
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Автоматически убираем фон у сфотографированного текста в Photoshop или ImageMagick
Хочу поделиться трюком, который немного помогает улучшить качество при печати в ч/б всякого рода конспектов, если их почему-то «оцифровали» фотоаппаратом вместо сканера.

Собственно г... | https://habr.com/ru/post/67976/ | null | ru | null |
# Импорт и преобразование словаря LinguaLeo в флэш-карты Anki
Постановка проблемы
-------------------
Те, кто учат английский язык наверняка знакомы с Anki — программой для запоминания слов, выражений и любой другой информации с помощью интервальных повторений.
Другой популярный сервис, не нуждающийся в представле... | https://habr.com/ru/post/345864/ | null | ru | null |
# Версионирование API в ASP.Net Core
Поддерживая существующие уже какое-то время Web API проекты, мы нередко сталкиваемся с проблемой устаревания логики методов контроллеров и необходимостью ее изменения в соответствии с новыми требованиями. Но, как правило, на момент возникновения такой необходимости, уже существует ... | https://habr.com/ru/post/649827/ | null | ru | null |
# Handy.CMS 3.1 build 2001
[](http://handycms.ru)
Вышел новый билд системы управления сайтом Handy.CMS. Среди значительных изменений: добавлена возможность создания ... | https://habr.com/ru/post/67504/ | null | ru | null |
# Приведение внешнего вида Ubuntu к Windows 7
Существует такой пакет, который поможет автоматически настроить внешний вид Вашего Linux-дистрибутива, похожим на внешний вид операционной системы Windows 7. Он называется Win2-7 Pack (для среды Gnome) и [Vistar7](http://kde-look.org/content/show.php/Vistar7+-+Windows+7+Tr... | https://habr.com/ru/post/102991/ | null | ru | null |
# Решение японских кроссвордов на Haskell
Японский кроссворд — головоломка, в которой по набору чисел нужно воссоздать исходное черно-белое изображение. Каждой строке и каждому столбцу пикселей соответствует свой набор, каждое число в котором, в свою очередь, соответствует длине блока подряд идущих черных пикселей. Ме... | https://habr.com/ru/post/151819/ | null | ru | null |
# Python на службе у конструктора. Укрощаем API Kompas 3D

Работая в конструкторском отделе, я столкнулся с задачей — рассчитать трудоёмкость разработки конструкторской документации. Если брать за осн... | https://habr.com/ru/post/323078/ | null | ru | null |
# Не умер ли ещё PHP (и ещё 11 вопросов, которые не стыдно задавать в 2022)
Уже который год во всех слаках, дискордах, телеграмах и форумах главный вопрос о любом языке программирования звучит так — стоит его учить В ЭТОМ ГОДУ, или лучше уже не надо? Взять какой-нибудь PHP — его же вечно хоронят, и всё никак.
Есть и ... | https://habr.com/ru/post/652277/ | null | ru | null |
# Google закрывает Cloud Print через 10 лет в статусе бета-версии
На прошлой неделе компания Google опубликовала [объявление](https://support.google.com/chrome/a/answer/9633006) о запланированном закрытии сервиса [Cloud Print](htt... | https://habr.com/ru/post/477270/ | null | ru | null |
# 16 инструментов React, которые пригодятся разработчикам интерфейсов

Для создания пользовательских интерфейсов существует большое количество инструментов (ваш К.О., не благодарите). Один из наиболее эффективных — React. Наверное, н... | https://habr.com/ru/post/416005/ | null | ru | null |
# Создание рождественской анимации с помощью Wolfram Language

Перевод блога [O Tannenbaum](http://community.wolfram.com/groups/-/m/t/1248938) Майкла Тротта, директора Wolfram|Alpha.
---
В этом ноутбуке описывается, как создать а... | https://habr.com/ru/post/345358/ | null | ru | null |
# «Оцифровываем» каптчу единого реестра сайтов, защищающего людей от информации
Совсем недавно открылся портал [Единого государственного реестра сайтов](http://zapret-info.gov.ru/). Отдельно от всего прочего мне приглянулась очень слабая каптча, и я решил её побороть.
Подобными вещами я уже занимался, правда, не в ... | https://habr.com/ru/post/157145/ | null | ru | null |
# Long Polling для Android
Прочитав [статью](http://habrahabr.ru/company/cackle/blog/167895/), стал внедрять в web проекты Long Polling. На nginx крутится серверная часть, на javascript клиенты слушают каналы. Прежде всего это было очень полезно для личных сообщений на сайте.
Потом в поддержку web проектов стали ра... | https://habr.com/ru/post/216713/ | null | ru | null |
# Управление Arduino через интернет с помощью ПК — опыт новичка
Всем привет. В этой статье расскажу о том, как мне удалось реализовать управление Arduino через интернет с помощью подключенного к интернету ПК. В общем случае данный способ можно использовать для любого микроконтроллера, например PIC. Способ довольно дуб... | https://habr.com/ru/post/491616/ | null | ru | null |
# Как эффективнее использовать kubectl: подробное руководство

Если вы работаете с Kubernetes, то, вероятно, kubectl — одна из самых используемых вами утилит. А всякий раз, когда вы тратите много времени на... | https://habr.com/ru/post/502828/ | null | ru | null |
# Восстановление PDP 11/04. Ленточная станция TU60
*Продолжение перевода статьи по восстановлению одной старой интересной машинки. В [первой](http://habrahabr.ru/post/243551/) части наладили основной блок плат. Много тяжелых картинок. Курсивом мои комментарии.*
### Стриммер TU60 и контроллер TA11
В 70х DEC создали... | https://habr.com/ru/post/243553/ | null | ru | null |
# Java 10 General Availability
> [Ссылка для скачивания](http://jdk.java.net/10/)
Последнюю половину года мы подробно обсуждали здесь новшества Java 10 и знаем их наизусть.
Но было бы странно, если самая главная Java-новость за ... | https://habr.com/ru/post/351694/ | null | ru | null |
# Знакомство с OCR библиотекой tessnet2 (язык C#)

Буквально на днях у меня появилась необходимость распознать простой текст на картинке и совсем не было желания реализовывать свой алгоритм, т.к. знаком с теор... | https://habr.com/ru/post/112599/ | null | ru | null |
# Swift Package Manager
Вместе с релизом в open source языка Swift 3 декабря 2015 года Apple представила децентрализованный менеджер зависимостей [Swift Package Manager](https://github.com/apple/swift-package-manager).
К публич... | https://habr.com/ru/post/348004/ | null | ru | null |
# SOAP-сервер на Rails 3.x (WashOut)
Поддержка SOAP (как сервера) в Rails ухудшалась от версии к версии. В версии 1.x рельсы комплектовались [AWS](http://aws.rubyonrails.org). В версии 2.x AWS распался на несколько форков, которые поддерживали энтузиасты. До версии 3.х, в стабильно работающем исполнении, AWS не дожил.... | https://habr.com/ru/post/135614/ | null | ru | null |
# Veeam Backup: миленькие хитрости
В преддверии Нового года я подумал: а не сделать ли скромный, но очень полезный подарок нашим читателям, рассказав про функции, на которые системные администраторы-пользователи Veeam Backup & Replication обычно не обращают внимания, а про некоторые из них даже и не знают? Так родилас... | https://habr.com/ru/post/273757/ | null | ru | null |
# О стримах и таблицах в Kafka и Stream Processing, часть 1
*\* Michael G. Noll — активный контрибьютор в Open Source проекты, в том числе в Apache Kafka и Apache Storm.
Статья будет полезна в первую очередь тем, кто только знакомится с Apache Kafka и/или потоковой обработкой [Stream Processing].*
В этой статье,... | https://habr.com/ru/post/353204/ | null | ru | null |
# Модули ввода-вывода ADAM-6200
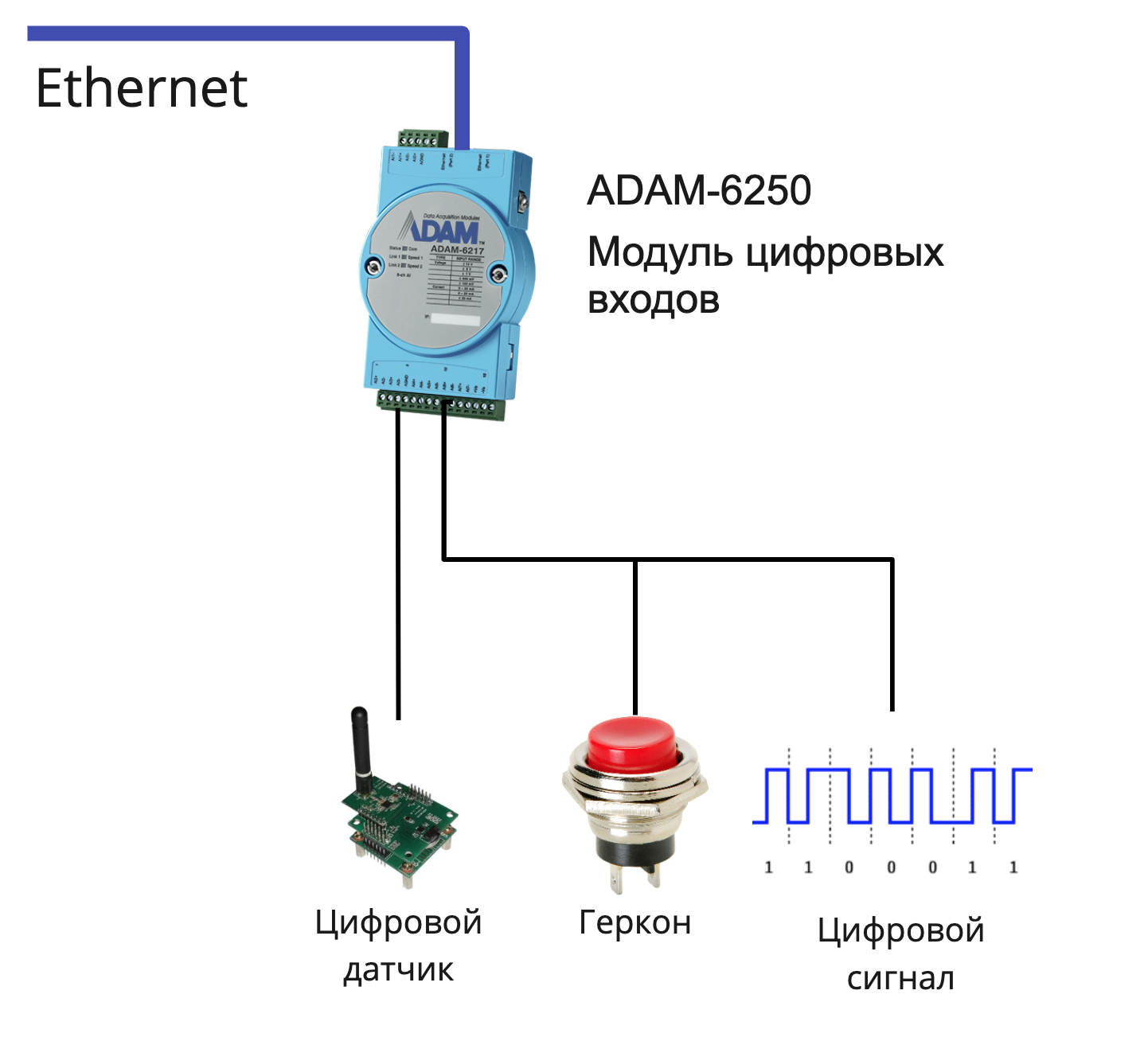
Модули удаленного ввода-вывода предназначены для связи с периферийными устройствами различных типов. Это важнейший элемент построения промышленных систем. Они могут как принимать сигналы от других уст... | https://habr.com/ru/post/468627/ | null | ru | null |
# Сколько углекислого газа «генерируют» биткоины

Не секрет, что для майнинга биткоинов требуются большие вычислительные мощности. Достаточно посмотреть [фоторепортаж с майнерской фермы](http://www.thecoinsman.com/2014/08/b... | https://habr.com/ru/post/376541/ | null | ru | null |
# Анализ потокобезопасности в С++
Писать многопоточные приложения нелегко. Некоторые средства статического анализа кода позволяют помочь разработчикам, давая возможность чётко определить политики поведения потоков и обеспечить автоматическую проверку выполнения этих политик. Благодаря этому появляется возможность отла... | https://habr.com/ru/post/304176/ | null | ru | null |
# Как разобрать URL в JavaScript?

Доброго времени суток, друзья!
Представляю Вашему вниманию перевод заметки [«How to Parse URL in JavaScript: hostname, pathname, query, hash»](https://dmitripavlutin.com/parse-url-javascript/) а... | https://habr.com/ru/post/510742/ | null | ru | null |
# Создание React VR-приложения, работающего в реальном времени

Библиотека React VR позволяет писать для веба приложения виртуальной реальности с использованием JavaScript и React поверх [WebVR API](https://webvr.info/). Эта сп... | https://habr.com/ru/post/331816/ | null | ru | null |
# Реализация итераторов в C# (часть 1)
От переводчика:
*Не так давно мой менее опытный коллега спросил меня о том, для чего используется yield return в C#. Я не очень часто пишу свои итераторы, поэтому, отвечая ему, я сомневался в своих словах. Справившись в MSDN, я укрепился в сказанном, но у меня возник вопрос: “... | https://habr.com/ru/post/136828/ | null | ru | null |
# Для этого не нужна ARIA
В веб-разработке написание семантического HTML важно для доступности, а также дает некоторые приятные побочные эффекты, такие как поддержка режима «чтения» в браузере, SEO, graceful degradation и возможность экспорта.
Реализуя семантический HTML, мы также значительно уменьшаем потребность в ... | https://habr.com/ru/post/706674/ | null | ru | null |
# Проектируем DataGrid на React так, чтобы сэкономить Boilerplate
Привет, Хабр! Некоторое время назад мне довелось участвовать в разработке админ-панели для видеоигры с уклоном на совместные соревнования. Так как финансирование осуществлялось [за счет гранта](https://near.org/grants/), был ограничен бюджет.
Возникла ... | https://habr.com/ru/post/677070/ | null | ru | null |
# Книга «Глубокое обучение с fastai и PyTorch: минимум формул, минимум кода, максимум эффективности»
[](https://habr.com/ru/company/piter/blog/674960/) Привет, Хаброжители! Обычно на глубокое обучение смотрят с ужасом, считая, чт... | https://habr.com/ru/post/674960/ | null | ru | null |
# Когда исчезнут JavaScript-фреймворки?
Автор материала, перевод которого мы сегодня публикуем, веб-разработчик, говорит, что он старается регулярно пересматривать набор инструментов, которыми пользуется. Делает он это для того, чтобы понять, может ли он без некоторых из них обойтись, решая свои обычные задачи. Недавн... | https://habr.com/ru/post/439824/ | null | ru | null |
# Рендеринг изоповерхностей с использованием алгоритма рейкастинга
В данной статье хочу рассказать вам про Isosurface rendering или рендеринг изоповерхностей.
По долгу работы я постоянно использую документацию лишь на английском или немецком языке. Поэтому в тексте я буду часто использовать для всяких терминов анг... | https://habr.com/ru/post/123632/ | null | ru | null |
# Android M и инструменты для разработчиков
Привет, Хабрахабр! В прошлом году мы впервые предоставили разработчикам тестовую версию Android L и получили множество полезных отзывов, которые касались Material Design, а также новых платформ Android Auto, TV и Wear. Вчера на конференции Google I/O мы объявили о повторении... | https://habr.com/ru/post/259123/ | null | ru | null |
# Разбираемся со считыванием и записью магнитных домофонных ключей
Приветствую всех!
Мы уже давно привыкли, что самыми распространёнными типами домофонных ключей являются Touch Memory (iButton) и EM-Marine. Набирают популярность Mifare и различные проприетарные решения в формате Touch Memory. Но, конечно, так было ... | https://habr.com/ru/post/710596/ | null | ru | null |
# Рисуем тайлы с данными для GoogleMap на PHP
##### Преамбула
В настоящее время очень популярно заниматься визуализацией каких-либо данных на картах. Да прочем и не только визуализацией, применений множество: игры, гео-сервисы, визуализация, статистика и многое-многое другое. С одной стороны, применение canvas это хо... | https://habr.com/ru/post/146107/ | null | ru | null |
# ExConsole — экстренная консоль для Python
Пост обещает быть сверхкратким.
**ExConsole** позволяет встроить интерактивную консоль-отладчик в Python-приложение. Консоль вызывается при фатальном исключении либо по приему SIGQUIT (он же Ctrl-\).
Пример использования:
```
import exconsole
exconsole.register()
d... | https://habr.com/ru/post/190924/ | null | ru | null |
# Создание агента расширения SNMP
Добрый день. Речь пойдет об использовании протокола SNMP, но немного не в том ключе, как все привыкли. Википедия сообщает, что данный «протокол обычно используется в системах сетевого управления для контроля подключенных к сети устройств на предмет условий, которые требуют внимания ад... | https://habr.com/ru/post/147365/ | null | ru | null |
# Избавляемся от дублей пакетов в бандлах
Существует много webpack пакетов находящих дубли в бандле, самый популярный из них [duplicate-package-checker-webpack-plugin](https://www.npmjs.com/package/duplicate-package-checker-webpack-plugin), но он требует пересборки проекта, а так как стояла задача автоматизировать под... | https://habr.com/ru/post/445878/ | null | ru | null |
# Защита от DDOS атак средствами BGP
Сервера, размещенные в сети администрируемой мной AS, часто подвергаются различным DDOS атакам. Целью атакующих могут быть, как отдельные ресурсы размещенные на серверах, сами сервера и вся площадка в целом. С каждым месяцем количество, сложность и мощность атак возрастает. Атаки в... | https://habr.com/ru/post/211176/ | null | ru | null |
# Сам себе туннельный брокер или нативный IPv6 на компе при помощи OpenVPN
Я — большой сторонник использования IPv6, стараюсь его использовать где это только возможно. Недавно подумав я решил, что на большинстве своих виртуалок переведу ssh на ipv6-only, биндить буду на рандомно выбранный при конфигурации адрес, котор... | https://habr.com/ru/post/321486/ | null | ru | null |
# Чистые и детерминированные функции
*Перевод [статьи Джастина Этеридж](http://www.codethinked.com/pure-and-deterministic-functions) (Justin Etheredge), в которой автор объясняет тонкую разницу между детерминированными и чистыми функциями.*
Вчера я читал [блог Мэтта Подвизоки](http://codebetter.com/matthewpodwysock... | https://habr.com/ru/post/149086/ | null | ru | null |
# BMW и диагностика по Ethernet: протокол HSFZ
Введение
--------
Разработчики автомобильных систем диагностики уже давно присматриваются к стандартам с большей скоростью передачи данных, чем классический CAN. С каждым новым поколением растет количество электронных блоков в автомобилях, их сложность и размер памяти. Б... | https://habr.com/ru/post/688580/ | null | ru | null |
# Пишем настоящий Pointer Analysis для LLVM. Часть 1: Введение или первое свидание с миром анализа программ
[](https://habrahabr.ru/company/solarsecurity/blog/317002/#habracut) Привет, Хабр!
Эта статья станет вступительной ... | https://habr.com/ru/post/317002/ | null | ru | null |
# Почему программное обеспечение не всегда товар и откуда в IT прибыль
С XVI века складывалась нынешняя система производства в которой мы живём. Эта система находит своё отражение во всех сферах, но именно в IT получает новое продолжение, новое рождение. Это статья о том, почему программное обеспечение формирует новый... | https://habr.com/ru/post/500800/ | null | ru | null |
# Управление несколькими сервоприводами с высокой точностью на МК ATmega16
Недавно ко мне обратились знакомые из макетной мастерской и предложили поработать над весьма интересным проектом. Им необходимо было выполнить макет, в котором бы двигались детали нескольких машин (кран, экскаватор, разрушитель). Логика несложн... | https://habr.com/ru/post/147940/ | null | ru | null |
# Почему (сегодня) return 444 не всегда полезен
В web-сервере Nginx есть замечательный код ответа 444, который «закрывает» соединение без отправки данных. Данный функционал весьма полезен при фильтрации паразитного трафика — если мы уверены, что клиент по каким-то критериям не является валидным, то нет необходимости е... | https://habr.com/ru/post/415565/ | null | ru | null |
# Background Dating — в поисках людей, с которыми интересно говорить
Итак, я давно хотел написать сайт знакомств, но при этом совершенно не хотелось, чтобы он был таким же, как и сотни других. В итоге стало ясно, что это должен быть не совсем сайт знакомств, а скорее некое место, где можно находить интересных людей. С... | https://habr.com/ru/post/159693/ | null | ru | null |
# Simplify.js — JavaScript-библиотека для упрощения ломаных линий
Рад представить вашему вниманию еще одну крохотную, но полезную open-source-утилиту своего авторства — [Simplify.js](http://mourner.github.com/simplify-js/).
 с недавних пор стали появляться ключи к Diablo III Beta. В 7-ми минутном ролике на секунду показывается ключ, кто его первый активирует, то и выигрывает. Вот так на стоп кадре выглядит ключ:

Иногда бывает необходимо принудительно разорвать активное соединение. Самый распространенный способ:
`**netstat -na
kill PID**`
Проблема в том, что один воркер может одновременно обс... | https://habr.com/ru/post/105441/ | null | ru | null |
# Знакомство с Node-RED и потоковое программирование в Yandex IoT Core

В этой статье я хочу разобрать один из самых популярных опенсорс-инструментов, [Node-RED](https://nodered.org), с точки зрения создания простых прототипов приложен... | https://habr.com/ru/post/519600/ | null | ru | null |
# Тишина должна быть в библиотеке! Как мы рефачили библиотеку для работы с API и создали свой Repository
Всем привет! Меня зовут Игорь Сорокин. В этой статье я поделюсь историей о том, куда нас завёл очередной рефакторинг, как мы оттуда выбрались, попутно разработав слой хранения данных. Также приведу практические при... | https://habr.com/ru/post/678120/ | null | ru | null |
# Вышла asyncpg — клиентская библиотека PostgreSQL для Python/asyncio
На конференции EuroPython 2016 Юрий Селиванов (автор async/await-синтаксиса и автор [uvloop](https://habrahabr.ru/post/282972/)) представил новую высокопроизводительную библиотеку для асинхронного доступа к PostgreSQL — [asyncpg](https://github.com/... | https://habr.com/ru/post/306196/ | null | ru | null |
# Агрегаты
> *Этот материал является* [*кросс-постом*](https://azhidkov.pro/posts/22/04/220401-aggregates/) *из моего блога*
>
> *Следить за обновлениями блога можно в моём канале:* [*Эргономичный код*](https://t.me/ergonomic_code)
>
>
Введение
--------
Я считаю, что именно агрегаты из Domain-Driven Design лежат ... | https://habr.com/ru/post/660599/ | null | ru | null |
# Python & оптимизация времени и памяти
Введение
--------
Зачастую скорость выполнения python оставляет желать лучшего. Некоторые отказываются от использования python именно по этой причине, но существует несколько способов оптимизировать код python как по времени, так и по используемой памяти.
Хотелось бы поделить... | https://habr.com/ru/post/551150/ | null | ru | null |
# Как правильно использовать доступный объем хранилища
Мы давно пользуемся облачными сервисами: почта, хранилища, соцсети, мессенджеры. Все они работают удаленно — отправляем сообщения и файлы, а хранятся и обрабатываются они на удаленных серверах. Также работает и облачный гейминг: пользователь подключается к сервису... | https://habr.com/ru/post/480622/ | null | ru | null |
# Как загрузить последний Office с сайта Microsoft без всякого App-V
На прошлой неделе я написал заметку [«Как загрузить виртуальный корпоративный Office 2013 с сайта Microsoft»](http://habrahabr.ru/post/245295/), где описал, как при помощи [Office Deployment Tool](http://www.microsoft.com/en-us/download/details.aspx?... | https://habr.com/ru/post/245677/ | null | ru | null |
# Остекляем Opera 10.50 в Windows Vista/7
Одним из главных новшеств Opera 10.50 под Windows стала полная поддержка эффектов Aero, в том числе и стеклянного интерфейса Aero Glass. Однако, распространилось это далеко не на все элементы браузера. Дизайнеры Opera сумели хорошо выдержать баланс между стеклом и классической... | https://habr.com/ru/post/85213/ | null | ru | null |
# Синхронные и асинхронные стектрейсы: опыт использования в Facebook
Здесь мы подробно поговорим о том, каковы технические отличия между реализацией асинхронных стектрейсов по сравнению с реализацией традици... | https://habr.com/ru/post/649725/ | null | ru | null |
# Средние highload паттерны на Go
Привет, Хабр! Меня зовут Агаджанян Давид и ранее я опубликовал статью [«простые highload паттерны на Go»](https://habr.com/ru/post/682618/), в которой были рассмотрены простые подходы увеличения пропускной способности отдельно взятого экземпляра приложения без хардкора. Мне импонируют... | https://habr.com/ru/post/684904/ | null | ru | null |
# Vertical Scaling in Java Cloud
Хочу поделится результатами внутренних тестов вертикального автоматического масштабирования памяти в [Jelastic](http://jelastic.com) — облачный хостинг для Java приложений.
... | https://habr.com/ru/post/118702/ | null | ru | null |
# От простых скриптов к клиент-серверному приложению на WCF своими руками: почему мне нравится работа в CM
Работа в команде Configuration Management связана с обеспечением функциональности билд-процессов — сборки продуктов компании, предварительной проверки кода, статистического анализа, ведения документации и многого... | https://habr.com/ru/post/417701/ | null | ru | null |
# Кто есть кто в кампании за отмену Столлмана
Кампания "за отмену Столлмана", начавшаяся с [публикации в Medium](https://selamjie.medium.com/remove-richard-stallman-fec6ec210794) предоставляет нам множество интересных данных. Так как подписание [открытых писем за отмену](https://rms-open-letter.github.io/) и [в поддер... | https://habr.com/ru/post/554724/ | null | ru | null |
# Создаем интернет-магазин на Nuxt.js 2 пошаговое руководство Часть 3

Как и обещал продолжаем.
В этой части:
* создадим блоки товаров "С этим товаром также покупают" и "Интересные товары"
* создадим иконку корзины с количеством то... | https://habr.com/ru/post/491190/ | null | ru | null |
# Nix как менеджер зависимостей для C++

В последнее время много разговоров идет о том, что для C++ нужен свой пакетный менеджер подобный pip, npm, maven, cargo и т.д. Все конкуренты имеют простой и стандартизиров... | https://habr.com/ru/post/281611/ | null | ru | null |
# Компиляция карт для Half-Life 1 на ТВ-приставке
Я уже не первый год занимаюсь моддингом легендарной Half-Life 1, и как-то совершенно спонтанно мне пришла в голову мысль, дескать, как было бы прикольно иметь возможность компилировать карты на какой-нибудь платформе, отличной от привычных всем x86 и amd64. Затем я всп... | https://habr.com/ru/post/707860/ | null | ru | null |
# Free Heroes of might and magic 2 – open-source проект, в котором хочется участвовать
Недавно в сети появилась новость о релизе новой версии проекта fheroes2. У нас в компании многие сотрудники являются поклонниками серии игр Heroes of Might and Magic, и естественно, мы не могли пройти мимо и в процессе ознакомления ... | https://habr.com/ru/post/543870/ | null | ru | null |
# Универсальное событие в Google Tag Manager
Если вы отслеживаете множество событий и то и дело добавляете новые, вам приходится выполнять серию одних и тех же операций:
1. Повесить событие на сайте.
2. Создать в GTM триггер.
3. Создать в GTM тэг отправки события в Google Analytics.
4. Создать в GTM тэг отправки собы... | https://habr.com/ru/post/501202/ | null | ru | null |
# Учебный курс по React, часть 7: встроенные стили
Сегодня, в следующей части курса по React, мы поговорим о встроенных стилях.
[](https://habr.com/company/ruvds/blog/435468/)
→ [Часть 1: обзор курса, причины популярности Rea... | https://habr.com/ru/post/435468/ | null | ru | null |
# Фильтрация изображений методом свертки
Автором данного топика является хабраюзер [Popik](https://habrahabr.ru/users/popik/), который сам не может запостить этот топик в силу астральных причин.
Введение.
---------
 Вероятно, большинство хабросообщества не п... | https://habr.com/ru/post/62738/ | null | ru | null |
# PortablePy: компьютер-раскладушка для MicroPython
Признаю: мне очень нравится та невероятная скорость, с которой загружаются домашние компьютеры 1980-х годов. Я какое-то время пытался оптимизировать время загрузки Raspberry Pi, но особенно далеко в этом деле не продвинулся. Я, кроме того, большой поклонник специализ... | https://habr.com/ru/post/537900/ | null | ru | null |
# Обрезаем фото в стиле «ВКонтакте»

В этом HOWTO я раскажу вам как обрезать фотографию до нужного вам размера и залить её на сервер с помощью Ruby on Rails.
Итак, для наших целей наиболее подходят... | https://habr.com/ru/post/62585/ | null | ru | null |
# C#: Внутреннее строение инициализаторов массивов
Наверняка почти каждому, кто имел дело с C#, известна подобная конструкция:
```
int[] ints = new int[3] { 1,2,3 };//А если уж вдруг и не была известна, то отныне и впредь уж точно
```
Вполне логично было-бы ожидать превращение этой конструкции в нечто подобное: ... | https://habr.com/ru/post/247047/ | null | ru | null |
# Рассуждения об asyncio.Semaphore
В Кремниевой долине есть очень особенный ресторан фаст-фуда, который всегда открыт. Там имеется один столик, за ним может разместиться лишь один посетитель, которому дадут совершенно фантастический гамбургер. Когда туда приходишь — ждёшь до тех пор, пока не настанет твоя очередь. Пот... | https://habr.com/ru/post/692292/ | null | ru | null |
# Знакомство с HealthKit
В этой статье про HealthKit вы узнаете, как запрашивать разрешение на доступ к данным HealthKit, а также считывать и записывать данные в центральный репозиторий HealthKit. В статье используется Swift 4, iOS 11, Xcode 9 версии.
**HealthKit** — это API, которое было представлено в iOS 8. *He... | https://habr.com/ru/post/434978/ | null | ru | null |
# Google Cloud Storage c Java: изображения и другие файлы в облаках
В продолжение [серии статей](http://habrahabr.ru/post/268863/) о веб-разработке на Java на платформе Google App Engine / Google Cloud Endpoints рассмотрим сервис для облачного хранения файлов Google Cloud Storage.
В целом схема выглядит следующим ... | https://habr.com/ru/post/275211/ | null | ru | null |
# Sync vs Async на примере Firebird

В этой публикации я поставил перед собой несколько целей:
* Сравнить разные стили программирования работы с БД Firebird в NodeJS;
* Найти наиболее производительный вариант;
* Получить в... | https://habr.com/ru/post/139708/ | null | ru | null |
# Миграция PostgreSQL в Kubernetes
Все больше компаний внедряют Kubernetes как из интереса к передовым технологиям, так и в рамках стратегии по трансформации бизнеса. Когда дело касается переноса приложений в... | https://habr.com/ru/post/576730/ | null | ru | null |
# Никто не знает, как работает каскад
Перед началом чтения пройдите простой тест — каким будет значение свойства `background-color` в первом и во втором варианте, и почему именно так?
Правильный ответ. В 1 в... | https://habr.com/ru/post/590779/ | null | ru | null |
# Поднимаем IDS/NMS: Mikrotik и Suricata c web-интерфейсом
У меня, видимо, такая карма: как ни возьмусь за реализацию какого-нибудь сервиса на опенсорсе, так обязательно найду кучу мануалов, каждый по отдельности из которых в моем конкретном случае не сработает, готовое решение толком не заведется или не понравится, с... | https://habr.com/ru/post/431600/ | null | ru | null |
# Чтение данных с весов Mettler Toledo PS60
Не так давно выиграл проект на Elance — сделать простое WinForms приложение на Visual Basic, которое будет отображать данные с весов Mettler Toledo PS60.
К счастью, данные весы являются HID-устройством, подключаемом по USB.
В этом посте я опишу как работать с подобным... | https://habr.com/ru/post/205462/ | null | ru | null |
# Основы моделирования в openEMS
В [прошлой части](http://habrahabr.ru/post/255317/) было рассказано как установить и настроить open-source электромагнитный симулятор [openEMS](http://openems.de/) . Теперь можно переходить к моделированию. Как производить моделирование ЭМВ при помощи openEMS и Octave будет рассказа... | https://habr.com/ru/post/258489/ | null | ru | null |
# Крохотные образы Docker, которые верили в себя*
[отсылка к американской детской сказке "Маленький паровозик, который верил в себя " ("The Little Engine That Could") — прим. пер.]\*

**Как автомагически создавать крохотные docker-о... | https://habr.com/ru/post/469947/ | null | ru | null |
# Немного о внутренностях WebKit
Задался я с задачей, ознакомится с тем как работает в том или ином виде основа всех современных браузеров — WebKit, как происходит процесс загрузки ресурсов, и что с этим всем, собственно, можно сделать. Документации по вопросу, в принципе, достаточно:
\* структурированная, но не по... | https://habr.com/ru/post/237771/ | null | ru | null |
# Мега-Учебник Flask, Часть 11: Поддержка e-mail
Это одиннадцатая статья в серии, где я описываю свой опыт написания веб-приложения на Python с использованием микрофреймворка Flask.
Цель данного руководства — разработать довольно функциональное приложение-микроблог, которое я за полным отсутствием оригинальности ре... | https://habr.com/ru/post/234737/ | null | ru | null |
# 7 вредных советов проектировщику REST API
*Адаптация статьи REST WORST PRACTICES, © Jacob Kaplan-Moss. Статья написана применительно к Django, но информация будет актуальна для широкого круга специалистов.*
Думаю что лучший способ понять как нужно делать, изучить как делать НЕ нужно. Представляю вашему вниманию в... | https://habr.com/ru/post/325884/ | null | ru | null |
# Программирование на Android для web разработчика или быстрый старт для самых маленьких. Часть 2
Приветствую!
Статья является продолжением начатой мной [части 1](http://habrahabr.ru/post/165105/).
#### Предостережение
**Важно**: данный урок не является профессиональным. Автор урока не является специалистом в п... | https://habr.com/ru/post/165251/ | null | ru | null |
# Изучаем протоколы со Scapy

Статья расскажет, как можно использовать Scapy для создания пакетов UDP и TCP протокола, так же попробуем реализовать взаимодействие по сети, отправив короткое сообщение с испо... | https://habr.com/ru/post/645627/ | null | ru | null |
# Policy-based Routing (PBR), как основное назначение (Часть 1)
**Что такое Policy-based Routing (PBR)**
Policy-based routing (PBR) перевод данного словосочетания несет смысл такого характера, как маршрутизация на основе определенных политик (правил, условий), которые являются относительно гибкими и устанавливаютс... | https://habr.com/ru/post/101796/ | null | ru | null |
# Детективная история про SQL injection, местами blind
Доброго времени суток!
Не подумал бы писать статью об этом, т.к. думал, что тема довольно заезжена. Но, судя по [этой статье](http://habrahabr.ru/blogs/infosecurity/134372/) аудитории интересно. Окончательно меня убедил в том, что писать надо [вот этот коммента... | https://habr.com/ru/post/134885/ | null | ru | null |
# Идеальный каталог, вариант реализации
В продолжении статьи "[Идеальный каталог, набросок архитектуры](https://habrahabr.ru/post/322930/)", я покажу на примерах как можно использовать предложенную структуру БД для хранения произвольных данных и выполнения произвольных поисков по этим данным. Скрипты лежат в репозитор... | https://habr.com/ru/post/323498/ | null | ru | null |
# Rust — сохраняем безразмерные типы в статической памяти
Не так давно в качестве хобби я решил погрузиться в изучение embedded разработки на Rust и через какое-то время мне захотелось сделать себе логгер, который бы просто писал логи через UART, но при этом не знал какая конкретно реализация используется. Вот тут я б... | https://habr.com/ru/post/561012/ | null | ru | null |
# Композиция компонентов в React JS
По прошествии 2-х лет работы с React у меня накопилось немного опыта, которым хотелось бы поделиться. Если вы только начали осваивать React, то надеюсь эта статья поможет выбрать правильный путь развития проекта из 1-5 форм до огромного набора компонентов и при этом не запутаться. ... | https://habr.com/ru/post/524276/ | null | ru | null |
# О разворачивании строк в Java
Прочитав хабротопик [О разворачивании строк в .Net/C# и не только](http://habrahabr.ru/blogs/net/58333/), меня заинтересовало а как обстоят дела с той же проблемой в Java.
Не имея под руками машины с медленной памятью пришлось ограничится тестами на одной.
Времени проводить такое ... | https://habr.com/ru/post/58382/ | null | ru | null |
# Динамические промо в Magento
Disclaimer: эта статья не предназначена для «зубров». Ее основная аудитория – начинающие web-мастеры, у которых появляется желание сделать все «по-взрослому», но не всегда хватает идей, как именно это сделать.
Итак, началось все с того, что мне захотелось как-то оживить первую страни... | https://habr.com/ru/post/76743/ | null | ru | null |
# Прочие варианты использования оператора else
Всем нам хорошо известен способ использования ключевого слова else совместно с if:
```
if x > 0:
print 'positive'
elif x < 0:
print 'negative'
else:
print 'zero'
```
Однако в Python’е существует и несколько других, неизвестных большинству программис... | https://habr.com/ru/post/148365/ | null | ru | null |
# Выпущен новый модуль управления сетью партнеров интернет-магазина — PHPShop Partners
Представляем вашему вниманию новый модуль для интернет-магазина PHPShop Enterprise, который позволяет создать сеть партнеров и автоматизировать процесс учета бонусов и скидок партнерской программы.
В последней версии самой продав... | https://habr.com/ru/post/123197/ | null | ru | null |
# Работа с FTP и выгрузка данных в xlsx (Caché Object Script)
Предлагаю Вашему вниманию статью на следующие на темы:
1. Работа с FTP сервером с помощью %Net.FtpSession
2. Простой способ выгрузки данных в формат xls
3. Несколько полезных советов
#### Работа с FTP сервером.
Вебсервисы? Не, не слышали.
Третьего д... | https://habr.com/ru/post/177609/ | null | ru | null |
# OpenToonz: снаружи и внутри

Прошло уже почти четыре года с тех пор, как PVS-Studio поверял исходный код OpenToonz. Этот проект является очень мощным инструментом для создания двухмерной анимаци... | https://habr.com/ru/post/494220/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.