
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
nonebot/nonebot2 | fastapi | 2,943 | Plugin: nonebot-plugin-githubmodels | ### PyPI 项目名
nonebot-plugin-githubmodels
### 插件 import 包名
githubmodels
### 标签
[]
### 插件配置项
```dotenv
GITHUB_TOKEN="hxjxnfkdmzjs"
```
| closed | 2024-09-12T15:43:52Z | 2024-09-12T15:51:08Z | https://github.com/nonebot/nonebot2/issues/2943 | [
"Plugin"
] | lyqgzbl | 2 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 1,115 | I can't make sense of this error... can somebody please help me | I made it to step 5 of installation without problems, and even received "all test passed" when running `python demo_cli.py`,
However, when i get to I get to launching the toolbox, `python demo_toolbox.py -d <datasets_root>` (where datasets_root points to train-clean-100 downloaded per step 4), I receive this error:... | closed | 2022-09-22T07:52:13Z | 2023-01-08T08:55:12Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1115 | [] | ikesaber | 0 |
ultralytics/yolov5 | pytorch | 12,897 | Running Hyperparameter Evolution raises ValueError | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and found no similar bug report.
### YOLOv5 Component
Training, Evolution
### Bug
I was trying to train my custom model locally on `Nvidia RTX 3050` but it raises a ValueError. I checked and it raises... | closed | 2024-04-08T15:12:26Z | 2024-10-20T19:43:15Z | https://github.com/ultralytics/yolov5/issues/12897 | [
"bug",
"Stale"
] | RAHUL01-09 | 3 |
microsoft/nni | deep-learning | 5,031 | How to set useActivateGpu=true in remote mode? | **Describe the issue**:
I can use the NNI normally with Remote mode on the CPU, although it is very slow.
When I try to use NNI to run the program on GPU under the remote mode, the program is always waiting but didn't run at all.
One possible reason is that all of the GPUs in the remote machine are partly occupied ... | closed | 2022-07-30T06:43:34Z | 2022-09-07T10:42:16Z | https://github.com/microsoft/nni/issues/5031 | [
"user raised",
"support",
"remote"
] | unikcc | 1 |
absent1706/sqlalchemy-mixins | sqlalchemy | 32 | Does BaseModel.set_session(session) only run once? | Or BaseModel.set_session(session) needs to run for every request? | closed | 2020-01-11T07:11:46Z | 2020-03-31T16:21:00Z | https://github.com/absent1706/sqlalchemy-mixins/issues/32 | [] | scil | 1 |
pytorch/vision | machine-learning | 8,389 | Compiling resize_image: function interpolate not_implemented | ### 🐛 Describe the bug
I am compiling a method (mode=default, fullgrph=True), which calls torchvision.transforms.v2.functional.resize_image. However, I receive an error, which indicates that the interpolate method is not implemented. I am using pytorch lightning and weirdly this only happens during validation. It wor... | open | 2024-04-19T18:04:08Z | 2024-04-29T13:10:51Z | https://github.com/pytorch/vision/issues/8389 | [] | treasan | 1 |
JaidedAI/EasyOCR | deep-learning | 629 | Why are there some pictures with errors? | The same code, Why are there some pictures with errors?
Here is the error message
```
CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU.
Traceback (most recent call last):
File "D:/code/python/base/test1.py", line 6, in <module>
result = reader.readtext('invoice.png')
... | closed | 2021-12-24T10:22:22Z | 2022-08-07T05:01:56Z | https://github.com/JaidedAI/EasyOCR/issues/629 | [] | jinhuiDing | 0 |
pykaldi/pykaldi | numpy | 90 | why do i get different result for computing fbank-feature between pykaldi and kaldi | i install the pykaldi from source.
then compare the result for using pykaldi to result for using compute-fbank-feats in kaldi with test.wav
1.code(use pykaldi)
sf_bank=16000.0
m3 = SubVector(mean(s3, axis=0))
f3=fbank.compute_features(m3,sf_fbank,1.00)
feature:
13.5067 10.8341 10.0170 ... 13.6531 13.5450... | closed | 2019-03-15T09:43:38Z | 2019-03-19T05:53:05Z | https://github.com/pykaldi/pykaldi/issues/90 | [] | liuchenbaidu | 6 |
jupyter/docker-stacks | jupyter | 2,083 | After starting the container with NB_USER=root, NB_UID=0, and NB_GID=0, $HOME environment variable is still /home/jovyan | ### What docker image(s) are you using?
datascience-notebook
### Host OS system
Ubuntu 22.04
### Host architecture
x86_64
### What Docker command are you running?
docker run -d --rm --user root -p 8888:8888 -e JUPYTER_TOKEN=123 -e NB_UID=0 -e NB_GID=0 -e NB_USER=root -e
NOTEBOOK_ARGS="--allow-root" quay.io/jup... | closed | 2024-01-17T12:12:14Z | 2024-01-17T12:31:08Z | https://github.com/jupyter/docker-stacks/issues/2083 | [
"type:Bug"
] | anil-resero | 3 |
Zeyi-Lin/HivisionIDPhotos | machine-learning | 158 | 想请教下各位大佬,nodejs有相关的库可以实现证件照图片处理的功能嘛 | closed | 2024-09-21T11:45:49Z | 2024-10-04T12:00:12Z | https://github.com/Zeyi-Lin/HivisionIDPhotos/issues/158 | [] | Chandie-Zhang | 3 | |
deepfakes/faceswap | deep-learning | 1,022 | Windows installer broken | **Crash reports MUST be included when reporting bugs.**
(check) CPU Supports SSE4 Instructions
(check) Completed check for installed applications
(check) Setting up for: cpu
Downloading Miniconda3...
Installing Miniconda3. This will take a few minutes...
Miniconda3 installed.
Initializing Conda...
Creating Co... | closed | 2020-05-11T07:01:49Z | 2020-05-13T11:32:29Z | https://github.com/deepfakes/faceswap/issues/1022 | [] | BlueONn | 1 |
tflearn/tflearn | data-science | 640 | a little error in the doc page | At doc page [get_started](http://tflearn.org/getting_started/), the first example of topic 'Layers':
```
with tf.name_scope('conv1'):
W = tf.Variable(tf.random_normal([5, 5, 1, 32]), dtype=tf.float32, name='Weights')
b = tf.Variable(tf.random_normal([32]), dtype=tf.float32, name='biases')
x = tf.nn.con... | closed | 2017-02-28T16:04:25Z | 2017-03-16T22:47:36Z | https://github.com/tflearn/tflearn/issues/640 | [] | cooljacket | 0 |
microsoft/nni | pytorch | 5,338 | Add a parameter in generate_scenario for the file 'scenario.txt' instead of harcoding | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
It would be great in the function https://github.com/microsoft/nni/blob/e85f029bd4e4b1bdf3e679893fb6447e4d6b2c79/nni/algorithms/hpo/smac_tuner/convert_ss_to_scenario.py#L192 to add a parameter for `scen... | closed | 2023-02-07T12:28:14Z | 2023-02-27T16:05:23Z | https://github.com/microsoft/nni/issues/5338 | [] | miguelgfierro | 0 |
ageitgey/face_recognition | python | 721 | Issue with dLib installation with Cuda and AVX support | * face_recognition version: Latest
* Python version: 3.7
* Operating System: Linux with GPU
### Description-- Please help - cmake version 2.8.12
Trying to install dLib with AVX and Cuda support
Command tried-
Paste the command(s) you ran and the output.
python3 setup.py install --yes USE_AVX_INSTRUCTIONS --... | open | 2019-01-22T10:02:03Z | 2019-01-22T10:02:03Z | https://github.com/ageitgey/face_recognition/issues/721 | [] | 74981 | 0 |
apachecn/ailearning | python | 484 | 无监督算法【需要完善+补充】 | 半监督学习(Semi-Supervised Learning,SSL)类属于机器学习(Machine Learning,ML)。
## 一 ML有两种基本类型的学习任务:
> 1.监督学习(Supervised Learning,SL)
根据输入-输出样本对L={(x1,y1),···,(xl,yl)}学习输入到输出的映射f:X->Y,来预测测试样例的输出值。SL包括分类(Classification)和回归(Regression)两类任务,分类中的样例xi∈Rm(输入空间),类标签yi∈{c1,c2,···,cc},cj∈N;回归中的输入xi∈Rm,输出yi∈R(输出空间)。
> 2. 无监督学习(... | closed | 2019-02-25T08:38:34Z | 2021-09-07T17:45:35Z | https://github.com/apachecn/ailearning/issues/484 | [] | jiangzhonglian | 0 |
fbdesignpro/sweetviz | data-visualization | 45 | Add box plots | version: 1.0.3
date: Jul 22, 2020
Currently "sweetviz" only has bar-charts for visualizations. For medium-size data analysis (such as titanic or Boston housing) it is not much costly to show box-plots as well as bar-plots. For a larger dataset, it can be made optional in `config.ini`file and can also be determi... | open | 2020-07-22T16:04:55Z | 2020-07-23T14:56:45Z | https://github.com/fbdesignpro/sweetviz/issues/45 | [
"feature request"
] | bhishanpdl | 0 |
graphistry/pygraphistry | jupyter | 440 | publish cucat | it should be clear how to get a versioned cucat
ideas:
- [x] pypi / pip
For now, instead, git tag so versioned pip install github ... tag <--- for now, use semvar: https://semver.org/ | open | 2023-02-20T23:32:51Z | 2023-12-07T06:13:24Z | https://github.com/graphistry/pygraphistry/issues/440 | [
"enhancement",
"p4",
"infra"
] | lmeyerov | 1 |
microsoft/unilm | nlp | 1,573 | Unable to use finetuned LayoutLMV3 for object detection task model for testing | **Describe**
Model I am using (LayoutLMV3):
I have sucessfully finetuned LayoutLMV3 model on custom dataset similar to publaynet dataset on object detection task , it saves a .pth model but when I try to use it for eval using this script :
python train_net.py --config-file cascade_layoutlmv3.yaml --eval-only --num-... | open | 2024-06-12T10:47:55Z | 2024-10-16T02:36:49Z | https://github.com/microsoft/unilm/issues/1573 | [] | maniyarsuyash | 1 |
roboflow/supervision | deep-learning | 1,376 | mAP for small, medium and large objects | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Description
I saw an issue online where the user demanded calculation of MeanAveragePrecision for small, medium and large objects for HBB and OBB detecti... | closed | 2024-07-17T15:15:41Z | 2024-07-17T16:16:32Z | https://github.com/roboflow/supervision/issues/1376 | [
"enhancement"
] | Bhavay-2001 | 2 |
aidlearning/AidLearning-FrameWork | jupyter | 74 | 请问可以支持预装最新版的wps office for linux arm吗,希望在大屏安卓平板上能有办公能力 | 请问可以支持预装最新版的wps office for linux arm吗,希望在大屏安卓能有办公能力
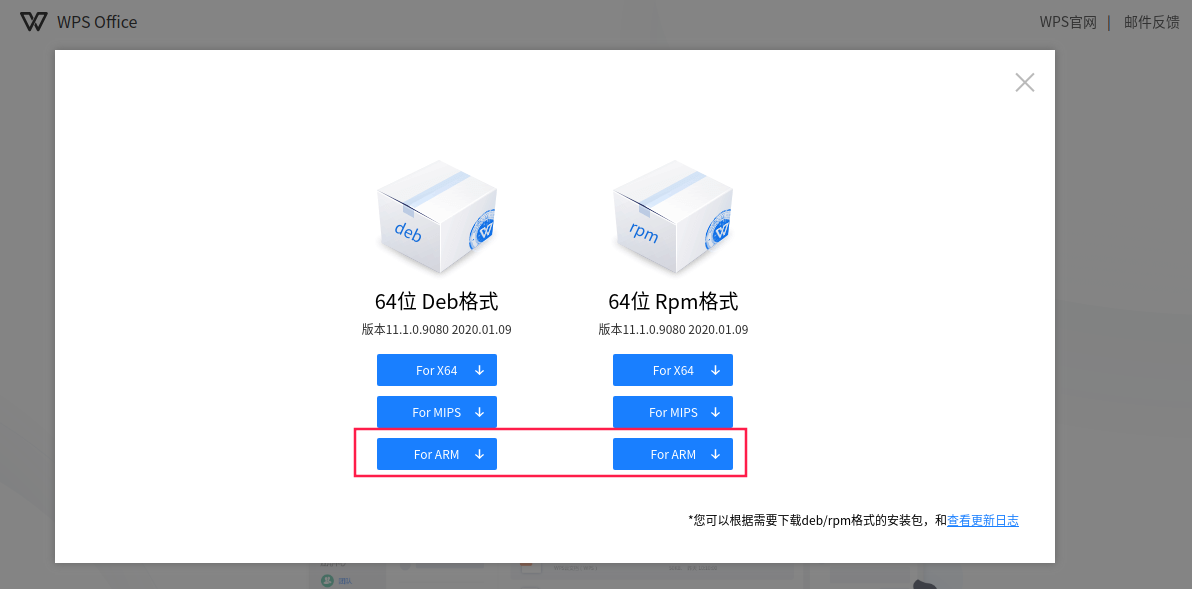
| closed | 2020-01-18T14:07:06Z | 2020-02-11T17:38:37Z | https://github.com/aidlearning/AidLearning-FrameWork/issues/74 | [] | zihaoxingstudy1 | 3 |
LAION-AI/Open-Assistant | machine-learning | 3,109 | Support user-level OAuth plugin authentication | Will support plugins for which `ai-plugin.json` contains:
```
"auth": {
"type": "oauth"
},
```
- [x] Plugin has client ID and secret, securely store encrypted version of client secret, store client ID
- [x] Mechanism for plugin author receiving verification token
- [x] Redirect user to plugin auth URL
- ... | open | 2023-05-09T19:48:03Z | 2023-06-06T15:12:53Z | https://github.com/LAION-AI/Open-Assistant/issues/3109 | [
"inference"
] | olliestanley | 0 |
dynaconf/dynaconf | django | 1,055 | Multiple cast validators get discarded | Hi there, thanks for this great project,
**Describe the bug**
After defining a dynaconf `cast` validator, attempting to define subsequent dynaconf `cast` validators on the same variable get discarded while they should also be taken into account
**To Reproduce**
1. Having the following a.toml file:
**a.to... | closed | 2024-02-20T12:57:19Z | 2024-03-25T17:08:52Z | https://github.com/dynaconf/dynaconf/issues/1055 | [
"bug"
] | nikoskoukis-slamcore | 0 |
hzwer/ECCV2022-RIFE | computer-vision | 203 | 使用Colab运行时遇到了问题 | 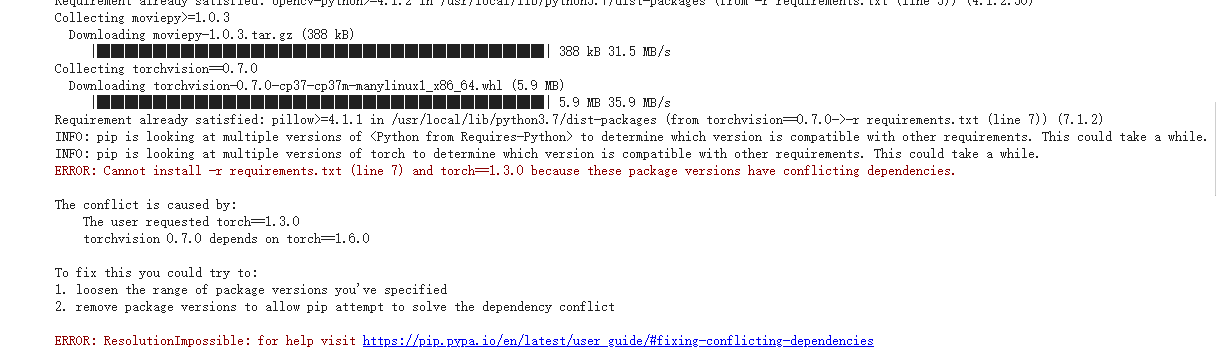
```
INFO: pip is looking at multiple versions of <Python from Requires-Python> to determine which version is compatible with other requirements. This could take a while.
INFO: pip is looking at multiple ve... | closed | 2021-10-07T12:16:57Z | 2021-10-08T05:13:11Z | https://github.com/hzwer/ECCV2022-RIFE/issues/203 | [] | Neycrol | 1 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 3,216 | Regression on Export/Download of Files introduced in 4.9.1 | **Describe the bug**
On selecting single/multiple reports and clicking "Export", I receive a popup message which says "Error!". When I look at the network tab, I can see that I'm getting an error "Method Not Implemented". Likewise, when I attempt to download an attachment on the report, it opens a new tab, which notif... | closed | 2022-04-15T20:32:32Z | 2022-04-16T10:02:06Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/3216 | [
"T: Bug",
"C: Client",
"C: Backend"
] | jennycalendar | 3 |
Farama-Foundation/PettingZoo | api | 1,150 | Passing the Parallel API tests in PettingZoo for custom multi-agent environment? | ### Question
```
from pettingzoo.test import (
parallel_api_test,
parallel_seed_test,
max_cycles_test,
performance_benchmark,
)
```
I have a custom multiagent environment that extends **ParallelEnv**, and since I passed the *parallel_api_test*,
I plan to pass the other ones as well before ... | closed | 2023-12-25T01:31:37Z | 2024-01-09T15:11:35Z | https://github.com/Farama-Foundation/PettingZoo/issues/1150 | [
"question"
] | hridayns | 3 |
DistrictDataLabs/yellowbrick | scikit-learn | 1,088 | AttributeError: 'KMeans' object has no attribute 'show' | **Describe the bug**
I am getting this AttributeError: 'KMeans' object has no attribute 'show' when implementing Elbow Method for KMeans clustering. The elbow graph is plotted after showing the error.
**To Reproduce**
```python
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from ye... | closed | 2020-07-28T13:38:10Z | 2020-07-28T16:26:30Z | https://github.com/DistrictDataLabs/yellowbrick/issues/1088 | [] | Gdkmak | 1 |
ultralytics/ultralytics | deep-learning | 19,316 | Inquiry Regarding Licensing for Commercial Use of YOLO with Custom Training Tool | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello,
I have developed a user-friendly tool (UI) that enables code-free tra... | open | 2025-02-19T16:45:49Z | 2025-02-24T07:08:11Z | https://github.com/ultralytics/ultralytics/issues/19316 | [
"question",
"enterprise"
] | DoBacc | 2 |
xinntao/Real-ESRGAN | pytorch | 340 | raise ValueError("Number of processes must be at least 1") | ### Can anyone help me, why is this?
┌─[Michael@code-me] - [~/Real-ESRGAN] - [Thu May 26, 00:40]
└─[$]> python3 inference_realesrgan_video.py -i /Users/Michael/Downloads/aa.mp4 -n realesr-animevideov3 -s 2 --suffix outx2
Traceback (most recent call last):
File "/Users/Michael/Real-ESRGAN/inference_realesrgan_vide... | open | 2022-05-25T16:55:29Z | 2022-09-07T14:42:14Z | https://github.com/xinntao/Real-ESRGAN/issues/340 | [] | smoosex | 3 |
lucidrains/vit-pytorch | computer-vision | 230 | Attention maps for PiT | @lucidrains maybe it's only a typo, but in the PiT example, it is said that the attention maps are also outputed, but in fact it is not we only get the predictions. Could help me get those attention maps ?
Thanks in advance | open | 2022-08-09T10:08:08Z | 2022-08-09T10:08:08Z | https://github.com/lucidrains/vit-pytorch/issues/230 | [] | Maxlanglet | 0 |
geex-arts/django-jet | django | 396 | persian calendar need | in Iran and many other cuntres | open | 2019-06-03T19:57:42Z | 2019-06-03T19:57:42Z | https://github.com/geex-arts/django-jet/issues/396 | [] | shahriardn | 0 |
Yorko/mlcourse.ai | scikit-learn | 22 | Решение вопроса 5.11 не стабильно | Даже при выставленных random_state параметрах, best_score лучшей модели отличается от вариантов в ответах.
Подтверждено запуском несколькими участниками.
Возможно влияют конкретные версии пакетов на расчеты.
Могу приложить ipynb, на котором воспроизводится. | closed | 2017-04-03T08:43:37Z | 2017-04-03T08:52:22Z | https://github.com/Yorko/mlcourse.ai/issues/22 | [] | coodix | 2 |
FlareSolverr/FlareSolverr | api | 988 | [yggtorrent] (testing) Exception (yggtorrent): FlareSolverr was unable to process the request, please check FlareSolverr logs | ### Have you checked our README?
- [X] I have checked the README
### Have you followed our Troubleshooting?
- [X] I have followed your Troubleshooting
### Is there already an issue for your problem?
- [X] I have checked older issues, open and closed
### Have you checked the discussions?
- [X] I have read the Dis... | closed | 2023-11-28T00:42:44Z | 2023-11-28T15:46:21Z | https://github.com/FlareSolverr/FlareSolverr/issues/988 | [
"more information needed"
] | tifo71 | 8 |
tflearn/tflearn | data-science | 1,094 | KeyError: "The name 'Momentum' refers to an Operation not in the graph | When I load a pretrained tflean model, an keyError is rased.
File "C:\Anaconda3\lib\site-packages\tensorflow\python\training\saver.py", line 1810, in import_meta_graph
**kwargs)
File "C:\Anaconda3\lib\site-packages\tensorflow\python\framework\meta_graph.py", line 696, in import_scoped_meta_graph
ops... | open | 2018-10-20T05:46:43Z | 2019-03-21T17:26:20Z | https://github.com/tflearn/tflearn/issues/1094 | [] | hongminli | 2 |
public-apis/public-apis | api | 3,843 | NASA API website | I just looked at the NASA API website and there it asks me to register with an API key.
Maybe I am getting something wrong here, but if not I would love to fix this. I haven't really done much open source work, but I would love to change that.
Here is the link: https://api.nasa.gov/
Someone who wants to join and he... | closed | 2024-04-28T02:57:55Z | 2024-04-28T03:39:27Z | https://github.com/public-apis/public-apis/issues/3843 | [] | Fooooooooool | 3 |
svc-develop-team/so-vits-svc | pytorch | 89 | [Help]: 4.0 不工作。在转换后的音频中引入不需要的失真。源音高未正确转换。4.0 Not working. introducing unwanted distortion in converted audio. source pitch not properly converted. | ### Please check the checkboxes below.
- [X] I have read *[README.md](https://github.com/svc-develop-team/so-vits-svc/blob/4.0/README.md)* and *[Quick solution in wiki](https://github.com/svc-develop-team/so-vits-svc/wiki/Quick-solution)* carefully.
- [X] I have been troubleshooting issues through various search en... | open | 2023-03-26T09:57:16Z | 2023-04-10T07:46:36Z | https://github.com/svc-develop-team/so-vits-svc/issues/89 | [
"help wanted"
] | MuruganR96 | 6 |
proplot-dev/proplot | matplotlib | 288 | Manually specify `title` and `abc` coordinate positions | <!-- Thanks for helping us make proplot a better package! If this is a bug report, please use the template provided below. If this is a feature request, you can delete the template text (just try to be descriptive with your request). -->
### Description
Hi, is it possible to make the abc labels slightly offset to... | open | 2021-09-27T22:08:14Z | 2022-07-08T15:54:21Z | https://github.com/proplot-dev/proplot/issues/288 | [
"feature"
] | scottstanie | 6 |
aiortc/aioquic | asyncio | 148 | Datagrams only getting sent every 15s | Hello,
I'm playing around with forwarding audio/video using aioquic as a server. Since I want the data to be delivered as quickly as possibly and unreliably, I'm using datagrams. aioquic basically receives datagrams from a "sender", and then sends them to however many "subscribers."
While the sender -> server dat... | closed | 2020-11-03T18:45:10Z | 2021-11-21T17:55:48Z | https://github.com/aiortc/aioquic/issues/148 | [] | dsafreno | 7 |
ITCoders/Human-detection-and-Tracking | numpy | 11 | Port to C++ | **Port this repo to C++**
- code should be written in C++.
- make a separate branch for this.
- functionality should be same and performance should be better.
- useful scripts in scripts folder should also be ported.
- multiple pull requests are allowed for this but make sure that you are on correct path
:smile: :smi... | closed | 2016-10-21T18:41:38Z | 2017-05-18T20:44:20Z | https://github.com/ITCoders/Human-detection-and-Tracking/issues/11 | [] | arpit1997 | 6 |
OFA-Sys/Chinese-CLIP | computer-vision | 162 | 梯度累积中的问题 | 关于梯度累积的代码,有几点不太明白,想请教一下。
1. accum_image_features 和accum_text_features已经得到了,为什么在get_loss中又要重新计算一个batch的特征。这样的话,所有的特征都被计算了两次,造成资源的浪费
2. get_loss进行了accum_freq次,但是每次的accum_image_features和accum_text_features并没有发生变化。loss的计算是否是重复了?
相关代码如下:
# First, cache the features without any gradient tracking.
... | open | 2023-07-14T08:59:21Z | 2023-07-29T08:07:41Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/162 | [] | ChaoLi977 | 1 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 240 | Not want to add a section | If I don't have a title blacklist, do I delete "word1" and "word2" and leave that area empty? Do I put "N/A"? Let me know. I also don't want to put in my GPA, can I leave that slot blank as well? | closed | 2024-09-02T18:18:45Z | 2024-09-03T16:04:40Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/240 | [] | pacman20011 | 1 |
thtrieu/darkflow | tensorflow | 996 | bash: flow: command not found | [root@localhost darkflow]# flow -h
bash: flow: command not found
[root@localhost darkflow]# sudo flow -h
sudo: flow: command not found
[root@localhost darkflow]# python3 setup.py build_ext
running build_ext
[root@localhost darkflow]# sudo pip3 install -e .
Obtaining file:///var/tmp/darkflow
Installing collected... | open | 2019-03-09T09:37:56Z | 2020-05-13T07:52:46Z | https://github.com/thtrieu/darkflow/issues/996 | [] | bewithme | 4 |
BeanieODM/beanie | pydantic | 769 | [BUG] Pylance strict mode: type of "delete_all" is partially unknown | When using pylance in strict mode a lot of static document methods have a typing issue
```
Type of "delete_all" is partially unknown
Type of "delete_all" is "(session: ClientSession | None = None, bulk_writer: BulkWriter | None = None, **pymongo_kwargs: Unknown) -> Coroutine[Any, Any, DeleteResult | None]"Pylance[... | closed | 2023-11-08T15:32:00Z | 2024-10-07T18:29:45Z | https://github.com/BeanieODM/beanie/issues/769 | [
"Stale"
] | dotKokott | 4 |
lukas-blecher/LaTeX-OCR | pytorch | 323 | incompatible error | Cannot mix incompatible Qt library (6.5.3) with this library (6.5.2) | open | 2023-10-11T12:59:12Z | 2023-10-11T14:27:24Z | https://github.com/lukas-blecher/LaTeX-OCR/issues/323 | [] | KarnanBala | 1 |
modin-project/modin | pandas | 7,191 | Fix ASV after changing default branch: "master" -> "main" | closed | 2024-04-16T18:28:16Z | 2024-04-16T20:40:16Z | https://github.com/modin-project/modin/issues/7191 | [
"Benchmarking 🏁",
"Testing 📈",
"P0"
] | anmyachev | 0 | |
scanapi/scanapi | rest-api | 435 | Remove generic exception and raise a more dedicated exception that isn't very common for Class EndpointNode::run() | The [run method ](https://github.com/scanapi/scanapi/blob/main/scanapi/tree/endpoint_node.py#L94-L94) in the Class EndpointNode's catches very generic Exception.
We would need to be precise in catching a particular Exception so it is likely to include many unrelated errors too.
```
def run(self):
f... | closed | 2021-07-29T12:43:27Z | 2022-04-10T13:01:17Z | https://github.com/scanapi/scanapi/issues/435 | [
"Refactor",
"Code Quality"
] | Pradhvan | 1 |
tradingstrategy-ai/web3-ethereum-defi | pytest | 5 | Get Aave lending and borrow rates directly from on-chain | [Aave has deployed its v3 version on Ethereum mainnet and Polygon](https://docs.aave.com/developers/getting-started/readme).
[See Ethereum markets - MetaMask required](https://app.aave.com/?marketName=proto_mainnet)
<img width="1310" alt="image" src="https://user-images.githubusercontent.com/49922/177447328-c157f... | closed | 2022-03-06T13:13:40Z | 2022-09-25T03:41:26Z | https://github.com/tradingstrategy-ai/web3-ethereum-defi/issues/5 | [] | miohtama | 0 |
pallets-eco/flask-sqlalchemy | sqlalchemy | 567 | Add "first" and "last" to Pagination class? | I'm new to Flask, and was wondering about a feature that I think would be useful to add to the Pagination class. Unless I'm missing it, there doesn't seem to be a built-in way to get the numbers of the items you're viewing on the page itself. That is, if you want to display "387 records found; displaying 26–50", you'd ... | closed | 2017-11-17T16:39:16Z | 2022-10-03T00:21:38Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/567 | [
"pagination"
] | jessesheidlower | 1 |
deepinsight/insightface | pytorch | 2,249 | The warning from `onnxruntime::VerifyEachNodeIsAssignedToAnEp` | I got this when I try to run insightface on Windows10 with CUDA/cuDNN:
```
2023-02-18 00:41:44.1541586 [W:onnxruntime:, session_state.cc:1136 onnxruntime::VerifyEachNodeIsAssignedToAnEp] Some nodes were not assigned to the preferred execution providers which may or may not have an negative impact on performance. e.g.... | closed | 2023-02-17T17:10:32Z | 2024-07-12T16:12:45Z | https://github.com/deepinsight/insightface/issues/2249 | [] | Chris-fullerton | 7 |
lexiforest/curl_cffi | web-scraping | 121 | ERROR: Failed building wheel for curl_cffi | When trying to install **curl_cffi** in Termux, via the `pip install curl_cffi` command, I get the error:
```
Collecting curl_cffi Using cached curl_cffi-0.5.7.tar.gz (27 kB) Installing build dependencies ... done Getting requirements to build wheel ... done Prepa... | closed | 2023-09-08T09:14:38Z | 2023-09-08T09:21:02Z | https://github.com/lexiforest/curl_cffi/issues/121 | [
"duplicate"
] | Gertasan | 1 |
AntonOsika/gpt-engineer | python | 893 | The term 'gpt-engineer' is not recognized | hey guys i'm on windows 11 and I installed via python 'pip install gpt-engineer'
everything seems to install fine
but now I get this in PowerShell
```
gpt-engineer : The term 'gpt-engineer' is not recognized as the name of a cmdlet, function, script file, or operable
program. Check the spelling of the name, o... | closed | 2023-12-08T21:35:41Z | 2023-12-09T01:32:09Z | https://github.com/AntonOsika/gpt-engineer/issues/893 | [
"documentation",
"triage"
] | wp-coin | 2 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 486 | [FEATURE]: Need an option to hide GPA crap at top of resume | ### Feature summary
Need an option to hide GPA crap at top of resume
### Feature description
Need an option to hide GPA crap at top of resume
### Motivation
I graduated from college 30 years ago, GPA is completely irrelevant for me.
### Alternatives considered
_No response_
### Additional context
_No response_ | closed | 2024-10-06T22:58:45Z | 2024-10-25T05:29:18Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/486 | [
"enhancement"
] | ralyodio | 0 |
plotly/dash | dash | 3,148 | Dash 3.0 feedback | Thanks for making the dash 3.0 pre-release available. 🎉
Just a couple questions and comments:
- Are you still planning on removing the `_timestamp` props? https://github.com/plotly/dash/issues/3055
- The `dcc.Dropdown` is still using `defaultProps` which is causing a warning in the console. There are other consol... | closed | 2025-02-03T15:37:26Z | 2025-03-06T21:34:49Z | https://github.com/plotly/dash/issues/3148 | [
"P1"
] | AnnMarieW | 31 |
killiansheriff/LovelyPlots | matplotlib | 3 | imshow | Well done for creating this library and getting it compatible with Adobe Illustrator (spent too many hours of my life fixing figures!). Are you planning to expand on other plots like [imshow](https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.imshow.html)? It does export correctly, but color scheme doesn't see... | closed | 2022-07-27T22:09:11Z | 2022-07-28T19:29:51Z | https://github.com/killiansheriff/LovelyPlots/issues/3 | [] | danchitnis | 2 |
ymcui/Chinese-BERT-wwm | nlp | 70 | 在预训练Roberta的时候需要像原来训练Bert一样加上CLS SEP SEP, 还是直接CLS SEP | @ymcui | closed | 2019-11-07T10:18:28Z | 2019-11-08T04:03:21Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/70 | [] | xiongma | 2 |
keras-rl/keras-rl | tensorflow | 343 | Where is the environment specified in DQNAgent | I am trying to understand where exactly in the DQNAgent is the environment specified. I see that there is mentions of self.step, self.recent_observation, self.recent_action, reward and terminal but I don't see where are these being generated. I am trying to develop my own environment and am trying to understand how it ... | closed | 2019-10-18T19:12:50Z | 2020-01-24T03:01:03Z | https://github.com/keras-rl/keras-rl/issues/343 | [
"wontfix"
] | kdawar1 | 1 |
ray-project/ray | tensorflow | 50,850 | [Dashboard] Serve Grafana panels shows metrics from multiple clusters instead of filtering on SessionName or ray_io_cluster | ### What happened + What you expected to happen
**Context**
We are running multiple Ray clusters on version 2.41.0 and sending metrics to a single c**ommon Thanos instance**.
Each Ray cluster is launched by the Kuberay operator
We are launching multiple Ray clusters by creating RayCluster and RayService custom resou... | open | 2025-02-24T07:26:58Z | 2025-02-24T17:24:20Z | https://github.com/ray-project/ray/issues/50850 | [
"bug",
"dashboard",
"triage"
] | frenoid | 0 |
explosion/spaCy | deep-learning | 13,039 | spacy.cli.download is no longer available | In the last release (3.7.0), the ability to call `spacy.cli.download(MODEL)` is no longer available.
Is there another way to download models through a Python script, or can the spacy.cli package be reintroduced?
[In our use case](https://github.com/microsoft/presidio/blob/7400dc4b357595406954e13c0ecbdee4b27e5cd8/pr... | closed | 2023-10-04T10:17:42Z | 2023-11-04T00:02:14Z | https://github.com/explosion/spaCy/issues/13039 | [
"bug",
"feat / cli"
] | omri374 | 5 |
pydantic/pydantic-core | pydantic | 913 | Maximum value of `int` field does not reflect bytes used when subclassing | Noticed this issue when working with documents from MongoDB (using `motor`).
It returns integers as [BSON types](https://pymongo.readthedocs.io/en/stable/api/bson/int64.html), which are subclasses of the `int` type.
Minimal reproduction examples: (pydantic 2.2.1)
```py
from pydantic import BaseModel
class ... | closed | 2023-08-21T21:59:15Z | 2023-08-23T12:50:32Z | https://github.com/pydantic/pydantic-core/issues/913 | [
"unconfirmed"
] | NiceAesth | 0 |
OpenInterpreter/open-interpreter | python | 1,063 | When refreshing screen it stores each snapshopt to scroll history on the terminal | ### Describe the bug
when running anything in the open-interpreter terminal installed from pip in linux, we get a history of EVERY "screen refersh" happened so far, this is annoying for scrolling, let me give you a screenshot
### Reproduce
instal open interpreter on linux
ask to code something
scroll up
### ... | closed | 2024-03-09T12:24:27Z | 2024-03-20T01:22:17Z | https://github.com/OpenInterpreter/open-interpreter/issues/1063 | [
"Bug"
] | Kreijstal | 1 |
biolab/orange3 | scikit-learn | 6,100 | Basic information about how data objects in Orange3 are handled in memory / tips for profiling add-on memory performance | <!--
Thanks for taking the time to submit a feature request!
For the best chance at our team considering your request, please answer the following questions to the best of your ability.
-->
## **What's your use case?**
<!-- In other words, what's your pain point? -->
<!-- Is your request related to a problem, ... | closed | 2022-08-19T00:15:11Z | 2022-09-10T06:07:48Z | https://github.com/biolab/orange3/issues/6100 | [] | fititnt | 3 |
thp/urlwatch | automation | 611 | How to install on MacOS in 2021? | Last year I had this working perfectly, but as soon as 2021 started something went wrong with my installation (MacOS Mojave) and I couldn't run urlwatch anymore.
I uninstalled it with `python3 -m pip uninstall urlwatch` to see if reinstalling a newer version would help, but after running `python3 -m pip install --u... | closed | 2021-01-09T17:40:42Z | 2021-01-11T19:44:04Z | https://github.com/thp/urlwatch/issues/611 | [] | Kezzsim | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 948 | Newer versions of CycleGAN? | Hi. I have worked with CycleGAN the last year and I really like it!. But since cyclegan is from 2017 it is almost 3 years old now. Do you know if there are some "better" versions of CycleGAN in 2020? Or some other extensions of GANs that does the image to image translation just as CycleGAN but just more optimal? | closed | 2020-03-07T12:54:57Z | 2020-03-31T06:41:12Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/948 | [] | kpagels | 4 |
polakowo/vectorbt | data-visualization | 585 | Exit after N days? | Using `from_signals_ method, is it possible to have a boolean signal for entries with a timed exit N days after entry? Simply shifting the entries dataframe forward by N rows doesn't work because the dataframe may have superfluous entry signals that are not used to actually enter a position because an open position alr... | closed | 2023-04-17T08:48:20Z | 2024-03-16T10:44:15Z | https://github.com/polakowo/vectorbt/issues/585 | [] | posidonius | 1 |
JaidedAI/EasyOCR | deep-learning | 936 | AttributeError: 'numpy.float64' object has no attribute 'lower' | Hi.
I am trying to train a model. I have created a dataset as required and I tried to run the training script.
This is the result:
```
File "Downloads/EasyOCR-master/trainer/start_train.py", line 30, in <module>
train(opt, amp=False)
File "Downloads/EasyOCR-master/trainer/train.py", line 40, in train
... | closed | 2023-01-25T09:14:06Z | 2024-02-13T11:07:46Z | https://github.com/JaidedAI/EasyOCR/issues/936 | [] | proclaim5584 | 1 |
modin-project/modin | pandas | 6,718 | Reimplement the `_axes_lengths` property to avoid materializing both axes at the same time | Source: https://github.com/modin-project/modin/pull/6700#pullrequestreview-1714797952 | closed | 2023-11-07T12:12:00Z | 2023-11-07T14:42:39Z | https://github.com/modin-project/modin/issues/6718 | [
"Performance 🚀"
] | anmyachev | 0 |
jmcnamara/XlsxWriter | pandas | 640 | Feature request: String formatting in chart title | While adding text to chart title, natively in Excel, some string elements could be formatted differently, despite 'general' format of the chart title, eg. while having regular font, some letters can be italic/bold, etc. Is this feature somewhere hidden in existing module or taken into consideration for development? | closed | 2019-07-01T14:10:56Z | 2020-09-19T19:59:59Z | https://github.com/jmcnamara/XlsxWriter/issues/640 | [
"feature request",
"long term"
] | oskaruchanski | 2 |
ultralytics/yolov5 | deep-learning | 13,341 | Significant Variations in Training Results with Same Dataset and Parameters | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hi everyone,
We’ve encountered a noticeable discrepancy in the performance metr... | open | 2024-10-03T03:47:05Z | 2024-11-09T06:29:48Z | https://github.com/ultralytics/yolov5/issues/13341 | [
"question"
] | timiil | 2 |
PokemonGoF/PokemonGo-Bot | automation | 5,622 | virtualenv does not exist (may be exits) | $ ./run.sh
Virtualenv does not exits
Run: ./setup.sh -i
| closed | 2016-09-22T21:33:30Z | 2016-09-24T17:24:39Z | https://github.com/PokemonGoF/PokemonGo-Bot/issues/5622 | [] | PeshBG | 8 |
indico/indico | sqlalchemy | 6,416 | Custom menu pages title leaked when access is deined | **Describe the bug**
The custom pages you can add to event menus all have an id. You can cycle through them by visiting e.g. https://events.example.com/event/12/page/345 which will redirect to https://events.example.com/event/12/page/345-sekrit-page . If the user doesn't have permission for that page, they can still r... | closed | 2024-06-24T19:31:19Z | 2024-06-25T16:08:51Z | https://github.com/indico/indico/issues/6416 | [
"bug"
] | kewisch | 3 |
whitphx/streamlit-webrtc | streamlit | 1,362 | Server to client media playback with frame-based processing | Many of the examples in this repo show client to server media sinks (mic / video capture), which have frame based callback processing. I am looking to do server to client media playback, with frame based callback processing. This would be useful for real-time audio playback with real-time processing.
After searchin... | open | 2023-08-25T00:19:15Z | 2024-10-30T10:31:19Z | https://github.com/whitphx/streamlit-webrtc/issues/1362 | [] | jamjambles | 3 |
jupyter/nbviewer | jupyter | 141 | Intelligently handle dropbox link | One of my favorite things to do is share notebooks that I have in my Dropbox using nbviewer. The only mildly annoying thing is that I have to manually change the url that dropbox gives me (`www.dropbox.com/...`) to (`dl.dropbox.com/...`) to force dropbox to cough up the file itself instead of serving their web interfac... | closed | 2013-12-10T23:40:37Z | 2014-01-14T17:51:54Z | https://github.com/jupyter/nbviewer/issues/141 | [
"type:Enhancement"
] | mwaskom | 5 |
google/trax | numpy | 976 | TPU deadlock | ### Description
Hello,
I am trying to train reformer model using Trax and JAX. The training seems to be fine on Google Colab, but when I run it on google cloud server + TPU, it hangs on the "trax.supervised.Trainer".
The warning is as follows:
`2020-08-26 17:46:37.421334: W external/org_tensorflow/tensorflow/... | open | 2020-08-26T15:58:20Z | 2020-08-26T15:58:20Z | https://github.com/google/trax/issues/976 | [] | agemagician | 0 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,389 | Rotating proxies im receiving selenium.common.exceptions.SessionNotCreatedException: Message: session not created | Im having this in order to rotate proxies, everytime a new_chrome starts it use a new proxy
```python
def navigate_selenium(self, doc_id):
while True:
try:
self.chrome = self.new_chrome()
self.chrome.get(self.origin + "/document/" + doc_id)
... | closed | 2023-07-12T07:28:02Z | 2023-07-19T10:54:21Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1389 | [] | juanfrilla | 2 |
vitalik/django-ninja | django | 585 | I need to comment the parameters in the URL address | Here's my view definition:
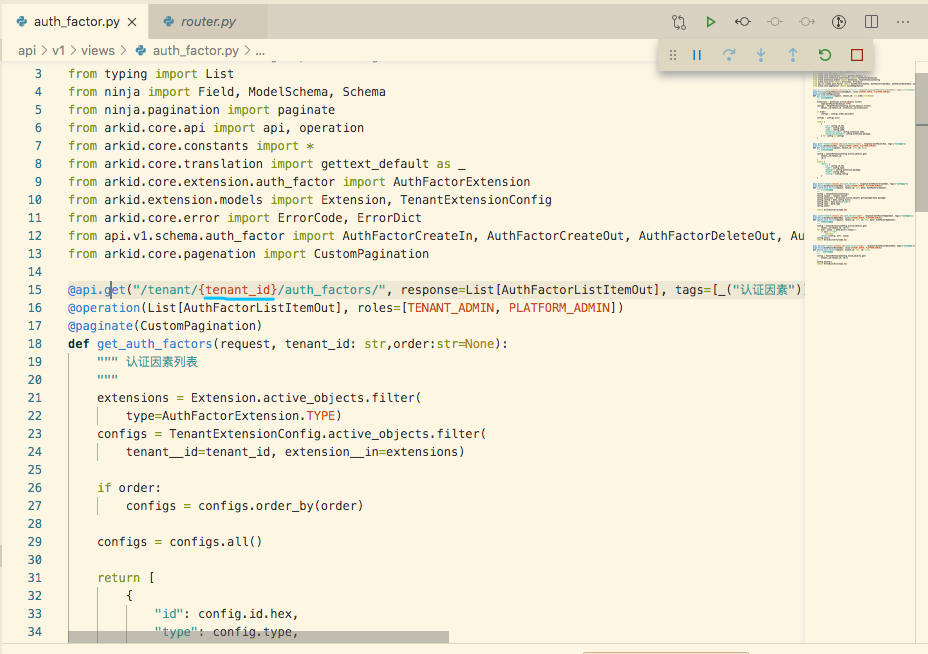
This is openapi. Json:
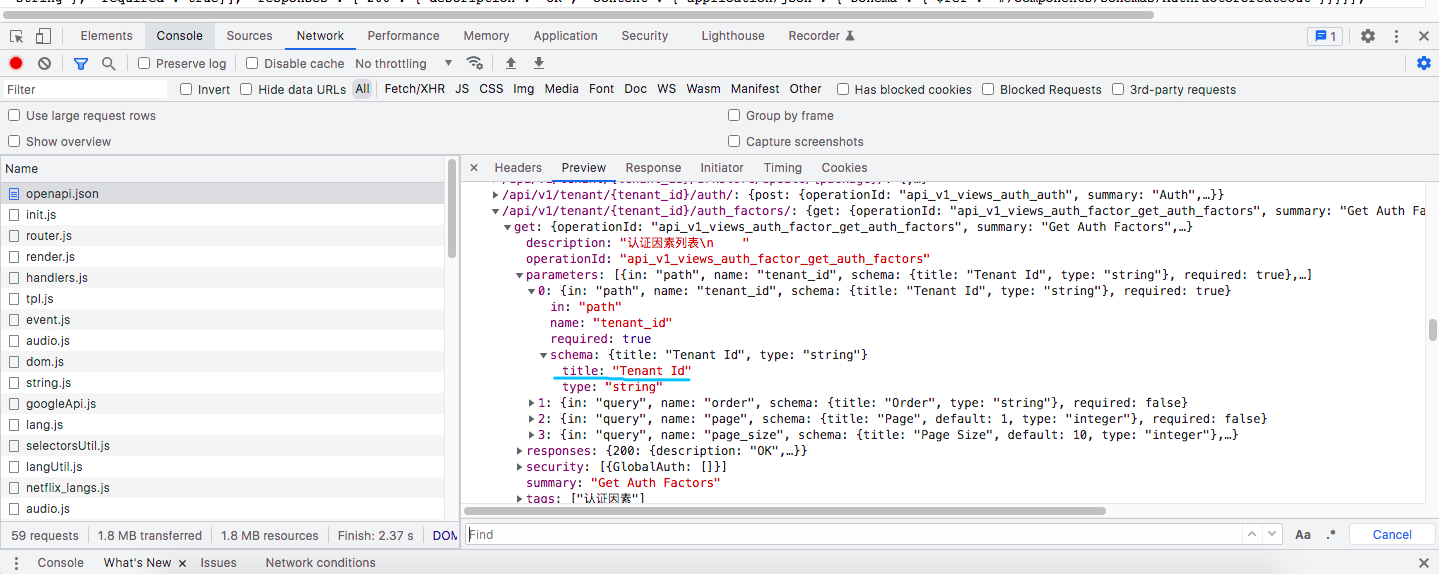
I need to change the title in the schema... | closed | 2022-10-10T06:56:10Z | 2022-10-27T06:32:41Z | https://github.com/vitalik/django-ninja/issues/585 | [] | hanbinloop | 2 |
MaartenGr/BERTopic | nlp | 1,697 | ValueError: setting an array element with a sequence. The requested array has an inhomogeneous shape after 1 dimensions. The detected shape was (2,) + inhomogeneous part. | Hi, I encountered the following error while performing semi-supervised training:
embeddings[indices] = np.average([embeddings[indices], seed_topic_embeddings[seed_topic]], weights=[3, 1])
ValueError: setting an array element with a sequence. The requested array has an inhomogeneous shape after 1 dimensions. The d... | closed | 2023-12-15T10:23:51Z | 2024-12-20T17:03:24Z | https://github.com/MaartenGr/BERTopic/issues/1697 | [] | shyzzz521 | 4 |
google-research/bert | nlp | 981 | "intermediate" hidden layer | Hi,
what is the purpose of this "intermediate" hidden layer with activation + output layer w/o activation?
https://github.com/google-research/bert/blob/cc7051dc592802f501e8a6f71f8fb3cf9de95dc9/modeling.py#L866
| open | 2020-01-03T09:34:38Z | 2020-01-03T09:34:38Z | https://github.com/google-research/bert/issues/981 | [] | congchan | 0 |
sigmavirus24/github3.py | rest-api | 1,160 | Add support for Deployment Environments | It appears that Deployment Environments ( https://docs.github.com/en/rest/deployments/environments?apiVersion=2022-11-28 ) are not currently supported. Unfortunately I don't have time to implement this myself, but wanted to open an issue to track the feature request. | open | 2023-09-15T12:02:13Z | 2023-12-15T12:57:55Z | https://github.com/sigmavirus24/github3.py/issues/1160 | [] | jantman | 1 |
pyg-team/pytorch_geometric | pytorch | 9,792 | Install a full PyG environment using only a single pip command | ### 😵 Describe the installation problem
The current installation process requires installing PyTorch first then running a second pip install for all the PyG components. This is because torch is required in the setup of the PyG components:
- https://github.com/pyg-team/pytorch_geometric/issues/861
- https://github... | open | 2024-11-15T21:02:49Z | 2025-02-14T11:05:07Z | https://github.com/pyg-team/pytorch_geometric/issues/9792 | [
"installation"
] | Anjum48 | 5 |
pyeve/eve | flask | 1,472 | 422 UNPROCESSABLE ENTITY when using user_id and data_relation on PATCH | ### Expected Behavior: 200 OK
### Actual Behavior: 422 UNPROCESSABLE ENTITY
If using `set_request_auth_value` on a schema and having defined a `data_relation` to a schema that is not using any auth value,
a PATCH operation will fail with the follwoing error:
```
value 'XXX' must exist in resource 'YYY', field ... | open | 2022-03-29T09:33:39Z | 2023-08-17T04:41:23Z | https://github.com/pyeve/eve/issues/1472 | [] | xibriz | 1 |
comfyanonymous/ComfyUI | pytorch | 6,984 | How to composite noise per region in regional sampling? | ### Your question
I want to have the effect equivalent of a "different denoise value" for each regional prompt in a RegionalSampler workflow. Is there an easy way to accomplish this? I was considering manually setting sigma schedules for the sampler in each regional prompt, but it's not clear to me how I'd then pre... | open | 2025-02-26T20:06:06Z | 2025-03-10T06:28:49Z | https://github.com/comfyanonymous/ComfyUI/issues/6984 | [
"User Support"
] | dtromb | 2 |
AirtestProject/Airtest | automation | 1,264 | error: metadata-generation-failed | ```bash
python --version
Python 3.13.0
```
```log
(.venv) PS xxx.air> pip install -U airtest
Looking in indexes: https://mirrors.aliyun.com/pypi/simple/
Collecting airtest
Using cached https://mirrors.aliyun.com/pypi/packages/b2/52/62391b32309ce0cbf5e2d2ba5751a6a4a4cf8aec470f3d94ec76f2d85099/airtest-1.3.5.t... | open | 2024-11-23T20:09:06Z | 2024-11-23T20:09:06Z | https://github.com/AirtestProject/Airtest/issues/1264 | [] | Ran-Xing | 0 |
microsoft/JARVIS | deep-learning | 190 | {available task list} slot is missing | in the Table 5 of the paper, it designs an injectable slot called {{available task list}} in the prompt for LLM. plz release more details about this slot.
| open | 2023-04-30T10:51:40Z | 2023-04-30T10:51:40Z | https://github.com/microsoft/JARVIS/issues/190 | [] | henern | 0 |
yezz123/authx | pydantic | 224 | Failed to import RedisCacheBackend and JWTBackend class from authx. Version 0.4.0 | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I already read and followed all the tutorial in the docs and didn't find an answer.
- [X] I already checked if it is not related to AuthX but to [Pydantic](https://github.com/samuelcolvin/pydantic).
- [X] I already checked if it is not related... | closed | 2022-04-04T14:21:11Z | 2023-03-06T09:31:41Z | https://github.com/yezz123/authx/issues/224 | [
"bug",
"question"
] | r-scheele | 3 |
lorien/grab | web-scraping | 69 | Очепятка в PyquerySelector | Файл selector/selector.py строка 296 - написано pyquery вместо query
``` python
class PyquerySelector(LxmlNodeBaseSelector):
__slots__ = ()
def pyquery_node(self):
return PyQuery(self.node)
def process_query(self, query):
return self.pyquery_node().find(pyquery)
```
должно быть
``` pyt... | closed | 2014-10-08T09:04:06Z | 2015-03-26T10:56:57Z | https://github.com/lorien/grab/issues/69 | [] | antipooh | 1 |
stanfordnlp/stanza | nlp | 1,057 | Problem when adding a new language |
Hi all!
First time posting a question, feel free to correct me if I'm not following conventions. I'm a Python newbie trying to start an NLP project, so all help is welcome!
I'm trying to add a new language (Old English) to Stanza, to train a model to automatically annotate OE texts. My data is converted into th... | closed | 2022-06-24T09:31:04Z | 2022-09-16T00:46:45Z | https://github.com/stanfordnlp/stanza/issues/1057 | [
"question",
"stale"
] | dmetola | 7 |
piskvorky/gensim | machine-learning | 3,108 | For sponsors | ## Thank you for your [Gensim sponsorship](https://github.com/sponsors/piskvorky) ❤️
I don't know who you are, I can only see your Github handle. So please leave your desired Twitter handle here as a comment, for a mention in the monthly [@gensim_py](https://twitter.com/gensim_py) tweet.
If you chose one of the t... | open | 2021-04-08T07:18:03Z | 2021-04-22T13:42:32Z | https://github.com/piskvorky/gensim/issues/3108 | [] | piskvorky | 1 |
ivy-llc/ivy | numpy | 28,765 | Fix Frontend Failing Test: tensorflow - tensor.torch.Tensor.new_zeros | To-do List: https://github.com/Transpile-AI/ivy/issues/27499 | open | 2024-06-17T09:46:14Z | 2025-03-18T14:49:08Z | https://github.com/ivy-llc/ivy/issues/28765 | [
"Sub Task"
] | Mubashirshariq | 1 |
browser-use/browser-use | python | 858 | Mistook My Instructions and sent the browser to a bad website! | ### Bug Description
I was trying to get the web browser to help me write some blogs and it took me to a tranny escort service website... WTF MAN??? NOT COOL! Now all three chats that I had started are not loading and there is no way to delete them? I would like a refund for my subscription please...
### Reproduction... | open | 2025-02-25T00:24:22Z | 2025-02-25T05:28:09Z | https://github.com/browser-use/browser-use/issues/858 | [
"bug"
] | SubliminalCoding | 1 |
wkentaro/labelme | computer-vision | 749 | Problem with python labelme2voc.py data_annotated data_dataset_voc --labels labels.txt in my data | dear all,
(tensorflow1x) D:\segmentation\labelme-master\examples\semantic_segmentation>python labelme2voc.py data_annotated data_dataset_voc --labels labels.txt
I try them with my data below
[labels.txt](https://github.com/wkentaro/labelme/files/5060621/labels.txt)
[data_annotated.zip](https://github.com/wkentaro... | closed | 2020-08-12T04:38:31Z | 2022-06-25T04:58:21Z | https://github.com/wkentaro/labelme/issues/749 | [] | NguyenDangBinh | 0 |
aio-libs-abandoned/aioredis-py | asyncio | 1,003 | [2.0] Use loop.time() instead of time.time() for health checks | In the 2.0 alpha, health checks are based around `time.time`. Using `asyncio.get_event_loop().time()` has several advantages:
- The default implementation uses a monotonic clock, so it won't go wonky if the system time is changed.
- It sticks to a consistent source of time relative to things like `async_timeout`, whi... | closed | 2021-06-08T18:49:33Z | 2021-07-22T00:37:20Z | https://github.com/aio-libs-abandoned/aioredis-py/issues/1003 | [
"enhancement"
] | bmerry | 2 |
biolab/orange3 | data-visualization | 6,169 | Splash screen on Windows with scaling | Splash screen on Widows is pixelated when using scaling. The screenshot below was captured using 125% scaling. The image is nice without scaling.

| closed | 2022-10-14T11:15:24Z | 2022-11-25T08:35:04Z | https://github.com/biolab/orange3/issues/6169 | [
"bug report"
] | thocevar | 0 |
microsoft/unilm | nlp | 1,032 | Pre-training code of BEiT-3 | Great work! However, the code of [BEiT-3](https://github.com/microsoft/unilm/tree/master/beit3) only includes code for various downstream tasks. Is there any way I can reproduce the pre-training task?
| closed | 2023-03-14T12:17:58Z | 2023-03-15T15:27:28Z | https://github.com/microsoft/unilm/issues/1032 | [] | MonsterZhZh | 3 |
serengil/deepface | deep-learning | 1,193 | 'dfs' is not recognized as an internal or external command, operable program or batch file. | Okay great but now i have a new issue i did your command with my specific addins to it but this came back of command prompt

I dont know maybe im just stupid and didnt comprehend something
Command Prompt
C:\W... | closed | 2024-04-18T05:39:12Z | 2024-04-18T07:54:51Z | https://github.com/serengil/deepface/issues/1193 | [
"invalid"
] | olstice | 6 |
supabase/supabase-py | fastapi | 926 | Supabase Client Requires Explicit `sign_out()` to Terminate Properly | ## Summary
The Supabase client currently requires an explicit call to `client.auth.sign_out()` for processes to terminate correctly. Without this, background WebSocket connections and other resources may remain active, leading to incomplete shutdowns and potential resource leaks.
## Problem Explanation:
The cu... | open | 2024-09-16T07:17:13Z | 2025-01-23T16:28:07Z | https://github.com/supabase/supabase-py/issues/926 | [
"bug"
] | sigridjineth | 7 |
miguelgrinberg/Flask-SocketIO | flask | 1,257 | Recursive stack overflow | **Describe the bug**
Occasional stack overflow happens, looks similar to #230 but i'm unsure if it's happening when I'm emitting a message.
```
# pip show flask_socketio
Name: Flask-SocketIO
Version: 4.2.1
Summary: Socket.IO integration for Flask applications
Home-page: http://github.com/miguelgrinberg/Flask-S... | closed | 2020-04-19T18:23:17Z | 2020-06-30T22:53:17Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1257 | [
"question"
] | dgtlmoon | 13 |
mljar/mercury | jupyter | 301 | Can you stream the output as the notebook is evaluating? | Currently, the output only displays after the entire notebook evaluates. However, you may have some computationally expensive cells. From a UI/UX perspective, it would be helpful to see the results get stream as they are available | open | 2023-05-29T19:02:54Z | 2023-05-30T10:07:09Z | https://github.com/mljar/mercury/issues/301 | [
"enhancement",
"help wanted"
] | kapily | 1 |
matplotlib/matplotlib | matplotlib | 29,534 | [Bug]: missing graph | ### Bug summary
Good day, I'm having issues with my graphs showing after running my command, I only get axis but no graph

### Code for reproduction
```Python
Gby_plt.plot()
```
### Actual outcome
 not present in response" | There is below the output of my test. How can I understand which item(s) doesn't present in a response:
the strict options provided for the whole file:
```yaml
strict:
- headers:off
- json:off
```
Format variables:
tavern.env_vars.PA_HOST = 'localhost:8080'
Source test stage (line 681):
```yaml
- nam... | closed | 2021-02-07T21:17:37Z | 2023-01-09T15:48:24Z | https://github.com/taverntesting/tavern/issues/640 | [] | rpoletaev | 1 |
SALib/SALib | numpy | 127 | morris analysis method requires problem['group'] to exist | The sample method uses problem.get('groups') and the analysis method should, too, to avoid requiring call to set problem['group'] = None. | closed | 2017-01-05T18:21:53Z | 2017-01-07T23:39:59Z | https://github.com/SALib/SALib/issues/127 | [
"bug"
] | rjplevin | 2 |
yezz123/authx | pydantic | 462 | 🔒️ Add Security Tests including Examples | In that situation, it is crucial to address the security of the backend system for the package.
This involves ensuring that we thoroughly adhere to each step we take in the process of token creation.
```py
config = AuthXConfig(
JWT_ALGORITHM = "HS256",
JWT_SECRET_KEY = "SECRET_KEY",
# Here in t... | closed | 2023-06-01T20:32:33Z | 2025-03-21T10:01:02Z | https://github.com/yezz123/authx/issues/462 | [
"enhancement",
"python"
] | yezz123 | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.