
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
amidaware/tacticalrmm | django | 1,861 | Tray Icon for TRMM | I'd love a feature like a trmm tray icon to be implemented into Tactical where a user can right-click on the tray Icon and be met with the following options
Identify My PC - This gives them an output of their hostname
Submit a support request - This gives them a text box where they can type in an issue they are exp... | closed | 2024-05-02T06:03:26Z | 2024-05-02T07:01:52Z | https://github.com/amidaware/tacticalrmm/issues/1861 | [] | screwlooseit | 1 |
davidsandberg/facenet | tensorflow | 1,133 | TypeError: '<=' not supported between instances of 'NoneType' and 'int' | File "src/train_softmax.py", line 308, in train │
if lr<=0: ... | open | 2020-01-31T13:45:55Z | 2020-07-01T08:46:38Z | https://github.com/davidsandberg/facenet/issues/1133 | [] | pasa13142 | 2 |
vaexio/vaex | data-science | 2,234 | [FEATURE-REQUEST] The join "how" doesn't support "cross" option | Hi sir, I use the vaex recently. Vaex is a awesome package. But I find that the vaex doesn't support the "cross" option of the join API. I want to cross-join two dataframes like [pandas](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.merge.html?highlight=merge#pandas.DataFrame.merge).
Can you help me? I... | closed | 2022-10-18T09:16:36Z | 2022-10-20T03:48:46Z | https://github.com/vaexio/vaex/issues/2234 | [] | hewittzgh | 2 |
albumentations-team/albumentations | deep-learning | 1,588 | [Speed up] Currently Gaussian Noise is not optimized for separate uint8 and float32 treatment | It could happen, that
```python
@clipped
def gauss_noise(image: np.ndarray, gauss: np.ndarray) -> np.ndarray:
image = image.astype("float32")
return image + gauss
```
could be optimized with something like:
```python
def gauss_noise_optimized(image: np.ndarray, gauss: np.ndarray) -> np.ndarray:
... | closed | 2024-03-16T00:52:09Z | 2024-10-31T02:20:47Z | https://github.com/albumentations-team/albumentations/issues/1588 | [
"good first issue",
"Speed Improvements"
] | ternaus | 3 |
activeloopai/deeplake | computer-vision | 2,977 | [BUG] Deeplake dataset row access fails under multiprocessing | ### Severity
P0 - Critical breaking issue or missing functionality
### Current Behavior
Accessing deeplake dataset rows under a multiprocessing library such as concurrent futures results in an error.
Consider the following script which creates a dummy deeplake dataset and tries to access it with multiprocessing
... | closed | 2024-10-25T22:03:10Z | 2024-11-08T03:45:47Z | https://github.com/activeloopai/deeplake/issues/2977 | [
"bug"
] | abhayv | 3 |
guohongze/adminset | django | 99 | 普通用户无法查看监控 | 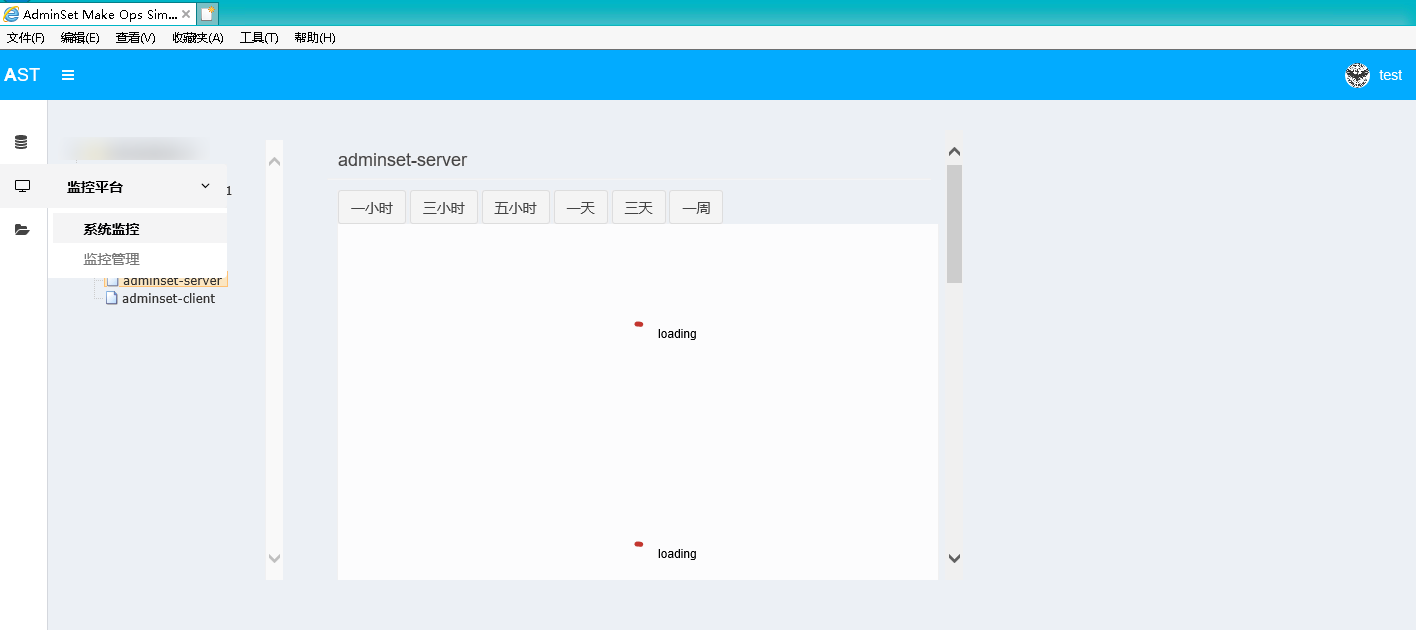
如图所示,test无法查看监控信息 | closed | 2019-03-05T12:00:13Z | 2019-03-06T03:51:00Z | https://github.com/guohongze/adminset/issues/99 | [] | DaRingLee | 2 |
CPJKU/madmom | numpy | 422 | Installation issue, mabe wheels-related | ### Expected behaviour
`pip install madmom==0.16.1`
should just work.
### Actual behaviour
```
>>> import madmom
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/stefan/miniconda3/envs/asr/lib/python3.6/site-packages/madmom/__init__.py", line 24, in <module>
from... | closed | 2019-03-13T14:23:07Z | 2019-03-15T09:38:15Z | https://github.com/CPJKU/madmom/issues/422 | [] | stefan-balke | 2 |
marcomusy/vedo | numpy | 752 | Cannot load texture | The result does not contain texture, why?
Here is result:

Here is code:
```
import sys
import os
import numpy as np
from tqdm import tqdm
from vedo import *
def render(mesh_file, output_path):
... | closed | 2022-12-12T11:17:58Z | 2022-12-12T11:29:47Z | https://github.com/marcomusy/vedo/issues/752 | [] | rlczddl | 1 |
koxudaxi/datamodel-code-generator | fastapi | 1,850 | null bytes (`\u0000`) not correctly escaped in generated code | **Describe the bug**
A schema containing a NUL character `\u0000` becomes a literal (i.e. not escaped) NUL in the generated Python file. This is a SyntaxError.
> SyntaxError: source code cannot contain null bytes
**To Reproduce**
Example schema:
```json
{
"$schema": "https://json-schema.org/draft/2020-12... | closed | 2024-02-09T11:58:51Z | 2025-01-12T15:31:11Z | https://github.com/koxudaxi/datamodel-code-generator/issues/1850 | [
"bug"
] | tim-timman | 0 |
2noise/ChatTTS | python | 742 | 为什么mac mps 加速比cpu 慢 | closed | 2024-09-04T03:33:46Z | 2024-09-09T00:18:21Z | https://github.com/2noise/ChatTTS/issues/742 | [
"documentation"
] | wuhongsheng | 3 | |
supabase/supabase-py | fastapi | 1,001 | Insert request made using service_role key still unable to bypass RLS | # Bug report
<!--
⚠️ We receive a lot of bug reports which have already been solved or discussed. If you are looking for help, please try these first:
- Docs: https://docs.supabase.com
- Discussions: https://github.com/supabase/supabase/discussions
- Discord: https://discord.supabase.com
Before opening a... | closed | 2024-11-22T11:50:16Z | 2024-11-22T16:11:57Z | https://github.com/supabase/supabase-py/issues/1001 | [
"bug"
] | akarshghale | 4 |
scanapi/scanapi | rest-api | 431 | add type hints to the project | ## Feature request
### Description the feature
I think it would be nice to add type hints to the codebase, as it helps with documentation, catching bugs, and to maintain the whole project.
### Is your feature request related to a problem?
Nope
### Do you have any suggestions on how to add this feature in sca... | closed | 2021-07-28T22:46:59Z | 2021-08-03T12:26:49Z | https://github.com/scanapi/scanapi/issues/431 | [
"Code Quality",
"Multi Contributors",
"Needs Design Discussion"
] | sleao | 7 |
python-restx/flask-restx | flask | 285 | Namespace error handlers broken when propagate_exceptions=True | ### Details
When an `errorhandler` is registered on a namespace, and `PROPAGATE_EXCEPTIONS` is set to `True` in the Flask app, then the namespace handler will not catch the exceptions. It looks like this is due to the `handle_error` function not checking the error handlers that exist in any child classes.
### **Cod... | closed | 2021-02-20T21:35:45Z | 2022-03-01T16:38:24Z | https://github.com/python-restx/flask-restx/issues/285 | [
"bug"
] | mjreiss | 0 |
pydata/xarray | pandas | 9,595 | Weighting a datatree by a tree of dataarrays | ### What is your issue?
This isn't currently possible - but it's not simple to imagine how it might work. See https://github.com/xarray-contrib/datatree/issues/193 for previous discussion. | open | 2024-10-08T16:43:01Z | 2024-10-08T16:43:01Z | https://github.com/pydata/xarray/issues/9595 | [
"API design",
"topic-groupby",
"topic-DataTree"
] | TomNicholas | 0 |
holoviz/panel | matplotlib | 7,272 | Inconsistent handling of (start, end, value) in DatetimeRangeSlider and DatetimeRangePicker widget | #### ALL software version info
<details>
<summary>Software Version Info</summary>
```plaintext
panel 1.4.5
param 2.1.1
```
</details>
#### Description of expected behavior and the observed behavior
* DatetimeRangePicker should allow changing `start` and `end` without raising out-of-bound excep... | open | 2024-09-13T13:52:03Z | 2024-09-13T19:23:43Z | https://github.com/holoviz/panel/issues/7272 | [] | rhambach | 0 |
autokey/autokey | automation | 353 | Manually added phrases work, but do not show up in GUI | ## Classification: UI/Usability
## Reproducibility: Always
## Version
AutoKey version: 0.95.9-0
Used GUI (Gtk, Qt, or both): Qt
If the problem is known to be present in more than one version, please list all of those.
Installed via: (deb file).
Linux Distribution: Kubuntu
## Summary
Manually... | closed | 2020-01-10T22:01:23Z | 2023-04-29T19:13:41Z | https://github.com/autokey/autokey/issues/353 | [
"user interface"
] | dulawcdo | 11 |
gradio-app/gradio | deep-learning | 9,964 | Custom Loading UI for `gr.render` | - [x] I have searched to see if a similar issue already exists.
**Is your feature request related to a problem? Please describe.**
Currently, when using `gr.render()` for dynamic rendering, there is no support for custom loading UI. The default loading indicator does not meet specific design needs and may not ali... | open | 2024-11-15T09:53:30Z | 2024-11-16T00:15:52Z | https://github.com/gradio-app/gradio/issues/9964 | [
"enhancement"
] | KeJunMao | 3 |
ultralytics/yolov5 | pytorch | 12,754 | --image-weights and background images | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
If I use --image-weights, does the training process ignore background images?
in train... | closed | 2024-02-22T09:46:24Z | 2024-04-07T00:23:30Z | https://github.com/ultralytics/yolov5/issues/12754 | [
"question",
"Stale"
] | tino926 | 4 |
polarsource/polar | fastapi | 4,497 | Root API endpoint (`/`) 404 vs. offers direction | ### Description
https://api.polar.sh is broken
### Current Behavior
If you visit https://docs.polar.sh/api#feedback
Clicking https://api.polar.sh/ shows a page saying "details not found"
### Expected Behavior
Link should work
### Screenshots
 or ("en", "de"), the resulting corpus consistently has German as the first language and English as the second language, regardless of the input order.
Upon reviewing the source code of OpusParallelCorpus, it appears... | closed | 2025-02-21T23:24:40Z | 2025-03-17T01:29:08Z | https://github.com/flairNLP/flair/issues/3620 | [
"bug"
] | chelseagzr | 0 |
mailgyc/doudizhu | sqlalchemy | 17 | Can't connect to MySQL server on'localhost' | Python: 3.6.3
MySQL: 8.0.17
你好,我按教程进行操作,进入8080后输入完账号密码,点击注册按钮时,游戏界面红色字体报错:
`pymysql.err.OperationalError: (2003, "Can't connect to MySQL server on'localhost'")`
以下是我的操作记录:
```
E:\Output\Python_output\CCP\doudizhu>net start mysql
mysql 服务正在启动 ..
mysql 服务已经启动成功。
E:\Output\Python_output\CCP\doudizhu>m... | closed | 2019-08-31T10:21:56Z | 2019-09-03T15:36:19Z | https://github.com/mailgyc/doudizhu/issues/17 | [] | HaozhengLi | 4 |
mwaskom/seaborn | data-science | 2,927 | Consider Plot.tweak method for accepting function that operates on matplotlib figure | In some cases, it will be easy for users to achieve some fussy customization by writing imperative matplotlib code rather than trying to fit it into the declarative seaborn spec.
We could/should make it possible to access the matplotlib figure / axes, so the plot could be compiled and then tweaked. Currently, `Plot.... | open | 2022-07-30T22:13:13Z | 2022-07-30T22:13:39Z | https://github.com/mwaskom/seaborn/issues/2927 | [
"objects-plot",
"feature"
] | mwaskom | 0 |
onnx/onnx | tensorflow | 6,634 | Link broken in CONTRIBUTING.md | # Bug Report
### Is the issue related to model conversion?
No
### Describe the bug
<!-- Please describe the bug clearly and concisely -->
I think under the Development section, there is a broken link directing to https://github.com/onnx/onnx#build-onnx-from-source, but that section does not exist.
| closed | 2025-01-09T04:39:02Z | 2025-01-19T16:51:12Z | https://github.com/onnx/onnx/issues/6634 | [
"topic: documentation"
] | harshil1973 | 1 |
Urinx/WeixinBot | api | 230 | 新注册微信号无法登录网页版 | 
机器人没法用了吗? | open | 2017-09-15T06:46:49Z | 2017-12-17T13:10:29Z | https://github.com/Urinx/WeixinBot/issues/230 | [] | chunyong1991 | 4 |
mljar/mercury | jupyter | 151 | Windows path output handling | Hi.
I'm getting errors when I try to output to a windows directory. I can actually get the application to write to the filesystem, but mercury throws errors preventing the app from running.
Here's my relevant yaml:
```
params:
output_dir:
output: dir
```
and my relevant python:
`output_... | closed | 2022-07-28T14:16:30Z | 2022-07-28T16:54:57Z | https://github.com/mljar/mercury/issues/151 | [
"bug"
] | tfluhr | 6 |
python-gitlab/python-gitlab | api | 2,618 | CLI cannot handle server response | ## Description of the problem, including code/CLI snippet
`gitlab -c ./gitlab-cli.cfg project-merge-request get --iid 98765 --project-id 12345`
with config file content being
```
[global]
default = foo
ssl_verify = False
timeout = 5
api_version = 4
[foo]
url=https://some-project.url
private_token=some-... | closed | 2023-07-18T09:35:18Z | 2024-10-13T07:13:22Z | https://github.com/python-gitlab/python-gitlab/issues/2618 | [
"need info",
"stale"
] | twil69 | 11 |
flairNLP/flair | nlp | 3,017 | Discrepancy when de-serializing TARSTagger in master branch vs last release | When de-serializing the tars-ner model, the word_dropout is missing from the model. In version 0.11.3, it is still there.
To reproduce, execute the following code in `master` branch and in `v0.11.3`:
```python
tars: TARSTagger = TARSTagger.load('tars-ner')
tagger = tars.tars_model
print(tagger)
```
In `... | closed | 2022-12-11T09:03:35Z | 2023-06-11T11:25:40Z | https://github.com/flairNLP/flair/issues/3017 | [
"wontfix"
] | alanakbik | 2 |
fastapi/sqlmodel | pydantic | 377 | How to dynamically create tables by sqlmodel? | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X... | open | 2022-07-14T03:55:05Z | 2023-07-28T16:32:25Z | https://github.com/fastapi/sqlmodel/issues/377 | [
"question"
] | jaytang0923 | 6 |
elliotgao2/toapi | flask | 54 | Setting and updating of storage and cache issues. | If sent error, don't set storage.
If parse error, don't set cache. | closed | 2017-12-12T15:34:33Z | 2017-12-14T03:21:29Z | https://github.com/elliotgao2/toapi/issues/54 | [] | elliotgao2 | 0 |
scrapehero-code/amazon-scraper | web-scraping | 3 | Can we use this for wine products? | I am looking for a scraper for Amazon Vine products
[https://www.amazon.it/vine/vine-items?queue=last_chance&size=60](this a example link, but you must be vine)
| closed | 2020-09-19T11:49:57Z | 2023-02-23T06:34:47Z | https://github.com/scrapehero-code/amazon-scraper/issues/3 | [] | realtebo | 0 |
graphql-python/graphene-django | django | 744 | Better error messages for model_operations | Currently it throws this error when doing a create mutation which its `model_operations` doesn't have create set in it:
Invalid update operation. Input parameter "id" required. | closed | 2019-08-12T08:06:37Z | 2019-10-25T10:09:20Z | https://github.com/graphql-python/graphene-django/issues/744 | [
"wontfix"
] | dan-klasson | 1 |
pytest-dev/pytest-flask | pytest | 103 | indeterminate live_server segfaults on macos (workaround: threading.Thread) | _Not sure this is short-run actionable, and I don't think it's actually a pytest-flask bug. If others encounter this it may still make sense to add something like the workaround I identified as an optional run mode or automatic fallback. Opening an issue in case it helps others or attracts more information/reports. The... | open | 2019-12-30T20:27:52Z | 2021-11-04T17:32:30Z | https://github.com/pytest-dev/pytest-flask/issues/103 | [
"stale"
] | abathur | 0 |
ijl/orjson | numpy | 370 | Preparing metadata (pyproject.toml) did not run successfully: Cargo, the Rust package manager, is not installed or is not on PATH. | ```
#0 0.956 Downloading orjson-3.8.9.tar.gz (657 kB)
#0 1.147 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 657.1/657.1 kB 3.4 MB/s eta 0:00:00
#0 1.203 Installing build dependencies: started
#0 3.158 Installing build dependencies: finished with status 'done'
#0 3.159 Getting requirements to build wheel: s... | closed | 2023-03-28T15:56:07Z | 2023-04-09T15:09:12Z | https://github.com/ijl/orjson/issues/370 | [] | btseytlin | 5 |
yeongpin/cursor-free-vip | automation | 287 | [Bug]: 在执行了完全重置命令之后,cursor被卸载了,然后重新安装cursor都运行不起来,总是提示没有权限 | ### 提交前检查
- [x] 我理解 Issue 是用于反馈和解决问题的,而非吐槽评论区,将尽可能提供更多信息帮助问题解决。
- [x] 我已经查看了置顶 Issue 并搜索了现有的 [开放 Issue](https://github.com/yeongpin/cursor-free-vip/issues)和[已关闭 Issue](https://github.com/yeongpin/cursor-free-vip/issues?q=is%3Aissue%20state%3Aclosed%20),没有找到类似的问题。
- [x] 我填写了简短且清晰明确的标题,以便开发者在翻阅 Issue 列表时能快速确定大致问题。而不是“一个... | open | 2025-03-18T02:39:51Z | 2025-03-19T01:25:07Z | https://github.com/yeongpin/cursor-free-vip/issues/287 | [
"bug"
] | jeffreycool | 2 |
jupyter/nbviewer | jupyter | 177 | Download an ipynb file on a windows machine | When trying to download an ipynb file, by clicking on the button displayed in nbviewer, on Windows one adds an extra extension, txt. If I choose save all types of files, the txt is not added, but when I try to open it on my computer, invoking ipython notebook, an error message is displayed:
Error loading notebook
Unre... | open | 2014-01-20T19:33:08Z | 2018-07-16T13:19:57Z | https://github.com/jupyter/nbviewer/issues/177 | [
"type:Bug"
] | empet | 4 |
erdewit/ib_insync | asyncio | 4 | Unfilled params | Intellij IDEA code inspection indicates incorrect call arguments for the following two methods:
- `def exerciseOptions` (ib.py, line 798): parameter 'override' unfilled
- `def reqHistogramDataAsync` (ib.py, line 1007): parameter 'timePeriod' unfilled | closed | 2017-08-11T09:40:53Z | 2017-08-12T12:24:39Z | https://github.com/erdewit/ib_insync/issues/4 | [] | Elektra58 | 3 |
pywinauto/pywinauto | automation | 1,170 | Unable to interact with grid/table | ## Expected Behavior
Would like to be able to read items, select items, etc. from this table/grid. It doesn't seem to be of any type that I can work with, as it is only labeled as a pane type. It only has one child which is the scroll bar. Is there any possible way to work with this?
Any advice or suggestions much ... | open | 2022-01-14T18:19:51Z | 2022-01-14T18:19:51Z | https://github.com/pywinauto/pywinauto/issues/1170 | [] | vectar7 | 0 |
pytorch/pytorch | machine-learning | 149,094 | How to skip backward specific steps in torch.compile | ### 🐛 Describe the bug
I couldn't find much documentation around how we can skip backward specific-steps in torch.compile/AOT autograd.
Some info would be helpful.
### Error logs
_No response_
### Versions
NA
cc @chauhang @penguinwu | open | 2025-03-13T02:12:44Z | 2025-03-17T23:55:31Z | https://github.com/pytorch/pytorch/issues/149094 | [
"triaged",
"oncall: pt2"
] | janak2 | 3 |
nteract/papermill | jupyter | 379 | ImportError when Running Code off python.exe | Hi,
When I run the following code it does as intended.
```
import papermill as pm
pm.execute_notebook('test.ipynb',
'test.ipynb',
parameters=dict())
```
However if I run the code off cmd like so:
`C:\Users\me> python.exe code_above.py`
I get
```
raise ImportError: 'nb... | closed | 2019-06-13T20:50:29Z | 2019-07-05T20:17:35Z | https://github.com/nteract/papermill/issues/379 | [] | GXAB | 2 |
torchbox/wagtail-grapple | graphql | 134 | Move away from accessing stream_data directly | Ref: https://github.com/wagtail/wagtail/pull/6485
tl;dr "external code should not be using stream_data" | closed | 2020-11-04T19:44:15Z | 2021-08-19T06:54:09Z | https://github.com/torchbox/wagtail-grapple/issues/134 | [
"type: Refactor"
] | zerolab | 3 |
amdegroot/ssd.pytorch | computer-vision | 109 | ValueError: optimizing a parameter that doesn't require gradients | I wanted to freeze the first two layers of the network. Based on [this](http://pytorch.org/docs/master/notes/autograd.html?#excluding-requires-grad)
I wrote a code to freeze the first two layers like this before the optimisation line 105 on [train.py](https://github.com/amdegroot/ssd.pytorch/blob/master/train.py)
... | open | 2018-02-21T05:58:18Z | 2018-02-22T09:10:30Z | https://github.com/amdegroot/ssd.pytorch/issues/109 | [] | santhoshdc1590 | 1 |
tensorflow/tensor2tensor | deep-learning | 1,917 | Question about bleu evaluation | Hi, I am a little bit confused why should we set `REFERENCE_TEST_TRANSLATE_DIR=t2t_local_exp_runs_dir_master/t2t_datagen/dev/newstest2014-deen-ref.en.sgm` . because in my mind, the reference should be `de.sgm`. Do you have any idea? Thanks!
| open | 2022-10-20T03:42:52Z | 2022-10-20T10:16:18Z | https://github.com/tensorflow/tensor2tensor/issues/1917 | [] | shizhediao | 1 |
pytest-dev/pytest-selenium | pytest | 194 | get_cookies() is empty | Hi All
I have a test suite which is working nicely when using standard desktop browser settings. (Chrome)
When I try to test as a mobile using the following options, pytest-selenium returns no cookies.
```python
@pytest.fixture()
def chrome_options(chrome_options):
mobile_emulation = { "deviceName": "iP... | closed | 2018-09-24T16:22:28Z | 2019-04-29T20:18:05Z | https://github.com/pytest-dev/pytest-selenium/issues/194 | [] | Bobspadger | 13 |
lexiforest/curl_cffi | web-scraping | 451 | Automatic decoding of the link, resulting in an error request | When using requests. When a session sends a request, the URL link is automatically decoded and sent. This leads to some request errors,
For example, you would:
q8gMIv%2F%2F%2F%2F%2F%2F%2F%2F%2F%2F%2FARAEGgw5Mjc
Decoded into:
q8gMIv///////////ARAEGgw5Mjc
Causing an error in the request, how can I submit the origi... | closed | 2024-12-02T14:51:31Z | 2024-12-03T09:19:43Z | https://github.com/lexiforest/curl_cffi/issues/451 | [
"bug"
] | zdoek001 | 2 |
allenai/allennlp | nlp | 5,276 | Add label smoothing to CopyNetSeq2Seq | **Is your feature request related to a problem? Please describe.**
I am wondering if it is possible to add label smoothing to [`CopyNetSeq2Seq`](https://github.com/allenai/allennlp-models/blob/main/allennlp_models/generation/models/copynet_seq2seq.py). Label smoothing is implemented for the other allennlp-models und... | closed | 2021-06-22T00:44:59Z | 2021-08-05T17:48:21Z | https://github.com/allenai/allennlp/issues/5276 | [
"Contributions welcome"
] | JohnGiorgi | 5 |
google/seq2seq | tensorflow | 128 | UnicodeEncodeError when doing En-De prediction | After training En-De model, I tried running inference task and got UnicodeEncodeError:
My training and prediction scripts are attached.
Error:
`Traceback (most recent call last):
File "/usr/lib/python2.7/runpy.py", line 174, in _run_module_as_main
"__main__", fname, loader, pkg_name)
File "/usr/lib/pyth... | closed | 2017-03-29T18:24:57Z | 2017-03-29T18:39:41Z | https://github.com/google/seq2seq/issues/128 | [] | okuchaiev | 2 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 599 | [Feature request] 作者你好,tiktok 关键字搜索视频数据抓取可不可以考虑加一下呢。 | open | 2025-03-23T07:04:51Z | 2025-03-23T07:04:51Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/599 | [
"enhancement"
] | palp1233211 | 0 | |
Nemo2011/bilibili-api | api | 419 | [提问] 直播弹幕接口只能获取第一条弹幕 | **Python 版本:3.11.4
**模块版本:15.5.3
**运行环境:Windows
<!-- 务必提供模块版本并确保为最新版 -->
---
今天直播弹幕ws突然无法获取接下来的弹幕了,只能获取前面的第一次弹幕或者入场信息。试过多个号和ip地址都不行,现在有携带Credential初始化LiveDanmaku | closed | 2023-08-10T08:43:11Z | 2023-09-01T23:53:56Z | https://github.com/Nemo2011/bilibili-api/issues/419 | [
"bug",
"solved"
] | xqe2011 | 29 |
pywinauto/pywinauto | automation | 507 | Getting/Setting slider values on OBS Studio 64 | I'm trying to get/set the range of a volume slider on OBS Studio 64 bit. https://obsproject.com/download
I'm on the latest version `21.1.2`. Here is my code:
```python
from pywinauto.application import Application
app = Application(backend='uia').connect(path='obs64.exe')
# Mixers area
mixers = app.top_wind... | closed | 2018-06-17T18:41:52Z | 2021-10-08T07:51:29Z | https://github.com/pywinauto/pywinauto/issues/507 | [
"enhancement",
"UIA-related",
"good first issue",
"refactoring_critical"
] | glenbot | 5 |
ethanopp/fitly | plotly | 14 | Trouble connecting oura | Hi, was having trouble trying to connect my oura account. I hit the 'connect oura' button on the setting page, I was redirected to the oura page to grant access to the app, I accept the grant, andwas redirected back the settings page, with the 'connect oura' button still there. In the debug output I see:
Exception ... | closed | 2021-01-05T04:51:12Z | 2021-01-09T19:36:15Z | https://github.com/ethanopp/fitly/issues/14 | [] | spawn-github | 4 |
python-gitlab/python-gitlab | api | 2,401 | Difficulties to print trace properly | Hello everybody,
I'm having trouble displaying the logs properly in the terminal. The aim is to allow non-gitlab users to launch pipelines from their machines (could be Shell or Powershell, so we write it in Python and wrap it).
I would like this to be as close as possible to what can be found on Gitlab interface... | closed | 2022-11-29T05:53:19Z | 2023-12-11T01:17:45Z | https://github.com/python-gitlab/python-gitlab/issues/2401 | [
"need info",
"support"
] | d3ployment | 2 |
clovaai/donut | nlp | 14 | How to perform text reading task | Hi, thanks for the great project!
I am exciting to integrate the model into my document understanding project, and I want to implement text reading task.
I have one question:
- According to my understanding, i should download the pretrained model from "naver-clova-ix/donut-base", but what would be the prompt word ... | closed | 2022-08-08T15:10:17Z | 2022-08-15T02:34:49Z | https://github.com/clovaai/donut/issues/14 | [] | mike132129 | 1 |
deezer/spleeter | tensorflow | 290 | Command not found: Spleeter | <img width="568" alt="Screen Shot 2020-03-12 at 9 33 25 AM" src="https://user-images.githubusercontent.com/58147163/76526825-87602400-6444-11ea-9ec2-a16ea279bd02.png">
Any ideas? I followed all the instructions. | closed | 2020-03-12T13:34:49Z | 2020-05-25T19:25:21Z | https://github.com/deezer/spleeter/issues/290 | [
"bug",
"invalid"
] | chrisgauthier9 | 2 |
serengil/deepface | machine-learning | 538 | Install issues | pip install deepface is resulting in the following error
"ImportError: cannot import name 'DeepFace' from partially initialized module 'deepface' (most likely due to a circular import)"
have deleted and recreated the environment multiple times and continue to get this message. Running the same install command 2 ... | closed | 2022-08-19T21:14:00Z | 2022-08-19T21:44:58Z | https://github.com/serengil/deepface/issues/538 | [
"question"
] | kg6kvq | 5 |
ray-project/ray | tensorflow | 51,514 | [Autoscaler] Add Support for BatchingNodeProvider in Autoscaler Config Option | ### Description
[KubeRay](https://docs.ray.io/en/latest/cluster/kubernetes/user-guides/configuring-autoscaling.html#overview) currently uses the BatchingNodeProvider to manage clusters externally (using the KubeRay operator), which enables users to interact with external cluster management systems. However, to support... | open | 2025-03-19T06:51:24Z | 2025-03-19T22:23:54Z | https://github.com/ray-project/ray/issues/51514 | [
"enhancement",
"P2",
"core"
] | nadongjun | 0 |
jupyterhub/repo2docker | jupyter | 852 | RShiny bus-dashboard example returns 500 | <!-- Thank you for contributing. These HTML commments will not render in the issue, but you can delete them once you've read them if you prefer! -->
### Bug description
<!-- Use this section to clearly and concisely describe the bug. -->
Running [RShiny bus-dashboard example](https://github.com/binder-examples/r) ... | closed | 2020-02-28T01:33:33Z | 2020-03-01T21:06:03Z | https://github.com/jupyterhub/repo2docker/issues/852 | [] | supern8ent | 5 |
coqui-ai/TTS | python | 3,099 | KeyError: 'xtts_v1' | Hey, when i run the following python api i encounter KeyError :'xtts_v1'
```
import torch
from TTS.api import TTS
# Get device
device = "cuda" if torch.cuda.is_available() else "cpu"
# List available 🐸TTS models
print(TTS().list_models())
# Init TTS
tts = TTS("tts_models/multilingual/multi-dataset/x... | closed | 2023-10-22T02:52:05Z | 2023-10-22T19:16:14Z | https://github.com/coqui-ai/TTS/issues/3099 | [] | a-3isa | 1 |
huggingface/transformers | nlp | 36,296 | tensor parallel training bug | ### System Info
transformers:4.45.dev0
python:3.11
linux
### Who can help?
#34194
### Information
- [x] The official example scripts
- [ ] My own modified scripts
### Tasks
- [x] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
##... | open | 2025-02-20T08:15:10Z | 2025-03-23T08:03:34Z | https://github.com/huggingface/transformers/issues/36296 | [
"bug"
] | iMountTai | 4 |
CorentinJ/Real-Time-Voice-Cloning | python | 289 | How do I use my own mp3? | I'm playing with the demo, and I only have an option to record, how do I import an audio file?
tnx.
| closed | 2020-02-26T00:24:56Z | 2020-07-04T22:35:07Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/289 | [] | orenong | 10 |
horovod/horovod | deep-learning | 3,027 | CMake Error in horovod/torch/CMakeLists.txt: Target "pytorch" requires the language dialect "CXX14" , but CMake does not know the compile flags to use to enable it. | **Environment:**
1. Framework: (PyTorch,)
2. Framework version:
3. Horovod version:
4. MPI version:
5. CUDA version:
6. NCCL version:
7. Python version:
8. Spark / PySpark version:
9. Ray version:
10. OS and version:
11. GCC version:
12. CMake version:
-- Configuring done
CMake Error in horovod/to... | closed | 2021-07-08T08:03:34Z | 2021-08-03T10:13:52Z | https://github.com/horovod/horovod/issues/3027 | [
"bug"
] | Junzh821 | 1 |
google-research/bert | tensorflow | 1,074 | Are adam weights and variances necessary to continue pretraining? | Before continuing pre-training from one of the checkpoints provided in the readme page, I reduced the size of the checkpoint by removing Adam weights and parameters, keeping only the model weights.
Do you think this might affect the performances of continuing the pre-training? (and/or even fine-tuning?)
In oth... | open | 2020-04-27T16:04:10Z | 2020-04-27T16:04:37Z | https://github.com/google-research/bert/issues/1074 | [] | pretidav | 0 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 773 | Slowly training speed? | Thanks for your great work in Cycle-GAN. However, when I use it in my data training, the training process seems so slow, almost 7 epochs a day. My training data contains 22000 images with size 256x256 in trainA. And the loss-curves seem no obviously changes. | closed | 2019-09-20T07:05:43Z | 2019-09-23T01:48:01Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/773 | [] | JerryLeolfl | 7 |
jina-ai/serve | fastapi | 6,030 | Flow with http doesn't support docarray float attribute | **Describe the bug**
<!-- A clear and concise description of what the bug is. -->
The flow will raise an error when sending float in HTTP. GRPC works fine
```python
from typing import Optional
from docarray import BaseDoc, DocList
from jina import Flow, Executor, requests
class DummyDoc(BaseDoc):
numb... | closed | 2023-08-17T10:41:38Z | 2024-03-18T10:30:14Z | https://github.com/jina-ai/serve/issues/6030 | [] | ZiniuYu | 0 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 15,840 | [Feature Request]: Option to save original mask image when inpainting | ### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What would your feature do ?
To be able to reproduce results, there should be an option to save the original mask image, which can later be used in the `inpaint upload` tab.
Currently there i... | open | 2024-05-19T16:22:55Z | 2024-05-19T16:22:55Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15840 | [
"enhancement"
] | Drake53 | 0 |
huggingface/datasets | tensorflow | 6,721 | Hi,do you know how to load the dataset from local file now? | Hi, if I want to load the dataset from local file, then how to specify the configuration name?
_Originally posted by @WHU-gentle in https://github.com/huggingface/datasets/issues/2976#issuecomment-1333455222_
| open | 2024-03-07T13:58:40Z | 2024-03-31T08:09:25Z | https://github.com/huggingface/datasets/issues/6721 | [] | Gera001 | 3 |
reloadware/reloadium | pandas | 179 | VSCode plugin roadmap | Dear Reloadium project maintainers,
I am captivated by the features of Reloadium as presented on your official website. Unfortunately, I use VSCode as my primary production tool, rather than PyCharm. Thus, I would like to inquire whether you could provide a more detailed roadmap for this project. Thank you! | closed | 2024-02-08T14:46:19Z | 2024-02-17T14:25:02Z | https://github.com/reloadware/reloadium/issues/179 | [] | Mirac-Le | 1 |
Johnserf-Seed/TikTokDownload | api | 229 | 用TikTokTool 和 TikTokDownload 下载视频的清晰度不一样。 | 用 TikTokTool.exe 批量下载的所有视频都是1080p,
用 TikTokDownload.exe下载的单个视频是720p,能否也上1080p?
测试抖音主页:https://v.douyin.com/MdRBCPk/ | closed | 2022-10-07T08:29:37Z | 2022-11-27T11:49:27Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/229 | [
"故障(bug)",
"额外求助(help wanted)",
"无效(invalid)"
] | happyaguang | 2 |
tensorpack/tensorpack | tensorflow | 1,121 | Assign model to my graph | When I try to use tensorpack as a part of my code to get an accuracy of a model, outside it I define a Keras model, but it turns out to have a conflict between the two models, when I add
```
child_graph = tf.Graph()
with child_graph.as_default():
```
before the tensorpack train, it is solved, I wonder if there... | closed | 2019-03-27T11:00:43Z | 2019-04-03T06:39:01Z | https://github.com/tensorpack/tensorpack/issues/1121 | [
"unrelated"
] | Guocode | 1 |
pyeventsourcing/eventsourcing | sqlalchemy | 284 | Exclude unnecessary packages (tests, examples) from distribution | When installing the `eventsourcing` package, unnecessary directories like `tests` and `examples` are included in the package by default. These folders are not required for production use and add extra size to the installation.
To improve the package structure and reduce its size, please adjust the build configurati... | closed | 2024-11-05T11:47:43Z | 2024-11-08T07:34:40Z | https://github.com/pyeventsourcing/eventsourcing/issues/284 | [] | vmorugin | 2 |
jina-ai/clip-as-service | pytorch | 386 | how could I support concurrency upto 50 a seconds? | **Prerequisites**
> Please fill in by replacing `[ ]` with `[x]`.
* [yes ] Are you running the latest `bert-as-service`?
* [yes ] Did you follow [the installation](https://github.com/hanxiao/bert-as-service#install) and [the usage](https://github.com/hanxiao/bert-as-service#usage) instructions in `README.md`?
*... | open | 2019-06-19T02:55:47Z | 2019-06-20T02:37:56Z | https://github.com/jina-ai/clip-as-service/issues/386 | [] | weizhenzhao | 1 |
itamarst/eliot | numpy | 75 | setup.py points to "hybridlogic" github url instead of "hybridcluster" | Fortunately the former is a redirect to the latter. Still would be better to point directly at the right page though.
| closed | 2014-05-15T15:49:58Z | 2018-09-22T20:59:13Z | https://github.com/itamarst/eliot/issues/75 | [
"documentation"
] | exarkun | 1 |
streamlit/streamlit | streamlit | 10,452 | v1.42.0 introduces call to asyncio.get_event_loop().is_running() which sometimes throws RuntimeError | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
Developer of aider here. After upgrading my s... | closed | 2025-02-19T22:00:35Z | 2025-03-24T02:24:06Z | https://github.com/streamlit/streamlit/issues/10452 | [
"type:bug",
"status:confirmed",
"priority:P1"
] | paul-gauthier | 5 |
autogluon/autogluon | data-science | 3,905 | Multilabel Predictor Issue | I have trained a model 'Multilabel Predictor' in my local computer. I need to run a airflow pipeline to predict the data and store predictions in a table in redshift. The issue with the model stored in my computer is that the pickle file has the hardcore path of my computer (screenshot 1: first line of the pickle file)... | open | 2024-02-06T18:57:17Z | 2024-11-25T22:47:10Z | https://github.com/autogluon/autogluon/issues/3905 | [
"bug",
"module: tabular",
"priority: 1"
] | YilanHipp | 0 |
BeanieODM/beanie | asyncio | 1,103 | [BUG] Inconsistent `before_event` trigger behavior | **Describe the bug**
I have a `before_event` annotation to update a field on a document every time it is updated. The behavior the event handling is inconsistent based on what update method I use. I have a full reproduction that shows updating 4 documents in 4 different ways, with differing results:
1. `find_one(...)... | open | 2025-01-03T18:40:13Z | 2025-03-16T14:48:44Z | https://github.com/BeanieODM/beanie/issues/1103 | [
"bug"
] | paulpage | 4 |
flavors/django-graphql-jwt | graphql | 250 | Does it really support Graphene V3 ? | Hello everyone !
According to [this commit](https://github.com/flavors/django-graphql-jwt/commit/d50a533e26f1509828ef9fc804b195ebdfc1c04e), Graphene V3 should be supported.
However if I use :
```
django==3.1.5
psycopg2==2.8.6
graphene-django==3.0.0b7
django-graphql-jwt==0.3.1
PyJWT>=1.5.0,<2
pyyaml==5.3.1
g... | closed | 2021-01-18T08:43:43Z | 2021-01-27T10:06:06Z | https://github.com/flavors/django-graphql-jwt/issues/250 | [] | laurent-brisbois | 4 |
automl/auto-sklearn | scikit-learn | 1,439 | Non-breaking ERROR printed: "init_dgesdd failed init" while running AutoSklearnClassifier | ## Describe the bug ##
Hi,
I am getting the Error 'init_dgesdd failed init' when I perform longer runs (> 46000 s) of the AutoSklearnClassifier. My dataset has the shape (42589, 26). The call still results in an optimized model. So I suspect that only some optimization runs are failing. The AutoSklearnClassifier ... | closed | 2022-04-13T13:16:07Z | 2022-04-24T13:37:14Z | https://github.com/automl/auto-sklearn/issues/1439 | [
"documentation"
] | teresa-m | 2 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 1,290 | Poor result for GTA to Cityscapes translation using cyclegan !! | Hello !!
I want generate more realistic images from GTA dataset,
So use Cyclegan to translate Gta to Cityscapes but it gives me poor result,
Anyone can helps me to fix that ?
... | open | 2021-06-21T13:27:00Z | 2021-11-04T06:41:13Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1290 | [] | soufianeao | 1 |
dynaconf/dynaconf | flask | 341 | 'box_it_up' key in dict | **Describe the bug**
Loading dictionary from yaml type config, adds additional pair: 'box_it_up': True
**To Reproduce**
1. create the following settings.yaml:
development:
WEEK_DAYS:
FRI: false
MON: false
SAT: false
SUN: false
THU: false
TUE: false
WED: false
2. Read using... | closed | 2020-05-15T22:29:35Z | 2020-07-27T19:45:24Z | https://github.com/dynaconf/dynaconf/issues/341 | [
"bug",
"Pending Release"
] | And2Devel | 2 |
guohongze/adminset | django | 2 | 关于adminset相关建议 | 测试了一下adminset,体验还不错。简洁明了,使用方便。在使用过程中有几个小小的建议,具体如下:
1. 资产管理,显示数据较少,具体如下图:

比如能再增加一些操作系统版本信息、CPU型号、硬盘大小等更好;
2. 增加一下用户的操作记录;
3. 对用户的权限增加做一些说明,比如下图:

### Steps to reproduce
Got to... | closed | 2024-07-15T13:10:38Z | 2024-08-15T03:04:08Z | https://github.com/paperless-ngx/paperless-ngx/issues/7253 | [
"bug",
"frontend"
] | umtauscher | 5 |
skypilot-org/skypilot | data-science | 4,433 | [Jobs/Serve] Warning for credentials that requires reauth | <!-- Describe the bug report / feature request here -->
For cloud credentials like AWS and GCP, they may have expiration, e.g. AWS SSO or gcloud reauth, which will cause significant leakage from the controller for jobs and service if we use these local credentials on the controller. We have multiple users encounte... | closed | 2024-12-03T18:36:24Z | 2025-01-09T22:14:50Z | https://github.com/skypilot-org/skypilot/issues/4433 | [
"P0"
] | Michaelvll | 2 |
Miserlou/Zappa | flask | 1,711 | How to call "xxx.so" file | Dear Zappa developers,
thanks for providing such a wonderful solution to help depoly python web services to Lambda.
i am trying to use Zappa to migrate my current Django project to lambda, the problem is some of my third-party packages are not pure python (example package "levenshtein") the output file was a "xxxxx... | closed | 2018-11-28T07:29:43Z | 2018-12-04T02:28:36Z | https://github.com/Miserlou/Zappa/issues/1711 | [] | wally-yu | 2 |
gradio-app/gradio | python | 10,557 | Add an option to remove line numbers in gr.Code | - [X ] I have searched to see if a similar issue already exists.
**Is your feature request related to a problem? Please describe.**
`gr.Code()` always displays line numbers.
**Describe the solution you'd like**
I propose to add an option `show_line_numbers = True | False` to display or hide the line numbers. The... | closed | 2025-02-10T11:38:07Z | 2025-02-21T22:11:43Z | https://github.com/gradio-app/gradio/issues/10557 | [
"enhancement",
"good first issue"
] | altomani | 1 |
d2l-ai/d2l-en | data-science | 2,076 | MaskedSoftmaxCELoss code wrong | this line:
weighted_loss = (unweighted_loss * weights).mean(dim=1)
should be corrected to:
weighted_loss = (unweighted_loss * weights).sum(dim=1)
reason:
when use `mean`, the padding locations will be calculated as denoimator to drag down the loss. In this case, model will learn to cheat by predicting as long ... | open | 2022-03-21T16:13:03Z | 2022-05-19T23:42:53Z | https://github.com/d2l-ai/d2l-en/issues/2076 | [] | Y-H-Joe | 2 |
feature-engine/feature_engine | scikit-learn | 764 | radial basis function | https://youtu.be/68ABAU_V8qI?feature=shared&t=373
Useful for time series. Need to investigate a bit more, leaving a note here | open | 2024-05-16T12:34:38Z | 2024-08-24T15:59:43Z | https://github.com/feature-engine/feature_engine/issues/764 | [] | solegalli | 1 |
holoviz/panel | matplotlib | 7,459 | Make it possible to ignore caching when using `--autoreload`. | When running Panel in production we would not expect source files css, html and Graphic Walker spec files to change. For performance reasons we would like to read and cache these. But during development with hot reload/ `--dev` we would like files to be reread.
Its not clear how this should be implemented. But I belie... | open | 2024-11-03T09:37:28Z | 2024-11-03T09:38:30Z | https://github.com/holoviz/panel/issues/7459 | [] | MarcSkovMadsen | 0 |
numba/numba | numpy | 9,826 | RecursionError from ssa.py due to repeated calls to a jitted function. |
## Reporting a bug
When running the same relatively simple function, jitted using `nb.njit(inline="always")`, a recursion error is raised by `numba/core/ssa.py`.
In the attached runnable, this bug occurs with 150 repeated calls to the function.
If additional type complexity is introduced to the file, the bug... | open | 2024-12-04T16:25:08Z | 2024-12-05T21:07:39Z | https://github.com/numba/numba/issues/9826 | [
"bug - failure to compile"
] | DSchab | 3 |
keras-team/keras | machine-learning | 20,118 | Testing functional models as layers | In keras V2 it was possible to test functional models as layers with TestCase.run_layer_test
But in keras V3 it is not due to an issue with deserialization https://colab.research.google.com/drive/1OUnnbeLOvI7eFnWYDvQiiZKqPMF5Rl0M?usp=sharing
The root issue is input_shape type in model config is a list, while laye... | closed | 2024-08-14T08:42:59Z | 2024-10-21T06:37:10Z | https://github.com/keras-team/keras/issues/20118 | [
"type:Bug"
] | shkarupa-alex | 3 |
jmcnamara/XlsxWriter | pandas | 1,069 | Chart: in a discontinuous series, the data label isn't displayed | ### Question
hello,
I have read the [chart-series-option-data-labels](https://xlsxwriter.readthedocs.io/working_with_charts.html#chart-series-option-data-labels) document
try to add data label in a discontinuous series, but it's not work.
thanks a lot
**example as follow**
version: 3.2.0
```
import xlsx... | closed | 2024-05-15T02:08:44Z | 2024-05-15T09:14:14Z | https://github.com/jmcnamara/XlsxWriter/issues/1069 | [
"question",
"awaiting user feedback"
] | youth54 | 3 |
Ehco1996/django-sspanel | django | 860 | feature reqeust: support upload node load when sync traffic | ## Feature Request
**Is your feature request related to a problem? Please describe:**
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
**Describe the feature you'd like:**
<!-- A clear and concise description of what you want to happen. -->
**Describe alte... | closed | 2023-08-16T06:30:33Z | 2023-08-25T00:22:23Z | https://github.com/Ehco1996/django-sspanel/issues/860 | [] | Ehco1996 | 1 |
MilesCranmer/PySR | scikit-learn | 173 | [BUG] PySR sometimes fails without internet | `update=False` should be set to a new default: `update=None`, and updates should only be performed if the internet is connected. | closed | 2022-08-04T17:44:35Z | 2022-11-28T23:22:00Z | https://github.com/MilesCranmer/PySR/issues/173 | [
"bug"
] | MilesCranmer | 1 |
hayabhay/frogbase | streamlit | 20 | CPU Dynamic Quantization | Would it be possible for you guys to add an option to enable dynamic quantization of the model when it's being run on a CPU? This would greatly improve the run-time performance of the OpenAI Whisper model (CPU-only) with minimal to no loss in performance.
The benchmarks for this are available [here](https://github.c... | closed | 2023-02-09T02:25:26Z | 2023-05-24T18:18:20Z | https://github.com/hayabhay/frogbase/issues/20 | [] | MiscellaneousStuff | 5 |
KaiyangZhou/deep-person-reid | computer-vision | 467 | feature_extractor + cuda error: out of memory | Hello Kaiyang, thank you for your amazing work on OSNet.
I am using torchreid as a feature extractor in my own project following the API given in your documentation and using an OSNet pretrained model (osnet_x0_25_imagenet) . When performing this inference using cpu, I am able to extract features of the query and ga... | closed | 2021-10-21T14:36:38Z | 2021-12-15T02:18:48Z | https://github.com/KaiyangZhou/deep-person-reid/issues/467 | [] | jovi-s | 0 |
vllm-project/vllm | pytorch | 14,507 | [Usage]: The example of using microsoft/Phi-4-multimodal-instruct audio | ### Your current environment
How to use microsoft/Phi-4-multimodal-instruct audio by using vllm?
[Here](https://github.com/vllm-project/vllm/pull/14343/files#diff-068f76c074ff2ec408347e0b9ff0b8ce78b75048a83343b71d684b68511480aa),
I can see an example of using vision, but how to use audio? Please help!
, TikTok begins to return only
{"code": "10000", "from": "", "type": "verify", "version": "", "region": "va", "subtype": "slide", "detail": "xEjm*7jBPnMllKzEUYW8xSJ-ivjFjq65ZCYvEfIj3pI1Z3VtwL-uBL4JnDUOshgBEzoHt7mfm6YHTheB0ulhLuQchGb6mFdS1tvGxJA08J9k8x37-lFZS... | closed | 2020-07-31T14:44:04Z | 2020-08-01T02:29:57Z | https://github.com/davidteather/TikTok-Api/issues/206 | [
"bug"
] | tarkhil | 6 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.