
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
PokeAPI/pokeapi | api | 824 | Internal Server Error | We are aware and fixing it | closed | 2023-01-23T15:24:39Z | 2023-01-23T15:32:29Z | https://github.com/PokeAPI/pokeapi/issues/824 | [] | Naramsim | 0 |
luispedro/mahotas | numpy | 134 | Python 3.11 wheels | Hi,
Python 3.11 is already out. It will be nice if wheels for python 3.11 will be uploaded to pypi.
I also see that you use NumPy as a build requirement which means using the latest available NumPy may lead to errors as described in #132 (the author of this issue has to old NumPy version).
I suggest switching ... | closed | 2022-12-30T10:34:09Z | 2024-04-17T12:28:49Z | https://github.com/luispedro/mahotas/issues/134 | [] | Czaki | 1 |
mwaskom/seaborn | matplotlib | 3,721 | Legend Overlaps with X-Axis Labels After Using move_legend in Seaborn | **Description:**
I'm encountering an issue with Seaborn's `relplot` function when using `sns.move_legend`. After moving the legend to the center-bottom of the plot, it overlaps with the x-axis labels. I've tried adjusting the subplot parameters and using `plt.rcParams['figure.autolayout']`, but the legend still over... | closed | 2024-07-02T07:25:26Z | 2024-07-08T02:47:26Z | https://github.com/mwaskom/seaborn/issues/3721 | [] | hasibagen | 2 |
tensorlayer/TensorLayer | tensorflow | 376 | [Discussion] dim equal assert in ElementwiseLayer | `TensorFlow` support broadcasting. I think it is no necessary to add the following assert in `ElementwiseLayer`:
```Python
assert str(self.outputs.get_shape()) == str(l.outputs.get_shape()), "Hint: the input shapes should be the same. %s != %s" % (self.outputs.get_shape() , str(l.outputs.get_shape()))
``` | closed | 2018-03-04T16:16:49Z | 2018-03-05T13:51:51Z | https://github.com/tensorlayer/TensorLayer/issues/376 | [] | auroua | 1 |
google-research/bert | tensorflow | 491 | Is it possible to replicate the results on XNLI dataset which are present on "Multilingual README" page ? | I am not able to replicate the results for "BERT - Translate Train Cased" system on English. Can anybody know the set hyperparameters which were used for fine-tuning of **BERT-Base, Multilingual Cased (New, recommended)** on English ? | open | 2019-03-10T14:00:24Z | 2019-07-22T17:55:01Z | https://github.com/google-research/bert/issues/491 | [] | gourango01 | 1 |
LibreTranslate/LibreTranslate | api | 14 | Translate complete websites? | How to translate full websites?
It would be good to put examples to translate webs into any other language. | open | 2021-01-16T22:07:53Z | 2024-10-24T03:59:12Z | https://github.com/LibreTranslate/LibreTranslate/issues/14 | [
"enhancement"
] | wuniversales | 7 |
tiangolo/uwsgi-nginx-flask-docker | flask | 10 | cant connect mongodb | why can,t connect mongodb
eg:
data=source_client.users.users.find({"_id":ObjectId('5840e3eaf1d30043c60cae53')})[0]
feedback:
<title>500 Internal Server Error</title>
<h1>Internal Server Error</h1>
<p>The server encountered an internal error and was unable to complete your request. Either the server is overloa... | closed | 2017-06-06T03:29:20Z | 2017-08-26T14:45:13Z | https://github.com/tiangolo/uwsgi-nginx-flask-docker/issues/10 | [] | habout632 | 3 |
KaiyangZhou/deep-person-reid | computer-vision | 339 | how can change the size of feature dim? | closed | 2020-05-13T01:54:44Z | 2020-05-18T10:09:08Z | https://github.com/KaiyangZhou/deep-person-reid/issues/339 | [] | qianjinhao | 4 | |
benbusby/whoogle-search | flask | 789 | [BUG] Images in search results are fetched using HTTP, even with HTTPS_ONLY=1 | **Describe the bug**
A clear and concise description of what the bug is.
Title
**To Reproduce**
Steps to reproduce the behavior:
1. Search anything
2. Look in the network tab
3. See that images are pulled in using HTTP
**Deployment Method**
- [ ] Heroku (one-click deploy)
- [ ] Docker
- [x] `run` executabl... | closed | 2022-06-15T03:42:39Z | 2022-06-27T13:41:02Z | https://github.com/benbusby/whoogle-search/issues/789 | [
"bug"
] | DUOLabs333 | 16 |
roboflow/supervision | computer-vision | 1,215 | Problems with tracker.update_with_detections(detections) | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar bug report.
### Bug
Somehow, I loose predicted bounding boxes in this line:
`tracker.update_with_detections(detections)`
In the plot from Ultralytics, everything ... | open | 2024-05-21T12:45:53Z | 2024-06-16T15:12:54Z | https://github.com/roboflow/supervision/issues/1215 | [
"bug"
] | CodingMechineer | 18 |
yunjey/pytorch-tutorial | deep-learning | 170 | Good tutorial and thank you! Very nice and simple! Can you update this to PyTorch 1.0? | In the PyTorch 1.0, there are some changes such as replace variable with tensor and so on.There most be some better practice. It would be nice to update this. | open | 2019-03-29T03:00:19Z | 2019-03-29T03:00:19Z | https://github.com/yunjey/pytorch-tutorial/issues/170 | [] | dayekuaipao | 0 |
ghtmtt/DataPlotly | plotly | 63 | Better error handling when subplotting not possible | https://github.com/ghtmtt/DataPlotly/blob/master/data_plotly_dialog.py#L1021
would be great to add a manual page that explains which plot type are not compatible and add a direct link to that page in the messageBar | closed | 2017-12-15T10:04:33Z | 2018-05-15T12:48:13Z | https://github.com/ghtmtt/DataPlotly/issues/63 | [
"enhancement",
"docs"
] | ghtmtt | 0 |
simple-login/app | flask | 2,408 | Job runner container rolling reboot - undefined db column | Please note that this is only for bug report.
For help on your account, please reach out to us at hi[at]simplelogin.io. Please make sure to check out [our FAQ](https://simplelogin.io/faq/) that contains frequently asked questions.
For feature request, you can use our [forum](https://github.com/simple-login/app/disc... | closed | 2025-03-05T09:49:27Z | 2025-03-05T10:15:18Z | https://github.com/simple-login/app/issues/2408 | [] | anarion80 | 1 |
microsoft/nni | tensorflow | 5,471 | Meet an error when we try to prune the yolov5s.pt | **Describe the bug**:
TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if self.onnx_dynamic or self.... | closed | 2023-03-23T07:21:20Z | 2023-04-07T03:03:55Z | https://github.com/microsoft/nni/issues/5471 | [] | Ku-Buqi | 4 |
ultralytics/ultralytics | deep-learning | 19,513 | pt model to an ONNX model, different result | When using the official tool to convert a PyTorch (pt) model to an ONNX model, it is found that when inferring the same image using the pt model and the ONNX model, the results are inconsistent. | open | 2025-03-04T09:16:58Z | 2025-03-12T22:44:15Z | https://github.com/ultralytics/ultralytics/issues/19513 | [
"non-reproducible",
"exports"
] | GXDD666 | 7 |
ydataai/ydata-profiling | data-science | 1,530 | No module named 'ydata_profiling' | ### Current Behaviour
after installing ydata using the following command
conda install -c conda-forge ydata-profiling
I can use
from ydata_profiling import ProfileReport
in the python cmd window. However, in the jupyter notebook I get the
following error:
ModuleNotFoundError: No module named 'ydata_... | closed | 2024-01-26T05:31:03Z | 2024-09-06T02:33:35Z | https://github.com/ydataai/ydata-profiling/issues/1530 | [
"needs-triage"
] | makgul1 | 4 |
dynaconf/dynaconf | django | 1,047 | Centralized config package | External hooks for `platformdirs`, __package__, package_dir, etc. | ## **Problem**
I am trying to set up a single configuration package that all of my other packages will "inherit" from (let's call it `confpkg`).
The idea is to be able to change the code in `confpkg` to add "standard" configuration values, which can then be overridden in whatever package is being developed (call it `... | open | 2024-02-01T20:36:52Z | 2024-07-08T18:37:53Z | https://github.com/dynaconf/dynaconf/issues/1047 | [
"Not a Bug",
"RFC"
] | chasealanbrown | 1 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 1,288 | the output only one second why | The code returns for one second and does not complete the text. Can anyone help me? | open | 2024-02-19T08:45:11Z | 2024-03-08T13:19:30Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1288 | [] | Aladdin30 | 1 |
vitalik/django-ninja | rest-api | 1,360 | [BUG] Unable to generate pydantic-core schema for <class 'ninja.orm.metaclass.ModelSchemaMetaclass'>. | **Describe the bug**
Have a model, a ModelSchema, and an API endpoint where the response type is this schema. `python manage.py runserver` fails with an internal Pydantic error:
```
pydantic.errors.PydanticSchemaGenerationError: Unable to generate pydantic-core schema for <class 'ninja.orm.metaclass.ModelSchemaM... | closed | 2024-12-15T00:26:20Z | 2024-12-15T00:33:36Z | https://github.com/vitalik/django-ninja/issues/1360 | [] | bozbalci | 1 |
Kanaries/pygwalker | matplotlib | 248 | Pygwalker 0.3.7 is missing on conda-forge | https://github.com/conda-forge/pygwalker-feedstock/pull/40
Looks like the automatic release is broken due to errors in Azure
Could you please release it on Conda too? | closed | 2023-09-27T21:31:00Z | 2023-10-02T21:38:17Z | https://github.com/Kanaries/pygwalker/issues/248 | [] | ilyanoskov | 1 |
ARM-DOE/pyart | data-visualization | 866 | Issues with CyLP | We're having issues getting cylp to run on jupyter notebooks - it immediately restarts the kernel when any phase processing is done, namely:
reproc_phase, kdp = pyart.correct.phase_proc_lp(radar,0., refl_field='reflectivity',
fzl=13000.,
... | closed | 2019-09-10T17:43:08Z | 2019-10-01T21:14:26Z | https://github.com/ARM-DOE/pyart/issues/866 | [] | saralytle | 5 |
google-research/bert | tensorflow | 964 | when we calculate loss, why we jsut calculate one token loss, rather than sum all token loss in one example | open | 2019-12-19T03:17:08Z | 2019-12-19T03:20:17Z | https://github.com/google-research/bert/issues/964 | [] | xiongma | 1 | |
drivendataorg/cookiecutter-data-science | data-science | 34 | Click seems to be flawed on Python 3 - Consider using docopt | I don't know much about click or docopt yet, so don't shoot me if i'm lost here. Click seems to be handling Python 3 a bit badly. Should we consider switching to http://docopt.org/ ?
By the way i manage to get Click working by running, `export LC_ALL=no_NO.utf-8` and `export LANG=no_NO.utf-8`. But It seems like there ... | closed | 2016-06-29T19:54:32Z | 2017-03-13T20:32:53Z | https://github.com/drivendataorg/cookiecutter-data-science/issues/34 | [
"needs-discussion"
] | ohenrik | 5 |
twopirllc/pandas-ta | pandas | 185 | VP indicator how width works? | **Which version are you running? The lastest version is on Github. Pip is for major releases.**
```python3.7
import pandas_ta as ta
print(ta.version)
```
**Upgrade.**
```sh
$ pip install -U git+https://github.com/twopirllc/pandas-ta
```
I'm calculating VP over 50 candles of 1h.
I don't understand how wi... | closed | 2021-01-07T01:32:45Z | 2021-01-17T17:39:22Z | https://github.com/twopirllc/pandas-ta/issues/185 | [
"enhancement",
"info"
] | casterock | 3 |
pyqtgraph/pyqtgraph | numpy | 2,372 | Typo? | in pyqtgraph/pgcollections.py:149:22:
```
def __init__(self, *args, **kwargs):
self.mutex = threading.RLock()
list.__init__(self, *args, **kwargs)
for k in self:
self[k] = mkThreadsafe(self[k])
^
```
should be
```
self[k] = makeTh... | closed | 2022-07-23T02:28:34Z | 2022-07-23T10:06:14Z | https://github.com/pyqtgraph/pyqtgraph/issues/2372 | [] | dingo9 | 2 |
benbusby/whoogle-search | flask | 363 | [FEATURE] Wikiless - wikipedia alternative | <!--
DO NOT REQUEST UI/THEME/GUI/APPEARANCE IMPROVEMENTS HERE
THESE SHOULD GO IN ISSUE #60
REQUESTING A NEW FEATURE SHOULD BE STRICTLY RELATED TO NEW FUNCTIONALITY
-->
**Describe the feature you'd like to see added**
Wikiless - privacy alternative to wikipedia
**Additional context**
https://codeberg.org/ore... | closed | 2021-06-19T09:39:19Z | 2022-01-14T16:59:04Z | https://github.com/benbusby/whoogle-search/issues/363 | [
"enhancement"
] | specter78 | 1 |
microsoft/JARVIS | deep-learning | 162 | Can't use gradio | Running the command per the README:
```
python run_gradio_demo.py --config config.yaml
```
Results in the following exception being thrown when submitting any prompts thru the Gradio page:
```
Traceback (most recent call last):
File "/home/ubuntu/.conda/envs/jarvis/lib/python3.8/site-packages/gradio/routes.p... | closed | 2023-04-17T22:11:31Z | 2023-04-18T03:19:25Z | https://github.com/microsoft/JARVIS/issues/162 | [] | tabrezm | 0 |
airtai/faststream | asyncio | 1,830 | Feature: Not update/create NATS streams/consumers | Hi, we are using NATS together with their k8s operator NACK which is used to provision stream & consumers (durable). Is there a way to disable create / updating of streams & consumers, and just rely them being provision by IAC. I haven't found this option, looking at example & docs, but I think it's a common use-case.... | closed | 2024-10-02T19:56:44Z | 2024-10-02T20:25:08Z | https://github.com/airtai/faststream/issues/1830 | [
"enhancement",
"NATS"
] | mkramb | 2 |
RomelTorres/alpha_vantage | pandas | 72 | alpha_vantage creates error | #source: https://quantdare.com/forecasting-sp-500-using-machine-learning/
from alpha_vantage.timeseries import TimeSeries
import pandas as pd
print('Pandas_Version: ' + pd.__version__)
symbol = 'GOOGL'
ts = TimeSeries(key='_my_key_', output_format='pandas')
close = ts.get_daily(symbol=symbol, outputsize='full... | closed | 2018-05-22T22:57:33Z | 2018-05-24T07:02:17Z | https://github.com/RomelTorres/alpha_vantage/issues/72 | [] | amadeus22 | 5 |
davidsandberg/facenet | tensorflow | 561 | ValueError: There should not be more than one meta file in the model directory | open | 2017-12-01T03:12:15Z | 2022-01-05T19:39:58Z | https://github.com/davidsandberg/facenet/issues/561 | [] | ronyuzhang | 2 | |
Gozargah/Marzban | api | 1,127 | بهم ریختن ترتیب کانفیگا در حالت کاستوم | بعد از اپدیت مرزبان به نسخه 0.5.1 و 0.5.2 ترتیب کانفیگادر حالت کاستوم از اینباند اخر به اول شده | closed | 2024-07-17T08:23:51Z | 2024-07-19T22:38:16Z | https://github.com/Gozargah/Marzban/issues/1127 | [
"Bug"
] | dvltak | 4 |
mwaskom/seaborn | pandas | 3,058 | unable to plot with custom color ramp seaborn 0.12.0 | I was trying to use seaborn kdeplot with custom colour ramp, it is working with seaboarn version 0.11.00, but not with seaboarn 0.12.0
**color ramp as below**
```
def make_Ramp( ramp_colors ):
from colour import Color
from matplotlib.colors import LinearSegmentedColormap
color_ramp = LinearSegme... | closed | 2022-10-07T16:51:19Z | 2022-10-08T23:02:17Z | https://github.com/mwaskom/seaborn/issues/3058 | [
"bug",
"mod:distributions"
] | Niransha | 5 |
sergree/matchering | numpy | 45 | Music Production | No issue here- just tried starting the repo under a new list "music production" but accidentally clicked "issue". | closed | 2022-11-24T20:21:20Z | 2023-01-30T19:57:33Z | https://github.com/sergree/matchering/issues/45 | [] | ActivateLLC | 1 |
psf/black | python | 4,362 | Black v24.4.1 & v24.4.2 fails to format f-strings containing multi-line strings | Black versions 24.4.1 and 24.4.2 encounter an issue when formatting Python code containing an f-string that includes a multi-line string. Example:
```python
s = f"""{'''a
b
c'''}"""
print(s)
```
this is valid python syntax, as it is executable, but black cannot format it, as indicat... | closed | 2024-05-14T15:05:54Z | 2024-07-31T18:07:52Z | https://github.com/psf/black/issues/4362 | [
"T: bug"
] | gbatagian | 4 |
liangliangyy/DjangoBlog | django | 641 | 请问对接memcached部分是那个配置文件啊 | <!--
如果你不认真勾选下面的内容,我可能会直接关闭你的 Issue。
提问之前,建议先阅读 https://github.com/ruby-china/How-To-Ask-Questions-The-Smart-Way
-->
**我确定我已经查看了** (标注`[ ]`为`[x]`)
- [ x] [DjangoBlog的readme](https://github.com/liangliangyy/DjangoBlog/blob/master/README.md)
- [ x] [配置说明](https://github.com/liangliangyy/DjangoBlog/blob/master/b... | closed | 2023-03-19T09:51:22Z | 2023-03-31T03:01:52Z | https://github.com/liangliangyy/DjangoBlog/issues/641 | [] | txbxxx | 1 |
miguelgrinberg/Flask-SocketIO | flask | 829 | Unable to run the example code | I must be doing something fundamentally wrong, but I'm unable to see what. I just tried the example in the documentation, and for some reason, the server keeps answering `200 Ok` instead of `101 Switching protocols`.
I did the following:
1. Copied the example code from the documentation:
```python
fro... | closed | 2018-11-08T18:57:44Z | 2019-04-07T10:08:15Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/829 | [
"question"
] | jldiaz | 3 |
plotly/dash-core-components | dash | 188 | Graph callbacks not always triggered by Dropdown value or Graph selectedData change events in 0.22.1 - maybe broken by initially returning empty dict | I have multiple apps that have Graph `figure` plotting callbacks triggered by multiple inputs, including Dropdown `value` events (both single and multi select) and `selectedData` events from other Graphs. As of version 0.22.1, none of my plots are triggered by these events initially. I can trigger the callbacks using s... | closed | 2018-04-20T14:09:45Z | 2023-01-28T14:25:37Z | https://github.com/plotly/dash-core-components/issues/188 | [] | slishak | 2 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 733 | ImportError: Failed to import any qt binding | I face the error when run demo_toolbox.py:
```
(venv2) C:\Users\dev_user\PycharmProjects\Real-Time-Voice-Cloning>python demo_toolbox.py
Traceback (most recent call last):
File "demo_toolbox.py", line 2, in <module>
from toolbox import Toolbox
File "C:\Users\dev_user\PycharmProjects\Real-Time-Voice-Cloni... | closed | 2021-04-11T14:46:26Z | 2021-04-22T20:18:15Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/733 | [] | 32r81b | 2 |
tartiflette/tartiflette | graphql | 292 | Cannot resolve extended types | With the schema
```
type Query {
hello: String
}
extend type Query {
world: String
}
```
I can see the extended fields in graphiql schema but as soon as i try to declare a resolver for the extended type like this
```
@Resolver('Query.world')
async def revolve_stuff(_, args, ctx, info):
retur... | closed | 2019-09-14T12:10:09Z | 2019-09-15T07:34:53Z | https://github.com/tartiflette/tartiflette/issues/292 | [
"bug"
] | remorses | 1 |
aidlearning/AidLearning-FrameWork | jupyter | 62 | Not Opening anything |
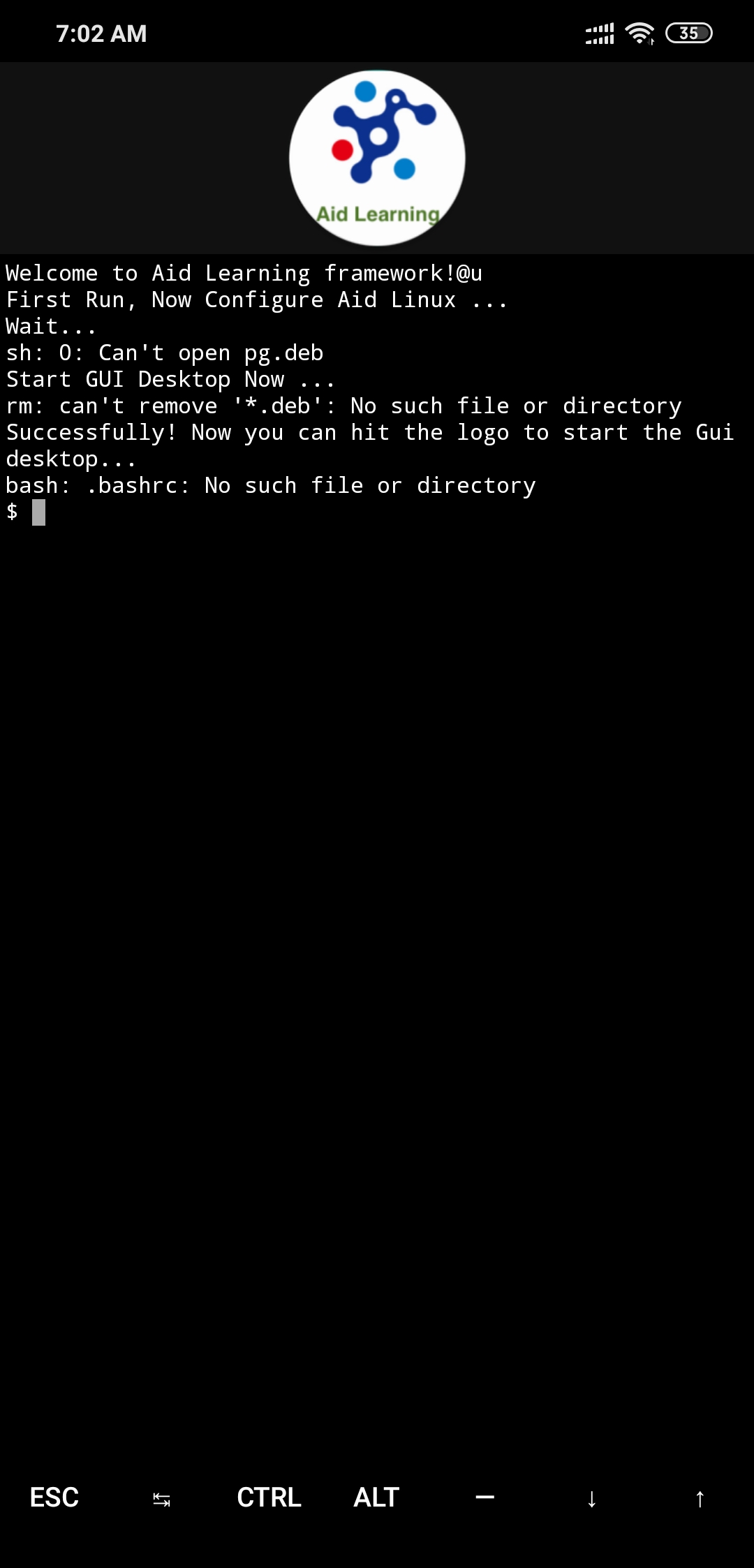
When I click on any Icon it goes blank | closed | 2019-11-12T01:32:59Z | 2020-07-29T01:18:55Z | https://github.com/aidlearning/AidLearning-FrameWork/issues/62 | [
"duplicate"
] | zuhairabs | 4 |
rasbt/watermark | jupyter | 4 | Allow storing watermark info in metadata? | Watermark looks great for reproducibility.
It would be nice to have an option to (also) store this data in the notebook `metadata`:
``` json
{
"metadata": {
"watermark": {
"date": "2015-17-06T15:04:35",
"CPython": "3.4.3",
"IPython": "3.1.0",
"compiler": "GCC 4.2.1 (Apple Inc. build 5577)",
"sys... | open | 2015-09-01T19:44:53Z | 2018-09-24T15:56:10Z | https://github.com/rasbt/watermark/issues/4 | [
"enhancement"
] | bollwyvl | 7 |
MagicStack/asyncpg | asyncio | 320 | Race condition on __async_init__ when min_size > 0 | ```python
def get_pool(loop=None):
global pool
if pool is None:
pool = asyncpg.create_pool(**config.DTABASE, loop=loop)
return pool
```
Task1:
```python
pool = get_pool()
await pool # init
```
Task2:
```python
pool = get_pool()
await pool # init
```
Got `AssertionError` for asyn... | closed | 2018-06-28T09:37:40Z | 2018-07-10T22:07:09Z | https://github.com/MagicStack/asyncpg/issues/320 | [
"enhancement"
] | spumer | 4 |
vitalik/django-ninja | pydantic | 1,085 | Need more comprehensive Docs/Tutorial like FastAPI | When I check out DRF / FastAPI docs, I find it quite comprehensive with examples given and explained.
They seem to be quite clear to understand.
It would be great if we could add a similar level of explanation in Django Ninja Docs.
PS: Just a beginner here, trying to use it over DRF for my project.
| open | 2024-02-16T19:22:50Z | 2024-03-24T21:02:35Z | https://github.com/vitalik/django-ninja/issues/1085 | [] | tushar9sk | 3 |
serengil/deepface | deep-learning | 1,451 | [FEATURE]: Add Angular Distance as a Distance Metric | ### Description
DeepFace currently supports cosine distance, Euclidean distance, and Euclidean L2 distance for face embedding comparisons. To enhance distance metric options, we should add angular distance, which is based on the angle between two embeddings. This metric is particularly useful for spherical embeddings ... | open | 2025-03-10T12:55:48Z | 2025-03-19T11:49:13Z | https://github.com/serengil/deepface/issues/1451 | [
"enhancement"
] | serengil | 1 |
JaidedAI/EasyOCR | machine-learning | 1,005 | Text Detection training code(craft) has BUG | hi @gmuffiness and anyone who can help :)
I've tried to train Craft with the Craft training code provided by the easyOCR repository, but I think the code has a bug. I trained with one sample image of the ICDAR dataset ( img_990.jpg, my training and validation dataset for finetuning was this image, just one image )... | open | 2023-05-03T06:32:55Z | 2024-11-14T23:03:42Z | https://github.com/JaidedAI/EasyOCR/issues/1005 | [] | masoudMZB | 4 |
fastapi/sqlmodel | fastapi | 164 | Enum types on inherited models don't correctly create type in Postgres | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X] I al... | closed | 2021-11-23T21:32:35Z | 2023-10-23T12:32:36Z | https://github.com/fastapi/sqlmodel/issues/164 | [
"answered"
] | chriswhite199 | 11 |
piskvorky/gensim | nlp | 2,948 | rename 8.6 tag to 0.8.6 | #### Problem description
There is a tag "8.6" in the repository that is between 0.8.7 and 0.8.5 in terms of when it was created, but it is missing the 0 at the start.
#### Steps/code/corpus to reproduce
```
git clone https://github.com/RaRe-Technologies/gensim.git
cd gensim
git tag | grep -v '^[0-3]'
```
... | closed | 2020-09-16T08:21:41Z | 2022-05-05T06:41:20Z | https://github.com/piskvorky/gensim/issues/2948 | [] | pabs3 | 11 |
ultralytics/ultralytics | computer-vision | 18,816 | looks like starting over again and again automatically??? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi, I encountered a problem when I read and run the source code of Ultralyti... | closed | 2025-01-22T08:11:36Z | 2025-03-13T09:09:31Z | https://github.com/ultralytics/ultralytics/issues/18816 | [
"question",
"detect"
] | AlbertMa123 | 19 |
pennersr/django-allauth | django | 3,405 | ModuleNotFoundError: No module named 'allauth.account.middleware' | Weird error won't let me import allauth.account.middleware
Any smart minds know what the issue could be? Can't find any similar.
Already tried: Upgrading to python3 and reinstalling django-allauth
Stack Overflow question link: https://stackoverflow.com/questions/77012106/django-allauth-modulenotfounderror-no-m... | closed | 2023-08-31T00:21:02Z | 2025-03-22T17:00:20Z | https://github.com/pennersr/django-allauth/issues/3405 | [] | pedro-santos21 | 5 |
electricitymaps/electricitymaps-contrib | data-visualization | 7,596 | CO2 net exchange chart is only presented for 24h and 72h - not for 30d, 12mo, all - missing `totalCo2Export` and `totalCo2Import` | ## Bug description / Feature request
Data (`totalCo2Export` and `totalCo2Import`) isn't available for a CO2 net exchange chart with 30d+ views, so it's only presented for the 24h and 72h views. This was surprising to me since `totalExport` and `totalImport` is around. Is not calculating the CO2 equivalent to `totalE... | open | 2024-12-20T18:43:47Z | 2024-12-20T23:22:33Z | https://github.com/electricitymaps/electricitymaps-contrib/issues/7596 | [] | consideRatio | 2 |
onnx/onnx | scikit-learn | 6,239 | Create 1.16.2 release? | # Ask a Question
### Question
Should we cut a 1.16.2 release to pull in some commits from main or wait for 1.17.0?
### Further information
Primary PRs of interest to pull (will add to list if more are requested):
* https://github.com/onnx/onnx/pull/6164
* https://github.com/onnx/onnx/pull/6222
### Notes
I... | closed | 2024-07-19T19:22:24Z | 2024-07-30T15:32:49Z | https://github.com/onnx/onnx/issues/6239 | [
"question"
] | cjvolzka | 12 |
jupyterlab/jupyter-ai | jupyter | 1,052 | v3.0.0 roadmap & release plan | Attention Jupyter AI users! I have some exciting news to share in this issue. We are currently planning, designing, and building the next major release of Jupyter AI, v3.0.0.
This issue is a living document that lists features planned for v3.0.0, and publicly tracks progress on v3.0.0 development. The list of planned ... | open | 2024-10-23T21:56:52Z | 2025-02-18T09:53:36Z | https://github.com/jupyterlab/jupyter-ai/issues/1052 | [
"enhancement"
] | dlqqq | 1 |
vanna-ai/vanna | data-visualization | 700 | Why do all routes point to index.html? | **Describe the bug**
all routes point to index.html
Once I specify index_html_path this happens
**To Reproduce**
Steps to reproduce the behavior:

**Expected behavior**
A clear and concise description of what you expec... | closed | 2024-11-14T02:14:01Z | 2024-11-14T06:35:10Z | https://github.com/vanna-ai/vanna/issues/700 | [
"bug"
] | SharkSyl | 0 |
stanfordnlp/stanza | nlp | 778 | How to apply Stanza nlp tokenizer on dataframe? |
### **Code Below**
```
import stanza
nlp = stanza.Pipeline('ur', processors='tokenize',tokenize_no_ssplit=True)
def tokenizee(text):
text=nlp(text)
return text
```
```
import urduhack
from urduhack.preprocessing import replace_urls
from urduhack.preprocessing import remove_english_alphabets
... | closed | 2021-07-27T12:52:08Z | 2021-07-27T18:23:33Z | https://github.com/stanfordnlp/stanza/issues/778 | [
"enhancement"
] | mahad-maqsood | 3 |
numpy/numpy | numpy | 27,934 | ENH: npy file format does not use standard JSON in header, change it to do so | ### Describe the issue:
I'm writing a loader for the npy file format in a non-Python language. Part of the header of this file is a JSON encoded dictionary. I am unable to parse it in my other language because the JSON numpy is generating does not conform to the JSON standard.
https://numpy.org/doc/stable/ref... | open | 2024-12-08T11:44:21Z | 2025-01-04T04:45:14Z | https://github.com/numpy/numpy/issues/27934 | [
"01 - Enhancement"
] | blackears | 5 |
coqui-ai/TTS | pytorch | 4,017 | VITS model gives bad results (training an italian tts model) | ### Describe the bug
Hi everyone. I'm new to the world of ML, so I'm not used to training AI models...
I really want to create my own TTS model using coqui's VITS trainer, so I've done a lot of research about it. I configured some dataset parameters and configuration functions and then started training. For the tra... | closed | 2024-10-09T20:29:06Z | 2024-12-28T11:58:24Z | https://github.com/coqui-ai/TTS/issues/4017 | [
"bug",
"wontfix"
] | iDavide | 6 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 1,280 | TypeError: melspectrogram() | Getting the mentioned error when running demo_cli.py (windows 10)
```
D:\Ai_audio\Real-Time-Voice-Cloning>python demo_cli.py
C:\Program Files\Python310\lib\site-packages\numpy\_distributor_init.py:30: UserWarning: loaded more than 1 DLL from .libs:
C:\Program Files\Python310\lib\site-packages\numpy\.libs\libope... | closed | 2024-01-03T19:41:48Z | 2024-01-03T19:46:17Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1280 | [] | stevens-Ai | 1 |
statsmodels/statsmodels | data-science | 8,951 | can I manually increase de number of iter, from 500 to 1000? or change the convergence criterion? | #### Is your feature request related to a problem? Please describe
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
#### Describe the solution you'd like
A clear and concise description of what you want to happen.
#### Describe alternatives you have considered
A clea... | closed | 2023-07-13T16:58:53Z | 2023-10-27T09:57:09Z | https://github.com/statsmodels/statsmodels/issues/8951 | [] | carloseduardosg | 0 |
cvat-ai/cvat | tensorflow | 8,354 | Custom model Fine tuned deployment - Using Hugging Face Sam Transformers | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
_No response_
### Expected Behavior
When I use my Fine tuned model it should generate masks, this works choosi... | closed | 2024-08-27T11:29:23Z | 2024-11-14T19:08:24Z | https://github.com/cvat-ai/cvat/issues/8354 | [
"question"
] | venuss920 | 0 |
streamlit/streamlit | machine-learning | 10,017 | `st.segmented_control`: Add vertical option | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [X] I added a descriptive title and summary to this issue.
### Summary
The segmented_control buttons are great. I'm interested in creating a similar set of buttons but vertically a... | open | 2024-12-13T03:55:44Z | 2025-01-19T16:10:55Z | https://github.com/streamlit/streamlit/issues/10017 | [
"type:enhancement",
"feature:st.segmented_control"
] | olliepro | 3 |
plotly/dash-core-components | dash | 965 | [Bug] Upload component won't broken in Dash 1.20.0 | Hi,
I am trying to use the upload component in one of my apps. Recently upgraded to dash 1.20.0 and have found that the component doesn't work anymore. The debug server gives me an error `Cannot read property 'call' of undefined`. I have also tried running the examples at https://dash.plotly.com/dash-core-components/u... | open | 2021-05-06T21:00:35Z | 2021-05-11T18:48:10Z | https://github.com/plotly/dash-core-components/issues/965 | [] | NicholasChin | 1 |
dask/dask | numpy | 10,945 | Pandas read_sql vs dask read_sql issues | Hello guys,
Help here. The same command works on pandas but does not work on dask:
Pandas
```
import pandas as pd
sql = """SELECT t1.NR_SEQL_SLCT_CPR
FROM ORANDPOW0000.SLCT_CPR_PRD_PCR t1
WHERE ROWNUM <= 1000"""
pd.read_sql(sql = sql, con=oracle.uri, index_col = 'nr_seql_slct_cpr')
```
It ... | open | 2024-02-21T18:57:15Z | 2024-05-24T19:06:10Z | https://github.com/dask/dask/issues/10945 | [
"needs triage"
] | frbelotto | 3 |
marshmallow-code/marshmallow-sqlalchemy | sqlalchemy | 33 | Using marshmallow schema to restrict update fields. | I'm developing an api in Flask,
In my update functions I would like to restrict the fields that can be updated e.g. I don't want users to be able to change their email at the moment.
To achieve this I have set up a schema (UserSchema) with its fields restricted by a tuple (UserSchemaTypes.UPDATE_FIELDS).The tuple do... | closed | 2015-10-09T13:08:42Z | 2015-10-20T09:15:42Z | https://github.com/marshmallow-code/marshmallow-sqlalchemy/issues/33 | [] | EdCampion | 2 |
saulpw/visidata | pandas | 2,165 | **DirSheet** makes changes without needing commit in v2.11 | ### Discussed in https://github.com/saulpw/visidata/discussions/2163
<div type='discussions-op-text'>
<sup>Originally posted by **proItheus** December 8, 2023</sup>
Any change in `dirsheet` is instantly committed to filesystem, without my executing `commit change` command.
[ breaks ProfileReport | ### Current Behaviour
```
pip install ydata-profiling
```
Then in Python:
```
from ydata_profiling import ProfileReport
```
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "[redacted]/lib/python3.8/site-packages/ydata_profiling/__init__.py", line 14, in <module>
from ydata_pro... | closed | 2025-03-05T16:19:06Z | 2025-03-11T15:16:03Z | https://github.com/ydataai/ydata-profiling/issues/1719 | [
"bug 🐛"
] | namiyousef | 2 |
LAION-AI/Open-Assistant | machine-learning | 2,690 | Clarify contributing frontend | This is something that's seemed to suddenly pick up quite a bit, but I've seen quite a lot of posts recently which seem to not be understanding the Chat section vs. the contributions section.
Example:

Lo... | closed | 2023-04-18T02:52:09Z | 2023-06-14T08:35:12Z | https://github.com/LAION-AI/Open-Assistant/issues/2690 | [
"website",
"needs discussion"
] | luphoria | 0 |
ageitgey/face_recognition | python | 718 | How to mapping image encoding based on folder name | Hello man,
I have a set of images of 1 person
My Image structure is like this:
```
Database/ Person1 / 1.jpg
Database/ Person1 / 2.jpg
Database/ Person1 / 3.jpg
Database/ Person1 / 4.jpg
....
Database/ Person9 / 1.jpg
Database/ Person9 / 2.jpg
Database/ Person9 / 3.jpg
Database/ Person9 / 4.jpg
... | open | 2019-01-15T12:57:49Z | 2019-01-17T11:40:58Z | https://github.com/ageitgey/face_recognition/issues/718 | [] | flyingduck92 | 1 |
scikit-optimize/scikit-optimize | scikit-learn | 678 | AttributeError: module 'skopt.callbacks' has no attribute 'CheckpointSaver' (dumping/loading results object) | Am I loading this incorrectly? It dumped without error but I'm not able to retrieve the results.
```python
skopt.__version__
'0.5.2'
```
```python
# Optimization
n_calls = 1000
kappa = 5.0
delta = 0.001
name = "forest.clustering"
callbacks = [skopt.callbacks.VerboseCallback(n_total=n_calls),
skopt.call... | closed | 2018-05-14T17:58:50Z | 2019-03-18T20:36:38Z | https://github.com/scikit-optimize/scikit-optimize/issues/678 | [] | jolespin | 10 |
Lightning-AI/pytorch-lightning | deep-learning | 19,768 | Script freezes when Trainer is instantiated | ### Bug description
I can run once a training script with pytorch-lightning. However, after the training finishes, if train to run it again, the code freezes when the `L.Trainer` is instantiated. There are no error messages.
Only if I shutdown and restart, I can run it once again, but then the problem persist for t... | closed | 2024-04-12T14:11:34Z | 2024-06-22T22:46:07Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19768 | [
"question"
] | PabloVD | 5 |
vitalik/django-ninja | pydantic | 405 | Custom ninja HttpRequest class, that includes an 'auth' property | **Is your feature request related to a problem? Please describe.**
All examples I saw use `django.http.HttpRequest` to annotate the request object in operations.
This is a problem when using an authentication. Now I need to work with `request.auth` but that property is not defined in the django HttpRequest class wh... | closed | 2022-03-26T01:26:44Z | 2023-10-13T14:37:03Z | https://github.com/vitalik/django-ninja/issues/405 | [] | geeshta | 3 |
open-mmlab/mmdetection | pytorch | 12,055 | Quantization Aware Training | Is there any instructions on how to do QAT in mmdetection ? | open | 2024-12-02T07:24:44Z | 2024-12-10T01:59:58Z | https://github.com/open-mmlab/mmdetection/issues/12055 | [] | HanXuMartin | 2 |
pallets-eco/flask-wtf | flask | 173 | Can't disable csrf per form | Just tried something like this:
```
class MyForm(Form):
class Meta:
csrf = False
```
And a csrf not present error was thrown. I need to disable csrf so that my GET form can be accessed from outside with query parameters directly.
| closed | 2015-02-22T19:00:04Z | 2021-05-28T01:03:52Z | https://github.com/pallets-eco/flask-wtf/issues/173 | [
"todo"
] | italomaia | 5 |
keras-team/keras | machine-learning | 20,437 | Add `ifft2` method to ops | I'm curious why there is no `ops.ifft2`. Given that there is already `fft` and `fft2`, implementing one is trivial.
Here is an example of what an `ifft2` would look like:
```python
import keras
def keras_ops_ifft2(fft_real,fft_imag):
"""
Inputs are real and imaginary parts of array
of shape [.... | closed | 2024-11-01T18:32:58Z | 2024-11-05T00:14:56Z | https://github.com/keras-team/keras/issues/20437 | [
"stat:contributions welcome",
"type:feature"
] | markveillette | 1 |
lucidrains/vit-pytorch | computer-vision | 109 | DINO training... getting it to work? | Has anyone been able to get DINO to converge? I’m running the example code given and not seeing anything happening. Is there a set of meta parameters that works for something like Imagenet? | open | 2021-05-06T14:40:07Z | 2021-08-05T08:27:58Z | https://github.com/lucidrains/vit-pytorch/issues/109 | [] | watts4speed | 1 |
widgetti/solara | flask | 633 | Documentation getting started introduction links lead to 404 not found | Hi,
Take note I just started looking at solara today. So total noob.
I was going thru the [Introduction](https://github.com/widgetti/solara/blob/master/solara/website/pages/documentation/getting_started/content/01-introduction.md) and found most of the link's are not working.
Is this the best place to start?
... | closed | 2024-05-06T14:06:28Z | 2024-05-07T15:14:33Z | https://github.com/widgetti/solara/issues/633 | [] | HugoP | 3 |
fugue-project/fugue | pandas | 128 | [FEATURE] Limit and Limit by Partition | Implement a new method/transformer to limit.
Look at the Spark documentation: https://spark.apache.org/docs/2.1.0/api/python/pyspark.sql.html#pyspark.sql.DataFrame.limit
Pandas doesn't have one. Maybe the backend can use df.head() or df.sample if we want it to be random. | closed | 2020-12-19T17:00:28Z | 2021-01-11T04:12:16Z | https://github.com/fugue-project/fugue/issues/128 | [
"enhancement",
"high priority",
"programming interface",
"core feature"
] | kvnkho | 1 |
cobrateam/splinter | automation | 1,327 | can't control edge with debuggerAddress | can't control edge opened with debuggerAddress
line 57 in splinter\driver\webdriver\edge.py is:
options = Options() or options
maybe it should be:
options = options or Options()
test code:will open a new edge ,that is not we expected
```
from selenium.webdriver.edge.options import Options
edge_options = Options()... | open | 2025-02-11T08:15:45Z | 2025-02-11T08:15:45Z | https://github.com/cobrateam/splinter/issues/1327 | [] | chengair | 0 |
jeffknupp/sandman2 | rest-api | 25 | Flask-admin version | We seem to be using an old flask-admin version, is this intentional? I am finding the admin page looks very strange, and wondering if I am using a vastly newer version - with regressions.
Jeff, what are you on?
| closed | 2016-01-25T16:46:57Z | 2016-01-26T13:49:30Z | https://github.com/jeffknupp/sandman2/issues/25 | [] | filmackay | 2 |
newpanjing/simpleui | django | 475 | 在fields中设置两个元素在同一行无效 | **bug描述**
* *Bug description * *
简单的描述下遇到的bug:
Briefly describe the bugs encountered:
想设置两个文本框在同一行, fields = (('t1', 't2'), 't3')
没有生效
**重现步骤**
** repeat step **
1. django默认主题,使用 fields = (('t1', 't2'), 't3'),效果如下:

| closed | 2023-09-25T09:07:22Z | 2023-09-30T20:32:25Z | https://github.com/sinaptik-ai/pandas-ai/issues/591 | [] | FrancescoRettondini | 6 |
geopandas/geopandas | pandas | 2,540 | BUG: no matching CRS warning for overlay | When using geopandas.overlay no warning is issued when the data frames are not using the same crs.
```py
import dask_geopandas
import geopandas
import libpysal.examples as exp
NYC = exp.load_example('NYC Education')
NYC.get_file_list()
df1 = geopandas.read_file('NYC_2000Census.shp')
'NOTE: maybe the file loca... | open | 2022-08-27T15:32:46Z | 2022-08-27T18:55:49Z | https://github.com/geopandas/geopandas/issues/2540 | [
"bug",
"needs triage"
] | slumnitz | 1 |
joerick/pyinstrument | django | 241 | Incorrect Session.program when running a module | Due to `sys.argv` modifications (in `__main__.py`?), the program name is stored incorrectly in `Session.program`:
actual output:
```console
$ pyinstrument -m mpi4py t.py -a
Program: mpi4py -a
```
expected output:
```console
$ pyinstrument -m mpi4py t.py -a
Program: mpi4py t.py -a
``` | closed | 2023-05-03T21:33:28Z | 2023-08-04T10:02:59Z | https://github.com/joerick/pyinstrument/issues/241 | [] | matthiasdiener | 3 |
autokey/autokey | automation | 60 | python3-xlib not found | Hi, after the most recent update 0.93.8-1 (from 0.93.7-1), autokey-gtk will no longer run. This is under Linux Mint 18.1/Ubuntu 16.04. Source is ppa:troxor/autokey
Autokey is a tremendous resource. Thank you for any help.
Traceback follows:
Traceback (most recent call last):
File "/usr/bin/autokey", li... | closed | 2017-01-09T18:15:31Z | 2018-01-17T15:04:58Z | https://github.com/autokey/autokey/issues/60 | [
"bug"
] | ghost | 5 |
marimo-team/marimo | data-visualization | 4,139 | MultiIndex not shown correctly in mo.ui.table | ### Describe the bug
When I pass in a multi-indexed pandas DataFrame into `marimo.ui.table` or `marimo.ui.dataframe`, the inner levels of the index are not shown correctly. The outermost index is repeated multiple times. See screenshot below
### Environment
<details>
```
{
"marimo": "0.11.21",
"OS": "Darwin",
... | closed | 2025-03-18T01:39:15Z | 2025-03-24T08:56:51Z | https://github.com/marimo-team/marimo/issues/4139 | [
"bug"
] | andy-lz | 1 |
mckinsey/vizro | plotly | 315 | Research and execute on docs to address plotly FAQs | We routinely tackle questions about plotly and it would be useful to have some standard answers (e.g. FAQs) or a document that guides readers. We may also be able to better link through to plotly docs in our content.
## Task
1. Make a list of common queries and answer these as standard FAQ. This may go into docs or... | closed | 2024-02-15T12:49:08Z | 2025-01-14T09:42:40Z | https://github.com/mckinsey/vizro/issues/315 | [
"Docs :spiral_notepad:"
] | stichbury | 1 |
sktime/sktime | scikit-learn | 7,725 | [BUG] post-fix issue shapelet transform: failing `test_st_on_unit_test` | `test_st_on_unit_test` is failing after the merge of https://github.com/sktime/sktime/pull/7499, on some PR.
This did not seem to fail in #7499 itself, so may be sporadic - but it is most likely in connection to that PR.
After the fix, https://github.com/sktime/sktime/pull/7726 should be reverted.
FYI @fnhirwa. | open | 2025-01-30T20:24:26Z | 2025-01-30T20:27:38Z | https://github.com/sktime/sktime/issues/7725 | [
"bug",
"module:transformations"
] | fkiraly | 0 |
erdewit/ib_insync | asyncio | 48 | coroutine 'Watchdog.watchAsync' was never awaited | ```
/usr/lib/python3.6/socketserver.py:544: RuntimeWarning:
coroutine 'Watchdog.watchAsync' was never awaited
```
ib_insync 0.9.3
I am getting this warning when using new `Watchdog`. It uses one of 3 `IB`s that are connected all the time, to keep TWS alive with ib-controller.
`Watchdog` and other 2 `IB`s ... | closed | 2018-03-02T14:28:34Z | 2018-05-16T11:14:34Z | https://github.com/erdewit/ib_insync/issues/48 | [] | radekwlsk | 6 |
scikit-hep/awkward | numpy | 3,129 | Long time to error on incompatible shapes in numpy-broadcasting | ### Version of Awkward Array
2.6.4
### Description and code to reproduce
When attempting to incorrectly broadcast regular arrays (which follow right-justified shape broadcast semantics as opposed to left-justified for ragged arrays), I get an error as I should
```python
import awkward as ak
import numpy as np
... | open | 2024-05-25T16:59:07Z | 2024-05-25T16:59:07Z | https://github.com/scikit-hep/awkward/issues/3129 | [
"performance"
] | nsmith- | 0 |
MagicStack/asyncpg | asyncio | 787 | asyncpg.exceptions.DataError: invalid input for query argument python | I have a problem insert to PostgreSQL. The column I'm trying to insert is of type JSONB. The type of the object is Counter().
At production its working but locally I have a problem.
The error is: asyncpg.exceptions.DataError: invalid input for query argument $16: Counter({'clearmeleva': 1, 'cr7fragrance... (expec... | open | 2021-07-27T09:06:41Z | 2023-08-04T06:15:33Z | https://github.com/MagicStack/asyncpg/issues/787 | [] | tomerTcm | 2 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 367 | RuntimeError: nonzero is not supported for tensors with more than INT_MAX elements | hello, I met a problem when I trained model with triplet-margin loss, the error message as follows:
```
File "/home/bengui/miniconda3/envs/torch1.7/lib/python3.6/site-packages/pytorch_metric_learning-0.9.99-py3.6.egg/pytorch_metric_learning/losses/base_metric_loss_function.py", line 34, in forward
File "/home/ben... | closed | 2021-09-23T07:44:50Z | 2022-08-03T18:51:07Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/367 | [
"documentation",
"question"
] | PuNeal | 5 |
nschloe/tikzplotlib | matplotlib | 4 | Loglog plot produces erroneous tex code (pgfplots 1.4) | When using loglog plots with matplot lib matplotlib2tikz produces
\begin{loglog} \end{loglog}
which is invalid (at least with pgfplots 1.4). The correct is `\begin{loglogaxis} \end{loglogaxis}` (line 218)
(Sorry for opening two tickets at pretty much the same time :/)
| closed | 2010-10-14T11:06:17Z | 2010-10-14T11:38:59Z | https://github.com/nschloe/tikzplotlib/issues/4 | [] | foucault | 1 |
yeongpin/cursor-free-vip | automation | 275 | [Bug]: 谷歌软件有要求? | ### 提交前检查
- [x] 我理解 Issue 是用于反馈和解决问题的,而非吐槽评论区,将尽可能提供更多信息帮助问题解决。
- [x] 我已经查看了置顶 Issue 并搜索了现有的 [开放 Issue](https://github.com/yeongpin/cursor-free-vip/issues)和[已关闭 Issue](https://github.com/yeongpin/cursor-free-vip/issues?q=is%3Aissue%20state%3Aclosed%20),没有找到类似的问题。
- [x] 我填写了简短且清晰明确的标题,以便开发者在翻阅 Issue 列表时能快速确定大致问题。而不是“一个... | closed | 2025-03-17T12:43:00Z | 2025-03-19T06:42:35Z | https://github.com/yeongpin/cursor-free-vip/issues/275 | [
"bug"
] | Tryoe | 4 |
deepspeedai/DeepSpeed | pytorch | 6,981 | [REQUEST] Please share WIndows WHL files now | @loadams in https://github.com/microsoft/DeepSpeed/issues/6871 you said...
> I'm able to build a whl locally, and tests seem to be fine. Working on getting these published sometime this week. I'll probably start with a 0.15.0 whl built with python 3.10 to confirm you're seeing things work there. I would upload here to... | closed | 2025-01-29T21:41:54Z | 2025-01-30T00:24:36Z | https://github.com/deepspeedai/DeepSpeed/issues/6981 | [
"enhancement",
"windows"
] | SoftologyPro | 2 |
pyro-ppl/numpyro | numpy | 1,726 | Support forward mode differentiation for SVI | Hello everybody. I am encountering a problem with the VonMises distribution, and in particular with its concentration parameter. I am trying to perform a very simple MLE of a hierarchical model.
```
def model(X):
plate = numpyro.plate("data", Nc)
kappa = numpyro.param("kappa", 1., constraint = nump... | closed | 2024-01-30T16:28:39Z | 2024-02-08T17:58:35Z | https://github.com/pyro-ppl/numpyro/issues/1726 | [
"enhancement",
"good first issue"
] | AndreaSalati | 1 |
tflearn/tflearn | tensorflow | 602 | Key is_training not found in checkpoint tflearn | I am saving and restoring models I created using TFLearn with
```
optimizer = tf.train.AdamOptimizer().minimize(model.loss_op)
# Initializing the variables
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
avg_time = 0
with tf.Session(config = con... | closed | 2017-02-11T16:34:59Z | 2017-02-12T11:22:31Z | https://github.com/tflearn/tflearn/issues/602 | [] | plooney | 2 |
PrefectHQ/prefect | automation | 17,334 | DaskTaskRunner tasks occasionally fail with `AttributeError: 'NoneType' object has no attribute 'address'` | ### Bug summary
Tasks launched via a `DaskTaskRunner` randomly fail with the following exception:
```python
File "/Users/kzvezdarov/git/prefect-dask-test/attr_err_flow.py", line 11, in load_dataframe
with get_dask_client():
^^^^^^^^^^^^^^^^^
File "/opt/homebrew/Cellar/python@3.12/3.12.9/Frameworks/Python... | open | 2025-03-02T01:07:22Z | 2025-03-02T01:07:22Z | https://github.com/PrefectHQ/prefect/issues/17334 | [
"bug"
] | kzvezdarov | 0 |
seleniumbase/SeleniumBase | pytest | 3,505 | CDP methods missing for element's parent | When using a UC CDP driver to find an element, cannot call CDP methods on its parent.
Code to reproduce:
```python
from seleniumbase import Driver
driver = Driver(uc=True)
driver.uc_activate_cdp_mode("https://google.com")
element = driver.cdp.find_element("textarea[aria-label='Search']")
print('element:', element)
pr... | closed | 2025-02-11T22:01:17Z | 2025-02-12T02:23:49Z | https://github.com/seleniumbase/SeleniumBase/issues/3505 | [
"invalid usage",
"workaround exists",
"UC Mode / CDP Mode"
] | julesmcrt | 1 |
modelscope/modelscope | nlp | 1,045 | ModuleNotFoundError: No module named 'modelscope.models.cv.facial_68ldk_detection' | ## Question
The module exists in GitHub's modelscope-v1.19.1 source code at [modelscope/models/cv/facial_68ldk_detection](https://github.com/modelscope/modelscope/tree/master/modelscope/models/cv/facial_68ldk_detection), but is not found using command *pip install modelscope[cv]*.
## Environment
Python-3.10.14 tor... | closed | 2024-10-23T07:50:16Z | 2024-11-06T04:14:33Z | https://github.com/modelscope/modelscope/issues/1045 | [] | f549263766 | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.