
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Мини-компьютер на базе микроконтроллера Parallax Propeller
Микроконтроллер фирмы Parallax под названием [Propeller](http://www.parallax.com/propeller/), в сравнении с «классикой» жанра типа PIC или AVR занимает несколько странную нишу. Про первые два можно сказать, что это архитектуры общего назначения. Создатели же... | https://habr.com/ru/post/159847/ | null | ru | null |
# Занимательный C#
Занимательный C#
Для оценки качества диагностик анализатора C# кода PVS-Studio мы проверяем большое количество различных проектов. Т.к. проекты пишутся разными людьми в различных командах в разных компаниях, нам приходится сталкиваться с различными стилями, сокращениями, да и просто возможностями... | https://habr.com/ru/post/303340/ | null | ru | null |
# Bad news, everyone! New hijack attack in the wild
On March 13, a [proposal](https://www.ripe.net/ripe/mail/archives/anti-abuse-wg/2019-March/004585.html) for the RIPE anti-abuse working group was submitted, stating that a BGP hijacking event should be treated as a policy violation. In case of acceptance, if you are ... | https://habr.com/ru/post/447776/ | null | en | null |
# Shared Hosting & mod_rewrite
Небольшой совет для тех кто пишет приложения на Zend Framework с использованием структуры директорий рекомендуемой в мануале и, по умолчанию, в Zend\_Tool и размещает их по тем или иным причинам на shared хостингах.
Структура ваших директорий имеет вид:
> `projectname/
> applic... | https://habr.com/ru/post/63053/ | null | ru | null |
# Как настроить HTTPS — поможет SSL Configuration Generator
Рассказываем об инструменте для конфигурации SSL, который разработали в Mozilla.
Под катом — о его возможностях и других утилитах для настройки сайтов.
[](https://habr... | https://habr.com/ru/post/459002/ | null | ru | null |
# Шифрование и генерация случайных чисел в Android приложениях. Тестовые примеры
В этой статье мы приведем тестовые фрагменты кода, реализующего две основополагающие с точки зрения безопасности функции в Android приложениях: генерацию случайных чисел и шифрование данных. Рекомендуем попробовать все приведенные вариант... | https://habr.com/ru/post/224285/ | null | ru | null |
# Руководство хакера по нейронным сетям. Глава 2: Машинное обучение. Бинарная классификация
Содержание:
**Глава 1: Схемы реальных значений**[Часть 1:](http://habrahabr.ru/company/paysto/blog/244723/)
```
Введение
Базовый сценарий: Простой логический элемент в схеме
Цель
Стратегия №1: П... | https://habr.com/ru/post/246523/ | null | ru | null |
# 7 бубей iOS разработчика игр
Долгих лет жизни читающему эти строчки.
В статье обобщен трехлетний опыт создания iOS игр для личного пользования.
Примеров программного кода не будет. За примерами программного Вы идите на [stackoverflow.com](http://www.stackoverflow.com).
В статье разбирается создание приложен... | https://habr.com/ru/post/158585/ | null | ru | null |
# System-on-Chip bus: AXI4 simplified and explained
Introduction
------------

Привет, Хабр! Очень много статей написано о PDO, но при этом очень мало реальных примеров. В этой статье я хочу представить свою версию класса для работы с базой данных (далее - БД). Эта статья будет полезна начинающим программистам, которые только осваивают эту технологию.
>... | https://habr.com/ru/post/535512/ | null | ru | null |
# Атаки на сеть. Часть 1
Цикл статей будет посвящен возможным атакам на современные сети. В первой части познакомимся теоретически с атаками и соберем необходимый инструментарий, в последующих попробуем воспр... | https://habr.com/ru/post/659181/ | null | ru | null |
# Всё, что вы хотели знать про GOPATH и GOROOT
Несмотря на то, что Go считается одним из самых легких для входа языков, приходится регулярно слышать: «как-то все непонятно, какие-то переменные GOROOT и GOPATH нужно устанавливать». И хотя тема полностью раскрыта на официальном сайте Go, не будет лишним объяснить совсем... | https://habr.com/ru/post/249545/ | null | ru | null |
# WiFiBeat: Обнаруживаем подозрительный трафик в беспроводной сети

В данной статье мы поговорим о WiFiBeat, агенте, который может отправлять 802.11 фреймы в Elasticsearch, где мы можем их анализировать, строить графики и обн... | https://habr.com/ru/post/335134/ | null | ru | null |
# Xiaomi Gateway MIEU01 как универсальный контроллер умного дома
[Home Assistant](https://www.home-assistant.io/) - прекрасное программное решение для умного дома. У него современный интерфейс, множество плагинов и дополнений почти на все случаи жизни. В интернете можно найти множество компонентов для самых экзотическ... | https://habr.com/ru/post/543568/ | null | ru | null |
# Сравнение матричной факторизации с трансформерами на наборе данных MovieLens с применением библиотеки pytorch-acceleratd
Современный человек много чем занимается в интернете: ходит по магазинам, слушает музыку, читает новости. Все эти задачи подразумевают поиск и выбор того, что ему нужно. При этом важную роль тут и... | https://habr.com/ru/post/645921/ | null | ru | null |
# Пишем плагин для GStreamer на MS Visual Studio
Меня всегда интересовали прикладные задачи обработки видеоданных в реальном времени. На Хабре я прочитал серию статей о мультимедиа фреймвоке GStreamer:
* [Знакомство с GStreamer: Введение](http://habrahabr.ru/post/178813/)
* [Знакомство с GStreamer: Источники данны... | https://habr.com/ru/post/221483/ | null | ru | null |
# Фрезеровка печатных плат в домашних условиях

Я не люблю травить печатные платы. Ну не нравится мне сам процесс возни с хлорным железом. Там напечатай, тут проутюжь, здесь фоторезист проэкспонируй — целая история каждый... | https://habr.com/ru/post/402047/ | null | ru | null |
# Python-пакеты и их использование

Всем добрый день!
На Хабре уже поднималась [тема](http://habrahabr.ru/blogs/Git/75964/) организации работы с внешними пакетами с использованием подмодулей или деревьев в Git. Это показалось хор... | https://habr.com/ru/post/127441/ | null | ru | null |
# Почему embedded-разработчикам следует использовать статический анализ кода

Решил кратко сформулировать 3 причины, по которым embedded-разработчикам полезны инструменты ст... | https://habr.com/ru/post/351020/ | null | ru | null |
# Автозагрузка в PHP: начали за здравие, а кончили за упокой
#### Предисловие переводчика
Данная статья является вольным переводом-пересказом поста [The End of Autoloading](http://propel.posterous.com/the-end-of-autoloading). Оригинальная статья не первой свежести, поэтому код приведенный в примерах может быть не акт... | https://habr.com/ru/post/138920/ | null | ru | null |
# Ещё один С++ plugin framework
Вступление
----------
Кого не посещала, пользуясь open-source библиотеками, мысль: *«Спасибо этим парням за эту крутую либу! Когда-нибудь и я напишу что-нибудь стоящее, и выложу это в public, чтоб другие пользовались!»*
Да всех! Или не ?..
С приходом стандарта C++17, наши `хотелки` р... | https://habr.com/ru/post/422401/ | null | ru | null |
# Приложение Дурак для Windows Store

*Поль Сезанн, «Игроки в карты»*
Давным-давно, в Windows 95 была игра Microsoft Hearts. Игра в карты по сети, с оппонентами по всему миру. Если мне не изменяет память, то в Windows for Workgr... | https://habr.com/ru/post/442746/ | null | ru | null |
# Golden Ticket: разбираем атаку и методы ее детекта
Привет, Хабр!
Сегодня мы хотим поговорить об атаке с применением известной техники Golden Ticket (T1558.001). О том, что лежит в основе Golden Ticket а... | https://habr.com/ru/post/686784/ | null | ru | null |
# Пишем собственные React-хуки на TypeScript и тестируем их с React Testing Library (часть 1)
Думаю, React-хуки не нуждаются в особом представлении, поэтому можно пропустить их описание и приступить сразу к д... | https://habr.com/ru/post/653431/ | null | ru | null |
# Использование PowerShell для повышения привилегий локальных учетных записей

Повышение привилегий — это использование злоумышленником текущих прав учетной записи для получения дополнительного, как правило, более высокого уровня д... | https://habr.com/ru/post/454160/ | null | ru | null |
# Производительность RemoteFX, часть 2
В [первой части исследования](https://habr.com/ru/company/cloud4y/blog/552034/) мы оценивали эффективность включения GPU-ускорения для RemoteFX в однопользовательском режиме. Это второй этап, в котором займёмся проверкой и оценкой производительности для нескольких одновременных т... | https://habr.com/ru/post/553132/ | null | ru | null |
# Высоконагруженный сервис для вычислений на GPU

Привет, Хабр! Я руковожу разработкой платформы [Vision](https://biz.mail.ru/vision/) — это наша публичная платформа, которая предоставляет доступ к моделям компьютерного зрения и по... | https://habr.com/ru/post/472928/ | null | ru | null |
# Облачное хранилище и консольные FTP-клиенты

Об особенностях работы с нашим хранилищем по FTP [мы уже писали](http://blog.selectel.ru/oblachnoe-xranilishhe-dostup-po-ftp/). Сегодня мы затронем более ... | https://habr.com/ru/post/213945/ | null | ru | null |
# Кросспостинг в twitter, facebook, livejournal, vkontakte

Когда я писал проект [crafthunters.com](http://crafthunters.com), я заметил что для раскрутки клиенты используют социальные сети. Пользовались виджетами и лайками, но по хорошему надо было попадать в ленту н... | https://habr.com/ru/post/131107/ | null | ru | null |
# IoT там, где вы не ждали. Разработка и тестирование (часть 2)
Продолжение первой части статьи [«IoT там, где вы не ждали. Разработка и тестирование (часть 1)»](https://habr.com/ru/company/jugru/blog/501922/) не заставила себя долго ждать. На этот раз я расскажу, какая была архитектура проекта и на какие грабли мы на... | https://habr.com/ru/post/502898/ | null | ru | null |
# Введение в SproutCore часть вторая
В [первой части](http://habrahabr.ru/blogs/javascript/125698) руководства по SproutCore рассказывалось о создании простого приложения.
Пришло время углубить знания и разобраться с Моделями в SproutCore.
После прочтения данного руководства вы сможете:
* Описывать модели с п... | https://habr.com/ru/post/126027/ | null | ru | null |
# Устраняем старый баг в NVIDIA GeForce Experience
Предыстория
===========
Несколько месяцев назад я решил попробовать сыграть в Microsoft Flight Simulator 2020. [Копия нашей планеты](https://www.youtube.com/watch?v=0w7q1ZFfsxs), созданная Asobo при помощи фотограмметрии и машинного обучения, казалась подходящим мест... | https://habr.com/ru/post/531746/ | null | ru | null |
# Ещё раз об ImmutableList в Java
В своей предыдущей статье "[Рукоблудие вокруг ImmutableList в Java](https://habr.com/ru/post/470257/)" я предложил вариант решения поднятой в статье "[Неизменяемых коллекций в Java не будет – ни сейчас, ни когда-либо](https://habr.com/ru/company/piter/blog/470149/)" проблемы отсутстви... | https://habr.com/ru/post/471344/ | null | ru | null |
# А мне летать охота, или как протестировать узлы квадрокоптера без аппаратуры радиоуправления
Начитавшись статей на Хабре про квадрокоптеры, и насмотревшись видео на YouTube, захотелось и мне сделать квадрокоптер.
Заказал я в чудесном китайском [магазине](http://www.rctimer.com/) деталек, за основу брал список из ... | https://habr.com/ru/post/147683/ | null | ru | null |
# Виджет комментариев вконтакте для вашего сайта и хранение количества комментариев на сервере
Двигаясь в ногу со временем, я решил разместить на своем сайте виджет комментариев «Вконтакте». Немного терпения, гугла и документации вполне достаточно для того чтобы достичь результата. Разместить сам виджет не составляет ... | https://habr.com/ru/post/130260/ | null | ru | null |
# Работа с куки на чистом JavaScript без головной боли
Привет, Хабр!
=============
Недавно я столкнулся с необходимостью работать с куки-файлами при помощи JavaScript. Когда я увидел, насколько ужасна работа с **document.cookie** на чистом JavaScript, я полез искать библиотеку для удобства работы с куками. Как оказал... | https://habr.com/ru/post/501724/ | null | ru | null |
# Разработка для SailfishOS: меню
Здравствуйте! Очередное продолжение цикла статей о разработке для мобильной платформы SaifishOS. На этот раз я хочу рассказать о том, как в приложении реализовать различного вида меню. Данная тема заслуживает отдельной статьи, поскольку меню в SailfishOS сами по себе выглядят достаточ... | https://habr.com/ru/post/308102/ | null | ru | null |
# Конференция BLACK HAT USA. Как Голливудский хакер использует камеры наблюдения. Часть 1
Я Грэг Хеффнер, и это разговор о том, как голливудский хакер использует камеры наблюдения. Некоторые из вас могут знать или не знать, что когда впервые была опубликована моя работа по этой теме, на интернет-портале Reuters об это... | https://habr.com/ru/post/427367/ | null | ru | null |
# ‘Hello World’ tutorial — Ваше первое приложение на Play framework (Часть 1)
Это очень поверхностное руководство, которое только познакомит с базовым функционалом Play framework на примере создания приложения ‘Hello World’.
Познакомиться с Play framework можно в статье [«Отличный Java MVC фреймворк — Play Framewor... | https://habr.com/ru/post/111420/ | null | ru | null |
# Tree-sitter: обзор инкрементального парсера
Некоторые IDE и текстовые редакторы парсят исходный файл целиком при каждом изменении, что может тормозить на больших файлах, а некоторые делают это построчно с помощью регулярных выражений, что тоже тормозит и не даёт качественной подсветки кода, т.к. теряется контекст. Д... | https://habr.com/ru/post/670140/ | null | ru | null |
# Решение задания с pwnable.kr 27 — tiny_easy. Разбираемся с Stack spraying

В данной статье решим 27-е задание с сайта [pwnable.kr](https://pwnable.kr/index.php) и разберемся с тем, что же такое Stack spraying.
**Организацио... | https://habr.com/ru/post/487620/ | null | ru | null |
# Моделирование динамических систем: задача внешней баллистики
Введение
========
Надеюсь что мы с вами набрались достаточно опыта, чтобы смоделировать что-нибудь более серьезное, чем полет камня. Предлагаю такую задачу
> Пушка, стреляющая сферическими ядрами сообщает им начальную скорость 400 м/с. Определить траек... | https://habr.com/ru/post/349262/ | null | ru | null |
# SOLID
> SOLID критикует тот, кто думает, что действительно понимает ООП
>
> © Куряшкин Виктор
Я знаком с принципами SOLID уже 6 лет, но только в последний год осознал, что они означают. В этой статье я дам простое объяснение этим принципам. Расскажу о минимальных требованиях к языку программирования для их реал... | https://habr.com/ru/post/348286/ | null | ru | null |
# Ответы на задачи со стенда PVS-Studio на конференциях 2018-2019

Привет! Несмотря на то, что сезон конференций 2019 года ещё в самом разгаре, мы бы хотели обсудить задачи, которые ранее предлагали ... | https://habr.com/ru/post/476272/ | null | ru | null |
# Веб-типографика сегодня. Часть IV
[Часть I](http://habrahabr.ru/blog/typography/42685.html) — [Часть II](http://habrahabr.ru/blog/typography/42697.html) — [Часть III](http://habrahabr.ru/blog/typography/42716.html) — [Часть IV](http://habrahabr.ru/blog/typography/42837.html) — [Часть V](http://habrahabr.ru/blog/typo... | https://habr.com/ru/post/25958/ | null | ru | null |
# Книга «Black Hat Python: программирование для хакеров и пентестеров, 2-е изд»
[](https://habr.com/ru/company/piter/blog/592287/) Привет, Хаброжители! Когда речь идет о создании мощных и эффективных хакерских инструментов, больш... | https://habr.com/ru/post/592287/ | null | ru | null |
# Снова про формы: значения по умолчанию
jQuery дает практически безграничные возможности по обогащению пользовательского интерфейса, а самое интересное зачастую связано с элементами управления на страницах, в частности с формами.
Современные интерфейсы часто стремятся к минимализму. При изяществе дизайна, вэб-техн... | https://habr.com/ru/post/98010/ | null | ru | null |
# SwiftUI по полочкам: Анимация. Часть 1

Недавно мне попалась свежая [статья](https://habr.com/ru/post/501790/), в которой ребята пытались воспроизвести интересный концепт средствами SwiftUI. Вот что у них получилось:
 , без прочтения которой, единственный вопрос, на который именно тут дается ответ - "почему на КДПВ этого цикла статей везде картинки авторств... | https://habr.com/ru/post/597851/ | null | ru | null |
# Реализация стека, очереди и дека на языке F# в функциональном стиле
Недавно я познакомился с концепцией функционального программирования. Возможно, в этой статье я изобретаю велосипед, однако я считаю, что эти действия являются весьма полезными для обучения, а также для более чёткого понимания функционального програ... | https://habr.com/ru/post/236375/ | null | ru | null |
# Как сделать Swift-friendly API с Kotlin Multiplatform Mobile
Kotlin Multiplatform Mobile позволяет компилировать Kotlin код в нативные библиотеки для Android и iOS. И если в случае с Android полученная из K... | https://habr.com/ru/post/571714/ | null | ru | null |
# Программирование с PyUSB 1.0
***От переводчика**:
Это перевод руководства [Programming with PyUSB 1.0](https://github.com/pyusb/pyusb/blob/master/docs/tutorial.rst)
Данное руководство написано силами разработчиков PyUSB, однако быстро пробежавшись по коммитам я полагаю, что основной автор руководства — [walac]... | https://habr.com/ru/post/430528/ | null | ru | null |
# Работа с частичными моками в PHPUnit 10
В этом году должен выйти PHPUnit 10 (релиз планировался на 2 апреля 2021 года, но был отложен). Если посмотреть на [список изменений](https://github.com/sebastianberg... | https://habr.com/ru/post/553782/ | null | ru | null |
# WebGLU: упрощаем работу с WebGL
Когда-то 3D в браузере было большой проблемой. К чему только не прибегали для создания объемной динамичной трехмерной графики в браузере: использованию псевдо-3D в SVG, построениям в canvas, использованию flash… Однако, прогресс не стоит на месте: наконец-то все современные браузеры с... | https://habr.com/ru/post/143680/ | null | ru | null |
# Безопасный хак для Safari
Имеем: навороченную форму без таблиц
Нужно: подвинуть съезжающий из-за сглаживания шрифтов label в Safari
Примечание: подвинуть безопасно, а не css3-свойствами.
Вуаля! есть замечательное свойство safari only позволяющее подвинуть что-угодно куда-угодно влево-вправо!
**-webkit-ma... | https://habr.com/ru/post/22266/ | null | ru | null |
# Теория категорий в API для консистентности Apache Cassandra
**DISCLAIMER**
> Ожидается, что читатель понимает структуру первичного ключа в таблицах и необходимость дублирования данных в Apache Cassandra. Статья даст лишь краткие объяснения, т.к. проектирование модели данных не является предметом данной статьи. Важн... | https://habr.com/ru/post/709508/ | null | ru | null |
# Создание Discord-бота, используя библиотеку discord.js | Часть №1
### Введение
В этой статье я подробно расскажу о том, как работать с библиотекой **discord.js**, создать своего Discord-бота, а также покажу несколько интересных и полезных команд.
Сразу хочу отметить, что я планирую сделать ряд подобных статей, н... | https://habr.com/ru/post/507948/ | null | ru | null |
# 7 советов по оптимизации CSS для ускорения загрузки страниц
В современном вебе, время загрузки страницы сайта — одна из важнейших метрик. Даже миллисекунды могу оказывать огромное влияние на Вашу прибыль и медленная загрузка страницы может легко навредить Вашим показателям конверсии. Существует много инструментов и ... | https://habr.com/ru/post/459878/ | null | ru | null |
# Пробуем на вкус API v2 карт под Android от Google
И на нашей улице переворачиваются грузовики с ~~печеньками~~ мороженым и мармеладками! Как уже было [сказано](http://www.google.com/url?q=http%3A%2F%2Fhabrahabr.ru%2Fpost%2F161247%2F&sa=D&sntz=1&usg=AFQjCNEFwVkvZxmxJ-lzndWFS3gOUUvUTA), вышла новая версия API. И даже ... | https://habr.com/ru/post/161457/ | null | ru | null |
# Визуализация графов. Метод связывания ребер
Иногда полезно представить граф в графической форме, так чтобы была видна структура. Можно привести десятки примеров, где это может пригодиться: визуализация иерархии классов и пакетов исходного кода какой-нибудь программы, визуализация социального графа (тот же Twitter ил... | https://habr.com/ru/post/116758/ | null | ru | null |
# STM32, C++ и FreeRTOS. Разработка с нуля. Часть 3 (LCD и Экраны)
#### Введение
В двух предыдущих частях [STM32, C++ и FreeRTOS. Разработка с нуля. Часть 1](http://habrahabr.ru/post/261807//) и [STM32, C++ и FreeRTOS. Разработка с нуля. Часть 2](http://habrahabr.ru/post/261823/) мною уже были реализованы требования... | https://habr.com/ru/post/261837/ | null | ru | null |
# Применение принципа DRY в RSpec

DRY(Don’t Repeat Yourself) — один из краеугольных принципов современной разработки, а особенно в среде ruby-программистов. Но если при написании обычного кода повторяющиеся фрагменты об... | https://habr.com/ru/post/160915/ | null | ru | null |
# Теория и практика unattended upgrades в Ubuntu
**Unattended upgrades** — это родной для Debian/Ubuntu (и других основанных на них дистрибутивов GNU/Linux) механизм автоматических обновлений. **По умолчанию** он включён в системе благодаря наличию установленного пакета `unattended-upgrades` и конфигурационного файла ... | https://habr.com/ru/post/330406/ | null | ru | null |
# Cтримим и кaстим youtube и не только… через raspberry pi c Gotubecast и KODI TubeCast

Насколько сложно передавать youtube музыку или видео через телефон или другие портативные, мобильные устройства... | https://habr.com/ru/post/503254/ | null | ru | null |
# Постим новости с картинкой в группы Вконтакта (Perl)
При создании информационных ресурсов часто приходится задумываться об автоматизации рутиной работы. В данной статье рассмотрим простой способ, при помощи нескольких строк Perl, как новости, спецпредложения, или другую полезную информацию, выложить на свою страничк... | https://habr.com/ru/post/211198/ | null | ru | null |
# Индексы в PostgreSQL — 8
Мы уже рассмотрели [механизм индексирования PostgreSQL](https://habrahabr.ru/company/postgrespro/blog/326096/), [интерфейс методов доступа](https://habrahabr.ru/company/postgrespro/blog/326106/) и все основные методы доступа, как то: [хеш-индексы](https://habrahabr.ru/company/postgrespro/blo... | https://habr.com/ru/post/343488/ | null | ru | null |
# Как работает Wargaming Common Menu
Доброго времени суток!
Хочу поделиться с сообществом опытом разработки JS-виджета межпроектной навигации. Он представляет собой модуль, который подключается на большинство сайтов вселенной Wargaming ([Порталы](http://wotblitz.ru/), [Wiki](http://wiki.wargaming.net/ru/), [WarGag]... | https://habr.com/ru/post/259687/ | null | ru | null |
# Использование составных ключей для манипуляции данными в memcached
Часто, при работе с [memcached](http://ru.wikipedia.org/wiki/Memcached), возникает ситуация, когда необходимо удалить данные в самых различных местах. Например, при добавлении нового комментария, необходимо обновить не только кеш самих комментариев э... | https://habr.com/ru/post/64976/ | null | ru | null |
# Квест от ЕРАМ: пять задач с собеседований по .NET

До того, как прийти в ЕРАМ, я побывал примерно на 20 собеседованиях в питерских IT-компаниях, и во многих давали задачи. Я синтезировал свой опыт и придумал пять задач, кот... | https://habr.com/ru/post/329998/ | null | ru | null |
# GITips & GITricks
Уже [было](http://habrahabr.ru/blogs/Git/75728/) [несколько](http://habrahabr.ru/blogs/Git/76084/) [статей](http://habrahabr.ru/blogs/development/28268/), где авторы рассказывали о том как скрасить консольные будни с git. В последней приведенной ссылке автор предлагает создавать алиасы, для работы ... | https://habr.com/ru/post/78058/ | null | ru | null |
# Пишем свой язык программирования без мам, пап и бизонов. Часть 0: теория
Тема написания своего ЯПа не дает мне покоя уже около полугода. Я не ставил перед собой цель "убить" **CoffeeScript**, **TypeScript**, **ELM**, [тысячи их](https://github.com/jashkenas/coffeescript/wiki/list-of-languages-that-compile-to-js), я ... | https://habr.com/ru/post/316460/ | null | ru | null |
# Новое API в Gingerbread — StrictMode. Или боремся с ANR-диалогами
Недавно открыл для себя StrictMode, прочитав [статью](http://android-developers.blogspot.com/2010/12/new-gingerbread-api-strictmode.html) на Android Developers Blog. Ниже представляю Вам ее перевод.
 и подумал: вот человек написал непонятную программу на bash, которая выводит «Happy new year». Но это ведь bash! Надо показать, что zsh не хуже, а даже намного лучше! И так, программа на zsh, выводящая «С новым годом!» (по... | https://habr.com/ru/post/247249/ | null | ru | null |
# Как анализатор PVS-Studio стал находить ещё больше ошибок в проектах на Unity

Разрабатывая статический анализатор PVS-Studio, мы стараемся развивать его в различных направлениях. Так, наша кома... | https://habr.com/ru/post/508706/ | null | ru | null |
# MikroTik & OpenWRT & DNSCrypt
Решение данного квеста навеяно этой [статьей](https://habr.com/post/353878/).
Данная статья рассчитана на пользователя, имеющего домашний роутер производства MikroTik, поэтому моменты, связанные непосредственно с компиляцией и сборкой, опущены, а примеры по MikroTik'у в картинках.
... | https://habr.com/ru/post/354710/ | null | ru | null |
# Портируем утилиту командной строки с Go/Rust на D
Несколько дней назад, на реддите в «программировании», [Paulo Henrique Cuchi поделился своим опытом разработки утилиты командной строки на Rust и на Go](https://cuchi.me/posts/go-vs-rust) ([перевод на Хабре](https://habr.com/ru/company/ruvds/blog/515674/)). Утилита, ... | https://habr.com/ru/post/517790/ | null | ru | null |
# Flash + вКонтакте API

По шагам описаны регистрация и создание flash приложения под социальную сеть вКонтакте, использующего вызовы вКонтакте API. Написан AS3 класс-обёртка для вКонтакте API.
[Приложение]... | https://habr.com/ru/post/71814/ | null | ru | null |
# [PHDays HackQuest 2017] Anonymizer: SSRF или чем может быть опасен curl
Разбор задания Anonymizer (пока еще доступно [тут](https://anonymizer.rosnadzorcom.ru)) с PHDays HackQuest 2017.
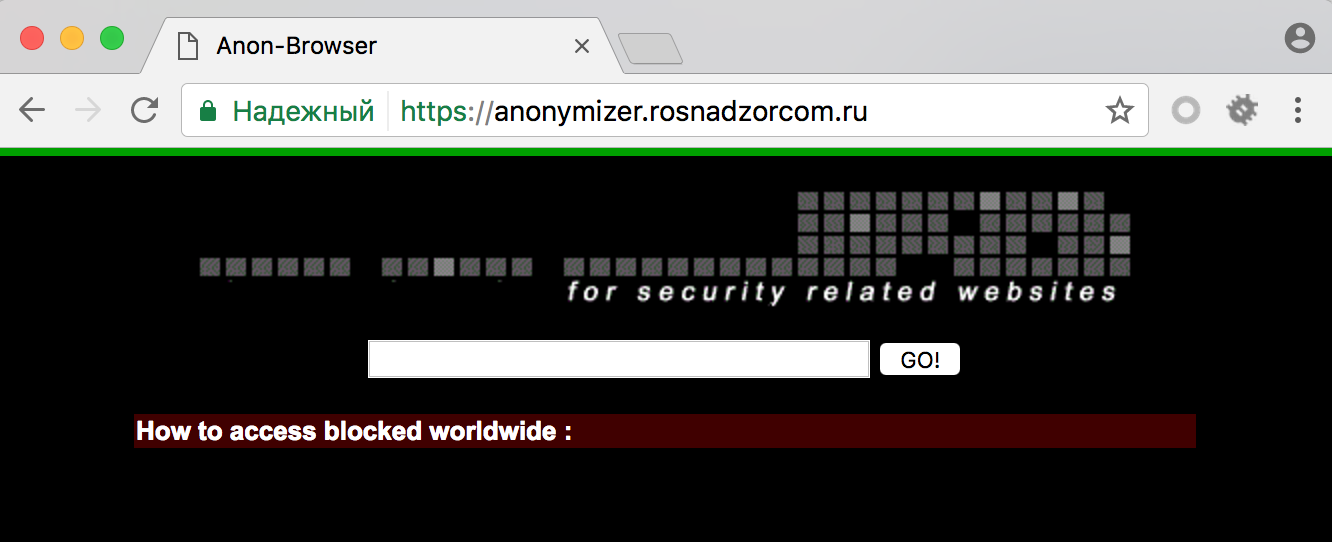
После нажатия кнопки "GO" к сайту уход... | https://habr.com/ru/post/328782/ | null | ru | null |
# Испытание по криминалистической экспертизе дампа .NET
[](https://habr.com/ru/company/ruvds/blog/598573/)
Это испытание с [MetaCTF CyberGames 2021](https://metactf.com/cybergames), в рамках которого нужно было выполнить криминалисти... | https://habr.com/ru/post/598573/ | null | ru | null |
# Глобальные объекты в Angular
В JavaScript мы часто используем сущности вроде `window`, `navigator`, `requestAnimationFrame` или `location`. Некоторые из этих объектов существуют испокон веков, некоторые — часть вечно растущего набора Web API. Возможно, вы встречали класс `Location` или токен `DOCUMENT` в Angular. Да... | https://habr.com/ru/post/548510/ | null | ru | null |
# Универсальный менеджер приложений (игр)
Любителям Linux-like систем наверняка приходилось устанавливать приложения по найденным руководствам в сети. В итоге описание оказывалось устаревшим/нерабочим, и для получения конечного результата приходилось собирать по крупицам и сводить воедино сведения из различных источни... | https://habr.com/ru/post/533984/ | null | ru | null |
# PVS-Studio идёт в облака – запуск анализа на Travis CI
На данный момент облачные CI-системы — очень востребованный сервис. В этой статье мы расскажем, как, с помощью уже существующих средств, доступных в PVS-Studio, можно интегрировать анализ исходного кода с облачной CI платформой, на примере сервиса Travis CI.
... | https://habr.com/ru/post/458072/ | null | ru | null |
# Грязные трюки с макросами C++
В этой статье я хочу сделать две вещи: рассказать, почему макросы — зло и как с этим бороться, а так же продемонстрировать пару используемых мной макросов C++, которые упрощают работу с кодом и улучшают его читаемость. Трюки, на самом деле, не такие уж и грязные:
* Безопасный вызов м... | https://habr.com/ru/post/246971/ | null | ru | null |
# Dart 2.12: Sound null safety и Dart FFI отправлены на стабильный канал
*Представляем вам перевод статьи, анонсирующей выход Dart 2.12. Да, знаем, что сильно опоздали с публикацией: оригинал вышел 3 марта. Тем не менее, Dart 2.12 — важный релиз, и мы решили опубликовать материал.*
Вышел Dart 2.12. В нём — стабильные... | https://habr.com/ru/post/548460/ | null | ru | null |
# Введение в $mol. Часть 1. Модульная система
1. [Предисловие](#%D0%BF%D1%80%D0%B5%D0%B4%D0%B8%D1%81%D0%BB%D0%BE%D0%B2%D0%B8%D0%B5)
1. [MAM](#mam)
2. [Реактивность](#%D1%80%D0%B5%D0%B0%D0%BA%D1%82%D0%B8%D0%B2%D0%BD%D0%BE%D1%81%D1%82%D1%8C)
3. [View-компоненты](#view-%D0%BA%D0%BE%D0%BC%D0%BF%D0%BE%D0%BD%D0%B5%D0%BD... | https://habr.com/ru/post/662680/ | null | ru | null |
# Xen Cloud Platform: Как поселить чужую VM в новый дом

Возникла у нас следующая задача:
* Есть подготовленный и настроенный в VMware образ виртуальной машины, в нашем конкретном случае FreeBSD 8.1
* Есть виртуальн... | https://habr.com/ru/post/177679/ | null | ru | null |
# «Идеальный» www кластер. Часть 1. Frontend: NGINX + Keepalived (vrrp) на CentOS

Этом цикле статей «Идеальный www кластер», я хочу передать базовые основы построения высокодоступного и высокопроизводител... | https://habr.com/ru/post/198934/ | null | ru | null |
# Как я Sberfight 2022 проходил на Swift
В 2021 году на просторах интернета случайно увидел Sber на geecko.com, тогда компания Sber проводила fight типа "староверы" против "новокодеров". (Простите за неточности, вспоминаю по памяти.)
И когда запустили конкурс Sberfight я уже автоматически попал в рассылку.
Я относит... | https://habr.com/ru/post/654659/ | null | ru | null |
# Рабочая среда «Деодар» для Линукс
Это Norton Commander? Это Volkov Commander? Это Dos Navigator? Это Far Manager?
Нет, это «Деодар» — новая рабочая среда для Линукс.
Деодар хостится на GitHub, основан на Node.js, написан на JavaScript плюс немного C++.
Распространяется по антилицензии Unlicense.org. Безвозм... | https://habr.com/ru/post/218073/ | null | ru | null |
# Принципы функционального программирования в JavaScript
Автор материала, перевод которого мы публикуем сегодня, говорит, что он, после того, как долго занимался объектно-ориентированным программированием, задумался о сложности систем. По словам [Джона Оустерхаута](https://ru.wikipedia.org/wiki/%D0%9E%D1%83%D1%81%D1%8... | https://habr.com/ru/post/434112/ | null | ru | null |
# Стандарты синтаксиса шаблонизаторов
Перестали ли вы слышать от новичков вопрос: «какой выбрать шаблонизатор?». Не думаю.
Единственное что можно с уверенностью сказать, что периодически некоторые решения становятся популярны в определенных кругах, но они по большей части органичение их области применения, это язык... | https://habr.com/ru/post/104921/ | null | ru | null |
# Автоматический синтез речи: взгляд лингвиста
Что первым придет в голову, если перед нами встанет задача автоматического порождения речи по тексту? Вероятнее всего, мы позаботимся о расстановке пауз между словами, постараемся правильно выбрать интонацию фразы и расставить смысловые акценты. Обязательно построим фонет... | https://habr.com/ru/post/679838/ | null | ru | null |
# DevSecOps: принципы работы и сравнение SCA. Часть первая
Значимость анализа сторонних компонентов ПО (англ. Software Composition Analysis — SCA) в процессе разработки растет по мере выхода ежегодных отчетов об уязвимостях open source библиотек, которые публикуются компаниями Synopsys, Sonatype, Snyk, White Source. С... | https://habr.com/ru/post/516660/ | null | ru | null |
# Параллельное программирование с помощью вычислительного графа
Есть приложения, которые хорошо реализуются как системы передачи сообщений. Сообщениями в широком смысле может быть что угодно – блоки данных, управляющие «сигналы» и т.д. Логика же состоит из узлов, обрабатывающих сообщения, и связей между ними. Такая ст... | https://habr.com/ru/post/157735/ | null | ru | null |
# Способы «защиты» flash-приложений

Здравствуйте. Я попытаюсь рассказать о нескольких способах защиты от исследования кода, мошенничества и воровства, используемых при разработке flash-приложений, а также о том, как можно обойти н... | https://habr.com/ru/post/110686/ | null | ru | null |
# Управление компьютером с помощью SMS
После первого топика про [управление компьютером через SMS](http://habrahabr.ru/blogs/sysadm/68989/) получил немало отзывов и пожеланий. Оказалось, что идея не такая уж и безумная, какой казалась на первый взгляд.
Раз идея прижилась — выкладываю [новую версию](http://intellowa... | https://habr.com/ru/post/75596/ | null | ru | null |
# Обход ограничений Web Store

Web Store довольно интересная площадка для рекламы своего продукта. Если сделать всё верно и чем-то заинтересовать пользователя — вы получите огромное количество новых пользователей, котор... | https://habr.com/ru/post/109884/ | null | ru | null |
# server-queryselector aka парсим html в nodejs
Итак, мы хотим получить информацию с веб сайта — это можно сделать в 3 шага
1) Получить html сайта (пропустим этот шаг)
2) Распарсить html строку и создать dom. — builderdom.js
3) Найти нужные dom\_node из dom по кссселекторам.
3.1) Распарсить строку кссселекторов и ... | https://habr.com/ru/post/703010/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.