
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
dropbox/sqlalchemy-stubs | sqlalchemy | 240 | Assigning to a Union of a nullable and non-nullable column fails | I'm running the latest (at the time of writing) `mypy` (0.950) and `sqlalchemy-stubs` (0.4) and hitting this issue:
```python
from sqlalchemy import Column, Integer
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Dog(Base):
__tablename__ = 'dogs'
age = Co... | open | 2022-05-16T20:00:08Z | 2022-05-16T20:00:08Z | https://github.com/dropbox/sqlalchemy-stubs/issues/240 | [] | Garrett-R | 0 |
holoviz/panel | plotly | 7,343 | Directly export notebook app into interactive HTML | <!--
Thanks for contacting us! Please read and follow these instructions carefully, then you can delete this introductory text. Note that the issue tracker is NOT the place for usage questions and technical assistance; post those at [Discourse](https://discourse.holoviz.org) instead. Issues without the required inform... | open | 2024-09-29T09:51:01Z | 2025-02-20T15:04:53Z | https://github.com/holoviz/panel/issues/7343 | [
"type: feature"
] | YongcaiHuang | 5 |
deezer/spleeter | deep-learning | 514 | Deleted pretrained_models folder and now it tracebacks when redownloading | I was cleaning up my home directory and deleted the pretrained_models folder a while ago. Now when I run Spleeter I get the traceback below. I'm not sure if this is user error or not. I solved it by manually downloading and extracting the models, so this isn't a blocker or anything.
C:\Users\Simon Jaeger>c:\python37... | closed | 2020-11-08T07:19:21Z | 2020-11-20T14:20:07Z | https://github.com/deezer/spleeter/issues/514 | [] | Simon818 | 1 |
ageitgey/face_recognition | python | 776 | face_landmarks not accurate | Hi,I am building a toy robot head with camera to imitate a human facial expression.
If I raise my eyebrow in front of the camera,the eyebrows in the face_landmark doesn't raise as much as I do,in fact,the landmark changes only a little. It seems like the algorithm is predicting where the eyebrow should be,rather than ... | open | 2019-03-18T16:21:28Z | 2019-03-18T16:21:28Z | https://github.com/ageitgey/face_recognition/issues/776 | [] | hyansuper | 0 |
idealo/imagededup | computer-vision | 74 | Duplicates not found, even if the source and test images are the same | I took the [CIFAR 10 example code](https://idealo.github.io/imagededup/examples/CIFAR10_deduplication/)
But I get following error even though `duplicates_test` variable contains two duplicates which are basically same images in both source and test folders `{'labels12-source.jpg': [], 'labels9-source.jpg': []}`
T... | closed | 2019-11-15T15:01:52Z | 2019-11-27T15:23:49Z | https://github.com/idealo/imagededup/issues/74 | [] | zubairahmed-ai | 3 |
deepinsight/insightface | pytorch | 1,963 | Can't train | I encountered the following problem when retraining the data, how should I solve it?
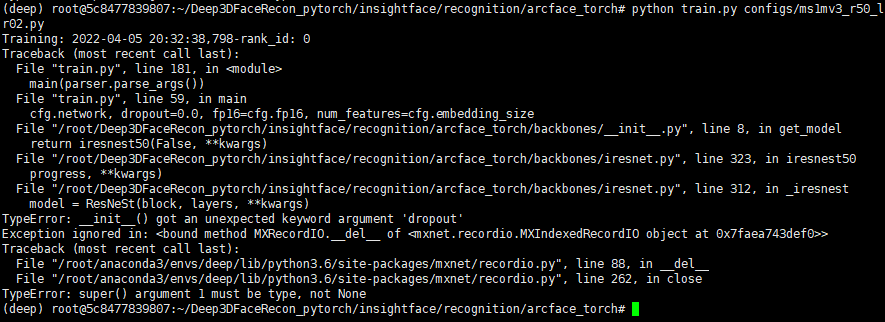
| open | 2022-04-05T12:36:31Z | 2022-04-06T01:41:48Z | https://github.com/deepinsight/insightface/issues/1963 | [] | NewtOliver | 2 |
dbfixtures/pytest-postgresql | pytest | 1,087 | Remove ability to pre-populate database on a client fixture level | closed | 2025-02-12T17:38:58Z | 2025-02-15T11:14:22Z | https://github.com/dbfixtures/pytest-postgresql/issues/1087 | [] | fizyk | 0 | |
widgetti/solara | fastapi | 497 | Fullscreen scrolling example is broken | The [fullscreen scrolling example](https://solara.dev/examples/fullscreen/scrolling) is currently broken:
<img width="261" alt="image" src="https://github.com/widgetti/solara/assets/37669773/d081f32c-7624-43ec-a31e-1e4a722b36a2">
| open | 2024-02-07T13:05:50Z | 2024-02-07T14:46:09Z | https://github.com/widgetti/solara/issues/497 | [] | langestefan | 3 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 16,487 | [Bug]: Non checkpoints found. Can't run without a checkpoint. | ### Checklist
- [ ] The issue exists after disabling all extensions
- [X] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [X] The issue exists in the current version of the webui
- [X] The issue has not been reported before... | closed | 2024-09-14T18:27:39Z | 2024-09-15T05:25:50Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16487 | [
"bug-report"
] | johngavingraham | 3 |
bendichter/brokenaxes | matplotlib | 85 | How to use a different scale in one part of the axis | I want to use a different scale in one part of the axis.
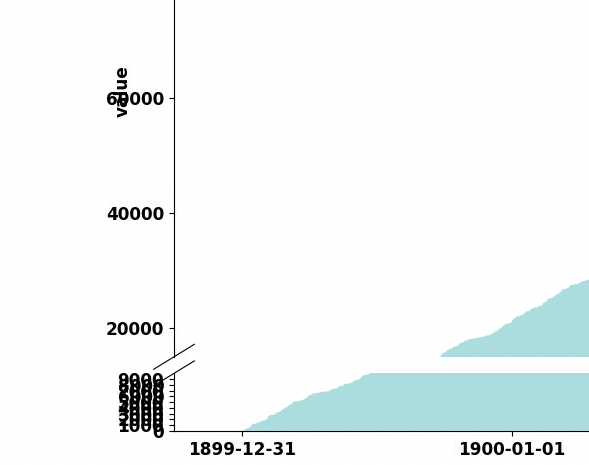
I tried to change the limits and tick count in the first part of yaxis but it did not work.
```
ax = bax.axs[1]
start, end = ax.get_ylim()... | closed | 2022-04-30T15:29:32Z | 2022-04-30T20:30:28Z | https://github.com/bendichter/brokenaxes/issues/85 | [] | sammy17 | 1 |
LibreTranslate/LibreTranslate | api | 134 | Add a parameter in the API to translate html |
Maybe you could add a parameter (format: text or html) in the API to allow translating html?
Thanks to [https://github.com/argosopentech/translate-html](argosopentech/translate-html)
I can do a pull request if interested. | closed | 2021-09-09T07:01:39Z | 2021-09-11T20:03:54Z | https://github.com/LibreTranslate/LibreTranslate/issues/134 | [
"enhancement",
"good first issue"
] | dingedi | 4 |
hack4impact/flask-base | sqlalchemy | 160 | Documentation on http://hack4impact.github.io/flask-base outdated. Doesn't match with README | Hi,
It seems that part of the documentation on https://hack4impact.github.io/flask-base/ are outdated.
For example, the **setup section** of the documentation mentions
```
$ pip install -r requirements/common.txt
$ pip install -r requirements/dev.txt
```
But there is no **requirements** folder.
Whereas... | closed | 2018-03-20T09:35:42Z | 2018-05-31T17:57:06Z | https://github.com/hack4impact/flask-base/issues/160 | [] | s-razaq | 0 |
ultralytics/ultralytics | pytorch | 19,743 | How to Train a Custom YOLO Pose Estimation Model for Object 6D Pose | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Dear Ultralytics Team,
I am currently working on 6D pose estimation for obj... | open | 2025-03-17T09:20:31Z | 2025-03-23T23:37:38Z | https://github.com/ultralytics/ultralytics/issues/19743 | [
"question",
"pose"
] | mike55688 | 5 |
AntonOsika/gpt-engineer | python | 835 | Azure OpenAI Integration is not working anymore | The last working version I think was around v0.0.6. v0.1.0 is not working anymore with the following effects:
## Expected Behavior
When using the `--azure` parameter, the Azure OpenAI endpoint should be used. (X.openai.azure.com)
## Current Behavior
Instead of the Azure OpenAI endpoint, the usual OpenAI end... | closed | 2023-11-02T08:40:17Z | 2023-12-24T09:52:48Z | https://github.com/AntonOsika/gpt-engineer/issues/835 | [
"bug"
] | niklasfink | 8 |
ultralytics/yolov5 | machine-learning | 13,228 | RuntimeError: Caught RuntimeError in replica 0 on device 0 | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
When training with yolov5x6. pt, setting the imagesize to 640 can be used for training, b... | closed | 2024-07-29T05:01:37Z | 2024-10-20T19:51:01Z | https://github.com/ultralytics/yolov5/issues/13228 | [
"question"
] | Bailin-He | 2 |
hyperspy/hyperspy | data-visualization | 3,223 | scipy.interp1d legacy | `interp1d` is a legacy function in SciPy that will be deprecated in the future: https://docs.scipy.org/doc/scipy/tutorial/interpolate/1D.html#legacy-interface-for-1-d-interpolation-interp1d
It is currently used 6 times in the codebase: (3 in hs, 1 in rsciio, 2 in eels): https://github.com/search?q=repo%3Ahyperspy%2F... | closed | 2023-09-01T23:11:37Z | 2023-09-28T07:31:15Z | https://github.com/hyperspy/hyperspy/issues/3223 | [] | jlaehne | 1 |
tensorlayer/TensorLayer | tensorflow | 615 | Failed: TensorLayer (a17229d4) | *Sent by Read the Docs (readthedocs@readthedocs.org). Created by [fire](https://fire.fundersclub.com/).*
---
| TensorLayer build #7203498
---
| 
---
| Build Failed for TensorLayer (1.3.2)
---
You can find out more about this failure here:
... | closed | 2018-05-17T07:58:11Z | 2018-05-17T08:00:30Z | https://github.com/tensorlayer/TensorLayer/issues/615 | [] | fire-bot | 0 |
serengil/deepface | machine-learning | 1,316 | [BUG]: broken weight files | ### Before You Report a Bug, Please Confirm You Have Done The Following...
- [X] I have updated to the latest version of the packages.
- [X] I have searched for both [existing issues](https://github.com/serengil/deepface/issues) and [closed issues](https://github.com/serengil/deepface/issues?q=is%3Aissue+is%3Aclosed) ... | closed | 2024-08-21T12:59:13Z | 2024-08-31T15:56:10Z | https://github.com/serengil/deepface/issues/1316 | [
"bug"
] | serengil | 0 |
proplot-dev/proplot | data-visualization | 86 | You also depend on pyyaml | https://github.com/lukelbd/proplot/blob/168df5109cc87e1f308711b2657f6126b82a19ff/proplot/rctools.py#L13 | closed | 2019-12-15T14:54:12Z | 2019-12-16T03:42:06Z | https://github.com/proplot-dev/proplot/issues/86 | [
"distribution"
] | hmaarrfk | 1 |
great-expectations/great_expectations | data-science | 10,607 | Improve OpenSSF Scorecard Report - remove critical issue by changing pr-title-checker.yml CI workflow | **Describe the bug**
Noticed when viewing the OpenSSF scorecard for the Great Expectations library at:
https://scorecard.dev/viewer/?uri=github.com/great-expectations/great_expectations
There is a critical *Dangerous-Workflow* pattern detected - the error is as follows:
> Warn: script injection with untrusted i... | closed | 2024-10-31T15:04:40Z | 2024-11-06T21:54:32Z | https://github.com/great-expectations/great_expectations/issues/10607 | [] | nils-woxholt | 0 |
ResidentMario/missingno | pandas | 81 | Problem exporting to PDF | When using msno.matrix() and trying to export to pdf using matplotlib:
`fig.savefig('fig1.pdf', format='pdf', bbox_inches='tight')`
I get a pdf file with a empty plot. All font components appears normally, as ticks, labels, titles, etc. But the plot itself is blank, as can be seen in the attached figure.
![scr... | closed | 2019-01-09T13:29:39Z | 2019-03-17T04:25:14Z | https://github.com/ResidentMario/missingno/issues/81 | [] | aguinaldoabbj | 3 |
ipyflow/ipyflow | jupyter | 27 | better logo for JupyterLab startup kernel | Maybe the Python logo where the snake is wearing a helmet, or something like that. | closed | 2020-05-12T18:45:44Z | 2020-05-13T22:31:55Z | https://github.com/ipyflow/ipyflow/issues/27 | [] | smacke | 0 |
pydantic/FastUI | pydantic | 154 | Question: Is there a way to redirect response to an end point or url that's not part of the fastui endpoints? | I tried using RedirectResponse from starlette.responses, like: return RedirectResponse('/logout') or return RedirectResponse('logout.html'). I also tried return [c.FireEvent(event=GoToEvent(url='/logout'))] but it always gives me this error: "Request Error Response not valid JSON". It seems the url is always captured b... | closed | 2024-01-16T10:43:50Z | 2024-02-18T10:50:42Z | https://github.com/pydantic/FastUI/issues/154 | [] | fmrib00 | 2 |
plotly/dash-table | plotly | 430 | [dash-table] Display problem for editable (dropdown) datatable with row_selectable | Hey :slightly_smiling_face:
This is my first post here…
I have a problem (see image) of shift between the lines of my datatable and the checkboxes.
This problem appeared with the addition of the ability to modify the data with a dropdown on a column.
If I change the parameter with “editable = False,” this prob... | open | 2019-05-13T15:47:34Z | 2019-05-13T15:50:22Z | https://github.com/plotly/dash-table/issues/430 | [] | cedricperrotey | 0 |
modelscope/data-juicer | data-visualization | 603 | FT-Data Ranker_大语言模型微调数据赛, 是否可以分享该比赛的数据用于对Data-Juicer项目的使用。 | 尊敬的Data-Juicer框架开发者,你们好。最近,我们有对大模型数据进行处理的需求。从论文“Data-Juicer: A One-Stop Data Processing System for Large Language Models”调研到Data-Juicer的开源大模型数据处理框架。我们想进一步使用和探索这个框架。正好,我们看到了你们在天池比赛中发布了“FT-Data Ranker_大语言模型微调数据赛(7B模型赛道)”比赛。但是比赛已经结束无法获取原始数据。是否可以提供原始数据以供我们探索和使用Data-Juicer框架。万分感谢🙏。 | open | 2025-03-03T09:45:30Z | 2025-03-04T06:27:35Z | https://github.com/modelscope/data-juicer/issues/603 | [
"question"
] | user2311717757 | 1 |
vitalik/django-ninja | django | 527 | Call result of another URL from another URL | In order to be able to get results and avoid an intermediate classic http call, I wanted to call the result of one URL from another, like so:
("Pseudocode").
```
@api.post("/test-dependent")
def composite_result(request):
result = {"icons": media_icon(request), "other": "whatever"}
return result
@api... | open | 2022-08-12T15:09:57Z | 2022-08-14T08:24:54Z | https://github.com/vitalik/django-ninja/issues/527 | [] | martinlombana | 1 |
Farama-Foundation/PettingZoo | api | 710 | Error running tutorial: 'ProcConcatVec' object has no attribute 'pipes' | I'm running into an error with this long stack trace when I try to run the 13 line tutorial:
```
/Users/erick/.local/share/virtualenvs/rl-0i49mzF7/lib/python3.9/site-packages/torch/utils/tensorboard/__init__.py:4: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
if not... | closed | 2022-05-29T13:17:28Z | 2022-08-14T18:22:20Z | https://github.com/Farama-Foundation/PettingZoo/issues/710 | [] | erickrf | 16 |
amidaware/tacticalrmm | django | 1,950 | Add info to Automation policy manager output summary | Add counts of each type of item and total and increase title to more chars
<img width="801" alt="2024-07-31_031728 - automation output" src="https://github.com/user-attachments/assets/a63695c5-1776-43d6-95e5-787e0ef3b434">
| open | 2024-07-31T07:20:29Z | 2024-11-04T15:15:09Z | https://github.com/amidaware/tacticalrmm/issues/1950 | [
"enhancement"
] | silversword411 | 1 |
scrapy/scrapy | web-scraping | 6,478 | Get rid of `testfixtures` | We only use `testfixtures.LogCapture` and I expect it should be easy, [though not trivial](https://docs.pytest.org/en/stable/how-to/unittest.html), to replace it with the pytest `caplog` fixture, reducing our test dependencies.
Alternatively we can try moving to [`twisted.logger.capturedLogs`](https://docs.twisted.o... | open | 2024-09-20T16:52:42Z | 2025-03-13T17:47:19Z | https://github.com/scrapy/scrapy/issues/6478 | [
"enhancement",
"CI"
] | wRAR | 8 |
AirtestProject/Airtest | automation | 376 | 执行脚本时 airtest 报错 | **描述问题 BUG**
执行脚本时 adb.py 抛出 AdbError
Log:
```
adb server version (40) doesn't match this client (39); killing...
[pocoservice.apk] stdout: b'\r\ncom.netease.open.pocoservice.InstrumentedTestAsLauncher:'
[pocoservice.apk] stderr: b''
[pocoservice.apk] retrying instrumentation PocoService
[05:00:12][DEBUG]<air... | closed | 2019-04-26T09:50:30Z | 2019-04-26T10:25:06Z | https://github.com/AirtestProject/Airtest/issues/376 | [] | i11m20n | 2 |
Kav-K/GPTDiscord | asyncio | 447 | [BUG] Taggable mentions overriding converse opener | **Describe the bug**
During a GPT converse with a custom opener set, using an @mention of the bot reverts back to the default
**To Reproduce**
Steps to reproduce the behaviour:
1. Start a /gpt converse with an opener or opener_file
2. Inside of the thread / conversation, send a message that begins with the tagg... | closed | 2023-12-11T07:11:23Z | 2023-12-31T10:05:17Z | https://github.com/Kav-K/GPTDiscord/issues/447 | [
"bug"
] | jeffe | 1 |
docarray/docarray | fastapi | 1,830 | Error on subindice Embedding type for Torch Tensor moving from GPU to CPU. | ### Initial Checks
- [X] I have read and followed [the docs](https://docs.docarray.org/) and still think this is a bug
### Description
I have found an issue with the following sequence:
Object
SubIndiceObject with an attribute Optional[AnyEmbedding]
I am running an operation on GPU and storing the TorchEmbedd... | open | 2023-11-06T19:44:17Z | 2023-12-23T14:52:32Z | https://github.com/docarray/docarray/issues/1830 | [] | vincetrep | 3 |
streamlit/streamlit | machine-learning | 9,947 | More consistent handling of relative paths | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [X] I added a descriptive title and summary to this issue.
### Summary
We have two main ways relative paths are parsed:
- For Page and navigation commands, paths are relati... | open | 2024-11-29T09:14:30Z | 2024-11-29T09:16:40Z | https://github.com/streamlit/streamlit/issues/9947 | [
"type:enhancement"
] | sfc-gh-dmatthews | 1 |
nltk/nltk | nlp | 3,165 | a lot of NLTK DATA does not express their license | Dear NLTK.
I read "NLTK corpora are provided under the terms given in the README file for each corpus; all are redistributable and available for non-commercial use."
But a lot of NLTK DATA did not write their license.
Please see below.
https://www.nltk.org/nltk_data/
It is very unfriendly for user. Please wr... | open | 2023-06-16T17:02:04Z | 2023-06-16T17:09:26Z | https://github.com/nltk/nltk/issues/3165 | [] | hiDevman | 0 |
timkpaine/lantern | plotly | 96 | Plotly probplot | closed | 2017-10-19T16:57:35Z | 2017-11-26T05:13:24Z | https://github.com/timkpaine/lantern/issues/96 | [
"feature",
"plotly/cufflinks"
] | timkpaine | 1 | |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,744 | "HTTP Error 404: Not Found" Showing when driver is initialised | For this simple code:
```
import undetected_chromedriver as uc
import time
if __name__ == '__main__':
driver = uc.Chrome()
time.sleep(20)
```
I get this error:
```
Traceback (most recent call last):
File "/home/omkmorendha/Desktop/Work/JSX_scraping/exp.py", line 5, in <module>
dr... | closed | 2024-02-15T12:25:30Z | 2024-02-15T12:43:12Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1744 | [] | omkmorendha | 2 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 792 | Datasets_Root | In the instructions to run the preprocess. With the datasets how to I figure where the dataset root is. What is the command line needed to do so.
I'm using Windows 10 BTW.
It launches and works without any dataset_root listed but I want to make it work better. And without the datasets I can't | closed | 2021-07-08T17:46:29Z | 2021-08-25T09:42:20Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/792 | [] | C4l1b3r | 10 |
sebp/scikit-survival | scikit-learn | 159 | Terminal Node Constraint for Random Survival Forests | Is there any parameter/variable which states the minimum number of "uncensored samples" required to be at a leaf node? I think it's called "a minimum of d0 > 0 unique deaths" in the original paper. | open | 2020-12-29T07:31:02Z | 2021-01-27T09:21:45Z | https://github.com/sebp/scikit-survival/issues/159 | [
"enhancement"
] | mastervii | 4 |
Yorko/mlcourse.ai | matplotlib | 358 | Add athlete_events.csv to data folder | The athlete_events.csv file seems to be missing from the data folder. Sure, it can be downloaded via the [Kaggle link][0] but it's not immediately obvious.
[0]: https://www.kaggle.com/heesoo37/120-years-of-olympic-history-athletes-and-results/version/2 | closed | 2018-10-01T11:37:05Z | 2018-10-04T14:11:54Z | https://github.com/Yorko/mlcourse.ai/issues/358 | [
"invalid"
] | morcmarc | 1 |
0b01001001/spectree | pydantic | 21 | falcon endpoint function doesn't get the right `self` | This is due to the decorator.
```py
class Demo:
def test(self): pass
def on_get(self, req, resp):
self.test() # this will raise AttributeError
pass
```
And the `parse_name` function for falcon endpoint function should return the class name instead of the method name. Since the method... | closed | 2020-01-09T08:25:43Z | 2020-01-12T10:20:55Z | https://github.com/0b01001001/spectree/issues/21 | [] | kemingy | 2 |
benbusby/whoogle-search | flask | 580 | Ratelimited | Hello, I still don't know how to solve this problem, all was working ok until today that I received this message when trying to use Whoogle.
Thanks | closed | 2021-12-15T11:02:38Z | 2021-12-24T00:07:44Z | https://github.com/benbusby/whoogle-search/issues/580 | [
"question"
] | gaditano66 | 10 |
shibing624/text2vec | nlp | 29 | 'Word2VecKeyedVectors' object has no attribute 'key_to_index' | Hi, how to fix 'Word2VecKeyedVectors' object has no attribute 'key_to_index' after loading GoogleNews-vectors-negative300.bin file in w2v = KeyedVectors.load_word2vec_format(word2vec_path, binary=True)
| closed | 2021-09-04T16:12:36Z | 2021-09-04T16:14:37Z | https://github.com/shibing624/text2vec/issues/29 | [
"bug"
] | AdhyaSuman | 0 |
gee-community/geemap | jupyter | 1,445 | The code "cartoee_subplots" does not work | Dear,
When I run "cartoee_subplots.ipynb" I get the following graphic with projection problem for the image (srtm):

I think the problem is in the following line:
cartoee.add_layer(ax, srtm, region=r... | closed | 2023-02-23T14:44:50Z | 2023-06-30T18:43:32Z | https://github.com/gee-community/geemap/issues/1445 | [
"bug"
] | raulpoppiel | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,222 | 'Namespace' object has no attribute 'n_epochs' | Hi, I was trying to run **train.py** for png sets.
The number of training images = 11036
`python3 train.py --dataroot datasets/AS2SE/ --name AS2SE_1 --model cycle_gan --phase train --gpu_ids 0,1,2 --batch_size 16 --preprocess none --load_size 170 --print_freq 1000 --save_epoch_freq 200 --input_nc 1 --output_nc 1`
... | open | 2021-01-11T13:05:36Z | 2021-01-12T01:40:50Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1222 | [] | lucid0921 | 1 |
pywinauto/pywinauto | automation | 906 | Announcement: I'm making a PyWinAutoUI (graphical) GUI with advanced features | My end goal is to do on-screen lessons with overlayed arrows as done on bubble.is (and their set of lessons), but since I don't want to always be coding to create a simple enough lesson, I thought I should give PyWinAuto a GUI frontend that detects / records clicks in .py script format.
Here's a screenshot:
![image... | closed | 2020-04-01T21:55:36Z | 2020-04-28T05:46:10Z | https://github.com/pywinauto/pywinauto/issues/906 | [
"enhancement",
"New Feature",
"success_stories"
] | enjoysmath | 30 |
aleju/imgaug | machine-learning | 119 | broblem load and show images | I tried but failed. this is my code and error,thanks
import imgaug as ia
from imgaug import augmenters as iaa
import numpy as np
import cv2
import scipy
from scipy import misc
ia.seed(1)
# Example batch of images.
# The array has shape (32, 64, 64, 3) and dtype uint8.
#scipy.ndimage.imread('cat.jpg', fl... | open | 2018-04-05T17:55:33Z | 2018-04-16T15:49:38Z | https://github.com/aleju/imgaug/issues/119 | [] | ghost | 7 |
modoboa/modoboa | django | 3,263 | Incorrect DNS status for subdomains | OS: Debian 12
Modoboa: 2.2.4
Installer used: Yes
Webserver: Nginx
Database: MySQL
I configured a subdomain in Modoboa, and all the records are correct in Cloudflare, and emails are sending and receiving. The issue is with the DNS status in Modoboa, it shows "Domain has no MX record" ("No MX record found for this... | closed | 2024-06-13T19:06:27Z | 2024-07-15T15:46:04Z | https://github.com/modoboa/modoboa/issues/3263 | [
"feedback-needed"
] | hugohamelcom | 17 |
nltk/nltk | nlp | 3,120 | nltk.download('punkt') not working | 
Please help me with this issue
| open | 2023-02-08T15:56:34Z | 2023-02-08T16:02:46Z | https://github.com/nltk/nltk/issues/3120 | [] | Bhargav2193 | 1 |
piskvorky/gensim | nlp | 2,844 | Conflicts between hyperparameters for negative sampling? | Hi,
I wonder if there are possible interactions/conflicts when you use negative sampling with `negative>0 `and have hierarchical softmax accidentally activated` hs=1`? The docs says that only if hs=0 negative sampling will be used (negative>0). So I can hope that still if hs=1 and `negative>0 ` hopefully _**no**_ n... | closed | 2020-05-18T16:30:41Z | 2020-10-28T02:08:32Z | https://github.com/piskvorky/gensim/issues/2844 | [
"question"
] | datistiquo | 1 |
snarfed/granary | rest-api | 163 | MF2-Atom missing published/updated dates | Using granary.io on aaronparecki.com (@aaronpk) is failing to parse the dt-published fields and include them in the atom feed.
https://granary.io/url?input=html&output=atom&url=https%3A//aaronparecki.com/&hub=https%3A//switchboard.p3k.io/ | closed | 2019-03-28T19:58:01Z | 2019-03-29T04:05:49Z | https://github.com/snarfed/granary/issues/163 | [] | alexmingoia | 1 |
MaartenGr/BERTopic | nlp | 1,153 | Change node colour in visualize_documents based on class | Hi,
Love the BERTopic library!
I wanted to ask whether in <code>.visualize_documents</code>, it would be possible to change the colour of the document nodes according to my own class labels. All my documents have labels for 'blue', 'white', and 'red', representing slower, faster or normal time perception. It wou... | closed | 2023-04-04T13:50:55Z | 2023-04-10T06:28:50Z | https://github.com/MaartenGr/BERTopic/issues/1153 | [] | Akseli-Ilmanen | 3 |
httpie/cli | python | 778 | body data by parts not printed even if written on a socket | Hi Devs,
I really like your software and the presentation of the data in the terminal!
However, in a case on a get with multiple body responses by parts and a keep-alive attribute, only the header is written on client side (httpie) once flushed on a socket. Nevertheless, curl does show each new data written on a ... | closed | 2019-05-17T18:02:39Z | 2019-08-29T11:50:16Z | https://github.com/httpie/cli/issues/778 | [] | binarytrails | 1 |
lepture/authlib | flask | 561 | OpenID Connect Front-Channel Logout | I suggest to implement helpers for [OpenID Connect Front-Channel Logout](https://openid.net/specs/openid-connect-frontchannel-1_0.html)
> This specification defines a logout mechanism that uses front-channel communication via the User Agent between the OP and RPs being logged out that does not need an OpenID Provide... | open | 2023-07-03T15:59:17Z | 2025-02-20T20:36:59Z | https://github.com/lepture/authlib/issues/561 | [
"spec",
"feature request"
] | azmeuk | 0 |
dpgaspar/Flask-AppBuilder | flask | 1,813 | OAUTH : Gitlab - The redirect URI included is not valid | ### Environment
Flask-Appbuilder version:
```
Flask 1.1.2
Flask-AppBuilder 3.4.4
Flask-Babel 2.0.0
Flask-Caching 1.10.1
Flask-JWT-Extended 3.25.1
Flask-Login 0.4.1
Flask-OpenID ... | closed | 2022-02-28T17:23:33Z | 2024-04-25T14:16:16Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1813 | [] | vparmeland | 1 |
onnx/onnxmltools | scikit-learn | 130 | new "Transpose" ops when transform keras to onnx | Hi,
Thank you for sharing this nice tool for converting keras to onnx.
I followed the [examples](https://github.com/onnx/onnxmltools#examples) to convert my keras model to onnx model, but encountered with some weird results.
The overall model structure keeps the same before and after the conversion, but the... | closed | 2018-08-23T10:14:44Z | 2018-08-29T06:39:23Z | https://github.com/onnx/onnxmltools/issues/130 | [] | yanghanxy | 3 |
hbldh/bleak | asyncio | 506 | AccessDenied when enumerating services on Windows | * bleak version: 0.11.0
* Python version: 3.8.x
* Operating System: Windows 10
* BlueZ version (`bluetoothctl -v`) in case of Linux: N/A
### Description
> Describe what you were trying to get done.
Trying to connect to LEGO Technic hub bootloader using Bleak.
> Tell us what happened, what went wrong, and... | closed | 2021-04-03T22:22:14Z | 2021-10-06T23:01:11Z | https://github.com/hbldh/bleak/issues/506 | [
"bug",
"Backend: pythonnet",
"Backend: WinRT"
] | dlech | 5 |
onnx/onnx | tensorflow | 6,428 | [Feature request] Support 1D vector for w_scale in QLinearConv reference implementation | ### System information
1.17.0 release
### What is the problem that this feature solves?
Documentation for `w_scale` argument to `QLinearConv` operator (https://github.com/onnx/onnx/blob/41cba9d512620781257163cb2ba072871456f8d3/docs/Operators.md#QLinearConv) states:
> It could be a scalar or a 1-D tensor, which me... | open | 2024-10-06T21:57:03Z | 2024-10-06T21:57:03Z | https://github.com/onnx/onnx/issues/6428 | [
"topic: enhancement"
] | mcollinswisc | 0 |
ijl/orjson | numpy | 130 | Raspberry Pi 4 - Cannot install orjson | I am trying to install orjson with Python 3.8, so far I have installed wheel, rust nightly and maturin "successfully". On orjson install when it comes to maturin it fails and I can't figure out a solution.
```
$ pip3 install orjson
Defaulting to user installation because normal site-packages is not writeable
Look... | closed | 2020-09-29T06:46:19Z | 2020-10-02T12:36:52Z | https://github.com/ijl/orjson/issues/130 | [] | QuentinDanjou | 4 |
chaoss/augur | data-visualization | 2,663 | repo_deps_libyear current_release_date and latest_release_date data type | current_release_date and latest_release_date is a string type not a date type, and the format is not convertible with pandas | open | 2024-01-02T20:07:16Z | 2025-02-10T23:14:50Z | https://github.com/chaoss/augur/issues/2663 | [
"add-feature"
] | cdolfi | 1 |
ageitgey/face_recognition | python | 1,098 | face_recogition.face_locations TypeError: 'list' object is not callable | * face_recognition version: 1.3.0
* Python version: 3.6.1
* Operating System: Manjaro
### Description
I installed dlib and face_recognition via pip in a conda envirnment. I am trying to do facial recognition via webcam. Is it possible that the way I install face_recognition is causing a problem. Or is there an... | closed | 2020-03-29T15:37:09Z | 2020-03-29T15:41:56Z | https://github.com/ageitgey/face_recognition/issues/1098 | [] | biographie | 2 |
python-restx/flask-restx | flask | 231 | When used with Flask-jwt-extended the exception in handler is thrown | ```python
from flask import Flask, jsonify
from flask_jwt_extended import JWTManager, jwt_required
from flask_restx import Api, Resource
app = Flask(__name__)
app.config['JWT_SECRET_KEY'] = 'super-secret'
jwt = JWTManager(app)
api = Api(app)
jwt._set_error_handler_callbacks(api)
@jwt.unauthorized_loader
... | open | 2020-09-29T18:43:10Z | 2021-04-04T15:45:35Z | https://github.com/python-restx/flask-restx/issues/231 | [
"bug"
] | KathRains | 8 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 958 | I have the problem No Module named torch | please send help | closed | 2021-12-25T12:15:31Z | 2021-12-28T12:34:21Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/958 | [] | santaonholidays | 0 |
pydata/pandas-datareader | pandas | 387 | I can't get kosdaq historical from yahoo and google. | hello. all.
I am korean.
there are two kinds of stock in korea. it is KRX and KOSDAQ.
I can get data KRX. but i cannot get data KOSDAQ.
i can get data KRX from that code.
`df = data.DataReader("KRX:035420", "google", start, end)`
but i cannot get data KOSDAT from code.
`df = data.DataReader("KOSDAQ:003... | closed | 2017-09-04T12:47:05Z | 2018-01-23T10:16:52Z | https://github.com/pydata/pandas-datareader/issues/387 | [
"google-finance",
"yahoo-finance"
] | ryulstory | 1 |
facebookresearch/fairseq | pytorch | 4,748 | Changes outputs directory during training |
#### What is your question?
Hi I'm changes outputs directory place during training mistakenly.. I'm just make new directory immediately
Now didn't append log and train info at hydra_train.log i'm use hydra-train
in this situation my question is new checkpoint is store in directory changed..?
#### What's your... | closed | 2022-09-29T04:50:23Z | 2022-09-29T08:04:28Z | https://github.com/facebookresearch/fairseq/issues/4748 | [
"question",
"needs triage"
] | Macsim2 | 1 |
chatanywhere/GPT_API_free | api | 217 | well done~! | 这是哪个菩萨产出的项目,上香~
| open | 2024-04-19T15:47:49Z | 2024-08-16T07:48:28Z | https://github.com/chatanywhere/GPT_API_free/issues/217 | [] | shiker1996 | 3 |
biolab/orange3 | numpy | 6,945 | Problems with Excel/csv reader in Orange 3.38 | **What's wrong?**
#6862 fixed reading of flags in 1-line header format, but it "recognizes" flags that are not.
The attached file has an attribute *1999-12-01 Towards a nuclear-weapon-free world:#the need for a new agenda*. The part before `#` is recognized as flag (I don't know which flags is it supposed to cont... | closed | 2024-12-01T20:02:42Z | 2024-12-24T10:01:40Z | https://github.com/biolab/orange3/issues/6945 | [
"bug report"
] | janezd | 1 |
tfranzel/drf-spectacular | rest-api | 960 | Serializer Extension Mapping Applies to Request Body for POST Requests | - Django 4.1.4
- DRF 3.14
- drf-spectacular 0.26.0
**Describe the bug**
My DRF Serializers are designed to return a custom response body by overriding the `to_representation` method. The parameters of the response object point to an object, rather than the value of the field. E.g.:
<img width="323" alt="ima... | closed | 2023-03-15T11:54:25Z | 2023-03-21T10:27:03Z | https://github.com/tfranzel/drf-spectacular/issues/960 | [] | Lawrence-Godfrey | 2 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 127 | Multi lingual | Hi,
how can I make this multi lingual to request the bot to read text in french (right now the title moderator do not work) and to generate resume in french too ?
if you point me where in the code, I might be able to participate in the evolution | closed | 2024-08-29T09:51:15Z | 2024-09-03T14:46:03Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/127 | [
"enhancement"
] | MaraScott | 1 |
littlecodersh/ItChat | api | 500 | AttributeError: module 'itchat' has no attribute 'auto_login | Traceback (most recent call last):
File "C:\Users\Administrator\Desktop\auto_aswer.py", line 2, in <module>
import itchat
File "C:\Users\Administrator\Desktop\itchat.py", line 3, in <module>
itchat.auto_login(hotReload=True)
AttributeError: module 'itchat' has no attribute 'auto_login'
这个是什么问题? 直接在IDL... | closed | 2017-08-29T05:42:34Z | 2023-01-12T11:14:49Z | https://github.com/littlecodersh/ItChat/issues/500 | [
"duplicate"
] | M737 | 6 |
simple-login/app | flask | 1,052 | [Feature Request] Send outgoing email using form on SimpleLogin | Hello,
I have structured this feature request using a user story:
**As a** user who often utilizes the reverse-alias functionality
**I want to** be able to send emails by replying to a reverse-alias or by sending an email to a recipient that I did not earlier contact, directly via a web form on SimpleLogin
... | closed | 2022-06-06T01:22:52Z | 2022-06-06T01:34:07Z | https://github.com/simple-login/app/issues/1052 | [] | ghost | 1 |
matterport/Mask_RCNN | tensorflow | 2,315 | inference very slow | I have test one image(1000 x1200x3),but the speed is really much slow! It unbelievably takes about 3 mins(160 seconds) to inference one image. My inference device is GTX 1660super. I would be very grateful if someone could help me. | open | 2020-08-11T00:55:05Z | 2020-12-27T09:35:05Z | https://github.com/matterport/Mask_RCNN/issues/2315 | [] | shining-love | 2 |
keras-team/keras | pytorch | 20,564 | Unable to Assign Different Weights to Classes for Functional Model | I'm struggling to assign weights to different classes for my functional Keras model. I've looked for solutions online and everything that I have tried has not worked. I have tried the following:
1) Assigning `class_weights` as an argument for `model.fit`. I convert my datasets to numpy iterators first as `tf.data.Data... | closed | 2024-11-29T02:25:58Z | 2024-11-29T06:49:47Z | https://github.com/keras-team/keras/issues/20564 | [] | Soontosh | 1 |
scikit-learn/scikit-learn | machine-learning | 30,692 | Inaccurate error message for parameter passing in Pipeline with enable_metadata_routing=True | ### Describe the issue linked to the documentation
**The following error message is inaccurate:**
```
Passing extra keyword arguments to Pipeline.transform is only supported if enable_metadata_routing=True, which you can set using sklearn.set_config.
```
**This can easily be done using `**params` as described in ... | closed | 2025-01-21T19:08:21Z | 2025-01-28T09:02:51Z | https://github.com/scikit-learn/scikit-learn/issues/30692 | [
"Documentation"
] | jakemdrew | 7 |
NVlabs/neuralangelo | computer-vision | 100 | Images instead of videos | Can I use the already captured images and obtain JSON files without using videos | open | 2023-09-02T03:11:39Z | 2023-09-18T01:58:19Z | https://github.com/NVlabs/neuralangelo/issues/100 | [
"enhancement"
] | mowangmodi | 4 |
RayVentura/ShortGPT | automation | 48 | ✨ [Feature Request / Suggestion]: GPT3 error: Rate limit | ### Suggestion / Feature Request
ERROR | Exception : GPT3 error: Rate limit reached for default-gpt-3.5-turbo in organization on requests per min. Limit: 3 / min. Please try again in 20s. Contact us through our help center at help.openai.com if you continue to have issues. Please add a payment method to your account t... | closed | 2023-07-26T06:21:35Z | 2023-10-01T18:24:29Z | https://github.com/RayVentura/ShortGPT/issues/48 | [] | donghao95 | 13 |
jacobgil/pytorch-grad-cam | computer-vision | 476 | gradcam for binary segmentaion network | The final output of my segmentation network is a single-channel prediction map, how can this situation be adjusted according to the tutorial? | open | 2024-01-10T07:29:49Z | 2024-01-10T07:29:49Z | https://github.com/jacobgil/pytorch-grad-cam/issues/476 | [] | King-king424 | 0 |
opengeos/leafmap | streamlit | 1,027 | add_raster doesn't work in container environment | <!-- Please search existing issues to avoid creating duplicates. -->
### Environment Information
- leafmap version: 0.42.6
- Python version: 3.11.6
- Operating System: Mac OS 14.6.1 (but running container giwqs/leafmap:latest)
### Description
I am having difficult getting leafmap to display a local ... | closed | 2025-01-05T16:06:45Z | 2025-02-25T16:17:02Z | https://github.com/opengeos/leafmap/issues/1027 | [
"bug"
] | ldemaz | 11 |
TheKevJames/coveralls-python | pytest | 73 | Coveralls and Tox 2.0 | I just found out today, that with the new tox release (https://testrun.org/tox/latest/changelog.html#id1), coveralls stops working on travis.
The reason is that tox 2.0 has environment isolation. You have to pass
the `TRAVIS` and `TRAVIS_JOB_ID` and probably `TRAVIS_BRANCH` envvar in you tox settings or coveralls will ... | closed | 2015-05-13T18:28:42Z | 2015-05-16T20:35:58Z | https://github.com/TheKevJames/coveralls-python/issues/73 | [] | storax | 3 |
kizniche/Mycodo | automation | 1,357 | Add notes via API | **Is your feature request related to a problem? Please describe.**
When on the farm I don't want to open a web app to add a note.
I'd like to be able to add them via an existing farm management app
**Describe the solution you'd like**
Expose the note functionality in the Rest API so that notes can be added by... | closed | 2023-12-16T19:45:28Z | 2024-10-04T03:54:54Z | https://github.com/kizniche/Mycodo/issues/1357 | [
"enhancement",
"Implemented"
] | samuk | 5 |
SciTools/cartopy | matplotlib | 2,199 | BUG: incompatibility with scipy 1.11.0 | ### Description
Scipy 1.11.0 (released yesterday) appear to break [use cases exercised in yt's CI](https://github.com/yt-project/yt/issues/4540)
More specifically the breaking change seems to be https://github.com/scipy/scipy/pull/18502
#### Code to reproduce
```python
import numpy as np
import cartopy.cr... | closed | 2023-06-26T18:17:01Z | 2023-07-14T14:12:03Z | https://github.com/SciTools/cartopy/issues/2199 | [] | neutrinoceros | 7 |
aeon-toolkit/aeon | scikit-learn | 1,766 | [DOC] Add Raises to docstrings for methods that can raise exceptions | ### Describe the issue linked to the documentation
We mostly do not document the errors raised and the reasons for them. It would be good to do so. This should be done incrementally and is a good first issue.
1. Pick and estimator and try break it/see what exceptions are present
2. Look at the docstrings (may be... | open | 2024-07-05T11:20:24Z | 2025-03-21T22:04:45Z | https://github.com/aeon-toolkit/aeon/issues/1766 | [
"documentation",
"good first issue"
] | TonyBagnall | 8 |
BeanieODM/beanie | asyncio | 306 | [Question] not insert None value | ```
class Student(Document):
name: Optional[str]
birth: Optional[datetime]
new_student = Student(name = "New Name")
```
I don't want to insert `Student .birth` to mongo becuase it's none.
How I can do it
Thanks to you all
| closed | 2022-07-19T06:47:22Z | 2022-07-20T13:57:45Z | https://github.com/BeanieODM/beanie/issues/306 | [] | joshung | 2 |
docarray/docarray | fastapi | 1,425 | Bug: cannot stack empty torch tensor | How to reproduce:
```python
from docarray import BaseDoc, DocVec
from docarray.typing import TorchTensor
class MyDoc(BaseDoc):
tens: Optional[TorchTensor]
vec = DocVec[MyDoc]([MyDoc(), MyDoc()])
```
```bash
Traceback (most recent call last):
File "/home/johannes/.cache/pypoetry/virtualenvs/docarray-EljsZLuq-... | closed | 2023-04-19T23:57:12Z | 2023-04-20T00:01:51Z | https://github.com/docarray/docarray/issues/1425 | [] | JohannesMessner | 1 |
plotly/dash-bio | dash | 488 | Rename async modules | Same as https://github.com/plotly/dash-core-components/issues/745 | closed | 2020-02-27T00:48:46Z | 2020-03-10T19:19:43Z | https://github.com/plotly/dash-bio/issues/488 | [
"dash-type-bug",
"size: 0.2"
] | Marc-Andre-Rivet | 0 |
xlwings/xlwings | automation | 2,310 | xlwings-error-python process exit before it was possible to create interface object | #### OS Windows 11
#### Versions of xlwings, Excel and Python (e.g. 0.30.10, Office 365, Python 3.11)
#### Describe your issue

I tried to implement my python codes in excel using xlwings, but every time I import... | open | 2023-07-30T17:21:25Z | 2024-12-16T20:14:01Z | https://github.com/xlwings/xlwings/issues/2310 | [] | LucyZZZen | 2 |
reiinakano/xcessiv | scikit-learn | 58 | Base Learner Correlation Matrix | First of all, big props for this project! A big help in constructing big stacking models.
It would maybe be interesting to get some visualizations in the tool, like e.g. a correlation matrix between the meta-features.
If I ever get some time to spare, I'll start reading up on the code base and see if I can integ... | open | 2018-02-16T10:19:29Z | 2018-02-16T10:19:29Z | https://github.com/reiinakano/xcessiv/issues/58 | [] | GillesVandewiele | 0 |
wkentaro/labelme | computer-vision | 925 | [Feature] human pose | Does it support human pose label?
For example:
The image have two person.
And label know the keypoint is which person.
| closed | 2021-10-01T02:55:31Z | 2023-02-28T05:26:31Z | https://github.com/wkentaro/labelme/issues/925 | [] | alicera | 4 |
lepture/authlib | django | 130 | Requesting empty scope removes scope from response | When this [request is made](https://httpie.org/doc#forms):
http -a client:secret -f :/auth/token grant_type=client_credentials scope=
I get response, without `scope` even if it was given in request.
Code responsible for this is here:
https://github.com/lepture/authlib/blob/master/authlib/oauth2/rfc6750/... | closed | 2019-05-13T06:29:32Z | 2019-05-14T05:27:16Z | https://github.com/lepture/authlib/issues/130 | [] | sirex | 2 |
docarray/docarray | fastapi | 1,192 | Pre-commit hook fails due to poetry issues | **Describe the bug**
When I tried to commit, the pre-commit hook failed and gave the following stack trace.
```
stderr:
error: subprocess-exited-with-error
× Preparing metadata (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> [14 lines of output]
Traceback (most ... | closed | 2023-03-01T10:41:08Z | 2023-05-06T09:36:33Z | https://github.com/docarray/docarray/issues/1192 | [] | hrik2001 | 0 |
TracecatHQ/tracecat | fastapi | 342 | [FEATURE IDEA] Add UI to show action if `run_if` is specified | ## Why
- It's hard to tell if a node has a conditional attached unless you select the node or gave it a meaningful title
## Suggested solution
- Add a greenish `#C1DEAF` border that shows up around the node
- Prompt the the user to give the "condition" a human-readable name (why? because the expression will proba... | open | 2024-08-22T17:08:12Z | 2024-08-22T17:17:01Z | https://github.com/TracecatHQ/tracecat/issues/342 | [
"enhancement",
"frontend"
] | topher-lo | 2 |
deepset-ai/haystack | machine-learning | 8,631 | Port Tools from experimental | After new `ChatMessage` is introduced, we should port into Haystack all the work done for Tools in haystack-experimental.
(most of the resources on Tools are collected here: https://github.com/deepset-ai/haystack-experimental/discussions/98)
```[tasklist]
### Tasks
- [x] Tool dataclass
- [x] HF API Chat Generato... | closed | 2024-12-12T10:29:17Z | 2024-12-20T14:35:30Z | https://github.com/deepset-ai/haystack/issues/8631 | [
"P1",
"topic:agent"
] | anakin87 | 1 |
stanfordnlp/stanza | nlp | 936 | relation changes in stanza (ex: dobj -> obj) | Hello,
I noticed this https://github.com/stanfordnlp/stanza/commit/b6d83e20a65a8cd46005f96dfa3a6d49d863759b commit, where the relation 'dobj' has been changed to 'obj'. Are there any other relations that have been changed with stanza compared to the previous corenlp java based server?
Thanks. | closed | 2022-02-02T06:22:24Z | 2022-02-09T17:55:35Z | https://github.com/stanfordnlp/stanza/issues/936 | [
"question"
] | swatiagarwal-s | 2 |
twopirllc/pandas-ta | pandas | 424 | Psar loop starting at wrong index 1 | **Pandas ta version**
```python
0.3.14b0
```
**Describe the bug**
When reviewing the code of psar (https://github.com/twopirllc/pandas-ta/blob/main/pandas_ta/trend/psar.py#L46) the loop starts at the wrong index 1, it should start at 2, (Line 46)
Because after we do this computation:
_sar = max(high.iloc[row -... | closed | 2021-11-05T14:06:31Z | 2022-02-09T17:15:47Z | https://github.com/twopirllc/pandas-ta/issues/424 | [] | DevDaoud | 6 |
nalepae/pandarallel | pandas | 167 | ValueError: cannot find context for fork |
'3.8.12 (default, Oct 12 2021, 03:01:40) [MSC v.1916 64 bit (AMD64)]'
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Input In [1], in <module>
----> 1 import pandarallel
File ~\Anaconda3\envs\pepti\l... | closed | 2022-02-03T07:47:20Z | 2022-02-06T17:51:05Z | https://github.com/nalepae/pandarallel/issues/167 | [] | jckkvs | 1 |
ultralytics/ultralytics | pytorch | 19,691 | Error occurred when training YOLOV11 on dataset open-images-v7 | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
train.py:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO11n mod... | closed | 2025-03-14T06:35:34Z | 2025-03-19T10:43:33Z | https://github.com/ultralytics/ultralytics/issues/19691 | [
"question",
"dependencies",
"detect"
] | 1623021453 | 10 |
aio-libs/aiomysql | asyncio | 154 | how does aiomysql know to reuse a mysql pool? | in my programe,i made a global engine by store it into a list,
however when i use the ab to test a simple mysql proxy server with : ab -n 10000 -c 1000 http://localhost
and the proxy server has 2 worker on a 2cpu machine
i got a very strange result ,cause i set the connect pool (min 10 ,maxsize 20), and run the ... | open | 2017-03-07T06:24:47Z | 2022-01-13T01:00:45Z | https://github.com/aio-libs/aiomysql/issues/154 | [
"question"
] | ihjmh | 12 |
manrajgrover/halo | jupyter | 25 | emojis not show | 
| open | 2017-10-11T02:07:09Z | 2020-03-07T23:06:31Z | https://github.com/manrajgrover/halo/issues/25 | [
"bug"
] | likezjuisee | 12 |
robotframework/robotframework | automation | 5,002 | "Parsing type failed"/"Type name missing" error message appears on the wrong argument | ```py
# a.py
from __future__ import annotations
from typing import Callable
def foo(a: Callable[[], None], b: asdf) -> None: ...
```
```
[ ERROR ] Error in library 'a': Adding keyword 'foo' failed: Parsing type 'Callable[[], None]' failed: Error at index 9: Type name missing.
```
removing the invalid `as... | closed | 2024-01-05T05:57:17Z | 2024-01-06T23:42:25Z | https://github.com/robotframework/robotframework/issues/5002 | [
"task",
"priority: low"
] | DetachHead | 1 |
tortoise/tortoise-orm | asyncio | 1,520 | Join the same table twice | **Is your feature request related to a problem? Please describe.**
When joining two tables, the generated query contains two names of the same table and this happens only if the second join table is the same as the base table (self.model._meta.basetable) in queryset.AwaitableQuery . According to this masterpiece [pypi... | open | 2023-11-29T00:14:05Z | 2023-11-29T00:14:05Z | https://github.com/tortoise/tortoise-orm/issues/1520 | [] | edimedia | 0 |
littlecodersh/ItChat | api | 386 | 启动时报错:SSL证书错误 | itchat v1.3.7 启动时报错提示SSL证书错误,在阿里云、腾讯云、bandwagon三个服务器上试过都是这样。
这三个服务器都曾经renew过一次SSL证书,不知道是不是跟这个有关,所以为什么我的服务器去登陆微信还需要我服务器的SSL?而且renew一次证书为什么就不能用了?😑
log如下:
```
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/itchat/utils.py", line 125, in test_connect
r = requests.get(conf... | closed | 2017-06-02T01:48:05Z | 2021-02-01T14:56:23Z | https://github.com/littlecodersh/ItChat/issues/386 | [
"question"
] | rikumi | 6 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.