
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
tflearn/tflearn | data-science | 943 | cross_product term | Anyone know how to use cross_product in tflearn?
Or how to transform tensorflow indicator to tensor for tflearn ?
```
tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_vocabulary_list(cc,cc_size[1]))
``` | open | 2017-10-26T16:52:06Z | 2017-10-26T16:52:06Z | https://github.com/tflearn/tflearn/issues/943 | [] | whizzalan | 0 |
whitphx/streamlit-webrtc | streamlit | 1,046 | ReferenceError: weakly-referenced object no longer exists | Updated to 0.43.3 but I still get the same error on Mac M1 Pro | closed | 2022-09-01T12:31:35Z | 2022-09-05T12:03:18Z | https://github.com/whitphx/streamlit-webrtc/issues/1046 | [] | creeksflowing | 12 |
home-assistant/core | asyncio | 140,995 | HomeKit Integration: Missing and Non-Functional Entities After Update (Smartmi Air Purifier P2) | ### The problem
Hello! First of all, thank you for your hard work on the HomeKit integration. I need your help with an issue that appeared after updating Home Assistant.
After the update, several entities in the HomeKit integration disappeared, and new ones appeared, but they are not working. Here are the details:
**... | open | 2025-03-20T14:01:02Z | 2025-03-20T17:27:04Z | https://github.com/home-assistant/core/issues/140995 | [
"integration: homekit"
] | FleshZLO | 1 |
tqdm/tqdm | jupyter | 1,438 | bar_format typeerror for {rate:.3f} format | ## my code
```py
from tqdm.auto import tqdm , trange
# from tqdm.notebook import tqdm
from time import sleep
with tqdm(total=10,
desc="desc", bar_format="[{desc}: {percentage:3.0f}%] |{bar}| [{n_fmt}/{total_fmt}] [{elapsed}<<{remaining}] [{rate:.3f} {unit}/s] "
) as t:
for i in range(10):... | open | 2023-03-02T13:51:56Z | 2025-02-09T21:54:41Z | https://github.com/tqdm/tqdm/issues/1438 | [] | ZX1209 | 1 |
wkentaro/labelme | computer-vision | 318 | libpng warning: iCCP: known incorrect sRGB profile | Hi, what does this warning mean? Although it doesn't affect my use.
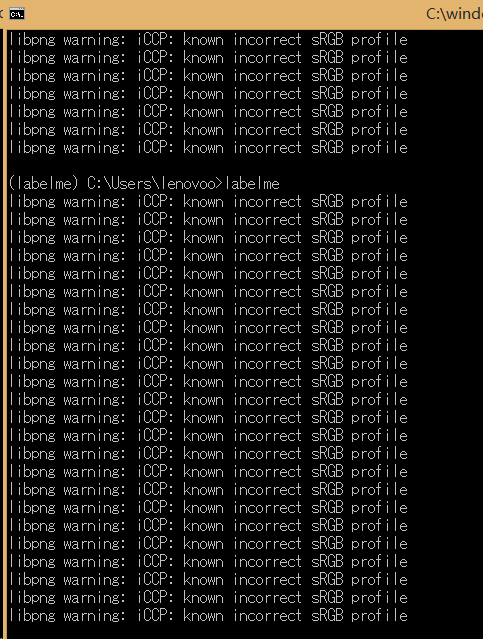
| closed | 2019-02-14T07:43:52Z | 2019-04-27T01:59:00Z | https://github.com/wkentaro/labelme/issues/318 | [] | lck1201 | 0 |
darrenburns/posting | rest-api | 160 | Scripting get_variable method not implemented | The docs [Scripting](https://posting.sh/guide/scripting/) contains a reference to the `posting.get_variable()` method, but it doesn't look like this has been implemented (yet).
As a workaround, looks like we could use `vars = posting.variables` and process the dict returned.
e.g.
```python
from posting import P... | closed | 2024-12-31T13:58:53Z | 2025-03-02T18:07:40Z | https://github.com/darrenburns/posting/issues/160 | [
"bug"
] | zDavidB | 2 |
axnsan12/drf-yasg | django | 691 | No utf-8 symbols support for generated JSON and YAML | When trying to generate files with ^swagger(?P<format>\.json|\.yaml)$ it gives no support for utf-8 symbols, though defined description my content such symbols | open | 2021-01-14T12:25:29Z | 2025-03-07T12:13:27Z | https://github.com/axnsan12/drf-yasg/issues/691 | [
"triage"
] | ProstoMaxim | 1 |
voila-dashboards/voila | jupyter | 1,341 | Persistent loop of Matplotlib figure animation results in flickering output when run in a thread | ## Description
The [Mesa](https://github.com/projectmesa/mesa) agent-based modeling library is looking to replace its self-hosted Tornado-based visualization server with Voilà. I have made a prototype in https://github.com/rht/mesa-examples/tree/voila. However, I encountered the flickering issue reported in #431. To... | open | 2023-06-26T10:06:20Z | 2024-02-12T23:25:17Z | https://github.com/voila-dashboards/voila/issues/1341 | [
"bug"
] | rht | 6 |
microsoft/nlp-recipes | nlp | 625 | [ASK] transformers.abstractive_summarization_bertsum.py not importing transformers | ### Description
I run in Google Colab the following code
```
!pip install --upgrade
!pip install -q git+https://github.com/microsoft/nlp-recipes.git
!pip install jsonlines
!pip install pyrouge
!pip install scrapbook
import os
import shutil
import sys
from tempfile import TemporaryDirectory
import tor... | open | 2022-01-11T10:21:31Z | 2022-02-17T23:23:40Z | https://github.com/microsoft/nlp-recipes/issues/625 | [] | neqkir | 1 |
Gerapy/Gerapy | django | 77 | 上传的项目py文件编辑不了 | 在项目的py文件中不能包含中文,我把全部中文换成英文后,可以编辑文件了,希望修复下。 | open | 2018-08-01T07:14:42Z | 2020-07-24T08:19:53Z | https://github.com/Gerapy/Gerapy/issues/77 | [] | ghost | 1 |
jina-ai/serve | deep-learning | 5,402 | Bind to `host` instead of `default_host` | **Describe the bug**
Flow accepts `host` parameter because it inherits from client and gateway but is confusing as shown in #5401 | closed | 2022-11-17T08:59:04Z | 2022-11-21T15:43:42Z | https://github.com/jina-ai/serve/issues/5402 | [
"area/community"
] | JoanFM | 5 |
psf/requests | python | 6,080 | How to uinstall requests library using setup.py? | We are in a factory environment where we cannot use pip.
We installed request library using python install setup.py.
Is it possible to uninstall requests library using setup.py. Please share the command. | closed | 2022-03-07T10:57:39Z | 2023-03-08T00:03:28Z | https://github.com/psf/requests/issues/6080 | [] | ashokchandran | 1 |
Tanuki/tanuki.py | pydantic | 35 | Align statements do not support lists or tuples | The following align statements error out with inputs Lists or tuples
```
@Monkey.patch
def classify_sentiment(input: List[str]) -> Literal['Good', 'Bad', 'Neutral']: # Multi-class classification
"""
Determine if the input is positive, negative or neutral sentiment
"""
@Monkey.align
def align():
... | closed | 2023-11-03T18:32:28Z | 2023-11-08T14:56:49Z | https://github.com/Tanuki/tanuki.py/issues/35 | [] | MartBakler | 0 |
tflearn/tflearn | data-science | 1,074 | tflearn does't work when using higher TensorFlow | I found that tflearn does't work when using higher TensorFlow.
Is it a bug?
My Tensorflow version: 1.8.0
TfLearn version: 0.3.2
OS: Win10 x64
Python version: 3.6.6 | open | 2018-07-16T06:55:25Z | 2018-07-16T06:55:25Z | https://github.com/tflearn/tflearn/issues/1074 | [] | polar99 | 0 |
koxudaxi/fastapi-code-generator | fastapi | 328 | [] in query parameter name generates code that cannot be formatted | When you have `[]` as prarameter name it fails to generate correct code. See this part of OpenAPI schema:
```yaml
parameters:
- in: query
name: color[]
schema:
type: array
items:
type: string
```
Possible solutions:
1. Correct schema to not use `[]`
2. Patch template to str... | open | 2023-03-01T23:23:32Z | 2023-03-01T23:23:32Z | https://github.com/koxudaxi/fastapi-code-generator/issues/328 | [] | Skyross | 0 |
chainer/chainer | numpy | 8,195 | ChainerX take allows OOB access | I think we should not allow this?
```
>>> x = chx.array([1,2])
>>> y = x.take(chx.array([3]), axis=0)
>>> y
array([2], shape=(1,), dtype=int64, device='native:0')
```
numpy raises an exception for this. | closed | 2019-09-29T04:36:42Z | 2019-10-10T03:52:57Z | https://github.com/chainer/chainer/issues/8195 | [
"pr-ongoing",
"ChainerX"
] | shinh | 1 |
twelvedata/twelvedata-python | matplotlib | 7 | [Bug] Technical Indicator Plotly | Hello,
I ran the 'static' (chart) example code from git without error using python 3.5.
The chart appeared in my browser.
However, the Technical Indicators are not appearing on the chart. (Compared to the image of the char on the git and pypi pages)
It seems that either there is a bug or,
Do I need ... | closed | 2020-04-26T05:54:30Z | 2020-04-26T16:28:56Z | https://github.com/twelvedata/twelvedata-python/issues/7 | [] | majikbyte | 2 |
jina-ai/clip-as-service | pytorch | 430 | Adding Bi-LSTM layer to word-level embeddings | Has anyone got any examples of them adding a classification layer (as per the Bert paper) for NER? | open | 2019-08-02T18:16:42Z | 2019-08-02T18:16:42Z | https://github.com/jina-ai/clip-as-service/issues/430 | [] | samjtozer | 0 |
kennethreitz/responder | flask | 45 | Probable bug in GraphQL JSON request handling | There seems to be a bug in parsing of JSON GraphQL requests.
Test case (disregard the fact that it would also fail if parsed successfully):
```python
def test_graphql_schema_json_query(api, schema):
api.add_route("/", schema)
r = api.session().post("http://;/", headers={"Accept": "json", "Content-type"... | closed | 2018-10-14T19:14:04Z | 2018-10-15T07:32:21Z | https://github.com/kennethreitz/responder/issues/45 | [] | artemgordinskiy | 2 |
twopirllc/pandas-ta | pandas | 381 | VWAP that matched values of TradingView VWAP indicator (anchor) | Running
python: 3.8.5
pandas_ta version: 0.3.14b0
Description:
Trying to get VWAP that matched values of TradingView indicator at this link.
https://www.tradingview.com/support/solutions/43000502018-volume-weighted-average-price-vwap/
I think the key to matching this TradingView indicator is its "Anchor Sett... | closed | 2021-08-31T05:37:20Z | 2021-09-07T01:07:04Z | https://github.com/twopirllc/pandas-ta/issues/381 | [
"info"
] | slhawk98 | 12 |
dbfixtures/pytest-postgresql | pytest | 574 | Maintain v3.x line with psycopg2 support | ### What action do you want to perform
Since `psycopg` 3 isn't slated to for GA with [SQLAlchemy until their 2.0 release](https://github.com/sqlalchemy/sqlalchemy/issues/6842), most users of SQLAlchemy are still using v1.4 with `psycopg2`. For those of us on SQLAlchemy v1.4, it doesn't really make sense to write tests... | open | 2022-03-07T14:10:22Z | 2022-03-08T12:54:43Z | https://github.com/dbfixtures/pytest-postgresql/issues/574 | [
"question"
] | winglian | 3 |
anselal/antminer-monitor | dash | 31 | Reboot when detected chips (Os) =/= 180 | I have a couple of weird D3s that sometimes say 175-179 chips are Os and the rest are Xs and are fixed with a simple reboot on their static ip page, it'd be great to have a built in option to automatically reboot the miner if any Xs are detected. | closed | 2017-11-27T08:36:39Z | 2017-11-27T20:32:49Z | https://github.com/anselal/antminer-monitor/issues/31 | [
":dancing_men: duplicate"
] | ckl33 | 4 |
Nemo2011/bilibili-api | api | 614 | [提问] 出现风控校验失败信息 | **Python 版本:** 3.12.1
**模块版本:** 16.1.1
**运行环境:** Windows
<!-- 务必提供模块版本并确保为最新版 -->
---
```
user_info = await bilibili_api.user.User(uid=uid, credential=credential).get_user_info()
bilibili_api.exceptions.ResponseCodeException.ResponseCodeException: 接口返回错误代码:-352,信息:风控校验失败。
{'code': -352, 'message': '... | closed | 2023-12-28T05:18:21Z | 2024-01-09T11:51:17Z | https://github.com/Nemo2011/bilibili-api/issues/614 | [
"need debug info",
"anti-spider"
] | iconFehu | 0 |
facebookresearch/fairseq | pytorch | 5,090 | NLLB License | ## ❓ Questions and Help
Here is the NLLB model's license, https://github.com/facebookresearch/fairseq/blob/nllb/LICENSE.model.md
Can we use NLLB model output (translation from language X to language Y) to train a model and release that model under a Commercially permitted license (i.e., Apache 2.0)? I understand ... | open | 2023-04-24T18:34:04Z | 2023-05-19T08:45:26Z | https://github.com/facebookresearch/fairseq/issues/5090 | [
"question",
"needs triage"
] | sbmaruf | 2 |
Farama-Foundation/Gymnasium | api | 742 | [Bug Report] gymnasium.error.NamespaceNotFound: Namespace gym_examples not found. | ### Describe the bug
I've followed https://gymnasium.farama.org/tutorials/gymnasium_basics/environment_creation/#creating-a-package.
I have successfully registered the environment, but when I try to use that environment, I receive the error mentioned in the title. I have seen a similar issue here (https://github.com/... | closed | 2023-10-16T15:47:38Z | 2024-04-06T13:15:36Z | https://github.com/Farama-Foundation/Gymnasium/issues/742 | [
"bug"
] | NghiaPhamttk27 | 2 |
ultralytics/yolov5 | deep-learning | 13,402 | Feature map channel not same as what I defined | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Recently I'm working on some head detection works, and to deploy the model on devices wit... | closed | 2024-11-07T06:27:23Z | 2024-11-08T20:26:33Z | https://github.com/ultralytics/yolov5/issues/13402 | [
"question",
"detect"
] | tobymuller233 | 3 |
syrupy-project/syrupy | pytest | 116 | Syrupy assertion diff does not show missing carriage return | **Describe the bug**
Syrupy assertion diff does not show missing carriage return.
**To Reproduce**
Add this test.
```python
def test_example(snapshot):
assert snapshot == "line 1\r\nline 2"
```
Run `pytest --snapshot-update`.
Remove the `\r` from the string in the test case so you get:
```py... | closed | 2020-01-15T14:40:21Z | 2020-03-08T04:23:00Z | https://github.com/syrupy-project/syrupy/issues/116 | [
"bug",
"released"
] | noahnu | 3 |
apify/crawlee-python | automation | 311 | Document tiered proxies | closed | 2024-07-16T07:12:48Z | 2024-07-18T15:48:15Z | https://github.com/apify/crawlee-python/issues/311 | [
"documentation",
"t-tooling"
] | vdusek | 0 | |
fastapi/sqlmodel | fastapi | 208 | Pylance / VSCode cannot find sqlmodel typings correctly | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X] I al... | open | 2021-12-29T23:05:18Z | 2021-12-30T01:04:05Z | https://github.com/fastapi/sqlmodel/issues/208 | [
"question"
] | amir20 | 2 |
chezou/tabula-py | pandas | 125 | read_pdf returns None on my Linux only | # Summary of your issue
I have moved from Mac to Linux mint. I tried to run the read_pdf and every attempt results in a dataframe containing "None". I have not seen similar issue online.
# Environment
- [x] Paste the output of `import tabula; tabula.environment_info()` on Python REPL: ?
```
If not possib... | closed | 2018-12-24T22:10:18Z | 2018-12-30T11:00:57Z | https://github.com/chezou/tabula-py/issues/125 | [] | nalsabhan | 5 |
waditu/tushare | pandas | 792 | stock_basic函数获得的结果不全 | ts_code
0 000001.SZ
1 000002.SZ
2 000004.SZ
3 000005.SZ
4 000006.SZ
5 000007.SZ
6 000008.SZ
7 000009.SZ
8 000010.SZ
9 000011.SZ
10 000012.SZ
11 000014.SZ
12 000016.SZ
13 000017.SZ
14 000018.SZ
15 000019.SZ
16 000020.SZ
17 000021.S... | closed | 2018-10-30T13:09:42Z | 2018-12-19T05:25:34Z | https://github.com/waditu/tushare/issues/792 | [] | zhanguoce | 5 |
saulpw/visidata | pandas | 2,379 | Can't disable mouse | **Small description**
Mouse-disable commands do nothing. In-session disable states invalid command. I'm running in a headless environment over SSH. Since I don't have access to a system clipboard, I need to be able to select values.
**Expected result**
I should be free to select terminal text with my mouse.
... | closed | 2024-04-12T05:17:25Z | 2024-04-12T19:52:02Z | https://github.com/saulpw/visidata/issues/2379 | [
"bug",
"fixed"
] | dsoprea | 2 |
ned2/slapdash | dash | 12 | Enable callback validation | Out of the box, a dynamic multi-page app like Slapdash requires callback validation to be turned off as callbacks will need to be defined that don't yet exist in the layout. the [Dash docs](https://dash.plot.ly/urls) have an example in the section titled "Dynamically Create a Layout for Multi-Page App Validation" that ... | closed | 2018-12-29T03:39:06Z | 2022-10-19T12:35:35Z | https://github.com/ned2/slapdash/issues/12 | [] | ned2 | 2 |
InstaPy/InstaPy | automation | 6,450 | acc.txt | Yountrust | closed | 2022-01-03T00:44:32Z | 2022-01-08T19:28:15Z | https://github.com/InstaPy/InstaPy/issues/6450 | [] | liyahworks | 1 |
cvat-ai/cvat | computer-vision | 8,263 | I want to work as a data annotator | I want to work for cvat.ai as a data annotator can you help me how to start? | closed | 2024-08-06T13:47:09Z | 2024-08-06T16:19:27Z | https://github.com/cvat-ai/cvat/issues/8263 | [
"invalid"
] | fatmard947 | 0 |
dask/dask | scikit-learn | 10,881 | applying tuple with pyarrow | <!-- Please include a self-contained copy-pastable example that generates the issue if possible.
Please be concise with code posted. See guidelines below on how to provide a good bug report:
- Craft Minimal Bug Reports http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports
- Minimal Complete Verifiab... | open | 2024-02-01T15:20:45Z | 2024-02-02T08:38:50Z | https://github.com/dask/dask/issues/10881 | [
"convert-string"
] | SurkynRik | 2 |
gunthercox/ChatterBot | machine-learning | 1,555 | AttributeError: 'ChatBot' object has no attribute 'set_trainer' | Hi,
Just after installing ChatterBot ( version is 1.0.0a3.) , I tried to execute the following code snippet from quick start guide:
```
from chatterbot import ChatBot
chatbot = ChatBot("Ron Obvious")
from chatterbot.trainers import ListTrainer
conversation = [
"Hello",
"Hi there!",
"How are yo... | closed | 2019-01-09T09:55:18Z | 2020-12-27T06:32:24Z | https://github.com/gunthercox/ChatterBot/issues/1555 | [
"answered"
] | achingacham | 18 |
ultralytics/ultralytics | pytorch | 19,566 | Cleanest way to customize the model.val() method for custom validation. | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello, I plan to customise the standard validation (see photo) to my needs (... | open | 2025-03-07T09:44:22Z | 2025-03-15T03:28:25Z | https://github.com/ultralytics/ultralytics/issues/19566 | [
"question",
"OBB"
] | Petros626 | 13 |
idealo/image-super-resolution | computer-vision | 17 | Weights | Really simple issue, but the weights for Large RDN model were updated in the wget command, but not in the execution of ISR_Prediction_Tutorial.ipynb (it's downloading PSNR-driven/rdn-C6-D20-G64-G064-x2_PSNR_epoch086.hdf5, but calling weights/rdn-C6-D20-G64-G064-x2_div2k-e086.hdf5) | closed | 2019-04-09T11:28:39Z | 2019-04-11T16:29:05Z | https://github.com/idealo/image-super-resolution/issues/17 | [] | victorca25 | 1 |
plotly/dash-table | plotly | 742 | Feature request: Clear cell selection | Hi!
It's a common question at the [community](https://community.plotly.com/t/deselect-cell-in-data-table/25447).
I know we can use `Output("table", "selected_cells")` to set an empty cell selection, but it still leaves some selection box like this:
. It was discovered late in the airlfow 3 beta process so, disabling it was a reasonable choice.
When time permits, one could look into restoring this capability, perha... | open | 2025-03-20T13:39:31Z | 2025-03-24T16:54:20Z | https://github.com/apache/airflow/issues/48009 | [
"kind:feature",
"kind:meta",
"area:dynamic-task-mapping",
"area:Triggerer"
] | dstandish | 0 |
tensorpack/tensorpack | tensorflow | 1,276 | Error when try to register my own dataset | Hi
I think I got the same error than #1215 https://github.com/tensorpack/tensorpack/issues/1215.
This is the structure of my own dataset
COCO/DIR/
_______|__annotations/
_________________|__instances_train2017.json
_________________|__instances_val2017.json
_______|__train2017
_______|__val2017
As it was... | closed | 2019-07-20T21:07:26Z | 2019-07-26T02:50:33Z | https://github.com/tensorpack/tensorpack/issues/1276 | [
"examples"
] | AlbertoMCS | 9 |
igorbenav/fastcrud | sqlalchemy | 81 | Deprecation warning missing from Depends handling | closed | 2024-05-10T05:07:32Z | 2024-05-10T05:16:16Z | https://github.com/igorbenav/fastcrud/issues/81 | [
"enhancement",
"Automatic Endpoint"
] | igorbenav | 0 | |
pyg-team/pytorch_geometric | pytorch | 9,600 | bunch of CI failures with latest updates | ### 🐛 Describe the bug
when updating from 8c849a482c3cf2326c1f493e79d04169b26dfb0b to the latest commit c0c2d5fefddbce412741db68cc7a74af225fa94a
we now see the following errors (their all pretty much the same, let me know if you want the full log)
```
______________________________ test_to_undirected _____________... | closed | 2024-08-16T20:30:13Z | 2024-08-27T19:58:21Z | https://github.com/pyg-team/pytorch_geometric/issues/9600 | [
"bug"
] | puririshi98 | 2 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 1,542 | Working with High Resolution Images | Hi, I want you to give some advice about the image load size as much as possible.
How will I know how much to reduce the size of the picture I will give to my model?
I don't know how this will affect my model. Is there any mathematical structure to understand this method?
Here is the section that you have mention... | open | 2023-02-10T22:26:21Z | 2023-02-14T21:59:08Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1542 | [] | AlicanAKCA | 1 |
bmoscon/cryptofeed | asyncio | 122 | module 'asyncio' has no attribute 'run' (In python3.6) | In setup.py, python version can be 3.6/3.7,but it raised exception when i run examples/demo_tcp.py used python=3.6.5.
```
File "demo_tcp.py", line 54, in <module>
asyncio.run(main())
AttributeError: module 'asyncio' has no attribute 'run'
```
Actually, asyncio.run is a Python 3.7 addition | closed | 2019-07-25T05:11:05Z | 2019-09-02T19:50:59Z | https://github.com/bmoscon/cryptofeed/issues/122 | [
"good first issue"
] | malone6 | 2 |
dagster-io/dagster | data-science | 28,530 | [dagster-components] `AssetSpecModel` does not resolve dep asset keys | ### What's the issue?
When using `AssetSpecModel` in a component, the resolution of dependencies with multi-part asset keys does not resolve them, and keeps them as a string.
Given the `component.yaml`:
```yaml
type: dagster_components.dagster.PipesSubprocessScriptCollectionComponent
attributes:
scripts:
- pat... | closed | 2025-03-16T08:48:43Z | 2025-03-18T15:01:13Z | https://github.com/dagster-io/dagster/issues/28530 | [
"type: bug",
"area: dagster-components"
] | stevenayers | 0 |
InstaPy/InstaPy | automation | 5,847 | Instapy get blocked instantly | Hi guys
I was using Instapy for like two days and then I get blocked by Instagram. Is there a way to avoid this? I searched for solutions but I din't found one. | closed | 2020-10-26T12:03:03Z | 2020-12-20T14:06:22Z | https://github.com/InstaPy/InstaPy/issues/5847 | [
"wontfix"
] | Atumos | 12 |
streamlit/streamlit | data-visualization | 10,383 | Make st.toast appear/bring it to the front (stack order) when used in st.dialog | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
Not sure to place this as a feature request o... | open | 2025-02-12T20:19:16Z | 2025-02-13T12:10:54Z | https://github.com/streamlit/streamlit/issues/10383 | [
"type:enhancement",
"feature:st.toast",
"feature:st.dialog"
] | Socvest | 4 |
explosion/spaCy | machine-learning | 13,468 | ⚠ Aborting and saving the final best model. Encountered exception: RuntimeError('Invalid argument') RuntimeError: Invalid argument | I had a problem when I used the GPU provided by kaggle to train my Chinese information extraction model, I used the config file generated by the config file generation method of the spacy official website.Your help is greatly appreciated
Some of my environmental information is as follows, if you need to provide othe... | closed | 2024-04-28T12:23:09Z | 2024-05-15T10:56:51Z | https://github.com/explosion/spaCy/issues/13468 | [
"lang / zh",
"training",
"gpu",
"feat / ner",
"feat / transformer"
] | Lance-Owen | 1 |
aminalaee/sqladmin | fastapi | 495 | View all columns | ### Checklist
- [X] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
Is there a configuration to display all columns of a table? Currently, I am using the following piece of code:
```
class ModelAdmin(ModelView, model=Model):
column_... | closed | 2023-05-14T13:54:41Z | 2023-06-06T09:04:42Z | https://github.com/aminalaee/sqladmin/issues/495 | [] | maurosaladino | 2 |
TencentARC/GFPGAN | pytorch | 46 | only paste back from already restored faces | Is it possible to do this without restoring faces again just with 2x esrgan?
like
"python inference_gfpgan.py --upscale 2 --model_path nomodel --test_path results/restored_faces --save_root results/restored_images --paste_back_only"
? | closed | 2021-08-18T16:41:59Z | 2021-08-25T10:20:22Z | https://github.com/TencentARC/GFPGAN/issues/46 | [] | NoUserNameForYou | 6 |
microsoft/qlib | deep-learning | 1,697 | 请求增加baostock日线数据collector | 请求增加baostock日线数据collector
谢谢 | open | 2023-11-22T08:31:12Z | 2023-11-22T08:31:12Z | https://github.com/microsoft/qlib/issues/1697 | [
"enhancement"
] | quant2008 | 0 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,376 | Makes a random command line window when compiled with pyinstaller | When compiled with pyinstaller, undetected-chromedriver makes a random command prompt window.
It looks like this: https://prnt.sc/mifqvFcQqGAW
| open | 2023-07-01T02:37:53Z | 2023-07-08T17:59:49Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1376 | [] | lukeprofits | 1 |
smarie/python-pytest-cases | pytest | 179 | Nested parametrize_with_cases does not collect test if fixture is used multiple times | Hello there!
First of all thanks for that package for it is very awesome!
I was working on doing some weird matrix testing to test permissions of user against other users resources. In order to do that I had large cases classes that boiled down to the minimum example below:
```
import pytest_cases as pytest
... | closed | 2021-01-23T12:38:39Z | 2021-01-25T16:14:29Z | https://github.com/smarie/python-pytest-cases/issues/179 | [] | reyreaud-l | 4 |
gee-community/geemap | jupyter | 527 | Add Planet global monthly/quarterly mosaic | Reference: https://developers.planet.com/quickstart/apis | closed | 2021-06-16T00:08:03Z | 2021-06-16T00:50:50Z | https://github.com/gee-community/geemap/issues/527 | [
"Feature Request"
] | giswqs | 2 |
sqlalchemy/alembic | sqlalchemy | 419 | AttributeError: 'Engine' object has no attribute 'in_transaction' | **Migrated issue, originally created by bretonium ([@bretonium](https://github.com/bretonium))**
Release 0.9.x broke our migrations, they now fail with traceback:
```
breton@breton-pc ~/src/mediagoblin (master*) $ ./bin/gmg dbupdate
WARNING: audiolab is not installed so wav2png will not work
INFO [alembic... | closed | 2017-03-03T21:13:12Z | 2017-03-04T22:15:19Z | https://github.com/sqlalchemy/alembic/issues/419 | [
"bug"
] | sqlalchemy-bot | 4 |
davidsandberg/facenet | computer-vision | 1,061 | A typo in train_softmax.py | It is in line 260:
for key, value in stat.iteritems():
Should it be " for key, value in stat.items(): " ? | closed | 2019-07-29T07:16:49Z | 2019-08-14T04:57:23Z | https://github.com/davidsandberg/facenet/issues/1061 | [] | XuJianxing | 2 |
alteryx/featuretools | scikit-learn | 2,458 | Add AgeToDesignation primitive | The following are the American Medical Associations’ age designations:
- Neonates or newborns (birth to 1 month)
- Infants (1 month to 1 year)
- Children (1 year through 12 years)
- Adolescents (13 years through 17 years. They may also be referred to as teenagers depending on the context.)
- Adults (18 years or ol... | open | 2023-01-20T17:03:05Z | 2023-06-26T19:16:19Z | https://github.com/alteryx/featuretools/issues/2458 | [] | gsheni | 0 |
pyeve/eve | flask | 578 | allow projections on embedded resources | Hi,
I have an embedded list of child objects referenced by ids in the parent object like so
```
parent: {
"children: [ "child1", "child2"]
}
```
The schema for my child object is like so
```
child: {
"a": "x",
"b": "y",
"c": "z"
}
```
I would like a way to retrieve a list of parent records, along with the ... | closed | 2015-03-19T22:38:04Z | 2018-05-18T16:19:35Z | https://github.com/pyeve/eve/issues/578 | [
"feature request",
"stale"
] | doshprompt | 12 |
pydata/xarray | pandas | 9,854 | Add FAQ answer about API stability / backwards compatibility? | ### What is your issue?
We try pretty hard to maintain backwards compatibility in xarray, and have informative deprecation cycles before any breaking changes. But this feature of the library isn't super-well advertised in the docs. The only places I can find it mentioned are deep in the [contributing guide](https://do... | closed | 2024-12-04T17:56:32Z | 2025-01-30T17:34:37Z | https://github.com/pydata/xarray/issues/9854 | [
"topic-documentation"
] | TomNicholas | 0 |
sherlock-project/sherlock | python | 1,824 | Mine | Here is a great file viewing app for Android. https://play.google.com/store/apps/details?id=com.sharpened.androidfileviewer | closed | 2023-06-27T10:52:48Z | 2023-08-29T12:36:31Z | https://github.com/sherlock-project/sherlock/issues/1824 | [] | Kitchenboy77 | 0 |
uriyyo/fastapi-pagination | fastapi | 1,286 | get_body_field() got an unexpected keyword argument 'dependant' | Not certain what's happening, but upgrading to pytest 8.3.3 from pytest 8.2.2 leads to this error, perhaps because of sub dependencies? Feel free to close the issue if there's no good way to investigate this.
```
INFO sqlalchemy.engine.Engine BEGIN (implicit)
INFO sqlalchemy.engine.Engine PRAGMA main.table_info("e... | closed | 2024-09-16T18:44:22Z | 2024-09-17T14:28:39Z | https://github.com/uriyyo/fastapi-pagination/issues/1286 | [
"bug"
] | zromick | 1 |
hootnot/oanda-api-v20 | rest-api | 144 | factory InstrumentsCandlesFactory Invalid value specified for 'to'. Time is in the future | Hi Mr Hootnot.
Not sure if this is an issue with the factory or Oanda have changed their behaviour in practice v20.
Seems that you can no longer get the last daily candle. Once upon a time the last candle would be returned for current day and then oanda would have an attribute in the json that showed the candle ... | closed | 2019-06-21T08:53:22Z | 2021-05-21T12:31:46Z | https://github.com/hootnot/oanda-api-v20/issues/144 | [] | svenissimo | 10 |
ClimbsRocks/auto_ml | scikit-learn | 120 | run DataFrameVectorizer before parallelization | right now it's quite memory inefficient- we essentially end up holding the entire thing in memory twice.
and it's somewhat computationally expensive (not hugely so, but noticeable). and it's basically doing the same thing each time.
so rather than doing this 8 times in parallel (essentially holding 16x our data in ... | closed | 2016-10-18T16:32:10Z | 2017-03-12T01:08:21Z | https://github.com/ClimbsRocks/auto_ml/issues/120 | [] | ClimbsRocks | 5 |
deepset-ai/haystack | machine-learning | 8,798 | Expand the functionality of the `DocumentCleaner` | **Is your feature request related to a problem? Please describe.**
We've found in practice that cleaning up files before being used in RAG pipelines does increase overall performance. For example, this Haystack [user](https://github.com/deepset-ai/haystack/issues/8761#issuecomment-2609529890) found the same.
We do ha... | open | 2025-02-03T12:19:59Z | 2025-03-14T14:28:23Z | https://github.com/deepset-ai/haystack/issues/8798 | [
"type:feature",
"P2"
] | sjrl | 1 |
mljar/mercury | jupyter | 386 | call to websocket keeps pending in mercury development server | Hi,
I execute `mercury run` from a folder containing some notebook files. Mercury start without any error. It opens the browser listing the notebooks from the folder. I select a notebook and it opens. So far so good.
But now the right side stays grayed out and shows 3 dots indicating that it is loading. With the ne... | closed | 2023-10-27T13:18:43Z | 2023-10-28T15:02:14Z | https://github.com/mljar/mercury/issues/386 | [] | robert-elles | 2 |
AirtestProject/Airtest | automation | 516 | airtestIDE的多设备测试入口在哪里 | @yimelia
我在教程上看到airtestIDE可以进行批量测试,教程界面截图如下:
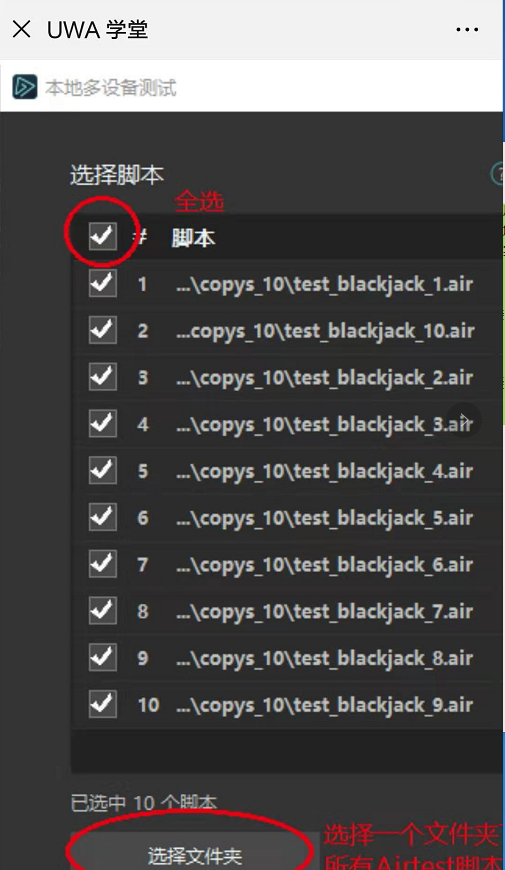
但是在我的airtestIDE上找不到对应入口,我的airtestIDE版本截图和界面截图如下:
. It'd be great if pytest-cov also supported this.
| closed | 2014-06-23T15:37:58Z | 2014-11-26T17:08:01Z | https://github.com/pytest-dev/pytest-cov/issues/13 | [
"help wanted"
] | rouge8 | 10 |
nvbn/thefuck | python | 690 | Using vim command success and type fuck cause display error | I an using SSH(tty) to connect to my pc.
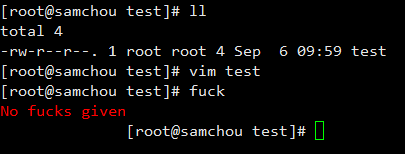
| open | 2017-09-06T02:08:05Z | 2017-09-06T02:08:05Z | https://github.com/nvbn/thefuck/issues/690 | [] | btstw | 0 |
autokey/autokey | automation | 421 | Phrase with <CTRL> modifier does not work with i3wm | ## Classification:
Bug
## Version
#### AutoKey version:
Used GUI Gtk
Installed via: AUR
#### Linux Distribution:
Manjaro + i3wm
## Steps to Reproduce (if applicable)
Install autokey and use i3wm. Set the phrase `<CTRL>+j` to send `<down>`.
## Expected Results
The application will receive `<down>` only
## A... | open | 2020-05-24T20:17:42Z | 2020-05-31T19:40:28Z | https://github.com/autokey/autokey/issues/421 | [] | pietrodito | 3 |
MagicStack/asyncpg | asyncio | 617 | set_type_codec() appears to assume a particular set_type_codec for the "char" datatype |
* **asyncpg version**: 0.21.0
* **PostgreSQL version**: 11.8 fedora
* **Do you use a PostgreSQL SaaS? If so, which? Can you reproduce
the issue with a local PostgreSQL install?**: N/A
* **Python version**: 3.8.3
* **Platform**: Fedora 31
* **Do you use pgbouncer?**: no
* **Did you install asyn... | closed | 2020-09-16T17:07:05Z | 2020-09-25T01:51:29Z | https://github.com/MagicStack/asyncpg/issues/617 | [] | zzzeek | 5 |
LibreTranslate/LibreTranslate | api | 476 | Errorneous file translation -- text translation box works. | 1. Goto the website: <https://libretranslate.com>
2. Paste the following in the "Translate from Spanish" text box:
> Recuerde que "con éxito completando" significa que ha leído el módulo antes del grupo, ha completado todos los Escribió ejercicios antes del grupo y luego compartió tus respuestas con el grupo de a... | open | 2023-08-03T22:23:00Z | 2023-11-09T03:11:11Z | https://github.com/LibreTranslate/LibreTranslate/issues/476 | [
"enhancement"
] | veganaize | 1 |
MycroftAI/mycroft-core | nlp | 2,238 | Installing Mycroft may uninstall WINE without notice | A [user on the forums reported](https://community.mycroft.ai/t/there-should-be-a-warning-that-mycroft-will-uninstall-wine-and-other-software/6995/2) that by installing Mycroft, their WINE installation and all programs using WINE were uninstalled without warning. Have requested further details about the users system.
... | closed | 2019-07-29T02:27:39Z | 2021-08-04T21:22:45Z | https://github.com/MycroftAI/mycroft-core/issues/2238 | [
"Type: Bug - complex"
] | krisgesling | 9 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,623 | How to use test.py to test both directions for cyclegan? | I ran test.py but it is only giving results from A to B, but I want the results from B to A also. Putting `--direction BtoA` only switches the input but not the model. Thank you | closed | 2024-02-06T16:13:44Z | 2024-02-14T18:48:48Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1623 | [] | lamwilton | 1 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 359 | Runtime error when using ArcFace without a miner | I tried to use ArcFace loss without a miner (empty dictionary) in the [TwoStreamMetricLoss.ipynb](https://github.com/KevinMusgrave/pytorch-metric-learning/blob/master/examples/notebooks/TwoStreamMetricLoss.ipynb) from examples on collab, but it fails with the following runtime error:
```
RuntimeError ... | closed | 2021-07-30T18:20:09Z | 2021-11-28T19:20:35Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/359 | [
"bug",
"fixed in dev branch"
] | gkouros | 2 |
automl/auto-sklearn | scikit-learn | 1,593 | Using recal with autosklearn 2 raised issue that `askl2_training_data.json` is not available | open | 2022-10-10T13:24:50Z | 2022-11-08T17:13:57Z | https://github.com/automl/auto-sklearn/issues/1593 | [] | eddiebergman | 1 | |
deepspeedai/DeepSpeed | pytorch | 6,687 | nv-nightly CI test failure | The Nightly CI for https://github.com/microsoft/DeepSpeed/actions/runs/11584608559 failed.
| closed | 2024-10-30T01:09:53Z | 2024-10-31T17:34:39Z | https://github.com/deepspeedai/DeepSpeed/issues/6687 | [
"ci-failure"
] | github-actions[bot] | 1 |
sinaptik-ai/pandas-ai | pandas | 1,310 | Is that a must to use the Docker component if I am using the agent function? | ### System Info
What's the need of the docker if i am not relying on the front hand? / doesn't need the front end.
### 🐛 Describe the bug
I am using my openAI model is there a need to spin up the docker? | closed | 2024-08-05T06:46:00Z | 2024-11-11T16:04:26Z | https://github.com/sinaptik-ai/pandas-ai/issues/1310 | [] | rogerlpag | 5 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 667 | [FEATURE]: Better job blacklisting (Title, Location) | ### Feature summary
Make title/location blacklisting better with better string matching or make it gpt powered
### Feature description
The current blacklisting is direct matching with the configuration file. This introduces multiple false positives.
Examples:
"Brazil" is blacklisted, but "Rio de Janeiro, Br... | closed | 2024-10-29T18:48:17Z | 2024-11-07T00:46:48Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/667 | [
"enhancement"
] | Jasar-k | 2 |
databricks/koalas | pandas | 1,456 | Add Spark JDBC read | For enterprise use, I'd like to poll the extension of read methods to JDBC, given that drivers are available in the Spark Context.
**Current Solutions**
```python
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
import databricks.koalas as ks
jdbc_options = dict()
jdbc_opt... | closed | 2020-05-01T11:14:12Z | 2020-12-10T17:41:54Z | https://github.com/databricks/koalas/issues/1456 | [] | sebastianvermaas | 6 |
aiortc/aioquic | asyncio | 501 | [SECURITY] Accepting and storing an unlimited number of CRYPTO frames within a single connection | - Aioquic may infinitely receive `CRYPTO` frames within a single connection, rapidly depleting memory and subsequently being forcefully closed by the operating system, leading to a denial of service attack.
- In line 1613 of `quic/connection.py`, the server only checks `offset + length < 2^62 - 1` when processing `CRY... | closed | 2024-05-27T17:32:02Z | 2024-06-18T14:53:41Z | https://github.com/aiortc/aioquic/issues/501 | [] | k4ra5u | 1 |
python-gino/gino | sqlalchemy | 457 | attribute 'db' in aiohttp.py |
### Description
Hi! I am using gino and aiohttp extension and in my application there is already a db attribute. Can send attribute name in arguments?
### For example:
```
def init_app(self, app, config = None, attr = 'db'):
app[attr] = self
```
https://github.com/fantix/gino/blob/d50fb882fbf3adf38b0... | closed | 2019-03-12T16:06:14Z | 2019-03-21T02:01:47Z | https://github.com/python-gino/gino/issues/457 | [
"help wanted",
"feature request"
] | EvgenyUsov | 2 |
huggingface/diffusers | pytorch | 10,416 | Euler flow matching scheduler is missing documentation for parameters | 
I think there are some undocumented parameters here. | closed | 2024-12-31T13:15:35Z | 2025-01-09T18:54:41Z | https://github.com/huggingface/diffusers/issues/10416 | [] | bghira | 4 |
onnx/onnx | pytorch | 5,957 | The error in the Installation of onnx |
# Ask a Question
When I install the cnocr with pip , there have a error in the installation of onnx,
## respose code:
[error in install.txt](https://github.com/onnx/onnx/files/14387640/error.in.install.txt)
### Further information
operating system : Windows 10 ltsc 1809;
cmake version: 3.29.0-rc1;
pip ... | open | 2024-02-23T16:30:20Z | 2024-03-12T05:18:10Z | https://github.com/onnx/onnx/issues/5957 | [
"question"
] | wk19941015 | 1 |
plotly/dash-table | dash | 249 | Select all rows | I don't think its possible to select all rows in the table / filtered view.
Is this something that can be added?
Thanks! And thanks for all your work on the project - excited to see how it develops | open | 2018-11-20T19:31:24Z | 2022-07-11T13:15:06Z | https://github.com/plotly/dash-table/issues/249 | [
"dash-type-enhancement",
"size: 2"
] | pmajmudar | 13 |
flasgger/flasgger | api | 621 | Flasgger still showing outdated docs | I once created the documentation using flasgger, but after I modified the endpoints' swag_from documentation, the newly run flask app still shows outdated documentation. | open | 2024-06-22T23:05:52Z | 2024-06-22T23:05:52Z | https://github.com/flasgger/flasgger/issues/621 | [] | NaviteLogger | 0 |
pydata/xarray | numpy | 9,455 | `DataTree.to_zarr()` is very slow writing to high latency store | ### What is your issue?
Repost of https://github.com/xarray-contrib/datatree/issues/277, with some updates.
## Test case
Write a tree containing 13 nodes and negligible data to S3/GCS with fsspec:
```python
import numpy as np
import xarray as xr
ds = xr.Dataset(
data_vars={
"a": xr.DataArra... | open | 2024-09-08T14:30:28Z | 2025-03-20T06:10:03Z | https://github.com/pydata/xarray/issues/9455 | [
"topic-backends",
"topic-performance",
"topic-zarr",
"topic-DataTree"
] | slevang | 3 |
Skyvern-AI/skyvern | api | 1,585 | Any effective way to change the value of a variable in the public docker image? | Is there any effective way to change the value of a variable in the public docker image when running docket locally? Thanks. | open | 2025-01-16T22:49:35Z | 2025-01-25T10:27:01Z | https://github.com/Skyvern-AI/skyvern/issues/1585 | [] | universe2jouney | 3 |
deezer/spleeter | deep-learning | 647 | [Discussion] use gpu in docker failed,can I use --gpus param? | this command work well
docker run --rm -v $(pwd):/output deezer/spleeter-gpu:3.8-2stems separate -o /output /output/3t.mp3
but these command failed
docker run --rm -v $(pwd):/output --gpus all deezer/spleeter-gpu:3.8-2stems separate -o /output /output/3t.mp3
docker run --rm -v $(pwd):/output --runtime=nvidia deez... | closed | 2021-08-08T08:05:13Z | 2021-08-29T02:03:50Z | https://github.com/deezer/spleeter/issues/647 | [
"question"
] | m986883511 | 3 |
deezer/spleeter | tensorflow | 259 | [Discussion] someone is using spleeter for commercial use. | <!-- Please respect the title [Discussion] tag. -->
Someone is using this model for commercial use. Is it ok?
Here is the link
https://dango.ai/
| closed | 2020-02-05T06:19:47Z | 2020-02-08T13:56:09Z | https://github.com/deezer/spleeter/issues/259 | [
"question"
] | blue-sky-2020 | 1 |
graphql-python/graphene-django | django | 594 | Building mutations from scratch - django form or DRF better? | I have a project from total stratch. In terms of simplicity which will be easier?
| closed | 2019-03-12T00:28:31Z | 2019-07-01T17:20:29Z | https://github.com/graphql-python/graphene-django/issues/594 | [
"question",
"wontfix",
"Docs enhancement"
] | gotexis | 5 |
matplotlib/matplotlib | matplotlib | 29,259 | [Bug]: No module named pyplot | ### Bug summary
No module named pyplot
### Code for reproduction
```Python
import matplotlib.pyplot as plt
import numpy as np
from scipy.integrate import solve_ivp
# Parámetros
miumax = 0.65
ks = 12.8
a = 1.12
b = 1
Sm = 98.3
Pm = 65.2
Yxs = 0.067
m = 0.230
alfa = 7.3
beta = 0 # 0.15
si = 54.45
x... | closed | 2024-12-08T21:01:23Z | 2024-12-09T16:15:33Z | https://github.com/matplotlib/matplotlib/issues/29259 | [
"Community support"
] | abelardogit | 3 |
rthalley/dnspython | asyncio | 738 | wrong answer returned | ```
resolver = dns.resolver.Resolver()
dnsreq = resolver.resolve(host, rdtype=dns.rdatatype.A, search=True)
sockset = set()
addrinfos = dnsreq.response.answer
for item in addrinfos:
for j in item:
print("==>",j, host)
ip = j.address
```
when I use multthread dealwith hosts,
the result remined '... | closed | 2021-12-16T07:50:00Z | 2021-12-16T13:28:38Z | https://github.com/rthalley/dnspython/issues/738 | [] | promlife | 1 |
explosion/spaCy | data-science | 13,154 | MemoryError: Unable to allocate 29.7 GiB for an array with shape (86399, 4, 4, 2880, 2) and data type float32 | ### Discussed in https://github.com/explosion/spaCy/discussions/13153
<div type='discussions-op-text'>
<sup>Originally posted by **nunu346** November 27, 2023</sup>
import xarray as xr
netcdf_file_in =r'C:\Users\Mg\Desktop\ops_exis-l1b-sfxr_g16_d20210601_v0-0-0.nc'
csv_file_out = r'C:\Users\Mg\Desktop\ops_exis... | closed | 2023-11-27T08:12:07Z | 2023-12-28T00:02:16Z | https://github.com/explosion/spaCy/issues/13154 | [] | nunu346 | 2 |
Anjok07/ultimatevocalremovergui | pytorch | 1,331 | UVR5 | Last Error Received:
Process: VR Architecture
If this error persists, please contact the developers with the error details.
Raw Error Details:
MemoryError: "Unable to allocate 1.64 GiB for an array with shape (219842879,) and data type float64"
Traceback Error: "
File "UVR.py", line 6638, in process_sta... | open | 2024-05-11T10:06:24Z | 2024-05-11T10:06:24Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1331 | [] | banduharisch | 0 |
JaidedAI/EasyOCR | deep-learning | 481 | BadZipFile error | 
Hi Guy
thanks for your great work!
Recently, I am using your program to make a tookit with a snap and ouput GUI interface. but see the attached image please. I can run the whole program at home, ... | closed | 2021-07-05T04:31:25Z | 2021-10-06T09:21:17Z | https://github.com/JaidedAI/EasyOCR/issues/481 | [] | Miaoqi-2010 | 3 |
TencentARC/GFPGAN | deep-learning | 176 | Some colors in black and white photo | A minor detail, in some black and white photos, colors appear that are not in the photo, but it seems that the model "suggests" what colors it should have. It is also remarkable the improvement of the V1.3 model. Although the 1.1 model has behaved very generous with this image. I must also add that some faces have been... | open | 2022-03-13T08:45:33Z | 2022-03-14T23:23:38Z | https://github.com/TencentARC/GFPGAN/issues/176 | [] | GOZARCK | 2 |
Guovin/iptv-api | api | 972 | [Bug]:Docker运行问题 | ### Don't skip these steps | 不要跳过这些步骤
- [x] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field | 我明白,如果我“故意”删除或跳过任何强制性的\*字段,我将被**限制**
- [x] I am sure that this is a running error exception problem and will not submit any problems unrelated to this project | 我确定这是运行报错异常问题,... | closed | 2025-03-17T08:43:38Z | 2025-03-18T01:58:22Z | https://github.com/Guovin/iptv-api/issues/972 | [
"invalid",
"wontfix"
] | WuLongMiTaoLaiYiDa | 3 |
gunthercox/ChatterBot | machine-learning | 2,382 | Error in installing Chatterbot. | Collecting chatterbot
Using cached ChatterBot-1.0.5-py2.py3-none-any.whl.metadata (8.1 kB)
Collecting mathparse<0.2,>=0.1 (from chatterbot)
Using cached mathparse-0.1.2-py3-none-any.whl.metadata (776 bytes)
Requirement already satisfied: nltk<4.0,>=3.2 in c:\users\--\appdata\local\programs\python\python312\lib\... | closed | 2024-11-07T03:52:04Z | 2025-02-09T17:24:35Z | https://github.com/gunthercox/ChatterBot/issues/2382 | [] | Prajapati-Shubham | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.