
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
mljar/mercury | data-visualization | 279 | ModuleNotFoundError | closed | 2023-05-18T05:49:31Z | 2023-05-18T13:45:42Z | https://github.com/mljar/mercury/issues/279 | [] | max-poltora | 0 | |
gradio-app/gradio | deep-learning | 10,116 | Apps breaking after updating to gradio 5.x when run behind app proxy | ### Describe the bug
After updating from gradio 4.44 to gradio 5.7.1 I observe two breaking changes. I think this is related to me working behind a reverse proxy.
1. Starting from Gradio 5.x files are not accessible anymore via even if they are in a subfolder of the project root. I update my code from "file=..." to... | closed | 2024-12-04T12:01:55Z | 2025-01-29T00:24:16Z | https://github.com/gradio-app/gradio/issues/10116 | [
"bug",
"cloud"
] | greg2705 | 4 |
seleniumbase/SeleniumBase | web-scraping | 2,225 | Struggling with Remote Debugging port | I am trying to run a script on a previously opened browser. I cannot connect to the browser instead my script opens up a new browser with each new run. The Browser opened -> [https://imgur.com/a/afBEAJX](https://imgur.com/a/afBEAJX)
I use this to spawn my browser:
cd C:\Program Files\Google\Chrome\Application
chro... | closed | 2023-10-30T08:04:30Z | 2023-11-02T20:38:14Z | https://github.com/seleniumbase/SeleniumBase/issues/2225 | [
"question",
"UC Mode / CDP Mode"
] | Dylgod | 8 |
noirbizarre/flask-restplus | flask | 674 | Tests not in tarball | It would be helpful to add `tests` dir to manifest. This is mainly for downstream packaging. While the tests can be seen passing in travis it's nice to run the test suite inside each image version that it will be packaged for. This ensures the package runs against the package dependency versions which are provided in e... | closed | 2019-07-19T15:53:42Z | 2019-10-31T17:46:03Z | https://github.com/noirbizarre/flask-restplus/issues/674 | [] | smarlowucf | 1 |
jupyter/nbviewer | jupyter | 776 | No Output provided by Jupyter Notebook | Whichever input i give, it does not provide me with the output ...please help
![error] (https://user-images.githubusercontent.com/40686853/42080058-079b0de6-7b9f-11e8-92ed-45a1b8009b26.jpeg)
Please Help me | closed | 2018-06-29T07:49:57Z | 2018-09-01T16:21:29Z | https://github.com/jupyter/nbviewer/issues/776 | [
"type:Question",
"tag:Other Jupyter Project"
] | Ruthz47 | 1 |
OthersideAI/self-operating-computer | automation | 240 | requirements.txt File: dependencies required for the project. |
*
requirements.txt File: dependencies required for the project.
must be run on: python 3.12
C:\Users\user\self-operating-computer\requirements.txt
numpy==1.26.2
Might need to Include other libraries if needed
---
********************
`C:\Users\user>pip install numpy==1.26.1
Defaulting to user installation because norm... | open | 2025-03-23T07:55:45Z | 2025-03-24T13:42:27Z | https://github.com/OthersideAI/self-operating-computer/issues/240 | [] | sprinteroz | 0 |
graphql-python/graphene-django | graphql | 1,291 | `DjangoObjectType` using the same django model do not resolve to correct relay object | > [!NOTE]
> This issue is a duplicate of #971 but includes a full description for searchability and links to history on the tracker itself.
## What is the Current Behavior?
Assume a fixed schema with two (or more) different GraphQL object types using `graphene_django.DjangoObjectType` linked to the same Django m... | open | 2022-01-23T22:47:56Z | 2024-08-19T15:42:51Z | https://github.com/graphql-python/graphene-django/issues/1291 | [
"🐛bug"
] | tony | 2 |
Lightning-AI/pytorch-lightning | machine-learning | 20,480 | Model diverges or struggles to converge with complex-valued tensors in DDP | ### Bug description
Hello,
I am using lightning to train a complex-valued neural networks with complex valued tensor. When I use single gpu training, there is no issue. When I train with multi-gpus with DDP, my training diverges. I try to train on only one gpu, and still declaring " strategy='ddp' " in the trainer,... | open | 2024-12-09T13:19:49Z | 2025-01-31T07:50:21Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20480 | [
"bug",
"3rd party",
"ver: 2.4.x"
] | ouioui199 | 5 |
svc-develop-team/so-vits-svc | deep-learning | 101 | 训练时GPU占用低,显存可以跑满,但是GPU利用率很低,如何多线程跑?(尝试过把num_works改成24,但是比原来更慢了) | closed | 2023-03-29T03:03:57Z | 2023-04-07T12:31:18Z | https://github.com/svc-develop-team/so-vits-svc/issues/101 | [
"not urgent"
] | TQG1997 | 6 | |
huggingface/transformers | machine-learning | 36,231 | Add Evolla model | ### Model description
# Model Name: Evolla
## Model Specifications
* **Model Type:** Protein-language generative model
* **Parameters:** 80 billion
* **Training Data:** AI-generated dataset with 546 million protein question-answer pairs and 150 billion word tokens
## Architecture
Multimodal model integrating a prote... | open | 2025-02-17T10:18:40Z | 2025-02-17T10:18:40Z | https://github.com/huggingface/transformers/issues/36231 | [
"New model"
] | zhoubay | 0 |
FlareSolverr/FlareSolverr | api | 1,451 | 500 internal server error : YggTorrent | ### Have you checked our README?
- [x] I have checked the README
### Have you followed our Troubleshooting?
- [x] I have followed your Troubleshooting
### Is there already an issue for your problem?
- [x] I have checked older issues, open and closed
### Have you checked the discussions?
- [x] I have read the Dis... | closed | 2025-02-22T16:53:19Z | 2025-02-23T09:44:04Z | https://github.com/FlareSolverr/FlareSolverr/issues/1451 | [] | bajire72 | 6 |
onnx/onnx | scikit-learn | 6,339 | Python 3.13 support | Python 3.13 is going to be released in October. | closed | 2024-09-02T13:36:04Z | 2025-03-17T18:08:22Z | https://github.com/onnx/onnx/issues/6339 | [
"contributions welcome"
] | justinchuby | 6 |
django-import-export/django-import-export | django | 1,901 | Handle confirm_form validation errors gracefully | **Describe the bug**
In case the `confirm_form` is overriden in the admin (as described [here](https://django-import-export.readthedocs.io/en/latest/admin_integration.html#customize-admin-import-forms)) and the form is invalid, currently an unhelpful exception is raised. Example:
```
Traceback (most recent call la... | closed | 2024-07-09T22:16:46Z | 2024-07-20T19:30:06Z | https://github.com/django-import-export/django-import-export/issues/1901 | [
"bug"
] | 19greg96 | 10 |
liangliangyy/DjangoBlog | django | 418 | es7.0有问题,doc_type不支持 | <!--
如果你不认真勾选下面的内容,我可能会直接关闭你的 Issue。
提问之前,建议先阅读 https://github.com/ruby-china/How-To-Ask-Questions-The-Smart-Way
-->
**我确定我已经查看了** (标注`[ ]`为`[x]`)
- [ ] [DjangoBlog的readme](https://github.com/liangliangyy/DjangoBlog/blob/master/README.md)
- [ ] [配置说明](https://github.com/liangliangyy/DjangoBlog/blob/master/bin... | closed | 2020-07-13T09:52:43Z | 2021-08-31T05:50:52Z | https://github.com/liangliangyy/DjangoBlog/issues/418 | [] | niweiwei789 | 0 |
PaddlePaddle/models | computer-vision | 5,737 | Compiled with WITH_GPU, but no GPU found in runtime | 
FROM paddlepaddle/paddle:2.4.2-gpu-cuda11.7-cudnn8.4-trt8.4
I have used above image as base image.
RUN python -m pip install --no-cache-dir paddlepaddle-gpu==2.4.2.post117 -f https://www.paddlepaddle.org.cn/whl/l... | open | 2023-09-11T06:15:40Z | 2024-02-26T05:07:42Z | https://github.com/PaddlePaddle/models/issues/5737 | [] | mahesh11T | 0 |
polakowo/vectorbt | data-visualization | 121 | Simulating on different price series? | Hi @polakowo, first of all, thanks for this great simulator. I have tried both this and backtesting.py, but I can say that vbt is by far more flexible and fast.
Now, to my point, in the `simulate_best_params` method of _WalkForwardOptimization_ example:
https://github.com/polakowo/vectorbt/blob/5fe7e0e6e485f58c15... | closed | 2021-04-04T22:27:00Z | 2021-04-06T19:45:28Z | https://github.com/polakowo/vectorbt/issues/121 | [] | emiliobasualdo | 1 |
graphql-python/graphene-django | django | 920 | Make graphene.Decimal consistent to models.DecimalField | Django's [DecimalField](https://docs.djangoproject.com/en/3.0/ref/models/fields/#decimalfield) `class DecimalField(max_digits=None, decimal_places=None, **options)` with `max_digits` and `decimal_places` is super useful. `graphene.Decimal` seems not to support definition of places before and after the point yet. What a... | open | 2020-04-03T15:02:51Z | 2022-07-04T09:38:36Z | https://github.com/graphql-python/graphene-django/issues/920 | [
"wontfix"
] | fkromer | 5 |
keras-rl/keras-rl | tensorflow | 376 | ValueError: probabilities contain NaN in policy.py | Hey community,
I made an environment with openai gym and now I am trying different settings and agents.
I started with the agent from the dqn_cartpole example (https://github.com/wau/keras-rl2/blob/master/examples/dqn_cartpole.py). At some point the calculation of the q-values failed because of a NaN value. I add... | closed | 2021-06-07T09:34:36Z | 2023-06-20T21:22:04Z | https://github.com/keras-rl/keras-rl/issues/376 | [
"wontfix"
] | ghost | 5 |
sinaptik-ai/pandas-ai | data-visualization | 1,340 | _is_malicious_code doesn't look for whole word | ### System Info
Pandas AI version: 2.2.14
Python Version: 3.10.0
### 🐛 Describe the bug
I was trying to run a query where I had mentioned OSE, and I got the error
```
"Code shouldn't use 'os', 'io' or 'chr', 'b64decode' functions as this could lead to malicious code execution."
```
So I went to [code_cleanin... | closed | 2024-08-28T14:37:16Z | 2024-12-19T08:35:12Z | https://github.com/sinaptik-ai/pandas-ai/issues/1340 | [
"bug"
] | shoebham | 5 |
assafelovic/gpt-researcher | automation | 1,210 | ModuleNotFoundError for the module zendriver while attempting to import it in the file nodriver_scraper.py | Full error:
gpt-researcher-1 | Traceback (most recent call last):
gpt-researcher-1 | File "/usr/local/bin/uvicorn", line 8, in <module>
gpt-researcher-1 | sys.exit(main())
gpt-researcher-1 | ^^^^^^
gpt-researcher-1 | File "/usr/local/lib/python3.11/site-packages/click/core.py", line 1161, in _... | closed | 2025-02-26T07:12:14Z | 2025-02-27T12:02:26Z | https://github.com/assafelovic/gpt-researcher/issues/1210 | [] | cristianstoica | 2 |
MaartenGr/BERTopic | nlp | 1,403 | Does BERTopic rely on *both* sentence_embeddings and word_embeddings | When exploring relationships *between* topics (2D visualisations, hierarchy) we need to represent *each topic* as a summary vector (cluster-level embedding).
The BERTopic source code stats
> `topic_embeddings_ (np.ndarray) : The embeddings for each topic. It is calculated by taking the weighted average of word e... | open | 2023-07-12T10:15:59Z | 2023-07-12T19:41:15Z | https://github.com/MaartenGr/BERTopic/issues/1403 | [] | matthewnour | 1 |
babysor/MockingBird | deep-learning | 208 | 事小白,用ceshi不知道为什么出现这样的问题,请教一下大佬 | 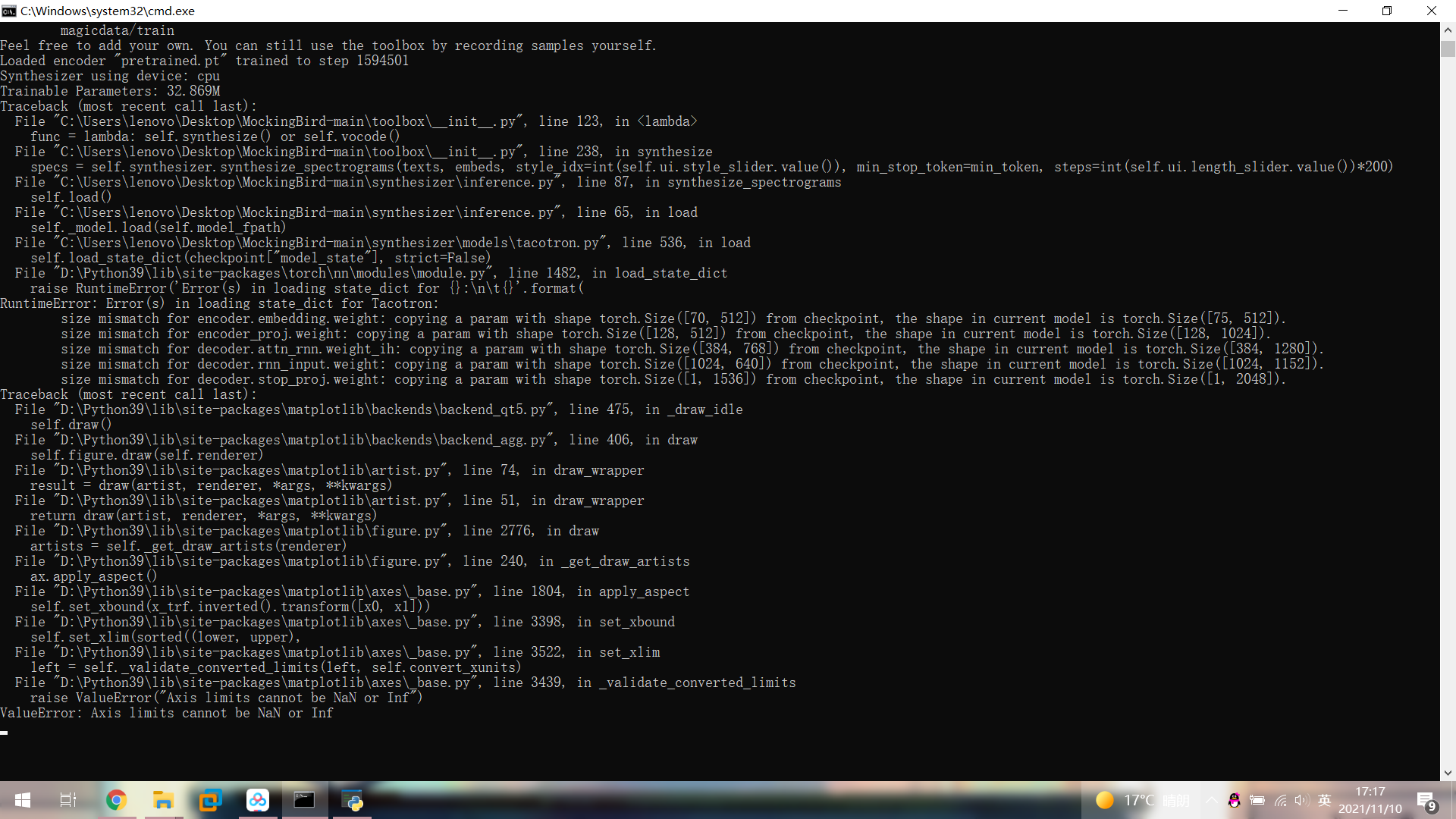
| open | 2021-11-10T09:19:30Z | 2021-11-11T01:29:27Z | https://github.com/babysor/MockingBird/issues/208 | [] | SSSSwater | 3 |
google-research/bert | nlp | 1,224 | For news classification long text tasks, BERT fine-tune, loss does not drop, training does not move, fixed classification to one category | For news classification long text tasks, BERT fine-tune, loss does not drop, training does not move, fixed classification to one category,why?
I am very anxious to seek help from Daniel | open | 2021-04-28T07:50:35Z | 2021-04-28T07:50:35Z | https://github.com/google-research/bert/issues/1224 | [] | iamsuarez | 0 |
tensorflow/tensor2tensor | machine-learning | 1,262 | Error with hparams.proximity_bias=True | ### Description
Error in common_attention.attention_bias_to_padding with setting `hparams.proximity_bias=True`
In the transformer_layers.transformer_encoder.transformer_encoder line 152, the `operation padding = common_attention.attention_bias_to_padding` performs `tf.squeeze(x, [1,2])`, but attention_bias tensor r... | closed | 2018-11-30T07:00:33Z | 2018-11-30T07:17:56Z | https://github.com/tensorflow/tensor2tensor/issues/1262 | [] | Leechung | 0 |
holoviz/panel | plotly | 7,583 | `panel compile <path>` error: Could not resolve "./Calendar" | I wanted to compile: https://github.com/panel-extensions/panel-full-calendar/tree/main
```bash
panel compile src/panel_full_calendar/main.py
```
```bash
Running command: npm install
npm output:
added 7 packages, and audited 8 packages in 2s
1 package is looking for funding
run `npm fund` for details
found 0 vul... | closed | 2025-01-04T01:01:31Z | 2025-01-17T17:04:45Z | https://github.com/holoviz/panel/issues/7583 | [] | ahuang11 | 6 |
postmanlabs/httpbin | api | 645 | Migrate from brotlipy to brotlicffi | `brotlipy` has not seen updates for 4 years: https://pypi.org/project/brotlipy/
It looks like the latest work is published under `brotlicffi`: https://github.com/python-hyper/brotlicffi
- https://pypi.org/project/brotlicffi/
https://github.com/postmanlabs/httpbin/blob/f8ec666b4d1b654e4ff6aedd356f510dcac09f83/set... | open | 2021-06-07T12:57:22Z | 2021-12-15T12:24:12Z | https://github.com/postmanlabs/httpbin/issues/645 | [] | johnthagen | 1 |
nteract/papermill | jupyter | 161 | consider black for code formatting | [black](https://black.readthedocs.io/en/stable/index.html) is awesome! We use [prettier](https://prettier.io/) in the monorepo and it is 😍. If folks are interested, it could be a good small project for a new contributor at the sprints 😄
| closed | 2018-07-30T16:26:40Z | 2018-08-14T16:45:55Z | https://github.com/nteract/papermill/issues/161 | [] | alexandercbooth | 6 |
Anjok07/ultimatevocalremovergui | pytorch | 601 | error when trying to seperate stems on demucs | Last Error Received:
Process: Demucs
If this error persists, please contact the developers with the error details.
Raw Error Details:
AssertionError: ""
Traceback Error: "
File "UVR.py", line 4716, in process_start
File "separate.py", line 478, in seperate
File "separate.py", line 622, in demix_de... | open | 2023-06-06T11:20:55Z | 2023-06-06T11:20:55Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/601 | [] | lastdaysofpompeii | 0 |
hankcs/HanLP | nlp | 672 | Python 调用时如何 enable debug 信息? | 当前最新版本号是:1.5.0
我使用的版本是: 1.5.0 portable
使用 Python 调用时希望打开调试信息查看词典是否加载成功,阅读了 jpype 的相关调用文档,发现由于 inner class 的问题并不能按常规方式调用
https://github.com/hankcs/HanLP/blob/master/src/main/java/com/hankcs/hanlp/HanLP.java#L53
`Config = JClass('com.hankcs.hanlp.HanLP$Config')`
请问应该如何打开调试信息呢?
PS:
```
Config = JClass('... | closed | 2017-11-13T07:49:52Z | 2017-11-13T07:52:14Z | https://github.com/hankcs/HanLP/issues/672 | [] | dofine | 0 |
openapi-generators/openapi-python-client | rest-api | 498 | Generate Pydoc on model properties. | **Is your feature request related to a problem? Please describe.**
I like well-documented APIs, and I can't figure out a way to get Pydoc (or even Python comments) attached to properties of a generated model class.
**Describe the solution you'd like**
OpenAPI objects in the `schemas` dict get turned into Python c... | closed | 2021-09-21T01:44:13Z | 2022-01-29T23:13:31Z | https://github.com/openapi-generators/openapi-python-client/issues/498 | [
"✨ enhancement"
] | jkinkead | 3 |
Farama-Foundation/Gymnasium | api | 1,061 | Setting up seed properly in Custom env | ### Question
`# Create the training environment
train_env = gym.make("BabyAI-GoToLocal-v0",max_episode_steps= 512)#, render_mode = "human")
train_env = RGBImgPartialObsWrapper(train_env)
train_env = CustomEnv(train_env, mission)
train_env = ImgObsWrapper(train_env)
train_env = Monitor(train_env)
train_env = Dumm... | closed | 2024-05-22T15:48:10Z | 2024-09-25T10:03:55Z | https://github.com/Farama-Foundation/Gymnasium/issues/1061 | [
"question"
] | Chainesh | 1 |
LAION-AI/Open-Assistant | machine-learning | 2,805 | Missing Authorize on some API's endpoints | Looking at the API, neither this endpoint ask for credentials

or this one

There is ... | open | 2023-04-21T08:13:26Z | 2023-05-11T12:11:47Z | https://github.com/LAION-AI/Open-Assistant/issues/2805 | [
"inference"
] | JonanOribe | 5 |
healthchecks/healthchecks | django | 1,093 | [Feature Request] do not display multiple timezones as an option if they are identical | I had a situation where the check's time zone was "Etc/UTC", and the browser's time zone was also UTC, but I had all 3 displayed:
UTC, Etc/UTC & Browser's time zone. This was very confusing. In reality, clicking any of these did not change anything because in fact they were representing the same time zone.
![image]... | open | 2024-11-28T22:48:30Z | 2025-02-20T13:15:06Z | https://github.com/healthchecks/healthchecks/issues/1093 | [] | seidnerj | 4 |
huggingface/datasets | deep-learning | 7,419 | Import order crashes script execution | ### Describe the bug
Hello,
I'm trying to convert an HF dataset into a TFRecord so I'm importing `tensorflow` and `datasets` to do so.
Depending in what order I'm importing those librairies, my code hangs forever and is unkillable (CTRL+C doesn't work, I need to kill my shell entirely).
Thank you for your help
🙏
... | open | 2025-02-24T17:03:43Z | 2025-02-24T17:03:43Z | https://github.com/huggingface/datasets/issues/7419 | [] | DamienMatias | 0 |
jina-ai/serve | deep-learning | 6,127 | `StableLM` example from the homepage doesn't work properly. | I was going through the small example on the [homepage of the docs](https://docs.jina.ai/), and it gives me a weird error:
```console
WARNI… gateway@6246 Getting endpoints failed: failed to connect to all [12/09/23 07:58:35]
addresses. Waiting for another trial ... | closed | 2023-12-09T08:21:00Z | 2023-12-11T12:20:43Z | https://github.com/jina-ai/serve/issues/6127 | [] | codetalker7 | 14 |
zappa/Zappa | flask | 1,035 | Updating a deployment fails at update_lambda_configuration | Updating a deployment fails at update_lambda_configuration due to a KeyError
## Context
I've had no problems updating this deployment until today. Python version is 3.8.10.
## Expected Behavior
Zappa should complete the update of the deployment successfully.
## Actual Behavior
Zappa fails with the following... | closed | 2021-09-14T01:55:52Z | 2022-03-16T06:43:55Z | https://github.com/zappa/Zappa/issues/1035 | [] | mdunc | 25 |
fastapi/sqlmodel | pydantic | 176 | How to accomplish Read/Write transactions with a one to many relationship | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X... | open | 2021-12-03T22:09:13Z | 2021-12-03T22:10:06Z | https://github.com/fastapi/sqlmodel/issues/176 | [
"question"
] | br-follow | 0 |
kennethreitz/responder | flask | 578 | [2025] Releasing version 3.0.0 | ## About
We are intending to release Responder 3.0.0.
## Notes
- responder 3.0.0 is largely compatible with responder 2.0.0,
and unlocks using it with Python 3.11 and higher.
- All subsystems have been refactored to be true extensions,
see `responder.ext.{cli,graphql,openapi,schema}`.
## Preview
Pre-release packa... | open | 2025-01-18T21:43:41Z | 2025-02-07T00:49:59Z | https://github.com/kennethreitz/responder/issues/578 | [] | amotl | 15 |
tensorflow/tensor2tensor | deep-learning | 1,379 | Defining a new Multi-Task Problem | Hello,
I am trying to define a new multi-task problem that predict the secondary structure protein from amino acids. I am using the transformer base model.
I am facing several problems/questions:
1) After training, when I change the decoding problem id, I get the same result for both problems. The output doesn... | closed | 2019-01-17T13:57:13Z | 2019-08-13T09:39:44Z | https://github.com/tensorflow/tensor2tensor/issues/1379 | [] | agemagician | 3 |
matplotlib/mplfinance | matplotlib | 18 | Trendlines | Hi Daniel,
Thanks for the work you put into this. I tried working with it and I want to do something that I'm not sure it's supported. I want to draw trendlines over the graph (just have list of values). Is this possible? | closed | 2020-01-25T15:00:44Z | 2020-01-27T21:20:19Z | https://github.com/matplotlib/mplfinance/issues/18 | [
"question"
] | VaseSimion | 3 |
sqlalchemy/sqlalchemy | sqlalchemy | 11,808 | I am getting File "src/pymssql/_pymssql.pyx", line 479, in pymssql._pymssql.Cursor.execute pymssql._pymssql.OperationalError: (3971, b'The server failed to resume the transaction. Desc:4900000003.DB-Lib error message 20018, severity 16:\nGeneral SQL Server error: Check messages from the SQL Server\n') | ### Describe the use case
File "src/pymssql/_pymssql.pyx", line 479, in pymssql._pymssql.Cursor.execute
pymssql._pymssql.OperationalError: (3971, b'The server failed to resume the transaction. Desc:4900000003.DB-Lib error message 20018, severity 16:\nGeneral SQL Server error: Check messages from the SQL Server\n')
#... | closed | 2024-08-30T11:18:43Z | 2024-08-30T12:01:09Z | https://github.com/sqlalchemy/sqlalchemy/issues/11808 | [
"SQL Server"
] | manmayaray | 1 |
tflearn/tflearn | data-science | 391 | Image Preprocessing to finetune/predict using pre trained VGG model | The example at https://github.com/tflearn/tflearn/blob/master/examples/images/vgg_network_finetuning.py shows how to fine tune the pre-trained VGG16 model.
However the trained model might have applied mean subtraction and Std normalization where the mean/STD values are calculated over entire training dataset.
if we n... | closed | 2016-10-12T13:01:44Z | 2016-10-13T15:56:14Z | https://github.com/tflearn/tflearn/issues/391 | [] | sudhashbahu | 4 |
tensorly/tensorly | numpy | 190 | Parafac with non-negativity breaks down if orthogonalize = True and normalize_factors = True? | Tensorly version 0.4.5
I am using parafac with non-negativity and orthogonality constraints and noticed that the non-negativity isn't respected when I set normalize_factors = True.
Here's a small reproducible snippet.
```
import numpy as np
import tensorly as tl
from tensorly.decomposition import parafac
... | closed | 2020-08-13T05:56:05Z | 2020-11-19T13:09:34Z | https://github.com/tensorly/tensorly/issues/190 | [] | rutujagurav | 1 |
NullArray/AutoSploit | automation | 333 | Unhandled Exception (98afa004a) | Autosploit version: `3.0`
OS information: `Linux-4.18.0-parrot20-amd64-x86_64-with-Parrot-4.4-stable`
Running context: `autosploit.py`
Error meesage: `global name 'Except' is not defined`
Error traceback:
```
Traceback (most recent call):
File "/home/lam/AutoSploit/autosploit/main.py", line 113, in main
loaded_exp... | closed | 2019-01-04T20:05:01Z | 2019-01-14T18:09:05Z | https://github.com/NullArray/AutoSploit/issues/333 | [] | AutosploitReporter | 0 |
Anjok07/ultimatevocalremovergui | pytorch | 617 | Computer literally reboots itself when using CPU convertion | Does anyone know why does that happen?? I have 16GB of ram and my CPU is an Intel Core i5-8600
Is it because of both CPU and RAM overflow? | open | 2023-06-16T07:15:09Z | 2023-06-16T07:15:09Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/617 | [] | kriterin | 0 |
cvat-ai/cvat | pytorch | 8,365 | "Cannot read properties of undefined (reading 'length')" when returning serverless predictions | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
I have been working from https://github.com/cvat-ai/cvat/tree/develop/serverless/openvino/omz/intel/semantic-segment... | closed | 2024-08-28T08:56:52Z | 2024-08-28T09:43:07Z | https://github.com/cvat-ai/cvat/issues/8365 | [
"question"
] | jphdotam | 2 |
deeppavlov/DeepPavlov | tensorflow | 1,599 | Doesn't work with recent version of pytorch-crf | Want to contribute to DeepPavlov? Please read the [contributing guideline](http://docs.deeppavlov.ai/en/master/devguides/contribution_guide.html) first.
Please enter all the information below, otherwise your issue may be closed without a warning.
**DeepPavlov version** (you can look it up by running `pip show ... | closed | 2022-11-10T18:07:51Z | 2022-11-11T14:49:33Z | https://github.com/deeppavlov/DeepPavlov/issues/1599 | [
"bug"
] | claell | 3 |
tortoise/tortoise-orm | asyncio | 1,115 | source_field break __iter__ | **Describe the bug**
When a field specifies `source_field`, `Model.__iter__()` no longer works.
**To Reproduce**
```python
from tortoise import Model
from tortoise.fields import BigIntField
class SampleModel(Model):
id_ = BigIntField(pk=True, source_field='id')
a = SampleModel(id_=1)
[i for i in a]... | open | 2022-04-28T15:50:32Z | 2022-04-28T16:04:43Z | https://github.com/tortoise/tortoise-orm/issues/1115 | [] | enneamer | 2 |
tatsu-lab/stanford_alpaca | deep-learning | 10 | Example of Instruction-Tuning Training | Hello, thank you for open-sourcing this work. We are now interested in generating our own instructions to fine-tune the Llama model based on your documentation and approach. Could you please advise on any resources or references we can use? Also, are these codes available on Hugging Face? | closed | 2023-03-14T06:09:43Z | 2023-03-15T16:35:39Z | https://github.com/tatsu-lab/stanford_alpaca/issues/10 | [] | BowieHsu | 5 |
seleniumbase/SeleniumBase | web-scraping | 3,510 | Redirect to "chrome-extension" URL? | Hi. My seleniumbase scraper has suddenly started redirecting URL requests to a strange URL. It only seems to this for a particular site.
I've got it down to this MRE:
```
import seleniumbase as sb
def main():
driver = sb.Driver(uc=True, headless=True)
url = "https://www.atptour.com/scores/results-archi... | closed | 2025-02-12T13:07:46Z | 2025-02-12T13:21:23Z | https://github.com/seleniumbase/SeleniumBase/issues/3510 | [
"can't reproduce",
"UC Mode / CDP Mode"
] | gottogethelp | 2 |
lensacom/sparkit-learn | scikit-learn | 29 | Spark 1.4 and python 3 support | Spark 1.4 now supports python 3 https://spark.apache.org/releases/spark-release-1-4-0.html
| closed | 2015-06-12T10:22:31Z | 2015-06-17T15:36:54Z | https://github.com/lensacom/sparkit-learn/issues/29 | [
"enhancement",
"priority"
] | kszucs | 0 |
TracecatHQ/tracecat | automation | 371 | [DOCS] Missing / outdated section on formulas | closed | 2024-08-28T19:17:25Z | 2024-11-06T01:19:59Z | https://github.com/TracecatHQ/tracecat/issues/371 | [
"documentation"
] | topher-lo | 2 | |
abhiTronix/vidgear | dash | 238 | Remove range from publication year in Copyright Notice | <!--
Please note that your issue will be fixed much faster if you spend about
half an hour preparing it, including the exact reproduction steps and a demo.
If you're in a hurry or don't feel confident, it's fine to report bugs with
less details, but this makes it less likely they'll get fixed soon... | closed | 2021-08-11T11:46:09Z | 2021-08-12T02:52:37Z | https://github.com/abhiTronix/vidgear/issues/238 | [
"BUG :bug:",
"SOLVED :checkered_flag:",
"DOCS :scroll:",
"META :thought_balloon:"
] | abhiTronix | 1 |
jpadilla/django-rest-framework-jwt | django | 253 | Authentication Validation | Hello
I have been using this great framework for a few months now. Just recently I have started digging a little more into the code and have noticed that when login credentials are checked a ValidationError is raised. Is there a reason why this is preffered over AuthenticationFailed (401 or 403 instead of 400) ?
Than... | open | 2016-08-17T08:48:11Z | 2017-11-05T13:57:09Z | https://github.com/jpadilla/django-rest-framework-jwt/issues/253 | [] | ghost | 6 |
Gerapy/Gerapy | django | 153 | What's the progress of V2 development? | closed | 2020-06-20T02:52:48Z | 2020-07-06T14:56:14Z | https://github.com/Gerapy/Gerapy/issues/153 | [
"bug"
] | haroldrandom | 1 | |
labmlai/annotated_deep_learning_paper_implementations | deep-learning | 218 | Wrong output of shift right example in the commnets? | https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/9a42ac2697cddc1bae83968eecb0ffa72cfbd714/labml_nn/transformers/xl/relative_mha.py#L28
this should be `[[1, 2 ,3], [0, 4, 5], [6, 0, 7]]` | closed | 2023-10-25T03:40:47Z | 2023-11-07T09:28:52Z | https://github.com/labmlai/annotated_deep_learning_paper_implementations/issues/218 | [] | harveyaot | 1 |
dunossauro/fastapi-do-zero | pydantic | 322 | Adicionar logging a erros | O curso não cobre logs em erros, seria interessante se isso fosse feito. Da maneira mais simples possível, com o handler do uvicorn mesmo.
Além de mais material, o nível de boas práticas é elevado.
O log deve ser testado usando caplog | closed | 2025-02-26T19:19:09Z | 2025-03-11T20:07:47Z | https://github.com/dunossauro/fastapi-do-zero/issues/322 | [] | dunossauro | 2 |
matterport/Mask_RCNN | tensorflow | 2,146 | AP is zero for every IoU | I am trying to run the nucleus detection model with the original data used in the paper.
I tried to used both resnet50 and coco weights, but they both show AP 0 for every IoU, and the detection is not working.
What can be the problem?
:
In 2.18.1, this works for values that included ampersand. For example:
?param1=something&bla¶m2=something2
would result in
kwargs[param1]='something&bla'
With 2.18.2 I get just:
kwargs[... | open | 2024-12-12T11:43:21Z | 2025-01-17T14:05:16Z | https://github.com/plotly/dash/issues/3106 | [
"regression",
"bug",
"P2"
] | ezwc | 6 |
tensorpack/tensorpack | tensorflow | 1,503 | Export with tensorpack error when using tensorflow serving | If you're asking about an unexpected problem which you do not know the root cause,
use this template. __PLEASE DO NOT DELETE THIS TEMPLATE, FILL IT__:
If you already know the root cause to your problem,
feel free to delete everything in this template.
### 1. What you did:
(1) **If you're using examples, what... | closed | 2021-01-14T12:06:04Z | 2021-02-17T23:53:08Z | https://github.com/tensorpack/tensorpack/issues/1503 | [
"unrelated"
] | xealml | 1 |
facebookresearch/fairseq | pytorch | 4,702 | Why parameters are still updated even if I set their requires_grads equal to "False" ? Fairseq transformer | I implemented a function in fairseq_cli/train.py, to freeze the parameters,
```
def freeze_param_grad_zero(model):
for name, param in model.named_parameters():
if "fc1" in name or "fc2" in name:
print("========= start freezing =========")
param.requires_grad = False
... | open | 2022-09-07T08:42:00Z | 2022-09-07T08:42:00Z | https://github.com/facebookresearch/fairseq/issues/4702 | [
"bug",
"needs triage"
] | robotsp | 0 |
simple-login/app | flask | 2,398 | Notification emails are not encrypted using PGP ("on behalf of" copies) | ## Prerequisites
- [x] I have searched open and closed issues to make sure that the bug has not yet been reported.
## Bug report
**Describe the bug**
1. Set up on alias, say a@example.com
2. Set the alias to forward to more than one mailbox, at least one of which has PGP setup, say encrypted@example.com
3. The alias... | open | 2025-02-26T01:45:36Z | 2025-02-26T01:45:36Z | https://github.com/simple-login/app/issues/2398 | [] | utf8please | 0 |
ivy-llc/ivy | numpy | 28,242 | Fix Ivy Failing Test: paddle - elementwise.equal | ToDo List:https://github.com/unifyai/ivy/issues/27501 | closed | 2024-02-10T18:45:45Z | 2024-02-25T10:50:47Z | https://github.com/ivy-llc/ivy/issues/28242 | [
"Sub Task"
] | marvlyngkhoi | 0 |
netbox-community/netbox | django | 18,535 | Allow NetBox to start cleanly if incompatible plugins are present | ### NetBox version
v4.2.2
### Feature type
Data model extension
### Proposed functionality
Currently we raise an `ImproperlyConfigured` exception and refuse to start NetBox at all if any plugin has `min_version` or `max_version` specified such that the installed version of NetBox is outside the compatible range.
... | closed | 2025-01-29T23:20:00Z | 2025-03-10T14:52:09Z | https://github.com/netbox-community/netbox/issues/18535 | [
"status: accepted",
"type: feature",
"complexity: medium"
] | bctiemann | 1 |
sktime/pytorch-forecasting | pandas | 1,207 | Pytorch-Forecasting imports deprecated property from transient dependency on numpy | - PyTorch-Forecasting version: 0.10.3
- PyTorch version: 1.12.1
- Python version: 3.8
- Operating System: Ubuntu 20.04
### Expected behavior
I created a simple `TimeSeriesDataset` without specifying an explicit `target_normalizer`. I expected it to simply create a default normalizer deduced from the other argu... | open | 2022-12-20T09:27:25Z | 2022-12-22T22:11:56Z | https://github.com/sktime/pytorch-forecasting/issues/1207 | [] | JeroenPeterBos | 1 |
python-gino/gino | sqlalchemy | 599 | Primary Key Columns with differing database names | * GINO version: 0.8.5
* Python version: 3.8
### Description
The current logic assumes that every primary key is named exactly the same way as the corresponding database column.
This seems to be because of the logic on the lines https://github.com/fantix/gino/blob/3109577271e59ab9cde169b5884403d8f41caa8b/gino... | closed | 2019-11-20T13:50:04Z | 2019-12-26T23:52:15Z | https://github.com/python-gino/gino/issues/599 | [
"feature request"
] | tr11 | 0 |
apify/crawlee-python | web-scraping | 442 | item_count double incremented when reloading dataset | When reusing a dataset with metadata, `item_count` is incremented after being loaded from the metadata file. It leads to non continuous file increments, and breaks multiple functions on Datasets (export to file, etc).
Issue: code paths with/without metadata overlap in `create_dataset_from_directory` | closed | 2024-08-19T14:09:24Z | 2024-08-30T12:24:03Z | https://github.com/apify/crawlee-python/issues/442 | [
"bug",
"t-tooling"
] | cadlagtrader | 1 |
SALib/SALib | numpy | 278 | Modify sample matrix before Sobol Analysis / Modificar matriz de muestra antes del análisis de Sobol | Hi everyone!
I'm doing Sobol analysis using Salib and getting sample matrix using saltelli.sample function. The equation Im analyzing include a inverse error function. Before the Sobols analysis its necessary to exclude some of the samples generated by saltelli sample method so the function domain make sense. I have... | closed | 2019-12-17T01:38:31Z | 2019-12-17T04:26:20Z | https://github.com/SALib/SALib/issues/278 | [] | rodrigojara | 1 |
coqui-ai/TTS | python | 3,573 | [Feature request] Appropriate intonation using xtts_v2 und voice cloning | <!-- Welcome to the 🐸TTS project!
We are excited to see your interest, and appreciate your support! --->
**🚀 Feature Description**
Appropriate intonation using xtts_v2 und voice cloning
**Solution**
There is a certain structure to intonation that gives a natural flow, the same with using pauses. So the sen... | closed | 2024-02-11T14:31:56Z | 2025-01-03T09:48:04Z | https://github.com/coqui-ai/TTS/issues/3573 | [
"wontfix",
"feature request"
] | Bardo-Konrad | 1 |
modelscope/modelscope | nlp | 933 | 时间轴有问题 | 版本
```
funasr 1.1.4
modelscope 1.16.1
```
运行代码(你们官方示例代码):
```
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
if __name__ == '__main__':
audio_in = 'https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_spe... | closed | 2024-07-29T06:40:07Z | 2024-09-04T01:57:42Z | https://github.com/modelscope/modelscope/issues/933 | [
"Stale"
] | Lixi20 | 6 |
sunscrapers/djoser | rest-api | 563 | French translations are not applied | I have been trying out djoser with django rest framework. Using 2.0.5 at the moment.
I noticed that the activation email was only partially translated, and digging into it I realized some of it is translated because by coincidence some of the translation keys used are also used by the admin django app.
Take the t... | open | 2020-12-06T18:46:02Z | 2020-12-31T18:37:50Z | https://github.com/sunscrapers/djoser/issues/563 | [] | connorsml | 2 |
dgtlmoon/changedetection.io | web-scraping | 1,707 | New version available notif showing up even when there is no new version | **Describe the bug**
I'm not sure what's going on here, but it seems that Change Detection is suggesting an update is available even though I am on the latest release.
**Version**
*Exact version* in the top right area: v0.44
**To Reproduce**
Steps to reproduce the behavior:
1. Selfhost (via docker)
2. Open h... | closed | 2023-07-31T03:10:40Z | 2023-08-02T13:42:45Z | https://github.com/dgtlmoon/changedetection.io/issues/1707 | [
"triage"
] | k4deng | 2 |
ydataai/ydata-profiling | jupyter | 1,299 | feature: Enable users to control the path for the generated visuals | ### Current Behaviour
Use the following codes to reproduce:
```python
import numpy as np
import pandas as pd
from ydata_profiling import ProfileReport
df = pd.DataFrame(np.random.rand(100, 5), columns=["a", "b", "c", "d", "e"])
profile = ProfileReport(df, title="Profiling Report", html={'inline':False})
profi... | open | 2023-03-28T12:15:02Z | 2023-04-12T16:58:17Z | https://github.com/ydataai/ydata-profiling/issues/1299 | [
"feature request 💬"
] | kaimo455 | 1 |
vaexio/vaex | data-science | 2,320 | Issue on page /faq.html | I am not able to install via pip install vaex
I install python version 3.11.1, error given below which I am getting when I try to install
Using cached numba-0.56.4.tar.gz (2.4 MB)
Preparing metadata (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py egg_info did not run su... | open | 2023-01-04T11:13:47Z | 2023-03-13T19:08:15Z | https://github.com/vaexio/vaex/issues/2320 | [] | navikaran1 | 1 |
coqui-ai/TTS | deep-learning | 3,641 | cannot import name 'magphase' from 'librosa' | ### Describe the bug
cannot import name 'magphase' from 'librosa'
I saw that yesterday there was an update in Librosa in my project I replaced the library with 0.9.0 version and everything worked.
### To Reproduce
from TTS.api import TTS
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2", gpu=True)
... | closed | 2024-03-20T08:57:36Z | 2025-01-03T08:48:56Z | https://github.com/coqui-ai/TTS/issues/3641 | [
"bug",
"wontfix"
] | Simaregele | 4 |
horovod/horovod | machine-learning | 3,482 | Gathering non numeric values | Hello! we are using hvd.allreduce to gather tensor values from different gpus. What if I have evaluation function which in result produces an answer dictionary for example {"0b014789":"yes", "0b458796":"in the school"} . Naturally we will have multiple dictionaries, is there an example how to gather these values from m... | closed | 2022-03-21T13:34:02Z | 2022-03-21T20:03:13Z | https://github.com/horovod/horovod/issues/3482 | [] | Arij-Aladel | 0 |
tflearn/tflearn | tensorflow | 474 | Allow empty for restorer_trainvars saver | In line 140 of [tflearn/helpers/trainer.py](https://github.com/tflearn/tflearn/blob/master/tflearn/helpers/trainer.py#L138), the saver should be created with `allow_empty=True`. Otherwise, it will raise error complaining no variables to restore when doing last-layer-fine-tuning.
In last layer fine tuning, we set all... | open | 2016-11-18T16:12:03Z | 2016-11-23T16:51:55Z | https://github.com/tflearn/tflearn/issues/474 | [] | pluskid | 1 |
samuelcolvin/watchfiles | asyncio | 169 | Errors on `WSL` and docker with windows | ### Description
`watchfiles` appears to be fully pip installable for windows, but I can't seem to get a minimal example working on Linux. The below MRE is straight from the docs and works great on windows. That is, when I change the foobar.py file the simple server is relaunched.
However if I try the same MRE on... | closed | 2022-07-19T00:15:05Z | 2024-08-31T20:32:55Z | https://github.com/samuelcolvin/watchfiles/issues/169 | [
"bug"
] | austinorr | 14 |
ghtmtt/DataPlotly | plotly | 185 | TypeError: setChecked(self, bool): argument 1 has unexpected type 'NoneType' | Hi, i got a new problem after upgrading to 3.2: It is linked to this #183 fix, since i had that before upgrading.
It seems to occur when i open a project wich was created before i upgraded this plugin. It does not occur when i start a new project in qgis.
Traceback (most recent call last):
File "C:... | closed | 2020-02-10T09:29:25Z | 2020-02-10T10:25:04Z | https://github.com/ghtmtt/DataPlotly/issues/185 | [] | danpejobo | 5 |
jazzband/django-oauth-toolkit | django | 724 | Missing self argument when trying to create Application from code | How would I create an application from a view? I've tried copying the management command as closely as I could, like this:
```
from oauth2_provider.models import get_application_model
Application = get_application_model()
Application(client_id=serializer.data['client_id'], user=request.user, redirect_uris="https:... | closed | 2019-07-25T16:27:53Z | 2019-07-25T16:30:35Z | https://github.com/jazzband/django-oauth-toolkit/issues/724 | [] | sometimescool22 | 1 |
xorbitsai/xorbits | numpy | 717 | BUG: `LogisticRegression.fit` has poor performance on speed | ### Describe the bug
`LogisticRegression.fit` never stops with a bit *larger* data.
### To Reproduce
When `max_iter=1` everything works fine
```python
from xorbits._mars.learn.glm import LogisticRegression
import numpy as np
n_rows = 100
n_cols = 2
X = np.random.randn(n_rows, n_cols)
y = np.random.ra... | open | 2023-09-24T11:03:42Z | 2024-12-16T01:52:34Z | https://github.com/xorbitsai/xorbits/issues/717 | [
"bug"
] | JiaYaobo | 2 |
PaddlePaddle/models | computer-vision | 4,802 | AI Studio环境CUDA出错 | 训练的模型是SimNet,无任何改动,报下面错误
ExternalError: Cuda error(38), no CUDA-capable device is detected.
[Advise: This indicates that no CUDA-capable devices were detected by the installed CUDA driver. ] at (/paddle/paddle/fluid/platform/gpu_info.cc:65) | closed | 2020-08-16T10:26:26Z | 2020-08-18T01:15:31Z | https://github.com/PaddlePaddle/models/issues/4802 | [] | hlzonWang | 1 |
chaoss/augur | data-visualization | 2,888 | Deal with Repo Group Placement Issue: https://github.com/oss-aspen/8Knot/issues/698 | This issue on 8Knot's repo: https://github.com/oss-aspen/8Knot/issues/698
Is about how Augur puts new repos into repo_groups. We need to discuss design and how it works. | open | 2024-08-08T22:40:51Z | 2024-11-14T15:25:50Z | https://github.com/chaoss/augur/issues/2888 | [] | sgoggins | 5 |
kennethreitz/responder | flask | 202 | Unable to include "parameters" in autogenerated documentation | Hello.
First of all, I would like to say thanks for providing this package.
I'm stuck trying to include a parameters section in the docstring associated to my route functions.
Using the Pets example, I always get the following error for docstrings containing the parameters section, when visiting the /docs path:
... | closed | 2018-11-06T11:38:45Z | 2018-11-06T12:28:34Z | https://github.com/kennethreitz/responder/issues/202 | [] | emacsuser123 | 5 |
lucidrains/vit-pytorch | computer-vision | 160 | Delete Issue | Delete Comment. | open | 2021-10-01T03:09:08Z | 2021-10-01T03:28:59Z | https://github.com/lucidrains/vit-pytorch/issues/160 | [] | nsriniva03 | 0 |
huggingface/datasets | numpy | 7,472 | Label casting during `map` process is canceled after the `map` process | ### Describe the bug
When preprocessing a multi-label dataset, I introduced a step to convert int labels to float labels as [BCEWithLogitsLoss](https://pytorch.org/docs/stable/generated/torch.nn.BCEWithLogitsLoss.html) expects float labels and forward function of models in transformers package internally use `BCEWithL... | open | 2025-03-21T07:56:22Z | 2025-03-21T07:58:14Z | https://github.com/huggingface/datasets/issues/7472 | [] | yoshitomo-matsubara | 0 |
lucidrains/vit-pytorch | computer-vision | 2 | Using masks as preprocessing for classification [FR] | Maybe it's a little bit too early to ask for this but could it be possible to specify regions within an image for `ViT` to perfom the prediction? I was thinking on a binary mask, for example, which could be used for the tiling step in order to obtain different images sequences.
I am thinking on a pipeline where, in... | closed | 2020-10-07T12:31:23Z | 2020-10-09T05:29:47Z | https://github.com/lucidrains/vit-pytorch/issues/2 | [] | Tato14 | 8 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 388 | US Sponsorship now or in the future Bug | Configured the `plain_test.yaml` as such:
> legal_authorization:
eu_work_authorization: "No"
us_work_authorization: "Yes"
requires_us_visa: "Yes "
requires_us_sponsorship: "Yes"
requires_eu_visa: "Yes"
legally_allowed_to_work_in_eu: "No"
legally_allowed_to_work_in_us: "Yes"
requires_eu_sponso... | closed | 2024-09-15T17:09:02Z | 2024-11-19T23:51:30Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/388 | [
"bug"
] | abrohit | 6 |
deezer/spleeter | tensorflow | 906 | [Discussion] numpy 1.22.4 is missing as a dependency from the pyproject.toml? | using Python 3.19.9 on Fedora Linux
` pip install spleeter` gives the following error
```
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
pandas 1.5.3 requires numpy>=1.20.3; python_ver... | open | 2024-09-05T11:02:48Z | 2024-09-05T11:02:48Z | https://github.com/deezer/spleeter/issues/906 | [
"question"
] | vin-cf | 0 |
dropbox/PyHive | sqlalchemy | 357 | Slow performance reading large Hive table in comparison with RJDBC | I'm trying to read a large table from Hive in python using pyhive, the table has about 16 millions of rows. But it is taking about to **33 minutes**. When I read the same table in R with RJDBC it takes about **13 minutes** to read the whole table. Here is my code.
``` R
library(RJDBC)
driver <- try(JDBC("org.apa... | open | 2020-07-31T16:50:13Z | 2020-07-31T16:50:30Z | https://github.com/dropbox/PyHive/issues/357 | [] | DXcarlos | 0 |
tartiflette/tartiflette | graphql | 127 | (SDL / Execution) Handle "input" type for mutation | Hello,
As specified in the specification, we have to use the type `input` type for complex inputs in mutation, instead of using the regular Object type which can contain interface, union or arguments.
## What we should do
```graphql
input RecipeInput {
id: Int
name: String
cookingTime: Int
}
type... | closed | 2019-02-26T16:34:49Z | 2019-03-04T16:22:59Z | https://github.com/tartiflette/tartiflette/issues/127 | [
"bug"
] | tsunammis | 0 |
jowilf/starlette-admin | sqlalchemy | 145 | Bug and Propose: build_full_text_search_query not use request, extend get_search_query | 1. you can safely remove `request` in build_full_text_search_query and nested function
2. require a way to easily customize search by fields
my case:
```python
def get_search_query(term: str, model) -> Any:
"""Return SQLAlchemy whereclause to use for full text search"""
clauses = []
for field_name, f... | closed | 2023-03-29T16:11:23Z | 2023-03-30T15:48:41Z | https://github.com/jowilf/starlette-admin/issues/145 | [
"bug"
] | MatsiukMykola | 1 |
Baiyuetribe/kamiFaka | flask | 88 | heroku在休眠唤醒后,数据库会重置回初始状态 | heroku在休眠唤醒后,数据库会重置回初始状态,包括登录密码,网站设置跟商品都变回刚安装完的初始状态,不知道是脚本的问题还是heroku自身的问题。 | closed | 2021-06-26T23:40:29Z | 2021-06-30T16:59:02Z | https://github.com/Baiyuetribe/kamiFaka/issues/88 | [
"bug",
"good first issue",
"question"
] | winww22 | 1 |
fastapi/sqlmodel | fastapi | 37 | FastAPI and Pydantic - Relationships Not Working | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X... | closed | 2021-08-26T22:40:52Z | 2024-08-22T16:54:39Z | https://github.com/fastapi/sqlmodel/issues/37 | [
"question"
] | Chunkford | 24 |
amisadmin/fastapi-amis-admin | fastapi | 147 | 如何自定义某个search_fields字段的UI组件 | 以教程中的示例代码为例,category的筛选需要下拉菜单dropdown list, 但是系统默认为input文本输入。如何重写并自定义该字段、并且不影响其它search_fields字段的自动生成。
```
from fastapi_amis_admin import admin
from fastapi_amis_admin.models.fields import Field
class Article(SQLModel, table=True):
id: int = Field(default=None, primary_key=True, nullable=False)
title: ... | open | 2023-12-05T16:29:45Z | 2024-02-25T03:53:09Z | https://github.com/amisadmin/fastapi-amis-admin/issues/147 | [] | lifengmds | 3 |
run-llama/rags | streamlit | 16 | If multiple PDF agents can be defined ? | Hi ,
I succeeded to create some PDF documnet agent . I wonder if it's possible to create agent on several PDFs or create agent per PDF and reference them by name or similar way in "Generated RAG Agent" chat ? | open | 2023-11-23T15:47:16Z | 2023-12-11T03:19:16Z | https://github.com/run-llama/rags/issues/16 | [] | snassimr | 4 |
ivy-llc/ivy | numpy | 28,526 | Fix Frontend Failing Test: tensorflow - math.paddle.diff | To-do List: https://github.com/unifyai/ivy/issues/27499 | closed | 2024-03-09T20:57:12Z | 2024-04-02T09:25:05Z | https://github.com/ivy-llc/ivy/issues/28526 | [
"Sub Task"
] | ZJay07 | 0 |
mljar/mercury | jupyter | 278 | Create widgets in the loop | Hi there,
I'm currently trying to figure out a way to dynamically add in `Select` widgets based on the categorical columns of a dataframe. Basically, I am trying to plot the data for different interactions of different categorical data. However, the columns between loaded dataframes might have different categorical... | closed | 2023-05-17T04:18:10Z | 2023-05-24T13:59:52Z | https://github.com/mljar/mercury/issues/278 | [
"enhancement"
] | danjgale | 5 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.