
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
keras-team/keras | python | 20,790 | Conv2D with torch backend causes errors (RuntimeError: view size is not compatible with input tensor's size and stride) | Running on Apple M1. This code works for `tensorflow` and `jax` backends, but fails when the backend is `torch`.
The reported error is:
`RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.`
Python 3.12... | closed | 2025-01-21T12:29:26Z | 2025-01-21T13:54:58Z | https://github.com/keras-team/keras/issues/20790 | [
"backend:torch"
] | gyohng | 5 |
datadvance/DjangoChannelsGraphqlWs | graphql | 46 | WebSocket connection to 'wss://api-such.andsuch.xyz/graphql/' failed: Error during WebSocket handshake: Unexpected response code: 400 | Hello @prokher, thanks for this great library. I recently deployed my application which uses [`django-graphql-playground`](https://github.com/jaydenwindle/django-graphql-playground) to test subscriptions. It works great locally. However in production, I get the following error in my browser console:
```
WebSocket c... | closed | 2020-09-01T05:13:07Z | 2020-10-17T04:09:10Z | https://github.com/datadvance/DjangoChannelsGraphqlWs/issues/46 | [] | Cimmanuel | 3 |
voxel51/fiftyone | data-science | 5,060 | [FR] Way to Pre-render thumbnails of the patches you see in patch view |
### Proposal Summary
maybe this already exists, but I want to be able to pre-render out the crops of the views you see in patch view, and have those load at run time
### Motivation
I have a dataset that i have been having major performance issues with. The full size images at 10,000 pixels wide and i have ab... | open | 2024-11-07T01:53:43Z | 2024-11-20T15:40:34Z | https://github.com/voxel51/fiftyone/issues/5060 | [
"feature"
] | quitmeyer | 3 |
clovaai/donut | computer-vision | 245 | Query Regarding Tree-Based Accuracy Calculation in Donut Model | Hello,
I am currently working on understanding the code within the donut model repository, specifically focusing on the tree-based accuracy calculation. While examining the codebase, I came across the utilization of the zss.distance function for accuracy calculation.
My inquiry pertains to the distance function, ... | open | 2023-08-31T09:38:02Z | 2023-08-31T09:38:02Z | https://github.com/clovaai/donut/issues/245 | [] | Mann1904 | 0 |
PaddlePaddle/PaddleHub | nlp | 2,072 | 安装模型报错 | 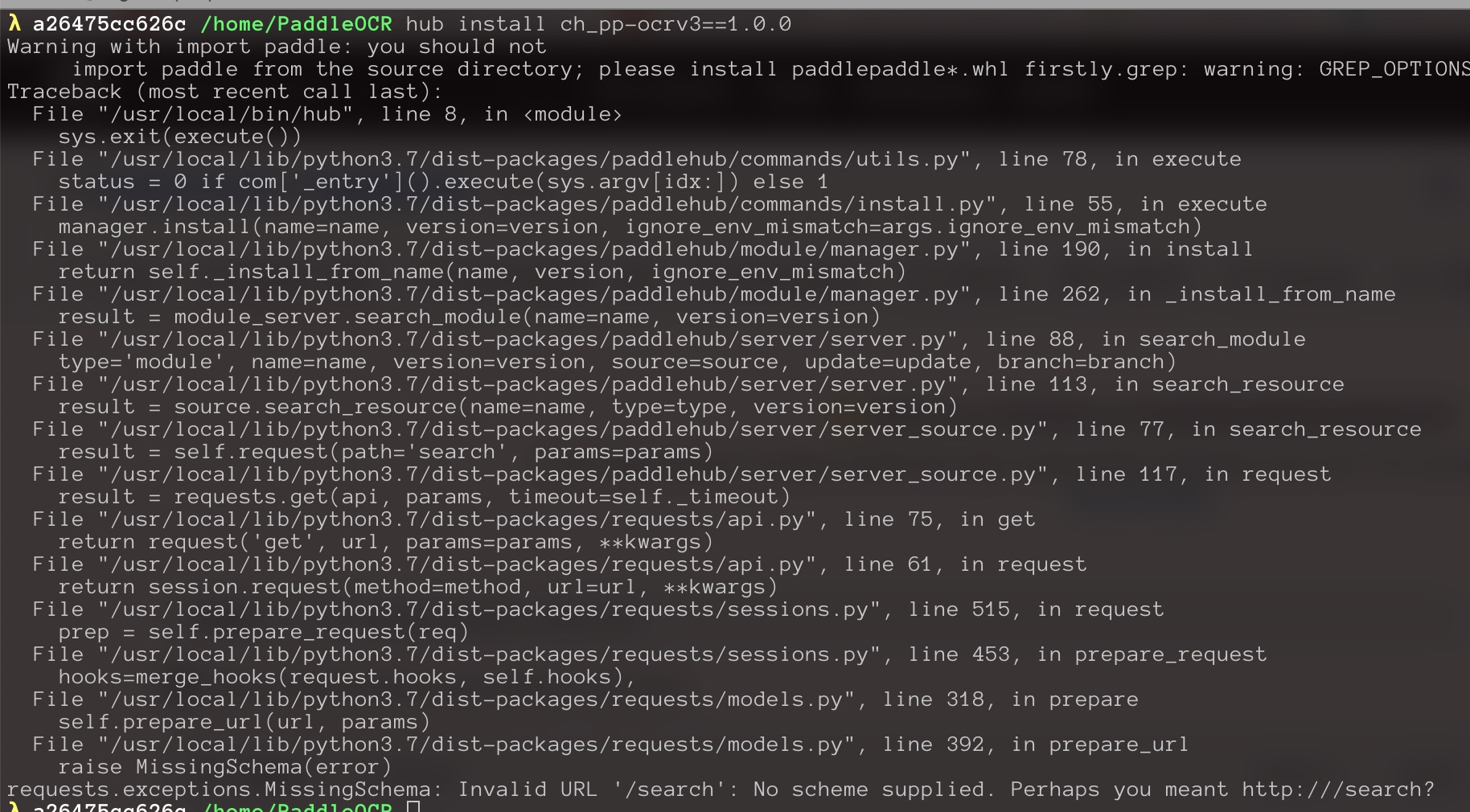
想试用模型,可是却报错了
paddlepaddle 2.3.0
paddle hub 2.3.0 | closed | 2022-10-14T03:11:37Z | 2022-10-14T06:52:15Z | https://github.com/PaddlePaddle/PaddleHub/issues/2072 | [] | hbo-lambda | 3 |
JoeanAmier/TikTokDownloader | api | 416 | 如何正确获取自己的账号主页链接? | 开始获取收藏数据
获取账号简略失败
self 获取账号信息失败
程序运行耗时 0 分钟 3 秒
已退出批量下载收藏作品(抖音)模式
请选择采集功能: | closed | 2025-03-04T01:26:14Z | 2025-03-04T10:50:35Z | https://github.com/JoeanAmier/TikTokDownloader/issues/416 | [
"文档补充(docs)",
"适合新手(good first issue)"
] | lenmao | 3 |
iperov/DeepFaceLab | machine-learning | 5,737 | not working on AMD GPU | After following the instructions and selecting a video file, the application stops working. It responds to inputs, but does not detect faces, swap them, or play the video.
OS: Windows 11
GPU: RX 7900 XTX 24Gb (latest drivers) | open | 2023-10-16T20:54:21Z | 2023-10-16T20:54:21Z | https://github.com/iperov/DeepFaceLab/issues/5737 | [] | f1am3d | 0 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 592 | Training on custom data | is there a guide for training this using custom voice data we collect on our own?
| closed | 2020-11-09T14:23:34Z | 2021-04-28T19:41:00Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/592 | [] | michaellin99999 | 1 |
facebookresearch/fairseq | pytorch | 5,195 | Dialogue Speech-to-Unit Encoder for dGSLM - checkpoint issues | ## 🐛 Bug
I tried to load the checkpoints (Fisher HuBERT model and k-means model) from
[Dialogue Speech-to-Unit Encoder for dGSLM: The Fisher HuBERT model](https://github.com/facebookresearch/fairseq/tree/main/examples/textless_nlp/dgslm/hubert_fisher)
and got the following error:
`No such file or director... | closed | 2023-06-06T10:55:16Z | 2023-06-06T15:26:00Z | https://github.com/facebookresearch/fairseq/issues/5195 | [
"bug",
"needs triage"
] | qianlivia | 2 |
JaidedAI/EasyOCR | machine-learning | 1,342 | Fine-Tuning EasyOCR on Urdu Textbooks | I'm fine-tuning the EasyOCR model (arabic.pth) for Urdu TextBooks text recognition. Currently, I'm passing the image of an entire page as input and providing the corresponding text for the entire page. However, the performance is almost zero.
My question is: Is this approach correct, or should I split the page (imag... | open | 2024-12-04T11:58:03Z | 2024-12-04T11:58:03Z | https://github.com/JaidedAI/EasyOCR/issues/1342 | [] | mujeeb-merwat | 0 |
man-group/notebooker | jupyter | 166 | pdf report generation broken in python 3.8 | In python 3.8 pdf reports are not showing correct charts but instead their string versions | closed | 2024-01-09T16:45:05Z | 2024-02-29T08:28:50Z | https://github.com/man-group/notebooker/issues/166 | [] | marcinapostoluk | 2 |
slackapi/python-slack-sdk | asyncio | 1,651 | How to share files in a ephermal way to a user in a channel or DM without making the files publicly available on the internet? | This is the upload method I'm using, to upload and post PDF files to Slack. The files are generated via a script on on google cloud run and uploaded directly to slack, they're not hosted on Google cloud run, it's serverless.
```
def upload_file(
self,
channel_id: str,
user_id: str,
... | closed | 2025-02-04T18:29:50Z | 2025-02-19T16:18:47Z | https://github.com/slackapi/python-slack-sdk/issues/1651 | [
"question",
"web-client",
"Version: 3x"
] | elieobeid7 | 4 |
huggingface/datasets | pytorch | 7,418 | pyarrow.lib.arrowinvalid: cannot mix list and non-list, non-null values with map function | ### Describe the bug
Encounter pyarrow.lib.arrowinvalid error with map function in some example when loading the dataset
### Steps to reproduce the bug
```
from datasets import load_dataset
from PIL import Image, PngImagePlugin
dataset = load_dataset("leonardPKU/GEOQA_R1V_Train_8K")
system_prompt="You are a helpful... | open | 2025-02-21T10:58:06Z | 2025-02-25T15:26:46Z | https://github.com/huggingface/datasets/issues/7418 | [] | alexxchen | 4 |
huggingface/datasets | machine-learning | 6,451 | Unable to read "marsyas/gtzan" data | Hi, this is my code and the error:
```
from datasets import load_dataset
gtzan = load_dataset("marsyas/gtzan", "all")
```
[error_trace.txt](https://github.com/huggingface/datasets/files/13464397/error_trace.txt)
[audio_yml.txt](https://github.com/huggingface/datasets/files/13464410/audio_yml.txt)
Python 3.11.5
... | closed | 2023-11-25T15:13:17Z | 2023-12-01T12:53:46Z | https://github.com/huggingface/datasets/issues/6451 | [] | gerald-wrona | 3 |
matplotlib/mplfinance | matplotlib | 450 | Where can I find help documentation of mplfinance parameters? | Hi, I saw other people mentioning "mpf.plot(df, type='pnf', pnf_params=dict(box_size=7))" parameters in other issue, but I did not find any documents containing these parameters on the mplfinance webpage(including github and pypi.org). Where did these parameters come from? Are there any more optional parameters can use... | closed | 2021-10-02T23:59:37Z | 2021-10-03T01:23:13Z | https://github.com/matplotlib/mplfinance/issues/450 | [
"question"
] | sunjar2020 | 1 |
zappa/Zappa | django | 558 | [Migrated] import routes causing 404 error | Originally from: https://github.com/Miserlou/Zappa/issues/1475 by [johnedstone](https://github.com/johnedstone)
What is it about the import statement `from app import routes` in this [example](https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-i-hello-world) that causes the app to fail (returns 404) whe... | closed | 2021-02-20T12:22:44Z | 2022-07-16T07:07:35Z | https://github.com/zappa/Zappa/issues/558 | [] | jneves | 1 |
axnsan12/drf-yasg | django | 422 | AttributeError: module 'ruamel.yaml' has no attribute 'SafeDumper' | Hello! After docker image build, trying to run containers via docker-compose up, and facing error:
Traceback (most recent call last):
django_1 | File "manage.py", line 21, in <module>
django_1 | main()
django_1 | File "manage.py", line 17, in main
django_1 | execute_from_command_line(sys.... | closed | 2019-07-26T10:52:12Z | 2019-09-29T15:41:58Z | https://github.com/axnsan12/drf-yasg/issues/422 | [] | Almaz97 | 2 |
sqlalchemy/alembic | sqlalchemy | 548 | create_module_proxy can be fooled when it wraps methods that have explciit arguments | There's an import artifact of some kind that is changing the behavior of `@contextlib.contextmanager` in one environment, such that `inspect.getargspec(fn)` of the function is returning it's full set of keyword defaults, rather than a generic `*arg, **kw`. We can simulate this by removing it from the method in questi... | closed | 2019-03-29T17:18:23Z | 2019-03-30T03:28:15Z | https://github.com/sqlalchemy/alembic/issues/548 | [] | zzzeek | 1 |
xuebinqin/U-2-Net | computer-vision | 160 | ModuleNotFoundError: No module named 'PIL' | Having problems with
from PIL import Image
though I have the following installed in PyCharm venv on Windows 10:
pillow
When trying to install PIL it tells me:
`pip install PIL
ERROR: Could not find a version that satisfies the requirement PIL
ERROR: No matching distribution found for PIL
` | open | 2021-01-31T13:45:58Z | 2021-01-31T13:45:58Z | https://github.com/xuebinqin/U-2-Net/issues/160 | [] | coveritytest | 0 |
strawberry-graphql/strawberry | django | 3,503 | Support explicit setting of federation version | ## Feature Request Type
- [ ] Core functionality
- [x] Alteration (enhancement/optimization) of existing feature(s)
- [ ] New behavior
## Description
The latest version of strawberry supports federation v2.7 and hardcodes the directive urls as such: https://github.com/strawberry-graphql/strawberry/pull/3420
... | open | 2024-05-16T16:46:49Z | 2025-03-20T15:56:44Z | https://github.com/strawberry-graphql/strawberry/issues/3503 | [
"enhancement",
"discussion",
"federation"
] | bradleyoesch | 5 |
Yorko/mlcourse.ai | seaborn | 678 | time series part 1: weighted_average, weights order | In the `weighted_average` function [here](https://mlcourse.ai/articles/topic9-part1-time-series/), larger weights need to be assigned to more recent observations, however, that's not the case for the implementation. | closed | 2021-01-03T23:52:28Z | 2021-01-04T00:15:14Z | https://github.com/Yorko/mlcourse.ai/issues/678 | [
"minor_fix"
] | Yorko | 1 |
suitenumerique/docs | django | 245 | Can't copy paste content from the doc itself | ## Bug Report
**Problematic behavior**
I can't copy paste content from the doc I'm working on.
When I copy paste from outside the docs it works
**Steps to Reproduce**
1. Select content on the doc
2. Ctrl + C
3. Ctrl + V
4. Nothing happens
**Environment**
docs.numerique.gouv.fr on firefox
- Impress ver... | closed | 2024-09-11T13:39:16Z | 2024-10-17T15:15:23Z | https://github.com/suitenumerique/docs/issues/245 | [
"bug",
"good first issue",
"frontend",
"editor",
"Firefox"
] | virgile-dev | 3 |
piskvorky/gensim | nlp | 2,760 | Proper tokenizers for pretrained word embeddings models? | #### Problem description
I wan't to tokenize the text the same way it was tokenized when the model was trained. For example, google-news word2vec has separate vectors for common phrases, like San Francisco. It is also not clear which tokenizer to use for other models, like, how to handle apostrophes in words like "s... | closed | 2020-02-24T09:29:42Z | 2020-02-24T10:18:02Z | https://github.com/piskvorky/gensim/issues/2760 | [] | IvanLazarevsky | 1 |
jupyter/docker-stacks | jupyter | 1,908 | Support installing RStudio Server on jupyter/datascience-notebook | ### What docker image(s) is this feature applicable to?
datascience-notebook
### What changes are you proposing?
I'm trying to install Rstudio-Server on `jupyter/datascience-notebook:hub-4.0.0`. However, facing error `libc6-i386 : Depends: libc6 (= 2.31-0ubuntu9.9) but 2.35-0ubuntu3.1 is to be installed`. Thanks.
... | closed | 2023-05-28T12:10:01Z | 2023-06-02T12:48:29Z | https://github.com/jupyter/docker-stacks/issues/1908 | [
"type:Enhancement",
"status:Need Info"
] | ShichenXie | 3 |
chezou/tabula-py | pandas | 217 | ImportError: No module named 'pandas.errors' while importing tabula | <!--- Provide a general summary of your changes in the Title above -->
# Summary of your issue
<!-- Write the summary of your issue here -->
`import tabula`
```
ImportError Traceback (most recent call last)
<ipython-input-36-21d3fd5ede8c> in <module>
----> 1 import tabula
... | closed | 2020-02-13T02:40:01Z | 2020-02-13T03:08:32Z | https://github.com/chezou/tabula-py/issues/217 | [] | zkid18 | 2 |
thtrieu/darkflow | tensorflow | 421 | AssertionError with four byte size difference when converting | I'm getting a rather weird error trying to convert a `darknet` trained Tiny YOLO (adjusted model, transfer learned using a custom dataset) using `flow --savepb`, which complains about finding an unexpected file size. The size difference appears to be exactly four bytes though:
```python
Traceback (most recent call ... | open | 2017-11-03T12:53:45Z | 2019-09-23T08:16:19Z | https://github.com/thtrieu/darkflow/issues/421 | [] | sunsided | 17 |
kiwicom/pytest-recording | pytest | 78 | [FEATURE] Parameterize vcr_config | **Is your feature request related to a problem? Please describe.**
I'm working on a library that supports multiple web services behind a single interface.
Now I've written some tests for that interface and would like to run them for each of the web services I support. This is where pytest's fixture parameterizati... | open | 2021-10-10T21:19:04Z | 2021-10-10T21:19:04Z | https://github.com/kiwicom/pytest-recording/issues/78 | [
"Status: Review Needed",
"Type: Feature"
] | dAnjou | 0 |
vimalloc/flask-jwt-extended | flask | 145 | Why do we need a separate fresh login endpoint? | Hi,
It's more of a best practice question. I've been working on this extension recently. And I noticed that in the documentation, it is recommended to create three endpoints `/login`, `/refresh` and `/fresh-login`.
I can understand that we don't want the user to login via credentials every time thus we need the ... | closed | 2018-05-03T19:46:38Z | 2018-05-03T22:31:09Z | https://github.com/vimalloc/flask-jwt-extended/issues/145 | [] | CristianoYL | 4 |
3b1b/manim | python | 1,294 | Subsequent fade on submobject of TexMobject not behaving as epected | I would like to fade out and fade in a submobject of a TexMobject. In my example below, I would like to see the "B" disappearing and appearing again. However, on my system the fade in does not work. The B remains faded out.
Is my assumption on the expected behavior correct? Or am I using the wrong approach for the ... | closed | 2020-12-19T18:15:04Z | 2020-12-20T08:24:05Z | https://github.com/3b1b/manim/issues/1294 | [] | msmart | 2 |
proplot-dev/proplot | matplotlib | 359 | ax.step where parameter | ### Description
In `ax.step`, the 'where' parameter doesn't do anything in proplot.
### Steps to reproduce
```python
import numpy as np
import proplot as pplt
x = np.linspace(-5.0, 5.0, 11)
y = np.exp(-0.5 * x**2)
fig, axes = pplt.subplots(nrows=3, figsize=(4.0, 3.0), spany=False)
for ax, where in zi... | closed | 2022-05-15T18:27:42Z | 2023-03-29T22:11:56Z | https://github.com/proplot-dev/proplot/issues/359 | [
"bug"
] | austin-hoover | 3 |
plotly/dash-table | dash | 450 | Conditional formatting in for loop broken since upgrade to 0.3.7 | The conditional formatting stopped working since upgrading to 0.3.7 when used in a for loop.
Below code used to work fine in previous versions:
```
[{
'if': {'column_id': str(x), 'filter': '{} < num(0.9)'.format(x)},
'background-color': '#9cd5ac'
} for x in ['column1','column2']
]
```
I fou... | closed | 2019-05-30T14:11:16Z | 2019-05-30T19:40:20Z | https://github.com/plotly/dash-table/issues/450 | [] | philspbr | 3 |
flairNLP/flair | nlp | 2,991 | Building token embeddings from subtokens (subtoken_pooling) | I have a question regarding how the (FLAIR) token embeddings are generated from the subtoken embeddings, which are the outputs of the TransformerWordEmbeddings.
In the [docs ](https://github.com/flairNLP/flair/blob/master/resources/docs/TUTORIAL_7_TRAINING_A_MODEL.md#training-a-named-entity-recognition-ner-model-with... | closed | 2022-11-16T10:08:57Z | 2023-06-11T11:25:47Z | https://github.com/flairNLP/flair/issues/2991 | [
"question",
"wontfix"
] | kobiche | 3 |
pallets/flask | flask | 4,656 | Two Flask server spawned using multiprocessing not working as expected. | **Issue Outline**
I tried to spawn two Flask processes using `multiprocessing` library as mentioned below.
The response from the server is fluctuating/crossing between the two server's '/' route.
More information on: https://stackoverflow.com/questions/72758633/two-flask-processes-spawned-using-multiprocessing-are-... | closed | 2022-06-28T15:32:51Z | 2022-07-02T21:56:23Z | https://github.com/pallets/flask/issues/4656 | [] | sssyam | 3 |
ckan/ckan | api | 7,576 | Cannot update language translations | CKAN version 2.9.8
Trying to update language translation in English to change default CKAN labels following: https://docs.ckan.org/en/2.9/contributing/i18n.html
No error messages when compiling po file to generate mo file. However, interface labels are not being updated. Tested this across different languages wit... | open | 2023-05-04T21:15:35Z | 2023-06-03T10:23:45Z | https://github.com/ckan/ckan/issues/7576 | [] | isomemo | 4 |
ray-project/ray | machine-learning | 51,634 | [core/scheduler] Split giant ray core C++ target into small ones | Subissue of #50586 . | open | 2025-03-24T06:35:47Z | 2025-03-24T06:37:37Z | https://github.com/ray-project/ray/issues/51634 | [
"enhancement",
"core"
] | Ziy1-Tan | 1 |
marcomusy/vedo | numpy | 939 | Allow for cloning a mesh-inherited class to retain its class type | Currently if you clone a vedo.Plane, it converts it into a vedo.Mesh (the parent class) and loses attributes such as "normal". It would be useful for the copy to remain as a vedo.Plane. | closed | 2023-10-03T22:44:49Z | 2023-11-16T10:53:10Z | https://github.com/marcomusy/vedo/issues/939 | [
"enhancement",
"fixed"
] | JeffreyWardman | 1 |
paperless-ngx/paperless-ngx | machine-learning | 8,418 | 2006, 'Server has gone away' | I see some issues and at least one discussion, regarding topic "2006, 'Server has gone away'". All of them are closed, some are marked as being not a bug. However, I am facing this issue as well when using paperless-ngx via docker compose, but using an external MariaDB instance.
It happens predictable, when process... | closed | 2024-12-03T14:52:47Z | 2024-12-03T15:00:41Z | https://github.com/paperless-ngx/paperless-ngx/issues/8418 | [
"not a bug"
] | m0wlheld | 2 |
python-gino/gino | asyncio | 632 | [question] how manage alter with Gino | * GINO version: 0.8.5
* Python version: 3.8.1
* asyncpg version: 0.20.1
* aiocontextvars version: 0.2.2
* PostgreSQL version: 11
### Description
I created a table `test` to see if alter are manager by Gino,
```
class Test(db.Model):
__tablename__ = "test"
id = db.Column(db.Integer(), primary_key=True)
... | closed | 2020-02-17T10:56:03Z | 2020-04-20T23:04:32Z | https://github.com/python-gino/gino/issues/632 | [
"question"
] | flapili | 4 |
google-research/bert | nlp | 885 | How many "num_tpu_cores" be set ? | I try to pretraining with **run_pretraining.py** using **tpu-v2-32**
How many "num_tpu_cores" be set ?
When tested with tpu-v2-8 worked fine(num_tpu_cores=8).
python3 run_pretraining.py \
--input_file=gs://... \
--output_dir=gs://... \
--do_train=True \
--do_eval=True \
--bert_config_file=/data/wo... | closed | 2019-10-25T05:27:02Z | 2020-08-08T12:39:57Z | https://github.com/google-research/bert/issues/885 | [] | jwkim912 | 2 |
microsoft/qlib | deep-learning | 1,791 | Client Error when downloading data | Dear authors:
I've just faced the client error when executing the codes illustrated in your official documentation:
> # download 1d
> python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn
>
> # download 1min
> python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_d... | closed | 2024-05-22T07:57:25Z | 2024-05-24T05:44:23Z | https://github.com/microsoft/qlib/issues/1791 | [
"question"
] | Yottaxx | 1 |
scrapy/scrapy | web-scraping | 6,553 | Recommendation for docstring for functions and classes in the file exporters.py | <!--
Thanks for taking an interest in Scrapy!
If you have a question that starts with "How to...", please see the Scrapy Community page: https://scrapy.org/community/.
The GitHub issue tracker's purpose is to deal with bug reports and feature requests for the project itself.
Keep in mind that by filing an iss... | closed | 2024-11-20T04:20:53Z | 2024-11-20T19:13:56Z | https://github.com/scrapy/scrapy/issues/6553 | [] | dami1025 | 2 |
horovod/horovod | tensorflow | 3,268 | Unable to load most recent checkpoint for Pytorch and Pytorch lightning Estimator | **Environment:**
1. Framework: PyTorch
2. Framework version: 1.8.1
3. Horovod version: 0.23.0
4. MPI version:
5. CUDA version:
6. NCCL version:
7. Python version: 3.8
8. Spark / PySpark version: 3.1.2
9. Ray version:
10. OS and version:
11. GCC version:
12. CMake version:
**Bug report:**
In case of pyto... | closed | 2021-11-10T11:34:06Z | 2021-11-23T07:12:35Z | https://github.com/horovod/horovod/issues/3268 | [
"bug"
] | kamalsharma2 | 3 |
learning-at-home/hivemind | asyncio | 581 | forking before initialization of the MPFuture handler - server runtime not initialized in WSL --new_hive | Apparently there is an issue of forking before initialization of the MPFuture handler. It happens when running private hive under WSL. No such problem happens when runnging pure linux or WSL with real hive.
What likely happens:
--> The ConnectionHandlers were created - as a process - while we were still initializ... | open | 2023-08-01T22:31:50Z | 2023-08-03T20:48:38Z | https://github.com/learning-at-home/hivemind/issues/581 | [
"bug"
] | poedator | 1 |
lanpa/tensorboardX | numpy | 158 | the problem about add_image | Hello,I want to draw a attention picture,but when I use the function of add_image,I find have no image to writer.However, the function of add_scaler to be used will generate some files.
PyTorch 0.4 / torchvision 0.2 / tensorboard 1.7.0 | closed | 2018-06-04T08:40:52Z | 2018-06-11T02:09:35Z | https://github.com/lanpa/tensorboardX/issues/158 | [] | travel-go | 3 |
AutoViML/AutoViz | scikit-learn | 115 | Issue installing AutoViz on Kaggle Notebook | Hi!
I have encountered the below error when trying to install AutoViz on Kaggle Notebook. Is there any solutions? thanks.

| closed | 2024-11-11T14:32:59Z | 2025-01-28T21:37:08Z | https://github.com/AutoViML/AutoViz/issues/115 | [] | vincentfeng9109 | 1 |
biolab/orange3 | data-visualization | 6,065 | Group By: Add quartile outputs | <!--
Thanks for taking the time to submit a feature request!
For the best chance at our team considering your request, please answer the following questions to the best of your ability.
-->
**What's your use case?**
I would like to summarize large datasets through the 5-number set (minimum, Q1, median, Q3, ma... | closed | 2022-07-18T13:27:47Z | 2023-01-27T13:55:22Z | https://github.com/biolab/orange3/issues/6065 | [
"wish",
"snack"
] | chourroutm | 4 |
onnx/onnx | machine-learning | 5,989 | SegFault during shape inference if the schema not be set inference function | # Bug Report
### Describe the bug
SegFault during shape inference if the schema not be set inference function
### Reproduction instructions
cpp (Optional):
```
ONNX_OPERATOR_SCHEMA(CustomOp);
```
python:
```
import onnx
from onnx import defs
input = """
<
ir_versi... | closed | 2024-03-02T15:23:13Z | 2024-03-04T22:07:42Z | https://github.com/onnx/onnx/issues/5989 | [
"bug"
] | OYCN | 0 |
adbar/trafilatura | web-scraping | 196 | updated benchmarks | there have been several significant releases since the last benchmark 10 months ago, I'm curious if there have been any notable changes there.
https://trafilatura.readthedocs.io/en/latest/evaluation.html#results-2021-06-07 | closed | 2022-04-13T21:57:58Z | 2022-05-18T20:41:00Z | https://github.com/adbar/trafilatura/issues/196 | [
"question"
] | derekperkins | 3 |
1313e/CMasher | matplotlib | 32 | Colormap summary table | You mention in a documentation note that colormaps are sorted according to minimum and maximum lightness values, Starting (sequential) or central (diverging and cyclic) lightness value, Difference between the minimum and maximum lightness values and RMSE (root mean square error) of the derivative of the lightness profi... | closed | 2021-04-06T10:02:44Z | 2021-05-11T06:48:32Z | https://github.com/1313e/CMasher/issues/32 | [
"feature request",
"awaiting response"
] | ycopin | 22 |
flairNLP/flair | nlp | 3,395 | Assertion error while reading training data | i am building it for my organisation, for indian addresses, i can import the libraries, make the labelled dataset
but while training the model there is a connection error, as my organisation doesn't allow pull requests from GitHub i guess
any workaround? | open | 2024-01-16T05:04:17Z | 2024-01-17T05:54:17Z | https://github.com/flairNLP/flair/issues/3395 | [
"question"
] | shubh-singhal | 0 |
pyqtgraph/pyqtgraph | numpy | 2,685 | This is not working in case parameterTree example | https://github.com/pyqtgraph/pyqtgraph/blob/7642e18e1d1ff569b1ef6db844c09280fc5fcddf/pyqtgraph/examples/_buildParamTypes.py#L1 | closed | 2023-04-11T11:54:56Z | 2023-05-24T00:09:33Z | https://github.com/pyqtgraph/pyqtgraph/issues/2685 | [
"cannot reproduce"
] | yashwanth-eng | 3 |
A3M4/YouTube-Report | matplotlib | 13 | Step 5 console error | I get this error when I try to do step 5. I tried to upgrade pip using 'python -m pip installs --upgrade pip' but still doesn't works.

| closed | 2019-12-15T12:23:24Z | 2019-12-15T22:28:31Z | https://github.com/A3M4/YouTube-Report/issues/13 | [] | SpicySnow | 2 |
s3rius/FastAPI-template | fastapi | 40 | Database is not initialized without migrations | If you choose to skip adding migrations, you'll face this issue.
We must add a function in application's startup that initializes database using metadata. | closed | 2021-10-10T05:57:07Z | 2021-10-13T10:03:45Z | https://github.com/s3rius/FastAPI-template/issues/40 | [
"bug"
] | s3rius | 2 |
pytest-dev/pytest-qt | pytest | 437 | BUG: Multiple `PyQt`/`PySide` Versions Not Supported | ### Bug
I ran into this issue when trying to fix a bug with [pyvistaqt](https://qtdocs.pyvista.org/). It appears, for some reason, when all of
- `PyQt5`
- `PySide2`
- `PyQt6`
- `PySide6`
are installed, `pytest-qt` fails to create a `QApplication` instance, causing tests to silently fail.
**NOTE**: `QT_AP... | open | 2022-06-27T16:19:50Z | 2022-07-04T04:28:52Z | https://github.com/pytest-dev/pytest-qt/issues/437 | [] | adam-grant-hendry | 9 |
ijl/orjson | numpy | 133 | orjson installation failed on github action MacOS + python 3.9 | Hi,
I'm using github action for CI and getting an error when trying to install orjson using pip.
Seems like a rustc issue. This only happens on python 3.9 + MacOS. I think Ubuntu and Windows + python 3.9 and MacOS + python 3.8- works fine.
I also tried to install the tool chain using actions-rs/toolchain@v1 b... | closed | 2020-10-07T04:56:38Z | 2020-10-07T05:10:22Z | https://github.com/ijl/orjson/issues/133 | [] | gaogaotiantian | 1 |
liangliangyy/DjangoBlog | django | 682 | sidebar bug: when not commented in template, this does not render. | <!--
如果你不认真勾选下面的内容,我可能会直接关闭你的 Issue。
提问之前,建议先阅读 https://github.com/ruby-china/How-To-Ask-Questions-The-Smart-Way
-->
**我确定我已经查看了** (标注`[ ]`为`[x]`)
- [ ] [DjangoBlog的readme](https://github.com/liangliangyy/DjangoBlog/blob/master/README.md)
- [ ] [配置说明](https://github.com/liangliangyy/DjangoBlog/blob/master/bin... | closed | 2023-10-04T17:32:53Z | 2023-11-06T06:15:43Z | https://github.com/liangliangyy/DjangoBlog/issues/682 | [] | jonascarvalh | 2 |
mckinsey/vizro | data-visualization | 220 | The graph sample from the doc doesn't work | ### Description
The vm.Graph sample doesn't work:
https://vizro.readthedocs.io/en/stable/pages/user_guides/graph/
### Expected behavior
_No response_
### vizro version
0.1.7
### Python version
3.11.5
### OS
Mac OS Sonoma 14.2
### How to Reproduce
Copy the sample to app.py and run
python app.py
### Output
... | closed | 2023-12-15T22:19:56Z | 2023-12-19T12:16:49Z | https://github.com/mckinsey/vizro/issues/220 | [
"Bug Report :bug:"
] | maajdl | 2 |
wger-project/wger | django | 1,402 | Add language dependant decimal separators | ## Steps to Reproduce
1. ... Open https://wger.de/en/software/features
2. ... Open https://wger.de/hr/software/features
3. ... Open https://wger.de/de/software/features
## See screenshot

**Exp... | closed | 2023-08-01T13:18:55Z | 2023-08-10T09:32:56Z | https://github.com/wger-project/wger/issues/1402 | [] | milotype | 6 |
mwaskom/seaborn | data-science | 2,785 | histplot stat=count does not count all data points | `import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
sns.set(style="whitegrid")
data_a = [1, 2, 3]
data_b = [2.4, 2.5, 2.6]
sns.histplot(np.array(data_a), color="red", binwidth=0.01, stat="count")
sns.histplot(np.array(data_b), color="blue", binwidth=0.01, stat="count")
`plt.s... | closed | 2022-04-28T08:18:26Z | 2022-05-18T10:47:26Z | https://github.com/mwaskom/seaborn/issues/2785 | [
"bug",
"mod:distributions"
] | cmayer | 1 |
sqlalchemy/sqlalchemy | sqlalchemy | 11,026 | Include dialect for YugabyteDB in documentation | ### Describe the use case
YugabyteDB is a cloud native distributed database compatible with Postgresql.
We have developed a YugabyteDB dialect for SQLAlchemy for adding enhancements specific to YugabyteDB.
Please let us know what are the steps to get it added in the documentation.
### Databases / Backends / Dri... | closed | 2024-02-16T06:30:33Z | 2024-02-22T19:38:31Z | https://github.com/sqlalchemy/sqlalchemy/issues/11026 | [
"documentation",
"use case"
] | Sfurti-yb | 2 |
jonaswinkler/paperless-ng | django | 520 | [BUG] Incorrect thumbnail on documents view | **Describe the bug**
I was doing a bulk import into a new paperless instance, and when browsing the documents view and previewing some documents I happen to notice that some have the incorrect thumbnail.
It seems to be incorrect on around 10% of the documents I've checked so far
Only the thumbnail image is incorrect... | closed | 2021-02-09T20:10:19Z | 2021-02-09T20:23:29Z | https://github.com/jonaswinkler/paperless-ng/issues/520 | [] | rknightion | 3 |
Johnserf-Seed/TikTokDownload | api | 673 | 下载抖音视频的时候,可以指定只下载视频吗?不下载图文 | 如题,与版本无关。 | closed | 2024-03-04T10:54:26Z | 2024-03-04T11:12:00Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/673 | [] | gkj17 | 2 |
harry0703/MoneyPrinterTurbo | automation | 571 | 我使用conda部署,在Linux服务器上。 前面的步骤都过去了。执行sh webui.sh端口也启动起来了。但是浏览器输入地址访问就出现了下面的问题 | ### 是否已存在类似问题?
- [X] 我已搜索现有问题
### 当前行为
ModuleNotFoundError: No module named 'app'
Traceback:
File "/root/anaconda3/envs/MoneyPrinterTurbo/lib/python3.10/site-packages/streamlit/runtime/scriptrunner/exec_code.py", line 88, in exec_func_with_error_handling
result = func()
File "/root/anaconda3/envs/MoneyPrinte... | closed | 2025-01-16T08:08:23Z | 2025-02-19T09:41:08Z | https://github.com/harry0703/MoneyPrinterTurbo/issues/571 | [
"bug"
] | mark988 | 2 |
paperless-ngx/paperless-ngx | django | 8,539 | [BUG] when using .devcontainer with VSCode | ### Description
when using .devcontainer with VSCode i get the error here below
An error has occurred: InvalidManifestError:
==> File /usr/src/paperless/.cache/pre-commit/repoggyqxbty/.pre-commit-hooks.yaml
==> At Hook(id='check-added-large-files')
==> At key: stages
==> At index 0
=====> Expected one of comm... | closed | 2024-12-22T21:56:27Z | 2024-12-22T22:03:03Z | https://github.com/paperless-ngx/paperless-ngx/issues/8539 | [
"not a bug"
] | orcema | 0 |
huggingface/diffusers | pytorch | 10,375 | [low priority] Please fix links in documentation | https://huggingface.co/docs/diffusers/main/en/api/pipelines/hunyuan_video
Both links are broken
Make sure to check out the Schedulers [guide](https://huggingface.co/docs/diffusers/main/en/using-diffusers/schedulers.md) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse co... | closed | 2024-12-25T09:04:33Z | 2024-12-28T20:01:27Z | https://github.com/huggingface/diffusers/issues/10375 | [] | nitinmukesh | 0 |
ionelmc/pytest-benchmark | pytest | 212 | Add type annotations | Type annotations would improve the editor experience and support static type checking. Type annotations would only *really* have to be added to user facing code but it would still be beneficial to type the whole codebase as well.
I'd be happy to help with this if it is deemed acceptable :) | open | 2022-01-16T00:33:01Z | 2024-12-19T09:02:34Z | https://github.com/ionelmc/pytest-benchmark/issues/212 | [] | RobertCraigie | 3 |
clovaai/donut | nlp | 118 | HuggingFace VisualEncoderDecoderModel performs better (but slower) | I first used the huggingface implementation of Donut to train for my specific use-case and it was working well but very slow, (10x times on epochs for example).
So I decided to switch to the official implementation and saw a massive increase in my training times, however I noticed that the valuation loss was actuall... | open | 2022-12-31T13:10:49Z | 2023-08-25T08:23:54Z | https://github.com/clovaai/donut/issues/118 | [] | maxjay | 2 |
inducer/pudb | pytest | 317 | ValueError: I/O operation on closed file | I run with pytorch dataloader and have this problem.
```
File "/home/foo/miniconda2/envs/env3.6/lib/python3.6/bdb.py", line 48, in trace_dispatch
return self.dispatch_line(frame)
File "/home/foo/miniconda2/envs/env3.6/lib/python3.6/site-packages/pudb/debugger.py", line 187, in dispatch_line
self.user_l... | closed | 2018-10-13T10:00:44Z | 2018-10-13T15:50:36Z | https://github.com/inducer/pudb/issues/317 | [] | Fangyh09 | 1 |
Miserlou/Zappa | flask | 2,136 | werkzeug==0.16.1 needs to be updated | Cannot set SameSite=None on session cookie | @Miserlou Long time :)
Please update werkzeug in requirement.txt to the latest. It has a fix for https://github.com/pallets/flask/issues/3469 | open | 2020-07-15T15:42:33Z | 2020-09-27T08:50:09Z | https://github.com/Miserlou/Zappa/issues/2136 | [] | wobeng | 1 |
ets-labs/python-dependency-injector | flask | 326 | How to inject dependency in class | i have class to be injected by repositry class with DI, it looks like this:
// handler.py
```
class Handler:
@inject
def __init__(self, rating_repo: Provide[Container.repo.rating] = None):
self.rating_repo = rating_repo
def save_rating(self, cmd: SaveRating):
runner_rating = Ru... | closed | 2020-11-19T09:52:22Z | 2020-11-19T16:02:16Z | https://github.com/ets-labs/python-dependency-injector/issues/326 | [
"question"
] | ijalalfrz | 2 |
graphistry/pygraphistry | jupyter | 83 | Increase CI warning sensitivity | See https://github.com/graphistry/pygraphistry/pull/81 : ` try removing --exit-zero from the second call into flake8` | closed | 2017-08-21T06:14:34Z | 2020-10-14T19:43:16Z | https://github.com/graphistry/pygraphistry/issues/83 | [
"p4"
] | lmeyerov | 1 |
faif/python-patterns | python | 29 | Make use of informal string representation for abstract_factory | Hey, thanks for putting this together. I noticed that in the `abstract_factory.py` script, the `show_pet` function does not format the strings together:
``` python
def show_pet(self):
"""Creates and shows a pet using the
abstract factory"""
pet = self.pet_factory.get_pet()
print("T... | closed | 2013-11-04T02:27:37Z | 2013-11-14T18:44:13Z | https://github.com/faif/python-patterns/issues/29 | [] | faizandfurious | 3 |
LibreTranslate/LibreTranslate | api | 667 | bug: Exception raised while handling cache file due to incomplete buffer | **Version:** libretranslate/libretranslate:v1.6.0 (`sha256:275ecc12a296a7f28148882c412298a212e1ccffd5595759d30bac5300ea5dbb`)
**Description:**
I am experiencing a recurring issue where LibreTranslate throws a `struct.error` exception when trying to remove expired cache files. The stacktrace suggests that the issu... | open | 2024-08-25T06:18:19Z | 2024-09-02T05:57:24Z | https://github.com/LibreTranslate/LibreTranslate/issues/667 | [
"possible bug"
] | silentoplayz | 0 |
roboflow/supervision | deep-learning | 1,719 | How to call YOLO's built-in API? | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
I want to call yolo's model.track so that I can use GPU or other yolo interfaces through yolo. Is this possible? thank you
` gotta be used. Is there a way to achiev... | closed | 2022-05-26T10:03:04Z | 2022-05-26T12:51:15Z | https://github.com/encode/httpx/issues/2248 | [] | myslak71 | 0 |
onnx/onnx | deep-learning | 6,368 | graph.input disappeared in extract_model | # Bug Report
### Is the issue related to model conversion?
<!-- If the ONNX checker reports issues with this model then this is most probably related to the converter used to convert the original framework model to ONNX. Please create this bug in the appropriate converter's GitHub repo (pytorch, tensorflow-onnx, sk... | closed | 2024-09-15T21:57:52Z | 2024-10-03T18:06:25Z | https://github.com/onnx/onnx/issues/6368 | [
"bug"
] | tonypottera24 | 4 |
Yorko/mlcourse.ai | scikit-learn | 364 | assignment1_pandas_olympic Q10 | https://github.com/Yorko/mlcourse.ai/blob/master/jupyter_english/assignments_fall2018/assignment1_pandas_olympic.ipynb
There was a question
> 10. What is the absolute difference between the number of unique sports at the 1995 Olympics and 2016 Olympics?
But in 1995 there was no official Olympic game. Nearest ga... | closed | 2018-10-07T16:09:16Z | 2018-10-09T15:47:39Z | https://github.com/Yorko/mlcourse.ai/issues/364 | [
"invalid"
] | VolodymyrGavrysh | 1 |
aminalaee/sqladmin | asyncio | 868 | Show Login error message on same page | ### Checklist
- [X] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
While login to the admin panel if there is any error it shows the error on another page.
### Describe the solution you would like.
Can we show the error message on the same pag... | open | 2025-01-01T06:26:50Z | 2025-01-01T06:26:50Z | https://github.com/aminalaee/sqladmin/issues/868 | [] | Suraj1089 | 0 |
marimo-team/marimo | data-visualization | 4,165 | Ability to hide columns in table viewer | ### Description
I want to be able to hide/show columns in the table viewer, so that I don't have to keep editing the code cell to specify what columns to show
### Suggested solution
similar to Excel functionality, where you can hide columns and then expand them again
### Alternative
_No response_
### Additional c... | open | 2025-03-19T19:12:45Z | 2025-03-19T21:12:37Z | https://github.com/marimo-team/marimo/issues/4165 | [
"enhancement"
] | delennc | 1 |
keras-team/autokeras | tensorflow | 1,204 | Training does not start if we feed ImageClassifier.fit with tf.Dataset | ### Bug Description
The first batch of images seems to load due to memory usage, but training does not start. I am using ImageClassifier and I feed the fit() method with a tf.Dataset.
### Bug Reproduction
Code for reproducing the bug:
```
import autokeras as ak
import os
from tensorflow.keras.preprocessing.im... | closed | 2020-06-24T15:51:05Z | 2021-03-24T16:35:39Z | https://github.com/keras-team/autokeras/issues/1204 | [
"bug report",
"wontfix"
] | castrovictor | 4 |
aimhubio/aim | tensorflow | 2,629 | Runs are in accessible from the web interface if NaNs are logged | ## 🐛 Bug
The website reports 500 and the server says:
`ValueError: Out of range float values are not JSON compliant` if NaN is added as run attribute.
### To reproduce
```python
run = aim.Run()
run['test'] = np.nan
```
### Environment
- Aim Version 3.17.2
- Python version 3.11
### Additional context... | closed | 2023-03-28T15:55:19Z | 2023-11-14T22:47:53Z | https://github.com/aimhubio/aim/issues/2629 | [
"type / bug",
"help wanted",
"area / Web-UI",
"phase / shipped"
] | n-gao | 4 |
Johnserf-Seed/TikTokDownload | api | 334 | [Question] getXbogus 请问这个功能的逻辑是怎么实现的? | 请问,在解析抖音资源的时候会call作者你部署的api 去 getXbogus,但是api的具体逻辑是什么呢?
| open | 2023-02-28T06:00:28Z | 2023-03-02T11:12:43Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/334 | [
"需求建议(enhancement)"
] | CoffeeHi | 4 |
davidsandberg/facenet | computer-vision | 1,255 | i-JOiN | open | 2024-10-28T08:53:34Z | 2024-10-28T08:53:34Z | https://github.com/davidsandberg/facenet/issues/1255 | [] | orb-jaydee | 0 | |
tflearn/tflearn | data-science | 980 | Natural Language Processing tutorial | Just a question, when do you think the tutorial on Natural Language Processing will be out? | open | 2017-12-15T22:12:03Z | 2017-12-15T22:12:03Z | https://github.com/tflearn/tflearn/issues/980 | [] | matthewchung74 | 0 |
yihong0618/running_page | data-visualization | 485 | GarminCN -> Strava时区问题 | 同步GraminCN到Strava目前遇到了时区问题,同步到的时间-8小时,貌似不是北京时区
<img width="368" alt="image" src="https://github.com/yihong0618/running_page/assets/1930500/7cbd8bd7-c52a-4ab8-bda2-2077d08f8cc5">
<img width="1007" alt="image" src="https://github.com/yihong0618/running_page/assets/1930500/632009a8-b9ba-443b-a790-257863f1cebc">
| closed | 2023-09-07T11:05:36Z | 2023-09-08T08:10:09Z | https://github.com/yihong0618/running_page/issues/485 | [] | donghao526 | 11 |
ResidentMario/geoplot | matplotlib | 62 | MatplotlibDeprecationWarning | When using kdeplot function with matplotlib 3.0.0, it raise the following warnings, which I think should be considered in future version:
```python
/home/user/Documents/geoplottest/env/lib/python3.6/site-packages/matplotlib/__init__.py:846: MatplotlibDeprecationWarning:
The text.latex.unicode rcparam was deprecated... | closed | 2018-10-24T18:17:35Z | 2018-11-18T05:56:40Z | https://github.com/ResidentMario/geoplot/issues/62 | [] | enadeau | 2 |
miguelgrinberg/flasky | flask | 516 | ImportError: cannot import name 'current_app' from partially initialized module 'flask' (most likely due to a circular import) | I can't find the problem where make it a circular import | closed | 2021-06-20T14:38:32Z | 2023-08-03T15:57:05Z | https://github.com/miguelgrinberg/flasky/issues/516 | [] | Yuluer | 3 |
AirtestProject/Airtest | automation | 487 | Airtest IDE corrupts Script code, If Windows 10 is not responding and a restart is needed. | **Describe the bug**
Airtest IDE corrupts Script code, If Windows 10 is not responding and a restart is needed.
**To Reproduce**
Steps to reproduce the behavior:
1. Wait for Windows 10 to crash while airtest project is on
2. When Windows 10 is unresponsive, force restart PC
3. Encounter error when airtest proje... | closed | 2019-08-07T02:43:47Z | 2019-08-09T03:32:26Z | https://github.com/AirtestProject/Airtest/issues/487 | [] | phantomsom | 1 |
mage-ai/mage-ai | data-science | 5,040 | [BUG] SalesForce integration problem with datatypes | ### Mage version
v0.9.68
### Describe the bug
1. When creating a integration pipeline between S3 and SalesForce the upload to SalesForce fails due to datatypes of certain columns being different in Mage and in SalesForce.
More precisely BillingAddress has a string/object dtype in Mage but Address dtype in SF and pi... | open | 2024-05-07T09:06:14Z | 2024-05-08T12:29:16Z | https://github.com/mage-ai/mage-ai/issues/5040 | [
"bug"
] | diatco | 1 |
ryfeus/lambda-packs | numpy | 8 | Python 3? | Any chance of a massive update to run with Python 3.6? I would be willing to help if you could teach me how you built the python 2 versions. | closed | 2017-08-29T17:10:02Z | 2019-05-26T06:24:44Z | https://github.com/ryfeus/lambda-packs/issues/8 | [
"help wanted"
] | MichaelMartinez | 9 |
aminalaee/sqladmin | sqlalchemy | 412 | Using `wtforms.fields.FieldList` in `form_overrides` raises `TypeError` | ### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
I am using FastAPI with SQLModel as my ORM. I have a model where one of the fields is a list of strings. In my postgresql database this is stored ... | closed | 2023-01-18T00:04:52Z | 2024-08-23T07:14:41Z | https://github.com/aminalaee/sqladmin/issues/412 | [] | FFX01 | 9 |
man-group/arctic | pandas | 157 | preserve the NaN | when I run the following code
store.initialize_library('test_lib')
lib = store['test_lib']
lib.write('tmp1', pd.Series(['test', nan]))
and then read back:
lib.read('tmp1')
nan will be converted to 'nan' in the store. of course there is a choice to preserve NaN instead of forcing it to be a string, just wonder if ther... | closed | 2016-06-26T05:24:17Z | 2018-11-05T13:02:26Z | https://github.com/man-group/arctic/issues/157 | [] | luli11 | 3 |
vanna-ai/vanna | data-visualization | 797 | Database Support | Does Vanna.ai support DM (Dameng) Database? | closed | 2025-03-10T05:12:59Z | 2025-03-10T13:33:27Z | https://github.com/vanna-ai/vanna/issues/797 | [] | junwei0001 | 0 |
explosion/spaCy | machine-learning | 13,701 | reference to obsolete thinc backend linalg | ```
ml/parser_model.pyx
line8: from thinc.backends.linalg cimport Vec, VecVec
```
https://github.com/explosion/thinc/pull/742
was obsoleted a couple of years ago, which is causing some downstream issues:
```
File "/usr/lib/python3.12/site-packages/auralis/models/xttsv2/config/tokenizer.py", line 12, in <modu... | closed | 2024-11-30T19:27:58Z | 2025-01-11T00:03:05Z | https://github.com/explosion/spaCy/issues/13701 | [] | envolution | 2 |
huggingface/transformers | pytorch | 36,002 | Mismatch Between Image Tokens and Features in LLaVA Model Fine-Tuning | **Model: llava-hf/llava-1.5-7b-hf**
**Issue Description**
When I try to generate a response using the fine-tuned model, I encounter the following error:
ValueError: Image features and image tokens do not match: tokens: 575, features: 576
This error occurs during the generate() call, indicating a mismatch between the n... | closed | 2025-02-01T12:15:54Z | 2025-02-21T09:01:48Z | https://github.com/huggingface/transformers/issues/36002 | [] | Md-Nasif03 | 6 |
assafelovic/gpt-researcher | automation | 1,148 | Front | **Describe the bug**
Download button disappeared!
"""
voyageai.error.RateLimitError: You have not yet added your payment method in the billing page and will have reduced rate limits of 3 RPM and 10K TPM. Please add your payment method in the billing page (https://dash.voyageai.com/billing/payment-methods) to unlock ... | closed | 2025-02-13T14:43:14Z | 2025-02-19T18:17:13Z | https://github.com/assafelovic/gpt-researcher/issues/1148 | [] | moghadas76 | 3 |
robotframework/robotframework | automation | 4,382 | Executing RobotFramework from PyInstaller generated exe gives error that log.html can't be found | Python version: Python 3.10.5
RF version: Robot Framework 5.0.1 (Python 3.10.5 on win32)
PyInstaller Version: 5.1
OS: Windows 10, build 19044.1766
I'm trying to package RobotFramework into an executable with PyInstaller. We have a packaged script which calls the robot file using robot.run('test.robot'). Robot fil... | closed | 2022-06-26T14:43:42Z | 2023-01-24T06:19:22Z | https://github.com/robotframework/robotframework/issues/4382 | [] | evmehok | 7 |
jofpin/trape | flask | 248 | NGROK NOT WORKING | Can anyone like fork this repo and fix the ngrok issue ,like include another tunnel like pagekite, localxpose and more _ | open | 2020-06-13T11:30:49Z | 2020-08-05T06:32:49Z | https://github.com/jofpin/trape/issues/248 | [] | Forbesgriffin | 7 |
HIT-SCIR/ltp | nlp | 453 | 1 | 1 | closed | 2020-12-14T10:42:11Z | 2020-12-14T10:44:17Z | https://github.com/HIT-SCIR/ltp/issues/453 | [] | glacierck | 0 |
run-llama/rags | streamlit | 53 | "Update Agent" creates an error and deletes the Agent | After creating an agent and navigating to "RAG Config" for the purpose of selecting the checkbox labeled "Include Summarization (only works for GPT-4)" an error is produced and the Agent is deleted after clicking "Update Agent".
Error:
![image](https://github.com/run-llama/rags/assets/133713208/90d3a231-d324-4406-a... | closed | 2023-12-05T21:49:49Z | 2023-12-07T18:29:04Z | https://github.com/run-llama/rags/issues/53 | [] | sorcery-ai | 3 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.