
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
ymcui/Chinese-BERT-wwm | tensorflow | 138 | 训练语料 | 请问训练语料可以公开吗? | closed | 2020-08-19T02:39:06Z | 2020-08-19T03:16:09Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/138 | [] | liuwei1206 | 1 |
ultralytics/ultralytics | pytorch | 18,851 | Why are the modules named AConv and ADown? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
I’m currently working on improving the `docstrings` in [block.py](https://gi... | open | 2025-01-23T15:38:27Z | 2025-01-23T16:04:33Z | https://github.com/ultralytics/ultralytics/issues/18851 | [
"documentation",
"question"
] | visionNoob | 2 |
huggingface/datasets | machine-learning | 7,386 | Add bookfolder Dataset Builder for Digital Book Formats | ### Feature request
This feature proposes adding a new dataset builder called bookfolder to the datasets library. This builder would allow users to easily load datasets consisting of various digital book formats, including: AZW, AZW3, CB7, CBR, CBT, CBZ, EPUB, MOBI, and PDF.
### Motivation
Currently, loading dataset... | closed | 2025-02-08T14:27:55Z | 2025-02-08T14:30:10Z | https://github.com/huggingface/datasets/issues/7386 | [
"enhancement"
] | shikanime | 1 |
vitalik/django-ninja | django | 521 | Router.path() doesn't exist. | When I started Djangoninja for the first time, I tried to configure the operation with Class based. But I followed the example below and found that router.path() is a non-existent function.
Is this function replaced or missing by another function?
```python
from ninja import Router
router = Router()
@r... | closed | 2022-08-04T01:15:13Z | 2022-08-04T07:58:58Z | https://github.com/vitalik/django-ninja/issues/521 | [] | shiroXgodG | 2 |
huggingface/datasets | machine-learning | 6,597 | Dataset.push_to_hub of a canonical dataset creates an additional dataset under the user namespace | While using `Dataset.push_to_hub` of a canonical dataset, an additional dataset was created under my user namespace.
## Steps to reproduce the bug
The command:
```python
commit_info = ds.push_to_hub(
"caner",
config_name="default",
commit_message="Convert dataset to Parquet",
commit_descriptio... | closed | 2024-01-16T11:27:07Z | 2024-02-05T12:29:37Z | https://github.com/huggingface/datasets/issues/6597 | [
"bug"
] | albertvillanova | 6 |
django-cms/django-cms | django | 7,225 | The fields `created_by` of PageUser, PageGroup and `user`/`group` of PagePermission can cause unwanted user/group deletion | ## Description
As all of these fields are defined as `on_delete=models.CASCADE`. That means, if I delete User A, that has previously created a `PageUser` B, the user B will be deleted as well. I never was really sure what these are anyway... see also #5517 .
## Steps to reproduce
Create User A. Log in with A, ... | closed | 2022-02-09T23:59:23Z | 2025-03-01T18:47:13Z | https://github.com/django-cms/django-cms/issues/7225 | [
"blocker",
"status: accepted"
] | benzkji | 17 |
Gozargah/Marzban | api | 1,158 | Fixed | Fixed | closed | 2024-07-21T03:58:20Z | 2024-07-22T09:00:57Z | https://github.com/Gozargah/Marzban/issues/1158 | [
"Feature"
] | mahdiismailpuri | 0 |
StackStorm/st2 | automation | 5,933 | run st2 with docker-compose, failed to connect to mongo | rabbitmq/mongo/redis are running OK, but st2 apps are always restarting.


| closed | 2023-03-13T10:03:25Z | 2023-03-18T13:13:34Z | https://github.com/StackStorm/st2/issues/5933 | [] | gudan803 | 2 |
allenai/allennlp | pytorch | 5,258 | Add a conda install for Mac | There is a [conda-forge](https://anaconda.org/conda-forge/allennlp) install for Linux. Could you please also add one for Mac?
https://conda-forge.org/#add_recipe
| closed | 2021-06-13T14:11:13Z | 2022-01-17T12:19:30Z | https://github.com/allenai/allennlp/issues/5258 | [
"Feature request"
] | codeananda | 19 |
neuml/txtai | nlp | 215 | Add Console Task | Add a new task that prints inputs and outputs to stdout. Mainly used for debugging. | closed | 2022-02-02T02:15:30Z | 2022-02-02T02:25:21Z | https://github.com/neuml/txtai/issues/215 | [] | davidmezzetti | 0 |
sanic-org/sanic | asyncio | 2,596 | Missing priority functionality in app-wide middlware | ## Description
In v22.9 the priority feature was added, but unfortunately it appears it was overlooked and there is priority parameter to `register_middleware()` for `Sanic`.
I am looking to use this feature because I have a Blueprint-specific middleware which appears to run before the application-wide middleware... | closed | 2022-11-05T14:29:00Z | 2022-12-19T17:14:48Z | https://github.com/sanic-org/sanic/issues/2596 | [
"bug"
] | Bluenix2 | 0 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 4,159 | handling of outlook safelink protection | ### Proposal
is it possible to make the password reset link able to be active with outlook/defender safelink protection by enabeling the link to be "clicked" two times?
### Motivation and context
when we reset the users password for their globaleaks account they cant use the link, because its already been clicked (... | closed | 2024-08-20T12:52:27Z | 2024-10-07T14:36:10Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/4159 | [] | FFD8FFE1 | 2 |
home-assistant/core | python | 141,180 | Changing water temperature not working | ### The problem
Hello,
When trying to change the hot water temperature of my GAS boiler, nothing happens. Although when changing it via TADO app, the change is communicated back to HA.
Would be great if I can change this value from HA.
Looking in the debug logs, nothing is crashing. The value is trying to be update... | open | 2025-03-23T09:14:45Z | 2025-03-23T09:14:50Z | https://github.com/home-assistant/core/issues/141180 | [
"integration: tado"
] | Formatrick | 1 |
MaartenGr/BERTopic | nlp | 1,344 | KeyBERTInspired issue running | Hi Marteen,
I was working on :
```
from umap import UMAP
from bertopic import BERTopic
# Using a custom UMAP model
umap_model = UMAP(n_neighbors=15, n_components=2, min_dist=0.0, metric='cosine', random_state=42)
# Train our model
topic_model = BERTopic(umap_model=umap_model)
i am trying: Topics ge... | closed | 2023-06-16T06:49:57Z | 2023-09-27T09:12:35Z | https://github.com/MaartenGr/BERTopic/issues/1344 | [] | andysingal | 7 |
dfki-ric/pytransform3d | matplotlib | 16 | Publish pytransform at JOSS | https://joss.theoj.org/
New publication: https://joss.theoj.org/papers/new | closed | 2018-10-29T21:44:06Z | 2019-01-31T17:28:13Z | https://github.com/dfki-ric/pytransform3d/issues/16 | [] | AlexanderFabisch | 1 |
DistrictDataLabs/yellowbrick | scikit-learn | 394 | Extend Missing Values Visualizers to plot missing values against the target (y) | Follow up item to #363
Extend Bar and Dispersion visualizers to create optionally create visualizers targeted against the target. For example, it would plot the number of missing values for each target variable.
| closed | 2018-04-26T01:58:47Z | 2018-07-24T14:40:59Z | https://github.com/DistrictDataLabs/yellowbrick/issues/394 | [
"type: feature"
] | ndanielsen | 2 |
stanford-oval/storm | nlp | 337 | [BUG]sample code spelling error | **Describe the bug**
in `readme.md` ,the sample code `costorm_runner.knowledge_base.reorganize()` should be `costorm_runner.knowledge_base.reogranize()`
| open | 2025-03-11T03:11:33Z | 2025-03-11T03:11:33Z | https://github.com/stanford-oval/storm/issues/337 | [] | JV-X | 0 |
encode/httpx | asyncio | 2,337 | closedResourceError intermittently when using httpx asyncclient to send the request | we are observing closedResourceError when sending multiple requests using httpx async client. httpx version used is 0.19.0. is this issue known and fixed in any later version?
Logs:
resp = await asyncio.gather(*[self.async_send_request(method,self.dest_host,self.dest_port,uri,i,payload=payload,headers=hea... | closed | 2022-08-12T04:58:47Z | 2023-10-21T10:17:23Z | https://github.com/encode/httpx/issues/2337 | [] | jainaj81 | 5 |
huggingface/transformers | deep-learning | 36,348 | None | closed | 2025-02-22T18:12:03Z | 2025-02-22T18:25:42Z | https://github.com/huggingface/transformers/issues/36348 | [] | Hashmapw | 0 | |
deepfakes/faceswap | deep-learning | 441 | Can’t handler occluded face such as using microphone | GAN (use perceptual loss) and Org are can’t handler occluded case such as microphone cover the mouth, may I know whether it is config problem or bug so that to solve it? Thank you.
| closed | 2018-06-22T01:27:09Z | 2018-06-22T08:41:00Z | https://github.com/deepfakes/faceswap/issues/441 | [] | g0147 | 5 |
iperov/DeepFaceLab | machine-learning | 666 | AMD GPU | hey guy,will it work on amd gpu? | closed | 2020-03-21T12:25:47Z | 2021-04-23T07:01:06Z | https://github.com/iperov/DeepFaceLab/issues/666 | [] | saltfishh | 4 |
yunjey/pytorch-tutorial | pytorch | 235 | ValueError: num_samples should be a positive integer value, but got num_samples=0 | Traceback (most recent call last):
File "D:/PycharmWorkspace/pytorch-tutorial/tutorials/01-basics/pytorch_basics/main.py", line 154, in <module>
train_loader = torch.utils.data.DataLoader(dataset=custom_dataset,
File "D:\anaconda3\envs\torch\lib\site-packages\torch\utils\data\dataloader.py", line 262, in __i... | open | 2021-08-26T18:07:06Z | 2022-04-12T16:37:06Z | https://github.com/yunjey/pytorch-tutorial/issues/235 | [] | zherCyber | 1 |
Neoteroi/BlackSheep | asyncio | 6 | Improve built-in synch logging | in the built-in integration with sync logging,
consider (TBD):
1. use a dedicated file for each process
1. create a file on disk only if sync logging is used
1. when logging exceptions (built-in error handling), include the `id` of the process that was handling the request | closed | 2019-02-20T10:28:12Z | 2019-02-20T16:17:46Z | https://github.com/Neoteroi/BlackSheep/issues/6 | [
"enhancement"
] | RobertoPrevato | 0 |
iperov/DeepFaceLab | deep-learning | 868 | hello, have this bug when use merger | when i try change mask_mode to some of Xseg, most time to xseg-prd*xseg-dst , console show mi this
DeepFaceLab_Linux/DeepFaceLab/merger/MergeMasked.py:238: RuntimeWarning: invalid value encountered in multiply
out_img = img_bgr*(1-img_face_mask_a) + (out_img*img_face_mask_a)
this show mi always, if i working... | open | 2020-08-20T10:55:00Z | 2023-06-08T21:21:19Z | https://github.com/iperov/DeepFaceLab/issues/868 | [] | tembel123456 | 5 |
wiseodd/generative-models | tensorflow | 68 | Typo mistakes | hey first of all thank you for your great job it's very clear in general and helpful
My first question is your loop enumerate V_s which is something completely random does it has to enumerate in X_mb
https://github.com/wiseodd/generative-models/blob/b930d5fa9e2f69adfd4ea8ec759f38f6ce6da4c2/RBM/rbm_binary_pcd.py... | open | 2018-12-22T18:13:58Z | 2018-12-22T18:27:23Z | https://github.com/wiseodd/generative-models/issues/68 | [] | karimkalimu | 0 |
QuivrHQ/quivr | api | 3,426 | Add Relevant Parameters to file endpoint | To Parse correctly the file we need the following parameters :
* Method to use {Unstructured, LlamaParse, Megaparse-Vision}
* If Unstructured, what strategy ? {fast, auto, hi_res}
* If Unstructured, do we use LLM Format Checker ? : bool | closed | 2024-10-25T08:18:14Z | 2024-11-07T09:29:42Z | https://github.com/QuivrHQ/quivr/issues/3426 | [
"enhancement"
] | chloedia | 1 |
matterport/Mask_RCNN | tensorflow | 2,785 | ROOT_DIR does not exist. Did you forget to read the instructions above? | Hi All,
I'm new here and trying to implement this code and faced the following error, any help please ??
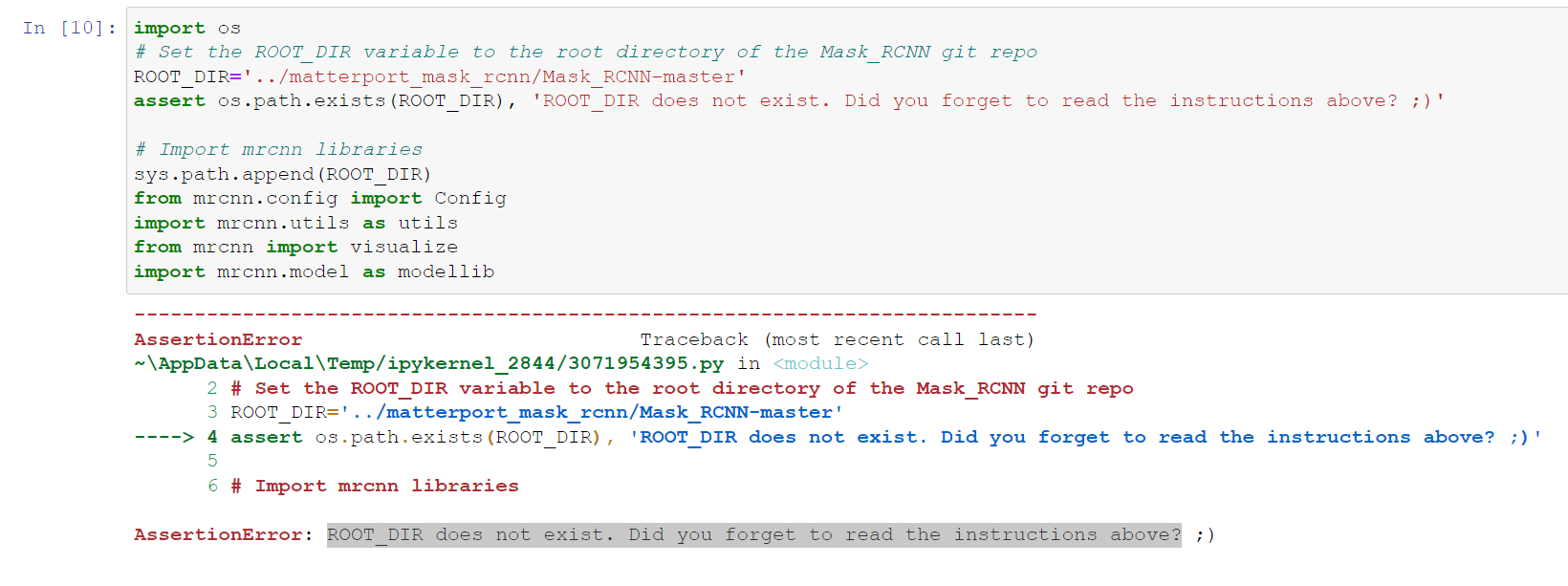
| open | 2022-03-06T05:57:36Z | 2022-03-06T05:57:36Z | https://github.com/matterport/Mask_RCNN/issues/2785 | [] | Isamalatby | 0 |
jupyter/nbgrader | jupyter | 1,159 | Unpin version of ipython in 0.5.6.dev and release 0.5.6 | The current release has `ipython` pinned to `<=6.2.1` and that is preventing us from installing `nbgrader` alongside modern packages. See https://github.com/jupyter/nbgrader/pull/1050
Looks like that limitation was already fixed. Can we get a new release? | closed | 2019-06-27T20:07:55Z | 2019-08-21T23:41:43Z | https://github.com/jupyter/nbgrader/issues/1159 | [
"maintenance"
] | ocefpaf | 12 |
Avaiga/taipy | automation | 1,605 | Scenario Selector returns an empty string when clicking on cycles | ### Description
The scenario selector returns an empty string when clicking on a cycle. This sometimes broke my code without my noticing it. It should return nothing or None, I imagine.
Run this code and click on the cycles appearing in the scenario selector. This returns an empty string.
```python
# Import nec... | closed | 2024-07-30T07:36:07Z | 2024-08-09T07:53:28Z | https://github.com/Avaiga/taipy/issues/1605 | [
"📈 Improvement",
"🖰 GUI",
"🟨 Priority: Medium"
] | FlorianJacta | 0 |
Gozargah/Marzban | api | 979 | کرش TeleBot | سلام، بعد مدتی فعال کردن لاگ های تلگرام این ارور رو میگیرم که باعث میشه کانفیگ ها تایموت بخورن و xray به درستی کار نمیکنه.
ERROR - TeleBot: "Infinity polling exception: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))"
این ارور در لاگ های مرزبان به صورت کرش پایتون میوفته.![... | closed | 2024-05-10T20:02:09Z | 2024-07-16T09:03:54Z | https://github.com/Gozargah/Marzban/issues/979 | [] | hoootan | 1 |
deepset-ai/haystack | pytorch | 8,297 | Remove Multiplexer from `Others` overview documentation page | We removed the Multiplexer from Haystack and also its documentation. We should also remove it from the `Others` overview documentation page: https://docs.haystack.deepset.ai/docs/other
https://github.com/deepset-ai/haystack/pull/8020 | closed | 2024-08-27T15:32:34Z | 2024-09-02T13:01:00Z | https://github.com/deepset-ai/haystack/issues/8297 | [
"type:documentation",
"P2"
] | julian-risch | 0 |
apache/airflow | machine-learning | 47,889 | OperatorExtra links xcom keys should be pushed to xcom db | ### Body
After #45481, we need to check if the operator extra links are being pushed to the right place and not to the custom xcom backend.
### Committer
- [x] I acknowledge that I am a maintainer/committer of the Apache Airflow project. | open | 2025-03-18T06:22:41Z | 2025-03-18T06:24:56Z | https://github.com/apache/airflow/issues/47889 | [
"area:core",
"area:core-operators",
"area:task-sdk"
] | amoghrajesh | 0 |
erdewit/ib_insync | asyncio | 43 | Allow download of expired futures historical data | Allow setting of includeExpired in contract field | closed | 2018-02-09T14:09:45Z | 2018-02-09T14:30:17Z | https://github.com/erdewit/ib_insync/issues/43 | [] | cwengc | 1 |
python-restx/flask-restx | flask | 144 | Future of Restx | **Ask a question**
I'm coming from the background of Flask Restplus and we have developed web apps and rest api's which were fully functional and working in production but the things gone really awry when we updated Werkzeug==1.0.0 and thereafter we learnt that flask restplus is dead ([Issue#770](https://github.com/no... | closed | 2020-05-28T15:58:43Z | 2020-05-29T13:02:08Z | https://github.com/python-restx/flask-restx/issues/144 | [
"question"
] | min2bro | 4 |
plotly/dash-bio | dash | 464 | Update pull request template to fix outdated sections | Re: https://github.com/plotly/dash-bio/pull/459#issuecomment-575357861
> Speaking of the PR template, it looks like the "steps to take before merging" and some other parts of it are outdated -- could you open up an issue and assign it to me to ensure that gets updated?
| closed | 2020-01-16T21:40:12Z | 2020-01-24T16:34:06Z | https://github.com/plotly/dash-bio/issues/464 | [] | josegonzalez | 0 |
matterport/Mask_RCNN | tensorflow | 2,736 | I want to train custom network | I followed up the guide, train the model using custom DataSet.
However, I worked at learning R&D to develop the custom Product,
So I want to train the optimized network(User-defined)
To do this, How can i do this?
| open | 2021-12-09T00:55:50Z | 2021-12-09T00:55:50Z | https://github.com/matterport/Mask_RCNN/issues/2736 | [] | donggru | 0 |
OFA-Sys/Chinese-CLIP | computer-vision | 130 | 请问制作长词条有什么好建议? | 1. 词条包含近50个字,有什么处理建议,我加了\,。类似的标号
2. 多大数据量finetune才会有效果?
3. 5000对finetune需要多大的迭代数?
@yangapku | open | 2023-06-05T09:31:13Z | 2024-12-18T06:24:18Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/130 | [] | Huang9495 | 3 |
microsoft/nni | machine-learning | 4,853 | nni=2.7; torch.cuda.is_available() is False in evaluate_model. | I coding as the script of https://github.com/microsoft/nni/blob/v2.7/examples/nas/multi-trial/mnist/search.py
nni version is 2.7
in "if __name__ == '__main__':",torch.cuda.is_available() is Triue
in function evaluate_model() ,torch.cuda.is_available() is False and os.environ["CUDA_VISIBLE_DEVICES"] is -1
I add one ... | closed | 2022-05-10T06:47:37Z | 2022-05-10T07:26:10Z | https://github.com/microsoft/nni/issues/4853 | [] | DavideHe | 1 |
plotly/dash | plotly | 2,525 | [BUG] | Hi everyone,
**Describe your context**
I'm trying to create a multi-page Dash application, using a Flask server.
Here are main requirements :
dash==2.7.1
flask==2.2.2
Here is my project folder:
dashapp/
- app.py
- pages /
- un.py
- deux.py
Content of app.py :
``` from dash import html
... | closed | 2023-05-05T12:12:24Z | 2023-05-05T13:40:06Z | https://github.com/plotly/dash/issues/2525 | [] | kevin35ledy | 1 |
litestar-org/litestar | asyncio | 4,019 | Bug: Documentation generation adding erroneus http 201 response | ### Description
Hello!
I'm using Litestar and it's automatic documentation generation (the Scalar variant if prevalent) and I've found that a POST request marking a HTTP 202 response seems to be adding an erroneous and bare HTTP 201 response to the openapi.json file.
### URL to code causing the issue
_No response_
... | closed | 2025-02-19T23:02:41Z | 2025-02-23T18:14:35Z | https://github.com/litestar-org/litestar/issues/4019 | [
"Bug :bug:"
] | AbstractUmbra | 6 |
ets-labs/python-dependency-injector | asyncio | 73 | Review and update ExternalDependency provider docs | closed | 2015-07-13T07:33:19Z | 2015-07-16T22:15:30Z | https://github.com/ets-labs/python-dependency-injector/issues/73 | [
"docs"
] | rmk135 | 0 | |
CPJKU/madmom | numpy | 518 | On the madmom version of drum transcription | There was an automatic drum transcription [model](https://arxiv.org/pdf/1806.06676.pdf) that included in madmom, mentioned at [here](http://ifs.tuwien.ac.at/~vogl/dafx2018/#:~:text=Trained%20models%20are%20available,in%20help%20and%20documentation.). But I cannot find the 0.16.dev version on the PyPI page, nor in the d... | closed | 2023-03-01T23:04:48Z | 2023-03-02T07:05:56Z | https://github.com/CPJKU/madmom/issues/518 | [] | nicolaus625 | 1 |
BeanieODM/beanie | pydantic | 538 | Add support for $explain operator | ### Discussed in https://github.com/roman-right/beanie/discussions/485
<div type='discussions-op-text'>
<sup>Originally posted by **suyashdeshpande** February 7, 2023</sup>
Add support for $explain operator so we can analyze query performance</div> | open | 2023-04-13T19:56:46Z | 2024-12-08T21:54:18Z | https://github.com/BeanieODM/beanie/issues/538 | [
"feature request"
] | roman-right | 1 |
idealo/imagededup | computer-vision | 203 | Filenames not being passed to plotter correctly? | Code:
```
import sys
import os
from imagededup.methods import PHash
import numpy as np
if __name__ == '__main__':
phasher = PHash()
encodings = phasher.encode_images(image_dir=r'mydir')
duplicates = phasher.find_duplicates(
encoding_map=encodings,
max_distance_threshold=0,
... | closed | 2023-08-02T06:02:18Z | 2023-08-02T15:56:43Z | https://github.com/idealo/imagededup/issues/203 | [] | biggestsonicfan | 2 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 665 | Visual artifacts | Hi,
Thank you for this great implementation!
I am using it to generate simple "maps", like a segmentation task.
I am trying your pix2pix unet256 implementation of the network with my own loader,
I get these artifacts : [sample image link](https://ibb.co/ctBykgk).
It is lots of single or dual pixels of r... | open | 2019-06-05T15:52:00Z | 2022-06-02T06:00:14Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/665 | [] | olivier-gillet | 4 |
httpie/cli | python | 567 | error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failure | New to HTTPie, this works in curl but not in HTTPie. I have not upgraded to python 3 as I am working on
AWS Lambda and it only supports python 2.7.
bpruss@Ubuntu-AWSD01:~/helloworld$ http --debug https://pdffjaur49.execute-api.us-east-1.amazonaws.com/dev/
HTTPie 1.0.0-dev
Requests 2.13.0
Pygments 2.2.0
Pytho... | closed | 2017-03-10T13:17:20Z | 2017-03-10T13:29:33Z | https://github.com/httpie/cli/issues/567 | [] | bpruss | 1 |
babysor/MockingBird | deep-learning | 64 | Mac下无法使用麦克风 Error opening InputStream: Internal PortAudio error | closed | 2021-08-30T13:59:32Z | 2021-08-30T14:00:47Z | https://github.com/babysor/MockingBird/issues/64 | [] | AeroXi | 1 | |
gunthercox/ChatterBot | machine-learning | 2,325 | not able to install chatterbot | every time when i am installing the chatterbot it is showing error , is it happening because of python version? | closed | 2023-09-14T11:02:03Z | 2025-02-17T19:23:15Z | https://github.com/gunthercox/ChatterBot/issues/2325 | [] | RohitGitTech | 2 |
huggingface/diffusers | pytorch | 10,075 | flux:different results on different machines. | Hi!
During the debugging phase, I've noticed that training the [FLUX-Controlnet-Inpainting](https://github.com/alimama-creative/FLUX-Controlnet-Inpainting) model yields different results on different machines.
Specifically, on one machine, everything trains fine,
but on another, I'm getting an error that says "... | open | 2024-12-02T07:22:00Z | 2025-01-01T15:03:03Z | https://github.com/huggingface/diffusers/issues/10075 | [
"stale"
] | D222097 | 3 |
clovaai/donut | nlp | 170 | Register Model in Mlfow | Hello guys I have trained my own custom Donut model and than I tried to use Mlflow for logging parameters, metrics and artifacts but I want to register model on Mlflow can anyone guide me on how do I that ??
Thanks in advance. | open | 2023-03-28T02:27:23Z | 2023-04-06T16:19:52Z | https://github.com/clovaai/donut/issues/170 | [] | rajsaraiya009 | 1 |
deepfakes/faceswap | machine-learning | 1,348 | Faceswap doesn't use RX 7900 XT | **Describe the bug**
When trying to extract faces, Faceswap falls back to CPU with this message:
2023-08-31 15:12:03.523307: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1990] Ignoring visible gpu device (device: 0, name: AMD Radeon RX 7900 XT, pci bus id: 0000:03:00.0) with AMDGPU version : gfx1100. The suppo... | closed | 2023-08-31T13:22:09Z | 2023-10-23T00:08:54Z | https://github.com/deepfakes/faceswap/issues/1348 | [] | RPochyly | 1 |
pydata/pandas-datareader | pandas | 4 | improve coverage | At the moment it's [](https://coveralls.io/r/pydata/pandas-datareader).
_Note: several tests are skipped atm (mostly these are labelled unreliable), this may partially explain results._
| closed | 2015-01-16T08:07:46Z | 2015-11-14T19:48:32Z | https://github.com/pydata/pandas-datareader/issues/4 | [] | hayd | 1 |
thtrieu/darkflow | tensorflow | 1,213 | Convert annotation video mat files to COCO | Hello, I have such a problem. I am part of the Ukrainian team that is developing a detection system that could help save many lives. I'm on the team as a data scientist. But I ran into a problem, I need to convert the annotations to the video in mat format to COCO format in order to train YOLOv7. Help me please.
<img ... | open | 2022-10-29T16:50:18Z | 2022-10-29T16:50:18Z | https://github.com/thtrieu/darkflow/issues/1213 | [] | UkranianAndreii | 0 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,059 | Failing to reconstruct high value pixels with pix2pix | Hi,
Using pix2pix I've experienced bad reconstructions related to colour consistency, especially with really high-valued pixels (white mainly that becomes grey). Firstly I thought it could be the way I was converting the numpy array (which ranges from [-1,1]) wrongly to 0-255:
```python
prediction = (0.5 * pred... | closed | 2020-06-09T13:37:13Z | 2024-02-27T18:26:41Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1059 | [] | adriacabeza | 6 |
vaexio/vaex | data-science | 1,378 | [FEATURE-REQUEST] Create OHLC from tick data | **Description**
Trying to create OHLC (Open High Low Close) data from price tick data. Can sort of create Open, High, Low, but Open is wrong and times have some offset. Not sure about close.
```python
import pandas as pd
import vaex
import numpy as np
import time
dates = pd.date_range("01-01-2019", "14-04-202... | closed | 2021-05-28T01:50:25Z | 2022-03-03T12:15:28Z | https://github.com/vaexio/vaex/issues/1378 | [] | Penacillin | 19 |
pallets-eco/flask-sqlalchemy | sqlalchemy | 507 | Defining your entry point module as "site.py" causes NoAppException | If you create a file called `site.py` which defines your Flask app, and then set the env var as `FLASK_APP="site.py"`, Flask will find the file but it can't find the application instance.
```
Traceback (most recent call last):
File "/asdf/venv/lib/python3.4/site-packages/flask/cli.py", line 48, in find_best_app... | closed | 2017-06-18T01:44:19Z | 2020-12-05T20:55:48Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/507 | [] | Kangaroux | 2 |
amisadmin/fastapi-amis-admin | fastapi | 95 | 在表中新建条目之后,并没有立马能够查询到,是缓存的问题吗? | 在表中新建条目之后,并没有立马能够查询到,是缓存的问题吗? | open | 2023-05-16T07:45:43Z | 2023-05-16T09:37:33Z | https://github.com/amisadmin/fastapi-amis-admin/issues/95 | [] | xuehaoweng | 1 |
widgetti/solara | fastapi | 599 | feat: support ibis tables (...and define a more formal protocol) | I would love to render (very very large, ie millions of rows) ibis tables in solara.DataTable. This currently doesn't work because
- solara calls `len(df)` on the data. ibis uses `.count()` instead, to make the execution very explicit
- the logic to go from ibis table to a list[dict] of records isn't implemented fo... | open | 2024-04-11T19:48:57Z | 2024-04-26T21:00:18Z | https://github.com/widgetti/solara/issues/599 | [] | NickCrews | 5 |
pytest-dev/pytest-cov | pytest | 161 | More tolerant in certain circumstances where report generation was failed | Back in version 2.2.1 [we were more tolerant](https://github.com/pytest-dev/pytest-cov/blob/0696bc72ad6f5ce0017d6904c04141376e291467/src/pytest_cov/plugin.py#L194-L198) when something went wrong with coverage report generation:
```
if not (self.failed and self.options.no_cov_on_fail):
try:
... | closed | 2017-06-21T22:05:51Z | 2017-08-01T12:17:20Z | https://github.com/pytest-dev/pytest-cov/issues/161 | [] | huyphan | 17 |
pallets/flask | python | 4,860 | Improve JSONIFY_MIMETYPE deprecation warning | With version 2.2 of flask, `JSONIFY_MIMETYPE` was deprecated in favor of `DefaultJSONProvider`'s `mimetype` class property.
When `JSONIFY_MIMETYPE` is still used, a `DeprecationWarning` is raised:
> The 'JSONIFY_MIMETYPE' config key is deprecated and will be removed in Flask 2.3. Set 'app.json.mimetype' instead.
... | closed | 2022-11-07T11:12:38Z | 2023-01-10T00:05:56Z | https://github.com/pallets/flask/issues/4860 | [] | mephinet | 2 |
dsdanielpark/Bard-API | api | 57 | Responce error | Response code not 200. Response Status is 302 | closed | 2023-06-08T04:44:37Z | 2023-06-08T12:26:00Z | https://github.com/dsdanielpark/Bard-API/issues/57 | [] | Ridoy302583 | 1 |
mwaskom/seaborn | pandas | 3,098 | Figure aspect ratio sometimes off in docs on mobile | I noticed this in portrait mode on Chrome on Android.
<details>
<summary>Example:</summary>
</details> | open | 2022-10-18T15:09:34Z | 2022-11-04T10:39:37Z | https://github.com/mwaskom/seaborn/issues/3098 | [
"docs"
] | zmoon | 0 |
fbdesignpro/sweetviz | data-visualization | 179 | module not found or their is no such module names "sweetviz" | When trying to import Sweetviz, it says that there is no such module. I tried all the possible solutions given on the library documentation page, but still, nothing is working. | open | 2024-09-10T06:18:53Z | 2024-11-21T16:01:02Z | https://github.com/fbdesignpro/sweetviz/issues/179 | [] | Nikhil-Bhalerao | 1 |
pyg-team/pytorch_geometric | deep-learning | 10,004 | add thumbnail for recently added GraphTransformer tutorial | ### 📚 Describe the documentation issue
@xnuohz
<img width="824" alt="Image" src="https://github.com/user-attachments/assets/b496009e-2c84-43e9-8b8e-880020b12515" />
https://pytorch-geometric--8144.org.readthedocs.build/en/8144/tutorial/application.html
I thoroughly read through your tutorial but i did not double ... | closed | 2025-02-05T15:59:21Z | 2025-02-10T17:31:30Z | https://github.com/pyg-team/pytorch_geometric/issues/10004 | [
"documentation"
] | puririshi98 | 0 |
influxdata/influxdb-client-python | jupyter | 231 | TypeError: query() got an unexpected keyword argument 'params' | Hi,
I'm trying to query some data according your example (Query: using Bind parameters). Instead of data I'm getting the following error:
```
Traceback (most recent call last):
File "test.py", line 53, in <module>
tables = query_api.query('''
TypeError: query() got an unexpected keyword argument 'params'... | closed | 2021-04-22T07:57:19Z | 2021-04-29T09:45:49Z | https://github.com/influxdata/influxdb-client-python/issues/231 | [
"question",
"wontfix"
] | staeglis | 2 |
ydataai/ydata-profiling | jupyter | 1,596 | How to get the dataframe cleaned (processed by ydata-profiling)? | ### Missing functionality
Getting the processed clean dataframe
### Proposed feature
Give an option to get the cleaned dataframe after processing it through ydata-profiling.
### Alternatives considered
_No response_
### Additional context
_No response_ | open | 2024-05-20T10:23:29Z | 2024-06-07T17:37:18Z | https://github.com/ydataai/ydata-profiling/issues/1596 | [
"feature request 💬"
] | francesco-gariboldi | 1 |
HIT-SCIR/ltp | nlp | 211 | 为何本地部署ltp,用python调用ltp_test.exe时显示停止运行? | 代码如下:
# -*- coding:UTF-8 -*-
import os
LTP_path = "D:\\myprojects\\LTP"
model_exe = "ltp_test"
threads_num = " --threads 3"
last_stage = " --last-stage" + "all"
input_path = " --input" + "D:\\myprojects\\LTP\\file\\test.txt"
seg_lexicon = ""
pos_lexicon = ""
output_path = "D:\\myprojects\\LTP\\result\\out.t... | closed | 2017-04-06T10:48:28Z | 2017-04-13T15:22:47Z | https://github.com/HIT-SCIR/ltp/issues/211 | [] | smallflying | 7 |
littlecodersh/ItChat | api | 838 | send_raw_msg type 42 能否实现发送好友名片? | 在提交前,请确保您已经检查了以下内容!
- [yes ] 您可以在浏览器中登陆微信账号
- [yes ] 我已经阅读并按[文档][document] 中的指引进行了操作
- [yes ] 您的问题没有在[issues][issues]报告,否则请在原有issue下报告
- [yes ] 本问题确实关于`itchat`, 而不是其他项目.
- [no ] 如果你的问题关于稳定性,建议尝试对网络稳定性要求极低的[itchatmp][itchatmp]项目
您的itchat版本为:`[1.3.10]`。
```
itchat.send_raw_msg(42, user_info_dict, 'filehelpe... | open | 2019-06-10T06:27:31Z | 2019-06-16T07:41:29Z | https://github.com/littlecodersh/ItChat/issues/838 | [] | coronin | 0 |
deepspeedai/DeepSpeed | machine-learning | 6,629 | when take --bind_cores_to_rank on,only half of CPUs is used | #!/bin/bash
NUM_NODES=1
NUM_GPUS=3
EXPERTS=3
deepspeed --num_nodes=${NUM_NODES}\
--num_gpus=${NUM_GPUS} \
--bind_cores_to_rank \
train_autodirect_moe.py \
--log-interval 100 \
--noisy-gate-policy 'RSample' \
--moe-param-group \
--config ../configs/autoDirectFinal/XXX.json \
--gpus ${N... | closed | 2024-10-16T08:54:33Z | 2024-10-25T17:24:02Z | https://github.com/deepspeedai/DeepSpeed/issues/6629 | [] | GensokyoLover | 2 |
littlecodersh/ItChat | api | 61 | 请问如何把微信群内某个人踢出 | closed | 2016-08-09T05:15:26Z | 2016-08-09T08:29:05Z | https://github.com/littlecodersh/ItChat/issues/61 | [
"question"
] | xxiyj | 1 | |
davidsandberg/facenet | computer-vision | 539 | the filter_dataset function don't filter the dataset | @davidsandberg I modify the filter_dataset function like this:
def filter_dataset(dataset, data_filename, percentile, min_nrof_images_per_class):
with h5py.File(data_filename,'r') as f:
distance_to_center = np.array(f.get('distance_to_center'))
label_list = np.array(f.get('label_list'))
... | open | 2017-11-17T08:30:08Z | 2017-11-17T08:33:41Z | https://github.com/davidsandberg/facenet/issues/539 | [] | allenxcp | 0 |
inventree/InvenTree | django | 8,980 | [FR] Convert purchased items to base currency on receipt | When receiving line items against a purchase order, it would be useful to automatically convert the "unit cost" of the received stock to the internal base currency.
This provides two major benefits:
### Consistent Pricing
Internal stock value is all tracked in the same currency, making for easier comparisons / stat... | closed | 2025-01-28T21:49:55Z | 2025-03-20T14:47:39Z | https://github.com/inventree/InvenTree/issues/8980 | [
"enhancement",
"pricing",
"feature"
] | SchrodingersGat | 0 |
ultralytics/yolov5 | pytorch | 13,367 | Issue using PaddleDetection's YOLOv5 model in val.py after converting to ONNX - Error with scale_factor | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hi all,
I'm working with a YOLOE plus model from PaddleDetection and trying to use its... | open | 2024-10-18T10:49:05Z | 2024-10-22T14:13:10Z | https://github.com/ultralytics/yolov5/issues/13367 | [
"question"
] | gauricollab09 | 3 |
kizniche/Mycodo | automation | 1,395 | devices/atlas_scientific_uart.py misses the build_string(data) function. |
### Versions:
- Mycodo Version: 8.16.0
- Raspberry Pi Version: 3B
- Raspbian OS Version: Bookworm
### Reproducibility
Please list specific setup details that are involved and the steps to reproduce the behavior:
If you activate a Atlas Scientific PH Sensor with uart interface and try to calibrate, y... | open | 2024-10-06T12:28:53Z | 2025-01-08T19:48:04Z | https://github.com/kizniche/Mycodo/issues/1395 | [
"bug"
] | domonoky | 1 |
MolSSI/cookiecutter-cms | pytest | 69 | Replacing Versioneer | The `versioneer` repository appears to be dead; however, this isn't necessarily a bad thing since `versioneer` works for all use cases and examples that we can find. In addition, versioneer is static and installed so there are no dependance issues. However, this likely will not be the case forever and watching for repl... | closed | 2019-02-14T14:41:28Z | 2019-06-05T15:49:36Z | https://github.com/MolSSI/cookiecutter-cms/issues/69 | [] | dgasmith | 1 |
neuml/txtai | nlp | 441 | Resolve application references in pipelines | Add logic to detect application pipelines that have a configuration parameter named `application`. When that parameter is passed as part of the pipeline configuration, it will be resolved to the currently running application.
The application framework already has similar logic for setting the `embeddings` on `extrac... | closed | 2023-02-23T20:33:45Z | 2023-02-23T20:36:45Z | https://github.com/neuml/txtai/issues/441 | [] | davidmezzetti | 0 |
darrenburns/posting | automation | 41 | Support for dev certificates | In our local dev environment we use self signed certs generated with mkcert. I do not want to disable ssl verification, but wasn't able to find a way to let posting use my local root CA generated by mkcert. I've tried injection python package "truststore" to posting as well as setting python config param global.cert.
... | closed | 2024-07-16T06:37:10Z | 2024-07-17T09:04:57Z | https://github.com/darrenburns/posting/issues/41 | [] | Persi | 9 |
charlesq34/pointnet | tensorflow | 150 | about prepare data | Hi,
When I sample points(use commends the function utils/data_pre_util.py/get_sampling_command provide),
pointnet-master/utils/third_party/mesh_sampling/build/pcsample ../data/my_data/veg.txt ../data/my_data/veg.ply -n_samples 2048 -leaf_size 0.005000
it occurs error like this,
pointnet-master/utils/third_par... | open | 2018-10-29T08:15:11Z | 2019-05-16T11:18:12Z | https://github.com/charlesq34/pointnet/issues/150 | [] | programmerkiki | 3 |
facebookresearch/fairseq | pytorch | 5,533 | Wav2Vec2 Pretraining | ## ❓ Questions and Help
#### I want to perform wav2vec2 Pretraining from scratch and while following the documentation for same on https://github.com/facebookresearch/fairseq/tree/main/examples/wav2vec it is mentioned that all audio clips should be in single directory. The issue is i have too much data to keep in a ... | open | 2024-08-08T07:49:08Z | 2024-09-02T13:43:22Z | https://github.com/facebookresearch/fairseq/issues/5533 | [
"question",
"needs triage"
] | rajeevbaalwan | 3 |
dunossauro/fastapi-do-zero | pydantic | 34 | [Aula 10] - Trabalhar a parte de variáveis de ambiente do CI | Como levantado em conversas no telegram, por Jorge Luiz Plautz, não foi exposto na aula uma forma de contornar o carregamento de variáveis de ambiente durante o CI. O que acarreta diversos erros na hora de executar os testes! | closed | 2023-10-21T22:20:11Z | 2023-12-09T20:20:57Z | https://github.com/dunossauro/fastapi-do-zero/issues/34 | [] | dunossauro | 3 |
comfyanonymous/ComfyUI | pytorch | 6,704 | Failed to import Omnigen | ### Your question
I have tried EVERYTHING guys. I dont know anymore what I can do to try to run omnigen
### Logs
```powershell
# ComfyUI Error Report
## Error Details
- **Node ID:** 21
- **Node Type:** ailab_OmniGen
- **Exception Type:** RuntimeError
- **Exception Message:** Failed to import OmniGen. Please check if... | closed | 2025-02-05T00:47:30Z | 2025-02-05T08:49:56Z | https://github.com/comfyanonymous/ComfyUI/issues/6704 | [
"User Support"
] | joako357 | 1 |
Gozargah/Marzban | api | 652 | add flow in hosts instead of users | it's better to include flow in hosts because if you use `xtls-rprx-vision` only reality work and if you have somthing like `vless tcp` or `vless ws` not connecting and if someone forgot to include flow for some user they can do it once in hosts not one by one for all users | closed | 2023-11-22T06:06:28Z | 2023-12-31T10:57:58Z | https://github.com/Gozargah/Marzban/issues/652 | [] | ImMohammad20000 | 1 |
AirtestProject/Airtest | automation | 525 | wda.WDARequestError: WDARequestError(status=13, value=Error Domain=XCTDaemonErrorDomain Code=14 | Remove any following parts if does not have details about
**Describe the bug**
A clear and concise description of what the bug is. Or paste traceback below.
执行时报错上述信息
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _... | open | 2019-09-11T07:35:52Z | 2019-10-11T03:36:38Z | https://github.com/AirtestProject/Airtest/issues/525 | [] | agoraHan | 1 |
ivy-llc/ivy | tensorflow | 28,539 | Fix Frontend Failing Test: torch - math.tensorflow.math.reduce_prod | To-do List: https://github.com/unifyai/ivy/issues/27498 | closed | 2024-03-11T10:56:03Z | 2024-04-02T09:31:09Z | https://github.com/ivy-llc/ivy/issues/28539 | [
"Sub Task"
] | ZJay07 | 0 |
activeloopai/deeplake | computer-vision | 2,369 | [FEATURE] Allow users to disable tiling when encoding images | ## 🚨🚨 Feature Request
- [ ] Related to an existing [Issue](../issues)
- [x] A new implementation (Improvement, Extension)
### Is your feature request related to a problem?
Nope, not for deeplake users!
### If your feature will improve `deeplake`
Being able to "disable" the tiling of images when very... | closed | 2023-05-22T19:08:42Z | 2023-05-23T14:44:08Z | https://github.com/activeloopai/deeplake/issues/2369 | [
"enhancement"
] | plstcharles | 4 |
explosion/spaCy | data-science | 12,919 | EntityRuler match order is dependent on Python's set implementation | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
This is not necessarily a bug, and I am not sure there's any elegant solution to the problem, but please hear me out. I was migrating my model from python 3.7 to 3.10, and I got some seemingly random differences. I drilled it dow... | closed | 2023-08-16T16:05:52Z | 2023-09-22T00:02:08Z | https://github.com/explosion/spaCy/issues/12919 | [
"compat",
"feat / spanruler"
] | nrodnova | 5 |
simple-login/app | flask | 1,655 | Logging out does not log out of Proton account | ## Prerequisites
- [x] I have searched open and closed issues to make sure that the bug has not yet been reported.
## Bug report
**Describe the bug**
1. Login to SimpleLogin with a Proton account by the `Log in with Proton` on the login screen. After logging in, you are automatically redirect to the SimpleLogin... | closed | 2023-03-23T03:06:24Z | 2023-03-24T00:10:04Z | https://github.com/simple-login/app/issues/1655 | [] | jbabyhacker | 1 |
plotly/jupyterlab-dash | dash | 6 | "jupyterlab_dash@0.1.0" is not compatible with the current JupyterLab | ValueError:
"jupyterlab_dash@0.1.0" is not compatible with the current JupyterLab
Conflicting Dependencies:
JupyterLab Extension Package
>=0.16.3 <0.17.0 >=0.19.1 <0.20.0 @jupyterlab/application
>=0.16.3 <0.17.0 >=0.19.2 <0.20.0 @jupyterlab/notebook
>=0.16.3 <0.17.0 >=0.1... | closed | 2019-01-04T16:47:53Z | 2019-04-17T06:57:31Z | https://github.com/plotly/jupyterlab-dash/issues/6 | [] | gusseppe | 4 |
python-gitlab/python-gitlab | api | 2,444 | Create CI/CD variable with "raw=true" parameter raises error, update works | ## Description of the problem, including code/CLI snippet
If you try to create a project or group variables with "raw" parameter set to True it raises error (see below)
```
def set_cicd_variable(project_or_group, key, value, is_file=False, raw=True):
try:
project_or_group.variables.create(
... | closed | 2023-01-02T10:55:26Z | 2024-04-08T01:15:59Z | https://github.com/python-gitlab/python-gitlab/issues/2444 | [
"need info",
"stale"
] | rabbagliettiandrea | 6 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 763 | using different discriminator | Hi Dr.Zhu
Sorry to bother you again.
Is it possible to use Relativistic Discriminators for CycleGAN training?

My concern is that for cycleGAN real and fake are different images, but RaD seems to be... | closed | 2019-09-11T02:20:48Z | 2019-09-25T08:29:32Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/763 | [] | wl082013 | 5 |
desec-io/desec-stack | rest-api | 125 | deSEC DNS Authenticator plugin for Certbot (Let's Encrypt) | Let's write a plugin like this one: https://github.com/certbot/certbot/tree/master/certbot-dns-cloudflare | closed | 2018-09-26T22:55:39Z | 2021-05-13T14:47:52Z | https://github.com/desec-io/desec-stack/issues/125 | [
"enhancement",
"help wanted",
"prio: medium",
"easy"
] | peterthomassen | 5 |
tiangolo/uwsgi-nginx-flask-docker | flask | 174 | Enabling DataDog ddtrace | We have a number of flask API's running as docker containers and using this as a base. We are in the process of implementing DataDog's ddtrace and need to call python as "ddtrace python3". Is there a way to hijack the entrypoint to do this? | closed | 2020-05-05T20:34:42Z | 2020-05-20T00:12:11Z | https://github.com/tiangolo/uwsgi-nginx-flask-docker/issues/174 | [] | jwodushek | 2 |
deepspeedai/DeepSpeed | deep-learning | 7,044 | [BUG] deepspeed zero2 training hangon and timeout after a fixed step | **Describe the bug**
I use deepspeed zero2 to train a transformer-based dit model. However, the script always gets stuck at a fixed step after one hour of training. When I disable deepspeed and use pure pytorch DDP to train the code, the problem disappears. Moreover, even if I change the mixed-precision from fp16 to bf... | open | 2025-02-17T07:47:44Z | 2025-03-13T02:29:38Z | https://github.com/deepspeedai/DeepSpeed/issues/7044 | [
"bug",
"training"
] | leeruibin | 8 |
modelscope/modelscope | nlp | 795 | 如何微调cv_resnest101_general_recognition模型 | **General Question**
Before asking a question, make sure you have:
* Searched the tutorial on modelscope [doc-site](https://modelscope.cn/docs)
* Googled your question.
* Searched related issues but cannot get the expected help.
* The bug has not been fixed in the latest version.
@wenmengzhou @tastelikefee... | closed | 2024-03-04T07:22:26Z | 2024-03-20T02:28:46Z | https://github.com/modelscope/modelscope/issues/795 | [] | AnitaSherry | 1 |
horovod/horovod | machine-learning | 4,066 | NCCL error while training (SGD optimizer). | Framework: (TensorFlow, Keras, PyTorch, MXNet) Tensorflow
Framework version: Whatever is in latest horovod container from docker hub (2.9.2)
Horovod version: Whatever is in latest docker hub image (not sure)
MPI version: OpenMPI 4.1.4
CUDA version: Whatever is in latest docker hub image (not sure)
... | open | 2024-08-16T18:20:29Z | 2024-08-16T18:20:29Z | https://github.com/horovod/horovod/issues/4066 | [
"bug"
] | laytonjbgmail | 0 |
chezou/tabula-py | pandas | 88 | Encoding | I can not use the tool for utf-8 encoding, it writes warning and prints only "?"-s | closed | 2018-04-30T13:57:25Z | 2018-05-02T01:15:32Z | https://github.com/chezou/tabula-py/issues/88 | [] | bekab95 | 10 |
twopirllc/pandas-ta | pandas | 861 | Attribute error when using yfinance for data loading | **Which version are you running? The lastest version is on Github. Pip is for major releases.**
```python
import pandas_ta as ta
print(ta.version)
```
[pandas_ta version 0.3.14b0]
**Do you have _TA Lib_ also installed in your environment?**
```sh
$ pip list
```
[Not the cause]
**Have you tried the _devel... | closed | 2024-12-14T14:32:11Z | 2024-12-16T06:55:15Z | https://github.com/twopirllc/pandas-ta/issues/861 | [
"bug",
"duplicate"
] | miracle-a-osigwe | 4 |
jmcnamara/XlsxWriter | pandas | 317 | Rearranging worksheets | It's "inadvisable" to rearrange worksheets once they have been added, according to [this Stack Overflow answer](http://stackoverflow.com/a/21124112/95852). So I looked into possible reasons why, and it seems to come down to the fact that `Workbook.worksheets_objs` and `Workbook.sheetnames` are independent lists, with n... | closed | 2015-12-15T18:57:43Z | 2016-01-05T10:56:44Z | https://github.com/jmcnamara/XlsxWriter/issues/317 | [
"question",
"ready to close"
] | jkyeung | 3 |
tqdm/tqdm | pandas | 1,259 | Force display of iterations per second (it/s) - instead of displaying inverse (s/it) based on rate | For a given code example:
```
from tqdm import tqdm
from time import sleep
for i in tqdm(range(100)):
sleep(1.5)
```
the output looks like this:
`6%|▌ | 6/100 [00:09<02:21, 1.50s/it]`
but I'd like for it to actually force display it/s (generally, units per time, and possibly vice versa) so... | open | 2021-10-11T03:28:23Z | 2024-05-08T08:46:15Z | https://github.com/tqdm/tqdm/issues/1259 | [] | tloki | 6 |
autokey/autokey | automation | 523 | Hold mouse button? | ## Classification:
Feature, Enhancement (maybe bug)
## Reproducibility:
Always
## Version
AutoKey version: 0.95.10
Used GUI: GTK
If the problem is known to be present in more than one version, please list all of those.
Installed via: (Debian/Ubuntu Repo).
Linux Distribution: Linux Mint
## ... | closed | 2021-03-29T20:56:20Z | 2021-04-01T11:29:52Z | https://github.com/autokey/autokey/issues/523 | [
"duplicate",
"enhancement",
"scripting"
] | thedocruby | 4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.