
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
liangliangyy/DjangoBlog | django | 529 | 功能确实 | <!--
如果你不认真勾选下面的内容,我可能会直接关闭你的 Issue。
提问之前,建议先阅读 https://github.com/ruby-china/How-To-Ask-Questions-The-Smart-Way
-->
**我确定我已经查看了** (标注`[ ]`为`[x]`)
- [ x] [DjangoBlog的readme](https://github.com/liangliangyy/DjangoBlog/blob/master/README.md)
- [ x] [配置说明](https://github.com/liangliangyy/DjangoBlog/blob/master/b... | closed | 2021-12-15T08:18:49Z | 2021-12-19T03:48:54Z | https://github.com/liangliangyy/DjangoBlog/issues/529 | [] | lmafeifeil | 9 |
wkentaro/labelme | computer-vision | 1,546 | Unable to start labelMe | ### Provide environment information
Python 3.8.10
```
> pip list
Package Version
------------------- -----------
annotated-types 0.7.0
beautifulsoup4 4.13.3
certifi 2025.1.31
charset-normalizer 3.4.1
click 8.1.8
colorama 0.4.6
coloredlogs 15.0.1
conto... | open | 2025-02-26T11:06:21Z | 2025-03-18T09:58:27Z | https://github.com/wkentaro/labelme/issues/1546 | [] | onnxruntime-user | 2 |
arogozhnikov/einops | numpy | 22 | Ellipsis not mentioned in docs | Great work!
I discovered in https://github.com/arogozhnikov/einops/blob/master/einops/einops.py#L199 that you also support ellipsis. Its an important feature so you may want to add it to the documentation. | open | 2018-12-01T10:52:24Z | 2025-03-02T20:41:12Z | https://github.com/arogozhnikov/einops/issues/22 | [] | LukasDrude | 14 |
strawberry-graphql/strawberry | asyncio | 3,656 | `ApolloTracingExtension` regression populating `resolvers` field. | <!-- Provide a general summary of the bug in the title above. -->
<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->
<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->
## Describe the Bug
```python
import asyncio
import str... | open | 2024-10-05T17:44:40Z | 2025-03-20T15:56:54Z | https://github.com/strawberry-graphql/strawberry/issues/3656 | [
"bug"
] | coady | 2 |
horovod/horovod | tensorflow | 3,511 | Horovod installation for TF CPU nightly fails with error: no member "tensorflow_gpu_device_info"! | **Environment:**
1. TensorFlow
2. Framework version: 2.10 nightly
3. Horovod version: 0.24.2 all the way up to tip of master
4. MPI version: 4.0.3
5. CUDA version: N/A this is CPU install
6. NCCL version: N/A
7. Python version: 3.8.10
8. Spark / PySpark version: N/A
9. Ray version: N/A
10. OS and version: Ubu... | closed | 2022-04-19T17:24:41Z | 2022-04-21T01:08:25Z | https://github.com/horovod/horovod/issues/3511 | [
"bug"
] | ashahba | 4 |
TracecatHQ/tracecat | automation | 429 | Improve Search in UI (Registry and Workflows) | **Describe the bug**
The Search could be inproved in UI (Registry and Workflows). Now it seems that search is done only in Action title, but Namespace (integration itself) field could also be used.
**To Reproduce**
1. Go to 'Workflows'
2. Add new 'Node'
3. Search for 'LDAP'
4. Only one action is returned
**E... | closed | 2024-10-15T06:32:28Z | 2024-11-06T20:33:23Z | https://github.com/TracecatHQ/tracecat/issues/429 | [] | skrilab | 1 |
hankcs/HanLP | nlp | 994 | pyhanlp安装JDK之后报错 | 报错信息
Traceback (most recent call last):
File "C:/zengxianfeng/lac/utils.py", line 4, in <module>
from pyhanlp import *
File "C:\zengxianfeng\Anaconda\lib\site-packages\pyhanlp\__init__.py", line 116, in <module>
_start_jvm_for_hanlp()
File "C:\zengxianfeng\Anaconda\lib\site-packages\pyhanlp\__init__... | closed | 2018-10-12T02:42:31Z | 2018-11-30T03:16:39Z | https://github.com/hankcs/HanLP/issues/994 | [] | SefaZeng | 1 |
d2l-ai/d2l-en | tensorflow | 2,638 | d2l broken (numpy) in colab with default pytorch 2.6.0 | Colab just updated pytorch to 2.6.0 and it breaks d2l:
```bash
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
[<ipython-input-2-a93af434f2cf>](https://localhost:8080/#) in <cell line: 0>()
1 get_ipython().r... | open | 2025-03-18T11:51:11Z | 2025-03-18T13:02:53Z | https://github.com/d2l-ai/d2l-en/issues/2638 | [] | drapado | 0 |
huggingface/diffusers | deep-learning | 10,277 | Using euler scheduler in fluxfill | ### Describe the bug
I am using the customfluxfill function and want to use the Euler scheduler (EulerAncestralDiscreteScheduler) in my code. However, I am encountering the following error:
### Reproduction
```
from diffusers.schedulers import (
DPMSolverMultistepScheduler,
EulerAncestralDiscreteSchedul... | open | 2024-12-18T04:15:02Z | 2025-02-02T15:02:54Z | https://github.com/huggingface/diffusers/issues/10277 | [
"bug",
"stale"
] | luna313 | 4 |
ansible/awx | django | 14,922 | Inventory and Host modules are not idempotent in --check mode | ### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software pro... | open | 2024-02-26T01:53:40Z | 2024-02-28T19:42:02Z | https://github.com/ansible/awx/issues/14922 | [
"type:bug",
"component:awx_collection",
"needs_triage",
"community"
] | kk-at-redhat | 4 |
explosion/spaCy | data-science | 12,566 | CLI benchmark accuracy doesn't save rendered displacy htmls | The accuracy benchmark of my model does not save rendered displacy htmls as requested. Benchmark works that's why I'm confused. The model contains only **transformers** and **spancat** components. Does **spancat** is not yet supported? 😞
DocBin does not contain any empty docs
CLI output:
```powershell
$ pyth... | closed | 2023-04-23T21:40:47Z | 2023-05-29T00:02:17Z | https://github.com/explosion/spaCy/issues/12566 | [
"bug",
"feat / cli",
"feat / spancat"
] | jamnicki | 3 |
ageitgey/face_recognition | python | 1,467 | Very slow. help me please | * face_recognition version: face-recognition 1.3.0
* Python version: 3.9.7
* Operating System: windows 11
### Description
I rec the video in brawser from webcam and send it to the python flask. video is 1 millisecond long. and than i have a pickle file with 6 persons encodes. i try to compare them and my 1ms vi... | open | 2023-01-23T18:00:33Z | 2023-01-23T18:00:33Z | https://github.com/ageitgey/face_recognition/issues/1467 | [] | Shoichii | 0 |
aleju/imgaug | deep-learning | 716 | How to work with landmarks and bounding boxes of objects | Dear,
As the title, I would like to augment data for objects which requires to have both bounding box and landmark. Have more than 1 object in a image!
Example:

Any sample code to deal with this?
T... | open | 2020-09-09T07:22:25Z | 2020-10-17T05:20:43Z | https://github.com/aleju/imgaug/issues/716 | [] | cannguyen275 | 6 |
TencentARC/GFPGAN | pytorch | 150 | How to run it on Windows? | Hi
Can anyone share how to run this on Windows?
Thank You | closed | 2022-01-22T14:34:43Z | 2023-05-17T19:02:05Z | https://github.com/TencentARC/GFPGAN/issues/150 | [] | rop12770 | 2 |
pallets-eco/flask-wtf | flask | 582 | flask-wtf i18n does not work without flask-babel | wtforms has no hard dependency to babel/flask-babel, and translations work out of the box when properly configured, e.g. `Form(flask.request.form, meta={"locales": ["fr"]})`
However translations for a simple flask-wtf form with the same configuration won't work, unless flask-babel is installed and initialized.
Th... | open | 2023-10-03T17:51:35Z | 2024-01-05T09:18:12Z | https://github.com/pallets-eco/flask-wtf/issues/582 | [
"bug",
"i18n"
] | azmeuk | 0 |
huggingface/datasets | numpy | 7,220 | Custom features not compatible with special encoding/decoding logic | ### Describe the bug
It is possible to register custom features using datasets.features.features.register_feature (https://github.com/huggingface/datasets/pull/6727)
However such features are not compatible with Features.encode_example/decode_example if they require special encoding / decoding logic because encod... | open | 2024-10-11T19:20:11Z | 2024-11-08T15:10:58Z | https://github.com/huggingface/datasets/issues/7220 | [] | alex-hh | 2 |
cookiecutter/cookiecutter-django | django | 4,755 | Add a citation file | Hi all -- I am using this in academic software. I would like the cite the repository, which I can of course do, but I would also like to credit authors and maintainers more explicitly.
I suggest that it would be a good idea to create a citation file, and possibly add a zenodo config, to make it easier to appropriate... | closed | 2023-12-19T16:58:04Z | 2023-12-20T17:52:54Z | https://github.com/cookiecutter/cookiecutter-django/issues/4755 | [
"enhancement"
] | cmatKhan | 6 |
ivy-llc/ivy | numpy | 27,968 | Fix Ivy Failing Test: tensorflow - elementwise.maximum | closed | 2024-01-20T16:18:41Z | 2024-01-25T09:54:03Z | https://github.com/ivy-llc/ivy/issues/27968 | [
"Sub Task"
] | samthakur587 | 0 | |
vvbbnn00/WARP-Clash-API | flask | 201 | [Feature request]建议增加一键部署 | 一键部署到Vercel或者Railway等平台。 | open | 2024-05-13T07:01:15Z | 2024-05-13T18:05:05Z | https://github.com/vvbbnn00/WARP-Clash-API/issues/201 | [
"enhancement"
] | sunzhuo | 0 |
ipython/ipython | jupyter | 14,355 | Word-based backward deletion? | Hi guys! I've been using your beautiful shell for like 10 years now. 🤗
I'm wondering if you already support this and I just could not find it in the docs, or if you don't - could you please give me some directions where to look in the sources and how would you implement it:
I really want to be able to configure... | closed | 2024-02-25T08:10:10Z | 2024-02-25T09:18:10Z | https://github.com/ipython/ipython/issues/14355 | [] | scythargon | 1 |
vitalik/django-ninja | rest-api | 377 | list value in form data is not parsed properly (it always returns list with length 1)[BUG] | Hi! Thanks for the amazing framework!
I think I found a possible bug and the fix please have a look :)
## Context
From the tutorial... I added a simple form data
```py
from django.http import HttpRequest
from ninja import NinjaAPI, Schema, Form
class MyModel(Schema):
my_list: list[str]
api = ... | closed | 2022-02-28T14:00:12Z | 2024-10-20T11:49:29Z | https://github.com/vitalik/django-ninja/issues/377 | [] | triumph1 | 5 |
Anjok07/ultimatevocalremovergui | pytorch | 1,013 | Any body help me? 有人能帮我吗? | My machine info:我的设备信息:
Intel MacOS 12.7.1
launch UVR fail, the error message is follow:启动UVR失败,下面是错误信息:
Traceback (most recent call last):
File "UVR.py", line 8, in <module>
File "<frozen importlib._bootstrap>", line 1176, in _find_and_load
File "<frozen importlib._bootstrap>", line 1147, in _find_and_lo... | open | 2023-12-07T15:09:19Z | 2023-12-08T03:39:00Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1013 | [] | Darling-Lee | 2 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 16,860 | [Bug]: When setting the LORA directory to a network storage device, the tree view disappears | ### Checklist
- [ ] The issue exists after disabling all extensions
- [ ] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [x] The issue exists in the current version of the webui
- [x] The issue has not been reported before... | closed | 2025-02-22T15:35:46Z | 2025-02-23T15:35:03Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16860 | [
"bug-report"
] | carey6409 | 5 |
horovod/horovod | pytorch | 4,069 | Unable to install horovod on aarch64 platfrom either in host or container | **Environment:**
1. Framework: (TensorFlow, Keras, PyTorch, MXNet) : All
2. Framework version: Tensorrt-llm
3. Horovod version: 0.28.1
5. CUDA version: 12.4
6. NCCL version: 2.21.5-1+cuda12.4
7. Python version: 3.10
10. OS and version: Ubuntu 22.04
11. GCC version: 4:11.2.0
12. CMake version: 3.29.2
**Bu... | open | 2024-08-21T01:59:59Z | 2024-10-18T09:29:04Z | https://github.com/horovod/horovod/issues/4069 | [
"bug"
] | rajeshitshoulders | 1 |
tfranzel/drf-spectacular | rest-api | 613 | How to extend action with several methods using OpenApiViewExtension? | I currently have an action on a view that support GET, POST and DELETE. How can I extend their schema by using the OpenApiViewExtensionClass?
```
class TestAPISchema(OpenApiViewExtension):
target_class = "test.views.TestAPI"
def view_replacement(self):
@extend_schema_view(
test_act... | closed | 2021-12-15T14:32:29Z | 2022-02-07T11:14:50Z | https://github.com/tfranzel/drf-spectacular/issues/613 | [] | MatejMijoski | 2 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,417 | How to use socks5 with auth proxy with undetected_chromedriver? |
At the moment, I have been trying for several days to find a way to make it work, but nothing works out for me.</div> | closed | 2023-07-25T01:26:47Z | 2023-07-26T15:13:46Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1417 | [] | dxdate | 2 |
deeppavlov/DeepPavlov | tensorflow | 717 | Getting Invalid syntax Error when installing en_ranker_tfidf_wiki | When running following command in linux (python 3.5):
`python -m deeppavlov install en_ranker_tfidf_wiki`
I get following error:
```
Traceback (most recent call last):
File "/usr/lib/python3.5/runpy.py", line 183, in _run_module_as_main
mod_name, mod_spec, code = _get_module_details(mod_name, _Error)
F... | closed | 2019-02-19T12:27:53Z | 2019-04-15T09:07:51Z | https://github.com/deeppavlov/DeepPavlov/issues/717 | [] | Benjamin-3281 | 2 |
deepfakes/faceswap | machine-learning | 728 | ImportError: Module use of python37.dll conflicts with this version of Python. | **Describe the bug**
Some python dll import error something something
**To Reproduce**
Steps to reproduce the behavior:
1. Run setup.exe
2. Error
**Expected behavior**
Install w/o error
**Installer Details**
```
(check) Git installed: git version 2.20.1.windows.1
(check) MiniConda installed: conda 4.5.... | closed | 2019-05-14T05:00:38Z | 2019-05-14T10:52:47Z | https://github.com/deepfakes/faceswap/issues/728 | [] | WSADKeysGaming | 1 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 653 | Cannot train vocoder for single-speaker fine tuning; vocoder_preprocess is not generating any mel gtas | I know vritually nothing about programming and am trying to use the tool. I got the voice cloning to work, but I would like to go further and fine-tune a model based on #437. I'm only using a small number of steps just to familiarise myself with the process before committing to using a larger set of utterances and trai... | closed | 2021-02-10T04:23:15Z | 2021-02-17T20:44:55Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/653 | [] | StElysse | 9 |
pallets/flask | flask | 5,653 | Flash message with Markup fails | Upgrading my platform from Python 3.8 + Flask 3.0.3 + Flask-Session 0.8.0 with redis backend, to Python 3.11 + Flask 3.1.0 + Flask-Session 0.8.0 with redis backend. Same user code.
Issue: fancy flash message breaks on the new platform (work fine on the old platform).
Flash message:
`flash(Markup('press the pla... | closed | 2024-12-10T18:08:02Z | 2024-12-26T00:10:42Z | https://github.com/pallets/flask/issues/5653 | [] | jeroen-80 | 1 |
autokey/autokey | automation | 632 | AutoKey process not killed by panel icon context menu Quit option | ## Classification:
Bug
## Reproducibility:
Always
## Autokey version:
autokey-gtk 0.96.0-beta.9
Used GUI:
Gtk
Installed via:
pip3
Linux distribution:
- Kubuntu 20.04 LTS running inside of VirtualBox
- KDE Plasma Version 5.18.5
- KDE Frameworks Version: 5.68.0
- Qt Version: 5.12.8
- Kernel Versi... | open | 2021-11-19T21:16:38Z | 2022-05-10T06:09:28Z | https://github.com/autokey/autokey/issues/632 | [
"bug",
"autokey-gtk",
"user interface"
] | Elliria | 26 |
InstaPy/InstaPy | automation | 6,582 | Error when trying to like/comment. | Hey, InstaPy worked flawlessly the last weeks. Now it automatically updated and I get this message before it stops:
```
--- Logging error ---
Traceback (most recent call last):
File "C:\Users\xDDra\AppData\Local\Programs\Python\Python39\lib\logging\__init__.py", line 1082, in emit
stream.write(msg + self.ter... | open | 2022-04-11T20:51:20Z | 2022-05-02T13:44:36Z | https://github.com/InstaPy/InstaPy/issues/6582 | [] | Anima1337 | 13 |
dask/dask | scikit-learn | 11,416 | Significant slowdown in Numba compiled functions from Dask 2024.8.1 | <!-- Please include a self-contained copy-pastable example that generates the issue if possible.
Please be concise with code posted. See guidelines below on how to provide a good bug report:
- Craft Minimal Bug Reports http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports
- Minimal Complete Verifiab... | closed | 2024-10-07T15:55:42Z | 2024-10-08T10:17:48Z | https://github.com/dask/dask/issues/11416 | [
"needs triage"
] | tomwhite | 2 |
CorentinJ/Real-Time-Voice-Cloning | python | 513 | i am confuse with the places of folders? | Hello i did downloaded the LibriSpeech/train-clean-100 (tar.gz 5gb) and extract it to the root of the app as LibriSpeech/
but i am getting this.
python3.7 demo_toolbox.py --low_mem -d LibriSpeech/
Arguments:
datasets_root: LibriSpeech
enc_models_dir: encoder/saved_models
syn_models_dir: sy... | closed | 2020-08-28T07:24:42Z | 2020-09-04T05:12:43Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/513 | [] | afantasialiberal | 6 |
ray-project/ray | python | 51,275 | [core][gpu-objects] Exception handling | ### Description
* Application-level exceptions
* System-level exceptions: If sender actor dies, receiver actor should throw an error to avoid hanging in recv
### Use case
_No response_ | open | 2025-03-11T22:33:38Z | 2025-03-11T22:42:35Z | https://github.com/ray-project/ray/issues/51275 | [
"enhancement",
"P1",
"core",
"gpu-objects"
] | kevin85421 | 1 |
fastapiutils/fastapi-utils | fastapi | 68 | [BUG] @repeat_every will have no stack trace in terminal | **Describe the bug**
No error will show
**To Reproduce**
```
from fastapi import FastAPI
from fastapi_utils.tasks import repeat_every
app = FastAPI()
items = {}
@app.on_event("startup")
@repeat_every(seconds=60)
async def startup_event():
raise Exception
items["foo"] = {"name": "Fighte... | closed | 2020-06-20T10:32:40Z | 2021-01-01T02:18:11Z | https://github.com/fastapiutils/fastapi-utils/issues/68 | [
"bug"
] | shizidushu | 2 |
ageitgey/face_recognition | python | 633 | face_detection: command not found | * face_recognition version: Latest
* Python version: Don't know
* Operating System: Linux
### Description
Paste the command(s) you ran and the output.
```$ face_detection
face_detection: command not found```
If there was a crash, please include the traceback here.
```
| open | 2018-09-28T10:48:22Z | 2019-10-18T14:12:45Z | https://github.com/ageitgey/face_recognition/issues/633 | [] | adv-ai-tech | 3 |
thtrieu/darkflow | tensorflow | 979 | what are the classes in VOC2007 and how many labels it contains | what are the classes in VOC2007 and how many labels it contain?
| closed | 2019-02-01T16:56:34Z | 2019-02-03T01:55:52Z | https://github.com/thtrieu/darkflow/issues/979 | [] | Francisobiagwu | 0 |
ResidentMario/missingno | data-visualization | 61 | Add continuous integration | Once #46 and #47 are resolved, it will be invaluable for you to set up continuous integration via [Travis-CI](https://travis-ci.org) or related services. That way every commit, PR, etc. will automatically be tested for you.
If you're unsure how to add CI to a GitHub repo, see the [GitHub docpage](https://github.com/... | closed | 2018-01-31T03:20:48Z | 2020-04-09T21:14:42Z | https://github.com/ResidentMario/missingno/issues/61 | [] | rhiever | 0 |
davidteather/TikTok-Api | api | 137 | [INSTALLATION] - All "api.___ " function is taking forever to execute" | **Describe the error**
All api.___() functions are taking forever to execute
**The buggy code**
`
from TikTokApi import TikTokApi
api = TikTokApi()
results = 10
trending = api.trending(count=results)
for tiktok in trending:
print(tiktok['desc'])
print(len(trending))
`
**Desktop (please ... | closed | 2020-06-11T06:12:08Z | 2020-09-06T06:54:21Z | https://github.com/davidteather/TikTok-Api/issues/137 | [
"bug",
"installation_help"
] | JoyceJiang73 | 7 |
chezou/tabula-py | pandas | 396 | Problem in output table characters | ### Summary
It seems it output a table with correct dimension but the content of each cell is ??????
### Did you read the FAQ?
- [X] I have read the FAQ
### Did you search GitHub issues?
- [X] I have searched the issues
### Did you search GitHub Discussions?
- [X] I have searched the discussions
### (Optional) ... | closed | 2024-08-01T14:26:10Z | 2024-08-01T15:36:39Z | https://github.com/chezou/tabula-py/issues/396 | [
"not a bug"
] | DsDastgheib | 1 |
dpgaspar/Flask-AppBuilder | flask | 1,839 | Reverse selection ( NOT ) | 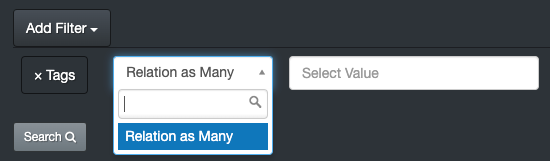
Hello all, is it possible have a search that reverse the selection on a relationship table ?
I look for having results thats does not match the tagse.
tags = relationship("Tags", secondary=assoc_tag... | open | 2022-05-01T13:09:14Z | 2022-05-03T19:22:47Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1839 | [
"question"
] | Th4nat0s | 3 |
babysor/MockingBird | deep-learning | 518 | n_fft参数设置 | Synthesizer和hifigan中的n_fft参数分别是800和1024,这样设置同一个波形文件处理的到的mels应该是不一样的,hifigan为什么会work呢 | open | 2022-04-26T09:23:34Z | 2022-04-26T09:23:34Z | https://github.com/babysor/MockingBird/issues/518 | [] | 1nlplearner | 0 |
aiortc/aiortc | asyncio | 1,176 | Lazy decoding of video frames | Hi,
First of all - thank you for all the effort you have put into building this useful package!
I was about to create a PR with the change I need but I thought I'd ask first to ensure it's aligned with your vision.
I would like to be able to prevent frames from being automatically decoded, and instead decode t... | closed | 2024-10-17T12:35:15Z | 2024-10-24T20:43:32Z | https://github.com/aiortc/aiortc/issues/1176 | [] | grzegorz-roboflow | 0 |
Gozargah/Marzban | api | 622 | اتصال نود در Haproxy | سلام ممنون بابت پروژه عالی مرزبان
مشکل اینجاست که سرور اصلی را با HAproxy تک پورت کردم ولی سرور نود را نمیتونم وصل کنم و هیچ اموزشی وجود نداره خواهشااا در این مورد راهنمایی کنید چون هیچ منبعی در این رابطه وجود نداره.
طبق مطلبی که در این اینجا هست
https://gozargah.github.io/marzban/examples/all-on-one-port
تمام ت... | closed | 2023-11-07T05:55:08Z | 2023-12-31T11:06:22Z | https://github.com/Gozargah/Marzban/issues/622 | [
"Feature"
] | reza3723 | 1 |
onnx/onnx | deep-learning | 6,751 | test source distribution / test_sdist_preview (3.10, arm64) fails | ```
2025-03-02T08:54:42.9539070Z Current runner version: '2.322.0'
2025-03-02T08:54:42.9555000Z ##[group]Operating System
2025-03-02T08:54:42.9555480Z macOS
2025-03-02T08:54:42.9555800Z 14.7.2
2025-03-02T08:54:42.9556110Z 23H311
2025-03-02T08:54:42.9556410Z ##[endgroup]
2025-03-02T08:54:42.9556810Z ##[group]Runner Imag... | closed | 2025-03-02T09:43:34Z | 2025-03-03T20:52:34Z | https://github.com/onnx/onnx/issues/6751 | [
"bug"
] | andife | 2 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,175 | Batch size > 1 during testing | Sorry to bother. I would like to set batch size >1 during testing. Current version is based on batchsize ==1. Could you tell me where to modify?
I have done some modification to make it work but there is still some problems. I trained a pix2pix model with batch normalization and batchsize ==1. It works fine when I se... | open | 2020-11-06T03:16:46Z | 2020-11-06T08:05:00Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1175 | [] | wangjialuu | 0 |
keras-team/keras | pytorch | 20,397 | Need to reenable coverage test on CI | I had to disable coverage testing here: https://github.com/keras-team/keras/blob/master/.github/workflows/actions.yml#L87-L101
because it was causing a failure on the torch backend CI. The failure was related to coverage file merging.
This does not appear to have been caused by a specific commit. None of our depend... | closed | 2024-10-23T03:37:42Z | 2024-10-23T14:47:30Z | https://github.com/keras-team/keras/issues/20397 | [] | fchollet | 0 |
mwaskom/seaborn | data-visualization | 3,428 | Seaborn 0.12.2 and NumPy 1.24.3 causing Python crash upon Ctrl+C (reproduces across multiple Windows PCs) | # Overview
Ok, here's a really puzzling and interesting bug:
With the latest Seaborn version, if the NumPy version is 1.24.3: **At any time after importing Seaborn into Python, pressing CTRL+C *reproducibly* causes the Python process to forcibly terminate.**
# Observed and Expected Behaviors
Below is a min... | closed | 2023-07-27T00:27:38Z | 2023-08-02T11:21:39Z | https://github.com/mwaskom/seaborn/issues/3428 | [] | peterdsharpe | 3 |
waditu/tushare | pandas | 923 | 业绩预告的调用方式希望与其他财务数据调用方式保持一致 | 业绩预告的必选参数 现在是 ann_date 或 period 二选一,但是其他所有财务数据的必选参数是或至少包含ts_code。希望修改业绩预告的必选参数以保持与其他api的一致(希望将ts_code加入必选、允许只输入ts_code以返回对应代码的业绩预告)。由于ann_date无法被预知,period无法被精确定位,实际上这两个参数在设定上需要站在已知此2字段的基础上,这与预告的更新逻辑略有冲突。 | closed | 2019-02-14T14:16:19Z | 2019-02-17T13:39:56Z | https://github.com/waditu/tushare/issues/923 | [] | ProV1denCEX | 1 |
mars-project/mars | pandas | 3,235 | [BUG] Dataframe setitem bug | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
A clear and concise description of what the bug is.
```python
import pandas as pd
import mars
import mars.dataframe as md
def calc_p... | closed | 2022-08-29T09:05:20Z | 2022-09-05T04:52:00Z | https://github.com/mars-project/mars/issues/3235 | [
"type: bug"
] | fyrestone | 0 |
kizniche/Mycodo | automation | 1,368 | Request to add DFRobot i2c Fermion: LWLP5000 Differential Pressure Sensor (±500pa) | Too keep negative pressure in the grow tent; box; room when using intake and exhaust fan in the setup.
Or filter clogging detection.
link to produkt: [https://www.dfrobot.com/product-2096.html](https://www.dfrobot.com/product-2096.html)
link to wiki page: [https://wiki.dfrobot.com/Differential_Pressure_Sensor_%C... | open | 2024-03-02T18:47:49Z | 2024-03-02T18:47:49Z | https://github.com/kizniche/Mycodo/issues/1368 | [] | silverhawk1983 | 0 |
encode/databases | sqlalchemy | 208 | aiopg engine raises ResourceWarning in transactions | Step to reproduce:
Python 3.7.7
```python3
import asyncio
from databases import Database
url = "postgresql+aiopg://localhost:5432"
async def generate_series(db, *args):
async with db.connection() as conn:
async for row in conn.iterate( # implicitly starts transaction
f"se... | open | 2020-05-20T10:55:25Z | 2021-03-16T16:59:38Z | https://github.com/encode/databases/issues/208 | [] | nkoshell | 3 |
deezer/spleeter | deep-learning | 82 | [Bug] Occur OMP:Waring #190 when execute on Docker | <!-- PLEASE READ THIS CAREFULLY :
- Any issue which does not respect following template or lack of information will be considered as invalid and automatically closed
- First check FAQ from wiki to see if your problem is not already known
-->
## Description
<!-- Give us a clear and concise description of the bu... | closed | 2019-11-13T06:47:02Z | 2019-11-15T10:24:45Z | https://github.com/deezer/spleeter/issues/82 | [
"bug",
"help wanted",
"MacOS",
"docker"
] | jaus14 | 3 |
tensorly/tensorly | numpy | 479 | Error reported when import tensorly (version: 0.8.0) in Python 3.7 | In Pyhone 3.7, importing TensorLy, `import tensorly as tl`, will get the following error message:
```
from .generalised_inner_product import inner
File "<fstring>", line 1
(tensor1.shape=)
^
SyntaxError: invalid syntax
```
The problem should be caused by the updates in the following ... | closed | 2023-01-17T17:44:30Z | 2023-01-24T00:54:02Z | https://github.com/tensorly/tensorly/issues/479 | [] | shuo-zhou | 3 |
tqdm/tqdm | pandas | 891 | Tqdm.Notebook does not show nested bars with get_fdata | - [ ] I have marked all applicable categories:
+ [ ] exception-raising bug
+ [x] visual output bug
+ [ ] documentation request (i.e. "X is missing from the documentation." If instead I want to ask "how to use X?" I understand [StackOverflow#tqdm] is more appropriate)
+ [ ] new feature request
- [x]... | open | 2020-02-10T03:33:51Z | 2020-08-11T06:21:35Z | https://github.com/tqdm/tqdm/issues/891 | [
"invalid ⛔",
"question/docs ‽",
"need-feedback 📢"
] | NeoShin96 | 2 |
nicodv/kmodes | scikit-learn | 75 | KModes module cannot be found | Hello,
Even if I downloaded the whole package and installed according to the instructions, I cannot use it. I want to use K-prototypes algorithm but it cannot even import k-modes in the first place. When I import k-modes like this :
`from kmodes.KModes import KModes`
I have this error:
> ModuleNotFoundError: ... | closed | 2018-06-01T22:47:25Z | 2025-03-14T23:42:23Z | https://github.com/nicodv/kmodes/issues/75 | [
"question"
] | bendiste | 8 |
plotly/dash | data-science | 3,199 | Update dcc.Markdown for react 18 compatibility | > @T4rk1n
> I just noticed that `dcc.Mardown` generates a warning in the console - which is weird because it's not a function component.
>Warning: v: Support for defaultProps will be removed from function components in a future major release. Use JavaScript default parameters instead. Error Component Stack
>
> ```
> ... | open | 2025-03-06T19:12:02Z | 2025-03-06T20:51:40Z | https://github.com/plotly/dash/issues/3199 | [
"feature",
"P1"
] | T4rk1n | 0 |
InstaPy/InstaPy | automation | 6,674 | i will try it | open | 2023-01-07T18:57:27Z | 2023-01-07T18:57:27Z | https://github.com/InstaPy/InstaPy/issues/6674 | [] | mohamedibrahimmorsi | 0 | |
pywinauto/pywinauto | automation | 835 | if absolute bug? | Is this a bug?
https://github.com/pywinauto/pywinauto/blob/69eedc759d9327c64305f95ba1b3f1593b0ebd14/pywinauto/controls/hwndwrapper.py#L1676-L1677
Should it be `if not absolute`? | closed | 2019-10-14T22:29:48Z | 2019-10-20T13:14:12Z | https://github.com/pywinauto/pywinauto/issues/835 | [
"duplicate"
] | Akababa | 3 |
erdewit/ib_insync | asyncio | 444 | How to get localSymbol from the API to qualify a Option Future contract? | closed | 2022-02-17T15:33:31Z | 2022-04-28T12:12:07Z | https://github.com/erdewit/ib_insync/issues/444 | [] | WesleySantosMaxtelll | 1 | |
hankcs/HanLP | nlp | 1,886 | phraseTree引发的import error | <!--
感谢找出bug,请认真填写下表:
-->
**Describe the bug**
python3.9+中将cgi.escape 移除,修改为html.escape ,新版本的nltk库中已经进行修改,但是由于本项目引用的是没有进行相关修改的phraseTree,因此在python 3.9+的环境中使用pretty_print方法会报错。
是否可以尝试将phraseTree都统一替换为nltk.tree 来解决此问题。
**Code to reproduce the issue**
```python
import hanlp
from hanlp_common.document impo... | closed | 2024-03-22T08:57:55Z | 2024-03-25T01:37:36Z | https://github.com/hankcs/HanLP/issues/1886 | [
"bug"
] | oasis-0927 | 2 |
vitalik/django-ninja | pydantic | 490 | TestClient does not use data as query parameters in a get request | Why does TestClient use the data parameter only for the post request. For a get request, it is not added as query parameters?
| open | 2022-06-29T14:13:52Z | 2024-05-05T17:42:46Z | https://github.com/vitalik/django-ninja/issues/490 | [] | iforvard | 3 |
alteryx/featuretools | scikit-learn | 2,151 | Replace tmpdir fixtures with tmp_path fixtures | Pytest recommends using `tmp_path` over `tmpdir`:
https://docs.pytest.org/en/latest/how-to/tmp_path.html#the-tmpdir-and-tmpdir-factory-fixtures | closed | 2022-06-27T15:33:06Z | 2022-10-31T20:45:32Z | https://github.com/alteryx/featuretools/issues/2151 | [] | rwedge | 0 |
schemathesis/schemathesis | graphql | 2,576 | [FEATURE] Support examples as hypotheses | ### Is your feature request related to a problem? Please describe
I would like the ability to add request examples to hypotheses to ensure there are accurate/valid tests conducted. This would reduce the amount of effort manually writing tests.
### Describe the solution you'd like
An additional flag in the CLI... | closed | 2024-11-13T19:36:56Z | 2024-11-13T20:37:53Z | https://github.com/schemathesis/schemathesis/issues/2576 | [
"Status: Needs Triage",
"Type: Feature"
] | depopry | 3 |
huggingface/datasets | machine-learning | 7,087 | Unable to create dataset card for Lushootseed language | ### Feature request
While I was creating the dataset which contained all documents from the Lushootseed Wikipedia, the dataset card asked me to enter which language the dataset was in. Since Lushootseed is a critically endangered language, it was not available as one of the options. Is it possible to allow entering la... | closed | 2024-08-04T14:27:04Z | 2024-08-06T06:59:23Z | https://github.com/huggingface/datasets/issues/7087 | [
"enhancement"
] | vaishnavsudarshan | 2 |
deezer/spleeter | tensorflow | 156 | [Discussion] What's the difference between Xstems and Xstems-finetune models ? | The github release links to 2 versions for each steams model (2/4/5) : Xstems and Xstems-finetune.
What's the difference between the 2 kind of models, and how/why would you use one over the other ?
| closed | 2019-12-01T19:36:00Z | 2019-12-02T13:20:05Z | https://github.com/deezer/spleeter/issues/156 | [
"question"
] | divideconcept | 1 |
strawberry-graphql/strawberry | asyncio | 3,699 | codegen doesn't properly handle postponed type annotations |
`strawberry codegen --schema schema.graphql` generates models referencing postponed types as its class variable instead of using a string to be deferred.
## Describe the Bug
From schema, the following code has been generated. In this example, AccessCredentialFilter is referencing itself inside the model
```python
... | open | 2024-11-14T22:19:42Z | 2025-03-20T15:56:56Z | https://github.com/strawberry-graphql/strawberry/issues/3699 | [
"bug"
] | jbkoh | 0 |
modelscope/data-juicer | streamlit | 398 | Heavy dependency of Data-Juicer | As the title say, the dependency of Data-Juicer is heavy. I must install the total environment if I only want to use one OP.
TODO: Set installment for each OP, for example `pip install .[OP_NAME]` | closed | 2024-08-22T07:45:51Z | 2024-09-25T06:18:36Z | https://github.com/modelscope/data-juicer/issues/398 | [
"enhancement"
] | BeachWang | 4 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 104 | Is there any filtering functionalities on triplet sampling? | I'd like to ask a question about how to implement sampling with this package in the following situations.
Now I have the following data.
- samples with the label "A"
- samples with the label "B".
- samples with the label "C".
- samples with the label "not A".
"not A" means "B or C, or an unkno... | closed | 2020-05-17T09:16:40Z | 2020-06-20T05:28:34Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/104 | [
"question"
] | knao124 | 2 |
aimhubio/aim | data-visualization | 3,143 | Using Aim package on FIPS compatible machine results in Error. | ## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
Running AIM with any script on a FIPS server results in errors like these making it unusable.
```
TypeError: 'digest_size' is an invalid keyword argument for openssl_blake2b()
TypeError: 'digest_size' is an invalid keyword argument for op... | open | 2024-05-06T13:55:19Z | 2024-09-11T11:29:42Z | https://github.com/aimhubio/aim/issues/3143 | [
"type / bug",
"help wanted"
] | dushyantbehl | 3 |
dpgaspar/Flask-AppBuilder | flask | 1,367 | name column resizing in ab_view_menu table | While working with apache-airflow when we enable rbac, all the tables related to flask-ui are added into the metadata. On that note, system tries to insert the rows in ab_view_menu table with respect to all the available DAGs. The length of the dag_id is 250 chars but in ab_view_menu the aligned column's (name) length ... | closed | 2020-05-05T19:33:37Z | 2020-05-21T09:57:10Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1367 | [] | guptakumartanuj | 1 |
tflearn/tflearn | data-science | 246 | Architecture Err when extending Titanic tutorial | I tried Quickstart titanic tutorial successfully and made some tests further.
I am predicting a float target by 8 float inputs, and I modified some of the tutorial then
'ValueError: Cannot feed value of shape (64,) for Tensor u'TargetsData/Y:0', which has shape '(?, 1)''
# Build neural network
net = tflearn.input_dat... | open | 2016-07-30T02:14:52Z | 2016-11-27T11:54:07Z | https://github.com/tflearn/tflearn/issues/246 | [] | forhonourlx | 5 |
biolab/orange3 | pandas | 6,860 | Path processing in the Formula widget | **What's your use case?**
This would be most useful for _Spectroscopy_ and similar workflows.
Files always come with a path that carry information about organization. In `Formula` it is possible to do plenty of math but not much of text processing (except for the obvious string operations). However, it would be awe... | open | 2024-07-23T08:00:43Z | 2024-07-23T08:00:43Z | https://github.com/biolab/orange3/issues/6860 | [] | borondics | 0 |
minimaxir/textgenrnn | tensorflow | 1 | Python 2 UnicodeDecode Error | Most of Python 2 works with the script, but need a noncomplicated way of handling UnicodeDecodeErrors when a Unicode character is chosen as the `next_char`. | closed | 2017-08-07T02:31:32Z | 2018-04-19T06:38:38Z | https://github.com/minimaxir/textgenrnn/issues/1 | [
"bug"
] | minimaxir | 1 |
ymcui/Chinese-LLaMA-Alpaca-2 | nlp | 231 | 如何增加chinese-llama2-Alpaca-2-16K(7B) 回复答案的长度? | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 我已阅读[项目文档](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki)和[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案。
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.cpp)、[LangChain](https://g... | closed | 2023-09-04T09:51:46Z | 2023-09-22T22:04:37Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/issues/231 | [
"stale"
] | dkw-wkd | 24 |
ageitgey/face_recognition | python | 674 | [WinError 3] The system cannot find the path specified: 'knn_examples/train' | I created the train directory but it gives out an error: [WinError 3] The system cannot find the path specified: 'knn_examples/train'
| closed | 2018-11-17T02:36:39Z | 2018-11-17T03:08:45Z | https://github.com/ageitgey/face_recognition/issues/674 | [] | nhangox22 | 0 |
explosion/spaCy | deep-learning | 13,625 | Cannot install spaCy 3.8 in python3.8 environment | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
## How to reproduce the behaviour
On a clean environment with python 3.8 and pip, try pip install spaCy==3.8
## Your Environment
<!-- Include details of your environment. You can also type `python -m spacy info --markdown`... | open | 2024-09-12T23:06:39Z | 2024-10-25T04:20:08Z | https://github.com/explosion/spaCy/issues/13625 | [
"deprecated",
"resolved"
] | jianlins | 6 |
lepture/authlib | django | 377 | httpx 0.18.x upgrade breaks addition of "Authorization" header | **Describe the bug**
An application was upgraded to httpx 0.18.2 and we discovered that the "Authorization" header was no longer being included in the request.
**Error Stacks**
403 Errors from downstream services.
Trace Logging revealed that the Authorization header was missing.
Using httpx 0.18.2
``... | closed | 2021-08-20T21:27:19Z | 2021-10-18T12:17:17Z | https://github.com/lepture/authlib/issues/377 | [
"bug"
] | timothyjlaurent | 4 |
betodealmeida/shillelagh | sqlalchemy | 212 | asyncio-compatible dialect | SQLAlchemy 1.4 now supports Python asyncio. In order to take advantage of this, the [dialect must be "asyncio-compatible"](https://docs.sqlalchemy.org/en/14/orm/extensions/asyncio.html#asynchronous-i-o-asyncio). It would be great to have a version of the base `Dialect` that can be used for this.
A discussion for wha... | open | 2022-03-24T20:47:58Z | 2023-10-27T15:46:24Z | https://github.com/betodealmeida/shillelagh/issues/212 | [
"enhancement"
] | cancan101 | 2 |
tableau/server-client-python | rest-api | 1,050 | Type hint issues | **Describe the bug**
Recently tried to bump tableauserverclient from version 0.16.0 to 0.18.0
**Versions**
Details of your environment, including:
- Tableau Server version : Tableau Online
- Python version: 3.9
- TSC library version: 0.18.0
- mypy version: mypy 0.942
**To Reproduce**
Create this simpli... | closed | 2022-05-31T10:56:14Z | 2024-09-19T21:41:02Z | https://github.com/tableau/server-client-python/issues/1050 | [
"bug",
"help wanted"
] | pierresouchay | 6 |
Esri/arcgis-python-api | jupyter | 1,359 | Job failed when publishing JSON file | I have a JSON file that I want to publish on a notebook (conda) used on maps.arcgis.com. As an example and for test, I replaced the JSON file directlty with a dictionnary but I have the same problem with a file. It looks like the problem doesn't come from the data as I have tried many différent ones.
This is my code... | closed | 2022-10-12T05:27:48Z | 2022-10-24T10:48:13Z | https://github.com/Esri/arcgis-python-api/issues/1359 | [
"help wanted"
] | jrmyyy | 5 |
ccxt/ccxt | api | 25,219 | XT.com - ccxt has no function for alter stop limit (/future/trade/v1/entrust/update-profit-stop) | ### Operating System
Debian 12
### Programming Languages
Python
### CCXT Version
4.4.50
### Description
Hi folks,
does anyone know how to use the defined API “/future/trade/v1/entrust/update-profit-stop” in xt.py?
Unfortunately I have not found a way to update a set stop loss or take profit with ccxt?
Thanks f... | closed | 2025-02-07T13:44:26Z | 2025-02-09T09:23:18Z | https://github.com/ccxt/ccxt/issues/25219 | [] | AltePfeife | 2 |
sunscrapers/djoser | rest-api | 248 | Guidance needed - user activation - how to POST | I am using DREF and Djoser for Authentication and User Registration. When a new user registers, Djoser sends an activation email with a link that does a GET request. In order to activate, I need to extract uid and token from the activation url and make a POST request for Djoser to be able to activate the user.
My en... | open | 2017-11-07T11:58:07Z | 2022-02-16T12:43:36Z | https://github.com/sunscrapers/djoser/issues/248 | [] | leferaycloud | 28 |
flasgger/flasgger | flask | 603 | Query parameter not getting picked up in `parsed_data` after 0.9.5 | I'm using openapi 3 documentations like this for `GET` requests with `parse=True`:
```
parameters:
- name: feature
required: false
in: query
schema:
type: string
explode: true
```
I've noticed since the upgrade to 0.9.7 that `request.parsed_data` only contains `{'path': {}}`, whereas previously ... | open | 2024-01-04T10:49:32Z | 2024-01-04T10:49:32Z | https://github.com/flasgger/flasgger/issues/603 | [] | totycro | 0 |
mwaskom/seaborn | data-visualization | 3,706 | UNITS of colorbar in 2D KDE plot? | Can someone please tell me what would be the unit of the colorbar on the 2D KDE plot? The document says that it is the normalized density. Normalized by what? And what would be the unit in that case. | closed | 2024-06-03T14:07:53Z | 2024-06-06T07:55:06Z | https://github.com/mwaskom/seaborn/issues/3706 | [] | ven1996 | 4 |
gee-community/geemap | jupyter | 448 | Impossible to load 1 band from a multi-band raster using add_raster method | ### Environment Information
- geemap version: 0.8.15
- Python version: 3.6.9
- Operating System: Linux Debian
### Description
when using a multi-band raster where 1,2 and 3 are not representing satellites bands but grid information (in my case the first band is the magnitude of change in the pixel duri... | closed | 2021-04-29T12:14:50Z | 2021-04-29T12:37:49Z | https://github.com/gee-community/geemap/issues/448 | [
"bug"
] | 12rambau | 1 |
yunjey/pytorch-tutorial | pytorch | 24 | beam search support | Hi, Is there a code version with beam search? currently the lstm uses greedy output | closed | 2017-04-21T05:53:12Z | 2017-04-21T09:43:16Z | https://github.com/yunjey/pytorch-tutorial/issues/24 | [] | sujayr91 | 1 |
jupyterhub/repo2docker | jupyter | 521 | Determine python version support | Split off from #520. What versions of python do we support for running repo2docker? Note that this is different from what version of python repositories being built with repo2docker can request. | open | 2018-12-18T18:21:55Z | 2019-05-21T07:55:30Z | https://github.com/jupyterhub/repo2docker/issues/521 | [
"needs: discussion"
] | yuvipanda | 3 |
matterport/Mask_RCNN | tensorflow | 2,966 | Multi Class - Imbalance Dataset | I am using instance segmentation task with SFPI dataset which has imbalance data.
These are the losses i could arrive at,
loss :0.5265
mrcnn_bbox_loss : 0.09073
mrcnn_class_loss :0.1468
mrcnn_mask_loss:0.2024
rpn_bbox_loss:0.07144
rpn_class_loss:0.01511
val_loss:0.5339
val_mrcnn_bbox_loss:0.09229
val_mrcnn_c... | open | 2023-06-30T04:53:00Z | 2023-07-18T05:03:44Z | https://github.com/matterport/Mask_RCNN/issues/2966 | [] | avinash-218 | 1 |
holoviz/panel | plotly | 7,427 | Cookiecutter/cruft for Panel extensions | I'd like to see some standard boilerplate of creating Panel extension repos, where directory, CI, documentation are automatically set up, and users just have to implement their feature and tweak a few settings to get it hosted.
Just as an example [prefect-collection-template](https://github.com/PrefectHQ/prefect-col... | open | 2024-10-21T18:11:54Z | 2024-10-25T13:00:56Z | https://github.com/holoviz/panel/issues/7427 | [] | ahuang11 | 9 |
pyg-team/pytorch_geometric | deep-learning | 9,808 | onnx problem with edge_index is [2, 0] | ### 🐛 Describe the bug
#### my model:
```
class MultiHeadAttentionPool(torch.nn.Module):
def __init__(self, input_dim, num_heads):
super(MultiHeadAttentionPool, self).__init__()
self.num_heads = num_heads
self.att_mlp = torch.nn.Linear(input_dim, num_heads)
def forward(self,... | open | 2024-11-27T03:14:12Z | 2024-11-27T03:40:36Z | https://github.com/pyg-team/pytorch_geometric/issues/9808 | [
"bug"
] | LQY404 | 0 |
JoeanAmier/TikTokDownloader | api | 106 | 下载完后保存在那里 | 没找到保存位置 | open | 2023-12-22T20:43:14Z | 2023-12-26T08:47:21Z | https://github.com/JoeanAmier/TikTokDownloader/issues/106 | [] | iapeng | 6 |
2noise/ChatTTS | python | 97 | 如何切换女生音色呢 | ```
spk_stat = torch.load('ChatTTS/asset/spk_stat.pt')
rand_spk = torch.randn(768) * spk_stat.chunk(2)[0] + spk_stat.chunk(2)[1]
params_infer_code = {'spk_emb' : rand_spk, 'temperature':.3}
params_refine_text = {'prompt':'[oral_2][laugh_0][break_4]'}
```
1. 是不是这个模型只有男生音色,没有女生音色?
2. 如果想切换女生音色 代码应该怎么写呢? | closed | 2024-05-30T11:34:27Z | 2024-07-17T04:01:43Z | https://github.com/2noise/ChatTTS/issues/97 | [
"stale"
] | CodeCat-maker | 4 |
freqtrade/freqtrade | python | 10,589 | Error Using Whitelisted Pairs on BloFin | ## Describe your environment
* Operating system: Debian Linux
* Python Version: 3.11.2
* CCXT version: _____ (`pip freeze | grep ccxt`) - This command returned nothing
* Freqtrade Version: 2024.7.1
Note: All issues other than enhancement requests will be closed without further comment if the above t... | closed | 2024-08-27T04:07:10Z | 2024-08-27T16:21:28Z | https://github.com/freqtrade/freqtrade/issues/10589 | [
"unsupported exchange"
] | MadMaximusJB | 2 |
CTFd/CTFd | flask | 1,981 | Deployment instructions for AWS Elastic Beanstalk | We've tried Procfiles and .ebextensions for WSGI. Are there known instructions for deploying to elastic beanstalk?
Procfile used:
`web: gunicorn --bind :8000 --workers 3 --threads 2 project.wsgi:application`
.ebextensions/python.config file used:
`option_settings:
"aws:elasticbeanstalk:container:python":... | open | 2021-08-31T12:20:00Z | 2021-08-31T12:20:00Z | https://github.com/CTFd/CTFd/issues/1981 | [] | bitshiftnetau | 0 |
InstaPy/InstaPy | automation | 6,148 | User biography | ## Expected Behavior
I want to get user biography when call `grab_following` function
## Current Behavior
Only return usernames
| closed | 2021-04-13T04:20:44Z | 2021-04-16T06:19:40Z | https://github.com/InstaPy/InstaPy/issues/6148 | [] | masihmoloodian | 0 |
ansible/ansible | python | 84,492 | Aws Ansible on prem server | ### Summary
Hello, Can aws ansible help me install some tools on a sever machine (on prem) or not ???
### Issue Type
Documentation Report
### Component Name
nothing
### Ansible Version
```console
$ ansible --version
```
### Configuration
```console
# if using a version older than ansible-core 2.12 you should... | closed | 2024-12-25T10:58:06Z | 2024-12-25T21:05:46Z | https://github.com/ansible/ansible/issues/84492 | [] | HamzaLghali | 2 |
pnkraemer/tueplots | matplotlib | 38 | ICML tutorial | With the ICML deadline approaching, it might be a good idea to have a minimal working example about tueplots-for-icml somewhere.
Presumably the readme? A notebook would also be neat, but a readme is easier to update in the future (i.e., after the conference). Deleting a file (a notebook) might be less fun. | closed | 2021-12-14T07:49:21Z | 2021-12-14T08:38:53Z | https://github.com/pnkraemer/tueplots/issues/38 | [] | pnkraemer | 0 |
albumentations-team/albumentations | machine-learning | 1,628 | [Tech debt] Improve interface for RandomSnow | Right now in the transform we have separate parameters for `snow_point_lower` and `snow_point_higher`
Better would be to have one parameter `snow_point_range = [snow_point_lower, snow_point_higher]`
=>
We can update transform to use new signature, keep old as working, but mark as deprecated.
----
PR could be... | closed | 2024-04-05T18:31:53Z | 2024-05-20T21:57:26Z | https://github.com/albumentations-team/albumentations/issues/1628 | [
"good first issue",
"Tech debt"
] | ternaus | 4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.