
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
430 | 2,862,172,125 | IssuesEvent | 2015-06-04 01:42:44 | rancherio/rancher | https://api.github.com/repos/rancherio/rancher | closed | Name is not set for containers deployed as part of a service. | area/service status/blocker status/to-test | Server version - rancher/server:v0.23.0-rc2
Steps to reproduce the problem:
Create a service providing name.
Activate service.
When containers get created , they have no name set.
| 1.0 | Name is not set for containers deployed as part of a service. - Server version - rancher/server:v0.23.0-rc2
Steps to reproduce the problem:
Create a service providing name.
Activate service.
When containers get created , they have no name set.
| non_process | name is not set for containers deployed as part of a service server version rancher server steps to reproduce the problem create a service providing name activate service when containers get created they have no name set | 0 |
17,806 | 6,517,012,795 | IssuesEvent | 2017-08-27 17:24:19 | mikeboers/PyAV | https://api.github.com/repos/mikeboers/PyAV | closed | Python3 on source scripts/activate.sh | bug build | ```
[w495@localhost PyAV]$ python --version
Python 3.6.1 :: Continuum Analytics, Inc.
[w495@localhost PyAV]$
[w495@localhost PyAV]$ source scripts/activate.sh
File "<string>", line 1
import sys; print sys.prefix
^
SyntaxError: invalid syntax
No $PYAV_LIBRARY_NAME set; defaulting ... | 1.0 | Python3 on source scripts/activate.sh - ```
[w495@localhost PyAV]$ python --version
Python 3.6.1 :: Continuum Analytics, Inc.
[w495@localhost PyAV]$
[w495@localhost PyAV]$ source scripts/activate.sh
File "<string>", line 1
import sys; print sys.prefix
^
SyntaxError: invalid syntax... | non_process | on source scripts activate sh python version python continuum analytics inc source scripts activate sh file line import sys print sys prefix syntaxerror invalid syntax no pyav library name set defaulting to ffmpeg no pyav library versi... | 0 |
784,433 | 27,570,590,688 | IssuesEvent | 2023-03-08 08:58:54 | canonical/vanilla-framework | https://api.github.com/repos/canonical/vanilla-framework | closed | Side navigation drawer on small screens doesn't trap the focus | Priority: Medium Bug 🐛 Accessibility | via @petermakowski comment via @petermakowski comment https://github.com/canonical/juju.is/pull/431#issuecomment-1231665391
> [...] the side navigation is missing a focus trap (if you keep pressing `Tab` you'll eventually start tabbing through elements on the page outside of it).
**Describe the bug**
The sid... | 1.0 | Side navigation drawer on small screens doesn't trap the focus - via @petermakowski comment via @petermakowski comment https://github.com/canonical/juju.is/pull/431#issuecomment-1231665391
> [...] the side navigation is missing a focus trap (if you keep pressing `Tab` you'll eventually start tabbing through elements... | non_process | side navigation drawer on small screens doesn t trap the focus via petermakowski comment via petermakowski comment the side navigation is missing a focus trap if you keep pressing tab you ll eventually start tabbing through elements on the page outside of it describe the bug the side navig... | 0 |
5,061 | 7,867,139,482 | IssuesEvent | 2018-06-23 04:08:57 | StrikeNP/trac_test | https://api.github.com/repos/StrikeNP/trac_test | closed | Include Lscale as a new panel in the default plotgen plots (Trac #496) | Migrated from Trac bladornr@uwm.edu enhancement post_processing | We include a lot of variables in our plotgen plots, but we omit one important one, namely, Lscale, which is output in clubb's zt files. Let's output Lscale for all our CLUBB cases on the standard plotgen plots.
The variables to plot in plotgen are specified in the case files. For instance, for RICO, the case file... | 1.0 | Include Lscale as a new panel in the default plotgen plots (Trac #496) - We include a lot of variables in our plotgen plots, but we omit one important one, namely, Lscale, which is output in clubb's zt files. Let's output Lscale for all our CLUBB cases on the standard plotgen plots.
The variables to plot in plotge... | process | include lscale as a new panel in the default plotgen plots trac we include a lot of variables in our plotgen plots but we omit one important one namely lscale which is output in clubb s zt files let s output lscale for all our clubb cases on the standard plotgen plots the variables to plot in plotgen ... | 1 |
547,320 | 16,041,177,771 | IssuesEvent | 2021-04-22 08:05:38 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | openvellum.ecollege.com - site is not usable | browser-firefox engine-gecko os-ios priority-normal | <!-- @browser: Firefox iOS 33.0 -->
<!-- @ua_header: Mozilla/5.0 (iPhone; CPU OS 14_4_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) FxiOS/33.0 Mobile/15E148 Safari/605.1.15 -->
<!-- @reported_with: mobile-reporter -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/71508 -->
**URL**: https:... | 1.0 | openvellum.ecollege.com - site is not usable - <!-- @browser: Firefox iOS 33.0 -->
<!-- @ua_header: Mozilla/5.0 (iPhone; CPU OS 14_4_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) FxiOS/33.0 Mobile/15E148 Safari/605.1.15 -->
<!-- @reported_with: mobile-reporter -->
<!-- @public_url: https://github.com/webco... | non_process | openvellum ecollege com site is not usable url browser version firefox ios operating system ios tested another browser no problem type site is not usable description browser unsupported steps to reproduce doesn’t allow mobile firefox which is disappointi... | 0 |
1,343 | 3,901,647,139 | IssuesEvent | 2016-04-18 11:48:48 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | closed | mRNA stability/turnover/degradation | auto-migrated PomBase RNA processes | 1\.
regulation of mRNA stability \(add related synonym mRNA turnover\)?
Any process that modulates the propensity of mRNA molecules to degradation. Includes processes that both stabilize and destabilize mRNAs.
has no relationship to
mRNA catabolic process
The chemical reactions and pathways resulting in the b... | 1.0 | mRNA stability/turnover/degradation - 1\.
regulation of mRNA stability \(add related synonym mRNA turnover\)?
Any process that modulates the propensity of mRNA molecules to degradation. Includes processes that both stabilize and destabilize mRNAs.
has no relationship to
mRNA catabolic process
The chemical rea... | process | mrna stability turnover degradation regulation of mrna stability add related synonym mrna turnover any process that modulates the propensity of mrna molecules to degradation includes processes that both stabilize and destabilize mrnas has no relationship to mrna catabolic process the chemical rea... | 1 |
8,531 | 11,705,511,057 | IssuesEvent | 2020-03-07 16:20:43 | Jeffail/benthos | https://api.github.com/repos/Jeffail/benthos | closed | Add flatten as a json operator | enhancement processors | ```json
{
"a": "b",
"c": { "d": "e", "f": "g" },
"h": [
{ "i": "j" },
{ "k": "l" }
]
}
```
becomes
```
{
"a": "b",
"c.d": "e",
"c.f": "g",
"h.0.i": "j",
"h.1.k": "l"
}
```
Not sure on the best representation of arrays, but a feature that flattened the json would be v... | 1.0 | Add flatten as a json operator - ```json
{
"a": "b",
"c": { "d": "e", "f": "g" },
"h": [
{ "i": "j" },
{ "k": "l" }
]
}
```
becomes
```
{
"a": "b",
"c.d": "e",
"c.f": "g",
"h.0.i": "j",
"h.1.k": "l"
}
```
Not sure on the best representation of arrays, but a feature t... | process | add flatten as a json operator json a b c d e f g h i j k l becomes a b c d e c f g h i j h k l not sure on the best representation of arrays but a feature t... | 1 |
10,927 | 13,726,946,577 | IssuesEvent | 2020-10-04 03:14:00 | SpencerTSterling/AdvancedWebsite | https://api.github.com/repos/SpencerTSterling/AdvancedWebsite | closed | Set up Continuous Integration with GitHub Actions | dev process | GitHub actions should be used to build the project on each commit | 1.0 | Set up Continuous Integration with GitHub Actions - GitHub actions should be used to build the project on each commit | process | set up continuous integration with github actions github actions should be used to build the project on each commit | 1 |
237,342 | 19,617,870,523 | IssuesEvent | 2022-01-07 00:07:51 | kubernetes/test-infra | https://api.github.com/repos/kubernetes/test-infra | closed | Feature request: ability to search through component logs from CI runs | area/prow sig/testing kind/feature lifecycle/rotten | <!-- Please only use this template for submitting enhancement requests -->
/area prow
**What would you like to be added**:
Search capability for CI logs so I can search for jobs that match certain failure text. For example, I would really like to be able to search for `Observed a panic` in component logs and f... | 1.0 | Feature request: ability to search through component logs from CI runs - <!-- Please only use this template for submitting enhancement requests -->
/area prow
**What would you like to be added**:
Search capability for CI logs so I can search for jobs that match certain failure text. For example, I would really... | non_process | feature request ability to search through component logs from ci runs area prow what would you like to be added search capability for ci logs so i can search for jobs that match certain failure text for example i would really like to be able to search for observed a panic in component logs and f... | 0 |
12,514 | 14,963,807,346 | IssuesEvent | 2021-01-27 11:04:20 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [PM] [Audit Logs] 'studyId','siteId' and 'appId' is incorrect for the events | Bug P2 Participant manager datastore Process: Fixed Process: Tested dev | **Issue 1: 'studyId','siteId' and 'appId' is incorrect for the events**
1. SITE_ADDED_FOR_STUDY
2. PARTICIPANT_EMAIL_ADDED
3. PARTICIPANTS_EMAIL_LIST_IMPORTED
4. PARTICIPANTS_EMAIL_LIST_IMPORT_FAILED
5. PARTICIPANTS_EMAIL_LIST_IMPORT_PARTIAL_FAILED
6. SITE_DECOMMISSIONED_FOR_STUDY
7. SITE_ACTIVATED_FOR_STUDY... | 2.0 | [PM] [Audit Logs] 'studyId','siteId' and 'appId' is incorrect for the events - **Issue 1: 'studyId','siteId' and 'appId' is incorrect for the events**
1. SITE_ADDED_FOR_STUDY
2. PARTICIPANT_EMAIL_ADDED
3. PARTICIPANTS_EMAIL_LIST_IMPORTED
4. PARTICIPANTS_EMAIL_LIST_IMPORT_FAILED
5. PARTICIPANTS_EMAIL_LIST_IMPO... | process | studyid siteid and appid is incorrect for the events issue studyid siteid and appid is incorrect for the events site added for study participant email added participants email list imported participants email list import failed participants email list import partial fai... | 1 |
68,129 | 8,216,809,553 | IssuesEvent | 2018-09-05 10:18:42 | WordPress/gutenberg | https://api.github.com/repos/WordPress/gutenberg | closed | Transform "Fix Toolbar to Top" into "Focus Mode" | Needs Design Feedback [Type] Enhancement | Inspired by the "Focus" mode that @mtias introduced in #8920, I'd like to propose we try a different kind of Focus Mode.
## Problem
A key feedback point we hear is that Gutenberg’s interface can be a little overwhelming. This often comes from users who more commonly focus on "writing" versus "building" their post... | 1.0 | Transform "Fix Toolbar to Top" into "Focus Mode" - Inspired by the "Focus" mode that @mtias introduced in #8920, I'd like to propose we try a different kind of Focus Mode.
## Problem
A key feedback point we hear is that Gutenberg’s interface can be a little overwhelming. This often comes from users who more commo... | non_process | transform fix toolbar to top into focus mode inspired by the focus mode that mtias introduced in i d like to propose we try a different kind of focus mode problem a key feedback point we hear is that gutenberg’s interface can be a little overwhelming this often comes from users who more commonly... | 0 |
7,615 | 4,020,461,369 | IssuesEvent | 2016-05-16 18:30:00 | mitchellh/packer | https://api.github.com/repos/mitchellh/packer | opened | Azure: Where's the Best Error Message | builder/azure | A customer experienced an issue when the *capture_name_prefix* was set to an unacceptable value (#3535). The method signature for the API call returns an HTTP response and an error. The Azure builder code discards the HTTP response, and checks the error only. The error's message is not intuitive, and does not return ... | 1.0 | Azure: Where's the Best Error Message - A customer experienced an issue when the *capture_name_prefix* was set to an unacceptable value (#3535). The method signature for the API call returns an HTTP response and an error. The Azure builder code discards the HTTP response, and checks the error only. The error's messag... | non_process | azure where s the best error message a customer experienced an issue when the capture name prefix was set to an unacceptable value the method signature for the api call returns an http response and an error the azure builder code discards the http response and checks the error only the error s message i... | 0 |
19,053 | 25,068,200,200 | IssuesEvent | 2022-11-07 10:01:30 | ESMValGroup/ESMValCore | https://api.github.com/repos/ESMValGroup/ESMValCore | closed | Anomaly calculation for OBS got broken early march. | bug preprocessor | **Describe the bug**
Unfortunately, it seems like none of the tests has flagged (something to look into later I would say!). But for several observational datasets the calculation of anomalies goes wrong with non-physical values coming out of the preprocessor. I could track down the problems to 3-4 March 2020. With ev... | 1.0 | Anomaly calculation for OBS got broken early march. - **Describe the bug**
Unfortunately, it seems like none of the tests has flagged (something to look into later I would say!). But for several observational datasets the calculation of anomalies goes wrong with non-physical values coming out of the preprocessor. I c... | process | anomaly calculation for obs got broken early march describe the bug unfortunately it seems like none of the tests has flagged something to look into later i would say but for several observational datasets the calculation of anomalies goes wrong with non physical values coming out of the preprocessor i c... | 1 |
20,781 | 27,518,422,464 | IssuesEvent | 2023-03-06 13:34:04 | oda-hub/dispatcher-app | https://api.github.com/repos/oda-hub/dispatcher-app | opened | if we have several frontends, each requesting the same dispatcher, what is the proper value for product_url option? | multi-process | asked by @dsavchenko
https://github.com/oda-hub/oda_api/issues/189 | 1.0 | if we have several frontends, each requesting the same dispatcher, what is the proper value for product_url option? - asked by @dsavchenko
https://github.com/oda-hub/oda_api/issues/189 | process | if we have several frontends each requesting the same dispatcher what is the proper value for product url option asked by dsavchenko | 1 |
22,690 | 15,378,073,333 | IssuesEvent | 2021-03-02 17:51:26 | department-of-veterans-affairs/va.gov-team | https://api.github.com/repos/department-of-veterans-affairs/va.gov-team | closed | Salesforce-GIBFT Connection for vets-api in STAGING not working | backend external-request infrastructure operations security | ## Description
Salesforce-GIBFT Connection for vets-api in STAGING is not working and VSP Operations DevOps engineers have been brought in to help debug and fix the connection. Users of the front end application are receiving an error when trying to submit data through the GI Bill Feedback Tool (https://staging.va.gov... | 1.0 | Salesforce-GIBFT Connection for vets-api in STAGING not working - ## Description
Salesforce-GIBFT Connection for vets-api in STAGING is not working and VSP Operations DevOps engineers have been brought in to help debug and fix the connection. Users of the front end application are receiving an error when trying to su... | non_process | salesforce gibft connection for vets api in staging not working description salesforce gibft connection for vets api in staging is not working and vsp operations devops engineers have been brought in to help debug and fix the connection users of the front end application are receiving an error when trying to su... | 0 |
44,709 | 11,493,613,457 | IssuesEvent | 2020-02-11 23:27:30 | ShabadOS/database | https://api.github.com/repos/ShabadOS/database | opened | Bot transformations on data via command line commit? | Priority: 2 Medium Scope: Build Status: In Research Type: Question | Let's say someone wants to make a mass change across all of the gurmukhi (renaming the field from "gurmukhi" to "bani" or such), or fixes a typo in the author's name. It affects like 4000 files, the transformation is applied locally, and then committed and diffed on GH.
Anyone looking at this might be confused on ho... | 1.0 | Bot transformations on data via command line commit? - Let's say someone wants to make a mass change across all of the gurmukhi (renaming the field from "gurmukhi" to "bani" or such), or fixes a typo in the author's name. It affects like 4000 files, the transformation is applied locally, and then committed and diffed o... | non_process | bot transformations on data via command line commit let s say someone wants to make a mass change across all of the gurmukhi renaming the field from gurmukhi to bani or such or fixes a typo in the author s name it affects like files the transformation is applied locally and then committed and diffed on g... | 0 |
9,790 | 12,805,793,127 | IssuesEvent | 2020-07-03 08:13:58 | prisma/prisma | https://api.github.com/repos/prisma/prisma | closed | Add new line checks to integration tests | kind/improvement process/candidate team/typescript topic: tests | Due to differences in operating systems / environment, I could not get the recent change of [adding trailing empty lines](https://github.com/prisma/prisma-engines/commit/ea035543e59571161e00ccd4063f5638283bfba7) working in the integration tests.
Instead for now I added a `.trim()` call to those tests to make them work... | 1.0 | Add new line checks to integration tests - Due to differences in operating systems / environment, I could not get the recent change of [adding trailing empty lines](https://github.com/prisma/prisma-engines/commit/ea035543e59571161e00ccd4063f5638283bfba7) working in the integration tests.
Instead for now I added a `.tr... | process | add new line checks to integration tests due to differences in operating systems environment i could not get the recent change of working in the integration tests instead for now i added a trim call to those tests to make them work we should look into it and find a way to get the tests running witho... | 1 |
22,753 | 32,074,922,908 | IssuesEvent | 2023-09-25 10:21:31 | equinor/flyt | https://api.github.com/repos/equinor/flyt | closed | Add Threat Modeling to issue templates | process improvement | Add threat modeling as a development checklist point in issue templates to make sure we continuously perform threat modeling. | 1.0 | Add Threat Modeling to issue templates - Add threat modeling as a development checklist point in issue templates to make sure we continuously perform threat modeling. | process | add threat modeling to issue templates add threat modeling as a development checklist point in issue templates to make sure we continuously perform threat modeling | 1 |
3,189 | 6,259,501,777 | IssuesEvent | 2017-07-14 18:13:12 | PeaceGeeksSociety/salesforce | https://api.github.com/repos/PeaceGeeksSociety/salesforce | opened | Publicize PeaceTalks, hackathons, volunteer/job opportunities to garner participants | Community Processes Recruitment Processes | We would like to publicize PeaceTalks, hackathons and volunteer/job opportunities with PG for the purpose of garnering participants.
Done when:
- PeaceTals: filter and send mail merge emails to PeaceTalks marketers, including: relevant student associations, academic departments, relevant professors, community group... | 2.0 | Publicize PeaceTalks, hackathons, volunteer/job opportunities to garner participants - We would like to publicize PeaceTalks, hackathons and volunteer/job opportunities with PG for the purpose of garnering participants.
Done when:
- PeaceTals: filter and send mail merge emails to PeaceTalks marketers, including: re... | process | publicize peacetalks hackathons volunteer job opportunities to garner participants we would like to publicize peacetalks hackathons and volunteer job opportunities with pg for the purpose of garnering participants done when peacetals filter and send mail merge emails to peacetalks marketers including re... | 1 |
11,467 | 14,289,748,127 | IssuesEvent | 2020-11-23 19:45:44 | Maximus5/ConEmu | https://api.github.com/repos/Maximus5/ConEmu | closed | "Failed to create/open registry key" popup | processes | ### Versions
ConEmu build: 201101 x64
OS version: Windows 10 x64
### Problem description
I've manually denied permission "Create Subkey" for HKCU\Console.
The reason is that I don't want every single app to have its own console settings permanently changed and stored there when I change their console propertie... | 1.0 | "Failed to create/open registry key" popup - ### Versions
ConEmu build: 201101 x64
OS version: Windows 10 x64
### Problem description
I've manually denied permission "Create Subkey" for HKCU\Console.
The reason is that I don't want every single app to have its own console settings permanently changed and store... | process | failed to create open registry key popup versions conemu build os version windows problem description i ve manually denied permission create subkey for hkcu console the reason is that i don t want every single app to have its own console settings permanently changed and stored there wh... | 1 |
10,490 | 13,257,910,830 | IssuesEvent | 2020-08-20 14:42:26 | kubeflow/kubeflow | https://api.github.com/repos/kubeflow/kubeflow | closed | PodDefaults needs an OWNERs file | area/community kind/process priority/p1 | /kind process
The directory for the PodDefaults controller is missing an OWNERs file
https://github.com/kubeflow/kubeflow/tree/master/components/admission-webhook
We should also consider renaming the directory.
@yanniszark mentioned in kubeflow/community#381 he might be willing to be an OWNER.
@discordianf... | 1.0 | PodDefaults needs an OWNERs file - /kind process
The directory for the PodDefaults controller is missing an OWNERs file
https://github.com/kubeflow/kubeflow/tree/master/components/admission-webhook
We should also consider renaming the directory.
@yanniszark mentioned in kubeflow/community#381 he might be will... | process | poddefaults needs an owners file kind process the directory for the poddefaults controller is missing an owners file we should also consider renaming the directory yanniszark mentioned in kubeflow community he might be willing to be an owner discordianfish might also be interested | 1 |
10,083 | 13,044,161,980 | IssuesEvent | 2020-07-29 03:47:28 | tikv/tikv | https://api.github.com/repos/tikv/tikv | closed | UCP: Migrate scalar function `SubTimeDurationNull` from TiDB | challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor |
## Description
Port the scalar function `SubTimeDurationNull` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src... | 2.0 | UCP: Migrate scalar function `SubTimeDurationNull` from TiDB -
## Description
Port the scalar function `SubTimeDurationNull` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- htt... | process | ucp migrate scalar function subtimedurationnull from tidb description port the scalar function subtimedurationnull from tidb to coprocessor score mentor s maplefu recommended skills rust programming learning materials already implemented expressions ported from tidb ... | 1 |
19,931 | 26,397,570,712 | IssuesEvent | 2023-01-12 20:58:45 | GoogleCloudPlatform/spring-cloud-gcp | https://api.github.com/repos/GoogleCloudPlatform/spring-cloud-gcp | closed | Missing information about Spring Cloud GCP 3.4.1 | priority: p1 type: process | I noticed that Spring Cloud GCP 3.4.1 was released to Maven Central last week: https://search.maven.org/artifact/com.google.cloud/spring-cloud-gcp-dependencies
However, there is no mention of version 3.4.1 on https://github.com/GoogleCloudPlatform/spring-cloud-gcp, which still lists 3.4.0 as the current version.
... | 1.0 | Missing information about Spring Cloud GCP 3.4.1 - I noticed that Spring Cloud GCP 3.4.1 was released to Maven Central last week: https://search.maven.org/artifact/com.google.cloud/spring-cloud-gcp-dependencies
However, there is no mention of version 3.4.1 on https://github.com/GoogleCloudPlatform/spring-cloud-gcp, ... | process | missing information about spring cloud gcp i noticed that spring cloud gcp was released to maven central last week however there is no mention of version on which still lists as the current version version is also not mentioned in the or overviews where can i... | 1 |
447,795 | 31,722,711,891 | IssuesEvent | 2023-09-10 15:44:01 | Reesfarrington/AGICyberSecTools- | https://api.github.com/repos/Reesfarrington/AGICyberSecTools- | opened | Lesson 1 GitHub Link on ipynb | documentation | So I'm new to the whole actual doings of this but I would like a link to the GitHub (even though it's on GitHub and hr YouTubelink as well. | 1.0 | Lesson 1 GitHub Link on ipynb - So I'm new to the whole actual doings of this but I would like a link to the GitHub (even though it's on GitHub and hr YouTubelink as well. | non_process | lesson github link on ipynb so i m new to the whole actual doings of this but i would like a link to the github even though it s on github and hr youtubelink as well | 0 |
11,626 | 14,485,398,912 | IssuesEvent | 2020-12-10 17:32:15 | Feryi/5a | https://api.github.com/repos/Feryi/5a | opened | fill_size_estimating_template | process_dashboard | -llenado de estimacion de linjeas de codigo en process dashboard y correr el probe wizard | 1.0 | fill_size_estimating_template - -llenado de estimacion de linjeas de codigo en process dashboard y correr el probe wizard | process | fill size estimating template llenado de estimacion de linjeas de codigo en process dashboard y correr el probe wizard | 1 |
1,178 | 3,681,568,353 | IssuesEvent | 2016-02-24 04:11:52 | 18F/FEC | https://api.github.com/repos/18F/FEC | closed | Positive: Calendar features | processed |
## What were you trying to do and how can we improve it?
I was checking out the cool new calendar features
## General feedback?
I like them!
## Tell us about yourself
I'm new to FEC.GOV
## Details
* URL: https://fec-proxy.18f.gov/calendar/
* User Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.10; rv:44.0... | 1.0 | Positive: Calendar features -
## What were you trying to do and how can we improve it?
I was checking out the cool new calendar features
## General feedback?
I like them!
## Tell us about yourself
I'm new to FEC.GOV
## Details
* URL: https://fec-proxy.18f.gov/calendar/
* User Agent: Mozilla/5.0 (Macintosh;... | process | positive calendar features what were you trying to do and how can we improve it i was checking out the cool new calendar features general feedback i like them tell us about yourself i m new to fec gov details url user agent mozilla macintosh intel mac os x rv gecko ... | 1 |
17,748 | 23,660,934,689 | IssuesEvent | 2022-08-26 15:30:08 | carbon-design-system/ibm-cloud-cognitive | https://api.github.com/repos/carbon-design-system/ibm-cloud-cognitive | opened | Update release review guidelines and template | type: process improvement | Discussing with @matthewgallo, we found some areas where we could clarify or elaborate further in our release review process.
> The UI produced is accessible, responsive, translatable, cross-browser, and responds to the currently set Carbon theme.
This step requires several important checks but wraps them into a sing... | 1.0 | Update release review guidelines and template - Discussing with @matthewgallo, we found some areas where we could clarify or elaborate further in our release review process.
> The UI produced is accessible, responsive, translatable, cross-browser, and responds to the currently set Carbon theme.
This step requires sev... | process | update release review guidelines and template discussing with matthewgallo we found some areas where we could clarify or elaborate further in our release review process the ui produced is accessible responsive translatable cross browser and responds to the currently set carbon theme this step requires sev... | 1 |
135,073 | 18,666,843,881 | IssuesEvent | 2021-10-30 01:08:43 | capitalone/global-attribution-mapping | https://api.github.com/repos/capitalone/global-attribution-mapping | opened | CVE-2021-42343 (High) detected in dask-2021.2.0-py3-none-any.whl | security vulnerability | ## CVE-2021-42343 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>dask-2021.2.0-py3-none-any.whl</b></p></summary>
<p>Parallel PyData with Task Scheduling</p>
<p>Library home page: <a ... | True | CVE-2021-42343 (High) detected in dask-2021.2.0-py3-none-any.whl - ## CVE-2021-42343 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>dask-2021.2.0-py3-none-any.whl</b></p></summary>
<p... | non_process | cve high detected in dask none any whl cve high severity vulnerability vulnerable library dask none any whl parallel pydata with task scheduling library home page a href path to dependency file global attribution mapping path to vulnerable library global attribut... | 0 |
15,605 | 19,728,131,972 | IssuesEvent | 2022-01-13 22:15:50 | DSpace/dspace-angular | https://api.github.com/repos/DSpace/dspace-angular | closed | Scripts & processes without parameter | bug e/2 tools:processes | **Describe the bug**
When starting a process without parameter, Angular refuses to start the process. This happens when no parameter was selected (but there was one), or for a script without parameters
**To Reproduce**
Steps to reproduce the behavior:
1. Open /processes/new in Angular
2. Start a process without ... | 1.0 | Scripts & processes without parameter - **Describe the bug**
When starting a process without parameter, Angular refuses to start the process. This happens when no parameter was selected (but there was one), or for a script without parameters
**To Reproduce**
Steps to reproduce the behavior:
1. Open /processes/new... | process | scripts processes without parameter describe the bug when starting a process without parameter angular refuses to start the process this happens when no parameter was selected but there was one or for a script without parameters to reproduce steps to reproduce the behavior open processes new... | 1 |
368,650 | 10,882,640,897 | IssuesEvent | 2019-11-18 01:22:21 | ArcBlock/forge-cli | https://api.github.com/repos/ArcBlock/forge-cli | closed | support custom config by a config file when create a chain | priority/blocking-dev | And some commands should support --yes param for automation:
1. forge chain:create
1. forge config | 1.0 | support custom config by a config file when create a chain - And some commands should support --yes param for automation:
1. forge chain:create
1. forge config | non_process | support custom config by a config file when create a chain and some commands should support yes param for automation forge chain create forge config | 0 |
8,970 | 12,086,628,740 | IssuesEvent | 2020-04-18 10:56:10 | spring-projects/spring-hateoas | https://api.github.com/repos/spring-projects/spring-hateoas | closed | URLs cannot contain a colon | process: waiting for feedback type: bug | I'm trying to create a resource whose ID contains a colon (f.e. "AB:TRE"). When I use createResourceWithId(), a UriComponentsBuilder is used to split the id wrongly into a scheme and ssp, even though it should only be part of the path. Thus, the resulting uri does not contain the id.
According to the relevant RFC 3986... | 1.0 | URLs cannot contain a colon - I'm trying to create a resource whose ID contains a colon (f.e. "AB:TRE"). When I use createResourceWithId(), a UriComponentsBuilder is used to split the id wrongly into a scheme and ssp, even though it should only be part of the path. Thus, the resulting uri does not contain the id.
Acco... | process | urls cannot contain a colon i m trying to create a resource whose id contains a colon f e ab tre when i use createresourcewithid a uricomponentsbuilder is used to split the id wrongly into a scheme and ssp even though it should only be part of the path thus the resulting uri does not contain the id acco... | 1 |
100,265 | 12,512,377,182 | IssuesEvent | 2020-06-02 22:38:11 | microsoft/vscode-azurestorage | https://api.github.com/repos/microsoft/vscode-azurestorage | reopened | The rule of naming resource group is unfriendly when creating a basic storage account | AT-CTI by design | **OS:** Mac
**Build Version:** 20200531.1
**Repro Steps:**
1. Create a basic storage account with name "test".
2. Delete this storage account.
3. Create a basic "test" storage account again.
4. Check the output log.
**Expect:**
The log should show "Creating resource group '**test1**' in location 'westus'... | 1.0 | The rule of naming resource group is unfriendly when creating a basic storage account - **OS:** Mac
**Build Version:** 20200531.1
**Repro Steps:**
1. Create a basic storage account with name "test".
2. Delete this storage account.
3. Create a basic "test" storage account again.
4. Check the output log.
**E... | non_process | the rule of naming resource group is unfriendly when creating a basic storage account os mac build version repro steps create a basic storage account with name test delete this storage account create a basic test storage account again check the output log expect ... | 0 |
11,816 | 14,631,549,773 | IssuesEvent | 2020-12-23 20:09:51 | googleapis/google-api-java-client | https://api.github.com/repos/googleapis/google-api-java-client | closed | CLIRR errors at head | type: process | [ERROR] 7006: com.google.api.client.googleapis.extensions.android.gms.auth.GooglePlayServicesAvailabilityIOException: Return type of method 'public com.google.android.gms.auth.GoogleAuthException getCause()' has been changed to java.lang.Throwable
[ERROR] 7006: com.google.api.client.googleapis.extensions.android.gms.a... | 1.0 | CLIRR errors at head - [ERROR] 7006: com.google.api.client.googleapis.extensions.android.gms.auth.GooglePlayServicesAvailabilityIOException: Return type of method 'public com.google.android.gms.auth.GoogleAuthException getCause()' has been changed to java.lang.Throwable
[ERROR] 7006: com.google.api.client.googleapis.e... | process | clirr errors at head com google api client googleapis extensions android gms auth googleplayservicesavailabilityioexception return type of method public com google android gms auth googleauthexception getcause has been changed to java lang throwable com google api client googleapis extensions android ... | 1 |
117,717 | 15,167,873,397 | IssuesEvent | 2021-02-12 18:28:41 | invenia/Transforms.jl | https://api.github.com/repos/invenia/Transforms.jl | opened | Use a consistent convention for `dims` | design | The `apply` method for `AbstractArray` in `transformers.jl` [uses `mapslices`](https://github.com/invenia/Transforms.jl/blob/0f49caa1fa35a7253c5880389aeee56e8630b458/src/transformers.jl#L75) to apply a transform on each slice of the array, along a given dimension `dims`.
Meanwhile, the equivalent `apply!` method [us... | 1.0 | Use a consistent convention for `dims` - The `apply` method for `AbstractArray` in `transformers.jl` [uses `mapslices`](https://github.com/invenia/Transforms.jl/blob/0f49caa1fa35a7253c5880389aeee56e8630b458/src/transformers.jl#L75) to apply a transform on each slice of the array, along a given dimension `dims`.
Mean... | non_process | use a consistent convention for dims the apply method for abstractarray in transformers jl to apply a transform on each slice of the array along a given dimension dims meanwhile the equivalent apply method the problem is that mapslices and eachslice have opposite notions of dims f... | 0 |
4,061 | 6,993,787,933 | IssuesEvent | 2017-12-15 12:54:55 | allinurl/goaccess | https://api.github.com/repos/allinurl/goaccess | closed | View details of per virtual host (filtering) | log-processing question | Hi Developers,
Thanks for this great application, it really helps me a lot.
There are many virtual hosting in my server.
Is it possible to view the detail of one selected virtual host ?
Thanks. | 1.0 | View details of per virtual host (filtering) - Hi Developers,
Thanks for this great application, it really helps me a lot.
There are many virtual hosting in my server.
Is it possible to view the detail of one selected virtual host ?
Thanks. | process | view details of per virtual host filtering hi developers thanks for this great application it really helps me a lot there are many virtual hosting in my server is it possible to view the detail of one selected virtual host thanks | 1 |
415,885 | 28,057,194,413 | IssuesEvent | 2023-03-29 10:08:25 | fedora-infra/fmn | https://api.github.com/repos/fedora-infra/fmn | closed | Document Architecture | documentation fmn-next | # Story
As a contributor to FMN,
I want that its architecture is documented,
so that I can get up to speed quickly and contribute effectively.
# Acceptance Criteria
- [x] Documentation exists describing the components that make up FMN, and how they relate to each other as well as services in Fedora infrastru... | 1.0 | Document Architecture - # Story
As a contributor to FMN,
I want that its architecture is documented,
so that I can get up to speed quickly and contribute effectively.
# Acceptance Criteria
- [x] Documentation exists describing the components that make up FMN, and how they relate to each other as well as serv... | non_process | document architecture story as a contributor to fmn i want that its architecture is documented so that i can get up to speed quickly and contribute effectively acceptance criteria documentation exists describing the components that make up fmn and how they relate to each other as well as servic... | 0 |
14,017 | 16,816,819,480 | IssuesEvent | 2021-06-17 08:23:08 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [iOS] Form step > Stats and Trends are not updated instantly unless user logs out and logs in | Bug P1 Process: Fixed Process: Tested QA Process: Tested dev iOS | **Steps:**
1. Add an activity with stats and Trends enabled for a form step
2. Submit the response from iOS mobile
3. Navigate to dashboard
4. Observe the stats and trends
**Actual:** Stats and Trends are not updated instantly unless user logs out and logs in
**Expected:** Stats and trends should be updated... | 3.0 | [iOS] Form step > Stats and Trends are not updated instantly unless user logs out and logs in - **Steps:**
1. Add an activity with stats and Trends enabled for a form step
2. Submit the response from iOS mobile
3. Navigate to dashboard
4. Observe the stats and trends
**Actual:** Stats and Trends are not update... | process | form step stats and trends are not updated instantly unless user logs out and logs in steps add an activity with stats and trends enabled for a form step submit the response from ios mobile navigate to dashboard observe the stats and trends actual stats and trends are not updated in... | 1 |
308,399 | 26,604,855,427 | IssuesEvent | 2023-01-23 18:27:24 | tailscale/tailscale | https://api.github.com/repos/tailscale/tailscale | opened | TestC2NPingRequest is flaky | testing | https://github.com/tailscale/corp/actions/runs/3989076415/jobs/6841058944
<details>
<summary>Click to expand test logs</summary>
```
panic: test timed out after 10m0s
goroutine 511 [running]:
testing.(*M).startAlarm.func1()
/home/ubuntu/.cache/tailscale-go/src/testing/testing.go:2036 +0xb4
created by t... | 1.0 | TestC2NPingRequest is flaky - https://github.com/tailscale/corp/actions/runs/3989076415/jobs/6841058944
<details>
<summary>Click to expand test logs</summary>
```
panic: test timed out after 10m0s
goroutine 511 [running]:
testing.(*M).startAlarm.func1()
/home/ubuntu/.cache/tailscale-go/src/testing/testi... | non_process | is flaky click to expand test logs panic test timed out after goroutine testing m startalarm home ubuntu cache tailscale go src testing testing go created by time gofunc home ubuntu cache tailscale go src time sleep go goroutine testing trunner ... | 0 |
27,215 | 4,288,086,238 | IssuesEvent | 2016-07-17 07:10:10 | ItsMeSterling/teenmade | https://api.github.com/repos/ItsMeSterling/teenmade | closed | Onboarding skip shop creation | Ready for Retest | After the page where you add your username and skills it takes you to a shop creation. . . If you want to make it so when you create profile it takes you to your profile rather than that page. . . We might add it later, so don't remove it completely. | 1.0 | Onboarding skip shop creation - After the page where you add your username and skills it takes you to a shop creation. . . If you want to make it so when you create profile it takes you to your profile rather than that page. . . We might add it later, so don't remove it completely. | non_process | onboarding skip shop creation after the page where you add your username and skills it takes you to a shop creation if you want to make it so when you create profile it takes you to your profile rather than that page we might add it later so don t remove it completely | 0 |
20,811 | 27,571,709,035 | IssuesEvent | 2023-03-08 09:48:41 | xataio/xata-py | https://api.github.com/repos/xataio/xata-py | opened | Filter to only failing records in `failed_batches` | bulk-processor | Currently, all records from a batch are stored in the `failed_batches` items. Filter out the records that went through and only keep the failed ones keep. | 1.0 | Filter to only failing records in `failed_batches` - Currently, all records from a batch are stored in the `failed_batches` items. Filter out the records that went through and only keep the failed ones keep. | process | filter to only failing records in failed batches currently all records from a batch are stored in the failed batches items filter out the records that went through and only keep the failed ones keep | 1 |
128,749 | 18,070,118,152 | IssuesEvent | 2021-09-21 01:13:23 | Tim-sandbox/barista | https://api.github.com/repos/Tim-sandbox/barista | opened | CVE-2021-3803 (Medium) detected in nth-check-1.0.2.tgz, nth-check-2.0.0.tgz | security vulnerability | ## CVE-2021-3803 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>nth-check-1.0.2.tgz</b>, <b>nth-check-2.0.0.tgz</b></p></summary>
<p>
<details><summary><b>nth-check-1.0.2.tgz</b><... | True | CVE-2021-3803 (Medium) detected in nth-check-1.0.2.tgz, nth-check-2.0.0.tgz - ## CVE-2021-3803 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>nth-check-1.0.2.tgz</b>, <b>nth-check-... | non_process | cve medium detected in nth check tgz nth check tgz cve medium severity vulnerability vulnerable libraries nth check tgz nth check tgz nth check tgz performant nth check parser compiler library home page a href path to dependency file bar... | 0 |
10,425 | 13,218,134,271 | IssuesEvent | 2020-08-17 08:11:13 | bisq-network/proposals | https://api.github.com/repos/bisq-network/proposals | closed | Content of the proposal details should be committed when proposal phase is over | a:proposal an:idea help wanted re:processes was:stalled | When a contributor files a proposal in the Bisq app they have to add the link to the Github issue where the content of the proposal is described.
Once the proposal period has ended the content of that link should be persisted to an immutable datastore so it cannot be changed or deleted.
It would be good if we ca... | 1.0 | Content of the proposal details should be committed when proposal phase is over - When a contributor files a proposal in the Bisq app they have to add the link to the Github issue where the content of the proposal is described.
Once the proposal period has ended the content of that link should be persisted to an im... | process | content of the proposal details should be committed when proposal phase is over when a contributor files a proposal in the bisq app they have to add the link to the github issue where the content of the proposal is described once the proposal period has ended the content of that link should be persisted to an im... | 1 |
11,594 | 14,448,151,903 | IssuesEvent | 2020-12-08 05:37:17 | A01731346/5a | https://api.github.com/repos/A01731346/5a | opened | complete_size_estimating_template | process-dashboard | Completar el formato de estimación de LOC con los valores reales obtenidos. | 1.0 | complete_size_estimating_template - Completar el formato de estimación de LOC con los valores reales obtenidos. | process | complete size estimating template completar el formato de estimación de loc con los valores reales obtenidos | 1 |
3,401 | 6,519,225,907 | IssuesEvent | 2017-08-28 11:51:08 | openvstorage/framework | https://api.github.com/repos/openvstorage/framework | closed | Display overview of storage nodes connected to a cluster similar to storage routers. | process_wontfix type_feature | If you install your cluster, you only see your storage nodes when you create a backend.
Wouldn't it be sane to add a page similar to that of the storage routers to the GUI?
| 1.0 | Display overview of storage nodes connected to a cluster similar to storage routers. - If you install your cluster, you only see your storage nodes when you create a backend.
Wouldn't it be sane to add a page similar to that of the storage routers to the GUI?
| process | display overview of storage nodes connected to a cluster similar to storage routers if you install your cluster you only see your storage nodes when you create a backend wouldn t it be sane to add a page similar to that of the storage routers to the gui | 1 |
13,859 | 16,617,648,448 | IssuesEvent | 2021-06-02 18:56:44 | googleapis/python-access-context-manager | https://api.github.com/repos/googleapis/python-access-context-manager | opened | Generate proto-plus types for this library | type: process | This library currently generates [`_pb2.py`](https://github.com/googleapis/python-access-context-manager/blob/master/google/identity/accesscontextmanager/v1/access_level_pb2.py) types via protoc.
I would like to move this set of protos to be generated via bazel. The repository will look like a full GAPIC library but... | 1.0 | Generate proto-plus types for this library - This library currently generates [`_pb2.py`](https://github.com/googleapis/python-access-context-manager/blob/master/google/identity/accesscontextmanager/v1/access_level_pb2.py) types via protoc.
I would like to move this set of protos to be generated via bazel. The repos... | process | generate proto plus types for this library this library currently generates types via protoc i would like to move this set of protos to be generated via bazel the repository will look like a full gapic library but only have types no services if access context manager adds a service in the future the chang... | 1 |
7,888 | 11,053,844,697 | IssuesEvent | 2019-12-10 12:16:58 | code4romania/expert-consultation-api | https://api.github.com/repos/code4romania/expert-consultation-api | closed | [Documents] Modify comment feature to take into account the new document format | document processing documents enhancement help wanted java spring | The Comment feature needs to be adapted to the changes to the document structure.
The article, chapter and document controllers need to be changed into a single controller for DocumentSection / DocumentNode comments.
The comment data model needs to be updated.
Linked to #64 | 1.0 | [Documents] Modify comment feature to take into account the new document format - The Comment feature needs to be adapted to the changes to the document structure.
The article, chapter and document controllers need to be changed into a single controller for DocumentSection / DocumentNode comments.
The comment dat... | process | modify comment feature to take into account the new document format the comment feature needs to be adapted to the changes to the document structure the article chapter and document controllers need to be changed into a single controller for documentsection documentnode comments the comment data model ne... | 1 |
34,493 | 2,781,551,954 | IssuesEvent | 2015-05-06 13:58:53 | handsontable/handsontable | https://api.github.com/repos/handsontable/handsontable | closed | minSpareRows > 0 crashes in datamap.get | Priority: normal | for (var i = 0, ilen = sliced.length; i < ilen; i++) {
out = out[sliced[i]];
if (typeof out === 'undefined') {
return null;
}
}
error: out is undefined
when you specify columns in which an array is inside an object, like:
columns: [
... | 1.0 | minSpareRows > 0 crashes in datamap.get - for (var i = 0, ilen = sliced.length; i < ilen; i++) {
out = out[sliced[i]];
if (typeof out === 'undefined') {
return null;
}
}
error: out is undefined
when you specify columns in which an array is inside an obj... | non_process | minsparerows crashes in datamap get for var i ilen sliced length i ilen i out out if typeof out undefined return null error out is undefined when you specify columns in which an array is inside an object like... | 0 |
7,965 | 11,147,134,021 | IssuesEvent | 2019-12-23 11:41:30 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | Question | Pri2 cxp doc-enhancement machine-learning/svc team-data-science-process/subsvc triaged | What's the point in using blob storage as a staging area for data transfer? Why isn't the data copied directly from SQL server to SQL Azure?
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 7827f519-aa8a-94e2-fd41-a0bda4ae8efb
* Version Indep... | 1.0 | Question - What's the point in using blob storage as a staging area for data transfer? Why isn't the data copied directly from SQL server to SQL Azure?
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 7827f519-aa8a-94e2-fd41-a0bda4ae8efb
* Ve... | process | question what s the point in using blob storage as a staging area for data transfer why isn t the data copied directly from sql server to sql azure document details ⚠ do not edit this section it is required for docs microsoft com ➟ github issue linking id version independent id ... | 1 |
21,283 | 28,455,678,875 | IssuesEvent | 2023-04-17 06:52:00 | TUM-Dev/NavigaTUM | https://api.github.com/repos/TUM-Dev/NavigaTUM | opened | [Entry] [5505.01.501]: Koordinate bearbeiten | entry webform delete-after-processing | Hallo, ich möchte diese Koordinate zum Roomfinder hinzufügen:
```yaml
"5505.01.501": { lat: 48.26555143737818, lon: 11.66884114191862 }
``` | 1.0 | [Entry] [5505.01.501]: Koordinate bearbeiten - Hallo, ich möchte diese Koordinate zum Roomfinder hinzufügen:
```yaml
"5505.01.501": { lat: 48.26555143737818, lon: 11.66884114191862 }
``` | process | koordinate bearbeiten hallo ich möchte diese koordinate zum roomfinder hinzufügen yaml lat lon | 1 |
10,672 | 13,460,464,385 | IssuesEvent | 2020-09-09 13:39:10 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | reopened | possible obsoletion "actin filament REorganization" | PomBase cellular processes | There are a bunch of terms
Process GO:0090527 actin filament reorganization
Process GO:0031532 actin cytoskeleton reorganization
Process GO:2000249 regulation of actin cytoskeleton reorganization
Process GO:0030037 actin filament reorganization involved in cell cycle
Process GO:2000250 negative regulat... | 1.0 | possible obsoletion "actin filament REorganization" - There are a bunch of terms
Process GO:0090527 actin filament reorganization
Process GO:0031532 actin cytoskeleton reorganization
Process GO:2000249 regulation of actin cytoskeleton reorganization
Process GO:0030037 actin filament reorganization involve... | process | possible obsoletion actin filament reorganization there are a bunch of terms process go actin filament reorganization process go actin cytoskeleton reorganization process go regulation of actin cytoskeleton reorganization process go actin filament reorganization involved in cell cycle proces... | 1 |
256,859 | 22,106,988,794 | IssuesEvent | 2022-06-01 17:46:28 | elastic/kibana | https://api.github.com/repos/elastic/kibana | opened | Failing test: X-Pack Saved Object Tagging API Integration Tests - Security and Spaces integration.x-pack/test/saved_object_tagging/api_integration/security_and_spaces/apis/get·ts - saved objects tagging API - security and spaces integration GET /api/saved_objects_tagging/tags/{id} "after all" hook for "returns expected... | failed-test | A test failed on a tracked branch
```
ResponseError: {"took":20,"timed_out":false,"total":5,"deleted":0,"batches":1,"version_conflicts":0,"noops":0,"retries":{"bulk":0,"search":0},"throttled_millis":0,"requests_per_second":-1,"throttled_until_millis":0,"failures":[{"index":".kibana_1","id":"space:space_1","cause":{"ty... | 1.0 | Failing test: X-Pack Saved Object Tagging API Integration Tests - Security and Spaces integration.x-pack/test/saved_object_tagging/api_integration/security_and_spaces/apis/get·ts - saved objects tagging API - security and spaces integration GET /api/saved_objects_tagging/tags/{id} "after all" hook for "returns expected... | non_process | failing test x pack saved object tagging api integration tests security and spaces integration x pack test saved object tagging api integration security and spaces apis get·ts saved objects tagging api security and spaces integration get api saved objects tagging tags id after all hook for returns expected... | 0 |
15,186 | 18,955,752,423 | IssuesEvent | 2021-11-18 20:02:46 | bazelbuild/bazel | https://api.github.com/repos/bazelbuild/bazel | closed | How to use protobuf well-known types in Bazel 4.2.1 | type: support / not a bug (process) untriaged | ### Problem description
I'd like to use google protobuf + bazel to set up communication between C++ and python parts of my program. I've got the following WORKSPACE file:
```
load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_archive")
http_archive(
name = "com_google_protobuf",
strip_prefix =... | 1.0 | How to use protobuf well-known types in Bazel 4.2.1 - ### Problem description
I'd like to use google protobuf + bazel to set up communication between C++ and python parts of my program. I've got the following WORKSPACE file:
```
load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_archive")
http_archive(
... | process | how to use protobuf well known types in bazel problem description i d like to use google protobuf bazel to set up communication between c and python parts of my program i ve got the following workspace file load bazel tools tools build defs repo http bzl http archive http archive ... | 1 |
52,344 | 22,155,746,358 | IssuesEvent | 2022-06-03 22:26:20 | hashicorp/terraform-provider-azurerm | https://api.github.com/repos/hashicorp/terraform-provider-azurerm | closed | Representation examples not working for Azure API operation requests or responses | bug crash service/api-management | <!--- Please keep this note for the community --->
### Community Note
* Please vote on this issue by adding a 👍 [reaction](https://blog.github.com/2016-03-10-add-reactions-to-pull-requests-issues-and-comments/) to the original issue to help the community and maintainers prioritize this request
* Please do not l... | 1.0 | Representation examples not working for Azure API operation requests or responses - <!--- Please keep this note for the community --->
### Community Note
* Please vote on this issue by adding a 👍 [reaction](https://blog.github.com/2016-03-10-add-reactions-to-pull-requests-issues-and-comments/) to the original is... | non_process | representation examples not working for azure api operation requests or responses community note please vote on this issue by adding a 👍 to the original issue to help the community and maintainers prioritize this request please do not leave or me too comments they generate extra noise fo... | 0 |
17,176 | 22,752,547,219 | IssuesEvent | 2022-07-07 14:09:31 | MicrosoftDocs/azure-docs | https://api.github.com/repos/MicrosoftDocs/azure-docs | closed | 'Third-party application access via OAuth' must be enabled (non-default) in order for this to work | automation/svc triaged cxp doc-enhancement process-automation/subsvc Pri2 | I was trying to set this up with a brand new Azure DevOps organisation and Azure Automation today and got 'SourceControls securityToken in invalid'
This is similar to the issue described here:
https://docs.microsoft.com/en-us/answers/questions/813444/an-error-occurred-while-creating-the-source-contro.html
I fo... | 1.0 | 'Third-party application access via OAuth' must be enabled (non-default) in order for this to work - I was trying to set this up with a brand new Azure DevOps organisation and Azure Automation today and got 'SourceControls securityToken in invalid'
This is similar to the issue described here:
https://docs.microso... | process | third party application access via oauth must be enabled non default in order for this to work i was trying to set this up with a brand new azure devops organisation and azure automation today and got sourcecontrols securitytoken in invalid this is similar to the issue described here i found that i ... | 1 |
12,763 | 15,116,341,626 | IssuesEvent | 2021-02-09 06:33:41 | yuta252/startlens_learning | https://api.github.com/repos/yuta252/startlens_learning | closed | TripletLossモデルへのサンプルデータ取得 | dev process | ## 概要
#1 で加工編集した画像ファイルから学習モデルへの入力層に渡す入力サンプルデータを生成する必要がある。
そこでGenerateSample classを実装した。
## 変更点
- input_generator.pyの作成
## サンプルデータの生成方法
TripletLossはanchor_inputとpositive_inputの距離をより小さくし、anchor_inputとnegative_inputの距離をより大きくするようにDeepLearningのパラメータを学習する方法である。そのため入力層へは3つのサンプルデータが必要となる。
* **anchor_i... | 1.0 | TripletLossモデルへのサンプルデータ取得 - ## 概要
#1 で加工編集した画像ファイルから学習モデルへの入力層に渡す入力サンプルデータを生成する必要がある。
そこでGenerateSample classを実装した。
## 変更点
- input_generator.pyの作成
## サンプルデータの生成方法
TripletLossはanchor_inputとpositive_inputの距離をより小さくし、anchor_inputとnegative_inputの距離をより大きくするようにDeepLearningのパラメータを学習する方法である。そのため入力層へは3つのサンプルデ... | process | tripletlossモデルへのサンプルデータ取得 概要 で加工編集した画像ファイルから学習モデルへの入力層に渡す入力サンプルデータを生成する必要がある。 そこでgeneratesample classを実装した。 変更点 input generator pyの作成 サンプルデータの生成方法 tripletlossはanchor inputとpositive inputの距離をより小さくし、anchor inputとnegative inputの距離をより大きくするようにdeeplearningのパラメータを学習する方法である。 。 anch... | 1 |
16,333 | 20,990,575,671 | IssuesEvent | 2022-03-29 08:56:03 | elastic/beats | https://api.github.com/repos/elastic/beats | closed | [Filebeat] decode_cef - recover from errors in the CEF header | bug Filebeat :Processors Team:Security-External Integrations | It would be nice if the CEF parser would recover from errors detected in the CEF header and try to resume parsing the CEF extensions. For example the header on this message is incomplete, but the remainder of the CEF extensions are good.
`Feb 11 19:12:22 ec2-54-211-162-22 2022-02-11 19:12:22,962 sentinel - CEF:0|... | 1.0 | [Filebeat] decode_cef - recover from errors in the CEF header - It would be nice if the CEF parser would recover from errors detected in the CEF header and try to resume parsing the CEF extensions. For example the header on this message is incomplete, but the remainder of the CEF extensions are good.
`Feb 11 19:12:2... | process | decode cef recover from errors in the cef header it would be nice if the cef parser would recover from errors detected in the cef header and try to resume parsing the cef extensions for example the header on this message is incomplete but the remainder of the cef extensions are good feb ... | 1 |
10,431 | 13,219,872,872 | IssuesEvent | 2020-08-17 11:19:37 | bisq-network/proposals | https://api.github.com/repos/bisq-network/proposals | closed | Create financial reserves and fix a resource leak | a:proposal re:processes | > _This is a Bisq Network proposal. Please familiarize yourself with the [submission and review process](https://docs.bisq.network/proposals.html)._
- there is a leak in Bisq that can cause Bisq revenue (created by trading fees payed in BTC) to not reach contributors
- fix it by stopping public trade events
- this... | 1.0 | Create financial reserves and fix a resource leak - > _This is a Bisq Network proposal. Please familiarize yourself with the [submission and review process](https://docs.bisq.network/proposals.html)._
- there is a leak in Bisq that can cause Bisq revenue (created by trading fees payed in BTC) to not reach contributo... | process | create financial reserves and fix a resource leak this is a bisq network proposal please familiarize yourself with the there is a leak in bisq that can cause bisq revenue created by trading fees payed in btc to not reach contributors fix it by stopping public trade events this supersedes n... | 1 |
8,697 | 11,839,973,467 | IssuesEvent | 2020-03-23 18:01:58 | prusa3d/PrusaSlicer | https://api.github.com/repos/prusa3d/PrusaSlicer | closed | Slicer can not slice anymore when deleting models while post processing script runs | background processing | ### Version
1.36.2
### Operating system type + version
Mac OS 10.12.5
### Behavior
Export gcode, while post processing runs click delete all. Drop another model into Slic3r, slice now button remains deactivated.
I'm using a GPX post processing and some magic to add information about material need and time req... | 1.0 | Slicer can not slice anymore when deleting models while post processing script runs - ### Version
1.36.2
### Operating system type + version
Mac OS 10.12.5
### Behavior
Export gcode, while post processing runs click delete all. Drop another model into Slic3r, slice now button remains deactivated.
I'm using a ... | process | slicer can not slice anymore when deleting models while post processing script runs version operating system type version mac os behavior export gcode while post processing runs click delete all drop another model into slice now button remains deactivated i m using a gpx post... | 1 |
4,266 | 7,189,385,934 | IssuesEvent | 2018-02-02 13:51:57 | Great-Hill-Corporation/quickBlocks | https://api.github.com/repos/Great-Hill-Corporation/quickBlocks | closed | Weird idea for syncing an Ethereum node | apps-blockScrape status-inprocess type-enhancement | 1. Find out how far back the --warp node stores full blocks and balance info
2. Run a full, archive node, and store all the blocks in QuickBlocks
3. After catching up to the --warp node, the archive node can be shut down (since QuickBlocks has a backed up history).
4. Shut down the archive node and work only with th... | 1.0 | Weird idea for syncing an Ethereum node - 1. Find out how far back the --warp node stores full blocks and balance info
2. Run a full, archive node, and store all the blocks in QuickBlocks
3. After catching up to the --warp node, the archive node can be shut down (since QuickBlocks has a backed up history).
4. Shut d... | process | weird idea for syncing an ethereum node find out how far back the warp node stores full blocks and balance info run a full archive node and store all the blocks in quickblocks after catching up to the warp node the archive node can be shut down since quickblocks has a backed up history shut d... | 1 |
20,419 | 27,080,522,041 | IssuesEvent | 2023-02-14 13:44:23 | evidence-dev/evidence | https://api.github.com/repos/evidence-dev/evidence | closed | Improved testing in development workspace | dev-process | It's clear to contributors how to add tests to the development workspace. Immediate goal here is _not_ high test coverage, just getting the systems in place in the development workspace.
Tests should include at least one example of:
- [ ] Unit testing supporting modules
- [ ] Unit testing an internal API
- [x] B... | 1.0 | Improved testing in development workspace - It's clear to contributors how to add tests to the development workspace. Immediate goal here is _not_ high test coverage, just getting the systems in place in the development workspace.
Tests should include at least one example of:
- [ ] Unit testing supporting modules... | process | improved testing in development workspace it s clear to contributors how to add tests to the development workspace immediate goal here is not high test coverage just getting the systems in place in the development workspace tests should include at least one example of unit testing supporting modules ... | 1 |
14,039 | 16,845,531,615 | IssuesEvent | 2021-06-19 11:54:53 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | closed | Performance regression: Process.GetCurrentProcess().Dispose() on Windows | area-System.Diagnostics.Process tenet-performance up-for-grabs | It looks like `Process.GetCurrentProcess()` have regressed on Windows.
```cmd
git clone https://github.com/dotnet/performance.git
cd performance
# if you don't have cli installed and want python script to download the latest cli for you
py .\scripts\benchmarks_ci.py -f netcoreapp2.2 netcoreapp3.0 --filter System... | 1.0 | Performance regression: Process.GetCurrentProcess().Dispose() on Windows - It looks like `Process.GetCurrentProcess()` have regressed on Windows.
```cmd
git clone https://github.com/dotnet/performance.git
cd performance
# if you don't have cli installed and want python script to download the latest cli for you
p... | process | performance regression process getcurrentprocess dispose on windows it looks like process getcurrentprocess have regressed on windows cmd git clone cd performance if you don t have cli installed and want python script to download the latest cli for you py scripts benchmarks ci py f ... | 1 |
9,066 | 12,138,926,484 | IssuesEvent | 2020-04-23 18:02:09 | GoogleCloudPlatform/python-docs-samples | https://api.github.com/repos/GoogleCloudPlatform/python-docs-samples | closed | remove gcp-devrel-py-tools from jobs/v3/api_client/requirements-test.txt | priority: p2 remove-gcp-devrel-py-tools type: process | remove gcp-devrel-py-tools from jobs/v3/api_client/requirements-test.txt | 1.0 | remove gcp-devrel-py-tools from jobs/v3/api_client/requirements-test.txt - remove gcp-devrel-py-tools from jobs/v3/api_client/requirements-test.txt | process | remove gcp devrel py tools from jobs api client requirements test txt remove gcp devrel py tools from jobs api client requirements test txt | 1 |
151,073 | 23,756,172,837 | IssuesEvent | 2022-09-01 03:27:33 | open-mmlab/mmengine | https://api.github.com/repos/open-mmlab/mmengine | closed | Unify the copy directory of config and model-index.yml. | P1 need-design | Unify the copy directory of config and model-index.yml, which are currently copied to package/.mim in mim. Consider copy to package/.mmengine? | 1.0 | Unify the copy directory of config and model-index.yml. - Unify the copy directory of config and model-index.yml, which are currently copied to package/.mim in mim. Consider copy to package/.mmengine? | non_process | unify the copy directory of config and model index yml unify the copy directory of config and model index yml which are currently copied to package mim in mim consider copy to package mmengine | 0 |
19,379 | 6,718,370,829 | IssuesEvent | 2017-10-15 12:01:34 | azerothcore/azerothcore-wotlk | https://api.github.com/repos/azerothcore/azerothcore-wotlk | closed | Cmake Issuse | type: build type: enhancement type: question | Hello,
I did everything according to the instructions and gives me a problem when cmake.
>
> "CMake Error at C:/Program Files/CMake/share/cmake-3.7/Modules/FindPackageHandleStandardArgs.cmake:138 (message):
> Could NOT find OpenSSL (missing: OPENSSL_LIBRARIES OPENSSL_INCLUDE_DIR)
> Call Stack (most recent c... | 1.0 | Cmake Issuse - Hello,
I did everything according to the instructions and gives me a problem when cmake.
>
> "CMake Error at C:/Program Files/CMake/share/cmake-3.7/Modules/FindPackageHandleStandardArgs.cmake:138 (message):
> Could NOT find OpenSSL (missing: OPENSSL_LIBRARIES OPENSSL_INCLUDE_DIR)
> Call Stack... | non_process | cmake issuse hello i did everything according to the instructions and gives me a problem when cmake cmake error at c program files cmake share cmake modules findpackagehandlestandardargs cmake message could not find openssl missing openssl libraries openssl include dir call stack ... | 0 |
698 | 3,194,196,399 | IssuesEvent | 2015-09-30 10:38:04 | arduino/Arduino | https://api.github.com/repos/arduino/Arduino | closed | Poor error description! | Component: Preprocessor Type: Bug | Hey,
I happened to miss one "

which got the IDE to stop / loop, it's been about 10 minutes now.
I run on W7 pro 64-bit. sp1, Arduino-1.6.6-nightly-windows_2015-07-03
/ Sincerely BG | 1.0 | Poor error description! - Hey,
I happened to miss one "

which got the IDE to stop / loop, it's been about 10 minutes now.
I run on W7 pro 64-bit. sp1, Arduino-1.6.6-nightly-windows_2015-07-03
/ Si... | process | poor error description hey i happened to miss one which got the ide to stop loop it s been about minutes now i run on pro bit arduino nightly windows sincerely bg | 1 |
129,471 | 18,102,524,889 | IssuesEvent | 2021-09-22 15:32:44 | gms-ws-demo/JS-Demo-Sep2021 | https://api.github.com/repos/gms-ws-demo/JS-Demo-Sep2021 | opened | WS-2018-0076 (Medium) detected in tunnel-agent-0.4.3.tgz | security vulnerability | ## WS-2018-0076 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>tunnel-agent-0.4.3.tgz</b></p></summary>
<p>HTTP proxy tunneling agent. Formerly part of mikeal/request, now a standal... | True | WS-2018-0076 (Medium) detected in tunnel-agent-0.4.3.tgz - ## WS-2018-0076 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>tunnel-agent-0.4.3.tgz</b></p></summary>
<p>HTTP proxy tunn... | non_process | ws medium detected in tunnel agent tgz ws medium severity vulnerability vulnerable library tunnel agent tgz http proxy tunneling agent formerly part of mikeal request now a standalone module library home page a href path to dependency file js demo package json pa... | 0 |
10,043 | 13,044,161,632 | IssuesEvent | 2020-07-29 03:47:24 | tikv/tikv | https://api.github.com/repos/tikv/tikv | closed | UCP: Migrate scalar function `SubDateDurationString` from TiDB | challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor |
## Description
Port the scalar function `SubDateDurationString` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/s... | 2.0 | UCP: Migrate scalar function `SubDateDurationString` from TiDB -
## Description
Port the scalar function `SubDateDurationString` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
-... | process | ucp migrate scalar function subdatedurationstring from tidb description port the scalar function subdatedurationstring from tidb to coprocessor score mentor s maplefu recommended skills rust programming learning materials already implemented expressions ported from tidb ... | 1 |
200,408 | 15,798,756,998 | IssuesEvent | 2021-04-02 19:22:38 | flutter/flutter | https://api.github.com/repos/flutter/flutter | closed | [web]: Web plugins not implemented | P3 d: examples documentation plugin | When following the guide [Developing plugin packages](https://flutter.dev/docs/development/packages-and-plugins/developing-packages#developing-plugin-packages), there is no implementation for a `web` plugin.
I created a project via the command:
```sh
flutter create --template=plugin -i swift -a kotlin hello
```... | 1.0 | [web]: Web plugins not implemented - When following the guide [Developing plugin packages](https://flutter.dev/docs/development/packages-and-plugins/developing-packages#developing-plugin-packages), there is no implementation for a `web` plugin.
I created a project via the command:
```sh
flutter create --template... | non_process | web plugins not implemented when following the guide there is no implementation for a web plugin i created a project via the command sh flutter create template plugin i swift a kotlin hello running the app actually works but it displays the platform version as unknown sh cd... | 0 |
7,469 | 10,565,744,395 | IssuesEvent | 2019-10-05 13:53:04 | linked-art/linked.art | https://api.github.com/repos/linked-art/linked.art | opened | Make a Google Drive for Linked Art | process |
We decided to collect slides in a google drive and link to them from the website, under events.
For this we should have a real drive associated with the community, not just a shared folder.
Rob to create an account for Linked Art, migrate the docs there, and make space for uploads.
(Very similar to the IIIF driv... | 1.0 | Make a Google Drive for Linked Art -
We decided to collect slides in a google drive and link to them from the website, under events.
For this we should have a real drive associated with the community, not just a shared folder.
Rob to create an account for Linked Art, migrate the docs there, and make space for uploa... | process | make a google drive for linked art we decided to collect slides in a google drive and link to them from the website under events for this we should have a real drive associated with the community not just a shared folder rob to create an account for linked art migrate the docs there and make space for uploa... | 1 |
313,434 | 26,930,155,371 | IssuesEvent | 2023-02-07 16:17:18 | btrfs/linux | https://api.github.com/repos/btrfs/linux | closed | [PATCH v3] btrfs: allow single disk devices to mount with older | 6.3 test sent | Link to patches
https://lore.kernel.org/linux-btrfs/6b1f037344cd8d24566f3d9873b820a73384242c.1598995167.git.josef@toxicpanda.com/
b4 am 6b1f037344cd8d24566f3d9873b820a73384242c.1598995167.git.josef@toxicpanda.com | 1.0 | [PATCH v3] btrfs: allow single disk devices to mount with older - Link to patches
https://lore.kernel.org/linux-btrfs/6b1f037344cd8d24566f3d9873b820a73384242c.1598995167.git.josef@toxicpanda.com/
b4 am 6b1f037344cd8d24566f3d9873b820a73384242c.1598995167.git.josef@toxicpanda.com | non_process | btrfs allow single disk devices to mount with older link to patches am git josef toxicpanda com | 0 |
17,551 | 23,362,875,847 | IssuesEvent | 2022-08-10 13:12:35 | prisma/prisma | https://api.github.com/repos/prisma/prisma | closed | OnUpdate default referential Integrity action while using Prisma to handle referential Integrity | bug/2-confirmed kind/bug process/candidate tech/engines team/client topic: database-provider/planetscale topic: referentialIntegrity | ### Intro
it is mentioned in the docs that the default referential integrity actions are these here

but it is also stated in the docs that while using Prisma to handle referential integrity that the avai... | 1.0 | OnUpdate default referential Integrity action while using Prisma to handle referential Integrity - ### Intro
it is mentioned in the docs that the default referential integrity actions are these here

but ... | process | onupdate default referential integrity action while using prisma to handle referential integrity intro it is mentioned in the docs that the default referential integrity actions are these here but it is also stated in the docs that while using prisma to handle referential integrity that the available ac... | 1 |
247,129 | 7,902,273,205 | IssuesEvent | 2018-07-01 01:29:22 | tgockel/zookeeper-cpp | https://api.github.com/repos/tgockel/zookeeper-cpp | opened | configuration defaults are not constant | bug lib/server priority/high | The "constant" values like `server::configuration::default_client_port` are completely editable by anyone. This is not meant to be. | 1.0 | configuration defaults are not constant - The "constant" values like `server::configuration::default_client_port` are completely editable by anyone. This is not meant to be. | non_process | configuration defaults are not constant the constant values like server configuration default client port are completely editable by anyone this is not meant to be | 0 |
13,574 | 16,109,503,241 | IssuesEvent | 2021-04-27 19:07:43 | MicrosoftDocs/azure-devops-docs | https://api.github.com/repos/MicrosoftDocs/azure-devops-docs | closed | Azure DevOps created a service account with cluster-admin role for a RBAC-enabled cluster | Pri2 devops-cicd-process/tech devops/prod doc-enhancement | 1) Created a new AKS cluster in the Azure portal
2) Enabled RBAC
3) Selected the new AKS cluster and namespace in the Azure DevOps "Add Kubernetes Resource" inside an Environment
4) Used kubectl to examine what Azure DevOps did
5) Verified **Azure DevOps created a service account with cluster-admin role for a RBAC-... | 1.0 | Azure DevOps created a service account with cluster-admin role for a RBAC-enabled cluster - 1) Created a new AKS cluster in the Azure portal
2) Enabled RBAC
3) Selected the new AKS cluster and namespace in the Azure DevOps "Add Kubernetes Resource" inside an Environment
4) Used kubectl to examine what Azure DevOps d... | process | azure devops created a service account with cluster admin role for a rbac enabled cluster created a new aks cluster in the azure portal enabled rbac selected the new aks cluster and namespace in the azure devops add kubernetes resource inside an environment used kubectl to examine what azure devops d... | 1 |
4,087 | 7,043,852,184 | IssuesEvent | 2017-12-31 13:58:25 | AkihikoWatanabe/paper_notes | https://api.github.com/repos/AkihikoWatanabe/paper_notes | opened | Artificial neural networks in business: Two decades of research, Tkac+, Applied Soft Computing 2016 | Neural Survey TimeSeriesDataProcessing | http://www.sciencedirect.com/science/article/pii/S1568494615006122 | 1.0 | Artificial neural networks in business: Two decades of research, Tkac+, Applied Soft Computing 2016 - http://www.sciencedirect.com/science/article/pii/S1568494615006122 | process | artificial neural networks in business two decades of research tkac applied soft computing | 1 |
733,453 | 25,306,698,913 | IssuesEvent | 2022-11-17 14:39:30 | airqo-platform/AirQo-frontend | https://api.github.com/repos/airqo-platform/AirQo-frontend | closed | do automated CI/CD for the mobile application | mobile-app priority-medium | **Is your feature request related to a problem? Please describe.**
Current process is a bit manual
**Describe the solution you'd like**
https://docs.flutter.dev/deployment/cd
**Describe alternatives you've considered**
- https://docs.flutter.dev/deployment/cd
- Integrating with current tools like Github Act... | 1.0 | do automated CI/CD for the mobile application - **Is your feature request related to a problem? Please describe.**
Current process is a bit manual
**Describe the solution you'd like**
https://docs.flutter.dev/deployment/cd
**Describe alternatives you've considered**
- https://docs.flutter.dev/deployment/cd
... | non_process | do automated ci cd for the mobile application is your feature request related to a problem please describe current process is a bit manual describe the solution you d like describe alternatives you ve considered integrating with current tools like github actions etc additional... | 0 |
5,674 | 8,556,797,530 | IssuesEvent | 2018-11-08 14:11:48 | easy-software-ufal/annotations_repos | https://api.github.com/repos/easy-software-ufal/annotations_repos | opened | khellang/Scrutor Validate whether a ServiceDescriptorAttribute has an invalid ServiceType | C# no operator test wrong processing | Issue: `https://github.com/khellang/Scrutor/pull/9`
PR: `https://github.com/khellang/Scrutor/pull/9` | 1.0 | khellang/Scrutor Validate whether a ServiceDescriptorAttribute has an invalid ServiceType - Issue: `https://github.com/khellang/Scrutor/pull/9`
PR: `https://github.com/khellang/Scrutor/pull/9` | process | khellang scrutor validate whether a servicedescriptorattribute has an invalid servicetype issue pr | 1 |
11,558 | 14,436,743,544 | IssuesEvent | 2020-12-07 10:32:41 | prisma/prisma | https://api.github.com/repos/prisma/prisma | opened | New count functionality | kind/feature process/candidate team/client tech/typescript | The latest DMMF from the query engine introduced a new feature as a side-effect of working on group by:
Being able to not just count by `*`, but specific columns, which can give a different result, if a column has NULL values.
Right now we don't expose this with the Client, but we should.
Proposal for the API:
``... | 1.0 | New count functionality - The latest DMMF from the query engine introduced a new feature as a side-effect of working on group by:
Being able to not just count by `*`, but specific columns, which can give a different result, if a column has NULL values.
Right now we don't expose this with the Client, but we should.
P... | process | new count functionality the latest dmmf from the query engine introduced a new feature as a side effect of working on group by being able to not just count by but specific columns which can give a different result if a column has null values right now we don t expose this with the client but we should p... | 1 |
340,651 | 10,276,768,461 | IssuesEvent | 2019-08-24 20:30:56 | Spartan97/OldTimeHockey | https://api.github.com/repos/Spartan97/OldTimeHockey | closed | Website standings page doesn't break ties correctly | Low Priority Website | Going to be difficult with H2H, so this might be a won't-fix. If we switch to PF as the only tiebreaker it will be correct. | 1.0 | Website standings page doesn't break ties correctly - Going to be difficult with H2H, so this might be a won't-fix. If we switch to PF as the only tiebreaker it will be correct. | non_process | website standings page doesn t break ties correctly going to be difficult with so this might be a won t fix if we switch to pf as the only tiebreaker it will be correct | 0 |
12,023 | 7,763,162,280 | IssuesEvent | 2018-06-01 15:39:42 | Azure/azure-cli | https://api.github.com/repos/Azure/azure-cli | closed | `az` does not complete, it would seem as if it does not return properly | Performance telemetry | **Describe the bug**
This is a theory, not something I can confirm completely but I was running some Azure CLI commands from home and they would take forever, to complete, like 10-30 minutes (or not at all). We use Azure CLI as part of our VSTS deployment process as well, and right now they don't complete at all, they... | True | `az` does not complete, it would seem as if it does not return properly - **Describe the bug**
This is a theory, not something I can confirm completely but I was running some Azure CLI commands from home and they would take forever, to complete, like 10-30 minutes (or not at all). We use Azure CLI as part of our VSTS ... | non_process | az does not complete it would seem as if it does not return properly describe the bug this is a theory not something i can confirm completely but i was running some azure cli commands from home and they would take forever to complete like minutes or not at all we use azure cli as part of our vsts de... | 0 |
362,438 | 25,376,106,431 | IssuesEvent | 2022-11-21 14:13:25 | ShSato4JPN/world-of-zono | https://api.github.com/repos/ShSato4JPN/world-of-zono | closed | stylelint についてまとめる | documentation | **Is your feature request related to a problem? Please describe.**
stylelint についてまとめる
**Describe the solution you'd like**
マークダウンファイルにまとめる
**Additional context**
参考サイト
[StyleLint](https://stylelint.io/)
[.stylelintrc(Qitta)](https://qiita.com/takeshisakuma/items/a7a3b8cc0ce05422f686)
[prettier, eslint, ... | 1.0 | stylelint についてまとめる - **Is your feature request related to a problem? Please describe.**
stylelint についてまとめる
**Describe the solution you'd like**
マークダウンファイルにまとめる
**Additional context**
参考サイト
[StyleLint](https://stylelint.io/)
[.stylelintrc(Qitta)](https://qiita.com/takeshisakuma/items/a7a3b8cc0ce05422f686)
... | non_process | stylelint についてまとめる is your feature request related to a problem please describe stylelint についてまとめる describe the solution you d like マークダウンファイルにまとめる additional context 参考サイト | 0 |
18,995 | 24,987,462,618 | IssuesEvent | 2022-11-02 16:02:49 | googleapis/sphinx-docfx-yaml | https://api.github.com/repos/googleapis/sphinx-docfx-yaml | closed | Presubmit failing for specifying branch on main | type: process priority: p1 | Branch parameter really isn't used anywhere. This could be taken out. | 1.0 | Presubmit failing for specifying branch on main - Branch parameter really isn't used anywhere. This could be taken out. | process | presubmit failing for specifying branch on main branch parameter really isn t used anywhere this could be taken out | 1 |
595,476 | 18,067,555,001 | IssuesEvent | 2021-09-20 21:04:43 | OpenMandrivaAssociation/test2 | https://api.github.com/repos/OpenMandrivaAssociation/test2 | closed | Fully update 2013 Beta fails to start display-manager. (Bugzilla Bug 99) | bug high priority major | This issue was created automatically with bugzilla2github
# Bugzilla Bug 99
Date: 2013-08-23 11:53:11 +0000
From: @benbullard79
To: OpenMandriva QA <<bugs@openmandriva.org>>
CC: @berolinux, @itchka, @robxu9, siriustheking@yahoo.com, @tpgxyz
Last updated: 2013-08-29 07:51:53 +0000
## Comment 492
Date: 2013-... | 1.0 | Fully update 2013 Beta fails to start display-manager. (Bugzilla Bug 99) - This issue was created automatically with bugzilla2github
# Bugzilla Bug 99
Date: 2013-08-23 11:53:11 +0000
From: @benbullard79
To: OpenMandriva QA <<bugs@openmandriva.org>>
CC: @berolinux, @itchka, @robxu9, siriustheking@yahoo.com, @t... | non_process | fully update beta fails to start display manager bugzilla bug this issue was created automatically with bugzilla bug date from to openmandriva qa lt gt cc berolinux itchka siriustheking yahoo com tpgxyz last updated comment date ... | 0 |
586,731 | 17,595,736,979 | IssuesEvent | 2021-08-17 04:40:09 | ita-social-projects/TeachUA | https://api.github.com/repos/ita-social-projects/TeachUA | closed | [Додати центр. Додати локацію] Incorrect cursor pointer if hover over '+Додати локацію' | bug UI Priority: Low | **Environment:** Windows 10, version 92.0.4515.107, (64)
**Reproducible:** always
**Build found:** last commit
**Steps to reproduce**
- Go to https://speak-ukrainian.org.ua/dev/
- Login as admin@gmail.com, 'Password'="admin";
- Click on user menu > 'Додати центр'
- pay attention to the cursor when hover it o... | 1.0 | [Додати центр. Додати локацію] Incorrect cursor pointer if hover over '+Додати локацію' - **Environment:** Windows 10, version 92.0.4515.107, (64)
**Reproducible:** always
**Build found:** last commit
**Steps to reproduce**
- Go to https://speak-ukrainian.org.ua/dev/
- Login as admin@gmail.com, 'Password'="ad... | non_process | incorrect cursor pointer if hover over додати локацію environment windows version reproducible always build found last commit steps to reproduce go to login as admin gmail com password admin click on user menu додати центр pay attention to the cu... | 0 |
406,749 | 11,902,434,638 | IssuesEvent | 2020-03-30 13:57:54 | openshift/odo | https://api.github.com/repos/openshift/odo | closed | Setup Openshift clusters on PSI for use by the team | area/release-eng kind/feature points/8 priority/High triage/needs-information | [kind/Enhancement]
<!--
Welcome! - We kindly ask you to:
1. Fill out the issue template below
2. Use the chat and talk to us if you have a question rather than a bug or feature request.
The chat room is at: https://chat.openshift.io/developers/channels/odo
Thanks for understanding, and for contribu... | 1.0 | Setup Openshift clusters on PSI for use by the team - [kind/Enhancement]
<!--
Welcome! - We kindly ask you to:
1. Fill out the issue template below
2. Use the chat and talk to us if you have a question rather than a bug or feature request.
The chat room is at: https://chat.openshift.io/developers/chan... | non_process | setup openshift clusters on psi for use by the team welcome we kindly ask you to fill out the issue template below use the chat and talk to us if you have a question rather than a bug or feature request the chat room is at thanks for understanding and for contributing to the... | 0 |
68,165 | 14,911,988,113 | IssuesEvent | 2021-01-22 11:57:01 | uniquelyparticular/sync-moltin-to-shippo | https://api.github.com/repos/uniquelyparticular/sync-moltin-to-shippo | opened | CVE-2020-28472 (High) detected in aws-sdk-2.469.0.tgz | security vulnerability | ## CVE-2020-28472 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>aws-sdk-2.469.0.tgz</b></p></summary>
<p>AWS SDK for JavaScript</p>
<p>Library home page: <a href="https://registry.np... | True | CVE-2020-28472 (High) detected in aws-sdk-2.469.0.tgz - ## CVE-2020-28472 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>aws-sdk-2.469.0.tgz</b></p></summary>
<p>AWS SDK for JavaScrip... | non_process | cve high detected in aws sdk tgz cve high severity vulnerability vulnerable library aws sdk tgz aws sdk for javascript library home page a href path to dependency file sync moltin to shippo package json path to vulnerable library sync moltin to shippo node modules aw... | 0 |
261,637 | 27,809,825,166 | IssuesEvent | 2023-03-18 01:50:56 | madhans23/linux-4.1.15 | https://api.github.com/repos/madhans23/linux-4.1.15 | closed | CVE-2016-2782 (Medium) detected in linux-stable-rtv4.1.33 - autoclosed | Mend: dependency security vulnerability | ## CVE-2016-2782 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linux-stable-rtv4.1.33</b></p></summary>
<p>
<p>Julia Cartwright's fork of linux-stable-rt.git</p>
<p>Library home pa... | True | CVE-2016-2782 (Medium) detected in linux-stable-rtv4.1.33 - autoclosed - ## CVE-2016-2782 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linux-stable-rtv4.1.33</b></p></summary>
<p>
... | non_process | cve medium detected in linux stable autoclosed cve medium severity vulnerability vulnerable library linux stable julia cartwright s fork of linux stable rt git library home page a href found in head commit a href found in base branch master vulner... | 0 |
9,161 | 12,218,639,085 | IssuesEvent | 2020-05-01 19:48:12 | Torbjornsson/DATX05-Master_Thesis | https://api.github.com/repos/Torbjornsson/DATX05-Master_Thesis | closed | Process/Development | Section: Process | - [x] Interactions
- [x] Environment
- [x] 3D-modelling
- [x] Puzzles
- [x] Tutorials
- [x] Sound-design
- [x] Builds
- [x] Corona: change of plans (?) | 1.0 | Process/Development - - [x] Interactions
- [x] Environment
- [x] 3D-modelling
- [x] Puzzles
- [x] Tutorials
- [x] Sound-design
- [x] Builds
- [x] Corona: change of plans (?) | process | process development interactions environment modelling puzzles tutorials sound design builds corona change of plans | 1 |
2,339 | 5,144,175,913 | IssuesEvent | 2017-01-12 17:53:33 | meteor/meteor | https://api.github.com/repos/meteor/meteor | closed | Warn when Meteor.Collection is used, and explain why you should use Mongo.Collection and depend on the 'mongo' package | Project:Mongo Driver Project:Release Process | Hello, defining a collection with either Mongo or Meteor before startup within the app directories (not packages) works fine even if not wrapped in Meteor.startup
Within a package however, the Mongo object is only available within Meteor.startup. However, like the app directories, outside of Meteor.startup, the Meteor... | 1.0 | Warn when Meteor.Collection is used, and explain why you should use Mongo.Collection and depend on the 'mongo' package - Hello, defining a collection with either Mongo or Meteor before startup within the app directories (not packages) works fine even if not wrapped in Meteor.startup
Within a package however, the Mongo... | process | warn when meteor collection is used and explain why you should use mongo collection and depend on the mongo package hello defining a collection with either mongo or meteor before startup within the app directories not packages works fine even if not wrapped in meteor startup within a package however the mongo... | 1 |
15,669 | 19,847,309,894 | IssuesEvent | 2022-01-21 08:19:10 | ooi-data/CE07SHSM-RID26-07-NUTNRB000-recovered_host-nutnr_b_dcl_full_instrument_recovered | https://api.github.com/repos/ooi-data/CE07SHSM-RID26-07-NUTNRB000-recovered_host-nutnr_b_dcl_full_instrument_recovered | opened | 🛑 Processing failed: ValueError | process | ## Overview
`ValueError` found in `processing_task` task during run ended on 2022-01-21T08:19:08.710897.
## Details
Flow name: `CE07SHSM-RID26-07-NUTNRB000-recovered_host-nutnr_b_dcl_full_instrument_recovered`
Task name: `processing_task`
Error type: `ValueError`
Error message: not enough values to unpack (expected ... | 1.0 | 🛑 Processing failed: ValueError - ## Overview
`ValueError` found in `processing_task` task during run ended on 2022-01-21T08:19:08.710897.
## Details
Flow name: `CE07SHSM-RID26-07-NUTNRB000-recovered_host-nutnr_b_dcl_full_instrument_recovered`
Task name: `processing_task`
Error type: `ValueError`
Error message: not... | process | 🛑 processing failed valueerror overview valueerror found in processing task task during run ended on details flow name recovered host nutnr b dcl full instrument recovered task name processing task error type valueerror error message not enough values to unpack expected ... | 1 |
17,416 | 23,231,398,825 | IssuesEvent | 2022-08-03 07:58:22 | jasperzhong/read-papers | https://api.github.com/repos/jasperzhong/read-papers | closed | aiDM '22 | GCNSplit: Bounding the State of Streaming Graph Partitioning | gnn graph processing systems / graph DB | https://sites.bu.edu/casp/files/2022/05/Zwolak22Bounding.pdf
very interesting !!! | 1.0 | aiDM '22 | GCNSplit: Bounding the State of Streaming Graph Partitioning - https://sites.bu.edu/casp/files/2022/05/Zwolak22Bounding.pdf
very interesting !!! | process | aidm gcnsplit bounding the state of streaming graph partitioning very interesting | 1 |
509,088 | 14,712,573,539 | IssuesEvent | 2021-01-05 09:08:03 | canonical-web-and-design/ubuntu.com | https://api.github.com/repos/canonical-web-and-design/ubuntu.com | opened | Sign up the newsletter from blog is broken | Priority: Critical | The newsletter signup form is missing grecaptcha.
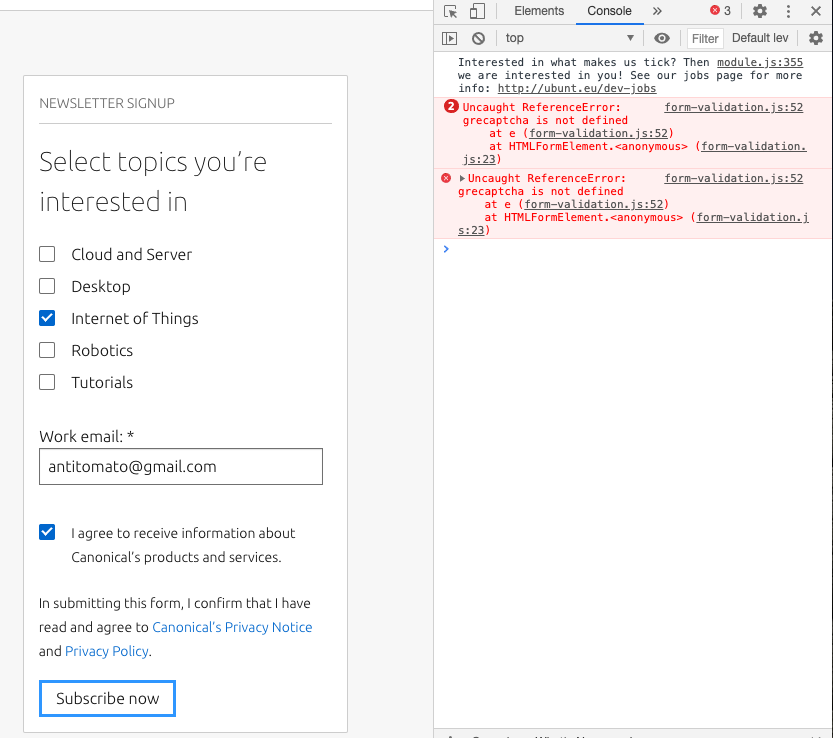
---
*Reported from: https://ubuntu.com/blog/install-amazon-eks-distro-anywhere* | 1.0 | Sign up the newsletter from blog is broken - The newsletter signup form is missing grecaptcha.

---
*Reported from: https://ubuntu.com/blog/install-amazon-eks-distro-anywh... | non_process | sign up the newsletter from blog is broken the newsletter signup form is missing grecaptcha reported from | 0 |
8,605 | 11,761,791,603 | IssuesEvent | 2020-03-13 22:49:38 | googleapis/nodejs-storage | https://api.github.com/repos/googleapis/nodejs-storage | closed | V4 Signed URL Pending work | api: storage type: process | Tracking issue for upcoming work on v4 Signed URL.
- [x] POST for resumable uploads
- will be fixed in #907
- this is failing because it represents users passing a `X-goog-resumable: start` extension header in the request.
- The nodejs-storage library applies this header for the user if the user specifie... | 1.0 | V4 Signed URL Pending work - Tracking issue for upcoming work on v4 Signed URL.
- [x] POST for resumable uploads
- will be fixed in #907
- this is failing because it represents users passing a `X-goog-resumable: start` extension header in the request.
- The nodejs-storage library applies this header for ... | process | signed url pending work tracking issue for upcoming work on signed url post for resumable uploads will be fixed in this is failing because it represents users passing a x goog resumable start extension header in the request the nodejs storage library applies this header for the us... | 1 |
532,523 | 15,558,618,166 | IssuesEvent | 2021-03-16 10:30:33 | epiphany-platform/epiphany | https://api.github.com/repos/epiphany-platform/epiphany | closed | [BUG] Erlang package versions specified in the requirements are missing from the external repository (RedHat/CentOS). | area/rabbit priority/critical type/bug | **Describe the bug**
Erlang packages in the version specified in the `requirements.txt` file are missing from the RabbitMQ Erlang repository.
It looks like new patches have been uploaded and old packages have been removed.
The script `download-requirements.sh` fails with error `ERROR: repoquery failed: package erlan... | 1.0 | [BUG] Erlang package versions specified in the requirements are missing from the external repository (RedHat/CentOS). - **Describe the bug**
Erlang packages in the version specified in the `requirements.txt` file are missing from the RabbitMQ Erlang repository.
It looks like new patches have been uploaded and old pac... | non_process | erlang package versions specified in the requirements are missing from the external repository redhat centos describe the bug erlang packages in the version specified in the requirements txt file are missing from the rabbitmq erlang repository it looks like new patches have been uploaded and old package... | 0 |
24,792 | 4,109,104,349 | IssuesEvent | 2016-06-06 18:21:48 | kubernetes/kubernetes | https://api.github.com/repos/kubernetes/kubernetes | closed | e2e test flake: should support exec [It] | area/test kind/flake team/CSI-API Machinery SIG | Noticed this in #22736
```
Failure [1664.033 seconds]
[k8s.io] Kubectl client
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/test/e2e/framework.go:420
[k8s.io] Simple pod
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/test/e2e/framework.go:420
should support ... | 1.0 | e2e test flake: should support exec [It] - Noticed this in #22736
```
Failure [1664.033 seconds]
[k8s.io] Kubectl client
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/test/e2e/framework.go:420
[k8s.io] Simple pod
/go/src/k8s.io/kubernetes/_output/dockerized/go/src/k8s.io/kubernetes/tes... | non_process | test flake should support exec noticed this in failure kubectl client go src io kubernetes output dockerized go src io kubernetes test framework go simple pod go src io kubernetes output dockerized go src io kubernetes test framework go should support exec ... | 0 |
7,097 | 10,245,370,024 | IssuesEvent | 2019-08-20 12:43:16 | nodejs/node | https://api.github.com/repos/nodejs/node | closed | child_process: exec EPIPE | child_process | Not sure if this is a bug. However, there doesn't seem to be a way to avoid `EPIPE` while piping to `exec()`. The only way is to listen to 'error' on the `stdin`. I would have expected that calling `unpipe()` on error would avoid the `EPIPE` error case.
```js
const { exec } = require('child_process')
const { Reada... | 1.0 | child_process: exec EPIPE - Not sure if this is a bug. However, there doesn't seem to be a way to avoid `EPIPE` while piping to `exec()`. The only way is to listen to 'error' on the `stdin`. I would have expected that calling `unpipe()` on error would avoid the `EPIPE` error case.
```js
const { exec } = require('ch... | process | child process exec epipe not sure if this is a bug however there doesn t seem to be a way to avoid epipe while piping to exec the only way is to listen to error on the stdin i would have expected that calling unpipe on error would avoid the epipe error case js const exec require ch... | 1 |
337,374 | 30,247,583,271 | IssuesEvent | 2023-07-06 17:44:03 | unifyai/ivy | https://api.github.com/repos/unifyai/ivy | reopened | Fix splitting_arrays.test_numpy_hsplit | NumPy Frontend Sub Task Failing Test | | | |
|---|---|
|jax|<a href="https://github.com/unifyai/ivy/actions/runs/5478319447"><img src=https://img.shields.io/badge/-failure-red></a>
|numpy|<a href="https://github.com/unifyai/ivy/actions/runs/5478319447"><img src=https://img.shields.io/badge/-success-success></a>
|tensorflow|<a href="https://github.co... | 1.0 | Fix splitting_arrays.test_numpy_hsplit - | | |
|---|---|
|jax|<a href="https://github.com/unifyai/ivy/actions/runs/5478319447"><img src=https://img.shields.io/badge/-failure-red></a>
|numpy|<a href="https://github.com/unifyai/ivy/actions/runs/5478319447"><img src=https://img.shields.io/badge/-success-success></a... | non_process | fix splitting arrays test numpy hsplit jax a href src numpy a href src tensorflow a href src torch a href src paddle a href src | 0 |
17,390 | 23,207,681,747 | IssuesEvent | 2022-08-02 07:21:30 | qgis/QGIS | https://api.github.com/repos/qgis/QGIS | closed | Not able to set scale parameter for SAGA Topographic Position Index | Plugins Processing Bug | ### What is the bug or the crash?
This bug seems related to the implementation of the SAGA TPI tool in QGIS. In the dialog window it is not possible to change the 'scale parameter'. Upon running the plugin, the log shows that the default values of 0;100 are used.
### Steps to reproduce the issue
1. Go to SAGA Topogr... | 1.0 | Not able to set scale parameter for SAGA Topographic Position Index - ### What is the bug or the crash?
This bug seems related to the implementation of the SAGA TPI tool in QGIS. In the dialog window it is not possible to change the 'scale parameter'. Upon running the plugin, the log shows that the default values of 0... | process | not able to set scale parameter for saga topographic position index what is the bug or the crash this bug seems related to the implementation of the saga tpi tool in qgis in the dialog window it is not possible to change the scale parameter upon running the plugin the log shows that the default values of ... | 1 |
18,015 | 24,032,591,083 | IssuesEvent | 2022-09-15 16:09:39 | googleapis/google-cloud-java | https://api.github.com/repos/googleapis/google-cloud-java | opened | Your .repo-metadata.json files have a problem 🤒 | type: process repo-metadata: lint | You have a problem with your .repo-metadata.json files:
Result of scan 📈:
* api_shortname 'apigee-registry' invalid in java-apigee-registry/.repo-metadata.json
* api_shortname 'beyondcorp-appconnections' invalid in java-beyondcorp-appconnections/.repo-metadata.json
* api_shortname 'beyondcorp-appconnectors' invali... | 1.0 | Your .repo-metadata.json files have a problem 🤒 - You have a problem with your .repo-metadata.json files:
Result of scan 📈:
* api_shortname 'apigee-registry' invalid in java-apigee-registry/.repo-metadata.json
* api_shortname 'beyondcorp-appconnections' invalid in java-beyondcorp-appconnections/.repo-metadata.json... | process | your repo metadata json files have a problem 🤒 you have a problem with your repo metadata json files result of scan 📈 api shortname apigee registry invalid in java apigee registry repo metadata json api shortname beyondcorp appconnections invalid in java beyondcorp appconnections repo metadata json... | 1 |
3,293 | 4,208,866,074 | IssuesEvent | 2016-06-29 01:18:02 | dotnet/roslyn-analyzers | https://api.github.com/repos/dotnet/roslyn-analyzers | closed | Build fails with "Access to the path '...\extensionSdks.en-US.cache' is denied." | Area-Infrastructure Bug | #### Repro steps
1. Follow steps at https://github.com/dotnet/roslyn-analyzers#getting-started on VS 2015 Update2
2. First error output for `msbuild src\Analyzers.sln`:
```
C:\Program Files (x86)\MSBuild\Microsoft\VisualStudio\v14.0\VSSDK\Microsoft.VsS
DK.targets(655,5): error VSSDK1040: There was a problem en... | 1.0 | Build fails with "Access to the path '...\extensionSdks.en-US.cache' is denied." - #### Repro steps
1. Follow steps at https://github.com/dotnet/roslyn-analyzers#getting-started on VS 2015 Update2
2. First error output for `msbuild src\Analyzers.sln`:
```
C:\Program Files (x86)\MSBuild\Microsoft\VisualStudio\v... | non_process | build fails with access to the path extensionsdks en us cache is denied repro steps follow steps at on vs first error output for msbuild src analyzers sln c program files msbuild microsoft visualstudio vssdk microsoft vss dk targets error there was a proble... | 0 |
267,299 | 23,290,959,298 | IssuesEvent | 2022-08-05 22:50:50 | danbudris/vulnerabilityProcessor | https://api.github.com/repos/danbudris/vulnerabilityProcessor | opened | HIGH vulnerability ALAS2-2021-1710 - ca-certificates affecting 1 resources | hey there test severity/HIGH | Issue auto cut by Vulnerability Processor
Processor Version: `v0.0.0-dev`
Message Source: `EventBridge`
Finding Source: `inspectorV2`
HIGH vulnerability ALAS2-2021-1710 detected in 1 resources
- arn:aws:ecr:us-west-2:338155784195:repository/test-inspector/sha256:7585bd31388fb7584260436e613c871868fd1509a728bf0c60bfe3f7... | 1.0 | HIGH vulnerability ALAS2-2021-1710 - ca-certificates affecting 1 resources - Issue auto cut by Vulnerability Processor
Processor Version: `v0.0.0-dev`
Message Source: `EventBridge`
Finding Source: `inspectorV2`
HIGH vulnerability ALAS2-2021-1710 detected in 1 resources
- arn:aws:ecr:us-west-2:338155784195:repository/t... | non_process | high vulnerability ca certificates affecting resources issue auto cut by vulnerability processor processor version dev message source eventbridge finding source high vulnerability detected in resources arn aws ecr us west repository test inspector affected packages ... | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.