
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
pytest-dev/pytest-django | pytest | 465 | Update setuptools_scm-1.11.1 requirement or unpin | I have a little question:
Do you really need a hard dependency to setuptools_scm-1.11.1.tar.gz?
I have some packages which needs setuptools_scm-1.15.0.tar.gz and collide with this.
Actually I do the following:
1. install setuptools_scm-1.11.1.tar.gz
2. install pytest-django-3.1.2.tar.gz
3. install setup... | closed | 2017-02-22T10:22:55Z | 2017-02-22T19:32:23Z | https://github.com/pytest-dev/pytest-django/issues/465 | [] | stephanema | 3 |
miguelgrinberg/microblog | flask | 2 | setup instructions don't mention mysql_config dependency | From the same build circumstances as mentioned in issue https://github.com/miguelgrinberg/microblog/issues/1
The step to build mysql-python fails for lack of mysql_config.
The fix is to run :
sudo apt-get -y install libmysqlclient-dev
| closed | 2013-06-29T10:57:09Z | 2013-06-30T01:31:19Z | https://github.com/miguelgrinberg/microblog/issues/2 | [] | martinhbramwell | 1 |
davidteather/TikTok-Api | api | 585 | [BUG] - playwright._impl._api_types.Error: Protocol error (Playwright.enable): Browser closed. on ubuntu server | It runs fine on my computer, but it doesn't run on my ubuntu server. I installed the package, and then I did the command
"python3 -m install playwright", and it installed everything but I still get the error on my ubuntu server. Any ideas on how to fix this? Here is the error that I get
- ubuntu: 20.04.2
- TikTo... | closed | 2021-05-10T22:52:41Z | 2021-05-14T17:05:51Z | https://github.com/davidteather/TikTok-Api/issues/585 | [
"bug"
] | DevJChen | 3 |
mljar/mercury | data-visualization | 1 | Clear all tasks on refresh in watch mode | closed | 2022-01-05T11:20:50Z | 2022-01-07T15:32:19Z | https://github.com/mljar/mercury/issues/1 | [] | pplonski | 0 | |
PrefectHQ/prefect | automation | 17,281 | Duplicate flow runs scheduled after upgrading server to 3.2.2 | ### Bug summary
After upgrading our self-hosted prefect server to 3.2.2 we found all already (cron) scheduled flow runs were duplicated. As many of our flows require resource locks we noticed this bug when flows started failing to acquire those locks as the duplicated flows created a race condition.
It appears that t... | closed | 2025-02-25T20:55:15Z | 2025-02-26T16:04:04Z | https://github.com/PrefectHQ/prefect/issues/17281 | [
"bug"
] | Ultramann | 2 |
huggingface/diffusers | pytorch | 10,412 | SD3.5-Large DreamBooth Training - Over 80GB VRAM Usage | ### Describe the bug
⚠️ We are running out of memory on step 0
❕It does work without '--train_text_encoder'. It seems that there might be a memory leak or issue with training the text encoder with the current script / model.
❓Does it make sense that the model uses over 80GB of VRAM?
❓Do you have any recommendatio... | open | 2024-12-30T15:01:12Z | 2025-01-29T15:02:52Z | https://github.com/huggingface/diffusers/issues/10412 | [
"bug",
"stale"
] | deman311 | 2 |
gradio-app/gradio | deep-learning | 10,795 | [NPM PACKAGE] unable to import Client. ERR_PACKAGE_PATH_NOT_EXPORTED | ### Describe the bug
Using NESTjs and want to call Gradio client, getting error:
```bash
[7:20:35 PM] File change detected. Starting incremental compilation...
[7:20:35 PM] Found 0 errors. Watching for file changes.
node:internal/modules/cjs/loader:553
throw e;
^
Error [ERR_PACKAGE_PATH_NOT_EXPORTED]: ... | open | 2025-03-12T13:57:54Z | 2025-03-12T19:56:36Z | https://github.com/gradio-app/gradio/issues/10795 | [
"bug",
"svelte",
"API"
] | Himasnhu-AT | 0 |
coqui-ai/TTS | pytorch | 3,735 | [Bug] Error during installation on Mac | ### Describe the bug
Error during installation throws the following error:
```
Error compiling Cython file:
------------------------------------------------------------
...
cdef BlasFunctions blas_functions
blas_functions.dot = _dot[double]
blas_functions... | closed | 2024-05-12T23:06:03Z | 2024-05-17T16:04:34Z | https://github.com/coqui-ai/TTS/issues/3735 | [
"bug"
] | mirodil-ml | 1 |
d2l-ai/d2l-en | data-science | 2,478 | Chapter 15.4. Pretraining word2vec: AttributeError: Can't pickle local object 'load_data_ptb.<locals>.PTBDataset' | AttributeError: Can't pickle local object 'load_data_ptb.<locals>.PTBDataset'

can anyone help with this error? | open | 2023-04-30T20:01:53Z | 2023-07-12T03:00:55Z | https://github.com/d2l-ai/d2l-en/issues/2478 | [] | keyuchen21 | 2 |
streamlit/streamlit | python | 10,383 | Make st.toast appear/bring it to the front (stack order) when used in st.dialog | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
Not sure to place this as a feature request o... | open | 2025-02-12T20:19:16Z | 2025-02-13T12:10:54Z | https://github.com/streamlit/streamlit/issues/10383 | [
"type:enhancement",
"feature:st.toast",
"feature:st.dialog"
] | Socvest | 4 |
pytest-dev/pytest-html | pytest | 466 | new feature request: adding a textfile as a clickable url to report | I'm trying to add a file in .extras as a file and clickable url.
extras.html adds html and extras.text adds text directly into the report
It is the collected log along with the test it is way to big to show in report, but you can click it as you can with extras.images
Anyone having an example or idea on how to d... | open | 2021-08-20T14:23:53Z | 2022-01-14T19:01:17Z | https://github.com/pytest-dev/pytest-html/issues/466 | [] | fenchu | 1 |
littlecodersh/ItChat | api | 750 | 请问有本项目的微信或者 qq 群吗 | 如题
希望有群可以交流,共同分享学习 | open | 2018-10-24T11:32:12Z | 2018-11-21T09:57:14Z | https://github.com/littlecodersh/ItChat/issues/750 | [] | kollyQAQ | 3 |
jupyter/nbgrader | jupyter | 1,297 | nbgrader issue with unicode | ### Operating system
Linux RedHat 7.4
### `nbgrader --version`
0.6.1
### `jupyterhub --version` (if used with JupyterHub)
1.0.0
### `jupyter notebook --version`
5.5.0
A prof ran into this problem while running nbgrader:
UnicodeEncodeError: 'charmap' codec can't encode character '\u2080' in position 54... | open | 2020-01-08T17:28:00Z | 2020-01-08T17:28:00Z | https://github.com/jupyter/nbgrader/issues/1297 | [] | jnak12 | 0 |
scrapy/scrapy | python | 6,307 | Scrapy and Great Expectations: Error - __provides__ | ### Description
I am trying to use Scrapy and Great Expectations in the same virtual environment but there is an issue depending on the order I import the packages in.
I created an issue for Great Expectations with additional [details](https://github.com/great-expectations/great_expectations/issues/9698).
They... | closed | 2024-04-05T15:00:38Z | 2024-06-22T12:05:35Z | https://github.com/scrapy/scrapy/issues/6307 | [
"bug"
] | culpgrant | 12 |
labmlai/annotated_deep_learning_paper_implementations | deep-learning | 1 | Save generator and load it only for prediction | Hello,
Thank you for your implementation of cycle gans, it is very clear. I would like to ask if there is a way to save the generators every 500 iterations (exactly when they predict the test images) so I can load them in a different moment and only perform prediction in a specific test set with the loaded model (in... | closed | 2020-10-15T04:12:30Z | 2020-10-27T12:04:35Z | https://github.com/labmlai/annotated_deep_learning_paper_implementations/issues/1 | [
"question"
] | agelosk | 2 |
aleju/imgaug | machine-learning | 687 | Grayscale uses too much memory | When grayscale with alpha=(0,1), it uses more than 20 times the original image.
When alpha=1, use only 5 times more.
Is there a way to make a similar effect by using less memory? | open | 2020-06-09T08:40:49Z | 2020-06-09T08:40:49Z | https://github.com/aleju/imgaug/issues/687 | [] | zmfkzj | 0 |
xlwings/xlwings | automation | 2,059 | Reader: add DateTime support for xls and xlsb | closed | 2022-10-17T13:55:17Z | 2023-05-25T09:12:47Z | https://github.com/xlwings/xlwings/issues/2059 | [
"engine: reader [calamine]"
] | fzumstein | 0 | |
tensorpack/tensorpack | tensorflow | 1,398 | Question about save and load ckpt | I read the doc 'Save and Load models' and use `load_ckpt_vars` to get variables dict from ckpt file. I found it contains all tensors except missing their slots variables like `BatchNorm/beta/Momentum`. When I made some changes and save to ckpt file then restore back to finetune, I found the warning `BatchNorm/beta/Mom... | closed | 2020-02-20T08:36:18Z | 2020-02-21T07:15:02Z | https://github.com/tensorpack/tensorpack/issues/1398 | [] | hunterkun | 2 |
sktime/sktime | data-science | 7,804 | [BUG] Segmentation fault in CI | In some recent PR worflow wuns, the tests settings `test-full` `macos` `python3.x` settings seems to be getting into segmentation faults.
The runners donot stop after these faults and keeps on running, holding up the runners leading to a creation of "queue" of PRs waiting for workflow runs.
segmentation fault tracebac... | open | 2025-02-10T15:41:22Z | 2025-02-10T21:06:27Z | https://github.com/sktime/sktime/issues/7804 | [
"bug",
"maintenance"
] | phoeenniixx | 1 |
yeongpin/cursor-free-vip | automation | 210 | [讨论]: 下载下来是文稿 无法打开 | ### Issue 检查清单
- [x] 我理解 Issue 是用于反馈和解决问题的,而非吐槽评论区,将尽可能提供更多信息帮助问题解决。
- [x] 我确认自己需要的是提出问题并且讨论问题,而不是 Bug 反馈或需求建议。
- [x] 我已阅读 [Github Issues](https://github.com/yeongpin/cursor-free-vip/issues) 并搜索了现有的 [开放 Issue](https://github.com/yeongpin/cursor-free-vip/issues) 和 [已关闭 Issue](https://github.com/yeongpin/cursor-free-vip... | closed | 2025-03-12T13:07:49Z | 2025-03-13T03:50:12Z | https://github.com/yeongpin/cursor-free-vip/issues/210 | [
"question"
] | adjoiningWang | 1 |
strawberry-graphql/strawberry-django | graphql | 488 | get_queryset() is not called | I'm trying to add a `.get_queryset()` class method to one of my types, but it is never called when querying. I just put a print on top of the method and it never happens. Fields on the type behave normally so I know the type is in use.
I can't get even the simple example from the docs to work:
```python
@strawbe... | closed | 2024-02-23T15:56:36Z | 2025-03-20T15:57:27Z | https://github.com/strawberry-graphql/strawberry-django/issues/488 | [
"bug"
] | alimony | 8 |
NullArray/AutoSploit | automation | 950 | Divided by zero exception326 | Error: Attempted to divide by zero.326 | closed | 2019-04-19T16:03:42Z | 2019-04-19T16:35:37Z | https://github.com/NullArray/AutoSploit/issues/950 | [] | AutosploitReporter | 0 |
comfyanonymous/ComfyUI | pytorch | 7,083 | Load workflows | ### Your question
Hi,
I've recently updated ComfyUI to v0.3.18 and am having trouble loading my saved workflows. I have multiple workflows stored in my pysssss-workflows folder (storage/pysssss-workflows on mimicpc), but I can't seem to find an option to open them in the new interface.
Previously, there was a Load but... | open | 2025-03-05T09:40:01Z | 2025-03-05T10:24:20Z | https://github.com/comfyanonymous/ComfyUI/issues/7083 | [
"User Support"
] | PaulEvans78 | 3 |
healthchecks/healthchecks | django | 440 | API: allow specifying enabled integrations by name | Suggested in [#376](https://github.com/healthchecks/healthchecks/issues/376#issuecomment-689814284):
> Another way of having less API calls is if you added a parameter to let you pass in the channels by name rather than by id (it would assume channel names are unique) - that way I could skip the extra API call to ge... | closed | 2020-10-07T10:13:28Z | 2020-10-14T12:37:29Z | https://github.com/healthchecks/healthchecks/issues/440 | [] | cuu508 | 0 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 681 | Bug in inference code |
synthesizer/inference.py:
len(inputs) returns you 1 (if demo_cli.py used), but inputs is a list which potentially can have any size. So batched_inputs is not "batched" in any sense.
# Batch inputs
batched_inputs = [inputs[i:i+hparams.synthesis_batch_size]
for i in ... | closed | 2021-02-25T10:20:18Z | 2021-02-28T06:45:25Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/681 | [] | MaratZakirov | 4 |
Skyvern-AI/skyvern | api | 1,586 | How to fix these many errors? | How to fix these errors:
"
Alembic mode: online
Traceback (most recent call last):
File "/usr/local/lib/python3.11/site-packages/sqlalchemy/engine/base.py", line 146, in __init__
self._dbapi_connection = engine.raw_connection()
... | open | 2025-01-17T03:57:07Z | 2025-01-31T20:11:16Z | https://github.com/Skyvern-AI/skyvern/issues/1586 | [
"answered"
] | computer2s | 4 |
takapy0210/nlplot | plotly | 30 | github pagesの追加 | open | 2021-07-11T09:52:34Z | 2021-07-11T09:52:34Z | https://github.com/takapy0210/nlplot/issues/30 | [] | takapy0210 | 0 | |
aeon-toolkit/aeon | scikit-learn | 2,411 | [ENH] AutoETS implementation | ### Describe the feature or idea you want to propose
Our new experimental forecasting module starts with a really fast ETS implementation. The next stage is AutoETS. But how to search the parameter space? There are many alternatives, grid search, nelder mead, stochastic gradient descent etc. It would be really good to... | open | 2024-11-28T09:08:53Z | 2025-01-28T16:50:11Z | https://github.com/aeon-toolkit/aeon/issues/2411 | [
"enhancement",
"forecasting"
] | TonyBagnall | 4 |
ranaroussi/yfinance | pandas | 1,925 | Throw specific errors instead of generic 'Exception' would make for safer and nicer client implementations | ## Summary
Not throwing specific exception make clients error handling to be coupled with weak interfaces in the library. Throwing specific errors means exposing more explicit and stable interface for errors.
## Example
In my implementation I had to look for a sub-string with the specific error message in the ... | closed | 2024-05-07T10:59:54Z | 2024-05-13T08:41:22Z | https://github.com/ranaroussi/yfinance/issues/1925 | [] | marcofognog | 3 |
lux-org/lux | jupyter | 366 | [Feature Request] Show distributions before Correlations | **Is your feature request related to a problem? Please describe.**
Distributions show single dimensions. There are fewer distribution plots than correlations so they can be explored more quickly. Also one has to understand the distributions before they can understand correlations. Therefore, I wonder whether it makes ... | open | 2021-04-19T15:38:45Z | 2021-04-21T22:39:00Z | https://github.com/lux-org/lux/issues/366 | [] | domoritz | 0 |
OFA-Sys/Chinese-CLIP | computer-vision | 87 | 如何将模型部署到移动端 | 仓库中已给出ONNX和TensorRT模型,如何将它们部署到安卓移动端呢? | open | 2023-04-16T08:19:28Z | 2023-04-25T02:36:31Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/87 | [] | SZN712 | 1 |
donnemartin/system-design-primer | python | 148 | Where is 'State' defined in social_graph_snippets.py? | __State__ is currently an _undefined name_ in the context of social_graph_snippets.py so the code would raise a NameError at runtime.
Is __State__ merely an Enum with two items (__visited__ and __unvisited__) or is it more complex than that? If it is just the simple Enum then perhaps it would be cleaner to rename t... | closed | 2018-03-14T11:46:56Z | 2018-07-15T00:01:58Z | https://github.com/donnemartin/system-design-primer/issues/148 | [
"bug"
] | cclauss | 2 |
databricks/koalas | pandas | 2,114 | Pandas 1.2.x support? | What are the plans for support of Pandas 1.2.x in a release? I saw that the CI system has moved there for testing already. Is this imminent or some time away?
**Background:** Pandas 1.2.x has support for `fsspec` to the extend that we need it. Would be nice to also use Koalas in the same session. | open | 2021-03-23T03:12:13Z | 2021-03-24T02:41:35Z | https://github.com/databricks/koalas/issues/2114 | [
"enhancement"
] | markusweimer | 2 |
explosion/spaCy | data-science | 13,528 | Numpy v2.0.0 breaks the ability to download models using spaCy | ## How to reproduce the behaviour
In my dockerfile, I run these commands:
```Dockerfile
FROM --platform=linux/amd64 python:3.12.4
RUN pip install --upgrade pip
RUN pip install torch --index-url https://download.pytorch.org/whl/cpu
RUN pip install spacy
RUN python -m spacy download en_core_web_lg
```
It... | open | 2024-06-16T15:42:21Z | 2024-12-29T11:20:23Z | https://github.com/explosion/spaCy/issues/13528 | [
"bug"
] | afogel | 16 |
mkhorasani/Streamlit-Authenticator | streamlit | 243 | Can't Login in any way | Hello,
I'm just following the official docs but it doesn't work, I can't login either with hashed or not hashed password...
```python
with open('./config.yaml') as file:
config = yaml.load(file, Loader=SafeLoader)
authenticator = stauth.Authenticate(
config['credentials'],
config['cookie']['name'],
... | open | 2024-11-25T11:51:02Z | 2025-03-04T18:07:38Z | https://github.com/mkhorasani/Streamlit-Authenticator/issues/243 | [
"help wanted"
] | diramazioni | 3 |
pywinauto/pywinauto | automation | 657 | Pywinauto type_keys() omits “%” in string | When attempting to input a string 'customer asked for 30% discount' to a form by using type_keys() in Pywinauto 0.6.5, the output it sends is 'customer asked for 30 discount" omitting `%.`
Tried escape character:
```
control.type_keys('customer asked for 30%% discount',with_spaces=True)
control.type_keys('custo... | closed | 2019-01-17T04:11:46Z | 2019-01-18T11:26:15Z | https://github.com/pywinauto/pywinauto/issues/657 | [
"question"
] | medert | 1 |
dmlc/gluon-nlp | numpy | 1,420 | Beam search scorer question | ## Description
Hello , I have a question about the beam search scorer function
scores = (log_probs + scores) / length_penalty
length_penalty = (\frac{K + length}{K + 1})^\alpha
https://github.com/dmlc/gluon-nlp/blob/0484e6494edf0a40c7bac220b5a10d8245324750/src/gluonnlp/sequence_sampler.py#L74
if K = 5, alpha = ... | closed | 2020-11-02T03:13:37Z | 2020-11-02T03:51:50Z | https://github.com/dmlc/gluon-nlp/issues/1420 | [
"bug"
] | carter54 | 1 |
pywinauto/pywinauto | automation | 892 | Click button with pywinauto implies crash of a simple widget QT 5.2 application | ## Expected Behavior
Click on PushButton works
## Actual Behavior
The QT 5.2 application crashes
## Steps to Reproduce the Problem
1. With QT 5.2.1 create a simple widget application with a button
2. Run this application
3. Click on the button with pywinauto (last version) (same behaviour => crash if... | closed | 2020-02-18T23:06:13Z | 2020-02-26T17:33:19Z | https://github.com/pywinauto/pywinauto/issues/892 | [
"duplicate",
"enhancement",
"question",
"3rd-party issue"
] | diblud13 | 3 |
psf/black | python | 4,231 | Remove parentheses around simple top-level expressions | ```
% cat parens.py
(x)
(1)
(yield 42)
([])
({})
(a + b)
% black --unstable --diff parens.py
All done! ✨ 🍰 ✨
1 file would be left unchanged.
```
I think all of these parentheses should be removed.
We should keep parentheses around a top-level expression (ast.Expr) only if:
- There is a comment associa... | open | 2024-02-13T18:27:29Z | 2024-02-13T18:27:29Z | https://github.com/psf/black/issues/4231 | [
"T: enhancement",
"F: parentheses"
] | JelleZijlstra | 0 |
google-research/bert | nlp | 906 | Processing book corpus | Hi team et al,
I'd like to know how to process bookcorpus to pre-training.
I am confusing to process this data.
Should I treat 1 book as a document including all sentences or 1 chapter as a document?
Thanks. | open | 2019-11-10T05:44:07Z | 2021-12-23T03:12:30Z | https://github.com/google-research/bert/issues/906 | [] | ngoanpv | 1 |
feature-engine/feature_engine | scikit-learn | 631 | remove the boston dataset from the user guides | For example for the arbitrary discretizer | closed | 2023-03-09T16:26:00Z | 2023-03-14T11:12:53Z | https://github.com/feature-engine/feature_engine/issues/631 | [] | solegalli | 2 |
idealo/imagededup | computer-vision | 229 | GPU usage suboptimal | So it works on GPU but only uses 6-10% of it. I assume you have not implemented batching yet, still a lot of room for improvement here. | open | 2025-01-20T11:29:10Z | 2025-01-20T11:29:10Z | https://github.com/idealo/imagededup/issues/229 | [] | asusdisciple | 0 |
plotly/dash-html-components | dash | 196 | Release v1.1.4 for Julia | closed | 2021-07-13T15:07:22Z | 2021-07-13T15:21:19Z | https://github.com/plotly/dash-html-components/issues/196 | [] | alexcjohnson | 2 | |
pallets/flask | python | 4,507 | Flask 2.1.0 can't handle request method properly when sending POST repeatedly with an empty body | With the following example:
```python
from flask import Flask
app = Flask(__name__)
@app.route('/', methods=['POST'])
def hello_world():
return 'Hello World!'
if __name__ == '__main__':
app.run()
```
When you set the request body to `{}` with Postman or any HTTP clients, the first request ... | closed | 2022-03-30T08:14:13Z | 2022-04-28T16:58:23Z | https://github.com/pallets/flask/issues/4507 | [] | eleven-f | 6 |
computationalmodelling/nbval | pytest | 147 | Bad magic unexpectedly passes | If I create a new notebook `nb.ipynb` with two cells:
In[1]:
```python
%notmagic
x = 0
raise TypeError
```
In[2]:
```python
x = 1
```
I would expect `python -m pytest -v --nbval-lax nb.ipynb` to fail, but it passes.
```
$ python -m pytest -v --nbval-lax nb.ipynb
==================================... | open | 2020-06-11T11:25:28Z | 2020-06-12T10:55:58Z | https://github.com/computationalmodelling/nbval/issues/147 | [] | ceball | 2 |
ading2210/poe-api | graphql | 51 | editbot bypassing method valid | edit bot to "beaver" or "a2_2",got "server error" response. | closed | 2023-04-18T13:45:12Z | 2023-04-18T18:34:57Z | https://github.com/ading2210/poe-api/issues/51 | [
"wontfix"
] | wingeva1986 | 2 |
fastapi/sqlmodel | sqlalchemy | 418 | Conda Forge | Hello! I have successfully put this package on to Conda Forge, and I have extending the invitation for the owner/maintainers of this package to be maintainers on Conda Forge as well. Let me know if you are interested! Thanks.
https://github.com/conda-forge/sqlmodel-feedstock | closed | 2022-08-28T19:00:47Z | 2022-08-30T17:49:57Z | https://github.com/fastapi/sqlmodel/issues/418 | [
"question",
"answered"
] | thewchan | 3 |
pallets/flask | python | 5,266 | Flask subdomain parameter doesn't work at version 2.3.3 | Bug:
Since Flask version 2.3.3 the subdomain parameter when defining a new route doesn't work only with blueprint.
Include a minimal reproducible example that demonstrates the bug:
An example route which will return 404 Not Found even it should:
```
from flask import Flask
app = Flask(__name__, template... | closed | 2023-09-25T13:50:36Z | 2023-10-11T00:05:25Z | https://github.com/pallets/flask/issues/5266 | [] | GoekhanDev | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 804 | Dataset for Colorization | Which dataset did you use for colorization? Can you share that? | open | 2019-10-18T08:00:21Z | 2019-11-19T20:40:37Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/804 | [] | rabiaali95 | 3 |
davidteather/TikTok-Api | api | 678 | by_trending returns wrong values | calling api.by_trending returns only 10 oficial tiktok video
for exemple this code:
```python
from TikTokApi import TikTokApi
# tested with and without custom_verifyFp
api = TikTokApi.get_instance(custom_verifyFp="" )
results = api.by_trending(count=20)
print(len(results))
for res in results:
print(re... | closed | 2021-08-28T17:31:20Z | 2021-08-28T17:34:11Z | https://github.com/davidteather/TikTok-Api/issues/678 | [] | teo-goulois | 1 |
fastapi-users/fastapi-users | fastapi | 1,301 | Support for Python 3.12 | ## Describe the bug
Importing `fastapi_users` fails with Python 3.12.
## To Reproduce
Steps to reproduce the behavior:
1. Install `fastapi-users` v12.1.2 and run Python 3.12.
2. Execute `import fastapi_users`.
3. See error `ModuleNotFoundError: No module named 'pkg_resources'`.
## Expected behavior
Fa... | closed | 2023-10-10T08:49:59Z | 2024-03-11T13:31:11Z | https://github.com/fastapi-users/fastapi-users/issues/1301 | [
"bug"
] | davidbrochart | 11 |
ivy-llc/ivy | numpy | 28,352 | fix `complex` dtype support at `paddle backend` in `ivy.maximum` | closed | 2024-02-20T15:18:59Z | 2024-02-20T17:59:05Z | https://github.com/ivy-llc/ivy/issues/28352 | [
"Sub Task"
] | samthakur587 | 0 | |
cobrateam/splinter | automation | 602 | Headless mode in remote webdriver | Not sure if its possible, but it would be great if we can look into getting headless mode working via remote webdriver.
Referencing discussion on https://github.com/cobrateam/splinter/issues/597#issuecomment-377111031 | closed | 2018-04-16T01:41:58Z | 2023-01-25T02:39:14Z | https://github.com/cobrateam/splinter/issues/602 | [] | j7an | 1 |
pyg-team/pytorch_geometric | pytorch | 8,817 | in utils.subgraph.py RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu) | ### 🐛 Describe the bug
in utils.subgraph.py
edge_mask = node_mask[edge_index[0]] & node_mask[edge_index[1]]
RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
because edge_index on 'cuda:0' and node_mask on 'cpu'
being solved with: node_mask=node_mask.to(device... | closed | 2024-01-24T16:07:02Z | 2024-01-29T13:01:03Z | https://github.com/pyg-team/pytorch_geometric/issues/8817 | [
"bug"
] | allierc | 4 |
sktime/pytorch-forecasting | pandas | 1,316 | Predicted output length for new test data is not correct (How do you define newly test data to the model) | - PyTorch-Forecasting version:2.0
- PyTorch version:2.0
- Python version 3.10
- Operating System:
Hi everyone,
I have trained an NBeats model from PyTorch forecasting using [[TimeSeriesDataSet — pytorch-forecasting documentation](https://pytorch-forecasting.readthedocs.io/en/stable/api/pytorch_forecasting.data.t... | open | 2023-05-27T08:11:04Z | 2023-06-03T17:45:01Z | https://github.com/sktime/pytorch-forecasting/issues/1316 | [] | manitadayon | 5 |
ageitgey/face_recognition | machine-learning | 698 | How can i do ? | Hello,
how can i do insert to db with this array and how can i do to convert this to json
```
unknown_face_encodings = face_recognition.face_encodings(img)
// export array
[-0.09634063, 0.12095481, -0.00436332, -0.07643753, 0.0080383,
0.01902981, -0.07184699, -0.09383309, ... | closed | 2018-12-07T10:23:23Z | 2018-12-09T11:44:54Z | https://github.com/ageitgey/face_recognition/issues/698 | [] | wwwakcan | 1 |
rthalley/dnspython | asyncio | 169 | Bad code type for URI RR conforming to RFC 7553 | Hi
Code type for URI RR IS set to 253 in CERT.py.
But the RFC tell us to use the type number 256.
Otherwise update request doesn't work with DNS server (i got FORMERR rcode)
Best regards
| closed | 2016-05-31T14:27:36Z | 2016-06-01T15:34:04Z | https://github.com/rthalley/dnspython/issues/169 | [] | Axili39 | 4 |
aio-libs/aiohttp | asyncio | 9,882 | Cathing internal exceptions | ### Describe the bug
How can I catch errors like this while using `aiohttp.web.Application()`:
```
Error handling request
Traceback (most recent call last):
File "/usr/local/lib/python3.11/dist-packages/aiohttp/web_protocol.py", line 332, in data_received
messages, upgraded, tail = self._request_parser.fe... | closed | 2024-11-14T19:05:06Z | 2024-11-15T01:17:31Z | https://github.com/aio-libs/aiohttp/issues/9882 | [
"bug"
] | daniel-kukiela | 1 |
litestar-org/litestar | api | 3,930 | Docs: Provide examples of how to create middleware | ### Summary
For those used to thinking of a [server as a function](https://monkey.org/~marius/funsrv.pdf), which Starlette's `BaseHTTPMiddleware` does (caveat: it [has its own problems](https://github.com/encode/starlette/issues/1678)), ASGI middleware can be quite confusing for two reasons:
1. The mapping of ASG... | open | 2025-01-07T00:08:01Z | 2025-01-07T00:08:23Z | https://github.com/litestar-org/litestar/issues/3930 | [
"Documentation :books:"
] | marcuslimdw | 0 |
yuka-friends/Windrecorder | streamlit | 262 | Search Annotation Idea | Hey man,
Do you think you can add a annotation feature to search results and save option like next to flag mark for notes etc?
We can highlight the video frame, draw, annotate, etc. also any where over the UI interface browser, and have it saved as a library of notes. Specifically for whatever we try to find in sear... | closed | 2025-01-27T09:23:31Z | 2025-02-08T01:45:18Z | https://github.com/yuka-friends/Windrecorder/issues/262 | [
"enhancement"
] | morningstar41131411811717116112213 | 8 |
mkhorasani/Streamlit-Authenticator | streamlit | 239 | using exact documentation, i can login rbriggs, but i cant login jsmith | hi, i try your code and your exact documentation, but why i can login "rbriggs" with his password "def", but i cant login jsmith with password "abc"? also you can update your documentation in installation section, add -> from streamlit_authenticator.utilities import (CredentialsError, ForgotError,Hasher,LoginError,Reg... | closed | 2024-10-29T11:50:28Z | 2024-10-29T13:43:35Z | https://github.com/mkhorasani/Streamlit-Authenticator/issues/239 | [
"help wanted"
] | rhavif-budiman | 12 |
coqui-ai/TTS | deep-learning | 2,800 | [Bug] FastSpeech2 Expanding Tensor RunTimeError | ### Describe the bug
I'm trying to train with Fastspeech2 on a custom dataset with the LJSpeech format and am running into this error (please note that I have done a clean install as directed by the repo):
The error message I got:
```
> EPOCH: 0/10000
--> /workspace/fastspeech2_ljspeech-July-25-2023_02+13PM-0... | closed | 2023-07-25T14:27:36Z | 2023-07-31T13:20:03Z | https://github.com/coqui-ai/TTS/issues/2800 | [
"bug"
] | zohaib-khan5040 | 2 |
plotly/dash | data-visualization | 3,106 | Search param removes values after ampersand, introduced in 2.18.2 | I pass to one of my pages a search string, like:
?param1=something¶m2=something2
Accessing it uding:
def layout(**kwargs):
In 2.18.1, this works for values that included ampersand. For example:
?param1=something&bla¶m2=something2
would result in
kwargs[param1]='something&bla'
With 2.18.2 I get just:
kwargs[... | open | 2024-12-12T11:43:21Z | 2025-01-17T14:05:16Z | https://github.com/plotly/dash/issues/3106 | [
"regression",
"bug",
"P2"
] | ezwc | 6 |
PokeAPI/pokeapi | api | 187 | super-contest-effect skips id | Hey there, thanks for this amazing resource!
I was making your recommendation and persisting the dataset to a personal database when I hit a snag. For super-contest-effects, I was looping over the results and would get a 404 on id 3. Sure enough, id 3 doesn't exist! I've handled this in my code, but I am unsure of how... | closed | 2016-05-12T12:31:37Z | 2016-05-13T03:37:03Z | https://github.com/PokeAPI/pokeapi/issues/187 | [] | zberk | 2 |
sinaptik-ai/pandas-ai | pandas | 1,263 | Update DuckDB version to the new major release 1.0 | ### 🚀 The feature
It would be a good time to upgrade the duckdb package version to the new major release 1.0, since it's the latest stable version from where most of the APIs should be final.
https://github.com/Sinaptik-AI/pandas-ai/blob/f895e5feb3a4a657ca866905748d323fe03d1adb/pyproject.toml#L19
### Motivati... | closed | 2024-07-02T11:31:40Z | 2024-10-08T16:08:22Z | https://github.com/sinaptik-ai/pandas-ai/issues/1263 | [
"enhancement"
] | pedrosalgadowork | 0 |
ultralytics/ultralytics | computer-vision | 19,239 | How to test the latency speed? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Thank you for your work. I would like to ask how you measured the speed of Y... | closed | 2025-02-14T03:04:48Z | 2025-02-15T03:17:23Z | https://github.com/ultralytics/ultralytics/issues/19239 | [
"question",
"detect",
"exports"
] | sunsmarterjie | 8 |
proplot-dev/proplot | matplotlib | 343 | Artefacts in hist2d and hexbin output | When I'm making hist2d or hexbin plots in `proplot`, I have an issue where in the hist2d the rectangles arent correctly shaped, specifically it seems the lowest pixel row, and when I use hexbin, some of the hexes appear to be smaller or below other hexes.
Proplot code:
```python
import proplot as pplt
import nump... | open | 2022-02-16T11:59:56Z | 2022-02-17T10:09:32Z | https://github.com/proplot-dev/proplot/issues/343 | [
"enhancement"
] | Jhsmit | 3 |
fastapi/sqlmodel | sqlalchemy | 308 | failed to sync data from sqlite to mysql using sqlmodel | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X] I al... | closed | 2022-04-20T09:26:05Z | 2022-04-26T02:58:49Z | https://github.com/fastapi/sqlmodel/issues/308 | [
"question"
] | mr-m0nst3r | 3 |
deezer/spleeter | deep-learning | 162 | [Bug] Resource exhausted | ## Resource exhausted: OOM when allocating tensor with shape[2,21803,2049]
I'm running `spleeter-gpu` and I get the following error amongst many more:
```
Resource exhausted: OOM when allocating tensor with shape[2,21803,2049] and type complex64 on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bf... | closed | 2019-12-05T13:41:22Z | 2020-05-23T02:25:53Z | https://github.com/deezer/spleeter/issues/162 | [
"bug",
"GPU",
"Tensorflow"
] | aidv | 8 |
encode/databases | sqlalchemy | 580 | create table does not create unique keys and indexes | By defining the index on the columns and as a unique key, the table is created with the CreateTable function, but the keys are not.
```py
users = Table(
'users',
metadata,
Column('id', Integer, primary_key=True),
Column('name', String(length=255)),
Column('email', String(length=255), unique... | open | 2024-01-20T15:39:45Z | 2024-01-20T15:39:45Z | https://github.com/encode/databases/issues/580 | [] | YuriFontella | 0 |
pandas-dev/pandas | pandas | 61,135 | Issue Title Here | Description of the issue goes here. | closed | 2025-03-17T07:41:22Z | 2025-03-17T07:42:01Z | https://github.com/pandas-dev/pandas/issues/61135 | [] | saurav-chakravorty | 0 |
deeppavlov/DeepPavlov | tensorflow | 1,467 | Windows support for DeepPavlov v0.14.1 and v0.15.0 | **DeepPavlov version** : 0.14.1 and 0.15.0
**Python version**: 3.7
**Operating system** (ubuntu linux, windows, ...): Windows 10
**Issue**:
Attempting to upgrade to v0.14.1 or v0.15.0 encounters an error on Windows as uvloop is not supported on Windows. Is this a noted issue or are there any workarounds?
See... | closed | 2021-07-21T19:24:20Z | 2022-11-09T00:15:14Z | https://github.com/deeppavlov/DeepPavlov/issues/1467 | [
"bug"
] | priyankshah7 | 6 |
jonaswinkler/paperless-ng | django | 794 | [BUG] Error storing parsed document to postgres | **Describe the bug**
This is against paperless-ng 1.3.2
Several (non-scanned) PDFs had the same error while being consumed:
`A string literal cannot contain NUL (0x00) characters`
I believe that's postgres complaining - the top search results give a very relevant [Django+Postgres issue](https://stackoverflow... | closed | 2021-03-19T18:31:29Z | 2021-04-06T19:55:21Z | https://github.com/jonaswinkler/paperless-ng/issues/794 | [
"bug",
"fixed in next release"
] | jessedp | 8 |
joouha/euporie | jupyter | 94 | Installation issues | Hi,
I think this could be a great deal for my dev workflow, only if I manage to get it to work. So far, nothing works as expected. Here some insights:

When opening euporie-notebook, the ... | closed | 2023-08-19T23:26:08Z | 2024-01-18T13:21:52Z | https://github.com/joouha/euporie/issues/94 | [] | datacubeR | 3 |
dmlc/gluon-cv | computer-vision | 1,079 | [Semantic Segmentation]`iters_per_epoch` computed incorrectly in training script? | Looking at the input to LRScheduler from Semantic segmentation [training script](https://github.com/dmlc/gluon-cv/blob/master/scripts/segmentation/train.py#L151), shouldn't it be `len(self.train_data) // self.args.batch_size` which is the number of batches? | closed | 2019-12-04T22:08:38Z | 2019-12-05T21:18:48Z | https://github.com/dmlc/gluon-cv/issues/1079 | [] | chenliu0831 | 4 |
microsoft/qlib | deep-learning | 1,884 | Which two time series is used in CORR5? | ## ❓ Questions and Help
I was unable to find how the technical indicator CORR5 is calculated. Please advice which two time series were taken?

Thank you,
Vishal | closed | 2025-01-14T11:56:49Z | 2025-01-19T11:34:18Z | https://github.com/microsoft/qlib/issues/1884 | [
"question"
] | vishalkhialani | 2 |
streamlit/streamlit | data-visualization | 10,722 | Add a bottom layout container | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
Add a `st.bottom` root container. This container behaves similarly to st.sidebar but is always pinned to the ... | open | 2025-03-11T18:37:29Z | 2025-03-11T19:22:06Z | https://github.com/streamlit/streamlit/issues/10722 | [
"type:enhancement",
"area:layout"
] | lukasmasuch | 1 |
sktime/sktime | scikit-learn | 7,325 | [MNT] CI timeouts on macos-13, test-full | The macos-13 CI times out in the `test_full` workflow - even on pull requests with minimal changes, where no suspect code should be run.
We ought to investigate this.
Example: https://github.com/sktime/sktime/pull/7288
Potential solution: https://github.com/sktime/sktime/pull/7275 | open | 2024-10-23T08:46:58Z | 2024-10-23T08:47:34Z | https://github.com/sktime/sktime/issues/7325 | [
"maintenance"
] | fkiraly | 0 |
flairNLP/flair | nlp | 3,024 | Wrong context preperation in SequenceTagger.predict() | Hi everyone,
I finetuned a TransformerWordEmbeddings based on 'microsoft/mdeberta-v3-base' for a NER task and set use_context=True. I noticed some discrepancy between the test that happens automatically after the training (implemented by flair) and the tests that I do with SequenceTagger manually afterwards. After d... | closed | 2022-12-13T13:28:39Z | 2023-02-20T22:57:09Z | https://github.com/flairNLP/flair/issues/3024 | [
"fix-for-release-0.12"
] | mohammad-al-zoubi | 4 |
saulpw/visidata | pandas | 1,568 | [sqlite/addcol-incr] addcol-incr column shows only null values in dup-selected sheet | **Small description**
In a SQLite sheet, addcol-incr `i`, then select some rows, then `"` dup-select. New sheet has the column but only with null values.
**Expected result**
The incr column would have the values from the original sheet.
**Actual result with screenshot**
https://asciinema.org/a/xIcI3lNiGpYtQ... | closed | 2022-10-15T18:53:58Z | 2023-01-06T01:07:42Z | https://github.com/saulpw/visidata/issues/1568 | [
"bug",
"fixed"
] | frosencrantz | 1 |
chatopera/Synonyms | nlp | 77 | absl-py version conflict | # description
synonyms依赖absl-py=0.1.10,但tensorflow1.13.1依赖absl-py>=0.4,无法共存。
## current
## expected
升级absl-py到0.4版本以上
# solution
# environment
ubuntu16.04,linux4.4.0,python2.7
* version:
The commit hash (`git rev-parse HEAD`)
| closed | 2019-03-11T02:51:31Z | 2019-04-21T01:20:22Z | https://github.com/chatopera/Synonyms/issues/77 | [] | andyxzq | 1 |
explosion/spaCy | data-science | 13,751 | Apple and Docker support | I'm using Spacy 3.8.4 on a MacMin with M4PRO chip and this works great.
When trying to build a Docker container it fails because of blis and thinc compatiblity.
SO i can run it from my virtual environment which works but on our development platform we use a MacBook Pro with M1Max chip and pip install spacy and pip inst... | open | 2025-02-12T13:22:27Z | 2025-03-20T11:39:33Z | https://github.com/explosion/spaCy/issues/13751 | [] | arikivandeput | 2 |
pytest-dev/pytest-html | pytest | 438 | Output the stdout in the use case to the console and html report at the same time | I‘m useing pytest-html and find the plugin generally fantastic.
But I have been in contact with pytest-html for a short time. During the use, I found that adding the'-s' parameter to the pytest command can display the standard output of the use case to the console, but the standard output of the html report cannot be ... | open | 2021-01-06T08:35:19Z | 2021-02-12T09:27:07Z | https://github.com/pytest-dev/pytest-html/issues/438 | [] | wangqian0818 | 2 |
gunthercox/ChatterBot | machine-learning | 2,330 | An error in installing chatterbot | I have used the command pip install git+git://github.com/gunthercox/ChatterBot.git@master.
But i received an error:subprocess-exited-with-error
Exit code:128
Note:This error originates from a subprocess and is likely not a problem with pip.
Kindly help me to fix this issue......
| closed | 2023-10-24T11:10:56Z | 2025-02-17T19:23:15Z | https://github.com/gunthercox/ChatterBot/issues/2330 | [] | AmalDeepthi | 2 |
healthchecks/healthchecks | django | 92 | expose publicly accessible OK/NOT_OK curlable URL per check | This idea is somewhat similar to the publicly accessible badges per tag, but the feature request here is a text string per check (rather then svg image per tag).
It would be cool if a keyword is exposed at a per check unique URL so that I can poll whether a healthcheck is still in good shape or not.
health check in g... | closed | 2016-10-08T09:55:39Z | 2017-06-29T13:12:59Z | https://github.com/healthchecks/healthchecks/issues/92 | [] | job | 8 |
SYSTRAN/faster-whisper | deep-learning | 584 | CUDA 12.1 and CUBLAS and CUDNN without having to compile from source | Is CUDA 12.1 support coming or in the works? Just curious since faster-whisper keeps looking for cublas11.dll...and although I don't use cudnn, I'm assuming that would be another aspect to consider? Thanks. | closed | 2023-11-26T16:40:45Z | 2024-11-26T12:28:21Z | https://github.com/SYSTRAN/faster-whisper/issues/584 | [] | BBC-Esq | 33 |
vitalik/django-ninja | rest-api | 1,159 | [BUG] CustomParser request header issue when sending json and file | **Bug description**
The challenge encountered arises within the `CustomParser` during the instantiation of the `parse_body` component. This occurs when handling requests that may include both file uploads and JSON payloads. The request is processed utilizing an instance from `_HttpRequest`. However, a noted limitation... | open | 2024-05-09T14:07:16Z | 2024-05-09T14:09:50Z | https://github.com/vitalik/django-ninja/issues/1159 | [] | BQBB | 0 |
scikit-tda/kepler-mapper | data-visualization | 160 | What is the meaning of colors? | Hello,
What is the meaning of colors in the visualization? Can you please update documentation with it?
Thanks! | closed | 2019-04-03T13:22:24Z | 2019-04-12T11:02:26Z | https://github.com/scikit-tda/kepler-mapper/issues/160 | [] | larionov-s | 4 |
axnsan12/drf-yasg | rest-api | 383 | Try-it-out presenting wrong input type in swagger's UI | Howdy - a deep dive into the documentation isn't getting me anywhere so hopefully someone can help here.
I've got a model with a lookup field generated using `hashid_field.HashidField()` as provided by the [django-hash-field](https://github.com/nshafer/django-hashid-field) library.
I've got my serializers all hoo... | closed | 2019-06-14T15:23:14Z | 2019-06-14T15:44:42Z | https://github.com/axnsan12/drf-yasg/issues/383 | [] | ColinWaddell | 3 |
pyro-ppl/numpyro | numpy | 1,921 | Raise a warning to disable progress_bar when chain_method is a callable | When chain_method is a callable, we can't control how progress bar logic is interacted with those callables, hence we should raise a warning to inform users to set `progress_bar=False` in the MCMC construction.
Context: https://github.com/pyro-ppl/numpyro/issues/1725#issuecomment-2508621736
cc @mdmould | closed | 2024-12-01T12:54:14Z | 2024-12-04T15:53:58Z | https://github.com/pyro-ppl/numpyro/issues/1921 | [
"warnings & errors"
] | fehiepsi | 0 |
jwkvam/bowtie | plotly | 262 | Error building with webpack | ```python
yarn install v1.22.4
warning package.json: No license field
warning No license field
[1/4] Resolving packages...
success Already up-to-date.
Done in 0.45s.
'.' is not recognized as an internal or external command,
operable program or batch file.
Traceback (most recent call last):
File "example.py"... | open | 2020-04-07T18:06:54Z | 2020-04-07T18:06:54Z | https://github.com/jwkvam/bowtie/issues/262 | [] | SabarishVT | 0 |
streamlit/streamlit | python | 10,424 | URL: http://localhost:8080 | ### Message
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false.
You can now view your Streamlit app in your browser.
URL: http://localhost:8080 | closed | 2025-02-18T07:39:53Z | 2025-02-18T09:58:29Z | https://github.com/streamlit/streamlit/issues/10424 | [
"type:kudos"
] | gn9209366 | 0 |
aminalaee/sqladmin | sqlalchemy | 474 | Detail and Edit view queries make joins for all related models even if those rrelationships are not specified as fields | ### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
My Stack:
- FastAPI
- SqlModel
- SqlAdmin
- PostgreSQL 12
If I have a SqlAdmin `ModelView` for a SqlModel model with many relationships def... | closed | 2023-04-19T17:07:26Z | 2023-05-10T23:34:18Z | https://github.com/aminalaee/sqladmin/issues/474 | [] | FFX01 | 2 |
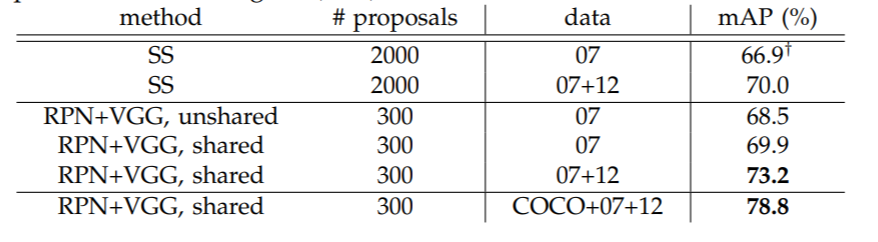
WZMIAOMIAO/deep-learning-for-image-processing | deep-learning | 254 | 在VOC07上跑的结果比原论文低了约7%的mAP[0.5] | 在VOC2007的trainval图片上训练,在VOC2007test图片上测试结果是63%mAP[0.5] 但是Faster RCNN论文中提到的 测试结果应该是接近70%的(不过论文中proposals是300) 请问是因为某些设定不一样嘛? 必如 冻结了backbone的一些层,可是如果VOC数据不够的话 冻结了效果不该更好吗?
| closed | 2021-05-10T20:39:29Z | 2021-05-22T02:19:35Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/254 | [] | LinfengYuan1997 | 1 |
axnsan12/drf-yasg | django | 140 | Allow use of custom OpenAPISchemaGenerator in generate_swagger command | The `generate_swagger` always uses `OpenAPISchemaGenerator`, it would be great to use custom schema generator defined via `SWAGGER_SETTINGS`. | closed | 2018-06-08T18:58:27Z | 2018-06-16T13:31:33Z | https://github.com/axnsan12/drf-yasg/issues/140 | [] | intellisense | 0 |
matplotlib/mplfinance | matplotlib | 51 | err = f'NOT is_color_like() for {key}[\'{updown}\'] = {colors[updown]}' | Hi,
Getting this error:
Debian, Python 3.5
import mplfinance as mpf
File "/usr/local/lib/python3.5/dist-packages/mplfinance/__init__.py", line 1, in <module>
from mplfinance.plotting import plot, make_addplot
File "/usr/local/lib/python3.5/dist-packages/mplfinance/plotting.py", line 15, in <modu... | closed | 2020-03-12T19:53:51Z | 2020-03-15T12:15:12Z | https://github.com/matplotlib/mplfinance/issues/51 | [
"question"
] | thePragmaticOwl | 8 |
ageitgey/face_recognition | machine-learning | 1,093 | face_distance function | * face_recognition version: 1.2.3
* Python version: 3.5.3
* Operating System: Debian Linux 9.9
Hi,
Just wanted to know the `face_distance` function. So if the distance is low does that mean they are more similar? Furthermore, is there a range for the euclidean distance for example between 0 and 1. Where 0 means... | open | 2020-03-24T11:31:41Z | 2020-03-24T15:01:52Z | https://github.com/ageitgey/face_recognition/issues/1093 | [] | MichaelSchroter | 1 |
QuivrHQ/quivr | api | 3,344 | Add ColPali on Diff Assistant | Investigate and implementation of the usage of ColPali for Diff Assistant : <br>[https://danielvanstrien.xyz/posts/post-with-code/colpali-qdrant/2024-10-02_using_colpali_with_qdrant.html](https://danielvanstrien.xyz/posts/post-with-code/colpali-qdrant/2024-10-02_using_colpali_with_qdrant.html) | closed | 2024-10-08T08:48:10Z | 2024-12-23T10:27:50Z | https://github.com/QuivrHQ/quivr/issues/3344 | [] | chloedia | 1 |
pmaji/crypto-whale-watching-app | dash | 99 | Time Stamping - Alt Coin Buzz | You guys have a great tool here! I haven't seen any work lately. I'd like to promote you on my segments that I do on Alt Coin Buzz. It's a TA segment along with the news. Are you still working on this? If so can I promote, or would it be better to wait?
Also wondering if you guys are working on a time stamp for the ... | closed | 2018-04-14T19:37:16Z | 2018-04-14T20:17:42Z | https://github.com/pmaji/crypto-whale-watching-app/issues/99 | [] | MarkyVee | 2 |
TencentARC/GFPGAN | deep-learning | 610 | Broken face ( GFPGAN - Reactor - SD ) | i don't know why, its been a while, face are slightly broken when i try to replace it using gfpgan model on reactor. have a solution? | open | 2025-03-19T06:31:39Z | 2025-03-19T06:31:39Z | https://github.com/TencentARC/GFPGAN/issues/610 | [] | Ryan-infitech | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.