
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
Nekmo/amazon-dash | dash | 36 | Raspberry install Failed | * amazon-dash version:0.4.1
* Python version:3.5
* Operating System:Raspbian Jessi Lite
### Description
When I execute sudo python -m amazon_dash.install it fails with the text:
"/usr/bin/python: No module named amazon_dash"
"/usr/bin/python3.5: Error while finding module specification for 'amazon_dash.instal... | closed | 2018-02-24T12:20:38Z | 2018-03-25T00:45:35Z | https://github.com/Nekmo/amazon-dash/issues/36 | [] | Marvv90 | 7 |
ymcui/Chinese-BERT-wwm | nlp | 6 | 请问这个训练模型有什么用? | 小白一个,请问这个有啥用啊,看起来好高大上,应用场景是什么呢? | closed | 2019-06-23T07:57:30Z | 2019-06-23T08:04:04Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/6 | [] | mmrwbb | 1 |
aiogram/aiogram | asyncio | 1,465 | aiogram\utils\formatting.py (as_section) | ### Checklist
- [X] I am sure the error is coming from aiogram code
- [X] I have searched in the issue tracker for similar bug reports, including closed ones
### Operating system
Windows 10
### Python version
3.12
### aiogram version
3.4.1
### Expected behavior
aiogram\utils\formatting.py (as_section)
...
... | closed | 2024-04-19T09:58:37Z | 2024-04-21T19:17:52Z | https://github.com/aiogram/aiogram/issues/1465 | [
"bug",
"good first issue"
] | post1917 | 2 |
pydantic/pydantic-ai | pydantic | 844 | api_key is required even if ignored | https://ai.pydantic.dev/models/#example-local-usage
The example does not indicate that you need to set a dummy api_key i.e.
*Does not work*
```ollama_model = OpenAIModel(model_name="llama3.2", base_url="http://127.0.0.1:11434/v1")```
neither does
```ollama_model = OpenAIModel(model_name="llama3.2", base_url="http://... | closed | 2025-02-03T10:07:18Z | 2025-02-04T01:10:29Z | https://github.com/pydantic/pydantic-ai/issues/844 | [
"bug"
] | hansharhoff | 2 |
Python3WebSpider/ProxyPool | flask | 9 | 如何在pycharm里调试该项目 | 我使用一个远程的环境,想在pycharm里调试该项目,但是每次Debug run.py 都显示文件无法找到,请问如何使用pycharm调试这个项目 | closed | 2018-07-06T06:08:43Z | 2020-02-19T16:56:08Z | https://github.com/Python3WebSpider/ProxyPool/issues/9 | [] | bbhl79 | 0 |
jina-ai/serve | machine-learning | 5,486 | do not apply limits when gpus all in K8s | Opening this issue to track: https://github.com/jina-ai/jina/pull/5485
Currently, when `gpus: all` is applied, `resources.limits` will be set to `all`. The desired behavior is to not have `resources.limits` in K8s yaml. An example of the desired K8s yaml for the Flow:
```yaml
jtype: Flow
with:
protocol: grpc... | closed | 2022-12-05T09:49:52Z | 2022-12-05T17:10:41Z | https://github.com/jina-ai/serve/issues/5486 | [] | winstonww | 0 |
clovaai/donut | nlp | 308 | What should be the configuration of the machine to train the model? | open | 2024-07-01T09:29:07Z | 2024-07-01T09:29:07Z | https://github.com/clovaai/donut/issues/308 | [] | anant996 | 0 | |
gradio-app/gradio | data-visualization | 10,783 | Gradio: predict() got an unexpected keyword argument 'message' | ### Describe the bug
Trying to connect my telegram-bot(webhook) via API with my public Gradio space on Huggingface.
Via terminal - all works OK.
But via telegram-bot always got the same issue: Error in connection Gradio: predict() got an unexpected keyword argument 'message'.
What should i use to work it properl... | closed | 2025-03-11T12:12:43Z | 2025-03-18T10:28:21Z | https://github.com/gradio-app/gradio/issues/10783 | [
"bug",
"needs repro"
] | brokerelcom | 11 |
koxudaxi/datamodel-code-generator | fastapi | 1,668 | Impossible to get the json schema of a json schema object | **Describe the bug**
```python
from datamodel_code_generator.parser.jsonschema import JsonSchemaObject
if __name__ == "__main__":
print(JsonSchemaObject.model_json_schema())
```
Raises
```
pydantic.errors.PydanticInvalidForJsonSchema: Cannot generate a JsonSchema for core_schema.PlainValidatorFuncti... | closed | 2023-11-08T17:31:29Z | 2023-11-09T00:59:54Z | https://github.com/koxudaxi/datamodel-code-generator/issues/1668 | [] | jboulmier | 1 |
davidsandberg/facenet | tensorflow | 931 | what is the trainset of LFW data ? | I am a newer in face recognition,and have a question on the LFW dataset.
I want to know the train_set of the LFW dataset,(I want to use the LFW data in unrestricted protocol way).I want to know whether the train set is the peopleDevTrain.txt.
| open | 2018-12-17T02:20:16Z | 2018-12-17T02:20:16Z | https://github.com/davidsandberg/facenet/issues/931 | [] | guojiapeng00 | 0 |
cupy/cupy | numpy | 8,103 | Noise in Complex Number Computations | ### Description
I am doing some experiments involving variations of the Mandelbrot set and as such iterations over the complex plane. I have noticed noisy results using cupy as compared to numpy.
### To Reproduce
```
import matplotlib.pyplot as plt
def main():
HEIGHT = 9
WIDTH = 16
RATIO = W... | open | 2024-01-11T12:12:08Z | 2024-02-07T19:54:36Z | https://github.com/cupy/cupy/issues/8103 | [
"issue-checked"
] | knods3k | 6 |
gee-community/geemap | jupyter | 950 | Specify a 'datetime' column when converting from (Geo)DataFrame to FeatureCollection |
### Description
When I convert from (Geo)DataFrame that contains a column with date to FeatureCollection, I cannot filter by date because the date is only stored in properties of the FeatureCollection.
### Source code
```
gdf_radd = gpd.read_file('RADD_alerts.gpkg')
alerts_subset = gdf_radd.query(''202101... | closed | 2022-02-28T11:54:53Z | 2022-03-03T11:09:28Z | https://github.com/gee-community/geemap/issues/950 | [
"Feature Request"
] | janpisl | 2 |
mckinsey/vizro | data-visualization | 888 | Multi-step wizard | ### Which package?
vizro
### What's the problem this feature will solve?
Vizro excels at creating modular dashboards, but as users tackle more sophisticated applications, the need arises for reusable and extensible complex UI components. These include multi-step wizards with dynamic behavior, CRUD operations, and se... | open | 2024-11-19T20:07:30Z | 2024-11-21T19:42:00Z | https://github.com/mckinsey/vizro/issues/888 | [
"Feature Request :nerd_face:"
] | mohammadaffaneh | 3 |
Teemu/pytest-sugar | pytest | 223 | Print test name before result in verbose mode | Without pytest-sugar, when running pytest in verbose mode, the name of the current test is printed immediately.
This is very useful for long running tests since you know which test is hanging, and which test might be killed.
However, with pytest-sugar, the name of the test is only printed when the test succeeds.
... | open | 2021-08-16T13:17:54Z | 2023-07-26T11:17:27Z | https://github.com/Teemu/pytest-sugar/issues/223 | [
"enhancement"
] | hmaarrfk | 4 |
man-group/arctic | pandas | 76 | With lib_type='TickStoreV3': No field of name index - index.name and index.tzinfo not preserved - max_date returning min date (without timezone) | Hello,
this code
``` python
from pandas_datareader import data as pdr
symbol = "IBM"
df = pdr.DataReader(symbol, "yahoo", "2010-01-01", "2015-12-29")
df.index = df.index.tz_localize('UTC')
from arctic import Arctic
store = Arctic('localhost')
store.initialize_library('library_name', 'TickStoreV3')
library = store['... | closed | 2015-12-29T21:30:39Z | 2016-01-04T20:56:42Z | https://github.com/man-group/arctic/issues/76 | [] | femtotrader | 13 |
chatanywhere/GPT_API_free | api | 3 | 能不能用于api.openai.com | 要是科学上网的话,host能不能写成api.openai.com 呢 | closed | 2023-05-16T02:21:56Z | 2023-05-24T03:54:28Z | https://github.com/chatanywhere/GPT_API_free/issues/3 | [] | MrGongqi | 3 |
modoboa/modoboa | django | 2,247 | Contacts and Calendar throw internal error | # Impacted versions
* OS Type: Debian
* OS Version: 10
* Database Type: MySQL
* Database version: 10.3.27-MariaDB-0+deb10u1
* Modoboa: 1.17.0
* installer used: Yes
* Webserver: Nginx
* python --version: Python 3.7.3
# Steps to reproduce
* Do a default install of Modoboa on Debian 10.
* [Using "mailsrv"... | open | 2021-05-16T01:35:14Z | 2021-06-12T23:56:49Z | https://github.com/modoboa/modoboa/issues/2247 | [
"bug"
] | mas1701 | 15 |
cvat-ai/cvat | tensorflow | 8,380 | > Hi, we have added SAM2 on SaaS (https://app.cvat.ai/) and for Enterprise customers: https://www.cvat.ai/post/meta-segment-anything-model-v2-is-now-available-in-cvat-ai | closed | 2024-08-30T13:01:42Z | 2024-08-30T13:06:55Z | https://github.com/cvat-ai/cvat/issues/8380 | [] | gauravlochab | 0 | |
keras-team/keras | deep-learning | 20,283 | Training performance degradation after switching from Keras 2 mode to Keras 3 using Tensorflow | I've been working on upgrading my Keras 2 code to just work with Keras 3 without going fully back-end agnostic. However, while everything works fine after resolving compatibility, my training speed has severely degraded by maybe even a factor 10. I've changed the following to get Keras 3 working:
1. Changed `tensorf... | open | 2024-09-24T07:50:53Z | 2024-10-14T07:00:40Z | https://github.com/keras-team/keras/issues/20283 | [
"type:bug/performance",
"stat:awaiting keras-eng"
] | DavidHidde | 3 |
ultralytics/ultralytics | pytorch | 18,871 | Does tracking mode support NMS threshold? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
I'm currently using YOLOv10 to track some objects and there are a lot of cas... | closed | 2025-01-24T20:48:06Z | 2025-01-26T19:08:07Z | https://github.com/ultralytics/ultralytics/issues/18871 | [
"question",
"track"
] | argo-gabriel | 5 |
bmoscon/cryptofeed | asyncio | 897 | BinanceDelivery Candles (Rest) | **General: Thank you**
First of all, I would like to convey my gratitude to you. You have created a fantastic library.
**Describe the bug**
The candles method defined in the Binance Rest Mixin considers limits and adjusts the window by updating the start time (forward request). This works for Spot and UM. Unfortun... | open | 2022-08-27T20:01:05Z | 2022-08-28T07:29:51Z | https://github.com/bmoscon/cryptofeed/issues/897 | [
"bug"
] | christophlins | 0 |
ageitgey/face_recognition | python | 887 | Wrong detection face | * face_recognition version: 1.2.3
* Python version: 3.6
* Operating System: Ubuntu 18.04
### Description
Hello, i got wrong detection face, use cartoon of cat face then it's detect as face
i'm use this to detect face location :
face_locations1 = face_recognition.face_locations(selfieimage, model="cnn")
... | open | 2019-07-23T07:51:46Z | 2019-07-25T22:04:54Z | https://github.com/ageitgey/face_recognition/issues/887 | [] | blinkbink | 1 |
plotly/plotly.py | plotly | 4,355 | Just a question | Im learning to use plotly and wanted to know some stuff about it,
is it possible to make a exe app with plotly inside?, by this i mean, is it possible to make a standalone software without depending on html or any web services to run plotly modules?.
And othe question, wich library could be usefull to combine with ... | closed | 2023-09-13T16:59:39Z | 2023-09-16T15:08:05Z | https://github.com/plotly/plotly.py/issues/4355 | [] | Kripishit | 2 |
PokeAPI/pokeapi | graphql | 290 | b | closed | 2017-05-31T19:09:10Z | 2017-05-31T19:09:29Z | https://github.com/PokeAPI/pokeapi/issues/290 | [] | thechief389 | 0 | |
supabase/supabase-py | flask | 1,025 | [Python Client] Sensitive Data Exposure in Debug Logs - No Built-in Redaction Mechanism | - [x] I confirm this is a bug with Supabase, not with my own application.
- [x] I confirm I have searched the [Docs](https://docs.supabase.com), GitHub [Discussions](https://github.com/supabase/supabase/discussions), and [Discord](https://discord.supabase.com).
## Describe the bug
The Supabase Python client expose... | closed | 2025-01-04T06:19:30Z | 2025-01-11T22:30:20Z | https://github.com/supabase/supabase-py/issues/1025 | [] | ganeshrvel | 6 |
huggingface/datasets | nlp | 7,254 | mismatch for datatypes when providing `Features` with `Array2D` and user specified `dtype` and using with_format("numpy") | ### Describe the bug
If the user provides a `Features` type value to `datasets.Dataset` with members having `Array2D` with a value for `dtype`, it is not respected during `with_format("numpy")` which should return a `np.array` with `dtype` that the user provided for `Array2D`. It seems for floats, it will be set to `f... | open | 2024-10-26T22:06:27Z | 2024-10-26T22:07:37Z | https://github.com/huggingface/datasets/issues/7254 | [] | Akhil-CM | 1 |
dnouri/nolearn | scikit-learn | 46 | No self.best_weights in the function train_loop() ? | It seems that the train_loop() function inside the NeuralNetwork does not provide a self.best_weights which save the ConvNet parameters for the highest validation accuracy along with the epoch iterations.
Or do I miss something? Hope someone could help. Thank you.
| closed | 2015-02-17T03:08:16Z | 2015-02-20T01:43:56Z | https://github.com/dnouri/nolearn/issues/46 | [] | pengpaiSH | 3 |
Asabeneh/30-Days-Of-Python | pandas | 400 | Pyton | closed | 2023-06-02T07:31:36Z | 2023-06-02T07:31:56Z | https://github.com/Asabeneh/30-Days-Of-Python/issues/400 | [] | Fazel-GO | 0 | |
apache/airflow | python | 47,597 | Hello, we can't run a single DAG 3000 mission | ### Apache Airflow version
Other Airflow 2 version (please specify below)
### If "Other Airflow 2 version" selected, which one?
2.10.4
### What happened?
Hello, at present, we can load about 1000 jobs in a single DAG can be scheduled normally, but when the number of jobs in a single DAG reaches 3000, the schedulin... | open | 2025-03-11T07:09:46Z | 2025-03-24T08:01:31Z | https://github.com/apache/airflow/issues/47597 | [
"kind:bug",
"area:Scheduler",
"area:core",
"needs-triage"
] | lzf12 | 12 |
nolar/kopf | asyncio | 173 | [PR] Don’t add finalizers to skipped objects | > <a href="https://github.com/dlmiddlecote"><img align="left" height="50" src="https://avatars0.githubusercontent.com/u/9053880?v=4"></a> A pull request by [dlmiddlecote](https://github.com/dlmiddlecote) at _2019-08-07 18:21:40+00:00_
> Original URL: https://github.com/zalando-incubator/kopf/pull/173
> Merged by... | closed | 2020-08-18T19:59:43Z | 2020-08-23T20:48:59Z | https://github.com/nolar/kopf/issues/173 | [
"enhancement",
"archive"
] | kopf-archiver[bot] | 0 |
FactoryBoy/factory_boy | django | 1,057 | Fields do not exist in this model errors with OneToOneField in Django 5 | #### Description
After upgrading from Django 4.2 to Django 5, some of our tests are failing. These are using a OneToOneField between two models. Creating one instance through a factory with an instance to the other model fails because the related name is not accepted by the Django model manager.
The workaround is v... | closed | 2024-01-09T15:33:20Z | 2024-04-21T12:26:34Z | https://github.com/FactoryBoy/factory_boy/issues/1057 | [] | Gwildor | 3 |
pytest-dev/pytest-xdist | pytest | 463 | gure | closed | 2019-08-22T15:06:08Z | 2019-08-22T15:06:11Z | https://github.com/pytest-dev/pytest-xdist/issues/463 | [] | vasilty | 0 | |
streamlit/streamlit | machine-learning | 10,041 | Implement browser session API | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [X] I added a descriptive title and summary to this issue.
### Summary
Browser sessions allow developers to track browser status in streamlit, so that they can implement fea... | open | 2024-12-18T02:12:59Z | 2025-01-06T15:40:04Z | https://github.com/streamlit/streamlit/issues/10041 | [
"type:enhancement"
] | link89 | 2 |
donnemartin/data-science-ipython-notebooks | scikit-learn | 50 | code | sir ,plz send me code along with churn dataset
| closed | 2017-07-19T10:28:06Z | 2017-11-30T01:08:52Z | https://github.com/donnemartin/data-science-ipython-notebooks/issues/50 | [] | sabamehwish | 1 |
A3M4/YouTube-Report | seaborn | 11 | Module Can not be found | I am getting this error running python report.py
File "C:\Users\jacob\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.7_qbz5n2kfra8p0\LocalCache\local-packages\Python37\site-packages\scipy\special\__init__.py", line 641, in <module>
from ._ufuncs import *
ImportError: DLL load failed: The specified mo... | open | 2019-12-15T04:54:25Z | 2019-12-17T16:18:26Z | https://github.com/A3M4/YouTube-Report/issues/11 | [] | jbenzaquen42 | 4 |
aimhubio/aim | tensorflow | 3,153 | Failed to delete run in aim web ui | ## 🐛 Bug
when deleting `run` in aim web ui, I got the following error, and the run is not deleted:
```
Error
Error while deleting runs.
Error
Failed to execute 'json' on 'Response': body stream already read
```
### To reproduce
deleting `run` in aim web ui.
### Expected behavior
`run` deleted.
... | open | 2024-05-31T10:11:04Z | 2024-06-25T07:34:01Z | https://github.com/aimhubio/aim/issues/3153 | [
"type / bug",
"help wanted"
] | zhiyxu | 3 |
MaxHalford/prince | scikit-learn | 186 | Eigenvalue correction for MCA | Hello! I just recently started using this package for analyzing some categorical data, and I noticed that the `fit()` method of the `mca.py` file contains the setup (i.e., `self.K_`, `self.J_`) for inertia correction using either the _Benzecri_ or _Greenacre_ methods. However, it's not clear to me where the inertia cor... | closed | 2025-03-07T18:28:02Z | 2025-03-07T22:04:26Z | https://github.com/MaxHalford/prince/issues/186 | [] | saatcheson | 2 |
dynaconf/dynaconf | django | 595 | [bug] SQLAlchemy URL object replaced with BoxList object | Using dynaconf with Flask and Flask-SQLAlchemy. If I initialize dynaconf, then assign a sqlalchemy `URL` object to a config key, the object becomes a `BoxList`, which causes sqlalchemy to fail later. Dynaconf should not replace arbitrary objects.
```python
app = Flask(__name__)
dynaconf.init_app(app)
app.config["... | closed | 2021-06-01T19:15:32Z | 2021-08-19T14:14:32Z | https://github.com/dynaconf/dynaconf/issues/595 | [
"bug",
"HIGH",
"backport3.1.5"
] | trickardy | 2 |
pandas-dev/pandas | python | 61,125 | ENH: Supporting third-party engines for all `map` and `apply` methods | In #54666 and #61032 we introduce the `engine` parameter to `DataFrame.apply` which allows users to run the operation with a third-party engine.
The rest of `apply` and `map` methods can also benefit from this.
In a first phase we can do:
- `Series.map`
- `Series.apply`
- `DataFrame.map`
Then we can continue with t... | open | 2025-03-15T03:21:13Z | 2025-03-20T15:31:54Z | https://github.com/pandas-dev/pandas/issues/61125 | [
"Apply"
] | datapythonista | 13 |
autogluon/autogluon | scikit-learn | 4,388 | How to obtain fitted values with TimeSeriesPredictor? | ## Description
When I run TimeSeriesPredictor and fit the model, I didn't find out whether or where the fitted in-sample values are provided.
Can anyone help me with it? Thanks!
| open | 2024-08-14T16:48:29Z | 2024-08-15T12:02:57Z | https://github.com/autogluon/autogluon/issues/4388 | [
"enhancement"
] | wenqiuma | 1 |
hzwer/ECCV2022-RIFE | computer-vision | 34 | A work-in-progress vulkan port :D | https://github.com/nihui/rife-ncnn-vulkan
| closed | 2020-11-25T03:46:44Z | 2020-11-28T04:37:44Z | https://github.com/hzwer/ECCV2022-RIFE/issues/34 | [] | nihui | 1 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 16,560 | Seed not returned via api | ### Checklist
- [X] The issue exists after disabling all extensions
- [X] The issue exists on a clean installation of webui
- [X] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [X] The issue exists in the current version of the webui
- [X] The issue has not been reported before... | closed | 2024-10-17T15:56:46Z | 2024-10-24T01:14:49Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16560 | [
"not-an-issue"
] | Marcophono2 | 2 |
Sanster/IOPaint | pytorch | 242 | Switch to sd1.5 model failed | I have this problem when choosing any Stable-Diffusion model. How to fix it?

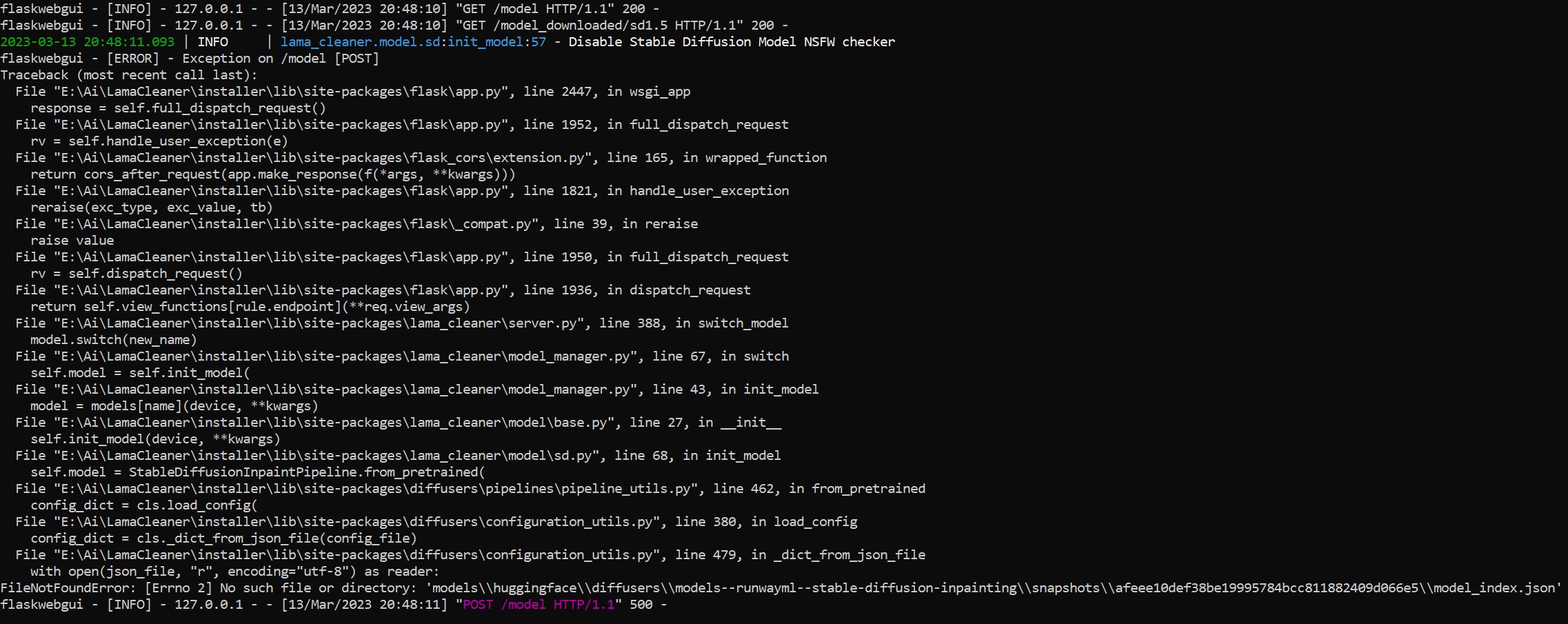
| closed | 2023-03-13T15:53:56Z | 2023-03-14T22:37:19Z | https://github.com/Sanster/IOPaint/issues/242 | [] | vasyaholly | 13 |
healthchecks/healthchecks | django | 1,134 | [Feature Request] Group Projects | Hi,
we've organized the different jobs in multiple projects, which already is nice. However, with more projects, it would be nice to have some control on how to organize the projects in the starting page. My usecases are e.g. to separate prod from dev jobs etc. So one way of achieving this would probably be to group t... | open | 2025-03-14T14:05:07Z | 2025-03-14T14:05:07Z | https://github.com/healthchecks/healthchecks/issues/1134 | [] | skr5k | 0 |
ckan/ckan | api | 7,579 | Function is dropped in CKAN 2.10 despite deprecation info | ## CKAN version
2.10
## Describe the bug
The `authz.auth_is_loggedin_user` function is dropped in CKAN 2.10. However, in CKAN 2.9, there was a deprecation notice _recommending_ this function, and there doesn't appear to be a clear replacement.
### Steps to reproduce
- Install a plugin that calls `auth_is... | open | 2023-05-09T03:04:46Z | 2023-05-09T13:57:04Z | https://github.com/ckan/ckan/issues/7579 | [] | ThrawnCA | 1 |
yt-dlp/yt-dlp | python | 12,109 | [Dropbox] Error: No video formats found! | ### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [x] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
### Checklist
- [x] I'm reporting that yt-dlp is broken on a **supported** site
- [x] I've verified that I have **updated yt-dlp to nightly or master** ([update instruc... | closed | 2025-01-16T19:53:26Z | 2025-01-29T16:56:07Z | https://github.com/yt-dlp/yt-dlp/issues/12109 | [
"NSFW",
"site-bug"
] | BenderBRod | 2 |
scikit-learn/scikit-learn | data-science | 30,461 | from sklearn.datasets import make_regression FileNotFoundError | ### Describe the bug
When running examples/application/plot_prediction_latency.py a FileNotFoundError occurs as there is no file named make_regression in datasets dir.
I have cloned the scikit-learn repo and installed it using ```pip install -e .```
Completely unable to ```import scikit_learn ``` or ```sklearn ... | closed | 2024-12-11T10:13:52Z | 2024-12-11T11:19:18Z | https://github.com/scikit-learn/scikit-learn/issues/30461 | [
"Bug",
"Needs Triage"
] | kayo09 | 1 |
nerfstudio-project/nerfstudio | computer-vision | 2,952 | Docker/singularity container doesn't seem to contain ns-* commands | **Describe the bug**
I built a singularity container from the Dockerhub address listed on the web page and then ran "singularity run --nv nerf.simg" and tried to find the ns-* files but I am unable to find them.
**To Reproduce**
Run:
singularity build nerf.simg docker://dromni/nerfstudio:1.0.2
singula... | open | 2024-02-23T22:05:32Z | 2024-09-05T22:07:46Z | https://github.com/nerfstudio-project/nerfstudio/issues/2952 | [] | cousins | 7 |
autokey/autokey | automation | 820 | keyboard.press_key freezes autokey | ### AutoKey is a Xorg application and will not function in a Wayland session. Do you use Xorg (X11) or Wayland?
Xorg
### Has this issue already been reported?
- [X] I have searched through the existing issues.
### Is this a question rather than an issue?
- [X] This is not a question.
### What type of ... | closed | 2023-03-25T02:31:58Z | 2023-04-25T21:14:31Z | https://github.com/autokey/autokey/issues/820 | [
"scripting",
"invalid",
"user support"
] | NicoReXDlol | 16 |
zappa/Zappa | flask | 652 | [Migrated] ResourceNotFoundException: An error occurred (ResourceNotFoundException) when calling the DescribeLogStreams | Originally from: https://github.com/Miserlou/Zappa/issues/1652 by [4lph4-Ph4un](https://github.com/4lph4-Ph4un)
When attempting to tail logs on dev the tailing is succesfull, however tailing environment on another account fails with:
```
Traceback (most recent call last):
File "/opt/kidday/env/lib/python3.6/sit... | closed | 2021-02-20T12:32:27Z | 2024-04-13T17:36:31Z | https://github.com/zappa/Zappa/issues/652 | [
"no-activity",
"auto-closed"
] | jneves | 3 |
neuml/txtai | nlp | 235 | API should raise an error if attempting to modify a read-only index | Currently, the API silently skips add/index/upsert/delete operations and returns a HTTP 200 code when an index is not writable. This leads to confusing behavior.
An error should be raised with a 403 Forbidden status code. | closed | 2022-03-01T18:58:49Z | 2022-03-01T18:59:58Z | https://github.com/neuml/txtai/issues/235 | [] | davidmezzetti | 0 |
lux-org/lux | jupyter | 376 | [BUG] Unexpected error in rendering Lux widget and recommendations when filtering does not produce results | **Describe the bug**
When filtering a dataframe based on row values does not produce results, the following error is thrown:
<user_path>site-packages\IPython\core\formatters.py:918: UserWarning:
Unexpected error in rendering Lux widget and recommendations. Falling back to Pandas display.
Please report the following... | closed | 2021-05-18T10:29:07Z | 2021-05-18T21:21:07Z | https://github.com/lux-org/lux/issues/376 | [] | Innko | 1 |
mwaskom/seaborn | matplotlib | 3,675 | Defining plot size in seaborn objects ? | Hi seaborn community
I could not find the setting of the size in seaborn objects API tutorials and documentation
I want to set plot size in a plot in a nice concise manner that works with seaborn objects:
Example:
`lineplop.facet('shift', wrap = 3).share(x= True, y = False)`
I can only do so as follo... | closed | 2024-04-13T08:40:00Z | 2024-04-18T13:23:59Z | https://github.com/mwaskom/seaborn/issues/3675 | [] | mat-ej | 1 |
sqlalchemy/alembic | sqlalchemy | 845 | failed to create process. Problem | When I try to run alembic any command its show me failed to create process. Problem | closed | 2021-05-19T10:36:30Z | 2021-05-20T17:29:29Z | https://github.com/sqlalchemy/alembic/issues/845 | [
"question",
"awaiting info",
"cant reproduce"
] | imrankhan441 | 2 |
nsidnev/fastapi-realworld-example-app | fastapi | 270 | User registration failed "relation "users" does not exist" | Dear nsidnev,
I'm a fan of your architecture in this application. Unfortunately, I cannot figure out the error from the registration side:
"asyncpg.exceptions.UndefinedTableError: relation "users" does not exist"
I attached an image on how it looks like. I hope we could figure this out.
![Screenshot 2022-04-1... | closed | 2022-04-16T11:22:10Z | 2022-08-21T00:20:09Z | https://github.com/nsidnev/fastapi-realworld-example-app/issues/270 | [] | Eternal-Engine | 3 |
sgl-project/sglang | pytorch | 4,055 | [Feature] Apply structured output sampling after reasoning steps in Reasoning models | ### Checklist
- [ ] 1. If the issue you raised is not a feature but a question, please raise a discussion at https://github.com/sgl-project/sglang/discussions/new/choose Otherwise, it will be closed.
- [ ] 2. Please use English, otherwise it will be closed.
### Motivation
Only apply constrained sampling only in the ... | open | 2025-03-04T07:58:42Z | 2025-03-24T07:04:02Z | https://github.com/sgl-project/sglang/issues/4055 | [] | xihuai18 | 10 |
freqtrade/freqtrade | python | 10,702 | Freqtrade process crashes | ## Describe your environment
* Operating system: Amazon Linux AMI
* Python Version: 3.9.16
* CCXT version: 4.3.88
* Freqtrade Version: 2024.8
## Describe the problem:
After running for a few hours service crashed.
### Steps to reproduce:
It's unclear how to reproduce the problem as it happen... | closed | 2024-09-24T06:11:47Z | 2024-09-24T07:24:58Z | https://github.com/freqtrade/freqtrade/issues/10702 | [
"Question"
] | vecktor | 1 |
charlesq34/pointnet | tensorflow | 102 | There is a problem when I run [collect_indoor_3d.py]. | When I downloaded and unzip the 4.09GB datasets, I still couldn't correctly run collect_indoor_3d.py.
And error is 【/path/data/StanfordDatasets v1.2 Aligned Version/Area../xxxx 1/Annotations, 'ERROR!'】
I don't know how can I solve this problem.
Do I make some wrong operation?
Thanks for your help!
| open | 2018-04-23T08:59:38Z | 2019-03-26T02:01:19Z | https://github.com/charlesq34/pointnet/issues/102 | [] | JinyuanShao | 1 |
pydantic/pydantic | pydantic | 11,576 | Invalid JSON Schema generated when constraints and validators are involved | ### Initial Checks
- [x] I confirm that I'm using Pydantic V2
### Description
The following generates an invalid JSON Schema:
```python
from typing import Annotated
from pydantic import BeforeValidator, Field, TypeAdapter
TypeAdapter(Annotated[int, Field(gt=2), BeforeValidator(lambda v: v), Field(lt=2)]).json_sch... | open | 2025-03-18T16:15:51Z | 2025-03-18T16:15:51Z | https://github.com/pydantic/pydantic/issues/11576 | [
"bug V2",
"topic-annotations"
] | Viicos | 0 |
FlareSolverr/FlareSolverr | api | 573 | [1337x] (testing) Exception (1337x): FlareSolverr was unable to process the request, please check FlareSolverr logs. Message: Error: Unable to process browser request. ProtocolError: Protocol error (Page.navigate): frameId not supported RemoteAgentError@chrome://remote/content/cdp/Error.jsm:29:5 | **Please use the search bar** at the top of the page and make sure you are not creating an already submitted issue.
Check closed issues as well, because your issue may have already been fixed.
### How to enable debug and html traces
[Follow the instructions from this wiki page](https://github.com/FlareSolverr/Fl... | closed | 2022-11-03T07:52:01Z | 2022-11-03T14:13:45Z | https://github.com/FlareSolverr/FlareSolverr/issues/573 | [
"duplicate"
] | karanrahar | 1 |
yeongpin/cursor-free-vip | automation | 41 | 无法设置密码 |  | closed | 2025-01-30T17:07:47Z | 2025-02-05T12:14:01Z | https://github.com/yeongpin/cursor-free-vip/issues/41 | [] | 1837620622 | 1 |
BeanieODM/beanie | asyncio | 102 | Text Search? | I couldn't find anything in the docs to do text search (https://docs.mongodb.com/manual/reference/operator/query/text/)
I have a document :
```python
class Location(Document):
name: str
private: bool = False
class Meta:
table = "locations"
```
I want to do a search like "where n... | open | 2021-08-29T07:17:29Z | 2024-12-08T14:30:17Z | https://github.com/BeanieODM/beanie/issues/102 | [
"documentation"
] | tonybaloney | 4 |
roboflow/supervision | pytorch | 1,144 | Multi-can tracking | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
I have 6 cams connected in a hallway and my task is to track and count people walking in it (there are always many people there), yet I do not u... | closed | 2024-04-26T11:54:47Z | 2024-04-26T12:09:35Z | https://github.com/roboflow/supervision/issues/1144 | [
"question"
] | Vdol22 | 1 |
proplot-dev/proplot | data-visualization | 441 | Nonsticky bounds | ### Description
I think it makes sense to use nonsticky bounds for some plots such as errorbar plot. Could you add an option for nonsticky bounds?
### Steps to reproduce
In this example, the errorbars in the edges are hidden.
```python
import numpy as np
import pandas as pd
import proplot as pplt
state = ... | open | 2023-11-17T19:23:57Z | 2023-11-17T19:23:57Z | https://github.com/proplot-dev/proplot/issues/441 | [] | kinyatoride | 0 |
plotly/plotly.py | plotly | 5,059 | `mpl_to_plotly` does not preserve axis labels (bar plots are useless) | While `mpl_to_plotly` is little known and receives little love, this bug is pretty easy to fix. Would you be open to a PR?
<details>
```python
import matplotlib.pyplot as plt
from plotly.tools import mpl_to_plotly
from plotly.offline import plot
```
</details>
In matplotlib this produces a barplot with labels:
```... | open | 2025-02-28T20:54:24Z | 2025-03-03T17:56:53Z | https://github.com/plotly/plotly.py/issues/5059 | [
"bug",
"P3"
] | krassowski | 1 |
pytest-dev/pytest-html | pytest | 530 | pytest-html doesn't always flush the results | I believe there is some sort of race condition going on, sometimes I get the report generated at the right time but the results are just not there.
My setup for pytest is very simple
```
# pytest.ini
addopts = --html=report.html --self-contained-html
``` | closed | 2022-07-14T12:19:01Z | 2023-03-05T16:18:37Z | https://github.com/pytest-dev/pytest-html/issues/530 | [
"needs more info"
] | 1Mark | 2 |
plotly/dash | flask | 2,423 | Add loading attribute to html.Img component | **Is your feature request related to a problem? Please describe.**
I'm trying to lazy load images using the in built browser functionality, but I can't because that's not exposed in the html.Img component.
**Describe the solution you'd like**
I'd like the loading attribute to be added to the html.Img built in comp... | open | 2023-02-13T12:15:58Z | 2024-08-13T19:26:45Z | https://github.com/plotly/dash/issues/2423 | [
"feature",
"P3"
] | LiamLombard | 1 |
jacobgil/pytorch-grad-cam | computer-vision | 397 | 'numpy.int64' object is not iterable | The model was trained with 'autocast()'.
MODEL_TYPE = 'efficientnet_b0'
model = CustomModel(1,config)
target_layers = [model.backbone.blocks[-1][-1]]
visual_cam = CAM(model, target_layers, type='GradCAM', use_cuda=DEVICE)
``` python
class CustomModel(nn.Module):
def __init__(self, num_classes, config... | closed | 2023-03-04T03:44:21Z | 2023-03-06T15:56:42Z | https://github.com/jacobgil/pytorch-grad-cam/issues/397 | [] | Fly-Pluche | 1 |
comfyanonymous/ComfyUI | pytorch | 7,344 | Do I need to install Python, Visual Studio and Git to use the Windows Portable Package? | ### Your question
Do I need to install Python, Visual Studio and Git to use the Windows Portable Package?
### Logs
```powershell
```
### Other
_No response_ | open | 2025-03-21T17:00:56Z | 2025-03-22T10:07:57Z | https://github.com/comfyanonymous/ComfyUI/issues/7344 | [
"User Support"
] | Sdreamtale | 3 |
miguelgrinberg/Flask-SocketIO | flask | 1,670 | The __version__ attribute disappeared from version 5.0.1 to version 5.1.1 | **Describe the bug**
Hi, I have been using `Flask-SocketIO` version 5.0.1 until today and when I queried the version with the `__version__` attribute it returned the current version as follows:
```
>>> import flask_socketio
>>> flask_socketio.__version__
'5.0.1'
```
But after upgrading the package to version... | closed | 2021-08-27T06:46:20Z | 2021-08-27T08:38:03Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1670 | [] | ribes4 | 3 |
qubvel-org/segmentation_models.pytorch | computer-vision | 615 | Multi-class segmentation can't predict classes other than 0, 1 | Hello,
Thanks for your great contribution. I used your model to train my images dataset, in which there are 5 classes. I tried Unet and DeepLabV3+ in different activation functions and loss = DiceLoss. However, I usually get perfect diceloss and iou because most of pixels belong to 0 class, but the model never can p... | closed | 2022-06-29T17:58:45Z | 2023-12-29T20:12:01Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/615 | [
"Stale"
] | wfeng66 | 8 |
2noise/ChatTTS | python | 634 | 请问chatts同时可以对多少个文本进行语音转写? | 我想开发一个API,供多人使用,请问CHATTTS并发时最多可以对多少个文本进行语音转写,我的显卡是4090 * 4 | closed | 2024-07-26T10:47:59Z | 2024-11-21T04:02:07Z | https://github.com/2noise/ChatTTS/issues/634 | [
"documentation",
"stale"
] | XuePeng87 | 2 |
erdewit/ib_insync | asyncio | 234 | I would like to get hisotrical data on the futur | Hello Everyone
contracts = Future('ES', '20200619', 'GLOBEX', includeExpired=True)
ib.qualifyContracts(contracts)
# ib.reqMarketDataType(4)
bars = ib.reqHistoricalData(
contracts,
"",
"5 Y",
"1 day",
"TRADES",
True
)
print(bars)
I have got this error
"Error 162, reqId 425... | closed | 2020-04-10T18:30:42Z | 2020-04-20T15:37:17Z | https://github.com/erdewit/ib_insync/issues/234 | [] | jiany30 | 1 |
home-assistant/core | asyncio | 140,329 | Abort SmartThings flow if default_config is not enabled #139700 breaks existing working setup | ### The problem
Hi @joostlek ,
I hope you're doing well. I noticed that the recent update "Abort SmartThings flow if default_config is not enabled #139700" seems to abort the SmartThings flow when the cloud is not enabled. However, I have been using the SmartThings integration for months without the cloud being enabl... | closed | 2025-03-11T00:31:26Z | 2025-03-15T16:07:26Z | https://github.com/home-assistant/core/issues/140329 | [
"integration: smartthings"
] | brendann993 | 2 |
sammchardy/python-binance | api | 1,277 | Execute trade with websocket? | Is it possible to execute a trade using the websocket? it looks like the create_order function just issues an http request. | closed | 2022-12-29T18:36:28Z | 2023-01-11T21:14:11Z | https://github.com/sammchardy/python-binance/issues/1277 | [] | OpenCoderX | 2 |
plotly/dash | data-science | 2,851 | Dash 2.17.0 prevents some generated App Studio apps from running | https://github.com/plotly/notebook-to-app/actions/runs/8974757424/job/24647808759#step:9:1283
We've reverted to 2.16.1 for the time being. | closed | 2024-05-06T20:27:02Z | 2024-07-26T13:45:34Z | https://github.com/plotly/dash/issues/2851 | [
"P2"
] | hatched | 2 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 15,437 | [Feature Request]: Using two GPUs | Would it be possible to use 2 GPUs in one system to generate an image?
| open | 2024-04-04T13:21:35Z | 2024-04-13T00:33:06Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15437 | [
"enhancement"
] | roda37 | 0 |
dunossauro/fastapi-do-zero | sqlalchemy | 284 | Adicionar cláusula no pyenv-win para erro de police | Comando:
```powershell
Set-ExecutionPolicy Unrestricted -Scope CurrentUser -Force;
``` | closed | 2025-01-24T19:54:47Z | 2025-01-29T05:36:40Z | https://github.com/dunossauro/fastapi-do-zero/issues/284 | [] | dunossauro | 0 |
pywinauto/pywinauto | automation | 890 | Can not launch SnippingTool (elevation is required) | ## Expected Behavior
Launch SnippingTool.exe
## Actual Behavior
Error log below
```
(PYWINA~1) f:\PCKLIB_Python\WinAutomation>python main.py
Traceback (most recent call last):
File "C:\Users\PIAODA~1\Envs\PYWINA~1\lib\site-packages\pywinauto\application.py", line 1047, in start
start_info) ... | open | 2020-02-16T13:41:58Z | 2021-03-22T01:28:22Z | https://github.com/pywinauto/pywinauto/issues/890 | [
"enhancement",
"question",
"Priority-Low"
] | 0xF217 | 9 |
keras-team/keras | deep-learning | 20,479 | [bug] TextVectorization + Sequential model doesn't work | Tensorflow version:
`2.19.0-dev20241108`
Keras version:
`3.7.0.dev2024111103`
Installation command: `pip install --pre tf-nightly`
Reproducing code:
```
import numpy as np
import tensorflow as tf
def get_text_vec_model(train_samples):
from tensorflow.keras.layers import TextVectorization
... | closed | 2024-11-11T11:00:56Z | 2024-11-11T17:51:23Z | https://github.com/keras-team/keras/issues/20479 | [
"type:Bug"
] | WeichenXu123 | 3 |
graphql-python/graphene-django | django | 972 | Instantiate Middleware from string | **Is your feature request related to a problem? Please describe.**
I want to be able to put strings in the MIDDLEWARE setting, as in default Django settings:
```
GRAPHENE = {
'MIDDLEWARE': [
'package1.middleware',
'package2.middleware',
]
}
```
**Describe the solution you'd like**
T... | closed | 2020-05-26T17:24:21Z | 2020-05-26T19:28:09Z | https://github.com/graphql-python/graphene-django/issues/972 | [
"✨enhancement"
] | wkoot | 1 |
supabase/supabase-py | fastapi | 486 | add documentation for update and delete in the supabase docs |
there is an insert and fetch example in the docs https://supabase.com/docs/reference/python/insert but there is no update nor delete. i think they should be added. | closed | 2023-07-02T19:50:10Z | 2024-04-28T22:02:13Z | https://github.com/supabase/supabase-py/issues/486 | [
"good first issue"
] | IanEvers | 3 |
hack4impact/flask-base | sqlalchemy | 26 | Give flask-base a real task queue | Right now, async code (e.g. `send_email`) is implemented with threads). We should have a worker process always running which completes tasks from the task queue instead. One problem with the current approach is that clients of the `send_email` function do not know that it is asynchronous unless they read the implementa... | closed | 2016-01-09T04:30:24Z | 2016-07-08T00:55:33Z | https://github.com/hack4impact/flask-base/issues/26 | [
"enhancement"
] | sandlerben | 4 |
Miserlou/Zappa | flask | 1,344 | Event schedule for async task is not updated | ## Context
I'm using dynamodb triggers which are calling my Lambda function. I did a setup in zappa_settings using "events" list and deployed it. DynamoDB triggers were created successfully.
There are two probelms with it:
1. I tried to change batch_size attribute.
2. I have deleted configuration for one of the tr... | open | 2018-01-09T22:34:14Z | 2018-02-23T22:10:58Z | https://github.com/Miserlou/Zappa/issues/1344 | [
"enhancement",
"non-bug",
"good-idea"
] | chekan-o | 1 |
sktime/pytorch-forecasting | pandas | 1,794 | [MNT] Upgrade to `torch>2.2.2` because of CVE-2024-5480 | Hi!
I cannot install pytorch-forecasting in my organization because of https://www.cvedetails.com/cve/CVE-2024-5480/. Can you upgrade the dependency in the pyproject.tmol to torch>2.2.2, please?
Thanks a lot!
Best
Robert | open | 2025-03-13T08:00:10Z | 2025-03-20T10:55:33Z | https://github.com/sktime/pytorch-forecasting/issues/1794 | [
"maintenance"
] | Garve | 4 |
aminalaee/sqladmin | sqlalchemy | 23 | Enable SQLAlchemy V2 features | Need to check SQLAlchemy V2 migration steps. As far as I can see we're using SQLAlchemy 1.4 features, It should be ready, but needs checking and fixing. | closed | 2022-01-19T14:03:33Z | 2023-01-05T15:26:37Z | https://github.com/aminalaee/sqladmin/issues/23 | [
"enhancement"
] | aminalaee | 2 |
TencentARC/GFPGAN | deep-learning | 472 | Sai | open | 2023-12-10T02:56:13Z | 2023-12-10T02:56:13Z | https://github.com/TencentARC/GFPGAN/issues/472 | [] | sai9232 | 0 | |
capitalone/DataProfiler | pandas | 916 | `DATAPROFILER_SEED` global input validation testing | **Is your feature request related to a problem? Please describe.**
We reference `DATAPROFILER_SEED` in a variety of locations throughout the repo. So right now the way we work with this env variable is incorrect in nearly every location except [here](https://github.com/capitalone/DataProfiler/blob/dev/dataprofiler/dat... | closed | 2023-06-27T17:23:40Z | 2023-08-01T13:59:49Z | https://github.com/capitalone/DataProfiler/issues/916 | [
"New Feature"
] | micdavis | 4 |
strawberry-graphql/strawberry | graphql | 3,713 | multipart_uploads_enabled not propagated in AsyncGraphQLView, causing file uploads to fail | **Describe the Bug**
In strawberry-graphql==0.253.0 and strawberry-graphql-django==0.50.0, setting multipart_uploads_enabled=True in the AsyncGraphQLView does not enable multipart uploads as expected. The self.multipart_uploads_enabled attribute remains False, causing file uploads via multipart/form-data to fail with ... | open | 2024-11-29T22:04:43Z | 2024-12-31T00:53:39Z | https://github.com/strawberry-graphql/strawberry/issues/3713 | [
"bug"
] | BranDavidSebastian | 2 |
OFA-Sys/Chinese-CLIP | nlp | 4 | RoBERTa-wwm-ext-base-chinese.json文件在? | ViT-B-16.json文件可以在open-clip下找到,请问这个在哪里能找到? | closed | 2022-07-13T10:52:53Z | 2022-11-03T11:03:08Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/4 | [] | PineREN | 3 |
flasgger/flasgger | flask | 422 | property field marked as required but flasgger still accepts it | From the todo example:
```
def post(self):
"""
This is an example
---
tags:
- restful
parameters:
- in: body
name: body
schema:
$ref: '#/definitions/Task'
responses:
201:
descri... | open | 2020-07-23T20:08:12Z | 2020-07-24T11:46:32Z | https://github.com/flasgger/flasgger/issues/422 | [] | patrickelectric | 1 |
huggingface/datasets | tensorflow | 7,040 | load `streaming=True` dataset with downloaded cache | ### Describe the bug
We build a dataset which contains several hdf5 files and write a script using `h5py` to generate the dataset. The hdf5 files are large and the processed dataset cache takes more disk space. So we hope to try streaming iterable dataset. Unfortunately, `h5py` can't convert a remote URL into a hdf5 f... | open | 2024-07-11T11:14:13Z | 2024-07-11T14:11:56Z | https://github.com/huggingface/datasets/issues/7040 | [] | wanghaoyucn | 2 |
graphql-python/graphql-core | graphql | 167 | Loss of precision in floating point values | Hello,
We are observing some surprising behavior with floating point numbers. Specifically, ast_from_value() appears to be converting python float values to strings in a lossy manner.
This appears to be happening in [this line](https://github.com/graphql-python/graphql-core/blob/main/src/graphql/utilities/ast_from_... | closed | 2022-04-04T18:15:59Z | 2022-04-10T16:50:49Z | https://github.com/graphql-python/graphql-core/issues/167 | [] | rpgreen | 4 |
microsoft/JARVIS | deep-learning | 86 | What does 72G of disk space refer to? | Dear jarvis team:
I'm sure my device has more than 72G of space. But when I run download.sh, it remains me "no space left on device". I used df -h to check my disk, and It was indeed full. Could you tell me what does 72G of disk space refer to?How much space do I need to run download.sh? | closed | 2023-04-07T07:14:55Z | 2023-04-07T08:07:36Z | https://github.com/microsoft/JARVIS/issues/86 | [] | CanIbeyourdog | 3 |
scikit-tda/kepler-mapper | data-visualization | 137 | Is it possible to calculate the Betti Numbers of the simplicial complex? | I would like to be able to evaluate the choice of parameter values for the Kepler Mapper using the Betti Numbers rather than visually (looking at the simplicial complex plotted). This would be helpful in making a more informed choice on parameter values and, in addition, would lead to allowing calculations of persisten... | open | 2019-02-22T09:40:16Z | 2019-11-22T17:14:49Z | https://github.com/scikit-tda/kepler-mapper/issues/137 | [] | karinsasaki | 6 |
browser-use/browser-use | python | 914 | Unable to identify non-index HTML element | ### Bug Description
Index is not available for add participant which just a div. Any possibility to click on non-index HTML element like div, request your guidance.

HTML: <div id="addParticipant" class="i-vertical span-add ">Ad... | closed | 2025-03-01T22:57:58Z | 2025-03-05T11:33:08Z | https://github.com/browser-use/browser-use/issues/914 | [
"bug"
] | kalirajann | 4 |
errbotio/errbot | automation | 1,480 | Proposal : Slack backend deprecation plan | # Description
The current situation for Slack is causing confusion for users and developers. For example
- Multiple PRs for the same features are being created.
- Features are applied to one slack backend but not the other.
- Inconsistent behaviour between backends makes debugging confusing.
- Users must be g... | closed | 2020-11-25T14:03:23Z | 2021-07-23T05:47:16Z | https://github.com/errbotio/errbot/issues/1480 | [
"backend: Slack",
"#release-process"
] | nzlosh | 6 |
rthalley/dnspython | asyncio | 401 | Refactor project documentation using epytext | In less than a month, `epydoc` will be [legacy](https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=881562) - "
```
Epydoc is basically unmaintained upstream. Also, it is only
supported for Python 2, so it will reach its end of life along with
Python 2 sometime in 2020.
```
"
This also means the markup langu... | closed | 2019-12-04T00:00:24Z | 2020-05-12T13:00:24Z | https://github.com/rthalley/dnspython/issues/401 | [
"Enhancement Request",
"Needs Author"
] | binaryflesh | 9 |
FujiwaraChoki/MoneyPrinterV2 | automation | 56 | RuntimeError: Incorrect response | when I run the code , I get this error ,how can I fix this bug?

| closed | 2024-03-05T03:33:09Z | 2024-03-06T02:10:51Z | https://github.com/FujiwaraChoki/MoneyPrinterV2/issues/56 | [] | 2679373161 | 2 |
tfranzel/drf-spectacular | rest-api | 565 | Add link to documentation in GitHub URL metadata | To make it easier to find the documentation for this project, consider adding a link to https://drf-spectacular.readthedocs.io/en/latest/ from the GitHub projects page.
Example see *Website*:
<img width="442" alt="Screen Shot 2021-10-12 at 1 41 44 PM" src="https://user-images.githubusercontent.com/10340167/137003... | closed | 2021-10-12T17:42:48Z | 2021-10-12T18:18:52Z | https://github.com/tfranzel/drf-spectacular/issues/565 | [] | johnthagen | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.