
license stringlengths 2 30 | tags stringlengths 2 513 | is_nc bool 1 class | readme_section stringlengths 201 597k | hash stringlengths 32 32 |
|---|---|---|---|---|
mit | [] | false | Usage ```python from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline model_name = 'w-m-vote-strict-epoch-3' tokenizer = AutoTokenizer.from_pretrained("dccuchile/bert-base-spanish-wwm-uncased") full_model_path = f'MartinoMensio/racism-models-{model_name}' model = AutoModelForSequenceClassification.from_pretrained(full_model_path) pipe = pipeline("text-classification", model = model, tokenizer = tokenizer) texts = [ 'y porqué es lo que hay que hacer con los menas y con los adultos también!!!! NO a los inmigrantes ilegales!!!!', 'Es que los judíos controlan el mundo' ] print(pipe(texts)) | dd0426fa17304824569e33b35ddcd6bd |
apache-2.0 | [] | false | This model is a BERT-based Location Mention Recognition model that is adopted from the [TLLMR4CM GitHub](https://github.com/rsuwaileh/TLLMR4CM/). The model identifies the toponyms' spans in the text and predicts their location types. The location type can be coarse-grained (e.g., country, city, etc.) and fine-grained (e.g., street, POI, etc.) The model is trained using the training splits of all events from [IDRISI-R dataset](https://github.com/rsuwaileh/IDRISI) under the `Type-based` LMR mode and using the `Random` version of the data. You can download this data in `BILOU` format from [here](https://github.com/rsuwaileh/IDRISI/tree/main/data/LMR/AR/gold-random-bilou/). More details about the models are available [here](https://github.com/rsuwaileh/IDRISI/tree/main/models). * Different variants of the model are available through HuggingFace: - [rsuwaileh/IDRISI-LMR-AR-random-typeless](https://huggingface.co/rsuwaileh/IDRISI-LMR-AR-random-typeless/) - [rsuwaileh/IDRISI-LMR-AR-timebased-typeless](https://huggingface.co/rsuwaileh/IDRISI-LMR-AR-timebased-typeless/) - [rsuwaileh/IDRISI-LMR-AR-timebased-typebased](https://huggingface.co/rsuwaileh/IDRISI-LMR-AR-timebased-typebased/) * English models are also available: - [rsuwaileh/IDRISI-LMR-EN-random-typeless](https://huggingface.co/rsuwaileh/IDRISI-LMR-EN-random-typeless/) - [rsuwaileh/IDRISI-LMR-EN-random-typebased](https://huggingface.co/rsuwaileh/IDRISI-LMR-EN-random-typebased/) - [rsuwaileh/IDRISI-LMR-EN-timebased-typeless](https://huggingface.co/rsuwaileh/IDRISI-LMR-EN-timebased-typeless/) - [rsuwaileh/IDRISI-LMR-EN-timebased-typebased](https://huggingface.co/rsuwaileh/IDRISI-LMR-EN-timebased-typebased/) To cite the models: ``` @article{suwaileh2022tlLMR4disaster, title={When a Disaster Happens, We Are Ready: Location Mention Recognition from Crisis Tweets}, author={Suwaileh, Reem and Elsayed, Tamer and Imran, Muhammad and Sajjad, Hassan}, journal={International Journal of Disaster Risk Reduction}, year={2022} } @inproceedings{suwaileh2020tlLMR4disaster, title={Are We Ready for this Disaster? Towards Location Mention Recognition from Crisis Tweets}, author={Suwaileh, Reem and Imran, Muhammad and Elsayed, Tamer and Sajjad, Hassan}, booktitle={Proceedings of the 28th International Conference on Computational Linguistics}, pages={6252--6263}, year={2020} } ``` To cite the IDRISI-R dataset: ``` @article{rsuwaileh2022Idrisi-r, title={IDRISI-R: Large-scale English and Arabic Location Mention Recognition Datasets for Disaster Response over Twitter}, author={Suwaileh, Reem and Elsayed, Tamer and Imran, Muhammad}, journal={...}, volume={...}, pages={...}, year={2022}, publisher={...} } ``` | 4c3b52f9362fddb0dfc21ee9ab7853c1 |
apache-2.0 | ['generated_from_keras_callback'] | false | Electra-base-squad-adversarialqa-epoch-2 This model is a fine-tuned version of [google/electra-base-discriminator](https://huggingface.co/google/electra-base-discriminator) on an unknown dataset. It achieves the following results on the evaluation set: - Train Loss: 0.9140 - Epoch: 1 | 75bcba5f4df5221062f02093db94d2f4 |
apache-2.0 | ['generated_from_keras_callback'] | false | Training hyperparameters The following hyperparameters were used during training: - optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 5e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 43062, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1104, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False} - training_precision: float32 | 66d8c5eb9a82b7ae0594c5519cfd6b07 |
mit | ['generated_from_trainer'] | false | roberta-base-finetuned-swag This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the swag dataset. It achieves the following results on the evaluation set: - Loss: 0.5190 - Accuracy: 0.8260 | d2638a9be259ac23a46d8484b8d55fdb |
mit | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 2 - eval_batch_size: 2 - seed: 42 - distributed_type: IPU - gradient_accumulation_steps: 16 - total_train_batch_size: 32 - total_eval_batch_size: 10 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 3 - training precision: Mixed Precision | 6deb9b64e88537b61940cca41cc0d152 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 1.0993 | 1.0 | 2298 | 0.5474 | 0.7871 | | 0.2222 | 2.0 | 4596 | 0.4744 | 0.8181 | | 0.1633 | 3.0 | 6894 | 0.5190 | 0.8260 | | ee28a0cca067df9344ca106824157c88 |
mit | [] | false | My hero academia style on Stable Diffusion This is the `<MHA style>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb). Here is the new concept you will be able to use as a `style`:         | 94c5c0810d7b34a69a0ef4500635ca34 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-clinc This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset. It achieves the following results on the evaluation set: - Loss: 0.7771 - Accuracy: 0.9135 | 304547c509f8d2e5a677da51a59058ad |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 4.2843 | 1.0 | 318 | 3.2793 | 0.7448 | | 2.6208 | 2.0 | 636 | 1.8750 | 0.8297 | | 1.5453 | 3.0 | 954 | 1.1565 | 0.8919 | | 1.0141 | 4.0 | 1272 | 0.8628 | 0.9090 | | 0.795 | 5.0 | 1590 | 0.7771 | 0.9135 | | d7eb0e1e3e4ef1b91869b6610db9f816 |
apache-2.0 | ['multiberts', 'multiberts-seed_1'] | false | MultiBERTs - Seed 1 MultiBERTs is a collection of checkpoints and a statistical library to support robust research on BERT. We provide 25 BERT-base models trained with similar hyper-parameters as [the original BERT model](https://github.com/google-research/bert) but with different random seeds, which causes variations in the initial weights and order of training instances. The aim is to distinguish findings that apply to a specific artifact (i.e., a particular instance of the model) from those that apply to the more general procedure. We also provide 140 intermediate checkpoints captured during the course of pre-training (we saved 28 checkpoints for the first 5 runs). The models were originally released through [http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our paper [The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163). This is model | 8c046f623cd6190599bcb95b08d322af |
apache-2.0 | ['multiberts', 'multiberts-seed_1'] | false | How to use Using code from [BERT-base uncased](https://huggingface.co/bert-base-uncased), here is an example based on Tensorflow: ``` from transformers import BertTokenizer, TFBertModel tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_1') model = TFBertModel.from_pretrained("google/multiberts-seed_1") text = "Replace me by any text you'd like." encoded_input = tokenizer(text, return_tensors='tf') output = model(encoded_input) ``` PyTorch version: ``` from transformers import BertTokenizer, BertModel tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_1') model = BertModel.from_pretrained("google/multiberts-seed_1") text = "Replace me by any text you'd like." encoded_input = tokenizer(text, return_tensors='pt') output = model(**encoded_input) ``` | 00e227c709777e70112a86105274b501 |
mit | ['PyLaia', 'PyTorch', 'Handwritten text recognition'] | false | Hugin-Munin handwritten text recognition This model performs Handwritten Text Recognition in Norwegian. It was was developed during the [HUGIN-MUNIN project](https://hugin-munin-project.github.io/). | 74cbb10c9f4d41c1b610ee7b2a062501 |
mit | ['PyLaia', 'PyTorch', 'Handwritten text recognition'] | false | Model description The model has been trained using the PyLaia library on the [NorHand](https://zenodo.org/record/6542056) document images. Line bounding boxes were improved using a post-processing step. Training images were resized with a fixed height of 128 pixels, keeping the original aspect ratio. | 1dcf4ff85a69631640c28b341b5dca3b |
mit | ['PyLaia', 'PyTorch', 'Handwritten text recognition'] | false | Evaluation results The model achieves the following results: | set | CER (%) | WER (%) | | ----- | ---------- | --------- | | train | 2.33 | 5.62 | | val | 8.20 | 24.75 | | test | 7.81 | 23.3 | Results improve on validation and test sets when PyLaia is combined with a 6-gram language model. The language model is trained on [this text corpus](https://www.nb.no/sprakbanken/en/resource-catalogue/oai-nb-no-sbr-73/) published by the National Library of Norway. | set | CER (%) | WER (%) | | ----- | ---------- | --------- | | train | 2.62 | 6.13 | | val | 7.01 | 19.75 | | test | 6.75 | 18.22 | | 9122af9ca75c1ae152f3099d456380ce |
mit | ['PyLaia', 'PyTorch', 'Handwritten text recognition'] | false | Cite us! ```bibtex @inproceedings{10.1007/978-3-031-06555-2_27, author = {Maarand, Martin and Beyer, Yngvil and K\r{a}sen, Andre and Fosseide, Knut T. and Kermorvant, Christopher}, title = {A Comprehensive Comparison of Open-Source Libraries for Handwritten Text Recognition in Norwegian}, year = {2022}, isbn = {978-3-031-06554-5}, publisher = {Springer-Verlag}, address = {Berlin, Heidelberg}, url = {https://doi.org/10.1007/978-3-031-06555-2_27}, doi = {10.1007/978-3-031-06555-2_27}, booktitle = {Document Analysis Systems: 15th IAPR International Workshop, DAS 2022, La Rochelle, France, May 22–25, 2022, Proceedings}, pages = {399–413}, numpages = {15}, keywords = {Norwegian language, Open-source, Handwriting recognition}, location = {La Rochelle, France} } ``` | 26ec8cc9458dffa7d6446e7f88a4fa02 |
apache-2.0 | ['generated_from_trainer'] | false | nmt-mpst-id-en-lr_0.0001-ep_30-seq_128_bs-32 This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset. It achieves the following results on the evaluation set: - Loss: 1.8218 - Bleu: 0.1371 - Meteor: 0.294 | b00f6983d97df094d37bf5d94b7372e5 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0001 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 30 | df0cc73818706ecbeefdc00f011609c0 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Bleu | Meteor | |:-------------:|:-----:|:----:|:---------------:|:------:|:------:| | No log | 1.0 | 202 | 2.6357 | 0.042 | 0.1513 | | No log | 2.0 | 404 | 2.4891 | 0.0526 | 0.1749 | | 2.781 | 3.0 | 606 | 2.3754 | 0.062 | 0.1918 | | 2.781 | 4.0 | 808 | 2.2946 | 0.0693 | 0.2047 | | 2.4692 | 5.0 | 1010 | 2.2262 | 0.0779 | 0.2175 | | 2.4692 | 6.0 | 1212 | 2.1729 | 0.0825 | 0.2231 | | 2.4692 | 7.0 | 1414 | 2.1226 | 0.0897 | 0.2328 | | 2.2484 | 8.0 | 1616 | 2.0789 | 0.0932 | 0.2381 | | 2.2484 | 9.0 | 1818 | 2.0450 | 0.1007 | 0.2478 | | 2.099 | 10.0 | 2020 | 2.0132 | 0.1041 | 0.255 | | 2.099 | 11.0 | 2222 | 1.9818 | 0.1085 | 0.2584 | | 2.099 | 12.0 | 2424 | 1.9608 | 0.113 | 0.2639 | | 1.9729 | 13.0 | 2626 | 1.9422 | 0.1165 | 0.2689 | | 1.9729 | 14.0 | 2828 | 1.9223 | 0.1186 | 0.2717 | | 1.8885 | 15.0 | 3030 | 1.9114 | 0.1219 | 0.2757 | | 1.8885 | 16.0 | 3232 | 1.9020 | 0.1238 | 0.2794 | | 1.8885 | 17.0 | 3434 | 1.8827 | 0.1254 | 0.2793 | | 1.8171 | 18.0 | 3636 | 1.8762 | 0.1278 | 0.2824 | | 1.8171 | 19.0 | 3838 | 1.8686 | 0.1298 | 0.285 | | 1.7597 | 20.0 | 4040 | 1.8595 | 0.1307 | 0.2864 | | 1.7597 | 21.0 | 4242 | 1.8533 | 0.1328 | 0.2891 | | 1.7597 | 22.0 | 4444 | 1.8453 | 0.1335 | 0.2901 | | 1.7183 | 23.0 | 4646 | 1.8400 | 0.1347 | 0.2912 | | 1.7183 | 24.0 | 4848 | 1.8342 | 0.135 | 0.2914 | | 1.6893 | 25.0 | 5050 | 1.8308 | 0.1355 | 0.2919 | | 1.6893 | 26.0 | 5252 | 1.8258 | 0.1357 | 0.2924 | | 1.6893 | 27.0 | 5454 | 1.8248 | 0.1365 | 0.2933 | | 1.6667 | 28.0 | 5656 | 1.8233 | 0.137 | 0.294 | | 1.6667 | 29.0 | 5858 | 1.8223 | 0.1371 | 0.2941 | | 1.6585 | 30.0 | 6060 | 1.8218 | 0.1371 | 0.294 | | 7517d8984e774f8725791ea82c4110a2 |
apache-2.0 | ['setfit', 'sentence-transformers', 'text-classification'] | false | davanstrien/dataset_mentions2 This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves: 1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning. 2. Training a classification head with features from the fine-tuned Sentence Transformer. | 3fcc25420ea9a2c5c8c43dff96880071 |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | sentence-transformers/paraphrase-MiniLM-L3-v2 This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search. | f15df99b861e4fc11bdd0a15762278a3 |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | Usage (Sentence-Transformers) Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed: ``` pip install -U sentence-transformers ``` Then you can use the model like this: ```python from sentence_transformers import SentenceTransformer sentences = ["This is an example sentence", "Each sentence is converted"] model = SentenceTransformer('sentence-transformers/paraphrase-MiniLM-L3-v2') embeddings = model.encode(sentences) print(embeddings) ``` | bb8f56340c459b2351edd369813e357f |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | Load model from HuggingFace Hub tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/paraphrase-MiniLM-L3-v2') model = AutoModel.from_pretrained('sentence-transformers/paraphrase-MiniLM-L3-v2') | 1664bf2612190d72fbe363cdb0129e5f |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | Evaluation Results For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/paraphrase-MiniLM-L3-v2) | f85c3c46462420936ddc3521aa16f851 |
apache-2.0 | ['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers'] | false | Full Model Architecture ``` SentenceTransformer( (0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel (1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False}) ) ``` | a69162cda9468333df591be2030324a6 |
apache-2.0 | ['generated_from_trainer'] | false | all-roberta-large-v1-kitchen_and_dining-1-16-5 This model is a fine-tuned version of [sentence-transformers/all-roberta-large-v1](https://huggingface.co/sentence-transformers/all-roberta-large-v1) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 2.3560 - Accuracy: 0.2692 | 968c9796b9335ccde9a611a7f8f80e47 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 2.7421 | 1.0 | 1 | 2.5878 | 0.2012 | | 2.1065 | 2.0 | 2 | 2.4975 | 0.2012 | | 1.5994 | 3.0 | 3 | 2.4274 | 0.2249 | | 1.1739 | 4.0 | 4 | 2.3808 | 0.2456 | | 1.083 | 5.0 | 5 | 2.3560 | 0.2692 | | f7aaeae128a0603cf175fb3e69dbb982 |
mit | ['AMRBART'] | false | AMRBART-large-finetuned-AMR2.0-AMR2Text This model is a fine-tuned version of [AMRBART-large](https://huggingface.co/xfbai/AMRBART-large) on an AMR2.0 dataset. It achieves a sacre-bleu score of 45.7 on the evaluation set: More details are introduced in the paper: [Graph Pre-training for AMR Parsing and Generation](https://arxiv.org/pdf/2203.07836.pdf) by bai et al. in ACL 2022. | c2278aae2f294835a69690ebe0ea215c |
mit | ['AMRBART'] | false | How to use Here is how to initialize this model in PyTorch: ```python from transformers import BartForConditionalGeneration model = BartForConditionalGeneration.from_pretrained("xfbai/AMRBART-large-finetuned-AMR2.0-AMR2Text") ``` Please refer to [this repository](https://github.com/muyeby/AMRBART) for tokenizer initialization and data preprocessing. | 6d483b15dfeb08ae94f6a4fd24c5e4ab |
mit | ['AMRBART'] | false | BibTeX entry and citation info Please cite this paper if you find this model helpful ```bibtex @inproceedings{bai-etal-2022-graph, title = "Graph Pre-training for {AMR} Parsing and Generation", author = "Bai, Xuefeng and Chen, Yulong and Zhang, Yue", booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)", month = may, year = "2022", address = "Online", publisher = "Association for Computational Linguistics", url = "todo", doi = "todo", pages = "todo" } ``` | 05ad1b1be5387cfd17483ae5963ab902 |
mit | ['generated_from_trainer'] | false | predict-perception-xlmr-cause-none This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on an unknown dataset. It achieves the following results on the evaluation set: - Loss: 1.8639 - Rmse: 1.3661 - Rmse Cause::a Spontanea, priva di un agente scatenante: 1.3661 - Mae: 1.0795 - Mae Cause::a Spontanea, priva di un agente scatenante: 1.0795 - R2: -1.7872 - R2 Cause::a Spontanea, priva di un agente scatenante: -1.7872 - Cos: -0.3043 - Pair: 0.0 - Rank: 0.5 - Neighbors: 0.3501 - Rsa: nan | 8bfd4cb5401bed1fdb043ee5d7f473f1 |
mit | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Rmse | Rmse Cause::a Spontanea, priva di un agente scatenante | Mae | Mae Cause::a Spontanea, priva di un agente scatenante | R2 | R2 Cause::a Spontanea, priva di un agente scatenante | Cos | Pair | Rank | Neighbors | Rsa | |:-------------:|:-----:|:----:|:---------------:|:------:|:------------------------------------------------------:|:------:|:-----------------------------------------------------:|:-------:|:----------------------------------------------------:|:-------:|:----:|:----:|:---------:|:---:| | 1.0626 | 1.0 | 15 | 0.6787 | 0.8244 | 0.8244 | 0.7453 | 0.7453 | -0.0149 | -0.0149 | 0.0435 | 0.0 | 0.5 | 0.2515 | nan | | 1.0186 | 2.0 | 30 | 0.6769 | 0.8233 | 0.8233 | 0.7457 | 0.7457 | -0.0122 | -0.0122 | 0.0435 | 0.0 | 0.5 | 0.2515 | nan | | 1.0346 | 3.0 | 45 | 0.6812 | 0.8259 | 0.8259 | 0.7489 | 0.7489 | -0.0187 | -0.0187 | 0.0435 | 0.0 | 0.5 | 0.2515 | nan | | 0.9481 | 4.0 | 60 | 1.0027 | 1.0020 | 1.0020 | 0.8546 | 0.8546 | -0.4994 | -0.4994 | -0.3043 | 0.0 | 0.5 | 0.2579 | nan | | 0.8838 | 5.0 | 75 | 0.9352 | 0.9677 | 0.9677 | 0.8463 | 0.8463 | -0.3985 | -0.3985 | -0.2174 | 0.0 | 0.5 | 0.2966 | nan | | 0.7971 | 6.0 | 90 | 0.9396 | 0.9700 | 0.9700 | 0.8608 | 0.8608 | -0.4050 | -0.4050 | -0.2174 | 0.0 | 0.5 | 0.3156 | nan | | 0.8182 | 7.0 | 105 | 0.9485 | 0.9746 | 0.9746 | 0.8509 | 0.8509 | -0.4184 | -0.4184 | -0.1304 | 0.0 | 0.5 | 0.2788 | nan | | 0.696 | 8.0 | 120 | 1.1396 | 1.0682 | 1.0682 | 0.9309 | 0.9309 | -0.7041 | -0.7041 | -0.1304 | 0.0 | 0.5 | 0.2899 | nan | | 0.6337 | 9.0 | 135 | 1.3064 | 1.1437 | 1.1437 | 0.9612 | 0.9612 | -0.9536 | -0.9536 | -0.3913 | 0.0 | 0.5 | 0.4018 | nan | | 0.5308 | 10.0 | 150 | 1.2403 | 1.1144 | 1.1144 | 0.9359 | 0.9359 | -0.8547 | -0.8547 | -0.3913 | 0.0 | 0.5 | 0.4018 | nan | | 0.5226 | 11.0 | 165 | 1.3433 | 1.1597 | 1.1597 | 0.9542 | 0.9542 | -1.0087 | -1.0087 | -0.3913 | 0.0 | 0.5 | 0.4018 | nan | | 0.474 | 12.0 | 180 | 1.5321 | 1.2386 | 1.2386 | 1.0340 | 1.0340 | -1.2910 | -1.2910 | -0.3043 | 0.0 | 0.5 | 0.3205 | nan | | 0.3899 | 13.0 | 195 | 1.6322 | 1.2784 | 1.2784 | 1.0083 | 1.0083 | -1.4408 | -1.4408 | -0.3043 | 0.0 | 0.5 | 0.3590 | nan | | 0.3937 | 14.0 | 210 | 1.7519 | 1.3244 | 1.3244 | 1.0540 | 1.0540 | -1.6197 | -1.6197 | -0.3913 | 0.0 | 0.5 | 0.4018 | nan | | 0.4128 | 15.0 | 225 | 1.8588 | 1.3643 | 1.3643 | 1.0765 | 1.0765 | -1.7797 | -1.7797 | -0.3913 | 0.0 | 0.5 | 0.4018 | nan | | 0.3424 | 16.0 | 240 | 1.7211 | 1.3128 | 1.3128 | 1.0217 | 1.0217 | -1.5737 | -1.5737 | -0.3913 | 0.0 | 0.5 | 0.4018 | nan | | 0.3307 | 17.0 | 255 | 1.7802 | 1.3351 | 1.3351 | 1.0790 | 1.0790 | -1.6621 | -1.6621 | -0.3043 | 0.0 | 0.5 | 0.3205 | nan | | 0.2972 | 18.0 | 270 | 1.5272 | 1.2366 | 1.2366 | 0.9945 | 0.9945 | -1.2837 | -1.2837 | -0.3043 | 0.0 | 0.5 | 0.3501 | nan | | 0.2862 | 19.0 | 285 | 1.7213 | 1.3128 | 1.3128 | 1.0574 | 1.0574 | -1.5740 | -1.5740 | -0.3913 | 0.0 | 0.5 | 0.3815 | nan | | 0.2844 | 20.0 | 300 | 1.8999 | 1.3793 | 1.3793 | 1.0930 | 1.0930 | -1.8411 | -1.8411 | -0.3043 | 0.0 | 0.5 | 0.3501 | nan | | 0.2404 | 21.0 | 315 | 1.9806 | 1.4082 | 1.4082 | 1.1221 | 1.1221 | -1.9617 | -1.9617 | -0.3913 | 0.0 | 0.5 | 0.3815 | nan | | 0.2349 | 22.0 | 330 | 1.8649 | 1.3665 | 1.3665 | 1.0953 | 1.0953 | -1.7888 | -1.7888 | -0.3913 | 0.0 | 0.5 | 0.3815 | nan | | 0.2323 | 23.0 | 345 | 1.8256 | 1.3520 | 1.3520 | 1.0694 | 1.0694 | -1.7299 | -1.7299 | -0.3913 | 0.0 | 0.5 | 0.4018 | nan | | 0.2217 | 24.0 | 360 | 1.9150 | 1.3847 | 1.3847 | 1.1017 | 1.1017 | -1.8636 | -1.8636 | -0.3043 | 0.0 | 0.5 | 0.3501 | nan | | 0.2262 | 25.0 | 375 | 1.8536 | 1.3624 | 1.3624 | 1.0667 | 1.0667 | -1.7719 | -1.7719 | -0.3043 | 0.0 | 0.5 | 0.3501 | nan | | 0.2052 | 26.0 | 390 | 1.7727 | 1.3323 | 1.3323 | 1.0475 | 1.0475 | -1.6508 | -1.6508 | -0.3043 | 0.0 | 0.5 | 0.3501 | nan | | 0.2121 | 27.0 | 405 | 1.8088 | 1.3458 | 1.3458 | 1.0588 | 1.0588 | -1.7048 | -1.7048 | -0.3043 | 0.0 | 0.5 | 0.3501 | nan | | 0.1723 | 28.0 | 420 | 1.8283 | 1.3530 | 1.3530 | 1.0628 | 1.0628 | -1.7340 | -1.7340 | -0.3043 | 0.0 | 0.5 | 0.3501 | nan | | 0.1932 | 29.0 | 435 | 1.8566 | 1.3635 | 1.3635 | 1.0763 | 1.0763 | -1.7764 | -1.7764 | -0.3043 | 0.0 | 0.5 | 0.3501 | nan | | 0.2157 | 30.0 | 450 | 1.8639 | 1.3661 | 1.3661 | 1.0795 | 1.0795 | -1.7872 | -1.7872 | -0.3043 | 0.0 | 0.5 | 0.3501 | nan | | 54b23adc59b0522b2388bb9220246147 |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_7_0', 'generated_from_trainer', 'robust-speech-event', 'hf-asr-leaderboard'] | false | wav2vec2-large-xls-r-300m-armenian This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_7_0 - HY-AM dataset. It achieves the following results on the evaluation set: - Loss: 0.9669 - Wer: 0.6942 | d1829812b60984b5dceb533d4ac28a85 |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_7_0', 'generated_from_trainer', 'robust-speech-event', 'hf-asr-leaderboard'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0003 - train_batch_size: 32 - eval_batch_size: 32 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 500 - num_epochs: 200.0 - mixed_precision_training: Native AMP | 4588975eb84c7ced8ae712f71047c02a |
apache-2.0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_7_0', 'generated_from_trainer', 'robust-speech-event', 'hf-asr-leaderboard'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:------:|:----:|:---------------:|:------:| | 1.7294 | 27.78 | 500 | 0.8540 | 0.9944 | | 0.8863 | 55.56 | 1000 | 0.7282 | 0.7312 | | 0.5789 | 83.33 | 1500 | 0.8178 | 0.8102 | | 0.3899 | 111.11 | 2000 | 0.8034 | 0.7701 | | 0.2869 | 138.89 | 2500 | 0.9061 | 0.6999 | | 0.1934 | 166.67 | 3000 | 0.9400 | 0.7105 | | 0.1551 | 194.44 | 3500 | 0.9667 | 0.6955 | | b2257ec708134a2187b4e5ddae223e5d |
creativeml-openrail-m | [] | false | waifu diffusion 1.3 base model with dreambooth training on images drawn by the artist "ozadomi" Can be used in StableDiffusion, including the extremely popular Web UI by Automatic1111, like any other model by placing the .CKPT file in the correct directory. Please consult the documentation for your installation of StableDiffusion for more specific instructions. Use "m_ozdartist" to activate | e60388ebf7cf52aad050990f6a5be2da |
mit | [] | false | model by Eddiefloat This your the Stable Diffusion model fine-tuned the kiril concept taught to Stable Diffusion with Dreambooth. It can be used by modifying the `instance_prompt`: **kiril** You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb). And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts) Here are the images used for training this concept:     | 6253eabcc72cfb6360512603eba23c9a |
creativeml-openrail-m | ['text-to-image'] | false | dreambooth-v2-1-512-deluha-0 Dreambooth model trained by tyoyo with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v2-1-512 base model You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts! Sample pictures of: deluha (use that on your prompt)  | b578d3cda72bb448432c52377a0482c3 |
apache-2.0 | ['medical'] | false | Dataset: https://www.kaggle.com/datasets/timmayer/covid-news-articles-2020-2022 Comprehensive guide can be found here: https://medium.com/@shankar.arunp/easily-build-your-own-gpt-from-scratch-using-aws-51811b6355d3 The model is GPT2 further pre-trained on the news articles to incorporate COVID-19 related context to the model. Similar article on how to further pre-train a BERT base model from scratch using the articles can be found here: https://medium.com/@shankar.arunp/training-bert-from-scratch-on-your-custom-domain-data-a-step-by-step-guide-with-amazon-25fcbee4316a | b299334be22c3862580f7f328502e283 |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-base-20sec-timit-and-dementiabank This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.4338 - Wer: 0.2313 | c5e8afca25e19999e95c53c232b7ea5e |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0001 - train_batch_size: 4 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 1000 - num_epochs: 20 - mixed_precision_training: Native AMP | 2b47a7e76a4f966a3a4b0d043e98cf8a |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:------:| | 3.6839 | 2.53 | 500 | 2.7287 | 1.0 | | 0.8708 | 5.05 | 1000 | 0.5004 | 0.3490 | | 0.2879 | 7.58 | 1500 | 0.4411 | 0.2872 | | 0.1877 | 10.1 | 2000 | 0.4359 | 0.2594 | | 0.1617 | 12.63 | 2500 | 0.4404 | 0.2492 | | 0.1295 | 15.15 | 3000 | 0.4356 | 0.2418 | | 0.1146 | 17.68 | 3500 | 0.4338 | 0.2313 | | 6b5e5c6634cd4ad5787a1a9141aa407a |
cc-by-sa-4.0 | ['serbian', 'masked-lm'] | false | Model Description This is a RoBERTa model in Serbian (Cyrillic and Latin) pre-trained on [srWaC](http://hdl.handle.net/11356/1063). You can fine-tune `roberta-base-serbian` for downstream tasks, such as [POS-tagging](https://huggingface.co/KoichiYasuoka/roberta-base-serbian-upos), dependency-parsing, and so on. | cf7a0130520d8d9262dfa7765d393fe8 |
cc-by-sa-4.0 | ['serbian', 'masked-lm'] | false | How to Use ```py from transformers import AutoTokenizer,AutoModelForMaskedLM tokenizer=AutoTokenizer.from_pretrained("KoichiYasuoka/roberta-base-serbian") model=AutoModelForMaskedLM.from_pretrained("KoichiYasuoka/roberta-base-serbian") ``` | f46ebaec4b51b21aa7e3c883c6042b0d |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Wav2Vec2-Large-XLSR-53-Arabic Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Arabic using the [Common Voice](https://huggingface.co/datasets/common_voice). When using this model, make sure that your speech input is sampled at 16kHz. | 69a5f0c17ad8ed05bbc67103b67ea93f |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Usage The model can be used directly (without a language model) as follows: ```python import torch import torchaudio from datasets import load_dataset from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor test_dataset = load_dataset("common_voice", "ar", split="test[:2%]") processor = Wav2Vec2Processor.from_pretrained("othrif/wav2vec2-large-xlsr-arabic") model = Wav2Vec2ForCTC.from_pretrained("othrif/wav2vec2-large-xlsr-arabic") resampler = torchaudio.transforms.Resample(48_000, 16_000) | c52594d3b06dfe29db823393f68bbe70 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Evaluation The model can be evaluated as follows on the Arabic test data of Common Voice. ```python import torch import torchaudio from datasets import load_dataset, load_metric from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor import re test_dataset = load_dataset("common_voice", "ar", split="test") wer = load_metric("wer") processor = Wav2Vec2Processor.from_pretrained("othrif/wav2vec2-large-xlsr-arabic") model = Wav2Vec2ForCTC.from_pretrained("othrif/wav2vec2-large-xlsr-arabic") model.to("cuda") chars_to_ignore_regex = '[\\\\\\\\\\\\\\\\؛\\\\\\\\\\\\\\\\—\\\\\\\\\\\\\\\\_get\\\\\\\\\\\\\\\\«\\\\\\\\\\\\\\\\»\\\\\\\\\\\\\\\\ـ\\\\\\\\\\\\\\\\ـ\\\\\\\\\\\\\\\\,\\\\\\\\\\\\\\\\?\\\\\\\\\\\\\\\\.\\\\\\\\\\\\\\\\!\\\\\\\\\\\\\\\\-\\\\\\\\\\\\\\\\;\\\\\\\\\\\\\\\\:\\\\\\\\\\\\\\\\"\\\\\\\\\\\\\\\\“\\\\\\\\\\\\\\\\%\\\\\\\\\\\\\\\\‘\\\\\\\\\\\\\\\\”\\\\\\\\\\\\\\\\�\\\\\\\\\\\\\\\\ | d8a9b27123494a8578712f507bfffc50 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | We need to read the audio files as arrays def speech_file_to_array_fn(batch): batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower() speech_array, sampling_rate = torchaudio.load(batch["path"]) batch["speech"] = resampler(speech_array).squeeze().numpy() return batch test_dataset = test_dataset.map(speech_file_to_array_fn) | 3d001fe9d8b266c76a6959e0eb9e7f99 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | We need to read the audio files as arrays def evaluate(batch): inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True) with torch.no_grad(): logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits pred_ids = torch.argmax(logits, dim=-1) batch["pred_strings"] = processor.batch_decode(pred_ids) return batch result = test_dataset.map(evaluate, batched=True, batch_size=8) print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"]))) ``` **Test Result**: 46.77 | 5c4e28171b95035f1e8b401114468939 |
apache-2.0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week'] | false | Training The Common Voice `train`, `validation` datasets were used for training. The script used for training can be found [here](https://huggingface.co/othrif/wav2vec2-large-xlsr-arabic/tree/main) | 29f5fd18dc38262970e2069320e8af92 |
apache-2.0 | ['automatic-speech-recognition', 'ar'] | false | exp_w2v2t_ar_vp-es_s601 Fine-tuned [facebook/wav2vec2-large-es-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-es-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (ar)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | fedcb3faa0fc07f00aa8361ee46ade5a |
apache-2.0 | ['generated_from_trainer'] | false | tiny-mlm-glue-wnli-target-glue-wnli This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-wnli](https://huggingface.co/muhtasham/tiny-mlm-glue-wnli) on the None dataset. It achieves the following results on the evaluation set: - Loss: 2.1020 - Accuracy: 0.1127 | f1dd8244d146be40fc367ee77f3d6c49 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.6885 | 25.0 | 500 | 0.7726 | 0.2394 | | 0.658 | 50.0 | 1000 | 1.1609 | 0.0986 | | 0.6084 | 75.0 | 1500 | 1.6344 | 0.1127 | | 0.5481 | 100.0 | 2000 | 2.1020 | 0.1127 | | 23a3f69efe606c2d60f944ad3220d867 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 5e-05 - train_batch_size: 16 - eval_batch_size: 64 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 500 - num_epochs: 3 | c63510283f186ea14c910f6c1a34b44b |
unknown | [] | false | Versions V1: - Fine-tunée avec [Max Woolf's "aitextgen — Train a GPT-2 (or GPT Neo)" colab](https://colab.research.google.com/drive/15qBZx5y9rdaQSyWpsreMDnTiZ5IlN0zD?usp=sharing) - Depuis le modèle gpt-2 124M [aquadzn/gpt2-french](https://github.com/aquadzn/gpt2-french/), version romans. - ~50 minutes on Colab Pro, P100 GPU, 3 batchs, 500 steps | 71c43b5e4c14c942bd57fabf5436d6e0 |
apache-2.0 | [] | false | NLG model trained on the rephrase generation dataset published by Fb Paper : https://research.fb.com/wp-content/uploads/2020/12/Sound-Natural-Content-Rephrasing-in-Dialog-Systems.pdf Paper Abstract : " We introduce a new task of rephrasing for a more natural virtual assistant. Currently, vir- tual assistants work in the paradigm of intent- slot tagging and the slot values are directly passed as-is to the execution engine. However, this setup fails in some scenarios such as mes- saging when the query given by the user needs to be changed before repeating it or sending it to another user. For example, for queries like ‘ask my wife if she can pick up the kids’ or ‘re- mind me to take my pills’, we need to rephrase the content to ‘can you pick up the kids’and ‘take your pills’. In this paper, we study the problem of rephrasing with messaging as a use case and release a dataset of 3000 pairs of original query and rephrased query.. " Training data : http://dl.fbaipublicfiles.com/rephrasing/rephrasing_dataset.tar.gz ```python from transformers import AutoTokenizer, AutoModelWithLMHead tokenizer = AutoTokenizer.from_pretrained("salesken/natural_rephrase") model = AutoModelWithLMHead.from_pretrained("salesken/natural_rephrase") Input_query="Hey Siri, Send message to mom to say thank you for the delicious dinner yesterday" query= Input_query + " ~~ " input_ids = tokenizer.encode(query.lower(), return_tensors='pt') sample_outputs = model.generate(input_ids, do_sample=True, num_beams=1, max_length=len(Input_query), temperature=0.2, top_k = 10, num_return_sequences=1) for i in range(len(sample_outputs)): result = tokenizer.decode(sample_outputs[i], skip_special_tokens=True).split('||')[0].split('~~')[1] print(result) ``` | 4432f7f0e005489483ae53477c95b80a |
creativeml-openrail-m | [] | false | Basic explanation Token and Class words are what guide the AI to produce images similar to the trained style/object/character. Include any mix of these words in the prompt to produce verying results, or exclude them to have a less pronounced effect. There is usually at least a slight stylistic effect even without the words, but it is recommended to include at least one. Adding token word/phrase class word/phrase at the start of the prompt in that order produces results most similar to the trained concept, but they can be included elsewhere as well. Some models produce better results when not including all token/class words. 3k models are are more flexible, while 5k models produce images closer to the trained concept. I recommend 2k/3k models for normal use, and 5k/6k models for model merging and use without token/class words. However it can be also very prompt specific. I highly recommend self-experimentation. These models are subject to the same legal concerns as their base models. | ac17d9b3136986a1d024aed9e39959a0 |
apache-2.0 | ['translation'] | false | opus-mt-ss-en * source languages: ss * target languages: en * OPUS readme: [ss-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/ss-en/README.md) * dataset: opus * model: transformer-align * pre-processing: normalization + SentencePiece * download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/ss-en/opus-2020-01-16.zip) * test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/ss-en/opus-2020-01-16.test.txt) * test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/ss-en/opus-2020-01-16.eval.txt) | dcafa3e37cddde69e0bafa98145591d9 |
apache-2.0 | ['deep-narrow'] | false | T5-Efficient-BASE-DL4 (Deep-Narrow version) T5-Efficient-BASE-DL4 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5). It is a *pretrained-only* checkpoint and was released with the paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*. In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures of similar parameter count. To quote the paper: > We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased > before considering any other forms of uniform scaling across other dimensions. This is largely due to > how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a > tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise, > a tall base model might also generally more efficient compared to a large model. We generally find > that, regardless of size, even if absolute performance might increase as we continue to stack layers, > the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36 > layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e., > params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params, > FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to > consider. To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially. A sequence of word embeddings is therefore processed sequentially by each transformer block. | 22851b1bac214359b09b90582ccf9872 |
apache-2.0 | ['deep-narrow'] | false | Details model architecture This model checkpoint - **t5-efficient-base-dl4** - is of model type **Base** with the following variations: - **dl** is **4** It has **147.4** million parameters and thus requires *ca.* **589.62 MB** of memory in full precision (*fp32*) or **294.81 MB** of memory in half precision (*fp16* or *bf16*). A summary of the *original* T5 model architectures can be seen here: | Model | nl (el/dl) | ff | dm | kv | nh | | 3654f71d6385b9a28d8fd0691c1de0a7 |
creativeml-openrail-m | ['stable-diffusion', 'prompt-generator', 'distilgpt2'] | false | DistilGPT2 Stable Diffusion Model Card <a href="https://huggingface.co/FredZhang7/distilgpt2-stable-diffusion-v2"> <font size="4"> <bold> Version 2 is here! </bold> </font> </a> DistilGPT2 Stable Diffusion is a text generation model used to generate creative and coherent prompts for text-to-image models, given any text. This model was finetuned on 2.03 million descriptive stable diffusion prompts from [Stable Diffusion discord](https://huggingface.co/datasets/bartman081523/stable-diffusion-discord-prompts), [Lexica.art](https://huggingface.co/datasets/Gustavosta/Stable-Diffusion-Prompts), and (my hand-picked) [Krea.ai](https://huggingface.co/datasets/FredZhang7/krea-ai-prompts). I filtered the hand-picked prompts based on the output results from Stable Diffusion v1.4. Compared to other prompt generation models using GPT2, this one runs with 50% faster forwardpropagation and 40% less disk space & RAM. | ec5922089e30af0f1ddb8076a1007ecb |
creativeml-openrail-m | ['stable-diffusion', 'prompt-generator', 'distilgpt2'] | false | print the 10 samples for i in range(len(outs)): outs[i] = str(outs[i]['generated_text']).replace(' ', '') print('\033[96m' + ins + '\033[0m') print('\033[93m' + '\n\n'.join(outs) + '\033[0m') ``` Example Output:  | dd9addf5de3710d78725e52fd85adeea |
creativeml-openrail-m | ['text-to-image', 'stable-diffusion'] | false | blue_back_pack Dreambooth model trained by nsaghatelyan with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb) Sample pictures of this concept: | 7d1db8cfab88c56adc14d7fb4cf7aeac |
mit | ['audio-generation'] | false | !pip install diffusers[torch] accelerate scipy from diffusers import DiffusionPipeline from scipy.io.wavfile import write model_id = "harmonai/jmann-small-190k" pipe = DiffusionPipeline.from_pretrained(model_id) pipe = pipe.to("cuda") audios = pipe(audio_length_in_s=4.0).audios | bcbe9917954eba9f6648d807a8734a51 |
mit | ['audio-generation'] | false | !pip install diffusers[torch] accelerate scipy from diffusers import DiffusionPipeline from scipy.io.wavfile import write import torch model_id = "harmonai/jmann-small-190k" pipe = DiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16) pipe = pipe.to("cuda") audios = pipeline(audio_length_in_s=4.0).audios | 3bd6f6f411486e0e149815df0cadcd7f |
creativeml-openrail-m | ['stable-diffusion', 'text-to-image'] | false | Openjourney v2 is an open source Stable Diffusion fine tuned model on +60k Midjourney images, by [PromptHero](https://prompthero.com/?utm_source=huggingface&utm_medium=referral) This repo is for testing the first Openjourney fine tuned model. It was trained over Stable Diffusion 1.5 with +60000 images, 4500 steps and 3 epochs. So "mdjrny-v4 style" is not necessary anymore (yay!) | b54602377922d1315b6d8b5cf9b14b8c |
apache-2.0 | ['translation'] | false | vie-ita * source group: Vietnamese * target group: Italian * OPUS readme: [vie-ita](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/vie-ita/README.md) * model: transformer-align * source language(s): vie * target language(s): ita * model: transformer-align * pre-processing: normalization + SentencePiece (spm32k,spm32k) * download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/vie-ita/opus-2020-06-17.zip) * test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/vie-ita/opus-2020-06-17.test.txt) * test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/vie-ita/opus-2020-06-17.eval.txt) | 1490b209b6b018104e7ca595000a5443 |
apache-2.0 | ['translation'] | false | System Info: - hf_name: vie-ita - source_languages: vie - target_languages: ita - opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/vie-ita/README.md - original_repo: Tatoeba-Challenge - tags: ['translation'] - languages: ['vi', 'it'] - src_constituents: {'vie', 'vie_Hani'} - tgt_constituents: {'ita'} - src_multilingual: False - tgt_multilingual: False - prepro: normalization + SentencePiece (spm32k,spm32k) - url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/vie-ita/opus-2020-06-17.zip - url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/vie-ita/opus-2020-06-17.test.txt - src_alpha3: vie - tgt_alpha3: ita - short_pair: vi-it - chrF2_score: 0.5479999999999999 - bleu: 31.2 - brevity_penalty: 0.932 - ref_len: 1774.0 - src_name: Vietnamese - tgt_name: Italian - train_date: 2020-06-17 - src_alpha2: vi - tgt_alpha2: it - prefer_old: False - long_pair: vie-ita - helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535 - transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b - port_machine: brutasse - port_time: 2020-08-21-14:41 | 74be8c7a4f27a798b430f4f24cc90642 |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-large-xls-r-300m-turkish-colab This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset. It achieves the following results on the evaluation set: - Loss: 3.2970 - Wer: 1.0 | 778514661171ed2b926d335671263da7 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.1 - train_batch_size: 16 - eval_batch_size: 8 - seed: 42 - gradient_accumulation_steps: 2 - total_train_batch_size: 32 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 500 - num_epochs: 10 - mixed_precision_training: Native AMP | dd520106576fb787ed61616b58c2a1ed |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:---:| | 6.1837 | 3.67 | 400 | 3.2970 | 1.0 | | 0.0 | 7.34 | 800 | 3.2970 | 1.0 | | 15ddb41b296e19150ac49e6207e0c59b |
apache-2.0 | ['background-removal', 'computer-vision', 'image-segmentation'] | false | IS-Net_DIS-general-use * Model Authors: Xuebin Qin, Hang Dai, Xiaobin Hu, Deng-Ping Fan*, Ling Shao, Luc Van Gool * Paper: Highly Accurate Dichotomous Image Segmentation (ECCV 2022 - https://arxiv.org/pdf/2203.03041.pdf * Code Repo: https://github.com/xuebinqin/DIS * Project Homepage: https://xuebinqin.github.io/dis/index.html Note that this is an _optimized_ version of the IS-NET model. From the paper abstract: > [...] we introduce a simple intermediate supervision baseline (IS- Net) using both feature-level and mask-level guidance for DIS model training. Without tricks, IS-Net outperforms var- ious cutting-edge baselines on the proposed DIS5K, mak- ing it a general self-learned supervision network that can help facilitate future research in DIS. 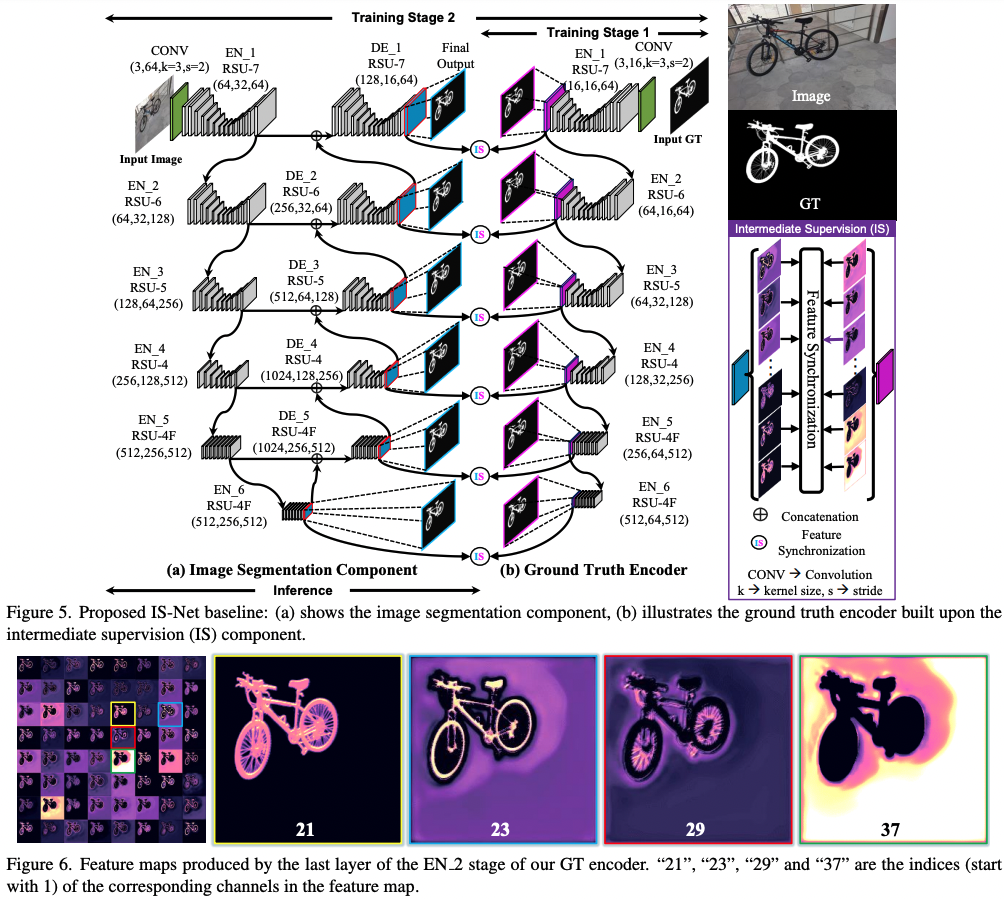 | ff34d7fc1a2f600943155f3645514ca9 |
apache-2.0 | ['background-removal', 'computer-vision', 'image-segmentation'] | false | Citation ``` @InProceedings{qin2022, author={Xuebin Qin and Hang Dai and Xiaobin Hu and Deng-Ping Fan and Ling Shao and Luc Van Gool}, title={Highly Accurate Dichotomous Image Segmentation}, booktitle={ECCV}, year={2022} } ``` | d585fffe8c5895c66945c97d57756c2d |
apache-2.0 | ['generated_from_trainer'] | false | mt5-small-finetuned-1epoch-opus_books-en-to-it This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the opus_books dataset. It achieves the following results on the evaluation set: - Loss: 3.3717 | b03a4aa1db061725dc68b97cfa3f95d7 |
apache-2.0 | ['automatic-speech-recognition', 'de'] | false | exp_w2v2r_de_vp-100k_gender_male-8_female-2_s874 Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0). When using this model, make sure that your speech input is sampled at 16kHz. This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool. | 97be8bd735aafbfb7e39bf9098a91fd0 |
creativeml-openrail-m | ['text-to-image'] | false | CR7_v2_768 Dreambooth model trained by Gumibit with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v2-768 base model You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts! Sample pictures of: CrisRo07 (use that on your prompt)  | 3a76aa24897d3edb59017783e620236a |
apache-2.0 | ['generated_from_trainer'] | false | bert-base-uncased-finetuned-wikitext2 This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset. It achieves the following results on the evaluation set: - Loss: 1.7295 | fae84e3810b6a08cd28d801a2dc7c12b |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | 1.9288 | 1.0 | 2319 | 1.7729 | | 1.8208 | 2.0 | 4638 | 1.7398 | | 1.7888 | 3.0 | 6957 | 1.7523 | | 5543eb7faa648e403c7264207ddeca15 |
apache-2.0 | ['image-classification', 'generated_from_trainer'] | false | vit-base-beans This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset. It achieves the following results on the evaluation set: - Loss: 0.0189 - Accuracy: 1.0 | b3326a81402d4baf7d6038d6f71713c1 |
apache-2.0 | ['image-classification', 'generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0002 - train_batch_size: 16 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - num_epochs: 4 - mixed_precision_training: Native AMP | 8d5aa70ada20b0e86fb5e87e0d7de24f |
apache-2.0 | ['image-classification', 'generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | 0.0568 | 1.54 | 100 | 0.0299 | 1.0 | | 0.0135 | 3.08 | 200 | 0.0189 | 1.0 | | ab0ac30af458c3e73f30a9f3d66319e9 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Model Details Neural machine translation model for translating from South Slavic languages (zls) to German (de). This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train). **Model Description:** - **Developed by:** Language Technology Research Group at the University of Helsinki - **Model Type:** Translation (transformer-big) - **Release**: 2022-07-26 - **License:** CC-BY-4.0 - **Language(s):** - Source Language(s): bos_Latn bul hbs hrv mkd slv srp_Cyrl srp_Latn - Target Language(s): deu - Language Pair(s): bul-deu hbs-deu hrv-deu mkd-deu slv-deu srp_Cyrl-deu srp_Latn-deu - Valid Target Language Labels: - **Original Model**: [opusTCv20210807_transformer-big_2022-07-26.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/zls-deu/opusTCv20210807_transformer-big_2022-07-26.zip) - **Resources for more information:** - [OPUS-MT-train GitHub Repo](https://github.com/Helsinki-NLP/OPUS-MT-train) - More information about released models for this language pair: [OPUS-MT zls-deu README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/zls-deu/README.md) - [More information about MarianNMT models in the transformers library](https://huggingface.co/docs/transformers/model_doc/marian) - [Tatoeba Translation Challenge](https://github.com/Helsinki-NLP/Tatoeba-Challenge/ | 17e4423cb62b90ec84dcec8f8a3debd3 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | How to Get Started With the Model A short example code: ```python from transformers import MarianMTModel, MarianTokenizer src_text = [ "Jesi li ti student?", "Dve stvari deca treba da dobiju od svojih roditelja: korene i krila." ] model_name = "pytorch-models/opus-mt-tc-big-zls-de" tokenizer = MarianTokenizer.from_pretrained(model_name) model = MarianMTModel.from_pretrained(model_name) translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True)) for t in translated: print( tokenizer.decode(t, skip_special_tokens=True) ) | 4fe9d2aa14f5bd827dbd1eef5f86c147 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Zwei Dinge sollten Kinder von ihren Eltern bekommen: Wurzeln und Flügel. ``` You can also use OPUS-MT models with the transformers pipelines, for example: ```python from transformers import pipeline pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-zls-de") print(pipe("Jesi li ti student?")) | d082b24af4975ad2cef6ece1aaa2aeb1 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Training - **Data**: opusTCv20210807 ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge)) - **Pre-processing**: SentencePiece (spm32k,spm32k) - **Model Type:** transformer-big - **Original MarianNMT Model**: [opusTCv20210807_transformer-big_2022-07-26.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/zls-deu/opusTCv20210807_transformer-big_2022-07-26.zip) - **Training Scripts**: [GitHub Repo](https://github.com/Helsinki-NLP/OPUS-MT-train) | 937588bb6f55e4cb3d69ee1c756a4642 |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | Evaluation * test set translations: [opusTCv20210807_transformer-big_2022-07-26.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/zls-deu/opusTCv20210807_transformer-big_2022-07-26.test.txt) * test set scores: [opusTCv20210807_transformer-big_2022-07-26.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/zls-deu/opusTCv20210807_transformer-big_2022-07-26.eval.txt) * benchmark results: [benchmark_results.txt](benchmark_results.txt) * benchmark output: [benchmark_translations.zip](benchmark_translations.zip) | langpair | testset | chr-F | BLEU | | 4066646d6a4ee3d2a2eb40729ccdf09f |
cc-by-4.0 | ['translation', 'opus-mt-tc'] | false | words | |----------|---------|-------|-------|-------|--------| | bul-deu | tatoeba-test-v2021-08-07 | 0.71220 | 54.5 | 314 | 2224 | | hbs-deu | tatoeba-test-v2021-08-07 | 0.71283 | 54.8 | 1959 | 15559 | | hrv-deu | tatoeba-test-v2021-08-07 | 0.69448 | 53.1 | 782 | 5734 | | slv-deu | tatoeba-test-v2021-08-07 | 0.36339 | 21.1 | 492 | 3003 | | srp_Latn-deu | tatoeba-test-v2021-08-07 | 0.72489 | 56.0 | 986 | 8500 | | bul-deu | flores101-devtest | 0.57688 | 28.4 | 1012 | 25094 | | hrv-deu | flores101-devtest | 0.56674 | 27.4 | 1012 | 25094 | | mkd-deu | flores101-devtest | 0.57688 | 29.3 | 1012 | 25094 | | slv-deu | flores101-devtest | 0.56258 | 26.7 | 1012 | 25094 | | srp_Cyrl-deu | flores101-devtest | 0.59271 | 30.7 | 1012 | 25094 | | 259e89326bfa25238998f91413c354da |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-finetuned-imdb This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset. It achieves the following results on the evaluation set: - Loss: 2.4028 | 533f6fe35b02a9d25789d2acdae3b30c |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | |:-------------:|:-----:|:----:|:---------------:| | 2.6323 | 1.0 | 313 | 2.4334 | | 2.5176 | 2.0 | 626 | 2.3852 | | 2.4864 | 3.0 | 939 | 2.3920 | | c9c73040c8af01a5369d4885cc803dd6 |
apache-2.0 | ['generated_from_trainer'] | false | distilbert-base-uncased-distilled-clinc This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset. It achieves the following results on the evaluation set: - Loss: 0.3038 - Accuracy: 0.9465 | cbb6c237ff76d3d1a5e0d2256ba4ed65 |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Accuracy | |:-------------:|:-----:|:----:|:---------------:|:--------:| | No log | 1.0 | 318 | 2.8460 | 0.7506 | | 3.322 | 2.0 | 636 | 1.4301 | 0.8532 | | 3.322 | 3.0 | 954 | 0.7377 | 0.9152 | | 1.2296 | 4.0 | 1272 | 0.4784 | 0.9316 | | 0.449 | 5.0 | 1590 | 0.3730 | 0.9390 | | 0.449 | 6.0 | 1908 | 0.3367 | 0.9429 | | 0.2424 | 7.0 | 2226 | 0.3163 | 0.9468 | | 0.1741 | 8.0 | 2544 | 0.3074 | 0.9452 | | 0.1741 | 9.0 | 2862 | 0.3054 | 0.9458 | | 0.1501 | 10.0 | 3180 | 0.3038 | 0.9465 | | 07736dac8be09bd70abe261ac280c633 |
apache-2.0 | ['generated_from_trainer'] | false | wav2vec2-base-timit-demo-colab This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset. It achieves the following results on the evaluation set: - Loss: 0.4701 - Wer: 0.4537 | dd5265c0b4896f8955eb21672ea4e772 |
apache-2.0 | ['generated_from_trainer'] | false | Training hyperparameters The following hyperparameters were used during training: - learning_rate: 0.0001 - train_batch_size: 32 - eval_batch_size: 8 - seed: 42 - optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 - lr_scheduler_type: linear - lr_scheduler_warmup_steps: 1000 - num_epochs: 10 - mixed_precision_training: Native AMP | bf37b0e3dfddb590cab1806ece924c7b |
apache-2.0 | ['generated_from_trainer'] | false | Training results | Training Loss | Epoch | Step | Validation Loss | Wer | |:-------------:|:-----:|:----:|:---------------:|:------:| | 3.5672 | 4.0 | 500 | 1.6669 | 1.0323 | | 0.6226 | 8.0 | 1000 | 0.4701 | 0.4537 | | 1e3f942f4cf3ef26b7b5302ea7a94638 |
other | [] | false | Upholstery Cleaning Plano TX https://carpetcleaningplanotx.com/upholstery-cleaning.html (469) 444-1903 We remove stains from sofas.When you have a nice, comfortable sofa in your home, spills are common.On that new couch, game day weekends can be difficult.When they are excited about who is winning on the playing field, friends, family, and pets can cause havoc.After a party, upholstery cleaning is not a problem.We can arrive with our mobile unit, which simplifies the task. | ec1718c7f37a31e8af2c948b0a0a637d |
apache-2.0 | [] | false | Model description **CAMeLBERT-Mix DID Madar Corpus26 Model** is a dialect identification (DID) model that was built by fine-tuning the [CAMeLBERT-Mix](https://huggingface.co/CAMeL-Lab/bert-base-arabic-camelbert-mix/) model. For the fine-tuning, we used the [MADAR Corpus 26](https://camel.abudhabi.nyu.edu/madar-shared-task-2019/) dataset, which includes 26 labels. Our fine-tuning procedure and the hyperparameters we used can be found in our paper *"[The Interplay of Variant, Size, and Task Type in Arabic Pre-trained Language Models](https://arxiv.org/abs/2103.06678)."* Our fine-tuning code can be found [here](https://github.com/CAMeL-Lab/CAMeLBERT). | 499b9a4861ec9236526eba6710ec6fed |
apache-2.0 | [] | false | Intended uses You can use the CAMeLBERT-Mix DID Madar Corpus26 model as part of the transformers pipeline. This model will also be available in [CAMeL Tools](https://github.com/CAMeL-Lab/camel_tools) soon. | 95baa2676a08c8f6f222e07aee95e398 |
apache-2.0 | [] | false | How to use To use the model with a transformers pipeline: ```python >>> from transformers import pipeline >>> did = pipeline('text-classification', model='CAMeL-Lab/bert-base-arabic-camelbert-mix-did-madar26') >>> sentences = ['عامل ايه ؟', 'شلونك ؟ شخبارك ؟'] >>> did(sentences) [{'label': 'CAI', 'score': 0.8751305937767029}, {'label': 'DOH', 'score': 0.9867215156555176}] ``` *Note*: to download our models, you would need `transformers>=3.5.0`. Otherwise, you could download the models manually. | 088a7a5f395d294a0035f528d8ac3271 |
mit | [] | false | GerPT2 German large and small versions of GPT2: - https://huggingface.co/benjamin/gerpt2 - https://huggingface.co/benjamin/gerpt2-large See the [GPT2 model card](https://huggingface.co/gpt2) for considerations on limitations and bias. See the [GPT2 documentation](https://huggingface.co/transformers/model_doc/gpt2.html) for details on GPT2. | cb6cd6d2c921db055b629b0690a0cb40 |
mit | [] | false | Comparison to [dbmdz/german-gpt2](https://huggingface.co/dbmdz/german-gpt2) I evaluated both GerPT2-large and the other German GPT2, [dbmdz/german-gpt2](https://huggingface.co/dbmdz/german-gpt2) on the [CC-100](http://data.statmt.org/cc-100/) dataset and on the German Wikipedia: | | CC-100 (PPL) | Wikipedia (PPL) | |-------------------|--------------|-----------------| | dbmdz/german-gpt2 | 49.47 | 62.92 | | GerPT2 | 24.78 | 35.33 | | GerPT2-large | __16.08__ | __23.26__ | | | | | See the script `evaluate.py` in the [GerPT2 Github repository](https://github.com/bminixhofer/gerpt2) for the code. | 806a50ab9e3ef9d83dbc9e560cfaca0f |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.