
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Как сделать веб-аналитику для SaaS через Google Analytics: введение и отслеживание воронки
В чем проблема и почему Google Analytics
----------------------------------------
Столкнулся с тем, что на нескольких SasS проектах не было нормальной аналитики, чтобы:
* Смотреть в разрезе каждого сегмента трафика, как поль... | https://habr.com/ru/post/428225/ | null | ru | null |
# Расширения для Opera: Обмен сообщениями
#### Вступление
С помощью расширений вы можете создавать и добавлять новую впечатляющую функциональность в браузер Opera. Как было упомянуто в других статьях, расширения для Opera содержат фоновый скрипт, внедряемый скрипт и, иногда, всплывающее окно. В этой статье мы рассмот... | https://habr.com/ru/post/107153/ | null | ru | null |
# Почта Mail.ru начинает в тестовом режиме применять политики MTA-STS
Если кратко, то MTA-STS — это способ дополнительно защитить письма от перехвата (т.е. атак злоумышленник-в-середине aka MitM) при передаче между почтовыми серве... | https://habr.com/ru/post/515746/ | null | ru | null |
# Конвертируем диапазон IP в бесклассовую адресацию (CIDR) и обратно в Go
При прохождения очередного собеседования мне задали небольшое тестовое задание, написать на Go сетевой сканер открытых портов. Задание в принципе не сложное, но одним из условий было, что в качестве параметра может быть передан как IP-адрес, так... | https://habr.com/ru/post/351574/ | null | ru | null |
# «Делай как я!» — изучаем имперсонатор
Самые интересные и перспективные разработки в области AI связаны с нейронными сетями. Сегодня рассмотрим Impersonator++ для накопления опыта в области Deep fake.
В нас... | https://habr.com/ru/post/546334/ | null | ru | null |
# Загрузчик модулей для node js с поддержкой локальных модулей и загрузки модулей по требованию
Я — frontend разработчик и в последнее время мне все чаще приходится пользоваться нодой, будь то использование webpack-а для сборки проекта, либо настройка различных gulp тасков. Хоть у меня и нету большого опыта в использо... | https://habr.com/ru/post/275011/ | null | ru | null |
# Выжимаем все соки из Chromium на Linux
В этой статье рассмотрим, как выжать все соки из Хромиума и максимально ускорить его или другой браузер на его движке (Chromium, Google Chrome, Opera, Vivaldi, Яндекс и др.). За счет включения многих экспериментальных возможностей по вынесу вычислений с процессора на видеокарту... | https://habr.com/ru/post/339238/ | null | ru | null |
# Mail.ru Group представила сервис «VK Почта», доступный только для пользователей «ВКонтакте»
Mail.ru Group [рассказала](https://corp.mail.ru/ru/press/releases/10980/) о новом элементе экосистемы VK — сервисе «VK Почта». Теперь пользователи могут зарегистрировать почту с коротким доменом `@vk.com` Почтовый сервис расс... | https://habr.com/ru/post/575570/ | null | ru | null |
# Как повысить безопасность вашего сайта на Wordpress

В этой статье описаны самые распространённые проблемы безопасности WordPress и способы их решения, включая советы, как избежать взлома.
Безопасность WordPress является важной ... | https://habr.com/ru/post/664004/ | null | ru | null |
# Правильное использование Exception’ов в PHP
Я рад бы написать что *“эта статья предназначена для новичков”*, но это не так. Большинство php-разработчиков, имея опыт 3, 5 и даже 7 лет, абсолютно не понимают как правильно использовать эксепшены. Нет, они прекрасно знают о их существовании, о том что их можно создавать... | https://habr.com/ru/post/264417/ | null | ru | null |
# Задачка на std::multiset или поиск по полям структуры
Попалась небольшая задачка, где-то на 4 часа кодирования, которую счел занимательной.
Есть база пользователей 10 миллионов:
```
class User{
int id;
time_t birthday; // дата рождения
int gender; // пол
int city_id; // место проживания
time_t time_... | https://habr.com/ru/post/312830/ | null | ru | null |
# Нулевой символ внутри тега
*Старый баг дороже новых двух?*
Сделал для себя интересное открытие, оказывается строчку
`<\0b>text` — где \0 — символ с кодом 0
IE интерпретирует как нормальный тег bold со всеми вытекающими, тоже самое касается тегов | https://habr.com/ru/post/57562/ | null | ru | null |
# Domain-driven design, Hexagonal architecture of ports and adapters, Dependency injection и Python
### Prologue
- Глянь, статью на Хабр подготовил.
- Эм... а почему заголовок на английском?
- "Предметно-ориентированное проектирование, Гексагональная архитектура портов и адаптеров, Внедрение зависимостей и Пайто.... | https://habr.com/ru/post/559560/ | null | ru | null |
# REST сервис на C++: POCO+Angular TODO
[POCO](http://pocoproject.org/) — кроссплатформенная open-source библиотека на С++ под Boost Software License: [ru.wikipedia.org/wiki/POCO](http://ru.wikipedia.org/wiki/POCO).
[POCO](http://pocoproject.org/) имеет в своем составе средства для создания веб-сервисов c [RESTful ... | https://habr.com/ru/post/252519/ | null | ru | null |
# MLBootCamp «Оценка производительности». Очень простой и быстрый вариант решения
В этой заметке хочу поделиться своей идеей решения задачи [MLBootCamp «Оценка производительности»](http://mlbootcamp.ru/championship/7/) от Mail.ru. Главное достоинство этого способа — в его простоте и скорости выполнения скрипта. И хотя... | https://habr.com/ru/post/306198/ | null | ru | null |
# Как начать разработку крупного, нетипичного проекта. Практическое пособие

##### **Выбор платформы для бекенда**
Чтобы создать качественное и производительное Web-приложение, необходимо уделить должное внимание выбору ... | https://habr.com/ru/post/304908/ | null | ru | null |
# Измеряем производительность String.format() в Java
### Бэкграунд
Я раньше считал, что JDK в целом хорошо оптимизирована, и если в JDK есть простой способ решения какой-то задачи, то он вполне подойдет для ... | https://habr.com/ru/post/580164/ | null | ru | null |
# Три слоя градиента одного слайдера
Мы в Тинькофф разрабатываем [библиотеку Taiga UI:](https://github.com/Tinkoff/taiga-ui) в ней сотни полезных компонентов, директив и сервисов. При разработке нам важно уделять внимание вопросу поддерживаемости кода, поэтому мы стараемся не писать лишнего кода и искать решения, рабо... | https://habr.com/ru/post/667254/ | null | ru | null |
# Восстановление данных PostgreSQL после потери pg_control
Для обеспечения отказоустойчивости СУБД PostgreSQL, как и многие базы данных, использует специальный журнал, в котором ведет историю изменения данных. Перед тем как записать данные в файлы БД, сервер PostgreSQL аккумулирует изменения в оперативной памяти и зап... | https://habr.com/ru/post/282770/ | null | ru | null |
# Kaggle: Британские спутниковые снимки. Как мы взяли третье место
Сразу оговорюсь, что данный текст — это не сухая выжимка основных идей с красивыми графиками и обилием технических терминов (такой текст называется научной ... | https://habr.com/ru/post/325096/ | null | ru | null |
# Разработка приложений на Elixir/Phoenix с помощью Docker

Под катом небольшое и простое руководство, в котором показано, как использовать Docker Compose для настройки и запуска приложения Elixir/Phoenix + PostgreSQL.
Подготовка
... | https://habr.com/ru/post/439718/ | null | ru | null |
# Слово на букву «М», или Монады уже здесь

Про монаду ходит множество мемов и легенд. Говорят, что каждый уважающий себя программист в ходе своего функционального возмужания должен написать хотя бы один туториал про монад... | https://habr.com/ru/post/262055/ | null | ru | null |
# Стоит ли Typescript усилий?

Typescript — это скриптовый язык, компилируемый в JavaScript. Разработка Microsoft, которая, на сегодняшний день, успела завоевать и фанатов и недоброжелателей. Главный ... | https://habr.com/ru/post/308374/ | null | ru | null |
# Форматирование милли/микро/нано секунд в java.sql.Timestamp
В JVM 1.8 отсутствует удобный и простой в использовании класс форматирования класса **java.sql.Timestamp** с микро и нано секундами. Есть специализированный пакет **java.time** с достаточно разнообразной функциональностью. Но его использование для преобразо... | https://habr.com/ru/post/700148/ | null | ru | null |
# Как собрать акустический левитатор. Инструкция с фотографиями
[](https://habr.com/ru/company/skillfactory/blog/693324/)
Чаще всего движущая сила левитации — это магниты. Но почему не что-нибудь другое? Например, звук, встречные вол... | https://habr.com/ru/post/693324/ | null | ru | null |
# Приручаем JMeter
Сегодня я хочу рассказать о замечательном инструменте, название которого вынесено в заголовок статьи. Разумеется, моей целью не является написание подробного руководства по [Apache JMe... | https://habr.com/ru/post/261483/ | null | ru | null |
# Использование Grab:Spider для парсинга сайтов
Всем привет!
Я активный пользователь open-source фрэймворка [Grab](http://grablib.org/) ([itforge](http://habrahabr.ru/users/itforge/) уже писал о нем [здесь](http://habrahabr.ru/blogs/python/127584/) и [здесь](http://habrahabr.ru/blogs/python/134918/)) и 1/2 проекта... | https://habr.com/ru/post/142212/ | null | ru | null |
# ETL процесс получения данных из электронной почты в Apache Airflow

Как бы сильно не развивались технологии, за развитием всегда тянется вереница устаревших подходов. Это может быть обусловлено плавным переходом, человеческим факторо... | https://habr.com/ru/post/495676/ | null | ru | null |
# Команда cp: правильное копирование папок с файлами в *nix
В этой статье будут раскрыты некоторые неочевидные вещи связанные с использованием [wildcards](https://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D0%BE%D0%B8... | https://habr.com/ru/post/471092/ | null | ru | null |
# Как встроить С-библиотеку в Swift-фреймворк
В 2014 году был представлен Swift, новый язык для разработки приложений экосистемы Apple. Новинка принесла не только новые возможности и функции, но и проблемы — тем, кто хотел пользов... | https://habr.com/ru/post/435650/ | null | ru | null |
# Диагностическая медицинская экспертная система на Prolog
Вступление
----------
Как то мне посчастливилось выбирать тему дипломной работы по специальности программная инженерия, и я выбрал написание экспертной системы, причем именно на языке Пролог. Хоть в промышленном программировании он почти не используется, он и... | https://habr.com/ru/post/436722/ | null | ru | null |
# Ванильный JavaScript и HTML. Никаких фреймворков. Никаких библиотек. Никаких проблем

Используете для создания приложений Vue, React, Angular или Svelte? Я использую, и если вы тоже, и уверен, что вам уже давно не приходилось пис... | https://habr.com/ru/post/483726/ | null | ru | null |
# Немного о проектировании самосинхронных схем
На форумах по электронике периодически вспоминают о самосинхронных схемах, но очень мало кто понимает, что это вообще такое, какие полезные свойства есть у самосинхронных схем, и какими недостатками они обладают. Краткий текст ниже позволит читателю ознакомиться с азами с... | https://habr.com/ru/post/306056/ | null | ru | null |
# Язык программирования C∀ (CForAll)
Мой интерес к дизайну языков программирования приводит меня иногда к интересным, но почти неизвестным в широких кругах проектам. Один из таких проектов - язык C∀ (CForAll... | https://habr.com/ru/post/587428/ | null | ru | null |
# Делаем собственный NTP-сервер Stratum-1
На написание этой заметки меня натолкнул хабраюзер [BarsMonster](https://habrahabr.ru/users/barsmonster/) со своим топиком [«О точном времени»](http://habrahabr.ru/blogs/sysadm/79461/).
В своей статье он призывал хабраюзеров «Давать больше Stratum-1 серверов», но не сказал ... | https://habr.com/ru/post/79629/ | null | ru | null |
# Анонсирована разработка шрифтов STIX версии 2.0.0, направленная на улучшение их текстовой составляющей

Создание так называемых «текстовых» шрифтов является одним из сложнейших, тончайших и благородн... | https://habr.com/ru/post/225165/ | null | ru | null |
# Пишем расширение под PHP (7.0.7) без знаний о С/C++ и как это вообще работает
Можно ли написать свой модуль (расширение) к PHP без особых знаний, требующих большого времени изучения теории? Если умеешь программировать на самом PHP, то написать простейший код на С не составит особого труда, тем более, что PHP позволя... | https://habr.com/ru/post/303572/ | null | ru | null |
# [Программирование] Работа со строкой состояния в Android
Статья рассказывает о том как работать со строкой состояния в Android. Статья рассчитана на начинающих программистов под Android только осваивающих раз... | https://habr.com/ru/post/111238/ | null | ru | null |
# Оптимизация расходов Yota: попытка #3
Привет, хабр!
Наступило лето и очень многие уезжают из города. Кто-то на время отпуска, а кто-то и на все лето (если работа позволяет). Но одна из главных проблем за городом (для всех людей, так или иначе связанных с IT) — отсутствие нормального проводного быстрого интернета.... | https://habr.com/ru/post/228959/ | null | ru | null |
# Detect it to pop it — используем “взрослые” инструменты Intel для решения “детской” задачи
Задачу обнаружения различных объектов сейчас модно решать на основе глубокого обучения. Но для этого нужно собрать ... | https://habr.com/ru/post/568408/ | null | ru | null |
# Разбираемся с условными брейкпоинтами в C++
Для большинства случаев дебаггинга вам должно с головой хватать стандартных точек останова (breakpoints или брейкпоинтов). Но иногда кода для проверки, объектов или случаев попросту слишком много. Что делать, если мы хотим отфильтровать код, генерирующий точку останова? Пр... | https://habr.com/ru/post/689212/ | null | ru | null |
# CSS Bugs. Ошибки, возникающие при верстке
### 1. Удвоение полей у плавающих (float) блоках в IE 5-6
**Проблема:** мы очень часто используем поля (margin) и не реже их применяем к блокам со свойством float, ожидая нужный результат, можно сильно удивиться, когда IE вдруг сдвинет наш блок на большее расстояние, чем пр... | https://habr.com/ru/post/9611/ | null | ru | null |
# Easy linux management over twitter
Доброго времени суток, дорогие Хабраюзеры.
Этот пост навеян появлением [статьи](http://habrahabr.ru/blogs/python/127237/) про Twitter бота и всяких свистелок-плясалок для него. Представляю вам свое видение api Твиттера. Добро пожаловать под кат.
~~Необходимо учесть, что данны... | https://habr.com/ru/post/127793/ | null | ru | null |
# Второй чемпионат по программированию: разбираем задачи ML-трека
В октябре состоялся второй чемпионат по программированию. Мы получили 12 500 заявок, более 6000 человек попробовали свои силы в соревнованиях. В этот раз участники могл... | https://habr.com/ru/post/477452/ | null | ru | null |
# Шесть простых примеров по Mockito (перевод)
**Маленький комментарий:**/\*
Решил ознакомиться с тем, что из себя представляет эта библиотека, и отыскал замечательную [статью](http://gojko.net/2009/10/23/mockito-in-six-easy-examples/), прочтение которой я хотел бы закрепить, для чего и решил перевести её на русский... | https://habr.com/ru/post/243155/ | null | ru | null |
# Микросервисы — MIF на C++
Около трех лет назад у меня была идея создания небольшого каркаса для разработки небольших сервисов, которые могли бы как-то взаимодействовать между собой, предоставлять API во вне, работать с базами д... | https://habr.com/ru/post/239571/ | null | ru | null |
# Расширяя границы или о задаче проверки гипотезы о нормальности многомерного распределения
*Краткий рассказ про пакет MVN*
### Минутка теории
Допустим, у нас есть некоторое совместное распределение n переменных – и нам необходимо проверить, является ли оно нормальным. Решить эту задачу просто нам мешает один малень... | https://habr.com/ru/post/597865/ | null | ru | null |
# SNMP + Java – личный опыт. Пишем парсер MIB-файлов
SNMP – не самый юзер-френдли протокол: MIB-файлы слишком длинные и запутанные, а OID'ы просто невозможно запомнить. А что если возникла необходимость работать с SNMP на Java? Например, написать автотесты для проверки API SNMP-сервера.
Путём проб и ошибок при нал... | https://habr.com/ru/post/427267/ | null | ru | null |
# Сжатие указателей в Java

В статье речь пойдет о реализации сжатия указателей в **Java Virtual Machine 64-bit**, которое контролируется опцией **UseCompressedOops** и включено по-умолчанию для 64 битных систем начиная с Java SE 6u2... | https://habr.com/ru/post/440166/ | null | ru | null |
# Атаки на трасты между доменами
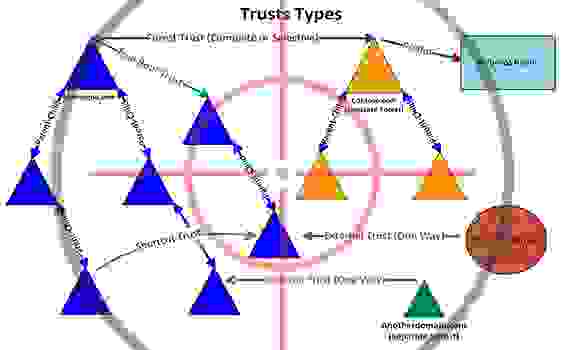
Рано или поздно в ходе пентеста встает задача компрометации всего леса — при условии, что есть какие-либо права в одном из доменов. В такие моменты возникает куча вопросов о трастах, их свойствах и... | https://habr.com/ru/post/466445/ | null | ru | null |
# Скрипт для мониторинга состояния хостов в сети
Я работаю админом и в моей зоне ответственности находится ряд серверов: роутеры, серверы БД, терминальные серверы и т.д. И хочется быть в курсе, если какойто из серверов вдруг пропал из сети — где-то упал линк с удаленной сетью, где-то вдруг произошел хрестоматийный слу... | https://habr.com/ru/post/66142/ | null | ru | null |
# Как мы делали Warface для Денди
В октябре 2020 мне написал мой друг Андрей Скочок, работающий в Mail.ru, и предложил сделать для них необычную промоакцию.
Суть в том, что в ноябре для их игры Warface выходило обновление, и Андрею пришла в голову идея разослать различным видеоблогерам картриджи для Денди, которые ... | https://habr.com/ru/post/657395/ | null | ru | null |
# Взгляд из Google на оптимизацию сайтов
На сайте моей компании я выложил свой перевод [интервью Андре Вейера](http://jamesnorquay.com/an-interview-ex-member-matt-cuttss-search-quality-team/) (Andre Weyher), в прошлом — сотрудника отдела качества поиска в Google, которое он дал австралийскому интернет-маркетологу Джей... | https://habr.com/ru/post/155459/ | null | ru | null |
# Переходим с STM32 на российский микроконтроллер К1986ВЕ92QI. Практическое применение: управляем яркостью светодиода
#### Вступление
В двух предыдущих статьях мы генерировали при помощи ШИМ тактовый сигнал нужной нам частоты, получая на светодиоде равный промежутки свечения и его отсутствия. Данная задача имеет мест... | https://habr.com/ru/post/270887/ | null | ru | null |
# Пишем Lisp-интерпретатор на Java
Некоторое время назад мне захотелось написать свой небольшой интерпретируемый скриптовый язык, просто ради фана, не ставя перед собой каких-либо серьезных задач. Я тогда активно читал изве... | https://habr.com/ru/post/281859/ | null | ru | null |
# Обзор и настройка расширения Unite
Был удивлен, что на хабре нет описания расширения Unite, которое позволяет заменить просто огромное количество плагинов для Vim. Unite сочетает в себе функционал таких расширений как: CtrlP, FuzzyFinder, ack, yankring, LustyJuggler, buffer explorer и т.д.
Все мы хотим быть в курсе происходящего поэтому часть своего времени тратим на чтение новостей, и сейчас все чаще новости приходят не из новостных сайтов или газет, а из ка... | https://habr.com/ru/post/540876/ | null | ru | null |
# Прогнозирование физики на стороне клиента в Unity

### TL;DR
Я создал демо, показывающее, как реализовать прогнозирование на стороне клиента физического движения игрока в Unity — [GitHub](https://github.com/spectre1989/unity_physics_... | https://habr.com/ru/post/432190/ | null | ru | null |
# Новые функции в репозитории фреймворка: ORM/ActiveRecord

Я хотел бы начать серию статей о развитии движка LiveStreet, а именно его *фреймворковой* части. LiveStreet получил довольно широкую популярность как *блогосоциальный хабраклон*, но за 2 года перерос уже в нечто з... | https://habr.com/ru/post/109571/ | null | ru | null |
# Настройка Sendmail для отправки почты без попадания в Спам
Столкнулся с проблемой: на правильно настроенном сервере Apache с установленными модулями и настроенными доменными записями у провайдера — письма отправленные через функцию mail из скриптов php попадали в спам или не доставлялись вовсе.
Начал разбираться ... | https://habr.com/ru/post/564750/ | null | ru | null |
# Список покупок
#### Описание
[](http://habrastorage.org/storage3/39c/547/9d3/39c5479d3712b7873d9dcd471dce7d07.jpg)У меня всегда неожиданно заканчиваются продукты. Казалось, ещё вчера был стратегический зап... | https://habr.com/ru/post/202550/ | null | ru | null |
# Знакомимся с Fabric.js. Часть 2-я
*Это вторая часть серии статей об открытой Javascript canvas библиотеке Fabric.js.*
В [первой части](http://habrahabr.ru/post/162367/) этой серии, мы ознакомились с самыми базовыми аспектами canvas библиотеки [Fabric.js](http://fabricjs.com). Мы узнали чем может быть полезна Fabr... | https://habr.com/ru/post/167119/ | null | ru | null |
# Создание переиспользуемых пайплайнов для GitLab CI на bash
За последние несколько лет я очень полюбил [GitLab CI](https://docs.gitlab.com/ee/ci/README.html). В основном за его простоту и функциональность. Достаточно просто создать в корне репозитория файл `.gitlab-ci.yml` , добавить туда [несколько строчек кода](htt... | https://habr.com/ru/post/557682/ | null | ru | null |
# Работа с квалифицированными сертификатами в свете новой редакции Приказа №795 ФСБ РФ от 21.01.2021. Часть II
После опубликования [статьи](https://habr.com/ru/post/588681), посвящённой требованиям Приказа №795 ФСБ России [в реда... | https://habr.com/ru/post/591369/ | null | ru | null |
# L-Systems — математическая красота растений
Красота растений привлекала внимание математиков веками. Активнее всего изучались интересные геометрические свойства растений, такие как симметрия листьев относительно центральной оси, радиальная симметрия цветов, и спиральное расположение семечек в шишках. «Красота связан... | https://habr.com/ru/post/69989/ | null | ru | null |
# Все нововведения Windows 10 2004 (20H1)
Сегодня вечером был выпущен финальный ISO-образ Windows 10 2004 (20H1). Им стал билд за номером **19041.208.vb\_release\_svc\_im.200416-2050**. Образы для разработчиков уже доступны на MSDN как вскоре и сами знаете где.

Как-то вечером, сидя за компьютером, я наткнулся на одну инди-игру под названием **«Shoot First»** (игру можно [скачать](http://teknopants.com/2011/05/shoot-first/... | https://habr.com/ru/post/257125/ | null | ru | null |
# Все ли вы знаете о React key?
Привет, Хабр!
Я время от времени провожу собеседования, и когда вопрос касается *React key*, чаще всего я вижу недоумевающий взгляд, намекающий “Да, там и спрашивать вроде нечего?”. Если Вам кажется *React key* понятным и простым, тогда давайте проведем мини собеседование ([данная стат... | https://habr.com/ru/post/527596/ | null | ru | null |
# О том, как мы писали асинхронного telegram-бота «ScipIO»
### Оглавление
* [Предисловие](#%D0%9F%D1%80%D0%B5%D0%B4%D0%B8%D1%81%D0%BB%D0%BE%D0%B2%D0%B8%D0%B5)
+ [Описание](#%D0%9E%D0%BF%D0%B8%D1%81%D0%B0%D0%BD%D0%B8%D0%B5)
+ [Откуда идея?](#%D0%9E%D1%82%D0%BA%D1%83%D0%B4%D0%B0_%D0%B8%D0%B4%D0%B5%D1%8F?)
+ [Почем... | https://habr.com/ru/post/658115/ | null | ru | null |
# Прозрачный прокси сервер Squid с паролем на Ubuntu 11.04
Недавно появилась задача реализовать некоторые функции Kerio в linux, а именно авторизацию
пользователей прокси сервера Squid в режиме transparent. Это сделать довольно просто и на
просторах интернета много статей как это сделать, но появилась проблема... | https://habr.com/ru/post/140052/ | null | ru | null |
# Советы по отладке в Visual Studio 2010
Это двадцать шестая публикация [в серии публикаций](http://weblogs.asp.net/scottgu/archive/2009/08/25/vs-2010-and-net-4-series.aspx) о VS 2010 и .NET 4.
Сегодняшняя публикация рассматривает некоторые полезные советы по отладке которые вы можете применять в Visual Studio. Мой... | https://habr.com/ru/post/102178/ | null | ru | null |
# Мониторинг служб systemd в реальном времени с помощью Chronograf
> Уже сегодня **стартуют занятия в новой группе курса** [**"Мониторинг и логирование: Zabbix, Prometheus, ELK"**](https://otus.pw/REqL/) **от OTUS**. В течении **ближайшей недели** у всех желающих будет возможность **присоединиться к курсу по** [**спец... | https://habr.com/ru/post/529468/ | null | ru | null |
# Студенты, лабы и python: обработка данных
В своей [предыдущей заметке](https://habr.com/ru/post/546956/) на тему обработки данных лабораторных работ я написал об использовании пакета [gnuplot](http://gnuplo... | https://habr.com/ru/post/548280/ | null | ru | null |
# Как предсказать цену акций: Алгоритм адаптивной фильтрации
[](http://habrahabr.ru/company/itinvest/blog/274821/)
Группа бразильских ученых опубликовала [исследование](http://arxiv.org/pdf/1501.07504.pdf), посвященное созд... | https://habr.com/ru/post/274821/ | null | ru | null |
# Как протестировать блокноты Jupyter с помощью pytest и nbmake
Файлы блокнотов Jupyter, в смысле количества одного из самых быстрорастущих типов файлов на Github, предоставляют простой интерфейс для итераций... | https://habr.com/ru/post/558326/ | null | ru | null |
# Что нового в Angular 8 версии
Вот и вышел angular 8, он включает в себя превью Ivy, поддержку service workers, дифференциальную загрузку и несколько других завершающих штрихов. [Manfred Steyer](https://www.softwarearchitekt.at/) объясняет наиболее важные изменения в новейшем релизе.
Как и планировалось, сюрпризов... | https://habr.com/ru/post/455493/ | null | ru | null |
# Метаклассы в C++
В этой статье мы поговорим о новом предложенном расширении языка С++ — метаклассах. Герб Саттер с коллегами работал над этим предложением около 2 лет и, наконец, этим летом [представил](https://herbsutter.files.wordpress.com/2017/07/p0707r1.pdf) его общественности.
Итак, что же такое «метакласс» ... | https://habr.com/ru/post/334284/ | null | ru | null |
# Android Process: Я тебя породил, я тебя и …

Вы когда-нибудь задумывались о том, что происходит с вашим приложением после того, как система убила его процесс за ненадобностью? Печально, но многие об этом даже не беспокоят... | https://habr.com/ru/post/261721/ | null | ru | null |
# Нескучный API

Как создать АПИ для умных? Такое апи, чтобы создание клиента для него было не скучным механическим процессом, а настоящим приключением с элементами детектива, хоррора и мистики? Такое апи, о котором пользователи... | https://habr.com/ru/post/344790/ | null | ru | null |
# Достать worklog из Jira
Всем привет, недвано я писал про api клиент для Jira. Разбираться с ним я начал, когда возникла необходимость автоматизировать формирование отчета по времени(отчеты нужны заказчику). В итоге получися небольшой инструмент который позволяет быстро и легко вытаскивать необходимые данные.

***Как читать эту статью**: прошу прощения за то, что текст получился таким длинным и хаотичным. Чтобы сэкономить ваше время, я каждую главу начинаю со вступления «Чему я научился», в котором одним-... | https://habr.com/ru/post/456392/ | null | ru | null |
# Иерархия исключений в современном PHP-приложении
Задача публикации: доступно изложить способ организации иерархии исключений и их обработки в приложении. Без привязки к фреймворкам и конкретной архитектуре. Описываемый способ является де-факто стандартом в сообществе: он используется во многих серьёзных библиотеках ... | https://habr.com/ru/post/329140/ | null | ru | null |
# Программирование под N900 на Python
Среди топиков на Хабре я нашел лишь руководство по программированию на Python для платформы S60. Являясь счастливым обладателем N900 и фанатом Python я решил это исправить.
##### Вступление
В данной статье предполагается знание синтаксиса языка Python, а также основной семант... | https://habr.com/ru/post/111370/ | null | ru | null |
# Установка и настройка CA Infrastructure Management. Часть первая. Performance Management
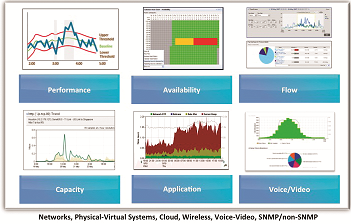 В последнее время на хабре стали всё чаще и чаще попадаться статьи, связанные с мониторингом.
Описаны такие продукты как MS SCOM, I... | https://habr.com/ru/post/246021/ | null | ru | null |
# Пишем бота-кликера на Python для Lineage 2

### Предисловие
Как можно развлечься в новогодние праздники? Поиграть в компьютерные игры? Нет! Лучше написать бота, который это будет делать за тебя, а самому пойти лепить снеговика и п... | https://habr.com/ru/post/346258/ | null | ru | null |
# Автоматизация загрузки изображений для товаров в интернет-каталогах

Занимаясь разработкой интернет-каталогов (или же интернет-магазинов) столкнулись с проблемой подбора картинок для товара. Не каждый заказчик может позволить внедрить в свои процессы фотографирован... | https://habr.com/ru/post/91162/ | null | ru | null |
# «Продам гараж»: фронт и реклама в hh.ru
Если ваш публичный проект может похвастаться внушительной аудиторией, вашими пользователями точно заинтересуются рекламные системы. Бизнес рано или поздно это замечает и закономерно пытается извлечь некоторые профиты.
По стечению обстоятельств большую часть времени я занималс... | https://habr.com/ru/post/552288/ | null | ru | null |
# Работа с геозонами (geofences) в Android
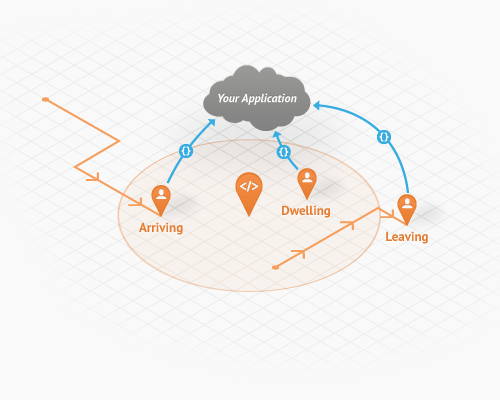
Добрый день, хабровчане. Сегодня я хотел бы рассказать о [Location APIs](https://developer.android.com/google/play-services/location.html) в общем и о геозонах (g... | https://habr.com/ru/post/210162/ | null | ru | null |
# Проверяем исходный код Roslyn

Время от времени мы возвращаемся к проектам, которые уже проверяли ранее с помощью PVS-Studio и писали про это статьи. Делать это интересно по двум причи... | https://habr.com/ru/post/446592/ | null | ru | null |
# Мой авторесайз IFRAME
Прочитав статейку Дмитрия Котерова о ресайзе ифрэймов решился поделиться своим решением.
Этим решением пользуемся на продуктивном сайте.
Итак, дано:
1. Нужно показывать в ифрэйме страницы с других доменов без скроллбара
2. Внутри ифрэйма могут совершаться переходы
3. Сайты в ифр... | https://habr.com/ru/post/78845/ | null | ru | null |
# Улучшаем экспорт в Excel для SharePoint
Стандартная возможность экспорта в Excel в SharePoint работает довольно необычным образом. При нажатии на кнопку экспорта SharePoint отдает файл запроса в специальном формате, который открывается Excel, и уже сам Excel затягивает данные.
Преимущество такого подхода в том, ч... | https://habr.com/ru/post/208948/ | null | ru | null |
# Загрузка моделей, трейтов
Итак, узнал сегодня небольшую *фитчу Laravel/Eloquent*, которая практически не описана и лишь вскользь упомянута в документации фреймовика.
*Перейдите к **TL;DR,** если вы просто хотите увидеть эту фичу.*
Возможно, вы уже знаете, что можно добавлять статические *boot*()-методы к *Elo... | https://habr.com/ru/post/259589/ | null | ru | null |
# Kivy. Xamarin. React Native. Три фреймворка — один эксперимент

Приветствую всех! Как только дым от жаркой дискуссии в комментариях к моей статье [Kivy — фреймворк для кроссплатформенной разработки №1](https://habr.com/post/418839/... | https://habr.com/ru/post/420691/ | null | ru | null |
# Новости из мира OpenStreetMap № 465 (11.06.2019-17.06.2019)

*Материалы конференции "[State of the Map France](https://wiki.openstreetmap.org/wiki/FR:State_of_the_Map_France_2019)" выложены в открытый д... | https://habr.com/ru/post/457404/ | null | ru | null |
# Deferred: все подробности
В [предыдущей статье](http://habrahabr.ru/blogs/twisted/51762/ "Асинхронное программирование: концепция Deferred") были описаны основные принципы работы Deferred и его применение в асинхронном программировании. Сегодня мы постараемся рассмотреть в деталях функционирование Deferred и примеры... | https://habr.com/ru/post/52924/ | null | ru | null |
# Руководство по WebKit-атрибуту srcset в тэге img
Свободный движок WebKit теперь поддерживает srcset атрибут изображений, IMG элементов ([официальная спецификация от W3C](http://www.w3.org/html/wg/drafts/srcset/w3c-srcset/)). Это позволяет вам, как разработчику, использовать картинки с высоким разрешением для пользов... | https://habr.com/ru/post/190464/ | null | ru | null |
# Настройка и использование Web Optimizer
[](http://code.google.com/p/web-optimizator/)Пока выпуск версии 0.5 веб-приложения, автоматизирующего клиентскую оптимизацию для PHP-сайтов, ото... | https://habr.com/ru/post/62009/ | null | ru | null |
# Как сделать трансформер чат-бот на Trax?
Экспериментировать с библиотекой Trax и архитектурой трансформер оказалось крайне увлекательно. Предыдущая статья была про [саммаризатор](https://habr.com/ru/post/543278/). В этой хочу рассказать о том, как я учил трансформер общаться **на русском языке**.
Сравнительно прост... | https://habr.com/ru/post/544494/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.