
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
ShishirPatil/gorilla | api | 905 | [BFCL] When will it be possible to evaluate deepseek-r1? | When will it be possible to evaluate deepseek-r1? | closed | 2025-02-08T09:27:17Z | 2025-03-16T07:03:04Z | https://github.com/ShishirPatil/gorilla/issues/905 | [] | destinyyzy | 1 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 16,699 | [Bug]: The WebUI fails to start | ### Checklist
- [X] The issue exists after disabling all extensions
- [ ] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [ ] The issue exists in the current version of the webui
- [ ] The issue has not been reported before... | closed | 2024-12-03T09:17:46Z | 2024-12-03T11:06:26Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16699 | [
"bug-report"
] | Zueuk | 1 |
coqui-ai/TTS | python | 3,498 | [Bug] Windows Installation Guide not working at step # 11 | ### Describe the bug
Following this guide:
https://stackoverflow.com/questions/66726331/how-can-i-run-mozilla-tts-coqui-tts-training-with-cuda-on-a-windows-system
I get an error output at step 11 which requires me to do the following:
11. Run the following command (this differs from the command you get from [t... | closed | 2024-01-06T16:23:37Z | 2024-02-18T08:58:20Z | https://github.com/coqui-ai/TTS/issues/3498 | [
"bug",
"wontfix"
] | Nikanoru | 2 |
Gozargah/Marzban | api | 665 | 🍆 TED nane jende, kiram to ghabre madare jendat | Hi,
As there is a TELEGRAM_DEFAULT_VLESS_FLOW
Please add DASHBOARD_DEFAULT_VLESS_FLOW
Until you add ability to set custom vless flow for each inbound
Thanks. | closed | 2023-11-30T14:25:38Z | 2025-01-21T19:49:35Z | https://github.com/Gozargah/Marzban/issues/665 | [
"Feature"
] | APT-ZERO | 1 |
freqtrade/freqtrade | python | 10,686 | Why only can not short in spot mode? | <!--
Have you searched for similar issues before posting it?
Did you have a VERY good look at the [documentation](https://www.freqtrade.io/en/latest/) and are sure that the question is not explained there
Please do not use the question template to report bugs or to request new features.
-->
## Describe your e... | closed | 2024-09-22T00:59:03Z | 2024-09-22T12:43:13Z | https://github.com/freqtrade/freqtrade/issues/10686 | [
"Question",
"Non-spot"
] | winsonet | 2 |
K3D-tools/K3D-jupyter | jupyter | 450 | Snapshot HTML produces invalid html file with Jupyter Notebook version 7 |
* K3D version: 2.15.3
* Python version: 2.15.3
* Operating System: MS Windows 11
### Description
The Snapshot HTML produces an invalid file when using Jupyter Notebook Version: 7.1.1
The same code produces a valid file when using Jupyter Notebook Version: 6.5.4 (significantly larger file size).
### Exam... | open | 2024-02-29T17:38:19Z | 2024-07-03T14:11:18Z | https://github.com/K3D-tools/K3D-jupyter/issues/450 | [
"Next release"
] | deankarlen | 0 |
jazzband/django-oauth-toolkit | django | 1,493 | Are there any open-source projects developed using django-oauth-toolkit? | <!-- What is your question? -->
| open | 2024-09-10T03:20:53Z | 2024-09-26T03:30:47Z | https://github.com/jazzband/django-oauth-toolkit/issues/1493 | [
"question"
] | dusens | 1 |
plotly/dash | dash | 2,862 | [BUG] callback dataflow display flickers at certain sizes | Thank you so much for helping improve the quality of Dash!
We do our best to catch bugs during the release process, but we rely on your help to find the ones that slip through.
**Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
- replace the result of `pip l... | closed | 2024-05-14T18:26:37Z | 2024-05-15T14:59:34Z | https://github.com/plotly/dash/issues/2862 | [
"bug"
] | gvwilson | 6 |
flairNLP/flair | pytorch | 3,113 | [Question]: Prepare test data for text classification | ### Question
Hi,
I would like to train a TextClassifier and have created tab separated csv-files with the columns "text" and "label". I am using the CSVClassificationCorpus when building the corpus for the training. After training I get the message "ACHTUNG! No gold labels and no all_predicted_values found! Could be ... | closed | 2023-02-17T12:02:47Z | 2023-04-24T11:53:56Z | https://github.com/flairNLP/flair/issues/3113 | [
"question"
] | NDTanja | 4 |
pydantic/logfire | pydantic | 335 | `test_logfire_api` doesn't look at `logfire_api.__all__` | It just uses `logfire.__all__` in both versions of `test_runtime`. `logfire_api.__all__` doesn't actually exist at runtime when logfire isn't importable. | open | 2024-07-24T17:27:27Z | 2024-12-27T08:16:32Z | https://github.com/pydantic/logfire/issues/335 | [
"good first issue",
"Logfire API"
] | alexmojaki | 4 |
ContextLab/hypertools | data-visualization | 97 | allow legend to be computed from group kwarg | Currently, legends are set explicitly by passing a list to the `plot` function. However, they could also be set automatically by passing a `group` list to the `legend` kwarg
e.g.
`hyp.plot(data, group=labels, legend=labels)` | closed | 2017-04-18T14:55:28Z | 2017-06-02T16:51:19Z | https://github.com/ContextLab/hypertools/issues/97 | [
"enhancement",
"low priority",
"mozilla sprint",
"easy(ish)"
] | andrewheusser | 4 |
kizniche/Mycodo | automation | 809 | Enhancement - mycodo allow changing pi root user | Leaving default pi root user is a security risk. mycodo should support removing default root user. | closed | 2020-08-08T02:18:12Z | 2020-08-08T21:19:02Z | https://github.com/kizniche/Mycodo/issues/809 | [] | stardawg | 3 |
wandb/wandb | tensorflow | 9,563 | [Bug-App]: Plotly figure rendered empty | ### Describe the bug
<!--- Describe your issue here --->
I am trying to log a simple plotly bar plot to wandb like shown in the minimal example below. Similar to https://github.com/wandb/wandb/issues/2191, the plot is rendered correctly when logged as an HTML but shows up empty when logged as plotly.
```python
impor... | open | 2025-03-06T00:04:04Z | 2025-03-17T11:05:46Z | https://github.com/wandb/wandb/issues/9563 | [
"ty:bug",
"a:app"
] | jonasjuerss | 5 |
tflearn/tflearn | data-science | 585 | model.load file name needs to start with ./ | It appears that when loading a model file from the current dir we must prepend "./" to the file name:
```python
model.load("./marker-classifier.tfl")
```
The documentation needs to mention this.
Reference: http://stackoverflow.com/a/41325679/1036017 | open | 2017-02-02T22:51:32Z | 2017-02-10T05:59:52Z | https://github.com/tflearn/tflearn/issues/585 | [] | bibhas2 | 1 |
apify/crawlee-python | automation | 560 | Unable to execute POST request with JSON payload | Example
```python
async def main() -> None:
crawler = HttpCrawler()
# Define the default request handler, which will be called for every request.
@crawler.router.default_handler
async def request_handler(context: HttpCrawlingContext) -> None:
context.log.info(f'Processing {context.req... | closed | 2024-10-02T00:48:27Z | 2024-10-24T11:44:12Z | https://github.com/apify/crawlee-python/issues/560 | [
"bug",
"t-tooling"
] | Mantisus | 2 |
pyro-ppl/numpyro | numpy | 1,191 | Clarify that `sample(..., obs_mask)` is only used for SVI | to avoid confusion as in this [forum thread](https://forum.pyro.ai/t/bayesian-imputation/3443). | closed | 2021-10-14T01:48:19Z | 2021-10-26T01:30:05Z | https://github.com/pyro-ppl/numpyro/issues/1191 | [
"documentation"
] | fehiepsi | 0 |
KaiyangZhou/deep-person-reid | computer-vision | 409 | Huge memory (RAM) consumption for evaluation stage | Please, fix `features = features.data.cpu()` => `features = features.cpu().clone()` in https://github.com/KaiyangZhou/deep-person-reid/blob/28430ec309d03908b757dc8610325c039dbaebbe/torchreid/engine/engine.py#L370 to avoid huge memory consumption for evaluation stage (to see the difference just evaluate msmt17)
possi... | closed | 2021-01-22T06:01:59Z | 2021-01-22T09:07:31Z | https://github.com/KaiyangZhou/deep-person-reid/issues/409 | [] | denisvmedyantsev | 1 |
Nemo2011/bilibili-api | api | 180 | [需求] API 信息缺少最基础的 HTTP 请求方法... | 突然疑惑,为啥有的没有标出是 GET 还是 POST 等...?
~~傻眼,任务挺大,但挺重要吧?~~
只有一部分,在补,看似是忘了 | closed | 2023-02-02T08:26:39Z | 2023-02-02T09:26:39Z | https://github.com/Nemo2011/bilibili-api/issues/180 | [
"need"
] | z0z0r4 | 1 |
blacklanternsecurity/bbot | automation | 1,841 | after install on windows error Failed to set new ulimit: No module named 'resource' | bbot.exe -t honda.com
______ _____ ____ _______
| ___ \| __ \ / __ \__ __|
| |___) | |__) | | | | | |
| ___ <| __ <| | | | | |
| |___) | |__) | |__| | | |
|______/|_____/ \____/ |_|
BIGHUGE BLS OSINT TOOL v2.0.1
www.blacklanternsecurity.com/bbot
Failed to set new ulimit: No module name... | closed | 2024-10-11T21:38:30Z | 2024-10-11T22:52:58Z | https://github.com/blacklanternsecurity/bbot/issues/1841 | [] | jinji9630 | 1 |
miguelgrinberg/Flask-Migrate | flask | 151 | Migrate model with multi-column UniqueConstraint | Hi, I'm trying to create a migration for the following model:
```
class Function(db.Model):
__tablename__ = 'function'
__table_args__ = tuple(UniqueConstraint('name', 'namespace', 'revision',
name='name_namespace_revision_unique_constraint'))
id = db.Column(db.Integer, p... | closed | 2017-03-01T20:25:57Z | 2019-08-16T19:02:04Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/151 | [
"question"
] | felipejfc | 6 |
LibreTranslate/LibreTranslate | api | 719 | I am a simple man: I ctrl+f "Requirements" or "self-host" and find 0 information in your Readme.md | You say we can self-host, but the Readme.md needs to be updated to mention in a reasonably easy to find fashion:
- what do I click to see steps on _how_ to self-host (as opposed to using the $29 / month portal.libretranslate.com api key).
- before I decide to start: what are roughly the (minimum) system requirements ... | closed | 2025-01-03T16:57:39Z | 2025-01-04T16:14:45Z | https://github.com/LibreTranslate/LibreTranslate/issues/719 | [
"enhancement"
] | tdbe | 2 |
plotly/dash | data-science | 2,992 | dcc.Graph rendering goes into infinite error loop when None is returned for Figure | **Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
```
dash 2.18.0
dash-core-components 2.0.0
dash-html-components 2.0.0
dash-table 5.0.0
```
- if frontend related, tell us your Browser,... | open | 2024-09-09T19:44:45Z | 2024-09-11T19:16:40Z | https://github.com/plotly/dash/issues/2992 | [
"bug",
"P3"
] | reggied | 0 |
fbdesignpro/sweetviz | pandas | 40 | compare infra fails with KeyError: 'cannot use a single bool to index into setitem' | This seems to be a possible bug:
```
Date: Jul 22, 2020
platform: Macos
environment: conda custom environment
sweetviz version: sweetviz==1.0b3
np.__version__ # 1.18.4
pd.__version__ # 1.0.3
```
# MWE
```python
import numpy as np
import pandas as pd
import seaborn as sns
import sweetviz
df = ... | closed | 2020-07-22T15:29:46Z | 2020-08-02T14:37:51Z | https://github.com/fbdesignpro/sweetviz/issues/40 | [
"bug"
] | bhishanpdl | 2 |
aminalaee/sqladmin | sqlalchemy | 624 | Customized sort_query | ### Checklist
- [X] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
At the moment, the admin panel does not support sorting by objects, but this can be solved using the custom sort_query method. Similar to list_query, search_query.
### Describe t... | closed | 2023-09-21T08:54:40Z | 2023-09-22T09:27:59Z | https://github.com/aminalaee/sqladmin/issues/624 | [] | YarLikviD | 1 |
jupyter-book/jupyter-book | jupyter | 2,144 | Display math in admonition | ### Describe the bug
**issue**
I tried to put some content with display math inside an admonition block, but the output html form is incorrect.
### Reproduce the bug
I tried to put the following content
~~~
A linear map $f:\mathbb{C}\to\mathbb{C}$ is of the form
$$f\left(z\right)=az+b$$
where $a,b\in\... | open | 2024-04-23T04:56:37Z | 2024-04-23T16:19:26Z | https://github.com/jupyter-book/jupyter-book/issues/2144 | [
"bug"
] | tyl012 | 1 |
jina-ai/clip-as-service | pytorch | 59 | Other Encoding block will be released ? | As you linked your [blog](https://hanxiao.github.io/2018/06/24/4-Encoding-Blocks-You-Need-to-Know-Besides-LSTM-RNN-in-Tensorflow/#pooling-block) in the README, I read it : it was so interesting !! Thanks for sharing it.
---
Now, the main pooling strategies are `REDUCE_MEAN` and `REDUCE_MAX`, as described in the f... | closed | 2018-11-27T08:24:45Z | 2018-12-19T10:18:36Z | https://github.com/jina-ai/clip-as-service/issues/59 | [] | astariul | 1 |
vaexio/vaex | data-science | 1,296 | Is it possible to merge two dataframes? | Hi there,
In pandas I'm joining two datrafarmes using merge, basically this:
`new_df = pd.merge(df, df2, how='left', on="ticker")`
but it keeps running out of memory so I thought I'd try vaex for the same item but I'm unsure how to merge. I searched the documentation and couldn't find anything. I looked around ... | closed | 2021-04-01T01:50:26Z | 2021-04-05T20:12:38Z | https://github.com/vaexio/vaex/issues/1296 | [] | gautambak | 4 |
marimo-team/marimo | data-science | 3,781 | KaTeX Macro Support | ### Description
As outlined in https://github.com/marimo-team/marimo/discussions/1941, I would love to be able to have some Macro Support for KaTeX.
This would come in handy for repeated use of convoluted symbols and would really help us for teaching and presenting our stuff in notebooks.
Our current workflow for jup... | closed | 2025-02-13T12:51:39Z | 2025-02-14T07:18:32Z | https://github.com/marimo-team/marimo/issues/3781 | [
"enhancement"
] | claudiushaag | 3 |
ultralytics/ultralytics | machine-learning | 19,310 | Device selection on export on multi-gpu systems | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
_No response_
### Bug
Greatings! 🚀
Sorry for my English. I ran into issue (latest version, February, 19th) when choosing ... | closed | 2025-02-19T10:30:55Z | 2025-02-20T18:39:51Z | https://github.com/ultralytics/ultralytics/issues/19310 | [
"exports"
] | liwtw | 4 |
JoeanAmier/XHS-Downloader | api | 55 | 使用油猴脚本 点击了提取发现作品链接 没有任何反应 | <img width="274" alt="image" src="https://github.com/JoeanAmier/XHS-Downloader/assets/23499946/ed5c4edb-14e1-412e-a82f-8262b0466d67">
| open | 2024-02-27T10:12:31Z | 2024-02-28T11:45:01Z | https://github.com/JoeanAmier/XHS-Downloader/issues/55 | [] | qiyaozu | 1 |
pydata/pandas-datareader | pandas | 769 | Could not find a version that satisfies the requirement tensorflow ,tensorflow download error | pip install --upgrade tensorflow

| closed | 2020-04-17T14:30:19Z | 2020-07-06T23:02:09Z | https://github.com/pydata/pandas-datareader/issues/769 | [] | ashutos-lab | 1 |
flasgger/flasgger | rest-api | 52 | Why docsstring in head method is not working in flasgger ? |
> Docstring in triple quotes is not working in the head method. I am using the package flassger. I am not able to use docstring in head method for swagger ui. However, it is working in patch, post, put, and get methods.
```
@app.route('/flight/<flight_no>', methods=['HEAD'])
def get_flight_exist(flight_no):
... | closed | 2017-03-17T07:57:22Z | 2017-03-22T16:57:43Z | https://github.com/flasgger/flasgger/issues/52 | [
"bug"
] | ravibhushan29 | 8 |
inventree/InvenTree | django | 8,690 | [PUI] Login broken with MFA enabled, template missing | ### Please verify that this bug has NOT been raised before.
- [x] I checked and didn't find a similar issue
### Describe the bug*
24f433c9482a152463c85d5dad4a105ba1508fec broken MFA login via PUI as `accounts/base.html` and dependencies got removed.
### Steps to Reproduce
1. Try and log in with 2FA enabled
2. In... | closed | 2024-12-17T11:33:22Z | 2024-12-19T20:21:24Z | https://github.com/inventree/InvenTree/issues/8690 | [
"bug",
"User Interface"
] | sur5r | 7 |
coqui-ai/TTS | deep-learning | 3,299 | [Bug] CUDA crash when running xttx inference in Fastapi for streaming endpoint. | ### Describe the bug
I am using code at: https://github.com/hengjiUSTC/xtts-streaming-server/blob/main/server/main.py Building a Fastapi server for streaming TTS service. Got following error
```
Traceback (most recent call last):
File "/home/ubuntu/xtts-streaming-server/server/venv/lib/python3.10/site-packages/... | closed | 2023-11-24T10:40:24Z | 2024-09-12T11:14:08Z | https://github.com/coqui-ai/TTS/issues/3299 | [
"bug"
] | hengjiUSTC | 8 |
PaddlePaddle/ERNIE | nlp | 23 | Run environment | 具体的运行环境能够介绍吗? | closed | 2019-03-16T13:10:47Z | 2019-03-19T13:18:00Z | https://github.com/PaddlePaddle/ERNIE/issues/23 | [] | cloudXia777 | 2 |
kizniche/Mycodo | automation | 1,189 | DFRobot PT1000 Temperature-Sensor - DFR0558 | As an alternative I2C-Method for the Atlas PT1000 Temperature Sensors, these ones from DFRobot only costs $25
would be great to have them as official input
https://www.dfrobot.com/product-1753.html
thanks | closed | 2022-05-12T14:30:34Z | 2022-05-20T02:37:46Z | https://github.com/kizniche/Mycodo/issues/1189 | [
"enhancement",
"Fixed and Committed"
] | snickers2k | 4 |
deepset-ai/haystack | machine-learning | 8,561 | AzureOCRDocumentConverter | I'm using the AzureOCRDocumentConverter and I'm struggling to understand how it can be useful.
How am i suppose to use the output documents of the AzureOCRDocumentConverter? All the extracted tables gets flatten out in the documents value entry of the returned dictionary. Wouldn't be better to convert that extracted... | closed | 2024-11-20T16:43:10Z | 2024-11-23T16:33:07Z | https://github.com/deepset-ai/haystack/issues/8561 | [] | CompareSan | 0 |
twopirllc/pandas-ta | pandas | 531 | FutureWarning: The series.append method is deprecated. Use pandas.concat instead. | **Which version are you running? The lastest version is on Github. Pip is for major releases.**
```python
import pandas_ta as ta
print(ta.version)
```
- 0.3.14b0
**Do you have _TA Lib_ also installed in your environment?**
- Nope
**Did you upgrade? Did the upgrade resolve the issue?**
- Yes
- Nope
**De... | open | 2022-05-11T04:31:07Z | 2024-01-25T02:08:30Z | https://github.com/twopirllc/pandas-ta/issues/531 | [
"duplicate",
"enhancement",
"help wanted"
] | hyxxsfwy | 2 |
graphdeco-inria/gaussian-splatting | computer-vision | 799 | Training Time Breakdown | In the paper, the author mentioned that "The majority (∼80%) of our training time is spent in Python code, since...". However, I did a runtime breakdown on training of 3DGS using torch.cuda.Event(), and it turns out that most of the time is spent on the backward propagation(which is implemented by CUDA), can anyone ple... | open | 2024-05-09T13:48:00Z | 2024-05-09T13:48:00Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/799 | [] | AmeYatoro | 0 |
huggingface/datasets | pytorch | 6,637 | 'with_format' is extremely slow when used together with 'interleave_datasets' or 'shuffle' on IterableDatasets | ### Describe the bug
If you:
1. Interleave two iterable datasets together with the interleave_datasets function, or shuffle an iterable dataset
2. Set the output format to torch tensors with .with_format('torch')
Then iterating through the dataset becomes over 100x slower than it is if you don't apply the torch... | open | 2024-02-01T17:16:54Z | 2024-02-05T10:43:47Z | https://github.com/huggingface/datasets/issues/6637 | [] | tobycrisford | 1 |
pytest-dev/pytest-xdist | pytest | 234 | Stop using master/slave terminology | Can xdist please stop using the master/slave terminology? Would you accept a PR changing "slave" to "worker"? The terminology is upsetting to some people (and I've already had complaints where I work) and there is no reason to use it when other words exist that do not offend people. Words do matter. | closed | 2017-09-27T15:44:58Z | 2018-02-06T09:28:00Z | https://github.com/pytest-dev/pytest-xdist/issues/234 | [
"enhancement",
"help wanted",
"easy"
] | timj | 9 |
amdegroot/ssd.pytorch | computer-vision | 332 | Randomly sampling a patch on data augmentation | Hi,
In randomly sampling a patch on the data augmentation, we have difference size of input images. In this case, we need to resize those image patches?
Thanks. | open | 2019-05-02T08:12:40Z | 2019-05-02T08:12:40Z | https://github.com/amdegroot/ssd.pytorch/issues/332 | [] | ardianumam | 0 |
ijl/orjson | numpy | 193 | Missing wheel for CentOS 7 | OS: CentOS 7
In the 3.6.1 change to `manylinux_2_24`, CentOS 7 x86 wheel support was dropped. CentOS 7 supports `manylinux2014`/`manylinux_2_17` but not `manylinux_2_24`. `aarch64` support for `manylinux2014` still exists because the build lines for 3.9/8/7/6 were not updated with the container.
I've currently so... | closed | 2021-08-04T21:45:58Z | 2021-08-05T14:40:52Z | https://github.com/ijl/orjson/issues/193 | [] | rafmagns-skepa-dreag | 5 |
tensorflow/tensor2tensor | machine-learning | 1,083 | InvalidArgumentError in Transformer model | ### Description
I am trying to run the `Transformer` model in training mode. I took the as the [`asr_transformer` notebook](https://github.com/tensorflow/tensor2tensor/blob/v1.9.0/tensor2tensor/notebooks/asr_transformer.ipynb) as example and built up on this.
> **Note:** For `hparams` the input and target modalit... | closed | 2018-09-20T10:45:00Z | 2018-09-20T12:20:46Z | https://github.com/tensorflow/tensor2tensor/issues/1083 | [] | stefan-falk | 1 |
ultralytics/ultralytics | deep-learning | 19,493 | How to handle cascade yolo models? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
I have three series yolo11 models. First method is track and others are pred... | open | 2025-03-02T16:04:40Z | 2025-03-07T04:35:46Z | https://github.com/ultralytics/ultralytics/issues/19493 | [
"question",
"track",
"detect"
] | erfansafaie | 4 |
fastapi-users/fastapi-users | asyncio | 168 | Use username instead of email ? | Quick question, can I change using a nick_name as a login name instead of email?
How to make email field optional, but not mandatory? | closed | 2020-04-27T12:59:10Z | 2023-11-07T01:27:29Z | https://github.com/fastapi-users/fastapi-users/issues/168 | [
"question"
] | galvakojis | 8 |
sepandhaghighi/samila | matplotlib | 19 | Alpha Value | Set default value of alpha to `DEFAULT_ALPHA=0.1`. | closed | 2021-09-28T05:51:08Z | 2021-09-28T10:35:46Z | https://github.com/sepandhaghighi/samila/issues/19 | [
"enhancement"
] | sadrasabouri | 0 |
adap/flower | scikit-learn | 4,345 | Baseline FedNova does not work with batchnorms | ### Describe the bug
I am currently running the baselines of Flower with different models. I tried Fednova and it seems to work well with the standard config. Once I activate batchnorms in the VGG model, an error gets thrown:
```
File "/home/korjakow/.cache/pypoetry/virtualenvs/fednova-0w39Djqe-py3.10/lib/python3.... | open | 2024-10-21T14:48:01Z | 2024-12-11T18:55:05Z | https://github.com/adap/flower/issues/4345 | [
"bug",
"stale",
"part: baselines"
] | wittenator | 0 |
Anjok07/ultimatevocalremovergui | pytorch | 956 | I've got this problem | closed | 2023-11-08T10:22:45Z | 2023-11-08T12:15:40Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/956 | [] | ahmedabdurrahman | 0 | |
gtalarico/django-vue-template | rest-api | 24 | Error | ```
xxxx-Pro:django-vue-template zz$ python3 manage.py migrate
Traceback (most recent call last):
File "manage.py", line 8, in <module>
from django.core.management import execute_from_command_line
ModuleNotFoundError: No module named 'django'
The above exception was the direct cause of the following excep... | closed | 2019-04-10T02:32:20Z | 2019-04-10T04:33:20Z | https://github.com/gtalarico/django-vue-template/issues/24 | [] | InVinCiblezz | 3 |
kaliiiiiiiiii/Selenium-Driverless | web-scraping | 315 | user_data_dir() got an unexpected keyword argument 'ensure_exists' | When importing `webdriver` through either of these methods:
```py
from selenium_driverless import webdriver
```
```py
import selenium_driverless.webbdriver
```
I get this error:
> Exception has occurred: TypeError
user_data_dir() got an unexpected keyword argument 'ensure_exists'
I have tried:
- Uninstalling and re... | closed | 2025-03-04T15:57:27Z | 2025-03-04T17:04:13Z | https://github.com/kaliiiiiiiiii/Selenium-Driverless/issues/315 | [] | IMakeThingsWithCode | 1 |
strawberry-graphql/strawberry | fastapi | 3,785 | `@oneOf` inputs do not support nullability | When an input class is marked as [`@oneOf`](https://www.apollographql.com/blog/more-expressive-schemas-with-oneof) and has a nullable field, it is not possible to actually provide a null value in the query, and the query completely fails.
## Describe the Bug
This bug relates to the usage of input classes that implem... | open | 2025-02-17T16:29:05Z | 2025-02-17T16:29:05Z | https://github.com/strawberry-graphql/strawberry/issues/3785 | [
"bug"
] | DevJake | 0 |
FactoryBoy/factory_boy | django | 275 | Wire together `random` from FactoryBoy hooks to Faker's random seed | Per https://github.com/rbarrois/factory_boy/pull/247#issuecomment-189897331
| closed | 2016-02-29T10:44:42Z | 2017-04-06T13:53:32Z | https://github.com/FactoryBoy/factory_boy/issues/275 | [] | jeffwidman | 2 |
pytest-dev/pytest-html | pytest | 439 | I did not find a method available to insert a Pie chart into the report,so i did it myself, and maybe someone esle need this too. | 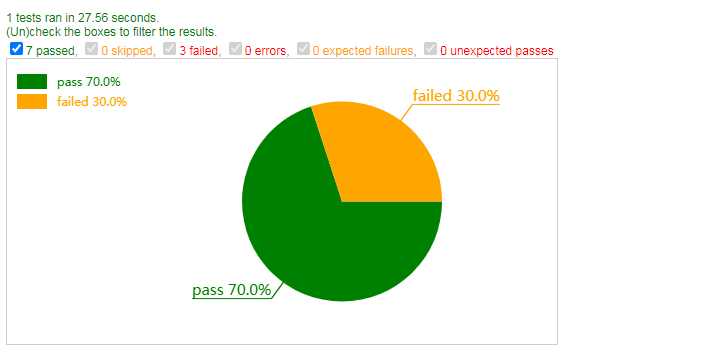
| open | 2021-01-21T10:11:25Z | 2024-10-04T15:02:11Z | https://github.com/pytest-dev/pytest-html/issues/439 | [] | xiaosanye886 | 2 |
AirtestProject/Airtest | automation | 348 | 调用其他脚本进行文件写入的时候,文件内容 | 调用其他脚本进行文件写入的时候,文件内容
主脚本air:
# -*- encoding=utf8 -*-
from airtest.core.api import *
import os
import subprocess
auto_setup(__file__)
str=('python /Users/ljh/Documents/test.py "11" ')
p=os.system(str)
print(p)
调入脚本名称为test.py 内容如下:
#coding=utf-8
import time
import os
file = r'test.txt'
with... | closed | 2019-04-08T12:51:43Z | 2019-04-09T01:42:57Z | https://github.com/AirtestProject/Airtest/issues/348 | [] | linjinghui01 | 4 |
apify/crawlee-python | web-scraping | 105 | System status reports "Total weight cannot be zero" | - Crawlee v0.0.2
- Script:
```python
import asyncio
import logging
from bs4 import BeautifulSoup
from crawlee.log_config import CrawleeLogFormatter
from crawlee.http_crawler import HttpCrawler
from crawlee.http_crawler.types import HttpCrawlingContext
from crawlee.storages import Dataset, RequestList
log... | closed | 2024-04-11T12:56:24Z | 2024-05-31T15:50:37Z | https://github.com/apify/crawlee-python/issues/105 | [
"bug",
"t-tooling"
] | vdusek | 0 |
jupyter/nbviewer | jupyter | 218 | Design explorations for nbviewer | I have been playing with some design ideas for nbviewer while watching a movie tonight. This is based on the discussion from this weeks dev meeting. Here are the goals:
- A top nav bar that contains provides a clear and unambiguous branding for the website.
- A simplified frontpage design that places more emphasis on ... | closed | 2014-03-15T04:39:57Z | 2015-03-03T18:03:16Z | https://github.com/jupyter/nbviewer/issues/218 | [] | ellisonbg | 5 |
tqdm/tqdm | jupyter | 687 | Tqdm notebook / trange prints nothing in Google Colab local runtime | - [x] I have visited the [source website], and in particular
read the [known issues]
- [x] I have searched through the [issue tracker] for duplicates
- [x] I have mentioned version numbers, operating system and
environment, where applicable:
This is using the jupyter notebook support.
I have been trying t... | closed | 2019-03-02T08:35:00Z | 2020-11-18T13:03:57Z | https://github.com/tqdm/tqdm/issues/687 | [
"question/docs ‽",
"p5-wont-fix ☮",
"p2-bug-warning ⚠",
"submodule-notebook 📓"
] | rnett | 5 |
ydataai/ydata-profiling | jupyter | 1,336 | "Generate Report Structure" progress bar doesn't track progress | ### Current Behaviour
The "Generate Report Structure" progress bar never moves. Other progress bars work.
I can see, since I'm running with `html.inline = False` that progress is happening as svg files are generated in the assets directly, however that progress is not tracked in the current bar.
### Expected Behav... | open | 2023-05-19T15:14:17Z | 2023-05-23T23:39:18Z | https://github.com/ydataai/ydata-profiling/issues/1336 | [
"information requested ❔"
] | gdevenyi | 5 |
django-oscar/django-oscar | django | 3,949 | Image cropper | Found a bug? Please fill out the sections below.
Sometimes imaages are uploaded with different aspec ratio. In Listview now product tiles have different heights.
A summary of the issue.
Upload in dashboard in 2 different products different images with differend aspect ratios and then go to listview of products... | closed | 2022-07-12T20:35:35Z | 2023-06-23T13:44:36Z | https://github.com/django-oscar/django-oscar/issues/3949 | [] | Bastilla123 | 1 |
ageitgey/face_recognition | machine-learning | 727 | Face Detection Score | * face_recognition version: Latest
* Python version: 3.7
* Operating System: MacOSX
### Description
I am doing a face detection project and I found this lib is pretty awesome. So far, I am able to use the high level API, such as `face_locations` to get and detect faces in a given image. However, I am wondering if... | open | 2019-01-29T06:52:17Z | 2019-01-31T02:32:37Z | https://github.com/ageitgey/face_recognition/issues/727 | [] | chrisbangun | 2 |
tqdm/tqdm | pandas | 1,284 | Bluetooth headphones issue | In telegram latest version 8.3.2 video 📹 chat of large number of members approximately more than 300 like meeting, Bluetooth earphone connection automatically moves to phone speaker 🔊, beside on other apps like WhatsApp, and normal use it doesn't happen, only happening with telegram. Is it bug? I don't think so ther... | closed | 2021-12-25T16:16:44Z | 2021-12-25T16:17:45Z | https://github.com/tqdm/tqdm/issues/1284 | [] | techknow7 | 0 |
pinry/pinry | django | 162 | Combine running Front-End and Back-End into single command | Concurrently is really good for this: https://www.npmjs.com/package/concurrently
Will need to improve makefile and development docs. | open | 2019-12-08T19:36:31Z | 2019-12-09T09:16:35Z | https://github.com/pinry/pinry/issues/162 | [
"enhancement",
"javascript",
"python"
] | overshard | 1 |
jpadilla/django-rest-framework-jwt | django | 411 | Explain better in documention the Logout Strategy | Initially, I thought the JWT token need to be deleted (I didn't understand the concept of Stateless yet), so my logout solution was to delete the token after X minutes. Many people think this way.
Now, I think the best solution is to set:
JWT_AUTH = {
'JWT_EXPIRATION_DELTA': datetime.timedelta(seconds=15*60)... | open | 2017-12-19T16:46:33Z | 2017-12-19T16:46:33Z | https://github.com/jpadilla/django-rest-framework-jwt/issues/411 | [] | LucasAmorimSilva | 0 |
3b1b/manim | python | 1,427 | Something wrong with DashedVMobject | There may be something wrong with DahsedVMobject. The problem may result from `pointwise_become_partial`? The points of the geometry seem to coincide...

```python
# part of my code
square = DashedVMobject... | open | 2021-03-03T03:27:40Z | 2021-03-03T03:28:42Z | https://github.com/3b1b/manim/issues/1427 | [] | widcardw | 0 |
explosion/spaCy | machine-learning | 13,725 | Empty MorphAnalysis Hash differs from Token.morph.key | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
Hello,
I've trained a Morphologizer and i saw that empty MorphAnalysis (`""`) actually have the hash value of `"_"`. Is it by design? Because the documentation doesn't mention this.
> key `int` | The hash of the features st... | open | 2024-12-26T10:07:16Z | 2024-12-26T10:07:40Z | https://github.com/explosion/spaCy/issues/13725 | [] | thjbdvlt | 0 |
jupyter/docker-stacks | jupyter | 1,881 | Image with jupyterHub | ### What docker image(s) is this feature applicable to?
datascience-notebook
### What changes are you proposing?
I would like an image with JupyterHub instead of JupyterLab.
### How does this affect the user?
It would enable a multi-user data science environment.
### Anything else?
_No response_ | closed | 2023-02-27T02:20:51Z | 2023-03-05T09:16:30Z | https://github.com/jupyter/docker-stacks/issues/1881 | [
"type:Enhancement",
"status:Need Info"
] | cairoapcampos | 2 |
sqlalchemy/alembic | sqlalchemy | 898 | alembic autogenerate migration fails with database file not found error for sqlite | **Describe the bug**
<!-- A clear and concise description of what the bug is. -->
Trying to auto-generate migrations fails with database file not found error when sqlite db file does not exist
**Expected behavior**
<!-- A clear and concise description of what you expected to happen. -->
When an sqlite db is no... | closed | 2021-09-02T05:19:16Z | 2022-05-03T07:38:16Z | https://github.com/sqlalchemy/alembic/issues/898 | [] | vikigenius | 1 |
brightmart/text_classification | tensorflow | 14 | ValueError: Variable Embedding already exists | Traceback (most recent call last):
File "p5_fastTextB_train.py", line 163, in <module>
tf.app.run()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/platform/app.py", line 48, in run
_sys.exit(main(_sys.argv[:1] + flags_passthrough))
File "p5_fastTextB_train.py", line 76, in main
f... | closed | 2017-08-20T05:24:38Z | 2017-08-20T11:13:07Z | https://github.com/brightmart/text_classification/issues/14 | [] | diaoxue | 1 |
dgtlmoon/changedetection.io | web-scraping | 2,377 | CSS weirdness on mobile | **DO NOT USE THIS FORM TO REPORT THAT A PARTICULAR WEBSITE IS NOT SCRAPING/WATCHING AS EXPECTED**
This form is only for direct bugs and feature requests todo directly with the software.
Please report watched websites (full URL and _any_ settings) that do not work with changedetection.io as expected [**IN THE DISC... | closed | 2024-05-19T08:44:10Z | 2024-05-22T11:45:13Z | https://github.com/dgtlmoon/changedetection.io/issues/2377 | [
"triage"
] | RayBB | 1 |
nltk/nltk | nlp | 2,369 | for features, labels in training_data: 2 x.append(features) 3 y.append(label) 4 x = np.array(x).reshape(-1, IMG_SIZE, IMG_SIZE, 1) ValueError: not enough values to unpack (expected 2, got 1) | Does anyone know why I got this error while running that piece of code? | closed | 2019-08-19T01:29:30Z | 2020-03-13T16:21:12Z | https://github.com/nltk/nltk/issues/2369 | [
"inactive"
] | tommieezpark | 1 |
pmaji/crypto-whale-watching-app | plotly | 92 | *-BTC pairs should be 5 decimals not 4 | E.g. ETH-BTC: 0.07564 BTC not 0.0756. | closed | 2018-03-06T18:50:17Z | 2018-03-07T02:02:30Z | https://github.com/pmaji/crypto-whale-watching-app/issues/92 | [] | mifunetoshiro | 5 |
ultralytics/yolov5 | pytorch | 12,875 | YOLOV5 no longer works on Nvidia Jetson Nano | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and found no similar bug report.
### YOLOv5 Component
Integrations
### Bug
YOLOV5 no longer works on NVIDIA Jetson Nano, don't waste your time until the ultralytics dependency is fixed or removed.
I... | closed | 2024-04-02T20:06:50Z | 2024-10-20T19:42:49Z | https://github.com/ultralytics/yolov5/issues/12875 | [
"bug",
"Stale"
] | gilmotta3 | 4 |
whitphx/streamlit-webrtc | streamlit | 1,682 | Video recording freezes using MediaRecorder | Hi!
Thank you for implementing this component; I found it really useful!
I am having some trouble recording the input video using the cookbooks/examples provided in the code.
My current code looks like this:
```
from aiortc.contrib.media import MediaRecorder
from streamlit_webrtc import WebRtcMode, webr... | open | 2024-06-20T09:30:37Z | 2024-06-20T11:45:03Z | https://github.com/whitphx/streamlit-webrtc/issues/1682 | [] | Spisor | 0 |
plotly/dash | jupyter | 2,688 | [Feature Request] Run dash in jupyter without additional server iframe | The problem with Iframe approach is that you need to pass additional ports from your dev environment which could be hard sometime, which makes troubles when you trying to make for example interactive chart, using dash-cytoscape
However as I understand jupyter have own data pipe between server and client.
So may b... | closed | 2023-11-11T05:25:21Z | 2024-07-25T13:33:48Z | https://github.com/plotly/dash/issues/2688 | [] | zba | 1 |
comfyanonymous/ComfyUI | pytorch | 7,100 | WanVideoSampler///Empty image embeds must be provided for T2V (Text to Video) | ### Expected Behavior
WanVideoSampler///Empty image embeds must be provided for T2V (Text to Video
### Actual Behavior
WanVideoSampler///Empty image embeds must be provided for T2V (Text to Video
### Steps to Reproduce
WanVideoSampler///Empty image embeds must be provided for T2V (Text to Video
### Debug Logs
``... | closed | 2025-03-06T11:47:07Z | 2025-03-06T15:56:16Z | https://github.com/comfyanonymous/ComfyUI/issues/7100 | [
"Potential Bug",
"Custom Nodes Bug"
] | renkunlong | 1 |
aiortc/aiortc | asyncio | 245 | MediaPlayer with multiple formats/inputs and/or merging audio+video from two different sources | I'm trying to add an audio input to a MediaPlayer using the FFMPEG options like so:
```python
player = MediaPlayer(':99', format='x11grab', options={'-f': 'pulse', '-i': 'default'})
```
However, `player.audio` resolves to `None`.
I'm not sure whether this is something that needs to be exposed in PyAV (or aior... | closed | 2019-12-28T07:47:02Z | 2019-12-30T07:51:04Z | https://github.com/aiortc/aiortc/issues/245 | [] | murlyn | 2 |
newpanjing/simpleui | django | 514 | 要在同一行显示多个字段,将这些字段包在自己的元组中。这个功能使用simpleui后失效了 | 要在同一行显示多个字段,将这些字段包在自己的元组中。这个功能使用simpleui后失效了 | open | 2025-03-17T10:35:53Z | 2025-03-17T10:35:53Z | https://github.com/newpanjing/simpleui/issues/514 | [
"bug"
] | djzbj | 0 |
donnemartin/system-design-primer | python | 531 | Convert to epub broken | There are several issues in the epub conversion script using pandoc
1) Seems like `--metadata-file` might have been renamed to `--epub-metadata`, but not entirely sure. Doesn't seem like it's picking up the yaml file after I renamed it. Ended up using command line arguments instead.
`--metadata=lang:en --metadata=ti... | open | 2021-04-28T20:01:30Z | 2022-04-23T13:17:27Z | https://github.com/donnemartin/system-design-primer/issues/531 | [
"needs-review"
] | Peppershaker | 3 |
dask/dask | numpy | 11,020 | `set_index` returns the divisions instead of the dataframe with query planning enabled | <!-- Please include a self-contained copy-pastable example that generates the issue if possible.
Please be concise with code posted. See guidelines below on how to provide a good bug report:
- Craft Minimal Bug Reports http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports
- Minimal Complete Verifiab... | closed | 2024-03-24T17:04:17Z | 2024-03-25T17:26:54Z | https://github.com/dask/dask/issues/11020 | [
"needs triage"
] | aazuspan | 0 |
cvat-ai/cvat | pytorch | 8,818 | I got a “Could not create the task” error. | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
-
### Expected Behavior
-
### Possible Solution
-
### Context
Hi,
Could you help me?
I am having trouble creating ... | closed | 2024-12-12T09:13:20Z | 2024-12-24T07:26:23Z | https://github.com/cvat-ai/cvat/issues/8818 | [
"bug",
"need info"
] | RainSmith21 | 1 |
lux-org/lux | pandas | 228 | Doc & Workflow | open | 2021-01-15T05:05:30Z | 2021-01-15T05:05:31Z | https://github.com/lux-org/lux/issues/228 | [
"Epic"
] | jinimukh | 0 | |
slackapi/bolt-python | fastapi | 422 | Reduce Spacing between two blocks | ### Is there a way to reduce spacing between the **section type** and **context type**
**Our Requirements:**
Text1 which is followed by text2, text 2 has to be in smaller font size as compare to text1 (that's why we are using type: "context" here). But while doing so there seems to be a good difference between the... | closed | 2021-07-25T09:07:47Z | 2021-08-06T09:55:57Z | https://github.com/slackapi/bolt-python/issues/422 | [
"question"
] | Cyb-Nikh | 2 |
graphistry/pygraphistry | pandas | 302 | [FEA] Graphistry UI: Type in filter box directly without having to select a property first | First: this is related to the Graphistry UI, but this repo still seemed like the most active place to register the request. If there's a better place then do let me know.
**Is your feature request related to a problem? Please describe.**
For our users 90% of the filters they want to add are `CONTAINS(prop, substri... | open | 2022-01-24T05:54:26Z | 2022-01-24T06:35:25Z | https://github.com/graphistry/pygraphistry/issues/302 | [
"enhancement"
] | DBCerigo | 1 |
jmcnamara/XlsxWriter | pandas | 286 | Append rows to table | I have an application that iterates through data from an external source. Would like to save that data to an Excel table as I'm walking through it, but **add_table** needs to know the number of rows in advance before I can write to it.
My workaround is to either walk the data twice (first time just to count the rows)... | closed | 2015-08-07T14:24:29Z | 2015-08-07T15:35:10Z | https://github.com/jmcnamara/XlsxWriter/issues/286 | [
"question",
"ready to close"
] | pmqs | 2 |
jeffknupp/sandman2 | sqlalchemy | 153 | Can Py2.7 be deprecated? | As everyone knows Python 2 is no longer supported. I think it makes sense for this project to drop the support for it as well. | open | 2020-04-28T01:59:36Z | 2020-04-28T02:20:18Z | https://github.com/jeffknupp/sandman2/issues/153 | [] | Qu4tro | 1 |
jina-ai/clip-as-service | pytorch | 317 | Can I use the C++ to connect the bert-serving-server? | **Prerequisites**
* [x] Are you running the latest `bert-as-service`?
* [x] Did you follow [the installation](https://github.com/hanxiao/bert-as-service#install) and [the usage](https://github.com/hanxiao/bert-as-service#usage) instructions in `README.md`?
* [x] Did you check the [FAQ list in `README.md`](https://... | open | 2019-04-12T10:43:00Z | 2019-04-15T07:49:11Z | https://github.com/jina-ai/clip-as-service/issues/317 | [] | shengfeng | 1 |
modelscope/data-juicer | data-visualization | 573 | DAAR文章里面图1的ef小标题是不是写错了 | ### Before Asking 在提问之前
- [x] I have read the [README](https://github.com/alibaba/data-juicer/blob/main/README.md) carefully. 我已经仔细阅读了 [README](https://github.com/alibaba/data-juicer/blob/main/README_ZH.md) 上的操作指引。
- [x] I have pulled the latest code of main branch to run again and the problem still existed. 我已经拉取了主分... | closed | 2025-02-11T06:02:14Z | 2025-02-11T08:24:40Z | https://github.com/modelscope/data-juicer/issues/573 | [
"question"
] | xiafeng-nb | 3 |
WZMIAOMIAO/deep-learning-for-image-processing | deep-learning | 629 | 1 | closed | 2022-08-22T12:53:43Z | 2022-09-30T06:35:56Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/629 | [] | XJWang628 | 0 | |
huggingface/datasets | pandas | 6,548 | Skip if a dataset has issues | ### Describe the bug
Hello everyone,
I'm using **load_datasets** from **huggingface** to download the datasets and I'm facing an issue, the download starts but it reaches some state and then fails with the following error:
Couldn't reach https://huggingface.co/datasets/wikimedia/wikipedia/resolve/4cb9b0d719291f1a10... | open | 2023-12-31T12:41:26Z | 2024-01-02T10:33:17Z | https://github.com/huggingface/datasets/issues/6548 | [] | hadianasliwa | 1 |
pytorch/vision | computer-vision | 8,745 | The link of `ImageNet()` doesn't have `ILSVRC2012_img_train.tar` and `ILSVRC2012_img_val.tar`. | ### 📚 The doc issue
[The link](https://image-net.org/challenges/LSVRC/2012/2012-downloads.php) of [ImageNet()](https://pytorch.org/vision/stable/generated/torchvision.datasets.ImageNet.html) doesn't have `ILSVRC2012_img_train.tar` and `ILSVRC2012_img_val.tar`.

```
And its work fine
In 3.1.2 version I start using a new confg.py mechanism:
.config.py (generated by dynaconf cli)
```
from d... | closed | 2020-10-12T14:06:12Z | 2020-10-12T19:15:48Z | https://github.com/dynaconf/dynaconf/issues/447 | [
"question"
] | dyens | 2 |
httpie/cli | python | 1,408 | backslashes that precede a number are not preserved | ## Checklist
- [x] I've searched for similar issues.
- [x] I'm using the latest version of HTTPie.
---
## Minimal reproduction code and steps
```sh
$ http --offline --print=B : \\0=
```
## Current result
```json
{
"0": ""
}
```
## Expected result
```json
{
"\\0": ""
}
```
---
... | open | 2022-06-06T21:31:41Z | 2022-06-07T11:57:53Z | https://github.com/httpie/cli/issues/1408 | [
"bug"
] | ducaale | 6 |
slackapi/bolt-python | fastapi | 699 | How can I respond to a OPTIONS request with bolt-python? | Im using bolt-python 1.14.3.
Im using the OAuthFlow and changing `handle_installation`.
I want to respond to `handle_installation` with:
```python
return BoltResponse(
status=200,
body=json.dumps({"install_url": url}),
headers=flow.append_set_cookie_headers(
{
... | closed | 2022-08-14T02:18:10Z | 2022-08-15T01:18:37Z | https://github.com/slackapi/bolt-python/issues/699 | [
"question"
] | Apollorion | 2 |
coqui-ai/TTS | python | 3,431 | VITS multi speaker not work.[Bug] | ### Describe the bug
After 130000 steps of vits multi-speaker training with aishell3, the generated wav belongs to one speaker voice regardless of the speaker_idx. I have debugged the inference process, which seems right.
Anyone can give me some insights?
### To Reproduce
{
"output_path": "/home/nfs02/wangzj/c... | closed | 2023-12-14T13:36:59Z | 2024-03-08T08:58:21Z | https://github.com/coqui-ai/TTS/issues/3431 | [
"bug",
"wontfix"
] | zjwang21 | 2 |
rthalley/dnspython | asyncio | 1,137 | DDR Test Anomolies | **Describe the bug**
As discussed in #1136, I've been having issues with the DDR tests. I've experimented further and have one finding. To gather more information, I modified tests/test_ddr.py::test_basic_ddr_sync to print out information instead of passing or failing based on the asserts and then raising an error a... | open | 2024-09-30T02:40:38Z | 2024-10-05T16:51:23Z | https://github.com/rthalley/dnspython/issues/1137 | [
"Enhancement Request",
"Future"
] | kitterma | 1 |
tensorflow/tensor2tensor | machine-learning | 1,460 | How to implement caching mechanism in universal transformer decoder? | Hi,
It seems to me that 'cache' is a quite important part @MostafaDehghani. It reduces the time complexity greatly. The only difficulty here may be that we don't know in advance how many recurrence steps we will take. Any idea about how to handle this?
https://github.com/tensorflow/tensor2tensor/blob/ac74489b6aa1e... | open | 2019-02-21T09:18:46Z | 2019-02-21T09:18:46Z | https://github.com/tensorflow/tensor2tensor/issues/1460 | [] | PANXiao1994 | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.