
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
kevlened/pytest-parallel | pytest | 82 | How to specify running order (both running in parallel and running in turn) when using multi-threaded/multi-process | How to specify running order (both running in parallel and running in turn) when using multi-threaded/multi-process.
I want three test files to run in parallel, with each test file running the test function in turn. How do I design this?
| open | 2020-08-26T09:07:14Z | 2020-08-26T09:07:14Z | https://github.com/kevlened/pytest-parallel/issues/82 | [] | 99Kies | 0 |
fastapi/sqlmodel | fastapi | 342 | Is it possible to instantiate a SQLModel object with relationships from a `dict` type? | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X... | open | 2022-05-17T04:29:36Z | 2022-09-07T16:18:27Z | https://github.com/fastapi/sqlmodel/issues/342 | [
"question"
] | JLHasson | 5 |
axnsan12/drf-yasg | django | 706 | How to disable swagger documentation in production server? | open | 2021-03-10T15:18:28Z | 2025-03-07T12:12:59Z | https://github.com/axnsan12/drf-yasg/issues/706 | [
"triage"
] | ruiqurm | 1 | |
pywinauto/pywinauto | automation | 525 | Listview - Getting error when trying to enter text in listview control | This is similar to issue #410.
The Listview properties is as below -

I need to be able to enter text in the editbox as below-
 does not satisfy Python>=3.9
and torchdata=... | closed | 2024-09-26T07:24:58Z | 2024-09-26T08:05:41Z | https://github.com/huggingface/datasets/issues/7171 | [
"bug"
] | albertvillanova | 0 |
RayVentura/ShortGPT | automation | 132 | 🐛 [Bug]: UnicodeDecodeError: 'charmap' codec can't decode byte 0x9d in position 845: character maps to <undefined> | ### What happened?
UnicodeDecodeError: 'charmap' codec can't decode byte 0x9d in position 845: character maps to <undefined>
### What type of browser are you seeing the problem on?
Chrome
### What type of Operating System are you seeing the problem on?
Windows
### Python Version
python 3.11
### Application Vers... | open | 2024-02-28T12:55:48Z | 2024-09-24T19:41:01Z | https://github.com/RayVentura/ShortGPT/issues/132 | [
"bug"
] | linhcentrio | 1 |
plotly/dash-core-components | dash | 752 | Inline CSS vs. build to separate CSS file | CSP ([Content Security Policy](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Security-Policy)) is a good tool for enhancing security of web applications. [Mozilla Observatory](https://observatory.mozilla.org/analyze/observatory.mozilla.org) is a good place to check for CSP implementation across web ... | open | 2020-02-07T14:57:15Z | 2020-02-10T17:24:33Z | https://github.com/plotly/dash-core-components/issues/752 | [] | anders-kiaer | 4 |
PokeAPI/pokeapi | graphql | 362 | Merging and linting strategies | Our two main repositories are now pokeapi and [ditto](https://github.com/PokeAPI/ditto/).
To reduce confusion for maintainers, it would probably be a good idea to standardise management of these repos, so I was looking at what is currently set up differently between the two. One item is the allowed merge strategies:... | closed | 2018-09-09T08:15:48Z | 2020-08-19T10:16:35Z | https://github.com/PokeAPI/pokeapi/issues/362 | [
"question"
] | tdmalone | 12 |
recommenders-team/recommenders | machine-learning | 1,964 | own train-test data split |
i am following this notebook https://github.com/microsoft/recommenders/blob/main/examples/02_model_collaborative_filtering/ncf_deep_dive.ipynb
but i dont have any timestamp related column in my dataset . i have created train-test split externally and want to feed it to NCFDataset class but i m getting "Empty file er... | closed | 2023-08-09T10:45:15Z | 2023-08-14T07:53:49Z | https://github.com/recommenders-team/recommenders/issues/1964 | [
"help wanted"
] | riyaj8888 | 1 |
netbox-community/netbox | django | 18,329 | [GraphQL] Only one primary IP is shown when querying | ### Deployment Type
Self-hosted
### Triage priority
N/A
### NetBox Version
v4.2.0
### Python Version
3.12
### Steps to Reproduce
1. Create multiple Devices and assign different IPs to this devices.
2. Mark these IPs as primary for the device.
3. Run this GraphQL query:
```
{
device_list {
primary_i... | closed | 2025-01-07T15:30:23Z | 2025-02-06T07:01:59Z | https://github.com/netbox-community/netbox/issues/18329 | [
"type: bug",
"status: accepted",
"severity: medium"
] | freym | 3 |
marcomusy/vedo | numpy | 397 | Resolve overlapping faces in the mesh | Dear @marcomusy,
Is it possible to remove or resolve the overlapping faces in the mesh using vedo library...?
if any possible way. I will be grateful to use it.
Thanks in advance
Regards,
E.davis | closed | 2021-05-16T12:37:43Z | 2021-05-20T04:42:00Z | https://github.com/marcomusy/vedo/issues/397 | [] | nikhilpatiltest | 4 |
developmentseed/lonboard | jupyter | 635 | DataFilterExtension for boolean arrays | Todo:
- [ ] Make deck.gl test app for Felix with Arrow point data and boolean array buffer | open | 2024-09-16T10:16:52Z | 2024-09-16T10:16:52Z | https://github.com/developmentseed/lonboard/issues/635 | [] | kylebarron | 0 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 3,787 | notification when a "whistleblower has selected you as a valuable recipient" has an unworkable access link | ### What version of GlobaLeaks are you using?
4.13.18
### What browser(s) are you seeing the problem on?
All
### What operating system(s) are you seeing the problem on?
Windows, Linux
### Describe the issue
In "Notifications > Templates > tip_mail_template" there is a link with a url for easy access to the relev... | open | 2023-11-16T14:44:50Z | 2023-11-17T08:07:22Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/3787 | [] | rodolfomatos | 1 |
hankcs/HanLP | nlp | 680 | 1.3.2版本 “停牌自查”在处于句末时进行分词,该词会消失 | 1.3.2版本中出现:
例句:武汉凡谷9日停牌自查
词语“停牌自查”在 segment.seg(sentence)操作后消失,仅出现‘武汉凡谷‘ 、’9日’;
除此之外还有些其它动词在句末时会显现此种情况。
望解决。
| closed | 2017-11-17T09:29:53Z | 2017-11-17T15:54:29Z | https://github.com/hankcs/HanLP/issues/680 | [
"invalid"
] | ZhoChoran | 1 |
ydataai/ydata-profiling | jupyter | 1,455 | AttritubeError mplDeprecation with matplotlib 3.8.0 | ### Current Behaviour
The following error occurs, when running a project with matplotlib 3.8.0
```
warnings.filterwarnings("ignore", category=matplotlib.cbook.mplDeprecation)
AttributeError: module 'matplotlib.cbook' has no attribute 'mplDeprecation'
```
Reported here as well: https://stackoverflow.com/ques... | closed | 2023-09-22T17:29:10Z | 2023-11-15T23:22:38Z | https://github.com/ydataai/ydata-profiling/issues/1455 | [
"bug 🐛"
] | erreurBarbare | 3 |
joke2k/django-environ | django | 224 | Any plan to support .toml format env file? | ### Any plan to support .toml format env file? Thanks! | closed | 2019-04-26T15:42:58Z | 2024-10-27T01:29:07Z | https://github.com/joke2k/django-environ/issues/224 | [
"enhancement"
] | wahello | 4 |
biolab/orange3 | pandas | 6,753 | Import Images Widget Info Typo | <!--
Thanks for taking the time to report a bug!
If you're raising an issue about an add-on (i.e., installed via Options > Add-ons), raise an issue in the relevant add-on's issue tracker instead. See: https://github.com/biolab?q=orange3
To fix the bug, we need to be able to reproduce it. Please answer the following... | closed | 2024-03-04T11:53:34Z | 2024-03-15T11:36:16Z | https://github.com/biolab/orange3/issues/6753 | [
"bug",
"snack"
] | foongminwong | 1 |
sanic-org/sanic | asyncio | 2,182 | Request streaming results in a phantom 503 | When streaming a request body, you end up with a phantom 503 response. To the client, everything looks fine. The data is transmitted, and a response received OK.
```
[2021-07-05 22:45:47 +0300] - (sanic.access)[INFO][127.0.0.1:34264]: POST http://localhost:9999/upload 201 4
[2021-07-05 22:45:47 +0300] - (sanic.ac... | closed | 2021-07-05T21:50:49Z | 2021-07-28T08:57:59Z | https://github.com/sanic-org/sanic/issues/2182 | [
"bug"
] | ahopkins | 1 |
great-expectations/great_expectations | data-science | 10,816 | gx.ValidationDefinition.run() adds the Validation Definition to Data Context | **Describe the bug**
When running `run()` method of a `gx.ValidationDefinition` instance the validation definition is being added to the File Data Context.
It is not the expected behavior according to `help(gx.ValidationDefinition.run)`. We have the `add()` method for to add validation definitions to the context.... | closed | 2025-01-02T15:20:56Z | 2025-01-21T21:47:03Z | https://github.com/great-expectations/great_expectations/issues/10816 | [
"request-for-help"
] | vasilijyaromenka | 4 |
jupyter/nbgrader | jupyter | 1,337 | FORMGRADER error | ### Operating system
UBUNTU Linux
### `nbgrader --version`
0.6.1
### `jupyter notebook --version`
jupyter (1.0.0)
jupyter-client (6.1.3)
jupyter-console (6.1.0)
jupyter-core (4.6.3)
### Expected behavior
Use Formgrader menu item in Jupyter
### Actual behavior
Browser screen:
nbgrader
Error
... | open | 2020-05-15T13:38:43Z | 2020-05-15T15:27:42Z | https://github.com/jupyter/nbgrader/issues/1337 | [] | mboldin-temple | 2 |
microsoft/MMdnn | tensorflow | 574 | Caffe to Keras: Layer weight shape (64,) not compatible with provided weight shape (1, 1, 1, 64) | Platform (like ubuntu 16.04/win10): ubuntu 16.04
Python version: Python 3.6.8
Source framework with version (like Tensorflow 1.4.1 with GPU): Caffe
Destination framework with version (like CNTK 2.3 with GPU): Keras
Pre-trained model path (webpath or webdisk path): ResNet-152 downloaded from mmdownload -f ca... | closed | 2019-01-28T06:17:04Z | 2019-03-12T06:52:29Z | https://github.com/microsoft/MMdnn/issues/574 | [] | MinhHuuNguyen | 3 |
robotframework/robotframework | automation | 5,189 | Make result file paths hyperlinks on terminal | Terminal emulators nowadays support hyperlinks pretty well.The [standard emerged in 2017](https://gist.github.com/egmontkob/eb114294efbcd5adb1944c9f3cb5feda) and the current list of [supporting terminal emulators](https://github.com/Alhadis/OSC8-Adoption/?tab=readme-ov-file) is pretty exhaustive. Based on a quick proto... | closed | 2024-08-29T10:36:16Z | 2024-09-04T10:04:15Z | https://github.com/robotframework/robotframework/issues/5189 | [
"enhancement",
"priority: high",
"rc 1",
"effort: medium"
] | pekkaklarck | 8 |
vaexio/vaex | data-science | 1,926 | [BUG-REPORT] CAN'T READ PARQUET FROM AMAZON S3 ON AN EC2 INSTANCE | **Description**
I can't load data from s3, by doing this
`import vaex`
`vaex.open("s3://myfile.parquet")`
I get the following error
```
error opening 's3://data-lake.e [__init__.py](file:///home/ubuntu/.pyenv/versions/3.7.5/lib/python3.7/site-packages/vaex/__init__.py):[259](file:///home/ubuntu/.pyenv/versions/... | open | 2022-02-15T16:56:26Z | 2022-07-22T13:22:48Z | https://github.com/vaexio/vaex/issues/1926 | [
"bug"
] | ivanachillee | 22 |
rio-labs/rio | data-visualization | 35 | FrostedGlassFill | closed | 2024-05-30T09:42:16Z | 2024-05-30T09:42:19Z | https://github.com/rio-labs/rio/issues/35 | [] | Sn3llius | 0 | |
explosion/spaCy | machine-learning | 13,056 | Displacy render: Spans are overlapped when rendered. | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
Hello,
I'm trying to display spans with displacy render where I built the span manually.
Several spans can be overlapped.
Sometimes when there are more than 3 spans overlapping, the rendering fails to render properly.... | closed | 2023-10-10T14:23:23Z | 2023-12-03T00:02:19Z | https://github.com/explosion/spaCy/issues/13056 | [
"bug",
"feat / visualizers"
] | mchlsam | 2 |
Miserlou/Zappa | django | 1,327 | Zappa generates zip file inside zip with absolute path on S3 | Zappa with slim_handler enabled, places a zip file inside another zip file with path from root that makes Lambda not finding the modules when loading from S3.
## Context
I am running a Python 3.6 in a virtual environment on AWS Linux AMI. I have my project placed in a directory say /home/ec2-user/rep/project and my v... | closed | 2018-01-02T22:50:38Z | 2018-03-05T20:18:47Z | https://github.com/Miserlou/Zappa/issues/1327 | [
"bug",
"has-pr",
"slim-handler"
] | hkgitter | 3 |
PaddlePaddle/PaddleHub | nlp | 2,131 | PaddleHub模型下载后在PaddleDetection中部署的问题 | 我想在PaddleDetection中使用C++运行 PaddleHub模型的模型。我下载了https://www.paddlepaddle.org.cn/hubdetail?name=pyramidbox_lite_mobile_mask&en_category=FaceDetection 中的模型,保存到本地后只有 __model__和__params__两个文件。但是PaddleDetection还需要infer_cfg.yml才可以运行,请问有什么方法能够得到模型对应的这个文件吗?
PaddleHub版本2.5
PaddleDetection版本2.5
| closed | 2022-11-21T08:30:57Z | 2022-11-23T03:11:42Z | https://github.com/PaddlePaddle/PaddleHub/issues/2131 | [] | bittergourd1224 | 6 |
voila-dashboards/voila | jupyter | 1,435 | Panel Tabulator on_click() and on_edit() callbacks not working in Voila | First of all thanks for this great project. I'm using voila quite heavily and I like how seamless a notebook can be shown as some kind of application. I hope the project persists for still a long time. Also thanks advance for helping with the issue.
## Description
<!--Describe the bug clearly and concisely. Inclu... | open | 2024-01-06T18:21:58Z | 2024-08-17T10:55:09Z | https://github.com/voila-dashboards/voila/issues/1435 | [
"bug"
] | Kalandoros | 4 |
pydantic/pydantic | pydantic | 11,538 | Convert any type to any type utility (like V1's `parse_obj_as`) | ### Initial Checks
- [x] I have searched Google & GitHub for similar requests and couldn't find anything
- [x] I have read and followed [the docs](https://docs.pydantic.dev) and still think this feature is missing
### Description
`parse_obj_as`, not only got deprecated for the TypeAdapter API in V2, but also removed... | closed | 2025-03-07T21:05:35Z | 2025-03-11T12:26:22Z | https://github.com/pydantic/pydantic/issues/11538 | [
"feature request"
] | avivgood | 1 |
recommenders-team/recommenders | data-science | 1,713 | [FEATURE] Implement dot product Matrix Factorization | ### Description
<!--- Describe your expected feature in detail -->
MF with CPU:
https://arxiv.org/abs/2005.09683
https://github.com/google-research/google-research/tree/master/dot_vs_learned_similarity
MF with PyTorch:
https://www.ethanrosenthal.com/2017/06/20/matrix-factorization-in-pytorch/
MF with PySpark... | open | 2022-05-06T10:58:44Z | 2022-05-06T10:59:15Z | https://github.com/recommenders-team/recommenders/issues/1713 | [
"enhancement"
] | miguelgfierro | 1 |
browser-use/browser-use | python | 65 | Interacting with elements within an iframe | If there is interactive content within an iframe, is it not possible to interact with it programmatically? | closed | 2024-11-27T10:47:52Z | 2025-01-16T15:57:34Z | https://github.com/browser-use/browser-use/issues/65 | [] | tusharmctrl | 4 |
cobrateam/splinter | automation | 520 | how to access element in iframe that has no tag | i'd like to try the way ----with browser.get_iframe("**") as iframe:
but the iframe doesn't has a tag of id or name even index,how could i access the element in this kind of frame
i want to click the date 20160925,the source code is something like this:
` will be triggered instead of `find_numerical_variables()` . Fo... | closed | 2024-09-09T20:06:27Z | 2024-10-04T12:41:20Z | https://github.com/feature-engine/feature_engine/issues/812 | [
"question"
] | AmMoPy | 3 |
qwj/python-proxy | asyncio | 146 | [Question] - How to tunnel through multiple jump server? | There is a total 4 servers:
**A** machine is my localhost, IP 127.0.0.1
**B** server is a http proxy, IP 10.10.10.10 port 1010
**C** server is a socks5 proxy, IP 10.20.20.20 port 2020
**D** server it the final destination, IP 10.100.100.100 port 22
I want to listen on machine A 127.0.0.1 port 5555 and
all con... | open | 2022-01-21T23:12:30Z | 2023-04-11T09:06:13Z | https://github.com/qwj/python-proxy/issues/146 | [] | indopay | 1 |
RobertCraigie/prisma-client-py | asyncio | 735 | Compatibility with Render.com | <!--
Thanks for helping us improve Prisma Client Python! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by enabling additional logging output.
See https://prisma-client-py.readthedocs.io/en/stable/reference/logging/ for how to enable additional log... | open | 2023-03-25T22:36:41Z | 2023-06-23T14:36:24Z | https://github.com/RobertCraigie/prisma-client-py/issues/735 | [
"bug/2-confirmed",
"kind/bug",
"priority/low",
"level/unknown",
"topic: binaries",
"topic: crash"
] | RobertCraigie | 1 |
seleniumbase/SeleniumBase | web-scraping | 3,147 | Any option to silence logs about starting uc_driver? | I recieve logs like this on every uc command.
`Started executable: `C:\Users\ruperson\AppData\Roaming\Python\Python311\site-packages\seleniumbase\drivers\uc_driver.exe` in a child process with pid: 20900 using 134217728 to output -1`
Is there an elegant approach to get rid of this kind of notifications? | closed | 2024-09-19T22:04:00Z | 2024-09-20T16:15:03Z | https://github.com/seleniumbase/SeleniumBase/issues/3147 | [
"external",
"not enough info"
] | ruperson | 1 |
robotframework/robotframework | automation | 4,557 | Bug in `--reportbackgroundcolor` documentation in the User Guide | _Observation_: User guide and robot mismatching in #setting-background-colors section
_User Guide_: If you specify three colors, the first one will be used when all the tests pass, the second when all tests have been skipped, and the last when there are any failures. (pass:skip:fail)
_Robot Command Line Help_: '-... | closed | 2022-12-07T09:21:25Z | 2022-12-20T21:40:17Z | https://github.com/robotframework/robotframework/issues/4557 | [
"bug",
"priority: low"
] | adiralashiva8 | 1 |
viewflow/viewflow | django | 329 | When 2.0.0a0 will be released? | I noticed pre-release version 2.0.0a0 has some great features.
Can you let me know when it will be released? | closed | 2021-09-09T08:58:21Z | 2023-02-09T10:13:56Z | https://github.com/viewflow/viewflow/issues/329 | [
"request/question"
] | Achilles0509 | 1 |
PaddlePaddle/models | computer-vision | 4,967 | PaddleNLP情感分析infer结果每次都不一致 | paddle版本:1.8.3
python版本:3.7.1
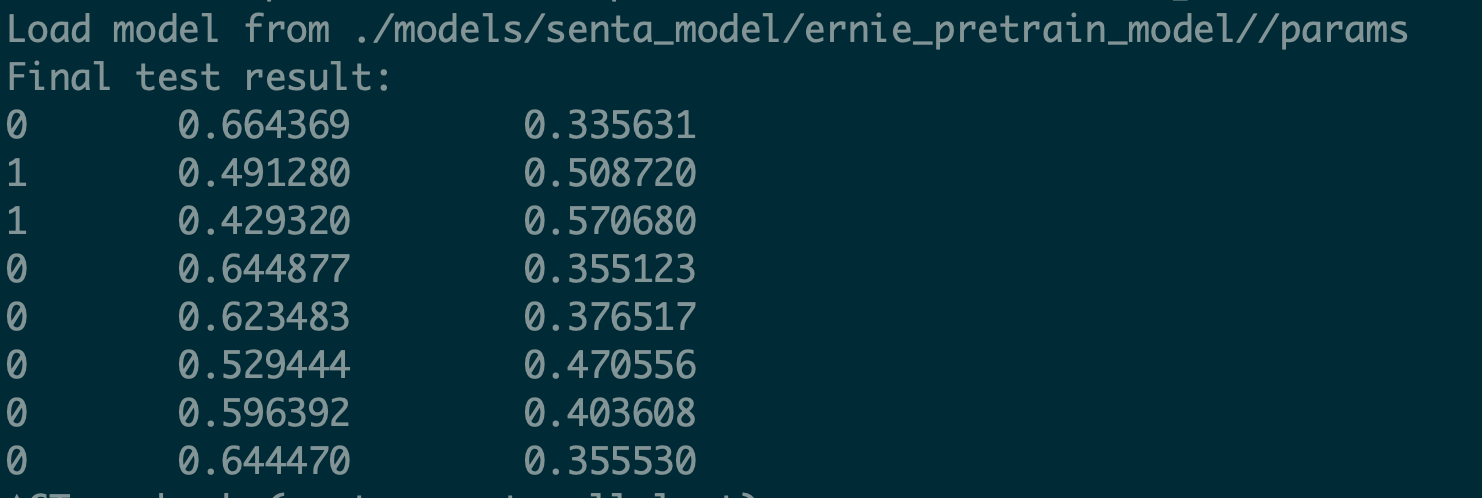
按照[Readme](https://github.com/PaddlePaddle/models/tree/release/1.8/PaddleNLP/sentiment_classification) 下载ernie预训练模型与数据进行infer,可以成功运行,同一份测试数据但每次infer的结果不一致,请问是什么问题?
 | We should switch to CD using GitHub Actions, where we:
- Automatically build nightly releases and push to Conda and PyPI
- Automatically build and release on Conda and PyPI when a new tag is pushed to this git repo
This will be especially useful once we have a more complicated build process (#297). | open | 2022-06-28T18:56:20Z | 2022-12-17T06:06:23Z | https://github.com/cleanlab/cleanlab/issues/299 | [
"needs triage"
] | anishathalye | 3 |
jupyterhub/jupyterhub-deploy-docker | jupyter | 29 | r | closed | 2016-11-30T14:08:35Z | 2016-12-07T14:32:44Z | https://github.com/jupyterhub/jupyterhub-deploy-docker/issues/29 | [] | bertrandrigaud | 0 | |
PeterL1n/RobustVideoMatting | computer-vision | 158 | 发现推理代码似乎有点问题 | 为什么inference.py中auto_downsample_ratio函数里面算缩放比例是min(512 / max(h, w), 1),而训练的时候数据处理缩放_downsample_if_needed函数里面算缩放比例是scale = self.size / min(w, h)?一个是max(h, w),一个是min(w, h),这里有问题吧? | closed | 2022-04-09T00:59:45Z | 2022-04-09T14:01:46Z | https://github.com/PeterL1n/RobustVideoMatting/issues/158 | [] | surifans | 2 |
sqlalchemy/alembic | sqlalchemy | 359 | Don't understand utf-8 encoding in windows cmd | **Migrated issue, originally created by sowingsadness ([@SowingSadness](https://github.com/SowingSadness))**
When I see sql errors I changed windows cmd encoding by chcp util.
But in some cases (ex.: history, current) alembic do not understand this encoding.
```
(pyramid_2) D:\Kir\Documents\Work\carwash>chcp 65001
Ac... | closed | 2016-02-24T03:23:46Z | 2017-11-12T05:59:58Z | https://github.com/sqlalchemy/alembic/issues/359 | [
"bug",
"low priority",
"command interface"
] | sqlalchemy-bot | 9 |
sktime/sktime | data-science | 7,958 | [BUG] `MACNNClassifier` and `MCDCNNCLassifier` fails multioutput and unit test data tests | `MACNNClassfier` and `MCDCNNCLassifier` fail the multioutput and unit test data tests, `test_multioutput` and `test_classifier_on_unit_test_data`.
This should be investigated. | open | 2025-03-10T08:28:53Z | 2025-03-11T10:08:16Z | https://github.com/sktime/sktime/issues/7958 | [
"bug",
"module:classification"
] | fkiraly | 0 |
SCIR-HI/Huatuo-Llama-Med-Chinese | nlp | 101 | 执行infer.sh出现非预期内容 | 执行infer.sh
```
python infer.py \
--base_model '/home/server/LLM/models/huozi-7b-rlhf' \
--lora_weights '/home/server/LLM/models/bentsao_lora_huozi' \
--use_lora True \
--instruct_dir './data/infer.json' \
--prompt_template 'bloom_deploy'
```
然后结果是如下的,怎么会有`将以下英文句子翻译成中文。
The quick brown fox ... | open | 2023-11-16T06:56:06Z | 2024-10-08T08:10:06Z | https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese/issues/101 | [] | lehug | 3 |
pydantic/FastUI | pydantic | 374 | can't get running in Lambda | I've followed a few YouTube videos on this and while FastAPI works, I can not get FastUI working despite investing significant hours of trial and error but no luck. I want to build and a web app and preferably host in Lambda but can not get a simple demo app working from a Lambda despite my best effort. Is this a futil... | open | 2025-01-02T20:22:06Z | 2025-01-08T03:26:22Z | https://github.com/pydantic/FastUI/issues/374 | [] | TechDH | 1 |
litestar-org/litestar | api | 3,206 | Enhancement: ParsedSignature to enable TypeVar expansion using signature namespace | ### Summary
ParsedSignature uses `typing.get_type_hints` which handles forward referencing but no TypeVar expansion. For instance,
```Python
from typing import TypeVar, Generic, get_type_hints
T = TypeVar("T")
class Foo(Generic[T]):
def bar(self, data: T) -> T:
pass
genericAliasFoo = Foo[str]
p... | closed | 2024-03-15T02:15:05Z | 2025-03-20T15:54:29Z | https://github.com/litestar-org/litestar/issues/3206 | [
"Enhancement"
] | harryle95 | 8 |
cvat-ai/cvat | computer-vision | 8,451 | OPAHealthCheck Internal Server Error for url: http://opa:8181/health?bundles | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
**CVAT Version:**
CVAT:DEV
Been running this for awhile now. Only decided to rebuild the container and since then this ap... | closed | 2024-09-17T21:30:44Z | 2024-09-25T21:11:23Z | https://github.com/cvat-ai/cvat/issues/8451 | [
"need info"
] | Shadowfear36 | 3 |
FlareSolverr/FlareSolverr | api | 1,431 | [yggtorrent] System.Threading.Tasks.TaskCanceledException: The request was canceled due to the configured HttpClient.Timeout of 60 seconds elapsing. | ### Have you checked our README?
- [X] I have checked the README
### Have you followed our Troubleshooting?
- [X] I have followed your Troubleshooting
### Is there already an issue for your problem?
- [X] I have checked older issues, open and closed
### Have you checked the discussions?
- [X] I have read the Dis... | closed | 2025-01-07T10:42:29Z | 2025-01-07T20:36:54Z | https://github.com/FlareSolverr/FlareSolverr/issues/1431 | [
"duplicate"
] | Rurtzane | 1 |
pyppeteer/pyppeteer | automation | 143 | RuntimeError('Event loop is closed'),sys:1: RuntimeWarning: coroutine 'Launcher.killChrome' was never awaited | here is my code:
async def fuzz_payload(browser, url, method, data, headers, celery_task_id, payload):
try:
page = await browser.newPage()
await page.setRequestInterception(True)
page.on(
'dialog',
lambda dialog: asyncio.ensure_future(
hook_dia... | closed | 2020-06-30T03:19:37Z | 2024-02-12T04:40:33Z | https://github.com/pyppeteer/pyppeteer/issues/143 | [] | LeoonZHANG | 9 |
mwaskom/seaborn | pandas | 3,346 | sns.pairplot() fails with ValueError: output array is read-only | Dataset:
[train.csv](https://github.com/mwaskom/seaborn/files/11337012/train.csv)
Code:
```python
import numpy as np
import pandas as pd
import plotly.express as px
import matplotlib.pyplot as plt
import seaborn as sns
train_df = pd.read_csv("train.csv")
train_df["CryoSleep"] = train_df["CryoSleep"]... | closed | 2023-04-26T20:40:22Z | 2023-04-26T22:30:28Z | https://github.com/mwaskom/seaborn/issues/3346 | [] | FlorinAndrei | 3 |
NullArray/AutoSploit | automation | 1,209 | Unhandled Exception (63c520708) | Autosploit version: `2.2.3`
OS information: `Linux-4.4.193-darkonahZ-armv8l-with-libc`
Running context: `/data/data/com.thecrackertechnology.andrax/ANDRAX/AutoSploit/autosploit.py`
Error meesage: ``
Error traceback:
```
Traceback (most recent call):
File "/data/data/com.thecrackertechnology.andrax/ANDRAX/AutoSploit/au... | closed | 2019-11-26T13:08:21Z | 2019-11-30T04:33:28Z | https://github.com/NullArray/AutoSploit/issues/1209 | [] | AutosploitReporter | 0 |
tflearn/tflearn | tensorflow | 1,026 | lstm with return_seq = True as input to a fully_connected, unintended behaviour? | [g = tflearn.lstm(g, 1024, return_seq=True)
g = tflearn.dropout(g, 0.85)
g = tflearn.fully_connected(g, len(char_idx), activation='softmax')](url)
This shouldn't work, should it? On GPU tensorflow, it doesn't complain, (and training converged). On the CPU version, it says:
> g = tflearn.fully_connected(g, l... | open | 2018-03-01T01:26:15Z | 2019-05-07T12:06:08Z | https://github.com/tflearn/tflearn/issues/1026 | [] | lk251 | 1 |
TencentARC/GFPGAN | deep-learning | 477 | How fast can you get GFPgan? Does it use GPU? | Hello, I have been founding GFPgan to be a bit slow, it might possibly explained by the fact I am not using GPU much?
Could someone share a screenshot of their GPU usage when running GFPgan? Can you tell me how fast you can process 10 sec or 1 minute video? (tell me the resolution of the video)
thanks | open | 2023-12-29T06:32:25Z | 2024-02-29T02:51:57Z | https://github.com/TencentARC/GFPGAN/issues/477 | [] | AIhasArrived | 2 |
mitmproxy/mitmproxy | python | 7,227 | mitmproxy 11 installed via pip fails due to new urwid requirement - undefined symbol: PyUnicode_AS_UNICODE | #### Problem Description
In taking a system (Ubuntu 24.04 with miniconda (Python 3.12)) that successfully had mitmproxy 10 installed, upgrading to mitmproxy 11 via pip causes installation of a new `urwid` package, which now errors out with: `undefined symbol: PyUnicode_AS_UNICODE`
#### Steps to reproduce the behavi... | open | 2024-10-03T15:09:56Z | 2024-12-09T10:42:32Z | https://github.com/mitmproxy/mitmproxy/issues/7227 | [
"kind/triage"
] | wdormann | 8 |
pytorch/pytorch | deep-learning | 149,065 | [ONNX Export] dynamic_shapes ignored during model export. | ### 🐛 Describe the bug
```python
from torch.export import Dim
from pathlib import Path
import onnx
import onnxruntime
import torch
model = model
model.load_state_dict(checkpoint.get("state_dict"), strict=True)
model.eval()
with torch.no_grad():
data = torch.randn(1, 3, 256, 256)
torch_outputs = model(data)... | closed | 2025-03-12T18:58:41Z | 2025-03-13T20:45:40Z | https://github.com/pytorch/pytorch/issues/149065 | [
"module: onnx",
"triaged"
] | spkgyk | 9 |
Johnserf-Seed/TikTokDownload | api | 604 | 怎么执行单视频下载? | open | 2023-11-20T23:46:22Z | 2023-11-20T23:46:22Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/604 | [
"无效(invalid)"
] | Virtual-human | 0 | |
holoviz/panel | plotly | 6,911 | Document how to use .from_param to create a widget from a reactive parameter | I can't figure out how to create a widget from a reactive parameter.
More specifically
```python
import panel as pn
pn.extension()
zoom = pn.rx(2)
slider = pn.widgets.IntSlider.from_param(zoom, start=1, end=10)
```
I get
```bash
AttributeError: 'rx' object has no attribute 'name'
Traceback (m... | open | 2024-06-10T19:32:03Z | 2024-07-16T14:37:47Z | https://github.com/holoviz/panel/issues/6911 | [
"type: docs",
"need input from Philipp"
] | MarcSkovMadsen | 5 |
skforecast/skforecast | scikit-learn | 314 | How to fill future known information from one of the exogenous variables? | Hi developers,
I have a question about fill future known information from one of the exogenous variables.
For example, I have a data where is y as target variable and three exogenous variables X1,X2, and X3. If I have future known information of X3, but no future information of X1,X2. Either using directed or recur... | closed | 2022-12-12T09:22:01Z | 2022-12-28T09:57:27Z | https://github.com/skforecast/skforecast/issues/314 | [
"question"
] | kennis222 | 3 |
iperov/DeepFaceLab | machine-learning | 5,515 | device_lib.list_local_devices() doesn't return in the CUDA build up to 2080 | Any batch script hangs, I traced it and it freezes in tensorflow when it calls **device_lib.list_local_devices()**
In: C:\DFL\DeepFaceLab_NVIDIA_up_to_RTX2080Ti\_internal\DeepFaceLab\core\leras\device.py
GPU: Geforce 750 Ti
Win 10
```
import tensorflow as tf
from tensorflow.python.client import device_lib
prin... | open | 2022-05-09T19:24:31Z | 2023-06-09T13:52:12Z | https://github.com/iperov/DeepFaceLab/issues/5515 | [] | Twenkid | 4 |
iperov/DeepFaceLab | machine-learning | 5,353 | The Specified module could not be found | It is showing that the "Import error : DLL load failed the specified module could not be found" how to resolve it ? | closed | 2021-06-20T10:58:43Z | 2021-06-26T08:10:50Z | https://github.com/iperov/DeepFaceLab/issues/5353 | [] | ghost | 0 |
ClimbsRocks/auto_ml | scikit-learn | 19 | consider having .train() and .customized_train() | .train() will just call .customized_train() with a series of defaults in place.
it'll have a much simpler interface, which would be nice.
| open | 2016-08-11T06:14:37Z | 2016-08-13T03:50:46Z | https://github.com/ClimbsRocks/auto_ml/issues/19 | [
"easy win"
] | ClimbsRocks | 1 |
floodsung/Deep-Learning-Papers-Reading-Roadmap | deep-learning | 104 | googleNet with VGG | can i use vgg with googleNet? | open | 2018-12-19T20:58:34Z | 2018-12-19T20:58:34Z | https://github.com/floodsung/Deep-Learning-Papers-Reading-Roadmap/issues/104 | [] | Emperor66 | 0 |
wyfo/apischema | graphql | 492 | Installation fails on Mac M1 | Installation fails on new Mac with M1 chips throwing the following error:
```
from apischema.serialization import serialize
File "/Users/my_user/.pyenv/versions/3.9.9/envs/cubist-games-manager/lib/python3.9/site-packages/apischema/serialization/__init__.py", line 34, in <module>
from apischema.serializati... | closed | 2022-10-18T08:43:59Z | 2023-11-15T18:44:03Z | https://github.com/wyfo/apischema/issues/492 | [
"question"
] | AnderUstarroz | 6 |
aws/aws-sdk-pandas | pandas | 2,844 | Athena query throws error with message "AttributeError: 'pyarrow._parquet.FileMetaData' object has no attribute 'total_byte_size'" | ### Describe the bug
Using the AWS Wrangler SDK to query a table using Athena results in error message "AttributeError: 'pyarrow._parquet.FileMetaData' object has no attribute 'total_byte_size'". This error happens when using modin.pandas and not with regular pandas library.
Environment: Juptyer notebook on Sagemak... | closed | 2024-06-04T16:22:05Z | 2024-07-26T08:08:39Z | https://github.com/aws/aws-sdk-pandas/issues/2844 | [
"bug"
] | leo4ever | 3 |
jina-ai/serve | fastapi | 5,534 | Maintainer Productivity Enhancement with Preview Environments for PRs | I would like to support Jina by implementing ephemeral preview environments, powered by [Uffizzi](https://github.com/UffizziCloud/uffizzi)
Uffizzi is an Open Source, full stack, previews engine, and our platform is available completely free for Jina (and all open source projects). An Uffizzi integration with Jina wi... | closed | 2022-12-16T14:57:16Z | 2023-04-01T00:18:40Z | https://github.com/jina-ai/serve/issues/5534 | [
"Stale"
] | daramayis | 1 |
litestar-org/litestar | asyncio | 3,854 | Enhancement: Allow the cache to specify the namespace on a route level | ### Summary
Today, every cached response is cached inside the namespace "response_cache" or any namespace you defined in a root level. However, I would like certain route to be cached on different namespace to manage the cache invalidation differently according to the response.
### Basic Example
```
@get(cache=True... | open | 2024-11-12T08:30:40Z | 2025-03-20T15:55:02Z | https://github.com/litestar-org/litestar/issues/3854 | [
"Enhancement"
] | dylandoamaral | 0 |
encode/apistar | api | 445 | apistar cant work and the commandline cant recognized from 0.4.1 above | and for 0.4.0, when enter apistar it will have the error like :
Traceback (most recent call last):
File "c:\users\williamchen\anaconda3\Lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "c:\users\williamchen\anaconda3\Lib\runpy.py", line 85, in _run_code
exec(code, run_global... | closed | 2018-04-16T08:20:31Z | 2018-04-17T10:05:06Z | https://github.com/encode/apistar/issues/445 | [] | youngorchen | 2 |
tfranzel/drf-spectacular | rest-api | 723 | Specifying a response leads to undesired parameters added automatically | The following code works as expected whereby I end up with only a "some_id" parameter showing up in SwaggerUI for the endpoint.
```py
@extend_schema(
description="Lists items",
parameters=[
OpenApiParameter(
"some_id",
required=True,
),... | closed | 2022-04-29T10:27:55Z | 2022-05-01T12:33:32Z | https://github.com/tfranzel/drf-spectacular/issues/723 | [] | bluelight773 | 4 |
graphql-python/graphene | graphql | 695 | Recipe for Snapshot'testing | I'm going to leave this here, and it can be closed. It's not really related to `graphene`, either, but because `snapshottest` is documented alongside `graphene` I figured this would be a handy place to share a recipe capturing type definitions.
```python
from graphql.utils.introspection_query import introspection_q... | closed | 2018-03-20T09:00:43Z | 2019-08-05T23:17:46Z | https://github.com/graphql-python/graphene/issues/695 | [
"wontfix",
"📖 documentation"
] | dfee | 2 |
pyeve/eve | flask | 1,278 | Eve is using Cerberus functionality that was deprecated in 2017 | ### Expected Behavior
Running the latest version of Eve with the latest version of Cerberus shouldn't raise deprecation warnings, at least not almost two year old deprecation warnings.
### Actual Behavior
Tell us what happens instead.
```
% python -Wd
<snipped non-Eve-related deprecat... | closed | 2019-05-29T12:17:47Z | 2022-03-17T18:07:50Z | https://github.com/pyeve/eve/issues/1278 | [] | sybrenstuvel | 11 |
tableau/server-client-python | rest-api | 774 | Having a permissions "Unknown" status | Hi,
Not sure if this is possible and if the documentation is out there for it, but I've noticed there are only two modes of Permissions right now based on the capability: `TSC.Permission.Mode.Allow` and `TSC.Permission.Mode.Deny`.
Within the GUI application, there is a way to have an unknown status for the capab... | open | 2021-01-14T22:32:57Z | 2021-02-23T01:17:02Z | https://github.com/tableau/server-client-python/issues/774 | [
"enhancement"
] | mbabatunde | 3 |
ansible/ansible | python | 84,148 | SSH mux does not distinguish different inventory files | ### Summary
I have to run an Ansible playbook on two sets of machines; each of them has an `inventory.ini` file that identifies them using their SSH config (the rest is the same).
When I actually ran it, I found that it ended up as the same playbook was run twice on the same set of machines (first inventory file u... | open | 2024-10-20T10:31:17Z | 2024-10-22T15:10:19Z | https://github.com/ansible/ansible/issues/84148 | [
"bug",
"affects_2.16"
] | yuxiaolejs | 3 |
mouredev/Hello-Python | fastapi | 451 | 网赌被黑不给提款?平台提款一直提示失败怎么办网赌平台出款通道维护风控审核不给提款怎么办? | 
诚信帮出黑咨询+微:xiaolu460570 飞机:@lc15688
切记,只要您赢钱了,遇到任何不给你提现的借口,基本表明您被黑了。
如果你出现以下这些情况,说明你已经被黑了:↓ ↓
【1】限制你账号的部分功能!出款和入款端口关闭,以及让你充值解开取款通道等等!
【2】客服找一些借口说什么系统维护,风控审核等等借口,就是不让取款!
【网赌被黑怎么办】【网赌赢了平台不给出款】【系统更新】【取款失败】【注单异常】【网络波动】【提交失败】
【单注... | closed | 2025-03-03T13:33:11Z | 2025-03-04T08:41:40Z | https://github.com/mouredev/Hello-Python/issues/451 | [] | 376838 | 0 |
vaexio/vaex | data-science | 1,650 | [BUG-REPORT] - ArrowInvalid: offset overflow while concatenating arrays | Thank you for reaching out and helping us improve Vaex!
Before you submit a new Issue, please read through the [documentation](https://docs.vaex.io/en/latest/). Also, make sure you search through the Open and Closed Issues - your problem may already be discussed or addressed.
**Description**
When doing operation... | closed | 2021-10-15T20:38:00Z | 2023-02-28T22:53:54Z | https://github.com/vaexio/vaex/issues/1650 | [
"bug"
] | Ben-Epstein | 11 |
huggingface/pytorch-image-models | pytorch | 1,984 | [FEATURE] Add SigLIP weights | Hello,
Google recently released weights of the [SigLIP paper](https://arxiv.org/abs/2303.15343) (see [here](https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/image_text/SigLIP_demo.ipynb)) with amazing zero shot performance (in particular a shape optimised ViT-L).
Do you have any pl... | closed | 2023-10-08T06:44:41Z | 2023-10-18T23:41:23Z | https://github.com/huggingface/pytorch-image-models/issues/1984 | [
"enhancement"
] | SimJeg | 2 |
vaexio/vaex | data-science | 1,367 | traitlets.traitlets.TraitError: The 'min' trait of an Axis instance expected a float, not the datetime64 numpy.datetime64 | **Description**
I'm trying to plot the following data:
x axis: dates
y axis: co2 data (floats)
Using the following code:
```
import numpy as np
import datetime
import vaex
df = vaex.from_csv('data.csv')
def convert_to_datetime(d):
dt = datetime.datetime.strptime(str(d),"%Y-%m-%d %H:%M:%S%z")
... | open | 2021-05-23T11:52:42Z | 2021-05-24T16:33:56Z | https://github.com/vaexio/vaex/issues/1367 | [] | chrisruk | 2 |
d2l-ai/d2l-en | deep-learning | 2,421 | Discussion Forum Not Showing up on Classic Branch | As the below image shows, none of the lessons on the classic website have functioning discussion forums (eg. http://classic.d2l.ai/chapter_recurrent-modern/beam-search.html). :

I've checked it on Firefo... | closed | 2022-12-28T16:41:41Z | 2023-01-06T11:27:15Z | https://github.com/d2l-ai/d2l-en/issues/2421 | [] | Vortexx2 | 2 |
zappa/Zappa | flask | 930 | [Migrated] Zappa support for permission boundaries? | Originally from: https://github.com/Miserlou/Zappa/issues/2196 by [christophersbarrett](https://github.com/christophersbarrett)
Does Zappa support adding a permission boundary onto the lambda execution role? | closed | 2021-02-20T13:24:40Z | 2024-04-13T19:36:48Z | https://github.com/zappa/Zappa/issues/930 | [
"no-activity",
"auto-closed"
] | jneves | 2 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 707 | I reduced the image size . but result is poor | Hello, I appreciate to your great research and implementations.
I would like to thank you for doing such a great job.
Anyway, I have a Question.
When I learned with 3x256x256 images , it was fine
but I learn with 1x50x50 image, it is poor
I want to learn with 1(channel) x 50 x 50 image from this model.
So I... | closed | 2019-07-17T08:17:48Z | 2019-07-19T03:52:11Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/707 | [] | Realdr4g0n | 2 |
pandas-dev/pandas | pandas | 60,802 | DOC: Specify what "non-null" means in DataFrame.info() | ### Pandas version checks
- [x] I have checked that the issue still exists on the latest versions of the docs on `main` [here](https://pandas.pydata.org/docs/dev/)
### Location of the documentation
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.info.html
### Documentation problem
Non-null is not sp... | open | 2025-01-27T22:18:02Z | 2025-03-14T10:19:32Z | https://github.com/pandas-dev/pandas/issues/60802 | [
"Docs",
"Missing-data"
] | jxu | 4 |
MilesCranmer/PySR | scikit-learn | 36 | Symbolic deep learning | Trying to recreate the examples from this [paper](https://arxiv.org/abs/2006.11287)
PySR is always predicting scalars as a low complexity solution, which doesn't make much sense, can you please elaborate on that?
And what is wrong why I'm unable to get the right expression?
```
Cycles per second: 3.050e+03
Progre... | open | 2021-03-04T19:49:15Z | 2024-11-21T09:00:09Z | https://github.com/MilesCranmer/PySR/issues/36 | [
"question"
] | abdalazizrashid | 14 |
nl8590687/ASRT_SpeechRecognition | tensorflow | 222 | 语音片段长度 | 测试的时候输入的语音片段长度时固定的吗?我使用test.py测试一个十几分钟的语音文件显示格式大小不匹配。
`Traceback (most recent call last):
File "test.py", line 34, in <module>
r = ms.RecognizeSpeech_FromFile('/home/user/XiJing/XiJing (1)/音频1.wav')
File "/home/user/ASRT_v0.6.1/SpeechModel251.py", line 382, in RecognizeSpeech_FromFile
r = self.Recogniz... | open | 2020-11-20T03:40:25Z | 2021-03-28T11:17:19Z | https://github.com/nl8590687/ASRT_SpeechRecognition/issues/222 | [] | tingxin1 | 3 |
drivendataorg/cookiecutter-data-science | data-science | 156 | integration with mlflows and snakemake | I think that logging via mlfows and make via snakemake can enhance this project | closed | 2018-12-16T18:54:00Z | 2019-04-15T11:30:52Z | https://github.com/drivendataorg/cookiecutter-data-science/issues/156 | [] | chanansh | 1 |
Miserlou/Zappa | flask | 1,652 | ResourceNotFoundException: An error occurred (ResourceNotFoundException) when calling the DescribeLogStreams | When attempting to tail logs on dev the tailing is succesfull, however tailing environment on another account fails with:
```
Traceback (most recent call last):
File "/opt/kidday/env/lib/python3.6/site-packages/zappa/cli.py", line 2693, in handle
sys.exit(cli.handle())
File "/opt/kidday/env/lib/python3.6... | open | 2018-10-12T13:14:23Z | 2018-10-12T13:14:23Z | https://github.com/Miserlou/Zappa/issues/1652 | [] | 4lph4-Ph4un | 0 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 538 | New pretrained synthesizer model (tensorflow) | Trained on LibriSpeech, using the current synthesizer (tensorflow). This performs similarly to the current model, with fewer random gaps appearing in the middle of synthesized utterances. It handles short input texts better too.
### Download link: https://www.dropbox.com/s/3kyjgew55c4yxtf/librispeech_270k_tf.zip?dl=... | closed | 2020-09-30T07:59:31Z | 2021-12-04T06:01:56Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/538 | [] | ghost | 3 |
kynan/nbstripout | jupyter | 89 | Possible to design a "smudge" git filter that reverses the stripping process? | I work on multiple servers for my research, and use git to sync my project repository between these servers servers. Sometimes this means I want to work on the same jupyter notebook on different servers. The problem with this is, if I make some changes on server A and want just the *code* changes on server B, after pus... | closed | 2018-11-01T07:14:37Z | 2021-04-25T17:45:53Z | https://github.com/kynan/nbstripout/issues/89 | [
"type:enhancement",
"resolution:obsolete"
] | lukelbd | 3 |
jschneier/django-storages | django | 640 | GoogleCloud Storage not respecting ACL setting when using default_storage class Django | When using default_storage class to write a file to google bucket, it is created as projectPrivate even if the acl setting is publicRead. | closed | 2018-12-20T10:27:17Z | 2019-09-10T07:35:15Z | https://github.com/jschneier/django-storages/issues/640 | [
"bug",
"google"
] | mj8894 | 3 |
zihangdai/xlnet | tensorflow | 142 | How long does it take to pretrain xlnet? | I have 8 TESLA K80 GPU with 11GB RAM each.
I am running `sudo python3 train_gpu.py --record_info_dir=fix3/tfrecords --train_batch_size=32 --seq_len=512 --reuse_len=256 --mem_len=384 --perm_size=256 --n_layer=6 --d_model=768 --d_embed=768 --n_head=6 --d_head=64 --d_inner=3072 --untie_r=True --model_dir=my_model --unc... | closed | 2019-07-09T06:54:58Z | 2019-07-10T07:36:25Z | https://github.com/zihangdai/xlnet/issues/142 | [] | Bagdu | 0 |
plotly/dash-bio | dash | 737 | Oncoprint error: Cannot read properties of undefined (reading 'displayName') | Hi Plotly / Dash,
I'm facing the error message `Cannot read properties of undefined (reading 'displayName')` for some alteration types in the oncoprint plot.
I'm quite convinced my code has worked before, but I can't tell you which version it worked/broke.
I've tried to create a minimal example below:
```pyth... | closed | 2023-04-30T09:43:22Z | 2023-06-18T14:10:01Z | https://github.com/plotly/dash-bio/issues/737 | [] | Donnyvdm | 1 |
predict-idlab/plotly-resampler | data-visualization | 169 | Add Mypy | Not sure if this is wanted or not but I was playing around with this and would either need to add a lot of `type: ignores` to the existing code or drop support for python 3.7 in the version where mypy is included as a few of the stubs needed to correctly type out some code do not support 3.7
Happy to hack on this if... | open | 2023-02-03T00:42:28Z | 2023-02-06T02:28:45Z | https://github.com/predict-idlab/plotly-resampler/issues/169 | [
"documentation",
"enhancement"
] | jayceslesar | 2 |
Lightning-AI/pytorch-lightning | data-science | 20,670 | Outdated Versioning Policy | ### 📚 Documentation
The [Compatibility Matrix](https://lightning.ai/docs/pytorch/stable/versioning.html#compatibility-matrix) on the Versioning Policy documentation page does not mention the 2.5 release series.
The v2.5 release notes [say](https://github.com/Lightning-AI/pytorch-lightning/releases/tag/2.5.0):
> Lig... | open | 2025-03-24T14:49:04Z | 2025-03-24T14:51:12Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20670 | [
"docs",
"needs triage"
] | iwr-redmond | 0 |
nonebot/nonebot2 | fastapi | 3,177 | Plugin: 南无阿弥陀佛 | ### PyPI 项目名
nonebot-plugin-amitabha
### 插件 import 包名
nonebot_plugin_amitabha
### 标签
[{"label":"念佛","color":"#fae1a9"},{"label":"阿弥陀佛","color":"#fab6a9"}]
### 插件配置项
```dotenv
send_interval=5
```
### 插件测试
- [ ] 如需重新运行插件测试,请勾选左侧勾选框 | closed | 2024-12-09T15:12:35Z | 2024-12-17T15:05:33Z | https://github.com/nonebot/nonebot2/issues/3177 | [
"Plugin",
"Publish"
] | Kaguya233qwq | 8 |
tqdm/tqdm | jupyter | 856 | Support skins | - [x] I have marked all applicable categories:
+ [x] new feature request
- [x] I have visited the [source website], and in particular
read the [known issues]
- [x] I have searched through the [issue tracker] for duplicates
https://github.com/verigak/progress/blob/master/progress/bar.py has skins. I guess w... | closed | 2019-11-30T08:01:03Z | 2019-11-30T14:01:24Z | https://github.com/tqdm/tqdm/issues/856 | [
"duplicate 🗐",
"question/docs ‽",
"need-feedback 📢"
] | KOLANICH | 2 |
zappa/Zappa | flask | 458 | [Migrated] IAM Role creation fails when generated role name is longer than 64 characters | Originally from: https://github.com/Miserlou/Zappa/issues/1223 by [philvarner](https://github.com/philvarner)
## Context
I created a deploy target:
```
"sandbox_enqueuer": {
"project_name": "dev_enqueuer_surveygizmo",
```
which gave me this output when deploying:
```
bash-3.2$ zappa deploy sandbox_en... | closed | 2021-02-20T08:35:08Z | 2024-04-13T16:18:18Z | https://github.com/zappa/Zappa/issues/458 | [
"no-activity",
"auto-closed"
] | jneves | 2 |
flairNLP/flair | nlp | 3,458 | [Question]: Resume training | ### Question
I'm trying to resume training according to :
[This code](https://github.com/flairNLP/flair/blob/8bcc3d9dac0b0e318e0bd0290af5a36f4d414fab/resources/docs/TUTORIAL_TRAINING_MORE.md?plain=1#L73)
where it says :
# 7. continue training at later point. Load previously trained model checkpoint, then resume
tr... | open | 2024-05-17T07:28:23Z | 2024-06-24T02:20:42Z | https://github.com/flairNLP/flair/issues/3458 | [
"question"
] | alfredwallace7 | 5 |
gradio-app/gradio | deep-learning | 10,722 | Antivirus Flagging frpc_darwin_arm64_v0.3 as Infostealer Breaks Gradio Share Functionality | Hello,
Our corporate security solution (e.g., SentinelOne Cloud) is flagging the file located at:
```
/opt/homebrew/anaconda3/envs/llms/lib/python3.11/site-packages/gradio/frpc_darwin_arm64_v0.3
```
as an "Infostealer." This file is a critical component used by Gradio's share functionality to create a tunnel for exp... | closed | 2025-03-04T01:23:58Z | 2025-03-19T19:56:41Z | https://github.com/gradio-app/gradio/issues/10722 | [
"bug",
"pending clarification"
] | Twodragon0 | 5 |
pbugnion/gmaps | jupyter | 74 | Full options for heatmap | It would be good to give access to the following options:
- dissipating
- opacity
- gradient
See, eg. issue #73 .
| closed | 2016-07-24T15:14:01Z | 2016-07-30T09:50:24Z | https://github.com/pbugnion/gmaps/issues/74 | [
"enhancement"
] | pbugnion | 1 |
wandb/wandb | data-science | 9,270 | [Bug]: wandb.login() hangs indefinitely under certain conditions | ### Describe the bug
Problem:
It seems that wandb.login() sometimes hangs forever. I've observed it happen under these conditions (not comprehensive):
* Multiple independent processes are simultaneously trying to use wandb.login() with the same key & project.
* Or when I'm training hundreds of models sequentially, it ... | open | 2025-01-15T21:31:19Z | 2025-02-10T20:05:52Z | https://github.com/wandb/wandb/issues/9270 | [
"ty:bug",
"a:sdk",
"c:sdk:login"
] | profPlum | 15 |
jupyterlab/jupyter-ai | jupyter | 492 | Missing/incorrect formatting in the Jupyternaut response | <!-- Welcome! Thank you for contributing. These HTML comments will not render in the issue.
Before creating a new issue:
* Search for relevant issues
* Follow the issue reporting guidelines:
https://jupyterlab.readthedocs.io/en/latest/getting_started/issue.html
-->
## Description
I am using the jupyter ai ex... | open | 2023-11-28T12:44:06Z | 2024-01-26T01:13:39Z | https://github.com/jupyterlab/jupyter-ai/issues/492 | [
"bug"
] | sundaraa-deshaw | 3 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.