
Unnamed: 0 int64 0 832k | id float64 2.49B 32.1B | type stringclasses 1
value | created_at stringlengths 19 19 | repo stringlengths 7 112 | repo_url stringlengths 36 141 | action stringclasses 3
values | title stringlengths 1 744 | labels stringlengths 4 574 | body stringlengths 9 211k | index stringclasses 10
values | text_combine stringlengths 96 211k | label stringclasses 2
values | text stringlengths 96 188k | binary_label int64 0 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
17,181 | 22,762,361,086 | IssuesEvent | 2022-07-07 22:40:23 | Carlosmtp/DomuzSGI | https://api.github.com/repos/Carlosmtp/DomuzSGI | closed | Añadir columnas en los indicadores de procesos | Enhancement High Process Management Reports Management | - [x] Crear columna goal en indicadores de procesos
- [x] Enviar los perodic_reports en la funcion para consultar los procesos
- [x] Crear la tabla process-periodic_records con campos de fecha:date, eficiencia:float e id del proceso al que hace referencia | 1.0 | Añadir columnas en los indicadores de procesos - - [x] Crear columna goal en indicadores de procesos
- [x] Enviar los perodic_reports en la funcion para consultar los procesos
- [x] Crear la tabla process-periodic_records con campos de fecha:date, eficiencia:float e id del proceso al que hace referencia | process | añadir columnas en los indicadores de procesos crear columna goal en indicadores de procesos enviar los perodic reports en la funcion para consultar los procesos crear la tabla process periodic records con campos de fecha date eficiencia float e id del proceso al que hace referencia | 1 |
1,657 | 4,287,664,497 | IssuesEvent | 2016-07-16 22:32:35 | pwittchen/NetworkEvents | https://api.github.com/repos/pwittchen/NetworkEvents | closed | Release v. 2.1.4 | release process | **Initial release notes**:
- changed implementation of the `OnlineChecker` in `OnlineCheckerImpl` class. Now it pings remote host.
- added `android.permission.INTERNET` to `AndroidManifest.xml`
- added back `NetworkHelper` class with static method `boolean isConnectedToWiFiOrMobileNetwork(context)`
- updated samp... | 1.0 | Release v. 2.1.4 - **Initial release notes**:
- changed implementation of the `OnlineChecker` in `OnlineCheckerImpl` class. Now it pings remote host.
- added `android.permission.INTERNET` to `AndroidManifest.xml`
- added back `NetworkHelper` class with static method `boolean isConnectedToWiFiOrMobileNetwork(contex... | process | release v initial release notes changed implementation of the onlinechecker in onlinecheckerimpl class now it pings remote host added android permission internet to androidmanifest xml added back networkhelper class with static method boolean isconnectedtowifiormobilenetwork contex... | 1 |
17,123 | 22,638,917,381 | IssuesEvent | 2022-06-30 22:23:21 | open-telemetry/opentelemetry-collector-contrib | https://api.github.com/repos/open-telemetry/opentelemetry-collector-contrib | opened | [processor/transform] Add option to define TQL with declarative syntax | priority:p2 comp: transformprocessor | **Is your feature request related to a problem? Please describe.**
Currently the only way to interact with the Telemetry Query Language is to use the language's SQL-style syntax:
```yaml
set(attribute["test"], "pass") where attribute["syntax style"] == "SQL"
```
This works great for the transform processor sin... | 1.0 | [processor/transform] Add option to define TQL with declarative syntax - **Is your feature request related to a problem? Please describe.**
Currently the only way to interact with the Telemetry Query Language is to use the language's SQL-style syntax:
```yaml
set(attribute["test"], "pass") where attribute["syntax ... | process | add option to define tql with declarative syntax is your feature request related to a problem please describe currently the only way to interact with the telemetry query language is to use the language s sql style syntax yaml set attribute pass where attribute sql this works great ... | 1 |
44,519 | 12,223,146,245 | IssuesEvent | 2020-05-02 16:19:17 | scipy/scipy | https://api.github.com/repos/scipy/scipy | closed | ValueError 'k exceeds matrix dimensions' for sparse.diagonal() when 0 in sparse.shape | defect good first issue scipy.sparse | When a sparse matrix has a 0 in its shape, such as `(0, 0)`, `(0, 1)` or `(1, 0)`, calling `diagonal()` fails. This differs to `np.diag` on the equivalent dense array, which succeeds, returning an empty array.
The best behaviour here seems like it'd be open for debate, but it's unfortunate that the default `diagonal... | 1.0 | ValueError 'k exceeds matrix dimensions' for sparse.diagonal() when 0 in sparse.shape - When a sparse matrix has a 0 in its shape, such as `(0, 0)`, `(0, 1)` or `(1, 0)`, calling `diagonal()` fails. This differs to `np.diag` on the equivalent dense array, which succeeds, returning an empty array.
The best behaviour ... | non_process | valueerror k exceeds matrix dimensions for sparse diagonal when in sparse shape when a sparse matrix has a in its shape such as or calling diagonal fails this differs to np diag on the equivalent dense array which succeeds returning an empty array the best behaviour ... | 0 |
276,800 | 24,021,054,494 | IssuesEvent | 2022-09-15 07:41:43 | chshersh/tool-sync | https://api.github.com/repos/chshersh/tool-sync | opened | Create 'AssetError' and test 'select_asset' function | good first issue test refactoring | This function selects an asset to download based on config:
https://github.com/chshersh/tool-sync/blob/b79eeb91cfdc3a122e6693d503117f68ff1fb44e/src/model/tool.rs#L72-L86
Currently, it returns `Result<Asset, String>` but the goal is to return a custom type for error: `Result<Asset, AssetError`.
The idea is to r... | 1.0 | Create 'AssetError' and test 'select_asset' function - This function selects an asset to download based on config:
https://github.com/chshersh/tool-sync/blob/b79eeb91cfdc3a122e6693d503117f68ff1fb44e/src/model/tool.rs#L72-L86
Currently, it returns `Result<Asset, String>` but the goal is to return a custom type for... | non_process | create asseterror and test select asset function this function selects an asset to download based on config currently it returns result but the goal is to return a custom type for error result asset asseterror the idea is to replace string a custom constructor and add tests for these cases ... | 0 |
367,242 | 25,728,661,215 | IssuesEvent | 2022-12-07 18:28:14 | Fiserv/Support | https://api.github.com/repos/Fiserv/Support | closed | Documentation section not rendering in Dev Studio | bug documentation Severity - High Priority - High BankingHub | # Reporting new issue for BankingHub tenant
Documentation section of Banking Hub is not displaying in Dev instance of Developer Studio.
https://dev-developerstudio.fiserv.com/product/BankingHub
Please refer the screenshot below.
 type: feature (minor) | Currently, learners can only respond with one point in an ImageClickInput, it would be nice to allow learners to respond with a set of points ("Pick all the fruits") and a sequence of points ("Pick the items in order of density"). This could be done as an entirely new widget or integrated with the existing ImageClickIn... | 1.0 | ImageClickInput: Allow learners to respond with a set/sequence of points - Currently, learners can only respond with one point in an ImageClickInput, it would be nice to allow learners to respond with a set of points ("Pick all the fruits") and a sequence of points ("Pick the items in order of density"). This could be... | non_process | imageclickinput allow learners to respond with a set sequence of points currently learners can only respond with one point in an imageclickinput it would be nice to allow learners to respond with a set of points pick all the fruits and a sequence of points pick the items in order of density this could be... | 0 |
180,713 | 30,554,442,667 | IssuesEvent | 2023-07-20 10:41:25 | DeveloperAcademy-POSTECH/MC3-Team11-BeyondThe3F | https://api.github.com/repos/DeveloperAcademy-POSTECH/MC3-Team11-BeyondThe3F | closed | [Design] Component 재활용성 수정 | Design | ## 이슈
- 기존 컴포넌트의 중복을 조금 줄이기 위해 재사용 가능한 코드로 수정
## To - Do
- [ ] 중복 컴포턴트 제거
- [ ] 컬러, 텍스트 의존성 주입
| 1.0 | [Design] Component 재활용성 수정 - ## 이슈
- 기존 컴포넌트의 중복을 조금 줄이기 위해 재사용 가능한 코드로 수정
## To - Do
- [ ] 중복 컴포턴트 제거
- [ ] 컬러, 텍스트 의존성 주입
| non_process | component 재활용성 수정 이슈 기존 컴포넌트의 중복을 조금 줄이기 위해 재사용 가능한 코드로 수정 to do 중복 컴포턴트 제거 컬러 텍스트 의존성 주입 | 0 |
353,734 | 25,133,750,669 | IssuesEvent | 2022-11-09 16:56:32 | extratone/WindowsIowa | https://api.github.com/repos/extratone/WindowsIowa | opened | Windows Iowa Theme for Blink Shell | documentation | 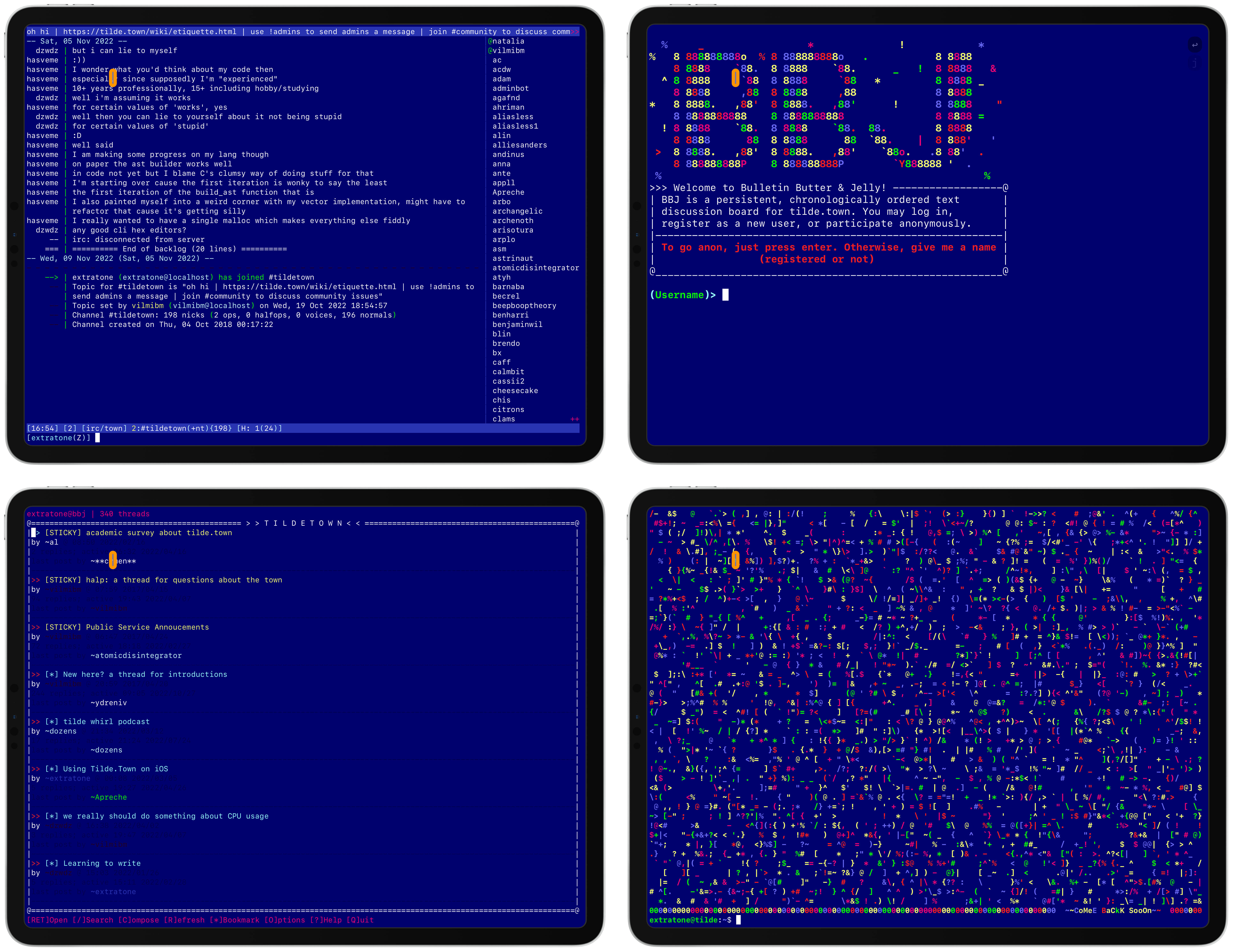
```js
t.prefs_.set('color-palette-overrides',["#050387", "#ff2320", "#00ff00", "#f5ff6f", "#2934b3", "#1f0022", "#c4f7f9", "#fff3e4", "#000051", "#ff1f1e", "#00ff00", "#f5ff6f", "#6869f3", "#ed0073", "#9... | 1.0 | Windows Iowa Theme for Blink Shell - 
```js
t.prefs_.set('color-palette-overrides',["#050387", "#ff2320", "#00ff00", "#f5ff6f", "#2934b3", "#1f0022", "#c4f7f9", "#fff3e4", "#000051", "#ff1f1e", "#00ff00",... | non_process | windows iowa theme for blink shell js t prefs set color palette overrides t prefs set foreground color ffffff t prefs set background color t prefs set cursor color ffffff | 0 |
9,929 | 12,966,752,642 | IssuesEvent | 2020-07-21 01:25:15 | googleapis/java-spanner | https://api.github.com/repos/googleapis/java-spanner | reopened | Update Dependencies (Renovate Bot) | api: spanner type: process | This [master issue](https://renovatebot.com/blog/master-issue) contains a list of Renovate updates and their statuses.
## Closed/Ignored
These updates were closed unmerged and will not be recreated unless you click a checkbox below.
- [ ] <!-- recreate-branch=renovate/org.apache.commons-commons-lang3-3.x -->[deps: ... | 1.0 | Update Dependencies (Renovate Bot) - This [master issue](https://renovatebot.com/blog/master-issue) contains a list of Renovate updates and their statuses.
## Closed/Ignored
These updates were closed unmerged and will not be recreated unless you click a checkbox below.
- [ ] <!-- recreate-branch=renovate/org.apache... | process | update dependencies renovate bot this contains a list of renovate updates and their statuses closed ignored these updates were closed unmerged and will not be recreated unless you click a checkbox below pull advanced check this box to trigger a request for renovate to run aga... | 1 |
2,393 | 2,611,713,688 | IssuesEvent | 2015-02-27 08:25:46 | dambileh/Abblar | https://api.github.com/repos/dambileh/Abblar | closed | As an app I need organisation category screen | Design Ready | This will simply list different categories of messages (channels) that the user can subscribe to. We probably need some sort of a list with a checkbox next to each item.
Just to give you an idea, take Telkom as an example, it could have "Fault report", "Promotions" and etc categories | 1.0 | As an app I need organisation category screen - This will simply list different categories of messages (channels) that the user can subscribe to. We probably need some sort of a list with a checkbox next to each item.
Just to give you an idea, take Telkom as an example, it could have "Fault report", "Promotions" and... | non_process | as an app i need organisation category screen this will simply list different categories of messages channels that the user can subscribe to we probably need some sort of a list with a checkbox next to each item just to give you an idea take telkom as an example it could have fault report promotions and... | 0 |
177,873 | 13,750,962,699 | IssuesEvent | 2020-10-06 12:46:27 | enthought/traitsui | https://api.github.com/repos/enthought/traitsui | closed | Occasional error from QAbstractItemModel events upon test tear down | component: test suite | The following error occurs once from this travis build (https://travis-ci.org/github/enthought/traitsui/jobs/706873557) :
```
======================================================================
FAIL: test_run (test_all_examples.TestExample) (file_path='/home/travis/build/enthought/traitsui/examples/demo/Advanced/... | 1.0 | Occasional error from QAbstractItemModel events upon test tear down - The following error occurs once from this travis build (https://travis-ci.org/github/enthought/traitsui/jobs/706873557) :
```
======================================================================
FAIL: test_run (test_all_examples.TestExample) (fi... | non_process | occasional error from qabstractitemmodel events upon test tear down the following error occurs once from this travis build fail test run test all examples testexample file path home travis build enthought traitsui examples demo a... | 0 |
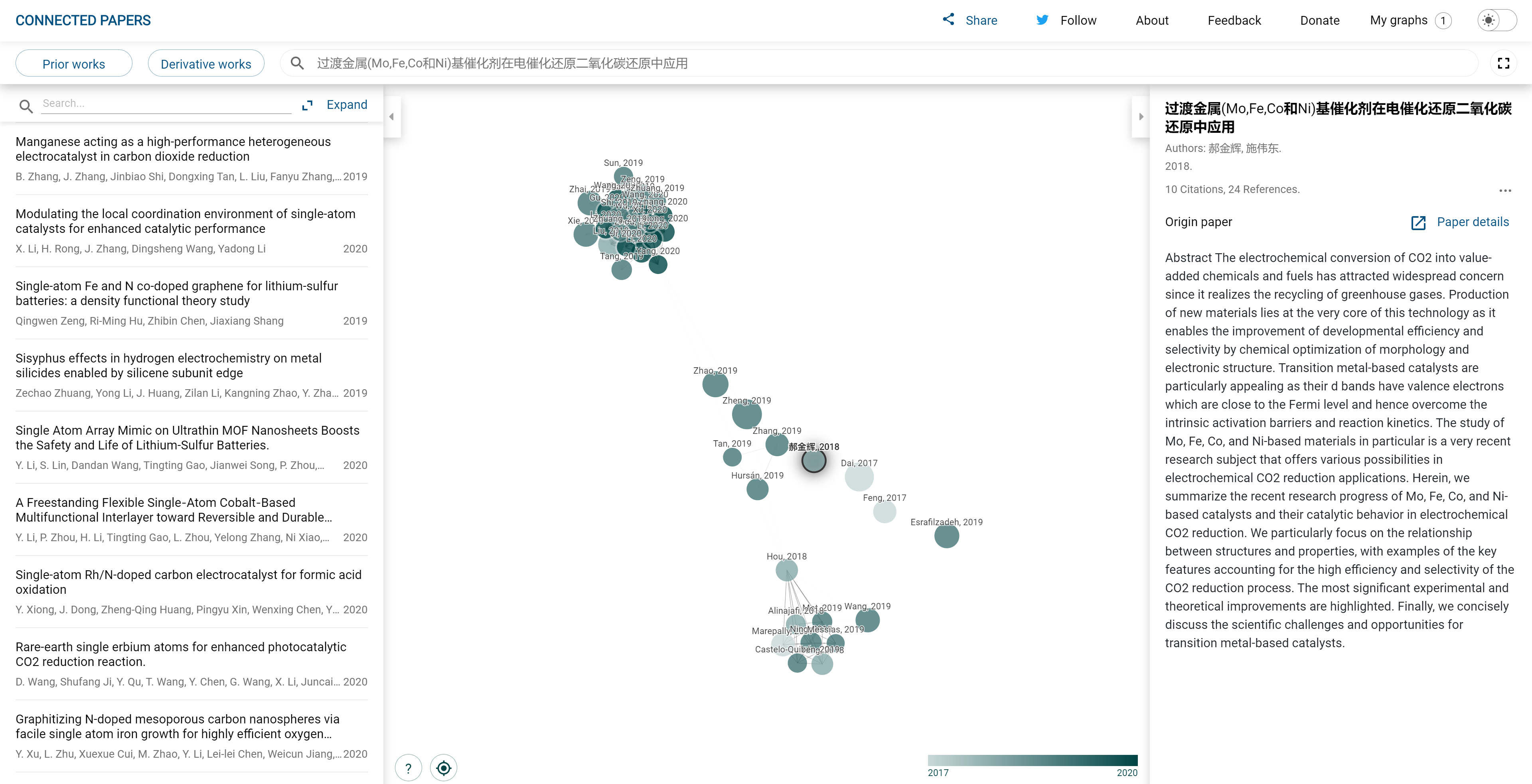
107,181 | 13,440,491,581 | IssuesEvent | 2020-09-08 01:05:35 | logseq/logseq | https://api.github.com/repos/logseq/logseq | closed | connectedpapers的UI设计非常漂亮logseq可以参考参考 | design | connectedpapers的UI设计非常漂亮logseq可以参考参考,roam research的UI都是对workflowy进行学习,但connectedpapers的界面设计例如动画效果、页面布局、隐喻等都也是很好看的。
https://www.connectedpapers.com/main/f4b5b7a08649811db655bc0fbc4d33b608617bab/MoFeCoNi/graph
... | 1.0 | connectedpapers的UI设计非常漂亮logseq可以参考参考 - connectedpapers的UI设计非常漂亮logseq可以参考参考,roam research的UI都是对workflowy进行学习,但connectedpapers的界面设计例如动画效果、页面布局、隐喻等都也是很好看的。
https://www.connectedpapers.com/main/f4b5b7a08649811db655bc0fbc4d33b608617bab/MoFeCoNi/graph

Failed test:
```
net6.0-windows-Release-x86-CoreCLR_release-Windows.7.Amd64.Open
- System.ServicePro... | 1.0 | Test failure System.ServiceProcess.Tests.ServiceControllerTests.Stop_FalseArg_WithDependentServices_ThrowsInvalidOperationException - Run: [runtime-libraries-coreclr outerloop 20210615.3](https://dev.azure.com/dnceng/public/_build/results?buildId=1187626&view=ms.vss-test-web.build-test-results-tab&runId=35678872&result... | process | test failure system serviceprocess tests servicecontrollertests stop falsearg withdependentservices throwsinvalidoperationexception run failed test windows release coreclr release windows open system serviceprocess tests servicecontrollertests stop falsearg withdependentservices throwsin... | 1 |
111,835 | 4,489,039,409 | IssuesEvent | 2016-08-30 09:33:23 | Victoire/victoire | https://api.github.com/repos/Victoire/victoire | opened | It's not possible to edit a widget list with a DQL query inside | bug Priority : Medium | Error 500 when i click on the widget (edition) | 1.0 | It's not possible to edit a widget list with a DQL query inside - Error 500 when i click on the widget (edition) | non_process | it s not possible to edit a widget list with a dql query inside error when i click on the widget edition | 0 |
66,965 | 8,059,810,153 | IssuesEvent | 2018-08-02 23:55:33 | kbase/narrative | https://api.github.com/repos/kbase/narrative | closed | Graphic design tweaks round 1 | enhancement graphic design minor | These are mostly minor and is not a comprehensive list. But some of the consistency issues should be fixed.
Design Throughout
- Separator lines are too pale, they should be #CECECE
- for all the lists (the data list, the apps & methods list), remove the separator at the very top
Header
- put spacing or even divider b... | 1.0 | Graphic design tweaks round 1 - These are mostly minor and is not a comprehensive list. But some of the consistency issues should be fixed.
Design Throughout
- Separator lines are too pale, they should be #CECECE
- for all the lists (the data list, the apps & methods list), remove the separator at the very top
Header... | non_process | graphic design tweaks round these are mostly minor and is not a comprehensive list but some of the consistency issues should be fixed design throughout separator lines are too pale they should be cecece for all the lists the data list the apps methods list remove the separator at the very top header... | 0 |
13,800 | 16,554,004,781 | IssuesEvent | 2021-05-28 11:56:00 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | [PM] Need to increase detectable area for Password Criteria icon (?) in change Password screen | Bug P2 Participant manager Process: Fixed Process: Tested QA Process: Tested dev | Steps:
1. Login into Participant manager
2. Navigate to My Account section
3. Click on Change Password link
4. Verify the password criteria icon in change password screen
**A/R**:- Detectable area for Password Criteria icon is very less.
**E/R**:- Detectable area should be increase for Password Criteria icon f... | 3.0 | [PM] Need to increase detectable area for Password Criteria icon (?) in change Password screen - Steps:
1. Login into Participant manager
2. Navigate to My Account section
3. Click on Change Password link
4. Verify the password criteria icon in change password screen
**A/R**:- Detectable area for Password Crite... | process | need to increase detectable area for password criteria icon in change password screen steps login into participant manager navigate to my account section click on change password link verify the password criteria icon in change password screen a r detectable area for password criteria... | 1 |
6,768 | 9,905,872,942 | IssuesEvent | 2019-06-27 12:41:16 | spring-projects/spring-hateoas | https://api.github.com/repos/spring-projects/spring-hateoas | closed | Switch to Spring's ServerWebExchangeContextFilter. | in: core process: in progress stack: webflux | This was completed on #983 and merged to `master`. But due to instabilities with Spring Framework upstream and Spring Data downstream, the effort was moved off to a branch to delay until we're all ready to accept it. | 1.0 | Switch to Spring's ServerWebExchangeContextFilter. - This was completed on #983 and merged to `master`. But due to instabilities with Spring Framework upstream and Spring Data downstream, the effort was moved off to a branch to delay until we're all ready to accept it. | process | switch to spring s serverwebexchangecontextfilter this was completed on and merged to master but due to instabilities with spring framework upstream and spring data downstream the effort was moved off to a branch to delay until we re all ready to accept it | 1 |
5,324 | 8,139,530,661 | IssuesEvent | 2018-08-20 18:01:11 | jfmcbrayer/brutaldon | https://api.github.com/repos/jfmcbrayer/brutaldon | closed | Multi-account support | enhancement inprocess | This would require a Django login and registration for brutaldon. And cross-account actions would require quite a bit of refactoring. But otherwise not hard. | 1.0 | Multi-account support - This would require a Django login and registration for brutaldon. And cross-account actions would require quite a bit of refactoring. But otherwise not hard. | process | multi account support this would require a django login and registration for brutaldon and cross account actions would require quite a bit of refactoring but otherwise not hard | 1 |
4,507 | 7,350,301,481 | IssuesEvent | 2018-03-08 13:56:04 | shobrook/BitVision | https://api.github.com/repos/shobrook/BitVision | closed | Instead of using Bitstamp price data, use data averaged across multiple exchanges | medium priority preprocessing | We want to avoid exchange-specific biases. | 1.0 | Instead of using Bitstamp price data, use data averaged across multiple exchanges - We want to avoid exchange-specific biases. | process | instead of using bitstamp price data use data averaged across multiple exchanges we want to avoid exchange specific biases | 1 |
5,499 | 8,364,474,082 | IssuesEvent | 2018-10-03 23:13:34 | w3c/w3process | https://api.github.com/repos/w3c/w3process | closed | Written notification? | AC-review Process2019Candidate | In section 3.6 Resignation from a group, it says "On written notification from an Advisory Committee representative...". Does the notification from SysBot (when an AC rep unhooks someone from the WG/IG) qualify as "written notification"? | 1.0 | Written notification? - In section 3.6 Resignation from a group, it says "On written notification from an Advisory Committee representative...". Does the notification from SysBot (when an AC rep unhooks someone from the WG/IG) qualify as "written notification"? | process | written notification in section resignation from a group it says on written notification from an advisory committee representative does the notification from sysbot when an ac rep unhooks someone from the wg ig qualify as written notification | 1 |
11,969 | 14,730,443,029 | IssuesEvent | 2021-01-06 13:13:24 | GoogleCloudPlatform/fda-mystudies | https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies | closed | To change term 'user' to 'admin' in the error and message codes of PM, also in PM emails | Feature request P1 Participant manager Process: Release 2 Process: Tested QA Process: Tested dev | Replace the word user with admin in the error and message codes of PM.
Also, we need to replace them in the emails of PM.
| 3.0 | To change term 'user' to 'admin' in the error and message codes of PM, also in PM emails - Replace the word user with admin in the error and message codes of PM.
Also, we need to replace them in the emails of PM.
| process | to change term user to admin in the error and message codes of pm also in pm emails replace the word user with admin in the error and message codes of pm also we need to replace them in the emails of pm | 1 |
517,612 | 15,017,110,680 | IssuesEvent | 2021-02-01 10:25:46 | webcompat/web-bugs | https://api.github.com/repos/webcompat/web-bugs | closed | xnxx.com - site is not usable | browser-focus-geckoview engine-gecko ml-needsdiagnosis-false priority-important | <!-- @browser: Firefox Mobile 84.0 -->
<!-- @ua_header: Mozilla/5.0 (Android 9; Mobile; rv:84.0) Gecko/84.0 Firefox/84.0 -->
<!-- @reported_with: unknown -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/66445 -->
<!-- @extra_labels: browser-focus-geckoview -->
**URL**: http://xnxx.com
**Browser / Ve... | 1.0 | xnxx.com - site is not usable - <!-- @browser: Firefox Mobile 84.0 -->
<!-- @ua_header: Mozilla/5.0 (Android 9; Mobile; rv:84.0) Gecko/84.0 Firefox/84.0 -->
<!-- @reported_with: unknown -->
<!-- @public_url: https://github.com/webcompat/web-bugs/issues/66445 -->
<!-- @extra_labels: browser-focus-geckoview -->
**URL**:... | non_process | xnxx com site is not usable url browser version firefox mobile operating system android tested another browser yes other problem type site is not usable description browser unsupported steps to reproduce videos doesn t display and unable to open site bro... | 0 |
196,157 | 22,441,002,875 | IssuesEvent | 2022-06-21 01:16:58 | JMD60260/fetchmeaband | https://api.github.com/repos/JMD60260/fetchmeaband | opened | CVE-2022-32209 (Medium) detected in rails-html-sanitizer-1.3.0.gem | security vulnerability | ## CVE-2022-32209 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>rails-html-sanitizer-1.3.0.gem</b></p></summary>
<p>HTML sanitization for Rails applications</p>
<p>Library home pag... | True | CVE-2022-32209 (Medium) detected in rails-html-sanitizer-1.3.0.gem - ## CVE-2022-32209 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>rails-html-sanitizer-1.3.0.gem</b></p></summary>... | non_process | cve medium detected in rails html sanitizer gem cve medium severity vulnerability vulnerable library rails html sanitizer gem html sanitization for rails applications library home page a href dependency hierarchy coffee rails gem root library railtie... | 0 |
53,045 | 13,260,844,386 | IssuesEvent | 2020-08-20 18:51:25 | icecube-trac/tix4 | https://api.github.com/repos/icecube-trac/tix4 | closed | boost port needs to fail, if it can't find python "devel" parts (Trac #625) | Migrated from Trac defect tools/ports |
<details>
<summary><em>Migrated from <a href="https://code.icecube.wisc.edu/projects/icecube/ticket/625">https://code.icecube.wisc.edu/projects/icecube/ticket/625</a>, reported by negaand owned by nega</em></summary>
<p>
```json
{
"status": "closed",
"changetime": "2014-10-22T17:41:41",
"_ts": "14139997... | 1.0 | boost port needs to fail, if it can't find python "devel" parts (Trac #625) -
<details>
<summary><em>Migrated from <a href="https://code.icecube.wisc.edu/projects/icecube/ticket/625">https://code.icecube.wisc.edu/projects/icecube/ticket/625</a>, reported by negaand owned by nega</em></summary>
<p>
```json
{
"st... | non_process | boost port needs to fail if it can t find python devel parts trac migrated from json status closed changetime ts description reporter nega cc resolution wontfix time component too... | 0 |
35,931 | 6,510,826,645 | IssuesEvent | 2017-08-25 06:40:58 | magenta-aps/mora | https://api.github.com/repos/magenta-aps/mora | opened | Dokumentation af autentificeringsmekanisme | documentation | Vi skal have tilføjet et afsnit om autentificeringsmekanismen i README-filen | 1.0 | Dokumentation af autentificeringsmekanisme - Vi skal have tilføjet et afsnit om autentificeringsmekanismen i README-filen | non_process | dokumentation af autentificeringsmekanisme vi skal have tilføjet et afsnit om autentificeringsmekanismen i readme filen | 0 |
21,953 | 30,452,539,832 | IssuesEvent | 2023-07-16 13:31:00 | h4sh5/pypi-auto-scanner | https://api.github.com/repos/h4sh5/pypi-auto-scanner | opened | etm-dgraham 5.1.13 has 4 GuardDog issues | guarddog exec-base64 silent-process-execution | https://pypi.org/project/etm-dgraham
https://inspector.pypi.io/project/etm-dgraham
```{
"dependency": "etm-dgraham",
"version": "5.1.13",
"result": {
"issues": 4,
"errors": {},
"results": {
"exec-base64": [
{
"location": "etm-dgraham-5.1.13/bump.py:121",
"code": " ... | 1.0 | etm-dgraham 5.1.13 has 4 GuardDog issues - https://pypi.org/project/etm-dgraham
https://inspector.pypi.io/project/etm-dgraham
```{
"dependency": "etm-dgraham",
"version": "5.1.13",
"result": {
"issues": 4,
"errors": {},
"results": {
"exec-base64": [
{
"location": "etm-dgraham-5... | process | etm dgraham has guarddog issues dependency etm dgraham version result issues errors results exec location etm dgraham bump py code check output f git commit a m tmsg ... | 1 |
90,023 | 8,224,943,689 | IssuesEvent | 2018-09-06 14:57:14 | magento-engcom/msi | https://api.github.com/repos/magento-engcom/msi | closed | [Configuration-Catalog-Products-Configurable product] Configurable Product created with text swatch attribute configuration and Default Source assigned by Admin user | MFTF (Functional Test Coverage) | 1. Login to backend as admin
2. Go to Catalog -> Categories
3. Select Default Category on Categories Tree
4. Click button "Add Subcategory"
5. set "Enable Category" to "Yes"
6. set "Include in Menu" to "Yes"
7. Fill in "Category Name" = "Category 1"
8. Click button "Save"
9. Success message "You saved the category." a... | 1.0 | [Configuration-Catalog-Products-Configurable product] Configurable Product created with text swatch attribute configuration and Default Source assigned by Admin user - 1. Login to backend as admin
2. Go to Catalog -> Categories
3. Select Default Category on Categories Tree
4. Click button "Add Subcategory"
5. set "Enab... | non_process | configurable product created with text swatch attribute configuration and default source assigned by admin user login to backend as admin go to catalog categories select default category on categories tree click button add subcategory set enable category to yes set include in menu to y... | 0 |
7,155 | 3,934,829,554 | IssuesEvent | 2016-04-26 00:50:00 | jens-maus/yam | https://api.github.com/repos/jens-maus/yam | closed | Send mails works only when "outgoing" folder is active | #major @normal bug fixed Mail Filter nightly build | **Originally by _stellan.pistoor@gmx.de_ on 2014-03-19 17:14:27 +0100**
___
If not the "outgoing" folder is active send mails doesn`t work (no progress window appears, mail(s) isn`t sent). When I select the "outgoing" folder it works as expected. | 1.0 | Send mails works only when "outgoing" folder is active - **Originally by _stellan.pistoor@gmx.de_ on 2014-03-19 17:14:27 +0100**
___
If not the "outgoing" folder is active send mails doesn`t work (no progress window appears, mail(s) isn`t sent). When I select the "outgoing" folder it works as expected. | non_process | send mails works only when outgoing folder is active originally by stellan pistoor gmx de on if not the outgoing folder is active send mails doesn t work no progress window appears mail s isn t sent when i select the outgoing folder it works as expected | 0 |
340,628 | 24,662,808,822 | IssuesEvent | 2022-10-18 08:05:14 | catalystneuro/neuroconv | https://api.github.com/repos/catalystneuro/neuroconv | closed | Simplify conversions with multiple interfaces | documentation enhancement | Right now we have the conversion gallery which as simple as possible illustrates how to do conversion with a single interface:
https://neuroconv.readthedocs.io/en/main/conversion_examples_gallery/conversion_example_gallery.html#extracellular-electrophysiology
On the other hand, our workwflow for handling conversion... | 1.0 | Simplify conversions with multiple interfaces - Right now we have the conversion gallery which as simple as possible illustrates how to do conversion with a single interface:
https://neuroconv.readthedocs.io/en/main/conversion_examples_gallery/conversion_example_gallery.html#extracellular-electrophysiology
On the ... | non_process | simplify conversions with multiple interfaces right now we have the conversion gallery which as simple as possible illustrates how to do conversion with a single interface on the other hand our workwflow for handling conversions with multiple interfaces relies on the nwbconverter object for which we also h... | 0 |
26,068 | 7,781,158,457 | IssuesEvent | 2018-06-05 22:41:46 | hashicorp/packer | https://api.github.com/repos/hashicorp/packer | closed | WinRM timouts on Creating encrypted win 2016 AMI on AWS | bug builder/amazon communicator/winrm question | - Packer version from `packer version`
1.2.3
- Host platform
Windows
- **Debug log output from `PACKER_LOG=1 packer build template.json`.
```
C:\Users\rahul18564\Desktop\2018\packer>packer build -debug sample13.json
Debug mode enabled. Builds will not be parallelized.
amazon-ebs output will be in this color.... | 1.0 | WinRM timouts on Creating encrypted win 2016 AMI on AWS - - Packer version from `packer version`
1.2.3
- Host platform
Windows
- **Debug log output from `PACKER_LOG=1 packer build template.json`.
```
C:\Users\rahul18564\Desktop\2018\packer>packer build -debug sample13.json
Debug mode enabled. Builds will not... | non_process | winrm timouts on creating encrypted win ami on aws packer version from packer version host platform windows debug log output from packer log packer build template json c users desktop packer packer build debug json debug mode enabled builds will not be parallelized ama... | 0 |
15,628 | 2,611,495,314 | IssuesEvent | 2015-02-27 05:35:02 | chrsmith/hedgewars | https://api.github.com/repos/chrsmith/hedgewars | closed | map size, no X and Y limit but a power of x and y that is the limit | auto-migrated Priority-Medium Type-Enhancement | ```
Please provide any additional information below.
hey,
i wonder if it is possible to have a map where the max size limit aren't just X
=4096 and Y =2048
but are calcul bye the power of the two widht and height (x and y)
we could set instead a max X and max Y, and max power of XandY
explemple : actually its... | 1.0 | map size, no X and Y limit but a power of x and y that is the limit - ```
Please provide any additional information below.
hey,
i wonder if it is possible to have a map where the max size limit aren't just X
=4096 and Y =2048
but are calcul bye the power of the two widht and height (x and y)
we could set instea... | non_process | map size no x and y limit but a power of x and y that is the limit please provide any additional information below hey i wonder if it is possible to have a map where the max size limit aren t just x and y but are calcul bye the power of the two widht and height x and y we could set instead a ma... | 0 |
245,322 | 20,762,002,056 | IssuesEvent | 2022-03-15 16:57:29 | Uuvana-Studios/longvinter-windows-client | https://api.github.com/repos/Uuvana-Studios/longvinter-windows-client | closed | inventory in chests issue | bug Not Tested | the inventory chest in my house has been resetting to previous contents and i'm losing everything i'm putting in there as i loot and try to progress. | 1.0 | inventory in chests issue - the inventory chest in my house has been resetting to previous contents and i'm losing everything i'm putting in there as i loot and try to progress. | non_process | inventory in chests issue the inventory chest in my house has been resetting to previous contents and i m losing everything i m putting in there as i loot and try to progress | 0 |
440,838 | 12,704,779,732 | IssuesEvent | 2020-06-23 02:31:21 | naphthasl/sakamoto | https://api.github.com/repos/naphthasl/sakamoto | closed | Add search functionality | enhancement medium priority | Navbar should have a simple search bar allowing users to search the contents of all the pages on the site. | 1.0 | Add search functionality - Navbar should have a simple search bar allowing users to search the contents of all the pages on the site. | non_process | add search functionality navbar should have a simple search bar allowing users to search the contents of all the pages on the site | 0 |
21,464 | 29,500,395,048 | IssuesEvent | 2023-06-02 21:03:48 | openslide/openslide | https://api.github.com/repos/openslide/openslide | closed | Consider disabling merge commits, requiring squash (and maybe rebase) only | enhancement development-process | https://github.com/openslide/openslide/settings
Merge commits add a new commit without content and can clutter history. Squash commits convert an entire pull request into a single commit, keeping minor changes made during review time out of the committed history.
It is a personal preference how this is configured... | 1.0 | Consider disabling merge commits, requiring squash (and maybe rebase) only - https://github.com/openslide/openslide/settings
Merge commits add a new commit without content and can clutter history. Squash commits convert an entire pull request into a single commit, keeping minor changes made during review time out of... | process | consider disabling merge commits requiring squash and maybe rebase only merge commits add a new commit without content and can clutter history squash commits convert an entire pull request into a single commit keeping minor changes made during review time out of the committed history it is a personal pr... | 1 |
1,902 | 4,728,385,901 | IssuesEvent | 2016-10-18 15:49:29 | opentrials/opentrials | https://api.github.com/repos/opentrials/opentrials | closed | Accept identifiers with whitespaces like "ISRCTN 47772397" | 4. Ready for Review Collectors Processors | For example, the trial http://www.isrctn.com/ISRCTN47772397 has 16 publications on PubMed according to ISRCTN's page. However, we have only [8 in our database](http://explorer.opentrials.net/trials/021c89e1-2d13-4e90-93e5-25439c804802). The publications we don't have are:
* http://www.ncbi.nlm.nih.gov/pubmed/1529713... | 1.0 | Accept identifiers with whitespaces like "ISRCTN 47772397" - For example, the trial http://www.isrctn.com/ISRCTN47772397 has 16 publications on PubMed according to ISRCTN's page. However, we have only [8 in our database](http://explorer.opentrials.net/trials/021c89e1-2d13-4e90-93e5-25439c804802). The publications we do... | process | accept identifiers with whitespaces like isrctn for example the trial has publications on pubmed according to isrctn s page however we have only the publications we don t have are apparently we have a publication that they don t have as well the r... | 1 |
315,844 | 27,110,809,719 | IssuesEvent | 2023-02-15 15:11:49 | containers/podman-desktop | https://api.github.com/repos/containers/podman-desktop | opened | Implement/extend UI test for the running application covering basic e2e scenario | kind/enhancement area/tests | ### Is your enhancement related to a problem? Please describe
We already have a playwright e2e test available. I would like to look at the framework used, play around and extend covered scenario.
### Describe the solution you'd like
Extend existing test or add new one that would test installed application instead of... | 1.0 | Implement/extend UI test for the running application covering basic e2e scenario - ### Is your enhancement related to a problem? Please describe
We already have a playwright e2e test available. I would like to look at the framework used, play around and extend covered scenario.
### Describe the solution you'd like
E... | non_process | implement extend ui test for the running application covering basic scenario is your enhancement related to a problem please describe we already have a playwright test available i would like to look at the framework used play around and extend covered scenario describe the solution you d like exten... | 0 |
11,240 | 14,015,261,680 | IssuesEvent | 2020-10-29 13:06:04 | tdwg/dwc | https://api.github.com/repos/tdwg/dwc | closed | Change term - https://dwc.tdwg.org/pw/#dwcpw_p045 | Class - Occurrence Process - implement Term - change | ## Change term
* Submitter: John Wieczorek
* Justification (why is this change necessary?): grammatical error
* Proponents (who needs this change): Everyone
Proposed new attributes of the term:
Change 'their' to 'there' in
* Definition of the term: Organisms transported and released by humans in a (semi)natur... | 1.0 | Change term - https://dwc.tdwg.org/pw/#dwcpw_p045 - ## Change term
* Submitter: John Wieczorek
* Justification (why is this change necessary?): grammatical error
* Proponents (who needs this change): Everyone
Proposed new attributes of the term:
Change 'their' to 'there' in
* Definition of the term: Organisms... | process | change term change term submitter john wieczorek justification why is this change necessary grammatical error proponents who needs this change everyone proposed new attributes of the term change their to there in definition of the term organisms transported and released by human... | 1 |
289,014 | 21,731,147,884 | IssuesEvent | 2022-05-11 12:08:27 | finalstate/WOLviaREST | https://api.github.com/repos/finalstate/WOLviaREST | closed | Very minimalist. Needs at least installation and usage docs | documentation | Needs at least installation and usage docs | 1.0 | Very minimalist. Needs at least installation and usage docs - Needs at least installation and usage docs | non_process | very minimalist needs at least installation and usage docs needs at least installation and usage docs | 0 |
13,550 | 16,092,446,723 | IssuesEvent | 2021-04-26 18:28:55 | unicode-org/icu4x | https://api.github.com/repos/unicode-org/icu4x | closed | Add roadmap | C-process T-docs-tests | We have an ICU4X quarter-by-quarter roadmap written up in some docs. We should put it publicly on the repo so that we can point people to it. | 1.0 | Add roadmap - We have an ICU4X quarter-by-quarter roadmap written up in some docs. We should put it publicly on the repo so that we can point people to it. | process | add roadmap we have an quarter by quarter roadmap written up in some docs we should put it publicly on the repo so that we can point people to it | 1 |
256,425 | 19,412,488,813 | IssuesEvent | 2021-12-20 11:08:51 | nhsx/AIF_Allocation_Tool | https://api.github.com/repos/nhsx/AIF_Allocation_Tool | opened | Add support email more prominently | documentation | ```
Need more help?
For queries on CCG Allocations or suggestions for ACRA’s work programme please email: england.revenue-allocations@nhs.net
``` | 1.0 | Add support email more prominently - ```
Need more help?
For queries on CCG Allocations or suggestions for ACRA’s work programme please email: england.revenue-allocations@nhs.net
``` | non_process | add support email more prominently need more help for queries on ccg allocations or suggestions for acra’s work programme please email england revenue allocations nhs net | 0 |
16,894 | 22,196,744,209 | IssuesEvent | 2022-06-07 07:39:37 | camunda/zeebe | https://api.github.com/repos/camunda/zeebe | reopened | Extend gateway's create process instance request mapping with start instructions | team/process-automation | The gateway maps the incoming gRPC CreateProcessInstanceRequest into a ProcessInstanceCreation record and sends it to the Broker. We need to extend this mapping with the start instructions.
Let's not map the start instructions for CreateProcessInstanceWithResult.
Blocked by #9388, #9396 | 1.0 | Extend gateway's create process instance request mapping with start instructions - The gateway maps the incoming gRPC CreateProcessInstanceRequest into a ProcessInstanceCreation record and sends it to the Broker. We need to extend this mapping with the start instructions.
Let's not map the start instructions for Cre... | process | extend gateway s create process instance request mapping with start instructions the gateway maps the incoming grpc createprocessinstancerequest into a processinstancecreation record and sends it to the broker we need to extend this mapping with the start instructions let s not map the start instructions for cre... | 1 |
64,804 | 18,909,787,128 | IssuesEvent | 2021-11-16 13:00:53 | scipy/scipy | https://api.github.com/repos/scipy/scipy | closed | BUG: dimension doesn't change after indexing sparse matrices, unlike numpy arrays | defect | Invalid: follows `np.matrix` behavior. | 1.0 | BUG: dimension doesn't change after indexing sparse matrices, unlike numpy arrays - Invalid: follows `np.matrix` behavior. | non_process | bug dimension doesn t change after indexing sparse matrices unlike numpy arrays invalid follows np matrix behavior | 0 |
169,255 | 13,131,606,722 | IssuesEvent | 2020-08-06 17:19:40 | elastic/kibana | https://api.github.com/repos/elastic/kibana | closed | [test-failed]: Chrome X-Pack UI Functional Tests1.x-pack/test/functional/apps/monitoring/beats/beat_detail·js - Monitoring app beats detail "before all" hook for "cluster status bar shows correct information" | failed-test test-cloud | **Version: 7.9.0**
**Class: Chrome X-Pack UI Functional Tests1.x-pack/test/functional/apps/monitoring/beats/beat_detail·js**
**Stack Trace:**
Error: retry.try timeout: TimeoutError: Waiting for element to be located By(css selector, [data-test-subj="clusterItemContainerBeats"] [data-test-subj="beatsListing"])
Wait tim... | 2.0 | [test-failed]: Chrome X-Pack UI Functional Tests1.x-pack/test/functional/apps/monitoring/beats/beat_detail·js - Monitoring app beats detail "before all" hook for "cluster status bar shows correct information" - **Version: 7.9.0**
**Class: Chrome X-Pack UI Functional Tests1.x-pack/test/functional/apps/monitoring/beats/b... | non_process | chrome x pack ui functional x pack test functional apps monitoring beats beat detail·js monitoring app beats detail before all hook for cluster status bar shows correct information version class chrome x pack ui functional x pack test functional apps monitoring beats beat detail·js stac... | 0 |
345,734 | 30,836,969,363 | IssuesEvent | 2023-08-02 08:05:08 | strimzi/strimzi-kafka-operator | https://api.github.com/repos/strimzi/strimzi-kafka-operator | opened | Re-factor applying NetworkPolicy with copying secrets | System tests | We should refactor our current way of creating an auxiliary namespace, application of NP and copying of pull secret (in system tests) and follow the rule DRY.
```java
KubeClusterResource.getInstance().createNamespace(CollectorElement.createCollectorElement(simpleClassName), Constants.TEST_SUITE_NAMESPACE);
Network... | 1.0 | Re-factor applying NetworkPolicy with copying secrets - We should refactor our current way of creating an auxiliary namespace, application of NP and copying of pull secret (in system tests) and follow the rule DRY.
```java
KubeClusterResource.getInstance().createNamespace(CollectorElement.createCollectorElement(sim... | non_process | re factor applying networkpolicy with copying secrets we should refactor our current way of creating an auxiliary namespace application of np and copying of pull secret in system tests and follow the rule dry java kubeclusterresource getinstance createnamespace collectorelement createcollectorelement sim... | 0 |
12,076 | 14,739,938,487 | IssuesEvent | 2021-01-07 08:13:07 | kdjstudios/SABillingGitlab | https://api.github.com/repos/kdjstudios/SABillingGitlab | closed | Send Emails - Error Missing Attachment | anc-process anp-1 ant-bug ant-enhancement ant-parent/primary | In GitLab by @kdjstudios on Sep 28, 2018, 10:24
Attachments at the site level for the email invoices are causing errors:
- We need to know why these attachments are suddenly disappearing? Users do not have access to delete these files.
- We need to update the "send emails" functionality to generate an error to the us... | 1.0 | Send Emails - Error Missing Attachment - In GitLab by @kdjstudios on Sep 28, 2018, 10:24
Attachments at the site level for the email invoices are causing errors:
- We need to know why these attachments are suddenly disappearing? Users do not have access to delete these files.
- We need to update the "send emails" fun... | process | send emails error missing attachment in gitlab by kdjstudios on sep attachments at the site level for the email invoices are causing errors we need to know why these attachments are suddenly disappearing users do not have access to delete these files we need to update the send emails functiona... | 1 |
16,985 | 12,159,228,869 | IssuesEvent | 2020-04-26 08:09:36 | microsoft/react-native-windows | https://api.github.com/repos/microsoft/react-native-windows | opened | Stop Publishing ReactUwp NuGet Package | Area: Infrastructure | We publish ReactUwp as a NuGet package for Stellar. We're no longer supporting ReactUwp for 0.62. We should stop publishing the package. | 1.0 | Stop Publishing ReactUwp NuGet Package - We publish ReactUwp as a NuGet package for Stellar. We're no longer supporting ReactUwp for 0.62. We should stop publishing the package. | non_process | stop publishing reactuwp nuget package we publish reactuwp as a nuget package for stellar we re no longer supporting reactuwp for we should stop publishing the package | 0 |
75,071 | 9,200,024,986 | IssuesEvent | 2019-03-07 16:09:35 | coreos/fedora-coreos-tracker | https://api.github.com/repos/coreos/fedora-coreos-tracker | closed | Host Installer for Fedora CoreOS (bare metal) | design priority/medium | Being that we are planning to boot from a common "image" on first boot in Fedora CoreOS we'd like an installer that can get that image onto a disk for a bare metal environment (cloud/VM environments should be using related image artifacts or pre-uploaded cloud artifacts). Anaconda can do this (i.e. write a pre-baked im... | 1.0 | Host Installer for Fedora CoreOS (bare metal) - Being that we are planning to boot from a common "image" on first boot in Fedora CoreOS we'd like an installer that can get that image onto a disk for a bare metal environment (cloud/VM environments should be using related image artifacts or pre-uploaded cloud artifacts)... | non_process | host installer for fedora coreos bare metal being that we are planning to boot from a common image on first boot in fedora coreos we d like an installer that can get that image onto a disk for a bare metal environment cloud vm environments should be using related image artifacts or pre uploaded cloud artifacts ... | 0 |
7,392 | 10,519,283,598 | IssuesEvent | 2019-09-29 16:53:18 | fluent/fluent-bit | https://api.github.com/repos/fluent/fluent-bit | closed | Stream processor Missing sub-key in Aggregate function | enhancement work-in-process | ## Bug Report
**Describe the bug**
This gives an error: "SELECT key['nestedkey'], SUM(key['nestedsumkey']) FROM STREAM:instream GROUP BY key['nestedkey']"
**To Reproduce**
- Rubular link if applicable:
- Example log message if applicable:
```
json structure:
{
"key": {
"nestedkey": "SomeKey",
... | 1.0 | Stream processor Missing sub-key in Aggregate function - ## Bug Report
**Describe the bug**
This gives an error: "SELECT key['nestedkey'], SUM(key['nestedsumkey']) FROM STREAM:instream GROUP BY key['nestedkey']"
**To Reproduce**
- Rubular link if applicable:
- Example log message if applicable:
```
json str... | process | stream processor missing sub key in aggregate function bug report describe the bug this gives an error select key sum key from stream instream group by key to reproduce rubular link if applicable example log message if applicable json structure key nestedkey ... | 1 |
15,575 | 19,703,507,506 | IssuesEvent | 2022-01-12 19:08:16 | googleapis/nodejs-dialogflow-cx | https://api.github.com/repos/googleapis/nodejs-dialogflow-cx | opened | Your .repo-metadata.json file has a problem 🤒 | type: process repo-metadata: lint | You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'dialogflow-cx' invalid in .repo-metadata.json
☝️ Once you correct these problems, you can close this issue.
Reach out to **go/github-automation** if you have any questions. | 1.0 | Your .repo-metadata.json file has a problem 🤒 - You have a problem with your .repo-metadata.json file:
Result of scan 📈:
* api_shortname 'dialogflow-cx' invalid in .repo-metadata.json
☝️ Once you correct these problems, you can close this issue.
Reach out to **go/github-automation** if you have any questions. | process | your repo metadata json file has a problem 🤒 you have a problem with your repo metadata json file result of scan 📈 api shortname dialogflow cx invalid in repo metadata json ☝️ once you correct these problems you can close this issue reach out to go github automation if you have any questions | 1 |
437 | 2,870,165,405 | IssuesEvent | 2015-06-06 22:17:39 | neuropoly/spinalcordtoolbox | https://api.github.com/repos/neuropoly/spinalcordtoolbox | closed | CSA results are different between v1.1.2 and v2.0.3 | priority: high sct_process_segmentation | https://sourceforge.net/p/spinalcordtoolbox/discussion/help/thread/ec2e6371/
data:
sct_example_data/t2
syntax v1.1.2:
~~~~
sct_process_segmentation -i t2_seg.nii.gz -p compute_csa
~~~~
syntax v2.0.3:
~~~~
sct_process_segmentation -i t2_seg.nii.gz -p csa
~~~~
result v1.1.2
~~~~
z=185: 80.9039201974 ... | 1.0 | CSA results are different between v1.1.2 and v2.0.3 - https://sourceforge.net/p/spinalcordtoolbox/discussion/help/thread/ec2e6371/
data:
sct_example_data/t2
syntax v1.1.2:
~~~~
sct_process_segmentation -i t2_seg.nii.gz -p compute_csa
~~~~
syntax v2.0.3:
~~~~
sct_process_segmentation -i t2_seg.nii.gz -p c... | process | csa results are different between and data sct example data syntax sct process segmentation i seg nii gz p compute csa syntax sct process segmentation i seg nii gz p csa result z mm z mm z mm z ... | 1 |
169,808 | 6,417,870,592 | IssuesEvent | 2017-08-08 17:43:00 | hackupc/backend | https://api.github.com/repos/hackupc/backend | closed | Add review applications view | enhancement low_priority | Admin only view similar to vote view that allows to manually accept knowing the current votes that the application has.
- Ordering should be for votes and submission_dates.
- Actions: Accept, Skip, Reject
- Note that as skip is a possible action, there should be a parameter that saves how many applications have be... | 1.0 | Add review applications view - Admin only view similar to vote view that allows to manually accept knowing the current votes that the application has.
- Ordering should be for votes and submission_dates.
- Actions: Accept, Skip, Reject
- Note that as skip is a possible action, there should be a parameter that save... | non_process | add review applications view admin only view similar to vote view that allows to manually accept knowing the current votes that the application has ordering should be for votes and submission dates actions accept skip reject note that as skip is a possible action there should be a parameter that save... | 0 |
747,836 | 26,100,651,854 | IssuesEvent | 2022-12-27 06:26:46 | bounswe/bounswe2022group4 | https://api.github.com/repos/bounswe/bounswe2022group4 | closed | Mobile: Doctor comments should be highlighted. | Category - To Do Category - Enhancement Priority - High Status: In Progress Language - Kotlin Team - Mobile Mobile | ### Description:
Doctors should have outshined comments.
### What to do:
- [x] Doctor specific comment fragment
### Deadline
27.11.2022, 12.00(GMT+3) | 1.0 | Mobile: Doctor comments should be highlighted. - ### Description:
Doctors should have outshined comments.
### What to do:
- [x] Doctor specific comment fragment
### Deadline
27.11.2022, 12.00(GMT+3) | non_process | mobile doctor comments should be highlighted description doctors should have outshined comments what to do doctor specific comment fragment deadline gmt | 0 |
740,964 | 25,775,798,193 | IssuesEvent | 2022-12-09 11:52:10 | zephyrproject-rtos/zephyr | https://api.github.com/repos/zephyrproject-rtos/zephyr | closed | RPI Pico usb hangs up in interrupt handler for composite devices | bug priority: low area: Drivers area: USB platform: Raspberry Pi Pico | **Describe the bug**
I am using the rp2040 with the cdc_acm_composite sample. When sending bytes
the first few bytes to the first acm port they will be echoed to the second acm port.
After a few more bytes the port will hang up.
**To Reproduce**
Steps to reproduce the behavior:
1. Build the cdc_acm_composite s... | 1.0 | RPI Pico usb hangs up in interrupt handler for composite devices - **Describe the bug**
I am using the rp2040 with the cdc_acm_composite sample. When sending bytes
the first few bytes to the first acm port they will be echoed to the second acm port.
After a few more bytes the port will hang up.
**To Reproduce**
... | non_process | rpi pico usb hangs up in interrupt handler for composite devices describe the bug i am using the with the cdc acm composite sample when sending bytes the first few bytes to the first acm port they will be echoed to the second acm port after a few more bytes the port will hang up to reproduce step... | 0 |
24,607 | 12,131,691,343 | IssuesEvent | 2020-04-23 05:30:49 | Azure/azure-sdk-for-net | https://api.github.com/repos/Azure/azure-sdk-for-net | opened | Provide Model Factory per .NET Mocking Guidelines | Client Cognitive Services FormRecognizer | https://azure.github.io/azure-sdk/dotnet_introduction.html#dotnet-mocking
✅ DO provide factory or builder for constructing model graphs returned from virtual service methods.
Model types shouldn’t have public constructors. Instances of the model are typically returned from the client library, and are not construc... | 1.0 | Provide Model Factory per .NET Mocking Guidelines - https://azure.github.io/azure-sdk/dotnet_introduction.html#dotnet-mocking
✅ DO provide factory or builder for constructing model graphs returned from virtual service methods.
Model types shouldn’t have public constructors. Instances of the model are typically re... | non_process | provide model factory per net mocking guidelines ✅ do provide factory or builder for constructing model graphs returned from virtual service methods model types shouldn’t have public constructors instances of the model are typically returned from the client library and are not constructed by the consumer ... | 0 |
9,345 | 12,345,928,718 | IssuesEvent | 2020-05-15 09:49:22 | tikv/tikv | https://api.github.com/repos/tikv/tikv | closed | UCP: Migrate scalar function `TimeToSec` from TiDB | challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor |
## Description
Port the scalar function `TimeToSec` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @sticnarf
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/rpn_expr... | 2.0 | UCP: Migrate scalar function `TimeToSec` from TiDB -
## Description
Port the scalar function `TimeToSec` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @sticnarf
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tik... | process | ucp migrate scalar function timetosec from tidb description port the scalar function timetosec from tidb to coprocessor score mentor s sticnarf recommended skills rust programming learning materials already implemented expressions ported from tidb | 1 |
209,955 | 23,730,981,154 | IssuesEvent | 2022-08-31 01:39:33 | Baneeishaque/FinPro-ERP-Web | https://api.github.com/repos/Baneeishaque/FinPro-ERP-Web | closed | CVE-2018-14040 (Medium) detected in bootstrap-3.3.7.min.js - autoclosed | security vulnerability | ## CVE-2018-14040 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>bootstrap-3.3.7.min.js</b></p></summary>
<p>The most popular front-end framework for developing responsive, mobile f... | True | CVE-2018-14040 (Medium) detected in bootstrap-3.3.7.min.js - autoclosed - ## CVE-2018-14040 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>bootstrap-3.3.7.min.js</b></p></summary>
<... | non_process | cve medium detected in bootstrap min js autoclosed cve medium severity vulnerability vulnerable library bootstrap min js the most popular front end framework for developing responsive mobile first projects on the web library home page a href path to vulnerable librar... | 0 |
13,340 | 15,801,045,539 | IssuesEvent | 2021-04-03 02:40:04 | PyCQA/flake8 | https://api.github.com/repos/PyCQA/flake8 | closed | Deadlock with very large number of files | component:multiprocessing component:performance help wanted priority:high | In GitLab by @asottile on Nov 18, 2016, 11:35
## Installing flake8
```
$ virtualenv venv -ppython2.7
$ venv/bin/pip install flake8
$ ./venv/bin/flake8 --bug-report
{
"dependencies": [
{
"dependency": "setuptools",
"version": "3.4.4"
}
],
"platform": {
"python_implementation": "CPython... | 1.0 | Deadlock with very large number of files - In GitLab by @asottile on Nov 18, 2016, 11:35
## Installing flake8
```
$ virtualenv venv -ppython2.7
$ venv/bin/pip install flake8
$ ./venv/bin/flake8 --bug-report
{
"dependencies": [
{
"dependency": "setuptools",
"version": "3.4.4"
}
],
"platfor... | process | deadlock with very large number of files in gitlab by asottile on nov installing virtualenv venv venv bin pip install venv bin bug report dependencies dependency setuptools version platform python implementa... | 1 |
16,644 | 5,266,423,909 | IssuesEvent | 2017-02-04 12:21:13 | jba0040/GGJ17Burgos | https://api.github.com/repos/jba0040/GGJ17Burgos | opened | Ataque cuerpo a cuerpo: funcionalidad | code enhancement | Sistema de ataque cuerpo a cuerpo. El objetivo es que desplace ligeramente al enemigo. El ataque podrá cargarse para aumentar la distancia de desplazamiento del enemigo. | 1.0 | Ataque cuerpo a cuerpo: funcionalidad - Sistema de ataque cuerpo a cuerpo. El objetivo es que desplace ligeramente al enemigo. El ataque podrá cargarse para aumentar la distancia de desplazamiento del enemigo. | non_process | ataque cuerpo a cuerpo funcionalidad sistema de ataque cuerpo a cuerpo el objetivo es que desplace ligeramente al enemigo el ataque podrá cargarse para aumentar la distancia de desplazamiento del enemigo | 0 |
14,108 | 16,998,222,779 | IssuesEvent | 2021-07-01 09:12:42 | hochschule-darmstadt/openartbrowser | https://api.github.com/repos/hochschule-darmstadt/openartbrowser | opened | New attributes | User Interface etl process feature medium priority question | **Reason (Why?)**
The wikidata datasource offers way more attributes to crawl.
**Solution (What?)**
Add the following attributes:
- for Buildings:
- Additional attributes are architect P84, which corresponds to the artist.
- architectural style P194 corresponds to movement
This is a good opportunity to c... | 1.0 | New attributes - **Reason (Why?)**
The wikidata datasource offers way more attributes to crawl.
**Solution (What?)**
Add the following attributes:
- for Buildings:
- Additional attributes are architect P84, which corresponds to the artist.
- architectural style P194 corresponds to movement
This is a good... | process | new attributes reason why the wikidata datasource offers way more attributes to crawl solution what add the following attributes for buildings additional attributes are architect which corresponds to the artist architectural style corresponds to movement this is a good oppo... | 1 |
2,135 | 4,974,558,330 | IssuesEvent | 2016-12-06 07:11:23 | opentrials/opentrials | https://api.github.com/repos/opentrials/opentrials | closed | Setup continuous processing | Processors | - [ ] add strategy to process only updated data in `warehouse`
- [ ] update `processors` stack to use this strategy and `make-initial-processing` to do not use
- [ ] run `processors` stack on docker-cloud
- [ ] remove `make-initial-processing` stack? all `processors` could check last day when objects was processed and ... | 1.0 | Setup continuous processing - - [ ] add strategy to process only updated data in `warehouse`
- [ ] update `processors` stack to use this strategy and `make-initial-processing` to do not use
- [ ] run `processors` stack on docker-cloud
- [ ] remove `make-initial-processing` stack? all `processors` could check last day w... | process | setup continuous processing add strategy to process only updated data in warehouse update processors stack to use this strategy and make initial processing to do not use run processors stack on docker cloud remove make initial processing stack all processors could check last day when obje... | 1 |
210,776 | 16,385,093,578 | IssuesEvent | 2021-05-17 09:23:50 | TeamPneumatic/pnc-repressurized | https://api.github.com/repos/TeamPneumatic/pnc-repressurized | closed | Technical typos in the PNC:R handbook | Bug Documentation Fixed in Dev | ### Minecraft Version
1.16.5
### Forge Version
36.1.16
### Mod Version
184
Some entries have certain strings that haven't been parsed correctly as contextual links.

So far I've seen this in: "Pneumati... | 1.0 | Technical typos in the PNC:R handbook - ### Minecraft Version
1.16.5
### Forge Version
36.1.16
### Mod Version
184
Some entries have certain strings that haven't been parsed correctly as contextual links.
 detected in linuxlinux-4.6 | Mend: dependency security vulnerability | ## CVE-2020-10732 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linuxlinux-4.6</b></p></summary>
<p>
<p>The Linux Kernel</p>
<p>Library home page: <a href=https://mirrors.edge.kern... | True | CVE-2020-10732 (Medium) detected in linuxlinux-4.6 - ## CVE-2020-10732 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>linuxlinux-4.6</b></p></summary>
<p>
<p>The Linux Kernel</p>
<p... | non_process | cve medium detected in linuxlinux cve medium severity vulnerability vulnerable library linuxlinux the linux kernel library home page a href found in head commit a href found in base branch main vulnerable source files fs binfmt elf c ... | 0 |
162,050 | 12,609,066,663 | IssuesEvent | 2020-06-12 00:21:40 | pantsbuild/pants | https://api.github.com/repos/pantsbuild/pants | opened | GoTestIntegrationTest.test_go_test_simple is flaky | flaky-test | ```
__________________ GoTestIntegrationTest.test_go_test_simple ___________________
self = <pants_test.contrib.go.tasks.test_go_test_integration.GoTestIntegrationTest testMethod=test_go_test_simple>
def test_go_test_simple(self):
args = ["test", "contrib/go/examples/src/go/libA"]
pants_run = s... | 1.0 | GoTestIntegrationTest.test_go_test_simple is flaky - ```
__________________ GoTestIntegrationTest.test_go_test_simple ___________________
self = <pants_test.contrib.go.tasks.test_go_test_integration.GoTestIntegrationTest testMethod=test_go_test_simple>
def test_go_test_simple(self):
args = ["test", "con... | non_process | gotestintegrationtest test go test simple is flaky gotestintegrationtest test go test simple self def test go test simple self args pants run self run pants args self assert success pants run liba depends on libb so... | 0 |
21,259 | 28,432,294,620 | IssuesEvent | 2023-04-15 00:02:44 | metallb/metallb | https://api.github.com/repos/metallb/metallb | closed | maintenership: document how to update the website | process lifecycle-stale | We should document on the website, how to upgrade the website. This come up here: https://github.com/metallb/metallb/pull/661#event-3624239546
The website is served from whatever is present in the `live-website` branch. The rules usually are:
* The `live-website` branch points to some commit in the current minor r... | 1.0 | maintenership: document how to update the website - We should document on the website, how to upgrade the website. This come up here: https://github.com/metallb/metallb/pull/661#event-3624239546
The website is served from whatever is present in the `live-website` branch. The rules usually are:
* The `live-website`... | process | maintenership document how to update the website we should document on the website how to upgrade the website this come up here the website is served from whatever is present in the live website branch the rules usually are the live website branch points to some commit in the current minor release ... | 1 |
671,170 | 22,746,437,861 | IssuesEvent | 2022-07-07 09:34:44 | feast-dev/feast | https://api.github.com/repos/feast-dev/feast | opened | Spark source unable to accept parquet file folder path | kind/bug priority/p2 | Spark source has been working well with providing a single parquet file path. But when a folder path is provided it shows following error:
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
07/07/2022 02:43:18 PM ERROR:Spark read of file source failed.
Traceback (most rece... | 1.0 | Spark source unable to accept parquet file folder path - Spark source has been working well with providing a single parquet file path. But when a folder path is provided it shows following error:
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
07/07/2022 02:43:18 PM ERRO... | non_process | spark source unable to accept parquet file folder path spark source has been working well with providing a single parquet file path but when a folder path is provided it shows following error to adjust logging level use sc setloglevel newlevel for sparkr use setloglevel newlevel pm error spark ... | 0 |
20,868 | 27,657,037,685 | IssuesEvent | 2023-03-12 03:48:57 | open-telemetry/opentelemetry-collector-contrib | https://api.github.com/repos/open-telemetry/opentelemetry-collector-contrib | closed | [processor/k8sattributes] setting container.id on traces | processor/k8sattributes | ### Component(s)
processor/k8sattributes
### Describe the issue you're reporting
Hi, I'm using the k8sattributes processor to enrich `container.id` on OTEL traces using `k8s.pod.ip` or `k8s.pod.uid` to match the pod and `k8s.container.name` and `k8s.container.restart_count` to match the container within the pod.
... | 1.0 | [processor/k8sattributes] setting container.id on traces - ### Component(s)
processor/k8sattributes
### Describe the issue you're reporting
Hi, I'm using the k8sattributes processor to enrich `container.id` on OTEL traces using `k8s.pod.ip` or `k8s.pod.uid` to match the pod and `k8s.container.name` and `k8s.containe... | process | setting container id on traces component s processor describe the issue you re reporting hi i m using the processor to enrich container id on otel traces using pod ip or pod uid to match the pod and container name and container restart count to match the container within the pod ... | 1 |
46,767 | 13,055,973,241 | IssuesEvent | 2020-07-30 03:16:38 | icecube-trac/tix2 | https://api.github.com/repos/icecube-trac/tix2 | opened | dst - test dst::dst16.py is failing across the board (Trac #1847) | Incomplete Migration Migrated from Trac combo reconstruction defect | Migrated from https://code.icecube.wisc.edu/ticket/1847
```json
{
"status": "closed",
"changetime": "2016-09-01T14:56:02",
"description": "{{{\n187/425 Test #187: dst::dst16.py ..................................................***Failed 6.66 sec\nINFO (I3Tray): qify-dst: WritePFrame = True (I3Tray.py:2... | 1.0 | dst - test dst::dst16.py is failing across the board (Trac #1847) - Migrated from https://code.icecube.wisc.edu/ticket/1847
```json
{
"status": "closed",
"changetime": "2016-09-01T14:56:02",
"description": "{{{\n187/425 Test #187: dst::dst16.py ..................................................***Failed ... | non_process | dst test dst py is failing across the board trac migrated from json status closed changetime description test dst py failed sec ninfo qify dst writepframe true py in call ... | 0 |
15,335 | 19,472,002,354 | IssuesEvent | 2021-12-24 03:51:20 | emily-writes-poems/emily-writes-poems-processing | https://api.github.com/repos/emily-writes-poems/emily-writes-poems-processing | closed | migrate: create collection | script migration processing | build Javascript/Electron functionality from existing Python script `mongo_collection.py`
insert new collection given collection id, collection name, and collection summary (optional) | 1.0 | migrate: create collection - build Javascript/Electron functionality from existing Python script `mongo_collection.py`
insert new collection given collection id, collection name, and collection summary (optional) | process | migrate create collection build javascript electron functionality from existing python script mongo collection py insert new collection given collection id collection name and collection summary optional | 1 |
1,786 | 4,519,124,961 | IssuesEvent | 2016-09-06 04:03:13 | csdperic/csdp | https://api.github.com/repos/csdperic/csdp | opened | 在offline的有个字段是reason,但是在web的页面上没有了,请加上 | ncm process | 
在web的页面上加上,是用来纪录rreassign,tryagain和suspend的原因的

在Reason那里,显示的格式如下,当点击suspend,在reason里面填写
... | 1.0 | 在offline的有个字段是reason,但是在web的页面上没有了,请加上 - 
在web的页面上加上,是用来纪录rreassign,tryagain和suspend的原因的

在... | process | 在offline的有个字段是reason,但是在web的页面上没有了,请加上 在web的页面上加上,是用来纪录rreassign,tryagain和suspend的原因的 在reason那里,显示的格式如下,当点击suspend,在reason里面填写 suspend: xxxxxxxx 如果是tryagain的,显示 tryagain: xxxxxx | 1 |
16,803 | 22,046,337,682 | IssuesEvent | 2022-05-30 02:26:36 | EveryAgile/Backend | https://api.github.com/repos/EveryAgile/Backend | opened | [FEAT] 회원 가입 및 로그인 | processing feature | ## 설명
회원 가입 및 로그인
## 체크사항
- [ ] AWS 프리티어 계정 생성
- [ ] 회원 엔티티 생성 후 디비 연동 (JPA 사용 예정)
- [ ] JWT 사용 및 토큰 디비 생성
- [ ] 스프링 시큐리티 적용
- [ ] 회원 가입 및 로그인 관련 컨트롤러 및 DAO 생성
- [ ] 회원 가입 및 로그인 관련 서비스 생성
- [ ] 에러 처리
## 참고자료
## 관련 논의
| 1.0 | [FEAT] 회원 가입 및 로그인 - ## 설명
회원 가입 및 로그인
## 체크사항
- [ ] AWS 프리티어 계정 생성
- [ ] 회원 엔티티 생성 후 디비 연동 (JPA 사용 예정)
- [ ] JWT 사용 및 토큰 디비 생성
- [ ] 스프링 시큐리티 적용
- [ ] 회원 가입 및 로그인 관련 컨트롤러 및 DAO 생성
- [ ] 회원 가입 및 로그인 관련 서비스 생성
- [ ] 에러 처리
## 참고자료
## 관련 논의
| process | 회원 가입 및 로그인 설명 회원 가입 및 로그인 체크사항 aws 프리티어 계정 생성 회원 엔티티 생성 후 디비 연동 jpa 사용 예정 jwt 사용 및 토큰 디비 생성 스프링 시큐리티 적용 회원 가입 및 로그인 관련 컨트롤러 및 dao 생성 회원 가입 및 로그인 관련 서비스 생성 에러 처리 참고자료 관련 논의 | 1 |
20,517 | 27,174,923,063 | IssuesEvent | 2023-02-17 23:52:49 | 0xPolygonMiden/miden-vm | https://api.github.com/repos/0xPolygonMiden/miden-vm | closed | Potential refactor of crypto operations | enhancement assembly processor | According to @bobbinth, we could make `mtree_set` a bit more efficient by changing semantics of `MRUPDATE` from:
[V, d, i, R, NV] -> [NR, d, i, R, NV]
to
[V, d, i, R, NV] -> [V, d, i, NR, NV]
This should shave off 3 VM cycles from `mtree_set` and get it down to 11 cycles, but:
- It would complic... | 1.0 | Potential refactor of crypto operations - According to @bobbinth, we could make `mtree_set` a bit more efficient by changing semantics of `MRUPDATE` from:
[V, d, i, R, NV] -> [NR, d, i, R, NV]
to
[V, d, i, R, NV] -> [V, d, i, NR, NV]
This should shave off 3 VM cycles from `mtree_set` and get it down... | process | potential refactor of crypto operations according to bobbinth we could make mtree set a bit more efficient by changing semantics of mrupdate from to this should shave off vm cycles from mtree set and get it down to cycles but it would complicate handling of const... | 1 |
142,310 | 19,089,401,393 | IssuesEvent | 2021-11-29 10:22:22 | tharun453/samples | https://api.github.com/repos/tharun453/samples | opened | CVE-2018-8292 (High) detected in system.net.http.4.3.0.nupkg, system.net.http.4.3.2.nupkg | security vulnerability | ## CVE-2018-8292 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>system.net.http.4.3.0.nupkg</b>, <b>system.net.http.4.3.2.nupkg</b></p></summary>
<p>
<details><summary><b>system.net... | True | CVE-2018-8292 (High) detected in system.net.http.4.3.0.nupkg, system.net.http.4.3.2.nupkg - ## CVE-2018-8292 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Libraries - <b>system.net.http.4.3.0.nupk... | non_process | cve high detected in system net http nupkg system net http nupkg cve high severity vulnerability vulnerable libraries system net http nupkg system net http nupkg system net http nupkg provides a programming interface for modern http applications i... | 0 |
147,046 | 13,200,153,179 | IssuesEvent | 2020-08-14 07:39:03 | MaSyMoS/masymos-core | https://api.github.com/repos/MaSyMoS/masymos-core | opened | test masymos docker, check documentation | check documentation help wanted | - test, if running
- check docs for
- is everything understandable
- grammar and typo
- is everything covered, did i miss something?
- please report in this issue!
- OS+version
- docker version
# ToDo
- [ ] check docs: [Minimal Userguide to get startet](https://masymos.readthedocs.io/en/l... | 1.0 | test masymos docker, check documentation - - test, if running
- check docs for
- is everything understandable
- grammar and typo
- is everything covered, did i miss something?
- please report in this issue!
- OS+version
- docker version
# ToDo
- [ ] check docs: [Minimal Userguide to get s... | non_process | test masymos docker check documentation test if running check docs for is everything understandable grammar and typo is everything covered did i miss something please report in this issue os version docker version todo check docs check docs ... | 0 |
81,067 | 30,694,105,239 | IssuesEvent | 2023-07-26 17:12:33 | idaholab/moose | https://api.github.com/repos/idaholab/moose | opened | Subdomain mesh adaptivity issues for finite volume problems | T: defect P: normal | ## Bug Description
Undesirable behavior and crashes are observed for finite volume problems that use mesh adaptivity on a subdomain.
## Steps to Reproduce
Consider the test input in moose/test/tests/indicators/gradient_jump_indicator/gradient_jump_indicator_test.i. This problem is split into 2 subdomains: the left... | 1.0 | Subdomain mesh adaptivity issues for finite volume problems - ## Bug Description
Undesirable behavior and crashes are observed for finite volume problems that use mesh adaptivity on a subdomain.
## Steps to Reproduce
Consider the test input in moose/test/tests/indicators/gradient_jump_indicator/gradient_jump_indic... | non_process | subdomain mesh adaptivity issues for finite volume problems bug description undesirable behavior and crashes are observed for finite volume problems that use mesh adaptivity on a subdomain steps to reproduce consider the test input in moose test tests indicators gradient jump indicator gradient jump indic... | 0 |
2,015 | 4,837,107,782 | IssuesEvent | 2016-11-08 21:36:05 | cliffparnitzky/FormDependentMandatoryField | https://api.github.com/repos/cliffparnitzky/FormDependentMandatoryField | closed | Wrong error message for "is_empty" condition | Defect Improvement ⚙ - Processed | Hi Cliff,
many thanks for your work, saved me from braindeath ;-)
I would suggest to add another condition labeled "empty" or "is empty" to the dependent fields list. Error messages should be adapted accordingly (in German like "keine Werte in Feld xyz"). I my understanding, currently you could build it with "!=" ... | 1.0 | Wrong error message for "is_empty" condition - Hi Cliff,
many thanks for your work, saved me from braindeath ;-)
I would suggest to add another condition labeled "empty" or "is empty" to the dependent fields list. Error messages should be adapted accordingly (in German like "keine Werte in Feld xyz"). I my underst... | process | wrong error message for is empty condition hi cliff many thanks for your work saved me from braindeath i would suggest to add another condition labeled empty or is empty to the dependent fields list error messages should be adapted accordingly in german like keine werte in feld xyz i my underst... | 1 |
21,991 | 30,485,794,952 | IssuesEvent | 2023-07-18 02:00:10 | lizhihao6/get-daily-arxiv-noti | https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti | opened | New submissions for Tue, 18 Jul 23 | event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB | ## Keyword: events
### Boundary-weighted logit consistency improves calibration of segmentation networks
- **Authors:** Neerav Karani, Neel Dey, Polina Golland
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2307.08163
- **Pdf link:** https://arxiv.org/pdf/23... | 2.0 | New submissions for Tue, 18 Jul 23 - ## Keyword: events
### Boundary-weighted logit consistency improves calibration of segmentation networks
- **Authors:** Neerav Karani, Neel Dey, Polina Golland
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2307.08163
- *... | process | new submissions for tue jul keyword events boundary weighted logit consistency improves calibration of segmentation networks authors neerav karani neel dey polina golland subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract n... | 1 |
52,619 | 22,321,575,044 | IssuesEvent | 2022-06-14 06:59:20 | Azure/azure-sdk-for-net | https://api.github.com/repos/Azure/azure-sdk-for-net | closed | [BUG][Storage mgmt Track2] RestoreBlobRanges' output TimeToRestore is always 1/1/0001 12:00:00 AM +00:00 | Storage Service Attention Client customer-reported question needs-team-attention | ### Library name and version
Azure.ResourceManager.Storage 1.0.0-beta.9
### Describe the bug
In RestoreBlobRanges' output, no matter what the user input of TimeToRestore is, the output TimeToRestore's value is always 1/1/0001 12:00:00 AM +00:00. This happens no matter if we put WaitUtil.Started or WaitUtil.Com... | 1.0 | [BUG][Storage mgmt Track2] RestoreBlobRanges' output TimeToRestore is always 1/1/0001 12:00:00 AM +00:00 - ### Library name and version
Azure.ResourceManager.Storage 1.0.0-beta.9
### Describe the bug
In RestoreBlobRanges' output, no matter what the user input of TimeToRestore is, the output TimeToRestore's val... | non_process | restoreblobranges output timetorestore is always am library name and version azure resourcemanager storage beta describe the bug in restoreblobranges output no matter what the user input of timetorestore is the output timetorestore s value is always am ... | 0 |
269,475 | 23,444,996,105 | IssuesEvent | 2022-08-15 18:39:37 | PowerShell/PowerShellGet | https://api.github.com/repos/PowerShell/PowerShellGet | closed | Review ProjectUri/Url and IconUri/Url in Publish-PSResource | feature_request Needs Testing | ### Summary of the new feature / enhancement
See: https://github.com/PowerShell/PowerShellGet/pull/551#issuecomment-1020034298
Ensure that 'ProjectUri' or 'ProjectUrl' and 'IconUri' and 'IconUrl' are being used in the appropriate spots and are being referenced correctly when reading from module manifests and writin... | 1.0 | Review ProjectUri/Url and IconUri/Url in Publish-PSResource - ### Summary of the new feature / enhancement
See: https://github.com/PowerShell/PowerShellGet/pull/551#issuecomment-1020034298
Ensure that 'ProjectUri' or 'ProjectUrl' and 'IconUri' and 'IconUrl' are being used in the appropriate spots and are being ref... | non_process | review projecturi url and iconuri url in publish psresource summary of the new feature enhancement see ensure that projecturi or projecturl and iconuri and iconurl are being used in the appropriate spots and are being referenced correctly when reading from module manifests and writing to nuspecs... | 0 |
10,820 | 8,183,521,817 | IssuesEvent | 2018-08-29 09:18:21 | primefaces/primefaces | https://api.github.com/repos/primefaces/primefaces | closed | fileUpload: filename returned by UploadedFile should be sanitized | 6.2.9 enhancement security | ## 1) Environment
- PrimeFaces version: primefaces-6.2.RC2-snapshot
- Application server + version: WildFly 11
- Affected browsers: all
## 2) Expected behavior
The filename returned by `UploadedFile ` should be sanitized. Otherwise, this may lead to path traversal vulnerabilities if developers use `UploadedFile.... | True | fileUpload: filename returned by UploadedFile should be sanitized - ## 1) Environment
- PrimeFaces version: primefaces-6.2.RC2-snapshot
- Application server + version: WildFly 11
- Affected browsers: all
## 2) Expected behavior
The filename returned by `UploadedFile ` should be sanitized. Otherwise, this may lea... | non_process | fileupload filename returned by uploadedfile should be sanitized environment primefaces version primefaces snapshot application server version wildfly affected browsers all expected behavior the filename returned by uploadedfile should be sanitized otherwise this may lead t... | 0 |
15,925 | 20,142,304,940 | IssuesEvent | 2022-02-09 01:20:54 | brucemiller/LaTeXML | https://api.github.com/repos/brucemiller/LaTeXML | opened | Model and styling for figures found in minipages | enhancement postprocessing schema | I will start collecting examples in an issue, ideally I go to 5-10 different articles in arXiv, to see the broad flavor of markup we get with minipages. Currently my CSS is consistently wrong for them, but I would like to double-check the underlying HTML is also sensible. I'll recruit help, as I'm looking into details.... | 1.0 | Model and styling for figures found in minipages - I will start collecting examples in an issue, ideally I go to 5-10 different articles in arXiv, to see the broad flavor of markup we get with minipages. Currently my CSS is consistently wrong for them, but I would like to double-check the underlying HTML is also sensib... | process | model and styling for figures found in minipages i will start collecting examples in an issue ideally i go to different articles in arxiv to see the broad flavor of markup we get with minipages currently my css is consistently wrong for them but i would like to double check the underlying html is also sensibl... | 1 |
10,418 | 13,210,736,096 | IssuesEvent | 2020-08-15 18:33:27 | km4ack/patmenu2 | https://api.github.com/repos/km4ack/patmenu2 | closed | Station List download recommendation | bug in process | I mistakenly chose to update my station list while offline. The result was my station list file was replaced with an empty list.
I would suggest the update script check to see if the new list is successfully downloaded before erasing the old list. If you don't have internet access and hit the wrong button, you w... | 1.0 | Station List download recommendation - I mistakenly chose to update my station list while offline. The result was my station list file was replaced with an empty list.
I would suggest the update script check to see if the new list is successfully downloaded before erasing the old list. If you don't have internet... | process | station list download recommendation i mistakenly chose to update my station list while offline the result was my station list file was replaced with an empty list i would suggest the update script check to see if the new list is successfully downloaded before erasing the old list if you don t have internet... | 1 |
495,594 | 14,284,675,146 | IssuesEvent | 2020-11-23 12:52:09 | SupremeObsidian/ProjectManager | https://api.github.com/repos/SupremeObsidian/ProjectManager | opened | Mobs falling apart when hit | High Priority bug | All of our mobs' geometry comes apart when they are hit by a player. This might be a problem in the future, especially if it's something that has to do with how we animate or create our models. | 1.0 | Mobs falling apart when hit - All of our mobs' geometry comes apart when they are hit by a player. This might be a problem in the future, especially if it's something that has to do with how we animate or create our models. | non_process | mobs falling apart when hit all of our mobs geometry comes apart when they are hit by a player this might be a problem in the future especially if it s something that has to do with how we animate or create our models | 0 |
19,121 | 25,171,933,958 | IssuesEvent | 2022-11-11 04:42:09 | emily-writes-poems/emily-writes-poems-processing | https://api.github.com/repos/emily-writes-poems/emily-writes-poems-processing | closed | react: feature page | processing | have these at least functioning from the react page:
- [x] create new feature
- [x] display all features table | 1.0 | react: feature page - have these at least functioning from the react page:
- [x] create new feature
- [x] display all features table | process | react feature page have these at least functioning from the react page create new feature display all features table | 1 |
9,218 | 12,254,378,263 | IssuesEvent | 2020-05-06 08:22:49 | python-trio/trio | https://api.github.com/repos/python-trio/trio | closed | Put process-creation into a thread | subprocesses | [Original title: Is process creation *actually* non-blocking?]
In https://github.com/python-trio/trio/issues/1104 I wrote:
> the actual process startup is synchronous, so you could just as well have a synchronous version
But uh... it just occurred to me that I'm actually not sure if this is true! I mean, right... | 1.0 | Put process-creation into a thread - [Original title: Is process creation *actually* non-blocking?]
In https://github.com/python-trio/trio/issues/1104 I wrote:
> the actual process startup is synchronous, so you could just as well have a synchronous version
But uh... it just occurred to me that I'm actually no... | process | put process creation into a thread in i wrote the actual process startup is synchronous so you could just as well have a synchronous version but uh it just occurred to me that i m actually not sure if this is true i mean right now we just use subprocess popen which is indeed a synchronous int... | 1 |
2,833 | 5,786,157,114 | IssuesEvent | 2017-05-01 08:57:13 | qgis/QGIS-Documentation | https://api.github.com/repos/qgis/QGIS-Documentation | closed | [FEATURE][processing] New algorithm for calculating feature bounding boxes | Processing Text | Original commit: https://github.com/qgis/QGIS/commit/0815ddd766cea48cf9c2eddde656943f8a1ecfda by nyalldawson
(cherry-picked from bd8db5d156071b308f9e091bc444857424879f06)
| 1.0 | [FEATURE][processing] New algorithm for calculating feature bounding boxes - Original commit: https://github.com/qgis/QGIS/commit/0815ddd766cea48cf9c2eddde656943f8a1ecfda by nyalldawson
(cherry-picked from bd8db5d156071b308f9e091bc444857424879f06)
| process | new algorithm for calculating feature bounding boxes original commit by nyalldawson cherry picked from | 1 |
20,022 | 26,499,969,196 | IssuesEvent | 2023-01-18 09:32:29 | dotnet/runtime | https://api.github.com/repos/dotnet/runtime | closed | Process.WaitForExit() deadlock when running multiple processes on linux with .net7 | area-System.Diagnostics.Process untriaged | ### Description
Running multiple processes concurrently using System.Diagnostics.Process causes a deadlock on linux with .net7. I checked [this](https://github.com/dotnet/runtime/issues/51277), but I believe it is something else.
### Reproduction Steps
A simple example to reproduce deadlock is [here](https://github.... | 1.0 | Process.WaitForExit() deadlock when running multiple processes on linux with .net7 - ### Description
Running multiple processes concurrently using System.Diagnostics.Process causes a deadlock on linux with .net7. I checked [this](https://github.com/dotnet/runtime/issues/51277), but I believe it is something else.
###... | process | process waitforexit deadlock when running multiple processes on linux with description running multiple processes concurrently using system diagnostics process causes a deadlock on linux with i checked but i believe it is something else reproduction steps a simple example to reproduce deadloc... | 1 |
50,655 | 13,550,102,994 | IssuesEvent | 2020-09-17 09:08:28 | symfony/symfony | https://api.github.com/repos/symfony/symfony | closed | [Security] New LoginFormAuthenticator fails on InsufficientAuthenticationException with missing AuthenticationEntryPoint | Bug Security Status: Needs Review | **Symfony version(s) affected**: 5.1
**Description**
I've replaced my guard login authenticator with a version based on the `AbstractLoginFormAuthenticator` and enabled the AuthenticationManager. Everyhing works fine except hitting a page which requires `IS_AUTHENTICATED_REMEMBERED` without actual being logged ... | True | [Security] New LoginFormAuthenticator fails on InsufficientAuthenticationException with missing AuthenticationEntryPoint - **Symfony version(s) affected**: 5.1
**Description**
I've replaced my guard login authenticator with a version based on the `AbstractLoginFormAuthenticator` and enabled the AuthenticationMa... | non_process | new loginformauthenticator fails on insufficientauthenticationexception with missing authenticationentrypoint symfony version s affected description i ve replaced my guard login authenticator with a version based on the abstractloginformauthenticator and enabled the authenticationmanager ev... | 0 |
9,832 | 12,828,086,804 | IssuesEvent | 2020-07-06 19:49:04 | googleapis/code-suggester | https://api.github.com/repos/googleapis/code-suggester | opened | Framework-core: handle existing PRs and existing branches | type: process | - [ ] When there is an existing PR on an up-stream repository and a PR from the same branch and same down-stream repository is opened, there will be an error thrown. Ensure that the latest version is made into a PR.
- [ ] When there is an existing branch and someone tries to apply changes onto an existing branch, opti... | 1.0 | Framework-core: handle existing PRs and existing branches - - [ ] When there is an existing PR on an up-stream repository and a PR from the same branch and same down-stream repository is opened, there will be an error thrown. Ensure that the latest version is made into a PR.
- [ ] When there is an existing branch and ... | process | framework core handle existing prs and existing branches when there is an existing pr on an up stream repository and a pr from the same branch and same down stream repository is opened there will be an error thrown ensure that the latest version is made into a pr when there is an existing branch and some... | 1 |
16,316 | 20,971,536,155 | IssuesEvent | 2022-03-28 11:52:15 | geneontology/go-ontology | https://api.github.com/repos/geneontology/go-ontology | closed | NTR modulation by symbiont of host system process | multi-species process | Hello,
The multiorganism working group proposes to create a new term, 'modulation by symbiont of host system process ', to organize the 'modulation by symbiont of host process' branch, which would group:
'modulation by symbiont of host digestive system process'
'modulation by symbiont of host endocrine process'
... | 1.0 | NTR modulation by symbiont of host system process - Hello,
The multiorganism working group proposes to create a new term, 'modulation by symbiont of host system process ', to organize the 'modulation by symbiont of host process' branch, which would group:
'modulation by symbiont of host digestive system process'... | process | ntr modulation by symbiont of host system process hello the multiorganism working group proposes to create a new term modulation by symbiont of host system process to organize the modulation by symbiont of host process branch which would group modulation by symbiont of host digestive system process ... | 1 |
438,699 | 30,657,707,697 | IssuesEvent | 2023-07-25 13:12:46 | eclipse-xpanse/xpanse | https://api.github.com/repos/eclipse-xpanse/xpanse | closed | review all API methods documentation | documentation api | Review all API methods documentation and update wherever necessary. | 1.0 | review all API methods documentation - Review all API methods documentation and update wherever necessary. | non_process | review all api methods documentation review all api methods documentation and update wherever necessary | 0 |
12,018 | 14,738,444,683 | IssuesEvent | 2021-01-07 04:47:05 | kdjstudios/SABillingGitlab | https://api.github.com/repos/kdjstudios/SABillingGitlab | closed | SA Billing - Rebillables / Vendor sort | anc-ops anc-process anc-report anc-ui anp-1 ant-bug ant-support | In GitLab by @kdjstudios on May 24, 2018, 12:47
**Submitted by:** Valerie Brown " <valerie.brown@answernet.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/2018-05-24-44361/conversation
**Server:** Internal (Both?)
**Client/Site:** NA
**Account:** NA
**Issue:**
I am having problems with t... | 1.0 | SA Billing - Rebillables / Vendor sort - In GitLab by @kdjstudios on May 24, 2018, 12:47
**Submitted by:** Valerie Brown " <valerie.brown@answernet.com>
**Helpdesk:** http://www.servicedesk.answernet.com/profiles/ticket/2018-05-24-44361/conversation
**Server:** Internal (Both?)
**Client/Site:** NA
**Account:** NA
... | process | sa billing rebillables vendor sort in gitlab by kdjstudios on may submitted by valerie brown helpdesk server internal both client site na account na issue i am having problems with the sa billing program if i try to sort by vendor name it get an erro... | 1 |
10,100 | 13,044,162,111 | IssuesEvent | 2020-07-29 03:47:29 | tikv/tikv | https://api.github.com/repos/tikv/tikv | closed | UCP: Migrate scalar function `AddDatetimeAndString` from TiDB | challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor |
## Description
Port the scalar function `AddDatetimeAndString` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/sr... | 2.0 | UCP: Migrate scalar function `AddDatetimeAndString` from TiDB -
## Description
Port the scalar function `AddDatetimeAndString` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @mapleFU
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- h... | process | ucp migrate scalar function adddatetimeandstring from tidb description port the scalar function adddatetimeandstring from tidb to coprocessor score mentor s maplefu recommended skills rust programming learning materials already implemented expressions ported from tidb ... | 1 |
2,912 | 5,903,441,800 | IssuesEvent | 2017-05-19 06:45:27 | inasafe/inasafe-realtime | https://api.github.com/repos/inasafe/inasafe-realtime | closed | Ordering issues in Realtime reports | bug realtime processor | Layer in map view were not ordered correctly.
Need workaround.
See original ticket at https://github.com/inasafe/inasafe/issues/3692 for further discussion. | 1.0 | Ordering issues in Realtime reports - Layer in map view were not ordered correctly.
Need workaround.
See original ticket at https://github.com/inasafe/inasafe/issues/3692 for further discussion. | process | ordering issues in realtime reports layer in map view were not ordered correctly need workaround see original ticket at for further discussion | 1 |
36,866 | 18,019,567,129 | IssuesEvent | 2021-09-16 17:36:18 | microsoft/react-native-windows | https://api.github.com/repos/microsoft/react-native-windows | closed | NuGet packages include symbols | enhancement Area: Performance Area: Developer Experience | The current nuget packages we produce (like v8jsi etc.) include PDBs which bloat the on-disk footprint, and 99% of developers won't need symbols for v8jsi, chakra, etc. These should instead be distributed via snupkg: https://docs.microsoft.com/en-us/nuget/create-packages/symbol-packages-snupkg
 include PDBs which bloat the on-disk footprint, and 99% of developers won't need symbols for v8jsi, chakra, etc. These should instead be distributed via snupkg: https://docs.microsoft.com/en-us/nuget/create-packages/symbol-packages... | non_process | nuget packages include symbols the current nuget packages we produce like etc include pdbs which bloat the on disk footprint and of developers won t need symbols for chakra etc these should instead be distributed via snupkg pdbs account for gb fullname length reactnativ... | 0 |
21,304 | 28,499,639,541 | IssuesEvent | 2023-04-18 16:21:23 | GoogleCloudPlatform/pgadapter | https://api.github.com/repos/GoogleCloudPlatform/pgadapter | closed | Difference in timezone for Egypt | type: process | ```
ITPsqlTest.testTimestamptzParsing:794 Timestamp: 2041-06-21 17:45:31, Timezone: Egypt expected:<...041-06-21 17:45:31+0[3]
(1 row)
> but was:<...041-06-21 17:45:31+0[2]
(1 row)
``` | 1.0 | Difference in timezone for Egypt - ```
ITPsqlTest.testTimestamptzParsing:794 Timestamp: 2041-06-21 17:45:31, Timezone: Egypt expected:<...041-06-21 17:45:31+0[3]
(1 row)
> but was:<...041-06-21 17:45:31+0[2]
(1 row)
``` | process | difference in timezone for egypt itpsqltest testtimestamptzparsing timestamp timezone egypt expected row but was row | 1 |
11,867 | 14,667,744,504 | IssuesEvent | 2020-12-29 19:25:17 | modi-w/AutoVersionsDB | https://api.github.com/repos/modi-w/AutoVersionsDB | opened | The log process window is responding slowly when it runs on a big project with a lot of scripts. | area-UI process-discussion type-bug | **Describe the bug**
The log process window is responding slowly when it runs on a big project with a lot of scripts.
**To Reproduce**
Steps to reproduce the behavior:
1. Define a big project with a lot of scripts with many scripts block.
2. Run all the scripts file with "Recreate"
3. after a while during the p... | 1.0 | The log process window is responding slowly when it runs on a big project with a lot of scripts. - **Describe the bug**
The log process window is responding slowly when it runs on a big project with a lot of scripts.
**To Reproduce**
Steps to reproduce the behavior:
1. Define a big project with a lot of scripts w... | process | the log process window is responding slowly when it runs on a big project with a lot of scripts describe the bug the log process window is responding slowly when it runs on a big project with a lot of scripts to reproduce steps to reproduce the behavior define a big project with a lot of scripts w... | 1 |
4,385 | 3,367,263,020 | IssuesEvent | 2015-11-22 01:33:08 | openhab/openhab | https://api.github.com/repos/openhab/openhab | closed | can't setup IDE | build-or-ide question | https://github.com/openhab/openhab/wiki/IDE-Setup
I read this tutorial , i install all required plugins on top of an existing Eclipse ,use this update site:http://yoxos.eclipsesource.com/userdata/profile/c5f3985b62c488f0df0dfbc369f9e057
there is an error while i isntalling it:"The installation cannot be completed... | 1.0 | can't setup IDE - https://github.com/openhab/openhab/wiki/IDE-Setup
I read this tutorial , i install all required plugins on top of an existing Eclipse ,use this update site:http://yoxos.eclipsesource.com/userdata/profile/c5f3985b62c488f0df0dfbc369f9e057
there is an error while i isntalling it:"The installation c... | non_process | can t setup ide i read this tutorial i install all required plugins on top of an existing eclipse use this update site there is an error while i isntalling it the installation cannot be completed as requested | 0 |
9,815 | 25,277,944,945 | IssuesEvent | 2022-11-16 13:55:27 | hzi-braunschweig/SORMAS-Project | https://api.github.com/repos/hzi-braunschweig/SORMAS-Project | opened | Clearly separate EJBs and services | refactoring change architecture | ### Problem Description
While working on #9708, I encountered a strange situation where the fact that EJBs and services receive their own `EntityManager` (via `AbstractBaseEjb` and `BaseAdoService` respectively) causes the creation of unnecessary transactions when you call from EJBs to services. In cases where an EJ... | 1.0 | Clearly separate EJBs and services - ### Problem Description
While working on #9708, I encountered a strange situation where the fact that EJBs and services receive their own `EntityManager` (via `AbstractBaseEjb` and `BaseAdoService` respectively) causes the creation of unnecessary transactions when you call from E... | non_process | clearly separate ejbs and services problem description while working on i encountered a strange situation where the fact that ejbs and services receive their own entitymanager via abstractbaseejb and baseadoservice respectively causes the creation of unnecessary transactions when you call from ejbs... | 0 |
60,477 | 25,147,969,166 | IssuesEvent | 2022-11-10 07:39:20 | Azure/azure-sdk-for-java | https://api.github.com/repos/Azure/azure-sdk-for-java | closed | sdk/servicebus/azure-messaging-servicebus - cspell found spelling errors in package | Service Bus Client Spelling | Spell check scanning of package at `sdk/servicebus/azure-messaging-servicebus` detected spelling errors in the public API surface. This directory is opted out of PR spell checking in PR #31526 to keep PRs unblocked.
## What to do
1. Ensure Node.js is installed (https://nodejs.org/en/download/).
1. Delete the entry in... | 1.0 | sdk/servicebus/azure-messaging-servicebus - cspell found spelling errors in package - Spell check scanning of package at `sdk/servicebus/azure-messaging-servicebus` detected spelling errors in the public API surface. This directory is opted out of PR spell checking in PR #31526 to keep PRs unblocked.
## What to do
1.... | non_process | sdk servicebus azure messaging servicebus cspell found spelling errors in package spell check scanning of package at sdk servicebus azure messaging servicebus detected spelling errors in the public api surface this directory is opted out of pr spell checking in pr to keep prs unblocked what to do ens... | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.