
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
plotly/dash | plotly | 2,297 | [BUG] High CPU usage when typing in text field and plotly graphs on screen |
**Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
- replace the result of `pip list | grep dash` below
```
dash 2.6.2
dash-bootstrap-components 1.2.1
dash-bootstrap-templates 1.0.4
dash-core-components ... | closed | 2022-11-03T13:29:58Z | 2024-07-24T17:38:49Z | https://github.com/plotly/dash/issues/2297 | [] | astrowonk | 1 |
google/trax | numpy | 1,685 | Reformer does not export to SavedModel format. | ### Description
...
### Environment information
tensorflow-gpu installed through anaconda, trax installed via pip.
```
OS: Ubuntu 20.04
$ pip freeze | grep trax
trax==1.3.9
$ pip freeze | grep tensor
tensorboard==2.6.0
tensorboard-data-server==0.6.1
tensorboard-plugin-wit==1.8.0
tensorflow==2.5.1
t... | open | 2021-08-17T02:17:12Z | 2021-08-17T03:22:44Z | https://github.com/google/trax/issues/1685 | [] | StewartSethA | 0 |
ionelmc/pytest-benchmark | pytest | 65 | defer disabled-by-xdist warning until a benchmark is actually disabled | Currently, if pytest-benchmark and pytest-xdist are both installed, `pytest -n $foo` will always cause pytest-benchmark to emit a disabled-by-xdist warning even if the current test suite does not include any benchmarks. Perhaps the warning could be deferred until a benchmark actually gets skipped? | open | 2017-01-08T18:32:40Z | 2019-01-02T22:13:30Z | https://github.com/ionelmc/pytest-benchmark/issues/65 | [
"bug",
"help wanted"
] | anntzer | 3 |
sktime/sktime | scikit-learn | 7,787 | [BUG] failure of `TestAllForecasters` collection due to `pytest` inheritance bug | Update with full suspected description.
The problem is `pytest` not collecting any tests at all from `TestAllForecasters`, due to what seems like a bug in `pytest`. Bug report here: https://github.com/pytest-dev/pytest/issues/13205
The reason, or at least the trigger, as identified by @yarnabrina, seems to be the mul... | closed | 2025-02-08T10:27:29Z | 2025-02-09T17:25:10Z | https://github.com/sktime/sktime/issues/7787 | [
"bug",
"module:forecasting",
"module:tests"
] | fkiraly | 4 |
geopandas/geopandas | pandas | 3,331 | BUG: autolim has no effect on point scatter plots | - [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on ~the latest version of~ geopandas 27de00c.
- [ ] (optional) I have confirmed this bug exists on the main branch of geopandas.
The bug will be reproducible on the main branch after #2817 is merged.
---
... | open | 2024-06-07T14:54:26Z | 2024-06-20T11:03:33Z | https://github.com/geopandas/geopandas/issues/3331 | [
"bug",
"upstream issue"
] | juseg | 1 |
strawberry-graphql/strawberry | django | 3,536 | field level relay results limit | ## Feature Request Type
- [ ] Core functionality
- [x] Alteration (enhancement/optimization) of existing feature(s)
- [x] New behavior
## Description
### Current:
The maximum of returned results for a relay connection defaults to 100 and can be changed by a schema wide setting: https://github.com/strawb... | open | 2024-06-08T14:45:40Z | 2025-03-20T15:56:45Z | https://github.com/strawberry-graphql/strawberry/issues/3536 | [] | Eraldo | 5 |
deepset-ai/haystack | nlp | 8,341 | Component with Variadic input is not run if some of its inputs are not sent | **Describe the bug**
`Pipeline.run()` doesn't run expected Component with Variadic input if some of its senders do not send it any input.
**Expected behavior**
`Pipeline.run()` runs Component with Variadic input as expected.
**Additional context**
This has been reported by a user on Discord in [this thre... | closed | 2024-09-09T07:51:55Z | 2024-09-10T12:59:55Z | https://github.com/deepset-ai/haystack/issues/8341 | [
"P1"
] | silvanocerza | 1 |
pytest-dev/pytest-qt | pytest | 117 | MultiSignalBlocker.args | It actually would be nice to have an `.args` attribute for `MultiSignalBlocker` too, which is just a list of emitted argument lists, e.g. `[['foo', 2342], ['bar', 1234]]`.
I'll work on this soon (I hope :laughing:)
| closed | 2015-12-17T06:11:14Z | 2016-10-19T00:11:16Z | https://github.com/pytest-dev/pytest-qt/issues/117 | [] | The-Compiler | 8 |
jonaswinkler/paperless-ng | django | 464 | consumer error on scanned pdf | Hi Jonas,
thank you for providing paperless-ng! It is an awesome project. However, my paperless-ng installation's consumer (1.0, docker, debian 10) fails to ocr a scanned pdf.
System:
` Operating System: Debian GNU/Linux 10 (buster)
Kernel: Linux 4.19.0-13-amd64
Architecture: x86-64`
Doc... | closed | 2021-01-28T22:14:56Z | 2021-01-28T22:55:44Z | https://github.com/jonaswinkler/paperless-ng/issues/464 | [] | msrv | 1 |
cvat-ai/cvat | tensorflow | 9,023 | Return storage location not supporting shared storage | when adding tasks trough the API, i can define where it should be saved, including shared storage. but when i want the metadata from a specific task i only get either local or cloud_storage. why doesn't it include share as a possible option? i can define this with each uploading task, but don't get it returned with Met... | closed | 2025-01-30T12:59:23Z | 2025-02-21T13:36:24Z | https://github.com/cvat-ai/cvat/issues/9023 | [] | Xterbione | 8 |
newpanjing/simpleui | django | 376 | TabularInline条目的original样式margin-top偏移量过大 | **bug描述**
在使用TabularInline的情况下,inline条目的original信息纵坐标偏移过大。
**重现步骤**
1.在ModelAdmin中内联TabularInline
2.进入change视图,见图
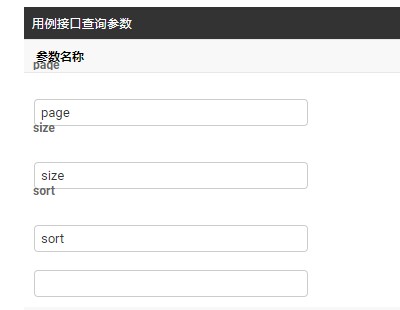
关联代码:
https://github.com/newpanjing/simpleui/blob/c5fdc1b7a1cda33b... | closed | 2021-05-17T08:09:15Z | 2021-07-21T01:28:33Z | https://github.com/newpanjing/simpleui/issues/376 | [
"bug"
] | yanhuixie | 1 |
akfamily/akshare | data-science | 5,806 | 东财接口临时解决方案 | 目前东方财富接口应该是在频繁修改,导致本周又出现相同问题。已收到星球用户和 github 用户反馈,可以在此 issue 留言,也欢迎提供更好的解决方案。 | closed | 2025-03-08T16:54:32Z | 2025-03-09T14:21:53Z | https://github.com/akfamily/akshare/issues/5806 | [] | albertandking | 10 |
lexiforest/curl_cffi | web-scraping | 29 | Pyinstaller Error | Pyinstaller Error in version 0.4.0:
Traceback (most recent call last):
File "lt1.py", line 8, in <module>
File "PyInstaller\loader\pyimod03_importers.py", line 540, in exec_module
File "curl_cffi\__init__.py", line 39, in <module>
ImportError: DLL load failed while importing _wrapper: | closed | 2023-03-21T08:15:53Z | 2023-05-23T03:41:20Z | https://github.com/lexiforest/curl_cffi/issues/29 | [] | mstplm | 3 |
qubvel-org/segmentation_models.pytorch | computer-vision | 60 | cannot import name 'cfg' | when I try to import the module, I get an error:
```python
cannot import name 'cfg'
```
want help!!! | closed | 2019-09-18T07:47:16Z | 2019-09-18T08:04:44Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/60 | [] | ZinuoCai | 1 |
PaddlePaddle/models | nlp | 5,315 | no have kpi.py | PaddleNLP\pretrain_language_models\BERT
run ./_run_ce.sh

no share all the code | closed | 2021-06-04T13:22:35Z | 2021-06-14T08:45:19Z | https://github.com/PaddlePaddle/models/issues/5315 | [
"user"
] | zhihuashan | 2 |
inducer/pudb | pytest | 136 | http://mathema.tician.de/software/pudb has gone 404 | The URL "http://mathema.tician.de/software/pudb" results in a 404 error
The URL is shown in the banner on GitHub. It was also the first link on the wiki page at http://wiki.tiker.net/PuDB, where I updated it to "http://pypi.python.org/pypi/pudb" as that is the URL listed as homepage in PyPi
| closed | 2015-04-30T10:38:03Z | 2015-05-01T16:03:56Z | https://github.com/inducer/pudb/issues/136 | [] | jalanb | 1 |
modelscope/modelscope | nlp | 508 | 安装Paraformer的时候,提示版本冲突 | **环境**
windows 10
python 3.7
**目标**
在本地环境安装Paraformer环境
当前已经安装好了modelscope环境,但是在安装modelscope[audio]的时候提示版本冲突

| closed | 2023-08-29T08:06:57Z | 2024-07-08T01:53:20Z | https://github.com/modelscope/modelscope/issues/508 | [
"Stale"
] | stoneHah | 3 |
plotly/dash | plotly | 2,653 | dcc.Dropdown has inconsistent layout flow with other common input components | **Describe your context**
```
dash 2.13.0
dash-core-components 2.0.0
dash-html-components 2.0.0
dash-table 5.0.0
```
**Describe the bug**
Many of the go-to Dash Core Components have the CSS style `display` set to `inline-block`, with a notable except... | open | 2023-10-05T15:35:07Z | 2024-08-13T19:38:28Z | https://github.com/plotly/dash/issues/2653 | [
"bug",
"P3"
] | ned2 | 0 |
erdewit/ib_insync | asyncio | 322 | Unable to fetch data for metals | I am so far unable to fetch data for metals, using the product listing located [here](https://www.interactivebrokers.com/en/index.php?f=2222&exch=idealpro_metals&showcategories=) for gold. There is sparse documentation on this, but I have tried:
```python
contract = Commodity('XAUUSD','IDEALPRO','USD')
```
and,
... | closed | 2020-12-10T00:56:49Z | 2020-12-13T10:22:49Z | https://github.com/erdewit/ib_insync/issues/322 | [] | Shellcat-Zero | 1 |
Nemo2011/bilibili-api | api | 276 | 【提问】{怎么获取艾特自己的消息} |
如题 找不到接口 | closed | 2023-05-05T07:25:15Z | 2024-01-19T04:19:07Z | https://github.com/Nemo2011/bilibili-api/issues/276 | [
"question"
] | Hzxxxx2002 | 4 |
PokeAPI/pokeapi | api | 643 | Missing TypeScript Wrapper Reference on Poke-Api Website | Hi, I noticed that the TypeScript Wrapper for the Poke Api is not being referenced in the official Website. The two documentations are not equal, as well the ts wrapper also has a logging feature.

![docwr... | closed | 2021-08-19T14:42:29Z | 2021-10-22T18:00:09Z | https://github.com/PokeAPI/pokeapi/issues/643 | [] | moyzlevi | 1 |
pallets/quart | asyncio | 77 | Motor MongoDB driver integration with Quart | Hi currently Flask doesn't support Motor driver for Mogodb but it supports MongoEngine which uses PyMongo driver internally which not asynchronous. Since Quart framework is built around Async IO, It will be much better if this paradigm is implemented in MongoDB Integration as well. And also Motor runs on async io. Is ... | closed | 2019-09-10T08:45:49Z | 2022-07-06T00:23:50Z | https://github.com/pallets/quart/issues/77 | [] | harshakumar347 | 1 |
plotly/dash | dash | 2,698 | [BUG] pattern-matching callback output "children" interpret an output list as multiple outputs | Thank you so much for helping improve the quality of Dash!
We do our best to catch bugs during the release process, but we rely on your help to find the ones that slip through.
**Describe your context**
Python 3.7.11 in a venv on Ubuntu 22.04
- replace the result of `pip list | grep dash` below
```
dash ... | closed | 2023-11-21T12:05:29Z | 2023-11-21T14:12:42Z | https://github.com/plotly/dash/issues/2698 | [] | claudiocmp | 0 |
deezer/spleeter | tensorflow | 874 | My batch script worked 2 days ago, doesnt work now. No changes done. | for %%a in ("*.wav") do spleeter separate -p spleeter:2stems -i "%%a" -o output
Now it just shows the text 50-60 times and quits.
How can that be? | open | 2023-10-21T14:19:39Z | 2023-10-21T15:14:34Z | https://github.com/deezer/spleeter/issues/874 | [
"bug",
"invalid"
] | manus693 | 3 |
vaexio/vaex | data-science | 1,969 | ArrowIndexError while using groupby | Hi Team,
We are using Dask + Vaex combination for one of our use cases. After the recent Blake3 version upgrade to 0.3.1 and vaex upgrade to 4.8.0 (Dask version: 2022.01.0), we started getting the following error in ‘groupby’ randomly (sometimes this works fine and sometimes we get the following error) –
`df = df... | open | 2022-03-11T12:59:23Z | 2022-03-21T15:46:56Z | https://github.com/vaexio/vaex/issues/1969 | [] | khus07hboo | 2 |
BeanieODM/beanie | asyncio | 1,132 | Document._class_id is always overwritten | **Describe the bug**
`Document._class_id` is overwritten. Document initialization should check if it's set before assigning a value. This messes up the customization of document discriminators and leads to failing queries (update, find, link fetching...).
**To Reproduce**
Create a couple of documents (with inherita... | open | 2025-02-24T10:00:20Z | 2025-02-24T11:36:20Z | https://github.com/BeanieODM/beanie/issues/1132 | [] | volfpeter | 0 |
microsoft/MMdnn | tensorflow | 335 | Mxnet->Tf | Hi kitstar,
I have met the same question:
Warning: MXNet Parser has not supported operator null with name data.
Warning: convert the null operator with name [data] into input layer.
Warning: MXNet Parser has not supported operator _minus_scalar with name _minusscalar0.
Warning: MXNet Parser has not supported ope... | open | 2018-07-27T03:06:04Z | 2018-07-31T02:11:52Z | https://github.com/microsoft/MMdnn/issues/335 | [] | xiangdeyizhang | 1 |
waditu/tushare | pandas | 1,653 | 最新代码是不是不开源了 | 看代码的commit很久之前了,和现有的代码的接口也对不上,这个项目是不是早就不再开源最新版本了 | open | 2022-05-22T08:57:08Z | 2022-05-22T08:57:08Z | https://github.com/waditu/tushare/issues/1653 | [] | hitflame | 0 |
Urinx/WeixinBot | api | 22 | [BUG] selector 为 6 时死循环 | 我看你代码里还是todo,想问下6是代表什么。我运行的时候经常碰到6然后死循环了。
| open | 2016-02-24T08:58:46Z | 2017-07-31T15:53:01Z | https://github.com/Urinx/WeixinBot/issues/22 | [
"bug"
] | Zcc | 9 |
PrefectHQ/prefect | automation | 16,828 | Process workpool doesn't make a flow run | ### Bug summary
I am hosting a Prefect server on ECS/AWS and have set up a ”Process” work pool on my local server.
When I tried to run a sample flow through the work pool, it crashed with the following log
```
Failed to submit flow run 'a33827d9-ae22-408c-a914-cfd926fa50ba' to infrastructure.
Traceback (most recent c... | closed | 2025-01-23T16:37:35Z | 2025-01-24T01:56:26Z | https://github.com/PrefectHQ/prefect/issues/16828 | [
"bug"
] | YukioKaneda | 2 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 3,548 | Next button does not seem to move to next questionnaire tab | ### What version of GlobaLeaks are you using?
4.12.2
### What browser(s) are you seeing the problem on?
Chrome
### What operating system(s) are you seeing the problem on?
Windows
### Describe the issue
[Next] button does not seem to move to next questionnaire tab.
In the specific questionnaire there is a condi... | closed | 2023-07-23T17:09:48Z | 2023-07-23T20:03:32Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/3548 | [
"T: Bug",
"C: Client"
] | elbill | 1 |
Johnserf-Seed/TikTokDownload | api | 136 | Web版现已发布 | # Web版项目
[Johnserf-Seed/TikTokWeb](https://github.com/Johnserf-Seed/TikTokWeb)

| open | 2022-04-18T13:35:00Z | 2022-04-18T14:47:56Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/136 | [
"小白必看(good first issue)"
] | Johnserf-Seed | 4 |
comfyanonymous/ComfyUI | pytorch | 6,380 | ControlNetFlux.forward() missing 1 required positional argument: 'y' | ### Your question


### Logs
_No response_
### Other
_No response_ | closed | 2025-01-07T13:13:35Z | 2025-01-11T15:38:24Z | https://github.com/comfyanonymous/ComfyUI/issues/6380 | [
"User Support"
] | Season0468 | 3 |
jowilf/starlette-admin | sqlalchemy | 297 | Bug: pagination size is not remembered | **Describe the bug**
If you change the pagination size to 25, the system does not remember this.
**To Reproduce**
Change the page size from 10 to 25. Then visit an entity, click around, go back to the list. The page size is back to 10.
**Environment (please complete the following information):**
- Starlet... | closed | 2023-09-06T21:42:46Z | 2023-09-09T03:32:02Z | https://github.com/jowilf/starlette-admin/issues/297 | [
"bug"
] | sglebs | 0 |
the0demiurge/ShadowSocksShare | flask | 76 | close | closed | 2019-08-31T06:41:39Z | 2019-08-31T14:52:30Z | https://github.com/the0demiurge/ShadowSocksShare/issues/76 | [] | loewe0202 | 0 | |
ndleah/python-mini-project | data-visualization | 221 | Python projects | closed | 2024-02-11T12:09:02Z | 2024-06-02T06:03:40Z | https://github.com/ndleah/python-mini-project/issues/221 | [] | busssanwesh | 0 | |
BeanieODM/beanie | pydantic | 525 | [BUG] Default values break behaviour of 'Indexed(...)' | **Describe the bug**
When creating a field with `Indexed(...)` type and a default type provided, in my case it is pydantic's `Field(...)`, the field is not being added into MongoDB's indexes.
**To Reproduce**
```python
from beanie import Document, Indexed
from pydantic import Field
class Test(Document):
s... | closed | 2023-04-01T20:54:19Z | 2023-05-05T23:52:28Z | https://github.com/BeanieODM/beanie/issues/525 | [
"bug"
] | yallxe | 1 |
widgetti/solara | flask | 850 | Inconsistent issue when removing a split map control from an ipyleaflet map | I am facing a very difficult issue to trace, so I came up with this [almost reproducible example](https://py.cafe/app/lopezv.oliver/solara-issue-850).
This animation shows the demo initially working as expected. Then, I refresh the app and there is an issue with the demo: the split-map control does not get removed c... | open | 2024-11-05T07:01:22Z | 2024-11-17T14:08:02Z | https://github.com/widgetti/solara/issues/850 | [] | lopezvoliver | 2 |
yeongpin/cursor-free-vip | automation | 230 | Auto continue after 25 tool calls | Can we auto continue after 25 tool calls, can you please look into it? | closed | 2025-03-14T16:48:24Z | 2025-03-16T17:05:42Z | https://github.com/yeongpin/cursor-free-vip/issues/230 | [] | Kabi10 | 1 |
Miserlou/Zappa | django | 2,146 | How to invoke or schedule functions from non wsgi app | Context
I have some code for automation https://github.com/manycoding/page-followers. I'd like to invoke functions to test from different files. I noticed when I run `zappa invoke dev "anything but lambda_handler" it actually invokes `lambda_handler`. Same with scheduling.
## Expected Behavior
I'd like to be abl... | closed | 2020-07-29T17:05:50Z | 2020-09-28T14:02:04Z | https://github.com/Miserlou/Zappa/issues/2146 | [] | manycoding | 3 |
zappa/Zappa | django | 922 | [Migrated] Add Docker Container Image Support | Originally from: https://github.com/Miserlou/Zappa/issues/2188 by [ian-whitestone](https://github.com/ian-whitestone)
Earlier this month, AWS [announced container image support](https://aws.amazon.com/blogs/aws/new-for-aws-lambda-container-image-support/) for AWS Lambda. This means you can now package and deploy lambd... | closed | 2021-02-20T13:24:34Z | 2024-04-13T19:36:38Z | https://github.com/zappa/Zappa/issues/922 | [
"no-activity",
"auto-closed"
] | jneves | 7 |
kynan/nbstripout | jupyter | 105 | Use within pre-commit on GitHub Actions fails with `.git/index.lock` error | This issue seems quite similar to https://github.com/kynan/nbstripout/issues/103
I run the following GitHub action which installs pre-commit and runs it on all files.
https://github.com/pymedphys/pymedphys/blob/9a484fd3273b2ea898924ec3efbc16b5bfde377a/.github/workflows/main.yml#L5-L19
Pay particular attention ... | closed | 2019-09-24T08:20:54Z | 2019-11-13T06:57:33Z | https://github.com/kynan/nbstripout/issues/105 | [
"type:bug",
"resolution:fixed"
] | SimonBiggs | 4 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 769 | Do you have this code available on a Google Colab VM? | I'm new to Python so I just found out that it makes no sense touching apps which make use of CUDA configurations (specially Macs which are not compatible with Nvidia drivers as of MacOS Catalina 10.15.x
Any suggestions... If you help me get going I can devote more time to train an spanish version of this amazing ... | closed | 2021-06-06T05:24:37Z | 2021-08-20T13:15:20Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/769 | [] | inglesuniversal | 2 |
apache/airflow | data-science | 47,511 | BranchPythonOperator.execute cannot be called outside TaskInstance! | ### Apache Airflow version
2.10.5
### If "Other Airflow 2 version" selected, which one?
_No response_
### What happened?
For some reason BranchPythonOperator reports warning:
```
[2025-03-07, 18:13:18 UTC] {local_task_job_runner.py:123} ▶ Pre task execution logs
[2025-03-07, 18:13:19 UTC] {baseoperator.py:424} WA... | open | 2025-03-07T18:43:00Z | 2025-03-10T00:28:23Z | https://github.com/apache/airflow/issues/47511 | [
"kind:bug",
"area:core",
"needs-triage"
] | tomplus | 3 |
nerfstudio-project/nerfstudio | computer-vision | 2,808 | Convert final transform.json camera poses into camera-2-world format | I have a question about converting the final transform.json file into camera-2-world format after running ns-process-data. My ultimate goal is to calculate the angular difference between cameras. Is there any flag or function that I can set to keep or convert the transform.json result into camera-2-world coordinates? A... | open | 2024-01-23T10:53:17Z | 2024-01-23T10:53:17Z | https://github.com/nerfstudio-project/nerfstudio/issues/2808 | [] | aeskandari68 | 0 |
jumpserver/jumpserver | django | 14,913 | [Question] How to connect in the DB using Dbeaver SSH Tunnel | ### Product Version
v4.5.0
### Product Edition
- [x] Community Edition
- [ ] Enterprise Edition
- [ ] Enterprise Trial Edition
### Installation Method
- [x] Online Installation (One-click command installation)
- [ ] Offline Package Installation
- [ ] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] Source Code
### ... | closed | 2025-02-21T19:42:16Z | 2025-03-17T14:47:03Z | https://github.com/jumpserver/jumpserver/issues/14913 | [
"🤔 Question"
] | joaoixc | 4 |
yt-dlp/yt-dlp | python | 12,278 | Extract cookies from Edge for youtube? | ### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [x] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
### Checklist
- [x] I'm asking a question and **not** reporting a bug or requesting a feature
- [x] I've looked through the [README](https://github.com/yt-dlp/yt-dlp#re... | closed | 2025-02-04T18:15:28Z | 2025-02-04T21:42:23Z | https://github.com/yt-dlp/yt-dlp/issues/12278 | [
"duplicate",
"spam"
] | Cryosim | 1 |
RobertCraigie/prisma-client-py | asyncio | 1,024 | quaint error | <!--
Thanks for helping us improve Prisma Client Python! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by enabling additional logging output.
See https://prisma-client-py.readthedocs.io/en/stable/reference/logging/ for how to enable additional log... | open | 2024-08-27T18:36:22Z | 2024-10-08T23:37:30Z | https://github.com/RobertCraigie/prisma-client-py/issues/1024 | [] | vikyw89 | 2 |
charlesq34/pointnet | tensorflow | 268 | cannot download the modelnet40 | ---021-03-07 00:08:33-- https://shapenet.cs.stanford.edu/media/modelnet40_ply_hdf5_2048.zip;
Resolving shapenet.cs.stanford.edu (shapenet.cs.stanford.edu)... 171.67.77.19
Connecting to shapenet.cs.stanford.edu (shapenet.cs.stanford.edu)|171.67.77.19|:443... connected.
WARNING: cannot verify shapenet.cs.stanford.edu... | open | 2021-03-06T16:13:51Z | 2024-11-07T15:13:16Z | https://github.com/charlesq34/pointnet/issues/268 | [] | noridayu1998 | 6 |
iperov/DeepFaceLab | deep-learning | 862 | Please add 2nd and 3rd pass to S3FD face detector just like in DFL 1.0 | Please add 2nd and 3rd pass to S3FD face detector just like in DFL 1.0
There are lots of false positive extracted images | open | 2020-08-15T01:14:37Z | 2020-08-15T01:14:37Z | https://github.com/iperov/DeepFaceLab/issues/862 | [] | justinjohn0306 | 0 |
vaexio/vaex | data-science | 1,938 | head() method not displaying result after doing a replace() with regex |
**Software information**
- Vaex version (`import vaex; vaex.__version__)`: 4.7.0
- Vaex was installed via: pip / conda-forge / from source : Vaex installed through conda-forge
- OS: macOS
- Conda 4.10.3
**Additional information**
Please state any supplementary information or provide additional context ... | closed | 2022-02-18T19:00:18Z | 2022-03-03T09:22:20Z | https://github.com/vaexio/vaex/issues/1938 | [] | omonmaxi | 9 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 280 | text-generation-webui方式运行dtype报错,效果有一些问题 | 感谢您使用Issue提问模板,请按照以下步骤提供相关信息。我们将优先处理信息相对完整的Issue,感谢您的配合。
*提示:将[ ]中填入x,表示打对钩。提问时删除上面这两行。请只保留符合的选项,删掉其他。*
### 详细描述问题
text-generation-webui 的方式运行报错,在此项目中文找对应的issue:
`python server.py --model llama-13b-hf --lora chinese-alpaca-lora-13b`
或者
`python server.py --model llama-7b-hf --lora chinese-alpaca-lora-7b`... | closed | 2023-05-09T09:24:33Z | 2023-05-20T22:02:07Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/280 | [
"stale"
] | brealisty | 3 |
idealo/imagededup | computer-vision | 187 | RuntimeError: stack expects a non-empty TensorList | I get the following Error running
` method_object = CNN()
duplicates = method_object.find_duplicates(image_dir=directory)`:
C:\Users\themc\AppData\Roaming\Python\Python39\site-packages\torchvision\models\_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the ... | closed | 2023-01-05T23:50:53Z | 2023-01-15T18:02:01Z | https://github.com/idealo/imagededup/issues/187 | [] | 11TheM | 2 |
Avaiga/taipy | data-visualization | 2,082 | [🐛 BUG] Column headers of Taipy table are truncated | ### What went wrong? 🤔
When having a lot of columns in a table, the columns headers becomes truncated.

This is a new behavior that didn't exist in 3.1.
` doesn't return the correct value, and `dialog.get_values()` doesn't even list it's key, wh... | open | 2025-03-12T09:04:13Z | 2025-03-12T09:04:13Z | https://github.com/frappe/frappe/issues/31668 | [] | cogk | 0 |
timkpaine/lantern | plotly | 80 | matplotlib support right y label | closed | 2017-10-18T02:05:21Z | 2018-02-05T21:29:06Z | https://github.com/timkpaine/lantern/issues/80 | [
"feature",
"matplotlib/seaborn"
] | timkpaine | 0 | |
autogluon/autogluon | data-science | 4,789 | [Feature Request]: Ensembling extra fitted models for `TimeSeriesPredictor` and `MultiModalPredictor` like for `TabularPredictor` with `fit_extra` method | ## Description
Sometimes we need to run several experiments one by one to gain insights for the project.
And we get many versions of Autogluon models.
Now I am interested in ensembling previous autogluon models together. This is different to the internel ensembling of each autogluon model itself.
## Referen... | open | 2025-01-12T18:33:05Z | 2025-01-13T20:26:22Z | https://github.com/autogluon/autogluon/issues/4789 | [
"enhancement",
"module: timeseries"
] | 2catycm | 3 |
ray-project/ray | pytorch | 51,445 | [<Ray component: java>] expose ObjectRef in DeploymentResponse class | ### Description
It is possible to convert a DeploymentResponse to an ObjectRef in Python, as described in
https://docs.ray.io/en/master/serve/model_composition.html#advanced-convert-a-deploymentresponse-to-a-ray-objectref. However, Ray Java lacks a similar capability, making certain use cases unsupported. It would be ... | open | 2025-03-18T07:15:52Z | 2025-03-24T03:21:35Z | https://github.com/ray-project/ray/issues/51445 | [
"java",
"enhancement",
"triage",
"serve"
] | zhiqiwangebay | 1 |
vitalik/django-ninja | django | 514 | How to handle custom headers with the interactive openAPI doc | For authentication I need to pass a header `x-team` together with a Bearer token to API endpoints.
This all works fine, however, I haven't been able to figure out how to successfully integrate this with the OpenAPI docs endpoint.
To make it appear in the (Swagger) UI, I need to specify it as a parameter in the endpoi... | closed | 2022-07-27T00:38:52Z | 2023-12-16T15:19:02Z | https://github.com/vitalik/django-ninja/issues/514 | [] | bjerzyna | 3 |
Johnserf-Seed/TikTokDownload | api | 307 | 12345 | 12345 | closed | 2023-02-08T05:01:21Z | 2023-02-15T07:48:56Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/307 | [
"故障(bug)",
"额外求助(help wanted)",
"无效(invalid)"
] | zzh151223 | 28 |
ydataai/ydata-profiling | jupyter | 1,316 | Using tsmode=True, check if data.index is a DateTime index, if so include it in the analysis | ### Missing functionality
I've used ProfileReport with tsmode=True on a pd.DataFrame indexed with a DateTime index. My assumption was that the report would provide some basic analysis on that index as well as on the values. The report indicates the number of missing values in all columns, which is great, but I could f... | closed | 2023-04-20T17:20:26Z | 2023-08-08T19:44:42Z | https://github.com/ydataai/ydata-profiling/issues/1316 | [
"feature request 💬"
] | CatChenal | 3 |
openapi-generators/openapi-python-client | rest-api | 613 | black posthook throws `ImportError: cannot import name 'izip_longest' from 'pathspec.compat'` | **Describe the bug**
During the `black .` post hook, openapi-python-client throws :
```
openapi-python-client update --url someurl.com/openapi.json
Updating my_project
Error(s) encountered while generating, client was not created
black failed
Traceback (most recent call last):
File "C:\Users\x\AppData\Loc... | open | 2022-05-11T18:28:11Z | 2022-05-11T18:32:12Z | https://github.com/openapi-generators/openapi-python-client/issues/613 | [
"🐞bug"
] | LaurentBergeron | 0 |
fastapi/sqlmodel | fastapi | 309 | Parent instance is not bound to a Session; lazy load operation of attribute cannot proceed | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X] I al... | closed | 2022-04-21T23:25:17Z | 2022-04-23T22:13:15Z | https://github.com/fastapi/sqlmodel/issues/309 | [
"question"
] | Maypher | 3 |
keras-team/keras | tensorflow | 20,953 | Function `openvino.core.custom_gradient()` should be a class | I'm not using this, but I saw by accident while browsing the code that `keras.backend.openvino.core.custom_gradient()` is a function that defines nested functions `__init__()` and `__call__()`, but doesn't do anything (in particular, it seems to return `None`):
https://github.com/keras-team/keras/blob/c03ae353f0702387... | open | 2025-02-24T13:52:06Z | 2025-03-06T04:06:03Z | https://github.com/keras-team/keras/issues/20953 | [
"type:Bug"
] | JulianJvn | 0 |
home-assistant/core | python | 140,781 | direction of camera streams, does not work | ### The problem
There is a function to align 90 degrees left/right or 180 degrees from the camera stream, but it is not useful because it does not work
### What version of Home Assistant Core has the issue?
core-2025.3.3
### What was the last working version of Home Assistant Core?
_No response_
### What type of ... | open | 2025-03-17T06:56:37Z | 2025-03-23T14:03:35Z | https://github.com/home-assistant/core/issues/140781 | [
"integration: camera"
] | rezueps | 3 |
mljar/mljar-supervised | scikit-learn | 303 | Better time limit for algorithm training | closed | 2021-01-25T08:06:21Z | 2021-01-25T20:00:29Z | https://github.com/mljar/mljar-supervised/issues/303 | [
"enhancement"
] | pplonski | 1 | |
pydata/xarray | numpy | 9,620 | Nightly Hypothesis tests failed | [Workflow Run URL](https://github.com/pydata/xarray/actions/runs/11318955291)
<details><summary>Python 3.12 Test Summary</summary>
```
properties/test_index_manipulation.py::DatasetTest::runTest: hypothesis.errors.FlakyFailure: Inconsistent results: An example failed on the first run but now succeeds (or fails with an... | closed | 2024-10-14T00:30:14Z | 2024-10-29T14:31:02Z | https://github.com/pydata/xarray/issues/9620 | [
"topic-hypothesis"
] | github-actions[bot] | 1 |
man-group/arctic | pandas | 281 | a | #### Arctic Version
```
# 1.30
```
#### Arctic Store
```
# VersionStore
```
#### Platform and version
Linux
#### Description of problem and/or code sample that reproduces the issue
Just a test
| closed | 2016-11-07T17:57:48Z | 2016-11-07T17:57:56Z | https://github.com/man-group/arctic/issues/281 | [] | bmoscon | 0 |
pydata/xarray | numpy | 9,340 | Allow symbolic links between datatree nodes? | ### What is your issue?
[It would be nice](https://github.com/pydata/xarray/issues/4118#issuecomment-875121115) if the tree could support internal symbolic links between nodes.
---
If someone actually wants this then please speak up! Otherwise we won't prioritise it, because it's not at all simple. | open | 2024-08-13T16:08:27Z | 2024-08-14T16:33:02Z | https://github.com/pydata/xarray/issues/9340 | [
"design question",
"topic-backends",
"topic-DataTree"
] | TomNicholas | 2 |
iperov/DeepFaceLab | deep-learning | 916 | Moving directory results "not found" (beauty-error) + strange side effects afterwards | Hello,
first of all let me tell you, that the error i want to mention is more something of a beauty problem instead of a real error!
Yesterday i moved some directories within my hard drive. One of those dirs was the DeepFaceLab directory. Today i wanted to test some ideas within an my first workspace (the one with ... | open | 2020-10-03T13:40:35Z | 2023-06-08T21:44:09Z | https://github.com/iperov/DeepFaceLab/issues/916 | [] | Void-Droid | 1 |
proplot-dev/proplot | data-visualization | 295 | Better warning dependency of cartopy package | ### Description
When I tried the basic geographic plot without cartopy installed
```
import proplot as pplt
pplt.subplots(proj='npstere')
```
I got this error:
```
ValueError: Unknown projection 'npstere'. Options are: '3d', 'basemap', 'cart', 'cartesian', 'cartopy', 'geo', 'geographic', 'polar', 'rect', 'r... | closed | 2021-10-11T12:51:22Z | 2021-10-15T21:30:18Z | https://github.com/proplot-dev/proplot/issues/295 | [
"enhancement"
] | zxdawn | 3 |
huggingface/peft | pytorch | 2,054 | Problem with model.merge_and_unload - the saved model is almost empty - 40kb | ### System Info
Ubuntu 22.04 all latest versions
### Who can help?
@BenjaminBossan @sayakpaul
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [x] An officially supported task in the `examples` folder
- [ ] My own task or dataset (give details below)
... | closed | 2024-09-07T22:57:29Z | 2024-10-16T15:03:56Z | https://github.com/huggingface/peft/issues/2054 | [] | Oxi84 | 4 |
Anjok07/ultimatevocalremovergui | pytorch | 567 | ValueError: Input signal length is too small=0 | Last Error Received:
Process: MDX-Net
If this error persists, please contact the developers with the error details.
Raw Error Details:
ValueError: "Input signal length=0 is too small to resample from 88200->44100"
Traceback Error: "
File "UVR.py", line 4716, in process_start
File "separate.py", line ... | open | 2023-05-22T23:26:46Z | 2023-05-22T23:26:46Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/567 | [] | Sebba1976 | 0 |
waditu/tushare | pandas | 1,556 | 689009的后复权数据出错了 | ID:125875
ts_code trade_date open high low close pre_close change pct_chg vol amount
1 689009.SH 20210611 NA NA NA NA NA 0.12 0.1485 21024.22 172997.233
2 689009.SH 20210610 NA NA NA NA NA -0.4 -0.4926 17102.09 139235.786
3 689009.SH 20210609 N... | open | 2021-06-15T06:31:45Z | 2021-06-15T06:31:45Z | https://github.com/waditu/tushare/issues/1556 | [] | cuberoocp | 0 |
NullArray/AutoSploit | automation | 1,247 | Unhandled Exception (c745f1000) | Autosploit version: `4.0`
OS information: `Linux-4.15.0-76-generic-x86_64-with-Ubuntu-18.04-bionic`
Running context: `autosploit.py`
Error mesage: `[Errno 2] No such file or directory: '/opt/AutoSploit/hosts.txt'`
Error traceback:
```
Traceback (most recent call):
File "/opt/AutoSploit/lib/term/terminal.py", line 721,... | closed | 2020-02-13T21:04:57Z | 2020-03-21T21:10:27Z | https://github.com/NullArray/AutoSploit/issues/1247 | [] | AutosploitReporter | 1 |
PablocFonseca/streamlit-aggrid | streamlit | 33 | General Question: plugging in custom components | Awesome library @PablocFonseca! A quick question for you:
My firm has an enterprise license for AGGrid, but we also have a number of custom "wrappers" around the library in order to modify the look/feel of components. If we wanted to plug these into what you have built here what would be the path forward to do so? R... | closed | 2021-09-15T03:38:52Z | 2024-04-04T17:52:25Z | https://github.com/PablocFonseca/streamlit-aggrid/issues/33 | [
"enhancement"
] | scottweitzner | 3 |
tflearn/tflearn | data-science | 1,098 | Prediction is slower when model is loaded than if it is fited during the process | Hello,
I have a strange issue, the DNN.predict method is quite slower when I load my model's weight than when I train with the fit method. I've also noted that when I run a prediction over a batch of images, it's getting faster and faster to predict.
Here is my code
`class Reseau(object):
def __init__(self, ... | open | 2018-11-09T11:20:27Z | 2018-11-09T11:20:27Z | https://github.com/tflearn/tflearn/issues/1098 | [] | AxelRagobert | 0 |
modin-project/modin | data-science | 6,535 | IO tests fail with the latest s3fs (2023.9.0) | ```python
import modin.experimental.pandas as pd
res = pd.read_csv_glob("s3://modin-datasets/testing/multiple_csv/", storage_options={"anon": True})
print(res)
```
this code works with `pip install s3fs==2023.6.0` and [fails](https://github.com/modin-project/modin/actions/runs/6081300714/job/16496861135#step:15:... | closed | 2023-09-05T14:17:00Z | 2023-09-05T15:20:26Z | https://github.com/modin-project/modin/issues/6535 | [
"bug 🦗",
"P0"
] | dchigarev | 0 |
qubvel-org/segmentation_models.pytorch | computer-vision | 764 | Binary Segmentation | Anyone care to share a working example for binary segmentation? The examples shared no longer work. Thank you very much :) | closed | 2023-05-21T01:32:29Z | 2023-07-12T09:45:26Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/764 | [] | chefkrym | 2 |
marimo-team/marimo | data-science | 3,800 | Plotly requires narwhals>=1.15.1, marimo.io/p/dev project stays at version 1.10 | ### Describe the bug
I'm trying to plot with Plotly on marimo.io/p/dev, through the project dashboard. Plotly needs narwhals>=1.15.1, but the Pyodide environment comes with version 1.10.0. Uninstalling, then reinstalling narwhals==1.26 showed narwhals==1.26 in the side bar, but the environment always starts up with 1.... | closed | 2025-02-14T15:46:03Z | 2025-02-14T16:20:09Z | https://github.com/marimo-team/marimo/issues/3800 | [
"bug"
] | essicolo | 1 |
recommenders-team/recommenders | machine-learning | 1,930 | [BUG] AttributeError: 'dict' object has no attribute '__LIGHTFM_SETUP__' | ### Description
My CICD is failing when installing recommenders. Previously this code was working correctly.
Full stacktrace :
```
9s
Run python -m pip install --upgrade pip
Requirement already satisfied: pip in /opt/hostedtoolcache/Python/3.8.[1](https://github.com/360Learning/course-recommendations/actio... | closed | 2023-05-22T10:00:09Z | 2024-03-05T13:13:41Z | https://github.com/recommenders-team/recommenders/issues/1930 | [
"bug"
] | benoit360l | 2 |
flaskbb/flaskbb | flask | 394 | Create a FAQ with some common questions and pitfalls | For example those are issues that could easily prevented with a FAQ (or better docs :P):
#372
#389
| closed | 2018-01-13T17:42:56Z | 2018-04-15T07:47:50Z | https://github.com/flaskbb/flaskbb/issues/394 | [
"enhancement"
] | sh4nks | 1 |
ivy-llc/ivy | numpy | 28,312 | householder_product | I will implement this as a composition function.
#28311 will be good to have for better implementation.
Conversation of torch.linealg locked! | closed | 2024-02-17T17:29:27Z | 2024-02-17T17:32:46Z | https://github.com/ivy-llc/ivy/issues/28312 | [
"Sub Task"
] | ZenithFlux | 0 |
google-research/bert | tensorflow | 889 | "model_fn should return an EstimatorSpec." Error when running "predicting_movie_reviews_with_bert_on_tf_hub.ipynb" for fine-tuning BERT-Chinese Model | I tried to run "predicting_movie_reviews_with_bert_on_tf_hub.ipynb", but fine-tuning on a Chinese-text csv with corresponding labels. As such I loaded 'https://tfhub.dev/google/bert_chinese_L-12_H-768_A-12/1' model instead of English-model in the original code
I only made minimum changes from the original jpynb for ... | closed | 2019-10-28T13:25:56Z | 2020-02-01T08:08:57Z | https://github.com/google-research/bert/issues/889 | [] | xinxu75 | 2 |
ultralytics/ultralytics | python | 19,732 | Pre processing paramaters | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi, the pre-processing during inference should be applied to the image the s... | open | 2025-03-16T21:50:07Z | 2025-03-17T09:45:08Z | https://github.com/ultralytics/ultralytics/issues/19732 | [
"question"
] | roy-orfaig | 3 |
marshmallow-code/flask-marshmallow | rest-api | 143 | Flask SQLAlchemy Integration - Documentation Suggestion | Firstly, thank you for the great extension!!
I've ran into an error that I'm sure others will have ran into, it may be worth updating the docs with a warning about it.
Our structure was as follows:
- Each model has it's own module
- Each model module also contains a Schema and Manager for example UserModel, U... | open | 2019-07-29T09:13:33Z | 2020-04-20T06:52:44Z | https://github.com/marshmallow-code/flask-marshmallow/issues/143 | [
"help wanted",
"docs"
] | williamjulianvicary | 4 |
Miserlou/Zappa | django | 2,089 | TypeError: 'NoneType' object is not callable | <!--- Provide a general summary of the issue in the Title above -->
## Context
<!--- Provide a more detailed introduction to the issue itself, and why you consider it to be a bug -->
<!--- Also, please make sure that you are running Zappa _from a virtual environment_ and are using Python 3.6/3.7/3.8 -->
First time ... | open | 2020-04-27T03:02:06Z | 2020-05-02T22:09:56Z | https://github.com/Miserlou/Zappa/issues/2089 | [] | alphahacker | 3 |
recommenders-team/recommenders | data-science | 1,345 | Getting com.microsoft.aad.msal4j.AcquireTokenSilentSupplier failed error on getting access token from clientSecret | Hi Team,
I am trying to get access token from clientSecret. Please find below code snippet.
`IClientCredential cred = ClientCredentialFactory.createFromSecret(clientSecret);
ConfidentialClientApplication app;
try {
// Build the MSAL application object for a client credential flow
app = ConfidentialClientAppli... | closed | 2021-03-15T08:39:29Z | 2021-03-16T16:51:59Z | https://github.com/recommenders-team/recommenders/issues/1345 | [
"help wanted"
] | SuryaAnand302 | 3 |
streamlit/streamlit | streamlit | 10,648 | adding the help parameter to a (Button?) widget pads it weirdly instead of staying to the left. | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
```python
st.page_link('sub_pages/resources/l... | closed | 2025-03-05T09:56:06Z | 2025-03-07T21:21:05Z | https://github.com/streamlit/streamlit/issues/10648 | [
"type:bug",
"status:confirmed",
"priority:P1",
"feature:st.download_button",
"feature:st.button",
"feature:st.link_button",
"feature:st.page_link"
] | thehamish555 | 2 |
chezou/tabula-py | pandas | 215 | CalledProcessError Tabula-py | <!--- Provide a general summary of your changes in the Title above -->
When running tabula-py I get a "CalledProcessError":
CalledProcessError at /api/uploadvendorchargefile/
Command '['java', '-Dfile.encoding=UTF8', '-jar', '/home2/backend/appvenv/lib/python3.5/site-packages/tabula/tabula-1.0.2-jar-with-dependenc... | closed | 2020-01-29T05:14:17Z | 2020-01-29T05:14:30Z | https://github.com/chezou/tabula-py/issues/215 | [] | ghost | 1 |
django-import-export/django-import-export | django | 1,150 | Django import export: it's not importing all column's data from csv. | i'm using django import export and it's importing first 3 columns and leaving rest of the columns blank.
from import_export import resources
#from import_export import instance_loaders
from import_export.admin import ImportExportModelAdmin
from .userB import User_Acadamic_Details_B
from import_export.fields impo... | closed | 2020-06-09T18:38:54Z | 2020-08-07T09:31:49Z | https://github.com/django-import-export/django-import-export/issues/1150 | [
"question"
] | AirnFire | 4 |
thunlp/OpenPrompt | nlp | 41 | TypeError: __init__() missing 1 required positional argument: 'tokenizer_wrapper_class' | When going through the [tutorial](https://thunlp.github.io/OpenPrompt/notes/examples.html)
In step 6, raised the errors below:
>>> data_loader = PromptDataLoader(
... dataset = dataset,
... tokenizer = bertTokenizer,
... template = promptTemplate,
... )
Traceback (most recent call last):
File ... | closed | 2021-11-09T04:19:44Z | 2021-11-11T06:44:49Z | https://github.com/thunlp/OpenPrompt/issues/41 | [] | dongxiaohuang | 4 |
microsoft/hummingbird | scikit-learn | 66 | pytorch problem with pip install on Python3.7 or Python3.8 | Doing pip install hummingbird-ml on Python3.7 or Python3.8 a user reported:
```
ERROR: Could not find a version that satisfies the requirement torch>=1.4.0 (from hummingbird-ml) (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2)
ERROR: No matching distribution found for torch>=1.4.0 (from hummingbird-ml)
```
L... | closed | 2020-05-12T17:44:46Z | 2020-06-03T05:12:00Z | https://github.com/microsoft/hummingbird/issues/66 | [] | ksaur | 6 |
xinntao/Real-ESRGAN | pytorch | 857 | How to setting gt_size | my gt = 512x512,and i want train 64x64 upscale 256x256,when i set gt_size=512 report an error:
### ValueError: LQ (100, 100) is smaller than patch size (128, 128). Please remove None.
and what is the relationship between the size of gt_size and the quality of the final generated image? | open | 2024-10-25T10:11:47Z | 2024-10-25T10:11:47Z | https://github.com/xinntao/Real-ESRGAN/issues/857 | [] | L-Teer | 0 |
influxdata/influxdb-client-python | jupyter | 432 | records with set time don't show up with flux | Hi,
I'm trying to insert data while manually setting the date field. I'm doing so as explained in
https://github.com/influxdata/influxdb-client-python/blob/20c867d6516511fe73b0cae36c1705131cfa92f7/influxdb_client/client/write/point.py#L158
(but with `datetime.now()`)
The trouble is that such entries doesn't show ... | closed | 2022-04-22T22:06:17Z | 2022-05-18T08:59:09Z | https://github.com/influxdata/influxdb-client-python/issues/432 | [
"wontfix"
] | atticus-sullivan | 3 |
tensorpack/tensorpack | tensorflow | 894 | HOW to get information about config in class Model(DQNModel)? | Hi, nice to meet you.
I wonder how to get information about config, such as current learning rate or exploration probability, in class Model(DQNModel), when the program is training. I have tried some method but failed.
| closed | 2018-09-14T08:46:37Z | 2018-09-21T03:53:58Z | https://github.com/tensorpack/tensorpack/issues/894 | [
"examples"
] | silentobservers | 1 |
kynan/nbstripout | jupyter | 147 | Binary file when outputs are not cleared | I use SourceTree, where I can see the changes on the right by clicking on a file.
I have created a new file and run all cells.
If I click on the file, I see this:

I I stage it, I get this message:
![im... | closed | 2021-03-02T14:56:04Z | 2022-10-02T09:59:17Z | https://github.com/kynan/nbstripout/issues/147 | [
"type:bug",
"help wanted",
"resolution:wontfix"
] | IsabellLehmann | 16 |
microsoft/nni | deep-learning | 5,012 | How to add skip connections in at least one type of search strategy? | For now I am only able to generate networks where data will flow through each layer one by one (when the searching process has finished). Is it possible to add in search space those skip connections like in ResNet, using `torch.concat` or `torch.sum` at the junction of the layers? | closed | 2022-07-21T19:58:58Z | 2022-07-25T09:58:16Z | https://github.com/microsoft/nni/issues/5012 | [] | alexeyshmelev | 4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.