
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
numba/numba | numpy | 9,424 | Support math.nextafter in nopython mode | <!--
Thanks for opening an issue! To help the Numba team handle your information
efficiently, please first ensure that there is no other issue present that
already describes the issue you have
(search at https://github.com/numba/numba/issues?&q=is%3Aissue).
-->
## Feature request
<!--
Please include d... | closed | 2024-02-07T18:02:20Z | 2024-04-26T16:32:23Z | https://github.com/numba/numba/issues/9424 | [
"feature_request",
"good first issue"
] | groutr | 8 |
widgetti/solara | fastapi | 1,013 | Potential issue: WebSocket already closed error | Solara attempts to send data over a closed WebSocket connection and then tries to close an already closed connection
This might be related to https://github.com/widgetti/solara/issues/1012
### Steps to Reproduce
While it's challenging to reproduce these issues consistently, I've observed them most frequently when:
Us... | open | 2025-03-03T08:45:27Z | 2025-03-03T08:45:27Z | https://github.com/widgetti/solara/issues/1013 | [] | JovanVeljanoski | 0 |
amidaware/tacticalrmm | django | 962 | How to put TRMM in NPM (Nginx Proxy Manager)? | **Server Info (please complete the following information):**
- OS: Debian 10
- Browser: Chrome
- RMM Version: v0.11.3
**Installation Method:**
- [x] Standard
- [ ] Docker
**Describe**
As part of a homelab, I did a basic installation of Tactical RMM. So, I wanted to put this one in NPM (Ngin... | closed | 2022-01-31T14:31:45Z | 2022-03-16T20:53:38Z | https://github.com/amidaware/tacticalrmm/issues/962 | [
"documentation"
] | Reaapers | 1 |
dpgaspar/Flask-AppBuilder | rest-api | 1,444 | formatters_columns dictionary has no effect on ListLinkWidget/ListThumbnail/ListItem/Listblock widgets | closed | 2020-07-24T09:46:17Z | 2020-12-12T20:55:23Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1444 | [
"stale"
] | ThomasP0815 | 2 | |
mlfoundations/open_clip | computer-vision | 945 | Fine Tune for emotion | Is it possible to finetune for emotion detection? How should we label the data for that? | closed | 2024-09-27T10:22:28Z | 2024-10-03T04:10:54Z | https://github.com/mlfoundations/open_clip/issues/945 | [] | SutirthaChakraborty | 0 |
cleanlab/cleanlab | data-science | 854 | Add method to compute Out-of-bag Data Shapely value | Add this efficient method for Data Shapely and Data Valuation w arbitrary ML models:
[Data-OOB: Out-of-bag Estimate as a Simple and Efficient Data Value](https://arxiv.org/abs/2304.07718)
Make sure the code runs quickly, but is numerically reproducible/stable too | open | 2023-09-30T04:42:39Z | 2023-11-23T18:43:46Z | https://github.com/cleanlab/cleanlab/issues/854 | [
"enhancement",
"good first issue",
"help-wanted"
] | jwmueller | 2 |
Yorko/mlcourse.ai | seaborn | 572 | typo in topic3_decision_trees_kNN article's image | Hello.
Typo in image [topic3_hse_instruction.png](https://github.com/Yorko/mlcourse.ai/blob/master/img/topic3_hse_instruction.png)
Arvix -> arXiv | closed | 2019-02-17T18:39:46Z | 2019-02-17T19:41:21Z | https://github.com/Yorko/mlcourse.ai/issues/572 | [] | klensy | 1 |
jina-ai/serve | deep-learning | 5,605 | [docs] request more examples | **Describe your proposal/problem**
I see that [the previous documentation](https://github.com/jina-ai/docs/blob/master/chapters/my_first_jina_app.md) and [examples](https://github.com/jina-ai/examples) have been archived, now [the examples](https://docs.jina.ai/get-started/create-app/) in the documentation are relat... | closed | 2023-01-17T09:56:44Z | 2023-05-02T00:17:35Z | https://github.com/jina-ai/serve/issues/5605 | [
"Stale"
] | songhn233 | 1 |
explosion/spaCy | deep-learning | 13,606 | Cannot complete a Docker image build with spaCy 3.7.6 | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
## How to reproduce the behaviour
<!-- Include a code example or the steps that led to the problem. Please try to be as specific as possible. -->
We use spaCy in our project, and as part of our regular work process, we build ... | closed | 2024-08-23T13:29:21Z | 2024-11-01T00:03:23Z | https://github.com/explosion/spaCy/issues/13606 | [] | erikspears | 10 |
python-gino/gino | sqlalchemy | 675 | Test is failing on SQLAlchemy 1.3.17 | * GINO version: 1.0, 1.1.x
* Python version: *
* asyncpg version: *
* aiocontextvars version: *
* PostgreSQL version: *
### Description
https://github.com/python-gino/gino/runs/695012657
maybe a bug? | closed | 2020-05-21T03:55:10Z | 2020-05-21T05:44:53Z | https://github.com/python-gino/gino/issues/675 | [
"bug"
] | fantix | 1 |
adamerose/PandasGUI | pandas | 68 | Indexing error? | Hey! Huge fan of your package. Tried it out the other day and it was great.
I am getting this error when I try to do show(raw_data). Any ideas?
`---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-... | closed | 2020-11-25T10:14:49Z | 2020-11-25T10:19:35Z | https://github.com/adamerose/PandasGUI/issues/68 | [] | lucashadin | 1 |
modin-project/modin | data-science | 6,553 | BUG: read_csv with `iterator=True` throws AttributeError | ### Modin version checks
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the latest released version of Modin.
- [ ] I have confirmed this bug exists on the main branch of Modin. (In order to do this you can follow [this guide](https://modin.readthe... | closed | 2023-09-12T14:51:00Z | 2023-09-13T18:12:25Z | https://github.com/modin-project/modin/issues/6553 | [
"bug 🦗",
"P1"
] | SiRumCz | 1 |
deezer/spleeter | tensorflow | 550 | Warning! ***HDF5 library version mismatched error*** | I installed the softwear but when i try to run it gives me this waring "Warning! ***HDF5 library version mismatched error***". I checked and found that i needed to update the h5py to 1.10.6, but when i did that the h5py install gave me this error.
`PackagesNotFoundError: The following packages are not available from c... | closed | 2021-01-06T22:27:46Z | 2021-01-08T12:10:49Z | https://github.com/deezer/spleeter/issues/550 | [
"bug",
"invalid"
] | bfp4 | 1 |
cs230-stanford/cs230-code-examples | computer-vision | 16 | Problem in Build the dataset of size 64x64 | Hello,
After I do the first step (Build the dataset of size 64x64), there is file 64x64_SIGNS file created, but there is no image in the train_signs. How to solve it? | closed | 2019-02-14T10:13:53Z | 2019-02-15T01:31:46Z | https://github.com/cs230-stanford/cs230-code-examples/issues/16 | [] | ChunJyeBehBeh | 0 |
proplot-dev/proplot | matplotlib | 104 | Add TeX Gyre fonts as the default serif, sans-serif, and monospace fonts | Currently, ProPlot makes some more widely-used (IMHO nicer) fonts the default rather than the DejaVu fonts. With the DejaVu fonts pushed to the back, the `rcParams` font family priorities are:
```yaml
# ProPlot changes
font.serif: New Century Schoolbook, Century Schoolbook L, Utopia, ITC Bookman, Bookman, Nimbus R... | closed | 2020-01-09T05:54:04Z | 2020-01-13T20:42:02Z | https://github.com/proplot-dev/proplot/issues/104 | [
"enhancement"
] | lukelbd | 1 |
gradio-app/gradio | python | 10,731 | The reply text rendered by the streaming chatbot page is incomplete | ### Describe the bug
The reply text rendered by the streaming chatbot page is incomplete and missing from the content of response_message in yield response_message, state
### Have you searched existing issues? 🔎
- [x] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
yi... | closed | 2025-03-05T07:11:51Z | 2025-03-07T14:27:22Z | https://github.com/gradio-app/gradio/issues/10731 | [
"bug",
"needs repro"
] | wuxianyess | 8 |
gradio-app/gradio | machine-learning | 10,863 | Support for a favicon | - [ X] I have searched to see if a similar issue already exists.
**Is your feature request related to a problem? Please describe.**
not a problem, just an improvement.
**Describe the solution you'd like**
eg ```demo.launch(favicon="/path/to/favicon.ico')```
**Additional context**
Add any other context or sc... | closed | 2025-03-22T16:42:06Z | 2025-03-23T21:31:12Z | https://github.com/gradio-app/gradio/issues/10863 | [] | rbpasker | 1 |
ultralytics/ultralytics | computer-vision | 18,958 | ablation experiments | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello author, I would like to ask you a question about ablation experiments.... | open | 2025-01-31T10:36:08Z | 2025-02-04T00:03:15Z | https://github.com/ultralytics/ultralytics/issues/18958 | [
"question"
] | Ellohiye | 11 |
shashankvemuri/Finance | pandas | 13 | On trading view | Hi Shashank,
I can not see which files/packages need to install before using fiance project?
Can you pelase let me know that step by step ?
| closed | 2021-07-23T18:32:29Z | 2023-04-29T18:16:30Z | https://github.com/shashankvemuri/Finance/issues/13 | [] | Amolkulkarni2 | 1 |
PaddlePaddle/models | computer-vision | 4,738 | BMN模型batch_size调小之后loss为nan | 在我把BMN的batch_size由16调成8时,训练loss会出现nan,继续调为2之后,启动训练会报错。下面为使用batch_size为8时的结果。使用的训练集是官方的示例
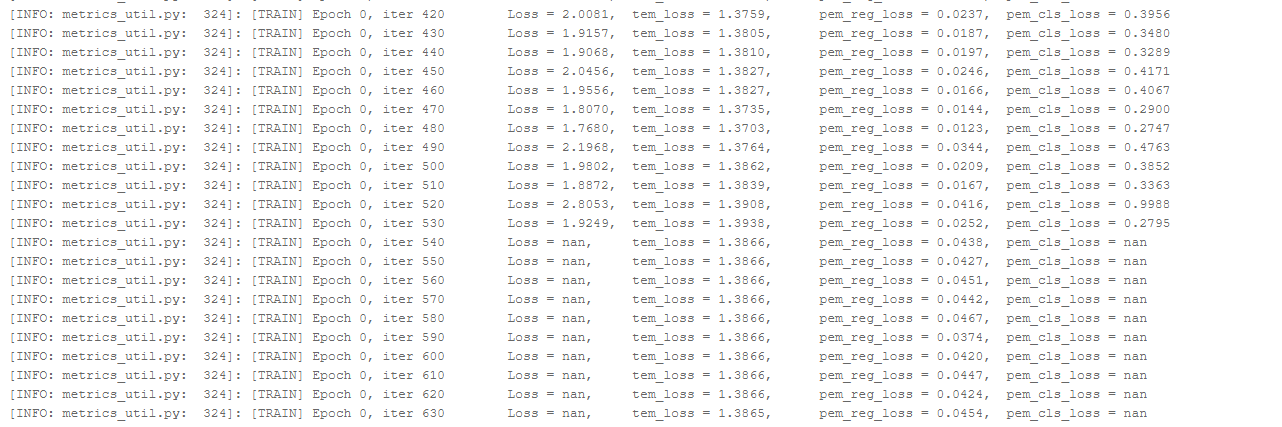
| open | 2020-07-03T08:20:02Z | 2020-07-06T10:36:00Z | https://github.com/PaddlePaddle/models/issues/4738 | [] | liu824 | 5 |
ultralytics/ultralytics | python | 18,817 | yolo11 RKNN autobackend bug | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
Integrations
### Bug
i am using rock 5b+ with python3.11 env, and i want to deploy yolov11 model on RK3588 follow this [do... | closed | 2025-01-22T08:41:26Z | 2025-01-22T09:32:44Z | https://github.com/ultralytics/ultralytics/issues/18817 | [
"embedded",
"exports"
] | ZIFENG278 | 4 |
twopirllc/pandas-ta | pandas | 783 | Discripency Between Yahoo Finance and Panda's TA in Accumulation/Distribution Indicator | **Which version are you running? The lastest version is on Github. Pip is for major releases.**
```python
import pandas_ta as ta
print(ta.version)
```
0.3.14b0
**Do you have _TA Lib_ also installed in your environment?**
```sh
$ pip list
```
pandas-ta 0.3.14b0
**Have you tried the _developmen... | closed | 2024-04-05T10:28:20Z | 2024-04-15T19:55:46Z | https://github.com/twopirllc/pandas-ta/issues/783 | [
"wontfix",
"info"
] | ibrahimmina | 1 |
K3D-tools/K3D-jupyter | jupyter | 240 | Assigning textures when getting vtk_polydata from glb/ obj+mtl | Hi I am trying to get a workflow to display ifc files in k3d with the correct textures in place. I have converted all my geometry to glb and obj+mtl to try to do this, while I am getting the geometry to display correctly, I am missing the textures.
I had opened these two issues on stack overflow, regarding this work... | closed | 2020-08-12T09:13:59Z | 2020-11-16T11:11:26Z | https://github.com/K3D-tools/K3D-jupyter/issues/240 | [] | BarusXXX | 1 |
falconry/falcon | api | 1,671 | [pylint E1101] [E] Module 'falcon' has no 'HTTP_200' member (no-member) | pylint is not recognizing falcon status codes. e.g HTTP_201
```python
import falcon
class ObjectRequestClass:
def on_get(self, req, resp):
resp.status = falcon.HTTP_201
``` | closed | 2020-02-15T16:46:15Z | 2020-02-16T14:13:15Z | https://github.com/falconry/falcon/issues/1671 | [
"duplicate"
] | zubairakram | 2 |
scanapi/scanapi | rest-api | 339 | Improve tests readability with pytest-it | ## Improve tests readability with pytest-it
https://pypi.org/project/pytest-it/ | closed | 2020-12-10T11:41:16Z | 2021-04-20T13:10:47Z | https://github.com/scanapi/scanapi/issues/339 | [
"Refactor"
] | camilamaia | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,522 | Visdom style.css error | **Hey Junyanz, thanks for your great work. I have the following issue:**
python -m visdom.server
Checking for scripts.
It's Alive!
ERROR:root:initializing
INFO:root:Application Started
INFO:root:Working directory: C:\Users\olive\.visdom
You can navigate to http://localhost:8097
INFO:tornado.access:304 GET / (... | open | 2022-12-24T21:21:26Z | 2023-07-26T03:11:22Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1522 | [] | MayuO2 | 1 |
deepfakes/faceswap | machine-learning | 870 | ValueError: not enough values to unpack (expected 2, got 0) | **Describe the bug**
When trying to run a train with Original, I get "not enough values to unpack" error/crash
This is on the Windows GUI build
Crash report:
```09/14/2019 21:16:09 MainProcess training_0 multithreading start DEBUG Starting thread 2 of 2: '_run_1'
09/14/2019 2... | closed | 2019-09-14T21:21:26Z | 2019-09-15T22:50:03Z | https://github.com/deepfakes/faceswap/issues/870 | [] | rknightion | 1 |
LAION-AI/Open-Assistant | python | 3,203 | Allow injecting system messages in chat | Feature Request: On the Open Assistant website, when on the chat with the assistant, allow for a single "Assistant" message to be injected before the user input.
Rationale:
The model gets additional training via the thumbs up and thumbs down buttons and we use this to score the responses. However, there are cases... | open | 2023-05-20T18:10:23Z | 2023-05-28T12:31:46Z | https://github.com/LAION-AI/Open-Assistant/issues/3203 | [
"feature"
] | deavid | 2 |
microsoft/qlib | deep-learning | 976 | how online_svr run backtest | i want use run backtest on rolling_online_management script 。
how can i do ? | closed | 2022-03-13T09:46:00Z | 2022-06-21T18:01:59Z | https://github.com/microsoft/qlib/issues/976 | [
"question",
"stale"
] | louis-xuy | 3 |
pbugnion/gmaps | jupyter | 87 | The ability to load arbitrary data sets | It would be great to have api support that allows you add any data set you want instead of just the few added.
| closed | 2016-10-03T17:18:56Z | 2016-10-04T16:11:23Z | https://github.com/pbugnion/gmaps/issues/87 | [] | gregv21v | 2 |
bmoscon/cryptofeed | asyncio | 118 | Coinbene publishes repeated trades | Coinbene uses REST for market data. To get trades, it's API allows you to request the last N trades, up to 2,000. (See https://github.com/Coinbene/API-Documents/wiki/1.1.2-Get-Trades-%5BMarket%5D ). Thus, a way to get trades is to repeatedly query the last trades and publish only non-repeated trades. The current code ... | closed | 2019-07-15T01:54:59Z | 2019-08-06T12:51:03Z | https://github.com/bmoscon/cryptofeed/issues/118 | [
"bug",
"good first issue"
] | glgnohk | 2 |
biolab/orange3 | pandas | 6,057 | Implementing Numba in Python and Apple Accelerate (matrix processor support) in Numpy? | <!--
Thanks for taking the time to submit a feature request!
For the best chance at our team considering your request, please answer the following questions to the best of your ability.
-->
**What's your use case?**
<!-- In other words, what's your pain point? -->
By using Numba and the Apple Accelerate (mat... | closed | 2022-07-11T13:24:43Z | 2023-01-10T10:59:35Z | https://github.com/biolab/orange3/issues/6057 | [] | stenerikbjorling | 1 |
hbldh/bleak | asyncio | 1,724 | Difficulty connecting to BLE devices on specific adapter | Problem: difficulty connecting (timeout or not found) to BLE devices using internal bluetooth adapter.
When using the Mediatek MT7922 802.11ax with bluetooth 5.2 support I have trouble connecting to 3 different BLE devices. I'm running:
- Ubuntu 24.04, 6.11.0-17-generic
- Bluez `5.72-0ubuntu5`
- bleak version `0.22.3... | open | 2025-02-22T22:28:32Z | 2025-02-22T22:40:46Z | https://github.com/hbldh/bleak/issues/1724 | [] | tahnok | 0 |
google-research/bert | nlp | 1,274 | use tensorflow2.0 | if I use tensorflow>=2.0 ,the model that have trained wether still useful? | open | 2021-11-03T01:08:53Z | 2022-06-08T13:07:21Z | https://github.com/google-research/bert/issues/1274 | [] | AutumnLeavesCHE | 3 |
ranaroussi/yfinance | pandas | 1,291 | Scraper error "TypeError: string indices must be integers" - Yahoo decrypt fail | ## Updates
### 2023 January 13
By the time of posting the issue (2023 January 12), the issue only occured sometimes. The library is now (2023 January 13) completely broken and I am unable to retrieve any stock informatio
### 2023 January 14
Fix has been merged to the branch `dev`
## Info about your system:
yfin... | closed | 2023-01-12T22:06:11Z | 2025-01-28T09:20:06Z | https://github.com/ranaroussi/yfinance/issues/1291 | [] | SamZhang02 | 39 |
scikit-image/scikit-image | computer-vision | 7,105 | invalid colour conversion raises error rather than warning | This seems like a bug in colour conversion.
```python
lab2rgb([0, 0, 28.0])
```
raises `TypeError: 'numpy.float64' object does not support item assignment`
while:
```python
lab2rgb([0, 0, 27.0])
```
works fine.
This difference is because the former results in a negative z-value in _lab2xyz conversion. T... | closed | 2023-08-21T15:20:39Z | 2023-09-16T14:16:36Z | https://github.com/scikit-image/scikit-image/issues/7105 | [
":beginner: Good first issue",
":bug: Bug"
] | marcusmchale | 2 |
TencentARC/GFPGAN | deep-learning | 74 | How to remove sharpening? | Hi. Thanks for your excellent research work.
I have a question about how to remove sharpening in v2 model? | open | 2021-10-08T00:41:18Z | 2021-10-08T00:41:18Z | https://github.com/TencentARC/GFPGAN/issues/74 | [] | xuewengeophysics | 0 |
opengeos/leafmap | jupyter | 737 | Styles are not working with streamlit | ### Environment Information
- leafmap version: lates
- Python version: 3.11
- Operating System: Linux
### Description
The Color Styles are not working with streamlit UI. I have followed below two approaches
1- Using ```m.add_gdf(gdf, layer_name = "ABD", style_callback= lambda feature: style_functio... | closed | 2024-05-10T10:58:20Z | 2024-06-16T23:18:04Z | https://github.com/opengeos/leafmap/issues/737 | [
"bug"
] | amjadraza | 3 |
tflearn/tflearn | data-science | 1,122 | Tensorboard Image Summaries with TFLearn? | Hello! I'm trying to see my feature maps in my neural network, or even just the kinds of outputs that my neural network is pumping out. I have no idea how to do this with tflearn though... What should I add to the following code so I can see some images in tensorboard?
`
import tflearn
import datautil
import tensor... | open | 2019-03-10T16:22:46Z | 2021-06-01T05:00:14Z | https://github.com/tflearn/tflearn/issues/1122 | [] | SinclairHudson | 2 |
netbox-community/netbox | django | 18,639 | Prefixes - Wrong depth | ### Deployment Type
Self-hosted
### NetBox Version
v4.2.3
### Python Version
3.10
### Steps to Reproduce
I creating prefixes via terraform
```
variable "networks" {
type = list(object({
cloud = string
prefix = string
labels = list(string)
status = optional(string)
}))
}
resource "netbox_pref... | closed | 2025-02-13T12:57:32Z | 2025-03-01T04:23:02Z | https://github.com/netbox-community/netbox/issues/18639 | [
"type: bug",
"status: revisions needed",
"pending closure"
] | rybakovanton-metta | 3 |
deepinsight/insightface | pytorch | 1,971 | partial fc petrained model inference: what to use for fp16 flag | I am trying to make an inference using the partialfc r100 and r50 models, and I have downloaded them from:
https://github.com/deepinsight/insightface/tree/master/recognition/partial_fc#5-pretrain-models
I see that the models are named `16_**` and `16*`
Is it safe to assume that these are fp16 models?
So, in l... | open | 2022-04-14T14:56:34Z | 2022-04-14T14:56:34Z | https://github.com/deepinsight/insightface/issues/1971 | [] | abaqusstudent | 0 |
wkentaro/labelme | deep-learning | 1,563 | Crash after creating a new polygon: 'NoneType' object has no attribute 'name' Unhandled Python exception | ### Provide environment information
**Environment**: Linux (local)
**Version**: 5.8.0
**Reproducible**: Yes
**Debugging info**:
```
which python; python --version; python -m pip list | grep labelme
/usr/bin/python
Python 3.12.8
labelme 5.8.0
labelme
2025-03-17 15:27:35.249 | INFO | labelme.config... | closed | 2025-03-17T19:35:13Z | 2025-03-24T03:37:22Z | https://github.com/wkentaro/labelme/issues/1563 | [
"issue::bug"
] | hack-r | 7 |
roboflow/supervision | deep-learning | 1,707 | Implement metrics comparison table & plotting | The metrics system allows the users to compute a metrics result - a class with values for a specific metrics run.
When comparing multiple models, a natural next step is to aggregate the results into a single table and/or plot them on a single chart.
Let's make this step easy!
I propose two new functions:
```p... | open | 2024-12-03T10:05:11Z | 2024-12-09T21:44:33Z | https://github.com/roboflow/supervision/issues/1707 | [
"enhancement"
] | LinasKo | 7 |
ClimbsRocks/auto_ml | scikit-learn | 206 | user validation: make sure there are at least two classes for classification problems | right now the error message is uninformative. | open | 2017-04-24T21:07:30Z | 2017-04-24T21:07:30Z | https://github.com/ClimbsRocks/auto_ml/issues/206 | [] | ClimbsRocks | 0 |
holoviz/panel | plotly | 7,281 | Tabulator: Separate aggregators for different columns blocked by type hint | <details>
<summary>Software Version Info</summary>
```plaintext
panel 1.4.5
```
</details>
#### Description of expected behavior and the observed behavior
- 'If separate aggregators for different columns are required the dictionary may be nested as {index_name: {column_name: aggregator}}'
- Aggre... | closed | 2024-09-15T09:12:49Z | 2024-12-02T13:17:57Z | https://github.com/holoviz/panel/issues/7281 | [
"component: tabulator"
] | AxZolotl | 2 |
Anjok07/ultimatevocalremovergui | pytorch | 1,276 | Error issues while extracting instrumental | Last Error Received:
Process: VR Architecture
If this error persists, please contact the developers with the error details.
Raw Error Details:
ValueError: "zero-size array to reduction operation maximum which has no identity"
Traceback Error: "
File "UVR.py", line 6638, in process_start
File "separat... | open | 2024-04-07T16:10:17Z | 2024-04-07T16:10:17Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1276 | [] | bachanstar | 0 |
jowilf/starlette-admin | sqlalchemy | 303 | Enhancement: `additional_js_links` in `BaseModelView` | **Is your feature request related to a problem? Please describe.**
If I want to include a js file in a view, (specifically a datatables plugin for the list view), currently it must be included with a field that is rendered on that page.
Additionally, if I want to include that file across all views in my application... | closed | 2023-09-22T16:56:40Z | 2023-09-22T23:18:27Z | https://github.com/jowilf/starlette-admin/issues/303 | [
"enhancement"
] | mrharpo | 0 |
django-oscar/django-oscar | django | 4,169 | Question: Best/proper way to install and use | I'm trying to understand the best way to use and customize Oscar.
For example, I want to be able to show all partners who are selling a product and let the user choose which one (like a selectable multi-vendor marketplace like Amazon's "view buying options":

- [ ] Offline Package Installation
- [ ] All-in-One
- [ ] 1Panel
- [x] Kubernetes
- [ ] Source Code
### En... | open | 2025-03-18T02:36:42Z | 2025-03-21T10:48:58Z | https://github.com/jumpserver/jumpserver/issues/15053 | [
"⏳ Pending feedback",
"🤔 Question"
] | yxxchange | 1 |
Lightning-AI/pytorch-lightning | machine-learning | 20,347 | Can't resume automatically a job, ckpt_path="hpc" throws ValueError from the start | ## Summary
When attempting to resume a job from where it left off before reaching wall-time on a SLURM cluster using PyTorch Lightning, the ckpt_path="hpc" option causes an error if no HPC checkpoint exists yet. This prevents the initial training run from starting.
## Expected Behavior
- The job should be able... | open | 2024-10-18T09:25:47Z | 2024-10-25T00:19:29Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20347 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | F-Barto | 1 |
marshmallow-code/flask-smorest | rest-api | 336 | description for route | Hi
how can I have `description` at route level ?
something like
```yaml
...
paths:
/api/adduser:
post:
description: |
test 1 \
test 2 :
* check 1
1. check 1\
1.1 check2
* *check 1*
* **check 1**
responses:
'201':... | closed | 2022-03-16T15:56:23Z | 2022-03-18T10:42:34Z | https://github.com/marshmallow-code/flask-smorest/issues/336 | [
"question"
] | arabnejad | 2 |
marshmallow-code/marshmallow-sqlalchemy | sqlalchemy | 223 | Error `TypeError: unhashable type: 'list'` | If to try to deserialize model which should have relationship one to many and put the array in this field then there will be an error `TypeError: unhashable type: 'list'` instead of ValidationError
Example
class M(Base):
....
store_id = Column(ForeignKey('stores.id'))
store = relationshi... | closed | 2019-07-03T10:43:57Z | 2025-01-17T19:24:42Z | https://github.com/marshmallow-code/marshmallow-sqlalchemy/issues/223 | [] | heckad | 3 |
autokey/autokey | automation | 444 | Unable to have AutoKey insert an em dash (—) | ## Classification: Bug
## Reproducibility: Always
## Version
AutoKey version: 0.95.10
Used GUI (Gtk, Qt, or both): Gtk
Linux Distribution: Mint
## Summary
Unable to have AutoKey insert an em dash (—)
## Steps to Reproduce (if applicable)
I create a simple phrase consisting entirely of the em dash c... | closed | 2020-09-23T15:42:32Z | 2022-06-23T07:55:18Z | https://github.com/autokey/autokey/issues/444 | [
"duplicate",
"wontfix"
] | xebico | 3 |
521xueweihan/HelloGitHub | python | 1,968 | 自荐项目 | Fantastic-admin - 一款开箱即用的 Vue 中后台管理系统框架 | ## 项目推荐
- 项目地址:https://github.com/hooray/fantastic-admin
- 类别:JS
- 项目后续更新计划:持续产出业务相关静态页面和 Vue3 版本视频教程
- 项目描述:
- 丰富的布局模式,覆盖市面上各种中后台布局,兼容PC、平板和移动端
- 提供主题配置文件,轻松实现个性化定制
- 精心设计的动效,让每一处的动画都干净利落
- 根据路由配置自动生成导航栏
- 支持全方位权限验证
- 集成多级路由缓存方案
- 推荐理由:不管是前端还是后端开发者,都可以快速上手
- 截图:
, this version of `black` is not compatible with newer versions of `click` and will throw an error upon execution of `black`.
## Recommendation
... | open | 2022-04-28T13:00:22Z | 2022-12-31T19:11:50Z | https://github.com/sourcery-ai/python-best-practices-cookiecutter/issues/18 | [] | rawrke | 1 |
aminalaee/sqladmin | fastapi | 854 | Integrate Pydantic models with sqladmin for simplified column and form management | ### Checklist
- [X] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
Currently, sqladmin requires explicit lists of columns (e.g. `column_list`, `column_details_list`, `form_columns`) to be specified in each `ModelView` configuration. I want ... | closed | 2024-11-05T10:49:09Z | 2024-12-02T11:35:32Z | https://github.com/aminalaee/sqladmin/issues/854 | [] | nimaxin | 0 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,303 | AssertionError: ./datasets/maps\trainA is not a valid directory | i have error too, after i run this"python train.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_gan", the cmd show me "Traceback (most recent call last):
File "train.py", line 29, in
dataset = create_dataset(opt) # create a dataset given opt.dataset_mode and other options
File "C:\Users\USER\Downloa... | closed | 2021-07-26T13:36:47Z | 2023-06-28T02:54:00Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1303 | [] | ChenShunHsu | 3 |
wkentaro/labelme | deep-learning | 1,233 | [Windows 10] labelme gui not opening | ### Provide environment information
python : 3.10.9
```
conda create --name=labelme python=3
conda activate labelme
pip install labelme
```
### What OS are you using?
Windows 10
### Describe the Bug
Please see in the taskbar, the white app icon is the the labelme. It just apears like this and no log message... | closed | 2023-02-05T15:37:17Z | 2024-05-17T06:20:01Z | https://github.com/wkentaro/labelme/issues/1233 | [
"issue::bug"
] | innat | 1 |
keras-team/keras | pytorch | 20,722 | Is it possible to use tf.data with tf operations while utilizing jax or torch as the backend? | Apart from tensorflow as backend, what are the proper approach to use basic operatons (i.e. tf.concat) inside the tf.data API pipelines? The following code works with tensorflow backend, but not with torch or jax.
```python
import os
os.environ["KERAS_BACKEND"] = "jax" # tensorflow, torch, jax
import keras
fr... | closed | 2025-01-03T19:44:45Z | 2025-01-04T22:44:43Z | https://github.com/keras-team/keras/issues/20722 | [] | innat | 1 |
eriklindernoren/ML-From-Scratch | machine-learning | 66 | mnist = fetch_mldata('MNIST original') | ```
URLError: <urlopen error [Errno 110] Connection timed out>
```
mldata.org appears to be down.
Please see:
https://github.com/scikit-learn/scikit-learn/issues/8588 | open | 2019-11-27T17:45:38Z | 2020-11-14T04:39:45Z | https://github.com/eriklindernoren/ML-From-Scratch/issues/66 | [] | dbl001 | 1 |
gradio-app/gradio | machine-learning | 10,437 | Create function to call current Session variable | * [x] **I have searched to see if a similar issue already exists.**
**Is your feature request related to a problem? Please describe.**
In php I just need to call the following code to get current session ID, and it persistence across all pages.
```php
<?php
session_start();
echo session_id();
```
but there is no ... | closed | 2025-01-26T06:55:32Z | 2025-01-26T07:19:36Z | https://github.com/gradio-app/gradio/issues/10437 | [] | ewwink | 1 |
ray-project/ray | tensorflow | 50,656 | [Core] Plugable storage backend besides Redis | ### Description
Redis as metadata storage backend has it only limitation, e.g. it can only guarantee eventual consistency instead of strong consistency.
It would be nice to be able to extend storage backend for the following reasons, as far as I can see.
1. uses prefer availability or consistency than performance
2.... | open | 2025-02-17T03:15:30Z | 2025-03-22T00:55:10Z | https://github.com/ray-project/ray/issues/50656 | [
"enhancement",
"P2",
"core"
] | zhengy001 | 1 |
iperov/DeepFaceLab | machine-learning | 527 | settings for highend workstations | Hi :)
i found 2 settings (converter and extraction) which doubles the speed on my system.
could u do a list which settings i can change to use the fuul power?
one i found was the used cores in the converter file and the extraction file.
Converting increased from 2.5 it/s to over 5 it/s.
I know, u have to set the... | closed | 2019-12-23T13:44:28Z | 2020-03-10T11:44:23Z | https://github.com/iperov/DeepFaceLab/issues/527 | [] | blanuk | 1 |
plotly/dash-table | plotly | 661 | [BUG] Editable table with dropdown presentation breaks with virtualization | Hi there,
similar to [https://community.plot.ly/t/dash-data-table-virtualization-completely-broken-with-an-editable-table/28565](url) (also here #583 and solved here #584 ), but now with dropdown in editable cell. An example:
```python
app = dash.Dash(__name__, external_stylesheets=['https://codepen.io/chriddyp/... | open | 2019-12-11T22:40:12Z | 2021-08-02T19:57:32Z | https://github.com/plotly/dash-table/issues/661 | [] | mirkomiorelli | 2 |
iterative/dvc | data-science | 10,363 | datasets: delta lake and huggingface | Following up on https://github.com/iterative/dvc/issues/10313 and related new features specifying `datasets` as dependencies, we can add more types of supported datasets:
- [delta lake](https://iterativeai.slack.com/archives/CB41NAL8H/p1709267375350649)
- hugging face
This could allow for setting these types of da... | open | 2024-03-19T19:51:59Z | 2024-03-21T14:22:42Z | https://github.com/iterative/dvc/issues/10363 | [
"feature request",
"p2-medium",
"A: data-management"
] | dberenbaum | 1 |
jupyterlab/jupyter-ai | jupyter | 1,010 | add VLLM support? | ### Problem/Solution
It has been great to see Ollama added as a first-class option in https://github.com/jupyterlab/jupyter-ai/pull/646, this has made it easy to access a huge variety of models and has been working very well us.
I increasingly see groups and university providers using [VLLM](https://github.com/... | closed | 2024-09-22T04:38:50Z | 2025-03-02T01:37:22Z | https://github.com/jupyterlab/jupyter-ai/issues/1010 | [
"enhancement"
] | cboettig | 17 |
firerpa/lamda | automation | 101 | 抓包的话没有lamda这个模块 | E:\Git\CodeHome\lamda\tools>python -u startmitm.py 172.16.1.15
Traceback (most recent call last):
File "E:\Git\CodeHome\lamda\tools\startmitm.py", line 34, in <module>
from lamda import __version__
ModuleNotFoundError: No module named 'lamda'
E:\Git\CodeHome\lamda\tools> | open | 2025-01-12T13:42:47Z | 2025-02-18T08:46:56Z | https://github.com/firerpa/lamda/issues/101 | [] | Linrupin | 3 |
horovod/horovod | tensorflow | 4,131 | imsham reham lekid videos | **Environment:**
1. Framework: (TensorFlow, Keras, PyTorch, MXNet)
2. Framework version:
3. Horovod version:
4. MPI version:
5. CUDA version:
6. NCCL version:
7. Python version:
8. Spark / PySpark version:
9. Ray version:
10. OS and version:
11. GCC version:
12. CMake version:
**Checklist:**
1. Did you ... | closed | 2024-11-18T23:34:44Z | 2024-11-20T12:23:50Z | https://github.com/horovod/horovod/issues/4131 | [
"bug"
] | mudasirbrohi | 0 |
ets-labs/python-dependency-injector | asyncio | 760 | Custom ResourceFactory provider help | Hi! I'm trying to handle SQLAlchemy sessions as a resource provider instead of using FastAPI's built-in `Depends`.
Let me share some code:
The database class:
```python
class Database:
"""Class to handle database connections and sessions"""
def __init__(self, db_url: str, **kwargs):
"""In... | open | 2023-11-01T21:19:15Z | 2025-01-07T16:23:39Z | https://github.com/ets-labs/python-dependency-injector/issues/760 | [] | agusmdev | 7 |
jpadilla/django-rest-framework-jwt | django | 307 | How can I add user data to the Response on login? | I'm trying to add information from the user model to the Response that is returns when a user logs-in with their username and password. Right now the `rest_framework_jwt.views.obtain_jwt_token` only returns the token. I've considered subclassing `ObtainJSONWebToken`, in an effort to add the user data by overriding the ... | closed | 2017-02-12T01:31:50Z | 2017-02-13T13:31:18Z | https://github.com/jpadilla/django-rest-framework-jwt/issues/307 | [] | JadSayegh | 2 |
widgetti/solara | fastapi | 850 | Inconsistent issue when removing a split map control from an ipyleaflet map | I am facing a very difficult issue to trace, so I came up with this [almost reproducible example](https://py.cafe/app/lopezv.oliver/solara-issue-850).
This animation shows the demo initially working as expected. Then, I refresh the app and there is an issue with the demo: the split-map control does not get removed c... | open | 2024-11-05T07:01:22Z | 2024-11-17T14:08:02Z | https://github.com/widgetti/solara/issues/850 | [] | lopezvoliver | 2 |
ionelmc/pytest-benchmark | pytest | 192 | side by side compare tables when doing parameterized benchmarks | in zokusei i compare different implementations of features using pytest-benchmark
with the standard output the long lists don't provide much of what iwant,
and id much rather see compact tables that pick specific values and line them up between test name and parameter value
a initial example is posted on https:/... | open | 2021-02-14T20:16:51Z | 2021-04-22T20:07:47Z | https://github.com/ionelmc/pytest-benchmark/issues/192 | [] | RonnyPfannschmidt | 9 |
iterative/dvc | data-science | 9,700 | Binary installers no longer attached to Github releases | # Bug Report
## Binaries no longer attached to release
## Description
For all releases until dvc [v3.1.0](https://github.com/iterative/dvc/releases/tag/3.1.0), the tagged release on Github had binary installers attached as assets:
 instead. Issues without t... | closed | 2021-05-11T21:09:40Z | 2021-05-12T13:33:14Z | https://github.com/holoviz/colorcet/issues/67 | [] | ivan-marroquin | 3 |
youfou/wxpy | api | 384 | 发送的文件中含中文字符报错 | os检查文件存在,只是文件名含有中文字符,最后发送失败,err_code是1,请问如何解决? | open | 2019-05-13T14:30:36Z | 2019-06-23T10:07:50Z | https://github.com/youfou/wxpy/issues/384 | [] | Nicolecnu | 4 |
erdewit/ib_insync | asyncio | 693 | Getting Error 478 on options expiring in Feb - leap year. | I have some option positions in my portfolio and extract it using the following function:
```python
def quick_pf(ib):
pf = ib.portfolio()
if pf != []:
df_pf = util.df(pf)
df_pf = df_pf.assign(conttract=df_pf.contract)
else:
df_pf = None
return df_pf
```
when an optio... | closed | 2024-02-13T13:19:02Z | 2024-02-16T12:14:36Z | https://github.com/erdewit/ib_insync/issues/693 | [] | reservoirinvest | 1 |
yt-dlp/yt-dlp | python | 12,131 | lower bitrate YT m4a audio formats disappeared in 2025.01.12 | ### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [x] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
### Checklist
- [x] I'm reporting that yt-dlp is broken on a **supported** site
- [x] I've verified that I have **updated yt-dlp to nightly or master** ([update instruc... | closed | 2025-01-19T05:00:11Z | 2025-01-19T05:18:21Z | https://github.com/yt-dlp/yt-dlp/issues/12131 | [
"question",
"site:youtube"
] | bughit | 3 |
jupyter/nbgrader | jupyter | 1,091 | Error when creating student version of Assignment | Hi,
I'm using nbgrader Version 0.5.5, Jupyterhub 0.9.6, Jupyter Notebook 5.7.8
When trying to create a student-version of an assignment using the formgrader, I get an error.
It looks like this:
Log Output:
>[INFO] Updating/creating assignment 'aufgabe1': {}
[INFO] Converting notebook kurs2/source/./aufgabe1/... | closed | 2019-05-27T14:09:09Z | 2019-05-30T14:27:15Z | https://github.com/jupyter/nbgrader/issues/1091 | [
"question"
] | DerFerdi | 4 |
koxudaxi/datamodel-code-generator | fastapi | 2,076 | in python could we sometimes use `default_factory` instead of `default`? | When generating a definitions from a schema, if defaults are used for dictionaries or arrays, **datamodel-code-generator** currently creates models using the `default` keyword for fields. In my opinion, this should really be the `default_factory` keyword.
NOTE: Fortunately, when using **pydantic** the use of `defaul... | open | 2024-08-20T05:50:14Z | 2024-08-23T06:02:16Z | https://github.com/koxudaxi/datamodel-code-generator/issues/2076 | [] | raj-open | 1 |
OFA-Sys/Chinese-CLIP | computer-vision | 99 | 执行bash命令报错 | 您好,我在执行bash命令时报错,具体如下:
![Uploading 1683526387801.png…]()
望您提供解决办法,期待您的回复!
| closed | 2023-05-08T06:15:26Z | 2023-05-08T10:04:03Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/99 | [] | Sally6651 | 2 |
ultralytics/yolov5 | machine-learning | 12,429 | Multi-node multi-GPU training wont run after loading images | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hello,
Thank you for taking the time to read my post. I have trying to run training on a... | closed | 2023-11-25T20:46:20Z | 2024-01-21T00:23:40Z | https://github.com/ultralytics/yolov5/issues/12429 | [
"question",
"Stale"
] | Tmkilduff | 8 |
sqlalchemy/alembic | sqlalchemy | 322 | Typo in docs | **Migrated issue, originally created by Tim Mitchell**
https://alembic.readthedocs.org/en/latest/api/autogenerate.html#fine-grained-autogenerate-generation-with-rewriters
The code sample has
```
from alembic import ops
```
instead of
```
from alembic.operations import ops
```
also the second argument to AlterColumn... | closed | 2015-08-27T06:02:27Z | 2018-11-30T15:39:16Z | https://github.com/sqlalchemy/alembic/issues/322 | [
"bug",
"documentation",
"easy"
] | sqlalchemy-bot | 4 |
NullArray/AutoSploit | automation | 1,155 | Unhandled Exception (7702fc06b) | Autosploit version: `2.2.3`
OS information: `Linux-3.4.113-armv7l-with-libc`
Running context: `/data/data/com.thecrackertechnology.andrax/ANDRAX/AutoSploit/autosploit.py`
Error meesage: `[Errno 2] No such file or directory: 'tinchi.hau.edu.vn'`
Error traceback:
```
Traceback (most recent call):
File "/data/data/com.th... | closed | 2019-08-17T07:44:02Z | 2019-08-30T21:59:26Z | https://github.com/NullArray/AutoSploit/issues/1155 | [] | AutosploitReporter | 0 |
ymcui/Chinese-BERT-wwm | tensorflow | 98 | 关于chinese-roberta-wwm-ext-large模型的问题 | 您好,我在用您的chinese-roberta-wwm-ext-large模型做MLM任务时发现好像有bug。我分别尝试过google/bert的inference代码以及huggingface的Transformers工具的inference代码,好像都有明显的问题。以下是调用Transformers的代码:
```python3
from transformers import *
import torch
from torch.nn.functional import softmax
tokenizer = BertTokenizer.from_pretrained("hfl/chinese-robert... | closed | 2020-03-31T10:34:24Z | 2021-02-13T15:06:37Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/98 | [] | pxxgogo | 3 |
modelscope/modelscope | nlp | 442 | _batch_encode_plus() got an unexpected keyword argument 'label2id' | /opt/homebrew/Caskroom/miniconda/base/envs/modelscope/bin/python /Users/edy/PycharmProjects/pythonProject2/test_structbert.py
2023-08-07 09:45:45,874 - modelscope - INFO - PyTorch version 1.11.0 Found.
2023-08-07 09:45:45,876 - modelscope - INFO - Loading ast index from /Users/edy/.cache/modelscope/ast_indexer
2023... | closed | 2023-08-07T01:46:24Z | 2024-07-20T01:52:14Z | https://github.com/modelscope/modelscope/issues/442 | [
"Stale"
] | 1034662268 | 3 |
kubeflow/katib | scikit-learn | 2,395 | [SDK] grpc-related bugs in Python SDK | ### What happened?


When I called `report_metrics` in the SDK built by myself, the first error above occurred.
After I modifie... | closed | 2024-07-25T06:49:57Z | 2024-08-23T11:13:00Z | https://github.com/kubeflow/katib/issues/2395 | [
"kind/bug",
"area/sdk"
] | Electronic-Waste | 10 |
AntonOsika/gpt-engineer | python | 771 | KeyError: "File 'roadmap' could not be found in '/content/gpt-engineer/gpt_engineer/cli/preprompts'" | ## Expected Behavior
gpt-engineer is reading the folder 'preprompt' from './gpt_engineer'.
## Current Behavior
gpt_engineer is expecting the folder 'preprompt' in './gpt_engineer/cli'. Most likely because main.py was earlier located in the same path as the folder preprompt.
## Failure Information
KeyError: "Fi... | closed | 2023-10-06T23:10:26Z | 2023-10-07T17:21:51Z | https://github.com/AntonOsika/gpt-engineer/issues/771 | [
"bug",
"triage"
] | chrisivogt | 1 |
sloria/TextBlob | nlp | 425 | AttributeError: module 'numpy' has no attribute '_no_nep50_warning' | Tried to ran:
```python
from textblob import TextBlob
s = TextBlob('Test Text.')
s
```
And this error came out.
Potentially about the versions of numpy? | closed | 2024-02-13T13:39:48Z | 2024-02-13T14:45:43Z | https://github.com/sloria/TextBlob/issues/425 | [] | austinmyc | 1 |
Sanster/IOPaint | pytorch | 306 | [Feature Request] Combing GroundingDINO and SAM for more automatic inpaint | Hello! Thanks for this great open-source project~
I think it will be more powerful to combine GroundingDINO and SAM and Lama-Cleaner together to build a powerful automatic inpaint system~
Here's our GroundingDINO and Grounded-SAM project:
- https://github.com/IDEA-Research/Grounded-Segment-Anything
- https://gi... | open | 2023-05-14T07:02:49Z | 2024-02-26T10:27:09Z | https://github.com/Sanster/IOPaint/issues/306 | [] | rentainhe | 6 |
kubeflow/katib | scikit-learn | 1,930 | Implement Readiness/LivenessProbe endpoint for katib-controller | /kind feature
**Describe the solution you'd like**
Even though katib-controller pod's status became ready. It does not mean that katib-controller is available for all feature.
For example, if user request `/validate-experiment` API to katib-controller, right after katib-controller was just created, It returns 20... | closed | 2022-08-17T14:01:00Z | 2022-10-11T16:50:28Z | https://github.com/kubeflow/katib/issues/1930 | [
"kind/feature"
] | anencore94 | 3 |
skforecast/skforecast | scikit-learn | 909 | Error when plotting plot_residuals | Hola chicos,
al tratar de hacer el plot residuals en Data Brics , me salta el error OptionError: No such keys(s): 'mode.use_inf_as_null', estoy usando las librerias como ustedes
Versión skforecast: 0.14.0
Versión scikit-learn: 1.5.2
Versión lightgbm: 4.4.0
Versión pandas: 2.2.3
Versión numpy: 1.24.4
Detalle del error... | closed | 2025-01-17T14:19:04Z | 2025-01-20T13:45:55Z | https://github.com/skforecast/skforecast/issues/909 | [] | azevallos | 3 |
ibis-project/ibis | pandas | 9,998 | feat: support unnest of struct with trino backend | ### Is your feature request related to a problem?
Disclaimer: I am quite new to ibis, so perhaps I missed something.
Let's say I have a table with a column that contains arrays of struct. For example, a struct with two fields:
| some_col | my_nested_column |
|---------- |---------------... | open | 2024-09-02T15:55:22Z | 2024-09-03T18:40:47Z | https://github.com/ibis-project/ibis/issues/9998 | [
"bug",
"feature",
"trino"
] | Ezibenroc | 4 |
unit8co/darts | data-science | 1,779 | Deterministic evaluation of probabilistic models (e.g. nbeats) | When predicting a time series, one can turn some models probabilistic by defining a likelihood parameter.
E.g.:
NBEATSModel(
...
likelihood=GaussianLikelihood(),
random_state=42
)
If done this way, the prediction is not deterministic any more. Two subsequent calls to
predict(series=.., n=1, num... | open | 2023-05-17T13:56:50Z | 2023-08-02T11:33:54Z | https://github.com/unit8co/darts/issues/1779 | [
"feature request",
"good first issue"
] | mrtn37 | 2 |
HumanSignal/labelImg | deep-learning | 986 | LabelImg not working on M1 mac | <!--
-->
I am using M1 mac. How to use labelimg? I tried all the possible ways mentioned in the readme file but it does't work for me. Please help.
- **OS:**
- **PyQt version:**
| closed | 2023-03-24T15:12:17Z | 2023-03-24T16:17:23Z | https://github.com/HumanSignal/labelImg/issues/986 | [] | Siddharth-2382 | 0 |
pytest-dev/pytest-xdist | pytest | 441 | the number of interpreters created with auto should be at most number of tests | At the moment even with 1 test, on a 12 core CPU 12 interpreters are spun up. | closed | 2019-06-13T14:23:06Z | 2019-06-14T15:32:41Z | https://github.com/pytest-dev/pytest-xdist/issues/441 | [] | gaborbernat | 3 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 550 | 现在获取单个作品数据接口不行了吗 | 
我本地测试报错,Cookie和User-Agent换过

报错信息如下
 | closed | 2025-02-12T06:28:51Z | 2025-02-14T02:41:17Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/550 | [] | lao-wen | 4 |
lepture/authlib | flask | 724 | RFC9126 Pushed Authorization Requests (PAR) | It would be nice for Authlib to support [Pushed Authorization Requests](https://www.rfc-editor.org/rfc/rfc9126.html) described in RFC9126. This would be a complement to #723
Basically, it consists in letting clients push a JWT with the authentication request detail to the authentication server, and get an URL on which ... | open | 2025-03-19T14:47:52Z | 2025-03-19T14:49:54Z | https://github.com/lepture/authlib/issues/724 | [
"spec"
] | azmeuk | 0 |
matterport/Mask_RCNN | tensorflow | 2,822 | Random results in demo and custom dataset detection | I used the code from this <a href="https://github.com/leekunhee/Mask_RCNN">fork</a> and the results are so random even in the demo.ipynb file. What might be the issue and what can I do to fix it. Thank you.
<img src="https://i.imgur.com/sUrZYsD.png"> | open | 2022-05-07T16:19:20Z | 2022-06-29T19:33:13Z | https://github.com/matterport/Mask_RCNN/issues/2822 | [] | MedAmine121 | 5 |
httpie/cli | rest-api | 1,418 | --help fails with a traceback when pip is not installed | ## Checklist
- [x] I've searched for similar issues.
- [x] I'm using the latest version of HTTPie.
---
## Minimal reproduction code and steps
1. `http --help` or `https --help`
## Current result
<details><summary>output with traceback</summary>
```py
$ http --help
Traceback (most recent call las... | closed | 2022-06-22T16:16:32Z | 2022-07-21T04:07:41Z | https://github.com/httpie/cli/issues/1418 | [
"bug",
"new"
] | classabbyamp | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.