
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
ScrapeGraphAI/Scrapegraph-ai | machine-learning | 893 | Empty JSON Output for prompt using LLM | I want to extract all providers listed in this url https://www.aetna.com/dsepublic/#/contentPage?page=providerResults¶meters=searchText%3D'Primary%20Care%20Physician%20(PCP)';isGuidedSearch%3Dtrue&site_id=asa&language=en
I can use selenium, Bsoup etc., but came across this tool
I'm getting empty array as output... | open | 2025-01-15T16:11:39Z | 2025-02-16T10:45:36Z | https://github.com/ScrapeGraphAI/Scrapegraph-ai/issues/893 | [
"bug"
] | SumanthMeenan | 12 |
tqdm/tqdm | pandas | 1,520 | Cli: fence-posting problem | - [x] I have marked all applicable categories:
+ [x] documentation request (i.e. "X is missing from the documentation." If instead I want to ask "how to use X?" I understand [StackOverflow#tqdm] is more appropriate)
+ [x] new feature request
- [x] I have visited the [source website], and in particular
rea... | open | 2023-10-05T20:27:28Z | 2023-10-05T20:27:28Z | https://github.com/tqdm/tqdm/issues/1520 | [] | LecrisUT | 0 |
ultralytics/ultralytics | computer-vision | 19,196 | Full-resolution sized ram caching (not linked to training size) | ### Search before asking
- [x] I have searched the Ultralytics [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar feature requests.
### Description
From memory, yolov5 used to have a "cache the image on disk/ram" in full resolution.
Here if the image training size is for example 640px... | open | 2025-02-12T06:57:54Z | 2025-02-12T06:58:23Z | https://github.com/ultralytics/ultralytics/issues/19196 | [
"enhancement"
] | ExtReMLapin | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,218 | How can to creat TF_XLA_FLAGS=--tf_xla_enable_xla_devices | Hi,
I have recently upgraded my system to the following configuration:
OS: Windows 10
cuda: 11.0
cuDNN:8.0.5.39
Tensorflow:2.3.0
My GPU spec: device: 0, name: NVIDIA Quadro GV100 32GB
Once Tensorflow installation is completed, i checked the following cpde:
with tf.device('/gpu:0'): a = tf.constant([1.0,... | closed | 2020-12-29T16:04:54Z | 2021-11-22T06:08:23Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1218 | [] | omid-ghozatlou | 1 |
gunthercox/ChatterBot | machine-learning | 2,052 | [Question] Whose are the statements of learn_response() of ChatBot | Hello there!
I want to know if current statement and previous statement are bot's and human's or both bot's?
e.g. in this conversation:
> human: Hello
> bot: Hi
> human: How are you?
> bot: Doing well
with having line 4 as the current statement, the previous one is line 3 or 2? | open | 2020-10-02T23:04:26Z | 2020-10-02T23:04:39Z | https://github.com/gunthercox/ChatterBot/issues/2052 | [] | farooqkz | 0 |
WeblateOrg/weblate | django | 13,300 | %% is not properly escaped in the java-printf-format check | ### Describe the issue
The `java-printf-format` check checks whether the source and translation strings have the same number of format arguments. But, `%%` escapes the `%` character in Java format strings. Therefore, `foo` and `bar %%s` have the same number of format specifiers because the `%` character before the `s`... | closed | 2024-12-15T21:28:25Z | 2024-12-28T07:30:16Z | https://github.com/WeblateOrg/weblate/issues/13300 | [
"bug"
] | Earthcomputer | 7 |
gradio-app/gradio | data-science | 10,600 | gradio cli cannot reload scripts with utf8-bom encoding | ### Describe the bug
As saying in this [documentation](https://www.gradio.app/guides/developing-faster-with-reload-mode):
> By default, the Gradio use UTF-8 encoding for scripts.
But it's not going to work with UTF-8 BOM encoding scripts.
``` bash
> gradio webui.py
Traceback (most recent call last):
File "D:\mini... | open | 2025-02-16T13:43:19Z | 2025-02-27T21:51:26Z | https://github.com/gradio-app/gradio/issues/10600 | [
"bug"
] | IceSandwich | 2 |
flasgger/flasgger | api | 68 | Create APISpec example | Using the example code from: http://apispec.readthedocs.io/en/latest/
```python
from apispec import APISpec
from flask import Flask, jsonify
from marshmallow import Schema, fields
# Create an APISpec
spec = APISpec(
title='Swagger Petstore',
version='1.0.0',
plugins=[
'apispec.ext.flas... | closed | 2017-03-28T15:15:39Z | 2017-03-30T21:36:15Z | https://github.com/flasgger/flasgger/issues/68 | [] | rochacbruno | 1 |
chainer/chainer | numpy | 7,923 | Fix to `F.max_pooling_2d` test input would make the test fail | ERROR: type should be string, got "https://github.com/chainer/chainer/blob/v7.0.0b2/tests/chainer_tests/functions_tests/pooling_tests/test_max_pooling_2d.py#L52\r\n```\r\n numpy.random.shuffle(x)\r\n```\r\n\r\nThis line should be `numpy.random.shuffle(x.ravel())` because `shuffle` only shuffles along the first axis.\r\nBut that fix would cause the test to fail (`test_double_backward` with cuDNN enabled).\r\n\r\n`pytest -m 'cudnn' -v -rfEX --tb=short tests/chainer_tests/functions_tests/pooling_tests/test_max_pooling_2d.py -k 'test_double_backward'`\r\n\r\n```\r\nE chainer.testing.function_link.FunctionTestError: Parameterized test failed.\r\nE\r\nE Base test method: TestMaxPooling2D_use_chainerx_false__chainerx_device_None__use_cuda_true__cuda_device_0__use_cudnn_always__cudnn_deterministic_false__autotune_false__cudnn_fast_batch_normalization_false__use_ideep_never.test_doubl$_backward\r\nE Test parameters:\r\nE contiguous: C\r\nE cover_all: False\r\nE dtype: <class 'numpy.float64'>\r\nE\r\nE\r\nE (caused by)\r\nE FunctionTestError: double backward is not implemented correctly\r\n\r\n:\r\n:\r\n\r\nE gradients (numeric): -0.005565301559232316\r\nE gradients (backward): 0.14605092276952303\r\nE\r\nE x: numeric gradient, y: backward gradient\r\nE Not equal to tolerance rtol=0.001, atol=0.0001\r\nE\r\nE Mismatch: 100%\r\nE Max absolute difference: 0.15161622\r\nE Max relative difference: 1.03810521\r\nE x: array(-0.005565)\r\nE y: array(0.146051)\r\nE\r\nE assert_allclose failed:\r\nE shape: () ()\r\nE dtype: float64 float64\r\nE i: (0,)\r\nE x[i]: -0.005565301559232316\r\nE y[i]: 0.14605092276952303\r\nE relative error[i]: 1.0381052132619162\r\nE absolute error[i]: 0.15161622432875535\r\nE relative tolerance * |y[i]|: 0.00014605092276952304\r\nE absolute tolerance: 0.0001\r\nE total tolerance: 0.00024605092276952306\r\nE x: -0.0055653\r\nE y: 0.14605092\r\n```" | closed | 2019-08-13T17:29:28Z | 2019-10-29T07:20:54Z | https://github.com/chainer/chainer/issues/7923 | [
"cat:test",
"prio:high"
] | niboshi | 2 |
jupyterhub/repo2docker | jupyter | 791 | [doc] conda export instructions reference the root environment | The [instructions for exporting a conda environment](https://repo2docker.readthedocs.io/en/latest/howto/export_environment.html#the-solution) state that the user should
> use conda env export -n root to print the environment
But the "user" dependencies (i.e. those not related to Binder) seem to be installed in t... | open | 2019-09-11T11:33:38Z | 2019-09-12T06:31:42Z | https://github.com/jupyterhub/repo2docker/issues/791 | [] | rprimet | 1 |
graphdeco-inria/gaussian-splatting | computer-vision | 966 | make_depth_scale.py - No module named 'read_write_model' | I created a depth image and tried to run `make_depth_scale.py`.
However, I got the following error
`ModuleNotFoundError: No module named 'joblib'`
I did `conda install joblib` to install the module.
However, when I ran python again, I got the following error
`ModuleNotFoundError: No module named 'read_write_mode... | closed | 2024-08-31T19:22:31Z | 2024-09-06T06:37:28Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/966 | [] | lileaLab | 2 |
jumpserver/jumpserver | django | 15,043 | [Bug] web应用部署成功,节点负载正常,website提示没有可使用的链接方式。 | ### Product Version
3.10.17
### Product Edition
- [x] Community Edition
- [ ] Enterprise Edition
- [ ] Enterprise Trial Edition
### Installation Method
- [x] Online Installation (One-click command installation)
- [ ] Offline Package Installation
- [ ] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] Source Code
###... | closed | 2025-03-17T07:00:37Z | 2025-03-18T00:37:25Z | https://github.com/jumpserver/jumpserver/issues/15043 | [
"🐛 Bug"
] | JzpWorkspace | 3 |
K3D-tools/K3D-jupyter | jupyter | 460 | plot.display does not show graphics |
* K3D version:2.17.0
* Python version:3.12
* Operating System: centos
### Description
I do:
import k3d
plot = k3d.plot()
plot.display()
I expect to see a Graph, but I only see:
Plot(antialias=3, axes=['x', 'y', 'z'], axes_helper=1.0, axes_helper_colors=[16711680, 65280, 255], background_color=1677721... | open | 2025-01-06T22:26:08Z | 2025-01-06T22:26:08Z | https://github.com/K3D-tools/K3D-jupyter/issues/460 | [] | gsohler | 0 |
plotly/dash | data-visualization | 2,566 | [BUG] Opacity update using Patch() for px.density_mapbox, not working. | Using python 3.11.3
```
dash 2.10.2
dash-core-components 2.0.0
dash-html-components 2.0.0
```
- OS: [macos]
- Browser [Chrome]
- Version [113.0.5672.92]
Bug Discription:
Using the new Patch() feature, Opacity attribute for px.density_mapbox will not update.
Her... | closed | 2023-06-15T07:37:20Z | 2024-07-25T13:18:23Z | https://github.com/plotly/dash/issues/2566 | [] | OMBeau | 4 |
ploomber/ploomber | jupyter | 192 | Set extract_product default to True | closed | 2020-07-15T02:52:39Z | 2020-07-20T22:00:37Z | https://github.com/ploomber/ploomber/issues/192 | [] | edublancas | 0 | |
ets-labs/python-dependency-injector | asyncio | 177 | Question on testing with python-dependency-injector | Hello and thank you for such a great library.
I have a question regarding of how to test application, that uses python-dependency-injector library.
Lets take simple usecase:
```
class EmailSender:
def send(self, email):
pass
class SmtpEmailSender:
# implementation with use of smpt librar... | closed | 2018-01-14T07:08:37Z | 2018-01-17T13:47:12Z | https://github.com/ets-labs/python-dependency-injector/issues/177 | [
"question"
] | asyncee | 9 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 403 | Will a larger value for partials_n_frames be better? | Hi, all.
In theory, using more frames as input to the model will include more information about the speaker.
So, I set the partials_n_frames to 160(exp1) and 300(exp2) respectively, and trained on the same training set.
On training set, the loss and EER of exp2 is slightly lower than that of exp1.But on test set ... | closed | 2020-07-06T02:46:40Z | 2020-08-13T06:23:41Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/403 | [] | Coastchb | 1 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 1,105 | How to make the perfect training data set? | I want to use this repo to clone my voice. How do I create the perfect training data set? Here are some ideas I have:
-Read a set of words that contains every letter in the alphabet
-Read a set of words in a normal tone, then read those same words with more energy/power, then read the same with more inflection, the... | open | 2022-08-26T23:00:02Z | 2022-08-26T23:00:02Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1105 | [] | CodingRox82 | 0 |
pennersr/django-allauth | django | 3,939 | headless support for custom form fields? | I'm just in the middle of integrating headless with DRF + Simple JWT for API-based signup/login etc.
I've used a custom adapter using `ACCOUNT_ADAPTER` to save a profile model linked to the User record created on signup, but I would like to pass and validate additional fields as part of the signup API call, e.g. fi... | closed | 2024-07-01T21:55:37Z | 2024-07-02T18:50:25Z | https://github.com/pennersr/django-allauth/issues/3939 | [] | PorridgeBear | 2 |
dfm/corner.py | data-visualization | 214 | Misplaced **hist_kwargs? | It seems that [this](https://github.com/dfm/corner.py/blob/e65dd4cdeb7a9f7f75cbcecb4f07a07de65e2cea/src/corner/core.py#L240) line inside core.py contains **hist_kwargs argument, even though it is a matplotlib.pyplot function that is called. Should instead this be passed a few lines above to the np.histogram call, i.e. ... | open | 2022-11-03T13:31:15Z | 2022-12-03T19:36:21Z | https://github.com/dfm/corner.py/issues/214 | [] | Cosmicstring | 4 |
huggingface/transformers | nlp | 36,439 | Apply dualpipe from deepseek-v3 to a trainer or model | ### Feature request
Applying deepseek's dual-pipe to transformers or accelrate
### Motivation
Recently, deepseek released the proposed [dual-pipe code](https://github.com/deepseek-ai/DualPipe) in the [DeepSeek-V3](https://arxiv.org/html/2412.19437v1) Technical Report.
Looking at the code structure, it is 100% python... | closed | 2025-02-27T02:44:42Z | 2025-02-27T05:59:56Z | https://github.com/huggingface/transformers/issues/36439 | [
"Feature request"
] | jp1924 | 0 |
strawberry-graphql/strawberry | fastapi | 2,826 | Microservices | ### Discussed in https://github.com/strawberry-graphql/strawberry/discussions/2803
<div type='discussions-op-text'>
<sup>Originally posted by **Roman-Ch-32** June 2, 2023</sup>
Вопрос, как наладить взаимодействие между сервисами. Проблема в том, что мне нужно перенаправить запрос на другой сервер, получить отве... | closed | 2023-06-08T12:24:54Z | 2025-03-20T15:56:12Z | https://github.com/strawberry-graphql/strawberry/issues/2826 | [] | Roman-Ch-32 | 1 |
mwaskom/seaborn | matplotlib | 3,609 | seaborn issue | dataset are not load in seaborn library | closed | 2024-01-02T06:01:47Z | 2024-01-10T11:55:52Z | https://github.com/mwaskom/seaborn/issues/3609 | [] | ponishadevi | 2 |
unionai-oss/pandera | pandas | 1,352 | Pandera timezone-agnostic datetime type | **Is your feature request related to a problem? Please describe.**
When defining a class that inherits from DataFrameModel, I want to define a field whose values are datetimes. Moreover, those values will have timezones. However, I will not be able to define during the class definition what timezone that may be. In ot... | open | 2023-09-26T21:50:44Z | 2024-08-23T22:44:58Z | https://github.com/unionai-oss/pandera/issues/1352 | [
"enhancement"
] | max-raphael | 8 |
hanwenlu2016/web-ui | pytest | 11 | 咨询个控制台输出 | 1、若直接运行debugrun console的输出会有乱码 ctrl shlft F10 运行的
2、若python run.py 运行 terminal输出 没有乱码 但是日志的格式也跟单独运行test_XXX的不一样
3、若直接运行方法,则日志格式输出正常
另外 yaml 编码格式都是 gbk的 如果编辑器 改成gkb的编码 那console输出都是乱码,智能是utf-8 然后把yaml单独reload成gkb 或者直接把yaml文件转成gkb编码的 | closed | 2021-11-10T02:53:19Z | 2022-02-25T09:25:54Z | https://github.com/hanwenlu2016/web-ui/issues/11 | [] | kadingzz1 | 5 |
zhiyiYo/Fluent-M3U8 | dash | 24 | [Bug]: 带参数的URL无法下载? | ### What happened?
版本:0.10.0.0
问题:下面这种带参数的连接贴入地址栏后,“下载”按钮不亮,无法点击。
https://kttvquizmz.cdn-centaurus.com/hls2/01/04120/65yc0r0erwg5_,n,h,x,.urlset/index-f3-v1-a1.m3u8?t=QBd_bR3CHGD5NaUL-2pNk2Ulg86aXptlurEGXBRU3lM&s=1741803549&e=129600&f=20602380&srv=rup99sdwt652&i=0.4&sp=500&p1=rup99sdwt652&p2=rup99sdwt652&asn=16509
注:... | closed | 2025-03-12T19:22:58Z | 2025-03-13T04:51:47Z | https://github.com/zhiyiYo/Fluent-M3U8/issues/24 | [
"bug"
] | doggybread | 1 |
yuka-friends/Windrecorder | streamlit | 186 | feat: Recognize multiple OCR languages simultaneously | Current situation: Only one language can be specified for Windows Media OCR to recognize. In the case of multiple languages, all texts cannot be recognized. This may cause inconvenience for multilingual users or learners.
Goal: Support users to configure multiple OCR languages for simultaneous recognition.
Spec... | closed | 2024-06-15T10:00:58Z | 2024-08-03T07:56:56Z | https://github.com/yuka-friends/Windrecorder/issues/186 | [
"enhancement"
] | Antonoko | 3 |
dynaconf/dynaconf | flask | 984 | [bug] KeyError: '_bypass_evaluation' in Dynaconf 3.2.1 | **Describe the bug**
The change introduced in PR #966 also introduced a KeyError in our tests.
**To Reproduce**
Steps to reproduce the behavior:
Not currently clear without digging further into the cause, but this was triggered in our tests using multi-threading. You can see the failures in the github action link... | closed | 2023-08-21T19:26:21Z | 2023-08-22T12:53:40Z | https://github.com/dynaconf/dynaconf/issues/984 | [
"bug"
] | JacobCallahan | 3 |
localstack/localstack | python | 12,139 | bug: Step function -> "Get S3 Object" Action's error handling not matching real AWS behaviour | ### Is there an existing issue for this?
- [x] I have searched the existing issues
### Current Behavior
I am using the attached state machine (simplified it for this issue reporting). It relies on a bucket named `test-bucket` (needs to be created to run the state machine).
When it is executed, I expected localstack... | closed | 2025-01-14T20:05:26Z | 2025-01-24T07:49:39Z | https://github.com/localstack/localstack/issues/12139 | [
"type: bug",
"aws:stepfunctions"
] | lagarwal-uic | 5 |
zappa/Zappa | flask | 1,151 | Remove python3.6 lambda runtime support | ## Context
AWS will depreciate the lambda `python3.6` runtime, where no lambdas will be able to create or update using `python3.6` from Aug 17, 2022 (this year).
https://docs.aws.amazon.com/lambda/latest/dg/lambda-runtimes.html
## Possible Fix
Remove python3.6 as a supported runtime from zappa
| closed | 2022-07-16T04:09:45Z | 2022-08-05T10:34:14Z | https://github.com/zappa/Zappa/issues/1151 | [] | monkut | 1 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 16,502 | Can model sharing be realized for two webui projects? I need to test the effect of different versions, now I have two versions of webui, but my model files need to be migrated a lot, is there any configuration file to support model path sharing? Like comfyui | ### Checklist
- [ ] The issue exists after disabling all extensions
- [ ] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [ ] The issue exists in the current version of the webui
- [X] The issue has not been reported before... | open | 2024-09-19T10:17:23Z | 2024-10-17T15:30:30Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16502 | [
"asking-for-help-with-local-system-issues"
] | huangjianyi0701 | 9 |
plotly/dash | data-science | 3,119 | pattern-matched long callbacks cancelled incorrectly | **Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
- replace the result of `pip list | grep dash` below
```
dash 2.18.2 /home/amorton/gh/dash
dash-core-components 2.0.0
dash_dangerously_set_inner_html ... | open | 2025-01-08T19:58:02Z | 2025-01-09T19:19:29Z | https://github.com/plotly/dash/issues/3119 | [
"bug",
"P2"
] | apmorton | 0 |
tensorpack/tensorpack | tensorflow | 974 | error when using get_global_step_var() as a parameter to modify the model graph computation | I am using tensorpack0.8.6 and have used the following code to feed the global_step as a parameter for the graph layer. This is an imagenet-resnet training task and the **1-epoch training went well** , but when 1 epoch ends, and the inference runner runs, the following error occurs:
```
[1106 20:21:22 @base.py:237]... | closed | 2018-11-06T12:59:24Z | 2018-12-12T17:55:07Z | https://github.com/tensorpack/tensorpack/issues/974 | [
"upstream issue"
] | brisker | 19 |
Skyvern-AI/skyvern | automation | 1,650 | Add GCP Cloud Storage File Upload Integration | ## Feature Request: GCP Cloud Storage File Upload Support
Currently, the project supports AWS S3 file uploads, but lacks integration with Google Cloud Platform (GCP) Cloud Storage. Adding GCP Cloud Storage support would:
- Provide flexibility for users leveraging GCP infrastructure
- Expand the project's cloud storage... | open | 2025-01-26T19:16:11Z | 2025-01-31T13:34:41Z | https://github.com/Skyvern-AI/skyvern/issues/1650 | [
"help wanted"
] | piyushmittal20 | 3 |
aiogram/aiogram | asyncio | 717 | Improve filters factory resolve error | closed | 2021-10-05T20:54:49Z | 2021-10-07T14:07:37Z | https://github.com/aiogram/aiogram/issues/717 | [] | JrooTJunior | 0 | |
jazzband/django-oauth-toolkit | django | 613 | Instropection not working with json | I have 'OAUTH2_BACKEND_CLASS' :'oauth2_provider.oauth2_backends.JSONOAuthLibCore' set like this to read json instead of x-www-form-urlenconded but when i try the /instrospect/ it always trying to read like x-www-form-urlenconded and not in json.
I already check instrospect.py and oauthlib_backend_class = oauth... | open | 2018-06-28T10:47:01Z | 2023-07-29T19:46:42Z | https://github.com/jazzband/django-oauth-toolkit/issues/613 | [] | tximpa91 | 1 |
yihong0618/running_page | data-visualization | 777 | 请教大佬,Action中有需要同步的gpx数据,同时也同步了coros数据,为啥执行的时候看日志,只有coros脚本执行了,gpx脚本没有执行啊 | 请教大佬,Action中有需要同步的gpx数据,同时也同步了coros数据,为啥执行的时候看日志,只有coros脚本执行了,gpx脚本没有执行啊 | closed | 2025-02-09T07:25:38Z | 2025-02-10T06:04:54Z | https://github.com/yihong0618/running_page/issues/777 | [] | Leerol | 6 |
nonebot/nonebot2 | fastapi | 2,989 | Plugin: nonechat | ### PyPI 项目名
nonebot-plugin-nonechat
### 插件 import 包名
nonebot_plugin_nonechat
### 标签
[{"label":"LLM","color":"#52eacf"}]
### 插件配置项
_No response_ | closed | 2024-10-01T07:54:41Z | 2024-10-04T02:53:25Z | https://github.com/nonebot/nonebot2/issues/2989 | [
"Plugin"
] | hanasa2023 | 3 |
adbar/trafilatura | web-scraping | 514 | Trafilatura to support more robust async library than standard request | This is request for Trafilatura to support a more robust async library, such as `asyncio/aiohttp` instead of underlying `urllib`, which has some issues.
Assisting conversation: https://github.com/adbar/trafilatura/discussions/515 | closed | 2024-02-26T14:56:54Z | 2025-02-25T04:51:35Z | https://github.com/adbar/trafilatura/issues/514 | [
"question"
] | krstp | 8 |
milesmcc/shynet | django | 12 | Single-command Docker-compose deploy | It'd be great to have a way to run shynet from scratch based on a single docker-compose file.
I finished most of the (minor) adaptations that are needed in order to get that running, so I'll PR when I'm done.
For transparency, modifications include:
- exposing current function Arguments as Environement variables... | closed | 2020-04-29T16:14:45Z | 2020-05-02T17:00:22Z | https://github.com/milesmcc/shynet/issues/12 | [
"enhancement"
] | Windyo | 2 |
ymcui/Chinese-BERT-wwm | tensorflow | 234 | 如何抽取特定layer的词向量? | 在尝试提取特定layer词向量时使用了以下代码:
# Get the word embeddings from layers 9 to 12
layer_start = 9 # Starting layer (inclusive)
layer_end = 13 # Ending layer (exclusive)
embeddings1 = []
embeddings2 = []
for layer in range(layer_start, layer_end):
embeddings1_layer = module.get_embedding(tokens1, use_specified_layer... | closed | 2023-06-19T03:40:17Z | 2023-09-17T02:51:45Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/234 | [
"stale"
] | Black-Rhen | 2 |
ipython-books/cookbook-2nd | data-visualization | 8 | Error with temp_fft = sp.fftpack.fft(temp) when run in Jupyter Notebook | Hello, the code does not function for me when run in Jupyter Notebook. I replaced `to_datetime` with `to_pydatetime`. That fixed one error but now I am getting an error with `temp_fft = sp.fftpack.fft(temp)` it is throwing the error `AttributeError: 'Series' object has no attribute 'flags'`
I have updated Conda and ... | open | 2020-10-09T20:14:47Z | 2020-10-09T20:14:47Z | https://github.com/ipython-books/cookbook-2nd/issues/8 | [] | armarvin | 0 |
serengil/deepface | deep-learning | 1,018 | how to retain only frontal faces with both eyes and face angle? | need help | closed | 2024-02-10T10:11:43Z | 2024-02-10T10:49:48Z | https://github.com/serengil/deepface/issues/1018 | [
"question"
] | Arslan-Mehmood1 | 3 |
twopirllc/pandas-ta | pandas | 116 | Supertrend indicator giving only short values | This is not a bug report, because i'm pretty sure it has to do with the OHLC data i'm feeding to pandas-ta.
I noticed that with some markets i'll get only short values, so on the chart the band will be red for the whole length of the chart itself. This "issue" seems to happen when i set an higher Accelerator, in th... | closed | 2020-09-06T13:54:09Z | 2022-02-20T18:55:01Z | https://github.com/twopirllc/pandas-ta/issues/116 | [] | Jacks349 | 9 |
modAL-python/modAL | scikit-learn | 12 | about learner.teach | it seems that each time we run the learner. teach, the model will fit the initial data plus the new data from the beginning just like an untrained new model, can the model just learn the new data with the weight which has been trained on the initial data? | closed | 2018-08-09T08:27:49Z | 2018-10-18T16:27:11Z | https://github.com/modAL-python/modAL/issues/12 | [] | luxu1220 | 7 |
rthalley/dnspython | asyncio | 1,037 | Default Branch Renaming on February 17, 2024 | I plan to rename the default branch, currently "master", to "main" sometime on or after Saturday, February 17, 2024.
If you have a checked out clone, after the renaming occurs you'll need to either [update it](https://docs.github.com/en/repositories/configuring-branches-and-merges-in-your-repository/managing-branche... | closed | 2024-02-05T22:48:03Z | 2024-02-20T22:02:58Z | https://github.com/rthalley/dnspython/issues/1037 | [
"Pinned"
] | rthalley | 1 |
pyeventsourcing/eventsourcing | sqlalchemy | 103 | Event migration | There are five approaches... it might be useful for the library to support them. | closed | 2017-08-01T05:37:24Z | 2019-06-27T12:49:43Z | https://github.com/pyeventsourcing/eventsourcing/issues/103 | [] | johnbywater | 12 |
microsoft/nni | data-science | 5,715 | How can I review the experiment that has been stopped? It seems that the Web can only show the detail of 'RUNNING' experiment. | closed | 2023-11-27T09:09:32Z | 2023-11-28T12:16:30Z | https://github.com/microsoft/nni/issues/5715 | [] | lightup666 | 1 | |
google/trax | numpy | 1,686 | Multiple heads option is not working in SelfAttention | ### Description
I use just some input activations, one SelfAttention layer and `n_heads=2`, but my code breaks. However, when I set `n_heads=1`, everything works fine.
### Environment information
```
OS: <MacOS>
$ pip freeze | grep trax
# your output here
trax==1.3.9
$ pip freeze | grep tensor
# your ... | open | 2021-08-17T16:39:28Z | 2021-09-01T00:42:59Z | https://github.com/google/trax/issues/1686 | [] | kenenbek | 1 |
ivy-llc/ivy | numpy | 27,930 | Fix Ivy Failing Test: numpy - statistical.min | closed | 2024-01-16T19:14:51Z | 2024-01-17T10:00:32Z | https://github.com/ivy-llc/ivy/issues/27930 | [
"Sub Task"
] | samthakur587 | 1 | |
mwaskom/seaborn | data-visualization | 3,002 | Global matplotlib style with objects interface | Hey! thanks for the amazing 0.12 release 🚀 !
I want to use the new object interface while using a global `matplotlib` style following https://seaborn.pydata.org/generated/seaborn.objects.Plot.theme.html#seaborn.objects.Plot.theme
I have tried:
```python
import matplotlib.pyplot as plt
import seaborn as sns
... | closed | 2022-09-06T13:18:09Z | 2022-09-08T10:38:00Z | https://github.com/mwaskom/seaborn/issues/3002 | [] | juanitorduz | 2 |
Miserlou/Zappa | flask | 1,668 | [Feature] Ability to pass function timeout to the manage command | Having a timeout of 30s is generally good for an API but when it comes to execute commands (invoke or manage), it would be useful to be able to pass a higher value like 900s. | open | 2018-10-19T10:15:46Z | 2018-10-19T11:11:46Z | https://github.com/Miserlou/Zappa/issues/1668 | [] | khamaileon | 1 |
dsdanielpark/Bard-API | api | 213 | AsyncClient.get() got an unexpected keyword argument 'follow_redirects | ```
async def generate_response(user_prompt):
response = await bard.get_answer(user_prompt)
return response
```
this was working until yesterday, until this error appeared randomly:
```
AsyncClient.get() got an unexpected keyword argument 'follow_redirects'
``` | closed | 2023-10-17T14:32:58Z | 2023-10-26T19:01:17Z | https://github.com/dsdanielpark/Bard-API/issues/213 | [] | odgtr | 2 |
ageitgey/face_recognition | python | 1,409 | Always get "Segmentation fault" when using threads? | closed | 2022-02-13T18:58:41Z | 2022-04-18T09:16:08Z | https://github.com/ageitgey/face_recognition/issues/1409 | [] | razrabotkajava | 1 | |
python-gino/gino | sqlalchemy | 647 | Gino transaction not rollback with Quart test_client | * GINO version:0.8.6
* Python version: 3.8
* asyncpg version: 0.18
* aiocontextvars version:0.2.2
* PostgreSQL version:
### Description
I'm trying to write tests for my Quart application. As per this ticket https://github.com/python-gino/gino/issues/512 it appears that pytest-async's fixtures doesn't allow us t... | open | 2020-04-02T14:53:31Z | 2020-04-20T23:09:48Z | https://github.com/python-gino/gino/issues/647 | [
"question"
] | lawrencealexander10 | 6 |
Kanaries/pygwalker | pandas | 101 | Colab Demo giving error (missing DC Bikes data URL) | This line of code gives a 404:
`df = pd.read_csv("https://raw.githubusercontent.com/Kanaries/pygwalker/main/tests/bike_sharing_dc.csv", parse_dates=['date'])`
I can make a PR, but this seems like a preference is good to discuss here. Keep it in this repo? Where? Fetch from somewhere else? Where? | closed | 2023-04-21T19:26:26Z | 2023-04-22T06:06:57Z | https://github.com/Kanaries/pygwalker/issues/101 | [] | bhollan | 2 |
keras-team/keras | tensorflow | 20,722 | Is it possible to use tf.data with tf operations while utilizing jax or torch as the backend? | Apart from tensorflow as backend, what are the proper approach to use basic operatons (i.e. tf.concat) inside the tf.data API pipelines? The following code works with tensorflow backend, but not with torch or jax.
```python
import os
os.environ["KERAS_BACKEND"] = "jax" # tensorflow, torch, jax
import keras
fr... | closed | 2025-01-03T19:44:45Z | 2025-01-04T22:44:43Z | https://github.com/keras-team/keras/issues/20722 | [] | innat | 1 |
postmanlabs/httpbin | api | 498 | 404s after deploy on ECS | Hi! Once I've deployed this on an ECS cluster with an ALB I get 404s from the Server: gunicorn/19.9.0 webserver.
I appreciate any help to push me in the right direction. | open | 2018-07-31T08:52:32Z | 2018-07-31T13:43:34Z | https://github.com/postmanlabs/httpbin/issues/498 | [] | etiennemunnich | 1 |
Lightning-AI/pytorch-lightning | pytorch | 20,307 | `Trainer`'s `.init_module()` context does not initialize model on target device | ### Bug description
I refer to the documentation on https://lightning.ai/docs/pytorch/stable/advanced/model_init.html which states "you can force PyTorch to create the model directly on the target device" when using the `.init_module()` context. However I have verified across different GPU machines that this is not th... | open | 2024-09-27T05:58:08Z | 2024-10-11T05:29:25Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20307 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | jin-zhe | 1 |
dynaconf/dynaconf | fastapi | 197 | [RFC] Allow dotted environment variables | **Is your feature request related to a problem? Please describe.**
Parameters defined in environment variables cannot be accessed with dotted key notation in the same way as parameters defined in settings files, which prevents overriding dotted key parameters with environment variables.
**Example:** Environment va... | closed | 2019-06-14T06:21:10Z | 2019-09-02T17:50:26Z | https://github.com/dynaconf/dynaconf/issues/197 | [
"Not a Bug",
"RFC",
"good first issue",
"HIGH"
] | ATXMJ | 3 |
graphql-python/graphene | graphql | 1,479 | Mutation error: must be a mapping (dict / OrderedDict) with field names as keys or a function | I'm trying to return an object / class in my mutation response but Im getting this error:
`AssertionError: Success fields must be a mapping (dict / OrderedDict) with field names as keys or a function which returns such a mapping.`
```
class SuccessResponse(ObjectType):
job_id = String
user = String
... | closed | 2022-11-22T01:00:25Z | 2022-11-22T11:06:31Z | https://github.com/graphql-python/graphene/issues/1479 | [
"🐛 bug"
] | simkessy | 0 |
numba/numba | numpy | 9,685 | Installation fails on termux Python 3.11 | <!--
Thanks for opening an issue! To help the Numba team handle your information
efficiently, please first ensure that there is no other issue present that
already describes the issue you have
(search at https://github.com/numba/numba/issues?&q=is%3Aissue).
-->
## Reporting a bug
<!--
Before submittin... | closed | 2024-08-03T17:57:50Z | 2024-08-06T21:30:27Z | https://github.com/numba/numba/issues/9685 | [
"bug - build/packaging"
] | not-lum | 3 |
seleniumbase/SeleniumBase | web-scraping | 3,264 | Add CDP Mode methods for handling `<input>` Sliders and `<select>` Dropdowns | ### Add CDP Mode methods for handling `<input>` Sliders and `<select>` Dropdowns
----
Specifically, I want to handle these:
<img width="368" alt="Screenshot" src="https://github.com/user-attachments/assets/b9a13bc7-ac81-4d94-a92c-fdf28a7c06bc">
----
These methods should be added into the API:
```pytho... | closed | 2024-11-14T19:13:11Z | 2024-11-14T21:44:55Z | https://github.com/seleniumbase/SeleniumBase/issues/3264 | [
"enhancement",
"UC Mode / CDP Mode"
] | mdmintz | 1 |
matplotlib/matplotlib | matplotlib | 28,891 | [Bug]: `GridSpecFromSubplotSpec` displayed incorrectly with `layout="constrained"` | ### Bug summary
When creating a nested grid of axes using `GridSpecFromSubplotSpec` (EG by calling `axis.get_subplotspec().subgridspec(...)`), and plotting a figure using `layout="constrained"`, the nested axes are not displayed correctly. Specifically, the inner grids do not respect the spacing between the outer grid... | open | 2024-09-26T01:08:57Z | 2024-09-26T17:25:25Z | https://github.com/matplotlib/matplotlib/issues/28891 | [] | jakelevi1996 | 7 |
Urinx/WeixinBot | api | 134 | Selector为3时出现死循环 | 代码中似乎没有处理Selector为3的情况,导致死循环。有人解决这个问题吗? | open | 2016-12-09T06:08:24Z | 2017-03-24T03:02:12Z | https://github.com/Urinx/WeixinBot/issues/134 | [] | wzw1990 | 1 |
tortoise/tortoise-orm | asyncio | 1,152 | transaction task not correctly exited at asyncio.exceptions.CancelledError | **Describe the bug**
I was using get_or_create as part of my atomic operation, basically tested it with exiting the task real quick. Then I found some errors blocking the server before it shutdown.
**To Reproduce**
[Code]
here is part of the code in a sanic server, routing to a websocket blueprint
```python
bp... | open | 2022-06-09T11:45:17Z | 2022-06-09T12:22:10Z | https://github.com/tortoise/tortoise-orm/issues/1152 | [] | jrayu | 0 |
pandas-dev/pandas | python | 60,515 | DOC: methods in see also section in the pandas.DataFrame.shape and pandas.DataFrame.ndim are not hyperlinks | ### Pandas version checks
- [X] I have checked that the issue still exists on the latest versions of the docs on `main` [here](https://pandas.pydata.org/docs/dev/)
### Location of the documentation
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.ndim.html
https://pandas.pydata.org/docs/reference/ap... | closed | 2024-12-07T06:39:22Z | 2024-12-08T14:04:33Z | https://github.com/pandas-dev/pandas/issues/60515 | [
"Docs"
] | Shubhank-Gyawali | 1 |
frappe/frappe | rest-api | 31,300 | Agkiya : Image required in the excel export report | Dear Team,
Please find below the requirement from our client. They need an Excel report that includes item images.
In the jewelry industry, multiple ERP companies have already implemented this feature. Therefore, I request you to enable a functionality where users can export stock reports or custom reports with item ... | open | 2025-02-18T08:44:37Z | 2025-03-06T22:22:25Z | https://github.com/frappe/frappe/issues/31300 | [
"feature-request"
] | Deepakjs5665 | 1 |
supabase/supabase-py | flask | 463 | Functions not working due invalid URL formatting | Hi all,
Calling functions using supabase-py for me allways results in the following response:
`{'data': b'Function not found', 'error': None}`
I believe this is due to the improper URL format in the `FunctionClient`:
https://github.com/supabase-community/supabase-py/blob/5c752443277de0a4a8dfd7d0d113f0d177efc... | closed | 2023-06-14T09:21:58Z | 2023-06-15T03:43:48Z | https://github.com/supabase/supabase-py/issues/463 | [
"duplicate"
] | tobias-scheepers | 2 |
shibing624/text2vec | nlp | 6 | 文本相似度 | 请问,为什么有些句子根本不搭边,但是分数还是大于0.5
a = 你吃饭了吗
b = 我会唱歌
score = 0.7190231597933535# Similarity().get_score(a, b) | closed | 2020-02-17T02:47:13Z | 2020-03-15T03:05:01Z | https://github.com/shibing624/text2vec/issues/6 | [
"question"
] | etrigger | 1 |
ultralytics/ultralytics | computer-vision | 18,707 | mAP always zero when training is resumed from a particular epoch | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
Train
### Bug
I had trained a model and had stopped it after a certain number of epochs. Then, to continue training, i use... | open | 2025-01-16T05:27:11Z | 2025-01-20T06:00:51Z | https://github.com/ultralytics/ultralytics/issues/18707 | [
"bug",
"segment"
] | AbhishekHollaAB | 10 |
mljar/mercury | data-visualization | 250 | strange shadow on mobile screen when app is busy | When app is in busy state there is a strange shadow over sidebar.
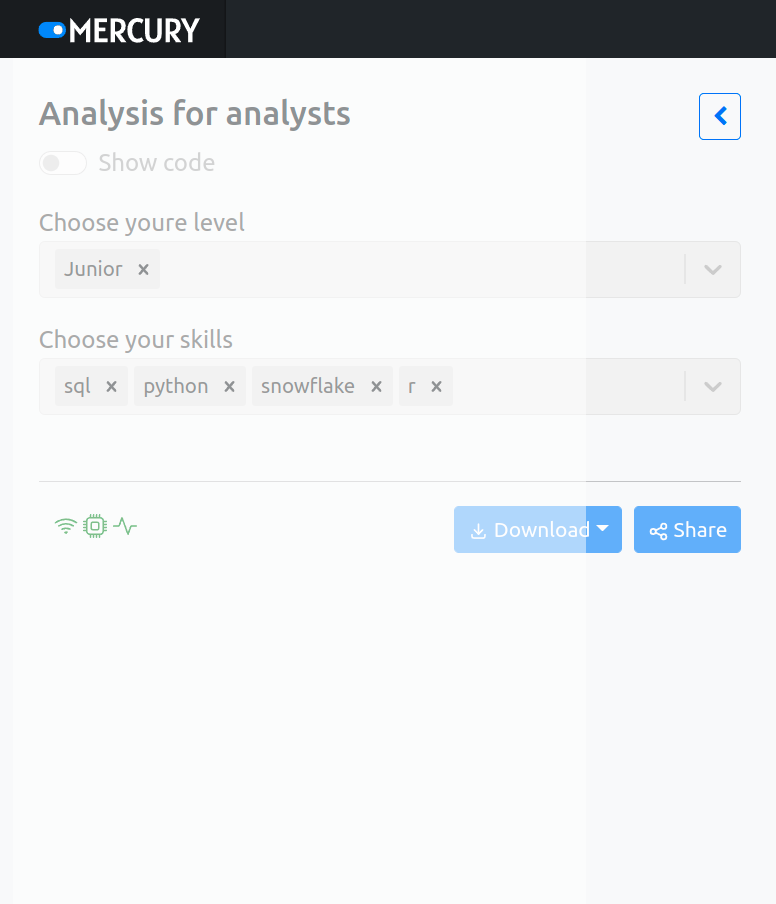
| closed | 2023-04-20T14:03:24Z | 2023-04-20T15:15:09Z | https://github.com/mljar/mercury/issues/250 | [
"bug"
] | pplonski | 0 |
darrenburns/posting | automation | 30 | Soften up python dependancies...? | Good afternoon!
I'm looking into packaging Posting for Fedora, but I'm hitting a wall regarding the package requiring very specific package versions. For example:
click-default-group ( == 1.2.4)
pydantic (==2.7.3)
textual (==0.72)
textual[syntax] (==0.72)
xdg-base-dirs (==6.0.1)
Would it be possible to rel... | closed | 2024-07-11T20:04:06Z | 2024-07-12T07:59:59Z | https://github.com/darrenburns/posting/issues/30 | [] | farchord | 1 |
thp/urlwatch | automation | 80 | urlwatch==2.3 package on PyPI is broken | I just wanted to report that the urlwatch package on PyPI was packaged incorrectly. I haven't looked into it much but it's missing a bunch of files. Appears to have been caused by 142a0e5e8c10b37344794a7056594e8079b6decb.
Running `pip install urlwatch` in a fresh virtualenv presents the following:
> ```
> Collecting ... | closed | 2016-07-12T16:05:59Z | 2016-07-12T18:29:36Z | https://github.com/thp/urlwatch/issues/80 | [] | brbsix | 0 |
LAION-AI/Open-Assistant | python | 3,027 | [SMALL Problem] MOVE 'wikihow' dataset to SUMMARISATION Datasets | Version : **v0.0.3-alpha24-3-g26acf953**
In the file `Open-Assistant/model/model_training/custom_datasets/__init__.py`, move 'wikihow' dataset from variable `QA_DATASETS` to the variable `SUMMARIZATION_DATASETS` | closed | 2023-05-03T15:25:53Z | 2023-05-05T09:36:50Z | https://github.com/LAION-AI/Open-Assistant/issues/3027 | [] | loloMD | 1 |
2noise/ChatTTS | python | 503 | 生成的语音不全 | 生成的语音不全,比如tell me again,经常出现 tell me 就结束了 | open | 2024-07-01T06:50:43Z | 2024-11-02T18:49:44Z | https://github.com/2noise/ChatTTS/issues/503 | [
"documentation",
"help wanted",
"algorithm"
] | PMPBinZhang | 6 |
igorbenav/FastAPI-boilerplate | sqlalchemy | 8 | Other settings should be based on app.core.config settings | Ex: if settings inherits from RedisCacheSettings, create_redis_cache_pool() and close_redis_cache_pool() should be added to startup and shutdown respectively in create_application | closed | 2023-10-16T07:45:07Z | 2023-10-24T02:36:13Z | https://github.com/igorbenav/FastAPI-boilerplate/issues/8 | [
"enhancement"
] | igorbenav | 1 |
ageitgey/face_recognition | machine-learning | 1,047 | Face recognition produce poor results on Raspbian Buster | * face_recognition version: 1.2.3
* Python version: 3.7.3
* Operating System: Raspbian Linux Buster
### Description
So, I installed the library via pip, everything ok, I've tried to install opencv (latest version) via pip as well, it installs, but when I tested opencv, it asks about __atomic_add_fetch_8. I foun... | open | 2020-02-05T13:40:33Z | 2020-03-16T03:42:49Z | https://github.com/ageitgey/face_recognition/issues/1047 | [] | Unicode-Hater | 2 |
wkentaro/labelme | computer-vision | 533 | How to add point for my annotated polygons? | Hi,thanks for your great work.But i met some problem recently.I have annotated some datas for sementic works before, and i want to add some points for per polygon in images i annotated,but i don't want to delete the annotated polygons to annotate again,I just want to add one or two point for the annotated polygon.But i... | closed | 2019-12-31T08:07:31Z | 2021-04-13T11:20:28Z | https://github.com/wkentaro/labelme/issues/533 | [] | chegnyanjun | 4 |
oegedijk/explainerdashboard | dash | 189 | Citation? | Hi - Is there any way you'd like the code to be cited in publications? | closed | 2022-02-25T15:37:10Z | 2022-05-04T19:34:17Z | https://github.com/oegedijk/explainerdashboard/issues/189 | [] | e5k | 6 |
joerick/pyinstrument | django | 145 | How to pass arguments to the script itself | How would I call a script with arguments
```bash
python script.py -n 1
```
with `pyinstrument`?
I've tried something like
```bash
pyinstrument script.py -- -n 1
```
but it doesn't seem to work. Is this possible?
| closed | 2021-08-12T02:32:12Z | 2021-08-12T02:51:41Z | https://github.com/joerick/pyinstrument/issues/145 | [] | dycw | 1 |
home-assistant/core | asyncio | 141,234 | Add support for switchbot roller shades | ### The problem
Add support for switchbot roller shades
https://us.switch-bot.com/products/switchbot-roller-shade
### What version of Home Assistant Core has the issue?
core-2025.3.4
### What was the last working version of Home Assistant Core?
n/a
### What type of installation are you running?
Home Assistant Co... | closed | 2025-03-23T17:49:22Z | 2025-03-23T21:04:06Z | https://github.com/home-assistant/core/issues/141234 | [
"integration: switchbot",
"feature-request"
] | joe81tx | 2 |
Farama-Foundation/PettingZoo | api | 744 | [Bug Report] Environment initialization error | I installed the latest 1.19.0 version of pettingzoo (pip and github cloning) to [colab](https://colab.research.google.com/drive/1Nt0umnAL4UkEge7yxCBoMoS2J_-3SABS?usp=sharing) and imported pong_v3 environment. However, when I tried to initialize the environment I got the following error:
env = pong_v3.env(num_players... | closed | 2022-07-30T18:54:32Z | 2022-07-31T12:39:34Z | https://github.com/Farama-Foundation/PettingZoo/issues/744 | [] | cinemere | 2 |
frappe/frappe | rest-api | 31,741 | Not possible to login since #31494 |
## Description of the issue
Since #31494 it is impossible to login with following error in console: ReferenceError: False is not defined
## Context information (for bug reports)
'is_fc_site': False seems to make problems. After changing it manually to 0, it works.
**Output of `bench version`**
15.58.1
```
## Step... | open | 2025-03-16T00:16:05Z | 2025-03-17T10:39:20Z | https://github.com/frappe/frappe/issues/31741 | [
"bug"
] | DrZoidberg09 | 3 |
Kanaries/pygwalker | matplotlib | 305 | New Environment: Flutter (Dart syntax) | Hi, it would be awesome if this package could support the Flutter Framework (dart). I would be willing to write it or help contribute to it - if someone could break down the services that the existing client environments use!
| closed | 2023-11-04T16:06:05Z | 2023-11-08T04:35:53Z | https://github.com/Kanaries/pygwalker/issues/305 | [] | ForeverAngry | 1 |
deepfakes/faceswap | deep-learning | 1,204 | Crash on starting. Potential fix provided | *Note: For general usage questions and help, please use either our [FaceSwap Forum](https://faceswap.dev/forum)
or [FaceSwap Discord server](https://discord.gg/FC54sYg). General usage questions are liable to be closed without
response.*
**Crash reports MUST be included when reporting bugs.**
**Describe the bug... | closed | 2022-01-16T12:30:47Z | 2022-05-15T01:26:41Z | https://github.com/deepfakes/faceswap/issues/1204 | [] | theFSO | 2 |
biolab/orange3 | data-visualization | 6,692 | Is there a limit to the number of algorithm widgets that should be run in a single workflow? | <!--
This is neither a bug report nor a feature request. We are using Orange for Kaggle competitions. To accomplish this we are adjusting every algorithm in multiple ways (HPO) leading to 100+ algorithms (widgets) per workflow. We have noticed that when we have a large number of widgets in a workflow the performance r... | closed | 2024-01-04T17:17:43Z | 2024-01-05T09:07:48Z | https://github.com/biolab/orange3/issues/6692 | [] | rehoyt | 1 |
plotly/plotly.py | plotly | 4,117 | Plotly Express constructor: lists passed to `x` and `y` params are mutated | When either the `x` or `y` parameters to the Plotly Express constructor are passed lists of values, they are mutated such that values are converted to string.
Expected behaviour: Plotly Express should not mutate objects supplied as arguments by the user.
Minimal example (tested on Plotly 5.13.1 and master branch... | open | 2023-03-21T06:01:51Z | 2024-08-12T20:50:43Z | https://github.com/plotly/plotly.py/issues/4117 | [
"bug",
"P3"
] | ned2 | 3 |
onnx/onnxmltools | scikit-learn | 477 | Support for Spark variable length features | Hello, I was wondering if there's support for variable length features. For example Spark's CountVectorizer can receive a list of strings of different sizes, and perform a sort of One Hot Encoding on the values.
See below:
+-----------------------+-------------------+
| csv | o... | closed | 2021-06-30T20:56:47Z | 2021-07-20T21:32:00Z | https://github.com/onnx/onnxmltools/issues/477 | [] | mhv777 | 2 |
kizniche/Mycodo | automation | 1,365 | Action - Ramp Value | Add a Action to Ramp a value x over time to value x
Like the Action - Ramp PWM
should be useful for many where PWM is not applicable to the used output or following function
| open | 2024-02-27T00:06:37Z | 2024-02-27T00:06:37Z | https://github.com/kizniche/Mycodo/issues/1365 | [] | silverhawk1983 | 0 |
FujiwaraChoki/MoneyPrinterV2 | automation | 83 | Youtube Account With multiple channels | this create youtube.json file only first time but 2nd time I can't create account disappear 2nd time.
so my question is what if I hv more then 1 youtube channel. how can i switch between diffrant chanels in headless mode it always upload video only default youtube chnl.
multiple profile takes alot time and storage. i... | open | 2024-09-01T21:17:21Z | 2024-09-02T05:20:42Z | https://github.com/FujiwaraChoki/MoneyPrinterV2/issues/83 | [] | asonsgh | 2 |
jonaswinkler/paperless-ng | django | 1,679 | [BUG] Scan produces word with spaces between letters | <!---
=> Before opening an issue, please check the documentation and see if it helps you resolve your issue: https://paperless-ng.readthedocs.io/en/latest/troubleshooting.html
=> Please also make sure that you followed the installation instructions.
=> Please search the issues and look for similar issues before open... | closed | 2022-03-04T21:46:39Z | 2022-03-05T12:31:14Z | https://github.com/jonaswinkler/paperless-ng/issues/1679 | [] | tpre | 1 |
automl/auto-sklearn | scikit-learn | 1,448 | [Question] Is there any straight forward way to retrieve the solution and prediction vector during CV? | Hello everyone!
I was wondering if there was any way to retrieve the predictions and associated solutions that were used to compute the metrics during training. Specifically, in the case of a 10 fold CV it would correspond to an array containing 10 entries with each entry having in turn the predictions and the labe... | open | 2022-04-21T13:05:59Z | 2022-06-10T13:01:32Z | https://github.com/automl/auto-sklearn/issues/1448 | [
"enhancement",
"question"
] | chogovadze | 3 |
mljar/mljar-supervised | scikit-learn | 75 | Add SHAP explanations to models | Please add
- SHAP summary plot
- SHAP dependence plots
- SHAP decision plots for top-10 best predictions and top-10 worst prediction (the later might be more important) | closed | 2020-04-24T12:28:16Z | 2023-06-06T06:38:27Z | https://github.com/mljar/mljar-supervised/issues/75 | [
"enhancement"
] | pplonski | 6 |
biolab/orange3 | pandas | 7,048 | Violin Plot: display datetime/time as datetime/time and not as a number | **What's your use case?**
On the axis, Violin Plot displays datetime variables as numbers (i.e., seconds since t=0):
<img width="730" alt="Image" src="https://github.com/user-attachments/assets/bce9cafc-f26c-46e6-bb30-d94250ff4141" />
**What's your proposed solution?**
Just like Box Plot, Violin plot should display d... | open | 2025-03-13T09:05:43Z | 2025-03-13T09:05:43Z | https://github.com/biolab/orange3/issues/7048 | [] | wvdvegte | 0 |
microsoft/nni | tensorflow | 5,018 | ERROR: aten::norm is not Supported! | When I use the NNI L1 method to prune the facenet model and perform speedup, I encounter an error indicating that aten::norm is not supported. How to solve this problem? My pytorch network structure is defined as follows:
![2022-07-25 17-03-15](https://user-images.githubusercontent.com/24822418/180740460-4626eb19-a7... | open | 2022-07-25T09:01:37Z | 2022-11-17T03:31:10Z | https://github.com/microsoft/nni/issues/5018 | [
"user raised",
"support",
"ModelSpeedup",
"v2.9.1"
] | jia0511 | 11 |
litl/backoff | asyncio | 102 | Option to use the "Retry-After" header | I think it would be a good idea if we could use the "Retry-After" header.
Either as the `base` arg to `backoff.expo` or just in itself.
I could create a PR this week if this sounds interesting. | closed | 2020-09-07T14:19:34Z | 2022-04-26T19:59:34Z | https://github.com/litl/backoff/issues/102 | [] | tiptop96 | 4 |
tensorflow/tensor2tensor | machine-learning | 1,624 | How to do online training? | Online training, or incremental training, refers to continue to train the model as new data comes in.
Does t2t support online training? How ? | open | 2019-07-07T14:14:05Z | 2019-07-07T14:14:05Z | https://github.com/tensorflow/tensor2tensor/issues/1624 | [] | PromptExpert | 0 |
pandas-dev/pandas | data-science | 60,394 | ENH: Add first_inverted and last_inverted options to keep in DataFrame.duplicated | ### Feature Type
- [X] Adding new functionality to pandas
- [ ] Changing existing functionality in pandas
- [ ] Removing existing functionality in pandas
### Problem Description
I suggest adding options `first_inverted` and `last_inverted` as `keep` options to function `pandas.DataFrame.duplicated`. Below an exam... | open | 2024-11-22T08:21:07Z | 2024-11-29T13:42:51Z | https://github.com/pandas-dev/pandas/issues/60394 | [
"Enhancement",
"Needs Discussion",
"duplicated",
"Closing Candidate"
] | tommycarstensen | 4 |
dpgaspar/Flask-AppBuilder | flask | 1,395 | Documentation incomplete | Hi, the views.py of the "Simple contacts application" outlined in the documentation misses some imports to be executable. Its corresponding project in GitHub seems to be complete, though.
from .models import Contact, ContactGroup
from . import appbuilder, db
Patrick | closed | 2020-06-09T13:12:10Z | 2020-09-15T01:29:51Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1395 | [
"stale"
] | pichlerpa | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.