
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
iterative/dvc | machine-learning | 10,428 | dvc exp run --run-all: One or two experiments are executed, than it hangs (JSONDecodeError) (similar to #10398) | # Bug Report
<!--
## Issue name
Issue names must follow the pattern `command: description` where the command is the dvc command that you are trying to run. The description should describe the consequence of the bug.
Example: `repro: doesn't detect input changes`
-->
## Description
When executing `dvc exp... | open | 2024-05-16T08:37:39Z | 2024-05-19T23:40:20Z | https://github.com/iterative/dvc/issues/10428 | [
"A: experiments"
] | AljoSt | 0 |
pydantic/pydantic-ai | pydantic | 158 | Is that an alternative to popular `guidance` or they can work together? | Thanks for your lib! It looks very interesting. I'm wondering if that is possible to use it with https://github.com/guidance-ai/guidance as latter is great in response shaping or you aim to replace that lib too? | closed | 2024-12-06T18:06:43Z | 2024-12-08T12:47:02Z | https://github.com/pydantic/pydantic-ai/issues/158 | [
"question"
] | pySilver | 3 |
kornia/kornia | computer-vision | 3,026 | K.Resize() doesn't work on MPS devices | ### Describe the bug
K.Resize() doesn't work if the device is `torch.device("mps")`
```
File "/Users/.../miniforge3/envs/ftw4/lib/python3.12/site-packages/kornia/utils/helpers.py", line 232, in _torch_solve_cast
out = torch.linalg.solve(A.to(torch.float64), B.to(torch.float64))
... | open | 2024-09-28T17:15:13Z | 2024-09-29T09:49:31Z | https://github.com/kornia/kornia/issues/3026 | [
"bug :bug:",
"help wanted"
] | calebrob6 | 1 |
datapane/datapane | data-visualization | 5 | Fix windows support | Window support is currently broken, as we shell out to certain libraries (such as gzip). We should use Python alternatives instead. | closed | 2020-05-01T17:42:53Z | 2020-05-07T17:41:24Z | https://github.com/datapane/datapane/issues/5 | [
"bug"
] | lanthias | 1 |
rthalley/dnspython | asyncio | 285 | Error in the example | ```
Python 3.6.3 (default, Oct 13 2017, 07:46:30)
[GCC 7.2.1 20170915 (Red Hat 7.2.1-2)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import dns.resolver
>>> resolver = dns.resolver.Resolver(configure=False)
>>> resolver.nameservers = ['8.8.8.8']
>>> results = resolver.que... | closed | 2017-11-15T01:31:54Z | 2018-02-20T19:54:58Z | https://github.com/rthalley/dnspython/issues/285 | [] | arcivanov | 0 |
miguelgrinberg/Flask-SocketIO | flask | 2,100 | Update 5.3.6 to 5.4.1 - test failed | Hello,
I'm trying to upgrade from 5.3.6 to 5.4.1 for openSUSE Tumbleweed (Rolling Release) and run into a test error:
[code]
```
[ 9s] + python3.10 -m unittest -v test_socketio.py
[ 10s] Traceback (most recent call last):
[ 10s] File "/usr/lib64/python3.10/runpy.py", line 196, in _run_module_as_main
[... | closed | 2024-10-04T17:31:02Z | 2024-11-08T10:24:45Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/2100 | [
"question"
] | coogor | 4 |
voxel51/fiftyone | computer-vision | 5,397 | [BUG] GraphQL Exception after pip install and running quickstart example |
### Describe the problem
I ran the pip install quickstart example and got this GraphQL exception:
```
GraphQL API Error
Cannot return null for non-nullable field Query.dataset.
```
Here is the exception stack:
```
File "/Users/cuongwilliams/anaconda3/envs/voxel51/lib/python3.10/site-packages/graphql/execution/execut... | closed | 2025-01-16T20:48:56Z | 2025-02-03T16:39:57Z | https://github.com/voxel51/fiftyone/issues/5397 | [
"bug"
] | sourcesync | 4 |
geex-arts/django-jet | django | 351 | Google analytics API request failed | Successfully setup django-jet and everything working. But after few hours google analytics data is not showing. And displaying API request failed.
Using django 2.0(django 2.1 has compatibility issue) with latest django-jet. | closed | 2018-09-05T03:43:41Z | 2018-09-07T20:38:04Z | https://github.com/geex-arts/django-jet/issues/351 | [] | nikolas-dev | 2 |
drivendataorg/cookiecutter-data-science | data-science | 3 | Add testing boilerplate/docs | closed | 2016-04-23T17:00:17Z | 2016-05-16T15:27:21Z | https://github.com/drivendataorg/cookiecutter-data-science/issues/3 | [] | pjbull | 1 | |
polarsource/polar | fastapi | 5,221 | Issue Funding: Script to remove badges | First run it on all issues without a pledge | closed | 2025-03-10T08:25:29Z | 2025-03-20T14:08:14Z | https://github.com/polarsource/polar/issues/5221 | [
"admin"
] | birkjernstrom | 0 |
unit8co/darts | data-science | 2,363 | hyperparameter TiDE and TFT no complete trials | Hi I dont think this is a bug, but I cant trace the error.
It might be due to the data it self as it is multivariate and grouped by ID.
score is returning [nan, nan, nan, nan...] leading to trial = study.best_trial
the val_loss=120 so it is very high, but i think it should still return validation score.
It mig... | closed | 2024-05-01T08:15:15Z | 2024-05-25T17:57:37Z | https://github.com/unit8co/darts/issues/2363 | [
"question"
] | flight505 | 3 |
sebp/scikit-survival | scikit-learn | 511 | brier_score and cumulative_dynamic_auc fail when there is a test time greater than a training time | I'm creating a new open issue related to [#478](https://github.com/sebp/scikit-survival/issues/478#issuecomment-2624334230)_ which is currently cosed because no reproducible example was provided.
Another user (@dpellow) reported that "brier_score" produces a ValueError when test time is greater than training time. I ... | open | 2025-01-31T10:56:09Z | 2025-02-15T14:41:37Z | https://github.com/sebp/scikit-survival/issues/511 | [
"documentation"
] | aliciaolivaresgil | 2 |
mwaskom/seaborn | data-science | 3,204 | Boxplot rcparams not working in seaborn | I'm trying to create a custom style for my plots. In order to do so I'm modifying the rcParameters in order to have a uniform style while using matplotlib or seaborn. I created a style that satisfies me but when I use it with seaborn specific parameters are ignored. Example:
```
import pandas as pd
import seaborn as... | closed | 2022-12-29T11:42:46Z | 2023-01-01T19:22:43Z | https://github.com/mwaskom/seaborn/issues/3204 | [] | GiuseppeMinardiWisee | 2 |
iMerica/dj-rest-auth | rest-api | 419 | Settings variable for enabling/disabling use of allauth forms/emails | There are a number of challenges that arise when we have `allauth` in our `INSTALLED_APPS` but don't want to use its email templates/password reset functionality, for instance #367. Could we have a settings toggle that allows us to very easily fix all these issues?
Essentially, anywhere we have:
```
if 'allauth' i... | closed | 2022-07-14T23:51:28Z | 2022-09-01T06:40:25Z | https://github.com/iMerica/dj-rest-auth/issues/419 | [
"enhancement"
] | kut | 2 |
sgl-project/sglang | pytorch | 4,245 | [Bug] vllm vs sglang performance test comparison | ### Checklist
- [x] 1. I have searched related issues but cannot get the expected help.
- [x] 2. The bug has not been fixed in the latest version.
- [x] 3. Please note that if the bug-related issue you submitted lacks corresponding environment info and a minimal reproducible demo, it will be challenging for us to repr... | open | 2025-03-10T02:07:14Z | 2025-03-10T07:40:08Z | https://github.com/sgl-project/sglang/issues/4245 | [] | luhairong11 | 5 |
pytest-dev/pytest-django | pytest | 424 | feature request: user_client fixture | In multiple cases I would like to test different behavior between an admin and an authenticated user. For example, admins are allowed to delete/modify everyone's data while a user is only allowed to delete/edit his own data.
I think many pytest-django users could use a `user_client` fixture for a regular logged in use... | closed | 2016-11-20T01:42:46Z | 2016-11-21T16:08:44Z | https://github.com/pytest-dev/pytest-django/issues/424 | [] | nirizr | 2 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 904 | Learning? | Hello,
Thank you for providing the code. I am using a custom dataset and generator, however my approach is based on pix2pix. I have noticed that the loss_D_fake and loss _D_real never oscillate after the first epoch! The average loss for these is around 0.25 for 21,000 images. According to [soumith point 10](https:... | open | 2020-01-23T13:12:41Z | 2020-01-27T18:45:37Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/904 | [] | DeepZono | 2 |
open-mmlab/mmdetection | pytorch | 11,245 | How to get GFL esk loss with segmentation masks | I have a heavily imbalanced dataset, GFL learns it really well, but I'm now in need of segmentation output and cascade mask rcnn seems to be struggling.
I'm a little limited in my choice because I want to be able to export to ONNX, so a change in loss would be ideal, but several other issues seemed to have had litt... | open | 2023-12-03T16:14:02Z | 2023-12-04T10:54:15Z | https://github.com/open-mmlab/mmdetection/issues/11245 | [] | GeorgePearse | 1 |
Allen7D/mini-shop-server | sqlalchemy | 108 | sqlalchemy 字段中设置默认值为UrlFromEnum.LOCAL 不能正确create | UrlFromEnum.LOCAL 来自配置文件中设置的变量 来源: 1 本地,2 公网
from app.libs.enums import UrlFromEnum
class File(Base):
__tablename__ = 'file'
id = Column(Integer, primary_key=True)
parent_id = Column(Integer, comment='父级目录id')
uuid_name = Column(String(100), comment='唯一名称')
name = Column(String(100), null... | closed | 2021-03-02T04:06:10Z | 2021-03-02T08:24:12Z | https://github.com/Allen7D/mini-shop-server/issues/108 | [] | TuLingZb | 0 |
streamlit/streamlit | deep-learning | 9,951 | Tabs dont respond when using nested cache functions | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
[, 0, dtype=torch.float)
hx = torch.full((0, 9), 0, dtype=torch.float)
cx = torch.full((0, 9), 0, dtype=torch.float)
w_ih = torch.full((1, 8), 1.251e+12, dtype=torch.f... | open | 2025-03-20T15:24:09Z | 2025-03-21T07:08:54Z | https://github.com/pytorch/pytorch/issues/149626 | [
"module: crash",
"module: rnn",
"triaged",
"bug",
"module: empty tensor",
"topic: fuzzer"
] | vwrewsge | 1 |
raphaelvallat/pingouin | pandas | 118 | Get residuals from anova | Hi, recently I have been playing with `statsmodels` and `pinguin` and I have not been able to figure out how to get residuals from pinguin. What I mean is (taking your example):
```python
df = pg.read_dataset('anova2')
# Pinguin
df.anova(dv="Yield", between=["Blend", "Crop"]).round(3)
# statsmodels
model = ols... | open | 2020-08-17T14:39:25Z | 2021-10-28T22:19:47Z | https://github.com/raphaelvallat/pingouin/issues/118 | [
"feature request :construction:"
] | jankaWIS | 1 |
iMerica/dj-rest-auth | rest-api | 326 | Rest-Auth+AllAuth+PhoneNumberField TypeError: 'PhoneNumber' object is not subscriptable | models.py:
```
class CustomUser(AbstractUser):
username = PhoneNumberField(unique=True)
```
payloads:
```
{
"username": "+8801700000000",
"password1": "demo",
"password2": "demo",
"email": "demo@demo.com",
}
```
response:
```
Internal Server Error: /api/rest-auth/registration/
Tra... | open | 2021-11-01T20:35:13Z | 2021-11-01T20:35:38Z | https://github.com/iMerica/dj-rest-auth/issues/326 | [] | nikolas-dev | 0 |
ultralytics/ultralytics | computer-vision | 19,821 | Train YOLOv11/v8 on Intel Arc Discrete GPU | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
What are the required changes to be made in ultralytics repository to train ... | closed | 2025-03-22T09:03:51Z | 2025-03-23T14:04:53Z | https://github.com/ultralytics/ultralytics/issues/19821 | [
"enhancement",
"question"
] | ramesh-dev-code | 5 |
proplot-dev/proplot | matplotlib | 132 | There is an bug with using matplotlib after using proplot | Hey guys. I met a problem today.
I firstly ran the first codes with proplot package, and got normal results.
After that, I ran my second codes with matplotlib, however, the figure doesn't perform well.
The first codes are from [web](https://proplot.readthedocs.io/en/latest/subplots.html) :
`import proplot as... | closed | 2020-03-12T14:37:45Z | 2020-05-09T12:00:44Z | https://github.com/proplot-dev/proplot/issues/132 | [
"support"
] | ZaamlamLeung | 1 |
mkhorasani/Streamlit-Authenticator | streamlit | 94 | Capturing username of failed login attempts | I would like to write code that blocks a user after 3 failed login attempts.
Currently, it seems like failed login attempts return the username None. | closed | 2023-10-12T19:52:14Z | 2024-01-25T20:55:07Z | https://github.com/mkhorasani/Streamlit-Authenticator/issues/94 | [] | IndigoJay | 1 |
biolab/orange3 | data-visualization | 6,485 | Pivot Table widget - wrong filtered data output | Hi there,
I am experiencing a problem with the Pivot Table Widget, specifically with the "filtered data" output. I want to use the functionality to select specific groups of my pivoted table to analyze separately. When I select one of the groups as intended, the routing towards the output of the widget does not work... | closed | 2023-06-21T07:13:27Z | 2023-07-04T11:34:41Z | https://github.com/biolab/orange3/issues/6485 | [
"bug report"
] | meritwagner | 2 |
chiphuyen/stanford-tensorflow-tutorials | tensorflow | 142 | 07_convnet_layers.py self.training should use tf.placeholder | If you use a Python bool, the value of training won't change because you already build the logits before the session and you can't change the graph during the session.
The correct way should use tf.placeholder like this:
`self.training = tf.placeholder(tf.bool, name='is_train')`
And set `sess.run(init, feed_dict={se... | open | 2019-02-27T03:24:55Z | 2019-02-27T03:24:55Z | https://github.com/chiphuyen/stanford-tensorflow-tutorials/issues/142 | [] | TonyZZX | 0 |
huggingface/peft | pytorch | 1,636 | Error running the deepspeed qlora example | ### System Info
Hi,
I am trying to run a qlora finetuning experiment on deepspeed similar to the one given in the sft folder.
I use the same requirements.txt as given. However, I face an issue
_
```
Traceback (most recent call last):
File "/opt/ml/code/train_qlora.py", line 161, in <module>
model_args,... | closed | 2024-04-09T14:30:55Z | 2024-04-11T14:41:41Z | https://github.com/huggingface/peft/issues/1636 | [] | AnirudhVIyer | 2 |
kizniche/Mycodo | automation | 1,211 | DHT22 not working | I'm using the last version of mycodo with a raspberries 3, and I'm having issue connecting my DHT22. Ive install pigpiod and when I'm sending: <<sudo systemctl enable pigpiod>> I receive: <<Failed to enable unit: Refusing to operate on alias name or linked unit file: pigpiod.service>> . Ive tried to enable remote GPIO... | closed | 2022-07-06T02:14:03Z | 2022-08-21T22:24:57Z | https://github.com/kizniche/Mycodo/issues/1211 | [] | Tommynator062 | 2 |
Kav-K/GPTDiscord | asyncio | 306 | System instruction setting guide | I've noticed that `/gpt instruction` command doesn't have a guide on proper usage. @Hikari-Haru would you be able to give me the points of how it works, I'd be happy to add it to the docs?
| closed | 2023-05-08T18:33:03Z | 2023-06-16T02:14:41Z | https://github.com/Kav-K/GPTDiscord/issues/306 | [] | Raecaug | 2 |
miguelgrinberg/flasky | flask | 378 | Question about the function send_async_mail | Instead of passing the object app to the new thread, i passed the object context to the thread and it worked. But i am not sure if it is right to do this.
my code:
```
def send_async_mail(msg, context):
with context:
mail.send(msg)
def send_mail(to, subject, template, **kwargs):
context = cur... | closed | 2018-08-17T02:44:06Z | 2018-08-17T08:06:43Z | https://github.com/miguelgrinberg/flasky/issues/378 | [
"question"
] | ChenYizhu97 | 2 |
keras-team/keras | machine-learning | 20,536 | BUG in load_weights_from_hdf5_group_by_name | https://github.com/keras-team/keras/blob/5d36ee1f219bb650dd108c35b257c783cd034ffd/keras/src/legacy/saving/legacy_h5_format.py#L521-L525
model.trainable_weights + model.non_trainable_weights references all weights instead of top-level | closed | 2024-11-22T19:49:14Z | 2024-11-30T11:00:53Z | https://github.com/keras-team/keras/issues/20536 | [
"type:Bug"
] | edwardyehuang | 1 |
vaexio/vaex | data-science | 1,478 | [BUG-REPORT] Unable to export dataframe to hdf5 when it includes multibyte named column (on Windows OS) | Hi, everyone
**Description**
Runtime Error at h5py when saving dataframe includes many columns, and one of them contains Multibyte string.
It might only happen on Windows. (It didn't happen when I tried it on MacOS and Ubuntu )
```python
import vaex
source_dict = {"東京": [1, 2, 3], "a": [1, 2, 3], "b": [1,2,... | closed | 2021-07-28T09:42:58Z | 2021-08-04T14:01:45Z | https://github.com/vaexio/vaex/issues/1478 | [
"bug"
] | SyureNyanko | 7 |
microsoft/nni | pytorch | 5,130 | speedup_model() causes a error: “NotImplementedError: There were no tensor arguments to this function (e.g., you passed an empty list of Tensors)” | **Describe the issue**:
[2022-09-16 15:20:07] start to speedup the model
[2022-09-16 15:20:09] infer module masks...
[2022-09-16 15:20:09] Update mask for net.conv1.conv1.0
[2022-09-16 15:20:09] Update mask for net.aten::cat.87
Traceback (most recent call last):
File "network_prune.py", line 587, in <module>
... | closed | 2022-09-16T07:45:10Z | 2023-03-08T08:52:52Z | https://github.com/microsoft/nni/issues/5130 | [
"support",
"ModelSpeedup",
"need more info"
] | missu123 | 3 |
flaskbb/flaskbb | flask | 345 | `flaskbb upgrade fixture` returns wrong number of settings | I just ran
` flaskbb upgrade --all --fixture settings` (to look into #336)
This returned
```
[+] Found config file 'flaskbb.cfg' in /home/student/Desktop/uni/coding/github/flaskbb
[+] Using config from: /home/student/Desktop/uni/coding/github/flaskbb/flaskbb.cfg
[+] Upgrading migrations to the latest version...
... | closed | 2017-09-16T16:01:04Z | 2018-04-15T07:47:47Z | https://github.com/flaskbb/flaskbb/issues/345 | [
"bug"
] | shunju | 2 |
uriyyo/fastapi-pagination | fastapi | 724 | TypeError("'ObjectId' object is not iterable") | Hi All
I'm trying to use this library to paginate data from a mongodb database using Motor.
I can get the `paginate()` query to work, and this returns the data from MongoDB/Motor - all good.
My issue comes when I try to then return this via fastAPI return_model and I get the following trace:
```python
Trac... | closed | 2023-06-29T10:51:39Z | 2023-07-03T09:24:09Z | https://github.com/uriyyo/fastapi-pagination/issues/724 | [
"question"
] | Bobspadger | 5 |
erdewit/ib_insync | asyncio | 417 | reqHistoricalData() raises a RuntimeError: There is no current event loop in thread 'Thread-1 (some_function)' | hi,
i'm trying to access the `reqHistoricalData()` api from `ib_insync` but i get a runtime error whny trying to run it async.
i'm using the `threading` module with `start()` and `join()` methods.
i also noticed that if i access `reqHistoricalDataAsync()` instead, it doesnt return a `BarDataList` anymore but inste... | closed | 2021-12-04T16:09:12Z | 2021-12-26T11:40:25Z | https://github.com/erdewit/ib_insync/issues/417 | [] | properchopsticks | 3 |
encode/httpx | asyncio | 3,176 | Stricter typing for request parameters. | Ref: https://github.com/encode/starlette/pull/2534#issuecomment-2067634124
This issue was opened to resolve all kinds of problems where third-party packages may need to use private imports. We should definitely expose them to avoid problems like https://github.com/encode/httpx/pull/3130#issuecomment-1974778017.
I... | open | 2024-04-21T09:09:58Z | 2024-09-27T11:18:25Z | https://github.com/encode/httpx/issues/3176 | [
"user-experience"
] | karpetrosyan | 12 |
holoviz/panel | matplotlib | 7,805 | Card layouts break and overlap when in a container of a constrained size and expanded | <details>
<summary>Software Version Info</summary>
```plaintext
panel == 1.6.1
```
</details>
#### Description of expected behavior and the observed behavior
I expect the cards to respect the overflow property of the container they are in and not overlap when expanded.
**Example 1 overflow: auto in column contai... | open | 2025-03-24T19:46:16Z | 2025-03-24T19:57:43Z | https://github.com/holoviz/panel/issues/7805 | [] | DmitriyLeybel | 2 |
flairNLP/flair | nlp | 3,292 | [Feature]: add BINDER | ### Problem statement
Extend the label verbalizer decoder to the [BINDER](https://openreview.net/forum?id=9EAQVEINuum) paper which is using a contrastive / similarity loss whereas the current implementation uses matrix multiplication.
### Solution
Write a new class that implements the BINDER paper.
### Additional C... | open | 2023-08-06T10:36:21Z | 2023-08-06T10:36:22Z | https://github.com/flairNLP/flair/issues/3292 | [
"feature"
] | whoisjones | 0 |
google/trax | numpy | 1,331 | How to get SQuAD in form of text instead of stream? | Hi,
I just can get the SQuAD in **generator** by `trax.data.tf_inputs.data_stream()`.
How can i get it in form of **text** instead of **generator**? Or at least how can i convert it into text?
| closed | 2020-12-21T04:17:36Z | 2020-12-24T06:18:55Z | https://github.com/google/trax/issues/1331 | [] | ngoquanghuy99 | 0 |
deepset-ai/haystack | nlp | 8,967 | Pipeline drawing: expose `timeout` parameter and increase the default | End-to-End Haystack tests (executed nightly) are failing due to [Mermaid timeouts](https://github.com/deepset-ai/haystack/actions/runs/13643217064/job/38137252561) during Pipeline drawing.
I can also reproduce this on Colab running one of our tutorials.
To resolve this before 2.11.0, I would:
- increase timeout (curre... | closed | 2025-03-04T17:26:01Z | 2025-03-05T10:49:35Z | https://github.com/deepset-ai/haystack/issues/8967 | [
"P1"
] | anakin87 | 0 |
pallets/flask | python | 4,816 | Speed up Dataclass JSON. | https://github.com/pallets/flask/blob/c34c84b69085e6bce67d0701b8f8ba3145f42ff2/src/flask/json/provider.py#L116-L117
asdict is super slow and unneeded. It makes a deep copy since the object is being encoded there is no need for a deep copy.
I can post some alternatives I have rattled around for this. If I remembe... | closed | 2022-09-12T18:48:43Z | 2022-09-28T00:12:03Z | https://github.com/pallets/flask/issues/4816 | [] | zrothberg | 1 |
kornia/kornia | computer-vision | 2,438 | Use Kornia Boxes utility to automаte the boxes conversion | Use Kornia Boxes utility to automаte the boxes conversion
_Originally posted by @edgarriba in https://github.com/kornia/kornia/pull/2363#discussion_r1257304152_
| open | 2023-07-08T16:18:50Z | 2023-07-08T16:19:14Z | https://github.com/kornia/kornia/issues/2438 | [
"enhancement :rocket:",
"module: contrib"
] | edgarriba | 0 |
ScottfreeLLC/AlphaPy | scikit-learn | 42 | Error while making a prediction with sflow | **Description of the error**
When following the NCAA Basketball Tutorial and trying to make a prediction on a date with the model created and trained, the system throws the following error:
"IndexError: boolean index did not match indexed array along dimension 1; dimension is 96 but corresponding boolean dimensio... | open | 2021-10-20T17:11:40Z | 2021-10-20T17:11:40Z | https://github.com/ScottfreeLLC/AlphaPy/issues/42 | [] | AlexVaPe | 0 |
quantmind/pulsar | asyncio | 243 | HTTPDigestAuth partially broken | If the credentials are incorrect, an http requets with HTTPDigestAuth seems to be stuck in a loop of redirection that end with :
```
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>400 Bad Request</title>
</head><body>
<h1>Bad Request</h1>
<p>Your browser sent a request that this server could n... | closed | 2016-09-08T13:38:12Z | 2016-09-09T09:47:06Z | https://github.com/quantmind/pulsar/issues/243 | [
"http",
"bug",
"tests required"
] | JordanP | 2 |
streamlit/streamlit | data-visualization | 10,828 | Upload files to disk with `st.file_uploader` | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
Add a way for `st.file_uploader` to upload files directly to disk. This should not store the file in memory.
... | open | 2025-03-18T19:56:48Z | 2025-03-19T16:19:16Z | https://github.com/streamlit/streamlit/issues/10828 | [
"type:enhancement",
"feature:st.file_uploader"
] | jrieke | 5 |
onnx/onnxmltools | scikit-learn | 499 | Error converting deserialized xgboost Booster | Hello.
I am trying to convert existing xgboost model file (which is created by `xgboost.Booster.save_model`) to onnx. While doing that I am getting the following error:
`AttributeError: 'Booster' object has no attribute 'best_ntree_limit'`
my environment
* OS: Windows 10 Home
* xgboost==1.4.2
* onnxmltoo... | open | 2021-09-18T16:34:28Z | 2022-02-01T10:16:50Z | https://github.com/onnx/onnxmltools/issues/499 | [] | ide-an | 2 |
postmanlabs/httpbin | api | 98 | Missing dependencies | A few dependencies are still missing;
- blinker
- raven
- Sentry
| closed | 2013-06-06T00:18:45Z | 2018-04-26T17:50:59Z | https://github.com/postmanlabs/httpbin/issues/98 | [] | ticky | 1 |
AirtestProject/Airtest | automation | 1,189 | 开启IDE情况下,命令行执行时获取的adb进程路径有时候空的 | **Describe the bug**
get_adb_path return None
**To Reproduce**
Steps to reproduce the behavior:
1. 打开airtestIDE的情况下
2. 命令行执行airtest脚本
非必现,有的时候出现,发现adb进程被airtestIDE占用,但是exe路径是空的, 如截图所示
**Expected behavior**
**Screenshots**
调试信息:
<img width="1409" alt="image" src="https://github.com/AirtestProject/... | closed | 2024-01-05T07:14:29Z | 2024-02-02T07:50:03Z | https://github.com/AirtestProject/Airtest/issues/1189 | [] | lzus | 1 |
jupyter-widgets-contrib/ipycanvas | jupyter | 312 | debug_output only works if calling display(canvas) | I have a complicated layout with HBox and VBox and contains a canvas as one part of the whole thing.
when using debug_output, it forces me to call display(canvas), or else debug_output does not show. but that means none of the other components show.
if I call HBox then debug_output, only a horizontal line shows... | closed | 2023-01-06T21:09:32Z | 2023-01-08T05:45:17Z | https://github.com/jupyter-widgets-contrib/ipycanvas/issues/312 | [] | bhomass | 1 |
chaos-genius/chaos_genius | data-visualization | 438 | [BUG] Snowflake connector mentions setting up with a hostname, where the hostname is actually not required | ## Describe the bug
When setting up the Snowflake connector, I thought I needed to type the whole domain. It isn't needed, just the first part.
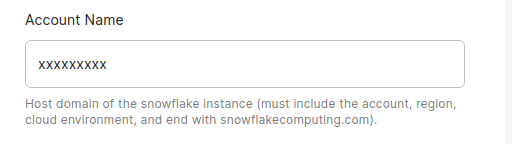
## Explain the environment
- **Chaos Genius version**: 0.1.... | closed | 2021-11-26T13:23:13Z | 2021-11-27T06:56:45Z | https://github.com/chaos-genius/chaos_genius/issues/438 | [] | joshuataylor | 1 |
opengeos/leafmap | jupyter | 118 | Add streamlit support for heremap module | To add stseamlit support for the heremap plotting backend, we need to save the map as an HTML file. However, it seems the exported HTML lose the map controls (e.g., zoom control, fullscreen control). @sackh Any advice?
```
import leafmap.heremap as leafmap
from ipywidgets.embed import embed_minimal_html
m = lea... | closed | 2021-10-02T19:28:56Z | 2021-10-18T01:26:06Z | https://github.com/opengeos/leafmap/issues/118 | [
"Feature Request"
] | giswqs | 2 |
modoboa/modoboa | django | 2,702 | OpenDKIM not sign mails | # Impacted versions
* OS Type: Ubuntu
* OS Version: Ubuntu 22.04.1 LTS
* Database Type: PostgreSQL
* Database version: 14
* Modoboa: 2.0.2
* installer used: No
* Webserver: Nginx
# Steps to reproduce
1. send some mail from any mail client
2. check DKIM sign with https://www.appmaildev.com/en/dkim
# Cur... | closed | 2022-11-30T18:36:48Z | 2023-04-25T20:32:22Z | https://github.com/modoboa/modoboa/issues/2702 | [
"feedback-needed",
"stale"
] | Quiver92 | 5 |
OpenBB-finance/OpenBB | machine-learning | 6,924 | [🕹️] Starry-eyed supporter | ### What side quest or challenge are you solving?
asked five of my friends to star the repository
### Points
150
### Description
_No response_
### Provide proof that you've completed the task
1. https://github.com/amannegi?tab=stars

| closed | 2022-07-12T14:01:07Z | 2023-02-04T18:58:56Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1095 | [] | timmosaurusrex | 2 |
NullArray/AutoSploit | automation | 523 | Unhandled Exception (ac906a5c4) | Autosploit version: `3.0`
OS information: `Linux-4.18.0-kali2-amd64-x86_64-with-Kali-kali-rolling-kali-rolling`
Running context: `autosploit.py`
Error meesage: `argument of type 'NoneType' is not iterable`
Error traceback:
```
Traceback (most recent call):
File "/root/AutoSploit/autosploit/main.py", line 117, in main
... | closed | 2019-03-02T05:11:53Z | 2019-03-03T03:31:53Z | https://github.com/NullArray/AutoSploit/issues/523 | [] | AutosploitReporter | 0 |
ludwig-ai/ludwig | data-science | 3,681 | RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument mat1 in method wrapper... | **Describe the bug**
I followed the steps from "how to contribute" and setting up Lugwig locally for development. When I run pytest I get

**Environment (please complete the following in... | closed | 2023-09-30T07:50:53Z | 2024-10-18T17:04:14Z | https://github.com/ludwig-ai/ludwig/issues/3681 | [] | karanjakhar | 2 |
RobertCraigie/prisma-client-py | pydantic | 33 | Improve type checking experience using a type checker without a plugin | ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
For example, using `pyright` to type check would result in false positive errors that are annoying to fix when including 1-to-many relational fields.
```py
user = await client.user.find_unique(wher... | open | 2021-07-02T13:42:25Z | 2022-02-01T15:31:51Z | https://github.com/RobertCraigie/prisma-client-py/issues/33 | [
"kind/improvement",
"topic: types",
"level/advanced",
"priority/low"
] | RobertCraigie | 0 |
vitalik/django-ninja | rest-api | 692 | [BUG] callable not working in schema Field definition using alias | **Describe the bug**
As mentioned in docs:
class TaskSchema(Schema):
type: str = Field(None)
type_display: str = Field(None, alias="get_type_display") # callable will be executed
When trying the same on a choice field the callable for getting the display value is not executed and getting None in result... | closed | 2023-03-06T06:45:49Z | 2023-03-15T12:31:04Z | https://github.com/vitalik/django-ninja/issues/692 | [] | sagar-punchh | 6 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,568 | WGAN produce very poor results | Hi
I am using Cyclegan for medical image translation however when I changed the WGAN, the results completely failed.
I have attached the original images and the generated results. I have trained for 400 epochs.
Anyone has any idea why this happens?
Fig 1 Real A
Fig 2 Real B
Fig 3 fake A from unet128+wgan
Fig ... | open | 2023-05-09T21:45:16Z | 2023-05-09T21:47:53Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1568 | [] | xintian-99 | 0 |
litestar-org/litestar | asyncio | 4,057 | Bug: `Makefile` doesn't show install | ### Description
It is not clear when running `make` or `make help` how to install the project if you skip the docs.
### MCVE
```python
litestar on v3/n [🤷✓] via 🎁 v2.15.1 via pyenv took 5s
➜ make
Usage:
make <target>
help Display this help text for Makefile
upgrade Upgrade all depe... | open | 2025-03-18T16:54:37Z | 2025-03-18T16:55:01Z | https://github.com/litestar-org/litestar/issues/4057 | [
"Bug :bug:"
] | JacobCoffee | 0 |
Evil0ctal/Douyin_TikTok_Download_API | api | 163 | [BUG] An unexpected error occurred, the input value has been recorded. | closed | 2023-03-04T02:23:08Z | 2023-03-11T00:40:54Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/163 | [
"BUG",
"enhancement"
] | robbinhust | 2 | |
s3rius/FastAPI-template | graphql | 204 | Fast api | open | 2024-03-07T00:26:41Z | 2024-03-07T00:26:41Z | https://github.com/s3rius/FastAPI-template/issues/204 | [] | Jaewook-github | 0 | |
SYSTRAN/faster-whisper | deep-learning | 1,086 | CUDA compatibility with CTranslate2 | Hi Everyone,
as per @BBC-Esq research, `ctranslate2>=4.5.0` uses CuDNN v9 which requires CUDA >= 12.3.
Since most issues occur from a conflicting `torch` and `ctranslate2` installations these are tested working combinations:
| Torch Version | CT2 Version |
|:-------------:|:-----------:|
| `2.*.*+cu121` | `<=4... | open | 2024-10-24T17:16:34Z | 2024-12-04T17:14:53Z | https://github.com/SYSTRAN/faster-whisper/issues/1086 | [] | MahmoudAshraf97 | 15 |
thp/urlwatch | automation | 542 | Matrix client dependency (migrate to matrix-nio) | When I look at the github page for the dependency of matrix_client at https://github.com/matrix-org/matrix-python-sdk it reads:
> We strongly recommend using the matrix-nio library rather than this sdk. It is both more featureful and more actively maintained.
Is there a plan to change to the matrix-nio library as... | open | 2020-07-29T03:36:26Z | 2020-07-30T18:34:37Z | https://github.com/thp/urlwatch/issues/542 | [
"enhancement"
] | pandrews255 | 2 |
pydantic/FastUI | pydantic | 198 | option to set dev mode via `prebuilt_html` | open | 2024-02-17T17:15:18Z | 2024-02-17T17:15:19Z | https://github.com/pydantic/FastUI/issues/198 | [] | samuelcolvin | 0 | |
waditu/tushare | pandas | 1,509 | daily_basic接口返回的数据不准确 | 测试步骤如下:
>>>profit_fore = pro.forecast(ts_code='600138.sh', period='20210205', fields='net_profit_min,net_profit_max')
>>>profit_fore.net_profit_max
Series([], Name: net_profit_max, dtype: object)
>>>profit_fore.net_profit_min
Series([], Name: net_profit_min, dtype: object)
实际查到的业绩预告见附图
id: 421774
![微信截图_2... | open | 2021-02-05T13:37:55Z | 2021-02-05T13:37:55Z | https://github.com/waditu/tushare/issues/1509 | [] | zjulkw | 0 |
google/trax | numpy | 1,463 | jaxboard_demo.py missing? | Cannot find the file jaxboard_demo.py as stated on line 18. Where is it located? Thanks
https://github.com/google/trax/blob/5b08d66a4e69cccbab5868697b207a8b71caa890/trax/jaxboard.py#L18 | open | 2021-02-15T17:29:20Z | 2022-03-04T22:15:43Z | https://github.com/google/trax/issues/1463 | [] | PizBernina | 1 |
ray-project/ray | python | 50,827 | CI test linux://python/ray/data:test_transform_pyarrow is flaky | CI test **linux://python/ray/data:test_transform_pyarrow** is flaky. Recent failures:
- https://buildkite.com/ray-project/postmerge/builds/8496#01952c44-0d09-4aa4-b1f3-e432b7ebfca1
- https://buildkite.com/ray-project/postmerge/builds/8495#01952b30-22c6-4a0f-9857-59a7988f67d8
- https://buildkite.com/ray-project/post... | closed | 2025-02-22T06:46:30Z | 2025-03-04T09:29:49Z | https://github.com/ray-project/ray/issues/50827 | [
"bug",
"triage",
"data",
"flaky-tracker",
"ray-test-bot",
"ci-test",
"weekly-release-blocker",
"stability"
] | can-anyscale | 31 |
long2ice/fastapi-cache | fastapi | 454 | How to correctly annotated the key builder in Pycharm | How to annoate `cache` decorator with key builder, even I use the default builer, it still show warning in pycharm.

The message:
```
Expected type 'KeyBuilder | None', got '(func: (...) -> Any, namespace: str, Any, request: ... | open | 2024-10-30T09:12:43Z | 2024-11-09T09:56:26Z | https://github.com/long2ice/fastapi-cache/issues/454 | [
"documentation",
"question"
] | allen0099 | 1 |
babysor/MockingBird | pytorch | 647 | 不能打开程序,提示缺少module。ffmpeg跟webrtcvad均正确下载 | 完成ffmpeg跟webrtcvad的下载,无误。在代码库路径下,运行 python demo_toolbox.py -d .\samples时提示缺少module,为PyQt5。自行下载并再次运行后,显示缺少更多module,为matplotlib,scipy,sklearn,scipy.stats._stats_py。除最后一个以外均已自行安装,最后这个不知如何下载,请求大佬解答。
python,mockingbird,ffmpeg均放置在E盘,调取ffmpeg的地址正确。
python版本3.9.13,ffmpeg版本4.4.1。
<img width="694" alt="problem" src="https://u... | open | 2022-07-14T20:53:58Z | 2022-09-15T19:15:18Z | https://github.com/babysor/MockingBird/issues/647 | [] | Audbrem507 | 6 |
Yorko/mlcourse.ai | plotly | 756 | Proofread topic 5 | - Fix issues
- Fix typos
- Correct the translation where needed
- Add images where necessary | closed | 2023-10-24T07:41:21Z | 2024-08-25T07:50:33Z | https://github.com/Yorko/mlcourse.ai/issues/756 | [
"enhancement",
"wontfix",
"articles"
] | Yorko | 1 |
Miksus/rocketry | automation | 222 | Is there any way to schedule an async function using 'threads' or 'processes'? | Currently, I have some async functions that I want to schedule, but the only viable execution seems to be async. Although these async functions are using async API, they also include CPU-intensive code, and using a separate thread or process should provide better concurrency.
There are several ways to run an async f... | open | 2023-10-09T01:13:33Z | 2023-10-09T01:13:33Z | https://github.com/Miksus/rocketry/issues/222 | [] | lkyhfx | 0 |
tqdm/tqdm | pandas | 1,197 | Segmentation fault (core dumped)-using tqdm | - [ ] I have marked all applicable categories:
+ [ ] exception-raising bug
+ [ ] visual output bug
- [ ] I have visited the [source website], and in particular
read the [known issues]
- [ ] I have searched through the [issue tracker] for duplicates
- [ ] I have mentioned version numbers, operating syste... | open | 2021-06-30T06:43:04Z | 2021-10-14T13:52:01Z | https://github.com/tqdm/tqdm/issues/1197 | [
"p0-bug-critical ☢",
"need-feedback 📢"
] | jingweirobot | 3 |
aleju/imgaug | machine-learning | 392 | Label Name | I was looking through the Bounding Boxes examples, and I noticed that there's no parameter for adding a name for each label.
Example: If I have a picture with two animals, I want to keep the labels animalA and animalB, not just that they are 2 different bounding boxes.
Example Code (that doesn't specify a label):
... | open | 2019-08-23T06:24:47Z | 2019-08-24T15:46:33Z | https://github.com/aleju/imgaug/issues/392 | [] | MentalGear | 3 |
microsoft/nni | tensorflow | 4,958 | HPO problem | When I set the search space use quniform like below in HPO.
<img width="234" alt="image" src="https://user-images.githubusercontent.com/11451001/175040897-0a8cbe73-fbb9-4a9e-85ff-f8025bb16c1a.png">
The parameters often become Long decimal, how can I fix it?
<img width="392" alt="image" src="https://user-images.git... | closed | 2022-06-22T13:29:47Z | 2022-06-27T03:05:20Z | https://github.com/microsoft/nni/issues/4958 | [
"question"
] | woocoder | 2 |
aiogram/aiogram | asyncio | 611 | [Tracking] Bot API 5.3 | ## Personalized Commands
- [x] Bots can now show lists of commands tailored to specific situations - including localized commands for users with different languages, as well as different commands based on chat type or for specific chats, and special lists of commands for chat admins.
- [x] Added the class [`BotComm... | closed | 2021-06-26T23:45:43Z | 2021-07-04T20:52:56Z | https://github.com/aiogram/aiogram/issues/611 | [
"api"
] | evgfilim1 | 1 |
ultrafunkamsterdam/undetected-chromedriver | automation | 786 | Not working on Replit | Hello, I'm trying to use this on Replit but it doesn't seem to work, while the normal selenium works just fine.
Here's the code:
import undetected_chromedriver as uc
driver = uc.Chrome()
driver.get('https://google.com')
I'm getting this error message:
Traceback (most recent call last):
File "main.py"... | open | 2022-08-19T07:34:01Z | 2024-03-18T16:50:54Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/786 | [] | lengvietcuong | 2 |
ploomber/ploomber | jupyter | 296 | Document and automate conda forge build | closed | 2021-05-18T13:45:50Z | 2021-08-13T13:15:43Z | https://github.com/ploomber/ploomber/issues/296 | [
"good first issue"
] | edublancas | 2 | |
SYSTRAN/faster-whisper | deep-learning | 265 | Improve Language detection | Since wishper detects language based on first 30 secs of the audio, sometimes there are errors in language detection. For example
[This video](https://www.youtube.com/watch?v=eGKFTUuJppU&pp=ygUPd2hvIGFtIGkgcGFydCAx ) is in english but both whisper and faster_whisper detects language as hindi "hi". There is a solution ... | open | 2023-05-30T07:13:48Z | 2024-05-13T11:41:41Z | https://github.com/SYSTRAN/faster-whisper/issues/265 | [] | ab-pandey | 6 |
freqtrade/freqtrade | python | 11,280 | Freqtrade exited with code 0 | ## Describe your environment
* Operating system: Ubuntu 24.04
* Python Version: 3.12.3
* CCXT version: 4.4.43
* Freqtrade Version: 2024.12
## Describe the problem:
I have a FreqAI strategy and once every 2 hours I got this error without any message and then the bot restarts.
```
2025-01-24 07:31:18,113 - f... | closed | 2025-01-24T10:16:55Z | 2025-01-24T15:25:32Z | https://github.com/freqtrade/freqtrade/issues/11280 | [
"Question",
"freqAI"
] | alfirin | 4 |
amidaware/tacticalrmm | django | 1,614 | Script Manager: Run As User flag is ignored when using environmental variables | **Server Info (please complete the following information):**
- OS: Ubuntu 20.04.4 LTS (Focal Fossa)
- Browser: Firefox 116.0.2 (64-bit)
- RMM Version (as shown in top left of web UI): v0.16.3
**Installation Method:**
- [x] Standard
- [ ] Docker
**Agent Info (please complete the following information):... | closed | 2023-08-24T00:59:04Z | 2023-09-02T01:06:58Z | https://github.com/amidaware/tacticalrmm/issues/1614 | [
"bug"
] | NiceGuyIT | 2 |
KrishnaswamyLab/PHATE | data-visualization | 130 | API Documentation not shown | Hi,
It seems like autodoc was not run on https://phate.readthedocs.io/en/stable/api.html | closed | 2023-02-21T10:03:19Z | 2023-02-21T22:39:21Z | https://github.com/KrishnaswamyLab/PHATE/issues/130 | [
"bug"
] | gjhuizing | 1 |
pytest-dev/pytest-html | pytest | 418 | Remove phantomjs dependency | Since we're using chrome headless, we can remove the phantomjs dependency from package.js. | closed | 2020-12-13T13:02:13Z | 2020-12-15T23:15:01Z | https://github.com/pytest-dev/pytest-html/issues/418 | [
"packaging"
] | BeyondEvil | 0 |
plotly/dash | plotly | 2,495 | Creating two different scatter_mapbox, one often fails | I create two different scatter_mapbox with similar data.
Sample:
```
div_mapbox = html.Div([dcc.Graph(figure=figure, id='figmapbox', style={'width': '90vw', 'height': '90vh'})],
id = 'divmapbox',
style={'width': '90%', 'display': 'inline-block', 'height': '90%... | open | 2023-04-04T10:59:45Z | 2024-08-13T19:30:49Z | https://github.com/plotly/dash/issues/2495 | [
"bug",
"P3"
] | jontis | 9 |
MaartenGr/BERTopic | nlp | 1,631 | Plotly Graphy produced shows datetime values as absolute numbers | <img width="1023" alt="image" src="https://github.com/MaartenGr/BERTopic/assets/147594747/05dbc751-e03c-4275-9be1-fa0e2d4bfb5f">
Hello BERTopic team, I am having an issue where the datetime values shown on the plotly graphy created from the visualize_topics_over_time function only show themselves as absolute numbers... | closed | 2023-11-15T08:13:51Z | 2023-11-16T15:18:48Z | https://github.com/MaartenGr/BERTopic/issues/1631 | [] | APVB12 | 4 |
Avaiga/taipy | data-visualization | 2,079 | [🐛 BUG] <write a small description here> | ### What went wrong? 🤔
e
### Expected Behavior
q
### Steps to Reproduce Issue
1. A code fragment
2. And/or configuration files or code
3. And/or Taipy GUI Markdown or HTML files
### Solution Proposed
d
### Screenshots

### Runtime Environment
Windows 11
### Browsers
Chrome
#... | closed | 2024-10-17T07:01:16Z | 2024-10-17T07:45:13Z | https://github.com/Avaiga/taipy/issues/2079 | [
"💥Malfunction"
] | predator2k5 | 0 |
axnsan12/drf-yasg | rest-api | 8 | Update README and add real docs | - [x] update README and setup.py descriptions
- [x] add sphinx documentation
- [x] upload to readthedocs
- [x] add docs build target
- [x] add source code documentation to classes and methods where possible | closed | 2017-12-08T15:01:33Z | 2017-12-12T16:31:46Z | https://github.com/axnsan12/drf-yasg/issues/8 | [] | axnsan12 | 1 |
coqui-ai/TTS | deep-learning | 4,149 | [Bug] Runtime Error | ### Describe the bug
RuntimeError: Input and output sizes should be greater than 0, but got input (W: 1) and output (W: 0)
Has anyone run into this issue while inferencing the xttsv2 model ??
what could be the possible cause of running into this error ??
### To Reproduce
Model inference.
### Expected behavior
_No... | closed | 2025-02-07T05:39:44Z | 2025-03-19T07:20:57Z | https://github.com/coqui-ai/TTS/issues/4149 | [
"bug",
"wontfix"
] | yushan1230 | 2 |
apache/airflow | machine-learning | 47,632 | Don't show task duration if we are missing start date | ### Apache Airflow version
main (development)
### If "Other Airflow 2 version" selected, which one?
_No response_
### What happened?
I noticed that I had a negative duration shown for a task when there isn't a start_date set. We should just show nothing in that instance.
:
content: Link[FileRecord]
some_props: List[str]
class PlaylistAbout(BaseModel):
name: str
description: str
class Playlist(Document):
about: PlaylistAbout
entries: List[PlaylistEntry] = Field(default_factory=list)
... | closed | 2022-07-05T14:00:29Z | 2023-09-14T09:24:22Z | https://github.com/BeanieODM/beanie/issues/301 | [
"Stale"
] | kpostekk | 6 |
ageitgey/face_recognition | machine-learning | 1,266 | Doing face encoding in nodejs | Hi,
Is there a supporting library that can run `face_recognition.face_encodings` in nodejs?
I don't want to pass the source image to the python server. just the encoded numbers.
Possible?
Thanks | open | 2021-01-10T10:40:26Z | 2021-01-27T09:51:16Z | https://github.com/ageitgey/face_recognition/issues/1266 | [] | avifatal | 1 |
jupyter/nbgrader | jupyter | 1,662 | How to execute a command on Jupyter Notebook Server Terminal via the Rest API or any Method | I have deployed Jupyterhub on Kubernetes following this guide <a href="https://zero-to-jupyterhub.readthedocs.io/en/latest/">link</a>, I have setup nbgrader and ngshare on jupyterhub using this guide <a href="https://nbgrader.readthedocs.io/en/stable/configuration/jupyterhub_config.html">link</a>, I have a Learning man... | open | 2022-09-07T23:04:46Z | 2024-02-23T12:26:56Z | https://github.com/jupyter/nbgrader/issues/1662 | [
"question"
] | adarshverma19 | 1 |
plotly/dash | plotly | 2,536 | [BUG] Turn twitter cards off by default to avoid security issues | - replace the result of `pip list | grep dash` below
```
dash 2.9.3
dash-auth 2.0.0
dash-bootstrap-components 1.4.1
dash-core-components 2.0.0
dash-extensions 0.1.13
dash-html-components 2.0.0
dash-table 5.0.0
```
- if frontend relate... | closed | 2023-05-22T05:00:50Z | 2023-05-25T16:12:38Z | https://github.com/plotly/dash/issues/2536 | [] | shankari | 4 |
dynaconf/dynaconf | django | 614 | [RFC] merge strategies/deep merge strategies for lazy objects | **Is your feature request related to a problem? Please describe.**
when performing deep merges, dynaconf always eagerly evaluates lazy objects
this can in particular end bad if one wants to configure dynaconf for usage with a loader based on config data
**Describe the solution you'd like**
have a merge strate... | closed | 2021-07-12T19:15:23Z | 2024-01-08T11:00:21Z | https://github.com/dynaconf/dynaconf/issues/614 | [
"wontfix",
"Not a Bug",
"RFC"
] | RonnyPfannschmidt | 1 |
Asabeneh/30-Days-Of-Python | matplotlib | 373 | DAY 1 VSCODE INSTALLATION | 
I dont know why the directory is so long. the underlined part in blue. how can i fix it | open | 2023-03-17T20:16:28Z | 2023-08-08T20:27:12Z | https://github.com/Asabeneh/30-Days-Of-Python/issues/373 | [] | AishaBell | 2 |
lucidrains/vit-pytorch | computer-vision | 278 | Saving and loading model seems to be regressing to lower performance | Hi, it is a great experience working with your library so far. I wanted to ask what the best way is to save and load the model.
I save:
```python3
model = ViT(hyperparams)
train(model)
torch.save(model.state_dict(), save_loc + f"model_e{epoch+1}.pth")
```
I load:
```python3
model = ViT(hyperparams) # exact s... | closed | 2023-09-10T07:44:12Z | 2023-09-11T07:54:12Z | https://github.com/lucidrains/vit-pytorch/issues/278 | [] | aperiamegh | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.