
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
django-oscar/django-oscar | django | 3,767 | OrderFactory.date_placed is inconsistent with other fields | ### Issue Summary
Creating an order with `OrderFactory(date_placed=...)` doesn’t actually create the order with the given date, but creates the order and then assigns the given date without saving it. This is inconsistent with the other fields, and yields unexpected results.
I’ve noticed [this field is explicitly... | closed | 2021-09-08T12:11:18Z | 2021-09-13T08:47:56Z | https://github.com/django-oscar/django-oscar/issues/3767 | [] | sephii | 2 |
fastapi-admin/fastapi-admin | fastapi | 138 | The python3.11 aioredis library is not supported, so use the redis library instead | The python3.11 aioredis library is not supported, so use the redis library instead | open | 2023-06-09T15:53:05Z | 2023-09-26T11:15:28Z | https://github.com/fastapi-admin/fastapi-admin/issues/138 | [] | liuxinyao666 | 5 |
python-visualization/folium | data-visualization | 1,520 | Tooltip and Popup don't work in GeoJson with MultiPoint geometry | **Describe the bug**
If you have MultiPoint geometry in your GeoJSON, Tooltip and Popup do not work. Normal Points are fine as well as MultiPolygons.
**To Reproduce**
```py
import json
import folium
geojson = '{"type": "FeatureCollection", "features": [{"id": "0", "type": "Feature", "properties": {"foo": 0}... | open | 2021-10-20T11:10:52Z | 2022-11-18T11:02:36Z | https://github.com/python-visualization/folium/issues/1520 | [
"bug"
] | martinfleis | 0 |
pallets/quart | asyncio | 294 | Support after_response | As after_request must run before the response has been sent, an after_response would be useful (and possible with ASGI) to run after the response has been sent. | open | 2023-11-26T21:17:37Z | 2023-11-26T21:17:37Z | https://github.com/pallets/quart/issues/294 | [] | pgjones | 0 |
graphistry/pygraphistry | pandas | 1 | Replace NaNs with nulls since node cannot parse JSON with NaNs | closed | 2015-06-23T21:06:19Z | 2015-08-06T13:54:24Z | https://github.com/graphistry/pygraphistry/issues/1 | [
"bug"
] | thibaudh | 1 | |
predict-idlab/plotly-resampler | data-visualization | 307 | [Request] when zoomed do not cut off lines | I found that once the user zooms and resampling is disabled the line un the frame is ended. It is counter intuitive as in fact there are more dots on the graph outside the box.

I suggest to show user dot... | open | 2024-06-05T09:48:14Z | 2025-03-06T15:01:50Z | https://github.com/predict-idlab/plotly-resampler/issues/307 | [
"enhancement"
] | lemikhovalex | 3 |
jina-ai/langchain-serve | fastapi | 91 | Cannot debug running process with PyCharm | After executed: lc-serve deploy local api.
Cannot debug running process with PyCharm.
| open | 2023-05-25T12:59:04Z | 2023-07-11T07:48:17Z | https://github.com/jina-ai/langchain-serve/issues/91 | [] | LawrenceHan | 2 |
blb-ventures/strawberry-django-plus | graphql | 74 | Query optimizer extension in docs does not work | So I tried adding the query optimizer using the instructions in the docs:
```
import strawberry
from strawberry_django_plus import gql
from strawberry_django_plus.optimizer import DjangoOptimizerExtension
schema = strawberry.Schema(query=Query, mutation=Mutation,
extension=[DjangoOptimizerExtension,]
... | closed | 2022-07-03T07:43:08Z | 2022-07-04T03:52:43Z | https://github.com/blb-ventures/strawberry-django-plus/issues/74 | [
"invalid"
] | ccsv | 3 |
miguelgrinberg/Flask-SocketIO | flask | 1,028 | nginx+redis multiple workers [DANGER] async queue is full !!! | ### uwsgi
```
[uwsgi]
http=0.0.0.0:8000
http=0.0.0.0:8001
http=0.0.0.0:8002
http=0.0.0.0:8003
chdir=/www/wwwroot/slf/chartFlask/
wsgi-file=/www/wwwroot/slf/chartFlask/socketRun.py
callable=app
master=true
processes=1
#threads=1
http-websockets = true
gevent = 1000
async = 30
py-autoreload=1
vacu... | closed | 2019-07-29T08:40:20Z | 2019-07-30T02:31:05Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1028 | [
"question"
] | huaSoftware | 6 |
Lightning-AI/pytorch-lightning | machine-learning | 20,605 | Training crashes when using RichProgressBar with num_sanity_val_steps but no validation dataloader | ### Bug description
When using the `RichProgressBar` callback and setting `num_sanity_val_steps > 0`, but not providing a validation dataloader in the `LightningDataModule`, the training crashes. This only happens when explicitly returning an empty list in val_dataloader.
### What version are you seeing the problem ... | open | 2025-02-27T06:48:10Z | 2025-02-27T06:48:25Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20605 | [
"bug",
"needs triage",
"ver: 2.5.x"
] | t-schanz | 0 |
coqui-ai/TTS | deep-learning | 3,841 | [Feature request] faster load at startup | <!-- Welcome to the 🐸TTS project!
We are excited to see your interest, and appreciate your support! --->
**🚀 Feature Description**
faster laod at startup
12sec and i use an NVSSD with 2GB/sec
**Solution**
leave unnessesary compling , checking, hash generation, save for next session ?!?
**Additional context... | closed | 2024-07-29T15:49:36Z | 2025-01-03T08:48:54Z | https://github.com/coqui-ai/TTS/issues/3841 | [
"wontfix",
"feature request"
] | kalle07 | 1 |
seleniumbase/SeleniumBase | pytest | 2,361 | Cannot pass cloudfare. Only PC restart helps | Hi, I'm using SB version 4.21.1, chrome version 120.0.6099.71.
I could use SB quite a while, but from time to time it gets detected and being blocked by cloudfare.
Only when I restart my PC (Windows 11), it can pass it again.
Any help is greatly appreciated, thanks! | closed | 2023-12-12T23:10:18Z | 2024-03-12T05:22:11Z | https://github.com/seleniumbase/SeleniumBase/issues/2361 | [
"can't reproduce",
"UC Mode / CDP Mode"
] | mdaliyot | 7 |
ets-labs/python-dependency-injector | flask | 816 | Cannot build using GCC v13 & v14 | Hello, I cannot install dependency injector having versions 13 and 14 of gcc on my system. Could you provide any information which versions of gcc are supported? | open | 2024-09-04T21:01:40Z | 2024-12-08T10:39:14Z | https://github.com/ets-labs/python-dependency-injector/issues/816 | [] | fedya-eremin | 1 |
TencentARC/GFPGAN | deep-learning | 75 | Currently, I have not updated the original architecture for GFPGANCleanv1-NoCE-C2.pth. So you could not finetune GFPGANCleanv1-NoCE-C2.pth. | Currently, I have not updated the original architecture for GFPGANCleanv1-NoCE-C2.pth. So you could not finetune GFPGANCleanv1-NoCE-C2.pth.
I may update it later.
_Originally posted by @xinntao in https://github.com/TencentARC/GFPGAN/issues/47#issuecomment-903889742_ | open | 2021-10-08T13:08:05Z | 2021-10-08T13:10:13Z | https://github.com/TencentARC/GFPGAN/issues/75 | [] | MDYLL | 1 |
CorentinJ/Real-Time-Voice-Cloning | python | 711 | Transitioning to the PyTorch version with Tensorflow-trained models | Hello, I've just discovered that the repo has changed over to the PyTorch, tensorflow-less version.
I still have old models trained with tensorflow that I wish to use for the creative project I've been working on. I've been following the process located in #437 for a couple of weeks now, and have produced very satis... | closed | 2021-03-23T23:30:31Z | 2021-11-04T06:29:13Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/711 | [] | StElysse | 9 |
PaddlePaddle/ERNIE | nlp | 890 | 序列标注任务 训练报错 | <img width="956" alt="image" src="https://user-images.githubusercontent.com/113650779/222683459-54a9afc8-cef6-4be0-8e69-45e619dc40d2.png">
我的环境:
<img width="316" alt="image" src="https://user-images.githubusercontent.com/113650779/222683706-eecf665f-07fe-4724-af0e-04d089eb4699.png">
运行序列标注任务是时 报错 说是没有erniekit模块 | closed | 2023-03-03T09:28:38Z | 2023-06-10T11:27:38Z | https://github.com/PaddlePaddle/ERNIE/issues/890 | [
"wontfix"
] | nTjing | 1 |
marimo-team/marimo | data-visualization | 4,146 | [Newbie Q] How to create a new notebook from the UI? | I can create a new notebook using `marimo new`.
But I can't seem a way to do this in the web UI.
Is it possible? If yes, how? | closed | 2025-03-18T14:28:54Z | 2025-03-18T14:41:56Z | https://github.com/marimo-team/marimo/issues/4146 | [] | dentroai | 3 |
vitalik/django-ninja | django | 359 | Dynamic Schema based on Authentication | Hi,
```
@router.patch('/{int:ID}', response={200: GetMember, 404: NotFound}, tags=["Members"])
async def update_member_details(request: HttpRequest, data: PatchMember, ID: int):
member = await sync_to_async(get_object_or_404, thread_sensitive=True)(klass=Members, idnum=CID)
return member
```
In this ... | closed | 2022-02-14T17:22:18Z | 2022-10-26T10:02:55Z | https://github.com/vitalik/django-ninja/issues/359 | [] | ryan1336 | 7 |
healthchecks/healthchecks | django | 1,076 | running local docker build crashes missing libexpat.so.1 | healthchecks version: 3.5.2
build env: same results in both WSL2/Ubuntu 22.04, and a native Ubuntu 22.04 VM.
docker version (windows): 27.2.0, build 3ab4256
```bash
$ git checkout v3.5.2
$ docker build -t healthchecks -f docker/Dockerfile .
$ docker run --rm -it healthchecks
uwsgi: error while loading shar... | closed | 2024-10-20T05:01:14Z | 2024-10-23T10:23:03Z | https://github.com/healthchecks/healthchecks/issues/1076 | [] | rophy | 3 |
simple-login/app | flask | 1,150 | KeyError: 'migrate' on running poetry run flask db upgrade | Please note that this is only for bug report.
For help on your account, please reach out to us at hi[at]simplelogin.io. Please make sure to check out [our FAQ](https://simplelogin.io/faq/) that contains frequently asked questions.
For feature request, you can use our [forum](https://github.com/simple-login/app... | closed | 2022-07-07T21:38:03Z | 2022-09-28T13:26:06Z | https://github.com/simple-login/app/issues/1150 | [] | mzch | 2 |
modin-project/modin | pandas | 6,756 | Don't materialize index when sorting | closed | 2023-11-19T22:35:50Z | 2023-11-20T16:50:40Z | https://github.com/modin-project/modin/issues/6756 | [
"Performance 🚀"
] | anmyachev | 0 | |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 659 | [QUESTION]: <Provide a short title>Easy Apply | ### Summary of your question
_No response_
### Question details
Does it only apply for Jobs with Easy Apply?
### Context for the question
I started using it and it only apply for jobs with easy apply button
### Additional context
_No response_ | closed | 2024-10-29T15:10:56Z | 2024-11-04T00:01:05Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/659 | [
"question"
] | Issac-Kondreddy | 1 |
Johnserf-Seed/TikTokDownload | api | 350 | [Feature]根据视频(点赞量)排序批量下载 | 在客户端的都抖音中,用户上传的视频有最新和最热两个排序方式。
批量下载的时候默认是按时间排序,能否添加按最热排序下载的功能? | open | 2023-03-15T04:44:01Z | 2023-03-15T04:44:01Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/350 | [
"需求建议(enhancement)"
] | ArvineKwok | 0 |
jackmpcollins/magentic | pydantic | 151 | Validation error on `list[str]` return annotation for Anthropic models | Hi @jackmpcollins, I'm busy testing the new 0.18 release, and using litellm==1.33.4.
Magentic seems to struggle to parse functions that are decorated using `list[str]` when using Anthropic's models via `litellm`.
Reproducible example:
```python
from magentic import prompt_chain
from magentic.chat_model.litel... | closed | 2024-03-22T10:17:03Z | 2024-04-15T06:36:06Z | https://github.com/jackmpcollins/magentic/issues/151 | [] | mnicstruwig | 4 |
PaddlePaddle/PaddleNLP | nlp | 9,388 | [Question]: paddlenlp调用PaddleCustomDevice custom_cpu报错 | ### 请提出你的问题
在一个容器里已经用paddle和pip install --upgrade paddlenlp==3.0.0b2跑通了
>>> from paddlenlp.transformers import AutoTokenizer, AutoModelForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B")
>>> model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B", dtype="float32")
>>> input_featur... | closed | 2024-11-07T08:37:12Z | 2025-01-22T00:20:41Z | https://github.com/PaddlePaddle/PaddleNLP/issues/9388 | [
"question",
"stale"
] | programmer-lxj | 2 |
miguelgrinberg/microblog | flask | 94 | OAuth insecure transport issue with gunicorn and nginx | Hi,
I have an issue if I do not use `OAUTHLIB_INSECURE_TRANSPORT = '1'` when running the application with https nginx serving the unsecure http gunicorn hosted app. If I do not enable this I get an 'Insecure Transport' error, because the redirect is http.
Should gunicorn also be secured with https even though ng... | closed | 2018-03-29T20:49:39Z | 2018-04-02T21:22:46Z | https://github.com/miguelgrinberg/microblog/issues/94 | [] | byronicle | 1 |
graphql-python/graphene-django | django | 648 | release 2.3.0 | it's been a while since v2.2.0, and how about releasing v2.3.0 soon. Are there any blocking issues or planned features?
I've installed graphene-django from pip, and most documentations didn't work due to version difference. Now I use it from master, and it works quite well for me. Also looking at releases I got an i... | closed | 2019-05-22T04:24:54Z | 2019-06-09T22:13:16Z | https://github.com/graphql-python/graphene-django/issues/648 | [] | dulmandakh | 5 |
flasgger/flasgger | rest-api | 422 | property field marked as required but flasgger still accepts it | From the todo example:
```
def post(self):
"""
This is an example
---
tags:
- restful
parameters:
- in: body
name: body
schema:
$ref: '#/definitions/Task'
responses:
201:
descri... | open | 2020-07-23T20:08:12Z | 2020-07-24T11:46:32Z | https://github.com/flasgger/flasgger/issues/422 | [] | patrickelectric | 1 |
python-gitlab/python-gitlab | api | 2,922 | Trigger a test project hook | ## Description of the problem, including code/CLI snippet
Need to trigget test of project hook https://docs.gitlab.com/ee/api/projects.html#trigger-a-test-project-hook
How I can do it with python-gitlab?
## Specifications
- python-gitlab version: 4.7
- API version you are using (v3/v4): v4
- Gitlab ... | closed | 2024-07-12T00:35:15Z | 2024-07-12T00:47:26Z | https://github.com/python-gitlab/python-gitlab/issues/2922 | [] | vasokot | 0 |
PaddlePaddle/ERNIE | nlp | 679 | 单机多卡训练时加载预训练模型出错 | PaddlePaddle版本:2.0.2
GPU:GTX 1080 Ti *4
系统环境:centos 7, python 3.7
在使用 python -m paddle.distributed.launch normaltrain.py 进行单机多卡训练时出错。经过试验发现是在载入预训练模型时出了问题。在载入ERNIE模型时报如下错误:
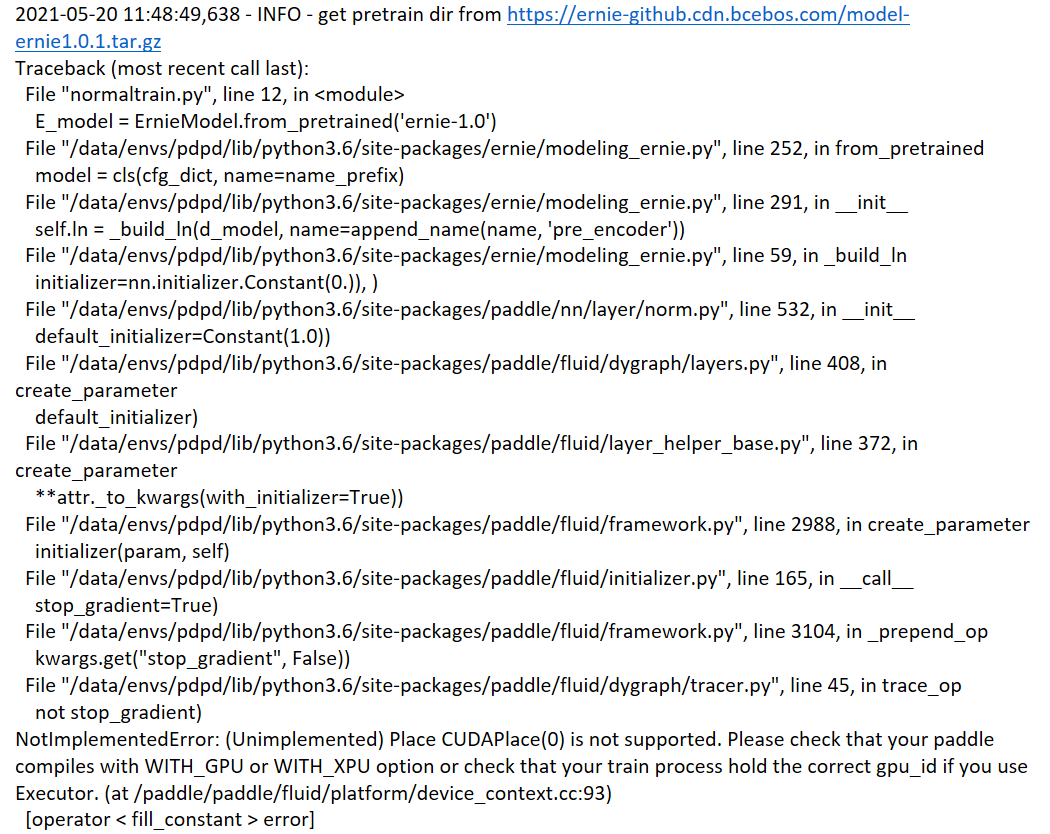
但是在不加载任何预训练模型,只使用基础API搭建自... | closed | 2021-05-26T01:18:02Z | 2021-08-01T06:50:13Z | https://github.com/PaddlePaddle/ERNIE/issues/679 | [
"wontfix"
] | junfeizhu | 2 |
google-research/bert | tensorflow | 904 | Bert similarity score high for non semantic similar sentences . | hidden_reps, cls_head = bert_model(token_ids, attention_mask = attn_maskT,token_type_ids = seg_idsT)
Is the output of the token embedding normalized in berth ? just like how its normalized in google universal sentence encoding where we use just np.inner to get the similarity between 2 vector ?
The problem here is ... | open | 2019-11-06T14:11:59Z | 2019-11-06T14:11:59Z | https://github.com/google-research/bert/issues/904 | [] | AjitAntony | 0 |
unit8co/darts | data-science | 2,505 | [QUESTION] Simple question regarding backtest() in Darts. | Hi,
I have a quick question regarding backtesting.
Given a target serie of size **500**, I train on the **400** first points, and validate on the last **100**. I use a horizon of **5** and input_chunk of **10**.
1) When backtesting on the entire dataset, when `retrain=False`, is the code loading the previou... | closed | 2024-08-18T16:59:34Z | 2024-08-19T09:52:47Z | https://github.com/unit8co/darts/issues/2505 | [
"question"
] | valentin-fngr | 2 |
biolab/orange3 | numpy | 6,665 | Stacking Widget: "Stack failed with an error" when using Time Slice as Data source | **What's wrong?**
When using the Stacking widget with Time Slice as Data source and Test and Score widget on the other side, a "Stack failed with an error" message appears (on the Test and Score widget).
There is no error if Data Sampler (or no widget) is used to slice the data instead the Time Slice widget.
The l... | closed | 2023-12-05T08:21:44Z | 2024-02-23T10:54:22Z | https://github.com/biolab/orange3/issues/6665 | [
"bug report"
] | ereztison | 6 |
NullArray/AutoSploit | automation | 772 | Divided by zero exception42 | Error: Attempted to divide by zero.42 | closed | 2019-04-19T16:00:35Z | 2019-04-19T16:37:55Z | https://github.com/NullArray/AutoSploit/issues/772 | [] | AutosploitReporter | 0 |
huggingface/transformers | python | 36,472 | Dtensor support requires torch>=2.5.1 | ### System Info
torch==2.4.1
transformers@main
### Who can help?
#36335 introduced an import on Dtensor https://github.com/huggingface/transformers/blob/main/src/transformers/modeling_utils.py#L44
but this doesn't exist on torch==2.4.1, but their is no guard around this import and setup.py lists torch>=2.0.
@Arthu... | closed | 2025-02-28T05:02:22Z | 2025-03-05T10:27:02Z | https://github.com/huggingface/transformers/issues/36472 | [
"bug"
] | winglian | 6 |
graphql-python/graphene-mongo | graphql | 70 | GenericReferenceField support | Hi, currently the field converter throws an exception on MongoEngine's `GenericReferenceField`:
```
Exception: Don't know how to convert the MongoEngine field <mongoengine.fields.GenericReferenceField object at 0x7f24dc4d03c8> (<class 'mongoengine.fields.GenericReferenceField'>)
```
It would be great to have su... | closed | 2019-02-06T16:36:59Z | 2019-04-22T03:17:12Z | https://github.com/graphql-python/graphene-mongo/issues/70 | [
"help wanted"
] | tambeta | 5 |
ResidentMario/geoplot | matplotlib | 144 | Propogate legend_values and legend_labels to colorbar legend | There are currently two types of legends in `geoplot`. If your legend variable is `hue` and you use a continuous colormap (`k=None`), a [colorbar legend](https://matplotlib.org/3.1.0/api/_as_gen/matplotlib.pyplot.colorbar.html) will be used. If your legend variable is `hue` and you use a categorical colormap (`k!=None`... | closed | 2019-07-05T15:47:40Z | 2019-12-04T14:52:44Z | https://github.com/ResidentMario/geoplot/issues/144 | [
"enhancement"
] | ResidentMario | 6 |
gee-community/geemap | streamlit | 971 | Multiple broken URLs/links in the example Jupyter notebooks | <!-- Please search existing issues to avoid creating duplicates. -->
### Environment Information
- geemap version: 0.11.7
- Python version: 3.9.10
- Operating System: Windows 11
### Description
I was trying the 13_zonal_statistic_by_group.ipynb and noticed the https://developers.google.com/earth-eng... | closed | 2022-03-12T15:10:01Z | 2022-08-25T21:25:38Z | https://github.com/gee-community/geemap/issues/971 | [
"bug"
] | owenlamont | 11 |
microsoft/unilm | nlp | 870 | How to Improve TrOCR output quality for custom use cases by applying constraint decoding | **Describe**
Model I am using TrOCR:
Hi, Thanks for providing such a wonderful model. It works really good.
**Context**
I am trying to use it to read handwritten forms. There are many fields in the form and i manage to crop different fields of the forms separately.
The provided pretrained weights gets confused wi... | open | 2022-09-16T12:49:45Z | 2022-09-16T12:49:45Z | https://github.com/microsoft/unilm/issues/870 | [] | prpankajsingh | 0 |
QingdaoU/OnlineJudge | django | 329 | 在特定网络环境下所有的 PUT 请求和 DELETE 请求都会出现异常 | 网络环境:北京某高校的校园网环境
出现问题:由于网络配置当中的某些策略,网站前后端交互所使用的PUT、DELETE请求失效,涉及该两种请求的功能全部无法使用,是否能够添加一项配置,支持将所有的PUT请求和DELETE请求全部转换为POST请求? | closed | 2020-10-09T07:58:06Z | 2020-10-09T08:41:53Z | https://github.com/QingdaoU/OnlineJudge/issues/329 | [] | catezi | 2 |
jupyterhub/repo2docker | jupyter | 542 | Set jupyter-notebook password on Google Cloud | I am trying to use repo2docker to deploy a repo with a jupyter notebook to Google cloud.
I am able to use docker2repo to run a docker container locally.
When I deploy to Google cloud I get asked for an authentication token.
Which I do not have since I did not see the output when the gcp instance started.
I have tri... | closed | 2019-01-03T22:58:16Z | 2019-03-24T08:29:07Z | https://github.com/jupyterhub/repo2docker/issues/542 | [] | mhlr | 5 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,011 | Can you please describe about the GAN mode in details? | Hi,
I would like to know the difference between each of the GAN mode. Can you please explain in short? I understand that vanilla GAN is used for pix2pix, lsGAN for cycleGAN. I have a paired dataset and using pix2pix model for kind of segmentation task. I get decent results with vanilla GAN but id like to improve th... | closed | 2020-04-29T12:04:16Z | 2020-06-26T13:51:41Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1011 | [] | kalai2033 | 1 |
Asabeneh/30-Days-Of-Python | pandas | 459 | Some challenges need improvement | The chapter day 14 higher order function is good as an introduction to concepts like closures, decorators but it should also teach, why do we need closures or decorators in first place and what advantages do it provide if we use closure rather than just doing it normally ? | open | 2023-11-21T12:28:42Z | 2023-11-21T12:29:00Z | https://github.com/Asabeneh/30-Days-Of-Python/issues/459 | [] | shokhie | 0 |
jazzband/django-oauth-toolkit | django | 614 | Signal on accesstoken revocation | The app_authorized is a great signal to do things when an app is authorized to access certain resources, however it makes sense to clean those 'things' up when an access token gets revoked.
This is yet not possible, if you think this would make sense I would love to make a PR :) | open | 2018-06-28T17:41:40Z | 2021-03-12T14:57:13Z | https://github.com/jazzband/django-oauth-toolkit/issues/614 | [] | gabn88 | 1 |
davidsandberg/facenet | computer-vision | 576 | How to align faces in an image containing multiple faces where images in dataset are rotated ? | I have dataset of a person , whose images are rotated 90° or 180° from which I have to crop faces and align using mtcnn or normal way ?
In contributed align_dataset_mtcnn.py is not much useful for alignment of faces which are rotated ? How to make images as rotationally invariant to crop and align faces | open | 2017-12-10T09:11:10Z | 2019-09-01T13:01:04Z | https://github.com/davidsandberg/facenet/issues/576 | [] | RaviRaaja | 1 |
tensorflow/tensor2tensor | deep-learning | 1,293 | Attention keys/queries and values | I'm following English-to-German translation model (translate_ende_wmt32k)
Where I can find dk and dv (where dk the size of the attention keys/queries and db the size of the attention values) variables in the hparams?
| open | 2018-12-11T14:38:30Z | 2018-12-12T15:58:52Z | https://github.com/tensorflow/tensor2tensor/issues/1293 | [] | bashartalafha | 2 |
jina-ai/serve | deep-learning | 5,467 | feat: run warmup requests on runtime startup to ensure that service is ready to accept connections | **Describe the feature**
<!-- A clear and concise description of what the feature is. -->
Warm up requests are executed before the service is reported ready so that new incoming requests can be readily served without having to create new network connections to database dependency or sidecar container, etc or load the... | closed | 2022-11-30T10:05:18Z | 2023-01-14T10:14:58Z | https://github.com/jina-ai/serve/issues/5467 | [] | girishc13 | 0 |
ultralytics/ultralytics | deep-learning | 19,450 | skipping frames on SAM2VideoPredictor | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello,
I am using SAM2VideoPredictor to generate ground-truth from videos. ... | open | 2025-02-26T18:58:55Z | 2025-02-27T06:51:07Z | https://github.com/ultralytics/ultralytics/issues/19450 | [
"question"
] | SebastianJanampa | 3 |
deezer/spleeter | tensorflow | 363 | [Bug] Spleeter has no output if filename ends with space | <!-- PLEASE READ THIS CAREFULLY :
- Any issue which does not respect following template or lack of information will be considered as invalid and automatically closed
- First check FAQ from wiki to see if your problem is not already known
-->
## Description
It seems that if the filename you are trying to split ... | closed | 2020-05-07T19:02:34Z | 2020-05-15T13:35:17Z | https://github.com/deezer/spleeter/issues/363 | [
"bug",
"invalid"
] | Christilut | 2 |
hbldh/bleak | asyncio | 1,336 | examples/service_explorer.py "Unknown ATT error" on macOS | * bleak version: bleak-0.21.0a
* Python version: Python 3.11.3
* Operating System: macOS 13.3.1 (a)
### Description
Testing examples/service_explorer.py on macOS since it doesn't work for me on Linux (https://github.com/hbldh/bleak/issues/1333 )
### What I Did
I tried to connect to a device named "Dropcam... | open | 2023-06-14T13:24:09Z | 2023-06-14T14:17:23Z | https://github.com/hbldh/bleak/issues/1336 | [
"3rd party issue",
"Backend: Core Bluetooth"
] | jsmif | 1 |
python-security/pyt | flask | 2 | Update Readme | use .rst format so it also can be used for pypi packaging
| closed | 2016-10-27T10:11:39Z | 2017-05-12T09:52:42Z | https://github.com/python-security/pyt/issues/2 | [] | Thalmann | 5 |
man-group/arctic | pandas | 755 | VersionStore: Incorrect number of segments without daterange |
#### Arctic Store
```
VersionStore
```
#### Description of problem and/or code sample that reproduces the
Reading a symbol from VersionStore causes an error like:
OperationFailure: Incorrect number of segments returned for XXX. Expected: 983, but got 962. XXX
But if I try to read the same with a date... | closed | 2019-04-30T10:27:03Z | 2019-05-03T08:37:44Z | https://github.com/man-group/arctic/issues/755 | [
"bug",
"hard"
] | shashank88 | 2 |
chatanywhere/GPT_API_free | api | 165 | 使用图像接口返回limit to use gpt-3.5-turbo, gpt-4 and embeddings | 使用图像接口返回limit to use gpt-3.5-turbo, gpt-4 and embeddings | closed | 2023-12-25T07:05:19Z | 2023-12-29T16:20:51Z | https://github.com/chatanywhere/GPT_API_free/issues/165 | [] | zybbq | 4 |
sammchardy/python-binance | api | 827 | Creating an OCO order using API causes Error code 1106 'stopLimitTimeInForce' sent when not required. | I'm trying to create an OCO order but I am getting StopLimitTimeInForce error. Where am I doing the mistake in the code?
```
from binance.enums import *
from binance.client import Client
client = Client("Credentials here")
coin_name = "BUSDUSDT"
quantity = "12"
loss_sell = "0.88"
profit_sell = "0.99"
creat... | open | 2021-05-07T04:00:55Z | 2021-05-07T04:02:48Z | https://github.com/sammchardy/python-binance/issues/827 | [] | bilalkhann16 | 0 |
sunscrapers/djoser | rest-api | 631 | Dynamic `is_active` field for Serializer Validations | I am using `django-tenant-users` which includes `is_active` and `is_verified` fields on the user models. I would like the serializers to validate using the `is_verified` field, but Djoser is currently hardcoded to only look at `is_active`. I can create a Pull Request that breaks out this attribute to a setting that def... | open | 2021-09-04T15:21:56Z | 2021-09-04T15:21:56Z | https://github.com/sunscrapers/djoser/issues/631 | [] | dstarner | 0 |
JoeanAmier/TikTokDownloader | api | 110 | 下载直播只能一直下载吗?中间暂停不会生成文件吗 | open | 2023-12-25T08:29:17Z | 2024-05-15T13:42:21Z | https://github.com/JoeanAmier/TikTokDownloader/issues/110 | [] | BowenHero | 3 | |
streamlit/streamlit | data-visualization | 10,120 | navbar compression | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
Hovering over the sidebar compresses the cont... | closed | 2025-01-07T10:02:28Z | 2025-01-13T14:03:00Z | https://github.com/streamlit/streamlit/issues/10120 | [
"type:bug",
"status:cannot-reproduce",
"feature:st.sidebar"
] | ankit-6937 | 6 |
keras-team/keras | tensorflow | 20,490 | ModelCheckpoint loses .h5 save support, breaking retrocompatibility | **Title:** ModelCheckpoint Callback Fails to Save Models in .h5 Format in TensorFlow 2.17.0+
**Description:**
I'm experiencing an issue with TensorFlow's `tf.keras.callbacks.ModelCheckpoint` across different TensorFlow versions on different platforms.
**Background:**
* **Platform 1:** Windows with TensorFlo... | closed | 2024-11-13T09:56:49Z | 2024-11-28T17:41:41Z | https://github.com/keras-team/keras/issues/20490 | [
"type:Bug"
] | TeoCavi | 3 |
matplotlib/matplotlib | data-visualization | 29,067 | [Bug]: `secondary_xaxis` produces ticks at incorrect locations | ### Bug summary
It is possible I'm doing this incorrectly, but for a very simple example `secondary_xaxis` puts tick marks at incorrect locations. Modifying slightly the interpolation example from here https://matplotlib.org/stable/gallery/subplots_axes_and_figures/secondary_axis.html:
### Code for reproduction
```P... | closed | 2024-11-04T14:34:54Z | 2024-11-21T20:44:19Z | https://github.com/matplotlib/matplotlib/issues/29067 | [
"Documentation: tutorials"
] | dkweiss31 | 9 |
BeanieODM/beanie | asyncio | 580 | [BUG] Updates on Documents with "BackLink" do not behave as expected. | **Describe the bug**
Several exceptions caused by `BackLink`.
**To Reproduce**
```python
import asyncio
from beanie import init_beanie, Document, BackLink, WriteRules, Link
from beanie.odm.operators.update.general import Set
from motor import motor_asyncio
from pydantic import Field
class Children(Docume... | closed | 2023-06-01T09:31:11Z | 2023-06-06T01:38:57Z | https://github.com/BeanieODM/beanie/issues/580 | [
"bug",
"documentation"
] | hgalytoby | 2 |
ultralytics/ultralytics | pytorch | 18,859 | how to fix image size for yolo prediction | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello! I have a dataset with images of size 1344 x 693. Firstly, I can no lo... | closed | 2025-01-24T06:46:23Z | 2025-01-25T10:57:40Z | https://github.com/ultralytics/ultralytics/issues/18859 | [
"question",
"segment"
] | w1nteer | 7 |
huggingface/pytorch-image-models | pytorch | 1,360 | [FEATURE] MobileOne Backbone | MobileOne: An Improved One millisecond Mobile Backbone.Its performance is much better than mobilenet. | closed | 2022-07-22T00:24:11Z | 2022-07-22T00:39:47Z | https://github.com/huggingface/pytorch-image-models/issues/1360 | [
"enhancement"
] | dsp6414 | 2 |
JaidedAI/EasyOCR | deep-learning | 330 | Circular Dependencies on Fresh Install | Ubuntu 18.04 (in docker), Ubuntu 20.04
> virtualenv .
> source bin/activate
> pip3 install easyocr
>
```
import easyocr as eo
reader = eo.Reader(['en'])
result = reader.readtext("srcdata/" + sys.argv[1])
```
Throws error:
```
Traceback (most recent call last):
File "easyocr.py", line 1, in <... | closed | 2020-12-15T18:41:58Z | 2023-02-26T15:54:47Z | https://github.com/JaidedAI/EasyOCR/issues/330 | [] | nsmithfs | 4 |
vitalik/django-ninja | rest-api | 1,092 | [BUG] ModelSchema & inheritance | Hey so
```
class AsdSchema(ModelSchema):
class Config:
model = Asd
model_fields = "__all__"
fields_optional = "__all__"
exclude = [
"id",
"lol_ptr_id",
] # Updated to include the Django foreign key field name
```
if Asd inherits from Lol... | open | 2024-02-20T06:01:00Z | 2024-02-20T07:51:01Z | https://github.com/vitalik/django-ninja/issues/1092 | [] | MadcowD | 1 |
suitenumerique/docs | django | 168 | ✨Add mail when add a new user to a doc | ## Feature Request
For the moment when we add a new user to a doc, we don't send any email.
We would like to send a email when we add a user to a doc as well.
When we call this endpoint, we should send a email:
https://github.com/numerique-gouv/impress/blob/83638f5ddb9d9f823c3273998c0b070c96d3dead/src/backend/... | closed | 2024-08-14T09:32:28Z | 2024-08-16T13:17:29Z | https://github.com/suitenumerique/docs/issues/168 | [
"backend"
] | AntoLC | 0 |
tflearn/tflearn | tensorflow | 457 | how to input image data in tflearn | Hi @aymericdamien,
in the example of googlenet.py, the image input is like this
''
X, Y = oxflower17.load_data(one_hot=True, resize_pics=(227, 227))
''
my problem is two classification, and I have two kinds image files like following,
''
a -- img1.jpg
img2.jpg
img3.jpg
...
b -- img1.jpg
img2.jpg
img3.jpg
... | open | 2016-11-13T13:19:43Z | 2018-02-07T09:21:54Z | https://github.com/tflearn/tflearn/issues/457 | [] | luoruisichuan | 5 |
rthalley/dnspython | asyncio | 546 | resolv.conf "options edns0" parser sets EDNS size to 0 | In 2.0.0, `Resolver.read_resolv_conf()` now checks for the "`options edns0`" option and enables EDNS if it's found. (Yay!)
However, it oddly sets the EDNS payload size to 0 instead of something like 512 or 1220.
https://github.com/rthalley/dnspython/blob/0a1a837e07016f63f88a52afc424a380a264d79e/dns/resolver.py#L8... | closed | 2020-07-21T01:46:11Z | 2020-07-29T17:34:11Z | https://github.com/rthalley/dnspython/issues/546 | [
"Bug",
"Fixed",
"Next Patch"
] | mnordhoff | 4 |
Nemo2011/bilibili-api | api | 208 | 【提问】关于comment模块 | 在使用get_comments()方法爬取评论区评论时,不爬取子评论,是因为“api.bilibili.com/x/v2/reply”返回的数据中最多只有三条子评论的原因吗。我想实现爬取子评论,请问有相关的api可以爬取子评论吗。 | closed | 2023-02-20T13:48:48Z | 2023-02-25T09:06:03Z | https://github.com/Nemo2011/bilibili-api/issues/208 | [
"question"
] | Doge-e7i | 5 |
keras-team/keras | machine-learning | 20,278 | Incompatibility of compute_dtype with complex-valued inputs | Hi,
In #19872, you introduced the possibility for layers with complex-valued inputs.
It then seems that this statement of the API Documentation is now wrong:

When I feed a complex-valued input tensor into a layer (as in ... | open | 2024-09-23T11:48:24Z | 2024-09-25T19:31:05Z | https://github.com/keras-team/keras/issues/20278 | [
"type:feature"
] | jhoydis | 1 |
marcomusy/vedo | numpy | 1,034 | hover_legend Triggers Button | I've run into an issue with using the hover_legend and a button in the same plot. If I add both of them, the button function is triggerd constantly while im hovering the button. As I'm new to using this wonderful library, I'm not sure if this is a but or if there is something I'm missing. I looked for the option to exc... | open | 2024-01-24T11:29:33Z | 2024-02-02T14:23:52Z | https://github.com/marcomusy/vedo/issues/1034 | [
"bug",
"enhancement",
"long-term"
] | MarkFerr | 3 |
lyhue1991/eat_tensorflow2_in_30_days | tensorflow | 17 | 5.5的损失函数有误 |
```
def focal_loss(gamma=2., alpha=.25):
def focal_loss_fixed(y_true, y_pred):
pt_1 = tf.where(tf.equal(y_true, 1), y_pred, tf.ones_like(y_pred))
pt_0 = tf.where(tf.equal(y_true, 0), y_pred, tf.zeros_like(y_pred))
loss = -tf.sum(alpha * tf.pow(1. - pt_1, gamma) * tf.log(1e-07+... | open | 2020-04-09T19:34:01Z | 2020-04-10T14:26:56Z | https://github.com/lyhue1991/eat_tensorflow2_in_30_days/issues/17 | [] | fecet | 1 |
huggingface/datasets | numpy | 6,699 | `Dataset` unexpected changed dict data and may cause error | ### Describe the bug
Will unexpected get keys with `None` value in the parsed json dict.
### Steps to reproduce the bug
```jsonl test.jsonl
{"id": 0, "indexs": {"-1": [0, 10]}}
{"id": 1, "indexs": {"-1": [0, 10]}}
```
```python
dataset = Dataset.from_json('.test.jsonl')
print(dataset[0])
```
Result:
```... | open | 2024-02-28T05:30:10Z | 2024-02-28T19:14:36Z | https://github.com/huggingface/datasets/issues/6699 | [] | scruel | 2 |
plotly/dash-bio | dash | 64 | Dash Bio apps - initial impressions | First-level impressions clicking through Dash Bio gallery beta apps: https://dash-gallery.plotly.host/dash-bio
### Header
Would be great to have a GitHub link in the upper-right of the header that links to the code for each app on GitHub.
### Dash Circos
- [x] A lot of stuff in this sidebar. Pretty overwhel... | closed | 2018-12-01T03:09:32Z | 2019-01-30T18:47:53Z | https://github.com/plotly/dash-bio/issues/64 | [] | jackparmer | 12 |
jschneier/django-storages | django | 781 | Static tag generating query string params | So, my webpage generates file that includes the access tokens when using the static tag in django to link to my static files
`<link rel="stylesheet" type="text/css" href="{% static 'css/main.css' %}">`
Right now its generating:
> https://******.digitaloceanspaces.com/fpl/static/css/main.css?AWSAccessKeyId=&Sig... | closed | 2019-10-21T17:17:13Z | 2019-10-21T17:25:06Z | https://github.com/jschneier/django-storages/issues/781 | [] | b99andla | 1 |
huggingface/transformers | machine-learning | 36,598 | lm_head parameters missing from named_parameters() in Qwen2.5-VL-3B-Instruct model | ### System Info
```
- `transformers` version: 4.49.0
- Platform: Linux-6.8.0-40-generic-x86_64-with-glibc2.35
- Python version: 3.10.16
- Huggingface_hub version: 0.27.1
- Safetensors version: 0.5.0
- Accelerate version: 1.0.1
- Accelerate config: - compute_environment: LOCAL_MACHINE
- distributed_type: DEE... | open | 2025-03-07T02:58:29Z | 2025-03-17T22:28:20Z | https://github.com/huggingface/transformers/issues/36598 | [
"bug"
] | Buhua-Liu | 2 |
iMerica/dj-rest-auth | rest-api | 663 | Demo instructions don't work | Steps to repro:
1) Go to https://dj-rest-auth.readthedocs.io/en/latest/demo.html
2) Follow the instructions. Will fail on this step: python manage.py migrate --settings=demo.settings --noinput
ModuleNotFoundError: No module named 'pkg_resources'
| open | 2024-10-31T22:03:18Z | 2024-10-31T22:03:18Z | https://github.com/iMerica/dj-rest-auth/issues/663 | [] | ra-dave | 0 |
mljar/mercury | data-visualization | 405 | creating buttons in a loop is not working | The following code:
`menu = ['GDP', 'Sector', 'test']`
`buttons = {key: mr.Button(label=key, style="primary") for key in menu}
`
Should create three buttons below each other. Instead it produces only one key. Its not always consistant which one. (I suspect it cheats them on top of each other.
| closed | 2023-12-17T12:43:41Z | 2023-12-18T10:20:59Z | https://github.com/mljar/mercury/issues/405 | [] | DavoudTaghawiNejad | 1 |
MaartenGr/BERTopic | nlp | 1,983 | Supervised topic model generating different topics to training data | I am trying to run a supervised topic model, but when i look at the results the model produces topic numbers that are different to those that i trained it on. Am I misunderstanding something. I thought the supervised model would produce the exact same results as the training data - i appreciate that results for test da... | open | 2024-05-09T23:22:19Z | 2024-05-12T18:45:35Z | https://github.com/MaartenGr/BERTopic/issues/1983 | [] | morrisseyj | 3 |
plotly/dash | data-science | 2,710 | [Feature Request] support multiple URL path levels in path template | I'd like to suggest the following behavior for interpreting path templates as part of the pages feature.
The following example can illustrate the requested behavior:
```
dash.register_page("reports", path_template="/reports/<product>/<feature>/<report_type>/<data_version>")
def layout(product: str | None = No... | closed | 2023-12-10T07:45:07Z | 2024-05-31T20:14:05Z | https://github.com/plotly/dash/issues/2710 | [] | yreiss | 1 |
NullArray/AutoSploit | automation | 1,177 | Unhandled Exception (41a08e155) | Autosploit version: `4.0.1`
OS information: `Darwin-17.4.0-x86_64-i386-64bit`
Running context: `autosploit.py`
Error mesage: `[Errno 2] No such file or directory: '/Users/admin/.autosploit_home/nmap_scans/xml/10.0.1.1/24_cEhjlNQrx.xml'`
Error traceback:
```
Traceback (most recent call):
File "/Users/admin/bin/python/a... | closed | 2019-09-16T15:56:55Z | 2019-10-06T19:21:24Z | https://github.com/NullArray/AutoSploit/issues/1177 | [] | AutosploitReporter | 0 |
sktime/sktime | scikit-learn | 7,805 | [ENH] Interfacing `TiDEModel` from `pytorch-forecasting` | **Is your feature request related to a problem? Please describe.**
As suggested by @fkiraly , a good addition to sktime would be the interfacing of `TiDEModel` from `pytorch-forecasting`.
Re: This model was implemented in the PR - https://github.com/sktime/pytorch-forecasting/pull/1734
| open | 2025-02-10T16:57:09Z | 2025-02-17T14:40:34Z | https://github.com/sktime/sktime/issues/7805 | [
"interfacing algorithms",
"module:forecasting",
"enhancement"
] | PranavBhatP | 4 |
bendichter/brokenaxes | matplotlib | 86 | Assigning colors to two arrays in the plot | Hi,
I am very happy I found your package. I would appreciate if you can help me to change the color of my plots. I will be generating the same plot for another dataset and I want to assign two different color for the second plot. But I do not understand how to assign two different colors to the two arrays inside 'x'... | closed | 2022-09-13T04:08:22Z | 2022-09-13T23:34:27Z | https://github.com/bendichter/brokenaxes/issues/86 | [] | Kalpi-ds | 5 |
jmcnamara/XlsxWriter | pandas | 1,090 | Bug: previous_row does not hold correctly the number of the last line where data is written | ### Current behavior
I've to admit that this is not a native approach based on the configuration, but traces in the code suggest that property to store that value.
However, by the time _write_single_row is invoked (and apparently almost all methods reach that function), the self.previous_row is reset to 0 unless the... | closed | 2024-09-04T09:10:24Z | 2024-09-04T11:08:48Z | https://github.com/jmcnamara/XlsxWriter/issues/1090 | [
"bug"
] | WSF-SEO-AM | 1 |
davidsandberg/facenet | tensorflow | 916 | Model loss is constant at alpha. | Hey, I tried porting your repository to a keras version , but for some reason, when I train, the validation loss is always 0.2 which is alpha for me, but training loss keeps on changing. My base network is
base_network = keras.applications.inception_resnet_v2.InceptionResNetV2(input_shape=input_shape,weights=None,... | open | 2018-11-07T06:57:13Z | 2019-09-13T06:13:10Z | https://github.com/davidsandberg/facenet/issues/916 | [] | hardik124 | 1 |
cobrateam/splinter | automation | 945 | Sample code in Splinter Documentation doesn't work | It has been noticed that the sample code given in [Splinter Documentation](https://splinter.readthedocs.io/en/latest/) is not updated according to change in Google Search. Currently when we run the code, it throw outs the following error:
```
splinter.exceptions.ElementDoesNotExist: no elements could be found with na... | closed | 2021-11-13T12:43:14Z | 2022-05-03T03:00:31Z | https://github.com/cobrateam/splinter/issues/945 | [] | athulvis | 3 |
waditu/tushare | pandas | 1,683 | 基础数据_股票列表_接口有 bug | data = pro.stock_basic(exchange='SSE', list_status='D', fields='ts_code,symbol,name,area,industry,fullname,enname,market,list_status,list_date,delist_date,is_hs')
获取上交所已退市股票,找到最后一只股票,
print(data.iloc[-1])
结果显示:
ts_code T00018.SH
symbol T0001... | open | 2022-11-24T10:11:29Z | 2024-06-12T08:29:12Z | https://github.com/waditu/tushare/issues/1683 | [] | 1051135268 | 1 |
apache/airflow | data-science | 47,782 | Not able to fetch asset info using triggering_asset_events | ### Apache Airflow version
3.0.0
### If "Other Airflow 2 version" selected, which one?
_No response_
### What happened?
Not able to fetch asset info using triggering_asset_events
**ERROR**
[2025-03-14, 12:01:20] ERROR - Task failed with exception source="task" error_detail=[{"exc_type":"KeyError","exc_value":"'tr... | closed | 2025-03-14T12:23:44Z | 2025-03-15T05:14:00Z | https://github.com/apache/airflow/issues/47782 | [
"kind:bug",
"priority:high",
"area:core",
"area:datasets",
"affected_version:3.0.0beta"
] | vatsrahul1001 | 2 |
sigmavirus24/github3.py | rest-api | 594 | Get repository stargazers with star creation timestamp | https://developer.github.com/v3/activity/starring/#list-stargazers - Check the "Alternative response with star creation timestamps".
I'd like to add a `Stargazer` class with the attributes `starred_at` and `user`. And return this class when calling `repo.stargazers()`.
##
<bountysource-plugin>
---
Want to back ... | closed | 2016-04-02T21:49:06Z | 2021-11-01T01:26:22Z | https://github.com/sigmavirus24/github3.py/issues/594 | [] | dnsv | 9 |
tortoise/tortoise-orm | asyncio | 1,365 | Auto ID for CockroachDB breaks Pydantic | **Describe the bug**
If one tries to use cockroachdb along with `pydantic_model_creator()` breaks when you try to convert a model object using `Object.from_tortoise_orm(tortoise_object)`
This error is encountered:
```python
Apr 3 05:32:11 PM return super().from_orm(obj)
Apr 3 05:32:11 PM ^^^^^^^^^... | open | 2023-04-03T12:08:52Z | 2023-04-03T12:08:52Z | https://github.com/tortoise/tortoise-orm/issues/1365 | [] | unownone | 0 |
mwaskom/seaborn | matplotlib | 3,775 | Adding bar_label to a barplot - changed behaviour with 0.13 when using palette without hue | Hello and thanks for this awesome visualisation library!
While migrating from 0.12 to 0.13, I've spotted the new behaviour of `palette` on a `barplot`, that now automatically uses `hue`.
This changes the returned `containers`, as in the past all bars where part of `containers[0]`, while with the `hue` parameter 1... | closed | 2024-10-29T11:44:15Z | 2024-10-29T17:21:23Z | https://github.com/mwaskom/seaborn/issues/3775 | [] | AlexTWeb | 1 |
ScottfreeLLC/AlphaPy | scikit-learn | 5 | Yahoo Finance Daily Data through icharts no longer available | If you haven't been able to download daily data through Yahoo lately, here's why:
https://github.com/pydata/pandas-datareader/issues/315
Yahoo has discontinued its free Finance API after many years, so we will search for another source of historical data. | closed | 2017-05-21T22:19:07Z | 2017-05-23T13:04:00Z | https://github.com/ScottfreeLLC/AlphaPy/issues/5 | [] | mrconway | 1 |
vaexio/vaex | data-science | 1,713 | [BUG-REPORT] vaex install via pip --prefix causing issues | **Description**
I'm trying to install vaex via pip with --prefix option and I see the contents of lib and lib64 different which is causing vaex import issues. Tried the same without --prefix option and I see the contents of lib and lib64 folder same and import is also working fine.
Installing via pip
lib and lib6... | closed | 2021-11-16T07:26:16Z | 2024-07-19T15:12:59Z | https://github.com/vaexio/vaex/issues/1713 | [] | aakashsoni | 4 |
aminalaee/sqladmin | asyncio | 556 | `expose` decorator doesn't trigger auth check | ### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
```py
from fastapi import FastAPI
from sqladmin import Admin, BaseView, expose
from sqladmin.authentication import AuthenticationBackend
from ... | closed | 2023-07-19T19:46:38Z | 2023-07-24T15:52:12Z | https://github.com/aminalaee/sqladmin/issues/556 | [] | uriyyo | 0 |
CTFd/CTFd | flask | 1,780 | Investigate submitting flags to API over regular POSTs as well as JSON | Investigate submitting flags to API over regular POSTs as well as JSON
Would help with themes not having to rely on JS. | closed | 2021-01-18T09:10:07Z | 2021-03-18T06:44:27Z | https://github.com/CTFd/CTFd/issues/1780 | [
"plugin idea"
] | ColdHeat | 1 |
pydata/xarray | numpy | 9,180 | DataArray.where() can truncate strings with `<U` dtypes | ### What happened?
I want to replace all `"="` occurrences in an xr.DataArray called `sign` with `"<="`.
```
sign_c = sign.where(sign != "=", "<=")
```
The resulting DataArray then does not contain `"<="` though, but `"<"`. This only happens if `sign` only has "=" entries.
### What did you expect to happen?
Tha... | closed | 2024-06-27T08:09:12Z | 2024-10-24T21:21:33Z | https://github.com/pydata/xarray/issues/9180 | [
"bug"
] | jacob-mannhardt | 8 |
explosion/spaCy | nlp | 12,585 | nlp.pipe does not work multithreaded on OSX M1 | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
## How to reproduce the behaviour
<!-- Include a code example or the steps that led to the problem. Please try to be as specific as possible. -->
It looks like `nlp.pipe` singled threaded works but `n_process=2` does not wo... | closed | 2023-04-29T02:07:28Z | 2023-05-02T06:02:16Z | https://github.com/explosion/spaCy/issues/12585 | [
"feat / pipeline",
"scaling"
] | tianhuil | 2 |
fastapi-users/fastapi-users | fastapi | 1,302 | The backend is not picked right with logout endpoint | ## Describe the bug
I have two auth routers:
```python
api_router.include_router(
fastapi_users.get_auth_router(auth_backend_mobile), prefix=jwt_url, tags=["auth"]
)
api_router.include_router(
fastapi_users.get_auth_router(auth_backend_dashboard), prefix=f"{jwt_url}/dashboard", tags=["auth"]
)
``... | closed | 2023-10-17T14:36:08Z | 2023-10-23T09:02:38Z | https://github.com/fastapi-users/fastapi-users/issues/1302 | [
"bug"
] | AndreMPCosta | 5 |
facebookresearch/fairseq | pytorch | 5,162 | For MMS TTS, is it possible to add pauses, emotion, inflection, ect? | ## ❓ Questions and Help
<!-- If you still can't find what you need: -->
#### What is your question?
I am playing with and learning about the MMS TTS. I have it running and am curious if it is possible to adjust the output to have things like pauses, emotion, & inflection.
| closed | 2023-05-26T08:36:49Z | 2023-06-20T10:24:07Z | https://github.com/facebookresearch/fairseq/issues/5162 | [
"question",
"needs triage"
] | JWesorick | 2 |
huggingface/text-generation-inference | nlp | 2,145 | Error "EOF while parsing an object..." with tool_calls | ### System Info
Hello!
Thank you very much for your product, very helpful!
### System Info:
```bash
2024-06-30T00:30:49.387947Z INFO text_generation_launcher: Runtime environment:
Target: x86_64-unknown-linux-gnu
Cargo version: 1.79.0
Commit sha: 192d49af0bfa71e886c27856232031f3935628ff
Docker label: sha-... | open | 2024-06-30T01:00:23Z | 2024-07-29T08:14:01Z | https://github.com/huggingface/text-generation-inference/issues/2145 | [] | ishelaputov | 7 |
miguelgrinberg/Flask-SocketIO | flask | 730 | Can't receive acks with multiple test clients | I instantiate 6 test clients with `test_client`, and the ack always makes it to the wrong test client instance's `.ack`. I've got a patch below, and will make a PR soon, but am not sure if this is the right approach.
More broadly, I'm surprised everything works when the same `self.socketio.server._send_packet` is mo... | closed | 2018-07-06T20:43:06Z | 2018-10-09T22:51:39Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/730 | [
"bug"
] | pilona | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.