
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Сквозная авторизация на своем сайте через Twitter
Прошли те времена, когда каждый форум на персональной страничке каждого Васисуалия Свердыщенко требовал отдельной регистрации.
Мы потихонечку привыкаем к тому, что оставить комментарий от имени своего OpenID/OAuth провайдера можно фактически везде. Также для всех ... | https://habr.com/ru/post/114955/ | null | ru | null |
# Сказ о том, как я настраивал Azure AD B2C на React и React Native Часть 2 (Туториал)

### Предисловие
Продолжение цикла по работе с Azure B2C. В данной статье я расскажу о самом сложном и неочевидном моменте, а именно Identit... | https://habr.com/ru/post/504030/ | null | ru | null |
# Lisp со вкусом Pascal или 8501-й язык программирования
Некоторое время назад (года три) решил почитать учебник по Лиспу. Без всякой конкретной цели, просто ради общего развития и возможности шокировать собеседников экзотикой (один раз кажется, даже получилось).
Но при ближайшем рассмотрении Лисп оказался действит... | https://habr.com/ru/post/424447/ | null | ru | null |
# Оптимизация хранимых данных на 93% (Redis)
Хотелось бы поделиться опытом оптимизации данных с целью уменьшения расходов на ресурсы.
В системе рано или поздно встает вопрос об оптимизации хранимых данных, особенно если данные хранятся в оперативной памяти. Примером такой БД является Redis.
Как временное решение, мо... | https://habr.com/ru/post/546734/ | null | ru | null |
# iPXE загрузка установщика Debian по HTTP
В этой статье хочу рассказать быстрый и удобный способ установить debian на виртуальную машину через iPXE.
Такой вариант мне нравится больше всего, т.к. не требует скачивания каких-либо ISO образов или дополнительной настройки DHCP и TFTPсерверов. Вся загрузка пойдет по HT... | https://habr.com/ru/post/188308/ | null | ru | null |
# Работа с библиотекой Newtonsoft.Json на реальном примере. Часть 2
В первой части статьи был рассмотрен механизм парсинга объектов JSON с динамически изменяющейся структурой. Данные объекты приводились к типам пространства имен newtonsoft.json.linq, и затем преобразовывались в структуры языка C#. В комментариях к пер... | https://habr.com/ru/post/482042/ | null | ru | null |
# Пробуем q-learning на вкус, повесть в трех частях
Эта статья — небольшая заметка о реализации алгоритма q-learning для управления агентом в стохастическом окружении. Первая часть статьи будет посвящена созданию окружения для проведения симуляций — мини-игр на поле nxn, в которых агент должен как можно дольше продерж... | https://habr.com/ru/post/345656/ | null | ru | null |
# Установка Debian по сети через netboot и ssh

Подходит для установки Debian Squeeze и старше. Установщик стандартный для дебиана — debian-installer (сокращенно d-i).
В случае невозможности получить физический доступ к консоли этот спос... | https://habr.com/ru/post/130978/ | null | ru | null |
# Пишем драйвер для ноутбука for fun and profit, или как закоммитить в ядро даже если ты дурак
С чего всё началось
-------------------
Начнём с постановки проблемы. Дано: один ноутбук. Новый ноутбук, геймерский. С RGB-подсветкой. Вот такой примерно ноутбук:

В настоящее время к современным устройствам и гаджетам предъявляются довольно-таки высокие требования. И я говорю не только о серфинге в ин... | https://habr.com/ru/post/262821/ | null | ru | null |
# Новый поток в C++20: std::jthread
> Привет, Хабр! Перевод статьи подготовлен в рамках курса ["**C++ Developer. Professional**"](https://otus.pw/Yf6l/)
>
>

---
Один из участников моего [семинара в рамк... | https://habr.com/ru/post/548316/ | null | ru | null |
# Как мы автоматизировали большой интернет-магазин и стали сопоставлять товары автоматически

Статья больше техническая, чем про бизнес, но какие-то итоги с точки зрения бизнеса мы тоже подведем. Больше всего внимания будет уд... | https://habr.com/ru/post/456604/ | null | ru | null |
# App Puzzle15. Дорога в Питер за android-фоном
Совсем недавно в славном городе на Неве проводился конкурс ребятами из местного GTUG, анонс конкурса ютится в [этом](http://habrahabr.ru/blogs/google_ch... | https://habr.com/ru/post/107229/ | null | ru | null |
# DIY автономный дрон с управлением через интернет. Часть 2 про ПО
Это продолжение повествования об автономном дроне. В [первой части](https://habr.com/post/414121/) говорилось про hardware, в этой речь пойдет про software. Для начала небольшой ликбез про взаимодействие оператора с коптером. Вот типичная схема у больш... | https://habr.com/ru/post/414587/ | null | ru | null |
# Многомодульность в Android с точки зрения архитектуры. От А до Я
Всем привет!
Не так давно мы с вами осознали, что мобильное приложение — это не просто тонкий клиент, а это действительно большое количество самой разной логики, которое нуждается в упорядочивании. Именно поэтому мы прониклись идеями Clean architect... | https://habr.com/ru/post/422555/ | null | ru | null |
# Как создавать «зеленый» код
 Что такое энерго-эффективность в применении к мобильным платформам? Простыми словами это возможность сделать больше, затратив при этом меньше энергии.
Каждому пользователю хо... | https://habr.com/ru/post/134559/ | null | ru | null |
# Ещё один способ оптимизации интерфейса Youtube
Прочитав свежую [статью о Youtube Center](http://habrahabr.ru/post/200990/), я решил поделиться с хабрасообществом своим способом укрощения разжиревшего интерфейса Youtube.
 я показал как создавать модуль под Drupal 7. И как я и обещал, теперь покажу как добавлять к модулям js-файлы (использовать в них jQuery) и как осуществляется его локализация.
#### Добавление js-файлов
Для ... | https://habr.com/ru/post/200382/ | null | ru | null |
# Voldemort типы в D
Данный пост расскажет об уникальной фишке D — Voldemort типы. Типы, которые можно использовать, но нельзя назвать. Данное название не очень подходит им, но Walter Bright очень любит так их называть. Voldemort типы очень часто встречаются в стандартной библиотеке Phobos, особенно в модулях [std.alg... | https://habr.com/ru/post/183488/ | null | ru | null |
# Дайджест интересных новостей и материалов из мира PHP № 35 (26 января — 9 февраля 2014)

Предлагаем вашему вниманию очередную подборку с ссылками на новости и материалы.
Приятного чтения!
### Ново... | https://habr.com/ru/post/211995/ | null | ru | null |
# Скачивание музыки из vk.com
После недавней шумихи вокруг аудиозаписей на сайте vk.com решил подстраховаться и скопировать всю свою коллекцию на жесткий диск. Для решения мною была написана простенькая утилита на Java. Ниже — её код c комментариями. Статья предназначена для читателей, знакомых с любым языком программ... | https://habr.com/ru/post/183546/ | null | ru | null |
# Учебник по симулятору сети ns-3. Глава 7

[[главы 1,2]](https://habr.com/ru/post/497106/)
[[глава 3]](https://habr.com/ru/post/497318/)
[[глава 4]](https://habr.com/ru/post/497478/)
[[глава 5]](https://habr.com/ru/pos... | https://habr.com/ru/post/507472/ | null | ru | null |
# Как я парсил БД C-Tree, разработанную 34 года назад

Прилетела мне недавно задача дополнить функционал одной довольно старой програмки (исходного кода программы нет). По сути нужно было просто сканить периодически БД, анализ... | https://habr.com/ru/post/351658/ | null | ru | null |
# Подключаем старую венгерскую клавиатуру Videoton по USB
Не знаю откуда она у меня взялась и зачем, но при очередной уборке на даче и спотыкания об эту доску который раз встал вопрос — выкинуть ее нафиг, или все-таки запустить зверушку и потом выкинуть?
](http://bestpractical.com/static/images/screenshots/rt/3.8/homepage.png)
Приветствую тебя, %habrauser%!
##### Предыстория:
В данный момент я работаю в небольшой конторе, которая... | https://habr.com/ru/post/112348/ | null | ru | null |
# Интеграция алгоритма стемминга русских слов в fts3 SQLite
В данной статье я хочу поделиться опытом интеграции расширения для [стемминга](http://ru.wikipedia.org/wiki/%D0%A1%D1%82%D0%B5%D0%BC%D0%BC%D0%B8%D0%BD%D0%B3) в код SQLite. Все действия выполнялись в ОС Ubuntu 11.10.
#### Проблема
В fts3 SQLite есть просто... | https://habr.com/ru/post/131265/ | null | ru | null |
# Экспорт, импорт в Node.JS
Вроде, все просто и ясно:
```
var module = require("./some_module.js");
module.f(); // запуск экспортируемой функции модуля
console.log(module.obj); // печать экспортируемого объекта модуля
module(); // запуск самого модуля
```
Что бы экспортировать что-то в самом модуле нужно прописат... | https://habr.com/ru/post/276791/ | null | ru | null |
# Истина прежде всего, или почему систему нужно проектировать, исходя из устройства базы данных
Привет, Хабр!
Мы продолжаем исследовать тему [Java](https://www.piter.com/collection/all/product/sovremennyy-yazyk-java-lyambda-vyrazheniya-potoki-i-funktsionalnoe-programmirovanie) и [Spring](https://www.piter.com/colle... | https://habr.com/ru/post/498816/ | null | ru | null |
# *nix-way: Даже если тебя съели, у тебя есть как минимум два выхода
В процессе работы с операционными системами GNU/Linux обычно привыкаешь делать какие-то операции одними и теми же средствами. Философия UNIX (\*nix-way) предполагает наличие большого количества простых программ для выполнения простых действий, а резу... | https://habr.com/ru/post/145073/ | null | ru | null |
# Apple Mac и причудливые устройства. LTO, SAS, Fibre Channel, eSATA
Темой настоящей статьи является подключение к Маку внешних устройств по интерфейсам SAS, Fibre Channel (FC), eSATA. Сразу оговоримся, что для решения задачи доступа к таким устройствам существует путь здорового человека: собрать дешёвый PC, воткнуть ... | https://habr.com/ru/post/503178/ | null | ru | null |
# Автоматизируем сборку Asterisk на Oracle 8
В какой-то момент у нас в компании назрела необходимость упростить развертывание ПО Asterisk
Основная проблема возникала при сборке Asterisk из исходников, так как необходимо выбирать нужные/ненужные модули, а простое копирование файла menuselect.makeopts при переходе от... | https://habr.com/ru/post/587548/ | null | ru | null |
# Why itertools rocks
zip vs izip или «ну кому ещё объяснить фишку итераторов?»
Таск прост: [0,1,2,3,...,99999] -> [(0,1), (2,3), ..., (99998, 99999)], т.е. выбрать элементы попарно. 100тыс это не так уж много — посему сделаем это по 150 раз для каждого варианта.
Т.к. тест тестит именно скорость выборки а не зас... | https://habr.com/ru/post/52474/ | null | ru | null |
# Мониторинг трафика на коммутаторах при помощи Wireshark + Plink
Сразу отмечу, что способ не мой, а подсмотренный у EVE-NG. Никаких особых преимуществ он не даёт, обладает массой ограничений, но кому-то, просто, удобнее работать с Wireshark в режиме реального времени.
Суть метода проста: перенаправить вывод от утили... | https://habr.com/ru/post/592895/ | null | ru | null |
# Иерархическое логирование приложения в Базу Данных
Всем, привет!
В статье я хотел бы рассказать об одном из подходов к логированию приложения, который сильно помогал мне и коллегам при отладке, поиске ошибок и анализе проблем производительности. Про необходимость логирования было написано множество хороших статей в... | https://habr.com/ru/post/500656/ | null | ru | null |
# Linux Kernel EFI Boot Stub или «Сам себе загрузчик»
#### Введение
Прочитав недавнюю статью [Загрузка ОС Linux без загрузчика](http://habrahabr.ru/post/196926/), понял две вещи: многим интересна... | https://habr.com/ru/post/197438/ | null | ru | null |
# Эмулятор CD-Rom для SonyPlaystation который я писал больше десяти лет. Часть 2
В [первой части](https://habr.com/ru/post/653507/). Мы поверхностно посмотрели, как работает микросхема CXD2545, которая является частью контроллера CDRom и стоит между данными считываемые лазером и остальной частью приставки. Я для себя ... | https://habr.com/ru/post/665660/ | null | ru | null |
# Почему я отказался от использования Smarty
##### Краткиий экскурс в историю
Когда я пришел на работу в одну американскую контору (удаленно конечно. и было это году так в 2000), то вынужден был использовать стандарты, принятые в этой организации. И одним из них было использование своего шаблонизатора, который выгляд... | https://habr.com/ru/post/200198/ | null | ru | null |
# Управляемая градиентная спираль на ассемблере в 256 байт (k29)
Эта статья посвящена созданию на ассемблере графического приложения весом в несколько сотен байт. После создания полноценной рабочей версии на 420 байт пришлось попотеть, чтобы запихать всё это добро в 256 байт. Результат вы можете лицезреть на видео. В ... | https://habr.com/ru/post/121999/ | null | ru | null |
# VectorDrawable — часть первая
*Предлагаю вашему вниманию перевод статьи "[VectorDrawables – Part 1](https://blog.stylingandroid.com/vectordrawables-part-1/)" с сайта blog.stylingandroid.com.*
По долгу службы потребовалось мне как-то разобраться с векторной графикой. Во время поиска наткнулся я на серию статей под н... | https://habr.com/ru/post/301578/ | null | ru | null |
# Установка пограничного контроллера сессий 3CX SBC на Windows, Raspberry Pi или Debian 9
Введение
--------
Пограничный контроллер сессий 3CX SBC используется для подключения удаленных офисов с небольшим количеством телефонов к центральному серверу 3CX. Он транслирует к серверу SIP-сигнализацию, используя собственную... | https://habr.com/ru/post/417243/ | null | ru | null |
# Оптимизация перебора
*Дисклеймер: для понимания этой статьи требуются начальные знания теории графов, в частности знание [поиска в глубину](http://ru.wikipedia.org/wiki/Поиск_в_глубину), [поиска в ширину](http://ru.wikipedia.org/wiki/Поиск_в_ширину) и [алгоритма Беллмана — Форда](http://ru.wikipedia.org/wiki/Алгорит... | https://habr.com/ru/post/190850/ | null | ru | null |
# Управляем светодиодом через интернет с использованием RaspberryPi
В наше время обычная вещь, подключённая к интернету, начинает становиться обыденностью. Даже появилось понятие — «интернет вещей» (Internet of Things, IoT). Но как подступиться к этому своеобразному интернету новичку — не всегда понятно, потому что хо... | https://habr.com/ru/post/242409/ | null | ru | null |
# Визуализация статических и динамических сетей на R, часть 2
В [первой части](http://habrahabr.ru/company/infopulse/blog/262079/):
* визуализация сетей: зачем? каким образом?
* параметры визуализации
* best practices — эстетика и производительность
* форматы данных и подготовка
* описание наборов данных, которые и... | https://habr.com/ru/post/263947/ | null | ru | null |
# Создание вашей первой игры на Phaser. Часть 3 — Создание игрового мира

Оглавление
----------
**0**. [Подготовка к работе](https://habrahabr.ru/post/324894/)
**1**. [Введение](https://habrahabr.ru/post/324896/)
... | https://habr.com/ru/post/325384/ | null | ru | null |
# Автоматизация миграций баз данных с помощью контейнеров и Git
> В преддверии старта курса [**"Инфраструктурная платформа на основе Kubernetes"**](https://otus.pw/ClsN/) приглашаем всех желающих на [бесплатный демо-урок](https://otus.pw/ClsN/), в рамках которого о*дним глазком посмотрим на устройство kubernetes, немн... | https://habr.com/ru/post/528354/ | null | ru | null |
# Хинты планера в PostgreSQL
Известно, что SQL — декларативный язык, который указывает, «что» мы хотим выбрать из базы, а «как» это сделать — СУБД решает сама. Задачу выбора для SQL-запроса конкретного способа его выполнения(плана) решает планировщик запросов, который есть практически в любой СУБД. Но иногда он выбира... | https://habr.com/ru/post/169751/ | null | ru | null |
# Неизвестная история Tesla, часть 1/3
### Работа, изобретения, озарения, предательство и создание электроавтомобиля
[](http://https:https://habrastorage.org/files/2eb/a50/c75/2eba50c75ff4409eabaf1fa86bd364ec.jpg)
*Реакция... | https://habr.com/ru/post/379633/ | null | ru | null |
# Поддержка multi-touch и жестов в Flash платформе
Эта статья описывает новые multi-touch API, доступные в Flash Player 10.1 beta и Adobe AIR 2 beta. multi-touch становится доступным на все большем количестве платформ, и пользователи хотят иметь возможность взаимодействовать с устройствами с помощью прикоcновений. Fla... | https://habr.com/ru/post/81241/ | null | ru | null |
# MODх — Учет посетителей сайта и график посещений
Как и многие программисты, я страдаю некоторой степенью подозрительности к чужим сервисам, и предпочитаю делать все сам.
К чужим сервисам, в частности относится liveinternet и другие счетчики посещений. Я им как то не доверяю, знаете ли.
Сейчас я вам расскажу (и... | https://habr.com/ru/post/111203/ | null | ru | null |
# Вышел релиз nginx 1.20.0

С момента выхода прошлой версии nginx прошел целый год. Сейчас [представлена](http://nginx.org/#2021-04-20) новая стабильная ветка nginx 1.20.0. По словам разработчиков, в нее в... | https://habr.com/ru/post/553362/ | null | ru | null |
# Простой GUI калькулятор на Python #1. Дизайн приложения
Штош. Наверное, каждый начинающий программист после *"Hello, world!"* хочет написать какой-нибудь простенький проект. Почти всегда в голову приходит и... | https://habr.com/ru/post/586730/ | null | ru | null |
# Грокаем RxJava, часть вторая: Операторы
В [первой части](http://habrahabr.ru/post/265269/) мы с вами рассмотрели основные строительные блоки RxJava, а также познакомились с оператором `map()`. Я могу понять тех из вас, кто всё ещё не чувствует желания всё бросить и начать использовать этот фреймворк, так как пока чт... | https://habr.com/ru/post/265583/ | null | ru | null |
# Начался 8-й конкурс Underhanded C для программистов-хакеров
По условиям конкурса [Underhanded C](http://www.underhanded-c.org/), исходный код программы должен быть читаемым, ясным, простым и совершенно невинным для постороннего взгляда. При этом программа выполняет некую вредоносную функцию, которая совершенно не оч... | https://habr.com/ru/post/357624/ | null | ru | null |
# Доступные методы борьбы с DDoS-атаками для владельцев vds/dedicated серверов с Linux
Начать свое присутствие на Хабре мы решили с материала, подготовленного для [Конференции уральских веб-разработчи... | https://habr.com/ru/post/149302/ | null | ru | null |
# ECS back and forth
Привет, Хабр! Представляю вашему вниманию перевод статьи [**"ECS back and forth** — Part 1 — Introduction"](https://skypjack.github.io/2019-02-14-ecs-baf-part-1/) автора [Michele **skypjack** Caini](https://github.com/skypjack).
ECS back and forth
==================
*Часть 1 — Введение.*
Когда ... | https://habr.com/ru/post/490500/ | null | ru | null |
# Используйте бандлер вместо практики rvm gemset per project
Наша команда долгое время использовала известную практику rvm [gemset per project](http://beginrescueend.com/rvm/best-practices/ "RVM Best Practices"). Однако, после работы с пакетным менеджером nodejs мы поняли, что гораздо удобнее складывать зависимости в ... | https://habr.com/ru/post/120272/ | null | ru | null |
# Как построить гибридную аналитическую платформу на базе SAP Analytics Cloud и локальных систем компании

Аналитические системы продолжают активно развиваться. По оценкам Gartner, объем мирового рынка BI-платформ и аналитичес... | https://habr.com/ru/post/516664/ | null | ru | null |
# CSS3: свойство Box-Sizing
Раньше, если мы делали div шириной и высотой 100px, добавляли padding 10px и border 10px, то получался квадрат не 100х100, а 140х140 px:
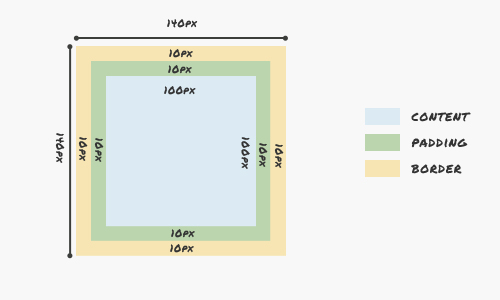
Но иногда требуется, чтобы div был фиксированной ши... | https://habr.com/ru/post/149441/ | null | ru | null |
# Язык программирования Rockstar: когда код выглядит как текст рок-хита

Словосочетание «rockstar developer» заставляет некоторых морщиться: «вот же глупый рекрутерский баззворд, среди самих разработчиков никто так себя не называет... | https://habr.com/ru/post/427877/ | null | ru | null |
# Теория игр: принятие решений с примерами на Kotlin
Теория игр — математическая дисциплина, рассматривающая моделирование действий игроков, которые имеют цель, заключающуюся в выбор оптимальных стратегий поведения в условиях конфликта. На Хабре эта тема уже [освещалась](https://habr.com/post/163681/), но сегодня мы п... | https://habr.com/ru/post/425609/ | null | ru | null |
# Магнитофон — инструмент для записи автотестов

Добрый день, уважаемые читатели. Меня зовут Виктор Буров. Я работаю разработчиком в компании ISPsystem и хочу поделиться опытом автоматизации тестирования.
Так сложилось, что у на... | https://habr.com/ru/post/421007/ | null | ru | null |
# Пишем своего бота для Google AI Challenge. Быстрый старт

Совсем скоро стартует Google AI Challenge Ants. Два дня назад уже был анонс на хабре про это состязание:
<http://habrahabr.ru/blogs/sport_programming/130457/>. Для те... | https://habr.com/ru/post/130582/ | null | ru | null |
# Пара историй про отличия Release от Debug
Все разработчики знают, что исполнение релизной версии может отличаться от отладочной. В этой статье я расскажу пару случаев из жизни, когда такие отличия приводили к ошибочному исполнению программы. Примеры не отличаются большой сложностью, но вполне могут уберечь от наступ... | https://habr.com/ru/post/127543/ | null | ru | null |
# Самое краткое введение в Reactive Programming
Цель данной статьи – показать на примере зачем нужно reactive programming, как оно связано с функциональным программированием, и как с его помощью можно писать декларативный код, который легко адаптировать к новым требованиям. Кроме того, хочется сделать это максимально ... | https://habr.com/ru/post/427467/ | null | ru | null |
# Что нового в первой CTP редакции SQL Server 2019
24 сентября была представлена первая редакция CTP выпуска SQL Server 2019, и, позвольте сказать, что он переполнен всевозможными улучшениями и новыми возможностями (многие из которых можно найти в форме предварительного просмотра в базе данных SQL Azure). У меня была ... | https://habr.com/ru/post/424441/ | null | ru | null |
# Как мы автоматизировали для пользователей работу с данными через Google Colab
Привет! Я Павел, тимлид группы DWH, отвечающей за сбор, хранение и выдачу потребителям аналитических данных. Эту статью мы написали вместе с руководителем Data Office Олегом Сахно.
Сегодня многие говорят об управлении на основе данных, ко... | https://habr.com/ru/post/567752/ | null | ru | null |
# Как запустить Jupyter Notebook в браузере без бэкенда
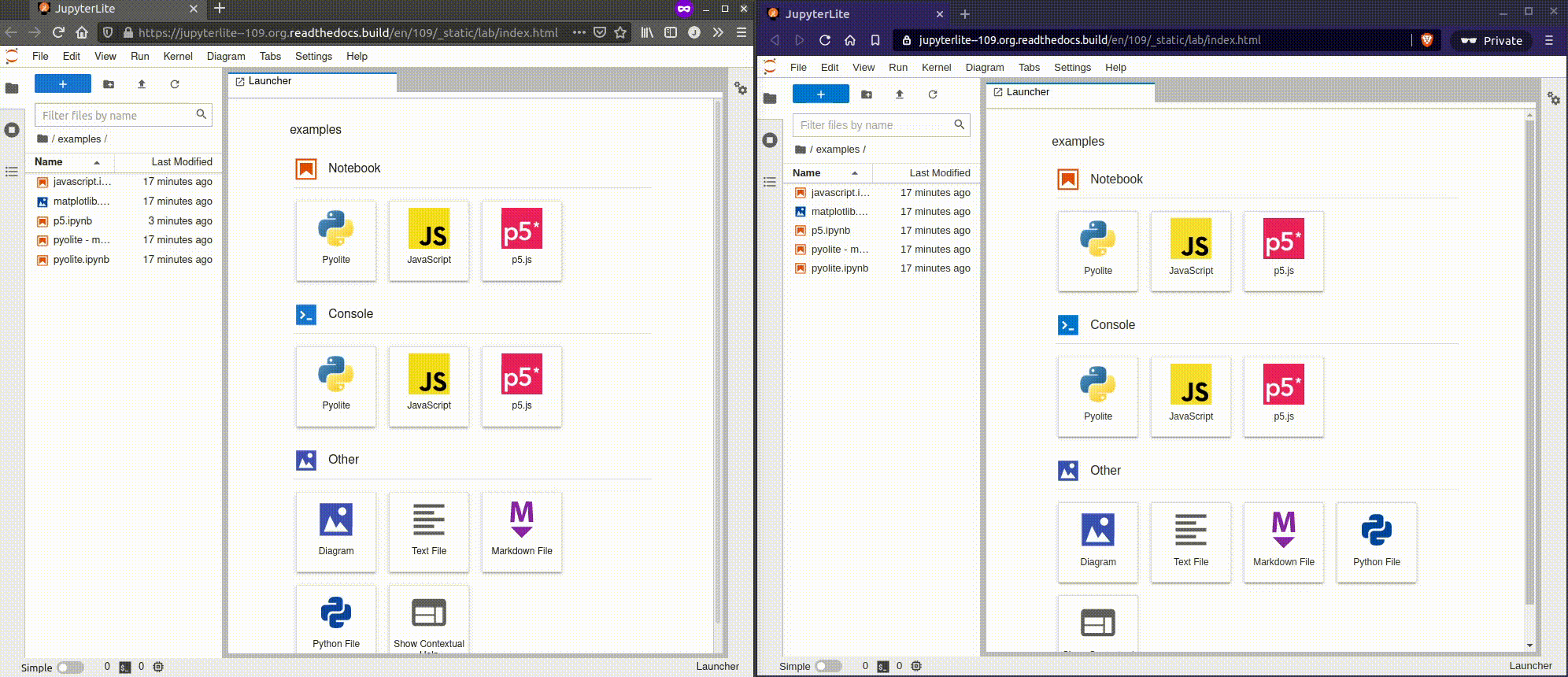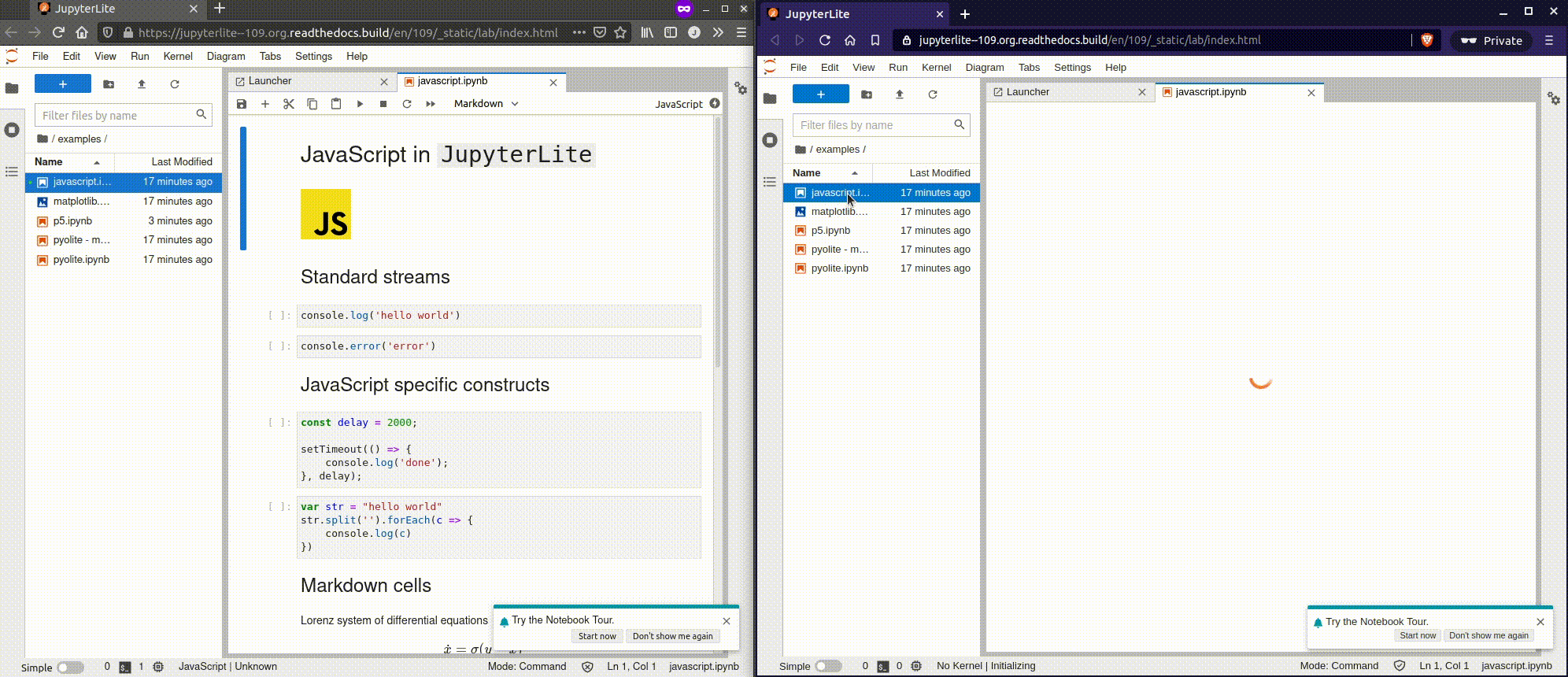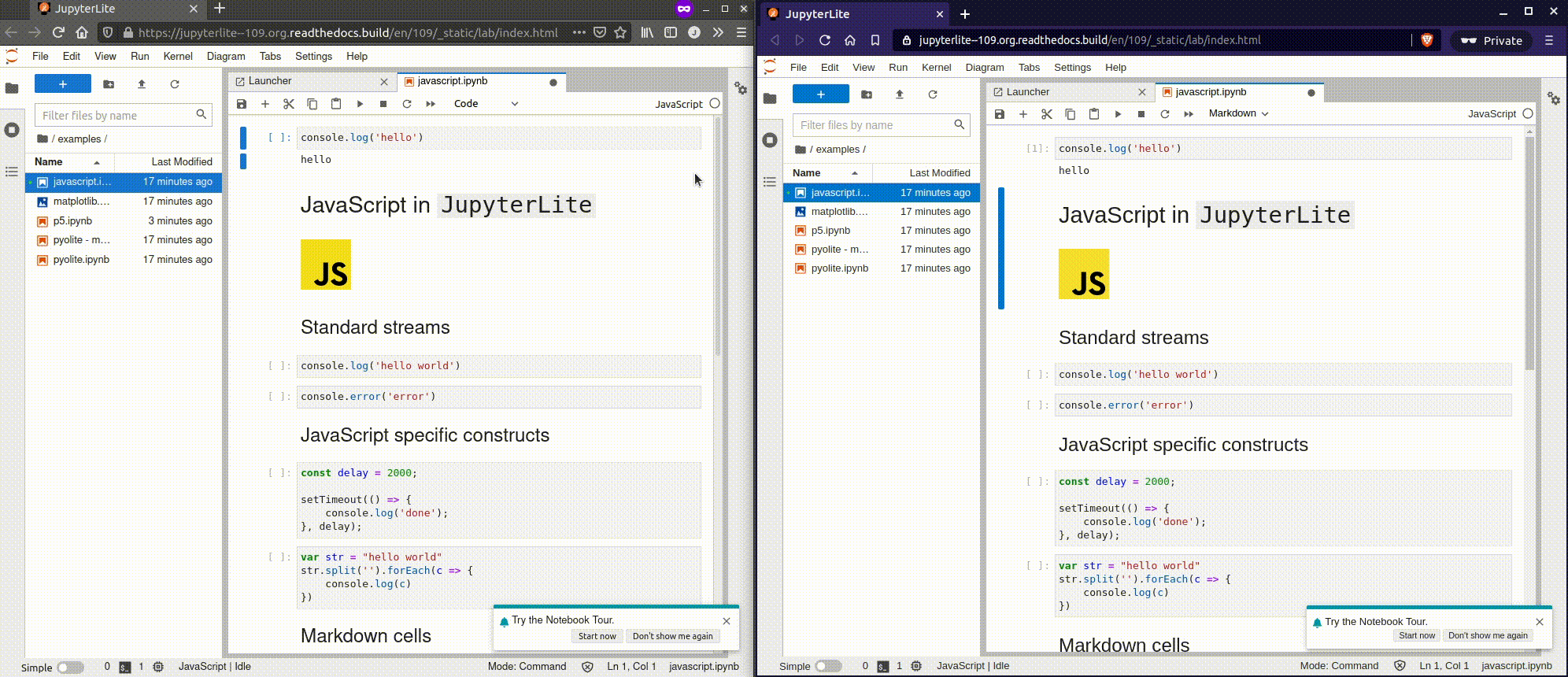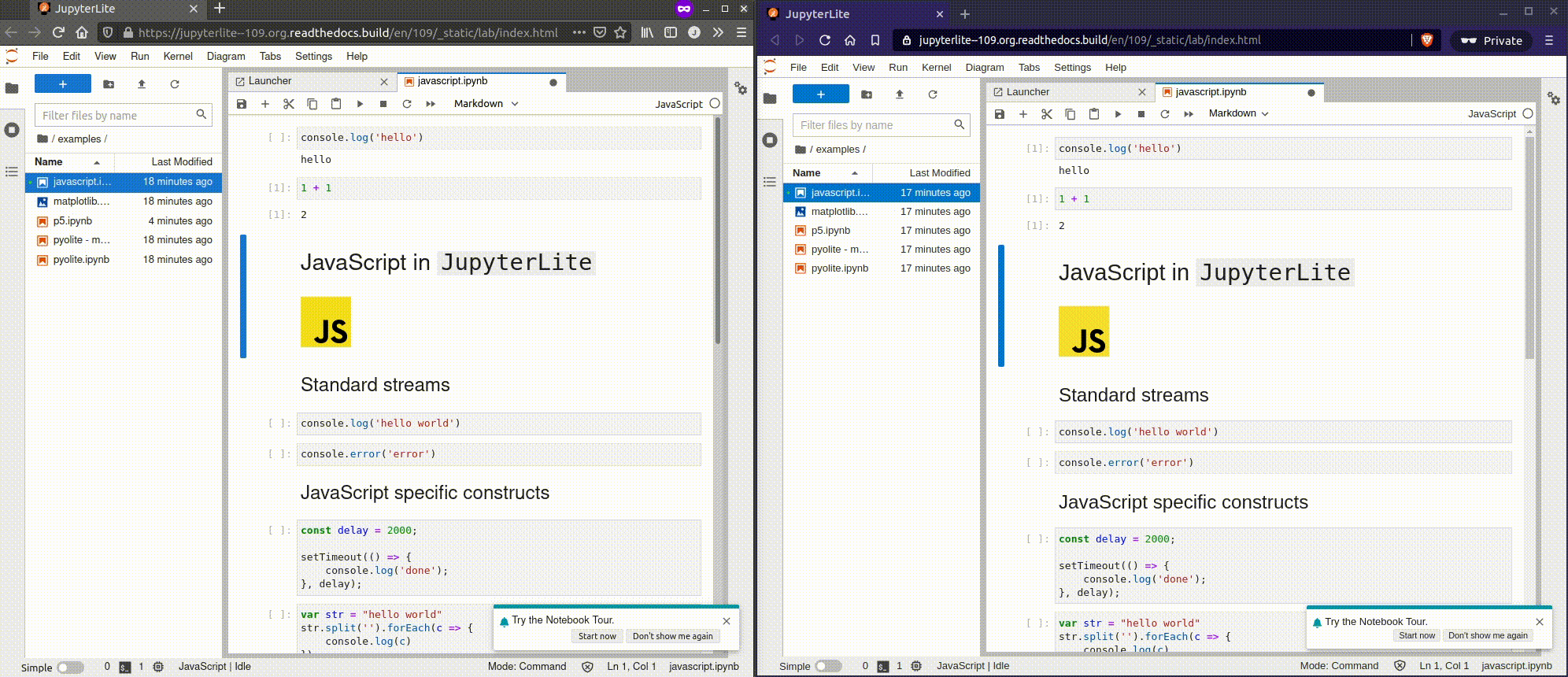К старту нашего флагманского [курса по Data Science](https://skillfactory.ru/dstpro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-scienc... | https://habr.com/ru/post/573726/ | null | ru | null |
# Инструменты Domain Driven Design
Синий кит — отличный пример того, как проектирование сложного проекта пошло не по плану. Кит внешне похож на рыбу, но он млекопитающее: кормит детенышей молоком, у него есть шерсть, а в плавниках до сих пор сохранились кости предплечья и кистей с пальцами, как у сухопутных. Он живет ... | https://habr.com/ru/post/488010/ | null | ru | null |
# Пять проблем при разработке мобильных free-to-play игр
Не секрет, что в последнее время кроссплатформенные мобильные free-to-play игры стали основным направлением деятельности большого числа игровых компаний. В этой статье мы не будем говорить ни о причинах, которые к этому привели, ни о перспективах данного направл... | https://habr.com/ru/post/192766/ | null | ru | null |
# Одной лишь мышкой
Всем привет, меня зовут Вячеслав и я программист, ну а конкретно сейчас я занимаюсь геймдевом на GodotEngine, и параллельно веду свой телеграмм канал, в котором пишу заметки по созданию своей игры на этом движке и подкидываю новичкам материал для изучения Годо.
А теперь перейдём к делу, а почему б... | https://habr.com/ru/post/555858/ | null | ru | null |
# Trafaret как парсер. Реализация JSON Schema
Intro
=====
Есть такой шаг в развитии языка, когда его компилятор написан на нем же.
Чтобы доказать крутость библиотеки trafaret я тоже решил сделать что-то такое же
рекурсивненькое, где надо идти глубже.
Напишем на трафарете парсер Json Schema, который на выходе в... | https://habr.com/ru/post/336282/ | null | ru | null |
# ТАУ для самых маленьких: пример реализации ПИД-регулятора в Unity3D
Вместо введения
===============
**Системы автоматического управления (САУ)** предназначены для автоматического изменения одного или нескольких параметров объекта управления с целью установления требуемого режима его работы. САУ обеспечивает поддерж... | https://habr.com/ru/post/345972/ | null | ru | null |
# Зафиксирована атака на криптовалютную биржу Gate.io
4 ноября злоумышленники скомпрометировали StatCounter, платформу для анализа веб-трафика. Сервис используется для сбора статистических данных о посетителях сайтов, примерно как Google Analytics. Для этого веб-мастера добавляют на каждую страницу сайта внешний тег J... | https://habr.com/ru/post/429050/ | null | ru | null |
# Вычислительная система пятого поколения
В 80 годы прошлого века правительство Японии совершило попытку создать распределенную вычислительную систему следующего поколения с элементами ИИ. Проект закончился ... | https://habr.com/ru/post/541968/ | null | ru | null |
# Linux DC++ и многопоточность
Всем доброго времени суток. В данном хабра топике хочу рассказать о работе в сетях DC под ос Linux. Сам я пишу из под Linux Mint 7, но на Ubuntu 9.04 всё идентично!
Итак, я обладатель доволь но медленного канала в Интернет. Всего, как заявлено в тарифе, 250 кбит(31.25кбайт). На деле ... | https://habr.com/ru/post/64775/ | null | ru | null |
# Переезд с SimpleTest на PHPUnit
Предыстория: одна из критических частей кода проекта покрыта юнит тестами основаными на фреймворке SimpleTest. В связи с переходом на PHPUnit необходимо было адаптировать существующие тесты под новый тестовый фреймворк.
Причем необходимо было оставить работающими тесты как в режиме... | https://habr.com/ru/post/55176/ | null | ru | null |
# Как импортозаместить CRM и систему управления проектами для малого бизнеса
Курс доллара как бы ненавязчиво намекает: использование для ведения бизнеса SaaS-решений с ценами в валюте скоро может сильно сказаться на бюджете небольшой компании.
Ну что ж, сыграем в модную игру *«Импортозамести меня полностью»*. Пусть... | https://habr.com/ru/post/364645/ | null | ru | null |
# Гарантированная локализация/русификация консоли Windows
Введение
--------
Консольные приложения до сих пор остаются наиболее востребованным видом приложений, большинство разработчиков оттачивают архитектуру и бизнес-логику именно в консоли. При этом они нередко сталкиваются с проблемой локализации - русский текст, ... | https://habr.com/ru/post/545330/ | null | ru | null |
# Симуляция эрозии рельефа на основе частиц

> Примечание: полный исходный код проекта, а также пояснения о его использовании и чтении можно найти на Github [[здесь](https://github.com/weigert/SimpleErosion)].
Я сделал перерыв в своей работ... | https://habr.com/ru/post/496762/ | null | ru | null |
# Когда умрёт мой SSD — расчёт срока жизни

У каждого SSD есть ресурс на количество циклов перезаписи, то есть объём записанной информации в течение всей жизни. Физика и механика SSD очень сложные, но долговечность накопителя в итоге... | https://habr.com/ru/post/660193/ | null | ru | null |
# Лень, рефлексия, атрибуты, динамические сборки
#### Небольшой опыт, полученный благодаря лени
Года три назад, работал я на одну фирму. Было нас 4 программиста. Один писал бизнес логику приложения. Описывал он ее с помощью интерфейсов (interface). Логические связи, зависимости и т. д. Наша же задача была реализовать... | https://habr.com/ru/post/316238/ | null | ru | null |
# Метод хранения материализованных путей в БД.
Основным преимуществом данного метода является доступ к дочерним узлам любого уровня в один запрос к БД (правда с INNER JOIN).
**Пример:**
необходимо в разделе /company/ добраться до списка новостей (item1, item2)
* /company/ О компании
+ /company/news/ Новос... | https://habr.com/ru/post/52298/ | null | ru | null |
# Разработка для Sailfish OS: таймеры и реализация экспорта в файл на примере примере приложения для ведения списка дел
Мы уже писали про опыт разработки [нашего первого приложения для мобильной платформы Sailfish OS](https://habrahabr.ru/post/312418/). Но на этом решили не останавливаться и сразу взялись за второе. Ц... | https://habr.com/ru/post/316082/ | null | ru | null |
# Visual Studio 2022 стильно и свежо. История о её поддержке в PVS-Studio
Кажется, анонс Visual Studio 2022 был только недавно, и вот она уже вышла. Это означало ровно одно – поддержать данную IDE нужно в ближайшем релизе PVS-Studio. О том, с какими сложностями пришлось столкнуться, а что прошло без проблем, мы сегодн... | https://habr.com/ru/post/651713/ | null | ru | null |
# Пять способов оптимизации кода для Android 5.0 Lollipop
Как сделать программы быстрее? Один из эффективных способов – оптимизация кода. Зная особенности платформы, для которой создаётся приложение, можно найти эффективные способы его ускорения.
[](https://habrahabr.ru/post/280674/), меня попросили написать статью, показывающую работу шейдера, переводящего изображение в «кофту».
Так что, давай рас... | https://habr.com/ru/post/280804/ | null | ru | null |
# Как не пропустить невалидный код в репозиторий
Зачем это необходимо
====================
Когда в твоей команде работают больше одного человека, так или иначе все сталкиваются с проблемой разных стилей кодирования каждого члена команды. Кто-то пишет скобки для блоков `if...else`, кто-то нет. Когда проект становится ... | https://habr.com/ru/post/488626/ | null | ru | null |
# Идеальный корпоративный почтовый клиент
Когда возникает необходимость настроить почтовую систему для компании в первую очередь на ум приходит использовать решения от Microsoft — Exchange и Outlook. К сожалению, эти р... | https://habr.com/ru/post/101905/ | null | ru | null |
# Инверсия зависимостей и 'import' в JS
В процессе обсуждения статьи "[Почему я «мучаюсь» с JS](https://habr.com/ru/post/569384/)" у меня сложилось понимание, что связка `export` / `import` в JS является базой для указания зависимостей между элементами кода (классами и функциями). А так как современные приложения вышл... | https://habr.com/ru/post/571598/ | null | ru | null |
# Охрана IT-решений в России
Цель данного поста донести информацию о способах охраны ИТ-решений в России — патенты, авторское право, ноу-хау. Протестующих против интеллектуальной собственности – просьба не сюда. Не будем разводить дебатов, сотни их…
Первым делом, давайте начнем с истоков, чтобы выстроить терминолог... | https://habr.com/ru/post/190712/ | null | ru | null |
# MugenMvvmToolkit — кроссплатформенный MVVM фреймворк
[MugenMvvmToolkit](https://github.com/MugenMvvmToolkit/MugenMvvmToolkit)
------------------------------------------------------------------------
Введение
--------
Паттерн MVVM хорошо известен, о нем написано много статей, наверное каждый NET-разработчик сталкив... | https://habr.com/ru/post/236745/ | null | ru | null |
# Наш опыт знакомства с Docker
Вместо предисловия
------------------

> *Сегодня приснился сон, как-будто меня ужали до размера нескольких
>
> килобайт, засунули в какой-то сокет и запустили в контейнере.
>
> Выдели... | https://habr.com/ru/post/278939/ | null | ru | null |
# RMI для нескольких сетевых интерфейсов
Здравствуй, Хабр!
В ходе работы появилась задача создать несколько RMI реестров, доступных через разные сетевые интерфейсы (локальная сеть и интернет). И к моему удивлению я ничего толком не нашел в сети по этому вопросу. Поэтому разобравшись сам, решил поделиться решением с... | https://habr.com/ru/post/185710/ | null | ru | null |
# Сторожевой таймер для 4G-модема в CentOS 7
Эта статья является дополнением моей предыдущий [публикации](http://habrahabr.ru/post/273547/) о настройке домашнего роутера / файл-сервера. Здесь речь пойдет о проблеме автоматического переподключения к интернету при зависании 4G-модема. На оригинальность идеи не претендую... | https://habr.com/ru/post/275551/ | null | ru | null |
# jsForms
Добрый вечер, после написания предыдущего поста прошло уже, наверное, более трех недель, с тех пор мое направление немножко изменилось, да MVC хороший паттерн, но сейчас для js он еще слишком громоздкий. Мы стремимся выбрать более прозрачные и тонкие решения, которые бы позволяли видеть как все работает, вот... | https://habr.com/ru/post/45361/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.