
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
koxudaxi/fastapi-code-generator | fastapi | 84 | ValueError: 'template/main.jinja2' is not in the subpath | I'm trying to make my project compatible with poetry so I have to add a start method where I invoke uvicorn so that I can have the following in the poetry run script:
```
[tool.poetry.scripts]
run = "skeleton_python_api.main:start"
```
I have the following structure of a project:
```
├── README.md
├── openapi... | closed | 2021-01-07T12:13:38Z | 2021-01-13T09:29:49Z | https://github.com/koxudaxi/fastapi-code-generator/issues/84 | [] | nadworny | 1 |
miguelgrinberg/python-socketio | asyncio | 338 | Python Server & Node Client , On Authentication Fail client receives 1 fix error in any scenario. | Hello,
I have a scenario where HTTPS Server is of Python and Client is from the nodeJs,
For a client, I need to show 2 different messages for the below scenario
-If a client tries to connect with invalid URL like 'abc.com', I need to show the message "server not found"
-If the user enters valid URL and... | closed | 2019-08-21T08:38:00Z | 2019-08-29T05:46:39Z | https://github.com/miguelgrinberg/python-socketio/issues/338 | [
"question"
] | harshkoralwala | 6 |
bmoscon/cryptofeed | asyncio | 332 | OHLCV Aggregation Coinbase fails with `unexpected keyword argument 'order_type'` | I use the script `examples/demo_ohlcv.py`
```
from cryptofeed import FeedHandler
from cryptofeed.backends.aggregate import OHLCV
from cryptofeed.callback import Callback
from cryptofeed.defines import TRADES
from cryptofeed.exchanges import Coinbase
from cryptofeed.exchanges import Binance
async def ohlcv... | closed | 2020-11-20T18:43:57Z | 2020-11-21T01:35:42Z | https://github.com/bmoscon/cryptofeed/issues/332 | [
"bug"
] | degloff | 1 |
coqui-ai/TTS | pytorch | 3,799 | [Bug] Demo Inference Produces Distorted Audio Output | ### Describe the bug
I followed the demo code provided by Coqui to create a simple dataset and fine-tune a model using Gradio. However, when I load the model and perform inference, the output audio is heavily distorted, resembling the sound of a hair shaving machine.
You can listen to the output at the following li... | closed | 2024-06-25T18:29:54Z | 2025-01-03T08:49:11Z | https://github.com/coqui-ai/TTS/issues/3799 | [
"bug",
"wontfix"
] | Heshamtr | 1 |
aio-libs/aiomysql | sqlalchemy | 195 | unable to perform operation on <TCPTransport closed=True reading=False 0x1e41248>; the handler is closed` | hi,i use
python3.5.3
aiohttp 2.0.7
aiomysql 0.0.9
sqlalchemy1.1.10
When i open the application for a long time.Throw the following error
`2017-07-27 10:28:13 rtgroom.py[line:141] ERROR Traceback (most recent call last):
File "/home/wwwroot/ykrealtime/rtgame/models/mysql/rtgroom.py", line 137, in get_invite... | closed | 2017-07-27T03:44:36Z | 2018-12-06T03:38:03Z | https://github.com/aio-libs/aiomysql/issues/195 | [] | larryclean | 4 |
taverntesting/tavern | pytest | 564 | Support using custom function in request.auth | As stated in the [requests document](https://requests.readthedocs.io/en/master/user/advanced/#custom-authentication), user may pass a sub class of AuthBase as the auth parameter. This is very useful when the authentication is a little bit more complicated than passing the session token or basic auth.
I guess this ca... | open | 2020-06-28T13:08:51Z | 2021-01-13T13:36:33Z | https://github.com/taverntesting/tavern/issues/564 | [] | sohoffice | 2 |
allenai/allennlp | data-science | 5,105 | Build Fairness Library | **Motivation:** As models and datasets become increasingly large and complex, it is critical to evaluate the fairness of models according to multiple definitions of fairness and mitigate bias in learned representations. This library aims to make fairness metrics, fairness training tools, and bias mitigation algorithms ... | open | 2021-04-08T21:25:54Z | 2022-12-15T16:09:49Z | https://github.com/allenai/allennlp/issues/5105 | [] | ArjunSubramonian | 38 |
jacobgil/pytorch-grad-cam | computer-vision | 491 | the example in README need to update | this link :https://jacobgil.github.io/pytorch-gradcam-book/Class%20Activation%20Maps%20for%20Semantic%20Segmentation.html

i found now the code can automatic use the same device of model:
```
class Bas... | open | 2024-03-14T07:33:48Z | 2024-03-14T07:37:37Z | https://github.com/jacobgil/pytorch-grad-cam/issues/491 | [] | 578223592 | 1 |
pywinauto/pywinauto | automation | 1,171 | {AttributeError}'EditWrapper' object has no attribute 'is_editable' | ## Expected Behavior
I get a edit control from a window. I want to check whether the control is editable.
[https://pywinauto.readthedocs.io/en/latest/code/pywinauto.controls.uia_controls.html?highlight=is_editable#pywinauto.controls.uia_controls.EditWrapper.is_editable](url)
According to the document, method "is_edi... | open | 2022-01-25T01:09:29Z | 2022-01-25T01:09:29Z | https://github.com/pywinauto/pywinauto/issues/1171 | [] | jiliguluss | 0 |
jschneier/django-storages | django | 1,243 | S3Boto3Storage.exists() always returns False | Hey guys, need a small help again
I'm having an issue with S3Boto3Storage.exists()
It always returns false even though I have that directory present in the bucket.
I need to know what is going wrong as I want to make sure that if a user uploads new file with same content but, with different file name I would w... | closed | 2023-04-24T16:08:38Z | 2023-05-20T18:06:14Z | https://github.com/jschneier/django-storages/issues/1243 | [] | bphariharan1301 | 1 |
holoviz/panel | jupyter | 7,150 | global loading spinner static asset not available | #### ALL software version info
panel 1.3.8
Docker version 26.1.3, build b72abbb
conda 24.1.2
the app is running locally within a docker container
#### Description of expected behavior and the observed behavior
I would expect the loading spinner to be loaded successfully.
#### Complete, minimal, self-contai... | closed | 2024-08-15T16:09:39Z | 2024-08-24T12:15:02Z | https://github.com/holoviz/panel/issues/7150 | [] | updiversity | 0 |
LAION-AI/Open-Assistant | machine-learning | 3,747 | Not able to get to the dashboard | There is no way for me to access the dashboard tools. I will see the dashboard for a split second, and then it just goes back to the main page, naming off contributors and affiliates. | closed | 2024-01-31T01:26:35Z | 2024-01-31T05:14:23Z | https://github.com/LAION-AI/Open-Assistant/issues/3747 | [] | RayneDrip | 1 |
labmlai/annotated_deep_learning_paper_implementations | deep-learning | 71 | Question about the framework | Thanks for your excellent wor for so many implementations, i was wondering that would you accept some algorithms that are implemented using tensorflow, mxnet or paddlepaddle, rather than pytorch? | closed | 2021-07-27T05:07:38Z | 2021-08-07T02:17:25Z | https://github.com/labmlai/annotated_deep_learning_paper_implementations/issues/71 | [
"question"
] | littletomatodonkey | 2 |
nl8590687/ASRT_SpeechRecognition | tensorflow | 142 | 提取发音的内容 | 有一份训练数据,每份语音内容包括空白内容跟人的发声内容。想请问下有什么方法可以把人的发声内容单独提取出来保存成wav? | closed | 2019-09-18T06:46:32Z | 2021-11-22T14:06:12Z | https://github.com/nl8590687/ASRT_SpeechRecognition/issues/142 | [] | zraul | 5 |
ultralytics/yolov5 | machine-learning | 12,527 | speed estimate using yolo5 - put coridantes of cars in xml file or csv | ### Search before asking
- [x] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
hi i am using yolo5 py porchand i can detect cars and everything ok but i have a code for... | closed | 2023-12-19T22:06:32Z | 2024-10-20T19:34:52Z | https://github.com/ultralytics/yolov5/issues/12527 | [
"question"
] | gchinta1 | 6 |
bmoscon/cryptofeed | asyncio | 217 | [Feature request] support to record "Market price" or "index" in bitmex | seems they are terribly out of line when things get funny | open | 2020-03-13T03:55:55Z | 2020-08-01T00:49:43Z | https://github.com/bmoscon/cryptofeed/issues/217 | [
"Feature Request"
] | xiandong79 | 7 |
jmcnamara/XlsxWriter | pandas | 193 | Problem with one formula | Hello.
I sorry, I don't speak English very well (I am French)
I have a small problem with a formula.
I reduced my program easier to explain my problem.
``` python
import xlsxwriter
workbook = xlsxwriter.Workbook('test.xlsx')
worksheet = workbook.add_worksheet()
worksheet.write('A1', 'SUCCEED')
worksheet.write('A2',... | closed | 2014-12-12T14:58:03Z | 2019-10-17T14:14:32Z | https://github.com/jmcnamara/XlsxWriter/issues/193 | [] | Keevar | 4 |
strawberry-graphql/strawberry | asyncio | 3,617 | Unable to import strawberry.django since v0.236.0 | I receive an error when trying to build the project since [`v0.236.0`](https://github.com/strawberry-graphql/strawberry/releases/tag/0.236.0)
## Describe the Bug
```
File "/Users/boesch/.pyenv/versions/project/lib/python3.10/site-packages/strawberry/django/__init__.py", line 16, in __getattr__
raise Attri... | closed | 2024-09-04T14:48:25Z | 2025-03-20T15:56:51Z | https://github.com/strawberry-graphql/strawberry/issues/3617 | [
"bug"
] | bradleyoesch | 3 |
gradio-app/gradio | python | 10,658 | Events injecting function instead of called function value for gr.State | ### Describe the bug
I've noticed that the render function is injecting the value of gr.State before the state value is called AND after the state value is called. It should only inject the called value not the callable itself if I understand correctly
### Have you searched existing issues? 🔎
- [x] I have searched... | open | 2025-02-23T00:57:41Z | 2025-03-03T07:31:16Z | https://github.com/gradio-app/gradio/issues/10658 | [
"bug"
] | brycepg | 1 |
robinhood/faust | asyncio | 535 | Consumer thread not yet started when enable_kafka = False | I'd like to run a Faust worker without doing anything with Kafka, for example to run timers.
## Steps to reproduce
```
import faust
from faust.app.base import BootStrategy
class App(faust.App):
class BootStrategy(BootStrategy):
enable_kafka = False
app = App('test')
```
## Expected beha... | closed | 2020-02-24T13:41:29Z | 2020-02-26T23:28:57Z | https://github.com/robinhood/faust/issues/535 | [] | joekohlsdorf | 1 |
aleju/imgaug | machine-learning | 669 | cval not behaving correctly when given float value | According to [the docs](https://imgaug.readthedocs.io/en/latest/source/api_augmenters_geometric.html) `cval` should accept float values and create new pixels according to the given value:
> **cval** (number ... ) – The constant value to use when filling in newly created pixels. ... _It may be a float value._
Howeve... | closed | 2020-05-20T15:18:42Z | 2020-05-25T19:47:49Z | https://github.com/aleju/imgaug/issues/669 | [
"bug"
] | cdjameson | 1 |
deepinsight/insightface | pytorch | 1,855 | RAM | ```
# our RAM is 256G
mount -t tmpfs -o size=140G tmpfs /train_tmp
```
How to find my computer size
htop ? Mem? | open | 2021-12-11T09:31:01Z | 2021-12-13T02:57:32Z | https://github.com/deepinsight/insightface/issues/1855 | [] | alicera | 2 |
wkentaro/labelme | deep-learning | 987 | [Question] Why Labelme GUI not add open flags.txt | closed | 2022-02-15T06:00:50Z | 2022-02-25T21:09:07Z | https://github.com/wkentaro/labelme/issues/987 | [] | YuaXan | 1 | |
pyjanitor-devs/pyjanitor | pandas | 570 | [ENH] Series toset() functionality | # Brief Description
<!-- Please provide a brief description of what you'd like to propose. -->
I would like to propose toset() functionality similar to [tolist()](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.tolist.html).
Basically it will be a function call to tolist and then conver... | closed | 2019-09-15T07:26:08Z | 2019-09-24T13:28:33Z | https://github.com/pyjanitor-devs/pyjanitor/issues/570 | [
"enhancement",
"good first issue",
"good intermediate issue",
"being worked on"
] | eyaltrabelsi | 5 |
hzwer/ECCV2022-RIFE | computer-vision | 332 | Question about tracking a point | Thank you for this library: I tried it with the `Dockerfile` - without `GPU` - and I was able to generate a new file right away.
Let's say I have an input video with two contiguous frames: `frame_1` and `frame_2`.
On the input video, on `frame_1`, I have a point with known coordinates.
On the output video, is ... | open | 2023-08-01T10:37:46Z | 2023-08-03T12:33:49Z | https://github.com/hzwer/ECCV2022-RIFE/issues/332 | [] | carlok | 2 |
comfyanonymous/ComfyUI | pytorch | 6,652 | Image generation on 3090 is sometimes broken and worse than on 2060, and can't reproduce it | ### Expected Behavior
I have a workflow that produces extremely different results on 2060 GPU on a different PC, and my 3090. This image looks correct, and was generated on 2060.

### Actual Behavior
This is what gets generated... | open | 2025-01-30T22:52:53Z | 2025-02-04T15:24:05Z | https://github.com/comfyanonymous/ComfyUI/issues/6652 | [
"Potential Bug"
] | Nekotekina | 4 |
jumpserver/jumpserver | django | 14,718 | [Question] JumpServer server requirement | ### Product Version
Latest
### Product Edition
- [X] Community Edition
- [ ] Enterprise Edition
- [ ] Enterprise Trial Edition
### Installation Method
- [X] Online Installation (One-click command installation)
- [ ] Offline Package Installation
- [ ] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] Source Code
### ... | closed | 2024-12-24T02:09:35Z | 2024-12-24T09:33:30Z | https://github.com/jumpserver/jumpserver/issues/14718 | [
"🤔 Question"
] | aryasenawiryady | 2 |
jumpserver/jumpserver | django | 14,383 | [Bug] 本地Golang代码连接PgSQL失败 | ### 产品版本
v3.10.13
### 版本类型
- [ ] 社区版
- [X] 企业版
- [ ] 企业试用版
### 安装方式
- [ ] 在线安装 (一键命令安装)
- [x] 离线包安装
- [ ] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] 源码安装
### 环境信息
Jumpserver版本:JumpServer Enterprise Edition Version: v3.10.13
部署架构: jumpserver server -> 公网网域网关 -> pgsql
### 🐛 缺陷描述
通过J... | closed | 2024-10-30T09:44:40Z | 2024-11-28T08:41:59Z | https://github.com/jumpserver/jumpserver/issues/14383 | [
"🐛 Bug",
"🔘 Inactive"
] | ChenTitan49 | 3 |
thunlp/OpenPrompt | nlp | 309 | import break when using latest transformers | file: pipeline_base.py
line: 4
code: `from transformers.generation_utils import GenerationMixin`
this is broken, should be replaced with `from transformers import GenerationMixin` | open | 2024-05-02T19:24:14Z | 2024-05-02T19:24:14Z | https://github.com/thunlp/OpenPrompt/issues/309 | [] | xiyang-aads-lilly | 0 |
Lightning-AI/pytorch-lightning | pytorch | 20,530 | Batch size finder code example in dark mode is light instead of dark | ### 📚 Documentation
On the [Batch size finder advanced tricks](https://lightning.ai/docs/pytorch/stable/advanced/training_tricks.html#batch-size-finder) page, in dark mode the example code is in light mode makes it hard to read:
<img width="891" alt="Hard to read light mode code example" src="https://github.com/us... | open | 2025-01-06T18:03:51Z | 2025-01-06T18:05:21Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20530 | [
"docs",
"needs triage"
] | nicolasperez19 | 0 |
Yorko/mlcourse.ai | seaborn | 169 | Missing image on Lesson 3 notebook | Hey,
Image _credit_scoring_toy_tree_english.png_ is missing on the topic3_decision_trees_kNN notebook. | closed | 2018-02-19T11:17:20Z | 2018-08-04T16:08:25Z | https://github.com/Yorko/mlcourse.ai/issues/169 | [
"minor_fix"
] | henriqueribeiro | 3 |
alteryx/featuretools | data-science | 2,399 | Refactor computation of primitive lists in `DeepFeatureSynthesis` `__init__` | When building the following lists, there is a lot of code duplication:
- `self.groupby_trans_primitives`
- `self.agg_primitives`
- `self.where_primitives`
- `self.trans_primitives`
Furthermore, refactoring this logic outside of the `__init__` would help make the code more expressive and testable. | open | 2022-12-13T05:03:45Z | 2023-03-15T22:48:59Z | https://github.com/alteryx/featuretools/issues/2399 | [
"enhancement",
"refactor",
"tech debt"
] | sbadithe | 0 |
oegedijk/explainerdashboard | dash | 220 | Feature value input to get_contrib_df | Hello,
I understand that the get_contrib_df function can be used to get the contributions of various features to the final predictions for a particular data index from the table. However, is it possible to get the contribution calculation/table by passing a list/array of data points to this function? I am guess this... | open | 2022-05-25T05:24:51Z | 2022-05-25T05:24:51Z | https://github.com/oegedijk/explainerdashboard/issues/220 | [] | andypatrac | 0 |
aeon-toolkit/aeon | scikit-learn | 2,043 | [ajb/remove_metric] is STALE | @TonyBagnall,
ajb/remove_metric has had no activity for 143 days.
This branch will be automatically deleted in 32 days. | closed | 2024-09-09T01:28:04Z | 2024-09-12T07:26:31Z | https://github.com/aeon-toolkit/aeon/issues/2043 | [
"stale branch"
] | aeon-actions-bot[bot] | 1 |
LAION-AI/Open-Assistant | machine-learning | 2,760 | 没有删除历史会话的功能 | Delete history session prompted by the assistant, not executable | closed | 2023-04-19T15:44:02Z | 2023-04-23T20:02:49Z | https://github.com/LAION-AI/Open-Assistant/issues/2760 | [] | taskmgr0 | 1 |
tflearn/tflearn | tensorflow | 882 | About loss in Tensorboard | Hello everyone,
I run the example of Multi-layer perceptron, and visualize the loss in Tensorboard.
Does "Loss" refer to the training loss on each batch? And "Loss/Validation" refers to the loss on validation set? What does "Loss_var_loss" refer to?
 / jit_cuda()
I am just trying a simplify version of your jit turtorial guide, and the code as below:
```
df = vaex.example()
def arc_distance(theta_1, phi_1, theta_2, phi_2):
"""
Calculates the pairwise arc ... | closed | 2022-08-24T06:03:54Z | 2022-08-26T09:18:59Z | https://github.com/vaexio/vaex/issues/2183 | [] | GMfatcat | 5 |
docarray/docarray | pydantic | 1,601 | Handle `max_elements` from HNSWLibIndexer | By default, `max_elements` is set to 1024. I believe this max_elements should be recomputed and indexes resized dynamically | closed | 2023-05-31T13:08:32Z | 2023-06-01T08:00:59Z | https://github.com/docarray/docarray/issues/1601 | [] | JoanFM | 0 |
supabase/supabase-py | fastapi | 717 | Test failures on Python 3.12 | # Bug report
## Describe the bug
Tests are broken against Python 3.12.
```AttributeError: module 'pkgutil' has no attribute 'ImpImporter'. Did you mean: 'zipimporter'?```
## To Reproduce
Run test script in a python 3.12 environment.
## Expected behavior
Tests should not fail.
## Logs
```bash
E... | closed | 2024-03-03T05:12:43Z | 2024-03-23T13:24:45Z | https://github.com/supabase/supabase-py/issues/717 | [
"bug"
] | tinvaan | 2 |
QingdaoU/OnlineJudge | django | 476 | 提交代码的时候显示system error |

在提交issue之前请
- 认真阅读文档 http://docs.onlinejudge.me/#/
- 搜索和查看历史issues
- 安全类问题请不要在 GitHub 上公布,请发送邮件到 `admin@qduoj.com`,根据漏洞危害程度发送红包感谢。
然后提交issue请写清楚下列事项
- 进行什么操作的时候遇到了什么问题,最好能有复现步骤
... | open | 2024-09-15T12:54:37Z | 2024-09-15T12:54:37Z | https://github.com/QingdaoU/OnlineJudge/issues/476 | [] | leeway-z | 0 |
hankcs/HanLP | nlp | 1,059 | 使用繁體分詞後,髮變發 | <!--
注意事项和版本号必填,否则不回复。若希望尽快得到回复,请按模板认真填写,谢谢合作。
-->
## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检... | closed | 2018-12-25T06:25:13Z | 2018-12-25T19:54:56Z | https://github.com/hankcs/HanLP/issues/1059 | [
"improvement"
] | gunblues | 1 |
nteract/papermill | jupyter | 405 | Using papermill to test notebooks | Hi,
I am using papermill to check that some notebooks run without problems. I don't need to output any notebook. Is there a way to run a notebook without output? | open | 2019-07-26T06:54:23Z | 2021-03-11T22:54:23Z | https://github.com/nteract/papermill/issues/405 | [
"question"
] | argenisleon | 3 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 16,376 | [Feature Request]: add support for stablediffusion.cpp inference. | ### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What would your feature do ?
stablediffusion.cpp works fast on cpu, use less memory than pytorch and support of quantized models which take much less space.
### Proposed workflow
1. Go to se... | open | 2024-08-13T03:48:05Z | 2024-08-13T03:48:05Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16376 | [
"enhancement"
] | sss123next | 0 |
gradio-app/gradio | data-visualization | 10,667 | gr.load_chat has no documentation on gradio.app | ### Describe the bug
The [How to Create a Chatbot with Gradio](https://www.gradio.app/guides/creating-a-chatbot-fast) guide references a URL that does not exist, this is the documentation for the `gr.load_chat` function.
https://www.gradio.app/docs/gradio/load_chat
https://github.com/gradio-app/gradio/blob/f0a920c... | closed | 2025-02-24T17:46:19Z | 2025-02-25T00:49:49Z | https://github.com/gradio-app/gradio/issues/10667 | [
"bug",
"docs/website"
] | alexandercarruthers | 1 |
sgl-project/sglang | pytorch | 4,436 | [Feature] enable SGLang custom all reduce by default | ### Checklist
- [ ] 1. If the issue you raised is not a feature but a question, please raise a discussion at https://github.com/sgl-project/sglang/discussions/new/choose Otherwise, it will be closed.
- [ ] 2. Please use English, otherwise it will be closed.
### Motivation
We need community users to help test these c... | open | 2025-03-14T19:46:52Z | 2025-03-18T08:29:14Z | https://github.com/sgl-project/sglang/issues/4436 | [
"good first issue",
"help wanted",
"high priority",
"performance"
] | zhyncs | 5 |
autokey/autokey | automation | 659 | Add return codes to mouse.wait_for_click and keyboard.wait_for_keypress | ### Has this issue already been reported?
- [X] I have searched through the existing issues.
### Is this a question rather than an issue?
- [X] This is not a question.
### What type of issue is this?
Enhancement
### Which Linux distribution did you use?
N/A
### Which AutoKey GUI did you use?
_No response_
###... | open | 2022-02-08T20:34:56Z | 2023-06-18T16:59:58Z | https://github.com/autokey/autokey/issues/659 | [
"enhancement",
"scripting",
"good first issue"
] | josephj11 | 21 |
sqlalchemy/sqlalchemy | sqlalchemy | 10,792 | Перестаньте делать из нормального языка франкенштейна какого-то | ### Describe the bug
Перестаньте делать из нормального языка франкенштейна какого-то
### Optional link from https://docs.sqlalchemy.org which documents the behavior that is expected
_No response_
### SQLAlchemy Version in Use
2.0.2
### DBAPI (i.e. the database driver)
psycopg2
### Database Vendor and Major Vers... | closed | 2023-12-26T11:54:45Z | 2023-12-26T12:00:04Z | https://github.com/sqlalchemy/sqlalchemy/issues/10792 | [] | undergroundenemy616 | 0 |
horovod/horovod | machine-learning | 3,091 | horovod installation: tensorflow not detected when using intel-tensorflow-avx512. | **Environment:**
1. Framework: TensorFlow
2. Framework version: intel-tensorflow-avx512==2.5.0
3. Horovod version: 0.22.1
4. MPI version: openmpi 4.0.3
5. CUDA version: N/A, cpu only
6. NCCL version: N/A, cpu only
7. Python version: 3.8
10. OS and version: Ubuntu focal
11. GCC version: 9.3.0
12. CMake version... | open | 2021-08-07T07:31:46Z | 2021-08-09T15:37:07Z | https://github.com/horovod/horovod/issues/3091 | [
"bug"
] | myoung3 | 4 |
Significant-Gravitas/AutoGPT | python | 8,740 | Add `integer` to `NodeHandle` type list | The JSON schema type `integer` is not defined in the type list in `<NodeHandle>`, causing it to show up as `(any)` rather than `(integer)` on block inputs/outputs with that type.
[https://github.com/Significant-Gravitas/AutoGPT/blob/86535b5811f8d1cc0bdde2232693919c4b1115e3/autogpt_platform/frontend/src/components/Node... | closed | 2024-11-21T17:34:39Z | 2024-12-10T17:46:17Z | https://github.com/Significant-Gravitas/AutoGPT/issues/8740 | [
"platform/frontend"
] | Pwuts | 0 |
howie6879/owllook | asyncio | 70 | 能不能更新下docker hub? | 对python有点不熟悉,一直没弄好。
docker hub那边的版本有点老了 | closed | 2019-09-01T12:11:34Z | 2019-09-02T02:56:40Z | https://github.com/howie6879/owllook/issues/70 | [] | henri001 | 2 |
gradio-app/gradio | data-science | 10,046 | HTML component issue | 
There is only one small problem, and I believe this problem occurs in the front-end code. When both the container and show_label attributes are set to True at the same time, there will be an obvious conflict between... | closed | 2024-11-27T06:06:52Z | 2024-11-28T19:13:57Z | https://github.com/gradio-app/gradio/issues/10046 | [
"bug"
] | nuclearrockstone | 0 |
airtai/faststream | asyncio | 1,414 | Bug: The Kafka consumer remains blocked indefinitely after commit failures, unable to recover | **Describe the bug**
In version 0.5.x, when using aiokafka with auto_commit=false, if Kafka rebalances causing consumer commit failures, the consumer remains indefinitely blocked, unable to resume normal consumption.
However, when I set auto_commit=true, or revert to version 0.4.7, the issue does not occur, and t... | closed | 2024-05-02T07:34:01Z | 2024-05-04T16:51:41Z | https://github.com/airtai/faststream/issues/1414 | [
"bug"
] | JohannT9527 | 0 |
InstaPy/InstaPy | automation | 6,000 | Setting timeout on join_pods function | Hi & Happy new year!
Can you please let me know if there is a way to stop `join_pods` interaction after some specified time?
The point is that currently it infinitely engages in interaction with the pods which results in Instagram blocking my activity.
I would therefore to set a time limit on that function.
Is th... | open | 2021-01-01T20:15:06Z | 2021-07-21T03:19:20Z | https://github.com/InstaPy/InstaPy/issues/6000 | [
"wontfix"
] | alinakhay | 1 |
d2l-ai/d2l-en | computer-vision | 1,737 | Search doesn't appear to work | Currently, the search page shows no results and just "Preparing search"...
http://d2l.ai/search.html?q=transformer
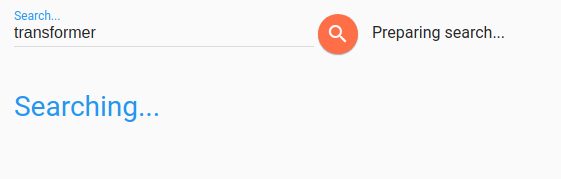
Possibly related to this error in the console:
 example, the example only works if the `labels` field already exists. As things are, `labels` has not been created at this point (and would likely be pruned if it was created and empty).
### Kopf version
1.36.0
### Kubernetes version
1.24.8
### Python version
3.... | open | 2023-03-28T05:50:42Z | 2023-03-28T05:51:12Z | https://github.com/nolar/kopf/issues/1018 | [
"bug"
] | jsolbrig | 0 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 897 | 在运行scripts/inference/inference_hf.py时,在seq_len> self.max_seq_len_cached部分,会出现RuntimeError: Boolean value of Tensor with more than one value is ambiguous | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 由于相关依赖频繁更新,请确保按照[Wiki](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki)中的相关步骤执行
- [X] 我已阅读[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.c... | closed | 2024-05-29T12:07:45Z | 2024-06-19T22:03:07Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/897 | [
"stale"
] | WWWWWWLLLL | 2 |
deezer/spleeter | tensorflow | 468 | Used conda to install, doesn't work | ````
Traceback (most recent call last):
File "C:\Users\admin\miniconda3\envs\py36\Scripts\spleeter-script.py", line 9, in <module>
sys.exit(entrypoint())
File "C:\Users\admin\miniconda3\envs\py36\lib\site-packages\spleeter\__main__.py", line 54, in entrypoint
main(sys.argv)
File "C:\Users\admin\mini... | closed | 2020-08-08T13:38:48Z | 2020-08-29T19:49:44Z | https://github.com/deezer/spleeter/issues/468 | [
"bug",
"invalid"
] | ghost | 1 |
sktime/sktime | data-science | 7,596 | [ENH] Interface `TiDE` from `darts` library | **Is your feature request related to a problem? Please describe.**
`TiDE` is similar to Transformers, but attempts to provide better performance in time series forecasting at lower computational cost by introducing multilayer perceptron (MLP)-based encoder-decoders without attention.
References:
https://arxiv.org/... | open | 2025-01-03T05:56:58Z | 2025-01-06T13:51:05Z | https://github.com/sktime/sktime/issues/7596 | [
"interfacing algorithms",
"module:forecasting",
"enhancement"
] | PranavBhatP | 1 |
aio-libs/aiopg | sqlalchemy | 411 | Broken compatibility with new release of SQLAlchemy 1.2.0 | Hello,
Yesterday released new version of SQLAlchemy (1.2.0) and new release incompatible with aiopg:
```
mymodule.py:42: in fetchone
result = await conn.execute(query)
.tox/py36-tests/lib/python3.6/site-packages/aiopg/utils.py:72: in __await__
resp = yield from self._coro
.tox/py36-tests/lib/python3.... | closed | 2017-12-28T06:15:27Z | 2018-01-03T20:13:36Z | https://github.com/aio-libs/aiopg/issues/411 | [] | Gr1N | 0 |
sgl-project/sglang | pytorch | 4,421 | [Bug] Docker run lmsysorg/sglang:v0.4.4.post1-rocm630 Error: no TensileLibrary_lazy_gfx90a.dat file. | ### Checklist
- [x] 1. I have searched related issues but cannot get the expected help.
- [x] 2. The bug has not been fixed in the latest version.
- [x] 3. Please note that if the bug-related issue you submitted lacks corresponding environment info and a minimal reproducible demo, it will be challenging for us to repr... | open | 2025-03-14T08:58:46Z | 2025-03-20T06:31:30Z | https://github.com/sgl-project/sglang/issues/4421 | [
"high priority"
] | luciaganlulu | 4 |
explosion/spaCy | machine-learning | 13,057 | Equals TypeError |
## How to reproduce the behaviour
nlp = spacy.load("en_core_web_lg")
text = "The quick brown fox jumps over the lazy dog"
doc = nlp(text)
token = doc[0]
span = doc[0:1]
print(span == token)
Actual Result: `TypeError: Argument 'other' has incorrect type (expected spacy.tokens.span.Sp... | closed | 2023-10-11T03:07:47Z | 2023-11-12T00:02:23Z | https://github.com/explosion/spaCy/issues/13057 | [
"bug",
"feat / doc"
] | TristynAlxander | 2 |
tensorly/tensorly | numpy | 274 | API Typo? | For the API reference for non_negative_parafac, I believe it's not the same as calling parafac(non_negative = True) anymore because it (non_negative) doesn't seem to be one of the fields of parafac anymore.
| closed | 2021-05-27T01:45:48Z | 2021-06-02T20:23:37Z | https://github.com/tensorly/tensorly/issues/274 | [] | VoliCrank | 1 |
onnx/onnx | pytorch | 6,590 | cumprod operation | ### System information
ONNX version: 1.17.0
### Notes
I just encountered while trying to serialize a torch model into ONNX that this operation is not yet supported. Like, is it such a strange operation?
I did a workaround by `x.log().cumsum().exp()` but it's hella slower.
Also how is it possible that cum... | open | 2024-12-19T16:39:56Z | 2025-02-19T17:33:26Z | https://github.com/onnx/onnx/issues/6590 | [
"topic: operator",
"topic: enhancement"
] | claverru | 6 |
huggingface/transformers | tensorflow | 35,981 | Docs: return type of `get_default_model_and_revision` might be incorrectly documented? | The return type here is documented as `Union[str, Tuple[str, str]]`
https://github.com/huggingface/transformers/blob/d7188ba600e36d3fd191b12e19f1b3bb81a8404f/src/transformers/pipelines/base.py#L385-L387
The docstring just says `str`
https://github.com/huggingface/transformers/blob/d7188ba600e36d3fd191b12e19f1b3bb81a... | closed | 2025-01-31T10:34:48Z | 2025-02-13T10:59:16Z | https://github.com/huggingface/transformers/issues/35981 | [] | MarcoGorelli | 1 |
jupyterlab/jupyter-ai | jupyter | 326 | generate fails if self.serverapp.root_dir not writable | Hello and thank you for this great extension 👍
## Description
We are facing a `Permission denied`-issue when jupyter-ai is asked to generate a notebook.
It tries to generate the file in the directory set by `self.serverapp.root_dir` which is not writable.
https://github.com/search?q=repo%3Ajupyterlab%2Fjupyter-... | closed | 2023-08-09T09:19:56Z | 2025-03-03T20:41:54Z | https://github.com/jupyterlab/jupyter-ai/issues/326 | [
"bug",
"status:triaged"
] | jhgoebbert | 2 |
MaxHalford/prince | scikit-learn | 151 | prince.PCA vs. sklearn.decomposition.PCA? | I'm comparing the PCA functionality from sklearn ([sklearn.decomposition.PCA](https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html)) with the one from prince. I cannot fully understand why the results differ.
**Example:**
```python
import prince
data = prince.datasets.load_energy_mi... | closed | 2023-05-30T00:38:37Z | 2023-05-30T18:34:12Z | https://github.com/MaxHalford/prince/issues/151 | [] | normanius | 3 |
strawberry-graphql/strawberry-django | graphql | 559 | prefetch_related and filtering in custom resolver | I need to filter related models. Query optimizer works fine, but I cannot get it working with filtering inside custom resolver (without using @strawberry.django.filter)
1. When I define my own Prefetch, I am getting double prefetch queries. One is mine, the other is from optimizer.
```python
@strawberry.djan... | closed | 2024-06-15T04:51:31Z | 2025-03-20T15:57:32Z | https://github.com/strawberry-graphql/strawberry-django/issues/559 | [
"enhancement"
] | tasiotas | 4 |
keras-team/autokeras | tensorflow | 1,078 | Enable limiting model size based on Keras Tuner | ### Bug Description
ImageRegressor training stops at random when training on dual RTX Titan GPUs. Error Message:
ResourceExhaustedError: OOM when allocating tensor with shape[32,1280,64,64] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[node model/separable_conv2d_15/sep... | closed | 2020-04-01T23:06:53Z | 2020-04-29T00:19:13Z | https://github.com/keras-team/autokeras/issues/1078 | [
"feature request",
"pinned"
] | ghost | 7 |
getsentry/sentry | python | 87,044 | Set Up Code Mapping fails when the file is at the top of the source repository | [On this event](https://demo.sentry.io/issues/6395093418/events/latest/?project=4508969830973440&query=is%3Aunresolved%20issue.priority%3A%5Bhigh%2C%20medium%5D&referrer=latest-event&sort=date&stream_index=1), I clicked on:

![I... | open | 2025-03-13T21:34:23Z | 2025-03-19T14:04:36Z | https://github.com/getsentry/sentry/issues/87044 | [
"Product Area: Issues"
] | bruno-garcia | 6 |
vitalik/django-ninja | rest-api | 341 | applying renderers and parsers to TestClient | Hey, how can I apply my own renderer and parser to TestClient? The API itself works correctly, but the TestClient only accepts and returns json format. It should be added to this that when using a custom renderer (for example, xml), the generated swager still sends the content type equal to app/json in the headers | closed | 2022-01-28T10:59:23Z | 2022-10-01T17:04:21Z | https://github.com/vitalik/django-ninja/issues/341 | [] | VityasZV | 1 |
littlecodersh/ItChat | api | 522 | 关于群消息包中ActualNickName的获取 | 在获取群消息时itchat在消息包中加入了三个键值
```
isAt: 判断是否@本号
ActualNickName: 实际NickName
Content: 实际Content
```
在截取信息的时候我发现ActualNickName这个键值很多时候什么都获取不到,因为是后来加的所以我认为这个功能应该是在itchat源码中处理而不是微信消息的原始数据。
附一个我抓取到的群消息包
```
msg = {
'MsgId': '3059713934041007946',
'FromUserName': '@1df538f516955a2d80a095506964426d',
'ToU... | closed | 2017-09-25T09:00:53Z | 2019-07-03T03:09:37Z | https://github.com/littlecodersh/ItChat/issues/522 | [
"question"
] | HardGaming01 | 5 |
ansible/awx | automation | 15,016 | duplicate key value violates unique constraint "pg_type_typname_nsp_index" | ### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software provide... | closed | 2024-03-21T13:51:33Z | 2024-03-27T12:48:52Z | https://github.com/ansible/awx/issues/15016 | [
"type:bug",
"component:api",
"needs_triage",
"community"
] | Klaas- | 10 |
harry0703/MoneyPrinterTurbo | automation | 577 | 修改配置文件的时候,只能配置OpenAI的API吗?DeepSeek的API可不可以 | ### 是否已存在类似问题?
- [ ] 我已搜索现有问题
### 当前行为
我配置完OpenAI的API之后都配置后面的东西了,才发现我配置的那串码是测试码。。。。要生成真正的码要 五刀 ,所以就想问DeepSeek的可以吗?
### 预期行为
怎么解决一下
### 重现步骤
无
### 堆栈追踪/日志
无
### Python 版本
v3.12.0
### 操作系统
macOS 12.7.6
### MoneyPrinterTurbo 版本
wu
### 其他信息
_No response_ | closed | 2025-01-25T12:13:16Z | 2025-02-05T06:52:30Z | https://github.com/harry0703/MoneyPrinterTurbo/issues/577 | [
"bug"
] | heizhijin | 1 |
xlwings/xlwings | automation | 1,642 | api.merge() freezes the program | #### OS Windows 10
#### Versions of xlwings, Excel and Python (0.23.4, Office 365, Python 3.9.6)
Hi,
I am trying to merge a range of cells using api.merge() and the program freezes and terminates after a few minutes. No tracebacks. If I remove api.merge() it just works.
```python
app = xw.App(visib... | closed | 2021-07-02T06:20:51Z | 2021-07-09T10:09:27Z | https://github.com/xlwings/xlwings/issues/1642 | [] | kameaplli | 1 |
snarfed/granary | rest-api | 150 | Atom titles when parsing microformats, 'note' type | So, this is more a support request. I'm trying to integrate with fediverse and want to expose an atom feed from my microformats page.
https://granary.io/url?url=https://realize.be/timeline&input=html&output=atom
It's almost good, apart from two things I can't put my finger on:
1. the title for entries which ar... | closed | 2018-05-25T10:08:40Z | 2018-05-25T18:13:46Z | https://github.com/snarfed/granary/issues/150 | [] | swentel | 4 |
mwaskom/seaborn | pandas | 3,697 | Split violin plots not working | Hi,
I am trying to re-run a previous code that worked very well to create grouped asymmetrical violin plots. I am getting several errors that were not happening (maybe 6 months ago) and now am I trying to constrain the errors. I think one of the issues is that I am not providing an x= value (because when I run [Sea... | closed | 2024-05-25T19:14:32Z | 2024-05-29T22:18:29Z | https://github.com/mwaskom/seaborn/issues/3697 | [] | mlldantas | 7 |
marcomusy/vedo | numpy | 1,055 | Error Encountered While Decimating Mesh with Default Function (Quadric) | Hi @marcomusy ,
I hope you remember me from the POLBIAS 2023 conference in Dresden last year. I work with @jo-mueller and @haesleinhuepf.
I am encountering an error when attempting to decimate my mesh using the default function, which employs quadric decimation. Below is the traceback of the error:
AttributeEr... | closed | 2024-02-19T12:14:16Z | 2024-03-09T14:12:51Z | https://github.com/marcomusy/vedo/issues/1055 | [] | maleehahassan | 8 |
huggingface/transformers | tensorflow | 36,272 | Device Movement Error with 4-bit Quantized LLaMA 3.1 Model Loading | ### System Info
```shell
I'm running into a persistent issue when trying to load the LLaMA 3.1 8B model with 4-bit quantization. No matter what configuration I try, I get this error during initialization:
pgsql
Copy
CopyValueError: `.to` is not supported for `4-bit` or `8-bit` bitsandbytes models. Please use the mode... | open | 2025-02-19T07:33:39Z | 2025-03-13T13:29:01Z | https://github.com/huggingface/transformers/issues/36272 | [] | Pritidhrita | 2 |
modoboa/modoboa | django | 3,130 | Cannot enable DKIM on new domains. | # Impacted versions
* OS Type: Ubuntu
* OS Version: 22.04.3 LTS
* Database Type: MySQL
* Database version: mariadb Ver 15.1
* Modoboa: 2.2.2
* installer used: Yes
* Webserver: Nginx
# Steps to reproduce
Upgraded a while back, attempted to add a new domain - but I cannot enable DKIM. I found that I can cr... | closed | 2023-12-02T23:45:00Z | 2024-01-28T23:31:32Z | https://github.com/modoboa/modoboa/issues/3130 | [] | stutteringp0et | 2 |
tqdm/tqdm | pandas | 971 | TypeError with Iterators using the GUI | - [ ] I have marked all applicable categories:
+ [X] exception-raising bug
+ [ ] visual output bug
+ [ ] documentation request (i.e. "X is missing from the documentation." If instead I want to ask "how to use X?" I understand [StackOverflow#tqdm] is more appropriate)
+ [ ] new feature request
- [ ]... | closed | 2020-05-14T22:40:45Z | 2020-06-28T22:25:09Z | https://github.com/tqdm/tqdm/issues/971 | [
"p0-bug-critical ☢",
"submodule ⊂",
"to-merge ↰",
"c1-quick 🕐"
] | rwhitt2049 | 1 |
babysor/MockingBird | deep-learning | 487 | 预处理ppg模型时出错 | Globbed 891 wav files.
Loaded encoder "pretrained_bak_5805000.pt" trained to step 5805001
Preprocessing: 0%| | 0/891 [00:00<?, ?wav/s]multiprocessing.pool.RemoteTraceback:
"""
Traceback (most recent call last):
File "C:\Users\CHOPY\AppData... | closed | 2022-04-04T03:49:02Z | 2022-09-21T09:36:54Z | https://github.com/babysor/MockingBird/issues/487 | [
"help wanted"
] | Chopin68 | 8 |
streamlit/streamlit | streamlit | 10,193 | Version information doesn't show in About dialog in 1.41 | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
We used to show which Streamlit version is ru... | closed | 2025-01-15T19:31:52Z | 2025-01-16T15:26:20Z | https://github.com/streamlit/streamlit/issues/10193 | [
"type:bug",
"status:awaiting-user-response"
] | jrieke | 3 |
scikit-optimize/scikit-optimize | scikit-learn | 658 | Interaction with Python logging module | When setting
> verbose = True
I would like to have the print outs go to my Python logger. Is there an easy way to do this? | open | 2018-04-09T08:50:22Z | 2018-04-10T10:07:15Z | https://github.com/scikit-optimize/scikit-optimize/issues/658 | [] | bstemper | 1 |
Nemo2011/bilibili-api | api | 728 | [提问] Bilibili API将废弃UID转向使用open_id的支持问题 | **Python 版本:** 3.11.5
**模块版本:** bilibili-api-python 16.2.0
**运行环境:** Windows
---
嘿,维护bilibili-api-python的朋友们,
看到Bilibili的API更新了,4月25日后UID就要退出历史舞台,open_id要开始大展拳脚了。我一直在用你们的库来做开发,目前库里似乎还没提到open_id的适配。
如果你们已经有更新计划,那太好了,直接把我的issue关了当我啥都没说。如果还在计划中,我只想跟你们提个醒。万一有更新的时间表,透露一二也是极好的,这样我也能同步我的开发节奏。
感谢啦,期待回音!
编... | closed | 2024-03-24T11:30:38Z | 2024-03-31T01:03:41Z | https://github.com/Nemo2011/bilibili-api/issues/728 | [
"question",
"need update"
] | oldip | 4 |
oegedijk/explainerdashboard | plotly | 75 | Sorting of variables in FeatureInputComponent | How is it working? Would it be possible to sort it manually?
In my current use case I have two normal categorical variables A & B and one multivalued, i.e. 0-1-encoded, variable C featured as C_1, C_2, ... . A and B are somewhere in the middle and the first row of the FeatureInputComponent is C_23, C_25, C_10, C_1, ... | closed | 2021-01-29T10:46:09Z | 2021-02-03T12:49:47Z | https://github.com/oegedijk/explainerdashboard/issues/75 | [] | hkoppen | 5 |
recommenders-team/recommenders | deep-learning | 1,264 | How can I add exclude items while using BPR | ### Adding exclude_items list when using BPR.recommend or recommend_all
So, I have a need where I must exclude certain list of items for recommendation when using recommend or recommend_all. Mainly due to time constraint.
How do I implement this?
I though about doing top_k * 3, then filtering on my own side bu... | open | 2020-12-24T08:18:58Z | 2020-12-24T08:24:31Z | https://github.com/recommenders-team/recommenders/issues/1264 | [
"help wanted"
] | bipinkc19 | 1 |
deepinsight/insightface | pytorch | 2,072 | insightface.data get_image() function tries to fetch images from library directories | 
| open | 2022-08-10T09:49:54Z | 2022-08-10T13:22:46Z | https://github.com/deepinsight/insightface/issues/2072 | [] | usmancheema89 | 1 |
littlecodersh/ItChat | api | 921 | 掉线 | 机器人自动掉线。。。 | closed | 2020-06-01T06:59:02Z | 2020-07-20T02:43:58Z | https://github.com/littlecodersh/ItChat/issues/921 | [] | 2905683882 | 1 |
plotly/dash | flask | 2,971 | Add a function to directly retrieve component property values in callbacks | For example, I currently have a dcc.Store component in the application. The Store component stores the data that is required for most callbacks. In the current application, I have to add the Store component to the State in each callback.
Just like below
```
@app.callback(
Output(...),
Input(...),
Sta... | open | 2024-08-29T01:37:06Z | 2024-09-12T14:09:39Z | https://github.com/plotly/dash/issues/2971 | [
"feature",
"P3"
] | insistence | 8 |
ydataai/ydata-profiling | jupyter | 1,633 | Add new metrics or report capability for descriptive, predictive and prescriptive | ### Missing functionality
No Descriptive Analysis, Predictive Analysis , Prescriptive Analysis possible for creating a combined report.
### Proposed feature
IDEA :- If we can do descriptive, predictive & prescriptive analysis also with exploratory data analysis, so it can make ydata very useful & generate a whole co... | open | 2024-07-30T13:48:19Z | 2024-08-01T10:17:33Z | https://github.com/ydataai/ydata-profiling/issues/1633 | [
"feature request 💬"
] | rohanot | 0 |
NullArray/AutoSploit | automation | 916 | Divided by zero exception292 | Error: Attempted to divide by zero.292 | closed | 2019-04-19T16:03:19Z | 2019-04-19T16:37:02Z | https://github.com/NullArray/AutoSploit/issues/916 | [] | AutosploitReporter | 0 |
nolar/kopf | asyncio | 730 | An alternative way to use indexes without propagating them through the call stack |
## Problem
I'm using in-memory indexes and overall I think they work really well. One thing that's been nagging me though is that you can only get to them through the kwargs injected in handlers. My pain point with this approach is that while practical, it gets ugly when working with nested indices.
Take this s... | open | 2021-04-02T12:15:38Z | 2021-07-12T19:08:18Z | https://github.com/nolar/kopf/issues/730 | [
"enhancement"
] | zoopp | 3 |
gunthercox/ChatterBot | machine-learning | 2,055 | Integrating this python chatbot on a PHP website | Hello,
The bot I've built works fine and I want to integrate it on my PHP website.
What I'm doing as of now is requesting the user a question through PHP, passing this question as a parameter to the python chatbot script, getting a response and displaying on the website.
Even though it works, there isn't much flexi... | closed | 2020-10-13T10:30:59Z | 2025-02-25T23:15:45Z | https://github.com/gunthercox/ChatterBot/issues/2055 | [] | Siddikulus | 2 |
allenai/allennlp | data-science | 5,448 | Predictor.from_path('coref-spanbert-large-2021.03.10.tar.gz') downloads model into cache though I provide a local copy of the model | I am trying to load a local copy of the `coref-spanbert` model using `Predictor.from_path` but it starts downloading the model again into cache/huggingface. How do I fix this.
>>> from allennlp.predictors import Predictor
>>> coref_model = Predictor.from_path('coref-spanbert-large-2021.03.10.tar.gz')
D... | closed | 2021-10-26T06:29:24Z | 2021-11-24T16:09:48Z | https://github.com/allenai/allennlp/issues/5448 | [
"question",
"stale"
] | irshadbhat | 3 |
numba/numba | numpy | 9,835 | Large overhead when launching kernel with torch tensors | When launching a CUDA kernel using a torch array as input, there is a significant overhead in the `as_cuda_array` call. Using this example (with `torch==2.5.1 numba==0.60.0`):
```python
import numba.cuda
import torch
from tqdm import tqdm
N_RUNS = 10_000
@numba.cuda.jit(
numba.void(
numba.typ... | closed | 2024-12-09T10:00:51Z | 2024-12-30T14:13:57Z | https://github.com/numba/numba/issues/9835 | [
"needtriage",
"CUDA"
] | materight | 2 |
dgtlmoon/changedetection.io | web-scraping | 1,684 | [feature] RSS feeds include BaseURL not set | **Version and OS**
- Change detection: v0.43.2 on Synology NAS Docker
**Is your feature request related to a problem? Please describe.**
I use FreshRSS (Docker on Synology NAS) for my feeds and Change detection creates those RSS feed for websites which has no feeds.
As it can be seen on the screenshot the link re... | closed | 2023-07-08T16:22:32Z | 2023-09-14T12:32:07Z | https://github.com/dgtlmoon/changedetection.io/issues/1684 | [
"enhancement"
] | update-freak | 11 |
activeloopai/deeplake | computer-vision | 2,932 | [FEATURE] Upgrade pillow >= 10.3.0 | ### Description
Consider updating to Pillow >= 10.3.0 due to [CVE-2024-28219](https://github.com/advisories/GHSA-44wm-f244-xhp3)
https://github.com/python-pillow/Pillow/releases/tag/10.3.0
### Use Cases
_No response_ | closed | 2024-08-26T08:42:44Z | 2024-09-17T17:25:51Z | https://github.com/activeloopai/deeplake/issues/2932 | [
"enhancement"
] | daniel-code | 1 |
ultralytics/yolov5 | machine-learning | 12,996 | The accuracy of the .pt model will decrease after being converted to .engine model. | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and found no similar bug report.
### YOLOv5 Component
Detection
### Bug
The results obtained by my inference using the .pt model and the .engine model are different.
### Environment
_No response_
... | closed | 2024-05-10T06:09:07Z | 2024-07-01T00:26:31Z | https://github.com/ultralytics/yolov5/issues/12996 | [
"bug",
"Stale"
] | arkerman | 6 |
AirtestProject/Airtest | automation | 1,028 | 使用相对路径选择图片定位时, logtohtml方法报错 | win10 ,
airtest 版本1.2.4 ,
python3.9 ,
使用pycharm运行 ,
在操作的时候如果使用了相对路径 , 在生成报告的时候就会出错
使用绝对路径可以正常生成报告

![image](https://user-images.githubusercontent.com/100344368/155489439-d4f0f9e3-8002-4766-bc78-b15... | open | 2022-02-24T08:44:19Z | 2022-02-24T08:44:19Z | https://github.com/AirtestProject/Airtest/issues/1028 | [] | helei0411 | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.