
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
davidteather/TikTok-Api | api | 463 | [FEATURE_REQUEST] - Account Names of Commenters | **Requested Feature**
Hi! I'm wondering if it's possible to get a feature that scrapes the account names of commenters for an inputted Tiktok.
(or if there is already a function that does this). Would be incredibly helpful!
**Additional context**
One of the use cases is after finding a Tiktok related to recruitin... | closed | 2021-01-07T21:24:55Z | 2022-02-14T03:08:06Z | https://github.com/davidteather/TikTok-Api/issues/463 | [
"feature_request"
] | ETedward | 2 |
comfyanonymous/ComfyUI | pytorch | 7,078 | load image No components choose image | ### Your question
After updating to the new version.0.3.19 load image No components choose image
### Logs
```powershell
```
### Other
_No response_ | closed | 2025-03-05T03:33:23Z | 2025-03-05T14:40:44Z | https://github.com/comfyanonymous/ComfyUI/issues/7078 | [
"User Support"
] | wangnima007 | 5 |
dbfixtures/pytest-postgresql | pytest | 918 | modulenotfounderror while using load in factory | ### What action do you want to perform
When I try to load an sql file through the load argument of the factory :
`postgresql_in_docker = factories.postgresql_noproc(user = DBConfig().user, password=DBConfig().password)
postgresql_mok = factories.postgresql("postgresql_in_docker",
... | closed | 2024-03-07T13:10:50Z | 2024-03-11T14:49:58Z | https://github.com/dbfixtures/pytest-postgresql/issues/918 | [] | GFuhr | 2 |
ibis-project/ibis | pandas | 10,135 | bug: polars flatten does not work as expected | ### What happened?
Following up on https://github.com/ibis-project/ibis/issues/9995
Thanks @gforsyth and @cpcloud for the quick fix of the above issue. However I don't think it totally fixed the issue.
I am trying to get an `array<array<int64>>` to become an `array<int64>`
Using Polars:
```python
import... | closed | 2024-09-16T06:48:57Z | 2024-09-23T13:27:50Z | https://github.com/ibis-project/ibis/issues/10135 | [
"bug"
] | GLeurquin | 9 |
ScottfreeLLC/AlphaPy | scikit-learn | 27 | Model.yml encoding error | Running this via Windows WSL (winbash).
Python 3.7
Run mflow and get this error:
Traceback (most recent call last):
File "/home/d/.local/bin/mflow", line 8, in <module>
sys.exit(main())
File "/home/d/.local/lib/python3.7/site-packages/alphapy/market_flow.py", line 412, in main
model_specs = get_m... | closed | 2020-03-01T02:16:40Z | 2020-03-03T01:57:46Z | https://github.com/ScottfreeLLC/AlphaPy/issues/27 | [] | thegamecat | 3 |
thunlp/OpenPrompt | nlp | 203 | Two placeholders are two restrictive. | Hi there,
I am working on a template that has three placeholders but InputExample only supports "text_a" and "text_b". I wonder if you can adapt it to more placeholders and let us define the names of the placehoders, instead of just "text_a" and "text_b". This will make it way more flexible. Thanks! | open | 2022-10-19T22:29:30Z | 2022-11-11T06:20:34Z | https://github.com/thunlp/OpenPrompt/issues/203 | [] | zihaohe123 | 1 |
dbfixtures/pytest-postgresql | pytest | 449 | documentation / new user issue: process fixture does not take kwarg 'load' | I'm reading the [intro documentation on pypi](https://pypi.org/project/pytest-postgresql/):
> The process fixture performs the load once per test session, and loads the data into the template database. Client fixture then creates test database out of the template database each test, which significantly speeds up the... | closed | 2021-06-17T16:03:29Z | 2021-06-18T08:26:06Z | https://github.com/dbfixtures/pytest-postgresql/issues/449 | [] | sinback | 2 |
dadadel/pyment | numpy | 46 | list, tuple, dict default param values are not parsed correctly | When a function has parameters with default values that are list, dictionary or tuple, Pyment will just consider several parameters splitting on coma.
The following python code:
```python
def func1(param1=[1, None, "hehe"]):
pass
def func2(param1=(1, None, "hehe")):
pass
def func3(param1={0: 1, "a"... | closed | 2017-10-01T13:26:57Z | 2021-03-08T13:50:12Z | https://github.com/dadadel/pyment/issues/46 | [] | dadadel | 1 |
voila-dashboards/voila | jupyter | 812 | Unpin xtl in the tests | In #808, we pinned to `xtl=0.6.23` to fix the tests (`xeus-cling` depends on `xtl`):
https://github.com/voila-dashboards/voila/blob/3209c1f5c2f6588645e6f046f62d893f8ec5d18a/.github/workflows/main.yml#L34
From https://github.com/voila-dashboards/voila/pull/808#issuecomment-764650478
> The xeus-cling stack must ... | closed | 2021-01-21T14:23:57Z | 2021-01-27T07:32:13Z | https://github.com/voila-dashboards/voila/issues/812 | [] | jtpio | 0 |
huggingface/datasets | machine-learning | 6,950 | `Dataset.with_format` behaves inconsistently with documentation | ### Describe the bug
The actual behavior of the interface `Dataset.with_format` is inconsistent with the documentation.
https://huggingface.co/docs/datasets/use_with_pytorch#n-dimensional-arrays
https://huggingface.co/docs/datasets/v2.19.0/en/use_with_tensorflow#n-dimensional-arrays
> If your dataset consists of ... | closed | 2024-06-04T09:18:32Z | 2024-06-25T08:05:49Z | https://github.com/huggingface/datasets/issues/6950 | [
"documentation"
] | iansheng | 2 |
albumentations-team/albumentations | deep-learning | 1,471 | Dynamic dependency on OpenCV is brittle | ## 🐛 Bug
The [dynamic dependency](https://github.com/albumentations-team/albumentations/blob/e3b47b3a127f92541cfeb16abbb44a6f8bf79cc8/setup.py#L10-L16) of `albumentations` on OpenCV means that downstream users who want to install the package at the same time as a pinned version of `opencv-python` may end up with si... | closed | 2023-08-09T18:40:47Z | 2024-05-28T22:44:16Z | https://github.com/albumentations-team/albumentations/issues/1471 | [] | jgerityneurala | 7 |
huggingface/transformers | nlp | 36,267 | ci/v4.49-release: tests collection fail with "No module named 'transformers.models.marian.convert_marian_to_pytorch'" on v4.48/v4.49 release branches | Tests collection fails with the following error in https://github.com/huggingface/transformers/tree/v4.49-release branch (and for v4.48-release branch too).
```
python3 -m pytest tests/
===================================================== test session starts =====================================================
platf... | closed | 2025-02-18T23:09:36Z | 2025-02-20T12:22:11Z | https://github.com/huggingface/transformers/issues/36267 | [] | dvrogozh | 1 |
kizniche/Mycodo | automation | 683 | Daemon Stops Running When SPI Enabled | ## Mycodo Issue Report:
- Specific Mycodo Version: 7.6.3
#### Problem Description
I am trying to add a Waveshare High Precision AD/DA (ADS1256) board for adding some analog sensors. After adding it in the output tab, an unmet dependencies warning popped up and I was prompted to to install the missing dependenc... | closed | 2019-09-03T21:24:53Z | 2019-09-11T21:31:59Z | https://github.com/kizniche/Mycodo/issues/683 | [] | smatthews95 | 9 |
tqdm/tqdm | jupyter | 1,415 | resizing spams the terminal??? | Category: visual output "bug" (not sure i'd call it a bug, but it's definitely different behavior than i would expect).
I have read the known issues
I have searched github open issues
I am using Python 3.10.7, tqdm 4.64.0, on ubuntu 22.10, with tqdm installed via apt-get (python3-tqdm version 4.64.0-2)
When i re... | open | 2023-01-11T17:39:44Z | 2023-01-11T17:40:21Z | https://github.com/tqdm/tqdm/issues/1415 | [] | tpchuckles | 0 |
yihong0618/running_page | data-visualization | 331 | riding data | If I want to download riding data from Keep, which parameters should be modified? | closed | 2022-10-27T02:42:39Z | 2022-10-31T05:59:23Z | https://github.com/yihong0618/running_page/issues/331 | [] | Dabao55 | 1 |
man-group/arctic | pandas | 211 | inconsistent behavior between update and append in chunkstore | ```
df = pd.DataFrame(data={'data': [1]}, index=pd.MultiIndex.from_tuples([(dt(2016,1,1), 1)], names=['date', 'id']))
df2 = pd.DataFrame(data={'data': [2]}, index=pd.MultiIndex.from_tuples([(dt(2016,1,2), 2)], names=['date', 'id']))
l.write('test', df, 'D')
l.append('test', df2)
--------------------------------------... | closed | 2016-09-07T18:22:38Z | 2016-09-07T18:41:24Z | https://github.com/man-group/arctic/issues/211 | [
"bug"
] | bmoscon | 1 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 769 | plus和pro模型的区别在什么地方呢? | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 由于相关依赖频繁更新,请确保按照[Wiki](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki)中的相关步骤执行
- [X] 我已阅读[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/ll... | closed | 2023-07-19T16:46:20Z | 2023-08-14T22:02:30Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/769 | [
"stale"
] | minlik | 9 |
xonsh/xonsh | data-science | 5,798 | pytest: The (fspath: py.path.local) argument to XshFile is deprecated. Please use the (path: pathlib.Path) argument instead. | ## Current Behavior
Currently if I try to add tests for functions in a xsh script (foo.xsh), say this script:
```xsh
def bar():
return 42
```
and I then use this test file (test_foo.xsh):
```xsh
from foo import bar
def test_foo():
assert 42 == bar()
```
Then if I run the test using pytest like so `pytest test_foo.x... | closed | 2025-02-24T12:42:29Z | 2025-02-25T11:56:39Z | https://github.com/xonsh/xonsh/issues/5798 | [
"to-close-in-the-future",
"pytest"
] | svenskmand | 4 |
microsoft/nni | deep-learning | 5,600 | How to specify the target of distilling when there are multiple outputs? | **Describe the issue**:
I am using the transcript of [pruning BERT on MNLI](https://nni.readthedocs.io/en/v3.0rc1/tutorials/new_pruning_bert_glue.html). I find a problem of distillation when I change the output format of the encoder, which is as follows.
``` python
layer_outputs = layer_module(hidden_states, ...) # ... | closed | 2023-06-07T09:02:02Z | 2023-06-09T12:40:13Z | https://github.com/microsoft/nni/issues/5600 | [] | hobbitlzy | 3 |
pytorch/vision | machine-learning | 8,625 | ImageReadMode should support strings | It's pretty inconvenient to have to import ImageReadMode just to ask `decode_*` for an RGB image. We should just allow strings as well.
Also, `RGBA` should be a valid option (like in PIL). `RGB_ALPHA` is... long. | closed | 2024-09-03T14:46:03Z | 2024-09-04T10:38:52Z | https://github.com/pytorch/vision/issues/8625 | [] | NicolasHug | 0 |
sigmavirus24/github3.py | rest-api | 497 | Add issue import beta endpoint(s) | https://gist.github.com/jonmagic/5282384165e0f86ef105
| closed | 2015-12-08T21:33:25Z | 2018-07-20T14:11:49Z | https://github.com/sigmavirus24/github3.py/issues/497 | [
"in progress"
] | sigmavirus24 | 9 |
vanna-ai/vanna | data-visualization | 702 | Error: The server returned an error. See the server logs for more details. If you are running in Colab, this function is probably not supported. Please try running in a local environment. | **Describe the bug**
I have vanna running in docker, but I'm getting the following error when submitting my training
> Error: The server returned an error. See the server logs for more details. If you are running in Colab, this function is probably not
> supported. Please try running in a local environment.
... | open | 2024-11-14T06:34:36Z | 2025-01-21T13:18:45Z | https://github.com/vanna-ai/vanna/issues/702 | [
"bug"
] | SharkSyl | 2 |
newpanjing/simpleui | django | 331 | 多标签标题更新错乱 | **bug描述**
* *Bug description * *
* 打开多个model标签(`首页`、`A`、`B`)后,在`A`标签刷新时马上切换到`B`标签,之后`A`标签刷新完成更新标签标题时,新标题名称被更新到`B`标签,`A`标签的标题未变;
* 打开多个model标签(`首页`、`A`、`B`)后,`A`标签页面点击任意一个条目进入详情页面,加载完成后,切换到`首页`标签,快捷操作中`A`标签对应model的文本标题变更为`A`标签的标题。
**环境**
** environment**
1.Operating System:Centos 6
2.Python Version:3.7.4
... | closed | 2020-12-31T03:14:22Z | 2021-01-26T07:28:35Z | https://github.com/newpanjing/simpleui/issues/331 | [
"bug"
] | eshxcmhk | 1 |
FactoryBoy/factory_boy | django | 340 | DESCRIPTION.rst and METADATA still refer to fake-factory | `factory_boy` no longer relies on `fake-factory`, but in `METADATA` and `DESCRIPTION.rst` there's still:
> For this, factory_boy relies on the excellent `fake-factory <https://pypi.python.org/pypi/fake-factory>`
Super minor and I'm happy to PR it, I just haven't set up dev for `factory_boy` before | closed | 2017-01-09T15:43:09Z | 2017-01-10T20:30:00Z | https://github.com/FactoryBoy/factory_boy/issues/340 | [] | jisantuc | 2 |
sczhou/CodeFormer | pytorch | 43 | metrics | In your article, you wrote:
For the evaluation on real-world datasets without ground truth, we employ the widely-used non-reference perceptual metrics: FID and NIQE.
Is FID a non-reference indicator?
I have some trouble understanding this sentence. Thanks! | open | 2022-10-05T08:20:22Z | 2022-11-01T01:22:04Z | https://github.com/sczhou/CodeFormer/issues/43 | [] | 123456789-qwer | 4 |
strawberry-graphql/strawberry | asyncio | 2,845 | relay: NodeID does not support auto | <!-- Provide a general summary of the bug in the title above. -->
Something like relay.NodeID[auto] is not possible. The evaled type is there auto not Annotated | open | 2023-06-12T22:49:54Z | 2025-03-20T15:56:13Z | https://github.com/strawberry-graphql/strawberry/issues/2845 | [
"bug"
] | devkral | 0 |
coleifer/sqlite-web | flask | 135 | Support multiple DB's | Hi there
I would like to use sqlite_web to display the gui for multiple db's, which almost works since I can use multiple calls to initialize_app. However, the globals in sqlite_web.py are a deal breaker. Would you accept a PR that simply turns the globals to a dict with the file_name as key or something the like? | closed | 2023-10-20T12:27:18Z | 2025-02-23T16:04:01Z | https://github.com/coleifer/sqlite-web/issues/135 | [] | aersam | 5 |
apache/airflow | machine-learning | 47,413 | Scheduler HA mode, DagFileProcessor Race Condition | ### Apache Airflow version
Other Airflow 2 version (please specify below)
### If "Other Airflow 2 version" selected, which one?
2.10.1
### What happened?
We use dynamic dag generation to generate dags in our Airflow environment. We have one base dag definition file, we will call `big_dag.py`, generating >1500 dags... | open | 2025-03-05T19:43:20Z | 2025-03-11T16:09:10Z | https://github.com/apache/airflow/issues/47413 | [
"kind:bug",
"area:Scheduler",
"area:MetaDB",
"area:core",
"needs-triage"
] | robertchinezon | 4 |
lyhue1991/eat_tensorflow2_in_30_days | tensorflow | 46 | tf serving预测会有错误 | tf serving预测会有错误帮忙看下
{ "error": "Malformed request: POST /v1/models/linear_model" }{ "error": "In[0] is not a matrix. Instead it has shape [3]\n\t [[{{node model/outputs/BiasAdd}}]]" }% | closed | 2020-05-29T07:01:30Z | 2020-05-29T07:03:51Z | https://github.com/lyhue1991/eat_tensorflow2_in_30_days/issues/46 | [] | binzhouchn | 0 |
huggingface/transformers | python | 36,227 | <spam> | spam | closed | 2025-02-17T09:39:21Z | 2025-02-17T16:17:43Z | https://github.com/huggingface/transformers/issues/36227 | [
"bug"
] | j3801996 | 0 |
plotly/dash-table | plotly | 294 | Defining copy and paste behaviour on editable and non-editable columns | Related to https://github.com/plotly/dash-table/pull/293#issuecomment-445967446 creating a test for checking behaviour of copying and pasting onto a table with both editable and non-editable cells:
what should the behaviour be when copying & pasting 2 cols onto another table with an editable col and non-editable col... | open | 2018-12-10T21:18:00Z | 2019-07-06T12:24:49Z | https://github.com/plotly/dash-table/issues/294 | [
"dash-type-enhancement",
"Status: Discussion Needed"
] | cldougl | 0 |
horovod/horovod | tensorflow | 2,983 | can not run "horovodrun -np 4 -H localhost:4 python keras_mnist_advanced.py" inside horovod container | System: 8 A100 PCIe NVIDIA GPU
CUDA: 11.2
Driver: 460.27.04
OS: Ubuntu 18.04.4 LTS
Run following cmd as horovod instructions:
```
docker pull horovod/horovod
docker run -it imageID
#example/keras horovodrun -np 4 -H localhost:4 python keras_mnist_advanced.py
```
getting following Errors, please help!
`... | open | 2021-06-15T00:55:56Z | 2022-08-11T15:38:47Z | https://github.com/horovod/horovod/issues/2983 | [
"bug"
] | jeff-yajun-liu | 3 |
recommenders-team/recommenders | machine-learning | 1,965 | [BUG] Error in lgithgbm quickstart due to change in API for early stopping | ### Description
<!--- Describe your issue/bug/request in detail -->
See https://github.com/microsoft/recommenders/actions/runs/5853247386/job/15866899086
```
tests/smoke/examples/test_notebooks_python.py F. [ 96%]
tests/integration/examples/test_notebooks_python.py . [100... | closed | 2023-08-14T08:59:51Z | 2023-08-18T22:45:30Z | https://github.com/recommenders-team/recommenders/issues/1965 | [
"bug"
] | miguelgfierro | 1 |
Yorko/mlcourse.ai | matplotlib | 360 | Add demo gif to README | __Disclaimer: This is a bot__
It looks like your repo is trending. The [github_trending_videos](https://www.instagram.com/github_trending_videos/) Instgram account automatically shows the demo gifs of trending repos in Github.
Your README doesn't seem to have any demo gifs. Add one and the next time the parser runs ... | closed | 2018-10-02T07:09:26Z | 2018-10-09T15:47:16Z | https://github.com/Yorko/mlcourse.ai/issues/360 | [
"invalid"
] | va3093 | 0 |
autokey/autokey | automation | 995 | Update or remove new_features.rst | ### AutoKey is a Xorg application and will not function in a Wayland session. Do you use Xorg (X11) or Wayland?
Xorg
### Has this issue already been reported?
- [X] I have searched through the existing issues.
### Is this a question rather than an issue?
- [X] This is not a question.
### What type of issue is thi... | open | 2024-12-21T04:04:08Z | 2024-12-26T13:22:30Z | https://github.com/autokey/autokey/issues/995 | [
"help-wanted",
"documentation",
"low-priority",
"technical debt"
] | josephj11 | 4 |
wandb/wandb | data-science | 9,203 | [Bug-App]: graphql: panic occurred: runtime error: invalid memory address or nil pointer dereference | ### Describe the bug
<!--- Describe your issue here --->
When I log into my account using Github, every wandb page shows this error
> graphql: panic occurred: runtime error: invalid memory address or nil pointer dereference
An application error occurred. | closed | 2025-01-07T20:19:48Z | 2025-01-08T15:52:50Z | https://github.com/wandb/wandb/issues/9203 | [
"ty:bug",
"a:app"
] | lhy0807 | 3 |
davidsandberg/facenet | computer-vision | 1,244 | Unable to use .pb in tensorflow's java api | I'm trying to use this pre-trained model in Java. I'm using Intellij Idea and I've added library dependency of TensorFlow and Added OpenCV via project structure.
`libraryDependency += "org.tensorflow" % "tensorflow" % "1.15.0"`
I've downloaded the VGGFace2 pre-trained model, and trying to use its .pb file and fin... | open | 2023-12-01T06:28:13Z | 2023-12-01T06:28:13Z | https://github.com/davidsandberg/facenet/issues/1244 | [] | zaryabRiasat | 0 |
clovaai/donut | nlp | 238 | How to estimate the required video memory? | when i adjust processor.image_processor.size from {'height': 960, 'width': 720} to higher, GPU said CUDA out of memory..
my Video Card 8GB video, i wanna know, if i wanna use {'height': 2560, 'width': 1920}, how much VRAM will be used? does 16GB ok ? | closed | 2023-08-11T08:19:48Z | 2023-10-17T00:34:17Z | https://github.com/clovaai/donut/issues/238 | [] | chopin1998 | 1 |
babysor/MockingBird | deep-learning | 691 | 关于语音转换Voice Conversion(PPG based)中的ppg2mel.yaml修改里面的地址指向预训练好的文件夹 | **Summary[问题简述(一句话)]**
原文件似乎是为linux环境创建的,没有说明如何在windows下修改地址,请教一下如何在windows下修改ppg2mel.yaml文件里的地址,有好多文件我并没有在预处理后文件夹中找到
**Env & To Reproduce[复现与环境]**
环境:windows11,anaconda:python3.9.12
数据集文件夹:C:\test\test8\aidatatang_200zh
 has incorrect description .
It is explaining `how to close notebook` instead of `how to change cell's type`.
Corresponding [file](https://github.com/joouha/euporie/blob/main/docs/apps/notebook.rst#changing-a-cel... | closed | 2022-12-06T03:03:02Z | 2023-01-23T19:30:58Z | https://github.com/joouha/euporie/issues/50 | [
"good first issue"
] | DivyanshuBist | 3 |
cleanlab/cleanlab | data-science | 1,019 | exact issue name should be listed for each issue type in the Datalab Issue Type Guide | Otherwise it's hard to know how to run an audit for this issue type (eg. data valuation say). | closed | 2024-02-20T09:15:40Z | 2024-02-24T02:09:33Z | https://github.com/cleanlab/cleanlab/issues/1019 | [
"next release"
] | jwmueller | 1 |
matplotlib/matplotlib | data-visualization | 29,711 | [ENH]: directional antialiasing filter | ### Problem
Currently, the antialiasing filter used by imshow() is applied both in the x and the y direction. There are cases where "image-like" data is highly sampled in one direction (requiring antialiasing) but not in the other, and also has some nans; an example is a kymograph like subfigure 1c at https://www.nat... | open | 2025-03-06T11:49:33Z | 2025-03-17T14:31:07Z | https://github.com/matplotlib/matplotlib/issues/29711 | [
"New feature",
"topic: images"
] | anntzer | 17 |
waditu/tushare | pandas | 1,043 | 具体赞助多少才能获取2000积分? | 现在需要抓取tushare_pro的数据 需要赞助多少才能拥有2000积分,5000积分又需要赞助多少呢? | closed | 2019-05-14T01:54:38Z | 2019-05-20T06:14:05Z | https://github.com/waditu/tushare/issues/1043 | [] | Anthony0722 | 1 |
chiphuyen/stanford-tensorflow-tutorials | nlp | 4 | lack of definition of CONTENT_WEIGHT, STYLE_WEIGHT(in style_transfer_sols.py), prev_layer_name (in vgg_model_sols.py) | HI, Tks for the post, very helpful.
As title, I found several variable undefined,
for prev_layer_name, I think, it should be prev_name.name, however ':' is not accepted as scope name. So I changed ':' to '_', and it works
For CONTENT_WEIGHT and STYLE_WEIGHT, how to define it ?
(of course, omitted the weight... | closed | 2017-03-01T06:27:02Z | 2017-03-01T22:58:01Z | https://github.com/chiphuyen/stanford-tensorflow-tutorials/issues/4 | [] | tcglarry | 1 |
jackmpcollins/magentic | pydantic | 194 | Are there some models in ollama can support function calling or object return? | closed | 2024-04-27T13:49:57Z | 2024-05-12T23:30:08Z | https://github.com/jackmpcollins/magentic/issues/194 | [] | chaos369 | 6 | |
pydantic/pydantic | pydantic | 10,525 | Unable to import JsonSchemaHandler | ### Initial Checks
- [X] I confirm that I'm using Pydantic V2
### Description

Hey, this piece of code has not been working since today morning (GMT +5:30). Checked all latest commits but still not sure w... | closed | 2024-10-01T06:04:04Z | 2024-10-01T15:00:14Z | https://github.com/pydantic/pydantic/issues/10525 | [
"bug V2",
"pending"
] | ShivamGoswami-TCL | 2 |
erdewit/ib_insync | asyncio | 468 | How to cancel all open orders and close all positions? | Currently I have orders that have OCA trailing stop and take profit for an order attached and at EOD I like to close all my positions. As such below code doesn't exit all positions, they tend to keep the opposite orders open. If I keep them open, in the falling market they r getting triggered and become a working marke... | closed | 2022-04-25T20:57:03Z | 2022-05-07T15:16:09Z | https://github.com/erdewit/ib_insync/issues/468 | [] | msacs09 | 3 |
remsky/Kokoro-FastAPI | fastapi | 30 | 🔄 Automatic master to develop merge failed | Automatic merge from master to develop failed.
Please resolve this manually
Workflow run: https://github.com/remsky/Kokoro-FastAPI/actions/runs/12737419308 | closed | 2025-01-12T22:00:10Z | 2025-01-12T22:01:12Z | https://github.com/remsky/Kokoro-FastAPI/issues/30 | [
"merge-failed",
"automation"
] | github-actions[bot] | 0 |
explosion/spaCy | machine-learning | 12,976 | span_ruler is not working on ENT patterns | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
Text : "A 50-year-old male patient lodges chief complaint pain in lower right side of chest for three days associated with burning in epigastrium. History is cuffed with sputum."
Get Ent in Doc :
0 | 50-year | 2 | 5 | Age
... | closed | 2023-09-12T12:50:18Z | 2023-09-13T06:21:35Z | https://github.com/explosion/spaCy/issues/12976 | [
"feat / spanruler"
] | kamlesh0606 | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 974 | Cityscapes label2photo evaluation issue | Hello!
I am trying to reproduce the results in Table 1 of the pix2pix paper by evaluating the results generated from pix2pix on the Cityscapes (label2photo) dataset using your scripts.
I resized all leftImg8bit images and gtFine images (incl. *_color.png, *_labels.png and *_instances.png, although I probably only... | open | 2020-04-01T12:07:29Z | 2020-04-01T18:36:54Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/974 | [] | parvanitis15 | 1 |
albumentations-team/albumentations | machine-learning | 2,293 | [Speed up] GaussianBlur | Benchmark shows that `imgaug` has faster GaussianBlur implementation => need to learn from it and fix. | closed | 2025-01-24T15:56:46Z | 2025-02-18T18:26:41Z | https://github.com/albumentations-team/albumentations/issues/2293 | [
"Speed Improvements"
] | ternaus | 3 |
microsoft/qlib | deep-learning | 1,859 | error: subprocess-exited-with-error note: This error originates from a subprocess, and is likely not a problem with pip. error: metadata-generation-failed. | ## ❓ Questions and Help
I try to install pyqlib in anaconda prompt cmd of windows 11, suffering from this when in subprogress collecting scs:
error: subprocess-exited-with-error
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed. | closed | 2024-11-11T11:13:06Z | 2024-11-13T02:45:23Z | https://github.com/microsoft/qlib/issues/1859 | [
"question"
] | Agvensome | 1 |
keras-team/autokeras | tensorflow | 1,719 | Would it be possible to add jax? | In according to Google's [JAX](https://jax.readthedocs.io/en/latest/notebooks/Common_Gotchas_in_JAX.html), would it be possible to include JAX into `AutoKeras`, please?
I guess, if no array-slicing would be performed, JAX should be fully working?
https://github.com/keras-team/autokeras/blob/c51da2dd87b195ab3bd0... | open | 2022-05-02T20:01:43Z | 2022-05-02T20:01:43Z | https://github.com/keras-team/autokeras/issues/1719 | [] | Anselmoo | 0 |
kizniche/Mycodo | automation | 963 | upstream variable name change breaks input: SCD30 CircuitPython (fix also enclosed here) | Please DO NOT OPEN AN ISSUE:
- If your Mycodo version is not the latest release version, please update your device before submitting your issue (unless your issue is related to not being able to upgrade). Your problem might already be solved.
- If your issue has been addressed before (i.e., duplicated issue), ple... | closed | 2021-03-26T14:34:29Z | 2021-04-24T18:22:34Z | https://github.com/kizniche/Mycodo/issues/963 | [
"bug",
"Fixed and Committed"
] | AKAMEDIASYSTEM | 1 |
hzwer/ECCV2022-RIFE | computer-vision | 96 | 训练最后会crash | 感谢楼主的辛苦付出,测了几段视频,大运动效果和纹理很稳定,重影很少。
所以尝试复现一下效果,用了你给的100个数据做了一下测试,跑20个epoch,跑完最后会crash
机器是P40,双卡。
脚本是:
`python3 -u -m torch.distributed.launch --nproc_per_node=1 train.py --local_rank=0`
所有输出的日志:
nohup: ignoring input
457012eb-9ba5-4d55-9bbe-a3f39dfe66c5:82576:82576 [0] NCCL INFO Bootstrap : Using [0]eth1:9.73.1... | closed | 2021-01-20T07:20:51Z | 2021-03-19T10:00:05Z | https://github.com/hzwer/ECCV2022-RIFE/issues/96 | [] | xiazhenyz | 8 |
docarray/docarray | pydantic | 939 | Figure out handling of Union types | Many features of our current implementation rely on the type hints under the hood to infer behaviour.
This break whenever the type hint is of form `Union` or `Optional`, since those cannot be used in instance and subclass checks.
This is especially problematic, since our type `Tensor` is a Union under the hood, and it... | closed | 2022-12-14T09:10:44Z | 2023-01-03T08:51:56Z | https://github.com/docarray/docarray/issues/939 | [
"DocArray v2"
] | JohannesMessner | 0 |
Hironsan/BossSensor | computer-vision | 20 | run boss_train.py error | I user tensorflow 0.12, and I put some pictures in boss and other directories, but when I run boss_train.py ,it report error:
Traceback (most recent call last):
File "/home/zxx/PycharmProjects/BossSensor/boss_train.py", line 176, in <module>
dataset.read()
File "/home/zxx/PycharmProjects/BossSensor/... | closed | 2017-03-12T15:49:31Z | 2019-03-22T10:32:04Z | https://github.com/Hironsan/BossSensor/issues/20 | [] | asd51731 | 1 |
raphaelvallat/pingouin | pandas | 19 | Epsilon and Mauchly interaction in rm_anova2 differ from JASP | open | 2019-04-26T17:16:24Z | 2019-08-06T15:14:55Z | https://github.com/raphaelvallat/pingouin/issues/19 | [
"bug :boom:",
"help wanted :bell:",
"invalid :triangular_flag_on_post:"
] | raphaelvallat | 3 | |
MycroftAI/mycroft-core | nlp | 3,156 | ModuleNotFoundError: No module named 'xdg.BaseDirectory' | **Describe the bug**
Hi, all. I cloned mycroft-core on my computer and installed it. But I get the following error when running.
**To Reproduce**
```sh
~$ source .venv/bin/activate
(.venv) blink@blink-eq:~/mycroft-core$ mycroft-skill-testrunner
Traceback (most recent call last):
File "<frozen runpy>", line ... | closed | 2023-09-13T05:24:25Z | 2024-09-08T08:15:27Z | https://github.com/MycroftAI/mycroft-core/issues/3156 | [
"bug"
] | yjdwbj | 1 |
graphql-python/graphene-django | django | 751 | How do I make the pagination like using django rest framework? | I didn't see any docs about pagination, will that be coming in future? | closed | 2019-08-18T02:58:49Z | 2019-10-25T11:15:06Z | https://github.com/graphql-python/graphene-django/issues/751 | [] | tinc0709 | 3 |
aiogram/aiogram | asyncio | 1,388 | Pretty work with state | ### aiogram version
3.x
### Problem
I've been writing telegram bots on aiogram for quite some time.
I like everything, but I don’t really like working with states. You have to write a lot of typical code.
You must describe the state model, and then write handlers for each item.
I believe that this can be im... | closed | 2024-01-02T12:17:32Z | 2024-08-17T13:56:59Z | https://github.com/aiogram/aiogram/issues/1388 | [
"enhancement"
] | dop3file | 4 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 707 | I reduced the image size . but result is poor | Hello, I appreciate to your great research and implementations.
I would like to thank you for doing such a great job.
Anyway, I have a Question.
When I learned with 3x256x256 images , it was fine
but I learn with 1x50x50 image, it is poor
I want to learn with 1(channel) x 50 x 50 image from this model.
So I... | closed | 2019-07-17T08:17:48Z | 2019-07-19T03:52:11Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/707 | [] | Realdr4g0n | 2 |
xlwings/xlwings | automation | 1,865 | Access to chart sheets Excel | #### OS (Windows 10)
#### Versions of xlwings, Excel and Python (xlwings 0.27.2, Microsoft Excel 2010, Python 3.6)
#### Describe your issue (incl. Traceback!)
Hallo,
I have a chart sheet in my Excel book.
If I try to find the sheets of my book the once which contains the chart is not listed out.
Also, if i... | closed | 2022-03-16T10:49:04Z | 2022-03-23T13:14:48Z | https://github.com/xlwings/xlwings/issues/1865 | [] | AlbertoCasetta | 1 |
anselal/antminer-monitor | dash | 54 | Support for avalon 741 and 821 | Anyone have an example of the JSON RPC data that cgminer returns?
I have some that are arriving and wanted to add support for this before they are here.
| open | 2018-01-17T14:37:19Z | 2018-02-12T08:51:26Z | https://github.com/anselal/antminer-monitor/issues/54 | [
":pick: miner_support"
] | sergioclemente | 7 |
ets-labs/python-dependency-injector | asyncio | 431 | service is not being injected, instead Provide object is present | ```
@auth_blp.route('/')
class Login(MethodView):
@auth_blp.arguments(schema=AuthLoginFormSchema, location="form", as_kwargs=True)
@auth_blp.response(status_code=200, schema=AuthLoginRespSchema)
def post(self, **kwargs):
"""
POST to login
"""
user = User.get_by_u... | closed | 2021-03-22T01:54:48Z | 2021-03-22T17:11:58Z | https://github.com/ets-labs/python-dependency-injector/issues/431 | [
"question"
] | zero-shubham | 2 |
keras-team/keras | python | 20,912 | What is the python package google used for? | The package was added to requirements.txt in https://github.com/keras-team/keras/commit/699e4c3174976d9b308a60458259a0e8544e0777 and is still present in requirements-common.txt as of https://github.com/keras-team/keras/commit/e045b6abe42ed9335a85b553cc9c609b76a8a54c. The package `google` on [pypi](https://pypi.org/proj... | closed | 2025-02-16T20:25:12Z | 2025-02-20T18:38:46Z | https://github.com/keras-team/keras/issues/20912 | [
"type:support",
"keras-team-review-pending"
] | loqs | 2 |
WZMIAOMIAO/deep-learning-for-image-processing | deep-learning | 512 | SSD error | **System information**
* Have I written custom code:
* OS Platform(e.g., window10 or Linux Ubuntu 16.04):
* Python version:
* Deep learning framework and version(e.g., Tensorflow2.1 or Pytorch1.3):
* Use GPU or not:
* CUDA/cuDNN version(if you use GPU):
* The network you trained(e.g., Resnet34 network):
**Des... | closed | 2022-04-10T13:17:39Z | 2022-04-11T00:49:01Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/512 | [] | shangshanghuiliyi | 2 |
deepset-ai/haystack | nlp | 9,016 | Add run_async for `AzureOpenAIDocumentEmbedder` | We should be able to reuse the implementation once it is made for the `OpenAIDocumentEmbedder` | open | 2025-03-11T11:07:12Z | 2025-03-23T07:08:53Z | https://github.com/deepset-ai/haystack/issues/9016 | [
"Contributions wanted!",
"P2"
] | sjrl | 0 |
e2b-dev/code-interpreter | jupyter | 23 | 401 Unauthorized when pushing new template | Would appreciate any help here. I tried logging out and logging back in, still seeing the same error.
```
gonzalonunez@Gonzalos-MacBook-Pro e2b % npx e2b template build -c "/root/.jupyter/start-up.sh"
Found sandbox template or4llhf3739qmlizq7u1 fluent-production-sandbox <-> ./e2b.toml
Found ./Dockerfile that wi... | closed | 2024-06-21T16:55:20Z | 2024-06-23T19:08:03Z | https://github.com/e2b-dev/code-interpreter/issues/23 | [] | gonzalonunez | 11 |
ShishirPatil/gorilla | api | 371 | Cannot load hugging face dataset for function calling | To repro, try the following:
```
from datasets import load_dataset
dataset = load_dataset("gorilla-llm/Berkeley-Function-Calling-Leaderboard")
```
You will get the following error
```
File "pyarrow/_json.pyx", line 308, in pyarrow._json.read_json
File "pyarrow/error.pxi", line 154, in pyarrow.lib.pyar... | closed | 2024-04-19T06:51:17Z | 2024-04-23T04:49:59Z | https://github.com/ShishirPatil/gorilla/issues/371 | [] | sebastiangonsal | 1 |
python-restx/flask-restx | flask | 83 | Upgrade packages in light of deprecation warnings | Currently the unit tests are always throwing the following DeprecationWarnings:
> app/lib/python3.8/site-packages/flask_restx/model.py:12
> /private/var/www/html/api/app/lib/python3.8/site-packages/flask_restx/model.py:12: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collect... | closed | 2020-03-12T23:48:35Z | 2020-03-22T23:35:16Z | https://github.com/python-restx/flask-restx/issues/83 | [
"enhancement"
] | andreixk | 2 |
pyro-ppl/numpyro | numpy | 1,045 | FR: Fail with informative error message when same plate name used with inconsistent dimensions | Currently reusing the same plate name with different arguments to e.g. dim will cause problems. Models like this could be rejected with an informative error message quickly, before confusing problems which can include arrays changing shape happen. See below for the current behaviour.
```py
import sys
import num... | closed | 2021-05-28T06:24:00Z | 2021-06-01T00:03:23Z | https://github.com/pyro-ppl/numpyro/issues/1045 | [
"warnings & errors"
] | frankier | 0 |
Farama-Foundation/PettingZoo | api | 844 | [Proposal] Use GitHub Issue Forms | ### Proposal
I propose to use [GitHub Issue Forms](https://docs.github.com/en/communities/using-templates-to-encourage-useful-issues-and-pull-requests/configuring-issue-templates-for-your-repository#creating-issue-forms) when an issue is created in this repo
### Motivation
This facilitates the proper filling ... | closed | 2022-10-31T09:03:12Z | 2022-10-31T16:29:10Z | https://github.com/Farama-Foundation/PettingZoo/issues/844 | [] | tobirohrer | 1 |
plotly/dash | data-visualization | 3,226 | add/change type annotations to satisfy mypy and other tools | With the release of dash 3.0 our CI/CD fails for stuff that used to work.
Here's a minimum working example:
```python
from dash import Dash, dcc, html
from dash.dependencies import Input, Output
from typing import Callable
app = Dash(__name__)
def create_layout() -> html.Div:
return html.Div([
dcc.Input(i... | open | 2025-03-18T10:25:57Z | 2025-03-20T16:30:13Z | https://github.com/plotly/dash/issues/3226 | [
"bug",
"P2"
] | gothicVI | 6 |
Miserlou/Zappa | django | 1,295 | PermissionError trying to make first deployment | ## Context
I'm trying to do my first Zappa deployment and hit an exception:
Calling deploy for stage dev..
Creating project-dev-ZappaLambdaExecutionRole IAM Role..
Creating zappa-permissions policy on project-dev-ZappaLambdaExecutionRole IAM Role.
Oh no! An error occurred! :(
=========... | closed | 2017-12-16T10:10:51Z | 2018-02-25T16:57:13Z | https://github.com/Miserlou/Zappa/issues/1295 | [] | rgov | 7 |
JoeanAmier/TikTokDownloader | api | 408 | 下载视频提示[配置文件cookie参数未登陆,数据获取已提前结束] |
使用chrome浏览器能正常获取cookie,下载视频提示[配置文件cookie参数未登陆,数据获取已提前结束],实际浏览器的账号是正常登陆状态,账号发布有53个视频,只能获取到18个视频,其他获取不到也无法下载.
 | open | 2025-02-26T03:00:44Z | 2025-02-28T02:07:53Z | https://github.com/JoeanAmier/TikTokDownloader/issues/408 | [] | yzy64 | 10 |
aidlearning/AidLearning-FrameWork | jupyter | 54 | Cannot use sklearn? | I install the sklearn lib using "pip3 install sklearn",then I import sklearn in the python3,there were many errors like this:
ImportError: cannot import name 'SemLock'
......
ImportError: This platform lacks a functioning sem_open implementation, therefore, the required synchronization primitives needed will not fun... | closed | 2019-09-21T05:26:17Z | 2020-08-02T01:43:43Z | https://github.com/aidlearning/AidLearning-FrameWork/issues/54 | [] | zwdnet | 1 |
clovaai/donut | computer-vision | 39 | Input size parameter clarification | I'm trying to run my own fine-tunning for document parsing. When building the train configuration I wondered: Is the input_size parameter related to the the size of the images in the dataset or is it only used for the Swin transfomer to create the embedding windows?
In case it's the second. When should it be customi... | closed | 2022-08-30T19:39:45Z | 2024-08-01T23:25:52Z | https://github.com/clovaai/donut/issues/39 | [] | leitouran | 3 |
kizniche/Mycodo | automation | 1,126 | Atlas Pump I2C connection doesn't understand command |
### Describe the problem/bug
We are using Mycodo with Raspberry Pi4 to automate pH monitoring of water. Everything seems to be working fine except for the pump. When given the command the pump changes the light color from blue to green to red and then back to blue. Troubleshooting with Atlas, we found that pump ca... | closed | 2021-12-21T14:33:26Z | 2022-03-28T22:40:25Z | https://github.com/kizniche/Mycodo/issues/1126 | [] | vipul-khatana | 1 |
ContextLab/hypertools | data-visualization | 163 | add soundtrack | include an animation flag that will (optionally) add a dramatic soundtrack (or a user-selected audio file) to animations.
eventually we could automatically generate an audio soundtrack using the data. 🎶 | open | 2017-10-24T17:16:31Z | 2017-10-24T17:16:31Z | https://github.com/ContextLab/hypertools/issues/163 | [] | jeremymanning | 0 |
frappe/frappe | rest-api | 31,815 | Dark Theme Color Issue | Like Button not showing clearly

Frappe Framework: v15.59.0 (version-15) | open | 2025-03-20T03:46:32Z | 2025-03-20T03:46:49Z | https://github.com/frappe/frappe/issues/31815 | [
"bug"
] | nilpatel42 | 0 |
ludwig-ai/ludwig | data-science | 3,462 | Image Classification: Config | The Config.

It starts a syntax error, it should actually be:
config = {
'input_features': [
{
'name': 'image_path',
'type': 'image',
'preprocessing': {'num_processes': 4},
'enco... | closed | 2023-07-13T11:01:32Z | 2024-10-18T13:48:23Z | https://github.com/ludwig-ai/ludwig/issues/3462 | [] | AnaMiguelRodrigues1 | 4 |
twopirllc/pandas-ta | pandas | 176 | Pandas TA strategy method goes into infinite loop: Windows Freeze Support Error | @twopirllc I was trying to run the below code on a dataframe
```python
df.ta.strategy("Momentum")
print(df)
```
It goes into infinite loop and consumes all CPU on my windows 10 laptop.
Then I need to kill all VSCodium and python exes.
Could you please help?
_Originally posted by @rahulmr in https://github.c... | closed | 2020-12-28T21:16:15Z | 2023-03-17T19:53:02Z | https://github.com/twopirllc/pandas-ta/issues/176 | [
"question",
"info"
] | twopirllc | 20 |
huggingface/transformers | tensorflow | 36,348 | None | closed | 2025-02-22T18:12:03Z | 2025-02-22T18:25:42Z | https://github.com/huggingface/transformers/issues/36348 | [] | Hashmapw | 0 | |
dmlc/gluon-cv | computer-vision | 844 | Failed loading Parameter | I have trained yolov3 on my own dataset and got params,and i have read some issues like #229,but still failed loading Parameter
In my training script train_yolo3.py, i added the following lines:
class VOCLike(VOCDetection):
CLASSES=['number']
def __init__(self,root,splits,transform=None,index_map=No... | closed | 2019-06-29T14:39:52Z | 2021-05-26T04:04:10Z | https://github.com/dmlc/gluon-cv/issues/844 | [] | narutobns | 3 |
streamlit/streamlit | streamlit | 10,162 | Redirect to last viewed page in multipage app after `st.login` | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [X] I added a descriptive title and summary to this issue.
### Summary
We're soon launching native authentication in Streamlit (see https://github.com/streamlit/streamlit/issues/85... | open | 2025-01-10T23:48:40Z | 2025-01-10T23:48:54Z | https://github.com/streamlit/streamlit/issues/10162 | [
"type:enhancement",
"feature:st.login"
] | jrieke | 1 |
onnx/onnx | deep-learning | 5,885 | [Feature request] Provide a means to convert to numpy array without byteswapping | ### System information
ONNX 1.15
### What is the problem that this feature solves?
Issue onnx/tensorflow-onnx#1902 in tf2onnx occurs on big endian systems, and it is my observation that attributes which end up converting to integers are incorrectly byteswapped because the original data resided within a tensor. If `n... | closed | 2024-01-31T20:58:56Z | 2024-02-02T16:52:35Z | https://github.com/onnx/onnx/issues/5885 | [
"topic: enhancement"
] | tehbone | 4 |
desec-io/desec-stack | rest-api | 389 | Extend API for easy access to TLSA, SSHFP, OPENPGPKEY, ... records | Setting these "DNSSEC-only" record types often requires complicated computations, let's do them on the API side wherever safely possible. | open | 2020-05-18T09:27:23Z | 2024-10-07T17:21:00Z | https://github.com/desec-io/desec-stack/issues/389 | [
"enhancement",
"api"
] | nils-wisiol | 0 |
mage-ai/mage-ai | data-science | 5,411 | Specify scheduler name on k8s executor | Is your feature request related to a problem? Please describe.
Currently, the scheduler pod name is not configurable in the k8sconfig file for Mage. This limitation forces users to rely on the default Kubernetes scheduler, which can be restrictive in scenarios where alternative schedulers are required, such as those o... | closed | 2024-09-12T15:07:15Z | 2024-09-18T20:54:50Z | https://github.com/mage-ai/mage-ai/issues/5411 | [] | messerzen | 1 |
pyro-ppl/numpyro | numpy | 1,989 | Check transformation domain in `TransformedDistribution` constructor? | ### Feature Summary
Distributions know their support. Transformations know their domain and codomain. As far as I can tell, it should therefore be possible to confirm that a transformation used in constructing a `TransformedDistribution` from a base distribution has a domain equal to the support of the base distributio... | open | 2025-02-27T17:35:16Z | 2025-03-01T19:23:20Z | https://github.com/pyro-ppl/numpyro/issues/1989 | [
"enhancement"
] | dylanhmorris | 2 |
pytorch/pytorch | python | 148,938 | [triton 3.3] `AOTInductorTestABICompatibleGpu.test_triton_kernel_tma_descriptor_1d_dynamic_False_cuda` | ### 🐛 Describe the bug
1. Update triton to `release/3.3.x` https://github.com/triton-lang/triton/tree/release/3.3.x
2. run `python test/inductor/test_aot_inductor.py -vvv -k test_triton_kernel_tma_descriptor_1d_dynamic_False_cuda`
Possibly an easier repro is
```
TORCHINDUCTOR_CPP_WRAPPER=1 python test/inductor/test_... | open | 2025-03-11T02:00:45Z | 2025-03-13T16:58:07Z | https://github.com/pytorch/pytorch/issues/148938 | [
"oncall: pt2",
"module: inductor",
"upstream triton",
"oncall: export",
"module: aotinductor",
"module: user triton"
] | davidberard98 | 1 |
opengeos/streamlit-geospatial | streamlit | 54 | Page not working | I am trying to access to this page to create a timelapse but it seems that is not working. | closed | 2022-07-04T09:54:57Z | 2022-07-06T18:13:03Z | https://github.com/opengeos/streamlit-geospatial/issues/54 | [] | marparven1 | 1 |
widgetti/solara | fastapi | 246 | Cached variables? | I have a rather large app now, so I don't have any good isolated examples, but on multiple occasions I've navigated the app, perform changes that are saved to a database, then refreshed and seen old states of variables appearing. Then, I restart the development with `solara run main.py` and I get the actual (correct) s... | open | 2023-08-18T18:11:58Z | 2023-09-16T08:34:54Z | https://github.com/widgetti/solara/issues/246 | [] | FerusAndBeyond | 3 |
lanpa/tensorboardX | numpy | 146 | histogramm error | pytorch 0.3.1.post2
TensorBoard 1.7.0
Tensorbord distributions consist of one value 3e+18.
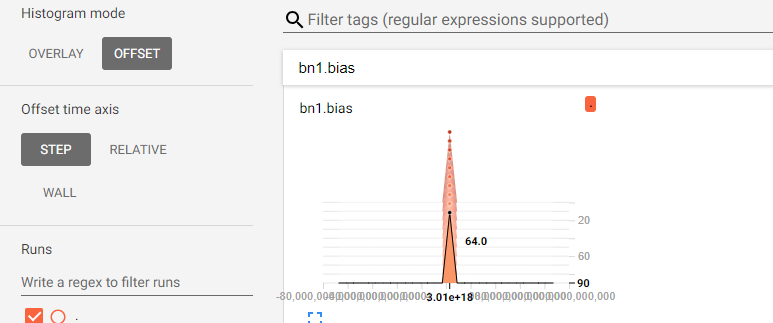
How can I fix it? | closed | 2018-05-24T15:34:19Z | 2018-05-24T17:48:01Z | https://github.com/lanpa/tensorboardX/issues/146 | [] | E1eMenta | 1 |
coqui-ai/TTS | python | 3,315 | [Feature request] Using local whisper transcription with word time stamps to remove tts hallucinations | **🚀 Feature Description**
Currently all the transformer based tts models I've run into deal with issues of hallucinations, especially at the end for instance even with XTTS V2, I was wondering if there was any planned way to remove at least the hallucinations that appear at the end of the generated audio, for instanc... | closed | 2023-11-27T02:46:22Z | 2024-01-28T22:40:19Z | https://github.com/coqui-ai/TTS/issues/3315 | [
"wontfix",
"feature request"
] | DrewThomasson | 2 |
keras-team/autokeras | tensorflow | 1,163 | Example code not working - MPG example | ### Bug Description
Trying to get started using AutoKeras and finding that most of the example code does not work.
### Bug Reproduction
Running the example here: https://autokeras.com/tutorial/structured_data_regression/
### Setup Details
Include the details about the versions of:
- OS type and version: ... | closed | 2020-06-02T15:50:26Z | 2023-03-27T09:19:30Z | https://github.com/keras-team/autokeras/issues/1163 | [
"bug report",
"pinned"
] | KirkDCO | 27 |
ScrapeGraphAI/Scrapegraph-ai | machine-learning | 415 | ImportError: cannot import name 'Required' from 'typing' (/usr/local/lib/python3.11/typing.py) | When I run this code
`from scrapegraphai.graphs import SmartScraperGraph
import nest_asyncio
graph_config = {
"llm": {
"model": "ollama/mistral",
"temperature": 0,
"format": "json", # Ollama needs the format to be specified explicitly
"base_url": "http://localhost:11434"... | closed | 2024-06-28T07:23:39Z | 2024-08-18T08:43:15Z | https://github.com/ScrapeGraphAI/Scrapegraph-ai/issues/415 | [] | sunejay | 2 |
polarsource/polar | fastapi | 4,729 | Cannot mark issue is not solved but closed/reject funding | ### Description
<!-- A brief description with a link to the page on the site where you found the issue. -->
An issue was not solved but closed.
How do I mark that?
### Current Behavior
<!-- A brief description of the current behavior of the issue. -->
I can only mark the issue as done and pay it out.... | closed | 2024-12-23T14:37:44Z | 2024-12-23T19:36:12Z | https://github.com/polarsource/polar/issues/4729 | [
"bug"
] | niccokunzmann | 1 |
pytorch/pytorch | machine-learning | 149,370 | UNSTABLE pull / cuda12.4-py3.10-gcc9-sm75 / test (pr_time_benchmarks) | See https://hud.pytorch.org/hud/pytorch/pytorch/main/1?per_page=50&name_filter=pr_time&mergeLF=true <- job passes and fails intermittently with no apparent commit that could have started it
cc @chauhang @penguinwu @seemethere @pytorch/pytorch-dev-infra | open | 2025-03-18T01:24:52Z | 2025-03-18T13:11:18Z | https://github.com/pytorch/pytorch/issues/149370 | [
"module: ci",
"triaged",
"oncall: pt2",
"unstable"
] | malfet | 2 |
twopirllc/pandas-ta | pandas | 699 | Schaff trend cycle (STC) giving negatively biased results: bug? | **Which version are you running? The lastest version is on Github. Pip is for major releases.**
pandas_ta: 0.3.14b0
**Do you have _TA Lib_ also installed in your environment?**
Yes: TA-Lib: 0.4.19
**Have you tried the _development_ version? Did it resolve the issue?**
No
**Describe the bug**
The values are... | open | 2023-06-26T17:23:45Z | 2023-10-12T21:15:09Z | https://github.com/twopirllc/pandas-ta/issues/699 | [
"bug",
"help wanted"
] | halterc | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.