
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
plotly/dash-core-components | dash | 778 | Undesired behaviour (interaction?) with two `dcc.Store` | The issue originates from https://community.plot.ly/t/components-triggered-by-table-not-updating/36288/4
With
```
import dash
import dash_table
import pandas as pd
import dash_html_components as html
import dash_core_components as dcc
from dash.dependencies import Input, Output, State
from dash.exceptions... | closed | 2020-03-17T19:21:11Z | 2020-05-05T00:10:57Z | https://github.com/plotly/dash-core-components/issues/778 | [] | emmanuelle | 1 |
davidteather/TikTok-Api | api | 572 | [BUG] - by_hashtag and get_hashtag_object both fail when using Selenium | **Describe the bug**
When using selenium, at least by_hashtag and get_hashtag_object fail.
If Selenium is not used, these two objects work as expected it is just when Selenium=True.
Changing out proxies, use_test_endpoints, custom_verifyFp doesn't seem to impact the response.
According to the error trace, TikT... | closed | 2021-04-22T21:38:06Z | 2021-08-07T00:30:33Z | https://github.com/davidteather/TikTok-Api/issues/572 | [
"bug"
] | bmader12 | 1 |
matplotlib/matplotlib | data-visualization | 29,219 | [Bug]: Missing axes limits auto-scaling support for LineCollection | ### Bug summary
Matplotlib is missing auto-scale support for LineCollection.
Related issues:
- https://github.com/matplotlib/matplotlib/issues/23317/
- https://github.com/matplotlib/matplotlib/pull/28403
### Code for reproduction
```Python
from matplotlib import pyplot as plt
from matplotlib.collections import... | open | 2024-12-02T19:38:32Z | 2024-12-07T12:35:01Z | https://github.com/matplotlib/matplotlib/issues/29219 | [
"status: confirmed bug"
] | carlosgmartin | 13 |
facebookresearch/fairseq | pytorch | 4,947 | what's the actual learning_rate in data2vec2.0 ? | Hi,
I noticed that in the data2vec2.0 code, the losses for different samples, patches and channels are accumulated with "sum" op instead of "mean":
```
# d2v loss is first computed in func d2v_loss:
loss = F.mse_loss(x, y, reduction="none") # data2vec2.py:708
scale = 1 / math.sqrt(x.size(-1)) # data2vec2.py:715
... | closed | 2023-01-18T04:27:04Z | 2024-04-27T09:56:39Z | https://github.com/facebookresearch/fairseq/issues/4947 | [
"question",
"needs triage"
] | flishwang | 0 |
deezer/spleeter | tensorflow | 199 | Please Add Freez model as well | ## Description
<!-- Describe your feature request here. -->
## Additional information
<!-- Add any additional description -->
I am getting error while freezing model please upload freezed model and see the opened issue.
| closed | 2019-12-26T09:10:38Z | 2019-12-30T14:58:00Z | https://github.com/deezer/spleeter/issues/199 | [
"enhancement",
"feature"
] | waqasakram117 | 1 |
biolab/orange3 | pandas | 6,576 | Distributions outputs wrong data | **What's wrong**
The widget's output does not match the selection.
**How can we reproduce the problem?**
Load Zoo and pass it to Distributions. Show "type" and check "Sort categories by frequency".
When selecting the n-th column, the widget outputs data referring to the n-th value of the variable in the or... | closed | 2023-09-14T14:45:06Z | 2023-09-20T20:21:07Z | https://github.com/biolab/orange3/issues/6576 | [
"bug",
"meal"
] | janezd | 4 |
pytorch/pytorch | python | 149,196 | (Will PR) Multiprocessing with CUDA_VISIBLE_DEVICES seems to give the wrong device | ### EDIT: PR to fix this
PR is here: https://github.com/pytorch/pytorch/pull/149248
### 🐛 Describe the bug
Hi thanks for the helpful library! When two processes have different CUDA_VISIBLE_DEVICES and pass around tensor between them, it seems the `.device` attribute is incorrect.
Example code:
```python
import os... | open | 2025-03-14T14:36:24Z | 2025-03-19T11:41:11Z | https://github.com/pytorch/pytorch/issues/149196 | [
"module: multiprocessing",
"module: cuda",
"triaged"
] | fzyzcjy | 10 |
LAION-AI/Open-Assistant | machine-learning | 2,953 | oasst-sft-1-pythia-12b model is giving weird answers | I run the Open Assistant but oasst-sft-1-pythia-12b model is giving weird answers
Hardware : Nvidia T4 , 8 cpu , 60GB ram
<img width="763" alt="image" src="https://user-images.githubusercontent.com/33727088/235101716-df320924-1e21-4d05-818e-1f661c439b6e.png">
| closed | 2023-04-28T09:04:03Z | 2023-04-29T10:15:11Z | https://github.com/LAION-AI/Open-Assistant/issues/2953 | [] | jithinkpraveen | 0 |
kymatio/kymatio | numpy | 480 | ModuleNotFoundErrors | - [x] 1D
- [x] 2D
- [x] 3D
Hi everyone,
In the current kymatio-v2 branch, there are no __init__.py files in the kymatio.frontend, kymatio.scattering2d.backend and kymatio.scattering2d.core packages. It leads on my side to ModuleNotFoundErrors when trying to run for instance examples/2d/cifar.py after installi... | closed | 2020-01-16T19:00:50Z | 2020-01-27T02:48:07Z | https://github.com/kymatio/kymatio/issues/480 | [] | anakin-datawalker | 2 |
python-visualization/folium | data-visualization | 1,402 | Get lat/lng programmatically from a mouse click event | Is it possible to get the lat/lng **programmatically** from a mouse click event on the map? The lat/lng is needed for subsequent computation. Thanks. | closed | 2020-10-26T22:33:03Z | 2020-10-27T08:35:43Z | https://github.com/python-visualization/folium/issues/1402 | [] | giswqs | 1 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,782 | Nodriver: Running in docker | I have trouble trying to get nodriver/undetected-chromedriver running in docker.
Nomatter what I do, I always end up with the following error:
```
File "/usr/local/lib/python3.12/socket.py", line 837, in create_connection
sock.connect(sa)
ConnectionRefusedError: [Errno 111] Connection refused
```
For... | open | 2024-03-10T09:16:23Z | 2025-01-25T21:16:29Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1782 | [] | ven0ms99 | 12 |
ccxt/ccxt | api | 25,174 | Binance Futures - Edit Order on Binance Futures doesn't work with priceMatch parameter | ### Operating System
Windows/Linux
### Programming Languages
JavaScript
### CCXT Version
4.4.53
### Description
### Issue Description
When using CCXT's editOrder with Binance's priceMatch parameter set to 'Queue' or other enum value, the price parameter must be undefined. However, CCXT currently throws an error ... | open | 2025-02-03T21:03:55Z | 2025-02-05T16:09:40Z | https://github.com/ccxt/ccxt/issues/25174 | [
"bug"
] | lostless13 | 3 |
scikit-hep/awkward | numpy | 2,513 | Error formatting is broken (an error in the error handling) | ### Version of Awkward Array
HEAD
### Description and code to reproduce
I have a real error and should be getting a properly formatted error message, but there's an error in the error-handling.
To reproduce it:
```python
import awkward as ak
f = ak.Array([[1, 2, 3], [], [4, 5]]).layout.form
ak.from_buffers(... | closed | 2023-06-07T22:35:51Z | 2023-06-14T18:44:03Z | https://github.com/scikit-hep/awkward/issues/2513 | [
"bug"
] | jpivarski | 4 |
pallets-eco/flask-sqlalchemy | sqlalchemy | 1,132 | Incompatibility between Flask-SQLAlchemy >= 3.0.0 and PySerde | It seems there is an incompatibility between Flask-SQLAlchemy >= 3.0.0 and PySerde ([https://github.com/yukinarit/pyserde](https://github.com/yukinarit/pyserde)) when applying ORM to a dataclass.
Example:
```
from dataclasses import dataclass
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
fro... | closed | 2022-10-26T14:25:36Z | 2023-02-01T01:18:10Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/1132 | [] | barsa-net | 5 |
zappa/Zappa | django | 648 | [Migrated] Delayed asynchronous task execution using SQS as a task source. | Originally from: https://github.com/Miserlou/Zappa/issues/1647 by [oliviersels](https://github.com/oliviersels)
## Context
Implement delayed asynchronous task execution using SQS as a task source.
Now that we have support for SQS as an event source we should extend this to have SQS as an asynchronous task source. ... | closed | 2021-02-20T12:32:23Z | 2024-04-13T17:36:24Z | https://github.com/zappa/Zappa/issues/648 | [
"no-activity",
"auto-closed"
] | jneves | 2 |
jupyterlab/jupyter-ai | jupyter | 352 | Better error handling in Chat UI | ## Description
Some users are encountering an error when opening the Chat UI, which is difficult to reproduce because the UI does not include any information regarding the error.
## Reproduce
See #346.
| open | 2023-08-18T15:38:56Z | 2023-08-30T18:30:14Z | https://github.com/jupyterlab/jupyter-ai/issues/352 | [
"enhancement"
] | dlqqq | 0 |
seleniumbase/SeleniumBase | pytest | 2,136 | `--driver-version="keep"` is only being applied to drivers in the `seleniumbase/drivers` folder | ## `--driver-version="keep"` is only being applied to drivers in the `seleniumbase/drivers` folder
It should also be applied to drivers that exist on the System PATH.
The current bug example: Setup: Chrome 117 was installed, with no driver in the `seleniumbase/drivers` folder, but chromedriver 115 on System PATH.... | closed | 2023-09-24T13:35:30Z | 2023-09-26T01:35:51Z | https://github.com/seleniumbase/SeleniumBase/issues/2136 | [
"bug"
] | mdmintz | 1 |
mljar/mljar-supervised | scikit-learn | 400 | How to know the order of classes for multiclass problem when using predict_proba? | Assume I have a multiclass classification problem where my target `y` in the training data is a 1D-vector with strings for the labels. In the example below, the labels can be `['Fair', 'Good', 'Ideal', 'Premium', 'Very Good']`.
After fitting a multiclass model given this `y`, I want to use the `predict_proba` funct... | closed | 2021-05-22T13:56:24Z | 2021-06-08T10:55:57Z | https://github.com/mljar/mljar-supervised/issues/400 | [
"docs"
] | juliuskittler | 2 |
pydantic/FastUI | pydantic | 241 | Plan for adding remark-math for math formula rendering in markdown? | As titled | open | 2024-03-11T06:01:43Z | 2024-03-14T10:25:19Z | https://github.com/pydantic/FastUI/issues/241 | [] | zhoubin-me | 3 |
python-gino/gino | asyncio | 439 | Load models from joined query automatically | ### Description
Hello. Thanks for the Gino, looks awesome! I gathered that Gino cannot yet load rows into models if joins are used in a query. Is it so? If yes, do you plan to add such feature, or is it even feasible, at least for simple cases?
| closed | 2019-02-13T20:16:31Z | 2019-03-03T09:10:31Z | https://github.com/python-gino/gino/issues/439 | [
"question"
] | WouldYouKindly | 4 |
davidteather/TikTok-Api | api | 652 | 'TikTokApi' object has no attribute 'region'tagtagtagtag | When I tried
api.by_hashtag('test')
or a few other functions, I got the error: 'TikTokApi' object has no attribute 'region'tagtagtagtag
However, api.get_user('test') works for me
A few other functions that run into the 'region' error
api.by_trending()
----------------------------------------------... | closed | 2021-08-06T06:05:56Z | 2022-05-04T09:39:47Z | https://github.com/davidteather/TikTok-Api/issues/652 | [] | michael01810 | 8 |
huggingface/datasets | pytorch | 7,112 | cudf-cu12 24.4.1, ibis-framework 8.0.0 requires pyarrow<15.0.0a0,>=14.0.1,pyarrow<16,>=2 and datasets 2.21.0 requires pyarrow>=15.0.0 | ### Describe the bug
!pip install accelerate>=0.16.0 torchvision transformers>=4.25.1 datasets>=2.19.1 ftfy tensorboard Jinja2 peft==0.7.0
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
c... | open | 2024-08-20T08:13:55Z | 2024-09-20T15:30:03Z | https://github.com/huggingface/datasets/issues/7112 | [] | SoumyaMB10 | 2 |
ultralytics/ultralytics | pytorch | 18,710 | Which hyperparameters are suitable for me? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/ultralytics/ultralytics/discussions) and found no similar questions.
### Question
Hello. I've already done finetuning and just trained YOLOv11 from scr... | open | 2025-01-16T11:51:54Z | 2025-01-24T06:07:24Z | https://github.com/ultralytics/ultralytics/issues/18710 | [
"question",
"detect"
] | Egorundel | 35 |
jupyterhub/repo2docker | jupyter | 843 | Failures to install readtext package | Hi,
I cannot install readtext package on binder. Here's part of the error message --
Configuration failed because poppler-cpp was not found. Try installing:
* deb: libpoppler-cpp-dev (Debian, Ubuntu, etc)
* On Ubuntu 16.04 or 18.04 use this PPA:
sudo add-apt-repository -y ppa:cran/poppler
sudo apt-... | closed | 2020-02-05T10:01:03Z | 2020-02-26T22:36:50Z | https://github.com/jupyterhub/repo2docker/issues/843 | [] | zwguo95 | 1 |
erdewit/ib_insync | asyncio | 397 | Crypto and Fractional Size | First off, thanks for the awesome library. I originally gave the native api a shot and it was a nightmare trying to navigate.
I am looking to trade crypto via the API, but am getting the following error around fractional size rules. It sounds like the IB API didn't allow fractional trading, however the below error ... | closed | 2021-10-05T23:51:14Z | 2022-08-13T10:00:32Z | https://github.com/erdewit/ib_insync/issues/397 | [] | fletch-man | 1 |
Farama-Foundation/PettingZoo | api | 691 | [Proposal] Fix pyright code checking | ### Proposal
Right now, `continue-on-error` is set to `true` in Linux tests for pyright checking. All of the errors are stemming from `utils/env.py`, and not all of them are solvable because of some stuff with gym. It would be great if we can set `continue-on-error` to `false` and have things pass tests. | closed | 2022-05-02T22:46:58Z | 2022-10-13T10:45:09Z | https://github.com/Farama-Foundation/PettingZoo/issues/691 | [
"bug",
"enhancement",
"help wanted",
"dependencies"
] | jjshoots | 2 |
numba/numba | numpy | 9,519 | [Feature Request] `key_equal`, `copy_key`, `zero_key` in dict is slower than direct assignment if key type is primitive | Hi, I noticed an unoptimized situation that `key_equal`, `copy_key`, `zero_key` in dict are slower than direct assignment if key type is primitive. The root cause is if key_type doesn't contain meminfo, then `key_equal` will rollback to using `memcmp`, which is pretty slow compared to directly `this_key == an_integer`.... | open | 2024-04-01T18:30:44Z | 2024-05-02T01:56:42Z | https://github.com/numba/numba/issues/9519 | [
"enhancement"
] | dlee992 | 3 |
microsoft/hummingbird | scikit-learn | 20 | Simplify convert_sklearn API | In its current implementation to convert a sklearn model we have something like:
```python
convert_sklearn(model, initial_types=[('input', FloatTensorType([4, 3]))])
```
but we actually don't need the specification of input types (this is more a onnx converter thing). So we can have something like:
```python
conv... | closed | 2020-04-06T23:15:25Z | 2020-04-07T22:32:48Z | https://github.com/microsoft/hummingbird/issues/20 | [] | interesaaat | 2 |
dask/dask | numpy | 11,679 | dask shuffle pyarrow.lib.ArrowTypeError: struct fields don't match or are in the wrong orders | Hello, I met a problem when I shuffle the data among 160 dask partitions.
I got the error when each partition contains 200 samples. But the error is gone when it contains 400 samples or more. I really appreciate it if someone can help me.
```bash
pyarrow.lib.ArrowTypeError: struct fields don't match or are in the wrong... | open | 2025-01-17T22:27:22Z | 2025-03-24T02:06:10Z | https://github.com/dask/dask/issues/11679 | [
"dataframe",
"needs attention",
"bug",
"dask-expr"
] | MikeChenfu | 0 |
aio-libs/aiohttp | asyncio | 10,027 | AssertionError | assert not url.absolute raisedon a WSS URL | ### Describe the bug
Discord's [` Get Gateway `](https://discord.com/developers/docs/events/gateway#get-gateway) endpoint returns a ` url ` field containing ` "wss://gateway.discord.gg" `. This WSS URL is used to establish connection with their gateway. Though this raises an exception:
```
File "...\aiohttp\clien... | closed | 2024-11-23T10:49:59Z | 2024-12-02T14:32:25Z | https://github.com/aio-libs/aiohttp/issues/10027 | [
"invalid",
"client"
] | demoutreiii | 4 |
DistrictDataLabs/yellowbrick | scikit-learn | 979 | Visualize the results without fitting the model | Let's say I have to visualize a confusion matrix.
I can use yellowbrick and use the LogisticRegression and visualize like this:
https://www.scikit-yb.org/en/latest/api/classifier/confusion_matrix.html
```
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split as tts
from skl... | closed | 2019-10-12T18:26:54Z | 2019-10-12T18:48:32Z | https://github.com/DistrictDataLabs/yellowbrick/issues/979 | [
"type: question"
] | bhishanpdl | 1 |
mljar/mljar-supervised | scikit-learn | 618 | AutoML import fails due to dependency ImportError: cannot import name 'Concatenate' from 'typing_extensions' | I installed `pip install mljar-supervised` and manually fixed a dependency conflict with numba and the numpy version, but when I try `from supervised.automl import AutoML`, it does not work due to an ImportError way down the dependencies.
The complete traceback:
```
---------------------------------------------... | open | 2023-05-15T11:00:22Z | 2023-05-15T14:30:43Z | https://github.com/mljar/mljar-supervised/issues/618 | [] | xekl | 2 |
JaidedAI/EasyOCR | machine-learning | 731 | finetuning easyocr using persian handwritten data | can easyocr be finetuned using persian handwritten data? | open | 2022-05-19T08:41:07Z | 2022-05-19T08:41:07Z | https://github.com/JaidedAI/EasyOCR/issues/731 | [] | Nadiam75 | 0 |
marcomusy/vedo | numpy | 1,133 | Axisymmetric mesh with extrude | Hello Marco,
I wanted to make an axisymmetric mesh and tried to use the extrude function for it, as recommended by you. I am now wondering how to 'sweep' the shape that I want to use as an outline (in my case it's a spline). If I set a single angle the outline is rotated but the connection between the two outlines i... | closed | 2024-06-04T08:42:39Z | 2024-06-10T07:59:34Z | https://github.com/marcomusy/vedo/issues/1133 | [] | IsabellaPa | 4 |
Lightning-AI/LitServe | rest-api | 282 | More complex model management (multiple models, model reloading etc...) | ## 🚀 Feature
Supporting model reloads (when a new version is available) and multiple models.
### Motivation
Other servers supports this so to be more attractive that would be a nice feature.
### Pitch
Right now it's obvious on how to serve one model, but what if there are multiple ones (and the request ... | closed | 2024-09-19T21:32:56Z | 2024-10-07T11:04:50Z | https://github.com/Lightning-AI/LitServe/issues/282 | [
"enhancement",
"help wanted"
] | bsergean | 2 |
Johnserf-Seed/TikTokDownload | api | 31 | 好看小姐姐投稿 | 小橙子 抖音主页: https://v.douyin.com/evLNohM/
黑色闪光 抖音主页: https://v.douyin.com/evLhSNB/ | open | 2021-07-27T08:42:18Z | 2021-07-28T07:04:41Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/31 | [
"需求建议(enhancement)"
] | dongbulang | 0 |
browser-use/browser-use | python | 732 | Assessment of Microsoft OmniParser 2.0 | ### Problem Description
Microsoft just released its OmniParser 2.0 model. Let's do assessment whether/if/how much it can be leveraged to advance BrowseUse.
This in turn fixes https://github.com/browser-use/browser-use/issues/206 so that would be awesome!
### Proposed Solution
Microsoft OmniParser 2.0.
Compare the p... | open | 2025-02-15T13:21:30Z | 2025-03-03T02:40:03Z | https://github.com/browser-use/browser-use/issues/732 | [
"enhancement",
"💎 Bounty"
] | vishaldwdi | 9 |
reloadware/reloadium | pandas | 19 | Pickle fails in Reloadium (at least from within PyCharm plugin) | **Describe the bug**
Pickling fails when Reloadium is used to run the following code. Non-reloadium runs fine.
**To Reproduce**
```
from builtins import *
import pickle
import jsonpickle
class A:
def __init__(self, *args, **kwargs):
self.b = None
def test_serializer(obj, pickler):
pickled_do... | closed | 2022-06-05T21:48:07Z | 2022-06-16T10:19:25Z | https://github.com/reloadware/reloadium/issues/19 | [] | erjo-mojo | 1 |
netbox-community/netbox | django | 18,780 | Connect to external databases | ### NetBox version
4.1.11
### Feature type
Data model extension
### Proposed functionality
I have a very specific use case, I'm developing a plugin, and I need to query an external DB.
I thought about being able to define the connection on `configuration.py` and them merging with Netbox's default db
Here's POC:
... | closed | 2025-02-28T18:06:12Z | 2025-03-17T17:34:28Z | https://github.com/netbox-community/netbox/issues/18780 | [
"status: accepted",
"type: feature",
"complexity: low"
] | fmluizao | 1 |
bmoscon/cryptofeed | asyncio | 21 | L3 messages feed and storage | If I was looking to store L3 book data (let's assume with Arctic), wouldn't it be more efficient to create and store a stream of standardized delta messages as opposed to the entire book?
I only ask because the book callback takes `feed`, `pair` and `book` as the inputs. Using that callback for book updates would no... | closed | 2018-05-09T21:23:52Z | 2018-07-04T21:49:55Z | https://github.com/bmoscon/cryptofeed/issues/21 | [] | rjbks | 10 |
vitalik/django-ninja | django | 1,093 | pydantic2 incompatibility with django-ninja 1.* | Hi there.
i am trying to install django-ninja 1.* (latest), on Linux, using pip and I am constantly having issues. These issues regard the incompatibility of django-ninja and pydantic2, calling for deprecation.
` File "/home/olddog/Documents/Python_Scipts/DOM_Webpage/WEBPAGE_Bilengual/Test3/.venv2/lib/python3.... | open | 2024-02-20T09:40:49Z | 2024-03-07T15:59:07Z | https://github.com/vitalik/django-ninja/issues/1093 | [] | MM-cyi | 3 |
kennethreitz/responder | graphql | 209 | Cannot set the same route on two different methods | Hello.
I'm using class-based views, and when I try to set the same route on two different methods, say get and put, each in a different class, I get an assertion error due to route already inserted.
> assert route not in self.routes
> AssertionError
>
If I move both method views under the same class, I do n... | closed | 2018-11-06T21:31:58Z | 2018-11-07T09:02:59Z | https://github.com/kennethreitz/responder/issues/209 | [] | emacsuser123 | 6 |
tflearn/tflearn | data-science | 990 | Cannot feed value of shape (96, 227, 227) for Tensor 'InputData/X:0', which has shape '(?, 227, 227, 1)' | I am trying to use different data in your example:
```
from __future__ import division, print_function, absolute_import
import scipy
import tflearn
from tflearn.data_utils import shuffle, to_categorical
from tflearn.layers.core import input_data, dropout, fully_connected
from tflearn.layers.conv import con... | closed | 2018-01-04T05:05:21Z | 2018-01-09T04:53:44Z | https://github.com/tflearn/tflearn/issues/990 | [] | Lan131 | 2 |
pallets/quart | asyncio | 224 | Unable to suppress Quart serving logs after Python 3.10 upgrade | I'm moving a Quart webapp from python 3.7 to python 3.10 and I'm suddenly unable to suppress the server logs.
I would expect `getLogger('quart.serving').setLevel(ERROR)` to suppress most logging messages, but after switching to 3.10 I get everything.
Environment:
- Python version: 3.10.9
- Quart version: 0.1... | closed | 2023-03-10T16:23:22Z | 2023-10-01T00:20:35Z | https://github.com/pallets/quart/issues/224 | [] | johndonor3 | 11 |
microsoft/nni | data-science | 5,586 | How to import L1FilterPruner ? | **Environment**: VS Code
- NNI version: 3.0
- Training service (local|remote|pai|aml|etc): remote
- Client OS: Windows
- Server OS (for remote mode only): Ubuntu
- Python version: 3.9
- PyTorch/TensorFlow version: PyTorch 1.12
- Is conda/virtualenv/venv used?: conda
- Is running in Docker?: No
Hi, I am tryin... | open | 2023-05-29T08:24:23Z | 2023-06-12T10:21:05Z | https://github.com/microsoft/nni/issues/5586 | [] | gkrisp98 | 10 |
lexiforest/curl_cffi | web-scraping | 466 | AsyncSession requests 特定情况下请求报错了 | **Describe the bug**
当去掉代码中的第一次请求, 只保留第二次请求,可以正常返回数据,
然而加上第一次请求, 就会报curl_cffi.requests.exceptions.ConnectionError: Failed to perform, curl: (55) Recv failure: Connection was reset.
**To Reproduce**
```
import asyncio
from curl_cffi.requests import AsyncSession
from httpx import AsyncClient
async def curl_cffi... | closed | 2024-12-19T09:04:32Z | 2024-12-19T09:21:12Z | https://github.com/lexiforest/curl_cffi/issues/466 | [
"bug"
] | PythonZhao | 2 |
modin-project/modin | pandas | 6,629 | PERF: HDK triggers LazyProxyCategoricalDtype materialization on merge | Before the merge, HDK checks dtypes and it triggers LazyProxyCategoricalDtype materialization. | closed | 2023-10-04T15:10:43Z | 2023-10-06T10:01:31Z | https://github.com/modin-project/modin/issues/6629 | [
"Performance 🚀",
"HDK"
] | AndreyPavlenko | 0 |
plotly/plotly.py | plotly | 4,829 | add "Zen of Plotly" similar to Narwhals | `import narwhals.this` prints a message about the project's philosophy - it would be a nice addition to Plotly / Plotly Express if `import plotly.this` (or similar) did the same. | open | 2024-10-24T14:33:49Z | 2024-10-24T14:34:04Z | https://github.com/plotly/plotly.py/issues/4829 | [
"feature",
"P3"
] | gvwilson | 0 |
CorentinJ/Real-Time-Voice-Cloning | python | 666 | No gui? | i run python demo_toolbox.py and what is returned is:
(voice-clone) S:\path\path\path\path\Real-Time-Voice-Cloning-master>python demo_toolbox.py
S:\path\path\path\path\Real-Time-Voice-Cloning-master\encoder\audio.py:13: UserWarning: Unable to import 'webrtcvad'. This package enables noise removal and is recommended... | closed | 2021-02-17T00:06:59Z | 2021-02-17T20:22:19Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/666 | [] | ghost | 3 |
lux-org/lux | jupyter | 362 | [BUG] Matplotlib code missing computed data for BarChart, LineChart and ScatterChart | **Describe the bug**
Without `self.code += f”df = pd.DataFrame({str(self.data.to_dict())})\n”`, exported BarChart, LineChart and ScatterChart that contain computed data throw an error.
**To Reproduce**
```
df = pd.read_csv('https://github.com/lux-org/lux-datasets/blob/master/data/hpi.csv?raw=true')
df
```
```... | open | 2021-04-15T18:25:33Z | 2021-04-15T20:47:32Z | https://github.com/lux-org/lux/issues/362 | [
"bug"
] | caitlynachen | 0 |
plotly/dash-core-components | dash | 547 | the options description for dcc.dropdown is not clear about the props rules | this will be an improvement for https://github.com/plotly/dash/issues/708 | closed | 2019-05-08T18:26:51Z | 2019-05-09T01:30:51Z | https://github.com/plotly/dash-core-components/issues/547 | [] | byronz | 0 |
deepfakes/faceswap | deep-learning | 710 | dlib no compile | **To Reproduce**
Steps to reproduce the behavior:
1. Run command "python setup.py -G ...." in INSTALL.md
2. Show error messages; no have parameter "--yes"
**Screenshots**
If applicable, add screenshots to help explain your problem.
['__builtins__']`. I suggest just use `try` to replace this check. The problem happens here: https://github.c... | closed | 2023-07-01T01:54:20Z | 2023-07-29T16:05:50Z | https://github.com/Textualize/rich/issues/3013 | [] | zhengyu-yang | 2 |
tensorpack/tensorpack | tensorflow | 907 | [Mask RCNN] HOW to deal with masks with holes? | @ppwwyyxx The masks in Mask RCNN are represented by polygons. If an object has holes, then it will contains multiple polygons. However, when the polygons are converted to mask, the holes become foreground masks(see [this line](https://github.com/tensorpack/tensorpack/blob/7b8728f96b76774a5d345390cfb5607c8935d9e3/exampl... | closed | 2018-09-23T14:28:18Z | 2023-06-18T22:00:32Z | https://github.com/tensorpack/tensorpack/issues/907 | [
"usage"
] | wangg12 | 8 |
pywinauto/pywinauto | automation | 741 | Add support for AtspiDocument interface | Creating this issue to define requirements for AtsiDocument support as below:
- Add or extend an existing GTK sample app with controls supporting AtspiDocument interface.
- Add low-level interface class AtspiDocument in atspi_objects.py
- Add support of AtspiDocument interface in atspi_element_element_info.py | closed | 2019-05-25T09:53:53Z | 2019-09-20T06:32:21Z | https://github.com/pywinauto/pywinauto/issues/741 | [
"atspi"
] | airelil | 0 |
Ehco1996/django-sspanel | django | 786 | support multi ehco config for proxy node | closed | 2023-02-02T23:55:56Z | 2023-04-30T02:16:25Z | https://github.com/Ehco1996/django-sspanel/issues/786 | [
"help wanted",
"Stale"
] | Ehco1996 | 0 | |
polakowo/vectorbt | data-visualization | 748 | VectorBT - Telegram - Issue: ImportError: cannot import Unauthorized, ChatMigrated | Hello
I am trying to install vbt on a win11 machine python 3.12 environment.
I am getting errors, even after having installed python-telegram-bot, v21.5:
"from telegram.error import Unauthorized, ChatMigrated; ImportError: cannot import name 'Unauthorized' from 'telegram.error'
I just saw that the teegram bot max ... | open | 2024-09-19T10:25:25Z | 2025-02-11T12:14:17Z | https://github.com/polakowo/vectorbt/issues/748 | [] | pte1601 | 7 |
tensorlayer/TensorLayer | tensorflow | 392 | How to use BiDynamicRNNLayer for Text classification?Do not support return_last at the moment ? | self.x = tf.placeholder("float", [None, None, alphabet_size], name="inputs")
self.y = tf.placeholder(tf.int64, [None, ], name="labels")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
#n_hidden = 64 # hidden layer num of features
self.network = tl.la... | closed | 2018-03-11T01:40:59Z | 2019-05-13T15:24:36Z | https://github.com/tensorlayer/TensorLayer/issues/392 | [] | chaiyixuan | 2 |
modelscope/modelscope | nlp | 783 | 请问modelscope的数据集部分可以添加上LLM的预训练,指令微调,奖励模型分类吗 | **Describe the feature**
Features description
**Motivation**
A clear and concise description of the motivation of the feature. Ex1. It is inconvenient when [....]. Ex2. There is a recent paper [....], which is very helpful for [....].
**Related resources**
If there is an official code release or third-party i... | closed | 2024-02-26T06:26:33Z | 2024-05-22T01:49:07Z | https://github.com/modelscope/modelscope/issues/783 | [
"Stale"
] | lainxx | 3 |
dynaconf/dynaconf | flask | 274 | [RFC] Add OS X to CI | Looks like we can have OSX builds
https://devblogs.microsoft.com/devops/azure-pipelines-now-supports-additional-hosted-macos-versions/
We need to add it to our Azure Pipeline | closed | 2019-12-16T19:46:25Z | 2020-03-02T01:55:40Z | https://github.com/dynaconf/dynaconf/issues/274 | [
"Not a Bug",
"RFC"
] | rochacbruno | 0 |
Kanaries/pygwalker | matplotlib | 619 | Possibility to save spec when spec param is not json file | Currently, the walker instance does not have updated spec unless you click on the save button that inject the newest spec back to python backend (which does not work when spec param is not json_file).
I am providing pygwalker in streamlit as a standalone application for a group of people as an online tool. Instead ... | closed | 2024-09-13T21:10:44Z | 2024-09-14T16:23:08Z | https://github.com/Kanaries/pygwalker/issues/619 | [] | ymurong | 2 |
pydantic/logfire | pydantic | 363 | Temporal.io integration | ### Description
[Temporal](https://temporal.io/) has a [python sdk](https://github.com/temporalio/sdk-python) with at least some level of [opentelemetry support](https://github.com/temporalio/sdk-python?tab=readme-ov-file#opentelemetry-support).
It would be great to be able to instrument it in logfire.
More in... | open | 2024-08-05T21:55:55Z | 2024-12-31T11:31:58Z | https://github.com/pydantic/logfire/issues/363 | [
"Feature Request"
] | slingshotvfx | 2 |
keras-team/keras | machine-learning | 20,350 | argmax returns incorrect result for input containing -0.0 (Keras using TensorFlow backend) | Description:
When using keras.backend.argmax with an input array containing -0.0, the result is incorrect. Specifically, the function returns 1 (the index of -0.0) as the position of the maximum value, while the actual maximum value is 1.401298464324817e-45 at index 2.
This issue is reproducible in TensorFlow and J... | closed | 2024-10-14T10:15:25Z | 2025-01-25T06:13:46Z | https://github.com/keras-team/keras/issues/20350 | [
"stat:awaiting keras-eng",
"type:Bug"
] | LilyDong0127 | 1 |
dpgaspar/Flask-AppBuilder | flask | 1,661 | encrypt uploaded file | hi, I need to encrypt the uploaded files and of course decrypt them on download.
I guess this needs to be done by defining a new filemanager but I don't know how to configure the app to use the new filemanager and not the default one.
Can you give me advice? | closed | 2021-06-23T10:30:13Z | 2021-06-24T07:22:35Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1661 | [] | enricosecco | 2 |
google-research/bert | nlp | 1,185 | mBERT Pre-training Procedure | I want to pre-train multilingual BERT using the existing mBERT weights.
I have tried to find it but I could not find any mention of how mBERT was pre-trained. Like
If data for all the languages was fed at once during pre-training ?
OR
Pre-trained for all languages one at a time like,
Pre-train for English
Us... | open | 2020-12-11T15:23:19Z | 2021-12-06T10:22:42Z | https://github.com/google-research/bert/issues/1185 | [] | muhammadfahid51 | 3 |
FactoryBoy/factory_boy | sqlalchemy | 902 | Use aware_time for DjangoModelFactory | Hi maintainers, thank you for this project :)
#### The problem
- Version info:
- Django: 3.2.10
- Faker: 11.1.0
I got warning message below, using `DjangoModelFactory` and `factory.Faker`.
```
~~/lib/python3.9/site-packages/django/db/models/fields/__init__.py:1416: RuntimeWarning: DateTimeField Acces... | closed | 2022-01-06T10:01:35Z | 2022-01-12T08:49:17Z | https://github.com/FactoryBoy/factory_boy/issues/902 | [
"Q&A",
"Fixed"
] | skokado | 2 |
huggingface/peft | pytorch | 1,579 | error merge_and_unload for adapter with a prefix | ### System Info
peft version: 0.9.0
transforemrs version: 4.37.2
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder
- [X] My own task or dataset (give details below)
### Reproduct... | closed | 2024-03-21T11:58:38Z | 2024-04-29T15:03:46Z | https://github.com/huggingface/peft/issues/1579 | [] | afalf | 23 |
sktime/sktime | scikit-learn | 7,671 | [BUG] The name for the timepoints index level is not included after prediction. | **Describe the bug**
The name for the timepoints index level is not included after prediction.
The other index names are, except for the timepoints.
**To Reproduce**
```python
from sktime.utils._testing.hierarchical import _make_hierarchical
from sktime.forecasting.arima import ARIMA
y = _make_hierarchical()
foreca... | open | 2025-01-20T12:33:35Z | 2025-02-11T08:58:47Z | https://github.com/sktime/sktime/issues/7671 | [
"bug",
"module:forecasting"
] | kdekker-kdr4 | 7 |
public-apis/public-apis | api | 4,140 | Add more | Add more API examples | open | 2025-02-11T22:09:36Z | 2025-02-11T22:09:36Z | https://github.com/public-apis/public-apis/issues/4140 | [] | HumaizaNaz | 0 |
marshmallow-code/flask-marshmallow | sqlalchemy | 59 | Project Status | Is this project still actively maintained? | closed | 2017-04-14T19:33:39Z | 2017-04-15T19:44:24Z | https://github.com/marshmallow-code/flask-marshmallow/issues/59 | [] | cesarmarroquin | 1 |
pallets-eco/flask-wtf | flask | 226 | how do i keep the original filestorage object inside the form when validation errors? | how do i keep the original filestorage object inside the form when validation errors?
scenario:
input 1 ok
input 2 failed
fileinput 1 ok
user POSTs
then error/validation on input 2 is not good, so it redirects them back to the same page with error in message box.
However, the fileinput is gone but is valid. It di... | closed | 2016-02-19T17:49:28Z | 2021-05-28T01:03:57Z | https://github.com/pallets-eco/flask-wtf/issues/226 | [] | rlam3 | 3 |
Netflix/metaflow | data-science | 1,630 | complicated flow support | ```python
class HelloFlow(FlowSpec):
alpha = Parameter("alpha", default=0.5)
@step
def start(self):
file_name = "abc.txt"
if not os.path.exists(file_name):
print("open and write file", file_name)
else:
print(file_name, "already exists")
sel... | closed | 2023-11-10T09:51:04Z | 2024-01-03T19:57:34Z | https://github.com/Netflix/metaflow/issues/1630 | [] | GarrickLin | 2 |
ivy-llc/ivy | numpy | 28,576 | Fix Frontend Failing Test: torch - creation.paddle.tril | To-do List: https://github.com/unifyai/ivy/issues/27498 | closed | 2024-03-13T00:19:26Z | 2024-03-21T19:50:03Z | https://github.com/ivy-llc/ivy/issues/28576 | [
"Sub Task"
] | ZJay07 | 0 |
albumentations-team/albumentations | deep-learning | 2,304 | Typing 0 after decimal resets the cursor while trying transformations on explore webpage | ## Describe the bug
In the text boxes where one can edit arguments to various transformations on the explore page are bugged on typing a 0 right after the decimal. Instead of the expected "0.0" the cursor is reset to the end of the text and the typed zero and the decimal disappears.
### To Reproduce
Steps to reprodu... | closed | 2025-01-25T11:37:13Z | 2025-02-28T02:17:09Z | https://github.com/albumentations-team/albumentations/issues/2304 | [
"bug"
] | anbilly19 | 1 |
NullArray/AutoSploit | automation | 848 | Divided by zero exception118 | Error: Attempted to divide by zero.118 | closed | 2019-04-19T16:01:31Z | 2019-04-19T16:37:26Z | https://github.com/NullArray/AutoSploit/issues/848 | [] | AutosploitReporter | 0 |
aminalaee/sqladmin | fastapi | 157 | Exception: Could not find field converter for column id (<class 'sqlmodel.sql.sqltypes.GUID'>) | ### Discussed in https://github.com/aminalaee/sqladmin/discussions/155
<div type='discussions-op-text'>
<sup>Originally posted by **Anton-Karpenko** May 26, 2022</sup>
Hey, I am using sqlmodel to create models. I use the UUID type for the id columns.
```
class RandomModel(SQLModel, table=True):
id: uu... | closed | 2022-05-26T21:27:02Z | 2022-05-27T07:57:56Z | https://github.com/aminalaee/sqladmin/issues/157 | [
"bug"
] | aminalaee | 0 |
cupy/cupy | numpy | 8,606 | Support ROCm 6.3 | ## [Tasks](https://github.com/cupy/cupy/wiki/Actions-Needed-for-Dependency-Update)
- [x] Read [ROCm Release Notes](https://docs.amd.com/).
- [x] Update AMD driver in Jenkins test infrastructure (ask @kmaehashi).
- [ ] Fix code and CI to support the new vesrion.
- **FlexCI**: Update `.pfnci/schema.yaml` and `.pf... | open | 2024-09-17T13:51:20Z | 2024-12-18T04:30:25Z | https://github.com/cupy/cupy/issues/8606 | [
"cat:enhancement",
"prio:high"
] | kmaehashi | 1 |
graphql-python/gql | graphql | 319 | File upload 'unable to parse the query' | **Describe the bug**
Getting the following exception while uploading the media to the saleor.
Exception -> ('Exception while uploading the file -> ', "{'message': 'Unable to parse query.', 'extensions': {'exception': {'code': 'str', 'stacktrace': []}}}")
I'm trying to upload a file to graphql from an external D... | closed | 2022-04-11T10:00:23Z | 2022-04-11T18:47:46Z | https://github.com/graphql-python/gql/issues/319 | [
"type: question or discussion"
] | g-londhe | 10 |
benbusby/whoogle-search | flask | 809 | [FEATURE] Can you add railway.app direct deployment ? | Just tested , it is working perfectly with a custom domain even . It has no downtime , a great alternative to heroku and replit.
| closed | 2022-07-07T02:12:43Z | 2022-08-28T12:21:35Z | https://github.com/benbusby/whoogle-search/issues/809 | [
"enhancement"
] | psbaruah | 1 |
ydataai/ydata-profiling | jupyter | 943 | unable to install pandas-profiling: neither 'setup.py' nor 'pyproject.toml' found | I am trying to install pandas profiling on my new Macbook pro M1 (have used pandas profiling on other pcs and it worked amazingly). However, I have tried installing using pip, from git, and from the source, and all requests returned the same output below:
Defaulting to user installation because normal site-packages ... | closed | 2022-03-20T07:19:02Z | 2022-03-22T07:39:59Z | https://github.com/ydataai/ydata-profiling/issues/943 | [] | ellieyuyw | 5 |
graphql-python/graphene-sqlalchemy | sqlalchemy | 7 | Incorrect repo in readme | The existing clone and cd are invalid for the `examples/flask_sqlalchemy/README.md` file. The README should read:
``` bash
# Get the example project code
git clone https://github.com/graphql-python/graphene-sqlalchemy.git
cd graphene-sqlalchemy/examples/flask_sqlalchemy
```
| closed | 2016-09-29T18:02:09Z | 2023-02-26T00:53:19Z | https://github.com/graphql-python/graphene-sqlalchemy/issues/7 | [] | erik-farmer | 2 |
tableau/server-client-python | rest-api | 726 | Problem using server.schedules.add_to_schedule | Hello,
I am trying to implement the refresh_schedule.py sample. Everything works well until I get to server.schedules.add_to_schedule.
When I do a print I see the schedule_id and the item_id which is a datasource. But I get an error saying it can't find the resource. And oddly, it says it can't find the workbo... | closed | 2020-11-07T19:20:37Z | 2022-06-17T20:18:45Z | https://github.com/tableau/server-client-python/issues/726 | [] | wesmott | 2 |
deezer/spleeter | tensorflow | 223 | [Discussion] Custom audio import gives NaN values in prediction. | Hi,
First, thank you for the amazing work on this tool, I've been using it a lot recently and it gives amazing results !
I'd like to share an issue I have when importing audio files from a python request.
Here is the code (from my Flask app) that is not working.
```
# imports
import io
import soundfile a... | closed | 2020-01-05T19:24:59Z | 2020-01-08T08:58:59Z | https://github.com/deezer/spleeter/issues/223 | [
"question"
] | julienbeisel | 1 |
docarray/docarray | fastapi | 930 | v2: add proper slice compatible getitem for document array | closed | 2022-12-12T13:09:44Z | 2023-01-05T09:36:57Z | https://github.com/docarray/docarray/issues/930 | [
"DocArray v2"
] | samsja | 0 | |
ipython/ipython | jupyter | 14,006 | Installed qt5 event loop hook. | <!-- This is the repository for IPython command line, if you can try to make sure this question/bug/feature belong here and not on one of the Jupyter repositories.
If it's a generic Python/Jupyter question, try other forums or discourse.jupyter.org.
If you are unsure, it's ok to post here, though, there are few ... | open | 2023-04-06T06:50:22Z | 2023-05-30T17:58:04Z | https://github.com/ipython/ipython/issues/14006 | [] | forallsunday | 21 |
AirtestProject/Airtest | automation | 1,024 | ios 点击系统弹窗报错,如图 | # iOS15.3系统弹窗
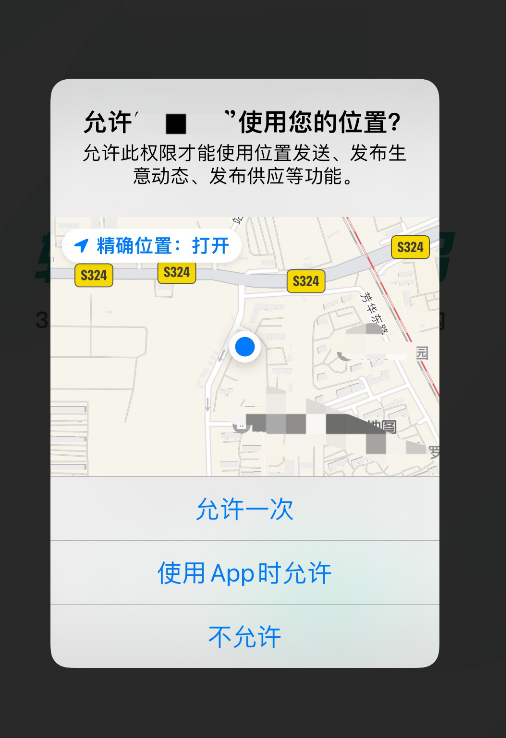
# 脚本
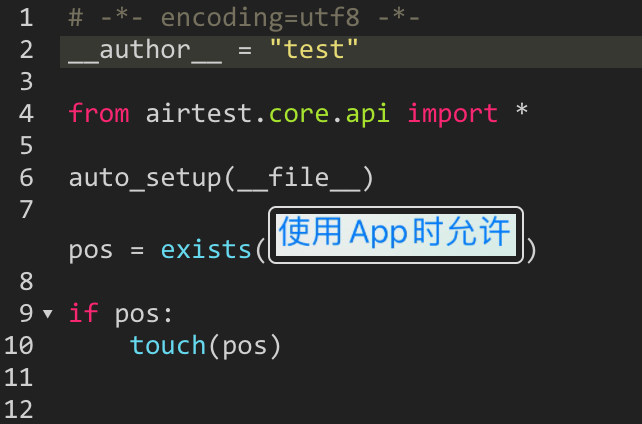
# 报错
`--------------------------------------------------------------... | open | 2022-02-12T14:37:13Z | 2022-03-10T13:54:21Z | https://github.com/AirtestProject/Airtest/issues/1024 | [] | Pactortester | 2 |
FactoryBoy/factory_boy | sqlalchemy | 796 | ImageField inside Maybe declaration no longer working since 3.1.0 | #### Description
In a factory that I defined for companies, I'm randomly generating a logo using a `Maybe` declaration. This used to work fine up to and including 3.0.1, but as of 3.1.0 it has different behaviour.
#### To Reproduce
##### Model / Factory code
Leaving out the other fields as they cannot be releva... | closed | 2020-10-13T13:53:14Z | 2020-12-23T17:21:32Z | https://github.com/FactoryBoy/factory_boy/issues/796 | [] | grondman | 2 |
huggingface/datasets | numpy | 6,894 | Better document defaults of to_json | Better document defaults of `to_json`: the default format is [JSON-Lines](https://jsonlines.org/).
Related to:
- #6891 | closed | 2024-05-13T13:30:54Z | 2024-05-16T14:31:27Z | https://github.com/huggingface/datasets/issues/6894 | [
"documentation"
] | albertvillanova | 0 |
ScrapeGraphAI/Scrapegraph-ai | machine-learning | 753 | Can I use a crawler and ScrapeGraphAI together? | **Is your feature request related to a problem? Please describe.**
To use a crawler like scrappy or crawlee with ScrapeGraphaAI together.
The crawler is responsible for crawl all the website, and filtering some contents. For example get the pages under the same path with the root HTTP url. Another example is I need ... | closed | 2024-10-15T07:22:15Z | 2024-10-15T09:10:10Z | https://github.com/ScrapeGraphAI/Scrapegraph-ai/issues/753 | [] | davideuler | 1 |
modelscope/data-juicer | streamlit | 113 | [MM] add face_area_filter OP | closed | 2023-12-04T11:43:25Z | 2023-12-06T06:21:57Z | https://github.com/modelscope/data-juicer/issues/113 | [
"enhancement",
"dj:multimodal"
] | drcege | 0 | |
unit8co/darts | data-science | 2,190 | Add `number_of_batch_per_epoch` parameters for torch forecasting models | ## feature request
**Is your feature request related to a current problem? Please describe.**
I once read an issue on GluonTS repository about why they are using both the batch_size and the number_of_batch_per_epoch (effectively fixing the number of samples per epoch). They argu that, sometimes, with panel time ser... | closed | 2024-01-26T16:18:03Z | 2024-02-01T14:31:14Z | https://github.com/unit8co/darts/issues/2190 | [
"question"
] | MarcBresson | 3 |
saulpw/visidata | pandas | 2,670 | [fuzzymatch] fuzzymatch shows matched items in lowercase | **Small description**
Fuzzymatch shows matches in lowercase.
**Steps to reproduce**
`vd sample_data/benchmark.csv`
`Space` `go-col-name` `date`
As soon as the first letter (`d`) of the search pattern is typed: the match for `Date` is shown in lowercase: `date`.
**Expected result**
I expect the match to pres... | open | 2025-01-08T04:49:48Z | 2025-01-08T04:49:48Z | https://github.com/saulpw/visidata/issues/2670 | [
"bug"
] | midichef | 0 |
harry0703/MoneyPrinterTurbo | automation | 67 | 生成视频时报错 | 报错内容如下:
tm.start(task_id=task_id, params=cfg)
File "/home/MoneyPrinterTurbo-main/app/services/task.py", line 133, in start
video.combine_videos(combined_video_path=combined_video_path,
File "/home/MoneyPrinterTurbo-main/app/services/video.py", line 84, in combine_videos
clip = clip.resize((video_wid... | closed | 2024-03-26T14:15:27Z | 2024-03-31T15:28:38Z | https://github.com/harry0703/MoneyPrinterTurbo/issues/67 | [
"bug"
] | xinjiangyin | 11 |
Urinx/WeixinBot | api | 270 | 微信网页版被关掉了,还能用吗? | 微信网页版被关掉了,还能用吗? | open | 2019-07-15T03:43:55Z | 2019-10-12T02:52:59Z | https://github.com/Urinx/WeixinBot/issues/270 | [] | zuijiu997 | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.