
Unnamed: 0
int64 0
832k
| id
float64 2.49B
32.1B
| type
stringclasses 1
value | created_at
stringlengths 19
19
| repo
stringlengths 7
112
| repo_url
stringlengths 36
141
| action
stringclasses 3
values | title
stringlengths 1
744
| labels
stringlengths 4
574
| body
stringlengths 9
211k
| index
stringclasses 10
values | text_combine
stringlengths 96
211k
| label
stringclasses 2
values | text
stringlengths 96
188k
| binary_label
int64 0
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
688,594
| 23,589,154,368
|
IssuesEvent
|
2022-08-23 13:58:03
|
huridocs/uwazi
|
https://api.github.com/repos/huridocs/uwazi
|
closed
|
Multi date range and multi date ranges are not supported by CSV import
|
Sprint Priority: High Feature Backend 💾
|
The property type date range and multi date range are not supported through csv import. At present, this type of information has to be manually entered into the database as the import leaves out these property types when trying to do an import.
User Story:
As an admin user responsible for the migration of a large dataset of existing data into Uwazi that contains crucial date range information, I would like to be able to import this information through the csv file as well instead of having to manually enter this into each entity after the import is completed.
|
1.0
|
Multi date range and multi date ranges are not supported by CSV import - The property type date range and multi date range are not supported through csv import. At present, this type of information has to be manually entered into the database as the import leaves out these property types when trying to do an import.
User Story:
As an admin user responsible for the migration of a large dataset of existing data into Uwazi that contains crucial date range information, I would like to be able to import this information through the csv file as well instead of having to manually enter this into each entity after the import is completed.
|
non_process
|
multi date range and multi date ranges are not supported by csv import the property type date range and multi date range are not supported through csv import at present this type of information has to be manually entered into the database as the import leaves out these property types when trying to do an import user story as an admin user responsible for the migration of a large dataset of existing data into uwazi that contains crucial date range information i would like to be able to import this information through the csv file as well instead of having to manually enter this into each entity after the import is completed
| 0
|
18,210
| 24,269,640,121
|
IssuesEvent
|
2022-09-28 09:15:41
|
hashgraph/hedera-json-rpc-relay
|
https://api.github.com/repos/hashgraph/hedera-json-rpc-relay
|
opened
|
Acceptance tests time out often when run locally
|
process
|
### Problem
When running the acceptance tests locally they often time out.
### Solution
Let's investigate and figure out why that is and what we can do to optimize the runs.
### Alternatives
_No response_
|
1.0
|
Acceptance tests time out often when run locally - ### Problem
When running the acceptance tests locally they often time out.
### Solution
Let's investigate and figure out why that is and what we can do to optimize the runs.
### Alternatives
_No response_
|
process
|
acceptance tests time out often when run locally problem when running the acceptance tests locally they often time out solution let s investigate and figure out why that is and what we can do to optimize the runs alternatives no response
| 1
|
131,616
| 18,248,379,616
|
IssuesEvent
|
2021-10-01 22:09:57
|
ghc-dev/Ryan-Rasmussen
|
https://api.github.com/repos/ghc-dev/Ryan-Rasmussen
|
opened
|
WS-2018-0111 (High) detected in base64-url-1.2.1.tgz
|
security vulnerability
|
## WS-2018-0111 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>base64-url-1.2.1.tgz</b></p></summary>
<p>Base64 encode, decode, escape and unescape for URL applications</p>
<p>Library home page: <a href="https://registry.npmjs.org/base64-url/-/base64-url-1.2.1.tgz">https://registry.npmjs.org/base64-url/-/base64-url-1.2.1.tgz</a></p>
<p>Path to dependency file: Ryan-Rasmussen/package.json</p>
<p>Path to vulnerable library: Ryan-Rasmussen/node_modules/base64-url/package.json</p>
<p>
Dependency Hierarchy:
- grunt-contrib-connect-0.10.1.tgz (Root Library)
- connect-2.30.2.tgz
- express-session-1.11.3.tgz
- uid-safe-2.0.0.tgz
- :x: **base64-url-1.2.1.tgz** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/ghc-dev/Ryan-Rasmussen/commit/4ab6cb55863cc1731cd89a0da07290be9ef8799e">4ab6cb55863cc1731cd89a0da07290be9ef8799e</a></p>
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Versions of base64-url before 2.0.0 are vulnerable to out-of-bounds read as it allocates uninitialized Buffers when number is passed in input.
<p>Publish Date: 2018-05-16
<p>URL: <a href=https://hackerone.com/reports/321692>WS-2018-0111</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>9.1</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: High
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://nodesecurity.io/advisories/660">https://nodesecurity.io/advisories/660</a></p>
<p>Release Date: 2018-01-27</p>
<p>Fix Resolution: 2.0.0</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":true,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"javascript/Node.js","packageName":"base64-url","packageVersion":"1.2.1","packageFilePaths":["/package.json"],"isTransitiveDependency":true,"dependencyTree":"grunt-contrib-connect:0.10.1;connect:2.30.2;express-session:1.11.3;uid-safe:2.0.0;base64-url:1.2.1","isMinimumFixVersionAvailable":true,"minimumFixVersion":"2.0.0"}],"baseBranches":["master"],"vulnerabilityIdentifier":"WS-2018-0111","vulnerabilityDetails":"Versions of base64-url before 2.0.0 are vulnerable to out-of-bounds read as it allocates uninitialized Buffers when number is passed in input.","vulnerabilityUrl":"https://hackerone.com/reports/321692","cvss3Severity":"high","cvss3Score":"9.1","cvss3Metrics":{"A":"High","AC":"Low","PR":"None","S":"Unchanged","C":"High","UI":"None","AV":"Network","I":"None"},"extraData":{}}</REMEDIATE> -->
|
True
|
WS-2018-0111 (High) detected in base64-url-1.2.1.tgz - ## WS-2018-0111 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>base64-url-1.2.1.tgz</b></p></summary>
<p>Base64 encode, decode, escape and unescape for URL applications</p>
<p>Library home page: <a href="https://registry.npmjs.org/base64-url/-/base64-url-1.2.1.tgz">https://registry.npmjs.org/base64-url/-/base64-url-1.2.1.tgz</a></p>
<p>Path to dependency file: Ryan-Rasmussen/package.json</p>
<p>Path to vulnerable library: Ryan-Rasmussen/node_modules/base64-url/package.json</p>
<p>
Dependency Hierarchy:
- grunt-contrib-connect-0.10.1.tgz (Root Library)
- connect-2.30.2.tgz
- express-session-1.11.3.tgz
- uid-safe-2.0.0.tgz
- :x: **base64-url-1.2.1.tgz** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/ghc-dev/Ryan-Rasmussen/commit/4ab6cb55863cc1731cd89a0da07290be9ef8799e">4ab6cb55863cc1731cd89a0da07290be9ef8799e</a></p>
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Versions of base64-url before 2.0.0 are vulnerable to out-of-bounds read as it allocates uninitialized Buffers when number is passed in input.
<p>Publish Date: 2018-05-16
<p>URL: <a href=https://hackerone.com/reports/321692>WS-2018-0111</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>9.1</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: High
- Integrity Impact: None
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://nodesecurity.io/advisories/660">https://nodesecurity.io/advisories/660</a></p>
<p>Release Date: 2018-01-27</p>
<p>Fix Resolution: 2.0.0</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":true,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"javascript/Node.js","packageName":"base64-url","packageVersion":"1.2.1","packageFilePaths":["/package.json"],"isTransitiveDependency":true,"dependencyTree":"grunt-contrib-connect:0.10.1;connect:2.30.2;express-session:1.11.3;uid-safe:2.0.0;base64-url:1.2.1","isMinimumFixVersionAvailable":true,"minimumFixVersion":"2.0.0"}],"baseBranches":["master"],"vulnerabilityIdentifier":"WS-2018-0111","vulnerabilityDetails":"Versions of base64-url before 2.0.0 are vulnerable to out-of-bounds read as it allocates uninitialized Buffers when number is passed in input.","vulnerabilityUrl":"https://hackerone.com/reports/321692","cvss3Severity":"high","cvss3Score":"9.1","cvss3Metrics":{"A":"High","AC":"Low","PR":"None","S":"Unchanged","C":"High","UI":"None","AV":"Network","I":"None"},"extraData":{}}</REMEDIATE> -->
|
non_process
|
ws high detected in url tgz ws high severity vulnerability vulnerable library url tgz encode decode escape and unescape for url applications library home page a href path to dependency file ryan rasmussen package json path to vulnerable library ryan rasmussen node modules url package json dependency hierarchy grunt contrib connect tgz root library connect tgz express session tgz uid safe tgz x url tgz vulnerable library found in head commit a href found in base branch master vulnerability details versions of url before are vulnerable to out of bounds read as it allocates uninitialized buffers when number is passed in input publish date url a href cvss score details base score metrics exploitability metrics attack vector network attack complexity low privileges required none user interaction none scope unchanged impact metrics confidentiality impact high integrity impact none availability impact high for more information on scores click a href suggested fix type upgrade version origin a href release date fix resolution isopenpronvulnerability true ispackagebased true isdefaultbranch true packages istransitivedependency true dependencytree grunt contrib connect connect express session uid safe url isminimumfixversionavailable true minimumfixversion basebranches vulnerabilityidentifier ws vulnerabilitydetails versions of url before are vulnerable to out of bounds read as it allocates uninitialized buffers when number is passed in input vulnerabilityurl
| 0
|
7,507
| 10,587,658,108
|
IssuesEvent
|
2019-10-08 22:51:59
|
MShooshtari/Kaggle_House_Prices
|
https://api.github.com/repos/MShooshtari/Kaggle_House_Prices
|
closed
|
Normalizing a column with many zeros
|
pre_process
|
Hey guys,
What is the best way to normalize a column that has many zeros? It happens when many houses do not have that feature, such as:
ScreenPorch: Screen porch area in square feet
OpenPorchSF: Open porch area in square feet
EnclosedPorch: Enclosed porch area in square feet
3SsnPorch: Three season porch area in square feet
BsmtFinSF1: Type 1 finished square feet
LowQualFinSF: Low quality finished square feet (all floors)
MiscVal: $Value of miscellaneous feature
|
1.0
|
Normalizing a column with many zeros - Hey guys,
What is the best way to normalize a column that has many zeros? It happens when many houses do not have that feature, such as:
ScreenPorch: Screen porch area in square feet
OpenPorchSF: Open porch area in square feet
EnclosedPorch: Enclosed porch area in square feet
3SsnPorch: Three season porch area in square feet
BsmtFinSF1: Type 1 finished square feet
LowQualFinSF: Low quality finished square feet (all floors)
MiscVal: $Value of miscellaneous feature
|
process
|
normalizing a column with many zeros hey guys what is the best way to normalize a column that has many zeros it happens when many houses do not have that feature such as screenporch screen porch area in square feet openporchsf open porch area in square feet enclosedporch enclosed porch area in square feet three season porch area in square feet type finished square feet lowqualfinsf low quality finished square feet all floors miscval value of miscellaneous feature
| 1
|
1,879
| 4,707,467,554
|
IssuesEvent
|
2016-10-13 20:14:18
|
w3c/activitypub
|
https://api.github.com/repos/w3c/activitypub
|
closed
|
ActivityPump Vocabulary and JSON-LD context
|
Needs Process Help
|
It looks like AP defines new vocabulary terms e.g. properties: inbox, outbox, followers, followings. I would see need to define a namespace (even temporary) and create JSON-LD context which one would use together with AS 2.0 context. Should I make PR?
|
1.0
|
ActivityPump Vocabulary and JSON-LD context - It looks like AP defines new vocabulary terms e.g. properties: inbox, outbox, followers, followings. I would see need to define a namespace (even temporary) and create JSON-LD context which one would use together with AS 2.0 context. Should I make PR?
|
process
|
activitypump vocabulary and json ld context it looks like ap defines new vocabulary terms e g properties inbox outbox followers followings i would see need to define a namespace even temporary and create json ld context which one would use together with as context should i make pr
| 1
|
13,485
| 16,018,385,871
|
IssuesEvent
|
2021-04-20 19:03:19
|
googleapis/python-storage
|
https://api.github.com/repos/googleapis/python-storage
|
opened
|
Unit tests must not depend on environment variables
|
priority: p1 type: process
|
E.g.,:
```bash
$ env | grep GOOGLE || echo NO
NO
$ nox -re unit-3.9 -- -x
_______________ Test_Blob.test_download_as_byte_w_custom_timeout _______________
self = <tests.unit.test_blob.Test_Blob testMethod=test_download_as_byte_w_custom_timeout>
def test_download_as_byte_w_custom_timeout(self):
> self._download_as_bytes_helper(raw_download=False, timeout=9.58)
tests/unit/test_blob.py:1714:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
tests/unit/test_blob.py:1557: in _download_as_bytes_helper
client = self._make_client()
tests/unit/test_blob.py:59: in _make_client
return Client(*args, **kw)
google/cloud/storage/client.py:122: in __init__
super(Client, self).__init__(
.nox/unit-3-9/lib/python3.9/site-packages/google/cloud/client.py:277: in __init__
_ClientProjectMixin.__init__(self, project=project, credentials=credentials)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <google.cloud.storage.client.Client object at 0x7fb9f31415b0>
project = None, credentials = None
def __init__(self, project=None, credentials=None):
# This test duplicates the one from `google.auth.default`, but earlier,
# for backward compatibility: we want the environment variable to
# override any project set on the credentials. See:
# https://github.com/googleapis/python-cloud-core/issues/27
if project is None:
project = os.getenv(
environment_vars.PROJECT,
os.getenv(environment_vars.LEGACY_PROJECT),
)
# Project set on explicit credentials overrides discovery from
# SDK / GAE / GCE.
if project is None and credentials is not None:
project = getattr(credentials, "project_id", None)
if project is None:
project = self._determine_default(project)
if project is None:
> raise EnvironmentError(
"Project was not passed and could not be "
"determined from the environment."
)
E OSError: Project was not passed and could not be determined from the environment.
.nox/unit-3-9/lib/python3.9/site-packages/google/cloud/client.py:228: OSError
```
|
1.0
|
Unit tests must not depend on environment variables - E.g.,:
```bash
$ env | grep GOOGLE || echo NO
NO
$ nox -re unit-3.9 -- -x
_______________ Test_Blob.test_download_as_byte_w_custom_timeout _______________
self = <tests.unit.test_blob.Test_Blob testMethod=test_download_as_byte_w_custom_timeout>
def test_download_as_byte_w_custom_timeout(self):
> self._download_as_bytes_helper(raw_download=False, timeout=9.58)
tests/unit/test_blob.py:1714:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
tests/unit/test_blob.py:1557: in _download_as_bytes_helper
client = self._make_client()
tests/unit/test_blob.py:59: in _make_client
return Client(*args, **kw)
google/cloud/storage/client.py:122: in __init__
super(Client, self).__init__(
.nox/unit-3-9/lib/python3.9/site-packages/google/cloud/client.py:277: in __init__
_ClientProjectMixin.__init__(self, project=project, credentials=credentials)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <google.cloud.storage.client.Client object at 0x7fb9f31415b0>
project = None, credentials = None
def __init__(self, project=None, credentials=None):
# This test duplicates the one from `google.auth.default`, but earlier,
# for backward compatibility: we want the environment variable to
# override any project set on the credentials. See:
# https://github.com/googleapis/python-cloud-core/issues/27
if project is None:
project = os.getenv(
environment_vars.PROJECT,
os.getenv(environment_vars.LEGACY_PROJECT),
)
# Project set on explicit credentials overrides discovery from
# SDK / GAE / GCE.
if project is None and credentials is not None:
project = getattr(credentials, "project_id", None)
if project is None:
project = self._determine_default(project)
if project is None:
> raise EnvironmentError(
"Project was not passed and could not be "
"determined from the environment."
)
E OSError: Project was not passed and could not be determined from the environment.
.nox/unit-3-9/lib/python3.9/site-packages/google/cloud/client.py:228: OSError
```
|
process
|
unit tests must not depend on environment variables e g bash env grep google echo no no nox re unit x test blob test download as byte w custom timeout self def test download as byte w custom timeout self self download as bytes helper raw download false timeout tests unit test blob py tests unit test blob py in download as bytes helper client self make client tests unit test blob py in make client return client args kw google cloud storage client py in init super client self init nox unit lib site packages google cloud client py in init clientprojectmixin init self project project credentials credentials self project none credentials none def init self project none credentials none this test duplicates the one from google auth default but earlier for backward compatibility we want the environment variable to override any project set on the credentials see if project is none project os getenv environment vars project os getenv environment vars legacy project project set on explicit credentials overrides discovery from sdk gae gce if project is none and credentials is not none project getattr credentials project id none if project is none project self determine default project if project is none raise environmenterror project was not passed and could not be determined from the environment e oserror project was not passed and could not be determined from the environment nox unit lib site packages google cloud client py oserror
| 1
|
8,373
| 11,520,991,199
|
IssuesEvent
|
2020-02-14 15:49:11
|
prisma/prisma2
|
https://api.github.com/repos/prisma/prisma2
|
closed
|
`warning In order to use "@prisma/client", please install prisma2. You can install it with "npm add -D prisma2"` is printed even when prisma2 is installed
|
bug/2-confirmed process/candidate topic: cli
|
The message is from https://github.com/prisma/prisma-client-js/blob/f41c2e3a0679a7b5de8fbc6fba37a65b0b297fac/packages/photon/scripts/postinstall.js#L31
And it is printed in 2 cases:
- When installing prisma2 and @prisma/client in an empty project
<img width="635" alt="Screen Shot 2020-02-14 at 15 34 37" src="https://user-images.githubusercontent.com/1328733/74540485-2413cc80-4f40-11ea-8fa9-0b4ed1db9cdc.png">
- hen installing prisma2 and @prisma/client in an empty project, after `prisma2 init`
<img width="629" alt="Screen Shot 2020-02-14 at 15 34 52" src="https://user-images.githubusercontent.com/1328733/74540495-27a75380-4f40-11ea-88ea-3fdfb2ba2285.png">
|
1.0
|
`warning In order to use "@prisma/client", please install prisma2. You can install it with "npm add -D prisma2"` is printed even when prisma2 is installed - The message is from https://github.com/prisma/prisma-client-js/blob/f41c2e3a0679a7b5de8fbc6fba37a65b0b297fac/packages/photon/scripts/postinstall.js#L31
And it is printed in 2 cases:
- When installing prisma2 and @prisma/client in an empty project
<img width="635" alt="Screen Shot 2020-02-14 at 15 34 37" src="https://user-images.githubusercontent.com/1328733/74540485-2413cc80-4f40-11ea-8fa9-0b4ed1db9cdc.png">
- hen installing prisma2 and @prisma/client in an empty project, after `prisma2 init`
<img width="629" alt="Screen Shot 2020-02-14 at 15 34 52" src="https://user-images.githubusercontent.com/1328733/74540495-27a75380-4f40-11ea-88ea-3fdfb2ba2285.png">
|
process
|
warning in order to use prisma client please install you can install it with npm add d is printed even when is installed the message is from and it is printed in cases when installing and prisma client in an empty project img width alt screen shot at src hen installing and prisma client in an empty project after init img width alt screen shot at src
| 1
|
8,357
| 11,503,761,253
|
IssuesEvent
|
2020-02-12 21:45:25
|
metabase/metabase
|
https://api.github.com/repos/metabase/metabase
|
opened
|
MBQL normalization bug: [:native :projections] gets incorrectly normalized
|
.Backend Priority:P3 Querying/Processor Type:Bug
|
Say I have a query like
```clj
{:type :native
:native {:projections ["share"]}
:database 1}
```
It unexpectedly gets normalized to
```clj
{:type :native
:native {:projections [:share]}
:database 1}
```
Not sure why `:projections` is getting normalized but I think in general `:native` should be hands-off any we shouldn't normalize random values like that.
Very minor issue since I can work around this without much trouble.
|
1.0
|
MBQL normalization bug: [:native :projections] gets incorrectly normalized - Say I have a query like
```clj
{:type :native
:native {:projections ["share"]}
:database 1}
```
It unexpectedly gets normalized to
```clj
{:type :native
:native {:projections [:share]}
:database 1}
```
Not sure why `:projections` is getting normalized but I think in general `:native` should be hands-off any we shouldn't normalize random values like that.
Very minor issue since I can work around this without much trouble.
|
process
|
mbql normalization bug gets incorrectly normalized say i have a query like clj type native native projections database it unexpectedly gets normalized to clj type native native projections database not sure why projections is getting normalized but i think in general native should be hands off any we shouldn t normalize random values like that very minor issue since i can work around this without much trouble
| 1
|
23,984
| 16,738,358,715
|
IssuesEvent
|
2021-06-11 06:37:23
|
sigp/lighthouse
|
https://api.github.com/repos/sigp/lighthouse
|
opened
|
Build Windows release binaries on CI
|
A1 t Infrastructure CI CD Docker Directories windows
|
## Description
With v1.4.0 we have beta Windows support. We should start Windows building binaries as part of the release flow here:
https://github.com/sigp/lighthouse/blob/3b600acdc5bf9726367c18277a22486573b8b457/.github/workflows/release.yml#L91
We can run on Github-hosted `windows-latest` machines, and can likely reuse large parts of the `release.yml` setup (although I don't think we'll want to build with `cross`).
|
1.0
|
Build Windows release binaries on CI - ## Description
With v1.4.0 we have beta Windows support. We should start Windows building binaries as part of the release flow here:
https://github.com/sigp/lighthouse/blob/3b600acdc5bf9726367c18277a22486573b8b457/.github/workflows/release.yml#L91
We can run on Github-hosted `windows-latest` machines, and can likely reuse large parts of the `release.yml` setup (although I don't think we'll want to build with `cross`).
|
non_process
|
build windows release binaries on ci description with we have beta windows support we should start windows building binaries as part of the release flow here we can run on github hosted windows latest machines and can likely reuse large parts of the release yml setup although i don t think we ll want to build with cross
| 0
|
225,885
| 17,928,644,665
|
IssuesEvent
|
2021-09-10 05:44:41
|
pingcap/tidb
|
https://api.github.com/repos/pingcap/tidb
|
closed
|
Timeout test `builtin_string_vec_test.go:529: testVectorizeSuite1.TestVectorizedBuiltinStringEvalOneVec`
|
type/bug component/test sig/execution severity/major
|
## Bug Report
Please answer these questions before submitting your issue. Thanks!
```
[2021-08-20T04:13:17.564Z] PASS: builtin_string_vec_test.go:529: testVectorizeSuite1.TestVectorizedBuiltinStringEvalOneVec 5.589s
```
### 1. Minimal reproduce step (Required)
in ci https://ci.pingcap.net/blue/organizations/jenkins/tidb_ghpr_check_2/detail/tidb_ghpr_check_2/27698/pipeline
<!-- a step by step guide for reproducing the bug. -->
### 2. What did you expect to see? (Required)
### 3. What did you see instead (Required)
### 4. What is your TiDB version? (Required)
<!-- Paste the output of SELECT tidb_version() -->
|
1.0
|
Timeout test `builtin_string_vec_test.go:529: testVectorizeSuite1.TestVectorizedBuiltinStringEvalOneVec` - ## Bug Report
Please answer these questions before submitting your issue. Thanks!
```
[2021-08-20T04:13:17.564Z] PASS: builtin_string_vec_test.go:529: testVectorizeSuite1.TestVectorizedBuiltinStringEvalOneVec 5.589s
```
### 1. Minimal reproduce step (Required)
in ci https://ci.pingcap.net/blue/organizations/jenkins/tidb_ghpr_check_2/detail/tidb_ghpr_check_2/27698/pipeline
<!-- a step by step guide for reproducing the bug. -->
### 2. What did you expect to see? (Required)
### 3. What did you see instead (Required)
### 4. What is your TiDB version? (Required)
<!-- Paste the output of SELECT tidb_version() -->
|
non_process
|
timeout test builtin string vec test go testvectorizedbuiltinstringevalonevec bug report please answer these questions before submitting your issue thanks pass builtin string vec test go testvectorizedbuiltinstringevalonevec minimal reproduce step required in ci what did you expect to see required what did you see instead required what is your tidb version required
| 0
|
293,907
| 25,332,834,733
|
IssuesEvent
|
2022-11-18 14:33:57
|
brave/brave-browser
|
https://api.github.com/repos/brave/brave-browser
|
opened
|
Follow up of #25789 - Choose new server throws Can't connect to server error in both profile 1 and profile 2
|
QA/Yes QA/Test-Plan-Specified OS/Desktop feature/vpn
|
<!-- Have you searched for similar issues? Before submitting this issue, please check the open issues and add a note before logging a new issue.
PLEASE USE THE TEMPLATE BELOW TO PROVIDE INFORMATION ABOUT THE ISSUE.
INSUFFICIENT INFO WILL GET THE ISSUE CLOSED. IT WILL ONLY BE REOPENED AFTER SUFFICIENT INFO IS PROVIDED-->
## Description
<!--Provide a brief description of the issue-->
Follow up of #25789 - Choose new server throws Can't connect to server error in both profile 1 and profile 2
## Steps to Reproduce
<!--Please add a series of steps to reproduce the issue-->
1. Please refer the STR from the issue https://github.com/brave/brave-browser/issues/25789#issue-1395810177
## Actual result:
<!--Please add screenshots if needed-->
Follow up of #25789 - Choose new server throws Can't connect to server error in both profile 1 and profile 2

## Expected result:
Should not throw any error
## Reproduces how often:
<!--[Easily reproduced/Intermittent issue/No steps to reproduce]-->
Easy
## Brave version (brave://version info)
<!--For installed build, please copy Brave, Revision and OS from brave://version and paste here. If building from source please mention it along with brave://version details-->
Brave | 1.46.117 Chromium: 107.0.5304.110 (Official Build) beta (64-bit)
-- | --
Revision | 2a558545ab7e6fb8177002bf44d4fc1717cb2998-refs/branch-heads/5304@{#1202}
OS | Windows 10 Version 21H2 (Build 19044.2251)
## Version/Channel Information:
<!--Does this issue happen on any other channels? Or is it specific to a certain channel?-->
- Can you reproduce this issue with the current release? NA
- Can you reproduce this issue with the beta channel? Yes
- Can you reproduce this issue with the nightly channel? Yes
## Other Additional Information:
- Does the issue resolve itself when disabling Brave Shields? NA
- Does the issue resolve itself when disabling Brave Rewards? NA
- Is the issue reproducible on the latest version of Chrome? NA
## Miscellaneous Information:
<!--Any additional information, related issues, extra QA steps, configuration or data that might be necessary to reproduce the issue-->
cc: @brave/qa-team @simonhong @bsclifton
|
1.0
|
Follow up of #25789 - Choose new server throws Can't connect to server error in both profile 1 and profile 2 - <!-- Have you searched for similar issues? Before submitting this issue, please check the open issues and add a note before logging a new issue.
PLEASE USE THE TEMPLATE BELOW TO PROVIDE INFORMATION ABOUT THE ISSUE.
INSUFFICIENT INFO WILL GET THE ISSUE CLOSED. IT WILL ONLY BE REOPENED AFTER SUFFICIENT INFO IS PROVIDED-->
## Description
<!--Provide a brief description of the issue-->
Follow up of #25789 - Choose new server throws Can't connect to server error in both profile 1 and profile 2
## Steps to Reproduce
<!--Please add a series of steps to reproduce the issue-->
1. Please refer the STR from the issue https://github.com/brave/brave-browser/issues/25789#issue-1395810177
## Actual result:
<!--Please add screenshots if needed-->
Follow up of #25789 - Choose new server throws Can't connect to server error in both profile 1 and profile 2

## Expected result:
Should not throw any error
## Reproduces how often:
<!--[Easily reproduced/Intermittent issue/No steps to reproduce]-->
Easy
## Brave version (brave://version info)
<!--For installed build, please copy Brave, Revision and OS from brave://version and paste here. If building from source please mention it along with brave://version details-->
Brave | 1.46.117 Chromium: 107.0.5304.110 (Official Build) beta (64-bit)
-- | --
Revision | 2a558545ab7e6fb8177002bf44d4fc1717cb2998-refs/branch-heads/5304@{#1202}
OS | Windows 10 Version 21H2 (Build 19044.2251)
## Version/Channel Information:
<!--Does this issue happen on any other channels? Or is it specific to a certain channel?-->
- Can you reproduce this issue with the current release? NA
- Can you reproduce this issue with the beta channel? Yes
- Can you reproduce this issue with the nightly channel? Yes
## Other Additional Information:
- Does the issue resolve itself when disabling Brave Shields? NA
- Does the issue resolve itself when disabling Brave Rewards? NA
- Is the issue reproducible on the latest version of Chrome? NA
## Miscellaneous Information:
<!--Any additional information, related issues, extra QA steps, configuration or data that might be necessary to reproduce the issue-->
cc: @brave/qa-team @simonhong @bsclifton
|
non_process
|
follow up of choose new server throws can t connect to server error in both profile and profile have you searched for similar issues before submitting this issue please check the open issues and add a note before logging a new issue please use the template below to provide information about the issue insufficient info will get the issue closed it will only be reopened after sufficient info is provided description follow up of choose new server throws can t connect to server error in both profile and profile steps to reproduce please refer the str from the issue actual result follow up of choose new server throws can t connect to server error in both profile and profile expected result should not throw any error reproduces how often easy brave version brave version info brave chromium official build beta bit revision refs branch heads os windows version build version channel information can you reproduce this issue with the current release na can you reproduce this issue with the beta channel yes can you reproduce this issue with the nightly channel yes other additional information does the issue resolve itself when disabling brave shields na does the issue resolve itself when disabling brave rewards na is the issue reproducible on the latest version of chrome na miscellaneous information cc brave qa team simonhong bsclifton
| 0
|
50,064
| 6,307,818,008
|
IssuesEvent
|
2017-07-22 05:23:48
|
CaerusKaru/ngvirtualgrade
|
https://api.github.com/repos/CaerusKaru/ngvirtualgrade
|
opened
|
feat(manage): create ability to manage higher-level components
|
enhancement needs design wip
|
This is a preliminary stub for the ability to "manage" the system. It has a lot of granularity and still needs to be fleshed out, but boils down to two components: the ability to manage departments and courses from a high level (creating departments/courses, etc), and the ability to manage the entire site (taking down for maintenance, looking up user profiles, etc).
|
1.0
|
feat(manage): create ability to manage higher-level components - This is a preliminary stub for the ability to "manage" the system. It has a lot of granularity and still needs to be fleshed out, but boils down to two components: the ability to manage departments and courses from a high level (creating departments/courses, etc), and the ability to manage the entire site (taking down for maintenance, looking up user profiles, etc).
|
non_process
|
feat manage create ability to manage higher level components this is a preliminary stub for the ability to manage the system it has a lot of granularity and still needs to be fleshed out but boils down to two components the ability to manage departments and courses from a high level creating departments courses etc and the ability to manage the entire site taking down for maintenance looking up user profiles etc
| 0
|
342,149
| 30,610,118,335
|
IssuesEvent
|
2023-07-23 13:58:49
|
IntellectualSites/FastAsyncWorldEdit
|
https://api.github.com/repos/IntellectualSites/FastAsyncWorldEdit
|
opened
|
java.lang.ArrayIndexOutOfBoundsException: Index 196 out of bounds for length 196
|
Requires Testing
|
### Server Implementation
Paper
### Server Version
1.20.1
### Describe the bug
I have this error in console: https://pastebin.com/vhLepHWU
### To Reproduce
1. Not sure
### Expected behaviour
No errors
### Screenshots / Videos
_No response_
### Error log (if applicable)
_No response_
### Fawe Debugpaste
Failed to upload files: request must contain a file list
### Fawe Version
FastAsyncWorldEdit-538
### Checklist
- [X] I have included a Fawe debugpaste.
- [X] I am using the newest build from https://ci.athion.net/job/FastAsyncWorldEdit/ and the issue still persists.
### Anything else?
_No response_
|
1.0
|
java.lang.ArrayIndexOutOfBoundsException: Index 196 out of bounds for length 196 - ### Server Implementation
Paper
### Server Version
1.20.1
### Describe the bug
I have this error in console: https://pastebin.com/vhLepHWU
### To Reproduce
1. Not sure
### Expected behaviour
No errors
### Screenshots / Videos
_No response_
### Error log (if applicable)
_No response_
### Fawe Debugpaste
Failed to upload files: request must contain a file list
### Fawe Version
FastAsyncWorldEdit-538
### Checklist
- [X] I have included a Fawe debugpaste.
- [X] I am using the newest build from https://ci.athion.net/job/FastAsyncWorldEdit/ and the issue still persists.
### Anything else?
_No response_
|
non_process
|
java lang arrayindexoutofboundsexception index out of bounds for length server implementation paper server version describe the bug i have this error in console to reproduce not sure expected behaviour no errors screenshots videos no response error log if applicable no response fawe debugpaste failed to upload files request must contain a file list fawe version fastasyncworldedit checklist i have included a fawe debugpaste i am using the newest build from and the issue still persists anything else no response
| 0
|
4,828
| 7,724,802,357
|
IssuesEvent
|
2018-05-24 16:00:55
|
cityofaustin/techstack
|
https://api.github.com/repos/cityofaustin/techstack
|
closed
|
Review EMS notes on content
|
Feature: Process Size: XS Team: Content
|
Paired down content in the new format was sent to the recruiting team to review what pieces are up for debate with the new contract.
I will review their comments and determine if the content is complete enough to begin rewrite.
|
1.0
|
Review EMS notes on content - Paired down content in the new format was sent to the recruiting team to review what pieces are up for debate with the new contract.
I will review their comments and determine if the content is complete enough to begin rewrite.
|
process
|
review ems notes on content paired down content in the new format was sent to the recruiting team to review what pieces are up for debate with the new contract i will review their comments and determine if the content is complete enough to begin rewrite
| 1
|
50,423
| 6,378,728,568
|
IssuesEvent
|
2017-08-02 13:23:18
|
MoreEventsMod/More_Events_Mod_Beta
|
https://api.github.com/repos/MoreEventsMod/More_Events_Mod_Beta
|
closed
|
LEX Integration
|
improvement needs testing needs translator redesign
|
We've done a baseline integration of @FrogBucket 's LEX mod into MEM, but we need to make it more thorough. Here are some things to consider (check them off as you do them; comment below if necessary):
* [x] Create test events to make easy to test from pre-existing late game empire saves
* [x] Test Throne Watchers (`mem_test_event.100` with a planet selected and explore the new system)
* [x] Test Gravekeeper (`mem_test_event.200` with a planet selected and explore the new system)
* [x] Test The Conduit (`mem_test_event.300` with a planet selected and explore the new system)
* [x] Revise Throne Watchers English localization
* [x] Revise Gravekeeper English localization
* [x] Revise The Conduit English localization
* [x] Fine-tune weapon stats
* [x] Consider removing leviathan country buff
* [ ] Look for other MEM events that could take advantage of these ships
|
1.0
|
LEX Integration - We've done a baseline integration of @FrogBucket 's LEX mod into MEM, but we need to make it more thorough. Here are some things to consider (check them off as you do them; comment below if necessary):
* [x] Create test events to make easy to test from pre-existing late game empire saves
* [x] Test Throne Watchers (`mem_test_event.100` with a planet selected and explore the new system)
* [x] Test Gravekeeper (`mem_test_event.200` with a planet selected and explore the new system)
* [x] Test The Conduit (`mem_test_event.300` with a planet selected and explore the new system)
* [x] Revise Throne Watchers English localization
* [x] Revise Gravekeeper English localization
* [x] Revise The Conduit English localization
* [x] Fine-tune weapon stats
* [x] Consider removing leviathan country buff
* [ ] Look for other MEM events that could take advantage of these ships
|
non_process
|
lex integration we ve done a baseline integration of frogbucket s lex mod into mem but we need to make it more thorough here are some things to consider check them off as you do them comment below if necessary create test events to make easy to test from pre existing late game empire saves test throne watchers mem test event with a planet selected and explore the new system test gravekeeper mem test event with a planet selected and explore the new system test the conduit mem test event with a planet selected and explore the new system revise throne watchers english localization revise gravekeeper english localization revise the conduit english localization fine tune weapon stats consider removing leviathan country buff look for other mem events that could take advantage of these ships
| 0
|
9,734
| 3,068,902,768
|
IssuesEvent
|
2015-08-18 17:50:53
|
hashplex/Lightning
|
https://api.github.com/repos/hashplex/Lightning
|
closed
|
`jsonrpcproxy` needs tests
|
enhancement server testing
|
I don't have any tests for `jsonrpcproxy.py` yet. When this breaks, debugging can be hard. Adding tests would alleviate this issue.
|
1.0
|
`jsonrpcproxy` needs tests - I don't have any tests for `jsonrpcproxy.py` yet. When this breaks, debugging can be hard. Adding tests would alleviate this issue.
|
non_process
|
jsonrpcproxy needs tests i don t have any tests for jsonrpcproxy py yet when this breaks debugging can be hard adding tests would alleviate this issue
| 0
|
1,089
| 3,560,239,413
|
IssuesEvent
|
2016-01-23 00:41:43
|
metabase/metabase
|
https://api.github.com/repos/metabase/metabase
|
closed
|
Viewing two columns with same name across tables fails
|
Bug Query Processor
|
Looks like there's no namespacing in effect when I do a join in the visual query builder to "view by data_table.col_name and connected_table.col_name" where the two tables are distinct but the column I'm asking for has the same field name for both.
Screenshot:
<img width="850" alt="screen shot 2015-11-04 at 5 34 49 pm" src="https://cloud.githubusercontent.com/assets/193187/10954355/e6a44f32-831a-11e5-83d3-b64910c6c85c.png">
Returns only 1 column in the results table instead of 2 columns, conceivably because the field names ("name" in this case) conflict?
I'm guessing the fix for this would be to "namespace" the fields by their parent table.
|
1.0
|
Viewing two columns with same name across tables fails - Looks like there's no namespacing in effect when I do a join in the visual query builder to "view by data_table.col_name and connected_table.col_name" where the two tables are distinct but the column I'm asking for has the same field name for both.
Screenshot:
<img width="850" alt="screen shot 2015-11-04 at 5 34 49 pm" src="https://cloud.githubusercontent.com/assets/193187/10954355/e6a44f32-831a-11e5-83d3-b64910c6c85c.png">
Returns only 1 column in the results table instead of 2 columns, conceivably because the field names ("name" in this case) conflict?
I'm guessing the fix for this would be to "namespace" the fields by their parent table.
|
process
|
viewing two columns with same name across tables fails looks like there s no namespacing in effect when i do a join in the visual query builder to view by data table col name and connected table col name where the two tables are distinct but the column i m asking for has the same field name for both screenshot img width alt screen shot at pm src returns only column in the results table instead of columns conceivably because the field names name in this case conflict i m guessing the fix for this would be to namespace the fields by their parent table
| 1
|
154,303
| 5,917,311,484
|
IssuesEvent
|
2017-05-22 12:58:13
|
ProgrammingLife2017/Desoxyribonucleinezuur
|
https://api.github.com/repos/ProgrammingLife2017/Desoxyribonucleinezuur
|
closed
|
Improve cold load parsing
|
enhancement priority: B time:13
|
The parser is currently much slower than it needs to be (not bound by file IO or CPU)
Suggested fix: multithreaded parser: create x threads and divide the file in x parts, each thread gets its own part of the file.
|
1.0
|
Improve cold load parsing - The parser is currently much slower than it needs to be (not bound by file IO or CPU)
Suggested fix: multithreaded parser: create x threads and divide the file in x parts, each thread gets its own part of the file.
|
non_process
|
improve cold load parsing the parser is currently much slower than it needs to be not bound by file io or cpu suggested fix multithreaded parser create x threads and divide the file in x parts each thread gets its own part of the file
| 0
|
7,262
| 10,420,653,353
|
IssuesEvent
|
2019-09-16 01:56:30
|
qgis/QGIS
|
https://api.github.com/repos/qgis/QGIS
|
closed
|
shp files in zip files files cannot be used in Processing with 3rd party providers (SAGA, GRASS...)
|
Bug Processing
|
Author Name: **Victor Olaya** (@volaya)
Original Redmine Issue: [21183](https://issues.qgis.org/issues/21183)
Affected QGIS version: 3.5(master)
Redmine category:processing/core
Assignee: Nyall Dawson
---
If the zip file itself is loaded when adding a layer, it can be used as an input for a SAGA algorithm. This is because the source of the corresponding layer will be ".zip", so it's identified as a non compatible extension, and will be exported to a temporary file.
However, if a shp file in a zip file is directly loaded (for instance, selecting that file in the QGIS browser panel instead of the zip file it belongs to), the algorithm fails. The reason for this is that the source of that layer will be something like "/vsizip//path/to/Archive.zip/points.shp". Having a shp extension, it's believed to be a "real" shapefile, and it is not exported. SAGA wont be able to handle the /vsizip stuff
The issue is in the QgsProcessingUtils::convertToCompatibleFormat method, which is called to ensure that a compatible file is passed to SAGA (and other providers). It just checks the file suffix, but doesnt check if it's a zipped file or not. Checking for the /vsizip prefix should fix it.
|
1.0
|
shp files in zip files files cannot be used in Processing with 3rd party providers (SAGA, GRASS...) - Author Name: **Victor Olaya** (@volaya)
Original Redmine Issue: [21183](https://issues.qgis.org/issues/21183)
Affected QGIS version: 3.5(master)
Redmine category:processing/core
Assignee: Nyall Dawson
---
If the zip file itself is loaded when adding a layer, it can be used as an input for a SAGA algorithm. This is because the source of the corresponding layer will be ".zip", so it's identified as a non compatible extension, and will be exported to a temporary file.
However, if a shp file in a zip file is directly loaded (for instance, selecting that file in the QGIS browser panel instead of the zip file it belongs to), the algorithm fails. The reason for this is that the source of that layer will be something like "/vsizip//path/to/Archive.zip/points.shp". Having a shp extension, it's believed to be a "real" shapefile, and it is not exported. SAGA wont be able to handle the /vsizip stuff
The issue is in the QgsProcessingUtils::convertToCompatibleFormat method, which is called to ensure that a compatible file is passed to SAGA (and other providers). It just checks the file suffix, but doesnt check if it's a zipped file or not. Checking for the /vsizip prefix should fix it.
|
process
|
shp files in zip files files cannot be used in processing with party providers saga grass author name victor olaya volaya original redmine issue affected qgis version master redmine category processing core assignee nyall dawson if the zip file itself is loaded when adding a layer it can be used as an input for a saga algorithm this is because the source of the corresponding layer will be zip so it s identified as a non compatible extension and will be exported to a temporary file however if a shp file in a zip file is directly loaded for instance selecting that file in the qgis browser panel instead of the zip file it belongs to the algorithm fails the reason for this is that the source of that layer will be something like vsizip path to archive zip points shp having a shp extension it s believed to be a real shapefile and it is not exported saga wont be able to handle the vsizip stuff the issue is in the qgsprocessingutils converttocompatibleformat method which is called to ensure that a compatible file is passed to saga and other providers it just checks the file suffix but doesnt check if it s a zipped file or not checking for the vsizip prefix should fix it
| 1
|
11,682
| 14,542,290,295
|
IssuesEvent
|
2020-12-15 15:32:40
|
dotnet/runtime
|
https://api.github.com/repos/dotnet/runtime
|
closed
|
Environment.GetEnvironmentVariables() should tolerate duplicate case-insensitive variable names
|
area-System.Diagnostics.Process os-windows
|
<!--This is just a template - feel free to delete any and all of it and replace as appropriate.-->
### Description
Some tools like Yarn will spawn nodeJS via CreateProcess and pass an environment block that contains duplicated environment variables, e.g:

Windows doesn't do any checking of environment variables being duplicated in CreateProcess so the node.exe process gets created with the two names. Then in our case, MSBuild (a .net app) gets launched from within node.exe, which later launches CL.exe and other build tools, which break because they don't expect to get the same variable twice in the env block.
The environment block as exposed in [` Process`](https://docs.microsoft.com/dotnet/api/system.diagnostics.process) should be cleaned up to remove duplicates (i.e. variables that appear more than once)
### Configuration
Windows 10, all .net versions, all archs.
### Regression?
### Other information
Related bugs:
https://github.com/actions/virtual-environments/pull/1566
https://github.com/nodejs/node/issues/35129
https://github.com/dotnet/msbuild/issues/5726
|
1.0
|
Environment.GetEnvironmentVariables() should tolerate duplicate case-insensitive variable names - <!--This is just a template - feel free to delete any and all of it and replace as appropriate.-->
### Description
Some tools like Yarn will spawn nodeJS via CreateProcess and pass an environment block that contains duplicated environment variables, e.g:

Windows doesn't do any checking of environment variables being duplicated in CreateProcess so the node.exe process gets created with the two names. Then in our case, MSBuild (a .net app) gets launched from within node.exe, which later launches CL.exe and other build tools, which break because they don't expect to get the same variable twice in the env block.
The environment block as exposed in [` Process`](https://docs.microsoft.com/dotnet/api/system.diagnostics.process) should be cleaned up to remove duplicates (i.e. variables that appear more than once)
### Configuration
Windows 10, all .net versions, all archs.
### Regression?
### Other information
Related bugs:
https://github.com/actions/virtual-environments/pull/1566
https://github.com/nodejs/node/issues/35129
https://github.com/dotnet/msbuild/issues/5726
|
process
|
environment getenvironmentvariables should tolerate duplicate case insensitive variable names description some tools like yarn will spawn nodejs via createprocess and pass an environment block that contains duplicated environment variables e g windows doesn t do any checking of environment variables being duplicated in createprocess so the node exe process gets created with the two names then in our case msbuild a net app gets launched from within node exe which later launches cl exe and other build tools which break because they don t expect to get the same variable twice in the env block the environment block as exposed in should be cleaned up to remove duplicates i e variables that appear more than once configuration windows all net versions all archs regression other information related bugs
| 1
|
2,854
| 5,823,928,029
|
IssuesEvent
|
2017-05-07 07:41:09
|
kerubistan/kerub
|
https://api.github.com/repos/kerubistan/kerub
|
closed
|
qemu-kvm path
|
bug component:data processing component:virtualization
|
qemu-kvm is located on different path on each OS, it must be detected and set correctly in the libvirt xml
|
1.0
|
qemu-kvm path - qemu-kvm is located on different path on each OS, it must be detected and set correctly in the libvirt xml
|
process
|
qemu kvm path qemu kvm is located on different path on each os it must be detected and set correctly in the libvirt xml
| 1
|
157,780
| 12,391,137,503
|
IssuesEvent
|
2020-05-20 11:58:33
|
Coderockr/backstage
|
https://api.github.com/repos/Coderockr/backstage
|
opened
|
Recoil - State management library for React apps
|
component frontend not tested yet react react native
|
Recoil is an experimental state management library for React apps. It provides several capabilities that are difficult to achieve with React alone, while being compatible with the newest features of React.
https://recoiljs.org/
[](https://www.youtube.com/watch?v=xYSDBevtEp0)
|
1.0
|
Recoil - State management library for React apps - Recoil is an experimental state management library for React apps. It provides several capabilities that are difficult to achieve with React alone, while being compatible with the newest features of React.
https://recoiljs.org/
[](https://www.youtube.com/watch?v=xYSDBevtEp0)
|
non_process
|
recoil state management library for react apps recoil is an experimental state management library for react apps it provides several capabilities that are difficult to achieve with react alone while being compatible with the newest features of react
| 0
|
1,830
| 2,671,749,370
|
IssuesEvent
|
2015-03-24 09:35:31
|
McStasMcXtrace/McCode
|
https://api.github.com/repos/McStasMcXtrace/McCode
|
opened
|
make grid work on localhost even without ssh installed
|
C: McCode tools enhancement P: minor
|
**Reported by farhi on 31 Mar 2010 16:31 UTC**
mcrun: make grid work on localhost even without ssh installed. Currently, not finding ssh disables this
|
1.0
|
make grid work on localhost even without ssh installed - **Reported by farhi on 31 Mar 2010 16:31 UTC**
mcrun: make grid work on localhost even without ssh installed. Currently, not finding ssh disables this
|
non_process
|
make grid work on localhost even without ssh installed reported by farhi on mar utc mcrun make grid work on localhost even without ssh installed currently not finding ssh disables this
| 0
|
21,050
| 27,993,808,081
|
IssuesEvent
|
2023-03-27 06:58:38
|
MicrosoftDocs/azure-devops-docs
|
https://api.github.com/repos/MicrosoftDocs/azure-devops-docs
|
closed
|
source pipeline misidentified in pipelines resource
|
doc-bug Pri1 azure-devops-pipelines/svc azure-devops-pipelines-process/subsvc
|
The sentence immediately before **download for pipelines** section should say:
> Your pipeline will run whenever the `SmartHotel-CI` pipelines runs on one of the
instead of:
> Your pipeline will run whenever the `SmartHotel` pipelines runs on one of the
---
#### Document Details
⚠ *Do not edit this section. It is required for learn.microsoft.com ➟ GitHub issue linking.*
* ID: ee4ec9d0-e0d5-4fb4-7c3e-b84abfa290c2
* Version Independent ID: 3e2b80d9-30e5-0c48-49f0-4fcdfedf5eee
* Content: [Define YAML resources for Azure Pipelines - Azure Pipelines](https://learn.microsoft.com/en-us/azure/devops/pipelines/process/resources?view=azure-devops&tabs=schema)
* Content Source: [docs/pipelines/process/resources.md](https://github.com/MicrosoftDocs/azure-devops-docs/blob/main/docs/pipelines/process/resources.md)
* Service: **azure-devops-pipelines**
* Sub-service: **azure-devops-pipelines-process**
* GitHub Login: @juliakm
* Microsoft Alias: **jukullam**
|
1.0
|
source pipeline misidentified in pipelines resource - The sentence immediately before **download for pipelines** section should say:
> Your pipeline will run whenever the `SmartHotel-CI` pipelines runs on one of the
instead of:
> Your pipeline will run whenever the `SmartHotel` pipelines runs on one of the
---
#### Document Details
⚠ *Do not edit this section. It is required for learn.microsoft.com ➟ GitHub issue linking.*
* ID: ee4ec9d0-e0d5-4fb4-7c3e-b84abfa290c2
* Version Independent ID: 3e2b80d9-30e5-0c48-49f0-4fcdfedf5eee
* Content: [Define YAML resources for Azure Pipelines - Azure Pipelines](https://learn.microsoft.com/en-us/azure/devops/pipelines/process/resources?view=azure-devops&tabs=schema)
* Content Source: [docs/pipelines/process/resources.md](https://github.com/MicrosoftDocs/azure-devops-docs/blob/main/docs/pipelines/process/resources.md)
* Service: **azure-devops-pipelines**
* Sub-service: **azure-devops-pipelines-process**
* GitHub Login: @juliakm
* Microsoft Alias: **jukullam**
|
process
|
source pipeline misidentified in pipelines resource the sentence immediately before download for pipelines section should say your pipeline will run whenever the smarthotel ci pipelines runs on one of the instead of your pipeline will run whenever the smarthotel pipelines runs on one of the document details ⚠ do not edit this section it is required for learn microsoft com ➟ github issue linking id version independent id content content source service azure devops pipelines sub service azure devops pipelines process github login juliakm microsoft alias jukullam
| 1
|
48,912
| 5,989,363,305
|
IssuesEvent
|
2017-06-02 08:24:13
|
openbakery/gradle-xcodePlugin
|
https://api.github.com/repos/openbakery/gradle-xcodePlugin
|
closed
|
Add bitcode Support
|
priority:high status:testing
|
Currently the gradle-xcodePlugin does not seem to have complete support for Bitcode. When exporting an app with Xcode that has bitcode enabled Xcode adds folders `Symbols` and `BCSymbolMaps`. The folders contain `.symbols` and `.bcsmybolmap` files respectively.
I tried to visualize the issue with a screenshot. The left shows the app exported using Xcode and the right is the version built using gradle.

The missing files are not necessary for the app to run. It seems Apple needs those files to be able to symbolicate crashlogs for apps build with bitcode enabled. For those app there is currently no other way that I know of to receive symbolicated crashlogs.
As bitcode is mandatory for some platforms (watchOS, tvOS) this is a real issue. When targeting those platforms gradle is not really usable for the App Store build as you lose the ability to receive useful crashlogs.
|
1.0
|
Add bitcode Support - Currently the gradle-xcodePlugin does not seem to have complete support for Bitcode. When exporting an app with Xcode that has bitcode enabled Xcode adds folders `Symbols` and `BCSymbolMaps`. The folders contain `.symbols` and `.bcsmybolmap` files respectively.
I tried to visualize the issue with a screenshot. The left shows the app exported using Xcode and the right is the version built using gradle.

The missing files are not necessary for the app to run. It seems Apple needs those files to be able to symbolicate crashlogs for apps build with bitcode enabled. For those app there is currently no other way that I know of to receive symbolicated crashlogs.
As bitcode is mandatory for some platforms (watchOS, tvOS) this is a real issue. When targeting those platforms gradle is not really usable for the App Store build as you lose the ability to receive useful crashlogs.
|
non_process
|
add bitcode support currently the gradle xcodeplugin does not seem to have complete support for bitcode when exporting an app with xcode that has bitcode enabled xcode adds folders symbols and bcsymbolmaps the folders contain symbols and bcsmybolmap files respectively i tried to visualize the issue with a screenshot the left shows the app exported using xcode and the right is the version built using gradle the missing files are not necessary for the app to run it seems apple needs those files to be able to symbolicate crashlogs for apps build with bitcode enabled for those app there is currently no other way that i know of to receive symbolicated crashlogs as bitcode is mandatory for some platforms watchos tvos this is a real issue when targeting those platforms gradle is not really usable for the app store build as you lose the ability to receive useful crashlogs
| 0
|
177,338
| 21,472,910,458
|
IssuesEvent
|
2022-04-26 11:10:16
|
elastic/kibana
|
https://api.github.com/repos/elastic/kibana
|
opened
|
[Security Solution][Detections] Pass rule execution statuses and metrics to Alerting Framework
|
Team:Detections and Resp Team: SecuritySolution Feature:Rule Monitoring Team:Detection Rules
|
**Depends on:** https://github.com/elastic/kibana/issues/112193
## Summary
We're consolidating rule execution statuses and metrics between Security Solution and Alerting Framework (see https://github.com/elastic/kibana/issues/112193 and [internal RFC](https://docs.google.com/document/d/1-tMHRS3liqhHf8YGVqR93rZg3zdoDe2nEfptkOw1Q-E/edit#heading=h.1w0d61eheso3)). When this is done and we have an API for passing statuses and metrics from our rule executors to the Framework, we will integrate with it and stop using our sidecar saved objects for storing this data.
- [ ] Pass execution statuses and metrics from rule executors to the Framework.
- [ ] Fetch execution statuses and metrics from rules themselves instead of the sidecar `siem-detection-engine-rule-execution-info` saved objects.
- [ ] Remove the `siem-detection-engine-rule-execution-info` saved objects type from the codebase. Mark it as deleted in Kibana Core.
|
True
|
[Security Solution][Detections] Pass rule execution statuses and metrics to Alerting Framework - **Depends on:** https://github.com/elastic/kibana/issues/112193
## Summary
We're consolidating rule execution statuses and metrics between Security Solution and Alerting Framework (see https://github.com/elastic/kibana/issues/112193 and [internal RFC](https://docs.google.com/document/d/1-tMHRS3liqhHf8YGVqR93rZg3zdoDe2nEfptkOw1Q-E/edit#heading=h.1w0d61eheso3)). When this is done and we have an API for passing statuses and metrics from our rule executors to the Framework, we will integrate with it and stop using our sidecar saved objects for storing this data.
- [ ] Pass execution statuses and metrics from rule executors to the Framework.
- [ ] Fetch execution statuses and metrics from rules themselves instead of the sidecar `siem-detection-engine-rule-execution-info` saved objects.
- [ ] Remove the `siem-detection-engine-rule-execution-info` saved objects type from the codebase. Mark it as deleted in Kibana Core.
|
non_process
|
pass rule execution statuses and metrics to alerting framework depends on summary we re consolidating rule execution statuses and metrics between security solution and alerting framework see and when this is done and we have an api for passing statuses and metrics from our rule executors to the framework we will integrate with it and stop using our sidecar saved objects for storing this data pass execution statuses and metrics from rule executors to the framework fetch execution statuses and metrics from rules themselves instead of the sidecar siem detection engine rule execution info saved objects remove the siem detection engine rule execution info saved objects type from the codebase mark it as deleted in kibana core
| 0
|
51,830
| 21,891,227,292
|
IssuesEvent
|
2022-05-20 02:01:50
|
microsoftgraph/msgraph-sdk-powershell
|
https://api.github.com/repos/microsoftgraph/msgraph-sdk-powershell
|
closed
|
Access denied for Get-MGEducationClassAssignment
|
Service issue Needs: Author Feedback no-recent-activity
|
I'm trying to get an overview off all assignments in our environment for reporting use. Unfortunatly there doesn't seem to be a function available to do this so i thought lets loop trough all Class teams and use Get-MgEducationClassAssignment to get this info per class.
But calling the function gives an error: "Get-MgEducationClassAssignment : Access denied" . Doesn't matter if it's on a class that i'm owner of or another class and i think i have enough permissions on the graph.
|
1.0
|
Access denied for Get-MGEducationClassAssignment - I'm trying to get an overview off all assignments in our environment for reporting use. Unfortunatly there doesn't seem to be a function available to do this so i thought lets loop trough all Class teams and use Get-MgEducationClassAssignment to get this info per class.
But calling the function gives an error: "Get-MgEducationClassAssignment : Access denied" . Doesn't matter if it's on a class that i'm owner of or another class and i think i have enough permissions on the graph.
|
non_process
|
access denied for get mgeducationclassassignment i m trying to get an overview off all assignments in our environment for reporting use unfortunatly there doesn t seem to be a function available to do this so i thought lets loop trough all class teams and use get mgeducationclassassignment to get this info per class but calling the function gives an error get mgeducationclassassignment access denied doesn t matter if it s on a class that i m owner of or another class and i think i have enough permissions on the graph
| 0
|
83,103
| 7,861,419,919
|
IssuesEvent
|
2018-06-22 00:19:59
|
Kademi/kademi-dev
|
https://api.github.com/repos/Kademi/kademi-dev
|
closed
|
Selected org is set to null by server
|
Help Wanted Ready to Test - Dev bug
|
When enabled rewardstore app, server set selectedOrg to be null. please see this
RewardService.java
```
Organisation org = _findPointsOrgForProfile(currentUser, reward, selOrg);
if ( org == null ) {
org = _findPointsOrgForProfile(currentUser, reward, null);
Response resp = HttpManager.response();
if ( resp != null ) {
log.info("Did not find selected org, so remove selected org cookie");
resp.setCookie("selectedOrg", null);
}
}
|
1.0
|
Selected org is set to null by server - When enabled rewardstore app, server set selectedOrg to be null. please see this
RewardService.java
```
Organisation org = _findPointsOrgForProfile(currentUser, reward, selOrg);
if ( org == null ) {
org = _findPointsOrgForProfile(currentUser, reward, null);
Response resp = HttpManager.response();
if ( resp != null ) {
log.info("Did not find selected org, so remove selected org cookie");
resp.setCookie("selectedOrg", null);
}
}
|
non_process
|
selected org is set to null by server when enabled rewardstore app server set selectedorg to be null please see this rewardservice java organisation org findpointsorgforprofile currentuser reward selorg if org null org findpointsorgforprofile currentuser reward null response resp httpmanager response if resp null log info did not find selected org so remove selected org cookie resp setcookie selectedorg null
| 0
|
10,064
| 13,044,161,797
|
IssuesEvent
|
2020-07-29 03:47:26
|
tikv/tikv
|
https://api.github.com/repos/tikv/tikv
|
closed
|
UCP: Migrate scalar function `AddDateStringInt` from TiDB
|
challenge-program-2 component/coprocessor difficulty/easy sig/coprocessor
|
## Description
Port the scalar function `AddDateStringInt` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @iosmanthus
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/rpn_expr)
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/expr)
|
2.0
|
UCP: Migrate scalar function `AddDateStringInt` from TiDB -
## Description
Port the scalar function `AddDateStringInt` from TiDB to coprocessor.
## Score
* 50
## Mentor(s)
* @iosmanthus
## Recommended Skills
* Rust programming
## Learning Materials
Already implemented expressions ported from TiDB
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/rpn_expr)
- https://github.com/tikv/tikv/tree/master/components/tidb_query/src/expr)
|
process
|
ucp migrate scalar function adddatestringint from tidb description port the scalar function adddatestringint from tidb to coprocessor score mentor s iosmanthus recommended skills rust programming learning materials already implemented expressions ported from tidb
| 1
|
50,361
| 12,503,084,741
|
IssuesEvent
|
2020-06-02 06:27:20
|
microsoft/fluentui
|
https://api.github.com/repos/microsoft/fluentui
|
closed
|
unable to build
|
Area: Build System Status: In PR Type: Bug :bug:
|
Repro steps:
$ git clone <repo>
$ yarn
$ yarn build
Expected: built repo
Actual:
```
@fluentui/ability-attributes: [11:32:40] Requiring external module @uifabric/build/babel/register
@fluentui/ability-attributes: internal/modules/cjs/loader.js:492
@fluentui/ability-attributes: throw new ERR_PACKAGE_PATH_NOT_EXPORTED(basePath, mappingKey);
@fluentui/ability-attributes: ^
@fluentui/ability-attributes: Error [ERR_PACKAGE_PATH_NOT_EXPORTED]: No "exports" main resolved in /Users/jdh/projects/office-ui-fabric-react/node_modules/@babel/helper-compilation-targets/package.json
@fluentui/ability-attributes: at applyExports (internal/modules/cjs/loader.js:492:9)
@fluentui/ability-attributes: at resolveExports (internal/modules/cjs/loader.js:508:23)
@fluentui/ability-attributes: at Function.Module._findPath (internal/modules/cjs/loader.js:632:31)
@fluentui/ability-attributes: at Function.Module._resolveFilename (internal/modules/cjs/loader.js:1001:27)
@fluentui/ability-attributes: at Function.Module._load (internal/modules/cjs/loader.js:884:27)
@fluentui/ability-attributes: at Module.require (internal/modules/cjs/loader.js:1074:19)
@fluentui/ability-attributes: at require (internal/modules/cjs/helpers.js:72:18)
@fluentui/ability-attributes: at Object.<anonymous> (/Users/jdh/projects/office-ui-fabric-react/node_modules/@babel/preset-env/lib/debug.js:8:33)
@fluentui/ability-attributes: at Module._compile (internal/modules/cjs/loader.js:1185:30)
@fluentui/ability-attributes: at Module._compile (/Users/jdh/projects/office-ui-fabric-react/node_modules/pirates/lib/index.js:99:24) {
@fluentui/ability-attributes: code: 'ERR_PACKAGE_PATH_NOT_EXPORTED'
@fluentui/ability-attributes: }
@fluentui/ability-attributes: error Command failed with exit code 1.
@fluentui/ability-attributes: info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.
```
|
1.0
|
unable to build - Repro steps:
$ git clone <repo>
$ yarn
$ yarn build
Expected: built repo
Actual:
```
@fluentui/ability-attributes: [11:32:40] Requiring external module @uifabric/build/babel/register
@fluentui/ability-attributes: internal/modules/cjs/loader.js:492
@fluentui/ability-attributes: throw new ERR_PACKAGE_PATH_NOT_EXPORTED(basePath, mappingKey);
@fluentui/ability-attributes: ^
@fluentui/ability-attributes: Error [ERR_PACKAGE_PATH_NOT_EXPORTED]: No "exports" main resolved in /Users/jdh/projects/office-ui-fabric-react/node_modules/@babel/helper-compilation-targets/package.json
@fluentui/ability-attributes: at applyExports (internal/modules/cjs/loader.js:492:9)
@fluentui/ability-attributes: at resolveExports (internal/modules/cjs/loader.js:508:23)
@fluentui/ability-attributes: at Function.Module._findPath (internal/modules/cjs/loader.js:632:31)
@fluentui/ability-attributes: at Function.Module._resolveFilename (internal/modules/cjs/loader.js:1001:27)
@fluentui/ability-attributes: at Function.Module._load (internal/modules/cjs/loader.js:884:27)
@fluentui/ability-attributes: at Module.require (internal/modules/cjs/loader.js:1074:19)
@fluentui/ability-attributes: at require (internal/modules/cjs/helpers.js:72:18)
@fluentui/ability-attributes: at Object.<anonymous> (/Users/jdh/projects/office-ui-fabric-react/node_modules/@babel/preset-env/lib/debug.js:8:33)
@fluentui/ability-attributes: at Module._compile (internal/modules/cjs/loader.js:1185:30)
@fluentui/ability-attributes: at Module._compile (/Users/jdh/projects/office-ui-fabric-react/node_modules/pirates/lib/index.js:99:24) {
@fluentui/ability-attributes: code: 'ERR_PACKAGE_PATH_NOT_EXPORTED'
@fluentui/ability-attributes: }
@fluentui/ability-attributes: error Command failed with exit code 1.
@fluentui/ability-attributes: info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.
```
|
non_process
|
unable to build repro steps git clone yarn yarn build expected built repo actual fluentui ability attributes requiring external module uifabric build babel register fluentui ability attributes internal modules cjs loader js fluentui ability attributes throw new err package path not exported basepath mappingkey fluentui ability attributes fluentui ability attributes error no exports main resolved in users jdh projects office ui fabric react node modules babel helper compilation targets package json fluentui ability attributes at applyexports internal modules cjs loader js fluentui ability attributes at resolveexports internal modules cjs loader js fluentui ability attributes at function module findpath internal modules cjs loader js fluentui ability attributes at function module resolvefilename internal modules cjs loader js fluentui ability attributes at function module load internal modules cjs loader js fluentui ability attributes at module require internal modules cjs loader js fluentui ability attributes at require internal modules cjs helpers js fluentui ability attributes at object users jdh projects office ui fabric react node modules babel preset env lib debug js fluentui ability attributes at module compile internal modules cjs loader js fluentui ability attributes at module compile users jdh projects office ui fabric react node modules pirates lib index js fluentui ability attributes code err package path not exported fluentui ability attributes fluentui ability attributes error command failed with exit code fluentui ability attributes info visit for documentation about this command
| 0
|
672,498
| 22,828,020,510
|
IssuesEvent
|
2022-07-12 10:19:08
|
ooni/test-lists-ui
|
https://api.github.com/repos/ooni/test-lists-ui
|
closed
|
Show "Add new URL" form also after the changes have been submitted
|
enhancement priority/medium
|
Currently, the form disappears after submission, but it should be instead visible.
|
1.0
|
Show "Add new URL" form also after the changes have been submitted - Currently, the form disappears after submission, but it should be instead visible.
|
non_process
|
show add new url form also after the changes have been submitted currently the form disappears after submission but it should be instead visible
| 0
|
8,240
| 11,419,861,503
|
IssuesEvent
|
2020-02-03 08:57:17
|
geneontology/go-ontology
|
https://api.github.com/repos/geneontology/go-ontology
|
closed
|
small synonym fix GO:0140403
|
multi-species process quick fix
|
remove
suppression of effector-triggered immunity (PTI) | exact
a) it would be ETI
b) this term is not specific for either ETI or PTI suppression
|
1.0
|
small synonym fix GO:0140403 -
remove
suppression of effector-triggered immunity (PTI) | exact
a) it would be ETI
b) this term is not specific for either ETI or PTI suppression
|
process
|
small synonym fix go remove suppression of effector triggered immunity pti exact a it would be eti b this term is not specific for either eti or pti suppression
| 1
|
21,110
| 28,069,566,724
|
IssuesEvent
|
2023-03-29 17:59:54
|
hashgraph/hedera-mirror-node
|
https://api.github.com/repos/hashgraph/hedera-mirror-node
|
opened
|
Release Checklist 0.77
|
enhancement process
|
### Problem
We need a checklist to verify the release is rolled out successfully.
### Solution
- [x] Milestone field populated on relevant [issues](https://github.com/hashgraph/hedera-mirror-node/issues?q=is%3Aclosed+no%3Amilestone+sort%3Aupdated-desc)
- [x] Nothing open for [milestone](https://github.com/hashgraph/hedera-mirror-node/issues?q=is%3Aopen+sort%3Aupdated-desc+milestone%3A0.77.0)
- [x] GitHub checks for branch are passing
- [x] Automated Kubernetes deployment successful
- [x] Tag release
- [x] Upload release artifacts
- [ ] Manual Submission for GCP Marketplace verification by google
- [ ] Publish marketplace release
- [x] Publish release
## Performance
- [x] Deployed
- [x] gRPC API performance tests
- [x] Importer performance tests
- [x] REST API performance tests
## Previewnet
- [x] Deployed
## Staging
- [ ] Deployed
## Testnet
- [ ] Deployed
## Mainnet
- [ ] Deployed to Kubernetes EU
- [ ] Deployed to Kubernetes NA
- [ ] Deployed to VM
- [ ] Deployed to ETL
### Alternatives
_No response_
|
1.0
|
Release Checklist 0.77 - ### Problem
We need a checklist to verify the release is rolled out successfully.
### Solution
- [x] Milestone field populated on relevant [issues](https://github.com/hashgraph/hedera-mirror-node/issues?q=is%3Aclosed+no%3Amilestone+sort%3Aupdated-desc)
- [x] Nothing open for [milestone](https://github.com/hashgraph/hedera-mirror-node/issues?q=is%3Aopen+sort%3Aupdated-desc+milestone%3A0.77.0)
- [x] GitHub checks for branch are passing
- [x] Automated Kubernetes deployment successful
- [x] Tag release
- [x] Upload release artifacts
- [ ] Manual Submission for GCP Marketplace verification by google
- [ ] Publish marketplace release
- [x] Publish release
## Performance
- [x] Deployed
- [x] gRPC API performance tests
- [x] Importer performance tests
- [x] REST API performance tests
## Previewnet
- [x] Deployed
## Staging
- [ ] Deployed
## Testnet
- [ ] Deployed
## Mainnet
- [ ] Deployed to Kubernetes EU
- [ ] Deployed to Kubernetes NA
- [ ] Deployed to VM
- [ ] Deployed to ETL
### Alternatives
_No response_
|
process
|
release checklist problem we need a checklist to verify the release is rolled out successfully solution milestone field populated on relevant nothing open for github checks for branch are passing automated kubernetes deployment successful tag release upload release artifacts manual submission for gcp marketplace verification by google publish marketplace release publish release performance deployed grpc api performance tests importer performance tests rest api performance tests previewnet deployed staging deployed testnet deployed mainnet deployed to kubernetes eu deployed to kubernetes na deployed to vm deployed to etl alternatives no response
| 1
|
15,183
| 18,955,080,849
|
IssuesEvent
|
2021-11-18 19:15:10
|
cypress-io/cypress
|
https://api.github.com/repos/cypress-io/cypress
|
closed
|
[tests] Investigate Percy Build Timeouts
|
process: tests type: chore stage: to do
|
### Current behavior
The following CI error can arise and the cause is unknown. This cause jobs to be flaky.

### Desired behavior
Percy snapshots are successfully uploaded when parallel builds complete.
### Test code to reproduce
Example failure: https://app.circleci.com/pipelines/github/cypress-io/cypress/26009/workflows/09201cea-c797-4827-954a-8d96abac4af7/jobs/978435
### Dependency Versions
cypress@8.7.0
@percy/cli@1.0.0-beta.48 <-- latest version is 1.0.0-beta.70.
@percy/cypress@3.1.0
|
1.0
|
[tests] Investigate Percy Build Timeouts - ### Current behavior
The following CI error can arise and the cause is unknown. This cause jobs to be flaky.

### Desired behavior
Percy snapshots are successfully uploaded when parallel builds complete.
### Test code to reproduce
Example failure: https://app.circleci.com/pipelines/github/cypress-io/cypress/26009/workflows/09201cea-c797-4827-954a-8d96abac4af7/jobs/978435
### Dependency Versions
cypress@8.7.0
@percy/cli@1.0.0-beta.48 <-- latest version is 1.0.0-beta.70.
@percy/cypress@3.1.0
|
process
|
investigate percy build timeouts current behavior the following ci error can arise and the cause is unknown this cause jobs to be flaky desired behavior percy snapshots are successfully uploaded when parallel builds complete test code to reproduce example failure dependency versions cypress percy cli beta latest version is beta percy cypress
| 1
|
20,235
| 15,172,225,010
|
IssuesEvent
|
2021-02-13 07:54:53
|
microsoft/win32metadata
|
https://api.github.com/repos/microsoft/win32metadata
|
closed
|
Many generated structs should be removed
|
broken api bug usability
|
Things like `__MIDL___MIDL_itf_UIAnimation_0000_0002_0003` should not appear in metadata.
```C#
public struct __MIDL___MIDL_itf_UIAnimation_0000_0002_0003
{
public int _;
}
```
|
True
|
Many generated structs should be removed - Things like `__MIDL___MIDL_itf_UIAnimation_0000_0002_0003` should not appear in metadata.
```C#
public struct __MIDL___MIDL_itf_UIAnimation_0000_0002_0003
{
public int _;
}
```
|
non_process
|
many generated structs should be removed things like midl midl itf uianimation should not appear in metadata c public struct midl midl itf uianimation public int
| 0
|
16,967
| 22,330,901,751
|
IssuesEvent
|
2022-06-14 14:26:56
|
hashgraph/hedera-json-rpc-relay
|
https://api.github.com/repos/hashgraph/hedera-json-rpc-relay
|
closed
|
eth_getBalance acceptance test failures for primary account
|
bug P2 process
|
### Description
The primary accounts balance check in acceptance tests started failing with changing values.
### Steps to reproduce
1. Run `./node_modules/ts-mocha/bin/ts-mocha ./packages/server/tests/acceptance.spec.ts -g 'eth_getBalance' --exit`
2. Observe balance hex mismatch
### Additional context
_No response_
### Hedera network
other
### Version
v0.2.0-SNAPSHOT
### Operating system
_No response_
|
1.0
|
eth_getBalance acceptance test failures for primary account - ### Description
The primary accounts balance check in acceptance tests started failing with changing values.
### Steps to reproduce
1. Run `./node_modules/ts-mocha/bin/ts-mocha ./packages/server/tests/acceptance.spec.ts -g 'eth_getBalance' --exit`
2. Observe balance hex mismatch
### Additional context
_No response_
### Hedera network
other
### Version
v0.2.0-SNAPSHOT
### Operating system
_No response_
|
process
|
eth getbalance acceptance test failures for primary account description the primary accounts balance check in acceptance tests started failing with changing values steps to reproduce run node modules ts mocha bin ts mocha packages server tests acceptance spec ts g eth getbalance exit observe balance hex mismatch additional context no response hedera network other version snapshot operating system no response
| 1
|
4,261
| 2,847,545,355
|
IssuesEvent
|
2015-05-29 17:35:44
|
opensim-org/opensim-core
|
https://api.github.com/repos/opensim-org/opensim-core
|
closed
|
Create a CHANGELOG.md file
|
Documentation
|
Start a running list of develop-oriented notes describing changes for 4.0. We'll need to then retroactively review closed PRs. This will help us then create a user-facing set of release notes (on confluence) at the time of release.
|
1.0
|
Create a CHANGELOG.md file - Start a running list of develop-oriented notes describing changes for 4.0. We'll need to then retroactively review closed PRs. This will help us then create a user-facing set of release notes (on confluence) at the time of release.
|
non_process
|
create a changelog md file start a running list of develop oriented notes describing changes for we ll need to then retroactively review closed prs this will help us then create a user facing set of release notes on confluence at the time of release
| 0
|
12,840
| 15,223,150,922
|
IssuesEvent
|
2021-02-18 01:58:55
|
qgis/QGIS
|
https://api.github.com/repos/qgis/QGIS
|
closed
|
[processing][xyz tiles] warn user when overwriting files/folders
|
Feature Request Feedback Processing stale
|
Author Name: **Saber Razmjooei** (@saberraz)
Original Redmine Issue: [21990](https://issues.qgis.org/issues/21990)
Redmine category:processing/qgis
---
Warn users of overwriting data if the selected output folder is not empty.
|
1.0
|
[processing][xyz tiles] warn user when overwriting files/folders - Author Name: **Saber Razmjooei** (@saberraz)
Original Redmine Issue: [21990](https://issues.qgis.org/issues/21990)
Redmine category:processing/qgis
---
Warn users of overwriting data if the selected output folder is not empty.
|
process
|
warn user when overwriting files folders author name saber razmjooei saberraz original redmine issue redmine category processing qgis warn users of overwriting data if the selected output folder is not empty
| 1
|
341,268
| 30,576,983,983
|
IssuesEvent
|
2023-07-21 06:34:44
|
milvus-io/milvus
|
https://api.github.com/repos/milvus-io/milvus
|
closed
|
[Bug]:[benchmark] Turn on mmap , insert 60 million data in vector column and 5 scalar columns. load with "reason: code: CollectionNotExists, reason: can't find collection".
|
kind/bug needs-triage test/benchmark
|
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Environment
```markdown
- Milvus version: master-20230719-227d2c8b
- Deployment mode(standalone or cluster):cluster
- MQ type(rocksmq, pulsar or kafka): pulsar
- SDK version(e.g. pymilvus v2.0.0rc2):
- OS(Ubuntu or CentOS):
- CPU/Memory:
- GPU:
- Others:
```
### Current Behavior
argo task : fouramf-gbxb7
server pod:
test time: 2023-07-20 10:33:26 ~ 2023-07-20 12:00:57
```
benchmark-hm-cluster-on-milvus-datacoord-867dd64dcf-cwbvr
benchmark-hm-cluster-on-milvus-datanode-d4b69db6b-5bn4h
benchmark-hm-cluster-on-milvus-indexcoord-57cd6ff6fb-22qt8
benchmark-hm-cluster-on-milvus-indexnode-564944bb4c-8zm6k
benchmark-hm-cluster-on-milvus-indexnode-7dc59df6f-b8wq4
benchmark-hm-cluster-on-milvus-proxy-5f64fdb6bd-lc22v
benchmark-hm-cluster-on-milvus-querycoord-69887447dc-gc46q
benchmark-hm-cluster-on-milvus-querynode-bcbbd8cd5-ngd2v
benchmark-hm-cluster-on-milvus-querynode-bcbbd8cd5-vp49w
benchmark-hm-cluster-on-milvus-querynode-bcbbd8cd5-sqsx8
benchmark-hm-cluster-on-milvus-rootcoord-75f5c967fc-tmvkf
```
client :
```
[2023-07-20 11:44:55,719 - INFO - fouram]: [Base] Start inserting, ids: 59950000 - 59999999, data size: 60,000,000 (base.py:323)
[2023-07-20 11:44:57,769 - INFO - fouram]: [Time] Collection.insert run in 2.0499s (api_request.py:45)
[2023-07-20 11:44:57,772 - INFO - fouram]: [Base] Number of vectors in the collection(fouram_qqi5lEvt): 59950000 (base.py:483)
[2023-07-20 11:44:57,826 - INFO - fouram]: [Base] Total time of insert: 2894.3025s, average number of vector bars inserted per second: 20730.3832, average time to insert 50000 vectors per time: 2.4119s (base.py:394)
[2023-07-20 11:44:57,842 - INFO - fouram]: [Base] Start flush collection fouram_qqi5lEvt (base.py:292)
[2023-07-20 11:44:59,872 - INFO - fouram]: [Base] Params of index: [{'float_vector': {'index_type': 'HNSW', 'metric_type': 'L2', 'params': {'M': 30, 'efConstruction': 360}}}] (base.py:456)
[2023-07-20 11:44:59,872 - INFO - fouram]: [Base] Start release collection fouram_qqi5lEvt (base.py:303)
[2023-07-20 11:44:59,875 - INFO - fouram]: [Base] Start build index of HNSW for collection fouram_qqi5lEvt, params:{'index_type': 'HNSW', 'metric_type': 'L2', 'params': {'M': 30, 'efConstruction': 360}} (base.py:442)
[2023-07-20 11:53:49,835 - INFO - fouram]: [Time] Index run in 529.9593s (api_request.py:45)
[2023-07-20 11:53:49,836 - INFO - fouram]: [CommonCases] RT of build index HNSW: 529.9593s (common_cases.py:96)
[2023-07-20 11:53:49,838 - INFO - fouram]: [Base] Params of index: [{'float_vector': {'index_type': 'HNSW', 'metric_type': 'L2', 'params': {'M': 30, 'efConstruction': 360}}}] (base.py:456)
[2023-07-20 11:53:49,838 - INFO - fouram]: [CommonCases] Prepare index HNSW done. (common_cases.py:99)
[2023-07-20 11:53:49,838 - INFO - fouram]: [CommonCases] No scalars need to be indexed. (common_cases.py:107)
[2023-07-20 11:53:49,840 - INFO - fouram]: [Base] Number of vectors in the collection(fouram_qqi5lEvt): 60000000 (base.py:483)
[2023-07-20 11:53:49,840 - INFO - fouram]: [Base] Start load collection fouram_qqi5lEvt,replica_number:1,kwargs:{} (base.py:298)
[2023-07-20 12:00:57,388 - ERROR - fouram]: RPC error: [get_loading_progress], <MilvusException: (code=1, message=code: UnexpectedError, reason: code: CollectionNotExists, reason: can't find collection: 442983635625970627)>, <Time:{'RPC start': '2023-07-20 12:00:57.386761', 'RPC error': '2023-07-20 12:00:57.388453'}> (decorators.py:108)
[2023-07-20 12:00:57,390 - ERROR - fouram]: RPC error: [wait_for_loading_collection], <MilvusException: (code=1, message=code: UnexpectedError, reason: code: CollectionNotExists, reason: can't find collection: 442983635625970627)>, <Time:{'RPC start': '2023-07-20 11:53:49.889671', 'RPC error': '2023-07-20 12:00:57.390113'}> (decorators.py:108)
[2023-07-20 12:00:57,390 - ERROR - fouram]: RPC error: [load_collection], <MilvusException: (code=1, message=code: UnexpectedError, reason: code: CollectionNotExists, reason: can't find collection: 442983635625970627)>, <Time:{'RPC start': '2023-07-20 11:53:49.841126', 'RPC error': '2023-07-20 12:00:57.390327'}> (decorators.py:108)
[2023-07-20 12:00:57,391 - ERROR - fouram]: (api_response) : <MilvusException: (code=1, message=code: UnexpectedError, reason: code: CollectionNotExists, reason: can't find collection: 442983635625970627)> (api_request.py:53)
[2023-07-20 12:00:57,391 - ERROR - fouram]: [CheckFunc] load request check failed, response:<MilvusException: (code=1, message=code: UnexpectedError, reason: code: CollectionNotExists, reason: can't find collection: 442983635625970627)> (func_check.py:52)
```
memory usage:

### Expected Behavior
can load it normally, or even if it fails, it shouldn't report can't find collection.
### Steps To Reproduce
```markdown
1. create a collection or use an existing collection
2. build index on vector column
3. insert a certain number of vectors
4. flush collection
5. build index on vector column with the same parameters
6. build index on on scalars column or not
7. count the total number of rows
8. load collection
9. perform concurrent operations
10. clean all collections or not
```
### Milvus Log
_No response_
### Anything else?
_No response_
|
1.0
|
[Bug]:[benchmark] Turn on mmap , insert 60 million data in vector column and 5 scalar columns. load with "reason: code: CollectionNotExists, reason: can't find collection". - ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Environment
```markdown
- Milvus version: master-20230719-227d2c8b
- Deployment mode(standalone or cluster):cluster
- MQ type(rocksmq, pulsar or kafka): pulsar
- SDK version(e.g. pymilvus v2.0.0rc2):
- OS(Ubuntu or CentOS):
- CPU/Memory:
- GPU:
- Others:
```
### Current Behavior
argo task : fouramf-gbxb7
server pod:
test time: 2023-07-20 10:33:26 ~ 2023-07-20 12:00:57
```
benchmark-hm-cluster-on-milvus-datacoord-867dd64dcf-cwbvr
benchmark-hm-cluster-on-milvus-datanode-d4b69db6b-5bn4h
benchmark-hm-cluster-on-milvus-indexcoord-57cd6ff6fb-22qt8
benchmark-hm-cluster-on-milvus-indexnode-564944bb4c-8zm6k
benchmark-hm-cluster-on-milvus-indexnode-7dc59df6f-b8wq4
benchmark-hm-cluster-on-milvus-proxy-5f64fdb6bd-lc22v
benchmark-hm-cluster-on-milvus-querycoord-69887447dc-gc46q
benchmark-hm-cluster-on-milvus-querynode-bcbbd8cd5-ngd2v
benchmark-hm-cluster-on-milvus-querynode-bcbbd8cd5-vp49w
benchmark-hm-cluster-on-milvus-querynode-bcbbd8cd5-sqsx8
benchmark-hm-cluster-on-milvus-rootcoord-75f5c967fc-tmvkf
```
client :
```
[2023-07-20 11:44:55,719 - INFO - fouram]: [Base] Start inserting, ids: 59950000 - 59999999, data size: 60,000,000 (base.py:323)
[2023-07-20 11:44:57,769 - INFO - fouram]: [Time] Collection.insert run in 2.0499s (api_request.py:45)
[2023-07-20 11:44:57,772 - INFO - fouram]: [Base] Number of vectors in the collection(fouram_qqi5lEvt): 59950000 (base.py:483)
[2023-07-20 11:44:57,826 - INFO - fouram]: [Base] Total time of insert: 2894.3025s, average number of vector bars inserted per second: 20730.3832, average time to insert 50000 vectors per time: 2.4119s (base.py:394)
[2023-07-20 11:44:57,842 - INFO - fouram]: [Base] Start flush collection fouram_qqi5lEvt (base.py:292)
[2023-07-20 11:44:59,872 - INFO - fouram]: [Base] Params of index: [{'float_vector': {'index_type': 'HNSW', 'metric_type': 'L2', 'params': {'M': 30, 'efConstruction': 360}}}] (base.py:456)
[2023-07-20 11:44:59,872 - INFO - fouram]: [Base] Start release collection fouram_qqi5lEvt (base.py:303)
[2023-07-20 11:44:59,875 - INFO - fouram]: [Base] Start build index of HNSW for collection fouram_qqi5lEvt, params:{'index_type': 'HNSW', 'metric_type': 'L2', 'params': {'M': 30, 'efConstruction': 360}} (base.py:442)
[2023-07-20 11:53:49,835 - INFO - fouram]: [Time] Index run in 529.9593s (api_request.py:45)
[2023-07-20 11:53:49,836 - INFO - fouram]: [CommonCases] RT of build index HNSW: 529.9593s (common_cases.py:96)
[2023-07-20 11:53:49,838 - INFO - fouram]: [Base] Params of index: [{'float_vector': {'index_type': 'HNSW', 'metric_type': 'L2', 'params': {'M': 30, 'efConstruction': 360}}}] (base.py:456)
[2023-07-20 11:53:49,838 - INFO - fouram]: [CommonCases] Prepare index HNSW done. (common_cases.py:99)
[2023-07-20 11:53:49,838 - INFO - fouram]: [CommonCases] No scalars need to be indexed. (common_cases.py:107)
[2023-07-20 11:53:49,840 - INFO - fouram]: [Base] Number of vectors in the collection(fouram_qqi5lEvt): 60000000 (base.py:483)
[2023-07-20 11:53:49,840 - INFO - fouram]: [Base] Start load collection fouram_qqi5lEvt,replica_number:1,kwargs:{} (base.py:298)
[2023-07-20 12:00:57,388 - ERROR - fouram]: RPC error: [get_loading_progress], <MilvusException: (code=1, message=code: UnexpectedError, reason: code: CollectionNotExists, reason: can't find collection: 442983635625970627)>, <Time:{'RPC start': '2023-07-20 12:00:57.386761', 'RPC error': '2023-07-20 12:00:57.388453'}> (decorators.py:108)
[2023-07-20 12:00:57,390 - ERROR - fouram]: RPC error: [wait_for_loading_collection], <MilvusException: (code=1, message=code: UnexpectedError, reason: code: CollectionNotExists, reason: can't find collection: 442983635625970627)>, <Time:{'RPC start': '2023-07-20 11:53:49.889671', 'RPC error': '2023-07-20 12:00:57.390113'}> (decorators.py:108)
[2023-07-20 12:00:57,390 - ERROR - fouram]: RPC error: [load_collection], <MilvusException: (code=1, message=code: UnexpectedError, reason: code: CollectionNotExists, reason: can't find collection: 442983635625970627)>, <Time:{'RPC start': '2023-07-20 11:53:49.841126', 'RPC error': '2023-07-20 12:00:57.390327'}> (decorators.py:108)
[2023-07-20 12:00:57,391 - ERROR - fouram]: (api_response) : <MilvusException: (code=1, message=code: UnexpectedError, reason: code: CollectionNotExists, reason: can't find collection: 442983635625970627)> (api_request.py:53)
[2023-07-20 12:00:57,391 - ERROR - fouram]: [CheckFunc] load request check failed, response:<MilvusException: (code=1, message=code: UnexpectedError, reason: code: CollectionNotExists, reason: can't find collection: 442983635625970627)> (func_check.py:52)
```
memory usage:

### Expected Behavior
can load it normally, or even if it fails, it shouldn't report can't find collection.
### Steps To Reproduce
```markdown
1. create a collection or use an existing collection
2. build index on vector column
3. insert a certain number of vectors
4. flush collection
5. build index on vector column with the same parameters
6. build index on on scalars column or not
7. count the total number of rows
8. load collection
9. perform concurrent operations
10. clean all collections or not
```
### Milvus Log
_No response_
### Anything else?
_No response_
|
non_process
|
turn on mmap insert million data in vector column and scalar columns load with reason code collectionnotexists reason can t find collection is there an existing issue for this i have searched the existing issues environment markdown milvus version master deployment mode standalone or cluster cluster mq type rocksmq pulsar or kafka pulsar sdk version e g pymilvus os ubuntu or centos cpu memory gpu others current behavior argo task fouramf server pod test time benchmark hm cluster on milvus datacoord cwbvr benchmark hm cluster on milvus datanode benchmark hm cluster on milvus indexcoord benchmark hm cluster on milvus indexnode benchmark hm cluster on milvus indexnode benchmark hm cluster on milvus proxy benchmark hm cluster on milvus querycoord benchmark hm cluster on milvus querynode benchmark hm cluster on milvus querynode benchmark hm cluster on milvus querynode benchmark hm cluster on milvus rootcoord tmvkf client start inserting ids data size base py collection insert run in api request py number of vectors in the collection fouram base py total time of insert average number of vector bars inserted per second average time to insert vectors per time base py start flush collection fouram base py params of index base py start release collection fouram base py start build index of hnsw for collection fouram params index type hnsw metric type params m efconstruction base py index run in api request py rt of build index hnsw common cases py params of index base py prepare index hnsw done common cases py no scalars need to be indexed common cases py number of vectors in the collection fouram base py start load collection fouram replica number kwargs base py rpc error decorators py rpc error decorators py rpc error decorators py api response api request py load request check failed response func check py memory usage expected behavior can load it normally or even if it fails it shouldn t report can t find collection steps to reproduce markdown create a collection or use an existing collection build index on vector column insert a certain number of vectors flush collection build index on vector column with the same parameters build index on on scalars column or not count the total number of rows load collection perform concurrent operations clean all collections or not milvus log no response anything else no response
| 0
|
154,135
| 12,194,353,800
|
IssuesEvent
|
2020-04-29 15:41:09
|
elastic/elasticsearch
|
https://api.github.com/repos/elastic/elasticsearch
|
opened
|
[CI] ExistsQueryBuilder testToQuery fails occasionally
|
:Search/Search >test-failure
|
https://gradle-enterprise.elastic.co/s/xzne2zm3o4ujs
Reproducible locally on 7.x with
```
./gradlew ':server:test' --tests "org.elasticsearch.index.query.ExistsQueryBuilderTests.testToQuery" -Dtests.seed=D22C32FE2BD8ABE1 -Dtests.security.manager=true -Dtests.locale=zh-TW -Dtests.timezone=America/Atka -Dcompiler.java=14 -Druntime.java=8
```
Error:
```
java.lang.AssertionError:
Expected: an instance of org.apache.lucene.search.ConstantScoreQuery
but: <MatchNoDocsQuery("User requested "match_none" query.")> is a org.apache.lucene.search.MatchNoDocsQuery
at __randomizedtesting.SeedInfo.seed([D22C32FE2BD8ABE1:25D730C05A5B6E0B]:0)
at org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:18)
at org.junit.Assert.assertThat(Assert.java:956)
at org.junit.Assert.assertThat(Assert.java:923)
at org.elasticsearch.index.query.ExistsQueryBuilderTests.doAssertLuceneQuery(ExistsQueryBuilderTests.java:75)
```
|
1.0
|
[CI] ExistsQueryBuilder testToQuery fails occasionally - https://gradle-enterprise.elastic.co/s/xzne2zm3o4ujs
Reproducible locally on 7.x with
```
./gradlew ':server:test' --tests "org.elasticsearch.index.query.ExistsQueryBuilderTests.testToQuery" -Dtests.seed=D22C32FE2BD8ABE1 -Dtests.security.manager=true -Dtests.locale=zh-TW -Dtests.timezone=America/Atka -Dcompiler.java=14 -Druntime.java=8
```
Error:
```
java.lang.AssertionError:
Expected: an instance of org.apache.lucene.search.ConstantScoreQuery
but: <MatchNoDocsQuery("User requested "match_none" query.")> is a org.apache.lucene.search.MatchNoDocsQuery
at __randomizedtesting.SeedInfo.seed([D22C32FE2BD8ABE1:25D730C05A5B6E0B]:0)
at org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:18)
at org.junit.Assert.assertThat(Assert.java:956)
at org.junit.Assert.assertThat(Assert.java:923)
at org.elasticsearch.index.query.ExistsQueryBuilderTests.doAssertLuceneQuery(ExistsQueryBuilderTests.java:75)
```
|
non_process
|
existsquerybuilder testtoquery fails occasionally reproducible locally on x with gradlew server test tests org elasticsearch index query existsquerybuildertests testtoquery dtests seed dtests security manager true dtests locale zh tw dtests timezone america atka dcompiler java druntime java error java lang assertionerror expected an instance of org apache lucene search constantscorequery but is a org apache lucene search matchnodocsquery at randomizedtesting seedinfo seed at org hamcrest matcherassert assertthat matcherassert java at org junit assert assertthat assert java at org junit assert assertthat assert java at org elasticsearch index query existsquerybuildertests doassertlucenequery existsquerybuildertests java
| 0
|
2,969
| 5,960,864,217
|
IssuesEvent
|
2017-05-29 15:17:29
|
orbardugo/Hahot-Hameshulash
|
https://api.github.com/repos/orbardugo/Hahot-Hameshulash
|
opened
|
Exception thrown if "ShowQuery" button pressed and no values in comboBoxes
|
Aviv bug Development Idan in process Or priorty 2 requirement Ruben Sapir
|
- [ ] #Change functionality
- [ ] #Add MessageBox to notify that ComboBoxes need to have values
|
1.0
|
Exception thrown if "ShowQuery" button pressed and no values in comboBoxes -
- [ ] #Change functionality
- [ ] #Add MessageBox to notify that ComboBoxes need to have values
|
process
|
exception thrown if showquery button pressed and no values in comboboxes change functionality add messagebox to notify that comboboxes need to have values
| 1
|
7,213
| 10,346,241,031
|
IssuesEvent
|
2019-09-04 14:55:37
|
allinurl/goaccess
|
https://api.github.com/repos/allinurl/goaccess
|
closed
|
question about Requested Files statistics
|
log-processing question
|
In the "Requested Files" panel, what does the line with Method "---" represent?
Method "---" has the largest share of requests when running goaccess on my apache logfile, so I'm concerned that I'm missing the actual URL of those requests.
Method "---" is line 26 in "Requested Files" panel of [the real-time demo](https://rt.goaccess.io/).
It also appears as the second line on [the goaccess homepage](https://goaccess.io/):

|
1.0
|
question about Requested Files statistics - In the "Requested Files" panel, what does the line with Method "---" represent?
Method "---" has the largest share of requests when running goaccess on my apache logfile, so I'm concerned that I'm missing the actual URL of those requests.
Method "---" is line 26 in "Requested Files" panel of [the real-time demo](https://rt.goaccess.io/).
It also appears as the second line on [the goaccess homepage](https://goaccess.io/):

|
process
|
question about requested files statistics in the requested files panel what does the line with method represent method has the largest share of requests when running goaccess on my apache logfile so i m concerned that i m missing the actual url of those requests method is line in requested files panel of it also appears as the second line on
| 1
|
10,005
| 13,042,487,238
|
IssuesEvent
|
2020-07-28 22:38:26
|
hashicorp/packer
|
https://api.github.com/repos/hashicorp/packer
|
closed
|
vmware-iso on remote esx5 with post-processor fails with invalid disk type
|
post-processor/vsphere
|
- Packer Version: 0.10.1
- Host platform: Ubuntu Linux 14.04.4
The VM build successfully and ships the OVA back to the Jenkins build node. Once there it attempts to upload it to 4 vCenters globally and fails on the first one with the following error.
```
Build 'vmware-iso' errored: 1 error(s) occurred:
* Post-processor failed: Failed: exit status 1
Stdout: Opening OVA source:trusty64-tmp/trusty64-tmp.ova/trusty64-tmp.ova
The manifest validates
Opening VMX target: "vi://USERNAME%40vsphere.local:REDACTED@REDACTED/SITE/host/CLUSTER/Resources/Bronze"
Error: Invalid target disk adapter type: "seSparse"
Deleting directory tree below: "vi:
Completed with errors
```
I get the same error if I do not set a disk_mode, but replace `seSparse` with `thick` or `thin`.
I have also tried this with `format: vmx` which also failed.
If I take the output from the debug log and run ovftool manually it works fine:
```
ovftool --noSSLVerify=true --acceptAllEulas --name="trusty64-vmx" --overwrite \
--datastore="DS" --diskMode="seSparse" --network="NETWORK" \
--vmFolder="Templates" trusty64-tmp.ova/trusty64-tmp.ova \
"vi://USERNAME%40vsphere.local:REDACTED@REDACTED/SITE/host/CLUSTER/Resources/Bronze"
```
|
1.0
|
vmware-iso on remote esx5 with post-processor fails with invalid disk type - - Packer Version: 0.10.1
- Host platform: Ubuntu Linux 14.04.4
The VM build successfully and ships the OVA back to the Jenkins build node. Once there it attempts to upload it to 4 vCenters globally and fails on the first one with the following error.
```
Build 'vmware-iso' errored: 1 error(s) occurred:
* Post-processor failed: Failed: exit status 1
Stdout: Opening OVA source:trusty64-tmp/trusty64-tmp.ova/trusty64-tmp.ova
The manifest validates
Opening VMX target: "vi://USERNAME%40vsphere.local:REDACTED@REDACTED/SITE/host/CLUSTER/Resources/Bronze"
Error: Invalid target disk adapter type: "seSparse"
Deleting directory tree below: "vi:
Completed with errors
```
I get the same error if I do not set a disk_mode, but replace `seSparse` with `thick` or `thin`.
I have also tried this with `format: vmx` which also failed.
If I take the output from the debug log and run ovftool manually it works fine:
```
ovftool --noSSLVerify=true --acceptAllEulas --name="trusty64-vmx" --overwrite \
--datastore="DS" --diskMode="seSparse" --network="NETWORK" \
--vmFolder="Templates" trusty64-tmp.ova/trusty64-tmp.ova \
"vi://USERNAME%40vsphere.local:REDACTED@REDACTED/SITE/host/CLUSTER/Resources/Bronze"
```
|
process
|
vmware iso on remote with post processor fails with invalid disk type packer version host platform ubuntu linux the vm build successfully and ships the ova back to the jenkins build node once there it attempts to upload it to vcenters globally and fails on the first one with the following error build vmware iso errored error s occurred post processor failed failed exit status stdout opening ova source tmp tmp ova tmp ova the manifest validates opening vmx target vi username local redacted redacted site host cluster resources bronze error invalid target disk adapter type sesparse deleting directory tree below vi completed with errors i get the same error if i do not set a disk mode but replace sesparse with thick or thin i have also tried this with format vmx which also failed if i take the output from the debug log and run ovftool manually it works fine ovftool nosslverify true acceptalleulas name vmx overwrite datastore ds diskmode sesparse network network vmfolder templates tmp ova tmp ova vi username local redacted redacted site host cluster resources bronze
| 1
|
26,040
| 12,342,246,633
|
IssuesEvent
|
2020-05-15 00:10:03
|
MicrosoftDocs/azure-docs
|
https://api.github.com/repos/MicrosoftDocs/azure-docs
|
closed
|
How to use GetModel instead of TrainModel?
|
Pri2 cognitive-services/svc cxp forms-recognizer/subsvc product-question triaged
|
I'm trying to use the GetModel (now preview) function from the Form Recognizer Logic app, but no avail. If I am to follow the document above, doesn't that mean that the model will be trained every single time an eligible email is received? If I'm to follow that then I get the error that my custom training set is too large ("over 50 files"). So how can use an existing model created by the Labelling Tool instead?
Is it true that the Logic App doesn't support v2? In that case how can we create a custom Logic App connector?
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 3ee885d7-a7d5-b26e-4958-072cd77c2212
* Version Independent ID: dc244ba3-d6ff-0fa8-5239-1349ab03b03c
* Content: [Tutorial: Use Form Recognizer with Azure Logic Apps to analyze invoices - Form Recognizer - Azure Cognitive Services](https://docs.microsoft.com/en-us/azure/cognitive-services/form-recognizer/tutorial-form-recognizer-with-logic-apps)
* Content Source: [articles/cognitive-services/form-recognizer/tutorial-form-recognizer-with-logic-apps.md](https://github.com/Microsoft/azure-docs/blob/master/articles/cognitive-services/form-recognizer/tutorial-form-recognizer-with-logic-apps.md)
* Service: **cognitive-services**
* Sub-service: **forms-recognizer**
* GitHub Login: @nitinme
* Microsoft Alias: **nitinme**
|
1.0
|
How to use GetModel instead of TrainModel? - I'm trying to use the GetModel (now preview) function from the Form Recognizer Logic app, but no avail. If I am to follow the document above, doesn't that mean that the model will be trained every single time an eligible email is received? If I'm to follow that then I get the error that my custom training set is too large ("over 50 files"). So how can use an existing model created by the Labelling Tool instead?
Is it true that the Logic App doesn't support v2? In that case how can we create a custom Logic App connector?
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 3ee885d7-a7d5-b26e-4958-072cd77c2212
* Version Independent ID: dc244ba3-d6ff-0fa8-5239-1349ab03b03c
* Content: [Tutorial: Use Form Recognizer with Azure Logic Apps to analyze invoices - Form Recognizer - Azure Cognitive Services](https://docs.microsoft.com/en-us/azure/cognitive-services/form-recognizer/tutorial-form-recognizer-with-logic-apps)
* Content Source: [articles/cognitive-services/form-recognizer/tutorial-form-recognizer-with-logic-apps.md](https://github.com/Microsoft/azure-docs/blob/master/articles/cognitive-services/form-recognizer/tutorial-form-recognizer-with-logic-apps.md)
* Service: **cognitive-services**
* Sub-service: **forms-recognizer**
* GitHub Login: @nitinme
* Microsoft Alias: **nitinme**
|
non_process
|
how to use getmodel instead of trainmodel i m trying to use the getmodel now preview function from the form recognizer logic app but no avail if i am to follow the document above doesn t that mean that the model will be trained every single time an eligible email is received if i m to follow that then i get the error that my custom training set is too large over files so how can use an existing model created by the labelling tool instead is it true that the logic app doesn t support in that case how can we create a custom logic app connector document details ⚠ do not edit this section it is required for docs microsoft com ➟ github issue linking id version independent id content content source service cognitive services sub service forms recognizer github login nitinme microsoft alias nitinme
| 0
|
20,100
| 26,636,329,510
|
IssuesEvent
|
2023-01-24 22:19:47
|
googleapis/google-cloudevents-python
|
https://api.github.com/repos/googleapis/google-cloudevents-python
|
closed
|
Refactor the Generator
|
type: process priority: p2 api: eventarc
|
## Expected Behavior
The generator should produce consistent results, ideally automated for producing the build.
We should not be removing folders and creating temporary folders if not needed.
https://github.com/googleapis/google-cloudevents-python/blob/master/gen.sh
## Actual Behavior
Right now we have a script that uses a `workplace` directory. The generator results are inconsistent across machines.
## Steps to Reproduce the Problem
Run the generator:
```
./gen.sh
```
Related issue: https://github.com/googleapis/google-cloudevents-python/issues/30
|
1.0
|
Refactor the Generator - ## Expected Behavior
The generator should produce consistent results, ideally automated for producing the build.
We should not be removing folders and creating temporary folders if not needed.
https://github.com/googleapis/google-cloudevents-python/blob/master/gen.sh
## Actual Behavior
Right now we have a script that uses a `workplace` directory. The generator results are inconsistent across machines.
## Steps to Reproduce the Problem
Run the generator:
```
./gen.sh
```
Related issue: https://github.com/googleapis/google-cloudevents-python/issues/30
|
process
|
refactor the generator expected behavior the generator should produce consistent results ideally automated for producing the build we should not be removing folders and creating temporary folders if not needed actual behavior right now we have a script that uses a workplace directory the generator results are inconsistent across machines steps to reproduce the problem run the generator gen sh related issue
| 1
|
18,047
| 24,057,521,733
|
IssuesEvent
|
2022-09-16 18:24:18
|
openxla/stablehlo
|
https://api.github.com/repos/openxla/stablehlo
|
closed
|
Set up regular integrates from StableHLO into MLIR-HLO
|
Process
|
The idea is to vendor StableHLO into the MLIR-HLO repository, so that existing MLIR-HLO users can experiment with StableHLO in a low-friction manner. StableHLO is GitHub-first, and MLIR-HLO is Google3-first, and that's the gap that we'll be bridging during these integrates.
|
1.0
|
Set up regular integrates from StableHLO into MLIR-HLO - The idea is to vendor StableHLO into the MLIR-HLO repository, so that existing MLIR-HLO users can experiment with StableHLO in a low-friction manner. StableHLO is GitHub-first, and MLIR-HLO is Google3-first, and that's the gap that we'll be bridging during these integrates.
|
process
|
set up regular integrates from stablehlo into mlir hlo the idea is to vendor stablehlo into the mlir hlo repository so that existing mlir hlo users can experiment with stablehlo in a low friction manner stablehlo is github first and mlir hlo is first and that s the gap that we ll be bridging during these integrates
| 1
|
15,873
| 20,049,294,003
|
IssuesEvent
|
2022-02-03 03:00:23
|
joelmiller/InfectiousMath
|
https://api.github.com/repos/joelmiller/InfectiousMath
|
opened
|
Branching processes and epidemic probability
|
Dynamical Systems Branching Process
|
If we start with an offspring distribution we can calculate the probability of an epidemic. This is a "Galton-Watson" process.
The probability of extinction by generation `g` can be expressed through a cobweb diagram.
|
1.0
|
Branching processes and epidemic probability - If we start with an offspring distribution we can calculate the probability of an epidemic. This is a "Galton-Watson" process.
The probability of extinction by generation `g` can be expressed through a cobweb diagram.
|
process
|
branching processes and epidemic probability if we start with an offspring distribution we can calculate the probability of an epidemic this is a galton watson process the probability of extinction by generation g can be expressed through a cobweb diagram
| 1
|
12,140
| 14,741,108,762
|
IssuesEvent
|
2021-01-07 10:06:39
|
kdjstudios/SABillingGitlab
|
https://api.github.com/repos/kdjstudios/SABillingGitlab
|
closed
|
Check All Site's accounts for 'nil' paid dates
|
anc-process anp-important ant-bug
|
In GitLab by @kdjstudios on Jan 2, 2019, 09:05
**Submitted by:** Kyle
**Helpdesk:** NA
**Server:** ALL
**Client/Site:** ALL
**Account:** ALL
**Issue:**
As discovered in #1303 there are historical invoices with 'nil' paid dates which are causing invalid late fees to be charged. We will want to rerun the check in #1160 to insure that there are no other accounts with this issue.
|
1.0
|
Check All Site's accounts for 'nil' paid dates - In GitLab by @kdjstudios on Jan 2, 2019, 09:05
**Submitted by:** Kyle
**Helpdesk:** NA
**Server:** ALL
**Client/Site:** ALL
**Account:** ALL
**Issue:**
As discovered in #1303 there are historical invoices with 'nil' paid dates which are causing invalid late fees to be charged. We will want to rerun the check in #1160 to insure that there are no other accounts with this issue.
|
process
|
check all site s accounts for nil paid dates in gitlab by kdjstudios on jan submitted by kyle helpdesk na server all client site all account all issue as discovered in there are historical invoices with nil paid dates which are causing invalid late fees to be charged we will want to rerun the check in to insure that there are no other accounts with this issue
| 1
|
100,814
| 30,783,981,418
|
IssuesEvent
|
2023-07-31 12:03:41
|
Or4cl3AI/AppGenieAI-
|
https://api.github.com/repos/Or4cl3AI/AppGenieAI-
|
closed
|
Lgtm
|
bitbuilder:create bitbuilder:review sweep
|
Sweep: Implementation Steps
Clone the repository
Clone the repository to your local machine using the command git clone https://github.com/Or4cl3AI/AppGenieAI-.git.
Navigate to the AppGenieAI directory
Navigate to the AppGenieAI directory in your local machine using the command cd AppGenieAI.
Install the required dependencies
Install the required dependencies by running pip install -r requirements.txt in the terminal.
Modify the scripts.js file
Open the scripts.js file located in the AppGenieAI directory. Modify the functions generateCode, setupProject, customizeApp, provideRecommendations, and assistAndroidDevelopment to implement the desired feature. Save the changes.
LGTM
|
2.0
|
Lgtm - Sweep: Implementation Steps
Clone the repository
Clone the repository to your local machine using the command git clone https://github.com/Or4cl3AI/AppGenieAI-.git.
Navigate to the AppGenieAI directory
Navigate to the AppGenieAI directory in your local machine using the command cd AppGenieAI.
Install the required dependencies
Install the required dependencies by running pip install -r requirements.txt in the terminal.
Modify the scripts.js file
Open the scripts.js file located in the AppGenieAI directory. Modify the functions generateCode, setupProject, customizeApp, provideRecommendations, and assistAndroidDevelopment to implement the desired feature. Save the changes.
LGTM
|
non_process
|
lgtm sweep implementation steps clone the repository clone the repository to your local machine using the command git clone navigate to the appgenieai directory navigate to the appgenieai directory in your local machine using the command cd appgenieai install the required dependencies install the required dependencies by running pip install r requirements txt in the terminal modify the scripts js file open the scripts js file located in the appgenieai directory modify the functions generatecode setupproject customizeapp providerecommendations and assistandroiddevelopment to implement the desired feature save the changes lgtm
| 0
|
8,904
| 12,003,370,902
|
IssuesEvent
|
2020-04-09 09:29:24
|
prisma/prisma
|
https://api.github.com/repos/prisma/prisma
|
opened
|
Add section in docs about how to compile & use binaries
|
kind/docs process/candidate topic: binaries
|
#### Needed: clear steps for people who want to compile the binaries, for example for Alpine or arm (related https://github.com/prisma/prisma/issues/1635)
- We have instructions on how to build in the README here: https://github.com/prisma/prisma-engines#building-prisma-engines
But it’s only "half of it" because this only mention compiling but not how to use the binaries with the env vars
- Best I found about the vars is the spec but there is so much stuff in there I’m afraid it could be confusing https://github.com/prisma/specs/blob/master/binaries/Readme.md#environment-variables
|
1.0
|
Add section in docs about how to compile & use binaries - #### Needed: clear steps for people who want to compile the binaries, for example for Alpine or arm (related https://github.com/prisma/prisma/issues/1635)
- We have instructions on how to build in the README here: https://github.com/prisma/prisma-engines#building-prisma-engines
But it’s only "half of it" because this only mention compiling but not how to use the binaries with the env vars
- Best I found about the vars is the spec but there is so much stuff in there I’m afraid it could be confusing https://github.com/prisma/specs/blob/master/binaries/Readme.md#environment-variables
|
process
|
add section in docs about how to compile use binaries needed clear steps for people who want to compile the binaries for example for alpine or arm related we have instructions on how to build in the readme here but it’s only half of it because this only mention compiling but not how to use the binaries with the env vars best i found about the vars is the spec but there is so much stuff in there i’m afraid it could be confusing
| 1
|
18,863
| 3,727,367,324
|
IssuesEvent
|
2016-03-06 07:38:05
|
F5Networks/f5-common-python
|
https://api.github.com/repos/F5Networks/f5-common-python
|
opened
|
Application Services Service must override exists() to build proper uri
|
enhancement functional test unit test
|
The uri for a service object on the BigIP follows the convention <base_uri>~<partition>~<<service_name>.app>~<service_name>
This must be built in the exists function, just as it is done in load. Implementing the override and the tests to keep 100% coverage.
|
2.0
|
Application Services Service must override exists() to build proper uri - The uri for a service object on the BigIP follows the convention <base_uri>~<partition>~<<service_name>.app>~<service_name>
This must be built in the exists function, just as it is done in load. Implementing the override and the tests to keep 100% coverage.
|
non_process
|
application services service must override exists to build proper uri the uri for a service object on the bigip follows the convention app this must be built in the exists function just as it is done in load implementing the override and the tests to keep coverage
| 0
|
3,094
| 6,108,373,544
|
IssuesEvent
|
2017-06-21 10:20:07
|
nodejs/node
|
https://api.github.com/repos/nodejs/node
|
reopened
|
Investigate flaky test/async-hooks/test-callback-error
|
async_hooks child_process test
|
* **Version**: v9.0.0-pre
* **Platform**: osx1010
* **Subsystem**: test, async_hooks, child_process
<!-- Enter your issue details below this comment. -->
https://ci.nodejs.org/job/node-test-commit-osx/10336/nodes=osx1010/console
```console
not ok 167 async-hooks/test-callback-error
---
duration_ms: 60.132
severity: fail
stack: |-
timeout
```
|
1.0
|
Investigate flaky test/async-hooks/test-callback-error - * **Version**: v9.0.0-pre
* **Platform**: osx1010
* **Subsystem**: test, async_hooks, child_process
<!-- Enter your issue details below this comment. -->
https://ci.nodejs.org/job/node-test-commit-osx/10336/nodes=osx1010/console
```console
not ok 167 async-hooks/test-callback-error
---
duration_ms: 60.132
severity: fail
stack: |-
timeout
```
|
process
|
investigate flaky test async hooks test callback error version pre platform subsystem test async hooks child process console not ok async hooks test callback error duration ms severity fail stack timeout
| 1
|
14,841
| 18,236,551,228
|
IssuesEvent
|
2021-10-01 07:43:16
|
quark-engine/quark-engine
|
https://api.github.com/repos/quark-engine/quark-engine
|
closed
|
Unable to get function involved in a 60% confident rule
|
issue-processing-state-02
|
For rules less than 100% confident, I would like to view **which portion of code is concerned**.
This _works very well with rules detected at 100%_ and option `-c`. I get the functions of the malware concerned by this or that crime. Example:

But **I am unable to get the same result with rules less than 100%.** I am using this [malicious sample](https://koodous.com/apks/a03ffa955d9b273cc22acae93dbad2ec8c023d7621b256ea93506587506e3eb3).
On my sample, Quark detects rule `00070.json` at 60% .
I tried: `quark -s -t 20 -c -a a03ffa955d9b273cc22acae93dbad2ec8c023d7621b256ea93506587506e3eb3.apk -r ./test-rules/`. Despite the `-c`, and `-t 20` to consider rules above 20%, I do not see the function involved.See image below: there is nothing underneath "Rules Classification".
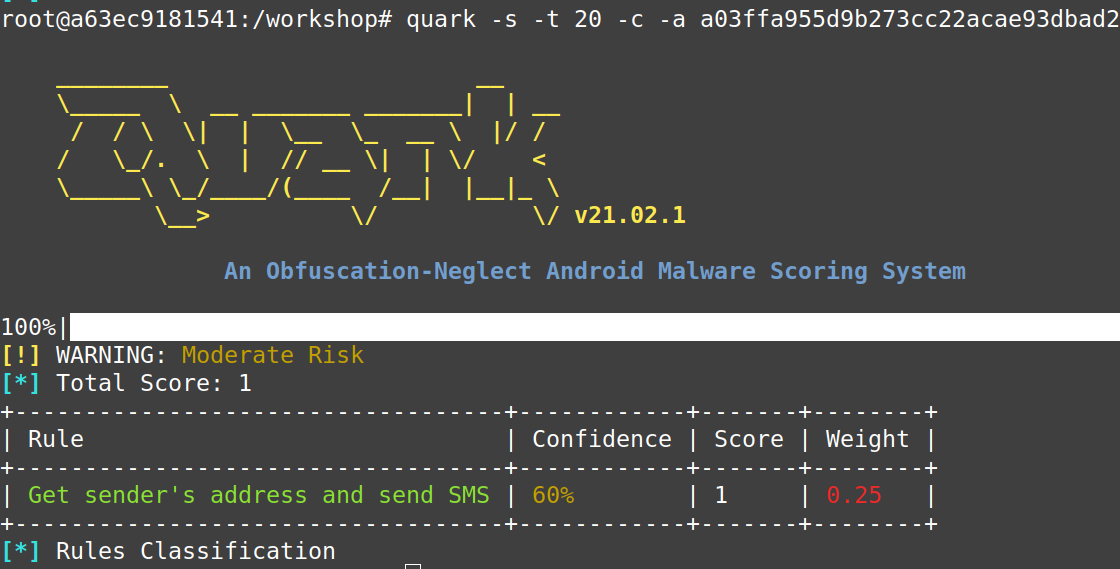
I also tried with `-d` instead of `-s`. Still do not get the function involved.
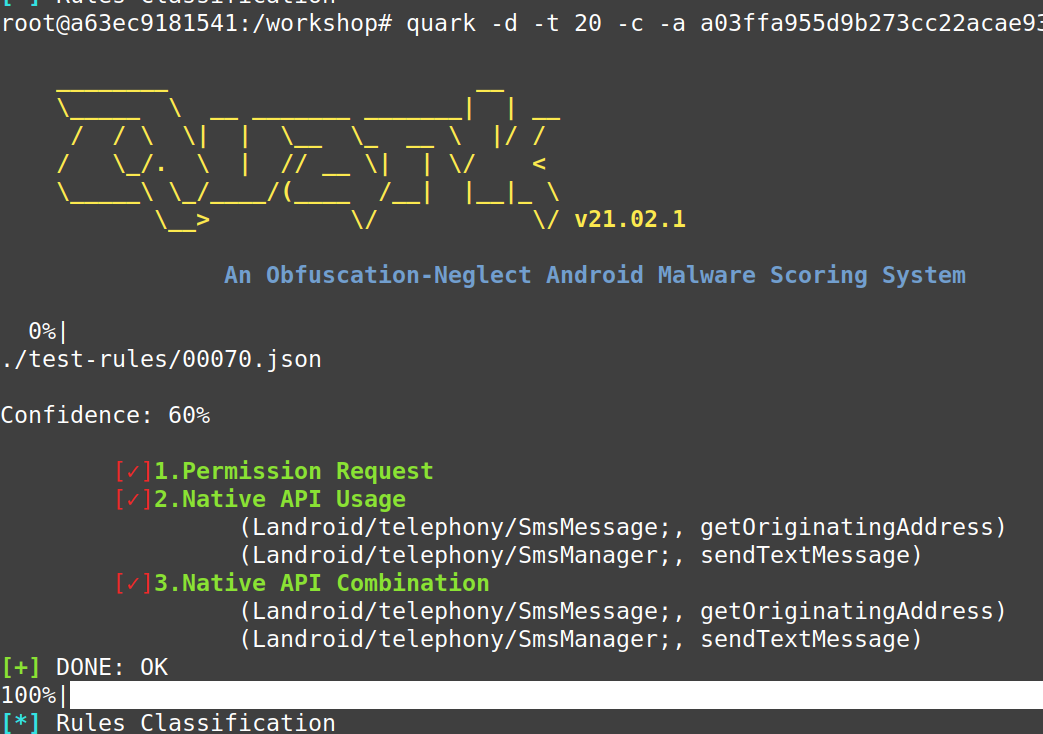
I tried with `-g` to generate the call graph, which should give me the information.
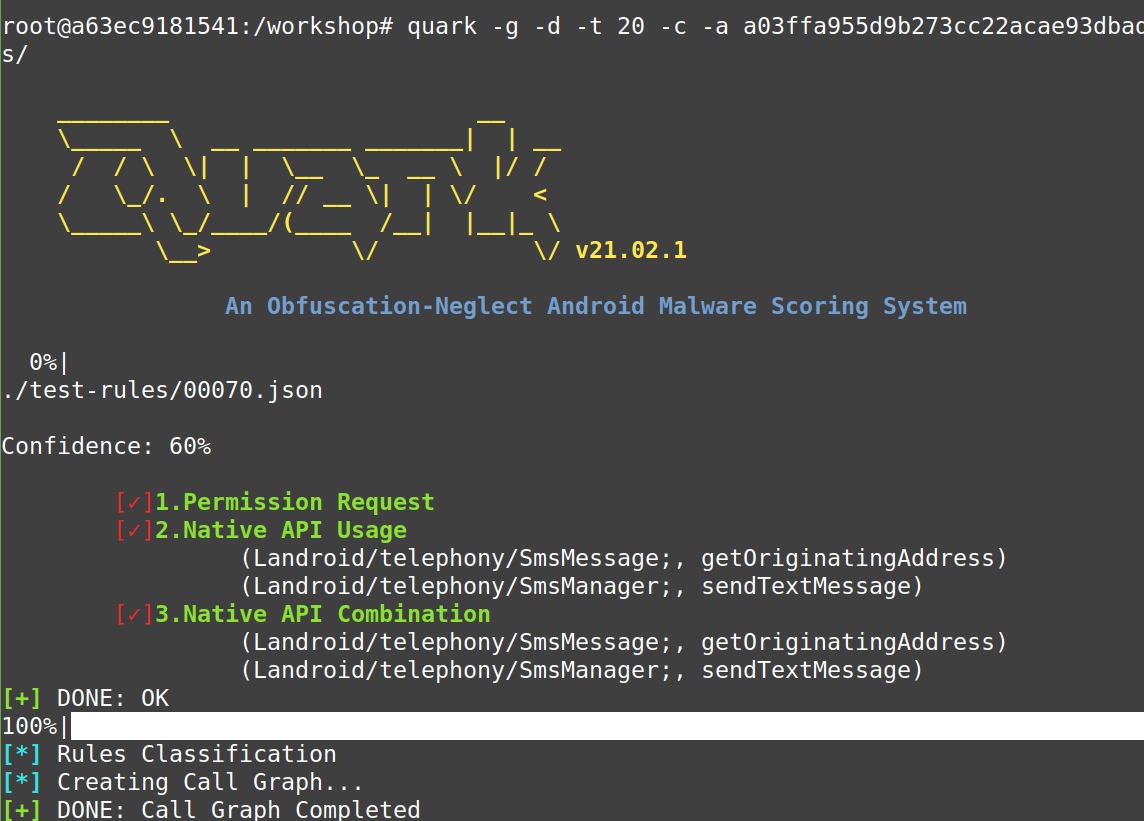
It says it generates the graph, but I am unable to find it. I did a `ls -lt` on the directory nothing recent, apart from a file `rules_classification.json` which contains:
```
{"rules_classification": []}
```
I suspect the issue is around this: for some reason, my rule does not get selected even the threshold is set, so therefore there is nothing to generate in the call graph.
Finally, I tried with an output report `-o` : `quark -a a03ffa955d9b273cc22acae93dbad2ec8c023d7621b256ea93506587506e3eb3.apk -r ./test-rules/ -s -c -o ./quark.output`
The output report says the following (but still unfortunately does not show the functions involved):
```json
{
"md5": "aaae379a27d5355231fcefb776f2df84",
"apk_filename": "a03ffa955d9b273cc22acae93dbad2ec8c023d7621b256ea93506587506e3eb3.apk",
"size_bytes": 475144,
"threat_level": "Moderate Risk",
"total_score": 1,
"crimes": [
{
"crime": "Get sender's address and send SMS",
"score": 1,
"weight": 0.25,
"confidence": "60%",
"permissions": [],
"native_api": [
{
"class": "Landroid/telephony/SmsMessage;",
"method": "getOriginatingAddress"
},
{
"class": "Landroid/telephony/SmsManager;",
"method": "sendTextMessage"
}
],
"combination": [
{
"descriptor": "()Ljava/lang/String;",
"class": "Landroid/telephony/SmsMessage;",
"method": "getOriginatingAddress"
},
{
"descriptor": "(Ljava/lang/String; Ljava/lang/String; Ljava/lang/String; Landroid/app/PendingIntent; Landroid/app/Pe
ndingIntent;)V",
"class": "Landroid/telephony/SmsManager;",
"method": "sendTextMessage"
}
],
"sequence": [],
"register": []
}
]
}
```
Settings:
- Quark Engine v21.02.1
- Linux Ubuntu 20.04.1 LTS
- Python 3.8.5
- I use default quark rules, in particular, I am testing over rule 00070.json
|
1.0
|
Unable to get function involved in a 60% confident rule - For rules less than 100% confident, I would like to view **which portion of code is concerned**.
This _works very well with rules detected at 100%_ and option `-c`. I get the functions of the malware concerned by this or that crime. Example:

But **I am unable to get the same result with rules less than 100%.** I am using this [malicious sample](https://koodous.com/apks/a03ffa955d9b273cc22acae93dbad2ec8c023d7621b256ea93506587506e3eb3).
On my sample, Quark detects rule `00070.json` at 60% .
I tried: `quark -s -t 20 -c -a a03ffa955d9b273cc22acae93dbad2ec8c023d7621b256ea93506587506e3eb3.apk -r ./test-rules/`. Despite the `-c`, and `-t 20` to consider rules above 20%, I do not see the function involved.See image below: there is nothing underneath "Rules Classification".

I also tried with `-d` instead of `-s`. Still do not get the function involved.

I tried with `-g` to generate the call graph, which should give me the information.

It says it generates the graph, but I am unable to find it. I did a `ls -lt` on the directory nothing recent, apart from a file `rules_classification.json` which contains:
```
{"rules_classification": []}
```
I suspect the issue is around this: for some reason, my rule does not get selected even the threshold is set, so therefore there is nothing to generate in the call graph.
Finally, I tried with an output report `-o` : `quark -a a03ffa955d9b273cc22acae93dbad2ec8c023d7621b256ea93506587506e3eb3.apk -r ./test-rules/ -s -c -o ./quark.output`
The output report says the following (but still unfortunately does not show the functions involved):
```json
{
"md5": "aaae379a27d5355231fcefb776f2df84",
"apk_filename": "a03ffa955d9b273cc22acae93dbad2ec8c023d7621b256ea93506587506e3eb3.apk",
"size_bytes": 475144,
"threat_level": "Moderate Risk",
"total_score": 1,
"crimes": [
{
"crime": "Get sender's address and send SMS",
"score": 1,
"weight": 0.25,
"confidence": "60%",
"permissions": [],
"native_api": [
{
"class": "Landroid/telephony/SmsMessage;",
"method": "getOriginatingAddress"
},
{
"class": "Landroid/telephony/SmsManager;",
"method": "sendTextMessage"
}
],
"combination": [
{
"descriptor": "()Ljava/lang/String;",
"class": "Landroid/telephony/SmsMessage;",
"method": "getOriginatingAddress"
},
{
"descriptor": "(Ljava/lang/String; Ljava/lang/String; Ljava/lang/String; Landroid/app/PendingIntent; Landroid/app/Pe
ndingIntent;)V",
"class": "Landroid/telephony/SmsManager;",
"method": "sendTextMessage"
}
],
"sequence": [],
"register": []
}
]
}
```
Settings:
- Quark Engine v21.02.1
- Linux Ubuntu 20.04.1 LTS
- Python 3.8.5
- I use default quark rules, in particular, I am testing over rule 00070.json
|
process
|
unable to get function involved in a confident rule for rules less than confident i would like to view which portion of code is concerned this works very well with rules detected at and option c i get the functions of the malware concerned by this or that crime example but i am unable to get the same result with rules less than i am using this on my sample quark detects rule json at i tried quark s t c a apk r test rules despite the c and t to consider rules above i do not see the function involved see image below there is nothing underneath rules classification i also tried with d instead of s still do not get the function involved i tried with g to generate the call graph which should give me the information it says it generates the graph but i am unable to find it i did a ls lt on the directory nothing recent apart from a file rules classification json which contains rules classification i suspect the issue is around this for some reason my rule does not get selected even the threshold is set so therefore there is nothing to generate in the call graph finally i tried with an output report o quark a apk r test rules s c o quark output the output report says the following but still unfortunately does not show the functions involved json apk filename apk size bytes threat level moderate risk total score crimes crime get sender s address and send sms score weight confidence permissions native api class landroid telephony smsmessage method getoriginatingaddress class landroid telephony smsmanager method sendtextmessage combination descriptor ljava lang string class landroid telephony smsmessage method getoriginatingaddress descriptor ljava lang string ljava lang string ljava lang string landroid app pendingintent landroid app pe ndingintent v class landroid telephony smsmanager method sendtextmessage sequence register settings quark engine linux ubuntu lts python i use default quark rules in particular i am testing over rule json
| 1
|
7,204
| 10,340,574,765
|
IssuesEvent
|
2019-09-03 22:26:09
|
googleapis/nodejs-bigquery
|
https://api.github.com/repos/googleapis/nodejs-bigquery
|
closed
|
bigquery: implement support use_avro_logical_types for export jobs
|
type: process
|
With the next discovery release, BigQuery will support control of logical type annotations when specifying export jobs that use the Apache Avro file format. This will be controlled via the use_avro_logical_types.
Description from the API layer:
[Optional] If destinationFormat is set to "AVRO", this flag indicates
whether to enable extracting applicable column types (such as TIMESTAMP) to
their corresponding AVRO logical types (timestamp-micros), instead of only
using their raw types (avro-long).
This should mirror reciprocal support in load jobs for specifying whether logical type annotations should be used when building the schema of a table.
|
1.0
|
bigquery: implement support use_avro_logical_types for export jobs - With the next discovery release, BigQuery will support control of logical type annotations when specifying export jobs that use the Apache Avro file format. This will be controlled via the use_avro_logical_types.
Description from the API layer:
[Optional] If destinationFormat is set to "AVRO", this flag indicates
whether to enable extracting applicable column types (such as TIMESTAMP) to
their corresponding AVRO logical types (timestamp-micros), instead of only
using their raw types (avro-long).
This should mirror reciprocal support in load jobs for specifying whether logical type annotations should be used when building the schema of a table.
|
process
|
bigquery implement support use avro logical types for export jobs with the next discovery release bigquery will support control of logical type annotations when specifying export jobs that use the apache avro file format this will be controlled via the use avro logical types description from the api layer if destinationformat is set to avro this flag indicates whether to enable extracting applicable column types such as timestamp to their corresponding avro logical types timestamp micros instead of only using their raw types avro long this should mirror reciprocal support in load jobs for specifying whether logical type annotations should be used when building the schema of a table
| 1
|
20,229
| 26,830,237,227
|
IssuesEvent
|
2023-02-02 15:32:44
|
evidence-dev/evidence
|
https://api.github.com/repos/evidence-dev/evidence
|
closed
|
Set up pre-release branch
|
enhancement dev-process
|
- Branch & release namespace should be titled next, and we should configure the changesets action to ship changes merged to this branch
- Will be the branch where we ship the first version fo
Other options, include:
How duckdb is shipping (seems like every commit?)
- Look at duckdb (seems like they are creating a new release tag for every... pr?)
- Ship svelte kit (#540) upgrade here
|
1.0
|
Set up pre-release branch - - Branch & release namespace should be titled next, and we should configure the changesets action to ship changes merged to this branch
- Will be the branch where we ship the first version fo
Other options, include:
How duckdb is shipping (seems like every commit?)
- Look at duckdb (seems like they are creating a new release tag for every... pr?)
- Ship svelte kit (#540) upgrade here
|
process
|
set up pre release branch branch release namespace should be titled next and we should configure the changesets action to ship changes merged to this branch will be the branch where we ship the first version fo other options include how duckdb is shipping seems like every commit look at duckdb seems like they are creating a new release tag for every pr ship svelte kit upgrade here
| 1
|
416,933
| 28,106,461,167
|
IssuesEvent
|
2023-03-31 01:23:45
|
javalin/javalin-openapi
|
https://api.github.com/repos/javalin/javalin-openapi
|
closed
|
What is openapi.groovy?
|
documentation question
|
Getting this log on stderr: "Note: /_project-path_/src/main/compile/openapi.groovy", I didn't see any mention of it in the docs, just curious to know what it is.
|
1.0
|
What is openapi.groovy? - Getting this log on stderr: "Note: /_project-path_/src/main/compile/openapi.groovy", I didn't see any mention of it in the docs, just curious to know what it is.
|
non_process
|
what is openapi groovy getting this log on stderr note project path src main compile openapi groovy i didn t see any mention of it in the docs just curious to know what it is
| 0
|
102,379
| 16,565,169,174
|
IssuesEvent
|
2021-05-29 08:44:27
|
MohamedElashri/blog-theme
|
https://api.github.com/repos/MohamedElashri/blog-theme
|
reopened
|
CVE-2019-10744 (High) detected in lodash.template-3.6.2.tgz
|
security vulnerability
|
## CVE-2019-10744 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>lodash.template-3.6.2.tgz</b></p></summary>
<p>The modern build of lodash’s `_.template` as a module.</p>
<p>Library home page: <a href="https://registry.npmjs.org/lodash.template/-/lodash.template-3.6.2.tgz">https://registry.npmjs.org/lodash.template/-/lodash.template-3.6.2.tgz</a></p>
<p>Path to dependency file: blog-theme/package.json</p>
<p>Path to vulnerable library: blog-theme/node_modules/lodash.template/package.json</p>
<p>
Dependency Hierarchy:
- gulp-minify-css-1.2.4.tgz (Root Library)
- gulp-util-3.0.8.tgz
- :x: **lodash.template-3.6.2.tgz** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/MohamedElashri/blog-theme/commit/c7939ca9cfb9a703f690395b2e84f88cab3b01f4">c7939ca9cfb9a703f690395b2e84f88cab3b01f4</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Versions of lodash lower than 4.17.12 are vulnerable to Prototype Pollution. The function defaultsDeep could be tricked into adding or modifying properties of Object.prototype using a constructor payload.
<p>Publish Date: 2019-07-26
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2019-10744>CVE-2019-10744</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>9.1</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://github.com/advisories/GHSA-jf85-cpcp-j695">https://github.com/advisories/GHSA-jf85-cpcp-j695</a></p>
<p>Release Date: 2019-07-08</p>
<p>Fix Resolution: lodash-4.17.12, lodash-amd-4.17.12, lodash-es-4.17.12, lodash.defaultsdeep-4.6.1, lodash.merge- 4.6.2, lodash.mergewith-4.6.2, lodash.template-4.5.0</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
True
|
CVE-2019-10744 (High) detected in lodash.template-3.6.2.tgz - ## CVE-2019-10744 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>lodash.template-3.6.2.tgz</b></p></summary>
<p>The modern build of lodash’s `_.template` as a module.</p>
<p>Library home page: <a href="https://registry.npmjs.org/lodash.template/-/lodash.template-3.6.2.tgz">https://registry.npmjs.org/lodash.template/-/lodash.template-3.6.2.tgz</a></p>
<p>Path to dependency file: blog-theme/package.json</p>
<p>Path to vulnerable library: blog-theme/node_modules/lodash.template/package.json</p>
<p>
Dependency Hierarchy:
- gulp-minify-css-1.2.4.tgz (Root Library)
- gulp-util-3.0.8.tgz
- :x: **lodash.template-3.6.2.tgz** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/MohamedElashri/blog-theme/commit/c7939ca9cfb9a703f690395b2e84f88cab3b01f4">c7939ca9cfb9a703f690395b2e84f88cab3b01f4</a></p>
<p>Found in base branch: <b>main</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
Versions of lodash lower than 4.17.12 are vulnerable to Prototype Pollution. The function defaultsDeep could be tricked into adding or modifying properties of Object.prototype using a constructor payload.
<p>Publish Date: 2019-07-26
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2019-10744>CVE-2019-10744</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>9.1</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://github.com/advisories/GHSA-jf85-cpcp-j695">https://github.com/advisories/GHSA-jf85-cpcp-j695</a></p>
<p>Release Date: 2019-07-08</p>
<p>Fix Resolution: lodash-4.17.12, lodash-amd-4.17.12, lodash-es-4.17.12, lodash.defaultsdeep-4.6.1, lodash.merge- 4.6.2, lodash.mergewith-4.6.2, lodash.template-4.5.0</p>
</p>
</details>
<p></p>
***
Step up your Open Source Security Game with WhiteSource [here](https://www.whitesourcesoftware.com/full_solution_bolt_github)
|
non_process
|
cve high detected in lodash template tgz cve high severity vulnerability vulnerable library lodash template tgz the modern build of lodash’s template as a module library home page a href path to dependency file blog theme package json path to vulnerable library blog theme node modules lodash template package json dependency hierarchy gulp minify css tgz root library gulp util tgz x lodash template tgz vulnerable library found in head commit a href found in base branch main vulnerability details versions of lodash lower than are vulnerable to prototype pollution the function defaultsdeep could be tricked into adding or modifying properties of object prototype using a constructor payload publish date url a href cvss score details base score metrics exploitability metrics attack vector network attack complexity low privileges required none user interaction none scope unchanged impact metrics confidentiality impact none integrity impact high availability impact high for more information on scores click a href suggested fix type upgrade version origin a href release date fix resolution lodash lodash amd lodash es lodash defaultsdeep lodash merge lodash mergewith lodash template step up your open source security game with whitesource
| 0
|
5,046
| 7,859,182,565
|
IssuesEvent
|
2018-06-21 15:50:59
|
Open-EO/openeo-api
|
https://api.github.com/repos/Open-EO/openeo-api
|
opened
|
How to interface processes job results in services?
|
feedback required processes service management
|
With the current API specification it is not possible any longer to operate web services on pre-processed data from jobs. How can we make this possible?
There are potentially two ways:
- Just add a process to do so (or use an existing process like load_data) and send a process graph that makes the connection.
- Send EITHER a process_graph or a job_id to the `POST /services` endpoint.
|
1.0
|
How to interface processes job results in services? - With the current API specification it is not possible any longer to operate web services on pre-processed data from jobs. How can we make this possible?
There are potentially two ways:
- Just add a process to do so (or use an existing process like load_data) and send a process graph that makes the connection.
- Send EITHER a process_graph or a job_id to the `POST /services` endpoint.
|
process
|
how to interface processes job results in services with the current api specification it is not possible any longer to operate web services on pre processed data from jobs how can we make this possible there are potentially two ways just add a process to do so or use an existing process like load data and send a process graph that makes the connection send either a process graph or a job id to the post services endpoint
| 1
|
75,908
| 7,495,852,069
|
IssuesEvent
|
2018-04-08 02:10:43
|
nodemules/SuperPlatformerBros
|
https://api.github.com/repos/nodemules/SuperPlatformerBros
|
opened
|
Negative x value placed enemies move incorrectly
|
bug gameplay playtesting
|
Enemies in negative x value ranges have a weird magnetic pull (the bounds are being set incorrectly in the bound adjustment to determine where the edges of platforms etc are)
|
1.0
|
Negative x value placed enemies move incorrectly - Enemies in negative x value ranges have a weird magnetic pull (the bounds are being set incorrectly in the bound adjustment to determine where the edges of platforms etc are)
|
non_process
|
negative x value placed enemies move incorrectly enemies in negative x value ranges have a weird magnetic pull the bounds are being set incorrectly in the bound adjustment to determine where the edges of platforms etc are
| 0
|
106,574
| 16,685,669,093
|
IssuesEvent
|
2021-06-08 07:47:25
|
SmartBear/fake-ap
|
https://api.github.com/repos/SmartBear/fake-ap
|
closed
|
CVE-2021-23364 (Medium) detected in browserslist-4.16.3.tgz - autoclosed
|
security vulnerability
|
## CVE-2021-23364 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>browserslist-4.16.3.tgz</b></p></summary>
<p>Share target browsers between different front-end tools, like Autoprefixer, Stylelint and babel-env-preset</p>
<p>Library home page: <a href="https://registry.npmjs.org/browserslist/-/browserslist-4.16.3.tgz">https://registry.npmjs.org/browserslist/-/browserslist-4.16.3.tgz</a></p>
<p>Path to dependency file: fake-ap/package.json</p>
<p>Path to vulnerable library: fake-ap/node_modules/browserslist</p>
<p>
Dependency Hierarchy:
- preset-env-7.14.4.tgz (Root Library)
- core-js-compat-3.10.1.tgz
- :x: **browserslist-4.16.3.tgz** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/SmartBear/fake-ap/commit/5b6fb12fa18f1dfe12ace4adb4be43c9b301cd48">5b6fb12fa18f1dfe12ace4adb4be43c9b301cd48</a></p>
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
The package browserslist from 4.0.0 and before 4.16.5 are vulnerable to Regular Expression Denial of Service (ReDoS) during parsing of queries.
<p>Publish Date: 2021-04-28
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-23364>CVE-2021-23364</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>5.3</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: Low
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-23364">https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-23364</a></p>
<p>Release Date: 2021-04-28</p>
<p>Fix Resolution: browserslist - 4.16.5</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":false,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"javascript/Node.js","packageName":"browserslist","packageVersion":"4.16.3","packageFilePaths":["/package.json"],"isTransitiveDependency":true,"dependencyTree":"@babel/preset-env:7.14.4;core-js-compat:3.10.1;browserslist:4.16.3","isMinimumFixVersionAvailable":true,"minimumFixVersion":"browserslist - 4.16.5"}],"baseBranches":["master"],"vulnerabilityIdentifier":"CVE-2021-23364","vulnerabilityDetails":"The package browserslist from 4.0.0 and before 4.16.5 are vulnerable to Regular Expression Denial of Service (ReDoS) during parsing of queries.","vulnerabilityUrl":"https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-23364","cvss3Severity":"medium","cvss3Score":"5.3","cvss3Metrics":{"A":"Low","AC":"Low","PR":"None","S":"Unchanged","C":"None","UI":"None","AV":"Network","I":"None"},"extraData":{}}</REMEDIATE> -->
|
True
|
CVE-2021-23364 (Medium) detected in browserslist-4.16.3.tgz - autoclosed - ## CVE-2021-23364 - Medium Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>browserslist-4.16.3.tgz</b></p></summary>
<p>Share target browsers between different front-end tools, like Autoprefixer, Stylelint and babel-env-preset</p>
<p>Library home page: <a href="https://registry.npmjs.org/browserslist/-/browserslist-4.16.3.tgz">https://registry.npmjs.org/browserslist/-/browserslist-4.16.3.tgz</a></p>
<p>Path to dependency file: fake-ap/package.json</p>
<p>Path to vulnerable library: fake-ap/node_modules/browserslist</p>
<p>
Dependency Hierarchy:
- preset-env-7.14.4.tgz (Root Library)
- core-js-compat-3.10.1.tgz
- :x: **browserslist-4.16.3.tgz** (Vulnerable Library)
<p>Found in HEAD commit: <a href="https://github.com/SmartBear/fake-ap/commit/5b6fb12fa18f1dfe12ace4adb4be43c9b301cd48">5b6fb12fa18f1dfe12ace4adb4be43c9b301cd48</a></p>
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/medium_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
The package browserslist from 4.0.0 and before 4.16.5 are vulnerable to Regular Expression Denial of Service (ReDoS) during parsing of queries.
<p>Publish Date: 2021-04-28
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-23364>CVE-2021-23364</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>5.3</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Network
- Attack Complexity: Low
- Privileges Required: None
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: None
- Integrity Impact: None
- Availability Impact: Low
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-23364">https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-23364</a></p>
<p>Release Date: 2021-04-28</p>
<p>Fix Resolution: browserslist - 4.16.5</p>
</p>
</details>
<p></p>
<!-- <REMEDIATE>{"isOpenPROnVulnerability":false,"isPackageBased":true,"isDefaultBranch":true,"packages":[{"packageType":"javascript/Node.js","packageName":"browserslist","packageVersion":"4.16.3","packageFilePaths":["/package.json"],"isTransitiveDependency":true,"dependencyTree":"@babel/preset-env:7.14.4;core-js-compat:3.10.1;browserslist:4.16.3","isMinimumFixVersionAvailable":true,"minimumFixVersion":"browserslist - 4.16.5"}],"baseBranches":["master"],"vulnerabilityIdentifier":"CVE-2021-23364","vulnerabilityDetails":"The package browserslist from 4.0.0 and before 4.16.5 are vulnerable to Regular Expression Denial of Service (ReDoS) during parsing of queries.","vulnerabilityUrl":"https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-23364","cvss3Severity":"medium","cvss3Score":"5.3","cvss3Metrics":{"A":"Low","AC":"Low","PR":"None","S":"Unchanged","C":"None","UI":"None","AV":"Network","I":"None"},"extraData":{}}</REMEDIATE> -->
|
non_process
|
cve medium detected in browserslist tgz autoclosed cve medium severity vulnerability vulnerable library browserslist tgz share target browsers between different front end tools like autoprefixer stylelint and babel env preset library home page a href path to dependency file fake ap package json path to vulnerable library fake ap node modules browserslist dependency hierarchy preset env tgz root library core js compat tgz x browserslist tgz vulnerable library found in head commit a href found in base branch master vulnerability details the package browserslist from and before are vulnerable to regular expression denial of service redos during parsing of queries publish date url a href cvss score details base score metrics exploitability metrics attack vector network attack complexity low privileges required none user interaction none scope unchanged impact metrics confidentiality impact none integrity impact none availability impact low for more information on scores click a href suggested fix type upgrade version origin a href release date fix resolution browserslist isopenpronvulnerability false ispackagebased true isdefaultbranch true packages istransitivedependency true dependencytree babel preset env core js compat browserslist isminimumfixversionavailable true minimumfixversion browserslist basebranches vulnerabilityidentifier cve vulnerabilitydetails the package browserslist from and before are vulnerable to regular expression denial of service redos during parsing of queries vulnerabilityurl
| 0
|
113,174
| 4,544,112,636
|
IssuesEvent
|
2016-09-10 14:10:38
|
HabitRPG/habitrpg
|
https://api.github.com/repos/HabitRPG/habitrpg
|
opened
|
Remove v2 code from /common/script
|
priority: medium status: issue: on hold type: website improvement
|
- Some ops/fns/... were only used in v2 and can be removed
- Some ops return different data if `req.v2 === true`, that code can be removed
|
1.0
|
Remove v2 code from /common/script - - Some ops/fns/... were only used in v2 and can be removed
- Some ops return different data if `req.v2 === true`, that code can be removed
|
non_process
|
remove code from common script some ops fns were only used in and can be removed some ops return different data if req true that code can be removed
| 0
|
19,462
| 25,756,864,245
|
IssuesEvent
|
2022-12-08 17:04:06
|
googleapis/python-bigquery
|
https://api.github.com/repos/googleapis/python-bigquery
|
opened
|
cleanup: Use logic from PyarrowVersions instead of comparing version strings outside of _helpers
|
type: process
|
Ideally we'd never need to compare PyArrow versions outside of the [PyarrowVersions](https://github.com/googleapis/python-bigquery/blob/40e4da78bb690ff4c94832321377bb1590e2eeaf/google/cloud/bigquery/_helpers.py#L97) class. We might need to add some additional methods / properties to do this.
Follow-up to https://github.com/googleapis/python-bigquery/pull/1282/files#discussion_r927998418
|
1.0
|
cleanup: Use logic from PyarrowVersions instead of comparing version strings outside of _helpers - Ideally we'd never need to compare PyArrow versions outside of the [PyarrowVersions](https://github.com/googleapis/python-bigquery/blob/40e4da78bb690ff4c94832321377bb1590e2eeaf/google/cloud/bigquery/_helpers.py#L97) class. We might need to add some additional methods / properties to do this.
Follow-up to https://github.com/googleapis/python-bigquery/pull/1282/files#discussion_r927998418
|
process
|
cleanup use logic from pyarrowversions instead of comparing version strings outside of helpers ideally we d never need to compare pyarrow versions outside of the class we might need to add some additional methods properties to do this follow up to
| 1
|
21,580
| 29,951,054,918
|
IssuesEvent
|
2023-06-23 01:09:26
|
h4sh5/pypi-auto-scanner
|
https://api.github.com/repos/h4sh5/pypi-auto-scanner
|
opened
|
etm-dgraham 5.1.7 has 2 GuardDog issues
|
guarddog exec-base64 silent-process-execution
|
https://pypi.org/project/etm-dgraham
https://inspector.pypi.io/project/etm-dgraham
```{
"dependency": "etm-dgraham",
"version": "5.1.7",
"result": {
"issues": 2,
"errors": {},
"results": {
"exec-base64": [
{
"location": "etm-dgraham-5.1.7/bump.py:128",
"code": " check_output(f\"git commit -a --amend -m '{tmsg}'\")",
"message": "This package contains a call to the `eval` function with a `base64` encoded string as argument.\nThis is a common method used to hide a malicious payload in a module as static analysis will not decode the\nstring.\n"
}
],
"silent-process-execution": [
{
"location": "etm-dgraham-5.1.7/etm/view.py:1524",
"code": " pid = subprocess.Popen(parts, stdin=subprocess.DEVNULL, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL).pid",
"message": "This package is silently executing an external binary, redirecting stdout, stderr and stdin to /dev/null"
}
]
},
"path": "/tmp/tmp6z9mt2mf/etm-dgraham"
}
}```
|
1.0
|
etm-dgraham 5.1.7 has 2 GuardDog issues - https://pypi.org/project/etm-dgraham
https://inspector.pypi.io/project/etm-dgraham
```{
"dependency": "etm-dgraham",
"version": "5.1.7",
"result": {
"issues": 2,
"errors": {},
"results": {
"exec-base64": [
{
"location": "etm-dgraham-5.1.7/bump.py:128",
"code": " check_output(f\"git commit -a --amend -m '{tmsg}'\")",
"message": "This package contains a call to the `eval` function with a `base64` encoded string as argument.\nThis is a common method used to hide a malicious payload in a module as static analysis will not decode the\nstring.\n"
}
],
"silent-process-execution": [
{
"location": "etm-dgraham-5.1.7/etm/view.py:1524",
"code": " pid = subprocess.Popen(parts, stdin=subprocess.DEVNULL, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL).pid",
"message": "This package is silently executing an external binary, redirecting stdout, stderr and stdin to /dev/null"
}
]
},
"path": "/tmp/tmp6z9mt2mf/etm-dgraham"
}
}```
|
process
|
etm dgraham has guarddog issues dependency etm dgraham version result issues errors results exec location etm dgraham bump py code check output f git commit a amend m tmsg message this package contains a call to the eval function with a encoded string as argument nthis is a common method used to hide a malicious payload in a module as static analysis will not decode the nstring n silent process execution location etm dgraham etm view py code pid subprocess popen parts stdin subprocess devnull stdout subprocess devnull stderr subprocess devnull pid message this package is silently executing an external binary redirecting stdout stderr and stdin to dev null path tmp etm dgraham
| 1
|
9,319
| 2,615,144,379
|
IssuesEvent
|
2015-03-01 06:19:59
|
chrsmith/html5rocks
|
https://api.github.com/repos/chrsmith/html5rocks
|
closed
|
Gears to HTML5 migration guide
|
auto-migrated Milestone-X Priority-Medium Tutorial Type-Defect
|
```
vli:
What are the equivalent in HTML5 to Gears, we need to tell developers how
you can use HTML5 offline features that are equivalent to Gears
```
Original issue reported on code.google.com by `paulir...@google.com` on 28 Jul 2010 at 12:13
|
1.0
|
Gears to HTML5 migration guide - ```
vli:
What are the equivalent in HTML5 to Gears, we need to tell developers how
you can use HTML5 offline features that are equivalent to Gears
```
Original issue reported on code.google.com by `paulir...@google.com` on 28 Jul 2010 at 12:13
|
non_process
|
gears to migration guide vli what are the equivalent in to gears we need to tell developers how you can use offline features that are equivalent to gears original issue reported on code google com by paulir google com on jul at
| 0
|
11,655
| 14,516,120,386
|
IssuesEvent
|
2020-12-13 14:52:35
|
luc-github/Repetier-Firmware-4-Davinci
|
https://api.github.com/repos/luc-github/Repetier-Firmware-4-Davinci
|
closed
|
Add Da Vinci Duo Chimera upgrade
|
Waiting to be processed enhancement
|
Hello,
I have created an upgrade to install the E3D Chimera in the Duo 2.0.
http://www.thingiverse.com/thing:2202297
Can someone tell me how I get rid of the commands that send the carriage to the left side of the print bed when loading the left extruder? My new design is small enough that both heads fit over the right drip tray and I want to remove the left tray to install a larger print bed.
Thanks
Jamskate
"If it ain't broke don't fix it. UPGRADE IT!!!!"
|
1.0
|
Add Da Vinci Duo Chimera upgrade - Hello,
I have created an upgrade to install the E3D Chimera in the Duo 2.0.
http://www.thingiverse.com/thing:2202297
Can someone tell me how I get rid of the commands that send the carriage to the left side of the print bed when loading the left extruder? My new design is small enough that both heads fit over the right drip tray and I want to remove the left tray to install a larger print bed.
Thanks
Jamskate
"If it ain't broke don't fix it. UPGRADE IT!!!!"
|
process
|
add da vinci duo chimera upgrade hello i have created an upgrade to install the chimera in the duo can someone tell me how i get rid of the commands that send the carriage to the left side of the print bed when loading the left extruder my new design is small enough that both heads fit over the right drip tray and i want to remove the left tray to install a larger print bed thanks jamskate if it ain t broke don t fix it upgrade it
| 1
|
7,796
| 10,949,669,450
|
IssuesEvent
|
2019-11-26 11:19:19
|
Open-EO/openeo-processes
|
https://api.github.com/repos/Open-EO/openeo-processes
|
closed
|
Change / iterate over dimension labels?
|
help wanted new process question
|
In a recent telco the question came up whether we need a way to iterate over the dimension labels. Something like apply not just for the pixel values, but also for the dimension labels.
With dimension labels I am referring to the values of a dimension, for example temporal representations for a temporal axis, lon/lat values for the spatial dimensions, band names for a spectral dimension etc.
Issue originated in #16. Related to #32.
|
1.0
|
Change / iterate over dimension labels? - In a recent telco the question came up whether we need a way to iterate over the dimension labels. Something like apply not just for the pixel values, but also for the dimension labels.
With dimension labels I am referring to the values of a dimension, for example temporal representations for a temporal axis, lon/lat values for the spatial dimensions, band names for a spectral dimension etc.
Issue originated in #16. Related to #32.
|
process
|
change iterate over dimension labels in a recent telco the question came up whether we need a way to iterate over the dimension labels something like apply not just for the pixel values but also for the dimension labels with dimension labels i am referring to the values of a dimension for example temporal representations for a temporal axis lon lat values for the spatial dimensions band names for a spectral dimension etc issue originated in related to
| 1
|
17,534
| 23,345,496,172
|
IssuesEvent
|
2022-08-09 17:33:00
|
googleapis/gapic-generator-python
|
https://api.github.com/repos/googleapis/gapic-generator-python
|
opened
|
Audit ReadTheDocs documentation for accuracy
|
type: process priority: p2
|
We should do a brief audit of our [ReadTheDocs documentation](https://googleapis.dev/python/gapic-generator-python/latest/index.html) to ensure the information there is still accurate and up to date. Most of the files have not been touched in a while.
|
1.0
|
Audit ReadTheDocs documentation for accuracy - We should do a brief audit of our [ReadTheDocs documentation](https://googleapis.dev/python/gapic-generator-python/latest/index.html) to ensure the information there is still accurate and up to date. Most of the files have not been touched in a while.
|
process
|
audit readthedocs documentation for accuracy we should do a brief audit of our to ensure the information there is still accurate and up to date most of the files have not been touched in a while
| 1
|
101,388
| 21,674,181,136
|
IssuesEvent
|
2022-05-08 12:52:08
|
llvm/llvm-project
|
https://api.github.com/repos/llvm/llvm-project
|
closed
|
Suboptimal multiplications in vectorized code
|
bugzilla llvm:codegen performance
|
| | |
| --- | --- |
| Bugzilla Link | [52039](https://llvm.org/bz52039) |
| Version | trunk |
| OS | Windows NT |
| CC | @RKSimon,@rotateright |
## Extended Description
```
int a [128];
int b[128] = {0};
void foo (void)
{
int k;
for(k=0; k<16; k++)
{
b[k] = 10 - b[k];
a[k] = b[k] * 3;
}
}
```
LLVM emits vpmulld ymm1, ymm1, ymm2, ICC prefers multiple vpaddd.
ICC block RThroughput: 8.0 vs 8.7 (LLVM).
https://godbolt.org/z/TYro7xcfn
If you change a[k] = b[k] * 3; to a[k] = b[k] * 2;
LLVM:
```
foo: # @foo
movdqa xmm1, xmmword ptr [rip + b]
movdqa xmm0, xmmword ptr [rip + .LCPI0_0] # xmm0 = [10,10,10,10]
movdqa xmm2, xmm0
psubd xmm2, xmm1
paddd xmm1, xmm1
movdqa xmmword ptr [rip + b], xmm2
movdqa xmm2, xmmword ptr [rip + .LCPI0_1] # xmm2 = [20,20,20,20]
movdqa xmm3, xmm2
psubd xmm3, xmm1
movdqa xmmword ptr [rip + a], xmm3
movdqa xmm1, xmmword ptr [rip + b+16]
movdqa xmm3, xmm0
psubd xmm3, xmm1
paddd xmm1, xmm1
movdqa xmmword ptr [rip + b+16], xmm3
movdqa xmm3, xmm2
psubd xmm3, xmm1
movdqa xmmword ptr [rip + a+16], xmm3
movdqa xmm1, xmmword ptr [rip + b+32]
movdqa xmm3, xmm0
psubd xmm3, xmm1
paddd xmm1, xmm1
movdqa xmmword ptr [rip + b+32], xmm3
movdqa xmm3, xmm2
psubd xmm3, xmm1
movdqa xmmword ptr [rip + a+32], xmm3
movdqa xmm1, xmmword ptr [rip + b+48]
psubd xmm0, xmm1
paddd xmm1, xmm1
movdqa xmmword ptr [rip + b+48], xmm0
psubd xmm2, xmm1
movdqa xmmword ptr [rip + a+48], xmm2
ret
```
vs ICC's:
```
foo:
movdqu xmm3, XMMWORD PTR .L_2il0floatpacket.0[rip] #11.12
movdqa xmm0, xmm3 #11.17
movdqa xmm1, xmm3 #11.17
movdqa xmm2, xmm3 #11.17
psubd xmm0, XMMWORD PTR b[rip] #11.17
psubd xmm1, XMMWORD PTR 16+b[rip] #11.17
psubd xmm2, XMMWORD PTR 32+b[rip] #11.17
psubd xmm3, XMMWORD PTR 48+b[rip] #11.17
movdqu XMMWORD PTR b[rip], xmm0 #11.5
paddd xmm0, xmm0 #12.19
movdqu XMMWORD PTR 16+b[rip], xmm1 #11.5
paddd xmm1, xmm1 #12.19
movdqu XMMWORD PTR 32+b[rip], xmm2 #11.5
paddd xmm2, xmm2 #12.19
movdqu XMMWORD PTR 48+b[rip], xmm3 #11.5
paddd xmm3, xmm3 #12.19
movdqu XMMWORD PTR a[rip], xmm0 #12.5
movdqu XMMWORD PTR 16+a[rip], xmm1 #12.5
movdqu XMMWORD PTR 32+a[rip], xmm2 #12.5
movdqu XMMWORD PTR 48+a[rip], xmm3 #12.5
ret
```
Maybe missing OneUse check somewhere?
|
1.0
|
Suboptimal multiplications in vectorized code - | | |
| --- | --- |
| Bugzilla Link | [52039](https://llvm.org/bz52039) |
| Version | trunk |
| OS | Windows NT |
| CC | @RKSimon,@rotateright |
## Extended Description
```
int a [128];
int b[128] = {0};
void foo (void)
{
int k;
for(k=0; k<16; k++)
{
b[k] = 10 - b[k];
a[k] = b[k] * 3;
}
}
```
LLVM emits vpmulld ymm1, ymm1, ymm2, ICC prefers multiple vpaddd.
ICC block RThroughput: 8.0 vs 8.7 (LLVM).
https://godbolt.org/z/TYro7xcfn
If you change a[k] = b[k] * 3; to a[k] = b[k] * 2;
LLVM:
```
foo: # @foo
movdqa xmm1, xmmword ptr [rip + b]
movdqa xmm0, xmmword ptr [rip + .LCPI0_0] # xmm0 = [10,10,10,10]
movdqa xmm2, xmm0
psubd xmm2, xmm1
paddd xmm1, xmm1
movdqa xmmword ptr [rip + b], xmm2
movdqa xmm2, xmmword ptr [rip + .LCPI0_1] # xmm2 = [20,20,20,20]
movdqa xmm3, xmm2
psubd xmm3, xmm1
movdqa xmmword ptr [rip + a], xmm3
movdqa xmm1, xmmword ptr [rip + b+16]
movdqa xmm3, xmm0
psubd xmm3, xmm1
paddd xmm1, xmm1
movdqa xmmword ptr [rip + b+16], xmm3
movdqa xmm3, xmm2
psubd xmm3, xmm1
movdqa xmmword ptr [rip + a+16], xmm3
movdqa xmm1, xmmword ptr [rip + b+32]
movdqa xmm3, xmm0
psubd xmm3, xmm1
paddd xmm1, xmm1
movdqa xmmword ptr [rip + b+32], xmm3
movdqa xmm3, xmm2
psubd xmm3, xmm1
movdqa xmmword ptr [rip + a+32], xmm3
movdqa xmm1, xmmword ptr [rip + b+48]
psubd xmm0, xmm1
paddd xmm1, xmm1
movdqa xmmword ptr [rip + b+48], xmm0
psubd xmm2, xmm1
movdqa xmmword ptr [rip + a+48], xmm2
ret
```
vs ICC's:
```
foo:
movdqu xmm3, XMMWORD PTR .L_2il0floatpacket.0[rip] #11.12
movdqa xmm0, xmm3 #11.17
movdqa xmm1, xmm3 #11.17
movdqa xmm2, xmm3 #11.17
psubd xmm0, XMMWORD PTR b[rip] #11.17
psubd xmm1, XMMWORD PTR 16+b[rip] #11.17
psubd xmm2, XMMWORD PTR 32+b[rip] #11.17
psubd xmm3, XMMWORD PTR 48+b[rip] #11.17
movdqu XMMWORD PTR b[rip], xmm0 #11.5
paddd xmm0, xmm0 #12.19
movdqu XMMWORD PTR 16+b[rip], xmm1 #11.5
paddd xmm1, xmm1 #12.19
movdqu XMMWORD PTR 32+b[rip], xmm2 #11.5
paddd xmm2, xmm2 #12.19
movdqu XMMWORD PTR 48+b[rip], xmm3 #11.5
paddd xmm3, xmm3 #12.19
movdqu XMMWORD PTR a[rip], xmm0 #12.5
movdqu XMMWORD PTR 16+a[rip], xmm1 #12.5
movdqu XMMWORD PTR 32+a[rip], xmm2 #12.5
movdqu XMMWORD PTR 48+a[rip], xmm3 #12.5
ret
```
Maybe missing OneUse check somewhere?
|
non_process
|
suboptimal multiplications in vectorized code bugzilla link version trunk os windows nt cc rksimon rotateright extended description int a int b void foo void int k for k k k b b a b llvm emits vpmulld icc prefers multiple vpaddd icc block rthroughput vs llvm if you change a b to a b llvm foo foo movdqa xmmword ptr movdqa xmmword ptr movdqa psubd paddd movdqa xmmword ptr movdqa xmmword ptr movdqa psubd movdqa xmmword ptr movdqa xmmword ptr movdqa psubd paddd movdqa xmmword ptr movdqa psubd movdqa xmmword ptr movdqa xmmword ptr movdqa psubd paddd movdqa xmmword ptr movdqa psubd movdqa xmmword ptr movdqa xmmword ptr psubd paddd movdqa xmmword ptr psubd movdqa xmmword ptr ret vs icc s foo movdqu xmmword ptr l movdqa movdqa movdqa psubd xmmword ptr b psubd xmmword ptr b psubd xmmword ptr b psubd xmmword ptr b movdqu xmmword ptr b paddd movdqu xmmword ptr b paddd movdqu xmmword ptr b paddd movdqu xmmword ptr b paddd movdqu xmmword ptr a movdqu xmmword ptr a movdqu xmmword ptr a movdqu xmmword ptr a ret maybe missing oneuse check somewhere
| 0
|
295,432
| 9,086,273,751
|
IssuesEvent
|
2019-02-18 10:31:23
|
our-city-app/mobicage-backend
|
https://api.github.com/repos/our-city-app/mobicage-backend
|
opened
|
Timestamp scheduled news item
|
priority_major type_bug
|
In be-gistel, at 11/02 a service planned a news item for 15/02. The news item appears between news items of 08/02 and 11/02 instead of 15/02. It shows 15/02 though.
So it looks like the `sort_timestamp` is built using the `creation_timestamp`, and not the `publish_timestamp`.
|
1.0
|
Timestamp scheduled news item - In be-gistel, at 11/02 a service planned a news item for 15/02. The news item appears between news items of 08/02 and 11/02 instead of 15/02. It shows 15/02 though.
So it looks like the `sort_timestamp` is built using the `creation_timestamp`, and not the `publish_timestamp`.
|
non_process
|
timestamp scheduled news item in be gistel at a service planned a news item for the news item appears between news items of and instead of it shows though so it looks like the sort timestamp is built using the creation timestamp and not the publish timestamp
| 0
|
16,184
| 20,626,403,341
|
IssuesEvent
|
2022-03-07 23:10:05
|
GSA/EDX
|
https://api.github.com/repos/GSA/EDX
|
closed
|
Website approval process
|
process touchpoints
|
### Proposed process
Each week,
the GSA Digital Council
reviews a list of `newly_requested` websites from Touchpoints.
A user can request a new website domain at the Touchpoints page [/admin/websites/new](https://github.com/GSA/touchpoints/wiki/Websites).
New websites are "approved" or "denied" by users who have an "Organizational Website Manager" permission role in Touchpoints.
|
1.0
|
Website approval process - ### Proposed process
Each week,
the GSA Digital Council
reviews a list of `newly_requested` websites from Touchpoints.
A user can request a new website domain at the Touchpoints page [/admin/websites/new](https://github.com/GSA/touchpoints/wiki/Websites).
New websites are "approved" or "denied" by users who have an "Organizational Website Manager" permission role in Touchpoints.
|
process
|
website approval process proposed process each week the gsa digital council reviews a list of newly requested websites from touchpoints a user can request a new website domain at the touchpoints page new websites are approved or denied by users who have an organizational website manager permission role in touchpoints
| 1
|
17,447
| 23,268,342,958
|
IssuesEvent
|
2022-08-04 19:48:07
|
MPMG-DCC-UFMG/C01
|
https://api.github.com/repos/MPMG-DCC-UFMG/C01
|
closed
|
Execução do coletor dinâmico em modo headful
|
[1] Requisito [0] Desenvolvimento [2] Média Prioridade [3] Processamento Dinâmico
|
## Comportamento Esperado
É desejável que seja possível executar o coletor dinâmico em modo "headful", onde o sistema abra uma janela do navegador para o usuário e execute os passos nessa janela.
## Comportamento Atual
Esse mecanismo não existe no sistema.
## Passos para reproduzir o erro
Não aplicável.
## Especificações da Coleta
Não aplicável.
|
1.0
|
Execução do coletor dinâmico em modo headful - ## Comportamento Esperado
É desejável que seja possível executar o coletor dinâmico em modo "headful", onde o sistema abra uma janela do navegador para o usuário e execute os passos nessa janela.
## Comportamento Atual
Esse mecanismo não existe no sistema.
## Passos para reproduzir o erro
Não aplicável.
## Especificações da Coleta
Não aplicável.
|
process
|
execução do coletor dinâmico em modo headful comportamento esperado é desejável que seja possível executar o coletor dinâmico em modo headful onde o sistema abra uma janela do navegador para o usuário e execute os passos nessa janela comportamento atual esse mecanismo não existe no sistema passos para reproduzir o erro não aplicável especificações da coleta não aplicável
| 1
|
97,109
| 16,196,399,517
|
IssuesEvent
|
2021-05-04 15:02:57
|
Raunak-S/security-advisor-alerts
|
https://api.github.com/repos/Raunak-S/security-advisor-alerts
|
opened
|
HIGH severity finding reported by IBM Security Advisor
|
IBM Security Advisor
|
**Source**: IBM Vulnerability Advisor
**Finding**: b71ac2564ef0b98f1032d189795994dc/providers/security-advisor/occurrences/va-iwvf-b71ac2564ef0b98f1032d189795994dc-uniack-cr%2Fsu-openshiftapp-latest
**Severity**: HIGH
[View in Security Advisor Dashboard](https://cloud.ibm.com/security-advisor#/findings?id=b71ac2564ef0b98f1032d189795994dc/providers/security-advisor/occurrences/va-iwvf-b71ac2564ef0b98f1032d189795994dc-uniack-cr%2Fsu-openshiftapp-latest®ion=us-south)
**Pretty Printed Info**: {
"security-advisor-alerts": [
{
"severity": "HIGH",
"issuer": "IBM Security Advisor",
"issuer-url": "https://cloud.ibm.com/security-advisor#/findings?id=b71ac2564ef0b98f1032d189795994dc/providers/security-advisor/occurrences/va-iwvf-b71ac2564ef0b98f1032d189795994dc-uniack-cr%2Fsu-openshiftapp-latest®ion=us-south",
"id": "b71ac2564ef0b98f1032d189795994dc/providers/security-advisor/occurrences/va-iwvf-b71ac2564ef0b98f1032d189795994dc-uniack-cr%2Fsu-openshiftapp-latest",
"payload-type": "findings",
"payload-link": "https://us-south.secadvisor.cloud.ibm.com/findings",
"provider": "us.icr.io/uniack-cr/su-openshiftapp:latest",
"payload": {
"author": {
"account_id": "b71ac2564ef0b98f1032d189795994dc",
"email": "gregh@us.ibm.com",
"id": "IBMid-270007GFUU",
"kind": "user"
},
"context": {
"account_id": "b71ac2564ef0b98f1032d189795994dc",
"region": "us-south",
"resource_id": "us.icr.io/uniack-cr/su-openshiftapp:latest",
"resource_name": "us.icr.io/uniack-cr/su-openshiftapp:latest",
"resource_type": "Image",
"service_id": "va"
},
"create_time": "2021-02-12T09:34:39.000Z",
"create_timestamp": 1613122479000,
"finding": {
"certainty": "HIGH",
"next_steps": [
{
"title": "Go to Vulnerability Advisor to see what the issues are and possible corrective actions.",
"url": "https://cloud.ibm.com/containers-kubernetes/registry/images/us.icr.io%252Funiack-cr%252Fsu-openshiftapp%253Alatest/issues?region=us-south&bss_account=b71ac2564ef0b98f1032d189795994dc"
}
],
"severity": "HIGH"
},
"id": "va-iwvf-b71ac2564ef0b98f1032d189795994dc-uniack-cr%2Fsu-openshiftapp-latest",
"insertion_timestamp": 1613122479000,
"kind": "FINDING",
"long_description": "Image with vulnerabilities",
"name": "b71ac2564ef0b98f1032d189795994dc/providers/security-advisor/occurrences/va-iwvf-b71ac2564ef0b98f1032d189795994dc-uniack-cr%2Fsu-openshiftapp-latest",
"note_name": "4263e551d4a9460e8cdaccc06414198b/providers/security-advisor/notes/va-image_with_vulnerabilities",
"provider_id": "security-advisor",
"provider_name": "b71ac2564ef0b98f1032d189795994dc/providers/security-advisor",
"reported_by": {
"id": "va",
"title": "IBM Vulnerability Advisor",
"url": "https://console.bluemix.net/docs/images/va/va_index.htm"
},
"short_description": "Image with vulnerabilities",
"update_time": "2021-04-30T08:00:06.000Z",
"update_timestamp": 1619769606000,
"update_week_date": "2021-W17-5",
"corelationId": "cbfbf587-d380-4726-a6b9-35906c20c967"
}
}
]
}
|
True
|
HIGH severity finding reported by IBM Security Advisor - **Source**: IBM Vulnerability Advisor
**Finding**: b71ac2564ef0b98f1032d189795994dc/providers/security-advisor/occurrences/va-iwvf-b71ac2564ef0b98f1032d189795994dc-uniack-cr%2Fsu-openshiftapp-latest
**Severity**: HIGH
[View in Security Advisor Dashboard](https://cloud.ibm.com/security-advisor#/findings?id=b71ac2564ef0b98f1032d189795994dc/providers/security-advisor/occurrences/va-iwvf-b71ac2564ef0b98f1032d189795994dc-uniack-cr%2Fsu-openshiftapp-latest®ion=us-south)
**Pretty Printed Info**: {
"security-advisor-alerts": [
{
"severity": "HIGH",
"issuer": "IBM Security Advisor",
"issuer-url": "https://cloud.ibm.com/security-advisor#/findings?id=b71ac2564ef0b98f1032d189795994dc/providers/security-advisor/occurrences/va-iwvf-b71ac2564ef0b98f1032d189795994dc-uniack-cr%2Fsu-openshiftapp-latest®ion=us-south",
"id": "b71ac2564ef0b98f1032d189795994dc/providers/security-advisor/occurrences/va-iwvf-b71ac2564ef0b98f1032d189795994dc-uniack-cr%2Fsu-openshiftapp-latest",
"payload-type": "findings",
"payload-link": "https://us-south.secadvisor.cloud.ibm.com/findings",
"provider": "us.icr.io/uniack-cr/su-openshiftapp:latest",
"payload": {
"author": {
"account_id": "b71ac2564ef0b98f1032d189795994dc",
"email": "gregh@us.ibm.com",
"id": "IBMid-270007GFUU",
"kind": "user"
},
"context": {
"account_id": "b71ac2564ef0b98f1032d189795994dc",
"region": "us-south",
"resource_id": "us.icr.io/uniack-cr/su-openshiftapp:latest",
"resource_name": "us.icr.io/uniack-cr/su-openshiftapp:latest",
"resource_type": "Image",
"service_id": "va"
},
"create_time": "2021-02-12T09:34:39.000Z",
"create_timestamp": 1613122479000,
"finding": {
"certainty": "HIGH",
"next_steps": [
{
"title": "Go to Vulnerability Advisor to see what the issues are and possible corrective actions.",
"url": "https://cloud.ibm.com/containers-kubernetes/registry/images/us.icr.io%252Funiack-cr%252Fsu-openshiftapp%253Alatest/issues?region=us-south&bss_account=b71ac2564ef0b98f1032d189795994dc"
}
],
"severity": "HIGH"
},
"id": "va-iwvf-b71ac2564ef0b98f1032d189795994dc-uniack-cr%2Fsu-openshiftapp-latest",
"insertion_timestamp": 1613122479000,
"kind": "FINDING",
"long_description": "Image with vulnerabilities",
"name": "b71ac2564ef0b98f1032d189795994dc/providers/security-advisor/occurrences/va-iwvf-b71ac2564ef0b98f1032d189795994dc-uniack-cr%2Fsu-openshiftapp-latest",
"note_name": "4263e551d4a9460e8cdaccc06414198b/providers/security-advisor/notes/va-image_with_vulnerabilities",
"provider_id": "security-advisor",
"provider_name": "b71ac2564ef0b98f1032d189795994dc/providers/security-advisor",
"reported_by": {
"id": "va",
"title": "IBM Vulnerability Advisor",
"url": "https://console.bluemix.net/docs/images/va/va_index.htm"
},
"short_description": "Image with vulnerabilities",
"update_time": "2021-04-30T08:00:06.000Z",
"update_timestamp": 1619769606000,
"update_week_date": "2021-W17-5",
"corelationId": "cbfbf587-d380-4726-a6b9-35906c20c967"
}
}
]
}
|
non_process
|
high severity finding reported by ibm security advisor source ibm vulnerability advisor finding providers security advisor occurrences va iwvf uniack cr openshiftapp latest severity high pretty printed info security advisor alerts severity high issuer ibm security advisor issuer url id providers security advisor occurrences va iwvf uniack cr openshiftapp latest payload type findings payload link provider us icr io uniack cr su openshiftapp latest payload author account id email gregh us ibm com id ibmid kind user context account id region us south resource id us icr io uniack cr su openshiftapp latest resource name us icr io uniack cr su openshiftapp latest resource type image service id va create time create timestamp finding certainty high next steps title go to vulnerability advisor to see what the issues are and possible corrective actions url severity high id va iwvf uniack cr openshiftapp latest insertion timestamp kind finding long description image with vulnerabilities name providers security advisor occurrences va iwvf uniack cr openshiftapp latest note name providers security advisor notes va image with vulnerabilities provider id security advisor provider name providers security advisor reported by id va title ibm vulnerability advisor url short description image with vulnerabilities update time update timestamp update week date corelationid
| 0
|
21,346
| 29,171,144,422
|
IssuesEvent
|
2023-05-19 02:00:10
|
lizhihao6/get-daily-arxiv-noti
|
https://api.github.com/repos/lizhihao6/get-daily-arxiv-noti
|
opened
|
New submissions for Fri, 19 May 23
|
event camera white balance isp compression image signal processing image signal process raw raw image events camera color contrast events AWB
|
## Keyword: events
### ReasonNet: End-to-End Driving with Temporal and Global Reasoning
- **Authors:** Hao Shao, Letian Wang, Ruobing Chen, Steven L. Waslander, Hongsheng Li, Yu Liu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
- **Arxiv link:** https://arxiv.org/abs/2305.10507
- **Pdf link:** https://arxiv.org/pdf/2305.10507
- **Abstract**
The large-scale deployment of autonomous vehicles is yet to come, and one of the major remaining challenges lies in urban dense traffic scenarios. In such cases, it remains challenging to predict the future evolution of the scene and future behaviors of objects, and to deal with rare adverse events such as the sudden appearance of occluded objects. In this paper, we present ReasonNet, a novel end-to-end driving framework that extensively exploits both temporal and global information of the driving scene. By reasoning on the temporal behavior of objects, our method can effectively process the interactions and relationships among features in different frames. Reasoning about the global information of the scene can also improve overall perception performance and benefit the detection of adverse events, especially the anticipation of potential danger from occluded objects. For comprehensive evaluation on occlusion events, we also release publicly a driving simulation benchmark DriveOcclusionSim consisting of diverse occlusion events. We conduct extensive experiments on multiple CARLA benchmarks, where our model outperforms all prior methods, ranking first on the sensor track of the public CARLA Leaderboard.
## Keyword: event camera
There is no result
## Keyword: events camera
There is no result
## Keyword: white balance
There is no result
## Keyword: color contrast
There is no result
## Keyword: AWB
### X-IQE: eXplainable Image Quality Evaluation for Text-to-Image Generation with Visual Large Language Models
- **Authors:** Yixiong Chen
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
- **Arxiv link:** https://arxiv.org/abs/2305.10843
- **Pdf link:** https://arxiv.org/pdf/2305.10843
- **Abstract**
This paper introduces a novel explainable image quality evaluation approach called X-IQE, which leverages visual large language models (LLMs) to evaluate text-to-image generation methods by generating textual explanations. X-IQE utilizes a hierarchical Chain of Thought (CoT) to enable MiniGPT-4 to produce self-consistent, unbiased texts that are highly correlated with human evaluation. It offers several advantages, including the ability to distinguish between real and generated images, evaluate text-image alignment, and assess image aesthetics without requiring model training or fine-tuning. X-IQE is more cost-effective and efficient compared to human evaluation, while significantly enhancing the transparency and explainability of deep image quality evaluation models. We validate the effectiveness of our method as a benchmark using images generated by prevalent diffusion models. X-IQE demonstrates similar performance to state-of-the-art (SOTA) evaluation methods on COCO Caption, while overcoming the limitations of previous evaluation models on DrawBench, particularly in handling ambiguous generation prompts and text recognition in generated images. Project website: https://github.com/Schuture/Benchmarking-Awesome-Diffusion-Models
### LLMScore: Unveiling the Power of Large Language Models in Text-to-Image Synthesis Evaluation
- **Authors:** Yujie Lu, Xianjun Yang, Xiujun Li, Xin Eric Wang, William Yang Wang
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
- **Arxiv link:** https://arxiv.org/abs/2305.11116
- **Pdf link:** https://arxiv.org/pdf/2305.11116
- **Abstract**
Existing automatic evaluation on text-to-image synthesis can only provide an image-text matching score, without considering the object-level compositionality, which results in poor correlation with human judgments. In this work, we propose LLMScore, a new framework that offers evaluation scores with multi-granularity compositionality. LLMScore leverages the large language models (LLMs) to evaluate text-to-image models. Initially, it transforms the image into image-level and object-level visual descriptions. Then an evaluation instruction is fed into the LLMs to measure the alignment between the synthesized image and the text, ultimately generating a score accompanied by a rationale. Our substantial analysis reveals the highest correlation of LLMScore with human judgments on a wide range of datasets (Attribute Binding Contrast, Concept Conjunction, MSCOCO, DrawBench, PaintSkills). Notably, our LLMScore achieves Kendall's tau correlation with human evaluations that is 58.8% and 31.2% higher than the commonly-used text-image matching metrics CLIP and BLIP, respectively.
## Keyword: ISP
### Multi-spectral Class Center Network for Face Manipulation Detection and Localization
- **Authors:** Changtao Miao, Qi Chu, Zhentao Tan, Zhenchao Jin, Wanyi Zhuang, Yue Wu, Bin Liu, Honggang Hu, Nenghai Yu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2305.10794
- **Pdf link:** https://arxiv.org/pdf/2305.10794
- **Abstract**
As Deepfake contents continue to proliferate on the internet, advancing face manipulation forensics has become a pressing issue. To combat this emerging threat, previous methods mainly focus on studying how to distinguish authentic and manipulated face images. Despite impressive, image-level classification lacks explainability and is limited to some specific application scenarios. Existing forgery localization methods suffer from imprecise and inconsistent pixel-level annotations. To alleviate these problems, this paper first re-constructs the FaceForensics++ dataset by introducing pixel-level annotations, then builds an extensive benchmark for localizing tampered regions. Next, a novel Multi-Spectral Class Center Network (MSCCNet) is proposed for face manipulation detection and localization. Specifically, inspired by the power of frequency-related forgery traces, we design Multi-Spectral Class Center (MSCC) module to learn more generalizable and semantic-agnostic features. Based on the features of different frequency bands, the MSCC module collects multispectral class centers and computes pixel-to-class relations. Applying multi-spectral class-level representations suppresses the semantic information of the visual concepts, which is insensitive to manipulations. Furthermore, we propose a Multi-level Features Aggregation (MFA) module to employ more low-level forgery artifacts and structure textures. Experimental results quantitatively and qualitatively indicate the effectiveness and superiority of the proposed MSCCNet on comprehensive localization benchmarks. We expect this work to inspire more studies on pixel-level face manipulation localization. The annotations and code will be available.
### Unsupervised Pansharpening via Low-rank Diffusion Model
- **Authors:** Xiangyu Rui, Xiangyong Cao, Zeyu Zhu, Zongsheng Yue, Deyu Meng
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
- **Arxiv link:** https://arxiv.org/abs/2305.10925
- **Pdf link:** https://arxiv.org/pdf/2305.10925
- **Abstract**
Pansharpening is a process of merging a highresolution panchromatic (PAN) image and a low-resolution multispectral (LRMS) image to create a single high-resolution multispectral (HRMS) image. Most of the existing deep learningbased pansharpening methods have poor generalization ability and the traditional model-based pansharpening methods need careful manual exploration for the image structure prior. To alleviate these issues, this paper proposes an unsupervised pansharpening method by combining the diffusion model with the low-rank matrix factorization technique. Specifically, we assume that the HRMS image is decomposed into the product of two low-rank tensors, i.e., the base tensor and the coefficient matrix. The base tensor lies on the image field and has low spectral dimension, we can thus conveniently utilize a pre-trained remote sensing diffusion model to capture its image structures. Additionally, we derive a simple yet quite effective way to preestimate the coefficient matrix from the observed LRMS image, which preserves the spectral information of the HRMS. Extensive experimental results on some benchmark datasets demonstrate that our proposed method performs better than traditional model-based approaches and has better generalization ability than deep learning-based techniques. The code is released in https://github.com/xyrui/PLRDiff.
### CDIDN: A Registration Model with High Deformation Impedance Capability for Long-Term Tracking of Pulmonary Lesion Dynamics
- **Authors:** Xinyu Zhao, Sa Huang, Wei Pang, You Zhou
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2305.11024
- **Pdf link:** https://arxiv.org/pdf/2305.11024
- **Abstract**
We study the problem of registration for medical CT images from a novel perspective -- the sensitivity to degree of deformations in CT images. Although some learning-based methods have shown success in terms of average accuracy, their ability to handle regions with local large deformation (LLD) may significantly decrease compared to dealing with regions with minor deformation. This motivates our research into this issue. Two main causes of LLDs are organ motion and changes in tissue structure, with the latter often being a long-term process. In this paper, we propose a novel registration model called Cascade-Dilation Inter-Layer Differential Network (CDIDN), which exhibits both high deformation impedance capability (DIC) and accuracy. CDIDN improves its resilience to LLDs in CT images by enhancing LLDs in the displacement field (DF). It uses a feature-based progressive decomposition of LLDs, blending feature flows of different levels into a main flow in a top-down manner. It leverages Inter-Layer Differential Module (IDM) at each level to locally refine the main flow and globally smooth the feature flow, and also integrates feature velocity fields that can effectively handle feature deformations of various degrees. We assess CDIDN using lungs as representative organs with large deformation. Our findings show that IDM significantly enhances LLDs of the DF, by which improves the DIC and accuracy of the model. Compared with other outstanding learning-based methods, CDIDN exhibits the best DIC and excellent accuracy. Based on vessel enhancement and enhanced LLDs of the DF, we propose a novel method to accurately track the appearance, disappearance, enlargement, and shrinkage of pulmonary lesions, which effectively addresses detection of early lesions and peripheral lung lesions, issues of false enlargement, false shrinkage, and mutilation of lesions.
## Keyword: image signal processing
There is no result
## Keyword: image signal process
There is no result
## Keyword: compression
### Boost Vision Transformer with GPU-Friendly Sparsity and Quantization
- **Authors:** Chong Yu, Tao Chen, Zhongxue Gan, Jiayuan Fan
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Performance (cs.PF)
- **Arxiv link:** https://arxiv.org/abs/2305.10727
- **Pdf link:** https://arxiv.org/pdf/2305.10727
- **Abstract**
The transformer extends its success from the language to the vision domain. Because of the stacked self-attention and cross-attention blocks, the acceleration deployment of vision transformer on GPU hardware is challenging and also rarely studied. This paper thoroughly designs a compression scheme to maximally utilize the GPU-friendly 2:4 fine-grained structured sparsity and quantization. Specially, an original large model with dense weight parameters is first pruned into a sparse one by 2:4 structured pruning, which considers the GPU's acceleration of 2:4 structured sparse pattern with FP16 data type, then the floating-point sparse model is further quantized into a fixed-point one by sparse-distillation-aware quantization aware training, which considers GPU can provide an extra speedup of 2:4 sparse calculation with integer tensors. A mixed-strategy knowledge distillation is used during the pruning and quantization process. The proposed compression scheme is flexible to support supervised and unsupervised learning styles. Experiment results show GPUSQ-ViT scheme achieves state-of-the-art compression by reducing vision transformer models 6.4-12.7 times on model size and 30.3-62 times on FLOPs with negligible accuracy degradation on ImageNet classification, COCO detection and ADE20K segmentation benchmarking tasks. Moreover, GPUSQ-ViT can boost actual deployment performance by 1.39-1.79 times and 3.22-3.43 times of latency and throughput on A100 GPU, and 1.57-1.69 times and 2.11-2.51 times improvement of latency and throughput on AGX Orin.
## Keyword: RAW
### Towards Robust Probabilistic Modeling on SO(3) via Rotation Laplace Distribution
- **Authors:** Yingda Yin, Jiangran Lyu, Yang Wang, He Wang, Baoquan Chen
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
- **Arxiv link:** https://arxiv.org/abs/2305.10465
- **Pdf link:** https://arxiv.org/pdf/2305.10465
- **Abstract**
Estimating the 3DoF rotation from a single RGB image is an important yet challenging problem. As a popular approach, probabilistic rotation modeling additionally carries prediction uncertainty information, compared to single-prediction rotation regression. For modeling probabilistic distribution over SO(3), it is natural to use Gaussian-like Bingham distribution and matrix Fisher, however they are shown to be sensitive to outlier predictions, e.g. $180^\circ$ error and thus are unlikely to converge with optimal performance. In this paper, we draw inspiration from multivariate Laplace distribution and propose a novel rotation Laplace distribution on SO(3). Our rotation Laplace distribution is robust to the disturbance of outliers and enforces much gradient to the low-error region that it can improve. In addition, we show that our method also exhibits robustness to small noises and thus tolerates imperfect annotations. With this benefit, we demonstrate its advantages in semi-supervised rotation regression, where the pseudo labels are noisy. To further capture the multi-modal rotation solution space for symmetric objects, we extend our distribution to rotation Laplace mixture model and demonstrate its effectiveness. Our extensive experiments show that our proposed distribution and the mixture model achieve state-of-the-art performance in all the rotation regression experiments over both probabilistic and non-probabilistic baselines.
### Scribble-Supervised Target Extraction Method Based on Inner Structure-Constraint for Remote Sensing Images
- **Authors:** Yitong Li, Chang Liu, Jie Ma
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
- **Arxiv link:** https://arxiv.org/abs/2305.10661
- **Pdf link:** https://arxiv.org/pdf/2305.10661
- **Abstract**
Weakly supervised learning based on scribble annotations in target extraction of remote sensing images has drawn much interest due to scribbles' flexibility in denoting winding objects and low cost of manually labeling. However, scribbles are too sparse to identify object structure and detailed information, bringing great challenges in target localization and boundary description. To alleviate these problems, in this paper, we construct two inner structure-constraints, a deformation consistency loss and a trainable active contour loss, together with a scribble-constraint to supervise the optimization of the encoder-decoder network without introducing any auxiliary module or extra operation based on prior cues. Comprehensive experiments demonstrate our method's superiority over five state-of-the-art algorithms in this field. Source code is available at https://github.com/yitongli123/ISC-TE.
### DiffUTE: Universal Text Editing Diffusion Model
- **Authors:** Chen, Haoxing, Xu, Zhuoer, Gu, Zhangxuan, Lan, Jun, Zheng, Xing, Li, Yaohui, Meng, Changhua, Zhu, Huijia, Wang, Weiqiang
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2305.10825
- **Pdf link:** https://arxiv.org/pdf/2305.10825
- **Abstract**
Diffusion model based language-guided image editing has achieved great success recently. However, existing state-of-the-art diffusion models struggle with rendering correct text and text style during generation. To tackle this problem, we propose a universal self-supervised text editing diffusion model (DiffUTE), which aims to replace or modify words in the source image with another one while maintaining its realistic appearance. Specifically, we build our model on a diffusion model and carefully modify the network structure to enable the model for drawing multilingual characters with the help of glyph and position information. Moreover, we design a self-supervised learning framework to leverage large amounts of web data to improve the representation ability of the model. Experimental results show that our method achieves an impressive performance and enables controllable editing on in-the-wild images with high fidelity. Our code will be avaliable in \url{https://github.com/chenhaoxing/DiffUTE}.
### X-IQE: eXplainable Image Quality Evaluation for Text-to-Image Generation with Visual Large Language Models
- **Authors:** Yixiong Chen
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
- **Arxiv link:** https://arxiv.org/abs/2305.10843
- **Pdf link:** https://arxiv.org/pdf/2305.10843
- **Abstract**
This paper introduces a novel explainable image quality evaluation approach called X-IQE, which leverages visual large language models (LLMs) to evaluate text-to-image generation methods by generating textual explanations. X-IQE utilizes a hierarchical Chain of Thought (CoT) to enable MiniGPT-4 to produce self-consistent, unbiased texts that are highly correlated with human evaluation. It offers several advantages, including the ability to distinguish between real and generated images, evaluate text-image alignment, and assess image aesthetics without requiring model training or fine-tuning. X-IQE is more cost-effective and efficient compared to human evaluation, while significantly enhancing the transparency and explainability of deep image quality evaluation models. We validate the effectiveness of our method as a benchmark using images generated by prevalent diffusion models. X-IQE demonstrates similar performance to state-of-the-art (SOTA) evaluation methods on COCO Caption, while overcoming the limitations of previous evaluation models on DrawBench, particularly in handling ambiguous generation prompts and text recognition in generated images. Project website: https://github.com/Schuture/Benchmarking-Awesome-Diffusion-Models
### Towards an Accurate and Secure Detector against Adversarial Perturbations
- **Authors:** Chao Wang, Shuren Qi, Zhiqiu Huang, Yushu Zhang, Xiaochun Cao
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2305.10856
- **Pdf link:** https://arxiv.org/pdf/2305.10856
- **Abstract**
The vulnerability of deep neural networks to adversarial perturbations has been widely perceived in the computer vision community. From a security perspective, it poses a critical risk for modern vision systems, e.g., the popular Deep Learning as a Service (DLaaS) frameworks. For protecting off-the-shelf deep models while not modifying them, current algorithms typically detect adversarial patterns through discriminative decomposition of natural-artificial data. However, these decompositions are biased towards frequency or spatial discriminability, thus failing to capture subtle adversarial patterns comprehensively. More seriously, they are typically invertible, meaning successful defense-aware (secondary) adversarial attack (i.e., evading the detector as well as fooling the model) is practical under the assumption that the adversary is fully aware of the detector (i.e., the Kerckhoffs's principle). Motivated by such facts, we propose an accurate and secure adversarial example detector, relying on a spatial-frequency discriminative decomposition with secret keys. It expands the above works on two aspects: 1) the introduced Krawtchouk basis provides better spatial-frequency discriminability and thereby is more suitable for capturing adversarial patterns than the common trigonometric or wavelet basis; 2) the extensive parameters for decomposition are generated by a pseudo-random function with secret keys, hence blocking the defense-aware adversarial attack. Theoretical and numerical analysis demonstrates the increased accuracy and security of our detector w.r.t. a number of state-of-the-art algorithms.
### Annotation-free Audio-Visual Segmentation
- **Authors:** Jinxiang Liu, Yu Wang, Chen Ju, Ya Zhang, Weidi Xie
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Multimedia (cs.MM)
- **Arxiv link:** https://arxiv.org/abs/2305.11019
- **Pdf link:** https://arxiv.org/pdf/2305.11019
- **Abstract**
The objective of Audio-Visual Segmentation (AVS) is to locate sounding objects within visual scenes by accurately predicting pixelwise segmentation masks. In this paper, we present the following contributions: (i), we propose a scalable and annotation-free pipeline for generating artificial data for the AVS task. We leverage existing image segmentation and audio datasets to draw links between category labels, image-mask pairs, and audio samples, which allows us to easily compose (image, audio, mask) triplets for training AVS models; (ii), we introduce a novel Audio-Aware Transformer (AuTR) architecture that features an audio-aware query-based transformer decoder. This architecture enables the model to search for sounding objects with the guidance of audio signals, resulting in more accurate segmentation; (iii), we present extensive experiments conducted on both synthetic and real datasets, which demonstrate the effectiveness of training AVS models with synthetic data generated by our proposed pipeline. Additionally, our proposed AuTR architecture exhibits superior performance and strong generalization ability on public benchmarks. The project page is https://jinxiang-liu.github.io/anno-free-AVS/.
### LLMScore: Unveiling the Power of Large Language Models in Text-to-Image Synthesis Evaluation
- **Authors:** Yujie Lu, Xianjun Yang, Xiujun Li, Xin Eric Wang, William Yang Wang
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
- **Arxiv link:** https://arxiv.org/abs/2305.11116
- **Pdf link:** https://arxiv.org/pdf/2305.11116
- **Abstract**
Existing automatic evaluation on text-to-image synthesis can only provide an image-text matching score, without considering the object-level compositionality, which results in poor correlation with human judgments. In this work, we propose LLMScore, a new framework that offers evaluation scores with multi-granularity compositionality. LLMScore leverages the large language models (LLMs) to evaluate text-to-image models. Initially, it transforms the image into image-level and object-level visual descriptions. Then an evaluation instruction is fed into the LLMs to measure the alignment between the synthesized image and the text, ultimately generating a score accompanied by a rationale. Our substantial analysis reveals the highest correlation of LLMScore with human judgments on a wide range of datasets (Attribute Binding Contrast, Concept Conjunction, MSCOCO, DrawBench, PaintSkills). Notably, our LLMScore achieves Kendall's tau correlation with human evaluations that is 58.8% and 31.2% higher than the commonly-used text-image matching metrics CLIP and BLIP, respectively.
## Keyword: raw image
There is no result
|
2.0
|
New submissions for Fri, 19 May 23 - ## Keyword: events
### ReasonNet: End-to-End Driving with Temporal and Global Reasoning
- **Authors:** Hao Shao, Letian Wang, Ruobing Chen, Steven L. Waslander, Hongsheng Li, Yu Liu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
- **Arxiv link:** https://arxiv.org/abs/2305.10507
- **Pdf link:** https://arxiv.org/pdf/2305.10507
- **Abstract**
The large-scale deployment of autonomous vehicles is yet to come, and one of the major remaining challenges lies in urban dense traffic scenarios. In such cases, it remains challenging to predict the future evolution of the scene and future behaviors of objects, and to deal with rare adverse events such as the sudden appearance of occluded objects. In this paper, we present ReasonNet, a novel end-to-end driving framework that extensively exploits both temporal and global information of the driving scene. By reasoning on the temporal behavior of objects, our method can effectively process the interactions and relationships among features in different frames. Reasoning about the global information of the scene can also improve overall perception performance and benefit the detection of adverse events, especially the anticipation of potential danger from occluded objects. For comprehensive evaluation on occlusion events, we also release publicly a driving simulation benchmark DriveOcclusionSim consisting of diverse occlusion events. We conduct extensive experiments on multiple CARLA benchmarks, where our model outperforms all prior methods, ranking first on the sensor track of the public CARLA Leaderboard.
## Keyword: event camera
There is no result
## Keyword: events camera
There is no result
## Keyword: white balance
There is no result
## Keyword: color contrast
There is no result
## Keyword: AWB
### X-IQE: eXplainable Image Quality Evaluation for Text-to-Image Generation with Visual Large Language Models
- **Authors:** Yixiong Chen
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
- **Arxiv link:** https://arxiv.org/abs/2305.10843
- **Pdf link:** https://arxiv.org/pdf/2305.10843
- **Abstract**
This paper introduces a novel explainable image quality evaluation approach called X-IQE, which leverages visual large language models (LLMs) to evaluate text-to-image generation methods by generating textual explanations. X-IQE utilizes a hierarchical Chain of Thought (CoT) to enable MiniGPT-4 to produce self-consistent, unbiased texts that are highly correlated with human evaluation. It offers several advantages, including the ability to distinguish between real and generated images, evaluate text-image alignment, and assess image aesthetics without requiring model training or fine-tuning. X-IQE is more cost-effective and efficient compared to human evaluation, while significantly enhancing the transparency and explainability of deep image quality evaluation models. We validate the effectiveness of our method as a benchmark using images generated by prevalent diffusion models. X-IQE demonstrates similar performance to state-of-the-art (SOTA) evaluation methods on COCO Caption, while overcoming the limitations of previous evaluation models on DrawBench, particularly in handling ambiguous generation prompts and text recognition in generated images. Project website: https://github.com/Schuture/Benchmarking-Awesome-Diffusion-Models
### LLMScore: Unveiling the Power of Large Language Models in Text-to-Image Synthesis Evaluation
- **Authors:** Yujie Lu, Xianjun Yang, Xiujun Li, Xin Eric Wang, William Yang Wang
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
- **Arxiv link:** https://arxiv.org/abs/2305.11116
- **Pdf link:** https://arxiv.org/pdf/2305.11116
- **Abstract**
Existing automatic evaluation on text-to-image synthesis can only provide an image-text matching score, without considering the object-level compositionality, which results in poor correlation with human judgments. In this work, we propose LLMScore, a new framework that offers evaluation scores with multi-granularity compositionality. LLMScore leverages the large language models (LLMs) to evaluate text-to-image models. Initially, it transforms the image into image-level and object-level visual descriptions. Then an evaluation instruction is fed into the LLMs to measure the alignment between the synthesized image and the text, ultimately generating a score accompanied by a rationale. Our substantial analysis reveals the highest correlation of LLMScore with human judgments on a wide range of datasets (Attribute Binding Contrast, Concept Conjunction, MSCOCO, DrawBench, PaintSkills). Notably, our LLMScore achieves Kendall's tau correlation with human evaluations that is 58.8% and 31.2% higher than the commonly-used text-image matching metrics CLIP and BLIP, respectively.
## Keyword: ISP
### Multi-spectral Class Center Network for Face Manipulation Detection and Localization
- **Authors:** Changtao Miao, Qi Chu, Zhentao Tan, Zhenchao Jin, Wanyi Zhuang, Yue Wu, Bin Liu, Honggang Hu, Nenghai Yu
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2305.10794
- **Pdf link:** https://arxiv.org/pdf/2305.10794
- **Abstract**
As Deepfake contents continue to proliferate on the internet, advancing face manipulation forensics has become a pressing issue. To combat this emerging threat, previous methods mainly focus on studying how to distinguish authentic and manipulated face images. Despite impressive, image-level classification lacks explainability and is limited to some specific application scenarios. Existing forgery localization methods suffer from imprecise and inconsistent pixel-level annotations. To alleviate these problems, this paper first re-constructs the FaceForensics++ dataset by introducing pixel-level annotations, then builds an extensive benchmark for localizing tampered regions. Next, a novel Multi-Spectral Class Center Network (MSCCNet) is proposed for face manipulation detection and localization. Specifically, inspired by the power of frequency-related forgery traces, we design Multi-Spectral Class Center (MSCC) module to learn more generalizable and semantic-agnostic features. Based on the features of different frequency bands, the MSCC module collects multispectral class centers and computes pixel-to-class relations. Applying multi-spectral class-level representations suppresses the semantic information of the visual concepts, which is insensitive to manipulations. Furthermore, we propose a Multi-level Features Aggregation (MFA) module to employ more low-level forgery artifacts and structure textures. Experimental results quantitatively and qualitatively indicate the effectiveness and superiority of the proposed MSCCNet on comprehensive localization benchmarks. We expect this work to inspire more studies on pixel-level face manipulation localization. The annotations and code will be available.
### Unsupervised Pansharpening via Low-rank Diffusion Model
- **Authors:** Xiangyu Rui, Xiangyong Cao, Zeyu Zhu, Zongsheng Yue, Deyu Meng
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
- **Arxiv link:** https://arxiv.org/abs/2305.10925
- **Pdf link:** https://arxiv.org/pdf/2305.10925
- **Abstract**
Pansharpening is a process of merging a highresolution panchromatic (PAN) image and a low-resolution multispectral (LRMS) image to create a single high-resolution multispectral (HRMS) image. Most of the existing deep learningbased pansharpening methods have poor generalization ability and the traditional model-based pansharpening methods need careful manual exploration for the image structure prior. To alleviate these issues, this paper proposes an unsupervised pansharpening method by combining the diffusion model with the low-rank matrix factorization technique. Specifically, we assume that the HRMS image is decomposed into the product of two low-rank tensors, i.e., the base tensor and the coefficient matrix. The base tensor lies on the image field and has low spectral dimension, we can thus conveniently utilize a pre-trained remote sensing diffusion model to capture its image structures. Additionally, we derive a simple yet quite effective way to preestimate the coefficient matrix from the observed LRMS image, which preserves the spectral information of the HRMS. Extensive experimental results on some benchmark datasets demonstrate that our proposed method performs better than traditional model-based approaches and has better generalization ability than deep learning-based techniques. The code is released in https://github.com/xyrui/PLRDiff.
### CDIDN: A Registration Model with High Deformation Impedance Capability for Long-Term Tracking of Pulmonary Lesion Dynamics
- **Authors:** Xinyu Zhao, Sa Huang, Wei Pang, You Zhou
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2305.11024
- **Pdf link:** https://arxiv.org/pdf/2305.11024
- **Abstract**
We study the problem of registration for medical CT images from a novel perspective -- the sensitivity to degree of deformations in CT images. Although some learning-based methods have shown success in terms of average accuracy, their ability to handle regions with local large deformation (LLD) may significantly decrease compared to dealing with regions with minor deformation. This motivates our research into this issue. Two main causes of LLDs are organ motion and changes in tissue structure, with the latter often being a long-term process. In this paper, we propose a novel registration model called Cascade-Dilation Inter-Layer Differential Network (CDIDN), which exhibits both high deformation impedance capability (DIC) and accuracy. CDIDN improves its resilience to LLDs in CT images by enhancing LLDs in the displacement field (DF). It uses a feature-based progressive decomposition of LLDs, blending feature flows of different levels into a main flow in a top-down manner. It leverages Inter-Layer Differential Module (IDM) at each level to locally refine the main flow and globally smooth the feature flow, and also integrates feature velocity fields that can effectively handle feature deformations of various degrees. We assess CDIDN using lungs as representative organs with large deformation. Our findings show that IDM significantly enhances LLDs of the DF, by which improves the DIC and accuracy of the model. Compared with other outstanding learning-based methods, CDIDN exhibits the best DIC and excellent accuracy. Based on vessel enhancement and enhanced LLDs of the DF, we propose a novel method to accurately track the appearance, disappearance, enlargement, and shrinkage of pulmonary lesions, which effectively addresses detection of early lesions and peripheral lung lesions, issues of false enlargement, false shrinkage, and mutilation of lesions.
## Keyword: image signal processing
There is no result
## Keyword: image signal process
There is no result
## Keyword: compression
### Boost Vision Transformer with GPU-Friendly Sparsity and Quantization
- **Authors:** Chong Yu, Tao Chen, Zhongxue Gan, Jiayuan Fan
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Performance (cs.PF)
- **Arxiv link:** https://arxiv.org/abs/2305.10727
- **Pdf link:** https://arxiv.org/pdf/2305.10727
- **Abstract**
The transformer extends its success from the language to the vision domain. Because of the stacked self-attention and cross-attention blocks, the acceleration deployment of vision transformer on GPU hardware is challenging and also rarely studied. This paper thoroughly designs a compression scheme to maximally utilize the GPU-friendly 2:4 fine-grained structured sparsity and quantization. Specially, an original large model with dense weight parameters is first pruned into a sparse one by 2:4 structured pruning, which considers the GPU's acceleration of 2:4 structured sparse pattern with FP16 data type, then the floating-point sparse model is further quantized into a fixed-point one by sparse-distillation-aware quantization aware training, which considers GPU can provide an extra speedup of 2:4 sparse calculation with integer tensors. A mixed-strategy knowledge distillation is used during the pruning and quantization process. The proposed compression scheme is flexible to support supervised and unsupervised learning styles. Experiment results show GPUSQ-ViT scheme achieves state-of-the-art compression by reducing vision transformer models 6.4-12.7 times on model size and 30.3-62 times on FLOPs with negligible accuracy degradation on ImageNet classification, COCO detection and ADE20K segmentation benchmarking tasks. Moreover, GPUSQ-ViT can boost actual deployment performance by 1.39-1.79 times and 3.22-3.43 times of latency and throughput on A100 GPU, and 1.57-1.69 times and 2.11-2.51 times improvement of latency and throughput on AGX Orin.
## Keyword: RAW
### Towards Robust Probabilistic Modeling on SO(3) via Rotation Laplace Distribution
- **Authors:** Yingda Yin, Jiangran Lyu, Yang Wang, He Wang, Baoquan Chen
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
- **Arxiv link:** https://arxiv.org/abs/2305.10465
- **Pdf link:** https://arxiv.org/pdf/2305.10465
- **Abstract**
Estimating the 3DoF rotation from a single RGB image is an important yet challenging problem. As a popular approach, probabilistic rotation modeling additionally carries prediction uncertainty information, compared to single-prediction rotation regression. For modeling probabilistic distribution over SO(3), it is natural to use Gaussian-like Bingham distribution and matrix Fisher, however they are shown to be sensitive to outlier predictions, e.g. $180^\circ$ error and thus are unlikely to converge with optimal performance. In this paper, we draw inspiration from multivariate Laplace distribution and propose a novel rotation Laplace distribution on SO(3). Our rotation Laplace distribution is robust to the disturbance of outliers and enforces much gradient to the low-error region that it can improve. In addition, we show that our method also exhibits robustness to small noises and thus tolerates imperfect annotations. With this benefit, we demonstrate its advantages in semi-supervised rotation regression, where the pseudo labels are noisy. To further capture the multi-modal rotation solution space for symmetric objects, we extend our distribution to rotation Laplace mixture model and demonstrate its effectiveness. Our extensive experiments show that our proposed distribution and the mixture model achieve state-of-the-art performance in all the rotation regression experiments over both probabilistic and non-probabilistic baselines.
### Scribble-Supervised Target Extraction Method Based on Inner Structure-Constraint for Remote Sensing Images
- **Authors:** Yitong Li, Chang Liu, Jie Ma
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
- **Arxiv link:** https://arxiv.org/abs/2305.10661
- **Pdf link:** https://arxiv.org/pdf/2305.10661
- **Abstract**
Weakly supervised learning based on scribble annotations in target extraction of remote sensing images has drawn much interest due to scribbles' flexibility in denoting winding objects and low cost of manually labeling. However, scribbles are too sparse to identify object structure and detailed information, bringing great challenges in target localization and boundary description. To alleviate these problems, in this paper, we construct two inner structure-constraints, a deformation consistency loss and a trainable active contour loss, together with a scribble-constraint to supervise the optimization of the encoder-decoder network without introducing any auxiliary module or extra operation based on prior cues. Comprehensive experiments demonstrate our method's superiority over five state-of-the-art algorithms in this field. Source code is available at https://github.com/yitongli123/ISC-TE.
### DiffUTE: Universal Text Editing Diffusion Model
- **Authors:** Chen, Haoxing, Xu, Zhuoer, Gu, Zhangxuan, Lan, Jun, Zheng, Xing, Li, Yaohui, Meng, Changhua, Zhu, Huijia, Wang, Weiqiang
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2305.10825
- **Pdf link:** https://arxiv.org/pdf/2305.10825
- **Abstract**
Diffusion model based language-guided image editing has achieved great success recently. However, existing state-of-the-art diffusion models struggle with rendering correct text and text style during generation. To tackle this problem, we propose a universal self-supervised text editing diffusion model (DiffUTE), which aims to replace or modify words in the source image with another one while maintaining its realistic appearance. Specifically, we build our model on a diffusion model and carefully modify the network structure to enable the model for drawing multilingual characters with the help of glyph and position information. Moreover, we design a self-supervised learning framework to leverage large amounts of web data to improve the representation ability of the model. Experimental results show that our method achieves an impressive performance and enables controllable editing on in-the-wild images with high fidelity. Our code will be avaliable in \url{https://github.com/chenhaoxing/DiffUTE}.
### X-IQE: eXplainable Image Quality Evaluation for Text-to-Image Generation with Visual Large Language Models
- **Authors:** Yixiong Chen
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
- **Arxiv link:** https://arxiv.org/abs/2305.10843
- **Pdf link:** https://arxiv.org/pdf/2305.10843
- **Abstract**
This paper introduces a novel explainable image quality evaluation approach called X-IQE, which leverages visual large language models (LLMs) to evaluate text-to-image generation methods by generating textual explanations. X-IQE utilizes a hierarchical Chain of Thought (CoT) to enable MiniGPT-4 to produce self-consistent, unbiased texts that are highly correlated with human evaluation. It offers several advantages, including the ability to distinguish between real and generated images, evaluate text-image alignment, and assess image aesthetics without requiring model training or fine-tuning. X-IQE is more cost-effective and efficient compared to human evaluation, while significantly enhancing the transparency and explainability of deep image quality evaluation models. We validate the effectiveness of our method as a benchmark using images generated by prevalent diffusion models. X-IQE demonstrates similar performance to state-of-the-art (SOTA) evaluation methods on COCO Caption, while overcoming the limitations of previous evaluation models on DrawBench, particularly in handling ambiguous generation prompts and text recognition in generated images. Project website: https://github.com/Schuture/Benchmarking-Awesome-Diffusion-Models
### Towards an Accurate and Secure Detector against Adversarial Perturbations
- **Authors:** Chao Wang, Shuren Qi, Zhiqiu Huang, Yushu Zhang, Xiaochun Cao
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV)
- **Arxiv link:** https://arxiv.org/abs/2305.10856
- **Pdf link:** https://arxiv.org/pdf/2305.10856
- **Abstract**
The vulnerability of deep neural networks to adversarial perturbations has been widely perceived in the computer vision community. From a security perspective, it poses a critical risk for modern vision systems, e.g., the popular Deep Learning as a Service (DLaaS) frameworks. For protecting off-the-shelf deep models while not modifying them, current algorithms typically detect adversarial patterns through discriminative decomposition of natural-artificial data. However, these decompositions are biased towards frequency or spatial discriminability, thus failing to capture subtle adversarial patterns comprehensively. More seriously, they are typically invertible, meaning successful defense-aware (secondary) adversarial attack (i.e., evading the detector as well as fooling the model) is practical under the assumption that the adversary is fully aware of the detector (i.e., the Kerckhoffs's principle). Motivated by such facts, we propose an accurate and secure adversarial example detector, relying on a spatial-frequency discriminative decomposition with secret keys. It expands the above works on two aspects: 1) the introduced Krawtchouk basis provides better spatial-frequency discriminability and thereby is more suitable for capturing adversarial patterns than the common trigonometric or wavelet basis; 2) the extensive parameters for decomposition are generated by a pseudo-random function with secret keys, hence blocking the defense-aware adversarial attack. Theoretical and numerical analysis demonstrates the increased accuracy and security of our detector w.r.t. a number of state-of-the-art algorithms.
### Annotation-free Audio-Visual Segmentation
- **Authors:** Jinxiang Liu, Yu Wang, Chen Ju, Ya Zhang, Weidi Xie
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Multimedia (cs.MM)
- **Arxiv link:** https://arxiv.org/abs/2305.11019
- **Pdf link:** https://arxiv.org/pdf/2305.11019
- **Abstract**
The objective of Audio-Visual Segmentation (AVS) is to locate sounding objects within visual scenes by accurately predicting pixelwise segmentation masks. In this paper, we present the following contributions: (i), we propose a scalable and annotation-free pipeline for generating artificial data for the AVS task. We leverage existing image segmentation and audio datasets to draw links between category labels, image-mask pairs, and audio samples, which allows us to easily compose (image, audio, mask) triplets for training AVS models; (ii), we introduce a novel Audio-Aware Transformer (AuTR) architecture that features an audio-aware query-based transformer decoder. This architecture enables the model to search for sounding objects with the guidance of audio signals, resulting in more accurate segmentation; (iii), we present extensive experiments conducted on both synthetic and real datasets, which demonstrate the effectiveness of training AVS models with synthetic data generated by our proposed pipeline. Additionally, our proposed AuTR architecture exhibits superior performance and strong generalization ability on public benchmarks. The project page is https://jinxiang-liu.github.io/anno-free-AVS/.
### LLMScore: Unveiling the Power of Large Language Models in Text-to-Image Synthesis Evaluation
- **Authors:** Yujie Lu, Xianjun Yang, Xiujun Li, Xin Eric Wang, William Yang Wang
- **Subjects:** Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
- **Arxiv link:** https://arxiv.org/abs/2305.11116
- **Pdf link:** https://arxiv.org/pdf/2305.11116
- **Abstract**
Existing automatic evaluation on text-to-image synthesis can only provide an image-text matching score, without considering the object-level compositionality, which results in poor correlation with human judgments. In this work, we propose LLMScore, a new framework that offers evaluation scores with multi-granularity compositionality. LLMScore leverages the large language models (LLMs) to evaluate text-to-image models. Initially, it transforms the image into image-level and object-level visual descriptions. Then an evaluation instruction is fed into the LLMs to measure the alignment between the synthesized image and the text, ultimately generating a score accompanied by a rationale. Our substantial analysis reveals the highest correlation of LLMScore with human judgments on a wide range of datasets (Attribute Binding Contrast, Concept Conjunction, MSCOCO, DrawBench, PaintSkills). Notably, our LLMScore achieves Kendall's tau correlation with human evaluations that is 58.8% and 31.2% higher than the commonly-used text-image matching metrics CLIP and BLIP, respectively.
## Keyword: raw image
There is no result
|
process
|
new submissions for fri may keyword events reasonnet end to end driving with temporal and global reasoning authors hao shao letian wang ruobing chen steven l waslander hongsheng li yu liu subjects computer vision and pattern recognition cs cv artificial intelligence cs ai arxiv link pdf link abstract the large scale deployment of autonomous vehicles is yet to come and one of the major remaining challenges lies in urban dense traffic scenarios in such cases it remains challenging to predict the future evolution of the scene and future behaviors of objects and to deal with rare adverse events such as the sudden appearance of occluded objects in this paper we present reasonnet a novel end to end driving framework that extensively exploits both temporal and global information of the driving scene by reasoning on the temporal behavior of objects our method can effectively process the interactions and relationships among features in different frames reasoning about the global information of the scene can also improve overall perception performance and benefit the detection of adverse events especially the anticipation of potential danger from occluded objects for comprehensive evaluation on occlusion events we also release publicly a driving simulation benchmark driveocclusionsim consisting of diverse occlusion events we conduct extensive experiments on multiple carla benchmarks where our model outperforms all prior methods ranking first on the sensor track of the public carla leaderboard keyword event camera there is no result keyword events camera there is no result keyword white balance there is no result keyword color contrast there is no result keyword awb x iqe explainable image quality evaluation for text to image generation with visual large language models authors yixiong chen subjects computer vision and pattern recognition cs cv artificial intelligence cs ai arxiv link pdf link abstract this paper introduces a novel explainable image quality evaluation approach called x iqe which leverages visual large language models llms to evaluate text to image generation methods by generating textual explanations x iqe utilizes a hierarchical chain of thought cot to enable minigpt to produce self consistent unbiased texts that are highly correlated with human evaluation it offers several advantages including the ability to distinguish between real and generated images evaluate text image alignment and assess image aesthetics without requiring model training or fine tuning x iqe is more cost effective and efficient compared to human evaluation while significantly enhancing the transparency and explainability of deep image quality evaluation models we validate the effectiveness of our method as a benchmark using images generated by prevalent diffusion models x iqe demonstrates similar performance to state of the art sota evaluation methods on coco caption while overcoming the limitations of previous evaluation models on drawbench particularly in handling ambiguous generation prompts and text recognition in generated images project website llmscore unveiling the power of large language models in text to image synthesis evaluation authors yujie lu xianjun yang xiujun li xin eric wang william yang wang subjects computer vision and pattern recognition cs cv computation and language cs cl arxiv link pdf link abstract existing automatic evaluation on text to image synthesis can only provide an image text matching score without considering the object level compositionality which results in poor correlation with human judgments in this work we propose llmscore a new framework that offers evaluation scores with multi granularity compositionality llmscore leverages the large language models llms to evaluate text to image models initially it transforms the image into image level and object level visual descriptions then an evaluation instruction is fed into the llms to measure the alignment between the synthesized image and the text ultimately generating a score accompanied by a rationale our substantial analysis reveals the highest correlation of llmscore with human judgments on a wide range of datasets attribute binding contrast concept conjunction mscoco drawbench paintskills notably our llmscore achieves kendall s tau correlation with human evaluations that is and higher than the commonly used text image matching metrics clip and blip respectively keyword isp multi spectral class center network for face manipulation detection and localization authors changtao miao qi chu zhentao tan zhenchao jin wanyi zhuang yue wu bin liu honggang hu nenghai yu subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract as deepfake contents continue to proliferate on the internet advancing face manipulation forensics has become a pressing issue to combat this emerging threat previous methods mainly focus on studying how to distinguish authentic and manipulated face images despite impressive image level classification lacks explainability and is limited to some specific application scenarios existing forgery localization methods suffer from imprecise and inconsistent pixel level annotations to alleviate these problems this paper first re constructs the faceforensics dataset by introducing pixel level annotations then builds an extensive benchmark for localizing tampered regions next a novel multi spectral class center network msccnet is proposed for face manipulation detection and localization specifically inspired by the power of frequency related forgery traces we design multi spectral class center mscc module to learn more generalizable and semantic agnostic features based on the features of different frequency bands the mscc module collects multispectral class centers and computes pixel to class relations applying multi spectral class level representations suppresses the semantic information of the visual concepts which is insensitive to manipulations furthermore we propose a multi level features aggregation mfa module to employ more low level forgery artifacts and structure textures experimental results quantitatively and qualitatively indicate the effectiveness and superiority of the proposed msccnet on comprehensive localization benchmarks we expect this work to inspire more studies on pixel level face manipulation localization the annotations and code will be available unsupervised pansharpening via low rank diffusion model authors xiangyu rui xiangyong cao zeyu zhu zongsheng yue deyu meng subjects computer vision and pattern recognition cs cv image and video processing eess iv arxiv link pdf link abstract pansharpening is a process of merging a highresolution panchromatic pan image and a low resolution multispectral lrms image to create a single high resolution multispectral hrms image most of the existing deep learningbased pansharpening methods have poor generalization ability and the traditional model based pansharpening methods need careful manual exploration for the image structure prior to alleviate these issues this paper proposes an unsupervised pansharpening method by combining the diffusion model with the low rank matrix factorization technique specifically we assume that the hrms image is decomposed into the product of two low rank tensors i e the base tensor and the coefficient matrix the base tensor lies on the image field and has low spectral dimension we can thus conveniently utilize a pre trained remote sensing diffusion model to capture its image structures additionally we derive a simple yet quite effective way to preestimate the coefficient matrix from the observed lrms image which preserves the spectral information of the hrms extensive experimental results on some benchmark datasets demonstrate that our proposed method performs better than traditional model based approaches and has better generalization ability than deep learning based techniques the code is released in cdidn a registration model with high deformation impedance capability for long term tracking of pulmonary lesion dynamics authors xinyu zhao sa huang wei pang you zhou subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract we study the problem of registration for medical ct images from a novel perspective the sensitivity to degree of deformations in ct images although some learning based methods have shown success in terms of average accuracy their ability to handle regions with local large deformation lld may significantly decrease compared to dealing with regions with minor deformation this motivates our research into this issue two main causes of llds are organ motion and changes in tissue structure with the latter often being a long term process in this paper we propose a novel registration model called cascade dilation inter layer differential network cdidn which exhibits both high deformation impedance capability dic and accuracy cdidn improves its resilience to llds in ct images by enhancing llds in the displacement field df it uses a feature based progressive decomposition of llds blending feature flows of different levels into a main flow in a top down manner it leverages inter layer differential module idm at each level to locally refine the main flow and globally smooth the feature flow and also integrates feature velocity fields that can effectively handle feature deformations of various degrees we assess cdidn using lungs as representative organs with large deformation our findings show that idm significantly enhances llds of the df by which improves the dic and accuracy of the model compared with other outstanding learning based methods cdidn exhibits the best dic and excellent accuracy based on vessel enhancement and enhanced llds of the df we propose a novel method to accurately track the appearance disappearance enlargement and shrinkage of pulmonary lesions which effectively addresses detection of early lesions and peripheral lung lesions issues of false enlargement false shrinkage and mutilation of lesions keyword image signal processing there is no result keyword image signal process there is no result keyword compression boost vision transformer with gpu friendly sparsity and quantization authors chong yu tao chen zhongxue gan jiayuan fan subjects computer vision and pattern recognition cs cv machine learning cs lg performance cs pf arxiv link pdf link abstract the transformer extends its success from the language to the vision domain because of the stacked self attention and cross attention blocks the acceleration deployment of vision transformer on gpu hardware is challenging and also rarely studied this paper thoroughly designs a compression scheme to maximally utilize the gpu friendly fine grained structured sparsity and quantization specially an original large model with dense weight parameters is first pruned into a sparse one by structured pruning which considers the gpu s acceleration of structured sparse pattern with data type then the floating point sparse model is further quantized into a fixed point one by sparse distillation aware quantization aware training which considers gpu can provide an extra speedup of sparse calculation with integer tensors a mixed strategy knowledge distillation is used during the pruning and quantization process the proposed compression scheme is flexible to support supervised and unsupervised learning styles experiment results show gpusq vit scheme achieves state of the art compression by reducing vision transformer models times on model size and times on flops with negligible accuracy degradation on imagenet classification coco detection and segmentation benchmarking tasks moreover gpusq vit can boost actual deployment performance by times and times of latency and throughput on gpu and times and times improvement of latency and throughput on agx orin keyword raw towards robust probabilistic modeling on so via rotation laplace distribution authors yingda yin jiangran lyu yang wang he wang baoquan chen subjects computer vision and pattern recognition cs cv artificial intelligence cs ai arxiv link pdf link abstract estimating the rotation from a single rgb image is an important yet challenging problem as a popular approach probabilistic rotation modeling additionally carries prediction uncertainty information compared to single prediction rotation regression for modeling probabilistic distribution over so it is natural to use gaussian like bingham distribution and matrix fisher however they are shown to be sensitive to outlier predictions e g circ error and thus are unlikely to converge with optimal performance in this paper we draw inspiration from multivariate laplace distribution and propose a novel rotation laplace distribution on so our rotation laplace distribution is robust to the disturbance of outliers and enforces much gradient to the low error region that it can improve in addition we show that our method also exhibits robustness to small noises and thus tolerates imperfect annotations with this benefit we demonstrate its advantages in semi supervised rotation regression where the pseudo labels are noisy to further capture the multi modal rotation solution space for symmetric objects we extend our distribution to rotation laplace mixture model and demonstrate its effectiveness our extensive experiments show that our proposed distribution and the mixture model achieve state of the art performance in all the rotation regression experiments over both probabilistic and non probabilistic baselines scribble supervised target extraction method based on inner structure constraint for remote sensing images authors yitong li chang liu jie ma subjects computer vision and pattern recognition cs cv artificial intelligence cs ai arxiv link pdf link abstract weakly supervised learning based on scribble annotations in target extraction of remote sensing images has drawn much interest due to scribbles flexibility in denoting winding objects and low cost of manually labeling however scribbles are too sparse to identify object structure and detailed information bringing great challenges in target localization and boundary description to alleviate these problems in this paper we construct two inner structure constraints a deformation consistency loss and a trainable active contour loss together with a scribble constraint to supervise the optimization of the encoder decoder network without introducing any auxiliary module or extra operation based on prior cues comprehensive experiments demonstrate our method s superiority over five state of the art algorithms in this field source code is available at diffute universal text editing diffusion model authors chen haoxing xu zhuoer gu zhangxuan lan jun zheng xing li yaohui meng changhua zhu huijia wang weiqiang subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract diffusion model based language guided image editing has achieved great success recently however existing state of the art diffusion models struggle with rendering correct text and text style during generation to tackle this problem we propose a universal self supervised text editing diffusion model diffute which aims to replace or modify words in the source image with another one while maintaining its realistic appearance specifically we build our model on a diffusion model and carefully modify the network structure to enable the model for drawing multilingual characters with the help of glyph and position information moreover we design a self supervised learning framework to leverage large amounts of web data to improve the representation ability of the model experimental results show that our method achieves an impressive performance and enables controllable editing on in the wild images with high fidelity our code will be avaliable in url x iqe explainable image quality evaluation for text to image generation with visual large language models authors yixiong chen subjects computer vision and pattern recognition cs cv artificial intelligence cs ai arxiv link pdf link abstract this paper introduces a novel explainable image quality evaluation approach called x iqe which leverages visual large language models llms to evaluate text to image generation methods by generating textual explanations x iqe utilizes a hierarchical chain of thought cot to enable minigpt to produce self consistent unbiased texts that are highly correlated with human evaluation it offers several advantages including the ability to distinguish between real and generated images evaluate text image alignment and assess image aesthetics without requiring model training or fine tuning x iqe is more cost effective and efficient compared to human evaluation while significantly enhancing the transparency and explainability of deep image quality evaluation models we validate the effectiveness of our method as a benchmark using images generated by prevalent diffusion models x iqe demonstrates similar performance to state of the art sota evaluation methods on coco caption while overcoming the limitations of previous evaluation models on drawbench particularly in handling ambiguous generation prompts and text recognition in generated images project website towards an accurate and secure detector against adversarial perturbations authors chao wang shuren qi zhiqiu huang yushu zhang xiaochun cao subjects computer vision and pattern recognition cs cv arxiv link pdf link abstract the vulnerability of deep neural networks to adversarial perturbations has been widely perceived in the computer vision community from a security perspective it poses a critical risk for modern vision systems e g the popular deep learning as a service dlaas frameworks for protecting off the shelf deep models while not modifying them current algorithms typically detect adversarial patterns through discriminative decomposition of natural artificial data however these decompositions are biased towards frequency or spatial discriminability thus failing to capture subtle adversarial patterns comprehensively more seriously they are typically invertible meaning successful defense aware secondary adversarial attack i e evading the detector as well as fooling the model is practical under the assumption that the adversary is fully aware of the detector i e the kerckhoffs s principle motivated by such facts we propose an accurate and secure adversarial example detector relying on a spatial frequency discriminative decomposition with secret keys it expands the above works on two aspects the introduced krawtchouk basis provides better spatial frequency discriminability and thereby is more suitable for capturing adversarial patterns than the common trigonometric or wavelet basis the extensive parameters for decomposition are generated by a pseudo random function with secret keys hence blocking the defense aware adversarial attack theoretical and numerical analysis demonstrates the increased accuracy and security of our detector w r t a number of state of the art algorithms annotation free audio visual segmentation authors jinxiang liu yu wang chen ju ya zhang weidi xie subjects computer vision and pattern recognition cs cv artificial intelligence cs ai multimedia cs mm arxiv link pdf link abstract the objective of audio visual segmentation avs is to locate sounding objects within visual scenes by accurately predicting pixelwise segmentation masks in this paper we present the following contributions i we propose a scalable and annotation free pipeline for generating artificial data for the avs task we leverage existing image segmentation and audio datasets to draw links between category labels image mask pairs and audio samples which allows us to easily compose image audio mask triplets for training avs models ii we introduce a novel audio aware transformer autr architecture that features an audio aware query based transformer decoder this architecture enables the model to search for sounding objects with the guidance of audio signals resulting in more accurate segmentation iii we present extensive experiments conducted on both synthetic and real datasets which demonstrate the effectiveness of training avs models with synthetic data generated by our proposed pipeline additionally our proposed autr architecture exhibits superior performance and strong generalization ability on public benchmarks the project page is llmscore unveiling the power of large language models in text to image synthesis evaluation authors yujie lu xianjun yang xiujun li xin eric wang william yang wang subjects computer vision and pattern recognition cs cv computation and language cs cl arxiv link pdf link abstract existing automatic evaluation on text to image synthesis can only provide an image text matching score without considering the object level compositionality which results in poor correlation with human judgments in this work we propose llmscore a new framework that offers evaluation scores with multi granularity compositionality llmscore leverages the large language models llms to evaluate text to image models initially it transforms the image into image level and object level visual descriptions then an evaluation instruction is fed into the llms to measure the alignment between the synthesized image and the text ultimately generating a score accompanied by a rationale our substantial analysis reveals the highest correlation of llmscore with human judgments on a wide range of datasets attribute binding contrast concept conjunction mscoco drawbench paintskills notably our llmscore achieves kendall s tau correlation with human evaluations that is and higher than the commonly used text image matching metrics clip and blip respectively keyword raw image there is no result
| 1
|
137,943
| 11,170,344,107
|
IssuesEvent
|
2019-12-28 12:49:55
|
ayumi-cloud/oc-security-module
|
https://api.github.com/repos/ayumi-cloud/oc-security-module
|
closed
|
Block probe scanning of README.txt and other .txt files
|
Add to Blacklist FINSIHED Firewall Priority: Medium Testing - Passed enhancement
|
### Enhancement idea
- [x] Block probe scanning of README.txt and other txt files.
|
1.0
|
Block probe scanning of README.txt and other .txt files - ### Enhancement idea
- [x] Block probe scanning of README.txt and other txt files.
|
non_process
|
block probe scanning of readme txt and other txt files enhancement idea block probe scanning of readme txt and other txt files
| 0
|
9,570
| 12,521,073,552
|
IssuesEvent
|
2020-06-03 16:54:00
|
bridgetownrb/bridgetown
|
https://api.github.com/repos/bridgetownrb/bridgetown
|
opened
|
Move Liquid filters into a separate gem
|
process
|
We have a monorepo with multiple gems now, but something we haven't done too much of yet is identify pieces of the core gem we can extract into a separate gem.
Filters seem to be a great place to start (and any utility methods they rely on). A few filters are very much tied to internal Bridgetown data structures, but many of them are pretty generic and can be used in any context. With a separate gem, other projects could simply require `bridgetown-filters` and use them without having to require any other gem in the project. For instance, Rails apps using view_component_liquid could easily make use of all these filters.
This would also be a good opportunity to identify new filters which might be useful to add. Jekyll 4.1 just added new `find-*` filters which seem quite helpful. (see https://github.com/jekyll/jekyll/pull/8171) I'd love to see a bunch more related to ActiveSupport as well. AS is a treasure-trove of cool enhancements to core Ruby data types and the more we can bring that goodness to Liquid templates the better IMHO.
|
1.0
|
Move Liquid filters into a separate gem - We have a monorepo with multiple gems now, but something we haven't done too much of yet is identify pieces of the core gem we can extract into a separate gem.
Filters seem to be a great place to start (and any utility methods they rely on). A few filters are very much tied to internal Bridgetown data structures, but many of them are pretty generic and can be used in any context. With a separate gem, other projects could simply require `bridgetown-filters` and use them without having to require any other gem in the project. For instance, Rails apps using view_component_liquid could easily make use of all these filters.
This would also be a good opportunity to identify new filters which might be useful to add. Jekyll 4.1 just added new `find-*` filters which seem quite helpful. (see https://github.com/jekyll/jekyll/pull/8171) I'd love to see a bunch more related to ActiveSupport as well. AS is a treasure-trove of cool enhancements to core Ruby data types and the more we can bring that goodness to Liquid templates the better IMHO.
|
process
|
move liquid filters into a separate gem we have a monorepo with multiple gems now but something we haven t done too much of yet is identify pieces of the core gem we can extract into a separate gem filters seem to be a great place to start and any utility methods they rely on a few filters are very much tied to internal bridgetown data structures but many of them are pretty generic and can be used in any context with a separate gem other projects could simply require bridgetown filters and use them without having to require any other gem in the project for instance rails apps using view component liquid could easily make use of all these filters this would also be a good opportunity to identify new filters which might be useful to add jekyll just added new find filters which seem quite helpful see i d love to see a bunch more related to activesupport as well as is a treasure trove of cool enhancements to core ruby data types and the more we can bring that goodness to liquid templates the better imho
| 1
|
2,510
| 5,284,268,614
|
IssuesEvent
|
2017-02-07 23:43:37
|
frc4571/FRC2017Robot
|
https://api.github.com/repos/frc4571/FRC2017Robot
|
closed
|
Take pictures of boiler + gear peg with retro reflective tape for CV
|
vision-processing
|
Create catalog of images to use for CV
|
1.0
|
Take pictures of boiler + gear peg with retro reflective tape for CV - Create catalog of images to use for CV
|
process
|
take pictures of boiler gear peg with retro reflective tape for cv create catalog of images to use for cv
| 1
|
199,670
| 6,992,936,771
|
IssuesEvent
|
2017-12-15 09:21:35
|
DOAJ/doaj
|
https://api.github.com/repos/DOAJ/doaj
|
closed
|
Another broken icon on admin interface
|
low priority tnm
|
Probably broken by the FontAwesome upgrade we had to do a long while back. We've caught all the public instances I think but this is on the Applications page for admins e.g.: https://doaj.org/admin/applications?source=%7B%22query%22%3A%7B%22query_string%22%3A%7B%22query%22%3A%2219167245%22%2C%22default_operator%22%3A%22AND%22%7D%7D%2C%22from%22%3A0%2C%22size%22%3A10%7D
Each application is supposed to have a little icon before the title.
Currently the CSS class string is `icon icon-signin`. It needs to be `fa fa-sign-in` (tested inline replacement in Chrome). It should take about 5 minutes to fix / rollout.
|
1.0
|
Another broken icon on admin interface - Probably broken by the FontAwesome upgrade we had to do a long while back. We've caught all the public instances I think but this is on the Applications page for admins e.g.: https://doaj.org/admin/applications?source=%7B%22query%22%3A%7B%22query_string%22%3A%7B%22query%22%3A%2219167245%22%2C%22default_operator%22%3A%22AND%22%7D%7D%2C%22from%22%3A0%2C%22size%22%3A10%7D
Each application is supposed to have a little icon before the title.
Currently the CSS class string is `icon icon-signin`. It needs to be `fa fa-sign-in` (tested inline replacement in Chrome). It should take about 5 minutes to fix / rollout.
|
non_process
|
another broken icon on admin interface probably broken by the fontawesome upgrade we had to do a long while back we ve caught all the public instances i think but this is on the applications page for admins e g each application is supposed to have a little icon before the title currently the css class string is icon icon signin it needs to be fa fa sign in tested inline replacement in chrome it should take about minutes to fix rollout
| 0
|
77,186
| 14,738,575,925
|
IssuesEvent
|
2021-01-07 05:09:21
|
kdjstudios/SABillingGitlab
|
https://api.github.com/repos/kdjstudios/SABillingGitlab
|
opened
|
Auto Pay and Save Payment Accounts - Update Process
|
anc-code anc-core anc-infrastructure anc-process anc-project anc-ui anp-3 ant-feature grt-payments pl-foran
|
In GitLab by @kdjstudios on Jun 21, 2018, 10:21
Three over viewing functionality processes:
- Add New Card (Internal and Client access) - Accept terms and conditions. [Completed in other tickets]
- Link to Existing Card (Internal access only) - Mainly used in setup new clients who already have CC vault. [Completed in other tickets]
- Once a card has been saved: Setup Auto Pay (Internal and Client access) - Schedule and accept an auto-pay terms and conditions.
Needs further discussion with Gary.
|
1.0
|
Auto Pay and Save Payment Accounts - Update Process - In GitLab by @kdjstudios on Jun 21, 2018, 10:21
Three over viewing functionality processes:
- Add New Card (Internal and Client access) - Accept terms and conditions. [Completed in other tickets]
- Link to Existing Card (Internal access only) - Mainly used in setup new clients who already have CC vault. [Completed in other tickets]
- Once a card has been saved: Setup Auto Pay (Internal and Client access) - Schedule and accept an auto-pay terms and conditions.
Needs further discussion with Gary.
|
non_process
|
auto pay and save payment accounts update process in gitlab by kdjstudios on jun three over viewing functionality processes add new card internal and client access accept terms and conditions link to existing card internal access only mainly used in setup new clients who already have cc vault once a card has been saved setup auto pay internal and client access schedule and accept an auto pay terms and conditions needs further discussion with gary
| 0
|
928
| 3,390,155,989
|
IssuesEvent
|
2015-11-30 09:07:52
|
kerubistan/kerub
|
https://api.github.com/repos/kerubistan/kerub
|
opened
|
keep the distribution object for the session
|
component:data processing enhancement priority: normal
|
the distribution object is needed to perform operations on the host
|
1.0
|
keep the distribution object for the session - the distribution object is needed to perform operations on the host
|
process
|
keep the distribution object for the session the distribution object is needed to perform operations on the host
| 1
|
9,821
| 12,827,386,520
|
IssuesEvent
|
2020-07-06 18:22:55
|
googleapis/google-cloud-ruby
|
https://api.github.com/repos/googleapis/google-cloud-ruby
|
closed
|
[Link checker] Omit the YARD link for the subject library
|
type: process
|
When initially generating a library, the reference docs (on googleapis.dev) aren't present yet because the library hasn't yet been released. This causes the link checker to fail. I think we can just configure linkinator to ignore that particular link.
|
1.0
|
[Link checker] Omit the YARD link for the subject library - When initially generating a library, the reference docs (on googleapis.dev) aren't present yet because the library hasn't yet been released. This causes the link checker to fail. I think we can just configure linkinator to ignore that particular link.
|
process
|
omit the yard link for the subject library when initially generating a library the reference docs on googleapis dev aren t present yet because the library hasn t yet been released this causes the link checker to fail i think we can just configure linkinator to ignore that particular link
| 1
|
14,650
| 17,775,720,764
|
IssuesEvent
|
2021-08-30 18:57:08
|
MicrosoftDocs/azure-devops-docs
|
https://api.github.com/repos/MicrosoftDocs/azure-devops-docs
|
closed
|
Scripting support?
|
doc-enhancement devops/prod devops-cicd-process/tech needs-sme
|
If I just created a new VM from ARM-template... how do I register it automatically as an environment?
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 91d0d31f-81ee-c024-db7e-daddbf525f71
* Version Independent ID: 330f1649-386c-d0aa-5f96-b8343a1480d3
* Content: [Environment - Virtual machine resource - Azure Pipelines](https://docs.microsoft.com/en-us/azure/devops/pipelines/process/environments-virtual-machines?view=azure-devops)
* Content Source: [docs/pipelines/process/environments-virtual-machines.md](https://github.com/MicrosoftDocs/azure-devops-docs/blob/master/docs/pipelines/process/environments-virtual-machines.md)
* Product: **devops**
* Technology: **devops-cicd-process**
* GitHub Login: @juliakm
* Microsoft Alias: **jukullam**
|
1.0
|
Scripting support? -
If I just created a new VM from ARM-template... how do I register it automatically as an environment?
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 91d0d31f-81ee-c024-db7e-daddbf525f71
* Version Independent ID: 330f1649-386c-d0aa-5f96-b8343a1480d3
* Content: [Environment - Virtual machine resource - Azure Pipelines](https://docs.microsoft.com/en-us/azure/devops/pipelines/process/environments-virtual-machines?view=azure-devops)
* Content Source: [docs/pipelines/process/environments-virtual-machines.md](https://github.com/MicrosoftDocs/azure-devops-docs/blob/master/docs/pipelines/process/environments-virtual-machines.md)
* Product: **devops**
* Technology: **devops-cicd-process**
* GitHub Login: @juliakm
* Microsoft Alias: **jukullam**
|
process
|
scripting support if i just created a new vm from arm template how do i register it automatically as an environment document details ⚠ do not edit this section it is required for docs microsoft com ➟ github issue linking id version independent id content content source product devops technology devops cicd process github login juliakm microsoft alias jukullam
| 1
|
452,252
| 13,047,521,014
|
IssuesEvent
|
2020-07-29 10:52:29
|
StrangeLoopGames/EcoIssues
|
https://api.github.com/repos/StrangeLoopGames/EcoIssues
|
closed
|
Report a Bug Dialog crash
|
Priority: Medium Status: Investigate
|
When attempting to report a bug (#8261) with the in-game _Report a Bug_ dialog, I pasted in a special character name, `𝕲𝖑𝖔𝖗𝖎𝖔𝖚𝖘𝕭𝖎𝖗𝖇`, into the reproductive steps text field and had the client crash to desktop with a crash dump (that I not can't locate again after closing the folder).
When attempting to reproduce the issue the client seem to simply have froze, but sound is still playing and the window (playing in window mode) is not unresponsive.
|
1.0
|
Report a Bug Dialog crash - When attempting to report a bug (#8261) with the in-game _Report a Bug_ dialog, I pasted in a special character name, `𝕲𝖑𝖔𝖗𝖎𝖔𝖚𝖘𝕭𝖎𝖗𝖇`, into the reproductive steps text field and had the client crash to desktop with a crash dump (that I not can't locate again after closing the folder).
When attempting to reproduce the issue the client seem to simply have froze, but sound is still playing and the window (playing in window mode) is not unresponsive.
|
non_process
|
report a bug dialog crash when attempting to report a bug with the in game report a bug dialog i pasted in a special character name 𝕲𝖑𝖔𝖗𝖎𝖔𝖚𝖘𝕭𝖎𝖗𝖇 into the reproductive steps text field and had the client crash to desktop with a crash dump that i not can t locate again after closing the folder when attempting to reproduce the issue the client seem to simply have froze but sound is still playing and the window playing in window mode is not unresponsive
| 0
|
214,370
| 24,069,540,863
|
IssuesEvent
|
2022-09-18 01:02:23
|
Gal-Doron/operator-registry
|
https://api.github.com/repos/Gal-Doron/operator-registry
|
closed
|
CVE-2021-41103 (High) detected in github.com/docker/docker-v20.10.16 - autoclosed
|
security vulnerability
|
## CVE-2021-41103 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>github.com/docker/docker-v20.10.16</b></p></summary>
<p>Moby Project - a collaborative project for the container ecosystem to assemble container-based systems</p>
<p>
Dependency Hierarchy:
- :x: **github.com/docker/docker-v20.10.16** (Vulnerable Library)
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
containerd is an open source container runtime with an emphasis on simplicity, robustness and portability. A bug was found in containerd where container root directories and some plugins had insufficiently restricted permissions, allowing otherwise unprivileged Linux users to traverse directory contents and execute programs. When containers included executable programs with extended permission bits (such as setuid), unprivileged Linux users could discover and execute those programs. When the UID of an unprivileged Linux user on the host collided with the file owner or group inside a container, the unprivileged Linux user on the host could discover, read, and modify those files. This vulnerability has been fixed in containerd 1.4.11 and containerd 1.5.7. Users should update to these version when they are released and may restart containers or update directory permissions to mitigate the vulnerability. Users unable to update should limit access to the host to trusted users. Update directory permission on container bundles directories.
<p>Publish Date: 2021-10-04
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-41103>CVE-2021-41103</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>7.8</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Local
- Attack Complexity: Low
- Privileges Required: Low
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: High
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://github.com/advisories/GHSA-c2h3-6mxw-7mvq">https://github.com/advisories/GHSA-c2h3-6mxw-7mvq</a></p>
<p>Release Date: 2021-10-04</p>
<p>Fix Resolution: v1.4.11,v1.5.7</p>
</p>
</details>
<p></p>
|
True
|
CVE-2021-41103 (High) detected in github.com/docker/docker-v20.10.16 - autoclosed - ## CVE-2021-41103 - High Severity Vulnerability
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/vulnerability_details.png' width=19 height=20> Vulnerable Library - <b>github.com/docker/docker-v20.10.16</b></p></summary>
<p>Moby Project - a collaborative project for the container ecosystem to assemble container-based systems</p>
<p>
Dependency Hierarchy:
- :x: **github.com/docker/docker-v20.10.16** (Vulnerable Library)
<p>Found in base branch: <b>master</b></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/high_vul.png' width=19 height=20> Vulnerability Details</summary>
<p>
containerd is an open source container runtime with an emphasis on simplicity, robustness and portability. A bug was found in containerd where container root directories and some plugins had insufficiently restricted permissions, allowing otherwise unprivileged Linux users to traverse directory contents and execute programs. When containers included executable programs with extended permission bits (such as setuid), unprivileged Linux users could discover and execute those programs. When the UID of an unprivileged Linux user on the host collided with the file owner or group inside a container, the unprivileged Linux user on the host could discover, read, and modify those files. This vulnerability has been fixed in containerd 1.4.11 and containerd 1.5.7. Users should update to these version when they are released and may restart containers or update directory permissions to mitigate the vulnerability. Users unable to update should limit access to the host to trusted users. Update directory permission on container bundles directories.
<p>Publish Date: 2021-10-04
<p>URL: <a href=https://vuln.whitesourcesoftware.com/vulnerability/CVE-2021-41103>CVE-2021-41103</a></p>
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/cvss3.png' width=19 height=20> CVSS 3 Score Details (<b>7.8</b>)</summary>
<p>
Base Score Metrics:
- Exploitability Metrics:
- Attack Vector: Local
- Attack Complexity: Low
- Privileges Required: Low
- User Interaction: None
- Scope: Unchanged
- Impact Metrics:
- Confidentiality Impact: High
- Integrity Impact: High
- Availability Impact: High
</p>
For more information on CVSS3 Scores, click <a href="https://www.first.org/cvss/calculator/3.0">here</a>.
</p>
</details>
<p></p>
<details><summary><img src='https://whitesource-resources.whitesourcesoftware.com/suggested_fix.png' width=19 height=20> Suggested Fix</summary>
<p>
<p>Type: Upgrade version</p>
<p>Origin: <a href="https://github.com/advisories/GHSA-c2h3-6mxw-7mvq">https://github.com/advisories/GHSA-c2h3-6mxw-7mvq</a></p>
<p>Release Date: 2021-10-04</p>
<p>Fix Resolution: v1.4.11,v1.5.7</p>
</p>
</details>
<p></p>
|
non_process
|
cve high detected in github com docker docker autoclosed cve high severity vulnerability vulnerable library github com docker docker moby project a collaborative project for the container ecosystem to assemble container based systems dependency hierarchy x github com docker docker vulnerable library found in base branch master vulnerability details containerd is an open source container runtime with an emphasis on simplicity robustness and portability a bug was found in containerd where container root directories and some plugins had insufficiently restricted permissions allowing otherwise unprivileged linux users to traverse directory contents and execute programs when containers included executable programs with extended permission bits such as setuid unprivileged linux users could discover and execute those programs when the uid of an unprivileged linux user on the host collided with the file owner or group inside a container the unprivileged linux user on the host could discover read and modify those files this vulnerability has been fixed in containerd and containerd users should update to these version when they are released and may restart containers or update directory permissions to mitigate the vulnerability users unable to update should limit access to the host to trusted users update directory permission on container bundles directories publish date url a href cvss score details base score metrics exploitability metrics attack vector local attack complexity low privileges required low user interaction none scope unchanged impact metrics confidentiality impact high integrity impact high availability impact high for more information on scores click a href suggested fix type upgrade version origin a href release date fix resolution
| 0
|
10,597
| 13,424,149,533
|
IssuesEvent
|
2020-09-06 03:17:49
|
qgis/QGIS
|
https://api.github.com/repos/qgis/QGIS
|
closed
|
"Export to GPKG" missing(?)
|
Feature Request Processing
|
In processing there is a "export to spatialite" tool, that does exactly what the name suggests.
Seems a bit weird that there is no equivalent "export to gpkg" tool, as we advertise the gpkg format as a first class citizen in QGIS.
One note:
this tool is very handy especially in batch mode, to export in one go several layers to a single datasource, anyway it is a bit unconvenient that the SL datasource must exist beforehand. It would be better the tool to be able to create one on the fly if necessary.
Second note: trying to use the "export to spatialite" on gpkg rather than a SL datasource makes qgis fails silently: no errors but also no layer exported.
|
1.0
|
"Export to GPKG" missing(?) - In processing there is a "export to spatialite" tool, that does exactly what the name suggests.
Seems a bit weird that there is no equivalent "export to gpkg" tool, as we advertise the gpkg format as a first class citizen in QGIS.
One note:
this tool is very handy especially in batch mode, to export in one go several layers to a single datasource, anyway it is a bit unconvenient that the SL datasource must exist beforehand. It would be better the tool to be able to create one on the fly if necessary.
Second note: trying to use the "export to spatialite" on gpkg rather than a SL datasource makes qgis fails silently: no errors but also no layer exported.
|
process
|
export to gpkg missing in processing there is a export to spatialite tool that does exactly what the name suggests seems a bit weird that there is no equivalent export to gpkg tool as we advertise the gpkg format as a first class citizen in qgis one note this tool is very handy especially in batch mode to export in one go several layers to a single datasource anyway it is a bit unconvenient that the sl datasource must exist beforehand it would be better the tool to be able to create one on the fly if necessary second note trying to use the export to spatialite on gpkg rather than a sl datasource makes qgis fails silently no errors but also no layer exported
| 1
|
315
| 2,756,683,523
|
IssuesEvent
|
2015-04-27 10:00:21
|
DynareTeam/dynare
|
https://api.github.com/repos/DynareTeam/dynare
|
closed
|
Allow specifying output directory for estimation
|
preprocessor
|
```dynare_estimation.m``` takes as an input ```dname```, but as far as I can see, there is no way to set this. ```ComputingTasks.cc``` in line 482 only writes ```var_list_``` as an argument.
|
1.0
|
Allow specifying output directory for estimation - ```dynare_estimation.m``` takes as an input ```dname```, but as far as I can see, there is no way to set this. ```ComputingTasks.cc``` in line 482 only writes ```var_list_``` as an argument.
|
process
|
allow specifying output directory for estimation dynare estimation m takes as an input dname but as far as i can see there is no way to set this computingtasks cc in line only writes var list as an argument
| 1
|
2,256
| 5,089,342,310
|
IssuesEvent
|
2017-01-01 14:54:49
|
coala/teams
|
https://api.github.com/repos/coala/teams
|
closed
|
Community Team Member application: Mariatta
|
community_team process/approved
|
# Bio
My name is Mariatta, and I'm extra super duper special because:
- At the time of applying, I'm the only woman in coala maintainers team.
- I'm on IMDb http://www.imdb.com/name/nm7641957/
My other community involvements include:
- co-organize Vancouver PyLadies meetups
- organized a screening of Code: Debugging the Gender Gap with VanPy User group
- mentored for Girls Learning Code and Ladies Learning Code
- speaking at conferences: Vancouver Python Day 2016, DjangoCon US 2016, PyCaribbean 2017
- attend local Python meetups
In essence, I've been part of the community already, you might as well just accept me 😜
# coala Contributions so far
- documentation
- review prs
- accept prs
- helped onboard newcomers and new contributors
# Road to the Future
- help improve newcomer's experience so that they'll stay and continue contributing
- help improve documentation
- help promote coala by giving lightning talks
- suggest that we adopt a Code of Conduct, similar to Python's or Django's CoC.
- be on the lookout for upcoming conferences for coala to make a presence
|
1.0
|
Community Team Member application: Mariatta - # Bio
My name is Mariatta, and I'm extra super duper special because:
- At the time of applying, I'm the only woman in coala maintainers team.
- I'm on IMDb http://www.imdb.com/name/nm7641957/
My other community involvements include:
- co-organize Vancouver PyLadies meetups
- organized a screening of Code: Debugging the Gender Gap with VanPy User group
- mentored for Girls Learning Code and Ladies Learning Code
- speaking at conferences: Vancouver Python Day 2016, DjangoCon US 2016, PyCaribbean 2017
- attend local Python meetups
In essence, I've been part of the community already, you might as well just accept me 😜
# coala Contributions so far
- documentation
- review prs
- accept prs
- helped onboard newcomers and new contributors
# Road to the Future
- help improve newcomer's experience so that they'll stay and continue contributing
- help improve documentation
- help promote coala by giving lightning talks
- suggest that we adopt a Code of Conduct, similar to Python's or Django's CoC.
- be on the lookout for upcoming conferences for coala to make a presence
|
process
|
community team member application mariatta bio my name is mariatta and i m extra super duper special because at the time of applying i m the only woman in coala maintainers team i m on imdb my other community involvements include co organize vancouver pyladies meetups organized a screening of code debugging the gender gap with vanpy user group mentored for girls learning code and ladies learning code speaking at conferences vancouver python day djangocon us pycaribbean attend local python meetups in essence i ve been part of the community already you might as well just accept me 😜 coala contributions so far documentation review prs accept prs helped onboard newcomers and new contributors road to the future help improve newcomer s experience so that they ll stay and continue contributing help improve documentation help promote coala by giving lightning talks suggest that we adopt a code of conduct similar to python s or django s coc be on the lookout for upcoming conferences for coala to make a presence
| 1
|
279,254
| 8,659,452,260
|
IssuesEvent
|
2018-11-28 06:11:10
|
ryuichl/v3-report
|
https://api.github.com/repos/ryuichl/v3-report
|
closed
|
【問題】專案封包下載功能
|
UI/UX priority-1
|
美好的早晨,大家好
李組長今早使用了下載專案的功能,發現大小動輒3XMB,發現案情並不單純
打開資料夾,發現把小積木裡的素材圖,介面icon,全都下載下來了
還請工程部的大人們協助查明真相
|
1.0
|
【問題】專案封包下載功能 - 美好的早晨,大家好
李組長今早使用了下載專案的功能,發現大小動輒3XMB,發現案情並不單純
打開資料夾,發現把小積木裡的素材圖,介面icon,全都下載下來了
還請工程部的大人們協助查明真相
|
non_process
|
【問題】專案封包下載功能 美好的早晨,大家好 李組長今早使用了下載專案的功能, ,發現案情並不單純 打開資料夾,發現把小積木裡的素材圖,介面icon,全都下載下來了 還請工程部的大人們協助查明真相
| 0
|
47,922
| 5,920,770,473
|
IssuesEvent
|
2017-05-22 21:06:17
|
kubernetes/kubernetes
|
https://api.github.com/repos/kubernetes/kubernetes
|
closed
|
Collect kubemark master logs even if start-kubemark script fails
|
area/test-infra kind/enhancement priority/important-longterm sig/scalability
|
We recently had 2 flaky runs (2825, 2826) in our kubemark-100 CI test and the problem was in kubemark apiserver failing to become healthy and the test timed out.
And since we don't currently collect kubemark master logs if the test fails during start-kubemark.sh step, we have no idea why it failed.
cc @wojtek-t @gmarek
|
1.0
|
Collect kubemark master logs even if start-kubemark script fails - We recently had 2 flaky runs (2825, 2826) in our kubemark-100 CI test and the problem was in kubemark apiserver failing to become healthy and the test timed out.
And since we don't currently collect kubemark master logs if the test fails during start-kubemark.sh step, we have no idea why it failed.
cc @wojtek-t @gmarek
|
non_process
|
collect kubemark master logs even if start kubemark script fails we recently had flaky runs in our kubemark ci test and the problem was in kubemark apiserver failing to become healthy and the test timed out and since we don t currently collect kubemark master logs if the test fails during start kubemark sh step we have no idea why it failed cc wojtek t gmarek
| 0
|
4,844
| 7,738,747,803
|
IssuesEvent
|
2018-05-28 13:13:40
|
UnbFeelings/unb-feelings-docs
|
https://api.github.com/repos/UnbFeelings/unb-feelings-docs
|
closed
|
[Não Conformidade] - Relatório de Desempenho Sprint 2
|
Processo medição
|
A auditoria do relatório de desempenho foi executada para verificar se a atividade de medição e análise foi realizada. O resultado da auditoria pode ser acessado através da seguinte página: [Auditoria Relatório de Desempenho sprint 2 - Ciclo 2](https://github.com/UnbFeelings/unb-feelings-GQA/wiki/Auditoria-Relatório-de-Desempenho-Sprint-2-Ciclo-2).
## Descrição
O documento **Relatório de Desempenho** não foi elaborado.
### Recomendações
Analisar as métricas existentes coletadas pela equipe de processo, e elaborar o documento
## Detalhes
**Autor:** Guilherme Sant'Ana
**Tipo:** Medição e Análise
**Prazo:** 28/05/18
|
1.0
|
[Não Conformidade] - Relatório de Desempenho Sprint 2 - A auditoria do relatório de desempenho foi executada para verificar se a atividade de medição e análise foi realizada. O resultado da auditoria pode ser acessado através da seguinte página: [Auditoria Relatório de Desempenho sprint 2 - Ciclo 2](https://github.com/UnbFeelings/unb-feelings-GQA/wiki/Auditoria-Relatório-de-Desempenho-Sprint-2-Ciclo-2).
## Descrição
O documento **Relatório de Desempenho** não foi elaborado.
### Recomendações
Analisar as métricas existentes coletadas pela equipe de processo, e elaborar o documento
## Detalhes
**Autor:** Guilherme Sant'Ana
**Tipo:** Medição e Análise
**Prazo:** 28/05/18
|
process
|
relatório de desempenho sprint a auditoria do relatório de desempenho foi executada para verificar se a atividade de medição e análise foi realizada o resultado da auditoria pode ser acessado através da seguinte página descrição o documento relatório de desempenho não foi elaborado recomendações analisar as métricas existentes coletadas pela equipe de processo e elaborar o documento detalhes autor guilherme sant ana tipo medição e análise prazo
| 1
|
14,141
| 17,031,878,298
|
IssuesEvent
|
2021-07-04 18:36:03
|
qgis/QGIS
|
https://api.github.com/repos/qgis/QGIS
|
closed
|
Export to spreadsheet adds ghost attribute
|
Bug Feedback Processing
|
<!--
Bug fixing and feature development is a community responsibility, and not the responsibility of the QGIS project alone.
If this bug report or feature request is high-priority for you, we suggest engaging a QGIS developer or support organisation and financially sponsoring a fix
Checklist before submitting
- [ ] Search through existing issue reports and gis.stackexchange.com to check whether the issue already exists
- [ ] Test with a [clean new user profile](https://docs.qgis.org/testing/en/docs/user_manual/introduction/qgis_configuration.html?highlight=profile#working-with-user-profiles).
- [ ] Create a light and self-contained sample dataset and project file which demonstrates the issue
-->
**Describe the bug**
<!-- A clear and concise description of what the bug is. -->
The "Export to spreadsheet" algorithm adds an attribute column with old values but only for a specific layer. I deleted the attribute but the algorithm still show the non-existent attribute with old values. This happens even after I exited and restarted QGIS.
The problem ghost attribute is not there if I save-as the layer to CSV or Excel. See the attached spreadsheet with the exported data and some screenshots. The layer is "Williston outer repeater FR" and the relevant Geopackage is also attached.
[MK+gpkg.zip](https://github.com/qgis/QGIS/files/6754111/MK%2Bgpkg.zip)
[Export to spreadsheet bug.xlsx](https://github.com/qgis/QGIS/files/6754085/Export.to.spreadsheet.bug.xlsx)
The log shows the following:
QGIS version: 3.18.3-Zürich
QGIS code revision: 735cc85be9
Qt version: 5.11.2
GDAL version: 3.1.4
GEOS version: 3.8.1-CAPI-1.13.3
PROJ version: Rel. 6.3.2, May 1st, 2020
Processing algorithm…
Algorithm 'Export to spreadsheet' starting…
Input parameters:
{ 'FORMATTED_VALUES' : False, 'LAYERS' : ['C:/Users/kobus.burger/OneDrive - Zutari/KBProjects/SKA MK+/Design/QGIS/MK+.gpkg|layername=Williston outer repeater fibre cable'], 'OUTPUT' : 'TEMPORARY_OUTPUT', 'OVERWRITE' : True, 'USE_ALIAS' : False }
Exporting layer 1/1: Williston outer repeater FR
Execution completed in 0.41 seconds
Results:
{'OUTPUT': 'C:/Users/kobus.burger/AppData/Local/Temp/1/processing_zSszPW/b9582bab926841e883aa4ab2f91d4943/OUTPUT.xlsx',
'OUTPUT_LAYERS': ['C:/Users/kobus.burger/AppData/Local/Temp/1/processing_zSszPW/b9582bab926841e883aa4ab2f91d4943/OUTPUT.xlsx|layername=Williston '
'outer repeater FR']}
Loading resulting layers
Algorithm 'Export to spreadsheet' finished
**How to Reproduce**
I on reproduce the problem on my project but I do not know it only happens with one specific layer.
<!-- Steps, sample datasets and qgis project file to reproduce the behavior. Screencasts or screenshots welcome -->
**QGIS and OS versions**
<!-- In the QGIS Help menu -> About, click in the table, Ctrl+A and then Ctrl+C. Finally paste here -->
<!--StartFragment--><!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd">
<html><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /><style type="text/css">
p, li { white-space: pre-wrap; }
</style></head><body>
QGIS version | 3.18.3-Zürich | QGIS code revision | 735cc85be9
-- | -- | -- | --
Compiled against Qt | 5.11.2 | Running against Qt | 5.11.2
Compiled against GDAL/OGR | 3.1.4 | Running against GDAL/OGR | 3.1.4
Compiled against GEOS | 3.8.1-CAPI-1.13.3 | Running against GEOS | 3.8.1-CAPI-1.13.3
Compiled against SQLite | 3.29.0 | Running against SQLite | 3.29.0
PostgreSQL Client Version | 11.5 | SpatiaLite Version | 4.3.0
QWT Version | 6.1.3 | QScintilla2 Version | 2.10.8
Compiled against PROJ | 6.3.2 | Running against PROJ | Rel. 6.3.2, May 1st, 2020
OS Version | Windows 10 (10.0)
Active python plugins | kmltools; db_manager; MetaSearch; processing
</body></html><!--EndFragment-->
**Additional context**
<!-- Add any other context about the problem here. -->
|
1.0
|
Export to spreadsheet adds ghost attribute - <!--
Bug fixing and feature development is a community responsibility, and not the responsibility of the QGIS project alone.
If this bug report or feature request is high-priority for you, we suggest engaging a QGIS developer or support organisation and financially sponsoring a fix
Checklist before submitting
- [ ] Search through existing issue reports and gis.stackexchange.com to check whether the issue already exists
- [ ] Test with a [clean new user profile](https://docs.qgis.org/testing/en/docs/user_manual/introduction/qgis_configuration.html?highlight=profile#working-with-user-profiles).
- [ ] Create a light and self-contained sample dataset and project file which demonstrates the issue
-->
**Describe the bug**
<!-- A clear and concise description of what the bug is. -->
The "Export to spreadsheet" algorithm adds an attribute column with old values but only for a specific layer. I deleted the attribute but the algorithm still show the non-existent attribute with old values. This happens even after I exited and restarted QGIS.
The problem ghost attribute is not there if I save-as the layer to CSV or Excel. See the attached spreadsheet with the exported data and some screenshots. The layer is "Williston outer repeater FR" and the relevant Geopackage is also attached.
[MK+gpkg.zip](https://github.com/qgis/QGIS/files/6754111/MK%2Bgpkg.zip)
[Export to spreadsheet bug.xlsx](https://github.com/qgis/QGIS/files/6754085/Export.to.spreadsheet.bug.xlsx)
The log shows the following:
QGIS version: 3.18.3-Zürich
QGIS code revision: 735cc85be9
Qt version: 5.11.2
GDAL version: 3.1.4
GEOS version: 3.8.1-CAPI-1.13.3
PROJ version: Rel. 6.3.2, May 1st, 2020
Processing algorithm…
Algorithm 'Export to spreadsheet' starting…
Input parameters:
{ 'FORMATTED_VALUES' : False, 'LAYERS' : ['C:/Users/kobus.burger/OneDrive - Zutari/KBProjects/SKA MK+/Design/QGIS/MK+.gpkg|layername=Williston outer repeater fibre cable'], 'OUTPUT' : 'TEMPORARY_OUTPUT', 'OVERWRITE' : True, 'USE_ALIAS' : False }
Exporting layer 1/1: Williston outer repeater FR
Execution completed in 0.41 seconds
Results:
{'OUTPUT': 'C:/Users/kobus.burger/AppData/Local/Temp/1/processing_zSszPW/b9582bab926841e883aa4ab2f91d4943/OUTPUT.xlsx',
'OUTPUT_LAYERS': ['C:/Users/kobus.burger/AppData/Local/Temp/1/processing_zSszPW/b9582bab926841e883aa4ab2f91d4943/OUTPUT.xlsx|layername=Williston '
'outer repeater FR']}
Loading resulting layers
Algorithm 'Export to spreadsheet' finished
**How to Reproduce**
I on reproduce the problem on my project but I do not know it only happens with one specific layer.
<!-- Steps, sample datasets and qgis project file to reproduce the behavior. Screencasts or screenshots welcome -->
**QGIS and OS versions**
<!-- In the QGIS Help menu -> About, click in the table, Ctrl+A and then Ctrl+C. Finally paste here -->
<!--StartFragment--><!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN" "http://www.w3.org/TR/REC-html40/strict.dtd">
<html><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /><style type="text/css">
p, li { white-space: pre-wrap; }
</style></head><body>
QGIS version | 3.18.3-Zürich | QGIS code revision | 735cc85be9
-- | -- | -- | --
Compiled against Qt | 5.11.2 | Running against Qt | 5.11.2
Compiled against GDAL/OGR | 3.1.4 | Running against GDAL/OGR | 3.1.4
Compiled against GEOS | 3.8.1-CAPI-1.13.3 | Running against GEOS | 3.8.1-CAPI-1.13.3
Compiled against SQLite | 3.29.0 | Running against SQLite | 3.29.0
PostgreSQL Client Version | 11.5 | SpatiaLite Version | 4.3.0
QWT Version | 6.1.3 | QScintilla2 Version | 2.10.8
Compiled against PROJ | 6.3.2 | Running against PROJ | Rel. 6.3.2, May 1st, 2020
OS Version | Windows 10 (10.0)
Active python plugins | kmltools; db_manager; MetaSearch; processing
</body></html><!--EndFragment-->
**Additional context**
<!-- Add any other context about the problem here. -->
|
process
|
export to spreadsheet adds ghost attribute bug fixing and feature development is a community responsibility and not the responsibility of the qgis project alone if this bug report or feature request is high priority for you we suggest engaging a qgis developer or support organisation and financially sponsoring a fix checklist before submitting search through existing issue reports and gis stackexchange com to check whether the issue already exists test with a create a light and self contained sample dataset and project file which demonstrates the issue describe the bug the export to spreadsheet algorithm adds an attribute column with old values but only for a specific layer i deleted the attribute but the algorithm still show the non existent attribute with old values this happens even after i exited and restarted qgis the problem ghost attribute is not there if i save as the layer to csv or excel see the attached spreadsheet with the exported data and some screenshots the layer is williston outer repeater fr and the relevant geopackage is also attached the log shows the following qgis version zürich qgis code revision qt version gdal version geos version capi proj version rel may processing algorithm… algorithm export to spreadsheet starting… input parameters formatted values false layers output temporary output overwrite true use alias false exporting layer williston outer repeater fr execution completed in seconds results output c users kobus burger appdata local temp processing zsszpw output xlsx output layers c users kobus burger appdata local temp processing zsszpw output xlsx layername williston outer repeater fr loading resulting layers algorithm export to spreadsheet finished how to reproduce i on reproduce the problem on my project but i do not know it only happens with one specific layer qgis and os versions about click in the table ctrl a and then ctrl c finally paste here doctype html public dtd html en p li white space pre wrap qgis version zürich qgis code revision compiled against qt running against qt compiled against gdal ogr running against gdal ogr compiled against geos capi running against geos capi compiled against sqlite running against sqlite postgresql client version spatialite version qwt version version compiled against proj running against proj rel may os version windows active python plugins kmltools db manager metasearch processing additional context
| 1
|
3,119
| 6,150,435,471
|
IssuesEvent
|
2017-06-27 22:34:37
|
rancher/rancher
|
https://api.github.com/repos/rancher/rancher
|
closed
|
Enhance the restrictions on the restricted user type
|
kind/enhancement process/cherry-pick process/cherry-picked status/resolved status/to-test version/1.6
|
The restricted role is currently only restricted from creating, updating, or deleting hosts. We're going to expand on that in the following ways:
- A restricted user cannot create, update, or delete infrastructure stacks, services, or containers
- A restricted user cannot exec into containers with the io.container.create_agent label
- A restricted user cannot exec into any containers belonging to infrastructure services
- A restricted user cannot set the `privileged` field to true on a service or container
- A restricted user cannot set the `capAdd` field on a service or container
- A restricted user can only perform host bind mounts to a whitelisted set of host directories (controlled by a setting in Rancher)
To implement the restrictions to CUDing infra services and execing into containers, we want to key off of the user's permissions to hosts as opposed to hardcoding it to specific roles. In other words, instead of checking if the user has the role "restricted", we want to check if the user is unable to create, update, or delete hosts. If that is true, then we'll remove the ability to CUD infra services or exec into their containers. We want to implement it this way so that our users can tweak other roles to not be able to create hosts and get the restricted infra-service behavior automatically.
|
2.0
|
Enhance the restrictions on the restricted user type - The restricted role is currently only restricted from creating, updating, or deleting hosts. We're going to expand on that in the following ways:
- A restricted user cannot create, update, or delete infrastructure stacks, services, or containers
- A restricted user cannot exec into containers with the io.container.create_agent label
- A restricted user cannot exec into any containers belonging to infrastructure services
- A restricted user cannot set the `privileged` field to true on a service or container
- A restricted user cannot set the `capAdd` field on a service or container
- A restricted user can only perform host bind mounts to a whitelisted set of host directories (controlled by a setting in Rancher)
To implement the restrictions to CUDing infra services and execing into containers, we want to key off of the user's permissions to hosts as opposed to hardcoding it to specific roles. In other words, instead of checking if the user has the role "restricted", we want to check if the user is unable to create, update, or delete hosts. If that is true, then we'll remove the ability to CUD infra services or exec into their containers. We want to implement it this way so that our users can tweak other roles to not be able to create hosts and get the restricted infra-service behavior automatically.
|
process
|
enhance the restrictions on the restricted user type the restricted role is currently only restricted from creating updating or deleting hosts we re going to expand on that in the following ways a restricted user cannot create update or delete infrastructure stacks services or containers a restricted user cannot exec into containers with the io container create agent label a restricted user cannot exec into any containers belonging to infrastructure services a restricted user cannot set the privileged field to true on a service or container a restricted user cannot set the capadd field on a service or container a restricted user can only perform host bind mounts to a whitelisted set of host directories controlled by a setting in rancher to implement the restrictions to cuding infra services and execing into containers we want to key off of the user s permissions to hosts as opposed to hardcoding it to specific roles in other words instead of checking if the user has the role restricted we want to check if the user is unable to create update or delete hosts if that is true then we ll remove the ability to cud infra services or exec into their containers we want to implement it this way so that our users can tweak other roles to not be able to create hosts and get the restricted infra service behavior automatically
| 1
|
7,388
| 10,516,417,387
|
IssuesEvent
|
2019-09-28 17:24:19
|
aiidateam/aiida-core
|
https://api.github.com/repos/aiidateam/aiida-core
|
closed
|
Except submitted processes whose class cannot be imported
|
priority/important topic/daemon topic/engine topic/processes type/bug
|
Currently, the process will simply except and acknowledge the task, but the node will remain in the `CREATED` state.
|
1.0
|
Except submitted processes whose class cannot be imported - Currently, the process will simply except and acknowledge the task, but the node will remain in the `CREATED` state.
|
process
|
except submitted processes whose class cannot be imported currently the process will simply except and acknowledge the task but the node will remain in the created state
| 1
|
565,356
| 16,760,015,298
|
IssuesEvent
|
2021-06-13 15:38:24
|
bounswe/2021SpringGroup2
|
https://api.github.com/repos/bounswe/2021SpringGroup2
|
closed
|
Creating an API for notifications
|
Backend priority: high
|
Writing a GET API for getting notifications and their unit tests.
|
1.0
|
Creating an API for notifications - Writing a GET API for getting notifications and their unit tests.
|
non_process
|
creating an api for notifications writing a get api for getting notifications and their unit tests
| 0
|
1,398
| 3,965,256,023
|
IssuesEvent
|
2016-05-03 07:19:56
|
opentrials/opentrials
|
https://api.github.com/repos/opentrials/opentrials
|
opened
|
Add nice titles to sources table
|
API Processors
|
For now it's kinda merged - name and slug like `nct`.
So we should move things like `nct` or `actrn` to `sources.slug` or `sources.id` (natural primary key is generally good for SQL) and have `sources.name` like `ClinicalTrials.gov`.
|
1.0
|
Add nice titles to sources table - For now it's kinda merged - name and slug like `nct`.
So we should move things like `nct` or `actrn` to `sources.slug` or `sources.id` (natural primary key is generally good for SQL) and have `sources.name` like `ClinicalTrials.gov`.
|
process
|
add nice titles to sources table for now it s kinda merged name and slug like nct so we should move things like nct or actrn to sources slug or sources id natural primary key is generally good for sql and have sources name like clinicaltrials gov
| 1
|
8,401
| 11,568,321,648
|
IssuesEvent
|
2020-02-20 15:42:12
|
Open-EO/openeo-api
|
https://api.github.com/repos/Open-EO/openeo-api
|
closed
|
Make optional fields nullable in process-related endpoints?
|
data discovery processes
|
Originated in #260: Usually in responses like GET /jobs/{job_id} or GET /services/{service_id} most (all?) optional fields can be set to null, which makes implementation a bit easier. For the process graphs at /process_graphs none of the fields can be set to null and so they must actually be missing from the response if no data is available. That's more difficult to implement, but aligned with /processes. Should we introduce nullable for some/all fields in /process_graphs and/or /processes?
More considerations:
There are different schemas for pre-defined processes, user-defined processes etc. Each of them required a different set of properties. Of course, the required properties should not be nullable. This means the OpenAPI schemas would get quite messy when allowing null only for optional fields.
Just allowing null everywhere would weaken the required contraint.
Maybe we need to look at the individual fields:
* id: Not sure, is usually required.
* summary: Maybe nullable? Could just respond with an empty string.
* description: Maybe nullable? Could just respond with an empty string.
* categories: Not nullable: it could simply be an empty array.
* parameters: Nullable. There's no default value one could use as an empty array means no parameter, which is different from not providing the data at all (unknown parameters).
* returns: Nullable? If specified, requires a schema. We could allow setting an empty array as "void" data type. An empty object is "any" data type.
* deprecated: Not nullable: it could simply be set to it's default value (false).
* experimental: Not nullable: it could simply be set to it's default value (false).
* exceptions: Not nullable: it could simply be an empty object.
* examples: Not nullable: it could simply be an empty array.
* links: Not nullable: it could simply be an empty array.
* process_graphs: Is usually required, except for pre-defined processes.
|
1.0
|
Make optional fields nullable in process-related endpoints? - Originated in #260: Usually in responses like GET /jobs/{job_id} or GET /services/{service_id} most (all?) optional fields can be set to null, which makes implementation a bit easier. For the process graphs at /process_graphs none of the fields can be set to null and so they must actually be missing from the response if no data is available. That's more difficult to implement, but aligned with /processes. Should we introduce nullable for some/all fields in /process_graphs and/or /processes?
More considerations:
There are different schemas for pre-defined processes, user-defined processes etc. Each of them required a different set of properties. Of course, the required properties should not be nullable. This means the OpenAPI schemas would get quite messy when allowing null only for optional fields.
Just allowing null everywhere would weaken the required contraint.
Maybe we need to look at the individual fields:
* id: Not sure, is usually required.
* summary: Maybe nullable? Could just respond with an empty string.
* description: Maybe nullable? Could just respond with an empty string.
* categories: Not nullable: it could simply be an empty array.
* parameters: Nullable. There's no default value one could use as an empty array means no parameter, which is different from not providing the data at all (unknown parameters).
* returns: Nullable? If specified, requires a schema. We could allow setting an empty array as "void" data type. An empty object is "any" data type.
* deprecated: Not nullable: it could simply be set to it's default value (false).
* experimental: Not nullable: it could simply be set to it's default value (false).
* exceptions: Not nullable: it could simply be an empty object.
* examples: Not nullable: it could simply be an empty array.
* links: Not nullable: it could simply be an empty array.
* process_graphs: Is usually required, except for pre-defined processes.
|
process
|
make optional fields nullable in process related endpoints originated in usually in responses like get jobs job id or get services service id most all optional fields can be set to null which makes implementation a bit easier for the process graphs at process graphs none of the fields can be set to null and so they must actually be missing from the response if no data is available that s more difficult to implement but aligned with processes should we introduce nullable for some all fields in process graphs and or processes more considerations there are different schemas for pre defined processes user defined processes etc each of them required a different set of properties of course the required properties should not be nullable this means the openapi schemas would get quite messy when allowing null only for optional fields just allowing null everywhere would weaken the required contraint maybe we need to look at the individual fields id not sure is usually required summary maybe nullable could just respond with an empty string description maybe nullable could just respond with an empty string categories not nullable it could simply be an empty array parameters nullable there s no default value one could use as an empty array means no parameter which is different from not providing the data at all unknown parameters returns nullable if specified requires a schema we could allow setting an empty array as void data type an empty object is any data type deprecated not nullable it could simply be set to it s default value false experimental not nullable it could simply be set to it s default value false exceptions not nullable it could simply be an empty object examples not nullable it could simply be an empty array links not nullable it could simply be an empty array process graphs is usually required except for pre defined processes
| 1
|
14,532
| 9,256,259,037
|
IssuesEvent
|
2019-03-16 17:31:42
|
Camelcade/Perl5-IDEA
|
https://api.github.com/repos/Camelcade/Perl5-IDEA
|
closed
|
Suggest to install necessary module before executing tool
|
Enchancement Execution Usability problem
|
Before starting debugging, testing or coverage, we could suggest to install all necessary modules.
Install `Devel::Cover` and then `JSON` is pretty annoying.
As alternative, we could check selected sdk for our kit, probably we should introduce a bundle.
Check for:
- App::cpanminus
- B::Deparse
- Config
- Devel::Cover
- Devel::Camelcadedb
- Devel::NYTProf
- File::Find
- JSON
- Perl::Critic
- Perl::Tidy
- Tap::Formatter::Camelcade
- Test::Harness
|
True
|
Suggest to install necessary module before executing tool - Before starting debugging, testing or coverage, we could suggest to install all necessary modules.
Install `Devel::Cover` and then `JSON` is pretty annoying.
As alternative, we could check selected sdk for our kit, probably we should introduce a bundle.
Check for:
- App::cpanminus
- B::Deparse
- Config
- Devel::Cover
- Devel::Camelcadedb
- Devel::NYTProf
- File::Find
- JSON
- Perl::Critic
- Perl::Tidy
- Tap::Formatter::Camelcade
- Test::Harness
|
non_process
|
suggest to install necessary module before executing tool before starting debugging testing or coverage we could suggest to install all necessary modules install devel cover and then json is pretty annoying as alternative we could check selected sdk for our kit probably we should introduce a bundle check for app cpanminus b deparse config devel cover devel camelcadedb devel nytprof file find json perl critic perl tidy tap formatter camelcade test harness
| 0
|
965
| 3,257,225,453
|
IssuesEvent
|
2015-10-20 16:55:25
|
EarthSystemCoG/COG
|
https://api.github.com/repos/EarthSystemCoG/COG
|
opened
|
Be able to prioritize SOLR results
|
data service Feature requests
|
WHO: Bjorn Stevens
It would be great if in the opening search window, on the home page, one could type, 1pctCO2 AMON rsut rlut tas and get all the latest versions of all models that did the 1pctCO2 run but only the monthly data of the three variables rsut rlut and tas. If one could do this almost all the rest would be gravy.
|
1.0
|
Be able to prioritize SOLR results - WHO: Bjorn Stevens
It would be great if in the opening search window, on the home page, one could type, 1pctCO2 AMON rsut rlut tas and get all the latest versions of all models that did the 1pctCO2 run but only the monthly data of the three variables rsut rlut and tas. If one could do this almost all the rest would be gravy.
|
non_process
|
be able to prioritize solr results who bjorn stevens it would be great if in the opening search window on the home page one could type amon rsut rlut tas and get all the latest versions of all models that did the run but only the monthly data of the three variables rsut rlut and tas if one could do this almost all the rest would be gravy
| 0
|
204,164
| 7,084,874,615
|
IssuesEvent
|
2018-01-11 08:59:40
|
wulkano/kap
|
https://api.github.com/repos/wulkano/kap
|
opened
|
Blacklist redundant apps from the window selector.
|
Priority: Medium
|
**Platform:** MacOS
**Kap Version:** 2.0.0-beta.4 (2.0.0-beta.4.556)
### Steps to reproduce
Currently, a vast amount of redundant apps show up in the window selector that are currently not recordable.
### Workaround
Suggestion: Create a blacklist of known redundant apps that shouldn't show up in the menu.
|
1.0
|
Blacklist redundant apps from the window selector. - **Platform:** MacOS
**Kap Version:** 2.0.0-beta.4 (2.0.0-beta.4.556)
### Steps to reproduce
Currently, a vast amount of redundant apps show up in the window selector that are currently not recordable.
### Workaround
Suggestion: Create a blacklist of known redundant apps that shouldn't show up in the menu.
|
non_process
|
blacklist redundant apps from the window selector platform macos kap version beta beta steps to reproduce currently a vast amount of redundant apps show up in the window selector that are currently not recordable workaround suggestion create a blacklist of known redundant apps that shouldn t show up in the menu
| 0
|
12,507
| 14,961,991,158
|
IssuesEvent
|
2021-01-27 08:38:40
|
GoogleCloudPlatform/fda-mystudies
|
https://api.github.com/repos/GoogleCloudPlatform/fda-mystudies
|
closed
|
Make auth server login screens error toasts more visible
|
Auth server Feature request P1 Process: Fixed Process: Tested dev
|
Right now when a user is not found or a password is expired the login screen (participant manager) shows a red toast at the bottom of the screen. It is currently difficult to see and notice. To make it easier to see:
1. Increase toast duration (currently it looks like 1 second, so perhaps 5 seconds would be good)
1. Move toast to the space between "sign in" and "email" if there is room (this is lower priority than making the duration longer as I imagine this is more work than changing the timer on the toast)
This same issue occurs in Android - the error message is often below the bottom of the screen and so goes unnoticed by the user.
|
2.0
|
Make auth server login screens error toasts more visible - Right now when a user is not found or a password is expired the login screen (participant manager) shows a red toast at the bottom of the screen. It is currently difficult to see and notice. To make it easier to see:
1. Increase toast duration (currently it looks like 1 second, so perhaps 5 seconds would be good)
1. Move toast to the space between "sign in" and "email" if there is room (this is lower priority than making the duration longer as I imagine this is more work than changing the timer on the toast)
This same issue occurs in Android - the error message is often below the bottom of the screen and so goes unnoticed by the user.
|
process
|
make auth server login screens error toasts more visible right now when a user is not found or a password is expired the login screen participant manager shows a red toast at the bottom of the screen it is currently difficult to see and notice to make it easier to see increase toast duration currently it looks like second so perhaps seconds would be good move toast to the space between sign in and email if there is room this is lower priority than making the duration longer as i imagine this is more work than changing the timer on the toast this same issue occurs in android the error message is often below the bottom of the screen and so goes unnoticed by the user
| 1
|
65,013
| 26,949,045,264
|
IssuesEvent
|
2023-02-08 10:17:51
|
tuna/issues
|
https://api.github.com/repos/tuna/issues
|
closed
|
使用llvm镜像404:https://mirrors.tuna.tsinghua.edu.cn/llvm-apt/
|
Service Issue
|
### 先决条件 (Prerequisites)
- [X] 我已确认这个问题没有在[其他 issues](https://github.com/tuna/issues/issues)中提出过。
I am sure that this problem has NEVER been discussed in [other issues](https://github.com/tuna/issues/issues).
### 发生了什么(What happened)
按照https://mirrors.tuna.tsinghua.edu.cn/help/llvm-apt/ 文档操作。执行apt-get update 报一下异常
```code
错误:11 https://mirrors.tuna.tsinghua.edu.cn/llvm-apt/jammy llvm-toolchain-jammy/main i386 Packages
404 Not Found [IP: 101.6.15.130 443]
```
### 期望的现象(What you expected to happen)
正常使用,不报404
### 如何重现此问题(How to reproduce it)
按照文档执行
### 操作系统(OS Version)
Ubuntu22.04
### 浏览器(如果适用)(Browser version, if applicable)
_No response_
### 其他环境(Other environments)
_No response_
### 其他需要说明的事项(Anything else we need to know)
_No response_
|
1.0
|
使用llvm镜像404:https://mirrors.tuna.tsinghua.edu.cn/llvm-apt/ - ### 先决条件 (Prerequisites)
- [X] 我已确认这个问题没有在[其他 issues](https://github.com/tuna/issues/issues)中提出过。
I am sure that this problem has NEVER been discussed in [other issues](https://github.com/tuna/issues/issues).
### 发生了什么(What happened)
按照https://mirrors.tuna.tsinghua.edu.cn/help/llvm-apt/ 文档操作。执行apt-get update 报一下异常
```code
错误:11 https://mirrors.tuna.tsinghua.edu.cn/llvm-apt/jammy llvm-toolchain-jammy/main i386 Packages
404 Not Found [IP: 101.6.15.130 443]
```
### 期望的现象(What you expected to happen)
正常使用,不报404
### 如何重现此问题(How to reproduce it)
按照文档执行
### 操作系统(OS Version)
Ubuntu22.04
### 浏览器(如果适用)(Browser version, if applicable)
_No response_
### 其他环境(Other environments)
_No response_
### 其他需要说明的事项(Anything else we need to know)
_No response_
|
non_process
|
: 先决条件 prerequisites 我已确认这个问题没有在 i am sure that this problem has never been discussed in 发生了什么(what happened) 按照 文档操作。执行apt get update 报一下异常 code 错误 llvm toolchain jammy main packages not found 期望的现象(what you expected to happen) 正常使用, 如何重现此问题(how to reproduce it) 按照文档执行 操作系统(os version) 浏览器(如果适用)(browser version if applicable) no response 其他环境(other environments) no response 其他需要说明的事项(anything else we need to know) no response
| 0
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.