on the [openbmb/UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback) dataset, which contains 64k prompts and model completions that are ranked by GPT-4. As a result, the model can be used for chat and you can check out our [demo](https://huggingface.co/spaces/HuggingFaceH4/zephyr-chat) to test its capabilities.
You can find the datasets used for training Zephyr-7B-β [here](https://huggingface.co/collections/HuggingFaceH4/zephyr-7b-6538c6d6d5ddd1cbb1744a66)
Here's how you can run the model using the `pipeline()` function from 🤗 Transformers:
```python
# Install transformers from source - only needed for versions <= v4.34
# pip install git+https://github.com/huggingface/transformers.git
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="HuggingFaceH4/zephyr-7b-beta", torch_dtype=torch.bfloat16, device_map="auto")
# We use the tokenizer's chat template to format each message - see https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
# <|system|>
# You are a friendly chatbot who always responds in the style of a pirate.</s>
# <|user|>
# How many helicopters can a human eat in one sitting?</s>
# <|assistant|>
# Ah, me hearty matey! But yer question be a puzzler! A human cannot eat a helicopter in one sitting, as helicopters are not edible. They be made of metal, plastic, and other materials, not food!
```
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Zephyr-7B-β has not been aligned to human preferences with techniques like RLHF or deployed with in-the-loop filtering of responses like ChatGPT, so the model can produce problematic outputs (especially when prompted to do so).
It is also unknown what the size and composition of the corpus was used to train the base model (`mistralai/Mistral-7B-v0.1`), however it is likely to have included a mix of Web data and technical sources like books and code. See the [Falcon 180B model card](https://huggingface.co/tiiuae/falcon-180B#training-data) for an example of this.
## Training and evaluation data
During DPO training, this model achieves the following results on the evaluation set:
- Loss: 0.7496
- Rewards/chosen: -4.5221
- Rewards/rejected: -8.3184
- Rewards/accuracies: 0.7812
- Rewards/margins: 3.7963
- Logps/rejected: -340.1541
- Logps/chosen: -299.4561
- Logits/rejected: -2.3081
- Logits/chosen: -2.3531
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 2
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 16
- total_train_batch_size: 32
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3.0
### Training results
The table below shows the full set of DPO training metrics:
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.6284 | 0.05 | 100 | 0.6098 | 0.0425 | -0.1872 | 0.7344 | 0.2297 | -258.8416 | -253.8099 | -2.7976 | -2.8234 |
| 0.4908 | 0.1 | 200 | 0.5426 | -0.0279 | -0.6842 | 0.75 | 0.6563 | -263.8124 | -254.5145 | -2.7719 | -2.7960 |
| 0.5264 | 0.15 | 300 | 0.5324 | 0.0414 | -0.9793 | 0.7656 | 1.0207 | -266.7627 | -253.8209 | -2.7892 | -2.8122 |
| 0.5536 | 0.21 | 400 | 0.4957 | -0.0185 | -1.5276 | 0.7969 | 1.5091 | -272.2460 | -254.4203 | -2.8542 | -2.8764 |
| 0.5362 | 0.26 | 500 | 0.5031 | -0.2630 | -1.5917 | 0.7812 | 1.3287 | -272.8869 | -256.8653 | -2.8702 | -2.8958 |
| 0.5966 | 0.31 | 600 | 0.5963 | -0.2993 | -1.6491 | 0.7812 | 1.3499 | -273.4614 | -257.2279 | -2.8778 | -2.8986 |
| 0.5014 | 0.36 | 700 | 0.5382 | -0.2859 | -1.4750 | 0.75 | 1.1891 | -271.7204 | -257.0942 | -2.7659 | -2.7869 |
| 0.5334 | 0.41 | 800 | 0.5677 | -0.4289 | -1.8968 | 0.7969 | 1.4679 | -275.9378 | -258.5242 | -2.7053 | -2.7265 |
| 0.5251 | 0.46 | 900 | 0.5772 | -0.2116 | -1.3107 | 0.7344 | 1.0991 | -270.0768 | -256.3507 | -2.8463 | -2.8662 |
| 0.5205 | 0.52 | 1000 | 0.5262 | -0.3792 | -1.8585 | 0.7188 | 1.4793 | -275.5552 | -258.0276 | -2.7893 | -2.7979 |
| 0.5094 | 0.57 | 1100 | 0.5433 | -0.6279 | -1.9368 | 0.7969 | 1.3089 | -276.3377 | -260.5136 | -2.7453 | -2.7536 |
| 0.5837 | 0.62 | 1200 | 0.5349 | -0.3780 | -1.9584 | 0.7656 | 1.5804 | -276.5542 | -258.0154 | -2.7643 | -2.7756 |
| 0.5214 | 0.67 | 1300 | 0.5732 | -1.0055 | -2.2306 | 0.7656 | 1.2251 | -279.2761 | -264.2903 | -2.6986 | -2.7113 |
| 0.6914 | 0.72 | 1400 | 0.5137 | -0.6912 | -2.1775 | 0.7969 | 1.4863 | -278.7448 | -261.1467 | -2.7166 | -2.7275 |
| 0.4655 | 0.77 | 1500 | 0.5090 | -0.7987 | -2.2930 | 0.7031 | 1.4943 | -279.8999 | -262.2220 | -2.6651 | -2.6838 |
| 0.5731 | 0.83 | 1600 | 0.5312 | -0.8253 | -2.3520 | 0.7812 | 1.5268 | -280.4902 | -262.4876 | -2.6543 | -2.6728 |
| 0.5233 | 0.88 | 1700 | 0.5206 | -0.4573 | -2.0951 | 0.7812 | 1.6377 | -277.9205 | -258.8084 | -2.6870 | -2.7097 |
| 0.5593 | 0.93 | 1800 | 0.5231 | -0.5508 | -2.2000 | 0.7969 | 1.6492 | -278.9703 | -259.7433 | -2.6221 | -2.6519 |
| 0.4967 | 0.98 | 1900 | 0.5290 | -0.5340 | -1.9570 | 0.8281 | 1.4230 | -276.5395 | -259.5749 | -2.6564 | -2.6878 |
| 0.0921 | 1.03 | 2000 | 0.5368 | -1.1376 | -3.1615 | 0.7812 | 2.0239 | -288.5854 | -265.6111 | -2.6040 | -2.6345 |
| 0.0733 | 1.08 | 2100 | 0.5453 | -1.1045 | -3.4451 | 0.7656 | 2.3406 | -291.4208 | -265.2799 | -2.6289 | -2.6595 |
| 0.0972 | 1.14 | 2200 | 0.5571 | -1.6915 | -3.9823 | 0.8125 | 2.2908 | -296.7934 | -271.1505 | -2.6471 | -2.6709 |
| 0.1058 | 1.19 | 2300 | 0.5789 | -1.0621 | -3.8941 | 0.7969 | 2.8319 | -295.9106 | -264.8563 | -2.5527 | -2.5798 |
| 0.2423 | 1.24 | 2400 | 0.5455 | -1.1963 | -3.5590 | 0.7812 | 2.3627 | -292.5599 | -266.1981 | -2.5414 | -2.5784 |
| 0.1177 | 1.29 | 2500 | 0.5889 | -1.8141 | -4.3942 | 0.7969 | 2.5801 | -300.9120 | -272.3761 | -2.4802 | -2.5189 |
| 0.1213 | 1.34 | 2600 | 0.5683 | -1.4608 | -3.8420 | 0.8125 | 2.3812 | -295.3901 | -268.8436 | -2.4774 | -2.5207 |
| 0.0889 | 1.39 | 2700 | 0.5890 | -1.6007 | -3.7337 | 0.7812 | 2.1330 | -294.3068 | -270.2423 | -2.4123 | -2.4522 |
| 0.0995 | 1.45 | 2800 | 0.6073 | -1.5519 | -3.8362 | 0.8281 | 2.2843 | -295.3315 | -269.7538 | -2.4685 | -2.5050 |
| 0.1145 | 1.5 | 2900 | 0.5790 | -1.7939 | -4.2876 | 0.8438 | 2.4937 | -299.8461 | -272.1744 | -2.4272 | -2.4674 |
| 0.0644 | 1.55 | 3000 | 0.5735 | -1.7285 | -4.2051 | 0.8125 | 2.4766 | -299.0209 | -271.5201 | -2.4193 | -2.4574 |
| 0.0798 | 1.6 | 3100 | 0.5537 | -1.7226 | -4.2850 | 0.8438 | 2.5624 | -299.8200 | -271.4610 | -2.5367 | -2.5696 |
| 0.1013 | 1.65 | 3200 | 0.5575 | -1.5715 | -3.9813 | 0.875 | 2.4098 | -296.7825 | -269.9498 | -2.4926 | -2.5267 |
| 0.1254 | 1.7 | 3300 | 0.5905 | -1.6412 | -4.4703 | 0.8594 | 2.8291 | -301.6730 | -270.6473 | -2.5017 | -2.5340 |
| 0.085 | 1.76 | 3400 | 0.6133 | -1.9159 | -4.6760 | 0.8438 | 2.7601 | -303.7296 | -273.3941 | -2.4614 | -2.4960 |
| 0.065 | 1.81 | 3500 | 0.6074 | -1.8237 | -4.3525 | 0.8594 | 2.5288 | -300.4951 | -272.4724 | -2.4597 | -2.5004 |
| 0.0755 | 1.86 | 3600 | 0.5836 | -1.9252 | -4.4005 | 0.8125 | 2.4753 | -300.9748 | -273.4872 | -2.4327 | -2.4716 |
| 0.0746 | 1.91 | 3700 | 0.5789 | -1.9280 | -4.4906 | 0.8125 | 2.5626 | -301.8762 | -273.5149 | -2.4686 | -2.5115 |
| 0.1348 | 1.96 | 3800 | 0.6015 | -1.8658 | -4.2428 | 0.8281 | 2.3769 | -299.3976 | -272.8936 | -2.4943 | -2.5393 |
| 0.0217 | 2.01 | 3900 | 0.6122 | -2.3335 | -4.9229 | 0.8281 | 2.5894 | -306.1988 | -277.5699 | -2.4841 | -2.5272 |
| 0.0219 | 2.07 | 4000 | 0.6522 | -2.9890 | -6.0164 | 0.8281 | 3.0274 | -317.1334 | -284.1248 | -2.4105 | -2.4545 |
| 0.0119 | 2.12 | 4100 | 0.6922 | -3.4777 | -6.6749 | 0.7969 | 3.1972 | -323.7187 | -289.0121 | -2.4272 | -2.4699 |
| 0.0153 | 2.17 | 4200 | 0.6993 | -3.2406 | -6.6775 | 0.7969 | 3.4369 | -323.7453 | -286.6413 | -2.4047 | -2.4465 |
| 0.011 | 2.22 | 4300 | 0.7178 | -3.7991 | -7.4397 | 0.7656 | 3.6406 | -331.3667 | -292.2260 | -2.3843 | -2.4290 |
| 0.0072 | 2.27 | 4400 | 0.6840 | -3.3269 | -6.8021 | 0.8125 | 3.4752 | -324.9908 | -287.5042 | -2.4095 | -2.4536 |
| 0.0197 | 2.32 | 4500 | 0.7013 | -3.6890 | -7.3014 | 0.8125 | 3.6124 | -329.9841 | -291.1250 | -2.4118 | -2.4543 |
| 0.0182 | 2.37 | 4600 | 0.7476 | -3.8994 | -7.5366 | 0.8281 | 3.6372 | -332.3356 | -293.2291 | -2.4163 | -2.4565 |
| 0.0125 | 2.43 | 4700 | 0.7199 | -4.0560 | -7.5765 | 0.8438 | 3.5204 | -332.7345 | -294.7952 | -2.3699 | -2.4100 |
| 0.0082 | 2.48 | 4800 | 0.7048 | -3.6613 | -7.1356 | 0.875 | 3.4743 | -328.3255 | -290.8477 | -2.3925 | -2.4303 |
| 0.0118 | 2.53 | 4900 | 0.6976 | -3.7908 | -7.3152 | 0.8125 | 3.5244 | -330.1224 | -292.1431 | -2.3633 | -2.4047 |
| 0.0118 | 2.58 | 5000 | 0.7198 | -3.9049 | -7.5557 | 0.8281 | 3.6508 | -332.5271 | -293.2844 | -2.3764 | -2.4194 |
| 0.006 | 2.63 | 5100 | 0.7506 | -4.2118 | -7.9149 | 0.8125 | 3.7032 | -336.1194 | -296.3530 | -2.3407 | -2.3860 |
| 0.0143 | 2.68 | 5200 | 0.7408 | -4.2433 | -7.9802 | 0.8125 | 3.7369 | -336.7721 | -296.6682 | -2.3509 | -2.3946 |
| 0.0057 | 2.74 | 5300 | 0.7552 | -4.3392 | -8.0831 | 0.7969 | 3.7439 | -337.8013 | -297.6275 | -2.3388 | -2.3842 |
| 0.0138 | 2.79 | 5400 | 0.7404 | -4.2395 | -7.9762 | 0.8125 | 3.7367 | -336.7322 | -296.6304 | -2.3286 | -2.3737 |
| 0.0079 | 2.84 | 5500 | 0.7525 | -4.4466 | -8.2196 | 0.7812 | 3.7731 | -339.1662 | -298.7007 | -2.3200 | -2.3641 |
| 0.0077 | 2.89 | 5600 | 0.7520 | -4.5586 | -8.3485 | 0.7969 | 3.7899 | -340.4545 | -299.8206 | -2.3078 | -2.3517 |
| 0.0094 | 2.94 | 5700 | 0.7527 | -4.5542 | -8.3509 | 0.7812 | 3.7967 | -340.4790 | -299.7773 | -2.3062 | -2.3510 |
| 0.0054 | 2.99 | 5800 | 0.7520 | -4.5169 | -8.3079 | 0.7812 | 3.7911 | -340.0493 | -299.4038 | -2.3081 | -2.3530 |
### Framework versions
- Transformers 4.35.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.12.0
- Tokenizers 0.14.0
## Citation
If you find Zephyr-7B-β is useful in your work, please cite it with:
```
@misc{tunstall2023zephyr,
title={Zephyr: Direct Distillation of LM Alignment},
author={Lewis Tunstall and Edward Beeching and Nathan Lambert and Nazneen Rajani and Kashif Rasul and Younes Belkada and Shengyi Huang and Leandro von Werra and Clémentine Fourrier and Nathan Habib and Nathan Sarrazin and Omar Sanseviero and Alexander M. Rush and Thomas Wolf},
year={2023},
eprint={2310.16944},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
| 38,370 | [
[
-0.0367431640625,
-0.05450439453125,
0.0162506103515625,
0.0163116455078125,
-0.0125885009765625,
-0.01412200927734375,
0.003795623779296875,
-0.039642333984375,
0.01119232177734375,
0.028564453125,
-0.045623779296875,
-0.0360107421875,
-0.0214080810546875,
... |
Srividhya9/my-pet-cat-ars | 2023-11-06T10:08:46.000Z | [
"diffusers",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Srividhya9 | null | null | Srividhya9/my-pet-cat-ars | 1 | 3,472 | diffusers | 2023-11-06T10:04:40 | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Cat-ARS Dreambooth model trained by Srividhya9 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MRCEW-349
Sample pictures of this concept:
.jpg)
| 400 | [
[
-0.051116943359375,
-0.02008056640625,
0.0246124267578125,
0.007122039794921875,
-0.0187835693359375,
0.046844482421875,
0.030975341796875,
-0.031036376953125,
0.0631103515625,
0.038665771484375,
-0.03955078125,
-0.00955963134765625,
-0.006282806396484375,
0... |
cedricolivier/naniohana | 2023-10-13T18:28:45.000Z | [
"diffusers",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | null | cedricolivier | null | null | cedricolivier/naniohana | 0 | 3,470 | diffusers | 2023-10-13T18:24:48 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### naniohana Dreambooth model trained by cedricolivier with TheLastBen's fast-DreamBooth notebook
| 208 | [
[
-0.021484375,
-0.058807373046875,
0.043853759765625,
0.037261962890625,
-0.03570556640625,
0.007366180419921875,
0.00788116455078125,
-0.0150146484375,
0.03607177734375,
0.03314208984375,
-0.022979736328125,
-0.039703369140625,
-0.058746337890625,
-0.0278472... |
sail-rvc/21savage | 2023-07-14T07:18:07.000Z | [
"transformers",
"rvc",
"sail-rvc",
"audio-to-audio",
"endpoints_compatible",
"region:us"
] | audio-to-audio | sail-rvc | null | null | sail-rvc/21savage | 0 | 3,465 | transformers | 2023-07-14T07:17:24 |
---
pipeline_tag: audio-to-audio
tags:
- rvc
- sail-rvc
---
# 21savage
## RVC Model

This model repo was automatically generated.
Date: 2023-07-14 07:18:07
Bot Name: juuxnscrap
Model Type: RVC
Source: https://huggingface.co/juuxn/RVCModels/
Reason: Converting into loadable format for https://github.com/chavinlo/rvc-runpod
| 376 | [
[
-0.0357666015625,
-0.0257110595703125,
0.021392822265625,
0.0121307373046875,
-0.0316162109375,
0.004047393798828125,
0.016510009765625,
-0.00226593017578125,
0.0240631103515625,
0.0738525390625,
-0.051910400390625,
-0.0450439453125,
-0.0352783203125,
-0.005... |
cgburgos/sdxl-1-0-base | 2023-08-02T20:02:56.000Z | [
"diffusers",
"onnx",
"text-to-image",
"stable-diffusion",
"arxiv:2307.01952",
"arxiv:2211.01324",
"arxiv:2108.01073",
"arxiv:2112.10752",
"license:openrail++",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | cgburgos | null | null | cgburgos/sdxl-1-0-base | 2 | 3,463 | diffusers | 2023-08-02T20:02:56 | ---
license: openrail++
tags:
- text-to-image
- stable-diffusion
duplicated_from: stabilityai/stable-diffusion-xl-base-1.0
---
# SD-XL 1.0-base Model Card

## Model

[SDXL](https://arxiv.org/abs/2307.01952) consists of an [ensemble of experts](https://arxiv.org/abs/2211.01324) pipeline for latent diffusion:
In a first step, the base model is used to generate (noisy) latents,
which are then further processed with a refinement model (available here: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/) specialized for the final denoising steps.
Note that the base model can be used as a standalone module.
Alternatively, we can use a two-stage pipeline as follows:
First, the base model is used to generate latents of the desired output size.
In the second step, we use a specialized high-resolution model and apply a technique called SDEdit (https://arxiv.org/abs/2108.01073, also known as "img2img")
to the latents generated in the first step, using the same prompt. This technique is slightly slower than the first one, as it requires more function evaluations.
Source code is available at https://github.com/Stability-AI/generative-models .
### Model Description
- **Developed by:** Stability AI
- **Model type:** Diffusion-based text-to-image generative model
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/LICENSE.md)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses two fixed, pretrained text encoders ([OpenCLIP-ViT/G](https://github.com/mlfoundations/open_clip) and [CLIP-ViT/L](https://github.com/openai/CLIP/tree/main)).
- **Resources for more information:** Check out our [GitHub Repository](https://github.com/Stability-AI/generative-models) and the [SDXL report on arXiv](https://arxiv.org/abs/2307.01952).
### Model Sources
For research purposes, we recommned our `generative-models` Github repository (https://github.com/Stability-AI/generative-models), which implements the most popoular diffusion frameworks (both training and inference) and for which new functionalities like distillation will be added over time.
[Clipdrop](https://clipdrop.co/stable-diffusion) provides free SDXL inference.
- **Repository:** https://github.com/Stability-AI/generative-models
- **Demo:** https://clipdrop.co/stable-diffusion
## Evaluation

The chart above evaluates user preference for SDXL (with and without refinement) over SDXL 0.9 and Stable Diffusion 1.5 and 2.1.
The SDXL base model performs significantly better than the previous variants, and the model combined with the refinement module achieves the best overall performance.
### 🧨 Diffusers
Make sure to upgrade diffusers to >= 0.19.0:
```
pip install diffusers --upgrade
```
In addition make sure to install `transformers`, `safetensors`, `accelerate` as well as the invisible watermark:
```
pip install invisible_watermark transformers accelerate safetensors
```
To just use the base model, you can run:
```py
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
# if using torch < 2.0
# pipe.enable_xformers_memory_efficient_attention()
prompt = "An astronaut riding a green horse"
images = pipe(prompt=prompt).images[0]
```
To use the whole base + refiner pipeline as an ensemble of experts you can run:
```py
from diffusers import DiffusionPipeline
import torch
# load both base & refiner
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
base.to("cuda")
refiner = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
)
refiner.to("cuda")
# Define how many steps and what % of steps to be run on each experts (80/20) here
n_steps = 40
high_noise_frac = 0.8
prompt = "A majestic lion jumping from a big stone at night"
# run both experts
image = base(
prompt=prompt,
num_inference_steps=n_steps,
denoising_end=high_noise_frac,
output_type="latent",
).images
image = refiner(
prompt=prompt,
num_inference_steps=n_steps,
denoising_start=high_noise_frac,
image=image,
).images[0]
```
When using `torch >= 2.0`, you can improve the inference speed by 20-30% with torch.compile. Simple wrap the unet with torch compile before running the pipeline:
```py
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
If you are limited by GPU VRAM, you can enable *cpu offloading* by calling `pipe.enable_model_cpu_offload`
instead of `.to("cuda")`:
```diff
- pipe.to("cuda")
+ pipe.enable_model_cpu_offload()
```
For more information on how to use Stable Diffusion XL with `diffusers`, please have a look at [the Stable Diffusion XL Docs](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl).
### Optimum
[Optimum](https://github.com/huggingface/optimum) provides a Stable Diffusion pipeline compatible with both [OpenVINO](https://docs.openvino.ai/latest/index.html) and [ONNX Runtime](https://onnxruntime.ai/).
#### OpenVINO
To install Optimum with the dependencies required for OpenVINO :
```bash
pip install optimum[openvino]
```
To load an OpenVINO model and run inference with OpenVINO Runtime, you need to replace `StableDiffusionXLPipeline` with Optimum `OVStableDiffusionXLPipeline`. In case you want to load a PyTorch model and convert it to the OpenVINO format on-the-fly, you can set `export=True`.
```diff
- from diffusers import StableDiffusionPipeline
+ from optimum.intel import OVStableDiffusionPipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
- pipeline = StableDiffusionPipeline.from_pretrained(model_id)
+ pipeline = OVStableDiffusionPipeline.from_pretrained(model_id)
prompt = "A majestic lion jumping from a big stone at night"
image = pipeline(prompt).images[0]
```
You can find more examples (such as static reshaping and model compilation) in optimum [documentation](https://huggingface.co/docs/optimum/main/en/intel/inference#stable-diffusion-xl).
#### ONNX
To install Optimum with the dependencies required for ONNX Runtime inference :
```bash
pip install optimum[onnxruntime]
```
To load an ONNX model and run inference with ONNX Runtime, you need to replace `StableDiffusionXLPipeline` with Optimum `ORTStableDiffusionXLPipeline`. In case you want to load a PyTorch model and convert it to the ONNX format on-the-fly, you can set `export=True`.
```diff
- from diffusers import StableDiffusionPipeline
+ from optimum.onnxruntime import ORTStableDiffusionPipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
- pipeline = StableDiffusionPipeline.from_pretrained(model_id)
+ pipeline = ORTStableDiffusionPipeline.from_pretrained(model_id)
prompt = "A majestic lion jumping from a big stone at night"
image = pipeline(prompt).images[0]
```
You can find more examples in optimum [documentation](https://huggingface.co/docs/optimum/main/en/onnxruntime/usage_guides/models#stable-diffusion-xl).
## Uses
### Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
Excluded uses are described below.
### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model struggles with more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The autoencoding part of the model is lossy.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
| 8,704 | [
[
-0.0309295654296875,
-0.062469482421875,
0.03802490234375,
0.00962066650390625,
-0.008056640625,
-0.023162841796875,
-0.0105438232421875,
-0.005886077880859375,
0.00923919677734375,
0.03192138671875,
-0.0225677490234375,
-0.037933349609375,
-0.045440673828125,
... |
nitrosocke/classic-anim-diffusion | 2023-05-16T09:23:56.000Z | [
"diffusers",
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | nitrosocke | null | null | nitrosocke/classic-anim-diffusion | 401 | 3,460 | diffusers | 2022-10-30T15:14:27 | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
---
### Classic Animation Diffusion
This is the fine-tuned Stable Diffusion model trained on screenshots from a popular animation studio.
Use the tokens **_classic disney style_** in your prompts for the effect.
**If you enjoy my work, please consider supporting me**
[](https://patreon.com/user?u=79196446)
**Characters rendered with the model:**

**Animals rendered with the model:**

**Cars and Landscapes rendered with the model:**

### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "nitrosocke/classic-anim-diffusion"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "classic disney style magical princess with golden hair"
image = pipe(prompt).images[0]
image.save("./magical_princess.png")
```
#### Prompt and settings for Helen Mirren:
**classic disney style helen mirren as a queen**
_Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 3496225274, Size: 512x704_
#### Prompt and settings for the Ford Model T:
**classic disney style Ford Model T - Negative prompt: person**
_Steps: 20, Sampler: DPM2 Karras, CFG scale: 7, Seed: 4817981, Size: 704x512_
This model was trained using the diffusers based dreambooth training by ShivamShrirao using prior-preservation loss and the _train-text-encoder_ flag in 9.000 steps.
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) | 3,080 | [
[
-0.038482666015625,
-0.06256103515625,
0.0177154541015625,
0.016387939453125,
-0.016571044921875,
-0.007720947265625,
0.001422882080078125,
-0.020599365234375,
0.0215301513671875,
0.048004150390625,
-0.0404052734375,
-0.029022216796875,
-0.0491943359375,
-0.... |
Yntec/Protogen | 2023-10-20T08:08:11.000Z | [
"diffusers",
"darkstorm2150",
"anime",
"art",
"artistic",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/Protogen | 1 | 3,460 | diffusers | 2023-10-20T06:26:53 | ---
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- darkstorm2150
- anime
- art
- artistic
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
inference: true
license: creativeml-openrail-m
---
# Protogen 2.2
<center><img src="https://cdn-uploads.huggingface.co/production/uploads/63239b8370edc53f51cd5d42/5O9f56_PJKRRfiH5UV8sR.png" style="height:512px; border-radius: 7%; border: 10px solid #663380; padding-top:0px;" span title="Protogen v2.2 Raw Output"></center>
768x768 version of this model for the inference API, the best version of Protogen for flat anime.
512x512 version: https://huggingface.co/darkstorm2150/Protogen_v2.2_Official_Release
Sample and prompt:

Cartoon Pretty CUTE LITTLE Girl, sitting on Overwatch, DETAILED CHIBI EYES, soaking in the rain, gorgeous detailed hair, Ponytail, Magazine ad, iconic, 1940, sharp focus, aerial photography, trending on artstation. Illustration By Nihei ROSSDRAWS and KlaysMoji and Dave Rapoza and artgerm and leyendecker and Clay | 1,157 | [
[
-0.03948974609375,
-0.0341796875,
0.028106689453125,
0.03167724609375,
-0.0294342041015625,
0.00042366981506347656,
0.0008826255798339844,
-0.053314208984375,
0.02764892578125,
0.01430511474609375,
-0.047760009765625,
-0.03216552734375,
-0.037841796875,
-0.0... |
THUDM/chatglm3-6b-32k | 2023-10-31T10:27:14.000Z | [
"transformers",
"pytorch",
"chatglm",
"glm",
"thudm",
"custom_code",
"zh",
"en",
"arxiv:2103.10360",
"arxiv:2210.02414",
"endpoints_compatible",
"region:us"
] | null | THUDM | null | null | THUDM/chatglm3-6b-32k | 115 | 3,455 | transformers | 2023-10-26T13:04:58 | ---
language:
- zh
- en
tags:
- glm
- chatglm
- thudm
---
# ChatGLM3-6B-32K
<p align="center">
💻 <a href="https://github.com/THUDM/ChatGLM" target="_blank">Github Repo</a> • 🐦 <a href="https://twitter.com/thukeg" target="_blank">Twitter</a> • 📃 <a href="https://arxiv.org/abs/2103.10360" target="_blank">[GLM@ACL 22]</a> <a href="https://github.com/THUDM/GLM" target="_blank">[GitHub]</a> • 📃 <a href="https://arxiv.org/abs/2210.02414" target="_blank">[GLM-130B@ICLR 23]</a> <a href="https://github.com/THUDM/GLM-130B" target="_blank">[GitHub]</a> <br>
</p>
<p align="center">
👋 Join our <a href="https://join.slack.com/t/chatglm/shared_invite/zt-25ti5uohv-A_hs~am_D3Q8XPZMpj7wwQ" target="_blank">Slack</a> and <a href="https://github.com/THUDM/ChatGLM/blob/main/resources/WECHAT.md" target="_blank">WeChat</a>
</p>
<p align="center">
📍Experience the larger-scale ChatGLM model at <a href="https://www.chatglm.cn">chatglm.cn</a>
</p>
## 介绍 (Introduction)
ChatGLM3-6B-32K在[ChatGLM3-6B](https://huggingface.co/THUDM/chatglm3-6b)的基础上进一步强化了对于长文本的理解能力,能够更好的处理最多32K长度的上下文。具体地,我们对位置编码进行了更新,并设计了更有针对性的长文本训练方法,在对话阶段使用 32K 的上下文长度训练。在实际的使用中,如果您面临的上下文长度基本在 **8K 以内**,我们推荐使用[ChatGLM3-6B](https://huggingface.co/THUDM/chatglm3-6b);如果您需要处理**超过 8K** 的上下文长度,我们推荐使用ChatGLM3-6B-32K。
ChatGLM3-6B 是 ChatGLM 系列最新一代的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
1. **更强大的基础模型:** ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的预训练模型中最强的性能。
2. **更完整的功能支持:** ChatGLM3-6B 采用了全新设计的 [Prompt 格式](PROMPT.md),除正常的多轮对话外。同时原生支持[工具调用](tool_using/README.md)(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
3. **更全面的开源序列:** 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究**完全开放**,在填写[问卷](https://open.bigmodel.cn/mla/form)进行登记后**亦允许免费商业使用**。
Based on [ChatGLM3-6B](https://huggingface.co/THUDM/chatglm3-6b), ChatGLM3-6B-32K further strengthens the ability to understand long texts and can better handle contexts up to 32K in length. Specifically, we update the position encoding and design a more targeted long text training method, using a context length of 32K for training in the conversation stage. In actual use, if the context length you face is basically within **8K**, we recommend using [ChatGLM3-6B](https://huggingface.co/THUDM/chatglm3-6b); if you need to handle **For context lengths exceeding 8K**, we recommend using ChatGLM3-6B-32K.
ChatGLM3-6B is the latest open-source model in the ChatGLM series. While retaining many excellent features such as smooth dialogue and low deployment threshold from the previous two generations, ChatGLM3-6B introduces the following features:
1. **More Powerful Base Model:** The base model of ChatGLM3-6B, ChatGLM3-6B-Base, employs a more diverse training dataset, more sufficient training steps, and a more reasonable training strategy. Evaluations on datasets such as semantics, mathematics, reasoning, code, knowledge, etc., show that ChatGLM3-6B-Base has the strongest performance among pre-trained models under 10B.
2. **More Comprehensive Function Support:** ChatGLM3-6B adopts a newly designed [Prompt format](https://github.com/THUDM/ChatGLM3/blob/main/PROMPT_en.md), in addition to the normal multi-turn dialogue. It also natively supports [function call](https://github.com/THUDM/ChatGLM3/blob/main/tool_using/README_en.md), code interpreter, and complex scenarios such as agent tasks.
3. **More Comprehensive Open-source Series:** In addition to the dialogue model ChatGLM3-6B, the base model ChatGLM-6B-Base and the long-text dialogue model ChatGLM3-6B-32K are also open-sourced. All the weights are **fully open** for academic research, and after completing the [questionnaire](https://open.bigmodel.cn/mla/form) registration, they are also **allowed for free commercial use**.
## 软件依赖 (Dependencies)
```shell
pip install protobuf transformers==4.30.2 cpm_kernels torch>=2.0 gradio mdtex2html sentencepiece accelerate
```
## 代码调用 (Code Usage)
可以通过如下代码调用 ChatGLM3-6B 模型来生成对话:
```ipython
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b-32k", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm3-6b-32k", trust_remote_code=True).half().cuda()
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
```
关于更多的使用说明,包括如何运行命令行和网页版本的 DEMO,以及使用模型量化以节省显存,请参考我们的 [Github Repo](https://github.com/THUDM/ChatGLM)。
For more instructions, including how to run CLI and web demos, and model quantization, please refer to our [Github Repo](https://github.com/THUDM/ChatGLM).
## 协议 (License)
本仓库的代码依照 [Apache-2.0](LICENSE) 协议开源,ChatGLM3-6B 模型的权重的使用则需要遵循 [Model License](MODEL_LICENSE)。
The code in this repository is open-sourced under the [Apache-2.0 license](LICENSE), while the use of the ChatGLM3-6B model weights needs to comply with the [Model License](MODEL_LICENSE).
## 引用 (Citation)
如果你觉得我们的工作有帮助的话,请考虑引用下列论文。
If you find our work helpful, please consider citing the following papers.
```
@article{zeng2022glm,
title={Glm-130b: An open bilingual pre-trained model},
author={Zeng, Aohan and Liu, Xiao and Du, Zhengxiao and Wang, Zihan and Lai, Hanyu and Ding, Ming and Yang, Zhuoyi and Xu, Yifan and Zheng, Wendi and Xia, Xiao and others},
journal={arXiv preprint arXiv:2210.02414},
year={2022}
}
```
```
@inproceedings{du2022glm,
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
pages={320--335},
year={2022}
}
```
| 6,428 | [
[
-0.03570556640625,
-0.06231689453125,
0.0107574462890625,
0.031341552734375,
-0.0263519287109375,
-0.00211334228515625,
-0.02398681640625,
-0.039825439453125,
0.006198883056640625,
0.0172271728515625,
-0.0399169921875,
-0.04888916015625,
-0.04010009765625,
-... |
TencentARC/t2i-adapter-canny-sdxl-1.0 | 2023-09-07T19:10:05.000Z | [
"diffusers",
"art",
"t2i-adapter",
"image-to-image",
"stable-diffusion-xl-diffusers",
"stable-diffusion-xl",
"arxiv:2302.08453",
"license:apache-2.0",
"has_space",
"diffusers:T2IAdapter",
"region:us"
] | image-to-image | TencentARC | null | null | TencentARC/t2i-adapter-canny-sdxl-1.0 | 25 | 3,451 | diffusers | 2023-09-03T14:19:29 | ---
license: apache-2.0
base_model: stabilityai/stable-diffusion-xl-base-1.0
tags:
- art
- t2i-adapter
- image-to-image
- stable-diffusion-xl-diffusers
- stable-diffusion-xl
---
# T2I-Adapter-SDXL - Canny
T2I Adapter is a network providing additional conditioning to stable diffusion. Each t2i checkpoint takes a different type of conditioning as input and is used with a specific base stable diffusion checkpoint.
This checkpoint provides conditioning on canny for the StableDiffusionXL checkpoint. This was a collaboration between **Tencent ARC** and [**Hugging Face**](https://huggingface.co/).
## Model Details
- **Developed by:** T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** Apache 2.0
- **Resources for more information:** [GitHub Repository](https://github.com/TencentARC/T2I-Adapter), [Paper](https://arxiv.org/abs/2302.08453).
- **Model complexity:**
| | SD-V1.4/1.5 | SD-XL | T2I-Adapter | T2I-Adapter-SDXL |
| --- | --- |--- |--- |--- |
| Parameters | 860M | 2.6B |77 M | 77/79 M | |
- **Cite as:**
@misc{
title={T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models},
author={Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, Xiaohu Qie},
year={2023},
eprint={2302.08453},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
### Checkpoints
| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
|---|---|---|---|
|[TencentARC/t2i-adapter-canny-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0)<br/> *Trained with canny edge detection* | A monochrome image with white edges on a black background.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_canny.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_canny.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_canny.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_canny.png"/></a>|
|[TencentARC/t2i-adapter-sketch-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-sketch-sdxl-1.0)<br/> *Trained with [PidiNet](https://github.com/zhuoinoulu/pidinet) edge detection* | A hand-drawn monochrome image with white outlines on a black background.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_sketch.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_sketch.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_sketch.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_sketch.png"/></a>|
|[TencentARC/t2i-adapter-lineart-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0)<br/> *Trained with lineart edge detection* | A hand-drawn monochrome image with white outlines on a black background.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_lin.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_lin.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_lin.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_lin.png"/></a>|
|[TencentARC/t2i-adapter-depth-midas-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-depth-midas-sdxl-1.0)<br/> *Trained with Midas depth estimation* | A grayscale image with black representing deep areas and white representing shallow areas.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_depth_mid.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_depth_mid.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_depth_mid.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_depth_mid.png"/></a>|
|[TencentARC/t2i-adapter-depth-zoe-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-depth-zoe-sdxl-1.0)<br/> *Trained with Zoe depth estimation* | A grayscale image with black representing deep areas and white representing shallow areas.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_depth_zeo.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_depth_zeo.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_depth_zeo.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_depth_zeo.png"/></a>|
|[TencentARC/t2i-adapter-openpose-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-openpose-sdxl-1.0)<br/> *Trained with OpenPose bone image* | A [OpenPose bone](https://github.com/CMU-Perceptual-Computing-Lab/openpose) image.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/openpose.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/openpose.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/res_pose.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/res_pose.png"/></a>|
## Example
To get started, first install the required dependencies:
```bash
pip install -U git+https://github.com/huggingface/diffusers.git
pip install -U controlnet_aux==0.0.7 # for conditioning models and detectors
pip install transformers accelerate safetensors
```
1. Images are first downloaded into the appropriate *control image* format.
2. The *control image* and *prompt* are passed to the [`StableDiffusionXLAdapterPipeline`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_xl_adapter.py#L125).
Let's have a look at a simple example using the [Canny Adapter](https://huggingface.co/Adapter/t2iadapter_canny_sdxlv1).
- Dependency
```py
from diffusers import StableDiffusionXLAdapterPipeline, T2IAdapter, EulerAncestralDiscreteScheduler, AutoencoderKL
from diffusers.utils import load_image, make_image_grid
from controlnet_aux.canny import CannyDetector
import torch
# load adapter
adapter = T2IAdapter.from_pretrained("TencentARC/t2i-adapter-canny-sdxl-1.0", torch_dtype=torch.float16, varient="fp16").to("cuda")
# load euler_a scheduler
model_id = 'stabilityai/stable-diffusion-xl-base-1.0'
euler_a = EulerAncestralDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
vae=AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
model_id, vae=vae, adapter=adapter, scheduler=euler_a, torch_dtype=torch.float16, variant="fp16",
).to("cuda")
pipe.enable_xformers_memory_efficient_attention()
canny_detector = CannyDetector()
```
- Condition Image
```py
url = "https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/org_canny.jpg"
image = load_image(url)
# Detect the canny map in low resolution to avoid high-frequency details
image = canny_detector(image, detect_resolution=384, image_resolution=1024)#.resize((1024, 1024))
```
<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_canny.png"><img width="480" style="margin:0;padding:0;" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_canny.png"/></a>
- Generation
```py
prompt = "Mystical fairy in real, magic, 4k picture, high quality"
negative_prompt = "extra digit, fewer digits, cropped, worst quality, low quality, glitch, deformed, mutated, ugly, disfigured"
gen_images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
image=image,
num_inference_steps=30,
guidance_scale=7.5,
adapter_conditioning_scale=0.8,
adapter_conditioning_factor=1
).images[0]
gen_images.save('out_canny.png')
```
<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_canny.png"><img width="480" style="margin:0;padding:0;" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_canny.png"/></a>
### Training
Our training script was built on top of the official training script that we provide [here](https://github.com/huggingface/diffusers/blob/main/examples/t2i_adapter/README_sdxl.md).
The model is trained on 3M high-resolution image-text pairs from LAION-Aesthetics V2 with
- Training steps: 20000
- Batch size: Data parallel with a single gpu batch size of `16` for a total batch size of `256`.
- Learning rate: Constant learning rate of `1e-5`.
- Mixed precision: fp16
| 8,946 | [
[
-0.046600341796875,
-0.025909423828125,
0.0257720947265625,
0.0333251953125,
-0.035797119140625,
-0.022735595703125,
0.006206512451171875,
-0.037933349609375,
0.045440673828125,
0.0016393661499023438,
-0.055572509765625,
-0.039215087890625,
-0.049835205078125,
... |
m3rg-iitd/matscibert | 2022-06-02T19:07:10.000Z | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | m3rg-iitd | null | null | m3rg-iitd/matscibert | 8 | 3,445 | transformers | 2022-03-02T23:29:05 | # MatSciBERT
## A Materials Domain Language Model for Text Mining and Information Extraction
This is the pretrained model presented in [MatSciBERT: A materials domain language model for text mining and information extraction](https://rdcu.be/cMAp5), which is a BERT model trained on material science research papers.
The training corpus comprises papers related to the broad category of materials: alloys, glasses, metallic glasses, cement and concrete. We have utilised the abstracts and full text of papers(when available). All the research papers have been downloaded from [ScienceDirect](https://www.sciencedirect.com/) using the [Elsevier API](https://dev.elsevier.com/). The detailed methodology is given in the paper.
The codes for pretraining and finetuning on downstream tasks are shared on [GitHub](https://github.com/m3rg-repo/MatSciBERT).
If you find this useful in your research, please consider citing:
```
@article{gupta_matscibert_2022,
title = "{MatSciBERT}: A Materials Domain Language Model for Text Mining and Information Extraction",
author = "Gupta, Tanishq and
Zaki, Mohd and
Krishnan, N. M. Anoop and
Mausam",
year = "2022",
month = may,
journal = "npj Computational Materials",
volume = "8",
number = "1",
pages = "102",
issn = "2057-3960",
url = "https://www.nature.com/articles/s41524-022-00784-w",
doi = "10.1038/s41524-022-00784-w"
}
``` | 1,454 | [
[
-0.020355224609375,
-0.034942626953125,
0.036346435546875,
-0.005298614501953125,
-0.02117919921875,
0.01074981689453125,
-0.0136871337890625,
0.002262115478515625,
-0.0094451904296875,
0.0285797119140625,
-0.041534423828125,
-0.05255126953125,
-0.05221557617187... |
sentence-transformers/all-mpnet-base-v1 | 2021-08-31T07:35:23.000Z | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"en",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | sentence-similarity | sentence-transformers | null | null | sentence-transformers/all-mpnet-base-v1 | 7 | 3,440 | sentence-transformers | 2022-03-02T23:29:05 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
language: en
license: apache-2.0
---
# all-mpnet-base-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-mpnet-base-v1')
model = AutoModel.from_pretrained('sentence-transformers/all-mpnet-base-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-mpnet-base-v1)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 128 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base). Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 920k steps using a batch size of 512 (64 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,124,818,467** | | 9,851 | [
[
-0.02764892578125,
-0.055023193359375,
0.023529052734375,
0.01134490966796875,
-0.00785064697265625,
-0.0244140625,
-0.016510009765625,
-0.0125732421875,
0.027557373046875,
0.015716552734375,
-0.033905029296875,
-0.039459228515625,
-0.052093505859375,
0.0077... |
Yntec/animeTEN | 2023-09-21T09:53:29.000Z | [
"diffusers",
"Anime",
"General Purpose",
"Ctuhulo",
"realisticElves",
"text-to-image",
"stable-diffusion",
"stable-diffusion-diffusers",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Yntec | null | null | Yntec/animeTEN | 2 | 3,440 | diffusers | 2023-09-21T08:18:50 | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- General Purpose
- Ctuhulo
- realisticElves
- text-to-image
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
---
# animeTEN
This model with the zVAE baken in.
Sample and prompt:

chibi character, breathtaking, 8 k resolution, pop corn, visible brushstrokes, extremely detailed, Cartoon Pretty CUTE LITTLE Girl, beautiful, establishing shot, artistic, dangelico pino, Iconic, DETAILED CHIBI EYES, 1949, sharp focus, beautiful face, octane render, cinematic lighting, dramatic lighting, A magic garden with vegetables, performing, a beautiful detailed legs, fruitcake, gorgeous detailed hair, Magazine ad, ritual
Original page: https://civitai.com/models/144023?modelVersionId=160609 | 916 | [
[
-0.039306640625,
-0.0247955322265625,
0.022430419921875,
0.0219573974609375,
-0.0240936279296875,
-0.0109100341796875,
0.0176544189453125,
-0.031768798828125,
0.046783447265625,
0.0274810791015625,
-0.07196044921875,
-0.032073974609375,
-0.0304412841796875,
... |
bigscience/bloomz-1b7 | 2023-05-27T17:26:25.000Z | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"bloom",
"text-generation",
"ak",
"ar",
"as",
"bm",
"bn",
"ca",
"code",
"en",
"es",
"eu",
"fon",
"fr",
"gu",
"hi",
"id",
"ig",
"ki",
"kn",
"lg",
"ln",
"ml",
"mr",
"ne",
"nso",
"ny",
"or",
"pa",
... | text-generation | bigscience | null | null | bigscience/bloomz-1b7 | 19 | 3,437 | transformers | 2022-10-08T19:24:39 | ---
datasets:
- bigscience/xP3
license: bigscience-bloom-rail-1.0
language:
- ak
- ar
- as
- bm
- bn
- ca
- code
- en
- es
- eu
- fon
- fr
- gu
- hi
- id
- ig
- ki
- kn
- lg
- ln
- ml
- mr
- ne
- nso
- ny
- or
- pa
- pt
- rn
- rw
- sn
- st
- sw
- ta
- te
- tn
- ts
- tum
- tw
- ur
- vi
- wo
- xh
- yo
- zh
- zu
programming_language:
- C
- C++
- C#
- Go
- Java
- JavaScript
- Lua
- PHP
- Python
- Ruby
- Rust
- Scala
- TypeScript
pipeline_tag: text-generation
widget:
- text: "一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。Would you rate the previous review as positive, neutral or negative?"
example_title: "zh-en sentiment"
- text: "一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。你认为这句话的立场是赞扬、中立还是批评?"
example_title: "zh-zh sentiment"
- text: "Suggest at least five related search terms to \"Mạng neural nhân tạo\"."
example_title: "vi-en query"
- text: "Proposez au moins cinq mots clés concernant «Réseau de neurones artificiels»."
example_title: "fr-fr query"
- text: "Explain in a sentence in Telugu what is backpropagation in neural networks."
example_title: "te-en qa"
- text: "Why is the sky blue?"
example_title: "en-en qa"
- text: "Write a fairy tale about a troll saving a princess from a dangerous dragon. The fairy tale is a masterpiece that has achieved praise worldwide and its moral is \"Heroes Come in All Shapes and Sizes\". Story (in Spanish):"
example_title: "es-en fable"
- text: "Write a fable about wood elves living in a forest that is suddenly invaded by ogres. The fable is a masterpiece that has achieved praise worldwide and its moral is \"Violence is the last refuge of the incompetent\". Fable (in Hindi):"
example_title: "hi-en fable"
model-index:
- name: bloomz-1b7
results:
- task:
type: Coreference resolution
dataset:
type: winogrande
name: Winogrande XL (xl)
config: xl
split: validation
revision: a80f460359d1e9a67c006011c94de42a8759430c
metrics:
- type: Accuracy
value: 51.14
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (en)
config: en
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 56.34
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (fr)
config: fr
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 55.42
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (jp)
config: jp
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 52.55
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (pt)
config: pt
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 53.23
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (ru)
config: ru
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 55.24
- task:
type: Coreference resolution
dataset:
type: Muennighoff/xwinograd
name: XWinograd (zh)
config: zh
split: test
revision: 9dd5ea5505fad86b7bedad667955577815300cee
metrics:
- type: Accuracy
value: 56.15
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r1)
config: r1
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 34.0
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r2)
config: r2
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 36.1
- task:
type: Natural language inference
dataset:
type: anli
name: ANLI (r3)
config: r3
split: validation
revision: 9dbd830a06fea8b1c49d6e5ef2004a08d9f45094
metrics:
- type: Accuracy
value: 37.08
- task:
type: Natural language inference
dataset:
type: super_glue
name: SuperGLUE (cb)
config: cb
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 71.43
- task:
type: Natural language inference
dataset:
type: super_glue
name: SuperGLUE (rte)
config: rte
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 76.17
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ar)
config: ar
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 50.04
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (bg)
config: bg
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 42.17
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (de)
config: de
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 42.73
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (el)
config: el
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 41.81
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (en)
config: en
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 55.02
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (es)
config: es
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 52.97
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (fr)
config: fr
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 52.21
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (hi)
config: hi
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 48.07
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ru)
config: ru
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 45.1
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (sw)
config: sw
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 44.34
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (th)
config: th
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 40.36
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (tr)
config: tr
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 37.15
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (ur)
config: ur
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 44.38
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (vi)
config: vi
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 51.08
- task:
type: Natural language inference
dataset:
type: xnli
name: XNLI (zh)
config: zh
split: validation
revision: a5a45e4ff92d5d3f34de70aaf4b72c3bdf9f7f16
metrics:
- type: Accuracy
value: 51.12
- task:
type: Program synthesis
dataset:
type: openai_humaneval
name: HumanEval
config: None
split: test
revision: e8dc562f5de170c54b5481011dd9f4fa04845771
metrics:
- type: Pass@1
value: 4.38
- type: Pass@10
value: 8.73
- type: Pass@100
value: 16.09
- task:
type: Sentence completion
dataset:
type: story_cloze
name: StoryCloze (2016)
config: "2016"
split: validation
revision: e724c6f8cdf7c7a2fb229d862226e15b023ee4db
metrics:
- type: Accuracy
value: 82.9
- task:
type: Sentence completion
dataset:
type: super_glue
name: SuperGLUE (copa)
config: copa
split: validation
revision: 9e12063561e7e6c79099feb6d5a493142584e9e2
metrics:
- type: Accuracy
value: 69.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (et)
config: et
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 50.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (ht)
config: ht
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 54.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (id)
config: id
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 61.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (it)
config: it
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 49.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (qu)
config: qu
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 56.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (sw)
config: sw
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 57.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (ta)
config: ta
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 56.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (th)
config: th
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 60.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (tr)
config: tr
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 59.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (vi)
config: vi
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 70.0
- task:
type: Sentence completion
dataset:
type: xcopa
name: XCOPA (zh)
config: zh
split: validation
revision: 37f73c60fb123111fa5af5f9b705d0b3747fd187
metrics:
- type: Accuracy
value: 67.0
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (ar)
config: ar
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 73.33
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (es)
config: es
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 77.96
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (eu)
config: eu
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 60.49
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (hi)
config: hi
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 72.87
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (id)
config: id
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 74.92
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (my)
config: my
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 51.09
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (ru)
config: ru
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 56.39
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (sw)
config: sw
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 61.28
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (te)
config: te
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 66.25
- task:
type: Sentence completion
dataset:
type: Muennighoff/xstory_cloze
name: XStoryCloze (zh)
config: zh
split: validation
revision: 8bb76e594b68147f1a430e86829d07189622b90d
metrics:
- type: Accuracy
value: 78.69
---

# Table of Contents
1. [Model Summary](#model-summary)
2. [Use](#use)
3. [Limitations](#limitations)
4. [Training](#training)
5. [Evaluation](#evaluation)
7. [Citation](#citation)
# Model Summary
> We present BLOOMZ & mT0, a family of models capable of following human instructions in dozens of languages zero-shot. We finetune BLOOM & mT5 pretrained multilingual language models on our crosslingual task mixture (xP3) and find the resulting models capable of crosslingual generalization to unseen tasks & languages.
- **Repository:** [bigscience-workshop/xmtf](https://github.com/bigscience-workshop/xmtf)
- **Paper:** [Crosslingual Generalization through Multitask Finetuning](https://arxiv.org/abs/2211.01786)
- **Point of Contact:** [Niklas Muennighoff](mailto:niklas@hf.co)
- **Languages:** Refer to [bloom](https://huggingface.co/bigscience/bloom) for pretraining & [xP3](https://huggingface.co/datasets/bigscience/xP3) for finetuning language proportions. It understands both pretraining & finetuning languages.
- **BLOOMZ & mT0 Model Family:**
<div class="max-w-full overflow-auto">
<table>
<tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/bigscience/xP3>xP3</a>. Recommended for prompting in English.
</tr>
<tr>
<td>Parameters</td>
<td>300M</td>
<td>580M</td>
<td>1.2B</td>
<td>3.7B</td>
<td>13B</td>
<td>560M</td>
<td>1.1B</td>
<td>1.7B</td>
<td>3B</td>
<td>7.1B</td>
<td>176B</td>
</tr>
<tr>
<td>Finetuned Model</td>
<td><a href=https://huggingface.co/bigscience/mt0-small>mt0-small</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-base>mt0-base</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-large>mt0-large</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-xl>mt0-xl</a></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl>mt0-xxl</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-560m>bloomz-560m</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-1b1>bloomz-1b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-1b7>bloomz-1b7</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-3b>bloomz-3b</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1>bloomz-7b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz>bloomz</a></td>
</tr>
</tr>
<tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/bigscience/xP3mt>xP3mt</a>. Recommended for prompting in non-English.</th>
</tr>
<tr>
<td>Finetuned Model</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl-mt>mt0-xxl-mt</a></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1-mt>bloomz-7b1-mt</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-mt>bloomz-mt</a></td>
</tr>
<th colspan="12">Multitask finetuned on <a style="font-weight:bold" href=https://huggingface.co/datasets/Muennighoff/P3>P3</a>. Released for research purposes only. Strictly inferior to above models!</th>
</tr>
<tr>
<td>Finetuned Model</td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/mt0-xxl-p3>mt0-xxl-p3</a></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><a href=https://huggingface.co/bigscience/bloomz-7b1-p3>bloomz-7b1-p3</a></td>
<td><a href=https://huggingface.co/bigscience/bloomz-p3>bloomz-p3</a></td>
</tr>
<th colspan="12">Original pretrained checkpoints. Not recommended.</th>
<tr>
<td>Pretrained Model</td>
<td><a href=https://huggingface.co/google/mt5-small>mt5-small</a></td>
<td><a href=https://huggingface.co/google/mt5-base>mt5-base</a></td>
<td><a href=https://huggingface.co/google/mt5-large>mt5-large</a></td>
<td><a href=https://huggingface.co/google/mt5-xl>mt5-xl</a></td>
<td><a href=https://huggingface.co/google/mt5-xxl>mt5-xxl</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-560m>bloom-560m</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-1b1>bloom-1b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-1b7>bloom-1b7</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-3b>bloom-3b</a></td>
<td><a href=https://huggingface.co/bigscience/bloom-7b1>bloom-7b1</a></td>
<td><a href=https://huggingface.co/bigscience/bloom>bloom</a></td>
</tr>
</table>
</div>
# Use
## Intended use
We recommend using the model to perform tasks expressed in natural language. For example, given the prompt "*Translate to English: Je t’aime.*", the model will most likely answer "*I love you.*". Some prompt ideas from our paper:
- 一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。你认为这句话的立场是赞扬、中立还是批评?
- Suggest at least five related search terms to "Mạng neural nhân tạo".
- Write a fairy tale about a troll saving a princess from a dangerous dragon. The fairy tale is a masterpiece that has achieved praise worldwide and its moral is "Heroes Come in All Shapes and Sizes". Story (in Spanish):
- Explain in a sentence in Telugu what is backpropagation in neural networks.
**Feel free to share your generations in the Community tab!**
## How to use
### CPU
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "bigscience/bloomz-1b7"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
### GPU
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers accelerate
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "bigscience/bloomz-1b7"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint, torch_dtype="auto", device_map="auto")
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
### GPU in 8bit
<details>
<summary> Click to expand </summary>
```python
# pip install -q transformers accelerate bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "bigscience/bloomz-1b7"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", load_in_8bit=True)
inputs = tokenizer.encode("Translate to English: Je t’aime.", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
</details>
<!-- Necessary for whitespace -->
###
# Limitations
**Prompt Engineering:** The performance may vary depending on the prompt. For BLOOMZ models, we recommend making it very clear when the input stops to avoid the model trying to continue it. For example, the prompt "*Translate to English: Je t'aime*" without the full stop (.) at the end, may result in the model trying to continue the French sentence. Better prompts are e.g. "*Translate to English: Je t'aime.*", "*Translate to English: Je t'aime. Translation:*" "*What is "Je t'aime." in English?*", where it is clear for the model when it should answer. Further, we recommend providing the model as much context as possible. For example, if you want it to answer in Telugu, then tell the model, e.g. "*Explain in a sentence in Telugu what is backpropagation in neural networks.*".
# Training
## Model
- **Architecture:** Same as [bloom-1b7](https://huggingface.co/bigscience/bloom-1b7), also refer to the `config.json` file
- **Finetuning steps:** 2000
- **Finetuning tokens:** 8.39 billion
- **Finetuning layout:** 1x pipeline parallel, 1x tensor parallel, 1x data parallel
- **Precision:** float16
## Hardware
- **CPUs:** AMD CPUs with 512GB memory per node
- **GPUs:** 64 A100 80GB GPUs with 8 GPUs per node (8 nodes) using NVLink 4 inter-gpu connects, 4 OmniPath links
- **Communication:** NCCL-communications network with a fully dedicated subnet
## Software
- **Orchestration:** [Megatron-DeepSpeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed)
- **Optimizer & parallelism:** [DeepSpeed](https://github.com/microsoft/DeepSpeed)
- **Neural networks:** [PyTorch](https://github.com/pytorch/pytorch) (pytorch-1.11 w/ CUDA-11.5)
- **FP16 if applicable:** [apex](https://github.com/NVIDIA/apex)
# Evaluation
We refer to Table 7 from our [paper](https://arxiv.org/abs/2211.01786) & [bigscience/evaluation-results](https://huggingface.co/datasets/bigscience/evaluation-results) for zero-shot results on unseen tasks. The sidebar reports zero-shot performance of the best prompt per dataset config.
# Citation
```bibtex
@article{muennighoff2022crosslingual,
title={Crosslingual generalization through multitask finetuning},
author={Muennighoff, Niklas and Wang, Thomas and Sutawika, Lintang and Roberts, Adam and Biderman, Stella and Scao, Teven Le and Bari, M Saiful and Shen, Sheng and Yong, Zheng-Xin and Schoelkopf, Hailey and others},
journal={arXiv preprint arXiv:2211.01786},
year={2022}
}
``` | 24,194 | [
[
-0.03167724609375,
-0.043121337890625,
0.0228729248046875,
0.03021240234375,
-0.005481719970703125,
-0.005825042724609375,
-0.0252227783203125,
-0.0253753662109375,
0.031829833984375,
-0.01273345947265625,
-0.06915283203125,
-0.039886474609375,
-0.04061889648437... |
Huffon/sentence-klue-roberta-base | 2021-06-20T17:32:17.000Z | [
"sentence-transformers",
"pytorch",
"roberta",
"ko",
"dataset:klue",
"arxiv:1908.10084",
"has_space",
"region:us"
] | null | Huffon | null | null | Huffon/sentence-klue-roberta-base | 6 | 3,434 | sentence-transformers | 2022-03-02T23:29:04 | ---
language: ko
tags:
- roberta
- sentence-transformers
datasets:
- klue
---
# KLUE RoBERTa base model for Sentence Embeddings
This is the `sentence-klue-roberta-base` model. The sentence-transformers repository allows to train and use Transformer models for generating sentence and text embeddings.
The model is described in the paper [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084)
## Usage (Sentence-Transformers)
Using this model becomes more convenient when you have [sentence-transformers](https://github.com/UKPLab/sentence-transformers) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
import torch
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("Huffon/sentence-klue-roberta-base")
docs = [
"1992년 7월 8일 손흥민은 강원도 춘천시 후평동에서 아버지 손웅정과 어머니 길은자의 차남으로 태어나 그곳에서 자랐다.",
"형은 손흥윤이다.",
"춘천 부안초등학교를 졸업했고, 춘천 후평중학교에 입학한 후 2학년때 원주 육민관중학교 축구부에 들어가기 위해 전학하여 졸업하였으며, 2008년 당시 FC 서울의 U-18팀이었던 동북고등학교 축구부에서 선수 활동 중 대한축구협회 우수선수 해외유학 프로젝트에 선발되어 2008년 8월 독일 분데스리가의 함부르크 유소년팀에 입단하였다.",
"함부르크 유스팀 주전 공격수로 2008년 6월 네덜란드에서 열린 4개국 경기에서 4게임에 출전, 3골을 터뜨렸다.",
"1년간의 유학 후 2009년 8월 한국으로 돌아온 후 10월에 개막한 FIFA U-17 월드컵에 출전하여 3골을 터트리며 한국을 8강으로 이끌었다.",
"그해 11월 함부르크의 정식 유소년팀 선수 계약을 체결하였으며 독일 U-19 리그 4경기 2골을 넣고 2군 리그에 출전을 시작했다.",
"독일 U-19 리그에서 손흥민은 11경기 6골, 2부 리그에서는 6경기 1골을 넣으며 재능을 인정받아 2010년 6월 17세의 나이로 함부르크의 1군 팀 훈련에 참가, 프리시즌 활약으로 함부르크와 정식 계약을 한 후 10월 18세에 함부르크 1군 소속으로 독일 분데스리가에 데뷔하였다.",
]
document_embeddings = model.encode(docs)
query = "손흥민은 어린 나이에 유럽에 진출하였다."
query_embedding = model.encode(query)
top_k = min(5, len(docs))
cos_scores = util.pytorch_cos_sim(query_embedding, document_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
print(f"입력 문장: {query}")
print(f"<입력 문장과 유사한 {top_k} 개의 문장>")
for i, (score, idx) in enumerate(zip(top_results[0], top_results[1])):
print(f"{i+1}: {docs[idx]} {'(유사도: {:.4f})'.format(score)}")
``` | 2,021 | [
[
-0.0250701904296875,
-0.0439453125,
0.021881103515625,
0.0312042236328125,
-0.0261688232421875,
-0.0043182373046875,
-0.004436492919921875,
-0.01296234130859375,
0.0204010009765625,
0.0142059326171875,
-0.03131103515625,
-0.046966552734375,
-0.04644775390625,
... |
asafaya/bert-base-arabic | 2023-03-17T11:32:17.000Z | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"ar",
"dataset:oscar",
"dataset:wikipedia",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | asafaya | null | null | asafaya/bert-base-arabic | 18 | 3,432 | transformers | 2022-03-02T23:29:05 | ---
language: ar
datasets:
- oscar
- wikipedia
---
# Arabic BERT Model
Pretrained BERT base language model for Arabic
_If you use this model in your work, please cite this paper:_
```
@inproceedings{safaya-etal-2020-kuisail,
title = "{KUISAIL} at {S}em{E}val-2020 Task 12: {BERT}-{CNN} for Offensive Speech Identification in Social Media",
author = "Safaya, Ali and
Abdullatif, Moutasem and
Yuret, Deniz",
booktitle = "Proceedings of the Fourteenth Workshop on Semantic Evaluation",
month = dec,
year = "2020",
address = "Barcelona (online)",
publisher = "International Committee for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.semeval-1.271",
pages = "2054--2059",
}
```
## Pretraining Corpus
`arabic-bert-base` model was pretrained on ~8.2 Billion words:
- Arabic version of [OSCAR](https://traces1.inria.fr/oscar/) - filtered from [Common Crawl](http://commoncrawl.org/)
- Recent dump of Arabic [Wikipedia](https://dumps.wikimedia.org/backup-index.html)
and other Arabic resources which sum up to ~95GB of text.
__Notes on training data:__
- Our final version of corpus contains some non-Arabic words inlines, which we did not remove from sentences since that would affect some tasks like NER.
- Although non-Arabic characters were lowered as a preprocessing step, since Arabic characters does not have upper or lower case, there is no cased and uncased version of the model.
- The corpus and vocabulary set are not restricted to Modern Standard Arabic, they contain some dialectical Arabic too.
## Pretraining details
- This model was trained using Google BERT's github [repository](https://github.com/google-research/bert) on a single TPU v3-8 provided for free from [TFRC](https://www.tensorflow.org/tfrc).
- Our pretraining procedure follows training settings of bert with some changes: trained for 3M training steps with batchsize of 128, instead of 1M with batchsize of 256.
## Load Pretrained Model
You can use this model by installing `torch` or `tensorflow` and Huggingface library `transformers`. And you can use it directly by initializing it like this:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("asafaya/bert-base-arabic")
model = AutoModelForMaskedLM.from_pretrained("asafaya/bert-base-arabic")
```
## Results
For further details on the models performance or any other queries, please refer to [Arabic-BERT](https://github.com/alisafaya/Arabic-BERT)
## Acknowledgement
Thanks to Google for providing free TPU for the training process and for Huggingface for hosting this model on their servers 😊
| 2,676 | [
[
-0.0340576171875,
-0.049774169921875,
0.007457733154296875,
0.0157928466796875,
-0.036956787109375,
-0.0037899017333984375,
-0.01959228515625,
-0.046112060546875,
-0.00266265869140625,
0.023284912109375,
-0.03363037109375,
-0.05157470703125,
-0.07379150390625,
... |
jphme/em_german_7b_leo | 2023-10-12T11:12:26.000Z | [
"transformers",
"safetensors",
"llama",
"text-generation",
"pytorch",
"german",
"deutsch",
"llama2",
"meta",
"facebook",
"leolm",
"custom_code",
"de",
"license:llama2",
"text-generation-inference",
"region:us"
] | text-generation | jphme | null | null | jphme/em_german_7b_leo | 4 | 3,420 | transformers | 2023-09-28T21:16:06 | ---
inference: false
language:
- de
library_name: transformers
license: llama2
model_creator: jphme
model_name: EM German
model_type: llama
pipeline_tag: text-generation
prompt_template: 'Du bist ein hilfreicher Assistent. USER: Was ist 1+1? ASSISTANT:'
tags:
- pytorch
- german
- deutsch
- llama2
- meta
- facebook
- leolm
---

**Many thanks to the [LeoLM](https://huggingface.co/LeoLM) team for the publication of a base model that has received continued pretraining with German texts, greatly improving generation capabilities.**
*If you get unsatisfying results with the LeoLM-based model version, please try setting `rope_scaling` to `2.0` manually, removing `repetition_penalty` and/or using a different model or version for your usecase (e.g. the Mistral-based version).*
# Table of Contents
1. [Introduction](#introduction)
2. [Links & Demos](#links--demos)
- [Model Links](#model-links)
- [Demos](#demos)
3. [Prompt Format](#prompt-format)
4. [Example Output](#example-output)
5. [Acknowledgements](#acknowledgements)
6. [Contact](#contact)
7. [Disclaimer](#disclaimer)
# Introduction
**EM German** is a Llama2/Mistral/LeoLM-based model family, finetuned on a large dataset of various instructions in German language. The models are optimized for German text, providing proficiency in understanding, generating, and interacting with German language content.
We offer versions based on 7b, 13b and 70b Llama-2, Mistral and LeoLM (Llama-2/Mistral with continued pretraining on German texts) models.
Please find all Informations, Example Outputs, the special RAG prompt format, output examples and eval results for the EM German Model family in [our Github Repository](https://github.com/jphme/EM_German). ([Deutsche Version](https://github.com/jphme/EM_German/blob/main/README_DE.md)). You will also find instructions on how to run the models with a GUI (GPT4All/LM Studio).
# Links & Demos
## Model Links
Should you only try one model version, I strongly recommend the **[LeoLM Mistral](https://huggingface.co/jphme/em_german_leo_mistral)** model which offers by far the best combination of performance and computing requirements!
| Base Model | HF | GPTQ | GGUF | AWQ |
|-------|-------|-------|-------|-------|
| Llama2 7b | [Link](https://huggingface.co/jphme/em_german_7b_v01) | [Link](https://huggingface.co/TheBloke/em_german_7b_v01-GPTQ) | [Link](https://huggingface.co/TheBloke/em_german_7b_v01-GGUF) | [Link](https://huggingface.co/TheBloke/em_german_7b_v01-AWQ) |
| Llama2 13b | [Link](https://huggingface.co/jphme/em_german_13b_v01) | [Link](https://huggingface.co/TheBloke/em_german_13b_v01-GPTQ) | [Link](https://huggingface.co/TheBloke/em_german_13b_v01-GGUF) | [Link](https://huggingface.co/TheBloke/em_german_13b_v01-AWQ) |
| Llama2 70b | [Link](https://huggingface.co/jphme/em_german_70b_v01) | [Link](https://huggingface.co/TheBloke/em_german_70b_v01-GPTQ) | [Link](https://huggingface.co/TheBloke/em_german_70b_v01-GGUF) | [Link](https://huggingface.co/TheBloke/em_german_70b_v01-AWQ) |
| [Mistral 7b](https://huggingface.co/mistralai/Mistral-7B-v0.1) | [Link](https://huggingface.co/jphme/em_german_mistral_v01) | [Link](https://huggingface.co/TheBloke/em_german_mistral_v01-GPTQ) | [Link](https://huggingface.co/TheBloke/em_german_mistral_v01-GGUF) | [Link](https://huggingface.co/TheBloke/em_german_mistral_v01-AWQ) |
| [LeoLM 7b](https://huggingface.co/LeoLM/leo-hessianai-7b) | [Link](https://huggingface.co/jphme/em_german_7b_leo) | [Link](https://huggingface.co/jphme/em_german_7b_leo_gptq) | [Link](hhttps://huggingface.co/jphme/em_german_7b_leo_gguf) | tbc |
| [LeoLM 13b](https://huggingface.co/LeoLM/leo-hessianai-13b) | soon | soon | [Link](https://huggingface.co/jphme/em_german_13b_leo_gguf) | tbc |
| [LeoLM Mistral](https://huggingface.co/LeoLM/leo-mistral-hessianai-7b) | [Link](https://huggingface.co/jphme/em_german_leo_mistral) | [Link](https://huggingface.co/TheBloke/em_german_leo_mistral-GPTQ) | [Link](https://huggingface.co/TheBloke/em_german_leo_mistral-GGUF) | [Link](https://huggingface.co/TheBloke/em_german_leo_mistral-AWQ) |
### Notes about the different versions:
See also the [comparison of example outputs](https://github.com/jphme/EM_German/blob/main/example_output_comparison.md) for a comparison of (7b) model capabilities.
If you get unsatisfying results with one or another EM German version, please try a different (and/or larger) model or version for your usecase.
## Demos:
You can use some of the models with **free** google Colab instances (e.g. the 7bn model in 8bit or the 13b model with GPTQ):
* [Example Colab Notebook for 13b with GPTQ](https://colab.research.google.com/drive/1IJfJdVwGkfe5MYOqHptystR3FBeEUdGn?usp=sharing)
* [Example Colab Notebook for 7b with 8bit-Loading](https://colab.research.google.com/drive/1bsv6vkLM4AlCpSyXA6ol9P32zxZmf7Zu?usp=sharing)
* [Example Colab Notebook for 7b Mistral GGUF with Grammar-based structured output](https://colab.research.google.com/drive/17O-a3D4BnVc_V9Of3dFfed18v1ULu1Sv?usp=sharing)
# Prompt Format
This model follows the Vicuna format without linebreaks (but should work with linebreaks as well). The format is as follows:
```
Du bist ein hilfreicher Assistent. USER: <instruction> ASSISTANT:
```
You can swap the standard system prompt for a better suited one (see below for RAG-tasks).
# Example Output
Please find a selection of various example outputs for all 7b versions of EM German [here](https://github.com/jphme/EM_German/blob/main/example_output_comparison.md).
**Prompt:**
> Erkläre die Bedeutung von drei wesentlichen Elementen der Bilanzierung und des Accountings nach IFRS für Unternehmen, die auf internationaler Ebene tätig sind.
**Antwort EM German Leo Mistral 7b:**
```
Die International Financial Reporting Standards (IFRS) sind eine Reihe von internationalen Rechnungslegungsstandards, die von der International Accounting Standards Board (IASB) entwickelt wurden. Sie sollen dazu beitragen, dass Finanzberichte vergleichbar, zuverlässig und relevant sind.
1. Fair Value: Dieses Konzept ist ein zentraler Bestandteil der IFRS. Es besagt, dass Vermögenswerte und Schulden zum fairen Wert bilanziert werden sollten, was dem Preis entspricht, zu dem sie zwischen Marktteilnehmern gehandelt werden könnten. Dadurch wird sichergestellt, dass das Unternehmen eine genaue Darstellung seiner finanziellen Lage liefert.
2. Konsolidierung: Die IFRS verlangen von Unternehmen, ihre Finanzergebnisse auf konsolidierter Basis darzustellen. Das bedeutet, dass alle Tochtergesellschaften und verbundenen Unternehmen in die Bilanz des Mutterunternehmens aufgenommen werden. Dadurch wird ein klareres Bild von der finanziellen Situation des Konzerns geschaffen.
3. Vollständigkeitsprinzip: Die IFRS verlangen von Unternehmen, alle relevanten Informationen offenzulegen. Dies umfasst sowohl positive als auch negative Faktoren, wie zum Beispiel Gewinne und Verluste, Einnahmen und Ausgaben sowie Risiken und Unsicherheiten. Durch dieses Prinzip wird sichergestellt, dass Investoren, Kreditgeber und andere Stakeholder eine umfassende Einschätzung der finanziellen Lage des Unternehmens vornehmen können.
```
**Prompt:**
> Ein Mensch atmet durchschnittlich 16 Mal pro Minute. Wie oft atmet er an einem Tag?
**Antwort EM German Leo Mistral 7b:**
```
Zuerst berechnen wir, wie oft eine Person in einer Stunde atmet. Wir wissen, dass eine Stunde 60 Minuten hat, also:
Atemzüge pro Stunde = Atemfrequenz * Minuten pro Stunde
= 16 Atemzüge pro Minute * 60 Minuten
= 960 Atemzüge
Um herauszufinden, wie viele Atemzüge eine Person an einem Tag macht, müssen wir diese stündliche Rate mit der Anzahl der Stunden an einem Tag multiplizieren, also 24:
Atemzüge pro Tag = Atemzüge pro Stunde * Stunden pro Tag
= 960 Atemzüge * 24 Stunden
= 23.040 Atemzüge
Also macht ein durchschnittlicher Mensch etwa 23.040 Atemzüge an einem Tag.
```
(For more examples, please visit [our Github Repository](https://github.com/jphme/EM_German).)
# Acknowledgements:
Many thanks to [winglian/caseus](https://huggingface.co/winglian) for his great work on Axolotl which I used to train the EM mdoels. I am also grateful to [Jon Durbin](https://huggingface.co/jondurbin) and his [Airoboros](https://huggingface.co/jondurbin/airoboros-l2-70b-2.2.1) models and code from which I borrowed many ideas and code snippets.
Additionally many thanks to [Björn Plüster](https://huggingface.co/bjoernp) and the LeoLM team for the outstanding pretraining work on LeoLM and last but not least many many thanks to [TheBloke](https://huggingface.co/TheBloke) for the preparation of quantized versions in all formats under the sun.
The 70b model was trained with support of the [OVH Cloud Startup Program](https://startup.ovhcloud.com/en/).
# Contact
For detailed feedback & feature requests, please open an issue or get in contact with me via [my website](https://www.jph.me).
*PS: We are also always interested in support for our startup [ellamind](https://ellamind.com), which will offer customized models for business applications in the future (we are currently still in stealth mode). If you use our models for business applications and have advanced needs for specialized capabilities, please get in touch.*
# Disclaimer:
I am not responsible for the actions of third parties who use this model or the outputs of the model. This model should only be used for research purposes. The original base model license applies and is distributed with the model files. | 9,548 | [
[
-0.04705810546875,
-0.047088623046875,
0.0215606689453125,
0.0421142578125,
-0.032958984375,
-0.0238494873046875,
-0.007289886474609375,
-0.043060302734375,
0.0406494140625,
0.004459381103515625,
-0.045654296875,
-0.0450439453125,
-0.03656005859375,
0.016906... |
yujiepan/llama-2-tiny-3layers-random | 2023-09-13T15:48:37.000Z | [
"transformers",
"pytorch",
"safetensors",
"openvino",
"llama",
"text-generation",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | yujiepan | null | null | yujiepan/llama-2-tiny-3layers-random | 0 | 3,418 | transformers | 2023-08-31T09:30:50 | ---
pipeline_tag: text-generation
inference: true
widget:
- text: 'Hello!'
example_title: Hello world
group: Python
library_name: transformers
---
# yujiepan/llama-2-tiny-3layers-random
This model is **randomly initialized**, using the config from [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/yujiepan/llama-2-tiny-3layers-random/blob/main/config.json) but with the following modifications:
```json
{
"hidden_size": 8,
"intermediate_size": 32,
"num_attention_heads": 2,
"num_hidden_layers": 3,
"num_key_value_heads": 2,
}
``` | 553 | [
[
-0.0292816162109375,
-0.058349609375,
0.0447998046875,
0.019195556640625,
-0.04534912109375,
0.011505126953125,
0.006275177001953125,
-0.042327880859375,
0.044525146484375,
0.05804443359375,
-0.0614013671875,
-0.0264892578125,
-0.046173095703125,
-0.00200271... |
timm/ViT-B-16-SigLIP | 2023-10-25T21:58:01.000Z | [
"open_clip",
"clip",
"siglip",
"zero-shot-image-classification",
"dataset:webli",
"arxiv:2303.15343",
"license:apache-2.0",
"region:us"
] | zero-shot-image-classification | timm | null | null | timm/ViT-B-16-SigLIP | 7 | 3,418 | open_clip | 2023-10-16T23:14:27 | ---
tags:
- clip
- siglip
library_name: open_clip
pipeline_tag: zero-shot-image-classification
license: apache-2.0
datasets:
- webli
---
# Model card for ViT-B-16-SigLIP
A SigLIP (Sigmoid loss for Language-Image Pre-training) model trained on WebLI.
This model has been converted to PyTorch from the original JAX checkpoints in [Big Vision](https://github.com/google-research/big_vision). These weights are usable in both OpenCLIP (image + text) and timm (image only).
## Model Details
- **Model Type:** Contrastive Image-Text, Zero-Shot Image Classification.
- **Original:** https://github.com/google-research/big_vision
- **Dataset:** WebLI
- **Papers:**
- Sigmoid loss for language image pre-training: https://arxiv.org/abs/2303.15343
## Model Usage
### With OpenCLIP
```
import torch
import torch.nn.functional as F
from urllib.request import urlopen
from PIL import Image
from open_clip import create_model_from_pretrained, get_tokenizer # works on open-clip-torch>=2.23.0, timm>=0.9.8
model, preprocess = create_model_from_pretrained('hf-hub:timm/ViT-B-16-SigLIP')
tokenizer = get_tokenizer('hf-hub:timm/ViT-B-16-SigLIP')
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
image = preprocess(image).unsqueeze(0)
labels_list = ["a dog", "a cat", "a donut", "a beignet"]
text = tokenizer(labels_list, context_length=model.context_length)
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
text_probs = torch.sigmoid(image_features @ text_features.T * model.logit_scale.exp() + model.logit_bias)
zipped_list = list(zip(labels_list, [round(p.item(), 3) for p in text_probs[0]]))
print("Label probabilities: ", zipped_list)
```
### With `timm` (for image embeddings)
```python
from urllib.request import urlopen
from PIL import Image
import timm
image = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_base_patch16_siglip_224',
pretrained=True,
num_classes=0,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(image).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
```
## Citation
```bibtex
@article{zhai2023sigmoid,
title={Sigmoid loss for language image pre-training},
author={Zhai, Xiaohua and Mustafa, Basil and Kolesnikov, Alexander and Beyer, Lucas},
journal={arXiv preprint arXiv:2303.15343},
year={2023}
}
```
```bibtex
@misc{big_vision,
author = {Beyer, Lucas and Zhai, Xiaohua and Kolesnikov, Alexander},
title = {Big Vision},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/google-research/big_vision}}
}
```
| 3,149 | [
[
-0.0284881591796875,
-0.040313720703125,
0.01458740234375,
0.017547607421875,
-0.035614013671875,
-0.02252197265625,
-0.029815673828125,
-0.030548095703125,
0.0244140625,
0.018218994140625,
-0.038909912109375,
-0.057769775390625,
-0.055999755859375,
-0.01307... |
lllyasviel/control_v11e_sd15_shuffle | 2023-05-04T18:51:03.000Z | [
"diffusers",
"art",
"controlnet",
"stable-diffusion",
"controlnet-v1-1",
"image-to-image",
"arxiv:2302.05543",
"license:openrail",
"has_space",
"diffusers:ControlNetModel",
"region:us"
] | image-to-image | lllyasviel | null | null | lllyasviel/control_v11e_sd15_shuffle | 6 | 3,416 | diffusers | 2023-04-14T19:25:23 | ---
license: openrail
base_model: runwayml/stable-diffusion-v1-5
tags:
- art
- controlnet
- stable-diffusion
- controlnet-v1-1
- image-to-image
duplicated_from: ControlNet-1-1-preview/control_v11e_sd15_shuffle
---
# Controlnet - v1.1 - *shuffle Version*
**Controlnet v1.1** was released in [lllyasviel/ControlNet-v1-1](https://huggingface.co/lllyasviel/ControlNet-v1-1) by [Lvmin Zhang](https://huggingface.co/lllyasviel).
This checkpoint is a conversion of [the original checkpoint](https://huggingface.co/lllyasviel/ControlNet-v1-1/blob/main/control_v11e_sd15_shuffle.pth) into `diffusers` format.
It can be used in combination with **Stable Diffusion**, such as [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5).
For more details, please also have a look at the [🧨 Diffusers docs](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/controlnet).
ControlNet is a neural network structure to control diffusion models by adding extra conditions.

This checkpoint corresponds to the ControlNet conditioned on **shuffle images**.
## Model Details
- **Developed by:** Lvmin Zhang, Maneesh Agrawala
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Resources for more information:** [GitHub Repository](https://github.com/lllyasviel/ControlNet), [Paper](https://arxiv.org/abs/2302.05543).
- **Cite as:**
@misc{zhang2023adding,
title={Adding Conditional Control to Text-to-Image Diffusion Models},
author={Lvmin Zhang and Maneesh Agrawala},
year={2023},
eprint={2302.05543},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
## Introduction
Controlnet was proposed in [*Adding Conditional Control to Text-to-Image Diffusion Models*](https://arxiv.org/abs/2302.05543) by
Lvmin Zhang, Maneesh Agrawala.
The abstract reads as follows:
*We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions.
The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k).
Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices.
Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data.
We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc.
This may enrich the methods to control large diffusion models and further facilitate related applications.*
## Example
It is recommended to use the checkpoint with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) as the checkpoint
has been trained on it.
Experimentally, the checkpoint can be used with other diffusion models such as dreamboothed stable diffusion.
**Note**: If you want to process an image to create the auxiliary conditioning, external dependencies are required as shown below:
1. Install https://github.com/patrickvonplaten/controlnet_aux
```sh
$ pip install controlnet_aux==0.3.0
```
2. Let's install `diffusers` and related packages:
**IMPORTANT:** Make sure that you have `diffusers.__version__ >= 0.16.0.dev0` installed!
```
$ pip install git+https://github.com/huggingface/diffusers.git transformers accelerate
```
3. Run code:
```python
import torch
import os
from huggingface_hub import HfApi
from pathlib import Path
from diffusers.utils import load_image
from PIL import Image
import numpy as np
from controlnet_aux import ContentShuffleDetector
from diffusers import (
ControlNetModel,
StableDiffusionControlNetPipeline,
UniPCMultistepScheduler,
)
checkpoint = "lllyasviel/control_v11e_sd15_shuffle"
image = load_image(
"https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/input.png"
)
prompt = "New York"
processor = ContentShuffleDetector()
control_image = processor(image)
control_image.save("./images/control.png")
controlnet = ControlNetModel.from_pretrained(checkpoint, torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
generator = torch.manual_seed(33)
image = pipe(prompt, num_inference_steps=30, generator=generator, image=control_image).images[0]
image.save('images/image_out.png')
```



## Other released checkpoints v1-1
The authors released 14 different checkpoints, each trained with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
on a different type of conditioning:
| Model Name | Control Image Overview| Condition Image | Control Image Example | Generated Image Example |
|---|---|---|---|---|
|[lllyasviel/control_v11p_sd15_canny](https://huggingface.co/lllyasviel/control_v11p_sd15_canny)<br/> | *Trained with canny edge detection* | A monochrome image with white edges on a black background.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_canny/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11e_sd15_ip2p](https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p)<br/> | *Trained with pixel to pixel instruction* | No condition .|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11e_sd15_ip2p/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_inpaint](https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint)<br/> | Trained with image inpainting | No condition.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/output.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint/resolve/main/images/output.png"/></a>|
|[lllyasviel/control_v11p_sd15_mlsd](https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd)<br/> | Trained with multi-level line segment detection | An image with annotated line segments.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_mlsd/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11f1p_sd15_depth](https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth)<br/> | Trained with depth estimation | An image with depth information, usually represented as a grayscale image.|<a href="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_normalbae](https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae)<br/> | Trained with surface normal estimation | An image with surface normal information, usually represented as a color-coded image.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_normalbae/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_seg](https://huggingface.co/lllyasviel/control_v11p_sd15_seg)<br/> | Trained with image segmentation | An image with segmented regions, usually represented as a color-coded image.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_seg/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_lineart](https://huggingface.co/lllyasviel/control_v11p_sd15_lineart)<br/> | Trained with line art generation | An image with line art, usually black lines on a white background.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_lineart/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15s2_lineart_anime](https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime)<br/> | Trained with anime line art generation | An image with anime-style line art.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_openpose](https://huggingface.co/lllyasviel/control_v11p_sd15s2_lineart_anime)<br/> | Trained with human pose estimation | An image with human poses, usually represented as a set of keypoints or skeletons.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_scribble](https://huggingface.co/lllyasviel/control_v11p_sd15_scribble)<br/> | Trained with scribble-based image generation | An image with scribbles, usually random or user-drawn strokes.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_scribble/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11p_sd15_softedge](https://huggingface.co/lllyasviel/control_v11p_sd15_softedge)<br/> | Trained with soft edge image generation | An image with soft edges, usually to create a more painterly or artistic effect.|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11e_sd15_shuffle](https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle)<br/> | Trained with image shuffling | An image with shuffled patches or regions.|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/control.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/control.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/image_out.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/image_out.png"/></a>|
|[lllyasviel/control_v11f1e_sd15_tile](https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile)<br/> | Trained with image tiling | A blurry image or part of an image .|<a href="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/original.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/original.png"/></a>|<a href="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/output.png"><img width="64" src="https://huggingface.co/lllyasviel/control_v11f1e_sd15_tile/resolve/main/images/output.png"/></a>|
## More information
For more information, please also have a look at the [Diffusers ControlNet Blog Post](https://huggingface.co/blog/controlnet) and have a look at the [official docs](https://github.com/lllyasviel/ControlNet-v1-1-nightly). | 15,429 | [
[
-0.04541015625,
-0.045379638671875,
0.00862884521484375,
0.046966552734375,
-0.022247314453125,
-0.01800537109375,
0.005664825439453125,
-0.0426025390625,
0.047088623046875,
0.0201263427734375,
-0.0567626953125,
-0.0270843505859375,
-0.055938720703125,
-0.01... |
MarieAngeA13/Sentiment-Analysis-BERT | 2023-07-01T18:26:06.000Z | [
"transformers",
"pytorch",
"bert",
"text-classification",
"sentiment",
"sentiment-analysis",
"en",
"license:bsd-3-clause",
"endpoints_compatible",
"has_space",
"region:us"
] | text-classification | MarieAngeA13 | null | null | MarieAngeA13/Sentiment-Analysis-BERT | 1 | 3,414 | transformers | 2023-07-01T17:42:40 | ---
license: bsd-3-clause
language:
- en
tags:
- sentiment
- bert
- sentiment-analysis
- transformers
pipeline_tag: text-classification
---
> Authors : GRP209
# User Comment Sentiment Analysis
This model aims to analyze user comments on products and extracting the expressed sentiments.
User ratings on the internet do not always provide detailed qualitative information about their experience.
Therefore, it is important to go beyond these ratings and extract more insightful information that can help a brand improve their product or service.
# Objective
The model utilizes the BERT architecture and is trained on a dataset of user comments with sentiment labels.
The model is capable of analyzing comments and extracting sentiments such as **positive**, **negative**, or **neutral**.
# Features
**Sentiment Classification**: The model can classify user comments into positive, negative, or neutral sentiments, providing an overall indication of the expressed opinion.
**Improvement Suggestions**: In cases where a comment expresses a negative or neutral sentiment, the model suggests an improved version of the text with a more positive sentiment.
This can help businesses understand consumer reactions and identify areas for product or service improvement.
# Usage
To use this sentiment analysis system, follow these steps:
- Install the required dependencies by running the command pip install -r requirements.txt.
- Once the training is complete, the best-trained model will be saved in the best_model_state.bin file.
- To make predictions on new comments, use the analyze_sentiment(comment_text) function, replacing comment_text with the actual comment text to analyze.
- The model will return the sentiment expressed in the comment.
- To suggest an improved version of a comment, use the suggest_improved_text(comment_text) function.
- If the comment expresses a negative or neutral sentiment, the function will generate an improved version of the text with a more positive sentiment. Otherwise, the original text will be returned without modification.
| 2,086 | [
[
-0.054168701171875,
-0.0307464599609375,
0.02313232421875,
0.0249176025390625,
-0.02752685546875,
-0.00457763671875,
0.002582550048828125,
-0.051849365234375,
0.0110626220703125,
0.036102294921875,
-0.054290771484375,
-0.031341552734375,
-0.041595458984375,
... |
NlpHUST/ner-vietnamese-electra-base | 2023-04-10T02:25:50.000Z | [
"transformers",
"pytorch",
"safetensors",
"electra",
"token-classification",
"named-entity-recognition",
"vi",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | NlpHUST | null | null | NlpHUST/ner-vietnamese-electra-base | 1 | 3,413 | transformers | 2022-10-28T05:26:38 | ---
widget:
- text: "Liên quan vụ việc CSGT bị tố đánh dân, trúng một cháu nhỏ đang ngủ, đang lan truyền trên mạng xã hội, Đại tá Nguyễn Văn Tảo, Phó Giám đốc Công an tỉnh Tiền Giang vừa có cuộc họp cùng Chỉ huy Công an huyện Châu Thành và một số đơn vị nghiệp vụ cấp tỉnh để chỉ đạo làm rõ thông tin."
tags:
- named-entity-recognition
language:
- vi
model-index:
- name: ner-vietnamese-electra-base
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vietnamese-ner
This model is a fine-tuned version of [NlpHUST/electra-base-vn](https://huggingface.co/NlpHUST/electra-base-vn) on an VLSP 2018 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0580
- Location Precision: 0.9353
- Location Recall: 0.9377
- Location F1: 0.9365
- Location Number: 2360
- Miscellaneous Precision: 0.5660
- Miscellaneous Recall: 0.6897
- Miscellaneous F1: 0.6218
- Miscellaneous Number: 174
- Organization Precision: 0.8610
- Organization Recall: 0.9068
- Organization F1: 0.8833
- Organization Number: 1878
- Person Precision: 0.9692
- Person Recall: 0.9637
- Person F1: 0.9664
- Person Number: 2121
- Overall Precision: 0.9122
- Overall Recall: 0.9307
- Overall F1: 0.9214
- Overall Accuracy: 0.9907
## Model description
More information needed
#### How to use
You can use this model with Transformers *pipeline* for NER.
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("NlpHUST/ner-vietnamese-electra-base")
model = AutoModelForTokenClassification.from_pretrained("NlpHUST/ner-vietnamese-electra-base")
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "Liên quan vụ việc CSGT bị tố đánh dân, trúng một cháu nhỏ đang ngủ, đang lan truyền trên mạng xã hội, Đại tá Nguyễn Văn Tảo, Phó Giám đốc Công an tỉnh Tiền Giang vừa có cuộc họp cùng Chỉ huy Công an huyện Châu Thành và một số đơn vị nghiệp vụ cấp tỉnh để chỉ đạo làm rõ thông tin."
ner_results = nlp(example)
print(ner_results)
```
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Framework versions
- Transformers 4.20.1
- Pytorch 1.8.0+cu111
- Datasets 2.4.0
- Tokenizers 0.12.1
### Contact information
For personal communication related to this project, please contact Nha Nguyen Van (nha282@gmail.com). | 2,829 | [
[
-0.023956298828125,
-0.043792724609375,
0.00931549072265625,
0.006145477294921875,
-0.025482177734375,
-0.0223541259765625,
-0.004482269287109375,
-0.01198577880859375,
0.02569580078125,
0.041961669921875,
-0.0220184326171875,
-0.041839599609375,
-0.045135498046... |
moka-ai/m3e-large | 2023-06-21T11:25:23.000Z | [
"sentence-transformers",
"pytorch",
"bert",
"embedding",
"text-embedding",
"zh",
"en",
"has_space",
"region:us"
] | null | moka-ai | null | null | moka-ai/m3e-large | 121 | 3,398 | sentence-transformers | 2023-06-21T09:07:12 | ---
language:
- zh
- en
tags:
- embedding
- text-embedding
library_name: sentence-transformers
---
# M3E Models
[m3e-small](https://huggingface.co/moka-ai/m3e-small) | [m3e-base](https://huggingface.co/moka-ai/m3e-base) | [m3e-large](https://huggingface.co/moka-ai/m3e-large)
M3E 是 Moka Massive Mixed Embedding 的缩写
- Moka,此模型由 MokaAI 训练,开源和评测,训练脚本使用 [uniem](https://github.com/wangyuxinwhy/uniem/blob/main/scripts/train_m3e.py) ,评测 BenchMark 使用 [MTEB-zh](https://github.com/wangyuxinwhy/uniem/tree/main/mteb-zh)
- Massive,此模型通过**千万级** (2200w+) 的中文句对数据集进行训练
- Mixed,此模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索
- Embedding,此模型是文本嵌入模型,可以将自然语言转换成稠密的向量
## 更新说明
- 2023.06.14,添加了三个中文开源文本嵌入模型到评测中,包括 UER, ErLangShen, DMetaSoul
- 2023.06.08,添加检索任务的评测结果,在 T2Ranking 1W 中文数据集上,m3e-base 在 ndcg@10 上达到了 0.8004,超过了 openai-ada-002 的 0.7786
- 2023.06.07,添加文本分类任务的评测结果,在 6 种文本分类数据集上,m3e-base 在 accuracy 上达到了 0.6157,超过了 openai-ada-002 的 0.5956
## 模型对比
| | 参数数量 | 维度 | 中文 | 英文 | s2s | s2p | s2c | 开源 | 兼容性 | s2s Acc | s2p ndcg@10 |
| --------- | -------- | -------- | -------- | -------- | -------- | -------- | -------- | ---- | ---------- | ------------ | -------- |
| m3e-small | 24M | 512 | 是 | 否 | 是 | 否 | 否 | 是 | 优 | 0.5834 | 0.7262 |
| m3e-base | 110M | 768 | 是 | 是 | 是 | 是 | 否 | 是 | 优 | 0.6157 | **0.8004** |
| m3e-large | 340M | 768 | 是 | 否 | 是 | 是 | 否 | 是 | 优 | **0.6231** | 0.7974 |
| text2vec | 110M | 768 | 是 | 否 | 是 | 否 | 否 | 是 | 优 | 0.5755 | 0.6346 |
| openai-ada-002 | 未知 | 1536 | 是 | 是 | 是 | 是 | 是 | 否 | 优 | 0.5956 | 0.7786 |
说明:
- s2s, 即 sentence to sentence ,代表了同质文本之间的嵌入能力,适用任务:文本相似度,重复问题检测,文本分类等
- s2p, 即 sentence to passage ,代表了异质文本之间的嵌入能力,适用任务:文本检索,GPT 记忆模块等
- s2c, 即 sentence to code ,代表了自然语言和程序语言之间的嵌入能力,适用任务:代码检索
- 兼容性,代表了模型在开源社区中各种项目被支持的程度,由于 m3e 和 text2vec 都可以直接通过 sentence-transformers 直接使用,所以和 openai 在社区的支持度上相当
- ACC & ndcg@10,详情见下方的评测
Tips:
- 使用场景主要是中文,少量英文的情况,建议使用 m3e 系列的模型
- 多语言使用场景,并且不介意数据隐私的话,我建议使用 openai text-embedding-ada-002
- 代码检索场景,推荐使用 openai text-embedding-ada-002
- 文本检索场景,请使用具备文本检索能力的模型,只在 S2S 上训练的文本嵌入模型,没有办法完成文本检索任务
## 使用方式
您需要先安装 sentence-transformers
```bash
pip install -U sentence-transformers
```
安装完成后,您可以使用以下代码来使用 M3E Models
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('moka-ai/m3e-base')
#Our sentences we like to encode
sentences = [
'* Moka 此文本嵌入模型由 MokaAI 训练并开源,训练脚本使用 uniem',
'* Massive 此文本嵌入模型通过**千万级**的中文句对数据集进行训练',
'* Mixed 此文本嵌入模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索,ALL in one'
]
#Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
#Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")
```
M3E 系列的所有模型在设计的时候就考虑到完全兼容 [sentence-transformers](https://www.sbert.net/) ,所以你可以通过**替换名称字符串**的方式在所有支持 sentence-transformers 的项目中**无缝**使用 M3E Models,比如 [chroma](https://docs.trychroma.com/getting-started), [guidance](https://github.com/microsoft/guidance), [semantic-kernel](https://github.com/microsoft/semantic-kernel) 。
## 训练方案
M3E 使用 in-batch 负采样的对比学习的方式在句对数据集进行训练,为了保证 in-batch 负采样的效果,我们使用 A100 80G 来最大化 batch-size,并在共计 2200W+ 的句对数据集上训练了 1 epoch。训练脚本使用 [uniem](https://github.com/wangyuxinwhy/uniem/blob/main/scripts/train_m3e.py),您可以在这里查看具体细节。
## 特性
- 中文训练集,M3E 在大规模句对数据集上的训练,包含中文百科,金融,医疗,法律,新闻,学术等多个领域共计 2200W 句对样本,数据集详见 [M3E 数据集](#M3E数据集)
- 英文训练集,M3E 使用 MEDI 145W 英文三元组数据集进行训练,数据集详见 [MEDI 数据集](https://drive.google.com/file/d/1vZ5c2oJNonGOvXzppNg5mHz24O6jcc52/view),此数据集由 [instructor team](https://github.com/HKUNLP/instructor-embedding) 提供
- 指令数据集,M3E 使用了 300W + 的指令微调数据集,这使得 M3E 对文本编码的时候可以遵从指令,这部分的工作主要被启发于 [instructor-embedding](https://github.com/HKUNLP/instructor-embedding)
- 基础模型,M3E 使用 hfl 实验室的 [Roberta](https://huggingface.co/hfl/chinese-roberta-wwm-ext) 系列模型进行训练,目前提供 small、base和large三个版本,大家则需选用
- ALL IN ONE,M3E 旨在提供一个 ALL IN ONE 的文本嵌入模型,不仅支持同质句子相似度判断,还支持异质文本检索,你只需要一个模型就可以覆盖全部的应用场景,未来还会支持代码检索
## 评测
- 评测模型,[text2vec](https://github.com/shibing624/text2vec), m3e-base, m3e-small, openai text-embedding-ada-002, [DMetaSoul](https://huggingface.co/DMetaSoul/sbert-chinese-general-v2), [UER](https://huggingface.co/uer/sbert-base-chinese-nli), [ErLangShen](https://huggingface.co/IDEA-CCNL/Erlangshen-SimCSE-110M-Chinese)
- 评测脚本,具体参考 [MTEB-zh] (https://github.com/wangyuxinwhy/uniem/blob/main/mteb-zh)
### 文本分类
- 数据集选择,选择开源在 HuggingFace 上的 6 种文本分类数据集,包括新闻、电商评论、股票评论、长文本等
- 评测方式,使用 MTEB 的方式进行评测,报告 Accuracy。
| | text2vec | m3e-small | m3e-base | m3e-large | openai | DMetaSoul | uer | erlangshen |
| ----------------- | -------- | --------- | -------- | ------ | ----------- | ------- | ----------- | ----------- |
| TNews | 0.43 | 0.4443 | 0.4827 | **0.4866** | 0.4594 | 0.3084 | 0.3539 | 0.4361 |
| JDIphone | 0.8214 | 0.8293 | 0.8533 | **0.8692** | 0.746 | 0.7972 | 0.8283 | 0.8356 |
| GubaEastmony | 0.7472 | 0.712 | 0.7621 | 0.7663 | 0.7574 | 0.735 | 0.7534 | **0.7787** |
| TYQSentiment | 0.6099 | 0.6596 | 0.7188 | **0.7247** | 0.68 | 0.6437 | 0.6662 | 0.6444 |
| StockComSentiment | 0.4307 | 0.4291 | 0.4363 | 0.4475 | **0.4819** | 0.4309 | 0.4555 | 0.4482 |
| IFlyTek | 0.414 | 0.4263 | 0.4409 | 0.4445 | **0.4486** | 0.3969 | 0.3762 | 0.4241 |
| Average | 0.5755 | 0.5834 | 0.6157 | **0.6231** | 0.5956 | 0.552016667 | 0.57225 | 0.594516667 |
### 检索排序
#### T2Ranking 1W
- 数据集选择,使用 [T2Ranking](https://github.com/THUIR/T2Ranking/tree/main) 数据集,由于 T2Ranking 的数据集太大,openai 评测起来的时间成本和 api 费用有些高,所以我们只选择了 T2Ranking 中的前 10000 篇文章
- 评测方式,使用 MTEB 的方式进行评测,报告 map@1, map@10, mrr@1, mrr@10, ndcg@1, ndcg@10
- 注意!从实验结果和训练方式来看,除了 M3E 模型和 openai 模型外,其余模型都没有做检索任务的训练,所以结果仅供参考。
| | text2vec | openai-ada-002 | m3e-small | m3e-base | m3e-large | DMetaSoul | uer | erlangshen |
| ------- | -------- | -------------- | --------- | -------- | --------- | ------- | ---------- | ---------- |
| map@1 | 0.4684 | 0.6133 | 0.5574 | **0.626** | 0.6256 | 0.25203 | 0.08647 | 0.25394 |
| map@10 | 0.5877 | 0.7423 | 0.6878 | **0.7656** | 0.7627 | 0.33312 | 0.13008 | 0.34714 |
| mrr@1 | 0.5345 | 0.6931 | 0.6324 | 0.7047 | **0.7063** | 0.29258 | 0.10067 | 0.29447 |
| mrr@10 | 0.6217 | 0.7668 | 0.712 | **0.7841** | 0.7827 | 0.36287 | 0.14516 | 0.3751 |
| ndcg@1 | 0.5207 | 0.6764 | 0.6159 | 0.6881 | **0.6884** | 0.28358 | 0.09748 | 0.28578 |
| ndcg@10 | 0.6346 | 0.7786 | 0.7262 | **0.8004** | 0.7974 | 0.37468 | 0.15783 | 0.39329 |
#### T2Ranking
- 数据集选择,使用 T2Ranking,刨除 openai-ada-002 模型后,我们对剩余的三个模型,进行 T2Ranking 10W 和 T2Ranking 50W 的评测。(T2Ranking 评测太耗内存了... 128G 都不行)
- 评测方式,使用 MTEB 的方式进行评测,报告 ndcg@10
| | text2vec | m3e-small | m3e-base |
| ------- | -------- | --------- | -------- |
| t2r-1w | 0.6346 | 0.72621 | **0.8004** |
| t2r-10w | 0.44644 | 0.5251 | **0.6263** |
| t2r-50w | 0.33482 | 0.38626 | **0.47364** |
说明:
- 检索排序对于 text2vec 并不公平,因为 text2vec 在训练的时候没有使用过检索相关的数据集,所以没有办法很好的完成检索任务也是正常的。
## M3E数据集
如果您想要使用这些数据集,你可以在 [uniem process_zh_datasets](https://github.com/wangyuxinwhy/uniem/blob/main/scripts/process_zh_datasets.py) 中找到加载 huggingface 数据集的脚本,非 huggingface 数据集需要您根据下方提供的链接自行下载和处理。
| 数据集名称 | 领域 | 数量 | 任务类型 | Prompt | 质量 | 数据提供者 | 说明 | 是否开源/研究使用 | 是否商用 | 脚本 | Done | URL | 是否同质 |
| -------------------- | ---- | --------- | ----------------- | ------ | ---- | ------------------------------------------------------------ | ------------------------------------------------------------ | ----------------- | -------- | ---- | ---- | ------------------------------------------------------------ | -------- |
| cmrc2018 | 百科 | 14,363 | 问答 | 问答 | 优 | Yiming Cui, Ting Liu, Wanxiang Che, Li Xiao, Zhipeng Chen, Wentao Ma, Shijin Wang, Guoping Hu | https://github.com/ymcui/cmrc2018/blob/master/README_CN.md 专家标注的基于维基百科的中文阅读理解数据集,将问题和上下文视为正例 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/cmrc2018 | 否 |
| belle_2m | 百科 | 2,000,000 | 指令微调 | 无 | 优 | LianjiaTech/BELLE | belle 的指令微调数据集,使用 self instruct 方法基于 gpt3.5 生成 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/BelleGroup/train_2M_CN | 否 |
| firefily | 百科 | 1,649,399 | 指令微调 | 无 | 优 | YeungNLP | Firefly(流萤) 是一个开源的中文对话式大语言模型,使用指令微调(Instruction Tuning)在中文数据集上进行调优。使用了词表裁剪、ZeRO等技术,有效降低显存消耗和提高训练效率。 在训练中,我们使用了更小的模型参数量,以及更少的计算资源。 | 未说明 | 未说明 | 是 | 是 | https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M | 否 |
| alpaca_gpt4 | 百科 | 48,818 | 指令微调 | 无 | 优 | Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, Jianfeng Gao | 本数据集是参考Alpaca方法基于GPT4得到的self-instruct数据,约5万条。 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/shibing624/alpaca-zh | 否 |
| zhihu_kol | 百科 | 1,006,218 | 问答 | 问答 | 优 | wangrui6 | 知乎问答 | 未说明 | 未说明 | 是 | 是 | https://huggingface.co/datasets/wangrui6/Zhihu-KOL | 否 |
| hc3_chinese | 百科 | 39,781 | 问答 | 问答 | 良 | Hello-SimpleAI | 问答数据,包括人工回答和 GPT 回答 | 是 | 未说明 | 是 | 是 | https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese | 否 |
| amazon_reviews_multi | 电商 | 210,000 | 问答 文本分类 | 摘要 | 优 | 亚马逊 | 亚马逊产品评论数据集 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/amazon_reviews_multi/viewer/zh/train?row=8 | 否 |
| mlqa | 百科 | 85,853 | 问答 | 问答 | 良 | patrickvonplaten | 一个用于评估跨语言问答性能的基准数据集 | 是 | 未说明 | 是 | 是 | https://huggingface.co/datasets/mlqa/viewer/mlqa-translate-train.zh/train?p=2 | 否 |
| xlsum | 新闻 | 93,404 | 摘要 | 摘要 | 良 | BUET CSE NLP Group | BBC的专业注释文章摘要对 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/csebuetnlp/xlsum/viewer/chinese_simplified/train?row=259 | 否 |
| ocnli | 口语 | 17,726 | 自然语言推理 | 推理 | 良 | Thomas Wolf | 自然语言推理数据集 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/clue/viewer/ocnli | 是 |
| BQ | 金融 | 60,000 | 文本分类 | 相似 | 良 | Intelligent Computing Research Center, Harbin Institute of Technology(Shenzhen) | http://icrc.hitsz.edu.cn/info/1037/1162.htm BQ 语料库包含来自网上银行自定义服务日志的 120,000 个问题对。它分为三部分:100,000 对用于训练,10,000 对用于验证,10,000 对用于测试。 数据提供者: 哈尔滨工业大学(深圳)智能计算研究中心 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/shibing624/nli_zh/viewer/BQ | 是 |
| lcqmc | 口语 | 149,226 | 文本分类 | 相似 | 良 | Ming Xu | 哈工大文本匹配数据集,LCQMC 是哈尔滨工业大学在自然语言处理国际顶会 COLING2018 构建的问题语义匹配数据集,其目标是判断两个问题的语义是否相同 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/shibing624/nli_zh/viewer/LCQMC/train | 是 |
| paws-x | 百科 | 23,576 | 文本分类 | 相似 | 优 | Bhavitvya Malik | PAWS Wiki中的示例 | 是 | 是 | 是 | 是 | https://huggingface.co/datasets/paws-x/viewer/zh/train | 是 |
| wiki_atomic_edit | 百科 | 1,213,780 | 平行语义 | 相似 | 优 | abhishek thakur | 基于中文维基百科的编辑记录收集的数据集 | 未说明 | 未说明 | 是 | 是 | https://huggingface.co/datasets/wiki_atomic_edits | 是 |
| chatmed_consult | 医药 | 549,326 | 问答 | 问答 | 优 | Wei Zhu | 真实世界的医学相关的问题,使用 gpt3.5 进行回答 | 是 | 否 | 是 | 是 | https://huggingface.co/datasets/michaelwzhu/ChatMed_Consult_Dataset | 否 |
| webqa | 百科 | 42,216 | 问答 | 问答 | 优 | suolyer | 百度于2016年开源的数据集,数据来自于百度知道;格式为一个问题多篇意思基本一致的文章,分为人为标注以及浏览器检索;数据整体质量中,因为混合了很多检索而来的文章 | 是 | 未说明 | 是 | 是 | https://huggingface.co/datasets/suolyer/webqa/viewer/suolyer--webqa/train?p=3 | 否 |
| dureader_robust | 百科 | 65,937 | 机器阅读理解 问答 | 问答 | 优 | 百度 | DuReader robust旨在利用真实应用中的数据样本来衡量阅读理解模型的鲁棒性,评测模型的过敏感性、过稳定性以及泛化能力,是首个中文阅读理解鲁棒性数据集。 | 是 | 是 | 是 | 是 | https://huggingface.co/datasets/PaddlePaddle/dureader_robust/viewer/plain_text/train?row=96 | 否 |
| csl | 学术 | 395,927 | 语料 | 摘要 | 优 | Yudong Li, Yuqing Zhang, Zhe Zhao, Linlin Shen, Weijie Liu, Weiquan Mao and Hui Zhang | 提供首个中文科学文献数据集(CSL),包含 396,209 篇中文核心期刊论文元信息 (标题、摘要、关键词、学科、门类)。CSL 数据集可以作为预训练语料,也可以构建许多NLP任务,例如文本摘要(标题预测)、 关键词生成和文本分类等。 | 是 | 是 | 是 | 是 | https://huggingface.co/datasets/neuclir/csl | 否 |
| miracl-corpus | 百科 | 4,934,368 | 语料 | 摘要 | 优 | MIRACL | The corpus for each language is prepared from a Wikipedia dump, where we keep only the plain text and discard images, tables, etc. Each article is segmented into multiple passages using WikiExtractor based on natural discourse units (e.g., \n\n in the wiki markup). Each of these passages comprises a "document" or unit of retrieval. We preserve the Wikipedia article title of each passage. | 是 | 是 | 是 | 是 | https://huggingface.co/datasets/miracl/miracl-corpus | 否 |
| lawzhidao | 法律 | 36,368 | 问答 | 问答 | 优 | 和鲸社区-Ustinian | 百度知道清洗后的法律问答 | 是 | 是 | 否 | 是 | https://www.heywhale.com/mw/dataset/5e953ca8e7ec38002d02fca7/content | 否 |
| CINLID | 成语 | 34,746 | 平行语义 | 相似 | 优 | 高长宽 | 中文成语语义推理数据集(Chinese Idioms Natural Language Inference Dataset)收集了106832条由人工撰写的成语对(含少量歇后语、俗语等短文本),通过人工标注的方式进行平衡分类,标签为entailment、contradiction和neutral,支持自然语言推理(NLI)的任务。 | 是 | 否 | 否 | 是 | https://www.luge.ai/#/luge/dataDetail?id=39 | 是 |
| DuSQL | SQL | 25,003 | NL2SQL | SQL | 优 | 百度 | DuSQL是一个面向实际应用的数据集,包含200个数据库,覆盖了164个领域,问题覆盖了匹配、计算、推理等实际应用中常见形式。该数据集更贴近真实应用场景,要求模型领域无关、问题无关,且具备计算推理等能力。 | 是 | 否 | 否 | 是 | https://www.luge.ai/#/luge/dataDetail?id=13 | 否 |
| Zhuiyi-NL2SQL | SQL | 45,918 | NL2SQL | SQL | 优 | 追一科技 刘云峰 | NL2SQL是一个多领域的简单数据集,其主要包含匹配类型问题。该数据集主要验证模型的泛化能力,其要求模型具有较强的领域泛化能力、问题泛化能力。 | 是 | 否 | 否 | 是 | https://www.luge.ai/#/luge/dataDetail?id=12 | 否 |
| Cspider | SQL | 7,785 | NL2SQL | SQL | 优 | 西湖大学 张岳 | CSpider是一个多语言数据集,其问题以中文表达,数据库以英文存储,这种双语模式在实际应用中也非常常见,尤其是数据库引擎对中文支持不好的情况下。该数据集要求模型领域无关、问题无关,且能够实现多语言匹配。 | 是 | 否 | 否 | 是 | https://www.luge.ai/#/luge/dataDetail?id=11 | 否 |
| news2016zh | 新闻 | 2,507,549 | 语料 | 摘要 | 良 | Bright Xu | 包含了250万篇新闻。新闻来源涵盖了6.3万个媒体,含标题、关键词、描述、正文。 | 是 | 是 | 否 | 是 | https://github.com/brightmart/nlp_chinese_corpus | 否 |
| baike2018qa | 百科 | 1,470,142 | 问答 | 问答 | 良 | Bright Xu | 含有150万个预先过滤过的、高质量问题和答案,每个问题属于一个类别。总共有492个类别,其中频率达到或超过10次的类别有434个。 | 是 | 是 | 否 | 是 | https://github.com/brightmart/nlp_chinese_corpus | 否 |
| webtext2019zh | 百科 | 4,258,310 | 问答 | 问答 | 优 | Bright Xu | 含有410万个预先过滤过的、高质量问题和回复。每个问题属于一个【话题】,总共有2.8万个各式话题,话题包罗万象。 | 是 | 是 | 否 | 是 | https://github.com/brightmart/nlp_chinese_corpus | 否 |
| SimCLUE | 百科 | 775,593 | 平行语义 | 相似 | 良 | 数据集合,请在 simCLUE 中查看 | 整合了中文领域绝大多数可用的开源的语义相似度和自然语言推理的数据集,并重新做了数据拆分和整理。 | 是 | 否 | 否 | 是 | https://github.com/CLUEbenchmark/SimCLUE | 是 |
| Chinese-SQuAD | 新闻 | 76,449 | 机器阅读理解 | 问答 | 优 | junzeng-pluto | 中文机器阅读理解数据集,通过机器翻译加人工校正的方式从原始Squad转换而来 | 是 | 否 | 否 | 是 | https://github.com/pluto-junzeng/ChineseSquad | 否 |
## 计划表
- [x] 完成 MTEB 中文评测 BenchMark, [MTEB-zh](https://github.com/wangyuxinwhy/uniem/tree/main/mteb-zh)
- [ ] 完成 Large 模型的训练和开源
- [ ] 完成支持代码检索的模型
- [ ] 对 M3E 数据集进行清洗,保留高质量的部分,组成 m3e-hq,并在 huggingface 上开源
- [ ] 在 m3e-hq 的数据集上补充 hard negative 的样本及相似度分数,组成 m3e-hq-with-score,并在 huggingface 上开源
- [ ] 在 m3e-hq-with-score 上通过 [cosent loss](https://github.com/wangyuxinwhy/uniem/blob/main/uniem/criteria.py#LL24C39-L24C39) loss 进行训练并开源模型,CoSent 原理参考这篇[博客](https://kexue.fm/archives/8847)
- [ ] 开源商用版本的 M3E models
## 致谢
感谢开源社区提供的中文语料,感谢所有在此工作中提供帮助的人们,希望中文社区越来越好,共勉!
## License
M3E models 使用的数据集中包括大量非商用的数据集,所以 M3E models 也是非商用的,仅供研究使用。不过我们已经在 M3E 数据集上标识了商用和非商用的数据集,您可以根据自己的需求自行训练。
## Citation
Please cite this model using the following format:
```
@software {Moka Massive Mixed Embedding,
author = {Wang Yuxin,Sun Qingxuan,He sicheng},
title = {M3E: Moka Massive Mixed Embedding Model},
year = {2023}
}
``` | 19,078 | [
[
-0.040283203125,
-0.0435791015625,
0.01678466796875,
0.0095977783203125,
-0.0236358642578125,
-0.021331787109375,
-0.021240234375,
-0.0097808837890625,
0.035980224609375,
0.0072479248046875,
-0.03582763671875,
-0.0540771484375,
-0.05078125,
-0.00959777832031... |
gijs/aces-roberta-13 | 2023-03-09T15:52:02.000Z | [
"transformers",
"pytorch",
"roberta",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | gijs | null | null | gijs/aces-roberta-13 | 0 | 3,396 | transformers | 2023-03-09T15:49:28 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: aces-roberta-13
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# aces-roberta-13
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4600
- Precision: 0.8364
- Recall: 0.8452
- F1: 0.8383
- Accuracy: 0.8452
- F1 Who: 0.9189
- F1 What: 0.8621
- F1 Where: 0.9231
- F1 How: 0.9141
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy | F1 Who | F1 What | F1 Where | F1 How |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|:------:|:-------:|:--------:|:------:|
| 1.9849 | 0.35 | 20 | 1.4123 | 0.5426 | 0.6351 | 0.5494 | 0.6351 | 0.1026 | 0.6222 | 0.3232 | 0.7857 |
| 1.2159 | 0.7 | 40 | 0.9450 | 0.6559 | 0.7188 | 0.6592 | 0.7188 | 0.6780 | 0.7539 | 0.7071 | 0.7882 |
| 0.8634 | 1.05 | 60 | 0.6885 | 0.7652 | 0.7994 | 0.7725 | 0.7994 | 0.9067 | 0.8152 | 0.8070 | 0.8940 |
| 0.6777 | 1.4 | 80 | 0.6144 | 0.7650 | 0.7946 | 0.7711 | 0.7946 | 0.9189 | 0.7876 | 0.8039 | 0.9085 |
| 0.6051 | 1.75 | 100 | 0.5485 | 0.8126 | 0.8278 | 0.8150 | 0.8278 | 0.9315 | 0.8362 | 0.8148 | 0.9241 |
| 0.5511 | 2.11 | 120 | 0.5264 | 0.8113 | 0.8167 | 0.8036 | 0.8167 | 0.9315 | 0.8444 | 0.8257 | 0.9199 |
| 0.486 | 2.46 | 140 | 0.4867 | 0.8230 | 0.8357 | 0.8248 | 0.8357 | 0.9315 | 0.8539 | 0.9091 | 0.9048 |
| 0.4813 | 2.81 | 160 | 0.4767 | 0.8285 | 0.8278 | 0.8213 | 0.8278 | 0.9189 | 0.8701 | 0.9076 | 0.9135 |
| 0.4494 | 3.16 | 180 | 0.5042 | 0.8152 | 0.8199 | 0.8126 | 0.8199 | 0.9315 | 0.8427 | 0.8333 | 0.8956 |
| 0.4018 | 3.51 | 200 | 0.4802 | 0.8248 | 0.8357 | 0.8249 | 0.8357 | 0.9189 | 0.8736 | 0.8780 | 0.9357 |
| 0.4205 | 3.86 | 220 | 0.4723 | 0.8340 | 0.8389 | 0.8346 | 0.8389 | 0.9189 | 0.8636 | 0.9138 | 0.8986 |
| 0.3535 | 4.21 | 240 | 0.4669 | 0.8324 | 0.8452 | 0.8364 | 0.8452 | 0.9189 | 0.8571 | 0.9138 | 0.9167 |
| 0.3808 | 4.56 | 260 | 0.4585 | 0.8349 | 0.8452 | 0.8383 | 0.8452 | 0.9189 | 0.8621 | 0.9231 | 0.9141 |
| 0.3491 | 4.91 | 280 | 0.4600 | 0.8364 | 0.8452 | 0.8383 | 0.8452 | 0.9189 | 0.8621 | 0.9231 | 0.9141 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu117
- Datasets 2.8.0
- Tokenizers 0.13.2
| 3,364 | [
[
-0.0443115234375,
-0.04498291015625,
0.0186920166015625,
0.0029449462890625,
-0.004245758056640625,
-0.0029697418212890625,
-0.0034160614013671875,
-0.0061798095703125,
0.04815673828125,
0.0252838134765625,
-0.05059814453125,
-0.048858642578125,
-0.04931640625,
... |
timm/maxvit_base_tf_512.in1k | 2023-05-10T23:58:36.000Z | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2204.01697",
"license:apache-2.0",
"region:us"
] | image-classification | timm | null | null | timm/maxvit_base_tf_512.in1k | 0 | 3,395 | timm | 2022-12-02T21:49:47 | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for maxvit_base_tf_512.in1k
An official MaxViT image classification model. Trained in tensorflow on ImageNet-1k by paper authors.
Ported from official Tensorflow implementation (https://github.com/google-research/maxvit) to PyTorch by Ross Wightman.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 119.9
- GMACs: 138.0
- Activations (M): 704.0
- Image size: 512 x 512
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('maxvit_base_tf_512.in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_base_tf_512.in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 256, 256])
# torch.Size([1, 96, 128, 128])
# torch.Size([1, 192, 64, 64])
# torch.Size([1, 384, 32, 32])
# torch.Size([1, 768, 16, 16])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxvit_base_tf_512.in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 16, 16) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
| 22,113 | [
[
-0.05242919921875,
-0.0303955078125,
0.0010662078857421875,
0.0311431884765625,
-0.024322509765625,
-0.0170745849609375,
-0.01104736328125,
-0.023834228515625,
0.054656982421875,
0.01654052734375,
-0.041168212890625,
-0.0469970703125,
-0.047332763671875,
-0.... |
HamzaFarhan/PDFSegs | 2023-05-31T07:25:42.000Z | [
"sentence-transformers",
"pytorch",
"mpnet",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] | text-classification | HamzaFarhan | null | null | HamzaFarhan/PDFSegs | 1 | 3,386 | sentence-transformers | 2023-05-21T02:08:09 | ---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# HamzaFarhan/PDFSegs
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification.
<br>The labels are: 'Work Experience', 'Education', and 'Certifications'.
<br>The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("HamzaFarhan/PDFSegs")
# Run inference
preds = model(['I worked at Google for 5 years.','I have a PhD in Computer Science.'])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
| 1,607 | [
[
0.0004982948303222656,
-0.0496826171875,
0.02490234375,
-0.00762176513671875,
-0.0027980804443359375,
-0.0175933837890625,
-0.0167999267578125,
-0.0153045654296875,
-0.021270751953125,
0.04034423828125,
-0.034576416015625,
-0.032470703125,
-0.04052734375,
0.... |
hearmeneigh/sd21-e621-rising-v2 | 2023-11-02T01:12:33.000Z | [
"diffusers",
"tensorboard",
"anthro",
"furry",
"e621",
"nsfw",
"not-for-all-audiences",
"text-to-image",
"dataset:hearmeneigh/e621-rising-v2-curated",
"dataset:hearmeneigh/e621-rising-v1-curated",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | hearmeneigh | null | null | hearmeneigh/sd21-e621-rising-v2 | 24 | 3,384 | diffusers | 2023-04-02T03:46:07 | ---
library_name: diffusers
pipeline_tag: text-to-image
datasets:
- hearmeneigh/e621-rising-v2-curated
- hearmeneigh/e621-rising-v1-curated
tags:
- anthro
- furry
- e621
- nsfw
- not-for-all-audiences
---
<div style='background: #ffeec0; border: 1px solid #ffd86d; padding:1em; border-radius:3px;'>
<h3 style='margin:0'>Outdated!</h3>
<p style='margin:0'>This model has been superseded by:</p>
<p style='margin:0'><a style="font-size: 2em;" href='https://huggingface.co/hearmeneigh/e621-rising-v3'>E621 Rising V3 (SDXL)</a></p>
</div>
<div style='background: #ffdddd; padding:0.5em;'>
Warning: This model is NOT suitable for use by minors. The model can/will generate X-rated/NFSW content.
</div>
<div style='background: #e5e5e5; margin-top: 1.5em; margin-bottom: 1.5em; padding:1em; font-weight: bold'>
<a href='https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/resolve/main/sd21-e621-rising-v2-epoch-29.fp16.ckpt'>Ckpt</a> |
<a href='https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/resolve/main/sd21-e621-rising-v2-epoch-29.fp16.safetensors'>Safetensors</a> |
<a href='https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/resolve/main/sd21-e621-rising-v2-epoch-29.fp16.yaml'>Yaml</a> |
<a href='https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/blob/main/meta/tag-counts-by-name.json'>Tags</a> |
<a href='https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/blob/main/PROMPT-GUIDE.md#prompt-examples'>Example Prompts</a> |
<a href='https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/blob/main/guides/WEBUI.md'>WebUI How-To</a>
</div>
# E621 Rising V2: A Stable Diffusion 2.1 Model [epoch 29]
* Guaranteed **NSFW** or your money back
* Fine-tuned from [Stable Diffusion v2-1-base](https://huggingface.co/stabilityai/stable-diffusion-2-1-base)
* Training continued from [E621 Rising V1](https://huggingface.co/hearmeneigh/sd21-e621-rising-v1)
* 10 additional epochs of 250,000 images each, collected from [E621](https://e621.net/)
* Trained with [6,246 tags](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/blob/main/meta/tag-counts-by-name.json)
* `512x512px`
* Compatible with 🤗 `diffusers`
* Compatible with `stable-diffusion-webui`
* Compatible with anything that accepts [`.ckpt`](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/resolve/main/sd21-e621-rising-v2-epoch-29.fp16.ckpt) and [`.yaml`](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/resolve/main/sd21-e621-rising-v2-epoch-29.fp16.yaml) files
## Getting Started
* [Stable Diffusion WebUI How-To](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/blob/main/guides/WEBUI.md)
* [Python How-To](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/blob/main/guides/PYTHON.md)
* [Prompt Guide](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/blob/main/PROMPT-GUIDE.md)
## Examples

[More examples and prompts here](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/blob/main/PROMPT-GUIDE.md#prompt-examples)
## Versions
| Precision | CKPT | Safetensors | YAML | Notes |
| :-------- | :--- | :---------- | :--- | :---- |
| `FP16` | [Download](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/resolve/main/sd21-e621-rising-v2-epoch-29.fp16.ckpt) | [Download](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/resolve/main/sd21-e621-rising-v2-epoch-29.fp16.safetensors) | [Download](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/resolve/main/sd21-e621-rising-v2-epoch-29.fp16.yaml) | Use this by default |
| `FP32` | [Download](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/resolve/main/sd21-e621-rising-v2-epoch-29.fp32.ckpt) | [Download](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/resolve/main/sd21-e621-rising-v2-epoch-29.fp32.safetensors) | [Download](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/resolve/main/sd21-e621-rising-v2-epoch-29.fp32.yaml) | |
| `BF16` | [Download](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/resolve/main/sd21-e621-rising-v2-epoch-29.bf16.ckpt) | [Download](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/resolve/main/sd21-e621-rising-v2-epoch-29.bf16.safetensors) | [Download](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/resolve/main/sd21-e621-rising-v2-epoch-29.bf16.yaml) | |
## Changes From E621
See a [complete list of tags here](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/blob/main/meta/tag-counts-by-name.json).
* Symbols have been prefixed with `symbol:`, e.g. `symbol:<3`
* All categories except `general` have been prefixed with the category name, e.g. `copyright:somename`. The categories are:
* `artist`
* `copyright`
* `character`
* `species`
* `invalid`
* `meta`
* `lore`
* Tag names are all lowercase and only contain `a-z`, `0-9`, `/`, and `_` letters
* `:` is used to separate the category name from the tag
### Additional Tags
* Image rating
* `rating:explicit`
* `rating:questionable`
* `rating:safe`
## Training Procedure
[Training legend](https://huggingface.co/hearmeneigh/sd21-e621-rising-v2/blob/main/examples/training-legend.jpg)
* 204-272 images per batch (epoch variant)
* `512x512px` image size
* Adam optimizer
* Beta1 = `0.9`
* Beta2 = `0.999`
* Weight decay = `1e-2`
* Epsilon = `1e-08`
* Constant learning rate `4e-6`
* `bf16` mixed precision
* 8 epochs of [V1 dataset](https://huggingface.co/datasets/hearmeneigh/e621-rising-v1-curated) samples stretched to `512x512px` (ignore aspect ratio)
* 9 epochs of V1 dataset samples resized to `512xH` or `Wx512px` with center crop (maintain aspect ratio)
* 2 epochs of V1 dataset samples resized to `< 512x512px` (maintain aspect ratio)
* 10 epochs of [V2 dataset](https://huggingface.co/datasets/hearmeneigh/e621-rising-v2-curated) samples resized to `< 512x512px` (maintain aspect ratio)
* Tags for each sample are shuffled for each epoch, starting from epoch 16 | 5,952 | [
[
-0.04949951171875,
-0.040771484375,
0.01318359375,
0.03314208984375,
-0.01451873779296875,
-0.011077880859375,
-0.001495361328125,
-0.039642333984375,
0.04241943359375,
0.01528167724609375,
-0.0672607421875,
-0.03778076171875,
-0.032318115234375,
0.005630493... |
Daniil-plotnikov/russian-vision-v6-2 | 2023-10-26T06:24:46.000Z | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"endpoints_compatible",
"has_space",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | Daniil-plotnikov | null | null | Daniil-plotnikov/russian-vision-v6-2 | 2 | 3,384 | diffusers | 2023-10-08T16:57:39 | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Russian-Vision-v6.2
| 104 | [
[
-0.01198577880859375,
0.01331329345703125,
0.028594970703125,
0.045074462890625,
-0.057952880859375,
0.0030727386474609375,
0.033111572265625,
-0.0017747879028320312,
0.01806640625,
0.0499267578125,
-0.041595458984375,
-0.03350830078125,
-0.04364013671875,
-... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.