
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
deepset-ai/haystack | machine-learning | 8,930 | Remove explicit mention of Haystack "2.x" in cookbooks | closed | 2025-02-25T10:56:07Z | 2025-03-11T09:05:31Z | https://github.com/deepset-ai/haystack/issues/8930 | [
"P2"
] | julian-risch | 0 | |
httpie/cli | api | 1,001 | https command not found after fresh installation | Hi guys,
Any time I install httpie on Ubuntu (`sudo apt-get install httpie`), the `http` command works perfectly fine afterwards.
However, `https` is never found.
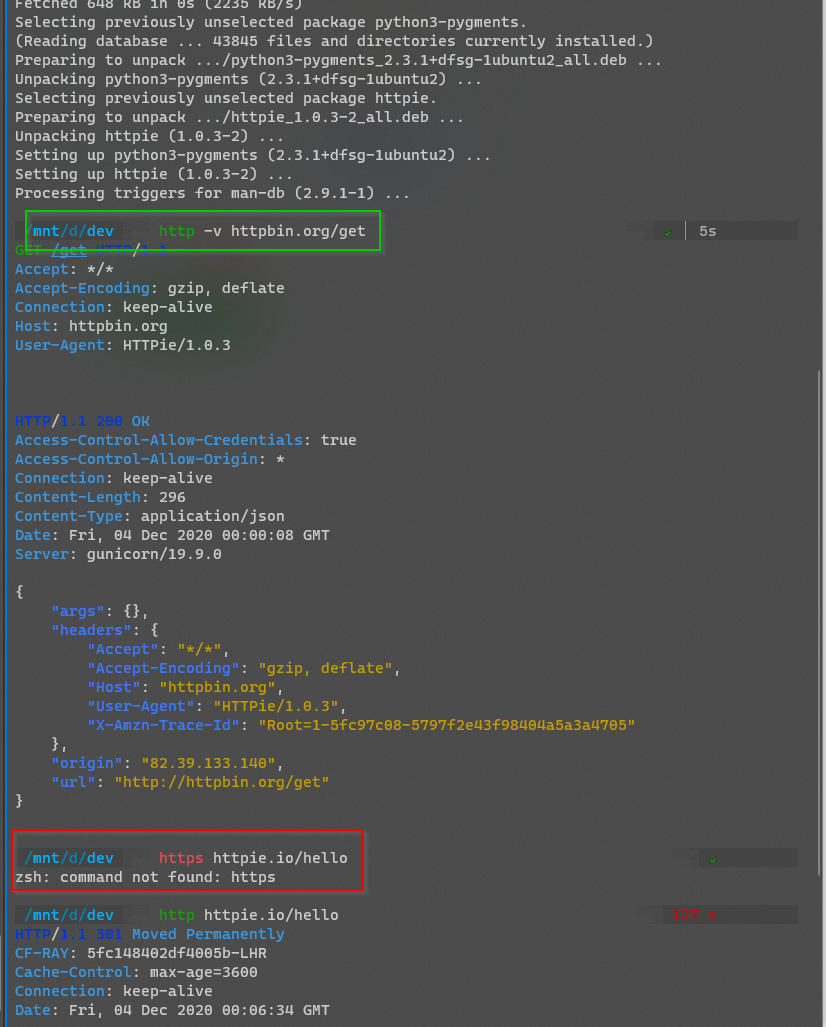
I have had this on all machines wh... | closed | 2020-12-04T00:11:38Z | 2021-09-22T15:56:45Z | https://github.com/httpie/cli/issues/1001 | [
"packaging"
] | batjko | 3 |
autogluon/autogluon | data-science | 3,838 | [BUG] GPU is not used in v1.0.0 | **Bug Report Checklist**
<!-- Please ensure at least one of the following to help the developers troubleshoot the problem: -->
- [x] I provided code that demonstrates a minimal reproducible example. <!-- Ideal, especially via source install -->
- [x] I confirmed bug exists on the latest mainline of AutoGluon via s... | open | 2023-12-22T16:10:14Z | 2024-11-05T18:04:12Z | https://github.com/autogluon/autogluon/issues/3838 | [
"bug",
"module: tabular",
"Needs Triage",
"priority: 1"
] | hanxuh-hub | 0 |
huggingface/diffusers | deep-learning | 10,969 | Run FLUX-controlnet zero3 training failed: 'weight' must be 2-D | ### Describe the bug
I am attempting to use Zero-3 for Flux Controlnet training on 8 GPUs following the guidance of [README](https://github.com/huggingface/diffusers/blob/main/examples/controlnet/README_flux.md#apply-deepspeed-zero3). The error below occured:
```
[rank0]: RuntimeError: 'weight' must be 2-D
```
### ... | open | 2025-03-05T02:14:09Z | 2025-03-24T02:24:04Z | https://github.com/huggingface/diffusers/issues/10969 | [
"bug"
] | alien-0119 | 1 |
tensorflow/tensor2tensor | deep-learning | 1,212 | Loading weights before decoding starts in interactive decoding | Hi,
I am trying to use interactive decoding using
```
t2t-decoder \
--data_dir=$DATA_DIR \
--problem=$PROBLEM \
--model=$MODEL \
--hparams_set=$HPARAMS \
--output_dir=$TRAIN_DIR \
--decode_hparams="beam_size=$BEAM_SIZE,alpha=$ALPHA" \
--decode_interactive
```
But in this case the checkpoint ... | open | 2018-11-12T05:41:26Z | 2018-11-13T06:14:05Z | https://github.com/tensorflow/tensor2tensor/issues/1212 | [] | sugeeth14 | 2 |
Johnserf-Seed/TikTokDownload | api | 375 | cookie用不长久 [BUG] | closed | 2023-03-29T10:07:15Z | 2023-04-03T07:11:36Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/375 | [
"故障(bug)",
"额外求助(help wanted)",
"无效(invalid)"
] | SCxiaozhouM | 1 | |
plotly/dash-core-components | dash | 67 | `dcc.DatePickerSingle` and `dcc.DatePickerRange` missing `style` and `className` properties | One of recent updates gave all components `style` and `className` properties to make styling easier. Two components added for date picking are missing them.
That can be useful when one wants to disable border on them to make them blend in better, or just change cursor to pointer when hovering. | open | 2017-08-30T13:32:20Z | 2019-09-22T16:30:09Z | https://github.com/plotly/dash-core-components/issues/67 | [
"dash-type-enhancement"
] | radekwlsk | 3 |
hankcs/HanLP | nlp | 727 | 如何在索引分词中只使用自定义词典分词 | ## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检索功能](https://github.com/hankcs/HanLP/issues)搜索了我的问题,也没有找... | closed | 2017-12-29T07:42:58Z | 2018-01-18T10:08:55Z | https://github.com/hankcs/HanLP/issues/727 | [
"question"
] | jimmy-walker | 4 |
psf/requests | python | 6,763 | Body with Special Characters Gets Cut | When sending a request with special characters using the requests module, the request gets cut and is not sent fully.
This seems to be caused by the requests module calculating the length of the original string, but once the request arrives at the urllib3 module, the urllib3 module encodes the request and calculates... | closed | 2024-07-08T14:33:37Z | 2024-07-08T18:35:44Z | https://github.com/psf/requests/issues/6763 | [] | Boris-Rozenfeld | 9 |
matplotlib/matplotlib | data-science | 29,595 | [Bug]: Setting alpha with an array is ignored with jupyterlab %inline backend | ### Bug summary
If alpha is set as an array (of equal shape as the image data), the alpha value is ignored.
This is failing for inline plots in Jupyter Lab.
### Code for reproduction
```Python
import matplotlib
print(matplotlib.__version__)
import numpy as np
import matplotlib.pyplot as plt
img_data = np.random.ra... | open | 2025-02-09T02:21:38Z | 2025-02-10T16:14:46Z | https://github.com/matplotlib/matplotlib/issues/29595 | [] | rhiannonlynne | 5 |
SALib/SALib | numpy | 41 | Compute Si for multiple outputs in parallel | It would be good to extend the existing Morris analysis code so that multiple results vectors could be computed from one call, with results passed as a numpy array, rather than just a vector.
At present, it is necessary to loop over each output you wish to compute the metrics for, calling the analysis procedure each t... | open | 2015-03-09T15:22:54Z | 2023-12-08T12:31:50Z | https://github.com/SALib/SALib/issues/41 | [
"enhancement"
] | willu47 | 10 |
cvat-ai/cvat | tensorflow | 8,859 | Why does the position of an already marked annotation box change? | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
1, fix a labeled object box use rectangle shape ,For example, changing the size of the box
2, Press the `F` key and th... | closed | 2024-12-23T09:44:11Z | 2025-03-05T20:45:37Z | https://github.com/cvat-ai/cvat/issues/8859 | [
"bug"
] | jaffe-fly | 11 |
httpie/cli | python | 1,417 | some issues with the copy button | when i click on the copy button . this what I get copied
"# Install httpie
choco install httpie"
so I think i will be be helpful if i can just copy the "choco install httpie" | open | 2022-06-20T09:26:53Z | 2022-10-10T21:22:56Z | https://github.com/httpie/cli/issues/1417 | [
"bug",
"website"
] | alidauda | 3 |
apragacz/django-rest-registration | rest-api | 143 | Cannot install dev dependencies | ### Describe the bug
Running `make install_dev` with Python 3.8 crashes, preventing to install dev dependencies.
### Expected behavior
Dependencies installed.
### Actual behavior
Crashes with:
```log
ERROR: Cannot install -r requirements/requirements-dev.lock.txt (line 164) and ipython==7.16.1 becaus... | closed | 2021-05-26T15:18:56Z | 2021-05-27T05:02:50Z | https://github.com/apragacz/django-rest-registration/issues/143 | [
"type:bug"
] | Neraste | 2 |
jadore801120/attention-is-all-you-need-pytorch | nlp | 209 | Performance Confusion | Hi, appreciate the awesome work, very impressive and concise implementation of the original paper!
Here is something confuses me that, is the performance benchmark link at the [home page](https://github.com/jadore801120/attention-is-all-you-need-pytorch#performance) for the WMT 2016 dataset or WMT 2017 dataset?
... | open | 2023-05-26T06:55:57Z | 2023-05-26T08:21:02Z | https://github.com/jadore801120/attention-is-all-you-need-pytorch/issues/209 | [] | Zarca | 0 |
yeongpin/cursor-free-vip | automation | 365 | [讨论]: 如果额度到150后怎么办 | ### Issue 检查清单
- [x] 我理解 Issue 是用于反馈和解决问题的,而非吐槽评论区,将尽可能提供更多信息帮助问题解决。
- [x] 我确认自己需要的是提出问题并且讨论问题,而不是 Bug 反馈或需求建议。
- [x] 我已阅读 [Github Issues](https://github.com/yeongpin/cursor-free-vip/issues) 并搜索了现有的 [开放 Issue](https://github.com/yeongpin/cursor-free-vip/issues) 和 [已关闭 Issue](https://github.com/yeongpin/cursor-free-vip... | open | 2025-03-23T16:04:21Z | 2025-03-24T15:44:56Z | https://github.com/yeongpin/cursor-free-vip/issues/365 | [
"question"
] | tianhuahao | 1 |
plotly/dash | flask | 2,547 | [BUG] Graphs in vertical tabs do not use available space | Installed Dash versions:
```
dash 2.9.2
dash-core-components 2.0.0
dash-html-components 2.0.0
dash-table 5.0.0
dash-testing-stub 0.0.2
```
Browsers/OS
- OS: Linux
- Browser ungoogled-chromium, firefox
**Describe the bug**
... | closed | 2023-05-28T13:11:46Z | 2023-05-31T13:06:14Z | https://github.com/plotly/dash/issues/2547 | [] | TheNyneR | 10 |
fastapi/sqlmodel | pydantic | 542 | Order of columns in the table created does not have 'id' first, despite the order in the SQLModel. Looks like it's prioritising fields with sa_column | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X... | open | 2023-01-29T14:11:08Z | 2024-11-22T11:57:33Z | https://github.com/fastapi/sqlmodel/issues/542 | [
"question"
] | epicwhale | 8 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 118 | 合并后没有量化的全量中文llama模型应该怎么推理?用原始的llama推理代码一直报词表数量无法整除 | AssertionError: 49953 is not divisible by 2
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 2276862 closing signal SIGTERM
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 2276861) of binary: /home/platform/anaconda3/envs/hcs/bin/python
Traceback (mos... | closed | 2023-04-11T04:06:56Z | 2023-06-15T12:51:47Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/118 | [] | WUHU-G | 1 |
gee-community/geemap | streamlit | 1,525 | I encountered an error using function: netcdf_to_ee | <!-- Please search existing issues to avoid creating duplicates. -->
### Environment Information
```python
colab
```
### Description
Hello, Professor Wu. I hope to get your help. I want to load the netCDF file on the hard disk into colab and convert it into image type for subsequent calculation.
**The... | closed | 2023-04-29T14:22:48Z | 2023-04-29T14:55:42Z | https://github.com/gee-community/geemap/issues/1525 | [
"bug"
] | xlsadai | 1 |
MagicStack/asyncpg | asyncio | 1,094 | Provide wheels for Python 3.12 as installing without C compiler currently fails | * **asyncpg version**: 0.28.0
* **Python version**: 3.12
* **Platform**: Linux
* **Did you install asyncpg with pip?**: yes
Hey, could you please either build the wheels for 0.28.0 / Python 3.12 or make a new release? We are moving the codebase to Python 3.12 and installations are currently failing without a C co... | closed | 2023-10-26T17:01:26Z | 2025-02-18T19:53:39Z | https://github.com/MagicStack/asyncpg/issues/1094 | [] | zyv | 4 |
dantaki/vapeplot | seaborn | 5 | Pip install error | pip install raises following error
`Command "python setup.py egg_info" failed with error code 1 in /private/var/folders/_1/hdrhn2y9719c6vnr54tsk2tc0000gn/T/pip-build-sl19a10_/vapeplot/` | closed | 2018-02-04T18:25:02Z | 2018-02-06T18:07:35Z | https://github.com/dantaki/vapeplot/issues/5 | [] | Dpananos | 5 |
noirbizarre/flask-restplus | api | 548 | "return make_response(body, status)" behaves differently from "return body, status" when @marshal_with is used | With "return make_response(body, status)" the status value is ignored (and set 200 by default)
With "return body, status" it isn't.
Is it an intended behavior?
It must be set somewhere here
https://github.com/noirbizarre/flask-restplus/blob/master/flask_restplus/marshalling.py#L248 | open | 2018-11-01T19:31:18Z | 2018-11-01T19:31:18Z | https://github.com/noirbizarre/flask-restplus/issues/548 | [] | andy-landy | 0 |
paperless-ngx/paperless-ngx | django | 8,795 | [BUG] Concise description of the issue | ### Description
While using devcontainer on VSCode I get the following error:
Start: Run: docker-compose -f /home/kanak/work/AI4Bhārat/contrib/paperless-ngx/.devcontainer/docker-compose.devcontainer.sqlite-tika.yml config
Stop (277 ms): Run: docker-compose -f /home/kanak/work/AI4Bhārat/contrib/paperless-ngx/.devconta... | closed | 2025-01-18T06:47:31Z | 2025-02-18T03:06:11Z | https://github.com/paperless-ngx/paperless-ngx/issues/8795 | [
"not a bug"
] | dteklavya | 3 |
matplotlib/matplotlib | data-visualization | 28,892 | [Doc]: Be more specific on dependencies that need to be installed for a "reasonable" dev environment | ### Documentation Link
https://matplotlib.org/devdocs/devel/development_setup.html#install-dependencies
### Problem
> Most Python dependencies will be installed when [setting up the environment](https://matplotlib.org/devdocs/devel/development_setup.html#dev-environment) but non-Python dependencies like C++ co... | closed | 2024-09-26T15:34:15Z | 2024-11-01T01:50:06Z | https://github.com/matplotlib/matplotlib/issues/28892 | [
"Documentation"
] | timhoffm | 1 |
dpgaspar/Flask-AppBuilder | rest-api | 2,275 | Demo url not working | http://flaskappbuilder.pythonanywhere.com is currently not working.
I have seen in the past other times there has been this problem and issue opened.
| open | 2024-10-11T14:42:51Z | 2025-02-21T12:30:31Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/2275 | [] | fedepad | 2 |
graphistry/pygraphistry | jupyter | 221 | [FEA] multi-gpu demo | See https://github.com/graphistry/graph-app-kit/issues/56
- [ ] download nb
- [ ] single gpu nb
- [ ] multi-gpu nb
- [ ] parallel io nb
- [ ] tutorial | open | 2021-03-18T06:31:33Z | 2021-03-18T06:32:22Z | https://github.com/graphistry/pygraphistry/issues/221 | [
"enhancement"
] | lmeyerov | 0 |
apachecn/ailearning | scikit-learn | 585 | AI | closed | 2020-05-13T11:04:46Z | 2020-11-23T02:05:17Z | https://github.com/apachecn/ailearning/issues/585 | [] | LiangJiaxin115 | 0 | |
wkentaro/labelme | computer-vision | 629 | [BUG] QT Error on Windows to Launch GUI | QT Error
```
qt.qpa.plugin: Could not find the Qt platform plugin "windows" in ""
This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem.
``` | closed | 2020-03-24T19:14:12Z | 2021-09-23T15:19:28Z | https://github.com/wkentaro/labelme/issues/629 | [
"issue::bug"
] | Zumbalamambo | 4 |
piskvorky/gensim | data-science | 2,957 | Clean up OOP / stub methods | Do we really need such stub methods that only call the same superclass method with the same arguments? That's already the default which occurs if no method is present. By my understanding, doc-comment tools like Sphinx will, in their current versions, already propagate superclass API docs down to subclasses.
The onl... | open | 2020-09-24T10:09:00Z | 2020-09-24T10:27:53Z | https://github.com/piskvorky/gensim/issues/2957 | [
"housekeeping"
] | piskvorky | 0 |
pytest-dev/pytest-cov | pytest | 288 | Regression in 2.7.1 when validating notebooks | I am running pytest for the [`krotov` package](https://travis-ci.org/qucontrol/krotov) with both pytest-cov and the [nbval plugin](https://nbval.readthedocs.io/en/latest/) to validate jupyter notebook in the documentation. Since `pytest-cov` was updated to version 2.7.1, there is extra output related to repr-strings of... | open | 2019-05-06T06:46:08Z | 2019-05-06T07:21:35Z | https://github.com/pytest-dev/pytest-cov/issues/288 | [] | goerz | 1 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 15,802 | Ui "screwed" up in Networks Tabs | ### Checklist
- [X] The issue exists after disabling all extensions
- [X] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [X] The issue exists in the current version of the webui
- [X] The issue has not been reported before... | open | 2024-05-15T14:39:23Z | 2024-06-20T19:20:36Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15802 | [
"bug-report"
] | OleJ1964 | 3 |
httpie/cli | api | 606 | output formatting on debian... | hi and thanks for a great tool :)
i'm not seeing json output formatted as it is in the screenshots here - i get just a single string of json that wraps at the terminal window edge - is there anything i should be doing differently that:
http [domain.blah]
?
thanks
| closed | 2017-09-05T20:57:23Z | 2017-09-05T22:59:31Z | https://github.com/httpie/cli/issues/606 | [] | fake-fur | 7 |
paperless-ngx/paperless-ngx | machine-learning | 9,390 | [BUG] Edit Permission not set | ### Description
The "Edit" Permission is not set in a document, although the permission is set in the workflow.
Workflow:
<img width="531" alt="Image" src="https://github.com/user-attachments/assets/6e79e8ca-08a7-4ca0-8d71-4afa647e3e9a" />
Document:
<img width="413" alt="Image" src="https://github.com/user-attachmen... | closed | 2025-03-13T15:00:45Z | 2025-03-13T17:59:59Z | https://github.com/paperless-ngx/paperless-ngx/issues/9390 | [
"cant-reproduce"
] | weizenmanncom | 5 |
3b1b/manim | python | 1,947 | Unused Function `digest_mobject_attrs` | I'm not quite sure if this function is used anymore. It was last changed about 3 years ago and doesn't seem to be used anymore and has no references either.
https://github.com/3b1b/manim/blob/fcff44a66b58a3af4070381afed0b4fad80768be/manimlib/mobject/mobject.py#L416-L423
(Currently working on updating the CE versi... | closed | 2022-12-28T21:15:38Z | 2023-01-05T00:54:47Z | https://github.com/3b1b/manim/issues/1947 | [] | MrDiver | 4 |
yt-dlp/yt-dlp | python | 12,377 | Add support for Public Radio Exchange (PRX) | ### Checklist
- [x] I'm reporting a new site support request
- [x] I've verified that I have **updated yt-dlp to nightly or master** ([update instructions](https://github.com/yt-dlp/yt-dlp#update-channels))
- [x] I've checked that all provided URLs are playable in a browser with the same IP and same login details
- [x... | open | 2025-02-16T02:08:15Z | 2025-02-16T16:02:51Z | https://github.com/yt-dlp/yt-dlp/issues/12377 | [
"site-request"
] | wkrick | 1 |
huggingface/datasets | numpy | 7,427 | Error splitting the input into NAL units. | ### Describe the bug
I am trying to finetune qwen2.5-vl on 16 * 80G GPUS, and I use `LLaMA-Factory` and set `preprocessing_num_workers=16`. However, I met the following error and the program seem to got crush. It seems that the error come from `datasets` library
The error logging is like following:
```text
Convertin... | open | 2025-02-28T02:30:15Z | 2025-03-04T01:40:28Z | https://github.com/huggingface/datasets/issues/7427 | [] | MengHao666 | 2 |
huggingface/datasets | tensorflow | 6,896 | Regression bug: `NonMatchingSplitsSizesError` for (possibly) overwritten dataset | ### Describe the bug
While trying to load the dataset `https://huggingface.co/datasets/pysentimiento/spanish-tweets-small`, I get this error:
```python
---------------------------------------------------------------------------
NonMatchingSplitsSizesError Traceback (most recent call last)
[<ipyth... | open | 2024-05-13T15:41:57Z | 2024-05-13T15:44:48Z | https://github.com/huggingface/datasets/issues/6896 | [] | finiteautomata | 0 |
nolar/kopf | asyncio | 810 | Handler starts but never finishes | ### Long story short
I have recently deploy our operator to an AKS cluster (its been running on EKS & on-prem clusters without any issue) & started noticing that it wasn't
handling changes to CRDs, restarting the container would trigger the handler successfully. At first I thought that we were missing events so expli... | closed | 2021-07-26T17:42:57Z | 2021-08-05T15:43:06Z | https://github.com/nolar/kopf/issues/810 | [
"bug"
] | euan-tilley | 3 |
widgetti/solara | fastapi | 182 | Passthrough kwargs to Tooltip | The Tooltip only allows a handful of options, but since it's a fairly thin wrapper around ipyvuetify Tooltip we could pass through **kwargs to the underlying tooltip (or enumerate every option but just passing kwargs is easier).
One situation where I would have found this useful is using together with ipyleaflet, si... | open | 2023-06-29T07:43:07Z | 2023-06-29T07:43:07Z | https://github.com/widgetti/solara/issues/182 | [] | mangecoeur | 0 |
geopandas/geopandas | pandas | 3,402 | Test with zoneinfo alongside pytz | > [...]we should probably parametrise the tests so we test the behaviour is right with zoneinfo too
_Originally posted by @m-richards in https://github.com/geopandas/geopandas/pull/3401#pullrequestreview-2242358553_
| closed | 2024-08-16T10:08:54Z | 2024-10-28T07:55:16Z | https://github.com/geopandas/geopandas/issues/3402 | [] | martinfleis | 0 |
microsoft/MMdnn | tensorflow | 730 | error converting from keras to caffe | Platform (like ubuntu 16.04/win10):ubuntu 16.04
Python version:Python 2.7.16
Source framework with version (like Tensorflow 1.4.1 with GPU):tensorflow 1.9.0
Destination framework with version (like CNTK 2.3 with GPU):caffe 1.0.0
Pre-trained model path (webpath or webdisk path):custom file
Running scripts... | open | 2019-09-05T16:46:33Z | 2019-09-09T02:44:19Z | https://github.com/microsoft/MMdnn/issues/730 | [] | TaeheeJeong | 1 |
aminalaee/sqladmin | asyncio | 721 | CSS and Javascript files for the Admin not loaded | ### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
I deployed my project on the server but the Admin is only HTML, I followed the steps in this link (https://aminalaee.dev/sqladmin/cookbook/deploym... | closed | 2024-02-29T10:12:28Z | 2024-03-13T12:21:05Z | https://github.com/aminalaee/sqladmin/issues/721 | [] | sharbelAllouneh | 2 |
recommenders-team/recommenders | data-science | 1,274 | [ASK] Rename master branch -> main | ### Description
Rename master branch -> main
### Other Comments
| closed | 2021-01-07T14:20:25Z | 2021-01-22T09:06:23Z | https://github.com/recommenders-team/recommenders/issues/1274 | [
"help wanted"
] | gramhagen | 1 |
HumanSignal/labelImg | deep-learning | 293 | Previous labels do not appear when I reopen an image file | <!--
Hi,
I worked on LableImg Windows_v1.6.1 and labelled some images.
Then I had the issue #221:
Before I use the solution on GitHub (i.e. to remove the file .labelImgSettings.pkl), I re-installed the same version of LabelImg. With the solution of GitHub, I can launch the program and continue my annotation ... | closed | 2018-05-11T09:39:24Z | 2018-05-22T06:51:18Z | https://github.com/HumanSignal/labelImg/issues/293 | [] | Bigoudom | 5 |
deepinsight/insightface | pytorch | 2,373 | Please provide 256 or 512 model for face swap. It will improve output quality. | Thanks for providing 128 size model for face swap.
Please provide 256 or 512 model.
It will greatly improve output quality.
Thanks a lot.
Waiting for your positive reply. | open | 2023-07-16T13:33:21Z | 2024-07-03T03:00:53Z | https://github.com/deepinsight/insightface/issues/2373 | [] | arnold408 | 2 |
fastapi/sqlmodel | sqlalchemy | 312 | TypeError: issubclass() arg 1 must be a class | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X] I al... | open | 2022-04-23T23:47:10Z | 2022-04-24T21:43:04Z | https://github.com/fastapi/sqlmodel/issues/312 | [
"question"
] | Maypher | 1 |
litestar-org/polyfactory | pydantic | 563 | Bug: `ModelFactory._create_model` not handling `_build_context = None` | ### Description
I'm getting errors from the `ModelFactory._create_model` function which is not handling when the passed in build context is `None`: https://github.com/litestar-org/polyfactory/pull/549/files#diff-58f44001d9e3d42e5c8fc55d621181dc66f78b37b46a414bb1bf6b6dd1d2bcbbR504
Should that line be:
```py
if ... | closed | 2024-07-08T05:24:59Z | 2025-03-20T15:53:17Z | https://github.com/litestar-org/polyfactory/issues/563 | [
"bug"
] | sam-or | 1 |
benbusby/whoogle-search | flask | 196 | [BUG] !bang-operators only work as prefix | **Describe the bug**
The !bang-operators adopted from DuckDuckGo only seem to be identified correctly when typed _in front of_ other search terms. On DDG they can be placed anywhere in the search e.g. "hello world !reddit" or even "hello !reddit world". Both would search the website reddit.com for "hello world".
**... | closed | 2021-02-12T08:53:52Z | 2021-02-20T20:32:55Z | https://github.com/benbusby/whoogle-search/issues/196 | [
"bug"
] | Wever1985 | 1 |
graphdeco-inria/gaussian-splatting | computer-vision | 781 | CUDA error: an illegal memory access was encountered | I have identified that the `identifyTileRanges` function is causing the issue, but I'm not quite sure how to resolve it. Do you have any constructive suggestions?
https://github.com/graphdeco-inria/diff-gaussian-rasterization/blob/59f5f77e3ddbac3ed9db93ec2cfe99ed6c5d121d/cuda_rasterizer/rasterizer_impl.cu#L116
**Od... | closed | 2024-04-30T07:21:18Z | 2025-01-05T10:48:49Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/781 | [] | baoachun | 16 |
unionai-oss/pandera | pandas | 1,032 | Cannot set pa.Column.nullable after it's been set | ```python
schm = pa.infer_schema(df)
for name, column in schm.columns.items():
column.checks = []
column.coerce = True
# column.nullable cannot be set :(
column.nullable = False
print(column.nullable)
break
```
I'm trying to correct the DataFrameSchema to do what I need it to do. Howev... | open | 2022-11-22T13:36:25Z | 2022-11-23T14:12:12Z | https://github.com/unionai-oss/pandera/issues/1032 | [
"bug"
] | bgalvao | 2 |
ultralytics/ultralytics | deep-learning | 18,796 | Number of class instances does not increase with training parameter `augment=True` | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
I was recently testing out the augmentation parameter `augment` to increase ... | open | 2025-01-21T10:08:12Z | 2025-01-21T10:15:39Z | https://github.com/ultralytics/ultralytics/issues/18796 | [
"question",
"detect"
] | fninsiima | 2 |
benbusby/whoogle-search | flask | 167 | [BUG] In consistent dark mode. | **Describe the bug**
Dark mode is inconsistent.
**To Reproduce**
Just deployed the latest container from docker hub and found it.
**Deployment Method**
- [ ] Heroku (one-click deploy)
- [*] Docker
- [ ] `run` executable
- [ ] pip/pipx
- [ ] Other: [describe setup]
**Version of Whoogle Search**
- [* ] L... | closed | 2021-01-15T10:21:41Z | 2021-01-23T19:25:37Z | https://github.com/benbusby/whoogle-search/issues/167 | [
"bug"
] | doloresjose | 3 |
twopirllc/pandas-ta | pandas | 27 | Minor issue in the example notebook | The example notebook shows
`e.ta.indicators()`
but I think this needs to be
`e().ta.indicators()`
Or you need to assign `e = pd.DataFrame()` ... coders choice. :)
| closed | 2019-07-20T04:35:50Z | 2019-07-31T17:38:11Z | https://github.com/twopirllc/pandas-ta/issues/27 | [] | bdowling | 5 |
aio-libs-abandoned/aioredis-py | asyncio | 1,206 | Health check fails when a pubsub has no subscriptions | ### Describe the bug
When a PubSub needs to issue a PING due to the health check feature, it does not consider that there might be no subscriptions at the moment. Redis responds differently to PING depending on whether there are active subscriptions or not: if there are no subscriptions it just returns the argument as... | open | 2021-11-17T07:08:41Z | 2021-11-18T05:02:49Z | https://github.com/aio-libs-abandoned/aioredis-py/issues/1206 | [
"bug"
] | bmerry | 2 |
twopirllc/pandas-ta | pandas | 559 | chandelier_exit | Here is a code that i have written for chandelier_exit, if possible add to repo
```python
def chandelier_exit(df1, atr_length=14, roll_length=22, mult=2, use_close=False):
df = df1.copy()
df.columns = df.columns.str.lower()
my_atr = ta.Strategy(
name="atr",
ta=[... | open | 2022-07-02T06:58:19Z | 2022-07-03T18:00:37Z | https://github.com/twopirllc/pandas-ta/issues/559 | [
"enhancement",
"help wanted",
"good first issue"
] | bibinvargheset | 5 |
521xueweihan/HelloGitHub | python | 2,898 | 【开源自荐】Graph Maker:免费在线折线图生成器,轻松在线制作各种图表 | 一、Graph Maker是什么
Graph Maker是一个功能强大的在线图表生成工具,专为需要可视化数据的用户量身打造。无论你是学生、老师,还是职场人士,只需简单几步,就能将数据转化为美观的图表,帮助你更好地理解和展示信息。
Graph Maker:免费在线折线图生成器,轻松在线制作各种图表

二、功能特征
Graph Maker的功能非常丰富,主要有以下几个亮点:
多种图表类型:支持折线图、柱状图、直方图等多种图表形式,满足不同数据展示需求。
... | open | 2025-02-08T03:09:23Z | 2025-02-08T03:09:23Z | https://github.com/521xueweihan/HelloGitHub/issues/2898 | [] | zhugezifang | 0 |
alteryx/featuretools | scikit-learn | 1,778 | Bug with parallel feature matrix calculation within sklearn cross-validation | ### Bug with parallel feature matrix calculation within sklearn cross-validation
-----
#### Bug Description
Hello, guys! Thank you for the quick release of featuretools 1.1.0 !
During my research I have faced the following bug:
I have an estimator which is actually an `imblearn Pipeline`. The estimator cons... | closed | 2021-11-11T10:49:38Z | 2021-11-25T13:40:54Z | https://github.com/alteryx/featuretools/issues/1778 | [] | VGODIE | 14 |
CTFd/CTFd | flask | 1,987 | Not able to install/run | I have cloned [CTFd](https://github.com/CTFd/CTFd.git) repository and then created a `secret key` I have docker and docker-compose working as well, but when I try to run `docker-compose` it shows me an error like this one, I have no idea can you please help me, I am installing on a VPS server and a codomain
```
ctfd... | closed | 2021-09-13T14:02:49Z | 2021-09-14T19:39:22Z | https://github.com/CTFd/CTFd/issues/1987 | [] | TheBlapse | 0 |
giotto-ai/giotto-tda | scikit-learn | 356 | Kernels on diagrams | #### Description
During development of #343 and following the discussion in #348 , we noticed that we are missing kernel methods as such. Maybe we could implement a `Kernel` transformer, with an API similar to `PairwiseDistances`, and a parameter `method`.
#### Steps/Code to Reproduce
```
kernel_method = Kernel(m... | closed | 2020-03-10T09:38:03Z | 2020-04-17T11:28:14Z | https://github.com/giotto-ai/giotto-tda/issues/356 | [
"enhancement",
"discussion"
] | wreise | 0 |
modin-project/modin | data-science | 7,051 | Update Exception message for `astype` function in the case of duplicated values | closed | 2024-03-11T19:46:26Z | 2024-03-12T09:44:17Z | https://github.com/modin-project/modin/issues/7051 | [
"Code Quality 💯"
] | anmyachev | 0 | |
miguelgrinberg/Flask-Migrate | flask | 169 | Generate upgrade command is wrong | """heheh
Revision ID: 10d1d4585f92
Revises: c6b2d0ca1b68
Create Date: 2017-08-29 15:44:42.160000
"""
from alembic import op
import sqlalchemy as sa
# revision identifiers, used by Alembic.
revision = '10d1d4585f92'
down_revision = 'c6b2d0ca1b68'
branch_labels = None
depends_on = None
def upgrade... | closed | 2017-08-29T07:57:32Z | 2019-01-13T22:20:35Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/169 | [
"question",
"auto-closed"
] | beckjing | 3 |
rio-labs/rio | data-visualization | 95 | Make `MultiLineTextInput` Always Fit Its Content | As it stands, multi line text inputs are awkward to use. By default they are (vertically) small, only fitting in very little text. This requires scrolling in any but the shortest texts.
A common solution to this is to assign a larger `height` on the Python side, but this results in awkwardly large inputs, and still ... | open | 2024-07-07T21:12:56Z | 2024-07-07T21:12:56Z | https://github.com/rio-labs/rio/issues/95 | [
"enhancement"
] | mad-moo | 0 |
awesto/django-shop | django | 819 | Problems accessing customerproxy addresses | > It's `admin:shop_customerproxy_changelist`
>
> Small hint to find out yourself:
>
> * Go to the admin page you are looking for.
> * Copy the URL without the site part, here `/en/admin/shop/customerproxy/`.
> * Run `./manage.py shell`
> * Use that URL in function `resolve`.
> * Recheck with `reverse` if the ... | closed | 2020-06-16T13:29:01Z | 2020-06-16T23:45:12Z | https://github.com/awesto/django-shop/issues/819 | [] | jhonvidal | 2 |
microsoft/hummingbird | scikit-learn | 528 | Fix icon consistency for dark theme | Sorry to say but this bugs the hell out of me 😁 Which one doesn't belong:

Can you change it to be more consistent or add an option for it? | closed | 2021-06-22T20:14:17Z | 2021-06-22T20:50:20Z | https://github.com/microsoft/hummingbird/issues/528 | [] | ronilaukkarinen | 2 |
seleniumbase/SeleniumBase | pytest | 2,252 | Can I change WebGL information | Is there a way to enter random information? When we tested on https://pixelscan.net/
Exemple:
languages=["en-US", "en"],
vendor="Google Inc.",
platform="Win32",
webgl_vendor="Intel Inc.",
renderer="Intel Iris OpenGL Engine",
fix_hairline=True,
more using in the SB model
```
with SB(uc=True, mobile=Fal... | closed | 2023-11-08T06:20:00Z | 2023-11-08T07:23:49Z | https://github.com/seleniumbase/SeleniumBase/issues/2252 | [
"duplicate",
"UC Mode / CDP Mode"
] | gupta723 | 1 |
thtrieu/darkflow | tensorflow | 934 | Annotation file type | I have 1000 image files and their annotation (file type txt). They are used in YOLO.
But Darkflow's annotation is required xml file type annotation.
Can I change my txt file to xml easily?
or I have to marking again?
| closed | 2018-11-14T14:26:14Z | 2018-12-27T13:12:10Z | https://github.com/thtrieu/darkflow/issues/934 | [] | murras | 7 |
Guovin/iptv-api | api | 602 | 新版docker缺少依赖 |

Starting periodic command scheduler: cron.
Traceback (most recent call last):
File "/tv-driver/main.py", line 5, in <module>
from utils.channel import (
File "/tv-driver/utils/channel.py", line 13, in <module>
from uti... | closed | 2024-11-30T08:17:11Z | 2024-12-02T02:27:37Z | https://github.com/Guovin/iptv-api/issues/602 | [
"invalid"
] | vbskycn | 1 |
ScrapeGraphAI/Scrapegraph-ai | machine-learning | 271 | gemini api is not set proxy , resulting in a 60s timeout. | I can't find any specific functionality in the LangChain framework or the langchain_google_genai module that allows you to set or modify the user agent in requests to the Google SDK.
I found that using the following code can force the proxy in Linux, but not in Windows.
```python
import os
os.environ["http_proxy"] ... | closed | 2024-05-20T05:52:55Z | 2024-10-10T09:11:26Z | https://github.com/ScrapeGraphAI/Scrapegraph-ai/issues/271 | [] | wrench1997 | 2 |
flairNLP/flair | pytorch | 2,758 | fine-tuning on ner-pooled with new dataset | Hey!
Right now, I am trying to fine-tune ner-pooled model on another dataset. After the training, I want to evaluate on validation and hyperparameter tune. And finalize by testing. However, when I train on the new dataset, I get scores of zeros.
My code is as follows, taking [issue: #1178](https://github.com/fla... | closed | 2022-05-10T21:23:36Z | 2022-11-01T15:05:06Z | https://github.com/flairNLP/flair/issues/2758 | [
"question",
"wontfix"
] | Nuveyla | 1 |
deeppavlov/DeepPavlov | tensorflow | 1,582 | 👩💻📞DeepPavlov Community Call #18 | Привет, друзья!
Мы рады вернуться в этом месяце с DeepPavlov Community Call на **русском языке.**
На предстоящем вебинаре к нам придет приглашенный гость **Борис Галицкий**, ассоциированный сотрудник лаборатории Интеллектуальных систем и структурного анализа НИУ ВШЭ, основатель нескольких стартапов в области ИИ, п... | closed | 2022-07-22T16:29:26Z | 2023-07-06T11:59:13Z | https://github.com/deeppavlov/DeepPavlov/issues/1582 | [
"discussion"
] | PolinaMrdv | 0 |
deepset-ai/haystack | pytorch | 8,114 | docs: clean up docstrings of PyPDFToDocument | closed | 2024-07-30T06:47:44Z | 2024-07-30T09:08:46Z | https://github.com/deepset-ai/haystack/issues/8114 | [] | agnieszka-m | 0 | |
scikit-learn/scikit-learn | machine-learning | 30,512 | Fail to pickle `SplineTransformer` with `scipy==1.15.0rc1` | ### Describe the bug
Spotted in scikit-lego, running `check_estimators_pickle` fails with `SplineTransformer` and `readonly_memmap=True`.
cc: @koaning
### Steps/Code to Reproduce
```py
from sklearn.utils.estimator_checks import check_estimators_pickle
from sklearn.preprocessing import SplineTransformer
che... | closed | 2024-12-19T15:36:53Z | 2025-01-04T04:32:31Z | https://github.com/scikit-learn/scikit-learn/issues/30512 | [
"Bug"
] | FBruzzesi | 8 |
profusion/sgqlc | graphql | 244 | Allow updating Operation name and args after its initialization | ## 🚀 Feature Request
## Description
Allow updating Operation name and args after its initialization
```
operation = Operation(query)
operation.name = "newlyNamedQuery"
operation.args = {"some_arg": Arg(SomeKindScalar)}
operation.find_something(some_args=Variable("some_arg"))
```
In some cases (for a... | open | 2024-08-19T18:34:22Z | 2024-09-15T14:19:07Z | https://github.com/profusion/sgqlc/issues/244 | [] | pwyllcrusader | 3 |
huggingface/pytorch-image-models | pytorch | 1,002 | vit_large_patch16_384 has incorrect settings | **Describe the bug**
When trying to use boilerplate code to predict using vit_large_patch16_384 an error occurs. This is due to the config for vit_large_patch16_384 containing input size (3, 224, 224) instead of (3, 384, 384). I suspect that vit_base_patch16_384 has the same issue, perhaps even more of these models.
... | closed | 2021-11-27T14:49:55Z | 2021-11-27T23:05:27Z | https://github.com/huggingface/pytorch-image-models/issues/1002 | [
"bug"
] | bjfranks | 3 |
matplotlib/matplotlib | matplotlib | 29,775 | [Doc]: Improve install guidance | ### Problem
We have
- https://matplotlib.org/stable/#install thought as short instructions on the landing page
- https://matplotlib.org/stable/install/index.html as the complete install guide
They are mostly fine.
Issues:
- [ ] There's https://matplotlib.org/stable/users/getting_started/#installation-quick-start, ... | open | 2025-03-18T23:35:39Z | 2025-03-19T00:08:23Z | https://github.com/matplotlib/matplotlib/issues/29775 | [
"Documentation"
] | timhoffm | 1 |
chatopera/Synonyms | nlp | 72 | 用nearby查处的是相关词,而不是同义词,有很多时候甚至是反义词 | # description
用nearby查处的是相关词,而不是同义词,有很多时候甚至是反义词,比如喜欢和讨厌
* version:
python 3.6.5
| closed | 2018-11-30T07:25:36Z | 2020-10-27T01:11:24Z | https://github.com/chatopera/Synonyms/issues/72 | [] | weihaixiaoseu | 9 |
pyeve/eve | flask | 1,259 | Improper authorization error when authenticating in eve/auth.py | ### Expected Behavior
When invalid credentials are supplied for Token based auth, 401 should be thrown as the last exception and that should be there in response message returned.
### Actual Behavior
```json
{
"_status": "ERR",
"_error": {
"code": 500,
"message": "__init__() got a... | closed | 2019-04-08T07:27:23Z | 2019-04-08T09:28:58Z | https://github.com/pyeve/eve/issues/1259 | [] | checkaayush | 6 |
ivy-llc/ivy | tensorflow | 27,969 | Fix Ivy Failing Test: torch - elementwise.maximum | closed | 2024-01-20T16:19:21Z | 2024-01-25T09:53:52Z | https://github.com/ivy-llc/ivy/issues/27969 | [
"Sub Task"
] | samthakur587 | 0 | |
microsoft/unilm | nlp | 1,562 | Fine tuning kosmos-2 | Hi @pengzhiliang. I want to finetune kosmos-2 on a VQA task that answer is a single word (like a multi-class classification task) and I call this single word label. I only have question answer pairs but not bounding boxes. I was wondering that I should use `<grounding>` or not. I mean should I use `<grounding> Question... | closed | 2024-05-23T11:08:27Z | 2024-06-21T11:22:18Z | https://github.com/microsoft/unilm/issues/1562 | [] | FarzanRahmani | 2 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 16,402 | [Bug]: ImportError: DLL load failed while importing onnx_cpp2py_export | ### Checklist
- [ ] The issue exists after disabling all extensions
- [ ] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [x] The issue exists in the current version of the webui
- [ ] The issue has not been reported ... | open | 2024-08-18T14:28:25Z | 2024-09-20T15:40:36Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16402 | [
"bug-report"
] | ZeroCool22 | 5 |
graphdeco-inria/gaussian-splatting | computer-vision | 786 | problems with camera pose recovery and rendering in different settings | Hello,
Currently, I'm working on recovering camera poses and 3D reconstruction using Gaussian splattings. The approach involves using depth maps to unproject pixels for a specific frame, fitting them tightly (overfitting), and then determining the relative transformation to the next frame. My aim is to learn these t... | open | 2024-05-02T22:09:51Z | 2024-05-08T03:26:11Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/786 | [] | ostapagon | 1 |
dmlc/gluon-cv | computer-vision | 1,769 | Reporting a vulnerability | Hello!
I hope you are doing well!
We are a security research team. Our tool automatically detected a vulnerability in this repository. We want to disclose it responsibly. GitHub has a feature called **Private vulnerability reporting**, which enables security research to privately disclose a vulnerability. Unfortun... | closed | 2023-04-10T11:07:21Z | 2023-07-18T06:32:57Z | https://github.com/dmlc/gluon-cv/issues/1769 | [
"Stale"
] | igibek | 1 |
pywinauto/pywinauto | automation | 1,152 | COMError when tested application puts data in Datagrid | ## Expected Behavior
Application IO-Link Analyzer 1.1.2 that allows to read data communication on IO-Link lines (something like Wireshark).
Pywinauto allows to start application and start sniffing, controls work proper.
Data is sniffed into control:
ListView - '' (L121, T275, R1087, B653)
['TransfersListView', ... | open | 2021-11-29T13:42:51Z | 2021-11-30T13:56:49Z | https://github.com/pywinauto/pywinauto/issues/1152 | [] | danielpyc | 1 |
tensorpack/tensorpack | tensorflow | 779 | HOW to fix assertionError:0, while running this code on single GPU (GeForce GTX 1080 Ti) | #!/usr/bin/env python
# -*- coding: UTF-8 -*-
import numpy as np
import tensorflow as tf
import argparse
import os
import cv2
os.environ["CUDA_VISIBLE_DEVICES"]="0"
from tensorpack import *
from tensorpack.tfutils.symbolic_functions import *
from tensorpack.tfutils.summary import *
from tensorpack.utils.... | closed | 2018-06-01T09:53:59Z | 2018-06-15T07:40:47Z | https://github.com/tensorpack/tensorpack/issues/779 | [
"usage"
] | AbidHussain70 | 1 |
openapi-generators/openapi-python-client | rest-api | 205 | Remove optional generated class attributes set to None from serialized payload | **Is your feature request related to a problem? Please describe.**
Given a generated class like:
```python
class MyModel:
required_property: str
optional_property: Optional[Dict[Any, Any]]
```
When communicating with an API, the requests are getting rejected for certain optional properties in which we'... | closed | 2020-10-02T21:03:13Z | 2020-11-06T16:48:53Z | https://github.com/openapi-generators/openapi-python-client/issues/205 | [
"✨ enhancement"
] | bowenwr | 7 |
freqtrade/freqtrade | python | 11,291 | FreqAI not finding the datasieve module | <!--
Have you searched for similar issues before posting it? I have searched and found one that was the same problem. It said that not all of the requirements had been installed and to reinstall them. So I did, but didn't fix the issue. I used "pip list" to check if it had been installed and it was installed. I cant ... | closed | 2025-01-27T01:41:37Z | 2025-01-29T05:57:02Z | https://github.com/freqtrade/freqtrade/issues/11291 | [
"Question",
"Install",
"freqAI"
] | Jigaliath1 | 1 |
wger-project/wger | django | 1,897 | Proposal: Back button to return to dashboard | ## Use case
When I was using the application, I found that it was hard for me to understand how to go back to the main page after I'd clicked into one of the sections, the only way I found to was to click the icon in the top left, which isn't the best from a usability heuristic standpoint.
## Proposal
I'd love to ad... | open | 2025-02-24T06:26:01Z | 2025-03-14T05:51:24Z | https://github.com/wger-project/wger/issues/1897 | [] | bernstna | 8 |
xinntao/Real-ESRGAN | pytorch | 296 | How can I test my model | When I finish the training and know the location of the model, how to test and verify it
I have put it in to experiments/pretrained_models/ | open | 2022-04-12T13:30:08Z | 2022-04-12T13:30:08Z | https://github.com/xinntao/Real-ESRGAN/issues/296 | [] | zzshzyl | 0 |
microsoft/MMdnn | tensorflow | 141 | Warning: MXNet Parser has not supported operator SoftmaxActivation with name cls_prob. | Platform (like ubuntu 16.04/win10): Ubuntu 16.04
Python version: 2.7.12
Source framework with version (like Tensorflow 1.4.1 with GPU): mxnet 1.1.0 with cu80 GPU
Destination framework with version (like CNTK 2.3 with GPU): IR
Pre-trained model path (webpath or webdisk path): N/A
Running scripts: python ... | closed | 2018-04-08T04:33:59Z | 2018-08-20T17:25:56Z | https://github.com/microsoft/MMdnn/issues/141 | [] | IamJasonYe | 3 |
gevent/gevent | asyncio | 1,129 | Update to latest libuv release for 1.3 | Currently we're on 1.18.x, should try 1.19.x
To solve #1126 we're going to have to apply patches to the libuv source code *anyway* so there's little point in being sure we work with older versions. | closed | 2018-03-02T12:31:43Z | 2018-03-30T22:13:35Z | https://github.com/gevent/gevent/issues/1129 | [] | jamadden | 0 |
NullArray/AutoSploit | automation | 642 | Unhandled Exception (12d820452) | Autosploit version: `3.0`
OS information: `Linux-4.19.0-parrot1-13t-amd64-x86_64-with-Parrot-4.5-stable`
Running context: `autosploit.py`
Error meesage: `global name 'Except' is not defined`
Error traceback:
```
Traceback (most recent call):
File "/root/greenterminal/AutoSploit/autosploit/main.py", line 113, in main
... | closed | 2019-04-08T16:15:50Z | 2019-04-17T18:33:01Z | https://github.com/NullArray/AutoSploit/issues/642 | [] | AutosploitReporter | 0 |
dask/dask | numpy | 11,314 | Expose a blockwise - reshape operation that doesn't guarantee to keep the ordering consistent for downstream libraries | @dcherian when we chatted you mentioned that Xarray would benefit if we could expose a blockwise reshaping operation that doesn't guarantee the same ordering as the NumPy equivalent.
The requirement that Xarray would have is that
```
arr = da.random.random((100, 100, 100), chunks=(10, 10, 10))
result = arr.blo... | closed | 2024-08-14T13:29:45Z | 2024-08-27T17:41:07Z | https://github.com/dask/dask/issues/11314 | [
"array",
"array-expr"
] | phofl | 5 |
allure-framework/allure-python | pytest | 752 | allure-pytest: using the same @pytest.mark.parametrize for tests with different browsers appear as retries of the same test in the test report. | Hi, I am conducting login tests on different browsers using `pytest-playwright`. I am using `@pytest.mark.parametrize` to run tests with different emails and passwords. However, I noticed that in the allure report, my tests for Edge and Chrome are grouped together as the same test case. The test that runs first becomes... | open | 2023-07-19T04:52:55Z | 2023-07-21T09:39:59Z | https://github.com/allure-framework/allure-python/issues/752 | [
"bug",
"theme:pytest",
"contribute"
] | win5923 | 7 |
shibing624/text2vec | nlp | 154 | 能否在文档说下 text2vec.SentenceModel 和 SentenceTransformer 到底有什么区别? | 能否在文档说下 text2vec.SentenceModel 和 SentenceTransformer 到底有什么区别?
我试了readme 给的例子,发现他们计算出的示例句子的词向量是一样的。
| closed | 2024-09-24T13:34:52Z | 2024-09-26T11:18:49Z | https://github.com/shibing624/text2vec/issues/154 | [
"question"
] | qiulang | 5 |
flaskbb/flaskbb | flask | 16 | Localization | Use Flask-Babel to support different languages.
| closed | 2014-02-27T13:18:41Z | 2018-04-15T07:47:30Z | https://github.com/flaskbb/flaskbb/issues/16 | [
"enhancement"
] | sh4nks | 27 |
svc-develop-team/so-vits-svc | deep-learning | 126 | [Help]: 每次训练都在 Epoch: 2 [42%], step: 800 的位置报错退出 | ### 请勾选下方的确认框。
- [x] 我已仔细阅读[README.md](https://github.com/svc-develop-team/so-vits-svc/blob/4.0/README_zh_CN.md)和[wiki中的Quick solution](https://github.com/svc-develop-team/so-vits-svc/wiki/Quick-solution)。
- [X] 我已通过各种搜索引擎排查问题,我要提出的问题并不常见。
- [X] 我未在使用由第三方用户提供的一键包/环境包。
### 系统平台版本号
Windows 10 家庭版
### GPU 型号
NVIDIA G... | closed | 2023-04-05T18:59:38Z | 2023-04-13T04:03:13Z | https://github.com/svc-develop-team/so-vits-svc/issues/126 | [
"help wanted"
] | AGuanDao | 5 |
unionai-oss/pandera | pandas | 1,551 | `import pandera` breaks SparkSession in AWS EMR | ## Problem
Whenever I import pandera in my EMR spark application it breaks the SparkSession.
```python
import os
import findspark
# sets SPARK_HOME
findspark.init()
# commenting out this fixes the error
import pandera as pa
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCr... | closed | 2024-04-03T08:22:53Z | 2024-04-03T19:30:07Z | https://github.com/unionai-oss/pandera/issues/1551 | [
"bug"
] | sam-goodwin | 0 |
bmoscon/cryptofeed | asyncio | 535 | Cannot save TRADES to Arctic DB | I am trying to save TRADES to Arctic db using cryptofeed but i am facing the issue below.
(I can save TICKER without any issues but TRADES seems to throw the error.)
Can someone please help ?
```
Traceback (most recent call last):
File "C:\Anaconda3\lib\site-packages\cryptofeed\connection_handler.py", line 6... | closed | 2021-06-24T06:32:03Z | 2021-07-01T23:50:21Z | https://github.com/bmoscon/cryptofeed/issues/535 | [
"bug"
] | sauravskumar | 4 |
healthchecks/healthchecks | django | 1,049 | Webhook should accept $SLUG as a placeholder | I am trying to create a Webhook integration that connects to [Home Assistant binary sensor](https://www.home-assistant.io/integrations/http/#binary-sensor). It requires a URL like `http://IP_ADDRESS:8123/api/states/binary_sensor.DEVICE_NAME` with `DEVICE_NAME` confirmed to its entity ID character limits, i.e., no space... | closed | 2024-08-16T07:26:50Z | 2024-08-16T10:34:47Z | https://github.com/healthchecks/healthchecks/issues/1049 | [] | timdream | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.