
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# MAYHEM — многоцелевой бот для *NIX-серверов. Расследование Яндекс.Безопасности
**UPD**. *Спустя несколько часов после публикации на Хабре англоязычная версия этого исследования команды Безопасного поиска Яндекса [вышла на Virus Bulletin](https://www.virusbtn.com/virusbulletin/archive/2014/07/vb201407-Mayhem). Чуть б... | https://habr.com/ru/post/230167/ | null | ru | null |
# MonIT + M\MonIT = простой и бесплатный мониторинг нескольких серверов
Возникла задача мониторинга нескольких серверов, находящихся в разных ДЦ, имеющих разные ОС и ПО.
ТЗ получилось примерно такое:
1. Мониторинг системы (cpu, mem, load average, bandwidth).
2. Мониторинг состояния сервисов (запущен или нет).
3.... | https://habr.com/ru/post/60078/ | null | ru | null |
# Как разделить роли в проекте на Laravel: обзорное сравнение RBAC-пакетов
При разработке веб-проекта, в котором есть учетные записи пользователей, зачастую встает вопрос об организации системы ролей и прав для разграничения доступов к тем или иным разделам и функциям системы. В этой статье мы сравним пакеты для управ... | https://habr.com/ru/post/481796/ | null | ru | null |
# Анимация аккордеона и свойства height (max-height) в чистом CSS
Всем привет, недавно я изучил формы и анимации, после чего мне пришлось очень долго промучаться с анимацией Аккордеона и свойства max-height не прибегая к помощи Js в вычислениях, и сейчас я поделюсь с вами оптимальным решением.
Код на Codepen <https:/... | https://habr.com/ru/post/669310/ | null | ru | null |
# WPF4 и Taskbar в Windows 7: Кнопки предпросмотра(Thumbnail buttons)
У панели задач Windows 7 есть много способов для приложений предоставлять уникальную информацию чтобы сделать UX ещё круче. Одна из них рассматривается в этой статье — кнопки панели предсмотра на таскбаре.
Существует вероятность что вы уже исполь... | https://habr.com/ru/post/78380/ | null | ru | null |
# Сборка sentry и его зависимостей в rpm. Установка sentry из rpm, базовая настройка. Подключение к LDAP
Сборка sentry и его зависимостей в rpm. Установка sentry из rpm, базовая настройка.
-----------------------------------------------------------------------------------
### Описание
**Sentry** — инструмент монитор... | https://habr.com/ru/post/500632/ | null | ru | null |
# Особенности работы со временем в различных временных зонах
В связи с тем, что накопилось несколько вопросов и решений по работе со временем, решил сделать небольшой обзор.

#### Работа с различными типа данных в баз... | https://habr.com/ru/post/162341/ | null | ru | null |
# Gatsby.js в деталях

Как известно на одних бойлерплейтах далеко не уедешь, поэтому приходится лезть вглубь любой технологии, чтобы научиться писать что-то стоящее. В этой статье рассмотрены детали **Gatsby.js**, знание которых позв... | https://habr.com/ru/post/442298/ | null | ru | null |
# Измеряем концентрацию CO2 в квартире с помощью MH-Z19
Практически любая метеостанция, включая дешевые китайские модели за несколько долларов, умеет измерять основные параметры воздуха — температуру и влажность. С углекислым газом все сложнее: бытовых приборов, способных его измерять, практически нет в продаже. Услож... | https://habr.com/ru/post/395755/ | null | ru | null |
# Книга «Linux. Книга рецептов. 2-е изд.»
[](https://habr.com/ru/company/piter/blog/658003/) Привет, Хаброжители! Книга рецептов обучит начинающих пользователей и администраторов Linux управлять системой, используя как графически... | https://habr.com/ru/post/658003/ | null | ru | null |
# Кастомизируем раскладку внешней клавиатуры на Android без root
Мне нравится раскладка клавиатур на Mac: Cmd(Ctrl) под большим пальцем и возможность, без шаманства, прямо в настройках изменить поведение CapsLock. Такого же результата легко добиться в Linux с помощью `setxkbmap` в консоли или, например, `gnome-tweak-t... | https://habr.com/ru/post/502274/ | null | ru | null |
# О настройке Open vSwitch непростым языком
 ***От переводчика**
SDN — программно определяемые сети — прочно вошли в нашу жизнь, однако материалов о низкоуровневой их работе на русском языке не так уж много. Предлагаю вашему... | https://habr.com/ru/post/325560/ | null | ru | null |
# PHP vs Node.js
*Это перевод статьи Крэга Баклера (Craig Buckler) [«SitePoint Smackdown: PHP vs Node.js»](http://www.sitepoint.com/sitepoint-smackdown-php-vs-node-js/) и [судейских решений](http://www.sitepoint.com/php-vs-node-js-smackdown-right-of-reply/) Бруно Шкворца и Джеймса Хиббарда (Bruno Škvorc, James Hibbard... | https://habr.com/ru/post/273259/ | null | ru | null |
# Моя лепта в экономию бумаги на производстве
Я работаю инженером АСУТП в одном из цехов металлургического производства. В цеху есть 3 довольно объемных агрегата и несколько небольших локальных систем, и естественно все они состоят из кучи механизмов, ПЛК, датчиков, клапанов, моторов и т.п. В нашей службе мы частично ... | https://habr.com/ru/post/663176/ | null | ru | null |
# Делаем свернутый контент доступным с помощью hidden=until-Found
Эта статья — перевод оригинальной статьи "[Making collapsed content accessible with hidden=until-found](https://developer.chrome.com/articles/hidden-until-found/)"
Также я веду телеграм канал “[Frontend по-флотски](https://t.me/frontend_pasta)”, где ра... | https://habr.com/ru/post/712562/ | null | ru | null |
# Ломаем iOS-приложение. Часть 1
Вы хорошо поработали, и вот ваше приложение в App Store!
* Храните учётные записи юзеров?
* Используете встроенные покупки?
* Не хотите показывать своё ноу-хау?
Повод задуматься о безопасности кода и данных! Мы будем искать уязвимости в тестовом приложении. В этой статье поговорим ... | https://habr.com/ru/post/199128/ | null | ru | null |
# Генератор космических кораблей из арматуры
Доброго времени на вашей стороне планеты, Хабр.
Сегодня на хабре прямо день космических кораблей, столько интересных статей про последнюю битву в EVE Online, ну а я в свободное время я продолжаю делать свою двухмерную космическую игру и после длительного перерыва взялся ... | https://habr.com/ru/post/210622/ | null | ru | null |
# Review- или динамические окружения. Теория и практика в Kubernetes
Статья посвящена так называемым review-окружениям, реализуемым в рамках кластеров Kubernetes. Ранее эта тема затрагивалась, например, в наш... | https://habr.com/ru/post/571482/ | null | ru | null |
# Swift. Менеджер сетевых запросов. DataLoader
XcodeПо крайней мере в последнее десятилетие, количество приложений, которым требуется доступ в интернет, неимоверно возросло. Причем для большинств... | https://habr.com/ru/post/676092/ | null | ru | null |
# Выходит первый Python 3.11. Что нового?
Делимся переводом документации альфы Python 3.11, которая выходит 4 октября, о разнице в сравнении с версией 3.10. Изменения касаются трассировки исключений, модулей ... | https://habr.com/ru/post/581270/ | null | ru | null |
# Как сделать триггер DAG'а в Airflow, используя Experimental API
При подготовке наших образовательных программ мы периодически сталкиваемся со сложностями с точки зрения работы с некоторыми инструментами. И на тот момент, когда мы с ними сталикваемся, не всегда есть достаточно документации и статей, которые помогли б... | https://habr.com/ru/post/445852/ | null | ru | null |
# Функциональный C#
C# — язык мультипарадигмальный. В последнее время крен наметился в сторону [функциональщины](https://habrahabr.ru/post/280978/). Можно пойти дальше и добавить еще немного методов-расширений, позволяющих писать меньше кода, не «залезая» при этом на территорию F#.
#### PipeTo
Пока [Pipe Operator]... | https://habr.com/ru/post/325308/ | null | ru | null |
# Сетевой поединок
#### Вступление
Я хочу рассказать вам почти детективную историю о сетевом поединке. Прошу прощения за длинное вступление, мне показалось, что без него не будет понятно, почему всё так вышло.
Одна сторона я — занимался администрированием лет 10 назад, в организации, где было около 150 компьютеров... | https://habr.com/ru/post/124658/ | null | ru | null |
# JavaScript API Яндекс.Карт — версия 2.1-beta — новый дизайн и новые возможности
Мы выпустили [бета-версию API Яндекс.Карт 2.1](http://api.yandex.ru/maps/). Главная ее особенность — полный редизайн интерфейса карты. Причем изменения затронули не только внешний вид, но и поведение элементов управления картой. Поскольк... | https://habr.com/ru/post/196288/ | null | ru | null |
# Внедрение Git в корпоративную систему разработки

Разработчиков, которые знают и умеют работать с git, за последнее время выросло на порядок. Привыкаешь к скорости выполнения команд. Привыкаешь к удобству веток и легкого отката изм... | https://habr.com/ru/post/412787/ | null | ru | null |
# Bison, dynamic linking и… обработка BMP изображений
В этом посте я постараюсь раскрыть тему написания несложного модульного приложения на языке C89 для обработки 24-битных BMP изображений, использующего в своей работе простой скриптовый язык.
Если вы заинтересованы в разработке языков или вам необходимо быстро разо... | https://habr.com/ru/post/529262/ | null | ru | null |
# Криптография в Java. Класс MessageDigest
Привет, Хабр! Представляю вашему вниманию перевод третьей статьи "Java MessageDigest" автора Jakob Jenkov из [серии статей для начинающих](http://tutorials.jenkov.com/java-cryptography/index.html), желающих освоить основы криптографии в Java.
Оглавление:
-----------
1. [Cry... | https://habr.com/ru/post/444974/ | null | ru | null |
# Игра на WinForms + C# в 16 лет (2 часть)
Предыстория
-----------
Прошло довольно много времени с момента написания предыдущей [статьи](http://habr.com/ru/post/458630/). Как и обещал я написал вторую часть. Хотелось бы сказать спасибо всем тем, кто давал советы в комментариях, из всех их я смог узнать что-то новое. ... | https://habr.com/ru/post/479864/ | null | ru | null |
# Kubernetes 1.21 — неожиданно много изменений…
Новая эмблема символизирует распределение членов команды выпуска релиза по земному шару — от UTC-8 до UTC+8 (похоже, ни японцев, ни корейцев в команде нет). Эм... | https://habr.com/ru/post/551684/ | null | ru | null |
# 10 интересных нововведений в JUnit 5
В минувшее воскресенье [Sam Brannen](https://twitter.com/sam_brannen) анонсировал выход [JUnit 5](http://junit.org/junit5/)! Ура!
Поздравляю всех участников [@JUnitTeam](https://twitt... | https://habr.com/ru/post/337700/ | null | ru | null |
# Разработка Return of Dr. Destructo: до чего дошёл Прогресс
Недавно я выпустил в свет свой первый законченный «домашний» проект — ремейк игры [«Island of Dr. Destructo»](http://www.youtube.com/watch?v=xi2inDOIz-U) (также известной как просто Destructo) с ZX Spectrum. В этом посте я хотел бы рассказать немного о том, ... | https://habr.com/ru/post/257497/ | null | ru | null |
# MySQL в миллион раз быстрее MemSQL
Пару дней назад по мировой технологической прессе распространился [пиар](http://habrahabr.ru/post/146023/) MemSQL — базы данных нового поколения от Никиты Шамгунова ([shamg](https://habrahabr.ru/users/shamg/)), которая якобы показывает скорость в 30 раз выше, чем MySQL и при этом «... | https://habr.com/ru/post/146592/ | null | ru | null |
# Kohana-form: модуль менеджмента и генерации форм
Здравствуйте. Этой статьей я хочу презентовать свой модуль форм для фреймворка Kohana, который написал вдохновившись аналогичным модулем для Django.
Я не буду глубоко вдаваться в предыстории и размышления, а перейду сразу к делу. Сначала опишем недостатки:
* Мод... | https://habr.com/ru/post/216187/ | null | ru | null |
# Непрофессиональное видеонаблюдение квартиры занятно и недорого
 С момента как у меня в квартире на страже появилась GSM сигнализация, появилась мысль о том, что неплохо бы иметь в мое отсутствие в квартире и «глаза» в случае срабаты... | https://habr.com/ru/post/420005/ | null | ru | null |
# История одного дня: PHPUnit, Selenium, Facebook
Сегодня я хочу рассказать о том как я мучался с [PHPUnit](http://www.phpunit.de "PHPUnit"), [Selenium RC](http://seleniumhq.org/download/ "Selenium") и Facebook'ом :)
Итак, мне была дана задача сделать систему ежедневного тестирования сайта и постинга багов в bugzi... | https://habr.com/ru/post/64240/ | null | ru | null |
# Викторина для тех, кто любит Javascript больше ECMAscript
Викторина для тех, кто любит JavaScript больше ECMAScript. Главный приз: пирожок на полке.
**Update:** Пояснение. Для тех кто совсем не в теме. ECMAScript — это стандарт языка, на котором основаны реализации JavaScript в современных браузерах. Именно этот ... | https://habr.com/ru/post/81571/ | null | ru | null |
# Как создать простую Tower Defense игру на Unity3D, часть первая
Здравствуйте! Давно уже хотел опубликовать эту статью, да не успевал выделить время. Заранее хотел бы предупредить, что статья рассчитана на не шибко знающего Unity3D пользователя, потому в тексте будет обилие пояснений.
[Часть вторая](http://habraha... | https://habr.com/ru/post/148410/ | null | ru | null |
# PowerShell в роли инструмента для пентеста: скрипты и примеры от Varonis

Хакеры любят использовать PowerShell для запуска «fileless malware» — бестелесных вредоносных программ, которые не являются традиционными бинарными файлами с... | https://habr.com/ru/post/471420/ | null | ru | null |
# Идеи о новых возможностях обычного/параллельного программирования (расширение C++)
Здравствуйте, уважаемые читатели.
Предлагаю всем, кто заинтересуется, обсудить некоторые основные идеи классического и параллельного программирования в расширении C++, основанном на процедурах/функциях с планированием повторного вх... | https://habr.com/ru/post/336458/ | null | ru | null |
# Пишем Pixel Art Maker на JavaScript

Доброго времени суток, друзья!
### Предисловие
Однажды веб серфинг привел меня к [этому](https://codepen.io/agilBAKA/pen/yJGobo).
Позже обнаружил [статью](https://css-tricks.com/fun-time... | https://habr.com/ru/post/495772/ | null | ru | null |
# Основы работы с IOKit. Тонкости программирования драйверов
В рамках поддержки блога разработки под Mac OS X, я представляю свою статью о низкоуровневой разработке под Mac OS X. Обычно тема разработки драйверов не столь популярна, однако и здесь Mac OS X выгодно выделяется из ряда прочих операционных систем. Да, писа... | https://habr.com/ru/post/36875/ | null | ru | null |
# Разработка директив angularjs — это просто
#### AngularJS директивы – это клево
[AngularJS](http://angular.ru/) является каркасом (фреймворком) для построения web приложений, который позволяет создавать сложные приложения достаточно просто. Одна из его лучших возможностей, это создание [директив](http://angular.ru/... | https://habr.com/ru/post/200620/ | null | ru | null |
# Пора избавляться от мышки или Hand Pose Estimation на базе LiDAR за 30 минут

Всем привет! Пока киберпанк еще не настолько вошел в нашу жизнь, и нейроинтерфейсы далеки от идеала, первым этапом на пути к будущему манипуляторо... | https://habr.com/ru/post/536602/ | null | ru | null |
# Самая простая и надежная реализация шаблона проектирования Dispose

Казалось бы, данный шаблон не просто прост, а очень прост, подробно разобран не в одной известной книге.
Тем не менее, до сих пор даже в рамках одного ... | https://habr.com/ru/post/270929/ | null | ru | null |
# Система хранения файлов с дедупликацией между пользователями
Начало этому проекту положила очень простая идея, о которой, я год назад [писал](http://habrahabr.ru/blogs/i_am_advertising/132323/) на страницах хабрахабра. Именно тогда, я задумался, почему все сервисы хранения файлов такие жадные? Почему они зарабатываю... | https://habr.com/ru/post/138080/ | null | ru | null |
# Чат-бот для отзывов из Google Play. Опыт QuData
Боты. В технических кругах о них не писал только ленивый.Мы хотим представить вам свою версию применения этой популярной и такой обсуждаемой темы.
Как все начиналось? Мы компания, которая делает игры. За время нашей работы у нас скопилось много интересных игр, которые... | https://habr.com/ru/post/565094/ | null | ru | null |
# Настройка веб-сервиса Cherokee под Ubuntu 11.04 для работы с WordPress
Недавно я захотел попробовать какую-нибудь альтернативу для домашнего веб-сервиса.
Не то чтобы меня чем-то не устраивал «станартный» Apache — просто хотелось расширить кругозор ну и, возможно, найти альтернативу получше.
Кандидат должен был... | https://habr.com/ru/post/140337/ | null | ru | null |
# Поиск и обработка информации на файловых ресурсах
Начнем с точки входа в приложение. Чтобы инструмент удобно было использовать, напишем приложение с командным интерфейсом. Перед началом работы также стоит ... | https://habr.com/ru/post/583344/ | null | ru | null |
# Переход с Vue-CLI и Webpack на Vitejs
[Веб-приложение Qvault, в котором размещаются все мои курсы по кодированию](https://qvault.io/), представляет собой одностраничное приложение, написанное на Vue 2, с пл... | https://habr.com/ru/post/572622/ | null | ru | null |
# Подавление шумов как задача диффузии
Hello, Хабр.
Недавно, так уж вышло, читал в своем старом лицее лекцию на тему того, зачем они учат математику и что с ней можно потом делать чуть более прикладного. Для школьников 10-го класса оказалось чуть сложновато, пожалуй. Надеюсь данная тема будет интересно кому нибудь ... | https://habr.com/ru/post/144288/ | null | ru | null |
# Реализация паттерна MVP на основе ApplicationController и IoC в WinForms приложении
Добрый день!
В этой статье я расскажу о том как я внедрял паттерн MVP в своём Windows Forms приложении и опишу практические ситуации и особенности использования IoC и ApplicationController. Переход от codebehind к MVP мне позволил... | https://habr.com/ru/post/502358/ | null | ru | null |
# GridmiAPI — простая и гибкая библиотека Android для работы с REST&RPC
Здравствуйте, хабровчане!
Когда занимаешься разработкой сетевых приложений под платформу Android, понимаешь, что одно и другое приложение похоже друг на друга. С этой мыслью у большинства разработчиков инициализируется и другая мысль — «Почему ... | https://habr.com/ru/post/470570/ | null | ru | null |
# [DotNetBook] Span, Memory и ReadOnlyMemory
 Этой статьей я продолжаю публиковать целую серию статей, результатом которой будет книга по работе .NET CLR, и .NET в целом. За ссылками — добро пожаловать под кат.
Memory и ReadOnlyMemory
... | https://habr.com/ru/post/420051/ | null | ru | null |
# C#, способы хранения настроек программы
#### Введение
В интернете приведено очень много способов хранения настроек программы, но все они как-то разбросаны, поэтому я решил их собрать вместе и расписать, как этим пользоваться.
#### C# и app.config
На хабре уже была посвящена этому тема, поэтому… [перейти](https:... | https://habr.com/ru/post/271483/ | null | ru | null |
# Microsoft извинилась за «оскорбление» в ядре Linux
13 июля один из разработчиков Linux Паоло Бонзини [заметил](https://lkml.org/lkml/2012/7/13/154) некрасивое слово в коде гипервизора HyperV, который был включён в ядро Linux усилиями Microsoft.
Функция сравнения версий Git выявила такой фрагмент:
```
+#define ... | https://habr.com/ru/post/148126/ | null | ru | null |
# Крэши, вызванные исключениями
На прошлой неделе я вместе с несколькими моими коллегами учавствовал в громкой речи о том факте, что Go обрабатывает ошибки в ожидаемых сценариях посредством возвращения кода ошибки вместо использования исключений или другого схожего механизма. Это довольно спорная тема, потому что люди... | https://habr.com/ru/post/178083/ | null | ru | null |
# Spring без XML. Часть 2
И снова день добрый. Пост в продолжение публикации [«Spring + Java EE + Persistence, без XML. Часть 1»](http://habrahabr.ru/post/262323/).
**Содержание**### [1. Введение](#1)
#### [1.1 Подгружаем проект](#11)
#### [1.2 Что мы будем делать в этой части?](#12)
### [2. Фиксим распределение... | https://habr.com/ru/post/262361/ | null | ru | null |
# Официальный релиз Red Hat Enterprise Linux 8
Релиз Red Hat Enterprise Linux 8 cостоялся 7-го мая 2019 года, основан на Fedora 28 и ядре 4.18. Скачать можно [здесь](https://developers.redhat.com/products/rhel/download/).
#### Ключевые изменения
* Версия Python по умолчанию теперь 3.6, версия 2.7 поддерживается ог... | https://habr.com/ru/post/451374/ | null | ru | null |
# GSM/3G/4G-модемы во встраиваемых системах на примере LTE-модема Quectel EC21 и Yocto Project

Многим устройствам на базе встраиваемых систем необходим интернет. Проводное подключение к интернету для них не всегда возможно, и е... | https://habr.com/ru/post/494838/ | null | ru | null |
# Виртуальная машина своими руками
Иногда в голову приходит какая-то мысль избавиться от которой очень сложно. Такое произошло и со мной.
Я решил создать виртуальную машину (VM), учитывая то, что на тот момент у меня не было идей, мне показалось, что это прекрасная мысль. Если вы заинтересовались, то вперёд под кат... | https://habr.com/ru/post/442988/ | null | ru | null |
# Не совсем обычное VPN соединение обычными средствами
Искал интересную тему, заслуживающую внимания, чтобы получить инвайт на Хаброхабре и вот нашёл. Такой особенный случай мне пришлось недавно реализовать.
#### Постановка задачи: Получить доступ к узлам удалённой сети.
Здесь мы будем говорить о двух сетях, котор... | https://habr.com/ru/post/80883/ | null | ru | null |
# Исчерпывающий список различий между VB.NET и C#. Часть 1

Согласно [рейтингу](https://www.tiobe.com/tiobe-index/) TIOBE в 2018 году VB.NET обогнал по популярности C#. Совпадение или нет, но в феврале Эрик Липперт, один из созд... | https://habr.com/ru/post/443684/ | null | ru | null |
# Моки без лишней мороки с mswjs+faker.js
Привет, Хабр! Меня зовут Виктор, я фронтенд-работчик в Admitad. Моя команда делает личный кабинет клиентов. Недавно я в очередной раз столкнулся с типичной проблемой: для создания нового функционала фронтенд и бэкенд нужно было реализовывать параллельно. Но как делать фронт, н... | https://habr.com/ru/post/574792/ | null | ru | null |
# Полезные мелочи Windows администратора, поиск компьютеров пользователей и не только
Как-то давно на хабре публиковалась статья [Опытные мелочи Windows-админа](https://habr.com/ru/post/121801). В ней рассказывалось как быстро и достаточно эффективно находить компьютеры на которых залогинился тот или иной пользователь... | https://habr.com/ru/post/579114/ | null | ru | null |
# Пишем HTTP/1.1 & HTTP/2 клиент и сервер на Golang

Golang — отличный язык программирования с широким спектром возможностей. В этой статье показано, как на Go можно написать клиент и сервер для протоколов ... | https://habr.com/ru/post/451032/ | null | ru | null |
# Как могла бы выглядеть поддержка JSON в современном С++
Хорошо в плане поддержки JSON живётся программистам на Javascript — *по какому-то невероятному стечению обстоятельств* там JSON входит в спецификацию самого языка: есть JSON — есть объект. Удобно. Неплохо дело обстоит и в языках, где JSON не входит в сам язык, ... | https://habr.com/ru/post/254075/ | null | ru | null |
# λ-исчисление и LISP

*Типичный любитель λ-исчисления.*
Однажды, бороздя просторы интернета, я наткнулся на новость о лиспоподобном, встраиваемом языке программирования [Shen](http://www.shenlanguage.org/). Раньше у них... | https://habr.com/ru/post/258825/ | null | ru | null |
# 50 вопросов и ответов для собеседования по Swift в 2022 году
Вопросы для собеседованияПеред вами список из 50 вопросов и ответов для собеседования по Swi... | https://habr.com/ru/post/659169/ | null | ru | null |
# Запускаем несколько копий Vivaldi в OSX
Всем привет!
Мы еженедельно выпускаем новые тестовые версии браузера Vivaldi, а для возможности сравнить несколько сборок было бы полезно иметь возможность устанавл... | https://habr.com/ru/post/274969/ | null | ru | null |
# PHP-Дайджест № 183 (22 июня – 5 июля 2020)
[](https://habr.com/ru/post/509738/)*Фото [James Titcumb](https://twitter.com/asgrim)*
Свежая подборка со ссылками на новости и материалы. В выпуске все про PHP 8: первая альфа, новое вы... | https://habr.com/ru/post/509738/ | null | ru | null |
# Эволюция подхода к развертыванию кода в Reddit

*Нам, в команде платежного блокчейн-сервиса [Wirex](https://wirexapp.com/ru/), на собственном опыте знакома необходимость постоянной доработки и совершенствования существу... | https://habr.com/ru/post/404577/ | null | ru | null |
# Многоликий ГОСТ Р 34.11-94

Готовил я как-то тесты для системы, один из модулей которой помимо всего остального вычислял значение хеш-функции для загружаемого файла. В ТЗ был прописан и необходимый алгоритм — ГОСТ Р 34.11... | https://habr.com/ru/post/279895/ | null | ru | null |
# Быстрое ознакомление с SwiftUI
SwiftUI — это новый удобный способ для создания пользовательских интерфейсов на Xcode. Если хотите быстрое ознакомление с SwiftUI, тогда этот блог пост для вас.
Для начала давайте создадим проект с поддержкой SwiftUI. Минимально необходимые для этого требования системы — это macOS C... | https://habr.com/ru/post/483316/ | null | ru | null |
# Базовые навыки для работы с Unity

Доброго времени суток, уважаемые хабаровчане!
Каждый разработчик хочет быстрее создать свою игру, но как сделать это? В этой статье рассмотрены базовые навыки, позволяющие сократить время разра... | https://habr.com/ru/post/459184/ | null | ru | null |
# График счастья с python, pandas и matplotlib
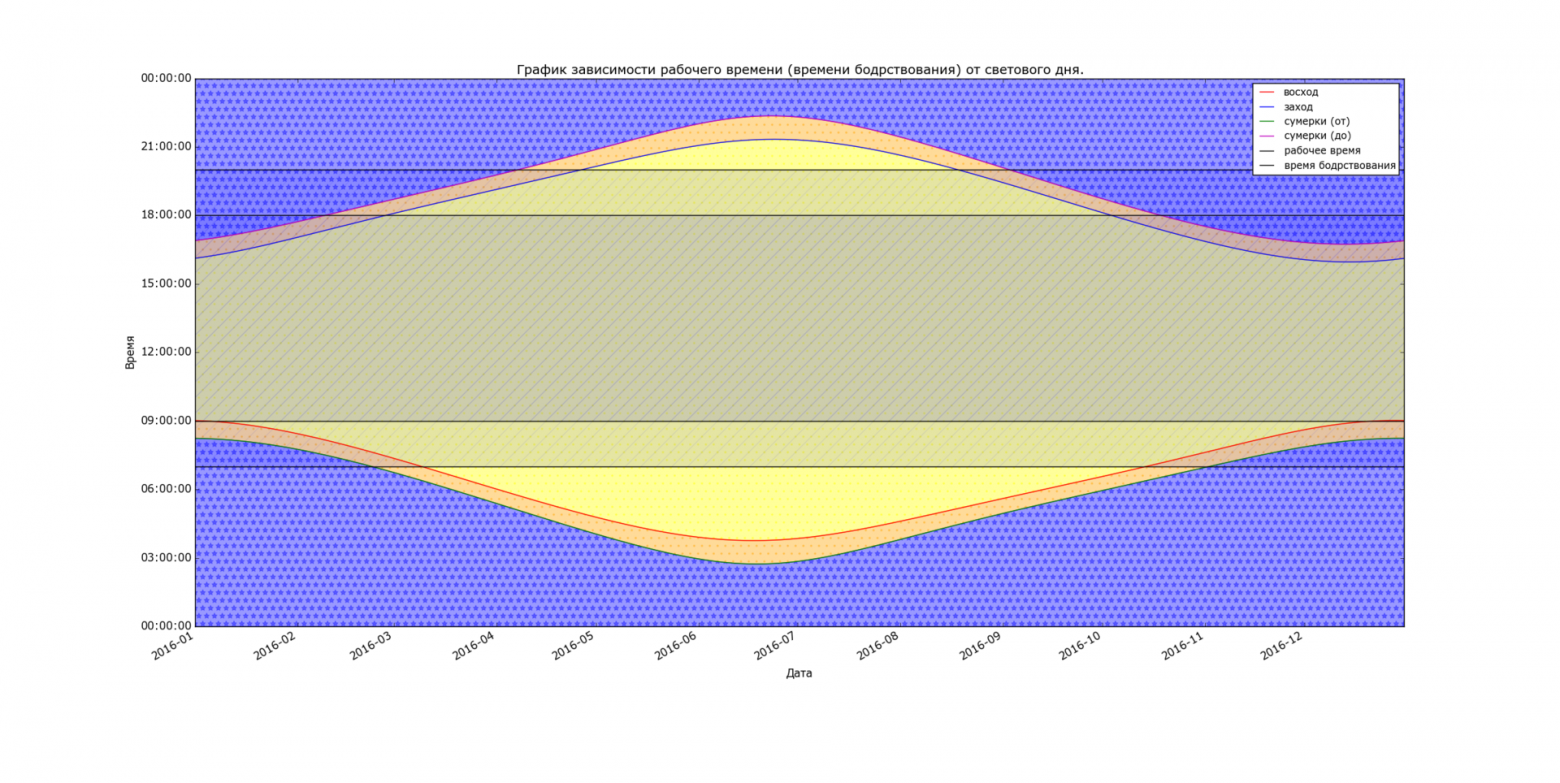
Зима — это по истине прекрасное время года. Но именно зимой я всегда задумываюсь о том, что встаю и ухожу на работу, а затем и возвращаюсь с работы, не видя солнечного све... | https://habr.com/ru/post/274927/ | null | ru | null |
# Как 10 лет назад начинался проект PVS-Studio

Десять лет назад мы создали простенькую утилиту под названием Viva64, предназначенную для выявления некоторых проблем в 64-битном коде. Так было залож... | https://habr.com/ru/post/318756/ | null | ru | null |
# Мой Boot Camp — куда хочу, туда и ставлю
Исторически сложилось, что на моем MacBookPro Mid 2010 одновременно стояли три оси: Mountain Lion (10.8.3), Lion (10.7) и Snow Leopard (10.6). Все было бы хорошо, если для MacOS существовали бы 3ds Max и утилитка для создания всевозможных текстур The Compressonator, а старый ... | https://habr.com/ru/post/177915/ | null | ru | null |
# AWS Lambda in Action. Часть 2: знакомимся с инструментами разработки и тестирования

Этот гайд — результат личного опыта разработки и тестирования Serverless-приложений, а также маневрирования между «костылями» и «велосипедами» при... | https://habr.com/ru/post/496756/ | null | ru | null |
# Grafana, InfluxDB, два тега и одна сумма. Или как посчитать сумму подгрупп?
[](https://habr.com/ru/company/raiffeisenbank/blog/490764/)
Всем привет!
Занимаюсь тестированием производительности. И очень люблю настраивать мониторин... | https://habr.com/ru/post/490764/ | null | ru | null |
# Gnome Forismatic Notify Applet
Добрый день!
Начав использовать python в своих адмниских целях, а-ля написание несложных скриптов, не мог нарадоваться простоте этого языка. Почти сразу же возникло желание попробовать написать полноценное приложение на python. Но никак не мог придумать, что б такого создать чтобы э... | https://habr.com/ru/post/102076/ | null | ru | null |
# Поиск в массиве (множестве) в JavaScript
Недавно решал задачу, когда нужно было определить, попадает ли определённое (строковое) значение во множество допустимых значений.
В JavaScript 1.6 существует [метод indexOf](https://developer.mozilla.org/En/Core_JavaScript_1.5_Reference:Objects:Array:indexOf) объекта Arra... | https://habr.com/ru/post/46787/ | null | ru | null |
# Handlebars. Руководство к действию
Данная статья содержит в себе описание основных возможностей шаблонизатора [Handlebars](http://handlebarsjs.com/) и является свободным переводом его официальной документации. Итак, поехали…
В этой статье я попыталась собрать несколько своих техник тестирования на Python. Не стоит воспринимать их как догму, поскольку, думаю, со временем я обновл... | https://habr.com/ru/post/556980/ | null | ru | null |
# Git для новичков (часть 2)
В [прошлой статье](https://habr.com/ru/post/541258/), я рассказал, что такое Git, как его установить и выложить свой код на GitHub. Сегодня мы поговорим про работу в команде над одним проектом. И как это устроено в Git.
В данной статье, вся работа с Git будет через командную строку.
### ... | https://habr.com/ru/post/542616/ | null | ru | null |
# Bad Rabbit: Petya возвращается
От [атаки](https://www.welivesecurity.com/2017/10/24/kiev-metro-hit-new-variant-infamous-diskcoder-ransomware/) шифратора Diskcoder.D (Bad Rabbit), начавшейся 24 октября, пострадали компании России и Украины, включая Киевский метрополитен. Собрали в посте первые результаты исследования... | https://habr.com/ru/post/340890/ | null | ru | null |
# Тихая установка программ на удалённый компьютер. Для самых маленьких
На текущий момент, когда многие зарубежные компании приостановили свою деятельность в России, всё более актуальным становится вопрос автоматизации рутинных рабочих процессов ~~подручными~~ доступными бесплатными средствами.
Предлагаю вашему вниман... | https://habr.com/ru/post/676064/ | null | ru | null |
# Выводы Grofers после двух лет Kubernetes в production
***Прим. перев.**: эта статья — опыт миграции на Kubernetes одного из крупнейших в Индии онлайн-магазинов продуктов. В ней Vaidik Kapoor, software engineer из Grofers, рассказывает о главных ошибках и препятствиях этого долгого путешествия, а также делится своими... | https://habr.com/ru/post/533736/ | null | ru | null |
# Сверхлегкая BDD: малая механизация автономных тестов
Тема автономного тестирования давняя, почтенная, разобранная до косточек. Кажется, что после отличной [книги Роя Ошероува](http://www.ozon.ru/context/detail/id/26230428/) и сказать особо нечего. Но на мой взгляд есть некоторая несбалансированность доступных инстру... | https://habr.com/ru/post/310942/ | null | ru | null |
# Как я написал самую эффективную библиотеку для реактивного состояния
[](https://habr.com/ru/company/ruvds/blog/713808/)
Всем привет, меня зовут Артём Арутюнян, и я уже пять лет изучаю реактивное программирование. Меня задела недавн... | https://habr.com/ru/post/713808/ | null | ru | null |
# Сертификаты Let's Encrypt и ACME вообще во внутренней сети
Обычно внутри корпоративной сети нынче полно всяких приложений, и хотелось бы чтобы они работали по SSL. Можно, конечно, поднять свой УЦ, раздать сертификаты, прописать пользователям свой корневой сертификат - и это будет работать. А можно просто воспользова... | https://habr.com/ru/post/708510/ | null | ru | null |
# Нарисуй сон
Нейронные сети, рисующие “всякое” по запросу, не обошли стороной и меня. После того, как наигрался, я решил, что так как тема из области искусственного интеллекта, то и интерфейс взаимодействия нужен со... | https://habr.com/ru/post/703292/ | null | ru | null |
# Flare-On 2019 write-up

-0x01 — Intro
-------------
Данная статья посвящена разбору всех заданий [Flare-On 2019](http://www.flare-on.com/) — ежегодного соревнования по реверс-инжинирингу от FireEye. В данных соревнованиях я приним... | https://habr.com/ru/post/469393/ | null | ru | null |
# GitHub добавил поддержку шаблонов для Issue и Pull-реквестов
Вчера, 17 февраля, команда разработчиков Github [анонсировала](https://github.com/blog/2111-issue-and-pull-request-templates) новый функционал, которого пользователям, участвующим в групповой разработке, могло серьезно недоставать: теперь в GitHub есть шаб... | https://habr.com/ru/post/277497/ | null | ru | null |
# Пропатчил Exim — пропатчь еще раз. Свежее Remote Command Execution в Exim 4.92 в один запрос

Совсем недавно, в начале лета, появились массовые призывы к обновлению Exim до версии 4.92 из-за уязвимости CVE-2019-10149 ([Срочно обнов... | https://habr.com/ru/post/467089/ | null | ru | null |
# Нагрузочное тестирование, история автоматизации процесса
Привет, Хабр! Я работаю системным администратором, совмещая это дело с организацией и проведением нагрузочного тестирования для различных проектов (как игровых, так и не очень). Так уж получилось, что нагрузкой занимается только один человек (это я).
В моей... | https://habr.com/ru/post/342380/ | null | ru | null |
# Как Kotlin может помочь в тестировании API: кейс Русфинанс Банка

Заявленный в заголовке Kotlin больше ассоциируется с Android-разработкой, но почему бы не поэкспериментировать? Мы с его помощью нашли способ немного упростить автом... | https://habr.com/ru/post/510268/ | null | ru | null |
# Отправка служебных сообщений в whatsapp через yowsup2 методом http-get, в том числе отчетов бэкап-сервера Bacula
 Достаточно много видел примеров использования whatsapp-уведомлений с zabbix, и другими системами мониторинга, н... | https://habr.com/ru/post/327404/ | null | ru | null |
# История URL, часть 2: путь, фрагмент, запрос и авторизация
> URL'ы не должны были стать тем, чем стали: мудрёным способом идентифицировать сайт в интернете для пользователя. К сожалению, мы не смогли стан... | https://habr.com/ru/post/305654/ | null | ru | null |
# CRLF-инъекции и HTTP Response Splitting
***Привет, Хабровчане! В преддверии старта занятий в ближайшей группе профессионального курса [«Безопасность веб-приложений»](https://otus.pw/xSFL/), мы подготовили для вас еще один полезный перевод.***
---
![](https://habrastorage.org/r/w1560/webt/7-/y1/2d/7-y12dlpdb-shacfj... | https://habr.com/ru/post/512226/ | null | ru | null |
# Веб-приложение размером с пигмея
Еще недели не прошло с анонса новых методов api вконтакте. Для владельцев сообществ выкатили возможность подписывать пользователей на уведомления от сообщества, что дает право владельцам писать подписчикам неограниченно. Не за горами приложения, ака рассылки по подписчикам сообщества... | https://habr.com/ru/post/312974/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.